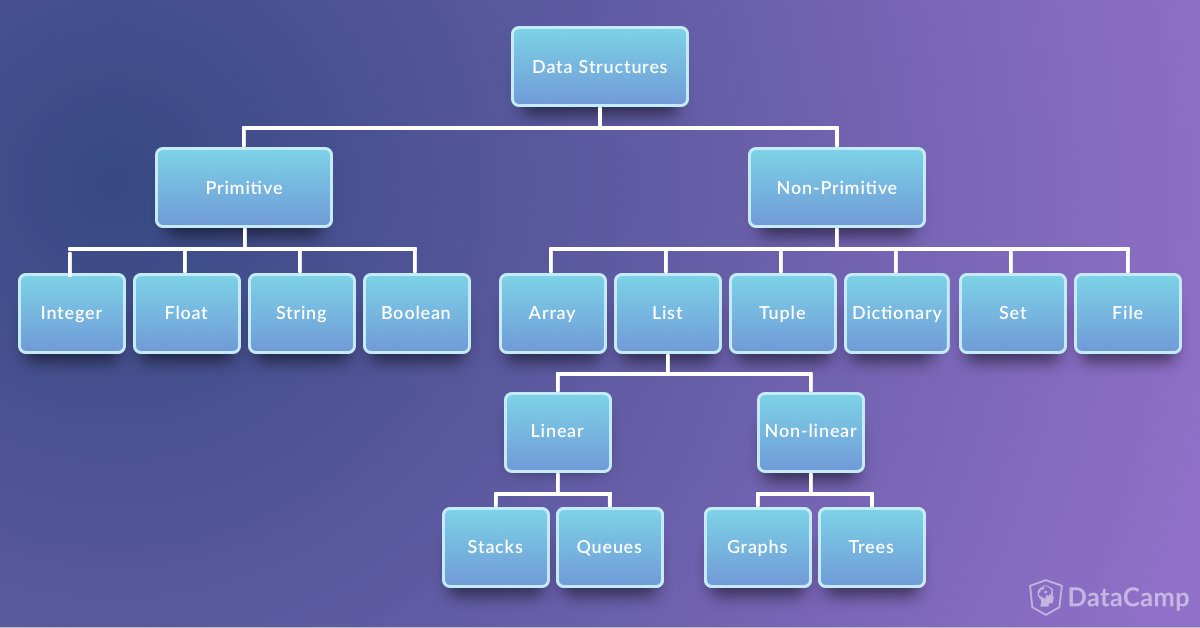
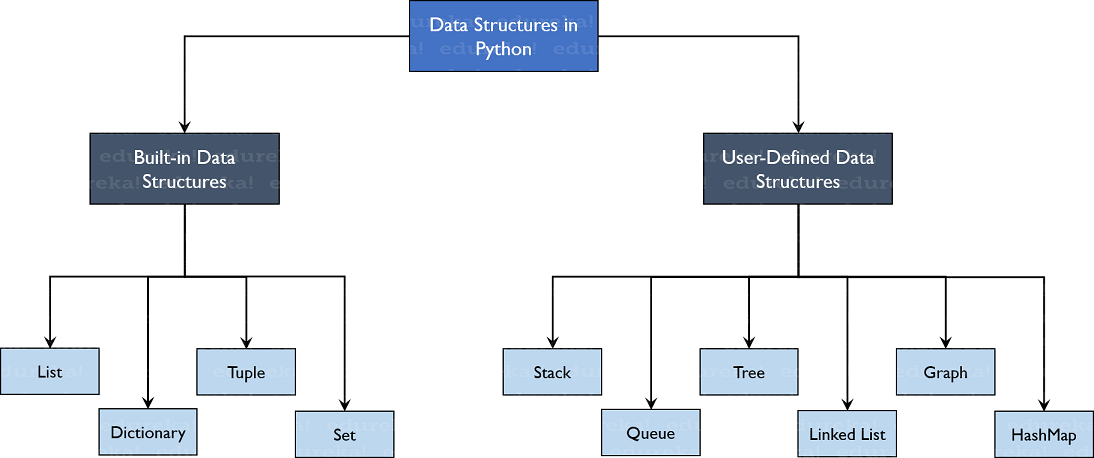
Подробное объяснение встроенных структур данных Python
В каждом языке программирования предусмотрены структуры данных. В языке программирования Python всего 4 встроенных структуры данных. Это список (list ), кортеж (tuple), словарь (dictionary ) и набор или множество(set). Каждый из них по-своему уникален.
Структуры данных — неотъемлемая часть программирования. Все хорошие книги по программированию на Python в той или иной степени подробно описывают структуры данных.
СписокСтруктура данных, в которой хранится упорядоченный набор элементов в Python, называется списком. Другими словами, список содержит последовательность элементов. Вам нужно поместить все элементы, разделенные запятыми, в квадратные скобки, чтобы Python знал, что список указан. Общий синтаксис списка:
some_list = [item 1, item 2, item 3,….., item n]
В любом списке может быть любое количество элементов и разные типы данных. Более того, в списке может быть другой список в качестве элемента. Такой список называется вложенным списком . Например,
Такой список называется вложенным списком . Например,
some_nested_list = [item 1, some_list, item 3,….., item n]
После создания списка в Python можно искать, добавлять и удалять элементы из списка. Список может быть помечен как изменяемый тип данных, потому что он может быть изменен путем добавления или удаления элементов.
Список на языке программирования Python — это пример использования объектов и классов. Например, присвоение значения, скажем 22, целочисленной переменной, пусть это будет i, создает объект класса integer. Таким образом, список также является типом класса в Python.
У любого класса могут быть методы, которые можно использовать только тогда, когда у нас есть объект этого конкретного класса. Например, метод append () позволяет добавить элемент в конец списка. Общий синтаксис метода:
some_list.append(‘some item’)
Здесь some_list — это имя списка, а some item — это элемент, который нужно добавить в список. Класс может иметь поля, которые представляют собой переменные, определенные для использования только с экземпляром этого класса. Ниже приведены различные методы, поддерживаемые списками в Python:
Ниже приведены различные методы, поддерживаемые списками в Python:
- append () — добавляет элемент в конец списка
- clear () — удаляет все элементы из списка
- copy () — возвращает копию списка
- count () — возвращает общее количество элементов, переданных в качестве аргумента
- extend () — добавляет все элементы списка в другой список
- index () — возвращает индекс элемента (Примечание: если один и тот же элемент появляется в списке несколько раз, возвращается индекс самого первого совпадения)
- insert () — вставляет элемент в список по заданному индексу
- pop () — Удаляет и возвращает элемент из списка
- remove () — удаляет элемент из списка
- reverse () — меняет порядок всех элементов списка на обратный
- sort () — сортирует все элементы списка в порядке возрастания
Подобно списку, кортеж — это встроенная структура данных в Python. Однако он не поддерживает такой же уровень обширной функциональности. Самое важное различие между списком и кортежем — это изменчивость. В отличие от списков, кортежи неизменяемы, т. е. не могут быть изменены.
Однако он не поддерживает такой же уровень обширной функциональности. Самое важное различие между списком и кортежем — это изменчивость. В отличие от списков, кортежи неизменяемы, т. е. не могут быть изменены.
Обычно кортеж в языке программирования Python определяется с помощью круглых скобок, где каждый элемент разделяется запятыми. Хотя добавление круглых скобок к кортежу не является обязательным, его рекомендуется использовать для четкого определения конца и начала кортежа. Общий синтаксис кортежа:
some_tuple = (item 1, item 2, item 3,….., item n)
Кортежи используются в сценариях, где точно известно, что (набор) значений, принадлежащих некоторому оператору или определяемой пользователем функции, не изменится.
Чтобы определить пустой кортеж, используется пустая пара круглых скобок. Например,
empty_tuple = ()
Определить кортеж с одним элементом немного сложно. Вам нужно указать то же самое, используя запятую после единственного элемента. Это сделано для того, чтобы позволить Python различать кортеж и пару круглых скобок, окружающих объект в некотором выражении.
Итак, кортеж, скажем singleton_tuple, с одним элементом, скажем, элементом 1, определяется как:
singleton_tuple = (item 1, )
Как и строковые индексы, индексы кортежей начинаются с 0. Как и строки, кортежи можно объединять и нарезать. Для кортежей доступны следующие методы:
- cmp () — сравнивает элементы двух кортежей
- len () — выдает общую длину некоторого кортежа
- max () — возвращает наибольшее значение из кортежа
- min () — возвращает наименьшее значение из кортежа
- tuple () — преобразует список в кортеж
Последовательности
Списки и кортежи могут называться последовательностями, как и строки. Наиболее отличительными особенностями последовательности являются тесты на членство и операции индексации. Последний позволяет напрямую извлекать элемент (ы) из последовательности.
Python обеспечивает поддержку трех типов последовательностей: списки, строки и кортежи. Каждый из них поддерживает операцию slicing . Это позволяет получить определенную часть последовательности.
СловарьДругой тип встроенной структуры данных в Python — это словарь. Он хранит данные в виде пар ключ-значение. Ключи, определенные для словаря, должны быть уникальными. Хотя значения в словаре могут быть изменяемыми или неизменяемыми объектами, для ключей разрешены только неизменяемые объекты.
Словарь в Python определяется с помощью пар ключ-значение, разделенных запятыми и заключенных в фигурные скобки. Ключ и значение разделяются двоеточием. Общий синтаксис словаря:
some_dictionary =
Пары ключ-значение в словаре не следуют определенному порядку. Следовательно, вам нужно отсортировать их вручную для поддержания определенного порядка. Любой словарь, определенный на языке программирования Python, является экземпляром класса dict .
Чтобы получить доступ к любой паре «ключ-значение», необходимо указать ключ с помощью оператора индексации. Оператор del используется для удаления одной или нескольких пар ключ-значение из словаря. Оператор in предназначен для проверки того, существует ли пара ключ-значение в словаре или нет.
Оператор индексации также используется для добавления новой пары «ключ-значение». Использование аргументов ключевого слова в функциях очень похоже на использование словарей.
НаборПроще говоря, набор — это неупорядоченный набор простых объектов в Python. Помимо того, что набор может быть повторяемым и изменяемым, он не имеет повторяющихся элементов. Любой набор, определенный в Python, является экземпляром класса набора .
По сравнению со списком, набор имеет преимущество благодаря наличию высокооптимизированного метода проверки того, содержится ли какой-либо элемент в наборе или нет. Общий синтаксис набора:
some_set = {“item 1”, “item 2”, “item 3”,…. ., “item n”}
., “item n”} ., “item n”}
., “item n”}Обычно набор используется, когда существование объекта в коллекции намного важнее, чем его порядок или частота (количество раз, когда он появляется).
Использование наборов позволяет проверять членство, например проверять, является ли набор подмножеством какого-либо другого набора, и находить пересечение между двумя наборами. Множества в Python следуют математической концепции теории множеств .
В Python есть замороженный набор — это набор, который поддерживает только те методы и операторы, которые производят результат, не затрагивая замороженный набор или наборы, к которым они применяются. Наборы поддерживают следующие методы:
- add () — добавляет элемент в набор (Примечание: поскольку наборы не имеют повторяющихся значений, элемент, который должен быть добавлен в набор, не должен уже быть членом набора).
- clear () — Удаляет все элементы набора
- разница () — возвращает набор со всеми элементами вызывающего набора, но не второго набора
- crossct () — возвращает пересечение двух множеств
- union () — возвращает объединение двух наборов
8 структур данных Python
Решая реальные проблемы кодирования, работодатели и рекрутеры стремятся как к эффективности времени выполнения, так и к ресурсоэффективности.
Знание того, какая структура данных лучше всего подходит для текущего решения, повысит производительность программы и сократит время, необходимое для её создания. По этой причине большинству ведущих компаний требуется чёткое понимание структур данных и их тщательное тестирование на собеседовании по кодированию.
Содержание
- Что такое структуры данных?
- Массивы (списки) в Python
- Очереди в Python
- Стеки в Python
- Связанные списки в Python
- Циркулярно связанные списки в Python
- Деревья в Python
- Графы в Python
- Хеш-таблицы в Python
- Заключение
Что такое структуры данных?
Структуры данных — это структуры кода для хранения и организации данных, которые упрощают изменение, навигацию и доступ к информации. Структуры данных определяют способ сбора данных, функциональные возможности, которые мы можем реализовать, и отношения между данными.
Структуры данных используются практически во всех областях информатики и программирования, от операционных систем до интерфейсной разработки и машинного обучения.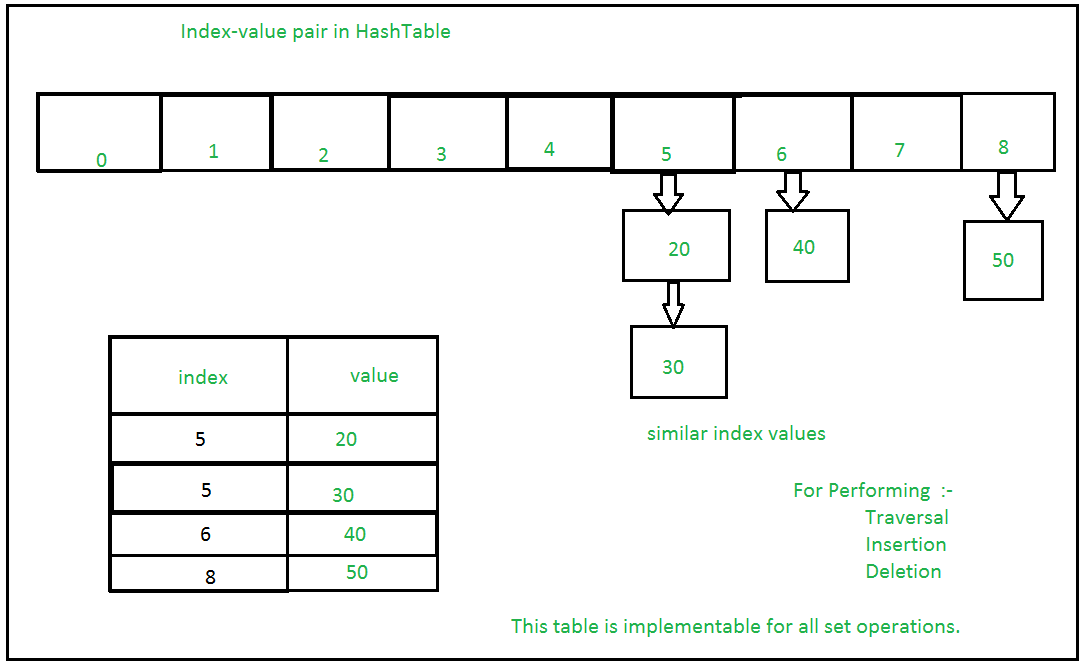
Структуры данных помогают:
- Управляйте большими наборами данных и используйте их.
- Быстрый поиск определённых данных в базе данных.
- Создавайте чёткие иерархические или реляционные связи между точками данных.
- Упростите и ускорьте обработку данных.
Структуры данных являются жизненно важными строительными блоками для эффективного решения реальных проблем. Структуры данных — это проверенные и оптимизированные инструменты, которые дают вам удобную основу для организации ваших программ. В конце концов, вам не нужно переделывать колесо (или конструкцию) каждый раз, когда это нужно.
У каждой структуры данных есть задача или ситуация, для решения которой она наиболее подходит. Python имеет 4 встроенных структуры данных, списки, словари, кортежи и наборы. Эти встроенные структуры данных поставляются с методами по умолчанию и негласной оптимизацией, которая упрощает их использование.
Большинство структур данных в Python являются их модифицированными формами или используют встроенные структуры в качестве основы.
- Список: структуры, похожие на массивы, которые позволяют сохранять набор изменяемых объектов одного и того же типа в переменную.
- Кортеж: кортежи — это неизменяемые списки, то есть элементы не могут быть изменены. Он объявлен в круглых скобках вместо квадратных.
- Набор: наборы — это неупорядоченные коллекции, что означает, что элементы неиндексированы и не имеют установленной последовательности. Они объявляются фигурными скобками.
- Словарь (dict): Подобно хэш-карте или хеш-таблицам на других языках, словарь представляет собой набор пар ключ / значение. Вы инициализируете пустой словарь пустыми фигурными скобками и заполняете его ключами и значениями, разделёнными двоеточиями. Все ключи — уникальные неизменяемые объекты.
Теперь давайте посмотрим, как мы можем использовать эти структуры для создания всех сложных структур, которые ищут интервьюеры.
Массивы (списки) в Python
Python не имеет встроенного типа массива, но вы можете использовать списки для всех тех же задач. Массив — это набор значений одного типа, сохранённых под тем же именем.
Массив — это набор значений одного типа, сохранённых под тем же именем.
Каждое значение в массиве называется «элементом», и индексирование соответствует его положению. Вы можете получить доступ к определённым элементам, вызвав имя массива с индексом желаемого элемента. Вы также можете получить длину массива с помощью len()метода.
В отличие от языков программирования, таких как Java, которые имеют статические массивы после объявления, массивы Python автоматически увеличиваются или уменьшаются при добавлении / вычитании элементов.
Например, мы могли бы использовать этот append()метод для добавления дополнительного элемента в конец существующего массива вместо объявления нового массива.
Это делает массивы Python особенно простыми в использовании и адаптируемыми на лету.
cars = [«Toyota», «Tesla», «Hyundai»]
print(len(cars))
cars.append(«Honda»)
cars.pop(1)
for x in cars:
print(x)
Преимущества:
- Простота создания и использования последовательностей данных.
- Автоматическое масштабирование в соответствии с меняющимися требованиями к размеру.
- Используется для создания более сложных структур данных.

Недостатки:
- Не оптимизирован для научных данных (в отличие от массива NumPy).
- Может управлять только крайним правым концом списка.
Приложения:
- Совместное хранилище связанных значений или объектов, т.е. myDogs.
- Коллекции данных, которые вы будете просматривать.
- Коллекции структур данных, например, список кортежей.
Общие вопросы собеседования с массивами в Python
- Удалить чётные числа из списка.
- Объединить два отсортированных списка.
- Найдите минимальное значение в списке.
- Подсписок максимальной суммы.
- Печать продукции всех элементов.
Очереди в Python
Очереди — это линейная структура данных, в которой данные хранятся в порядке «первым пришёл — первым ушёл» (FIFO). В отличие от массивов, вы не можете получить доступ к элементам по индексу, а вместо этого можете извлечь только следующий самый старый элемент. Это делает его отличным решением для задач, чувствительных к заказу, таких как обработка онлайн-заказов или хранение голосовой почты.
В отличие от массивов, вы не можете получить доступ к элементам по индексу, а вместо этого можете извлечь только следующий самый старый элемент. Это делает его отличным решением для задач, чувствительных к заказу, таких как обработка онлайн-заказов или хранение голосовой почты.
Вы можете представить очередь как очередь в продуктовом магазине; кассир не выбирает, кого проверять следующим, а скорее обрабатывает человека, который дольше всех стоял в очереди.
Мы могли бы использовать список Python с append()и pop()методами для реализации очереди. Однако это неэффективно, потому что списки должны сдвигать все элементы на один индекс всякий раз, когда вы добавляете новый элемент в начало.
Вместо этого лучше всего использовать dequeкласс из collectionsмодуля Python. Deques оптимизированы для операций добавления и извлечения. Deque реализация также позволяет создавать двухсторонние очереди, которые могут получить доступ к обеим сторонам очередей через popleft()и popright()методы.
from collections import deque
# Initializing a queue
q = deque()
# Adding elements to a queue
q.append(‘a’)
q.append(‘b’)
q.append(‘c’)
print(«Initial queue»)
print(q)
# Removing elements from a queue
print(«\nElements dequeued from the queue»)
print(q.popleft())
print(q.popleft())
print(q.popleft())
print(«\nQueue after removing elements»)
print(q)
# Uncommenting q.popleft()
# will raise an IndexError
# as queue is now empty
Преимущества:
- Автоматически упорядочивает данные в хронологическом порядке.
- Весы в соответствии с требованиями к размеру.
- Эффективное время с dequeклассом.
Недостатки:
- Доступ к данным возможен только на концах.
Приложения:
- Операции с общим ресурсом, таким как принтер или ядро ЦП.
- Служит временным хранилищем для пакетных систем.
- Обеспечивает простой порядок по умолчанию для задач равной важности.

Общие вопросы на собеседовании в очереди на Python
- Обратить первые k элементов очереди.
- Реализуйте очередь, используя связанный список.
- Реализуйте стек с помощью очереди.
Стеки в Python
Стеки представляют собой последовательную структуру данных, которая действует как версия очередей «последний пришёл — первым ушёл» (LIFO). Последний элемент, вставленный в стек, считается верхним в стеке и является единственным доступным элементом. Чтобы получить доступ к среднему элементу, вы должны сначала удалить достаточное количество элементов, чтобы нужный элемент находился на вершине стека.
Многие разработчики представляют стопки как стопку обеденных тарелок; вы можете добавлять или убирать тарелки в верхнюю часть стопки, но вам нужно переместить всю стопку, чтобы разместить одну внизу.
Добавление элементов называется выталкиванием, а удаление элементов — всплывающим сообщением.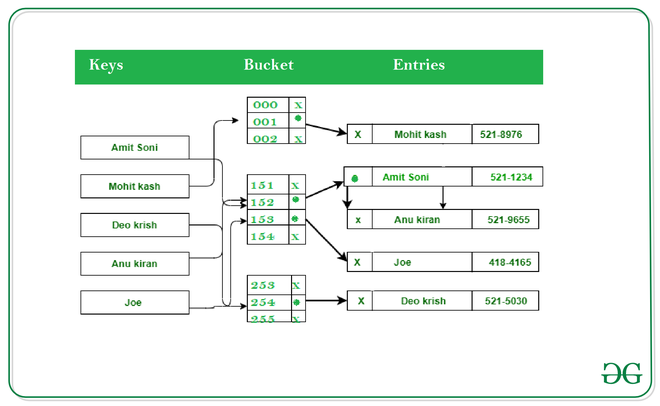 Вы можете реализовать стеки в Python, используя встроенную структуру списка. При реализации списка в операциях push используется append()метод, а в операциях pop — pop().
Вы можете реализовать стеки в Python, используя встроенную структуру списка. При реализации списка в операциях push используется append()метод, а в операциях pop — pop().
stack = []
# append() function to push
# element in the stack
stack.append(‘a’)
stack.append(‘b’)
stack.append(‘c’)
print(‘Initial stack’)
print(stack)
# pop() function to pop
# element from stack in
# LIFO order
print(‘\nElements popped from stack:’)
print(stack.pop())
print(stack.pop())
print(stack.pop())
print(‘\nStack after elements are popped:’)
print(stack)
# uncommenting print(stack.pop())
# will cause an IndexError
# as the stack is now empty
Преимущества:
- Предлагает управление данными LIFO, которое невозможно с массивами.
- Автоматическое масштабирование и очистка объекта.
- Простая и надёжная система хранения данных.
Недостатки:
- Память стека ограничена.
- Слишком много объектов в стеке приводит к ошибке переполнения стека.
Приложения:
- Используется для создания высокореактивных систем.
- Системы управления памятью используют стеки для обработки в первую очередь самых последних запросов.
- Полезно для таких вопросов, как сопоставление скобок.
Общие вопросы собеседования по стекам в Python
- Реализуйте очередь, используя стеки.
- Вычислить выражение Postfix с помощью стека.
- Следующий по величине элемент, использующий стек.
- Создать min()функцию с использованием стека.
Связанные списки в Python
Связанные списки — это последовательный набор данных, который использует реляционные указатели на каждом узле данных для связи со следующим узлом в списке.
В отличие от массивов, связанные списки не имеют объективных позиций в списке. Вместо этого у них есть относительные позиции, основанные на их окружающих узлах.
Вместо этого у них есть относительные позиции, основанные на их окружающих узлах.
Первый узел в связанном списке называется головным узлом, а последний — хвостовым узлом, который имеет nullуказатель.
Связанные списки могут быть односвязными или дважды связанными в зависимости от того, имеет ли каждый узел только один указатель на следующий узел или он также имеет второй указатель на предыдущий узел.
Вы можете думать о связанных списках как о цепочке; отдельные ссылки имеют связь только со своими ближайшими соседями, но все ссылки вместе образуют более крупную структуру.
Python не имеет встроенной реализации связанных списков и поэтому требует, чтобы вы реализовали Nodeкласс для хранения значения данных и одного или нескольких указателей.
class Node:
def __init__(self, dataval=None):
self.dataval = dataval
self.nextval = None
class SLinkedList:
def __init__(self):
self.
list1 = SLinkedList()
list1.headval = Node(«Mon»)
e2 = Node(«Tue»)
e3 = Node(«Wed»)
# Link first Node to second node
list1.headval.nextval = e2
# Link second Node to third node
e2.nextval = e3
 headval = None
headval = NoneСвязанные списки в основном используются для создания расширенных структур данных, таких как графики и деревья, или для задач, требующих частого добавления / удаления элементов по всей структуре.
Преимущества:
- Эффективная вставка и удаление новых элементов.
- Проще реорганизовать, чем массивы.
- Полезно в качестве отправной точки для сложных структур данных, таких как графики или деревья.
Недостатки:
- Хранение указателей с каждой точкой данных увеличивает использование памяти.
- Всегда должен перемещаться по связанному списку от узла Head, чтобы найти определённый элемент.
Приложения:
- Строительный блок для расширенных структур данных.
- Решения, требующие частого добавления и удаления данных.

Общие вопросы собеседования по связному списку в Python
- Распечатать средний элемент данного связанного списка.
- Удалить повторяющиеся элементы из отсортированного связного списка.
- Проверьте, является ли односвязный список палиндромом.
- Объединить K отсортированных связанных списков.
- Найдите точку пересечения двух связанных списков.
Циркулярно связанные списки в Python
Основным недостатком стандартного связного списка является то, что вам всегда нужно начинать с узла Head.
Циклический связанный список устраняет эту проблему, заменяя nullуказатель узла Tail указателем на узел Head. При обходе программа будет следовать указателям, пока не достигнет узла, на котором она была запущена.
Преимущество этой настройки заключается в том, что вы можете начать с любого узла и пройти по всему списку. Это также позволяет вам использовать связанные списки в качестве зацикленной структуры, задав желаемое количество циклов через структуру.
Списки с круговой связью отлично подходят для процессов, которые зацикливаются в течение длительного времени, например, распределение ЦП в операционных системах.
Преимущества:
- Может просматривать весь список, начиная с любого узла.
- Делает связанные списки более подходящими для циклических структур.
Недостатки:
- Сложнее найти узлы Head и Tail списка без nullмаркера.
Приложения:
- Регулярно зацикливающиеся решения, такие как планирование ЦП.
- Решения, в которых вам нужна свобода начать обход с любого узла.
Общие вопросы собеседования со связным списком в Python
- Обнаружить петлю в связанных списках.
- Перевернуть круговой связанный список.
- Обратный круговой связанный список в группах заданного размера.
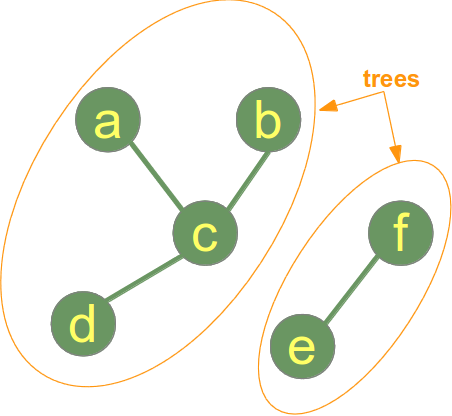
Деревья в Python
Деревья — это ещё одна основанная на отношениях структура данных, которая специализируется на представлении иерархических структур. Как и связанный список, они заполняются Nodeобъектами, которые содержат значение данных и один или несколько указателей для определения его отношения к непосредственным узлам.
Как и связанный список, они заполняются Nodeобъектами, которые содержат значение данных и один или несколько указателей для определения его отношения к непосредственным узлам.
Каждое дерево имеет корневой узел, от которого отходят все остальные узлы. Корень содержит указатели на все элементы непосредственно под ним, которые известны как его дочерние узлы. Эти дочерние узлы могут иметь собственные дочерние узлы. У двоичных деревьев не может быть узлов с более чем двумя дочерними узлами.
Любые узлы на одном уровне называются одноуровневыми узлами. Узлы без подключённых дочерних узлов называются листовыми узлами.
Наиболее распространённое применение двоичного дерева — это двоичное дерево поиска. Деревья двоичного поиска превосходно подходят для поиска больших наборов данных, поскольку временная сложность зависит от глубины дерева, а не от количества узлов.
Деревья двоичного поиска имеют четыре строгих правила:
- Левое поддерево содержит только узлы с элементами меньше корня.
- Правое поддерево содержит только узлы с элементами больше корня.
- Левое и правое поддеревья также должны быть двоичным деревом поиска. Они должны следовать приведённым выше правилам с «корнем» своего дерева.
- Не может быть повторяющихся узлов, т.е. никакие два узла не могут иметь одинаковое значение.

class Node:
def __init__(self, data):
self.left = None
self.right = None
self.data = data
def insert(self, data):
# Compare the new value with the parent node
if self.data:
if data < self.data:
if self.left is None:
self.left = Node(data)
else:
self.left.insert(data)
elif data > self.data:
if self.right is None:
self.right = Node(data)
else:
self.
else:
self.data = data
# Print the tree
def PrintTree(self):
if self.left:
self.left.PrintTree()
print( self.data),
if self.right:
self.right.PrintTree()
# Use the insert method to add nodes
root = Node(12)
root.insert(6)
root.insert(14)
root.insert(3)
root.PrintTree()
 right.insert(data)
right.insert(data)Преимущества:
- Подходит для представления иерархических отношений.
- Динамический размер, отличный масштаб.
- Операции быстрой вставки и удаления.
- В двоичном дереве поиска вставленные узлы сразу же упорядочиваются..
- Деревья двоичного поиска эффективны при поиске; длина толькоO (высота)О ( ч е я г ч т ).
Недостатки:
- Время дорогое, O (войти) 4O ( l o g n ) 4, чтобы изменить или «сбалансировать» деревья или извлечь элементы из известного местоположения.
- Дочерние узлы не содержат информации о своих родительских узлах, и их трудно перемещать назад.
- Работает только для отсортированных списков. Несортированные данные превращаются в линейный поиск.

Приложения:
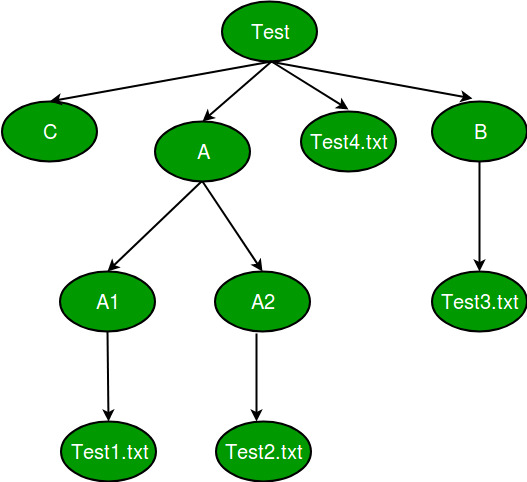
- Отлично подходит для хранения иерархических данных, таких как расположение файла.
- Используется для реализации лучших алгоритмов поиска и сортировки, таких как двоичные деревья поиска и двоичные кучи.
Общие вопросы на собеседовании с деревом в Python
- Проверьте, идентичны ли два двоичных дерева.
- Реализовать обход порядка уровней бинарного дерева.
- Распечатайте периметр двоичного дерева поиска.
- Суммируйте все узлы на пути.
- Подключите всех братьев и сестёр двоичного дерева.
Графы в Python
Графы — это структура данных, используемая для визуального представления взаимосвязей между вершинами данных (узлами графа). Связи, соединяющие вершины вместе, называются рёбрами.
Рёбра определяют, какие вершины соединяются, но не указывают направление потока между ними. Каждая вершина имеет соединения с другими вершинами, которые сохраняются в вершине в виде списка, разделённого запятыми.
Undirected
Существуют также специальные графы, называемые ориентированными графами, которые определяют направление взаимосвязи, аналогично связному списку. Направленные графы полезны при моделировании односторонних отношений или структур, подобных блок-схемам.
Directed
Они в основном используются для передачи визуальных сетей веб-структур в кодовой форме. Эти структуры могут моделировать множество различных типов отношений, таких как иерархии, ветвящиеся структуры или просто быть неупорядоченной реляционной сетью. Универсальность и интуитивность графиков делают их фаворитом в науке о данных.
При написании в виде обычного текста графы имеют список вершин и рёбер:
V = {a, b, c, d, e}
E = {ab, ac, bd, cd, de}В Python графы лучше всего реализовать с использованием словаря с именем каждой вершины в качестве ключа и списком рёбер в качестве значений.
# Create the dictionary with graph elements
graph = { «a» : [«b»,»c»],
«b» : [«a», «d»],
«c» : [«a», «d»],
«d» : [«e»],
«e» : [«d»]
}
# Print the graph
print(graph)
Преимущества:
- Быстро передавайте визуальную информацию с помощью кода.
- Подходит для моделирования широкого спектра реальных проблем.
- Простой в освоении синтаксис.
Недостатки:
- Связи вершин трудно понять в больших графах.
- Дорогое время для анализа данных с графика.
Приложения:
- Отлично подходит для моделирования сетей или веб-структур.
- Используется для моделирования сайтов социальных сетей, таких как Facebook.
Общие вопросы собеседования с графиком в Python
- Обнаружить цикл в ориентированном графе.
- Найдите «материнскую вершину» в ориентированном графе.
- Подсчитать количество рёбер в неориентированном графе.
- Проверить, существует ли путь между двумя вершинами.
- Найдите кратчайший путь между двумя вершинами.

Хеш-таблицы в Python
Хеш-таблицы — это сложная структура данных, способная хранить большие объёмы информации и эффективно извлекать определённые элементы.
В этой структуре данных используются пары ключ / значение, где ключ — это имя желаемого элемента, а значение — это данные, хранящиеся под этим именем.
Каждый входной ключ проходит через хеш-функцию, которая преобразует его из начальной формы в целочисленное значение, называемое хешем. Хеш-функции всегда должны генерировать один и тот же хэш из одного и того же ввода, должны быстро вычислять и выдавать значения фиксированной длины. Python включает встроенную hash()функцию, ускоряющую реализацию.
Затем таблица использует хеш-код для нахождения общего местоположения желаемого значения, называемого корзиной хранения. После этого программе нужно будет искать нужное значение только в этой подгруппе, а не во всём пуле данных.
После этого программе нужно будет искать нужное значение только в этой подгруппе, а не во всём пуле данных.
Помимо этой общей структуры, хеш-таблицы могут сильно отличаться в зависимости от приложения. Некоторые могут разрешать ключи из разных типов данных, в то время как некоторые могут иметь разные настройки сегментов или разные хеш-функции.
Вот пример хеш-таблицы в коде Python:
import pprint
class Hashtable:
def __init__(self, elements):
self.bucket_size = len(elements)
self.buckets = [[] for i in range(self.bucket_size)]
self._assign_buckets(elements)
def _assign_buckets(self, elements):
for key, value in elements: #calculates the hash of each key
hashed_value = hash(key)
index = hashed_value % self.bucket_size # positions the element in the bucket using hash
self.buckets[index].append((key, value)) #adds a tuple in the bucket
def get_value(self, input_key):
hashed_value = hash(input_key)
index = hashed_value % self.
bucket = self.buckets[index]
for key, value in bucket:
if key == input_key:
return(value)
return None
def __str__(self):
return pprint.pformat(self.buckets) # pformat returns a printable representation of the object
if __name__ == «__main__»:
capitals = [
(‘France’, ‘Paris’),
(‘United States’, ‘Washington D.C.’),
(‘Italy’, ‘Rome’),
(‘Canada’, ‘Ottawa’)
]
hashtable = Hashtable(capitals)
print(hashtable)
print(f»The capital of Italy is {hashtable.get_value(‘Italy’)}»)
 bucket_size
bucket_sizeПреимущества:
- Может скрывать ключи в любой форме в целочисленные индексы.
- Чрезвычайно эффективен для больших наборов данных.
- Очень эффективная функция поиска.
- Постоянное количество шагов для каждого поиска и постоянная эффективность добавления или удаления элементов.
- Оптимизирован в Python 3.
Недостатки:
- Хэши должны быть уникальными, преобразование двух ключей в один и тот же хэш вызывает ошибку коллизии.
- Ошибки коллизии требуют полного пересмотра хэш-функции.
- Сложно построить для новичков.
Приложения:
- Используется для больших баз данных, в которых часто ведётся поиск.
- Системы поиска, использующие клавиши ввода.
Общие вопросы собеседования с хеш-таблицей в Python
- Создать хеш-таблицу с нуля (без встроенных функций).
- Формирование слова с помощью хеш-таблицы.
- Найдите два числа, которые в сумме дают «k».
- Реализовать открытую адресацию для обработки коллизий.
- Определите, является ли список циклическим, используя хеш-таблицу.
Заключение
Для каждой из этих 8 структур данных существуют десятки вопросов и форматов интервью. Лучший способ подготовиться к собеседованию — продолжать решать практические задачи.
Создание простейших структур данных с помощью функций в Python / Хабр
Вступление: Позапрошлым летом я открыл для себя великолепную книгу SICP — чтение только первого раздела книги открыло для меня новый мир функционального программирования. Анонимные функции, функции, что возвращают функции, функции высших порядков. Во втором разделе книги авторы показали, что возможно с помощью одних только функций создавать различные структуры данных, такие как пара, список, или даже деревья! Сегодня мне бы хотелось реализовать кое-какие идеи из этой книги на языке программирования Python. Конечно же, исключительно с помощью функций.
Начало: Python – это замечательный язык программирования, который поддерживает практически все парадигмы программирования. Python прост в понимании, и для чтения этой статьи достаточно базового знания языка. Не будет также лишним немного просмотреть эту статью.
I. Создание пары.Что такое пара?
Пара — это упорядоченный набор, который состоит из двух элементов, предположительно, разных типов. Стоит отметить, что в ЯП Python, кортеж ( пара — это частный случай кортежа) — это особый тип данных, который очень часто используется, и создается следующим образом: p = (a1,a2,..,an). Но так как мы условились использовать только функции, нам придется создать свою собственную реализацию пары:
Стоит отметить, что в ЯП Python, кортеж ( пара — это частный случай кортежа) — это особый тип данных, который очень часто используется, и создается следующим образом: p = (a1,a2,..,an). Но так как мы условились использовать только функции, нам придется создать свою собственную реализацию пары:
def make_pair(x,y):
return lambda n: x if n==0 else y
def first(p):
return p(0)
def second(p):
return p(1)
Постойте! Но ведь make_pair возвращает функцию, а не пару. На самом деле – пара в нашем представлении это и есть функция, что принимает на вход аргумент любое число, и возвращает первый элемент, если аргумент равен 0, и второй в противоположном случае. Для повышения уровня абстракции мы также создали функции доступа к элементам нашей пары: first и second. Убедимся, что наша реализация пары работает, как нужно:
p = make_pair(5,6)
first(p) #5
second(p) #6
p1 = make_pair('hello',6)
first(p1) #'hello'
II.
Список — это абстрактный тип данных, представляющий собой упорядоченный набор значений, в котором некоторое значение может встречаться более одного раза.
Сейчас мы реализуем связный список — одну из возможных реализаций списка.
Свя́зный спи́сок — базовая динамическая структура данных в информатике, состоящая из узлов, каждый из которых содержит как собственно данные, так и одну или две ссылки («связки») на следующий и/или предыдущий узел списка
На самом деле, связный список можно представить, как пару, которая состоит из двух значений: «голова» списка и его «хвост». К примеру, список [1,2,3,4] можно представить следующим образом:
l = make_pair(1,make_pair(2,make_pair(3,4))) first(l) #1 first(second(l)) #2
Теперь добавим поддержку пустых списков. Пустой список — это список, который не содержит ни одного элемента.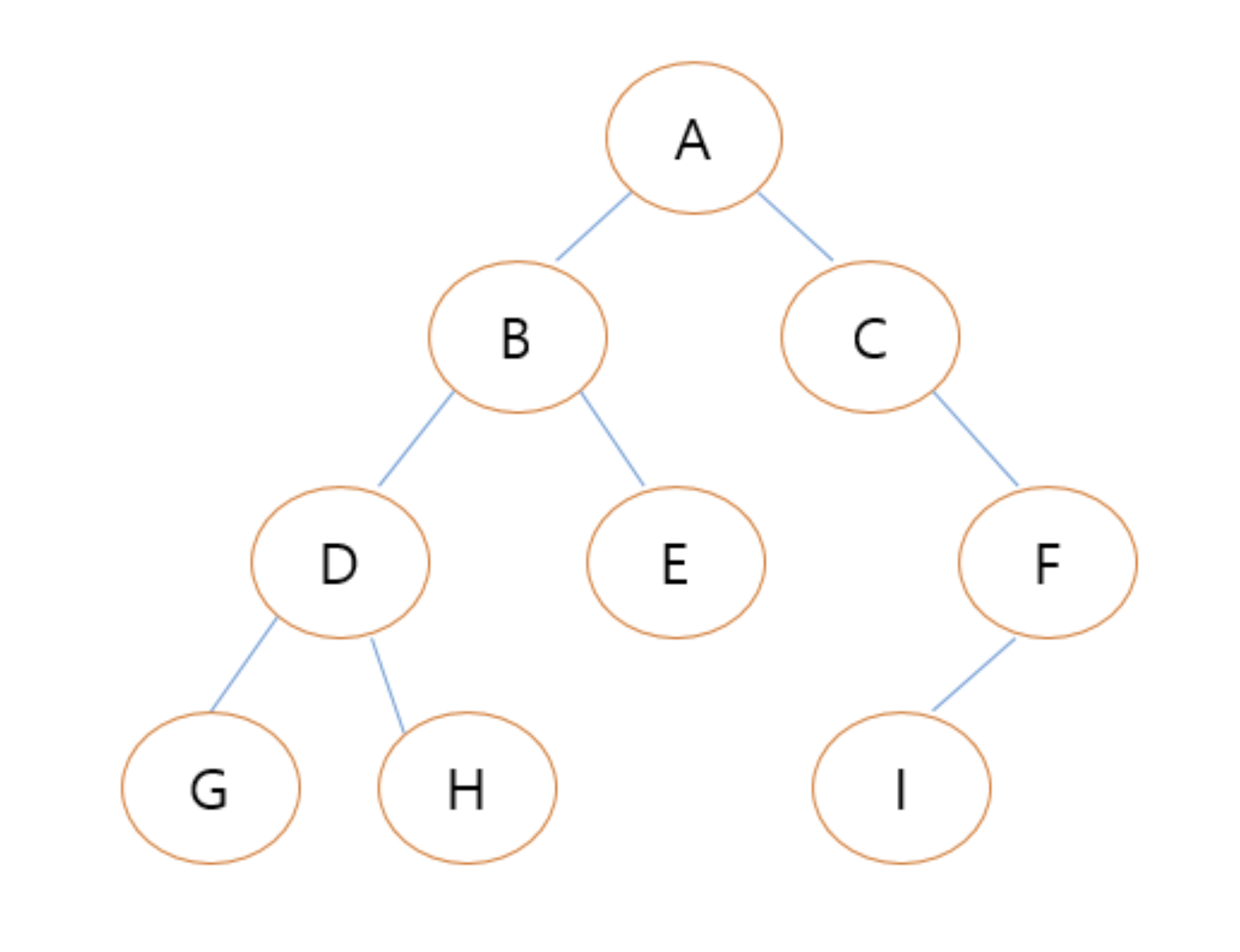 При обращении к его элементам, он должен каким-то образом сообщать об ошибке.
При обращении к его элементам, он должен каким-то образом сообщать об ошибке.
def nil():
def closure(n):
raise Exception
return closure
null = nil()
first(null) #Exception
second(null) #Exception
def create_list(x):
return make_pair(x,null)
К сожалению, функции first и second не являются интуитивно-понятными функциями доступа к элементам списка. Гораздо привычнее работать с функциями head и tail
def head(l): return first(l) def tail(l): return second(l)
Здесь стоит вспомнить о том, что в Python функции являются объектами первого класса
Поэтому, код можно значительно упростить:
head = first tail = second
Базовой операцией над списком есть добавление нового элемента в голову списка:
def add_to_list(l,x): return make_pair(x,l)
Все исключительно просто: мы создаем новый список, «головой» которого будет новый элемент, а «хвостом» — предыдущий список.
Здесь можно остановиться, ведь фактически мы создали полноценный тип данных — список, но, пожалуй, стоит также рассмотреть операции обхода списка.
def iterate_over_list(l,f): if l==null: return else: f(head(l)) iterate_over_list(tail(l),f)
Самая простая операция — проход по всем элементам и вызов некоторой функции f к каждому элементу списка. К примеру, с помощью этой функции можно вывести список на экран:
def print_list(l): def put(n): print n iterate_over_list(l,put) l = create_list(5) l =add_to_list(l,6) l = add_to_list(l,7) print_list(l) #7 6 5
Каким образом работает функция iterate_over_list? Она рекурсивно применяет функцию f к голове списка L, пока L не станет равен пустому списку.
Теперь реализуем базовые функциональные операции над списками:
map(l,f) — это функция, которая переводит список в новый список, применяя к его элементам некоторую функцию f.
filter(l,p) — это функция, которая создает новый список, в который попадают только те элементы, которые соответствуют некоторому предикату p.
accumulate(l,op,initial) — более известна, как reduce.
Функция _map работает рекурсивно: если список пуст, то возвращаем пустой список, в противоположном случае возвращаем новый список, «головой» которого будет результат применения функции f к первому элементу списка l, а «хвостом» будет результат применения функции _map к «хвосту» списка l.
def _map(l,f):
if null_seq(l):
return null
else:
return make_pair(f(head(l)),_map(tail(l),f))
l = make_list(5)
l = add_to_list(l,6)
l = add_to_list(l,7)
l2 = _map(l,lambda n: n*n)
iterate_over_list(l2,pr) # 49 36 25
def _filter(l,p):
if null_seq(l):
return null
else:
if p(head(l)):
return make_pair(head(l),_filter(tail(l),p))
else:
return _filter(tail(l),p)
def accumulate(l,op,initial):
if null_seq(l):
return initial
else:
return accumulate(tail(l),op,op(initial,head(l)))
#вычисление суммы списка с помощью функции accumulate
from operator import add
_sum = accumulate(l,add,0)
И последний штрих — функция range. Если вы дочитали до этого элемента — то наверняка в состоянии реализовать эту функцию самостоятельно.
Если вы дочитали до этого элемента — то наверняка в состоянии реализовать эту функцию самостоятельно.
Решение
Содержимое
def create_range(start,end): if start==end: return null else: return make_pair(start,create_range(start+1,end)) l = create_range(0,10) print_list(l) #0 1 2 3 4 5 6 7 8 9
Вместо заключения
Конечно, никто не станет использовать подобные техники в «настоящем» программировании, но я надеюсь, что эта статья все-таки сможет кому-то помочь освоиться в функциональном программировании.
структур данных Python | Coursera
Об этом курсе
817 712 недавних просмотров
Этот курс знакомит с основными структурами данных языка программирования Python. Мы пройдем мимо основ процедурного программирования и изучим, как мы можем использовать встроенные структуры данных Python, такие как списки, словари и кортежи, для выполнения все более сложного анализа данных. Этот курс охватывает главы 6-10 учебника «Python для всех». Этот курс охватывает Python 3.
Этот курс охватывает главы 6-10 учебника «Python для всех». Этот курс охватывает Python 3.
Результаты карьеры учащегося
Направление карьеры19%
начал новую карьеру после прохождения этих курсов твое расписание.
Общий сертификатОбщий сертификат
Получите сертификат по завершении
100% онлайн100% онлайн
Начните сразу и учитесь по собственному графику.
СпециализацияКурс 2 из 5 в рамках специализации
Python для всех
Часов для прохожденияПрибл. 19 часов
Доступные языкиАнглийский
Субтитры: арабский, французский, португальский (европейский), китайский (упрощенный), итальянский, вьетнамский, корейский, немецкий, русский, английский, испанский
Чему вы научитесь
Объяснить принципы структур данных и их использование
Создание программ, способных читать и записывать данные из файлов
Хранить данные в виде пары ключей/значения с использованием словарей Python
выполнять многоступенчатые задачи, такие как сортировка или петля с использованием Couples
, вы получите
- Python Syntax и Semantics 9003
- Python Syntax и Semantics 9003
- Python Syntax и Semantics 9003
- Python Syntax и Semantics
- Python Syntax и Semantics
- . Кортеж
- Программирование на Python
Результаты карьеры учащегося
Направление карьеры19%
начал новую карьеру после прохождения этих курсов
Карьера29%
получил ощутимую пользу в карьере от этого курса
Гибкие срокиГибкие сроки
Сброс сроков в соответствии с вашим графиком.
Общий сертификатОбщий сертификат
Получите сертификат по завершении
100% онлайн100% онлайн
Начните сразу и учитесь по собственному графику.
СпециализацияКурс 2 из 5 в рамках специализации
Python для всех
Часов на выполнениеПрибл. 19 часов
Доступные языкиАнглийский
Субтитры: арабский, французский, португальский (европейский), китайский (упрощенный), итальянский, вьетнамский, корейский, немецкий, русский, английский, испанский
Инструктор
Чарльз Рассел Северанс
Клинический профессор
Школа информации
3 572 514 Учащиеся
48 Курсы
Мичиганский университет
0009
Миссия Мичиганского университета состоит в том, чтобы служить народу Мичигана и всего мира посредством превосходства в создании, общении, сохранении и применении знаний, искусства и академических ценностей, а также в развитии лидеров и граждан, которые будут бросать вызов современности и обогащать будущее.
Graduation CapНачните работать над получением степени магистра
Этот курс является частью 100% онлайн-курса магистра прикладных наук о данных Мичиганского университета. Если вы допущены к полной программе, ваши курсы засчитываются для получения степени.
Learn More
Reviews
4.9
Filled StarFilled StarFilled StarFilled StarFilled Star16009 reviews
5 stars
87.56%
4 stars
11.30%
3 stars
0.90%
2 зв.0005
«Полезные задания» в 254 обзорах
ЛУЧШИЕ ОТЗЫВЫ ИЗ СТРУКТУР ДАННЫХ PYTHON
Заполнено StarFilled StarFilled StarFilled StarStarот HA16 июля 2016 г.
Курс мне очень понравился. Я просто хочу, чтобы было больше практики, и лекции были больше разбиты, и во время лекций были викторины, чтобы вы больше занимались и делали их более интерактивными.
Заполнено StarFilled StarFilled StarFilled StarStarот VRA 18 августа 2017 г.
Я узнал, что такое python, сейчас на этом этапе я могу программировать на python, и я рекомендую всем, кто хочет изучить python, пройти этот курс и испытать, и действительно спасибо Доктор ЧАК
Filled StarFilled StarFilled StarFilled StarFilled Starby DANov 10, 2017
Я чувствую себя невероятно, что всего месяц назад я почти ничего не знал о программировании. Теперь я прошел два курса специализации и действительно могу понимать другие базовые коды. Отличный курс!
Filled StarFilled StarFilled StarFilled StarFilled Starот SPA 31 августа 2020 г.
Я так счастлив пройти курс Python Data Structures от доктора Чака, и изучение нового языка программирования становится страстью к тому, что вы делаете. Спасибо, что поделились с нами своим опытом.
Просмотреть все отзывы
О специализации Python для всех
Эта специализация основывается на успехе курса Python для всех и знакомит с фундаментальными концепциями программирования, включая структуры данных, сетевые интерфейсы прикладных программ и базы данных, с использованием языка Python язык программирования.
В проекте Capstone вы будете использовать технологии, изученные в рамках специализации, для разработки и создания собственных приложений для поиска, обработки и визуализации данных.Часто задаваемые вопросы
Когда я получу доступ к лекциям и заданиям?
Что я получу, если подпишусь на эту специализацию?
Доступна ли финансовая помощь?
Есть вопросы? Посетите Справочный центр для учащихся.
Структуры данных в Python | List, Tuple, Dict, Sets, Stack, Queue
Стать сертифицированным специалистом
Python используется во всем мире для различных областей, таких как создание веб-сайтов, искусственный интеллект и многое другое. Но чтобы все это стало возможным, данные играют очень важную роль, а это означает, что эти данные должны храниться эффективно, а доступ к ним должен быть своевременным. Так как же этого добиться? Мы используем то, что называется структурами данных.
С учетом сказанного давайте рассмотрим темы, которые мы рассмотрим в Структурах данных в Python.Статья разбита на следующие части:
- Что такое структура данных?
- Типы структур данных в Python
- Built-in Data Structures
- List
- Dictionary
- Tuple
- Sets
- User-Defined Data Structures
- Arrays vs. List
- Stack
- Queue
- Trees
- Linked Lists
- Graphs
- HashMaps
Итак, приступим 🙂
Что такое структура данных?Организация , управление и , хранящие данные , важны, поскольку они обеспечивают более легкий доступ и эффективные модификации. Структуры данных позволяют организовать ваши данные таким образом, чтобы вы могли хранить наборы данных, связывать их и выполнять с ними соответствующие операции.
Типы структур данных в PythonPython имеет неявную поддержку структур данных, которые позволяют хранить данные и получать к ним доступ. Эти структуры называются List, Dictionary, Tuple и Set.
Python позволяет своим пользователям создавать свои собственные структуры данных, что дает им полный контроль над их функциональностью. Наиболее известными структурами данных являются стек, очередь, дерево, связанный список и т. д., которые также доступны вам на других языках программирования. Итак, теперь, когда вы знаете, какие типы вам доступны, почему бы нам не перейти к структурам данных и не реализовать их с помощью Python.
Встроенные структуры данныхКак следует из названия, эти структуры данных встроены в Python, что упрощает программирование и помогает программистам использовать их для более быстрого получения решений. Давайте подробно обсудим каждый из них.
СпискиСписки используются для последовательного хранения данных различных типов. Каждому элементу списка присвоены адреса, которые называются индексами. Значение индекса начинается с 0 и продолжается до последнего элемента, называемого положительным индексом 9.0116 . Существует также отрицательный индекс , который начинается с -1, что позволяет вам обращаться к элементам от последнего к первому. Давайте теперь лучше разберемся со списками с помощью примера программы.
Узнайте о нашем обучении Python в лучших городах/странах
Создание спискаЧтобы создать список, вы используете квадратные скобки и добавляете в него элементы соответствующим образом. Если вы не передадите какие-либо элементы внутри квадратных скобок, вы получите пустой список в качестве вывода.
my_list = [] #создать пустой список распечатать (мой_список) my_list = [1, 2, 3, 'пример', 3.
132] # создание списка с данными
распечатать (мой_список)
Вывод:
Добавление элементов
[]
[1, 2, 3, ‘пример’, 3.132]Добавление элементов в список может быть достигнуто с помощью append(), extend() и функции вставки().
- Функция append() добавляет все переданные ей элементы как один элемент.
- Функция extend() добавляет элементы в список один за другим.
- Функция insert() добавляет переданный элемент к значению индекса и также увеличивает размер списка.
мой_список = [1, 2, 3] распечатать (мой_список) my_list.append([555, 12]) #добавить как отдельный элемент распечатать (мой_список) my_list.extend([234, 'more_example']) #добавить как разные элементы распечатать (мой_список) my_list.insert(1, 'insert_example') #добавить элемент i распечатать (мой_список)
Вывод:
Удаление элементов
[1, 2, 3]
[1, 2, 3, [555, 12]]
[1, 2, 3, [555, 12], 234, «more_example»]
[1, ‘insert_example’, 2, 3, [555, 12], 234, ‘more_example’]- Чтобы удалить элементы, используйте ключевое слово del , встроенное в Python. но это ничего нам не возвращает.
- Если вы хотите вернуть элемент, используйте функцию pop(), которая принимает значение индекса.
- Чтобы удалить элемент по его значению, используйте функцию remove().
Пример:
my_list = [1, 2, 3, 'пример', 3.132, 10, 30] del my_list[5] #удалить элемент с индексом 5 распечатать (мой_список) my_list.remove('example') #удалить элемент со значением распечатать (мой_список) a = my_list.pop(1) #выбрать элемент из списка print('Извлеченный элемент: ', a, 'Оставшийся список: ', my_list) my_list.clear() # очистить список распечатать (мой_список)Вывод:
Доступ к элементам
[1, 2, 3, ‘пример’, 3.132, 30]
[1, 2, 3, 3.132, 30]
Выдвинутый элемент: 2 Осталось списка: [1, 3, 3.132, 30 ]
[]Доступ к элементам аналогичен доступу к строкам в Python. Вы передаете значения индекса и, следовательно, можете получать значения по мере необходимости.
my_list = [1, 2, 3, 'пример', 3.132, 10, 30] для элемента в my_list: #доступ к элементам один за другим печать (элемент) print(my_list) #доступ ко всем элементам print(my_list[3]) #доступ к элементу индекса 3 print(my_list[0:2]) #доступ к элементам от 0 до 1 и исключение 2 print(my_list[::-1]) #доступ к элементам в обратном порядкеВыход:
Другие функции
1
2
3
Пример
3.132
10
30
[1, 2, 3, пример ‘, 3,132, 10, 30]
Пример
[1, 2]
, 10, 30]
. 10, 3.132, ‘пример’, 3, 2, 1]У вас есть несколько других функций, которые можно использовать при работе со списками.
- Функция len() возвращает нам длину списка.
- Функция index() находит значение индекса переданного значения там, где оно встречается в первый раз.
- Функция count() находит количество переданного ей значения.
- Функции sorted() и sort() делают одно и то же, то есть сортируют значения списка. sorted() имеет возвращаемый тип, тогда как sort() изменяет исходный список.
мой_список = [1, 2, 3, 10, 30, 10] print(len(my_list)) # найти длину списка print(my_list.index(10)) # найти индекс элемента, который встречается первым print(my_list.count(10)) #найти количество элементов print(sorted(my_list)) #печатать отсортированный список, но не изменять исходный my_list.sort(reverse=True) #сортировка исходного списка распечатать (мой_список)
Выход:
6 3 2 [1, 2, 3, 10, 10, 30] [30, 10, 10, 3, 2, 1]
СловарьСловари используются для хранения пар ключ-значение . Чтобы лучше понять, представьте себе телефонный справочник, в который добавлены сотни и тысячи имен и соответствующих им номеров. Теперь постоянными значениями здесь являются Имя и Телефонные номера, которые называются ключами. А различные имена и номера телефонов — это значения, которые были переданы на ключи. Если вы получите доступ к значениям ключей, вы получите все имена и номера телефонов.
Создание словаря Вот что такое пара ключ-значение. А в Python эта структура хранится с помощью словарей. Давайте лучше поймем это на примере программы.Словари можно создавать с помощью фигурных скобок или функции dict(). Вам нужно добавлять пары ключ-значение всякий раз, когда вы работаете со словарями.
my_dict = {} #пустой словарь печать (мой_дикт) my_dict = {1: 'Python', 2: 'Java'} #словарь с элементами печать (мой_дикт)Вывод:
Изменение и добавление пар ключей и значений
{}
{1: ‘Python’, 2: ‘Java’}Чтобы изменить значения словаря, вам нужно сделать это с помощью ключи. Итак, вы сначала получаете доступ к ключу, а затем соответствующим образом меняете значение. Чтобы добавить значения, вы просто добавляете еще одну пару ключ-значение, как показано ниже.
my_dict = {'Первый': 'Питон', 'Второй': 'Ява'} печать (мой_дикт) my_dict['Second'] = 'C++' #изменение элемента печать (мой_дикт) my_dict['Third'] = 'Ruby' #добавление пары ключ-значение печать (мой_дикт)Вывод:
Удаление пар ключей и значений
{‘Первый’: ‘Python’, ‘Второй’: ‘Java’}
{‘Первый’: ‘Python’, ‘Второй’: ‘C++’}
{‘Первый’: ‘Python ‘, ‘Второй’: ‘C++’, ‘Третий’: ‘Ruby’}- Чтобы удалить значения, вы используете функцию pop(), которая возвращает значение, которое было удалено .
- Чтобы получить пару ключ-значение, вы используете функцию popitem(), которая возвращает кортеж из ключа и значения.
- Чтобы очистить весь словарь, используйте функцию clear().
my_dict = {'Первый': 'Python', 'Второй': 'Java', 'Третий': 'Ruby'} a = my_dict.pop('Третий') #элемент pop print('Значение:', а) print('Словарь:', my_dict) b = my_dict.popitem() # извлекает пару ключ-значение print('Ключ, пара значений:', b) print('Словарь', my_dict) my_dict.clear() #пустой словарь печать('n', my_dict)Вывод:
Значение: Ruby
Словарь: {‘First’: ‘Python’, ‘Second’: ‘Java’}Ключ, пара значений: (‘Second’, ‘Java’)
Dictionary { «Первый»: «Python»}{}
Доступ к элементамВы можете получить доступ к элементам, используя только ключи. Вы можете использовать либо функцию get(), либо просто передать значения ключей, и вы получите значения.
my_dict = {'Первый': 'Питон', 'Второй': 'Ява'} print(my_dict['First']) #доступ к элементам с помощью ключей печать (my_dict. get («Второй»))
Вывод:
Другие функции
Python
JavaУ вас есть разные функции, которые возвращают нам ключи или значения пары ключ-значение в соответствии с keys(), values(), items( ) работает соответственно.
my_dict = {'Первый': 'Python', 'Второй': 'Java', 'Третий': 'Ruby'} print(my_dict.keys()) #получить ключи print(my_dict.values()) #получить значения print(my_dict.items()) #получить пары ключ-значение печать (my_dict.get («Первый»))Вывод:
Кортеж
dict_keys([‘Первый’, ‘Второй’, ‘Третий’])
dict_values([‘Python’, ‘Java’, ‘Ruby’])
dict_items([(‘Первый’, ‘Python ‘), (‘Второй’, ‘Java’), (‘Третий’, ‘Ruby’)])
PythonКортежи аналогичны спискам, за исключением того, что данные, однажды введенные в кортеж не может быть изменен ни на что. Единственное исключение — когда данные внутри кортежа изменяемы, только тогда можно изменить данные кортежа.
Создание кортежа Пример программы поможет вам лучше понять.Вы создаете кортеж, используя скобки или функцию tuple().
my_tuple = (1, 2, 3) #создать кортеж печать (мой_кортеж)
Вывод:
Доступ к элементам
(1, 2, 3)Доступ к элементам аналогичен доступу к значениям в списках.
my_tuple2 = (1, 2, 3, 'edureka') #доступ к элементам для x в my_tuple2: печать (х) печать (my_tuple2) печать (my_tuple2 [0]) печать (my_tuple2 [:]) печать (my_tuple2 [3] [4])Output:
Appending Elements
1
2
3
edureka
(1, 2, 3, ‘edureka’)
1
(1, 2, 3, ‘edureka’)
eЧтобы добавить значения, вы используете оператор «+», который присоединяется к другому кортежу.
my_tuple = (1, 2, 3) my_tuple = my_tuple + (4, 5, 6) # добавить элементы печать (мой_кортеж)
Выход:
Другие функции
(1, 2, 3, 4, 5, 6)Эти функции такие же, как и для списков.
my_tuple = (1, 2, 3, ['хинди', 'питон']) my_tuple[3][0] = 'английский' печать (мой_кортеж) печать (my_tuple.count (2)) печать (my_tuple.index (['английский', 'питон']))
Вывод:
Наборы
(1, 2, 3, [‘english’, ‘python’])
1
3Наборы представляют собой наборы неупорядоченных уникальных элементов. Это означает, что даже если данные повторяются более одного раза, они будут введены в набор только один раз. Это напоминает наборы, которые вы изучали в арифметике. Операции такие же, как и с арифметическими множествами. Пример программы поможет вам лучше понять.
Создание набораНаборы создаются с помощью фигурных скобок, но вместо добавления пар ключ-значение вы просто передаете ему значения.
my_set = {1, 2, 3, 4, 5, 5, 5} #создать набор печать (мой_набор)Вывод:
Добавление элементов
{1, 2, 3, 4, 5}Чтобы добавить элементы, вы используете функцию add() и передаете ей значение.
my_set_2)
my_set.clear()
печать (мой_набор) - Функция union() объединяет данные, присутствующие в обоих наборах.
- Функция crossover() находит данные, присутствующие только в обоих наборах.
- Функция Differenti() удаляет данные, присутствующие в обоих, и выводит данные, присутствующие только в переданном наборе.
- Функция symmetric_difference() делает то же самое, что и функция Differenti(), но выводит данные, оставшиеся в обоих наборах.
Вывод:
{1, 2, 3, 4, 5, 6} ———- {1, 2, 3, 4, 5, 6}
{3, 4} ———- {3, 4}
{1, 2} ———- {1, 2}
{1, 2, 5, 6} ———- {1, 2, 5 , 6}
set()Теперь, когда вы поняли встроенные структуры данных, давайте начнем с пользовательских структур данных. Определяемые пользователем структуры данных, само название предполагает, что пользователи определяют, как будет работать структура данных, и определяют в ней функции. Это дает пользователю полный контроль над тем, как данные должны быть сохранены, обработаны и так далее.
Давайте двигаться вперед и изучать наиболее известные структуры данных в большинстве языков программирования.
Пользовательские структуры данных Массивы и спискиМассивы и списки имеют одну и ту же структуру с одним отличием. Списки позволяют хранить разнородные элементы данных, тогда как массивы позволяют хранить в них только однородные элементы.
СтекСтеки представляют собой линейные структуры данных, основанные на принципе «последний пришел — первый обслужен» (LIFO), где данные, которые вводятся последними, будут доступны первыми. Он построен с использованием структуры массива и имеет операции, а именно: вталкивание (добавление) элементов, извлечение (удаление) элементов и доступ к элементам только из одной точки в стеке, называемой ТОР. Этот TOP является указателем на текущую позицию стека. Стеки широко используются в таких приложениях, как рекурсивное программирование, обращение слов, механизмы отмены в текстовых редакторах и так далее.
ОчередьОчередь также представляет собой линейную структуру данных, основанную на принципе «первым пришел — первым обслужен» (FIFO), где данные, введенные первыми, будут доступны первыми. Он построен с использованием структуры массива и имеет операции, которые могут выполняться с обоих концов Очереди, то есть по принципу «голова-хвост» или «вперед-назад». Такие операции, как добавление и удаление элементов, называются En-Queue и De-Queue, и можно выполнять доступ к элементам. Очереди используются в качестве сетевых буферов для управления перегрузкой трафика, используются в операционных системах для планирования заданий и во многих других случаях.
ДеревоДеревья представляют собой нелинейные структуры данных, которые имеют корень и узлы. Корень — это узел, из которого берутся данные, а узлы — это другие доступные нам точки данных. Узел, который предшествует, является родителем, а узел после называется дочерним.
Есть уровни дерева, чтобы показать глубину информации. Последние узлы называются листьями. Деревья создают иерархию, которую можно использовать во многих реальных приложениях, таких как HTML-страницы, использующие деревья, чтобы различать, какой тег относится к какому блоку. Это также эффективно в целях поиска и многое другое.
Связанный списокСвязанные списки — это линейные структуры данных, которые не хранятся последовательно, а связаны друг с другом с помощью указателей. Узел связанного списка состоит из данных и указателя, называемого next. Эти структуры наиболее широко используются в приложениях для просмотра изображений, музыкальных проигрывателях и т.д.
ГрафикГрафики используются для хранения набора данных о точках, называемых вершинами (узлами) и ребрами (ребрами). Графики можно назвать наиболее точным представлением карты реального мира. Они используются для нахождения различной стоимости-расстояния между различными точками данных, называемыми узлами, и, следовательно, для нахождения наименьшего пути.
Многие приложения, такие как Google Maps, Uber и многие другие, используют графики, чтобы найти наименьшее расстояние и наилучшим образом увеличить прибыль.
HashMapsHashMaps аналогичны словарям в Python. Их можно использовать для реализации таких приложений, как телефонные книги, заполнение данными по спискам и многое другое.
Это обобщает все известные структуры данных в Python. Я надеюсь, вы поняли встроенные, а также определяемые пользователем структуры данных, которые есть в Python, и почему они важны.
Теперь, когда вы поняли, что такое структуры данных в Python, ознакомьтесь с сертификацией Python 9.0373 от Edureka, надежной компании онлайн-обучения, сеть которой насчитывает более 250 000 довольных учащихся по всему миру.
Учебный курс Edureka по сертификации программирования на Python предназначен для студентов и профессионалов, которые хотят получить степень магистра программирования на Python.
Курс разработан, чтобы дать вам преимущество в программировании на Python и обучить вас как основным, так и продвинутым концепциям. Оставайтесь на шаг впереди в области технологий с помощью этой программы последипломного образования в области искусственного интеллекта и машинного обучения в партнерстве с Академией E&ICT, Национальный технологический институт, Варангал. Этот курс искусственного интеллекта создан для достижения наилучших результатов.
Есть к нам вопрос? Пожалуйста, укажите это в разделе комментариев этого блога «Структуры данных, которые вам нужно изучить с помощью Python», и мы свяжемся с вами как можно скорее.
Какую структуру данных Python следует использовать? | by Yasmine Hejazi
Списки, кортежи, наборы, словари… Когда какую встроенную структуру данных вы используете?
Фото Викториано Искьердо на UnsplashPython — это язык объектно-ориентированного программирования (ООП). Классы и объекты используются для структурирования и модуляции кода, чтобы его можно было повторно использовать и легко модифицировать.
ООП требует использования структуры данных для организации и хранения данных таким образом, чтобы к ним можно было эффективно получить доступ.Python имеет примитивных (или базовых) структур данных, таких как числа с плавающей запятой, целые числа, строки и логические значения. Python также имеет 90 115 непримитивных 90 116 структур данных, таких как списки, кортежи, словари и наборы. Непримитивные структуры данных хранят набор значений в различных форматах, а не одно значение. Некоторые могут хранить структуры данных внутри структуры данных, создавая глубину и сложность возможностей хранения данных.
Фото автораВ этой статье мы рассмотрим каждую встроенную структуру данных, чтобы решить, когда целесообразно использовать одну вместо другой.
Что такое изменчивость?
Изменяемость означает, что данные в структуре данных могут быть изменены (добавлены, удалены или изменены) после создания. Изменчивость — важный фактор, который следует учитывать при выборе структуры данных.
Если вы знаете, что вам не нужно будет изменять внутреннее состояние, рассмотрите возможность использования неизменяемого объекта, чтобы гарантировать, что он потокобезопасен и ничто не сможет перезаписать ваши данные.Для представления последовательности элементов, проиндексированных по их целочисленному положению, вы можете использовать одну структуру данных — список. Списки содержат ноль или более элементов и могут содержать элементы разных типов (даже объекты!). Это делает списки мощным инструментом, поскольку они позволяют создавать глубокие и сложные структуры данных.
Списки являются изменяемыми , что означает, что вы можете гибко добавлять, удалять или изменять элементы. Другой последовательной структурой данных является кортеж ; разница между ними в том, что кортежи неизменяемы.
Поскольку списки имеют последовательный элемент: если вы хотите отслеживать только уникальных значения и не заботитесь о порядке, используйте набор Python .
Создание списков с помощью
[]илиlist(). Приведение типов с использованиемlist().Некоторые известные методы и советы
Элементы списка доступа:
my_list[0]получает элемент списка по смещению. Как и строки, отрицательные индексы можно использовать для обратного отсчета с конца.
my_list[0] = ‘новый элемент’изменяет элемент списка по смещению.
my_list[0:2]среза для извлечения элементов по смещению. В этом примере возвращаются первые 2 элементаmy_list.Добавить элементы списка:
append()добавляет элемент в конец списка.
extend()или+=объединяет один список в другой.
insert()добавляет элемент перед любым смещением.Удалить элементы списка:
remove()удаляет значение элемента из списка.
pop()удаляет последний (или указанный) элемент, одновременно возвращая значение.
delудаляет элемент по его положению в списке.del— это оператор Python, а не метод списка.join()возвращает строку объединенных элементов списка. Аргументом дляjoin()является строка или любая итерируемая последовательность строк.
len()возвращает количество элементов в списке.count()возвращает количество вхождений указанного значения.Кортежи также представляют собой упорядоченную структуру данных, как и списки. Однако кортежи неизменяемы; нельзя добавлять, удалять или изменять элементы после создания кортежа. Кортежи отличаются от списков тем, что имеют гораздо меньше функций, потому что их нельзя изменить после определения. Кортежи содержат ноль или более элементов и могут содержать элементы разных неизменяемых типов.
Преимущества кортежей перед списками:
- Кортежи занимают меньше места
- Неизменяемость предотвращает ошибочное изменение элементов кортежа
- Кортежи можно использовать в качестве ключей словаря
- Аргументы функций передаются как кортежи элементы без окружающих скобок или фигурных скобок. Приведение типов с использованием
tuple().Некоторые известные методы и советы
count()возвращает количество раз, когда элемент встречается в кортеже
index()возвращает позицию индекса элементаВместо использования смещения словари используют ключи для связи с каждым значением. Это означает, что порядок не отслеживается и не имеет значения, если вы планируете использовать словарь. Словарные ключи неизменны и уникальны, однако словари изменяемы ; элементы ключ-значение могут быть добавлены, удалены или изменены. Короче говоря, словари очень похожи на хеш-карты .
Создание словарей с помощью
{}. Приведение типов с использованиемdict().Некоторые известные методы и советы
my_dict['key']получает элемент по его ключу
my_dict['key'] = 'value'использует ключ для добавления (или изменения, если он уже существует) ценность.
update()объединяет ключи и значения одного словаря в другой.
delудаляет элемент по указанному ключу.del— это оператор Python, а не метод словаря.
ключи()возвращает все ключи словаря.values()возвращает все значения в словаре.items()возвращает все пары ключ-значение словаря.Набор подобен словарю, в котором только ключи, а не значения. Это означает, что наборы уникальны и не являются последовательными (хранятся неупорядоченно). Наборы также изменяемые . Наборы содержат ноль или более элементов и могут содержать элементы разных неизменяемых типов.
По сути, наборы используются, когда вы хотите знать, существует ли что-то, и больше ничего об этом. Если важно отслеживать порядок значений или хранить несколько одинаковых значений, рассмотрите возможность использования компактного размера 9.0115 вместо кортежа .
Создание наборов с помощью
set().
- .
 Кортеж
Кортеж

 В проекте Capstone вы будете использовать технологии, изученные в рамках специализации, для разработки и создания собственных приложений для поиска, обработки и визуализации данных.
В проекте Capstone вы будете использовать технологии, изученные в рамках специализации, для разработки и создания собственных приложений для поиска, обработки и визуализации данных. С учетом сказанного давайте рассмотрим темы, которые мы рассмотрим в Структурах данных в Python.
С учетом сказанного давайте рассмотрим темы, которые мы рассмотрим в Структурах данных в Python.
 132] # создание списка с данными
распечатать (мой_список)
132] # создание списка с данными
распечатать (мой_список)
 но это ничего нам не возвращает.
но это ничего нам не возвращает.
 sorted() имеет возвращаемый тип, тогда как sort() изменяет исходный список.
sorted() имеет возвращаемый тип, тогда как sort() изменяет исходный список. Вот что такое пара ключ-значение. А в Python эта структура хранится с помощью словарей. Давайте лучше поймем это на примере программы.
Вот что такое пара ключ-значение. А в Python эта структура хранится с помощью словарей. Давайте лучше поймем это на примере программы.
 get («Второй»))
get («Второй»))
 Пример программы поможет вам лучше понять.
Пример программы поможет вам лучше понять.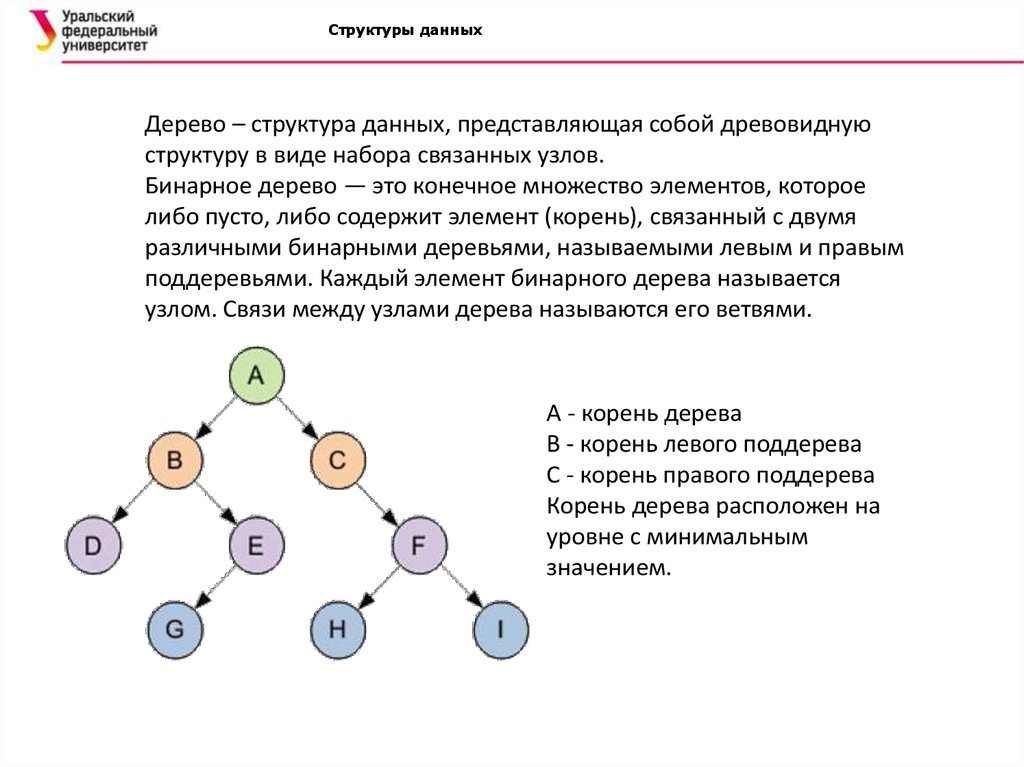
 my_set_2)
my_set.clear()
печать (мой_набор)
my_set_2)
my_set.clear()
печать (мой_набор) 

 Есть уровни дерева, чтобы показать глубину информации. Последние узлы называются листьями. Деревья создают иерархию, которую можно использовать во многих реальных приложениях, таких как HTML-страницы, использующие деревья, чтобы различать, какой тег относится к какому блоку. Это также эффективно в целях поиска и многое другое.
Есть уровни дерева, чтобы показать глубину информации. Последние узлы называются листьями. Деревья создают иерархию, которую можно использовать во многих реальных приложениях, таких как HTML-страницы, использующие деревья, чтобы различать, какой тег относится к какому блоку. Это также эффективно в целях поиска и многое другое. Многие приложения, такие как Google Maps, Uber и многие другие, используют графики, чтобы найти наименьшее расстояние и наилучшим образом увеличить прибыль.
Многие приложения, такие как Google Maps, Uber и многие другие, используют графики, чтобы найти наименьшее расстояние и наилучшим образом увеличить прибыль.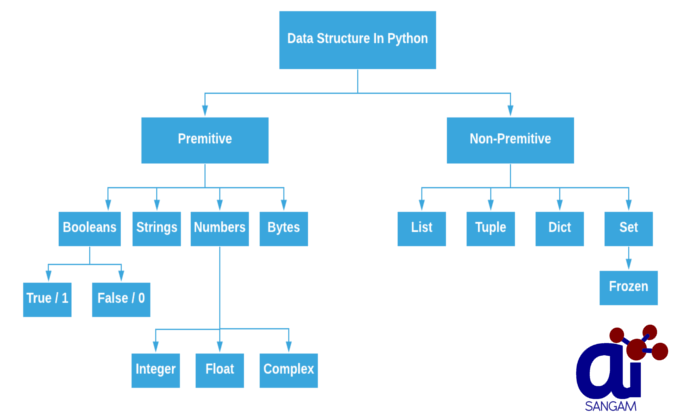 Курс разработан, чтобы дать вам преимущество в программировании на Python и обучить вас как основным, так и продвинутым концепциям.
Курс разработан, чтобы дать вам преимущество в программировании на Python и обучить вас как основным, так и продвинутым концепциям.  ООП требует использования структуры данных для организации и хранения данных таким образом, чтобы к ним можно было эффективно получить доступ.
ООП требует использования структуры данных для организации и хранения данных таким образом, чтобы к ним можно было эффективно получить доступ. Если вы знаете, что вам не нужно будет изменять внутреннее состояние, рассмотрите возможность использования неизменяемого объекта, чтобы гарантировать, что он потокобезопасен и ничто не сможет перезаписать ваши данные.
Если вы знаете, что вам не нужно будет изменять внутреннее состояние, рассмотрите возможность использования неизменяемого объекта, чтобы гарантировать, что он потокобезопасен и ничто не сможет перезаписать ваши данные.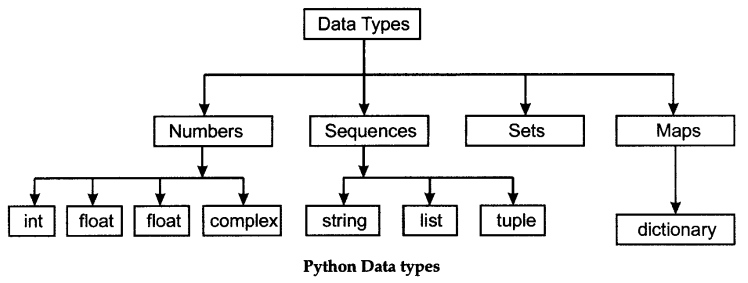

 Приведение типов с использованием
Приведение типов с использованием