«Как проверить индексацию сайта в Яндексе?» — Яндекс Кью
ГлавнаяСообществаСервисы яндексаСчетчикиИндексация сайтов
Надя Иванова ·7,8 KPostium
Postium: бизнес, реклама и digital-маркетинг. · 6 авг 2021 · postium.ru
ОтвечаетАнатолий ЧупинЧтобы проверить индексацию сайта в поисковых системах, можно сделать следующее.
Способ 1. Введите в поиске специальный запрос: оператор [site] и адрес сайта (без пробела).
Пример: site:postium.ru.
Актуально, как для Яндекса, так и для Google.
Способ 2: Как узнать сколько страниц проиндексировал Яндекс.
Заходим в Яндекс.Вебмастер и переходим «Индексирование — Структура сайта». Напротив своего сайта, в столбце «В поиске» вы увидите количество проиндексированных страниц.
Способ 3: Как узнать сколько страниц проиндексировал Google.
Заходим в Search Console и открываем раздел «Покрытие». Здесь также показывается количество проиндексированных страниц, и страницы с ошибками.
Здесь также показывается количество проиндексированных страниц, и страницы с ошибками.
Способ 4. Расширения для браузера, такой как, например RDS-бар.
Способ 5. Различные SEO-сервисы для анализа сайтов: Serpstat, Netpeak Checker, Pr-cy и прочие.
Секреты и фишки соцсетей в нашем новом Телеграм-канале — подпишись >>Перейти на t.me/anatol_chupinСергей И.
SMM как профессия Быстрее скорости света · 16 нояб 2020 · inkocoin.ru
Перейдите на сайт https://a.pr-cy.ru/ и в строку «введите домен» впишите ссылку на сайт и нажмите «Анализировать«. По завершению анализа, отчет о индексации и других параметрах, сразу будет доступен вам.
С благодарностью, от сайта: InkoCoin
МСК-ремонт
Ответы на вопросы по работе с бытовой, компьютерной техникой и интернетом. · 4 мая 2020 · 499remont.ru
ОтвечаетДмитрий МиловановДобрый день, из простого воспользуйтесь сервисом https://a. pr-cy.ru/ в бесплатном пакете он покажет Ваши позиции, кажеться 10 самых популярных. Для более профиссиональной работы я использую сервис https://seolib.ru/ можно задать список поисковиков по которым будет статистика, глубину просмотра и регулярнось генерации отчетов.
pr-cy.ru/ в бесплатном пакете он покажет Ваши позиции, кажеться 10 самых популярных. Для более профиссиональной работы я использую сервис https://seolib.ru/ можно задать список поисковиков по которым будет статистика, глубину просмотра и регулярнось генерации отчетов.
Максим
9 ноября 2020Здравствуйте эксперт. Мой изначальный вопрос был о том, как быстрее проиндексировать статью, которую только… Читать дальше
Никитина Валя
4 мая 2020
Оператор « site :» выдает информацию о приблизительном количестве проиндексированных страниц. Для проверки в строке поиска Google или Яндекс введите « site :[url вашего сайта ]».Подробней о поисковых операторах можно прочитать здесь: https://www.rookee.ru/learn/operatoryi-poiskovyix-sistem-google-i-yandeks/
Stilistica.ru
25 августа 2020site:URL
Без пробела после «site»
Проверка индексации сайта в Яндекс и Гугл
11 дек. , 2017
, 2017
В данной статье мы рассмотрим, как проверить индексацию страницы в Яндексе и Google, что для этого делают опытные SEO-специалисты, а также какие есть способы массовой проверки индексации страниц.
Индексируем или сканируем?
Прежде чем мы приступим к рассмотрению вопроса статьи, сделаем небольшое замечание: часто читатели и начинающие владельцы сайтов путают такие понятия, как сканирование страницы и её индексация.
При индексации поисковый робот добавляет все важные сведения о сайте и странице в индекс (отдельную базу данных). После того, как это произошло, запросы в поисковой системе ведут только на те страницы, которые уже были ранее проиндексированы. Сканирование сайта – чуть другая вещь, предусматривающая изучение поисковым роботом сайта согласно с данными, указанными в robots.txt. Но вернемся к нашей теме – как может проводиться массовая проверка индексации сайтов?
Проверяем индексацию в панели вебмастера
Базовый и самый простой способ как для вебмастера, так и для владельца сайта:
Проверка сайта в Google.
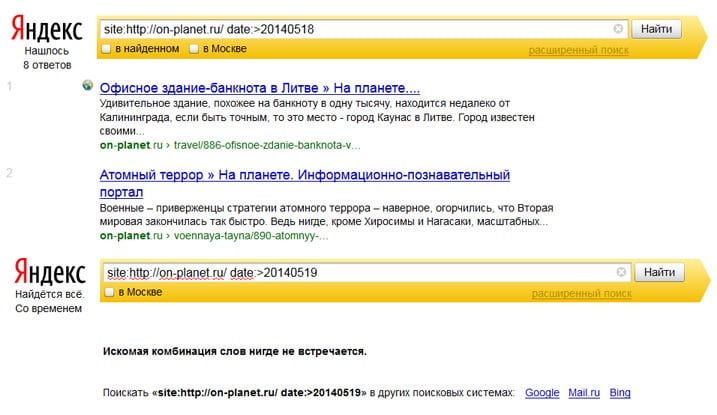
 В случае, если проводится проверка проиндексированности страниц в Гугле, следует зайти в Search Console и там найти вкладку «Индекс Google», а далее перейти к просмотру статуса индексирования.
В случае, если проводится проверка проиндексированности страниц в Гугле, следует зайти в Search Console и там найти вкладку «Индекс Google», а далее перейти к просмотру статуса индексирования.Проверка сайта в Yandex. Если же аналогичные данные нужно получить от Яндекса, то в панели «Яндекс.Вебмастер» следует пройти по маршруту «Индексирование сайта» → «Страницы в поиске». Там же, к слову, можно посмотреть и динамику индексации сайта и его страниц.
 В случае, если проводится проверка проиндексированности страниц в Гугле, следует зайти в Search Console и там найти вкладку «Индекс Google», а далее перейти к просмотру статуса индексирования.
В случае, если проводится проверка проиндексированности страниц в Гугле, следует зайти в Search Console и там найти вкладку «Индекс Google», а далее перейти к просмотру статуса индексирования.Для того, чтобы получить эти данные, нужно иметь соответствующий доступ к панели вебмастера и в Гугле, и в Яндексе.
Ниже вы можете увидеть пример сайта, который имеет хорошие показатели индексации…
…и не очень хорошие показатели, появившиеся вследствие запрета на проведение индексации в файле robots.txt.
Работаем с операторами поисковых запросов
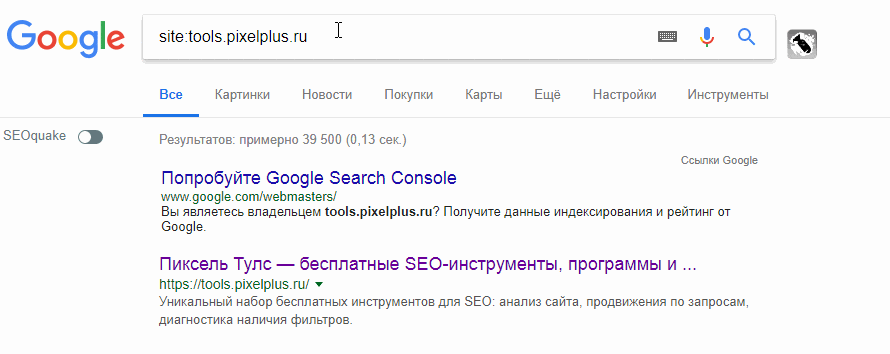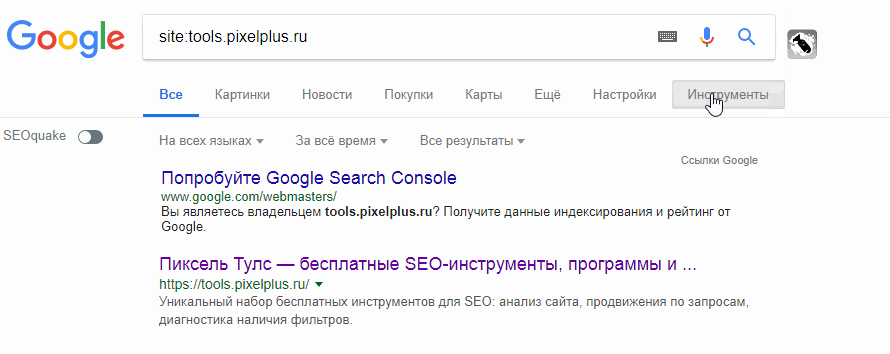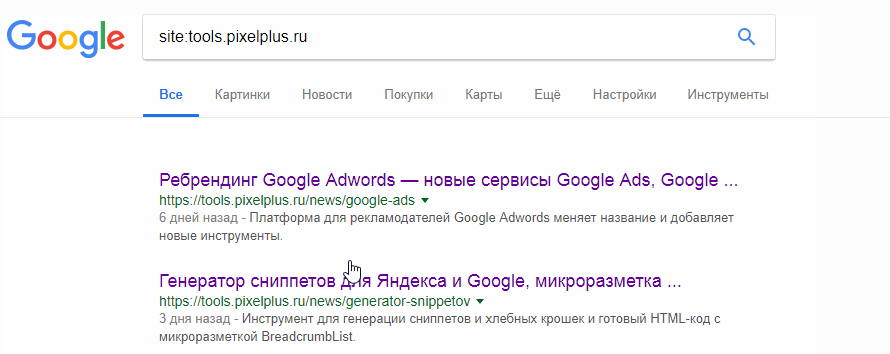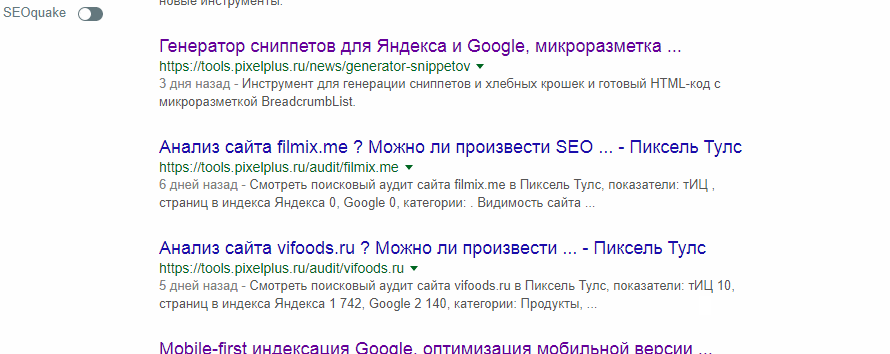
С помощью поисковых операторов можно уточнить те или иные результаты поиска. Так, с помощью оператора «site:» можно узнать о примерном количестве страниц, которые находятся в индексе.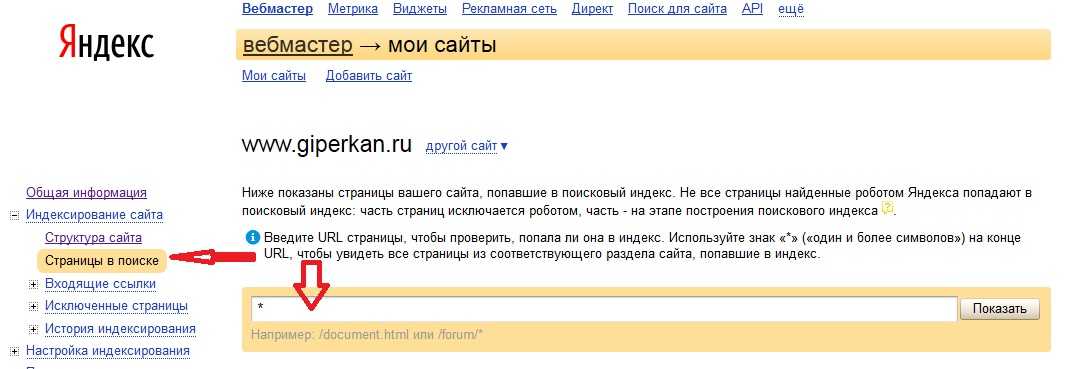
Для того, чтобы получить такую информацию, достаточно лишь в поисковой строке ввести site:[url сайта]. Кстати говоря – подобная проверка является своеобразным триггером для некоторых случаев. Так, при слишком большой разнице между результатами в Гугле и Яндексе можно сделать вывод, что у сайта есть какие-то проблемы в одной из поисковых систем. Например – наложенный фильтр.
В Google массовую проверку индексации страниц помогают провести дополнительные инструменты поиска. Например, тут можно увидеть, что за последний час появилось 49 страниц в русскоязычной Википедии:
Используем плагины и расширения для браузеров
Не будем давать рекламу тем или иным браузерным расширениям или плагинам, которые могут использоваться для проверки индексации страниц. Отметим только, что они представляют собой небольшие части java-кода, которые размещаются в браузере и позволяют проводить проверку индексации в автоматическом режиме.
Есть также специальные сервисы-краулеры, которые используются для проверки страниц. Их огромное множество, и большинство способны предоставить даже больше данных, чем просто сведения об индексации (например, редиректы, битые ссылки, переадресацию, каноникал, метаописание и т.д.).
Их огромное множество, и большинство способны предоставить даже больше данных, чем просто сведения об индексации (например, редиректы, битые ссылки, переадресацию, каноникал, метаописание и т.д.).
В Интернете также можно встретить множество сайтов, которые предлагают провести проверку индексации страниц сайта. Некоторые специально «заточены» для таких задач, другие же предоставляют комплексный анализ. Но во всех случаях мы рекомендуем использовать вышеперечисленные варианты – они показывают наиболее точные данные, а получение информации и проверка проиндексированности страниц происходит очень быстро.
Онлайн-сервисы для проверки индексации
В случае, если вам необходимо проверить индексацию страниц без использования сервисов аналитики поисковых систем, вы можете воспользоваться функционалом следующих онлайн-сервисов:
Google Index Checker от Small SEO Tools
Всё, что вам нужно, чтобы проверить индексацию сайта за несколько секунд — использование сервиса Google Index Checker. Для получения информации вам будет необходимо ввести URL и нажать кнопку “Check”, после чего вы получите данные о количестве проиндексированных страниц.
Для получения информации вам будет необходимо ввести URL и нажать кнопку “Check”, после чего вы получите данные о количестве проиндексированных страниц.
Index Checking
Ещё один сервис, который позволяет проверить индексацию сайта в Гугле, это Index Checking. С его помощью вы также можете получить информацию об индексации любого URL вашего сайта, а в режиме проверки вы можете вводить до 25 URL за один раз.
Почему сайт не индексируется?
Индексация сайта в некоторых случаях может содержать ошибки. В частности, проверка индексации сайта может показать, что поисковые системы не видят много страниц. Почему в таком случае сайт не индексируется?
- Новый сайт. Несмотря на то, что официально поисковые системы заявляют об отсутствии т.н. “Песочниц”, молодые сайты не сразу попадают в индекс, а потому этот процесс может затянуться на несколько месяцев.
- Отсутствует sitemap. При отсутствии карты сайта краулеры поисковых систем могут индексировать сайт куда дольше.
- Ошибки с мета-тегом robots. Проверьте мета-тег на страницах — если у вас в мета-теге содержится директива noindex, поисковые системы не смогут проиндексировать сайт.
- Ошибки в htaccess/robots.txt. Проверьте эти файлы и убедитесь в том, что вы не закрыли доступ поисковым ботам.

Ну и напоследок — если кроме индексации вас интересуют еще и позиции — наш сервис поможет вампроверить сайт в Google или в Yandex, а также и в других поисковых системах. Просто введите ваш домен в форму ниже. Это бесплатно.
Web Crawlers — 10 самых популярных
Бен Итон
Обновлено 16 декабря 2022 г.
Во всемирной паутине есть как плохие, так и хорошие боты. Вы определенно хотите избежать плохих ботов, поскольку они потребляют вашу пропускную способность CDN, занимают ресурсы сервера и крадут ваш контент. С другой стороны, с хорошими ботами (также известными как поисковые роботы) следует обращаться с осторожностью, поскольку они являются жизненно важной частью индексации вашего контента поисковыми системами, такими как Google, Bing и Yahoo. В этом сообщении блога мы рассмотрим десятку самых популярных поисковых роботов.
В этом сообщении блога мы рассмотрим десятку самых популярных поисковых роботов.
Что такое поисковые роботы?
Веб-сканеры — это компьютерные программы, которые методично и автоматически просматривают Интернет. Их также называют роботами, муравьями или пауками.
Поисковые роботы посещают веб-сайты и читают их страницы и другую информацию, чтобы создать записи для индекса поисковой системы. Основная цель поискового робота — предоставить пользователям полный и актуальный индекс всего доступного онлайн-контента.
Кроме того, поисковые роботы также могут собирать определенные типы информации с веб-сайтов, например контактную информацию или данные о ценах. Используя поисковые роботы, компании могут поддерживать актуальность и эффективность своего присутствия в Интернете (например, SEO, оптимизация внешнего интерфейса и веб-маркетинг).
Поисковые системы, такие как Google, Bing и Yahoo, используют сканеры для правильного индексирования загруженных страниц, чтобы пользователи могли быстрее и эффективнее находить их при поиске. Без поисковых роботов не было бы ничего, что могло бы сказать им, что на вашем сайте есть новый и свежий контент. Карты сайта также могут играть роль в этом процессе. Так что поисковые роботы, по большей части, это хорошо.
Без поисковых роботов не было бы ничего, что могло бы сказать им, что на вашем сайте есть новый и свежий контент. Карты сайта также могут играть роль в этом процессе. Так что поисковые роботы, по большей части, это хорошо.
Однако иногда возникают проблемы с планированием и загрузкой, поскольку поисковый робот может постоянно опрашивать ваш сайт. И здесь в игру вступает файл robots.txt. Этот файл может помочь контролировать сканирующий трафик и гарантировать, что он не перегрузит ваш сервер.
Веб-сканеры идентифицируют себя для веб-сервера с помощью заголовка запроса User-Agent в HTTP-запросе, и каждый сканер имеет свой уникальный идентификатор. В большинстве случаев вам нужно будет просматривать журналы реферера вашего веб-сервера, чтобы просмотреть трафик поискового робота.
Robots.txt
Поместив файл robots.txt в корень вашего веб-сервера, вы можете определить правила для поисковых роботов, например разрешить или запретить сканирование определенных ресурсов. Поисковые роботы должны следовать правилам, определенным в этом файле. Вы можете применить общие правила ко всем ботам или сделать их более детализированными и указать их конкретные
Поисковые роботы должны следовать правилам, определенным в этом файле. Вы можете применить общие правила ко всем ботам или сделать их более детализированными и указать их конкретные User-Agent строка.
Пример 1
Этот пример предписывает всем роботам поисковых систем не индексировать содержимое веб-сайта. Это определяется путем запрета доступа к корневому каталогу / вашего веб-сайта.
Агент пользователя: * Запретить: /
Пример 2
Этот пример противоположен предыдущему. В этом случае инструкции по-прежнему применяются ко всем пользовательским агентам. Однако в инструкции Disallow ничего не определено, а это означает, что все может быть проиндексировано.
Агент пользователя: * Запретить:
Чтобы увидеть больше примеров, обязательно ознакомьтесь с нашим подробным сообщением о том, как использовать файл robots.txt.
10 лучших поисковых роботов и поисковых роботов
Существуют сотни поисковых роботов и поисковых роботов, прочесывающих Интернет, но ниже приведен список из 10 популярных поисковых роботов и поисковых роботов, которые мы собрали на основе тех, которые мы регулярно видим в журналах нашего веб-сервера.
1. GoogleBot
Являясь крупнейшей в мире поисковой системой, Google использует поисковые роботы для индексации миллиардов страниц в Интернете. Googlebot — это поисковый робот, который Google использует именно для этого.
Googlebot — это два типа поисковых роботов: настольный поисковый робот, который имитирует человека, просматривающего компьютер, и мобильный поисковый робот, который выполняет те же функции, что и iPhone или телефон Android.
Строка пользовательского агента запроса может помочь вам определить подтип Googlebot. Googlebot Desktop и Googlebot Smartphone, скорее всего, будут сканировать ваш веб-сайт. С другой стороны, оба типа сканеров принимают один и тот же токен продукта (токен пользовательского агента) в файле robots.txt. Вы не можете использовать robots.txt для выборочного таргетинга Googlebot Smartphone или Desktop.
Googlebot — очень эффективный поисковый робот, который может быстро и точно индексировать страницы. Однако у него есть некоторые недостатки. Например, робот Googlebot не всегда сканирует все страницы веб-сайта (особенно если веб-сайт большой и сложный).
Например, робот Googlebot не всегда сканирует все страницы веб-сайта (особенно если веб-сайт большой и сложный).
Кроме того, робот Googlebot не всегда сканирует страницы в режиме реального времени, а это означает, что некоторые страницы могут быть проиндексированы только через несколько дней или недель после их публикации.
Агент пользователя Googlebot
Полный
User-Agent stringMozilla/5.0 (совместимый; Googlebot/2.1; +http://www.google.com/bot.html)
Пример робота Googlebot в robots.txt
В этом примере несколько более подробно описаны определенные инструкции. Здесь инструкции относятся только к Googlebot. В частности, он говорит Google не индексировать определенную страницу ( /no-index/your-page.html ).
Агент пользователя: Googlebot Запретить: /no-index/your-page.html
Помимо поискового робота Google, у них на самом деле есть 9дополнительные поисковые роботы:
| Поисковый робот | User-Agent string |
|---|---|
| Googlebot News | Googlebot-New s |
| Googlebot Images | Googlebot-Image/1. 0 0 |
| Googlebot Video | Googlebot-Video/1.0 |
| Google Mobile (feat. телефон) | SAMSUNG-SGH-E250/1.0 Profile/MIDP-2.0 Configuration/CLDC-1.1 UP.Browser/6.2.3.3.c.1.101 (GUI) MMP/2.0 (совместимый; Googlebot-Mobile/2.1; +http://www.google.com/bot.html) |
| Смартфон Google | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (совместимый; робот Googlebot) /2.1; +http://www.google.com/bot.html) |
| Google Mobile Adsense | (совместимо; Mediapartners-Google/2.1; +http://www.google.com/bot.html) |
| Google Adsense | 90 101 Mediapartners-Google|
| Google AdsBot (качество целевой страницы PPC) | AdsBot-Google (+http://www.google.com/adsbot.html) |
| Сканер приложений Google (извлечение ресурсов для мобильных устройств) | AdsBot-Google-Mobile-Apps |
Вы можете использовать инструмент Fetch в Google Search Console, чтобы проверить, как Google сканирует или отображает URL-адрес на вашем сайте. Узнайте, может ли робот Googlebot получить доступ к странице на вашем сайте, как он отображает страницу и заблокированы ли какие-либо ресурсы страницы (например, изображения или сценарии) для робота Googlebot.
Узнайте, может ли робот Googlebot получить доступ к странице на вашем сайте, как он отображает страницу и заблокированы ли какие-либо ресурсы страницы (например, изображения или сценарии) для робота Googlebot.
Вы также можете просмотреть статистику сканирования Googlebot за день, количество загруженных килобайт и время, затраченное на загрузку страницы.
См. документацию robots.txt для робота Google.
2. Bingbot
Bingbot — это поисковый робот, развернутый Microsoft в 2010 году для предоставления информации их поисковой системе Bing. Это замена того, что раньше было ботом MSN.
Агент пользователя Bingbot
Полный
User-Agent stringMozilla/5.0 (совместимый; Bingbot/2.0; +http://www.bing.com/bingbot.htm)
У Bing также есть очень похожий на Google инструмент, называемый Fetch as Bingbot, в Инструментах для веб-мастеров Bing. Fetch As Bingbot позволяет запросить сканирование страницы и показать ее вам так, как ее увидит наш сканер.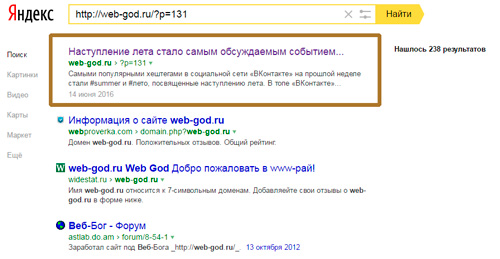 Вы увидите код страницы так, как его увидит Bingbot, что поможет вам понять, видят ли они вашу страницу так, как вы предполагали.
Вы увидите код страницы так, как его увидит Bingbot, что поможет вам понять, видят ли они вашу страницу так, как вы предполагали.
См. документацию Bingbot robots.txt.
3. Slurp Bot
Результаты поиска Yahoo поступают от поискового робота Yahoo Slurp и поискового робота Bing, так как большая часть Yahoo работает на базе Bing. Сайты должны разрешать доступ Yahoo Slurp, чтобы они отображались в результатах поиска Yahoo Mobile.
Кроме того, Slurp делает следующее:
- Собирает контент с партнерских сайтов для включения в такие сайты, как Yahoo News, Yahoo Finance и Yahoo Sports.
- Доступ к страницам сайтов в Интернете для подтверждения точности и улучшения персонализированного контента Yahoo для наших пользователей.
Агент пользователя Slurp
Полный
User-Agent stringMozilla/5.0 (совместимый; Yahoo! Slurp; http://help.yahoo.com/help/us/ysearch/slurp)
См.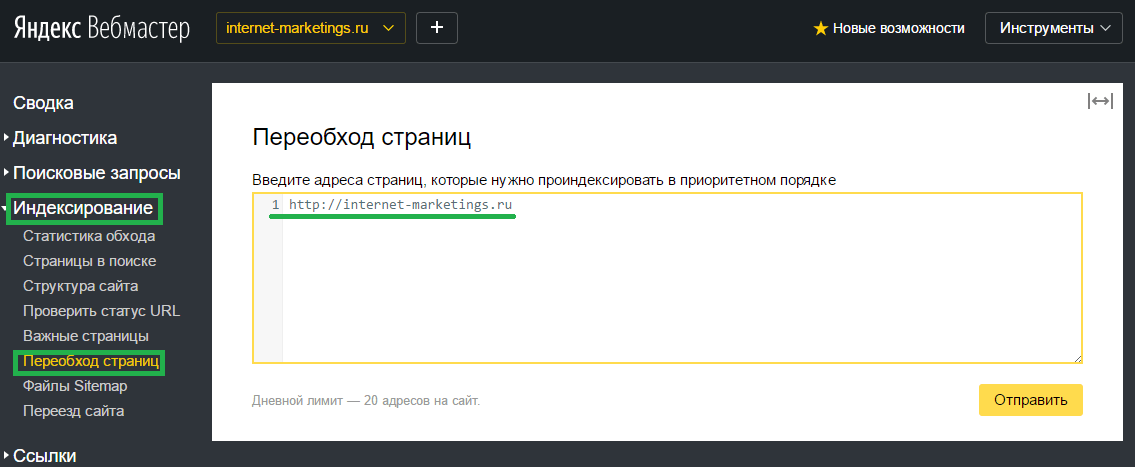 документацию Slurp robots.txt.
документацию Slurp robots.txt.
4. DuckDuckBot
DuckDuckBot — это веб-сканер для DuckDuckGo, поисковой системы, которая стала довольно популярной, поскольку известна своей конфиденциальностью и отсутствием слежки за вами. Теперь он обрабатывает более 93 миллионов запросов в день. DuckDuckGo получает результаты из разных источников. К ним относятся сотни вертикальных источников, предоставляющих нишевые мгновенные ответы, DuckDuckBot (их поисковый робот) и краудсорсинговые сайты (Википедия). У них также есть более традиционные ссылки в результатах поиска, которые они получают от Yahoo! и Бинг.
Агент пользователя DuckDuckBot
Полный
User-Agent stringDuckDuckBot/1.0; (+http://duckduckgo.com/duckduckbot.html)
Он соответствует WWW::RobotRules и происходит со следующих IP-адресов:
- 72.94.249.34
- 72.94.249.35
- 72.94.249.36 90 189 72.94.249.37
- 72. 94.249.38
 94.249.38
94.249.385. Baiduspider
Baiduspider — официальное название поисковой системы китайской Baidu. Он сканирует веб-страницы и возвращает обновления в индекс Baidu. Baidu — ведущая китайская поисковая система, на долю которой приходится 80% всего рынка поисковых систем материкового Китая.
Агент пользователя Baiduspider
Full
User-Agent stringMozilla/5.0 (совместимо; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)
Помимо поискового робота Baidu, у них есть еще 6 поисковых роботов:
| Поисковый робот | User-Agent string | Поиск изображений | Baiduspider-image |
|---|---|
| Поиск видео | Baiduspider-video |
| Поиск новостей | Baiduspider-новости |
| Списки желаний Baidu | Baiduspider-favo 901 02 |
| Baidu Union | Baiduspider-cpro |
| Business Search | Baiduspider-ads |
| Другие страницы поиска |
См. документацию Baidu robots.txt.
документацию Baidu robots.txt.
6. Яндекс Бот
ЯндексБот — поисковый робот для одной из крупнейших российских поисковых систем Яндекс.
User-Agent ЯндексБот
Full
User-Agent stringMozilla/5.0 (совместимо; YandexBot/3.0; +http://yandex.com/bots)
Существует множество различных строк User-Agent, которые ЯндексБот может отображать в логах вашего сервера.
7. Sogou Spider
Sogou Spider — поисковый робот для Sogou.com, ведущей китайской поисковой системы, запущенной в 2004 году.
Примечание: Веб-паук Sogou не соблюдает стандарт исключения роботов и поэтому запрещен на многих веб-сайтах из-за чрезмерного сканирования.
User-Agent Sogou Pic Spider/3.0 (http://www.sogou.com/docs/help/webmasters.htm#07) Головной паук Sogou/3.0 (http://www.sogou.com/docs/help/webmasters.htm#07) Веб-паук Sogou/4.0 (+http://www.sogou.com/docs/help/webmasters.htm#07) Паук Sogou Orion/3.0 (http://www.sogou.com/docs/help/webmasters.htm#07) Sogou-Test-Spider/4.0 (совместимый; MSIE 5.5; Windows 98)
8. Exabot
Exabot — поисковый робот для Exalead, поисковой системы, базирующейся во Франции. Он был основан в 2000 году и имеет более 16 миллиардов проиндексированных страниц.
User-Agent Mozilla/5.0 (совместимый; Konqueror/3.5; Linux) KHTML/3.5.5 (как Gecko) (Exabot-Thumbnails) Mozilla/5.0 (совместимо; Exabot/3.0; +http://www.exabot.com/go/robot)
См. документацию Exabot robots.txt.
9. Facebook external hit
Facebook позволяет своим пользователям отправлять ссылки на интересный веб-контент другим пользователям Facebook. Часть того, как это работает в системе Facebook, включает временное отображение определенных изображений или деталей, связанных с веб-контентом, таких как название веб-страницы или встроенный тег видео. Система Facebook извлекает эту информацию только после того, как пользователь предоставит ссылку.
Один из их основных роботов-сканеров — Facebot, предназначенный для повышения эффективности рекламы.
User-Agent фейсбот facebookexternalhit/1.0 (+http://www.facebook.com/externalhit_uatext.php) facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php)
См. документацию Facebot robots.txt.
10. Applebot
Бренд компьютерных технологий Apple использует поисковый робот Applebot, в частности Siri и Spotlight Suggestions, для предоставления персонализированных услуг своим пользователям.
Агент пользователя Applebot
Full
User-Agent stringMozilla/5.0 (Device; OS_version) AppleWebKit/WebKit_version (KHTML, как Gecko) Версия/Safari_версия Safari/WebKit_версия (Applebot/Applebot_version)
Другие популярные поисковые роботы
Apache Nutch
Apache Nutch — поисковый робот с открытым исходным кодом, написанный на Java. Он выпущен под лицензией Apache и управляется Apache Software Foundation.
Nutch может работать на одной машине, но чаще используется в распределенной среде. На самом деле, Nutch был разработан с нуля, чтобы быть масштабируемым и легко расширяемым.
Он выпущен под лицензией Apache и управляется Apache Software Foundation.
Nutch может работать на одной машине, но чаще используется в распределенной среде. На самом деле, Nutch был разработан с нуля, чтобы быть масштабируемым и легко расширяемым.
Орех очень гибкий и может использоваться для различных целей. Например, Nutch можно использовать для обхода всего Интернета или только определенных веб-сайтов. Кроме того, Nutch можно настроить на индексацию страниц в режиме реального времени или по расписанию.
Одним из основных преимуществ Apache Nutch является его масштабируемость. Nutch можно легко масштабировать для обработки больших объемов данных и трафика. Например, большой веб-сайт электронной коммерции может использовать Apache Nutch для сканирования и индексации своего каталога продуктов. Это позволит клиентам искать продукты на своем веб-сайте с помощью внутренней поисковой системы компании.
Кроме того, Apache Nutch можно использовать для сбора данных о веб-сайтах.
Screaming Frog
Screaming Frog SEO Spider — это настольная программа (ПК или Mac), которая сканирует ссылки, изображения, CSS, скрипты и приложения веб-сайтов с точки зрения SEO.
Он извлекает ключевые элементы сайта для SEO, представляет их на вкладках по типам и позволяет вам фильтровать общие проблемы SEO или нарезать данные так, как вам нравится, экспортируя их в Excel.
Вы можете просматривать, анализировать и фильтровать данные сканирования по мере их сбора и извлечения в режиме реального времени с помощью простого интерфейса.
Программа бесплатна для небольших сайтов (до 500 URL). Для больших сайтов требуется лицензия.
Screaming Frog использует Chromium WRS для сканирования динамических веб-сайтов с большим количеством JavaScript, таких как Angular, React и Vue.js. Создание карты сайта WordPress, извлечение XPath и визуализация архитектуры сайта — другие важные функции.
Платформа обслуживает такие корпорации, как Apple, Amazon, Disney и даже Google. Screaming Frog также является популярным инструментом среди владельцев агентств и SEO-специалистов, которые управляют SEO для нескольких клиентов.
Deepcrawl
Deepcrawl — это облачный поисковый робот, который позволяет пользователям сканировать веб-сайты и собирать данные об их структуре, содержании и производительности.
DeepCrawl предоставляет пользователям несколько функций и опций, включая возможность сканирования веб-сайтов на основе JavaScript, настройку процесса сканирования и создание подробных отчетов.
Одной из самых уникальных функций Deepcrawl является его способность сканировать веб-сайты, созданные с помощью JavaScript. Это возможно, потому что Deepcrawl использует безголовый браузер (например, Chrome) для отображения содержимого веб-сайта перед его сканированием.
Это означает, что Deepcrawl может сканировать и собирать данные о веб-сайтах, которые не всегда могут быть доступны другим поисковым роботам.
Помимо гибких API, данные Deepcrawl интегрируются с Google Analytics, Google Search Console и другими популярными инструментами. Это позволяет пользователям легко сравнивать данные своего веб-сайта с данными конкурентов. Это также позволяет им связывать бизнес-данные (например, данные о продажах) с данными своего веб-сайта, чтобы получить полное представление о том, как работает их веб-сайт.
Deepcrawl лучше всего подходит для компаний с большими веб-сайтами с большим количеством контента и страниц. Платформа менее подходит для небольших веб-сайтов или тех, которые не меняются очень часто.
Deepcrawl предлагает три различных продукта:
- Automation Hub: этот продукт интегрируется с конвейером CI/CD и автоматически сканирует ваш веб-сайт с более чем 200 правилами тестирования SEO QA.
- Центр аналитики: этот продукт позволяет вам получать полезную информацию из данных вашего веб-сайта и улучшать SEO вашего веб-сайта.
- Концентратор мониторинга: этот продукт отслеживает изменения на вашем веб-сайте и уведомляет вас о появлении новых проблем.
Предприятия используют эти три продукта для улучшения SEO своего веб-сайта, отслеживания изменений и сотрудничества с командами разработчиков.
Octoparse
Octoparse — это удобное клиентское программное обеспечение для сканирования веб-страниц, которое позволяет извлекать данные со всего Интернета. Программа специально разработана для людей, не являющихся программистами, и имеет простой интерфейс «укажи и щелкни».
С помощью Octoparse вы можете запускать запланированные облачные извлечения для извлечения динамических данных, создавать рабочие процессы для автоматического извлечения данных с веб-сайтов и использовать его API парсинга веб-страниц для доступа к данным.
Его прокси-серверы IP позволяют сканировать веб-сайты без блокировки, а встроенная функция Regex автоматически очищает данные.
Благодаря готовым шаблонам скрейпера вы можете начать извлекать данные с популярных веб-сайтов, таких как Yelp, Google Maps, Facebook и Amazon, за считанные минуты. Вы также можете создать свой собственный парсер, если его нет в наличии для ваших целевых веб-сайтов.
HTTrack
Вы можете использовать бесплатное ПО HTTrack для загрузки целых сайтов на свой компьютер. Благодаря поддержке Windows, Linux и других систем Unix этот инструмент с открытым исходным кодом может использоваться миллионами.
Средство копирования веб-сайтов HTTrack позволяет загружать веб-сайты на компьютер, чтобы вы могли просматривать их в автономном режиме. Программу также можно использовать для зеркалирования веб-сайтов, что означает, что вы можете создать точную копию веб-сайта на своем сервере.
Программа проста в использовании и имеет множество функций, в том числе возможность возобновлять прерванные загрузки, обновлять существующие веб-сайты и создавать статические копии динамических веб-сайтов.
Вы можете получить файлы, фотографии и HTML-код с зеркального веб-сайта и возобновить прерванную загрузку.
Хотя HTTrack можно использовать для загрузки веб-сайтов любого типа, он особенно полезен для загрузки веб-сайтов, которые больше не доступны в сети.
HTTrack — отличный инструмент для тех, кто хочет загрузить весь веб-сайт или создать его зеркальную копию. Однако следует отметить, что программу можно использовать для загрузки нелегальных копий веб-сайтов.
Таким образом, вы должны использовать HTTrack только в том случае, если у вас есть разрешение от владельца веб-сайта.
SiteSucker
SiteSucker — это приложение для macOS, которое загружает веб-сайты. Он асинхронно копирует веб-страницы сайта, изображения, PDF-файлы, таблицы стилей и другие файлы на ваш локальный жесткий диск, дублируя структуру каталогов сайта.
Вы также можете использовать SiteSucker для загрузки определенных файлов с веб-сайтов, таких как файлы MP3.
Программа может использоваться для создания локальных копий веб-сайтов, что делает ее идеальной для просмотра в автономном режиме.
Это также полезно для загрузки целых сайтов, чтобы вы могли просматривать их на своем компьютере без подключения к Интернету.
Одним из недостатков SiteSucker является то, что он не может обрабатывать Javascript (хотя может обрабатывать Flash). Тем не менее, он по-прежнему полезен для загрузки веб-сайтов на ваш Mac.
Webz.io
Пользователи могут использовать веб-приложение Webz.io для получения данных в режиме реального времени путем сканирования онлайн-источников по всему миру в различных удобных форматах. Этот поисковый робот позволяет вам сканировать данные и извлекать ключевые слова на нескольких языках на основе многочисленных критериев из различных источников.
Архив позволяет пользователям получать доступ к историческим данным. Пользователи могут легко индексировать и искать структурированные данные, просканированные Webhose, используя его интуитивно понятный интерфейс/API. Вы можете сохранять очищенные данные в форматах JSON, XML и RSS. Кроме того, Webz.io поддерживает до 80 языков с результатами сканирования данных.
Кроме того, Webz.io поддерживает до 80 языков с результатами сканирования данных.
Freemium бизнес-модель Webz.io должна подойти для предприятий с базовыми требованиями к сканированию. Для предприятий, которым требуется более надежное решение, Webz.io также предлагает поддержку мониторинга СМИ, угроз кибербезопасности, анализа рисков, финансового анализа, веб-аналитики и защиты от кражи личных данных.
Они даже поддерживают решения API даркнета для бизнес-аналитики.
UiPath
UiPath — это приложение Windows, которое можно использовать для автоматизации повторяющихся задач. Это полезно для парсинга веб-страниц, поскольку оно может автоматически извлекать данные с веб-сайтов.
Программа проста в использовании и не требует знаний в области программирования. Он имеет визуальный интерфейс перетаскивания, который упрощает создание сценариев автоматизации.
С помощью UiPath вы можете извлекать табличные данные и данные на основе шаблонов с веб-сайтов, PDF-файлов и других источников. Программу также можно использовать для автоматизации таких задач, как заполнение онлайн-форм и загрузка файлов.
Программу также можно использовать для автоматизации таких задач, как заполнение онлайн-форм и загрузка файлов.
Коммерческая версия инструмента предоставляет дополнительные возможности сканирования. При работе со сложными пользовательскими интерфейсами этот подход очень эффективен. Инструмент очистки экрана может извлекать данные из таблиц как по отдельным словам, так и по группам текста, а также по блокам текста, таким как RSS-каналы.
Кроме того, вам не нужны навыки программирования для создания интеллектуальных веб-агентов, но если вы хакер .NET, вы сможете полностью контролировать их данные.
Плохие боты
Хотя большинство поисковых роботов безопасны, некоторые из них могут использоваться в злонамеренных целях. Эти вредоносные веб-сканеры, или «боты», могут использоваться для кражи информации, проведения атак и совершения мошенничества. Также все чаще обнаруживается, что эти боты игнорируют директивы robots.txt и переходят непосредственно к сканированию веб-сайтов.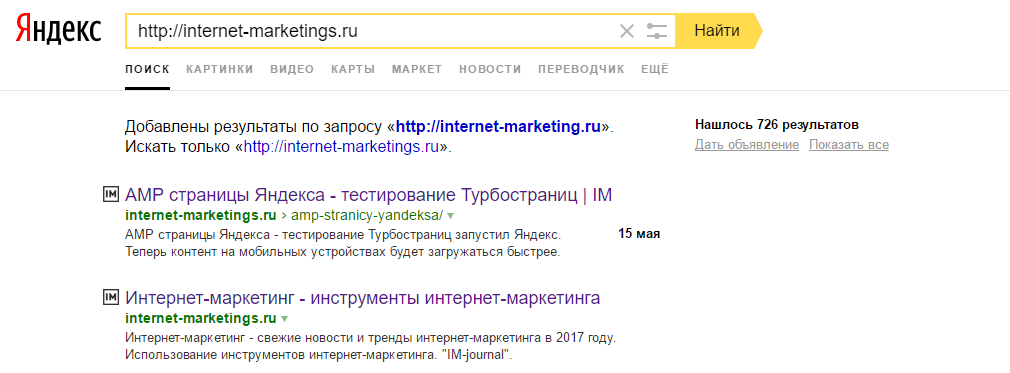
Некоторые известные плохие боты перечислены ниже:
- PetalBot
- SEMrushBot
- Majestic
- DotBot
- AhrefsBot
Защита вашего сайта от вредоносных поисковых роботов
Чтобы защитить свой сайт от вредоносных ботов, вы можете использовать брандмауэр веб-приложений (WAF) для защиты вашего сайта от ботов и других угроз. WAF — это часть программного обеспечения, которое находится между вашим веб-сайтом и Интернетом и фильтрует трафик до того, как он попадет на ваш сайт.
CDN также может помочь защитить ваш сайт от ботов. CDN — это сеть серверов, которые доставляют контент пользователям в зависимости от их географического положения.
Когда пользователь запрашивает страницу с вашего веб-сайта, CDN направляет запрос на сервер, ближайший к местоположению пользователя. Это может помочь снизить риск атаки ботов на ваш сайт, поскольку им придется нацеливаться на каждый сервер CDN в отдельности.
В KeyCDN есть замечательная функция, которую вы можете включить на своей панели инструментов, которая называется «Блокировка плохих ботов». KeyCDN использует полный список известных вредоносных ботов и блокирует их на основе их
KeyCDN использует полный список известных вредоносных ботов и блокирует их на основе их User-Agent строка.
При добавлении новой зоны для функции Блокировать плохих ботов устанавливается значение отключено . Этот параметр можно установить на с включенным вместо этого, если вы хотите, чтобы плохие боты автоматически блокировались.
Ресурсы бота
Возможно, вы видите в своих журналах некоторые строки пользовательского агента, которые вас беспокоят. У Кайо Алмейды также есть неплохой список в его проекте GitHub для поисковых агентов.
Резюме
Существуют сотни различных поисковых роботов, но, надеюсь, вы уже знакомы с несколькими наиболее популярными из них. Опять же, вы должны быть осторожны при блокировании любого из них, так как они могут вызвать проблемы с индексацией. Всегда полезно проверить журналы вашего веб-сервера, чтобы узнать, как часто они сканируют ваш сайт.
Какой ваш любимый поисковый робот? Дайте нам знать в комментариях ниже.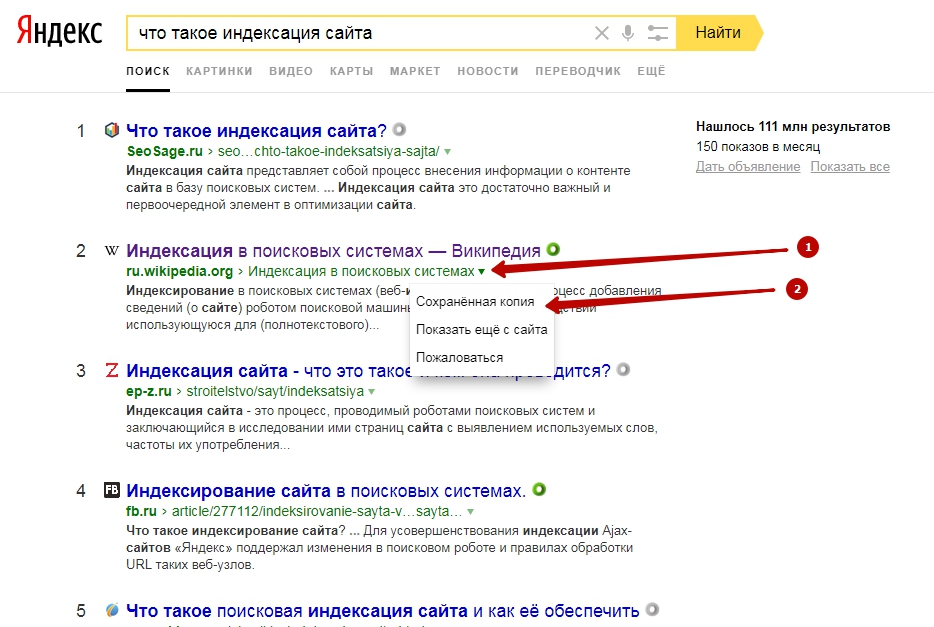
Google Index Checker: проверьте индексацию вашего сайта
Получите 100% точные данные об индексации вашего
страницы в гугле и яндексе с космической скоростью
Первые 7 дней бесплатно.
Кредитная карта не нужна!
Основные
функции инструмента проверки индекса GoogleБыстрая проверка индексации
- Испытайте быструю проверку индекса Google с помощью Rush Analytics. Наши инструменты SEO могут быстро оценить Google на предмет текущего статуса индексации ваших URL-адресов, что позволит вам увидеть, насколько быстро Google замечает и индексирует ваш контент.
- Позволяет проверить индексацию 100 000 веб-страниц за 10 минут
- Космические скорости для поисковых систем Google и Яндекс
Удобные форматы загрузки страниц
- Rush Analytics принимает любое количество страниц и поддерживает различные форматы загрузки для удобства работы. Эффективно проиндексируйте все свои страницы, так как наш инструмент проверки индекса Google позволяет загружать, проверять статус индекса и отслеживать индексацию ваших страниц.
 Эффективно проиндексируйте все свои страницы, так как наш инструмент проверки индекса Google позволяет загружать, проверять статус индекса и отслеживать индексацию ваших страниц.
Эффективно проиндексируйте все свои страницы, так как наш инструмент проверки индекса Google позволяет загружать, проверять статус индекса и отслеживать индексацию ваших страниц.Любое количество страниц
- Не нужно беспокоиться о количестве страниц, которые необходимо проиндексировать. Rush Analytics может обрабатывать все страницы, независимо от их количества. Каждый индексный URL-адрес тщательно анализируется, что помогает вам понять, как Google анализирует ваш сайт.
Что такое проверка индексных страниц Google?
Google Index Pages Checker — ценный инструмент для специалистов по поисковой оптимизации. Он проверяет количество URL-адресов веб-сайта, проиндексированных поисковой системой Google. Просто вводя URL-адрес веб-сайта, этот инструмент сканирует базу данных Google, предоставляя информацию о том, насколько хорошо веб-страницы распознаются, что позволяет использовать эффективные стратегии для повышения видимости и вовлеченности в Интернете. Это важный ресурс для оценки доступности вашего сайта в самой распространенной поисковой системе Интернета.
Это важный ресурс для оценки доступности вашего сайта в самой распространенной поисковой системе Интернета.
Об инструменте проверки индекса Google Rush Analytics
Rush Analytics Инструмент проверки индекса Google — это современное решение, которое позволяет легко проверить, индексируются ли ваши веб-страницы Google. Этот замечательный инструмент проверяет все веб-страницы на вашем сайте, гарантируя, что каждая из них будет замечена. Благодаря простому и удобному интерфейсу инструмент проверки индекса Google обеспечивает видимость вашего веб-сайта, предлагая важную информацию для оптимизации ваших усилий по SEO. Раскройте потенциал каждой веб-страницы с помощью нашего комплексного инструмента проверки уже сегодня.
Дополнительные
функции инструмента проверки индекса GoogleУ нас есть экспертные возможности для проверки статуса индекса Google любого сайта в Google
Мощный API
Получайте данные об индексации вашего сайта Google в режиме реального времени с помощью API.
Учет косой черты «/»
Мы знаем, как проверить индексацию URL-адресов веб-сайтов с косой чертой в конце и без нее.
Проверка индексации URL-адресов в верхнем и нижнем регистре
Если на вашем сайте есть URL-адреса как в верхнем, так и в нижнем регистре, у нас есть специальный параметр для их проверки.

Как
работает программа проверки индекса Google Современный рынок требует новых технологий и подходов к решению задач SEO.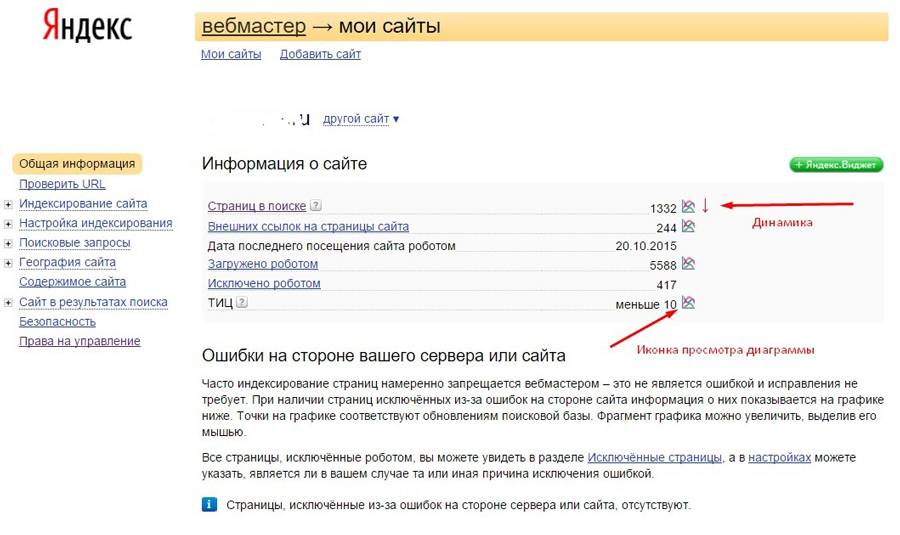
Добавьте URL-адреса для проверки индексации Google
Любым способом: перечислите, загрузите файл Excel или предоставьте ссылку на файл Sitemap.xml
.Выберите поисковик
Проверяем индексацию в Гугле и Яндексе одинаково быстро и качественно
Получить готовый к использованию отчет об индексации
Через несколько минут вы получите статус каждой страницы, независимо от того, проиндексирована ли она Google или другими поисковыми системами.
Google или нет
 Google или нет
Google или нетНачните использовать Rush Analytics сегодня
Получите 7-дневный бесплатный пробный доступ ко всем инструментам.
Кредитная карта не нужна!
Попользовавшись Rush Analytics пару месяцев, могу сказать, что это один из лучших трекеров на рынке. Он может очень быстро проверять позиции ключевых слов, даже для 100 000+ ключевых слов. Отличный инструмент для ваших нужд SEO.
Rush Analytics — самый важный инструмент SEO, который я использую.
Мне больше всего нравится трекер рангов и оптимизатор контента, они дают мне реальные данные, которые помогают догнать и обогнать конкурентов.
в соответствии с вашими потребностями
Старт
19
- долларов США Количество сайтов
- Количество потоков API
- Гостевой доступ
Подписаться Подписаться
Pro
49
- долларов США Количество сайтов
- Количество потоков API 1
- Гостевой доступ
Подписаться Подписаться
Команда
169
- долларов США Количество сайтов
- Количество потоков API 20
- Гостевой доступ
Подписаться Подписаться
Выберите план подписки
Rush Analytics по сравнению с бесплатными инструментами Средство проверки индекса Google от Rush Analytics поднимает ваш веб-сайт и SEO-оптимизацию, предлагая точные данные о значении индекса и быструю функцию «проверки индекса Google».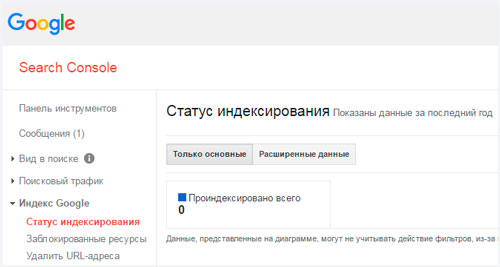 В отличие от бесплатных инструментов для веб-мастеров, Rush Analytics обеспечивает углубленный анализ страниц вашего сайта, включая html-теги, обеспечивая всесторонний анализ, необходимый для привлечения органического трафика.
В отличие от бесплатных инструментов для веб-мастеров, Rush Analytics обеспечивает углубленный анализ страниц вашего сайта, включая html-теги, обеспечивая всесторонний анализ, необходимый для привлечения органического трафика.
Его «проверка индекса Google» позволяет вам одновременно вводить несколько URL-адресов, экономя драгоценное время при оптимизации вашего веб-сайта. Эта функция явно перевешивает базовый ввод одного URL-адреса бесплатных инструментов, что иллюстрирует эффективность Rush Analytics.
Наконец, Rush Analytics сияет в отслеживании статуса вашего нового индекса страницы. В динамичном цифровом ландшафте понимание статуса индекса вашей страницы в режиме реального времени имеет решающее значение для разработки стратегии контента и получения максимального органического трафика. Оцените преимущества Rush Analytics уже сегодня и раскройте весь потенциал своего сайта.
Получите 7-дневный бесплатный пробный доступ ко всем инструментам.

Подберите правильные ключевые слова из предложений Google, YouTube и Яндекса
Попробуйте бесплатно FAQ по проверке индексаУзнайте больше об этом инструменте в нашем Руководстве по часто задаваемым вопросам ➜
Как я могу проверить свой индекс Google?Вы можете провести проверку индекса с помощью инструментов проверки индексов Google, таких как Rush Analytics. Мы предоставим вам эффективное, быстрое и последовательное решение, которое поможет вам проверить количество страниц за 10 минут.
Как проверить, проиндексировал ли Google страницу? Все, что вам нужно сделать, это открыть программу проверки индексов Google, например, Rush Analytics, создать новую задачу, выбрать интересующую вас поисковую систему и добавить URL-адреса страниц, которые вы хотите проверить. Как только все будет готово, проверка проиндексированных страниц Google предложит вам отчет, где вы сможете увидеть, были ли ваши страницы проиндексированы поисковой системой или нет.