3 способа проверить посещаемость сайта
Стася Аветисян
Июн 19, 2018 | Время чтения: 11 мин
Показатели посещаемости сайта отображают количество людей, которые зашли на сайт за определенный период времени. Эти данные позволяют дать базовую оценку эффективности как всего ресурса, так и отдельных его разделов. Нужно это в первую очередь владельцам сайта, но знать подобную информацию о конкурентах и партнерах – бесценно.
В каких случаях вам может понадобиться статистика посещаемости сайта:
- Это ваш конкурент. Зная активности ресурса соперника, вы сможете сориентироваться в общей ситуации на рынке, определить потенциальный объем трафика, выделить его сезонные колебания, посмотреть, как эксперименты конкурирующего бизнеса (продуктовые, маркетинговые, технические) влияют на трафик его сайта.

- Вы собираетесь купить рекламу на этом сайте. Вам как рекламодателю важно знать, какой охват аудитории могут получить ваши материалы. Сайты, публикующие рекламу, учитывают это и чаще всего оставляют данные счетчика посещений открытыми. В некоторых случаях, они могут опубликовать инфо сводку о трафике на странице, специально подготовленной для привлечения рекламодателей.
- Вы думаете о покупке или договорном размещении ссылок. Во-первых, посещаемость сайта может косвенно указывать на его трастовость. Во-вторых, если при размещении ссылки ваша цель не только укрепить ссылочный профиль, но и привлечь аудиторию, то данные о популярности целевого сайта для вас must-have.
Возможность узнать посещаемость сайта напрямую зависит от того, открыл ли сайт счетчик для просмотра. Но даже если цифры скрыты, есть способы узнать ориентировочную статистику посещений, а также объем поискового трафика сайта.

Итак, три основных способа подсмотреть посещаемость чужого сайта:
1. Счетчики для просмотра посещаемости
Счетчики трафика устанавливаются владельцами сайта, чтобы знать, сколько пользователей зашли на сайт, сколько страниц они посетили, откуда они перешли и т.п. То есть к счетчикам относятся и инструменты веб-аналитики, включая Google Analytics и Яндекс.Метрику. Но если данные первого закрыты от посторонних глаз, то информер Метрики может быть доступен.
- Яндекс.Метрика. Если данные Метрики открыты, можно посмотреть количество просмотров и визитов. Если разделим первую величину на вторую, получим среднее число страниц, которые посещает пользователь за один визит. Так можно подсмотреть цифры за семидневный период. Одна беда – сайтов с открытым информером Метрики сейчас не более 10%. Среди коммерческих – единицы.
- Liveinternet. Счетчик, пик популярности которого приходится на середину 2000-х. Но и сейчас можно найти ресурсы, использующие его.
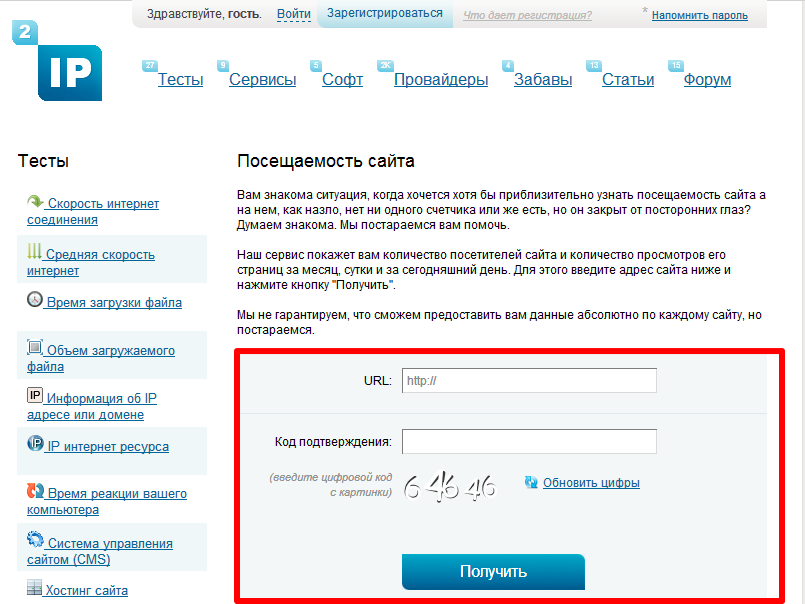
Если статистика сайта закрыта для просмотра, введите в строку браузера: https://counter.yadro.ru/values?site=tvoysite.com, где tvoysite.com – это домен сайта, посещаемость которого вы хотите узнать. Вы увидите данные в таком виде:
Чтобы быстрее определять, есть ли на сайте счётчик и доступны ли его данные, можно воспользоваться плагином
2. Инструменты для оценки поискового трафика
Кроме инструментов общего подсчета посещений, есть сервисы для анализа отдельного канала переходов – поискового. Это нужно, чтобы понять, какой SEO-потенциал у вашего сайта, у конкурентов и в нише в целом.
Это нужно, чтобы понять, какой SEO-потенциал у вашего сайта, у конкурентов и в нише в целом.
SE Ranking
SE Ranking позволяет решить полный круг SEO-задач, одна из которых – анализ конкурентов. Важная часть такого анализа – изучение потока пользователей, которые приходят на сайт именно из поиска. Какие ключевые слова приводят наибольшее количество людей на сайт? Какие страницы сайта получают больше переходов из поиска, чем другие? Какая доля поискового трафика приходит из рекламы? На эти и другие вопросы можно найти ответы используя специальный модуль «Анализ конкурентов».
С помощью этого инструмента для любого домена можно получить следующую информацию:
1. Обзор органического и платного трафика с приблизительной оценкой его стоимости и количества кликов (переходов из поиска) за месяц.
2. Какие страницы и поддомены привлекают наибольшее количество пользователей
3. Какую долю посетителей приводят те или иные ключевые слова и во сколько это обходится:
Все эти данные нужны, чтобы “прощупать” свою нишу. Хотя цифры, которые вы увидите – приблизительные, они станут хорошим подспорьем для определения SEO и PPC стратегий и планирования бюджета. Тем более, что сервис постоянно развивается, добавляя новые базы данных по регионам и расширяя существующие.
Хотя цифры, которые вы увидите – приблизительные, они станут хорошим подспорьем для определения SEO и PPC стратегий и планирования бюджета. Тем более, что сервис постоянно развивается, добавляя новые базы данных по регионам и расширяя существующие.
SEMrush – многофункциональная платформа для интернет-маркетологов, сердца которых бьются чаще от графиков и статистики как по своим проектам, так и по чужим. Что можно узнать о трафике другого сайта с помощью этого инструмента?
2. Долю трафика, привлекаемого топ-ключевыми словами, а также его примерную стоимость и динамику.
То же самое можно узнать для платной выдачи:
C осени 2016 года SEMrush запустил модуль для общего анализа посещаемости сайтов, тем не менее, сервис силен именно в аналитике поисковых каналов.
Как определяется SEO трафик?
Сервисы собирают данные о частотности (популярности) запросов, потом снимают позиции сайта и учитывая средний CTR каждой позиции, формируют информацию о посещаемости.
Кроме этого, существуют инструменты, готовые решить ваши проблемы, даже если вам важно знать общую посещаемость сайта, а счетчиков на нужных ресурсах нет.
Речь идет о сервисах, которые собирают кликстрим данные с помощью собственных тулбаров, по договоренности со сторонними приложениями и другими способами. То есть они определяют трафик сайта без интеграции с ним, а отслеживая пул переходов со стороны пользователей. Самые известные из таких сервисов Alexa и SimilarWeb.
AlexaAlexa – дочерняя компания Amazon. Основная задача проекта – сбор информации о посещаемости сайтов. У Alexa есть собственный рейтинг (Alexa Rank), построенный на статистике трафика различных ресурсов. В этом рейтинге меньшая оценка соответствует большей посещаемости, то есть самая высокая оценка – 1 (у Google.com).
Основная задача проекта – сбор информации о посещаемости сайтов. У Alexa есть собственный рейтинг (Alexa Rank), построенный на статистике трафика различных ресурсов. В этом рейтинге меньшая оценка соответствует большей посещаемости, то есть самая высокая оценка – 1 (у Google.com).
Информация о посещаемости сайта дополнены демографическими данными:
Как Alexa собирает информацию?
- Alexa Toolbar. Основной источник данных Алексы – плагин, который дает возможность видеть статистику посещений каждого сайта, количество обратных ссылок на сайт, оценку согласно рейтингу Алексы и т.д. Чтобы подключить Alexa Toolbar, нужно разрешить плагину отслеживать сайты которые мы посещаем.
- Другие плагины и расширения для браузеров. Алекса покупает данные о пользовательской активности у других приложений. Компания открыто об этом говорит, хотя и не называет, с какими именно сервисами сотрудничает:
Alexa’s traffic panel is based on millions of people using over 25,000 different browser extensions that appeal to a wide audience.
- Alexa Certify – код, который можно добавить на сайт, чтобы Alexa присвоила ему статус “сертифицирован” и могла считывать статистику напрямую. Так, Alexa Rank сайта будет точнее, а вебмастер получит возможность видеть отчеты по посещаемости в красивых графиках. Устанавливая Alexa Certify, вы даете Алексе полный прямой доступ к своим данным.
Как Alexa определяет трафик сайтов, по которым у нее нет информации?
Статистику, собранную с помощью тулбара, кода Certify и сторонних плагинов, Алекса анализирует и экстраполирует на весь остальной веб. То есть она распространяет выводы по доступной части информации на те сайты, по которым данных у нее нет. С одной стороны, такой индуктивный подход дает возможность составить глобальный рейтинг, с другой, оставляет место для значительных просчетов. Чем моложе и меньше сайт, тем больше будет погрешность. И это касается результатов любой проверки, которая проводится в обход счетчиков.
Второй большой игрок на рынке сервисов статистики – SimilarWeb. Как и Alexa, он предлагает посмотреть не только посещаемость ресурса, а еще несколько важных блоков данных:
- Доли мобильного и десктопного трафика.
- Гендерные и возрастные пропорции.
- Распределение трафика по странам.
- Процент посетителей из каждого канала (прямые переходы, почта, рефералка, соцсети, органика, платная выдача и баннерная реклама).
Как SimilarWeb собирает информацию?
- Панель девайсов и сервисов (Global Panel). Кроме цифр, получаемых благодаря собственному плагину, SimilarWeb, как и Alexa, получает статистику по пользователям у тысяч других расширений, приложений и плагинов. SimilarWeb скрывает, у кого именно берет информацию.
- Данные провайдеров (ISP data). Сервис сотрудничает и с интернет-провайдерами, собирая данные о том, какие сайты посещают пользователи, какие страницы просматривают, сколько времени на них проводят и т. п.
- Crawlers. У сервиса есть свои поисковые боты, которые сканируют сайты и составляют собственную статистическую карту веба.
- Прямой подсчет (Direct Measurement). Некоторые сайты и приложения дают SimilarWeb доступ к данным установленных счетчиков.
Источник: SimilarWeb
 п.
п.Широкая платформа для сбора статистики позволяет SimilarWeb оценивать трафик сайтов точнее, чем другие подобные сервисы. Но для него тоже сохраняется закономерность – чем популярнее сайт, тем более точной будет оценка его посещаемости.
Альтернативный метод просмотра статистикиЕсли вы не настроены заморачиваться с разными сервисами, а просто хотите узнать, у какого сайта больше посетителей, посмотрите на рейтинги (та же Alexa, Рейтинг Liveinternet, Рамблер Топ-100 и другие) – они классифицируют ресурсы по посещаемости. Найдя в рейтинге необходимый ресурс, посмотрите его ближайших соседей. Если повезет, среди соседствующих сайтов найдете ресурс с открытой статистикой. По нему-то и можно ориентировочно прикинуть трафик нужного сайта.
По нему-то и можно ориентировочно прикинуть трафик нужного сайта.
Но чаще всего альтернативные способы просмотра посещаемости эффективны примерно так же, как и альтернативная медицина.
Резюме
Посещаемость – один из основных показателей эффективности сайта. И у каждого серьезного маркетолога должен быть под рукой свой набор инструментов для анализа трафика чужих сайтов.
Есть три основных способа посмотреть количество посетителей на стороннем ресурсе:
- Счетчики (самый точный).
- Инструменты для анализа поискового трафика.
- Сервисы, собирающие пользовательские данные для определения посещаемости сайтов (точность зависит от популярности анализируемого ресурса. Чем больше у него посетителей → тем больше по нему данных → тем они точнее).
Если вы когда-нибудь сравнивали, как разные сервисы веб-аналитики определяют трафик вашего сайта, замечали, что даже счетчики, код которых добавлен на сайт, могут выдавать разные цифры. Что уж говорить о ресурсах, которые пытаются определить посещаемость сайтов опосредованно, изучая активность пользователей. Они тоже будут показывать разные данные – и это нормально.
Что уж говорить о ресурсах, которые пытаются определить посещаемость сайтов опосредованно, изучая активность пользователей. Они тоже будут показывать разные данные – и это нормально.
Сегодня рынок вспомогательных SEO и маркетинговых сервисов так богат, что каждый спец найдет то, что подходит для решения его задач лучше всего. Тестируйте различные инструменты, комбинируйте их, экспериментируйте. Не забывайте, кто ищет, тот всегда найдет.
Просмотры: 533 339
Стася пишет простые тексты о сложных вопросах SEO и маркетинга, генерирует креативные идеи и преподает философию.
Как парсить информацию с любого сайта при помощи Screaming Frog
Если вам нужно просто собрать с сайта мета-данные, можно воспользоваться бесплатным парсером системы Promopult. Но бывает, что надо копать гораздо глубже и добывать больше данных, и тут уже без сложных (и небесплатных) инструментов не обойтись.
Но бывает, что надо копать гораздо глубже и добывать больше данных, и тут уже без сложных (и небесплатных) инструментов не обойтись.
Евгений Костин рассказал о том, как спарсить любой сайт, даже если вы совсем не дружите с программированием. Разбор сделан на примере Screaming Frog Seo Spider.
Что такое парсинг и зачем он нужен
ПО для парсинга
Пример 1. Как спарсить цену
Пример 2. Как спарсить фотографии
Пример 3. Как спарсить характеристики товаров
Пример 4. Как парсить отзывы (с рендерингом)
Пример 5. Как спарсить скрытые телефоны на сайте ЦИАН
Пример 6. Как парсить структуру сайта на примере DNS-Shop
Возможности парсинга на основе XPath
Ограничения при парсинге
Что такое парсинг и зачем он нужен
Парсинг нужен, чтобы получить с сайтов некую информацию. Например, собрать данные о ценах с сайтов конкурентов.
Одно из применений парсинга — наполнение каталога новыми товарами на основе уже существующих сайтов в интернете.
Упрощенно, парсинг — это сбор информации. Есть более сложные определения, но так как мы говорим о парсинге «для чайников», то нет никакого смысла усложнять терминологию. Парсинг — это сбор, как правило, структурированной информации. Чаще всего — в виде таблицы с конкретным набором данных. Например, данных по характеристикам товаров.
Парсер — программа, которая осуществляет этот сбор. Она ходит по ссылкам на страницы, которые вы указали, и собирает нужную информацию в Excel-файл либо куда-то еще.
Парсинг работает на основе XPath-запросов. XPath — язык запросов, который обращается к определенному участку кода страницы и собирает из него заданную информацию.
ПО для парсинга
Здесь есть важный момент. Если вы введете в поисковике слово «парсинг» или «заказать парсинг», то, как правило, вам будут предлагаться услуги от компаний, которые создадут парсер под ваши задачи. Стоят такие услуги относительно дорого. В результате программисты под заказ напишут некую программу либо на Python, либо на каком-то еще языке, которая будет собирать информацию с нужного вам сайта. Эта программа нацелена только на сбор конкретных данных, она не гибкая и без знаний программирования вы не сможете ее самостоятельно перенастроить для других задач.
Эта программа нацелена только на сбор конкретных данных, она не гибкая и без знаний программирования вы не сможете ее самостоятельно перенастроить для других задач.
При этом есть готовые решения, которые можно под себя настраивать как угодно и собирать что угодно. Более того, если вы — SEO-специалист, возможно, одной из этих программ вы уже пользуетесь, но просто не знаете, что в ней есть такой функционал. Либо знаете, но никогда не применяли, либо применяли не в полной мере.
Вот две программы, которые являются аналогами.
Эти программы занимаются сбором информации с сайта. То есть они анализируют, например, его заголовки, коды, теги и все остальное. Помимо прочего, они позволяют собрать те данные, которые вы им зададите.
Профессиональные инструменты PromoPult: быстрее, чем руками, дешевле, чем у других, бесплатные опции.
Съем позиций, кластеризация запросов, парсер Wordstat, сбор поисковых подсказок, сбор фраз ассоциаций, парсер мета-тегов и заголовков, анализ индексации страниц, чек-лист оптимизации видео, генератор из YML, парсер ИКС Яндекса, нормализатор и комбинатор фраз, парсер сообществ и пользователей ВКонтакте.

Давайте смотреть на реальных примерах.
Пример 1. Как спарсить цену
Предположим, вы хотите с некого сайта собрать все цены товаров. Это ваш конкурент, и вы хотите узнать, сколько у него стоят товары.
Возьмем для примера сайт mosdommebel.ru.
У нас есть страница карточки товара, есть название и есть цена этого товара. Как нам собрать эту цену и цены всех остальных товаров?
Мы видим, что цена отображается вверху справа, напротив заголовка h2. Теперь нам нужно посмотреть, как эта цена отображается в html-коде.
Нажимаем правой кнопкой мыши прямо на цену (не просто на какой-то фон или пустой участок). Затем выбираем пункт Inspect Element для того, чтобы в коде сразу его определить (Исследовать элемент или Просмотреть код элемента, в зависимости от браузера — прим. ред.).
Мы видим, что цена у нас помещается в тег с классом totalPrice2. Так разработчик обозначил в коде стоимость данного товара, которая отображается в карточке.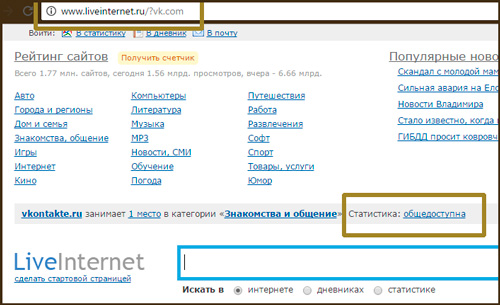
Фиксируем: есть некий элемент span с классом totalPrice2. Пока это держим в голове.
Есть два варианта работы с парсерами.
Первый способ. Вы можете прямо в коде (любой браузер) нажать правой кнопкой мыши на тег <span> и выбрать Скопировать > XPath. У вас таким образом скопируется строка, которая обращается к данному участку кода.
Выглядит она так:
/html/body/div[1]/div[2]/div[4]/table/tbody/tr/td/div[1]/div/table[2]/tbody/tr/td[2]/form/table/tbody/tr[1]/td/table/tbody/tr[1]/td/div[1]/span[1]Но этот вариант не очень надежен: если у вас в другой карточке товара верстка выглядит немного иначе (например, нет каких-то блоков или блоки расположены по-другому), то такой метод обращения может ни к чему не привести. И нужная информация не соберется.
Поэтому мы будем использовать второй способ. Есть специальные справки по языку XPath. Их очень много, можно просто загуглить «XPath примеры».
Например, такая справка:
Здесь указано как что-то получить. Например, если мы хотим получить содержимое заголовка h2, нам нужно написать вот так:
//h2/text()Если мы хотим получить текст заголовка с классом productName, мы должны написать вот так:
//h2[@class="productName"]/text()То есть поставить «//» как обращение к некому элементу на странице, написать тег h2 и указать в квадратных скобках через символ @ «класс равен такому-то».
То есть не копировать что-то, не собирать информацию откуда-то из кода. А написать строку запроса, который обращается к нужному элементу. Куда ее написать — сейчас мы разберемся.
Куда вписывать XPath-запрос
Мы идем в один из парсеров. В данном случае — Screaming Frog Seo Spider.
Эта программа бесплатна для анализа небольшого сайта — до 500 страниц.
Интерфейс Screaming Frog Seo Spider
Например, мы можем — бесплатно — посмотреть заголовки страниц, проверить нет ли у нас каких-нибудь пустых тайтлов или дубликатов тега h2, незаполненных метатегов или каких-нибудь битых ссылок.
Но за функционал для парсинга в любом случае придется платить, он доступен только в платной версии.
Предположим, вы оплатили годовую лицензию и получили доступ к полному набору функций сервиса. Если вы серьезно занимаетесь анализом данных и регулярно нуждаетесь в функционале сервиса — это разумная трата денег.
Во вкладке меню Configuration у нас есть подпункт Custom, и в нем есть еще один подпункт Extraction. Здесь мы можем дополнительно что-то поискать на тех страницах, которые мы укажем.
Заходим в Extraction. Нам нужно с сайта Московского дома мебели собрать цены товаров.
Мы выяснили в коде, что у нас все цены на карточках товара обозначаются тегом <span> с классом totalPrice2. Формируем вот такой XPath запрос:
//span[@class="totalPrice2"]/spanИ указываем его в разделе Configuration > Custom > Extractions. Для удобства можем назвать как-нибудь колонку, которая у нас будет выгружаться. Например, «стоимость»:
Например, «стоимость»:
Таким образом мы будем обращаться к коду страниц и из этого кода вытаскивать содержимое стоимости.
Также в настройках мы можем указать, что парсер будет собирать: весь html-код или только текст. Нам нужен только текст, без разметки, стилей и других элементов.
Нажимаем ОК. Мы задали кастомные параметры парсинга.
Как подобрать страницы для парсинга
Дальше есть еще один важный этап. Это, собственно, подбор страниц, по которым будет осуществляться парсинг.
Если мы просто укажем адрес сайта в Screaming Frog, парсер пойдет по всем страницам сайта. На инфостраницах и страницах категорий у нас нет цен, а нам нужны именно цены, которые указаны на карточках товара. Чтобы не тратить время, лучше загрузить в парсер конкретный список страниц, по которым мы будем ходить, — карточки товаров.
Откуда их взять? Как правило, на любом сайте есть карта сайта XML, и находится она чаще всего по адресу: «адрес сайта/sitemap.xml». В случае с сайтом из нашего примера — это адрес:
В случае с сайтом из нашего примера — это адрес:
https://www.mosdommebel.ru/sitemap.xml.Либо вы можете зайти в robots.txt (site.ru/robots.txt) и посмотреть. Чаще всего в этом файле внизу содержится ссылка на карту сайта.
Ссылка на карту сайта в файле robots.txt
Даже если карта называется как-то странно, необычно, нестандартно, вы все равно увидите здесь ссылку.
Но если не увидите — если карты сайта нет — то нет никакого решения для отбора карточек товара. Тогда придется запускать стандартный режим в парсере — он будет ходить по всем разделам сайта. Но нужную вам информацию соберет только на карточках товара. Минус здесь в том, что вы потратите больше времени и дольше придется ждать нужных данных.
У нас карта сайта есть, поэтому мы переходим по ссылке https://www.mosdommebel.ru/sitemap.xml и видим, что сама карта разделяется на несколько карт. Отдельная карта по статичным страницам, по категориям, по продуктам (карточкам товаров), по статьям и новостям.
Ссылки на отдельные sitemap-файлы под все типы страниц
Нас интересует карта продуктов, то есть карточек товаров.
Ссылка на sitemap-файл для карточек товара
Возвращаемся в Screaming Frog Seo Spider. Сейчас он запущен в стандартном режиме, в режиме Spider (паук), который ходит по всему сайту и анализирует все страницы. Нам нужно его запустить в режиме List.
Мы загрузим ему конкретный список страниц, по которому он будет ходить. Нажимаем на вкладку Mode и выбираем List.
Жмем кнопку Upload и кликаем по Download Sitemap.
Указываем ссылку на Sitemap карточек товара, нажимаем ОК.
Программа скачает все ссылки, указанные в карте сайта. В нашем случае Screaming Frog обнаружил более 40 тысяч ссылок на карточки товаров:
Нажимаем ОК, и у нас начинается парсинг сайта.
После завершения парсинга на первой вкладке Internal мы можем посмотреть информацию по всем характеристикам: код ответа, индексируется/не индексируется, title страницы, description и все остальное.
Это все полезная информация, но мы шли за другим.
Вернемся к исходной задаче — посмотреть стоимость товаров. Для этого в интерфейсе Screaming Frog нам нужно перейти на вкладку Custom. Чтобы попасть на нее, нужно нажать на стрелочку, которая находится справа от всех вкладок. Из выпадающего списка выбрать пункт Custom.
И на этой вкладке из выпадающего списка фильтров (Filter) выберите Extraction.
Вы как раз и получите ту самую информацию, которую хотели собрать: список страниц и колонка «Стоимость 1» с ценами в рублях.
Задача выполнена, теперь все это можно выгрузить в xlsx или csv-файл.
После выгрузки стандартной заменой вы можете убрать букву «р», которая обозначает рубли. Просто, чтобы у вас были цены в чистом виде, без пробелов, буквы «р» и прочего.
Таким образом, вы получили информацию по стоимости товаров у сайта-конкурента.
Если бы мы хотели получить что-нибудь еще, например, дополнительно еще собрать названия этих товаров, то нам нужно было бы зайти снова в Configuration > Custom > Extraction. И выбрать после этого еще один XPath-запрос и указать, например, что мы хотим собрать тег <h2>.
Просто запустив еще раз парсинг, мы собираем уже не только стоимость, но и названия товаров.
В результате получаем такую связку: url товара, его стоимость и название этого товара.
Если мы хотим получить описание или что-то еще — продолжаем в том же духе.
Важный момент: h2 собрать легко. Это стандартный элемент html-кода и для его парсинга можно использовать стандартный XPath-запрос (посмотрите в справке). В случае же с описанием или другими элементами нам нужно всегда возвращаться в код страницы и смотреть: как называется сам тег, какой у него класс/id либо какие-то другие атрибуты, к которым мы можем обратиться с помощью XPath-запроса.
Например, мы хотим собрать описание. Нужно снова идти в Inspect Element.
Оказывается, все описание товара лежит в теге <table> с классом product_description. Если мы его соберем, то у нас в таблицу выгрузится полное описание.
Здесь есть нюанс. Текст описания на странице сайта сделан с разметкой. Например, здесь есть переносы на новую строчку, что-то выделяется жирным.
Если вам нужно спарсить текст описания с уже готовой разметкой, то в настройках Extraction в парсере мы можем выбрать парсинг с html-кодом.
Если вы не хотите собирать весь html-код (потому что он может содержать какие-то классы, которые к вашему сайту никакого отношения не имеют), а нужен текст в чистом виде, выбираем только текст. Но помните, что тогда переносы строк и все остальное придется заполнять вручную.
Собрав все необходимые элементы и прогнав по ним парсинг, вы получите таблицу с исчерпывающей информацией по товарам у конкурента.
Такой парсинг можно запускать регулярно (например, раз в неделю) для отслеживания цен конкурентов. И сравнивать, у кого что стоит дороже/дешевле.
Пример 2. Как спарсить фотографии
Рассмотрим вариант решения другой прикладной задачи — парсинга фотографий.
На сайте Эльдорадо у каждого товара есть довольно-таки немало фотографий. Предположим, вы их хотите взять — это универсальные фото от производителя, которые можно использовать для демонстрации на своем сайте.
Задача: собрать в Excel адреса всех картинок, которые есть у разных карточек товара. Не в виде файлов, а в виде ссылок. Потом по ссылкам вы сможете их скачать либо напрямую загрузить на свой сайт. Большинство движков интернет-магазинов, таких как Битрикс и Shop-Script, поддерживают загрузку фотографий по ссылке. Если вы в CSV-файле, который используете для импорта-экспорта, укажете ссылки на фотографии, то по ним движок сможет загрузить эти фотографии.
Ищем свойства картинок
Для начала нам нужно понять, где в коде указаны свойства, адрес фотографии на каждой карточке товара.
Нажимаем правой клавишей на фотографию, выбираем Inspect Element, начинаем исследовать.
Смотрим, в каком элементе и с каким классом у нас находится данное изображение, что оно из себя представляет, какая у него ссылка и т.д.
Изображения лежат в элементе <span>, у которого id — firstFotoForma. Чтобы спарсить нужные нам картинки, понадобится вот такой XPath-запрос:
//*[@id="firstFotoForma"]/*/img/@srcУ нас здесь обращение к элементам с идентификатором firstFotoForma, дальше есть какие-то вложенные элементы (поэтому прописана звездочка), дальше тег img, из которого нужно получить содержимое атрибута src. То есть строку, в которой и прописан URL-адрес фотографии. Попробуем это сделать.
Берем XPath-запрос, в Screaming Frog переходим в Configuration > Custom > Extraction, вставляем и жмем ОК.
Для начала попробуем спарсить одну карточку. Нужно скопировать ее адрес и добавить в Screaming Frog таким образом: Upload > Paste
Нажимаем ОК. У нас начинается парсинг.
Screaming Frog спарсил одну карточку товара и у нас получилась такая табличка. Рассмотрим ее подробнее.
Мы загрузили один URL на входе, и у нас автоматически появилось сразу много столбцов «фото товара». Мы видим, что по этому товару собралось 9 фотографий.
Для проверки попробуем открыть одну из фотографий. Копируем адрес фотографии и вставляем в адресной строке браузера.
Фотография открылась, значит парсер сработал корректно и вытянул нужную нам информацию.
Теперь пройдемся по всему сайту в режиме Spider (для переключения в этот режим нужно нажать Mode > Spider). Укажем адрес https://www.eldorado.ru, нажимаем старт и запускаем парсинг.
Так как программа парсит весь сайт, то по страницам, которые не являются карточками товара, ничего не находится.
А с карточек товаров собираются ссылки на все фотографии.
Таким образом мы сможем собрать их и положить в Excel-таблицу, где будут указаны ссылки на все фотографии для каждого товара.
Если бы мы собирали артикулы, то еще раз зашли бы в Configuration > Custom > Extraction и добавили бы еще два XPath-запроса: для парсинга артикулов, а также тегов h2, чтобы собрать еще названия. Так мы бы убили сразу двух зайцев и собрали бы связку: название товара + артикул + фото.
Пример 3. Как спарсить характеристики товаров
Следующий пример — ситуация, когда нам нужно насытить карточки товаров характеристиками. Представьте, что вы продаете книжки. Для каждой книги у вас указано мало характеристик — всего лишь год выпуска и автор. А у Озона (сильный конкурент, сильный сайт) — характеристик много.
Вы хотите собрать в Excel все эти данные с Озона и использовать их для своего сайта. Это техническая информация, вопросов с авторским правом нет.
Изучаем характеристики
Нажимаете правой кнопкой по характеристике, выбираете Inspect Element и смотрите, как называется элемент, который содержит каждую характеристику.
У нас это элемент <div>, у которого в качестве класса указана строка eItemProperties_Line.
И дальше внутри каждого такого элемента <div> содержится название характеристики и ее значение.
Значит нам нужно собирать элементы <div> с классом eItemProperties_Line.
Для парсинга нам понадобится вот такой XPath-запрос:
//*[@class="eItemProperties_line"]Идем в Screaming Frog, Configuration > Custom > Extraction. Вставляем XPath-запрос, выбираем Extract Text (так как нам нужен только текст в чистом виде, без разметки), нажимаем ОК.
Переключаемся в режим Mode > List. Нажимаем Upload, указываем адрес страницы, с которой будем собирать характеристики, нажимаем ОК.
После завершения парсинга переключаемся на вкладку Custom, в списке фильтров выбираем Extraction.
И видим — парсер собрал нам все характеристики. В каждой ячейке находится название характеристики (например, «Автор») и ее значение («Игорь Ашманов»).
Пример 4. Как парсить отзывы (с рендерингом)
Следующий пример немного нестандартен — на грани «серого» SEO. Это парсинг отзывов с того же Озона. Допустим, мы хотим собрать и перенести на свой сайт тексты отзывов ко всем книгам.
Покажем процесс на примере одного URL. Начнем с того, что посмотрим, где отзывы лежат в коде.
Они находятся в элементе <div> с классом jsCommentContent:
Следовательно, нам нужен такой XPath-запрос:
//*[@class="jsCommentContents"]Добавляем его в Screaming Frog. Теперь копируем адрес страницы, которую будем анализировать, и загружаем в парсер.
Жмем ОК и видим, что никакие отзывы у нас не загрузились:
Почему так? Разработчики Озона сделали так, что текст отзывов грузится в момент, когда вы докручиваете до места, где отзывы появляются (чтобы не перегружать страницу). То есть они изначально в коде нигде не видны.
Чтобы с этим справиться, нам нужно зайти в Configuration > Spider, переключиться на вкладку Rendering и выбрать JavaScript. Так при обходе страниц парсером будет срабатывать JavaScript и страница будет отрисовываться полностью — так, как пользователь увидел бы ее в браузере. Screaming Frog также будет делать скриншот отрисованной страницы.
Мы выбираем устройство, с которого мы якобы заходим на сайт (десктоп). Настраиваем время задержки перед тем, как будет делаться скриншот, — одну секунду.
Нажимаем ОК. Введем вручную адрес страницы, включая #comments (якорная ссылка на раздел страницы, где отображаются отзывы).
Для этого жмем Upload > Enter Manually и вводим адрес:
Обратите внимание! При рендеринге (особенно, если страниц много) парсер может работать очень долго.
Итак, парсер собрал 20 отзывов. Внизу они показываются в качестве отрисованной страницы. А вверху в табличном варианте мы видим текст этих отзывов.
Пример 5. Как спарсить скрытые телефоны на сайте ЦИАН
Следующий пример — сбор телефонов с сайта cian.ru. Здесь есть предложения о продаже квартир. Допустим, стоит задача собрать телефоны с каких-то предложений или вообще со всех.
У этой задачи есть особенности. На странице объявления телефон скрыт кнопкой «Показать телефон».
После клика он виден. А до этого в коде видна только сама кнопка.
Но на сайте есть недоработка, которой мы воспользуемся. После нажатия на кнопку «Показать телефон» мы видим, что она начинается «+7 967…». Теперь обновим страницу, как будто мы не нажимали кнопку, посмотрим исходный код страницы и поищем в нем «967».
И вот, мы видим, что этот телефон уже есть в коде. Он находится у ссылки, с классом a10a3f92e9—phone—3XYRR. Чтобы собрать все телефоны, нам нужно спарсить содержимое всех элементов с таким классом.
Используем этот класс в XPath-запросе:
//*[@class="a10a3f92e9--phone--3XYRR"]Идем в Screaming Frog, Custom > Extraction. Указываем XPath-запрос и даем название колонке, в которую будут собираться телефоны:
Берем список ссылок (для примера я отобрал несколько ссылок на страницы объявлений) и добавляем их в парсер.
В итоге мы видим связку: адрес страницы — номер телефона.
Также мы можем собрать в дополнение к телефонам еще что-то. Например, этаж.
Алгоритм такой же:
- Кликаем по этажу, Inspect Element.
- Смотрим, где в коде расположена информация об этажах и как обозначается.
- Используем класс или идентификатор этого элемента в XPath-запросе.
- Добавляем запрос и список страниц, запускаем парсер и собираем информацию.
Пример 6. Как парсить структуру сайта на примере DNS-Shop
И последний пример — сбор структуры сайта. С помощью парсинга можно собрать структуру какого-то большого каталога или интернет-магазина.
Рассмотрим, как собрать структуру dns-shop.ru. Для этого нам нужно понять, как строятся хлебные крошки.
Нажимаем на любую ссылку в хлебных крошках, выбираем Inspect Element.
Эта ссылка в коде находится в элементе <span>, у которого атрибут itemprop (атрибут микроразметки) использует значение «name».
Используем элемент span со значением микроразметки в XPath-запросе:
//span[@itemprop="name"]Указываем XPath-запрос в парсере:
Пробуем спарсить одну страницу и получаем результат:
Таким образом мы можем пройтись по всем страницам сайта и собрать полную структуру.
Возможности парсинга на основе XPath
Что можно спарсить:
1. Любую информацию с почти любого сайта.
Нужно понимать, что есть сайты с защитой от парсинга. Например, если вы захотите спарсить любой проект Яндекса — у вас ничего не получится. Авито — тоже довольно-таки сложно. Но большинство сайтов можно спарсить.
2. Цены, наличие товаров, любые характеристики, фото, 3D-фото.
3. Описание, отзывы, структуру сайта.
4. Контакты, неочевидные свойства и т.д.
Любой элемент на странице, который есть в коде, вы можете вытянуть в Excel.
Ограничения при парсинге
- Бан по user-agent. При обращении к сайту парсер отсылает запрос user-agent, в котором сообщает сайту информацию о себе. Некоторые сайты сразу блокируют доступ парсеров, которые в user-agent представляются как приложения. Это ограничение можно легко обойти. В Screaming Frog нужно зайти в Configuration > User-Agent и выбрать YandexBot или Googlebot.
Подмена юзер-агента вполне себе решает данное ограничение. К большинству сайтов мы получим доступ таким образом.
- Запрет в robots.txt. Например, в robots.txt может быть прописан запрет индексирования каких-то разделов для Google-бота. Если мы user-agent настроили как Googlebot, то спарсить информацию с этого раздела не сможем.
Чтобы обойти ограничение, заходим в Screaming Frog в Configuration > Robots.txt > Settings
И выбираем игнорировать robots.txt
- Бан по IP. Если вы долгое время парсите какой-то сайт, то вас могут заблокировать на определенное или неопределенное время. Здесь два варианта решения: использовать VPN или в настройках парсера снизить скорость, чтобы не делать лишнюю нагрузку на сайт и уменьшить вероятность бана.
- Анализатор активности / капча. Некоторые сайты защищаются от парсинга с помощью умного анализатора активности. Если ваши действия похожи на роботизированные (когда обращаетесь к странице, у вас нет курсора, который двигается, или браузер не похож на стандартный), то анализатор показывает капчу, которую парсер не может обойти. Такое ограничение можно обойти, но это долго и дорого.
Теперь вы знаете, как собрать любую нужную информацию с сайтов конкурентов. Пользуйтесь приведенными примерами и помните — почти все можно спарсить. А если нельзя — то, возможно, вы просто не знаете как.
Как занять топовые позиции в Google, используя уязвимость XML-карт в Search Console
11.0К просмотров
В 2017 году Google заплатил около 3 млн. долларов экспериментаторам в рамках Vulnerability Reward Program, нашедшим уязвимости в продуктах Google. На этой неделе также получил вознаграждение Tom Anthony, сеошник из Великобритании, за выявление уязвимости, из-за которой можно было быстро индексироваться и получать чужой трафик. Ниже представлен перевод поста Тома с подробностями взлома.
Краткая версия:
Google имеет URL, по которому можно пингануть XML Sitemap. После пинга Google сканирует карту и парсит адреса в нём. Для любых сайтов с открытым редиректом (таких как LinkedIn, Facebook и тысячи eCommerce-сайтов) возможно пингануть сайтмап, который хостится у вас, и Google будет доверять этой карте также, как и зараженному сайту.
Используя в карте сайта большого интернет-магазина в Великобритании директиву hreflang я моментально был в ТОПе по разным конкурентным запросам в США.
Google уже пофиксил баг и заплатил вознаграждение в размере $1337.
Недавно мне удалось найти особенность в Google, которая позволяет атакующему отправить XML sitemap для сайта, к которому нет доступа. Так как этот файл может содержать директивы индексации, такие как hreflang, это позволяет атакующему использовать эти директивы и помогать своим сайтам ранжироваться в Google. В рамках эксперимента мне удалось попасть новым доменом без обратных ссылок на первую страницу поиска по очень сладким ключевым словам.
XML Sitemap и механизм пинга
Google позволяет владельцам сайтов отправлять xml-сайтмапы, это помогает ему узнать о новых адресах для краулинга, но также учитывает директивы hreflang, которые помогают узнать о существовании международных версий страницы. Google не рассказывает, как именно учитываются эти директивы в алгоритмах, однако, hreflang позволяет получать ссылочный вес и траст с другого урла, используя эти сигналы для ранжирования новых URL (например, многие люди ссылаются на английскую .com версию сайта, немецкая версия использует эти сигналы и лучше ранжируется в Google.de).
Вы можете отправлять сайтмапы для домена через Search Console, внутри файла robots.txt или с помощью специального URL для пинга. После отправки sitemap.xml с помощью ping Google сканирует файл в течение 10-15 секунд. Но это сканирование не будет отображаться в Search Console.
Помимо hreflang в sitemap.xml я пробовал другие директивы, такие как noindex или rel-canonical, но Google похоже их не использует.
Отправка файла в Google Search Console
Если вы попробуете отправить в GSC sitemap.xml, который включает урлы на другой домен, не принадлежащий вам, то консоль отклонит их.
Мы вернемся к этому моменту позже (извини, Jono!).
Открытые редиректы
Многие сайты используют URL-параметры для управления редиректами.
В этом примере после логина вас должно средиректить на page.html. Некоторые сайты с плохой гигиеной позволяют совершать открытые редиректы на другие домены. Часто даже не нужно дополнительное взаимодействие типа логина, они сразу перенаправляют пользователя.
Открытые редиректы встречаются часто и не рассматриваются, как опасные. Однако, некоторые компании пытаются защититься от подобных багов, но часто вы можете обойти их защиту.
Tesco является крупным ретейлером в Великобритании с оборотом £50 млрд. Я отправил этот пример Tesco (а также другим компаниям, об уязвимостях которых я знал в рамках эксперимента) и они уже это пофиксили.
Пинг sitemap.xml через открытые редиректы
Вышло так, что когда вы пингуете sitemap.xml, Google следует по редиректу, даже если он кросс-доменный. И что важно, он ассоциирует этот XML с доменом, который сделал редирект, и обрабатывает эту карту как для подтвержденного сайта.
В этом примере, evil.xml хостится на blue.com, но Google ассоциирует его с green.com. Используя это, вы можете отправлять сайтмапы для сайтов, которые вам не принадлежат, и отправить в них нужные директивы.
Эксперимент: Использование hreflang для воровства авторитета и бесплатного ранжирования
Мне было интересно, действительно ли Google доверяет кросс-доменным редиректам и пришлось провести эксперимент.
Я создал фейковый домен для компании в Великобритании, которая не работает в США и установил AWS сервер. Имитация сайта включала сбор нужного контента и небольшую перенастройку, смену валют/адресов и пр). Я не называю здесь имени компании, чтобы не навредить, поэтому назовем их условно victim.com.
Далее я создал фейковый sitemap, который хостился на evil.com, но содержащий только урлы с victim.com. Эти адреса содержали hreflang и ссылались на эквивалентный адрес на evil.com, указывая, что это US-версия victim.com. Далее я отправил этот sitemap через открытый редирект на victim.com через механизм пинга от Google.
В течение 48 часов сайт начал получать небольшое количество трафика по низкочастотным запросам (см. скриншот из Семраша).
Через несколько дней сайт начал показываться в ТОПе по конкурентным запросам на первой странице, насмотря на наличие в выдаче Amazon и Walmart.
Далее, для домена evil.com в панели для вебмастеров появилась ссылка с victim.com, хотя самой ссылки не было.
И тут я обнаружил, что могу отправлять sitemap.xml для victim.com прямо внутри Search Console домена evil.com.
Похоже, что Google связал сайты и Search Console для домена evil.com имеет возможность влиять на victim.com.
Searchmetrics показала увеличение трафика.
По отчетам Google Search Console сайт заработал миллионы показов и более 10 000 кликов из поиска, при этом я не сделал ничего для продвижения, а всего лишь отправил sitemap.xml!
Должен сказать, что я не давал людям возможность оплаты на evil.com, но если бы хотел, то можно было украсть много денег, настроить рекламу или как-то иначе монетизировать трафик. На мой взгляд это серьезные риски для пользователей Google, а также для компаний, которые полагаются на трафик из Google. Трафик моего сайта рос, но я остановил эксперимент.
Заключение
Этот метод полностью незаметный для victim.com — карты сайта не показываются на их стороне. Это первый известный мне пример прямого эксплойта алгоритма, а не простое манипулирование поисковыми факторами. Таким черным методом можно иметь неочевидное финансовое влияние на ряд компаний.
Первый баг-репорт был отправлен в Google 23 сентября 2017. 25 марта Google пофиксил все дырки и разрешил опубликовать эту статью.
Названы способы узнать баланс чужой карты: Банки: Экономика: Lenta.ru
У мошенников есть несколько способов узнать баланс банковской карты чужого человека, причем не от всех из них можно защититься. Опрошенные РИА Новости эксперты описали ситуации, при которых чувствительная для граждан информация может оказаться в чужих руках.
Глава отдела анализа защищенности веб-приложений Positive Technologies Ярослав Бабин назвал основным вариантом уязвимости в банковских приложениях. По его оценкам, в последнее время проблемы встречаются в каждом третьем приложении, а годом ранее их можно было найти в двух из трех.
Материалы по теме
00:01 — 23 января
00:01 — 11 января
Из-за них злоумышленники зачастую могут посмотреть сумму счетов других клиентов или же получить доступ к выпискам, шаблонам операций и предыдущим переводам.
Иногда речь идет даже не об уязвимостях, а о критических ошибках в принципах работы. Например, один из сервисов перевода с карты на карту, разработанный банком, выводил сообщение о нехватке средств на карте для перевода до запроса каких-либо других данных. То есть любой мог ввести номер карты и узнать, больше или меньше на ней средств. В этом случае клиент вообще не мог хоть как-то повлиять на сохранность своих данных.
Старший преподаватель кафедры банковского дела университета «Синергия» Дмитрий Ферапонтов отметил, что социальная инженерия также остается действенным методом. Мошенники втираются в доверие к человеку и манипулируют им. Хотя перед этим они должны получить какую-то информацию о клиенте банка, а это случается в результате утечек.
Данные преступникам предоставляют различные площадки — доставка, такси, каршеринг, маркетплейсы. Торговать персональными данными могут и нечистоплотные банковские сотрудники, хотя последние случаи, подчеркнул эксперт, случаются все реже и реже. Как правило, каждый из них заканчивается массовым исходом клиентов, даже лояльных, так что кредитные организации все плотнее занимаются безопасностью.
Самым простым, но работающим способом Ферапонтов назвал подглядывание из-за спины на экран банкомата или в смартфон во время использования его в людных местах. Из-за этого банки начали вводить функцию «скрыть остатки».
Ранее Центробанк предупредил о новой мошеннической рекламе, в рамках которой гражданам обещают выплату от имени регулятора. Для этого ему предлагают перейти на сайт с символикой ЦБ и ввести все данные своей карты, в том числе CVC-код.
Быстрая доставка новостей — в «Ленте дня» в Telegram
Как узнать номер карты Сбербанка?
Пластиковые карты Сбербанка России выдаются клиентам для доступа к их расчётному счёту. Банковская карточка имеет собственный 16- или 18-значный номер (в некоторых случаях пластику присваивается 19-значный код). Он отличается от номера счёта клиента.
Содержание
Скрыть- Зачем нужен номер карты?
- В каких случаях можно предоставлять номер карты?
- Как узнать номер своей карты Сбербанка?
- Карты с номерами на лицевой стороне
- Номер карты в договоре
- Узнать номер карты по телефону
- Информация о номере при посещении офиса Сбербанка
- Узнать номер через Сбербанк Онлайн
- Другие способы
- Можно ли узнать номер чужой карты?
- Правила безопасности и конфиденциальности
Зачем нужен номер карты?
Если расчётный счёт клиента – это по своей сути кошелёк человека, в котором он хранит свои деньги, то пластиковая карта является инструментом, который обеспечивает доступ в этот кошелёк. С её помощью происходит:
- идентификация клиента в системе Сбербанка;
- снятие наличных средств с банкомата;
- оплата покупок безналичным расчётом;
- оплата товаров и услуг в интернет-магазинах;
- перевод денег на другую карту или счёт.
Если клиент звонит на горячую линию, то для быстрого доступа к информации ему необходимо лишь назвать номер своей карты. А удобная оплата коммунальных платежей и пополнение счёта через «Сбербанк Онлайн», безналичный расчёт с помощью карты в магазине или снятие налички банкомата – это вообще ежедневная практика. Такая система очень удобна, и представить современную жизнь без пластиковых карт достаточно сложно.
В каких случаях можно предоставлять номер карты?
Номер карты не является секретной информацией. Её, в отличие от других данных пластика, можно сообщать третьим лицам. К примеру, когда осуществляется перевод денежных средств с карты на карту, у человека просят указать реквизиты (собственно говоря, номер пластиковой карточки) и ФИО владельца, чтобы удостовериться, что адресат указан правильно. Это безопасно при условии, что карта защищена дополнительно (запрос CVV2 кода карты, одноразовый пароль в смс) и другую информацию (секретный код, код из смс, срок действия пластика) клиент никому не сообщает.
Как узнать номер своей карты Сбербанка?
В некоторых случаях держатель карты не знает её номера. При наличии пластика с указанием всех цифр (иногда указывается лишь часть) это не составляет труда. Но иногда карточка отсутствует, а её реквизиты нужны. Есть несколько способов узнать номер своей карты.
Карты с номерами на лицевой стороне
Проще всего прочитать номер карты на её лицевой стороне. Там же указывается срок действия пластика и имя клиента (если карта именная). С обратной стороны карточки можно увидеть код CVV2, необходимый при совершении онлайн-покупок и другие данные. Но если полностью номер карты не указан, то есть ещё несколько способов, как его узнать.
Номер карты в договоре
В том случае, если нет возможности прочесть номер карты, следует найти договор, который выдал банк при её оформлении. При внимательном прочтении человек без труда найдёт интересующую его информацию.
Узнать номер карты по телефону
Горячая линия Сбербанка обеспечивает круглосуточную техподдержку клиентов. Это ещё один способ узнать номер своей карты. Совершив звонок на бесплатный номер 8-800-555-5550, человек, пройдя стандартную процедуру идентификации клиента, может узнать у оператора данные по своей пластиковой карте, состояние счёта и другую необходимую информацию. Этот вариант удобен, когда под рукой лишь телефон.
Информация о номере при посещении офиса Сбербанка
Посетив любое отделение банка, клиент непременно сможет не только выяснить номер своей карты, но и совершить любые другие действия, недоступные для совершения через телефон или интернет. Для этого необходимо иметь при себе паспорт.
Узнать номер через Сбербанк Онлайн
Выяснить номер своей карты можно и через интернет. Клиентам, которые активно используют сервис «Сбербанк Онлайн», это не составит труда. Войдя в личный кабинет, человек может посмотреть номера всех своих карт.
Другие способы
Есть также и другие варианты. Узнать номер своей карты клиент может, написав письмо на электронную почту Сбербанка. Для обращений и заявлений граждан существует отдельный e-mail: [email protected]. Именно по этому адресу следует направлять свой запрос о номере карты.
Можно ли узнать номер чужой карты?
Узнать номер карты Сбербанка не составляет особого труда, если вы – владелец этого пластика. Но порой возникают ситуации, когда нужно получить номер чужой карточки. Не всегда эта необходимость вызвана какими-то коварными планами по получению чужих денег, а порой просто связана с желанием сделать человеку подарок в виде определённой суммы денежных средств.
Сбербанк защищает своих клиентов. В целях безопасности информация по карте не разглашается третьим лицам. Узнать заветные цифры можно у самого человека, придумав какую-то уловку или спросив напрямую.
Правила безопасности и конфиденциальности
В первую очередь сам держатель карты Сбербанка должен соблюдать бдительность. Уже при оформлении договора со Сбербанком рекомендуется выбрать тип карты с дополнительной защитой (протокол 3-D Secure). Она предполагает запрос ввода одноразового пароля из смс при пересылке денег, введение кода CVV2 и срока действия карты при оплате товаров и услуг в интернете или при других действий, связанных с изменением баланса клиента.
Не следует никого оповещать об этих секретных данных. Если злоумышленники узнают номер карты, имя владельца (нередко требуется на сайтах интернет-покупок), код CVV2 и срок действия карты, то финансовые потери держателя карты могут быть очень серьёзными. Особенно в том случае, если хозяин карты не сразу заметит пропажу денег. Если карта кредитная, то её владельцу придётся ещё и возмещать банку долг.
Всем клиентам рекомендуется своевременно оповещать банк об изменении личной информации, в особенности, о смене мобильного номера, к которому привязана карта. Ведь рано или поздно другой человек получит этот же номер телефона и сможет при желании перенаправить деньги на свой мобильный счёт.
Следует также помнить, что любая банковская информация, опубликованная в интернете, представляет потенциальную опасность для человека. Посты в социальных сетях или на форумах с указанием номера карты, ФИО человека и мобильного телефона играет на руку мошенникам. Они очень часто реагируют на подобные заметки. Под любым предлогом злоумышленники могут позвонить и предложить сообщить секретные данные карты или сказать код, присланный Сбербанком в смс. Нередко такие люди представляются сотрудниками банка.
Проверка кредитной карты
Редкий гражданин ответит на вопрос, какого типа у него банковская карта. Это не проблема, ведь при необходимости достаточно обратиться в банк, выпустивший карту. Менеджеры кредитного учреждения ответят на все интересующие клиента вопросы.
Но как быть, когда не хочется тратить время на визит в банк или нужно проверить кредитную карту другого человека?
Когда нужна проверка кредитной карты?
Банковские пластиковые карты разделяются на два типа: дебетовые и кредитные. При покупке или оплате каких-либо услуг на территории России тип карты не имеет практического значения.
А вот при оплате через интернет, например, авиационного билета, цена товара или услуги нередко отличается в зависимости от типа банковской карточки. При этом покупателю предлагают указать, какого именно типа карта.
Информация о чужой банковской карточке становится актуальной, если предстоит перевести деньги за товар или услугу малознакомому человеку.
Например, при покупке через социальные сети, где нередко встречаются мошенники. Также проверка кредитных карт актуальна для тех, кто нанимает людей для работы через интернет. Если работа строится на авансовой системе оплаты, заказчику стоит проверить, соответствуют ли личные данные владельца карты информации о нанятом работнике.
Какую информацию содержит карта?
Нужные сведения содержатся не только в магнитной полосе на карте, но и в номере, находящемся на её лицевой стороне. Именно этот номер нужно указывать при переводе денег через интернет-банк или при оплате услуг или товаров на сайтах. В России распространены карты со следующим количеством цифр в номере.
- Тринадцатизначные (VISA).
- Шестнадцатизначные (MasterCard или Visa).
- Девятнадцатизначные (American Express).
Чаще всего российские банки выпускают карточки с шестнадцатизначными номерами, но встречаются и другие варианты. Итак, в первых шести цифрах любой дебетовой или кредитной карты зашифрована информация о платёжной системе, типе карточки и банке, который её выпустил. Первые шесть цифр называются BIN, что расшифровывается как Bank Identification Number.
В частности, если первая цифра в номере банковской карты «3», то она числится за American Express, «4» – за VISA, «5» – за MasterCard.
В следующих трёх цифрах указан код банка, выпустившего карточку. В цифрах с седьмой по четырнадцатую скрыта информация о идентификационном номере банковского счёта держателя карты. Последняя цифра нужна для проверки правильности ввода номера карты. Она генерируется при помощи специального алгоритма.
При проверке кредитных карт, как и дебетовых, интерес представляет только BIN-номер. Информация о идентификационном номере счёта бесполезна, так как не позволяет получить сведения о держателе карты и требуется исключительно для идентификации карточки в платёжной системе.
Проверка кредитной карты по BIN-номеру
Для такой проверки целесообразно использовать специализированные сайты, например, https://www.bindb.com/bin-database.html. Этот ресурс за несколько секунд проверяет BIN-код и выдаёт следующую информацию.
- Платёжная система.
- Банк, выпустивший карту.
- Тип карты (кредитная либо дебетовая).
- Уровень привилегий (например, стандартный, золотой, платиновый).
- Сайт и контактный телефон банка, выпустившего карту.
Приведённые данные можно получить и по-другому: обратившись в банк или воспользовавшись интернет-поисковиком, но проверка кредитных карт через специальный сайт занимает намного меньше времени.
При этом владелец карты ничем не рискует, так как указывает лишь первые шесть цифр номера карточки и не указывает код безопасности.
Код безопасности – три цифры на обороте карты, расположенные рядом с графой «Подпись». Нельзя сообщать этот код посторонним. При наличии номера карточки и кода злоумышленники смогут оплачивать покупки в интернет-магазинах.
Как получить личные данные при проверке кредитной карты?
В номере карты нет сведений о личных данных её держателя. Такая информация есть только у кредитного учреждения, выпустившего карточку. Однако при желании всё-таки можно узнать имя, отчество и первую букву фамилии владельца карты без обращения в банк.
Для получения этих сведений нужно воспользоваться личным кабинетом какого-либо банка, например, Сбербанка России, карты которого есть у большинства россиян.
В процессе перевода денег на карту другого гражданина через личный кабинет пользователю сообщают имя, отчество и первую букву фамилии адресата.
Если эти данные не совпадают с фактической информацией о получателе перевода, то владелец карты:
- допустил ошибку в номере;
- умышленно указал чужой номер.
В обоих случаях стоит отменить перевод и связаться с владельцем карты для уточнения её номера. Вполне вероятно, что получатель перевода попросту ошибся. Если же очевидно умышленное искажение номера карты, значит её держатель преднамеренно обманул отправителя, что косвенно указывает на дурные намерения.
Проверка кредитных карт с чипом
Российские банки всё чаще выдают клиентам карты с электронным чипом на лицевой стороне. Такие карты гораздо труднее подделать, ведь электронный чип устроен сложнее, чем привычная магнитная полоса на оборотной стороне карточки.
Пока большинство карт с чипом имеют ещё и магнитную полосу. Однако в дальнейшем платёжные системы планируют отказаться от магнитной полосы в пользу чипов. При этом комбинированный вариант нужен на переходный период, чтобы у банкиров было время заменить считывающее оборудование.
В чипе содержится больше сведений о карте и её держателе, потому такая информация представляется более интересной, чем данные с магнитной полосы, но получить её практически невозможно.
Для проверки кредитной карты по чипу потребуется не только оборудование для считывания информации, но и пин-код.
Такая проверка возможна только при наличии самой карты, а значит не подходит для случаев, когда нужно получить информацию о чужой карточке. То есть фактически нельзя проверить кредитные карты по чипу. Однако для комбинированных карт подходят уже упомянутые способы проверки.
Вопросы и ответы | Банк УРАЛСИБ
Убедитесь, что ваш компьютер не заражён какими-либо вирусами. Установите и активизируйте антивирусные программы, старайтесь их постоянно обновлять. Только постоянное обновление антивирусных программ позволит вам своевременно обнаружить и предотвратить появление вируса.
Рекомендуется использовать программное обеспечение, которое отслеживает и борется с программным обеспечением Spyware. Spyware — вид программного обеспечения, который пытается запомнить ваши клавиатурные последовательности и передать их третьим лицам.
Настоятельно рекомендуется использование виртуальной клавиатуры при вводе пароля на всех этапах работы с Интернет-банком. Использование виртуальной клавиатуры позволит избежать компрометации пароля в случае заражения ПК программным обеспечением Spyware.
Рекомендуется использовать межсетевой экран (firewall) при входе в интернет или установить персональный межсетевой экран (firewall) на вашем компьютере. При использовании межсетевого экрана (firewall) несанкционированный вход в систему вашего компьютера через интернет будет весьма затруднен или предотвращён.
Используйте программное обеспечение (операционные системы, приложения) из проверенных и надёжных источников. Откажитесь от использования и инсталляции программного обеспечения из непроверенных источников.
В случае подключения через модем обратите, пожалуйста, внимание на набираемый номер. В случае обнаружения несовпадения номера удалите неизвестный вам номер.
Сконфигурируйте ваш обозреватель таким образом, чтобы установки настройки кэширования не допускали сохранения конфиденциальных страниц (SSL-page).
Контролируйте свою электронную почту, не открывайте сообщения от неизвестных адресатов, не передавайте свои личные данные. Никогда не открывайте подозрительные файлы, присланные вам по электронной почте. Не отвечайте на электронные письма, в которых якобы от имени банка, вас просят предоставить персональную информацию. Никогда не следуйте по ссылкам в таких письмах (даже на сайт банка), т.к. они могут вести на мошеннические сайты.
Проверяйте адреса интернет-сайтов, к которым вы подключаетесь, т.к. злоумышленники могут использовать похожие названия для создания мошеннических ресурсов.
Избегайте пользоваться услугами интернет-ресурсов сомнительного содержания; зачастую они создаются специально для получения информации о банковских картах и последующего ее неправомерного использования.
Совершайте покупки только со своего компьютера, не пользуйтесь интернет-кафе и другими доступными средствами, где могут быть установлены программы-шпионы, запоминающие вводимые вами конфиденциальные данные.
Выбирайте нетривиальные пароли, которые не связаны с вашим днем рождения или другими персональными данными. Если возможно, выбирайте символьно-цифровые пароли. Не записывайте пароли и никому не сообщайте их. Если вы боитесь забыть свой пароль, придумайте понятную только вам систему его записи (например, в виде номера телефона или адреса в телефонной книжке).
Банк никогда не осуществляет рассылку электронных писем с просьбой предоставить конфиденциальную информацию, или таких, которые содержат компьютерные программы.
Если вы получили письмо от имени банка, содержание которого вызывает подозрение, либо с вами связались по телефону от имени банка, с просьбой установить некоторое программное обеспечение, просьба связаться со службой поддержки банка и уточнить ситуацию. Всегда используйте контактную информацию служб поддержки банка, указанную в официальных источниках информации, и не используйте контактную информацию, указанную в полученном письме или полученную в ходе телефонного разговора.
Любые электронные сообщения, отправленные с бесплатных почтовых служб интернета (@mail.ru, @yandex.ru, @rambler.ru, @gmail.com, @yahoo.com и т.п.), не являются почтой, отправленной банком.
Как найти карту сайта на любом сайте
Чтобы найти карту сайта для своего веб-сайта, достаточно просто поискать в нужных местах. Если он существует, эти шаги помогут вам найти его в 99% случаев.
Обратите внимание, что в этой статье мы говорим о карте сайта XML.
Что такое XML-карта сайта?
XML-карта сайта — это список URL-адресов вашего веб-сайта, предоставленный поисковым системам. Он написан в формате кода, описанном sitemaps.org, который является авторитетом в области XML-карт сайта.
Как выглядит наша XML-карта сайта WriteMaps…Зачем мне искать карту сайта?
Вам нужно найти XML-карту сайта для своего веб-сайта, чтобы проверить, есть ли она у вас, проверить ее действительность, а затем отправить URL-адрес поисковым системам.
Лучше всего поместить файл карты сайта в корневую папку домена.
например https://writemaps.com/sitemap.xml
Но его можно хранить где угодно, даже на другом домене!
Наличие карты сайта не обязательно, но она помогает поисковым системам быстрее находить и индексировать новые веб-сайты или обновленные веб-страницы.
Как найти карту сайта
Первые три основных места, где можно найти карту сайта:
- Попробуйте ввести свое доменное имя, например https://writemaps.com со следующими окончаниями
/ sitemap
/sitemap.xml
/sitemap_index.xml
- Попробуйте ввести свое доменное имя, например https://writemaps.com плюс /robots.txt
например. https://writemaps.com/robots.txt
Совет: замените writemaps.com на свое доменное имя
Посмотрите файл robots.txt для URL-адреса карты сайта, так как это стандартная практика — помещать его сюда, потому что это первое место, куда смотрят поисковые системы. - Выполните поиск по сайту в Google, набрав свой сайт и выполнив поиск файла типа XML в поисковой системе.
например "site: writemaps.com filetype: xml"
Если вы получите много результатов из этого поиска, вы можете уточнить поиск. Попробуйте добавить критерий наличия «карты сайта» в URL
, например "сайт: карты записи.com filetype: xml inurl: sitemap "
Advanced — как найти карту сайта
Если ни один из основных методов не помог, вы можете попробовать воспользоваться службой веб-сканирования для поиска вашей карты сайта.
Быстрый и простой способ попробовать — это инструмент карты сайта SEO Site Checkup. Просто введите свой URL и дайте им понять, смогут ли они найти вашу карту сайта.
Во-вторых, вы можете попробовать создать бесплатную учетную запись на Spotibo и просканировать свой веб-сайт.Затем вам нужно будет просмотреть только типы файлов XML, чтобы узнать, есть ли у вас карта сайта.
Как найти карту сайта на Shopify и Squarespace
Shopify и Squarespace автоматически создают карты сайта в формате XML. И обе платформы помещают их в файл sitemap.xml в корневой папке вашего домена. Так что попробуйте ввести это прямо в свой браузер:
https://yourwebsite.com/sitemap.xml
Совет: замените yourwebsite.com своим доменным именем
Этот файл карты сайта часто может действовать как индексная страница карты сайта и ссылаться на другие карты сайта, которые, взятые вместе, содержат URL-адреса вашего веб-сайта.
Как и любая хорошая платформа или плагин, эти карты сайта автоматически обновляются в течение 24 часов, когда вы добавляете новые страницы или контент. Невозможно напрямую редактировать карту сайта.
При настройке Google Search Console вам может потребоваться подтвердить право собственности на свой сайт, прежде чем вы сможете отправить карту сайта.
На Shopify вам нужно будет следовать их пошаговому руководству, чтобы добавить метатег google-site-verify на свой сайт.
Squarespace предлагает несколько другие методы проверки вашего сайта с помощью консоли поиска Google, чтобы вы могли затем отправить свою карту сайта.
Как найти карту сайта на WordPress
WordPress не создает автоматически карты сайта в формате XML, и эту работу обычно выполняет плагин.
Если вы настраиваете свой веб-сайт впервые, скорее всего, у вас не будет карты сайта.
Добавьте плагин, например Google XML Sitemaps, для простого инструмента, работающего только с картой сайта. Или попробуйте Yoast SEO, который также легко создает карту сайта XML, но также предоставляет множество других инструментов SEO.
Если в создании вашего веб-сайта принимал участие кто-то другой, возможно, у вас уже есть плагин карты сайта в действии.
Большинство плагинов помещают вашу карту сайта в / sitemap, /sitemap.xml или /sitemap_index.xml, поэтому попробуйте сначала поискать URL-адрес карты сайта там или в файле yourwebsite.com/robots.txt.
В противном случае войдите в свою админку WordPress и осмотритесь в следующих местах:
- «Плагины» — посмотрите на свои активные плагины, чтобы узнать, какие из них могут быть связаны с картой сайта. Если да, то вы сможете прочитать его документацию, чтобы узнать, где изменить его настройки.
- «Инструменты» или «Настройки» — и вы ищете что-то вроде «Sitemap» или «XML Sitemap»
- «SEO»> «XML Sitemaps» — если у вас уже есть плагин Yoast SEO (который очень распространен), то убедитесь, что здесь включено автоматическое создание XML-карты сайта.
Что будет дальше?
Если вы не можете найти карту сайта , возможно, вам потребуется создать карту сайта.
Если вы нашли свою карту сайта , то вам нужно убедиться, что Google знает об этом.Следуйте этим инструкциям, чтобы отправить карту сайта в Google Search Console.
Эти советы помогут вам найти карту сайта и сообщить о ней поисковым системам.
Удачи в дикой природе, дикой природе, паутине…
Как найти карту сайта (7 быстрых способов) 🔍
Последнее обновление 4 мая 2021 г.
В этом кратком руководстве я покажу вам, как найти карту сайта любого веб-сайта 7 простыми способами.
У вас есть проблемы с поиском карты сайта для веб-сайта? Если да, то это руководство специально для вас.
Поиск карты сайта для веб-сайта — довольно простая и стандартная задача, которую большинство специалистов по поисковой оптимизации выполняют каждый раз, когда им нужно проанализировать или проверить веб-сайт.
Обычно найти карту сайта довольно просто при условии, что она есть на веб-сайте и… вы знаете, где ее искать.
Как найти XML-карту сайта любого веб-сайта 8 способами
Если вам интересно узнать о теории, лежащей в основе карт сайта, о том, что они из себя представляют, для чего они нужны, перейдите прямо в Центр поиска Google в раздел, посвященный картам сайта, или ознакомьтесь с моими другими руководствами по картам сайта (скоро).
И прежде чем мы начнем, обратите внимание, что:
- Самым распространенным и стандартным местом расположения карты сайта, конечно же, является корневой каталог домена.
- Однако это местоположение не является требованием или каким-либо официальным стандартом, а это означает, что карту сайта можно также разместить в подкаталоге или даже в совершенно другом домене. Некоторые делают это, чтобы скрыть свои карты сайта от конкурентов.
- То же самое верно и для имени файла, которое не обязательно должно быть «карта сайта» или содержать слово «карта сайта».
Вот почему я показываю вам все более и менее очевидные местоположения карты сайта веб-сайта. Это все вариации, которые я видел за 8 лет работы в качестве специалиста по поисковой оптимизации.
Как выглядит карта сайта?
И еще кое-что. Приятно точно знать, что вы ищете! Посетите Sitemaps.org, чтобы узнать, как выглядит XML-карта сайта и как она создается, если вы этого не знаете.
Вот скриншот из образца XML-карты сайта, показанной на карте сайта.org:
А вот скриншот индекса карты сайта на моем сайте:
Ладно, пора наконец приступить к детективной работе.
# 1: Вручную проверьте общие расположения XML-карты сайта
Это наиболее очевидный и самый быстрый способ найти карту сайта для веб-сайта. В большинстве случаев это все, что вам нужно сделать, чтобы обнаружить XML-карту сайта веб-сайта.
Наиболее распространенные местоположения для карты сайта:
-
/sitemap.xml -
/ sitemap_index.xml(который является индексом карт сайта) -
/ sitemap /(который часто перенаправляет на sitemap.xml)
Конечно, все, что идет перед «/», является доменным именем вашего веб-сайта.
В случае моего веб-сайта (который основан на WordPress) расположение карты сайта по умолчанию https://seosly.com/sitemap.xml перенаправляет на https://seosly.com/sitemap_index.xml.
Как видите, индекс карты сайта содержит следующие две карты сайта:
А вот и другие возможные имена файлов для карты сайта или индекса карты сайта:
-
/ карта сайта.php -
/sitemap.txt -
/sitemap.xml.gz(с использованием сжатия gzip) -
/sitemap1.xml(если есть несколько карт сайта, это может быть первая карта сайта в группе) -
/post-sitemap.xml(карта сайта сообщений, как на моем веб-сайте) -
/page-sitemap.xml(карта сайта, также как и на моем веб-сайте) -
/ карта сайта -index.xml(со знаком «-» вместо «_») -
/ sitemapindex.xml(без разделения) -
/sitemap_index.xml.gz(с использованием сжатия Gzip) -
/sitemap/index.xml(во вложенной папке)
И веб-сайт также может использовать свой канал в качестве карты сайта в этом случае карта сайта может иметь вид:
-
/ rss /(RSS-канал как карта сайта) -
/rss.xml(RSS-канал как карта сайта) -
/atom.xml(канал Atom как карта сайта)
Понимаете? Множество возможностей.
# 2: проверьте файл robots.txt
Еще один очевидный и быстрый способ обнаружить файл XML — это проверить robots.txt.
Robots.txt — специальный файл, содержащий директивы для роботов поисковых систем. Это также место для включения ссылки на карту сайта, чтобы поисковым системам было проще обнаруживать карту сайта и сканировать веб-сайт.
Чтобы просмотреть файл robots.txt любого веб-сайта, просто добавьте в домен /robots.tx t. В случае моего веб-сайта это https: // seosly.ru / robots.txt.
Вот содержание файла robots.txt моего веб-сайта:
Последняя строка указывает расположение карты сайта.
☝️ СОВЕТ ПРОФЕССИОНАЛА: Если у веб-сайта нестандартное расположение карты сайта, то это должно быть указано в файле robots.txt.
Если вы хотите узнать больше о robots.txt, о том, что это такое, для чего он нужен и как его использовать, ознакомьтесь с введением в robots.txt в Центре поиска Google.
⚡ Если вы используете WordPress, ознакомьтесь с моим руководством о том, как получить доступ к robots.txt в WordPress .
# 3: Используйте операторы поиска Google
Вы также можете искать XML-файл с помощью поисковых операторов Google (щелкните, чтобы просмотреть полный список работающих в настоящее время поисковых операторов в Google).
Есть по крайней мере несколько операторов, которые вы можете использовать, чтобы попытаться найти XML-карту сайта веб-сайта:
-
site: -
filetype:илиext: -
inurl:
Давайте попробуем найти XML карту сайта moz.com, используя эти операторы поиска.
Команда site: moz.com filetype: xml или site: moz.com ext: xml будет искать файлы XML в домене moz.com.
Вы также можете немного сузить область поиска и попробовать что-то вроде site: moz.com filetype: xml inurl: sitemap или site: moz.com ext: xml inurl: sitemap , который будет искать файлы XML с расширением слово «карта сайта» в домене moz.com.
Вы также можете искать карты сайта, которые имеют другой тип файла, чем XML, например текстовые файлы.
Для этого вы можете использовать команду site: moz.com filetype: txt inurl: sitemap или site: moz.com ext: txt inurl: sitemap , которая будет искать текстовые файлы, содержащие слово «sitemap» в домене moz.com
СОВЕТ ПРОФЕССИОНАЛА: Обратите внимание, что этот метод будет работать, только если карта сайта XML индексируется (и фактически индексируется Google).
PRO TIP 2: Многие популярные плагины WordPress, которые автоматически генерируют карты сайта в формате XML (например, Rank Math), добавляют к этим файлам тег «noindex, follow».
В этом случае вы не сможете найти карту сайта с помощью операторов поиска Google. Вот как создается карта сайта в формате XML на моем веб-сайте. Если бы я хотел найти его с помощью поискового оператора, у меня не получилось бы.
Нет результатов, хотя у меня есть карта сайта.
# 4: проверьте консоль поиска Google
Еще одно место для поиска карты сайта — это консоль поиска Google. Этот шаг будет работать только в том случае, если у вас есть доступ к учетной записи GSC для веб-сайта.Если он у вас есть, вот что вам нужно сделать:
- Войдите в Google Search Console.
- Под индексом перейдите к Sitemaps .
- Если карта сайта XML была отправлена в Google, вы увидите ее под заголовком Отправленная карта сайта s.
Если вы новичок в Google Search Console или на анализируемом веб-сайте нет учетной записи GSC, обязательно ознакомьтесь с основным руководством по Google Search Console в Центре поиска Google.
PRO TIP: Google Search Console — это инструмент, который должен использовать любой веб-сайт, который хочет быть видимым в Google.
Говоря о GSC, вы можете узнать о новом отчете по статистике сканирования в Google Search Console. Также ознакомьтесь с моим руководством о том, как добавить нового пользователя в GSC, если вы хотите, чтобы кто-то еще имел доступ к вашим данным GSC.
# 5: проверьте инструменты Bing для веб-мастеров
Вы также можете поискать XML-карту сайта в инструментах Bing для веб-мастеров, как вы это делали в Google Search Console.
Этот шаг имеет смысл, только если у веб-сайта есть учетная запись в Bing Webmaster Tools. Вот как проверить, была ли отправлена карта сайта XML:
- Если есть какие-либо отправленные карты сайта, вы увидите их справа под Sitemap s.
☝️ СОВЕТ ПРОФЕССИОНАЛА: Это также место, где вы можете отправить карту сайта в Bing.
# 6: Используйте инструмент проверки сайта SEO
Поскольку мы говорим об инструментах, вы также можете использовать онлайн-инструмент, созданный специально для проверки наличия на веб-сайте карты сайта XML.
URL-адрес инструмента : https://seositecheckup.com/tools/sitemap-test
Вот как с помощью инструмента SEO Site Checkup проверить, есть ли на веб-сайте карта сайта в формате XML:
- Введите URL-адрес веб-сайта, который хотите проверить.
- Нажмите Enter или нажмите Checkup . Результаты будут доступны в течение нескольких секунд.
- Вы также можете добавить другие URL-адреса (например, URL-адреса конкурентов) и сравнить результаты.
☝️ СОВЕТ ПРОФЕССИОНАЛА: Обратите внимание, что этот инструмент проверяет возможные стандартные местоположения карты сайта XML и иногда может не обнаружить карту сайта, даже если она есть на веб-сайте.
# 7: Проверить CMS сайта
В зависимости от CMS веб-сайта карты сайта XML могут быть доступны по разным URL-адресам.
Самые популярные системы управления контентом имеют свои собственные местоположения XML-карты сайта по умолчанию, которые также стоит проверить.
- Если вам известна CMS исследуемого веб-сайта, скорее всего, его XML-карта сайта находится в местоположении по умолчанию для этой CMS.
- Если вы не знаете CMS, вы можете проверить ее с помощью такого инструмента, как CMS Detect. Все, что вам нужно сделать, это ввести URL-адрес и нажать «Определить CMS».
Ниже приведены местоположения XML-карты сайта по умолчанию для наиболее популярных систем управления контентом и ссылки на документацию.
Расположение карты сайта по умолчанию в WordPress
С июля 2020 года в WordPress 5.5 появилась новая функция карты сайта XML. Это означает, что вам не нужен какой-либо плагин для создания карты сайта для вашего сайта WordPress.
Если веб-сайт WordPress использует эту функцию, то его карта сайта доступна по адресу /wp-sitemap.xml .
Если веб-сайт WordPress использует один из плагинов, который автоматически генерирует карту сайта, то он доступен по одному из следующих адресов:
-
/sitemap.xml -
/sitemap_index.xml -
/post-sitemap.xml -
/page-sitemap.xml -
/ category-sitemap.xml -
/tag-sitemap.xml
Вы также можете просто проверить настройки плагина, чтобы увидеть точное местоположение карты сайта. Большинство автоматически генерируемых карт сайта в WordPress также добавляют запись карты сайта в robots.txt.
Расположение карты сайта по умолчанию в Wix
Wix автоматически позаботится о карте сайта, и ваша единственная задача — отправить ее в Google Search Console. Местоположение по умолчанию для основной карты сайта в Wix также / sitemap.xml .
Другие URL-адреса в Wix для разных карт сайта следующие:
-
/pages-sitemap.xmlдля Pages -
/blog-pages-sitemap.xmlдля нового блога Wix -
/store-products-sitemap.xmlдля Wix Stores -
/ booking-services -sitemap.xmlдля Wix Bookings -
/forum-pages-sitemap.xmlдля Wix Forum -
/event-pages-sitemap.xmlдля Wix Events -
/ member-profile-sitemap.xmlдля участников -
/dynamic-pages-sitemap.xmlдля страниц данных и маршрутизатора Wix -
/other-pages-sitemap.xmlдля других страниц, не принадлежащих ни к одной из вышеперечисленных категорий
Вы можете узнать больше о файлах Sitemap в Wix здесь.
Расположение карты сайта по умолчанию в Squarespace
Squarespace, как и Wix, заботится о карте сайта. Расположение карты сайта по умолчанию для веб-сайтов Squarespace также / sitemap.xml .
Вы можете узнать больше о файлах Sitemap в Squarespace здесь.
Расположение карты сайта по умолчанию в Shopify
В Shopify карта сайта также имеет стандартное расположение: /sitemap.xml .
Вы можете узнать больше о файлах Sitemap в Shopify здесь.
Расположение карты сайта по умолчанию в Joomla
Расширения, доступные для Joomla, также автоматически создают карту сайта веб-сайта. Стандартное расположение карты сайта Joomla XML — это просто / sitemap.xml .
Вы можете узнать больше о файлах Sitemap в Joomla здесь.
Расположение карты сайта по умолчанию в Magento
И напоследок пару слов о картах сайта в Magento. Здесь также используется стандартное расположение карты сайта: /sitemap.xml , но вы можете изменить его, если хотите.
Вы можете узнать больше о файлах Sitemap в Magento здесь.
# 8: Найдите другие типы файлов Sitemap
XML — это наиболее распространенный формат карты сайта, который используется для информирования роботов о веб-страницах веб-сайта.Однако существуют и другие возможные форматы файлов Sitemap, которые роботы поисковых систем признают и уважают:
- HTML , который обычно предназначен для пользователей, но также может помочь роботам обнаруживать веб-страницы. Расположение карты сайта HTML может быть
/ sitemap /. - RSS , где веб-сайт может использовать RSS-канал в качестве карты сайта. Расположение карты сайта RSS-канала обычно
/ rss /или/rss.xml. - Atom , где веб-сайт может использовать канал Atom в качестве карты сайта.Расположение карты сайта фида Atom обычно
/atom.xml. - TXT , который представляет собой просто текстовый файл. Расположение текстовой карты сайта часто —
/sitemap.txt.
Если вы обнаружите любой из перечисленных выше типов файлов Sitemap, не паникуйте. Они тоже приемлемы.
Нашли карту сайта? Вот что делать дальше.
Если вы хотите узнать больше о картах сайта, обязательно ознакомьтесь с моими другими мини-руководствами из серии советов по картам сайта (скоро).
И есть много чего интересного о файлах Sitemap прямо из Google. Я очень рекомендую вам проверить следующее:
Не нашли карту сайта? Сделай это.
Скорее всего, на сайте просто нет карты сайта. В таком случае следующим шагом должно быть создание или рекомендация создать его. Вы можете проверить руководство Google по созданию и отправке карты сайта.
Знаете ли вы какие-либо другие способы обнаружения карты сайта веб-сайта? Не стесняйтесь делиться своими мыслями.Вы можете оставить мне комментарий в поле для комментариев ниже или связаться со мной напрямую.
Если вам нравится это руководство и вы считаете его полезным, поделитесь им с другими. Спасибо! ❤️
Ольга Зарзечна — старший SEO-специалист с опытом работы более 8 лет. Она занималась поисковой оптимизацией как для крупнейших мировых брендов, так и для малых предприятий. На данный момент она провела более 100 SEO-аудитов. Ольга закончила курсы SEO и получила ученую степень в университетах, таких как Калифорнийский университет в Дэвисе, Мичиганский университет и Университет Джона Хопкинса.Она также закончила Академию Moz! И, конечно же, имеет сертификаты Google. Она продолжает изучать SEO, и ей это нравится. Ольга также является экспертом по продуктам Google, специализируясь в таких областях, как поиск Google и веб-мастера Google.
Как найти карту сайта для веб-сайта
Не можете найти карту сайта для веб-сайта?
Иногда бывает сложно найти карту сайта, так как существует несколько способов ее создания.
Кроме того, существуют различные типы файлов XML, TXT, RSS и ATOM.С чего начать?
Я дам вам 5 способов найти карту сайта на любом сайте.
Прежде чем мы начнем, давайте определимся, что такое карта сайта. Зная это, мы сможем найти, где прячется карта сайта.
Вы не можете скрыть карту сайта, мы к вам!
Найдя карту сайта, не забудьте отправить ее в Google и Bing.
Что такое карта сайта?
Карта сайта — это список всех страниц вашего сайта.
Программное обеспечение, которое посещает ваш веб-сайт, называется сканером, использует эту карту сайта, чтобы найти свой путь.
Хорошим примером поискового робота является Googlebot. Робот Googlebot посещает ваши страницы, чтобы прочитать их и добавить контент в поиск Google.
Вот почему карта сайта так полезна. Вместо того, чтобы искать все страницы роботом Googlebot, тяжелую работу выполняет карта сайта. Ускорение поиска ваших страниц роботом Googlebot.
Помимо карты сайта, вы также должны сообщить Google, где вы ее храните. После этого робот Googlebot может использовать эту карту сайта при следующем посещении.
Чтобы сообщить Google, добавьте карту сайта в Google Search Console.
Но что именно мы подаем?
Существует несколько форматов файлов Sitemap, например:
- XML
- Файл RSS / ATOM
- Обычный текстовый файл
Самым распространенным является XML, поскольку он наиболее гибкий. Он позволяет связывать карты сайта вместе и ссылаться на страницы на определенном языке.
Этот файл выглядит как HTML, например:
http://www.example.com/foo.html
4 июня 2018 г.
... В этом примере перечислены страницы сайта, а также время последнего изменения страницы с помощью тега lastmod .
То же самое можно сделать и с RSS- или ATOM-каналами. Это XML-каналы в другом формате.
Почти все программное обеспечение для блогов может создавать RSS- или ATOM-каналы. Но будьте осторожны с этим.
Некоторые программы для ведения блогов создают только список последних сообщений в блогах.Вы должны указать все страницы вашего сайта в вашей карте сайта.
Последний тип — это простой текстовый файл. Хотя это встречается реже, но все еще используется, вот образец карты сайта от Starbucks:
https://www.starbucks.com/menu
https://www.starbucks.com/menu/drinks
https://www.starbucks.com/menu/drinks/hot-coffees
... Текстовый файл содержит только список страниц сайтов, по одной странице в каждой строке. Нет никакой дополнительной информации, такой как дата последнего изменения.Это самый простой, но и наименее гибкий.
Если вам нужно создать карту сайта для нового сайта, используйте формат XML.
Множество файлов Sitemap
При посещении крупных сайтов, таких как BBC, вы обнаружите, что у них много карт сайта. Это связано с тем, что существует ограничение в 50 000 страниц и ограничение на размер файла в 50 МБ.
Чтобы связать карты сайта вместе, можно иметь основную карту сайта, которая ссылается на все остальные.
Для этого вы должны использовать XML и тег карты сайта , как показано ниже:
...
<карта сайта>
https://example.com/hats/sitemap.xml
... Мы рассмотрели, что такое карты сайта и как они разбиваются на множество файлов. давайте посмотрим, как можно найти карту сайта.
Как найти карту сайта?
Есть 5 способов найти карту сайта на сайте. Это:
- Используйте Robots.txt
- Вручную
- Воспользуйтесь поиском Google
- Найти RSS-карту сайта в источнике
- Консоль поиска Google
Начиная с самого простого к самому сложному.Начнем с роботов!
Используйте Robots.txt
Если вам повезет, карта сайта будет в файле robots.txt.
Как и карта сайта, файл robots также используется поисковыми роботами.
Сканер Googlebot использует файл robots.txt, чтобы узнать, куда ему можно, а куда нельзя.
Вы найдете этот файл, добавив /robots.txt в конец URL-адреса. Например:
https://exmaple.com/robots.txt
Каждая строка в этом файле представляет собой «правило», и поисковый робот следует каждому из перечисленных правил.
Сканер должен знать, куда идти, и правило Sitemap: показывает поисковому роботу, где находятся все страницы.
Например, если мы посмотрим на txt-файл robots с Airbnb, мы увидим карты сайта, перечисленные в конце файла:
Карта сайта: https://www.airbnb.com/sitemap-master-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-p2-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-p2_poi-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-homes_filters_expansion-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-homes_pdp-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-things_to_do_cities_and_categories-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-places_pdp-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-experiences_p2-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-experiences_pdp-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-additional_things_to_do-urls-index.xml.gz Если вам повезет, теперь у вас есть карта сайта.Если нет, то давайте посмотрим на ручную проверку.
Вручную
Один из способов найти карту сайта — это попробовать разные общие URL-адреса. Наиболее частое расположение карты сайта — sitemap.xml . Итак, добавив это в конец имени домена, вы можете проверить, существует ли карта сайта:
https://example.com/sitemap.xml
Если вы получите ошибку 404, значит карта сайта не найдена, и мы можем попробовать другое имя файла.
sitemap.xml — самый распространенный, но не единственный.
Чтобы получить список других распространенных имен файлов карты сайта, мы просмотрели карты сайта 7000+ веб-сайтов.
Вот список распространенных имен файлов для карты сайта, основанный на этом исследовании:
- /sitemap.xml
- /sitemap_index.xml
- /sitemap-index.xml
- / карта сайта /
- /post-sitemap.xml
- /sitemap/sitemap.xml
- /sitemap/index.xml
- / RSS /
- /rss.xml
- /sitemapindex.xml
- / карта сайта.xml.gz
- /sitemap_index.xml.gz
- /sitemap.php
- /sitemap.txt
- /atom.xml
Если ничего из этого не работает, добавьте заглавную букву, например, /Sitemap.xml . Попробуйте добавить заглавную букву к любому из названий файлов выше.
Если у вас все еще ничего нет, давайте рассмотрим поиск в Google.
Воспользуйтесь поиском Google
Мы можем использовать волшебство Google Search для поиска файлов XML. Мы также можем сузить поиск до определенного сайта.
Для поиска файлов XML на BBC мы будем использовать поиск:
inurl: bbc.co.uk тип файла: xml
В результате возвращается карта сайта:
Если вы получаете много страниц в результатах, вы можете сузить их, выполнив поиск по карте сайта в URL-адресе, например:
site: example.com inurl: sitemap filetype: xml
Не забывайте, что карты сайта также могут быть текстовыми файлами. Проделав то же самое для Starbucks, вы можете найти карту сайта:
сайт: starbucks.com inurl: тип файла карты сайта: txt
Приведенный выше поиск возвращает карту сайта:
Если вы все еще не можете найти его, давайте посмотрим, является ли это RSS-канал.
Вы можете использовать RSS-канал в качестве карты сайта, и многие блоги создают этот файл по умолчанию.
Чтобы найти файлы, посмотрите исходный код HTML-страницы.
Например, если мы откроем браузер Chrome и перейдем на страницу новостей SpaceX. Мы можем проверить источник страницы, щелкнув страницу правой кнопкой мыши и выбрав параметр «Проверить».
Если вы находитесь на вкладке «Элементы», вы можете выполнить поиск по коду:
application / rss + xml показывает наличие RSS-канала:
Если RSS-канал отсутствует, а карту сайта по-прежнему не удается найти. Есть еще одно место, куда стоит заглянуть.
Консоль поиска Google
Если все вышеперечисленное не помогло, то получите доступ к сайтам Google Search Console.
Чтобы помочь Google сканировать ваш веб-сайт, вы можете отправить карту сайта в Google Search Console.
Если в Google Search Console добавлена карта сайта, вы найдете ее в списке, перейдя в Индекс> Карты сайта.
Любые отправленные карты сайта будут выглядеть так:
Как найти карту сайта для веб-сайта: последние мысли
К настоящему времени вы нашли карту сайта. Отличная работа!
У нас есть общее представление о том, что такое карты сайта и что они бывают трех разных форматов:
- XML
- Файл RSS / ATOM
- Обычный текстовый файл
У вас есть 5 способов найти карты сайта, поскольку они не всегда находятся в одном и том же месте.
- Используйте Robots.txt
- Вручную
- Воспользуйтесь поиском Google
- Найти RSS-карту сайта в источнике
- Консоль поиска Google
Если эти 5 способов не сработали или у вас есть другой способ попробовать, оставьте комментарий ниже.
Как найти карту сайта для веб-сайта
Не можете найти карту сайта для веб-сайта?
Иногда бывает сложно найти карту сайта, так как существует несколько способов ее создания.
Кроме того, существуют различные типы файлов XML, TXT, RSS и ATOM.С чего начать?
Я дам вам 5 способов найти карту сайта на любом сайте.
Прежде чем мы начнем, давайте определимся, что такое карта сайта. Зная это, мы сможем найти, где прячется карта сайта.
Вы не можете скрыть карту сайта, мы к вам!
Найдя карту сайта, не забудьте отправить ее в Google и Bing.
Что такое карта сайта?
Карта сайта — это список всех страниц вашего сайта.
Программное обеспечение, которое посещает ваш веб-сайт, называется сканером, использует эту карту сайта, чтобы найти свой путь.
Хорошим примером поискового робота является Googlebot. Робот Googlebot посещает ваши страницы, чтобы прочитать их и добавить контент в поиск Google.
Вот почему карта сайта так полезна. Вместо того, чтобы искать все страницы роботом Googlebot, тяжелую работу выполняет карта сайта. Ускорение поиска ваших страниц роботом Googlebot.
Помимо карты сайта, вы также должны сообщить Google, где вы ее храните. После этого робот Googlebot может использовать эту карту сайта при следующем посещении.
Чтобы сообщить Google, добавьте карту сайта в Google Search Console.
Но что именно мы подаем?
Существует несколько форматов файлов Sitemap, например:
- XML
- Файл RSS / ATOM
- Обычный текстовый файл
Самым распространенным является XML, поскольку он наиболее гибкий. Он позволяет связывать карты сайта вместе и ссылаться на страницы на определенном языке.
Этот файл выглядит как HTML, например:
http://www.example.com/foo.html
4 июня 2018 г.
... В этом примере перечислены страницы сайта, а также время последнего изменения страницы с помощью тега lastmod .
То же самое можно сделать и с RSS- или ATOM-каналами. Это XML-каналы в другом формате.
Почти все программное обеспечение для блогов может создавать RSS- или ATOM-каналы. Но будьте осторожны с этим.
Некоторые программы для ведения блогов создают только список последних сообщений в блогах.Вы должны указать все страницы вашего сайта в вашей карте сайта.
Последний тип — это простой текстовый файл. Хотя это встречается реже, но все еще используется, вот образец карты сайта от Starbucks:
https://www.starbucks.com/menu
https://www.starbucks.com/menu/drinks
https://www.starbucks.com/menu/drinks/hot-coffees
... Текстовый файл содержит только список страниц сайтов, по одной странице в каждой строке. Нет никакой дополнительной информации, такой как дата последнего изменения.Это самый простой, но и наименее гибкий.
Если вам нужно создать карту сайта для нового сайта, используйте формат XML.
Множество файлов Sitemap
При посещении крупных сайтов, таких как BBC, вы обнаружите, что у них много карт сайта. Это связано с тем, что существует ограничение в 50 000 страниц и ограничение на размер файла в 50 МБ.
Чтобы связать карты сайта вместе, можно иметь основную карту сайта, которая ссылается на все остальные.
Для этого вы должны использовать XML и тег карты сайта , как показано ниже:
...
<карта сайта>
https://example.com/hats/sitemap.xml
... Мы рассмотрели, что такое карты сайта и как они разбиваются на множество файлов. давайте посмотрим, как можно найти карту сайта.
Как найти карту сайта?
Есть 5 способов найти карту сайта на сайте. Это:
- Используйте Robots.txt
- Вручную
- Воспользуйтесь поиском Google
- Найти RSS-карту сайта в источнике
- Консоль поиска Google
Начиная с самого простого к самому сложному.Начнем с роботов!
Используйте Robots.txt
Если вам повезет, карта сайта будет в файле robots.txt.
Как и карта сайта, файл robots также используется поисковыми роботами.
Сканер Googlebot использует файл robots.txt, чтобы узнать, куда ему можно, а куда нельзя.
Вы найдете этот файл, добавив /robots.txt в конец URL-адреса. Например:
https://exmaple.com/robots.txt
Каждая строка в этом файле представляет собой «правило», и поисковый робот следует каждому из перечисленных правил.
Сканер должен знать, куда идти, и правило Sitemap: показывает поисковому роботу, где находятся все страницы.
Например, если мы посмотрим на txt-файл robots с Airbnb, мы увидим карты сайта, перечисленные в конце файла:
Карта сайта: https://www.airbnb.com/sitemap-master-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-p2-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-p2_poi-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-homes_filters_expansion-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-homes_pdp-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-things_to_do_cities_and_categories-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-places_pdp-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-experiences_p2-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-experiences_pdp-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-additional_things_to_do-urls-index.xml.gz Если вам повезет, теперь у вас есть карта сайта.Если нет, то давайте посмотрим на ручную проверку.
Вручную
Один из способов найти карту сайта — это попробовать разные общие URL-адреса. Наиболее частое расположение карты сайта — sitemap.xml . Итак, добавив это в конец имени домена, вы можете проверить, существует ли карта сайта:
https://example.com/sitemap.xml
Если вы получите ошибку 404, значит карта сайта не найдена, и мы можем попробовать другое имя файла.
sitemap.xml — самый распространенный, но не единственный.
Чтобы получить список других распространенных имен файлов карты сайта, мы просмотрели карты сайта 7000+ веб-сайтов.
Вот список распространенных имен файлов для карты сайта, основанный на этом исследовании:
- /sitemap.xml
- /sitemap_index.xml
- /sitemap-index.xml
- / карта сайта /
- /post-sitemap.xml
- /sitemap/sitemap.xml
- /sitemap/index.xml
- / RSS /
- /rss.xml
- /sitemapindex.xml
- / карта сайта.xml.gz
- /sitemap_index.xml.gz
- /sitemap.php
- /sitemap.txt
- /atom.xml
Если ничего из этого не работает, добавьте заглавную букву, например, /Sitemap.xml . Попробуйте добавить заглавную букву к любому из названий файлов выше.
Если у вас все еще ничего нет, давайте рассмотрим поиск в Google.
Воспользуйтесь поиском Google
Мы можем использовать волшебство Google Search для поиска файлов XML. Мы также можем сузить поиск до определенного сайта.
Для поиска файлов XML на BBC мы будем использовать поиск:
inurl: bbc.co.uk тип файла: xml
В результате возвращается карта сайта:
Если вы получаете много страниц в результатах, вы можете сузить их, выполнив поиск по карте сайта в URL-адресе, например:
site: example.com inurl: sitemap filetype: xml
Не забывайте, что карты сайта также могут быть текстовыми файлами. Проделав то же самое для Starbucks, вы можете найти карту сайта:
сайт: starbucks.com inurl: тип файла карты сайта: txt
Приведенный выше поиск возвращает карту сайта:
Если вы все еще не можете найти его, давайте посмотрим, является ли это RSS-канал.
Вы можете использовать RSS-канал в качестве карты сайта, и многие блоги создают этот файл по умолчанию.
Чтобы найти файлы, посмотрите исходный код HTML-страницы.
Например, если мы откроем браузер Chrome и перейдем на страницу новостей SpaceX. Мы можем проверить источник страницы, щелкнув страницу правой кнопкой мыши и выбрав параметр «Проверить».
Если вы находитесь на вкладке «Элементы», вы можете выполнить поиск по коду:
application / rss + xml показывает наличие RSS-канала:
Если RSS-канал отсутствует, а карту сайта по-прежнему не удается найти. Есть еще одно место, куда стоит заглянуть.
Консоль поиска Google
Если все вышеперечисленное не помогло, то получите доступ к сайтам Google Search Console.
Чтобы помочь Google сканировать ваш веб-сайт, вы можете отправить карту сайта в Google Search Console.
Если в Google Search Console добавлена карта сайта, вы найдете ее в списке, перейдя в Индекс> Карты сайта.
Любые отправленные карты сайта будут выглядеть так:
Как найти карту сайта для веб-сайта: последние мысли
К настоящему времени вы нашли карту сайта. Отличная работа!
У нас есть общее представление о том, что такое карты сайта и что они бывают трех разных форматов:
- XML
- Файл RSS / ATOM
- Обычный текстовый файл
У вас есть 5 способов найти карты сайта, поскольку они не всегда находятся в одном и том же месте.
- Используйте Robots.txt
- Вручную
- Воспользуйтесь поиском Google
- Найти RSS-карту сайта в источнике
- Консоль поиска Google
Если эти 5 способов не сработали или у вас есть другой способ попробовать, оставьте комментарий ниже.
Как найти карту сайта для веб-сайта
Не можете найти карту сайта для веб-сайта?
Иногда бывает сложно найти карту сайта, так как существует несколько способов ее создания.
Кроме того, существуют различные типы файлов XML, TXT, RSS и ATOM.С чего начать?
Я дам вам 5 способов найти карту сайта на любом сайте.
Прежде чем мы начнем, давайте определимся, что такое карта сайта. Зная это, мы сможем найти, где прячется карта сайта.
Вы не можете скрыть карту сайта, мы к вам!
Найдя карту сайта, не забудьте отправить ее в Google и Bing.
Что такое карта сайта?
Карта сайта — это список всех страниц вашего сайта.
Программное обеспечение, которое посещает ваш веб-сайт, называется сканером, использует эту карту сайта, чтобы найти свой путь.
Хорошим примером поискового робота является Googlebot. Робот Googlebot посещает ваши страницы, чтобы прочитать их и добавить контент в поиск Google.
Вот почему карта сайта так полезна. Вместо того, чтобы искать все страницы роботом Googlebot, тяжелую работу выполняет карта сайта. Ускорение поиска ваших страниц роботом Googlebot.
Помимо карты сайта, вы также должны сообщить Google, где вы ее храните. После этого робот Googlebot может использовать эту карту сайта при следующем посещении.
Чтобы сообщить Google, добавьте карту сайта в Google Search Console.
Но что именно мы подаем?
Существует несколько форматов файлов Sitemap, например:
- XML
- Файл RSS / ATOM
- Обычный текстовый файл
Самым распространенным является XML, поскольку он наиболее гибкий. Он позволяет связывать карты сайта вместе и ссылаться на страницы на определенном языке.
Этот файл выглядит как HTML, например:
http://www.example.com/foo.html
4 июня 2018 г.
... В этом примере перечислены страницы сайта, а также время последнего изменения страницы с помощью тега lastmod .
То же самое можно сделать и с RSS- или ATOM-каналами. Это XML-каналы в другом формате.
Почти все программное обеспечение для блогов может создавать RSS- или ATOM-каналы. Но будьте осторожны с этим.
Некоторые программы для ведения блогов создают только список последних сообщений в блогах.Вы должны указать все страницы вашего сайта в вашей карте сайта.
Последний тип — это простой текстовый файл. Хотя это встречается реже, но все еще используется, вот образец карты сайта от Starbucks:
https://www.starbucks.com/menu
https://www.starbucks.com/menu/drinks
https://www.starbucks.com/menu/drinks/hot-coffees
... Текстовый файл содержит только список страниц сайтов, по одной странице в каждой строке. Нет никакой дополнительной информации, такой как дата последнего изменения.Это самый простой, но и наименее гибкий.
Если вам нужно создать карту сайта для нового сайта, используйте формат XML.
Множество файлов Sitemap
При посещении крупных сайтов, таких как BBC, вы обнаружите, что у них много карт сайта. Это связано с тем, что существует ограничение в 50 000 страниц и ограничение на размер файла в 50 МБ.
Чтобы связать карты сайта вместе, можно иметь основную карту сайта, которая ссылается на все остальные.
Для этого вы должны использовать XML и тег карты сайта , как показано ниже:
...
<карта сайта>
https://example.com/hats/sitemap.xml
... Мы рассмотрели, что такое карты сайта и как они разбиваются на множество файлов. давайте посмотрим, как можно найти карту сайта.
Как найти карту сайта?
Есть 5 способов найти карту сайта на сайте. Это:
- Используйте Robots.txt
- Вручную
- Воспользуйтесь поиском Google
- Найти RSS-карту сайта в источнике
- Консоль поиска Google
Начиная с самого простого к самому сложному.Начнем с роботов!
Используйте Robots.txt
Если вам повезет, карта сайта будет в файле robots.txt.
Как и карта сайта, файл robots также используется поисковыми роботами.
Сканер Googlebot использует файл robots.txt, чтобы узнать, куда ему можно, а куда нельзя.
Вы найдете этот файл, добавив /robots.txt в конец URL-адреса. Например:
https://exmaple.com/robots.txt
Каждая строка в этом файле представляет собой «правило», и поисковый робот следует каждому из перечисленных правил.
Сканер должен знать, куда идти, и правило Sitemap: показывает поисковому роботу, где находятся все страницы.
Например, если мы посмотрим на txt-файл robots с Airbnb, мы увидим карты сайта, перечисленные в конце файла:
Карта сайта: https://www.airbnb.com/sitemap-master-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-p2-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-p2_poi-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-homes_filters_expansion-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-homes_pdp-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-things_to_do_cities_and_categories-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-places_pdp-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-experiences_p2-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-experiences_pdp-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-additional_things_to_do-urls-index.xml.gz Если вам повезет, теперь у вас есть карта сайта.Если нет, то давайте посмотрим на ручную проверку.
Вручную
Один из способов найти карту сайта — это попробовать разные общие URL-адреса. Наиболее частое расположение карты сайта — sitemap.xml . Итак, добавив это в конец имени домена, вы можете проверить, существует ли карта сайта:
https://example.com/sitemap.xml
Если вы получите ошибку 404, значит карта сайта не найдена, и мы можем попробовать другое имя файла.
sitemap.xml — самый распространенный, но не единственный.
Чтобы получить список других распространенных имен файлов карты сайта, мы просмотрели карты сайта 7000+ веб-сайтов.
Вот список распространенных имен файлов для карты сайта, основанный на этом исследовании:
- /sitemap.xml
- /sitemap_index.xml
- /sitemap-index.xml
- / карта сайта /
- /post-sitemap.xml
- /sitemap/sitemap.xml
- /sitemap/index.xml
- / RSS /
- /rss.xml
- /sitemapindex.xml
- / карта сайта.xml.gz
- /sitemap_index.xml.gz
- /sitemap.php
- /sitemap.txt
- /atom.xml
Если ничего из этого не работает, добавьте заглавную букву, например, /Sitemap.xml . Попробуйте добавить заглавную букву к любому из названий файлов выше.
Если у вас все еще ничего нет, давайте рассмотрим поиск в Google.
Воспользуйтесь поиском Google
Мы можем использовать волшебство Google Search для поиска файлов XML. Мы также можем сузить поиск до определенного сайта.
Для поиска файлов XML на BBC мы будем использовать поиск:
inurl: bbc.co.uk тип файла: xml
В результате возвращается карта сайта:
Если вы получаете много страниц в результатах, вы можете сузить их, выполнив поиск по карте сайта в URL-адресе, например:
site: example.com inurl: sitemap filetype: xml
Не забывайте, что карты сайта также могут быть текстовыми файлами. Проделав то же самое для Starbucks, вы можете найти карту сайта:
сайт: starbucks.com inurl: тип файла карты сайта: txt
Приведенный выше поиск возвращает карту сайта:
Если вы все еще не можете найти его, давайте посмотрим, является ли это RSS-канал.
Вы можете использовать RSS-канал в качестве карты сайта, и многие блоги создают этот файл по умолчанию.
Чтобы найти файлы, посмотрите исходный код HTML-страницы.
Например, если мы откроем браузер Chrome и перейдем на страницу новостей SpaceX. Мы можем проверить источник страницы, щелкнув страницу правой кнопкой мыши и выбрав параметр «Проверить».
Если вы находитесь на вкладке «Элементы», вы можете выполнить поиск по коду:
application / rss + xml показывает наличие RSS-канала:
Если RSS-канал отсутствует, а карту сайта по-прежнему не удается найти. Есть еще одно место, куда стоит заглянуть.
Консоль поиска Google
Если все вышеперечисленное не помогло, то получите доступ к сайтам Google Search Console.
Чтобы помочь Google сканировать ваш веб-сайт, вы можете отправить карту сайта в Google Search Console.
Если в Google Search Console добавлена карта сайта, вы найдете ее в списке, перейдя в Индекс> Карты сайта.
Любые отправленные карты сайта будут выглядеть так:
Как найти карту сайта для веб-сайта: последние мысли
К настоящему времени вы нашли карту сайта. Отличная работа!
У нас есть общее представление о том, что такое карты сайта и что они бывают трех разных форматов:
- XML
- Файл RSS / ATOM
- Обычный текстовый файл
У вас есть 5 способов найти карты сайта, поскольку они не всегда находятся в одном и том же месте.
- Используйте Robots.txt
- Вручную
- Воспользуйтесь поиском Google
- Найти RSS-карту сайта в источнике
- Консоль поиска Google
Если эти 5 способов не сработали или у вас есть другой способ попробовать, оставьте комментарий ниже.
Как найти карту сайта для веб-сайта
Не можете найти карту сайта для веб-сайта?
Иногда бывает сложно найти карту сайта, так как существует несколько способов ее создания.
Кроме того, существуют различные типы файлов XML, TXT, RSS и ATOM.С чего начать?
Я дам вам 5 способов найти карту сайта на любом сайте.
Прежде чем мы начнем, давайте определимся, что такое карта сайта. Зная это, мы сможем найти, где прячется карта сайта.
Вы не можете скрыть карту сайта, мы к вам!
Найдя карту сайта, не забудьте отправить ее в Google и Bing.
Что такое карта сайта?
Карта сайта — это список всех страниц вашего сайта.
Программное обеспечение, которое посещает ваш веб-сайт, называется сканером, использует эту карту сайта, чтобы найти свой путь.
Хорошим примером поискового робота является Googlebot. Робот Googlebot посещает ваши страницы, чтобы прочитать их и добавить контент в поиск Google.
Вот почему карта сайта так полезна. Вместо того, чтобы искать все страницы роботом Googlebot, тяжелую работу выполняет карта сайта. Ускорение поиска ваших страниц роботом Googlebot.
Помимо карты сайта, вы также должны сообщить Google, где вы ее храните. После этого робот Googlebot может использовать эту карту сайта при следующем посещении.
Чтобы сообщить Google, добавьте карту сайта в Google Search Console.
Но что именно мы подаем?
Существует несколько форматов файлов Sitemap, например:
- XML
- Файл RSS / ATOM
- Обычный текстовый файл
Самым распространенным является XML, поскольку он наиболее гибкий. Он позволяет связывать карты сайта вместе и ссылаться на страницы на определенном языке.
Этот файл выглядит как HTML, например:
http://www.example.com/foo.html
4 июня 2018 г.
... В этом примере перечислены страницы сайта, а также время последнего изменения страницы с помощью тега lastmod .
То же самое можно сделать и с RSS- или ATOM-каналами. Это XML-каналы в другом формате.
Почти все программное обеспечение для блогов может создавать RSS- или ATOM-каналы. Но будьте осторожны с этим.
Некоторые программы для ведения блогов создают только список последних сообщений в блогах.Вы должны указать все страницы вашего сайта в вашей карте сайта.
Последний тип — это простой текстовый файл. Хотя это встречается реже, но все еще используется, вот образец карты сайта от Starbucks:
https://www.starbucks.com/menu
https://www.starbucks.com/menu/drinks
https://www.starbucks.com/menu/drinks/hot-coffees
... Текстовый файл содержит только список страниц сайтов, по одной странице в каждой строке. Нет никакой дополнительной информации, такой как дата последнего изменения.Это самый простой, но и наименее гибкий.
Если вам нужно создать карту сайта для нового сайта, используйте формат XML.
Множество файлов Sitemap
При посещении крупных сайтов, таких как BBC, вы обнаружите, что у них много карт сайта. Это связано с тем, что существует ограничение в 50 000 страниц и ограничение на размер файла в 50 МБ.
Чтобы связать карты сайта вместе, можно иметь основную карту сайта, которая ссылается на все остальные.
Для этого вы должны использовать XML и тег карты сайта , как показано ниже:
...
<карта сайта>
https://example.com/hats/sitemap.xml
... Мы рассмотрели, что такое карты сайта и как они разбиваются на множество файлов. давайте посмотрим, как можно найти карту сайта.
Как найти карту сайта?
Есть 5 способов найти карту сайта на сайте. Это:
- Используйте Robots.txt
- Вручную
- Воспользуйтесь поиском Google
- Найти RSS-карту сайта в источнике
- Консоль поиска Google
Начиная с самого простого к самому сложному.Начнем с роботов!
Используйте Robots.txt
Если вам повезет, карта сайта будет в файле robots.txt.
Как и карта сайта, файл robots также используется поисковыми роботами.
Сканер Googlebot использует файл robots.txt, чтобы узнать, куда ему можно, а куда нельзя.
Вы найдете этот файл, добавив /robots.txt в конец URL-адреса. Например:
https://exmaple.com/robots.txt
Каждая строка в этом файле представляет собой «правило», и поисковый робот следует каждому из перечисленных правил.
Сканер должен знать, куда идти, и правило Sitemap: показывает поисковому роботу, где находятся все страницы.
Например, если мы посмотрим на txt-файл robots с Airbnb, мы увидим карты сайта, перечисленные в конце файла:
Карта сайта: https://www.airbnb.com/sitemap-master-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-p2-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-p2_poi-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-homes_filters_expansion-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-homes_pdp-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-things_to_do_cities_and_categories-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-places_pdp-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-experiences_p2-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-experiences_pdp-urls-index.xml.gz
Карта сайта: https://www.airbnb.com/sitemap-additional_things_to_do-urls-index.xml.gz Если вам повезет, теперь у вас есть карта сайта.Если нет, то давайте посмотрим на ручную проверку.
Вручную
Один из способов найти карту сайта — это попробовать разные общие URL-адреса. Наиболее частое расположение карты сайта — sitemap.xml . Итак, добавив это в конец имени домена, вы можете проверить, существует ли карта сайта:
https://example.com/sitemap.xml
Если вы получите ошибку 404, значит карта сайта не найдена, и мы можем попробовать другое имя файла.
sitemap.xml — самый распространенный, но не единственный.
Чтобы получить список других распространенных имен файлов карты сайта, мы просмотрели карты сайта 7000+ веб-сайтов.
Вот список распространенных имен файлов для карты сайта, основанный на этом исследовании:
- /sitemap.xml
- /sitemap_index.xml
- /sitemap-index.xml
- / карта сайта /
- /post-sitemap.xml
- /sitemap/sitemap.xml
- /sitemap/index.xml
- / RSS /
- /rss.xml
- /sitemapindex.xml
- / карта сайта.xml.gz
- /sitemap_index.xml.gz
- /sitemap.php
- /sitemap.txt
- /atom.xml
Если ничего из этого не работает, добавьте заглавную букву, например, /Sitemap.xml . Попробуйте добавить заглавную букву к любому из названий файлов выше.
Если у вас все еще ничего нет, давайте рассмотрим поиск в Google.
Воспользуйтесь поиском Google
Мы можем использовать волшебство Google Search для поиска файлов XML. Мы также можем сузить поиск до определенного сайта.
Для поиска файлов XML на BBC мы будем использовать поиск:
inurl: bbc.co.uk тип файла: xml
В результате возвращается карта сайта:
Если вы получаете много страниц в результатах, вы можете сузить их, выполнив поиск по карте сайта в URL-адресе, например:
site: example.com inurl: sitemap filetype: xml
Не забывайте, что карты сайта также могут быть текстовыми файлами. Проделав то же самое для Starbucks, вы можете найти карту сайта:
сайт: starbucks.com inurl: тип файла карты сайта: txt
Приведенный выше поиск возвращает карту сайта:
Если вы все еще не можете найти его, давайте посмотрим, является ли это RSS-канал.
Вы можете использовать RSS-канал в качестве карты сайта, и многие блоги создают этот файл по умолчанию.
Чтобы найти файлы, посмотрите исходный код HTML-страницы.
Например, если мы откроем браузер Chrome и перейдем на страницу новостей SpaceX. Мы можем проверить источник страницы, щелкнув страницу правой кнопкой мыши и выбрав параметр «Проверить».
Если вы находитесь на вкладке «Элементы», вы можете выполнить поиск по коду:
application / rss + xml показывает наличие RSS-канала:
Если RSS-канал отсутствует, а карту сайта по-прежнему не удается найти. Есть еще одно место, куда стоит заглянуть.
Консоль поиска Google
Если все вышеперечисленное не помогло, то получите доступ к сайтам Google Search Console.
Чтобы помочь Google сканировать ваш веб-сайт, вы можете отправить карту сайта в Google Search Console.
Если в Google Search Console добавлена карта сайта, вы найдете ее в списке, перейдя в Индекс> Карты сайта.
Любые отправленные карты сайта будут выглядеть так:
Как найти карту сайта для веб-сайта: последние мысли
К настоящему времени вы нашли карту сайта. Отличная работа!
У нас есть общее представление о том, что такое карты сайта и что они бывают трех разных форматов:
- XML
- Файл RSS / ATOM
- Обычный текстовый файл
У вас есть 5 способов найти карты сайта, поскольку они не всегда находятся в одном и том же месте.
- Используйте Robots.txt
- Вручную
- Воспользуйтесь поиском Google
- Найти RSS-карту сайта в источнике
- Консоль поиска Google
Если эти 5 способов не сработали или у вас есть другой способ попробовать, оставьте комментарий ниже.
Как найти вашу карту сайта
Карта сайта — это список индексируемых страниц веб-сайта. Наиболее распространенный тип карты сайта, который обычно упоминается в SEO, отформатирован для поисковых систем, чтобы помочь их поисковым роботам находить все URL-адреса в домене.Карты сайта в формате HTML могут также существовать в виде страниц на сайте и обычно предназначены для помощи пользователям-людям, предоставляя список страниц для доступа ко всем из одного места.
Файлы Sitemapявляются одними из основных элементов здорового веб-сайта, но если вы не соберете их и не загрузите на свой сервер напрямую, вы можете не знать, есть ли он у вас и где он находится. Хотя файлы Sitemap не требуются, они могут гарантировать, что Google обнаружит все ваши URL-адреса. Они особенно полезны, если у вас плохая иерархия сайтов и / или внутренние ссылки.
Основным органом, отвечающим за управление стандартом для карт сайта, является sitemaps.org. Google поддерживает различные типы форматов файлов Sitemap, в том числе:
- XML
- RSS, mRSS и Atom 1.0
- Текст
- Сайтов Google
- HTML
Кроме того, доступно множество расширений, помогающих предоставить дополнительную информацию о содержании, содержащемся в вашем файле карты сайта. К ним относятся специальные протоколы для:
В дополнение к URL-адресам карты сайта вы также можете создать файл индекса карты сайта, который по сути является картой сайта из карт сайта.Включая ссылки на другие файлы карты сайта в индекс, вы можете организовать свои URL-адреса иерархически по разделам сайта или включить более 50000 URL-адресов на карту сайта, требуемую Google.
Вот некоторые из распространенных причин, по которым вы можете захотеть найти мошенническую карту сайта:
- Найдите старые карты сайта в своем домене, которые могут быть устаревшими
- Получить список всех страниц на сайте
- Плечо для конкурентного анализа (посмотрите, как конкуренты структурируют свои индексы карты сайта или каталоги сайтов)
- Найдите URL-адрес вашей карты сайта для отправки поисковым роботам (особенно, если ваша карта сайта автоматически создается системой управления контентом)
1.Проверить общие места
XML-файл карты сайта обычно находится в корневом каталоге вашего домена (например, https://www.websitedomain.com/sitemap.xml). Имя файла может быть любым, определенным веб-мастером, и файл может находиться где угодно, что является общедоступным в домене веб-сайта. Их можно поместить в подпапку, что иногда делается для того, чтобы скрыть карту сайта от конкурентов, ищущих простой способ обнаружить все URL-адреса в домене.
Если это ваш домен, вы можете получить доступ к каталогу файлов вашего веб-сайта через FTP, чтобы посмотреть, где может находиться xml-файл карты сайта.Если у вас нет прямого доступа к файлам вашего сайта, вы можете попробовать ввести некоторые общие соглашения об именах для файлов Sitemap в своем браузере, чтобы узнать, есть ли у вас активные файлы, к которым вы можете получить доступ. Например:
- https://www.websitedomain.com/sitemap.xml
- https://www.websitedomain.com/sitemap_index.xml
- https://www.websitedomain.com/sitemap1.xml
2. Проверьте файл robots.txt
На всех сайтах должен быть файл robots.txt, содержащий указания для поисковых роботов и веб-роботов, и этот файл обычно включает ссылку на карту сайта, чтобы помочь поисковым системам быстро найти файл карты сайта и начать сканирование.Стандартное расположение файла robots.txt находится непосредственно в основном каталоге сайта, то есть: https://www.websitedomain.com/robots.txt
.Вы можете попробовать это для любого домена, и если объявлена карта сайта, вы увидите запись строки, например:
Карта сайта: https://www.websitedomain.com/sitemap.xml
3. Используйте операторы расширенного поиска
Существует ряд операторов расширенного поиска, которые могут помочь уточнить поиск в Google. Если в домене есть карта сайта, которая не находится в стандартном местоположении или не указана в файле robots.txt, это лучший вариант для поиска карт сайта, обнаруженных и проиндексированных Google.
Существует два способа поиска в домене карт сайта xml, оба с использованием site: поиск по домену с поиском идентифицированных типов файлов XML. Попробуйте ввести один из них в Google, чтобы увидеть, есть ли результаты:
.сайт: websitedomain.com тип файла: xml
ИЛИ
сайт: websitedomain.com ext: xml
Если это возвращает много страниц файлов, которые не имеют отношения к делу, вы можете дополнительно уточнить поиск, добавив:
сайт: websitedomain.com filetype: xml inurl: карта сайта
ИЛИ
сайт: websitedomain.com ext: xml inurl: карта сайта
Это будет искать файлы XML в вашем домене со словом «карта сайта», включенным в имя файла или подкаталог.
4. Используйте инструмент (например, Google Search Console)
Если у вас есть соответствующий веб-сайт (возможно, это новый клиент или вы новичок в команде), и для этого сайта уже настроено свойство консоли поиска Google, войдите в систему, чтобы увидеть, есть ли карта сайта, объявленная, что Google уже является ползание.
Кроме того, существуют другие инструменты, которые сканируют Интернет и предлагают инструменты для проверки доменов для карт сайта. У SEO Site Checkup есть инструмент карты сайта, который очень прост в использовании, просто введите свой домен, и он сообщит вам, нашел ли он файл карты сайта (примечание: это не гарантируется).
5. Проверьте свою CMS
Если вы используете обычную CMS, возможно, они автоматически создают карту сайта. Проверьте документацию в зависимости от вашей CMS, чтобы узнать, есть ли какие-либо подробности о файлах Sitemap.Мы включили некоторую информацию о некоторых из наиболее распространенных CMS ниже:
Как найти свою карту сайта на WordPressWordPress не имеет встроенных функций для автоматического создания карт сайта, однако есть много плагинов, которые предоставляют эту функцию. Наиболее распространенными плагинами являются Yoast SEO и Google XML Sitemaps.
Плагиныне устанавливаются по умолчанию, поэтому это не относится к новым веб-сайтам, только к существующим сайтам или сайтам, которые были настроены разработчиком, который, возможно, установил их для дополнительных функций.Чтобы узнать, какие плагины установлены на вашем сайте WordPress, вам нужно щелкнуть ссылку «Плагины» в левой части панели управления WordPress. Если «Yoast SEO» является активным плагином, у вас будет ссылка «SEO» на левой боковой панели, и вы найдете файлы Sitemap под дополнительной ссылкой «XML Sitemaps».
Если эти плагины специально не настроены для размещения файлов Sitemap в определенных каталогах, вы обычно найдете их в стандартных местоположениях / именах файлов, описанных в совете №1.
Помимо плагинов, вы также можете проверить любые настройки пользовательской темы, «Инструменты» и «Настройки» и найти любые настройки XML или Sitemap.Если сомневаетесь, проверьте свою документацию.
Как найти свою карту сайта на Squarespace, Shopify или WixВсе три из этих платформ автоматически генерируют карты сайта в формате XML и размещают их в виде файла sitemap.xml в вашем домене. Вы сможете найти свою карту сайта, добавив /sitemap.xml в конец своего домена в браузере.
Пример: https://www.websitedomain.com/sitemap.xml
Хотя эти службы не позволяют напрямую изменять файлы карты сайта, они автоматически обновляются с новыми URL-адресами при их создании, если вы явно не укажете, что они должны быть исключены на уровне страницы.
После того, как вы определили или создали карту сайта, вам нужно будет подтвердить, что файл действителен. Вы можете использовать такой инструмент, как этот валидатор, с сайта XML-Sitemaps.com. Если у вас есть действующий файл карты сайта, выполните следующие действия, чтобы максимально повлиять на SEO:
- Убедитесь, что ваша карта сайта актуальна, а URL-адреса действительны: помимо допустимого формата файла карта сайта должна содержать только точные URL-адреса. Все старые или неправильные карты сайта следует удалить, чтобы не запутать ботов.
- Добавьте объявление карты сайта в файл robots.txt (необязательно): это хорошая идея для других поисковых систем, не являющихся Google или Bing, но если вы беспокоитесь о том, что конкуренты получают ценную информацию через вашу карту сайта, это необязательно.
- Отправьте карту сайта в Google через консоль поиска Google: GSC предоставляет ценную информацию о том, как Google обрабатывает файл карты сайта.
- Отправьте карту сайта в Bing с помощью инструментов Bing для веб-мастеров: Bing также предоставляет инструмент для отправки карты сайта.