Простые SQL запросы — короткая справка и примеры
Простые SQL запросы
Запросы написаны без экранирующих кавычек, так как у MySQL, MS SQL и PostGree они разные.
SQL запрос: получение указанных (нужных) полей из таблицы
SELECT id, country_title, count_people FROM table_name
Получаем список записей: ВСЕ страны и их население. Название нужных полей указываются через запятую.
SELECT * FROM table_name
* обозначает все поля. То есть, будут показы АБСОЛЮТНО ВСЕ поля данных.
SQL запрос: вывод записей из таблицы исключая дубликаты
SELECT DISTINCT country_title FROM table_name
Получаем список записей: страны, где находятся наши пользователи. Пользователей может быть много из одной страны. В этом случае это ваш запрос.
SQL запрос: вывод записей из таблицы по заданному условию
SELECT id, country_title, city_title FROM table_name WHERE count_people>100000000
Получаем список записей: страны, где количество людей больше 100 000 000.
SQL запрос: вывод записей из таблицы с упорядочиванием
SELECT id, city_title FROM table_name ORDER BY city_title
Получаем список записей: города в алфавитном порядке. В начале А, в конце Я.
SELECT id, city_title FROM table_name ORDER BY city_title DESC
Получаем список записей: города в обратном (DESC) порядке. В начале Я, в конце А.
SQL запрос: подсчет количества записей
SELECT COUNT(*) FROM table_name
Получаем число (количество) записей в таблице. В данном случае НЕТ списка записей.
SQL запрос: вывод нужного диапазона записей
SELECT * FROM table_name LIMIT 2, 3
Получаем 2 (вторую) и 3 (третью) запись из таблицы. Запрос полезен при создании навигации на WEB страницах.
SQL запросы с условиями
Вывод записей из таблицы по заданному условию с использованием логических операторов.
SQL запрос: конструкция AND (И)
SELECT id, city_title FROM table_name WHERE country="Россия" AND oil=1
Получаем список записей: города из России И имеют доступ к нефти. Когда используется оператор AND, то должны совпадать оба условия.
SQL запрос: конструкция OR (ИЛИ)
SELECT id, city_title FROM table_name WHERE country="Россия" OR country="США"
Получаем список записей: все города из России ИЛИ США. Когда используется оператор OR, то должно совпадать ХОТЯ БЫ одно условие.
SQL запрос: конструкция AND NOT (И НЕ)
SELECT id, user_login FROM table_name WHERE country="Россия" AND NOT count_comments<7
Получаем список записей: все пользователи из России
SQL запрос: конструкция IN (В)
SELECT
id,
user_login
FROM table_name
WHERE country IN ("Россия", "Болгария", "Китай")
Получаем список записей: все пользователи, которые проживают в (IN) (России, или Болгарии, или Китая)
SQL запрос: конструкция NOT IN (НЕ В)
SELECT
id,
user_login
FROM table_name
WHERE country NOT IN ("Россия","Китай")
Получаем список записей: все пользователи, которые проживают не в (NOT IN) (России или Китае).
SQL запрос: конструкция IS NULL (пустые или НЕ пустые значения)
SELECT id, user_login FROM table_name WHERE status IS NULL
SELECT id, user_login FROM table_name WHERE state IS NOT NULL
Получаем список записей: все пользователи, где status определен (НЕ НОЛЬ).
SQL запрос: конструкция LIKE
SELECT id, user_login FROM table_name WHERE surname LIKE "Иван%"
Получаем список записей: пользователи, у которых фамилия начинается с комбинации «Иван». Знак % означает ЛЮБОЕ количество ЛЮБЫХ символов. Чтобы найти знак % требуется использовать экранирование «Иван\%».
SQL запрос: конструкция BETWEEN
SELECT id, user_login FROM table_name WHERE salary BETWEEN 25000 AND 50000
Получаем список записей: пользователи, которые получает зарплату от 25000 до 50000 включительно.
Логических операторов ОЧЕНЬ много, поэтому детально изучите документацию по SQL серверу.
Сложные SQL запросы
SQL запрос: объединение нескольких запросов
(SELECT id, user_login FROM table_name1 ) UNION (SELECT id, user_login FROM table_name2 )
Получаем список записей: пользователи, которые зарегистрированы в системе, а также те пользователи, которые зарегистрированы на форуме отдельно. Оператором UNION можно объединить несколько запросов. UNION действует как SELECT DISTINCT, то есть отбрасывает повторяющиеся значения. Чтобы получить абсолютно все записи, нужно использовать оператор UNION ALL.
SQL запрос: подсчеты значений поля MAX, MIN, SUM, AVG, COUNT
Вывод одного, максимального значения счетчика в таблице:
SELECT MAX(counter) FROM table_name
Вывод одного, минимальный значения счетчика в таблице:
SELECT MIN(counter) FROM table_name
Вывод суммы всех значений счетчиков в таблице:
SELECT SUM(counter) FROM table_name
Вывод среднего значения счетчика в таблице:
SELECT AVG(counter) FROM table_name
Вывод количества счетчиков в таблице:
SELECT COUNT(counter) FROM table_name
Вывод количества счетчиков в цехе №1, в таблице:
SELECT COUNT(counter) FROM table_name WHERE office="Цех №1"
Это самые популярные команды. Рекомендуется, где это возможно, использовать для подсчета именно SQL запросы такого рода, так как ни одна среда программирования не сравнится в скорости обработки данных, чем сам SQL сервер при обработке своих же данных.
SQL запрос: группировка записей
SELECT continent, SUM(country_area) FROM country GROUP BY continent
Получаем список записей: с названием континента и с суммой площадей всех их стран. То есть, если есть справочник стран, где у каждой страны записана ее площадь, то с помощью конструкции GROUP BY можно узнать размер каждого континента (на основе группировки по континентам).
SQL запрос: использование нескольких таблиц через алиас (alias)
SELECT o.order_no, o.amount_paid, c.company FROM orders AS o, customer AS с WHERE o.custno=c.custno AND c.city="Тюмень"
Получаем список записей: заказы от покупателей, которые проживают только в Тюмени.
На самом деле, при правильном запроектированной базе данных данного вида запрос является самым частым, поэтому в MySQL был введен специальный оператор, который работает в разы быстрее, чем выше написанный код.
SELECT o.order_no, o.amount_paid, z.company FROM orders AS o LEFT JOIN customer AS z ON (z.custno=o.custno)
Рекомендуется использовать в запросах именно такой вид оформления SQL запросов.
Вложенные подзапросы
SELECT * FROM table_name WHERE salary=(SELECT MAX(salary) FROM employee)
Получаем одну запись: информацию о пользователе с максимальным окладом.
Внимание! Вложенные подзапросы являются одним из самых узких мест в SQL серверах. Совместно со своей гибкостью и мощностью, они также существенно увеличивают нагрузку на сервер. Что приводит к катастрофическому замедлению работы других пользователей. Очень часты случаи рекурсивных вызовов при вложенных запросах. Поэтому настоятельно рекомендую НЕ использовать вложенные запросы, а разбивать их на более мелкие. Либо использовать вышеописанную комбинацию LEFT JOIN. Помимо этого данного вида запросы являются повышенным очагом нарушения безопасности. Если решили использовать вложенные подзапросы, то проектировать их нужно очень внимательно и первоначальные запуски сделать на копиях баз (тестовые базы).
Пример оформления сложных SQL запросов.
SQL запросы изменяющие данные
SQL запрос: INSERT
Инструкция INSERT позволяют вставлять записи в таблицу. Простыми словами, создать строчку с данными в таблице.
Вариант №1. Часто используется инструкция:
INSERT INTO table_name (id, user_login) VALUES (1, "ivanov"), (2, "petrov")
В таблицу «table_name» будет вставлено 2 (два) пользователя сразу.
Вариант №2. Удобнее использовать стиль:
INSERT table_name SET id=1, user_login="ivanov"; INSERT table_name SET id=2, user_login="petrov";
В этом есть свои преимущества и недостатки.
Основные недостатки:
- Множество мелких SQL запросов выполняются чуть медленнее, чем один большой SQL запрос, но при этом другие запросы будут стоять в очереди на обслуживание. То есть, если большой SQL запрос будет выполняться 30 минут, то в все это время остальные запросы будут курить бамбук и ждать своей очереди.
- Запрос получается массивнее, чем предыдущий вариант.
Основные преимущества:
- Во время мелких SQL запросов, другие SQL запросы не блокируются.
- Удобство в чтении.
- Гибкость. В этом варианте, можно не соблюдать структуру, а добавлять только необходимые данные.
- При формировании подобным образом архивов, можно легко скопировать одну строчку и запустить ее через командную строку (консоль), тем самым не восстанавливая АРХИВ целиком.
- Стиль записи схож с инструкцией UPDATE, что легче запоминается.
SQL запрос: UPDATE
UPDATE table_name SET user_login="ivanov", user_surname="Иванов" WHERE id=1
В таблице «table_name» в записи с номером id=1, будет изменены значения полей user_login и user_surname на указанные значения.
SQL запрос: DELETE
DELETE FROM table_name WHERE id=3
В таблице table_name будет удалена запись с id номером 3.
SQL рекомендации
- Все названия полей рекомендуются писать маленькими буквами и если надо, разделять их через принудительный пробел «_» для совместимости с разными языками программирования, таких как Delphi, PHP, Perl, Python и Ruby.
- SQL команды писать БОЛЬШИМИ буквами для удобочитаемости. Помните всегда, что после вас могут читать код и другие люди, а скорее всего вы сами через N количество времени.
- Называть поля с начала существительное, а потом действие. Например: city_status, user_login, user_name.
- Стараться избегать слов резервных в разных языках которые могут вызывать проблемы в языках SQL, PHP или Perl, типа (name, count, link). Например: link можно использовать в MS SQL, но в MySQL зарезервировано.
Данный материал является короткой справкой для повседневной работы и не претендует на супер мега авторитетный источник, коим является первоисточник SQL запросов той или иной базы данных.
sd-company.su
запрос в запросе. MySQL: примеры запросов. Вложенные запросы MySQL
В настоящее время каждый человек может наблюдать стремительный рост объема цифровой информации. А так как большая часть этой информации является важной, возникает необходимость ее сохранения на цифровых носителях для последующего использования. В данной ситуации могут применяться такие современные технологии, как базы данных. Они обеспечивают надежное хранение любой цифровой информации, а доступ к данным может быть осуществлен в любой точке земного шара. Одной из рассматриваемых технологий является система управления базами данных MySQL.
СУБД MySQL – что это?
Реляционная система управления базами данных MySQL является одной из самых востребованных и часто используемых технологий хранения информации. Ее функциональные возможности превосходят по многим показателям существующие СУБД. В частности, одной из главных особенностей является возможность использовать вложенные запросы MySQL.

Поэтому многие проекты, где важно время быстродействия и необходимо обеспечить хранение информации, а также осуществлять сложные выборки данных, разрабатываются на базе СУБД MySQL. Большую часть таких разработок составляют интернет-сайты. При этом MySQL активно внедряется при реализации как небольших (блоги, сайт-визитки и т. п.), так и достаточно крупных задач (интернет-магазины, хранилище данных и т. д.). В обоих случаях для отображения информации на странице сайта применяется MySQL-запрос. В запросе разработчики стараются максимально использовать имеющиеся возможности, которые предоставляет система управления базами данных.
Как должно быть организовано хранение данных
Для удобного хранения и последующей обработки данные обязательно упорядочиваются. Структура данных позволяет определить, каким образом будут выглядеть таблицы, использующиеся для хранения информации. Таблицы базы данных представляют собой набор полей (столбцов), отвечающих за каждое определенное свойство объекта данных.
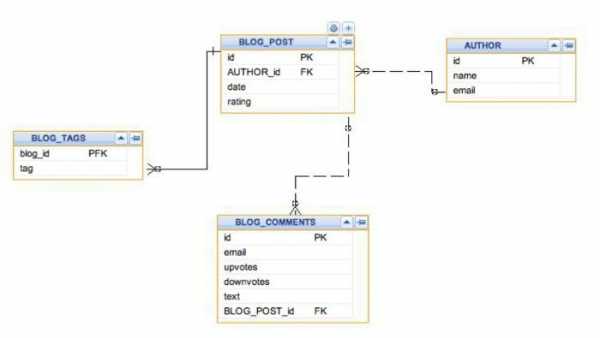
Например, если составляется таблица сотрудников определенной компании, то ее самая простая структура будет иметь следующий вид. За каждым сотрудником закреплен уникальный номер, который, как правило, используется в качестве первичного ключа к таблице. Затем в таблицу заносятся персональные данные сотрудника. Это может быть что угодно: Ф. И. О., номер отдела, за которым он закреплен, телефон, адрес и прочее. Согласно требованиям нормализации (6 нормальных форм баз данных), а также для того, чтобы MySQL-запросы выстраивались структурированно, поля таблицы должны быть атомарными, то есть не иметь перечислений или списков. Поэтому, как правило, в таблице существуют отдельные поля для фамилии, имени и т. д.
Employee_id | Surname | Name | Patronymic | Department_id | Position | Phone | Employer_id |
1 | Иванов | Иван | Иванович | Администрац. | Директор | 495**** | null |
2 | Петров | Петр | Петрович | Администрац. | Зам. директора | 495*** | 1 |
3 | Гришин | Григорий | Григорьевич | Продажи | Начальник | 1 | |
… | … | … | … | … | … | … | … |
59 | Сергеев | Сергей | Сергеевич | Продажи | Продавец-консульт. | 495*** | 32 |
Выше представлен тривиальный пример структуры таблицы базы данных. Однако она ещё не до конца отвечает основным требованиям нормализации. В реальных системах создается дополнительная таблица отделов. Поэтому приведенная таблица вместо слов в колонке «Отдел» должна содержать номера отделов.
Каким образом происходит выборка данных
Для получения данных из таблиц в СУБД используется специальная команда MySQL – запрос Select. Для того чтобы сервер базы данных правильно отреагировал на обращение, запрос должен быть корректно сформирован. Структура запроса формируется следующим образом. Любое обращение к серверу БД начинается с ключевого слова select. Именно с него строятся все в MySQL запросы. Примеры могут иметь различную сложность, но принцип построения очень похож.
Затем необходимо указать, с каких полей требуется выбрать интересующую информацию. Перечисление полей происходит через запятую после предложения select. После того как все необходимые поля были перечислены, в запросе указывается объект таблицы, из которого будет происходить выборка, при помощи предложения from и указания имени таблицы.
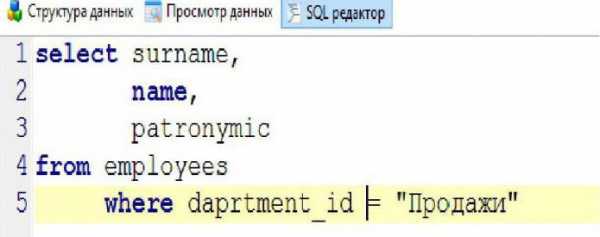
Для ограничения выборки в MySQL-запросы добавляются специальные операторы, предусмотренные СУБД. Для выборки неповторяющихся (уникальных) данных используется предложение distinct, а для задания условий – оператор where. В качестве примера, применимого к вышеуказанной таблице, можно рассмотреть запрос, требующий информацию о Ф.И.О. сотрудников, работающих в отделе «Продажи». Структура запроса примет вид, как в таблице ниже.
Понятие вложенного запроса
Но главная особенность СУБД, как было указано выше, возможность обрабатывать вложенные запросы MySQL. Как он должен выглядеть? Из названия логически понятно, что это запрос, сформированный в определенной иерархии из двух или более запросов. В теории по изучению особенностей СУБД сказано, что MySQL не накладывает ограничений на количество MySQL-запросов, которые могут быть вложены в главный запрос. Однако можно поэкспериментировать на практике и убедиться, что уже после второго десятка вложенных запросов время отклика серьезно увеличится. В любом случае на практике не встречаются задачи, требующие использовать чрезвычайно сложный MySQL-запрос. В запросе может потребоваться максимально до 3-5 вложенных иерархий.
Построение вложенных запросов
При анализе прочитанной информации возникает ряд вопросов о том, где могут быть использованы вложенные запросы и нельзя ли решить задачу разбиением их на простые без усложнения структуры. На практике вложенные запросы используются для решения сложных задач. К такому типу задач относятся ситуации, когда заранее неизвестно условие, по которому будет происходить ограничение дальнейшей выборки значений. Решить такие задачи невозможно, если просто использовать обычный MySQL-запрос. В запросе, состоящем из иерархий, будет происходить поиск ограничений, которые могут меняться с течением времени или заранее не могут быть известны.
Если рассматривать таблицу, приведенную выше, то в качестве сложной задачи можно привести следующий пример. Допустим, нам необходимо узнать основную информацию о сотрудниках, находящихся в подчинении Гришина Григория Григорьевича, который является начальником отдела продаж. При формировании запроса нам неизвестен его идентификационный номер. Поэтому изначально нам необходимо его узнать. Для этого используется простой запрос, который позволит найти решение главного условия и дополнит основной MySQL-запрос. В запросе наглядно представлено, что подзапрос получает идентификационный номер сотрудника, который в дальнейшем определяет ограничение главного запроса:
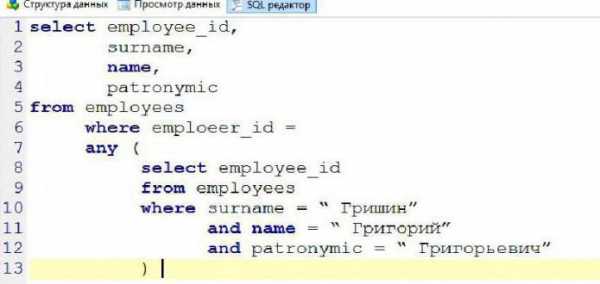
В данном случае предложение any используется для того, чтобы исключить возникновение ошибок, если сотрудников с такими инициалами окажется несколько.
Итоги
Подводя итог, необходимо отметить, что существует ещё много других дополнительных возможностей, которые значительно облегчают построение запросов, так как СУБД MySQL – мощное средство с богатым арсеналом инструментов для хранения и обработки данных.
fb.ru
Примеры сложных запросов для выборки данных в СУБД MySQL
Окт 23 2014
Всего лишь пару лет назад, в проектах, которые предусматривали работу с базами данных и построением статистики, основным изобилием используемых SQL-запросов, преобладало в основном множество запросов, ориентированных на стандартную выборку данных и нечасто можно было увидеть другие, которые безо всяких сомнений можно было бы отнести к “эксклюзиву”. Хотя сложность запроса и зависит от количества используемых таблиц, но если мы всего лишь возьмем и выведем данные полей трех или более таблиц имеющих стандартное объединение, то явная сложность такого запроса не выйдет за пределы стандартной.
В данной статье по мере возможности будут рассматриваться те запросы, примеры которых мне найти не удалось и которые, по моему мнению, не относятся к классу простых.
Сравнение данных за две даты
Хотя данная статистика из рода задач довольно редко встречаемых, но все-таки необходимость в ее получении иногда существует. И получить такую статистику ничуть не сложнее других.
Работать мы будем с двумя таблицами, структура которых представлена ниже:
Структура таблицы products
CREATE TABLE IF NOT EXISTS `products` ( `id` int(11) NOT NULL AUTO_INCREMENT, `ShopID` int(11) NOT NULL, `Name` varchar(150) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=10 ;
Структура таблицы statistics
CREATE TABLE IF NOT EXISTS `statistics` ( `id` int(11) NOT NULL AUTO_INCREMENT, `ProductID` bigint(20) NOT NULL, `Orders` int(11) NOT NULL, `Date` date NOT NULL DEFAULT '0000-00-00', PRIMARY KEY (`id`), KEY `ProductID` (`ProductID`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=20 ;
Дело в том, что стандарт языка SQL допускает использование вложенных запросов везде, где разрешается использование ссылок на таблицы. Здесь вместо явно указанных таблиц, благодаря использованию псевдонимов, будут применяться результирующие таблицы вложенных запросов с имеющейся связью один – к – одному. Результатом каждой результирующей таблицы будут данные о количестве произведенных заказов некоего товара за определенную дату, полученные путем выполнения запроса на выборку данных из таблицы statistics по требуемым критериям. Иными словами мы свяжем таблицу statistics саму с собой. Пример запроса:
SELECT stat1.Name, stat1.Orders, stat1.Date, stat2.Orders, stat2.Date FROM (SELECT statistics.ProductID, products.Name, statistics.Orders, statistics.Date FROM products JOIN statistics ON products.id = statistics.ProductID WHERE DATE(statistics.date) = '2014-09-04') AS stat1 JOIN (SELECT statistics.ProductID, statistics.Orders, statistics.Date FROM statistics WHERE DATE(statistics.date) = '2014-09-12') AS stat2 ON stat1.ProductID = stat2.ProductID
В итоге имеем такой результат:
+------------------------+----------+------------+----------+------------+ | Name | Orders1 | Date1 | Orders2 | Date2 | +------------------------+----------+------------+----------+------------+ | Процессоры Pentium II | 1 | 2014-09-04 | 1 | 2014-09-12 | | Процессоры Pentium III | 1 | 2014-09-04 | 10 | 2014-09-12 | | Оптическая мышь Atech | 10 | 2014-09-04 | 3 | 2014-09-12 | | DVD-R | 2 | 2014-09-04 | 5 | 2014-09-12 | | DVD-RW | 22 | 2014-09-04 | 18 | 2014-09-12 | | Клавиатура MS 101 | 5 | 2014-09-04 | 1 | 2014-09-12 | | SDRAM II | 26 | 2014-09-04 | 12 | 2014-09-12 | | Flash RAM 8Gb | 8 | 2014-09-04 | 7 | 2014-09-12 | | Flash RAM 4Gb | 18 | 2014-09-04 | 30 | 2014-09-12 | +------------------------+----------+------------+----------+------------+
Подстановка нескольких значений из другой таблицы
Необходимость в данном запросе не является повседневной, но возникает не совсем уж и редко. Самый распространенный пример, это обычная сетевая игра. Где создается сессия на два игрока. Соответственно в таблице с данными об играх имеются два поля с идентификаторами зарегистрированных игроков. Для того чтобы вывести информацию об имеющихся играх, мы не можем обойтись стандартным объединением таблицы с данными об игроках и таблицы об имеющихся играх. Так как мы имеем два поля с идентификаторами неких игроков. Но мы можем обратиться опять за помощью к псевдонимам таблиц.
Демонстрация данного запроса будет происходить на другом примере, а не на примере сетевой игры. Это чтобы не создавать заново все необходимые таблицы. В качестве данных возьмем таблицу products из примера “сравнение данных за две даты” и создадим еще одну недостающую таблицу replace_com, структура которой представлена ниже:
CREATE TABLE IF NOT EXISTS `replace_com` ( `id` int(11) NOT NULL AUTO_INCREMENT, `sProductID` int(11) NOT NULL, `rProductID` int(11) NOT NULL, `Date` date NOT NULL DEFAULT '0000-00-00', PRIMARY KEY (`id`), KEY `sProductID` (`sProductID`,`rProductID`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=4 ;
Предположим, что у нас есть некий компьютерный салон и мы проводим модификации некоторых компьютерных составляющих, а все операции по замене комплектующих заносим в базу данных. В таблице replace_com интересующими нас полями являются: sProductID и rProductID. Где sProductID – идентификатор заменяемого модуля, а rProductID – идентификатор заменяющего модуля. Запрос, реализующий вывод данных о совершенных операциях выглядит следующим образом:
SELECT sProducts.Name AS sProduct, rProducts.Name AS rProduct, replace_com.Date FROM replace_com JOIN products AS sProducts ON sProducts.id = replace_com.sProductID JOIN products AS rProducts ON rProducts.id = replace_com.rProductID
Результирующая таблица данных:
+-----------------------+------------------------+------------+ | sProduct | rProduct | Date | +-----------------------+------------------------+------------+ | Процессоры Pentium II | Процессоры Pentium III | 2014-09-15 | | Flash RAM 4Gb | Flash RAM 8Gb | 2014-09-17 | | DVD-R | DVD-RW | 2014-09-18 | +-----------------------+------------------------+------------+
Вывод статистики с накоплением по дате
Предположим, что у нас имеется склад с некими товарами. Товары периодически поступают, и нам бы хотелось видеть в отчете остатки товаров по дням. Поскольку данные о наличии товаров необходимо накапливать, то мы введем пользовательскую переменную. Но есть одно небольшое “но”. Мы не можем использовать в запросе переменные пользователя и группировку данных одновременно (вернее можем, но в итоге получим, не то, что ожидаем), но мы можем использовать вложенный запрос, вместо явно указанной таблицы. Данные в таблице будут предварительно сгруппированы по дате. И уже затем на основе этих данных мы произведем расчет статистики с накоплением.
На первом этапе требуется установить переменную и присвоить ей нулевое значение:
SET @cvalue = 0
В следующем запросе, мы созданную ранее переменную и применим:
SELECT products.Name AS Name, (@cvalue := @cvalue + Orders) as Orders, Date FROM (SELECT ProductID AS ProductID, SUM(Orders) AS Orders, DATE(date) AS Date FROM statistics WHERE ProductID = '1' GROUP BY date) AS statistics JOIN products ON statistics.ProductID = products.id
Итоговый отчет:
+-----------------------+--------+------------+ | Name | Orders | Date | +-----------------------+--------+------------+ | Процессоры Pentium II | 1 | 2014-09-04 | | Процессоры Pentium II | 2 | 2014-09-12 | | Процессоры Pentium II | 4 | 2014-09-14 | | Процессоры Pentium II | 6 | 2014-09-15 | +-----------------------+--------+------------+
Получить используемую в примерах базу данных можно здесь.
Рубрики: MySQL / Метки: MySQL, базы данных, статистика
swblog.ru
MySQL On air. Мониторим SQL запросы / Habr
Разбираясь как работает та или иная CMS приходится использовать различные инструменты, облегчающие работу.
Наиболее интересная тема — это работа с баз(ой|ами) данных. Естественно для изучения запросов и результатов запросов нужно использовать что-то универсальное. Что-то, что будет работать стабильно как с известным движком, так и с самописной системой.
Предположим у вас оказалась система управления контентом и вам необходимо посмотреть как реализовано добавление новых пользователей или смена паролей.
Большинство инструментов позволяющих мониторить работу с БД являются платными [раз, два]. Я хотел что-то более легкое и удобное, поэтому выбрал mysql-proxy. Хотя возможности утилиты гораздо шире чем мне требуется, я опишу лишь основное. Работает как под Windows, так и под Unix системами.
Скачать можно тут: dev.mysql.com/downloads/mysql-proxy
Первым делом нужно определиться с выбором дистрибутива. На данный момент новейшей версией является «MySQL Proxy 0.8.3 alpha», в качестве ОС у меня стоит Windows 7, поэтому все тесты будут на ней.
После нажатия на кнопку «Download» вас попросят авторизироваться либо зарегистрировать, но снизу есть ссылка для скачивания без лишних действий. (В репозиториях Ubuntu и Debian есть готовые пакеты, так что: sudo apt-get install mysql-proxy)
Хочу заметить, что при размере в 7.9Мб в дистрибутив входит Lua с поддержкой основых модулей.
После скачивания архива его нужно распаковать в удобную для вас директорию, возьмем для примера C:\mysql-proxy
Для запуска приложения нужно определиться с параметрами.
В данном контексте многое зависит от того, что у вас установлено. В качестве LAMP я использую Winginx, прочитать об этой связке можно тут: winginx.ru
По умолчанию MySQL работает на 3306 порту, его мы трогать не будем.
Нам нужно изменить порт для подключения php к базе. Для этого необходимо поправить php.ini
Найдем строку «mysql.default_port» и установим порт (по умолчанию 4040). Для более универсальной работы измените и «mysqli.default_port» на 4040
Подготовительная часть пройдена, перейдем к делу.
Вариант 1. Мониторинг запросов.
Для простого мониторинга необходимо использовать Lua скрипт. Как я уже говорил Lua идет в комплекте, так что ничего нового устанавливать не надо.
Создадим простой скрипт view.lua в директории C:\mysql-proxy\ с содержимым:
function read_query(packet)
if string.byte(packet) == proxy.COM_QUERY then
print(string.sub(packet, 2))
end
end
Теперь можно проверить результат.
Для удобства создадим в директории C:\mysql-proxy файл view.bat c содержимым:
C:\mysql-proxy\bin\mysql-proxy.exe --proxy-lua-script=C:\mysql-proxy\view.lua --log-file="C:\mysql-proxy\mysql-proxy-log.txt" --proxy-backend-addresses=localhost:3306
—proxy-backend-addresses — адрес MySQL сервера на который будем проксировать запрос.
Запустив вэб-сервер и выполнив какие либо запросы к базе можете увидеть такое:
Запросы отображаются, хорошо.
Вариант 2. Мониторинг запросов и запись в файл.
Для записи запросов в файл будем использовать штатные возможности Lua.
Создадим файл view-write.lua в директории C:\mysql-proxy\ с содержимым:
function read_query(packet)
if string.byte(packet) == proxy.COM_QUERY then
local file = io.open("C:\\mysql-proxy\\sql-log.txt", "a")
file:write(string.sub(packet, 2) .. "\n")
file:close()
print(string.sub(packet, 2))
end
end
и bat файл — «view-write.bat»
C:\mysql-proxy\bin\mysql-proxy.exe --proxy-lua-script="C:\mysql-proxy\view-write.lua" --log-file="C:\mysql-proxy\mysql-proxy-log.txt" --proxy-backend-addresses=localhost:3306
Результат после выполнения запросов (по адресу «C:\mysql-proxy\sql-log.txt»)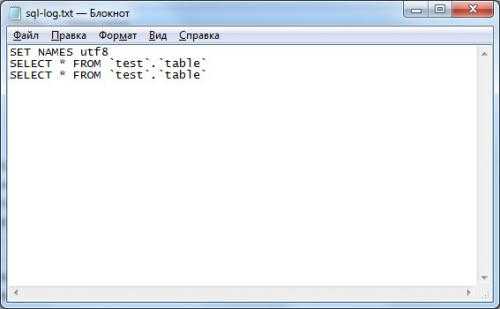
Помимо отображения самих запросов, нам может понадобиться вывод результатов этих запросов.
Вариант 3. Запросы и результат
По той-же схеме создаём скрипт «view-result.lua»:
function read_query( packet )
if packet:byte() == proxy.COM_QUERY then
print("Query: " .. string.sub(packet, 2))
local file = io.open("C:\\mysql-proxy\\sql-log.txt", "a")
file:write("Query: " .. string.sub(packet, 2) .. "\n")
file:close()
proxy.queries:append(2, string.char(proxy.COM_QUERY) .. string.sub(packet, 2), {resultset_is_needed = true} )
proxy.queries:append(1, packet, {resultset_is_needed = true})
return proxy.PROXY_SEND_QUERY
end
end
function read_query_result(inj)
if inj.id == 1 then
for row in inj.resultset.rows do
local i = 1
local fields = {}
while row[i] do
if row[i] == row then break end
local file = io.open("C:\\mysql-proxy\\sql-log.txt", "a")
file:write("Response field: " .. inj.resultset.fields[i].name .. " => " .. row[i] .. "\n")
file:close()
print("Response field: " .. inj.resultset.fields[i].name .. " => " .. row[i])
i = i + 1
end
end
return proxy.PROXY_IGNORE_RESULT
end
end
И view-result.bat
C:\mysql-proxy\bin\mysql-proxy.exe --proxy-lua-script="C:\mysql-proxy\view-result.lua" --log-file="C:\mysql-proxy\mysql-proxy-log.txt" --proxy-backend-addresses=localhost:3306
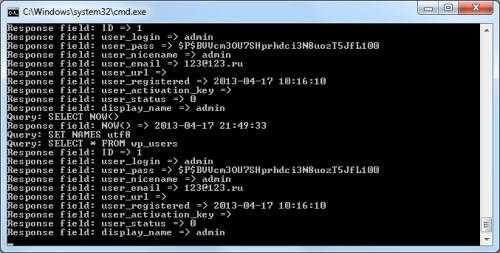
В результате получаем полное логирование запросов и ответов в читаемом виде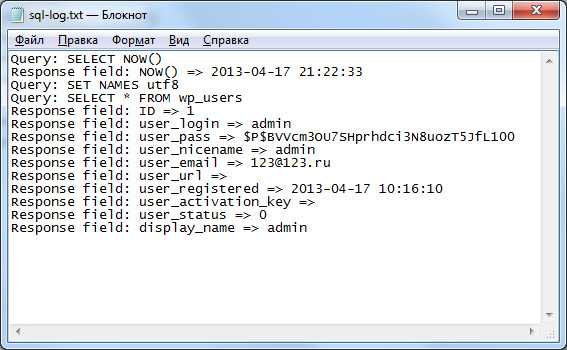
habr.com
Какие запросы к MySQL называют медленными?
Всем привет. Любая база данных — это набор букв, цифр и символов. Чтобы, сервер смог быстро запросить и получить те или иные данные, в базе они хранятся в таблицах, разделённых на множество строк и ячеек. Для пользователя данные в таком виде будут практически нечитаемы, а учитывая их объёмы и структуру информации, даже программисту без специальных инструментов будет сложно собрать одну строку воедино.
При запросе страницы сайта компьютер пользователя обращается к скрипту, а тот, в свою очередь, уже делает запрос к базе данных и обрабатывает полученную информацию. После того, как информация будет обработана сервером, она будет передана на компьютер пользователя, а только после этого может быть представлена в виде той страницы, которую видит посетитель сайта в своём браузере.
Выражаясь простым языком, работа с базой данных — это целый комплекс программных действий. Каждое из этих действий может вызывать ошибки, сбои и приводить к иным проблемам, способным повлиять на конечный результат и скорость его получения. К одному из таких нюансов относятся медленные запросы к базе данных — запросы, на обработку которых серверу требуется много времени. Для среднестатистических сайтов это временной промежуток более одной секунды.
Несмотря на мизерный промежуток времени, запрос, выполнение которого занимает более одной секунды, очень громоздкий. Дело в том, что запрос к базе данных — это лишь меньшая часть той работы, которую предстоит выполнить серверу для обработки запроса страницы посетителем сайта. Пока запросы не будут обработаны, не начнётся компиляция кода страницы, следовательно пользователь не увидит данные, которые запросил. Редкий посетитель сайта готов ждать и не предпочтёт уйти на другой ресурс. Следовательно, медленные запросы не только требуют больших затрат ресурсов сервера, но и могут ударить по репутации сайта.
Наиболее распространённым причинами возникновения медленных запросов являются ошибки при обращении к базе данных- ошибки 404, проблемы безопасности сайта, не оптимизированные таблицы и высокая нагрузка на сервер, во время которой ресурсов CPU не хватает для обработки запроса. Чтобы обращения пользователя к сайту не приводили к созданию множества медленных запросов, необходимо создавать дополнительные проверки, позволяющие корректировать и делать более точный запрос, следить за настройками и оптимизировать сервер баз данных.
Оптимизация медленных запросов MySQL.
Для самописных систем управления сайтом одной из наиболее распространённых ошибок является вывод более 50 строк на странице результатов поиска или на странице с контентом. Посетитель, имея возможность получать за раз все записи или большую их часть, создаёт большую нагрузку на сервер запросом одной страницы, а при посещении сайта роботом такая нагрузка и вовсе может привести к непредсказуемым результатам. Злоумышленники могут этим воспользоваться, чтобы сделать сайт временно недоступным.
Сервер управления базами данных MySQL имеет встроенный инструмент, позволяющий логировать медленные запросы. В нём же можно указать промежуток времени, по истечении которого запрос попадает в список медленных. Изучив содержимое лог-файла данного инструмента, можно понять, какие запросы наиболее часто выполняются дольше и в каких, соответственно, могут быть ошибки.
Включение логирования медленных запросов в MySQL производится в конфигурационном файле. В нём нужно вписать всего лишь две строчки, в одной из которых указать время, по истечению которого обрабатываемый запрос считается медленным, в другой — путь к лог-файлу, в который будет производиться запись:
long_query_time = 3
log-slow-queries = /var/log/mysqld-slow-query.log
После внесения изменений необходимо перезагрузить сервер MySQL, чтобы конфигурационный файл был перечитан и изменения в нём вступили в силу. Так мы включили логирование запросов, обработка которых занимает более трёх секунд, и записываем их в файл /var/log/mysqld-slow-query.log (для операционных систем семейства Windows путь к файлу будет другим).
Проверять лог-файл следует спустя сутки или двое, так как медленные запросы в редких случаях наблюдаются постоянно. Если же после проверки файла выяснилось, что медленные запросы создаются ежеминутно или того чаще, есть весомый повод задуматься о работе над сайтом.
goldserfer.ru