Создание запросов на создание таблицы — Visual Database Tools
Twitter LinkedIn Facebook Адрес электронной почты
- Статья
- Чтение занимает 2 мин
Область применения: SQL Server (все поддерживаемые версии)
При помощи запросов на создание таблицы в новую таблицу можно копировать строки, что может оказаться полезным для создания подмножества данных и копирования содержимого таблиц из одной базы данных в другую. Запрос на создание таблицы похож на запрос на вставку результатов, но создает новую таблицу, в которую затем копируются строки.
Запрос на создание таблицы похож на запрос на вставку результатов, но создает новую таблицу, в которую затем копируются строки.
При создании запроса на создание таблицы указывают:
Имя новой таблицы базы данных (целевой таблицы).
Таблицу или таблицы, из которых копируются строки (исходную таблицу). Можно копировать данные из одной таблицы или из соединенных таблиц.
Столбцы в исходной таблице, содержимое которых нужно скопировать.
Порядок сортировки, когда нужно скопировать строки в определенном порядке.
Условия поиска для выборки строк, которые нужно скопировать.
Параметры группировки для случаев, когда нужно скопировать только сводные данные.
Например, следующий запрос создает новую таблицу с именем uk_customers и копирует в нее данные из таблицы customers:
SELECT * INTO uk_customers FROM customers WHERE country = 'UK'
Для успешного выполнения запроса на создание таблицы:
Создание запроса на создание таблицы
Добавьте на панели «Диаграмма» исходную таблицу или таблицы.

В меню Конструктор запросов наведите указатель на пункт Тип изменения, а затем выберите пункт Создать таблицу.
В диалоговом окне Создать таблицу введите имя целевой таблицы. Конструктор запросов и представлений не проверяет, есть ли уже такое имя и имеется ли разрешение на создание таблицы.
Чтобы создать целевую таблицу в другой базе данных, укажите полное имя целевой таблицы, состоящее из имени целевой базы данных, имени владельца (если требуется) и имени таблицы.
Укажите столбцы, из которых будут копироваться данные, добавив их к запросу. Дополнительные сведения см. в статье Добавление столбцов в запросы (визуальные инструменты для баз данных). Копируются только те столбцы, которые добавлены в запрос. Чтобы скопировать строки целиком, выберите * (все столбцы).
Конструктор запросов и представлений добавляет выбранные столбцы к столбцу Столбец панели критериев.
Чтобы скопировать строки в определенном порядке, укажите порядок сортировки. Дополнительные сведения см. в разделе
Укажите, какие строки необходимо копировать, введя условия поиска. Дополнительные сведения см. в разделе Определение критериев поиска.
Если условия поиска не заданы, в целевую таблицу будут скопированы все строки исходной таблицы.
Примечание
При добавления столбца для поиска на панели критериев конструктор запросов и представлений также включит его в список столбцов, подлежащих копированию. Если столбец необходим для поиска, но копировать его не нужно, снимите флажок рядом с именем этого столбца в прямоугольнике, представляющем таблицу или объект со структурой таблицы.
Чтобы скопировать сводные данные, укажите параметры Group By. Дополнительные сведения см. в разделе Резюмирование результатов запросов.

При выполнении запроса на создание таблицы в панели результатовне выводятся никакие результаты. Вместо этого появляется сообщение о количестве скопированных строк.
Вместо этого появляется сообщение о количестве скопированных строк.
Разделы по конструированию запросов и представлений (визуальные инструменты для баз данных)
[Типы запросов(../../ssms/visual-db-tools/types-of-queries-visual-database-tools.md)
Базы данных. SQL. Создание таблиц. Оператор CREATE TABLE
Перед изучением данной темы рекомендуется ознакомиться с темой:
Содержание
- 1. Оператор CREATE TABLE. Создание таблицы. Общая форма
- 2. Примеры создания таблиц
- 2.1. Пример создания простейшей таблицы учета товаров в магазине
- 2.2. Пример создания таблицы учета телефонов абонентов
- 2.3. Пример создания таблицы учета заработной платы и отчислений в организации
- Связанные темы
Поиск на других ресурсах:
1.
 Оператор CREATE TABLE. Создание таблицы. Общая форма
Оператор CREATE TABLE. Создание таблицы. Общая формаТаблица является основным элементом любой реляционной базы данных. Вся необходимая информация, которая должна храниться в базе данных, размещается в таблицах. Таблицы могут быть связаны между собой. Количество таблиц в базе данных не ограничено и зависит от сложности решаемой задачи.
Для создания таблицы в языке SQL используется оператор CREATE TABLE. В простейшем случае общая форма оператора CREATE TABLE следующая
CREATE TABLE Table_Name (
Field_Name_1 Type_1,
Field_Name_2 Type_2,
...
Field_Name_N Type_N
)здесь
- Table_Name – имя таблицы базы данных. Если в базе данных есть таблица с таким именем, то возникнет ошибка;
- Field_Name_1, Field_Name_2, Field_Name_N – имена полей (столбцов) таблицы базы данных. Имя каждого поля должно быть уникальным. В разных таблицах имена полей могут совпадать;
- Type_1, Type_2, Type_N – соответственно типы полей Field_Name_1, Field_Name_2, Field_Name_N такие как INTEGER, DECIMAL, DATE и другие.

На поля Field_Name_1, Field_Name_2, Field_Name_N могут накладываться ограничения. Каждое ограничение указывается после имени поля. В этом случае общая форма оператора CREATE TABLE выглядит примерно следующим образом:
CREATE TABLE Table_Name (
Field_Name_1 Type_1 Attribute_1,
Field_Name_2 Type_2 Attribute_2,
...
Field_Name_N Type_N Attribute_N
)здесь
- Attribute_1, Attribute_2, Attribute_N – ограничения, накладываемые на поля Field_Name_1, Field_Name_2, Field_Name_N. Ограничения задаются одним из возможных слов: NULL, NOT NULL, UNIQUE, CHECK, PRIMARY KEY, FOREIGN KEY и других.
Рассмотрение существующих полей атрибутов в языке SQL не является предметом изучения данной темы.
⇑
2. Примеры создания таблиц
2.1. Пример создания простейшей таблицы учета товаров в магазине
Условие задачи.
- Используя средства языка SQL создать таблицу с именем Product, которая будет отображать следующую информацию об учете товаров в магазине
| Название товара | Стоимость закупки, грн. | Количество, штук | Дата получения | Примечание |
| … | … | … | … | … |
- Таблица обязана содержать первичный ключ и обеспечивать уникальность записей.
Решение.
- Для обеспечения уникальности записей в таблице нужно создать дополнительное поле, которое будет являться счетчиком (автоинкрементом). Название поля – ID_Product. Это поле есть первичным ключом. Также это поле имеет ограничение NOT NULL (непустое поле).
- Следующим шагом решения есть назначение имен полям таблицы. В связи с тем, что не все системы управления базами данных (СУБД) поддерживают символы кириллицы, имена полей таблицы будут задаваться латинскими символами. В нашем случае формируются имена и типы данных, сформированные в следующей таблице:
| Название поля в условии задачи | Название поля на языке SQL | Тип поля | Объяснение |
| ID_Product | ID_Product | INTEGER | Первичный ключ, счетчик, NOT NULL |
| Название товара | [Name] | VARCHAR(100) | Строковый тип переменной длины максимум до 100 символов |
| Стоимость закупки | Price | DECIMAL(15, 2) | Точность равна 15 знакам, масштаб равен 2 знакам после запятой |
| Количество штук | [Count] | INTEGER | Целое число |
| Дата получения | [Date] | DATE | |
| Примечание | Note | VARCHAR(200) |
- Написание кода на языке SQL с учетом особенностей предыдущих шагов. Текст программы создания таблицы на языке SQL следующий
 Текст программы создания таблицы на языке SQL следующий
Текст программы создания таблицы на языке SQL следующий
CREATE TABLE [Product] (
[ID_Product] Integer Not Null Primary Key,
[Name] VarChar(100) ,
[Price] Decimal(15, 2),
[Count] Integer,
[Date] Date,
[Note] VarChar(200)
)В Microsoft SQL Server допускается задавать имена полей без их обрамления в квадратные скобки []. То есть, предыдущая команда может быть переписана следующим образом
CREATE TABLE Product (
ID_Product Integer Not Null Primary Key,
Name VarChar(100) ,
Price Decimal(15, 2),
Count Integer,
Date Date,
Note VarChar(200)
)В приведенном выше коде для поля ID_Product задаются ограничения Not Null и Primary Key. В результате запуска программы на SQL будет создана следующая таблица
| ID_Product | Name | Price | Count | Date | Note |
| … | … | … | … | … | … |
На рисунке 1 отображаются поля созданной таблицы в Microsoft SQL Server Management Studio.
Рисунок 1. Этапы создания таблицы Product в Microsoft SQL Server Management Studio 18: 1 – создание файла; 2 – набор SQL-запроса; 3 – запуск запроса на выполнение; 4 – результирующая таблица
Конечно, можно создать таблицу, в которой нет поля ID_Product и нету первичного ключа. Такая таблица не будет обеспечивать уникальность записей, поскольку возможна ситуация, когда данные в двух записях могут совпасть. В этом случае SQL код программы имеет вид
CREATE TABLE Product (
Name VarChar(100) ,
Price Decimal(15, 2),
Count Integer,
Date Date,
Note VarChar(200)
)⇑
2.2. Пример создания таблицы учета телефонов абонентов
Условие задачи.
Используя средства языка SQL (T-SQL) создать таблицу учета телефонов абонентов.
| Name | Address | Phone Number 1 | Phone Number 2 | Phone Number 3 |
Ivanov I. I. I. | New York | 123456 | 067-1234567 | – |
| Johnson J. | Kiev | 789012 | 033-7777778 | 102 |
| Petrenko P.P. | Warshaw | 044-2521412 | – | – |
| … | … | … | … | … |
Обеспечить уникальность и корректное сохранение записей таблицы.
Решение.
Для обеспечения уникальности записей нужно создать дополнительное поле – счетчик. Это поле будет увеличивать свое значение на 1 при каждом добавлении новой записи. Если запись будет удаляться, текущее максимальное значение счетчика не будет уменьшаться. Таким образом, все числовые значения этого поля будут различаться между собой (будут уникальными). В нашем случае добавляется поле ID_Subscriber. Это поле не допускает нулевые значения (NULL).
Для полей Name и [Phone Number 1] целесообразно задать ограничение (атрибут) NOT NULL. Это означает, что в эти поля обязательно нужно ввести значение. Это логично, поскольку абонент в базе данных должен иметь как минимум имя и хотя бы один номер телефона.
Это логично, поскольку абонент в базе данных должен иметь как минимум имя и хотя бы один номер телефона.
После внесенных изменений поля таблицы будут иметь следующие свойства
| Название поля | Тип данных | Объяснение |
| ID_Subscriber | INTEGER | Первичный ключ, счетчик, NOT NULL |
| Name | VARCHAR(50) | Фамилия и имя абонента |
| Address | VARCHAR(100) | Адрес |
| [Phone Number 1] | VARCHAR(20) | NOT NULL |
| [Phone Number 2] | VARCHAR(20) | |
| [Phone Number 3] | VARCHAR(20) |
Учитывая вышесказанное, команда CREATE TABLE на языке Transact-SQL (T-SQL) будет выглядеть следующим образом
Create Table Subscriber (
ID_Subscriber Int Not Null Primary Key,
[Name] VarChar(50) Not Null,
[Address] VarChar(100),
[Phone Number 1] VarChar(20) Not Null,
[Phone Number 2] VarChar(20),
[Phone Number 3] VarChar(20)
)В запросе имена полей
[Phone Number 1] [Phone Number 2] [Phone Number 3]
обязательно должны быть в квадратных скобках [], поскольку имена состоят из нескольких слов (между словами есть символ пробела).
На рисунке 2 показаны этапы создания таблицы в системе Microsoft SQL Server Management Studio.
Рисунок 2. Окно Microsoft SQL Server Management Studio. Этапы формирования запроса: 1 — создание файла «SQL Query 2.sql»; 2 — набор SQL-запроса; 3 — выполнение; 4 — результирующая таблица
⇑
2.3. Пример создания таблицы учета заработной платы и отчислений в организации
Условие задачи
Используя язык SQL сделать таблицу Account, в которой ведется учет начисленной заработной платы в некой организации. Образец таблицы следующий
| Name | Position | Accrued salary | Date of employment | Gender |
| Johnson J. | Manager | 3200.00 | 01.02.2128 | M |
| Petrova M.P. | Clerk | 2857.35 | 02.03.2125 | F |
Williams J. | Secretary | 3525.77 | 01.08.2127 | F |
| Wilson K. | Recruiter | 1200.63 | 22.07.2125 | F |
| … | … | … | … | … |
Таблицу реализовать так, чтобы обеспечивалась уникальность записей.
Решение.
Чтобы обеспечить уникальность записей, создается дополнительное поле-счетчик ID_Account типа Int. Это поле целесообразно выбрать первичным ключом, если нужно будет использовать данные этой таблицы в других связанных таблицах.
После модификации поля таблицы будут иметь следующие свойства.
| Название поля (атрибут) | Тип данных | Дополнительные объяснения |
| ID_Account | Int | Автоинкремент (счетчик), первичный ключ (Primary Key), ненулевое поле (Not Null), обеспечивает уникальность записей |
| [Name] | VARCHAR(50) | Фамилия и имя, не нулевое поле (Not Null) |
| Position | VARCHAR(100) | Должность, не нулевое поле (Not Null) |
| Salary | DECIMAL | Тип, предназначенный для сохранения денежных величин |
| [Employment Date] | DATE | Дата, не нулевое поле (Not Null) |
| Gender | CHAR(1) | Стать, не нулевое поле (Not Null) |
В модифицированной таблице поле Salary допускает нулевые (Null) значения. Таким случаем может быть, например, когда человек принят на работу, но заработная плата ему еще не начислена. В данной ситуации временно устанавливается Null-значение. Все остальные поля обязательны для заполнения.
Таким случаем может быть, например, когда человек принят на работу, но заработная плата ему еще не начислена. В данной ситуации временно устанавливается Null-значение. Все остальные поля обязательны для заполнения.
Запрос на язык SQL, создающий вышеприведенную таблицу имеет вид
/* Create the Account table */
Create Table Account (
ID_Account Int Not Null Primary Key,
[Name] VarChar(50) Not Null,
[Position] VarChar(100) Not Null,
Salary Decimal Null,
[Employment Date] Date Not Null,
Gender Char(1)
)Результат выполнения SQL-запроса показан на рисунке 3
Рисунок 3. Результат выполнения запроса на языке Transact-SQL (T-SQL)
⇑
Связанные темы
- Microsoft SQL Server Management Studio 18. Пример создания простейшего запроса
- Модификация таблиц. Оператор ALTER TABLE. Примеры
⇑
Пошаговое создание таблицы SQL
Прежде чем приступать к созданию таблицы SQL, необходимо определить модель базы данных.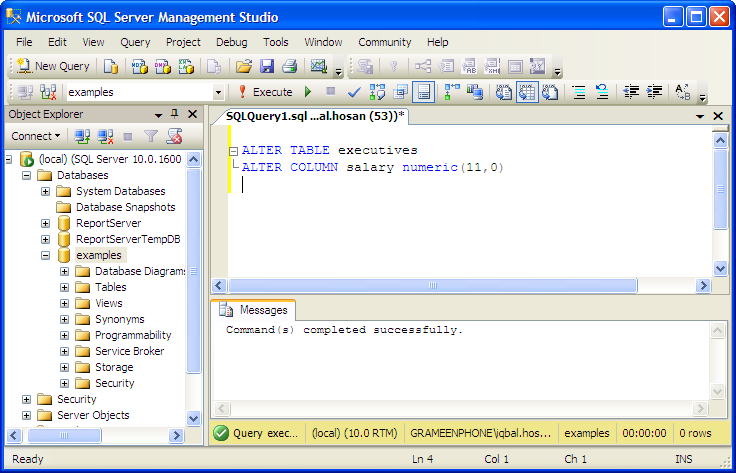 Спроектировать ER-диаграмму, в которой определить сущности, атрибуты и связи.
Спроектировать ER-диаграмму, в которой определить сущности, атрибуты и связи.
Основные понятия
Сущности – предметы или факты, информацию о которых необходимо хранить. Например, сотрудник фирмы или проекты, реализуемые предприятием. Атрибуты – составляющая, которая описывает или квалифицирует сущность. Например, атрибут сущности «работник» — заработная плата, а атрибут сущности «проект» — сметная стоимость. Связи – ассоциации между двумя элементами. Она может быть двунаправленная. Также существует рекурсивная связь, то есть связь сущности с самой собой.
Также необходимо определить ключи и условия, при которых сохранится целостность базы данных. Что это значит? Другими словами — ограничения, которые помогут сохранить базы данных в правильном и согласованном виде.
Переход от ER-диаграммы к табличной модели
Правила перехода к табличной модели:
- Преобразовать все сущности в таблицы.
- Преобразовать все атрибуты в столбцы, то есть каждый атрибут сущности должен быть отображен в имени столбца таблицы.
- Уникальные идентификаторы преобразовать в первичные ключи.
- Все связи преобразовать во внешние ключи.
- Осуществить создание таблицы SQL.

Создание базы
Сначала неоходимо запустить сервер MySQL. Для его запуска следует зайти в меню «Пуск», затем в «Программы», далее в MySQL и MySQL Server, выбрать MySQL-Command-Line-Client.
Для создания базы данных применяется команда Create Database. Данная функция имеет следующий формат:
CREATE DATABASE название_базы_данных.
Ограничения на название базы следующие:
- длина составляет до 64 знаков и может включать буквы, цифры, символы «» и «»;
- имя может начинаться с цифры, но в нем должны присутствовать буквы.
Нужно помнить и общее правило: любой запрос или команда заканчиваются разделителем (delimiter). В SQL принято в качестве разделителя использовать точку с запятой.
Серверу необходимо указать, с какой базой данных нужно будет работать. Для этого существует оператор USE. Этот оператор имеет простой синтаксис: USE название_базы_данных.
Этот оператор имеет простой синтаксис: USE название_базы_данных.
Создание таблицы SQL
Итак, модель спроектирована, база данных создана, и серверу указано, как именно с ней нужно работать. Теперь можно начинать создавать таблицы SQL. Существует язык определения данных (DDL). Он используется для создания таблицы MS SQL, а также для определения объектов и работы с их структурой. DDL включает в себя набор команд.
SQL Server создания таблицы
Используя всего лишь одну команду DDL, можно создавать различные объекты базы, варьируя ее параметры. Для создания таблицы SQL применяется команда Create Table. Формат tt выглядит следующим образом:
CREATE TADLE название_таблицы, (название_столбца1 тип данных [DEFAULT выражение] [ограничение_столбца], название_столбца2 тип данных [DEFAULT выражение] [ограничение_столбца],[ограничения_таблицы]).
Следует подробнее описать синтаксис указанной команды:
- Название таблицы должно иметь длину до 30 символов и начинаться с буквы. Допустимы только символы алфавита, буквы, а также символы «_», «$» и «#». Разрешено использование кириллицы. Важно отметить, что имена таблиц не должны совпадать с именами других объектов и с зарезервированными словами сервера базы данных, таких как Column, Table, Index и т. д.
- Для каждого столбца следует обязательно указать тип данных. Существует стандартный набор, используемый большинством. Например, Char, Varchar, Number, Date, тип Null и т. д.
 Допустимы только символы алфавита, буквы, а также символы «_», «$» и «#». Разрешено использование кириллицы. Важно отметить, что имена таблиц не должны совпадать с именами других объектов и с зарезервированными словами сервера базы данных, таких как Column, Table, Index и т. д.
Допустимы только символы алфавита, буквы, а также символы «_», «$» и «#». Разрешено использование кириллицы. Важно отметить, что имена таблиц не должны совпадать с именами других объектов и с зарезервированными словами сервера базы данных, таких как Column, Table, Index и т. д.- С помощью параметра Default можно задать значение по умолчанию. Это гарантирует, что в таблице не будет неопределенных значений. Как это понимать? Значением по умолчанию может быть символ, выражение, функция. Важно помнить, что тип этих данных, заданных по умолчанию, должен совпадать с типом вводимых данных столбца.
- Ограничения на каждый столбец используют для реализации обеспечения условий целостности для данных на уровне таблицы. Есть и еще нюансы. Запрещено удалять таблицу, если есть зависимые от нее другие таблицы.

Как работать с базой
Для реализации крупных проектов чаще всего требуется создание нескольких баз данных, и каждая требует множество таблиц. Конечно, удержать всю информацию в голове пользователям невозможно. Для этого предусмотрена возможность посмотреть структуру баз данных и таблиц в них. Существует несколько команд, а именно:
- SHOW DATABASES – показывает на экране все созданные базы данных SQL;
- SHOW TABLES – выводит список всех таблиц для текущей базы данных, которые выбираются командой USE;
- DESCRIBE название_таблицы – показывает описание всех столбцов таблицы.
- ALTER TABLE – позволяет изменять структуру таблицы.
Последняя команда позволяет:
- добавить в таблицу столбец или ограничение;
- изменить существующий столбец;
- удалить столбец или столбцы;
- удалить ограничения целостности.
Синтаксис этой команды выглядит так: ALTER TABLE название_таблицы { [ADD название_столбца или ограничения] | [MODIFY название_изменяемого_столбца] | [DROP название_удалаяемого_столбца(ов)] | [DROP удаляемое_ограничение] | [{ENABLE | DISABLE} CONSTANT имя_ограничения ] | }.
Существуют и другие команды:
- RENAME – переименование таблицы.
- TRUNCATE TABLE -удаляет все строки из таблицы. Эта функция может быть нужна, когда необходимо заполнить таблицу заново, а хранить предыдущие данные нет необходимости.
Также бывают ситуации, когда структура базы поменялась и таблицу следует удалить. Для этого существует команда DROP. Конечно, предварительно нужно выбрать базу данных, из которой нужно удалить таблицу, если она отличается от текущей.
Синтаксис команды довольно простой: DROP TABLE название_таблицы.
В SQL Access создание таблиц и их изменение осуществляется теми же командами, перечисленными выше.
С помощью CREATE TABLE можно создать пустую таблицу и в дальнейшем заполнить ее данными. Но это еще не все. Также можно сразу создавать таблицу из другой таблицы. Как это? То есть существует возможность определить таблицу и заполнить ее данными другой таблицы. Для этого существует специальное ключевое слово AS.
Синтаксис очень простой:
- CREATE TABLE название_таблицы [(определение_столбцов)] AS подзапрос;
- определение_столбцов – имена столбцов, правила целостности для столбцов вновь создаваемой таблицы и значения по умолчанию;
- подзапрос – возвращает такие строки, которые нужно добавить в новую таблицу.
Таким образом, такая команда создает таблицу с определенными столбцами, вставляет в нее строки, которые возвращаются в запросе.
Временные таблицы
Временные таблицы — это таблицы, данные в которых стираются в конце каждого сеанса или раньше. Они используются для записи промежуточных значений или результатов. Их можно применять в качестве рабочих таблиц. Определять временные можно в любом сеансе, а пользоваться их данными можно только в текущем сеансе. Создание временных таблиц SQL происходит аналогично обычным, с использованием команды CREATE TABLE. Для того чтобы показать системе, что таблица временная, нужно использовать параметр GLOBAL TEMPORARY.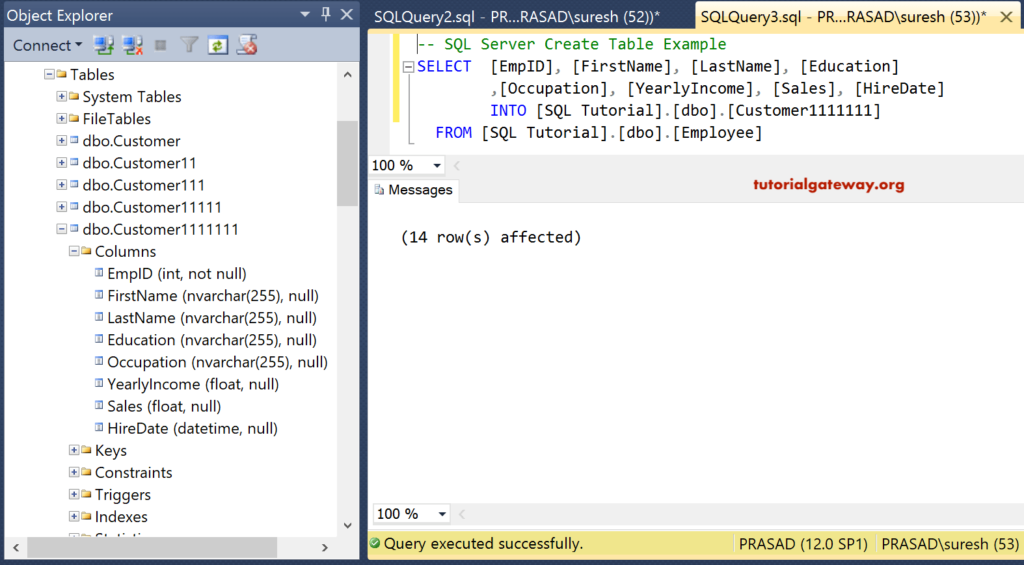
Предложение ON COMMIT устанавливает время жизни данных в такой таблице и может выполнять следующие действия:
- DELETE ROWS –очистить временную таблицу (удалить все данные сеанса) после каждого завершения транзакции. Обычно это значение используется по умолчанию.
- PRESERVE ROWS –оставить данные для использования их в следующей транзакции. Помимо этого, можно очистить таблицу только после завершения сеанса. Но есть особенности. Если произошел откат транзакции (ROLLBACK), таблица будет возвращена к состоянию на конец предыдущей транзакции.
Синтаксис создания временной таблицы может быть представлен таким образом: CREATE [GLOBAL TEMPORARY] TABLE название_таблицы, (название_столбца1 тип данных [DEFAULT выражение] [ограничение_столбца], название_столбца2 тип данных [DEFAULT выражение] [ограничение_столбца], [ограничения_таблицы]).
Создание таблиц в Transact-SQL — Transact-SQL В подлиннике : Персональный сайт Михаила Флёнова
В последствии мы будем рассматривать различные возможности базы данных последовательно – создание, удаление и редактирование. Но иногда мы будем отходить от этой последовательности, как сейчас. Мы пока научились только создавать и удалять базу данных, но тут же переходим к рассмотрению создания таблиц, а редактирование баз увидим чуть позже (разд. 1.3).
Но иногда мы будем отходить от этой последовательности, как сейчас. Мы пока научились только создавать и удалять базу данных, но тут же переходим к рассмотрению создания таблиц, а редактирование баз увидим чуть позже (разд. 1.3).
Когда мы создали базу данных, можно переходить к созданию таблиц, которые будут содержать непосредственно данные. Если сравнить базу данных с файловой системой, то ее можно рассматривать как папку, а таблицы можно рассматривать как файлы в этой папке. Только базы данных не поддерживают вложенности, т.е. в одной базе не может быть другой базы данных.
База данных сама по себе не несет никакой пользы, как и папка без файлов, потому что и то и другое не могут хранить данные. Данные хранятся в таблицах (файлах файловой системы) и именно их мы научимся создавать в этом разделе.
Что такое таблица в базе данных MS SQL Server? Данный сервер работает с реляционными таблицами, которые представляют собой двухмерный массив данных, в котором колонка определяет значение, а строки – это данные. Например, таблица базы данных схожа с классическими таблицами (списками), которые мы строим в программе Excel или на бумаге в рефератах/курсовых.
Например, таблица базы данных схожа с классическими таблицами (списками), которые мы строим в программе Excel или на бумаге в рефератах/курсовых.
Рассмотрим таблицу на примере. Допустим, что нам надо хранить в таблице список жителей дома. Не задумываясь о базах данных, а просто на бумаге для решения поставленной задачи мы нарисуем таблицу 1.1.
Таблица 1.1. Список жителей дома
| Фамилия | Имя | Отчество | Дата рождения | Адрес |
|---|---|---|---|---|
| Иванов | Иван | Иванович | 1.1.1950 | Шаболовка 37 |
| Петров | Петр | Петрович | 4.7.1967 | Королева 12 |
| … | … | … | … | … |
В ведении мы уже кратко говорили об уникальности, а сейчас нам предстоит поговорить об этом более подробно. Исходя из реляционной модели, все строки в базе данных должны быть уникальными. Это значит, что не может быть в списке жителей дома две записи для одного и того же жителя. Некоторые могут сказать, что это не проблема, потому что вероятность того, что в одном доме будет жить два человека с одними и теми же данными в полях ФИО и даты рождения. Вероятность маленькая, но она же есть! А ведь есть еще вероятность ошибки пользователя программы, который может ввести дважды одного и того же человека. Вот это уже станет действительно проблемой.
Некоторые могут сказать, что это не проблема, потому что вероятность того, что в одном доме будет жить два человека с одними и теми же данными в полях ФИО и даты рождения. Вероятность маленькая, но она же есть! А ведь есть еще вероятность ошибки пользователя программы, который может ввести дважды одного и того же человека. Вот это уже станет действительно проблемой.
Чтобы понять, какие проблемы могут возникнуть при появлении в таблице одинаковых записей, представим, что у нас в списке 10 человек с одинаковыми ФИО и дата рождения (адрес опустим и не учитываем, чтобы пример был более реальным). Такой пример вполне реален. Если взять всех жителей России, то количество людей с фамилией Иванов будет не просто большим, а огромным, а совпадение остальных параметров также возможно.
Теперь представим, что у одной из записей, фамилия введена неверно и запись случайно двоит с 10 другими записями. Какую из 10 одинаковых строк должен изменить сервер? Любую, потому что записи одинаковые? Это не очень корректный выход, поэтому в стандарте SQL-92 сказано, что в реляционной таблице не может быть двух абсолютно одинаковых записей, хотя многие базы данных позволяют нарушить это ограничение и MS SQL Server не является исключением.
Чтобы обеспечить уникальность, было введено понятие ключевое поле. Это одно или несколько полей, которые обеспечивают уникальность строк в таблице. В нашем случае, ключевыми можно сделать ФИО и дату рождения. В этом случае, при попытке добавить новую строку, в которой значения в этих полях будут одинаковы с любой из уже существующих строк таблицы, база данных возвратит ошибку и не сможет добавить такую строку. Получается, что с помощью ключевых полей базы данных обеспечивают уникальность и по ним гарантировано можно найти одну и только одну запись. То есть, запросив из базы данных строку с определенными ФИО и датой рождения, мы получим только одну запись.
Некоторые базы данных позволяют создавать таблицы без ключевых полей, но я не рекомендую этого делать без особой надобности. Всегда создавайте ключевое поле. В MS SQL Server для этого можно использовать автоматически увеличиваемое поле, которое не требует дополнительных расходов на сопровождение.
В настоящее время Microsoft не рекомендует использовать в качестве ключа автоматически увеличиваемые поля. Да, эти поля достаточно просты в сопровождении, но не всегда эффективны, потому что автоматически увеличиваемое поле нельзя редактировать. Сейчас рекомендуется для ключа создавать поле типа GUID (Global Unique Identifier, Глобально Уникальный Идентификатор). Значения полей этого типа можно редактировать и достаточно просто сгенерировать самостоятельно.
Да, эти поля достаточно просты в сопровождении, но не всегда эффективны, потому что автоматически увеличиваемое поле нельзя редактировать. Сейчас рекомендуется для ключа создавать поле типа GUID (Global Unique Identifier, Глобально Уникальный Идентификатор). Значения полей этого типа можно редактировать и достаточно просто сгенерировать самостоятельно.
Пессимисты считают, что GUID не могут быть идеальным решением проблемы ключевого поля, потому что значение генерируется и может возникнуть ситуация, когда будут сгенерированы два одинаковых значения. Оптимисты утверждают, что даже если все компьютеры в мире будут одновременно генерировать GUID, вероятность получения двух одинаковых значений стремиться к нулю.
В оптимистическое утверждение мне вериться с трудом, ведь количество возможных GUID ограничено и после генерации хотя бы 1/3 из этих значений вероятность получения повтора увеличивается в два раза. Но к пессимистам меня тоже отнести нельзя, потому что возможных вариантов GUID настолько много, что хватит даже для очень большой базы данных, с которой вы скорей всего никогда не встретитесь в своей практике.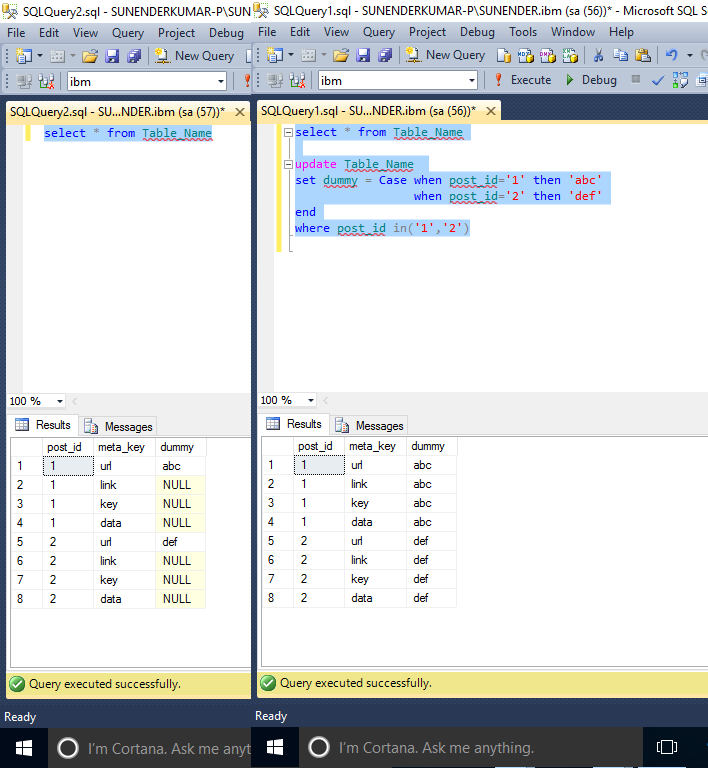 Поэтому, я использую GUID поля (и пока не разу не встречался с конфликтами GUID), о которых мы еще поговорим в разделе 2.24. А в этом разделе мы будем в основном создавать таблицы с ключевым полем в виде автоматически увеличиваемого поля, что намного удобнее при изучении языка запросов SQL.
Поэтому, я использую GUID поля (и пока не разу не встречался с конфликтами GUID), о которых мы еще поговорим в разделе 2.24. А в этом разделе мы будем в основном создавать таблицы с ключевым полем в виде автоматически увеличиваемого поля, что намного удобнее при изучении языка запросов SQL.
Теперь посмотрим, как сервер хранит данные в строке. Иногда возникает необходимость хотя бы приблизительно рассчитать размер строки, а лучше всегда знать это значение. Это позволит вам более эффективно управлять размером базы данных.
Строка данных состоит из строки заголовка и порции данных. Заголовок содержит 4 байта информации о поле строки данных, таких как указатель, на расположение конца фиксированной порции данных строки, и какой размер переменной используется в строке.
Поле может содержать следующие элементы:
- Данные фиксированной длины (char, int и.т.д.) – помещаются в страницу перед данными, переменной длинны.
- Нулевые блоки (NULL) — это набор байтов переменной длинны.
- Переменные блоки (varchar) – содержат два байта, описывающие, какой длинны колонка. Дополнительные два байта на колонку указывают на конец каждой колонки, переменной длинны.
- Данные переменной длины (text, image) – Данные переменной длины хранятся в странице после переменных блоков.
По возможности, делайте размер строки (общий размер всех полей) компактным, что позволяет поместить больше строк в страницу. Это позволит уменьшить операции ввода вывода и улучшить работу буфера. Для того, чтобы размер строки был компактным, необходимо выделять каждому полю только необходимый размер. Например, для хранения данных о фамилии вполне достаточно 20 символов строки переменной длинны varchar, и не имеет смысла выделять поле типа char, фиксированной длинны в 50 символов.
Тип char имеет фиксированную длину, и в странице данных будет всегда съедать определенный размер данных (в данном случае 50 символов). Тип varchar будет отнимать только столько, сколько необходимо. Например, вы объявили поле типа varchar размером 50 символов, но записали в него только 10. В странице данных на диске будет выделено (помимо заголовка) только 10 символов и не каплей больше.
Например, вы объявили поле типа varchar размером 50 символов, но записали в него только 10. В странице данных на диске будет выделено (помимо заголовка) только 10 символов и не каплей больше.
Типы данных переменной длины (text, ntext и image) могут храниться как одна коллекция страниц или данные в строке. Посмотрим, как они хранятся:
- text – может хранить 2 147 483 647 символов. Не Unicode текстовые данные не могут использоваться в качестве переменных или параметров в хранимых на сервере процедурах.
- ntext – может хранить 1 073 741 823 символа или 2 147 483 647 Unicode данных переменной длины.
- image – может хранить от 0 до 2 147 483 647 бинарных данных.
Так как text, ntext и image типы данных обычно большие, SQL Server хранит их вне строк. В строке на хранящиеся данные указывает только шестнадцати битный указатель. Если эти типы данных хранят небольшое количество данных, то вы можете включить опцию text in row. Вы можете также указать предел от 24 до 7000 байтов. Эту опцию для таблицы можно включить, используя системную процедуру sp_tableoption.
Эту опцию для таблицы можно включить, используя системную процедуру sp_tableoption.
В следующем примере с помощью функции sp_tableoption устанавливается опция text in row и указывается, что до 1000 символов будет храниться в строке:
EXEC sp_tableoption N'TestDatabase', 'text in row', '1000'
Для вас пока может быть не очень понятна эта команда, потому что хранимые процедуры мы еще не изучали. Но в третьей главе мы рассмотрим эту тему более подробно.
Когда вы создаете таблицу, вы должны указать имя таблицы, имена колонок и типы данных колонок. Имена колонок должны быть уникальными для определенной таблицы, но вы можете использовать одно и то же имя в разных таблицах одной базы данных.
MS SQL Server позволяет создавать до 2 биллионов таблиц в базе данных, каждая таблица может содержать до 1024 колонки и общий размер полей в таблице может достигать 8060 байтов на строку (без учета text, ntext и image). Это действительно очень много. Превысить этот предел очень сложно, и я пока не слышал, чтобы кому-то его не хватило. Если вам все же не хватит количества полей, то можно создать две таблицы и связать их один к одному. Для этого используются внешние ключи, о которых мы будем говорить в разделе 1.2.6.
Если вам все же не хватит количества полей, то можно создать две таблицы и связать их один к одному. Для этого используются внешние ключи, о которых мы будем говорить в разделе 1.2.6.
1.2.1. Оператор CREATE TABLE
С теорией таблиц закончено, теперь попробуем эту таблицу рассмотреть с точки зрения базы данных. Имена колонок в списке баз данных называются именами полей. Нам необходимо только создать таблицу в базе данных с такими полями и все готово для хранения списка.
Общий вид команды CREATE TABLE показан в листинге 1.5.
Листинг 1.5. Общий вид команды CREATE TABLE
CREATE TABLE
[ database_name.[ owner ] . | owner. ] table_name
( { < column_definition >
| column_name AS computed_column_expression
| < table_constraint > ::= [ CONSTRAINT constraint_name ]}
| [ { PRIMARY KEY | UNIQUE } [ ,...n ]
)
[ ON { filegroup | DEFAULT } ]
[ TEXTIMAGE_ON { filegroup | DEFAULT } ]
< column_definition > ::= { column_name data_type }
[ COLLATE < collation_name > ]
[ [ DEFAULT constant_expression ]
| [ IDENTITY [ ( seed , increment ) [ NOT FOR REPLICATION ] ] ]
]
[ ROWGUIDCOL]
[ < column_constraint > ] [ . ..n ]
< column_constraint > ::= [ CONSTRAINT constraint_name ]
{ [ NULL | NOT NULL ]
| [ { PRIMARY KEY | UNIQUE }
[ CLUSTERED | NONCLUSTERED ]
[ WITH FILLFACTOR = fillfactor ]
[ON {filegroup | DEFAULT} ] ]
]
| [ [ FOREIGN KEY ]
REFERENCES ref_table [ ( ref_column ) ]
[ ON DELETE { CASCADE | NO ACTION } ]
[ ON UPDATE { CASCADE | NO ACTION } ]
[ NOT FOR REPLICATION ]
]
| CHECK [ NOT FOR REPLICATION ]
( logical_expression )
}
< table_constraint > ::= [ CONSTRAINT constraint_name ]
{ [ { PRIMARY KEY | UNIQUE }
[ CLUSTERED | NONCLUSTERED ]
{ ( column [ ASC | DESC ] [ ,...n ] ) }
[ WITH FILLFACTOR = fillfactor ]
[ ON { filegroup | DEFAULT } ]
]
| FOREIGN KEY
[ ( column [ ,. ..n ] ) ]
REFERENCES ref_table [ ( ref_column [ ,...n ] ) ]
[ ON DELETE { CASCADE | NO ACTION } ]
[ ON UPDATE { CASCADE | NO ACTION } ]
[ NOT FOR REPLICATION ]
| CHECK [ NOT FOR REPLICATION ]
( search_conditions )
}
 ..n ]
< column_constraint > ::= [ CONSTRAINT constraint_name ]
{ [ NULL | NOT NULL ]
| [ { PRIMARY KEY | UNIQUE }
[ CLUSTERED | NONCLUSTERED ]
[ WITH FILLFACTOR = fillfactor ]
[ON {filegroup | DEFAULT} ] ]
]
| [ [ FOREIGN KEY ]
REFERENCES ref_table [ ( ref_column ) ]
[ ON DELETE { CASCADE | NO ACTION } ]
[ ON UPDATE { CASCADE | NO ACTION } ]
[ NOT FOR REPLICATION ]
]
| CHECK [ NOT FOR REPLICATION ]
( logical_expression )
}
< table_constraint > ::= [ CONSTRAINT constraint_name ]
{ [ { PRIMARY KEY | UNIQUE }
[ CLUSTERED | NONCLUSTERED ]
{ ( column [ ASC | DESC ] [ ,...n ] ) }
[ WITH FILLFACTOR = fillfactor ]
[ ON { filegroup | DEFAULT } ]
]
| FOREIGN KEY
[ ( column [ ,.
..n ]
< column_constraint > ::= [ CONSTRAINT constraint_name ]
{ [ NULL | NOT NULL ]
| [ { PRIMARY KEY | UNIQUE }
[ CLUSTERED | NONCLUSTERED ]
[ WITH FILLFACTOR = fillfactor ]
[ON {filegroup | DEFAULT} ] ]
]
| [ [ FOREIGN KEY ]
REFERENCES ref_table [ ( ref_column ) ]
[ ON DELETE { CASCADE | NO ACTION } ]
[ ON UPDATE { CASCADE | NO ACTION } ]
[ NOT FOR REPLICATION ]
]
| CHECK [ NOT FOR REPLICATION ]
( logical_expression )
}
< table_constraint > ::= [ CONSTRAINT constraint_name ]
{ [ { PRIMARY KEY | UNIQUE }
[ CLUSTERED | NONCLUSTERED ]
{ ( column [ ASC | DESC ] [ ,...n ] ) }
[ WITH FILLFACTOR = fillfactor ]
[ ON { filegroup | DEFAULT } ]
]
| FOREIGN KEY
[ ( column [ ,.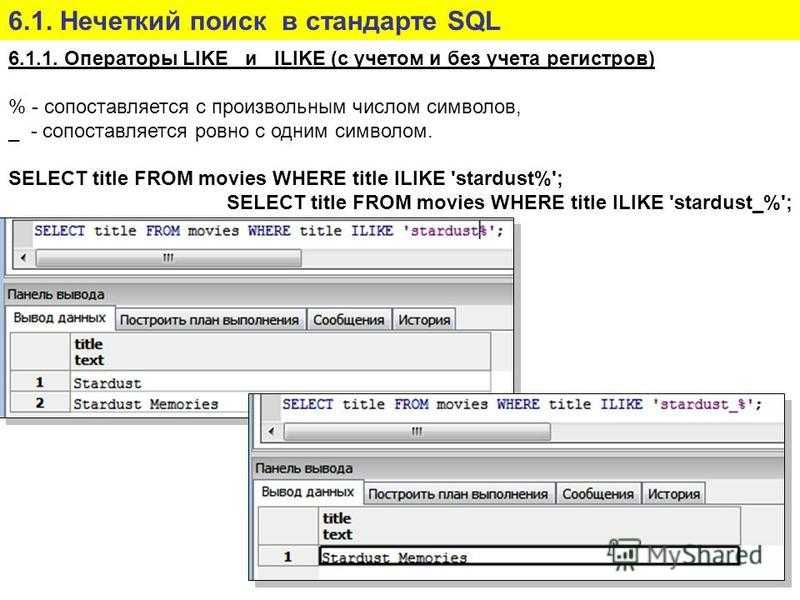 ..n ] ) ]
REFERENCES ref_table [ ( ref_column [ ,...n ] ) ]
[ ON DELETE { CASCADE | NO ACTION } ]
[ ON UPDATE { CASCADE | NO ACTION } ]
[ NOT FOR REPLICATION ]
| CHECK [ NOT FOR REPLICATION ]
( search_conditions )
}
..n ] ) ]
REFERENCES ref_table [ ( ref_column [ ,...n ] ) ]
[ ON DELETE { CASCADE | NO ACTION } ]
[ ON UPDATE { CASCADE | NO ACTION } ]
[ NOT FOR REPLICATION ]
| CHECK [ NOT FOR REPLICATION ]
( search_conditions )
}
Команда CREATE TABLE достаточно большая и сложная, потому что включает в себя не только создание самой таблицы, но и описание полей, ограничений, первичных и вторичных ключей. Поэтому, описание команды отнимет достаточно много времени, потому что без рассмотрения оператора CREATE TABLE по частям нам не обойтись, чем мы и будем заниматься ближайшие пару десятков страниц.
Прежде чем создавать какую-либо тестовую таблицу, давайте создадим базу данных, в которой будут проходить все следующие тестирования SQL запросов. Все предыдущие тестовые базы данных можно удалить и создать новую, чистую базу данных. Я для этого создал базу данных с именем TestDatabase с параметрами по умолчанию.
Теперь посмотрим, как создать таблицу и удалить ее. Подключитесь к своей тестовой базе данных (TestDatabase) и выполните следующий запрос:
CREATE TABLE TestTable ( id int )
Невозможно создавать пустую таблицу, без описания полей. Хотя бы одно поле должно быть создано. В данном примере создается таблица с именем TestTable. После имени в скобках указываются имена и типы полей в формате:
имя тип параметры
Обязательными являются только имя и тип, как в примере выше, а параметры могут отсутствовать. В этом случае, поле не будет обладать никакими дополнительными параметрами.
Если полей несколько, то все они перечисляются в скобках через запятую. В данном случае, описано только одно поле с именем id, тип int, и без параметров. Какие могут быть типы данных? Стандарт SQL описывает только основные типы: строка, число и т.д., но в MS SQL Server их намного больше. Все типы, которые поддерживает SQL Server 2000 можно увидеть в приложении 1.
Для удаления таблицы используется команда:
DROP TABLE имя
Где имя – это имя удаляемой таблицы. При этом вы должны быть подключены к серверу, таблицу которого вы удаляете, т.е. удаление происходит в текущей базе данных.
Следующий запрос показывает, как удалить таблицу TestTable, созданную нами ранее:
DROP TABLE TestTable
Если полей в таблице несколько, то их необходимо указывать в круглых скобках через запятую. Например:
CREATE TABLE TestTable ( id int, vcName varchar(30), vcLastName varchar(30), vcSurName varchar(30), cPol char(1), dBirthDay datetime )
В качестве дополнительных параметров можно указывать, например, явную кодировку (Collation) для поля. В следующем примере создается таблица с двумя текстовыми полями. В первом поле для хранения фамилии не указывается кодировка, поэтому для него будет взято значение из базы данных, а у второго поля явно указываем латинскую кодировку:
CREATE TABLE TestTable ( Famil varchar(10), Name varchar(10) collate latin1_general_cs_as )
При создании таблицы можно указать файловую группу, в которой должны храниться данные этой таблицы. Имя группы указывается после ключевого слова ON, за объявлением всех полей. В следующем примере создается таблица, данные которой будут помещены в группу с именем group1:
Имя группы указывается после ключевого слова ON, за объявлением всех полей. В следующем примере создается таблица, данные которой будут помещены в группу с именем group1:
CREATE TABLE TestTable ( Famil varchar(10), Name varchar(10) collate latin1_general_cs_as ) ON group1
Если файловая группа не указана, то таблица создается в группе по умолчанию. Если вы создали пользовательскую группу, но она не является группой по умолчанию, то обязательно указывайте ее явно.
1.2.2. Автоинкрементные поля
Очень часто необходим какое-либо поле-счетчик, значение которого будет автоматически увеличиваться без вмешательства пользователя. Например, таким образом часто создаются ключевые поля и об этом методе мы говорили в разделе 1.2. Опытные программисты, которые работают с базами данных уже не первый день, с помощью таких полей добиваются уникальности данных. Например, очень часто можно видеть таблицы, в которых первое поле называется «id» (я люблю именовать их как Key1 или префикс id+имя таблицы), которое автоматически увеличивается при добавлении новых строк.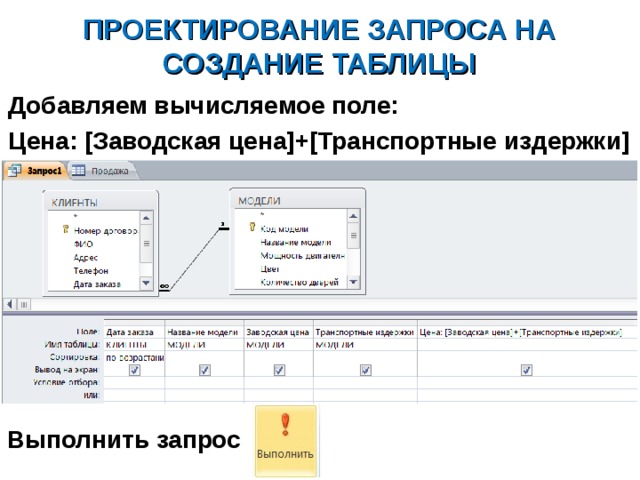 Таким образом, можно сказать, что это поле всегда уникально.
Таким образом, можно сказать, что это поле всегда уникально.
Вы можете использовать свойство Identity (тождество) для создания колонки, которая содержит сгенерированное системой следующее значение, определяющее каждую строку, вставленную в таблицу. Тождественная колонка может использоваться не только для хранения значения первичного ключа, но и для определения строки, которая была вставлена в таблицу последней, ведь каждая новая строка будет получать число, которое больше любого существующего.
Когда SQL Server автоматически предоставляет значение ключа, можно уменьшить затраты, потому что облегчается программирование, первичный ключ будет коротким и уменьшаются пользовательские транзакции.
Автоматически увеличиваемое поле имеет следующие ограничения:
- В таблице может быть только одна Identity колонка, да я и не вижу смысла от создания двух автоматически увеличиваемых полей;
- Она должна использоваться с целочисленными типами данных, дробные типы запрещены;
- Значение в этом поле не может обновляться. В MS SQL Server есть способ обойти это ограничение (мы его увидим далее в этом разделе), но так можно нарушить целостность данных, поэтому этот метод обхода ограничения на редактирование поля необходимо использовать аккуратно и только в крайних случаях;
- Не разрешаются нулевые значения. Колонка всегда должна быть заполнена, и при этом, значение заноситься только сервером, вы не можете на него повлиять.
 В MS SQL Server есть способ обойти это ограничение (мы его увидим далее в этом разделе), но так можно нарушить целостность данных, поэтому этот метод обхода ограничения на редактирование поля необходимо использовать аккуратно и только в крайних случаях;
В MS SQL Server есть способ обойти это ограничение (мы его увидим далее в этом разделе), но так можно нарушить целостность данных, поэтому этот метод обхода ограничения на редактирование поля необходимо использовать аккуратно и только в крайних случаях;При разработке запросов вы можете использовать ключевое слово IDENTITYCOL в месте с именем колонки в запросе. Это позволяет вам ссылаться на колонку в таблице со свойством Identity, не зная имени колонки. Так как в таблице может быть только одна колонка со свойством Identity, сервер сам сможет найти нужное поле.
Вы можете управлять свойством Identity несколькими путями:
- Тождественное свойство не обеспечивает уникальности. Для уникальности автоматически увеличиваемого поля создавайте уникальный индекс. Да, он создается по умолчанию, но удалять его не стоит, иначе сервер не сможет гарантировать уникальности;
- Автоматическое увеличение можно устанавливать на поля следующих типов: tinyint, smallint, int, bigint, decimal(n,0) или numeric(n,0). Обратите внимание, что у типов decimal и numeric в качестве значения точности (количество знаков после запятой) должно быть 0, то есть дробной части не должно быть. Вы должны также учитывать, что количество возможных записей в таблице зависит от выбранного типа. Это значит, если выбрать тип tinyint (может принимать значения от 0 до 255), то в таблице может быть только 256 записей (если расчет начать с нуля). Дальше увеличение будет невозможно, а значит, новая запись не сможет быть добавлена. Выбирайте тот тип, которого будет достаточно.
 Обратите внимание, что у типов decimal и numeric в качестве значения точности (количество знаков после запятой) должно быть 0, то есть дробной части не должно быть. Вы должны также учитывать, что количество возможных записей в таблице зависит от выбранного типа. Это значит, если выбрать тип tinyint (может принимать значения от 0 до 255), то в таблице может быть только 256 записей (если расчет начать с нуля). Дальше увеличение будет невозможно, а значит, новая запись не сможет быть добавлена. Выбирайте тот тип, которого будет достаточно.
Обратите внимание, что у типов decimal и numeric в качестве значения точности (количество знаков после запятой) должно быть 0, то есть дробной части не должно быть. Вы должны также учитывать, что количество возможных записей в таблице зависит от выбранного типа. Это значит, если выбрать тип tinyint (может принимать значения от 0 до 255), то в таблице может быть только 256 записей (если расчет начать с нуля). Дальше увеличение будет невозможно, а значит, новая запись не сможет быть добавлена. Выбирайте тот тип, которого будет достаточно.В современных базах данных для обеспечения уникальности рекомендуют использовать глобально уникальные идентификаторы GUID (Globally Unique Identifier). Это действительно более мощный способ обеспечения целостности, но не очень удобный с точки зрения использования, поэтому программисты старой закалки продолжают использовать автоматическое увеличение.
Некоторые базы данных создают GUID идентификаторы для каждой строки, даже если пользователь не затребовал этого. При этом, идентификатор прячется и для его отображения необходимо включать специальную опцию или использовать специальную команду в SQL запросе. В MS SQL Server идентификаторы GUID создаются автоматически, если таблица участвует в репликации.
При этом, идентификатор прячется и для его отображения необходимо включать специальную опцию или использовать специальную команду в SQL запросе. В MS SQL Server идентификаторы GUID создаются автоматически, если таблица участвует в репликации.
В таблице может быть только одна колонка с автоматически увеличиваемым значением. Чтобы задать данный тип поля, необходимо среди параметров указать ключевое слово IDENTITY в следующем виде:
IDENTITY [ ( seed , increment ) [ NOT FOR REPLICATION ] ]
После слова IDENTITY необходимо в круглых скобках указать два параметра – начальное значение (будет присвоено первой строке в таблице) и приращение. По умолчанию обоим параметрам присваивается значение 1. Следующий пример, показывает создание таблицы, с автоматически увеличиваемым полем ID:
CREATE TABLE TestTable ( id int IDENTITY(100, 2) )
В качестве начального значения выбрано число 100. При добавлении каждой последующей строки в поле будет записываться число на 2 больше, т. е. 102, 104, 106, 108 и т.д.
е. 102, 104, 106, 108 и т.д.
Для чего нужен ключ NOT FOR REPLICATION (не для репликации)? Допустим, что у вас есть два сервера баз данных, которые расположены в разных офисах и не объединены каналом связи. Необходимо иметь какую-то возможность объединения баз данных в одно целое. В MS SQL Server есть удобный инструмент решения данной проблемы – репликация. Репликация — это процесс слияния двух баз данных.
Но тут есть одна проблема. Допустим, у вас есть две базы данных DB1 и DB2. В базе данных DB1 может быть добавлена новая строка с определенным идентификатором, который был назначен автоматически. Во время репликации эта строка должна попасть в базу данных DB2, но при вставке средствами репликации в поле id будет сгенерировано другое значение. Строки получаться не одинаковыми и нарушается целостность данных.
Чтобы решить проблему, для поля с автоматически увеличиваемым значением можно указать ключ NOT FOR REPLICATION. В этом случае, при вставке новой строки из DB1 в DB2 во время репликации новый id не будет генерироваться, а будет использоваться тот, который был указан в DB1.
Но это не решает проблемы полностью, потому что идентификатор строки из DB1 может конфликтовать с уже существующей строкой в DB2, а это недопустимо. Эта проблема решается намного проще. В DB1 для поля ID задаем начальное значение 1, а для DB2 задаем начальное значение 100 000 000. Теперь новые строки в DB1 будут иметь номера 1, 2, 3, а в DB2 на 100 000 000 больше и пересечение в идентификаторах произойдет не скоро, а точнее, когда в DB1 будет добавлено 100 000 000 строк.
В общей базе данных у вас будут строки с идентификаторами из обеих таблиц, и по номеру вы можете легко определить, из какой базы данных он попал к вам в руки. Если поле id более 100 000 000, то это явно DB2.
Необходимо сделать одно замечание (хотя оно и выходит за рамки книги) – когда будете настраивать репликацию, обе базы данных должны иметь одинаковую структуру, а в мастере необходимо указать, что структуру базы данных реплицировать не надо. Если вы этого не сделаете, то сразу после выполнения мастера структура базы данных DB1 будет скопирована в DB2, и все настройки идентификаторов и начальных значений уничтожаться.
Итак, посмотрим на пример создания таблицы с автоматически увеличиваемым идентификатором и не участвующем в репликации:
CREATE TABLE TestTable1 ( id int IDENTITY(100, 2) NOT FOR REPLICATION )
Если вы используете автоматически увеличиваемое поле только для того, чтобы создать первичный ключ, то это не совсем корректное решение для базы данных, с которой работает множество человек. Дело в том, что в языках программирования строка добавляется на стороне клиента. В этот момент в этой строке значение автоматически увеличиваемого поля будет нулевым, и заполниться только после завершения ввода данных и выполнения оператора INSERT (мы его рассмотрим во 2-й главе). Очень часто это неудобно и в этом случае лучшим вариантом будет использование глобально уникальные идентификаторы GUID.
Если после ключевого слова IDENTITY ничего не указано, то подразумевается, что начальное значение и увеличение равно 1. Посмотрим на следующий запрос:
CREATE TABLE TestTable2 ( id int IDENTITY )
Он идентичен следующему:
CREATE TABLE TestTable2 ( id int IDENTITY(1,1) )
Начальное значение и приращение в виде единицы встречаются наверно в 90% случаев, и именно поэтому эти значения используется по умолчанию для IDENTITY полей.
Создание базы данных SQL и таблиц базы данных на примере
Связанные темы
- Реляционная модель данных
- Основы проектирования баз данных
| Назад | Листать | Вперёд>>> |
Создадим базу данных, краткое описание проекта которой — в статье Основы проектирования базы данных — пример.
Для этого понадобится установленная система управления базами данных (СУБД) DB2. Мы будем использовать диалект языка SQL, который используется именно в этой СУБД.
Первая команда, которую мы будем применять для создании базы данных — это команда CREATE DATABASE. Её синтаксис следующий:
CREATE DATABASE ИМЯ_БАЗЫ ДАННЫХ
Далее для создания таблиц нашей базы данных будем многократно использовать команду CREATE TABLE. Её синтаксис следующий:
Её синтаксис следующий:
CREATE TABLE ИМЯ_ТАБЛИЦЫ (имя_первого_столбца тип данных, …, имя_последнего_столбца тип данных, первичный ключ, ограничения (не обязательно))
Так как наша база данных моделирует сеть аптек, то в ней есть такие сущности, как «Аптека» (таблица Pharmacy в нашем примере создания базы данных), «Препарат» (таблица Preparation в нашем примере создания базы данных), «Доступность (препаратов в аптеке)» (таблица Availability в нашем примере создания базы данных), «Клиент» (таблица Client в нашем примере создания базы данных) и другие, которые здесь подробно и разберём.
Разработке модели «сущность-связь» можно посвятить не одну статью, но если нас прежде
всего интересуют команды языка SQL для создания базы данных и таблиц в ней, то условимся
считать, что связи между сущностями уже нам понятны. На рисунке ниже
приведено представление модели нашей базы данных с атрибутами сущностей (таблиц) и связями
между таблицами.
Для увеличения рисунка можно нажать на него левой кнопкой мыши.
При создании базы данных, в которой таблицы связаны между собой, важно позаботиться о целостности данных. Это означает, например, что если если удалить препарат из таблицы Preparation, то должны удалиться все записи этого препарата в таблице Availability. Ещё пример ограничения целостности: нужно установить запрет на удаление названия группы препарата из таблицы Group, если существует хотя бы один препарат этой группы. Особый случай составляет изменение данных в одной таблице, когда производятся действия с данными в другой таблице. Об этом поговорим в конце статьи. Можно также углубиться в теорию на уроке Реляционная модель данных.
Как уже говорилось, в разбираемом здесь примере создания базы данных использовался вариант языка SQL, который
используется в системе управления базами данных (СУБД) DB2. Он является регистронезависимым,
то есть не имеет значение, набраны ли команды и отдельные слова в них строчными или
прописными буквами. Для иллюстрации этой особенности приведены команды без особой системы
набранные строчными и прописными буквами.
Для иллюстрации этой особенности приведены команды без особой системы
набранные строчными и прописными буквами.
Теперь приступим к созданию команд. Первая наша команда SQL создаёт базу данных PHARMNETWORK:
Код SQL
CREATE DATABASE PHARMNETWORK
Описание таблицы PHARMACY (Аптека):
| Имя поля | Тип данных | Описание |
| PH_ID | smallint | Идентификационный номер аптеки |
| Address | varchar(40) | Адрес аптеки |
Пишем команду, которая создаёт таблицу PHARMACY (Аптека), значения первичного ключа PH_ID генерируются автоматически от 1 с шагом 1, вносится проверка на то, чтобы значения атрибута Address в этой таблице были уникальными:
Код SQL
CREATE TABLE PHARMACY(PH_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), Address varchar(40) NOT NULL, PRIMARY KEY(PH_ID), CONSTRAINT PH_UNIQ UNIQUE(Address))
Следует обратить внимание на то, что автоматическое генерирование первичного ключа с приращением обеспечено средствами, применяемыми в диалекте SQL для DB2:
Код SQL
PH_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1)
Средства автоматического генерирования первичного ключа с приращением (кратко это называется
автоинкрементом) в разных диалектах SQL различаются. Так, в MySQL используется ключевое слово
AUTO_INCREMENT и соответствующая часть запроса на создание таблицы выглядит следующим образом:
Так, в MySQL используется ключевое слово
AUTO_INCREMENT и соответствующая часть запроса на создание таблицы выглядит следующим образом:
Код SQL
PH_ID int(4) NOT NULL AUTO_INCREMENT
В SQL Server механизм автоинктемента обеспечивается так:
Код SQL
PH_ID int IDENTITY(1, 1) PRIMARY KEY
Запись (1, 1) здесь означает, что значения первичного ключа должны создаваться начиная с 1 с приращением на 1. Итак, помните о том, что в зависимости от СУБД и диалекта SQL механизмы автоинкремента различаются, а далее для краткости будем приводить запросы на создание таблиц в соответствии с синтаксисом для DB2.
Описание таблицы GROUP (Группа препаратов):
| Имя поля | Тип данных | Описание |
| GR_ID | smallint | Идентификационный номер группы препаратов |
| Name | varchar(40) | Название группы препаратов |
Пишем команду, которая создаёт таблицу Group (Группа препаратов), значения первичного ключа GR_ID генерируются автоматически от 1 с шагом 1, проводится проверка уникальности наименования группы (для этого используется ключевое слово CONSTRAINT):
Код SQL
CREATE TABLE GROUP(GR_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), Name varchar(40) NOT NULL, PRIMARY KEY(GR_ID), CONSTRAINT GR_UNIQ UNIQUE(Name))
Описание таблицы PREPARATION (Препарат):
| Имя поля | Тип данных | Описание |
| PR_ID | smallint | Идентификационный номер препарата |
| GR_ID | smallint | Идентификационный номер группы препарата |
| Name | varchar(40) | Название препарата |
Команда, которая создаёт таблицу PREPARATION, значения первичного ключа PR_ID генерируются автоматически от 1 с шагом 1, определяется, что значения внешнего ключа GR_ID (Группа препаратов) не могут принимать значение NULL, определена проверка уникальности значений атрибута Name:
Код SQL
CREATE TABLE PREPARATION(PR_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), Name varchar(40) NOT NULL, GR_ID int NOT NULL, PRIMARY KEY(PR_ID), constraint PR_UNIQ UNIQUE(Name))
Далее нам требуется позаботиться об ограничениях целостности. Это очень удобно слелать с помощью
команды alter table. Эта команда изучается на уроке SQL ALTER TABLE — изменение таблицы базы данных.
Это очень удобно слелать с помощью
команды alter table. Эта команда изучается на уроке SQL ALTER TABLE — изменение таблицы базы данных.
Теперь самое время создать таблицу AVAILABILITY (Доступность или Наличие препарата в аптеке). Её описание:
| Имя поля | Тип данных | Описание |
| A_ID | smallint | Идентификационный номер записи о доступности |
| PH_ID | smallint | Идентификационный номер аптеки |
| PR_ID | smallint | Идентификационный номер препарата |
| Quantity | int | Количество доступного препарата |
| DateStart | varchar(20) | Дата начала работы аптеки с данным препаратом |
| DateEnd | varchar(20) | Дата окончания работы аптеки с данным препаратом |
| Mart | varchar(3) | Выставлен ли препарат на витрину |
Пишем команду, которая создаёт таблицу AVAILABILITY. Определяются даты начала (не может быть NULL) и окончания (по умолчанию NULL).
Определяются даты начала (не может быть NULL) и окончания (по умолчанию NULL).
Код SQL
CREATE TABLE AVAILABILITY(A_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), PH_ID INT NOT NULL, PR_ID INT NOT NULL, DateStart varchar(20) NOT NULL, DateEnd varchar(20) DEFAULT NULL, QUANTITY INT NOT NULL, MART varchar(3) DEFAULT NULL, PRIMARY KEY(A_ID), CONSTRAINT AVA_UNIQ UNIQUE(PH_ID, PR_ID))
Создаём таблицу DEFICIT (Дефицит препарата в аптеке, то есть, неудовлетворённый запрос). Её описание:
| Имя поля | Тип данных | Описание |
| D_ID | smallint | Идентификационный номер записи о дефиците |
| PH_ID | smallint | Идентификационный номер аптеки |
| PR_ID | smallint | Идентификационный номер препарата |
| Solution | varchar(40) | Решение проблемы дефицита |
| DateStart | varchar(20) | Дата появления проблемы |
| DateEnd | varchar(20) | Дата решения проблемы |
Пишем команду, которая создаёт таблицу DEFICIT:
Код SQL
CREATE TABLE DEFICIT(D_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), PH_ID INT NOT NULL, PR_ID INT NOT NULL, Solution varchar(40) NOT NULL, DateStart varchar(20) NOT NULL, DateEnd varchar(20) DEFAULT NULL)
Осталось немного.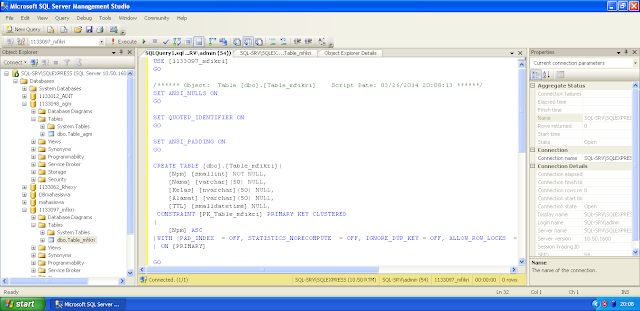 Мы уже дошли до команды, которая создаёт таблицу Employee (Сотрудник). Её описание:
Мы уже дошли до команды, которая создаёт таблицу Employee (Сотрудник). Её описание:
| Имя поля | Тип данных | Описание |
| E_ID | smallint | Идентификационный номер сотрудника |
| PH_ID | smallint | Идентификационный номер аптеки |
| FName | varchar(40) | Имя сотрудника |
| LName | varchar(40) | Фамилия сотрудника |
| Post | varchar(40) | Должность |
Пишем команду, которая создаёт таблицу Employee (Сотрудник), с первичным ключом, генерируемым по тем же правилам, что и первичные ключи предыдущих таблиц, в которых они существуют. Внешним ключом PH_ID Сотрудник связан с PHARMACY (Аптекой).:
Код SQL
CREATE TABLE EMPLOYEE(E_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), F_Name varchar(40) NOT NULL, L_Name varchar(40) NOT NULL, POST varchar(40) NOT NULL, PH_ID INT NOT NULL, PRIMARY KEY(E_ID))
Очередь дошла до создании таблицы CLIENT (Клиент). Её описание:
Её описание:
| Имя поля | Тип данных | Описание |
| C_ID | smallint | Идентификационный номер клиента |
| FName | varchar(40) | Имя клиента |
| LName | varchar(40) | Фамилия клиента |
| DateReg | varchar(20) | Дата регистрации |
Пишем команду, создающую таблицу CLIENT (Клиент), в отношении первичного ключа которого справедливо предыдущее описание. Особенность этой таблицы в том, что её атрибуты F_Name и L_Name имеют по умолчанию значение NULL. Это связано с тем, что клиенты могут быть как зарегистрированными, так и незарегистрированными. У последних значения имени и фамилии как раз и будут неопределёнными (то есть NULL):
Код SQL
CREATE TABLE CLIENT(C_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), FName varchar(40) DEFAULT NULL, LName varchar(40) DEFAULT NULL, DateReg varchar(20), PRIMARY KEY(C_ID))
Предпоследняя таблица в нашей базе данных — таблица BASKET (Корзина покупок). Её описание:
Её описание:
| Имя поля | Тип данных | Описание |
| BS_ID | smallint | Идентификационный номер корзины покупок |
| E_ID | smallint | Идентификационный номер сотрудника, оформившего корзину |
| C_ID | smallint | Идентификационный номер клиента |
Пишем команду, создающую таблицу BASKET (Корзина покупок), так же с уникальным и инкрементируемым первичным ключом и связанную внешним ключами C_ID и E_ID с Клиентом и Сотрудником соответственно:
Код SQL
CREATE TABLE BASKET(BS_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), C_ID INT NOT NULL, E_ID INT NOT NULL, PRIMARY KEY(BS_ID))
И, наконец, последняя таблица в нашей базе данных — таблица BUYING (покупка). Её описание:
| Имя поля | Тип данных | Описание |
| B_ID | smallint | Идентификационный номер покупки |
| PH_ID | smallint | Идентификационный номер аптеки |
| PR_ID | smallint | Идентификационный номер препарата |
| BS_ID | varchar(40) | Идентификационный номер корзины покупок |
| Price | varchar(20) | Цена |
| Date | varchar(20) | Дата |
Пишем команду, создающую таблицу BUYING (покупка), так же с уникальным и инкрементируемым первичным ключом и связанную внешними ключами BS_ID, PH_ID, PR_ID с Корзиной покупок, Аптекой и Препаратом соответственно:
Код SQL
CREATE TABLE BUYING(B_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), BS_ID INT NOT NULL, PH_ID INT NOT NULL, PR_ID INT NOT NULL, DateB varchar(20) NOT NULL, Price Double NOT NULL, PRIMARY KEY(B_ID))
И совсем уже в завершение темы создания базы данных обещанное отступление о соблюдении
ограничений целостности, когда решение — более сложное, чем написание команды. В нашем примере
необходимо соблюдать следующее условие: при покупке единицы препарата значение количества
этого препарата в таблице AVAILABILITY должно соответственно уменьшиться. Вообще говоря,
для таких операций в языке SQL существуют особые средства, называемые триггерами. Но триггеры —
вещь капризная: на практике они могут и не сработать или
сработать не так, как предусмотрено. Поэтому разработчики по возможности ищут
программные средства решения таких задач, пример которых упомянут в этом абзаце.
В нашем примере
необходимо соблюдать следующее условие: при покупке единицы препарата значение количества
этого препарата в таблице AVAILABILITY должно соответственно уменьшиться. Вообще говоря,
для таких операций в языке SQL существуют особые средства, называемые триггерами. Но триггеры —
вещь капризная: на практике они могут и не сработать или
сработать не так, как предусмотрено. Поэтому разработчики по возможности ищут
программные средства решения таких задач, пример которых упомянут в этом абзаце.
И действительно, есть программное средство решение обозначенной
выше задачи уменьшения значения количества препарата. А именно: в условии добавления
соответствующего препарата в таблицу BUYING (Покупка) пишется функция на языке программирования,
на котором выполнено приложение, с запросом с ключевым словом
UPDATE на замену значения количества этого препарата на единицу меньше в той же аптеке.
И таблица BUYING, и таблица AVAILABILITY имеют внешний ключ PH_ID — идентификатор
определённой аптеки.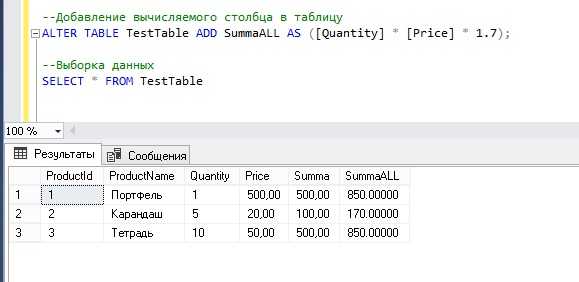
На этом многогранная тема создания баз данных прерывается…
Поделиться с друзьями
| Назад | Листать | Вперёд>>> |
Создание таблиц в базе данных SQL Server. Обработка баз данных на Visual Basic®.NET
Создание таблиц в базе данных SQL Server. Обработка баз данных на Visual Basic®.NETВикиЧтение
Обработка баз данных на Visual Basic®.NET
Мак-Манус Джеффри П
Содержание
Создание таблиц в базе данных SQL Server
В Microsoft SQL Server таблицы можно создавать двумя способами:
• с помощью языка определения данных (Data Definition Language — DDL), который подробно описывается в главе 2, «Запросы и команды на языке SQL»;
• с помощью графических инструментов программы SQL Server Enterprise Manager.
Оба способа создания таблиц имеют как преимущества, так и недостатки. DDL-команды языка SQL довольно сложные, особенно если вы до этого никогда их не использовали. Применение команд SQL позволяет более гибко создавать и поддерживать код создания базы данных. С другой стороны, DDL-команды могут быть полностью автоматизированы, например с помощью одного щелчка можно запустить сценарий создания базы данных. Они также предлагают более богатый уровень функциональности, который не предусмотрен в графических инструментах программы SQL Server Enterprise Manager. Кроме того, с помощью DDL-команд хотя и очень грубо, но все же можно документировать схему базы данных.
Тем не менее использование программы SQL Server Enterprise Manager позволяет быстро и легко создавать структуру базы данных с помощью инструментов с графическим пользовательским интерфейсом. Однако в программе SQL Server Enterprise Manager не так просто автоматизировать выполнение многих операций.
Некоторые разработчики предпочитают использовать для создания баз данных только команды SQL, потому что у них в распоряжении всегда остается запись выполняемых действий (в виде DDL-кода). Выбор способа создания баз данных зависит от персональных предпочтений, стандартов работы в вашей организации, а также вида создаваемых приложений для работы с базами данных. Оба способа создания базы данных рассматриваются далее в главе.
Выбор способа создания баз данных зависит от персональных предпочтений, стандартов работы в вашей организации, а также вида создаваемых приложений для работы с базами данных. Оба способа создания базы данных рассматриваются далее в главе.
СОВЕТ
SQL Server 2000 содержит специальный элемент для генерации DDL-команд SQL для объектов базы данных. Его можно щелкнув правой кнопкой мыши на базе данных в папке Databases окна Microsoft SQL Servers, а затем выбрав в контекстном меню команду All Tasks?Generate SQL Scripts (Все задачи?Генерация сценариев SQL) для открытия диалогового окна Generate SQL Scripts (Генерация сценариев SQL).
2.4.8 Просмотр имен в базе данных DNS
2.4.8 Просмотр имен в базе данных DNS
Как и многие системы TCP/IP, используемый нами локальный хост имеет клиентское приложение nslookup (от network server lookup — просмотр сетевого сервера), которое разрешает пользователю интерактивно запросить базу данных DNS. Ниже показан пример вывода
Ниже показан пример вывода
20.6.1 Идентификация значений в базе данных MIB
20.6.1 Идентификация значений в базе данных MIB Для описания реального значения в базе данных устройства в конец идентификатора объекта добавляется еще одно число. Например, если информация обо всех интерфейсах устройства хранится в таблице, а идентификатор объекта для
Виды ограничений в базе данных
Виды ограничений в базе данных Существуют следующие виды ограничений в базе данных InterBase:* первичный ключ — PRIMARY KEY;* уникальный ключ — UNIQUE KEY;* внешний ключ — FOREIGN KEY- может включать автоматические триггеры ON UPDATE и ON DELETE;* проверки — CHECK.В предыдущих главах уже упоминались
Подключение к базе данных
Подключение к базе данных
Очевидно, что прежде чем начать работать с базой данных, надо к ней подключиться.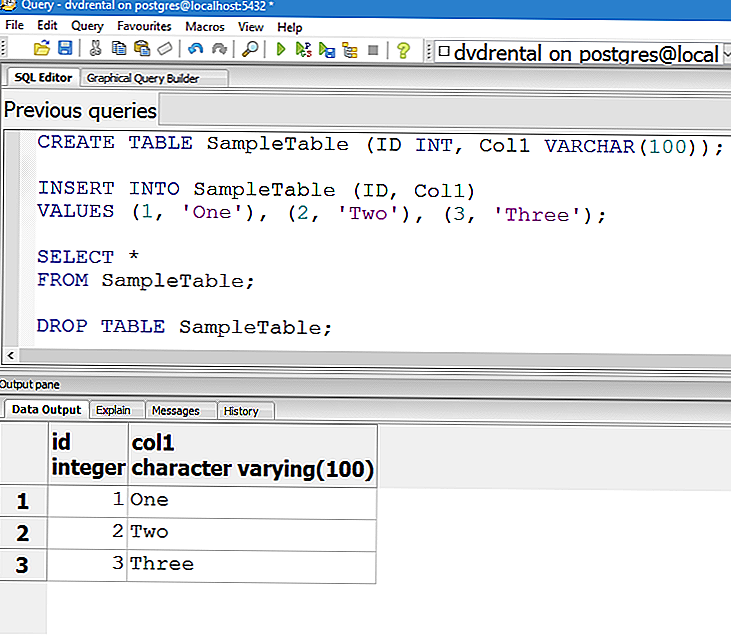 Специально для этого в состав IBX включен компонент TIBDatabase.Для наших примеров в этой главе мы будем использовать базу данных Employee.gdb, которая поставляtnся вместе с
Специально для этого в состав IBX включен компонент TIBDatabase.Для наших примеров в этой главе мы будем использовать базу данных Employee.gdb, которая поставляtnся вместе с
Подключение к базе данных и работа с записями
Подключение к базе данных и работа с записями Нет ничего проще, чем создать приложение на основе Windows Forms. И в этом заявлении нет никакого преувеличения; более того, если вас интересует лишь просмотр содержимого базы данных, вам вообще не придется писать ни единой строки
Создание базы данных с помощью программы SQL Server Enterprise Manager
Создание базы данных с помощью программы SQL Server Enterprise Manager После регистрации сервера можно приступить к созданию рабочей базы данных и ее объектов: таблиц, представлений и хранимых процедур.Это можно выполнить с помощью команд SQL, но лучше воспользоваться программой SQL
Использование программы SQLServer Enterprise Manager для создания таблиц базы данных SQL Server
Использование программы SQLServer Enterprise Manager для создания таблиц базы данных SQL Server
После создания базы данных необходимо создать в ней таблицы. Для этого с помощью программы SQL Server Enterprise Manager выполните ряд действий.1. В окне Microsoft SQL Servers программы SQL Server Enterprise Manager щелкните на
Для этого с помощью программы SQL Server Enterprise Manager выполните ряд действий.1. В окне Microsoft SQL Servers программы SQL Server Enterprise Manager щелкните на
Доступ к базе данных с помощью ASP.NET
Доступ к базе данных с помощью ASP.NET Ядром любого приложения баз данных является база данных. Для использования базы данных необходимо иметь надежный и безопасный способ подключения. На платформе .NET этот способ реализуется с помощью пространства имен System.Data и одной
Получение информации о базе данных
Получение информации о базе данных После того как вы создали базу данных и подтвердили создание (commit), вы можете в isql отобразить ее детали, используя команду SHOW DATABASE:SQL> SHOW DATABASE;Database: /opt/databases/mydatabase.fdbOwner: ADMINUSRPAGE_SIZE 8192Number of DB pages allocated = 176Sweep interval = 20000Forced Writes are ONTransaction — oldest =
Жестко закодированные пути к базе данных
Жестко закодированные пути к базе данных
Строка соединения, например, WlNSERVER:C:Program FilesFirebirdFirebird 1 5 employee. fdb, жестко закодированная в вашем приложении, явно вызовет проблемы при установке вашего программного обеспечения на другой машине. Ваш код должен адаптироваться к
fdb, жестко закодированная в вашем приложении, явно вызовет проблемы при установке вашего программного обеспечения на другой машине. Ваш код должен адаптироваться к
Глава 3 Создание таблиц новой базы данных
Глава 3 Создание таблиц новой базы данных Как уже было сказано в главе 2, разработка новой базы данных «Контрольно-измерительные приборы» производится в программной среде Access 2002.Формирование БД в Access состоит из ряда последовательных этапов, описываемых ниже. Первый этап
Признаки почерка в базе данных
Признаки почерка в базе данных Чтобы удовлетворить приведенным выше требованиям, множество признаков почерка формировалось на основе нескольких принципов.Первый принцип формирования множества признаков почерка: в качестве источников выбирались публикации,
Психологические характеристики в базе данных
Психологические характеристики в базе данных
Одно из требований к базе данных графологического обеспечения, сформулированных выше, касается непосредственно психологических характеристик. Оно сводится к тому, что их множество должно быть минимальным. При этом,
Оно сводится к тому, что их множество должно быть минимальным. При этом,
Графологические функции в базе данных
Графологические функции в базе данных Графологические функции являются третьим из основных элементов базы данных графологической информации. Они отражают саму суть графологического анализа. Эти функции связывают между собой определенные признаки почерка с
Практическая работа 54. Просмотр и редактирование таблиц. Поиск и сортировка в базе данных
Практическая работа 54. Просмотр и редактирование таблиц. Поиск и сортировка в базе данных Задание 1. Дополните таблицы Товары и Сотрудники базы данных Борей собственными данными используя как непосредственный ввод данных в таблицу, так и соответствующие
Создание запросов Make Table — визуальные инструменты для баз данных
Обратная связь Редактировать
Твиттер LinkedIn Фейсбук Эл.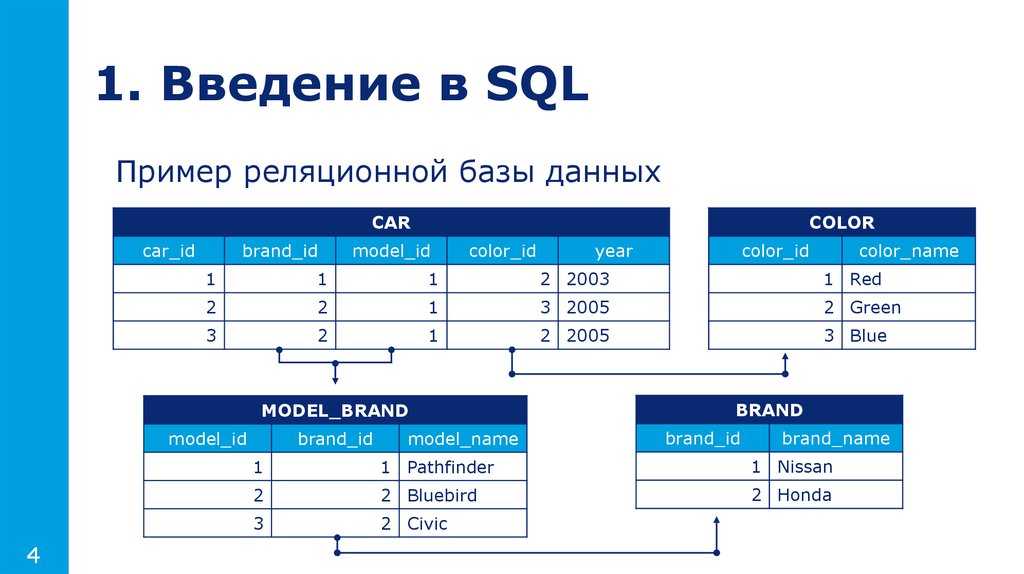 адрес
адрес
- Статья
- 2 минуты на чтение
Применимо к: SQL Server (все поддерживаемые версии)
Вы можете копировать строки в новую таблицу с помощью запроса Make Table, который полезен для создания подмножеств данных для работы или копирования содержимого таблицы из одной базы данных в другую. Запрос «Создать таблицу» похож на запрос «Вставить результаты», но создает новую таблицу, в которую копируются строки.
При создании запроса на создание таблицы вы указываете:
Имя новой таблицы базы данных (целевой таблицы).
Таблица или таблицы, из которых необходимо скопировать строки (исходная таблица). Вы можете копировать из одной таблицы или из объединенных таблиц.
Столбцы в исходной таблице, содержимое которых вы хотите скопировать.
Порядок сортировки, если вы хотите копировать строки в определенном порядке.
Условия поиска для определения копируемых строк.
Параметры группировки, если вы хотите скопировать только сводную информацию.
Например, следующий запрос создает новую таблицу с именем uk_customers и копирует в нее информацию из таблицы customers :
SELECT * INTO uk_customers ОТ клиентов ГДЕ страна = 'Великобритания'
Для успешного использования запроса на создание таблицы:
Для создания запроса на создание таблицы
Добавьте исходную таблицу или таблицы на панель диаграммы.
В меню Query Designer выберите Change Type , а затем щелкните Make Table .
В диалоговом окне Создать таблицу введите имя целевой таблицы.
Конструктор запросов и представлений не проверяет, используется ли имя уже или есть ли у вас разрешение на создание таблицы.Чтобы создать целевую таблицу в другой базе данных, укажите полное имя таблицы, включая имя целевой базы данных, владельца (если требуется) и имя таблицы.
Укажите столбцы для копирования, добавив их в запрос. Дополнительные сведения см. в разделе Добавление столбцов в запросы. Столбцы будут скопированы, только если вы добавите их в запрос. Чтобы скопировать строки целиком, выберите * (Все столбцы) .
Конструктор запросов и представлений добавляет выбранные вами столбцы в столбец Столбец панели Критерии.
Если вы хотите копировать строки в определенном порядке, укажите порядок сортировки. Дополнительные сведения см. в разделе Сортировка и группировка результатов запроса 9.0020 .
Укажите строки для копирования, введя условия поиска. Дополнительные сведения см.
в разделе Указание критериев поиска.Если не указать условие поиска, все строки из исходной таблицы будут скопированы в целевую таблицу.
Примечание
Когда вы добавляете столбец для поиска на панель критериев, конструктор запросов и представлений также добавляет его в список копируемых столбцов. Если вы хотите использовать столбец для поиска, но не копировать его, снимите флажок рядом с именем столбца в прямоугольнике, представляющем таблицу или объект с табличной структурой.
Если вы хотите скопировать сводную информацию, укажите параметры «Группировать по». Дополнительные сведения см. в разделе Суммирование результатов запроса.
 Конструктор запросов и представлений не проверяет, используется ли имя уже или есть ли у вас разрешение на создание таблицы.
Конструктор запросов и представлений не проверяет, используется ли имя уже или есть ли у вас разрешение на создание таблицы. в разделе Указание критериев поиска.
в разделе Указание критериев поиска.При выполнении запроса на создание таблицы в области результатов не отображаются результаты. Вместо этого появляется сообщение, указывающее, сколько строк было скопировано.
См. также
Разделы с практическими рекомендациями по разработке запросов и представлений
[Типы запросов (.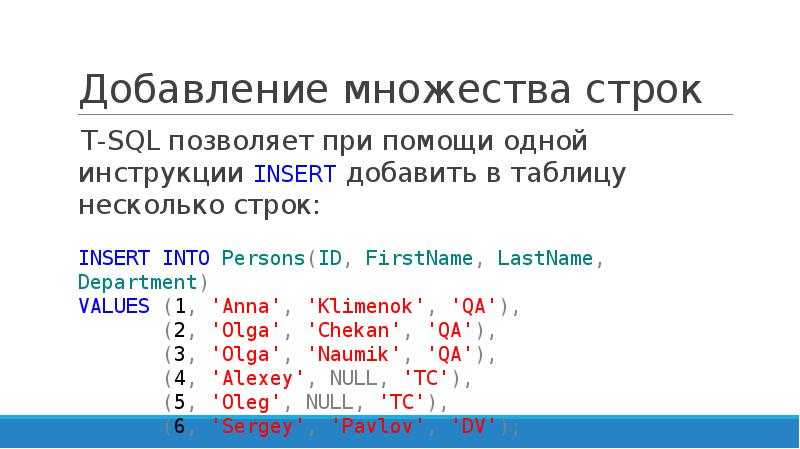 ./../ssms/visual-db-tools/types-of-queries-visual-database-tools.md)
./../ssms/visual-db-tools/types-of-queries-visual-database-tools.md)
Обратная связь
Отправить и просмотреть отзыв для
Этот продукт Эта страница
Просмотреть все отзывы о странице
Создание таблицы — основы SQL
[00:00]
Целью этой серии тем является взаимодействие с данными в нашей базе данных с помощью запроса. Использование этих данных в компонентах в рамках проекта зажигания будет обсуждаться в следующем разделе. Цель этого урока — рассказать, как создать таблицу в базе данных. Мы можем создать таблицу в нашей базе данных, используя определенный тип запроса. Теперь мы можем запустить этот запрос из нашего браузера запросов к базе данных в меню инструментов или мы можем перейти к программному обеспечению для управления базой данных и запустить наш запрос там, но я собираюсь выполнять все запросы в этой серии тем, используя именованный запрос. Я собираюсь создать новый именованный запрос, щелкнув правой кнопкой мыши и выбрав новый запрос, и я назову этот запрос для создания таблицы.
Я собираюсь создать новый именованный запрос, щелкнув правой кнопкой мыши и выбрав новый запрос, и я назову этот запрос для создания таблицы.
[01:00]
Затем я нажму кнопку «Создать» и перейду на вкладку «Авторство». Первое, что я хочу сделать, это установить подключение к базе данных, которое я собираюсь использовать для этого именованного запроса, поэтому я перейду в раскрывающийся список подключения к базе данных и выберу подключение к базе данных InternalDB. Я хочу отметить, что база данных, которую я здесь использую, — это встроенная база данных SQLite, которую вы можете настроить. Для получения дополнительной информации о настройке соединений с базами данных вы можете посмотреть другие видеоролики Inductive University или перейти к нашему руководству пользователя. Далее мне нужно указать тип запроса, который я хочу запустить. В этом случае я не буду извлекать данные из базы данных, а буду создавать новую таблицу, что аналогично вставке или обновлению базы данных. Поэтому я собираюсь изменить свой тип запроса, чтобы обновить запрос. В данном конкретном случае мне не нужны никакие параметры, поэтому я могу удалить два параметра, которые у меня есть прямо сейчас.
Поэтому я собираюсь изменить свой тип запроса, чтобы обновить запрос. В данном конкретном случае мне не нужны никакие параметры, поэтому я могу удалить два параметра, которые у меня есть прямо сейчас.
[02:00]
Наконец, я собираюсь вставить свой запрос в область запросов здесь. Чтобы создать таблицу в базе данных, мы начинаем с команды create table, за которой следует имя таблицы, которую мы хотим создать. В этом случае моя таблица будет называться inventory. Затем в скобках мы перечисляем имена столбцов, которые мы хотим создать в нашей таблице, а также их типы данных. Итак, вы можете видеть, что у меня есть три столбца: имя, местоположение и количество, с типами данных текст, текст и целое число соответственно. Я хочу отметить, что этот синтаксис может отличаться в зависимости от того, какой тип базы данных вы используете. Имейте в виду, что мы используем внутреннее соединение с базой данных SQLite. Ваша таблица может иметь любое количество столбцов, а столбцы могут иметь несколько разных типов данных, опять же, имена типов данных различаются в зависимости от того, какой тип базы данных вы используете.
Ваша таблица может иметь любое количество столбцов, а столбцы могут иметь несколько разных типов данных, опять же, имена типов данных различаются в зависимости от того, какой тип базы данных вы используете.
[03:02] После ввода нашего запроса мы можем запустить его, просто перейдя на вкладку тестирования и нажав кнопку выполнения запроса. Мы не ожидали никаких данных, поэтому я не ожидал увидеть здесь что-либо в этом списке результатов, но если я вернусь на вкладку разработки, мы должны увидеть, что теперь в моем браузере таблиц у меня есть таблица инвентаризации. и если мы развернем его, я увижу три столбца, которые я добавил в эту таблицу: имя, местоположение и количество.
Целью этой серии тем является взаимодействие с данными в нашей базе данных с помощью запроса. Использование этих данных в компонентах в рамках проекта зажигания будет обсуждаться в следующем разделе.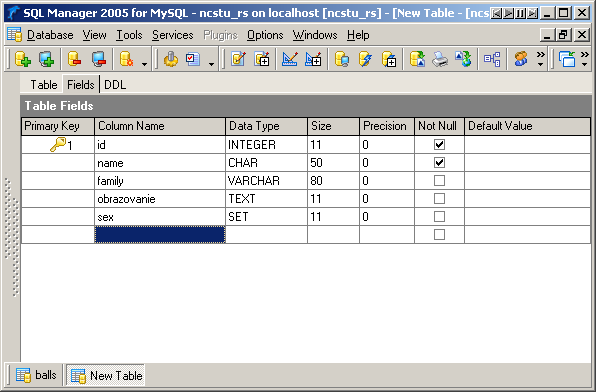 Цель этого урока — рассказать, как создать таблицу в базе данных. Мы можем создать таблицу в нашей базе данных, используя определенный тип запроса. Теперь мы можем запустить этот запрос из нашего браузера запросов к базе данных в меню инструментов или мы можем перейти к программному обеспечению для управления базой данных и запустить наш запрос там, но я собираюсь выполнять все запросы в этой серии тем, используя именованный запрос. Я собираюсь создать новый именованный запрос, щелкнув правой кнопкой мыши и выбрав новый запрос, и я назову этот запрос для создания таблицы.
[01:00] Затем я нажму кнопку «Создать» и перейду на вкладку «Авторство». Первое, что я хочу сделать, это установить подключение к базе данных, которое я собираюсь использовать для этого именованного запроса, поэтому я перейду в раскрывающийся список подключения к базе данных и выберу подключение к базе данных InternalDB. Я хочу отметить, что база данных, которую я здесь использую, — это встроенная база данных SQLite, которую вы можете настроить.
Цель этого урока — рассказать, как создать таблицу в базе данных. Мы можем создать таблицу в нашей базе данных, используя определенный тип запроса. Теперь мы можем запустить этот запрос из нашего браузера запросов к базе данных в меню инструментов или мы можем перейти к программному обеспечению для управления базой данных и запустить наш запрос там, но я собираюсь выполнять все запросы в этой серии тем, используя именованный запрос. Я собираюсь создать новый именованный запрос, щелкнув правой кнопкой мыши и выбрав новый запрос, и я назову этот запрос для создания таблицы.
[01:00] Затем я нажму кнопку «Создать» и перейду на вкладку «Авторство». Первое, что я хочу сделать, это установить подключение к базе данных, которое я собираюсь использовать для этого именованного запроса, поэтому я перейду в раскрывающийся список подключения к базе данных и выберу подключение к базе данных InternalDB. Я хочу отметить, что база данных, которую я здесь использую, — это встроенная база данных SQLite, которую вы можете настроить.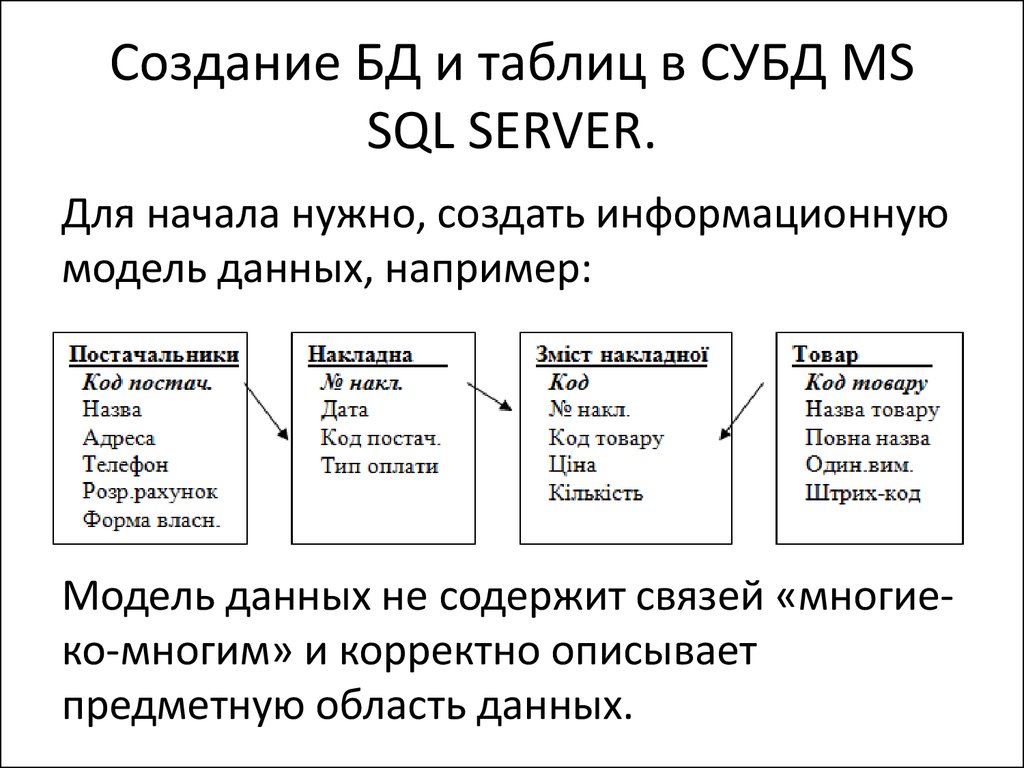 Для получения дополнительной информации о настройке соединений с базами данных вы можете посмотреть другие видеоролики Inductive University или перейти к нашему руководству пользователя. Далее мне нужно указать тип запроса, который я хочу запустить. В этом случае я не буду извлекать данные из базы данных, а буду создавать новую таблицу, что аналогично вставке или обновлению базы данных. Поэтому я собираюсь изменить свой тип запроса, чтобы обновить запрос. В данном конкретном случае мне не нужны никакие параметры, поэтому я могу удалить два параметра, которые у меня есть прямо сейчас.
[02:00] Наконец, я собираюсь вставить свой запрос в область запросов здесь. Чтобы создать таблицу в базе данных, мы начинаем с команды create table, за которой следует имя таблицы, которую мы хотим создать. В этом случае моя таблица будет называться inventory. Затем в скобках мы перечисляем имена столбцов, которые мы хотим создать в нашей таблице, а также их типы данных. Итак, вы можете видеть, что у меня есть три столбца: имя, местоположение и количество, с типами данных текст, текст и целое число соответственно.
Для получения дополнительной информации о настройке соединений с базами данных вы можете посмотреть другие видеоролики Inductive University или перейти к нашему руководству пользователя. Далее мне нужно указать тип запроса, который я хочу запустить. В этом случае я не буду извлекать данные из базы данных, а буду создавать новую таблицу, что аналогично вставке или обновлению базы данных. Поэтому я собираюсь изменить свой тип запроса, чтобы обновить запрос. В данном конкретном случае мне не нужны никакие параметры, поэтому я могу удалить два параметра, которые у меня есть прямо сейчас.
[02:00] Наконец, я собираюсь вставить свой запрос в область запросов здесь. Чтобы создать таблицу в базе данных, мы начинаем с команды create table, за которой следует имя таблицы, которую мы хотим создать. В этом случае моя таблица будет называться inventory. Затем в скобках мы перечисляем имена столбцов, которые мы хотим создать в нашей таблице, а также их типы данных. Итак, вы можете видеть, что у меня есть три столбца: имя, местоположение и количество, с типами данных текст, текст и целое число соответственно. Я хочу отметить, что этот синтаксис может отличаться в зависимости от того, какой тип базы данных вы используете. Имейте в виду, что мы используем внутреннее соединение с базой данных SQLite. Ваша таблица может иметь любое количество столбцов, а столбцы могут иметь несколько разных типов данных, опять же, имена типов данных различаются в зависимости от того, какой тип базы данных вы используете.
[03:02] Теперь, когда мы ввели наш запрос, мы можем запустить его, просто перейдя на вкладку «Тестирование» и нажав кнопку «Выполнить запрос». Мы не ожидали никаких данных, поэтому я не ожидал увидеть здесь что-либо в этом списке результатов, но если я вернусь на вкладку разработки, мы должны увидеть, что теперь в моем браузере таблиц у меня есть таблица инвентаризации. и если мы развернем его, я увижу три столбца, которые я добавил в эту таблицу: имя, местоположение и количество.
Я хочу отметить, что этот синтаксис может отличаться в зависимости от того, какой тип базы данных вы используете. Имейте в виду, что мы используем внутреннее соединение с базой данных SQLite. Ваша таблица может иметь любое количество столбцов, а столбцы могут иметь несколько разных типов данных, опять же, имена типов данных различаются в зависимости от того, какой тип базы данных вы используете.
[03:02] Теперь, когда мы ввели наш запрос, мы можем запустить его, просто перейдя на вкладку «Тестирование» и нажав кнопку «Выполнить запрос». Мы не ожидали никаких данных, поэтому я не ожидал увидеть здесь что-либо в этом списке результатов, но если я вернусь на вкладку разработки, мы должны увидеть, что теперь в моем браузере таблиц у меня есть таблица инвентаризации. и если мы развернем его, я увижу три столбца, которые я добавил в эту таблицу: имя, местоположение и количество.
Как создать таблицу в SQL Server
4 сентября 2021 г.
В этом руководстве вы увидите полные шаги по созданию таблицы в SQL Server.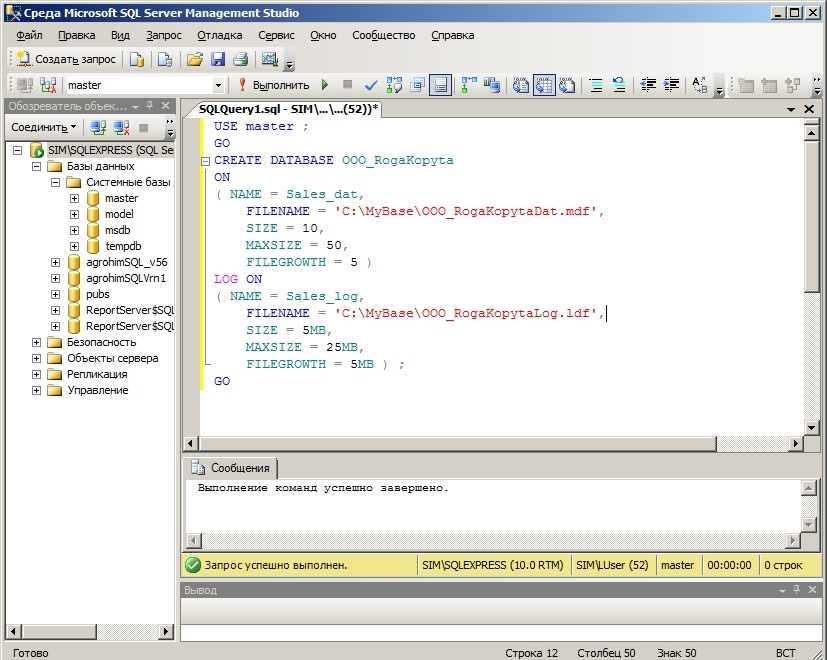 Пример также рассматривается в демонстрационных целях.
Пример также рассматривается в демонстрационных целях.
Действия по созданию таблицы в SQL Server
Шаг 1. Создайте базу данных
Если вы еще этого не сделали, создайте базу данных, в которой будет храниться таблица. Например, вы можете использовать следующий запрос для создания базы данных с именем test_database :
СОЗДАТЬ БАЗУ ДАННЫХ test_database
Шаг 2: Создайте таблицу
Далее создайте таблицу в своей базе данных.
Например, давайте создадим таблицу с именем « products », которая содержит 2 столбца:
- product_name
- цена
В таблице должны храниться следующие данные:
| product_name | цена |
| Настольный компьютер | 800 |
| Ноутбук | 1200 |
| Планшет | 200 |
| Монитор | 350 |
| Принтер | 150 |
Где тип данных для столбца « product_name » будет nvarchar(50) , а тип данных для столбца « price » будет int (для целых чисел).
Затем вы можете создать таблицу, используя следующий запрос CREATE TABLE в своей базе данных:
CREATE TABLE products ( product_name nvarchar(50), цена инт )
Шаг 3: Вставьте значения в таблицу
Теперь добавим следующие значения в таблицу «products»:
| product_name | цена |
| Настольный компьютер | 800 |
| Ноутбук | 1200 |
| Планшет | 200 |
| Монитор | 350 |
| Принтер | 150 |
Вы можете вставить значения в таблицу с помощью запроса INSERT INTO:
INSERT INTO products (product_name, price) ЦЕННОСТИ («Настольный компьютер», 800), («Ноутбук», 1200), («Таблетка», 200), («Монитор», 350), («Принтер», 150)
Шаг 4. Убедитесь, что значения были вставлены в таблицу
Наконец, выполните следующий запрос SELECT, чтобы убедиться, что значения были вставлены в таблицу:
SELECT * FROM products
Вы должны получить следующие результаты:
| product_name | цена |
| Настольный компьютер | 800 |
| Ноутбук | 1200 |
| Планшет | 200 |
| Монитор | 350 |
| Принтер | 150 |
Создайте таблицу в SQL Server с первичным ключом и столбцом идентификаторов
Первичный ключ уникально идентифицирует каждую запись (т. применяется к вашему столбцу всякий раз, когда в таблицу вставляется новая запись.
применяется к вашему столбцу всякий раз, когда в таблицу вставляется новая запись.
Допустим, вы хотите создать таблицу с первичным ключом и столбцом идентификации.
Например, предположим, что вы хотите воссоздать таблицу « products » со следующими тремя столбцами:
- product_id
- имя_продукта
- цена
Где столбец product_id будет выбран в качестве первичного ключа , а также столбца идентификатора .
Вот как новые продукты 9Таблица 0020 должна выглядеть так:
| product_id | имя_продукта | цена |
| 1 | Настольный компьютер | 800 |
| 2 | Ноутбук | 1200 |
| 3 | Планшет | 200 |
| 4 | Монитор | 350 |
| 5 | Принтер | 150 |
Теперь давайте воссоздадим эту таблицу с помощью запросов.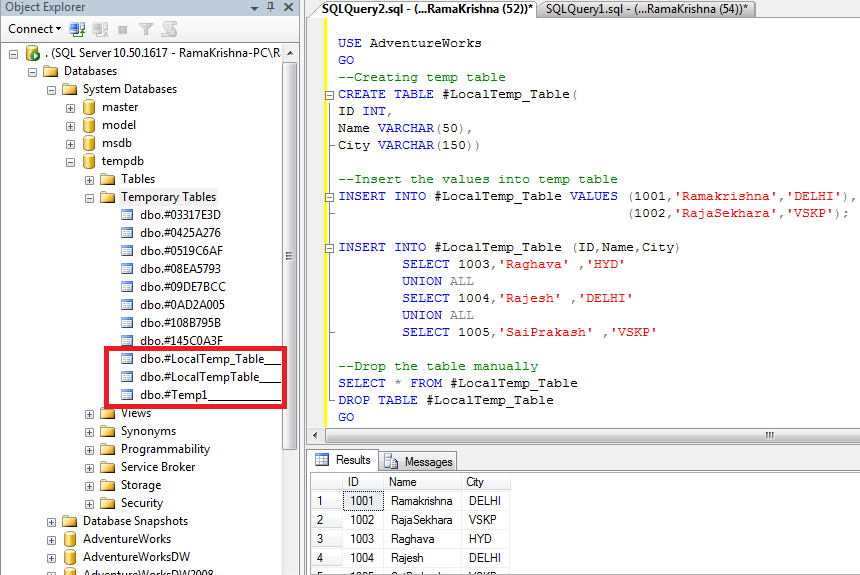
Для начала бросьте таблицу «продукты», чтобы начать с нуля. Вы можете удалить таблицу «products», используя следующий запрос:
DROP TABLE products
Затем заново создайте таблицу с помощью запроса CREATE TABLE:
CREATE TABLE products ( product_id int identity(1,1) первичный ключ, product_name nvarchar(50), цена инт )
Затем вы можете добавить записи в таблицу, выполнив этот запрос INSERT INTO:
INSERT INTO products (product_name, price)
ЦЕННОСТИ
(«Настольный компьютер», 800),
(«Ноутбук», 1200),
(«Таблетка», 200),
(«Монитор», 350),
('Printer',150) 5 новых записей будут вставлены в таблицу (обратите внимание, что не было необходимости заполнять столбец product_id с помощью запроса на вставку. Это было сделано путем установки столбца product_id в качестве столбца идентификаторов) .
Повторите запрос SELECT, чтобы увидеть окончательные результаты:
SELECT * FROM products
Как видите, все записи теперь присутствуют в таблице «products» (куда столбец product_id добавлен с автоинкрементом):
| product_id | имя_продукта | цена |
| 1 | Настольный компьютер | 800 |
| 2 | Ноутбук | 1200 |
| 3 | Планшет | 200 |
| 4 | Монитор | 350 |
| 5 | Принтер | 150 |
Оператор CREATE TABLE SQL Server
В этом руководстве по SQL объясняется, как использовать оператор CREATE TABLE в SQL Server. Этот учебник является первой частью двух сообщений, описывающих операторы DDL (язык определения данных) в SQL Server.
Этот учебник является первой частью двух сообщений, описывающих операторы DDL (язык определения данных) в SQL Server.
Операторы DDL представляют собой подмножество операторов SQL, используемых для создания, изменения или удаления структур базы данных. В этом посте вы узнаете, как создавать и удалять таблицы.
Это руководство позволит вам ознакомиться со следующими темами:
- Создание новых таблиц
- Определение типов данных
- Определение значения по умолчанию
- Определение ограничений
- Ограничения уровня столбца
- Первичный ключ
- Уникальный
- Не нуль
- Чек
- Внешний ключ
- Ограничения уровня таблицы
- Удалить существующую таблицу
В следующем посте будет описано, как использовать инструкцию SQL Server ALTER TABLE.
Оператор SQL Server CREATE TABLE
Оператор SQL Server CREATE TABLE используется для создания новых таблиц в базе данных.
Типы данных
| Тип столбца | Описание | Пример |
| VARCHAR (размер ) | Строковый столбец. Значение в скобках указывает максимальный размер каждого поля в столбце (в символах) 90 183 | VARCHAR(3) → ‘АВС’ VARCHAR(3) → ‘AB’ |
| Десятичный (p,s) | Числовой столбец. P recision — количество цифр, S cale — сколько цифр находится после запятой | ДЕСЯТИЧНОЕ (5,2) → 476,29 ДЕСЯТИЧНОЕ (5,2) → 6,29 |
| ДАТА | Столбец формата даты | ‘ГГГГ-ММ-ДД’ |
Значение по умолчанию SQL Server
Столбцу можно присвоить значение по умолчанию с помощью ключевого слова DEFAULT. Ключевое слово DEFAULT предоставляет значение по умолчанию для столбца, когда инструкция SQL Server INSERT INTO не предоставляет конкретное значение.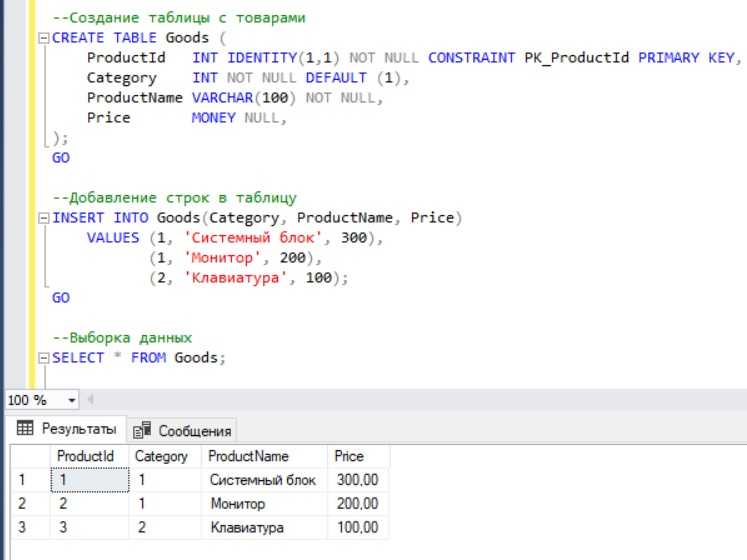 Значение по умолчанию может быть буквальным значением, выражением или функцией SQL, например GETDATE().
Значение по умолчанию может быть буквальным значением, выражением или функцией SQL, например GETDATE().
Чтобы определить значение по умолчанию, используйте следующий синтаксис:
ПО УМОЛЧАНИЮ default_value
Например:
СОЗДАТЬ ТАБЛИЦУ demo_tbl ( зарплата DECIMAL(8,2) ПО УМОЛЧАНИЮ 9500, найм_дата ДАТА ПО УМОЛЧАНИЮ '2011-01-27', дата рождения ДАТА ПО УМОЛЧАНИЮ GETDATE() ) ВСТАВИТЬ В demo_tbl ЗНАЧЕНИЯ (ПО УМОЛЧАНИЮ, ПО УМОЛЧАНИЮ, ПО УМОЛЧАНИЮ) ВЫБРАТЬ * ИЗ demo_tbl зарплата наем_дата дата рождения ------ --------- ---------- 9500 27 января 2011 г. 13 января 2014 г.
Создание ограничений SQL Server
Ограничения применяют правила к данным в таблице всякий раз, когда строка вставляется, удаляется или обновляется. Ограничения можно определить на уровне столбца или таблицы.
Определение ограничений на уровне столбца
Ограничение, применяемое на уровне столбца:
- Создается как часть определения столбца
- Всегда относится к одному столбцу
- Ограничение на уровне столбца имеет следующую структуру:
CONSTRAINT имя_ограничения тип_ограничения
- Constraint_type — тип ограничения, которое должно быть применено к столбцу (например, Unique или Not Null)
- Constraint_name — хотя и не обязательно, всегда рекомендуется давать ограничению имя, что позволит вам легко его идентифицировать.
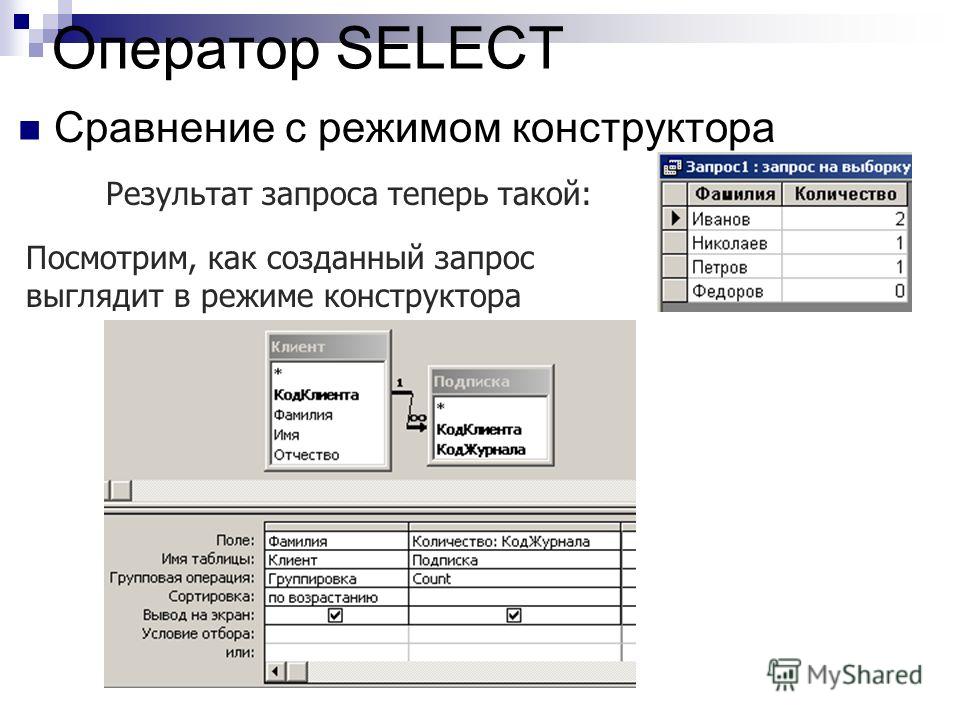
Следующее соглашение об именах обычно используется многими разработчиками баз данных:
<имя таблицы>_<имя_столбца>_<аббревиатура ограничения>
Например:
Первичный ключ (PK)
В SQL Server ограничение первичного ключа представляет собой столбец (или набор столбцов), однозначно идентифицирующий каждую строку в таблице. Это ограничение обеспечивает уникальность и гарантирует что ни один столбец, являющийся частью первичного ключа, не может содержать значение NULL. Для каждой таблицы может быть создан только один первичный ключ.
Синтаксис для определения ограничения первичного ключа следующий:
имя_столбца column_DataType [значение ПО УМОЛЧАНИЮ] [CONSTRAINT имя_ограничения] ПЕРВИЧНЫЙ КЛЮЧ,
Например:
СОЗДАТЬ ТАБЛИЦУ (emp_id decimal(3) ОГРАНИЧЕНИЕ emps_empid_pk ПЕРВИЧНЫЙ КЛЮЧ, emp_name varchar(25))
Обратите внимание: квадратные скобки в этой демонстрации (и в последующих) указывают на то, что то, что заключено в них, является необязательным, квадратные скобки не являются частью оператора CREATE TABLE.
Not Null (NN)
В SQL Server ограничение Not Null гарантирует, что столбец не содержит значений NULL. Синтаксис для определения ограничения Not Null следующий:
имя_столбца column_DataType [значение ПО УМОЛЧАНИЮ] [CONSTRAINT имя_ограничения] NOT NULL,
Например:
СОЗДАТЬ ТАБЛИЦУ (emp_id decimal(3) ОГРАНИЧЕНИЕ emps_empid_pk ПЕРВИЧНЫЙ КЛЮЧ, emp_name varchar(25) ОГРАНИЧЕНИЕ emps_emnm_nn НЕ NULL)
Это ограничение может быть определено только на уровне столбца
UNIQUE (UQ)
В SQL Server ограничение Unique требует, чтобы каждое значение в столбце (или наборе столбцов) было уникальным. Синтаксис определения ограничения UNIQUE следующий:
имя_столбца column_DataType [значение ПО УМОЛЧАНИЮ] [CONSTRAINT имя_ограничения] UNIQUE,
Например:
СОЗДАТЬ ТАБЛИЦУ (emp_id decimal(3) ОГРАНИЧЕНИЕ emps_empid_pk ПЕРВИЧНЫЙ КЛЮЧ, emp_name varchar(25) ОГРАНИЧЕНИЕ emps_emnm_nn НЕ NULL, emp_phone varchar(25)ОГРАНИЧЕНИЕ emps_empn_uq УНИКАЛЬНОЕ)
CHECK (CK)
В SQL Server ограничение Check определяет условие, которому должна удовлетворять каждая строка. Синтаксис определения Check Constraint следующий:
Синтаксис определения Check Constraint следующий:
имя_столбца column_DataType [значение ПО УМОЛЧАНИЮ] [CONSTRAINT имя_ограничения] CHECK (условие),
- Условие, записанное в CHECK, очень похоже по своей структуре на каждое из условий, записанных в операторе WHERE.
- Условие в части CHECK не должно включать:
- Значения, возвращаемые в результате использования SEQUENCES
- Функции, такие как GETDATE()
- Подзапросы
Например:
СОЗДАТЬ ТАБЛИЦУ (emp_id decimal(3) ОГРАНИЧЕНИЕ emps_empid_pk ПЕРВИЧНЫЙ КЛЮЧ, emp_name varchar(25) ОГРАНИЧЕНИЕ emps_emnm_nn НЕ NULL, emp_phone varchar(25) ОГРАНИЧЕНИЕ emps_empn_uq УНИКАЛЬНОЕ, emp_mail varchar(25) ОГРАНИЧЕНИЕ emps_emml_ck ПРОВЕРКА (emp_mail LIKE _%@%.%'))
Другой пример:
СОЗДАТЬ ТАБЛИЦУ (emp_id decimal(3) ОГРАНИЧЕНИЕ emps_empid_pk ПЕРВИЧНЫЙ КЛЮЧ, emp_name varchar(25) ОГРАНИЧЕНИЕ emps_emnm_nn НЕ NULL, emp_phone varchar(25) ОГРАНИЧЕНИЕ emps_empn_uq УНИКАЛЬНОЕ, emp_mail varchar(25) ОГРАНИЧЕНИЕ emps_emml_ck ПРОВЕРКА (emp_mail LIKE '_%@%.
 %'),
emp_sal decimal(8,2) ОГРАНИЧЕНИЕ emp_sal_ck ПРОВЕРКА (emp_sal &lt;&gt; 5000))
%'),
emp_sal decimal(8,2) ОГРАНИЧЕНИЕ emp_sal_ck ПРОВЕРКА (emp_sal &lt;&gt; 5000))
FOREIGN KEY (FK)
В SQL Server ограничение внешнего ключа определяет столбец (или набор столбцов) как внешний ключ и устанавливает связь между первичным ключом (или уникальным) в другой таблице (или в таблице). та же таблица). Синтаксис для определения контрольного ограничения следующий:
имя_столбца … [ОГРАНИЧЕНИЕ имя_ограничения] ССЫЛКИ имя_таблицы (имя_столбца) [НА КАСКАДНОМ УДАЛЕНИИ] [НА УДАЛЕНИИ SET NULL]
Пример:
Родительская таблица
СОЗДАТЬ ТАБЛИЦУ (dep_id decimal(3) ОГРАНИЧЕНИЕ deps_id_pk ПЕРВИЧНЫЙ КЛЮЧ, dep_name varchar(25))
Детский стол
СОЗДАТЬ ТАБЛИЦУ (emp_id decimal(3) ОГРАНИЧЕНИЕ emps_empid_pk ПЕРВИЧНЫЙ КЛЮЧ, emp_name varchar2(25) ОГРАНИЧЕНИЕ emps_emnm_nn НЕ НУЛЕВОЕ, emp_phone varchar2(25) ОГРАНИЧЕНИЕ emps_empn_uq УНИКАЛЬНОЕ, emp_mail varchar2(25) ОГРАНИЧЕНИЕ emps_emml_ck ПРОВЕРКА (emp_mail LIKE '_%@%.
 %'),
emp_sal decimal(8,2) ОГРАНИЧЕНИЕ emp_sal_ck ПРОВЕРКА (emp_sal &gt; 5000),
dep_id decimal(3) ОГРАНИЧЕНИЕ emp_depid_fk ССЫЛКИ deps(dep_id))
%'),
emp_sal decimal(8,2) ОГРАНИЧЕНИЕ emp_sal_ck ПРОВЕРКА (emp_sal &gt; 5000),
dep_id decimal(3) ОГРАНИЧЕНИЕ emp_depid_fk ССЫЛКИ deps(dep_id))
Ограничения уровня таблицы
- Создано после определения различных столбцов.
- Может ссылаться на более чем один столбец (ограничение, объединяющее два столбца).
- Позволяет создавать несколько ограничений для одного столбца.
- С помощью этого метода невозможно создать ограничение NOT NULL.
Например:
СОЗДАТЬ ТАБЛИЦУ (emp_id ДЕСЯТИЧНОЕ (3), emp_f_name VARCHAR(25) , emp_l_name VARCHAR(25) , emp_phone VARCHAR(25) ОГРАНИЧЕНИЕ emps_empn_nn НЕ NULL, emp_mail VARCHAR(25) , emp_sal ДЕСЯТИЧНОЕ(8,2) , dep_id ДЕСЯТИЧНОЕ (3), ОГРАНИЧЕНИЕ emps_empid_pk ПЕРВИЧНЫЙ КЛЮЧ (emp_id), ОГРАНИЧЕНИЕ emps_empn_uq UNIQUE(emp_f_name, emp_l_name), ОГРАНИЧЕНИЕ ПРОВЕРКА emps_emml_ck1 (emp_mail LIKE '_%@%.%'), ПРОВЕРКА ОГРАНИЧЕНИЯ emps_emml_ck2 (ДЛИНА (emp_mail) &amp;gt; 15), ОГРАНИЧЕНИЕ emps_emml_uq УНИКАЛЬНЫЙ (emp_mail) , ОГРАНИЧЕНИЕ emp_sal_ck ПРОВЕРКА (emp_sal &amp;gt; 5000), ОГРАНИЧЕНИЕ emp_depid_fk ВНЕШНИЙ КЛЮЧ (dep_id) ССЫЛКИ deps(dep_id))
Удаление существующей таблицы
Для удаления существующей таблицы в SQL Server используется следующий синтаксис:
УДАЛИТЬ ТАБЛИЦУ имя_таблицы
Например,
УДАЛИТЬ ТАБЛИЦУ сотрудников
Лучший способ заполнения таблиц базы данных [обновлено]
Таблицы являются основой любой системы баз данных и могут хранить более 30 типов данных. Таблицы обеспечивают систематический способ хранения данных для организации вашей базы данных. Команда вставки SQL является неотъемлемой частью SQL, и если пользователи не выполняют ее должным образом, невозможно сохранить данные в таблицах базы данных.
Таблицы обеспечивают систематический способ хранения данных для организации вашей базы данных. Команда вставки SQL является неотъемлемой частью SQL, и если пользователи не выполняют ее должным образом, невозможно сохранить данные в таблицах базы данных.
Что такое вставка SQL?
Команда «INSERT INTO» является частью языка манипулирования данными (DML), подъязыка SQL, который позволяет изменять и извлекать информацию из объектов базы данных. Эта команда позволяет sus вставлять строки в таблицы.
С помощью этой команды вы можете вставлять значения во все столбцы или выбранные столбцы таблицы. Эту вставку можно выполнить в существующей таблице или в таблице, которую вы создаете с помощью команды «CREATE TABLE».
Давайте разберемся с синтаксисом команды вставки SQL.
Синтаксис команды SQL Insert INTO
Существует два синтаксиса для команды «INSERT INTO». Первый синтаксис выглядит следующим образом:
- Оператор «INSERT INTO» сообщает системе базы данных, что вы хотите вставить строки в таблицу, указанную в параметре table_name
- Укажите столбцы таблицы, в которые вы хотите вставить значения, заключенные во внутренние скобки. Используйте запятые для разделения столбцов
- Оператор «VALUES» сообщает системе базы данных, что вставляемые значения указываются
- Затем соответствующие значения каждого столбца указываются в том же порядке, что и столбцы в квадратных скобках, с использованием запятых для разделения этих значений
 Используйте запятые для разделения столбцов
Используйте запятые для разделения столбцовЕсли вы хотите вставить значения во все столбцы таблицы, нет необходимости указывать столбцы в команде. Для этой цели вы можете использовать следующий синтаксис:
- Здесь важно убедиться, что все указанные значения находятся в правильном порядке, соответствующем их соответствующим столбцам в таблице
Вставляемые значения должны быть типами данных, которые соответствуют тому, что было определено в соответствующих столбцах во время создания таблицы.
Давайте попробуем заполнить всю таблицу, используя эти понятия.
Вставка значений во все столбцы таблицы
- Первое, что мы сделаем, это создадим собственную таблицу с помощью команды «CREATE TABLE»
Мы создадим таблицу с именем «Сотрудник», используя следующий запрос:
Как видите, «EmployeeID» — это первичный ключ, а «Имя» имеет определенное для него ОГРАНИЧЕНИЕ NULL, поэтому ни один из этих атрибутов нельзя оставлять пустым во время вставки. Кроме того, «EmployeeID» не может иметь одинаковое значение для нескольких строк.
Кроме того, «EmployeeID» не может иметь одинаковое значение для нескольких строк.
«Имя» и «Город» будут содержать типы данных строковых символов, поэтому при вставке значения будут заключены в одинарные кавычки. В противном случае значения не будут приняты.
- Давайте вставим значения в нашу таблицу, используя следующий запрос:
Если какое-либо из правил не соблюдается, система отобразит сообщение об ошибке, поясняющее, в чем проблема. Например, если мы попытаемся вставить другую запись со столбцом «EmployeeID» как одну, это приведет к следующему:
- Давайте вставим больше допустимых значений в нашу таблицу «Сотрудник»
- Чтобы увидеть нашу таблицу, мы будем использовать следующий запрос:
ВЫБЕРИТЕ * ОТ Сотрудника; |
Это приведет к следующему:
Иногда у нас нет информации обо всех атрибутах, и мы хотим вставить значения только для нескольких столбцов. Давайте посмотрим, как этого можно достичь.
Давайте посмотрим, как этого можно достичь.
Вставка значений в определенные столбцы
В нашей таблице «Сотрудник» EmployeeID является первичным ключом, а «Имя» имеет ОГРАНИЧЕНИЕ NULL, поэтому нам нужно ввести явные значения для каждой строки столбца. Столбцы «Город» и «Зарплата» могут содержать значения NULL.
- Например, если у вас есть информация только об идентификаторе и имени определенного сотрудника, вы можете использовать следующий запрос для вставки этих значений:
Когда мы не вставляем точное значение для атрибута NULL CONSTRAINT, такого как «Имя», мы видим следующую ошибку:
Как видно из этого сообщения об ошибке, мы должны вводить явные значения для каждой записи в этих столбцах с ограничениями.
- Давайте вставим дополнительные строки в нашу таблицу, используя следующий запрос:
- Чтобы просмотреть таблицу, воспользуемся командой SELECT.
Если вы не введете явное значение ни для одной из записей в столбце без ограничений, они будут представлены как значения NULL, поскольку значение по умолчанию для любого столбца без ограничений — «NULL».
Иногда нам требуется скопировать значения одной таблицы в другую таблицу. Давайте посмотрим, как это можно сделать.
Заполнение таблицы с помощью другой таблицы
Вы можете заполнить таблицу, используя другую таблицу с помощью команды «INSERT INTO SELECT». Синтаксис этой команды следующий:
ВСТАВИТЬ В таблицу_назначения (столбец_1, столбец_2,… столбец_n) ВЫБЕРИТЕ столбец_1, столбец_2,… столбец_n ИЗ исходной_таблицы ГДЕ [условие]; |
- Параметр destination_table указывает таблицу, в которую мы хотим вставить значения, а параметр source_table указывает таблицу, из которой вставляются значения
- Здесь нам нужно убедиться, что мы копируем только типы данных из столбцов, которые поступают из одних и тех же исходных и целевых таблиц
- Столбцы с первичным ключом или ограничениями NOT NULL в исходной таблице также должны присутствовать в целевой таблице и быть скопированы
- Эта команда содержит необязательное условие WHERE
Из исходной таблицы можно указать условие, по которому следует выбирать строки в параметре «условие» этого предложения. Если его нет в запросе, все строки столбцов вставляются в целевую таблицу.
Если его нет в запросе, все строки столбцов вставляются в целевую таблицу.
Например, если мы хотим вставить значения из нашей таблицы «Сотрудники» в таблицу «Зарплата», которая имеет только три столбца (ID сотрудника, Имя и Зарплата), мы будем использовать следующий запрос:
Чтобы просмотреть нашу таблицу «Зарплата», мы будем использовать команду SELECT следующим образом:
Это показывает, что все значения из указанных столбцов таблицы Employee были вставлены в таблицу Salary.
Вы также можете вставлять записи из всех столбцов таблицы в другую таблицу. Синтаксис этой команды следующий:
ВСТАВИТЬ В таблицу_назначения ВЫБЕРИТЕ * ИЗ исходной_таблицы ГДЕ [условие]; |
Например, если мы дублируем нашу таблицу Employee и называем ее «EmployeeCopy», и эта копия включает те же столбцы из оригинала, мы можем использовать следующий запрос, чтобы вставить значения всех столбцов из исходной таблицы в таблицу. новая таблица:.
новая таблица:.
ВСТАВИТЬ В EmployeeCopy ВЫБЕРИТЕ * ОТ Сотрудника; |
Чтобы просмотреть нашу новую таблицу, мы будем использовать команду SELECT.
Теперь, когда мы знаем разные способы вставки строк в таблицу, давайте посмотрим, как эти строки удалять.
Удаление строк из таблицы
Иногда нам нужно удалить некоторые (или все) строки из таблицы. Это можно сделать с помощью команды «УДАЛИТЬ», которая является частью языка манипулирования данными. Синтаксис этой команды следующий:
УДАЛИТЬ ИЗ имя_таблицы ГДЕ [условие]; |
Эта команда использует предложение «ГДЕ». Вы можете указать условие, согласно которому строки должны быть удалены в параметре «условие» этого предложения. Если этого нет в запросе, все строки таблицы будут удалены.
Например, если мы хотим удалить все записи о сотрудниках с зарплатой меньше или равной 25000 из нашей таблицы «Сотрудники», мы будем использовать следующий запрос:
В результате получится следующая таблица:
Как видно, две строки были удалены.
Если мы хотим удалить все строки из таблицы, мы будем использовать следующий запрос:
УДАЛИТЬ ОТ Сотрудника; |
Все строки из этой таблицы удаляются, но таблицу можно использовать для вставки новых строк.
Получите опыт работы с новейшими инструментами и методами бизнес-аналитики с помощью магистерской программы бизнес-аналитика. Зарегистрируйтесь сейчас!
Следующие шаги
В заключение, очень важно вставлять правильные типы значений в столбцы, так как это данные, с которыми вы собираетесь работать. Любые ошибки при вставке потенциально могут привести к некоторым ошибкам.
Теперь, когда вы знаете, как заполнять таблицы, следующим шагом в вашем путешествии по SQL будет запрос данных для извлечения полезной информации. Если вам понравилась эта статья и вы хотите пройти сертификацию, ознакомьтесь с магистерской программой бизнес-аналитика Simplilearn, в которой очень подробно рассматривается SQL.
У вас есть к нам вопросы? Оставьте комментарий, и наши специалисты ответят на него за вас.
SQL Create Table — Хранение всех вещей
Назад Таблица создания SQL — хранение всех вещей
Реляционные базы данных хранят информацию в таблицах со столбцами, которые аналогичны элементам в структуре данных, и строками, которые являются одним экземпляром этой структуры данных, которые создаются с помощью инструкции SQL Create Table. При создании таблиц каждый указанный столбец может иметь две характеристики:
- тип — какие данные могут храниться
- ограничение — ограничения на данные
В этой записи блога рассматриваются многие распространенные типы данных SQL и ограничения, которые могут на них накладываться. Предоставляются практические примеры и исходный код. Структура таблицы может быть изменена после создания с помощью оператора SQL Alter.
Типы данных SQL
Поскольку поставщики баз данных выбирают, какой стандарт ANSI SQL использовать для реализации, а стандарт развивается, вам придется проверять вашу конкретную базу данных на наличие допустимых типов данных и синонимов. Как правило, все базы данных поддерживают следующие типы данных:
Как правило, все базы данных поддерживают следующие типы данных:
| Data Type | SQL | |
| Character | CHAR, VARCHAR, CLOB | |
| Binary | BINARY, VARBINARY, BLOB | |
| Numeric (exact) | NUMERIC, DECIMAL, SMALLINT, INTEGER, BIGINT | |
| Числовое (приблизительное) | FLOAT, REAL, DOUBLE | |
| Время | Другое DATE, TIME, TIMESTAMP 909 90 9 0 7 8 1 8 9 0 8 1 8 | INTERVAL, BOOLEAN, XML, JSON |
Ограничения данных SQL
Ограничения — это необязательные правила, ограничивающие ввод данных в описываемый столбец. Поскольку поставщики баз данных могут настраивать свои предложения, проверьте, какие ограничения поддерживаются. Общие ограничения:
| Ограничение | Описание |
| ПРОВЕРКА | Убедитесь, что все значения столбцов удовлетворяют определенным условиям. |
| ПО УМОЛЧАНИЮ | Установите значение столбца, если оно не указано. |
| FOREIGN KEY | Уникально идентифицирует строку/запись в другой таблице. |
| ИНДЕКС | Оптимизация для быстрого поиска данных. |
| NOT NULL | Убедитесь, что значение столбца содержит значение, отличное от NULL. |
| PRIMARY KEY | Уникальная идентификация каждой строки с помощью комбинации NOT NULL и UNIQUE. |
| UNIQUE | Убедитесь, что все значения в столбце различны. |
Базовый SQL Create Table & Constraint Examples
Оператор SQL Create Table выглядит так:
CREATE TABLE имя_таблицы ( столбец_1 тип_данных столбец_ограничение, столбец_2 тип_данных столбец_ограничение, столбец_3 тип_данных столбец_ограничение, ...);
Для иллюстрации давайте создадим таблицу для компаний и их биржевых кодов. И символ тикера, и названия компаний должны содержать что-то (например, NOT NULL ), а символы должны быть уникальными (как на реальных фондовых рынках).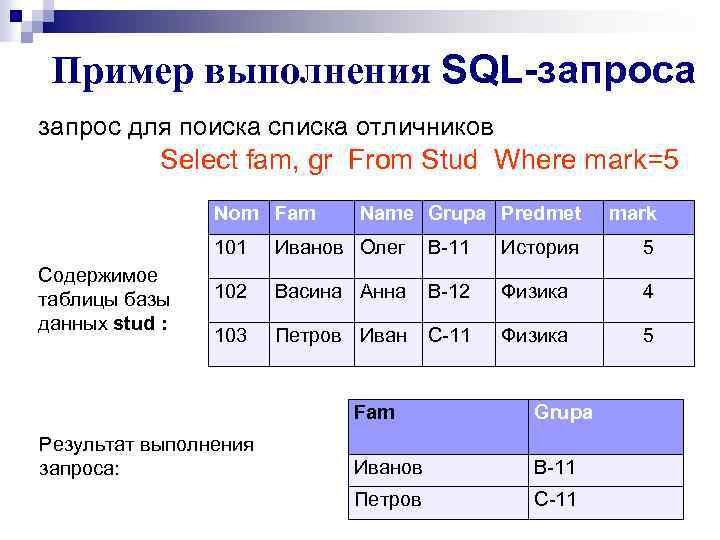
СОЗДАТЬ ТАБЛИЦУ компании ( символ VARCHAR(6) НЕ NULL УНИКАЛЬНЫЙ, имя VARCHAR(40) НЕ NULL, ИНДЕКС(символ) ); ВСТАВИТЬ В КОМПАНИИ ЦЕННОСТИ («GBTC», «Оттенки серого»), («МСТР», «МикроСтратегия»), («ЦЛА», «Тесла»); ВЫБЕРИТЕ * ОТ компаний;
| символ | название |
| GBTC | Оттенки серого |
| MSTR | MicroStrategy |
| TSLA | Tesla |
Еще одну таблицу мы заполним биографическими данными о корпоративных сотрудниках, покупающих активы, их компании, информацию о покупках. Мы ограничиваем возраст, чтобы гарантировать, что офицеры являются совершеннолетними, мы добавляем значение по умолчанию к сумме покупки и заставляем базу данных создавать идентификатор транзакции — монотонно возрастающее целочисленное значение, — которое мы идентифицируем как первичный ключ (для быстрого поиска). . Мы связываем таблицы закупок и компаний через тикер компании в качестве внешнего ключа (для проверки символов).
СОЗДАТЬ ТАБЛИЦУ покупок (
транзакция INT NOT NULL AUTO_INCREMENT,
покупатель ВАРЧАР(50),
age INT CHECK (возраст >= 18),
компания ВАРЧАР(33),
количество FLOAT ПО УМОЛЧАНИЮ 0.0,
ПЕРВИЧНЫЙ КЛЮЧ (транзакция),
FOREIGN KEY (компания) REFERENCES компании (символ)
) ;
ВСТАВИТЬ В покупки (покупатель, возраст, компания, сумма)
ЦЕННОСТИ
("Барри Силберт", 43 года, "GBTC", 449596),
(«Майкл Сэйлор», 56, «МСТР», 71079),
("Илон Маск", 49, "ЦЛА", 44776119)
;
ВЫБЕРИТЕ * ИЗ покупок ; | transaction | buyer | age | company | amount |
| 1 | Barry Silbert | 43 | GBTC | 449596 |
| 2 | Майкл Сэйлор | 56 | MSTR | 71079 |
| 3 | Илон Маск | 1 8 TS | 0180 44776119
Ограничения, защищающие целостность данных
Попытка вставить в таблицу закупок строку со строкой компании, которая не отображается в таблице компаний, вызовет ошибку проверки данных (как и следовало ожидать, учитывая FOREIGN).). Например: ограничение KEY
ограничение KEY
ВСТАВЬТЕ В ПОКУПКИ (покупатель, возраст, компания, сумма)
ЗНАЧЕНИЯ ("Стив Джобс", 99, "AAPL", 0); возвращает следующую ошибку, показывающую, что ограничение внешнего ключа защитило целостность данных значений таблицы.
Невозможно добавить или обновить дочернюю строку: ограничение внешнего ключа не работает (`database`.`purchases`, CONSTRAINT `purchases_ibfk_1` FOREIGN KEY (`company`) REFERENCES `companies` (`symbol`))
Попытка вставка значения возраста менее 18 лет приведет к аналогичной ошибке.
SQL Create Table From
Поскольку эти таблицы сейчас «в производстве» — и, следовательно, их нельзя подделывать — создать тестовую таблицу и заполнить ее датами, которые в настоящее время находятся в таблице закупок, мы можем:
СОЗДАТЬ ТАБЛИЦУ Purchases_copy КАК ВЫБРАТЬ компанию, сумму ИЗ покупок ;
SQL Drop Table
Аналогом создания таблиц является оператор SQL Drop Table, который удаляет структуру таблицы и данные внутри.