Что такое XML / Хабр
Если вы тестируете API, то должны знать про два основных формата передачи данных:- XML — используется в SOAP (всегда) и REST-запросах (реже);
- JSON — используется в REST-запросах.
XML, в переводе с англ eXtensible Markup Language — расширяемый язык разметки. Используется для хранения и передачи данных. Так что увидеть его можно не только в API, но и в коде.
Этот формат рекомендован Консорциумом Всемирной паутины (W3C), поэтому он часто используется для передачи данных по API. В SOAP API это вообще единственно возможный формат входных и выходных данных!
См также:Так что давайте разберемся, как он выглядит, как его читать, и как ломать! Да-да, а куда же без этого? Надо ведь выяснить, как отреагирует система на кривой формат присланных данных.
Что такое API — общее знакомство с API
Что такое JSON — второй популярный формат
Введение в SOAP и REST: что это и с чем едят — видео про разницу между SOAP и REST.

Содержание
- Как устроен XML
- Теги
- Корневой элемент
- Значение элемента
- Атрибуты элемента
- XML пролог
- XSD-схема
- Практика: составляем свой запрос
- Well Formed XML
- 1. Есть корневой элемент
- 2. У каждого элемента есть закрывающийся тег
- 3. Теги регистрозависимы
- 4. Правильная вложенность элементов
- 5. Атрибуты оформлены в кавычках
- Итого
Как устроен XML
Возьмем пример из документации подсказок Дадаты по ФИО:
<req> <query>Виктор Иван</query> <count>7</count> </req>И разберемся, что означает эта запись.
Теги
В XML каждый элемент должен быть заключен в теги. Тег — это некий текст, обернутый в угловые скобки:<tag>Текст внутри угловых скобок — название тега.

Тега всегда два:
- Открывающий — текст внутри угловых скобок
<tag>
- Закрывающий — тот же текст (это важно!), но добавляется символ «/»
Ой, ну ладно, подловили! Не всегда. Бывают еще пустые элементы, у них один тег и открывающий, и закрывающий одновременно. Но об этом чуть позже!
С помощью тегов мы показываем системе «вот тут начинается элемент, а вот тут заканчивается». Это как дорожные знаки:
— На въезде в город написано его название: Москва
— На выезде написано то же самое название, но перечеркнутое: Москва*
* Пример с дорожными знаками я когда-то давно прочитала в статье Яндекса, только ссылку уже не помню. А пример отличный!
Корневой элемент
В любом XML-документе есть корневой элемент. Это тег, с которого документ начинается, и которым заканчивается. В случае REST API документ — это запрос, который отправляет система.
Чтобы обозначить этот запрос, нам нужен корневой элемент. В подсказках корневой элемент — «req».
Он мог бы называться по другому:
<main>
<sugg>Да как угодно. Он показывает начало и конец нашего запроса, не более того. А вот внутри уже идет тело документа — сам запрос. Те параметры, которые мы передаем внешней системе. Разумеется, они тоже будут в тегах, но уже в обычных, а не корневых.
Значение элемента
Значение элемента хранится между открывающим и закрывающим тегами. Это может быть число, строка, или даже вложенные теги!Вот у нас есть тег «query». Он обозначает запрос, который мы отправляем в подсказки.
Внутри — значение запроса.
Это как если бы мы вбили строку «Виктор Иван» в GUI (графическом интерфейсе пользователя):
Пользователю лишняя обвязка не нужна, ему нужна красивая формочка. А вот системе надо как-то передать, что «пользователь ввел именно это». Как показать ей, где начинается и заканчивается переданное значение? Для этого и используются теги.
Как показать ей, где начинается и заканчивается переданное значение? Для этого и используются теги.
Система видит тег «query» и понимает, что внутри него «строка, по которой нужно вернуть подсказки».
Параметр count = 7 обозначает, сколько подсказок вернуть в ответе. Если тыкать подсказки на демо-форме Дадаты, нам вернется 7 подсказок. Это потому, что туда вшито как раз значение count = 7. А вот если обратиться к документации метода, count можно выбрать от 1 до 20.
Откройте консоль разработчика через f12, вкладку Network, и посмотрите, какой запрос отправляется на сервер. Там будет значение count = 7.Обратите внимание:См также:
Что тестировщику надо знать про панель разработчика — подробнее о том, как использовать консоль.
- Виктор Иван — строка
- 7 — число

Атрибуты элемента
У элемента могут быть атрибуты — один или несколько. Их мы указываем внутри отрывающегося тега после названия тега через пробел в виденазвание_атрибута = «значение атрибута»Например:
<query attr1=“value 1”>Виктор Иван</query> <query attr1=“value 1” attr2=“value 2”>Виктор Иван</query>
Зачем это нужно? Из атрибутов принимающая API-запрос система понимает, что такое ей вообще пришло.
Например, мы делаем поиск по системе, ищем клиентов с именем Олег. Отправляем простой запрос:
<query>Олег</query>А в ответ получаем целую пачку Олегов! С разными датами рождения, номерами телефонов и другими данными. Допустим, что один из результатов поиска выглядит так:
<party type="PHYSICAL" sourceSystem="AL" rawId="2">
<field name=“name">Олег </field>
<field name="birthdate">02.01.1980</field>
<attribute type="PHONE" rawId="AL.
2.PH.1">
<field name="type">MOBILE</field>
<field name="number">+7 916 1234567</field>
</attribute>
</party>
Давайте разберем эту запись. У нас есть основной элемент party.
У него есть 3 атрибута:
- type = «PHYSICAL» — тип возвращаемых данных. Нужен, если система умеет работать с разными типами: ФЛ, ЮЛ, ИП. Тогда благодаря этому атрибуту мы понимаем, с чем именно имеем дело и какие поля у нас будут внутри. А они будут отличаться! У физика это может быть ФИО, дата рождения ИНН, а у юр лица — название компании, ОГРН и КПП
- sourceSystem = «AL» — исходная система. Возможно, нас интересуют только физ лица из одной системы, будем делать отсев по этому атрибуту.
- rawId = «2» — идентификатор в исходной системе. Он нужен, если мы шлем запрос на обновление клиента, а не на поиск. Как понять, кого обновлять? По связке sourceSystem + rawId!
Внутри party есть элементы field.
У элементов field есть атрибут name. Значение атрибута — название поля: имя, дата рождения, тип или номер телефона. Так мы понимаем, что скрывается под конкретным field.
Это удобно с точки зрения поддержки, когда у вас коробочный продукт и 10+ заказчиков. У каждого заказчика будет свой набор полей: у кого-то в системе есть ИНН, у кого-то нету, одному важна дата рождения, другому нет, и т.д.
Но, несмотря на разницу моделей, у всех заказчиков будет одна XSD-схема (которая описывает запрос и ответ):
— есть элемент party;
— у него есть элементы field;
— у каждого элемента field есть атрибут name, в котором хранится название поля.
А вот конкретные названия полей уже можно не описывать в XSD. Их уже «смотрите в ТЗ». Конечно, когда заказчик один или вы делаете ПО для себя или «вообще для всех», удобнее использовать именованные поля — то есть «говорящие» теги. Какие плюшки у этого подхода:
— При чтении XSD сразу видны реальные поля.
— Запрос легко дернуть вручную в SOAP Ui — он сразу создаст все нужные поля, нужно только значениями заполнить. Это удобно тестировщику + заказчик иногда так тестирует, ему тоже хорошо.
В общем, любой подход имеет право на существование. Надо смотреть по проекту, что будет удобнее именно вам. У меня в примере неговорящие названия элементов — все как один будут field. А вот по атрибутам уже можно понять, что это такое.
Помимо элементов field в party есть элемент attribute. Не путайте xml-нотацию и бизнес-прочтение:
- с точки зрения бизнеса это атрибут физ лица, отсюда и название элемента — attribute.
- с точки зрения xml — это элемент (не атрибут!), просто его назвали attribute. XML все равно (почти), как вы будете называть элементы, так что это допустимо.
У элемента attribute есть атрибуты:
- type = «PHONE» — тип атрибута. Они ведь разные могут быть: телефон, адрес, емейл…
- rawId = «AL.2.PH.1» — идентификатор в исходной системе. Он нужен для обновления. Ведь у одного клиента может быть несколько телефонов, как без ID понять, какой именно обновляется?
 Они ведь разные могут быть: телефон, адрес, емейл…
Они ведь разные могут быть: телефон, адрес, емейл…Такая вот XML-ка получилась. Причем упрощенная. В реальных системах, где хранятся физ лица, данных сильно больше: штук 20 полей самого физ лица, несколько адресов, телефонов, емейл-адресов…
Но прочитать даже огромную XML не составит труда, если вы знаете, что где. И если она отформатирована — вложенные элементы сдвинуты вправо, остальные на одном уровне. Без форматирования будет тяжеловато…
А так всё просто — у нас есть элементы, заключенные в теги. Внутри тегов — название элемента. Если после названия идет что-то через пробел: это атрибуты элемента.
XML пролог
Иногда вверху XML документа можно увидеть что-то похожее:<?xml version="1.0" encoding="UTF-8"?>Эта строка называется XML прологом.
 Она показывает версию XML, который используется в документе, а также кодировку. Пролог необязателен, если его нет — это ок. Но если он есть, то это должна быть первая строка XML документа.
Она показывает версию XML, который используется в документе, а также кодировку. Пролог необязателен, если его нет — это ок. Но если он есть, то это должна быть первая строка XML документа.UTF-8 — кодировка XML документов по умолчанию.
XSD-схема
XSD (XML Schema Definition) — это описание вашего XML. Как он должен выглядеть, что в нем должно быть? Это ТЗ, написанное на языке машины — ведь схему мы пишем… Тоже в формате XML! Получается XML, который описывает другой XML.Фишка в том, что проверку по схеме можно делегировать машине. И разработчику даже не надо расписывать каждую проверку. Достаточно сказать «вот схема, проверяй по ней».
Если мы создаем SOAP-метод, то указываем в схеме:
- какие поля будут в запросе;
- какие поля будут в ответе;
- какие типы данных у каждого поля;
- какие поля обязательны для заполнения, а какие нет;
- есть ли у поля значение по умолчанию, и какое оно;
- есть ли у поля ограничение по длине;
- есть ли у поля другие параметры;
- какая у запроса структура по вложенности элементов;
- . ..
 ..
..Поэтому зачем запускать сложную процедуру, если запрос заведом «плохой»? И выдавать ошибку через 5 минут, а не сразу? Валидация по схеме помогает быстро отсеять явно невалидные запросы, не нагружая систему.
Более того, похожую защиту ставят и некоторые программы-клиенты для отправки запросов. Например, SOAP Ui умеет проверять ваш запрос на well formed xml, и он просто не отправит его на сервер, если вы облажались. Экономит время на передачу данных, молодец!
А простому пользователю вашего SOAP API схема помогает понять, как составить запрос. Кто такой «простой пользователь»?
- Разработчик системы, использующей ваше API — ему надо прописать в коде, что именно отправлять из его системы в вашу.
- Тестировщик, которому надо это самое API проверить — ему надо понимать, как формируется запрос.

Итого, как используется схема при разработке SOAP API:
- Наш разработчик пишет XSD-схему для API запроса: нужно передать элемент такой-то, у которого будут такие-то дочерние, с такими-то типами данных. Эти обязательные, те нет.
- Разработчик системы-заказчика, которая интегрируется с нашей, читает эту схему и строит свои запросы по ней.
- Система-заказчик отправляет запросы нам.
- Наша система проверяет запросы по XSD — если что-то не так, сразу отлуп.
- Если по XSD запрос проверку прошел — включаем бизнес-логику!
 Чтобы отправить запрос, мы должны передать email, name и password. Есть куча способов написать запрос правильно и неправильно:
Попробуем написать для него схему. В запросе должны быть 3 элемента (email, name, password) с типом «string» (строка). Пишем:
Чтобы отправить запрос, мы должны передать email, name и password. Есть куча способов написать запрос правильно и неправильно:
Попробуем написать для него схему. В запросе должны быть 3 элемента (email, name, password) с типом «string» (строка). Пишем:<xs:element name="doRegister ">
<xs:complexType>
<xs:sequence>
<xs:element name="email" type="xs:string"/>
<xs:element name="name" type="xs:string"/>
<xs:element name="password" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>
А в WSDl сервиса она записана еще проще:<message name="doRegisterRequest"> <part name="email" type="xsd:string"/> <part name="name" type="xsd:string"/> <part name="password" type="xsd:string"/> </message>Конечно, в схеме могут быть не только строковые элементы. Это могут быть числа, даты, boolean-значения и даже какие-то свои типы:
<xsd:complexType name="Test">
<xsd:sequence>
<xsd:element name="value" type="xsd:string"/>
<xsd:element name="include" type="xsd:boolean" minOccurs="0" default="true"/>
<xsd:element name="count" type="xsd:int" minOccurs="0" length="20"/>
<xsd:element name="user" type="USER" minOccurs="0"/>
</xsd:sequence>
</xsd:complexType>
А еще в схеме можно ссылаться на другую схему, что упрощает написание кода — можно переиспользовать схемы для разных задач.
См также:
XSD — умный XML — полезная статья с хабра
Язык определения схем XSD — тут удобные таблички со значениями, которые можно использовать
Язык описания схем XSD (XML-Schema)
Пример XML схемы в учебнике
Официальный сайт w3.org
Практика: составляем свой запрос
Ок, теперь мы знаем, как «прочитать» запрос для API-метода в формате XML. Но как его составить по ТЗ? Давайте попробуем. Смотрим в документацию. И вот почему я даю пример из Дадаты — там классная документация!Что, если я хочу, чтобы мне вернулись только женские ФИО, начинающиеся на «Ан»? Берем наш исходный пример:
<req> <query>Виктор Иван</query> <count>7</count> </req>В первую очередь меняем сам запрос. Теперь это уже не «Виктор Иван», а «Ан»:
<req> <query>Ан</query> <count>7</count> </req>Далее смотрим в ТЗ. Как вернуть только женские подсказки? Есть специальный параметр — gender.
 Название параметра — это название тегов. А внутри уже ставим пол. «Женский» по английски будет FEMALE, в документации также. Итого получили:
Название параметра — это название тегов. А внутри уже ставим пол. «Женский» по английски будет FEMALE, в документации также. Итого получили:<req> <query>Ан</query> <count>7</count> <gender>FEMALE</gender> </req>Ненужное можно удалить. Если нас не волнует количество подсказок, параметр count выкидываем. Ведь, согласно документации, он необязательный. Получили запрос:
<req> <query>Ан</query> <gender>FEMALE</gender> </req>Вот и все! Взяли за основу пример, поменяли одно значение, один параметр добавили, один удалили. Не так уж и сложно. Особенно, когда есть подробное ТЗ и пример )))
Попробуй сам!
Напишите запрос для метода MagicSearch в Users. Мы хотим найти всех Ивановых по полному совпадению, на которых висят актуальные задачи.
Well Formed XML
Разработчик сам решает, какой XML будет считаться правильным, а какой нет. Но есть общие правила, которые нельзя нарушать. XML должен быть well formed, то есть синтаксически корректный.
Но есть общие правила, которые нельзя нарушать. XML должен быть well formed, то есть синтаксически корректный.
Чтобы проверить XML на синтаксис, можно использовать любой XML Validator (так и гуглите). Я рекомендую сайт w3schools. Там есть сам валидатор + описание типичных ошибок с примерами.
В готовый валидатор вы просто вставляете свой XML (например, запрос для сервера) и смотрите, всё ли с ним хорошо. Но можете проверить его и сами. Пройдитесь по правилам синтаксиса и посмотрите, следует ли им ваш запрос.
Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.
Давайте пройдемся по каждому правилу и обсудим, как нам применять их в тестировании. То есть как правильно «ломать» запрос, проверяя его на well-formed xml. Зачем это нужно? Посмотреть на фидбек от системы. Сможете ли вы по тексту ошибки понять, где именно облажались?
Сможете ли вы по тексту ошибки понять, где именно облажались?
См также:
Сообщения об ошибках — тоже документация, тестируйте их! — зачем тестировать сообщения об ошибках
1. Есть корневой элемент
Нельзя просто положить рядышком 2 XML и полагать, что «система сама разберется, что это два запроса, а не один». Не разберется. Потому что не должна.И если у вас будет лежать несколько тегов подряд без общего родителя — это плохой xml, не well formed. Всегда должен быть корневой элемент:
2. У каждого элемента есть закрывающийся тег
Тут все просто — если тег где-то открылся, он должен где-то закрыться. Хотите сломать? Удалите закрывающийся тег любого элемента.Но тут стоит заметить, что тег может быть один. Если элемент пустой, мы можем обойтись одним тегом, закрыв его в конце:
<name/>Это тоже самое, что передать в нем пустое значение
<name></name>Аналогично сервер может вернуть нам пустое значение тега.
 Можно попробовать послать пустые поля в Users в методе FullUpdateUser. И в запросе это допустимо (я отправила пустым поле name1), и в ответе SOAP Ui нам именно так и отрисовывает пустые поля.
Можно попробовать послать пустые поля в Users в методе FullUpdateUser. И в запросе это допустимо (я отправила пустым поле name1), и в ответе SOAP Ui нам именно так и отрисовывает пустые поля.Итого — если есть открывающийся тег, должен быть закрывающийся. Либо это будет один тег со слешом в конце.
Для тестирования удаляем в запросе любой закрывающийся тег.
3. Теги регистрозависимы
Как написали открывающий — также пишем и закрывающий. ТОЧНО ТАК ЖЕ! А не так, как захотелось.А вот для тестирования меняем регистр одной из частей. Такой XML будет невалидным
4. Правильная вложенность элементов
Элементы могут идти друг за другомОдин элемент может быть вложен в другой
Но накладываться друг на друга элементы НЕ могут!
5. Атрибуты оформлены в кавычках
Даже если вы считаете атрибут числом, он будет в кавычках:<query attr1=“123”>Виктор Иван</query> <query attr1=“атрибутик” attr2=“123” >Виктор Иван</query>Для тестирования пробуем передать его без кавычек:
<query attr1=123>Виктор Иван</query>
Итого
XML (eXtensible Markup Language) используется для хранения и передачи данных.
Передача данных — это запросы и ответы в API-методах. Если вы отправляете SOAP-запрос, вы априори работаете именно с этим форматом. Потому что SOAP передает данные только в XML. Если вы используете REST, то там возможны варианты — или XML, или JSON.Формат XML подчиняется стандартам. Синтаксически некорректный запрос даже на сервер не уйдет, его еще клиент порежет. Сначала проверка на well formed, потом уже бизнес-логика.Хранение данных — это когда XML встречается внутри кода. Его легко понимает как машина, так и человек. В формате XML можно описывать какие-то правила, которые будут применяться к данным, или что-то еще.
Вот пример использования XML в коде open-source проекта folks. Я не знаю, что именно делает JacksonJsonProvider, но могу «прочитать» этот код — есть функционал, который мы будем использовать (featuresToEnable), и есть тот, что нам не нужен(featuresToDisable).
Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.

Если вы тестировщик, то при тестировании запросов в формате XML обязательно попробуйте нарушить каждое правило! Да, система должна уметь обрабатывать такие ошибки и возвращать адекватное сообщение об ошибке. Но далеко не всегда она это делает.
А если система публичная и возвращает пустой ответ на некорректный запрос — это плохо. Потому что разработчик другой системы налажает в запросе, а по пустому ответу даже не поймет, где именно. И будет приставать к поддержке: «Что же у меня не так?», кидая информацию по кусочкам и в виде скринов исходного кода. Оно вам надо? Нет? Тогда убедитесь, что система выдает понятное сообщение об ошибке!
См также:
Что такое XML
Учебник по XML
Изучаем XML. Эрик Рэй (книга по XML)
Заметки о XML и XLST
Что такое JSON — второй популярный формат
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале
А полезные видео — на моем youtube-канале
Что такое XML / Хабр
Если вы тестируете API, то должны знать про два основных формата передачи данных:- XML — используется в SOAP (всегда) и REST-запросах (реже);
- JSON — используется в REST-запросах.
XML, в переводе с англ eXtensible Markup Language — расширяемый язык разметки. Используется для хранения и передачи данных. Так что увидеть его можно не только в API, но и в коде.
Этот формат рекомендован Консорциумом Всемирной паутины (W3C), поэтому он часто используется для передачи данных по API. В SOAP API это вообще единственно возможный формат входных и выходных данных!
См также:Так что давайте разберемся, как он выглядит, как его читать, и как ломать! Да-да, а куда же без этого? Надо ведь выяснить, как отреагирует система на кривой формат присланных данных.
Что такое API — общее знакомство с API
Что такое JSON — второй популярный формат
Введение в SOAP и REST: что это и с чем едят — видео про разницу между SOAP и REST.

Содержание
- Как устроен XML
- Теги
- Корневой элемент
- Значение элемента
- Атрибуты элемента
- XML пролог
- XSD-схема
- Практика: составляем свой запрос
- Well Formed XML
- 1. Есть корневой элемент
- 2. У каждого элемента есть закрывающийся тег
- 3. Теги регистрозависимы
- 4. Правильная вложенность элементов
- 5. Атрибуты оформлены в кавычках
- Итого
Как устроен XML
Возьмем пример из документации подсказок Дадаты по ФИО:
<req> <query>Виктор Иван</query> <count>7</count> </req>И разберемся, что означает эта запись.
Теги
В XML каждый элемент должен быть заключен в теги. Тег — это некий текст, обернутый в угловые скобки:<tag>Текст внутри угловых скобок — название тега.

Тега всегда два:
- Открывающий — текст внутри угловых скобок
<tag>
- Закрывающий — тот же текст (это важно!), но добавляется символ «/»
</tag>
Ой, ну ладно, подловили! Не всегда. Бывают еще пустые элементы, у них один тег и открывающий, и закрывающий одновременно. Но об этом чуть позже!
С помощью тегов мы показываем системе «вот тут начинается элемент, а вот тут заканчивается». Это как дорожные знаки:
— На въезде в город написано его название: Москва
— На выезде написано то же самое название, но перечеркнутое: Москва*
* Пример с дорожными знаками я когда-то давно прочитала в статье Яндекса, только ссылку уже не помню. А пример отличный!
Корневой элемент
В любом XML-документе есть корневой элемент. Это тег, с которого документ начинается, и которым заканчивается. В случае REST API документ — это запрос, который отправляет система. Или ответ, который она получает.
Или ответ, который она получает.Чтобы обозначить этот запрос, нам нужен корневой элемент. В подсказках корневой элемент — «req».
Он мог бы называться по другому:
<main>
<sugg>Да как угодно. Он показывает начало и конец нашего запроса, не более того. А вот внутри уже идет тело документа — сам запрос. Те параметры, которые мы передаем внешней системе. Разумеется, они тоже будут в тегах, но уже в обычных, а не корневых.
Значение элемента
Значение элемента хранится между открывающим и закрывающим тегами. Это может быть число, строка, или даже вложенные теги!Вот у нас есть тег «query». Он обозначает запрос, который мы отправляем в подсказки.
Внутри — значение запроса.
Это как если бы мы вбили строку «Виктор Иван» в GUI (графическом интерфейсе пользователя):
Пользователю лишняя обвязка не нужна, ему нужна красивая формочка. А вот системе надо как-то передать, что «пользователь ввел именно это». Как показать ей, где начинается и заканчивается переданное значение? Для этого и используются теги.
Как показать ей, где начинается и заканчивается переданное значение? Для этого и используются теги.
Система видит тег «query» и понимает, что внутри него «строка, по которой нужно вернуть подсказки».
Параметр count = 7 обозначает, сколько подсказок вернуть в ответе. Если тыкать подсказки на демо-форме Дадаты, нам вернется 7 подсказок. Это потому, что туда вшито как раз значение count = 7. А вот если обратиться к документации метода, count можно выбрать от 1 до 20.
Откройте консоль разработчика через f12, вкладку Network, и посмотрите, какой запрос отправляется на сервер. Там будет значение count = 7.Обратите внимание:См также:
Что тестировщику надо знать про панель разработчика — подробнее о том, как использовать консоль.
- Виктор Иван — строка
- 7 — число

Атрибуты элемента
У элемента могут быть атрибуты — один или несколько. Их мы указываем внутри отрывающегося тега после названия тега через пробел в виденазвание_атрибута = «значение атрибута»Например:
<query attr1=“value 1”>Виктор Иван</query> <query attr1=“value 1” attr2=“value 2”>Виктор Иван</query>
Зачем это нужно? Из атрибутов принимающая API-запрос система понимает, что такое ей вообще пришло.
Например, мы делаем поиск по системе, ищем клиентов с именем Олег. Отправляем простой запрос:
<query>Олег</query>А в ответ получаем целую пачку Олегов! С разными датами рождения, номерами телефонов и другими данными. Допустим, что один из результатов поиска выглядит так:
<party type="PHYSICAL" sourceSystem="AL" rawId="2">
<field name=“name">Олег </field>
<field name="birthdate">02.01.1980</field>
<attribute type="PHONE" rawId="AL. 2.PH.1">
<field name="type">MOBILE</field>
<field name="number">+7 916 1234567</field>
</attribute>
</party>
Давайте разберем эту запись. У нас есть основной элемент party. 2.PH.1">
<field name="type">MOBILE</field>
<field name="number">+7 916 1234567</field>
</attribute>
</party>
2.PH.1">
<field name="type">MOBILE</field>
<field name="number">+7 916 1234567</field>
</attribute>
</party>У него есть 3 атрибута:
- type = «PHYSICAL» — тип возвращаемых данных. Нужен, если система умеет работать с разными типами: ФЛ, ЮЛ, ИП. Тогда благодаря этому атрибуту мы понимаем, с чем именно имеем дело и какие поля у нас будут внутри. А они будут отличаться! У физика это может быть ФИО, дата рождения ИНН, а у юр лица — название компании, ОГРН и КПП
- sourceSystem = «AL» — исходная система. Возможно, нас интересуют только физ лица из одной системы, будем делать отсев по этому атрибуту.
- rawId = «2» — идентификатор в исходной системе. Он нужен, если мы шлем запрос на обновление клиента, а не на поиск. Как понять, кого обновлять? По связке sourceSystem + rawId!
Внутри party есть элементы field.
У элементов field есть атрибут name. Значение атрибута — название поля: имя, дата рождения, тип или номер телефона. Так мы понимаем, что скрывается под конкретным field.
Это удобно с точки зрения поддержки, когда у вас коробочный продукт и 10+ заказчиков. У каждого заказчика будет свой набор полей: у кого-то в системе есть ИНН, у кого-то нету, одному важна дата рождения, другому нет, и т.д.
Но, несмотря на разницу моделей, у всех заказчиков будет одна XSD-схема (которая описывает запрос и ответ):
— есть элемент party;
— у него есть элементы field;
— у каждого элемента field есть атрибут name, в котором хранится название поля.
А вот конкретные названия полей уже можно не описывать в XSD. Их уже «смотрите в ТЗ». Конечно, когда заказчик один или вы делаете ПО для себя или «вообще для всех», удобнее использовать именованные поля — то есть «говорящие» теги. Какие плюшки у этого подхода:
— При чтении XSD сразу видны реальные поля. ТЗ может устареть, а код будет актуален.
ТЗ может устареть, а код будет актуален.
— Запрос легко дернуть вручную в SOAP Ui — он сразу создаст все нужные поля, нужно только значениями заполнить. Это удобно тестировщику + заказчик иногда так тестирует, ему тоже хорошо.
В общем, любой подход имеет право на существование. Надо смотреть по проекту, что будет удобнее именно вам. У меня в примере неговорящие названия элементов — все как один будут field. А вот по атрибутам уже можно понять, что это такое.
Помимо элементов field в party есть элемент attribute. Не путайте xml-нотацию и бизнес-прочтение:
- с точки зрения бизнеса это атрибут физ лица, отсюда и название элемента — attribute.
- с точки зрения xml — это элемент (не атрибут!), просто его назвали attribute. XML все равно (почти), как вы будете называть элементы, так что это допустимо.
У элемента attribute есть атрибуты:
- type = «PHONE» — тип атрибута. Они ведь разные могут быть: телефон, адрес, емейл…
- rawId = «AL.2.PH.1» — идентификатор в исходной системе. Он нужен для обновления. Ведь у одного клиента может быть несколько телефонов, как без ID понять, какой именно обновляется?
Такая вот XML-ка получилась. Причем упрощенная. В реальных системах, где хранятся физ лица, данных сильно больше: штук 20 полей самого физ лица, несколько адресов, телефонов, емейл-адресов…
Но прочитать даже огромную XML не составит труда, если вы знаете, что где. И если она отформатирована — вложенные элементы сдвинуты вправо, остальные на одном уровне. Без форматирования будет тяжеловато…
А так всё просто — у нас есть элементы, заключенные в теги. Внутри тегов — название элемента. Если после названия идет что-то через пробел: это атрибуты элемента.
XML пролог
Иногда вверху XML документа можно увидеть что-то похожее:<?xml version="1.0" encoding="UTF-8"?>Эта строка называется XML прологом.
 Она показывает версию XML, который используется в документе, а также кодировку. Пролог необязателен, если его нет — это ок. Но если он есть, то это должна быть первая строка XML документа.
Она показывает версию XML, который используется в документе, а также кодировку. Пролог необязателен, если его нет — это ок. Но если он есть, то это должна быть первая строка XML документа.UTF-8 — кодировка XML документов по умолчанию.
XSD-схема
XSD (XML Schema Definition) — это описание вашего XML. Как он должен выглядеть, что в нем должно быть? Это ТЗ, написанное на языке машины — ведь схему мы пишем… Тоже в формате XML! Получается XML, который описывает другой XML.Фишка в том, что проверку по схеме можно делегировать машине. И разработчику даже не надо расписывать каждую проверку. Достаточно сказать «вот схема, проверяй по ней».
Если мы создаем SOAP-метод, то указываем в схеме:
- какие поля будут в запросе;
- какие поля будут в ответе;
- какие типы данных у каждого поля;
- какие поля обязательны для заполнения, а какие нет;
- есть ли у поля значение по умолчанию, и какое оно;
- есть ли у поля ограничение по длине;
- есть ли у поля другие параметры;
- какая у запроса структура по вложенности элементов;
- . ..
 ..
..Поэтому зачем запускать сложную процедуру, если запрос заведом «плохой»? И выдавать ошибку через 5 минут, а не сразу? Валидация по схеме помогает быстро отсеять явно невалидные запросы, не нагружая систему.
Более того, похожую защиту ставят и некоторые программы-клиенты для отправки запросов. Например, SOAP Ui умеет проверять ваш запрос на well formed xml, и он просто не отправит его на сервер, если вы облажались. Экономит время на передачу данных, молодец!
А простому пользователю вашего SOAP API схема помогает понять, как составить запрос. Кто такой «простой пользователь»?
- Разработчик системы, использующей ваше API — ему надо прописать в коде, что именно отправлять из его системы в вашу.
- Тестировщик, которому надо это самое API проверить — ему надо понимать, как формируется запрос.

Итого, как используется схема при разработке SOAP API:
- Наш разработчик пишет XSD-схему для API запроса: нужно передать элемент такой-то, у которого будут такие-то дочерние, с такими-то типами данных. Эти обязательные, те нет.
- Разработчик системы-заказчика, которая интегрируется с нашей, читает эту схему и строит свои запросы по ней.
- Система-заказчик отправляет запросы нам.
- Наша система проверяет запросы по XSD — если что-то не так, сразу отлуп.
- Если по XSD запрос проверку прошел — включаем бизнес-логику!
 Чтобы отправить запрос, мы должны передать email, name и password. Есть куча способов написать запрос правильно и неправильно:
Попробуем написать для него схему. В запросе должны быть 3 элемента (email, name, password) с типом «string» (строка). Пишем:
Чтобы отправить запрос, мы должны передать email, name и password. Есть куча способов написать запрос правильно и неправильно:
Попробуем написать для него схему. В запросе должны быть 3 элемента (email, name, password) с типом «string» (строка). Пишем:<xs:element name="doRegister ">
<xs:complexType>
<xs:sequence>
<xs:element name="email" type="xs:string"/>
<xs:element name="name" type="xs:string"/>
<xs:element name="password" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>
А в WSDl сервиса она записана еще проще:<message name="doRegisterRequest"> <part name="email" type="xsd:string"/> <part name="name" type="xsd:string"/> <part name="password" type="xsd:string"/> </message>Конечно, в схеме могут быть не только строковые элементы. Это могут быть числа, даты, boolean-значения и даже какие-то свои типы:
<xsd:complexType name="Test">
<xsd:sequence>
<xsd:element name="value" type="xsd:string"/>
<xsd:element name="include" type="xsd:boolean" minOccurs="0" default="true"/>
<xsd:element name="count" type="xsd:int" minOccurs="0" length="20"/>
<xsd:element name="user" type="USER" minOccurs="0"/>
</xsd:sequence>
</xsd:complexType>
А еще в схеме можно ссылаться на другую схему, что упрощает написание кода — можно переиспользовать схемы для разных задач.
См также:
XSD — умный XML — полезная статья с хабра
Язык определения схем XSD — тут удобные таблички со значениями, которые можно использовать
Язык описания схем XSD (XML-Schema)
Пример XML схемы в учебнике
Официальный сайт w3.org
Практика: составляем свой запрос
Ок, теперь мы знаем, как «прочитать» запрос для API-метода в формате XML. Но как его составить по ТЗ? Давайте попробуем. Смотрим в документацию. И вот почему я даю пример из Дадаты — там классная документация!Что, если я хочу, чтобы мне вернулись только женские ФИО, начинающиеся на «Ан»? Берем наш исходный пример:
<req> <query>Виктор Иван</query> <count>7</count> </req>В первую очередь меняем сам запрос. Теперь это уже не «Виктор Иван», а «Ан»:
<req> <query>Ан</query> <count>7</count> </req>Далее смотрим в ТЗ. Как вернуть только женские подсказки? Есть специальный параметр — gender.
 Название параметра — это название тегов. А внутри уже ставим пол. «Женский» по английски будет FEMALE, в документации также. Итого получили:
Название параметра — это название тегов. А внутри уже ставим пол. «Женский» по английски будет FEMALE, в документации также. Итого получили:<req> <query>Ан</query> <count>7</count> <gender>FEMALE</gender> </req>Ненужное можно удалить. Если нас не волнует количество подсказок, параметр count выкидываем. Ведь, согласно документации, он необязательный. Получили запрос:
<req> <query>Ан</query> <gender>FEMALE</gender> </req>Вот и все! Взяли за основу пример, поменяли одно значение, один параметр добавили, один удалили. Не так уж и сложно. Особенно, когда есть подробное ТЗ и пример )))
Попробуй сам!
Напишите запрос для метода MagicSearch в Users. Мы хотим найти всех Ивановых по полному совпадению, на которых висят актуальные задачи.
Well Formed XML
Разработчик сам решает, какой XML будет считаться правильным, а какой нет. Но есть общие правила, которые нельзя нарушать. XML должен быть well formed, то есть синтаксически корректный.
Но есть общие правила, которые нельзя нарушать. XML должен быть well formed, то есть синтаксически корректный.
Чтобы проверить XML на синтаксис, можно использовать любой XML Validator (так и гуглите). Я рекомендую сайт w3schools. Там есть сам валидатор + описание типичных ошибок с примерами.
В готовый валидатор вы просто вставляете свой XML (например, запрос для сервера) и смотрите, всё ли с ним хорошо. Но можете проверить его и сами. Пройдитесь по правилам синтаксиса и посмотрите, следует ли им ваш запрос.
Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.
Давайте пройдемся по каждому правилу и обсудим, как нам применять их в тестировании. То есть как правильно «ломать» запрос, проверяя его на well-formed xml. Зачем это нужно? Посмотреть на фидбек от системы. Сможете ли вы по тексту ошибки понять, где именно облажались?
Сможете ли вы по тексту ошибки понять, где именно облажались?
См также:
Сообщения об ошибках — тоже документация, тестируйте их! — зачем тестировать сообщения об ошибках
1. Есть корневой элемент
Нельзя просто положить рядышком 2 XML и полагать, что «система сама разберется, что это два запроса, а не один». Не разберется. Потому что не должна.И если у вас будет лежать несколько тегов подряд без общего родителя — это плохой xml, не well formed. Всегда должен быть корневой элемент:
2. У каждого элемента есть закрывающийся тег
Тут все просто — если тег где-то открылся, он должен где-то закрыться. Хотите сломать? Удалите закрывающийся тег любого элемента.Но тут стоит заметить, что тег может быть один. Если элемент пустой, мы можем обойтись одним тегом, закрыв его в конце:
<name/>Это тоже самое, что передать в нем пустое значение
<name></name>Аналогично сервер может вернуть нам пустое значение тега.
 Можно попробовать послать пустые поля в Users в методе FullUpdateUser. И в запросе это допустимо (я отправила пустым поле name1), и в ответе SOAP Ui нам именно так и отрисовывает пустые поля.
Можно попробовать послать пустые поля в Users в методе FullUpdateUser. И в запросе это допустимо (я отправила пустым поле name1), и в ответе SOAP Ui нам именно так и отрисовывает пустые поля.Итого — если есть открывающийся тег, должен быть закрывающийся. Либо это будет один тег со слешом в конце.
Для тестирования удаляем в запросе любой закрывающийся тег.
3. Теги регистрозависимы
Как написали открывающий — также пишем и закрывающий. ТОЧНО ТАК ЖЕ! А не так, как захотелось.А вот для тестирования меняем регистр одной из частей. Такой XML будет невалидным
4. Правильная вложенность элементов
Элементы могут идти друг за другомОдин элемент может быть вложен в другой
Но накладываться друг на друга элементы НЕ могут!
5. Атрибуты оформлены в кавычках
Даже если вы считаете атрибут числом, он будет в кавычках:<query attr1=“123”>Виктор Иван</query> <query attr1=“атрибутик” attr2=“123” >Виктор Иван</query>Для тестирования пробуем передать его без кавычек:
<query attr1=123>Виктор Иван</query>
Итого
XML (eXtensible Markup Language) используется для хранения и передачи данных.
Передача данных — это запросы и ответы в API-методах. Если вы отправляете SOAP-запрос, вы априори работаете именно с этим форматом. Потому что SOAP передает данные только в XML. Если вы используете REST, то там возможны варианты — или XML, или JSON.Формат XML подчиняется стандартам. Синтаксически некорректный запрос даже на сервер не уйдет, его еще клиент порежет. Сначала проверка на well formed, потом уже бизнес-логика.Хранение данных — это когда XML встречается внутри кода. Его легко понимает как машина, так и человек. В формате XML можно описывать какие-то правила, которые будут применяться к данным, или что-то еще.
Вот пример использования XML в коде open-source проекта folks. Я не знаю, что именно делает JacksonJsonProvider, но могу «прочитать» этот код — есть функционал, который мы будем использовать (featuresToEnable), и есть тот, что нам не нужен(featuresToDisable).
Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.

Если вы тестировщик, то при тестировании запросов в формате XML обязательно попробуйте нарушить каждое правило! Да, система должна уметь обрабатывать такие ошибки и возвращать адекватное сообщение об ошибке. Но далеко не всегда она это делает.
А если система публичная и возвращает пустой ответ на некорректный запрос — это плохо. Потому что разработчик другой системы налажает в запросе, а по пустому ответу даже не поймет, где именно. И будет приставать к поддержке: «Что же у меня не так?», кидая информацию по кусочкам и в виде скринов исходного кода. Оно вам надо? Нет? Тогда убедитесь, что система выдает понятное сообщение об ошибке!
См также:
Что такое XML
Учебник по XML
Изучаем XML. Эрик Рэй (книга по XML)
Заметки о XML и XLST
Что такое JSON — второй популярный формат
PS — больше полезных статей ищите в моем блоге по метке «полезное».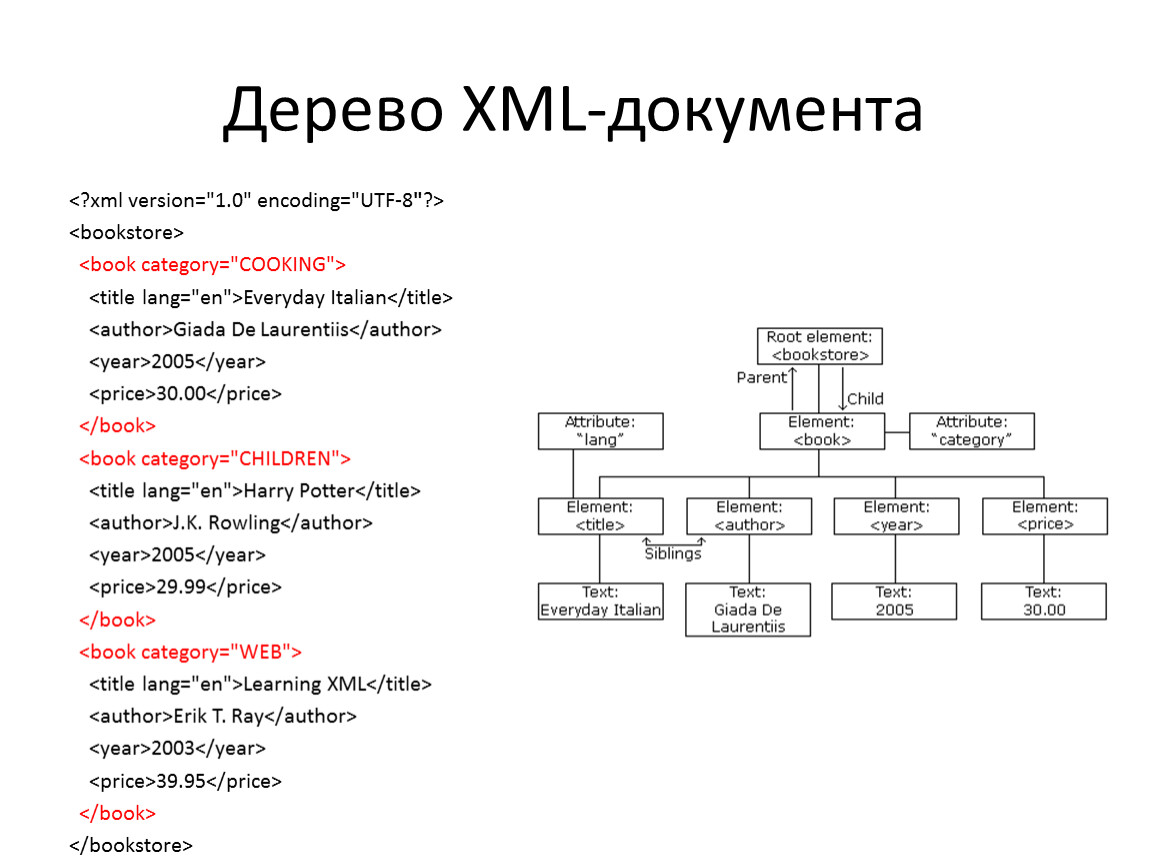 А полезные видео — на моем youtube-канале
А полезные видео — на моем youtube-канале
Понимание XML, его элементов и преимуществ | Spiceworks
- Расширяемый язык разметки (XML) определяется как язык разметки, который описывает правила и протоколы, используемые для определения, хранения и обмена данными между компьютерными системами.
- В этой статье подробно объясняется XML, его ключевые элементы и преимущества.
Содержание
- Что такое XML?
- Ключевые элементы XML
- Преимущества использования XML
Что такое XML?
Расширяемый язык разметки (XML) — это язык разметки, описывающий правила и протоколы, используемые для определения, хранения и обмена данными между компьютерными системами. Эти правила упрощают обмен данными между веб-сайтами, приложениями и базами данных в любой сети. Благодаря их удобочитаемости для человека и машины стороны, участвующие в обмене данными, могут легко читать и расшифровывать данные, скрытые в XML-файлах.
Язык XML не может выполнять операции вычисления данных. Вместо этого он полагается на другие языки программирования или программное обеспечение. В результате он обеспечивает структурированное управление данными документов и файлов. Например, рассмотрим простой текстовый документ, который позволяет добавлять предложения с помощью комментариев. Комментариев может быть:
- Выделите подзаголовок курсивом.
- Изменить имя автора.
- Обновите верхний и нижний колонтитулы документа.
Подобные комментарии повышают удобство использования текста, не затрагивая содержание документа. Как и в приведенном выше примере, XML опирается на символы разметки или теги, которые предоставляют дополнительную информацию о базовых файлах. Используя эту информацию, другое программное обеспечение или приложения могут более эффективно выполнять задачи по обработке данных. Он также обеспечивает целостность структурированных данных.
Теги XML
В XML символы разметки, также называемые тегами, определяют данные или файлы. Давайте разберемся на примере. Для представления данных фильма, основанного на романе, вы можете создать такие теги, как
Давайте разберемся на примере. Для представления данных фильма, основанного на романе, вы можете создать такие теги, как
Теги XML, подобные этим, обеспечивают систематическое кодирование данных, которое раскрывает поток информации между вычислительными системами. Это означает, что программное обеспечение может использовать эти теги для определения стратегий обработки данных документа. Например, вы можете определить, как должен обрабатываться документ или файл, порядок обработки и даже порядок отображения файла.
Эти теги или элементы являются фундаментальными для XML. Даже если вы передаете XML-файлы по разным сетям или платформам через Интернет, система-получатель все равно может анализировать данные в этих XML-файлах. В первую очередь это связано со стандартизированным форматом XML, который остается одинаковым во всех системах.
Кроме того, XML позволяет создавать или определять собственный язык. Например, такие языки, как XHTML, Mathematical Markup Language (MathML) и SVG, создаются с использованием метаязыка XML.
XML против HTML
Язык HTML был специально разработан для отображения документов в веб-браузерах. Однако с появлением мобильных устройств отображение данных на них усложнилось. Кроме того, сложные задачи, такие как перевод содержимого файла с одного языка на другой, были практически невозможны. Было очевидно, что у HTML есть серьезное узкое место, поскольку язык изначально был разработан только для создания веб-документов, которыми можно было поделиться с другими.
XML стал преемником HTML. Он не только подходил для веб-приложений, но и мог выполнять другие сложные задачи, такие как перевод документов между разными языками или отображение контента на устройствах с разными размерами экрана. В отличие от HTML, который был разработан для представления и отображения данных, он может хранить и передавать данные. Кроме того, HTML использует предопределенные теги, тогда как XML позволяет создавать и определять собственные теги.
Кроме того, HTML использует предопределенные теги, тогда как XML позволяет создавать и определять собственные теги.
Таким образом, HTML можно назвать языком, используемым для представления документов, а XML предназначен для описания документов.
Подробнее: Что такое язык программирования COBOL? Определение, примеры, использование и проблемы
Ключевые элементы XML
Файл XML похож на любой текстовый документ, который позволяет записывать и сохранять данные. Он имеет расширение «.xml». Файл можно создать или отредактировать с помощью любого из следующих средств:
- Приложения для создания заметок или редакторы, такие как Notepad или Notepad++
- Любой веб-редактор файлов XML, например Emacs или Adobe FrameMaker
- Браузеры или другое коммуникационное программное обеспечение
Типичный XML-файл состоит из следующих ключевых компонентов:
Ключевые элементы XML
1. XML-документ
XML-файл начинается с тегов Данные, записанные между этими тегами, являются частью XML-документа. Программное обеспечение для обработки XML использует эти специальные теги в качестве опорных точек для вычисления кода XML.
2. Объявление XML
Файл XML имеет открывающее объявление, определяющее версию XML, используемую в документе. Он инициирует XML-процессор для разбора XML-документа. Он имеет следующий синтаксис:
версия = «номер_версии»
encoding = «объявление_кодирования»
standalone = «standalone_status»
?>
Здесь version = стандартная версия XML, encoding = кодировка символов, standalone = данные, которые информируют синтаксический анализатор, если XML-документ использует информацию из внешнего источника.
Простым примером такого синтаксиса может быть:
3. Элементы XML
Остальные теги в документе XML, за исключением тегов вышеуказанных компонентов, помечаются как элементы XML. Они содержат такие функции, как текст, атрибуты и другие элементы файла XML. Корневой элемент отмечает начало XML-документа.
Например, давайте напишем XML-код, идентифицирующий офис-менеджеров, которые собираются посетить офисную новогоднюю вечеринку.
<офис>
<менеджеры>
Здесь ,
4. Атрибуты XML
Атрибуты XML относятся к дескрипторам, предоставляющим сведения об элементах XML. Вы можете написать имена атрибутов и соответствующие значения в кавычках.
Например,
5. Содержимое XML
Данные, встроенные в файлы XML, называются содержимым XML.
Например,
Здесь значения Дональд и Брендон описываются как XML содержание .
6. XML-схема
XML-схема устанавливает границы файловой структуры XML. Он выражает правила и ограничения, которым должен подчиняться XML-документ.
Например,
- Порядок элементов XML определяется правилами грамматики текста
- Критерии, которым должен соответствовать XML-контент (т. е. условия «Да» или «Нет»)
- Типы данных содержимого XML
Рассмотрим схему XML для библиотеки, которая устанавливает следующие ограничения:
Элемент библиотеки может иметь атрибуты книги и предмета.
- Элемент библиотеки будет подпадать под элемент вложенной категории и также будет иметь имя атрибута
- Автор книги будет отдельным элементом под вложенным библиотечным элементом
Вышеупомянутые ограничения соблюдаются путем написания XML-кода, как показано ниже:
<имя категории=«Наука»>
<книга библиотеки=«Биология веры», тема=«Сознание»>
<автор>Брюс Lipton
Схемы XML позволяют программным приложениям легко создавать файлы XML и управлять ими. Отрасли обычно занимаются передачей данных между предприятиями. В результате несколько компаний внедряют XML-схемы, которые соответствуют их бизнес-операциям и помогают сократить усилия и ресурсы, затрачиваемые на написание XML-кода, предназначенного для обмена информацией.
Отрасли обычно занимаются передачей данных между предприятиями. В результате несколько компаний внедряют XML-схемы, которые соответствуют их бизнес-операциям и помогают сократить усилия и ресурсы, затрачиваемые на написание XML-кода, предназначенного для обмена информацией.
Например, Scalable Vector Graphics (SVG) — это язык на основе XML, который задает ограничения, связанные с векторной графикой. Разработчики используют язык SVG для удовлетворения отраслевых требований и удовлетворения потребностей в передаче данных, которые могут возникнуть в будущих бизнес-сценариях.
7. Анализатор XML
Анализатор XML относится к программному обеспечению, которое проверяет файлы XML путем оценки их синтаксиса. Впоследствии он обрабатывает или считывает XML-документы для извлечения соответствующей информации. Кроме того, он также проверяет, подчиняется ли файл XML правилам схемы XML.
В случае синтаксических ошибок синтаксический анализатор отклоняет файл XML и не обрабатывает его. Например, синтаксический анализатор XML выдает ошибки в следующих ситуациях:
Например, синтаксический анализатор XML выдает ошибки в следующих ситуациях:
- Отсутствуют открывающие или закрывающие теги
- Атрибуты XML без кавычек
- XML-файл не соответствует ограничениям схемы
Подробнее: Веб-разработчик: описание работы, ключевые навыки и зарплата в 2022 году
Преимущества использования XML
В реальных условиях вычислительные системы часто сталкиваются с проблемой управления несовместимыми форматами данных. В результате связь и обмен данными между отдельными наборами устройств и баз данных затруднены. В таких случаях XML представляет собой стоящее решение, которое устраняет разрыв в общении между предприятиями.
Давайте рассмотрим некоторые ключевые преимущества использования XML.
Преимущества XML
1. Стимулирует межкоммерческие сделки
Компании, как правило, сотрудничают, продавая друг другу свои услуги или товары. Такие деловые связи происходят на фоне интенсивного обмена информацией между участвующими организациями. Чтобы обеспечить беспрепятственные деловые операции между ними, такая информация, как стоимость услуг, спецификации продуктов или графики поставок, должна передаваться своевременно и понятно.
Чтобы обеспечить беспрепятственные деловые операции между ними, такая информация, как стоимость услуг, спецификации продуктов или графики поставок, должна передаваться своевременно и понятно.
Здесь XML играет ключевую роль. XML позволяет обмениваться информацией между компаниями в электронном формате. Организации могут положиться на него, чтобы продвигать и продвигать деловые диалоги без вмешательства человека.
2. Обеспечивает целостность данных
XML обеспечивает целостность данных при обмене данными между несколькими операционными системами, приложениями или браузерами. Это связано со способностью XML передавать описание данных вместе с самими данными. Описательная информация файла XML может использоваться для следующих целей:
- Для оценки точности данных
- Представление данных различным пользователям индивидуализированным образом
- Поддерживайте согласованность в хранении данных на разных платформах.
3. Оптимизация операций поиска
Благодаря XML программы, лежащие в основе поисковых систем, могут классифицировать и разделять документы XML более эффективно, чем документы любого другого типа. Например, слово может действовать как существительное или прилагательное в зависимости от того, где оно используется в предложении. Поисковые системы используют теги XML для точной классификации на основе их использования. В результате поисковая система показывает релевантные результаты поиска и отсеивает бессмысленные. Следовательно, XML является ключом к повышению эффективности поиска, позволяя компьютерам правильно интерпретировать естественные языки.
Например, слово может действовать как существительное или прилагательное в зависимости от того, где оно используется в предложении. Поисковые системы используют теги XML для точной классификации на основе их использования. В результате поисковая система показывает релевантные результаты поиска и отсеивает бессмысленные. Следовательно, XML является ключом к повышению эффективности поиска, позволяя компьютерам правильно интерпретировать естественные языки.
4. Поддержка гибких приложений
Некоторые современные технологии имеют встроенную поддержку XML. Это позволяет легко изменять или обновлять дизайн приложений. Благодаря поддержке XML XML-документы можно читать и обрабатывать без внесения каких-либо изменений в формат данных баз данных.
5. Международный стандарт
XML — это стандарт, управляемый Консорциумом World Wide Web (W3C), который занимается внедрением веб-стандартов. Он не привязан к какой-либо конкретной компании или приложению. Кроме того, благодаря гибкости XML файлы можно создавать и редактировать с помощью любого текстового или XML-редактора на любой платформе. В результате XML-документы подходят для распределенных приложений, которым требуется общий формат представления данных.
В результате XML-документы подходят для распределенных приложений, которым требуется общий формат представления данных.
6. Позволяет повторно использовать содержимое
Язык XML поддерживает повторное использование содержимого. Это означает, что вы можете создать документ XML, а затем повторно использовать содержимое документа для создания различных документов, поддерживаемых различными платформами или приложениями. Это экономит компаниям много денег, поскольку XML-файлы, однажды созданные, можно повторно использовать повторно для различных приложений, которые подходят разным аудиториям.
Например, eXtensible Stylesheet Language Transformations (XSLT) — это спецификация XML, предназначенная для преобразования XML-файлов в другие форматы, такие как HTML, что позволяет повторно использовать содержимое XML для веб-приложений, мобильных приложений, социальных сетей и даже контекстов Web 2.0.
Другим примером является DITA (Открытая Дарвиновская архитектура типизации информации OASIS). Этот стандарт на основе XML был первоначально разработан IBM в 2000-х годах для структурирования, публикации и повторного использования контента в документации по продукту. DITA снижает вероятность человеческой ошибки (например, копирования и вставки) при документировании продуктов. Кроме того, он обеспечивает автоматизированный способ синхронизации обновлений содержимого в различных документах по продуктам. Ведущие компании, такие как Cisco, Nokia, Oracle и IBM, широко использовали DITA для технической документации.
Этот стандарт на основе XML был первоначально разработан IBM в 2000-х годах для структурирования, публикации и повторного использования контента в документации по продукту. DITA снижает вероятность человеческой ошибки (например, копирования и вставки) при документировании продуктов. Кроме того, он обеспечивает автоматизированный способ синхронизации обновлений содержимого в различных документах по продуктам. Ведущие компании, такие как Cisco, Nokia, Oracle и IBM, широко использовали DITA для технической документации.
7. Обновлен стиль форматирования
Формат файла XML остается изолированным от содержимого XML. Это означает, что файлы форматирования XML помещаются в отдельные таблицы стилей. Такая функциональность позволяет вам обновлять формат документа всякий раз, когда возникает необходимость, не беспокоясь о содержимом XML. Кроме того, различные наборы документов могут, таким образом, принять согласованный стиль форматирования.
8. Способствует эффективному написанию XML-документов
XML поддерживает многоязычную публикацию. Это позволяет вам работать с документами на разных языках, полученными из одного исходного XML-файла. В результате стоимость языкового перевода значительно снижается. Таким образом, XML позволяет создавать и публиковать документы на разных языках. Кроме того, вам не нужно беспокоиться о формате документа, поскольку исходный стиль форматирования XML-файлов легко применяется к новым документам при публикации документа.
Это позволяет вам работать с документами на разных языках, полученными из одного исходного XML-файла. В результате стоимость языкового перевода значительно снижается. Таким образом, XML позволяет создавать и публиковать документы на разных языках. Кроме того, вам не нужно беспокоиться о формате документа, поскольку исходный стиль форматирования XML-файлов легко применяется к новым документам при публикации документа.
Основные области применения XML
Технология XML используется в различных приложениях, от простого программного обеспечения для обработки текста, веб-публикаций и онлайн-бизнеса до сложного управления конфигурацией программного обеспечения. Такие компании, как Salesforce, Foretag, Scopeland Technology GmbH и многие другие, используют XML для веб-приложений, электронного бизнеса и портативных приложений.
Давайте рассмотрим некоторые ключевые XML-приложения в современном мире.
- Интернет-публикации: XML часто используется для создания интуитивно понятных, но настраиваемых приложений электронной коммерции, включающих интерактивные веб-страницы. XML позволяет единовременно создавать контент, который можно использовать на разных устройствах или в разных представлениях. Например, процессоры XSLT определяют формат, в котором должно отображаться содержимое XML.
- Эффективный веб-поиск: В качестве примера рассмотрим веб-страницы на основе HTML. Допустим, вы выполняете поиск в Интернете исследовательских работ, автором которых является Стивен Хокинг, в поисковой системе. В этом случае в результатах поиска могут быть случаи, когда слово «Хокинг» вырвано из контекста. Однако язык XML решает эту проблему, назначая соответствующий тег (тег
). Это гарантирует, что веб-поиск покажет только релевантные результаты. - Бизнес-приложения: XML является ключом к электронному обмену данными (EDI) между предприятиями и потенциальными клиентами. Это способ обмена информацией, который регулирует межхозяйственные транзакции.
- Повсеместно распространенные вычислительные приложения: XML гарантирует, что приложения и устройства различных типов могут хранить, отображать, повторно использовать и обмениваться данными между собой. Сюда входят вычислительные устройства, такие как смартфоны, КПК и другие.
 XML позволяет единовременно создавать контент, который можно использовать на разных устройствах или в разных представлениях. Например, процессоры XSLT определяют формат, в котором должно отображаться содержимое XML.
XML позволяет единовременно создавать контент, который можно использовать на разных устройствах или в разных представлениях. Например, процессоры XSLT определяют формат, в котором должно отображаться содержимое XML. Сюда входят вычислительные устройства, такие как смартфоны, КПК и другие.
Сюда входят вычислительные устройства, такие как смартфоны, КПК и другие.Кроме того, несколько других стандартов на основе XML, таких как Wireless Markup Language (WML) и VoiceXML, разработаны для расширения функциональности XML для повсеместно используемых вычислительных приложений. VoiceXML — это стандарт, который разрабатывает распределенные голосовые приложения, тогда как стандарт WML ориентирован на обеспечение доступа к веб-контенту на портативных устройствах, таких как сотовые телефоны, с ограничениями пропускной способности.
Подробнее: Что такое интегрированная среда разработки (IDE)? Значение, программное обеспечение, типы и важность
Вывод
XML — это язык описания данных, который определяет данные в символах разметки или тегах. Иерархический язык используется для хранения и обмена данными между сетевыми системами. Благодаря своей гибкости языковые стандарты вездесущи, от технической документации до компьютерной графики.
Помогла ли вам эта статья понять роль XML в корпоративных вычислениях? Дайте нам знать на FacebookОткрывается в новом окне , Twitter открывает новое окно или LinkedInоткрывает новое окно . Мы хотели бы услышать от вас!
Мы хотели бы услышать от вас!
Источник изображения: Shutterstock.
XML | Определение и факты
- Развлечения и поп-культура
- География и путешествия
- Здоровье и медицина
- Образ жизни и социальные вопросы
- Литература
- Философия и религия
- Политика, право и правительство
- Наука
- Спорт и отдых
- Технология
- Изобразительное искусство
- Всемирная история
- Этот день в истории
- Викторины
- Подкасты
- Словарь
- Биографии
- Резюме
- Популярные вопросы
- Инфографика
- Демистификация
- Списки
- #WTFact
- Товарищи
- Галереи изображений
- Прожектор
- Форум
- Один хороший факт
- Развлечения и поп-культура
- География и путешествия
- Здоровье и медицина
- Образ жизни и социальные вопросы
- Литература
- Философия и религия
- Политика, право и правительство
- Наука
- Спорт и отдых
- Технология
- Изобразительное искусство
- Всемирная история
- Britannica объясняет
В этих видеороликах Britannica объясняет различные темы и отвечает на часто задаваемые вопросы. - Britannica Classics
Посмотрите эти ретро-видео из архивов Encyclopedia Britannica. - Demystified Videos
В Demystified у Britannica есть все ответы на ваши животрепещущие вопросы. - #WTFact Видео
В #WTFact Britannica делится некоторыми из самых странных фактов, которые мы можем найти. - На этот раз в истории
В этих видеороликах узнайте, что произошло в этом месяце (или любом другом месяце!) в истории.

- Студенческий портал
Britannica — лучший ресурс для учащихся по ключевым школьным предметам, таким как история, государственное управление, литература и т. д. - Портал COVID-19
Хотя этот глобальный кризис в области здравоохранения продолжает развиваться, может быть полезно обратиться к прошлым пандемиям, чтобы лучше понять, как реагировать сегодня. - 100 женщин
Britannica празднует столетие Девятнадцатой поправки, выделяя суфражисток и политиков, творящих историю.
