Sql запрос вложенный запрос. Разделить запрос SQL во вложенный запрос (подзапрос)
ГлавнаяРазноеSql запрос вложенный запрос
sql — Как создать вложенный запрос select в sql
То, что я пытаюсь сделать, это создать раздел комментариев для веб-сайта,
Комментарии состоят из имени пользователя, электронной почты и комментариев. Я храню эти данные в таблице комментариев
CREATE TABLE `comments` ( `commentid` int(5) NOT NULL auto_increment, `user` varchar(40) NOT NULL default », `email` varchar(100) NOT NULL default », `comment` text NOT NULL, PRIMARY KEY (`commentid`) )
То, что я хочу сделать, это выполнить запрос, который захватывает все эти данные, а также проверяет адрес электронной почты в таблице «users» , чтобы узнать, существует ли он. Если это так, возьмите аватар из таблицы «misc». Если письмо не существует в таблице «users» , оно просто осталось пустым.
В настоящий момент с запросом, который я попробовал, он захватывает только данные из трех таблиц, если письмо существует в таблице «users» . У меня есть еще один комментарий, который, как анонимный пользователь, оставил, но не получил захват запроса.
У меня есть еще один комментарий, который, как анонимный пользователь, оставил, но не получил захват запроса.
CREATE TABLE `users` ( `userid` int(25) NOT NULL auto_increment, `email` varchar(255) NOT NULL default », `username` varchar(25) NOT NULL default », PRIMARY KEY (`userid`) ) CREATE TABLE `misc` ( `miscid` int(4) NOT NULL auto_increment, `userid` varchar(3) NOT NULL default », `avatar` varchar(100) NOT NULL default », PRIMARY KEY (`miscid`) )
Я уверен, что мне нужно вложенное select в качестве имени столбца, чтобы, если есть электронное сообщение, оно отображается там… если оно не осталось пустым.
EDIT:
Создал структуры таблиц, как это должно быть.
Это запрос, который я только что попробовал, но он отображает только строку с адресом электронной почты. должен быть другой без адреса электронной почты
SELECT c.comment, c.user, av.avatar FROM comments c INNER JOIN users u ON c. email = u.email LEFT OUTER JOIN ( SELECT userid, avatar FROM misc ) AS av ON av.userid = u.userid
email = u.email LEFT OUTER JOIN ( SELECT userid, avatar FROM misc ) AS av ON av.userid = u.userid
qaru.site
sql — Этот запрос SQL требует вложенного запроса SELECT?
Вот что я до сих пор, но результаты ошибочны.
SELECT c.CompanyName, COUNT(o.OrderID) AS [Total Orders], SUM( (od.UnitPrice — (od.UnitPrice * od.Discount))* Quantity) AS [Purchase Total] FROM Customers AS c, Orders AS o, [Order Details] AS od WHERE c.CustomerID = o.CustomerID AND o.OrderID = od.OrderID GROUP BY c.CompanyName ORDER BY c.CompanyName;
Проблема, с которой я столкнулась, — это счет, он выключен двойным или более. Я считаю, что это связано с тем, что OrderID появляется несколько раз в таблице «Сведения о заказе». Я думаю, мне нужен вложенный оператор SELECT, но я не уверен, как это сделать.
Удаляю ли я выражение SUM(), информацию о заказе и предложение AND из первого запроса? Или я в отъезде?
С помощью я получил поле COUNT для работы, но теперь мое поле SUM ошибочно. Это моя самая последняя попытка, и она дает одинаковое значение для каждого клиента.
Это моя самая последняя попытка, и она дает одинаковое значение для каждого клиента.
SELECT c.CompanyName, COUNT(o.OrderID) AS [Total Orders], (SELECT SUM( (odIN.UnitPrice — (odIN.UnitPrice * odIN.Discount)) * odIN.Quantity) AS [OrderTotal] FROM [Order Details] AS odIN, Orders As oIN WHERE odIN.OrderID = oIN.OrderID) AS [Purchase Total] FROM Customers AS c, Orders AS o WHERE c.CustomerID = o.CustomerID GROUP BY c.CompanyName ORDER BY c.CompanyName;
Мне не удалось получить запрос, чтобы он полностью работал так, как я этого хотел. Тогда я понял, что, может быть, я искал неправильные данные. Поэтому я переключил имя для поля COUNT на Num Products Purchased.
Я все равно хотел бы работать по-другому, но я думаю, что для этого потребуется создать временную таблицу или представление, которое можно было бы использовать для выполнения одного из вычислений, а затем вызвать его из запроса. Это то, что мне нужно будет выяснить.
Спасибо за ваши попытки помочь.
qaru.site
Разделить запрос SQL во вложенный запрос (подзапрос) MS SQL Server
Изменить: добавьте все столбцы из
Возможно, я больше не могу редактировать свой комментарий, но это должно сделать трюк для второго запроса:
SELECT a.* , «AM-Martin_bin».dbo.CpCore_Image.Bytes FROM ( SELECT DISTINCT «AM-Martin».dbo.CpCore_Site.Number , «AM-Martin».dbo.CpCore_Site.Latitude , «AM-Martin».dbo.CpCore_Site.Longitude , «AM-Martin».dbo.CpSm_Face.RetiredOn , «AM-Martin».dbo.CpCore_Site.Name , «AM-Martin».dbo.CpCore_Site.Zipcode , «AM-Martin».dbo.CpSm_Face.Oid FROM «AM-Martin».dbo.CpCore_Site INNER JOIN «AM-Martin».dbo.CpSm_Face on «AM-Martin».dbo.CpSm_Face.SiteId = «AM-Martin».dbo.CpCore_Site.Oid WHERE «AM-Martin».dbo.CpSm_Face.RetiredOn LIKE ‘%9999%’ AND «AM-Martin».dbo.CpCore_Site.Number LIKE N’%LA%’ OR «AM-Martin».dbo.CpCore_Site.Number LIKE N’%LC%’ OR «AM-Martin».dbo.CpCore_Site.Number LIKE N’%BH%’ AND «AM-Martin».
Примечание. Я удалил GROUP BY из внутреннего запроса и вместо этого добавил DISTINCT, чтобы избавиться от возможных дубликатов. Однако я не могу проверить, будет ли это работать, поскольку я не знаю ваших данных.
Для удобства чтения я бы рекомендовал вам использовать псевдонимы ваших таблиц, а не повторять всю часть «AM-MARTIN».dbo.<tablename> (что первоначально меня отбросило с точки зрения поиска правильных столбцов и т. Д.).
Пример:
 Number LIKE N’%LA%’ OR b_inner.Number LIKE N’%LC%’ OR b_inner.Number LIKE N’%BH%’ AND b_inner.Latitude > 0.0 ) AS a INNER JOIN «AM-Martin_bin».dbo.CpCore_Image b on a.Oid = b.OwnerId;
Number LIKE N’%LA%’ OR b_inner.Number LIKE N’%LC%’ OR b_inner.Number LIKE N’%BH%’ AND b_inner.Latitude > 0.0 ) AS a INNER JOIN «AM-Martin_bin».dbo.CpCore_Image b on a.Oid = b.OwnerId;Обратите внимание, что я использовал псевдонимы a_inner и b_inner для подзапроса. Однако вы могли бы просто использовать a и b . Я очень хотел убедиться, что вы увидите разницу, вместо того, чтобы задаваться вопросом, откуда идут столбцы.
sqlserver.bilee.com
Вложенные запросы в SQL Безопасный SQL
Цель моего запроса состоит в том, чтобы вернуть название страны и ее главы государства, если у главы headststate есть имя, начинающееся с A, а в столице страны более 100 000 человек, использующих вложенный запрос.
Вот мой запрос:
SELECT country.name as country, (SELECT country.headofstate from country where country.headofstate like ‘A%’) from country, city where city.population > 100000;
Я попытался изменить его, поместив в предложение where и т. Д. Я не получаю вложенные запросы. Я просто возвращаю ошибки, например, «subquery возвращает более одной строки» и т. Д. Если кто-то может помочь мне в том, как его заказать, и объяснить, почему это должно быть определенным образом, это было бы здорово.
Д. Я не получаю вложенные запросы. Я просто возвращаю ошибки, например, «subquery возвращает более одной строки» и т. Д. Если кто-то может помочь мне в том, как его заказать, и объяснить, почему это должно быть определенным образом, это было бы здорово.
Solutions Collecting From Web of «Вложенные запросы в SQL»
Если он должен быть «вложенным», это будет одним из способов, чтобы выполнить вашу работу:
SELECT o.name AS country, o.headofstate FROM country o WHERE o.headofstate like ‘A%’ AND ( SELECT i.population FROM city i WHERE i.id = o.capital ) > 100000
Однако JOIN будет более эффективным, чем коррелированный подзапрос. Неужели тот, кто когда-либо давал вам эту задачу, не в состоянии ускорить себя?
Вам нужно join к двум таблицам, а затем отфильтровать результат в where :
SELECT country.name as country, country.headofstate from country inner join city on city.id = country.capital where city. population > 100000 and country.headofstate like ‘A%’
population > 100000 and country.headofstate like ‘A%’
Запрос ниже должен помочь вам достичь того, чего вы хотите.
select scountry, headofstate from data where data.scountry like ‘a%’and ttlppl>=100000
То, как я это вижу, единственное место для вложенного запроса будет в предложении WHERE, поэтому, например, SELECT country.name, country.headofstate FROM country WHERE country.headofstate LIKE ‘A%’ AND country.id in (SELECT country_id FROM city WHERE population > 100000)
Кроме того, я должен согласиться с Адрианом: почему, черт возьми, вы должны использовать вложенные запросы?
sql.fliplinux.com
php — SQL Вложенный запрос вставки
Сегодня у меня есть база данных с 3 запросами для статистики в тестовых окнах. Я использую php для создания веб-сайта, но запросы выполняются слишком долго, поэтому я не могу показать полную статистику сайта, как я этого не сделал. Так как сейчас база данных обновляется редко в пакетах, поэтому я могу создавать события, которые ежедневно обновляют базы данных ежедневно/еженедельно.
У меня есть следующие 3 запроса сегодня, чтобы отобразить информацию, которую я хочу:
SELECT key FROM testcase GROUP BY key;
Это дает мне список с int из 4-10 групп тестов. скажем, 1,2,3,4 для аргумента. Затем я повторяю это в подзапросах как ключ, чтобы получить количество пройденных тестов, а количество тестов не прошло со следующими двумя запросами:
SELECT COUNT(*) AS passed FROM testcase INNER JOIN testcases ON testcase.ID = testcases.testcaseid WHERE pass = 1 AND key = %value%;
а также
SELECT COUNT(*) AS failed FROM testcase INNER JOIN testcases ON testcase.ID = testcases.testcaseid WHERE pass = 0 AND key = %value%;
вот как это работает сегодня. Запросы занимают около 25-30 секунд для каждого ключа и это делает тайм-аут сайта. (% value% — псевдокод для текущего значения из цикла for)
Вместо этого я думал о sql-запросе, который добавил это в таблицу базы данных, которая состоит из таблиц «ключ», «проход», «сбой», которые я заполняю ежедневно/еженедельно, чтобы показывать на сайте статистику. Я видел некоторые случаи, когда вы можете выполнять итерацию с помощью подзапроса, но поскольку 2 выполненных запроса являются противоположностями, я не вижу никакого решения для этого.
Я видел некоторые случаи, когда вы можете выполнять итерацию с помощью подзапроса, но поскольку 2 выполненных запроса являются противоположностями, я не вижу никакого решения для этого.
Я попытался индексировать значения, которые я использую в запросах, без успеха (что также может быть ошибочным).
//Андреас (начинающий SQL)
Редактировать:
О, дилемма, где, чтобы установить решение, я сделал комбинат от Гордона и Джо, чтобы сделать быстрый запрос, который работал как шарм:
INSERT INTO statistics (key,passed,failed) SELECT key, SUM(case when T.pass = 1 then T.matches else 0 end) as passed, SUM(case when T.pass = 0 then T.matches else 0 end) as failed FROM (SELECT key,pass,COUNT(*) AS matches FROM testcase INNER JOIN testcases ON testcase.ID = testcases.testcaseid GROUP BY key,pass)T GROUP BY key
qaru.site
sql — SQL Server: вложенный запрос выбора
У меня есть SQL-запрос, возвращающий результаты на основе предложения where.
Я хотел бы добавить еще несколько результатов из той же таблицы в зависимости от того, что найдено в первом выборе.
Мой выбор возвращает строки с идентификатором, который соответствует критериям. Случается, что в таблице больше строк с этим идентификатором, но это не соответствует исходным критериям. Вместо того, чтобы повторно запрашивать БД отдельным вызовом, я хотел бы использовать один оператор select, чтобы также получить эти дополнительные строки с тем же идентификатором. ID не является индексом/идентификатором. Это соглашение об именах, которое я использую здесь.
Псевдо: (два шага)
1: select * from table where condition=xxx 2: for each row returned, (select * from table where id=row.id)
Я хочу делать:
select id as thisID, field1, field2, (select id, field1, field2 from table where id = thisID) from table where condition=xxx
У меня есть несколько объединений в моем реальном запросе, и просто не могу заставить выше работать. К сожалению, я не могу предоставить реальный запрос, но я получаю сообщение об ошибке:
К сожалению, я не могу предоставить реальный запрос, но я получаю сообщение об ошибке:
В списке выбора может быть указано только одно выражение, если подзапрос не вводится с EXISTS. Недопустимое имя столбца ‘thisID’
Мой запрос отлично работает с несколькими объединениями, без вышеуказанного. Я пытаюсь получить эти дополнительные записи как часть текущего рабочего запроса.
Пример:
ТАБЛИЦА
select * from table where col3 = ‘green’ id, col1, col2, col3 123 | blue | red | green ————————- 567 | blue | red | green ————————- 123 | blue | red | blue ————————- 890 | blue | red | green ————————-
Я хочу вернуть все 4 строки, потому что хотя row 3 терпит неудачу при условии where, она имеет то же значение col1 что и row 1 (123), и мне нужно включить ее, поскольку она является частью «набора», который мне нужно найти/импортировать, вызывать/ссылаться на id=123.
То, что я делаю вручную сейчас, получает строку 1, а затем запускает другой запрос на основе идентификатора строки 1, чтобы получить строку 3.
qaru.site
Вложенные запросы sql примеры
Здравствуйте, уважаемые читатели! В этой статье мы поговорим о том, что такое вложенные запросы в SQL. Традиционно, рассмотрим несколько примеров с той базой данных, которую создавали в первых статьях.
Введение
Итак, само название говорит о том, что запрос во что-то вложен. Так вот, вложенный запрос в SQL означает, что запрос select выполняется в еще одном запросе select — на самом деле вложенность может быть и многоуровневой, то есть select в select в select и т.д.
Так вот, вложенный запрос в SQL означает, что запрос select выполняется в еще одном запросе select — на самом деле вложенность может быть и многоуровневой, то есть select в select в select и т.д.
Такие запросы обычно используются для получения данных из двух и более таблиц. Они нужны чтобы данные из разных таблиц можно было соотнести и по зависимости осуществить выборку. У вложенных запросов есть и недостаток — зачастую слишком долгое время работы занимает запрос, потому что идет большая нагрузка на сервер. Тем не менее, саму конструкцию необходимо знать и использовать при возможности.
Структура ранее созданных таблиц
Прежде чем перейдем к простому примеру, напомним структуру наших таблиц, с которыми будем работать:
— Таблица Salespeole (продавцы):
| snum | sname | city | comm |
|---|---|---|---|
| 1 | Колованов | Москва | 10 |
| 2 | Петров | Тверь | 25 |
| 3 | Плотников | Москва | 22 |
| 4 | Кучеров | Санкт-Петербург | 28 |
| 5 | Малкин | Санкт-Петербург | 18 |
| 6 | Шипачев | Челябинск | 30 |
| 7 | Мозякин | Одинцово | 25 |
| 8 | Проворов | Москва | 25 |
— Таблица Customers (покупатели):
| сnum | сname | city | rating | snum |
|---|---|---|---|---|
| 1 | Деснов | Москва | 90 | 6 |
| 2 | Краснов | Москва | 95 | 7 |
| 3 | Кириллов | Тверь | 96 | 3 |
| 4 | Ермолаев | Обнинск | 98 | 3 |
| 5 | Колесников | Серпухов | 98 | 5 |
| 6 | Пушкин | Челябинск | 90 | 4 |
| 7 | Лермонтов | Одинцово | 85 | 1 |
| 8 | Белый | Москва | 89 | 3 |
| 9 | Чудинов | Москва | 96 | 2 |
| 10 | Лосев | Одинцово | 93 | 8 |
— Таблица Orders (заказы)
| onum | amt | odate | cnum | snum |
|---|---|---|---|---|
| 1001 | 128 | 2016-01-01 | 9 | 4 |
| 1002 | 1800 | 2016-04-10 | 10 | 7 |
| 1003 | 348 | 2017-04-08 | 2 | 1 |
| 1004 | 500 | 2016-06-07 | 3 | 3 |
| 1005 | 499 | 2017-12-04 | 5 | 4 |
| 1006 | 320 | 2016-03-03 | 5 | 4 |
| 1007 | 80 | 2017-09-02 | 7 | 1 |
| 1008 | 780 | 2016-03-07 | 1 | 3 |
| 1009 | 560 | 2017-10-07 | 3 | 7 |
| 1010 | 900 | 2016-01-08 | 6 | 8 |
Основы вложенных запросов в SQL
Вывести сумму заказов и дату, которые проводил продавец с фамилией Колованов.
Начнем с такого примера и для начала вспомним, как бы делали этот запрос ранее: посмотрели бы в таблицу Salespeople, определили бы snum продавца Колыванова — он равен 1. И выполнили бы запрос SQL с помощью условия WHERE. Вот пример такого SQL запроса:
Очевидно, какой будет вывод:
| amt | odate |
|---|---|
| 348 | 2017-04-08 |
| 80 | 2017-09-02 |
Такой запрос, очевидно, не очень универсален, если нам захочется выбрать тоже самое для другого продавца, то всегда придется определять его snum. А теперь посмотрим на вложенный запрос:
В этом примере мы определяем с помощью вложенного запроса идентификатор snum по фамилии из таблицы salespeople, а затем, в таблице orders определяем по этому идентификатору нужные нам значения. Таким образом работают вложенные запросы SQL.
Рассмотрим еще один пример:
Показать уникальные номера и фамилии продавцов, которые провели сделки в 2016 году.
Этот SQL запрос отличается тем, что вместо знака = здесь используется оператор IN. Его следует использовать в том случае, если вложенный подзапрос SQL возвращает несколько значений. То есть в запросе происходит проверка, содержится ли идентификатор snum из таблицы salespeople в массиве значений, который вернул вложенный запрос. Если содержится, то SQL выдаст фамилию этого продавца.
Получился такой результат:
| snum | sname |
|---|---|
| 3 | Плотников |
| 4 | Кучеров |
| 7 | Мозякин |
| 8 | Проворов |
Вложенные запросы SQL с несколькими параметрами
Те примеры, которые мы уже рассмотрели, сравнивали в условии WHERE одно поле. Это конечно хорошо, но стоит отметить, что в SQL предусмотрена возможность сравнения сразу нескольких полей, то есть можно использовать вложенный запрос с несколькими параметрами.
Вывести пары покупателей и продавцов, которые осуществили сделку между собой в 2017 году.
Запрос чем то похож на предыдущий, только теперь мы добавляем еще одно поле для сравнения. Итоговый запрос SQL будет выглядеть таким образом:
| Покупатель | Продавец |
|---|---|
| Краснов | Колованов |
| Колесников | Кучеров |
| Лермонтов | Колованов |
| Кириллов | Мозякин |
В этом примере мы сравниваем сразу два поля одновременно по идентификаторам. То есть из таблицы orders берутся те строки, которые удовлетворяют условию по 2017 году, затем вместо идентификаторов подставляются значение имен покупателей и продавцов.
На самом деле, такой запрос SQL используется крайне редко, обычно используют оператор INNER JOIN, о котором будет сказано в следующей статье.
Дополнительно скажем о конструкциях, которые использовались в этом запросе. Оператор as нужен для того, чтобы при выводе SQL показывал не имена полей, а то, что мы зададим. И после оператора FROM за именами таблиц стоят сокращения, которые потом используются — это псевдонимы. Псевдонимы можно называть любыми именами, в этом запросе они используются для явного определения поля, так как мы несколько раз обращаемся к одному и тому же полю, только из разных таблиц.
И после оператора FROM за именами таблиц стоят сокращения, которые потом используются — это псевдонимы. Псевдонимы можно называть любыми именами, в этом запросе они используются для явного определения поля, так как мы несколько раз обращаемся к одному и тому же полю, только из разных таблиц.
Примеры на вложенные запросы SQL
1.Напишите запрос, который бы использовал подзапрос для получения всех Заказов для покупателя с фамилией Краснов. Предположим, что вы не знаете номера этого покупателя, указываемого в поле cnum.
2. Напишите запрос, который вывел бы имена и рейтинг всех покупателей, которые имеют Заказы, сумма которых выше средней.
3. Напишите запрос, который бы выбрал общую сумму всех приобретений в Заказах для каждого продавца, у которого эта общая сумма больше, чем сумма наибольшего Заказа в таблице.
4. Напишите запрос, который бы использовал подзапрос для получения всех Заказов для покупателей проживающих в Москве.
5. Используя подзапрос определить дату заказа, имеющего максимальное значение суммы приобретений (вывести даты и суммы приобретений).
6. Определить покупателей, совершивших сделки с максимальной суммой приобретений.
Заключение
На этом сегодня все, мы познакомились с вложенными запросам в SQL. Очевидно, что это достаточно удобный и понятный способ получения данных из таблиц, но не всегда рационален с точки зрения скорости и нагрузки на сервер. Основные примеры, которые мы разобрали, действительно встречаются на практике языка SQL.
Приветствую Вас на сайте Info-Comp.ru! В этой заметке мы рассмотрим вложенные запросы языка SQL, я расскажу, что такое вложенные запросы, где и в каких конструкциях их можно использовать, покажу примеры их использования, а также расскажу про особенности и некоторые ограничения вложенных SQL запросов или, как еще их иногда называют, подзапросов SQL.
Что такое вложенные запросы SQL?
Вложенный SQL запрос – это отдельный запрос, который используется внутри SQL инструкции. Вложенный запрос также называют внутренним SQL запросом или подзапросом, а инструкцию, в которой используется вложенный запрос, называют внешним SQL запросом.
Вложенный запрос также называют внутренним SQL запросом или подзапросом, а инструкцию, в которой используется вложенный запрос, называют внешним SQL запросом.
Вложенные SQL запросы могут быть использованы везде, где разрешено использовать SQL выражения, это может быть и секция SELECT, и FROM, и WHERE, и даже JOIN, чуть ниже я покажу примеры использования вложенных запросов в каждой из перечисленных выше секций.
Использовать вложенные запросы иногда бывает очень удобно, но обязательно стоит отметить и то, что в некоторых случаях использование вложенного SQL запроса может снизить производительность, т.е. замедлить работу всей SQL инструкции. Тем более что не редко вложенный SQL запрос можно заменить простым объединением.
Кроме того, вложенные запросы могут быть вложены друг в друга (в некоторых случаях вплоть до 32-го уровня), но тем самым значительно снижается читабельность SQL инструкций и ее понятность, а также повышается ее сложность.
Кстати, о том, как писать хорошие понятные SQL инструкции на языке T-SQL, которые будут понятны и Вам спустя время, и другим программистам, я подробно рассказал в своей книге – «Стиль программирования на T-SQL – основы правильного написания кода».
Если Вы новичок и хотите освоить T-SQL с нуля, то рекомендую почитать другую мою книгу «Путь программиста T-SQL», в ней я подробно рассказываю про все конструкции языка T-SQL (включая вложенные запросы), и последовательно перехожу от простого к сложному, рекомендую ее для комплексного изучения языка T-SQL.
 Если Вы новичок и хотите освоить T-SQL с нуля, то рекомендую почитать другую мою книгу «Путь программиста T-SQL», в ней я подробно рассказываю про все конструкции языка T-SQL (включая вложенные запросы), и последовательно перехожу от простого к сложному, рекомендую ее для комплексного изучения языка T-SQL.
Если Вы новичок и хотите освоить T-SQL с нуля, то рекомендую почитать другую мою книгу «Путь программиста T-SQL», в ней я подробно рассказываю про все конструкции языка T-SQL (включая вложенные запросы), и последовательно перехожу от простого к сложному, рекомендую ее для комплексного изучения языка T-SQL.Особенности вложенных запросов
Вложенные SQL запросы имеют несколько важных особенностей, про которые не стоит забывать при конструировании SQL инструкций:
- Вложенный запрос всегда заключен в скобки;
- Вложенный запрос не может содержать предложения COMPUTE, INTO и FOR BROWSE;
- Вложенный запрос может содержать конструкцию сортировки ORDER BY, только если он содержит оператор TOP, т.е. без TOP, ORDER BY в подзапросе использовать не получится;
- Если вложенный запрос используется в операции сравнения (за исключением операторов EXISTS и IN), он должен возвращать одно значение и один столбец;
- Типы данных ntext, text и image не могут участвовать в списке выбора вложенных запросов.

Примеры вложенных SQL запросов в Microsoft SQL Server
Ну а теперь пора переходить к практике, сейчас мы рассмотрим несколько примеров использования вложенных SQL запросов, при этом я, как и обещал, покажу применение вложенных запросов в разных конструкциях языка T-SQL.
Примечание! Все примеры тестовые, они сконструированы исключительно для демонстрации работы вложенных запросов.
Исходные данные для примеров
Сначала давайте определимся с исходными данными, чтобы Вы понимали, какие именно данные у нас есть, и наглядно видели, каким образом в примерах ниже получаются те или иные результаты.
Также сразу скажу, что в качестве SQL сервера у меня выступает версия Microsoft SQL Server 2017 Express.
Следующая инструкция создает таблицы, которые мы будет использовать в примерах, и добавляет в них данные.
Подробно останавливаться на том, что делает представленная выше инструкция, в этой статье я не буду, так как это совершенно другая тема, но если эта SQL инструкция Вам не понятна, и Вам интересно узнать, что конкретно она делает, можете почитать следующие статьи, а для комплексного изучения языка T-SQL — книгу, которую я уже упоминал:
Пример 1 – Вложенный запрос в секции SELECT
В этом примере мы рассмотрим стандартную ситуацию использования вложенного запроса в списке выборки оператора SELECT.
Допустим, что нам нужно получить список товаров с названием категорий, а так как названия категории в таблице Goods у нас нет, это название мы будем получать из таблицы Categories.
Это можно сделать с помощью вложенного запроса, в котором будет происходить объединение с внешним запросом в секции WHERE, посредством уточняющих псевдонимов. В данном случае вложенный запрос обязательно должен возвращать одно значение и один столбец.
А также это можно реализовать и с помощью объединения JOIN, что на самом деле предпочтительней, и в подобных случаях я рекомендую использовать именно JOIN, тем самым SQL запрос становится более читабельным и простым для понимания. Ниже я представлю оба SQL запроса.
Пример 2 – Вложенный запрос в секции FROM
Сейчас давайте я покажу, как можно использовать вложенный запрос в секции FROM в качестве источника данных. Такие вложенные запросы обычно называют – Производные таблицы, так как они возвращают табличные данные.
В данном примере в качестве источника данных в секции FROM мы указали вложенный запрос, который возвращает идентификатор и наименование товаров из первой категории.
Пример 3 – Вложенный запрос в секции JOIN
В этом примере мы используем вложенный запрос в конструкции объединения JOIN, такие вложенные запросы также называют производными таблицами, так как в этом случае они возвращают табличные данные.
Здесь во вложенном запросе мы получаем идентификатор и наименование первой категории, а затем полученные табличные данные объединяем с таблицей Goods.
Пример 4 – Вложенный запрос в секции WHERE
Очень часто вложенные запросы используют в условии WHERE, при этом здесь стоит понимать, с каким именно оператором сравнения используется вложенный запрос, так как это важно.
Например, если использовать вложенный запрос с оператором равно (=), то он не может возвращать больше одного значения, т.е. если он вернет больше одного значения, выйдет ошибка, и SQL запрос не выполнится. Однако если использовать вложенный запрос с оператором IN (включая NOT IN) или EXISTS (включая NOT EXISTS), то вложенный запрос уже может возвращать список значений.
Вложенный запрос с оператором = (равно)
В этом запросе мы выводим все товары из таблицы Goods, у которых идентификатор категории равен значению, которое возвращает вложенный запрос, а он возвращает идентификатор категории с наименованием «Комплектующие ПК», таким образом, в нашем случае вложенный запрос возвращает только одно значение.
Вложенный запрос с оператором IN
Здесь мы используем для сравнения оператор IN, поэтому вложенный запрос в таком случае может уже возвращать несколько значений, для примера мы просто уберем условие WHERE во вложенном запросе.
Пример 5 – Множественная вложенность SQL запросов
Как я уже отмечал, вложенный запрос может быть вложен в другой вложенный SQL запрос, тем самым получается множественная вложенность.
В этом примере мы в качестве источника данных укажем вложенный SQL запрос, т.е. производную таблицу, который в свою очередь также будет содержать еще один вложенный запрос.
Дополнительные примеры использования вложенных запросов, например, с использованием оператора EXISTS, можете посмотреть в статье – Логический оператор EXISTS в T-SQL – Описание и примеры.
На сегодня у меня все, надеюсь, материал был Вам полезен, пока!
Вложенный запрос – это запрос, который находится внутри другого SQL запроса и встроен внутри условного оператора WHERE.
Данный вид запросов используется для возвращения данных, которые будут использоваться в основном запросе, как условие для ограничения получаемых данных.
Вложенные запросы должны следовать следующим правилам:
- Вложенный запрос должен быть заключён в родительский запрос.
- Вложенный запрос может содержать только одну колонку в операторе SELECT.
- Оператор ORDER BY не может быть использован во вложенном запросе. Для обеспечения функционала ORDER BY, во вложенном запросе может быть использован GROUP BY.
- Вложенные запросы, возвращающие более одной записи могут использоваться с операторами нескольких значений, как оператор IN.
- Вложенный запрос не может заканчиваться в функции.
- SELECT не может включать никаких ссылок на значения BLOB, ARRAY, CLOB и NCLOB.
- Оператор BETWEEN не может быть использован вместе с вложенным запросом.
Вложенный запрос имеет следующий вид:
Предположим, что у нас есть таблица developers, которая содержит следующие записи:
Попробуем выполнить следующий вложенный запрос:
Предположим, что у нас есть клон таблицы developers, который имеет имя developers_clone и имеет следующую структуру:
И не содержит данных:
Теперь попробуем выполнить для этой же таблицы следующий запрос:
В результате выполнения данного запроса таблица developers_clone будет содержать следующие данные:
Другими словами, мы скопировали все данные из таблицы developers в таблицу developers_clone.
Теперь мы изменим данные в таблице developers воспользовавшись данными из таблицы developers_clone с помощью следующего запроса:
В результате этого наша таблица содержащая изначальные данные:
Будет хранить следующие данные:
И наконец, попробуем выполнить удаление данных из таблицы с помощью вложенного запроса:
В результате таблица developers содерит следующие записи:
Очистим таблицу developers:
Теперь восстановим данные таблицы developers, с помощью резервной таблицы developers_clone используя следующий запрос:
Наша таблица developers имеет исходный вид:
На этом мы заканчиваем изучение вложенных запросов.
В следующей статье мы рассмотрим использование последовательностей.
2.14. Подзапросы — Transact-SQL В подлиннике : Персональный сайт Михаила Флёнова
Наиболее сложной, но в то же время наиболее интересной темой являются подзапросы. Это достаточно мощное средство получения необходимых данных, а с другой стороны, это средство очень сильно бьет по производительности обработки запроса сервером. Сначала мы научимся работать с подзапросами, потому что с их помощью можно быстро решить поставленную задачу, а потом будем учиться избавляться от подзапросов, что идентично оптимизации.
Рассмотрим пример, как можно определить номера телефонов, у которых установлен тип ‘Сотовый рабочий’. Для этого сначала необходимо узнать, какой первичный ключ у нужного типа телефона в таблице tbPhoneType:
SELECT idPhoneType
FROM tbPhoneType
WHERE vcTypeName = ('Сотовый рабочий')
После этого уже находим все записи в таблице tbPhoneNumbers, где поле «idPhoneType» содержит найденное значение типа телефона:
SELECT * FROM tbPhoneNumbers WHERE idPhoneType = идентификатор
Эта задача достаточно просто решается с помощью подзапросов:
SELECT *
FROM tbPhoneNumbers
WHERE idPhoneType =
(
SELECT idPhoneType
FROM tbPhoneType
WHERE vcTypeName = ('Сотовый рабочий')
)
В данном примере мы выбираем все записи из таблицы tbPhoneNumbers. При этом, поле «idPhoneType» сравнивается с результатом подзапроса, который пишется в круглых скобках. Так как стоит знак равенства, то результат подзапроса должен быть из одного поля и одной строки. Если результатом будет два поля или более одной строки, то сервер вернет нам ошибку.
При этом, поле «idPhoneType» сравнивается с результатом подзапроса, который пишется в круглых скобках. Так как стоит знак равенства, то результат подзапроса должен быть из одного поля и одной строки. Если результатом будет два поля или более одной строки, то сервер вернет нам ошибку.
Попробуем выполнить следующий запрос:
SELECT *
FROM tbPhoneNumbers
WHERE idPhoneType =
(
SELECT idPhoneType
FROM tbPhoneType
WHERE vcTypeName in ('Сотовый рабочий', 'Сотовый домашний')
)
Этот запрос вернет две строки с двумя значениями первичного ключа. В ответ на это, сервер вернет ошибку:
Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <= , >, >= or when the subquery is used as an expression.
(Подзапрос возвращает более чем 1 значение. Это не позволено, когда подзапрос следует после знаков =, !=, <, <= , >, >= или когда подзапрос используется как выражение)
А что же тогда можно использовать? Если немного подумать, то для такого запроса знак равенства нужно заменить на оператор IN:
SELECT *
FROM tbPhoneNumbers
WHERE idPhoneType IN
(
SELECT idPhoneType
FROM tbPhoneType
WHERE vcTypeName in ('Сотовый рабочий', 'Сотовый домашний')
)
Сначала SQL выполнит внутренний запрос, который расположен в скобках и результат подставит во внешний запрос.
Я уже намекнул на то, что результат подзапроса должен состоять только из одной колонки. Это значит, что вы не можете написать во внутреннем запросе SELECT *, а можно только SELECT ИмяОдногоПоля. Помните, что имя должно быть только одно и тип его должен совпадать с типом сравниваемого значения. Подзапросы нужно использовать очень аккуратно, потому что они могут привести к ошибке.
Очень важно, что подзапрос находиться в скобках и справа от знака равенства. Стандарт не позволяет писать подзапросы слева. Это значит, что следующий запрос не верный:
SELECT *
FROM tbPhoneNumbers
WHERE
(
SELECT idPhoneType
FROM tbPhoneType
WHERE vcTypeName = ('Сотовый рабочий')
) = idPhoneType
В этом примере сначала идет подзапрос, потом знак равенства и только после этого указывается поле, с которым необходимо произвести сравнение.
Основной запрос (так же называемый внешним) может обращаться к подзапросу (внутренний запрос). Для этого таблицам необходимо указать псевдонимы. Посмотрим на следующий запрос:
Для этого таблицам необходимо указать псевдонимы. Посмотрим на следующий запрос:
SELECT *
FROM tbPhoneNumbers ot
WHERE idPhoneType IN
(
SELECT idPhoneType
FROM tbPhoneType it
WHERE vcTypeName in ('Сотовый рабочий', 'Сотовый домашний')
AND ot.vcPhoneNumber LIKE '(923)%'
)
Обратите внимание на предпоследнюю строку:
AND ot.vcPhoneNumber LIKE '(923)%'
Здесь происходит сравнение поя «vcPhoneNumber» таблицы ot с шаблоном. Самое интересное здесь в том, что ot – это псевдоним таблицы tbPhoneNumbers, которая описана в секции FROM внешнего запроса. Но, не смотря на это, мы можем из подзапроса обращаться по псевдониму к столбцам внешних запросов. Таким образом, можно наводить достаточно сложные связи между запросами.
Такой запрос будет выполняться по следующему алгоритму:
- Выбрать строку из таблицы tbPhoneNumbers в внешнем запросе. Это будет текущая строка-кандидат.
- Сохранить значения из этой строки-кандидата в псевдониме с именем ot.
- Выполнить подзапрос, при этом, во время поиска участвует и внешний запрос.
- Оценить «idPhoneType» внешнего запроса на основе результатов подзапроса выполняемого в предыдущем шаге. Он определяет — выбирается ли строка-кандидат для вывода на экран.

Подзапросы могут быть не только в секции WHERE, но и в секции SELECT и в секции FROM. Давайте рассмотрим сначала подзапросы из FROM, для этого поставим достаточно сложную, но интересную задачу. Во время группировки мы смогли научиться определять количество пользователей с именем Андрей. А что если создать таблицу, которая будет состоять из трех колонок:
- Имя;
- Количество пользователей с таким именем;
- Количество номеров телефонов для каждого имени.
В виде двух запросов эта задача решается достаточно просто. Следующий запрос определяет количество каждого имени в таблице:
SELECT p.vcName, COUNT (*) as PeopleNumber FROM tbPeoples p GROUP BY p.
 vcName
vcName
Такой запрос мы уже разбирали.
Теперь определим количество телефоном для каждого имени. Именно имени, а не работника. Нас интересует, сколько номеров телефонов у всех Андреев, Иванов и т.д. Эта задача решается с помощью связи из таблиц работников и телефонов, группировкой по имени и подсчетом количества телефонов:
SELECT pl.vcName, COUNT(vcPhoneNumber) AS PhoneNum FROM tbPeoples pl, tbPhoneNumbers pn WHERE pl.idPeoples *= pn.idPeoples GROUP BY vcName
У нас получилось две разных таблицы. А как теперь их объединить в одно целое? Попробуйте самостоятельно решить эту задачу. Мое решение можно увидеть в листинге 2.3.
Листинг 2.3. Получение количества имен и количества телефонов у каждого имени
SELECT * FROM (SELECT p.vcName, COUNT(*) as PeopleNumber FROM tbPeoples p GROUP BY p.vcName) p1, (SELECT pl.vcName, COUNT(vcPhoneNumber) AS PhoneNum FROM tbPeoples pl, tbPhoneNumbers pn WHERE pl.
 idPeoples *= pn.idPeoples
GROUP BY vcName) p2
WHERE p1.vcName=p2.vcName
idPeoples *= pn.idPeoples
GROUP BY vcName) p2
WHERE p1.vcName=p2.vcName
В секции FROM, вместо указания таблиц стоят вышеописанные запросы, заключенные в круглые скобки. Для каждого запроса указывается псевдоним, иначе невозможно работать с полями запросов. Получается, что вместо того, чтобы получить данные непосредственно из таблицы, мы получаем их из запроса.
Для таких запросов, есть только одно ограничение – у каждого поля в подзапросе секции FROM должно быть имя. У нас есть поля, подсчитывающие количество записей и для таких полей имя не устанавливается, поэтому я установил псевдонимы. В первом подзапросе колонка с количеством записей названа как PeopleNumber, а во втором подзапросе — PhoneNum.
Внешний объединяющий запрос связывает обе полученные таблицы через поле имени «vcName», а результатом будет общая таблица (см. рис. 2.7), состоящая из четырех колонок – имя и количество из первого запроса, и имя и количество из второго запроса. Одну из колонок имен можно убрать, потому что они идентичны, но я решил оставить, чтобы вы могли увидеть связь.
Результат объединения двух таблиц
Теперь посмотрим, как можно писать подзапросы в секции SELECT. Я не нашел интересного примера, поэтому просто решил вывести всех работников и их телефоны. Но при этом, не наводить связь между таблицами работников и телефонами в секции FROM, а искать номера с помощью подзапросов в секции SELECT:
SELECT pl.*, ( SELECT vcPhoneNumber FROM tbPhoneNumbers pn WHERE pn.idPhoneNumbers=pl.idPeoples ) FROM tbPeoples pl
В секции SELECT сначала запрашиваем все колонки из таблицы tbPeoples (pl.*). После этого, вместо очередного поля в скобках указывается подзапрос, который выбирает данные. При этом в подзапросе в секции WHERE наводиться связь между таблицами. Получается, что и из этого подзапроса мы можем обращаться к полям внешнего запроса.
Единственное ограничение – подзапрос в секции SELECT должен возвращать только одну строку. Если результатом будет несколько строк, то запрос возвращает ошибку.
Все примеры, которые мы рассматривали выше, достаточно просто реализовать, без использования подзапросов. Например, посмотрим на следующий запрос:
SELECT *
FROM tbPhoneNumbers
WHERE idPhoneType =
(
SELECT idPhoneType
FROM tbPhoneType
WHERE vcTypeName = ('Сотовый рабочий')
)
Эта же задача решается следующим образом:
SELECT pn.*
FROM tbPhoneNumbers pn, tbPhoneType pt
WHERE pn.idPhoneType = pt.idPhoneType
AND vcTypeName = ('Сотовый рабочий')
Просто связываем обе таблицы и указываем то же самое условие. Таким образом, мы избавились от подзапроса, и теперь сервер сможет выполнить задачу быстрее. Большинство задач можно решить без подзапросов, если правильно связать таблицы. Именно поэтому, в данной книге я постараюсь минимально пользоваться подзапросами, и все постараемся решать одним оператором SELECT.
А вот следующий запрос, достаточно сложно сделать без подзапросов. Допустим, что вам нужно определить данные последней, добавленной в таблицу строки. Если в качестве первичного ключа используется автоматически увеличиваемое поле, то необходимо узнать наибольшее значение первичного ключа с помощью оператора MAX, а потом найти строку с этим ключом. Вот как определяется последняя строка в таблице tbPeoples:
Допустим, что вам нужно определить данные последней, добавленной в таблицу строки. Если в качестве первичного ключа используется автоматически увеличиваемое поле, то необходимо узнать наибольшее значение первичного ключа с помощью оператора MAX, а потом найти строку с этим ключом. Вот как определяется последняя строка в таблице tbPeoples:
SELECT *
FROM tbPeoples
WHERE idPeoples=
(SELECT MAX(idPeoples) FROM tbPeoples)
Такой запрос нам очень поможет, когда мы будем учиться добавлять записи в таблицу, чтобы быстро можно было увидеть результат работы.
EXISTS SQL и проверка существования набора значений
Оглавление
- Назначение предиката SQL EXISTS
- Наиболее простые запросы с предикатом SQL EXISTS
- Различия предикатов EXISTS и IN
- Запросы с предикатом EXISTS и дополнительными условиями
- Запросы с предикатом EXISTS к двум таблицам
- Предикат EXISTS в соединениях более двух таблиц
Связанные темы
- Оператор SELECT
- Реляционная алгебра и её операции
- Аналогии между INTERSECT и EXISTS, EXCEPT и NOT EXISTS: более сложные примеры
| Назад | Листать | Вперёд>>> |
Предикат языка SQL EXISTS выполняет логическую задачу. В запросах SQL этот предикат используется
в выражениях вида
В запросах SQL этот предикат используется
в выражениях вида
EXISTS (SELECT * FROM ИМЯ_ТАБЛИЦЫ…).
Это выражение возвращает истину, когда по запросу найдена одна или более строк, соответствующих условию, и ложь, когда не найдено ни одной строки.
Обычно предикат EXISTS применяется в случаях, когда необходимо найти значения, соответствующие основному условию, заданному в секции WHERE, и дополнительному условию, заключённому в подзапрос, являющийся аргументом предиката.
Для NOT EXISTS всё наоборот. Выражение
NOT EXISTS (SELECT * FROM ИМЯ_ТАБЛИЦЫ…)
возвращает истину, когда по запросу не найдено ни одной строки, и ложь, когда найдена хотя бы одна строка.
Если вы хотите выполнить запросы к базе данных из этого урока на MS SQL Server, но эта СУБД
не установлена на вашем компьютере, то ее можно установить, пользуясь инструкцией по этой ссылке.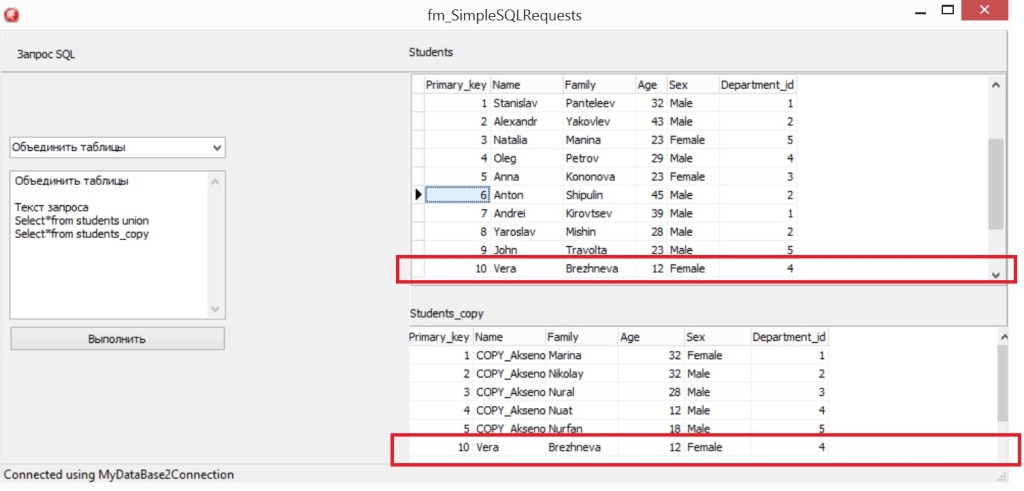
В примерах работаем с базой данных библиотеки и ее таблицами «Книга в пользовании» (BOOKINUSE) и «Пользователь» (USER). Пока нам потребуется лишь таблица «Книга в пользовании» (BOOKINUSE).
Скрипт для создания базы данных библиотеки, её таблиц и заполения таблиц данными — в файле по этой ссылке.
| Author | Title | Pubyear | Inv_No | Customer_ID |
| Толстой | Война и мир | 2005 | 28 | 65 |
| Чехов | Вишневый сад | 2000 | 17 | 31 |
| Чехов | Избранные рассказы | 2011 | 19 | 120 |
| Чехов | Вишневый сад | 1991 | 5 | 65 |
| Ильф и Петров | Двенадцать стульев | 1985 | 3 | 31 |
| Маяковский | Поэмы | 1983 | 2 | 120 |
| Пастернак | Доктор Живаго | 2006 | 69 | 120 |
| Толстой | Воскресенье | 2006 | 77 | 47 |
| Толстой | Анна Каренина | 1989 | 7 | 205 |
| Пушкин | Капитанская дочка | 2004 | 25 | 47 |
| Гоголь | Пьесы | 2007 | 81 | 47 |
| Чехов | Избранные рассказы | 1987 | 4 | 205 |
| Пушкин | Сочинения, т. 1 1 | 1984 | 6 | 47 |
| Пастернак | Избранное | 2000 | 137 | 18 |
| Пушкин | Сочинения, т.2 | 1984 | 8 | 205 |
| NULL | Наука и жизнь 9 2018 | 2019 | 127 | 18 |
| Чехов | Ранние рассказы | 2001 | 171 | 31 |
Пример 1. Определить ID пользователей, которым выданы книги Толстого, которым также выданы книги Чехова. Во внешнем запросе отбираются данные о пользователях, которым выданы книги Толстого, а предикат EXISTS задаёт дополнительное условие, которое проверяется в во внутреннем запросе — пользователи, которым выданы книги Чехова. Дополнительным условием во внутреннем запросе является совпадение идентификаторов пользователей из внешнего и внутреннего запросов: Customer_ID=tols_user.Customer_id. Запрос будет следующим:
SELECT Customer_ID FROM Bookinuse
AS tols_user
WHERE Author=’Толстой’
AND EXISTS (SELECT
Customer_ID FROM Bookinuse
WHERE Author=’Чехов’
AND Customer_ID=tols_user. Customer_id)
Customer_id)
Этот запрос вернёт следующий результат:
| Customer_ID |
| 65 |
| 205 |
- Аналогии между INTERSECT и EXISTS, EXCEPT и NOT EXISTS: более сложные примеры
Далее — пример использования NOT EXISTS в запросе, решающем похожую задачу.
Пример 2. Определить ID пользователей, которым выданы книги Чехова, и которым при этом не выданы книги Ильфа и Петрова. Конструкция запроса аналогична конструкции из предыдущего примера с той разницей, что дополнительное условие задаётся предикатом NOT EXISTS. Запрос будет следующим:
SELECT Customer_ID FROM Bookinuse AS cheh_user WHERE Author=’Чехов’ AND NOT EXISTS (SELECT Customer_ID FROM Bookinuse WHERE Author=’Ильф и Петров’ AND Customer_ID=cheh_user.Customer_id)
Этот запрос вернёт следующий результат:
| User_ID |
| 120 |
| 65 |
| 205 |
Написать запрос SQL с предикатом EXISTS самостоятельно, а затем посмотреть решение
Пример 3. Определить автора (авторов), книги которого выданы
пользователю с ID 120, а также с ID 18.
Определить автора (авторов), книги которого выданы
пользователю с ID 120, а также с ID 18.
Правильное решение и ответ.
При первом взгляде на запросы с предикатом EXISTS может возникнуть впечатление, что он идентичен предикату IN. Это не так. Хотя они очень похожи. Предикат IN ведет поиск значений из диапазона, заданного в его аргументе, и если такие значения есть, то выбираются все строки, соответствующие этому диапазону. Результат же действия предиката EXISTS представляет собой ответ «да» или «нет» на вопрос о том, есть ли вообще какие-либо значения, соответствующие указанным в аргументе. Кроме того, перед предикатом IN указывается имя столбца, по которому следует искать строки, соответствующие значениям в диапазоне. Разберём пример, показывающий отличие предиката EXISTS от предиката IN, и задачу, решаемую с помощью предиката IN.
Пример 4. Определить ID пользователей, которым выданы книги
авторов, книги которых выданы пользователю с ID 31. Запрос будет следующим:
Запрос будет следующим:
SELECT Customer_ID FROM Bookinuse WHERE Author IN (SELECT Author FROM Bookinuse WHERE Customer_ID=31)
Результатом выполнения запроса будет следующая таблица:
| User_ID |
| 120 |
| 65 |
| 205 |
Внутренний запрос (после IN) выбирает авторов: Чехов; Ильф и Петров. Внешний запрос выбирает всех пользователей, которым выданы книги этих авторов. Видим, что, в отличие от предиката EXISTS, предикат IN предваряется именем столбца, в данном случае — Author.
Если дополнительно к предикату EXISTS в запросе применить хотя бы одно дополнительное условие, например, заданное с помощью агрегатных функций, то такие запросы могут служить уже для простого анализа данных. Продемонстрируем это на следующем примере.
Пример 5. Определить ID пользователей, которым выдана
хотя бы одна книга Пастернака, и которым при этом выдано более 2 книг. Пишем следующий запрос, в котором
первое условие задаётся предикатом EXISTS со вложенным запросом, а второе условие с оператором HAVING
всегда должно следовать после вложенного запроса:
Пишем следующий запрос, в котором
первое условие задаётся предикатом EXISTS со вложенным запросом, а второе условие с оператором HAVING
всегда должно следовать после вложенного запроса:
SELECT Customer_ID FROM Bookinuse AS pas_user WHERE EXISTS (SELECT Customer_ID FROM Bookinuse WHERE Author=’Пастернак’ AND Customer_ID=pas_user.Customer_ID) GROUP BY Customer_ID HAVING COUNT(Title) > 2
Результат выполнения запроса:
| User_ID |
| 120 |
Как видно из таблицы BOOKINUSE, книга Пастернака выдана также пользователю с
ID 18, но ему выдана всего одна книга и он не попадает в выборку. Если применить к подобному запросу ещё раз
функцию COUNT, но уже для подсчёта выбранных строк (потренируйтесь в этом самостоятельно), то
можно получить сведения о том, сколько пользователей, читающих книги Пастернака, при этом читают
также книги других авторов. Это уже из сферы анализа данных.
Это уже из сферы анализа данных.
- Аналогии между INTERSECT и EXISTS, EXCEPT и NOT EXISTS: более сложные примеры
Запросы с предикатом EXISTS могут извлекать данные из более чем одной таблицы. Многие задачи можно с тем же результатом решить с помощью оператора JOIN, но в ряде случаев использование EXISTS позволяет составить менее громоздкий запрос. Использовать EXISTS предпочительнее в тех случаях, когда в результирующую таблицу попадут столбцы лишь из одной таблицы.
В следующем примере из той же базы данных помимо таблицы BOOKINUSE потребуется также таблица «Пользователь» (CUSTOMER).
| Customer_ID | Surname |
| 18 | Зотов |
| 31 | Перов |
| 47 | Васин |
| 65 | Тихонов |
| 120 | Краснов |
| 205 | Климов |
Пример 6. Определить авторов, книги которых выданы пользователю
по фамилии Краснов. Пишем следующий запрос, в котором предикатом EXISTS задано единственное условие:
Пишем следующий запрос, в котором предикатом EXISTS задано единственное условие:
SELECT DISTINCT Author FROM Bookinuse bk WHERE EXISTS (SELECT * FROM Customer cs WHERE cs.Customer_ID=bk.Customer_ID AND Surname=’Краснов’)
Результатом выполнения запроса будет следующая таблица:
| Author |
| Чехов |
| Маяковский |
| Пастернак |
Как и в случае использования оператора JOIN, в случаях более одной таблицы следует использовать псевдонимы таблиц для проверки соответствия значений ключей, соединяющих таблицы. В нашем примере псевдонимы таблиц — bk и us, а ключ, соединяющий таблицы — User_ID.
Примеры запросов к базе данных «Библиотека» есть также в уроках по операторам GROUP BY, IN и функциям CONCAT, COALESCE.
- Аналогии между INTERSECT и EXISTS, EXCEPT и NOT EXISTS: более сложные примеры
Сейчас мы увидим более предметно, почему использовать EXISTS
предпочительнее в тех случаях, когда в результирующую таблицу попадут столбцы лишь из одной таблицы.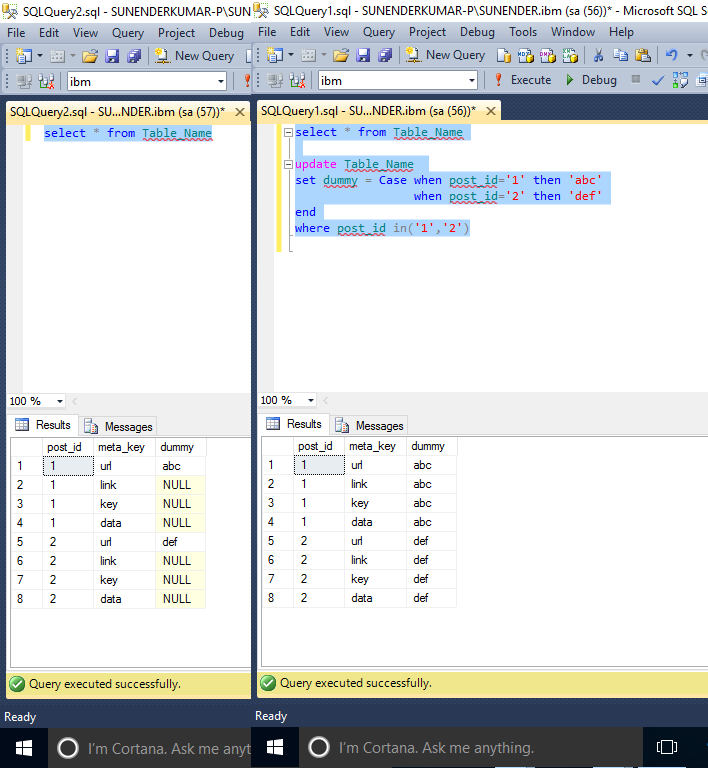
Работаем с базой данных «Недвижимость». Скрипт для создания этой базы данных, её таблиц и заполения таблиц данными — в файле по этой ссылке.
Таблица Deal содержит данные о сделках. Для наших заданий в этой таблице будет важен столбец Type с данными о типе сделки — продажа или аренда. Таблица Object содержит данные об объектах. В этой таблице нам понадобятся значения столбцов Rooms (число комнат) и LogBalc, содержащего данные о наличии лоджии или балкона в булевом формате: 1 (да) или 0 (нет). Таблицы Client, Manager и Owner содержат данные соответственно о клиентах, менеджерах фирмы и собственниках объектов недвижимости. В этих таблицах FName и LName соответственно имя и фамилия.
Пример 7. Определить клиентов, купивших или взявших в аренду объекты, у которых нет лоджии или балкона. Пишем следующий запрос, в котором предикатом EXISTS задано обращение к результату соединения двух таблиц:
SELECT cl. * FROM Client cl
WHERE EXISTS (SELECT 1
FROM Deal de JOIN Object ob
ON ob.Obj_ID=de.Object_ID
WHERE de.Client_ID=cl.Client_ID
AND ob.LogBalc=0)
* FROM Client cl
WHERE EXISTS (SELECT 1
FROM Deal de JOIN Object ob
ON ob.Obj_ID=de.Object_ID
WHERE de.Client_ID=cl.Client_ID
AND ob.LogBalc=0)
Так как из таблицы Client столбцы выбираются при помощи оператора «звёздочка», то будут выведены все столбцы этой таблицы, в которой будет столько строк, сколько насчитывается клиентов, соответствующих условию, заданному предикатом EXISTS. Из таблиц, к соединению которых обращается вложенный запрос, нам не требуется выводить ни одного столбца. Поэтому для экономии машинного времени извлекается лишь один столбец. Для этого после слова SELECT прописана единица. Этот же приём применён и в запросах в следующих примерах.
Написать запрос SQL с предикатом EXISTS самостоятельно, а затем посмотреть решение
Пример 3. Определить менеджеров, которые провели сделки с объектами с числом комнат больше 2.
Правильное решение.
Продолжаем писать вместе запросы SQL с предикатом EXISTS
Пример 9. Определить собственников объектов, которые были взяты в аренду. Пишем следующий запрос, в котором предикатом EXISTS также задано обращение к результату соединения двух таблиц:
SELECT ow.* FROM Owner ow WHERE EXISTS (SELECT 1 FROM Object ob JOIN Deal de ON de.Object_ID=ob.Obj_ID WHERE ow.Owner_ID=ob.Owner_ID AND de.Type=’rent’)
Как и в предыдущем примере, из таблицы, к которой обращён внешний запрос, будут выведены все поля.
Пример 10. Определить число собственников, с объектами которых провёл менеджер Савельев. Пишем запрос, в котором внешний запрос обращается к соединению трёх таблиц, а предикатом EXISTS задано обращение лишь к одной таблице:
SELECT COUNT(*) FROM Object ob
JOIN Deal de ON
de.Object_ID=ob.Obj_ID
JOIN Owner ow ON
ob. Owner_ID=ow.Owner_ID
WHERE EXISTS (SELECT 1
FROM Manager ma WHERE
de.Manager_ID=ma.Manager_ID
AND ma.LName=’Савельев’)
Owner_ID=ow.Owner_ID
WHERE EXISTS (SELECT 1
FROM Manager ma WHERE
de.Manager_ID=ma.Manager_ID
AND ma.LName=’Савельев’)
Все запросы проверены на существующей базе данных. Успешного использования!
Примеры запросов к базе данных «Недвижимость» есть также в уроках по операторам GROUP BY и IN.
- Аналогии между INTERSECT и EXISTS, EXCEPT и NOT EXISTS: более сложные примеры
Поделиться с друзьями
| Назад | Листать | Вперёд>>> |
Подзапросы, возвращающие несколько значений
Подзапросы, возвращающие несколько значений
Эта группа включает подзапросы, начинающиеся с IN, NOT IN или оператора сравнения с ключевыми словами ANY или ALL.
Подзапросы, начинающиеся с IN и NOT IN
Результатом
выполнения подзапроса, начинающиеся с ключевых слов IN и NOT IN,
является список,
включающий от нуля до нескольких значений. После того как подзапрос
возвратит
результаты, к их обработке приступит внешний запрос.
После того как подзапрос
возвратит
результаты, к их обработке приступит внешний запрос.
Список выбора внутреннего подзапроса, может включать только одно выражение или имя столбца.
Столбец, имя которого вы указываете в предложении WHERE внешнего оператора, должен быть совместимым для сравнения со столбцом, имя которого вы указываете в списке выбора подзапроса.
Пример
Получить список клиентов из Сиэтла, заключивших договор на аренду оборудования (Equipment rental).
SQL:
SELECT lastname, name, region
FROM tbl_clients
WHERE region = ‘Seattle’
AND client_id IN (
SELECT client_id
FROM tbl_contract
JOIN tbl_service ON tbl_contract.service_id=tbl_service.service_id
WHERE service = ‘Equipment
rental’)
Результат:
| lastname | name | region |
| Stolz | Barbara | Seattle |
| Perez | Linda | Seattle |
| Haines | Elsie | Seattle |
| Varrik | Kaarel | Seattle |
| Donegan | Janet | Seattle |
| Card | Richard | Seattle |
| Jones | Jeffrey | Seattle |
| Green | Jonas | Seattle |
| Patterson | William | Seattle |
Обратите
внимание на допустимость использования объединения и нескольких условий
в
предложение WHERE как во внутреннем, так и во внешнем запросе.
Получить список клиентов из Сиэтла, заключивших договор на аренду оборудования (пример, обратный приведенному выше).
SQL:
SELECT lastname, name, region
FROM tbl_clients
WHERE region = ‘Seattle’
AND client_id NOT IN (
SELECT client_id
FROM tbl_contract
JOIN tbl_service ON tbl_contract.service_id=tbl_service`service_id
WHERE service = ‘Equipment
rental’)
Подзапросы, начинающиеся с операторов сравнения и включающие ключевые слова ANY или ALL
В другом виде подзапросов, которые не возвращают или возвращают несколько строк, используется оператор сравнения, модифицированный ключевыми словами ANY или ALL.
Если подзапросу будет
предшествовать ключевое слово ALL,
условие сравнения считается выполненным только в том случае, если оно
выполняется
для всех значений в результирующем столбце подзапроса.
Пример
SQL:
SELECT contract_id, contract_date
FROM tbl_contract
WHERE
contract_date > ALL
(
SELECT contract_date
FROM tbl_contract
JOIN tbl_service ON tbl_contract.service_id=tbl_service.service_id
WHERE service = ‘Equipment rental’)
Выполнение запроса происходит в 2 этапа. Сначала внутренний запрос выбирает список дат, когда были заключены договора на аренду оборудования. Внешний запрос находит наибольшее значение в списке дат и для каждого договора в таблице tbl_contract определяет не содержится ли в поле contract_date большая дата.
Таким образом, мы получаем список договоров, заключенных после всех договоров на аренду оборудования.
Оператор
ALL, как правило, эффективно используется с неравенствами, а не с
равенствами,
поскольку значение «равно всем»,
которое должно
получиться в этом случае в результате выполнения подзапроса, может
иметь место,
только если все результаты идентичны.
В SQL выражение < > ALL реально означает не равно ни одному из результатов подзапроса.
Если тексту подзапроса предшествует ключевое слово ANY, то условие сравнения будет считаться выполненным, если оно удовлетворяется хотя бы для какого-либо (одного или нескольких) значения в результирующем столбце подзапроса.
Пример
SQL:
SELECT contract_id, contract_date
FROM tbl_contract WHERE contract_date < ANY (
SELECT contract_date
FROM tbl_contract JOIN tbl_serviceON
tbl_contract.service_id=tbl_service.service_id
WHERE
service = ‘Equipment
rental’)
Приведенный запрос находит договора, заключенные раньше, чем был заключен первый договор на обслуживание.
Если
внутренний подзапрос,
начинающийся с ALL или ANY, возвращает пустое значение, считается, что
запрос в целом
завершился неудачно. В этом случае вы не получите никаких результатов,
поскольку невозможно выполнить сравнение со значением NULL.
В этом случае вы не получите никаких результатов,
поскольку невозможно выполнить сравнение со значением NULL.
« Previous | Next »
Язык запросов sql многотабличные запросы
Содержание
- Основы Transact SQL: Сложные (многотабличные запросы)(Урок 5, часть 1)
- Многотабличные запросы, оператор JOIN
- Многотабличные запросы
- Общая структура многотабличного запроса
- INNER JOIN
- Использование WHERE для соединения таблиц
- OUTER JOIN
- Внешнее левое соединение (LEFT OUTER JOIN)
- Язык запросов SQL
- MySQL
- Установка
- Выполнение запросов
- Оператор SQL create database: создание новой базы данных
- Оператор create table: создание таблиц
- Первичный ключ
- Оператор insert into: добавление записи в таблицу
- Оператор select: чтение информации из БД
- Оператор update: обновление информации в БД
- Оператор join: объединение записей из двух таблиц
- Многотабличные запросы SQL
- Введение
- Объединение таблиц в SQL
- Видео
Основы Transact SQL: Сложные (многотабличные запросы)(Урок 5, часть 1)
Основы Transact SQL: Сложные (многотабличные запросы)
В SQL сложные запросы являются комбинацией простых SQL-запросов. Каждый простой запрос в качестве ответа возвращает набор записей (таблицу), а комбинация простых запросов возвращает результат тех или иных операций над ответами на простые запросы.
Каждый простой запрос в качестве ответа возвращает набор записей (таблицу), а комбинация простых запросов возвращает результат тех или иных операций над ответами на простые запросы.
В SQL сложные запросы получаются из других запросов следующими способами:
Подзапросы
Подзапрос — это запрос на выборку данных, вложенный в другой запрос. Подзапрос всегда заключается в круглые скобки и выполняется до содержащего выражения. Внешний запрос, содержащий подзапрос, если только он сам не является подзапросом, не обязательно должен начинаться с оператора SELECT. В свою очередь, подзапрос может содержать другой подзапрос и т. д. При этом сначала выполняется подзапрос, имеющий самый глубокий уровень вложения, затем содержащий его подзапрос и т. д. Часто, но не всегда, внешний запрос обращается к одной таблице, а подзапрос — к другой. На практике именно этот случай наиболее интересен.
Простые подзапросы
Простые подзапросы характеризуются тем, что они формально никак не связаны с содержащими их внешними запросами. Это обстоятельство позволяет сначала выполнить подзапрос, результат которого затем используется для выполнения внешнего запроса. Кроме простых подзапросов, существуют еще и связанные (коррелированные) подзапросы, которые будут рассмотрены в следующем разделе.
Это обстоятельство позволяет сначала выполнить подзапрос, результат которого затем используется для выполнения внешнего запроса. Кроме простых подзапросов, существуют еще и связанные (коррелированные) подзапросы, которые будут рассмотрены в следующем разделе.
Рассматривая простые подзапросы, следует выделить три частных случая:
Тип возвращаемой подзапросом таблицы определяет, как можно ее использовать и какие операторы можно применять в содержащем выражении для взаимодействия с этой таблицей. По завершении выполнения содержащего выражения таблицы, возвращенные любым подзапросом, выгружаются из памяти. Таким образом, подзапрос действует как временная таблица, областью видимости которой является выражение (т. е. после завершения выполнения выражения сервер высвобождает всю память, отведенную под результаты подзапроса).
Подзапросы, возвращающие единственное значение
Допустим, из таблицы Customer требуется выбрать данные обо всех клиентах из Казани. Это можно сделать с помощью следующего запроса.
Это можно сделать с помощью следующего запроса.
WHERE IdCity = ( SELECT idCity FROM City WHERE CityName = ‘Казань’ )
В данном запросе сначала выполняется подзапрос (SELECT idCity FROM City WHERE CityName = ‘Казань’). Он возвращает единственное значение (а не набор записей, поскольку по полю City организовано ограничение уникальности) – уникальный идентификатор города Казань. Если сказать точнее, то данный подзапрос возвращает единственную запись, содержащую единственное поле. Далее выполняется внешний запрос, который выводит все столбцы таблицы Customer и записи, в которых значение столбца IdCity равно значению, полученному с помощью подзапроса. Таким образом, сначала выполняется подзапрос, а затем внешний запрос, использующий результат подзапроса.
Задание для самостоятельной работы: По аналогии с предыдущим примером сформулируйте запрос, возвращающий все заказы, в которых содержится заданный товар (по названию товара).
Подзапросы, возвращающие список значений из одного столбца таблицы
Подзапрос, вообще говоря, может возвращать несколько записей. Чтобы в этом случае в условии внешнего оператора WHERE можно было использовать операторы сравнения, требующие единственного значения, используются кванторы, такие как ALL (все) и SOME (или ANY) (некоторый).
Чтобы в этом случае в условии внешнего оператора WHERE можно было использовать операторы сравнения, требующие единственного значения, используются кванторы, такие как ALL (все) и SOME (или ANY) (некоторый).
Рассмотрим общий случай использования запросов с кванторами ALL и SOME. Пусть имеются две таблицы: T1, содержащая как минимум столбец A, и T2, содержащая, по крайней мере, один столбец B. Тогда запрос с квантором ALL можно сформулировать следующим образом:
WHERE A оператор_сравнения ALL ( SELECT B FROM T2)
Здесь оператор_сравнения обозначает любой допустимый оператор сравнения. Данный запрос должен вернуть список всех тех значений столбца A, для которых оператор сравнения истинен для всех значений столбца B.
Запрос с квантором SOME, очевидно, имеет аналогичную структуру. Он должен вернуть список всех тех значений столбца A, для которых оператор сравнения истинен хотя бы для какого-нибудь одного значения столбца B.
Запрос: Список всех клиентов, проживающих в городах Казань или Елабуга.
Предыдущий запрос может быть также реализован и с использованием оператора IN, который рассматривался в разделе “Фильтрация данных”.
WHERE IdCity IN ( SELECT IdCity FROM City WHERE CityName IN ( ‘Казань’, ‘Елабуга’ ))
Напомним — он проверяет вхождение элемента во множество, в качестве элемента может выступать имя столбца или скалярное выражение, а в качестве множества — явно заданный список значений или подзапрос. Использование подзапроса в качестве второго операнда IN также как и кванторы позволяет избежать ограничения на единственность значения, возвращаемого подзапросом.
С помощью оператора IN можно проверять не только наличие значения в наборе значений, но и его отсутствие. Делается это добавлением оператора отрицания NOT. Вот другой вариант предыдущего запроса:
WHERE IdCity NOT IN ( SELECT IdCity FROM City WHERE CityName IN ( ‘Казань’, ‘Елабуга’ ))
Этот запрос возвращает всех клиентов, кроме тех которые проживают в городах Казань и Елабуга.
Аналогичный запрос с использование квантора ALL:
Задание для самостоятельной работы: Cформулируйте запрос, возвращающий список всех клиентов (с указанием фамилии и имени), совершивших заказ за определенный период времени.
Подзапросы, возвращающие набор записей
Подзапрос можно вставлять не только в операторы WHERE и HAVING, но и в оператор FROM.
Здесь таблице, возвращаемой подзапросом в операторе FROM, присваивается псевдоним t, а внешний запрос выделяет столбцы этой таблицы и, возможно, записи в соответствии с некоторым условием, которое указано в операторе WHERE.
Связанные (коррелированные) подзапросы
Все приведенные до сих пор запросы не зависели от своих содержащих выражений, т. е. могли выполняться самостоятельно и представлять свои результаты для проверки. Связанный подзапрос (коррелированный), напротив, зависит от содержащего выражения, из которого он ссылается на один или более столбцов. В отличие от несвязанного подзапроса, который выполняется непосредственно перед выполнением содержащего выражения, связанный подзапрос выполняется по разу для каждой строки-кандидата (это строки, которые предположительно могут быть включены в окончательные результаты). Например, следующий запрос использует связанный подзапрос для подсчета количества заказов у каждого клиента. Затем основной запрос выбирает тех клиентов, у которых больше одного заказа.
Например, следующий запрос использует связанный подзапрос для подсчета количества заказов у каждого клиента. Затем основной запрос выбирает тех клиентов, у которых больше одного заказа.
WHERE 1 SELECT COUNT (*) FROM [Order] r WHERE r.IdCust = c.IdCust)
Связанные подзапросы часто используются с условиями сравнения (в предыдущем примере SELECT IdProd, [Description]
WHERE EXISTS ( SELECT * FROM OrdItem oi WHERE oi.IdProd = p.IdProd)
Для поиска подзапросов, не возвращающих строки, можно использовать оператор EXISTS совместно с оператором отрицания NOT. В частности чтобы предыдущий запрос возвращал все товары, которые ни разу не заказывались, его можно модифицировать следующим образом.
SELECT IdProd, [Description]
WHERE NOT EXISTS ( SELECT * FROM OrdItem oi WHERE oi.IdProd = p.IdProd)
Задание для самостоятельной работы: Cформулируйте запрос, возвращающий список всех заказов с суммарной стоимость более заданной величины.
Источник
Многотабличные запросы, оператор JOIN
Многотабличные запросы
В предыдущих статьях описывалась работа только с одной таблицей базы данных. В реальности же очень часто приходится делать выборку из нескольких таблиц, каким-то образом объединяя их. В данной статье вы узнаете основные способы соединения таблиц.
В реальности же очень часто приходится делать выборку из нескольких таблиц, каким-то образом объединяя их. В данной статье вы узнаете основные способы соединения таблиц.
Общая структура многотабличного запроса
Эту же структуру можно переписать следующим образом:
В большинстве случаев условием соединения является равенство столбцов таблиц ( таблица_1.поле = таблица_2.поле ), однако точно так же можно использовать и другие операторы сравнения.
Соединение бывает внутренним (INNER) или внешним (OUTER), при этом внешнее соединение делится на левое (LEFT), правое (RIGHT) и полное (FULL).
INNER JOIN
По умолчанию, если не указаны какие-либо параметры, JOIN выполняется как INNER JOIN, то есть как внутреннее (перекрёстное) соединение таблиц.
Например, объединим таблицы покупок ( Payments ) и членов семьи ( FamilyMembers ) таким образом, чтобы дополнить каждую покупку данными о том, кто её совершил.
Данные в таблице Payments:
| payment_id | date | family_member | good | amount | unit_price |
|---|---|---|---|---|---|
| 1 | 2005-02-12 00:00:00 | 1 | 1 | 1 | 2000 |
| 2 | 2005-03-23 00:00:00 | 2 | 1 | 1 | 2100 |
| 3 | 2005-05-14 00:00:00 | 3 | 4 | 5 | 20 |
| 4 | 2005-07-22 00:00:00 | 4 | 5 | 1 | 350 |
| 5 | 2005-07-26 00:00:00 | 4 | 7 | 2 | 150 |
| 6 | 2005-02-20 00:00:00 | 5 | 6 | 1 | 100 |
| 7 | 2005-07-30 00:00:00 | 2 | 6 | 1 | 120 |
| 8 | 2005-09-12 00:00:00 | 2 | 16 | 1 | 5500 |
| 9 | 2005-09-30 00:00:00 | 5 | 15 | 1 | 230 |
| 10 | 2005-10-27 00:00:00 | 5 | 15 | 1 | 230 |
| 11 | 2005-11-28 00:00:00 | 5 | 15 | 1 | 250 |
| 12 | 2005-12-22 00:00:00 | 5 | 15 | 1 | 250 |
| 13 | 2005-08-11 00:00:00 | 3 | 13 | 1 | 2200 |
| 14 | 2005-10-23 00:00:00 | 2 | 14 | 1 | 66000 |
| 15 | 2005-02-03 00:00:00 | 1 | 9 | 5 | 8 |
| 16 | 2005-03-11 00:00:00 | 1 | 9 | 5 | 7 |
| 17 | 2005-03-18 00:00:00 | 2 | 9 | 3 | 8 |
| 18 | 2005-04-20 00:00:00 | 1 | 9 | 8 | 8 |
| 19 | 2005-05-13 00:00:00 | 1 | 9 | 5 | 7 |
| 20 | 2005-06-11 00:00:00 | 2 | 9 | 3 | 150 |
| 21 | 2006-01-12 00:00:00 | 3 | 10 | 1 | 100 |
| 22 | 2006-03-12 00:00:00 | 1 | 5 | 3 | 10 |
| 23 | 2005-06-05 00:00:00 | 1 | 8 | 1 | 300 |
| 24 | 2005-06-20 00:00:00 | 3 | 6 | 8 | 150 |
Данные в таблице FamilyMembers:
| member_id | status | member_name | birthday |
|---|---|---|---|
| 1 | father | Headley Quincey | 1960-05-13 00:00:00 |
| 2 | mother | Flavia Quincey | 1963-02-16 00:00:00 |
| 3 | son | Andie Quincey | 1983-06-05 00:00:00 |
| 4 | daughter | Lela Quincey | 1985-06-07 00:00:00 |
| 5 | daughter | Annie Quincey | 1988-04-10 00:00:00 |
| 6 | father | Ernest Forrest | 1961-09-11 00:00:00 |
| 7 | mother | Constance Forrest | 1968-09-06 00:00:00 |
Для того, чтобы решить поставленную задачу выполним запрос, который объединяет поля строки из одной таблицы с полями другой, если выполняется условие, что покупатель товара ( family_member ) совпадает с идентификатором члена семьи ( member_id ):
В результате вы можете видеть, что каждая строка из таблицы Payments дополнилась данными о члене семьи, который совершил покупку. Обратите внимание на поля family_member и member_id — они одинаковы, что и было отражено в запросе.
Обратите внимание на поля family_member и member_id — они одинаковы, что и было отражено в запросе.
| payment_id | date | family_member | good | amount | unit_price | member_id | status | member_name | birthday |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2005-02-12 00:00:00 | 1 | 1 | 1 | 2000 | 1 | father | Headley Quincey | 1960-05-13 00:00:00 |
| 2 | 2005-03-23 00:00:00 | 2 | 1 | 1 | 2100 | 2 | mother | Flavia Quincey | 1963-02-16 00:00:00 |
| 3 | 2005-05-14 00:00:00 | 3 | 4 | 5 | 20 | 3 | son | Andie Quincey | 1983-06-05 00:00:00 |
| 4 | 2005-07-22 00:00:00 | 4 | 5 | 1 | 350 | 4 | daughter | Lela Quincey | 1985-06-07 00:00:00 |
| 5 | 2005-07-26 00:00:00 | 4 | 7 | 2 | 150 | 4 | daughter | Lela Quincey | 1985-06-07 00:00:00 |
| 6 | 2005-02-20 00:00:00 | 5 | 6 | 1 | 100 | 5 | daughter | Annie Quincey | 1988-04-10 00:00:00 |
| 7 | 2005-07-30 00:00:00 | 2 | 6 | 1 | 120 | 2 | mother | Flavia Quincey | 1963-02-16 00:00:00 |
| 8 | 2005-09-12 00:00:00 | 2 | 16 | 1 | 5500 | 2 | mother | Flavia Quincey | 1963-02-16 00:00:00 |
| 9 | 2005-09-30 00:00:00 | 5 | 15 | 1 | 230 | 5 | daughter | Annie Quincey | 1988-04-10 00:00:00 |
| 10 | 2005-10-27 00:00:00 | 5 | 15 | 1 | 230 | 5 | daughter | Annie Quincey | 1988-04-10 00:00:00 |
| 11 | 2005-11-28 00:00:00 | 5 | 15 | 1 | 250 | 5 | daughter | Annie Quincey | 1988-04-10 00:00:00 |
| 12 | 2005-12-22 00:00:00 | 5 | 15 | 1 | 250 | 5 | daughter | Annie Quincey | 1988-04-10 00:00:00 |
| 13 | 2005-08-11 00:00:00 | 3 | 13 | 1 | 2200 | 3 | son | Andie Quincey | 1983-06-05 00:00:00 |
| 14 | 2005-10-23 00:00:00 | 2 | 14 | 1 | 66000 | 2 | mother | Flavia Quincey | 1963-02-16 00:00:00 |
| 15 | 2005-02-03 00:00:00 | 1 | 9 | 5 | 8 | 1 | father | Headley Quincey | 1960-05-13 00:00:00 |
| 16 | 2005-03-11 00:00:00 | 1 | 9 | 5 | 7 | 1 | father | Headley Quincey | 1960-05-13 00:00:00 |
| 17 | 2005-03-18 00:00:00 | 2 | 9 | 3 | 8 | 2 | mother | Flavia Quincey | 1963-02-16 00:00:00 |
| 18 | 2005-04-20 00:00:00 | 1 | 9 | 8 | 8 | 1 | father | Headley Quincey | 1960-05-13 00:00:00 |
| 19 | 2005-05-13 00:00:00 | 1 | 9 | 5 | 7 | 1 | father | Headley Quincey | 1960-05-13 00:00:00 |
| 20 | 2005-06-11 00:00:00 | 2 | 9 | 3 | 150 | 2 | mother | Flavia Quincey | 1963-02-16 00:00:00 |
| 21 | 2006-01-12 00:00:00 | 3 | 10 | 1 | 100 | 3 | son | Andie Quincey | 1983-06-05 00:00:00 |
| 22 | 2006-03-12 00:00:00 | 1 | 5 | 3 | 10 | 1 | father | Headley Quincey | 1960-05-13 00:00:00 |
| 23 | 2005-06-05 00:00:00 | 1 | 8 | 1 | 300 | 1 | father | Headley Quincey | 1960-05-13 00:00:00 |
| 24 | 2005-06-20 00:00:00 | 3 | 6 | 8 | 150 | 3 | son | Andie Quincey | 1983-06-05 00:00:00 |
Использование WHERE для соединения таблиц
OUTER JOIN
Внешнее соединение может быть трёх типов: левое (LEFT), правое (RIGHT) и полное (FULL). По умолчанию оно является полным.
По умолчанию оно является полным.
Главным отличием внешнего соединения от внутреннего является то, что оно обязательно возвращает все строки одной (LEFT, RIGHT) или двух таблиц (FULL).
Внешнее левое соединение (LEFT OUTER JOIN)
Соединение, которое возвращает все значения из левой таблицы, соединённые с соответствующими значениями из правой таблицы если они удовлетворяют условию соединения, или заменяет их на NULL в обратном случае.
Для примера получим из базы данных расписание звонков объединённых с соответствующими занятиями в расписании занятий:
Данные в таблице Timepair (расписание звонков):
Источник
Язык запросов SQL
Система управления базами данных (СУБД) — это отдельная программа, которая работает как сервер, независимо от PHP.
Создавать свои базы данных, таблицы и наполнять их данными можно прямо из этой же программы, но для выполнения этих операций прежде придётся познакомиться с ещё одним языком программирования — SQL.
SQL или Structured Query Language (язык структурированных запросов) — язык программирования, предназначенный для управления данными в СУБД. Все современные СУБД поддерживают SQL.
Все современные СУБД поддерживают SQL.
На языке SQL выражаются все действия, которые можно провести с данными: от записи и чтения данных, до администрирования самого сервера СУБД.
Для повседневной работы совсем не обязательно знать весь этот язык; достаточно ознакомиться лишь с основными понятиями синтаксиса и ключевыми словами. Кроме того, SQL очень простой язык по своей структуре, поэтому его освоение не составит большого труда.
Язык SQL — это в первую очередь язык запросов, а кроме того он очень похож на естественный язык.
Каждый раз, когда требуется прочитать или записать любую информацию в БД, требуется составить корректный запрос. Такой запрос должен быть выражен в терминах SQL.
Если перевести этот запрос на язык SQL, то корректным результатом будет:
Теперь напишем запрос на добавление в таблицу города нового города:
Эта команда создаст в таблице ‘города’ новую запись, где полю ‘имя города’ будет присвоено значение ‘Санкт-Петербург’.
С помощью SQL можно не только добавлять и читать данные, но и:
MySQL
Существует множество различных реляционных СУБД. Самая известная СУБД — это Microsoft Access, входящая в состав офисного пакета приложений Microsoft Office.
Самая известная СУБД — это Microsoft Access, входящая в состав офисного пакета приложений Microsoft Office.
Нет никаких препятствий для использования в качестве СУБД MS Access, но для задач веб-программирования гораздо лучше подходит альтернативная программа — MySQL.
В отличие от MS Access, MySQL абсолютно бесплатна, может работать на серверах с Linux, обладает гораздо большей производительностью и безопасностью, что делает её идеальным кандидатом на роль базы данных в веб-разработке.
Подавляющее большинство сайтов и приложений на PHP используют в качестве СУБД именно MySQL.
Установка
Если для своей работы вы используете программную среду OpenServer, то этот раздел можно смело пропустить, так как в состав OpenServer уже входит свежая версия MySQL.
Последняя версия MySQL доступна для загрузке по ссылке: https://dev.mysql.com/downloads/mysql/
На этой странице следует выбрать «MySQL Installer for Windows» и нажать на кнопку «Download» для загрузки.
В процессе установки запомните директорию, куда вы устанавливаете MySQL (скрывается под ссылкой «Advanced options»).
На шаге «Accounts and Roles» установщик потребует придумать пароль для доступа к БД (MySQL Root Password) — обязательно запомните или запишите этот пароль — он вам ещё понадобится.
Выполнение запросов
По умолчанию, если вы не устанавливали дополнительные программы, у MySQL нет графического интерфейса пользователя. Это значит, что единственный способ работы с ней — это использование командной строки.
Если вы всё выполнили верно, то в командной строке запустится клиент для работы с MySQL (вы поймете это по строке приглашения «mysql>»). С этого момента можно вводить любые SQL запросы, но каждый запрос обязательно должен заканчиваться точкой с запятой ;
Оператор SQL create database: создание новой базы данных
Приступим к практике — начнём создавать базу данных для ведения погодного дневника.
Начать следует с создания новой базы данных для нашего сайта.
Новая БД в MySQL создаётся простой командой: CREATE DATABASE
Оператор create table: создание таблиц
Создав новую БД, сообщим MySQL, что теперь мы собираемся работать именно с ней.
Выбор активной БД выполняется командой: USE ;
Пришло время создать первые таблицы!
Для ведения дневника по всем правилам, понадобится создать три таблицы: города (cities), пользователи (users) и записи о погоде (weather_log).
В подразделе «Запись» этой главы описано, как должна выглядеть структура таблицы weather_log. Переведём это описание на язык SQL:
Чтобы ввести многострочную команду в командной строке используйте символ \ в конце каждой строки (кроме последней).
Теперь создадим таблицу городов:
Первичный ключ
Оператор insert into: добавление записи в таблицу
Начнём с добавления новых данных в таблицу. Для добавления записи используется следующий синтаксис:
В начале добавим город в таблицу городов:
При добавлении записи не обязательно указывать значения для всех полей. Многие из полей имеют значения по умолчанию, которые сами заполняются при сохранении.
Например, чтобы получить список всех доступных городов:
Все погодные записи:
При добавлении записи очень легко совершить ошибку: сделать опечатку, не указать значение для одного из полей, и так далее.
Естественно, язык SQL предлагает возможности для редактирования уже созданных записей.
Но чтобы правильно составить запрос, необходимо определить условие для поиска записи, которую предлагается обновить. В противном случае, если не указать это условие, то будут обновлены абсолютно все записи в таблице.
В качестве такого условия лучше всего использовать первичный идентификатор записи. Поэтому, прежде чем выполнять запрос обновления, нужно выполнить запрос на чтение информации из таблицы, чтобы узнать, под каким идентификатором сохранилась ошибочная запись.
Допустим, этот идентификатор — единица, а правильная дата — пятое сентября 2017 года.
Запрос на обновление:
Оператор join: объединение записей из двух таблиц
Поменяем запрос на показ погодных записей, чтобы он объединял две таблицы, а в поле города показывалось его название, а не идентификатор:
Источник
Многотабличные запросы SQL
Здравствуйте! До сих пор в нашем курсе мы разбирали упражнения, которые оперировали данными только из одной таблицы.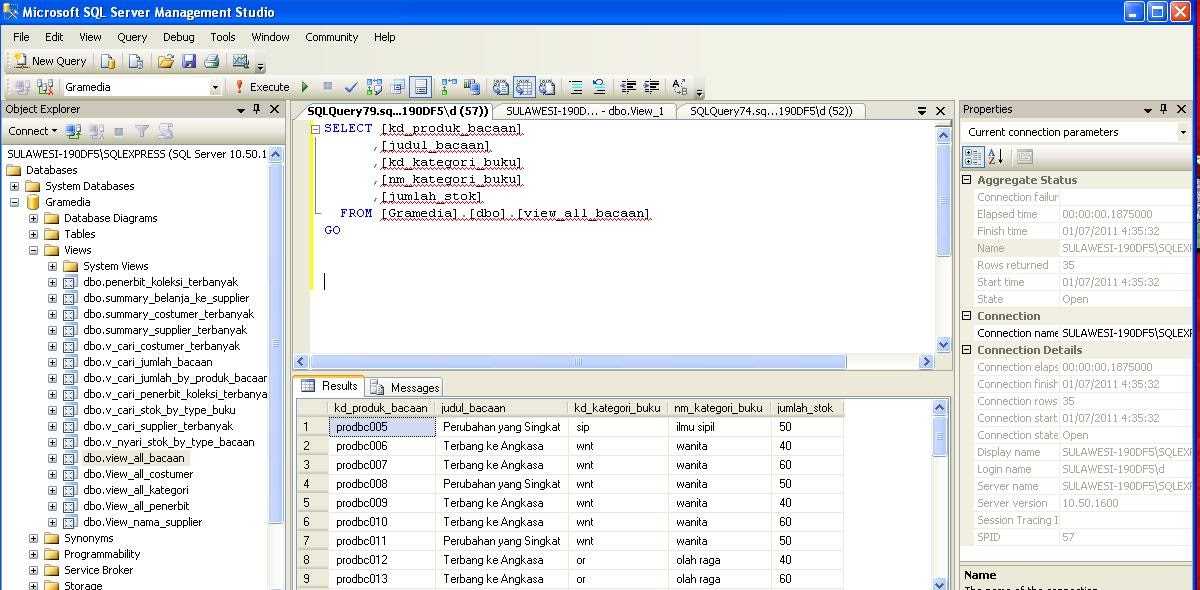 Сегодня мы это исправим и научимся делать запросы сразу к нескольким таблицам в одной базе данных.
Сегодня мы это исправим и научимся делать запросы сразу к нескольким таблицам в одной базе данных.
Введение
Итак, в прошлых статьях, например по оператору SELECT в SQL, мы прописывали что то похожее:
На самом деле изначально в языке SQL было предписано указывать поле, которое хотим выбрать в явном виде, а именно так:
Мы указываем через оператор доступа «точка» то поле, которое нужно. С течением времени, SQL стал гораздо умнее и понятнее, и на данный момент он сам понимает из какой таблице мы хотим выбрать поля, если речь идет о запросах с одной таблицей.
Если же обращаться к данным из нескольких таблиц, то хорошим тоном будет указывать явно поля, так как иногда в таблицах могут содержаться поля с одинаковыми названиями, а это потенциальная ошибка.
В SQL для многотабличных запросов продумали объединение таблиц несколькими способами, о них мы и поговорим подробнее.
Объединение таблиц в SQL
Начнем с самого простого способа, в котором будем явно указывать поля и условия, при котором их нужно выводить. Вот пример:
Вот пример:
Вывести попарно продавцов и покупателей из одного города.
Поскольку, нужно вывести попарно то придется перебрать все комбинации — SQL сделает это:
| sname | cname | city |
|---|---|---|
| Колованов | Деснов | Москва |
| Плотников | Деснов | Москва |
| Проворов | Деснов | Москва |
| Колованов | Краснов | Москва |
| Плотников | Краснов | Москва |
| Проворов | Краснов | Москва |
| Петров | Кириллов | Тверь |
| Шипачев | Пушкин | Челябинск |
| Мозякин | Лермонтов | Одинцово |
| Колованов | Белый | Москва |
| Плотников | Белый | Москва |
| Проворов | Белый | Москва |
| Колованов | Чудинов | Москва |
| Плотников | Чудинов | Москва |
| Проворов | Чудинов | Москва |
| Мозякин | Лосев | Одинцово |
Это пример объединения таблиц с использованием явного определения полей.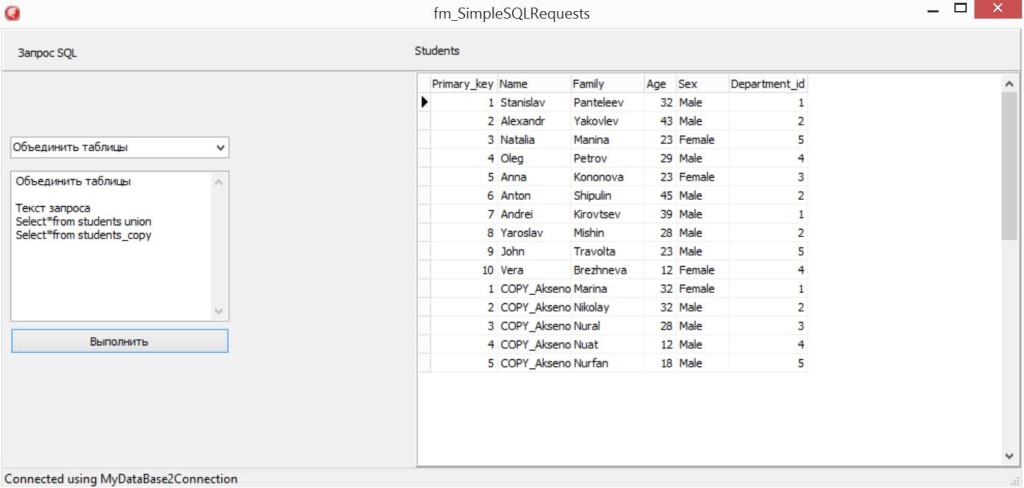 Такой запрос вполне понятен, но в будущем если будет возможность обойтись без префиксов, мы будем обходиться без них.
Такой запрос вполне понятен, но в будущем если будет возможность обойтись без префиксов, мы будем обходиться без них.
Источник
Видео
Запрос данных из нескольких таблиц: JOIN | Основы SQL
SQL для начинающих / Урок 1. Первые SQL запросы
SQL на котиках: Джоины (Joins)
01 — Уроки SQL. Вложенные запросы SQL
06 — Многотабличные запросы
Начальный курс SQL.Вложенные запросы
Базы данных SQL уроки для начинающих. SELECT, JOINS, GROUP BY, INSERT, UPDATE, WHERE
Урок 13. Язык запросов SQL
SQL вложенные запросы в EXISTS, IN, FROM, SELECT. Практика SQL
Запросы в 1С за 3 часа
Внутренние функции: функции SQL
Функция SQL может использоваться для чтения, вставки, обновления или удаления данных из базы данных SQL. Когда вы подключаете свою базу данных к Internal, базовые функции SQL, соответствующие каждой таблице в вашей базе данных, автоматически генерируются для вас. Вы можете создавать дополнительные функции SQL с помощью редактора функций.
Начало работы с редактором функций
Чтобы создать или отредактировать функцию, вам потребуется использовать редактор функций. Вы можете получить доступ к Редактору функций из одного из двух мест:
- Из пространства: Перейдите в режим редактирования и щелкните значок данных приложения в левой навигационной панели.
- Из настроек компании: Перейдите в раздел «Данные и функции», щелкните нужную базу данных и щелкните вкладку «Функции».
Открыв редактор функций, назовите свою функцию и выберите базу данных (если она еще не выбрана), для которой вы хотите создать функцию.
Настройка
Чтобы настроить функцию, сначала выберите тип функции, которую вы хотите создать. Вы можете выбрать «Вставить», «Обновить» и «Выбрать функции».
Функции вставки, обновления, удаления Используйте функцию вставки для создания новых записей в базе данных и функцию обновления для обновления записей в базе данных. Чтобы создать функцию, сначала выберите таблицу, которую вы хотите изменить с помощью функции. Затем вы укажете точные данные, которые будут изменены в этом ресурсе:
Чтобы создать функцию, сначала выберите таблицу, которую вы хотите изменить с помощью функции. Затем вы укажете точные данные, которые будут изменены в этом ресурсе:
Фильтр поИспользуйте фильтры, чтобы указать записи, которые будет изменять эта функция. (Вы пропустите этот шаг, если создаете функцию вставки). Вы можете ввести значение или динамические параметры для значений переменных. Каждый фильтр представляет собой оператор «И», поэтому записи должны соответствовать всем критериям фильтрации.
Пример 1: Функция, которая обновляет записи, где company_id равен 1:
Пример 2: Функция, которая обновляет записи, где company_id равен динамическому параметру company_id.
Примечание: company_id — это строка, поэтому динамический параметр должен быть в форме литерала шаблона Javascript с синтаксисом ${expression}. Нестроковые поля принимают стандартные выражения JavaScript.
Set Установите поля, которые ваша функция должна изменять для каждой записи. Вы можете либо установить конкретное значение для каждого поля, либо использовать динамические параметры для переменных входных данных.
Вы можете либо установить конкретное значение для каждого поля, либо использовать динамические параметры для переменных входных данных.
Пример: функция, которая устанавливает для параметра company_id значение new_company_id для всех записей, где company_id равен указанному company_id.
Разрешить обновление нескольких записейЭтот флажок обеспечивает дополнительную защиту на тот случай, если вы не собираетесь использовать эту функцию для выполнения действий массового обновления. Если этот флажок не установлен, функция потерпит неудачу, если попытается воздействовать на более чем одну запись.
Функции выбораЭтот тип функций используется для чтения данных из вашей базы данных. Введите запрос SQL, чтобы создать функцию. Когда вы создаете функцию Select, она автоматически включает фильтрацию и разбиение на страницы, поэтому вам не нужно об этом беспокоиться.
 youtube.com/embed/uRK-YAgO5Mk»> Raw SQL Exec
youtube.com/embed/uRK-YAgO5Mk»> Raw SQL Exec Этот тип функции может использоваться для запуска любого необработанного оператора SQL, включая хранимые процедуры (в настоящее время поддерживается только для SQL Server, PostgreSQL и Snowflake).
Необработанный SQL-запросЭтот тип функции можно использовать для запуска пользовательских запросов на вставку, обновление, удаление и выбор, которые возвращают данные (в настоящее время поддерживается только для SQL Server, PostgreSQL и Snowflake).
Следует ли использовать запрос Raw SQL Exec или Raw SQL?
Запрос Raw SQL считывает строки с сервера и возвращает их, в то время как Raw Exec этого не делает.
Если вы будете использовать возвращаемые строки, используйте запрос Raw SQL, иначе Exec будет (иногда значительно) быстрее.
Как правило, это означает, что лучше всего использовать запрос Raw SQL для SELECT и Raw Exec для всего остального (INSERT/UPDATE/DELETE/и т. д.), но, как всегда, есть крайние случаи — например: вы должны использовать запрос с INSERT … ВОЗВРАТ в Postgresql.
д.), но, как всегда, есть крайние случаи — например: вы должны использовать запрос с INSERT … ВОЗВРАТ в Postgresql.
Это также относится к хранимым процедурам: если запрос возвращает строки, требуется запрос Raw SQL, в противном случае используйте исполняемый файл Raw SQL.
Параметры SQL
Вы можете добавить параметры SQL в свою функцию, чтобы создать переменные входные данные, которые могут быть предоставлены вашим пользователем или настроены в вашем приложении позже. Вам нужно будет использовать синтаксис, специфичный для вашей базы данных.
SQL Server (именованные параметры с использованием синтаксиса @name)
MySql (позиционные параметры с использованием синтаксиса ?. Их порядок в запросе определяет значения, данные им при выполнении)
PostgreSQL & Amazon Redshift (нумерация параметров с использованием синтаксиса $n.$1 относится к первому аргументу, $2 — ко второму и т. д.)
После того, как вы добавили параметр, вы увидите, что он появляется справа от вашего запроса, где вы можете использовать Javascript для дальнейшей обработки ввода.
Выполнить функцию
Примечание: Функция предварительного просмотра не использует поток «Аутентификация» для выполнения функций. В результате любой поток, который использует аутентификацию, должен быть проверен из связанного с ним пространства или его аутентификация временно приостановлена.
Если вы хотите запустить функцию, чтобы убедиться, что она работает должным образом, выберите среду и нажмите кнопку «Запустить функцию».
Примечание: Эти функции работают с вашей базой данных. Если вы создаете функцию «Вставка» или «Обновление», будьте особенно осторожны, так как запуск вашей функции изменит данные в вашей базе данных. Мы рекомендуем настроить промежуточную среду и запустить в ней вашу функцию.
Входы
В этом разделе вы можете просматривать и настраивать функциональные входы. Думайте о входных данных как о полях в компоненте формы, вводе первичного ключа, который используется для извлечения записи, или о фильтрации или сортировке входных данных для компонента таблицы.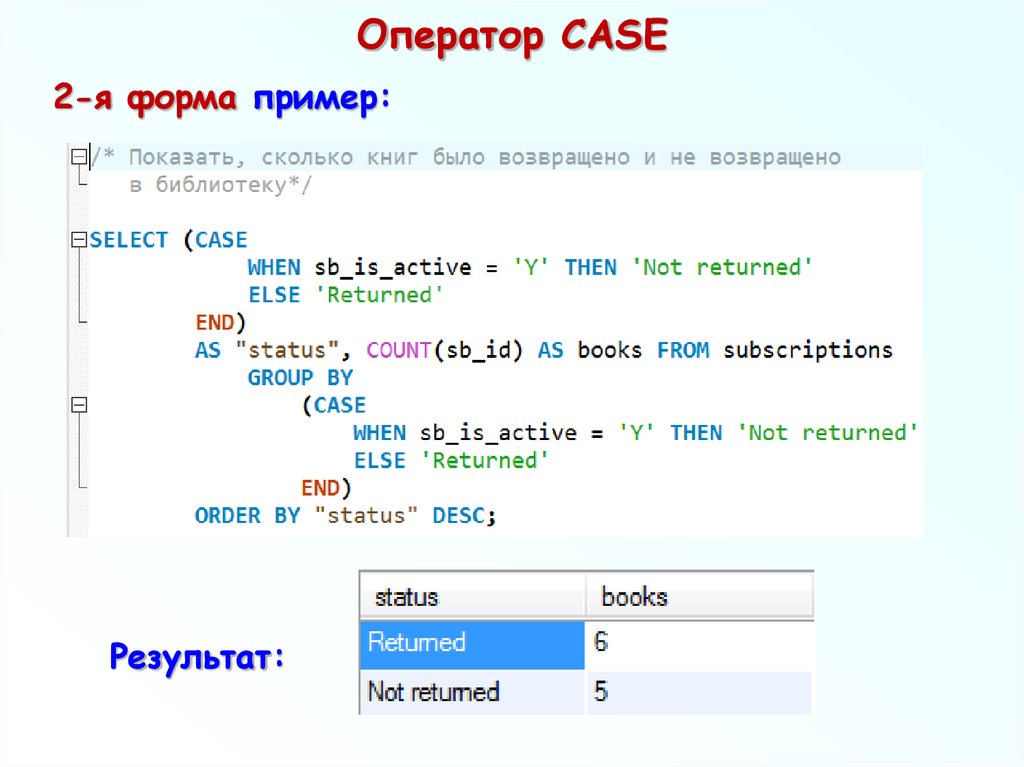
Входные данные для функций вставки или обновления
При использовании динамического параметра на вкладке «Настройка» они автоматически отображаются на вкладке «Входные данные». Вы можете указать тип поля и пометить поле как обязательное.
Входные данные для функций выбора
Входные данные фильтра и сортировки автоматически заполняются на вкладке «Входные данные» после того, как вы напишете свой запрос на вкладке «Конфигурация». Эти входы доступны только для чтения.
Выходы
В этом разделе вы можете просматривать и настраивать функциональные выходы. Думайте о выводах как о столбцах таблицы или полях, отображаемых в компоненте сведений.
Выходные данные для функций вставки или обновления
Выходные данные для функций INSERT, UPDATE и DELETE автоматически генерируются Internal и доступны в качестве привязок для компонентов в пространстве. Эти выходы можно редактировать.
Чтобы использовать вывод одного из вышеупомянутых методов, создайте компонент, который делает вызов к базе данных. Затем создайте еще один компонент, который будет привязываться к выходным данным выполнения этих компонентов этого метода. Вы можете найти эту привязку в меню «Источник» на правой панели конфигурации данного пространства.
Затем создайте еще один компонент, который будет привязываться к выходным данным выполнения этих компонентов этого метода. Вы можете найти эту привязку в меню «Источник» на правой панели конфигурации данного пространства.
Эта функциональность особенно полезна в ситуациях, когда создание одного объекта БД зависит от другого, но неразрывно связано. Например, создать функциональный конвейер для создания нового ПОЛЬЗОВАТЕЛЯ и связанной с ним ГРУППЫ для этого пользователя, сначала создав ГРУППУ, а затем используя возвращенный GROUP_ID из функции в качестве входных данных в функцию для создания нового ПОЛЬЗОВАТЕЛЯ.
Выходные данные для SelectFunctions
Выходные данные автоматически заполняются на основе SQL-запроса, введенного на вкладке «Настройка». Вы можете установить ключ (комбинацию атрибутов, которые делают строку уникальной), установив соответствующий флажок. Это используется дополнительными функциями, такими как автоматическое обновление строк и автоматическое связывание.
Возвращает один объект
Можно вернуть один объект из запроса SQL с помощью Transformer. По умолчанию запросы SQL возвращают массив. В результате вы будете использовать тело ввода Transformer для вызова первого элемента в возвращаемом массиве, ссылаясь на них со значением индекса: `data[0]`.
То, что это делается с помощью JavaScript, позволяет выполнять другие манипуляции/фильтрацию вывода помимо простого вызова первого результата из массива.
Выходные данные автоматически заполняются для возвратов одного объекта. Эти выходы можно редактировать и использовать в качестве фильтров. Если вы используете некоторую смесь `data` и `data[0]`, автоматически сгенерированные выходные данные для функции не будут работать; Выходы должны быть настроены вручную.
Разрешения
Вы можете настроить разрешения для функций SQL в разделе «Роли и разрешения» в настройках компании. Учить больше.
Пошаговое руководство по SQL Inner Join
Каждую минуту организации генерируют и анализируют непревзойденные объемы данных. В этой статье мы покажем, как мы можем использовать SQL Inner Join для запроса и доступа к данным из нескольких таблиц, которые хранят эти постоянно растущие данные в базах данных SQL.
В этой статье мы покажем, как мы можем использовать SQL Inner Join для запроса и доступа к данным из нескольких таблиц, которые хранят эти постоянно растущие данные в базах данных SQL.
Соединения SQL
Прежде чем мы начнем с SQL Inner Join, я хотел бы вызвать здесь SQL Join. Присоединение — это широко используемое предложение в SQL Server, в основном для объединения и извлечения данных из двух или более таблиц. В реальной реляционной базе данных данные структурированы в большом количестве таблиц, и поэтому существует постоянная потребность в объединении этих нескольких таблиц на основе логических связей между ними. В SQL Server существует четыре основных типа соединений: внутреннее, внешнее (левое, правое, полное), самостоятельное и перекрестное соединение. Чтобы получить краткий обзор всех этих объединений, я бы порекомендовал пройти по этой ссылке, обзору типов соединений SQL и учебному пособию.
Эта статья посвящена внутреннему соединению в SQL Server, так что давайте перейдем к нему.
Определение внутреннего соединения SQL
Предложение Inner Join в SQL Server создает новую таблицу (не физическую) путем объединения строк, имеющих совпадающие значения в двух или более таблицах. Это объединение основано на логической связи (или общем поле) между таблицами и используется для извлечения данных, которые появляются в обеих таблицах.
Предположим, у нас есть две таблицы, таблица A и таблица B, которые мы хотели бы соединить с помощью SQL Inner Join. Результатом этого соединения будет новый результирующий набор, возвращающий совпадающие строки в обеих этих таблицах. Часть пересечения, выделенная черным цветом ниже, показывает данные, полученные с помощью Inner Join в SQL Server.
Синтаксис внутреннего соединения SQL Server
Ниже приведен основной синтаксис Inner Join.
SELECT Column_list
FROM TABLE1
INNER JOIN TABLE2
ON Table1.ColName = Table2. ColName
ColName
Синтаксис внутреннего соединения в основном сравнивает строки таблицы Table1 с таблицей Table2, чтобы проверить, совпадает ли что-либо на основе условия, указанного в предложении ON. Когда условие соединения выполнено, оно возвращает совпадающие строки в обеих таблицах с выбранными столбцами в предложении SELECT.
Предложение SQL Inner Join такое же, как и предложение Join, и работает так же, если мы не указываем тип (INNER) при использовании предложения Join. Короче говоря, внутреннее соединение — это ключевое слово по умолчанию для соединения, и оба они могут использоваться взаимозаменяемо.
Примечание. Мы будем использовать ключевое слово «внутреннее» соединение в этой статье для большей ясности. Вы можете опустить его при написании своих запросов и также можете использовать только «Присоединиться».
Внутреннее соединение SQL в действии
Давайте попробуем понять концепцию внутреннего соединения на примере интересной выборки данных, касающейся пиццерии и ее распределения продуктов питания. Сначала я собираюсь создать две таблицы: таблицу «PizzaCompany», которая управляет различными филиалами пиццерий в нескольких городах, и таблицу «Foods», в которой хранятся данные о распределении продуктов питания по этим компаниям. Вы можете выполнить приведенный ниже код, чтобы создать и заполнить данные в этих двух таблицах. Все эти данные являются гипотетическими и вы можете создать их в любой из ваших существующих баз данных.
Сначала я собираюсь создать две таблицы: таблицу «PizzaCompany», которая управляет различными филиалами пиццерий в нескольких городах, и таблицу «Foods», в которой хранятся данные о распределении продуктов питания по этим компаниям. Вы можете выполнить приведенный ниже код, чтобы создать и заполнить данные в этих двух таблицах. Все эти данные являются гипотетическими и вы можете создать их в любой из ваших существующих баз данных.
1 2 3 4 5 6 7 8 10 110003 12 13 14 1991000 3 13 14 9000.9000 313 14 9000 2 | CREATE TABLE [dbo].[PizzaCompany] ( [CompanyId] [int] IDENTITY(1,1) PRIMARY KEY CLUSTERED, [CompanyName] [CompanyName](50) , 3 90 varchar](30)) SET IDENTITY_INSERT [dbo]. ВСТАВИТЬ В [dbo].[PizzaCompany] ([CompanyId], [CompanyName], [CompanyCity]) VALUES(1,’Dominos’,’Los Angeles’) ; ВСТАВИТЬ В [dbo].[PizzaCompany] ([CompanyId], [CompanyName], [CompanyCity]) VALUES(2,’Pizza Hut’,’Сан-Франциско’) ; ВСТАВИТЬ В [dbo].[PizzaCompany] ([CompanyId], [CompanyName], [CompanyCity]) VALUES(3,’Папа Джонс’,’Сан-Диего’) ; ВСТАВИТЬ В [dbo].[PizzaCompany] ([CompanyId], [CompanyName], [CompanyCity]) VALUES(4,’Ah Pizz’,’Fremont’) ; ВСТАВИТЬ В [dbo].[PizzaCompany] ([CompanyId], [CompanyName], [CompanyCity]) VALUES(5,’Nino Pizza’,’Las Vegas’) ; ВСТАВИТЬ В [dbo].[PizzaCompany] ([CompanyId], [CompanyName], [CompanyCity]) VALUES(6,’Пиццерия’,’Бостон’) ; ВСТАВИТЬ В [dbo].[PizzaCompany] ([CompanyId], [CompanyName], [CompanyCity]) VALUES(7,’chuck e cheese’,’Chicago’) ;
ВЫБЕРИТЕ * ОТ PizzaCompany: |
 [PizzaCompany] ON;
[PizzaCompany] ON;Вот как выглядят данные в таблице PizzaCompany:
Давайте сейчас создадим и заполним таблицу Foods.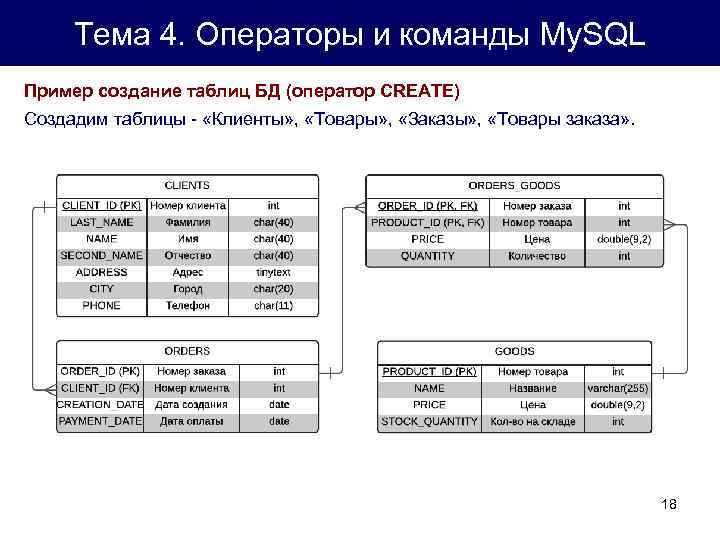 CompanyID в этой таблице — это внешний ключ, который ссылается на первичный ключ таблицы PizzaCompany, созданной выше.
CompanyID в этой таблице — это внешний ключ, который ссылается на первичный ключ таблицы PizzaCompany, созданной выше.
1 2 3 4 5 6 7 8 10 110003 12 13 14 19990001 14 9000 3 9000 3 9000 3 9000 2 9000 214 9000 3 9000 3 9000 29000 3 9000 3 9000 3 18 | Создание таблицы [dbo]. [Foods] ( [itemid] int Первичные ключевые кластеры, [itemname] varchar (50), (CompanyID) ССЫЛКИ PizzaCompany(CompanyID) ) ВСТАВИТЬ В [dbo].[Foods] ([ItemId], [ItemName], [UnitsSold], [CompanyId]) VALUES(1,’Большая пицца’,5, 2) ВСТАВИТЬ В [dbo].[Foods] ([ItemId], [ItemName], [UnitsSold], [CompanyId]) VALUES(2,’чесночные узлы’,6,3) ВСТАВИТЬ В [dbo].[Foods] ([ItemId], [ItemName], [UnitsSold], [CompanyId]) VALUES(3,’Большая пицца’,3,3) ВСТАВИТЬ В [dbo]. ВСТАВИТЬ В [dbo].[Foods] ([ItemId], [ItemName ], [UnitsSold], [CompanyId]) VALUES(5,’Breadsticks’,7,1) ВСТАВИТЬ В [dbo].[Foods] ([ItemId], [ItemName], [UnitsSold], [CompanyId]) VALUES(6,’Средняя пицца’,11,1) ВСТАВИТЬ В [dbo].[Foods] ([ItemId], [ItemName], [UnitsSold], [CompanyId]) VALUES(7,’Маленькая пицца’, 9,6) ВСТАВИТЬ В [dbo].[Foods] ([ItemId], [ItemName], [UnitsSold], [CompanyId]) VALUES(8,’Small Pizza’,6,7)
SELECT * ИЗ продуктов питания |
 [ Foods] ([ItemId], [ItemName], [UnitsSold], [CompanyId]) VALUES(4,’Средняя пицца’,8,4)
[ Foods] ([ItemId], [ItemName], [UnitsSold], [CompanyId]) VALUES(4,’Средняя пицца’,8,4)В следующей таблице показаны данные из таблицы «Продукты». В этой таблице хранится такая информация, как количество проданных единиц продуктов питания, а также пиццерия (CompanyId), которая ее доставляет.
Теперь, если мы хотим увидеть товары, а также единицы, проданные каждой компанией по производству пиццы, мы можем объединить эти две таблицы с помощью предложения внутреннего соединения, используемого в поле CompanyId (в нашем случае это разделяет отношение внешнего ключа ).
SELECT pz.CompanyCity, pz.CompanyName, pz.CompanyId AS PizzaCompanyId, f.CompanyID AS FoodsCompanyId, f.ItemName, f.UnitsSold ИЗ PizzaCompany pz INNER JOIN Foods f pz. Идентификатор компании |
Ниже приведен набор результатов приведенного выше запроса внутреннего соединения SQL. Для каждой строки в таблице PizzaCompany функция Inner Join сравнивает и находит совпадающие строки в таблице Foods и возвращает все совпадающие строки, как показано ниже. И если вы заметили, CompanyId = 5 исключается из результата запроса, так как не соответствует таблице Foods.
С помощью приведенного выше набора результатов мы можем разобрать товары, а также количество товаров, доставленных пиццериями в разных городах. Например, компания Dominos доставила в Лос-Анджелес 7 хлебных палочек и 11 средних пицц.
Внутреннее соединение SQL для трех таблиц
Давайте подробнее рассмотрим это объединение и предположим, что в штате откроются три аквапарка (похоже на лето), и эти аквапарки будут брать еду из пиццерий, упомянутых в таблице PizzaCompany.
Я собираюсь быстро создать таблицу WaterPark и загрузить в нее произвольные данные, как показано ниже.
1 2 3 4 5 6 7 8 10 110003 12 13 14 | CREATE TABLE [dbo].[WaterPark] ( [WaterParkLocation] VARCHAR(50), [CompanyId] int, FOREIGN KEY(CompanyID) REFERENCES PizzaCompany(CompanyID) ) ВСТАВИТЬ В [dbo].[WaterPark] ([WaterParkLocation], [CompanyId]) VALUES(‘Street 14 ) ВСТАВИТЬ В [dbo].[WaterPark] ([WaterParkLocation], [CompanyId]) VALUES(‘Boulevard 2’,2) ВСТАВИТЬ В [dbo].[WaterPark] ([WaterParkLocation], [CompanyId]) VALUES(‘Rogers 54’,4) INSERT INTO [dbo].[WaterPark] ([WaterParkLocation], [CompanyId]) VALUES(‘Street 14’,3) ВСТАВИТЬ В [dbo].[WaterPark] ([WaterParkLocation], [CompanyId]) VALUES(‘Rogers 54’,5) ВСТАВИТЬ В [dbo].
ВЫБЕРИТЕ * ИЗ Аквапарка |
 [WaterPark] ([WaterParkLocation], [CompanyId]) VALUES (‘Бульвар 2’,5)
[WaterPark] ([WaterParkLocation], [CompanyId]) VALUES (‘Бульвар 2’,5)И ниже вывод этой таблицы.
Как говорится, картинка стоит тысячи слов. Давайте быстро посмотрим на схему базы данных этих трех таблиц с их отношениями, чтобы лучше понять их.
Теперь мы собираемся включить эту третью таблицу в предложение SQL Inner Join, чтобы посмотреть, как это повлияет на набор результатов. Согласно данным в таблице WaterPark, три аквапарка передавали еду от всех пиццерий, кроме Pizzeria (Id = 6) и chuck e cheese (Id = 7). Выполните приведенный ниже код, чтобы увидеть всю раздачу еды в аквапарках по точкам Pizza.
1 2 3 4 5 6 | ВЫБЕРИТЕ pz.CompanyId, pz.CompanyCity, pz.CompanyName,f.ItemName, f.UnitsSold, w.WaterParkLocation ИЗ PizzaCompany pz INNER JOIN Foods f ON pz. ЗАКАЗ ПО pz.CompanyId |
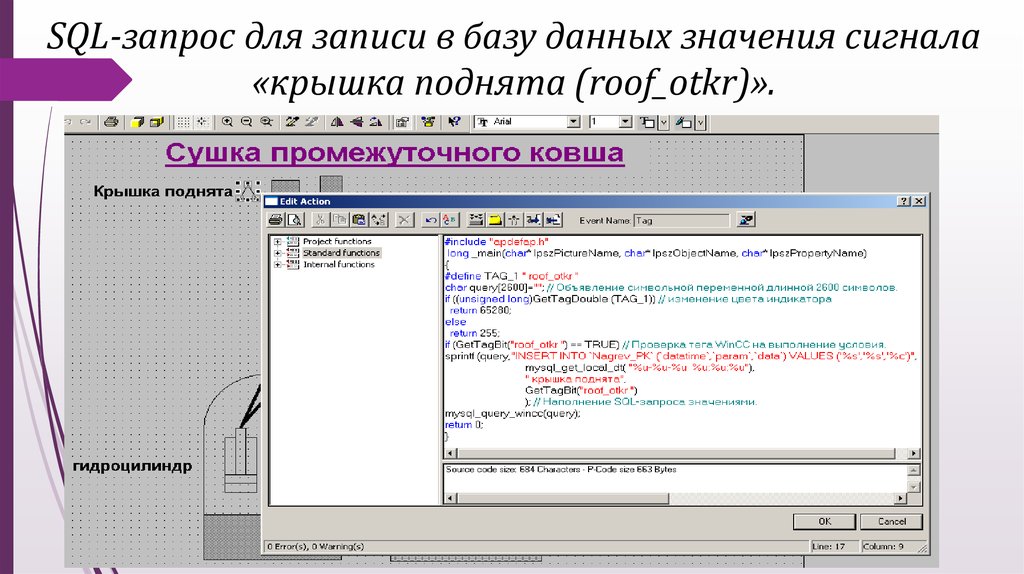 9000CompanyId = f.00002 ПРИСОЕДИНЯЙТЕСЬ к WaterPark w ON w.CompanyId = pz.CompanyId
9000CompanyId = f.00002 ПРИСОЕДИНЯЙТЕСЬ к WaterPark w ON w.CompanyId = pz.CompanyIdНа основе CompanyId SQL Inner Join сопоставляет строки в обеих таблицах, PizzaCompany (таблица 1) и Foods (таблица 2), а затем ищет совпадение в WaterPark (таблица 3), чтобы вернуть строки. Как показано ниже, с добавлением внутреннего соединения в WaterPark CompanyId (6,7 (кроме 5)) также исключается из окончательного набора результатов, поскольку условие w.CompanyId = pz.CompanyId не выполняется для идентификаторов (6, 7). Вот как внутреннее соединение SQL помогает возвращать определенные строки данных из нескольких таблиц.
Давайте углубимся в SQL Inner Join еще с несколькими предложениями T-SQL.
Использование WHERE с внутренним соединением
Мы можем фильтровать записи на основе указанного условия, когда внутреннее соединение SQL используется с предложением WHERE. Предположим, что мы хотим получить строки, в которых продано больше 6 единиц.
В следующем запросе добавлено предложение WHERE для извлечения результатов со значением более 6 для проданных единиц.
ВЫБЕРИТЕ pz.CompanyId, pz.CompanyCity, pz.CompanyName,f.ItemName, f.UnitsSold ИЗ PizzaCompany pz INNER JOIN Foods f ON pz.CompanyId = f.CompanyId 9000WHERE f.6 ЗАКАЗАТЬ pz.CompanyCity |
Выполните приведенный выше код в SSMS, чтобы увидеть результат ниже. Этот запрос возвращает четыре таких записи.
Использование Group By с внутренним соединением
SQL Inner Join позволяет нам использовать предложение Group by вместе с агрегатными функциями для группировки результирующего набора по одному или нескольким столбцам. Группировка по обычно работает с внутренним соединением над окончательным результатом, возвращаемым после объединения двух или более таблиц. Если вы не знакомы с предложением Group by в SQL, я бы посоветовал пройти его, чтобы быстро понять эту концепцию. Ниже приведен код, в котором используется предложение Group By с внутренним соединением.
Ниже приведен код, в котором используется предложение Group By с внутренним соединением.
ВЫБЕРИТЕ pz.CompanyCity, pz.CompanyName, SUM(f.UnitsSold) AS TotalQuantitySold FROM PizzaCompany pz INNER JOIN Foods f ON pz.CompanyId = f.CompanyId PROUP 90CCompany BY pz.Company ЗАКАЗАТЬ pz.CompanyCity |
Здесь мы намерены получить общее количество товаров, проданных каждой пиццерией, присутствующей в городе. Как вы можете видеть ниже, совокупный результат в столбце «Общее количество проданных» равен 18 (7+11) и 9.(6+3) для Лос-Анджелеса и Сан-Диего соответственно.
Краткая заметка об Equi и Theta Join
Прежде чем мы закончим эту статью, давайте быстро пробежимся по терминам, которые разработчик SQL может время от времени слышать — Equi и Theta Join.
Equi Join
Как следует из названия, эквивалентное соединение содержит оператор равенства «=» либо в предложении Join, либо в условии WHERE.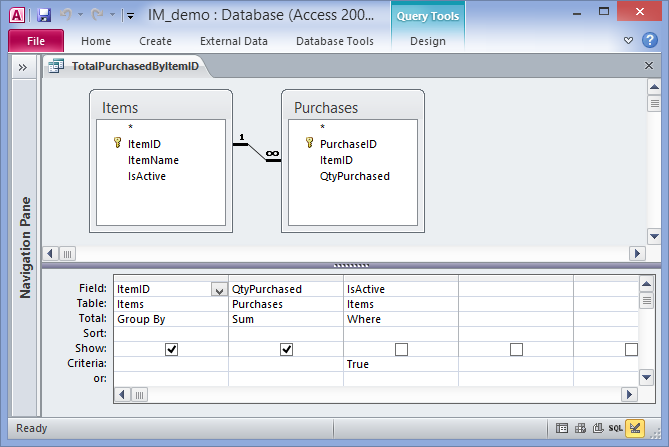 SQL Inner, Left, Right — все это эквивалентные соединения, когда оператор «=» используется в качестве оператора сравнения. Обычно, когда упоминается внутреннее соединение SQL, оно рассматривается как внутреннее равное соединение, только в необычной ситуации оператор равенства не используется.
SQL Inner, Left, Right — все это эквивалентные соединения, когда оператор «=» используется в качестве оператора сравнения. Обычно, когда упоминается внутреннее соединение SQL, оно рассматривается как внутреннее равное соединение, только в необычной ситуации оператор равенства не используется.
Чтобы упростить задачу, я собираюсь обратиться к образцу базы данных AdventureWorksDW2017 и запустить запрос к существующим таблицам, чтобы продемонстрировать, как выглядит эквивалентное соединение.
ВЫБЕРИТЕ e.EmployeeKey, e.FirstName, e.Title, e.HireDate, fs.SalesAmountQuota FROM DimEmployee e INNER JOIN FactSalesQuota fs ON e.Employey 9mployeeK208Key = fs. |
Тета-соединение (неэквивалентное соединение)
Соединение без эквивалента в основном противоположно соединению по эквивалентности и используется, когда мы присоединяемся к условию, отличному от оператора «=». Этот тип редко используется на практике. Ниже приведен пример, в котором используется тета-соединение с оператором неравенства (<) для оценки прибыли путем оценки себестоимости и продажных цен в двух таблицах.
Этот тип редко используется на практике. Ниже приведен пример, в котором используется тета-соединение с оператором неравенства (<) для оценки прибыли путем оценки себестоимости и продажных цен в двух таблицах.
SELECT * FROM Table1 T1, Table2 T2 WHERE T1.ProductCost < T2.SalesPrice |
Заключение
Я надеюсь, что эта статья о «Внутреннем соединении SQL» обеспечивает понятный подход к одному из важных и часто используемых предложений — «Внутреннее соединение» в SQL Server для объединения нескольких таблиц. Если у вас есть какие-либо вопросы, пожалуйста, не стесняйтесь задавать их в разделе комментариев ниже.
Чтобы продолжить изучение SQL Joins, вы можете обратиться к следующим сообщениям:
- SQL OUTER JOIN обзор и примеры
- SQL Join введение и обзор
- Автор
- Последние сообщения
Гаури Махаджан
Гаури является специалистом по SQL Server и имеет более чем 6-летний опыт работы с глобальными многонациональными консалтинговыми и технологическими организациями.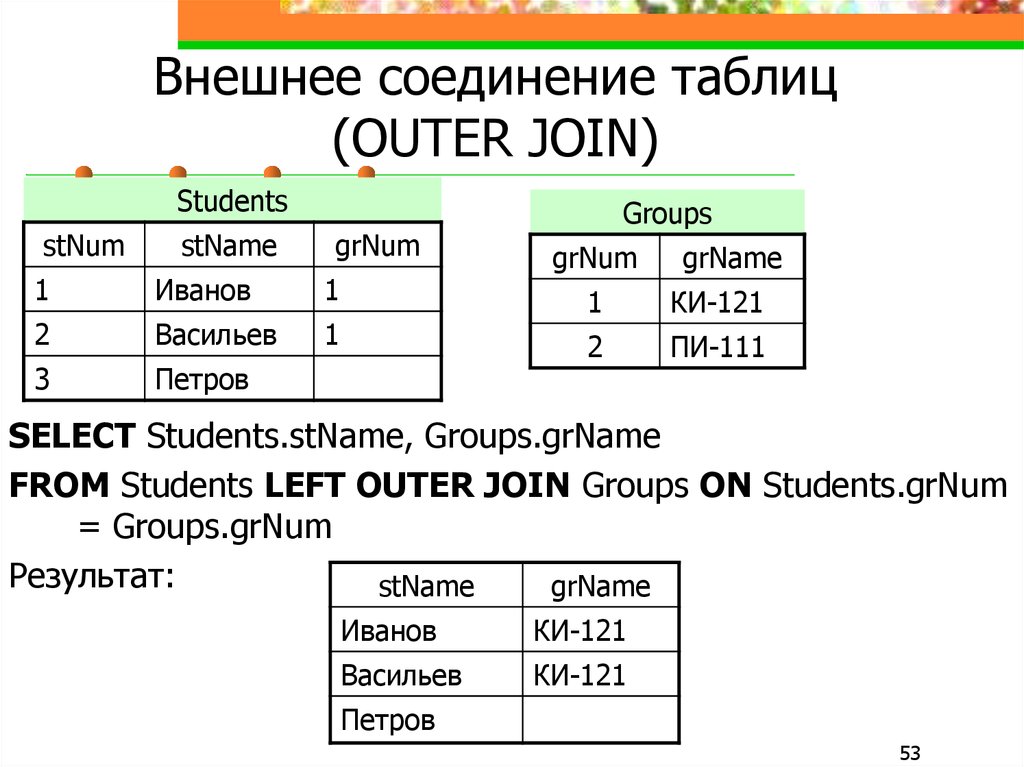 Она очень увлечена работой над темами SQL Server, такими как база данных SQL Azure, службы отчетов SQL Server, R, Python, Power BI, ядро базы данных и т. д. Она имеет многолетний опыт работы с технической документацией и увлекается разработкой технологий.
Она очень увлечена работой над темами SQL Server, такими как база данных SQL Azure, службы отчетов SQL Server, R, Python, Power BI, ядро базы данных и т. д. Она имеет многолетний опыт работы с технической документацией и увлекается разработкой технологий.
У нее большой опыт в разработке решений для обработки данных и аналитики, а также в обеспечении их стабильности, надежности и производительности. Она также сертифицирована по SQL Server и прошла такие сертификаты, как 70-463: Реализация хранилищ данных с Microsoft SQL Server.
Просмотреть все сообщения Гаури Махаджана
Последние сообщения Гаури Махаджана (посмотреть все)
Подзапрос: Внутренние запросы (Библиотека SAP
Второй SELECT оператор (подзапрос (подзапрос)) может быть включен в инструкцию SELECT. Значение или набор values генерируется подзапросом как часть основного оператора.
Предпосылки
Вам нужны демонстрационные данные для Учебник по SQL.
Запустить запрос
инструмент SQL Studio от имени администратора базы данных MONA с паролем RED и войдите в
экземпляр демонстрационной базы данных DEMODB.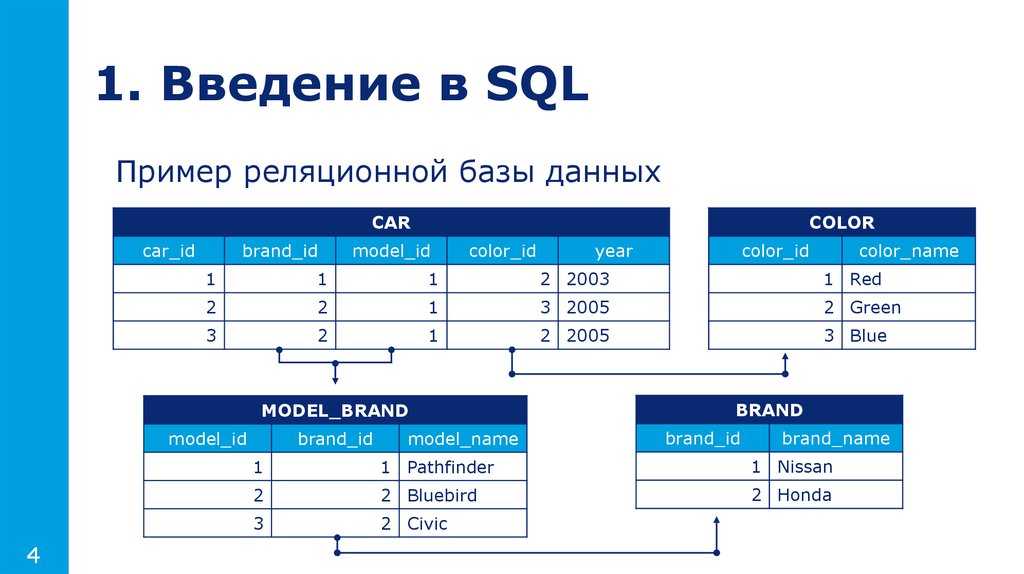
Примеры
ВЫБЕРИТЕ имя, почтовый индекс
ОТ отеля.заказчик
ГДЕ zip = (ВЫБЕРИТЕ МАКС(zip) ОТ
hotel.customer)
Отображение клиент с наибольшим почтовым индексом
Результат
ИМЯ | Почтовый индекс |
Доу | 97213 |
См. также:
Справочное руководство по SQL, Предикат сравнения (comparison_predicate)
SELECT hno, name, zip
ОТ отеля.отель
ГДЕ zip IN(ВЫБЕРИТЕ zip ИЗ hotel.customer ГДЕ
титул = ‘миссис’)
Отображение отели, расположенные в городах/местах, в которых также проживают клиенты-женщины
Результат
HNO | ИМЯ | Почтовый индекс |
10 | Конгресс | 20005 |
См.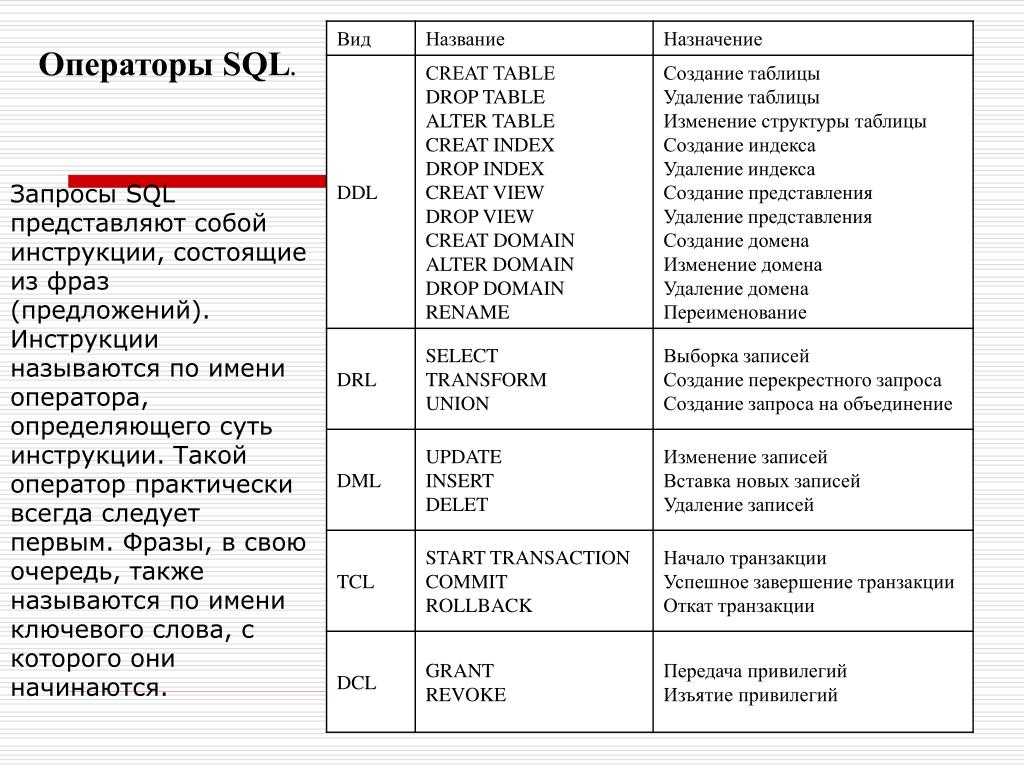 также:
также:
Справочное руководство по SQL, предикат IN (в_предикате)
ВЫБРАТЬ hno, имя
ОТ отеля.отель
ГДЕ имя = ЛЮБОЕ (ВЫБЕРИТЕ имя ИЗ
hotel.city)
Отображение отелей которые имеют то же имя, что и другие города в таблице городов. Внутренний запрос определяет список названий городов, с которыми связаны названия отелей по сравнению.
Результат
HNO | ИМЯ |
20 | Лонг-Айленд |
120 | Лонг Бич |
ВЫБЕРИТЕ cno, имя
ОТ отеля.заказчик
ГДЕ cno = ANY(ВЫБЕРИТЕ cno FROM hotel.reservation
ГДЕ прибытие > ‘2005-01-01’)
Отображение клиенты, которые сделали все бронирования на указанную дату
Результат
CNO | ИМЯ |
3600 | Смит |
3900 | Хоу |
Используйте ЛЮБОЙ, если
подзапрос возвращает более одного значения, и вы хотите принять это во внимание.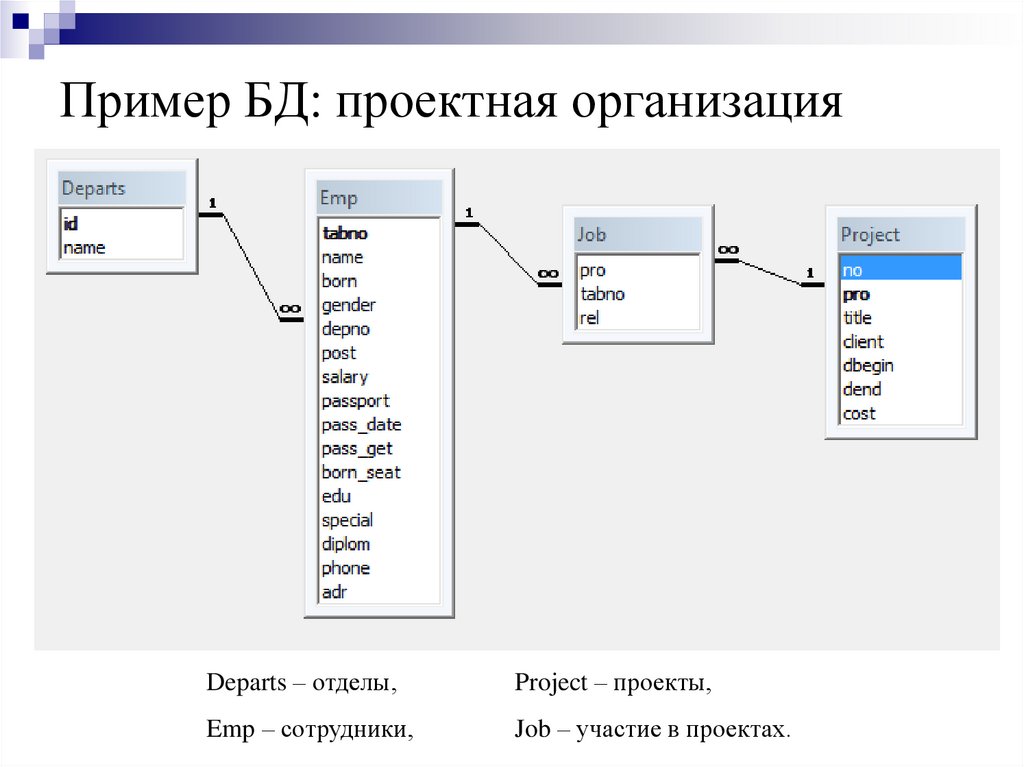 рассмотрение в условии предложения WHERE, которое обычно требует ровно одного
ценность.
рассмотрение в условии предложения WHERE, которое обычно требует ровно одного
ценность.
См. также:
Справочное руководство по SQL, количественный предикат (quantified_predicate)
Коррелированный подзапрос
Можно использовать коррелированные подзапросы для формулирования условий выбора строк; эти условия должны применяться только к группам строк, а не ко всем строкам в стол.
В то время как подзапросы оцениваются только один раз, коррелированные подзапросы оцениваются для каждой строки в внешний стол, изнутри наружу, в случае соединения подзапросы.
ВЫБЕРИТЕ номер, тип, цена
ИЗ отеля.номер room_table
ГДЕ цена =
(ВЫБЕРИТЕ МАКС(цену) ИЗ hotel.room, ГДЕ тип =
room_table.type)
Отображение гостиницы (в виде номера гостиницы) чьи номера в отдельных типах (одноместный, двухместный или люкс) имеют самую высокую цену
Так как в этом
Например, во внешнем операторе SELECT используется та же таблица, что и в
подзапрос, вы должны указать ссылочное имя (room_table).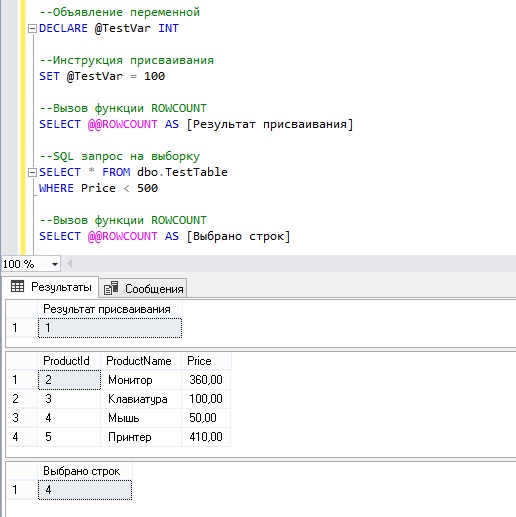 Строка из результата внешнего SELECT
оператор связан (сопоставлен) со значением в подзапросе.
Строка из результата внешнего SELECT
оператор связан (сопоставлен) со значением в подзапросе.
Пояснение
●
ВЫБЕРИТЕ номер, тип, цену ОТ отеля.номер
room_table
Ищет номер отеля, тип номера и цену в таблице room и переименовывает таблицу room_table .
●
ГДЕ цена=
Содержит строку, в которой цена совпадает в результате следующего
подзапрос:
●
(ВЫБЕРИТЕ МАКС(цена)
ИЗ отеля.номер
(Запустить подзапрос) ищет максимальную цену в номере
таблица
●
ГДЕ тип = room_table.type)
типы комнат здесь должны совпадать с типами комнат в найденных строках
выше
Результат
HNO | ТИП | ЦЕНА |
130 | двойной | 270 |
130 | одинарный | 160 |
130 | Люкс | 700 |
ВЫБЕРИТЕ cno, title, name FROM hotel.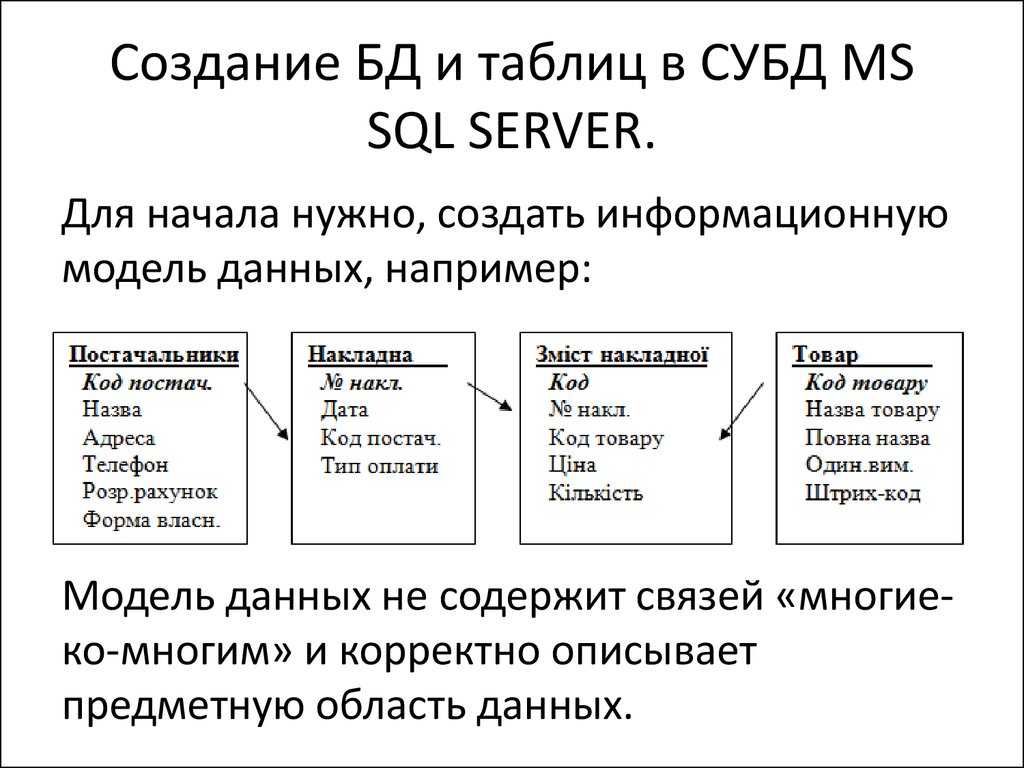 customer
customer
ГДЕ СУЩЕСТВУЕТ
(ВЫБЕРИТЕ * ОТ отеля.reservation
ГДЕ hotel.customer.cno =
hotel.reservation.cno)
Только просмотр те клиенты из клиентского стола, для которых одно или несколько бронирований есть
Результат
CNO | НАЗВАНИЕ | ИМЯ |
3000 | миссис | Портер |
3100 | г-н | Коричневый |
3200 | Компания | Датасофт |
3600 | миссис | Смит |
3900 | г-н | Хоу |
4100 | миссис | Бейкер |
4300 | Компания | ИНСТРУМЕНТЫ |
4400 | г-н | Дженкинс |
Используйте EXISTS, если вы
только хотите, чтобы подзапрос узнал, существует ли строка, которая выполняет
конкретное состояние.
См. также:
Справочное руководство по SQL, предикат EXISTS (exists_predicate)
Еще примеры для Данные Запрос
Сбой соединения Внутренние ошибки монитора SQL – поддержка
Монитор SQL сообщает « Сбой соединения внутренняя ошибка монитора SQL » и Показать журнал имеет «недопустимый класс» или «неизвестная ошибка». Типичный пример: « 0x80041010 (WBEM_E_INVALID_CLASS) Недопустимый класс ». Часто «недопустимый» класс WMI отключается, но иногда эти классы становятся поврежденными, и их необходимо перестроить. Вы можете увидеть связанные ошибки с вариациями номера ошибки 0x800410xx или 0x800440xx.
ПРИМЕЧАНИЕ : Эти проблемы связаны с ошибками подключения Windows WMI, а не с ошибками монитора SQL. Вы сможете воспроизвести ошибку, запустив внешние тесты подключения к SQL Monitor, используя wbemtest или PowerShell. В приведенных ниже рекомендациях обобщается наш предыдущий опыт решения этих проблем, типичные основные причины и возможные решения, которые сработали для других клиентов. Помимо этого, Redgate не может оказывать дальнейшую поддержку по этим экологическим проблемам. Как только вы устраните внешнюю проблему, ошибка подключения будет устранена в SQL Monitor.
Помимо этого, Redgate не может оказывать дальнейшую поддержку по этим экологическим проблемам. Как только вы устраните внешнюю проблему, ошибка подключения будет устранена в SQL Monitor.
0x80041010 Действия по устранению
Эти ошибки возникают из-за того, что один из классов WMI Windows, к которому SQL Monitor требуется доступ на удаленном компьютере, по какой-то причине недоступен или недоступен. SQL Monitor должен запрашивать классы WMI на удаленном сервере, чтобы собирать данные мониторинга об этом сервере, экземплярах и базах данных, которые он размещает (дополнительные сведения см. в разделе Как SQL Monitor подключается к отслеживаемым серверам в документации).
Об этом часто сообщается как о «внутренней ошибке монитора SQL», потому что, когда он не может достичь класса, необходимого для выборки данных, это вызывает ошибку внутри монитора SQL. Однако на самом деле это внешняя ошибка WMI. Об этом можно сообщить как « CIMException «, так как командлеты CIM используются для доступа к удаленным объектам WMI.
Следующие проверки и действия помогли другим клиентам решить эти проблемы, но могут быть неправильным решением в вашем случае. Пожалуйста, поделитесь ими со своей командой системных администраторов. , а также подробные сообщения об ошибках и результаты WBEMtest и действуйте в соответствии с их рекомендациями.0011 — Диагностика — Получение файлов журнала )
Использование имени затронутого сервера в качестве ссылки. Вы увидите ошибки WMI для « неверный класс » с такими терминами, как « cimv2 » (пространство имен WMI по умолчанию), за которым следует запрос, предпринятый для «недопустимого» счетчика WMI, например « Win32_PerfRawData_PerfDisk_LogicalDisk » или « Win32_PerfRawData_PerfProc_Process «.
Вы сможете воспроизвести эту ошибку извне, запросив те же счетчики из WBEMTest (см.0112 Внешняя проверка ошибки с помощью раздела WBEMTest в конце этой статьи).
2. Проверьте, не отключен ли класс
Если вы видите ошибку при запросе, например, класса PerfDisk или PerfProc , то наиболее распространенной причиной является то, что он отключен. SQL Monitor необходим доступ к этим классам для сбора данных из содержащихся в них счетчиков производительности. Есть несколько способов сделать это.
а. Из командной строки
На машине, к которой вы пытаетесь подключиться, выполните следующую команду из командной строки с повышенными привилегиями, чтобы найти все отключенные счетчики:
lodctr /q | findstr Disabled
Для отключенного счетчика PerfDisk (или, возможно, только первой строки) будет показано что-то вроде этого:
[PerfDisk] Счетчики производительности (отключено)
Имя DLL: %SystemRoot%\System32\perfdisk.dll
Процедура открытия: OpenDiskObject
Процедура сбора: CollectDiskObjectData
Процедура закрытия: CloseDiskObject
И запустите это, чтобы включить их (пример для PerfDisk выше):
lodctr /e:PerfDisk
b. Проверьте разделы реестра
Проверьте разделы реестра
Кроме того, вы можете проверить соответствующие разделы реестра на машине, например:
Computer\HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\PerfProc\Performance \SYSTEM\CurrentControlSet\Services\PerfDisk\Performance
Убедитесь, что справа от ключа «Отключить счетчики производительности» есть запись DWORD . Если установлено значение 1, установите для него значение 0, чтобы включить счетчики и продолжить сбор. Если он уже установлен на ноль или нет записи DWORD , то отключенные счетчики не являются проблемой.
3. Перестроение счетчиков
Если вы видите ошибку при запросе класса, но она не отключена и не отсутствует, возможно, счетчики повреждены и их необходимо перестроить. Вы можете сделать это с помощью следующей команды (опять же из командной строки с повышенными правами). Он использует lodctr /R , чтобы перестроить счетчики, а последняя строка повторно синхронизирует их с WMI. Пример для классов счетчиков производительности ( PerfDisk или PerfProc ):
Пример для классов счетчиков производительности ( PerfDisk или PerfProc ):
c:
cd c:\windows\system32
lodctr /R
cd c:\windows\sysWOW64
lodctr /R WINMG.EXE
/RESYNCPERF
Обратите внимание, что перестроение/повторная синхронизация счетчиков производительности может занять некоторое время. После завершения перезапустите службу инструментария управления Windows и службу базового монитора.
Если вы используете wbemtest, вам следует повторно запустить запрос wbemtest , чтобы убедиться, что он выполнен успешно.
4. Повторная компиляция MOF-файла
Если проблема не устранена, вам может потребоваться использовать утилиту MOFCOMP для повторной компиляции базового файла .MOF (файл формата управляемых объектов), в котором содержатся классы.
Например, файл WMIPERFINST.mof динамически передает данные счетчиков производительности счетчикам WMI на PerfDisk и Классы PerfProc (и любые другие классы, содержащие счетчики производительности).
Из командной строки с повышенными привилегиями запустите в каталоге C:\Windows\System32\Wbem :
mofcomp.exe WMIPERFINST.MOF
Конечно, повреждаются не только классы, содержащие счетчики производительности, но и и разные классы имеют разные файлы MOF, связанные с ними. Инструмент WMIDiag может помочь вам определить, какой MOF-файл содержит поврежденный класс, или попробуйте выполнить поиск по такому запросу, как «9».0112 учебник, как исправить повреждение WMI «.
Устранение связанных ошибок
Существует несколько связанных ошибок WMI с шаблоном 0x800410xx, а также другие, такие как 0x800440xx, которые все сообщают как «внутренние ошибки монитора SQL. Все это указывает на сбой конкретной операции WMI из-за недостаточных привилегий или проблемы с инфраструктурой WMI.
0x80041017 — Неверный запрос
Если в журналах ошибок SQL Monitor отображаются запросы, подобные показанным ранее для классов счетчиков производительности, но ошибка является «недопустимым запросом», а не недопустимым классом, то в wbemtest стоит заменить IDProcess с ProcessID и перезапуском запроса. Если это удается, то проблема заключается в том, что мы обычно видим во французских выпусках Windows Server, и решение состоит в том, чтобы просто обновить Windows, поскольку это исправило это поведение для других клиентов.
Если это удается, то проблема заключается в том, что мы обычно видим во французских выпусках Windows Server, и решение состоит в том, чтобы просто обновить Windows, поскольку это исправило это поведение для других клиентов.
Мы видели, что эта ошибка в других случаях может быть устранена путем перестроения счетчиков производительности (шаг 3 выше)
Отсутствующие или недопустимые пространства имен или поставщики WMI
Иногда мы наблюдали проблемы с отсутствующими или недействительными пространствами имен или поставщиками WMI. В следующей статье перечислены наиболее распространенные из них и даны некоторые рекомендации по работе с отсутствующими классами или пространствами имен: https://techcommunity.microsoft.com/t5/ask-the-performance-team/wmi-missing-or-failing-wmi-providers. -или-инвалид-wmi-класс/ба-р/375485
Внешняя проверка ошибки с помощью WBEMTest
Чтобы воспроизвести точную ошибку извне, используйте инструмент WBEMTest .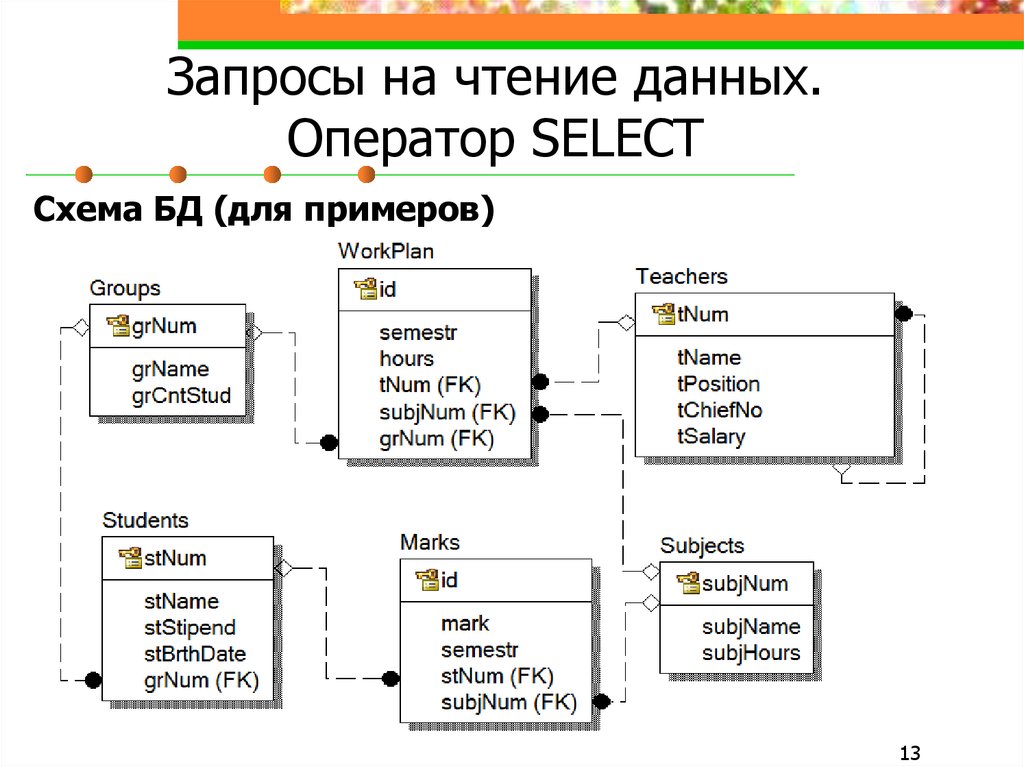 Выполните шаги, описанные в документации по тестированию соединения WMI с помощью WBEMTest (при подключении через DCOM или PowerShell в противном случае). Однако вместо общего запроса SELECT Name FROM Win32_Service (шаг 7) выполните запрос счетчика, соответствующего сообщению об ошибке в журналах, например:
Выполните шаги, описанные в документации по тестированию соединения WMI с помощью WBEMTest (при подключении через DCOM или PowerShell в противном случае). Однако вместо общего запроса SELECT Name FROM Win32_Service (шаг 7) выполните запрос счетчика, соответствующего сообщению об ошибке в журналах, например:
выберите ElapsedTime, IDProcess, Name, PercentPrivilegedTime, PercentUserTime, PrivateBytes, WorkingSet. из Win32_PerfRawData_PerfProc_Process
В случае возникновения проблемы вы получите номер ошибки WMI и сообщение.
Ваша база данных SQL может быть внутренним инструментом
)На значения можно ссылаться, используя номер ID или имя поля.
В этом примере мы создали таблицу с именем Contact с тремя полями: ID , Name и EmailAddress . Вы можете использовать номер ID или имя поля для ссылки на эти значения при вставке записей в таблицу. Обратите внимание, что в этом примере используются стандартные идентификаторы Salesforce, которые представляют собой целые числа с автоматическим увеличением, начинающиеся с 1. Если вы используете другую систему, ваши идентификаторы, скорее всего, будут другими.
Обратите внимание, что в этом примере используются стандартные идентификаторы Salesforce, которые представляют собой целые числа с автоматическим увеличением, начинающиеся с 1. Если вы используете другую систему, ваши идентификаторы, скорее всего, будут другими.
После выполнения запроса вставки вы должны увидеть список записей в таблице.
Создание структур данных с помощью SQL-запросов
Далее вам нужно создать несколько структур данных, которые будут хранить ваши данные. Это больше объектов базы данных для вашей таблицы. Вот код для их создания:
CREATE VIEW Salesforce_ContactsList AS SELECT * FROM Salesforce_Contacts
CREATE TRIGGER Salesforce_ContactUpdate
Мы будем использовать 9Представления 0010 и запускают в этом руководстве, которые являются объектами базы данных, которые используются для обеспечения соблюдения бизнес-правил. Представления доступны только для чтения копии ваших данных, а триггеры также применяют изменения. Вы можете думать о представлении как о способе облегчить другим людям в вашей компании с меньшими знаниями SQL доступ к записям в вашей таблице, не путаясь в том, что они видят. Триггер — это способ автоматического обновления ваших данных при их изменении. Это может быть полезно для отслеживания изменений или поддержания ссылочной целостности между таблицами.
Вы можете думать о представлении как о способе облегчить другим людям в вашей компании с меньшими знаниями SQL доступ к записям в вашей таблице, не путаясь в том, что они видят. Триггер — это способ автоматического обновления ваших данных при их изменении. Это может быть полезно для отслеживания изменений или поддержания ссылочной целостности между таблицами.
В нашем примере мы просто будем использовать представление для вывода списка всех записей в нашей таблице. Оператор CREATE VIEW создает новое представление с именем Salesforce_ContactsList со всеми записями в нашей таблице Salesforce_Contacts . Это представление можно использовать для отображения списка ваших контактов или просто для извлечения из него некоторых полей, если вы используете эти данные для другой цели. Мы также использовали команду SELECT *, которая является сокращением для выбора всех доступных полей в вашем запросе. Вы можете увидеть список всех доступных полей , взглянув на схему для вашей таблицы.
Вы можете увидеть список всех доступных полей , взглянув на схему для вашей таблицы.
Триггер как триггер каскадного удаления
СОЗДАТЬ ТРИГГЕР Salesforce_ContactCascadeDelete ПОСЛЕ УДАЛЕНИЯ ON Salesforce_Contacts
Далее мы создадим триггер для обработки каскадного удаления при удалении контакта из нашей таблицы. Этот триггер будет называться Salesforce_ContactCascadeDelete и сработает после удалить событие. Это означает, что он будет выполняться после того, как контакт будет удален, независимо от того, было ли удаление успешным или нет.
Код триггера очень прост. Он просто содержит одну инструкцию DELETE , которая удаляет все записи из таблицы Salesforce_ContactCascade . Эта таблица представляет собой простой контейнер для хранения номеров ID любых контактов, которые были удалены из Salesforce_Contacts 9. 0011 таблица.
0011 таблица.
Триггер автоматически удалит все записи в этой таблице, которые имеют номер ID , совпадающий с одним из ID в таблице Salesforce_Contacts . Это обеспечит автоматическое удаление любых записей в таблице Salesforce_ContactCascade , которых больше нет в таблице Salesforce_Contacts .
Триггер настроен как триггер каскадного удаления , который является типом удаления триггер , который обычно используется для обеспечения ссылочной целостности между таблицами. Триггер каскадного удаления автоматически удалит записи в другой таблице, связанные с удаляемыми записями. Это значительно затрудняет сохранение потерянных записей в базе данных после того, как они больше не нужны.
Эту часть нашего примера можно продолжать до бесконечности, но для каждого действия, которое должен предпринять ваш внутренний инструмент, вам потребуется сделать необходимые запросы.
Далее мы рассмотрим шаги высокого уровня по созданию графического интерфейса для вашего внутреннего инструмента, чтобы сделать эти запросы более готовыми к использованию.
Создание графического интерфейса для вашего внутреннего инструмента
Теперь мы рассмотрим, как создать графический интерфейс, который облегчит вам и, что более важно, вашим пользователям использование этих инструментов. Вы можете создать графический интерфейс на многих разных языках, но здесь мы будем использовать Python из-за его простоты и простоты.
Вы можете сократить этот следующий раздел, используя одну из многих доступных библиотек пользовательского интерфейса, которые предлагают готовые компоненты. Они могут дать вам строительные блоки, которые вам нужны
Общие шаги, необходимые для создания графического интерфейса для внутренних инструментов:
- Создайте окно и заполните его рядом кнопок для управления выполнением ваших запросов.
- Создайте «цикл событий», который отслеживает нажатия кнопок пользователем и выполняет соответствующий запрос в зависимости от того, какая кнопка была нажата.
- Подключите прослушиватели событий к различным кнопкам, чтобы они выполняли соответствующую команду при нажатии.
- Убедитесь, что в главном окне есть инструкции, сообщающие конечному пользователю, как использовать ваше приложение. Бонусные баллы, если инструкции относятся к варианту использования. Например, повседневный язык для групп, работающих с клиентами, которые могут пытаться решить проблемы, с которыми сталкиваются клиенты.
Окно
Сначала мы создадим окно, которое будет содержать наш графический интерфейс. Это окно можно создать с помощью следующего кода:
window = tk.Tk()
Этот код создает новый объект окна с именем window и присваивает его переменной «tk.Tk». Этот объект window используется для создания нашего графического интерфейса.
Кнопка
Теперь мы добавим кнопку в наше окно . Кнопки могут быть созданы с помощью следующего кода:
button = tk.
 Button(window, text="Query Contacts", command=query_contacts)
Button(window, text="Query Contacts", command=query_contacts) В этом коде мы создаем кнопку с текстом Query Contacts и устанавливаем ее команду равной наша функция называется query_contacts . Это означает, что когда пользователь нажимает на эту кнопку , он выполняет нашу функцию query_contacts . Расположение по умолчанию в Python для функций находится внутри файла с именем main.py . Вы можете создать этот файл с помощью следующего кода:
import tk
def query_contacts():
Этот код создаст функцию с именем query_contacts , которую наша кнопка будет выполнять при нажатии.
Метка
Мы также добавим метку к нашему окну , чтобы пользователь знал, что делает кнопка . Метки можно создать с помощью следующего кода:
label = tk.
 Label(window, text="Query Contacts")
Label(window, text="Query Contacts") В этом коде мы создаем новый объект метки с именем метка и назначение ее циклу событий .
Цикл событий
Теперь нам нужно создать цикл событий , который будет прослушивать нажатий кнопки от пользователя и выполнять соответствующий запрос. Это можно сделать с помощью следующего кода:
event_loop = tk.EventLoop()
Объект цикла событий позволит нам прослушивать кнопок , нажатых пользователем, и выполнять наши запросы соответствующим образом.
Нажатия кнопок
Теперь нам нужно подключить наши слушатели событий к нашим нажатиям кнопки . Мы делаем это с помощью следующего кода:
event_loop.connect(button, "1", query_contacts)
Эта строка кода указывает нашему циклу событий выполнять нашу функцию при нажатии кнопки (это то, что мы установить на шаге 2).
Эту часть обучения можно продолжать вечно. Для целей этой статьи мы перейдем к тестированию и развертыванию
Тестирование вашего нового внутреннего инструмента
На этом шаге вы создали новый внутренний инструмент и пришло время его протестировать. Вы захотите убедиться, что все работает так, как вы ожидаете. Если что-то не так, исправьте это перед развертыванием. Следующим шагом будет развертывание вашего инструмента в среде, где пользователи могут получить к нему доступ без необходимости находиться в той же локальной сети, что и сервер.
Развертывание
Вариантов развертывания множество, но наиболее популярным вариантом будет использование облачных сервисов, таких как Amazon Web Services (AWS), или размещение в собственной инфраструктуре.
Развертывание вашего графического интерфейса в AWS или другом облачном сервисе
AWS предлагает три разных сервиса: EC2 Elastic Compute Cloud, S3 Simple Storage Service и Lambda Functions. Мы будем использовать EC2 для развертывания нашего графического интерфейса.
Мы будем использовать EC2 для развертывания нашего графического интерфейса.
Во-первых, нам нужно создать образ машины Amazon (AMI) нашего сервера. Затем нам нужно создать экземпляр EC2.
Далее, на серверной части, вам нужно будет получить данные из вашей базы данных. Для этого вам понадобится пользователь с правами на чтение базы данных.
После подключения к базе данных вы можете выполнить любой запрос.
Использование собственной среды хостинга (самостоятельное размещение инструмента)
Вы также можете самостоятельно размещать и использовать собственную инфраструктуру, что предпочтительнее, если вы работаете в таких отраслях, как здравоохранение или финансовые технологии. Это дает много преимуществ для безопасности. Узнайте больше об использовании собственной инфраструктуры здесь.
Теперь вы готовы начать тестирование с пользователями бета-версии в вашей компании.
Более быстрые способы создания внутренних инструментов и внутренних приложений
Теперь вы знаете, что если вы в настоящее время используете базу данных SQL, вы можете использовать ее для создания новых внутренних инструментов. Используя свои знания системы баз данных и немного кода Python, вы можете создать что-то нестандартное, что облегчит работу вашим коллегам.
Используя свои знания системы баз данных и немного кода Python, вы можете создать что-то нестандартное, что облегчит работу вашим коллегам.
Но у вас может не быть времени или ресурсов прямо сейчас для создания приложения с нуля. Вместо этого вы можете начать с использования того, что уже доступно в вашей организации, а именно базы данных SQL, чтобы приступить к созданию прототипов решений уже сегодня.
Ускорение создания лучших внутренних инструментов
Если у вас уже есть база данных SQL, вы можете сделать все, что описано выше, примерно за три минуты, а также сделать вашу базу данных совместной для всех ваших внутренних пользователей.
Именно поэтому мы создали Baseash.
Это самый быстрый встроенный конструктор инструментов с простым в использовании интерфейсом и безопасным доступом для пользователей. Проверьте это бесплатно.
Что такое Базедаш?
Базадеш в 90 секунд
Узнайте, на что способен Baseash и как он меняет традиционные внутренние инструменты.
Сборка приложения за 5 минут
См. полное приложение, которое подключается к базе данных Postgres и внешнему API, созданное с нуля.
Действия на основе
Расширьте данные вашей базы данных, чтобы взаимодействовать с внутренними и внешними API.
Отправляйте товар быстрее.
Меньше беспокойтесь о внутренних инструментах.
Кредитная карта не требуется.
Больше подобных сообщений
Внутренняя разработка программного обеспечения: плюсы и минусы создания внутренних инструментов
29 сентября 2022 г.
Джордан Чавис
Внутренняя разработка программного обеспечения может быть мощным инструментом для бизнеса, особенно если у вас есть особые потребности, которые не может удовлетворить широкодоступное программное обеспечение. адрес. В этой статье объясняются преимущества компании, использующей внутренний подход, и перевешивают ли их недостатки. Хотя это не правильный выбор для каждой компании, его преимущества трудно игнорировать.
Преимущества создания внутреннего инструмента
Джордан Чавис
Отслеживание многочисленных процессов, происходящих в вашей организации, и своевременная отчетность по ним может оказаться сложной задачей, особенно если эти процессы распределены по нескольким системам. Так почему бы не создать внутренний инструмент и не подключить источники данных к одному пользовательскому интерфейсу (UI), чтобы упростить и ускорить рабочие процессы?
Альтернативы phpMyAdmin: подробное руководство
27 сентября 2022 г.
Max Musing
PhpMyAdmin — это бесплатный инструмент администрирования с открытым исходным кодом для MySQL и MariaDB, но по мере роста ваших потребностей вы можете искать альтернативные продукты, которые помогут оставаться в курсе потребностей вашей базы данных.
Более простой способ создания блок-схем в Notion и Github
26 сентября 2022 г.
Джереми Сарчет
Рано или поздно в процессе разработки наступает момент, когда вам просто нужна блок-схема. Недавно мы начали использовать Mermaid, синтаксис уценки, поддерживаемый Notion и Github, чтобы документировать, делиться и комментировать новые функции в режиме реального времени, вместо того, чтобы использовать инструмент проектирования или рисовать их вручную.
Недавно мы начали использовать Mermaid, синтаксис уценки, поддерживаемый Notion и Github, чтобы документировать, делиться и комментировать новые функции в режиме реального времени, вместо того, чтобы использовать инструмент проектирования или рисовать их вручную.
Как привлечь собственных пользователей в качестве участников исследования
21 сентября 2022 г.
Том Джонсон
Проводить исследования пользователей сложно само по себе, но независимо от того, насколько хорошо вы умеете задавать правильные вопросы, собирать данные, выводов из исследований и использования этих данных. Одной из наиболее важных частей исследования пользователей является поиск подходящих пользователей, с которыми можно поговорить в первую очередь.
Внутреннее соединение SQL Server на практических примерах
Резюме : в этом руководстве вы узнаете, как использовать предложение SQL Server INNER JOIN для запроса данных из нескольких таблиц.
Введение в SQL Server
INNER JOIN Внутреннее соединение является одним из наиболее часто используемых соединений в SQL Server. Предложение внутреннего соединения позволяет запрашивать данные из двух или более связанных таблиц.
См. следующие продукты и категории таблицы:
Следующий оператор извлекает информацию о продукте из производство.продукты стол:
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБЕРИТЕ наименование товара, список цен, ид_категории ИЗ производство.продукция СОРТИРОВАТЬ ПО имя_продукта DESC;
Запрос возвратил только список идентификационных номеров категорий, а не имена категорий. Чтобы включить имена категорий в набор результатов, используйте предложение INNER JOIN следующим образом:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT наименование товара, категория_имя, список цен ИЗ производство.
 продукция р
ВНУТРЕННЕЕ СОЕДИНЕНИЕ производство.категории c
ВКЛ c.category_id = p.category_id
СОРТИРОВАТЬ ПО
имя_продукта DESC;
продукция р
ВНУТРЕННЕЕ СОЕДИНЕНИЕ производство.категории c
ВКЛ c.category_id = p.category_id
СОРТИРОВАТЬ ПО
имя_продукта DESC;
В этом запросе:
. Делая это, когда вы ссылаетесь на столбец в этих таблицах, вы можете использовать alias.column_name вместо использования table_name.column_name . Например, запрос использует c.category_id вместо 9.1605 production.categories.category_id . Следовательно, это избавляет вас от набора текста.
Для каждой строки в таблице production.products предложение внутреннего соединения сопоставляет ее с каждой строкой в таблице product.categories на основе значений столбца category_id :
- Если обе строки имеют такое же значение в столбце
category_id, внутреннее соединение формирует новую строку, столбцы которой взяты из строкproduction.и categories production.productsтаблиц в соответствии со столбцами в списке выбора и включает эту новую строку в набор результатов. - Если строка в таблице
production.productsне соответствует строке из таблицыproduction.categories, предложение внутреннего соединения просто включает эти строки и не включает их в результирующий набор.
 categories
categories SQL Server
INNER JOIN синтаксис Ниже показан синтаксис SQL Server INNER JOIN пункт:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT select_list ИЗ Т1 ВНУТРЕННЕЕ СОЕДИНЕНИЕ T2 ON join_predicate;
В этом синтаксисе запрос извлекает данные из обеих таблиц T1 и T2:
- Сначала укажите основную таблицу (T1) в
FROMпредложение - Во-вторых, укажите вторую таблицу в предложении
INNER JOIN(T2) и предикате соединения. Только строки, в которых предикат соединения оценивается как TRUEвключены в набор результатов.
 Только строки, в которых предикат соединения оценивается как
Только строки, в которых предикат соединения оценивается как Предложение INNER JOIN сравнивает каждую строку таблицы T1 со строками таблицы T2, чтобы найти все пары строк, которые удовлетворяют предикату соединения. Если предикат соединения оценивается как TRUE , значения столбцов совпадающих строк T1 и T2 объединяются в новую строку и включаются в набор результатов.
В следующей таблице показано внутреннее соединение двух таблиц T1 (1,2,3) и T2 (A, B, C). Результат включает строки: (2, A) и (3, B), поскольку они имеют одинаковые шаблоны.
Обратите внимание, что ключевое слово INNER является необязательным, его можно пропустить, как показано в следующем запросе:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT select_list ИЗ Т1 ПРИСОЕДИНЯЙТЕСЬ к T2 ON
Дополнительные примеры внутреннего соединения SQL Server
ВНУТРЕННЕЕ СОЕДИНЕНИЕ предложений для запроса данных из трех таблиц:
SELECT наименование товара, категория_имя, имя бренда, список цен ИЗ производство.
