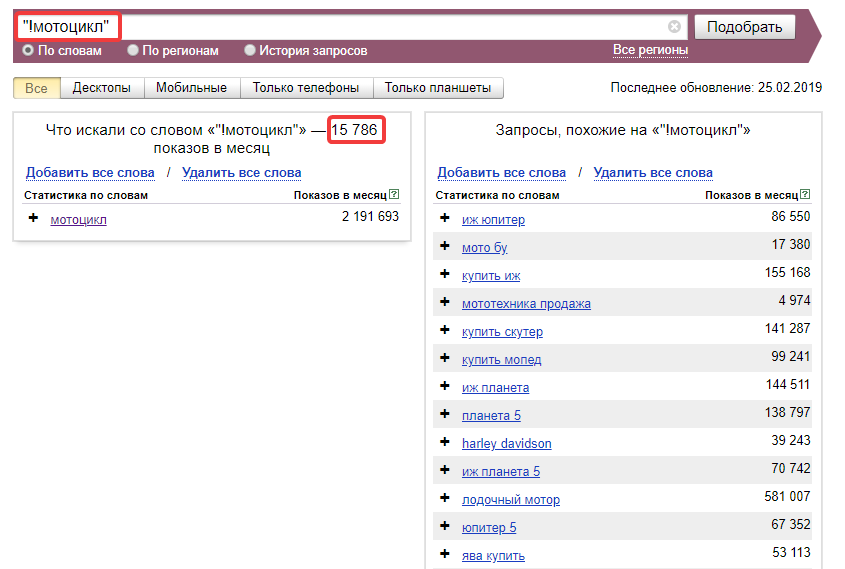
Как сделать анализ ключевых слов в Директе с помощью Вордстат
Одним из самых популярных инструментов подбора ключевых слов является «Яндекс.Вордстат» (Yandex Wordstat). Он демонстрирует статистику поисковых запросов Yandex («Яндекс») и ключевые слова, которые могут быть использованы рекламодателями.
При работе с «Вордстатом» необходимо учитывать некоторые его особенности.
— «Вордстат» обобщает все словоформы (падежные, мн. и ед. число), то есть запросы «автомобиль», «автомобилю», «автомобилем» и «автомобили» являются для него равнозначными.
— «Вордстат» не учитывает предлоги: за, на, под и т. д., если они не помечены знаками «+» или «!», то есть если вы хотите найти ключевые слова по запросу «продажа автомобилей в Москве», необходимо записать это словосочетание как «продажа автомобилей !в Москве».
Не учитываются и вопросительные слова «что», «когда», «как» и т. п., которые так же можно пометить «+» или «!», если необходимо их обязательно учесть.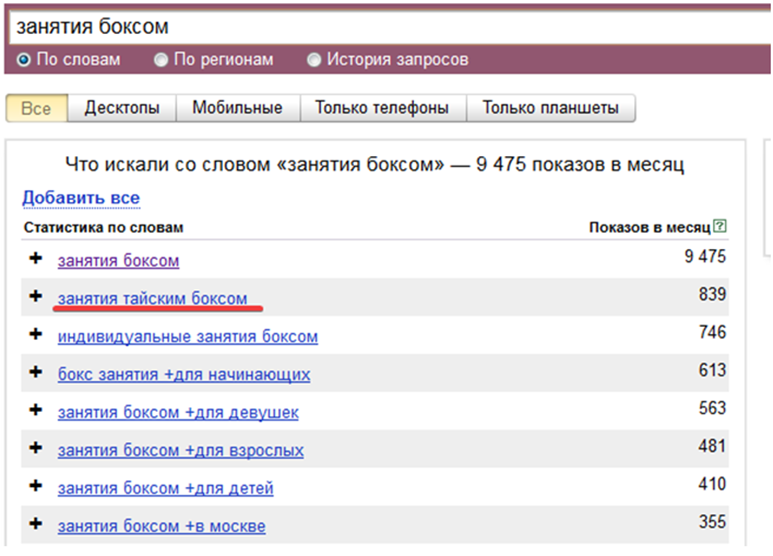
Ключевые слова Yandex в Wordstat сортируются по убыванию количества показов. Именно анализ поисковых запросов «Яндекса» позволяет рекламодателю подобрать достаточное количество низкочастотных ключевых слов (с количеством запросов менее 300 в месяц) и тем самым регулировать частоту показов своего объявления, стоимость рекламной кампании и поток посетителей на сайт.
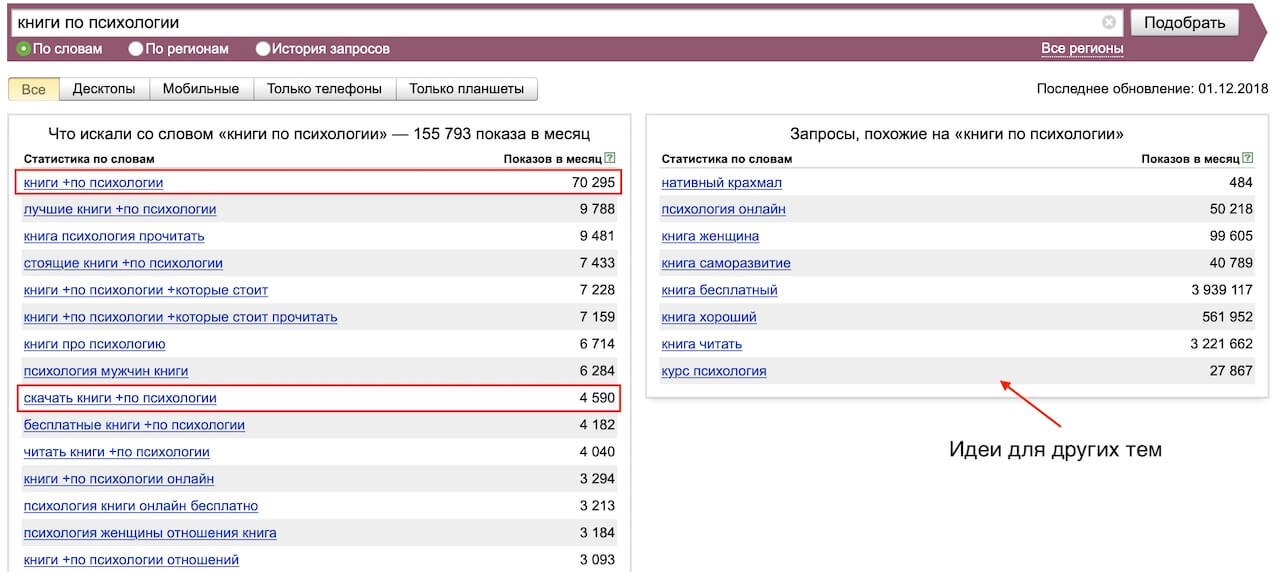
Помимо информации о количестве запросов по ключевому слову, Wordstat предлагает «подсказки»: под заголовком «Ищут также» отображаются похожие словосочетания, синонимы и близкие по темам запросы.
Анализ ключевых слов «Яндекса» позволяет подобрать список ключевых слов для размещения контекстной рекламы, который будет отвечать целям и задачам рекламодателя, будет соответствовать интересам аудитории и сути рекламного предложения. Кроме того, «Яндекс.Вордстат» предоставляет возможность анализировать популярность ключевых слов по отдельным регионам и странам.
Анализ поисковых запросов «Яндекса» также позволяет правильно «отминусовать» лишние запросы.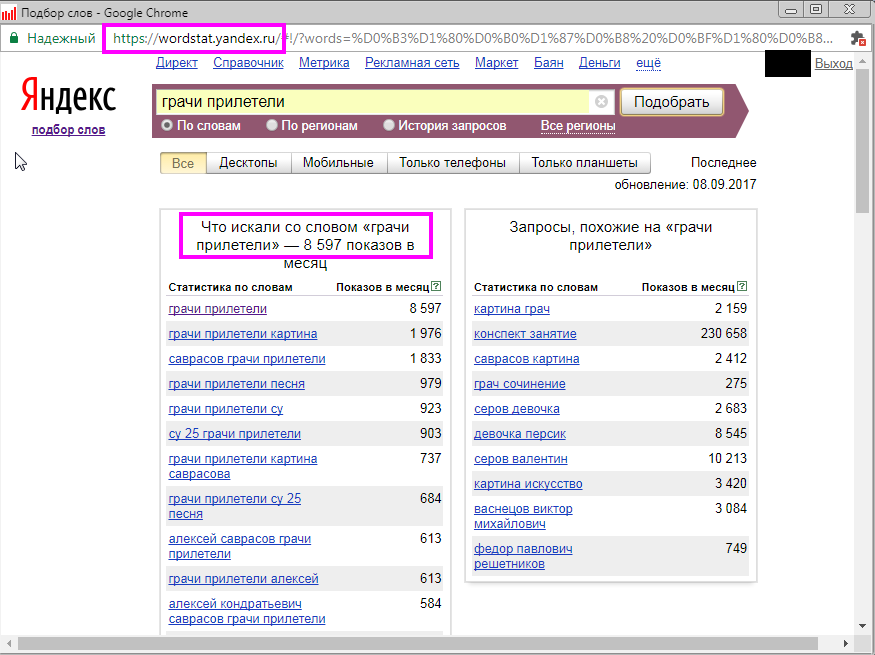
Например, при размещении рекламы медицинского центра по ключевому слову «клиника» необходимо «отминусовать» такие слова, как «скачать», «онлайн», «сериал», «серия», «ветеринарная», «собака» и т. п. Это позволит избежать показов объявления незаинтересованной аудитории.
Учитывая популярность поисковой системы «Яндекс» в Рунете, статистику ключевых слов и поисковых запросов «Яндекс.Директ» можно считать весьма репрезентативной.
Типы соответствия ключевых слов в Google Рекламе и Яндекс.Директ — подробная инструкция
Чтобы контекстная реклама приводила на сайт заинтересованных посетителей, недостаточно подобрать ключевые слова, важно правильно их использовать. Один из базовых этапов — подбор подходящего типа соответствия. В этой статье я расскажу, какие типы соответствий ключевых слов бывают и как с ними работать.
Как работают типы соответствий в Google Рекламе?
1. Широкое соответствие
Этот тип соответствия предназначен для максимально широкого охвата: рекламные объявления будут показаны по всем возможным поисковым запросам, имеющим отношение к ключевому слову: по фразам с ошибками, в разных словоформах, с разным порядком слов.
Этот тип целесообразно использовать, когда нужно привлечь максимальное количество трафика, или вы работаете с очень узкой тематикой. Более подробно о работе с широким соответствием — в этом посте.
При использовании широкого соответствия для поисковых кампаний необходимо тщательно подбирать минус-слова (далее я расскажу об этом более подробно).
В кампаниях с таргетингом на контекстно-медийную сеть ключевые слова чаще используются именно в широком соответствии, чтобы не сужать охват.
2. Модификатор широкого соответствия
Используя модификатор, вы можете контролировать, какие слова будут в поисковых запросах. При этом слова могут быть в разных словоформах и с ошибками, а их порядок не имеет значения.
По умолчанию вы не можете выбрать этот тип соответствия в интерфейсе аккаунта или Редактора Google Рекламы.
Вам нужно выбрать широкое соответствие и добавить знак «+» к каждому слову (для удобства используйте автозамену). Обратите внимание, что ключевые слова «+купить +подарок» и «+подарок +купить» — это дубликаты («ключи» в вашем аккаунте, которые конкурируют между собой).
Перед предлогами и союзами знак «+» можно не использовать, чтобы рекламные объявления показывались как по фразам, содержащим предлог или союз, так и без них.
Хотите больших полезных статей по контекстной рекламе? Заполняйте форму:
{«0»:{«lid»:»1573230077755″,»ls»:»10″,»loff»:»»,»li_type»:»em»,»li_name»:»email»,»li_ph»:»Email»,»li_req»:»y»,»li_nm»:»email»},»1″:{«lid»:»1596820612019″,»ls»:»20″,»loff»:»»,»li_type»:»hd»,»li_name»:»country_code»,»li_nm»:»country_code»}}
Истории бизнеса и полезные фишки
3. Фразовое соответствие
Чтобы зафиксировать порядок слов в фразе, нужно заключить ее в кавычки. Таким образом другие слова будут добавляться только в начало или конец фразы. Словоформы также могут быть разные.
4. Точное соответствие
Если вы заключите ключевую фразу в квадратные скобки, то избежите показов по поисковым запросам, содержащим другие слова. При использовании данного типа соответствия значительно сужается охват, но появляется возможность получить минимальное количество нерелевантных запросов.
Обратите внимание, что даже при использовании точного соответствия допускается изменение словоформы.
Как работают типы соответствия для минус-слов?
Чтобы показывать рекламу нужной аудитории, обязательно надо подобрать «минуса» — при наличии этих слов в поисковом запросе ваше объявление не будет показываться. Чем шире охват обеспечивает тип соответствия ключевой фразы, тем тщательней стоит проработать минус-слова.
В Google Рекламе можно выбрать широкий, фразовый или точный тип соответствия для минус-слова.
1. Широкое соответствие
Предотвращает показ объявления, если пользователь вводит любой запрос, в котором содержится минус-слово.
Обратите внимание, что даже в широком соответствии для минус-слов не учитываются словоформы или ошибки, поэтому стоит просклонять подобранные слова и прописать возможные варианты с ошибками. Если пользователь вводит очень длинный поисковый запрос и ваш «минус» будет находится после десятого слова — показ состоится.
2. Фразовое соответствие
Если нужно заблокировать показ только при определенном сочетании слов, используйте фразовое соответствие. В этом случае объявления не будут показываться, если поисковый запрос содержит исключенную фразу с этим же порядком слов (даже если до и после словосочетания пользователь введет другие слова).
3. Точное соответствие
Если исключить фразу в точном соответствии, то показы объявлений не состоятся только в случае, если поисковый запрос будет содержать те же слова и в том же порядке.
Как узнать, что минус-слова блокируют показы нужных ключевых слов?
Минус-слова в Google Рекламе находятся в приоритете перед ключевыми словами. Это означает, что при совпадении минус-слова с ключевым словом показы будут блокироваться.
Узнать о том, что в аккаунте минус-слова блокируют показы некоторых ключевых слов, можно двумя способами. Первый — оповещение в интерфейсе Рекламы в правом верхнем углу.
Подобные оповещения появляются не всегда, поэтому существует второй способ — диагностика ключевых слов. Для этого нужно зайти на вкладку «Ключевые слова», нажать кнопку «Подробности» и выбрать в выпадающем меню пункт «Диагностика ключевых слов». Когда Google Реклама проанализирует ключевые фразы, обратите внимание на те, в которых появится статус «Не показывается (другие причины)». При клике на этот статус вы сможете увидеть, какое именно минус-слово блокирует показы.
Для этого нужно зайти на вкладку «Ключевые слова», нажать кнопку «Подробности» и выбрать в выпадающем меню пункт «Диагностика ключевых слов». Когда Google Реклама проанализирует ключевые фразы, обратите внимание на те, в которых появится статус «Не показывается (другие причины)». При клике на этот статус вы сможете увидеть, какое именно минус-слово блокирует показы.
Типы соответствий в Яндекс.Директ
Принципы работы ключевых слов в Яндекс.Директ отличаются от Google Рекламы.
1. Широкое соответствие
Этот тип соответствия похож на модификатор широкого соответствия в Google Рекламе: показы объявления возможны только в случае, если в поисковом запросе присутствуют все слова из ключевой фразы, независимо от словоформы. Порядок слов не имеет значения.
2. Фразовое соответствие
Заключив фразу в квадратные скобки, вы зафиксируете порядок слов, но при вводе ключевого слова в другой словоформе показы будут. До и после ключевой фразы могут находиться дополнительные слова.
3. Точное соответствие
Если вы возьмете в кавычки ключевую фразу в Яндекс.Директ, то по всем запросам с дополнительными словами она не будет показываться (порядок слов и словоформы могут быть разными). В отличие от рекламы в Google, Яндекс позволяет зафиксировать словоформу ключевого слова — для этого используется восклицательный знак. Если нужно максимальное совпадение поискового запроса с ключевым словом, используйте восклицательный знак в комбинации с кавычками.
4. Как работать со стоп-словами
Поисковая система по умолчанию игнорирует предлоги, союзы и местоимения в ключевых фразах. Если необходимо, чтобы эта часть обязательно присутствовала в поисковом запросе, — поставьте знак «+».
5. Как работать с минус-словами
Чтобы исключить показ объявлений по нерелевантным словам, используйте знак «-». Яндекс.Директ автоматически учитывает все словоформы минус-слова, поэтому, если нужно исключить только одну словоформу, следует использовать знак «!».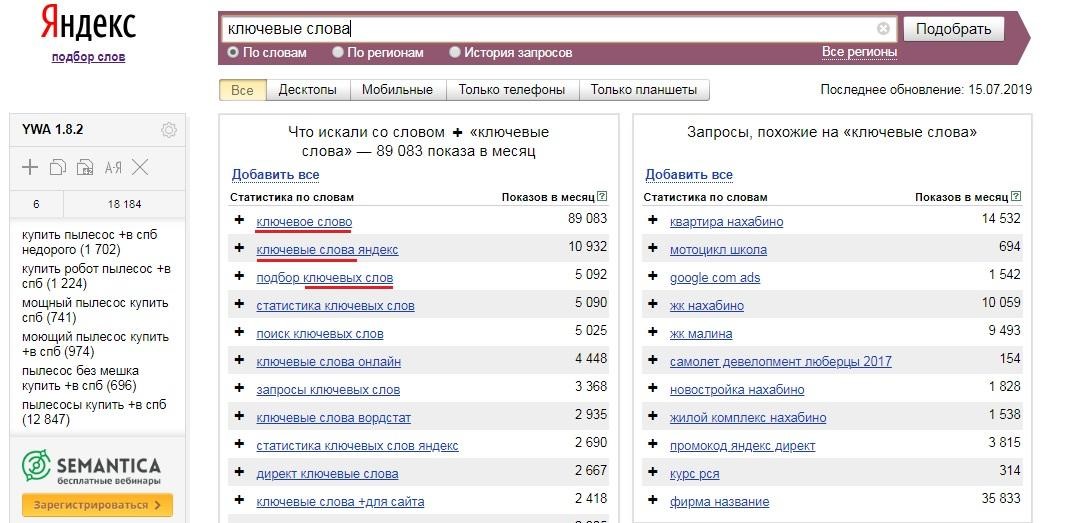
Еще одно отличие минус-слов в Яндекс.Директ в том, что приоритет имеют «ключи»: при конфликте показы не блокируются.
Выводы
Google Реклама и Яндекс.Директ предоставляют достаточное количество инструментов, чтобы эффективно настроить рекламные кампании. Для качественной работы с ключевыми словами необходимо знать и уметь использовать разные типы соответствия.
Суммируем:
1. При использовании широкого соответствия в Google Рекламе объявления будут показываться по самым разным вариациям ключевого слова и даже похожим формулировкам. Если вы хотите максимальный охват, то стоит использовать этот тип соответствия, но тогда релевантность ваших объявлений поисковым запросам будет ниже.
2. Широкое соответствие в Яндекс.Директ работает как ключевые слова с модификатором в Google Рекламе (слова, возле которых стоит «+», точно будут присутствовать в поисковом запросе). Показов по фразам с похожим смыслом не будет.
3. Фразовое соответствие в этих двух популярных поисковиках работает аналогично, но в Google Рекламе нужно заключить фразу в кавычки, а в Яндекс.Директ — в квадратные скобки.
Фразовое соответствие в этих двух популярных поисковиках работает аналогично, но в Google Рекламе нужно заключить фразу в кавычки, а в Яндекс.Директ — в квадратные скобки.
4. Наиболее точное соответствие можно получить в Яндекс.Директ: кавычки фиксируют порядок слов, а восклицательный знак — словоформу. В Google Рекламе нельзя зафиксировать словоформу «ключей» (разве что отминусовать лишние).
5. Принципы работы минус-слов:
- в Google Рекламе нужно просклонять слова и прописать варианты с распространенными ошибками;
- Яндекс.Директ автоматически учтет все словоформы, если вы не поставите восклицательный знак перед словом.
6. В случае конфликта «минусов» в Директе не блокируются показы ключевых слов, тогда как в Google Рекламе приоритет отдается именно минус-слову. Поэтому стоит обращать внимание на соответствующие оповещения или проводить диагностику.
Как бесплатно парсить ключевые слова и объявления конкурентов в «Яндексе» и Google
Перед запуском рекламной кампании полезно посмотреть, как с контекстной рекламой работают конкуренты: какие ключи используют, на какие регионы таргетируются, как составляют тексты объявлений. Так вы пополните семантику, почерпнете идеи для объявлений и получите представление о масштабах рекламной активности конкурентов.
Так вы пополните семантику, почерпнете идеи для объявлений и получите представление о масштабах рекламной активности конкурентов.
Этот инструмент покажет, сколько активных объявлений, в каких регионах и по каким ключевикам запускали конкуренты за последние 3 года. Инструмент работает для Яндекса и Google, в нем есть возможность сужать поиск так, как это вам необходимо.
Для примера возьмем онлайн-магазин подарков и рассмотрим, как парсить ключевые слова и объявления конкурентов для решения различных задач.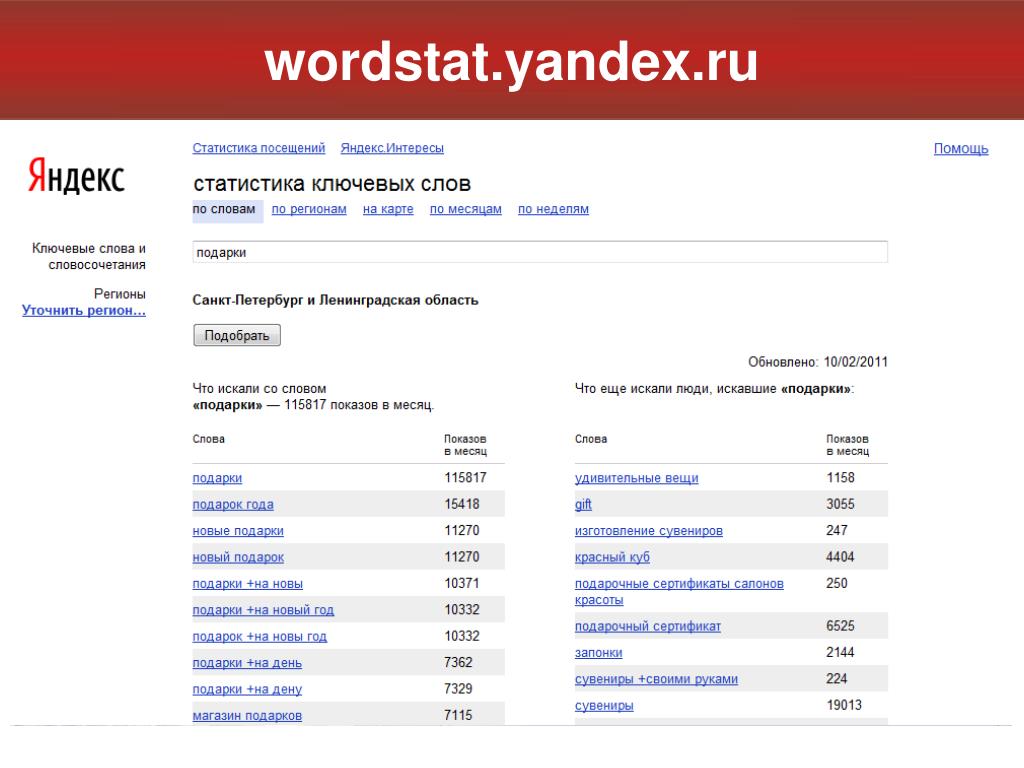
Готовимся к анализу конкурентов: собираем домены
Перед началом анализа нужно понять, кто, собственно, наши конкуренты в поисковой выдаче. Для этого открываем поисковик (Яндекс или Google) и вбиваем основной запрос, по которому планируем рекламироваться. Вот результаты выдачи:
Нам нужны домены из платной выдачи, поэтому копируем URL первых четырех объявлений, указанных на скрине выше.
Под органической выдачей тоже можно найти нескольких конкурентов.
Проделываем те же операции с поисковиком Google. Наш список конкурентов пополняется тремя URL — topbox.ru, dolina-podarkov.ru и giftbaskets.ru.
Если нужно расширить список, указываем еще несколько запросов по нашей тематике и добавляем новые домены. Для привязки к региону нужно уточнить поиск. Используйте запрос по шаблону «купить [товар] + [регион]».
Итак, список конкурентов готов. Переходим к парсингу.
Приступаем к парсингу конкурентов
Рассмотрим 5 ситуаций, в которых пригодится парсер.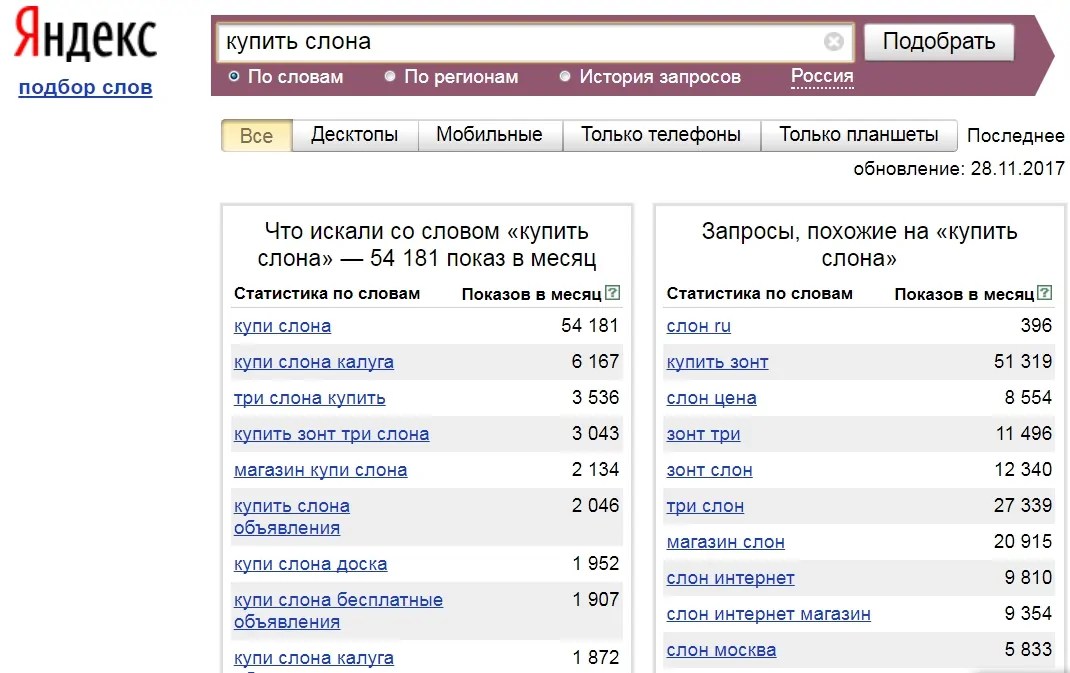 Детально покажем, как и что делать.
Детально покажем, как и что делать.
1. Выгружаем сразу все ключевики и объявления конкурентов
Также в него можно попасть, если у вас уже создан проект в Click.ru — инструмент находится в левом боковом меню в разделе «Инструменты». Кликаем по кнопке «Объявления» и выбираем инструмент.
Второй способ загрузки доменов — через XLSX-файл.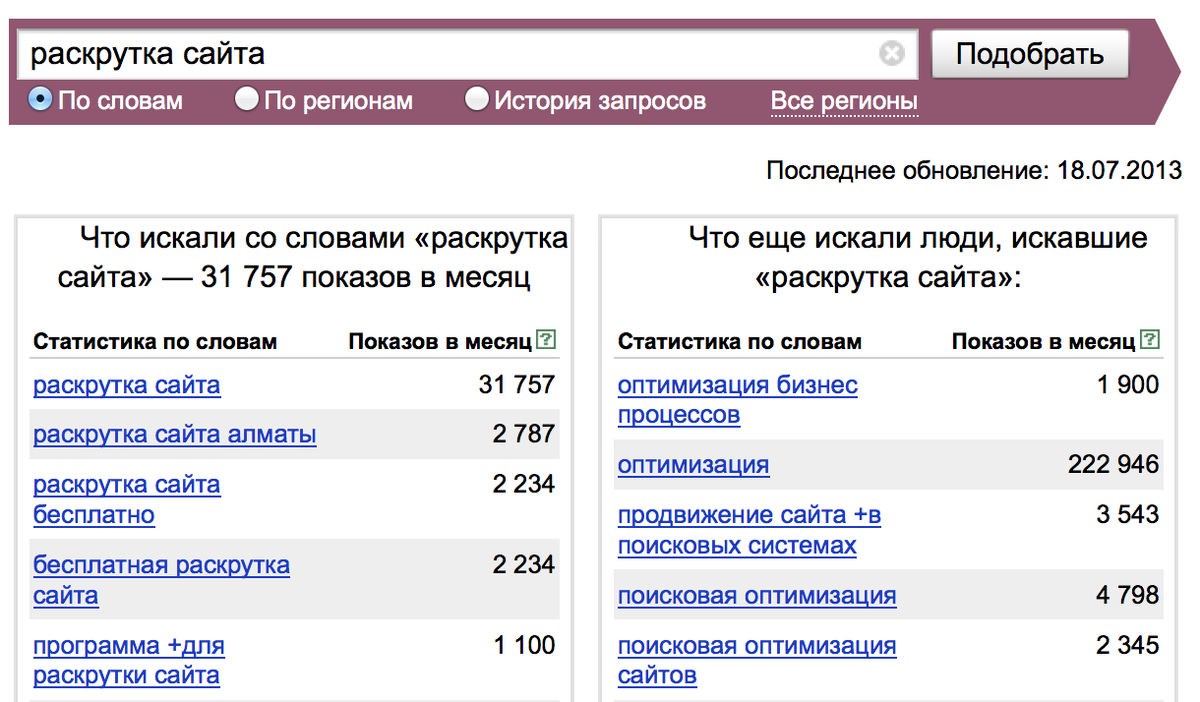 Для этого адреса конкурентов нужно оформить в таблице Excel. Каждый URL должен находиться в отдельной ячейке, а весь список — на одном листе.
Для этого адреса конкурентов нужно оформить в таблице Excel. Каждый URL должен находиться в отдельной ячейке, а весь список — на одном листе.
Под блоком с задачами расположены «Профессиональные настройки». Сейчас они нам не понадобятся, поэтому не обращаем на них внимания.
Также нужно отметить, в каких поисковиках будем парсить данные. Изначально сервис советует собирать их и в Яндексе, и в Google. Поэтому галочки снимать не будем.
Ниже можно выбрать, как будут представлены результаты парсинга. Если не снимать галочку, то они будут на одном листе таблицы. Количество URL на вид отчета не повлияет.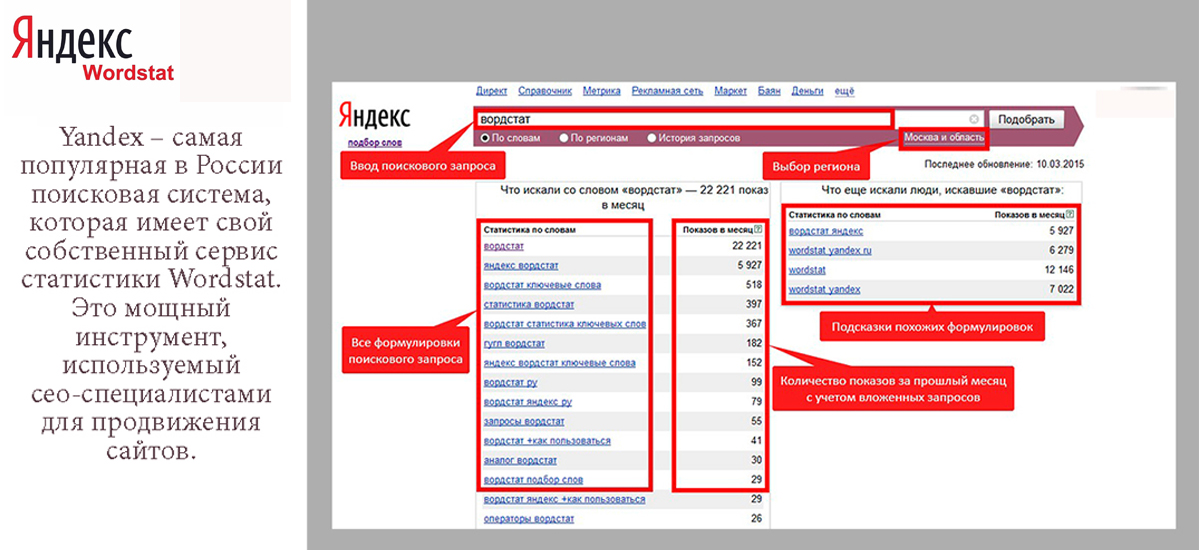
Какой вид отчета с результатами парсинга выбрать?
Если вы собираете ключи и объявления для списка, где меньше пяти доменов, лучше получить результаты на одной странице в XLS. Такую выборку проще анализировать, когда она представлена на одном листе.
В ином случае стоит убрать галочку из пункта выше. Большое число URL и данных по ним сложно обрабатывать на едином листе. Удобнее, чтобы сервис представил результаты по каждому URL-адресу на отдельной странице.
У нас второй вариант, поэтому галочку снимаем.
Затем нажимаем на кнопку «Запустить проверку», чтобы начать парсинг.
Чтобы посмотреть статус сбора данных, откройте раздел «Список задач»:
Инструмент работает в облаке. Поэтому можно не ждать завершения парсинга. Закрытие и перезагрузка страницы не остановят сбор данных.
Когда парсинг будет завершен, список задач обновится — здесь будет статус «Выполнен». В столбце «Действия» нажимаем на иконку документа Excel, после чего начнется загрузка результатов.
Для парсинга мы выбрали выгрузку результатов по каждому домену на отдельном листе. Расскажем, как отобразится итог работы инструмента в обоих случаях.
Результаты в виде «Один домен — один лист»
Скачиваем архив с файлом rezyltati.xlsx:
Открываем таблицу. Видим большое количество листов — на каждом из них собраны данные по каждому конкуренту:
В документе также есть три дополнительных листа: на двух представлена информация по всем доменам, а еще один — сервисный лист. Рассмотрим все виды листов:
Рассмотрим все виды листов:
1. «Rezyltati_obschie». Здесь указана статистика по всем конкурентам: число объявлений и регионы их показа. К примеру, количество объявлений у домена manbox.ru в Яндексе в регионе Москва — 742, а в Google— 65.
2. «Slova». На этом листе собраны все уникальные ключевики, используемые для рекламы доменов конкурентов. Мы провели парсинг по десяти URL-адресам — в результате инструмент нашел 35 тысяч ключевых слов.
3. «Ish_nastroiki». Перечислены домены конкурентов, а также варианты настроек парсинга.
Каждая из оставшихся страниц в документе посвящена отдельному домену.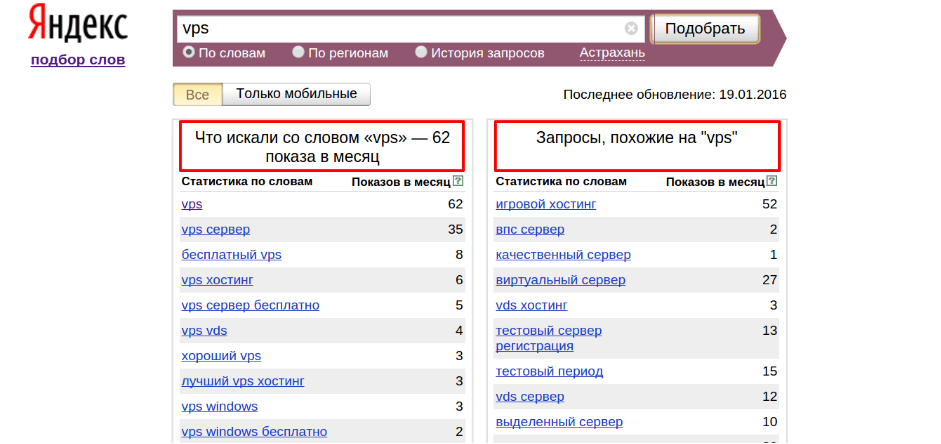 Откроем лист dolina-podarkov.ru. Здесь такие столбцы:
Откроем лист dolina-podarkov.ru. Здесь такие столбцы:
- Domain — название домена, по которому парсили данные.
- Region — показывает, в каком регионе рекламируется конкурент. Можно отфильтровать информацию по конкретному региону и проанализировать объявления.
- Search engine — поисковик (Яндекс или Google). Настройте фильтр только на Яндекс, если планируете рекламную кампанию в этой системе. Можно оценить рекламу конкурента в Яндексе, а также ключи, заголовки и тексты объявлений.
Важно! При показе объявление может содержать расширение (например, быстрые ссылки). В таком случае при парсинге инструмент соберет их вместе с текстом.
Все домены на одной странице
Загруженный документ в этом случае будет состоять из четырех листов.
Первый лист — «Rezyltati_obschie». В нем указана информация об объявлениях по всем конкурентам (регионы и количество). Ее можно отфильтровать по региону и поисковой системе.
Второй лист — «Slova_i_obyavleniya». Можно посмотреть всю текстовую часть парсинга — заголовки и тексты объявлений, а также ключевые слова.
Важно! Если вы парсили большое количество доменов, то и итоговая таблица по ключевым словам и объявлениям будет огромной. Чтобы с ней было удобно работать, стоит отфильтровать информацию — по домену, региону или поисковику.
Оставшиеся две страницы («Slova» и «Ish-nastroiki») совпадают по содержанию с листами из документа с разбивкой по доменам, который мы разбирали выше.
2. Находим упущенные ключевые слова
Для настройки действующей кампании полезно собрать упущенные ключи, чтобы запустить рекламу по ним. Это ключи, которые не используются в нашей рекламной кампании, но по которым рекламируются конкуренты.
Парсим упущенные ключевики
Вначале выгружаем список ключевых слов, по которым вы рекламируетесь в Яндекс.Директе и Google Ads. Списки не смешиваем — будем собирать упущенные слова по каждой рекламной системе отдельно.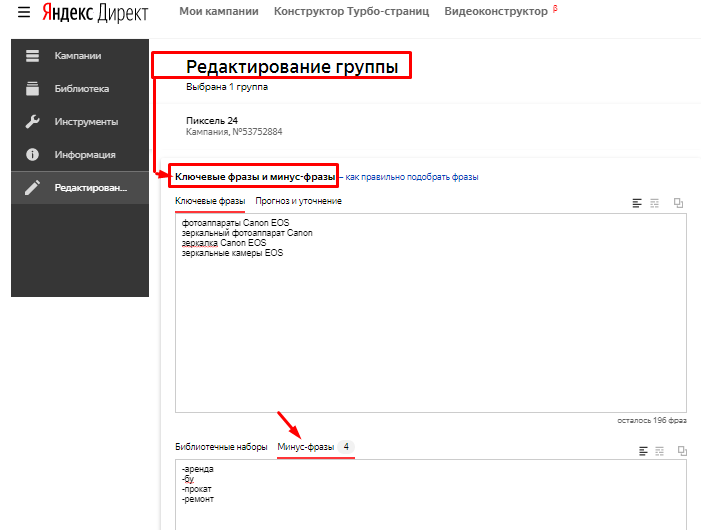
Открываем парсер конкурентов Click.ru и указываем домены конкурентов, по которым нужно собрать данные. В блоке «Профессиональные настройки» заполняем поле с минус-словами. Сюда вставляем список наших ключей. Таким образом, система исключит их из парсинга и соберет только те ключевые слова конкурентов, которые мы не используем.
Обратите внимание, что для точности подбора должна стоять галочка напротив пункта «Точное вхождение без учета морфологии».
3. Исключаем из парсинга определенные товары/категории
Нет смысла собирать ключи и тексты объявлений конкурентов по группам товаров, не представленных на вашем сайте. Конечно, при анализе результатов парсинга можно их отфильтровать и не использовать в своей кампании. Но быстрее и проще изначально настроить инструмент так, чтобы он не учитывал данные по тем товарам конкурентов, которых у вас нет.
Конечно, при анализе результатов парсинга можно их отфильтровать и не использовать в своей кампании. Но быстрее и проще изначально настроить инструмент так, чтобы он не учитывал данные по тем товарам конкурентов, которых у вас нет.
С этим нам помогут минус-слова. Прописываем в поле товары и услуги, которые хотим исключить. Также есть смысл сразу добавить минус-слова, по которым пойдет нецелевой трафик (вроде «бесплатно» или «бу»). При этом важно снять галочку с пункта «Точное вхождение без учета морфологии».
В примере мы указали четыре минус-слова для исключения групп товаров. Поэтому в документ с результатами парсинга не попадут такие ключевики, как например, «сувенирные подарки» или «подарки идея».
4. Парсим ключи и объявления по отдельным услугам/товарам/категориям
Парсим ключи и объявления по отдельным услугам/товарам/категориям
Теперь покажем процесс, обратный исключению товаров из парсинга. Предположим, что нам нужно настроить парсер только на те ключи и объявления, которые подходят для рекламы конкретных товаров.
Для примера возьмем группу товаров «Подарки для мужчин» — посмотрим, какие слова и объявления используют конкуренты для ее рекламы.
В поле «Фиксированный список слов» прописываем несколько слов, похожих по тематике на выбранную группу товаров. Не забываем убрать галочку в строчке «Точное вхождение».
Кликаем «Запустить проверку» и смотрим результаты.
5. Собираем объявления по конкретным ключевикам
Составляем список ключевых фраз, по которым будем парсить объявления конкурентов. Открываем парсер конкурентов Click.ru, прописываем URL конкурентов, по которым будет собирать информацию.
Нам вновь понадобится блок «Фиксированный список слов». Вставляем сюда подобранные фразы. Ставим галочку в пункте «Точное вхождение». Тогда инструмент будет собирать объявления только по точным вхождениям указанных ключей.
Запускаем инструмент, а потом скачиваем документ с результатами.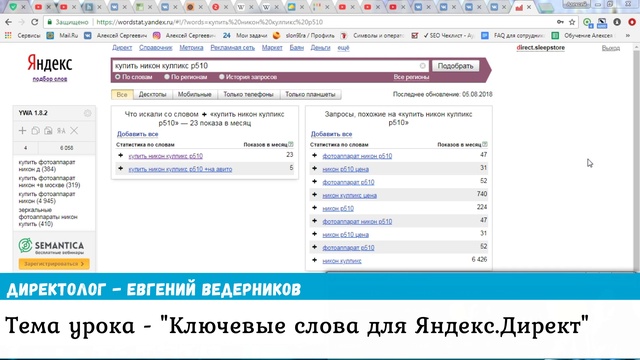 Там будут тексты объявлений конкурентов, запщенные по указанным ключам.
Там будут тексты объявлений конкурентов, запщенные по указанным ключам.
Как использовать результаты парсинга конкурентов
Их нужно проанализировать и выбрать те слова, заголовки и тексты, которые помогут улучшить качество вашей кампании.
Можно расширить семантическое ядро за счет упущенных ключевиков. Это поможет достучаться до большего числа потенциальных клиентов и сэкономить бюджет.
Изучите тексты объявлений. Некоторые формулировки и формы предложений можно использовать в своей кампании.
Посмотрите на структуру объявлений — на чем сделан упор, на каких преимуществах продукта акцентировано внимание и что конкуренты предлагают. Не исключено, что вы можете предложить больше.
Как подобрать минус-слова для Яндекс.Директа и Google Adwords
Содержание статьи:
Минус-слова–ключевые слова, по запросам которых исключается показ контекстного объявления. В списке ключевиков кампании обозначаются минусами, откуда и получили название.
При подборе минус-слов маркетологи опираются на следующие параметры:
Другая тематика.
Следуют исключить слова из областей, которые не связаны с рекламируемым продуктом. Например, компания продает шубы и меховые изделия. Другие виды товаров и услуг (рецепт, доставка еды) минусуются из рекламной кампании.
Услуги.
Товары и предложения, которых нет на сайте.География.
Страны и регионы, не задействованные в рекламной кампании.Некоммерческие запросы.
К ним относятся: бесплатно, даром, самостоятельно, самодельный, инструкция и т.д. То, что представляет пользователя не в качестве потенциального клиента.Информационные запросы.
Конкуренты.
Фирменные наименования и названия компаний в той же рекламной нише.Площадки:
- В РСЯ (Рекламной Сети Яндекса) минус-слова отсекают платформы для размещения рекламы. Система, ориентируясь на тематику публикации, отображает объявление только целевым пользователям.
Нерелевантные площадки.
Директ минусует платформы, где компания не хочет размещать рекламу. Достаточно указать минус-слова, связанные с нежелательным ресурсом.
Готовые списки.
Существуют как универсальные списки, так и по тематикам. В случае, если использовать ключевые слова из готовых вариантов, эффективность будет невысокой. Зачастую в таком перечне встречаются целевые запросы для рекламной кампании. Необходимо сначала проанализировать специфику слов, прежде чем их использовать.
 В случае, если использовать ключевые слова из готовых вариантов, эффективность будет невысокой. Зачастую в таком перечне встречаются целевые запросы для рекламной кампании. Необходимо сначала проанализировать специфику слов, прежде чем их использовать.
В случае, если использовать ключевые слова из готовых вариантов, эффективность будет невысокой. Зачастую в таком перечне встречаются целевые запросы для рекламной кампании. Необходимо сначала проанализировать специфику слов, прежде чем их использовать.Эффективность минус-слов выражается в снижении нецелевых кликов, что сохраняет бюджет кампании и улучшает трафик. Также происходит рост таких показателей, как релевантность, CTR, ROI, которые играют ключевую роль в контекстной рекламе.
Для того, чтобы эффективность минус-слов была максимальной, учитываются следующие особенности:
Точная словоформа.
Яндекс.Директ использует минус-слова и фразы во всех падежах, временах и числах. Так, если задать ключевое слово, система исключит все возможные словообразования в кампании. Это же относится к словам-омонимам.Оценка эффективности.
Для лучшего результата рекламной кампании следуют регулярно проверять эффективность ключевых слов. Периодическое обновления списка с минус-словами гарантирует точное попадание в целевую аудиторию. Уровни.
В Яндекс.Директе существует 3 уровня минус-слов:
 Периодическое обновления списка с минус-словами гарантирует точное попадание в целевую аудиторию.
Периодическое обновления списка с минус-словами гарантирует точное попадание в целевую аудиторию. - Рекламная кампания
- Группа объявлений
- Ключевое слово/фраза
В случае, если минус-слово задано на уровне кампании, оно минусуется и в объявлениях, и в ключевиках. Так, необходимо определить какие из ключевых слов релевантны для отдельных групп, а какие для кампании в целом.
Использовать слова в РСЯ (Рекламная Сеть Яндекса) нужно осторожно, так как при неправильном подборе можно отсечь часть релевантной аудитории.
Способы, чтобы этого избежать:
Блокировка площадок.
Предугадать все возможные варианты минус-слов невозможно. Примитивный метод – ничего не минусовать при запуске кампании. Ориентироваться на показатели отказов и по факту блокировать площадки.Самостоятельный отбор.
Использовать лично проверенные списки минус-слов, которые показали эффективность кампании. Анализировать результаты рекламной кампании в Яндекс.Метрике и обновлять ключевики. Сервисы по подбору.
Официальный сервис по подбору ключевых запросов Яндекса – WordStat.
Структура подбора:
.jpg) Анализировать результаты рекламной кампании в Яндекс.Метрике и обновлять ключевики.
Анализировать результаты рекламной кампании в Яндекс.Метрике и обновлять ключевики. - Введение запроса
- Выбор региона
- Поиск нерелевантных запросов
- Добавление минус-слов в Директ на уровне кампании
Особенности Яндекс. Директа:
- Для исключения слова используется оператор “-”.
В случае, если минусуется одно слово в ключевой фразе, это выглядит так: “настроить интернет-эквайринг -бесплатно”. Если вычитается словосочетание, то так: “настроить интернет-эквайринг -бесплатно -самостоятельно”. Каждый ключевик минусуется отдельно. Пересекающиеся фразы.
Например, в кампании задана минус-фраза “Купить телефон” и ключевая фраза “Купить зарядку для телефона”. В этом случае, так как все слова из минус-фразы входят в ключевую, – минусовик игнорируется и показы по запросу “купить телефон” будут идти.
Следующие способы:
Google Analytics.
Анализ и обновление ключевых слов с помощью аналитики платформы.Планировщик ключевых слов.
Встроенный инструмент по подбору ключевиков, который помогает определить популярные минус-слова для рекламной кампании.Анализ поисковых запросов.
Статистика Google Adwords дает отчет о том, какие рекламные объявления принесли высокую эффективность. На основании результатов обновляются и расширяются ключевые фразы кампании.
Особенности Google Adwords:
- По сравнению с Директом платформа не минусует все словоформы. Например, если указать в кампании минус-слово “дверь”, то рекламное объявление по запросу “заказать двери” отобразится.
- Adwords минусует фразы с одним оператором. В Директе, для того чтобы исключить словосочетание, вычитается каждый ключевик. Здесь же фраза минусуется наравне с одним словом.
Операторы и типы соответствия Яндекс Директ
PrintАртем Акулов
Со временем у каждого (адекватного) рекламодателя любой системы контекстной рекламы встает разумный вопрос.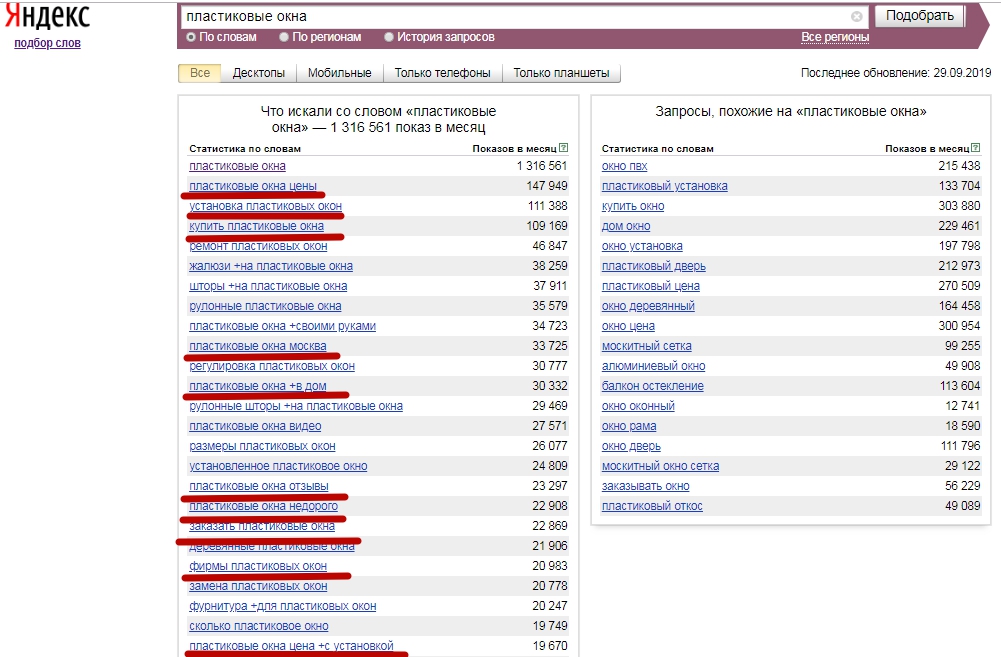 Хорошо, рекламу запустили, показы идут, даже переходы по объявлениям проскакивают. Но почему-то покупают мало?
Хорошо, рекламу запустили, показы идут, даже переходы по объявлениям проскакивают. Но почему-то покупают мало?
Да и, вообще, я рекламируюсь по одному ключевому слову, а объявления показываются по другим, вы продаете услуги автосервиса, а люди переходят в поисках инструментов для автосервиса. Все бы ничего, да только за все такие вот левые переходы рекламодатель платит из своего кармана.
Выхода в данной ситуации два:
- Увеличивать и дальше бюджет на рекламную кампанию (самый крайний вариант, доверить его слить рекламному агентству)
- Сложный. Включить голову и использовать операторы соответствия
Вот сегодня о них и поговорим. На повестке дня операторы соответствия Яндекс Директа и Google AdWords. Чем они отличаются? — Они разные!
Операторы Яндекс Директа
Директ предлагает такие варианты операторов:
1. Широкое соответствие
2. Принудительное вхождение слова в запрос (в основном используется для предлогов и союзов)
3. Фразовое соответствие
4. Соответствие с фиксированным порядком слов в запросе
Соответствие с фиксированным порядком слов в запросе
5. Точное соответствие
6. Минус-слова
Примечание: по тексту слова, написанные курсивом — это ключевые слова контекстных объявлений (если указанные слова присутствуют в запросе пользователя, то ему показывается ваше рекламное объявление).
Широкое соответствие
Это запрос без каких либо уточнений (вариант по умолчанию). Объявления будут показываться каждому встречному-поперечному, запросившему/вбившему в Яндексе запрос, содержащий все слоформы ключевого слова (падежи, единственное/множественное число) и любые другие слова.
Например, по ключевому слову тур в таиланд объявления будут показываться по таким поисковым запросам:
- туры недорого в таиланд
- что взять с собой в тур в таиланд
- скачать реферат тур по таиланду без регистрации и много еще каким
То есть вы видите, что большая часть запросов вообще мимо целевой аудитории туристической кампании, которая запустила такую рекламу. Это ведет к следующему
Это ведет к следующему
- Количество показов многократно растет (большое количество мусорных и нецелевых запросов)
- При большом количестве нецелевых показов резко падает CTR объявлений, а стоимость клика неуклонно лезет в гору.
Тем самым увеличивается бюджет рекламной кампании и скорость его расхода. Это любимый способ «грамотных» рекламных агентств, он позволяет быстро освоить клиентские бюджеты, а на вопросы предъявить список ключевых слов. Но клиент-то чаще всего не знает, что в них используется широкое соответствие.
Важный момент. Яндекс, по-умолчанию, исключает из ключевых слов предлоги, союзы и служебные слова, а это часто бывает очень важно. Так, при широком соответствии ключевой запрос билет в Москву = билет Москва = билеты по Москве = твоя Москва билет
Что называется, почувствуйте разницу.
Напоследок о широком соответствии нужно добавить ложку меда. Порой его использование вполне адекватно. Например, когда целевых запросов очень мало (меньше 30-50 в месяц).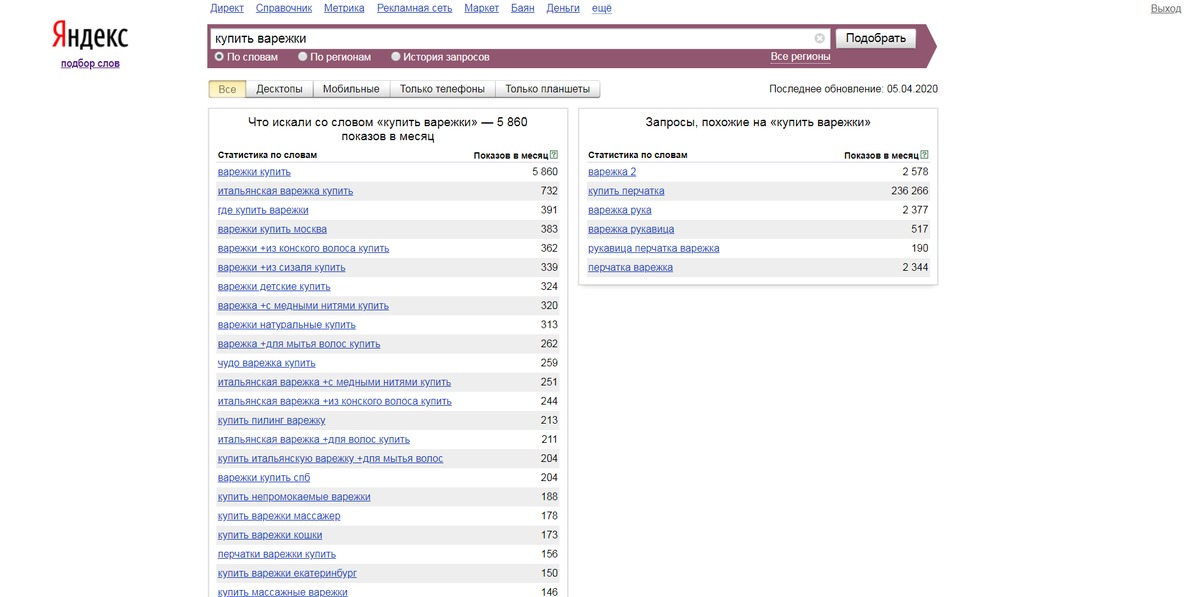 Сидеть и фильтровать лишние запросы просто дороже по времени.
Сидеть и фильтровать лишние запросы просто дороже по времени.
Или вот такая ситуация характерная для регионов Дальнего Востока:
- ключевой запрос Фуюань для Хабаровского края и Хабаровска
- ключевой запрос Суйфеньхе для Приморского края
- ключевой запрос Хейхе для Амурской области и Благовещенска
Запросов содержащих эти ключевые слова в месяц не так уж и мало (wordstat вам в помощь), и в 85% случаев людям нужен тур или шоп-тур в один из этих городов. Берите пользуйтесь, мне не жалко. (:
Принудительное вхождение слова в запрос
Яндекс Директ не учитывает предлоги и союзы в ключевой фразе, если их принудительно не добавить к ключевой фразе. Такие слова называются стоп-словами.
Оператор плюс +, ставится перед стоп-словом, которое обязательно должно быть в запросе. Чаще всего используется с предлогами, местоимениями и союзами. Как я уже говорил выше, по-умолчанию, Яндекс выкидывает эти слова и не учитывает их.
То есть при таком ключевом запросе как билет +в Москву, объявление не будет показываться тем, кто ищет билеты по Москве. Но будет показываться по запросу билеты в Москве — помним о широком соответствии.
Фразовое соответствие
Ключевое слово, заключенное в кавычки «» будет показываться по запросам, содержащим только данное ключевое слово в его словоформах. Пример ключевое слово «билет в Москву из Владивостока».
Объявление будет показано по запросам
- билет в Москву из Владивостока
- билет из Владивостока в Москву
- из Москвы билет во Владивосток
И не будет показано искавшим
- купить билет в Москву
- дешевый билет в Москву из Владивостока
- билет на теплоход из Владивостока в Москве
Лучше? А кто бы спорил. Довольно существенную часть нецелевых запросов удалось исключить, хотя отпала и часть целевых запросов. Например, про купить билет в Москву (при показе этого объявления жителю Владивостока).
Например, про купить билет в Москву (при показе этого объявления жителю Владивостока).
Слова стоящие внутри кавычек, по-умолчанию, считаются принудительно включенными в запрос. То есть ключевой запрос «купить билет в Москве» абсолютно эквивалентен ключевому запросу «купить билет +в Москве»
Соответствие с фиксированным порядком слов в запросе
Оператор квадратные скобки [ и ]. Позволяет принудительно указать в каком порядке должны находиться ключевые слова в запросе пользователя. При другом порядке слов объявления показываться не будут. Это особенно актуально при продаже скажем билетов.
Если для рекламного объявления в Директе просто задать ключевое слово билет Владивосток-Хабаровск, то объявление будет показано и людям желающим перелететь из Хабаровска в Москву (купить билет Хабаровск-Владивосток), так и наоборот (купить билет Владивосток-Хабаровск).
А вот если указать ключевое слово вот так билет [Владивосток-Хабаровск], то:
а) Объявление будет показано только людям запросившим билет Владивосток-Хабаровск или купить билет Владивосток-Хабаровск, но не искавшим билет на обратное направление
б) Это позволяет конкретизировать предложение рекламодателя, показывать людям билеты именно из Владивостока в Хабаровск.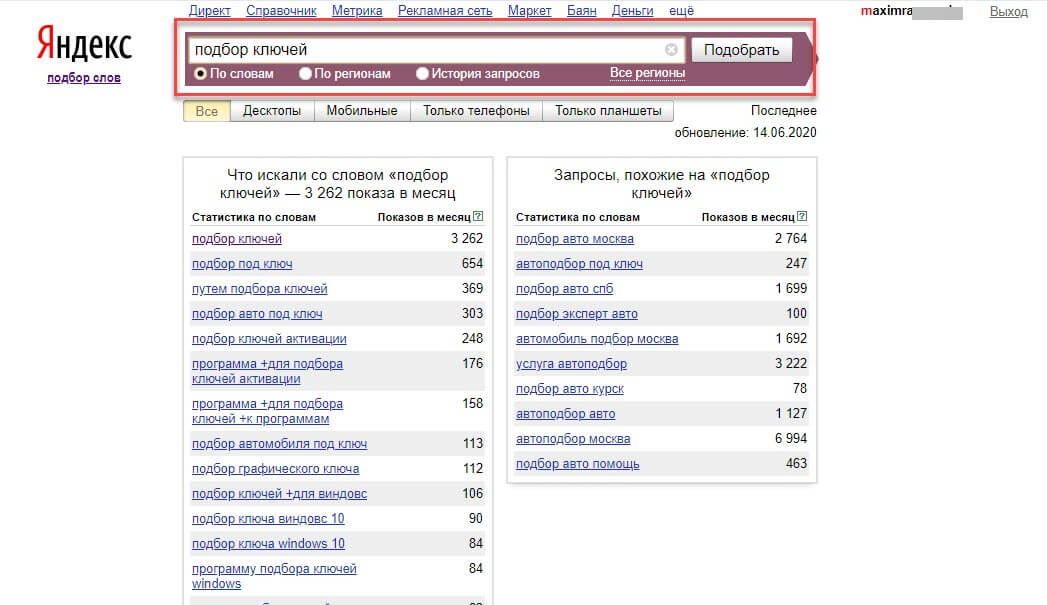 А чем конкретнее рекламное предложение, тем выше его эффективность.
А чем конкретнее рекламное предложение, тем выше его эффективность.
Данные оператор можно с успехом применять не только для продажи через интернет билетов. А например включить в квадратные скобки название книги или такой вариант.
Допустим есть реклама «банка Москвы» (есть такой банк), если просто использовать его название в качестве ключевого слова, то рекламу увидят все люди, искавшие любые банки в Москве. Например: кредит в Москве банка ВТБ 24 или где в Москве банк Авангард.
Оптимальное решение — использовать принудительный порядок слов в ключевом слове: кредит [банк Москвы]. Работаем только с клиентами указанного банка.
Аналогично, есть хоккейная команда в Хабаровске «Амурские тигры», а есть настоящие животные тигры Амурские. Продавать хоккейную атрибутику или билеты на матч, очевидно, эффективнее любителям хоккея.
Точное соответствие
Оператор позволяет зафиксировать словоформу ключевого слова в запросе (падеж, склонение, число и тому подобное).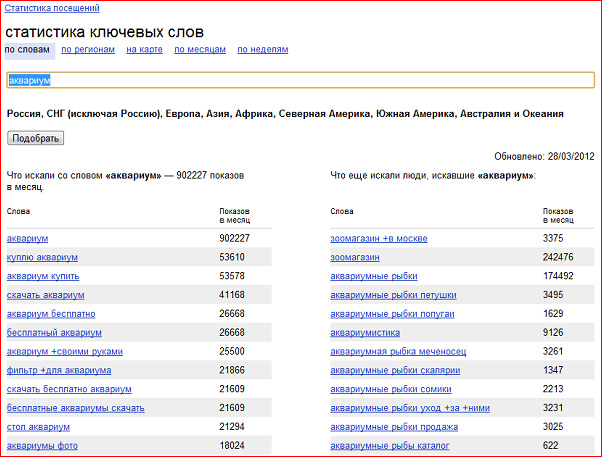 Перед нужным словом ставится восклицательный знак.
Перед нужным словом ставится восклицательный знак.
Богатый лексический аппарат Яндекса безусловно огромный плюс, но порой им необходимо управлять, что называется, в ручном режиме. Например город Дели и слово день для Яндекса одно и тоже, т.к. это словоформы глагола «деть». Соответственно, можно сильно пролететь рекламируя туры в Дели, людям интересующимися днем космонавтики. Я утрирую, но все же.
Для первых нужно будет использовать тур в !Дели, а для вторых !день космонавтики. Еще один вариант, уже набивший оскомину в интернете, пример с городом Киев. Если кратко, то «Киев» для Директа равен по смыслу слову «кий» (бильярдный).
Минус-слова
Вот этим оператором рекламодатели уже охотно (бывает (: ) пользуются. Позволяет исключить из запроса не нужные и нецелевые слова. Чаще всего такие как: форум, скачать, бесплатно, дешево, реферат и т.п.
Позволяют не продавать системы кондиционирования, ищущим курсовую на указанную тему. Для этого просто к ключевому слову системы кондиционирования добавляется слово реферат со знаком минус. Получается системы кондиционирования -реферат
Для этого просто к ключевому слову системы кондиционирования добавляется слово реферат со знаком минус. Получается системы кондиционирования -реферат
Такой момент. Бывают ситуации, когда таких вот паразитных запросов просто огромное количество, счет может идти на сотни, они могут составлять до 70-80% всех связанных запросов. Часто рекламодатели использую так называемую портянку из минус слов (когда таких минус-слов указывается 30-40 ато и больше).
Это позволяет сузить целевую область, но все-равно останутся нецелевые показы, которые будут тянуть CTR объявления вниз и цену за клик вверх. Один из вариантов выхода из такой ситуации закавычивание (использование фразового соответствия). Но т-с-с. Пусть конкуренты сливают деньги.
UPD. По настройке и использованию минус-слов в Яндекс Директе вышла отдельная статья. Там же об особенностях их использования в Директе.
Хотел написать в одной заметке и про Яндекс Директ, и про Google AdWords, но вижу, лучше все-таки разделить их на два материала для удобства чтения и восприятия. Ждите второй части с описанием операторов соответствия Google AdWords.
Ждите второй части с описанием операторов соответствия Google AdWords.
На сегодня все.
UPD Вышла вторая часть этой записи. В ней про операторы соответствия Google AdWords.
Понравилась статья? Ставьте лайк
Как подобрать ключевые слова для контекстной рекламы в Яндекс.Директ?
5 — рейтинг статьи
14 Окт 2019
Ответственный этап запуска контекстной рекламы в Яндекс.Директ – подбор ключевых слов. Перечень запросов определяет аудиторию, которая будет видеть объявления. Очень важно, чтобы эта аудитория была целевой – то есть заинтересованной в предлагаемом продукте. Ключевые фразы должны точно отражать реальные потребности потенциальных клиентов компании. И чем точнее это попадание, тем больше будет конверсионных кликов и переходов на сайт. В этой статье мы расскажем, как подобрать ключевые слова для Директа, чтобы реклама была эффективной.
Контекстные объявления в поисковой выдаче и рекламной сети
Для начала рассмотрим общий принцип использования ключей при размещении контекстных объявлений в поисковой выдаче Яндекса. В настройках указывается несколько словосочетаний, связанных единой тематикой. Реклама показывается в том случае, если в пользовательский запрос входят все слова ключевой фразы. Например, при выборе ключа «продвижение сайтов» объявление может быть показано в ответ на запрос «недорогое продвижение сайтов». При этом учитывается как прямое вхождение, так и словоформы с изменением числа и падежа. Некоторые слова Яндекс может заменять синонимами. Например, словосочетания «продвижение сайтов недорого» и «продвижение сайтов дешево» могут считаться идентичными.
Помимо поисковой выдачи, Яндекс предлагает размещать рекламу на сайтах Рекламной сети (РСЯ). В данном случае ключевыми фразами определяется:
- тематика площадки, на которой будет показываться объявление – например, по фразе «сео продвижение» объявление может быть показано на страницах известного сео-блогера;
- интересы аудитории – в рассмотренном выше примере рекламу увидит пользователь, который ранее интересовался продвижением, при этом тематика сайта может быть любой.
Как подобрать ключевые слова для Яндекс Директ?
Основные этапы выбора ключевых запросов для контекстных объявлений:
- анализ рынка, конкурентов и особенности ЦА;
- четкая формулировка запросов пользователей с использованием названия или назначения товара/услуги;
- проверка выбранных словосочетаний в сервисе Яндекс.Вордстат.
Яндекс.Вордстат для подбора ключевых слов для контекстной рекламы
Перечень фраз, которые предположительно отражают потребности пользователей, необходимо проверить в специальном сервисе Яндекс.Вордстат. Порядок использования этого инструмента:
- выбрать регион, в котором предполагается показывать рекламу;
- добавить ключ и нажать кнопку «Подобрать»;
- изучить список полученных поисковых запросов;
- найти подходящие варианты и оценить количество их показов;
- выбрать среднечастотные запросы, исключив ВЧ и НЧ фразы;
- найти минус-слова, которые не должны учитываться в запросах;
- добавить полученный список ключей в Яндекс Директ.
По умолчанию Яндекс Директ автоматически добавляет дополнительные релевантные ключи, которые могут повысить эффективность рекламной кампании, увеличить охват и получить больше показов.
Собирая семантику, нужно принимать во внимание синонимы, сленговые выражения, специализированные термины, ассоциативные понятия. Если слово может быть прописано и латиницей, и кириллицей, то нужно проработать оба варианта: например, «seo» и «сео». В зависимости от специфики коммерческого предложения могут быть использованы дополнительные слова, поясняющие цель запроса:
- для продающих страниц — «купить», «на заказ», «недорого», «цена» и пр.;
- для информационных ресурсов – «инструкция», «описание», «фото», «характеристики» и пр.;
- для офлайн-представительств – «адрес», «как добраться», «магазин» и т. д.
Что такое минус-слова и стоп-слова?
Как мы писали выше, кроме ключевой фразы и ее словоформ в состав пользовательского запроса могут входить и другие слова. Некоторые из них могут кардинально изменить суть запроса, в результате объявления будут показываться нецелевой аудитории. Например, по словосочетанию «продвижение сайтов вакансии» будут приходить не потенциальные клиенты компании, а люди, которые ищут работу. Поэтому в данном примере слово «вакансии» помечается как стоп-слово и исключается из семантики. Минус-слова можно указывать как для отдельного запроса, так и для группы объявлений или для всей рекламной кампании.
Предлоги, местоимения и другие слова, не меняющие общий смысл фразы, называются стоп-словами и не учитываются в запросах. Если их не убрать, система сделает это автоматически. Например, фраза «продвижение сайта в москве» будет интерпретирована как «продвижение сайта москва». Если по обоснованным причинам стоп-слово нужно оставить, то перед ним ставится знак «+». Например, «+как запустить контекстную рекламу».
Частотность ключевых запросов для Директа
Все пользовательские запросы делятся на высоко-, средне- и низкочастотные. ВЧ фразы, как правило, состоят из двух-трех слов, не содержат конкретики и не дают четко понять, чего хочет пользователь. Например, высокочастотник «квартиры +в москве» имеет почти миллион показов. Одна часть аудитории хочет купить квартиру, другая – арендовать. Используя этот ВЧ запрос, компания получит большой процент бессмысленных нецелевых показов. Поэтому продавцы квартир должны рекламироваться по ключам «продажа квартир +в москве» или «купить квартиру +в москве», а арендодатели – по словосочетаниям «аренда квартир +в москве» или «снять квартиру +в москве». Эти ключи являются среднечастотными – они более точно охватывают целевую аудиторию. Низкочастотники дают малое количество переходов, поэтому практически не используются для запуска контекстной рекламы.
Какие фразы принесли наибольшую пользу – можно увидеть в разделе Статистика. Эта информация полезна для корректировки списка ключей и минус-слов. Если нужно запустить рекламу в срочном порядке и нет времени заниматься подбором ключевых слов для Яндекс Директ, можно воспользоваться функцией автотаргетинга. Система автоматически определит тематику по тексту объявления и контенту посадочной страницы, на основании чего сформирует аудиторию для показа рекламы. После запуска такой кампании можно будет оценить ее эффективность и отобрать список наиболее успешных запросов.
Хотите настроить рекламу в Яндекс Директ, но не знаете с чего начать? Ознакомьтесь с нашей статьей «Контекст для чайников» или обратитесь к специалистам компании Авада за профессиональной помощью.
Как подобрать ключевые слова для Яндекс Директ
Прочитав статью вы сможете подобрать ключевые слова для систем Яндекс Директ и Google Adwords на базовом уровне.
Какой раздел знаний охватывает статья:
Сбор информации → Стратегия → Первичная настройка аналитики → Подбор ключевых слов → Сортировка ключевых слов → Разработка объявлений → Разработка рекламных кампаний → Анализ данных → Оптимизация → Масштабирование → Поддержка
Каких тем коснемся: карта покрытия, перемножение, парсинг, wordstat.yandex.ru
Вы могли заметить, что перед подбором ключевых фраз для сайта стоит еще 3 пункта, так как материалов по ним у нас еще нету, то изложим их в тезисах:
- Вы должны понимать, кто ваш покупатель и какие запросы он будет вводить в поиск.
- Общие концепции стратегии можно почерпнуть из первой части статьи “Как бесплатно сделать лендинг за вечер?”
- Установите код Яндекс Метрики и Google Analytics себе на сайт, настройте цели
Статья подразумевает, что вы уже разбираетесь в понятиях: вордстат, показы, клики, минус-слова, кросс-минусовка, типы соответствий ключевых слова, частота слов, релевантность. А если и не разбираетесь, то cможете найти их в интернете.
Как подобрать ключевые запросы? Существует много приемов и инструментов для сбора ключевых слов: выгрузка из счетчиков, сбор с сайтов конкурентов, генерация из YML, поиск похожих по ТОПу фраз, автоматический подбор ключевых запросов на основании вашего сайта в поисковой выдаче и другие. Мы поговорим об основных методах, а точнее о wordstat.yandex.ru.
- Создаем таблицу Excel (советую использовать Google Docs, вот наш шаблон) и делаем в ней матрицу, как на скрине:
Для примера сделаем семантическое ядро для сайта schoolmasters.ru, который предлагает летнюю математическую школу в Болгарии. - Думаем, по каким бы запросам нас могли искать наши потенциальные клиенты, слова берем из головы и распределяем их по столбикам:
Яндекс различает части речи, поэтому «математика» и «математический», это 2 разных ключевых слова, но в то же время Яндекс не различает склонения и числа.Расширяем матрицу новыми словами:
- ищем похожие слова на wordstat.yandex.ru в правом столбике
- добавляем имеющиеся слова в разных частях речи
- исследуем, по каким словам дают рекламу и находятся в ТОПе ваши конкуренты на сайте advse.ru
- добавляем специальные термины, жаргоны, которые можно найти на сайтах конкурентов и форумах
- схожие по ассоциациям слова на wordassociations.ru
Для настройки на среднем уровне этого достаточно, перед тем, как расширять матрицу, прочтите теорию.
Теоретический блок
Мы знаем, что такое ключевая фраза в wordstat, она имеет частоту (показы в месяц), это среднее количество запросов за последние 3 месяца и 1 месяц год назад. Все фразы ниже, это входящие запросы, то есть запросы, которые содержат фразу, которую мы ввели, в разных склонениях и числах. Так же вы можете изучить частоту вашего запроса в разрезе регионов и сезонности во вкладках «По регионам» и «История запросов».
Рассматривайте ключевые слова, как сегменты одного бесконечного массива, из которого мы хотим выделить те сегменты, которые будут релевантны нашему сайту. Например, на картинке ниже, пересечение красного цвета содержит самые целевые запросы «математическая летняя школа», а зеленое пересечение «математическая школа» содержит запросы более широкого вида, а еще есть запрос «школа», который содержит 99% не релевантных для нас запросов.
Так вот к чему я веду? Мы возьмем для ручной сортировки все входящие запросы фраз «математическая летняя школа» и «математическая школа», а «школа» не возьмем, так как мы не хотим сортировать 99% запросов, чтобы найти 1% своих.
Матрица нужна, как материал, для составления ключевых фраз (сегментов). Не стоит добавлять в матрицу все слова, которые только возможны. Например, мы не будем добавлять слова «2016», «купить», «погода», так как мы не берем для ручной сортировки сегмент «математическая летняя школа купить», он уже будет содержаться в сегменте «математическая летняя школа», как входящий запрос. Чтобы ориентировать в том, какие слова стоит добавлять в матрицу, а какие нет, нужен опыт.
Так же вы могли заметить, что сегменты «математическая летняя школа» и «математическая школа» пересекаются, следовательно, мы должны вычесть из запроса «математическая школа» слово «летний». Для этого существуют минус-слова, но об этом позже.
Я не могу описать весь процесс, так как нюансов бесконечно много, но могу подсказать вам ключевые точки, следуя которым вы будете двигаться в верном направлении.- Составляем сегменты из матрицы. Открываем wordstat.yandex.ru и вводим первое слово из первого столбика «лагерь» — видим, что более 70-ти % входящих запросов нам не подходят. Попутно высматриваем новые ключевые слова и пополняем нашу матрицу, но учтите, что если вы добавляете новое хорошее слово, то оно может быть использовано в предыдущих сегментах.
Как определить ключевые слова, другими словами, что ищут пользователи, когда вводят конкретный запрос? Вбейте в Яндекс и посмотрите поисковую выдачу, как правило, на первых позициях содержится именно та информация, которая интересна пользователям. - Вы скажете, что аудитория, которая вводит «детский лагерь», могла бы заинтересоваться нашим предложением, но нет, потенциальных клиентов в этом сегменте не более 5%, следовательно, стоимость клиента будет такой высокой, что бы не сможем конкурировать с обычными детскими лагерями.
- Так как по запросу «лагерь» более 70% не релевантных ключевых слов, то мы начинаем усекать аудиторию, добавляя уточнения из других столбиков, например во фразе «лагерь математический» почти все внутренние запросы нам подходят, а значит добавляем их в сегменты для последующей обработки, такую операцию нам нужно проделать с каждым ключевым словом, идя от общего «лагерь» и сужая сегменты к частному «детский», «болгария».
Как правило в каждом сегменте есть слова, которые нам не подходят, например:
Мы добавляем эти слова в строку поиска с символом минус и снова нажимаем «Подобрать», чтобы получить тот же список ключевых слов, но уже без содержания минус-слов.
- Чтобы не запутаться, мы по-очередности ищем и добавляем сегменты ключевых слов в отдельное место справа от матрицы, как в шаблоне. К каждому сегменту добавляем минус-слова.
Помните про пересечение сегментов, на данном этапе нам нужно провести кросс-минусовку между сегментами.
Таким образом, получается карта охвата, смотря на нее, мы четко представляем по каким ключевым словам будут показываться наши объявления.
- Теперь нам нужно получить список ключевых слов из этой карты, для этого мы прибегнем к методу перемножения. Используем сервис py7.ru/tools/text/, но в нем нужно немного разобраться.
Суть метода перемножения ключевых в том, чтобы избежать ручной работы.В поле шаблон у нас сразу есть 4 переменные, если мы хотим перемножить 2 столбика, то нам нужно оставить только переменные %(a)s и %(b)s, а %(c)s и %(d)s удалить. Если мы хотим перемножить 3 столбика, то нужно удалить только %(d)s — количество переменных равно количество столбиков.
Нам нужно поочередно перемножить каждый сегмент, берем первый и распределяем слова по столбикам в сервисе py7.ru
Жмем кнопку «Генерация» и получаем результат:
лагерь математика
лагерь математический - Далее, на новом листе создаем столбики под каждый сегмент и в них распределяем ключевые слова после генерации.
Парсинг ключевых слов — сбор входящих запросов, аналогично тому, что мы введем ключевое слово в вордстат и скопируем все входящие запросы.Вы можете заметить, что возле каждой группы у нас появился столбик «минус-слов», туда мы вручную переносим слова для кросс-минусовки наших сегментов и общие списки для каждого сегмента, например:
- Теперь нужно собрать входящие запросы (далее спарсить) для каждой группы, есть 3 варианта:
- вручную копировать из wordstat.yandex.ru
- использовать topvisor.ru, но придется вручную фильтровать и удалять минус-слова
- keycollector, несомненно лучший, но самый сложный вариант
Мы используем wordstat.yandex.ru. По очереди берем каждое ключевое слово из каждой группы, добавляем к нему минус-слова и вставляем в wordstat
Обратите внимание, что мы выбираем параметр «все регионы», чтобы получить более усредненную статистику.
У нас выходит список входящих запросов на нескольких страницах, мы копируем запросы до значения показов в месяц 50
И вставляем в нашу таблицу на тот же лист под сегментом.
Почему до 50 показов в месяц, ведь все только что и говорят о количестве ключевых слов? Количество ключевых слов не является показателем качества рекламной кампании, чаще, это говорит о некомпетентности и непонимания механизмов работы контекстной рекламы.
Какой толк от низкочастотных запросов?
- Мы делаем для каждого ключевого слова свое объявление, что немного повышает его CTR, но и повышает объем работы, что не всегда оправдывается экономически.
- Чем больше ключевых слов, тем больше сегментов для аналитических систем, а значит больше возможностей для оптимизации, но тогда должно быть много статистики.
- Снижение стоимости клика, это миф, ниже 50-ти запросов можно снизить только в редки случаях.
Подытожим: для интернет-магазина собирайте до 50-ти показов, а для услуг до 20-30-ти показов.
Все ли вам понятно? Есть вопросы? Стоит ли нам запилить видео на эту тему?
Искаженные утверждения о вирусной фотографии мужчины, несущего жену во время войны 1971 года
Изображение мужчины, несущего на руках женщину с разорванной одеждой, стало вирусным в социальных сетях. Согласно сопроводительному сообщению, фотография взята из книги покойного поэта и автора доктора Дхарамвира Бхарти. Утверждается, что на снимке запечатлена сцена из индийско-пакистанской войны 1971 года, когда муж несет свою жену, которую несколько раз изнасиловали. Сообщение заканчивается утверждением, что на фотографии изображено притеснение индуистов в Пакистане и Бангладеш.
[Перевод с तस्वीर डॉ धर्मवीर भारती जी की पुस्तक गयी हैं, 1971 भारत पाकिस्तान युद्ध का हैं, जहाँ पति अपनी पत्नी की (लगातार बलात्कार की गयी) अस्मत बचा ना सका, लाश हो चुकी लेकर जाये? यही तो पूरा पाकिस्तान 1947 से और 1971 के बाद से बांग्लादेश में हिन्दुओं] ”
Примечательно, что изображение распространяется на фоне противоречивого Закона о поправках к гражданству (CAA), который стремится предоставить возможность немусульманским мигрантам из Бангладеш, Пакистана и Афганистана подать заявление на получение индийского гражданства.
Пользователь Twitter @ChaanchalMaurya разместил (ссылка на архив) вирусное изображение. Его ретвитнули более 5000 раз.
Точно так же многие пользователи Facebook и Twitter поделились этим изображением.
Проверка фактов
Alt News выполнил обратный поиск изображений на Яндексе и нашел видео YouTube, содержащее вирусное изображение. Согласно видео, загруженному Грейси Росадо в октябре 2014 года, на вирусное изображение нажал фотограф Марк Эдвардс.
Также прочтите: Поддельный твит, в котором Аманатулла Хан говорит, что «Ислам победит во всей Индии»
Выполнив поиск по ключевым словам, Alt News нашла вирусное изображение на веб-сайте благотворительной организации Hard Rain Project, основанной Эдвардсом. Фотография была нажата самим фотографом и описана так: «Беженцы из Восточного Пакистана прибывают в Индию во время войны в Бангладеш в 1971 году.
Книга « Body Horror: Photojournalism, Catastrophe and War » Джона Тейлора также приписывает Эдвардсу это изображение.
Во время разговора с сайтом Rare Historical Photos (RHP) в августе 2014 года Эдвардс сказал: «Я сделал эту глубоко тревожную фотографию мужчины, несущего свою больную холерой жену во время войны в Бангладеш в 1971 году. Десять миллионов человек пересекли Восточный Пакистан ( Бангладеш) граничит с Индией, чтобы избежать ужасов этой кровавой войны ».
По данным нескольких интернет-источников, в 1971 году в Бангладеш произошла вспышка холеры.
Alt News обратился к Эдвардсу по электронной почте для получения более подробной информации.Он сообщил: «Я не знаю, умерла она от холеры или нет, но нет абсолютно никаких признаков того, что она была изнасилована».
Таким образом, фотография распространяется с необоснованными заявлениями в свете недавно принятого Закона о гражданстве.
Статья изначально была опубликована на Alt News . Вы можете прочитать это здесь.
Комплексный контроль координационных и скоростно-силовых способностей в огневых видах спорта
1. Ляч В.И. Теория тестов и тестирование физической подготовки студентов.Физическая культура в школе. 2007; 6: 2–7. 2. Пойскич Х., Шепарович В., Муратович М., Юянин Э. Взаимосвязь между физической подготовкой и точностью стрельбы профессиональных баскетболистов. Motriz. Revista de Educacao Fisica. 2014. 4 (20): 408–417.
https://doi.org/10.1590/S1980-65742014000400007
3. Прочтите PJ, Hughes J, Stewart P, Chavda S, Bishop C, Edwards M, et al. Батарея анализа потребностей и полевых испытаний для баскетбола. Журнал силы и кондиционирования.2014; 3 (36): 13–20.
https://doi.org/10.1519/SSC.0000000000000051
4. Саву К.Ф., Пехою К. Особенности обучения координации и усвоения учебной программы физического воспитания с использованием специальных средств игры в баскетбол. Revista Romaneasca Pentru Educatie Mul Tidimensionala. 2018; 4 (10): 217–227.
https://doi.org/10.18662/rrem/83
5. Ляч В.И., Витковски З. Развитие и тренировка координационных навыков у футболистов от 11 до 19 лет.Физиология человека. 2010. 1 (36): 64–71.
https://doi.org/10.1134/S0362119710010081
6. Каццола Д., Павей Г., Преатони Э. Может ли изменчивость координации определять факторы производительности и уровень навыков в соревновательном спорте? Случай спортивной ходьбы. Журнал науки о спорте и здоровье. 2016; 1 (5): 35–43.
https://doi.org/10.1016/j.jshs.2015.11.005
7. Зиерис Э. Использовать комплексный тест на универсальность. Теория и практика физической культуры, 1984; 2: 124–125.
8.Палагина Н, Дорогова Ю.А., Полевщиков М, Фамильникова Н.В. Стандартизация тестирования уровня физической подготовленности студентов 18–20 лет. Средиземноморский журнал социальных наук. 2015; 6 (3): 887–896.
https://doi.org/10.5901/mjss.2015.v6n3s7p265
9. Ляч В.И. Развитие координационных способностей у детей школьного возраста. Москва; 1990.
10. Германов Г.Н., Сморчков В.А., Машошина И.В. Соответствие средств и методов профессиональной и прикладной физической подготовки курсантов институтов государственной пожарной службы МЧС России требованиям служебной деятельности.Ученые записки университета имени П.Ф. Лесгафта. 2014; 2 (108): 57–60. (На русском языке)
https://doi.org/10.5930/issn.1994-4683.2014.02.108
11. Berges A, Fernandez-Del-Rio E, Ramos-Villagrasa PJ. Прогнозирование квалификации пожарных: исследование прогнозируемой достоверности в Испании. Журнал трудовой и организационной психологии, 2018; 34 (1): 10–15.
12. Калинин А.П. Современный пожарно-спасательный спорт: учеб. стипендия для широкого круга любителей спасательного и пожарного спорта, спортсменов различной квалификации, слушателей образовательных учреждений МЧС России, специалистов и тренеров по спасению и пожаротушению.Москва: Российская Федерация; 2004.
13. Клейнберг ЧР, Райан Э.Д., Твиделл А.Дж., Барнетт Т.Дж., Ваггонер Ч.В. Влияние размера и качества мышц нижних конечностей на показатели подъема по лестнице у профессиональных пожарных. Журнал исследований силы и кондиционирования. 2016; 6 (30): 1613–1618.
https://doi.org/10.1519/JSC.0000000000001268
14. Вишомирска И., Иванска Д., Табор П. Образец устойчивости осанки как важный фактор безопасности пожарных. Рабочий журнал по оценке профилактики и реабилитации.2019; 62 (3): 469–476.
https://doi.org/10.3233/WOR-192881
15. Гуминяк Р.Дж., Гледхилл Н., Ямник В.К. Стандарт физической занятости для канадских пожарных из диких земель: проверка надежности повторных тестов и влияния ознакомления и тренировок по физической подготовке. Эргономика журнала. 2018; 10 (61): 1324–1333.
https://doi.org/10.1080/00140139.2018.1464213
16. Донг Х., Фигероа Н., Эль-Саддик А. Контроль «баланса нагрузки» для опорно-двигательного аппарата гуманоидной руки в движении настольного тенниса.Международный журнал автоматизации и систем управления, 2015; 4 (13): 887–896.
https://doi.org/10.1007/s12555-014-0038-z
17. Морель Э.А., Загатто AM. Адаптация тестов на лактатный минимум, критическую мощность и анаэробный порог для оценки перехода к аэробному / анаэробному режиму в протоколе, специфичном для настольного тенниса. Revista Brasileira de Medicina do Esporte. 2008. 6 (14): 518–522.
https://doi.org/10.1590/S1517-86922008000600009
18. Wong TKK, Ma AWW, Liu KPY, Chung LMY, Bae YH, Fong SSM, Ganesan B, Wang HK.Контроль равновесия, ловкость, координация глаз и рук и спортивные результаты игроков в бадминтон-любителей: перекрестное исследование. Медицина. 2019; 2 (98): 13–20.
https://doi.org/10.1097/MD.0000000000014134
19. Спорт. Проверка физической подготовленности. Еврофит. Экспериментальная батарея. Предварительный справочник [Интернет]. 2011. [обновлено 2020; цитируется 23 марта 2020 г.]. Доступно по адресу: https://bitworks-engineering.co.uk/linked/eurofit%20provisional%20handbook%20leger%20beep%20test%201983.pdf
20.Германов Г.Н., Корольков А.Н., Шалагинов В.Д., Сморчков В.А., Машошина И.В., Георгиева М.П. Модельные характеристики соревновательной деятельности спортсменов различных возрастных и половых групп в спасательном и пожарно-спасательном спорте. Ученые записки университета имени П.Ф. Лесгафта, 2016; 6 (30): 60–69. (На русском языке)
https://doi.org/10.5930/issn.1994-4683.2016.01.131
21. Шалагинов В.Д., Корольков А.Н., Сморчков В.А. Определение оптимального соотношения скорости бега и торможения при выполнении подсоединения пожарного шланга к ответвлению в пожарных и прикладных видах спорта.Ученые записки университета имени П.Ф. Лесгафта, 2015; 4 (117): 196–199. (На русском языке)
https://doi.org/10.5930/issn.1994-4683.2015.04.122
22. Ким Т.К. Т-тест как параметрическая статистика. Корейский журнал анестезиол. 2015; 68 (6): 540–546.
https://doi.org/10.4097/kjae.2015.68.6.540
23. Железняк Ю.Д., Петров П.С. Основы научно-методической деятельности по физическому воспитанию и спорту. Москва: Академия; 2002.
24.Акгюль М. Влияние высокоинтенсивных интервальных тренировок на основе Вингейта на аэробные и анаэробные показатели кикбоксеров. Физическое воспитание студентов. 2019; 23 (4): 167-71.
https://doi.org/10.15561/20755279.2019.0401
25. Берр Дж. Ф., Ямник Р. К., Бейкер Дж., Макферсон А., Гледхилл Н., Макгуайр Э. Дж. Взаимосвязь результатов тестирования физической подготовленности и хоккейного потенциала хоккеистов высокого уровня. Журнал исследований силы и кондиционирования. 2008. 22 (5): 1535–1543.
https: // doi.org / 10.1519 / JSC.0b013e318181ac20
26. Лотурко И., Контрерас Б., Кобаль Р., Фернандес В., Моура Н., Сикейра Ф., Винклер С., Сухомель Т., Перейра Л.А. Вертикально и горизонтально направленные силовые упражнения для мышц: взаимосвязь с высшим уровнем спринтерских результатов. PLoS ONE. 2018; 13 (7): 1–12.
https://doi.org/10.1371/journal.pone.0201475
27. Ван П.Ф., Ту М.Х., Фу LL. Результаты поэтапного тестирования физических нагрузок и специальной подготовленности игроков в настольный теннис. Медицина и наука в спорте и физических упражнениях.2014. 5 (46): 55–55.
https://doi.org/10.1249/01.mss.0000493331.97748.e8
28. Генч Х, Сигерчи А., Север О. Влияние 8-недельных основных тренировочных упражнений на физические и физиологические параметры гандболисток. Физическое воспитание студентов. 2019; 23 (6): 297–05.
https://doi.org/10.15561/20755279.2019.0604
29. Зерф М., Хаджар Херфане М., Кохли К., Луглайб Л. Взаимосвязь между максимальной аэробной скоростью и способностями к силовому взрыву двигателя в волейболе.Теория та методика Физического Вихованной, 2019; 19 (4), 179–185.
https://doi.org/10.17309/tmfv.2019.4.03
Может ли многоязычие улучшить биомедицинское устранение неоднозначности?
Основные моменты
- •
Графики совместной встречаемости обеспечивают конкурентные результаты в биомедицинской WSD.
- •
Многоязычность улучшает одноязычные результаты для графиков, построенных с небольшим количеством документов.
- •
Небольшие корпуса, связанные с тестовым набором данных, работают лучше, чем большие несвязанные корпуса.
- •
Автоматический перевод предлагает те же улучшения, что и ручной перевод.
- •
Новые языки улучшают результаты, если они достаточно разные, чтобы предлагать новую информацию.
Abstract
Неопределенность в биомедицинской области представляет собой серьезную проблему при выполнении задач обработки естественного языка над огромным объемом доступной информации в полевых условиях. По этой причине устранение неоднозначности слов имеет решающее значение для создания точных систем, способных решать сложные задачи, такие как извлечение информации, обобщение или классификация документов.В этой работе мы исследуем, может ли многоязычие помочь решить проблему неоднозначности, а также условия, необходимые для того, чтобы система улучшила результаты, полученные с помощью одноязычных подходов. Кроме того, мы анализируем лучшие способы создания этих полезных многоязычных ресурсов и изучаем разные языки и источники знаний. Предлагаемая система, основанная на графах совместной встречаемости, содержащих биомедицинские концепции и текстовую информацию, оценивается на тестовом наборе данных, часто используемом в биомедицине. Мы можем сделать вывод, что многоязычные ресурсы способны обеспечить явное улучшение более чем на 7% по сравнению с одноязычными подходами для графиков, построенных из небольшого количества документов.Кроме того, эмпирические результаты показывают, что автоматически переводимые ресурсы являются полезным источником информации для этой конкретной задачи.
Ключевые слова
Биомедицинское устранение неоднозначности смысла слов
Многоязычность
Графические системы
Единая система медицинского языка
Неконтролируемые системы
Параллельные и сопоставимые корпуса
Рекомендуемые статьи
. Все права защищены.
Рекомендуемые статьи
Цитирующие статьи
Как найти музыку из видео: 14 проверенных способов
Как найти музыку из видео с любого устройства
1. Найдите песню по словам в Интернете
Это самый простой и очевидный способ узнать, какая музыка была использована в видео. Наверняка вы начали его искать. Но если нет, просто попробуйте набрать в браузере несколько слов из песни. Для пояснения вы можете добавить «песню», «текст» или текст, если это песня на иностранном языке.
2. Ознакомьтесь с саундтреком
Если мы говорим о фильме, вы всегда можете обратиться к официальному саундтреку. Обычно в него входят все композиции, использованные в картине. Просто введите название фильма + OST или саундтрек в поиск. Проблема вполне может заключаться в ссылке на полный список треков.
3. Проверьте описание и комментарии на YouTube
Практически любой клип, рекламный ролик или трейлер к фильму можно найти на YouTube. Откройте этот сервис и найдите видео по ключевым словам.Тогда проверьте его описание. Именно там авторы часто указывают музыку, которую они используют. Чтобы перейти к описанию под видео, нажмите «Еще».
Если дорожки нет в описании, проверьте комментарии к видео. Возможно, кто-то из пользователей уже пытался узнать название песни и задал вопрос автору. Если не было ответа, можете спросить себя.
4. Воспользуйтесь веб-службой Midomi
Эта веб-служба поможет вам узнать, какая музыка звучит прямо сейчас.Для этого на главной странице сайта вам достаточно нажать на микрофон и разрешить прослушивание. В случае с одним и тем же YouTube вы можете запускать видео в одной вкладке браузера, а Midomi — в другой.
Если под рукой нет видео, песню можно петь, насвистывать или пилить — Midomi попытается угадать.
Перейти в Midomi →
5. Запустить бота Яндекс.Музыка в Telegram
Если вы активный пользователь Telegram, добавьте бота в популярный музыкальный сервис.Зажмите микрофон в строке отправки сообщения и дайте боту послушать песню. К каждому найденному треку добавлена ссылка на «Яндекс.Музыку».
Добавить бота «Яндекс.Музыки» →
6. Спросите бота Подтверждение в Telegram
Менее популярный, но вполне рабочий вариант — бот Подтверждения. Он также довольно точен и быстр, но для его работы необходимо подписаться на канал Bassmuzic. Подтверждение отслеживания дополняется ссылками на Spotify и YouTube.
Добавить бота Подтвердить →
Как обойти блокировку Telegram →
7.Смотрите в аудиозаписи «ВКонтакте»
Будь то реклама на ТВ, чей-то самодельный клип или музыка из фильма, вы всегда можете ввести название видео прямо в поиске аудиозаписей «ВКонтакте». В выпуске вполне может быть звуковая дорожка из видео с указанием исполнителя или просто название песни с пометкой, в каком ролике она использовалась.
8. Спрашивайте в специальных группах «ВКонтакте»
Например, здесь и здесь прямо на стене можно просто разместить ссылку или прикрепить само видео.Ваше сообщение увидят тысячи пользователей, и велика вероятность, что кто-то сможет дать ответ.
Попробуйте, особенно если ищете малоизвестный трек, не распознающий спецслужбы.
Как найти музыку из вашего видео с помощью смартфона
1. Используйте Google Audio Search на Android
Стандартный виджет поиска аудио доступен вместе с приложением Google. Просто включите прослушивание во время воспроизведения видео, и ваша проблема будет решена.
2. Спросите Siri для iOS
Для владельцев iPhone при просмотре видео просто спросите Siri: «Какая песня играет?» Или «Кто поет?».
3. Задайте вопрос «Алисе»
Пользователи мобильного поиска «Яндекс» могут задать вопрос помощнику, который также научился распознавать музыку, которую слушал долгое время. Достаточно сказать: «Угадай песню» или «Кто поет?» — и пусть «Алиса» послушает запись.
4. Запустите приложение Shazam
С помощью Shazam вы можете не только определить название и исполнителя песни, но также найти текст и узнать, где песню можно купить.
5. Или SoundHound
Известный аналог Shazam, который может распознать даже поющую вам песню. Каждый трек дополнен информацией об исполнителе и ссылкой для покупки в Google Play.
Как найти музыку из видео с помощью компьютера
1. Используйте Shazam на macOS
Держатели компьютеров на macOS могут использовать официальное приложение-сервис Shazam, доступное в App Store.Просто включите его при просмотре видео — и трек, если он есть в базе, будет распознан.
(PDF) Анализ важности длинного хвоста в маркетинге в поисковых системах
Таблица 4 показывает, что 100 самых популярных ключевых слов за первые 10 недель
генерируют подавляющее большинство поисков, кликов и конверсий за
в последующие недели, но они делают это со снижающейся скоростью. Для примера
100 самых популярных ключевых слов кампании «Путешествие 1» составили
, которые съели 91.59% поисков, 74,61% кликов и 81,01% конверсий
на 15 неделе, но их доля снижается до 52,81% поисков, 46,47%
кликов и 52,77% конверсий на 35 неделе. оставшиеся две кампании показывают более стабильную долю ключевых слов
100, эта доля также снижается. Столбец «Все еще используется
» в Таблице 4 показывает, что компания прекратила использовать 23% из
топ-100 ключевых слов в кампании «Путешествие 1», что может объяснить
, почему акции упали более резко в этом кампании, чем в
других двух кампаниях.Таблица 4 также показывает, что нет четкой тенденции
в том, как новые ключевые слова или бывшие нижние ключевые слова, которые
не входили в 100 лучших ключевых слов в первые 10 недель, присоединились к
ключевым словам в последующие недели. Доля новых ключевых слов на
выше для первой кампании, но ниже для второй и третьей
кампаний. Доля бывших нижних ключевых слов выше для
первой и третьей кампаний, но ниже для второй кампании
.
Таблица 5 показывает соответствующие результаты для 100 самых популярных ключей —
слов в зависимости от количества кликов (в отличие от поисков
в Таблице 4). Оба результата довольно похожи, что указывает на то, что набор
из 100 самых популярных ключевых слов со временем меняется. Таким образом, мы находим лишь
умеренной поддержки нашего предложения 3.
6. Заключение
Начиная с Андерсона (2006), термин «длинный хвост» пользуется огромной популярностью
, а рекламные агентства и блоггеры утверждают, что
Успехв поисковом маркетинге обусловлен длинным хвостом, который
мы определили в этом исследовании как множество менее популярных ключевых слов, вводимых пользователями для поиска в Интернете.Рекламные агентства имеют
сильных стимулов утверждать, что маркетинговые кампании в поисковых системах
должны содержать сотни или тысячи ключевых слов. Однако результаты наших эмпирических исследований
говорят о другом: 100 самых популярных ключевых слов
— а не очень длинный хвост, состоящий из других ключевых слов:
генерируют большинство поисков, кликов и конверсий. На первые
20% наиболее популярных ключевых слов приходится 98,16% всех
поисковых запросов, 97.21% всех кликов и 94,32% конверсий, а
топ-100 ключевых слов охватывают 88,57% всех поисковых запросов, 81,40% всех кликов
и 79,45% всех конверсий.
Мы показываем, что эти результаты довольно стабильны между изменениями в
общего количества ключевых слов, поскольку увеличение количества ключевых слов на
сверх 100 самых популярных ключевых слов лишь незначительно увеличивает количество поисков, кликов и конверсий на
. Вывод из этого поиска
состоит в том, что довольно небольшое количество ключевых слов важно для создания
подавляющего большинства поисковых запросов, кликов и конверсий.Тем не менее, наши результаты
также показывают, что набор 100 самых популярных ключевых слов меняется в течение
раз, и новые ключевые слова, а также ключевые слова, которые ранее имели не очень высокую эффективность
, могут заменить некоторые из 100 лучших ключевых слов.
В результате рекламодателям необходимо постоянно анализировать, какие из
ключевых слов работают лучше всего, но они по-прежнему могут сосредоточиться на 100 самых популярных ключевых словах —
словах для дальнейшего анализа успешности своих кампаний поисковых систем —
.
Источники
Андерсон К. «Длинный хвост»: почему будущее бизнеса — продавать меньше, а больше.
Hyperion, New York, 2006.
Brynjolfsson, E., Hu, Y., and Simester, D. Прощай, принцип Парето, привет, длинный хвост:
Влияние затрат на поиск на концентрацию продаж продукта. Рабочий документ,
Sloan School of Management, Массачусетский технологический институт, Кембридж, Массачусетс, 2007.
Брюнйолфссон, Э., Ху, Й. Дж. И Смит, Мэриленд Избыток потребителей в цифровой экономике:
оценка стоимости увеличения разнообразия продуктов на книжные магазины онлайн.
Наука управления, 49, 11, 2003, 1580–1596.
Чен Дж., Лю Д. и Уинстон А. Б. Аукцион по ключевым словам при онлайн-поиске. Журнал
Маркетинг, 73, 4, 2009, 125–141.
Эдельман Б., Островский М. Стратегическое поведение участников аукциона в спонсируемом поиске
аукционов. Системы поддержки принятия решений, 43, 1, 2007, 192–198.
Эдельман Б., Островский М. и Шварц М. Интернет-реклама и обобщенный аукцион второй цены
: продажа
ключевых слов на миллиарды долларов.Американский экономический обзор, 97, 1, 2006, 242–259.
Elberse, A. Стоит ли инвестировать в «длинный хвост»? Harvard Business Review, 86, 7/8, 2008,
88–96.
Эльберс, А., Обергольцер-Джи, Ф. Суперзвезды и аутсайдеры: исследование феномена
«длинного хвоста» в продаже видеопродукции. Рабочий документ № 07-15, Гарвард
Business School, Бостон, Массачусетс, 2006.
Фэн Дж. Оптимальный механизм для продажи набора объектов с общим рейтингом. Маркетинг
Наука, 27, 3, 2008, 501–512.
Фен, Дж., Бхаргава, Х. К. и Пеннок, Д. М. Внедрение спонсируемого поиска в сети
поисковые системы: вычислительная оценка альтернативных механизмов. INFORMS
Journal on Computing, 19, 1, 2007, 137–148.
Фледер Д. и Хосанагар К. Следующий подъем или падение культуры блокбастеров: влияние систем рекомендаций
на разнообразие продаж. Management Science, 55, 5, 2009, 697–
712.
Ghose, A., и Gu, B. Стоимость поиска, структура спроса и длинный хвост на электронных рынках
: теория и доказательства.Рабочий документ № 06-19, Net Institute, Stern
Школа бизнеса, Нью-Йоркский университет, Нью-Йорк, штат Нью-Йорк, 2006.
Ghose, A., and Yang, S. Эмпирический анализ рекламы в поисковых системах:
спонсируемый поиск в электронные рынки. Наука управления, 55, 10, 2009,
1605–1622.
Хе К. и Чен Ю. Управление электронными торговыми площадками: стратегический анализ неценовой рекламы.
. Маркетинговая наука, 25, 2, 2006, 175–187.
Эрвас-Дран, А.Сарафанное радио и рекомендательные системы: теория длинного хвоста
. Рабочий документ № 07-41, Институт Сети, Школа бизнеса Стерна, Нью-Йорк
Университет, Нью-Йорк, 2007.
Хотчкисс, Г., Алстон, С., и Эдвардс, Г., 2005. Отчет Google по отслеживанию глаз, 2005.
Доступно на www.enquiroresearch.com/eyetracking-report.aspx.
IAB. Отчет IAB о доходах от интернет-рекламы: результаты за 2009 год.
PriceWaterhouse Coopers, Нью-Йорк, 2010.Доступно на www.iab.net/media/
файл/ IAB-Ad-Revenue-Full-Year-2009.pdf.
Киттс Б. и Леблан Б. Оптимальные ставки на аукционах по ключевым словам. Электронные рынки,
14, 3, 2004, 186–201.
Лилиенталь, М., Скиера, Б. Разложение эффекта увеличения поиска
рекламных расходов на цены за клик и количество кликов. Рабочий документ
, Франкфуртский университет, Франкфурт, Германия, 2010 г.
Лю Д., Чен Дж. И Уинстон А.Б. Предварительная информация и дизайн аукционов по ключевому слову
. Исследования информационных систем, в печати.
Махдиан М. и Томак К. Модель оплаты за действие для интернет-рекламы.
Международный журнал электронной торговли, 13, 2, 2008 г., 113–128.
Мидха, В. Проблема в онлайн-рекламе: исследование мошенничества с кликами в рекламных программах с оплатой за клик
. Международный журнал электронной коммерции, 13, 2, 2008 г.,
91–112.
Рангасвами, А., Джайлз, К. Л., и Серес, С. Стратегический взгляд на поисковые системы:
конфет для практиков и исследователей. Журнал интерактивного маркетинга,
23, 1, 2009, 49–60.
Рутц, О. Дж., И Баклин, Р. Э. От универсального к фирменному: модель распространения в платной поисковой рекламе
. Журнал маркетинговых исследований, в печати.
Такер К. и Чжан Дж. Длинный или крутой хвост? Полевое расследование того, как информация о популярности в Интернете
влияет на выбор клиентов дистрибьютора.Рабочий документ
, статья 4655-07, Школа менеджмента Sloan, Массачусетский технологический институт, Кембридж, Массачусетс, 2007.
Вариан, Х. Р. Позиционные аукционы. Международный журнал промышленной организации, 25, 6,
2006, 1163–1178.
Уилбур К. и Чжу Ю. Мошенничество с кликами. Маркетинговая наука, 28, 2, 2009, 293–308.
Янг С. и Гхош А. Анализ взаимосвязи между органической и спонсируемой
поисковой рекламы: положительная, отрицательная или нулевая взаимозависимость? Маркетинг
Наука, в печати.
494 B. Skiera et al. / Electronic Commerce Research and Applications 9 (2010) 488–494
Используйте InVid-WeVerify — «швейцарский армейский нож» цифровой проверки — Citizen Evidence Lab — Amnesty International
Необходимые инструменты: подключаемый модуль InVid-WeVerify, установленный в Chrome или Firefox
Уровень квалификации: Средний — требуются некоторые проверочные знания
Одним из основных инструментов, которые мы в лаборатории доказательств Amnesty International рекомендуем всем исследователям открытого исходного кода, является подключаемый модуль InVid-WeVerify для браузера Chrome или Firefox.Он построен как швейцарский армейский нож для проверки, содержит несколько инструментов в одном месте, включая экстрактор ключевых кадров для видео, экстрактор метаданных для фотографий и видео, обратный поиск изображений по ключевым кадрам, инструмент увеличения для фотографий и аккуратный интерфейс. для расширенного поиска Twitter. Мы объясняем, сколько из этих функций работает, в этом сообщении блога, которое адаптировано из большей части руководств, доступных в подключаемом модуле.
Этот инструмент является результатом сотрудничества InVid (или In Video Veritas) и WeVerify, финансируемого Европейским Союзом.Цель — помочь журналистам, следователям по правам человека и другим исследователям проверять контент в социальных сетях.
Когда инструмент установлен, в верхней части браузера появляется небольшой значок запуска.
ЗАПУСК INVID-WEVERIFY
При щелчке программа запуска предоставляет пользователю три варианта.
Открыть InVID запускает плагин.
URL-адреса видео отображает URL-адрес видео, представленного на веб-странице.
URL-адреса изображения отображает URL-адрес изображения, представленного на веб-странице.
Последние два параметра могут быть особенно полезны, если, например, фото или видео встроены в новостной сайт. Скопируйте и вставьте URL-адреса, чтобы использовать их при открытии InVid-WeVerify.
ОТКРЫТИЕ INVID-WEVERIFY
После открытия инструмента пользователь увидит несколько вкладок.
Мы обращаемся к каждой из этих вкладок ниже (кроме вкладки «Права на видео», которая предназначена для журналистов, занимающихся вопросами авторского права).
Вкладка «Анализ » — это улучшенная программа просмотра метаданных для общедоступных видео YouTube, Twitter и Facebook. Он позволяет пользователю получать контекстную информацию, местоположение (если обнаружено), наиболее интересные комментарии, а также применять обратный поиск изображений и проверять наличие твитов на видео (на YouTube). Для Facebook пользователь должен войти в учетную запись Facebook, чтобы иметь возможность обрабатывать ссылки.
Вкладка Keyframes позволяет пользователю копировать URL-адрес видео (с YouTube, Twitter, Facebook, Daily Motion или Dropbox) или загружать локальный видеофайл (в mp4, webm, avi, mov, wmv, ogv, mpg, flv и mkv), чтобы разбить видео на ключевые кадры.После сегментации ключевые кадры можно искать, щелкнув левой кнопкой мыши на Google Image Search или с помощью контекстного меню (правой кнопкой мыши) на изображениях Google, Yandex, Tineye, Bing, Karma Decay (для Reddit) и Baidu.
Вкладка YouTube Thumbnails позволяет пользователю быстро запускать обратный поиск изображений в Google, Bing, Tineye или Yandex Images с четырьмя миниатюрами, извлеченными из видео YouTube. В браузере автоматически открываются до четырех вкладок (в зависимости от количества доступных эскизов) с результатами обратного поиска изображений, в то время как четыре эскиза также отображаются на странице плагина.Эта вкладка несколько дублирует то, что можно сделать с помощью вкладки Анализ , но она очень быстрая и эффективная, если пользователю нужно узнать, публиковалось ли ранее видео на YouTube.
Вкладка поиска в Twitter — это расширенный расширенный поиск в Twitter по ключевым словам или хэштегам с использованием операторов Since и until для сокращения временного интервала запроса до одной минуты. Он автоматически переводит календарную дату, час и минуту в метку времени unix для облегчения запроса, например.g., первых изображений или видеороликов в пределах временного диапазона сразу после события, связанного с экстренной передачей новостей. Вкладка также включает другие функции расширенного поиска Twitter, такие как геокодирование, близость, откуда, язык и различные операторы фильтров.
Вкладка лупы позволяет пользователю отображать изображение по его URL-адресу, а также увеличивать или применять увеличительную линзу к изображению, чтобы помочь декодировать и читать трудно различимые детали изображения, такие как номерные знаки автомобилей, военные знаки отличия, знаки и баннеры.Пользователь может либо ввести URL-адрес изображения, либо загрузить изображение с локального диска с помощью кнопки локального файла. После того, как изображение отображается с URL-адреса, вы можете выполнять обратный поиск изображений в Google, Яндекс, Tineye и Baidu или использовать вкладку «Криминалистическая экспертиза изображений», описанная ниже. На этой вкладке доступны и другие инструменты: повышение резкости, отражение изображения и кадрирование.
Вкладка «Метаданные» позволяет пользователю проверять данные Exif изображения jpeg или метаданные видео в формате mp4 / m4v. Это либо ссылка, либо локальный файл.
Вкладка Forensic предоставляет восемь различных фильтров, которые могут быть применены к изображениям, чтобы помочь пользователю обнаружить фальсификацию цифрового изображения — например, использование программного обеспечения для редактирования Photoshop. Это требует глубоких знаний о том, как работают фильтры изображений, поэтому эту вкладку не рекомендуется использовать новичкам для исследования открытого исходного кода.
КОНТЕКСТНОЕ МЕНЮ
Подключаемый модуль InVid-WeVerify также открывает в браузере контекстное меню .Это активируется щелчком правой кнопкой мыши по изображению или URL-адресу видео в сети.
Это меню позволяет пользователю запускать этот плагин для неподвижного изображения или ссылки на видео YouTube. При щелчке правой кнопкой мыши по изображению будет предложено либо открыть изображение в лупе, чтобы изучить его более внимательно, либо запустить криминалистический анализ или обратный поиск изображений этого изображения. Щелчок правой кнопкой мыши по ссылке на видео предлагает либо анализ видео InVID-WeVerify, либо обратный поиск по миниатюрам YouTube.
Консорциум InVid-WeVerify финансируется программой Horizon 20:20 Европейского Союза и состоит из: Agence France-Presse, Deutsche Welle, Центра исследований и технологий Hellas (CERTH) — Института информационных технологий (ITI), Modul Technology GmbH, Universitat de Lleida, Exo Makina, WebLyzard Technology GmbH, Condat AG, APA-IT Informations Technologie GmbH, Шеффилдский университет, Афинский технологический центр и EU Disinfolab.
Эта статья была частично адаптирована из учебника InVid-WeVerify Browser Plug-in, автором которого является Дени Тейсу из Agence France-Presse.
Агробиология: 4-2020 Ильина
doi: 10.15389 / agrobiology.2020.4.697eng
УДК: 636.294: 579.62: 577.2
Благодарностей:
При финансовой поддержке Российского научного фонда проект № 17-76-20026 «Микробиоценоз рубца Rangifer tarandus Российской Арктики как основа перспективных биотехнологий животных»
ИЗМЕНЕНИЕ РУССКОГО АРКТИЧЕСКОГО ОЛЕНЯ ( Rangifer tarandus ) МИКРОБИОМ РУМЫ, СВЯЗАННЫЙ С ИЗМЕНЕНИЕМ СЕЗОНА
л.Ильина А.А. 1 , В.А. Филиппова 1 , К.А. Лайшев 2 , Е.А. Йилдирим 1 ,
Т.П. Дуняшев 1 , Е.А. Бражник 1 , А.В. Дубровин 1 , Д.В. Соболев 1 ,
Д.Г. Тюрина 1 , Н.И. Новикова 1 , Г.Ю. Лаптев 1 , А.А. Южаков 2 ,
Т.М. Романенко 3 , Ю.П. Вилко 3
1 АО Биотроф +, 19, корп.Россия, 192284, Санкт-Петербург, Загребский бульвар, 1, e-mail [email protected] (✉ автор-корреспондент), [email protected], [email protected], [email protected], dubrowin.av@yandex .ru, [email protected], [email protected], [email protected];
2 Северо-Западный центр междисциплинарных исследований проблем продовольственной безопасности, 7, ш. Подбельского, Санкт-Петербург, 196608, Пушкин, Россия, e-mail [email protected], [email protected];
3 Федеральный центр комплексных исследований Арктики им. М.В. Лаверова РАН, Нарьян-Марская агроэкспериментальная станция, , 1а, ул.Рыбникова, Россия, 166004, Нарьян-Мар, Ненецкий АО, e-mail [email protected], [email protected]
ORCID:
Ильина Л.А. orcid.org/0000-0003-2789-4844
Соболев Д.В. orcid.org/0000-0002-3238-979X
Лаишев К.А. orcid.org/0000-0003-2490-6942
Новикова Н.И. orcid.org/0000-0002-9647-4184
Йилдирим Э.А. orcid.org/0000-0002-5846-5105
Лаптев Г.Ю. orcid.org/0000-0002-8795-6659
Филиппова В.А. orcid.org/0000-0001-8789-9837
Южаков А.А. orcid.org/0000-0002-0633-4074
Дуняшев Т.P. orcid.org/0000-0002-3918-0948
Романенко Т.М. orcid.org/0000-0003-0034-7453
Дубровин А.В. orcid.org/0000-0001-8424-4114
Вилко Ю.П. orcid.org/0000-0002-6168-8262
Поступила 15.04.2020
Северный олень ( Rangifer tarandus ) — крупное голарктическое травоядное животное, среда обитания которого, включая его существование при низких температурах и плохом питании, привела к эволюционному развитию их уникальной микробиоты рубца, которая необходима для эффективной ассимиляции Арктическая флора.Зимой большую часть кормовых растений северного оленя составляют лишайники, богатые вторичными метаболитами, которые могут влиять на представителей микробного консорциума пищеварительного тракта. Ранее сообщалось о токсическом воздействии некоторых метаболитов лишайников (например, усниновой кислоты) на ряд микроорганизмов ( Clostridiales , Enterococcus , Staphylococcus aureus , Escherichia coli и т. Д.), А также на жвачных животных (лося). . Однако мало что известно о влиянии потребления лишайников на микробиом рубца северного оленя.С помощью молекулярного анализа мы впервые изучили сезонные закономерности формирования микробных сообществ рубца северного оленя Rangifer tarandus , обитающего в Российской Арктике. Целью исследования было сравнение состава бактериального сообщества рубца северного оленя в летне-осенний и зимне-весенний периоды методом NGS-секвенирования. При анализе микробных сообществ оценивались биоразнообразие, таксономическая структура и взаимосвязь этих показателей с особенностями питания оленей в связи с сезонными изменениями.Образцы содержимого рубца были собраны в летне-осенний и зимне-весенний периоды 2017-2018 гг. От 20 ненецких северных оленей (телята 4-8 месяцев и взрослые животные 3-6 лет, n = 3 на каждую возрастную группу. ) в Ненецком автономном округе (АД). Сезонные различия, в отличие от пола и возраста, оказались основным фактором, влияющим на бактериальное сообщество рубца северных оленей, что, скорее всего, связано с различиями в составе пастбищного рациона. В летне-осенний период отмечалось значительное увеличение α-биоразнообразия микробиома рубца по сравнению с зимне-весенним временем по количеству ОТЕ, индексов Чао1 и Шеннона.Сравнение β-разнообразия состава микробиоты рубца северного оленя показало наличие выраженного кластерообразования для проб, собранных в разные сезоны года. Несмотря на то, что в зимний период рацион северных оленей в основном был представлен лишайниками, которые не являются типичной пищей для других жвачных животных (таких как крупный рогатый скот, овцы и т. Д.), Интересно отметить, что в целом полученный микробиом профили соответствуют современным представлениям о микробиоте рубца жвачных животных.Тем не менее, в разные сезонные периоды были отмечены значительные изменения в представлении ряда таксонов, наиболее явные из которых были обнаружены для микроорганизмов, связанных с ферментацией кормовых полисахаридов. Так, в зимне-весенний период наблюдается значительный рост микроорганизмов, разлагающих полисахариды лишайников, в том числе гемицеллюлозу ( Butyrivibrio , Ruminococcus ) и лихенин ( Succiniclasticum , Paraprevotellaceae и Prevotella ).В летне-осенний период отмечается значительное увеличение доли целлюлозолитических бактерий (Clostridium , Blautia , Clostridial e s , Christensenellaceae Mogibacteriaceae , Prevotellaceae ). Кроме того, было показано, что в летний период в рубце северного оленя размножается целый спектр микроорганизмов, относящихся к бактериальным возбудителям, в том числе Erysipelotrichaceae , Coriobacteriaceae , Mycoplasmataceae и Rickettsiales .В целом полученные результаты позволяют заключить, что микробиом рубца северного оленя достаточно четко связан с питательными особенностями в различные сезонные периоды, которые определяют адаптацию к условиям окружающей среды.
Ключевые слова: Rangifer tarandus , северный олень, рубец, микробиом, сезонные изменения, NGS, Российская Арктика.
ССЫЛКИ
- Моргави Д.П., Келли В.Дж., Янссен П.Х., Аттвуд Г.Т. Микробная (мета) геномика рубца и ее применение в производстве жвачных животных. Животное , 2013, 7 (1): 184-201 CrossRef
- Mathiesen S.D., Mackie R.I., Aschfalk A., Ringø E., Sundset M.A. Микробная экология пищеварительного тракта северного оленя: сезонные изменения. В: Биология растущих животных. Vol. 2 Микробная экология растущих животных . W.H. Хольцапфель, П.Дж. Нотон, С.Г. Пьержиновски, Р. Забельски, Э. Салек (ред.). Elsevier Ltd., Эдинбург, 2005: 75-102 CrossRef
- Aagnes T.H., Sørmo W., Mathiesen S.D. Микробное пищеварение рубца в условиях свободного проживания, у содержащихся в неволе лишайников и голодных северных оленей ( Rangifer tarandus tarandus ) зимой. Прикладная и экологическая микробиология , 1995, 61 (2): 583-591.
- Орпин К.Г., Матизен С.Д., Гринвуд Ю., Бликс А.С. Сезонные изменения микрофлоры рубца высокоарктического северного оленя Шпицбергена ( Rangifer tarandus platyrhynchus ). Прикладная и экологическая микробиология , 1985, 50 (1): 144-151.
- Sundset M.A., Kohn A., Mathiesen S.D., Praesteng K.E. Eubacterium rangiferina , новая устойчивая к усниновой кислоте бактерия из рубца северного оленя. Naturwissenschaften , 2008, 95 (8): 741-749 CrossRef
- Карцев В., Личицкий Б., Героникаки А., Петру А., Смилькович М., Костич М., Раданович О., Сокович М. Дизайн, синтез и антимикробная активность производных усниновой кислоты. Med. Chem. Commun ., 2018, 9 (5): 870-882 CrossRef
- Роуч Дж.A.G., Musser S.M., Morehouse K., Woo J.Y.J. Определение усниновой кислоты в лишайниках, токсичных для лосей, методом жидкостной хроматографии с ультрафиолетовым и тандемным масс-спектрометрическим определением. J. Agric. Еда. Chem ., 2006, 54 (7): 2484-2490 CrossRef
- Дейли Р.Н., Монтгомери Д.Л., Ингрэм Дж. Т., Симион Р., Васкес М., Райсбек М.Ф. Токсичность вторичного метаболита лишайника (+) — усниновой кислоты у домашних овец. Ветеринарная патология , 2008, 45 (1): 19-25 CrossRef
- Пало Р.T. Усниновая кислота, вторичный метаболит лишайников, и ее влияние на усвояемость оленей in vitro. Rangifer , 1993, 13 (1): 39-43 CrossRef
- Сундсет М.А., Барбоза П.С., Грин Т.К., Фолкоу Л.П., Бликс А.С., Матизен С.Д. Микробная деградация усниновой кислоты в рубце северного оленя. Naturwissenschaften , 2010, 97: 273-278 CrossRef
- Henderson G., Cox F., Ganesh S., Jonker A., Young W., Global Rumen Census Collaborators, Янссен П.H. Состав микробного сообщества рубца варьируется в зависимости от диеты и хозяина, но основной микробиом встречается в широком географическом диапазоне. Научные отчеты , 2015, 5: 14567 CrossRef
- Фонти Г., Джоблин К., Чаваро М., Ру Р., Нейлор Г., Михаллон Ф. Создание и развитие рубцовых гидрогенотрофов у ягнят без метаногена. Прикладная и экологическая микробиология , 2007, 73 (20): 6391-6403 CrossRef
- Сундсет М.А., Прастенг К.Э., Канн И.К., Матизен С.Д., Маки Р.И. Новое бактериальное разнообразие рубца у двух географически разделенных подвидов северных оленей. Microb. Ecol ., 2007, 54 (3): 424-438 CrossRef
- Кратер А.Р., Барбоза П.С., Форстер Р. Регулирование ферментации рубца во время сезонных колебаний в потреблении овцебыка. Сравнительная биохимия и физиология. Часть A, Молекулярная и интегративная физиология , 2007, 146 (2): 233-241 CrossRef
- Рустомо Б., Аль-Захал О., Одонго Н., Даффилд Т.Ф., Макбрайд Б.В. Влияние кислотной нагрузки рубца от размера частиц корма и кормов на pH рубца и потребление сухого вещества у лактирующих молочных коров. Journal of Dairy Science , 2006, 89 (12): 4758-4768 CrossRef
- Kleen J.L., Hooijer G.A., Rehage J., Noordhuizen J.P. Подострый ацидоз рубца (SARA): обзор. Журнал ветеринарной медицины, серия A , 2003, 50 (8): 406-414 CrossRef
- Макьюэн Н.Р., Абесия Л., Регенсбогенова М., Адам С.Л., Финдли П.А., Ньюболд С.Д. Динамика микробной популяции рубца в ответ на фотопериод. Письма по прикладной микробиологии , 2005, 41 (1): 97-101 CrossRef
- Уйено Ю., Секигучи Ю., Таджима К., Такенака А., Курихара М., Камагата Ю. Анализ на основе рРНК для оценки влияния теплового стресса на микробный состав рубца телок голштинской породы. Анаэроб , 2010, 16 (1): 27-33 CrossRef
- Ромеро-Перес Г.А., Омински К.Х., Макаллистер Т.А., Краузе Д.О. Влияние факторов окружающей среды и влияние биогеографии рубца и задней кишки на бактериальные сообщества бычков. Прикладная и экологическая микробиология , 2011, 77 (1): 258-268 CrossRef
- Olsen M.A., Aagnes T.H., Mathiesen S.D. Влияние силоса тимофеевки на бактериальную популяцию в рубцовой жидкости северного оленя ( Rangifer tarandus tarandus ) с естественных летних и зимних пастбищ. FEMS Microbiology Ecology , 1997, 24 (2): 127-136 CrossRef
- Ван Т.Y., Chen HL, Lu MJ, Chen YC, Sung HM, Mao CT, Cho HY, Ke HM, Hwa TY, Ruan SK, Hung KY, Chen CK, Li JY, Wu YC, Chen YH, Chou SP, Tsai YW , Chu TC, Ши CA, Ли WH, Ши MC Функциональная характеристика целлюлаз, идентифицированных из гриба рубца коров Neocallimastix patriciarum W5 с помощью транскриптомного и секретомного анализов. Биотехнология . Биотопливо , 2011, 4:24 CrossRef
- Фонти Г., Джоблин К.N. Анаэробные грибы рубца: их роль и взаимодействие с другими микроорганизмами рубца в отношении переваривания клетчатки. В: Физиологические аспекты пищеварения и обмена веществ у жвачных животных . Academic Press, Торонто, Онтарио, 1990: 665-680.
- Сундсет М.А., Эдвардс Дж.Э., Ченг Ю.Ф., Сеносиан Р.С., Фрайл М.Н., Нортвуд К.С., Престенг К.Э., Глад Т., Матизен С.Д., Райт А.Д.Г. Молекулярное разнообразие микробиома рубца норвежских северных оленей на естественных летних пастбищах. Microb. Ecol ., 2009, 57 (2): 335-348 CrossRef
- Сундсет М.А., Эдвардс Дж.Э., Ченг Ю.Ф., Сеносиайн Р.С., Фрайле М.Н., Нортвуд К.С., Престенг К.Э., Глад Т., Матизен С.Д., Райт А.Д. Микробное разнообразие рубца у северных оленей Свальбарда, с особым акцентом на метаногенных архей. FEMS Microbiology Ecology , 2009, 70 (3): 553-562 CrossRef
- Салгадо-Флорес А., Хаген Л.Х., Исхак С.Л., Заманзаде М., Райт А.Д.Г., Папа П.Б., Сундсет М.A. Микробиомы рубца и слепой кишки северного оленя ( Rangifer tarandus tarandus ) изменяются в ответ на лишайниковую диету и могут влиять на кишечные выбросы метана. PLoS ONE , 2016, 11 (5): e0155213 CrossRef
- Полежаев А.Н., Беркутенко А.Н. Определитель кормовых растений северного оленя: Магаданская область . Магадан, 1981.
- Мотовилов К.Я., Булатов А.П., Позняковский П.М., Ланцева Н.Н., Миколайчик И.Н. Экспертиза кормов и кормовых добавок. Новосибирск, 2004.
- Caporaso JG, Kuczynski J., Stombaugh J., Bittinger K., Bushman FD, Costello EK, Fierer N., Pesa AG, Goodrich JK, Gordon JI, Huttley GA, Kelley ST, Knights D., Koenig JE, Ley RE , Lozupone CA, McDonald D., Muegge BD, Pirrung M., Reeder J., Sevinsky JR, Turnbaugh PJ, Walters WA, Widmann J., Yatsunenko T., Zaneveld J., Knight R. QIIME позволяет анализировать высокопроизводительные данные секвенирования сообщества. Природные методы , 2010, 7: 335-336 CrossRef
- Оливерос Дж. К. Венни. Интерактивный инструмент для сравнения списков с диаграммами Венна. 2007 г. Источник: http://bioinfogp.cnb.csic.es/tools/venny/index.html. Без даты.
- Warton D.I., Wright T.W., Wang Y. Многофакторный анализ на основе расстояний, влияющий на местоположение и дисперсию. Методы в экологии и эволюции , 2012, 3 (1): 89-101 CrossRef
- Моргави Д.П., Келли В.Дж., Янссен П.Х., Аттвуд Г.Т. Микробная (мета) геномика рубца и ее применение в производстве жвачных животных. Животное , 2013, 7 (1): 184-201 CrossRef
- Person S.J., White R.G., Luick J.R. Определение питательной ценности ареала северного оленя и карибу, In: Proceedings of the 2nd International Reindeer and Caribou Symposium . Э. Реймерс, Э. Гааре, С. Скеннеберг (ред.). Директорат для vilt og ferskvannsfisk, Тронхейм, Норвегия, 1980: 224-239.
- Черч Д.C. Жвачные животные: физиология пищеварения и питание . Прентис Холл, Нью-Джерси, 1993.
- Hungate R.E. Рубец и его микробы . Academic Press, NY, 1966.
- Hackmann T.J., Испания J.N. Приглашенный обзор: экология и эволюция жвачных животных: перспективы, полезные для исследований и производства жвачных животных. Журнал молочной промышленности , 2010, 93 (4): 1320-1334 CrossRef
- Пэн С., Инь Дж., Лю X., Цзя Б., Чанг З., Лу Х., Цзян Н., Чен К. Первые сведения о микробном разнообразии омасума и ретикулума крупного рогатого скота с использованием секвенирования Illumina. J. Appl. Генетика , 2015, 56 (3): 393-401 CrossRef
- Смит С.С.Р., Сноуберг Л.К., Грегори С.Дж., Найт Р., Болник Д.И. Диетический вклад микробов и генетическая изменчивость хозяина формируют межпопуляционные различия микробиоты кишечника колюшки. ISME J ., 2015, 9 (11): 2515-2526 CrossRef
- Фиере Н.Принятие неизвестного: раскрытие сложностей микробиома почвы. Nature Reviews Microbiology , 2017, 15: 579-590 CrossRef
- Шен Дж., Чжэн Л., Чен Х., Хань Х., Цао Й., Яо Дж. Метагеномный анализ микробных и углеводно-активных ферментов в рубце молочных коз, получавших различные разлагаемые в рубце крахмалы. Границы микробиологии , 2020, 11: 1003 CrossRef
- Ли З.П., Лю Х.Л., Гуан Ю.Л., Бао К., Ван К.Ю., Сюй К., Ян Ю.Ф., Ян Х.Ф., Райт А.Д.Г. Молекулярное разнообразие бактериальных сообществ рубца из богатых танинами и богатых клетчаткой кормов, получаемых от домашних пятнистых оленей ( Cervus nippon ) в Китае. BMC Microbiol ., 2013, 13: 151 CrossRef
- Ли Ф., Ли К., Чен Ю., Лю Дж. Генетика хозяина влияет на микробиоту рубца, а наследственные микробные особенности рубца связаны с эффективностью корма крупного рогатого скота. Микробиом , 2019, 7: 92 CrossRef
- Zielińska S., Kidawa D., Stempniewicz L., oś M., oś J.M. Новое понимание микробиоты северного оленя Свальбарда Rangifer tarandus platyrhynchus . Границы микробиологии , 2016, 7: 170 CrossRef
- Mathiesen S.D, Haga Ø.E, Kaino T., Tyler N.J.C. Состав рациона, расслоение рубца и поддержание массы туши у самок норвежского северного оленя ( Rangifer tarandus tarandus ) зимой. Зоологический журнал , 2000, 251 (1): 129-138 CrossRef
- Чжоу М., Пэн Ю., Чен Ю., Клингер К., Масахито О., Лю Дж., Гуан Л. Оценка изменений микробиома после трансфаунации рубца: влияние на повышение эффективности кормов у мясного скота. Микробиом , 2018, 6: 62 CrossRef
- Казановский Е.С., Карабанов В.П., Клебенсон К.А. Болезни северных оленей . Сыктывкар, 2011.
- Морита Х., Ширатори К., Мураками М., Таками Х., Тох Х., Като Ю., Накадзима Ф., Такаги М., Акита Х., Масаока Т., Хаттори М. Sharpea azabuensis gen. nov., sp. nov., грамположительная строго анаэробная бактерия, выделенная из фекалий породистых лошадей. Международный журнал систематической и эволюционной микробиологии , 2008, 58 (12): 2682-2686 CrossRef
- Ночек Дж. Э. Ацидоз крупного рогатого скота: последствия для ламинита. Journal of Dairy Science , 1997, 80: 1005-1028 CrossRef