Python SQLite: вложенные SQL-запросы
Смотреть материал на видео
На этом занятии поговорим о возможности создавать вложенные запросы к СУБД. Лучше всего это понять на конкретном примере. Предположим, что у нас имеются две таблицы:
Первая students содержит информацию о студентах, а вторая marks – их отметки по разным дисциплинам. Каждый из студентов (кроме четвертого) проходил язык Си. От нас требуется выбрать всех студентов, у которых оценка по языку Си выше, чем у Маши (студент с id = 2). По идее нам тут нужно реализовать два запроса: первый получает значение оценки для Маши по языку Си:
SELECT mark FROM marks WHERE id = 2 AND subject LIKE 'Си'
А второй выбирает всех студентов, у которых оценка по этому предмету выше, чем у Маши:
SELECT name, subject, mark FROM marks JOIN students ON students.rowid = marks.id WHERE mark > 3 AND subject LIKE 'Си'
Так вот, в языке SQL эти два запроса можно объединить, используя идею вложенных запросов:
SELECT name, subject, mark FROM marks JOIN students ON students.rowid = marks.id WHERE mark > (SELECT mark FROM marks WHERE id = 2 AND subject LIKE 'Си') AND subject LIKE 'Си'
 rowid = marks.id
WHERE mark > (SELECT mark FROM marks
WHERE id = 2 AND subject LIKE 'Си')
AND subject LIKE 'Си'
rowid = marks.id
WHERE mark > (SELECT mark FROM marks
WHERE id = 2 AND subject LIKE 'Си')
AND subject LIKE 'Си'Мы здесь во второй запрос вложили первый для определения оценки Маши по предмету Си. Причем, этот вложенный запрос следует записывать в круглых скобках, говоря СУБД, что это отдельная конструкция, которую следует выполнить независимо. То, что будет получено на его выходе и будет фигурировать в качестве Машиной оценки.
Но, что если вложенный запрос вернет несколько записей (оценок), например, если записать его вот так:
SELECT name, subject, mark FROM marks JOIN students ON students.rowid = marks.id WHERE mark > (SELECT mark FROM marks WHERE id = 2 ) AND subject LIKE 'Си'
В этом случае будет использован только первый полученный результат, другие попросту проигнорируются и результат будет тем же (так как первое значение – это оценка Маши по предмету Си).
Если же
вложенный SELECT ничего не
находит (возвращает значение NULL), то внешний запрос не будет возвращать
никаких записей.
Также следует обращать внимание, что подзапросы не могут обрабатывать свои результаты, поэтому в них нельзя указывать, например, оператор GROUP BY. Но агрегирующие функции вполне можно использовать, например, так:
SELECT name, subject, mark FROM marks JOIN students ON students.rowid = marks.id WHERE mark > (SELECT avg(mark) FROM marks WHERE id = 2 ) AND subject LIKE 'Си'
Вложения в команде INSERT
Вложенные запросы можно объявлять и в команде INSERT. Предположим, что у нас имеется еще одна таблица female вот с такой структурой:
Она идентична по структуре таблице students со списком студентов. Наша задача добавить в female всех студентов женского пола.
Для начала запишем запрос выбора девушек из таблицы students:
SELECT * FROM students WHERE sex = 2
А, затем, укажем, что их нужно поместить в таблицу female:
INSERT INTO female SELECT * FROM students WHERE sex = 2
После выполнения этого запроса таблица female будет содержать следующие записи:
Но если
выполнить запрос еще раз, то возникнет ошибка, т.
Чтобы поправить ситуацию, можно вложенный запрос написать так:
INSERT INTO female SELECT NULL, name, sex, old FROM students WHERE sex = 2
Мы здесь в качестве значения первого поля указали NULL и, соответственно, СУБД вместо него сгенерирует уникальный ключ для добавляемых записей. Теперь таблица female выглядит так:
Вложения в команде UPDATE
Похожим образом можно создавать вложенные запросы и для команды UPDATE. Допустим, мы хотим обнулить все оценки в таблице marks, которые меньше или равны минимальной оценки студента с id = 1. Такой запрос можно записать в виде:
UPDATE marks SET mark = 0 WHERE mark <= (SELECT min(mark) FROM marks WHERE id = 1)
И на выходе получим измененную таблицу:
Как видите,
минимальная оценка у первого студента была равна 3 и все тройки обнулились.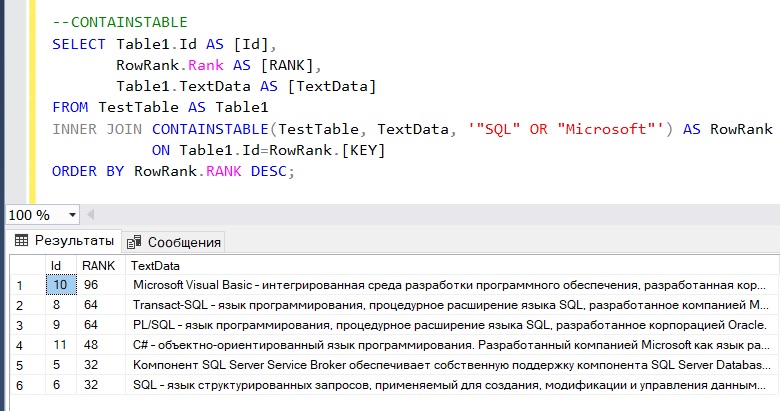
Вложения в команде DELETE
Ну, и наконец, аналогичные действия можно выполнять и в команде DELETE. Допустим, требуется удалить из таблицы students всех студентов, возраст которых меньше, чем у Маши (студента с id = 2). Запрос будет выглядеть так:
DELETE FROM students WHERE old < (SELECT old FROM students WHERE id = 2)
В результате, получим таблицу:
Вот так создаются вложенные запросы в языке SQL. Однако, прибегать к ним следует в последнюю очередь, если никакими другими командами не удается решить поставленную задачу. Так как они создают свое отдельное обращение к БД и на это тратятся дополнительные вычислительные ресурсы.
Конечно, на этом
занятии мы лишь рассмотрели примеры, принцип создания вложенных запросов. На
практике они могут разрастаться и становиться довольно объемными, включать в
себя различные дополнительные операции для выполнения нетривиальных действий с таблицами
БД.
На этом мы завершим обзор SQL-языка. Этого материала вам будет вполне достаточно для начальной работы с БД. По мере развития сможете дальше углубляться в эту тему и узнавать множество новых подходов к реализации различных задач с помощью SQL-запросов.
Видео по теме
Python SQLite #1: что такое СУБД и реляционные БД
Python SQLite #2: подключение к БД, создание и удаление таблиц
Python SQLite #3: команды SELECT и INSERT при работе с таблицами БД
Python SQLite #4: команды UPDATE и DELETE при работе с таблицами
Python SQLite #5: агрегирование и группировка GROUP BY
Python SQLite #6: оператор JOIN для формирования сводного отчета
Python SQLite #7: оператор UNION объединения нескольких таблиц
Python SQLite #8: вложенные SQL-запросы
Python SQLite #9: методы execute, executemany, executescript, commit, rollback и свойство lastrowid
Python SQLite #10: методы fetchall, fetchmany, fetchone, Binary, iterdump
Видео курс SQL Essential.
 Вложенные запросы
Вложенные запросы- Главная >
- Каталог >
- SQL Базовый >
- Вложенные запросы
Для прохождения теста нужно авторизироваться
Войти Регистрация
×
Вы открыли доступ к тесту! Пройти тест
Для просмотра полной версии видеокурса, онлайн тестирования и получения доступа к дополнительным учебным материалам купите курс Купить курс
Для просмотра всех видеокурсов ITVDN, представленных в Каталоге, а также для получения доступа к учебным материалам и онлайн тестированию купите подписку Купить подписку
№1
Введение в SQL
0:59:17
Материалы урокаДомашние заданияТестирование
На этом уроке по SQL Вы получите необходимые знания о базах данный – ознакомитесь с терминологией, узнаете принцип функционирования SQL сервера и его архитектуру. На уроке Вы узнаете о программной среде SQL Management Studio, в которой будете работать на протяжении всех последующих уроков. Вы ознакомитесь с правилами построения запросов и изучите типы данных, которые используются в SQL Server. После прохождения этого урока Вы сможете создать базу данных с несколькими таблицами, определить содержимое таблиц, указав типы данных и названия колонок, а также сможете создать простые SQL запросы для того, чтобы получить данные из таблиц.
На уроке Вы узнаете о программной среде SQL Management Studio, в которой будете работать на протяжении всех последующих уроков. Вы ознакомитесь с правилами построения запросов и изучите типы данных, которые используются в SQL Server. После прохождения этого урока Вы сможете создать базу данных с несколькими таблицами, определить содержимое таблиц, указав типы данных и названия колонок, а также сможете создать простые SQL запросы для того, чтобы получить данные из таблиц.
Читать дальше…
Запросы. Манипуляция данными.
0:55:28
Материалы урокаДомашние заданияТестирование
На этом уроке по SQL Вы научитесь манипулировать данными, хранящимися в таблицах базы данных. Вы узнаете, как можно добавить, удалить, изменить или просто прочитать информацию, которая находится в таблице. Вы познакомитесь с командами SQL SELECT, INSERT, UPDATE, DELETE и научитесь правильно их использовать.
Читать дальше…
Основы DDL.
1:27:42
Материалы урокаДомашние заданияТестирование
На этом видео уроке из курса SQL Essential Вы познакомитесь с языком описания структуры хранения данных Data Definition Language. В этом уроке Вы изучите основные команды (CREATE, ALTER, DROP) для создания, редактирования и удаления сущностный в базе данных. Также Вы узнаете, что такое реляционная база данных и как строятся связи между таблицами в базах данных, что такое первичный ключ и внешний ключ, для чего они нужны в базе. В конце урока Вы увидите, как можно создать диаграмму базы данных для того, чтобы графически представить структуру таблиц и связи между ними.
В этом уроке Вы изучите основные команды (CREATE, ALTER, DROP) для создания, редактирования и удаления сущностный в базе данных. Также Вы узнаете, что такое реляционная база данных и как строятся связи между таблицами в базах данных, что такое первичный ключ и внешний ключ, для чего они нужны в базе. В конце урока Вы увидите, как можно создать диаграмму базы данных для того, чтобы графически представить структуру таблиц и связи между ними.
Читать дальше…
Проектирование БД
0:41:32
Материалы урокаДомашние заданияТестирование
Видео урок расскажет о сложностях проектирования базы данных. Чтобы создать правильную структуру базы данных, нужно следовать различным рекомендациям и лучшим практикам. На занятии подробно расматриваетчся набор правил, которые следует помнить и соблюдать при проектировании баз данных. Вы узнаете, что такое нормализация баз данных и какие нормальные формы баз данных существуют. Этот урок даст Вам представление о том, как должна выглядеть правильно спроектированная база данных.
Читать дальше…
Команда JOIN
0:38:29
Материалы урокаДомашние заданияТестирование
Редко вся информация, которая нам необходима, находится в одной таблице. Зачастую в реляционных базах данные находятся в разных таблицах и связанны между собой. В этом видеоуроке по SQL Вы изучите команды JOIN, LEFT JOIN, RIGHT JOIN, CROSS JOIN, которые используются для получения данных из связанных таблиц.
Читать дальше…
Вложенные запросы
0:59:18
Материалы урокаДомашние заданияТестирование
Иногда для того, чтобы получить всю необходимую информацию из базы, простого запроса не достаточно. В данном видео уроке по SQL для начинающих Вы увидите, как можно создавать запросы со вложенными запросами для создания сложных правил выборки данных из базы. Также Вы узнаете, что такое курсор и на примерах увидите в каких ситуациях можно применять курсоры.
Читать дальше…
Индексирование
0:55:11
Материалы урокаДомашние заданияТестирование
На этом видео уроке Вы узнаете, как SQL сервер организовывает хранение данных таблиц на жестком диске. Вы узнаете, что такое B-деревья и индексы, научитесь использовать индексы для более быстрого поиска информации в базе данных.
Вы узнаете, что такое B-деревья и индексы, научитесь использовать индексы для более быстрого поиска информации в базе данных.
Читать дальше…
Хранимые процедуры. Пользовательские функции
1:24:53
Материалы урокаДомашние заданияТестирование
Для того, чтобы оптимизировать работу базы и не отправлять на сервер большие объемы SQL запросов, можно создать хранимую процедуру, которая будет представлять блок кода, хранящийся на сервере для неоднократного запуска со стороны клиента. В этом видео уроке по SQL Вы изучите тонкости написания хранимых процедур, а также научитесь создавать функции, которые также помогут оптимизировать и упростить работу с данными.
Читать дальше…
Транзакции. Триггеры
0:49:13
Материалы урокаДомашние заданияТестирование
Для того, чтобы гарантировать целостность информации в базе данных после применения ряда запросов, в SQL сервере используются транзакции. В этом видео уроке Вы узнаете, как выполнять запросы в контексте транзакции. На уроке будут рассмотрены триггеры, порядок их создания, задачи, которые принято решать с помощью триггеров.
В этом видео уроке Вы узнаете, как выполнять запросы в контексте транзакции. На уроке будут рассмотрены триггеры, порядок их создания, задачи, которые принято решать с помощью триггеров.
Читать дальше…
Следующий курс:
Entity Framework 6
ПОКАЗАТЬ ВСЕ
основные темы, рассматриваемые на уроке
0:00:00
Рассмотрение понятия «Подзапрос»
0:05:45
Связанные запросы
0:09:18
Пример создания вложенных запросов
0:15:43
Пример создания вложенного запроса совместно с JOIN
0:19:16
Пример создания связанного вложенного запроса
0:26:22
Связанный вложенный запрос — EXISTS
0:43:28
Временные таблицы
0:46:13
Связанные вложенные запросы — WITH … AS
0:49:23
Пример создания и использования «Курсора»
ПОКАЗАТЬ ВСЕ
Рекомендуемая литература
Ицик Бен-Ган- Microsoft SQL Server 2008. Основы T-SQL В книге изложены теоретические основы формирования запросов и программирования на языке T-SQL: однотабличные запросы, соединения, подзапросы, табличные выражения, операции над множествами, реорганизация данных и наборы группирования. Описываются различные аспекты извлечения и модификации данных, обсуждаются параллелизм и транзакции, приводится обзор программируемых объектов. Для дополнения теории практическими навыками в книгу включены упражнения, в том числе и повышенной сложности.
Описываются различные аспекты извлечения и модификации данных, обсуждаются параллелизм и транзакции, приводится обзор программируемых объектов. Для дополнения теории практическими навыками в книгу включены упражнения, в том числе и повышенной сложности.
Крис Дейт- Введение в системы баз данных. 8-е издание Новое издание фундаментального труда Криса Дейта представляет собой исчерпывающее введение в очень обширную в настоящее время теорию систем баз данных. С помощью этой книги читатель сможет приобрести фундаментальные знания в области технологии баз данных, а также ознакомиться с направлениями, по которым рассматриваемая сфера деятельности, вероятно, будет развиваться в будущем. Книга предназначена для использования в основном в качестве учебника, а не справочника, поэтому, несомненно, вызовет интерес у программистов-профессионалов, научных работников и студентов, изучающих соответствующие курсы в высших учебных заведениях. В ней сделан акцент на усвоении сути и глубоком понимании излагаемого материала, а не просто на его формальном изложении. Книга, безусловно, будет полезна всем, кому приходится работать с базами данных или просто пользоваться ими.
Книга, безусловно, будет полезна всем, кому приходится работать с базами данных или просто пользоваться ими.
Титры видеоурока
Титров к данному уроку не предусмотрено
ПОДРОБНЕЕ
ПОДРОБНЕЕ
ПОДРОБНЕЕ
ПОДРОБНЕЕ
Исследование эффективности способов написания SQL запросов с использованием СТЕ и подзапросов
Авторы: Коптенок Елизавета Викторовна, Сухарев Евгений Александрович, Савенко Арсений Витальевич, Трунников Максим Владиславович, Лагерева Наталья Валерьевна
Рубрика: Информатика и кибернетика
Опубликовано в Техника.
Дата публикации: 28.01.2020
Статья просмотрена: 79 раз
Скачать электронную версию
Библиографическое описание:Исследование эффективности способов написания SQL запросов с использованием СТЕ и подзапросов / Е. В. Коптенок, Е. А. Сухарев, А. В. Савенко [и др.]. — Текст : непосредственный // Техника. Технологии. Инженерия. — 2020. — № 1 (15). — С. 13-18. — URL: https://moluch.ru/th/8/archive/152/4832/ (дата обращения: 08.10.2022).
Любая база данных существует для хранения данных и предоставления доступа к этим данным пользователю. Информацию из базы пользователь получает с помощью запроса.
Запрос — средство поиска данных в базе из одной или нескольких таблиц по определенному пользовательскому условию.
Вложенный запрос— это запрос, который используется внутри другой запроса.
Чтобы улучшить читабельность запросов, включающих в себя подзапросы, применяются
[ WITH [ ,…n ] ]
::=
expression_name [ ( column_name [ ,…n ] ) ]
AS
( CTE_query_definition )
После объявления CTE может применяться в тех же секциях, что и вложенные запросы (SELECT, FROM, WHERE, JOIN).
В результате выполнения обобщенного табличного выражения создается временная таблица, к которой можно выполнять другие запросы.
Использование CTE позволяет выполнять рекурсивные запросы, что может быть также удобно при работе с базой данных.
Целю работы является выяснить, влияет ли использование CTE на время выполнения запроса.
Для проведения исследования будет использована база данных, таблицы которой содержат не менее 1000000 записей. Будет учитываться усредненное время многократно выполнения аналогичных запросов без применения и с применением CTE.
Диаграмма базы данных база данных представлена на рис.1.
Исследуется время выполнения следующих запросов:
- Фамилии всех директоров и школьников, связанных с олимпиадами по самому популярному предмету.
- Список всех школ, учащиеся которых заняли первое место.
- Вывести все предметы, по которым не проводились олимпиады.
- Призеров районных олимпиад из школ, в которых меньше 20 учеников.
Для примера на рис.2 и рис.3. приведены листинги первого запроса с использованием и без использования обобщенных табличных выражений.
Рис. 1. ER-диаграмма базы данных
Рис. 2. Первый запрос с применением CTE
Рис. 3. Первый запрос без применения CTE
Результаты усредненного измерения времени запросов представлены в табл. 1.
1.
Таблица 1
Результаты
№запроса | Без использования CTE, мс | С использованием CTE, мс |
1 | 86 | 98 |
2 | 90 | 100 |
3 | 40 | 45 |
4 | 516 | 550 |
Среднее | 183 | 198.25 |
Визуально время выполнения запросов представлено на рис.4.
Рис. 4. Время выполнения запросов
Определить, насколько процентов в среднем выполнение запроса без CTE быстрее, чем с ним, можно следующим образом:
(98−8698∗100 %+ 100−90100∗100 %+ 45−4045∗100 % +
+ 550−516550∗100 %)/4 = 9,84 %
Таким образом, по результатам проведенных тестов, в среднем, применение CTE увеличивает время выполнения запроса на 9,84 %. Таким образом, применение СTE упрощает читаемость запроса, но незначительно увеличивает время его выполнения.
Таким образом, применение СTE упрощает читаемость запроса, но незначительно увеличивает время его выполнения.
Литература:
- Язык запросов SQL [Электронный ресурс]. — Режим доступа: https://sql-language.ru/
- Вложенные запросы (SQL Server) [Электронный ресурс]. — Режим доступа: https://docs.microsoft.com/ru-ru/sql/relational-databases/performance/
- WITH обобщенное_табличное_выражение (Transact-SQL) [Электронный ресурс]. — Режим доступа: https://docs.microsoft.com/ru-ru/sql/t-sql/queries/with-common-table-expression-transact
Основные термины (генерируются автоматически): CTE, база данных, запрос, FROM, JOIN, SELECT, WHERE, WITH, время выполнения запроса, время выполнения запросов.
Похожие статьи
Асинхронное
выполнение SQL-запросов на языке… В данной работе представлены результаты исследования и использования асинхронных SQL-запросов с помощью скриптового языка PHP, которые позволят значительно ускорить выполнение массивного SQL-запроса с помощью использования логических ядер процессора.
Применение секционирования таблиц для ускорения
запросов…На Рис. 2 представлено сравнение времени выполнения запросов данных к секционированным и несекционированным таблицам. Полученные результаты показывают, что запросы к секционированным таблицам обрабатываются примерно за то же время…
Методы
выполнения запросов к хранилищу данных в Hadoop…Классификация методов выполнения запросов в Hadoop и Spark. В реляционных базах данные хранятся в рамках заранее разработанной схемы, и единственный способ получить к ним доступ — это использовать язык структурированных запросов SQL.
Применение индексирования для ускорения
запросов к базе. ..
..Для начала, рассмотрим время выполнения запросов с выборкой только проиндексированного столбца. Будем рассматривать запросы на выборку по всей таблице с сортировкой, группировкой по числовому столбцу, выборку по условию (≈40 % от всей таблицы)…
Анализ производительности подходов обработки информации на…
Поток выполнения есть наименьшая единица обработки команд в приложении.
Данное время возможно было использовать на выполнение некоторой другой работы.
Другой подход для обработки запросов имеет структурные отличия в технической реализации.
Интеграция Telegram-ботов в информационных системах
– формируем запросы из базы информационных систем для отображения в боте; – экспортируем результаты запроса в формат *. csv
csv
Язык SQL — это язык выполнения запросов для базы данных. В третьих, в структуре запросов (не только базы данных)…
Особенности реализации MVC-архитектуры в веб-приложениях
Пользователь направляет запрос в контроллер (в случае веб-приложений – это обращение по
Таким образом, запрос на получение данных предпочтительнее инициировать в контроллере, а в
Данный код эквивалентен вызову запроса: SELECT * FROM user WHERE id = ?
Использование апостериорного анализа
данных для обнаружения…Однако если рассматривать запрос уже после его выполнения, то цель запроса становится известной – СУБД возвратит данные
Следует отметить, что осуществление анализа запроса уже после его выполнения не является преградой для обеспечения предотвращения утечки. ..
..
Редактор языковых
баз Wordnet с использованием гиперграфовой…В таком случае наши запросы к такой базе данных будут содержать в себе вложенные команды select или join, и с каждой такой командой время выполнения запроса будет расти. Более наглядная иллюстрация подобной базы данных изображена на рис 4.
Аспекты написания XPath-
запросов | Статья в журнале…Запросы с относительным путем разрабатываются быстрее, и как правило, выходят более компакты чем запросы с абсолютным путем
Парсер, в свою очередь, проходит по узлам этого дерева и на каждом шаге получает данные из базы данных путем выполнения SQL.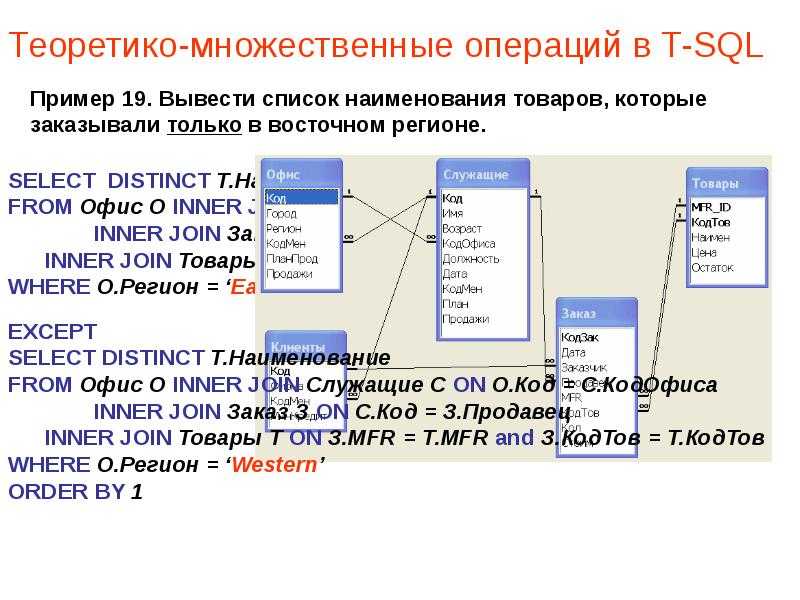 ..
..
- Как издать спецвыпуск?
- Правила оформления статей
- Оплата и скидки
Похожие статьи
Асинхронное
выполнение SQL-запросов на языке…В данной работе представлены результаты исследования и использования асинхронных SQL-запросов с помощью скриптового языка PHP, которые позволят значительно ускорить выполнение массивного SQL-запроса с помощью использования логических ядер процессора.
Применение секционирования таблиц для ускорения
запросов…На Рис. 2 представлено сравнение времени выполнения запросов данных к секционированным и несекционированным таблицам. Полученные результаты показывают, что запросы к секционированным таблицам обрабатываются примерно за то же время.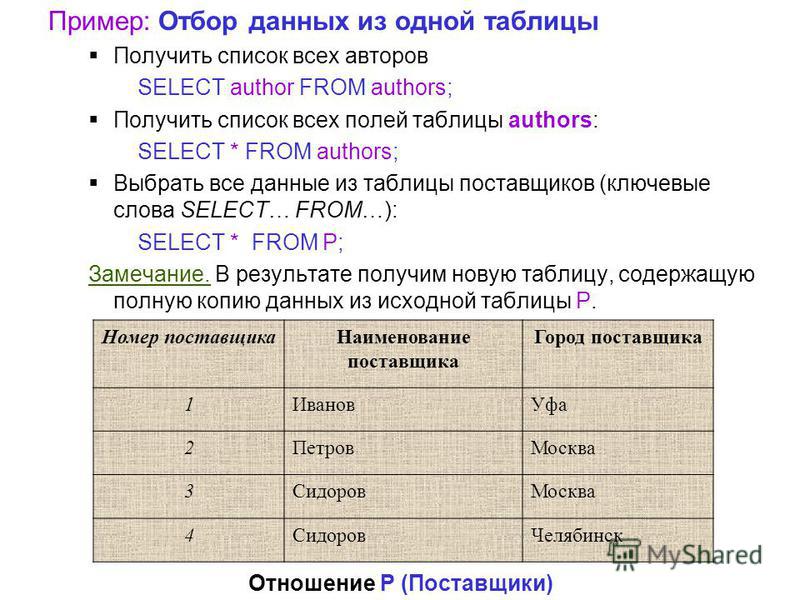 ..
..
Методы
выполнения запросов к хранилищу данных в Hadoop…Классификация методов выполнения запросов в Hadoop и Spark. В реляционных базах данные хранятся в рамках заранее разработанной схемы, и единственный способ получить к ним доступ — это использовать язык структурированных запросов SQL.
Применение индексирования для ускорения
запросов к базе…Для начала, рассмотрим время выполнения запросов с выборкой только проиндексированного столбца. Будем рассматривать запросы на выборку по всей таблице с сортировкой, группировкой по числовому столбцу, выборку по условию (≈40 % от всей таблицы)…
Анализ производительности подходов обработки информации на.
 ..
..Поток выполнения есть наименьшая единица обработки команд в приложении.
Данное время возможно было использовать на выполнение некоторой другой работы.
Другой подход для обработки запросов имеет структурные отличия в технической реализации.
Интеграция Telegram-ботов в информационных системах
– формируем запросы из базы информационных систем для отображения в боте; – экспортируем результаты запроса в формат *.csv
Язык SQL — это язык выполнения запросов для базы данных. В третьих, в структуре запросов (не только базы данных)…
Особенности реализации MVC-архитектуры в веб-приложениях
Пользователь направляет запрос в контроллер (в случае веб-приложений – это обращение по
Таким образом, запрос на получение данных предпочтительнее инициировать в контроллере, а в
Данный код эквивалентен вызову запроса: SELECT * FROM user WHERE id = ?
Использование апостериорного анализа
данных для обнаружения. ..
..Однако если рассматривать запрос уже после его выполнения, то цель запроса становится известной – СУБД возвратит данные
Следует отметить, что осуществление анализа запроса уже после его выполнения не является преградой для обеспечения предотвращения утечки…
Редактор языковых
баз Wordnet с использованием гиперграфовой…В таком случае наши запросы к такой базе данных будут содержать в себе вложенные команды select или join, и с каждой такой командой время выполнения запроса будет расти. Более наглядная иллюстрация подобной базы данных изображена на рис 4.
Аспекты написания XPath-
запросов | Статья в журнале. ..
..Запросы с относительным путем разрабатываются быстрее, и как правило, выходят более компакты чем запросы с абсолютным путем
Парсер, в свою очередь, проходит по узлам этого дерева и на каждом шаге получает данные из базы данных путем выполнения SQL…
Пример вложенного подзапроса SQL Вопрос для собеседования
Обзор вложенных запросов
Вложенный запрос SQL, также известный как подзапрос или подзапрос, представляет собой метод запроса SELECT, встроенный в другой запрос. Это эффективный способ получить желаемый результат, который может потребовать нескольких шагов запроса или для обработки взаимозависимых запросов.
Когда использовать вложенные подзапросы
Вложенные подзапросы можно использовать несколькими способами:
- Вы можете запрашивать подзапросы (например, выбирать из подзапроса)
- Вы можете заменить одномерные массивы (например, типичный список элементов) и соединения отдельных полей одним подзапросом в предложении WHERE или HAVING
Чтобы использовать подзапрос, необходимо соблюдать несколько синтаксических правил:
- Подзапрос должен быть заключен в круглые скобки
- В зависимости от используемого механизма SQL вам может потребоваться псевдоним для данного подзапроса
- При использовании в предложении WHERE или HAVING инструкция SELECT подзапроса может возвращать только одно оцениваемое поле
Пример вопроса SQL для собеседования с использованием вложенного подзапроса
Предположим, вам дана следующая таблица, показывающая продажи компании:
 01.2020
01.2020Рассчитать совокупный процент от общего объема продаж в данный день. Вывод таблицы должен выглядеть примерно так, как показано ниже.
| дата | pct_total_sales |
|---|---|
| 05.01.2020 | Х% |
| 07.01.2020 | Д% |
Вы можете работать с этим примером, используя интерактивную скрипку SQL здесь.
Прежде чем мы начнем писать SQL, мы разобьем вопрос на этапы:
- Подсчитаем общий объем продаж за день
- Рассчитать кумулятивную сумму общего объема продаж за день и общего объема продаж за все дни
- Разделить общий объем продаж за день на общую сумму
1. Подсчитайте общий объем продаж за день
Подсчитайте общий объем продаж за день
Сначала мы напишем базовый запрос, который на следующем шаге станет подзапросом. Приведенный ниже запрос вычисляет общий объем продаж за день, и вы можете взаимодействовать с запросом с помощью этой скрипки SQL.
ВЫБОР #нам нужно просуммировать sale_usd по дате свидание, сумма (sale_usd) как total_usd ОТ sales_info #поскольку мы агрегируем sale_usd по дате, нам нужно #нужно группировать по дате ГРУППИРОВАТЬ ПО дате
2. Рассчитать кумулятивную сумму общего объема продаж за день и общего объема продаж за все дни
Приведенный ниже запрос вычисляет кумулятивную сумму общего объема продаж за день и общего объема продаж за все дни. Вы можете взаимодействовать с приведенным ниже запросом с помощью этой скрипты SQL.
На этом шаге вы заметите, что мы строим запрос на основе предыдущего запроса из предыдущего шага. Чтобы успешно построить подзапрос, нам нужно было заключить подзапрос в круглые скобки и убедиться, что мы используем псевдоним для таблицы (поскольку мы используем MySQL, обратите внимание, что это не является требованием для некоторых вариантов SQL). Нам также необходимо убедиться, что мы включили все поля, необходимые для внешнего запроса (например, дату и общий объем продаж).
Нам также необходимо убедиться, что мы включили все поля, необходимые для внешнего запроса (например, дату и общий объем продаж).
ВЫБОР
#в этом запросе мы не группируем по, так как используем оконную функцию
свидание,
СУММА(total_usd) ПРЕВЫШЕ (
ORDER BY даты ASC строки
МЕЖДУ неограниченной предыдущей и текущей строкой)
as cum_total, # это оконная функция для
# вычисляем общую сумму
SUM(total_usd) OVER () как итог # это оконная функция для
# подсчитать итог
ИЗ(
ВЫБРАТЬ
#нам нужно просуммировать sale_usd по дате
свидание,
сумма (sale_usd) как total_usd
ОТ sales_info
#поскольку мы агрегируем sale_usd по дате, нам нужно
#нужно группировать по дате
СГРУППИРОВАТЬ ПО дате
) as q1 #создаем псевдоним для этой таблицы, как того требует MySQL 3. Разделите совокупный общий объем продаж на совокупную сумму
Последним шагом является деление cum_total на общую сумму. Мы можем сделать это на том же шаге, что и выше (просто разделив две оконные функции), или мы можем построить подзапрос поверх предыдущего шага. В приведенном ниже запросе используется другой подзапрос, в результате чего конечный запрос имеет 2 вложенных подзапроса. Вы можете взаимодействовать с приведенным ниже запросом с помощью этой скрипты SQL.
В приведенном ниже запросе используется другой подзапрос, в результате чего конечный запрос имеет 2 вложенных подзапроса. Вы можете взаимодействовать с приведенным ниже запросом с помощью этой скрипты SQL.
ВЫБОР
свидание,
100 * cum_total / всего как
ИЗ(
#в этом запросе мы не группируем по
#поскольку мы используем оконную функцию
ВЫБРАТЬ
свидание,
СУММ(total_usd) ПРЕВЫШЕНО (ПО ДАТЕ ASC
строки МЕЖДУ неограниченной предыдущей и текущей строкой)
as cum_total, # это оконная функция для
# вычисляем общую сумму
SUM(total_usd) OVER () как итог # это оконная функция
# для расчета суммы
ИЗ(
ВЫБРАТЬ
#нам нужно просуммировать sale_usd по дате
свидание,
сумма(sale_usd) как total_usd
ОТ sales_info
#поскольку мы агрегируем sale_usd по дате, нам нужно
#нужно группировать по дате
СГРУППИРОВАТЬ ПО дате
) as q1 #мы создаем псевдоним для этой таблицы, как того требует MySQL
) как q2 Вложенные запросы — данные отчета
[00:00]
В этом уроке я покажу вам, как настроить в отчете вложенный запрос, чтобы использовать результаты одного запроса для управления другим. Давайте сначала взглянем на два примера таблиц, которые есть в моей базе данных. Сначала у меня есть таблица с записями оборудования. Он имеет столбцы имени идентификатора и описания. Кроме того, есть таблица, содержащая информацию о событиях простоя. В нем есть столбец с идентификатором события простоя, столбец с идентификатором оборудования, которое вышло из строя, а затем столбцы с указанием причины простоя и минут, в течение которых оно было недоступно. Я хочу включить данные из обеих этих таблиц в свой отчет. Мы можем видеть, что они связаны между собой через столбец ID в таблице Equipment_table и ID оборудования в таблице downtime_table. Что я хотел бы сделать, так это запустить запрос, который возвращает данные о каждой единице оборудования, а затем я могу использовать его, чтобы сообщить мне о любом времени простоя для каждой единицы оборудования. К счастью, вложенный запрос поможет мне сделать это. Я начну с создания источника данных SQL-запроса и изменю имя ключа данных на «оборудование».
Давайте сначала взглянем на два примера таблиц, которые есть в моей базе данных. Сначала у меня есть таблица с записями оборудования. Он имеет столбцы имени идентификатора и описания. Кроме того, есть таблица, содержащая информацию о событиях простоя. В нем есть столбец с идентификатором события простоя, столбец с идентификатором оборудования, которое вышло из строя, а затем столбцы с указанием причины простоя и минут, в течение которых оно было недоступно. Я хочу включить данные из обеих этих таблиц в свой отчет. Мы можем видеть, что они связаны между собой через столбец ID в таблице Equipment_table и ID оборудования в таблице downtime_table. Что я хотел бы сделать, так это запустить запрос, который возвращает данные о каждой единице оборудования, а затем я могу использовать его, чтобы сообщить мне о любом времени простоя для каждой единицы оборудования. К счастью, вложенный запрос поможет мне сделать это. Я начну с создания источника данных SQL-запроса и изменю имя ключа данных на «оборудование». У меня уже есть скопированный запрос, который я вставлю сюда, и мы можем быстро перейти к нему.
У меня уже есть скопированный запрос, который я вставлю сюда, и мы можем быстро перейти к нему.
[01:07]
По сути, этот запрос возвращает каждый из столбцов из таблицы Equipment_table и назначает им псевдонимы. Идентификатор становится идентификационным номером оборудования, имя становится именем оборудования, а описание становится описанием оборудования. Это будет мой родительский запрос. Чтобы добавить дочерний запрос. Я перейду к разделу вложенных запросов и щелкну значок плюса. Мне нужен только один ребенок для этого примера. Но если вам нужно больше в вашей вложенной системе запросов, вы можете продолжать щелкать значок плюса, чтобы добавить дочерние элементы к своему дочернему, или вы также можете добавить одноранговые узлы. Я изменю ключ данных своего дочернего запроса, чтобы оборудовать время простоя, и возьму другой запрос. Этот запрос возвращает столбцы причины и минут простоя из таблицы времени простоя и назначает им псевдонимы. Он также использует предложение «где» для фильтрации результатов в столбце Equipment_ID. Я хочу отфильтровать результаты этого запроса на основе результатов родительского запроса, чтобы сделать это. Мне понадобится параметр, использующий синтаксис фигурных скобок. И тогда моим именем параметра будет имя столбца из первой таблицы, которая относится к этой таблице. Если вы помните, этот столбец называется «id», но я указал его в псевдониме «идентификационный номер оборудования» в своем запросе.
Он также использует предложение «где» для фильтрации результатов в столбце Equipment_ID. Я хочу отфильтровать результаты этого запроса на основе результатов родительского запроса, чтобы сделать это. Мне понадобится параметр, использующий синтаксис фигурных скобок. И тогда моим именем параметра будет имя столбца из первой таблицы, которая относится к этой таблице. Если вы помните, этот столбец называется «id», но я указал его в псевдониме «идентификационный номер оборудования» в своем запросе.
[02:17]
Таким образом, я могу использовать идентификационный номер оборудования в качестве своего параметра, если бы я не использовал псевдоним, я бы просто использовал здесь идентификатор. Это хорошая идея использовать здесь псевдонимы, потому что если бы я этого не сделал и у меня была бы опечатка в поле параметра, дочерний элемент будет искать совпадение в каждом столбце каждого родительского запроса, а если он не нашел бы его там, он бы искал в параметры для матча, а также. Если в конечном итоге он найдет что-то с похожим названием, вы можете оказаться в ситуации, когда вы просматриваете неправильные данные, и может быть трудно определить, почему. Так что псевдонимы могут быть здесь полезны. Итак, у меня настроен вложенный запрос, и я хочу проверить это. Я перейду на вкладку предварительного просмотра, и мы сможем посмотреть на результаты. Я не буду рассказывать, как я устанавливал этот стол. При желании вы можете сослаться на страницу групп таблиц в руководстве пользователя. Все, что вам нужно знать, это то, что результаты родительского запроса отображаются серым цветом, а результаты дочернего запроса — красным.
Если в конечном итоге он найдет что-то с похожим названием, вы можете оказаться в ситуации, когда вы просматриваете неправильные данные, и может быть трудно определить, почему. Так что псевдонимы могут быть здесь полезны. Итак, у меня настроен вложенный запрос, и я хочу проверить это. Я перейду на вкладку предварительного просмотра, и мы сможем посмотреть на результаты. Я не буду рассказывать, как я устанавливал этот стол. При желании вы можете сослаться на страницу групп таблиц в руководстве пользователя. Все, что вам нужно знать, это то, что результаты родительского запроса отображаются серым цветом, а результаты дочернего запроса — красным.
[03:04]
Это работает так, что родительские запросы, выполняемые в, возвращают определенное количество строк. Затем дочерние запросы выполняются для каждой строки, возвращаемой родителем. Важно отметить, что для каждой строки, возвращаемой родительским запросом, запускается новый запрос. Если у вас есть дополнительные вложенные дочерние запросы, которые выполняются для каждой строки, возвращаемой первым набором дочерних элементов. Количество запросов может увеличиваться в геометрической прогрессии. Важно знать о последствиях во время выполнения. Производительность системы может снизиться из-за достаточно сложной системы запросов, и вам, возможно, придется некоторое время ждать результатов. Теперь вы можете подумать, что этот пример также можно реализовать с помощью соединения SQL, и вы будете правы. Однако вложенные запросы выгодны, поскольку их гораздо проще писать и поддерживать по сравнению со сложными операторами соединения, и они обеспечивают больший контроль. Самым большим преимуществом также является то, что вложенные запросы имеют гораздо меньше ограничений, чем соединение SQL, если бы вложенные запросы можно было настроить для связывания данных между базами данных различных схем и даже другими источниками данных, такими как архиватор тегов, что делает их чрезвычайно мощным инструментом.
Если у вас есть дополнительные вложенные дочерние запросы, которые выполняются для каждой строки, возвращаемой первым набором дочерних элементов. Количество запросов может увеличиваться в геометрической прогрессии. Важно знать о последствиях во время выполнения. Производительность системы может снизиться из-за достаточно сложной системы запросов, и вам, возможно, придется некоторое время ждать результатов. Теперь вы можете подумать, что этот пример также можно реализовать с помощью соединения SQL, и вы будете правы. Однако вложенные запросы выгодны, поскольку их гораздо проще писать и поддерживать по сравнению со сложными операторами соединения, и они обеспечивают больший контроль. Самым большим преимуществом также является то, что вложенные запросы имеют гораздо меньше ограничений, чем соединение SQL, если бы вложенные запросы можно было настроить для связывания данных между базами данных различных схем и даже другими источниками данных, такими как архиватор тегов, что делает их чрезвычайно мощным инструментом.
В этом уроке я покажу вам, как настроить в отчете вложенный запрос, чтобы использовать результаты одного запроса для управления другим. Давайте сначала взглянем на два примера таблиц, которые есть в моей базе данных. Сначала у меня есть таблица с записями оборудования. Он имеет столбцы имени идентификатора и описания. Кроме того, есть таблица, содержащая информацию о событиях простоя. В нем есть столбец с идентификатором события простоя, столбец с идентификатором оборудования, которое вышло из строя, а затем столбцы с указанием причины простоя и минут, в течение которых оно было недоступно. Я хочу включить данные из обеих этих таблиц в свой отчет. Мы можем видеть, что они связаны между собой через столбец ID в таблице Equipment_table и ID оборудования в таблице downtime_table. Что я хотел бы сделать, так это запустить запрос, который возвращает данные о каждой единице оборудования, а затем я могу использовать его, чтобы сообщить мне о любом времени простоя для каждой единицы оборудования. К счастью, вложенный запрос поможет мне сделать это. Я начну с создания источника данных SQL-запроса и изменю имя ключа данных на «оборудование». У меня уже есть скопированный запрос, который я вставлю сюда, и мы можем быстро перейти к нему.
[01:07] По сути, этот запрос возвращает каждый из столбцов из таблицы Equipment_table и назначает им псевдонимы. Идентификатор становится идентификационным номером оборудования, имя становится именем оборудования, а описание становится описанием оборудования. Это будет мой родительский запрос. Чтобы добавить дочерний запрос. Я перейду к разделу вложенных запросов и щелкну значок плюса. Мне нужен только один ребенок для этого примера. Но если вам нужно больше в вашей вложенной системе запросов, вы можете продолжать щелкать значок плюса, чтобы добавить дочерние элементы к своему дочернему, или вы также можете добавить одноранговые узлы. Я изменю ключ данных своего дочернего запроса, чтобы оборудовать время простоя, и возьму другой запрос. Этот запрос возвращает столбцы причины и минут простоя из таблицы времени простоя и назначает им псевдонимы.
К счастью, вложенный запрос поможет мне сделать это. Я начну с создания источника данных SQL-запроса и изменю имя ключа данных на «оборудование». У меня уже есть скопированный запрос, который я вставлю сюда, и мы можем быстро перейти к нему.
[01:07] По сути, этот запрос возвращает каждый из столбцов из таблицы Equipment_table и назначает им псевдонимы. Идентификатор становится идентификационным номером оборудования, имя становится именем оборудования, а описание становится описанием оборудования. Это будет мой родительский запрос. Чтобы добавить дочерний запрос. Я перейду к разделу вложенных запросов и щелкну значок плюса. Мне нужен только один ребенок для этого примера. Но если вам нужно больше в вашей вложенной системе запросов, вы можете продолжать щелкать значок плюса, чтобы добавить дочерние элементы к своему дочернему, или вы также можете добавить одноранговые узлы. Я изменю ключ данных своего дочернего запроса, чтобы оборудовать время простоя, и возьму другой запрос. Этот запрос возвращает столбцы причины и минут простоя из таблицы времени простоя и назначает им псевдонимы. Он также использует предложение «где» для фильтрации результатов в столбце Equipment_ID. Я хочу отфильтровать результаты этого запроса на основе результатов родительского запроса, чтобы сделать это. Мне понадобится параметр, использующий синтаксис фигурных скобок. И тогда моим именем параметра будет имя столбца из первой таблицы, которая относится к этой таблице. Если вы помните, этот столбец называется «id», но я указал его в псевдониме «идентификационный номер оборудования» в своем запросе.
[02:17] Таким образом, я могу использовать идентификационный номер оборудования в качестве своего параметра, если бы я не использовал псевдоним, я бы просто использовал идентификатор здесь. Это хорошая идея использовать здесь псевдонимы, потому что если бы я этого не сделал и у меня была бы опечатка в поле параметра, дочерний элемент будет искать совпадение в каждом столбце каждого родительского запроса, а если он не нашел бы его там, он бы искал в параметры для матча, а также. Если в конечном итоге он найдет что-то с похожим названием, вы можете оказаться в ситуации, когда вы просматриваете неправильные данные, и может быть трудно определить, почему.
Он также использует предложение «где» для фильтрации результатов в столбце Equipment_ID. Я хочу отфильтровать результаты этого запроса на основе результатов родительского запроса, чтобы сделать это. Мне понадобится параметр, использующий синтаксис фигурных скобок. И тогда моим именем параметра будет имя столбца из первой таблицы, которая относится к этой таблице. Если вы помните, этот столбец называется «id», но я указал его в псевдониме «идентификационный номер оборудования» в своем запросе.
[02:17] Таким образом, я могу использовать идентификационный номер оборудования в качестве своего параметра, если бы я не использовал псевдоним, я бы просто использовал идентификатор здесь. Это хорошая идея использовать здесь псевдонимы, потому что если бы я этого не сделал и у меня была бы опечатка в поле параметра, дочерний элемент будет искать совпадение в каждом столбце каждого родительского запроса, а если он не нашел бы его там, он бы искал в параметры для матча, а также. Если в конечном итоге он найдет что-то с похожим названием, вы можете оказаться в ситуации, когда вы просматриваете неправильные данные, и может быть трудно определить, почему. Так что псевдонимы могут быть здесь полезны. Итак, у меня настроен вложенный запрос, и я хочу проверить это. Я перейду на вкладку предварительного просмотра, и мы сможем посмотреть на результаты. Я не буду рассказывать, как я устанавливал этот стол. При желании вы можете сослаться на страницу групп таблиц в руководстве пользователя. Все, что вам нужно знать, это то, что результаты родительского запроса отображаются серым цветом, а результаты дочернего запроса — красным.
[03:04] Это работает так, что родительские запросы, выполняемые в, возвращают определенное количество строк. Затем дочерние запросы выполняются для каждой строки, возвращаемой родителем. Важно отметить, что для каждой строки, возвращаемой родительским запросом, запускается новый запрос. Если у вас есть дополнительные вложенные дочерние запросы, которые выполняются для каждой строки, возвращаемой первым набором дочерних элементов. Количество запросов может увеличиваться в геометрической прогрессии. Важно знать о последствиях во время выполнения.
Так что псевдонимы могут быть здесь полезны. Итак, у меня настроен вложенный запрос, и я хочу проверить это. Я перейду на вкладку предварительного просмотра, и мы сможем посмотреть на результаты. Я не буду рассказывать, как я устанавливал этот стол. При желании вы можете сослаться на страницу групп таблиц в руководстве пользователя. Все, что вам нужно знать, это то, что результаты родительского запроса отображаются серым цветом, а результаты дочернего запроса — красным.
[03:04] Это работает так, что родительские запросы, выполняемые в, возвращают определенное количество строк. Затем дочерние запросы выполняются для каждой строки, возвращаемой родителем. Важно отметить, что для каждой строки, возвращаемой родительским запросом, запускается новый запрос. Если у вас есть дополнительные вложенные дочерние запросы, которые выполняются для каждой строки, возвращаемой первым набором дочерних элементов. Количество запросов может увеличиваться в геометрической прогрессии. Важно знать о последствиях во время выполнения. Производительность системы может снизиться из-за достаточно сложной системы запросов, и вам, возможно, придется некоторое время ждать результатов. Теперь вы можете подумать, что этот пример также можно реализовать с помощью соединения SQL, и вы будете правы. Однако вложенные запросы выгодны, поскольку их гораздо проще писать и поддерживать по сравнению со сложными операторами соединения, и они обеспечивают больший контроль. Самым большим преимуществом также является то, что вложенные запросы имеют гораздо меньше ограничений, чем соединение SQL, если бы вложенные запросы можно было настроить для связывания данных между базами данных различных схем и даже другими источниками данных, такими как архиватор тегов, что делает их чрезвычайно мощным инструментом.
Производительность системы может снизиться из-за достаточно сложной системы запросов, и вам, возможно, придется некоторое время ждать результатов. Теперь вы можете подумать, что этот пример также можно реализовать с помощью соединения SQL, и вы будете правы. Однако вложенные запросы выгодны, поскольку их гораздо проще писать и поддерживать по сравнению со сложными операторами соединения, и они обеспечивают больший контроль. Самым большим преимуществом также является то, что вложенные запросы имеют гораздо меньше ограничений, чем соединение SQL, если бы вложенные запросы можно было настроить для связывания данных между базами данных различных схем и даже другими источниками данных, такими как архиватор тегов, что делает их чрезвычайно мощным инструментом.
Соединения и подзапросы в SQL
Оператор SQL Join используется для объединения данных или строк из двух или более таблиц на основе общего поля между ними. Подзапрос — это запрос, вложенный в инструкцию SELECT, INSERT, UPDATE или DELETE или в другой подзапрос.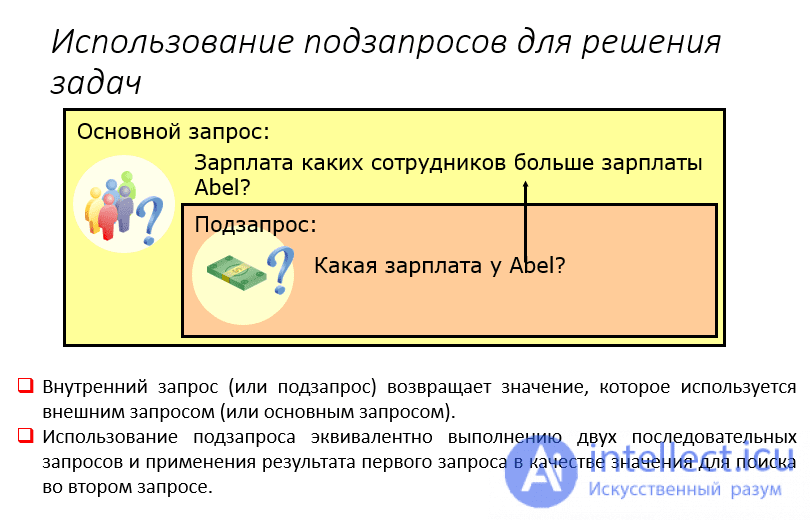
Узнайте все, что вам нужно знать о соединениях и подзапросах SQL, и многое другое!
Продолжайте читать…
Оператор SQL Join используется для объединения данных или строк из двух или более таблиц на основе общего поля между ними.
Подзапрос — это запрос, вложенный в оператор SELECT , INSERT , UPDATE или DELETE , либо внутри другого подзапроса.
Соединения и подзапросы используются для объединения данных из разных таблиц в один результат.
Первичный ключ – это столбец в таблице, который используется для уникальной идентификации строки в этой таблице.
А 9Внешний ключ 0201 используется для формирования связи между двумя таблицами. Например, предположим, что у вас есть отношение «один ко многим» между клиентами в таблице CUSTOMER и заказами в таблице ORDER. Чтобы связать две таблицы, вы должны определить столбец ORDER_ID в таблице CUSTOMER, который соответствует столбцу ORDER_ID в таблице ORDER.
Чтобы связать две таблицы, вы должны определить столбец ORDER_ID в таблице CUSTOMER, который соответствует столбцу ORDER_ID в таблице ORDER.
Примечание. Имя столбца внешнего ключа не обязательно должно совпадать с именем столбца первичного ключа.
Значения, определенные в столбце внешнего ключа, ДОЛЖНЫ соответствовать значениям, определенным в столбце первичного ключа. Это называется ссылочной целостностью и обеспечивается реляционной СУБД. Если первичный ключ для таблицы является составным ключом, внешний ключ также должен быть составным ключом.
1.2
Внутренние Соединения Внутренние соединения используются для объединения связанной информации из нескольких таблиц. Внутреннее соединение извлекает совпадающие строки между двумя таблицами. Совпадения обычно выполняются на основе существующих отношений между первичным и внешним ключами. Если есть совпадение, строка включается в результаты. В противном случае это не так.
В противном случае это не так.
Синтаксис:
SELECT
Из
Соединение
на
Если первичный ключ и внешний ключ являются составными ключами, то при указании соединения вы должны объединить И вместе с любыми дополнительными столбцами.
Например, если у вас есть составной ключ из двух столбцов, синтаксис будет следующим:
SELECT
FROM
JOIN
ON
AND
Схема базы данных представляет организацию и структуру базы данных. Он содержит таблицы и другие объекты базы данных (например, представления, индексы, хранимые процедуры).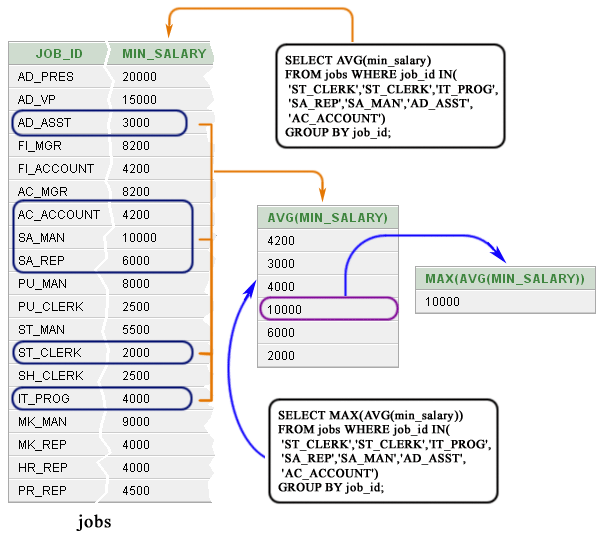 База данных может иметь более одной схемы, как в данном случае. База данных AdventureWorks на самом деле имеет 6 схем (dbo, HumanResources, Person, Production, Purchases и Sales). В SQL Server dbo является схемой по умолчанию. С другой стороны, Northwind имеет только схему dbo.
База данных может иметь более одной схемы, как в данном случае. База данных AdventureWorks на самом деле имеет 6 схем (dbo, HumanResources, Person, Production, Purchases и Sales). В SQL Server dbo является схемой по умолчанию. С другой стороны, Northwind имеет только схему dbo.
В приведенном выше примере идентификатор HumanResources.Employee означает, что HumanResources — это имя схемы, а Employee — имя таблицы. Персона. Идентификатор человека означает, что Person — это имя схемы, а Person — имя таблицы.
1.3 Внутреннее соединение
ПримерыОбъединение 2 таблиц:
SELECT Персона.Имя, Персона.Фамилия, Сотрудник.ДатаРождения, Сотрудник.НаемДата ОТ HumanResources.Employee ПРИСОЕДИНЯЙТЕСЬ к Person.Person ON Сотрудник.BusinessEntityID = Person.BusinessEntityID
Объединение N таблиц:
SELECT Person.FirstName, Person.LastName, Employee.BirthDate, Employee.HireDate, EmailAddress.EmailAddress ОТ HumanResources.
 Employee
ПРИСОЕДИНЯЙТЕСЬ к Человеку.Человеку
ON Сотрудник.BusinessEntityID = Person.BusinessEntityID
ПРИСОЕДИНЯЙТЕСЬ к Person.EmailAddress
ON Person.BusinessEntityID = EmailAddress.BusinessEntityID
Employee
ПРИСОЕДИНЯЙТЕСЬ к Человеку.Человеку
ON Сотрудник.BusinessEntityID = Person.BusinessEntityID
ПРИСОЕДИНЯЙТЕСЬ к Person.EmailAddress
ON Person.BusinessEntityID = EmailAddress.BusinessEntityID
Эта статья была адаптирована из нашего курса Введение в обучение SQL .
Узнайте все о соединениях и подзапросах в SQL и многое другое!
Свяжитесь с нами, чтобы получить код скидки
50%
на этот курс.
1.4
Префикс столбцов с именами таблицОбычно рекомендуется ставить имена столбцов с именами таблиц, чтобы было ясно, из какой таблицы взяты столбцы. Однако, если нет двусмысленности, т. е. в обеих таблицах нет одних и тех же столбцов, их можно опустить.
Пример:
ВЫБОР Имя Фамилия, Дата Рождения, Дата Найма ОТ HumanResources.Employee ПРИСОЕДИНЯЙСЯ ON Employee.Запрос транзакционных и аналитических баз данных с использованием SQL , MDX и DAX
 BusinessEntityID = Person.BusinessEntityID
BusinessEntityID = Person.BusinessEntityID Посмотрите наше видео на YouTube прямо сейчас!
Транзакционные базы данных (также известные как OLTP) оптимизированы для большого объема транзакций, таких как вставка, обновление и удаление.
В основном они используются приложениями для ввода данных.
Аналитические базы данных (также известные как OLAP) оптимизированы для больших объемов данных, которые часто запрашиваются для принятия бизнес-решений/отчетности. Вам нужно использовать различные языки запросов для запросов к этим разным типам баз данных.
Присоединяйтесь к нам в этом часовом видеоролике, в котором будут изучены такие языки запросов, как SQL , MDX и DAX .
1.5 Использование псевдонимов таблиц
Чтобы сделать имена столбцов короче и удобнее для чтения при объединении двух таблиц, мы можем использовать псевдонимы таблиц. Псевдонимы таблиц аналогичны псевдонимам столбцов. Вместо сокращения имени столбца мы сокращаем имя таблицы. Часто псевдонимы таблиц имеют длину в один или два символа. Псевдонимы таблиц можно использовать, даже если вы не объединяете таблицы.
Синтаксис:
SELECT
FROM
<Таблица 2>
соединение
на
1.6 Использование таблицы
9659565 9565 9565995659565656565656565656569.
ВЫБЕРИТЕ р. Имя, стр. Фамилия, эл. Дата Рождения, г. н.э. HireDate ОТ HumanResources.
 Employee e
СОЕДИНИТЬ Person.Person p
ПО эл. BusinessEntityID = р. BusinessentityId
Employee e
СОЕДИНИТЬ Person.Person p
ПО эл. BusinessEntityID = р. BusinessentityId Наши следующие предстоящие
бесплатные веб -бинарПолучите много действенных знаний за короткое время
1,7 Altrate
. join, который использует предложение WHERE для указания критериев соединения. Вы можете увидеть, что этот стиль соединения используется в устаревшем коде SQL.Синтаксис:
ВЫБЕРИТЕ
ИЗ ,
ГДЕ . знак равно
Пример:
ВЫБОР Персона.Имя, Персона.Фамилия, Сотрудник.ДатаРождения, Сотрудник.НаемДата ИЗ HumanResources.Сотрудник, Человек.Человек WHERE Employee.BusinessEntityID = Person.BusinessEntityID
Чтобы указать внешние соединения, необходимо использовать синтаксис, зависящий от поставщика. Например, в Oracle вам нужно использовать оператор (+), а в SQL Server вам нужно использовать операторы *= и =*.
Эта статья была адаптирована из нашего курса
Введение в SQL .
Узнайте здесь все и НАМНОГО больше!
Способность писать на языке SQL — краеугольном камне всех операций с реляционными базами данных — необходима для всех, кто разрабатывает приложения для баз данных.
Научитесь использовать все возможности языка SQL.
Посмотреть сведения о курсе
1.8
Внешний СоединенияЧто произойдет, если вы выполняете внутреннее соединение и одной из записей в таблице не соответствует запись в другой таблице?
Тогда в результирующем наборе не появится ни одной строки. Однако вы можете по-прежнему захотеть увидеть эту строку в своем отчете.
Например, у вас может быть клиент, но он еще не размещал заказы. Вы все еще хотите перечислить клиента.
Вот где внешний присоединяется к и приходит на помощь. Есть несколько типов внешних соединений которые мы обсудим далее.
Есть несколько типов внешних соединений которые мы обсудим далее.
Свяжитесь с Web Age Solutions, чтобы получить
СКИДКА 50%Скидка на курс «Введение в SQL» операции с базами данных —
необходим для всех, кто разрабатывает приложения для баз данных.Научитесь использовать все возможности языка SQL.
В этом учебном курсе «Введение в SQL» вы узнаете, как оптимизировать доступность и обслуживание данных с помощью языка программирования SQL, а также получите прочную основу для создания баз данных, выполнения запросов и управления ими.
Узнайте, как быстро и эффективно извлекать большие объемы данных.
Начните работу с Web Age Введение в SQL Обучение сегодня!
Просмотреть сведения о курсе
1.9
Слева Внешние соединения A левое внешнее соединение возвращает все записи из таблицы слева и соответствующие записи из таблицы справа.
Если соответствующей записи нет, то для любых столбцов, выбранных из таблицы справа, возвращается NULL.
Это эквивалент внутреннего соединения плюс несопоставленные строки из таблицы слева.
Синтаксис:
SELECT
FROM
LEFT JOIN <таблица2>
ON <таблица1>.<столбецA> = <таблица2>.<столбецB>
1.10 Левое внешнее соединение
Примеры совпадающие идентификаторы заказов на покупку.ВЫБОР e.BusinessEntityID, p.PurchaseOrderID ОТ HumanResources.Employee e LEFT JOIN Purchasing.PurchaseOrderHeader p ON e.BusinessEntityID = p.EmployeeID
Получить обратно все идентификаторы сотрудников (т. е. идентификаторы бизнес-объектов) и любые соответствующие идентификаторы кандидатов на работу и резюме
ВЫБЕРИТЕ e.BusinessEntityID, j.JobCandidateID, j.Resume ОТ HumanResources.
 Employee e
LEFT JOIN HumanResources.JobCandidate j
ON e.BusinessEntityID = j.BusinessEntityID
ЗАКАЗАТЬ ПО j.JobCandidateID DESC
Employee e
LEFT JOIN HumanResources.JobCandidate j
ON e.BusinessEntityID = j.BusinessEntityID
ЗАКАЗАТЬ ПО j.JobCandidateID DESC
1.11
Правое Внешнее соединениеA Правое внешнее соединение является противоположностью левому внешнему соединению.
Правое внешнее соединение возвращает все записи из таблицы справа и соответствующие записи из таблицы слева. Если соответствующей записи нет, то для любых столбцов, выбранных из таблицы слева, возвращается NULL.
Эквивалент внутреннего соединения плюс несовпадающие строки из таблицы справа .
Синтаксис:
SELECT
FROM
RIGHT JOIN
ON
Пример:
7 резюме и любые соответствующие идентификаторы сотрудников (например, идентификаторы бизнес-объектов)
SELECT e.
 BusinessEntityID, j.JobCandidateID, j.Resume
ОТ HumanResources.Employee e
ПРАВОЕ ПРИСОЕДИНЕНИЕ HumanResources.JobCandidate j
ON e.BusinessEntityID = j.BusinessEntityID
ЗАКАЗАТЬ ПО e.BusinessEntityID DESC
BusinessEntityID, j.JobCandidateID, j.Resume
ОТ HumanResources.Employee e
ПРАВОЕ ПРИСОЕДИНЕНИЕ HumanResources.JobCandidate j
ON e.BusinessEntityID = j.BusinessEntityID
ЗАКАЗАТЬ ПО e.BusinessEntityID DESC Хотите попрактиковаться в работе с соединениями и подзапросами SQL
?
Загрузите нашу БЕСПЛАТНУЮ практическую лабораторию
Соединения SQL — внутренние и внешние соединения
Бесплатно для вас!
1.12
Полное Внешние соединения Полное внешнее соединение возвращает все совпадающие записи между таблицами слева и справа, а также все несовпадающие записи с обеих сторон. Это эквивалент внутреннего соединения плюс несовпадающие строки из таблицы слева и несовпадающие строки из таблицы справа.
Синтаксис:
SELECT <столбцы>
Из <Таблица1>
Полное соединение <Таблица 2>
на Пример: Получить все идентификаторы сотрудников (т. е. идентификаторы бизнес-объектов), а также идентификаторы и резюме всех кандидатов на работу. Сопоставьте вместе любые записи. Самосоединение — это соединение, при котором таблица соединяется сама с собой. Обычно он используется, когда между сущностями существует иерархическая связь (например, сотрудник-менеджер), или вы хотите сравнить строки в одной таблице. Он использует синтаксис либо внутреннего соединения, либо левого внешнего соединения. Псевдонимы таблиц используются для присвоения разных имен одной и той же таблице в запросе. Синтаксис: SELECT FROM JOIN . Пример: Чтобы сопоставить адреса из одного и того же города, используйте следующий запрос: Подзапрос — это вложенный запрос (внутренний запрос), который используется для фильтрации результатов внешнего запроса. Подзапросы могут использоваться как альтернатива соединениям. Подзапрос обычно вложен в предложение WHERE. Синтаксис: SELECT <столбцы> FROM WHERE (SELECT FROM ) Подзапросы всегда должны заключаться в круглые скобки. Оператору может соответствовать одно из следующих значений: IN, =, <>, <, >, >=, <= Если подзапрос возвращает более одного результата, то можно использовать только оператор IN Таблица, указанная в подзапросе, обычно отличается от таблицы во внешнем запросе, но может совпадать. Учебные курсы по SQL Обновите свои навыки работы с ведущими на рынке системами баз данных от Microsoft. Web Age Solutions предлагает обучение для администраторов баз данных, разработчиков, разработчиков бизнес-аналитики и других специалистов по базам данных. Обучение SQL Веб-семинары Web Age предоставляет бесплатные ежемесячные веб-семинары по многим актуальным и своевременным темам. Бесплатные вебинары Блоги Читайте последние размышления, идеи и аналитические материалы непосредственно от наших талантливых экспертов. Блоги запрос и выполняется один раз. Его результаты используются внешним запросом. С другой стороны, коррелированный подзапрос зависит от внешнего запроса и выполняется один раз для каждой строки, возвращаемой внешним запросом. Его также называют повторяющимся подзапросом . Поскольку коррелированные подзапросы выполняются несколько раз, они могут выполняться медленно. Пример: Чтобы получить продавцов, процент комиссионных которых составляет 1%, мы можем использовать следующий коррелированный подзапрос. Получите много практических знаний за короткий промежуток времени В этом руководстве мы рассмотрели, как: Способность писать на языке SQL — краеугольном камне всех операций с реляционными базами данных — необходима для всех, кто разрабатывает приложения для баз данных.
ВЫБЕРИТЕ e.BusinessEntityID, j.JobCandidateID, j.Resume
ОТ HumanResources.Employee e
ПОЛНОЕ СОЕДИНЕНИЕ HumanResources.JobCandidate j
ON e.BusinessEntityID = j.BusinessEntityID
ORDER BY e.BusinessEntityID DESC
1.13
Strong Соединения AS
AS
 ON
ON SELECT a1.AddressID, a2.AddressID, a1.City
ОТ Лицо.Адрес a1
ПРИСОЕДИНЯЙТЕСЬ к лицу.Адрес a2
ON a1.AddressID > a2.AddressID
ГДЕ a1.City = a2.City
1.14 Что такое подзапрос
? 
1.15 Подзапрос
Примеры SELECT Name, ProductNumber
ОТ Производство.Продукт
ГДЕ ProductID В
(ВЫБЕРИТЕ ProductID
ОТ Purchasing.PurchaseOrderDetail
ГДЕ OrderQty > 5)
ВЫБЕРИТЕ Имя, Фамилия
ОТ Лицо.Лицо р
ГДЕ BusinessEntityID =
(ВЫБЕРИТЕ BusinessEntityID
ОТ HumanResources.Employee
ГДЕ NationalIDNumber = 295847284)
У нас много ресурсов
SQL . Будьте готовы смеяться и учиться с нашими экспертами.
Будьте готовы смеяться и учиться с нашими экспертами. 1.16
Обычный Подзапрос против Коррелированный Подзапрос 1.17 Коррелированный подзапрос
Пример  Внешний запрос извлекает каждого сотрудника. Внутренний запрос оценивает каждую строку, чтобы увидеть, составляет ли их процент комиссии 1%.
Внешний запрос извлекает каждого сотрудника. Внутренний запрос оценивает каждую строку, чтобы увидеть, составляет ли их процент комиссии 1%. ВЫБЕРИТЕ e.BusinessEntityID, p.FirstName, p.LastName
ОТ Лицо.Лицо р
ПРИСОЕДИНЯЙТЕСЬ к HumanResources.Employee
ON e.BusinessEntityID = p.BusinessEntityID
ГДЕ 0,01 В
(ВЫБРАТЬ s.CommissionPct
ОТ Sales.SalesPerson s
ГДЕ e.BusinessEntityID = s.BusinessEntityID) Наш следующий предстоящий
БЕСПЛАТНЫЙ веб-семинар 1.18
Резюме 