Базы данных
Общие понятия
Базы данных – что это? Ведь ранее мы говорили об информационных хранилищах. Информационное хранилище является частью информационной системы. Но мы никак не уточняли, какова структура таких хранилищ. В действительности обычному пользователю нет нужды знать эту структуру. При работе с ИС он оперирует профессиональными терминами и понятиями. Например, бухгалтер, при работе с бухгалтерской информационной системой имеет дело с такими объектами как счет, проводка, журнал, платежный документ и т.д. Он не знает, как в действительности устроено информационное хранилище, да и не должен знать, так как каждый должен заниматься своим делом, а поверхностные знания, часто приводят к отрицательным результатам.
Таким образом, информационное хранилище является общим
понятием, отражающим факт наличия в системе хранимых данных. Для пользователя
те объекты, которыми он оперирует при работе с ИС и есть те самые хранимые
данные.
И так для конечного
пользователя информационное хранилище состоит из значений тех показателей,
которыми он оперирует в силу своей профессиональной деятельности. Для
системного программиста информационное хранилище представляет собой набор файлов.
Для прикладного же программиста и администратора ИС информационное хранилище
представляет собой некоторое абстрактную структуру, отражающую предметную
область. Этот уровень и принято
описывать с помощью понятия
Для
системного программиста информационное хранилище представляет собой набор файлов.
Для прикладного же программиста и администратора ИС информационное хранилище
представляет собой некоторое абстрактную структуру, отражающую предметную
область. Этот уровень и принято
описывать с помощью понятия
Рис. 2.3. Три уровня восприятия данных
Определение
Базой данных будем называть именованную часть
информационного хранилища, структура
которой описывается на языке некоторой модели данных.
СУБД
СУБД – это
система управления базами данных. Для того чтобы понять, что такое СУБД
обратимся снова к рисунку 2.3. Для
того, чтобы прикладные программисты видели базу данных
не в виде набора файлов, а как некоторую структуру, которая описывает
предметную область, между ними и файловой системой должна быть некоторая
прослойка. Это прослойка представляет собой набор процедур (программный
интерфейс), с помощью которого прикладной программист может управлять базой
данных. Эту функцию выполняет СУБД.
Другими словами СУБД отделяет работу прикладного программиста от
физической структуры базы данных. В простейшем случае СУБД состоит только из
программного интерфейса. Так обстоит дело в некоторых системах
программирования. В более сложных системах мы имеем также и интегрированную
среду, позволяющую в интерактивном режиме управлять базами данных.
На рисунке 2.4 представлена схема взаимодействие СУБД и прикладного программного обеспечения в схеме построения информационной системы. Тут важно понять, что база данных в определенной модели существует для прикладного программного обеспечения, тогда как программное обеспечение СУБД взаимодействует с данными на уровне файловой системы и системных вызовов операционной системы.
Рис. 2.4.
Все СУБД могут быть поделены на
настольные и промышленные. Настольные СУБД, такие как Access, FoxPro предназначены для создания либо
автономных информационных систем, либо ИС файл-серверного
типа. Промышленные СУБД, такие как Oracle, MS SQL Server,
Postgress и др. предназначены для
построения клиент-серверных информационных систем. СУБД,
как правило, предоставляет разработчику язык программирования, который включает
в себя специализированный язык управления базами данных. Для наиболее распространенных баз данных реляционного типа таким языком является
язык SQL.
Промышленные СУБД, такие как Oracle, MS SQL Server,
Postgress и др. предназначены для
построения клиент-серверных информационных систем. СУБД,
как правило, предоставляет разработчику язык программирования, который включает
в себя специализированный язык управления базами данных. Для наиболее распространенных баз данных реляционного типа таким языком является
язык SQL.
Использование СУБД при построении информационных систем призвано реализовать физическую и логическую независимость прикладного программирования от данных. Физическая независимость от данных заключается в том, что работа программного обеспечения ИС не будет зависеть от изменений, которые могут происходить на внутреннем, физическом уровне. Эти изменения могут заключаться, например, в том, что будет изменена файловая система или же в том, что изменится структура тех файлов, которые составляют базу данных.
Логическая независимость прикладного программирования от данных при использовании СУБД в трехуровневой структуре доступа к данным (
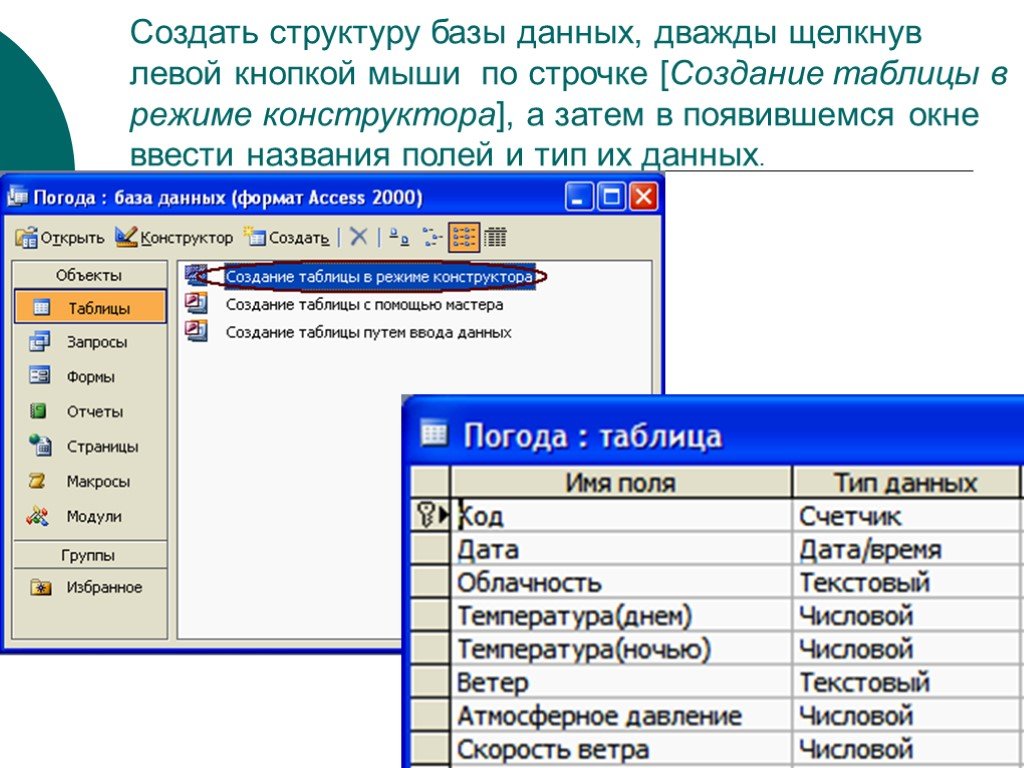 рисунок 2.3) заключается, прежде
всего, в том, что добавление новых элементов (например, добавление нового
столбца в таблицу) в структуру данных никак не влияет на функционирование
программного обеспечения.
рисунок 2.3) заключается, прежде
всего, в том, что добавление новых элементов (например, добавление нового
столбца в таблицу) в структуру данных никак не влияет на функционирование
программного обеспечения.Модели данных
Рассмотрим основные модели данных, которые используются (или использовались) при создании информационных систем. Перечень существующих моделей данных являются в тоже время и хронологическими метками истории развития баз данных и информационных систем.
Файловая модель
Иногда файловую модель, на мой взгляд, очень неудачно,
называют файловой системой. При этом упускается из вида тот факт, что данный
термин используется для обозначения
организации данных во внешней памяти, которую поддерживают и используют операционные системы. Файловая модель была
первой моделью, используемой при разработке информационных систем[1].
Точнее модель, как таковая, отсутствовала. Можно сказать, что файловая модель – это модель без СУБД.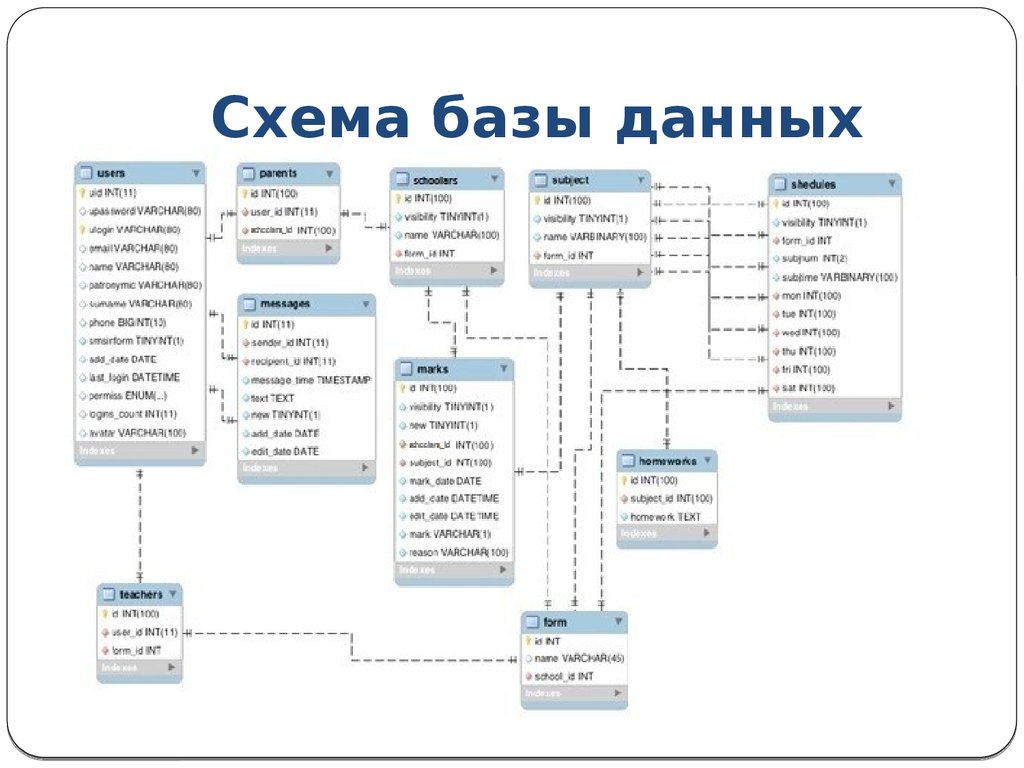
· Структуру базы данных приходилось разрабатывать каждый раз при разработке информационной системы, что требовало определенных усилий и времени.
·
Поскольку алгоритм управления такой базой данных
был полностью заложен в программном обеспечении информационной системы, то при
необходимости изменить структуру данных каждый раз приходилось вносить
изменения и в программное обеспечение.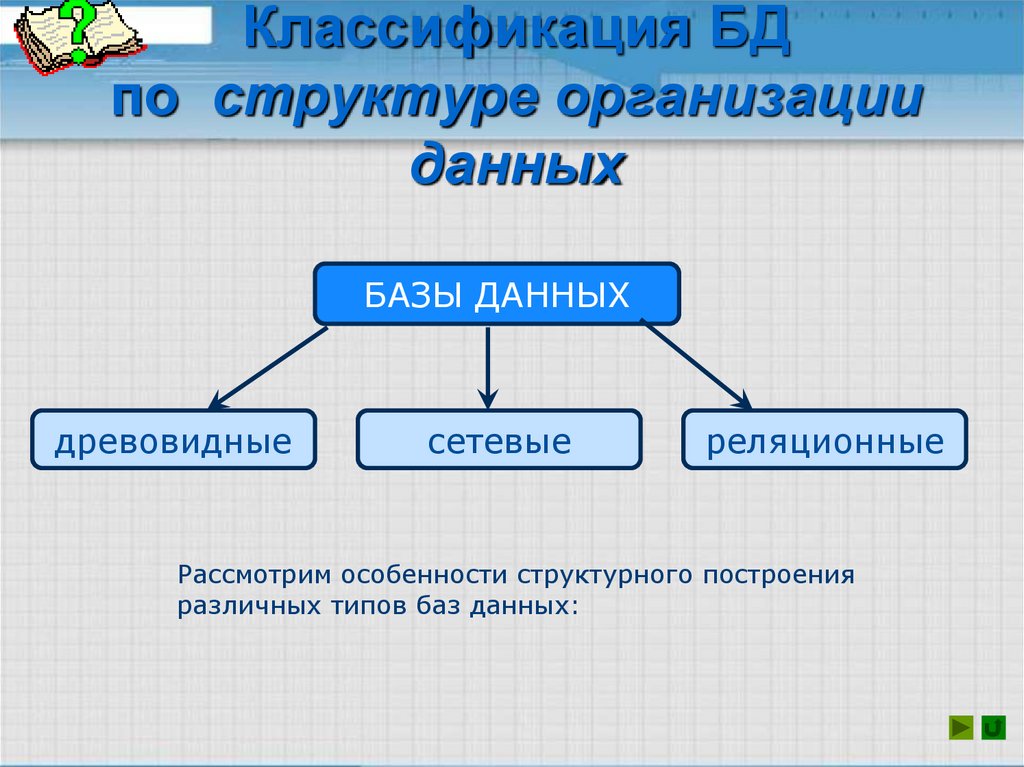
· Часто даже в одной фирме создавалось несколько информационных систем (для каждого отдела, а зачастую для каждого рода деятельности), каждая из которых оперировала своими структурами данных. Бесконечной головной болью был перенос данных из одной ИС в другую, ведь структуры данных еще и периодически менялись. Так что часть программистов непрерывно писали программы преобразования данных из одного формата в другой.
·
Децентрализованное хранение приводила к тому, что в различных отделах приходилась
дублировать одни и те же данные. Что,
во-первых, требовало дополнительных ресурсов (времени и денег), а во-вторых,
хранение дополнительных данных требовало и дополнительной внешней памяти.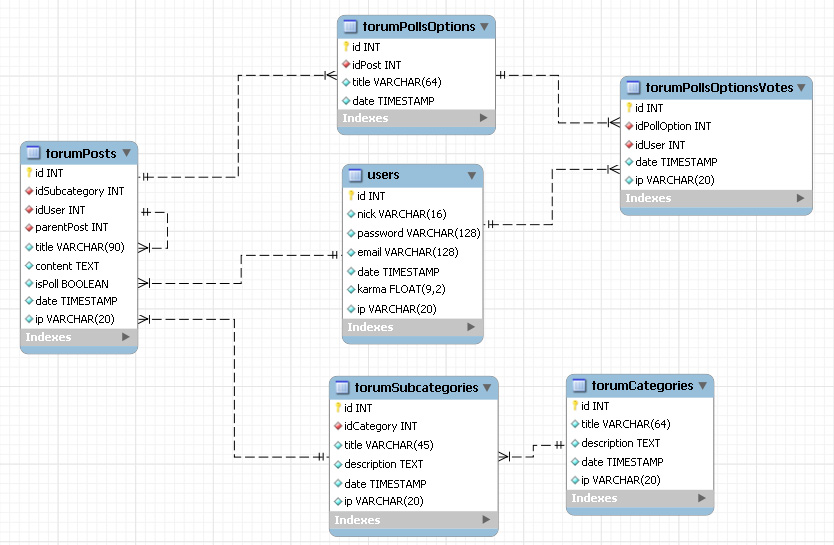 Но
головная боль начиналась тогда, когда нарушалась согласованность данных об
одном и том объекте, но из разных информационных систем. Для обнаружения и
исправления таких ошибок требовались большие усилия.
Но
головная боль начиналась тогда, когда нарушалась согласованность данных об
одном и том объекте, но из разных информационных систем. Для обнаружения и
исправления таких ошибок требовались большие усилия.
· Работа того или иного отдела требовала все новых и новых форм отчетности. Но для каждого нового отчета приходилось писать программный код, что увеличивало дополнительную нагрузку программистов. При этом, опять же после изменения структуры данных, все процедуры формирования отчетов приходилось снова переписывать.
· Разные фирмы часто пользовались различными языками программирования, отличающимися друг от друга структурой создаваемых ими файлов. Возникали, т.о. дополнительные сложности совместимости форматов файлов.
Замечание
Строго говоря, файловая модель данных нельзя назвать моделью в
полном смысле этого слова, так как здесь мы четко видим зависимость описания
данных от таких факторов, как файловая система и программное обеспечение.
Сетевая модель
Сетевая модель относится к ранним моделям данных. Сейчас информации об этой модели данных почти не встретишь, даже такой специалист как К. Дейт при переиздании своей классической книги «Введение в системы баз данных» исключил вопросы, касающиеся сетевой и иерархической модели данных (см. [8] и [15]). Впрочем, в последнее время снова заговорили о сетевой модели в связи с распределенными информационными системами, а также с развитием объектных моделей данных.
В 1971 группа DTBG (Database Task Group) представила в американский национальный институт стандартов отчет, который послужил в дальнейшем основой для разработки сетевых систем управления базами данных. Стандарт сетевой модели впервые был определен в 1975 году организацией CODASYL (Conference of Data System Languages), которая определила базовые понятия модели и формальный язык описания.
Сетевая модель данных опирается на математическую теорию
направленных графов. Базовыми элементами сетевой модели являются:
Базовыми элементами сетевой модели являются:
· Элемент данных – минимальная информационная единица доступная пользователю.
· Агрегат данных – именованная совокупность элементов данных внутри записи или другого агрегата. Агрегат бывает двух видов – агрегат типа вектор и агрегат типа повторяющаяся группа. Например, агрегат <город, улица, дом, квартира>, которому можно присвоить имя Адрес, является агрегатом типа вектор. Примером, агрегата типа повторяющаяся группа может служить агрегат <месяц, сумма> с названием Зарплата. Агрегат повторяющаяся группа характеризуется числом повторений. В данном примере это число повторений равно 12.
·
Запись — совокупность агрегатов или элементов
данных, отражающих некоторую сущность предметной области. Например, записью
будет <Фамилия, Зарплата>, где Фамилия – это элемент данных, а Зарплата –
агрегат.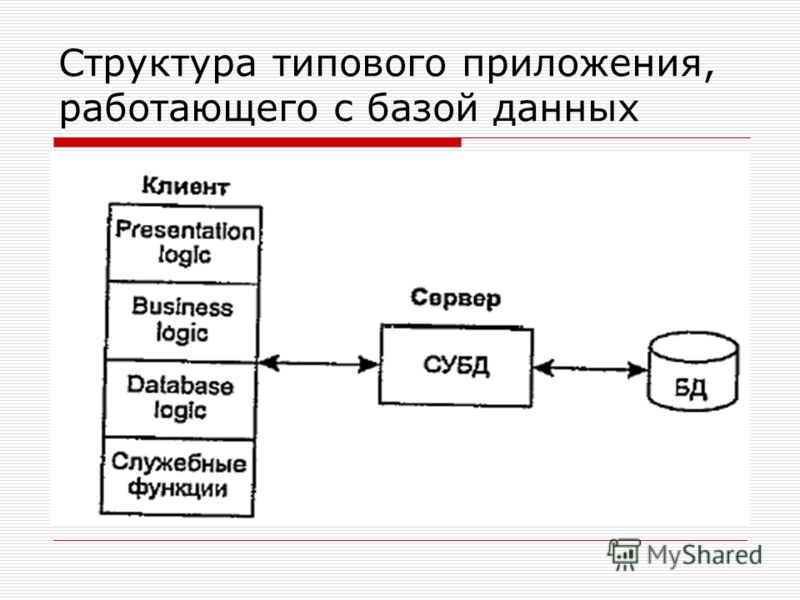 Данную запись можно назвать Зарплата сотрудника.
Данную запись можно назвать Зарплата сотрудника.
· Тип записей – эта совокупность подобных записей. Например, в предыдущем случае типом записи будет совокупность всех записей Зарплата сотрудника, выражающая множество сотрудников некоторого отдела. Тип записей представляет (моделирует) некоторый класс реального мира.
·
Набор —
именованная двухуровневая иерархическая
структура, которая содержит запись владельца и запись (или записи) членов.
Наборы отражают связи «один ко многим» и «один к одному» между двумя типами
записей. На рисунке 2.5 представлен
пример набора. Здесь Отдел – запись–владелец, сотрудник — запись-член. Тип набора определяет связь между двумя
типами записей. Каждый экземпляр типа
набора содержит один экземпляр записи владельца и произвольное количество
записей-членов (для связи типа «один ко многим»). Обратите внимание, как на рисунке 2. 5 обозначается связь «один ко
многим». Разветвление на конце указывает
на множество экземпляров некоторого
объекта. Такой способ обозначения связей мы будем использовать и далее. Среди всех наборов в сетевой модели допускается существование
наборов, не имеющих владельцев. Такие наборы называются сингулярными. Владельцами
сингулярных наборов формально считается система. Сингулярные наборы
предназначены для доступа к экземплярам отдельных записей.
5 обозначается связь «один ко
многим». Разветвление на конце указывает
на множество экземпляров некоторого
объекта. Такой способ обозначения связей мы будем использовать и далее. Среди всех наборов в сетевой модели допускается существование
наборов, не имеющих владельцев. Такие наборы называются сингулярными. Владельцами
сингулярных наборов формально считается система. Сингулярные наборы
предназначены для доступа к экземплярам отдельных записей.
Рис. 2.5. Набор в сетевой модели данных
Резюмируя выше сказанное, будем говорить, что структура базы данных в сетевой модели задается типами записей и типами наборов.
Отметим некоторые особенности построения сетевой модели.
· База данных может состоять из произвольного количества записей и наборов различных типов.
· Связь между двумя записями может выражаться произвольным количеством наборов.
·
В любом наборе может быть только один владелец.
· Тип записи может быть владельцем в одних типах наборов и членом в других типах наборов.
· Тип записи может не входить ни в какой тип наборов.
Для управления сетевой базой данных используется специальный язык, который можно разбить на следующие разделы.
· Язык описания данных в сетевой модели.
o Описание базы данных (размещение).
o Описание элементов, агрегатов и записей.
o Описание наборов.
· Язык манипулирования данными.
o Навигационные операции. С помощью операций навигации (группа операций FIND) двигаясь по связям можно переходить от одной текущей записи к другой. Соответственно операции модификации осуществляются над текущей записью.
o Операции модификации. Операции модификации осуществляют:
§ Добавление новых экземпляров отдельных типов записей.
§
Экземпляров новых наборов.
§ Удаление экземпляров записей и наборов.
§ Модификацию отдельных составляющих внутри конкретных экземпляров записей.
Иерархическая модель.
Исторически иерархическая модель появилась раньше сетевой. Она наиболее проста из всех моделей данных. Самой известной иерархической системой позволяющей создавать иерархические базы данных является система IMS (Information Management System) фирмы IBM, используемая в свое время для поддержки лунного проекта «Аполлон». Появление иерархической модели связано с тем, что в реальном мире очень многие связи соответствуют иерархии, когда один объект выступает как родительский, а с ним может быть связано множество подчиненных объектов.
Основными информационными единицами в иерархической модели
являются: база данных (БД), сегмент[2] и поле. Поле
данных определяется как минимальная, неделимая единица данных, доступная
пользователю с помощью СУБД. Выделяют также тип
поля, представляющий собой совокупность полей одного типа. Сегмент состоит
из конкретных экземпляров полей. Тип
сегмента — совокупность
входящих в него типов полей.
Иерархическая модель представляет собой неориентированный граф, в
вершинах которого располагаются сегменты (или типы сегмента). Дуги, соединяющие
узлы, представляют собой связи или типы связей. Особенностью такой модели
является то, что каждый сегмент может иметь не более одного предка, произвольное количество потомков и, по
крайней мере, одно поле. Сегмент, который не имеет потомков, называют листовым сегментом. Иерархическое дерево начинается с одного
сегмента, называемого корневым сегментом.
Очень важно, что каждый сегмент должен иметь свое уникальное имя или идентификатор.
Выделяют также тип
поля, представляющий собой совокупность полей одного типа. Сегмент состоит
из конкретных экземпляров полей. Тип
сегмента — совокупность
входящих в него типов полей.
Иерархическая модель представляет собой неориентированный граф, в
вершинах которого располагаются сегменты (или типы сегмента). Дуги, соединяющие
узлы, представляют собой связи или типы связей. Особенностью такой модели
является то, что каждый сегмент может иметь не более одного предка, произвольное количество потомков и, по
крайней мере, одно поле. Сегмент, который не имеет потомков, называют листовым сегментом. Иерархическое дерево начинается с одного
сегмента, называемого корневым сегментом.
Очень важно, что каждый сегмент должен иметь свое уникальное имя или идентификатор.
На рисунке 2.6
схематически представлена иерархическая структура. Узлы (сегменты) соединены
друг с другом связующими дугами.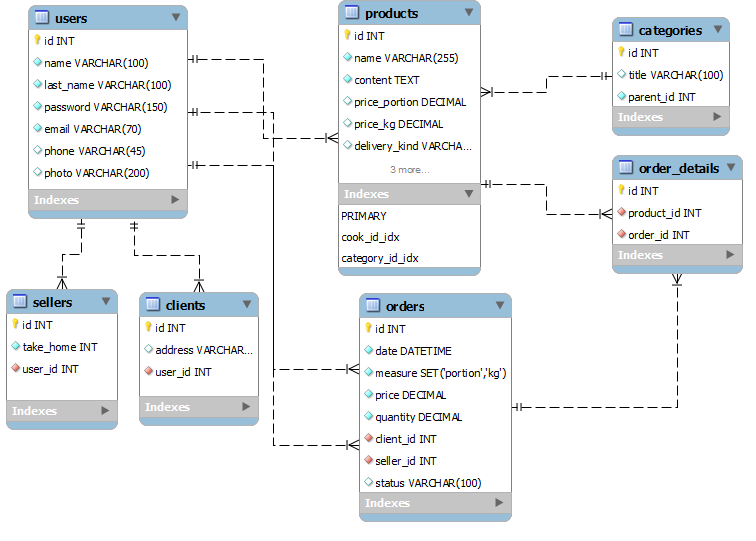 Сегмент A
является корневым сегментом. Сегменты B, E, H, J, I
являются листовыми сегментами. Каждый сегмент, при этом, может содержать
произвольное количество полей.
Сегмент A
является корневым сегментом. Сегменты B, E, H, J, I
являются листовыми сегментами. Каждый сегмент, при этом, может содержать
произвольное количество полей.
Для иерархической модели данных выделяют два языковых средства: язык описания данных и язык модификации данных. Описание базы данных предполагает описание всех ее сегментов и установление связей между ними.
Рис. 2.6. Иерархическая структура
Иерархическая модель довольно удобна для представления
предметных областей, так как иерархические отношения довольно часто встречаются
между сущностями реального мира. Но иерархическая модель не поддерживает
отношения «многие ко многим», когда множество объектов одного типа связаны с
множеством объектов другого типа. Предположим, что требуется построить модель
отношения между множеством собственников жилья и множеством квартир. Если
основной вопрос будет заключаться в определении того, каким жильем владеет тот
или иной собственник, то естественно взять в качестве родительских узлов данные о собственнике. При этом каждый
сегмент — собственник будет связан с N узлами – квартирами. Таким
образом, по собственнику мы легко найдем все квартиры, которые находятся в его
собственности. Однако проблема заключается в том, что у одной и той же квартиры
может быть несколько собственников. Т.е. одна и та же квартира может встречаться
в разных деревьях. В результате решения таких задач, как получение списка всех
квартир, или получения всех собственников конкретной квартиры, будут уже не столь очевидными. Кроме того, сложной выглядит даже операция
удаления из базы конкретной квартиры, поскольку для этого придется
просматривать все деревья. Можно, конечно, построить параллельно деревья, в
которых родительскими сегментами будут
данные о квартирах, а порождаемыми сегментами – данные о владельцах, но в
результате мы получим еще
избыточность данных, что породит
дополнительную проблему их согласованности.
При этом каждый
сегмент — собственник будет связан с N узлами – квартирами. Таким
образом, по собственнику мы легко найдем все квартиры, которые находятся в его
собственности. Однако проблема заключается в том, что у одной и той же квартиры
может быть несколько собственников. Т.е. одна и та же квартира может встречаться
в разных деревьях. В результате решения таких задач, как получение списка всех
квартир, или получения всех собственников конкретной квартиры, будут уже не столь очевидными. Кроме того, сложной выглядит даже операция
удаления из базы конкретной квартиры, поскольку для этого придется
просматривать все деревья. Можно, конечно, построить параллельно деревья, в
которых родительскими сегментами будут
данные о квартирах, а порождаемыми сегментами – данные о владельцах, но в
результате мы получим еще
избыточность данных, что породит
дополнительную проблему их согласованности.
Основной единицей обработки в иерархической модели
является сегмент. К сегментам могут применяться такие операции как запомнить,
модифицировать, удалить, извлечь, найти. Операция поиска сводится к одной из
возможных процедур обхода дерева. Иерархические СУБД поддерживают, обычно,
правило: никакой сегмент не может существовать без своего родителя (исключая
корневой сегмент). Подобные правила, поддерживаемые СУБД, называют
ограничениями целостности.
К сегментам могут применяться такие операции как запомнить,
модифицировать, удалить, извлечь, найти. Операция поиска сводится к одной из
возможных процедур обхода дерева. Иерархические СУБД поддерживают, обычно,
правило: никакой сегмент не может существовать без своего родителя (исключая
корневой сегмент). Подобные правила, поддерживаемые СУБД, называют
ограничениями целостности.
В качестве примера реально работающей иерархической модели данных можно привести устройство реестра, поддерживаемое операционными системами семейства Windows.
Реляционная модель.
Основателем реляционной модели данных является сотрудник фирмы IBM Э.Ф.
Кодд. В статье «A Relation Model of Data for Large Shared Data Banks», которая вышла в 1970
году, он показал, что любое представление данных может быть сведено к
совокупности двумерных таблиц, которые в математике называются отношениями (relations, отсюда термин «реляционный»). Мы подробно рассмотрим
реляционную модель данных в разделе «Основы теории реляционных баз данных»
текущей главы.
Объектная и объектно-реляционная модели.
Объектные СУБД призваны интегрировать свойства баз данных и объектных языков программирования. В 1993 году был принять стандарт объектных баз данных ODMG-93 (ODMG это Object Database Management Group – группа управления объектными базами данных, образована в 1991 году). В последнее время ведущие производители реляционных СУБД ради повышения конкурентоспособности своих продуктов пытаются внести в них элементы объектного проектирования.
Логическая структура реляционной базы данных
Логическая структура реляционной базы данных Access является адекватным отображением полученной информационно-логической модели предметной области. Для канонической модели не требуется дополнительных преобразований. Каждый информационный объект модели данных отображается соответствующей реляционной таблицей. Структура реляционной таблицы определяется реквизитным составом соответствующего информационного объекта, где каждый столбец (поле) соответствует одному из реквизитов объекта. Ключевые реквизиты объекта образуют уникальный ключ реляционной таблицы. Для каждого столбца таблицы (поля) задается тип, размер данных и другие свойства. Строки (записи) таблицы соответствуют экземплярам объекта и формируются при загрузке таблицы.
Ключевые реквизиты объекта образуют уникальный ключ реляционной таблицы. Для каждого столбца таблицы (поля) задается тип, размер данных и другие свойства. Строки (записи) таблицы соответствуют экземплярам объекта и формируются при загрузке таблицы.
Связи между объектами модели данных реализуются одинаковыми реквизитами — ключами связи в соответствующих таблицах. При этом ключом связи типа 1 : M всегда является уникальный ключ главной таблицы. Ключом связи в подчиненной таблице является либо некоторая часть уникального ключа в ней, либо поле, не входящее в состав первичного ключа (например, код фирмы в таблице СКЛАД). Ключ связи в подчиненной таблице называется внешним ключом.
Все связи в полученной информационно-логической модели предметной области «Поставка товара» характеризуются отношением типа 1 : M. Соответственно, связь между таблицами ПОКУПАТЕЛЬ и ДОГОВОР осуществляется по коду покупателя (КОД_ПОК), который является уникальным идентификатором главного объекта ПОКУПАТЕЛЬ и неключевым в объекте ДОГОВОР (см.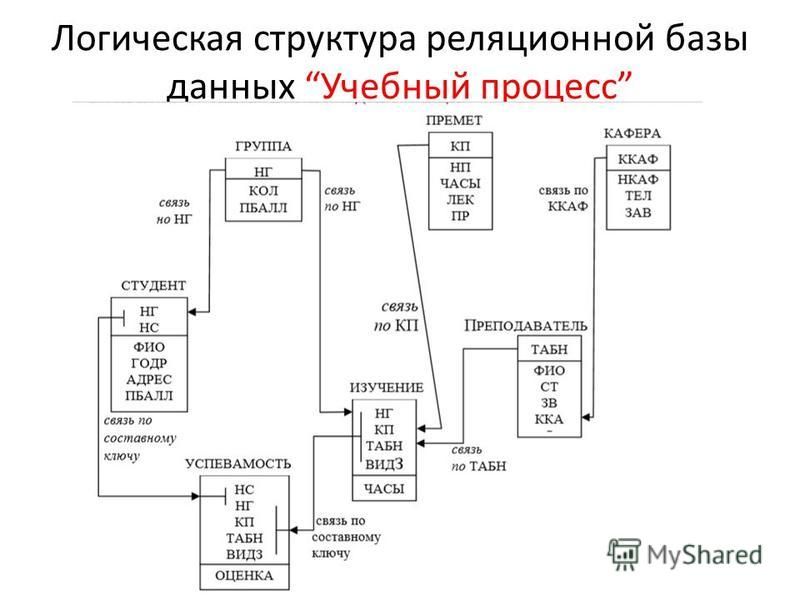 табл. 2.6).
табл. 2.6).
Связь между таблицами ТОВАР и ПОСТАВКА_ПЛАН осуществляется по уникальному ключу главного объекта ТОВАР — Коду товара, который в подчиненном объекте ПОСТАВКА_ПЛАН является частью ключа (см. табл. 2.6). Аналогично связь между таблицами ТОВАР и ОТГРУЗКА осуществляется по уникальному ключу главного объекта ТОВАР — Коду товара.
Связь между таблицами ДОГОВОР и НАКЛАДНАЯ осуществляется по уникальному ключу главного объекта ДОГОВОР — Номеру договора (НОМ_ДОГ), который в подчиненном объекте НАКЛАДНАЯ не входит в состав ключа (см. табл. 2.7).
Связь между таблицами ДОГОВОР и ПОСТАВКА_ПЛАН осуществляется по уникальному ключу главного объекта ДОГОВОР — Номеру договора (НОМ_ДОГ), который в подчиненном объекте ПОСТАВКА_ПЛАН является частью ключа (см. табл. 2.6). Аналогично связь между таблицами НАКЛАДНАЯ и ОТГРУЗКА осуществляется по уникальному составному ключу главного объекта НАКЛАДНАЯ — НОМ_НАКЛ + + КОД_СК, который в подчиненном объекте ОТГРУЗКА является частью ключа (см. табл. 2.7).
табл. 2.7).
В Access может быть создана схема данных, наглядно отображающая логическую структуру базы данных. Определение одно-многозначных связей в этой схеме должно осуществляться в соответствии с построенной моделью данных. Топология проекта схемы данных практически совпадает с топологией информационно-логической модели. Для модели данных предметной области (см. рис. 2.18), построенной в рассмотренном примере, логическая структура базы данных в виде схемы данных Access приведена на рис. 2.19.
На этой схеме прямоугольники отображают таблицы базы данных с полным списком их полей, а связи показывают, по каким полям осуществляется взаимосвязь таблиц. Имена ключевых полей для наглядности выделены и находятся в верхней части полного списка полей каждой таблицы.
Что такое схема базы данных
PINGDOM_CANARY_STRING
Какая схема базы данных вам нужна?
Я новичок в диаграммах баз данных и хочу узнать больше.
Я хочу создать собственную диаграмму базы данных в Lucidchart.
Я хочу создать диаграмму базы данных из шаблона Lucidchart.
Термин «схема базы данных» может относиться к визуальному представлению базы данных, набору правил, управляющих базой данных, или ко всему набору объектов, принадлежащих конкретному пользователю. Читайте дальше, чтобы узнать больше о схемах баз данных и о том, как они используются.
4 минуты чтения
Хотите создать собственную диаграмму базы данных? Попробуйте Люсидчарт. Это быстро, просто и совершенно бесплатно.
Сделать схему базы данных
Что такое схема базы данных?
Схема базы данных представляет собой логическую конфигурацию всей или части реляционной базы данных. Он может существовать как в визуальном представлении, так и в виде набора формул, известных как ограничения целостности, которые управляют базой данных. Эти формулы выражаются на языке определения данных, таком как SQL. Являясь частью словаря данных, схема базы данных указывает, как сущности, составляющие базу данных, связаны друг с другом, включая таблицы, представления, хранимые процедуры и т. д.
Эти формулы выражаются на языке определения данных, таком как SQL. Являясь частью словаря данных, схема базы данных указывает, как сущности, составляющие базу данных, связаны друг с другом, включая таблицы, представления, хранимые процедуры и т. д.
Обычно разработчик базы данных создает схему базы данных, чтобы помочь программистам, чье программное обеспечение будет взаимодействовать с базой данных. Процесс создания схемы базы данных называется моделированием данных. При следовании трехсхемному подходу к проектированию базы данных этот шаг будет следовать за созданием концептуальной схемы. Концептуальные схемы фокусируются на информационных потребностях организации, а не на структуре базы данных.
Существует два основных типа схемы базы данных:
- Логическая схема базы данных передает логические ограничения, применимые к хранимым данным. Он может определять ограничения целостности, представления и таблицы.
- Физическая схема базы данных показывает, как данные физически хранятся в системе хранения с точки зрения файлов и индексов.

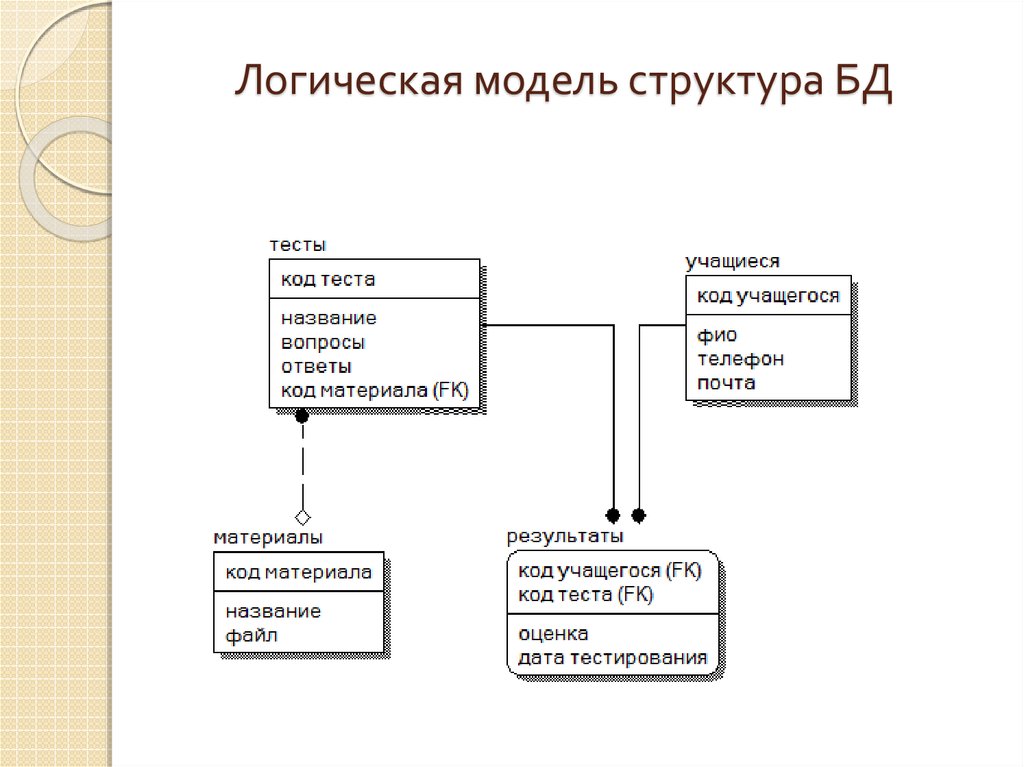
На самом базовом уровне схема базы данных указывает, какие таблицы или отношения составляют базу данных, а также поля, включенные в каждую таблицу. Таким образом, термины схемы схемы и диаграммы сущность-связь часто взаимозаменяемы.
Схема в системе базы данных Oracle
В системе базы данных Oracle термин схема базы данных , также известный как «схема SQL», имеет другое значение. Здесь база данных может иметь несколько схем (или «схем», если вам так хочется). Каждый из них содержит все объекты, созданные конкретным пользователем базы данных. Эти объекты могут включать таблицы, представления, синонимы и многое другое. Некоторые объекты не могут быть включены в схему, например пользователи, контексты, роли и объекты каталогов.
Пользователям может быть предоставлен доступ для входа в отдельные схемы в каждом конкретном случае, а право собственности может передаваться.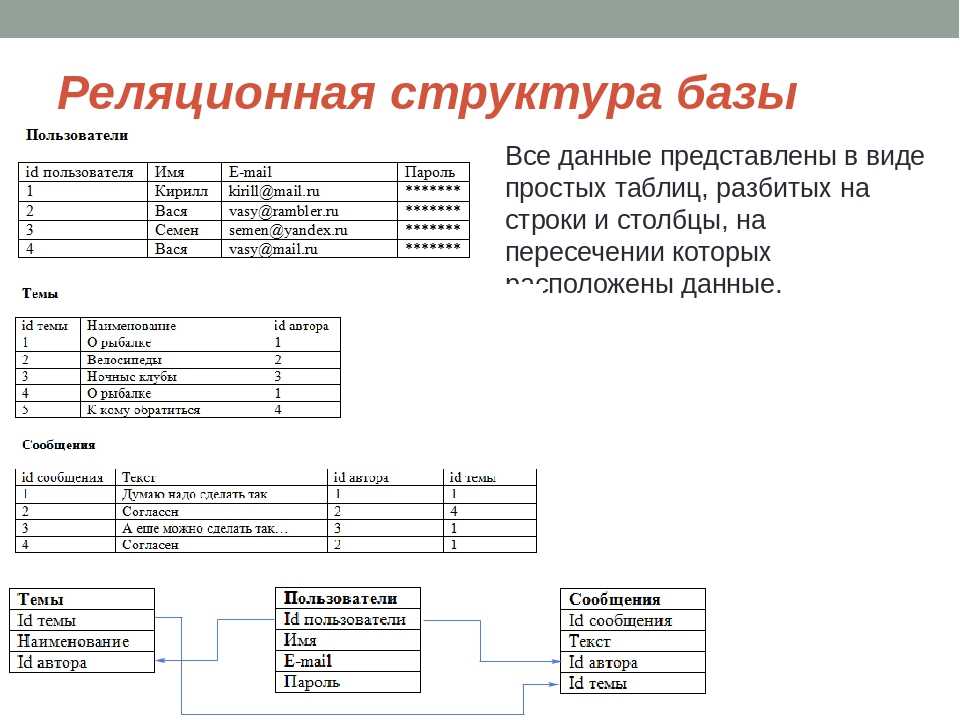 Поскольку каждый объект связан с определенной схемой, которая служит своего рода пространством имен, полезно дать несколько синонимов, которые позволяют другим пользователям получать доступ к этому объекту, не обращаясь сначала к схеме, к которой он принадлежит.
Поскольку каждый объект связан с определенной схемой, которая служит своего рода пространством имен, полезно дать несколько синонимов, которые позволяют другим пользователям получать доступ к этому объекту, не обращаясь сначала к схеме, к которой он принадлежит.
Эти схемы не обязательно указывают способы физического хранения файлов данных. Вместо этого объекты схемы логически хранятся в табличном пространстве. Администратор базы данных может указать, сколько места будет отведено конкретному объекту в файле данных.
Наконец, схемы и табличные пространства не обязательно идеально совпадают: объекты из одной схемы можно найти в нескольких табличных пространствах, а табличное пространство может включать объекты из нескольких схем.
С Lucidchart можно быстро и легко строить диаграммы. Начните бесплатную пробную версию сегодня, чтобы начать создавать и сотрудничать.
Создать диаграмму базы данных
Экземпляр базы данных или схему базы данных?
Эти термины, хотя и связаны между собой, не означают одно и то же. Схема базы данных — это эскиз планируемой базы данных. На самом деле в нем нет никаких данных.
Схема базы данных — это эскиз планируемой базы данных. На самом деле в нем нет никаких данных.
Экземпляр базы данных, с другой стороны, является моментальным снимком базы данных, существовавшей в определенное время. Таким образом, экземпляры базы данных могут меняться со временем, в то время как схема базы данных обычно статична, так как сложно изменить структуру базы данных после того, как она начнет работать.
Схемы баз данных и экземпляры баз данных могут влиять друг на друга через систему управления базами данных (СУБД). СУБД гарантирует, что каждый экземпляр базы данных соответствует ограничениям, наложенным разработчиками базы данных в схему базы данных.
Требования к интеграции схемы
Может оказаться полезным интегрировать несколько источников в одну схему. Убедитесь, что соблюдены следующие требования для плавного перехода:
Сохранение перекрытий
Каждый перекрывающийся элемент в схемах, которые вы интегрируете, должен находиться в таблице схемы базы данных.
Расширенное сохранение перекрытия
Элементы, которые появляются только в одном источнике, но связаны с перекрывающимися элементами, должны быть скопированы в результирующую схему базы данных.
Нормализация
Независимые отношения и объекты не должны быть объединены в одной таблице в схеме базы данных.
Минимальность
Идеально, если ни один из элементов ни в одном из источников не потерян.
Типы схемы базы данных
При разработке схемы базы данных были разработаны определенные шаблоны.
Широко используемая схема «звезда» также является самой простой. В нем одна или несколько таблиц фактов связаны с любым количеством таблиц измерений. Лучше всего подходит для обработки простых запросов.
Связанная схема снежинки также используется для представления многомерной базы данных. Однако в этом шаблоне размеры нормализуются во множество отдельных таблиц, создавая эффект расширения структуры, похожей на снежинку.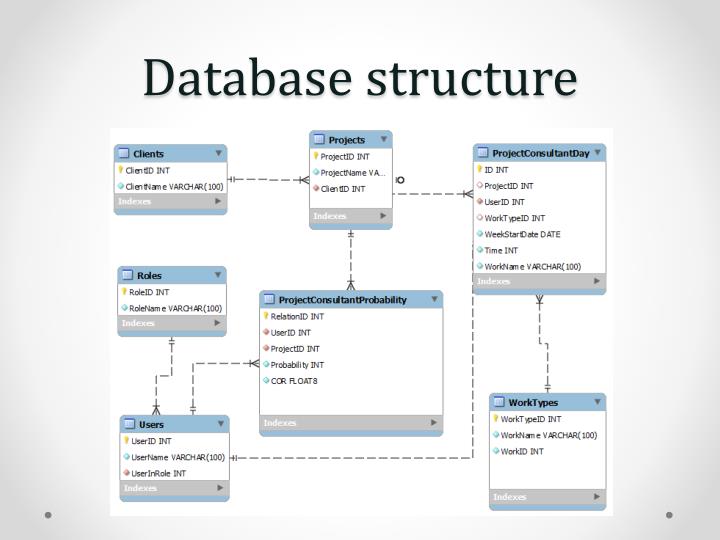
Полезные ресурсы
- Что такое модель базы данных? . Лучше всего то, что вы можете импортировать и экспортировать из SQL по мере необходимости. Начните бесплатную пробную версию сегодня!
Хотите создать собственную схему базы данных? Попробуйте Люсидчарт. Это быстро, просто и совершенно бесплатно.
Создайте диаграмму базы данных
6 Примеры схемы базы данных и способы их использования
Мы знаем, что при построении базы данных требуется много размышлений. Перед созданием любой базы данных разработчики тратят время на планирование того, что она будет включать и как все будет работать вместе. Этот этап планирования имеет решающее значение, поскольку он помогает убедиться, что структура базы данных соответствует предполагаемому использованию.
Вот несколько вариантов использования 6 самых популярных схем:
- Плоская модель: лучшая модель для небольших простых приложений.
- Иерархическая модель: для вложенных данных, таких как XML или JSON.
- Сетевая модель: полезна для картографирования и пространственных данных, а также для отображения рабочих процессов.
- Реляционная модель: лучше всего отражает приложения объектно-ориентированного программирования.
- Модель звезды: для анализа больших одномерных наборов данных. Модель
- Snowflake: для анализа больших и сложных наборов данных.
Схемы баз данных — это чертежи, которые помогают разработчикам визуализировать, как должны создаваться базы данных. Они обеспечивают контрольную точку, указывающую, какие поля информации содержит проект. Если при создании базы данных возникают какие-либо проблемы или путаница, разработчики могут просто обратиться к схеме, и в ней должны быть ответы на все вопросы.
Администраторы данных также используют схемы для решения потенциальных проблем задолго до внедрения. Это экономит драгоценное время и деньги, потому что после внедрения базы данных внесение изменений может быть затруднено.
При выборе схемы все заинтересованные стороны должны полностью учитывать каждый аспект проекта, чтобы снизить вероятность того, что в дальнейшем потребуются серьезные изменения.В этом руководстве мы разберем шесть самых популярных примеров схемы базы данных и обсудим соображения и варианты использования каждого из них.
Содержание
- Почему важен выбор правильной схемы?
- Плоская модель
- Иерархическая модель
- Сетевая модель
- Реляционная модель
- Звездная схема
- Схема снежинки
- Оптимизируйте управление данными с помощью Integrate.io \
Единый стек для современных групп данных
Получите персонализированную демонстрацию платформы и 30-минутную сессию вопросов и ответов с инженером по решениям
Почему так важен выбор правильной схемы?
Выбор неправильной схемы базы данных для проекта может привести к возникновению узких мест в приложении и дорогостоящему рефакторингу.
Например, если вы заранее не поняли, что ваше приложение будет полагаться на несколько JOIN таблиц, ваша служба в конечном итоге остановится, когда вы достигнете определенного количества пользователей и данных.Чтобы решить эту проблему, данные, скорее всего, придется переместить в новые таблицы, код должен будет указать на эти новые таблицы, а затем для этих таблиц потребуются соответствующие соединения. Это означает, что вам потребуется мощная тестовая среда (база данных и исходный код ) для проверки ваших изменений, план управления целостностью данных и план одновременного обновления базы данных и исходного кода .
Как только вы начнете миграцию базы данных на новую схему, пути назад уже почти не будет. Выбор правильной схемы базы данных на первом этапе может избавить от многих страданий и душевных страданий на протяжении всего жизненного цикла программного проекта.
Плоская модель
Структура базы данных плоской модели представляет собой единый двумерный массив, в котором элементы в каждом столбце представляют собой данные одного типа, а элементы в одной строке связаны друг с другом.
Думайте об этом как об одной несвязанной таблице базы данных, такой как электронная таблица Excel. Если вы управляете небольшим бизнесом с несколькими сотрудниками и хотите хранить только информацию об их зарплатах, то одной плоской модели данных будет достаточно. Эта модель соответствует принципу KISS.
Иерархическая модель
Иерархические схемы базы данных имеют древовидную структуру с «корневым» узлом данных и дочерними узлами, отходящими от этого корня. Между родительским и дочерним узлами существует связь «один ко многим». Этот тип схемы данных лучше всего отражается в файлах XML или JSON, где объект может иметь вложенные объекты, которые не используются совместно с другими объектами.
Иерархическая структура базы данных отлично подходит для хранения вложенных данных, таких как изучение таксономии.
Сетевая модель
Сетевая модель похожа на иерархическую модель тем, что представляет ряд узлов и вершин; однако, в отличие от иерархической модели, она допускает отношения «многие ко многим».
С теоретической точки зрения это означает, что граф может иметь циклы. Цикл на графе указывает, что существует путь вершин, в котором вы можете начать и закончить в одном и том же узле.Миллиарды долларов зависят от способности компании эффективно перемещать свои товары из пункта А в пункт Б, поэтому крайне важно глубокое понимание того, как применять сетевую модель. Большинству приложений, которым требуются пространственные вычисления, скорее всего, будет полезно хранить данные в базе данных, смоделированной по сети. ГИС (Географические информационные системы) — это программное обеспечение, позволяющее пользователям эффективно хранить и анализировать картографические данные.
Сетевая модель также полезна при изображении рабочих процессов, особенно при наличии нескольких путей к одному и тому же результату. Возьмем, к примеру, сеть ресторанов, где типичный рабочий процесс — это сервер, говорящий повару, что приготовить. Повар взбивает каждое блюдо в билете и объявляет: «Заказывайте!» Затем официант возьмет тарелку и проведет окончательную проверку качества, чтобы убедиться, что это то, о чем просил посетитель.
В этом сценарии существует связь «многие ко многим» между едой и различными категориями сотрудников. Таким образом, этот рабочий процесс лучше всего структурировать с использованием структуры сетевой базы данных.Реляционная модель
Введение модели реляционной базы данных открыло новую эру обработки данных. Интересно, что у изобретателя реляционной базы данных Эдгара Кодда из IBM в 1970-х годах было другое определение того, что означает «реляционная».
Однако за десятилетия использования сообщество программистов пришло к более универсальному пониманию того, что такое реляционная база данных. То есть мы храним данные в виде отношений (т. е. таблиц), и есть реляционные операторы, которые мы выполняем над данными, чтобы манипулировать ими и вычислять из них.
Имея это в виду, реляционные базы данных лучше всего рассматривать как ряд сущностей, некоторые из которых определенным образом связаны друг с другом. Важно рассматривать каждую сущность как отдельную.
Если вы создаете часть программного обеспечения, которое следует подходу объектно-ориентированного программирования, было бы лучше хранить данные каждого объекта в виде отдельной таблицы с базой данных.Вот хороший пример схемы реляционной базы данных: если вы программируете автомобиль, у вас может быть объект для шин, осей, двигателя, сидений, краски и т. д. Шины прикрепляются к осям, которые вращаются из-за двигателя. , и так далее. Представление каждого из этих объектов в виде отдельной таблицы со связью между соответствующими объектами (шина и ось, ось и двигатель и т. д.) было бы оптимальным способом аккуратного хранения данных и понимания того, как работает автомобиль.
Люди используют системы управления реляционными базами данных для управления своими реляционными базами данных. Прочтите наше подробное погружение в СУБД здесь.
Схема звезды
Когда вы визуализируете пример схемы базы данных звезды, все становится немного интереснее. Схема «звезда» — это другой способ организации данных.
Это один из лучших примеров проектирования баз данных при хранении и анализе огромных объемов данных. Одна из причин, по которой схема «звезда» сияет, заключается в том, что она опирается на использование «фактов» и «измерений».«Факт» — это числовая точка данных, управляющая бизнес-процессами, а «измерение» — это описание этого факта. Например, при использовании данных о продажах автомобилей таблица «фактов» будет содержать информацию о количестве проданных единиц, а соответствующая таблица «размеров» будет содержать цвета этих автомобилей.
Преимущество звездообразных схем в том, что они являются просто абстракциями над традиционными реляционными базами данных. То есть, если у вас есть РСУБД, вы можете использовать ее для структурирования данных в структуру базы данных по схеме «звезда».
Связанное чтение: Схемы-снежинки против схем-звезд Его название происходит от того, как можно изобразить диаграмму отношения объектов (ERD) схемы снежинки: как вы уже догадались, она начинает выглядеть как снежинка.
Как и схема «звезда», схема «снежинка» имеет центральную таблицу фактов, в которой хранятся основные точки данных и ссылки на таблицы измерений. В отличие от схемы «звезда», таблицы измерений схемы «снежинка» могут иметь свои собственные таблицы измерений, что расширяет возможности описательного измерения.
Используя наш пример схемы базы данных автомобилей, предположим, что отдел эксплуатации должен спрогнозировать, какие ресурсы им потребуются для сборки их автомобилей. Как и отдел продаж, они хотят знать, какие автомобили были проданы и сколько.
В приведенном выше примере схемы базы данных у нас была размерная таблица, указывающая цвет проданных автомобилей. Операционный отдел может захотеть узнать больше о краске, кроме цвета: торговая марка, стоимость, количество слоев и так далее. В этом сценарии схема снежинки была бы полезна, потому что таблица размеров цвета требует своих собственных таблиц размеров (марка краски, стоимость, количество слоев и т. д.).
Оптимизируйте управление данными с помощью Integrate.io
В конечном счете, вы можете выбрать любой из этих примеров проектирования базы данных для структурирования своей новой базы данных, но крайне важно, чтобы вы делали это с умом. Если вы начинаете с нуля, найдите время, чтобы сесть с ключевыми заинтересованными сторонами и оценить размер и сложность вашей базы данных. Также подумайте о типе информации, которую вы будете хранить, и наметьте отношения всех этих точек данных задолго до того, как кто-либо погрузится в код.
Хотя поначалу этап планирования может показаться слишком трудоемким, в долгосрочной перспективе он сэкономит вам бесчисленные часы переделок и приведет вас к мощной и надежной схеме базы данных, на которую ваш бизнес сможет рассчитывать долгие годы.
Когда вы планируете новую структуру базы данных, это также отличная возможность посмотреть, как ваши данные хранятся, перемещаются и используются. Если вам нужна помощь в построении конвейера интеграции данных без кода, способного обрабатывать даже самые сложные и массивные наборы данных, не ищите ничего, кроме Integrate.
- Плоская модель: лучшая модель для небольших простых приложений.

 При выборе схемы все заинтересованные стороны должны полностью учитывать каждый аспект проекта, чтобы снизить вероятность того, что в дальнейшем потребуются серьезные изменения.
При выборе схемы все заинтересованные стороны должны полностью учитывать каждый аспект проекта, чтобы снизить вероятность того, что в дальнейшем потребуются серьезные изменения. Например, если вы заранее не поняли, что ваше приложение будет полагаться на несколько JOIN таблиц, ваша служба в конечном итоге остановится, когда вы достигнете определенного количества пользователей и данных.
Например, если вы заранее не поняли, что ваше приложение будет полагаться на несколько JOIN таблиц, ваша служба в конечном итоге остановится, когда вы достигнете определенного количества пользователей и данных.
 С теоретической точки зрения это означает, что граф может иметь циклы. Цикл на графе указывает, что существует путь вершин, в котором вы можете начать и закончить в одном и том же узле.
С теоретической точки зрения это означает, что граф может иметь циклы. Цикл на графе указывает, что существует путь вершин, в котором вы можете начать и закончить в одном и том же узле.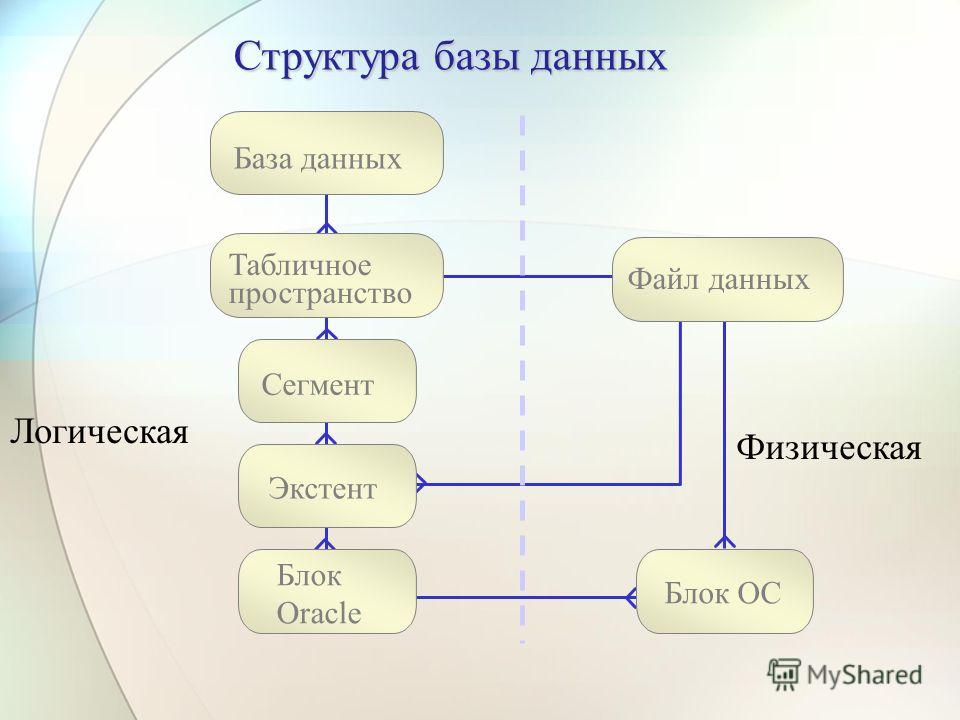 В этом сценарии существует связь «многие ко многим» между едой и различными категориями сотрудников. Таким образом, этот рабочий процесс лучше всего структурировать с использованием структуры сетевой базы данных.
В этом сценарии существует связь «многие ко многим» между едой и различными категориями сотрудников. Таким образом, этот рабочий процесс лучше всего структурировать с использованием структуры сетевой базы данных. Если вы создаете часть программного обеспечения, которое следует подходу объектно-ориентированного программирования, было бы лучше хранить данные каждого объекта в виде отдельной таблицы с базой данных.
Если вы создаете часть программного обеспечения, которое следует подходу объектно-ориентированного программирования, было бы лучше хранить данные каждого объекта в виде отдельной таблицы с базой данных. Это один из лучших примеров проектирования баз данных при хранении и анализе огромных объемов данных. Одна из причин, по которой схема «звезда» сияет, заключается в том, что она опирается на использование «фактов» и «измерений».
Это один из лучших примеров проектирования баз данных при хранении и анализе огромных объемов данных. Одна из причин, по которой схема «звезда» сияет, заключается в том, что она опирается на использование «фактов» и «измерений».