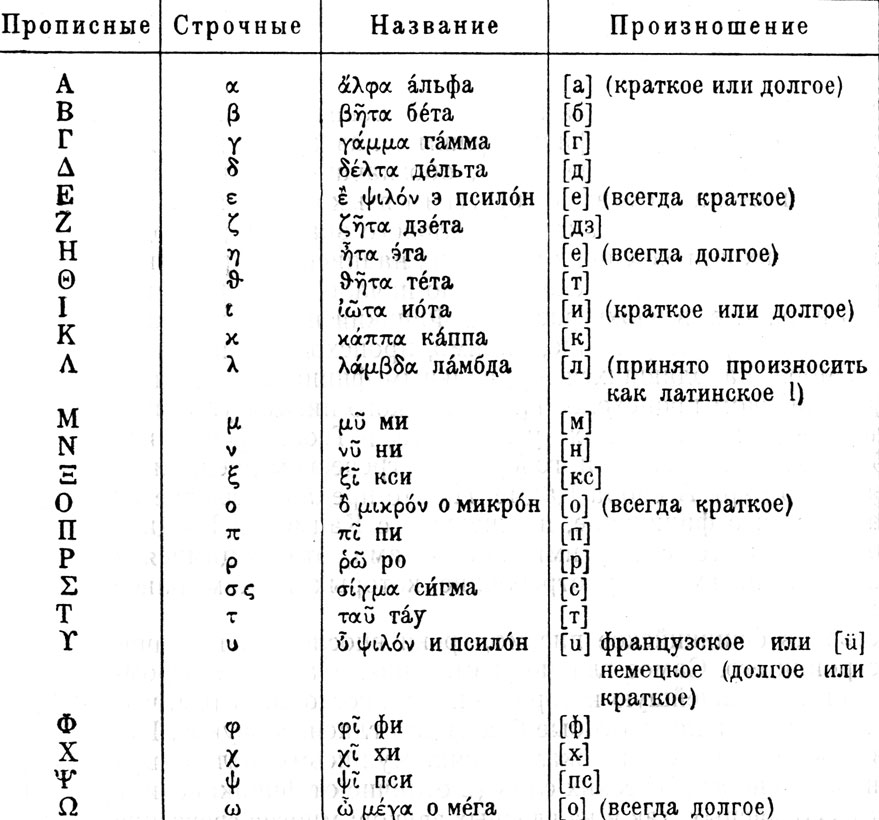
Прописные и строчные буквы. Что значит строчная и прописная буква в
Изначально не существовало разделения букв на строчные и прописные. Все буквы писались одинаково. Но со временем многие народы оценили эту инновацию, позволяющую легче воспринимать текст.
В разных языках большие и маленькие буквы могут использоваться немного по-разному. Например, в русском языке с большой буквы пишутся лишь имена собственные, а в немецком — вообще все существительные.
Есть языки, где не существует разделения на прописные и строчные буквы — например, нет его в арабском и еврейском алфавите.
Какие слова пишутся с большой буквы
В русском языке с большой буквы пишутся:
Первое слово в предложении, в цитате, в прямой речи.
Имена собственные.
Первое слово в названии исторического события или эпохи: Вторая мировая война, Октябрьская революция.
Названия праздников, мероприятий: Новый год, Олимпийские игры.
Имена мифических или религиозных персонажей. Слова «Он», «Всевышний», «Бог», если речь идет о верховном божестве в монотеистических религиях. (Но во фразеологизмах вроде «бог с тобой» это слово пишется с маленькой буквы.)
Названия компаний.
В официальных документамх — некоторые должности и титулы: Президент РФ, Его Святейшество.
Слово «Родина» — как синоним названия родной страны.
Местоимение «Вы» в качестве вежливого обращения в официальных документах и деловой переписке может писаться с большой буквы, однако это не обязательно.
В официальных документах при обозначении сторон, документов: Заказчик, Исполнитель, Соглашение.
Во всех сложных случаях лучше консультироваться со словарем.
Строчные и прописные буквы на клавиатуре
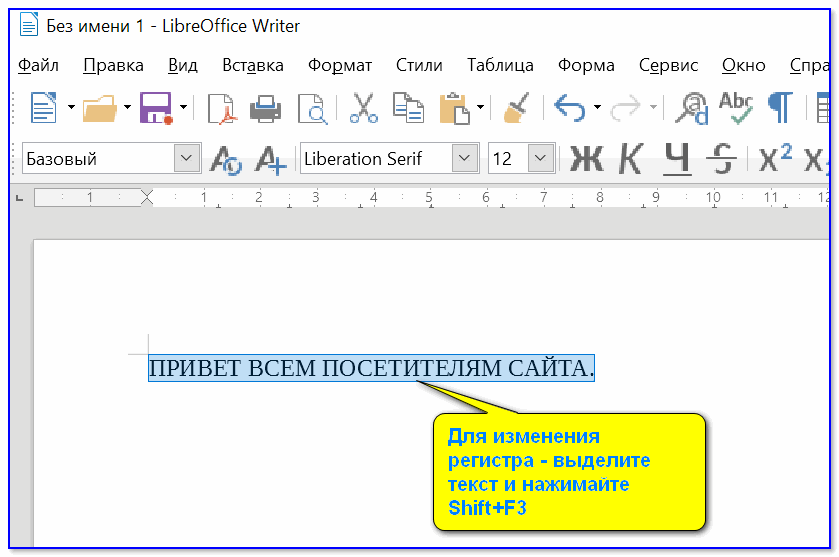
Чтобы набрать прописную букву на клавиатуре компьютера, необходимо либо зажать клавишу shift и одновременно набрать нужную букву, либо сменить регистр с помощью клавиши caps lock — в этом случае все буквы будут прописными. Повторное нажатие caps lock сменит регистр обратно, на экране опять будут появляться маленькие буквы.
Повторное нажатие caps lock сменит регистр обратно, на экране опять будут появляться маленькие буквы.
Помните, что в интернет-переписке использовать только большие буквы считается неприличным. Собеседник воспримет это как ГРОМКИЙ КРИК. Это называется «писать капсом» (от названия caps lock), и допускается лишь в исключительных случаях.
Как использовать прописные буквы в пароле. Пример
Иногда компьютерные пароли могут быть чувствительными к регистру — в этом случае важно, набираете вы большую или маленькую букву. Компьютер воспримет строчную «а» и прописную «А» как разные символы, а пароли «abc123» и «ABC123» — как два разных пароля.
Если в пароле есть и строчные, и прописные буквы, злоумышленникам сложнее подобрать его. Поэтому некоторые сайты или программы обязательно требуют использовать в пароле по меньшей мере одну маленькую, и одну большую букву. Например, использовать пароль не vasya99, а VasYa99.
Строковые методы
Изменение заглавной буквы строки
Тип строки Python предоставляет множество функций, которые влияют на использование заглавных букв в строке. Они включают :
Они включают :
str.casefoldstr.upperstr.lowerstr.capitalizestr.titlestr.swapcase
С юникод строк (по умолчанию в Python 3), эти операции не являются 1: 1 отображения или обратимым. Большинство из этих операций предназначены для отображения, а не нормализации.
Методы casefold (), upper(), lower(), capitalize(), title(), swapcase()
str.casefold() — создает строчную строку, которая подходит для случая нечувствительных сравнений. Это более агрессивный , чем str.lower и может изменить строки, которые уже находятся в нижнем регистре или вызывают строки , чтобы расти в длину, и не предназначена для отображения.
"XßΣ".casefold() # 'xssσ' "XßΣ".lower() # 'xßς'
Преобразования, которые происходят в рамках casefolding, определяются Консорциумом Unicode в файле CaseFolding.txt на их веб-сайте.
str.upper() — принимает каждый символ в строке и преобразует его в верхнем регистре эквивалента, например:
"This is a 'string'.".upper() # "THIS IS A 'STRING'."
str.lower() — делает обратное; он берет каждый символ в строке и преобразует его в строчный эквивалент:
"This IS a 'string'.".lower() # "this is a 'string'."
str.capitalize() — возвращает заглавную версию строки, то есть, он делает первый символ имеет верхний регистр , а остальные нижние:
"this Is A 'String'.".capitalize() # Capitalizes the first character and lowercases all others # "This is a 'string'."
str.title() — возвращает название обсаженной версии строки, то есть, каждая буква в начале слова производится в верхнем регистре , а все остальные сделаны в нижнем регистре:
"this Is a 'String'".title() # "This Is A 'String'"
str.swapcase() — str.swapcase возвращает новый объект строки , в которой все строчные символы поменяны местами в верхний регистр и все символы верхнего регистра в нижний:
"this iS A STRiNG".swapcase() #Swaps case of each character # "THIS Is a strIng"
 swapcase() #Swaps case of each character
# "THIS Is a strIng"
swapcase() #Swaps case of each character
# "THIS Is a strIng"Использование в качестве str методов класса
Следует отметить , что эти методы могут быть названы либо на струнных объектов (как показано выше) или как метод класса от str класса (с явным вызовом str.upper и т.д.)
str.upper("This is a 'string'")
# "THIS IS A 'STRING'"Это особенно полезно при применении одного из этих методов для многих строк сразу, скажем, на map функции.
map(str.upper,["These","are","some","'strings'"]) # ['THESE', 'ARE', 'SOME', "'STRINGS'"]
Разбить строку на основе разделителя на список строк
str.split(sep=None, maxsplit=-1)
str.split принимает строку и возвращает список подстрок исходной строки. Поведение отличается в зависимости от того sep предусмотрен или опущен аргумент.
Если sep не предусмотрен, или нет None , то происходит расщепление везде , где есть пробела. Однако начальные и конечные пробелы игнорируются, и несколько последовательных пробельных символов обрабатываются так же, как один пробельный символ:
Однако начальные и конечные пробелы игнорируются, и несколько последовательных пробельных символов обрабатываются так же, как один пробельный символ:
"This is a sentence.".split() # ['This', 'is', 'a', 'sentence.'] " This is a sentence. ".split() # ['This', 'is', 'a', 'sentence.'] " ".split() #[]
sep параметр может быть использован для определения строки разделителей. Исходная строка разделяется там, где встречается строка-разделитель, а сам разделитель отбрасывается. Несколько последовательных разделители не обрабатываются так же , как однократный, а вызвать пустые строки , которые будут созданы.
"This is a sentence.".split('')
# ['This', 'is', 'a', 'sentence.']
"Earth,Stars,Sun,Moon".split(',')
# ['Earth', 'Stars', 'Sun', 'Moon']
" This is a sentence. ".split('')
# ['', 'This', 'is', '', '', '', 'a', 'sentence.', '', '']
"This is a sentence.".split('e')
# ['This is a s', 'nt', 'nc', '.']
"This is a sentence.".split('en')
# ['This is a s', 't', 'ce. ']
По умолчанию заключается в разделении на каждом появлении разделителя, однако maxsplit параметр ограничивает количество расщеплений , которые происходят. Значение по умолчанию -1 означает , что нет предела:
"This is a sentence.".split('e', maxsplit=0)
# ['This is a sentence.']
"This is a sentence.".split('e', maxsplit=1)
# ['This is a s', 'ntence.']
"This is a sentence.".split('e', maxsplit=2)
# ['This is a s', 'nt', 'nce.']
"This is a sentence.".split('e', maxsplit=-1)
# ['This is a s', 'nt', 'nc', '.']str.rsplit(sep=None, maxsplit=-1)
str.rsplit ( «правый раскол») отличается от str.split ( «левый сплит») , когда maxsplit указано. Расщепление начинается в конце строки, а не в начале:
"This is a sentence.".rsplit('e', maxsplit=1)
# ['This is a sentenc', '.']
"This is a sentence.".rsplit('e', maxsplit=2)
# ['This is a sent', 'nc', '.']Примечание: Python определяет максимальное число разделений , выполняемых, в то время как большинство других языков программирования указать максимальное количество подстрок
 Это может создать путаницу при переносе или сравнении кода.
Это может создать путаницу при переносе или сравнении кода.Заменить все вхождения одной подстроки другой подстрокой
Пайтона str типа также есть метод для замены вхождений одной подстроки с другой подстроки в заданной строке. Для более сложных случаев можно использовать re.sub. str.replace(old, new[, count]) :
str.replace принимает два аргумента , old и new , содержащий old подстроку , которая должна быть заменена на count определяет число замен , чтобы быть:
Например, для того , чтобы заменить 'foo' с 'spam' в следующей строке, мы можем назвать str.replace с old = 'foo' и new = 'spam' :
"Make sure to foo your sentence.".replace('foo', 'spam')
# "Make sure to spam your sentence."Если данная строка содержит несколько примеров , которые соответствуют old аргументу, все вхождения заменяются значением подаваемого в new :
"It can foo multiple examples of foo if you want.".replace('foo', 'spam') # "It can spam multiple examples of spam if you want."

если, конечно, мы не поставляем значение для count.В этом случае count вхождения собираются заменяются:
"""It can foo multiple examples of foo if you want, \
or you can limit the foo with the third argument.""".replace('foo', 'spam', 1)
# 'It can spam multiple examples of foo if you want, or you can limit the foo with the third argument.'str.format и f-strings: форматировать значения в строку
Python обеспечивает интерполяцию строки и функциональность форматирования через str.format функции, введенной в версии 2.6 и F-строк , введенных в версии 3.6.
Даны следующие переменные:
i = 10
f = 1.5
s = "foo"
l = ['a', 1, 2]
d = {'a': 1, 2: 'foo'}
Давайте посмотрим разное форматирование строки
"{} {} {} {} {}".format(i, f, s, l, d)
str.format("{} {} {} {} {}", i, f, s, l, d)
"{0} {1} {2} {3} {4}".format(i, f, s, l, d)
"{0:d} {1:0. 1f} {2} {3!r} {4!r}".format(i, f, s, l, d)
"{i:d} {f:0.1f} {s} {l!r} {d!r}".format(i=i, f=f, s=s, l=l, d=d)  1f} {2} {3!r} {4!r}".format(i, f, s, l, d)
"{i:d} {f:0.1f} {s} {l!r} {d!r}".format(i=i, f=f, s=s, l=l, d=d)
1f} {2} {3!r} {4!r}".format(i, f, s, l, d)
"{i:d} {f:0.1f} {s} {l!r} {d!r}".format(i=i, f=f, s=s, l=l, d=d) Все утверждения выше эквивалентны "10 1.5 foo ['a', 1, 2] {'a': 1, 2: 'foo'}"
f"{i} {f} {s} {l} {d}"
f"{i:d} {f:0.1f} {s} {l!r} {d!r}"Для справки, Python также поддерживает классификаторы в стиле C для форматирования строк. Примеры , приведенные ниже, эквивалентны тем , которые выше, но
"%d %0.1f %s %r %r" % (i, f, s, l, d) "%(i)d %(f)0.1f %(s)s %(l)r %(d)r" % dict(i=i, f=f, s=s, l=l, d=d)
Скобки используются для интерполяции в str.format также может быть пронумерована для уменьшения дублирования при форматировании строк. Например, следующее эквивалентно:
"I am from {}. I love cupcakes from {}!".format("Australia", "Australia")
#"I am from Australia. I love cupcakes from Australia!"
"I am from {0}. I love cupcakes from {0}!".format("Australia")
#"I am from Australia. I love cupcakes from Australia!"
В то время как официальная документация питона, как обычно, достаточно тщательно, pyformat.info имеет большой набор примеров с подробными объяснениями.
Кроме того, { и } символы могут быть экранированы с помощью двойных скобок:
"{{'{}': {}, '{}': {}}}".format("a", 5, "b", 6)
# "{'a': 5, 'b': 6}"См Строка форматирования для получения дополнительной информации. str.format() был предложен в PEP 3101 и F-строк в PEP 498 .
Подсчет количества появлений подстроки в строке
str.count. str.count(sub[, start[, end]])str.count возвращает int , указывающее количество неперекрывающихся вхождений подстрок sub в другой строке. Необязательные аргументы start и end указывают на начало и конец , в котором поиск будет происходить. По умолчанию
По умолчанию start = 0 и end = len(str) означает всю строку будет искать:
s = "She sells seashells by the seashore."
s.count("sh")
# 2
s.count("se")
# 3
s.count("sea")
# 2
s.count("seashells")
# 1Задавая различные значения для start , end , мы можем получить более локализованный поиск и сосчитать, например, если start равно 13 призыва к:
s.count("sea", start)
# 1эквивалентно:
t = s[start:]
t.count("sea")
# 1 Проверьте начальный и конечный символы строки
Для того , чтобы проверить начало и окончание данной строки в Python, можно использовать методы str.startswith() и str.endswith(). str.startswith(prefix[, start[, end]])
Как следует это имя, str.startswith используется для проверки , начинается ли заданная строка с заданными символами в prefix .
s = "This is a test string" s.
 startswith("T")
# True
s.startswith("Thi")
# True
s.startswith("thi")
# False
startswith("T")
# True
s.startswith("Thi")
# True
s.startswith("thi")
# FalseНеобязательные аргументы start и end указать начальную и конечную точки , из которых тестирование будет начать и закончить. В следующем примере, указав начальное значение 2 наша строка будет просматриваться с позиции 2 , а затем:
s.startswith("is", 2)
# TrueЭто дает True , так как s[2] == 'i' и s[3] == 's' .
Вы можете также использовать tuple , чтобы проверить , если он начинается с какой — либо из набора строк
s.startswith(('This', 'That'))
# True
s.startswith(('ab', 'bc'))
# Falsestr.endswith(prefix[, start[, end]]) — точно похож на str.startswith с той лишь разницей, что он ищет окончание символов и не начиная символов. Например, чтобы проверить, заканчивается ли строка полной остановкой, можно написать:
s = "this ends in a full stop.
 "
s.endswith('.')
# True
s.endswith('!')
# False
"
s.endswith('.')
# True
s.endswith('!')
# Falseкак и с startswith более одного символа может использоваться как окончание последовательности:
s.endswith('stop.')
# True
s.endswith('Stop.')
# FalseВы можете также использовать tuple , чтобы проверить , если он заканчивается любой из набора строк
s.endswith(('.', 'something'))
# True
s.endswith(('ab', 'bc'))
# FalseПроверка того, из чего состоит строка
Пайтона str тип также имеет целый ряд методов , которые могут быть использованы для оценки содержимого строки. Это str.isalpha , str.isdigit , str.isalnum , str.isspace.Капитализация может быть проверена с str.isupper , str.islower и str.istitle. str.isalpha
str.isalpha не принимает никаких аргументов и возвращает True , если все символы в данной строке являются буквенными, например:
"Hello World".
 isalpha() # contains a space
# False
"Hello2World".isalpha() # contains a number
# False
"HelloWorld!".isalpha() # contains punctuation
# False
"HelloWorld".isalpha()
# True
isalpha() # contains a space
# False
"Hello2World".isalpha() # contains a number
# False
"HelloWorld!".isalpha() # contains punctuation
# False
"HelloWorld".isalpha()
# TrueВ краевой случае пустая строка вычисляет значение False при использовании "".isalpha(). str.isupper , str.islower , str.istitle
Эти методы проверяют использование заглавных букв в заданной строке.
str.isupper это метод , который возвращает True , если все символы в данной строке в верхнем регистре и False иначе.
"HeLLO WORLD".isupper() # False "HELLO WORLD".isupper() # True "".isupper() # False
С другой стороны , str.islower это метод , который возвращает True , если все символы в данной строке в нижнем регистре и False иначе.
"Hello world".islower() # False "hello world".islower() # True "".islower() # False
str. возвращает  istitle
istitleTrue , если данная строка названия обсаженное; то есть каждое слово начинается с заглавной буквы, за которой следуют строчные буквы.
"hello world".istitle() # False "Hello world".istitle() # False "Hello World".istitle() # True "".istitle() False
Методы str.isdecimal , str.isdigit , str.isnumeric
str.isdecimal возвращает строка , является ли последовательность десятичных цифр, пригодная для представления десятичного числа.
str.isdigit включает в себя цифру не в форме , подходящей для представления десятичного числа, такие , как надстрочные цифры.
str.isnumeric включает в себя любые числовые значения, даже если не цифры, такие как значения вне диапазона 0-9.
isdecimal isdigit isnumeric 12345 True True True ១2߃໔5 True True True ①²³🄅₅ False True True ⑩⒓ False False True Five False False False
Байтовые строки ( bytes в Python 3, str в Python 2), поддерживает только isdigit , который проверяет только основные ASCII цифр.
Как str.isalpha пустая строка вычисляет значение False. str.isalnum
Это сочетание str.isalpha и str.isnumeric , в частности , он имеет значение True , если все символы в данной строке являются буквенно — цифровыми, то есть они состоят из буквенных или цифровых символов:
"Hello2World".isalnum() # True "HelloWorld".isalnum() # True "2022".isalnum() # True "Hello World".isalnum() # contains whitespace # False
str.isspace — Возвращает True , если строка содержит только пробельные символы.
"\t\r\n".isspace() # True " ".isspace() # True
Иногда строка выглядит «пустой», но мы не знаем, так ли это, потому что она содержит только пробелы или вообще не содержит символов
"".isspace() # False
Чтобы покрыть этот случай нам нужен дополнительный тест
my_str = '' my_str.isspace() # False my_str.
 isspace() or not my_str
# True
isspace() or not my_str
# TrueНо самый короткий путь , чтобы проверить , если строка пуста или содержит только пробельные символы, чтобы использовать strip (без аргументов она удаляет все начальные и конечные пробельные символы)
not my_str.strip() # True
str.translate: перевод символов в строке
Python поддерживает translate метод на str типа , который позволяет указать таблицу преобразования (используется для замены), а также любые символы , которые должны быть удалены в процессе.
str.translate(table[, deletechars]) — параметр table — это таблица поиска, которая определяет отображение от одного символа к другому. deletechars — список символов, которые должны быть удалены из строки.
maketrans метод ( str.maketrans в Python 3 и string.maketrans в Python 2) позволяет создать таблицу перевода.
translation_table = str.
 maketrans("aeiou", "12345")
my_string = "This is a string!"
translated = my_string.translate(translation_table)
# 'Th4s 3s 1 str3ng!'
maketrans("aeiou", "12345")
my_string = "This is a string!"
translated = my_string.translate(translation_table)
# 'Th4s 3s 1 str3ng!'translate метод возвращает строку , которая является переведенной копией исходной строки. Вы можете установить table аргумент None , если требуется только для удаления символов.
'this syntax is very useful'.translate(None, 'aeiou') 'ths syntx s vry sfl'
Удаление нежелательных начальных / конечных символов из строки
Три метода при условии , что предлагают возможность раздеться начальные и конечные символы из строки: str.strip , str.rstrip и str.lstrip.Все три метода имеют одинаковую подпись, и все три возвращают новый строковый объект с удаленными нежелательными символами. str.strip([chars])
str.strip действует на заданной строки и удаляет (полоски) или каких — либо ведущих задних символов , содержащихся в аргументе chars ; если chars не входит в комплект или нет None , все пробельные символы удаляются по умолчанию. Например:
Например:
" a line with leading and trailing space ".strip() # 'a line with leading and trailing space'
Если chars поставляются, все символы , содержащиеся в нем, удаляются из строки, которая возвращается. Например:
">>> a Python prompt".strip('>') # убирает символ '>' и пробел после него
#'a Python prompt'
str.rstrip([chars]) и str.lstrip([chars]) — Эти методы имеют ту же семантику и аргументы с str.strip() , их отличие заключается в том направлении , откуда они начинаются. str.rstrip() начинается с конца строки в то время как str.lstrip() расщепляется с начала строки.
Например, при использовании str.rstrip :
" spacious string ".rstrip() # ' spacious string'
В то время как, используя str.lstrip :
" spacious string ".rstrip() # 'spacious string ' " spacious string ".
 rstrip().lstrip()
# 'spacious string'
rstrip().lstrip()
# 'spacious string'Сравнение строк без учета регистра
Сравнение строки без учета регистра кажется чем-то тривиальным, но это не так. В этом разделе рассматриваются только строки Unicode (по умолчанию в Python 3). Обратите внимание, что Python 2 может иметь незначительные недостатки по сравнению с Python 3 — более поздняя обработка юникода гораздо более полная.
Первое, на что следует обратить внимание, это то, что преобразования с удалением регистра в юникоде не являются тривиальными. Существует текст , для которого text.lower() != text.upper().lower() , Например, "ß" :
>>> "ß".lower() 'ß' >>> "ß".upper().lower() 'ss'
Но предположим, что вы хотели регистронезависмо сравнивать "BUSSE" и "Buße".Черт возьми, вы , вероятно , также хотят , чтобы сравнить "BUSSE" и "BUẞE" равный — это новая форма капитала. Рекомендуемый способ заключается в использовании casefold :
help(str.
 casefold)
"""
Help on method_descriptor:
casefold(self, /)
Return a version of the string suitable for caseless comparisons
"""
casefold)
"""
Help on method_descriptor:
casefold(self, /)
Return a version of the string suitable for caseless comparisons
"""Не просто использовать lower.Если casefold не доступен, делая .upper().lower() помогает (но только немного).
Тогда вы должны рассмотреть акценты. Если визуализатор шрифт хорошо, вы , вероятно , думаете , "ê" == "ê" — но это не так :
"ê" == "ê" # False
Это потому что они на самом деле
unicodedata [unicodedata.name(char) for char in "ê"] # ['LATIN SMALL LETTER E WITH CIRCUMFLEX'] [unicodedata.name(char) for char in "ê"] # ['LATIN SMALL LETTER E', 'COMBINING CIRCUMFLEX ACCENT'
Самый простой способ справиться с этим unicodedata.normalize.Вы , вероятно , хотите использовать NFKD нормализации, но не стесняйтесь проверить документацию. Тогда один
unicodedata.normalize("NFKD", "ê") == unicodedata.normalize("NFKD", "ê")
# True Чтобы закончить, здесь это выражается в функциях:
import unicodedata def normalize_caseless(text): return unicodedata.
 normalize("NFKD", text.casefold())
def caseless_equal(left, right):
return normalize_caseless(left) == normalize_caseless(right)
normalize("NFKD", text.casefold())
def caseless_equal(left, right):
return normalize_caseless(left) == normalize_caseless(right)Объединить список строк в одну строку
Строка может быть использована в качестве разделителя , чтобы присоединиться к списку строк вместе в одну строку с помощью join() метод. Например, вы можете создать строку, где каждый элемент в списке разделен пробелом.
" ".join(["once","upon","a","time"]) # "once upon a time"
В следующем примере строковые элементы разделяются тремя дефисами.
"---".join(["once", "upon", "a", "time"]) # "once---upon---a---time"
Полезные константы строкового модуля
Пайтона string модуль предоставляет константы для операций , связанных строк. Для того, чтобы использовать их, импортировать string модуля:
import string
Сочетание ascii_lowercase и ascii_uppercase :
string.ascii_letters # 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
Строку можно реверсировать с использованием встроенной функции В то время как с использованием Python предоставляет функции для выравнивания строк, позволяя заполнять текст, чтобы упростить выравнивание различных строк. Ниже приведен пример Содержимое файлов и сетевых сообщений может представлять собой закодированные символы. Их часто нужно преобразовывать в юникод для правильного отображения. В Python 3 вам может потребоваться преобразовать массивы байтов (называемые «байтовым литералом») в строки символов Unicode. По умолчанию теперь строка Unicode, и байтовой строки литералов теперь должны быть введены как Python делает его чрезвычайно интуитивным, чтобы проверить, содержит ли строка заданную подстроку. Примечание: тестирование пустой строки всегда будет приводить Сохранить это слово! «Маленькие буквы»; буквы алфавита, которые не являются заглавными или прописными буквами. ВИКТОРИНА ВСЕ ЗА(U)R ЭТОГО БРИТАНСКОГО ПРОТИВ. АМЕРИКАНСКИЙ АНГЛИЙСКИЙ ВИКТОРИНА Существует огромное количество различий между тем, как люди говорят по-английски в США и Великобритании. Способны ли ваши языковые навыки определить разницу? Давай выясним! Вопрос 1 из 7 Правда или ложь? Британский английский и американский английский различаются только сленговыми словами. Нижний Баррелл, Нижняя Калифорния, Нижняя Канада, Восстание Нижней Канады, нижний регистр, строчные буквы, нижняя палата, Нижний Чинук, низший класс, низший класс, низшая критика Новый культурный словарь Грамотность, третье издание
Авторское право © 2005 г., издательство Houghton Mifflin Harcourt Publishing Company. Опубликовано издательством Houghton Mifflin Harcourt Publishing Company. Все права защищены.string. _`{|}~ \t\n\r\x0b\x0c'
_`{|}~ \t\n\r\x0b\x0c' Сторнирование строки (reverse)
reversed() , которая принимает строку и возвращает итератор в обратном порядке.reversed('hello')
# <reversed object at 0x0000000000000000>
[char for char in reversed('hello')]
# ['o', 'l', 'l', 'e', 'h'] reversed() могут быть обернуты в вызове ''.join() , чтобы сделать строку из итератора.''.join(reversed('hello'))
# 'olleh'reversed() может быть более удобными для чтения для непосвященных пользователей Python, используя расширенную нарезку с шагом -1 быстрее и более кратким. Вот, попробуйте реализовать это как функцию:def reversed_string(main_string):
return main_string[::-1]
reversed_string('hello')
# 'olleh'Выравнивание строк

str.ljust и str.rjust :interstates_lengths = {
5: (1381, 2222),
19: (63, 102),
40: (2555, 4112),
93: (189,305),
}
for road, length in interstates_lengths.items():
miles,kms = length
print('{} -> {} mi. ({} km.)'.format(str(road).rjust(4), str(miles).ljust(4), str(kms).ljust(4)))
# 5 -> 1381 mi. (2222 km.)
# 19 -> 63 mi. (102 km.)
# 40 -> 2555 mi. (4112 km.)
# 93 -> 189 mi. (305 km.)
ljust и rjust очень похожи. Оба имеют width параметр и необязательный fillchar параметр. Любая строка , создаваемая эти функции, по крайней мере до тех пор , как width параметр , который был передан в функцию. Если строка длиннее , чем width alread, она не усекается. fillchar аргумент, который по умолчанию используется символ пробела ' ' должен быть один символ, а не multicharacter строка.
ljust функция подушечки конца строки она называется на с fillchar до тех пор, пока width длиной символов. rjust функция подушечки начала строки в подобной манере. Таким образом, l и r в названиях этих функций относятся к стороне , что исходная строка, а не fillchar , расположена в выходной строке.Преобразование между str или байтовыми данными и символами юникода
b'' , b"" , и т.д. Байт буквальным будет возвращать True в isinstance(some_val, byte) , предполагая some_val быть строка , которая может быть закодированы в байтах.
# You get from file or network "© abc" encoded in UTF-8
s = b'\xc2\xa9 abc' # s is a byte array, not characters
# In Python 3, the default string literal is Unicode; byte array literals need a leading b
s[0] # b'\xc2' - meaningless byte (without context such as an encoding)
type(s) # bytes - now that byte arrays are explicit, Python can show that.
u = s.decode('utf-8') # '© abc' on a Unicode terminal
# bytes.decode конвертирует byte массив в строчку (которая в Python 3 будет Unicode)
u[0] # '\u00a9' - Unicode Character 'COPYRIGHT SIGN' (U+00A9) '©'
type(u) # str
# Строковый литерал по умолчанию в Python 3 — UTF-8 Unicode.
u.encode('utf-8') # b'\xc2\xa9 abc'
# str.encode выдает массив byte, показываю ASCII-range bytes как незаменные символы.Строка содержит
 Просто используйте
Просто используйте in операторе:"foo" in "foo.baz.bar"
# True
True :"" in "test"
# True
Строчные буквы Определение и значение

Слова рядом со строчными буквами
ПОДРОБНЕЕ О СТРОЧНЫХ БУКВАХ
Что такое
строчные буквы ?Строчные буквы — это более короткие и меньшие версии букв (например, w ), в отличие от более крупных и высоких версий (например, W ), которые называются прописными буквами или заглавными буквами .
Прилагательное в нижнем регистре также может использоваться как существительное, означающее то же, что и 9.0039 строчная буква , хотя это используется гораздо реже.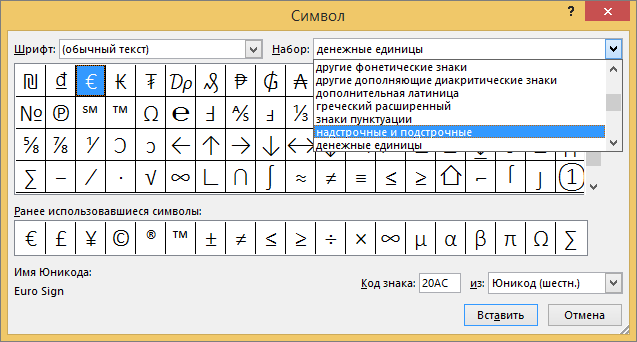 Прилагательное в верхнем регистре также может использоваться как существительное таким образом. В качестве прилагательного прописные означают то же самое, что и заглавные , а прописные буквы тоже могут называться заглавными .
Прилагательное в верхнем регистре также может использоваться как существительное таким образом. В качестве прилагательного прописные означают то же самое, что и заглавные , а прописные буквы тоже могут называться заглавными .
Некоторые строчные буквы являются просто более короткими, уменьшенными версиями своих прописных аналогов (например, строчные w и прописные W или строчные c и прописные C ), но во многих случаях две версии буквы принимают разные формы, например строчные a и прописные A или строчные b и прописные B .
Чтобы сделать слово заглавным, нужно сделать его первую букву заглавной или заглавной. Слово в верхнем регистре может использоваться как глагол, означающий то же самое. Слово в нижнем регистре может использоваться как глагол, означающий перевод буквы в нижний регистр. Например, до нижний регистр слово польский (которое здесь пишется с заглавной буквы p ), вы должны написать его строчными P , как польский .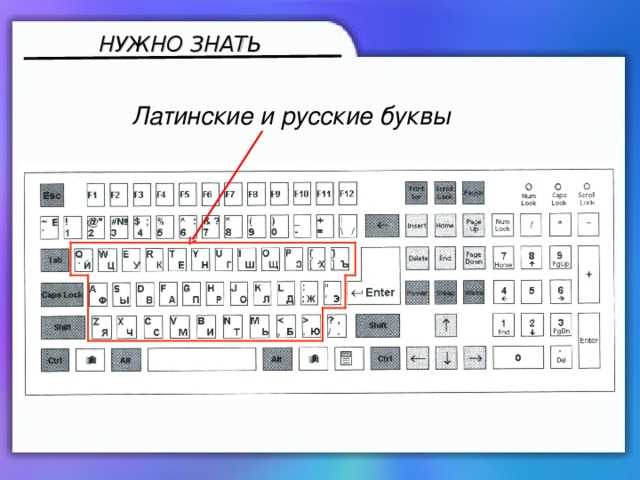
В английском языке прописные буквы используются в начале слов по нескольким причинам. Стандартным правилом английского языка считается использование заглавной буквы в начале имен собственных (которые представляют собой существительные, которые относятся к определенным людям, местам или вещам — то есть те, у кого есть определенные имена), например 9.0039 Джесс , Мексика и Нинтендо . Использование прописной или строчной буквы в начале слова может изменить то, как читатель интерпретирует его значение, как в случае полировать (глагол, означающий сделать что-то более блестящим) и полировать (прилагательное, описывающее кого-либо). из Польши) или яблоко (плод) и яблоко (компания).
Мы также используем заглавную букву для первой буквы первого слова в предложении. Иногда мы используем заглавную букву для первой буквы каждого слова в названии, например, 9.0039 Всем парням, которых я любила раньше .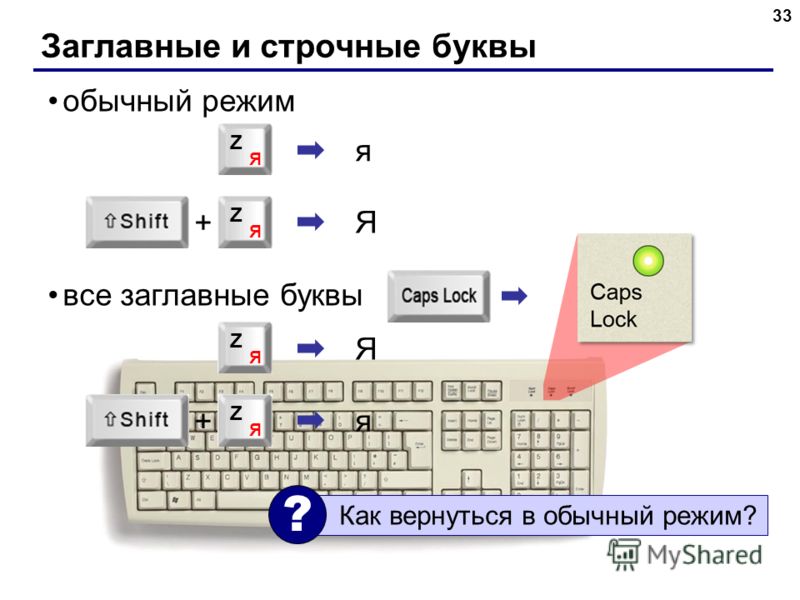 Это иногда называют титульным регистром .
Это иногда называют титульным регистром .
Некоторые аббревиатуры и аббревиатуры пишутся с использованием заглавных букв, например NASA и U.S. . Говорят, что слово, полностью написанное заглавными буквами (например, ЧТО ), написано заглавными буквами или заглавными буквами .
Использование строчных букв в любом из этих случаев обычно указывает на то, что общение носит случайный или неформальный характер, например, в текстовых сообщениях или онлайн-сообщениях.
Пример: Многие люди используют только строчные буквы в текстовых сообщениях, если только они не хотят что-то подчеркнуть.
Откуда
строчная буква ? Термин строчная буква используется по крайней мере с 1680-х годов. Слова в верхнем регистре и в нижнем регистре взяты из печати. Процесс физической печати вещей с помощью печатных станков включал лотки, называемые ящиками , которые были разделены на отсеки для хранения различных типов шрифтов (блоков с буквами на них). В верхнем регистре были заглавные буквы, а в нижнем — то, что стало известно как 9.0039 строчных букв .
В верхнем регистре были заглавные буквы, а в нижнем — то, что стало известно как 9.0039 строчных букв .
В определенных ситуациях может возникнуть путаница при использовании прописных или строчных букв , но руководство по использованию заглавных букв может помочь.
Знаете ли вы...?
Какие другие формы связаны со строчной буквой ?
- строчная буква (через дефис)
- строчная буква (альтернативное написание двух слов)
Какие есть синонимы к строчная буква ?
- нижний регистр (когда нижний регистр используется как существительное)
Какие слова имеют общий корень или элемент слова с строчной буквой ?
- нижний регистр
- верхний регистр
- прописная буква
- письмо
Какие слова часто используются при обсуждении строчной буквы ?
- заглавная буква
- заглавная
- капитализация
- написание
- первый
- слово
- предложение
- название
Как
строчных букв используются в реальной жизни? В большинстве контекстов большинство букв в тексте составляют строчных букв . Прописные буквы используются в начале имен и других имен собственных, в начале предложений, в начале слов в названиях и в некоторых сокращениях. Неформальное общение, такое как текстовые сообщения и сообщения в Интернете, иногда полностью пишется на 9-м языке.0039 строчных букв .
Прописные буквы используются в начале имен и других имен собственных, в начале предложений, в начале слов в названиях и в некоторых сокращениях. Неформальное общение, такое как текстовые сообщения и сообщения в Интернете, иногда полностью пишется на 9-м языке.0039 строчных букв .
Заглавная буква в моем коде вместо строчной просто сводила меня с ума на четыре часа, потому что я ее не видел.
— Кайл Рот (@jkroth2987) 22 октября 2015 г.
Определение и сопоставление прописных и строчных букв с помощью этих красочных карточек с подводной тематикой. Игры делают обучение веселым! 🐟 🐠 #IslipENL #LearningIsFun @WingElemIslip pic.twitter.com/QjUSLvuZ57
— Жаклин Брэди (@JaclynBrady17) 5 февраля 2021 г.
у меня новый телефон, и моя новая клавиатура не знает, что я использую только строчные буквы, поэтому теперь все мои тексты автоматически исправляются в официальные рабочие электронные письма
— noor body, noorcrime (@abnoormality) 17 января 2019 г.

Попробуйте использовать
строчных букв !Какая из следующих букв является строчной буквой ?
A. e
B. h
C. r
D. все перечисленное
Как использовать строчные буквы в предложении
Некоторые особенности его истории позволяют предположить, почему это может быть так.
Anti-Fluoriders Are OG Anti-Vaxxers|Michael Schulson|27 июля 2016|DAILY BEAST
И, по крайней мере, в случае с фтором, это сомнение может быть оправдано.
Сторонники фтора — антипрививочники|Майкл Шульсон|27 июля 2016 г.|DAILY BEAST
Ее последняя книга Еретик: аргументы в пользу мусульманской реформации будет опубликована в апреле издательством HarperCollins.
Аяан Хирси Али: наш долг — сохранить существование Charlie Hebdo|Аяан Хирси Али|8 января 2015 г.|DAILY BEAST
Их дружба началась, когда Краусс, который был главой физического факультета Case Western в Кливленде, искал вышел Эпштейн.
Двойная жизнь неряшливого миллиардера: пляжные вечеринки со Стивеном Хокингом | М.Л. Nestel|8 января 2015 г.|DAILY BEAST

Большой присяжный по делу Фергюсона предъявляет иск, чтобы иметь возможность объяснить, что именно произошло в зале суда.
Политики любят журналистов только тогда, когда они мертвы|Люк О’Нил|8 января 2015 г.|DAILY BEAST
Дело касалось нападения и избиения, которое произошло между двумя мужчинами по имени Браун и Хендерсон.
Книга Анекдотов и Бюджет Веселья;|Разное
В этом случае, я подозреваю, у сооператора была ярко выраженная детская черта, любовь к произведению эффекта.
Children's Ways|James Sully
В верхней части стебля мутовки расположены очень близко друг к другу, но в нижней части они более широко расставлены.
Как узнать папоротники|S. Leonard Bastin
Известно, что иногда у крупных растений на кончиках ветвей болотного хвоща образуются шишки.
Как узнать папоротники|S. Leonard Bastin
Однако, как правило, даже в случае экстремальных разновидностей тщательное изучение образца позволяет его идентифицировать.
Как узнать папоротники|S. Леонард Бастин

Что такое строчные и прописные буквы?
Определение строчных букв: Строчные буквы — это все остальные буквы, кроме прописных.
Определение прописной буквы: Прописные буквы — это буквы, обозначающие начало предложения или имя собственное.
Что такое строчные буквы?
В письме большинство букв строчные. Строчные буквы — это все буквы, которые не начинают предложение и не относятся к имени собственному.
Строчные буквы английского алфавита: a b c d e f g h i j k l m n o p q r s t u v w x y z.
Примеры строчных букв:
- слово
- В приведенном выше слове используются только строчные буквы.
- В приведенном выше предложении есть строчные буквы после первой буквы предложения.
- В этом предложении и в предыдущем предложении все строчные буквы, кроме «Т».

Что такое заглавные буквы?
Прописные буквы также известны как заглавные. Прописные буквы сигнализируют читателю о том, что что-то важно или значимо.
Прописные буквы английского алфавита: A B C D E F G H I J K L M N O P Q R S T U V W X Y Z.
Примеры прописных букв:
- Jones
- Это имя собственное, поэтому первая буква титула и фамилия пишутся с большой буквы
- Главная улица
- Это имя собственное, поэтому первая буква каждого слова пишется с большой буквы
Когда использовать заглавные буквы
В английском языке первая буква каждого предложения пишется с большой буквы. Заглавная буква сигнализирует читателю, что начинается новое предложение.
Другие способы использования заглавных букв подробно описаны ниже.
Заголовки Все заголовки считаются именами собственными и требуют написания с заглавной буквы.
Примеры:
- Мисс Мабри
- Неверно: мисс Мабри
- Мазерс
- Неверно: г-н. матери
- Мадам Локфилд
- Неверно: мадам Локфилд
- Леди Грейс
- Неверно: леди Грейс
- Янки
- Неверно: госпожа. джэнкс
Акронимы — это тип аббревиатуры. Акронимы — это слова, образованные из других букв для образования нового слова. Однако они требуют, чтобы заглавные буквы сигнализировали читателю, что эти буквы что-то обозначают, а не являются одним словом.
Примеры:
- НАТО
- Организация Североатлантического договора
- ЮНИСЕФ
- Международный чрезвычайный детский фонд Организации Объединенных Наций
- АКВАЛУН
- Автономный подводный дыхательный аппарат
Все имена собственные должны быть написаны с заглавной буквы.
Примеры:
- В субботу мы посетили музей Бауэрса.
- Неверно: В субботу мы посетили музей беседки.
- Я хочу совершить экскурсию по Эйфелевой башне.
- Неправильно: Я хочу совершить экскурсию по Эйфелевой башне.
- Их зовут Джейк и Сьюзи.
- Неверно: их зовут Джейк и Сьюзи.
Когда использовать строчные буквы
Используйте строчные буквы для всех букв, кроме первой в предложении, при условии, что в предложении не требуется использование прописных букв.
Примеры :
- Каждое слово в этом предложении, кроме первого, написано строчными буквами.
- Единственными словами в этом предложении, которые требуют прописных букв, являются имена собственные, Лондон и Париж.
Все существительные, не являющиеся именами собственными, называются именами нарицательными. Все нарицательные существительные используют строчные буквы (если только нарицательное не начинается предложение).
Примеры:
- дерево
- собака
- птица
- вода
- воздух
- звезда
- улица
- девушка
- ребенок
Резюме
Определение строчных букв: строчные буквы — это буквы, используемые для имен нарицательных и внутренних слов.
Определение заглавных букв: прописные буквы (также называемые заглавными) — это буквы, обозначающие начало предложения или имя собственное .
Таким образом,
- Прописные и строчные буквы относятся ко всем буквам, используемым для составления английского языка.
- Прописные буквы используются для начала предложений, а также для имен собственных.
- Строчными буквами считаются все буквы, с которых не начинается предложение.
Содержание
- 1 Что такое строчные буквы?
- 2 Что такое заглавные буквы?
- 3 Когда использовать заглавные буквы
- 3.
- 3.