Что такое база данных? Определение и примеры использования от экспертов Эльбрус
Разберемся, что такое база данных, для чего она нужна и каким задачи помогает решать. Материал подойдет для начинающих, все понятия в нем объясняются максимально просто.
Что такое база данных
Самое простое определение БД — это виртуальное хранилище данных. Это не единственное отличие базы данных от физических накопителей, например, от SSD — последний предоставляет лишь определенный объем памяти, в то время как база данных упорядочена по определенному принципу.
База данных лежит в основе любого современного приложения, интернет-магазина или сервиса: в ней хранят сведения о товарах, покупателях и зарегистрированных пользователях. Пока объем данных небольшой, их можно хранить хоть на своем домашнем компьютере в виде отдельных файлов (правда, придется постоянно держать ПК включенным, чтобы приложение работало без перебоев). Но как только информации становится слишком много, для ее хранения лучше использовать не множество обособленных файлов, с которыми неудобно работать, а единую базу данных.
База данных представляет собой что-то вроде Excel-таблицы, где у каждого элемента есть несколько характеристик. Предположим, что у вас есть онлайн-магазин, и вам нужно составить перечень зарегистрированных клиентов, чтобы присылать им персональные предложения. При регистрации человек может указать имя, фамилию, дату рождения, адрес электронной почты и пароль для входа. В этом случае каждая строка базы данных с клиентами будет содержать все эти пять столбцов и к ним можно будет легко обратиться, чтобы составить список для рассылки.
Свойства базы данных
Базе данных одновременно свойственны стабильность и переменчивость. Ее постоянство заключается в составе и структуре: если база уже разработана, то ее столбцы, структура и тип представления данных обычно не меняются в течение времени. Если вы видите базу данных, у которой постоянно меняется число или расположение столбцов, то она, скорее всего, все еще находится в процессе разработки.
Переменчивость баз данных — это свойство, которое относится к ее строкам.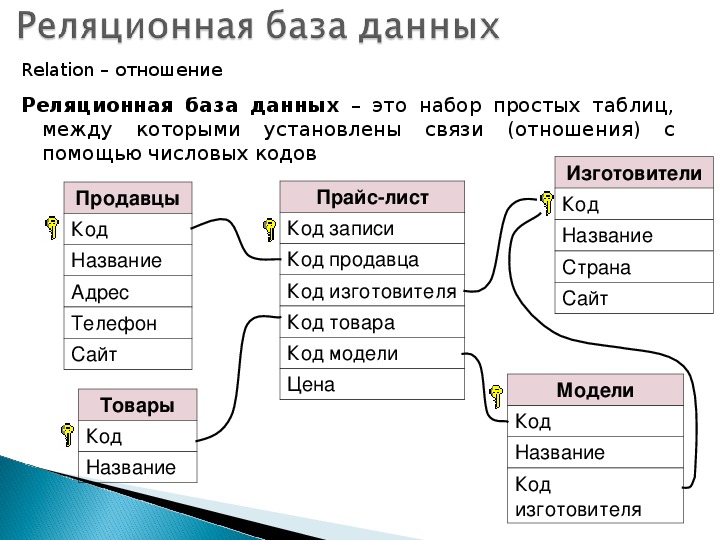 Вернемся к примеру с зарегистрированными покупателями: если количество и название столбцов остаются неизменными, то значения строк постоянно меняются. Человек может сменить пароль, указать новую почту или фамилию. Могут появиться новые пользователи, которые тоже становятся частью изменений в БД.
Вернемся к примеру с зарегистрированными покупателями: если количество и название столбцов остаются неизменными, то значения строк постоянно меняются. Человек может сменить пароль, указать новую почту или фамилию. Могут появиться новые пользователи, которые тоже становятся частью изменений в БД.
Что такое язык структурированных запросов (SQL)?
SQL (или Structured Query Language) — это язык структурированных запросов, с помощью которого разработчик общается с базой данных. Если вы раньше работали с Excel, то наверняка знаете, что нужные строки или столбцы в ней можно выделить с помощью фильтра. В базе данных такой возможности нет, поэтому при работе с ней используются специальные команды на языке структурированных запросов. Рассмотрим, как это выглядит, на коротком примере.
Рассмотрим, как это выглядит, на коротком примере.
Предположим, что у вас есть база данных с названием my_clients. В ней нужно найти все данные по пользователю с конкретным адресом почты. Чтобы получить их, надо написать: «select * from my_clients where email = ‘[email protected]’». Разберем этот код:
- select * — помогает выбрать все столбцы. Звездочка заменяет слово «все». Если нужно выбрать только конкретные столбцы (например, узнать только имя или только дату рождения), то звездочку заменяют на названия этих столбцов;
- from my_clients — ищет данные в таблице с названием my_clients. Можно искать сразу в нескольких таблицах, что значительно упрощает поиск при огромном количестве данных;
- where email = ‘[email protected]’ — задает параметры для всех строк, где значение столбца email будет равно [email protected].
В чем разница между базой данных и электронной таблицей?
Как уже говорилось выше, база данных очень похожа на таблицу в Google Документах или Excel. Зачем же вообще переходить с таких таблиц на БД? Тому есть три важные причины:
Зачем же вообще переходить с таких таблиц на БД? Тому есть три важные причины:
- Скорость чтения данных. Когда работа ведется с небольшими объемами информации, разница в скорости между Excel и базой данных будет незаметна. Но с ростом количества данных Excel будет постепенно отставать от базы данных. В крупных проектах разница будет колоссальна.
- Нацеленность на большие объемы. В одной таблице Excel можно уместить максимум миллион строк (если быть точнее, то 1 048 576). Это достаточно большое число, но для крупных проектов такого количества данных не хватит. У баз данных число строк не ограничено.
- Независимое редактирование. Сейчас у многих онлайн-документов есть функция совместного редактирования, но она не так удобна, как совместная работа в БД. Несколько авторизованных пользователей могут одновременно вносить изменения в базу данных, и эти изменения будут автоматически синхронизироваться.
Эволюция базы данных
Термин «база данных» появился в 1960-х годах. Тогда программисты стали часто обращаться к данным из разных точек, а существовавших на тот момент решений оказалось недостаточно. Данные должны были храниться независимо друг от друга, чтобы несколько пользователей могли одновременно их редактировать. В 1967 году под руководством ассоциации CODASYL началась работа над созданием структуры, подходящей для независимого хранения больших массивов информации.
Тогда программисты стали часто обращаться к данным из разных точек, а существовавших на тот момент решений оказалось недостаточно. Данные должны были храниться независимо друг от друга, чтобы несколько пользователей могли одновременно их редактировать. В 1967 году под руководством ассоциации CODASYL началась работа над созданием структуры, подходящей для независимого хранения больших массивов информации.
Следующим важным этапом стала разработка реляционной модели базы данных в 1970-х годах, за которую Эдгар Кодд получил премию Тьюринга.
В дальнейшем развитие баз данных шло в основном по пути увеличения объемов: главной задачей программистов было не создать новый тип, а расширить возможности уже существующего.
Типы баз данных
Типология баз данных — это очень обширная тема, поэтому мы рассмотрим только основные классификации.
Форма представления информации
База данных может представлять информацию в разном виде:
- Фактографические БД — это таблицы, где каждому столбцу соответствует определенный факт, представленный в виде короткого значения.
 Такие базы данных обычно используют в интернет-магазинах (артикул, цена, число просмотров, покупок и так далее).
Такие базы данных обычно используют в интернет-магазинах (артикул, цена, число просмотров, покупок и так далее). - Документальные БД представляют текстовые данные. Обычно это базы данных периодических изданий.
- Мультимедийные БД содержат изображения, видео или музыку. Яркий пример — БД YouTube.
 Такие базы данных обычно используют в интернет-магазинах (артикул, цена, число просмотров, покупок и так далее).
Такие базы данных обычно используют в интернет-магазинах (артикул, цена, число просмотров, покупок и так далее).Тип используемой модели данных
Обычно базы данных — это таблицы, к которым можно обращаться на SQL. Такие БД называют реляционными.
Второй тип — нереляционные базы данных, которые представлены не в виде таблиц. Чаще всего это иерархические структуры, похожие на JSON.
Топология хранения
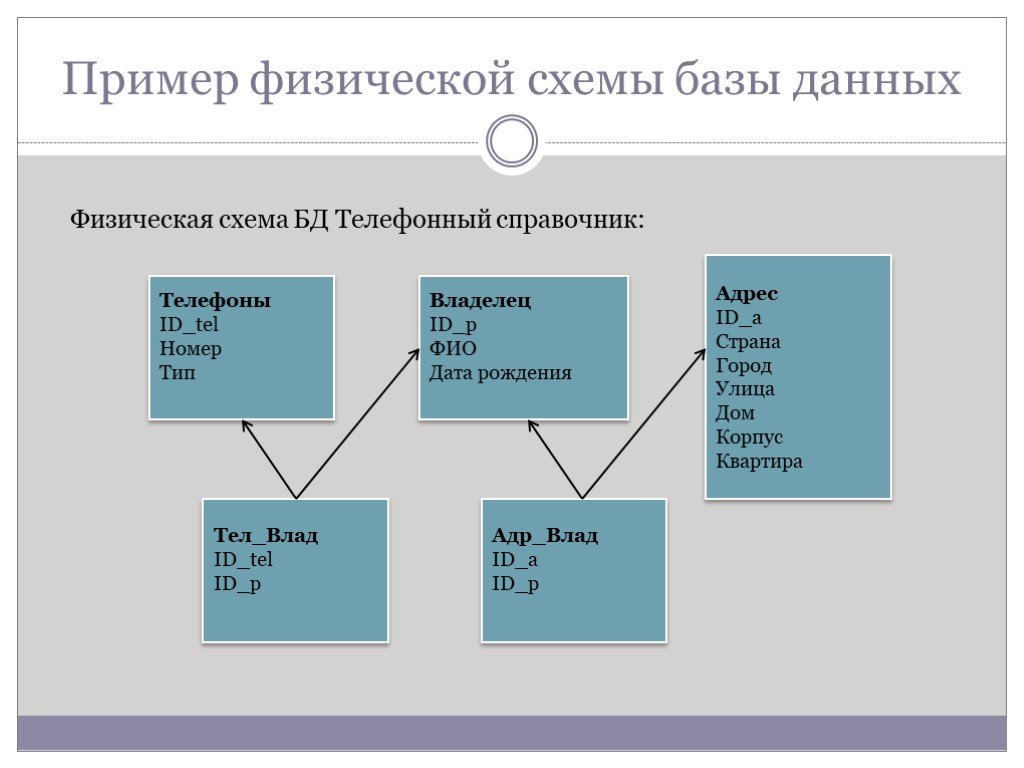
Выше мы говорили, что данные можно хранить и на домашнем компьютере. В этом случае БД будет локальной. Локальная БД — это любая база, которая полностью хранится на одном устройстве. Ее противоположность — распределенная БД, которая хранится на нескольких машинах.
Функциональное назначение
Базы данных могут быть операционными и справочно-информационными. В первом случае они часто изменяются: в них вносят данные, изменяют их, удаляют записи и так далее. Во втором случае содержимое базы используется преимущественно для чтения.
В первом случае они часто изменяются: в них вносят данные, изменяют их, удаляют записи и так далее. Во втором случае содержимое базы используется преимущественно для чтения.
Степень доступности
База данных может быть общедоступной — как, например, Wikipedia. Доступ к ней бесплатный, и любой желающий может читать данные из нее. Базы данных с ограниченным доступом обычно платные или изначально предназначены для ограниченного круга лиц.
Популярные системы управления базами данных (СУБД)
Чтобы работать с базой данных, нужно удобное программное обеспечение — СУБД, или DBMS (английский аналог русской аббревиатуры). Это специальная программа, которая используется для создания, редактирования и обслуживания файлов базы данных. Это посредник между пользователем и БД. Без СУБД юзеру пришлось бы самостоятельно искать данные во всех файлах базы данных. Вместо этого гораздо проще направить в программу запрос, который она целиком отработает и выдаст результаты в удобном для человека виде.
MySQL
Это самая популярная СУБД, которая используется в большинстве компаний, включая крупные (Amazon, LinkedIn). У нее открытое программное обеспечение, поэтому для MySQL есть много удобных дополнений. Программа работает с реляционными базами данных.
Oracle
Эта СУБД «понимает» язык SQL и Java. Основная особенность Oracle — надежная защита данных.
PostgreSQL
Это бесплатная СУБД объектно-реляционного типа. Она менее популярна, чем MySQL, но обладает аналогичным функционалом.
MongoDB
В отличие от предыдущих СУБД, MongoDB относится к NoSQL-системам. Хранение данных организовано в JSON-подобном формате.
Redis
Данные в этой СУБД хранятся в формате типа «ключ — значение», то есть Redis тоже относится к NoSQL-системам.
Elasticsearch
Эта СУБД основана на Java-библиотеке Lucene. Она умеет работать со структурированными и полуструктурированными данными. Elasticsearch подходит для быстрого поиска в режиме реального времени среди большого объема данных — это типичная задача для поисковиков.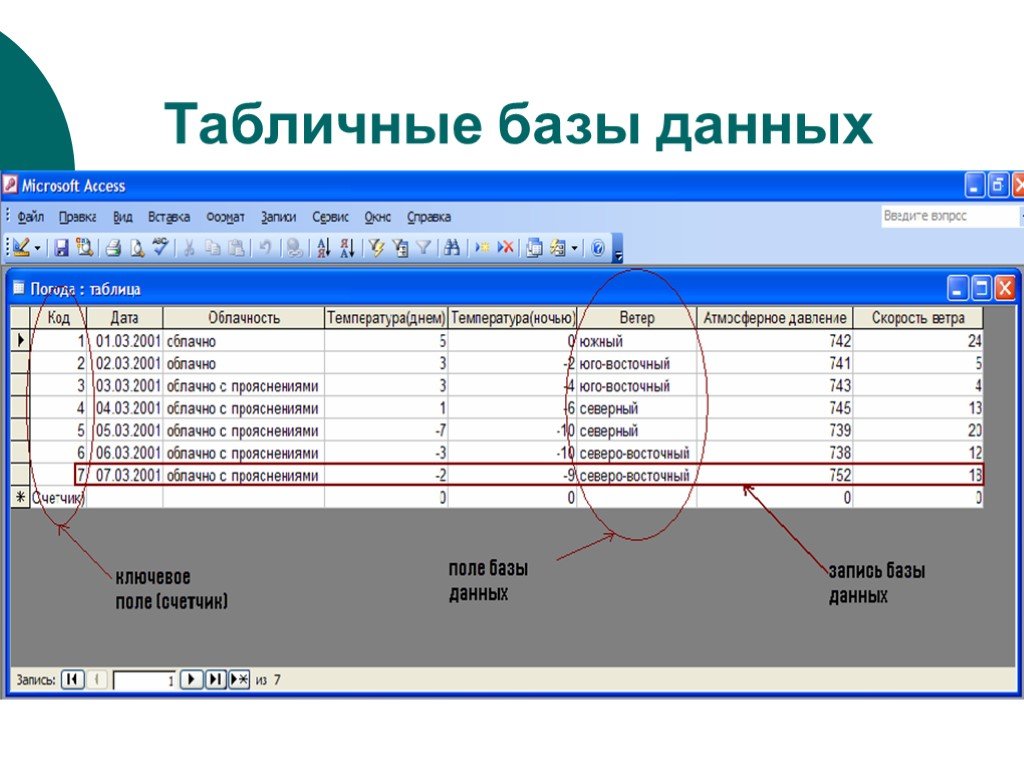
SQLite
Эта реляционная СУБД представляет собой библиотеку для С. Ее можно встроить напрямую в приложение. SQLite поставляется с нулевой конфигурацией, так что она не нуждается в настройке или первичном администрировании. СУБД полностью автономна, для ее корректной работы не нужно устанавливать дополнительные внешние зависимости.
Neo4j
Основное назначение этой СУБД — хранение и анализ наборов данных, связанных между собой. Это не просто таблица данных, а система взаимосвязей между элементами базы данных.
Что такое база данных MySQL?
База данных MySQL — это любая база данных, которая работает на реляционной СУБД на основе языка SQL. Проще говоря, если вы создаете и редактируете БД в MySQL, то вы используете базу данных MySQL.
Использование баз данных для повышения производительности бизнеса и улучшения процесса принятия решений
Большинство компаний так или иначе собирают данные. Когда их становится слишком много, бизнес может испытывать трудности, причем как информационно-технологические, так и общеделовые. Чем больше информации хранится в неправильно систематизированной базе данных, тем больше времени занимают практически все бизнес-процессы.
Чем больше информации хранится в неправильно систематизированной базе данных, тем больше времени занимают практически все бизнес-процессы.
Базы данных позволяют бизнес-аналитикам эффективно использовать массив собираемых данных. Грамотная разработка БД обеспечивает гибкость и масштабируемость системы, повышает пропускную способность для данных, ускоряя таким образом работу.
Задачи для баз данных
Сейчас перед базами данных стоит ряд задач, обусловленных быстрым развитием технологий:
- Значительно возросшие объемы данных. Еще в 2006 году объем данных Google был равен всего лишь 850 терабайт. Сейчас этот же показатель оценивается примерно в 15 эксабайт (10 квинтиллионов байт).
- Обеспечение безопасности данных. Утечка персональных данных — бич современной IT-сферы. Даже крупнейшие компании страдают от воровства сведений, которое в итоге ведет к серьезным финансовым потерям.
- Удовлетворение растущих потребностей. Каждый день перед IT-сферой встают новые задачи, порой принципиально отличающиеся от предыдущих. Их быстрое решение — одна из задач современных БД.
- Управление и обслуживание базы данных и инфраструктуры. Чем сложнее становятся базы данных, тем меньше людей способны их администрировать.
- Устранение границ масштабируемости. Идеальная база данных будет работать одинаково быстро и при 10, и при 101000 записей. Администраторам баз данных всегда сложно предугадать, какие мощности потребуются бизнесу, поэтому важно с самого начала делать БД, способную быстро работать с достаточно большими объемами.
- Соблюдение требований к размещению данных, суверенитету данных и времени ожидания. Совместная работа — важная часть баз данных, и ее можно реализовать по-разному. Иногда компании нужно, чтобы базы данных работали только в локальной среде. В других случаях им требуется максимальный доступ для большого числа пользователей.
 Каждый день перед IT-сферой встают новые задачи, порой принципиально отличающиеся от предыдущих. Их быстрое решение — одна из задач современных БД.
Каждый день перед IT-сферой встают новые задачи, порой принципиально отличающиеся от предыдущих. Их быстрое решение — одна из задач современных БД.Как автономные технологии улучшают управление базами данных
Автономные базы данных — это сравнительно новая технология, которая значительно ускоряет бизнес-процессы. Такая система может самообучаться за счет использования ИИ, а скорость ее работы обеспечивается облачными вычислениям. Последние выполняются на мощном стороннем сервере, а на компьютер с базой данных приходит готовое решение.
Такая система может самообучаться за счет использования ИИ, а скорость ее работы обеспечивается облачными вычислениям. Последние выполняются на мощном стороннем сервере, а на компьютер с базой данных приходит готовое решение.
Главное преимущество автономных БД — это автоматизация рутинных процессов: защиты, резервного копирования, обновления. Хорошо настроенная автономная БД нуждается в минимальном внимании администратора.
Будущее обычных и автономных баз данных
Сейчас автономные базы данных признаны перспективной и многообещающей технологией. Основная проблема современных БД — это недостаток людей, умеющих их администрировать. Автоматизация рутинных процессов сможет уменьшить влияние этой трудности.
Ключевое направление развития баз данных сейчас — это увеличение пропускной способности для данных. Объем информации растет в геометрической прогрессии (вспомните пример про базы данных Google в 2006 году и сейчас), и в ближайшее время средний объем хранимых в БД сведений должен увеличиться вдвое. Новые базы данных должны уметь быстро работать со всей этой информацией.
Новые базы данных должны уметь быстро работать со всей этой информацией.
Работа с базами данных — это навык, который наверняка потребуют от тестировщика на собеседовании. Теперь вы в общих чертах представляете себе, что такое базы данных и СУБД, и готовы к более глубокому изучению этих понятий.
Образцы баз данных AdventureWorks — SQL Server
Twitter LinkedIn Facebook Адрес электронной почты- Статья
Применимо к: SQL Server Azure SQL DatabaseУправляемый экземпляр SQL AzureAzure Synapse Analytics AnalyticsPlatform System (PDW)
В этой статье приводятся прямые ссылки для скачивания AdventureWorks примеров баз данных и инструкции по их восстановлению в базе данных SQL Server и Azure SQL.
Дополнительные сведения о примерах см. в репозитории Примеры GitHub.
Предварительные требования
- База данных SQL Server или Azure SQL
- SQL Server Management Studio (SSMS) или Azure Data Studio
Скачивание файлов резервной копии
Используйте эти ссылки, чтобы скачать соответствующий пример базы данных для вашего сценария.
- Данные OLTP
- Data Warehouse данных для рабочих нагрузок хранения данных.
- Упрощенные данные (LT) — это упрощенная и упрощенная версия примера OLTP .
Если вы не уверены, что вам нужно, начните с версии OLTP, которая соответствует версии SQL Server.
| OLTP | хранилище данных | упрощенный интерфейс, |
|---|---|---|
| AdventureWorks2022.bak | AdventureWorksDW2022.bak | AdventureWorksLT2022. |
| AdventureWorks2019.bak | AdventureWorksDW2019.bak | AdventureWorksLT2019.bak |
| AdventureWorks2017.bak | AdventureWorksDW2017.bak | AdventureWorksLT2017.bak |
| AdventureWorks2016.bak | AdventureWorksDW2016.bak | AdventureWorksLT2016.bak |
| AdventureWorks2016_EXT.bak | AdventureWorksDW2016_EXT.bak | Н/Д |
| AdventureWorks2014.bak | AdventureWorksDW2014.bak | AdventureWorksLT2014.bak |
| AdventureWorks2012.bak | AdventureWorksDW2012.bak | AdventureWorksLT2012.bak |
| AdventureWorks2008R2.bak | AdventureWorksDW2008R2.bak | Н/Д |
Дополнительные файлы можно найти непосредственно на сайте GitHub:
- SQL Server 2014 –2022 гг.
- SQL Server 2012
- SQL Server 2008 и 2008R2
Восстановление в SQL Server
С помощью .bak файла можно восстановить образец базы данных в экземпляре SQL Server. Это можно сделать с помощью команды RESTORE (Transact-SQL) или графического интерфейса (GUI) в SQL Server Management Studio (SSMS) или Azure Data Studio.
Это можно сделать с помощью команды RESTORE (Transact-SQL) или графического интерфейса (GUI) в SQL Server Management Studio (SSMS) или Azure Data Studio.
- SQL Server Management Studio (SSMS)
- Transact-SQL (T-SQL)
- Azure Data Studio
Если вы не знакомы с использованием SQL Server Management Studio (SSMS), вы можете увидеть запрос подключения & для начала работы.
Чтобы восстановить базу данных в SSMS, выполните следующие действия.
Скачайте соответствующий
.bakфайл по одной из ссылок, указанных в разделе Скачивание файлов резервной копии .Переместите файл в
.bakрасположение резервной копии SQL Server. Это зависит от расположения установки, имени экземпляра и версии SQL Server. Например, расположение по умолчанию для экземпляра SQL Server 2019 (15.x) по умолчанию:C:\Program Files\Microsoft SQL Server\MSSQL15.. MSSQLSERVER\MSSQL\BackupОткройте SSMS и подключитесь к SQL Server.
Щелкните правой кнопкой мыши Базы данных в обозреватель объектов>База данных хранилища… , чтобы запустить мастер восстановления базы данных.
Выберите Устройство , а затем нажмите кнопку с многоточием (…), чтобы выбрать устройство.
Нажмите кнопку Добавить , а затем выберите файл,
Нажмите кнопку ОК , чтобы подтвердить выбор резервного копирования базы данных, и закройте окно Выбор устройств резервного копирования .
Перейдите на вкладку Файлы и убедитесь, что в мастере
Чтобы восстановить базу данных, нажмите кнопку ОК.
 MSSQLSERVER\MSSQL\Backup
MSSQLSERVER\MSSQL\Backup
Дополнительные сведения о восстановлении базы данных SQL Server см. в статье Восстановление резервной копии базы данных с помощью SSMS.
Развертывание в Базе данных SQL Azure
У вас есть два варианта просмотра примеров данных Azure SQL базы данных. Вы можете использовать пример при создании базы данных или развернуть базу данных из SQL Server непосредственно в Azure с помощью SSMS.
Чтобы получить образцы данных для Управляемый экземпляр SQL Azure, см. статью Восстановление World Wide Importers в Управляемый экземпляр SQL.
Развертывание нового примера базы данных
При создании базы данных в Azure SQL Database можно создать пустую базу данных, выполнить восстановление из резервной копии или выбрать пример данных для заполнения новой базы данных.
Чтобы добавить пример данных в новую базу данных, выполните следующие действия.
Подключитесь к портал Azure.
Выберите Создать ресурс в левом верхнем углу области навигации.
Выберите Базы данных, а затем База данных SQL.
Введите запрошенные сведения для создания базы данных.
На вкладке Дополнительные параметры выберите Пример существующих данных в разделе Источник данных:
Выберите Создать, чтобы создать новую База данных SQL, которая является восстановленной копией
Развертывание базы данных из SQL Server
SSMS позволяет развертывать базу данных непосредственно в Azure SQL Database. В настоящее время этот метод не обеспечивает проверку данных, поэтому он предназначен для разработки и тестирования и не должен использоваться в рабочей среде.
Чтобы развернуть пример базы данных из SQL Server в базу данных Azure SQL, выполните следующие действия.
Подключитесь к SQL Server в SSMS.
Если вы еще не сделали этого, восстановите образец базы данных в SQL Server.
Щелкните правой кнопкой мыши восстановленную базу данных в обозреватель объектов>Задачи>Развернуть базу данных в База данных SQL Microsoft Azure….
Следуйте указаниям мастера, чтобы подключиться к базе данных Azure SQL и развернуть базу данных.
Создание скриптов
Вместо восстановления базы данных можно использовать скрипты для создания AdventureWorks баз данных независимо от их версии.
Приведенные ниже скрипты можно использовать для создания всей AdventureWorks базы данных:
- AdventureWorks OLTP Scripts Zip
- AdventureWorks DW Scripts Zip
Дополнительные сведения об использовании скриптов можно найти на сайте GitHub.
Дальнейшие действия
После восстановления примера базы данных воспользуйтесь следующими руководствами, чтобы приступить к работе с SQL Server:
- Руководства по ядру СУБД SQL Server
- Подключение и выполнение запросов с помощью SQL Server Management Studio (SSMS)
- Подключение и выполнение запросов с помощью Azure Data Studio
Основы NoSQL: функции, типы и примеры
Базы данных NoSQL определяются как нетабличные базы данных, которые обрабатывают хранение данных иначе, чем реляционные таблицы. Типы баз данных NoSQL классифицируются в соответствии с моделью данных, а популярные типы включают документ, график, столбец и ключ-значение. В этой статье подробно описаны функции, типы и примеры NoSQL.
Содержание
- Что такое NoSQL?
- Особенности баз данных NoSQL
- Типы базы данных NoSQL
- Примеры NoSQL
Что такое NoSQL?
Базы данных NoSQL не являются табличными и обрабатывают хранение данных иначе, чем реляционные таблицы. Эти базы данных классифицируются в соответствии с моделью данных, а популярные типы включают документ, график, столбец и ключ-значение.
Эти базы данных классифицируются в соответствии с моделью данных, а популярные типы включают документ, график, столбец и ключ-значение.
Нереляционная по своей природе, основная функция NoSQL заключается в предоставлении механизма для хранения и извлечения информации. Моделирование данных происходит с использованием средств, не включенных в табличные отношения, связанные с реляционными базами данных.
Самая ранняя форма баз данных NoSQL существовала в 1960-х годах. Однако тогда они не были известны как NoSQL; это прозвище возникло только после того, как такие базы данных приобрели популярность на рубеже тысячелетий.
Важнейшие преимущества NoSQL включают гибкие схемы и простоту масштабирования даже при работе с большим количеством пользователей и огромными объемами данных. Этот класс баз данных полезен в пространстве больших данных и для веб-приложений реального времени.
Термин «NoSQL» изначально мог означать «не SQL»; однако со временем он стал более широко восприниматься как «не только SQL». Это подчеркивает тот факт, что NoSQL поддерживает языки запросов, подобные SQL.
Это подчеркивает тот факт, что NoSQL поддерживает языки запросов, подобные SQL.
Ключевые особенности NoSQL включают в себя простой дизайн, плавную горизонтальную масштабируемость и детальный контроль доступности. Быстрые операции также являются преимуществом NoSQL, вызванным разницей в структурах данных по сравнению со значениями по умолчанию, используемыми в реляционных базах данных.
NoSQL иногда отказывается от согласованности в обмен на более высокую скорость, устойчивость к разделам и доступность. Эта гибкость структур данных NoSQL позволяет этим базам данных решать различные бизнес-задачи.
Хотя у NoSQL есть несколько преимуществ (которые мы обсудим в следующем разделе), у него есть и несколько недостатков. Например, базы данных NoSQL имеют узкую область применения, поскольку они в основном предназначены для хранения данных. Для таких приложений, как управление транзакциями, реляционные базы данных обычно являются лучшим выбором.
Помимо этого, отсутствие общепринятых бизнес-стандартов для NoSQL часто означает, что две независимые системы баз данных не равны. Это также может создать препятствия для управления более обширными базами данных NoSQL, проблема, которую не облегчает отсутствие хорошо известных и широко используемых инструментов режима графического интерфейса. Наконец, определенные системы баз данных NoSQL хранят данные в формате JSON, что приводит к созданию больших документов.
Это также может создать препятствия для управления более обширными базами данных NoSQL, проблема, которую не облегчает отсутствие хорошо известных и широко используемых инструментов режима графического интерфейса. Наконец, определенные системы баз данных NoSQL хранят данные в формате JSON, что приводит к созданию больших документов.
Подробнее: Что такое SQL? Определение, элементы, примеры и использование в 2022 году
Особенности баз данных NoSQL
Хотя реляционные базы данных по-прежнему используются для различных бизнес-функций, использование баз данных NoSQL становится все более популярным. Сегодня компании во всех отраслях промышленности полагаются на базы данных NoSQL для обработки своих облачных, веб-приложений и приложений для работы с большими данными в режиме реального времени.
Ключевые особенности баз данных NoSQL:
1. Совместимость с несколькими моделями данных
Реляционные базы данных обычно требуют, чтобы данные были помещены в табличную форму, прежде чем они смогут получить к ним доступ и проанализировать их. Они, как правило, негибки в обработке данных, требуя, чтобы информация была хорошо структурирована, прежде чем ее можно будет принять.
Они, как правило, негибки в обработке данных, требуя, чтобы информация была хорошо структурирована, прежде чем ее можно будет принять.
Это не ограничение в случае NoSQL, совместимость которого с несколькими моделями данных делает его очень гибким в отношении обработки данных. Он может принимать неструктурированные, полуструктурированные и структурированные данные с одинаковой скоростью и легкостью. Это особенно полезно, поскольку для конкретных приложений требуются определенные модели данных.
Базы данных NoSQL пользуются популярностью у архитекторов и разработчиков, поскольку они нацелены на быстрое и эффективное выполнение различных требований гибкой разработки. Поддерживая многочисленные модели данных, NoSQL позволяет использовать одни и те же данные в различных типах моделей данных без необходимости управления отдельными базами данных.
2. Повышенная масштабируемость и доступность
Реляционные базы данных, несомненно, масштабируемы. Однако их традиционная серверно-клиентская архитектура делает как горизонтальное, так и вертикальное масштабирование ресурсоемким процессом.
Напротив, решения NoSQL могут предлагать бессерверную одноранговую архитектуру с согласованными свойствами для всех узлов. Это обеспечивает упрощенную масштабируемость, что делает NoSQL легко адаптируемым для облачных приложений. Также повышается производительность, что обеспечивает более высокую скорость чтения и записи и непрерывную доступность.
Базы данных NoSQL также используют сегментирование для горизонтального масштабирования. В этом процессе данные разделяются и размещаются на нескольких машинах, чтобы сохранить их порядок. Высокая гибкость NoSQL позволяет эффективно обрабатывать огромные объемы данных.
Наконец, возможность автоматической репликации NoSQL также помогает обеспечить высокую доступность, поскольку решение отвечает репликацией в последнее известное согласованное состояние в случае любого сбоя.
3. Глобальное распространение данных
Передовые базы данных NoSQL могут обеспечить распространение данных в глобальном масштабе.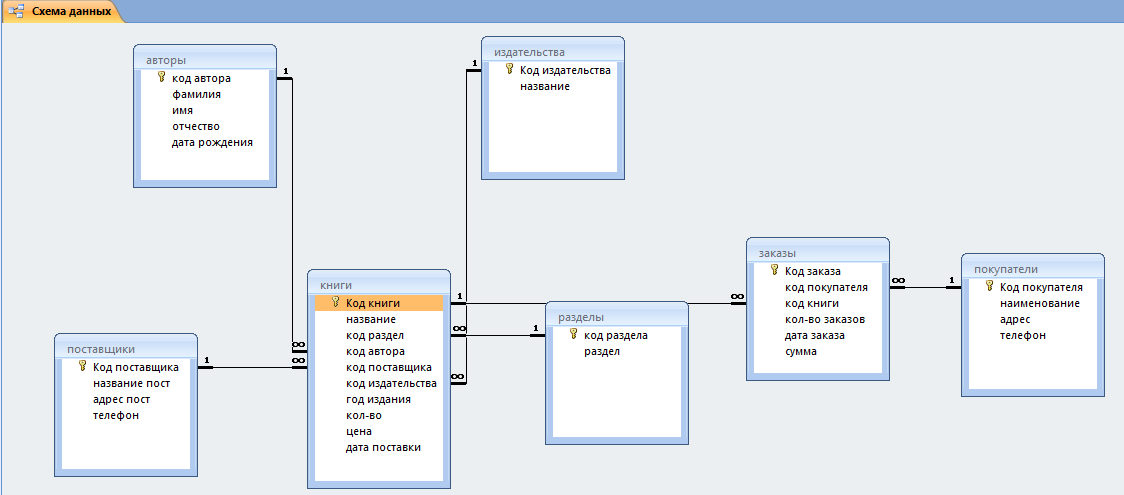 Это достигается за счет нескольких облачных регионов и центров обработки данных для операций чтения и записи в нескольких местах.
Это достигается за счет нескольких облачных регионов и центров обработки данных для операций чтения и записи в нескольких местах.
Это контрастирует с реляционными базами данных, которые обычно полагаются на централизованные приложения, зависящие от местоположения, для операций чтения и записи. Распределяя несколько копий данных, чтобы гарантировать, что информация находится как можно ближе к тому месту, где она должна быть, глобально распределенные базы данных NoSQL обеспечивают минимальное время ожидания.
4. Минимальное время простоя
Наконец, базы данных NoSQL надежны и имеют минимальное время простоя. Непрерывность бизнеса поддерживается за счет бессерверной архитектуры и создания нескольких копий данных, которые должны храниться на узлах. В случае неисправности узла другой узел предоставит доступ к своей копии данных.
Может ли NoSQL полностью заменить реляционные базы данных?
Одним словом, нет. NoSQL лучше подходит для конкретных случаев использования, тогда как реляционные базы данных хорошо подходят для других. Выбор зависит от конкретных потребностей принимающей организации. В некоторых случаях предприятия могут даже развернуть оба типа баз данных вместе, поскольку эти решения способны дополнять друг друга.
Выбор зависит от конкретных потребностей принимающей организации. В некоторых случаях предприятия могут даже развернуть оба типа баз данных вместе, поскольку эти решения способны дополнять друг друга.
Пользователи, имеющие дело с несколькими типами данных одновременно, обычно предпочитают NoSQL. Это решение хорошо подходит для создания мощных облачных и веб-приложений для широко рассредоточенной и быстро растущей аудитории. Его гибкость, многомодальность, масштабируемость, доступность и высокая степень распространения делают NoSQL идеальным для таких приложений.
Узнать больше: Что такое нейронная сеть? Определение, работа, типы и приложения в 2022 году
Типы баз данных NoSQL
Базы данных NoSQL бывают пяти основных вариантов, каждый из которых имеет свои преимущества и ограничения. Не существует «идеального» варианта; предприятия должны выбирать типы баз данных в зависимости от потребностей своего бизнеса.
Типы баз данных NoSQL:
1.
 Пара «ключ-значение»
Пара «ключ-значение»В этом типе базы данных NoSQL, как следует из названия, информация хранится в виде ключа и значения. Например, пара ключ-значение может состоять из ключа «Город» со связанным значением «Чикаго».
Хранение данных происходит в виде хеш-таблицы с уникальными ключами. Значения могут храниться в нескольких форматах, включая строку, JSON или BLOB. Этот вариант предназначен для обработки больших объемов данных.
Разработчики часто полагаются на ключ-значение NoSQL для хранения данных без схемы. Компании используют эту простую базу данных NoSQL для таких приложений, как словари, коллекции и ассоциативные массивы. Часто встречающееся использование пары «ключ-значение» — это корзины покупок на веб-сайтах электронной коммерции.
Пара «ключ-значение» NoSQL концептуально основан на хеш-таблицах, использующих уникальный ключ и указатель на определенный элемент данных. Хранилище «ключ-значение» может включать в себя совершенно новые наборы пар «ключ-значение», захваченные как объекты. Однако, несмотря на самый простой процесс реализации, он неэффективен для запроса или обновления частичных значений.
Однако, несмотря на самый простой процесс реализации, он неэффективен для запроса или обновления частичных значений.
Решения NoSQL типа «ключ-значение» включают Dynamo, Redis, Riak, Tokyo Cabinet/Tyrant, Voldemort, Amazon SimpleDB и Oracle BDB.
2. Столбец
Базы данных NoSQL на основе столбцов работают со столбцами, причем каждый столбец обрабатывается независимо. Из-за наличия готовых данных в виде столбца этот тип базы данных предпочтителен для высокопроизводительной доставки в случаях, связанных с запросами агрегирования, такими как COUNT, SUM, MIN и AVG.
Предприятия используют столбцовые базы данных NoSQL для хранения и обработки больших объемов данных, распределенных по множеству компьютеров. Непрерывное хранение значений в одностолбцовых базах данных является важной особенностью этого типа баз данных.
Расположение столбцов происходит на основе семейства столбцов, и хотя в этом типе NoSQL существуют ключи, они указывают на несколько столбцов. Такие базы данных в основном используются для управления такими приложениями, как бизнес-аналитика, хранилища данных, каталоги библиотечных карт и CRM.
Такие базы данных в основном используются для управления такими приложениями, как бизнес-аналитика, хранилища данных, каталоги библиотечных карт и CRM.
Примеры баз данных NoSQL на основе столбцов включают Cassandra, HBase и Hypertable.
3. Документ
В документно-ориентированной базе данных NoSQL хранение и извлечение данных происходит в формате пары ключ-значение. Однако значения сохраняются в форме документа в формате JSON или XML. База данных понимает значения и позволяет более эффективно запрашивать их.
Документ Базы данных NoSQL хранят данные, такие как объекты JSON. Пользователям не нужно определять данные, что повышает гибкость. Приложения документо-ориентированных баз данных NoSQL включают платформы для ведения блогов, системы CMS, электронную коммерцию и аналитику в реальном времени.
На самом поверхностном уровне в этой модели NoSQL используются документы с версиями, представляющие собой наборы баз данных «ключ-значение». Такие форматы, как JSON, используются для хранения этих полуструктурированных документов.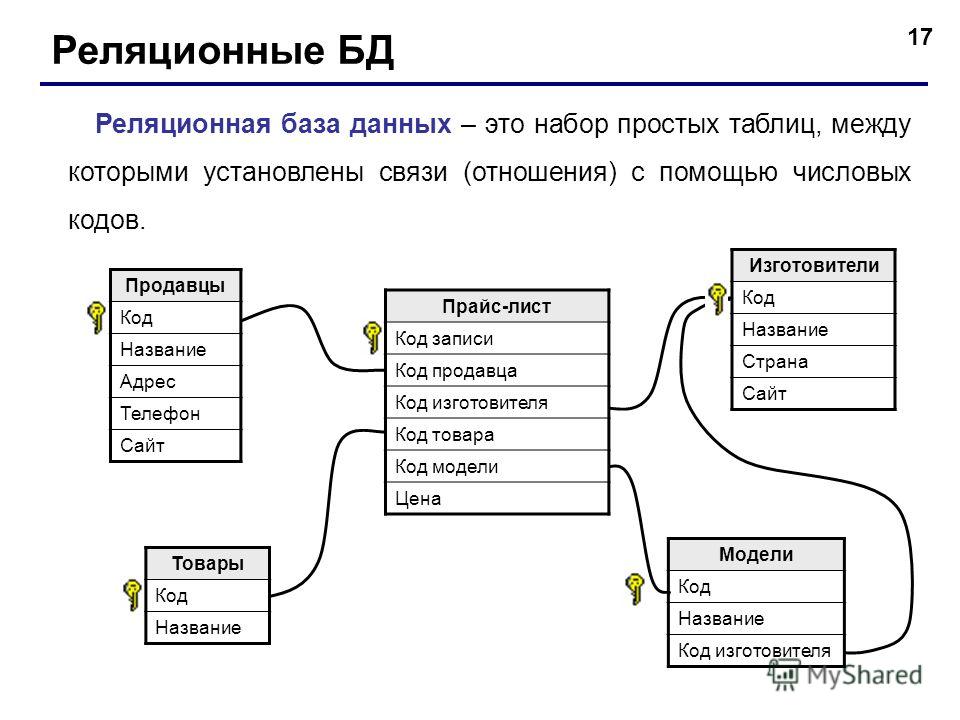
По сути, документо-ориентированные базы данных NoSQL представляют собой следующий уровень баз данных типа «ключ-значение», позволяющий каждому ключу иметь связанное вложенное значение. Однако этот тип базы данных не идеален для сложных транзакций, требующих нескольких запросов или операций с различными агрегатными структурами.
Давайте посмотрим на пример этого типа базы данных в действии. В реляционной базе данных набор статей из исследовательских журналов будет разделен на текст в одной таблице, информацию об исследователях в другой и, возможно, цитаты, используемые в каждой статье, в третьей. Однако в базе данных NoSQL, ориентированной на документы, вся статья и все связанные с ней данные будут храниться как единый объект. Это уменьшает сложности, связанные с операциями с данными.
Документо-ориентированные решения баз данных NoSQL включают MongoDB, CouchDB, Riak, Amazon SimpleDB и Lotus Notes.
4. График
Базы данных NoSQL графического типа хранят сущности вместе с отношениями между ними. Каждый объект рассматривается как узел во время хранения, а отношения сохраняются как ребра. Ребро устанавливает отношения между узлами. Каждому узлу и ребру присваивается отдельный идентификатор.
Каждый объект рассматривается как узел во время хранения, а отношения сохраняются как ребра. Ребро устанавливает отношения между узлами. Каждому узлу и ребру присваивается отдельный идентификатор.
В то время как слабосвязанные таблицы являются жизненно важным аспектом реляционных баз данных, графовые базы данных NoSQL являются мультиреляционными. Здесь установление взаимосвязей является быстрым процессом, поскольку данные уже имеются и их не нужно вычислять. Этот тип базы данных в основном используется для таких приложений, как логистика, социальные сети и анализ пространственных данных.
Данной модели базы данных не мешают недостатки, связанные с таблицами строк и столбцов и негибкой структурой SQL. Вместо этого он использует гибкую графовую модель, которую можно масштабировать в различных системах.
Двумя компонентами баз данных NoSQL типа Graph являются узел и край. Каждый узел представляет собой сущность, например, людей в приложении социальной сети. С другой стороны, край — это отношения между сущностями. Каждое отношение имеет свои свойства и обычно изображается линией. Ребро обычно имеет направление; например, стрелка указывает на превосходство в иерархии организации.
Каждое отношение имеет свои свойства и обычно изображается линией. Ребро обычно имеет направление; например, стрелка указывает на превосходство в иерархии организации.
Крупномасштабное развертывание графа NoSQL может значительно усложниться из-за множества типов сущностей и взаимосвязей. Решения для баз данных NoSQL на основе графов включают Neo4J, Infinite Graph и FlockDB.
5. Многомодельные
Наконец, многомодельные базы данных NoSQL созданы для обработки множества моделей данных в рамках одной интегрированной серверной части. Обычно системы управления базами данных поддерживают одну модель данных; однако базы данных с несколькими моделями могут хранить, запрашивать и индексировать данные из нескольких моделей.
Пользователи полагаются на базы данных с несколькими моделями из-за преимуществ моделирования, связанных с многоязычным постоянством, без необходимости комбинировать различные модели. Эта гибкость позволяет хранить данные различными способами, что приводит к более быстрому Agile-программированию и минимизации избыточности данных.
Ключевой особенностью мультимодельных баз данных является преобразование данных между форматами; например, можно быстро преобразовать данные, хранящиеся в формате JSON, в XML. Другие преимущества мультимодельных баз данных включают непротиворечивость данных между моделями благодаря общему бэкэнду и соответствие требованиям ACID, что обеспечивает более высокую отказоустойчивость.
Примеры мультимодельных решений для баз данных NoSQL включают OrientDB, ArangoDB и MarkLogic Server. Этот тип базы данных NoSQL хорошо подходит для сложных проектов, требующих нескольких представлений данных.
Узнать больше: Что такое глубокое обучение? Определение, методы и варианты использования
Примеры NoSQL
В предыдущем разделе мы уже рассмотрели различные решения NoSQL. Теперь мы подробно рассмотрим примеры NoSQL.
1. MongoDB
MongoDB — одна из передовых систем NoSQL с открытым исходным кодом. Это документно-ориентированная база данных, которая использует динамические схемы для хранения документов в формате JSON. Это решение для базы данных имеет гибкую модель данных, позволяющую пользователям хранить неструктурированные данные. Пользователи также могут получить доступ к полной поддержке индексации и репликации через интуитивно понятный API.
Это решение для базы данных имеет гибкую модель данных, позволяющую пользователям хранить неструктурированные данные. Пользователи также могут получить доступ к полной поддержке индексации и репликации через интуитивно понятный API.
Популярность MongoDB среди разработчиков обусловлена ее гибкой моделью данных и интуитивно понятным API. Другие ключевые особенности этого решения включают в себя:
- Специальные запросы: Поддержка запросов диапазона, полей и регулярных выражений, которые могут возвращать полные документы, определенные поля из внутренних документов и даже случайные выборки результатов.
- Репликация: Высокая доступность достигается за счет наборов реплик, включающих несколько копий данных. Первичная реплика обрабатывает записи, а любая реплика может обслуживать запросы на чтение. В случае сбоя первичной реплики вторичная реплика берет на себя роль первичной реплики.
- Индексирование: Поддержка различных типов индексов, включая однополевое, многоключевое (массив), составное (несколько полей), геопространственное, хэшированное и текстовое. Поля документа можно индексировать с использованием как первичных, так и вторичных индексов.
 Поля документа можно индексировать с использованием как первичных, так и вторичных индексов.
Поля документа можно индексировать с использованием как первичных, так и вторичных индексов.2. Apache CouchDB
Эта веб-ориентированная база данных NoSQL имеет открытый исходный код и хранит документы в формате обмена данными JSON. CouchDB API основан на HTTP, а решение использует JavaScript для индексации, преобразования и объединения документов. В отличие от реляционных баз данных, он использует модель данных без схемы, чтобы упростить управление записями между конечными точками.
CouchDB поддерживается активным сообществом разработчиков, которое постоянно работает над тем, чтобы упростить его использование и обеспечить ориентированность на Интернет. Кроме того, его природа с открытым исходным кодом сводит к минимуму вероятность «привязки к поставщику», что не наблюдается в случае проприетарных решений NoSQL.
CouchDB можно использовать бесплатно и быстро интегрировать в существующую инфраструктуру управления данными. Расширение пользовательского контроля также означает большую гибкость и применимость для различных бизнес-потребностей; решение оптимизировано для хранения документов общего назначения, эффективной синхронизации данных и даже для настройки в автономном режиме.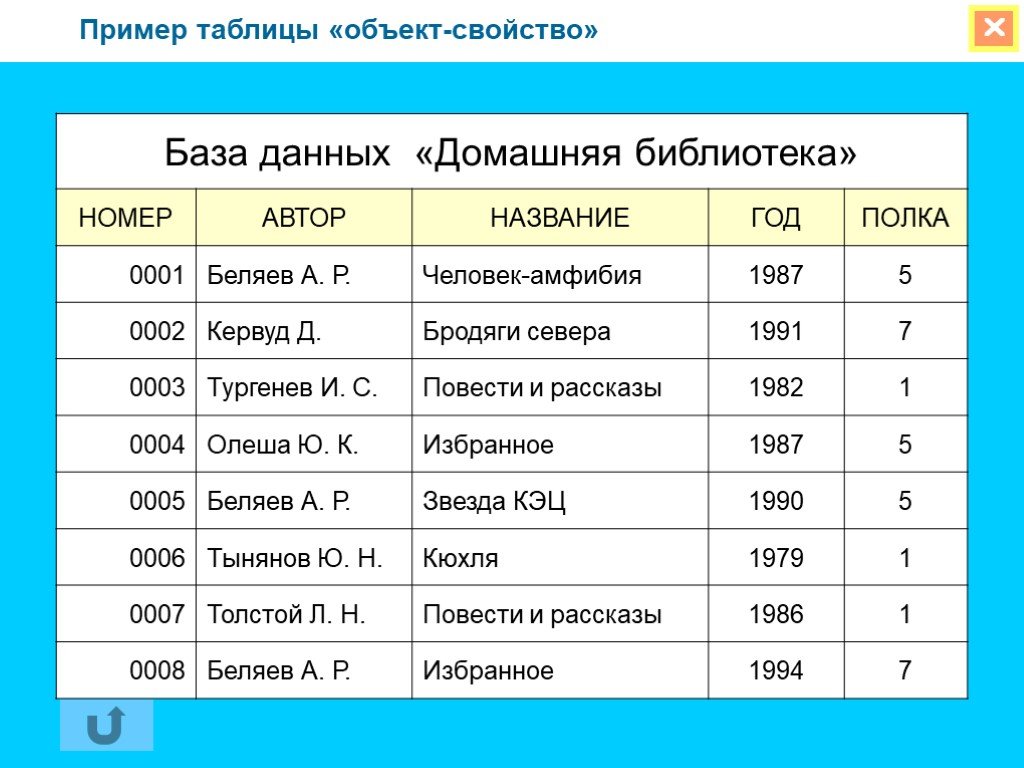 Организации полагаются на CouchDB для создания масштабируемой, надежной и долговечной инфраструктуры.
Организации полагаются на CouchDB для создания масштабируемой, надежной и долговечной инфраструктуры.
3. База данных Oracle NoSQL
Эта проприетарная база данных NoSQL поддерживает модели данных «ключ-значение» и таблицы JSON и предназначена для работы как локально, так и в облаке. Разработчики используют Oracle NoSQL Database Cloud Service для создания приложений с использованием моделей данных столбцов, документов и ключей-значений.
Ключевые особенности базы данных Oracle NoSQL включают:
- Обеспечение предсказуемого времени отклика в пределах миллисекунд и высокая доступность благодаря надежной репликации данных.
- Поддержка режимов предоставления ресурсов и ресурсов по запросу.
- транзакций ACID, комплексная безопасность, низкие цены с оплатой по факту использования и бессерверное масштабирование.
- Упрощенный доступ через удобный интерфейс прикладного программирования (API).
- Широкая поддержка моделей данных для различных бизнес-требований.
- Полная совместимость с локальной базой данных Oracle NoSQL.
- Поддержка современных языков разработки, позволяющая пользователям получать программный доступ к базам данных NoSQL с помощью SDK для Python, Java, Spring, Node.JS, Go и .NET, а также прямой доступ через RESTful API.
- Выполнение приложений и хранение данных в облачных и локальных службах без риска привязки к поставщику.
- Интеграция средств разработки позволяет командам разработчиков использовать предпочитаемые интегрированные среды разработки, такие как IntelliJ или Eclipse, для запросов к облачным службам NoSQL с помощью готовых подключаемых модулей.
- Расширенное индексирование в JSON позволяет пользователям повысить производительность запросов, создавая индекс для любого поля JSON на любом уровне иерархии документа. Поддержка встроенной аналитики
- позволяет разработчикам анализировать данные NoSQL в исходном виде, включая параллельную масштабируемость и запросы между коллекциями, без необходимости перемещения данных.

4. Riak
Созданная Basho Technologies, эта база данных NoSQL с хранилищем ключей и значений имеет открытый исходный код и написана на Erlang. Он имеет автоматическое распределение данных и встроенную отказоустойчивую репликацию, что отличает его производительность от некоторых других решений в этой области.
Это решение для базы данных NoSQL масштабируется через Интернет и основано на системе баз данных Dynamo. Он высокораспределенный, масштабируемый и надежный в различных бизнес-средах. Решение создано для Интернета, мобильных устройств и облака. Помимо бесплатной версии с открытым исходным кодом, у Riak есть коммерческая версия для корпоративного использования.
Отказоустойчивость Riak обусловлена его высоким распределением по нескольким узлам и внедрением без мастера, что помогает избежать единой точки отказа. Он идеально подходит для распределенных облачных архитектур данных и приложений чтения и записи большого объема. Пользователи обычно предпочитают Riak для создания облачных файловых систем.
5. Объективность InfiniteGraph
InfiniteGraph — это узкоспециализированная графовая база данных, ориентированная на графовые модели данных. Он реализован на Java и идеально подходит для выявления скрытых тенденций в массивных, сложных и тесно связанных наборах данных. Это решение для базы данных NoSQL распространяется по своей природе и реализовано на C++ и Java.
InfiniteGraph является масштабируемым, кросс-платформенным, облачным и созданным для работы с высокими уровнями пропускной способности. Он способен быстро и эффективно выполнять запросы, которые в противном случае было бы трудно выполнить, например, поиск всех путей или кратчайшего пути, соединяющего два элемента.
InfiniteGraph — это предпочтительное решение NoSQL для служб и приложений, связанных с решением задач с графами в бизнес-среде. Его язык запросов «DO» поддерживает сложные графы и запросы на основе значений. Помимо графовых баз данных, он также может обрабатывать сложные объектные запросы. Это решение широко используется в отраслевых вертикалях, включая управление, здравоохранение, телекоммуникации, кибербезопасность, финансы, производство и сети.
Это решение широко используется в отраслевых вертикалях, включая управление, здравоохранение, телекоммуникации, кибербезопасность, финансы, производство и сети.
Узнать больше: Что такое компьютерное зрение? Значение, примеры и приложения в 2022 году
Выводы
Реляционные базы данных широко используются сегодня из-за их согласованности. Однако они не всегда являются идеальным решением для обеспечения высокой производительности, особенно для приложений, которые часто используют для хранения и обработки данных в больших масштабах. Высокая производительность, простота доступа и высокая масштабируемость — основные причины растущей популярности баз данных NoSQL.
Однако NoSQL — это надежное решение, которое значительно расширяет существующие стандарты баз данных; это не универсальная замена реляционным базам данных. Он обменивает согласованность и надежность на масштабируемость и производительность, что делает его специализированным решением, на которое может положиться относительно ограниченное число приложений.
Тем не менее, это передовое решение для баз данных представлено в нескольких типах и поддерживается несколькими популярными решениями, разработанными экспертами и используемыми во многих отраслях.
Помогла ли вам эта статья получить новые сведения о NoSQL? Присоединяйтесь к обсуждению на Facebook Открывает новое окно , Twitter Открывает новое окно 9 0004 или LinkedIn Открывает новое окно !
БОЛЬШЕ ОБ ИИ- Что такое квантовые вычисления? Работа, важность и использование
- Что такое анализ настроений? Определение, инструменты и приложения
- Что такое параллельная обработка? Определение, типы и примеры
- OLAP и OLTP: понимание 13 важных различий
- Что такое обучение с подкреплением? Работа, алгоритмы и использование
Что такое база данных CRM? примеры + как построить
Никогда еще компаниям не было так легко общаться со своими клиентами. С помощью социальных сетей, электронной почты, телефона, приложений для обмена сообщениями и чата компании могут быстро и легко привлекать своих клиентов к наиболее важным для них каналам. Эта многоканальная экосистема обеспечивает значительные преимущества как для клиентов, так и для компаний, а ключевым инструментом, оптимизирующим эту среду поддержки, является база данных CRM.
С помощью социальных сетей, электронной почты, телефона, приложений для обмена сообщениями и чата компании могут быстро и легко привлекать своих клиентов к наиболее важным для них каналам. Эта многоканальная экосистема обеспечивает значительные преимущества как для клиентов, так и для компаний, а ключевым инструментом, оптимизирующим эту среду поддержки, является база данных CRM.
CRM, что означает управление взаимоотношениями с клиентами, использует базы данных, которые используются для автоматического сбора, хранения и анализа всей информации, которую компания собирает о своих клиентах, будь то публикация в учетной записи в социальной сети, покупка, сделанная в магазине. Интернет-магазин, звонок в службу поддержки или участие в вебинаре. Затем база данных CRM делает всю эту информацию доступной на одной настраиваемой панели инструментов.
Вот что CRM делает лучше всего: упрощает связь между продажами, маркетингом и поддержкой, помогает организовать потенциальных клиентов в одном месте и, что наиболее важно, обеспечивает глобальный взгляд на качество обслуживания клиентов, которое подпитывает усилия по удержанию и лояльности.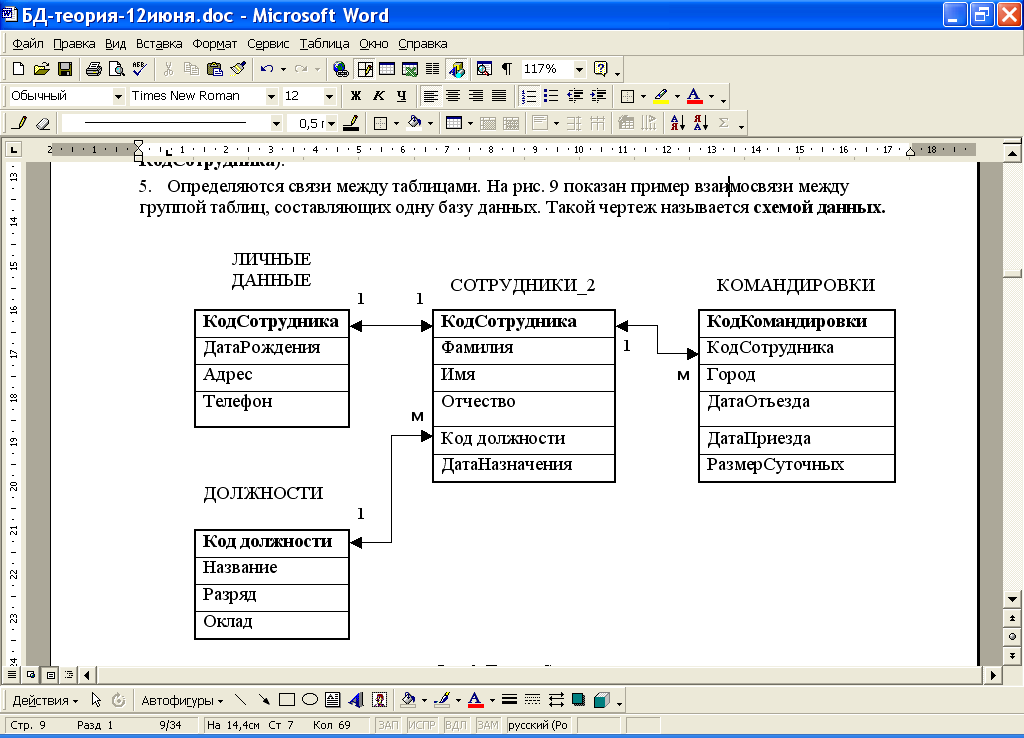 В этой статье мы рассмотрим более тонкие детали базы данных CRM, в том числе то, как ее создать и, в конечном счете, максимально увеличить ее влияние на ваш бизнес.
В этой статье мы рассмотрим более тонкие детали базы данных CRM, в том числе то, как ее создать и, в конечном счете, максимально увеличить ее влияние на ваш бизнес.
Что такое база данных CRM?
База данных CRM — это инструмент управления взаимоотношениями с клиентами, который собирает все взаимодействия компании с клиентами в одном месте, а затем делает всю эту информацию доступной для компании на одной настраиваемой панели инструментов. Это означает, что агентам службы поддержки не нужно входить и выходить из нескольких систем, копируя и вставляя номера счетов в различные программные инструменты, чтобы получить основную информацию о клиенте. С CRM все данные о клиентах, созданные с помощью разрозненных инструментов, учетных записей и систем, автоматически сохраняются в базе данных и легко доступны для всех в команде.
Базы данных CRM сильно изменились за последние 30 лет. Первоначально CRM была местом, куда менеджеры могли обратиться, чтобы понять воронку продаж своей компании.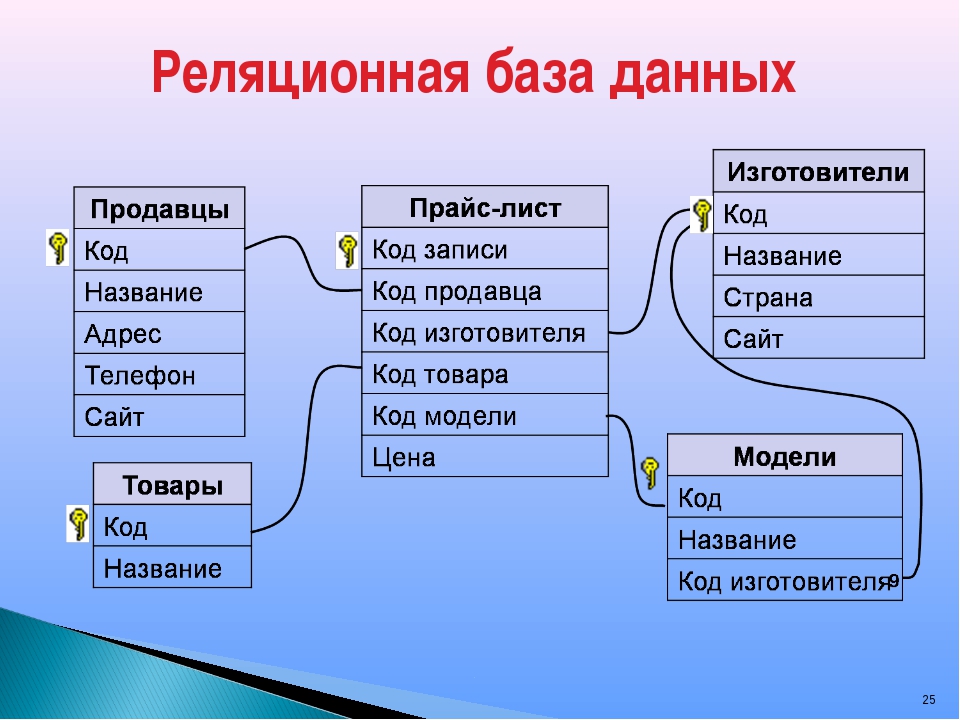 Часто эта информация хранилась в простом инструменте, таком как электронная таблица, которая помогала торговым представителям и высшему руководству составлять планы на следующий квартал или год. С тех пор современные CRM-системы превратились в сложные программные базы данных, которые могут подключаться к любому инструменту, который компания использует для взаимодействия со своими клиентами. Базы данных CRM упрощают улучшение качества обслуживания клиентов, предоставляя компании инструменты для увеличения продаж и предоставления своим клиентам исключительной поддержки.
Часто эта информация хранилась в простом инструменте, таком как электронная таблица, которая помогала торговым представителям и высшему руководству составлять планы на следующий квартал или год. С тех пор современные CRM-системы превратились в сложные программные базы данных, которые могут подключаться к любому инструменту, который компания использует для взаимодействия со своими клиентами. Базы данных CRM упрощают улучшение качества обслуживания клиентов, предоставляя компании инструменты для увеличения продаж и предоставления своим клиентам исключительной поддержки.
CRM также помогает компаниям разобраться во всех данных, которые они собирают о своих клиентах, с помощью глубокой и действенной аналитики, которая помогает им понять путь клиента и то, как сделать его счастливым. Это может принимать форму оценки эффективности кампаний по автоматизации маркетинга, поиска ценных возможностей перекрестных продаж или определения способов повышения скорости и эффективности работы представителей службы поддержки клиентов или отдела продаж.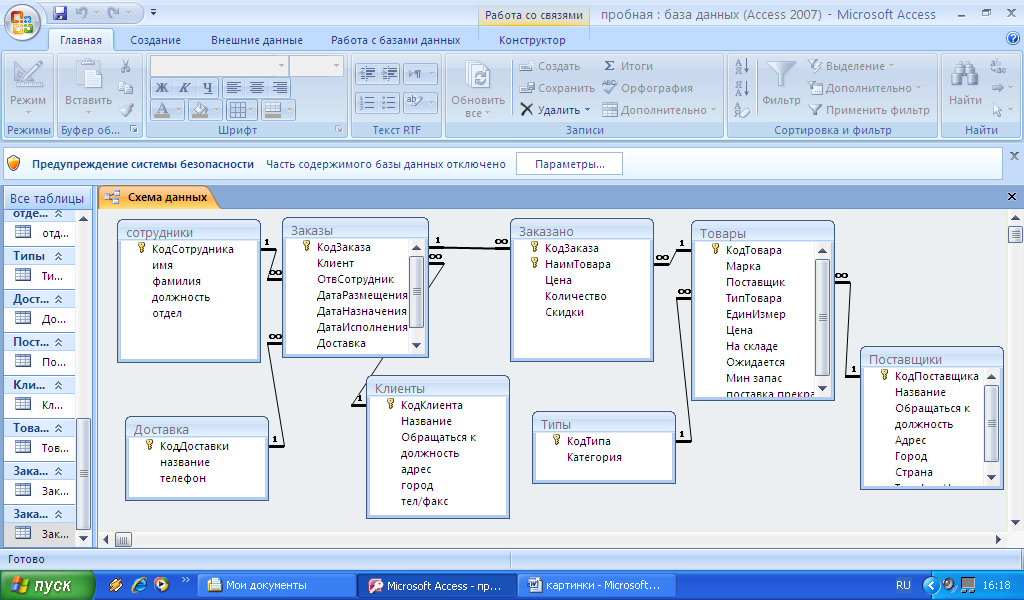 Компании могут создавать настраиваемые отчеты на основе ключевых показателей эффективности, которые наиболее важны для них и их рабочего процесса. И, конечно же, как и CRM прошлых дней, он может предоставить ценную информацию о воронке продаж компании, помогая направлять планирование и прогнозы компании.
Компании могут создавать настраиваемые отчеты на основе ключевых показателей эффективности, которые наиболее важны для них и их рабочего процесса. И, конечно же, как и CRM прошлых дней, он может предоставить ценную информацию о воронке продаж компании, помогая направлять планирование и прогнозы компании.
Примеры того, почему вам может понадобиться база данных CRM
- Управление лидами
- Длительные и сложные циклы продаж
- Разрозненные данные клиента
- Автоматизация маркетинга Решения
Есть ряд моментов, которые компании должны учитывать при оценке того, подходит ли CRM-решение для их бизнеса. Во-первых, нужна ли бизнесу помощь в управлении лидами? CRM может быть очень полезна для компаний с большим объемом потенциальных клиентов, поскольку она создает временные рамки для каждого контакта, которые легко отслеживать. CRM также позволяет компаниям устанавливать автоматические напоминания для каждого контакта, поэтому потенциальные клиенты назначаются конкретным продавцам, и ничего не ускользает.
Система управления отношениями с клиентами также может быть чрезвычайно полезна для организаций, чьи лидеры продаж имеют несколько точек соприкосновения внутри компании или имеют длинные и сложные циклы продаж.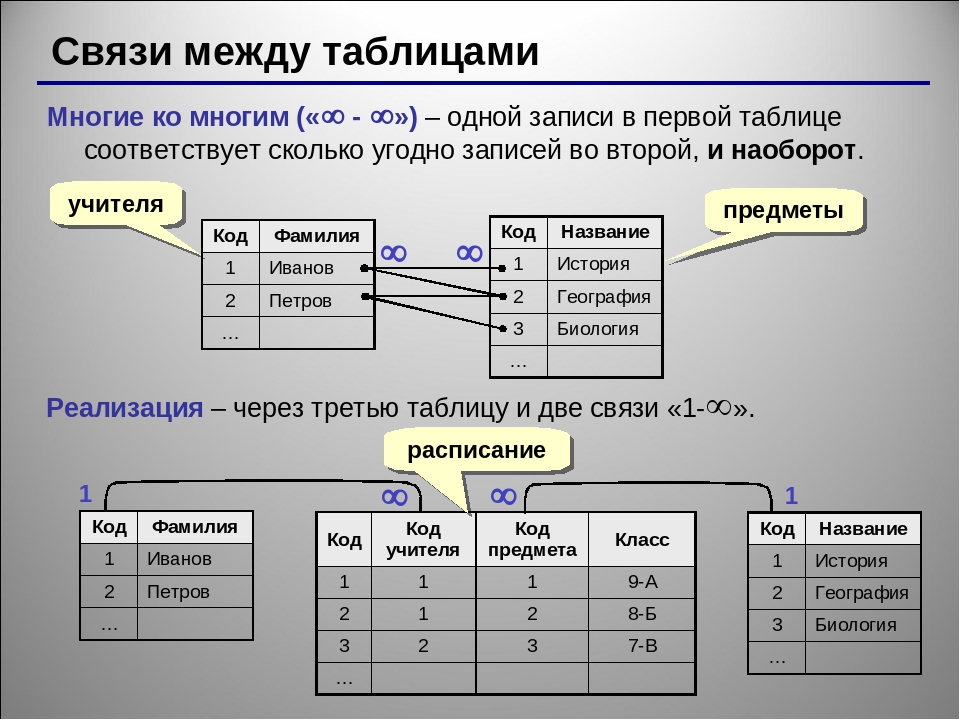 Если клиент связан с продажами, поддержкой и продуктом, CRM-система поможет компаниям убедиться, предоставляя 360-градусное представление о клиенте, что они не дублируют работу и не мешают потенциальному клиенту, запрашивая одно и то же. информацию несколько раз.
Если клиент связан с продажами, поддержкой и продуктом, CRM-система поможет компаниям убедиться, предоставляя 360-градусное представление о клиенте, что они не дублируют работу и не мешают потенциальному клиенту, запрашивая одно и то же. информацию несколько раз.
Компании, ориентированные на данные, также могут многое выиграть, рассматривая базу данных CRM. Объединив все источники данных компании в одном месте, CRM может создавать действенные отчеты практически по любому аспекту бизнеса компании, от прогнозов продаж до показателей удовлетворенности клиентов, таких как Net Promoter Score℠ и CSAT.
CRM также ценны для компаний, которые хотят автоматизировать маркетинг, например, маркетинговые кампании по электронной почте. CRM позволяет легко делать все, от рассылки информационных бюллетеней всей клиентской базе компании до реализации сложной сегментации для узконаправленных предложений.
Каковы основные элементы построения базы данных CRM?
CRM может стать мощным дополнением практически для любой организации, но ее влияние будет зависеть от того, какие данные в нее помещаются и как они используются внутри организации.
1. Управление персоналом
Первым ключевым элементом CRM-системы является управление персоналом. Как отмечалось ранее, CRM позволяет легко задействовать людей в организации для решения проблем клиентов, отслеживания потенциальных клиентов или управления кампаниями по автоматизации маркетинга. Но программное обеспечение CRM также позволяет менеджерам назначать и отслеживать работу для всех в команде, а также обеспечивать прозрачность состояния проектов, циклов продаж и многого другого.
2. Управление контактами
Управление контактами также является важным элементом платформ управления взаимоотношениями с клиентами. Благодаря хранению всех контактов компании в одном месте, которое автоматически обновляется, вся компания может легко получить быстрый доступ к наиболее важной информации. Когда торговые представители могут тратить больше времени на работу с клиентами и меньше времени на обновление контактной информации, они могут заключать больше сделок и быстрее.
Когда торговые представители могут тратить больше времени на работу с клиентами и меньше времени на обновление контактной информации, они могут заключать больше сделок и быстрее.
3. Управление лидами
Еще одним элементом программного обеспечения CRM является управление лидами. Когда лиды вводятся в систему, CRM позволяет легко автоматически назначать продавцов, определять следующие шаги и отслеживать их прогресс. Это также позволяет легко оставаться в курсе следующих шагов для потенциальных клиентов, которые могут иметь несколько точек взаимодействия в компании. В CRM есть одно централизованное место для обновлений, поэтому несколько членов команды не ищут постоянно новую информацию.
Автоматизация задач по продажам — еще один ключевой элемент баз данных CRM. Автоматизируя многие бизнес-задачи, связанные с продажами, такие как обработка заказов, обмен информацией, отслеживание заказов и управление контактами, управление продажами помогает отделам продаж работать бесперебойно и эффективно, позволяя уделять больше внимания клиентам, а не административным задачам.
4. Обслуживание клиентов
Обслуживание клиентов также является ключевым элементом баз данных CRM. Поскольку CRM выводит каждое взаимодействие с клиентом на унифицированную информационную панель, у агентов по обслуживанию клиентов есть все необходимое для решения проблем клиентов — нет необходимости входить и выходить из разных систем, чтобы получить такую информацию, как номера счетов, историю заказов или предыдущие взаимодействия с клиентами. обслуживание и поддержка. Это означает, что клиенты не ждут с нетерпением, пока представитель службы поддержки пытается получить полную картину, и, что важно, это избавляет потребителей от необходимости повторять свои действия, особенно если их переводят к другому члену команды.
5. Автоматизация маркетинга
Базы данных CRM также могут играть ключевую роль в обеспечении автоматизации маркетинга. Предоставляя маркетологам эффективные способы сегментации своих клиентов и, что особенно важно, интегрируясь с такими распространенными инструментами, как MailChimp, CRM помогает компаниям проводить и измерять успех таких программ, как маркетинговые кампании по электронной почте.
6. Отчетность и аналитика
Наконец, отчетность и аналитика являются центральным компонентом CRM-систем. Компании могут использовать CRM для создания информационных панелей и отчетности на основе своих уникальных ключевых показателей эффективности и бизнес-требований. CRM-системы упрощают улучшение отношений с клиентами, начиная от отслеживания времени обработки обращений в службу поддержки клиентов и заканчивая пониманием всей цепочки продаж компании за год.
Какие выгоды получают компании от создания базы данных CRM?
Вот несколько преимуществ базы данных CRM.
- Централизованная база данных для отделов продаж
- Одно место для всех коммуникаций с клиентами
- Автоматизированный ввод данных
- Контакты организованной компании Преимущества
- Сегментация клиентов
- Отчеты о продажах
- Оптимизированные коммуникации
- Стабильность
Одним из самых больших преимуществ, которые компании могут ожидать от использования базы данных CRM, является централизованная база данных для организации продаж. Устраняя необходимость в том, чтобы отдельные торговые представители выполняли утомительную работу, необходимую для ведения своих личных баз данных, CRM автоматизирует процесс и позволяет любому сотруднику компании получать самую свежую информацию с информационной панели CRM.
CRM также упрощает управление коммуникациями со всеми клиентами и потенциальными клиентами в одном месте. Компании, использующие CRM, могут видеть всю историю компании, общаясь с каждым клиентом одним нажатием кнопки. База данных CRM также упрощает управление отношениями, позволяя устанавливать напоминания и назначать агентов для поддержания сделок, обеспечивая при этом прозрачность для менеджеров, чтобы убедиться, что заявки отслеживаются.
Автоматизация ввода данных — еще одно преимущество для компаний, внедряющих решение CRM. Торговым представителям и агентам не нужно обновлять информацию о своих звонках или электронных письмах с клиентами в другой системе. Все автоматически регистрируется в решении CRM, освобождая сотрудников для выполнения более важной работы по заключению сделок и решению проблем клиентов.
CRM также включают эффективные способы организации всех контактов компании. CRM позволяет легко увидеть, посещал ли клиент веб-сайт, связывался со службой поддержки, запрашивал демонстрацию, а также заметки от агентов, которые обрабатывали предыдущие взаимодействия. CRM также делает все эти данные доступными для поиска, независимо от того, где находится клиент.
CRM позволяет легко увидеть, посещал ли клиент веб-сайт, связывался со службой поддержки, запрашивал демонстрацию, а также заметки от агентов, которые обрабатывали предыдущие взаимодействия. CRM также делает все эти данные доступными для поиска, независимо от того, где находится клиент.
Еще одним важным преимуществом CRM-систем является возможность легко сегментировать клиентов компании. Когда маркетинговые команды могут сегментировать своих клиентов, они могут проводить маркетинговые кампании по электронной почте, которые являются более персонализированными и эффективными. С помощью CRM возможна сегментация по демографическим и географическим данным, а также более подробная информация, например, сколько времени прошло с тех пор, как клиент посещал веб-сайт или просматривал ли он конкретное предложение.
«Магический квадрант Gartner 2021» для центра взаимодействия с клиентами CRM
Отчет «Магический квадрант Gartner 2021» доступен для бесплатной загрузки в течение ограниченного времени.
Получить бесплатный отчет
CRM также дает предприятиям возможность создавать отчеты о продажах, которые помогают им управлять своей воронкой продаж с помощью настраиваемых информационных панелей, точно настроенных для отслеживания наиболее важных ключевых показателей эффективности компании. Отчеты CRM предоставляют такие данные, которые позволяют менеджерам понять работу, выполняемую для закрытия сделок, а также дают представление о прогнозах доходов для руководства.
Компании, использующие CRM, также получают выгоду от возможности оптимизировать коммуникации между многими разрозненными командами. Поскольку все работают на одной и той же панели CRM, независимо от того, занимаются ли они продажами, обслуживанием, поддержкой или управлением, легко назначать работу, отслеживать прогресс и сотрудничать с товарищами по команде, чтобы решать проблемы клиентов, поддерживать сделки и открывать новые возможности. .
.
Еще одним преимуществом CRM для растущих компаний является возможность использовать одно и то же программное обеспечение по мере роста бизнеса. Поскольку CRM универсальна, особенно облачные версии программного обеспечения как услуги (SaaS), компании могут добавлять функции и функциональные возможности не только по мере изменения ожиданий и потребностей клиентов, но и по мере развития программного обеспечения для бизнеса, будь то новое поставляемое программное обеспечение, социальные сети. торговые точки или бухгалтерские инструменты.
Для чего можно использовать базу данных CRM?
Гибкость систем CRM означает, что они в высшей степени настраиваемые, обеспечивая такую гибкость, которая позволяет им вписываться в рабочие процессы компаний, начиная от глобальных предприятий и заканчивая предпринимательскими стартапами. Консолидируя информацию о клиентах в единой среде и обеспечивая настройку рабочего процесса, CRM могут, например, помочь отделу продаж создать повторяемый процесс продаж для большей эффективности. Имея инструкцию по заключению сделок и инструмент, который автоматически обновляет каждый контакт с клиентом без ручного ввода данных, отделы продаж могут больше сосредоточиться на построении отношений, а не на рутинной работе.
Имея инструкцию по заключению сделок и инструмент, который автоматически обновляет каждый контакт с клиентом без ручного ввода данных, отделы продаж могут больше сосредоточиться на построении отношений, а не на рутинной работе.
В то время как сотрудники могут работать более эффективно с CRM, их руководители также могут использовать этот инструмент для управления своими командами. Эти лидеры могут обратиться к CRM за помощью в назначении работы, получении информации о ходе выполнения и отслеживании показателей без необходимости запрашивать кропотливо созданные отчеты от других команд.
Между тем, CRM также является эффективным способом управления организациями по обслуживанию клиентов. Предоставляя агентам службы поддержки доступ ко всей информации о клиенте в одном месте, службам поддержки клиентов и службам поддержки проще решать проблемы клиентов без необходимости перетасовывать клиентов между разными командами — ключевая проблема, которая приводит к снижению удовлетворенности клиентов — или входить в систему. и из разрозненных систем, чтобы получить информацию о таких вещах, как доставка, выполнение заказа или прошлые обращения в службу поддержки. А базы данных CRM также помогают группам поддержки предоставлять упреждающие услуги, автоматизируя некоторые из этих распространенных запросов клиентов, таких как статус заказа или возврат.
и из разрозненных систем, чтобы получить информацию о таких вещах, как доставка, выполнение заказа или прошлые обращения в службу поддержки. А базы данных CRM также помогают группам поддержки предоставлять упреждающие услуги, автоматизируя некоторые из этих распространенных запросов клиентов, таких как статус заказа или возврат.
Инструменты, необходимые для создания базы данных CRM
Базы данных CRM представляют собой сложные части программного обеспечения; создание пользовательской базы данных CRM с нуля требует обширных навыков разработки программного обеспечения и дорогих локальных серверов для хостинга. Хотя создание собственной локальной базы данных CRM является вариантом, обратите внимание, что для этого требуется команда ИТ-специалистов для администрирования службы, постепенного добавления функций и управления безопасностью для обеспечения безопасности данных клиентов.
Тем не менее, уже существуют популярные программные пакеты баз данных CRM, которые могут удовлетворить потребности подавляющего большинства предприятий. Для большинства компаний проще работать с поставщиком услуг, чтобы либо приобрести и установить лицензии на программное обеспечение базы данных CRM, либо настроить базу данных с открытым исходным кодом, либо использовать облачную CRM.
Для большинства компаний проще работать с поставщиком услуг, чтобы либо приобрести и установить лицензии на программное обеспечение базы данных CRM, либо настроить базу данных с открытым исходным кодом, либо использовать облачную CRM.
Типы баз данных CRM
Вот 3 основных типа баз данных CRM.
1. CRM-системы с открытым исходным кодом
CRM-системы с открытым исходным кодом — это программные решения, которые доступны в Интернете и загружаются и устанавливаются на собственные серверы компании. Одним из преимуществ CRM с открытым исходным кодом является то, что он позволяет компаниям создавать и настраивать решения для конкретных случаев использования. Он также обеспечивает полный контроль над данными клиентов и является недорогим, поскольку доступно множество бесплатных опций.
Конечно, как и любое бесплатное решение CRM, вы получаете то, за что платите, используя CRM с открытым исходным кодом. Многие решения предлагают только базовую функциональность и требуют значительной работы для настройки. При использовании CRM с открытым исходным кодом компании должны самостоятельно устанавливать, управлять и настраивать систему CRM, что требует дорогостоящего оборудования и специализированных ИТ-специалистов для управления решением. Решения CRM с открытым исходным кодом также требуют от компаний управления собственными мерами безопасности данных, чтобы обеспечить безопасность важной информации о клиентах.
При использовании CRM с открытым исходным кодом компании должны самостоятельно устанавливать, управлять и настраивать систему CRM, что требует дорогостоящего оборудования и специализированных ИТ-специалистов для управления решением. Решения CRM с открытым исходным кодом также требуют от компаний управления собственными мерами безопасности данных, чтобы обеспечить безопасность важной информации о клиентах.
2. Локальная
Локальная CRM — это еще один тип CRM, который могут оценить предприятия. Как и решения с открытым исходным кодом, локальные решения размещаются на собственных серверах компании. Локальные решения также требуют специального оборудования и ИТ-персонала для управления, эксплуатации и обслуживания программного обеспечения CRM. В отличие от бесплатных CRM-систем с открытым исходным кодом, локальные варианты могут быть гораздо более надежными и многофункциональными. Локальные решения также являются самыми дорогими вариантами CRM, поскольку они требуют крупного авансового платежа для покупки программного обеспечения.
3. Облачная CRM
Облачная CRM — отличный вариант для компаний, которые хотят быстро и легко начать работу с CRM без необходимости самостоятельно управлять программным обеспечением. Облачные CRM-решения управляются поставщиками услуг и предлагаются компаниям по модели SaaS.
В облачных решениях CRM-система работает на серверах провайдера. Это означает, что компаниям не нужно беспокоиться об обслуживании собственных серверов или наличии группы ИТ-специалистов для управления системой. В облачных CRM-компаниях также есть большие группы экспертов по безопасности, которые постоянно контролируют систему, которая также включает множество уровней протоколов и мер безопасности корпоративного уровня.
Используя облачную CRM, компании просто входят в систему из любого места, где есть подключение к Интернету, и начинают работать. И в отличие от локальных услуг, которые требуют больших первоначальных затрат, решения SaaS позволяют компаниям платить по мере их использования с ежемесячной платой за использование услуги. Еще одним преимуществом веб-систем CRM является то, что компании могут добавлять или удалять функции и возможности по мере роста и развития своих компаний.
Еще одним преимуществом веб-систем CRM является то, что компании могут добавлять или удалять функции и возможности по мере роста и развития своих компаний.
Каждая компания уникальна, и их конкретные потребности в CRM также различаются. Однако для предприятий важно разработать стратегию CRM, поскольку они оценивают потенциальных поставщиков CRM. Чем больше компания знает о своем клиентском пути, какие инструменты ей необходимы для интеграции в базу данных CRM, а также о том, какие отчеты и аналитика важны для нее, тем легче ей будет оценивать различных поставщиков.
Еще одним ключевым моментом для любой компании, которая оценивает различные пакеты программного обеспечения базы данных CRM, являются функции и ресурсы безопасности. Данные о клиентах в системах CRM могут быть привлекательным призом для хакеров, поэтому очень важно, чтобы компании учитывали, кто будет управлять и контролировать протоколы безопасности CRM.
При изучении различных поставщиков также рекомендуется, чтобы предприятия искали рекомендации от аналогичных компаний, которые успешно внедрили базу данных CRM, поскольку истории клиентов и тематические исследования могут быть отличным руководством.
Как система CRM помогает систематизировать данные о клиентах?
Одной из наиболее важных функций программного обеспечения для управления взаимоотношениями с клиентами является его способность помочь бизнесу организовать свои данные о клиентах. Данные о клиентах могут поступать из десятков источников внутри компании, будь то посещение веб-сайта, звонок в службу поддержки, запрос на демонстрацию или адрес доставки из онлайн-заказа. Результатом обычно является хаотическая смесь различных типов данных, поступающих из ряда различных программных решений, электронных таблиц, управляемых вручную, и почтовых ящиков. CRM помогает навести порядок в хаосе.
Когда компания развертывает CRM-платформу, одна из самых важных вещей, которую она делает, если хочет извлечь из решения максимальную пользу, — это разработка продуманной CRM-стратегии. Это требует понимания пути клиента: шагов (и болевых точек), которые начинаются с того, что кто-то становится потенциальным клиентом, до момента, когда он становится клиентом и, в конечном итоге, постоянным клиентом.