azure-docs.ru-ru/sql-query-subquery.md at master · MicrosoftDocs/azure-docs.ru-ru · GitHub
| title | description | author | ms.service | ms.subservice | ms.topic | ms.date | ms.author | ms.openlocfilehash | ms.sourcegitcommit | ms.translationtype | ms.contentlocale | ms.lasthandoff | ms.locfileid |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Вложенные запросы SQL для Azure Cosmos DB | Сведения о вложенных запросах SQL и их типичных сценариях использования и различных типах вложенных запросов в Azure Cosmos DB | timsander1 | cosmos-db | cosmosdb-sql | conceptual | 12/02/2019 | tisande | f5f209229d17a2587258d21ee90e7560e629d082 | 867cb1b7a1f3a1f0b427282c648d411d0ca4f81f | MT | ru-RU | 03/19/2021 | 93340861 |
[!INCLUDEappliesto-sql-api]
Вложенный запрос — это запрос, расположенный в другом запросе. Вложенный запрос также называется внутренним запросом или внутренней выборкой. Инструкция, содержащая вложенный запрос, обычно называется внешним запросом.
Вложенный запрос также называется внутренним запросом или внутренней выборкой. Инструкция, содержащая вложенный запрос, обычно называется внешним запросом.
В этой статье описываются вложенные запросы SQL и их распространенные варианты использования в Azure Cosmos DB. Все примеры запросов в этом документе можно выполнить для набора данных информации питании, который предварительно загружен на Площадка для тестирования запросов Azure Cosmos DB.
Типы вложенных запросов
Существует два основных типа вложенных запросов:
- Коррелированный: вложенный запрос, который ссылается на значения из внешнего запроса. Вложенный запрос вычисляется один раз для каждой строки, обрабатываемой внешним запросом.
- Некоррелированный: вложенный запрос, который не зависит от внешнего запроса. Его можно выполнять самостоятельно, не полагаясь на внешний запрос.
[!NOTE] Azure Cosmos DB поддерживает только коррелированные вложенные запросы.
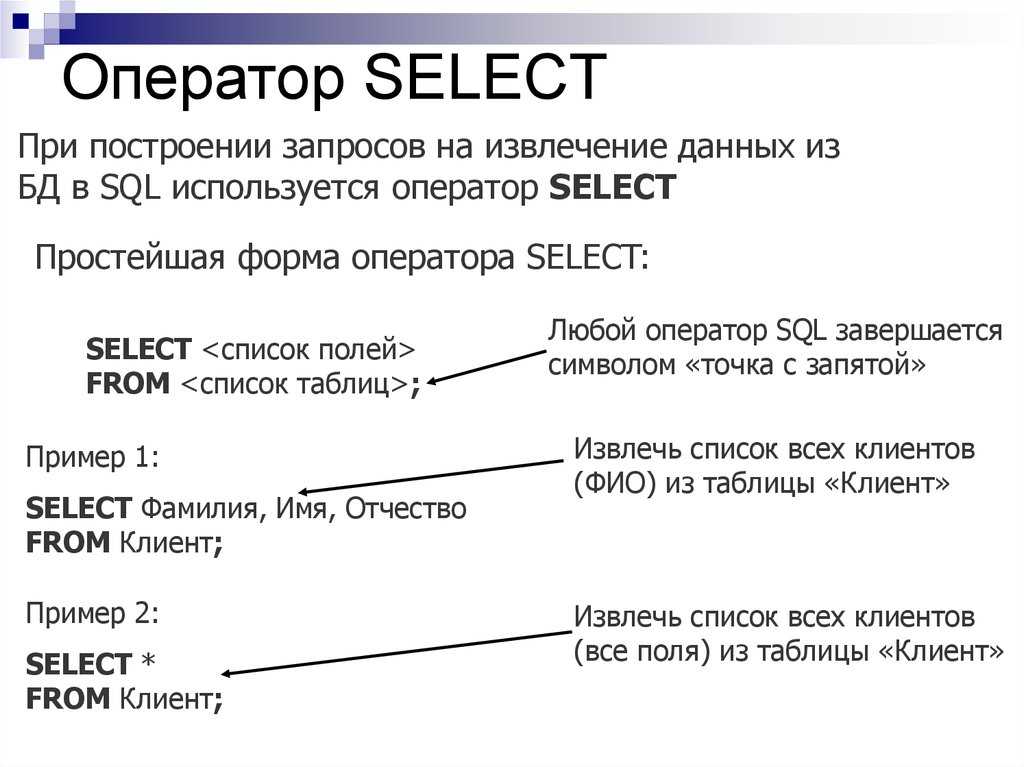
Вложенные запросы можно дополнительно классифицировать на основе числа возвращаемых строк и столбцов. Здесь возможны три варианта:
- Table: возвращает несколько строк и несколько столбцов.
- Множественное значение: возвращает несколько строк и один столбец.
- Scalar: Возвращает одну строку и один столбец.
SQL-запросы в Azure Cosmos DB всегда возвращают один столбец (простое значение или сложный документ). Таким образом, в Azure Cosmos DB применимы только многозначные и скалярные вложенные запросы. Вложенный запрос с несколькими значениями можно использовать только в предложении FROM в качестве реляционного выражения. Скалярный вложенный запрос можно использовать в качестве скалярного выражения в предложении SELECT или WHERE или в качестве реляционного выражения в предложении FROM.
Вложенные запросы с несколькими значениями
Вложенные запросы с несколькими значениями возвращают набор документов и всегда используются в предложении FROM. Они используются для:
Они используются для:
- Оптимизация выражений соединений.
- Оценка дорогостоящих выражений один раз и многократная ссылка.
Выражения оптимизации соединений
Вложенные запросы с несколькими значениями могут оптимизировать выражения объединения, помещая предикаты после каждого выражения SELECT-many, а не после всех перекрестных соединений в предложении WHERE.
Обратите внимание на следующий запрос:
SELECT Count(1) AS Count FROM c JOIN t IN c.tags JOIN n IN c.nutrients JOIN s IN c.servings WHERE t.name = 'infant formula' AND (n.nutritionValue > 0 AND n.nutritionValue < 10) AND s.amount > 1
Для этого запроса индекс будет соответствовать любому документу с тегом с именем «Формула новорожденный». Это элемент нутриент со значением от 0 до 10 и обслуживающим элементом с суммой больше 1. Выражение JOIN здесь выполняет перекрестное произведение всех элементов тегов, нутриентс и обслуживает массивы для каждого соответствующего документа до применения любого фильтра.
Затем предложение WHERE применит предикат фильтра для каждого <ного кортежа c, t, n, s>. Например, если в соответствующем документе в каждом из трех массивов было 10 элементов, оно будет расширено до 1 x 10 x 10 x 10 (то есть 1 000) кортежей. С помощью вложенных запросов можно фильтровать соединяемые элементы массива перед присоединением к следующему выражению.
Этот запрос эквивалентен предыдущему, но использует вложенные запросы:
SELECT Count(1) AS Count FROM c JOIN (SELECT VALUE t FROM t IN c.tags WHERE t.name = 'infant formula') JOIN (SELECT VALUE n FROM n IN c.nutrients WHERE n.nutritionValue > 0 AND n.nutritionValue < 10) JOIN (SELECT VALUE s FROM s IN c.servings WHERE s.amount > 1)
Предположим, что только один элемент в массиве Tags соответствует фильтру, а для нутриентс и обслуживания массивов существует пять элементов. Затем выражения объединения разворачиваются до 1 x 1 x 5 x 5 = 25 элементов, а не 1 000 элементов в первом запросе.
Многократное вычисление и ссылка
Вложенные запросы могут помочь оптимизировать запросы с дорогостоящими выражениями, такими как определяемые пользователем функции (UDF), сложные строки или арифметические выражения. Можно использовать вложенный запрос вместе с выражением объединения для вычисления выражения, но ссылаться на него много раз.
Следующий запрос дважды запускает определяемую пользователем функцию GetMaxNutritionValue :
SELECT c.id, udf.GetMaxNutritionValue(c.nutrients) AS MaxNutritionValue FROM c WHERE udf.GetMaxNutritionValue(c.nutrients) > 100
Ниже приведен эквивалентный запрос, запускающий UDF только один раз:
SELECT TOP 1000 c.id, MaxNutritionValue FROM c JOIN (SELECT VALUE udf.GetMaxNutritionValue(c.nutrients)) MaxNutritionValue WHERE MaxNutritionValue > 100
[!NOTE] Учитывайте поведение перекрестного произведения выражений JOIN.
Если выражение UDF может принимать значение undefine, следует убедиться, что выражение JOIN всегда создает одну строку, возвращая объект из вложенного запроса, а не значение напрямую.
 Если выражение UDF может принимать значение undefine, следует убедиться, что выражение JOIN всегда создает одну строку, возвращая объект из вложенного запроса, а не значение напрямую.
Если выражение UDF может принимать значение undefine, следует убедиться, что выражение JOIN всегда создает одну строку, возвращая объект из вложенного запроса, а не значение напрямую.Вот похожий пример, возвращающий объект, а не значение:
SELECT TOP 1000 c.id, m.MaxNutritionValue FROM c JOIN (SELECT udf.GetMaxNutritionValue(c.nutrients) AS MaxNutritionValue) m WHERE m.MaxNutritionValue > 100
Этот подход не ограничивается UDF. Он применяется к любому потенциально дорогостоящему выражению. Например, можно использовать тот же подход с математической функцией avg :
SELECT TOP 1000 c.id, AvgNutritionValue FROM c JOIN (SELECT VALUE avg(n.nutritionValue) FROM n IN c.nutrients) AvgNutritionValue WHERE AvgNutritionValue > 80
Имитировать соединение с внешними эталонными данными
Часто бывает необходимо ссылаться на статические данные, которые редко изменяются, например единицы измерения или коды стран. Лучше не дублировать эти данные для каждого документа. Избежание этого дублирования позволит экономить место на хранении и повышать производительность операций записи, сохраняя размер документа. Вложенный запрос можно использовать для имитации семантики внутреннего объединения с помощью коллекции ссылочных данных.
Лучше не дублировать эти данные для каждого документа. Избежание этого дублирования позволит экономить место на хранении и повышать производительность операций записи, сохраняя размер документа. Вложенный запрос можно использовать для имитации семантики внутреннего объединения с помощью коллекции ссылочных данных.
Например, рассмотрим следующий набор ссылочных данных:
| Единица измерения | имя; | Множитель | Базовая единица |
|---|---|---|---|
| NG | Микрограмматика | 1,00 e-09 | Gram |
| μг | микрограм | 1,00 e-06 | Gram |
| миллиграм | 1,00 e-03 | Gram | |
| н | Gram | 1,00 e + 00 | Gram |
| кг | Килограмм | 1,00 e + 03 | Gram |
| MG | мегаграм | 1,00 e + 06 | Gram |
| GG | гигаграм | 1,00 e + 09 | Gram |
| nJ | наножауле | 1,00 e-09 | жауле |
| μж | микрожауле | 1,00 e-06 | жауле |
| mJ | миллижауле | 1,00 e-03 | жауле |
| J | жауле | 1,00 e + 00 | жауле |
| kJ | киложауле | 1,00 e + 03 | жауле |
| MJ | мегажауле | 1,00 e + 06 | жауле |
| гж | гигажауле | 1,00 e + 09 | жауле |
| Cal | калорие | 1,00 e + 00 | калорие |
| ккал | калорие | 1,00 e + 03 | калорие |
| IU | Международные единицы |
Следующий запрос имитирует соединение с этими данными, чтобы добавить в выходные данные имя единицы измерения:
SELECT TOP 10 n.
 id, n.description, n.nutritionValue, n.units, r.name
FROM food
JOIN n IN food.nutrients
JOIN r IN (
SELECT VALUE [
{unit: 'ng', name: 'nanogram', multiplier: 0.000000001, baseUnit: 'gram'},
{unit: 'µg', name: 'microgram', multiplier: 0.000001, baseUnit: 'gram'},
{unit: 'mg', name: 'milligram', multiplier: 0.001, baseUnit: 'gram'},
{unit: 'g', name: 'gram', multiplier: 1, baseUnit: 'gram'},
{unit: 'kg', name: 'kilogram', multiplier: 1000, baseUnit: 'gram'},
{unit: 'Mg', name: 'megagram', multiplier: 1000000, baseUnit: 'gram'},
{unit: 'Gg', name: 'gigagram', multiplier: 1000000000, baseUnit: 'gram'},
{unit: 'nJ', name: 'nanojoule', multiplier: 0.000000001, baseUnit: 'joule'},
{unit: 'µJ', name: 'microjoule', multiplier: 0.000001, baseUnit: 'joule'},
{unit: 'mJ', name: 'millijoule', multiplier: 0.001, baseUnit: 'joule'},
{unit: 'J', name: 'joule', multiplier: 1, baseUnit: 'joule'},
{unit: 'kJ', name: 'kilojoule', multiplier: 1000, baseUnit: 'joule'},
{unit: 'MJ', name: 'megajoule', multiplier: 1000000, baseUnit: 'joule'},
{unit: 'GJ', name: 'gigajoule', multiplier: 1000000000, baseUnit: 'joule'},
{unit: 'cal', name: 'calorie', multiplier: 1, baseUnit: 'calorie'},
{unit: 'kcal', name: 'Calorie', multiplier: 1000, baseUnit: 'calorie'},
{unit: 'IU', name: 'International units'}
]
)
WHERE n.
id, n.description, n.nutritionValue, n.units, r.name
FROM food
JOIN n IN food.nutrients
JOIN r IN (
SELECT VALUE [
{unit: 'ng', name: 'nanogram', multiplier: 0.000000001, baseUnit: 'gram'},
{unit: 'µg', name: 'microgram', multiplier: 0.000001, baseUnit: 'gram'},
{unit: 'mg', name: 'milligram', multiplier: 0.001, baseUnit: 'gram'},
{unit: 'g', name: 'gram', multiplier: 1, baseUnit: 'gram'},
{unit: 'kg', name: 'kilogram', multiplier: 1000, baseUnit: 'gram'},
{unit: 'Mg', name: 'megagram', multiplier: 1000000, baseUnit: 'gram'},
{unit: 'Gg', name: 'gigagram', multiplier: 1000000000, baseUnit: 'gram'},
{unit: 'nJ', name: 'nanojoule', multiplier: 0.000000001, baseUnit: 'joule'},
{unit: 'µJ', name: 'microjoule', multiplier: 0.000001, baseUnit: 'joule'},
{unit: 'mJ', name: 'millijoule', multiplier: 0.001, baseUnit: 'joule'},
{unit: 'J', name: 'joule', multiplier: 1, baseUnit: 'joule'},
{unit: 'kJ', name: 'kilojoule', multiplier: 1000, baseUnit: 'joule'},
{unit: 'MJ', name: 'megajoule', multiplier: 1000000, baseUnit: 'joule'},
{unit: 'GJ', name: 'gigajoule', multiplier: 1000000000, baseUnit: 'joule'},
{unit: 'cal', name: 'calorie', multiplier: 1, baseUnit: 'calorie'},
{unit: 'kcal', name: 'Calorie', multiplier: 1000, baseUnit: 'calorie'},
{unit: 'IU', name: 'International units'}
]
)
WHERE n. units = r.unit
units = r.unitскалярные вложенные запросы;
Скалярное выражение вложенного запроса — это вложенный запрос, результатом которого является единственное значение. Значением скалярного выражения вложенного запроса является значение проекции (предложение SELECT) вложенного запроса. Можно использовать скалярное выражение вложенного запроса во многих местах, где допустимо использование скалярного выражения. Например, можно использовать скалярный вложенный запрос в любом выражении в предложениях SELECT и WHERE.
Однако использование скалярного вложенного запроса не всегда помогает оптимизировать. Например, передача скалярного вложенного запроса в качестве аргумента в системную или определяемую пользователем функцию не дает никаких преимуществ в использовании единицы ресурсов (RU) или задержке.
Скалярные вложенные запросы можно дополнительно классифицировать следующим образом:
- Скалярные вложенные запросы в простых выражениях
- Агрегирование скалярных вложенных запросов
Скалярные вложенные запросы в простых выражениях
Скалярный вложенный запрос с простым выражением — это Коррелированный вложенный запрос, имеющий предложение SELECT, которое не содержит статистических выражений. Эти вложенные запросы не дают никаких преимуществ оптимизации, поскольку компилятор преобразует их в одно более крупное простое выражение. Нет коррелированного контекста между внутренними и внешними запросами.
Эти вложенные запросы не дают никаких преимуществ оптимизации, поскольку компилятор преобразует их в одно более крупное простое выражение. Нет коррелированного контекста между внутренними и внешними запросами.
Рассмотрим несколько примеров.
Пример 1
SELECT 1 AS a, 2 AS b
Можно переписать этот запрос с помощью скалярного вложенного запроса простого выражения, чтобы:
SELECT (SELECT VALUE 1) AS a, (SELECT VALUE 2) AS b
Эти выходные данные создаются в обоих запросах:
[
{ "a": 1, "b": 2 }
]Пример 2
SELECT TOP 5 Concat('id_', f.id) AS id
FROM food fМожно переписать этот запрос с помощью скалярного вложенного запроса простого выражения, чтобы:
SELECT TOP 5 (SELECT VALUE Concat('id_', f.id)) AS id
FROM food fВыходные данные запроса:
[
{ "id": "id_03226" },
{ "id": "id_03227" },
{ "id": "id_03228" },
{ "id": "id_03229" },
{ "id": "id_03230" }
]Пример 3
SELECT TOP 5 f.
 id, Contains(f.description, 'fruit') = true ? f.description : undefined
FROM food f
id, Contains(f.description, 'fruit') = true ? f.description : undefined
FROM food fМожно переписать этот запрос с помощью скалярного вложенного запроса простого выражения, чтобы:
SELECT TOP 10 f.id, (SELECT f.description WHERE Contains(f.description, 'fruit')).description FROM food f
Выходные данные запроса:
[
{ "id": "03230" },
{ "id": "03238", "description":"Babyfood, dessert, tropical fruit, junior" },
{ "id": "03229" },
{ "id": "03226", "description":"Babyfood, dessert, fruit pudding, orange, strained" },
{ "id": "03227" }
]Агрегирование скалярных вложенных запросов
Статистический скалярный вложенный запрос — это вложенный запрос, имеющий агрегатную функцию в проекции или фильтре, результатом которой является единственное значение.
Пример 1.
Вот вложенный запрос с одним выражением агрегатной функции в его проекции:
SELECT TOP 5
f. id,
(SELECT VALUE Count(1) FROM n IN f.nutrients WHERE n.units = 'mg'
) AS count_mg
FROM food f id,
(SELECT VALUE Count(1) FROM n IN f.nutrients WHERE n.units = 'mg'
) AS count_mg
FROM food f
id,
(SELECT VALUE Count(1) FROM n IN f.nutrients WHERE n.units = 'mg'
) AS count_mg
FROM food fВыходные данные запроса:
[
{ "id": "03230", "count_mg": 13 },
{ "id": "03238", "count_mg": 14 },
{ "id": "03229", "count_mg": 13 },
{ "id": "03226", "count_mg": 15 },
{ "id": "03227", "count_mg": 19 }
]Пример 2
Вот вложенный запрос с несколькими выражениями агрегатных функций:
SELECT TOP 5 f.id, (
SELECT Count(1) AS count, Sum(n.nutritionValue) AS sum
FROM n IN f.nutrients
WHERE n.units = 'mg'
) AS unit_mg
FROM food fВыходные данные запроса:
[
{ "id": "03230","unit_mg": { "count": 13,"sum": 147.072 } },
{ "id": "03238","unit_mg": { "count": 14,"sum": 107.385 } },
{ "id": "03229","unit_mg": { "count": 13,"sum": 141.579 } },
{ "id": "03226","unit_mg": { "count": 15,"sum": 183.91399999999996 } },
{ "id": "03227","unit_mg": { "count": 19,"sum": 94. 788999999999987 } }
] 788999999999987 } }
]
788999999999987 } }
]Пример 3
Вот запрос со статистическим вложенным запросом как в проекции, так и в фильтре:
SELECT TOP 5
f.id,
(SELECT VALUE Count(1) FROM n IN f.nutrients WHERE n.units = 'mg') AS count_mg
FROM food f
WHERE (SELECT VALUE Count(1) FROM n IN f.nutrients WHERE n.units = 'mg') > 20Выходные данные запроса:
[
{ "id": "03235", "count_mg": 27 },
{ "id": "03246", "count_mg": 21 },
{ "id": "03267", "count_mg": 21 },
{ "id": "03269", "count_mg": 21 },
{ "id": "03274", "count_mg": 21 }
]Более оптимальный способ написания этого запроса — соединение во вложенном запросе и ссылка на псевдоним вложенного запроса в предложениях SELECT и WHERE. Этот запрос более эффективен, поскольку необходимо выполнить вложенный запрос только внутри инструкции JOIN, а не в проекции и фильтре.
SELECT TOP 5 f.id, count_mg FROM food f JOIN (SELECT VALUE Count(1) FROM n IN f.
 nutrients WHERE n.units = 'mg') AS count_mg
WHERE count_mg > 20
nutrients WHERE n.units = 'mg') AS count_mg
WHERE count_mg > 20Выражение EXISTs
Azure Cosmos DB поддерживает выражения EXISTs. Это совокупный скалярный вложенный запрос, встроенный в Azure Cosmos DB API SQL. EXISTs является логическим выражением, которое принимает выражение вложенного запроса и возвращает значение true, если вложенный запрос возвращает какие-либо строки. В противном случае возвращается значение false.
Так как API Azure Cosmos DB SQL не различает логические выражения и другие скалярные выражения, можно использовать в предложениях SELECT и WHERE. Это отличается от T-SQL, где логическое выражение (например, EXISTs, BETWEEN и IN) ограничено фильтром.
Если вложенный запрос EXISTs возвращает одиночное значение, которое не определено, то параметр EXISTs принимает значение false. Например, рассмотрим следующий запрос, результатом которого является значение false:
SELECT EXISTS (SELECT VALUE undefined)
Если ключевое слово VALUE в предыдущем вложенном запросе опущено, результатом вычисления запроса будет значение true:
SELECT EXISTS (SELECT undefined)
Вложенный запрос будет заключать список значений в выбранном списке в объекте. Если выбранный список не содержит значений, вложенный запрос возвратит единственное значение » {} «. Это значение определено, поэтому EXISTs вычисляется как true.
Если выбранный список не содержит значений, вложенный запрос возвратит единственное значение » {} «. Это значение определено, поэтому EXISTs вычисляется как true.
Пример: перезапись ARRAY_CONTAINS и присоединение как существует
Распространенным вариантом использования ARRAY_CONTAINS является фильтрация документа по существованию элемента в массиве. В этом случае мы проверяя, содержит ли массив Tags элемент с именем «оранжевый».
SELECT TOP 5 f.id, f.tags
FROM food f
WHERE ARRAY_CONTAINS(f.tags, {name: 'orange'})Вы можете переписать тот же запрос, чтобы использовать EXISTs:
SELECT TOP 5 f.id, f.tags FROM food f WHERE EXISTS(SELECT VALUE t FROM t IN f.tags WHERE t.name = 'orange')
Кроме того, ARRAY_CONTAINS может проверять, равно ли значение любому элементу в массиве. Если требуются более сложные фильтры для свойств массива, используйте JOIN.
Рассмотрим следующий запрос, который фильтруется на основе единиц и nutritionValue свойств в массиве:
SELECT VALUE c.
 description
FROM c
JOIN n IN c.nutrients
WHERE n.units= "mg" AND n.nutritionValue > 0
description
FROM c
JOIN n IN c.nutrients
WHERE n.units= "mg" AND n.nutritionValue > 0Для каждого документа в коллекции перекрестное произведение выполняется с элементами массива. Эта операция объединения позволяет фильтровать свойства в массиве. Однако этот запрос будет иметь большое количество запросов. Например, если в 1 000 документах в каждом массиве содержалось 100 элементов, оно будет расширено до 1 000 x 100 (т. е. 100 000) кортежей.
Использование EXISTs может помочь избежать этого дорогостоящего перекрестного произведения:
SELECT VALUE c.description
FROM c
WHERE EXISTS(
SELECT VALUE n
FROM n IN c.nutrients
WHERE n.units = "mg" AND n.nutritionValue > 0
)В этом случае вы фильтруете элементы массива внутри вложенного запроса EXISTs. Если элемент массива соответствует фильтру, то его проект и EXISTs будут иметь значение true.
Псевдоним также может существовать и ссылаться на него в проекции:
SELECT TOP 1 c.
 description, EXISTS(
SELECT VALUE n
FROM n IN c.nutrients
WHERE n.units = "mg" AND n.nutritionValue > 0) as a
FROM c
description, EXISTS(
SELECT VALUE n
FROM n IN c.nutrients
WHERE n.units = "mg" AND n.nutritionValue > 0) as a
FROM cВыходные данные запроса:
[
{
"description": "Babyfood, dessert, fruit pudding, orange, strained",
"a": true
}
]Выражение массива
Можно использовать выражение массива для проецирования результатов запроса в виде массива. Это выражение можно использовать только в предложении SELECT запроса.
SELECT TOP 1 f.id, ARRAY(SELECT VALUE t.name FROM t in f.tags) AS tagNames FROM food f
Выходные данные запроса:
[
{
"id": "03238",
"tagNames": [
"babyfood",
"dessert",
"tropical fruit",
"junior"
]
}
]Как и в случае с другими вложенными запросами, возможны фильтры с выражением массива.
SELECT TOP 1 c.id, ARRAY(SELECT VALUE t FROM t in c.
 tags WHERE t.name != 'infant formula') AS tagNames
FROM c
tags WHERE t.name != 'infant formula') AS tagNames
FROM cВыходные данные запроса:
[
{
"id": "03226",
"tagNames": [
{
"name": "babyfood"
},
{
"name": "dessert"
},
{
"name": "fruit pudding"
},
{
"name": "orange"
},
{
"name": "strained"
}
]
}
]Выражения массива могут также следовать после предложения FROM во вложенных запросах.
SELECT TOP 1 c.id, ARRAY(SELECT VALUE t.name FROM t in c.tags) as tagNames FROM c JOIN n IN (SELECT VALUE ARRAY(SELECT t FROM t in c.tags WHERE t.name != 'infant formula'))
Выходные данные запроса:
[
{
"id": "03238",
"tagNames": [
"babyfood",
"dessert",
"tropical fruit",
"junior"
]
}
]Дальнейшие действия
- Примеры . NET для Azure Cosmos DB
- Данные документов модели
 NET для Azure Cosmos DB
NET для Azure Cosmos DBMySQL. Вложеные запросы. JOIN LEFT/RIGHT….
В SQL подзапросы — или внутренние запросы, или вложенные запросы — это запрос внутри другого запроса SQL, который вложен в условие WHERE.
Вложеные запросы
SQL подзапрос — это запрос, вложенный в другой запрос.
Подзапрос используется для возврата данных, которые будут использоваться в основном запросе, в качестве условия для дальнейшей фильтрации данных, подлежащих извлечению.
Существует несколько правил, которые применяются к подзапросам:
- Подзапросы должны быть заключены в круглые скобки.
- Подзапрос может иметь только один столбец в условии SELECT, если только несколько столбцов не указаны в основном запросе для подзапроса для сравнения выбранных столбцов.
- Подзапросы, которые возвращают более одной строки, могут использоваться только с несколькими операторами значений, такими как оператор IN.
- Команда ORDER BY не может использоваться в подзапросе, хотя в основном запросе она использоваться может. В подзапросе может использоваться команда GROUP BY для выполнения той же функции, что и ORDER BY.
- С подзапросом не может использоваться оператор BETWEEN. Однако оператор BETWEEN может использоваться внутри подзапроса.
- Не рекомендуется создавать запросы со степенью вложения больше трех. Это приводит к увеличению времени выполнения и к сложности восприятия кода.

SELECT
Подзапросы чаще всего используются с инструкцией SELECT. При этом используется следующий синтаксис
SELECT имя_столбца FROM имя_таблицы WHERE часть условия IN
(SELECT имя_столбца FROM имя_таблицы WHERE часть условия IN
(SELECT имя_столбца FROM имя_таблицы WHERE условие)
...
)
;
Ниже представлена струтура таблицы для демонстрации примеров
| snum | sname | city | comm |
|---|---|---|---|
| 1 | Колованов | Москва | 10 |
| 2 | Петров | Тверь | 25 |
| 3 | Плотников | Москва | 22 |
| 4 | Кучеров | Санкт-Петербург | 28 |
| 5 | Малкин | Санкт-Петербург | 18 |
| 6 | Шипачев | Челябинск | 30 |
| 7 | Мозякин | Одинцово | 25 |
| 8 | Проворов | Москва | 25 |
| cnum | cname | city | rating | snum |
|---|---|---|---|---|
| 1 | Деснов | Москва | 90 | 6 |
| 2 | Краснов | Москва | 95 | 7 |
| 3 | Кириллов | Тверь | 96 | 3 |
| 4 | Ермолаев | Обнинск | 98 | 3 |
| 5 | Колесников | Серпухов | 98 | 5 |
| 6 | Пушкин | Челябинск | 90 | 4 |
| 7 | Белый | Одинцово | 85 | 1 |
| 8 | Чудинов | Москва | 89 | 3 |
| 9 | Проворов | Москва | 95 | 2 |
| 10 | Лосев | Одинцово | 75 | 8 |
| onum | amt | odate(YEAR) | cnum | snum |
|---|---|---|---|---|
| 1001 | 420 | 2013 | 9 | 4 |
| 1002 | 653 | 2005 | 10 | 7 |
| 1003 | 960 | 2016 | 2 | 1 |
| 1004 | 320 | 2016 | 3 | 3 |
| 1005 | 200 | 2015 | 5 | 4 |
| 1006 | 2560 | 2014 | 5 | 4 |
| 1007 | 1200 | 2013 | 7 | 1 |
| 1008 | 50 | 2017 | 1 | 3 |
| 1009 | 564 | 2012 | 3 | 7 |
| 1010 | 900 | 2018 | 6 | 8 |
Вывести суммы заказов и даты, которые проводил продавец с фамилией «Плотников».

Начнем с такого примера и для начала вспомним, как бы делали этот запрос ранее: посмотрели бы в таблицу SALES(или выполнили отдельный запрос), определили бы snum продавца «Плотников» — он равен 3. И выполнили бы запрос SQL с помощью условия WHERE.
SELECT amt, odate
FROM orders
WHERE snum = 3
| amt | odate |
|---|---|
| 320 | 2016 |
| 50 | 2017 |
Такой запрос, очевидно, не очень универсален, если нам захочется выбрать тоже самое для другого продавца, то всегда придется определять его snum. В SQL предусмотрена возможность объединять такие запросы в один путем превращения одного из них в подзапрос (вложенный запрос).
SELECT amt, odate
FROM orders
WHERE snum = ( SELECT snum
FROM sales
WHERE sname = 'Плотников')
В этом примере мы определяем с помощью вложенного запроса идентификатор snum по фамилии из таблицы SALES, а затем, в таблице ORDERS определяем по этому идентификатору нужные нам значения.
Показать уникальные номера и фамилии продавцов, которые провели сделки в 2016 году.
SELECT snum, sname
FROM sales
WHERE snum IN ( SELECT snum
FROM orders
WHERE odate = 2016)
Этот SQL запрос отличается тем, что вместо знака = здесь используется оператор IN.
Оператор IN следует использовать в том случае, если вложенный подзапрос SQL возвращает несколько значений.
То есть в запросе происходит проверка, содержится ли идентификатор snum из таблицы SALES в массиве значений, который вернул вложенный запрос. Если содержится, то SQL выдаст фамилию этого продавца.
| snum | sname |
|---|---|
| 1 | Колованов |
| 3 | Плотников |
Предыдущие примеры, которые мы уже рассмотрели, сравнивали в условииWHEREодно поле.
 Это конечно хорошо, но стоит отметить, что в SQL предусмотрена возможность сравнения сразу нескольких полей, то есть можно использовать вложенный запрос с несколькими параметрами.
Это конечно хорошо, но стоит отметить, что в SQL предусмотрена возможность сравнения сразу нескольких полей, то есть можно использовать вложенный запрос с несколькими параметрами.Вывести пары покупателей и продавцов, которые осуществили сделку между собой, но не позднее 2014 года
Запрос чем то похож на предыдущий, только теперь мы добавляем еще одно поле для сравнения.
SELECT cname as 'Покупатель', sname as 'Продавец'
FROM customers cus, sales sal
WHERE (cus.cnum, sal.snum) IN ( SELECT cnum, snum
FROM orders
WHERE odate < 2014 )
| Покупатель | Продавец |
|---|---|
| Проворов | Кучеров |
| Лосев | Мозякин |
| Белый | Колованов |
| Кириллов | Мозякин |
В этом примере мы сравниваем сразу два поля одновременно по идентификаторам. То есть из таблицы
То есть из таблицы ORDERS берутся те строки, которые удовлетворяют условию не позднее 2014 года, затем вместо идентификаторов подставляются значение имен покупателей и продавцов.
На самом деле, такой запрос SQL используется крайне редко, обычно используют оператор INNER JOIN.
Оператор as нужен для того, чтобы при выводе SQL показывал не имена полей, а то, что мы зададим. И после оператора FROM за именами таблиц стоят сокращения, которые потом используются — это псевдонимы. Псевдонимы можно называть любыми именами, в этом запросе они используются для явного определения поля, так как мы несколько раз обращаемся к одному и тому же полю, только из разных таблиц.
Подзапросы могут использоваться с инструкциямиSELECT,INSERT,UPDATEиDELETEвместе с операторами типа=,<,>,>=,<=,IN,BETWEENи т.
 д.
д.Далее будут показы примеры использования вложеных запросов с использованием базы данныхworld. БД находится в папке_lec\7\dbвместе с лекцией.
CREATE
Данный пример несовсем относится к теме занятия, но по жизни он очень может пригодиться.
Задача — создать копию существующей таблицы.
Копия существующей таблицы может быть создана с помощью комбинации CREATE TABLE и SELECT.
Новая таблица будет имеет те же определение столбцов, могут быть выбраны все столбцы или отдельные столбцы. При создании новой таблицы с помощью существующей таблицы, новая таблица будет заполняться с использованием существующих значений в старой таблице.
CREATE TABLE NEW_TABLE_NAME AS
SELECT [ column1, column2. ..columnN ]
FROM EXISTING_TABLE_NAME
[ WHERE ]
 ..columnN ]
FROM EXISTING_TABLE_NAME
[ WHERE ]
..columnN ]
FROM EXISTING_TABLE_NAME
[ WHERE ]
Создадим копию таблицы city. Вопрос — почему 1=0?
CREATE TABLE city_bkp AS
SELECT *
FROM city
WHERE 1=0
INSERT
Задача — создать копию существующей таблицы.
Подзапросы также могут использоваться с инструкцией INSERT. Инструкция INSERT использует данные, возвращаемые из подзапроса, для вставки в другую таблицу. Выбранные в подзапросе данные могут быть изменены. Основной синтаксис следующий.
INSERT INTO table_name [ (column1 [, column2 ]) ]
SELECT [ *|column1 [, column2 ]
FROM table1 [, table2 ]
[ WHERE VALUE OPERATOR ]
Копирование всей таблицы полностью
INSERT INTO city_bkp SELECT * FROM city
Копируем города которые находся в стране с численостью не меньше 500тыс. человек, но не больше 1 миллиона.
человек, но не больше 1 миллиона.
INSERT INTO city_bkp
SELECT * FROM city
WHERE CountryCode IN
(SELECT Code FROM country
WHERE Population < 1000000 AND Population > 500000)
UPDATE
Подзапрос может использоваться в сочетании с инструкцией UPDATE. Один или несколько столбцов в таблице могут быть обновлены при использовании подзапроса с помощью инструкции UPDATE. Основной синтаксис следующий.
UPDATE table
SET column_name = new_value
[ WHERE OPERATOR [ VALUE ]
(SELECT COLUMN_NAME
FROM TABLE_NAME)
[ WHERE) ]
Исходя из того, что у нас есть таблица CITY_BKP, которая является резервной копией таблицы CITY, в следующем примере для всех записей, для которых Population больше или равно 100000, применяет коэффициент 0,25.
UPDATE city_bkp SET Population = Population * 0.25
WHERE Population IN (
SELECT Population FROM city
WHERE Population >= 100000 )
DELETE
Подзапрос может использоваться в сочетании с инструкцией DELETE, так же как и со всеми описанными выше инструкциями. Основной синтаксис следующий.
DELETE FROM TABLE_NAME
[ WHERE OPERATOR [ VALUE ]
(SELECT COLUMN_NAME
FROM TABLE_NAME)
[ WHERE) ]
Далее будут показы примеры использования вложеных запросов с использованием базы данныхworld. БД находится в папке_lec\7\dbвместе с лекцией.
Внутреннее объединение
Вывести идентификатор и название города, а так же страну нахождения
Для этого проще всего обратиться к таблице CITY
SELECT ID, Name, CountryCode FROM city
Но, что если нам необходимо, чтобы в ответе на запрос был не код страны, а её название? Вложенные запросы нам не помогут. А нам надо получить данные из двух таблиц и объединить их в одну. Запросы, которые позволяют это сделать, в SQL называются объединениями. Синтаксис самого простого объединения следующий:
А нам надо получить данные из двух таблиц и объединить их в одну. Запросы, которые позволяют это сделать, в SQL называются объединениями. Синтаксис самого простого объединения следующий:
SELECT city.ID, city.Name, country.Name FROM city, country
Получилось не совсем то, что мы ожидали. Такое объединение научно называется декартовым произведением, когда каждой строке первой таблицы ставится в соответствие каждая строка второй таблицы.
Чтобы результирующая таблица выглядела так, как мы хотели, необходимо указать условие объединения. Мы связываем наши таблицы по идентификатору, это и будет нашим условием.
SELECT city.ID, city.Name, country.Name
FROM city, country
WHERE city.CountryCode = country.Code
Т.е. мы в запросе сделали следующее условие: если в обеих таблицах есть одинаковые идентификаторы, то строки с этим идентификатором необходимо объединить в одну результирующую строку.
Как вы понимаете, объединения дают возможность выбирать любую информацию из любых таблиц, причем объединяемых таблиц может быть и три, и четыре, да и условие для объединения может быть не одно.
JOIN LEFT/RIGHT
JOIN — оператор языка SQL, который является реализацией операции соединения реляционной алгебры. Входит в предложение FROM операторов SELECT, UPDATE и DELETE.
JOIN используется для объединения строк из двух или более таблиц на основе соответствующего столбца между ними.
Операция соединения, как и другие бинарные операции, предназначена для обеспечения выборки данных из двух таблиц и включения этих данных в один результирующий набор.
Особенности операции соединения
- в схему таблицы-результата входят столбцы обеих исходных таблиц
- каждая строка таблицы-результата является «сцеплением» строки из одной таблицы со строкой второй таблицы
Определение того, какие именно исходные строки войдут в результат и в каких сочетаниях, зависит от типа операции соединения и от явно заданного условия соединения. Условие соединения, то есть условие сопоставления строк исходных таблиц друг с другом, представляет собой логическое выражение (предикат).
Условие соединения, то есть условие сопоставления строк исходных таблиц друг с другом, представляет собой логическое выражение (предикат).
Ниже представлена струтура таблицы для демонстрации примеров
| id | name | city_id |
|---|---|---|
| 1 | Колованов | 1 |
| 2 | Петров | 3 |
| 3 | Плотников | 12 |
| 4 | Кучеров | 4 |
| 5 | Малкин | 2 |
| 6 | Иванов | 13 |
Ниже представлена струтура таблицы для демонстрации примеров
| id | name | population |
|---|---|---|
| 1 | Москва | 100 |
| 2 | Нижний Новгород | 25 |
| 3 | Тверь | 22 |
| 4 | Санкт-Петербург | 80 |
| 5 | Выборг | 18 |
| 6 | Челябинск | 30 |
| 7 | Одинцово | 5 |
| 8 | Павлово | 5 |
INNER JOIN
Оператор внутреннего соединения INNER JOIN соединяет две таблицы. Порядок таблиц для оператора неважен, поскольку оператор является симметричным.
Порядок таблиц для оператора неважен, поскольку оператор является симметричным.
Заголовок таблицы-результата является объединением (конкатенацией) заголовков соединяемых таблиц.
SELECT * FROM Person
INNER JOIN
City
ON Person.city_id = City.id
| Person.id | Person.name | Person.city_id | City.id | City.name | City.population |
|---|---|---|---|---|---|
| 1 | Колованов | 1 | 1 | Москва | 100 |
| 2 | Петров | 3 | 3 | Тверь | 22 |
| 4 | Кучеров | 4 | 4 | Санкт-Петербург | 80 |
| 5 | Малкин | 2 | 2 | Нижний Новгород | 25 |
INNER JOINТело результата логически формируется следующим образом. Каждая строка одной таблицы сопоставляется с каждой строкой второй таблицы, после чего для полученной «соединённой» строки проверяется условие соединения (вычисляется предикат соединения). Если условие истинно, в таблицу-результат добавляется соответствующая «соединённая» строка.
Каждая строка одной таблицы сопоставляется с каждой строкой второй таблицы, после чего для полученной «соединённой» строки проверяется условие соединения (вычисляется предикат соединения). Если условие истинно, в таблицу-результат добавляется соответствующая «соединённая» строка.
В SQL существуют разные типы объединений. Мы рассмотрим только некоторые из них.
LEFT JOIN
Возвращает все строки из левой таблицы, даже если в правой таблице нет совпадений.
LEFT JOIN
SELECT * FROM Person
LEFT JOIN
City
ON Person.city_id = City.id
Для записей неудовлетворяющих условия объединения поля правой таблицы заполняются значениями NULL
| Person.id | Person. name name | Person.city_id | City.id | City.name | City.population |
|---|---|---|---|---|---|
| 1 | Колованов | 1 | 1 | Москва | 100 |
| 2 | Петров | 3 | 3 | Тверь | 22 |
| 3 | Плотников | 12 | NULL | NULL | NULL |
| 4 | Кучеров | 4 | 4 | Санкт-Петербург | 80 |
| 5 | Малкин | 2 | 2 | Нижний Новгород | 25 |
| 6 | Иванов | 13 | NULL | NULL | NULL |
RIGHT JOIN
Возвращает все строки из правой таблицы, даже если в левой таблице нет совпадений.
RIGHT JOIN
SELECT * FROM Person
RIGHT JOIN
City
ON Person.city_id = City.id
Для записей неудовлетворяющих условия объединения поля левой таблицы заполняются значениями NULL
Person. id id | Person.name | Person.city_id | City.id | City.name | City.population |
|---|---|---|---|---|---|
| 1 | Колованов | 1 | 1 | Москва | 100 |
| 2 | Петров | 3 | 3 | Тверь | 22 |
| 4 | Кучеров | 4 | 4 | Санкт-Петербург | 80 |
| 5 | Малкин | 2 | 2 | Нижний Новгород | 25 |
| NULL | NULL | NULL | 5 | Выборг | 18 |
| NULL | NULL | NULL | 6 | Челябинск | 30 |
| NULL | NULL | NULL | 7 | Одинцово | 5 |
| NULL | NULL | NULL | 8 | Павлово | 5 |
Написание подзапросов в SQL | Расширенный SQL
Начиная здесь? Этот урок является частью полного учебника по использованию SQL для анализа данных. Проверьте начало.
В этом уроке мы рассмотрим:
- Основы подзапросов
- Использование подзапросов для агрегирования в несколько этапов
- Подзапросы в условной логике
- Объединение подзапросов
- Подзапросы и UNION
На этом уроке вы продолжите работать с теми же данными о преступности в Сан-Франциско, что и на предыдущем уроке.
Основы подзапросов
Подзапросы (также известные как внутренние запросы или вложенные запросы) — это инструмент для выполнения операций в несколько шагов. Например, если вы хотите взять суммы нескольких столбцов, а затем усреднить все эти значения, вам нужно будет выполнить каждую агрегацию на отдельном шаге.
Подзапросы могут использоваться в нескольких местах внутри запроса, но проще всего начать с оператора FROM . Вот пример простого подзапроса:
SELECT sub.*
ОТ (
ВЫБИРАТЬ *
ИЗ tutorial.sf_crime_incidents_2014_01
ГДЕ day_of_week = 'Пятница'
) суб
ГДЕ подразрешение = 'НЕТ'
Давайте разберем, что происходит, когда вы выполняете приведенный выше запрос:
Сначала база данных выполняет «внутренний запрос» — часть в круглых скобках:
SELECT * ИЗ tutorial.sf_crime_incidents_2014_01 ГДЕ day_of_week = 'Пятница'
Если бы вы запустили этот запрос самостоятельно, он выдал бы набор результатов, как и любой другой запрос. Это может показаться пустяком, но это важно: ваш внутренний запрос должен фактически выполняться сам по себе, так как база данных будет рассматривать его как независимый запрос. После запуска внутреннего запроса внешний запрос будет запущен с использованием результатов внутреннего запроса в качестве базовой таблицы :
Это может показаться пустяком, но это важно: ваш внутренний запрос должен фактически выполняться сам по себе, так как база данных будет рассматривать его как независимый запрос. После запуска внутреннего запроса внешний запрос будет запущен с использованием результатов внутреннего запроса в качестве базовой таблицы :
SELECT sub.*
ОТ (
<<результаты внутреннего запроса идут сюда>>
) суб
ГДЕ подразрешение = 'НЕТ'
Подзапросы должны иметь имена, которые добавляются после круглых скобок так же, как вы добавляете псевдоним к обычной таблице. В данном случае мы использовали имя «sub».
Небольшое замечание по форматированию. Важно помнить, что при использовании подзапросов необходимо предоставить читателю возможность легко определить, какие части запроса будут выполняться вместе. Большинство людей делают это, тем или иным образом делая отступ в подзапросе. Примеры в этом руководстве имеют довольно большой отступ — вплоть до круглых скобок. Это нецелесообразно, если вы вкладываете много подзапросов, поэтому довольно часто отступ делается только на два пробела или около того.
Это нецелесообразно, если вы вкладываете много подзапросов, поэтому довольно часто отступ делается только на два пробела или около того.
Практическая задача
Напишите запрос, который выбирает все ордера на арест из набора данных tutorial.sf_crime_incidents_2014_01 , а затем оберните его во внешний запрос, который отображает только неразрешенные инциденты.
Попробуйте См. ответ
Вышеприведенные примеры, как и практическая задача, на самом деле не требуют подзапросов — они решают проблемы, которые также можно решить, добавив несколько условий в предложение WHERE . В следующих разделах приводятся примеры, для которых подзапросы являются лучшим или единственным способом решения соответствующих проблем.
Использование подзапросов для агрегирования в несколько этапов
Что делать, если вы хотите выяснить, сколько инцидентов сообщается в каждый день недели? А что, если вы хотите узнать, сколько инцидентов происходит в среднем в пятницу декабря? В январе? Этот процесс состоит из двух шагов: подсчет количества инцидентов каждый день (внутренний запрос), затем определение среднемесячного значения (внешний запрос):
суб. день_недели,
AVG(sub.incidents) КАК среднее_происшествие
ОТ (
ВЫБЕРИТЕ день_недели,
дата,
COUNT(incidnt_num) инцидентов AS
ИЗ tutorial.sf_crime_incidents_2014_01
СГРУППИРОВАТЬ НА 1,2
) суб
СГРУППИРОВАТЬ НА 1,2
ЗАКАЗАТЬ ПО 1,2
день_недели,
AVG(sub.incidents) КАК среднее_происшествие
ОТ (
ВЫБЕРИТЕ день_недели,
дата,
COUNT(incidnt_num) инцидентов AS
ИЗ tutorial.sf_crime_incidents_2014_01
СГРУППИРОВАТЬ НА 1,2
) суб
СГРУППИРОВАТЬ НА 1,2
ЗАКАЗАТЬ ПО 1,2
Если вы не можете понять, что происходит, попробуйте запустить внутренний запрос отдельно, чтобы понять, как выглядят его результаты. В общем, проще всего сначала написать внутренние запросы и пересматривать их до тех пор, пока результаты не станут для вас понятными, а затем перейти к внешнему запросу.
Практическая задача
Напишите запрос, отображающий среднее количество инцидентов в месяц для каждой категории. Подсказка: используйте tutorial.sf_crime_incidents_cleandate , чтобы немного облегчить себе жизнь.
Попробуйте См. ответ
Подзапросы в условной логике
Вы можете использовать подзапросы в условной логике (в сочетании с WHERE , JOIN / ON или CASE ). Следующий запрос возвращает все записи с самой ранней даты в наборе данных (теоретически — плохое форматирование столбца даты на самом деле заставляет возвращать значение, отсортированное первым в алфавитном порядке):
Следующий запрос возвращает все записи с самой ранней даты в наборе данных (теоретически — плохое форматирование столбца даты на самом деле заставляет возвращать значение, отсортированное первым в алфавитном порядке):
SELECT *
ИЗ tutorial.sf_crime_incidents_2014_01
ГДЕ Дата = (ВЫБЕРИТЕ МИН (дата)
ИЗ tutorial.sf_crime_incidents_2014_01
)
Приведенный выше запрос работает, поскольку результатом подзапроса является только одна ячейка. Большая часть условной логики будет работать с подзапросами, содержащими результаты с одной ячейкой. Однако IN — это единственный тип условной логики, который будет работать, когда внутренний запрос содержит несколько результатов:
SELECT *
ИЗ tutorial.sf_crime_incidents_2014_01
ГДЕ Дата В (ВЫБЕРИТЕ дату
ИЗ tutorial.sf_crime_incidents_2014_01
ЗАКАЗАТЬ ПО дате
ПРЕДЕЛ 5
)
Обратите внимание, что вы не должны включать псевдоним при написании подзапроса в условном выражении. Это связано с тем, что подзапрос обрабатывается как отдельное значение (или набор значений в случае
Это связано с тем, что подзапрос обрабатывается как отдельное значение (или набор значений в случае IN ), а не как таблица.
Объединение подзапросов
Возможно, вы помните, что вы можете фильтровать запросы в соединениях. Довольно часто присоединяется к подзапросу, который обращается к той же таблице, что и внешний запрос, а не фильтруется в предложении WHERE . Следующий запрос дает те же результаты, что и в предыдущем примере:
ВЫБОР *
ИЗ tutorial.sf_crime_incidents_2014_01 происшествий
ПРИСОЕДИНЯЙТЕСЬ ( ВЫБЕРИТЕ дату
ИЗ tutorial.sf_crime_incidents_2014_01
ЗАКАЗАТЬ ПО дате
ПРЕДЕЛ 5
) суб
ON инциденты.дата = суб.дата
Это может быть особенно полезно в сочетании с агрегатами. При присоединении требования к выходным данным вашего подзапроса не такие строгие, как при использовании предложения WHERE . Например, ваш внутренний запрос может выводить несколько результатов. Следующий запрос ранжирует все результаты в зависимости от того, сколько инцидентов было зарегистрировано в данный день. Он делает это путем агрегирования общего количества инцидентов каждый день во внутреннем запросе, а затем использует эти значения для сортировки внешнего запроса:
Следующий запрос ранжирует все результаты в зависимости от того, сколько инцидентов было зарегистрировано в данный день. Он делает это путем агрегирования общего количества инцидентов каждый день во внутреннем запросе, а затем использует эти значения для сортировки внешнего запроса:
ВЫБЕРИТЕ инциденты.*,
sub.incidents AS инциденты_этот_день
ИЗ tutorial.sf_crime_incidents_2014_01 происшествий
ПРИСОЕДИНЯЙТЕСЬ ( ВЫБЕРИТЕ дату,
COUNT(incidnt_num) инцидентов AS
ИЗ tutorial.sf_crime_incidents_2014_01
СГРУППИРОВАТЬ ПО 1
) суб
ON инциденты.дата = суб.дата
ORDER BY sub.incidents DESC, время
Практическая задача
Напишите запрос, который отображает все строки из трех категорий с наименьшим количеством зарегистрированных инцидентов.
ПопробуйтеСмотреть ответ
Подзапросы могут быть очень полезны для повышения производительности ваших запросов. Давайте кратко вернемся к данным Crunchbase. Представьте, что вы хотите собрать все компании, получающие инвестиции, и компании, приобретаемые каждый месяц. Вы можете сделать это без подзапросов, если хотите, но на самом деле не запускайте это, так как для возврата :
Представьте, что вы хотите собрать все компании, получающие инвестиции, и компании, приобретаемые каждый месяц. Вы можете сделать это без подзапросов, если хотите, но на самом деле не запускайте это, так как для возврата :
SELECT COALESCE(acquisitions.acquired_month, Investments.funded_month) AS month,
COUNT(DISTINCT Acquirements.company_permalink) КАК компании_приобретены,
COUNT(DISTINCT Investments.company_permalink) КАК инвестиции
ИЗ приобретения tutorial.crunchbase_acquisitions
FULL JOIN tutorial.crunchbase_investments инвестиции
ON приобретения.acquired_month = инвестиции.funded_month
СГРУППИРОВАТЬ ПО 1
Обратите внимание, что для того, чтобы сделать это правильно, вы должны соединить поля даты, что вызывает массовый «взрыв данных». По сути, происходит то, что вы соединяете каждую строку в данном месяце из одной таблицы с каждым месяцем в данной строке в другой таблице, поэтому количество возвращаемых строк невероятно велико. Из-за этого мультипликативного эффекта вы должны использовать
Из-за этого мультипликативного эффекта вы должны использовать COUNT(DISTINCT) вместо COUNT , чтобы получить точные подсчеты. Вы можете увидеть это ниже:
Следующий запрос показывает 7414 строк:
ВЫБРАТЬ СЧЕТЧИК(*) ИЗ tutorial.crunchbase_acquisitions
Следующий запрос показывает 83 893 строки:
SELECT COUNT(*) FROM tutorial.crunchbase_investments
Следующий запрос показывает 6 237 396 строк:
SELECT COUNT(*)
ИЗ приобретения tutorial.crunchbase_acquisitions
FULL JOIN tutorial.crunchbase_investments инвестиции
ON приобретения.acquired_month = инвестиции.funded_month
Если вы хотите понять это немного лучше, вы можете провести дополнительное исследование декартовых произведений. Также стоит отметить, что FULL JOIN и COUNT , приведенные выше, на самом деле работают довольно быстро — это COUNT(DISTINCT) , который занимает вечность. Подробнее об этом в уроке по оптимизации запросов.
Подробнее об этом в уроке по оптимизации запросов.
Конечно, вы могли бы решить эту проблему намного эффективнее, объединив две таблицы по отдельности, а затем соединив их вместе, чтобы подсчеты выполнялись для гораздо меньших наборов данных: приобретения.companies_acquired, Investments.companies_rec_investment ОТ ( ВЫБЕРИТЕ приобретаете_месяц КАК месяц, COUNT(DISTINCT company_permalink) AS company_acquired ИЗ tutorial.crunchbase_acquisitions СГРУППИРОВАТЬ ПО 1 ) приобретения ПОЛНОЕ СОЕДИНЕНИЕ ( ВЫБЕРИТЕ funded_month AS месяц, COUNT(DISTINCT company_permalink) КАК company_rec_investment ИЗ tutorial.crunchbase_investments СГРУППИРОВАТЬ ПО 1 )вложения ON приобретения.месяц = инвестиции.месяц ЗАКАЗАТЬ ПО 1 ДЕСК
Примечание. Мы использовали FULL JOIN выше на тот случай, если в одной таблице были наблюдения за месяц, которых не было в другой таблице. Мы также использовали
Мы также использовали COALESCE для отображения месяцев, когда в подзапросе поступлений не было записей о месяцах (предположительно, в эти месяцы не было поступлений). Мы настоятельно рекомендуем вам повторно выполнить запрос без некоторых из этих элементов, чтобы лучше понять, как они работают. Вы также можете запускать каждый из подзапросов независимо, чтобы лучше понять их.
Практическая задача
Напишите запрос, который подсчитывает количество основанных и приобретенных компаний по кварталам, начиная с первого квартала 2012 года. Создайте агрегации в двух отдельных запросах, а затем соедините их.
Попробуйте См. ответ
Подзапросы и ОБЪЕДИНЕНИЯ
В следующем разделе мы возьмем урок, посвященный ОБЪЕДИНЕНИЯМ, снова используя данные Crunchbase:
SELECT * ИЗ tutorial.crunchbase_investments_part1 СОЮЗ ВСЕХ ВЫБИРАТЬ * ИЗ tutorial.crunchbase_investments_part2
Набор данных нередко бывает разделен на несколько частей, особенно если данные проходят через Excel в какой-либо момент (Excel может обрабатывать только около 1 млн строк на электронную таблицу). Две использованные выше таблицы можно рассматривать как разные части одного и того же набора данных — почти наверняка вы захотите выполнять операции со всем объединенным набором данных, а не с отдельными его частями. Вы можете сделать это с помощью подзапроса:
Две использованные выше таблицы можно рассматривать как разные части одного и того же набора данных — почти наверняка вы захотите выполнять операции со всем объединенным набором данных, а не с отдельными его частями. Вы можете сделать это с помощью подзапроса:
SELECT COUNT(*) AS total_rows
ОТ (
ВЫБИРАТЬ *
ИЗ tutorial.crunchbase_investments_part1
СОЮЗ ВСЕХ
ВЫБИРАТЬ *
ИЗ tutorial.crunchbase_investments_part2
) суб
Это довольно просто. Попробуйте сами:
Практическая задача
Напишите запрос, который ранжирует инвесторов из приведенного выше комбинированного набора данных по общему количеству сделанных ими инвестиций.
ПопробуйтеСмотреть ответ
Практическая задача
Напишите запрос, который делает то же самое, что и в предыдущей задаче, но только для компаний, которые все еще работают. Подсказка: рабочий статус указан в tutorial. crunchbase_companies 9.0030 .
crunchbase_companies 9.0030 .
ПопробуйтеСмотреть ответ
Подзапросов в инструкциях SELECT
Подзапросов в инструкциях SELECT
|
Следующие ситуации определяют типы подзапросов, которые поддерживает сервер баз данных:
- Оператор SELECT , вложенный в SELECT список других операторов SELECT
- оператор SELECT , вложенный в предложение WHERE другого оператора SELECT (или в оператор INSERT , DELETE или UPDATE )
Каждый подзапрос должен содержать предложение SELECT и предложение FROM . Подзапросы могут быть коррелированными или некоррелированными . Подзапрос (или внутренний SELECT ) коррелируется, когда значение, которое он производит, зависит от значения, созданного внешним оператором SELECT , который его содержит. Любой другой вид подзапроса считается некоррелированным.
Подзапросы могут быть коррелированными или некоррелированными . Подзапрос (или внутренний SELECT ) коррелируется, когда значение, которое он производит, зависит от значения, созданного внешним оператором SELECT , который его содержит. Любой другой вид подзапроса считается некоррелированным.
Важной особенностью коррелированного подзапроса является то, что, поскольку он зависит от значения из внешнего SELECT , он должен выполняться многократно, по одному разу для каждого значения, которое производит внешний SELECT . Некоррелированный подзапрос выполняется только один раз.
Вы можете создать оператор SELECT с подзапросом для замены двух отдельных операторов SELECT .
Подзапросы в операторах SELECT позволяют выполнять следующие действия:
- Сравните выражение с результатом другого оператора SELECT
- Определить, включают ли результаты другого оператора SELECT выражение
- Определить, есть ли другой SELECT 9Оператор 0226 выбирает любые строки
Необязательное предложение WHERE в подзапросе часто используется для сужения условий поиска.
Подзапрос выбирает и возвращает значения первому или внешнему оператору SELECT . Подзапрос может не возвращать значения, одно значение или набор значений, как показано ниже:
- Если подзапрос возвращает без значения , запрос не возвращает никаких строк. Такой подзапрос эквивалентен нулевому значению.
- Если подзапрос возвращает одно значение , это значение имеет форму либо одного агрегатного выражения, либо ровно одной строки и одного столбца. Такой подзапрос эквивалентен одному числу или символьному значению.
- Если подзапрос возвращает список или набор значений, значения представляют либо одну строку, либо один столбец.
Подзапросы в списке выбора
Подзапрос может появиться в списке выбора другого оператора SELECT . Запрос 5-20 показывает, как вы можете использовать подзапрос в списке выбора, чтобы вернуть общую стоимость доставки (из заказы таблица) для каждого клиента в таблице клиентов . Вы также можете написать этот запрос как соединение между двумя таблицами.
Вы также можете написать этот запрос как соединение между двумя таблицами.
Запрос 5-20
- ВЫБЕРИТЕ customer.customer_num,
- (ВЫБЕРИТЕ СУММУ(ship_charge)
- ОТ заказов
- ГДЕ клиент.номер_клиента = заказы.номер_клиента)
- КАК total_ship_chg
- ОТ заказчика
Результат запроса 5-20 |
Подзапросы в пунктах WHERE
В этом разделе описываются подзапросы, которые встречаются как оператор SELECT , вложенный в предложение WHERE другого оператора SELECT .
Следующие ключевые слова вводят подзапрос в предложение WHERE оператора SELECT :
- ВСЕ
- ЛЮБОЙ
- В
- СУЩЕСТВУЕТ
Вы можете использовать любой реляционный оператор с ALL и ANY , чтобы сравнить что-то с каждым из ( ALL ) или с любым из ( ANY ) значений, которые производит подзапрос. Вы можете использовать ключевое слово SOME вместо ANY . Оператор IN эквивалентен = ANY . Чтобы создать противоположное условие поиска, используйте ключевое слово NOT или другой оператор отношения.
Вы можете использовать ключевое слово SOME вместо ANY . Оператор IN эквивалентен = ANY . Чтобы создать противоположное условие поиска, используйте ключевое слово NOT или другой оператор отношения.
Оператор EXISTS проверяет подзапрос на наличие каких-либо значений; то есть он спрашивает, не является ли результат подзапроса нулевым. Нельзя использовать ключевое слово EXISTS в подзапросе, который содержит столбец с типом данных TEXT или BYTE .
Синтаксис, который вы используете для создания условия с подзапросом, см. в Informix Guide to SQL : Syntax .
Использование ВСЕХ
Используйте ключевое слово ALL перед подзапросом, чтобы определить, верно ли сравнение для каждого возвращаемого значения. Если подзапрос не возвращает никаких значений, условием поиска является true . (Если он не возвращает никаких значений, условие истинно для всех нулевых значений. )
)
Запрос 5-21 перечисляет следующую информацию для всех заказов, содержащих товар, общая цена которого меньше общей цены на каждые товара в заказе с номером 1023.
Запрос 5-21
- ВЫБЕРИТЕ order_num, stock_num, manu_code, total_price
ИЗ товаров
WHERE total_price < ALL
(ВЫБЕРИТЕ total_price ИЗ товаров
WHERE order_num = 1023)
Результат запроса 5-21 |
Использование ЛЮБОГО
Используйте ключевое слово ANY (или его синоним SOME ) перед подзапросом, чтобы определить, верно ли сравнение хотя бы для одного из возвращаемых значений. Если подзапрос не возвращает значений, условие поиска равно 9.0041 ложь . (Поскольку значений не существует, условие не может быть истинным ни для одного из них.)
Запрос 5-22 находит номер заказа всех заказов, содержащих товар, общая цена которого больше, чем общая цена любых одного товаров в заказе номер 1005.
Запрос 5-22
- ВЫБЕРИТЕ ОТЛИЧНЫЙ номер_заказа
ИЗ элементов
ГДЕ общая_цена > ЛЮБОЙ
(ВЫБЕРИТЕ общую цену
ИЗ элементов
ГДЕ номер_заказа = 1005)
Результат запроса 5-22 |
Однозначные подзапросы
Вам не нужно включать ключевое слово ВСЕ или ЛЮБОЙ , если вы знаете, что подзапрос может вернуть ровно одно значение в запрос внешнего уровня. Подзапрос, возвращающий ровно одно значение, можно рассматривать как функцию. Этот вид подзапроса часто использует агрегатную функцию, поскольку агрегатные функции всегда возвращают одиночные значения.
Запрос 5-23 использует агрегатную функцию MAX в подзапросе, чтобы найти order_num для заказов, включающих максимальное количество волейбольных сеток.
Запрос 5-23
- ВЫБЕРИТЕ order_num ИЗ товаров
ГДЕ stock_num = 9
И количество =
(ВЫБЕРИТЕ МАКС (количество)
ИЗ товаров
ГДЕ stock_num = 9)
Результат запроса 5-23 |
Запрос 5-24 использует агрегатную функцию MIN в подзапросе для выбора товаров, общая цена которых превышает минимальную цену более чем в 10 раз.
Запрос 5-24
- ВЫБЕРИТЕ order_num, stock_num, manu_code, total_price
FROM товаров x
WHERE total_price >
(SELECT 10 * MIN (total_price)
FROM items
WHERE order_num = x.order_num)
Результат запроса 5-24 |
Коррелированные подзапросы
Запрос 5-25 является примером коррелированного подзапроса, который возвращает список из 10 последних дат отгрузки в таблице заказов . Он включает предложение ORDER BY после подзапроса для упорядочения результатов, поскольку вы не можете включить ORDER BY в подзапрос.
Он включает предложение ORDER BY после подзапроса для упорядочения результатов, поскольку вы не можете включить ORDER BY в подзапрос.
Запрос 5-25
- ВЫБРАТЬ po_num, ship_date ИЗ основных заказов
ГДЕ 10 >
(ВЫБЕРИТЕ СЧЕТЧИК (РАЗЛИЧНЫЕ даты отгрузки)
ИЗ заказов sub
ГДЕ sub.ship_date < main.ship_date)
AND ship_date НЕ NULL
ЗАКАЗ ПО ship_date, po_num
Подзапрос коррелирован, потому что число, которое он выдает, зависит от main.ship_date , значения, которое выдает внешний SELECT . Таким образом, подзапрос должен выполняться повторно для каждой строки, которую рассматривает внешний запрос.
Запрос 5-25 использует COUNT Функция для возврата значения в основной запрос. Затем предложение ORDER BY упорядочивает данные. Запрос находит и возвращает 16 строк с 10 последними датами доставки, как показано в результате запроса 5-25.
Результат запроса 5-25 |
Если вы используете коррелированный подзапрос, такой как запрос 5-25, в большой таблице, вы должны проиндексировать столбец ship_date для повышения производительности. В противном случае это Оператор SELECT неэффективен, поскольку он выполняет подзапрос один раз для каждой строки таблицы. Сведения об индексации и проблемах с производительностью см. в Руководстве администратора и в Руководстве по производительности .
Использование EXISTS
Ключевое слово EXISTS известно как квалификатор существования , потому что подзапрос истинен только в том случае, если внешний SELECT , как показывает запрос 5-26a, находит хотя бы одну строку.
Запрос 5-26а
- ВЫБЕРИТЕ УНИКАЛЬНОЕ имя_производителя, время выполнения
ОТ производителя
ГДЕ СУЩЕСТВУЕТ
(ВЫБЕРИТЕ * ИЗ ЗАПАСА
ГДЕ описание СООТВЕТСТВУЕТ '*shoe*'
AND manufact.
 manu_code = stock.manu_code)
manu_code = stock.manu_code) Часто можно создать запрос с EXISTS , который эквивалентен запросу, использующему IN . В запросе 5-26b используется предикат IN для создания запроса, возвращающего тот же результат, что и в запросе 5-26a.
Запрос 5-26b
- ВЫБЕРИТЕ УНИКАЛЬНОЕ manu_name, lead_time
СО склада, manufact
ГДЕ manu_code СО склада
(ВЫБЕРИТЕ manu_code ИЗ стока
WHERE description MATCHES '*shoe*')
AND stock.manu_code = manufact.manu_code
Запрос 5-26a и запрос 5-26b возвращают строки для производителей, которые производят определенную обувь, а также время выполнения заказа на продукт. Результат запроса 5-26 показывает возвращаемые значения.
Результат запроса 5-26 |
Добавьте ключевое слово NOT к IN или к EXISTS , чтобы создать условие поиска, противоположное условию в предыдущих запросах. Вы также можете заменить != ВСЕ на НЕ В .
Вы также можете заменить != ВСЕ на НЕ В .
Запрос 5-27 показывает два способа сделать одно и то же. Один способ может позволить серверу базы данных выполнять меньше работы, чем другой, в зависимости от структуры базы данных и размера таблиц. Чтобы узнать, какой запрос может быть лучше, используйте SET EXPLAIN команда для получения списка плана запроса. SET EXPLAIN обсуждается в Руководстве по производительности и Informix Guide to SQL : Syntax .
Запрос 5-27
- ВЫБЕРИТЕ номер_клиента, компанию ОТ клиента
ГДЕ номер_клиента НЕ В
(ВЫБЕРИТЕ номер_клиента ИЗ заказов
ГДЕ номер_клиента = номер_заказа)
ВЫБЕРИТЕ номер_клиента, компанию ИЗ клиента
ГДЕ НЕ СУЩЕСТВУЕТ
(ВЫБЕРИТЕ * ИЗ заказов
, ГДЕ customer.customer_num = orders.customer_num)
Каждый оператор в запросе 5-27 возвращает строки, показанные в результате запроса 5-27, которые идентифицируют клиентов, которые не размещали заказы.
Результат запроса 5-27 |
Ключевые слова EXISTS и IN используются для операции множества, известной как пересечение , а ключевые слова NOT EXISTS и NOT IN используются для операции установки, известной как разность . Эти концепции обсуждаются в разделе Операции над множествами.
Запрос 5-28 выполняет подзапрос к таблице товаров для определения всех товаров в таблице запасов , которые еще не были заказаны.
Запрос 5-28
- ВЫБЕРИТЕ * ИЗ запасов
ГДЕ НЕ СУЩЕСТВУЕТ
(ВЫБЕРИТЕ * ИЗ товаров
ГДЕ stock.stock_num = items.stock_num
И stock.manu_code = items.manu_code)
Запрос 5-28 возвращает строки, показанные в Результате Запроса 5-28.
Результат запроса 5-28 |
Не существует логического ограничения на количество подзапросов, которые может иметь оператор SELECT , но размер любого оператора физически ограничен, когда он рассматривается как строка символов. Однако этот предел, вероятно, больше, чем любое практическое утверждение, которое вы, вероятно, сочините.
Однако этот предел, вероятно, больше, чем любое практическое утверждение, которое вы, вероятно, сочините.
Возможно, вы хотите проверить, правильно ли введена информация в базу данных. Один из способов найти ошибки в базе данных — написать запрос, возвращающий выходные данные только при наличии ошибок. Подзапрос этого типа служит своего рода контрольным запросом , как показано в запросе 5-29.
Запрос 5-29
- ВЫБЕРИТЕ * ИЗ товаров
ГДЕ общая_цена != количество *
(ВЫБЕРИТЕ цену за единицу ИЗ запаса
ГДЕ запас.инвентарный_номер = товарный_номер
И stock.manu_code = items.manu_code)
Запрос 5-29 возвращает только те строки, для которых общая цена товара в заказе не равна цене единицы запаса, умноженной на количество заказа. Если скидка не применялась, вероятно, такие строки были неправильно введены в базу данных. Запрос возвращает строки только при возникновении ошибок. Если информация правильно вставлена в базу данных, строки не возвращаются.