Основы XML — разметка и структура XML документов
В данной статье мы начинаем изучение языка XML и подробно рассмотрим такие моменты, как разметка и структура XML-документа. Данная информация есть базовой в изучении XML, поэтому рекомендую тщательно проработать этот материал, чтобы не оставалось никаких вопросов. От этого зависит ваш успех в будущем и скорость изучения как самого XML, так и XSLT, который мы будем изучать сразу после освоения XML.
Итак, XML (eXtensible Markup Language) – это язык для текстового выражения информации в стандартном виде. Сам по себе он не имеет операторов и не выполняет никаких вычислений. Таким образом, XML – это метаязык, главной задачей которого есть описание новых языков документа.
Чтобы лучше понять суть вышесказанного, давайте перейдем непосредственно к примерам и первым делом рассмотрим разметку XML-документов.
Разметка XML документов
Разметка XML-документа практически ничем не отличается от разметки обычного HTML-документа (Как создать HTML страницу. HTML теги и атрибуты. Работа с текстом, списками и изображениями в HTML). Одним из преимуществ XML являет то, что он позволяет создавать неограниченное количество тегов. Таким образом, каждый тег имеет свою семантику, то есть несет определенный смысл. Для наглядности давайте рассмотрим XML-документ со списком книг.
<books> <book> <author>Автор 1</author> <name>Название 1</name> <price>Цена 1</price> </book> <book> <author>Автор 2</author> <name>Название 2</name> <price>Цена 2</price> </book> <book> <author>Автор 3</author> <name>Название 3</name> <price>Цена 3</price> </book> </books>
Как видно с примера выше, все очень банально и просто. При этом XML-документ несет куда более подробную информацию по сравнению с обычным HTML-документом. В нашем примере очень просто понять, что тег <author> отвечает за автора книги, тег <name> — за название, тег <price> — за цену и т.д. Таким образом, каждый тег имеет свой смысл.
Одной из самых важных особенностей XML-документов является то, что их можно легко обрабатывать программно. Например, обработав пример вышеприведенного текста, можно с легкостью получить нужную информацию по книгам, вывести цены на книги по их названиям и т.д. При этом полностью сохраняется возможность визуального представления документа. Для этого достаточно лишь определить, как будет выглядеть тот или иной элемент.
Таким образом, XML позволяет отделять данные от их представления и создавать в текстовом виде документы со структурой, указанной явным образом. Если быть точным, то только лишь за счет расширения количества тегов мы сделали следующее:
- Явным образом выделили в XML-документе структуру, что в свою очередь сделало возможным дальнейшую программную обработку документа, например, при помощи технологии XSLT, которую мы будем изучать чуть позже. При этом одной из главных особенностей является то, что данный документ по прежнему остается понятным обычному человеку.
- Отделили данные в XML-документе от того, каким образом они должны быть представлены визуально. Это в свою очередь дало широкие возможности для публикации данных на разных носителях, например, на бумаге или в сети интернет.
Подводя итог вышесказанному, можно сделать вывод, что синтаксически в XML практически нет ничего нового по сравнению с HTML. XML является таким же текстом, размеченным тегами. Единственная разница лишь в том, что XML позволяет создавать любую разметку, которая может понадобиться для описания документа, при том как в HTML существует лишь ограниченный набор тегов, которые можно использовать.
Одним словом, XML является очень простым языком с небольшим набором основных конструкций, но в то же время он предоставляет неограниченные возможности для описания данных. Таким образом, каждый разработчик как бы сам изобретает свой собственный язык, который ограничивается лишь фантазией самого разработчика.
Структура XML документов
Для того чтобы представить структуру XML документов давайте рассмотрим самый простой пример документа XML.
<?xml version="1.0" encoding="utf-8"?> <pricelist> <book> <title>Книга 1</title> <author>Автор 1</author> <price>Цена 1</price> </book> <book> <title>Книга 2</title> <author>Автор 2</author> <price>Цена 2</price> </book> <book> <title>Книга 3</title> <author>Автор 3</author> <price>Цена 3</price> </book> </pricelist>
Итак, мы видим, что данный пример практически ничем не отличается от предыдущего за исключением немного изменившихся тегов и нескольких атрибутов. Главное отличие здесь заключается в первой строчке, которая определяет файл как XML документ, построенный в соответствии с первой версией языка. Более подробно об этом мы поговорим в следующих статьях рубрики «Уроки XML и XSLT».
На данный момент нам важнее всего понять, что это очень простой язык, который очень похож на обычный HTML. В примере выше мы видим, что XML тоже имеет теги, которые могут быть вложенными, то есть содержать внутри себя другие теги. При этом теги в XML не просто ограничивают часть текста, а формируют отдельный элемент. Исходя из этого, то, что выделено тегами, в XML принято называть элементами.
Стоит также заметить, что в XML есть также атрибуты, комментарии и множество других элементов и конструкций. К сожалению одной статьи недостаточно для того чтобы обо всем подробно написать, поэтому будут написаны отдельные статьи по каждой теме. Если вы не хотите их пропустить, то рекомендую подписаться на новостную рассылку любым удобным для вас способом в пункте «Подписка» либо воспользоваться формой ниже.
На этом все. Удачи вам и успехов в изучении основ XML.
Обнаружили ошибку? Выделите ее и нажмите Ctrl+Enter
archive.dmitriydenisov.com
Структура XML-документа
Вы здесь: Главная — XML — XML Основы — Структура XML-документа
Давайте сразу приведу простой пример XML-документа:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE shop [
<!ENTITY n "Ноутбук">
<!ENTITY g "Игра">
]>
<shop>
<notebooks>
<prod>&n; IBM Lenovo V570</prod>
<prod>&n; DELL Inspiron N5010</prod>
</notebooks>
<games>
<prod>&g; Готика 2</prod>
<prod>&g; Might & Magic 6</prod>
</games>
</shop>
В самом начале идёт заголовок XML-документа. Заголовок в примере является универсальным, единственное, что кодировка иногда бывает разной. Я поставил наиболее распространённую — UTF-8.
Дальше идёт секция DOCTYPE, в которой описываются различные сущности. Мы описали две: «n» со значением «Ноутбук» и «g» со значением «Игра«. Сущность — это, в некотором смысле, константа, которую мы можем использовать в теле XML-документа для сокращения записи и более лёгкой сопровождаемости в дальнейшем.
После секции DOCTYPE идёт тело XML-документа. Здесь всё аналогично синтаксису языка HTML, то есть имеются теги (они же элементы), они имеют атрибуты, а также внутренние теги. Но в отличии от HTML, здесь Вы сами придумываете названия элементов, также в XML очень строгий синтаксис, то есть не должно быть никаких незакрывающих тегов или пропущенных кавычек в значениях атрибутов у тегов.
Обратите внимание на то, как используются описанные нами в секции CDATA сущности. Если требуется вывести какой-нибудь спецсимвол, например, & или <, то необходимо использовать соответствующие зарезервированные сущности.
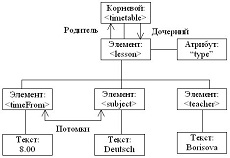
Что касается взаимосвязи между различными элементами. Есть
- Родитель. Родителем для заданного является тот элемент, который находится ровно на 1 уровень выше. Например, для элемента «notebooks» родителем является «shop«.
- Дочерний элемент. Противоположность родителю. Дочерним элементом является тот, который находится ровно на 1 уровень ниже и находится внутри заданного элемента. Например, дочерними элементами «shop» являются «notebooks» и «games«. Обратите внимание, что родитель всегда один, тогда как дочерних элементом может быть много.
- Предок. Предком является тот элемент для заданного, который находится на более, чем
- Потомок. Аналогично дочернему элементу, но только элементы должны быть ниже 1-го уровня вложенности в заданный элемент. Например, для «shop» потомком является «prod«.
- Брат. Элемент называется братом другому элементу, если он находится на том же уровне, что и другой. Безусловно, помимо одного уровня требуется и наличие общего родителя. Например, элементы «notebooks» и «games» являются братьями.
Вот и всё, что мне хотелось бы рассказать Вам о структуре XML-документа. И для закрепления рекомендую Вам сделать простенькую задачку: сделать внутри элемента prod ещё два элемента, один из которых будет содержать название продукта, а другой — его цену. Чтобы проверить правильность XML-документа, откройте его в браузере. Если никаких ошибок не возникло, значит, синтаксически всё написано правильно.
-
 Создано 08.09.2011 18:14:15
Создано 08.09.2011 18:14:15 -
Михаил Русаков
 Создано 08.09.2011 18:14:15
Создано 08.09.2011 18:14:15Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov.ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.
Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Порекомендуйте эту статью друзьям:
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
-
Кнопка:
<a href=»https://myrusakov.ru» target=»_blank»><img src=»https://myrusakov.ru/images/button.gif» alt=»Как создать свой сайт» /></a>Она выглядит вот так:
-
Текстовая ссылка:
<a href=»https://myrusakov.ru» target=»_blank»>Как создать свой сайт</a>Она выглядит вот так: Как создать свой сайт
- BB-код ссылки для форумов (например, можете поставить её в подписи):
[URL=»https://myrusakov.ru»]Как создать свой сайт[/URL]

myrusakov.ru
Расширяемый язык разметки XML. Синтаксис XML. Структура XML документа. Применение XML
Здравствуйте, уважаемые посетители моего скромного блога для начинающих вебразработчиков и web мастеров ZametkiNaPolyah.ru. Сегодня решил открыть рубрику Заметки о XML и XLST. В которой постараюсь на пальцах объяснить, что такое язык разметки XML. Рассказать о том, что такое XML схемы, подробно остановиться на вопросе применения языка XML. Собственно про сам расширяемый язык разметки можно рассказать в одной или двух статья, все будет зависит от того на сколько объемной получится статья, собственно в это статье я собираюсь поговорить о синтаксисе XML, о представление данных в языке разметки XML, о грамматике, семантике и синтаксисе XML элементов. Так же мы поговорим, о XML тегах и применение XML. Где, зачем и как можно применять XML.
Собственно про сам расширяемый язык разметки можно рассказать в одной или двух статья, все будет зависит от того на сколько объемной получится статья, собственно в это статье я собираюсь поговорить о синтаксисе XML, о представление данных в языке разметки XML, о грамматике, семантике и синтаксисе XML элементов. Так же мы поговорим, о XML тегах и применение XML. Где, зачем и как можно применять XML.
Что такое XML. Дифирамбы расширяемому языку разметки.
Содержание статьи:
XML — это язык, язык разметки, если HTML является языком разметки гипертекста, то XML является языком, который позволяет представлять какие-либо структурированные данные. В то время как HTML позволяет нам представлять структуру документа, какие-либо элементы, строки, блоки и прочее. XML позволяет нам создать структуру, в которой достаточно удобно хранить данные.
У всех языков разметки есть один, но очень большой недостаток. Все тот же HTML позволяет нам представлять веб страницы или HTML-документы и все эту красоту мы можем наблюдать в наших браузерах, но не факт, что в каких-то других клиентах или программах или для каких-то других целей HTML будет удобен. В XML таких недочетов нет. Не случайно он называется расширяемым, буковка X — eXtensible, что переводится как расширяемый.
XML абсолютно универсальный и абсолютно расширяемый язык разметки данных. За счет расширяемости XML мы получаем в свои руки мощнейший инструмент, на базе которого можно самому придумать язык разметки и им пользоваться. Еще одним несомненным плюсом XML является его независимость от платформы. То есть нам по барабану, с какой операционной системой работать, в какой программе работать с XML, какой язык программирования использовать, всё это для XML по барабану.
Плюс ко всему, помимо самих данных XML позволяет описать структуру данных, а так же метаданные или по рабоче-крестьянски описательная информация, о том что мы собираемся сохранить или передать. Все выше перечисленное делает XML очень мощным и гибким инструментом, даже в кривых руках. XML является промышленным стандартом.
XML документ. Структура XML документа. Что может содержать XML документ.
Давайте теперь поговорим о XML документах, познакомимся со структурой XML документа, а так же рассмотрим, что можно положить в XML документ. Назначение XML — представление данных в удобной форме и на удобной для вас платформе, при помощи удобного для вас языка программирования. С ума сойти можно как все круто.
И так XML документ содержит: данные, структуру этих данных, а так же уровень представления данных. Вообще с документами мы сталкиваемся очень часто, в почтовых ящиках в виде спама приходят различные прайс листы в экселе, я вчера в школе я сдавал реферат по географии, конец четверти как никак, оценки подтягивать надо, так этот самый реферат был тоже документом, но уже в док формате.
И так в реферате по географии были данные, о том, что Земля круглая и она вертится, биография Галилео Галилея — это все данные. У моего реферата по географии была структура, то есть введение, в котором я рассказал, про что мой реферат и с какой целью я его пишу(естественно, что цель у меня была сугубо корыстная, получить трояк, что бы двойки за четверть не было, но во введение я ее не написал), было заключение, в котором я подвел итоги проделанной работе(нервным ночным копипастам из википедии и с сайтов рефератов и дз), так же для удобства я разбил реферат на несколько логических частей: Биография Галилео Галилея, Планета Земля, Планета Земля как объект Солнечной системы. Все это является структурой моего реферата, так же и в XML мы можем создавать структуру XML документа самостоятельно. Обычно у XML документа древовидная структура, ее можно сравнить с договорами, ну например с договором ипотеке, пункт 1, подпункт 1.1 далее подподпункт 1.1.1, кто оформлял знает, вообщем-то это бюрократическая структура. Все это можно назвать вложенностью или деревом или древовидной структурой, вот примерно такая структура у XML документа.
Уровень представления XML или представление XML документа. Ну это все очень просто, уровень представления это то как вы видите документ, на экране монитора, в браузере, на принтере и так далее, вернемся к моему реферату, оформляя его я выделял жирным заголовки, сделал их 16 размером шрифта, а так же сделал их курсивными, отступ слева я сделал 20 мм, справа, снизу и сверху по 5 мм. Для текста в реферате я задал шрифт Times New Roman, размером 14, без дополнительных стилей, межстрочный интервал был 1.5, все это можно назвать представлением документа, который можно видеть, как на экране в Ворде, так и после того как я отправил свой реферат по географии на печать. У XML так же имеется представление документа.
Но у XML есть очень важное отличие от других языков разметки, опять же HTML — это язык описания обычной страничке, где будут расположены элементы, как они будут расположены, размеры этих элементов и прочее. А вот в XML нет уровня представления, при помощи XML можно описать только данные и отношения. Наш ботаник с первой парты, любимчик Надежды Петровны(учитель математике), обязательно спросил бы — Как это можно понять? Или в каком виде XML представляет данные? Ответ на этот вопрос прост — XML ни в каком виде не представляет данные, пока вы этого не захотите и причем документ будет выглядеть так, как этого хотите именно вы, но стандартно в XML этого нет.
Или такой вопрос, как XML документ будет выглядеть на экране браузера? Ответ — XML документ никак не будет выглядеть на экране браузера. Просто на экран браузера напечатается сам XML документ. XML очень абстрактный язык, при помощи которого можно сделать свой документ и делать с ним все, что душе угодно.
XML теги и XML элементы.
Поскольку XML разрабатывал w3.org, он, как и язык разметки гипертекста HTML, описывает документ при помощи тегов. Тег это слово, которое обрамлено треугольными скобками, вот так <слово> — данная конструкция является тегом, теги в XML бывают двух видов, открывающий тег и закрывающий тег, как и в языке HTML, но в HTML есть одиночные теги, а в XML одиночных тегов нет. То есть в XML есть открывающий тег <открывающий>Содержание элемента, которое пишется между тегами</закрывающий>. Так же у XML есть закрывающий тег </слово>, а между открывающим и закрывающим тегами пишется содержание или контент или значение. В HTML есть одиночные теги, в XML по определению одиночных тегов нет.
Что бы не было путаницы, я опять же уточню, тег это метка написанная в текстовом редакторе(например, в Notepad++), а элемент это, то что в итоге нам выведется, то есть содержание плюс метка является XML элементом или HTML элементом, в случае если вы открыли HTML-документ. Если в HTML элементы могут быть блочными и строчными, то в XML элементы не делятся никак, просто XML элемент. И понятно, что все эти элементы могут быть вложенными друг в друга:
<pricelist> <book> <title>Как взломать сайт Пентагона</title> <author>Васька Хакер</author> <price currency=»RUB»>2200</price> </book> </pricelist>
<pricelist> <book> <title>Как взломать сайт Пентагона</title> <author>Васька Хакер</author> <price currency=»RUB»>2200</price> </book> </pricelist> |
Внутри элемента price, находится элемент book, а внутри XML элемента book, находятся еще два элемента, title и price. XML регистрочувствительный язык, то есть в какими буковками вы написали открывающий тег, такими буковками надо писать и закрывающий тег. Теги <title> и <Title> — разные теги.
А теперь давайте рассмотрим такой вопрос, где искать XML теги, хотя это не правильная постановка вопроса, кто придумывает XML теги? XML теги придумываете вы самостоятельно, захотели создали тег <school>, захотели создали тег <vosmoi_A_klass>, все эти теги имеют право на существование.
Отличие HTML от XML. Синтаксис XML. Грамматика языка разметки XML. Семантика XML.
К XML тегам мы еще вернемся, но чуть позже. Сейчас надо бы поговорить, о структуре языка разметки XML. И в чем отличие XML от HTML. Любой язык разметки, любой язык программирования, да и русский язык имеют синтаксис, грамматику и семантику, можно сказать три уровня и нам необходимо знать назначение каждого из этих уровней, для того что бы успешно и правильно пользоваться языком. XML в этом плане не исключение.
Синтаксис языка — это правило записи, для примера возьмем наш великий и могучий, слово «пАгАвАрить» пишется как «поговорить» и никак иначе. Только в русском языке на контрольно за написанное слово пАгАвАрить мне Анджела Робертовна пАставила двойку и фиг с ним. А вот с языками разметки такой подход не пройдет. Здесь нужно точно писать теги. Если заголовок первого уровня в HTML пишется как <h2>, то его нужно писать <h2>, а не <x1> или <hodin>. Но в HTML теги можно писать хоть маленькими, хоть большими буквами, например тег авторского форматирования <pre>, можно писать как <PRE> или <PrE>, <pRe> — без разницы, а вот в XML в каком регистре написан открывающий тег, в таком регистре извольте писать и закрывающий тег, то есть тег <title> нужно закрывать тегом </title>, но никак не </Title>.
У любого языка есть грамматика — например, в русском языке деепричастные обороты выделяются запятыми. Например, «Просматривая рубрику Заметки для вебмастера, меня заинтересовал раздел Счетчики посещений». Просматривая рубрику Заметки для вебмастера — деепричастный оборот, после которого обязательно ставится запятая. Грамматика есть и у языков программирования например цикл while, если внутри цикла гоняется несколько инструкций, то их обязательно выделяют фигурными скобками или тело функции выделяется фигурными скобками. У HTML, тоже есть грамматика, например таблицы HTML 4, внутрь тега <table> по стандарту HTML 4, внутри тега <table> обязательно следует писать теги <tbody>, <tfoot>, <thead>, а внутри этих тегов уже <tr>.
Так же у любого языка есть семантика, семантика — это смысл, например «дать ремня», у данного выражения очень стимулирующий смысл в плане успеваемости, никто не хочет «получать ремня». Или слово «замок», тут два смысла, замок — как сооружение и замок — как средство защиты от грабителя. Опять же в HTML, так же имеется семантика, например два тега, тег <p> параграф или абзац и тег <div> раздел или два тега <b> и <strong> и как ни странно писать HTML-документы будет намного легче, если вы их будете писать с пониманием смысла, а не выковыривая теги из памяти и вспоминая стандарты и прочее. Например, почему внутри элемента <p>, нельзя создать еще один HTML элемент <p> или элемент div (ведь P элемент блочный и DIV блочный HTML элемент), если понять смыл тега <p>, то все становится очевидным, элемент P это параграф, кто-нибудь видел внутри параграфа параграф? А элемент DIV это раздел, кто-нибудь видел внутри параграфа раздел? Внутри параграфа, могут быть списки, изображения, тексты и так далее, но никак не раздел. А вот внутри раздела может быть сколь угодно много параграфов и разделов.
Или скажем тег <b> и <strong>, b — от англицкого слова bold, то есть жирный, текст заключенный между тегами <b>…</b> становится жирным и все, а strong — переводится как сильный или важный и смысл его в том, что бы указать браузере, что данный фрагмент текста очень важный и сделай ка ты нам его мужик как-то по особенному, в обычных браузерах текст выделится жирным, а в голосовых говорилка изменит интонацию или громкость произношения, что в случае с тегом <b> не наблюдается.
А теперь вернемся к примеру XML документа:
<pricelist> <book> <title>Как взломать сайт Пентагона</title> <author>Васька Хакер</author> <price currency=»RUB»>2200</price> </book> </pricelist>
<pricelist> <book> <title>Как взломать сайт Пентагона</title> <author>Васька Хакер</author> <price currency=»RUB»>2200</price> </book> </pricelist> |
И первый же вопрос, у XML тегов и XML документов есть смысл? Нет, не так(в конкретных ситуациях и на готовых решениях у XML тегов смысл есть), у очевидно ли будет правило, что книга как взломать сайт Пентагона, является частью прайс-листа? Ответ — все зависит от ситуации. Второй вопрос, что означает тег <book>, очевидно ли что это действительно книга, а может это брошурка, атлас или журнал Весёлые картинки(old scholl заулыбался). То есть мы приходим к выводу, что у XML тегов смысла нет.
Таким образом, мы приходим к выводу, что у языка разметки XML есть синтаксис, но в чистом XML нет ни семантики, ни грамматики, пока мы ее не создадим их самостоятельно. Запомните, ни один тег ничего не обозначает и придумываем XML теги мы самостоятельно. Возникает тогда вопрос, сколько тегов в XML, правильный ответ будет ноль, в XML нет тегов, но придумать XML теги мы можем и причем сколь угодно много. По моему гениально, за счет того, что тегов в XML нет(ни один тег не определен), тегов в XML бесконечно много.
Поэтому, у XML нет грамматики, нет тегов нет грамматики, нет семантики так как нет тегов, справедливый вопрос в консорциум w3 org прислал слесарь Калистрат Федорович Иванов из Новосибирска, «А на хрена нам тогда нужен язык разметки без правил и смыла?». Ответ очень прост, смысл у XML появляется при данных конкретных решениях, так же как и правила XML появляются тогда, когда мы начинаем работать над конкретной задачей. Все свойства, весь смысл находится в вашей голове, то есть на базе XML вы создаете свой собственный язык разметки, у которого есть смысл, есть грамматика. Как в моем примере я решил, что внутри XML элемента <book> будет находится информация о продаваемой книге(цена, автор книги, число страниц, название книги, издательство и т.д.) А внутри элемента <title> я решил держать информацию о название книги. И у всех моих тегов появился сразу же смысл.
То есть расширять XML можно бесконечно и язык разметки на базе XML, с которым вы будете работать зависит от вашей фантазии. После того, как вы создадите свой язык разметки на основе XML, вы сможете декларировать его правила(схемы XML и DTD), грубо говоря вы говорите, вот мой язык разметки пацаны и вы можете им пользоваться, только соблюдайте мои правила и все у вас нормально будет. В одну статью, я к сожалению не уложился, поэтому продолжение следует.
На этом всё, спасибо за внимание, надеюсь, что был хоть чем-то полезен и до скорых встреч на страницах блога для начинающих вебразработчиков и вебмастеров ZametkiNaPolyah.ru
- Возможно, вам будет интересно:
- HTML атрибуты, для чего используются HTML атрибуты, какие бывают HTML атрибуты, синтаксис и назначение атрибутов в HTML
- HTML тэги часть 2. HTML тэг p — параграф или абзац. HTML тэг blockquote — блочная цитата. HTML тэг address — адреса и информация об авторе
- Цвета в HTML, коды и таблица RGB цветов для Вашего сайта
- HTML теги, часть 1. Тэг PRE авторское форматирование, тэг BR перенос строк. Пробельные символы
- Блочные и строчные элементы. Теги HTML заголовков h2-H6
- Структура HTML документа. Тэги html, head, body и title
- Что такое теги, какие теги бывают и где их искать
- Заметки о инструментах вебмастера, предоставляемых поисковыми системами
zametkinapolyah.ru
IT Notes: Структура XML-документа
XML-документ состоит из деклараций, элементов, комментариев, специальных символов и директив.
1. Элементы и атрибуты
XML — это теговый язык разметки документов. Иными словами, любой документ на языке XML представляет собой набор элементов, причем начало и конец каждого элемента обозначается специальными пометками, называемыми тегами. То есть, как и HTML, язык XML для описания данных использует тэги. Но, в отличие от HTML, XML позволяет использовать неограниченный набор пар тэгов, каждая из которых представляет не то, как заключенные в нее данные должны выглядеть, а то, что они означают.
Элемент состоит из трех частей: начального тега, содержимого и конечного тега. Тег — это текст, заключенный в угловые скобки «<» и «>». Конечный тег имеет то же имя, что начальный тег, но начинается с косой черты «/». Пример XML-элемента:
<author>Сергей Довлатов</author>
Имена элементов зависят от регистра, т. е. <author>, <Author> и <AUTHOR> — это имена различных элементов. Наличие закрывающего тега всегда обязательно. Если тег является пустым, т. е. не имеет содержимого и закрывающего тега, то он имеет специальную форму:
<элемент/>
Любой элемент может иметь атрибуты, содержащие дополнительную информацию об элементе. Атрибуты всегда включаются в начальный тег элемента и имеют вид:
имя_атрибута="значение_атрибута"
Аттрибут обязан иметь значение, которое всегда должно быть заключено в одинарные или двойные кавычки. Имена атрибутов также зависят от регистра. Пример элемента, имеющего атрибут:
<author country="USA">Сергей Довлатов</author>
Элементы должны либо следовать друг за другом, либо быть вложены один в другой:
<books>
<book isbn="5887821192">
<title>Часть речи</title>
<author>Бродский, Иосиф</author>
<present/>
</book>
<book isbn="0345374827">
<title>Марш одиноких</title>
<author>Довлатов, Сергей</author>
<present/>
</book>
</books>
Здесь элемент books (книги) содержит два вложенных элемента book (книга), которые, в свою очередь, имеют атрибут isbn и содержат три последовательных элемента: title (название), author (автор) и present (есть в наличии), причем последний пуст, т. к. в данном случае соответствует логическому флажку.
Из приведенного описания видно, что синтаксис XML напоминает синтаксис HTML (что естественно, т. к. оба они являются диалектами одного языка SGML), но требования к оформлению правильных XML-документов выше. Еще одним очень важным отличием XML от HTML является то, что содержимое элементов, т. е. все, что содержится между начальным и конечным тегами, считается данными. Это означает, что XML не игнорирует символы пробела и разрыва строк, как это делает HTML.
2. Пролог и директивы
Любой XML-документ состоит из пролога и корневого элемента, например:
<?xml version="1.0"?>
<books>
<book isbn="0345374827">
<title>Марш одиноких</title>
<author>Довлатов, Сергей</author>
<present/>
</book>
</books>
В этом примере пролог сводится к единственной директиве (первая строка документа), указывающей версию XML. За ней следует XML-элемент с уникальным именем, который содержит в себе все остальные элементы и называется корневым. Директива (processing instruction) — это выражение, заключенное в специальные теги «<?» и «?>», которое содержит указания программе, обрабатывающей XML-документ.
Стандарт XML резервирует только одну директиву <?xml version="1.0"?>, указывающую на версию языка XML, которой соответствует данный документ (второй версии XML пока нет). В действительности, эта директива несколько богаче и в самом общем виде выглядит так:
<?xml version="1.0" encoding="ISO-8859-1" standalone="yes"?>
Здесь атрибут encoding задает кодировку символов документа. По умолчанию считается, что XML-документы должны создаваться в формате UTF-8 или UTF-16. Если же используется какая-либо другая кодировка символов, то ее название должно быть указано в данном атрибуте, как показано в примере. Атрибут standalone говорит о том, содержит ли данный документ внешние разделы. Значение yes означает, что таких разделов нет, значение no — что они есть.
В общем случае, пролог может содержать также декларации типа документа.
3. Комментарии
XML-документы могут содержать комментарии, которые игнорируются приложением, обрабатывающим документ. Комментарии строятся по тем же правилам, что и в HTML:
- начинайте комментарий с символов «<!—«,
- завершайте комментарий символами «—>»,
- не используйте внутри комментария символов «—«.
Пример комментариев:
<!-- это комментарий -->
<!-- а вот еще комментарий,
занимающий более одной строки -->
4. Имена и данные
Все имена элементов, атрибутов и разделов должны начинаться с буквы Unicode и состоять из букв, цифр, символов точки (.), подчеркивания (_) и дефиса (-). Единственное ограничение состоит в том, что они не должны начинаться с комбинации букв xml в любом регистре; подобные имена зарезервированы для будущих расширений языка. Существенно, что стандарт допускает использование в именах не только английских букв, но и любых других, хотя существующие XML-процессоры часто ограничены теми системами кодировок, которые в них заложены создателями. Поэтому мы в своих примерах пишем имена по-английски.
Данные, т. е. содержимое элементов и значения атрибутов, могут состоять из любых символов, кроме перечисленных в следующем разделе.
5. Специальные символы
Ряд символов в языке XML зарезервирован и должен представляться специальным образом:
левая угловая скобка («<«) | < |
правая угловая скобка («>») | > |
амперсант («&») | & |
двойная кавычка («) в значениях атрибутов | " |
одинарная кавычка (‘) в значениях атрибутов | ' |
При желании можно пользоваться числовой кодировкой символов в стандарте Unicode. При этом символ может быть задан своим десятичным кодом (&#код;) или шестнадцатеричным кодом (&#xкод;). Например © представляет символ авторского права ©, а А – русскую букву А. Как мы увидим в дальнейшем, XML гораздо богаче, чем HTML, в использовании подобных конструкций, поскольку позволяет осуществлять подстановку в текст документов любых символьных выражений.
6. Секции CDATA
Еще одним способом включения в содержимое XML-элементов недопустимых символов является использование т. н. секций CDATA (сокр. от Character DATA, т. е. символьные данные). Допустим, что мы хотим сделать содержимым элемента layout фрагмент HTML-текста, например:
<layout>
<h2>Заголовок</h2>
</layout>
Подобная конструкция неверна, т. к. HTML-тег h2 будет в данном случае воспринят как тег XML. Для того, чтобы все содержимое элемента layout воспринималось как данные, мы должны заключить его в секцию CDATA:
<layout>
<![CDATA[<h2>Заголовок</h2>]]>
</layout>
Как мы видим из этого примера, секция CDATA заключается в ограничители <![CDATA[ и ]]>. Все внутри этой секции считается символьными данными; в частности, секции CDATA не могут вкладываться друг в друга.
Разделы и их декларации
1. Разделы XML-документа
Физически XML-документ может состоять из несколько разделов (entities). При этом корневой элемент документа также является разделом, который называется разделом документа, хотя он никак специально не оформлен. Все разделы имеют содержимое; все они, кроме раздела документа и внешней DTD, имеют имя.
С точки зрения синтаксического разбора документа разделы подразделяются на анализируемые и неанализируемые. Неанализируемый раздел (unparsed entity) — это ресурс, содержимое которого XML-процессор воспринимает как внешние данные без их синтаксического анализа (например, текст, не являющийся XML-документом). Неанализируемые разделы всегда имеют нотацию, указывающую на их формат. Анализируемые разделы (parsed entities) предназначены для текстовой подстановки: всякий раз, когда XML-процессор встречает в документе имя такого раздела, он заменяет его на содержимое этого раздела.
2. Внутренние разделы
Декларации разделов подразделяются на внутренние и внешние. Декларация внутреннего раздела выглядит так:
<!ENTITY имя значение>
Она включает в себя содержимое объекта (параметр значение) и используется для подстановки этого значения вместо имени раздела. Мы можем, например, ввести в пример с книгами атрибут жанр и использовать для задания жанра внутренние разделы:
<!DOCTYPE spec [
<!ENTITY pr "проза">
<!ENTITY po "поэзия">
]>
<books>
<book genre="&po;">
<title>Часть речи</title>
<author>Бродский, Иосиф</author>
</book>
<book genre="≺">
<title>Марш одиноких</title>
<author>Довлатов, Сергей</author>
</book>
</books>
Из этого примера видно, что ссылка на раздел (entity reference) выглядит точно так же, как ссылка на специальный символ, т. е. имеет вид &имя;. На самом деле, специальные символы — это точно такие же ссылки, но соответствующие разделы заданы неявно во внутренней декларации языка XML. Подобные текстовые подстановки удобны для задания сокращений, позволяющих уменьшить объем документа, и для введения обозначений для часто изменяемых полей документа. Так, например, мы можем вынести во внутренний раздел дату очередной ревизии публикации и затем изменять только значение этого раздела.
3. Внешние разделы
Существуют два варианта деклараций внешнего раздела:
<!ENTITY имя SYSTEM URI [NDATA нотация]?>
<!ENTITY имя PUBLIC строка? URI [NDATA нотация]?>
Первый вариант называется системным разделом, второй — публичным разделом. Они оба связывают имя раздела с внешним ресурсом, заданным своим URI, который должен иметь кодированную форму и не содержать закладок. URI внешнего ресурса называется системным идентификатором раздела. Использование внешнего ресурса зависит от нескольких факторов:
- Если декларация содержит параметр NDATA, задающий нотацию раздела, то раздел является неанализируемым.
- Если параметр NDATA не задан, то раздел анализируемый, и соответствующий ресурс должен быть XML-документом. Это означает, что вместо ссылки на раздел в текст документа будет включаться текст соответствующего ресурса.
- Публичный раздел может содержать строку, задающую публичный идентификатор раздела. XML-процессор может использовать этот идентификатор для генерации альтернативного URI данного раздела. Если ему это не удалось, то он должен использовать системный идентификатор для загрузки содержимого раздела.
Примеры деклараций внешних ресурсов:
<!-- неанализируемый ресурс: GIF-образ -->
<!ENTITY photo SYSTEM "images/photo.gif" NDATA gif>
<!-- системный анализируемый ресурс -->
<!ENTITY hatch SYSTEM "http://www.textuality.com/boilerplate/hatch.xml">
<!-- публичный анализируемый ресурс -->
<!ENTITY hatch PUBLIC "-//Textuality//TEXT Standard hatch boilerplate//EN"
"http://www.textuality.com/boilerplate/hatch.xml">
Внешний анализируемый раздел должен начинаться с директивы <?xml …?>, которая может не содержать номера версии, но обязана содержать кодировку символов. Эта директива не входит в состав подставляемого текста.
kavayii.blogspot.com
Вид, создание и структура XML-файла
XML — это расширение файла Extensible Markup Language, применяемого для создания общих информационных форматов и совместного использования как формата, так и данных во Всемирной паутине, интрасетях и в других местах с использованием стандартного текста ASCII. Это универсальный формат данных и структурированных документов с расширением XML. Как и HTML, он использует теги слова, разделенные символами «>» и «<» для структурирования данных в документе. Но что входит в структуру XML-файла?
Краткое введение в язык

Изучаемый язык (EXtensible Markup Language) начал развиваться с сентября 1996 года, при поддержке W3C, с целью создания оптимизированного инструмента для интернета. Структура XML-файла сочетает простоту HTML с выразительными возможностями своего предшественника, SGML. В его разработке приняли участие такие компании, как Microsoft, IBM, Sun Microsystems, Novell и Hewlett-Packard. Версия 1.0 была ратифицирована W3C на конференции SGML/XML, состоявшейся в Вашингтоне в декабре 1997 года. Через несколько лет XML стал языком, оказавшим наибольшее влияние на разработку приложений для публикации контента в интернете.

Редакция документов преследует следующие цели:
- Различать содержание и структуру XML-файла по представлению на бумаге или на экране.
- Уточнять устройство и информативное содержание.
- Создавать документы, которыми можно обмениваться и легко обрабатывать в разнородных компьютерных системах.
- Создание форматов, в котором метки устанавливаются в тексте документов, чтобы различать его части или элементы структуры XML-файла.
Основными характеристиками языка являются:
- Возможность описательной маркировки, с открытым набором меток. В HTML и XML метки перемежаются в документах. Основное различие между тем и другим заключается в функции этих брендов.
- Функция дифференциации информативного содержимого документов по сравнению с использованием в HTML, где метки служат для указания того, как содержимое должно просматриваться.
- С другой стороны, в то время, как HTML сообщает, какие метки можно использовать при создании документа, изучаемый язык не определяет допустимый набор меток. Но он предлагает правила создания XML-файла, которые позволяют устанавливать новые словари и наборы меток для различных типов.
- В нем установлена четкая разница между структурой документа и его представлением. Метки XML-документа ничего не указывают на то, как он должен быть представлен. Чтобы представить его на экране или на бумаге, необходимо будет создать отдельную таблицу стилей и связать ее позже с документом.
При подключении клиентского компьютера к базе данных, SQL отправляется в БД объединения использует оболочку XML для доступа к ним из файла. Они возвращаются на клиентский компьютер в виде структурированных данных, содержащихся в реляционной таблице результатов.
С помощью оболочки XML можно отображать данные из внешнего источника в реляционную схему, состоящую из набора псевдонимов. Структура документа логически эквивалентна реляционной схеме, где повторяющиеся и вложенные элементы моделируются как отдельные таблицы с внешними ключами.
Непрерывная эволюция языка
Со времени своего первоначального выхода в интернет язык XML вызвал большое количество инициатив, связанных с обменом и кодированием контента и метаданных. XML единогласно стал основным вариантом для управления и восстановления данных. Список инициатив является широким, и хотя не все из них достигли одинакового уровня принятия, существуют многочисленные примеры успешного применения языка в академической, деловой и институциональной сферах.
В течение 2004 года появились публикации новых предложений и инициатив, связанных с использованием языка. В качестве примеров можно упомянуть постоянную публикацию новых версий компьютерных приложений, предназначенных для работы с XML, разработку новых словарей или принятие языка в различных областях работы.
Extensible Markup Language имеет большую поддержку со стороны международных органов стандартизации, что позволило обеспечить высокий уровень стандартизации сферы электронной торговли между компаниями. Доказательством этого является публикация в качестве стандарта ISO спецификаций языка и недавнее обновление стандарта UDDI (универсальное описание структуры XML-файла и обнаружения). Эти два стандарта пробудили интерес к новым инвестициям в информационные технологии, который в предыдущие годы замедлился из-за недоверия к интернет-рынкам.
Расширяемый язык разметки
XML похож на HTML. Они содержат символы разметки для описания страниц или файла. HTML, однако, описывает содержание веб-страницы в основном в виде текстовых и графических изображений, только с точки зрения того, как они должны отображаться и взаимодействовать.
XML описывает в терминах содержимое того, какие данные описываются. Например, слово «phonenum», помещенное в теги разметки, может указывать, что последующими данными будет номер телефона. Файл XML может обрабатываться программой исключительно как данные, храниться с аналогичными на другом компьютере или отображаться, как файл HTML. Например, в зависимости от того, как приложение на принимающем компьютере будет обрабатывать номер телефона, оно может быть сохранено, отображено или набрано.
XML считается расширяемым, потому что, в отличие от HTML, символы разметки являются неограниченными и самоопределяющими. XML — это более простое и легкое в использовании подмножество стандарта Standard Generalized Markup Language (SGML) для создания структуры документа. Ожидается, что HTML и XML будут использоваться вместе во многих веб-приложениях. Например, разметка XML может отображаться на странице HTML.
Псевдонимы соответствия

Псевдонимы, соответствующие XML-документу, организованы в древовидную структуру, где дочерние псевдонимы соотносятся с элементами, соответствующие родительскому. Когда они повторяются или имеют дифференцированные идентификаторы со сложными структурами, можно указать разные псевдонимы для каждого вложенного элемента.
Псевдонимы родители и дети связаны первичными и внешними ключами, генерируемыми оболочкой. Выражения XPath используются для корреляции документа XML с реляционной схемой, состоящей из набора псевдонимов. XPath — это механизм адресации для идентификации частей файла XML, например, групп узлов и атрибутов в дереве документа XML.
Основной его синтаксис аналогичен адресации файловой системы. Каждый псевдоним определяется выражением XPath, которое идентифицирует элементы представляющие отдельные кортежи, и набор выражений, устанавливающих, как извлекать значения столбцов каждого элемента.
XML-документа соотносится с набором псевдонимов, а родительские и дочерние отношения устанавливаются с использованием внешнего и первичного ключей. Выражения XPath используются для определения отдельных кортежей, и столбцов в каждом элементе документа, а также способ выполнения запроса в документе XML после его регистрации в системе объединения.
Древовидная структура образца документа
Документы XML обязаны иметь корневой элемент — родительский для всех остальных. Они могут содержать вложенные элементы, текст и атрибуты. Дерево, представленное таким документом, начинается с элемента-корня и ветвится до самого низшего уровня элементов. Хотя нет единого мнения о терминологии, используемой в деревьях XML, W3C выпустил по крайней мере две стандартные терминологии:
- Терминология, используемая в модели данных XPath.
- Терминология, используемая в информационном наборе XML.
XPath определяет синтаксис с именем выражений, который идентифицирует один или несколько внутренних компонентов элементов и атрибутов документа XML. XPath широко используется для доступа к XML-кодированным данным.
Информационный набор XML описывает абстрактную модель данных для документов в терминах информационных элементов. Он часто используется в спецификациях собственного языка для удобства описания ограничений на конструкции, допускаемые ими.
Обмен данными
Возможность отделять хранение данных от просмотра означает, что с XML можно хранить свои данные в одном формате и просматривать их различными способами, не меняя способ хранения. Язык может описывать то, что представляют данные. Это означает, что можно описать, как их отображать — цвет, шрифт и форматирование, и что они представляют, например, сигнал, полученный с осциллографа, значение индикатора тревоги и многое другое.
Вместе эти преимущества позволяют хранить любую информацию в едином формате хранения, которые можно определить для приложений. Также можно получить доступ к ним в любом другом приложении, просто зная, что оно читает файлы XML. Это полезно на одном компьютере для обмена данными между приложениями, но реальное преимущество этой функциональности заключается в мультикомпьютерной среде.
Можно использовать следующий пример в качестве модели того, как создать файл-XML и отобразить данные из него. Предположим, завершено получение ряда точек данных с тестовой платформы и проведен некоторый базовый анализ этих данных.
Далее потребуется записать все эти необработанные данные вместе с анализом в файл. Чтобы вывести их в файл, необходимо спланировать, как должен выглядеть XML-файл, который нужно создать. С помощью этой схемы записываются все данные и результаты анализа в файл XML. Возможность настраивать поля в файле, такие как «данные», «среднее», «max» и «min», является частью гибкости и мощи XML.
Разработка тестовых приложений
Когда у пользователя есть файл XML, который содержит полезные данные, рано или поздно, потребуется их применить. Для этого можно легко отобразить их в любом текстовом редакторе или открыть в браузере с поддержкой XML, например, в Microsoft Internet Explorer. Если нужно отобразить их не просто в виде текста, можно использовать все — от приложений базы данных до веб-браузеров.
Для чтение XML-файла этим приложениям нужна таблица стилей. Используя таблицы стилей, можно просматривать одни и те же данные разными способами. Например одну таблицу стилей для отображения информации для клиентов и другую для представления информации специалистам, которым может потребоваться конкретная информация для устранения проблемы. И также можно использовать третью таблицу стилей для загрузки всех данных в общую систему БД предприятия.
При выполнении этой задачи заранее нужно будет создать три разных метода вывода данных. Используя XML и таблицы стилей, нужно всего лишь создать один файл данных, который можно просматривать в нескольких форматах, соответствующих конкретным задачам. Более того, больше не нужно указывать тип приложения, которое будет просматривать данные, потому что конечный пользователь может создать свою собственную таблицу стилей для удовлетворения потребностей приложения, как только будет предоставлен файл XML.
XML определит общекорпоративные стандарты данных, поэтому разработчику нужно будет спроектировать только один файл схемы, который может использовать, применяя соответствующие части схемы в соответствии с потребностями своего приложения. Затем остается только разработать таблицу стилей для каждого представления данных.
С помощью этой системы тестовые и измерительные программы могут легко обмениваться данными с любым приложением на предприятии и каждое из них может создавать данные и отображать их в другом.
Механизм XDTO в 1С

Создатели 1С, ставя перед собой задачу обмена данных с использованием изучаемого языка, разработали механизм — XDTO для объектов передачи структуры XML-файла 1С. Каковы преимущества? Версия программы 8.1 и выше позволяет обмен информацией с системами, не углубляясь в темы создания XML-файла, решая большинство проблем 1С. И также можно отправлять только необходимую информацию для образования документа. Для этого программисту потребуется заранее выполнить некоторые процедуры.
Для загрузки файла XML с использованием XDTO, нужно передать структуру файла 1C с помощью набора схем, созданных в текстовом редакторе или использовать специальное ПО. Результатом должен быть файл, описывающий уникальный тип и структуру, использующих в XML. Прежде чем прочитать или писать последний файл, программист загружает полученную конфигурацию в области «Пакеты XDTO». Для воссоздания у пользователя должен быть основной элемент и вложения с атрибутами. Полученная схема экспортируется в файл XSD и отправляется совместно с изучаемым, таким образом формируя пакет XDTO.
Самое большое различие между использованием для отображения данных в интернете и другими технологиями заключается в том, что перед тем как создать XML-файл сначала необходимо использовать его для отображения данных на веб-странице, которое аналогично использованию электронной таблицы.
Распространенные ошибки
Язык XML настолько прост, что его может освоить практически каждый. Широкий доступ является ключевым преимуществом языка. Недостатком XML является то, что правила, которые существуют в языке, являются абсолютными. Синтаксические анализаторы XML оставляют мало места для ошибок. Независимо от того, является ли разработчик новичком или много лет работал на языке, одни и те же распространенные ошибки появляются снова и снова. Рассмотрим их, чтобы не допускать.
Итак, распространенные ошибки структуры XML файла:
- Нужно указать язык с помощью оператора объявления, чтобы браузер понимал код, на котором он написан.
- XML работает в иерархическом стиле. Это означает, что все дочерние элементы должны иметь родителей, строки данных должны быть между тегами элемента, комментарии должны быть внутри тегов.
- XML требует, чтобы были закрыты все теги. В HTML можно избежать случайного открытия тега, и некоторые браузеры даже закрывают теги при отображении страницы. Документ XML с открытым тегом всегда будет выдавать ошибку.
- Поскольку изучаемый язык работает в древовидной структуре, каждая страница должна иметь корневой элемент на вершине дерева. Имя элемента не имеет значения, но оно должно быть там перед тем, как получить структуру XML-файла. Иначе последующие теги не будут должным образом вложены.
- XML интерпретирует 50 пробелов так же, как и один. Язык собирает несколько пробелов, известных как пробельные символы, и скомпактирует их в один. Это не имеет ничего общего с визуальным отображением или дизайном. Пробел, используемый для выравнивания текста, ничего не значит в коде XML, поэтому если разработчик добавляет много лишних пробелов, чтобы попытаться продемонстрировать какой-то визуальный макет или дизайн, он просто теряет время.
XML предлагает хорошее решение для обмена данными для широкого круга заинтересованных потребителей в удобном и простом в использовании формате. Такие приложения, как 1 С, продолжают интегрировать новые технологии, такие как XML, чтобы предоставить пользователю новые возможности обработки данных.
fb.ru
Запись адреса в формате XML
Информационный анализ в двух словах

Майкл Р. Хан
Опубликовано 10.11.2010
XML стал вездесущим инструментом обработки информации, проникая во все от традиционных публикаций до бизнес-транзакций и твиттера. Стереотип «XML – это просто!» нередко приводит к тому, что набор тегов, выбранных для XML-приложения, может оказаться неоптимальным при использовании информационного набора в реальной жизни. Плохая организация информации может осложнить кодирование, необходимое для манипулирования информационным набором и его представления. К счастью, немного дополнительной работы в начале может упростить дальнейшее движение по пути разработки.
Часто используемые сокращения
- IEC: International Electrotechnical Commission – Международная электротехническая комиссия
- ISO: International Organization for Standardization – Международная организация по стандартизации
- SGML: Standard Generalized Markup Language – язык разметки стандартный обобщенный
- W3C: World Wide Web Consortium – Консорциум по разработке и распространению стандартов и протоколов для WWW-системы
- XML: Extensible Markup Language – расширяемый язык разметки
- XSLT: Extensible Stylesheet Language Transformations – расширяемый язык таблиц стилей
Проектирование информационной структуры сводится к решению трех главных вопросов:
- Что представляют собой полезные элементы информационного набора?
- Каковы отношения между этими элементами?
- Нужно ли знать об этих элементах что-то еще?
Рассмотрим типичный информационный набор и возможные XML-структуры, которые можно использовать при обработке данных.
Анализ записи адреса
Запись адреса появляется в самых разнообразных формах и контекстах: она может оказаться в центре другого информационного набора или в составе коллекции, хранящейся в базе данных, и служить для формирования запросов или распечатки в виде этикеток. Типичная запись адреса может выглядеть примерно так, как в листинге 1.
Листинг 1. Запись имени и адреса
John Q. Public 1234 Main Street Anytown, Anystate 54321-6789
С точки зрения XML ее структура может быть простейшей, как в листинге 2.
Листинг 2. Запись имени и адреса с простой разметкой
<address_rec> <line>John Q. Public</line> <line>1234 Main Street</line> <line>Anytown, Anystate 54321-6789</line> </address_rec>
Или же она может быть сложной, как в листинге 3.
Листинг 3. Запись имени и адреса со сложной разметкой
<address_rec>
<name>
<given_name>John</given_name>
<middle>Q.</middle>
<family_name>Public</family_name>
</name>
<address>
<street>1234 Main Street</street>
<city>Anytown</city>
<state>Anystate</state>
<zip_code>54321-6789</zip_code>
</address>
</address_rec>Эту структуру можно разложить еще дальше, маркируя знаки пунктуации (точку, запятую и дефис) или разбив почтовый индекс на две части. Кроме того, можно добавить такую информацию, как номер телефона, номер факса, адрес электронной почты или Web-сайт.
Определение требований, предъявляемых к записи адреса
Однако прервемся на минуту и вспомним приведенные выше главные вопросы. Что представляют собой полезные элементы? Для их определения сначала нужно решить, каковы ваши требования и намерения в отношении этих данных. Будете ли вы:
- распечатывать этикетки;
- сортировать записи по фамилии или почтовому индексу;
- производить поиск имен, городов или штатов?
То, как планируется использовать данные, может повлиять на выбор разбивки этих данных на полезные элементы. Поэтому первым шагом информационного анализа должно быть выявление критических требований. Определение набора контейнеров (или выбор набора из существующего стандарта) зависит от конкретных потребностей по использованию информационного набора. Вероятно, недостаточно разбить таблицу на строки и столбцы – структура записей реляционной таблицы может не допускать некоторых полезных группировок.
В целом требования, предъявляемые к информационному набору, можно разделить на три категории:
- Обязательные. Если эти требования не выполнены, проект явно не удался.
- Желательные. Если эти требования удастся выполнить, пользователи получат дополнительные выгоды.
- Если бы ресурсы были неограниченными (варианты типа «журавль в небе»). Это «мечты», которые, скорее всего, выходят за рамки данного проекта.
При сегодняшних бюджетах и сроках – выполнить бы обязательные требования и, возможно, захватить несколько желательных. Тем не менее, будет полезно записать все требования – даже «журавлиные». То, что группа рассматривает как требование «журавля в небе», может оказаться побочным продуктом одного из обязательных требований.
Определение и уточнение модели записи адреса
Структура XML, как правило, состоит из элементов и атрибутов: на самом базовом уровне элементы – это контейнеры для данных, а атрибуты – ярлыки контейнеров с данными. При первоначальном построении XML-модели информационного набора часто бывает полезно определить информационный набор как совокупность элементов и уточнить структуру элементов с помощью атрибутов.
В примере с записью адреса как простые, так и сложные структуры выражены только с использованием элементов; с помощью атрибутов можно уточнить и усовершенствовать эту структуру – например, добавив ключи сортировки. Если не применять стандартный словарь, а разрабатывать свой собственный, то структура и выбор имен атрибутов и элементов целиком зависит от разработчика. Выбор элементов или атрибутов для идентификации полезных единиц информации определяется небольшим количеством технических ограничений, но в остальном он вполне произвольный.
Рассмотрим более сложный пример из листинга 3. Сложный пример, казалось бы, удовлетворяет всем высказанным до сих пор требованиям:
- записи можно распечатать. В самом деле, каждую запись можно распечатать в форме со строкой для составляющих имени, строкой для улицы и строкой для города, штата и почтового индекса;
- фамилию и почтовый индекс мы уже определили, так что компоненты
address_recможно отсортировать по содержанию этих элементов; - мы определили имена и их компоненты вместе с городом и штатом, так что можно искать строки символов и выходить на эти элементы.
Похоже, что мы выполнили все исходные требования. Хотя структуру можно было бы усовершенствовать для удовлетворения будущих требований, на данный момент можно объявить, что работа выполнена. Помните старую пословицу: можно не означает должно?
Как можно было бы усовершенствовать эту структуру?
Базы данных любят ключи, так добавим к каждому компоненту address_rec запись ключа, как в листинге 4.
Листинг 4. Запись имени и адреса с атрибутом ключа
<address_rec key="1234">
<name>
<given_name>John</given_name>
<middle>Q.</middle>
<family_name>Public</family_name>
</name>
<address>
<street>1234 Main Street</street>
<city>Anytown</city>
<state>Anystate</state>
<zip_code>54321-6789</zip_code>
</address>
</address_rec>Если записи извлекаются из базы данных для создания XML-документов, ключ базы данных можно перенести непосредственно в атрибут key элемента address_rec.
С функциональной точки зрения атрибут key соответствует ярлыку на контейнере address_rec, который служит уникальным идентификатором записи.
Хотя вам вряд ли придется печатать на своих гипотетических этикетках телефонные номера, можно собрать другую контактную информацию, которая будет передаваться в XML-документы address_rec.
Номера телефонов и другие виды электронной контактной информации можно включить в структуру, как показано в листинге 5.
Листинг 5. Запись имени и адреса с дополнительной контактной информацией
<address_rec key="1234">
<name>
<given_name>John</given_name>
<middle>Q.</middle>
<family_name>Public</family_name>
</name>
<address>
<street>1234 Main Street</street>
<city>Anytown</city>
<state>Anystate</state>
<zip_code>54321-6789</zip_code>
</address>
<phone>316-555-1234</phone>
<email>[email protected]</email>
<web>http://www.mydomain.com/john</web>
</address_rec>Если наш мифический John Q. Public проводит столько же времени за компьютером, сколько я, он, вероятно, имеет несколько точек контакта. Можно создать отдельный элемент для каждого из них или использовать один повторяющийся элемент с подходящим атрибутом для идентификации каждого из его адресов. Давайте попробуем это сделать. Можно также позволить указывать несколько телефонных номеров, как в листинге 6.
Листинг 6. Запись имени и адреса с еще более подробной контактной информацией
<address_rec key="1234">
<name>
<given_name>John</given_name>
<middle>Q.</middle>
<family_name>Public</family_name>
</name>
<address>
<street>1234 Main Street</street>
<city>Anytown</city>
<state>Anystate</state>
<zip_code>54321-6789</zip_code>
</address>
<phone type="home">316-555-1234</phone>
<phone type="fax">316-555-1235</phone>
<phone type="mobile">316-555-1236</phone>
<web type="email">[email protected]</web>
<web type="email">[email protected]</web>
<web type="homepage">http://www.mydomain.com/john</web>
<web type="twitter">johnqpublic</web>
</address_rec>Выбор элементов и атрибутов имен произволен (если вы не адаптируете чью-то структуру), равно как и значения атрибутов типа. Но этот выбор может быть и обусловлен требованиями, определенными для приложения или системы.
Самая важная часть процесса – удовлетворение требований: если то, что вы намеревались сделать, возможно, то задача уже практически решена.
Схемы и проверка: обязательно или желательно?
Определив полезные элементы информационного набора и составив, а затем уточнив модель, впору задать вопрос: «И это все?» Для некоторых приложений XML действительно достаточно пометить полезные элементы информации и использовать их для последующей обработки.
То, что мы создали до сих пор, представляет собой «добротно сформированные» XML-документы: они следуют очень небольшому числу правил и подходят для многих различных видов обработки. Для многих приложений добротно сформированные XML-документы – именно то, что нужно.
Но что, если требуется соблюдать более строгие правила? XML-документы можно валидировать, т. е. проверить с помощью программы на соответствие определенному набору правил и отношений, и можно написать среду валидации, пользуясь одним или несколькими формальными языками валидации. Вот общепринятые языки валидации:
- Document Type Definition (DTD). DTD – это самые старые языки валидации, восходящие к SGML (ISO 8879, «Стандартный обобщенный язык разметки»), которые входят в «Рекомендации W3C по XML».
- W3C XML Schema. Разработанный W3C и получивший широкое распространение, этот язык включает в себя контроль типов данных и записывается в виде XML-документа.
- RELAX NG. Разработанный в Организации по улучшению стандартов структурированной информации (OASIS), а затем вошедший в состав стандарта ISO – ISO/IEC 19757-2:2008, – RELAX NG имеет как форму XML-документа, так и компактную не-XML форму.
Дополнительные правила, не предусмотренные указанными языками схемы, можно выразить на Schematron, языке валидации на базе XSLT, который используется для проверки содержания документов и их структуры.
Схемы могут оказаться полезными и для передачи структуры и желаемых отношений – особенно для человеко-машинных интерфейсов, таких как формы или средства разработки. Они представляют собой договор между поставщиком и потребителем информации – «Вот что я надеюсь получить, и вот как это должно быть организовано».
Валидация не является обязательной частью XML-приложений, но часто это полезный инструмент контроля за созданием XML-документов или обеспечения контроля качества XML-документов, полученных из других источников.
Нужна ли схема? Создание схемы требует знаний, времени и усилий: если это не полезная часть разрабатываемого приложения или системы, она легко может оказаться пустой тратой ресурсов. Примите к сведению следующие рекомендации:
- Ваша информация сгенерирована машиной или подготовлена человеком? Схемы – удобный способ передачи требований, предъявляемых к структуре и содержанию информационного набора, особенно для средств разработки.
- Используется ли информация, полученная из неподконтрольных вам источников? В этом случае схема – способ убедиться в том, что внешний источник информации поставляет XML-документы с соблюдением структуры, которую вы ожидаете получить.
- Требуется ли от вас валидация? Система или клиент могут требовать валидации в рамках системы, а формальная валидация потребует схемы в той или иной форме.
- Требуют ли схему инструменты, входящие в технологическую цепочку? Инструменты для работы с готовыми XML-документами, вероятно, не потребуют схему, но средства разработки, скорее всего, потребуют.
Помните, что и здесь работает старая поговорка: можно не означает должно. В некоторых случаях разработка схемы для определенного информационного набора не требуется, не будет полезна или даже может оказаться невозможной из-за чрезмерного объема работы. Полезные схемы тяготеют к приложениям, в которых данные носят относительно предсказуемый характер – чем более изменчив набор данных, тем сложнее схемы.
Заключение. Информационный анализ в двух словах
Процесс выявления полезных элементов информационного набора XML теперь должен быть достаточно ясен:
- Определение требований к информационному набору.
- Изучение образцов информационного набора.
- Определение элементов информационного набора и отношений между элементами, которые удовлетворяют требованиям.
Создание прочной основы для XML-приложения может снизить потребность в сложном кодировании в процессе дальнейшей разработки.
Ресурсы для скачивания
Похожие темы
- Оригинал статьи (EN).
- Рекомендации по XML (включая DTD): документ со стандартами W3C, в котором подробно описаны XML и DTD.
- Рекомендация W3C XML Schema, часть 0 – основные понятия: стандарт, знакомящий с языком XML-схемы W3C.(EN)
- Информационный сайт RELAX NG: ссылки и информация о стандарте ISO/IEC 19757-2:2008. (EN)
- OASIS: подробнее об этой организации открытых стандартов. (EN)
- Основы XML для начинающих пользователей: введение в правильную разметку (Kay Whatley, developerWorks, февраль 2009 г.). Основы построения хорошо оформленных XML-документов, содержащих соглашения об именах, правильно вложенные теги, описания атрибутов, декларации, сущности плюс валидация как по DTD, так и по схеме (EN).
- Справка по RELAX NG (developerWorks, апрель 2007 г.): грамматические правила лексикона XML (EN).
- О RELAX NG в цикле статей Дэвида Мерца «Расслабимся с RELAX NG», опубликованном в его колонке «Вопросы XML» на DeveloperWorks:
- Часть 1 (февраль 2003 г.): общая семантика RELAX NG и основы контроля типов данных (EN).
- Часть 2 (март 2003 г.): обсуждение нескольких дополнительных вопросов семантики и знакомство с инструментами для работы с RELAX NG (EN).
- Часть 3 (май 2003 г.): подробно о компактном синтаксисе RELAX NG и о соответствии между компактным и XML-синтаксисом (EN).
- Schematron: выражение лексики XML в виде набора простых правил (developerWorks, апрель 2007 г.): откройте для себя преимущества стандарта Schematron для определения и ограничения словарей XML отдельно или в сочетании с другими языками XML-схемы (EN).
- XML Schema 1.1: введение в XML Schema 1.1 (Neil Delima, Sandy Gao, Michael Glavassevich, Khaled Noaman):
цикл статей на DeveloperWorks о возможностях нового стандарта:
- Часть 1 (декабрь 2008 г.): обзор функциональных возможностей, а также дополнения и изменения в типах данных (EN).
- Часть 2 (январь 2009 г.): механизмы совместных ограничений, в частности, новые функции, относящиеся к утверждениям и альтернативным типам (EN).
- Часть 3 (ноябрь 2009 г.): функции версионности с новыми мощными механизмами шаблонов и открытым контентом (EN).
- Сертификация IBM по XML: как стать сертифицированным разработчиком IBM по XML и связанным с ним технологиям.(EN)
- Подкасты developerWorks: интересные интервью и дискуссии разработчиков программного обеспечения.(EN)
Подпишите меня на уведомления к комментариям
www.ibm.com
XML Schema (XML схема) — описание структуры XML-документов
В предыдущей статье про XML мы рассмотрели такой уже устаревший способ валидации XML-документов, как XML DTD. Данный способ до сих пор применяется для проверки XML-данных, но с каждым днем его все больше и больше вытесняет новая технология под названием XML Schema. В XML схемах было исправлено множество недоработок, которые были в XML DTD, поэтому на данный момент все передовые разработчики для валидации документов применяют только XML схемы.
Чтобы оценить преимущество XML схем (XML Schema) перед DTD, давайте более подробно рассмотрим основные недостатки DTD, которые с успехом были исправлены в XML схемах. О них я уже упоминал в статье «XML DTD», но для лучшего понимания давайте повторим.
Недостатки XML DTD перед XML Schema
- Отличный от XML синтаксис языка. То есть, DTD не является XML. В связи с этим могут возникать разнообразные проблемы с кодировкой и верификацией XML-документов.
- Нет проверки типов данных. В XML DTD существует лишь один тип данных – строка. В связи с этим, например, если в числовом поле будет текст, документ все равно пройдет верификацию, так как XML DTD не может проверить тип данных.
- Нельзя поставить в соответствие одному XML-документу больше одного DTD описания. То есть, верифицировать документ можно лишь одним DTD описанием. Если их несколько, то придется переделывать описания и совмещать все в одном файле, что очень неудобно.
Это были основные недостатки XML DTD, которые с успехом исправлены в промышленном стандарте описания XML-документов XML Schema.
XML Schema – промышленный стандарт описания XML-документов
Если быть кратким, то XML Schema делает следующее:
- Описывает названия элементов и атрибутов (словарь).
- Описывает взаимосвязь между элементами и атрибутами, а также их структуру (модель содержания).
- Описывает типы данных.
Также хочу заметить, что на данный момент при помощи схем можно описывать практически все. То есть, схема – это универсальный способ описания грамматики данных, который может применяться не только для верификации XML-документов, но и описания баз данных и т.д. Таким образом, область применения схем на данный момент очень широкая.
Пример XML Schema для валидации XML-документа
Как показывает практика, материал намного лучше усваивается, если сразу начинать изучение с примеров. Сразу скажу, что углубляться во все тонкости мы не будем, так как материал очень сложный, особенно если изучать его в текстовом виде.
Пример простой схемы XML
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="книга" type="Книга" />
<xs:complexType name="Книга">
<xs:sequence>
<xs:element name="название" type="xs:string" />
<xs:element name="цена" type="xs:decimal" />
</xs:sequence>
</xs:complexType>
</xs:schema>При помощи данной схемы можно проверить XML-документ следующего содержания.
<книга xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation = "book.xsd">
<название>Основы XML</название>
<цена>300</цена>
</книга>Итак, вернемся к нашей XML схеме. Как вы уже заметили, для создания XML схем используется уже известный нам XML. Единственное отличие здесь в том, что в XML Schema уже определены элементы, в отличие от обычного XML. В связи с этим используются пространства имен. В данном случае обязательным пространством имен будет «http://www.w3.org/2001/XMLSchema», которое будет задаваться при помощи префиксов «xs».
Сразу хочу заметить, что можно использовать как префиксы пространств имен, так и задавать пространство имен для корневого элемента. Как таковой разницы здесь нет. Каждый сам решает, как ему поступать в данной ситуации. Скажу только, что обычно используются префиксы «xs» или «xsd».
Ну а теперь давайте разберемся, как же расшифровать вышеприведенную схему. Как уже говорилось выше, XML Schema это описание словаря и типов данных. Отталкиваясь от этого, произведем расшифровку каждого элемента.
- <xs:element name=»книга» type=»Книга» /> — объявляем элемент «книга» с типом «Книга».
- <xs:complexType name=»Книга»> — объявляем комплексный тип с именем «Книга» (xs:complexType – может содержать в себе вложенные элементы).
- <xs:sequence> — объявление вложенности. То есть, тип будет содержать вложенные элементы.
- <xs:element name=»название» type=»xs:string» /> — объявляем элемент с именем «название» (стандартного типа «строка» — xs:string).
- <xs:element name=»цена» type=»xs:decimal» /> — объявляем элемент с именем «цена» (стандартного типа «число» — xs:decimal).
Как видите, ничего сверхсложного здесь нет. Если вдуматься, то все очень просто.
Основные элементы XML Schema
Если быть кратким, то XML схему можно описать следующим образом.
<xsd:schema
xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:annotation>
<xsd:documentation>
Ваша схема
</xsd:documentation>
</xsd:annotation>
…
</xsd:schema>Как видно с примера, каждая XML схема состоит с корневого элемента «schema» и обязательного пространства имен «http://www.w3.org/2001/XMLSchema». Далее идет описание схемы и собственно сама схема. При этом очень часто в очень качественных схемах описание бывает куда большим, чем сама XML Schema.
Описание элементов в XML Schema
В начале статьи мы уже рассмотрели пример простейшей XML схемы. В ней мы отдельно описывали элементы и типы. При этом сразу хочу заметить, что последовательность здесь не играет роли. Схема будет работать в любом случае.
Теперь давайте рассмотрим второй способ написания XML Schema, который основывается на том, чтобы описывать тип сразу внутри элемента. Данный способ подойдет в том случае, если вы не планируете использовать одно и то же описание для разных элементов. Для наглядности рассмотрим пример.
<?xml version="1.0" encoding="utf-8" ?>
<xs:schema
xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="root">
<xs:complexType>
<xs:sequence>
<xs:element name="name" type="xs:string" />
<xs:element name="age" type="xs:integer" />
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>Как видно с примера, элемент объявляется при помощи специальной конструкции «element» с использованием соответствующего префикса. В данном случае мы определяем элемент с названием «root» без указания типа (type), так как он будет описан внутри элемента. То есть, есть два способа описания элементов.
1 способ
<xs:element name="название элемента" type="название типа" />
<xs:complexType name="название типа">
Описание типа
</xs:complexType>2 способ
<xs:element name="root">
Описание типа элемента
</xs:element>Вы можете использовать как первый способ, так и второй. Все они работают одинаково. Вопрос лишь в удобстве в данном конкретном случае.
Далее после объявления элемента мы указываем, что он комплексного типа (<xs:complexType>) и перечисляем (<xs:sequence>) вложенные элементы. В данном случае это элементы name и age с типами «xs:string» и «xs:integer». Префикс xs означает, что это базовый тип, который уже описан в стандарте XML Schema.
Как видите, пока все довольно просто. Опять же, углубляться во все подробности мы не будем, так как данная статья предназначена для ознакомления с XML Schema, а не ее детальным изучением.
Как ставится в соответствие XML Schema и документ
Особенностью XML Schema является то, что она описывает не сам документ, а пространство имен. В связи с этим чаще всего никаких упоминаний о ней в документе нет. Обработчик сам ставит в соответствие нужную вам схему без использования каких-либо инструкций в XML-документе.
На случай, если обработчик не знает где лежит схема, мы можем указать, где ее искать. Делается это при помощи специального атрибута «schemaLocation». Поскольку этот атрибут принадлежит другому пространству имен, то перед началом использования атрибута пространство тоже нужно указать. Для наглядности рассмотрим пример.
XML Schema
<?xml version="1.0" ?>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.site.com"
...XML-документ
<?xml version="1.0" ?>
<my:product xmlns:my="http://www.site.com"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.site.com/product.xsd"
…Теперь давайте подробно разберем каждую строчку.
- targetNamespace=»http://www.site.com» – указываем для какого пространства имен эта XML Schema.
- xmlns:xsi=»http://www.w3.org/2001/XMLSchema-instance» – подключаем пространство имен в котором описан атрибут «schemaLocation».
- xsi:schemaLocation=»http://www.site.com/product.xsd» – указываем, где можно найти схему на случай, если парсер не знает где она лежит. Если XML-документ не принадлежит никакому пространству имен, а следовательно и в схеме нет на него указания, то атрибут «schemaLocation» заменяется на «noNamespaceSchemaLocation» (указание на схему без определения пространств имен).
Рекомендую также ознакомиться с другими статьями по XML и XSLT:
На этом я заканчиваю данную статью. Надеюсь, мне удалось объяснить этот сложный материал и вышеизложенная информация будет вам полезна. Если не хотите пропустить выпуска других статей по XML, рекомендую подписаться на новостную рассылку, воспользовавшись формой ниже.
На этом все. Удачи вам и успехов в изучении XML!
Обнаружили ошибку? Выделите ее и нажмите Ctrl+Enter
archive.dmitriydenisov.com