Сжатие изображений при помощи модели Stable Diffusion / Хабр
На сегодняшний день Stable Diffusion является источником вдохновения для сообщества любителей опенсорсного машинного обучения и в то же время источником расстройства для художников всего мира. Мне стало любопытно, что ещё может сделать эта важная технология кроме того, как подвергать угрозе рабочие места профессиональных художников и дизайнеров.
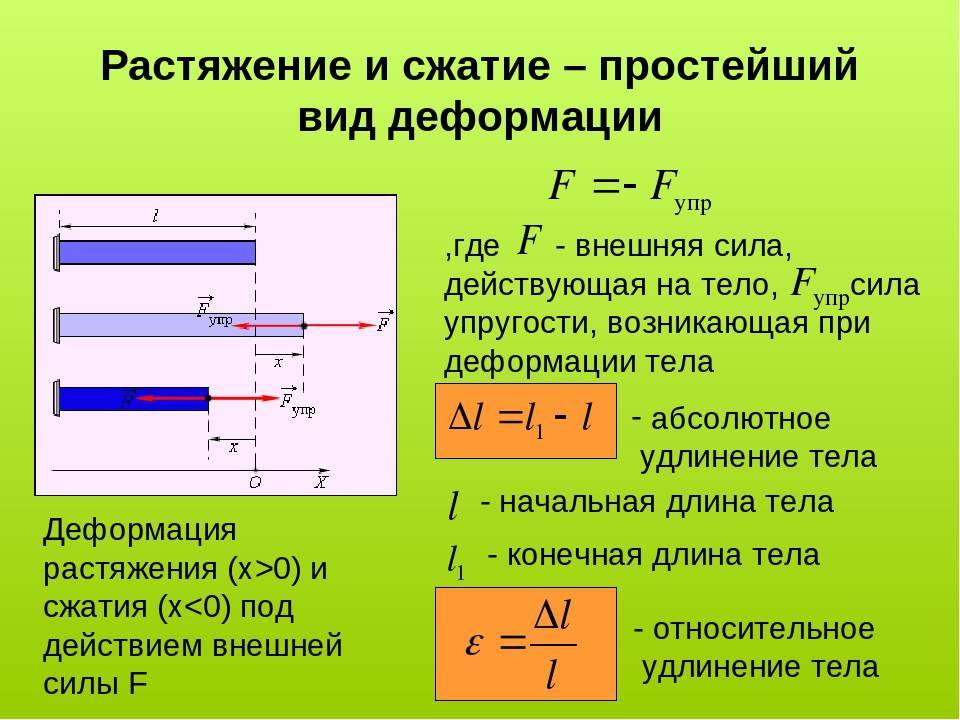
В процессе экспериментов с моделью я обнаружил, что она подходит в качестве чрезвычайно эффективного кодека сжатия изображений с потерями. Прежде чем приступать к описанию своей методики и демонстрации кода, вот несколько результатов модели по сравнению с JPG и WebP с высокой степенью сжатия. Все изображения имеют разрешение 512×512 пикселей:
Сан-Франциско, сверху вниз: JPG (6,16 Кбайт), WebP (6,80 Кбайт), Stable Diffusion: (4,96 Кбайт)
Кондитерская, сверху вниз: JPG (5,68 Кбайт), WebP (5,71 Кбайт), Stable Diffusion (4,98 Кбайт)
Анна, сверху вниз: JPG (5,66 Кбайт), WebP (6,74 Кбайт), Stable Diffusion (4,97 Кбайт)
Из этих примеров достаточно очевидно, что сжатие изображений при помощи Stable Diffusion обеспечивает гораздо большее качество изображения при меньшем размере файла по сравнению с JPG и WebP. Это качество несёт с собой и некоторые важные особенности, которые нужно учитывать; подробнее я расскажу об этом ниже. Однако на первый взгляд это очень многообещающий вариант для агрессивного сжатия изображений с потерями.
Это качество несёт с собой и некоторые важные особенности, которые нужно учитывать; подробнее я расскажу об этом ниже. Однако на первый взгляд это очень многообещающий вариант для агрессивного сжатия изображений с потерями.
- Variational Auto Encoder
- U-Net
- Text Encoder
VAE кодирует изображение в это скрытое пространство следующим образом: она обучается в процессе тренировки, то есть описания скрытого пространства разных версий модели с большой вероятностью при дальнейшем обучении будут выглядеть по-разному. В Stable Diffusion v1. 4 описание исходного изображения из начала статьи выглядит так (после преобразования и интерпретации в качестве изображения с четырёхканальным цветом):
4 описание исходного изображения из начала статьи выглядит так (после преобразования и интерпретации в качестве изображения с четырёхканальным цветом):
Один цикл кодирования/декодирования при помощи этой VAE выглядит так:
Цикл VAE, сверху вниз: исходное изображение 512×512@24bpp, описание скрытого пространства 64×64@128bpp, декодированное изображение 512×512@24bpp
Обратите внимание, что этот цикл работает с потерями. Например, имя Анны на её наморднике после декодирования менее читаемо. VAE версии Stable Diffusion 1.4 в целом не очень хорошо справляется с описанием мелкого текста (а также лиц; надеюсь, в версии 1.5 обученной модели ситуация улучшится).
Основной алгоритм Stable Diffusion, генерирующий изображения из коротких текстовых описаний, работает с этим описанием изображений в скрытом пространстве. Он начинает со случайного шума в описании скрытого пространства, а затем итеративно избавляет это изображение в скрытом пространстве от шума при помощи обученной U-Net
Он начинает со случайного шума в описании скрытого пространства, а затем итеративно избавляет это изображение в скрытом пространстве от шума при помощи обученной U-Net

Квантизация данных из значений с плавающей запятой в 8-битные беззнаковые integer при помощи масштабирования, усечения и преобразования приводит лишь к очень малозаметной погрешности воссоздания:
Сверху: декодировано из 32-битных данных с плавающей запятой скрытого пространства. Посередине: исходное изображение. Снизу: декодировано из 8-битных данных integer скрытого пространства
Для квантизации сгенерированных VAE изображений я сначала отмасштабировал их в соотношении 1 / 0,18215 — это число вы можете найти в исходном коде Stable Diffusion. Похоже, деление данных скрытого пространства на это число достаточно хорошо преобразует их в диапазон [-1, 1], однако частичное ограничение всё равно применяется.
После квантизации данных скрытого пространства до 8 бит описание изображения имеет размер 64*64*4*8 бит = 16 Кбайт (исходное изображение без сжатия имеет размер 512*512*3*8 бит = 768 Кбайт).
В моих экспериментах квантизация до менее чем 8 бит не давала хороших результатов, однако на удивление хорошо подошла дальнейшая квантизация при помощи палитр и дизеринга. Я создал палитризированное описание при помощи палитры скрытого пространства из 256 векторов 4*8 бит и дизеринга по методу Флойда-Стейнберга. Использование палитры из 256 элементов позволяет описать каждый вектор скрытого пространства при помощи одного 8-битного индекса, что снижает размер данных до 64*64*8+256*4*8 бит = 5 Кбайт
Однако палитризированное описание приводит к заметным артефактам при декодировании их непосредственно с помощью VAE:
Сверху: 32-битные данные скрытого пространства. Посередине: 8-битные квантизованные данные. Внизу: палитризированные 8-битные данные с дизерингом по методу Флойда-Стейнберга (обратите внимание на заметные искажения)
Дизеринг палитризированных данных добавил шума, что исказило декодированный результат. Но поскольку работа Stable Diffusion основана на устранении шума из данных скрытого пространства, мы можем использовать U-Net для устранения шума, добавленного дизерингом. Спустя всего четыре итерации результат воссоздания визуально очень близок к неквантизованной версии:
Но поскольку работа Stable Diffusion основана на устранении шума из данных скрытого пространства, мы можем использовать U-Net для устранения шума, добавленного дизерингом. Спустя всего четыре итерации результат воссоздания визуально очень близок к неквантизованной версии:
Сверху: после палитизирования и дизеринга данных скрытого пространства. Посередине: после четырёх этапов устранения шума. Внизу: исходное изображение
Хотя результат можно считать очень хорошим, учитывая огромное снижение размера данных (коэффициент сжатия 155x по сравнению с несжатым исходным изображением), наблюдатель может заметить добавившиеся артефакты, например, глянцевый оттенок на сердечке, которого до сжатия не было. Однако, интересно, что добавленные схемой сжатия артефакты больше влияют на содержимое изображения, а не на его качество, и важно помнить о том, что сжатые таким образом изображения могут содержать подобные артефакты сжатия.
Далее я сжал без потери палитру и индексы при помощи zlib; в результате размер большинства образцов, на которых я выполнял тестирование, оказалось чуть меньше 5 Кбайт.

Важно заметить, что, хотя результаты Stable Diffusion субъективно выглядят гораздо лучше изображений, сжатых JPG и WebP, они ненамного лучше (но и не хуже) с точки зрения стандартных метрик наподобие PSNR или SSIM. Добавляемые SD артефакты намного менее заметны, потому что они больше влияют на содержимое изображения, а не на его качество. В этом и заключается небольшая опасность данной методики: не нужно обманываться качеством воссозданных результатов, так как на содержимое могли повлиять артефакты сжатия, даже если оно выглядит очень чётко. Например, посмотрим на деталь тестового изображения с видом Сан-Франциско:
Сверху: сжатие JPG. Посередине: исходное изображение.
 Снизу: сжатие Stable Diffusion
Снизу: сжатие Stable DiffusionКак видите, хотя Stable Diffusion в качестве кодека гораздо лучше сохраняет качественные аспекты изображения, вплоть до зернистости камеры (с которой испытывают трудности большинство традиционных алгоритмов сжатия), на содержимое всё равно влияют артефакты сжатия, а такие мелкие детали, как форма зданий, могут меняться. Хотя в сжатом JPG совершенно точно нельзя распознать больше исходного изображения по сравнению со сжатием Stable Diffusion, высокое визуальное качество результата SD может быть обманчивым, так как артефакты сжатия в JPG и WebP гораздо проще выявить как артефакты.
На данный момент некоторые признаки не очень хорошо сохраняются VAE модели Stable Diffusion; в частности, возникают проблемы с мелким текстом и лицами (это согласуется с «Ограничениями и искажениями» версии 1.4 модели SD, перечисленными в карточке модели). Вот три примера, иллюстрирующих это:Сверху: исходное изображение. Посередине: непосредственный цикл VAE (32-битные данные скрытого пространства).
 Снизу: декодировано из палитризованных и избавленных от шума 8-битных данных скрытого пространства
Снизу: декодировано из палитризованных и избавленных от шума 8-битных данных скрытого пространстваСверху: исходное изображение. Посередине: непосредственный цикл VAE (32-битные данные скрытого пространства). Снизу: декодировано из палитризованных и избавленных от шума 8-битных данных скрытого пространства
Сверху: исходное изображение. Посередине: непосредственный цикл VAE (32-битные данные скрытого пространства). Снизу: декодировано из палитризованных и избавленных от шума 8-битных данных скрытого пространства
Как видно по изображениям посередине, актуальная VAE модели Stable Diffusion 1.4 не очень хорошо сохраняет в скрытом пространстве мелкий текст и лица, поэтому данная схема сжатия наследует эти ограничения. Но поскольку версия 1.5 Stable Diffusion, пока доступная только в Dreamstudio компании stability.ai, гораздо лучше справляется с лицами, я хочу дополнить эту статью после публикации модели 1.5 для общего доступа.
Глубокое обучение очень успешно используется для восстановления испорченных изображений и видео или для увеличения их разрешения. Чем эта методика отличается от восстановления изображений, испорченных сжатием?
Чем эта методика отличается от восстановления изображений, испорченных сжатием?Важно понимать, что Stable Diffusion не используется для восстановления изображения, которое было испорчено сжатием в пространстве изображения, а применяет сжатие с потерями к внутреннему пониманию моделью Stable Diffusion этого изображения и пытается «починить» повреждения, которые причинило внутреннему описанию сжатие с потерями (что отличается от восстановления испорченного изображения).
Например, эта методика сохраняет зернистость камеры (в качественном выражении), а также все другие качественные ухудшения, в то время как восстановление сильно сжатого JPG при помощи ИИ не сможет восстановить эту зернистость, поскольку из данных информация о ней пропала.
Аналогия этого различия: допустим, у нас есть художник, обладающий фотографической памятью. Мы показываем ему изображение, а затем просим воссоздать его, и он создаёт почти идеальную копию по памяти. Фотографическая память этого художника и есть VAE модели Stable Diffusion.
В случае восстановления мы бы показали этому художнику изображение, сильно повреждённое сжатием, и попросили бы его воссоздать это изображение по памяти, но так, как, по его мнению, оно выглядело до того, как было испорчено.
Однако в описанной в статье ситуации мы показываем ему оригинальное несжатое изображение и просим максимально хорошо его запомнить. Затем мы выполняем операцию на его мозге и ужимаем данные в его памяти, применив сжатие с потерями, устраняющее нюансы, которые кажутся неважными, и заменяя схожие вариации концепций и аспектов запомненного изображения такой же вариацией.
После операции мы просим его создать идеальную копию изображения по памяти. Он по-прежнему помнит все важные аспекты изображения: от содержимого до качественных свойств — например, зернистости камеры, размещения и общего внешнего вида каждого увиденного им здания, однако конкретное расположение каждой точки зернистости камеры уже стали другими, а некоторые запомненные им здания теперь имеют странные дефекты, не имеющие смысла.
Затем мы просим его снова нарисовать изображение, но на этот раз, если он помнит некоторые аспекты очень странными и не имеющими смысла, он должен воспользоваться своим опытом и нарисовать эти объекты так, чтобы они были логичными (стоит заметить, что «не имеющий смысла» не всегда означает «плохой»: размытое или поцарапанное фото является плохим, но эти дефекты вполне логичны).
То есть в обоих случаях мы попросили художника рисовать так, как должна выглядеть картина, исходя из его опыта, но поскольку сжатие было применено к описанию изображения в его памяти, которая больше хранит концепции, а не пиксели, уменьшилось только информационное содержимое концепций; в случае восстановления изображения, испорченного сжатием, снижаются и визуальное качество, и концептуальное содержимое, художник должен восстановить их самостоятельно.
Благодаря этой аналогии очевидно, что данная схема сжатия ограничена тем, насколько хорошо работает фотографическая память художника. В случае Stable Diffusion v1. 4 он не очень хорошо справляется с запоминанием лиц, а также страдает от дислексии.
4 он не очень хорошо справляется с запоминанием лиц, а также страдает от дислексии.
https://colab.research.google.com/drive/1Ci1VYHuFJK5eOX9TB0Mq4NsqkeDrMaaH?usp=sharing
Stable Diffusion кажется очень перспективной в качестве основы для схемы сжатия изображений с потерями.Мои эксперименты были довольно поверхностными, и я считаю, что есть гораздо больший потенциал сжатия описаний в скрытом пространстве, чем раскрытая в посте методика, но даже эта относительно простая схема с квантизацией и дизерингом уже позволяет добиться очень впечатляющих результатов.
Хотя с этой задачей, скорее всего, лучше будет справляться VAE, специально спроектированная и обученная под неё, огромное преимущество использования VAE модели Stable Diffusion заключается в том, что шести-семизначные суммы в долларах, которые уже были инвестированы в обучение Stable Diffusion, можно напрямую использовать без необходимости вложений огромных сумм в обучение новой модели под эту задачу.
Сверху: JPG. Посередине: WebP. Снизу:: Stable Diffusion. Во всех случаях изображение SD сжимается в меньший размер, чем соответствующие JPG и WebP. Результаты специально не выбирались.
Сжатие изображений — пакет разработки Learn — Contributor guide
Twitter LinkedIn Facebook Адрес электронной почты- Статья
Имя расширения
Пакет разработки Learn состоит из нескольких вложенных расширений. Эта функция изображений включена в расширение Learn Images . Он автоматически включается в пакет разработки Learn, поэтому его не нужно устанавливать отдельно.
Эта функция изображений включена в расширение Learn Images . Он автоматически включается в пакет разработки Learn, поэтому его не нужно устанавливать отдельно.
Итоги
Вся документация предоставляется через Интернет, за исключением PDF-версий статей документации. При обслуживании статического содержимого лучше свести к минимуму количество байтов, отправляемых по сети. Одним из способов сделать это является сжатие неактивных изображений.
Расширение Learn Images в пакете разработки Learn включает пункты контекстного меню сжатия изображений. Поддерживаются следующие типы изображений и расширения.
- *.png
- *.jpg
- *.jpeg
- *.gif
- *.svg
- *.webp
По возможности используются алгоритмы сжатия изображений без потерь.
Сжатие изображения
На панели навигации Обозреватель щелкните правой кнопкой мыши файл изображения, а затем выберите пункт Сжать изображение. Изображение сжимается.
Изображение сжимается.
Сжатие изображения в папке
На панели навигации Обозреватель щелкните правой кнопкой мыши папку с изображением, а затем выберите пункт Сжать изображение в папке. Все изображения в папке сжимаются.
Рекомендации
Изображения с большими разрешениями неявно изменяют размер. Максимальный размер зависит от рекомендуемой максимальной ширины 1,200px на платформе. Максимальное значение используется только в том случае, если размер изображений превышает рекомендуемый размер. Они сохраняют пропорции при автоматическом изменении размера.
Параметры
Максимальные размеры можно настроить, но по умолчанию используется максимальная ширина 1200 пикселей. Чтобы настроить максимальный размер, выберите Файл -> Настройки -> Параметры и отфильтруйте результаты по "Learn Images Extension".
Примечание
Значение 0 в полях Максимальная ширина или Максимальная высота будет просто игнорировать различия разрешения.
В действии
Ниже приведена краткая демонстрация этой функции.
Как сжатие изображений влияет на время загрузки вашего веб-сайта
Изображения часто могут улучшить качество вашего веб-сайта, и они играют ключевую роль в реализации стратегии визуального маркетинга. Тем не менее, чем больше мультимедийных материалов на вашем сайте, тем больше это влияет на время загрузки. Если ваш сайт загружается слишком долго, неважно, насколько потрясающе он выглядит — это отпугнет посетителей.
Ответ – сжимайте или оптимизируйте изображения, чтобы они становились меньше без потери качества. В этой статье мы поговорим подробнее о сжатии изображений, о том, как оно может вам помочь, и используем данные, чтобы продемонстрировать, насколько сильно оно может повлиять на время загрузки. Давайте приступим!
- 1 Что такое сжатие изображений (и как оно может вам помочь)
- 2 Как сжатие изображений влияет на время загрузки вашего сайта (в цифрах)
- 3 О чем говорят нам результаты
- 4 Заключение
Что такое сжатие изображений (и как оно может вам помочь)
Сжатие изображений — отличный способ оптимизировать время загрузки вашего сайта.
В двух словах, сжатие изображений включает в себя уменьшение размера их файлов, чтобы они занимали меньше места, и существует два метода: «с потерями» и «без потерь». Первый радикально оптимизирует ваши изображения, потенциально снижая визуальное качество, а второй только максимально сжимает ваши файлы, не влияя на то, как они выглядят.
Обычно вам нужна оптимизация без потерь. Однако разница с методами с потерями не обязательно очевидна невооруженным глазом. Давайте посмотрим на пример с исходным изображением слева и оптимизированной версией справа:
.Вы сможете заметить некоторые различия, если приблизите изображение. Однако, поскольку мы не показываем ни одно из изображений в полном разрешении, различия трудно разглядеть. Учитывая нехватку места на многих веб-сайтах, нет причин загружать высококачественное изображение размером 5 МБ, когда сжатая версия размером 500 КБ может быть столь же подходящей.
В любом случае главное преимущество оптимизации изображения легко понять. Чем меньше места для хранения занимает ваша графика, тем светлее будут ваши страницы. Это означает, что пользователи смогут быстрее загружать ваш сайт, что напрямую повлияет на его удобство использования и «прилипчивость». Имея это в виду, давайте выясним, насколько сильно сжатие изображений действительно влияет на производительность среднего веб-сайта.
Чем меньше места для хранения занимает ваша графика, тем светлее будут ваши страницы. Это означает, что пользователи смогут быстрее загружать ваш сайт, что напрямую повлияет на его удобство использования и «прилипчивость». Имея это в виду, давайте выясним, насколько сильно сжатие изображений действительно влияет на производительность среднего веб-сайта.
Как сжатие изображений влияет на время загрузки вашего сайта (в цифрах)
Никакие два веб-сайта не будут иметь одинаковое время загрузки, поскольку все они уникальны. Короче говоря, цель этого теста — установить (в среднем), насколько оптимизация изображения влияет на время загрузки. С этой целью мы создали веб-сайт с тремя отдельными страницами, созданными с помощью Divi. На первой странице представлен макет Портфолио главной страницы , который мы настроили для включения десяти изображений:
Ни одно из этих изображений не оптимизировано, и в сумме страница весит 1,7 МБ. У нас также нет активных плагинов на этом тестовом веб-сайте, чтобы избежать каких-либо элементов, которые могут повлиять на наши результаты. После всех настроек мы проверили, сколько времени потребовалось для загрузки этой страницы с помощью сервера Pingdom Tools в Сан-Хосе, Калифорния:
После всех настроек мы проверили, сколько времени потребовалось для загрузки этой страницы с помощью сервера Pingdom Tools в Сан-Хосе, Калифорния:
Позже мы покажем вам результаты нашего теста в цифрах. Сейчас мы собираемся настроить одну дополнительную тестовую страницу Divi, чтобы у нас было больше данных для подтверждения наших результатов. Для нашей второй записи мы выбрали макет Masonry Blog , так как он дает нам возможность красиво продемонстрировать несколько избранных изображений (в данном случае семь):
Эта страница весила 1,3 МБ и содержала тот же набор неоптимизированных изображений, что и в предыдущем примере, но с другим макетом:
Теперь мы создадим копии обеих страниц и заменим их изображения оптимизированными версиями. С этой целью мы будем использовать два разных плагина для оптимизации изображений по отдельности — Compress JPEG и PNG Images и WP Smush. Оба плагина были исключением в нашем предыдущем сравнении плагинов для оптимизации изображений, поэтому они должны дать нам четкое представление о том, чего ожидать. Вот результаты с обеих страниц, с использованием каждого плагина отдельно:
Вот результаты с обеих страниц, с использованием каждого плагина отдельно:
| Начальный размер страницы | Оптимизированный размер страницы | Время начальной загрузки | Сжатие результатов изображений JPEG и PNG | Результаты WP Smush | |
|---|---|---|---|---|---|
| Домашняя страница Портфолио | 1,3 МБ | 1 МБ (-23,07%) | 2,84 секунды | 2,15 секунды (-24,29%) | 2,45 секунды (-13,73%) |
| Каменный блог | 1,7 МБ | 1,3 МБ (-23,52%) | 1,69секунд | 1,49 секунды (-11,83%) | 1,52 секунды (-10,05%) |
Здесь много информации, которую нужно распаковать, поэтому давайте поговорим о том, что означают эти цифры.
Что говорят нам результаты
Согласно нашим результатам, оптимизация изображений оказывает значительное влияние на время загрузки веб-сайта. Чтобы быть более конкретным, наши тесты показали, что в среднем вы можете ожидать улучшения времени загрузки как минимум на 10%, если оптимизируете каждое изображение на своем сайте.
Чтобы быть более конкретным, наши тесты показали, что в среднем вы можете ожидать улучшения времени загрузки как минимум на 10%, если оптимизируете каждое изображение на своем сайте.
Некоторые из вас могут подумать, что 10% недостаточно, чтобы оправдать хлопоты по сжатию каждого отдельного изображения на вашем веб-сайте. Однако существует множество способов автоматизировать этот процесс в WordPress. Если вы этого не сделаете, вы, по сути, скажете «Нет» повышению производительности.
Что еще более важно, оптимизация изображений — это лишь одна из многих настроек, которые вы должны внедрить на свой сайт, чтобы сократить время загрузки. Например, можно принять во внимание кэширование, сжатие GZIP, использование хорошо оптимизированной темы и многие другие аспекты. Если вы реализуете их все, ваш сайт должен быть невероятно быстрым!
Наконец, стоит отметить, что 10% находятся в нижней части наших результатов оценки. Ваш выигрыш будет зависеть от того, сколько изображений в среднем содержится на ваших страницах и какие инструменты сжатия вы используете. По всей вероятности, время загрузки улучшится еще больше. Однако вы не узнаете, пока не попробуете сами.
По всей вероятности, время загрузки улучшится еще больше. Однако вы не узнаете, пока не попробуете сами.
Заключение
Оптимизация изображений — один из многих способов сократить время загрузки вашего веб-сайта. Однако часто трудно представить, какое влияние это может оказать на общую производительность. В любом случае, WordPress предлагает множество инструментов, которые вы можете использовать для оптимизации ваших изображений. Вы даже можете автоматизировать процесс, если хотите, поэтому нет причин его избегать.
Во время тестирования мы обнаружили, что сжатие изображений в большинстве случаев сокращает время загрузки примерно на 10 %. Однако это нижняя граница шкалы. Во время тестирования мы увидели еще лучшие результаты, вплоть до увеличения производительности на 24,29%. Ваши собственные результаты во многом будут зависеть от того, сколько изображений в среднем содержится на ваших страницах, и от используемых вами инструментов оптимизации.
У вас есть вопросы о том, какой плагин оптимизации изображений следует использовать для WordPress? Давайте поговорим о них в разделе комментариев ниже!
Миниатюра статьи от VectorKnight / Shutterstock. com.
com.
SVD-Demo: Сжатие изображений
Интерактивная демонстрация выполняется исключительно на стороне клиента. Поэтому вы должны включить JavaScript, чтобы наслаждаться им.
О разложении по единственному значению
Матрица размера m × n представляет собой сетку действительных чисел, состоящую из m строк и n столбцов. В линейной алгебре, разделе математики, матрицы размера m × n описывают линейные отображения из n-мерного пространства в m-мерное. Слово «линейный» примерно означает, что прямые линии отображаются в прямые линии, а начало координат в n-мерном пространстве отображается в начало координат в m-мерном пространстве. Когда у нас есть (m × n)-матрица A и (n × k)-матрица B, мы можем вычислить произведение AB, которое представляет собой (m × k)-матрицу. Отображение, соответствующее AB, есть в точности композиция отображений, соответствующих A и B соответственно.
Разложение по сингулярным числам (SVD) утверждает, что каждая (m × n)-матрица A может быть записана как произведение
=
п
п
В Т где U и V — ортогональные матрицы, а матрица Σ состоит из убывающих неотрицательных значений по диагонали и нулей в других местах. Записи σ 1 ≥ σ 2 ≥ σ 3 ≥ … ≥ 0 на диагонали Σ называются сингулярных значения (SVs) A.
Геометрически Σ отображает j-й единичный координатный вектор n-мерного пространства в j-й координатный вектор m-мерного пространства, масштабированный с помощью коэффициента σ j .
Ортогональность U и V означает, что они соответствуют вращениям (возможно, с последующим отражением) m-мерного и n-мерного пространства соответственно.
Поэтому только Σ изменяет длину векторов.
Записи σ 1 ≥ σ 2 ≥ σ 3 ≥ … ≥ 0 на диагонали Σ называются сингулярных значения (SVs) A.
Геометрически Σ отображает j-й единичный координатный вектор n-мерного пространства в j-й координатный вектор m-мерного пространства, масштабированный с помощью коэффициента σ j .
Ортогональность U и V означает, что они соответствуют вращениям (возможно, с последующим отражением) m-мерного и n-мерного пространства соответственно.
Поэтому только Σ изменяет длину векторов.
Использование SVD для сжатия изображений
Мы можем разложить данное изображение на три цветовых канала: красный, зеленый и синий. Каждый канал может быть представлен в виде матрицы (m × n) со значениями в диапазоне от 0 до 255. Теперь мы сожмем матрицу A, представляющую один из каналов.
Для этого мы вычисляем аппроксимацию матрицы A, которая занимает лишь часть пространства для хранения. А теперь самое замечательное в SVD: данные в матрицах U, Σ и V сортируются по тому, какой вклад они вносят в матрицу A в произведении.
Это позволяет нам получить достаточно хорошее приближение, просто используя только самые важные части матриц.
А теперь самое замечательное в SVD: данные в матрицах U, Σ и V сортируются по тому, какой вклад они вносят в матрицу A в произведении.
Это позволяет нам получить достаточно хорошее приближение, просто используя только самые важные части матриц.
Теперь мы выбираем число k сингулярных значений, которые мы собираемся использовать для аппроксимации. Чем выше это число, тем лучше становится качество аппроксимации, но также тем больше данных требуется для ее кодирования. Теперь возьмем только первые k столбцов U и V и верхний левый (k × k)-квадрат Σ, содержащий k наибольших (и, следовательно, наиболее важных) сингулярных значений. Тогда у нас есть
&прибл.
м
№
к
к
Σн
н
к
В ТКоличество данных, необходимых для хранения этого приближения, пропорционально закрашенной области:
сжатый размер = m × k + k + k × n = k × (1 + m + n)
(На самом деле требуется немного меньше места из-за ортогональности U и V. )
Можно доказать, что это приближение является в определенном смысле оптимальным.
)
Можно доказать, что это приближение является в определенном смысле оптимальным.
Эта демонстрация позволяет выбрать количество сингулярных значений k и посмотреть, как этот выбор влияет на качество аппроксимации и степень сжатия. Обратите внимание, что для всех фотографий график, показывающий сингулярные значения, выглядит как гипербола: есть только несколько действительно больших КА и длинный хвост относительно меньших КА. Напротив, для изображения случайного шума график SV выглядит примерно линейным.
SVD обычно используется в статистике для анализа главных компонентов и в численном моделировании для уменьшения порядка моделей. Для сжатия изображений более сложные методы, такие как JPG, учитывающие человеческое восприятие, обычно превосходят сжатие с использованием SVD.
Об этой демонстрации
Вычисление SVD выполняется на стороне клиента с помощью WebAssembly.