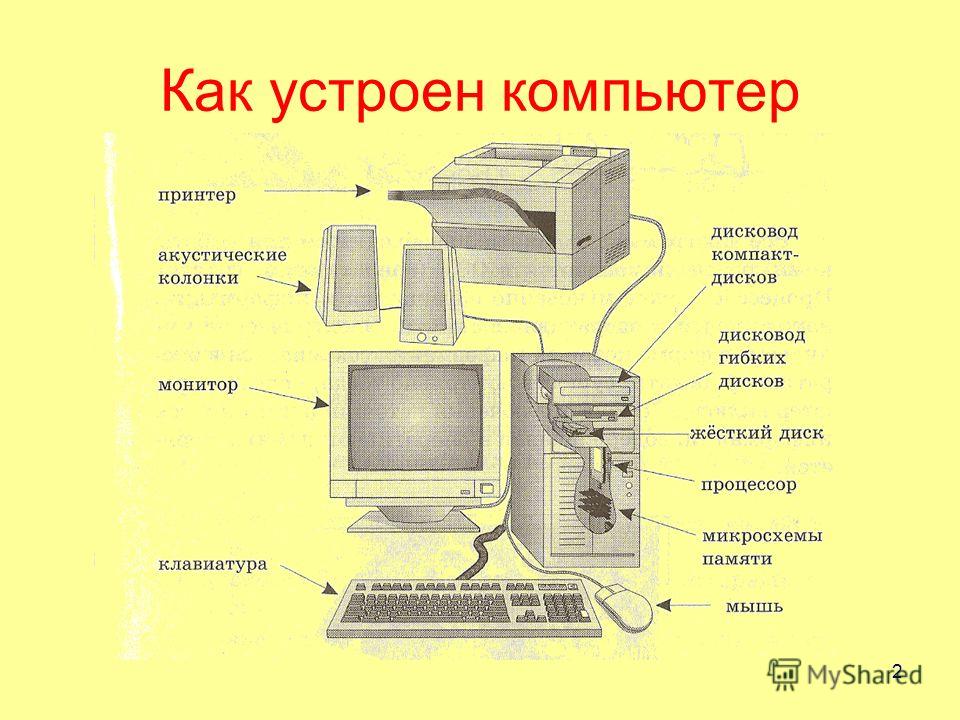
Как работает веб-сайт технические моменты для начинающих
Как работает веб-сайт со стороны пользователя выглядит довольно просто: это всего лишь набор отображаемых в браузере страниц с элементами навигации, баннеров, новостей и прочей информации.
На самом деле, если заглянуть по другую сторону страницы отображаемой браузером, все эту информацию выводит в окне браузера специальные языки программирования (php), разметки (html, xhtml), стилей (css), скриптов (JavaScript) и отвечают за динамическое содержимое.
Информация от пользователя в виде нажатия на ссылку или ввода определенного запроса в окно поиска, поступает на сервер, где обрабатывается и выводится, уже в готовом виде и посетителю сайта абсолютно все равно, какое программное обеспечение установлено на сервере и как оно работает.
Содержание
- Техническая сторона работы веб – сайта
- Что такое клиент
- Что такое сервер
- Что такое ресурс
- СистемаDNS
- Протокол передачи данных
- Как работает веб – сайт созданный наcms
- Сервер глазами администратора
- Заключение
Клиентом является программа-браузер (opera, google, mozilla), которая работает на вашем компьютере или любом другом девайсе (телефон, часы, ноутбук и пр. )
)
Под сервером понимают две вещи:
Во-первых – это главный компьютер, на котором все работает. Он расположен в дата-центре, в какой-то интернет-компании.
И с другой стороны – под сервером понимают приложение, которое работает на этом компьютере. Т. есть, приложение называют веб-сервером.
Клиент – это браузер, сервер – это веб-сервер.
Сам сайт хранится на стороне сервера. Клиент обращается к серверу, открывает сетевое соединение, отправляет запрос, веб-сервер отвечает на этот запрос и возвращает в браузер HTML-страничку.
Другими словами – сама html-страница хранится на веб-сервере, клиент получает её от сервера по сети.
Важно понимать, что веб-сайты (веб-приложения) работают в режиме запрос – ответ. Как правило, на каждый запрос открывается одно сетевое соединение.
Что такое ресурсКусочки информации в вебе называются ресурсами:
- Веб-страница – это ресурс;
- Картинка, которая хранится на сервере – это тоже ресурс.

У каждого ресурса есть уникальный идентификатор – URL.
Браузер обращается к серверу, открывает сетевое соединение, отправляет идентификатор ресурса (имя ресурса, которое он хочет получить), веб-сервер возвращает через это же соединение ему этот ресурс.
Иными словами, происходит запрос – происходит ответ. После чего сетевое соединение закрывается.
Идея очень простая.
Браузер – это программа для просмотра ресурсов. Ресурсы бывают разными, например, html-странички. Браузер получает этот ресурс и пытается отобразить по определенным правилам.
Если есть текст – он отображает текст, если это картинка, он отображает картинку, гиперссылку и т. далее.
Один ресурс может содержать в себе другие. Например, вы загружаете веб-страницу, она может содержать в себе картинки.
В таком случае, браузер проанализирует страницу, поймет, что она содержит в себе картинки, их идентификаторы и ссылки (URL), после этого он запросит с веб-сервера недостающие ему ресурсы. И когда все ресурсы будут загружены, браузер может целиком отобразить страницу.
И когда все ресурсы будут загружены, браузер может целиком отобразить страницу.
Это цикл работы веб-приложений. После того, как пользователь делает какое-то действие, цикл повторяется.
К примеру, пользователь нажимает на ссылку переходит на другую страницу, браузер все действия повторяет.
Как это происходит более подробно, или с чего все начинается?
Пользователь вбивает в адресной строке некоторые слова, как правило, это доменное имя (mail.ru, вконтакте). Первое что нужно сделать – это преобразовать доменное имя в IP-адрес.
Система DNSКаждая машина (компьютер) сети интернет имеют уникальную адресацию. Адрес каждой машины называют IP-адресом, который представляется в виде набора чисел.
Сейчас существует две версии айпи-адресов:
IP в версии 4, состоящие из 4-х байт и IP версии 6. Понятно, что запоминать все IP-адреса, всех веб-серверов – это не реально, поэтому для этого используется система DNS – распределённая база данных, которая хранит в себе отображение имён на IP-адреса.
Распределённая она по причине того, что все записи хранить в одной машине невозможно, слишком большая нагрузка и объём данных.
Поэтому система DNS иерархическая. Все доменные имена разделены точками. Самая правая часть – это домен верхнего уровня.
Какая-то группа машин, которая называется корневыми серверами DNS, хранит информацию о доменах верхнего уровня:
.ru – Россия
.de – Германия
.kz – Казахстан
Браузер вначале обращается именно к этим DNS-серверам, эти машины уже отправляют его туда, где хранятся DNS-сервера более низкого уровня (mail.ru).
Браузер по очереди, с помощью какой-то библиотеки, опрашивает все сервера и в конечном итоге находит сервер, который выдает ему нужный IP-адрес.
Другими словами, система DNS преобразует доменное имя понятное и запоминаемое в IP-адрес.
Что происходит после того, как браузер получил IP-адрес?
Он устанавливает сетевое соединение. В свою очередь, сетевое соединение (IP-соединение) для браузера выглядит фактически как файл, в который он может что-то записать и с которым может что-то прочитать, называется socket.
Браузер открывает socket, который устанавливает сетевое соединение с удаленной машиной. Далее, по этому сокету передает какой-то запрос и получает ответ.
В каком формате передавать запрос?
Протокол передачи данныхПротоколов передачи данных множество. Для повсеместной работы в основном используются два вида протокола:
HTTP (англ. «протокол передачи гипертекста») — сетевой протокол верхнего уровня для передачи гипертекстовых и произвольных данных в интернете.
При помощи HTTP браузер получает данные от веб-серверов и может отображать их в понятном виде. Точно также происходит и обратный процесс — отправку пользовательских данных обратно, на сервер (например, при регистрации).
HTTPS (HyperText Transfer Protocol Secure) – это расширенный HTTP – протокол, поддерживающий шифрование.
Более подробно об этих протоколах можно узнать в документации microsoft
Поисковые системы, в первую очередь, отдают предпочтения сайтам с протоколом HTTPS (https://starting-constructor. ru).
ru).
Еще по теме: Ошибка протокола https в wordpress
Как работает веб – сайт созданный на cmsСайт, на котором часто обновляется информация, требует мобильного управления.
Страницы, которые часто изменяются, называются динамическими и для создания динамических страниц необходим движок, или говоря современным языком, система управления содержимым (Content Management System, CMS).
Именно движок формирует веб-страницы в соответствии с запросами пользователя.
В CMS-системах есть два интерфейса:
пользовательский и администраторский.
Пользовательский — сторона сайта, которую видят пользователи.
Администраторский — внутренняя сторона сайта, доступ к которой выдает администратор.
Все управление сайтом производится из администраторского раздела: добавление страниц, статей, различных модулей, управление пользователями, рассылками, баннерами, созданием ссылок, авторизации и многое другое.
Чтобы добавить информацию в CMS, особых знаний не требуется. Редактирования текста производится WYSIWYG-редактором, напоминающим Word. Система сама сохраняет загруженные файлы в нужном месте и при необходимости переименовывает их, а все настройки устанавливаются с помощью простого и понятного графического интерфейса.
Для тех, кто имеет небольшие познания в области программирования и веб-верстки, есть возможность применить их для редактирования и ручной правки html-кода cms-системы, а также написания собственных модулей, тем и стилей.
В cms это возможно, так как исходный код открыт для редактирования.
Сервер глазами администратораДля работы CMS необходимо, чтобы на сервере было установлено соответствующее программное обеспечение.
Большинство CMS-систем написано на языке программирования (php), если это так, то на сервере должна быть установлена соответствующая среда исполнения (интерпретатор php) и система управления базами данных (СУБД), которая будет хранить все настройки и элементы содержимого сайта.
Так же, необходим веб-сервер – программа, принимающая запросы пользователей, запускающая CMS и передающая обратно готовые веб-страницы.
Для системы управления содержимым в конечном счете безразлично, какая операционная система установлена на сервере.
Конечно, современные движки (CMS) – это не панацея, есть и другие способы создания сайтов, но это самый популярный, быстрый и простой способ создать достойный проект.
Как работает веб-сайт можно протестировать прямо на компьютере, не покупая хостинг и доменное имя. Для этих целей существует как минимум, десяток локальных серверов, имеющих похожий функционал как на удаленном хостинге.
Подробнее: Openserver установка и настройка
Заключение
Подробные технические моменты как работает веб-сайт в большей степени, пригодятся для создания приложений. С позиции простого пользователя самым удобным и доступным является способ создания проектов на cms – системах, не требующих знаний языков программирования.
В них уже все есть для нормальной работы современного сайта.
Как работает сайт? — Meduza
1
Сайт — это вообще что?
Это несколько связанных между собой страниц с текстом, картинками и всем остальным, что бывает в интернете. Если вы читаете эти карточки через браузер — значит, вы на сайте «Медузы». Ваш браузер скачал эту статью в виде страницы на языке HTML (именно на нем пишутся, а точнее — размечаются веб-страницы) и считал специальные разметки — наборы букв и символов, преобразовав их в нечто более симпатичное, чем просто текст. Поэтому вы видите аккуратно отформатированный текст с фоном, картинками, ссылками, кнопками и так далее. Например, текст вида <strong>«Медуза»</strong> преобразуется на сайте так, что слово «Медуза» становится выделено полужирным.
2
Но по сути сайт — это просто страница с текстом?
Не всегда. Бывают статические и динамические сайты. Статические — это готовые HTML-страницы: например, сайты-визитки с контактами, прайс-листом и другой информацией, которую не нужно часто менять. Когда прайс-лист устареет, придется зайти на сервер и обновить файл. А если у сайта сотня страниц, которые нужно обновить, тогда придется заменить сто файлов, даже если некоторые из них одинаковые. Чтобы упростить этот процесс, были придуманы динамические сайты. В их основе — веб-сервер, специальная программа, которая принимает запрос пользователя и каждый раз генерирует для него новый файл с той страницей, запрос к которой он отправил. Веб-сервер может предоставить хостинг-компания, или вы должны установить программу на сервер сами (о хостинге и сервере мы расскажем ниже). Потом эту программу можно менять, подключать к ней базу данных (например, с пользователями или товарами), выносить повторяющиеся элементы в отдельные шаблоны. Именно так сейчас делаются все большие сайты — онлайн-магазины, медиа, да что угодно. В том числе и сайт «Медузы».
Когда прайс-лист устареет, придется зайти на сервер и обновить файл. А если у сайта сотня страниц, которые нужно обновить, тогда придется заменить сто файлов, даже если некоторые из них одинаковые. Чтобы упростить этот процесс, были придуманы динамические сайты. В их основе — веб-сервер, специальная программа, которая принимает запрос пользователя и каждый раз генерирует для него новый файл с той страницей, запрос к которой он отправил. Веб-сервер может предоставить хостинг-компания, или вы должны установить программу на сервер сами (о хостинге и сервере мы расскажем ниже). Потом эту программу можно менять, подключать к ней базу данных (например, с пользователями или товарами), выносить повторяющиеся элементы в отдельные шаблоны. Именно так сейчас делаются все большие сайты — онлайн-магазины, медиа, да что угодно. В том числе и сайт «Медузы».
3
Хорошо. Но как управлять информацией на этом веб-сервере?
С помощью системы управления контентом (CMS — Content Management System) — в простонародье админки. Они различаются в зависимости от задач, для которых предназначены. Для блогов это одни (например, WordPress), для интернет-магазинов — другие (такие как «1С-Битрикс»). Бывают ситуации, когда компания не может найти на рынке готовое решение под свои задачи, тогда им приходится создавать CMS самостоятельно. По этому пути пошла и «Медуза». У нас есть собственная система «Монитор» — она же и внутренний редактор. Через нее загружаются и публикуются тексты, здесь работает вся редакция.
Они различаются в зависимости от задач, для которых предназначены. Для блогов это одни (например, WordPress), для интернет-магазинов — другие (такие как «1С-Битрикс»). Бывают ситуации, когда компания не может найти на рынке готовое решение под свои задачи, тогда им приходится создавать CMS самостоятельно. По этому пути пошла и «Медуза». У нас есть собственная система «Монитор» — она же и внутренний редактор. Через нее загружаются и публикуются тексты, здесь работает вся редакция.
4
Для сайта нужно установить здоровенный сервер?
Сервер нужен. Но обычно владельцы сайта покупают вычислительные мощности у сторонних компаний. Эта услуга называется хостингом, ее предоставляет множество компаний с различными ценами, оборудованием и скоростью интернета в дата-центрах — специальных зданиях, где установлено серверное оборудование. Если нужен хостинг для простого сайта, обычно покупается так называемый виртуальный сервер — это когда на одном физическом сервере находится сразу несколько сайтов, не связанных друг с другом, при этом каждый из них получает ограниченный доступ к мощности сервера. Если сайт сложный, то берется в аренду физический сервер — тогда вся его мощность будет в вашем распоряжении, но вам же придется заниматься его настройкой. «Медуза» берет в аренду серверы в нескольких компаниях и дата-центрах сразу. Так мы, во-первых, страхуем себя от ситуаций, когда с одним дата-центром что-то случится (например, выключится электричество), а во-вторых, так мы можем находиться ближе к читателю. То есть наш сервер может быть неподалеку от вас, что позволяет данным перемещаться до вашего компьютера быстрее.
Если сайт сложный, то берется в аренду физический сервер — тогда вся его мощность будет в вашем распоряжении, но вам же придется заниматься его настройкой. «Медуза» берет в аренду серверы в нескольких компаниях и дата-центрах сразу. Так мы, во-первых, страхуем себя от ситуаций, когда с одним дата-центром что-то случится (например, выключится электричество), а во-вторых, так мы можем находиться ближе к читателю. То есть наш сервер может быть неподалеку от вас, что позволяет данным перемещаться до вашего компьютера быстрее.
5
То есть сайты медленно работают из-за того, что их серверы далеко?
Не только из-за этого. Скорость загрузки сайта зависит как от хостинга, так и от сложности его архитектуры и количества пользователей, которые одновременно на него заходят. Скорость может зависеть и от вашего интернет-соединения, и от мощности вашего устройства. Одна из задач разработчиков — сделать обмен информацией между пользователем и сервером максимально быстрым. Существуют разные способы этого добиться. Например, при помощи CDN — сетей доставки контента — можно быстрее «отдавать» пользователю некоторые элементы сайта. Также нужно оптимизировать код, обновлять оборудование и программное обеспечение. Пренебрежительное отношение к «железу», «софту» или коду сайта запросто может привести к потере аудитории и другим неприятным последствиям. В интернет-магазине уменьшится число продаж или возникнут проблемы с оформлением заказов, сайт популярного медиа не справится с пиковой нагрузкой в ответственный момент и так далее.
Например, при помощи CDN — сетей доставки контента — можно быстрее «отдавать» пользователю некоторые элементы сайта. Также нужно оптимизировать код, обновлять оборудование и программное обеспечение. Пренебрежительное отношение к «железу», «софту» или коду сайта запросто может привести к потере аудитории и другим неприятным последствиям. В интернет-магазине уменьшится число продаж или возникнут проблемы с оформлением заказов, сайт популярного медиа не справится с пиковой нагрузкой в ответственный момент и так далее.
6
Понятно. Но в целом все сайты устроены одинаково? Есть какой-то базовый набор страниц?
Единого набора нет. Архитектура может быть очень разной. Но у сайта всегда (за очень редким исключением) есть главная страница. Также все сайты делятся на фронтэнд и бекэнд. Фронтэнд — это фасад сайта, то, с чем взаимодействует посетитель: весь текст, картинки, кнопки и так далее. Бекэнд — это задний двор: устройство веб-сервера, которое отвечает за то, чтобы код работал правильно, письма отправлялись, статьи отображались и так далее. Бекэнд может быть устроен по-разному. Некоторые сайты работают благодаря единой программе, другие имеют так называемую микросервисную архитектуру — то есть состоят из множества разных, слабо связанных друг с другом программ. Когда одна выходит из строя, другие части продолжают нормально работать. Как раз так устроена «Медуза».
Бекэнд может быть устроен по-разному. Некоторые сайты работают благодаря единой программе, другие имеют так называемую микросервисную архитектуру — то есть состоят из множества разных, слабо связанных друг с другом программ. Когда одна выходит из строя, другие части продолжают нормально работать. Как раз так устроена «Медуза».
7
Как насчет мобильной версии сайта? Ее нужно делать отдельно?
Вообще есть два способа сделать так, чтобы сайт нормально отображался и на телефоне, и на компьютере. Первый: делаются две разные версии сайта, и в зависимости от того, с какого устройства на него заходит пользователь, ему отдается подходящая. Второй: сайт автоматически меняется в зависимости от ширины экрана. Такой подход требует более глубокой проработки дизайна, но плюс в том, что нам не нужно поддерживать две версии сайта. Понять, как именно сделан сайт, можно просто: откройте сайт в браузере на компьютере и уменьшите окно. Если он хорошо выглядит в узком окне — он сверстан адаптивно. «Медуза» и большинство новых сайтов сделаны именно так.
«Медуза» и большинство новых сайтов сделаны именно так.
8
Какие еще внутри сайта есть хитрости, которые не видит пользователь?
Существуют разные служебные разделы. Например, файл robots.txt позволяет сайту попадать в выдачу результатов поиска «Яндекса» и Google или, наоборот, запрещает поисковикам индексировать некоторые страницы. Еще есть .htaccess — он регулирует разные правила: например, перенаправляет пользователя на главную, если он вдруг зашел на несуществующую страницу.
9
А есть у сайта «Медузы» что-то особенное?
Мы в «Медузе» любим экспериментальные технологии — пусть они недоработанные и с ними приходится сложнее, зато они дают технологические преимущества. Например, мы пользуемся языком Elixir. Он молодой и непопулярный, но на нем можно очень быстро писать realtime-системы, например наши чаты, — такие мало где есть. Но, конечно, не везде допустимы эксперименты. Те части сайта, которые должны работать предсказуемо и надежно, пишутся на проверенных технологиях и языках.![]() CMS написана на Ruby on Rails — этому фреймворку уже больше десяти лет, и непонятных ситуаций с ним возникает куда меньше, чем с более новыми разработками.
CMS написана на Ruby on Rails — этому фреймворку уже больше десяти лет, и непонятных ситуаций с ним возникает куда меньше, чем с более новыми разработками.
10
С надежностью понятно, а что с безопасностью сайта?
Безопасность бывает разной. Нужно стремиться к тому, чтобы сайт нельзя было взломать, но достичь этого на 100% практически невозможно. Если вас очень захотят «хакнуть», то сделают это — вопрос только в цене. Именно на это стоит делать расчет и приложить все усилия к тому, чтобы стоимость взлома была очень высокой. Есть несколько способов этого достичь. Во-первых, стоит провести независимый аудит безопасности. Это дорого, но дешевле, чем последствия взлома. Во-вторых, нужно обновлять не только код, но и все программное обеспечение администраторов сайта. В-третьих, нужно проводить тренинги для сотрудников и обучать их правилам безопасности. В-четвертых, нужно позаботиться и о безопасности посетителей вашего сайта — использовать HTTPS, проверять партнёров, рекламные сети, сторонние скрипты. Наконец, контролируйте среду, в которой работают ваши программисты — настройте доступы таким образом, чтобы разработчики имели доступ только к тем частям системы, которые нужны для их работы. Соблюдение этих правил позволит вашему сайту жить долго и счастливо, а вашим посетителям — быстро и качественно получать то, за чем они пришли.
Наконец, контролируйте среду, в которой работают ваши программисты — настройте доступы таким образом, чтобы разработчики имели доступ только к тем частям системы, которые нужны для их работы. Соблюдение этих правил позволит вашему сайту жить долго и счастливо, а вашим посетителям — быстро и качественно получать то, за чем они пришли.
Этот материал мы подготовили вместе с DataLine. Узнать больше о хостинге и поддержке веб-проектов на аутсорсинге можно на сайте компании.
Наполнение страницы: как работают браузеры — Производительность в Интернете
Пользователи хотят работать в Интернете с контентом, который быстро загружается и с которым легко взаимодействовать. Поэтому разработчик должен стремиться к достижению этих двух целей.
Чтобы понять, как улучшить производительность и воспринимаемую производительность, нужно понять, как работает браузер.
Быстрые сайты обеспечивают лучший пользовательский опыт. Пользователи хотят и ожидают веб-интерфейса с контентом, который быстро загружается и с которым легко взаимодействовать.
Две основные проблемы с веб-производительностью — это проблемы, связанные с задержкой, и проблемы, связанные с тем фактом, что по большей части браузеры являются однопоточными.
Задержка — самая большая угроза нашей способности обеспечить быструю загрузку страницы. Цель разработчиков — сделать так, чтобы сайт загружался как можно быстрее — или, по крайней мере, отображалось как для сверхбыстрой загрузки — чтобы пользователь как можно быстрее получал запрошенную информацию. Сетевая задержка — это время, необходимое для передачи байтов по воздуху на компьютеры. Веб-производительность — это то, что мы должны сделать, чтобы страница загружалась как можно быстрее.
По большей части браузеры считаются однопоточными. То есть они выполняют задачу от начала до конца, прежде чем приступить к другой задаче. Для плавного взаимодействия цель разработчика — обеспечить эффективное взаимодействие с сайтом, от плавной прокрутки до отклика на прикосновение. Время рендеринга является ключевым моментом, так как главный поток может завершить всю работу, которую мы на него возлагаем, и при этом всегда быть доступным для обработки взаимодействий с пользователем. Веб-производительность может быть улучшена за счет понимания однопоточной природы браузера и сведения к минимуму обязанностей основного потока, где это возможно и уместно, чтобы обеспечить плавность рендеринга и немедленные ответы на взаимодействия.
Веб-производительность может быть улучшена за счет понимания однопоточной природы браузера и сведения к минимуму обязанностей основного потока, где это возможно и уместно, чтобы обеспечить плавность рендеринга и немедленные ответы на взаимодействия.
Навигация — это первый шаг в загрузке веб-страницы. Это происходит всякий раз, когда пользователь запрашивает страницу, вводя URL-адрес в адресную строку, щелкая ссылку, отправляя форму, а также выполняя другие действия.
Одна из целей веб-производительности — свести к минимуму время, необходимое для завершения навигации. В идеальных условиях это обычно не занимает слишком много времени, но задержка и пропускная способность являются врагами, которые могут вызывать задержки.
DNS-поиск
Первым шагом при переходе на веб-страницу является определение местоположения ресурсов этой страницы. Если вы перейдете к https://example.com , HTML-страница расположена на сервере с IP-адресом 93. . Если вы никогда не посещали этот сайт, необходимо выполнить поиск DNS. 184.216.34
184.216.34
Ваш браузер запрашивает поиск DNS, который в конечном итоге обрабатывается сервером имен, который, в свою очередь, отвечает IP-адресом. После этого первоначального запроса IP-адрес, скорее всего, будет кэшироваться на некоторое время, что ускоряет последующие запросы за счет извлечения IP-адреса из кэша вместо повторного обращения к серверу имен.
DNS-запросы обычно нужно выполнять только один раз для каждого имени хоста для загрузки страницы. Однако поиск DNS должен выполняться для каждого уникального имени хоста, на которое ссылается запрошенная страница. Если ваши шрифты, изображения, сценарии, реклама и метрики имеют разные имена хостов, для каждого из них необходимо выполнить поиск в DNS.
Это может отрицательно сказаться на производительности, особенно в мобильных сетях. Когда пользователь находится в мобильной сети, каждый поиск DNS должен идти с телефона на вышку сотовой связи, чтобы достичь авторитетного DNS-сервера. Расстояние между телефоном, вышкой сотовой связи и сервером имен может увеличить задержку.
Расстояние между телефоном, вышкой сотовой связи и сервером имен может увеличить задержку.
TCP Handshake
Когда IP-адрес известен, браузер устанавливает соединение с сервером через трехстороннее TCP-рукопожатие. Этот механизм разработан таким образом, что два объекта, пытающиеся установить связь, — в данном случае браузер и веб-сервер — могут согласовать параметры сетевого TCP-сокета перед передачей данных, часто по протоколу HTTPS.
Метод трехэтапного квитирования TCP часто называют «SYN-SYN-ACK» или, точнее, SYN, SYN-ACK, ACK, поскольку протокол TCP передает три сообщения для согласования и запуска сеанса TCP между двумя компьютерами. . Да, это означает еще три сообщения взад и вперед между каждым сервером, и запрос еще не сделан.
Согласование TLS
Для безопасных соединений, установленных через HTTPS, требуется еще одно «рукопожатие». Это рукопожатие или, скорее, согласование TLS определяет, какой шифр будет использоваться для шифрования связи, проверяет сервер и устанавливает наличие безопасного соединения перед началом фактической передачи данных.
Хотя обеспечение безопасности соединения увеличивает время загрузки страницы, безопасное соединение стоит затрат на задержку, поскольку данные, передаваемые между браузером и веб-сервером, не могут быть расшифрованы третьей стороной.
После 8 обходов браузер, наконец, может выполнить запрос.
Как только мы установили соединение с веб-сервером, браузер отправляет начальный HTTP-запрос GET от имени пользователя, который для веб-сайтов чаще всего представляет собой HTML-файл. Как только сервер получит запрос, он ответит соответствующими заголовками ответа и содержимым HTML.
<голова>
<метакодировка="UTF-8" />
Моя простая страница
<ссылка rel="stylesheet" href="styles.css" />
<тело>
Моя страница
com/about">ссылкой
<дел>


Этот ответ на этот первоначальный запрос содержит первый байт полученных данных. Время до первого байта (TTFB) — это время между тем, когда пользователь сделал запрос, например, нажав на ссылку, и получением этого первого пакета HTML. Первый фрагмент контента обычно составляет 14 КБ данных.
В нашем примере выше размер запроса определенно меньше 14 КБ, но связанные ресурсы не запрашиваются до тех пор, пока браузер не обнаружит ссылки во время синтаксического анализа, описанного ниже.
Медленный запуск TCP / 14 КБ правило
Размер первого ответного пакета составляет 14 КБ. Это часть алгоритма медленного старта TCP, который уравновешивает скорость сетевого соединения. Медленный старт постепенно увеличивает объем передаваемых данных до тех пор, пока не будет определена максимальная пропускная способность сети.
При медленном запуске TCP после получения исходного пакета сервер удваивает размер следующего пакета примерно до 28 КБ. Последующие пакеты увеличиваются в размере до тех пор, пока не будет достигнут заданный порог или не возникнет перегрузка.
Если вы когда-либо слышали о правиле 14 КБ для начальной загрузки страницы, медленный запуск TCP является причиной того, что начальный ответ составляет 14 КБ, и почему оптимизация веб-производительности требует фокусировки оптимизации с учетом этого начального ответа 14 КБ. Медленный запуск TCP постепенно увеличивает скорость передачи, соответствующую возможностям сети, чтобы избежать перегрузки.
Управление перегрузкой
Когда сервер отправляет данные в TCP-пакетах, клиент пользователя подтверждает доставку, возвращая подтверждения или ACK. Соединение имеет ограниченную пропускную способность в зависимости от оборудования и сетевых условий. Если сервер отправляет слишком много пакетов слишком быстро, они будут отброшены. То есть признания не будет. Сервер регистрирует это как отсутствующие ACK. Алгоритмы управления перегрузкой используют этот поток отправленных пакетов и ACK для определения скорости отправки.
То есть признания не будет. Сервер регистрирует это как отсутствующие ACK. Алгоритмы управления перегрузкой используют этот поток отправленных пакетов и ACK для определения скорости отправки.
Как только браузер получит первый фрагмент данных, он может начать анализ полученной информации. Синтаксический анализ — это шаг, который браузер выполняет, чтобы преобразовать данные, которые он получает по сети, в DOM и CSSOM, которые используются визуализатором для отображения страницы на экране.
DOM — это внутреннее представление разметки для браузера. DOM также открыт, и им можно манипулировать с помощью различных API-интерфейсов в JavaScript.
Даже если HTML-код запрошенной страницы больше исходного пакета размером 14 КБ, браузер начнет синтаксический анализ и попытается отобразить интерфейс на основе имеющихся у него данных. Вот почему для оптимизации веб-производительности важно включить все, что нужно браузеру для начала рендеринга страницы, или, по крайней мере, шаблон страницы — CSS и HTML, необходимые для первого рендеринга — в первые 14 килобайт. Но прежде чем что-либо отобразится на экране, необходимо проанализировать HTML, CSS и JavaScript.
Но прежде чем что-либо отобразится на экране, необходимо проанализировать HTML, CSS и JavaScript.
Построение дерева DOM
Мы описываем пять шагов критического пути рендеринга.
Первым шагом является обработка разметки HTML и построение дерева DOM. Парсинг HTML включает в себя токенизацию и построение дерева. Маркеры HTML включают начальный и конечный теги, а также имена и значения атрибутов. Если документ правильно сформирован, его разбор выполняется просто и быстро. Синтаксический анализатор анализирует токенизированный ввод в документ, создавая дерево документа.
Дерево DOM описывает содержимое документа. Элемент — это первый тег и корневой узел дерева документа. Дерево отражает отношения и иерархию между различными тегами. Теги, вложенные в другие теги, являются дочерними узлами. Чем больше количество узлов DOM, тем больше времени требуется для построения дерева DOM.
Когда синтаксический анализатор находит неблокирующие ресурсы, такие как изображение, браузер запрашивает эти ресурсы и продолжает синтаксический анализ.
<ссылка rel="stylesheet" href="styles.css" />
async или атрибут defer 9.0026, если важен разбор и порядок выполнения JavaScript. Ожидание получения CSS не блокирует синтаксический анализ или загрузку HTML, но блокирует JavaScript, поскольку JavaScript часто используется для запроса влияния свойств CSS на элементы.
Построение CSSOM
Вторым шагом критического пути рендеринга является обработка CSS и построение дерева CSSOM. Объектная модель CSS похожа на DOM. DOM и CSSOM — это деревья. Это независимые структуры данных. Браузер преобразует правила CSS в карту стилей, которую он может понять и с которой может работать. Браузер просматривает каждый набор правил в CSS, создавая дерево узлов с родительскими, дочерними и одноуровневыми отношениями на основе селекторов CSS.
Как и в случае с HTML, браузеру необходимо преобразовать полученные правила CSS во что-то, с чем он сможет работать. Следовательно, он повторяет процесс преобразования HTML в объект, но для CSS.
Дерево CSSOM включает стили из таблицы стилей пользовательского агента. Браузер начинает с наиболее общего правила, применимого к узлу, и рекурсивно уточняет вычисленные стили, применяя более конкретные правила. Другими словами, он каскадирует значения свойств.
Создание CSSOM выполняется очень быстро и не отображается уникальным цветом в текущих инструментах разработчика. Скорее, «Пересчитать стиль» в инструментах разработчика показывает общее время, необходимое для синтаксического анализа CSS, построения дерева CSSOM и рекурсивного вычисления вычисляемых стилей. С точки зрения оптимизации веб-производительности, есть более низкие висящие плоды, так как общее время для создания CSSOM, как правило, меньше, чем время, необходимое для одного поиска DNS.
Другие процессы
Компиляция JavaScript
Пока выполняется синтаксический анализ CSS и создается CSSOM, другие активы, включая файлы JavaScript, загружаются (благодаря сканеру предварительной загрузки). JavaScript интерпретируется, компилируется, анализируется и выполняется. Сценарии анализируются в виде абстрактных синтаксических деревьев. Некоторые браузерные движки берут абстрактное синтаксическое дерево и передают его интерпретатору, выводя байт-код, который выполняется в основном потоке. Это известно как компиляция JavaScript.
Построение дерева специальных возможностей
Браузер также строит дерево специальных возможностей, которое вспомогательные устройства используют для анализа и интерпретации содержимого. Объектная модель доступности (AOM) похожа на семантическую версию DOM. Браузер обновляет дерево специальных возможностей при обновлении DOM. Дерево специальных возможностей не может быть изменено самими вспомогательными технологиями.
Пока AOM не будет построен, содержимое недоступно для программ чтения с экрана.
Шаги рендеринга включают стиль, компоновку, рисование и, в некоторых случаях, композитинг. Деревья CSSOM и DOM, созданные на этапе синтаксического анализа, объединяются в дерево рендеринга, которое затем используется для вычисления макета каждого видимого элемента, который затем отображается на экране. В некоторых случаях контент можно продвигать по отдельным слоям и компоновать, повышая производительность за счет рисования частей экрана на графическом процессоре, а не на ЦП, освобождая основной поток.
Стиль
Третий шаг критического пути рендеринга — объединение DOM и CSSOM в дерево рендеринга. Вычисленное дерево стилей или дерево рендеринга начинается с корня дерева DOM, обходя каждый видимый узел.
Теги, которые не будут отображаться, например и его дочерние элементы, а также любые узлы с display: none , например, скрипт { display: none; } , которые вы найдете в таблицах стилей пользовательского агента, не включены в дерево рендеринга, поскольку они не будут отображаться в выводе рендеринга. Узлы с 9Видимость 0025: скрытые примененные
включены в дерево рендеринга, так как они занимают место. Поскольку мы не дали никаких директив для переопределения значения по умолчанию для пользовательского агента, узел сценария в нашем примере кода выше не будет включен в дерево рендеринга.К каждому узлу применяются свои правила CSSOM. Дерево рендеринга содержит все видимые узлы с содержимым и вычисленными стилями — все соответствующие стили сопоставляются с каждым видимым узлом в дереве DOM и определяются на основе каскада CSS, какие вычисленные стили предназначены для каждого узла.
Макет
Четвертый этап критического пути рендеринга — запуск макета в дереве рендеринга для вычисления геометрии каждого узла. Макет — это процесс, посредством которого определяются ширина, высота и расположение всех узлов в дереве рендеринга, а также определение размера и положения каждого объекта на странице. Reflow — любое последующее определение размера и положения любой части страницы или всего документа.
После построения дерева рендеринга начинается компоновка. Дерево рендеринга определило, какие узлы отображаются (даже если они невидимы) вместе с их вычисленными стилями, но не размерами или расположением каждого узла. Чтобы определить точный размер и местоположение каждого объекта, браузер начинает с корня дерева рендеринга и просматривает его.
На веб-странице почти все представляет собой коробку. Разные устройства и разные настройки рабочего стола означают неограниченное количество разных размеров области просмотра. На этом этапе, принимая во внимание размер области просмотра, браузер определяет размеры всех различных блоков, которые будут отображаться на экране. Принимая за основу размер окна просмотра, компоновка обычно начинается с тела, раскладывая размеры всех потомков тела, со свойствами блочной модели каждого элемента, предоставляя пространство-заполнитель для замененных элементов, размеры которых неизвестны, например как наш образ.
Первое определение размера и положения узлов называется компоновкой . Последующие перерасчеты размера и расположения узлов называются перекомпоновками . В нашем примере предположим, что первоначальный макет происходит до того, как изображение будет возвращено. Поскольку мы не объявляли размер нашего изображения, после того, как размер изображения станет известен, будет произведена перекомпоновка.
Отрисовка
Последним шагом критического пути отрисовки является отрисовка отдельных узлов на экране, первое вхождение которого называется первой осмысленной отрисовкой. На этапе рисования или растеризации браузер преобразует каждое поле, рассчитанное на этапе макета, в фактические пиксели на экране. Рисование включает в себя отрисовку каждой визуальной части элемента на экране, включая текст, цвета, границы, тени и замененные элементы, такие как кнопки и изображения. Браузер должен делать это очень быстро.
Чтобы обеспечить плавную прокрутку и анимацию, все, что занимает основной поток, включая вычисление стилей, а также перекомпоновку и рисование, должно выполняться браузером менее чем за 16,67 мс. При разрешении 2048 X 1536 iPad имеет более 3 145 000 пикселей, которые нужно отобразить на экране. Это очень много пикселей, которые нужно очень быстро закрашивать. Чтобы гарантировать, что перерисовка может быть выполнена еще быстрее, чем первоначальная краска, рисунок на экране обычно разбивается на несколько слоев. Если это происходит, то необходимо композитинг.
Рисование может разбить элементы в дереве макета на слои. Продвижение содержимого по слоям на графическом процессоре (вместо основного потока на ЦП) повышает производительность рисования и перерисовки. Существуют определенные свойства и элементы, которые создают экземпляр слоя, в том числе и , а также любой элемент со свойствами CSS opacity , 3D transform , will-change и несколько других. Эти узлы будут прорисованы на своем собственном слое вместе со своими потомками, если только потомку не потребуется собственный слой по одной (или нескольким) из вышеперечисленных причин.
Уровни действительно повышают производительность, но требуют больших затрат, когда речь идет об управлении памятью, поэтому не следует злоупотреблять ими в рамках стратегий оптимизации веб-производительности.
Композитинг
Когда части документа отрисовываются в разных слоях, перекрывая друг друга, компоновка необходима для обеспечения того, чтобы они отображались на экране в правильном порядке и содержимое отображалось правильно.
Поскольку страница продолжает загружать активы, может произойти перекомпоновка (вспомните наш пример изображения, которое прибыло с опозданием). Переплавка вызывает перерисовку и повторную композицию. Если бы мы определили размер нашего изображения, перекомпоновка не потребовалась бы, и только тот слой, который нужно было перерисовать, был бы перерисован и, при необходимости, скомпонован. Но мы не включили размер изображения! Когда изображение получено с сервера, процесс рендеринга возвращается к шагам компоновки и перезапускается оттуда.
Когда основной поток закончит рисовать страницу, можно подумать, что все готово. Это не обязательно так. Если загрузка включает в себя JavaScript, который был правильно отложен и выполняется только после срабатывания события
Время до интерактивности (TTI) — это измерение того, сколько времени прошло от первого запроса, который привел к поиску DNS и соединению SSL, до момента, когда страница стала интерактивной. отвечает на действия пользователя в течение 50 мс. Если основной поток занят синтаксическим анализом, компиляцией и выполнением JavaScript, он недоступен и, следовательно, не может своевременно (менее 50 мс) реагировать на действия пользователя.
В нашем примере, возможно, изображение загрузилось быстро, но, возможно, файл
.
В этом примере выполнение JavaScript заняло более 1,5 секунд, и все это время основной поток был полностью занят, не реагируя на события кликов или касания экрана.
- Веб-производительность
Обнаружили проблему с содержанием этой страницы?
- Отредактируйте страницу на GitHub.
- Сообщить о проблеме с содержимым.
- Просмотрите исходный код на GitHub.
Хотите принять участие?
Узнайте, как внести свой вклад.
Последний раз эта страница была изменена участниками MDN.
Как работает Интернет
Интернет повсюду!
Мы используем его больше, чем когда-либо раньше, в том числе во многих местах, где вы его можете не увидеть. Потому что «Интернет» — это больше, чем просто веб-сайты, которые вы посещаете, вводя URL-адрес в своем браузере.
Независимо от того, проверяете ли вы электронную почту на своем мобильном телефоне или отправляете твит, вы пользуетесь Интернетом (т. е. «Интернетом»).
Как все это работает? Какие технологии задействованы и чему вам нужно научиться (и в какой степени), если вы хотите стать веб-разработчиком?
Важно
В этой статье и видео (см. выше) я буду , а не погружаться во все технические детали. Это должно быть хорошим обзором веб-функциональности.
#
Как работают веб-сайты
Начнем с наиболее очевидного способа использования Интернета: вы посещаете веб-сайт, например, academind.com.
В тот момент, когда вы вводите этот адрес в браузере и нажимаете ENTER, происходит много разных вещей:
URL-адрес разрешается
Запрос отправляется на сервер веб-сайта
ответ сервера анализируется
Страница отрисовывается и отображается
На самом деле, каждый шаг можно разделить на несколько других шагов, но для хорошего представления о том, как все это работает, мы можем здесь проигнорировать это. Давайте посмотрим на все четыре шага.
#
Шаг 1 — URL-адрес получает разрешение
Очевидно, что код веб-сайта не хранится на вашем компьютере и, следовательно, его необходимо получить с другого компьютера, на котором он хранится. Этот «другой компьютер» называется «сервером». Поскольку он служит какой-то цели, в нашем случае он служит веб-сайту.
Вы вводите «academind.com» (это называется «домен»), но на самом деле сервер, на котором размещен исходный код веб-сайта, идентифицируется с помощью IP-адресов (= интернет-протокола). Браузер отправляет «запрос» (см. шаг 2) на сервер с введенным вами IP-адресом (косвенно — вы, конечно, ввели «academind.com»).
Важно
На самом деле вы также часто вводите "academind.com/learn" или что-то в этом роде. "academind.com" - это домен , "/learn" это так называемый путь . Вместе они составляют «URL» («Единый указатель ресурсов»).
Кроме того, вы можете посетить большинство веб-сайтов через "www.academind.com" или просто "academind.com" . Технически "www" является субдоменом , но большинство веб-сайтов просто перенаправляют трафик с "www" на главную страницу.
IP-адрес обычно выглядит так: 172.56.180.5 (хотя существует и более «современная» форма, называемая IPv6, но давайте пока ее проигнорируем). Вы можете узнать больше об IP-адресах в Википедии.
Как домен «academind.com» преобразуется в его IP-адрес?
В Интернете существует особый тип серверов - не один, а множество серверов этого типа. Так называемый «сервер имен» или «сервер DNS» (где DNS = «система доменных имен»).
Работа этих DNS-серверов заключается в преобразовании доменов в IP-адреса. Вы можете представить эти серверы как огромные словари, в которых хранятся таблицы перевода: Домен => IP-адрес .
Когда вы вводите «academind. com», браузер сначала получает IP-адрес с такого DNS-сервера.
Если вам интересно: Браузер знает адреса этих доменных серверов наизусть, они, так сказать, запрограммированы в браузере.
Как только IP-адрес известен, мы переходим к шагу 2.
#
Шаг 2 — Запрос отправлен
После определения IP-адреса браузер продолжает и отправляет запрос на сервер с этим IP-адресом.
"Просьба" - это не просто термин. Это действительно техническая вещь, которая происходит за кулисами.
Браузер объединяет кучу информации (Какой точный URL? Какой тип запроса следует сделать? Должны ли быть прикреплены метаданные) и отправляет этот пакет данных на IP-адрес.
Данные отправляются через «Протокол передачи гипертекста» (известный как «HTTP») — стандартизированный протокол, который определяет, как должен выглядеть запрос (и ответ), какие данные могут быть включены (и в какой форме). ) и как запрос будет отправлен. Вы можете узнать больше о HTTP здесь.
Важно
Поскольку используется протокол HTTP, полный URL-адрес выглядит следующим образом: http://academind.com. Браузер автоматически заполнит его для вас.
А еще есть HTTPS - это как HTTP но зашифровано . Большинство современных страниц (включая academind.com) используют его вместо HTTP. Полный URL-адрес становится следующим: https://academind.com.
Поскольку весь процесс и формат стандартизированы, нет никаких предположений о том, как этот запрос должен быть прочитан сервером.
Затем сервер соответствующим образом обрабатывает запрос и возвращает так называемый «ответ». Опять же, «ответ» — это техническая вещь, похожая на «запрос». Можно сказать, что это в основном «запрос» в противоположном направлении.
Как и запрос, ответ может содержать данные, метаданные и т. д. При запросе такой страницы, как academind.com, ответ будет содержать код, необходимый для отображения страницы на экране.
Что происходит на сервере?
Это определено веб-разработчиками. В конце концов, ответ должен быть отправлен. Этот ответ не обязательно должен содержать «веб-сайт». Он может содержать любые данные — в том числе файлы или изображения.
Некоторые серверы запрограммированы на динамическое создание веб-сайтов на основе запроса (например, страница профиля, содержащая ваши личные данные), другие серверы возвращают предварительно созданные страницы HTML (например, страницу новостей). Или и то, и другое — для разных частей веб-страницы. Существует также и третья альтернатива: заранее созданные веб-сайты, которые меняют свой внешний вид и данные в браузере.
Important
Различные типы веб-сайтов не являются предметом рассмотрения в этой статье. Если вы хотите узнать об этом больше, ознакомьтесь с этой статьей + видео.
В нашем простом случае у нас есть сервер, который возвращает код для отображения веб-сайта. Итак, давайте продолжим с шага 3.
#
Шаг 3 - Анализ ответа
Браузер получает ответ, отправленный сервером. Только это ничего не отображает на экране.
Вместо этого следующим шагом является анализ ответа браузером. Так же, как это сделал сервер с запросом. Опять же, стандартизация, навязанная HTTP, конечно, помогает.
Браузер проверяет данные и метаданные, содержащиеся в ответе. И исходя из этого решает, что делать.
Возможно, у вас были случаи, когда PDF-файл открывался в вашем браузере. Это произошло потому, что ответ сообщил браузеру, что данные не являются веб-сайтом, а представляют собой PDF-документ. И браузер пытается выбрать наилучший механизм обработки для любого типа данных, который он обнаруживает.
Вернуться к сценарию нашего веб-сайта.
В этом случае ответ будет содержать определенную часть метаданных, которая сообщает браузеру, что данные ответа относятся к типу 9.0025 текст/html .
Это позволяет браузеру анализировать фактические данные, прикрепленные к ответу, в виде HTML-кода.
HTML — это основной «язык программирования» (технически это не язык программирования — на нем нельзя написать никакой логики) Интернета. HTML расшифровывается как «язык гипертекстовой разметки» и описывает структуру веб-страницы.
Код выглядит так:
Последние новости!
Веб-сайты работают, потому что браузер понимает HTML!
и
Каждый HTML-тег имеет определенное семантическое значение, понятное браузеру, поскольку HTML также стандартизирован. Следовательно, нет никаких предположений о том, что означает тег .
Браузер знает, как анализировать HTML, и теперь просто просматривает все данные ответа (также называемые «телом ответа») для отображения веб-сайта.
#
Шаг 4 - Страница отображается
Как уже упоминалось, браузер просматривает HTML-данные, возвращенные сервером, и на их основе создает веб-сайт.
Хотя важно знать, что HTML не содержит инструкций относительно того, как должен выглядеть сайт (т. е. как он должен быть оформлен). На самом деле он только определяет структуру и сообщает браузеру, какой контент является заголовком, какой контент является изображением, какой контент является абзацем и т. д. Это особенно важно для доступности — программы чтения с экрана получают всю полезную информацию из структуры HTML.
Страница, содержащая только HTML, будет выглядеть так:
Не очень красиво, правда?
Вот почему существует еще одна важная технология (еще один «язык программирования», который на самом деле не является языком программирования): CSS («Каскадные таблицы стилей»).
CSS предназначен для добавления стилей к веб-сайту. Это делается с помощью «правил CSS»:
h2 {
color: blue;
}
Это правило окрасит все тегов синего цвета.
Подобные правила можно добавлять в код HTML, но обычно они являются частью отдельных файлов .css , которые запрашиваются отдельно.
Не вдаваясь в подробности, из этого следует один важный вывод: веб-сайт может состоять не только из данных первого ответа, который мы получаем.
На практике веб-сайты получают много дополнительных данных (через дополнительные запросы и ответы), которые запускаются после получения первого ответа.
Как это работает?
Ну, HTML-код первого ответа просто содержит инструкции для извлечения дополнительных данных с помощью новых запросов — и браузер понимает эти инструкции:
Важно
Опять же, я не буду вдаваться в подробности. Если вы хотите узнать больше о CSS, наше Полное руководство будет очень полезно!
Вместе с CSS браузер может отображать веб-страницы следующим образом:
На самом деле задействован еще один язык программирования (на этот раз это действительно язык программирования!): JavaScript.
Это не всегда видно, но весь динамический контент, который вы найдете на веб-сайте (например, вкладки, оверлеи и т. д.), на самом деле возможен только благодаря JavaScript. Это позволяет веб-разработчикам определять код, который запускается в браузере (, а не на сервере), поэтому JavaScript можно использовать для изменения веб-сайта, пока пользователь просматривает его.
Как и прежде, если вы хотите узнать больше, ознакомьтесь с нашими ресурсами JavaScript, например, с нашим полным курсом.
Это четыре шага, которые всегда выполняются, когда вы вводите адрес страницы, такой как academind.com, и после этого вы видите содержимое веб-сайта в своем браузере.
#
На стороне сервера и на стороне браузера
Из четырех шагов выше вы узнали, что мы можем различать две основные «стороны», когда говорим о сети: На стороне сервера и На стороне браузера (или : На стороне клиента , так как мы также можем получить доступ к Интернету без браузера - см. ниже!).
Если вы хотите стать веб-разработчиком, важно знать, что для этих целей вы используете разные технологии и языки программирования.
#
Серверная сторона
Вам нужны серверные языки программирования, то есть языки, которые не работают в браузере, но могут работать на обычном компьютере (сервер, в конце концов, это просто обычный компьютер).
Примеры:
Node.js
PHP
Python
Важно: За исключением PHP, вы также можете использовать эти языки программирования для других целей, кроме веб-разработки.
Хотя Node.js действительно в основном используется для программирования на стороне сервера (хотя технически он этим не ограничивается), Python также очень популярен для обработки данных и машинного обучения.
#
На стороне браузера
В браузере есть ровно три языка/технологии, которые вам нужно выучить. Но в то время как серверные языки были альтернативой, эти три браузерных языка являются обязательными для знания и понимания:
HTML (для структуры)
CSS (для стилей)
JavaScript (для динамического контента)
#
"3" 3" 0 90 252 "За Интернетом" 0002 До сих пор мы обсуждали сайты.
т.е. случай, когда вы вводите URL-адрес (например, «academind.com/learn») в браузер и получаете взамен веб-сайт.Но Интернет — это нечто большее. Действительно, вы используете его не только для этого каждый день!
Основная идея запросов и ответов всегда одна и та же. Но не каждый ответ обязательно является веб-сайтом. И не каждый запрос хочет веб-сайт.
Метаданные, прикрепленные к запросам и ответам, определяют, какие данные запрашиваются и возвращаются. Конечно, обе вовлеченные стороны (т. е. клиент и сервер) должны поддерживать запросы и отправленные данные.
Например, вы не можете запросить PDF-файл с "academind.com" . Вы можете отправить такой запрос, но вы не получите PDF-файл — просто потому, что мы не поддерживаем такие запрашиваемые данные для этого конкретного URL-адреса.
Но есть много серверов, которые специализируются на предоставлении URL-адресов, которые возвращают определенные фрагменты данных. Такие службы также называются «API» («Интерфейс прикладного программирования»).