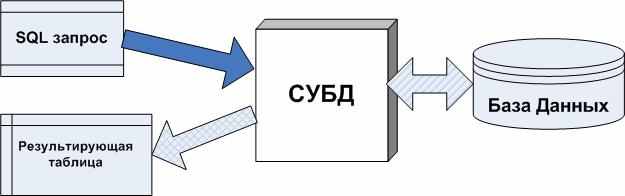
ТОП-10 систем управления базами данных в 2019 году
Умение выбрать СУБД важно при разработке любого ПО. Мы собрали 10 систем управления базами данных и разобрались в их преимуществах.
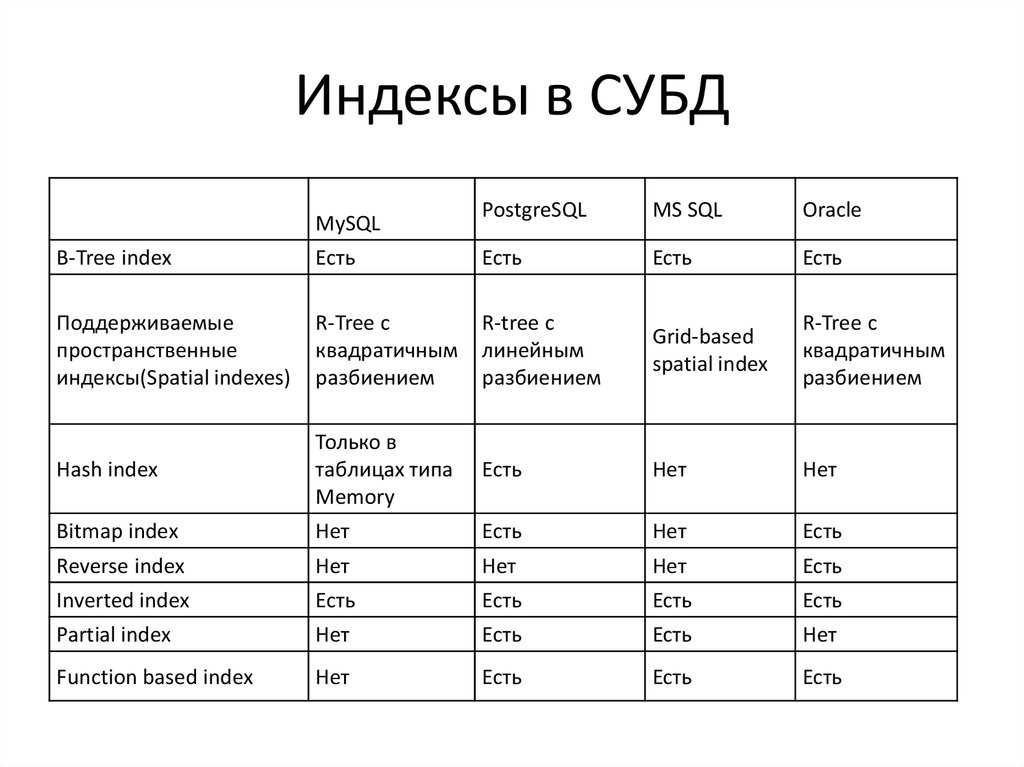
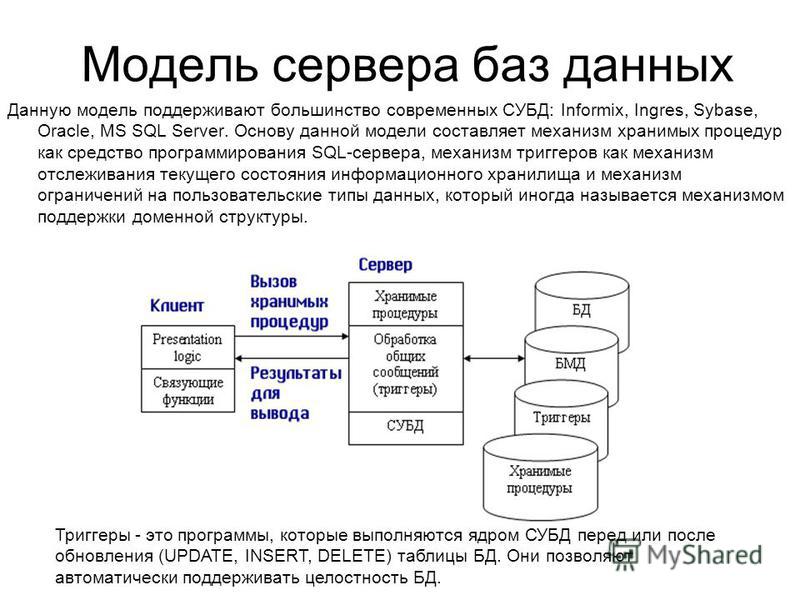
Популярные системы управления базами данных
| Разработчик | Лицензия | Написана на | |
| Oracle | Oracle Corporation | Проприетарная | Assembly, C, C++ |
| MySQL | Oracle Corporation | GPL v2 или проприетарная | C, C++ |
| Microsoft SQL Server | Microsoft Corporation | Проприетарная | C, C++ |
| PostgreSQL | PostgreSQL Global Development Group | Лицензия PostgreSQL (бесплатное ПО с открытым исходным кодом, либеральная лицензия) | C |
| MongoDB | MongoDB Inc. | Различные варианты лицензирования | C++, C, JavaScript |
| DB2 | IBM | Проприетарная EULA | Assembly, C, C++ |
| Microsoft Corporation | Пробное ПО | ||
| Redis | Salvatore Sanfilippo | Лицензия BSD | ANSI C |
SQL-базы данных
1. Oracle
Oracle RDBMS (она же Oracle Database) на первом месте среди СУБД. Система популярна у разработчиков, проста в использовании, у нее понятная документация, поддержка длинных наименований, JSON, улучшенный тег списка и Oracle Cloud.
- Разработчик: Oracle Corporation
- Написана на:Assembly, C, C++
- Блог: Oracle NoSQL
- Скачать: Oracle NoSQL
- Последняя версия: 18.3
Особенности
- Обрабатывает большие данные.
- Поддерживает SQL, к нему можно получить доступ из реляционных БД Oracle.

- Oracle NoSQL Database с Java/C API для чтения и записи данных.

2. MySQL
MySQL работает на Linux, Windows, OSX, FreeBSD и Solaris. Можно начать работать с бесплатным сервером, а затем перейти на коммерческую версию. Лицензия GPL с открытым исходным кодом позволяет модифицировать ПО MySQL.
Эта система управления базами данных использует стандартную форму SQL. Утилиты для проектирования таблиц имеют интуитивно понятный интерфейс. MySQL поддерживает до 50 миллионов строк в таблице. Предельный размер файла для таблицы по умолчанию 4 ГБ, но его можно увеличить. Поддерживает секционирование и репликацию, а также Xpath и хранимые процедуры, триггеры и представления.
- Разработчик: Oracle Corporation
- Написана на C, C++
- Последняя версия: 8.0.16
- Скачать: MySql
Особенности
- Масштабируемость.
- Лёгкость использования.
- Безопасность.
- Поддержка Novell Cluster.
- Скорость.
- Поддержка многих операционных систем.

3. Microsoft SQL Server
Самая популярная коммерческая СУБД. Она привязана к Windows, но это плюс, если вы пользуетесь продуктами Microsoft. Зависит от платформы. И графический интерфейс, и программное обеспечение основаны на командах. Поддерживает SQL, непроцедурные, нечувствительные к регистру и общие языки баз данных.
- Разработчик: Microsoft Corporation
- Написана на C, C++
- Блог: SQL Server Blog
- Скачать: Microsoft SQL Server
Особенности
- Высокая производительность.
- Зависимость от платформы.
- Возможность установить разные версии на одном компьютере.
- Генерация скриптов для перемещения данных.
4. PosgreSQL
Масштабируемая объектно-реляционная база данных, работающая на Linux, Windows, OSX и некоторых других системах. В PostgreSQL 10 есть такие функции, как логическая репликация, декларативное разбиение таблиц, улучшенные параллельные запросы, более безопасная аутентификация по паролю на основе SCRAM-SHA-256.
- Разработчик: PostgreSQL Global Development Group
- Написана на C
- Используется в компаниях: Apple, Cisco, Fujitsu, Skype, and IMDb
- Последняя версия: 11.2
- Блог: PostgreSQL
- Скачать: PostgreSQL
Особенности
- Поддержка табличных пространств, а также хранимых процедур, объединений, представлений и триггеров.
- Восстановление на момент времени (PITR).
- Асинхронная репликация.
NoSQL-базы данных
5. MongoDB
Самая популярная NoSQL система управления базами данных. Лучше всего подходит для динамических запросов и определения индексов. Гибкая структура, которую можно модифицировать и расширять. Поддерживает Linux, OSX и Windows, но размер БД ограничен 2,5 ГБ в 32-битных системах. Использует платформы хранения MMAPv1 и WiredTiger.
- Разработчик: MongoDB Inc. в 2007
- Написана на C++
- Последняя версия: 4.1.9
- Блог: MongoDB
- Скачать: MongoDB
Особенности
- Высокая производительность.
- Автоматическая фрагментация.
- Работа на нескольких серверах.
- Поддержка репликации Master-Slave.
- Данные хранятся в форме документов JSON.
- Возможность индексировать все поля в документе.
- Поддержка поиска по регулярным выражениям.
6. DB2
Работает на Linux, UNIX, Windows и мейнфреймах. Эта СУБД идеально подходит для хост-сред IBM. Версию DB2 Express-C нельзя использовать в средах высокой доступности (при репликации, кластеризации типа active-passive и при работе с синхронизируемым доступом к разделяемым данным).
- Разработчик: IBM
- Написана на C, C++, Assembly
- Последняя версия: 11.1
- Скачать: DB2
Особенности DB2 11.1
- Улучшенное встроенное шифрование.
- Упрощённая установка и развёртывание.
7. Microsoft Access
Система управления базами данных от Microsoft, которая сочетает в себе реляционное ядро БД Microsoft Jet с графическим интерфейсом пользователя и инструментами разработки ПО.
Идеально подходит для начала работы с данными, но производительность не рассчитана на большие проекты. В MS Access можно использовать C, C#, C++, Java, VBA и Visual Rudimental.NET. Access хранит все таблицы БД, запросы, формы, отчёты, макросы и модули в базе данных Access Jet в виде одного файла.
- Разработчик: Microsoft Corporation
- Последняя версия: 16.0
- Скачать: Microsoft Access
Особенности
- Можно использовать VBA для создания многофункциональных решений с расширенными возможностями управления данными и пользовательским контролем.
- Импорт и экспорт в форматы Excel, Outlook, ASCII, dBase, Paradox, FoxPro, SQL Server и Oracle.
- Формат базы данных Jet.
8. Cassandra
СУБД активно используется в банковском деле, финансах, а также в Facebook и Twitter. Поддерживает Windows, Linux и OSX. Для запросов к БД Cassandra используется SQL-подобный язык — Cassandra Query Language (CQL).
- Разработчик: Apache Software Foundation
- Написана на: Java
- Последняя версия: 3. 11.4
- Блог: Cassandra
- Скачать: Cassandra
 11.4
11.4Особенности
- Линейная масштабируемость.
- Быстрое время отклика.
- Поддержка MapReduce и Apache Hadoop.
- Максимальная гибкость.
- P2P архитектура.
9. Redis
Redis или Remote Dictionary Server — СУБД с открытым исходным кодом, которая снабжена механизмами журналирования и снимков. Поддерживаются списки, строки, хэши, наборы. Используется для БД, брокеров сообщений и кэшей. Все операции в Redis атомарные. Система написана на языке C и поддерживается практически всеми языками программирования.
- Разработчик: Salvatore Sanfilippo
- Последняя версия: 5.0.5
- Блог: Redis
- Скачать: Redis
Особенности
- Автоматическая обработка отказа.
- Транзакции.
- Сценарии LUA.
- Вытеснение LRU-ключей.
- Поддержка Publish/Subscribe.
10. Elasticsearch
Легко масштабируемая поисковая система корпоративного уровня с открытым исходным кодом. Благодаря обширному и продуманному API обеспечивает чрезвычайно быстрый поиск, работает в том числе с приложениями для обнаружения данных. Используется такими компаниями, как Википедия, The Guardian, StackOverflow, GitHub. ElasticSearch позволяет создавать копии индексов и сегментов.
Благодаря обширному и продуманному API обеспечивает чрезвычайно быстрый поиск, работает в том числе с приложениями для обнаружения данных. Используется такими компаниями, как Википедия, The Guardian, StackOverflow, GitHub. ElasticSearch позволяет создавать копии индексов и сегментов.
- Разработчик: Elastic NV
- Написана на Java
- Последняя версия: 7.2.0
- Блог: Elasticsearch
- Скачать: Elasticsearch
Особенности
- Масштабируемость вплоть до нескольких петабайт структурированных и неструктурированных данных.
- Многопользовательская поддержка.
- Масштабируемый поиск, поиск в режиме реального времени.
Рейтинги СУБД
| Рейтинг | СУБД | Модель базы данных | Балл | ||||
| Июль 2017 | Июнь 2017 | Июль 2016 | Июль 2017 | Июнь 2017 | Июль 2016 | ||
| 1 | 1 | 1 | Oracle | Реляционная СУБД | 1374. 88 88 | +23.11 | -66.65 |
| 2 | 2 | 2 | MySQL | Реляционная СУБД | 1349.11 | +3.8 | -14.18 |
| 3 | 3 | 3 | Microsoft SQL Server | Реляционная СУБД | 1226 | +27.03 | +33.11 |
| 4 | 4 | 5↑ | PostgreSQL | Реляционная СУБД | 369.44 | +0.89 | +58.28 |
| 5 | 5 | 4↓ | MongoDB | Документная СУБД | 332.77 | -2.23 | +17.77 |
| 6 | 6 | 6 | DB2 | Реляционная СУБД | 191.25 | +3.74 | +6.17 |
| 7 | 7 | 8↑ | Microsoft Access | Реляционная СУБД | 126.13 | -0.42 | +1.23 |
| 8 | 8 | 7↓ | Cassandra | СУБД типа BigTable | 124. 12 12 | -0.0 | -6.58 |
| 9 | 9 | 10↑ | Redis | СУБД типа «ключ-значение» | 121.51 | +2.63 | +13.48 |
| 10 | 11↑ | 11↑ | Elasticsearch | Поисковая система | 115.98 | +4.42 | +27.36 |
А какую СУБД предпочитаете вы? Аргументируйте свой выбор 😉
Какую СУБД выбрать и почему? (Статья 1) / Хабр
Это первый выпуск в серии статей про СУБД, в рамках которых буду достаточно простыми словами давать информацию про то, что сейчас есть на рынке баз данных, и что выбрать для решения своих задач.
Заметил, что когда спрашиваешь кого-нибудь, особенно на собеседовании, какие типы СУБД существуют, то первое что вспоминают многие – это реляционные базы данных, и NoSQL, а вот про разновидности часто забывают или не могут сформулировать их отличие.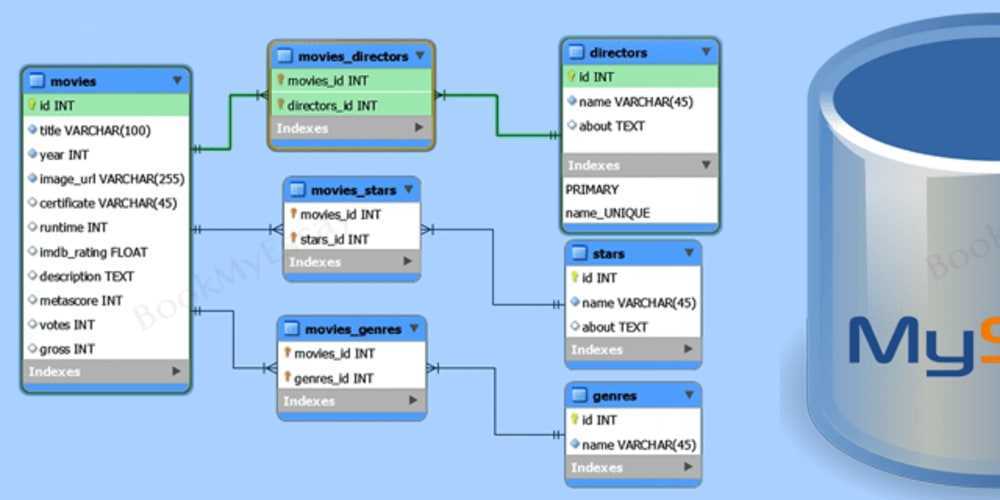 Поэтому начнем с простого перечисления наиболее используемых.
Поэтому начнем с простого перечисления наиболее используемых.
Реляционные
Ключ-значение
Документные
Графовые
Колоночные
Тем, кому не хочется долго читать, может сразу перейти на итоговую таблицу.
Нужно обязательно сделать ремарку, что некоторые крупные производители, имеют в своем арсенале несколько типов СУБД, как в виде отдельных продуктов, так и в виде внутренней реализации. Например, у Oracle на самом деле чего только нет, начиная с классической реляционной СУБД, продолжая с отдельным продуктом Oracle NoSQL Database, который может использоваться и как документная, и как колоночная, и как ключ-значение. Отдельное решение от того же Oracle, Autonomous Data Warehouse – это уже специализированное решение для хранилищ данных. Еще один отдельный продукт от Oracle – Oracle Graph Server для работы с графами, и еще много другого. Этому можно посвятить отдельную серию статей.
Реляционные СУБД
Начнем по порядку, классические, реляционные СУБД чаще всего используются для построения решений OLTP (Online Transaction Processing). В таких решениях СУБД работает с небольшими по размерам транзакциями, но идущими большим потоком, и при этом от системы требуется минимальное время отклика, а так же возможность, при определенных условиях, отменить любые изменения выполняемых в рамках транзакции. Если вы строите систему, в рамках которой требуется хранить значительное количество сущностей (таблиц), с различными типами связей между ними (один-к-одному, один-к-многим, многие-ко-многим), то это скорее всего про реляционные СУБД.
В таких решениях СУБД работает с небольшими по размерам транзакциями, но идущими большим потоком, и при этом от системы требуется минимальное время отклика, а так же возможность, при определенных условиях, отменить любые изменения выполняемых в рамках транзакции. Если вы строите систему, в рамках которой требуется хранить значительное количество сущностей (таблиц), с различными типами связей между ними (один-к-одному, один-к-многим, многие-ко-многим), то это скорее всего про реляционные СУБД.
Наиболее известные СУБД такого типа — Oracle, Microsoft SQL, PostgreSQL, MySQL.
Когда выбирать реляционную СУБД
Один из основных признаков, который говорит о том что нужно выбирать реляционную СУБД – это высокая нормализация данных. Дополнительными признаками будет необходимость обработки большого кол-ва коротких транзакций, с большей долей операций на вставку
Когда не выбирать реляционную СУБД
Если предполагается хранить не структурируемые данные, или наоборот очень простые структуры типа ключ-значение, то лучше посмотреть в сторону документных СУБД и специализированных СУБД типа ключ-значение соответственно.
Так же один из признаков, что имеет смысл подумать не о реляционных СУБД, это такой факт как необходимость часто обновлять значения в одних и тех же строках. Обычно это обходится «дорого» в реляционных СУБД, и нужно применять «продвинутую магию» что бы делать это корректно.
Конечно, тут есть много «но», или «а если очень хочется», и других ситуаций, когда данные рекомендации можно игнорировать. Это нормально, особенно когда за дело берется эксперт, который знает как это сделать.
СУБД типа ключ-значение
Наверное один из самых простых типов СУБД. В упрощенном виде, это некая таблица с уникальным ключом и собственно связанным с ним значением, в котором может быть что угодно. Чаще всего такие СУБД используют для кэширования, т.к. они очень быстро работают, а это и не сложно, когда есть уникальный ключ, и запрос возвращает только одно значение. У некоторых представителей данных СУБД есть возможность работать полностью в памяти, а так же есть возможность задавать срок жизни записи, после истечения которого, записи будут автоматически удаляться.
Наиболее известные СУБД такого типа — Redis и Memcached.
Когда выбирать СУБД ключ-значение
Если СУБД будет использоваться для кэширования данных или для брокеров сообщений, то это очень подходящий тип. Так же, такая СУБД хорошо подходит для баз где нужно хранить достаточно простые структуры, и иметь к ним очень быстрый доступ.
Когда не выбирать СУБД ключ-значение
Если вы предполагаете хранить в базе данных много сущностей (таблиц), а у сущностей будут сложные структуры с разными типами данных. Так же, если вы предполагаете делать из этой таблицы сложные запросы которые возвращают множества строк.
Документные СУБД
Документные или документно-ориентированные СУБД — это одна из наиболее популярных разновидностей NoSQL СУБД, где основной единицей логической модели данных является документ — структурированный текст, с определенным синтаксисом.
Иногда встречаются мнения что модель данных в документных БД похожа на модель данных в объектно-ориентированных базах данных. В этом есть доля правды, единственная реальная разница между ними заключается в том, что базы данных документов только сохраняют состояние, но не поведение.
В этом есть доля правды, единственная реальная разница между ними заключается в том, что базы данных документов только сохраняют состояние, но не поведение.
Так же, само название «документо-ориентированная» подчас вводит в заблуждение, и мне встречались коллеги, которые считали, что это база для систем документооборота. Нет, это не так.
Интересно, что документные СУБД развиваются достаточно активно, и сейчас некоторые из них, в том числе, поддерживают проверку схемы.
Известными представителями таких СУБД являются CouchDB, MongoDB, Amazon DocumentDB.
Когда выбирать документную СУБД
Если нужно хранить объекты в одной сущности, но с разной структурой. Если нужно хранит структуры, включая объекты, списки и словари, особенно в формате близкому к JSON.
На самом деле область применения документных СУБД очень широкая. Их можно использовать как компактную базу данных для отдельно взятого микро-сервиса, так и для вполне масштабных решений, в качестве хранилища состояний чего-либо.
Когда не выбирать документную СУБД
Не самое лучшее решение для реализации транзакционная модели, и точно не лучший вариант для формирования отчетности.
Графовые СУБД
Графовые СУБД — специфичный тип, предназначены для работы с графами, с их узлами, свойствами, и произвольными отношениями между узлами.
Очень простой пример, это организация связей в различного типа социальных сетях, где нужно хранить связи между пользователями (узлами) по разным критериям (родственные связи, коллеги, общие интересы).
Известные представители этого типа субд — Neo4j, Amazon Neptune, InfiniteGraph, InfoGrid.
Когда выбирать графовые СУБД
Точно стоит обратить внимание на графовые СУБД, если строите какое-то подобие социальной сети, или реализуете систему оценок и рекомендаций. Ну и во всех случаях когда вы хорошо понимаете что такое графы, и для чего это нужно.
Когда не выбирать графовые СУБД
Практически во всех остальных случаях, кроме указанных выше, лучше воздержаться от использования графовых СУБД.
Колоночные СУБД
Колоночные СУБД очень похожи на реляционные. Они так же состоят из строк, которые имеют атрибуты, а строки группируются в таблицах. Различия в логических моделях несущественные, а вот на уровне физического хранения данных различия значительные.
В реляционных СУБД данные хранятся «построчно», это означает что для считывания значения определенной колонки, придется прочитать практически всю строку, как минимум от первой до нужной колонки. В колоночной СУБД данные хранятся «поколоночно», т.е. колонка — это как отдельная таблица. Соответственно чтение будет происходить из конкретного столбца сразу. На практике это реально работает очень быстро (проверено мной на нескольких реализованных хранилищах данных).
Основные преимущества колоночных СУБД – эффективное выполнения сложных аналитических запросов на больших объемах, и легкое, практически мгновенное, изменение структуры таблиц с данными, плюс существенная компрессия и сжатие, которое позволяет значительно экономить место.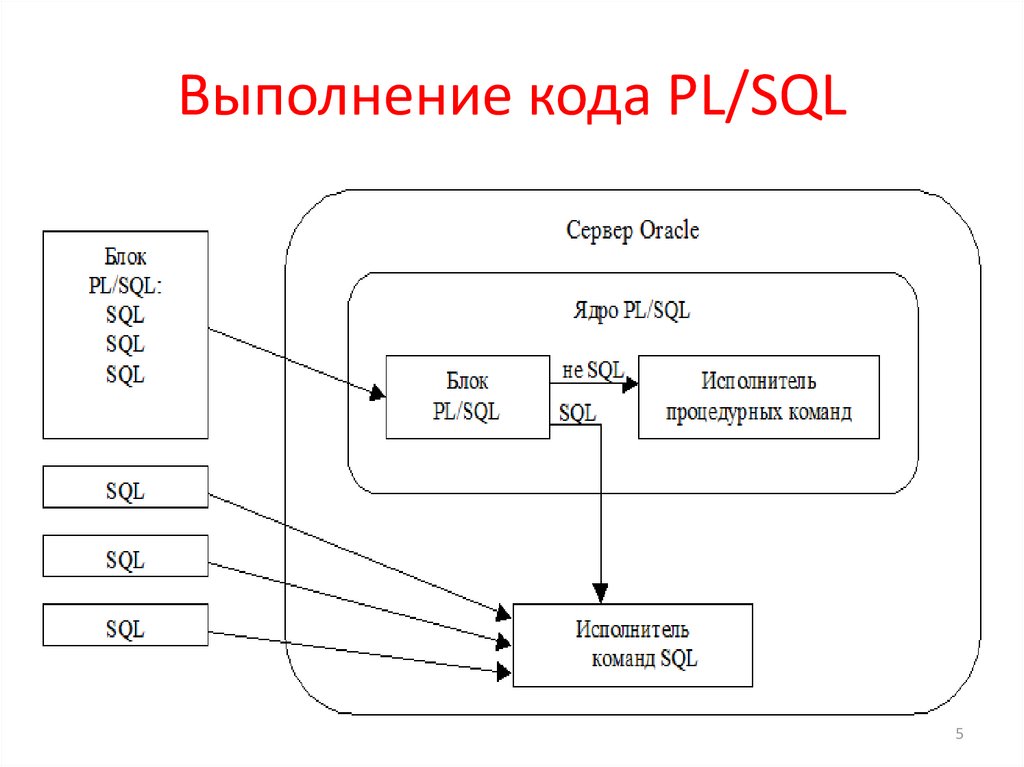
Яркие представители колоночных СУБД — Sybase IQ (ныне SAP IQ), Vertica, ClickHouse, Google BigTable, InfoBright, Cassandra.
Когда выбирать колоночные СУБД
Один из весомых аргументов за использование именно колоночной СУБД — это если вы хотите построить хранилище данных, и планируете делать выборки со сложными аналитическими вычислениями. Косвенный признак, который так же может сигнализировать о том, что имеет смысл, хотя бы посмотреть в сторону колоночных СУБД — это если количество строк, из которых делаются выборки, превышает сотни миллионов.
Когда не выбирать колоночные СУБД
Учитывая специфику колоночных СУБД, будет не эффективно ее использовать, если выборки достаточно простые, параметры выборки статичны, и если преобладают выборки по ключевым значениям. Так же, если количество строк в таблице, из которой делается выборка, меньше сотен миллионов строк, то скорее всего не будет большого преимущества, по сравнению с реляционной СУБД.
Нужно так же иметь ввиду, что в колоночных СУБД могут быть и другие ограничения. Например, может отсутствовать поддержка транзакций, а язык запросов может отличаться от классического SQL, и прочее.
Например, может отсутствовать поддержка транзакций, а язык запросов может отличаться от классического SQL, и прочее.
Итоги
Важное замечание – не пытайтесь сразу все задачи решить в рамках одной СУБД. Это более чем нормально иметь несколько разных типов СУБД. Так же, не пытайтесь сразу определиться с производителем СУБД, или связать свою жизнь с одним конкретным брендом.
При выборе типа СУБД следует, прежде всего, исходить из типа решаемых задач, типов обрабатываемых данных, перспектив роста и масштабирования.
Обращайте так же внимание на популярность и наличие широкого круга разработчиков и средств разработки – это даст вам возможность, при необходимости, найти ответ на возникший вопрос быстро.
В данной статье я намеренно не делаю акцент на выбор между облачными и on-premise решениями — эта тема одной из следующих статей.
Итак, в таблице представленной ниже, кратко собрано то, что описано выше в статье.
Тип СУБД | Когда выбирать | Примеры популярных СУБД |
Реляционные | Нужна транзакционность; высокая нормализация; большая доля операций на вставку | Oracle, MySQL, Microsoft SQL Server, PostgreSQL |
Ключ-значение | Задачи кэширования и брокеры сообщений | Redis, Memcached |
Документные | Для хранения объектов в одной сущности, но с разной структурой; хранение структур на основе JSON | CouchDB, MongoDB, Amazon DocumentDB |
Графовые | Задачи подобные социальным сетям; системы оценок и рекомендаций | Neo4j, Amazon Neptune, InfiniteGraph, InfoGrid |
Колоночные | Хранилища данных; выборки со сложными аналитическими вычислениями; количество строк в таблице превышает сотни миллионов | Vertica, ClickHouse, Google BigTable, Sybase \ SAP IQ, InfoBright, Cassandra |
Надеюсь данная статья оказалась полезной.
В следующих статьях посмотрим на выбор между облачными и on-premise СУБД, платными и бесплатными, и многое другое.
Субъекты (ядро СУБД) — SQL Server
Twitter LinkedIn Facebook Адрес электронной почты
- Статья
- Чтение занимает 3 мин
Применимо к: SQL Server (все поддерживаемые версии) Azure SQL database Управляемый экземпляр SQL Azure Azure Synapse Analytics Analytics Platform System (PDW)
Субъекты — это сущности, которые могут запрашивать ресурсы SQL Server . Как и другие компоненты модели авторизации SQL Server , участников можно иерархически упорядочить. Область влияния субъекта зависит от области его определения: Windows, сервер, база данных, — а также от того, неделимый это субъект или коллекция. Имя входа Windows является примером индивидуального (неделимого) субъекта, а группа Windows — коллективного. Каждый субъект имеет идентификатор безопасности (SID). Этот раздел относится ко всем версиям SQL Server, но в База данных SQL или Azure Synapse Analytics существуют некоторые ограничения на субъекты уровня сервера.
Как и другие компоненты модели авторизации SQL Server , участников можно иерархически упорядочить. Область влияния субъекта зависит от области его определения: Windows, сервер, база данных, — а также от того, неделимый это субъект или коллекция. Имя входа Windows является примером индивидуального (неделимого) субъекта, а группа Windows — коллективного. Каждый субъект имеет идентификатор безопасности (SID). Этот раздел относится ко всем версиям SQL Server, но в База данных SQL или Azure Synapse Analytics существуют некоторые ограничения на субъекты уровня сервера.
Субъекты уровня SQL Server:
- имя входа для проверки подлинности SQL Server;
- имя входа для проверки подлинности Windows для пользователя Windows;
- имя входа для проверки подлинности Windows для группы Windows;
- имя входа для проверки подлинности Azure Active Directory для пользователя AD;
- имя входа для проверки подлинности Azure Active Directory для группы AD.
- Роль сервера
Субъекты уровня базы данных
- Пользователь базы данных (существует 12 типов пользователей. Дополнительные сведения см. в разделе CREATE USER.)
- Роль базы данных
- Роль приложения
 Дополнительные сведения см. в разделе CREATE USER.)
Дополнительные сведения см. в разделе CREATE USER.)Имя входа SA
Имя для входа sa в SQL Server является субъектом серверного уровня. По умолчанию оно создается при установке экземпляра. Начиная с версии SQL Server 2005 (9.x)базой данных для имени входа sa по умолчанию является master. Это поведение было изменено по сравнению с предыдущими версиями SQL Server. Имя входа sa является участником предопределенной роли сервера sysadmin. sa имеет все разрешения на сервере и не может быть ограничено. Имя входа sa нельзя удалить, но его можно отключить, чтобы никто не смог его использовать.
Пользователь и схема dbo
Пользователь dbo — это особый субъект-пользователя, содержащийся в любой базе данных. Все администраторы SQL Server, участники предопределенной роли сервера sysadmin, имя входа sa и владельцы баз данных подключаются к базам данных в качестве пользователя dbo.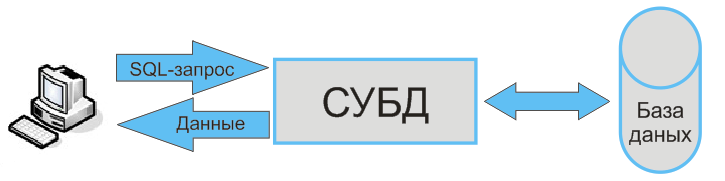 Пользователь
Пользователь dbo имеет все разрешения в базе данных и не может быть ограничен или удален. dbo означает владельца базы данных, но учетная запись пользователя dbo не совпадает с предопределенной ролью базы данных db_owner, а предопределенная роль базы данных db_owner не соответствует учетной записи пользователя, помеченной как владелец базы данных.
Пользователь dbo является владельцем схемы dbo. Если не указана другая схема, то схема dbo является схемой по умолчанию для всех пользователей. Схема dbo не может быть удалена.
Роль сервера public и роль базы данных
Каждое имя входа принадлежит к предопределенной роли сервера public, а каждый пользователь базы данных является участником роли базы данных public. Если имени входа или пользователю не были предоставлены или запрещены особые разрешения на доступ к защищаемому объекту, то они наследуют для него разрешения роли public.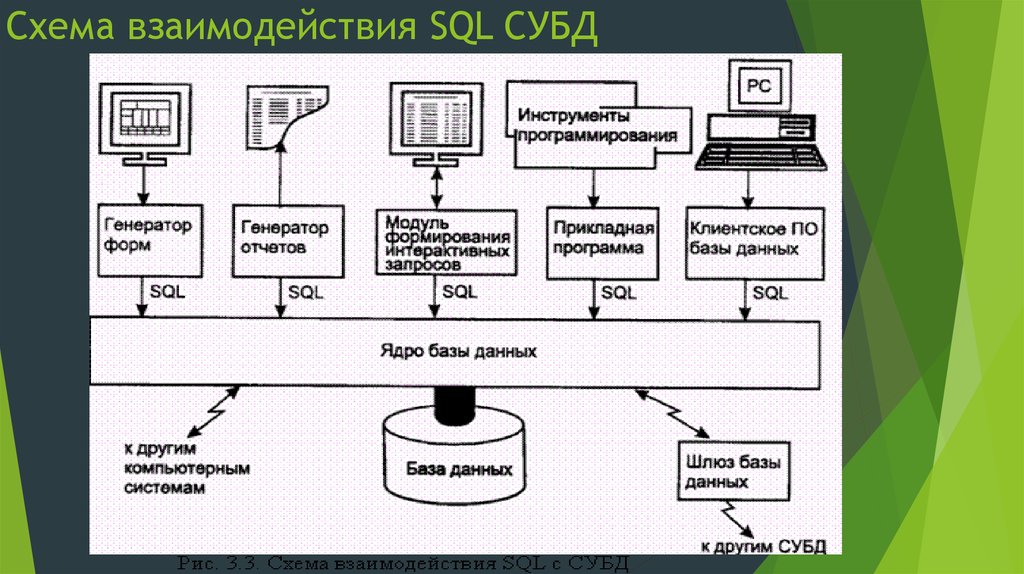 Предопределенная роль сервера
Предопределенная роль сервера public и предопределенная роль базы данных public не могут быть удалены. Однако можно отменить разрешения для ролей public. Существует множество разрешений, назначенных ролям public по умолчанию. Большая часть этих разрешений необходимы для выполнения повседневных операций в базе данных (операции, которые должен выполнять каждый). Будьте внимательны при отмене разрешения для общедоступного имени входа или пользователя, так как это повлияет на все имена входа и на всех пользователей. Обычно не следует запрещать разрешения для общедоступной роли public, так как инструкция DENY переопределяет любые инструкции GRANT, которые можно выдать для пользователей.
Каждая база данных включает в себя две сущности, которые отображены в качестве пользователей в представлениях каталога: INFORMATION_SCHEMA и sys. Они необходимы для внутреннего применения ядром СУБД. Их нельзя изменить или удалить.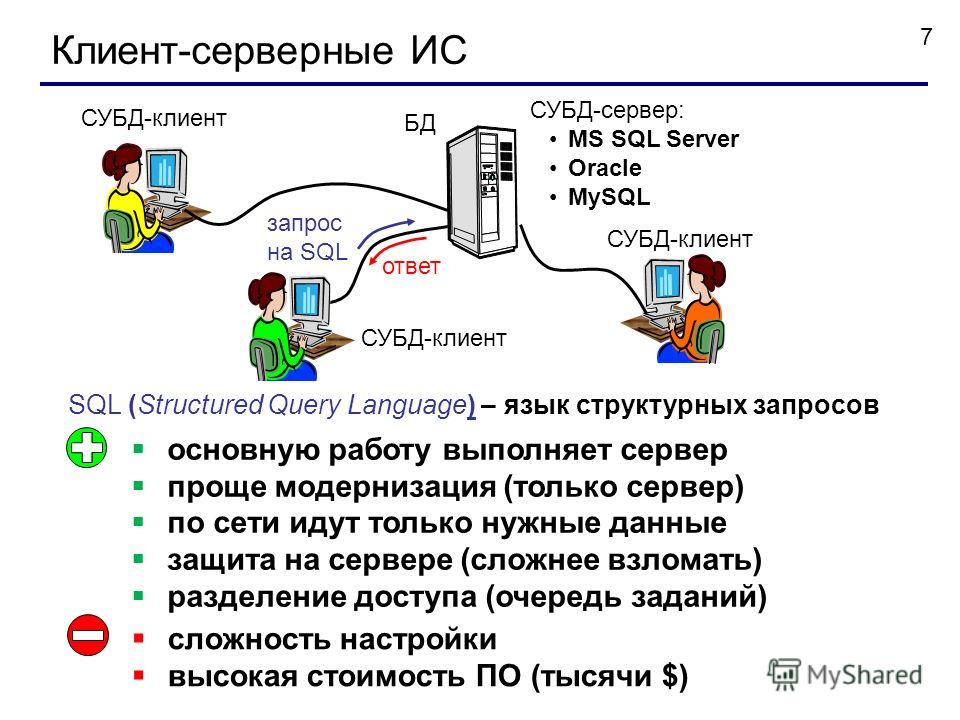
Имена входа SQL Server на основе сертификата
Субъекты уровня сервера, имеющие имена, заключенные в хэш-символы (##), — только для внутреннего системного пользования. Следующие участники создаются из сертификатов при установке SQL Server и не должны удаляться.
- ##MS_SQLResourceSigningCertificate##
- ##MS_SQLReplicationSigningCertificate##
- ##MS_SQLAuthenticatorCertificate##
- ##MS_AgentSigningCertificate##
- ##MS_PolicyEventProcessingLogin ##
- ##MS_PolicySigningCertificate ##
- ##MS_PolicyTsqlExecutionLogin ##
В учетных записях субъектов нет паролей, доступных для изменения администраторам, так как они основаны на сертификатах, выданных Майкрософт.
Пользователь-гость
Каждая база данных включает в себя пользователя guest. Разрешения, предоставленные пользователю guest , наследуются пользователями, которые имеют доступ к базе данных, но не обладают учетной записью пользователя в ней. Пользователя
Пользователя guest нельзя удалить, но его можно отключить, если отменить его разрешение CONNECT. Разрешение CONNECT можно отменить, выполнив инструкцию REVOKE CONNECT FROM GUEST; в любой базе данных, кроме master или tempdb.
Сведения о проектировании системы разрешений см. в статье Getting Started with Database Engine Permissions.
Данный раздел электронной документации по SQL Server содержит следующие подразделы.
Инструкции по управлению именами входа, пользователями и схемами
Роли уровня сервера
Роли уровня базы данных
Роли приложений
См. также:
Обеспечение безопасности SQL Server
sys.database_principals (Transact-SQL)
sys.server_principals (Transact-SQL)
sys.sql_logins (Transact-SQL)
sys.database_role_members (Transact-SQL)
Роли уровня сервера
Роли уровня базы данных
Разделение данных в таблице
Michael —
Вы имеете в виду метод оптимизации, называемый горизонтальное разбиение .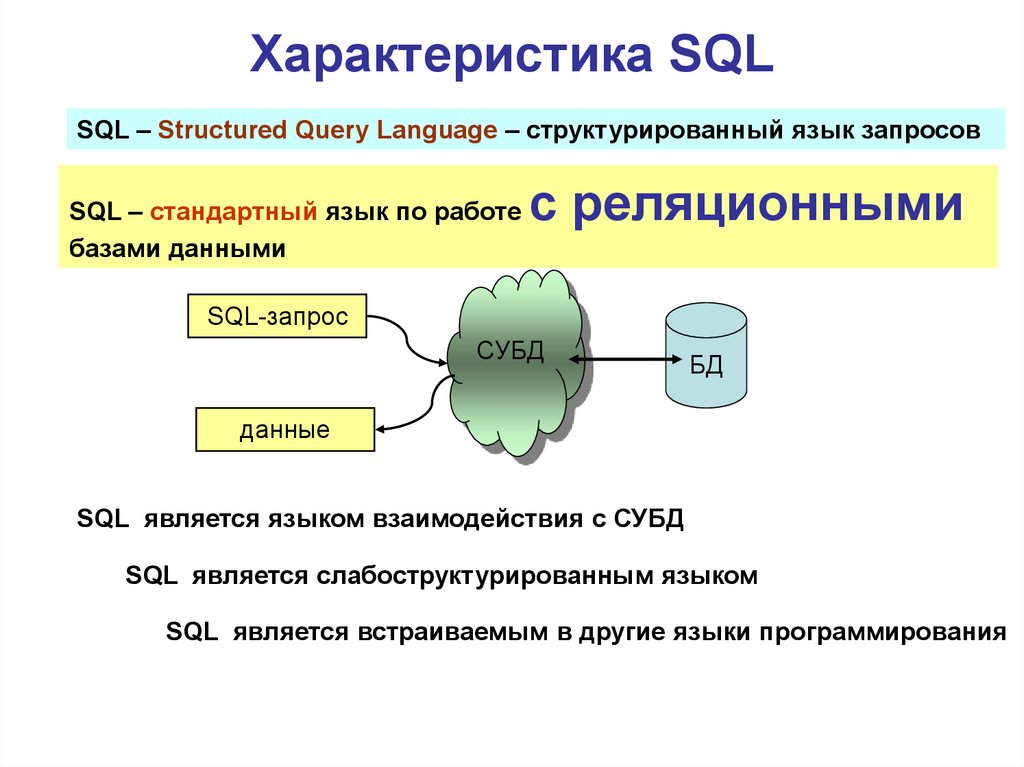 То есть таблица разбивается на несколько меньших таблиц, содержащих такое же количество столбцов, но меньшее количество строк. Сравните это с вертикальным секционированием , в котором таблица разбита на несколько меньших таблиц с таким же количеством строк, но меньшим количеством столбцов.
То есть таблица разбивается на несколько меньших таблиц, содержащих такое же количество столбцов, но меньшее количество строк. Сравните это с вертикальным секционированием , в котором таблица разбита на несколько меньших таблиц с таким же количеством строк, но меньшим количеством столбцов.
И да, это конструктивное решение часто принимается для повышения производительности. Горизонтальное разбиение таблицы дает нам некоторые преимущества:
- В каждой таблице разделов будет меньше строк; если вам нужно (не дай бог) сканировать данные по таблице, это займет меньше времени.
- Индексы в каждой таблице разделов будут меньше (= более быстрый поиск), чем соответствующий индекс в неразделенной таблице.
- Если вам нужно, вы можете поместить каждую таблицу разделов в другую файловую группу и разделить данные между несколькими дисками/томами RAID/контроллерами дисков.
- Если вы пытаетесь превзойти бенчмарк Oracle TPC-C, вы можете рассмотреть возможность разделения данных между несколькими федеративные серверы в SQL Server 2000. (Хотя для хранения информации о жилых подразделениях это может быть немного чрезмерным.)
- Если вы создаете секционированное представление на секционированных таблицах, вы можете обращаться с представлением так, как оно есть всю таблицу, а QP (обработчик запросов) будет касаться только тех таблиц, которые ему необходимы для выполнения запроса. Вы получаете преимущества горизонтального секционирования без головной боли запросов.
 (Хотя для хранения информации о жилых подразделениях это может быть немного чрезмерным.)
(Хотя для хранения информации о жилых подразделениях это может быть немного чрезмерным.) Итак, как видите, горизонтальное секционирование — это разделение рабочей нагрузки — распределение доступа к данным между таблицами, индексами, дисками и серверами.
Зачем вам это? Ну, может быть, у вас есть большая таблица — например, сотни миллионов строк. А может не так много строк, а больших строк. Или, может быть, у вас есть таблица в хранилище данных, которая содержит часто и редко используемые строки. Все эти ситуации являются кандидатами на разбиение.
Во всем этом есть два больших недостатка:
- Если вы не используете секционированное представление для доступа к данным, вам придется встроить в свое приложение логику для доступа к правильной таблице, а это очень хлопотно. фактор. Пожалуйста, пожалуйста, используйте раздельный вид.
- На самом деле вам нужно разделить данные. И поддерживать его. И создайте разделенное представление. При необходимости сбалансируйте объем данных в каждой секционированной таблице. Другими словами, страшные «административные накладные расходы».
 фактор. Пожалуйста, пожалуйста, используйте раздельный вид.
фактор. Пожалуйста, пожалуйста, используйте раздельный вид. Хорошо, поскольку я рекламирую разделенное представление, позвольте мне быстро объяснить, как его создать. Я буду использовать информацию из вопроса Майкла в качестве примера. Во-первых, таблицы:
CREATE TABLE Subdiv_ClaireRidgeEstates (SubdivID int, LotID int /*, etc.*/)
CREATE TABLE Subdiv_TibetianYakFarms (SubdivID int, LotID int /* и т. д.*/)
Вы могли заметить, что я включил идентификатор подразделения в каждую таблицу. Это важно; чтобы секционированное представление работало наиболее эффективно, QP должен знать, что каждая таблица разделов будет содержать данные только определенного типа. Для этого вам нужно создать ограничения
Для этого вам нужно создать ограничения CHECK для каждой таблицы с идентификатором, который вы секционируете на . Поскольку вы разбиваете данные по подразделениям, вы построите Проверка Ограничения на подразделении:
Альтер Таблица Subdiv_ClaireridgeStates Добавить ограничение CK_CRE_SUBDIV Проверка (Subdivid = 42)
Альтер -таблица subdiv_tibetianyakfarms Add Constrast Ck_tyf_subdivif и присвоение диапазона ключевых значений каждой таблице разделов. Или путем разделения по дате и использования диапазона дат для каждого значения раздела. Несмотря на это, вам все еще нужны эти ПРОВЕРЬТЕ ограничения для каждой таблицы.
После фактического создания таблиц разделов, распределения данных и создания ограничений CHECK построить представление довольно просто. Вы просто SELECT * из каждой таблицы разделов и используете UNION ALL для объединения результатов запроса:
CREATE VIEW Subdivision
AS
SELECT * FROM Subdiv_ClaireRidgeEstates
UNION ALL
SELECT * FROM Subdiv_Tibetian9Y0082Теперь, если вы следовали примеру, попробуйте вставить несколько строк в каждую таблицу:
90 в опции «Показать план выполнения» в анализаторе запросов и выполните следующие запросы:
INSERT Subdiv_ClaireRidgeEstates VALUES (42,9999)
INSERT Subdiv_TibetianYakFarms VALUES (9538,1234 Now, Turn,
SELECT * FROM Subdivision WHERE SubdivID = 42
SELECT * FROM Subdivision WHERE SubdivID = 9538
SELECT * FROM SubdivisionВы заметите, что для первых двух запросов SQL Server извлекает информацию только из требуемой таблицы разделов.
В SQL Server 7.0, к сожалению, нельзя обновлять данные в секционированном представлении. Однако это ВОЗМОЖНО в SQL Server 2000. Ознакомьтесь с электронной документацией по SQL Server (особенно если вы собираетесь использовать распределенные секционированные представления), чтобы узнать, что можно и чего нельзя делать при секционировании данных.
У Майкла было два очень хороших вопроса. Ответ на этот утомил меня, так что я должен опубликовать следующий завтра. :)
ОБНОВЛЕНО 20.09.00 - вот дополнительный вопрос, который касается разделения баз данных приложения на несколько аналогичных баз данных для каждого клиента, использующего приложение.
-SQLGuru
оракул - объединение четырех таблиц SQL
Задавать вопрос
Спросил
Изменено 5 лет, 1 месяц назад
Просмотрено 83 раза
Новинка! Сохраняйте вопросы или ответы и организуйте свой любимый контент.
Узнать больше.У меня есть четыре таблицы, как показано ниже, в Oracle DB, список сотрудников сопоставляется с идентификаторами офисов (m_office содержит идентификаторы офисов и имена офисов). Все офисы являются либо подразделениями, либо подразделениями. Опять же, все подразделения принадлежат подразделениям. Мне нужно узнать количество сотрудников по подразделениям (количество подразделений также должно включать сотрудников, принадлежащих подразделению), как показано в последней таблице.
(поскольку это рабочая база данных, поэтому нельзя изменить структуру). Не получается найти решение. Любая помощь очень ценна. Заранее спасибо.
TEST_EMPLOYEELIST
EmpId EmpName Office_id -------------------------------- 1 Алекс О1 2 Джон О1 3 Боб О3 4 макс О5 5 Ник О5 6 Джек О1 7 Пол О2TEST_M_OFFICE
office_id имя_офиса ------------------------------ O1 Камруп Дивизион O2 Налбарский дивизион Дивизион O3 Барпета O4 Налбари RR Подразделение O5 Barpeta SR Подразделение O6 Barpeta RR ПодразделениеTEST_DIVISION
Division_id имя_подразделения -------------------------------------------------- D1 Камруп Дивизион D2 Дивизия Налбари D3 Дивизион Барпета D4 Бонгайгонский дивизион D5 Дивизия РангиаTEST_DIV_SUBDIV_MAPPING
subdivision_id subdivision_name Division_id -------------------------------------------------- ---- S1 Налбари RR Подразделение D2 S2 Барпета СР Подразделение D3 S3 Барпета RR Подразделение D3 S4 Rangia RR Подразделение D5 S5 Камруп RR Подразделение D1Требуется: количество записей Division_wise (включая количество подразделений)
количество Division_name ---------------------------- Камруп Дивизион 3 Налбари Дивизион 1 Барпета Дивизион 3 Бонгайгон Дивизион 0 Рангия Дивизион 0Это то, что я пробовал до сих пор:
выберите b.
 Только в последнем запросе, где мы не фильтруем по SubdivID, QP извлекает данные из каждой таблицы разделов.
Только в последнем запросе, где мы не фильтруем по SubdivID, QP извлекает данные из каждой таблицы разделов. 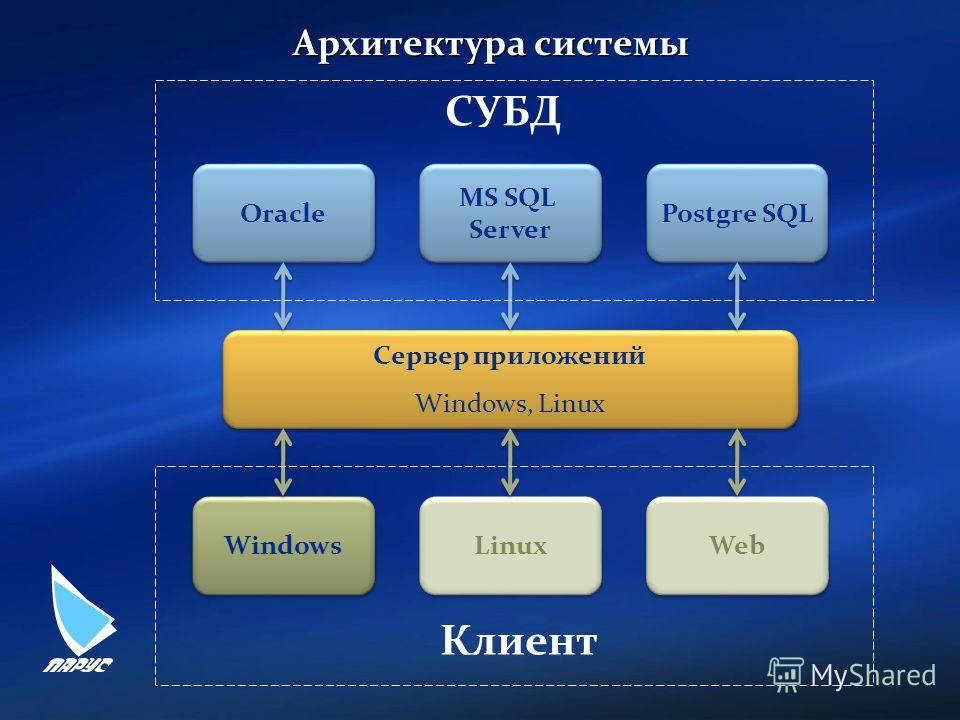
 office_name,
считать(*)
из test_employeelist,
test_m_office б
где a.officeid = b.office_id
сгруппировать по b.office_name;
office_name,
считать(*)
из test_employeelist,
test_m_office б
где a.officeid = b.office_id
сгруппировать по b.office_name;
- sql
- оракул
- oracle11g
- oracle-sqldeveloper
6
Попробуйте это.
ВЫБЕРИТЕ имя_подразделения,
считать(*)
ИЗ
(ВЫБЕРИТЕ b.office_name имя_подразделения
ОТ test_employeelist a,
test_m_office б,
ТЕСТ_ОТДЕЛ c
ГДЕ a.office_id=b.office_id
И b.office_name=c.division_name
СОЮЗ ВСЕХ
ВЫБЕРИТЕ c.division_name Division_name
ОТ test_employeelist a,
test_m_office б,
ТЕСТ_ОТДЕЛ c,
TEST_DIV_SUBDIV_MAPPING д
ГДЕ a.office_id=b.office_id
И b.office_name = d.subdivision_name
И c.division_id = d.division_id )
СГРУППИРОВАТЬ ПО имя_подразделения;
1
Это очень плохая модель данных. Поскольку нельзя создавать внешние ключи для имен, простая опечатка делает записи несвязанными.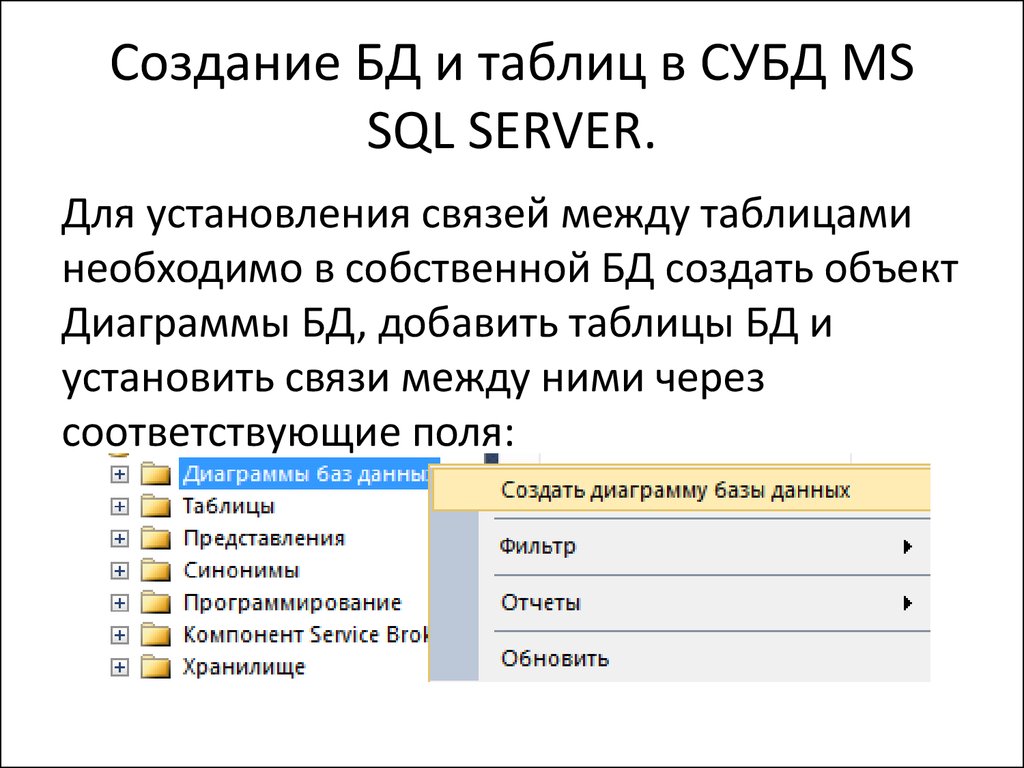
Однако у вас есть офисы, которые являются подразделениями, и офисы, которые являются подразделениями подразделений. Используйте UNION ALL, чтобы объединить их и получить промежуточную таблицу, относящуюся к офису и подразделению.
выбрать dv.division_name, count(e.empid) как employee_count из ( выберите d.division_id, d.division_name, d.division_name как office_name из test_division d союз всех выберите d.division_id, d.division_name, sd.subdivision_name как office_name из test_div_subdiv_mapping SD присоединиться к test_division d на d.division_name = sd.division_id ) дв присоединиться к test_m_office o на o.office_name = dv.office_name левый присоединиться к test_employeelist e на e.office_id = o.office_id группировать по dv.division_id, dv.division_name;
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Все слои и таблицы (землеустройство/свидетельство о собственности)
- 4 33333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333. иль.
- ОБЪЕКТID ( тип: esriFieldTypeOID, псевдоним: OBJECTID )
- ПАРИД ( тип: esriFieldTypeString, псевдоним: PARID, длина: 30 )
- ПОДПИСЬ ( тип: esriFieldTypeString, псевдоним: SUBDNUM, длина: 20 )
- АДРЕС ( тип: esriFieldTypeString, псевдоним: ADDRESS, длина: 50 )
- PERMIT_TYPE ( тип: esriFieldTypeString, псевдоним: PERMIT_TYPE, длина: 30 )
- PERMIT_NO ( тип: esriFieldTypeString, псевдоним: PERMIT_NO, длина: 12 )
- PERMIT_ISSUE ( тип: esriFieldTypeDate, псевдоним: PERMIT_ISSUE, длина: 8 )
- PERMIT_UNITS ( тип: esriFieldTypeDouble, псевдоним: PERMIT_UNITS )
- ВЫБЕРИТЕ ПИН-код ( тип: esriFieldTypeString, псевдоним: SELECTPIN, длина: 30 )
- ПОДРАЗДЕЛЕНИЕ ( тип: esriFieldTypeString, псевдоним: SUBDIVISION, длина: 40 )
- СТАТ ( тип: esriFieldTypeString, псевдоним: STAT, длина: 1 )
- C_O_ISSUE ( тип: esriFieldTypeDate, псевдоним: C_O_ISSUE, длина: 8 )
- ФОРМА ( тип: esriFieldTypeGeometry, псевдоним: SHAPE )
Слой: Жилой (0)
Имя: ResidentialПоле отображения: PARID
Тип: Feature Layer
Тип геометрии: esriGeometryPoint
Описание:
Текст авторского права:
По умолчанию видимость: True
MaxRecordCount: 1000
Поддержка Query Formats: JSON, GeoJson
9004 MIN.
Поддерживает расширенные запросы: true
Поддерживает статистику: true
Имеет метки: false
Может изменять слой: false
Символы Can Scale: false
Поддерживает преобразование данных: true
Extent:
- XMin: -9205101,027948786
YMin: 3153296,8995812954
XMax: -9135431,812809477
YMax: 3204339,7510664086
Пространственная привязка: 102100 (3857)
Информация о чертеже:
- Рендерер:
- Простой визуализатор:
Символ:
Описание:
Информация о маркировке:
- Поддерживает статистику: true
Поддерживает OrderBy: true
Поддерживает Distinct: true
Поддерживает нумерацию страниц: true
Поддерживает TrueCurve: true
Поддерживает возвращаемый объем запроса: true
Поддерживает запрос с расстоянием: true
Поддерживает выражение Sql: true
Поддерживает запрос с типом результата: false
Поддерживает возврат центроида геометрии: false
HASZ: False
Hasm: False
Имеет вложения: False
HTML Popup Type: ESRISERVERHTMLPOPUPTYPEASHTMLTEXT
 иль.
иль.Слой: Нежилой (1)
Name: Non-ResidentialDisplay Field: PARID
Type: Feature Layer
Geometry Type: esriGeometryPoint
Description:
Copyright Text:
Default Visibility: true
MaxRecordCount: 1000
Поддерживаемые форматы запросов: JSON, geoJSON
Минимальный масштаб: 100000
Мас.