Что такое XML / Хабр
Если вы тестируете API, то должны знать про два основных формата передачи данных:
- XML — используется в SOAP (всегда) и REST-запросах (реже);
- JSON — используется в REST-запросах.
Сегодня я расскажу вам про XML.
XML, в переводе с англ eXtensible Markup Language — расширяемый язык разметки. Используется для хранения и передачи данных. Так что увидеть его можно не только в API, но и в коде.
Этот формат рекомендован Консорциумом Всемирной паутины (W3C), поэтому он часто используется для передачи данных по API. В SOAP API это вообще единственно возможный формат входных и выходных данных!
См также:
Что такое API — общее знакомство с API
Что такое JSON — второй популярный формат
Введение в SOAP и REST: что это и с чем едят — видео про разницу между SOAP и REST.

Так что давайте разберемся, как он выглядит, как его читать, и как ломать! Да-да, а куда же без этого? Надо ведь выяснить, как отреагирует система на кривой формат присланных данных.
Содержание
- Как устроен XML
- Теги
- Корневой элемент
- Значение элемента
- Атрибуты элемента
- XML пролог
- XSD-схема
- Практика: составляем свой запрос
- Well Formed XML
- 1. Есть корневой элемент
- 2. У каждого элемента есть закрывающийся тег
- 3. Теги регистрозависимы
- 4. Правильная вложенность элементов
- 5. Атрибуты оформлены в кавычках
- Итого
Как устроен XML
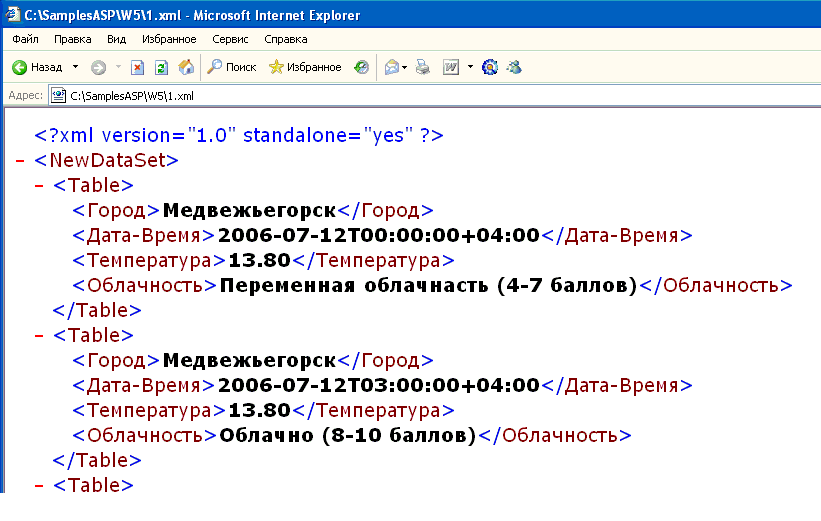
Возьмем пример из документации подсказок Дадаты по ФИО:
<req> <query>Виктор Иван</query> <count>7</count> </req>
И разберемся, что означает эта запись.
Теги
В XML каждый элемент должен быть заключен в теги. Тег — это некий текст, обернутый в угловые скобки:
<tag>
Тега всегда два:
- Открывающий — текст внутри угловых скобок
<tag>
- Закрывающий — тот же текст (это важно!), но добавляется символ «/»
</tag>
Ой, ну ладно, подловили! Не всегда. Бывают еще пустые элементы, у них один тег и открывающий, и закрывающий одновременно. Но об этом чуть позже!
С помощью тегов мы показываем системе «вот тут начинается элемент, а вот тут заканчивается». Это как дорожные знаки:
— На въезде в город написано его название: Москва
— На выезде написано то же самое название, но перечеркнутое: Москва
* Пример с дорожными знаками я когда-то давно прочитала в статье Яндекса, только ссылку уже не помню. А пример отличный!
А пример отличный!
Корневой элемент
В любом XML-документе есть корневой элемент. Это тег, с которого документ начинается, и которым заканчивается. В случае REST API документ — это запрос, который отправляет система. Или ответ, который она получает.
Чтобы обозначить этот запрос, нам нужен корневой элемент. В подсказках корневой элемент — «req».
Он мог бы называться по другому:
<main>
<sugg>
Значение элемента
Значение элемента хранится между открывающим и закрывающим тегами. Это может быть число, строка, или даже вложенные теги!
Вот у нас есть тег «query». Он обозначает запрос, который мы отправляем в подсказки.
Он обозначает запрос, который мы отправляем в подсказки.
Внутри — значение запроса.
Это как если бы мы вбили строку «Виктор Иван» в GUI (графическом интерфейсе пользователя):
Пользователю лишняя обвязка не нужна, ему нужна красивая формочка. А вот системе надо как-то передать, что «пользователь ввел именно это». Как показать ей, где начинается и заканчивается переданное значение? Для этого и используются теги.
Система видит тег «query» и понимает, что внутри него «строка, по которой нужно вернуть подсказки».
Параметр count = 7 обозначает, сколько подсказок вернуть в ответе. Если тыкать подсказки на демо-форме Дадаты, нам вернется 7 подсказок. Это потому, что туда вшито как раз значение count = 7. А вот если обратиться к документации метода, count можно выбрать от 1 до 20.
Откройте консоль разработчика через f12, вкладку Network, и посмотрите, какой запрос отправляется на сервер. Там будет значение count = 7. 
См также:
Что тестировщику надо знать про панель разработчика — подробнее о том, как использовать консоль.

Обратите внимание:
- Виктор Иван — строка
- 7 — число
Но оба значения идут
безкавычек. В XML нам нет нужды брать строковое значение в кавычки (а вот в JSON это сделать придется).
Атрибуты элемента
У элемента могут быть атрибуты — один или несколько. Их мы указываем внутри отрывающегося тега после названия тега через пробел в виде
название_атрибута = «значение атрибута»
Например:
<query attr1=“value 1”>Виктор Иван</query> <query attr1=“value 1” attr2=“value 2”>Виктор Иван</query>
Зачем это нужно? Из атрибутов принимающая API-запрос система понимает, что такое ей вообще пришло.
Например, мы делаем поиск по системе, ищем клиентов с именем Олег. Отправляем простой запрос:
<query>Олег</query>
А в ответ получаем целую пачку Олегов! С разными датами рождения, номерами телефонов и другими данными. Допустим, что один из результатов поиска выглядит так:
<party type="PHYSICAL" sourceSystem="AL" rawId="2">
<field name=“name">Олег </field>
<field name="birthdate">02.01.1980</field>
<attribute type="PHONE" rawId="AL.2.PH.1">
<field name="type">MOBILE</field>
<field name="number">+7 916 1234567</field>
</attribute>
</party>Давайте разберем эту запись. У нас есть основной элемент party.
У него есть 3 атрибута:
- type = «PHYSICAL» — тип возвращаемых данных. Нужен, если система умеет работать с разными типами: ФЛ, ЮЛ, ИП. Тогда благодаря этому атрибуту мы понимаем, с чем именно имеем дело и какие поля у нас будут внутри. А они будут отличаться! У физика это может быть ФИО, дата рождения ИНН, а у юр лица — название компании, ОГРН и КПП
- sourceSystem = «AL» — исходная система. Возможно, нас интересуют только физ лица из одной системы, будем делать отсев по этому атрибуту.
- rawId = «2» — идентификатор в исходной системе. Он нужен, если мы шлем запрос на обновление клиента, а не на поиск. Как понять, кого обновлять? По связке sourceSystem + rawId!
 Тогда благодаря этому атрибуту мы понимаем, с чем именно имеем дело и какие поля у нас будут внутри. А они будут отличаться! У физика это может быть ФИО, дата рождения ИНН, а у юр лица — название компании, ОГРН и КПП
Тогда благодаря этому атрибуту мы понимаем, с чем именно имеем дело и какие поля у нас будут внутри. А они будут отличаться! У физика это может быть ФИО, дата рождения ИНН, а у юр лица — название компании, ОГРН и КППВнутри party есть элементы field.
У элементов field есть атрибут name. Значение атрибута — название поля: имя, дата рождения, тип или номер телефона. Так мы понимаем, что скрывается под конкретным field.
Это удобно с точки зрения поддержки, когда у вас коробочный продукт и 10+ заказчиков. У каждого заказчика будет свой набор полей: у кого-то в системе есть ИНН, у кого-то нету, одному важна дата рождения, другому нет, и т.
Но, несмотря на разницу моделей, у всех заказчиков будет одна XSD-схема (которая описывает запрос и ответ):
— есть элемент party;
— у него есть элементы field;
— у каждого элемента field есть атрибут name, в котором хранится название поля.
А вот конкретные названия полей уже можно не описывать в XSD. Их уже «смотрите в ТЗ». Конечно, когда заказчик один или вы делаете ПО для себя или «вообще для всех», удобнее использовать именованные поля — то есть «говорящие» теги. Какие плюшки у этого подхода:
— При чтении XSD сразу видны реальные поля. ТЗ может устареть, а код будет актуален.
В общем, любой подход имеет право на существование. Надо смотреть по проекту, что будет удобнее именно вам. У меня в примере неговорящие названия элементов — все как один будут field.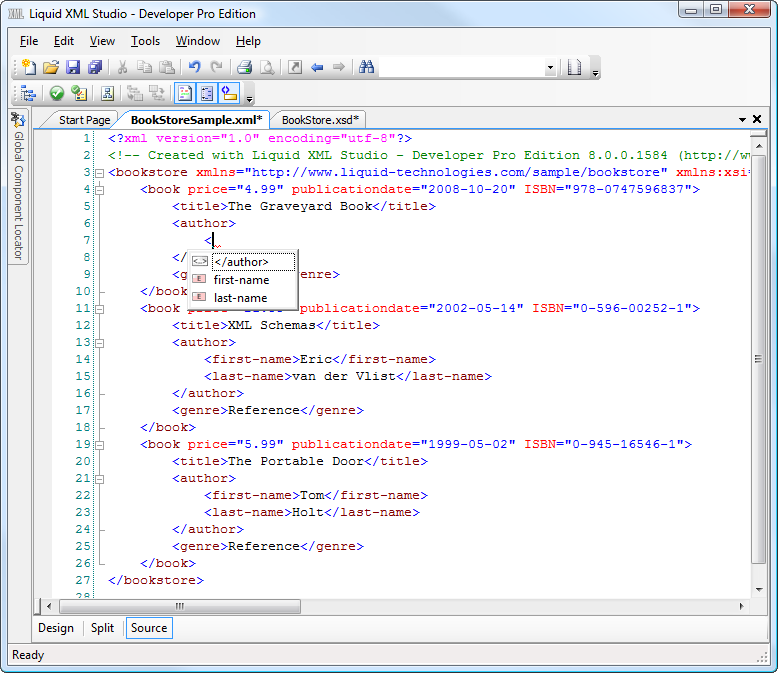 А вот по атрибутам уже можно понять, что это такое.
А вот по атрибутам уже можно понять, что это такое.
Помимо элементов field в party есть элемент attribute. Не путайте xml-нотацию и бизнес-прочтение:
- с точки зрения бизнеса это атрибут физ лица, отсюда и название элемента — attribute.
- с точки зрения xml — это элемент (не атрибут!), просто его назвали attribute. XML все равно (почти), как вы будете называть элементы, так что это допустимо.
У элемента attribute есть атрибуты:
- type = «PHONE» — тип атрибута. Они ведь разные могут быть: телефон, адрес, емейл…
- rawId = «AL.2.PH.1» — идентификатор в исходной системе. Он нужен для обновления. Ведь у одного клиента может быть несколько телефонов, как без ID понять, какой именно обновляется?
Такая вот XML-ка получилась. Причем упрощенная. В реальных системах, где хранятся физ лица, данных сильно больше: штук 20 полей самого физ лица, несколько адресов, телефонов, емейл-адресов…
Но прочитать даже огромную XML не составит труда, если вы знаете, что где. И если она отформатирована — вложенные элементы сдвинуты вправо, остальные на одном уровне. Без форматирования будет тяжеловато…
И если она отформатирована — вложенные элементы сдвинуты вправо, остальные на одном уровне. Без форматирования будет тяжеловато…
А так всё просто — у нас есть элементы, заключенные в теги. Внутри тегов — название элемента. Если после названия идет что-то через пробел: это атрибуты элемента.
XML пролог
Иногда вверху XML документа можно увидеть что-то похожее:
<?xml version="1.0" encoding="UTF-8"?>
Эта строка называется XML прологом. Она показывает версию XML, который используется в документе, а также кодировку. Пролог необязателен, если его нет — это ок. Но если он есть, то это должна быть первая строка XML документа.
UTF-8 — кодировка XML документов по умолчанию.
XSD-схема
XSD (XML Schema Definition) — это описание вашего XML. Как он должен выглядеть, что в нем должно быть? Это ТЗ, написанное на языке машины — ведь схему мы пишем… Тоже в формате XML! Получается XML, который описывает другой XML.
Фишка в том, что проверку по схеме можно делегировать машине. И разработчику даже не надо расписывать каждую проверку. Достаточно сказать «вот схема, проверяй по ней».
Если мы создаем SOAP-метод, то указываем в схеме:
- какие поля будут в запросе;
- какие поля будут в ответе;
- какие типы данных у каждого поля;
- какие поля обязательны для заполнения, а какие нет;
- есть ли у поля значение по умолчанию, и какое оно;
- есть ли у поля ограничение по длине;
- есть ли у поля другие параметры;
- какая у запроса структура по вложенности элементов;
- …
Теперь, когда к нам приходит какой-то запрос, он сперва проверяется на корректность по схеме. Если запрос правильный, запускаем метод, отрабатываем бизнес-логику. А она может быть сложной и ресурсоемкой! Например, сделать выборку из многомиллионной базы. Или провести с десяток проверок по разным таблицам базы данных…
Поэтому зачем запускать сложную процедуру, если запрос заведом «плохой»? И выдавать ошибку через 5 минут, а не сразу? Валидация по схеме помогает быстро отсеять явно невалидные запросы, не нагружая систему.
Более того, похожую защиту ставят и некоторые программы-клиенты для отправки запросов. Например, SOAP Ui умеет проверять ваш запрос на well formed xml, и он просто не отправит его на сервер, если вы облажались. Экономит время на передачу данных, молодец!
А простому пользователю вашего SOAP API схема помогает понять, как составить запрос. Кто такой «простой пользователь»?
- Разработчик системы, использующей ваше API — ему надо прописать в коде, что именно отправлять из его системы в вашу.
- Тестировщик, которому надо это самое API проверить — ему надо понимать, как формируется запрос.
Да-да, в идеале у нас есть подробное ТЗ, где всё хорошо описано. Но увы и ах, такое есть не всегда. Иногда ТЗ просто нет, а иногда оно устарело. А вот схема не устареет, потому что обновляется при обновлении кода. И она как раз помогает понять, как запрос должен выглядеть.
Итого, как используется схема при разработке SOAP API:
- Наш разработчик пишет XSD-схему для API запроса: нужно передать элемент такой-то, у которого будут такие-то дочерние, с такими-то типами данных. Эти обязательные, те нет.
- Разработчик системы-заказчика, которая интегрируется с нашей, читает эту схему и строит свои запросы по ней.
- Система-заказчик отправляет запросы нам.
- Наша система проверяет запросы по XSD — если что-то не так, сразу отлуп.
- Если по XSD запрос проверку прошел — включаем бизнес-логику!
 Эти обязательные, те нет.
Эти обязательные, те нет.А теперь давайте посмотрим, как схема может выглядеть! Возьмем для примера метод doRegister в Users. Чтобы отправить запрос, мы должны передать email, name и password. Есть куча способов написать запрос правильно и неправильно:
Попробуем написать для него схему. В запросе должны быть 3 элемента (email, name, password) с типом «string» (строка). Пишем:
<xs:element name="doRegister ">
<xs:complexType>
<xs:sequence>
<xs:element name="email" type="xs:string"/>
<xs:element name="name" type="xs:string"/>
<xs:element name="password" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>А в WSDl сервиса она записана еще проще:
<message name="doRegisterRequest"> <part name="email" type="xsd:string"/> <part name="name" type="xsd:string"/> <part name="password" type="xsd:string"/> </message>
Конечно, в схеме могут быть не только строковые элементы. Это могут быть числа, даты, boolean-значения и даже какие-то свои типы:
Это могут быть числа, даты, boolean-значения и даже какие-то свои типы:
<xsd:complexType name="Test">
<xsd:sequence>
<xsd:element name="value" type="xsd:string"/>
<xsd:element name="include" type="xsd:boolean" minOccurs="0" default="true"/>
<xsd:element name="count" type="xsd:int" minOccurs="0" length="20"/>
<xsd:element name="user" type="USER" minOccurs="0"/>
</xsd:sequence>
</xsd:complexType>А еще в схеме можно ссылаться на другую схему, что упрощает написание кода — можно переиспользовать схемы для разных задач.
См также:
XSD — умный XML — полезная статья с хабра
Язык определения схем XSD — тут удобные таблички со значениями, которые можно использовать
Язык описания схем XSD (XML-Schema)
Пример XML схемы в учебнике
Официальный сайт w3.org
Практика: составляем свой запрос
Ок, теперь мы знаем, как «прочитать» запрос для API-метода в формате XML. Но как его составить по ТЗ? Давайте попробуем. Смотрим в документацию. И вот почему я даю пример из Дадаты — там классная документация!
Но как его составить по ТЗ? Давайте попробуем. Смотрим в документацию. И вот почему я даю пример из Дадаты — там классная документация!
Что, если я хочу, чтобы мне вернулись только женские ФИО, начинающиеся на «Ан»? Берем наш исходный пример:
<req> <query>Виктор Иван</query> <count>7</count> </req>
В первую очередь меняем сам запрос. Теперь это уже не «Виктор Иван», а «Ан»:
<req> <query>Ан</query> <count>7</count> </req>
Далее смотрим в ТЗ. Как вернуть только женские подсказки? Есть специальный параметр — gender. Название параметра — это название тегов. А внутри уже ставим пол. «Женский» по английски будет FEMALE, в документации также. Итого получили:
<req> <query>Ан</query> <count>7</count> <gender>FEMALE</gender> </req>
Ненужное можно удалить. Если нас не волнует количество подсказок, параметр count выкидываем. Ведь, согласно документации, он необязательный. Получили запрос:
Если нас не волнует количество подсказок, параметр count выкидываем. Ведь, согласно документации, он необязательный. Получили запрос:
<req> <query>Ан</query> <gender>FEMALE</gender> </req>
Вот и все! Взяли за основу пример, поменяли одно значение, один параметр добавили, один удалили. Не так уж и сложно. Особенно, когда есть подробное ТЗ и пример )))
Попробуй сам!
Напишите запрос для метода MagicSearch в Users. Мы хотим найти всех Ивановых по полному совпадению, на которых висят актуальные задачи.
Well Formed XML
Разработчик сам решает, какой XML будет считаться правильным, а какой нет. Но есть общие правила, которые нельзя нарушать. XML должен быть well formed, то есть синтаксически корректный.
Чтобы проверить XML на синтаксис, можно использовать любой XML Validator (так и гуглите). Я рекомендую сайт w3schools. Там есть сам валидатор + описание типичных ошибок с примерами.
В готовый валидатор вы просто вставляете свой XML (например, запрос для сервера) и смотрите, всё ли с ним хорошо. Но можете проверить его и сами. Пройдитесь по правилам синтаксиса и посмотрите, следует ли им ваш запрос.
Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.
Давайте пройдемся по каждому правилу и обсудим, как нам применять их в тестировании. То есть как правильно «ломать» запрос, проверяя его на well-formed xml. Зачем это нужно? Посмотреть на фидбек от системы. Сможете ли вы по тексту ошибки понять, где именно облажались?
См также:
Сообщения об ошибках — тоже документация, тестируйте их! — зачем тестировать сообщения об ошибках
1. Есть корневой элемент
Нельзя просто положить рядышком 2 XML и полагать, что «система сама разберется, что это два запроса, а не один». Не разберется. Потому что не должна.
Не разберется. Потому что не должна.
И если у вас будет лежать несколько тегов подряд без общего родителя — это плохой xml, не well formed. Всегда должен быть корневой элемент:
Что мы делаем для тестирования этого условия? Правильно, удаляем из нашего запроса корневые теги!
2. У каждого элемента есть закрывающийся тег
Тут все просто — если тег где-то открылся, он должен где-то закрыться. Хотите сломать? Удалите закрывающийся тег любого элемента.
Но тут стоит заметить, что тег может быть один. Если элемент пустой, мы можем обойтись одним тегом, закрыв его в конце:
<name/>
Это тоже самое, что передать в нем пустое значение
<name></name>
Аналогично сервер может вернуть нам пустое значение тега. Можно попробовать послать пустые поля в Users в методе FullUpdateUser.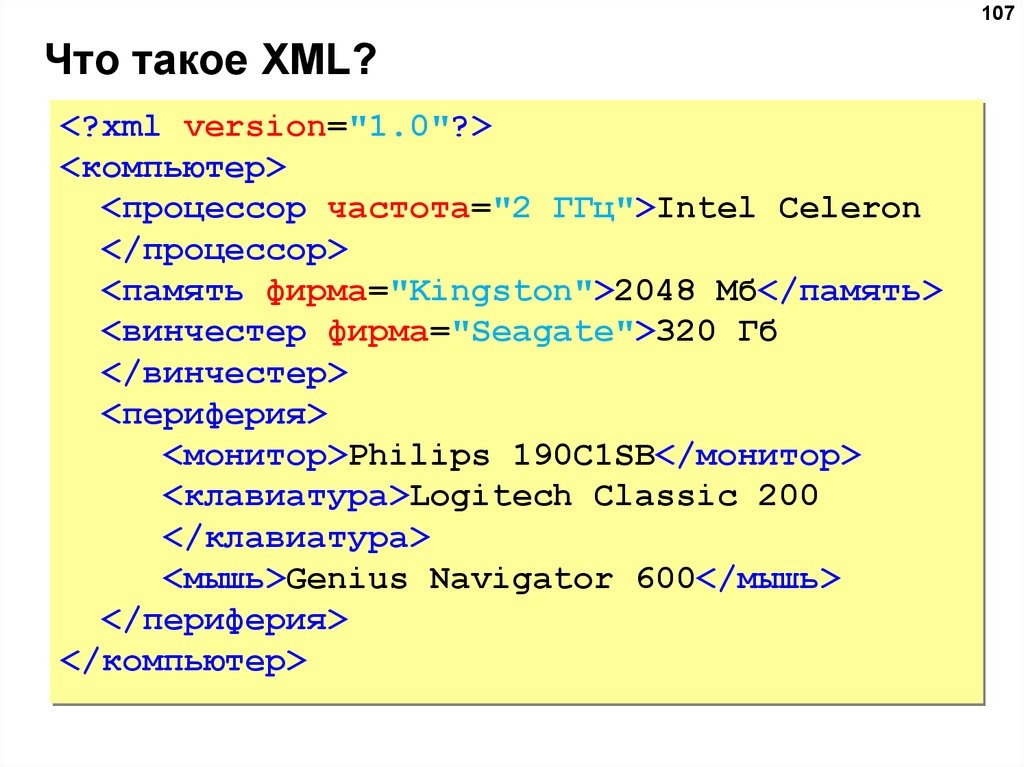 И в запросе это допустимо (я отправила пустым поле name1), и в ответе SOAP Ui нам именно так и отрисовывает пустые поля.
И в запросе это допустимо (я отправила пустым поле name1), и в ответе SOAP Ui нам именно так и отрисовывает пустые поля.
Итого — если есть открывающийся тег, должен быть закрывающийся. Либо это будет один тег со слешом в конце.
Для тестирования удаляем в запросе любой закрывающийся тег.
3. Теги регистрозависимы
Как написали открывающий — также пишем и закрывающий. ТОЧНО ТАК ЖЕ! А не так, как захотелось.
А вот для тестирования меняем регистр одной из частей. Такой XML будет невалидным
4. Правильная вложенность элементов
Элементы могут идти друг за другом
Один элемент может быть вложен в другой
Но накладываться друг на друга элементы НЕ могут!
5. Атрибуты оформлены в кавычках
Даже если вы считаете атрибут числом, он будет в кавычках:
<query attr1=“123”>Виктор Иван</query> <query attr1=“атрибутик” attr2=“123” >Виктор Иван</query>
Для тестирования пробуем передать его без кавычек:
<query attr1=123>Виктор Иван</query>
Итого
XML (eXtensible Markup Language) используется для хранения и передачи данных.
Передача данных — это запросы и ответы в API-методах. Если вы отправляете SOAP-запрос, вы априори работаете именно с этим форматом. Потому что SOAP передает данные только в XML. Если вы используете REST, то там возможны варианты — или XML, или JSON.Хранение данных — это когда XML встречается внутри кода. Его легко понимает как машина, так и человек. В формате XML можно описывать какие-то правила, которые будут применяться к данным, или что-то еще.
Вот пример использования XML в коде open-source проекта folks. Я не знаю, что именно делает JacksonJsonProvider, но могу «прочитать» этот код — есть функционал, который мы будем использовать (featuresToEnable), и есть тот, что нам не нужен(featuresToDisable).
Формат XML подчиняется стандартам. Синтаксически некорректный запрос даже на сервер не уйдет, его еще клиент порежет. Сначала проверка на well formed, потом уже бизнес-логика.
Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.

Если вы тестировщик, то при тестировании запросов в формате XML обязательно попробуйте нарушить каждое правило! Да, система должна уметь обрабатывать такие ошибки и возвращать адекватное сообщение об ошибке. Но далеко не всегда она это делает.
А если система публичная и возвращает пустой ответ на некорректный запрос — это плохо. Потому что разработчик другой системы налажает в запросе, а по пустому ответу даже не поймет, где именно. И будет приставать к поддержке: «Что же у меня не так?», кидая информацию по кусочкам и в виде скринов исходного кода. Оно вам надо? Нет? Тогда убедитесь, что система выдает понятное сообщение об ошибке!
См также:
Что такое XML
Учебник по XML
Изучаем XML. Эрик Рэй (книга по XML)
Заметки о XML и XLST
Что такое JSON — второй популярный формат
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале
А полезные видео — на моем youtube-канале
Что такое XML
Язык XML это программно и аппаратно независимый инструмент, предназначенный для хранения и передачи данных. HTML же предназначен для отображения данных.
Прежде чем продолжить, убедитесь, что вы обладаете базовыми знаниями в HTML. Если вы не знаете что такое HTML, то разобраться в этом вам поможет наш учебник HTML для начинающих. Итак,
Что такое XML?
- XML — аббревиатура от англ. eXtensible Markup Language (англ. Расширяемый язык разметки).
- XML – язык разметки, который напоминает HTML.
- XML предназначен для передачи данных, а не для их отображения.
- Теги XML не предопределены. Вы должны сами определять нужные теги.
- XML описан таким образом, чтобы быть самоопределяемым.
Разница между XML и HTML
XML не является заменой HTML. Они предназначены для решения разных задач: XML решает задачу хранения и транспортировки данных, фокусируясь на том, что такое эти самые данные, HTML же решает задачу отображения данных, фокусируясь на том, как эти данные выглядят. Таким образом, HTML заботится об отображении информации, а XML о транспортировке информации.
Они предназначены для решения разных задач: XML решает задачу хранения и транспортировки данных, фокусируясь на том, что такое эти самые данные, HTML же решает задачу отображения данных, фокусируясь на том, как эти данные выглядят. Таким образом, HTML заботится об отображении информации, а XML о транспортировке информации.
XML ничего не делает
Возможно вам будет несколько странным это узнать, но XML ничего не делает. Он был создан для структурирования, хранения и передачи информации.
Следующий пример представляет некую заметку от Джени к Тови, сохраненную в формате XML:
<?xml version="1.0" encoding="UTF-8"?> <note> <to>Tove</to> <from>Jani</from> <heading>Напоминание</heading> <body>Не забудь обо мне в эти выходные!</body> </note>
Приведенная запись вполне самоописательна:
- Здесь есть информация об отправителе
- Есть информация о получателе
- Присутствует заголовок
- И также есть само сообщение
И при всем при этом данный документ XML не делает ничего. Это просто информация, обернутая в теги.
Это просто информация, обернутая в теги.
Кто-то должен написать программу, которая будет отсылать, получать и отображать эти данные. Например, так:
Заметка
Кому: Tove
От: Jani
Напоминание
Не забудь обо мне в эти выходные!
В XML вы изобретаете свои собственные теги
Теги в вышеприведенном примере (например, <to> и <from>) не определяются никакими стандартами XML. Эти теги были «изобретены» автором этого XML документа.
Все потому, что в языке XML нет предопределенных тегов.
Так, в HTML все используемые теги предопределены. HTML документы могут использовать только те теги, которые определяются в стандартах HTML (<p>, <li> и т. д.).
XML позволяет автору самому определять свои языковые теги и свою структуру документа.
XML легко расширяем
Большинство приложений для работы с XML будут продолжать работать, как и раньше, даже в том случае, если будут добавлены новые данные или какие-то данные будут удалены.
Представьте, что есть некое приложение, которое отображает данные нашего оригинального файла note.xml (с тегами <to>, <from>, <heading>, <body>).
Теперь представьте, что мы получаем новую версию файла note.xml, в котором добавлены теги <date> и <hour> и удален элемент <heading>.
XML разработан таким образом, что старая версия приложения все равно будет работать:
<?xml version="1.0" encoding="UTF-8"?> <note> <date>2015-09-01</date> <hour>08:30</hour> <to>Tove</to> <from>Jani</from> <body>Не забудь обо мне в эти выходные!</body> </note>
Старая версия
Новая версия
Заметка
Кому: Tove
От: Jani
Дата: 2015-09-01 08:30
Не забудь обо мне в эти выходные!
XML – это не замена HTML
XML – это дополнение HTML.
Важно понять, что XML не является заменой HTML. В большинстве веб-приложениях XML используется для транспортировки данных, а HTML для форматирования и отображения данных.
XML — это программно и аппаратно независимый инструмент для транспортировки информации.
XML — везде
В настоящее время XML также важен для сети, как когда-то был важен HTML для рождения современного Интернета. XML – это общий инструмент передачи данных между всеми видами приложений.
404: Страница не найдена
Страница, которую вы пытались открыть по этому адресу, похоже, не существует. Обычно это результат плохой или устаревшей ссылки. Мы извиняемся за любые неудобства.
Что я могу сделать сейчас?
Если вы впервые посещаете TechTarget, добро пожаловать! Извините за обстоятельства, при которых мы встречаемся. Вот куда вы можете пойти отсюда:
Поиск- Пожалуйста, свяжитесь с нами, чтобы сообщить, что эта страница отсутствует, или используйте поле выше, чтобы продолжить поиск
- Наша страница «О нас» содержит дополнительную информацию о сайте, на котором вы находитесь, WhatIs.com.
- Посетите нашу домашнюю страницу и просмотрите наши технические темы
Просмотр по категории
Сеть
-
ACK (подтверждение)
В некоторых протоколах цифровой связи ACK — сокращение от «подтверждение» — относится к сигналу, который устройство посылает, чтобы указать.
.. -
поставщик сетевых услуг (NSP)
Поставщик сетевых услуг (NSP) — это компания, которая владеет, управляет и продает доступ к магистральной инфраструктуре Интернета и …
-
неэкранированная витая пара (UTP)
Неэкранированная витая пара (UTP) — это повсеместно распространенный тип медных кабелей, используемых в телефонной проводке и локальных сетях (LAN).
 ..
.. Безопасность
-
деинициализация
Деинициализация — это часть жизненного цикла сотрудника, в ходе которой лишаются прав доступа к программному обеспечению и сетевым службам.
-
Требования PCI DSS 12
Требования PCI DSS 12 представляют собой набор мер безопасности, которые предприятия должны внедрить для защиты данных кредитных карт и соблюдения …
-
данные держателя карты (CD)
Данные держателя карты (CD) — это любая личная информация (PII), связанная с лицом, у которого есть кредитная или дебетовая карта.

ИТ-директор
-
Общее управление качеством (TQM)
Total Quality Management (TQM) — это система управления, основанная на вере в то, что организация может добиться долгосрочного успеха, …
-
системное мышление
Системное мышление — это целостный подход к анализу, который фокусируется на том, как взаимодействуют составные части системы и как…
-
краудсорсинг
Краудсорсинг — это практика обращения к группе людей для получения необходимых знаний, товаров или услуг.
HRSoftware
-
вовлечения сотрудников
Вовлеченность сотрудников — это эмоциональная и профессиональная связь, которую сотрудник испытывает к своей организации, коллегам и работе.
-
кадровый резерв
Кадровый резерв — это база данных кандидатов на работу, которые могут удовлетворить немедленные и долгосрочные потребности организации.
-
разнообразие, равенство и инклюзивность (DEI)
Разнообразие, равенство и инклюзивность — термин, используемый для описания политики и программ, которые способствуют представительству и …

Обслуживание клиентов
-
требующий оценки
Оценка потребностей — это систематический процесс, в ходе которого изучается, какие критерии должны быть соблюдены для достижения желаемого результата.
-
точка взаимодействия с клиентом
Точка соприкосновения с покупателем — это любой прямой или косвенный контакт покупателя с брендом.
-
устав обслуживания клиентов
Устав обслуживания клиентов — это документ, в котором описывается, как организация обещает работать со своими клиентами наряду с …
Введение в XML — XML: расширяемый язык разметки
XML (расширяемый язык разметки) — это язык разметки, аналогичный HTML, но без предопределенных тегов. Вместо этого вы определяете свои собственные теги, разработанные специально для ваших нужд. Это мощный способ хранения данных в формате, удобном для хранения, поиска и совместного использования. Что наиболее важно, поскольку основной формат XML стандартизирован, если вы делитесь или передаете XML между системами или платформами, локально или через Интернет, получатель все равно может анализировать данные благодаря стандартизированному синтаксису XML.
Вместо этого вы определяете свои собственные теги, разработанные специально для ваших нужд. Это мощный способ хранения данных в формате, удобном для хранения, поиска и совместного использования. Что наиболее важно, поскольку основной формат XML стандартизирован, если вы делитесь или передаете XML между системами или платформами, локально или через Интернет, получатель все равно может анализировать данные благодаря стандартизированному синтаксису XML.
Существует множество языков, основанных на XML, включая XHTML, MathML, SVG, RSS и RDF. Вы также можете определить свои собственные.
Вся структура XML и языков на основе XML построена на тегах.
Объявление XML
XML — объявление не является тегом. Он используется для передачи метаданных документа.
Атрибуты
-
версия -
Используемая версия XML в этом документе.
-
кодирование -
Используемая кодировка в этом документе.
Правильные правила проектирования
Чтобы XML-документ был правильным, должны выполняться следующие условия:
- Документ должен быть правильно сформирован.
- Документ должен соответствовать всем правилам синтаксиса XML.
- Документ должен соответствовать семантическим правилам, которые обычно устанавливаются в схеме XML или DTD ( Определение типа документа) .
Пример
<сообщение>
<предупреждение>
Привет, мир
Теперь давайте посмотрим на исправленную версию того же документа:
<сообщение>
<предупреждение>
Привет, мир
Документ, содержащий неопределенный тег, недействителен. Например, если мы никогда не определяли , документ выше недействителен.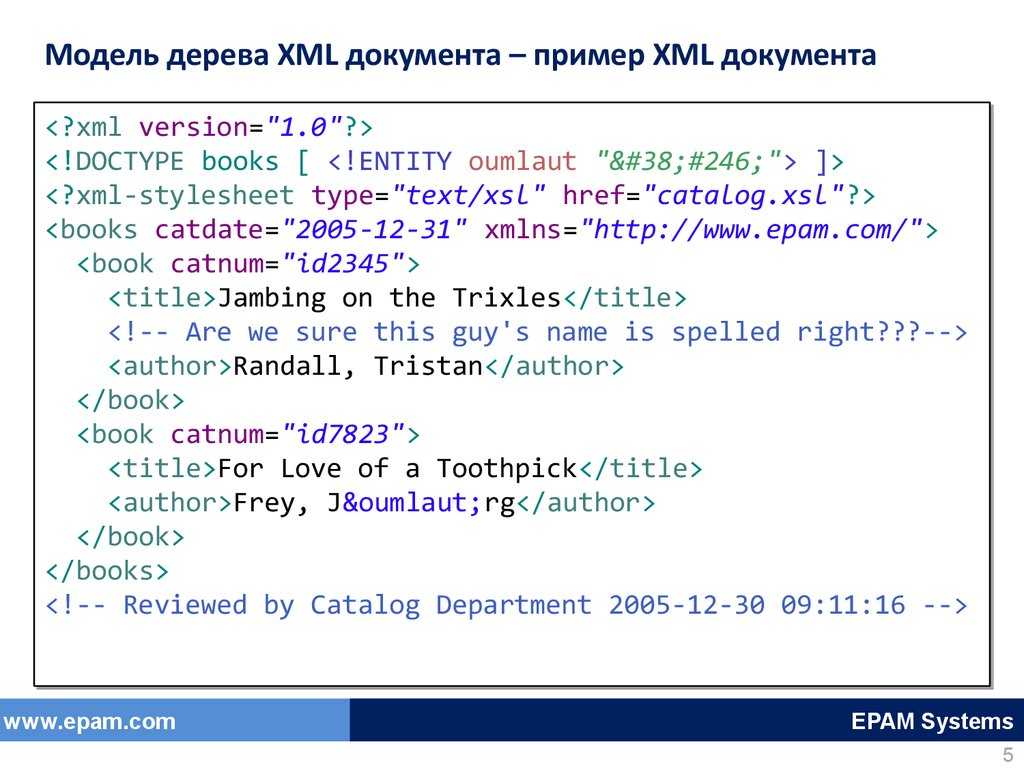
Большинство браузеров предлагают отладчик, который может идентифицировать XML-документы неправильного формата.
Как и HTML, XML предлагает методы (называемые объектами) для ссылки на некоторые специальные зарезервированные символы (например, знак больше, который используется для тегов). Вы должны знать пять таких символов:
| Entity | Персонаж | Описание |
|---|---|---|
| < | < | Знак меньше |
| > | > | Знак больше |
| & | и | Амперсанд |
| " | » | Одна двойная кавычка |
| ‘ | ‘ | Один апостроф (или одинарная кавычка) |
Несмотря на то, что объявлено всего 5 объектов, можно добавить больше, используя определение типа документа. Например, чтобы создать новый
Например, чтобы создать новый &warning; , вы можете сделать это:
]> <тело> <сообщение> &предупреждение;
Вы также можете использовать числовые ссылки на символы для указания специальных символов; например, © является символом «©».
XML обычно используется в описательных целях, но существуют способы отображения XML-данных. Если не указать конкретный способ отображения XML, необработанный XML отображается в браузере.
Один из способов оформления вывода XML — указать CSS для применения к документу с помощью инструкции обработки xml-stylesheet .
Существует еще один более мощный способ отображения XML: Extensible Stylesheet Language Transformations (XSLT), который можно использовать для преобразования XML в другие языки, такие как HTML.