Digital-агентство. Честное SEO, Контекстная и таргетированная реклама. Только белые… · 28 июл 2021 · smenik-agency.ru
Отвечает
Павел Ильинский
На данный момент самый простой способ, это использование сторонних сервисов, благо они сейчас в профиците. Это могут быть расширения для браузера chrome, mozilla и оpera. Второй вариант это сайты, например 2ip.ru, itrack.ru, be1.ru и т.д. В большинстве случаев этого хватит и один из сервисов подсветят вам cms. Есть обходные пути, иногда cms предоставляющая услуги (особенно на бесплатной основе) помещают ссылку на себя в футер.
Если ответ вам понравился — поставьте лайк! 👍
Перейти на smenik-agency.ru
Комментировать ответ…Комментировать…
Вы знаете ответ на этот вопрос?
Поделитесь своим опытом и знаниями
Войти и ответить на вопрос
Ответы на похожие вопросы
Как узнать CMS сайта? — 25 ответов, задан
Владислав Фисенко
6,5 K
Предприниматель. Маркетолог. Спортсмен. Турист. · 30 мар 2019 ·
vladislavfis
Для того, чтобы узнать на какой платформе сделан сайт, нужно скопировать ссылку сайта и вставить на одном из нижеперечисленных сервисов. Если сайт не самописный, то вы узнаете CMS.
2ip.ru
itrack.ru
seotoolz.ru
raskruty.ru
IT-предприниматель, SMM, SEO, спортсмен. Создатель и автор каналов.
Перейти на instagram.com/vladislavfis
12,1 K
Комментировать ответ…Комментировать…
Как узнать CMS сайта? — 25 ответов, задан
Firemarketing
504
🖥 Разработка и продвижение сайтов · 22 мар 2020 · firemarketing.ru
Отвечает
Дмитрий Титов
Самый быстрый способ — проверить в файле robots.txt.
Для этого в адреса сайта после домена необходимо добавить «/robots.txt».
Пример: https://вашсайт.рф/robots.txt
Все популярные CMS используют свои именные файлы в корневом каталоге сайта. Например, CMS WordPress содержит в файле robots.txt записи «wp-content», «wp-admin» и т.д.
По записям можно быстро вычислить используемую систему управления сайтом.
Заказать продвижение
Перейти на firemarketing.ru
Комментировать ответ…Комментировать…
Как узнать CMS сайта? — 25 ответов, задан
Firemarketing
504
🖥 Разработка и продвижение сайтов · 25 авг 2020 · firemarketing.ru
Отвечает
Дмитрий Титов
Быстрее всего зайти в файл robots.txt (yoursite.com/robots.txt). В нем обязательно будут идентификаторы разных CMS. Если ничего нет, то скорее всего, сайт самописный.
Заказать продвижение
Перейти на firemarketing.ru
Комментировать ответ…Комментировать…
Как узнать CMS сайта? — 25 ответов, задан 277Z»>13 июля 2018
Евгений Юдин
Маркетинг
372
Seo-оптимизатор · 14 нояб 2018 · rotgar.ru
Проще простого!
Используете этот сервис, он знает все популярные CMS и с 95% вероятностью угадывает CMS по особым отличиям.
Вот два бесплатных проверенных сервиса:
https://2ip.ru/cms/
https://itrack.ru/whatcms/
Переходите, вводите адрес сайта и получаете результат.
26,3 K
Комментировать ответ…Комментировать…
Как узнать CMS сайта? — 25 ответов, задан
Дима Былов
4
Специалист по поисковому продвижению сайтов. · 18 окт 2019
Самый популярный сервис по проверке cms сайта : https://2ip.ru/cms/
Очень часто движок сайта можно определить по самой структуре визуально, например опенкарт.
И еще если сервис не видит какой у сайта cms можно зайти в код, часто используют Вордпресс, там в начале вы увидите /wp-content, системные папки, которые принадлежат данному движку.
Комментировать ответ…Комментировать…
Как узнать CMS сайта? — 25 ответов, задан
Hardkod.ru
212
Hardkod оказывает услуги удаленной технической поддержки и продвижения сайтов в Москве и… · 16 мар 2020 · hardkod.ru
Отвечает
Эксперт по SEO
Нажать на странице Ctrl+U и попробовать найти в коде сайта:
wordpress
joomla
bitrix
Также посмотреть в каких папках лежат файлы CSS и медиаконтент — адреса папок могут рассказать о CMS.
Также загляните в robots.txt
🚀 Окажем техническую поддержку сайта и поможем достигнуть ТОПа Яндекса и Google
Перейти на hardkod. ru/poiskovoe-prodvizhenie-saytov
Комментировать ответ…Комментировать…
Как узнать CMS сайта? — 25 ответов, задан
Инна Самарина
1
28 мая 2020
https://pr-cy.ru/cms-checker/
Cервис от PR-CY определяет CMS, может не показать результат, если движок самописный, но все популярные движки определяет точно.
Комментировать ответ…Комментировать…
Как узнать CMS сайта? — 25 ответов, задан
Zoola
320
Комплексный Digital-маркетинг для бизнеса · 6 мая 2020 · zoola.ru
Отвечает
Константин Шумейко
Раньше, помню, когда не было готовых сервисов, определяли по наличию соответствующей админки. Например:
Битрикс — /bitrix/admin,
WordPress — /wp-login.php
Joomla — /administrator
Opencart — /admin
Drupal — /user
ModX — /manager
Еще вариант — по записям в файле /robots.txt. Там часто видно, к какой CMS относятся записи. К примеру строка «Allow: /bitrix/js/» явно указывает на 1С-Bitrix.
Ну и, разумеется, бесплатные онлайн сервисы. Лучше использовать сразу несколько, т.к. иногда редкая система управления одному сервису известна, а другому нет. К тому же бывают некорректные определения.
Вот несколько из них:
https://2ip.ru/cms/
https://itrack.ru/whatcms/
https://pr-cy.ru/cms-checker/
https://be1.ru/cms/
↓ Поддержите лайком, если помог советом.
Узнайте подробнее об агентстве Zoola на нашем сайте
Перейти на zoola.ru
Комментировать ответ…Комментировать…
Как узнать CMS сайта? — 25 ответов, задан 277Z»>13 июля 2018
Если давно занимаешься разработкой сайтов, то можно на глаз увидеть элементы на сайте, которые присуще той или другой CMS. Если нет, то можно в браузере открыть исходный код Ctrl + U и по названиям и путям файлов определить систему. Ещё как вариант попробовать зайти в админку /bitrix /admin /administrator /manager и т.д.
Комментировать ответ…Комментировать…
Как узнать CMS сайта? — 25 ответов, задан
Виктория Пинина
Маркетинг
3
Пишу информационные и продающие статьи, SEO-тексты, тексты для лендингов, создаю… · 5 февр 2021
Есть несколько способов определить движок сайта. Сначала нужно понимать какие бывают виды систем, есть хороший обзор самых популярных CMS, смотрите по ссылке https://workspace. ru/cms/. На разных страницах сайта могут стоять разные движки, например, главная – на самописной системе, а блог – на WordPress. Поэтому проверять нужно конкретную страницу.
Узнать CMS можно так:
Посмотреть служебный файл robots.txt, для этого в адресной строке браузера ввести – название сайта/robots.txt, пример на скрине. Этим способом можно определить популярные системы.
Например, сайт workspace.ru стоит на системе Битрикс
Посмотреть подвал сайта. Иногда сразу видно, что сайт создан на конструкторе. Иногда внизу страницы стоит активная ссылка на разработчиков.
С помощью расширения для браузера, автоматически определяющего движок. Инструмент выбираете сами, читайте подробно о расширениях для Mozilla Firefox, Chrome, Яндекс.Браузер
Если способы выше не подошли, скорее всего, сайт стоит на студийной или самописной CMS. Платформу можно уточнить у владельца веб-ресурса напрямую, данные ищите в разделе «Контакты».
Комментировать ответ…Комментировать…
Узнать CMS сайта — как определить на каком движке он сделан и способы проверить админку
Бывало ли вам интересно узнать, как работают веб-ресурсы: как их делают красивыми, удобными и функциональными? Понять это полезно еще и с практической стороны: если вы разрабатываете собственную платформу, хорошо бы знать CMSку конкурента.
В статье расскажем, как узнать, на какой CMS сделан сайт: определить движок и админку ресурса.
Определение административной панели вручную
Просмотр исходного кода
Проверка пути к файлам оформления
Служебные страницы в robots.txt
Вход в административную панель
Поиск движка в футере сайта
Определение структуры URL
Онлайн-сервисы для проверки панели управления
Be1
2ip
iTrack. ru
WhatCMS
Built With
Браузерные расширения
Wappalyzer
iTrack
RDS Bar
Что делать, если ничего не помогло
Заключение
Определение административной панели вручную
Эти способы не предполагает использования специальных сервисов или утилит. Сделать это можно прямо в окне браузера.
Просмотр исходного кода
Для этого откройте html-код страницы, используя команду CTRL + U. Затем вызовите поисковую строку с помощью комбинации клавиш CTRL + G и введите там тег «generator».
Способ не самый эффективный – эту строчку можно удалить без вреда для функционала (многие сисадмины так и делают). Следовательно, поиск ничего не покажет.
Проверка пути к файлам оформления
Этот метод реализуется так же, как предыдущий – через поиск информации в коде. Внутри тега head вы можете найти важные системные файлы с указанием CMS.
У каждой админки есть своя структура, по которой ее можно отличить от других. Для WordPress это будет wp-content или wp-includes, для Битрикс /bitrix/panel/, /bitrix/templates/. Для других аналогично – в html-коде будет буквенное обозначение панели.
Служебные страницы в robots.txt
У каждого сайта независимо от движка есть файл robots txt – он управляет трафиком поисковых роботов на веб-ресурсе. Найти его можно через поисковую строку браузера, введя в ней https://site.ru/robots.txt/. В нем можно увидеть признаки используемой системы управления.
Для Вордпресс
Для Битрикс
Для Джумла
Для Тильда
Вход в административную панель
Можно попробовать такой способ – ввести в строке поиска один из вариантов url для входа в админку. Для каждой системы управления он будет свой.
Не получилось с одним – используйте другой. Это не очень удобно и эффективно, но попытаться стоит.
Вот несколько вариантов для входа в популярные CMS:
WP — site.ru/wp-admin/
Bitrix — site.ru/bitrix/admin/
Joomla — site.ru/administrator/
Drupal — site.ru/user/
Поиск движка в футере сайта
Загляните в подвал. Возможно там, за мелким шрифтом, скрыта информация, какую ЦМС использовали разработчики при создании ресурса. Практического назначения эта отметка не несет и ни на что не влияет, поэтому её очень редко размещают.
Исключением могут стать случаи, когда в разработке использовался готовый шаблон и нужно указать его автора.
Определение структуры URL
Еще вы можете посмотреть, как выглядят ссылки на страницы. Но получится это, только если у домена не настроено формирование человекопонятных урлов.
Если вам удалось найти такой, то определить админку можно по следующим признакам:
необработанный адрес для Вордпресс выглядит так: site. ru/р=245
для Битрикс, например: #PRODUCT_URL#?id=#ID#
для Joomla: site.com/content/view/44/896/
Онлайн-сервисы для проверки панели управления
Если все, что вы попробовали сделать самостоятельно не помогло, есть еще один способ, как узнать на какой платформе сделан сайт – понять на чем он написан через online-сервисы.
Be1
Поможет понять, проверить и определить движок CMS. По утверждению создателей, работает благодаря уникальному алгоритму, который за несколько секунд выдает готовый ответ. Имеет возможность массовой проверки, единоразово можно просканировать до 10 адресов.
База для анализа состоит из 78 вариантов ЦМС – популярных и не очень.
Если при проверке вы видите прочерк, значит, сервису не известен движок или это самописка.
Такой способ создания используют, если нужно разработать особенный функционал, который не может предоставить ни одно из готовых решений.
Но минусов у самописных веб-ресурсов больше, чем плюсов:
Отсутствие документации. Все инструкции пишутся разработчиками для себя, что увеличивает порог вхождения и осложняет работу.
Сложности с поиском техподдержки. Большинство программистов работают с готовыми панелями. Найти человека, готового разобраться с новым функционалом с нуля, достаточно сложно.
Если специалисты, занимающиеся разработкой, уйдут из проекта, очень сложно будет его изменять и масштабировать.
2ip
Поможет определить систему управления сайтом. Проверка происходит по ряду признаков, характерных для тех или иных административных панелей.
Во время анализа можно увидеть, среди каких движков происходит поиск. Если ЦМС удалось определить, вы увидите в строке напротив надпись «найдены признаки использования».
iTrack.ru
Этот сервис создан для определения платформы CMS: на нем можно посмотреть, на каком движке или конструкторе работает сайт. Имеет в базе 80 систем управления для анализа.
Проверка происходит по «отпечаткам» админки – проще говоря, по ключевым фразам, которые встречается в определенной административной панели.
WhatCMS
Позволяет определить не только систему управления контентом, а еще хостинг-провайдера и язык программирования. В базу входит 390 ЦМС – среди них есть даже MediaWiki, которую не видят большинство аналогичных программ.
Built With
Сервис поможет узнать, на какой платформе создан сайт: здесь можно определить, какой движок CMS использует ресурс, зная его доменное имя, и увидеть, какие аналитики и функции подключены для домена.
Объем отображаемой информации достаточно большой. Чтобы найти упоминание админки, придется немного проскролить страницу.
Браузерные расширения
Если проверки нужно проводить много и часто, удобнее воспользоваться инструментом в браузере. Такие дополнения могут не только показать админку, но иногда и другую полезную информацию, например, плагины.
Wappalyzer
Подходит для Chrome, Safari и Firefox. Определяет технологию, с помощью которой создан ресурс. Еще показывает метрики, фреймворки и библиотеки.
iTrack
Подходит для Chrome. Мы говорили о нем выше, теперь презентуем в формате утилиты. Позволяет узнать ЦМС онлайн или вставить ссылку в окно интерфейса.
RDS Bar
Расширение позволит понять, на чем построен сайт: сделан он на движке WordPress или создан на конструкторе, например, на Tilda или Wix. Его функционал достаточно обширный, поэтому он подойдет для опытных seo-специалистов. Здесь есть: проверка хоста и ip, robots.txt и sitemap, просмотр исходного кода и веса страниц, определение RSS-каналов и скорости загрузки. Можно использовать в Chrome, Яндекс.Браузере, Opera и Firefox.
Что делать, если ничего не помогло
Если проверка сайта на движок CMS ни одним из вышеперечисленных способов не получилась, это значит, что он сделан на самописке. Если вам все же необходимо узнать эту информацию, снова загляните в подвал. Возможно, там вы найдете ссылку на разработчика и сможете написать ему напрямую.
Заключение
Способов узнать админку много, и все они отличаются уровнем сложности и информативности. Конечно, проще всего использовать программы, которые определят CMSку и покажут вам результат. Но опытный специалист должен уметь обходиться без вспомогательных инструментов и знать базовые моменты, как проверить и определить движок CMS. Это говорит о профессионализме и понимании процессов.
Узнаем как узнать движок сайта, и зачем это надо?
Наверное, многие пользователи сети Интернет знают, что при создании веб-сайтов используются различные готовые средства. Их называют движками или CMS. Как определить, какой движок используется на сайте, и зачем это надо, пойдёт речь далее в нашей статье.
Что такое движок сайта, и для чего он нужен?
Движок сайта — это автоматизированное средство для управления и настройки. В частности, многие CMS позволяют изменить внешний вид чего-либо, применив шаблон, добавить новый контент, меню, целую страничку или раздел.
Из наиболее известных можно выделить такие, как WordPress, Joomla, Drupal, отечественный «Битрикс» и многие другие.
Как узнать движок сайта
Движок можно узнать несколькими способами:
проанализировав страницу вручную;
определив по типичным характеристикам;
используя онлайн-сервисы.
Для анализа сайта подручными средствами нужно открыть исходный код страницы. Небольшая пробежка по строкам может дать много полезной информации.
Практически каждый сайт имеет в теле своего кода тег meta name с именем generator. В нем может быть указана система управления контентом, а может, и нет. Все зависит от того, предпринял ли админ портала средства сокрытия.
Узнать движок сайта также можно из строк с CSS и JavaScript. Пути к файлам стилей и скриптов могут содержать части стандартных для CMS размещений. Например, типичные для WordPress состоят из ключевых слов: wp-content.
Узнать, на каком движке сайт, можно просмотрев файл robots.txt. Он предназначен для запрета посещений определённых страниц поисковыми машинами. Стало быть в нем могут содержаться стандартные пути для некоторых CMS. Естественно, нужно знать структуру файлов и папок наиболее популярных движков.
Внешний вид ссылок на странице также способен помочь узнать движок сайта. Если CMS не использует сторонних решений для формирования ссылок, то, по умолчанию, они могут выглядеть так:
/p=501 — актуальный вид ссылки для WordPress;
/index.php?option=com_content… — данный шаблон используется в Joomla по умолчанию;
page/название_страницы — так выглядит адрес в MaxSite.
Узнать движок сайта поможет способ с подстановкой адресов админок известных CMS. Стоит попробовать подставить к домену следующие пути:
wp-admin — панель администратора на WordPress;
administrator — такой адрес использует Joomla;
admin — а этот принадлежит MaxSite.
Сканирование ответов сервера также может помочь узнать, на каком движке сайт. Сделать это можно с помощью специальных средств. В ответе от сервера нас интересует http header. Он может содержать поле со значением X-Powered-CMS.
Имеет смысл просмотреть и сохранённые куки сайта. Для этого тоже могут понадобиться специальные средства, называемые снифферами. Среди строк куки можно найти части названий популярных CMS, например, wp или umicms.
Онлайн-сервисы
Первый из инструментов — Itrack. В своей базе он имеет характеристики более 50 средств управления контентом для того, чтобы узнать движок сайта онлайн. Достаточно посетить сайт, ввести имя желаемого домена, капчу и нажать «Проверить». Через некоторое время сервис просканирует указанный сайт и вынесет свой вердикт. И если имеется CMS, то она отобразится.
Ещё один неплохой многофункциональный сервис для того, чтобы узнать движок сайта онлайн, — 2ip. Тут вводится адрес сканируемого ресурса и нажимается кнопка «Узнать». Система переберёт все известные CMS, отображая их поочерёдно. И как только наткнётся на совпадающую, оповестит об этом.
Зачем может понадобиться проверка движка сайта
Такая информация всегда будет полезна злоумышленнику-хакеру. Как он сможет это использовать? Очень просто. Все средства управления контентом пишутся людьми. Соответственно в проектах и сайтах могут присутствовать ошибки. Какие-то очень быстро исправляются, какие-то остаются. Зная типичные ошибки конкретной CMS и будучи уверенным, что именно она установлена на атакуемом сайте, хакер может применить различные подходы, используя уязвимости и эксплойты.
Также тип движка может понадобиться веб-программисту, который хочет создать примерно такой же сайт для себя или заказчику. А может, тот же разработчик хочет посмотреть насколько легко определит хакер CMS на его сайте.
Сокрытие сведений о движке
Как видите, скрыв данные о том, какая из CMS используется, можно дополнительно обезопасить свой сайт от несанкционированного доступа в результате хакерской атаки. На самом деле, этому посвящены многие статьи в Интернете, на форумах и в различных инструкциях. Какой-либо универсальной формулы для сокрытия типа движка для всех CMS сразу не бывает. Для каждой придётся действовать по-своему.
Например, Joomla генерирует тег Generator. А это означает, что необходимо поправить файл index.php текущего шаблона. В него нужно добавить строку <?php $this->setGenerator(«)?> где-то между другими мета-тегами.
Сменить отображение адресов веб-страниц вручную очень сложно. Но есть уже готовые решения, что-то типа JoomSEF. Они генерируют ссылки на основании названий материалов, и внешний вид адресной строки становится более читаемым и не отличающимся от большинства сайтов.
Также Joomla сайт можно узнать по известной иконке в заголовке браузера. Называется она favicon.ico и лежит в корне сайта или папке текущего шаблона.
Очень часто CMS определяется по стандартной странице 404, повествующей об ошибке. Рекомендуется сразу же поменять её после настройки и конфигурации.
Заключение
Перед тем как узнать, какой движок использует сайт, придётся сначала поискать в Интернете данные о том, какие типичные признаки и параметры есть у тех или иных CMS. Ну, или обратиться онлайн-площадками. А для того чтобы своими руками скрыть использование системы управления контентом на своем ресурсе, придётся ещё овладеть азами PHP и HTML. Хотя и здесь на всех известных CMS имеются уже готовые решения в виде плагинов, модулей и компонентов. Многие из которых, кстати, тоже снижают устойчивость сайта к атакам. Какой выбирать подход — решать веб-разработчику.
что это, ТОП-6 систем управления сайтом
CMS (Content Management System) — это система управления контентом вашего сайта: редактирование и удаление текущих, создание новых страниц или разделов. Благодаря ей можно делать не имея навыков программирования и не обращаясь к веб-разработчикам.
Зачем сайту нужна CMS?
Она может решить следующие задачи:
Полное администрирование сайта — даже без знания HTML и CSS.
Создание новых страниц.
Редактирование страниц.
Публикация нового контента.
Совместная работа над созданием и редактированием контента.
Выставление прав для разных групп пользователей и назначение ролей для пользователей.
Изменения структурного элемента сайта.
Изменение дизайна.
Внедрение нового функционала.
Поисковая оптимизация страниц.
Список самых популярных систем по версии iTrack.ru
Не следует путать с конструкторами тип: WIX, Tilda, Webflow, uKit и другими. CMS — это самостоятельный движок, позволяющий расширять функционал сайта, добавлять новые возможности, менять дизайн. Конструктор значительно ограничен с точки зрения функциональных возможностей. Он позволяет создавать только простые сайты на основе готовых, а вмешиваться в шаблон ни один SaaS-сервис не разрешит.
Главные достоинства
Есть бесплатные варианты.
Стоимость платных решений в основном ниже, чем долгосрочное использование конструкторов WIX, Tilda.
У большинства систем управления предусмотрены готовые инструменты для поисковой оптимизации страниц.
Для создания и редактирования страниц не нужно кодить. И даже создать сайт с нуля можно самостоятельно.
Легко изменить дизайн всего сайта, его структуру, добавить необходимый функционал.
У многих CMS в Рунете существуют большие сообщества, по каждой системе есть официальная документация. Все вместе позволит решить большинство вопросов без привлечения разработчика.
Недостатки
Уязвимость для внешних атак и опасность взлома сайта. Особенно в зоне риска администраторы сайтов, которые давно не обновляли текущую версию.
Плагины могут создавать большую статическую нагрузку на хостинг и значительно снижать скорость загрузки страниц.
Некоторые CMS потребуют первоначального обучения — пользователю, никогда не имевшему дела с такими системами, понадобится время освоиться.
В идеале нужно знать HTML, PHP, CSS, JavaScript. Ведь часто требуется внести в чужой код (самого WP или плагина, например) определенные изменения. Например, необходимый вам плагин конфликтует с темой, и сайт «падает». Конечно, можно восстановить его из бэкапа на хостинге, но лучше собственноручно найти проблему и закрыть ее. А без знания основных языков и технологий сделать вы этого не сможете. Равно как и кастомизировать функционал CMS.
Как работает CMS
Современные CMS работают прямо в браузере — чтобы управлять внешним интерфейсом сайта и его серверной частью, не обязательно переключаться между несколькими программами.
У каждой есть редактор содержимого — он используется для создания и редактирования новых страниц. Публикация черновика происходит нажатием одной кнопки.
Создание новых страниц происходит по запросу или при их редактировании. Для создания и редактирования содержимого внутри административной панели CMS используется приложение управления контентом CMA (Content Management Application).
Кроме CMA, в любой системе управления содержимым есть CDA-компонент— это службы администрирования и доставки содержимого.
Читайте также:
Как создать карту сайта (sitemap.xml)
Как определить CMS сайта
Для определения CMS чужого сайта совсем не обязательно ковыряться в коде страниц или анализировать стандарт исключения роботов.
Самый простой способ узнать — воспользоваться сервисом iTrack. Просто указываем доменное имя и нажимаем кнопку «Определить CMS»:
Вводим адрес и проверяем
Еще один вариант — сервис 2ip.ru. Благодаря ему вы можете узнать CMS сайта любого доменного ресурса. Открываем инструмент, указываем URL или IP-адрес:
Можно проверить систему управления на домене или IP-адресе
Если информацию об используемой системе управления при помощи сервисов получить не удалось, посмотрите футер сайта. Иногда там можно найти информацию об используемом движке:
Сайт сделан на Tilda
Также определить можно в режиме просмотра кода страницы. Откройте главную страницу интересующего вас сайта и нажмите клавиши Ctrl + U. Откроется код страницы:
Исходный код страницы
Нажимаем сочетание горячих клавиш Ctrl + F. Откроется окно поиска:
Указываем метатег Generator и смотрим значение для content=. Это и есть CMS, используемая на сайте
ТОП-6 самых популярных CMS
Drupal
CMS особенно востребована при создании корпоративных сайтов. В Drupal нет традиционной административной панели, зато он более гибок, чем тот же WP.
Достоинства Drupal
Движок позволяет работать с любыми функциями, реализовывать их на уровне всего сайта или отдельных страниц.
Готовые инструменты для SEO.
Тысячи модулей позволяют рекомендовать эту CMS для создания сайтов любой сложности.
Сообщество по Drupal в России живое и обновляется.
Главное русскоязычное сообщество по Drupal
Недостатки Drupal
Без обучения, особенно если вы далеки от веб-разработки, разобраться в Drupal точно не получится.
Чтобы пользоваться Drupal, обязательно знать хотя бы азы HTML, PHP, CSS, JavaScript.
Пожалуй, самая запутанная для новичка из всех популярных CMS, что я видел.
WordPress
Самый популярный в мире блоговый движок. Но развертывать на нем можно не только блоги, но и форумы, агрегаторы и даже интернет-магазины.
Достоинства WordPress
Полностью бесплатный.
Максимально отзывчивый и понятный интерфейс.
Открытый код.
Огромная коллекция плагинов для внедрения любых функций.
Бета-плагины WordPress. Сейчас они находятся в разработке и возможно будут включены в будущую версию WordPress
Недостатки WordPress
Архаичность кода.
Спартанская функциональность из коробки.
Уязвимость.
Требовательность к серверным ресурсам.
Читайте также:
Подробный гайд по оптимизации сайта на WordPress
«1С-Битрикс: Управление сайтом»
Тяжелый, «монструозный» по функциональности и во многом неповоротливый движок отечественного производителя. Здесь есть то, что может понадобиться именно российскому бизнесу. Эта CMS подойдет скорее большим предприятиям, магазинам, маркетплейсам, чем небольшому контентному сайту.
Достоинства «1С-Битрикс: Управление сайтом»
Поддержка сервисов 1С.
Поддержка CRM.
Интеграция инструментов E-mail маркетинга.
Саппорт на русском языке.
Учет специфики российского бизнеса (предусмотрена связь с бухгалтерией, например).
Соответствие российскому законодательству, включая ФЗ-54.
Недостатки «1С-Битрикс: Управление сайтом»
Сложность управления.
Платность любой отсутствующей функции.
Запутанный интерфейс.
Продукт «1С-Битрикс: Управление сайтом» имеет пять разных лицензий: – «Старт», «Стандарт», «Малый бизнес», «Бизнес» и «Энтерпрайз».
OpenCart
Система, созданная специально для интернет-магазинов. Полная поддержка e-commerce и самое быстрое решение, если вам нужен готовый интернет-магазин.
Достоинства OpenCart
Полностью бесплатный open-source проект.
Отзывчивая административная панель.
Подробные маркетинговые отчеты, включая, отчеты по доходности, продажам, ценности клиента.
SEO уже предусмотрено.
Позволяет создать магазин с более десятком способов оплаты и поддержкой самых востребованных валют.
Примеры модулей OpenCart для добавления новых функций
Недостатки OpenCart
Нет встроенных инструментов для удаления дублей контента.
Выгрузка товара не очень удобная.
Плагины могут конфликтовать с CMS после ее обновления.
Высокая нагрузка на хостинг, особенно при задействовании плагинов.
Читайте также:
Продвижение интернет-магазина: пошаговый план работы, советы и рекомендации по нишам
Joomla
Универсальный движок для создания сайтов практически любых типов. Административная панель и визуальный редактор здесь гораздо проще, чем в том же WordPress.
Достоинства Joomla
Универсальность — можно создать сайт практически любой сложности.
Не пожирает ресурсы хостинга.
Имеет тысячи функциональных плагинов (здесь они называются модулями).
Базовые инструменты для поисковой оптимизации страниц.
На Joomla себя уютно чувствуют сайты любых, даже очень крупных масштабов. Единственное исключение — магазины. Для них движок не совсем подходит.
Официальный сайт Deep Purple создан на Joomla
Недостатки Joomla
Платные расширения.
Некоторые вебмастеры сообщают о проблеме с индексацией новых страниц.
Структурный элемент CRM мог быть лучше.
Расширения из неофициальных источников могут стать причиной атак или взлома сайта.
Magento
Еще одна CMS для создания интернет-магазинов. Поправка — не для российских магазинов: в Magento до сих пор нет элементарных решений по оплате популярными у нас способами, нет интеграции с отечественными продуктами типа 1С. Так что Magento действительно может все, кроме специфических потребностей отечественного бизнеса.
Достоинства Magento
Полная поддержка электронной коммерции и коммерческих показателей в отчетах.
Собственный алгоритм кэширования страниц.
Адаптивные шаблоны.
Поддержка глобальных изменений в карточках товаров.
Полная поддержка «Google Аналитики».
Пример магазина на Magento
Недостатки Magento
Тяжелая и очень требовательная к ресурсам сервера.
Отсутствует визуальный редактор — все действия по управлению сайтом, например создание новых страниц, происходит прямо в административной панели.
Установка Magento будет не под силу простому пользователю, нужен веб-разработчик.
Сотрудникам обязательно понадобится обучение, так как Magento мало похожа на традиционную систему управления контентом.
Читайте также:
Внутренняя оптимизация сайтов
Необходимый функционал
Все они будут полезными практически для всех типов сайтов:
Генерация пользовательской и XML-карты сайта.
Быстрое внедрение кода schema.org на страницу.
Автоматическая публикация новых страниц в социальных сетях.
Добавление кнопок расшаривания контента страницы в социальных сетях.
Быстрое добавление метаописания страницы.
Автоматическое сохранение черновиков при работе в редакторе содержимого / визуальном редакторе.
Возможность активировать ленивую загрузку изображений в один клик.
Поддержка CDN (для очень крупных сайтов с большим количеством медиафайлов).
Удобный визуальный редактор с отзывчивым интерфейсом и понятным управлением.
Встроенное кэширование страниц.
Быстрая настройка мобильной версии сайта.
Редактирование стандарта исключения для роботов прямо из панели управления.
Автоматическая или ручная компрессия загружаемых изображений.
Тегирование страниц.
Возможность указания canonical-версии страницы.
Удобное управление редиректами.
Быстрая интеграция e-commerce на сайт (актуально для магазинов).
Интеграция сторонних сервисов, необходимых для работы вашего бизнеса: например, сервисы 1С или электронная касса, сервис рассылок.
Читайте также:
Микроразметка Schema.org: полное руководство
Все вместе эти функции невозможно встретить ни в одной современной системе управления. Часто добавлять их приходится с помощью плагинов. Попробуйте составить список самых необходимых возможностей, а уже затем приступайте к изучению функций.
Как расширить функционал
Расширение стандартного функционала CMS происходит при помощи плагинов. Плагины позволяют добавить отсутствующую функцию без вмешательства в код.
Например, ваш сайт работает на WordPress и вам нужно срочно добавить кэширование страниц, так как нагрузка на сервер остается очень высокой. Плагин позволит решить эту проблему быстрее всего. В самом общем виде процедура выглядит так:
Устанавливаем плагин W3 Total Cache или любой другой плагин с аналогичным функционалом через административную панель WordPress.
Активируем плагин.
Настраиваем его.
Всё — кэширование страниц добавлено на сайт.
В условиях самописного движка внедрение такого функционала заняло бы гораздо больше времени. Самая большая коллекция плагинов на сегодняшний день у движка WordPress. У других CMS коллекции гораздо скромнее.
Плагины для связи с сервисами Google
Есть у плагинов и минусы:
Нередко они создают большую нагрузку на сервер и снижают скорость загрузки сайта. Особенно если плагин не оптимизирован. Да и вообще практически любой плагин повышает нагрузку.
Могут приводить к ошибкам или конфликтам программной среды. Например, во многих CMS изменить дизайн сайта можно, сменив тему или шаблон. Но любое глобальное изменение структуры сайта может привести к ошибкам: нарушению форматирования страниц, удалению тегов, слёту адаптивного дизайна, скриптов, рекламных блоков, нарушению семантической разметки, возврату HTTP-протокола, нарушению сформированного семантического URL.
При изменении темы может поменяться стандартный вид URL. Это грозит утратой текущих позиций сайта и дальнейшим падением трафика. Изменение вида ссылки приведет к потере уже набранной ссылочной массы.
Так что при тестировании новых тем лучше создать копию сайта на новом домене — так ваш основной сайт будет в безопасности и вы сможете экспериментировать без ущерба для него.
Продвижение сайта в ТОП-10
Оплата по дням нахождения в ТОП
Подбираем запросы, которые приводят реальных покупателей!
Как выбрать CMS для сайта
Прежде чем выбирать систему управления, ответьте на вопросы:
Какой тип сайта вы планируете создать?
Нужен ли вам специфический функционал на сайте, например система купонов для магазина, калькулятор стоимости работ, обработка массивов данных?
Каким бюджетом на создание сайта вы располагаете?
Планируете ли вы заниматься администрированием сайта самостоятельно или командой?
У многих есть своя специализация. Например, движок OpenCart принято связывать с созданием интернет-магазинов, Drupal — с корпоративными сайтами. Важно разделять главный сценарий использования системы управлениям контентом сайта. Вот несколько таких сценариев:
Магазин на Россию — PrestaShop, «1С Битрикс: Управление сайтом», Drupal, OpenCart.
Магазин на США или Европу — Magento.
Большой контентный сайт, например, сайт СМИ / новостной сайт — Drupal, «1С Битрикс: Управление сайтом», Joomla.
Корпоративный сайт — Drupal.
Присоединяйтесь к нашему Telegram-каналу!
Теперь Вы можете читать последние новости из мира интернет-маркетинга в мессенджере Telegram на своём мобильном телефоне.
Для этого вам необходимо подписаться на наш канал.
как проверить на чем сделан сайт
Владельцы бизнеса, которые планируют сделать сайт, долго не могут выбрать подходящую CMS (систему создания и управления сайтом). Одни знакомые советуют Тильду, другие рекомендуют остановиться на Битрикс, третьи утверждают, что WordPress — это лучшее решение для бизнеса. Получив тонну рекомендаций, предприниматели начинают детально разбирать плюсы и минусы всех движков, «примерять» каждую CMS на свой бизнес. На поиски решения уходит уйма времени, а вопрос создания сайта превращается в головную боль.
Некоторым все же удается быстро найти сайты, которые хочется взять за основу и заказать в агентстве то же самое, только в своих фирменных цветах. Но как узнать, на каком движке сделан сайт, если вы совсем новичок и у вас нет доступа к админке?
В этой статье мы собрали для вас список сервисов, с помощью которых можно за пару минут определить CMS любого сайта. Без просмотра кода, регистраций, установок и SMS.
Как узнать CMS сайта: 5 удобных сервисов для проверки
Самый простой способ узнать CMS чужого сайта — проверить его в автоматических сервисах. Вам понадобится только браузер и адрес ресурса. Если сайт создан на конструкторе или коробочной CMS, сервисы найдут их признаки в два счета. Давайте разбираться, какие инструменты лучше использовать.
2IP
2IP — это бесплатный многофункциональный сервис. С его помощью вы можете посмотреть свой или чужой IP адрес, проверить скорость интернет-соединения, а также определить CMS сайта.
Вам не нужно регистрироваться, чтобы понять, на каком движке создан ресурс. Просто перейдите на эту страницу, введите домен и запустите поиск.
В 2IP для определения CMS можно использовать домен или IP адрес.
За пару минут 2IP проверит ресурс и выдаст результаты в том же окне. Если инструмент говорит, что «признаков использования не найдено», возможно сайт создан на самописной CMS.
Be1
Be1 — это онлайн-сервис, который часто используют в работе SEO-специалисты. С его помощью можно определить CMS, провести аудит сайта, проверить тексты на антиплагиат, получить данные о ссылочной массе и многое другое.
Чтобы определить движок сайта, перейдите на эту страницу, введите URL и нажмите на кнопку «Проверить».
В течение нескольких минут Be1 определит движок, а вы сможете ознакомиться с результатами проверки на той же странице.
Еще один плюс Be1 — это бесплатные пакетные проверки, которые позволяют сэкономить время. Если вы нашли сразу несколько интересных ресурсов и хотите понять, на каких движках они работают, просто перечислите в окне поиска до 10 адресов. Каждый URL нужно указывать с новой строки.
Через пару минут сервис выдаст результаты, которыми можно поделиться по ссылке или выгрузить таблицей в формате . csv.
PR-CY
PR-CY — это еще один сервис для определения движка сайта. Учтите, что в нем есть ограничение на количество проверок — на бесплатном тарифе можно посмотреть не более пяти доменов в сутки.
Периодически PR-CY выдает результат «CMS не определена». Это значит, что ресурс сделан на движке, которого нет в базе сервиса.
Иногда сервис находит признаки сразу нескольких движков. Это не ошибка. Если вы видите такой результат, значит разделы сайта сделаны на разных CMS. Например, для создания каталога разработчики использовали Битрикс, а блог сделали на WordPress.
iTrack
iTrack тоже подходит для определения CMS, но его база содержит в основном данные о коробочных движках и конструкторах. Если данных о CMS нет в базе, сервис выдаст вот такой результат:
В сервисе iTrack проверяем движок по такому же принципу — открываем эту страницу, вводим адрес сайта и нажимаем на кнопку «Определить CMS».
What CMS
У англоязычного сервиса What CMS более обширная база, в которой содержатся данные о более чем 1200 CMS. Работать с ним так же просто — вводите URL на этой странице, запускаете проверку и получаете результаты в течение минуты.
Сервис не только покажет, на каких CMS сделаны определенные разделы сайта, но и соберет ссылки на соцсети, привязанные к ресурсу, а также сообщит, какие страницы не были проверены.
У некоторых сервисов из списка есть расширения для браузеров. Устанавливаете их один раз и мгновенно получаете информацию о движке при посещении любого сайта. Самые популярные расширения с таким функционалом — Wappalyzer, Be1, iTrack.
Выводы
Чтобы посмотреть движок понравившегося ресурса, совсем необязательно лезть в код страницы и проверять десятки строк. В интернете можно найти удобные сервисы, которые в считаные минуты показывают, на какой CMS работает сайт. Практически все сервисы бесплатные и не требуют регистрации перед проверкой. Нужен только браузер и URL проверяемого сайта.
Если у вас есть список конкурентов и вы хотите проверить сразу несколько ресурсов, используйте сервис Be1. В нем можно запускать пакетные проверки и выгружать данные таблицей.
Сервис 2IP не только определяет движок, но и выдает техническую информацию — возраст домена, скорость ответа сервера, данные о посещаемости сайта и многое другое. Для этого придется запускать несколько проверок.
Если некоторые сервисы из списка не находят признаки использования CMS, попробуйте What CMS. У него самая обширная база данных. Также с помощью сервиса вы сможете понять, в каких соцсетях продвигаются ваши конкуренты. Делаете проверку движка и одновременно собираете информацию обо всех каналах продвижения конкурентов. Что может быть удобнее?
В заключение отметим, что, создавая сайт, необходимо отталкиваться от своих бизнес-целей, а не просто следовать за конкурентами. Если у понравившихся коробочных CMS или конструкторов нет нужного функционала, лучше наймите команду разработчиков. Иначе через какое-то время придется переезжать на другой движок, а такие работы стоят недешево.
4 способа как узнать на каком CMS движке сделан сайт
Иногда бывает очень трудно решить, какой движок выбрать для создания сайта, но вот вы видите сайты успешных конкурентов или ресурсы с большими возможностями, которые тоже хотите применить в своём проекте, и возникают естественные вопросы: “А на каком движке сделан их сайт?”, “Какие технологии позволили им всё это реализовать?”. Если сайты успешных конкурентов сделаны на определённой CMS системе, то этот же движок вполне может подойти и для реализации ваших идей.
Теперь перейдём к самому важному — как узнать cms движок сайта.
Онлайн-сервис определения CMS сайта
Я попробовал несколько онлайн-сервисов и был очень удивлён, что они не смогли определить на каком движке сделан наш сайт или откровенно врали. Наш сайт сделан на CMS Joomla и мы это не скрываем. Удалили только одну строчку кода для большей безопасности.
Вот список этих ресурсов:
itrack.ru — дал ответ, что обнаружена система управления сайтами VamShop;
2ip.ru — была долгая проверка движка сайта по 68 разным CMS и напротив каждой было написано — “признаков использования не найдено”;
pr-cy.ru и raskruty.ru — показали несколько технологий, которые мы используем, но CMS определить не смогли;
majento.ru — уверенно наврал, что сайт сделан на MODx;
builtwith — только этот онлайн-сервис смог определить используемую нами CMS, а также показал очень много других полезных данных: сервер, хостинг, скрипты, системы статистики и виджеты подключенные к сайту.
Способ 1 — узнать CMS сайта онлайн, воспользовавшись сервисом builtwith. com
Определить CMS движок сайта вручную
Задача такая — посмотреть код сайта и найти признаки для определения CMS на которой он сделан. Код можно увидеть многими способами, но сейчас не об этом, поэтому приведу пример только одного, самого популярного способа:
Открываем нужный сайт в браузере Google Chrome.
Жмём правой кнопкой мышки в любом месте и выбираем “Посмотреть код”.
Первым делом смотрим на строки кода, которые находятся вверху, между тегами <head> и </head>. Посмотрите, нет ли там такой строчки <meta name="generator" content="xxxxxx" />. Обычно именно в мета теге generator написано название CMS движка и вместо “xxxxxx” вполне может быть то, что вы ищете.
Многие удаляют этот тег, чтобы вредные боты и вирусы не узнали CMS и не пытались применить известные им методы взлома для данного движка.
Понять на каком движке сделан сайт можно и по другим признакам. По структуре расположения файлов или по названию шаблона, если вбить его в поиск, то можно узнать для какой CMS сделан этот шаблон.
В верхней строке панели просмотра кода выберите вкладку Sources, и вы увидите структуру папок хранящих файлы для этого ресурса. Ищите папку template или theme в таких папках хранятся шаблоны. Как видно из снимка, наш шаблон называется rt_salient.
В этом же снимке видно ещё один способ. Можно открывать разные файлы сайта и смотреть на комментарии в этих файлах (зелёный цвет текста). В этих комментариях часто пишется информация о коде: кто его написал; для какого шаблона; для какого CMS движка и так далее.
Способ 2 — определить CMS самостоятельно по мета тегу generator или по другим признакам в коде сайта.
Найти адрес входа в админку и посмотреть там
Ещё один хороший ручной способ. Просто дописываем в URL адресе строку /admin и вполне вероятно, что вас перекинет на страницу входа в админку.
Если не получилось, то попробуйте посмотреть файл robots.txt — очень часто там закрывают админку от поисковых ботов и вы сможете понять по какому адресу она находится.
Конечно у вас нет логина и пароля, чтобы войти, но нам и не нужно входить. На этой странице обычно написано, в админку какой системы мы входим.
Многие CMS движки ставят крупный логотип на этой странице, а некоторые дают внизу ссылку.
Способ 3 — посмотреть что написано при входе в панель управления административной частью сайта.
Узнать движок у людей, делавших сайт
Иногда внизу сайта указана веб-студия, которая его делала. Нет ни чего трудного в том, чтобы спросить у веб-студии или у самого владельца сайта, на каком движке им удалось реализовать подобное.
Похвалите, укажите те моменты, которые вам понравились больше всего. Пожелайте его сайту процветания. Объясните, что вы тоже думаете о создании подобного ресурса. Если это ваш прямой конкурент, то можно немного приврать и сказать, что ваш сайт будет на другую тематику, но со схожим функционалом.
После всего этого можно спросить, сколько времени понадобилось на создание, на каком CMS движке сделан сайт, кто его делал, сколько было затрачено средств на разработку и сколько нужно на поддержание и сопровождение такого ресурса.
Думаете не ответят? Я задавал подобные вопросы 5-6 раз и мне всегда отвечали. Попробуйте! Вы же ни чего не теряете, особенно если первые 3 способа вам не помогли.
Способ 4 — спросить у разработчиков или владельца, обратившись по указанным на сайте контактам.
Если наша статья была для вас полезной, то ставьте “лайк”. А если вы так и не смогли узнать движок сайта, то возможно он сделан без использования CMS. Напишите об этом в комментариях и мы вместе постараемся это выяснить.
Search Network
ExtremeCloud IQ — поиск Site Engine — это мощный диагностический инструмент для обнаружения сетевого устройства или конечной системы, в которой вы хотите устранить неполадки, позволяя отображать их в PortView. Вы можете выполнять поиск по MAC-адресу, IP-адресу или серийному номеру точки доступа, а также по имени конечной системы ExtremeControl, имени пользователя и атрибутам пользовательского поля регистрации. Кроме того, вы можете искать устройство на карте или выполнять поиск по компасу. Чтобы поиск работал, устройство должно быть в базе данных ExtremeCloud IQ — Site Engine или быть клиентом устройства в базе данных. Для клиентского устройства должен быть включен либо сбор статистики, либо клиент должен быть авторизованным клиентом ExtremeControl.
Для просмотра ExtremeCloud IQ — поисковой сети Site Engine вы должны быть участником
группе авторизации назначена функция XIQ-SE OneView > Access OneView Search. Для выполнения поиска с помощью Compass у вас также должна быть возможность ExtremeCloud IQ — Site Engine Console > Запустить клиент ExtremeCloud IQ — Site Engine Console.
Чтобы получить доступ к вкладке Search , выберите значок увеличительного стекла в верхней части окна ExtremeCloud IQ — Site Engine в меню.
В этом разделе справки содержится информация по следующим темам:
Использование ExtremeCloud IQ — поисковая сеть Site Engine
Поиск
Карты поиска
Поиск с помощью компаса
Типы поиска компаса
Примеры поиска
Найдите в сети MAC-адрес конечной системы.
Найдите в сети IP-адрес клиента, прошедший проверку подлинности ExtremeControl.
Найдите в сети IP-адрес устройства
Параметры поиска/ограничения
madcapsoftware.com/Schemas/MadCap.xsd»> В поле Address введите MAC-адрес или IP-адрес. Вы можете скопировать IP-адрес или MAC-адрес из другого источника и ввести его в поле Address . Вы также можете выполнять поиск по серийным номерам точек доступа и по имени хоста конечной системы ExtremeControl, имени пользователя и атрибутам настраиваемых полей регистрации.
Поиск
В зависимости от типа элемента, который вы ищете, на вторичной панели навигации отображается один или несколько Вкладки PortView с информацией, относящейся к элементу поиска.
Всегда отображается вкладка Обзор , которая обеспечивает топологическое отображение взаимосвязей устройств. Вы можете щелкнуть правой кнопкой мыши устройства в топологии, чтобы запустить дополнительные отчеты для устройства. Дополнительные сведения см. в разделе справки PortView.
Поиск на картах
Позволяет выполнять поиск на существующих картах для поиска проводного или беспроводного клиента или устройства. Если клиент или устройство, которое вы искали, включены только в одну карту, она открывается. В поле «Результат поиска» отображается несколько путей карты, если клиент или устройство, которое вы искали, включены в более чем одну карту. Выберите любой путь карты, чтобы отобразить карту. Дополнительные сведения о картах см. в разделе Обзор карт.
Поиск с компасом
Параметр «Поиск с компасом» предоставляет множество поисковых фильтров, позволяющих сузить параметры поиска. Компас — это мощный инструмент поиска, предоставляющий информацию о состоянии,
конфигурация и действия в точках входа в вашу сеть. Это обеспечивает
простой способ поиска конечных станций или пользователей на конечных станциях.
Для выполнения поиска укажите следующую информацию:
Группа устройств (область поиска) — используйте раскрывающийся список, чтобы ограничить поиск определенной группой устройств.
Тип поиска компаса
— В раскрывающемся списке доступно несколько типов поиска. См. следующий раздел для описания каждого типа.
Адрес (параметры поиска) — если указать конкретные параметры поиска (например, IP-адрес или MAC-адрес), Compass
возвращает информацию об этих параметрах, если находит
их в выбранной группе устройств. Если вы не укажете конкретные параметры поиска, Compass вернет
информация обо всем в группе устройств.
Когда поиск завершен,
результаты отображаются в виде таблицы. Вы можете манипулировать данными таблицы
несколькими способами настроить вид под свои нужды:
Выберите заголовки столбцов для выполнения
сортировка по возрастанию или убыванию данных столбца.
Используйте стрелку раскрывающегося списка заголовков столбцов, чтобы выбрать параметр Столбцы и скрыть или отобразить различные
столбцы в таблице.
Используйте стрелку раскрывающегося списка заголовка столбца для фильтрации, сортировки и поиска данных.
в каждом столбце
в таблице.
madcapsoftware.com/Schemas/MadCap.xsd»> Вы можете определить параметры поиска, используемые Compass Search, на вкладке Администрирование > Параметры (Администрирование > Параметры > Компас). Эти параметры определяют данные
источники, используемые при поиске Compass. В дополнение к параметрам поиска вы также можете настроить параметры ограничения поиска, которые помогают ограничить ресурсы сервера ExtremeCloud IQ — Site Engine, используемые для поиска.
Типы поиска компаса
Доступны следующие типы поиска компаса.
Авто — Автоматический поиск автоматически определяет формат адреса, который вы
введите в поле Адрес и выполните соответствующий поиск.
Введите полный IP-адрес, MAC-адрес или имя пользователя в поле Address и выберите группу устройств в качестве области поиска.
Все — В
Весь поиск находит любой сетевой элемент, знающий об устройствах
в пределах выбранной области и перечисляет адреса, с которыми они связаны. Данные собираются из всех MIB, реализованных Compass. Поиск All игнорирует любые параметры поиска, введенные в поле 9.0008 Поле адреса .
MAC-адрес — поиск MAC-адреса находит любое устройство, знающее указанный MAC-адрес.
в пределах выбранной области и перечисляет связанные с ней адреса.
IP-адрес — поиск IP-адреса находит любое устройство, знающее указанный IP-адрес.
адрес/имя хоста в пределах выбранной области и список адресов, с которыми он связан.
IP-подсеть — поиск IP-подсети находит любое устройство, известное об указанной IP-подсети. в пределах выбранной области и перечисляет конечные станции в подсети IP. Адрес должен содержать как адрес, так и маску, разделенные знаком «/».
Имя пользователя — поиск по имени пользователя находит любое устройство, знающее указанное имя пользователя.
в пределах выбранной области и перечисляет адреса, с которыми он связан.
Адрес многоадресной рассылки — поиск адреса многоадресной рассылки находит любое устройство, знающее указанный адрес многоадресной рассылки.
в пределах выбранной области и перечисляет адреса, с которыми он связан.
Примеры поиска
Ниже приведены несколько примеров различных видов поиска, которые вы можете выполнять с помощью ExtremeCloud IQ — поисковой сети Site Engine.
Поиск в сети MAC-адреса конечной системы
Вы можете выполнить поиск по MAC-адресу конечной системы. Например, вы можете скопировать MAC-адрес конечной системы, указанный в представлении End-System на вкладке Control , и вставить MAC-адрес в поле Search Network .
Поиск в сети IP-адреса клиента, прошедшего проверку подлинности ExtremeControl
Вы также можете выполнить поиск по IP-адресу конечной системы, прошедшей проверку подлинности ExtremeControl. Например, вы можете скопировать IP-адрес конечной системы из Control на вкладке End-Systems и вставьте его в поле Search Network .
Найдите в сети IP-адрес устройства
madcapsoftware.com/Schemas/MadCap.xsd»> Чтобы выполнить поиск на устройстве, вы можете скопировать IP-адрес устройства с вкладки Сеть . В результатах поиска отображается только одно устройство. Щелкните устройство правой кнопкой мыши, чтобы открыть дополнительные отчеты.
Параметры/ограничения поиска
Максимальное количество результатов поиска PortView, отображаемых одновременно, настраивается в Site Engine — Параметры (Администрирование > Параметры > Site Engine — Общие > Ограничения сеансов). Максимальное количество по умолчанию — пять. Когда предел достигнут, отображается диалоговое окно, указывающее, что предел достигнут, и существующее представление должно быть закрыто.
На вкладке Обзор (результаты поиска) отображается топология устройства, показывающая отношения между определенным набором устройств: контроллер беспроводной сети, шлюз идентификации и доступа, точка доступа, коммутатор и клиент. Максимальное количество отображаемых устройств — пять устройств для беспроводного клиента в аутентифицированной среде ExtremeControl (шесть устройств могут быть возвращены, если клиент также подключен по проводу). Количество возвращенных устройств становится меньше по мере поиска одного из пяти устройств. Например, если вы ищете точку доступа вместо клиента, возвращаются четыре устройства. При поиске беспроводного контроллера, шлюза ExtremeControl или коммутатора возвращается одно устройство.
Для получения информации по связанным разделам справки:
Для получения информации о связанных вкладках:
Администрация
Сигналы тревоги и события
Сеть
Отчеты
Беспроводная связь
madcapsoftware.com/Schemas/MadCap.xsd»>
Выделенные IP-адреса, IP-адрес | Поддержка HostGator
В этой статье обсуждается, что такое IP-адрес, в чем разница между общим IP-адресом и выделенным IP-адресом и каковы преимущества выделенного IP-адреса.
Нажмите на ссылки ниже для получения более подробной информации.
Что такое IP-адрес? ⤵
Общий IP-адрес или выделенный IP-адрес ⤵
Могу ли я использовать выделенный IP-адрес для своего плана хостинга? ⤵
Часто задаваемые вопросы (FAQ) ⤵
Что такое IP-адрес?
Адрес Интернет-протокола , чаще всего известный как IP-адрес, представляет собой уникальную строку чисел, которая выглядит примерно так: 123.45.67.89 и идентифицирует компьютер, подключенный к Интернету. Подобно вашему домашнему адресу, он определяет местоположение определенного сервера, подключенного к Интернету. Без установленного IP-адреса ваш компьютер не сможет взаимодействовать с другими компьютерами, подключенными к сети, например к Интернету.
IP-адреса являются частью системы доменных имен (DNS), которая представляет собой одну гигантскую адресную книгу. Доменные имена сопоставляются с различными IP-адресами. Когда вы вводите домен в свой веб-браузер, ваш интернет-провайдер ищет доменное имя, видит связанный с ним IP-адрес, а затем открывает сайт, отвечающий на этот IP-адрес. Все эти задачи происходят непосредственно за кулисами и занимают менее пары секунд.
Общий IP-адрес и выделенный IP-адрес
По умолчанию все учетные записи общего и реселлерского хостинга имеют только один общий IP-адрес и не имеют выделенного IP-адреса. Вы можете найти текущий общий IP-адрес вашего сайта в разделе «Общая информация», расположенном в правой части вашей cPanel.
Общие IP-адреса встречаются чаще, чем выделенные IP-адреса. С общим IP-адресом у вас есть несколько сайтов, использующих один и тот же IP-адрес. Веб-браузер пользователя будет связываться с DNS и сервером для отображения правильного веб-сайта. С общим IP-адресом сотни сайтов могут использовать один и тот же IP-адрес.
Выделенный IP-адрес — это место, где у вас есть один IP-адрес, который принадлежит только вам и вашему сайту. Это означает, что вы не будете делиться IP-адресом с какими-либо другими сайтами, даже если вы используете один и тот же сервер.
Если вам не нужны уникальные преимущества выделенного IP-адреса, вам, вероятно, подойдет общий IP-адрес.
Могу ли я получить выделенный IP-адрес для моего плана хостинга? Оптимизированный хостинг WordPress
Оптимизированные пакеты хостинга WordPress в настоящее время не подходят для выделенного IP-адреса.
Выделенные IP-адреса для общего и облачного хостинга
Учетные записи общего хостинга имеют только одну cPanel, поэтому им разрешен только один выделенный IP-адрес. Если вы выберете выделенный IP-адрес, все ваши надстройки и субдомены будут использовать выделенный IP-адрес. Электронные письма по-прежнему будут использовать общий IP-адрес.
Наш общий бизнес-план включает один бесплатный выделенный IP-адрес.
Планы Hatchling, Baby и Business имеют право на выделенный IP-адрес. Чтобы получить выделенный IP-адрес для общего плана, свяжитесь с нами по телефону или в чате.
Выделенные IP-адреса для общего хостинга Windows
Учетные записи общего хостинга Windows имеют ограничение в один (1) выделенный IP-адрес на учетную запись. Если вы решите использовать выделенный IP-адрес, все ваши дополнительные домены и поддомены будут использовать один и тот же IP-адрес. Электронные письма по-прежнему будут использовать общий IP-адрес.
Windows Shared Enterprise Hosting поставляется с одним бесплатным выделенным IP-адресом.
Чтобы получить выделенный IP-адрес для общего плана Windows, свяжитесь с нами по телефону или в чате.
Выделенные IP-адреса для реселлерского хостинга
Реселлерский хостинг Учетные записи могут иметь неограниченное количество IP-адресов (по одному на каждую cPanel). Просто сначала создайте cPanel, а затем свяжитесь с нами по телефону или в чате, чтобы приобрести IP.
Если вы выберете выделенный IP-адрес, все ваши надстройки и субдомены в одной cPanel будут использовать выделенный IP-адрес. Электронные письма по-прежнему будут использовать общий IP-адрес.
Выделенные IP-адреса для VPS-хостинга
Каждый план VPS включает 2 IP-адреса, один из которых по умолчанию является общим IP-адресом. Вы можете назначить эти IP-адреса по своему усмотрению. Если вы хотите приобрести дополнительные IP-адреса, свяжитесь с нами по телефону или в чате.
Выделенные IP-адреса для выделенного хостинга
Все наши серверы выделенного хостинга изначально имеют 2 выделенных IP-адреса, но в зависимости от типа плана серверов владельцы выделенных серверов могут запросить до максимального количества Выделенные IP-адреса на сервере, как указано в таблице ниже.
Server Type
IP Addresses
Value
3 Dedicated IPs
Power
3 Dedicated IPs
Enterprise
3 Dedicated IPs
HostGator’s методы обоснования распределения IP-адресов могут быть изменены, чтобы оставаться в соответствии с политикой Американского реестра интернет-номеров (ARIN). Мы оставляем за собой право отклонить любой запрос на выделенный IP-адрес на основании недостаточного обоснования или текущего использования IP-адреса.
Для разрешения изменения выделенного IP-адреса требуется 4 часа. В это время может показаться, что ваш сайт не работает. Вам НЕ нужно будет менять серверы имен.
Если вы обнаружите, что ваш приобретенный пакет не содержит выделенных IP-адресов, перечисленных выше, свяжитесь с нами по телефону или в чате, чтобы выделить дополнительные IP-адреса для вашего сервера или приобрести дополнительные IP-адреса по цене 4 доллара США в месяц за IP-адрес.
Часто задаваемые вопросы (FAQ)
Действительно ли мне нужен выделенный IP-хостинг?
Обратите внимание, что выделенные IP-адреса — это не то же самое, что получение выделенной учетной записи хостинга. У вас могут быть общие IP-адреса на выделенном сервере, точно так же, как у вас могут быть выделенные IP-адреса на общем сервере.
Если это ваш первый веб-сайт, маловероятно, что вам потребуется перейти на выделенный IP-адрес.
Если вы ищете значительно улучшенные преимущества сайта, подумайте о том, чтобы полностью перейти на Выделенный хостинг с включенным выделенным IP-адресом.
Может ли торговый посредник купить один выделенный IP-адрес и сделать его общим IP-адресом для назначения другим cPanel?
Да, можно приобрести выделенный IP-адрес и сделать его общим IP-адресом для назначения другим cPanels. Реселлерам, желающим сделать это, необходимо связаться с нами по телефону или в чате.
Владельцы выделенных серверов могут сделать это через WHM. Подробнее читайте в следующей статье:
Купить выделенный IP-адрес и сделать его общим
Политики на основе геолокации — Ranger
Перейти к концу метаданных аудиторская проверка. В версии 0.5 Apache Ranger представил стековую модель, чтобы облегчить новым компонентам использование авторизации и аудита Apache Ranger. Кроме того, чтобы обеспечить возможность расширения/адаптации Apache Ranger для новых или специфичных для развертывания требований авторизации, модель стека предоставляет крючки, такие как средства обогащения контекста и условия политик.
В этом документе мы увидим подробности расширения Apache Ranger для поддержки авторизации на основе местоположения, из которого осуществляется доступ, т. е. страны/штата/города, из которого осуществляется доступ к ресурсу.
Вот краткое описание задач, которые необходимо выполнить:
Подготовить файл данных о местоположении, содержащий сопоставление IP-адреса и сведений о местоположении
Зарегистрировать обработчик контекста, добавляющий сведения о местоположении в запрос
Зарегистрировать политику- условие для проверки того, что расположение клиента соответствует расположению, указанному в политике
Создание/обновление политик Apache Ranger для указания местоположений для разрешения/запрета доступа
Файл данных IP-местоположения представляет собой текстовый файл, содержащий поля, разделенные запятыми. Каждая строка в файле содержит сведения о местоположении для диапазона IP-адресов. Формат файла данных о местоположении IP приведен ниже:
Каждая строка состоит из полей, разделенных запятыми
Первая строка рассматривается как заголовок, содержащий имена для каждого поля
адреса
Первое поле — начальный IP-адрес диапазона
Второе поле — конечный IP-адрес диапазона
Остальные поля содержат данные о местоположении для IP-диапазона, указанного в первых двух полях (включительно)
IP -адреса должны быть указаны как длинные целые числа; но обогащающий контекст может читать адреса в точечной нотации, когда IPInDotFormat для IP-адреса клиента true
Этот формат данных аналогичен коммерчески доступным данным от таких поставщиков, как IP2Location. В зависимости от требований файл данных может быть либо получен от коммерческого поставщика данных (например, IP2Location), либо создан с учетом конкретных сведений о развертывании.
Когда подключаемый модуль Apache Ranger получает запрос на авторизацию, этот запрос проходит через зарегистрированные средства обогащения контекста. Обогатители контекста имеют доступ к различным сведениям о запросе, таким как пользователь, доступ к ресурсу, тип доступа, IP-адрес средства доступа и т. д. Обогатители контекста могут обновлять контекст запроса дополнительной информацией, которую можно использовать при оценке политик Ranger.
Средство обогащения контекста RangerFileBasedGeolocationProvider , доступное в ветви политики тегов, добавляет данные о географическом местоположении в контекст запроса на основе сведений о местоположении, доступных в файле данных. Чтобы зарегистрировать средство обогащения контекста для компонента (например, HDFS/Hive/HBase/..), обновите service-def компонента, включив следующее:
Когда RangerFileBasedGeolocationProvider получает запрос авторизации, он находит запись в данных IP-местоположения для IP-адреса клиента, указанного в запросе. Если запись найдена, каждое поле записи будет добавлено в контекст запроса.
Следующий пример должен помочь понять детали контекстных данных, добавляемых обогатителем:
IP-адрес клиента: 20.0.100.85
Соответствующая запись в данных IP-местоположения:
IP_FROM, IP_TO, COUNTRY_CODE, COUNTRY_NAME, REGION, CITY
Записи, добавленные в контекст запроса:
location_country_code = US
location_country_name = Соединенные Штаты
location_region = Colorado
location_city = Broomfield
. Пожалуйста, будет отметить, что указание на то, что будет отмечать, что будет.
Apache Ranger предоставляет перехватчики условий политики для выполнения настраиваемых условий при оценке запросов авторизации. Чтобы определить результат авторизации, механизм политик Apache Ranger оценивает политики, применимые к ресурсу, к которому осуществляется доступ. Только когда различные критерии, такие как пользователь/группа, тип доступа и условия политики, указанные в политике, соответствуют запросу, механизм политики будет использовать политику для определения результата.
Условие политики RangerContextAttributeValueNotInCondition , доступный в ветке tag-policy, возвращает true только тогда, когда указанное значение контекста запроса не соответствует значениям, указанным в политике. Это можно использовать для проверки того, находится ли местоположение в контексте запроса (которое заполняется описанным выше средством обогащения контекста) за пределами значений, указанных в политике, — например, для отказа в доступе к запросам, которые исходят за пределами указанных стран. Чтобы зарегистрировать условие политики для компонента (например, HDFS/Hive/HBase/..), обновите service-def компонента, включив следующее:
После того, как это условие политики зарегистрировано в Ranger, пользовательский интерфейс «Редактирование политики» будет предпринять для значений состояния во время оценки - как показано ниже:
99995959504
9000 9000
9000 9000 9000 9000 9000
9000 9000
9000 9000 9000 9000 9000 9000
9000 9000 9000 9000 9000 9000 9000 9000 9000 9000
9000 9000 9000 9000 9000 9000 9000 9000 9000
. В этом разделе мы увидим подробности политики Apache Ranger, которая запрещает доступ к определенной таблице Hive при доступе из местоположения за пределами определенной страны. В этом примере используется средство обогащения контекста и условие политики, описанные ранее в этом документе.
Инфраструктура, ориентированная на приложения Cisco — информационный документ по обучению оконечных устройств ACI Fabric
Введение
В этом разделе представлен обзор целей и предварительных условий этого документа.
Цели данного документа
Решение Cisco ® Application Centric Infrastructure (Cisco ACI ® ) может хранить информацию о расположении MAC-адресов и адресов IPv4 (/32) и IPv6 (/128) конечных точек в Ткань Cisco ACI. Помимо использования для маршрутизации и соединения трафика, информация о конечных точках может быть полезна для оптимизации трафика, отслеживания местоположения конечных точек и устранения неполадок.
В этом документе описывается поведение и развертывание конечных точек Cisco ACI при обучении, а также представлены различные варианты оптимизации. Основное внимание уделяется конкретным вариантам использования поведения при изучении IP-адреса конечной точки.
Предварительные требования
Чтобы лучше понять конструкцию, представленную в этом документе, читатель должен иметь базовые практические знания технологии Cisco ACI. Дополнительные сведения см. в технических документах Cisco ACI, доступных на сайте Cisco.com: https://www.cisco.com/c/en/us/solutions/data-center-virtualization/application-centric-infrastructure/white-paper- листинг.html.
Краткий обзор
В этом документе рассматриваются функции до версии Cisco ACI 5.2(1g). В нем обсуждаются варианты развертывания с использованием вариантов обучения плоскости данных, перечисленных в таблице 1. Подробные варианты использования и пояснения представлены далее в этом документе.
Таблица 1. Варианты оптимизации обучения конечной точки
Отключает обучение плоскости данных конечной точки IP для каждой подсети домена моста или IP
Обучение плоскости данных IP
Арендатор > Сеть > VRF > VRF
Выпуск 4. 0(1ч)
Отключает обучение плоскости данных конечной точки IP в экземпляре Virtual Routing and Forwarding (VRF)
-
Отключить дистанционное обучение EP (на пограничном листе)
Система > Системные настройки > Настройка для всей сети
До версии APIC 3.0 (1k): Fabric > Политики доступа > Глобальные политики > Политика настройки для всей сети > Отключить дистанционное обучение EP
Версия 2.2(2e)
Отключает изучение удаленных конечных точек IP на пограничных листовых коммутаторах для экземпляров VRF; пограничные листовые коммутаторы используют исключительно прокси-сервер позвоночника
До выпуска Cisco ACI 3.0 (2h) этот параметр требовал принудительного применения политики входа в экземпляре VRF.
Для листовых коммутаторов второго поколения удаленное изучение IP разрешено только для многоадресной рассылки уровня 3, чтобы должным образом пересылать (S, G) пакеты. Листовые коммутаторы первого поколения не поддерживают многоадресную рассылку уровня 3.
Принудительная проверка подсети
Система > Системные настройки > Настройка для всей сети
До выпуска APIC 3.0 (2h): Fabric > Политики доступа > Глобальные политики > Политика настройки для всей структуры > Принудительная проверка подсети
Версия 2.2(2q) *
Предотвращает неправильное изучение IP-адресов, которые могут не принадлежать фабрике
Этот параметр применяется только к концевым коммутаторам Cisco ACI второго поколения.
Ограничивает изучение как локальной, так и удаленной конечной точки экземплярами только в том случае, если исходный IP-адрес принадлежит подсети мостового домена в экземпляре VRF
Предотвращает неправильное изучение IP-адресов, которые могут не принадлежать фабрике
Старение IP
Система > Параметры системы > Элементы управления оконечными точками > Устаревание IP
До версии APIC 3. 0 (1k): Fabric > Политики доступа > Глобальные политики > Политика настройки всей структуры > Устаревание IP
Версия 2.1(1ч)
Отслеживание и определение возраста неиспользуемых IP-адресов на конечной точке
Этот параметр является настройкой по умолчанию для Cisco ACI версии 2.1 (1h) и более поздних версий.
Предотвращает прилипание IP-адресов к конечной точке, даже если IP-адрес больше не используется
Разбойник EP Control
Система > Системные настройки > Конечные точки управления > Rogue EP Control
Выпуск 3.2(1л)
Обнаруживает конечные точки, которые часто перемещаются, и отключает обучение конечных точек только для этих конечных точек
Начиная с версии 5. 2(3) Cisco ACI можно настроить список «исключений» MAC-адресов, к которым не применяется политика Rogue EP Control.
Выявляет мошеннические конечные точки и сводит к минимуму вызванное ими воздействие
Демпфирование конечной точки COOP
Доступно только через API.
Версия 4.2(3)
Смягчить влияние необоснованного количества обновлений конечной точки конечной точки на узлы позвоночника
Это включено по умолчанию после выпуска Cisco ACI 4.2(3).
* Хотя параметр Enforce Subnet Check впервые появился в версии 2.2(2q) и доступен в более поздних выпусках Cisco ACI Release 2.2, он недоступен в Cisco ACI Release 2.3 или 3.0(1x) - например, он недоступен в версиях 2.3(1f) или 3.0(1k). Он поддерживается начиная с версии 3. 0 (2h).
В таблице 2 перечислены способы обучения конечной точки в различных комбинациях вариантов обучения конечной точки.
Таблица 2. Сравнение режимов обучения конечных точек
Конфигурации
Обучение поведению
Обучение IP Data-plane (onVRF, подсеть BD или подсеть EPG
Обучение плоскости данных конечной точки (на BD)
Дистанционное обучение EP (на пограничном листе) 1
Локальный MAC-адрес
Локальный IP-адрес
Удаленный MAC-адрес
Удаленный IP (одноадресный)
Удаленный IP (многоадресный)
Инвалид
Отключено/Включено
Отключено/Включено
Выучено *5
Не обучен 2
Выучено *3 *5
Не обучен
Не изучено *6
Включено
Отключено
Отключено/Включено
Выучено
Не обучен 2
Не обучен
Не обучен
Не обучен
Включено
Включено
Отключено
Выучено
Выучил
Выучено
Не обучен 4
Выучено
Включено
Включено
Включено
Выучено
Выучено
Выучено
Выучил
Выучено
1 Этот параметр называется «Отключено дистанционное обучение EP» в графическом интерфейсе APIC в разделе «Системные настройки».
2 Обучение не через уровень данных, а обучение через уровень управления, например ARP.
3 В концевых коммутаторах Cisco ACI первого поколения удаленный MAC-адрес не запоминается.
4 Не изучен только на концевых выключателях.
5 В случае опции в подсети BD или подсети EPG, она не изучается через запрос ARP от конечной точки к конечной точке, который не достигает ЦП. (Запрос ARP к шлюзу SVI домена моста по-прежнему изучается.) В случае варианта с VRF локальные и удаленные MAC-адреса узнаются через запрос ARP между конечными точками.
6 До выпуска Cisco ACI 5.2(1g) он изучен.
В таблице 3 перечислены конечные коммутаторы Cisco ACI по поколениям.
Таблица 3. Поколения листовых коммутаторов Cisco ACI
Поколение
Переключатель
Номер детали
Листовые коммутаторы Cisco ACI первого поколения
Коммутатор Cisco Nexus ® 9332PQ
Коммутатор Cisco Nexus 9372PX
Коммутатор Cisco Nexus 9372PX-E
Коммутатор Cisco Nexus 9372TX
Коммутатор Cisco Nexus 9372TX-E
Коммутатор Cisco Nexus 9396PX
Коммутатор Cisco Nexus 9396TX
Коммутатор Cisco Nexus
TX
Коммутатор Cisco Nexus
TX 4 4
N9K-C9332PQ
N9K-C9372PX
N9K-C9372PX-E
N9K-C9372TX
N9K-C9372TX-E
N9K-C9396PX
N9K-C9396TX
N9K-C
TX
N9K-C
TX
Листовые коммутаторы Cisco ACI второго поколения и более поздние версии
Cisco Nexus
YC-EX
Cisco Nexus
YC-FX
Cisco Nexus
TC-EX
Cisco Nexus
TC-FX
Cisco Nexus
LC-EX
Cisco Nexus 9348GC-FXP
Cisco Nexus 9336C-FX2
Cisco Nexus
YC-FX2
Cisco Nexus
TC-FX2
Cisco NexusYC-FX2
Cisco Nexus
YC-FX3
Cisco Nexus
TC-FX3P
Cisco Nexus 9316D-GX
Cisco Nexus
CD-GX
Cisco Nexus 9364C-FX
N9K-C
YC-EX
N9K-C
YC-FX
N9K-C
TC-EX
N9K-C
TC-FX
N9K-C
LC-EX
N9K-C9348GC-FXP
N9K-C9336C-FX2
N9K-C
YC-FX2
N9K-C
TC-FX2
N9K-CYC-FX2
N9K-C9
N9K-C9364C-GX
3180YC-FX3
N9K-C
TC-FX3P
N9K-C9316D-GX
Поведение конечных точек Cisco ACI при обучении
В этом разделе представлен обзор поведения конечных точек Cisco ACI при обучении.
Cisco ACI и конечные точки
Cisco ACI использует конечные точки для пересылки трафика. Конечная точка состоит из одного MAC-адреса и нуля или более IP-адресов. Каждая конечная точка представляет собой одно сетевое устройство (рис. 1).
Рисунок 1.
Cisco ACI и конечные точки
В традиционной сети для хранения сетевых адресов внешних устройств используются три таблицы: таблица MAC-адресов для переадресации на уровне 2, база информации о маршрутизации (RIB) для переадресации на уровне 3 и таблица ARP. таблица комбинаций IP-адресов и MAC-адресов. Однако Cisco ACI хранит эту информацию другим способом, как показано в таблице 4.
Таблица 4. Cisco ACI и традиционные сети
Традиционная сеть
Сиско АКИ
Стол
Роль стола
Стол
Роль стола
РИБ
● IPv4-адреса (/32 и не-/32)
● IPv6-адреса (/128 и не-/128)
РИБ
● IPv4 (не-/32 * )
● IPv6 (не/128 * )
Таблица MAC-адресов
MAC-адреса
Конечная точка
MAC- и IP-адреса (только /32 или /128)
Таблица ARP
Связь IP с MAC
АРП
Отношение IP к MAC (только для Уровня 3 вне соединений [L3Out])
* Cisco ACI bridge domain Switch Virtual Interfaces (SVI), IP-адреса маршрутизируемых портов и подинтерфейсов, а также объявленные и статические маршруты находятся в RIB независимо от того, является ли он /32 (IPv4) или /128 (IPv6) .
Как показано в таблице 4, Cisco ACI заменила таблицу MAC-адресов и таблицу ARP одной таблицей, называемой таблицей конечных точек. Это изменение означает, что Cisco ACI получает эту информацию иначе, чем в традиционной сети. Cisco ACI изучает MAC- и IP-адреса в аппаратном обеспечении, просматривая MAC-адрес источника пакета и исходный IP-адрес в плоскости данных вместо того, чтобы полагаться на ARP для получения MAC-адреса следующего перехода для IP-адресов. Такой подход уменьшает количество ресурсов, необходимых для обработки и генерации трафика ARP. Это также позволяет обнаруживать перемещение IP-адреса и MAC-адреса без необходимости ждать GARP, пока некоторый трафик отправляется с нового хоста.
L3Out и обычные конечные точки
Хотя Cisco ACI в основном использует таблицу конечных точек вместо таблиц MAC-адресов и ARP, он по-прежнему использует RIB и таблицу ARP. Эта возможность особенно важна для связи L3Out, поскольку максимальное количество IP-адресов на одной конечной точке (один MAC-адрес) ограничено, и может быть огромное количество IP-адресов за одним MAC-адресом следующего перехода (внешний маршрутизатор) на соединение L3Out. Сведения о разрешенном количестве адресов см. в руководстве по масштабируемости для используемого вами выпуска. (Для Cisco ACI версии 5.2(1g) максимальное количество записей равно 409.6.)
Несмотря на это ограничение, поддерживать все внешние IP-адреса как отдельные конечные точки /32 или /128 неэффективно. Cisco ACI должен знать, как получить доступ к этим IP-адресам в виде префиксов через протоколы маршрутизации, такие как Open Shortest Path First (OSPF), который работает так же, как и для традиционных маршрутизаторов. Однако Cisco ACI необходимо знать только следующий переход (внешний маршрутизатор) для этих префиксов. Из-за этого соображения Cisco ACI использует поведение, подобное тому, которое используется в традиционных сетях для подключения L3Out. Домен Cisco ACI L3Out узнает MAC-адрес только из плоскости данных. IP-адреса не извлекаются из плоскости данных в домене L3Out; вместо этого Cisco ACI использует ARP для разрешения взаимосвязей IP и MAC следующего перехода для достижения префиксов за внешними маршрутизаторами.
Локальные конечные точки и удаленные конечные точки
Листовой коммутатор имеет два типа конечных точек: локальные конечные точки и удаленные конечные точки. Локальные конечные точки для LEAF1 находятся непосредственно на LEAF1 (например, напрямую подключены), тогда как удаленные конечные точки для LEAF1 находятся на других конечных точках (рис. 2).
Рис. 2.
Локальные и удаленные конечные точки
Хотя и локальные, и удаленные конечные точки изучаются из плоскости данных, удаленные конечные точки представляют собой просто кэш, локальный для каждого листа. Локальные конечные точки являются основным источником информации о конечных точках для всей структуры Cisco ACI. Каждый лист отвечает за передачу своих локальных конечных точек в базу данных Совета Oracle Protocol (COOP), расположенную на каждом коммутаторе позвоночника, что означает, что вся информация о конечных точках в фабрике Cisco ACI хранится в базе данных COOP позвоночника. Поскольку эта база данных доступна, каждому листу не нужно знать обо всех удаленных конечных точках для пересылки пакетов на удаленные конечные точки листа. Вместо этого лист может пересылать пакеты на коммутаторы позвоночника, даже если лист не знает о конкретной удаленной конечной точке. Такое поведение пересылки называется прокси-сервером позвоночника.
Значение удаленных конечных точек
Из-за прокси-сервера позвоночника пересылка пакетов Cisco ACI будет работать без обучения удаленных конечных точек. Прокси-сервер Spine позволяет листовым коммутаторам перенаправлять трафик непосредственно в базу данных COOP, расположенную на коммутаторах Spine. Удаленное обучение конечных точек помогает Cisco ACI более эффективно пересылать пакеты, позволяя конечным коммутаторам отправлять пакеты непосредственно конечным коммутаторам назначения, не используя ресурсы коммутатора позвоночника, которые использовались бы для поиска конечных точек в базе данных COOP, которая содержит все конечные точки фабрики. Информация.
Удаленные конечные точки узнаются из трафика плоскости данных, как и локальные конечные точки. Таким образом, только листовые коммутаторы с фактическим коммуникационным трафиком создают запись в кэше для удаленных конечных точек (диалоговое обучение), чтобы пересылать пакеты непосредственно к конечному листу. Удаленные конечные точки имеют либо один MAC-адрес, либо один IP-адрес для каждой конечной точки, а не комбинацию MAC-адреса и IP-адреса, как в случае с локальными конечными точками (как показано на рис. 2). Одна из причин этого различия заключается в том, что преобразование IP в MAC-адрес следующего перехода может выполняться на целевом листе, а MAC-адрес следующего перехода не требуется только для достижения целевого листа. Такое поведение также помогает каждому листу сохранять свои ресурсы для этих кэшей. Кроме того, таймер возраста для удаленной конечной точки короче, чем для локальной конечной точки, потому что удаленная конечная точка — это просто кеш и не должна присутствовать после прекращения диалога и исчезновения исходной локальной конечной точки на другом листе.
Одноранговая конечная точка — это вариант удаленной конечной точки. Эти конечные точки являются удаленными конечными точками, которые указывают на порт, который не является частью виртуального канала порта (vPC), также называемого потерянным портом, на одноранговом листе vPC. Они являются специальными конечными точками, потому что они удалены, но они изучаются посредством синхронизации vPC на плоскости управления, а не посредством обучения плоскости данных на основе фактического трафика. В результате синхронизации vPC одноранговые конечные точки имеют информацию о MAC-адресе, IP-адресе и EPG, в отличие от других удаленных конечных точек, которые имеют информацию либо о домене моста (MAC-адрес), либо о VRF (IP-адрес).
В таблице 5 приведены различия между локальными и удаленными конечными точками.
Таблица 5. Различия между локальными и удаленными конечными точками
Функция
Локальная конечная точка
Удаленная конечная точка
1 конечная точка
1 MAC-адрес и n IP-адреса
1 MAC-адрес или 1 IP-адрес
Объем
Сообщается в базе данных Spine COOP
Только на каждом листе как запись кэша
Таймер хранения конечной точки *
900 секунд (по умолчанию)
300 секунд (по умолчанию)
* Вы можете настроить таймер хранения конечной точки в Tenant > Networking > Protocol Policies >
Удержание конечной точки.
IP-адреса локальной конечной точки могут устаревать отдельно в зависимости от политики устаревания IP-адресов. Дополнительные сведения см. в разделе «Политика устаревания IP» этого документа.
На рис. 3 показан пример вывода интерфейса командной строки (CLI) для локальной и удаленной конечных точек на листовом коммутаторе.
Рисунок 3.
Вывод CLI локальной и удаленной конечной точки на каждом концевом коммутаторе
Обучение конечной точки
Описанное здесь поведение обучения конечной точки основано на предположении, что одноадресная маршрутизация включена в домене моста. Если одноадресная маршрутизация не включена, лист Cisco ACI не может выполнять маршрутизацию и не может узнать какие-либо IP-адреса. Он узнает только MAC-адреса и выполняет коммутацию. Дополнительные сведения см. в разделе «Опции одноадресной маршрутизации» этого документа.
Изучение локальной конечной точки
Cisco ACI изучает MAC-адрес (и IP) в качестве локальной конечной точки, когда пакет поступает в конечный коммутатор Cisco ACI через его порты на передней панели.
Порты на передней панели являются южными портами с точки зрения Cisco ACI и не обращены к коммутаторам позвоночника.
Конечный коммутатор Cisco ACI выполняет следующие действия, чтобы узнать MAC-адрес и IP-адрес локальной конечной точки:
1. Лист Cisco ACI получает пакет с MAC-адресом источника (MAC A) и IP-адресом источника (IP A).
2. Лист Cisco ACI узнает MAC A как локальную конечную точку.
3а. Если пакет представляет собой запрос ARP, лист Cisco ACI узнает IP A, связанный с MAC A, на основе заголовка ARP.
3б. Если пакет является IP-пакетом и маршрутизация выполняется листом Cisco ACI, лист Cisco ACI узнает IP A, связанный с MAC A, на основе заголовка IP.
Таким образом, если коммутируется пакет, а не пакет ARP, лист Cisco ACI никогда не узнает IP-адрес, а только MAC-адрес. Это поведение такое же, как и при традиционном изучении MAC-адреса на традиционном коммутаторе.
Конечные коммутаторы первого поколения не могут отражать перемещение IP-адресов между двумя MAC-адресами на одном интерфейсе с одной и той же VLAN в базу данных конечных точек. Такое перемещение IP-адреса может произойти в сценарии аварийного переключения с высокой доступностью, в котором GARP обычно используется для обновления отношения IP к MAC на восходящих сетевых устройствах. Это поведение разрешается путем включения опции обнаружения движения EP на основе GARP, которая обсуждается далее в этом документе.
Обучение удаленной конечной точки
Cisco ACI изучает MAC- или IP-адрес удаленной конечной точки, когда пакет поступает в листовой коммутатор Cisco ACI от другого концевого коммутатора через коммутатор позвоночника. Когда пакет отправляется с одного листа на другой лист, Cisco ACI инкапсулирует исходный пакет с внешним заголовком, представляющим конечную точку туннеля (TEP) исходного и конечного листьев, и заголовком Virtual Extensible LAN (VXLAN), который содержит домен моста или VRF. Информация об исходном пакете.
Коммутируемые пакеты содержат информацию о домене моста. Маршрутизируемые пакеты содержат информацию VRF.
Листовой коммутатор Cisco ACI выполняет следующие действия, чтобы узнать MAC- или IP-адрес удаленной конечной точки:
1. Листовой коммутатор Cisco ACI получает пакет с исходным MAC-адресом A и исходным IP-адресом A от коммутатора позвоночника.
2. Лист Cisco ACI узнает MAC A как удаленную конечную точку, если VXLAN содержит информацию о домене моста.
3. Лист Cisco ACI узнает IP A как удаленную конечную точку, если VXLAN содержит информацию VRF.
На рисунках 4 и 5 показаны примеры обучения локальных и удаленных конечных точек.
Рис. 4.
Пример изучения локальной и удаленной конечной точки (MAC-адреса)
На рис. 4 пакет представляет собой трафик уровня 2 без какой-либо маршрутизации в Cisco ACI. Следовательно, только MAC-адрес (Src MAC S на рисунке) запоминается как локальная конечная точка на LEAF1 и удаленная конечная точка на LEAF2.
Рисунок 5.
Пример изучения локальной и удаленной конечной точки (IP-адреса)
На рис. 5 пакет представляет собой трафик уровня 3 с виртуальным интерфейсом коммутатора домена моста Cisco ACI (SVI) в качестве шлюза по умолчанию. Следовательно, и MAC-адрес, и IP-адрес (Src MAC S и Src IP 192.168.1.1 на рисунке) запоминаются как одна локальная конечная точка на LEAF1, и только IP-адрес 192.168.1.1 изучается как удаленная конечная точка на LEAF2.
Старение оконечных устройств
Таймер устаревания (или таймер хранения) конечных точек в ACI настраивается с помощью Политики хранения конечных точек . Локальные и удаленные конечные точки имеют разные интервалы устаревания, и интервал для удаленных конечных точек всегда должен быть короче, чем для локальных конечных точек.
Для локальных конечных точек, с которыми связаны IP-адреса, конечные коммутаторы выполняют Отслеживание узлов на 75 процентах интервала устаревания, если в течение этого интервала не было получено пакетов с одного и того же IP-адреса. Отслеживание хоста всегда включено и отправит три запроса ARP на IP-адрес, чтобы убедиться, что IP-адрес все еще отвечает. Если пакет с IP-адреса был получен хотя бы один раз в течение интервала устаревания (точнее, в течение 75 процентов интервала), Host Tracking не выполняется, а интервал устаревания сбрасывается в момент времени Host Tracking (75 процентов интервала). Обратите внимание, что интервал не сбрасывается при получении пакета. Это означает, что если пакет был получен очень рано в интервале устаревания, а не после него, таймер старения продолжает работать до тех пор, пока не истечет 9 секунд.0008 Интервал Host Tracking истекает, что может привести к тому, что конечная точка будет изучаться почти в два раза дольше настроенного интервала устаревания в худшем случае. IP-адреса локальной конечной точки могут устаревать отдельно, в зависимости от политики устаревания IP. Дополнительные сведения см. в разделе «Политика устаревания IP» этого документа.
Для локальных конечных точек без IP-адресов и удаленных конечных точек Отслеживание хоста не выполняется. Если пакет с того же адреса вообще не был получен в течение интервала устаревания, конечная точка устаревает и удаляется. Если пакет с одного и того же адреса был получен хотя бы один раз в течение интервала, устаревание сбрасывается в конце интервала, и конечная точка остается изученной в течение другого интервала устаревания. Это означает, что, как и в случае с локальными конечными точками IP, конечная точка может оставаться изученной почти в два раза больше настроенного интервала в зависимости от того, когда был получен последний пакет.
Записи о перемещении и отказе конечной точки
Существует несколько сценариев, в которых конечная точка перемещается между двумя конечными коммутаторами Cisco ACI, например, в случае аварийного переключения или миграции виртуальной машины в среде гипервизора. Обучение конечных точек плоскости данных Cisco ACI быстро обнаруживает эти события и обновляет базу данных конечных точек Cisco ACI на новом листе. В дополнение к обучению плоскости данных Cisco ACI использует записи отказов для управления старой информацией о конечных точках на исходном листе.
Когда на листе обнаруживается новая локальная конечная точка, лист обновляет базу данных COOP на коммутаторах позвоночника своей новой локальной конечной точкой. Если база данных COOP уже получила ту же конечную точку от другого листа, COOP распознает это событие как перемещение конечной точки и сообщит об этом перемещении исходному листу, содержащему информацию о старой конечной точке. Старый лист, который получает это уведомление, удалит свою старую запись конечной точки и создаст запись возврата, которая будет указывать на новый лист. Запись возврата — это, по сути, удаленная конечная точка, созданная с помощью связи COOP вместо обучения плоскости данных.
Разница между записью возврата и удаленной конечной точкой заключается в том, перезаписывает ли лист IP-адрес внешнего источника пакета. Когда пакет использует обычную удаленную конечную точку, лист Cisco ACI использует свой собственный адрес TEP в качестве IP-адреса внешнего источника, поэтому удаленный лист узнает этот пакет со своим собственным TEP. Когда в пакете используется запись об отказе, лист Cisco ACI не перезаписывает IP-адрес внешнего источника, поэтому обучение удаленной плоскости данных будет вести себя так, как если бы пакет пришел из исходного листа, а не из промежуточного листа «отказов».
Значение таймера хранения конечной точки (интервал устаревания) для записи возврата составляет 630 секунд по умолчанию. Вы можете настроить это значение, перейдя в Tenant > Networking > Protocol Policies > End Point Retention, где вы также можете найти другие таймеры удержания конечной точки.
На рис. 6 показан пример движения конечной точки и входа с отказом.
Рисунок 6.
Пример записи возврата Cisco ACI
На первом этапе на рис. 6 LEAF1 узнает местоположение удаленной конечной точки для IP2, указывающего на LEAF2, из плоскости данных.
На втором этапе конечная точка с MAC2 и IP2 на LEAF2 перемещается на LEAF4, а новая локальная конечная точка создается на LEAF4. Эта новая локальная конечная точка передается в базу данных COOP на коммутаторах позвоночника, которая, в свою очередь, уведомляет LEAF2 об этом перемещении, а LEAF2 устанавливает записи отказов для MAC2 и IP2. Записи отказов в основном аналогичны удаленным конечным точкам. Следовательно, на шаге 2 на рис. 6 создаются две записи отказов для MAC- и IP-адресов.0004
Примечание: Если только MAC2 перемещается с LEAF2 на LEAF4 без соответствующего IP-адреса, MAC запоминается как новая конечная точка на LEAF4, и LEAF2 устанавливает запись о возврате только для MAC2. В настоящее время ACI Fabric не уверен, переместился ли IP2 вместе с MAC2. Следовательно, LEAF2 вместо этого установит запись bounce-to-proxy для IP2, которая указывает на основной прокси вместо LEAF4.
На данный момент LEAF1 все еще имеет старую удаленную конечную точку для IP2, которая все еще указывает на старое расположение: LEAF2. Если в это время пакет отправляется с LEAF1 на IP2, LEAF1 перенаправляет его на LEAF2 вместо LEAF4 на основе кэша удаленной конечной точки. Из-за записей отказов LEAF2 уже подготовлен для такого рода переадресации от листовых коммутаторов со старыми удаленными конечными точками. Затем LEAF2 перенаправит пакет новому LEAF4 на основе его записей о возврате. Эта запись возврата является резервным механизмом для этого типа сценария. Таким образом, запись возврата не будет использоваться, если новый трафик от IP2 на LEAF4 достигнет LEAF1 до того, как LEAF1 отправит пакеты на IP2, потому что старая удаленная конечная точка на LEAF1 будет обновлена непосредственно трафиком уровня данных от нового листа.
Преимуществом этой реализации является масштаб. Независимо от того, сколько листовых коммутаторов получили информацию о конечных точках, после перемещения конечной точки необходимо будет обновить только три компонента. Этими тремя компонентами являются база данных COOP, новый конечный коммутатор, на который переместилась конечная точка, и старый конечный коммутатор, с которого переместилась конечная точка. В конце концов, все остальные конечные коммутаторы в фабрике будут обновлять свою информацию о местонахождении конечной точки посредством трафика уровня данных. Однако есть несколько крайних случаев, когда другие конечные коммутаторы сохраняют устаревшую информацию об удаленной конечной точке даже после того, как запись о возврате устареет. Это может привести к «черной дыре» трафика из-за отправки трафика на лист, у которого нет конечной точки назначения или записи о возврате. Пример углового случая упоминается в разделе «Отключить удаленное обучение EP» (на пограничном листе) с CSCva56754. Чтобы решить эту проблему, были введены следующие сообщения оповещения конечной точки.
Endpoint Announce Enhancement
Endpoint Announce Сообщения были улучшены, чтобы охватить крайние случаи, когда неподходящие удаленные конечные точки должны быть удалены на всех листовых коммутаторах на основе события обучения конечной точки, которое произошло на одном конкретном листе. Как правило, это не требуется для нашего механизма записи отказов, поскольку информация о конечных точках на листовых коммутаторах, которым не принадлежит конечная точка (то есть удаленная конечная точка), обновляется посредством обучения плоскости данных посредством диалогов после перемещения конечной точки. Пока этого не произойдет, о трафике позаботится запись отказов. Однако в некоторых крайних случаях последующий диалог не состоялся или обучение плоскости данных не обновляло удаленные конечные точки, как ожидалось. Конечная точка объявляет сообщений, адресованных к этим крайним случаям. Объявления конечной точки сообщения всегда включены и не могут быть отключены.
Триггер
Описание
Встроенный переключатель ACI
Старение из-за отказа
Когда запись о возврате устареет, соответствующие удаленные конечные точки на других листовых коммутаторах будут сброшены, если удаленные конечные точки указывают на неправильный лист.
13,2 (2 л) - CSCvj17665
Изменение pcTag EPG
При изменении pcTag EPG соответствующие удаленные конечные точки на других концевых коммутаторах будут сброшены.
14,0 (1 ч) - CSCvk22720
Одноадресная маршрутизация отключена или подсеть BD удалена при включенной одноадресной маршрутизации
При срабатывании триггера листовые коммутаторы, на которых локально развернут соответствующий BD, сбрасывают соответствующие конечные точки IP, как локальные, так и удаленные, независимо от сообщений анонса конечных точек. Сообщения об объявлении конечной точки улучшают это, чтобы сбросить соответствующие удаленные конечные точки IP на всех других листовых коммутаторах.
14,0(1ч)
Порт vPC начинает работать
Если порт vPC работает только на одном из конечных коммутаторов в паре vPC, удаленные конечные точки для конечных точек порта vPC будут указывать на физический TEP (PTEP) рабочего листа. Когда порт vPC на другом листе также становится рабочим, эти удаленные конечные точки теперь должны указывать на виртуальный TEP (VTEP), представляющий оба листовых коммутатора. Сообщения с анонсами конечных точек очищают удаленные конечные точки, которые все еще указывают на PTEP.
14.2(1i) - CSCvp97665
Соображения относительно тихих хостов
В случае тихих хостов, где лист ACI не узнал локальную конечную точку, ACI имеет некоторые механизмы для обнаружения этих тихих хостов. Некоторые из них контролируются конфигурациями BD. Ниже приведены пояснения по каждому сценарию с соответствующими конфигурациями BD.
Для коммутируемого трафика (L2) на неизвестный MAC для параметра L2 Unknown Unicast в BD может потребоваться установить значение «Flood». Это связано с тем, что структура ACI с конфигурацией L2 Unknown Unicast «Hardware-Proxy» отбрасывает пакеты одноадресной рассылки L2 на магистраль в тех случаях, когда MAC-адрес назначения не был получен в качестве конечной точки где-либо на BD в ACI, а база данных COOP не не располагаю информацией.
Для маршрутизируемого трафика (L3) на неизвестный IP-адрес лист ACI сгенерирует запрос ARP от своего IP-адреса BD SVI (повсеместный шлюз) к неизвестному IP-адресу, чтобы обнаружить и узнать неизвестный IP-адрес. Только лист с IP-адресом BD SVI для неизвестной IP-подсети будет генерировать запрос ARP. Изначально такое поведение вызывается позвоночником, когда позвоночник не может найти неизвестный IP-адрес даже в базе данных COOP. Такое поведение называется автоматическим обнаружением хоста или подбором ARP. Такое поведение для маршрутизируемого трафика (L3) происходит независимо от конфигурации, такой как неизвестная одноадресная рассылка L2 или лавинная рассылка ARP (упомянутая ниже), если трафик направляется на неизвестный IP-адрес.
Для запросов ARP с широковещательным MAC-адресом назначения параметр лавинной рассылки ARP в BD управляет поведением лавинной рассылки. Структура ACI будет выполнять лавинную рассылку запросов ARP в пределах BD, если включена опция лавинной рассылки ARP. Поскольку кадр рассылается по всему BD, любой молчащий хост получит пакет и отреагирует соответствующим образом. В случаях, когда параметр лавинной рассылки ARP отключен, структура ACI будет выполнять одноадресную маршрутизацию по целевому IP-адресу, указанному в заголовке ARP, вместо лавинной рассылки. Если целевой IP-адрес является молчаливым хостом и неизвестен конечным узлам и узлам (COOP), конечные коммутаторы ACI будут следовать той же процедуре, что и сценарий маршрутизации трафика (L3), описанный ранее (подбор ARP), и сгенерировать запрос ARP от своего BD. SVI (повсеместный шлюз), даже если целевой IP-адрес и исходный IP-адрес находятся в одной подсети. Это означает, что как включение, так и отключение параметра лавинной рассылки ARP может обнаруживать большинство «молчаливых» хостов.
Различие между включением и отключением параметра лавинной рассылки ARP появляется после того, как ACI узнает IP-адрес узла без вывода сообщений. Одним из преимуществ включения лавинной рассылки ARP является возможность обнаружения скрытого IP-адреса, который перемещался из одного места в другое без уведомления листа ACI. Поскольку запрос ARP пересылается внутри BD, даже если лист ACI все еще считает, что IP-адрес находится в старом местоположении, хост с молчаливым IP-адресом ответит соответствующим образом, чтобы лист ACI мог соответствующим образом обновить свою запись. Если лавинная рассылка ARP отключена, лист ACI будет продолжать пересылать запрос ARP только в старое местоположение до тех пор, пока конечная точка IP не устареет. С другой стороны, преимущество отключения лавинной рассылки ARP заключается в возможности оптимизировать поток трафика, отправляя запрос ARP непосредственно в местоположение целевого IP-адреса, предполагая, что ни одна конечная точка не перемещается без уведомления о своем перемещении через GARP и тому подобное.
При этом до тех пор, пока конечная точка отправляет запрос ARP на молчащие хосты, тихие хосты могут быть обнаружены фабрикой ACI независимо от параметра L2 Unknown Unicast, упомянутого ранее, даже в случае (L2) связи внутри подсети. В этом случае ACI рассылает запрос ARP или выполняет сбор ARP после просмотра запроса ARP. Обратите внимание, что только запрос ARP, а не какой-либо другой трафик уровня данных, инициирует сбор данных ARP в случае связи внутри подсети (L2).
Дополнительные сведения об опциях ACI BD см. в следующих документах:
● Руководство по проектированию инфраструктуры Cisco Application Centric Технический документ — Переключение в оверлее
● Информационный документ Cisco Application Centric Infrastructure Design Design — Рекомендации по проектированию домена моста
Рекомендации по vPC
В случае vPC каждая VLAN заключена в мост Домен должен быть развернут симметрично на обоих листовых коммутаторах пары vPC, чтобы предотвратить несоответствия синхронизации конечных точек. Это достигается автоматически при развертывании VLAN на порту vPC. Если VLAN развертывается только на потерянном порту, который является портом, который не является портом vPC, но все еще находится на одном из конечных коммутаторов пары vPC, убедитесь, что ваша конфигурация развертывает одну и ту же encap VLAN на обоих конечных коммутаторах пары vPC. Примером конфигурации является развертывание одной и той же encap VLAN на потерянных портах на обоих листовых коммутаторах пары vPC.
Вопросы обучения конечных точек L3Out
Трафик L3Out ведет себя иначе, чем обычный трафик конечных точек, как упоминалось ранее в разделе L3Out и обычные конечные точки.
В таблице 6 перечислены основные аспекты обучения конечной точки. Ниже приводится подробный пример для каждого сценария.
Таблица 6. Обучение конечной точки с соединениями L3Out
Сценарий
Поведение, характерное для L3Out
Соображения
Сценарий 1
Изучение локальной конечной точки с входящим пакетом из L3Out в Cisco ACI:
В качестве локальной конечной точки изучается только исходный MAC-адрес. Исходный IP-адрес не запоминается как локальная конечная точка.
–
Сценарий 2
Изучение удаленной конечной точки с помощью входящего пакета из L3Out в Cisco ACI:
Никакой исходный MAC-адрес или IP-адрес не определяется пакетом как новая удаленная конечная точка. *
Таймер сохранения конечной точки для существующей удаленной конечной точки обновляется этим пакетом из L3Out, даже если другая информация, такая как исходный конечный коммутатор, не обновляется.
Это поведение может привести к неправильному устареванию устаревшей удаленной конечной точки после миграции конечной точки на L3Out из Cisco ACI.
Вы можете использовать функцию принудительной проверки подсети, чтобы смягчить эту ситуацию.
Сценарий 3
Изучение удаленной конечной точки с исходящим пакетом на L3Out от Cisco ACI:
Исходный MAC-адрес или IP-адрес не изучается как новая удаленная конечная точка, если режим VRF является принудительным применением политик.
Такое поведение наблюдается только в том случае, если пакет на L3Out исходит от листового коммутатора первого поколения.
Таймер сохранения конечной точки для существующей удаленной конечной точки обновляется этим пакетом до L3Out, даже если другая информация, такая как исходный конечный коммутатор, не обновляется.
Такое поведение может привести к неправильному устареванию устаревшей удаленной конечной точки после перемещения конечной точки на другой лист.
Вы можете использовать функцию Disable Remote EP Learn на пограничном листе, чтобы предотвратить эту ситуацию.
Сценарий 4
Исходный IP-адрес, попадающий под маршруты L3Out, не запоминается как конечная точка:
(Обратите внимание, что 0.0.0.0/0 не имеет такого эффекта.)
Такое поведение наблюдается только для листовых коммутаторов второго поколения.
Это поведение устраняет непредвиденную проблему обучения конечной точки, вызванную спуфинговым пакетом или неправильно настроенной конечной точкой.
* Существует исключение для удаленного изучения MAC-адреса, когда пакет поступает из L3Out в Cisco ACI. Если трафик ARP поступает от SVI L3Out, а не от подинтерфейса маршрутизируемого порта, трафик ARP перенаправляется на другие конечные коммутаторы с тем же SVI L3Out. Такое поведение может привести к удаленному изучению MAC-адреса на другом пограничном листовом коммутаторе.
Сценарий 1: Изучение локальной конечной точки с входящим пакетом от L3Out
Для этого сценария нет особых соображений.
Сценарий 2: пример устаревшей удаленной конечной точки с входящим трафиком L3Out
На рис. 7 показан пример сценария 2 в табл. 6. Хотя это не распространенный сценарий, при выполнении такой операции обратите внимание на такое поведение.
Рис. 7.
Устаревшая конечная точка после миграции конечной точки на L3Out из Cisco ACI (сценарий 2)
Сначала IP2 на LEAF2 изучается на LEAF1 как удаленная конечная точка из-за трафика с IP2 на IP1. После этого устройство с IP2 перемещается в сеть за соединением L3Out и возобновляет связь с IP1 до того, как удаленная конечная точка для IP2 на LEAF1 устареет. В этот момент удаленная конечная точка по-прежнему указывает на старую запись LEAF2 вместо новой записи LEAF 3, но эта старая удаленная конечная точка никогда не будет обновляться, чтобы указывать на LEAF3, и она не устареет из-за особого поведения на L3Out. подключение, как описано для сценария 2 (пример устаревшей удаленной конечной точки с входящим трафиком L3Out) в таблице 6.
В сценарии 2 запись о возврате для IP2 на LEAF2 не создается, поскольку запись о возврате создается только тогда, когда лист Cisco ACI обнаруживает тот же MAC-адрес и/или IP-адрес, что и локальная конечная точка на другом листе. Cisco ACI не может обнаружить это перемещение, если конечная точка перемещается на соединение L3Out.
Из-за этой устаревшей удаленной конечной точки любой трафик от LEAF1 к IP2 будет терпеть неудачу, поскольку LEAF1 отправляет пакеты не на тот лист.
Эту устаревшую удаленную конечную точку на LEAF1 необходимо очистить вручную, чтобы возобновить связь. Ниже показан синтаксис команды для ручной очистки конкретной удаленной конечной точки IP:
LEAF1# clear system internal epm endpoint key vrf ip
Синтаксис команды для ручной очистки всех удаленных конечных точек (обе MAC и IP) в одном экземпляре VRF показан здесь:
LEAF1# clear system internal epm endpoint vrf remote
Пример. )
LEAF1# очистить системный внутренний ключ конечной точки epm vrf TK:VRF1 ip 192.168.2.2
Обратите внимание, что при миграции устройства с Cisco ACI на внешний Cisco ACI , вам необходимо рассмотреть некоторые дополнительные действия, такие как остановка трафика на время, достаточное для устаревания удаленных конечных точек до того, как произойдет миграция, или готовность вручную очистить удаленные конечные точки.
С помощью функции принудительной проверки подсети этот сценарий можно предотвратить. Однако для того, чтобы эта функция предотвратила этот сценарий, необходимо удалить конфигурацию подсети домена моста для IP2, поскольку эта функция не позволяет листу Cisco ACI изучать конечные точки только в том случае, если IP-адрес не принадлежит ни к одной из подсетей домена моста в тот же экземпляр VRF. Дополнительные сведения см. в разделе «Принудительная проверка подсети» далее в этом документе.
Сценарий 3: Пример устаревшей удаленной конечной точки с исходящим трафиком L3Out
На рисунке 8 показан пример сценария 3 в таблице 6. Обратите внимание, что экземпляр VRF в этом примере использует режим принудительного применения политики входа. Такое поведение наблюдается только тогда, когда источником трафика являются конечные коммутаторы первого поколения.
Режим применения политики входящего трафика для VRF изменяет расположение, в котором контракт применяется к пакету, исходящему из обычной конечной точки, в сторону подключения L3Out (трафик от неграничного листа к пограничному листу). До этой функции использовался режим принудительного применения исходящей политики. В этом случае контракт для этого потока пакетов всегда применялся на пограничном листе (выход), где пропускная способность TCAM для контрактов могла быть узким местом. В режиме применения политики входа контракт для этого потока применяется к неграничному листу (вход). Обратитесь к разделу «Управление применением политики» в руководстве ACI Fabric L3Out для получения подробной информации о режиме применения политики входящего трафика в экземплярах VRF. В разделе «Основы инфраструктуры, ориентированной на приложения» Cisco, этот режим обсуждается в разделе «Выходной уровень 3 для маршрутизируемого подключения к внешним сетям».
Рис. 8.
Устаревшая конечная точка после перемещения конечной точки с режимом принудительного ввода VRF (сценарий 3)
Сначала IP1 на LEAF1 узнается на границе LEAF3 как удаленная конечная точка из-за трафика с IP1 на IP2. IP2 — это обычная конечная точка на пограничном листе LEAF3. Если бы IP1 отправлял трафик только на внешние устройства, проходящие через соединение L3Out, а не на IP2, это поведение не создало бы удаленную конечную точку для IP1 на LEAF3, поскольку исходный MAC-адрес или IP-адрес не узнается пакетом как новая удаленная конечная точка. к соединению L3Out (когда для режима VRF установлено принудительное применение политики входа).
После получения информации об удаленной конечной точке на LEAF3 устройство с IP1 прекращает отправку трафика на IP2 и переходит на LEAF2. Далее, если IP1 отправляет трафик на внешние устройства, проходящие через соединение L3Out, или если он начинает отправлять трафик на соединение L3Out до того, как старая удаленная конечная точка для IP1 на LEAF3 устаревает, старая удаленная конечная точка не будет обновлена новой. исходной информации (LEAF2), и запись не устаревает из-за особого поведения, описанного для L3Out в сценарии 3 в таблице 6.
Из-за этой устаревшей удаленной конечной точки любой трафик от LEAF3 к IP1 может завершиться ошибкой, поскольку LEAF3 отправляет пакет не на тот лист. Этот трафик не может дать сбой сразу после перемещения конечной точки, потому что запись о возврате на LEAF1 может перенаправить трафик к IP1 на правильный LEAF2. Однако трафик начнет давать сбои, как только срок действия записи о возврате на LEAF1 устаревает.
Эту устаревшую удаленную конечную точку на LEAF3 необходимо очистить вручную, чтобы возобновить надлежащую связь. Обратитесь к сценарию 2 за синтаксисом команды для очистки удаленных конечных точек.
Этот сценарий можно предотвратить, если LEAF3 является выделенным пограничным листом без каких-либо вычислительных ресурсов. Этот сценарий также можно предотвратить, если функция «Отключить удаленное обучение EP» включена на пограничном листе. Дополнительные сведения см. в разделе «Отключение параметра дистанционного обучения EP (на пограничном листе)».
Рекомендуется иметь выделенные пограничные конечные коммутаторы, используемые только для связи L3Out и не используемые совместно с обычными конечными точками (например, на пограничном листе не размещаются вычислительные ресурсы).
Сценарий 4. Обучение конечной точки с конечным коммутатором второго поколения и L3Out
На рисунке 9 показаны преимущества обучения конечных точек второго поколения, как указано в сценарии 4 в таблице 6.
Листовой коммутатор второго поколения выигрывает от ограничения ненужного обучения конечных точек (сценарий 4)
В этом примере фабрика Cisco ACI получает маршруты 10.0.0.0/16 от внешнего маршрутизатора через соединение L3Out на LEAF3. Этот маршрут перераспределяется на LEAF1 и LEAF2 через многопротокольный протокол пограничного шлюза (MP-BGP) в сети инфраструктуры Cisco ACI. Однако из-за неправильной настройки или такого события, как подмена IP-адреса, конечная точка на LEAF2 отправляет пакеты с исходным IP-адресом 10.0.0.9.9, который не должен существовать в Cisco ACI, а должен существовать только за соединением L3Out. Из-за этого поддельного трафика LEAF2 попытается узнать исходный MAC-адрес A и исходный IP-адрес 10. 0.0.99 в качестве локальной конечной точки. Кроме того, LEAF1 попытается узнать исходный IP-адрес 10.0.0.99 в качестве удаленной конечной точки из-за изучения плоскости данных конечной точки Cisco ACI. Если LEAF1 и LEAF2 являются конечными коммутаторами второго поколения, это обучение (обучение локальной конечной точки MAC/IP-адреса и обучение удаленной конечной точки IP-адреса) будет предотвращено в этом сценарии, поскольку исходный IP-адрес 10.0.0.99 классифицируется по маршрутам, полученным от L3Out, что означает, что этот IP-адрес не должен быть локальным для Cisco ACI.
Однако, как указано в Таблице 6, если структура Cisco ACI получает маршрут 0.0.0.0/0 вместо 10.0.0.0/16 от внешнего маршрутизатора, этот механизм предотвращения не будет активирован. Кроме того, этот механизм предотвращения не будет активирован, если либо подсети мостового домена, либо маршруты, полученные от соединения L3Out, не покрывают 10.0.0.99.
Таким образом, несмотря на то, что листовые коммутаторы второго поколения обеспечивают хороший встроенный механизм защиты, вам все же следует настроить функцию Enforce Subnet Check. Дополнительные сведения см. в разделе «Принудительная проверка подсети» далее в этом документе.
Ни встроенный механизм предотвращения для листовых коммутаторов второго поколения, ни функция Enforce Subnet Check недоступны для конечных коммутаторов первого поколения. Вместо этого можно настроить параметр «Ограничить обучение IP до подсети» и параметр «Отключить дистанционное обучение EP» на пограничном листе. Обратитесь к разделу, в котором обсуждается каждая функция, чтобы узнать о различиях между функциями.
Преимущества обучения конечных точек Cisco ACI
Возможность обучения конечных точек Cisco ACI обеспечивает эффективную и масштабируемую пересылку внутри фабрики. Например, при записи отказов и обучении плоскости данных, независимо от того, сколько листовых коммутаторов содержит структура, необходимо обновить только три компонента для получения информации о перемещении конечных точек. (Дополнительную информацию см. в разделе Записи о перемещении и отказе конечной точки ранее в этом документе.) Кроме того, конечные коммутаторы не должны потреблять свои аппаратные ресурсы для хранения информации обо всех конечных точках на других конечных коммутаторах. Используя обучение уровня данных, листовые коммутаторы потребляют ресурсы для хранения только необходимой информации для удаленных конечных точек, с которыми лист активно взаимодействует. Экономия аппаратных ресурсов является огромным преимуществом для масштабируемой структуры.
Это изучение удаленных конечных точек на уровне данных вместо того, чтобы полагаться на прокси-сервер позвоночника (с использованием базы данных COOP на коммутаторах позвоночника) для всего трафика, помогает оптимизировать поток трафика. Например, обучение удаленных конечных точек уменьшает трафик, проходящий через фабрику, позволяя входному листу применять политику контракта и при необходимости отбрасывать пакеты перед отправкой пакетов через фабрику. В примере на рис. 10, если лист-потребитель (LEAF1) не знает информации о конечной точке назначения (192.168.2.1), трафик идет к листу-поставщику (LEAF2) на основе прокси-сервера ствола, а LEAF2 узнает конечную точку источника (19).2.168.1.1) информация посредством обучения плоскости данных. Затем на LEAF2 применяется политика контракта, где может быть разрешена информация об источнике и получателе EPG. Если обратный трафик поступает на LEAF2, политика контракта применяется к LEAF2, который является входным листом, а не выходным листом (LEAF1), поскольку LEAF2 уже знает 192.168.1.1. Таким образом предотвращается пересечение фабрики ненужного трафика, если трафик запрещен контрактом на этом входном листе (LEAF2).
Рисунок 10.
Пример потока трафика
Другое преимущество изучения конечной точки через трафик плоскости данных заключается в том, что это может помочь в сценариях, в которых коммутатор может пропустить пакеты плоскости управления ARP, ранее отправленные конечной точкой, или по ошибке кэшировать устаревшую конечную точку. Информация о местонахождении.
Несмотря на упомянутые здесь преимущества, в некоторых случаях может потребоваться отключить функцию обучения конечной точки. В оставшейся части этого документа эти варианты использования описываются более подробно.
Параметры оптимизации обучения конечных точек
Для установки параметров обучения конечных точек Cisco ACI доступны различные ручки конфигурации. В этом разделе описываются ручки, связанные с обучением конечной точки, для EPG, мостового домена и конфигураций всей матрицы. Также представлены варианты использования этих ручек.
Таблица 1 в начале этого документа содержит сводку всех функций, обсуждаемых в этом разделе.
Параметры конфигурации на уровне EPG
В этом разделе обсуждаются параметры, применимые к EPG.
Виртуальные IP-адреса L4-L7
Опция виртуальных IP-адресов L4-L7 была введена в контроллере инфраструктуры политик приложений Cisco (APIC) версии 1.2 (1m). Этот параметр находится в разделе Арендатор > Профили приложений > EPG приложений (рис. 11). Этот параметр используется для отключения обучения IP плоскости данных для определенного IP-адреса для случаев прямого возврата сервера или DSR. По умолчанию эта функция не включена. Опция виртуальных IP-адресов L4-L7 в EPG uSeg не поддерживается. Виртуальный IP-адрес DSR должен быть частью базового EPG, который не является uSeg EPG.
Рисунок 11.
Виртуальные IP-адреса L4-L7 в EPG приложений
Вариант использования виртуальных IP-адресов L4-L7
Единственный протестированный и поддерживаемый вариант использования виртуальных IP-адресов L4-L7 — с DSR уровня 2. Опция DSR развертывается в основном, когда с сервера поступает большой объем обратного трафика. Как правило, балансировщик нагрузки находится на пути между клиентом и сервером: как для входящего трафика от клиента к серверу, так и для обратного трафика от сервера к клиенту. Если объем возвращаемого трафика велик, трафик будет потреблять ресурсы балансировщика нагрузки, что создаст узкое место. Чтобы предотвратить эту ситуацию, при развертывании DSR обратный трафик напрямую возвращается к клиенту, минуя балансировщик нагрузки.
В развертывании DSR ответ ARP должен подавляться на реальных серверах. Предполагается, что только балансировщик нагрузки должен отвечать на запросы ARP с целью определения MAC-адреса, связанного с виртуальным IP-адресом, но настоящие серверы используют виртуальный IP-адрес для трафика между серверами и клиентами. В традиционной сети этот обратный трафик не обновляет информацию об IP, но с помощью Cisco ACI структура узнает виртуальный IP-адрес посредством обучения IP на уровне данных, что приводит к возникновению проблемы.
По умолчанию DSR не работает в Cisco ACI из-за изучения IP уровня данных. Этот параметр отключает изучение IP плоскости данных для конкретного виртуального IP-адреса DSR. Если не отключить изучение IP для виртуального IP-адреса DSR, конечная точка IP будет переключаться между разными местоположениями в структуре Cisco ACI.
Например, как показано на рис. 12, 172.16.1.1 пытается подключиться к 192.168.1.100 (виртуальный IP-адрес DSR), и трафик направляется балансировщику нагрузки, поскольку балансировщик нагрузки ответил на запрос ARP для 192.168.1.100. . Затем трафик распределяется по нагрузке на один из реальных серверов путем перезаписи MAC-адреса назначения. Наконец, на сервере генерируется трафик между серверами. Этот обратный трафик использует 192.168.1.100 в качестве исходного IP-адреса. Ткань Cisco ACI будет обучаться 192.168.1.100 из разных мест: с балансировщика нагрузки и с реальных серверов. Следовательно, необходимо предотвратить изучение IP-адреса плоскости данных для виртуального IP-адреса DSR.
Рис. 12.
Почему необходимо отключить изучение IP плоскости данных для виртуального IP-адреса
Если эта функция включена для виртуального IP-адреса DSR (192.168.1.100 в этом примере), лист Cisco ACI будет узнавать IP-адрес только из плоскость управления (ARP, GARP или обнаружение соседей) из EPG с настроенным виртуальным IP-адресом DSR. Cisco ACI также отключит обучение плоскости данных для одного и того же IP-адреса на связанных листовых коммутаторах.
В следующих абзацах объясняется область действия этой конфигурации виртуального IP-адреса DSR, например, на каком листе отключено изучение IP в плоскости данных.
Конфигурация DSR загружается на все конечные коммутаторы, на которых развернута EPG с виртуальным IP-адресом L4-L7 или на которых развернута EPG с контрактом с EPG с виртуальным IP-адресом L4-L7, независимо от направления контракта. Например, предположим, что у вас есть клиентский EPG, LB EPG и веб-EPG, а также виртуальный IP-адрес L4–L7, настроенный для LB EPG. Конфигурация виртуального IP-адреса DSR будет загружена в LEAF1, LEAF2 и LEAF3, так как LEAF2 имеет LB EPG с настроенным виртуальным IP-адресом L4-L7, а LEAF1 и LEAF3 имеют веб- или клиентские EPG, которые имеют контракты с LB EPG ( Рисунок 13).
Рисунок 13.
Пример взаимосвязей и конфигурации EPG
Все коммутаторы верхней части стойки, загруженные с конфигурацией DSR, не узнают виртуальный IP-адрес L4-L7 из трафика пути данных, и они не узнают его из других EPG, даже если он ARP, GARP или обнаружение соседей. Например, 192.168.1.100 узнается из LB EPG только через плоскость управления. Такое поведение предотвращает ситуации, в которых виртуальный IP-адрес L4-L7 ошибочно узнается из веб-EPG.
Например, предположим, что кто-то подключил веб-сервер, классифицированный для веб-EPG, и забыл подавить ARP. Несмотря на то, что трафик ARP получен, LEAF2 не узнает 192.168.1.100 из веб-EPG (рис. 14).
Рис. 14.
Пример взаимосвязей и конфигурации EPG
Дополнительные сведения о DSR см. в Руководстве по развертыванию сервисов уровней 4–7 по адресу https://www.cisco.com/c/en/us/td/docs/switches/datacenter. /aci/apic/sw/1-x/L4-L7_Services_Deployment/b_L4L7_Deploy_ver222/b_L4L7_Deploy_ver221_chapter_01010.html.
Хотя DSR описан в Руководстве по развертыванию сервисов L4-L7, реализация параметра конфигурации DSR не требует интеграции сервисного графа Cisco ACI.
Обучение плоскости данных IP на хост
Существует три различных области и уровня конфигурации обучения плоскости данных IP, как показано ниже:
● Подсеть EPG — на хост (/32 для IPv4 или /128 для IPv6)
● Подсеть BD — для каждой подсети
● VRF — для каждой VRF
В этом разделе обсуждается параметр обучения плоскости данных IP, применимый к подсети EPG. Конфигурация уровня EPG функционально эквивалентна опции для каждой подсети BD, с той ключевой разницей, что конфигурация уровня EPG предназначена для добавления конкретных хостов, для которых необходимо отключить обучение IP Data-plane, тогда как опция для каждой подсети BD предназначена для ввода подсетей. (для чего обучение IP-Data-plane должно быть отключено). Вариант в подсети домена моста см. в подразделе «Обучение плоскости данных IP» в параметрах конфигурации уровня домена моста. Информацию об опции на VRF см. в подразделе «Обучение плоскости данных IP» в параметрах конфигурации на уровне VRF.
Опция обучения плоскости данных IP в подсети EPG была введена в Cisco APIC версии 5.2 (1g), которая предназначена для отключения обучения плоскости данных IP для каждого хоста. Этот параметр находится в разделе Арендатор > Профили приложений > EPG приложений > Подсети (рис. 15). Обучение плоскости данных IP включено по умолчанию. Используя этот параметр, вы можете отключить (или повторно включить) изучение IP плоскости данных конечной точки для адреса хоста (или адресов), которые вы добавили в конфигурации «подсети» EPG. Параметр может быть установлен на «Отключено» при следующих условиях:
● Маска подсети IP-адреса: /32 для IPv4 или /128 для IPv6
● «Тип позади подсети» — «Нет» или «Anycast MAC» которому принадлежит эта конфигурация EPG, должна быть установлена для неизвестной одноадресной рассылки. Это связано с тем, что в противном случае разрешение ARP для определенных хостов, которые вы настроили, не будет работать правильно. Подробнее см. в разделе Рассмотрение неизвестной одноадресной рассылки L2.
Рисунок 15.
Включение и отключение обучения плоскости данных конечной точки в подсети EPG
Сведения о поведении, примерах использования и рекомендациях по обучению плоскости данных IP см. в подразделе «Обучение плоскости данных IP» в параметрах конфигурации уровня VRF.
Параметры конфигурации на уровне домена моста
В этом разделе обсуждаются параметры, применимые к доменам моста.
Одноадресная маршрутизация
Опция Одноадресная маршрутизация была реализована с первого выпуска Cisco ACI. Он находится в разделе Tenants > Networking > Bridge Domains в графическом интерфейсе APIC (рис. 16).
Рисунок 16.
Одноадресная маршрутизация в домене моста
Эта функция включает одноадресную IP-маршрутизацию в домене моста. Если эта функция не включена, подсети, настроенные в домене моста, не передаются на конечные коммутаторы, и маршрутизация не выполняется. Кроме того, домен-мост с отключенной маршрутизацией Unicast не будет запоминать какой-либо IP-адрес в качестве конечной точки. Таким образом, этот домен моста будет использоваться только для связи уровня 2, и конечные точки в этом домене моста должны иметь свои шлюзы по умолчанию за пределами Cisco ACI.
Включение одноадресной маршрутизации без подсети не рекомендуется. Если Одноадресная маршрутизация включена без настроенных подсетей домена моста, IP-информация в домене моста по-прежнему может быть получена через ARP в плоскости данных, но маршрутизация не будет выполняться, поскольку не будет SVI для выполнения маршрутизации в домене моста. Пожалуйста, обратитесь к следующему разделу «Сценарий использования одноадресной маршрутизации (отключить для домена моста уровня 2)», чтобы понять причины, лежащие в основе этой рекомендации. Также не забудьте включить Enforce Subnet Проверьте , чтобы оптимизировать изучение локальных и удаленных конечных точек IP на основе подсетей, настроенных в каждом домене моста.
При отключении Unicast Routing информация о конечной точке MAC и IP сбрасывается для BD. Это поведение было улучшено для сброса только IP-информации на основе подсетей, настроенных в BD из Cisco APIC Release 3.1(1i). Это изменение было введено посредством этого усовершенствования:
CSCvd
: конечные точки L2 сбрасываются при переключении BD с маршрутизации на коммутацию
Когда подсеть BD удаляется, когда Одноадресная маршрутизация все еще включена, сброс конечных точек также выполняется для соответствующей информации IP.
Очистка выполняется как для локальных, так и для удаленных конечных точек IP на конечных узлах, где развернут соответствующий BD SVI. Начиная с версии коммутатора Cisco ACI 14.0(1), удаленные конечные точки IP на листовых узлах, не имеющие соответствующего BD SVI, также сбрасываются с помощью сообщений оповещения конечных точек.
Вариант использования одноадресной маршрутизации (отключить для мостового домена уровня 2)
Этот вариант использования демонстрирует , почему одноадресную маршрутизацию следует отключать , когда домен-мост должен выполнять только коммутацию уровня 2 (например, когда шлюз конечной точки по умолчанию находится за пределами Cisco ACI). Домен моста с такой конфигурацией называется доменом моста уровня 2 (L2BD). На рисунках 17, 18 и 19 показано, что происходит, когда опция Unicast Routing не отключена на L2BD. В этом примере BD1, BD2 и соединение L3Out находятся в одном и том же экземпляре VRF.
Рисунок 17.
Зачем нужно отключать индивидуальную маршрутизацию для L2BD (часть 1: ожидаемый поток)
Рисунок 18.
Почему необходимо отключить маршрутизацию одноадресной рассылки для L2BD (часть 2: изучение IP на L2BD)
Рисунок 19.
Зачем нужно отключать маршрутизацию Unicast для L2BD (часть 3: проблемы с изучением IP на L2BD)
В этом примере предполагается, что BD1 является L2BD. На рис. 16 показан ожидаемый поток трафика, который проходит через шлюз по умолчанию всякий раз, когда конечная точка в BD1 (IP 192.168.1.1) общается с устройством за пределами своей подсети. Однако если одноадресная маршрутизация не отключена на BD1, как показано на рисунках, LEAF1 узнает IP 192. 168.1.1 из запроса ARP (рисунок 17). В результате изучения IP-адреса этой новой конечной точки (192.168.1.1) трафик на 192.168.1.1 с целевого устройства (192.168.2.1) пытается перейти непосредственно к фактическому исходному устройству, минуя шлюз источника по умолчанию: например , брандмауэр (рис. 18). В этом сценарии LEAF1 никогда не должен узнавать IP 19.2.168.1.1 с фактического хост-устройства. Трафик на 192.168.1.1 должен сначала идти на устройство шлюза, а устройство шлюза должно пересылать обратный трафик на MAC S1 (источник).
Если одноадресная маршрутизация отключена на BD1, который выполняет только пересылку уровня 2, LEAF1 никогда не узнает ни одного IP-адреса в BD1, как показано на рис. 20.
рис. 20.
Вариант использования с отключенной маршрутизацией одноадресной рассылки
На рис. 21 показано концептуальное изображение L2BD, в котором опция маршрутизации одноадресной рассылки отключена. Поскольку в этом мостовом домене нет маршрутизации или изучения IP, этот L2BD закрыт в своем мостовом домене, даже если он принадлежит экземпляру VRF. Таким образом, его можно описать как изолированный от других доменов пересылки в том же экземпляре VRF.
Рисунок 21.
Концепция L2BD
Режим обнаружения перемещения EP на основе GARP
Режим обнаружения перемещения EP с GARP был представлен в версии APIC 1.1(1j) со следующим улучшением: под тем же intf
Этот параметр находится в Tenant > Networking > Bridge Domain (рис. 22). Эта опция отключена по умолчанию. Этот параметр доступен только в доменах-мостах, в которых включена лавинная рассылка ARP.
Рисунок 22.
Режим обнаружения перемещения EP в конфигурации BD L3
Несмотря на то, что Cisco ACI может обнаруживать перемещение MAC-адресов и IP-адресов между портами конечных коммутаторов, конечными коммутаторами, мостовыми доменами и EPG, оно не обнаруживает перемещение IP-адреса на новый MAC-адрес. адрес, если новый MAC-адрес принадлежит тому же интерфейсу и тому же EPG, что и старый MAC-адрес.
Если включена опция обнаружения на основе GARP, Cisco ACI инициирует перемещение конечной точки на основе пакетов GARP, если перемещение происходит на том же интерфейсе и в том же EPG. Если пакет GARP поступает с одного и того же интерфейса и одного и того же EPG, то обучение конечной точки запускается только в том случае, если для домена моста включены одноадресная маршрутизация, флудинг ARP и «обнаружение на основе GARP».
Хотя этот сценарий не был широко распространен среди нашей клиентской базы, в некоторых случаях клиенты меняют привязку IP-адреса к MAC-адресу, и им необходимо включить обнаружение на основе GARP.
Вариант использования режима обнаружения движения EP на основе GARP
Рассмотрим сценарий на рисунке 23. На рисунке показан один хост VMware ESXi, подключенный к фабрике Cisco ACI, и несколько виртуальных машин, находящихся в одном EPG.
Рисунок 23.
Тот же интерфейс и тот же EPG: VM1
Проблема возникает, когда питание VM1 выключено, а питание VM2 включено. ВМ2 получает тот же IP-адрес, который ранее принадлежал ВМ1 (рис. 24). Если обнаружение на основе GARP не включено, Cisco ACI не будет обновлять запись конечной точки для VM1 и ошибочно отправит трафик на старую запись MAC-адреса, которая принадлежала VM1. Это связано с тем, что нам необходимо включить обнаружение на основе GARP в случаях, когда перемещение IP-адреса к MAC-адресу происходит на одном и том же интерфейсе и в одном и том же EPG.
Рисунок 24.
Тот же интерфейс и тот же EPG: VM2
Ограничить изучение IP до подсети
Параметр Ограничить изучение IP до подсети изначально назывался Принудительно проверять подсеть для изучения IP. Он был представлен в выпуске APIC 1.1(1j) со следующим усовершенствованием:
CSCuu09759: добавлена ручка конфигурации для включения/отключения проверки подсети BD для получения IP-адреса
Он находится в разделе Арендатор > Сеть > Домен моста (рис. 25). .
Начиная с версий APIC 2.3(1e) и 3.0(1k), этот параметр включен по умолчанию со следующим улучшением:
CSCvb16668: принудительная проверка подсети должна быть включена по умолчанию
До этих выпусков этот параметр был отключен по умолчанию.
Если этот параметр включен, структура будет узнавать IP-адреса только для подсетей, настроенных в домене моста.
Рис. 25.
Ограничить обучение IP до подсети в домене моста
До выпуска Cisco ACI 3.0 (1k), если этот параметр отключен или включен в уже настроенном домене моста, происходит следующее:
● Cisco ACI сбрасывает все IP-адреса конечных точек, полученные в домене моста.
● Cisco ACI приостанавливает изучение MAC- и IP-адресов на 120 секунд.
Это поведение было улучшено по сравнению с выпуском 3.0 (1k) Cisco ACI путем усовершенствования CSCve29663. Начиная с версии 3.0(1k), если этот параметр включен в домене-мосте, в котором этот параметр отключен, происходит следующее:
● Cisco ACI не сбрасывает IP-адреса конечных точек, принадлежащие подсети. (IP-адреса конечных точек, которые не принадлежат подсети мостового домена, сбрасываются.)
● Изучение MAC- или IP-адреса не приостанавливается на 120 секунд.
Если этот параметр отключен в домене моста, в котором он был включен, происходит следующее:
● Cisco ACI не сбрасывает IP-адреса конечных точек, полученные в домене моста.
● Изучение MAC- или IP-адреса не приостанавливается на 120 секунд.
До выпуска Cisco ACI 3.0(1k), если параметр Ограничить обучение IP до подсети был включен, когда домен моста был настроен для одноадресной изучение IP-адресов будет приостановлено (на 120 секунд).
При миграции подключения шлюза уровня 3 (L3GW) к Cisco ACI можно смягчить это влияние, включив параметр Ограничить обучение IP до подсети, когда домен моста настроен как домен моста только для уровня 2. После того, как вы включили эту опцию, подождите 120 секунд, пока не истечет время таймера. Затем включите параметр «Одноадресная маршрутизация». Поскольку вы не изучаете конечные точки IP в домене моста (поскольку это L2BD), 120-секундный таймер не повлияет на изучение новых конечных точек на основе MAC-адресов.
На листе выполните команду vsh –c 'показать системный внутренний epm vlan vlan-id детали' и найдите параметр Learn Enable. Для этого параметра должно быть установлено значение Да (Рисунок 26).
Рисунок 26.
Проверка включения параметра «Ограничить обучение IP до подсети»
Вариант использования «Ограничить обучение IP до подсети»
Если домен-мост настроен с адресом подсети 192.168.1.254/24, структура не узнает IP-адрес локальной конечной точки. адрес, например 192.168.2.1/24, то есть вне этого диапазона. Такое поведение предотвращает ненужное изучение IP-адресов, как показано на рис. 27, на котором показаны конечные точки с неправильным настроенным IP-адресом.
Рисунок 27.
Ограничение обучения IP подсетью
Хотя эта функция предотвращает изучение локального IP, локальный лист по-прежнему узнает MAC-адрес, а удаленный лист по-прежнему изучает IP и MAC-адреса (хотя локальный лист не узнает IP-адрес, он не отбрасывает пакет). Например, LEAF1 не запоминает 192.168.2.1, но он узнает MAC B, а LEAF2 узнает 192.168.2.1 и MAC B (рис. 28).
Рисунок 28.
Ограничить обучение IP подсетью (удаленное обучение IP)
Обучение плоскости данных конечной точки
Параметр обучения плоскости данных конечной точки был представлен в Cisco APIC версии 2.0 (1m). Он находится в разделе Арендатор > Сеть > Домен моста (рис. 29). Начиная с версии APIC 5.0(1), этот параметр перемещен на вкладку «Дополнительно/Устранение неполадок» на вкладке «Политика» в домене невесты.
Эта опция включена по умолчанию; он включает и отключает изучение IP плоскости данных конечной точки.
На момент написания этой статьи (Cisco ACI Release 3.0(1k)) единственным протестированным и поддерживаемым вариантом использования этого параметра является использование графов услуг с перенаправлением на основе политик или PBR.
Рисунок 29.
Включение и отключение обучения плоскости данных конечной точки в домене моста
Обратите внимание, что если вы отключите обучение плоскости данных конечной точки, сняв флажок с параметра «Обучение плоскости данных конечной точки», параметр «Ограничить обучение IP до подсети» не будет отображаться в APIC (рис. 30). Параметр Ограничить обучение IP до подсети недоступен, поскольку обучение IP на удаленных и локальных листовых коммутаторах уже отключено. Таким образом, пока вы отключаете опцию обучения конечной точки Dataplane Learning, сервисный лист не обучается 192.168.1.1 из домена Svc-internal-bridge в примере PBR, показанном на рисунке.
Рисунок 30.
Отключить обучение плоскости данных конечной точки и скрыть параметр «Ограничить обучение IP до подсети» Домен моста подключен к устройству сервисного графа с помощью функции PBR. Устройство сервисного графа с функцией PBR обычно называется узлом PBR. На рис. 31 показан пример. В этом примере показан двунаправленный PBR с узлом PBR, брандмауэром, вставленным между клиентом и веб-EPG.
Начиная с версии APIC 3.1, отключение обучения плоскости данных конечной точки в домене моста узла PBR не является обязательным, если это листовой коммутатор второго поколения. Параметр обучения плоскости данных конечной точки в EPG узла PBR автоматически отключается во время создания экземпляра графа службы.
Рисунок 31.
Отключение обучения плоскости данных конечной точки (вариант использования PBR)
Необходимо отключить параметр обучения плоскости данных конечной точки для сервисного графа с PBR, поскольку конечные коммутаторы, участвующие в потоке трафика PBR, могут в противном случае столкнуться с нежелательным поведением обучения конечной точки, если этот параметр оставить включенным. на мостовых доменах для узла PBR.
Например, как показано на рис. 32, исходный IP-адрес трафика, возвращающегося с узла PBR, по-прежнему равен 192.168.1.1 даже после применения PBR, поэтому лист провайдера будет получать пакеты с внутренним исходным IP-адресом 192.168.1.1 и IP-адрес внешнего источника в качестве листа VTEP сервисного узла. Таким образом, лист провайдера узнает 192.168.1.1 через VTEP IP листа сервисного узла, даже если 192.168.1.1 фактически находится под другим листом.
Если отключить обучение плоскости данных на Svc-internal-BD, домене моста для стороны поставщика узла PBR, лист поставщика не обучается2. 168.1.1 через трафик от узла PBR.
Рисунок 32.
Почему необходимо отключить обучение плоскости данных в домене моста узла PBR
Для поддержания симметричного трафика в этом примере также требуется PBR для обратного трафика. Параметр Endpoint Dataplane Learning также должен быть установлен в Disabled на Svc-external-BD, чтобы не допустить, чтобы конечные коммутаторы потребителя изучали 192.168.2.1 через сервисный лист после применения PBR.
В дополнение к двунаправленному PBR можно использовать однонаправленный PBR: например, в случае PBR для обратного трафика при интеграции с балансировщиком нагрузки.
Например, как показано на рис. 33, поскольку IP-адрес назначения от клиента является виртуальным IP-адресом в подсистеме балансировки нагрузки, PBR не требуется для трафика между клиентом и Интернетом. Если балансировщик нагрузки не транслирует исходный IP-адрес, требуется PBR для обратного трафика; в противном случае обратный трафик не вернется к балансировщику нагрузки. Вы должны отключить обучение плоскости данных на Load-balancer-BD, к которому подключен балансировщик нагрузки и узел PBR, чтобы лист провайдера не обучался 192.168.1.1 через лист сервисного узла.
Рис. 33.
Отключение обучения плоскости данных (случай использования однонаправленного PBR)
Даже если конечные точки потребителя и поставщика, например 192.168.1.1 и 192.168.2.1, находятся на одном листе, лист не узнает локальные конечные точки как удаленные конечные точки. через служебный лист.
Дополнительные сведения о PBR см. в Руководстве по развертыванию служб уровней 4–7 по адресу 9.0009 https://www.cisco.com/c/en/us/td/docs/switches/datacenter/aci/apic/sw/1-x/L4-L7_Services_Deployment/guide/b_L4L7_Deploy_ver211.html .
Обучение плоскости данных IP на подсеть
Существует три различных области и уровня конфигурации обучения плоскости данных IP, как показано ниже:
● Подсеть EPG — на хост (/32 для IPv4 или /128 для IPv6)
● Подсеть BD — для каждой подсети
● VRF — для каждой VRF
В этом разделе обсуждается параметр обучения плоскости данных IP, применимый к подсети мостового домена. Информацию об опции в подсети EPG для IP см. в разделе «Обучение плоскости данных IP» в разделе «Параметры конфигурации на уровне EPG». Информацию об опции на VRF см. в разделе «Обучение плоскости данных IP» в разделе «Параметры конфигурации на уровне VRF».
Параметр обучения плоскости данных IP для домена моста подсети был представлен в Cisco APIC Release 5.2(1g). Этот параметр находится в разделе Арендатор > Сеть > Мостовые домены > BD > Подсети (рис. 34). Обучение IP плоскости данных включено по умолчанию, но вы можете использовать этот параметр, чтобы отключить (или снова включить) изучение IP плоскости данных конечной точки для подсети домена моста.
При отключении обучения плоскости данных IP с помощью этого параметра необходимо также убедиться, что параметр подсети «Нет шлюза SVI по умолчанию» НЕ установлен. Параметр «Нет шлюза SVI по умолчанию» обычно выбирается при добавлении более конкретных подсетей (например, при добавлении двух подсетей /25 в дополнение к основной подсети /24), но в конкретном случае добавления подсетей, для которых вы хотите отключить IP-данные -plane Learning, вы не должны выбирать «Нет шлюза SVI по умолчанию». Это происходит из-за того, как аппаратное обеспечение запрограммировано при использовании как глобальной Enforce Subnet Check, так и (без) изучения IP-плоскости данных.
Домен моста, который содержит подсети, в которых отключено обучение плоскости данных IP, должен быть настроен с неизвестной одноадресной рассылкой вместо аппаратного прокси. Это связано с тем, что при отключенном обучении плоскости данных IP в подсети исходный MAC-адрес конечных точек не узнается из трафика ARP между конечными точками (с настроенным прокси-сервером ARP или без него), поэтому с BD, установленным для аппаратного прокси-сервера, разрешение ARP между новые конечные точки не будут успешно завершены. Подробнее см. в разделе Рассмотрение неизвестной одноадресной рассылки L2.
Рисунок 34.
Включение и отключение обучения плоскости данных конечной точки в подсети домена моста
Сведения о поведении, примерах использования и рекомендациях по обучению плоскости данных IP см. в подразделе «Обучение плоскости данных IP» в параметрах конфигурации уровня VRF.
Политика хранения конечной точки
Конфигурация политики хранения конечной точки находится в разделе Арендатор > Политики > Протокол > Хранение конечной точки (рис. 35) и связана с мостовым доменом (BD) или VRF (рис. 36). По умолчанию BD или VRF относятся к политике по умолчанию, определенной в общем клиенте.
Рисунок 35.
Политика хранения конечной точки
Рисунок 36.
Выберите политику хранения конечной точки
Этот параметр используется для указания жизненного цикла конечных точек с использованием следующих значений:
● Интервал удержания: количество времени в секундах, в течение которого обучение конечной точки отключено в домене моста из-за цикла EP. Защита (BD Learn Disable) или подавление движения конечной точки, которое срабатывает на основе приведенной ниже частоты движения. Интервал по умолчанию составляет 300 секунд.
● Интервал устаревания записи о возврате: количество времени в секундах до истечения срока действия записи о возврате в таблице конечных точек на конечном узле. Интервал по умолчанию составляет 630 секунд.
● Интервал устаревания локальной конечной точки: время в секундах, в течение которого конечный узел может хранить каждую локальную конечную точку в своей таблице конечных точек без дальнейших обновлений. Интервал по умолчанию составляет 900 секунд. Если достигнуто 75 процентов интервала, конечный узел отправляет три запроса ARP для проверки наличия конечной точки. Если ответ не получен, конечная точка удаляется.
● Интервал устаревания удаленной конечной точки: время в секундах, в течение которого конечный узел может хранить каждую удаленную конечную точку в своей таблице конечных точек без дальнейших обновлений. Интервал по умолчанию составляет 300 секунд.
● Частота перемещения: максимальное количество перемещений конечных точек, разрешенное в секунду в домене моста на каждом конечном узле. Число считается как общее перемещение любой конечной точки в заданном BD, будь то один лоскут конечной точки, одновременное перемещение нескольких конечных точек или их комбинация. Если количество движений в секунду превышает частоту перемещения, срабатывает интервал удержания (описанный выше), и изучение новой конечной точки в BD отключается до истечения интервала удержания. Функция называется Частота движения BD или Амортизация движения конечной точки . Значение по умолчанию — 256.
Пожалуйста, обратитесь к разделу поведения обучения конечной точки Cisco ACI этого документа для получения подробной информации о входе возврата, локальных конечных точках и удаленных конечных точках. В этом разделе в основном объясняются интервал удержания и частота перемещения для демпфирования конечной точки.
При указанных выше параметрах конфигурации по умолчанию функция подавления перемещений конечных точек отключает обучение конечных точек в домене моста на 300 секунд, если число перемещений конечных точек превышает 256 раз в секунду.
Пример использования подавления перемещений конечной точки
Подавление перемещения конечной точки смягчает влияние необоснованного количества перемещений конечной точки в течение короткого периода времени (то есть 1 секунда для защиты плоскости управления ACI от необходимости управлять слишком большим количеством перемещений конечной точки, Это может быть вызвано петлей L2. Это также необходимо для защиты структуры ACI от таких проблем, как множественные нестабильные конечные точки из-за неподходящих конфигураций или конструкций. Пример показан на рисунке 37. Петля L2 приводит к большому количеству перемещений конечных точек между конечными узлами, что потенциально может стоить огромного ресурса плоскости управления ACI.Endpoint Damping подсчитывает перемещения конечных точек и отключает обучение конечных точек для каждого домена моста для каждого конечного узла, что позволяет структуре ACI сузить область воздействия до каждого отдельного домена моста на конкретном конечном узле. не затрагивая другие работоспособные мостовые домены или конечные узлы.
Рисунок 37.
Пример использования демпфирования перемещения конечной точки
Ниже приведены рекомендации по демпфированию перемещения конечной точки:
● Амортизация перемещения конечной точки не различает локальные и удаленные перемещения; любое изменение интерфейса считается перемещением конечной точки.
● Обучение конечных точек отключено в мостовых доменах, где превышено количество перемещений конечных точек в секунду, и это может повлиять на другие работоспособные конечные точки в том же домене-спутнике. В таких случаях эти другие конечные точки все еще имеют шансы взаимодействовать через структуру ACI по двум причинам;
(a) Существующие конечные точки по-прежнему запоминаются (не сбрасываются).
(b) Трафик к новым конечным точкам, которые не могут быть изучены в течение некоторого времени, просто рассылается в домене моста, если для неизвестной одноадресной рассылки уровня 2 в домене моста настроена лавинная рассылка.
Однако есть два сценария, которые могут повлиять на трафик для работоспособных конечных точек в том же домене моста.
1. Если для параметра L2 Unknown Unicast установлено значение hardware-proxy, трафик к новым необученным конечным точкам будет направляться на магистраль для позвоночника-прокси и отбрасываться.
2. Если существующая конечная точка перемещается между интерфейсами или виртуальными локальными сетями или новый IP-адрес узнается по MAC-адресу существующей конечной точки в домене моста с отключенным обучением, это приводит к сбросу конечной точки, поскольку ACI обнаружил, что информация о существующей конечной точке больше не является точным, пока изучение новой информации о конечной точке отключено.
● Если вы предпочитаете отключить изучение конечной точки для конкретной конечной точки, которая часто перемещается, а не для всего домена невесты, см. параметр Rogue EP Control.
● Если включен Rogue EP Control, подавление движения конечной точки не сработает.
● Если в домене моста есть много IP-адресов, которые, как ожидается, будут перемещены одновременно, может потребоваться увеличить частоту перемещения, чтобы предотвратить отключение обучения конечных точек в домене моста. Например, при отработке отказа восходящего канала сервера, содержащего сотни виртуальных машин, сотни перемещений конечных точек будут обнаружены в структуре ACI за короткий период времени. Или когда активный/резервный отказоустойчивость происходит на служебном устройстве L4-L7, таком как брандмауэр и балансировщик нагрузки, новое активное служебное устройство обычно отправляет GARP для IP-адресов, о которых оно собирается заботиться, например, активный IP-адрес и балансировщик нагрузки. VIP-персоны и т. д., чтобы сообщить о новой активной службе.
Параметры конфигурации на уровне VRF
Существует три различных области и уровня конфигурации в обучении плоскости данных IP, как показано ниже:
● Подсеть EPG — на хост (/32 для IPv4 или /128 для IPv6)
● Подсеть BD — на каждую подсеть
● VRF — на каждый VRF
Параметр обучения плоскости данных IP для каждого VRF был представлен в Cisco APIC версии 4. 0 (1h). Этот параметр находится в разделе Арендатор > Сеть > VRF. Он включен по умолчанию и включает и отключает изучение IP плоскости данных конечной точки в VRF.
Информацию о других местах конфигурации обучения плоскости данных IP см. в подразделе «Обучение плоскости данных IP» в параметрах конфигурации уровня домена моста и в подразделе «Обучение плоскости данных IP» в параметрах конфигурации уровня EPG.
Рисунок 38.
Включение и отключение обучения плоскости данных конечной точки в VRF
Отключение обучения плоскости данных IP: поведение пересылки и соображения по проектированию
В этом разделе более подробно анализируется пересылка ACI, когда обучение плоскости данных IP отключено. В этом разделе представлены соображения и варианты использования, применимые к опции обучения плоскости данных IP в VRF, подсети мостового домена и подсети EPG.
Обучение IP и MAC-адресам с отключенным обучением уровня данных IP
Когда параметр обучения уровня данных IP отключен, поведение конечной точки на листе ACI изменяется следующим образом:
● Локальные и удаленные MAC-адреса узнаются через данные плоскости (без изменений с этой опцией).
● Локальные IP-адреса не изучаются через уровень данных.
● Локальные IP-адреса узнаются из ARP/GARP/ND через плоскость управления.
● Удаленные IP-адреса не извлекаются из одноадресных пакетов через уровень данных.
● Удаленные IP-адреса узнаются из многоадресных пакетов через уровень данных.
Примечание для опции в VRF: Вышеупомянутые режимы удаленного обучения MAC применимы к конечным коммутаторам второго поколения. Если это листовой коммутатор первого поколения, удаленный MAC-адрес не запоминается, поэтому необходимо настроить режим аппаратного прокси на соответствующих BD. В противном случае трафик L2-моста всегда рассылается, если исходная и целевая конечные точки в одном и том же BD находятся под разными конечными коммутаторами. Дополнительные сведения см. в разделе «Вопросы листового коммутатора первого поколения» ниже.
Примечание для параметра в подсети домена моста или в подсети EPG: Если есть связь между конечными точками в одном домене моста, для параметра «L2 Unknown Unicast» должно быть установлено значение «Flood» в домене моста, что означает, что лавинная рассылка ARP тоже должен быть включен; в противном случае ARP между конечными точками в одном домене моста не будет разрешен. Подробнее см. в разделе Рассмотрение неизвестной одноадресной рассылки L2 ниже.
Если параметр обучения плоскости данных IP отключен, существующие удаленные конечные точки IP немедленно очищаются, в то время как записи отказов сохраняются и устаревают обычным образом. Существующие локальные конечные точки IP также не сбрасываются, но в конечном итоге они устареют, если только пакеты уровня управления, такие как ARP, не сохранят их работоспособность.
Когда параметр IP Data-plane Learning отключен, рекомендуется также включить параметр IP Aging. Это делается для того, чтобы отслеживание хоста, которое отправляет ARP/ND для локальной конечной точки IP с 75% таймера хранения, всегда запускалось для правильного отслеживания статуса IP через плоскость управления. Если параметр IP Aging не включен, локальные конечные точки IP могут неправильно устаревать из-за трафика плоскости данных, даже если отключено обучение IP плоскости данных.
В отличие от параметра обучения плоскости данных конечной точки в BD в предыдущем разделе, параметр обучения плоскости данных IP в VRF, подсети мостового домена и подсети EPG не ограничивается только вариантами использования PBR.
Когда отключать обучение IP-плоскости данных
Параметр обучения IP-плоскости данных должен быть отключен, если существует вероятность того, что структура ACI получает трафик с одним и тем же исходным IP-адресом из разных мест, что приводит к IP-адресу конечной точки. и обновления привязки MAC, которые происходят из-за трафика плоскости данных. Например, таким образом ведут себя подключение VIPA мейнфрейма и режим динамической балансировки нагрузки для объединения сетевых карт в Microsoft Windows.
Другой вариант использования — когда несколько устройств используют один и тот же IP-адрес, например виртуальный IP-адрес (VIP), и ARP/GARP/ND используется для утверждения права собственности на VIP среди устройств. В этой ситуации эти внешние устройства могут одновременно получать трафик данных от одного и того же виртуального IP-адреса, например, при отработке отказа. Это может привести к тому, что структура ACI будет изучать VIP из нескольких мест через плоскость данных. Такого рода проблем можно избежать, отключив обучение плоскости данных IP.
См. рисунки 39через 40 на примере этого вопроса.
Рис. 39.
Зачем нужно отключать обучение плоскости данных конечной точки (сервер 1 активен)
В этом примере показаны активные-резервные серверы, которые совместно используют один и тот же активный IP-адрес, который в основном принадлежит активному серверу. Когда server1 активен, а server2 находится в режиме ожидания, server1 заботится о 192.168.2.100, полученном на Leaf2 E1/1.
Рисунок 40.
Зачем нужно отключать обучение плоскости данных конечной точки (сервер2 становится активным)
Когда server2 берет на себя активную роль, server2 отправляет GARP, и теперь 192. 168.2.100 изучен на Leaf2 E1/2.
Рисунок 41.
Зачем нужно отключать изучение плоскости данных конечной точки (сервер 1 отправляет TCP RESET)
Проблема возникает, если сервер 1 отправляет TCP RESET с виртуального адреса 192.168.2.100 для завершения существующих сеансов TCP, которые обрабатывал сервер 1. Этот TCP RESET приводит к изучению IP плоскости данных для виртуального IP-адреса 192.168.2.100 на Leaf2 E1/1.
Рисунок 42.
Зачем нужно отключать обучение плоскости данных конечной точки (трафик идет на сервер 1)
Если сервер 2 снова не отправит GARP для виртуального IP-адреса, трафик к виртуальному IP-адресу 192.168.2.100 будет перенаправлен на сервер 1, который в данный момент находится в режиме ожидания, и который отбрасывает пакет .
На рис. 43 показано, как можно избежать этой проблемы, отключив обучение плоскости данных IP. Если обучение плоскости данных IP отключено, информация об обучении конечной точки не обновляется через RST с server1.
Вариант использования с отключением обучения плоскости данных конечной точки
Примечание. В этом примере трафика, маршрутизируемого из EPG в EPG, политика контракта будет применяться к выходному листу, поскольку IP-адрес удаленной конечной точки не изучен. Если это мостовой трафик EPG-EPG, политика контракта может быть применена к входному листу, поскольку удаленный MAC-адрес все еще изучен.
В случае использования DSR по-прежнему рекомендуется использовать параметр виртуальных IP-адресов L4-L7, поскольку параметр VIP L4-L7 может предотвратить получение VIP из других EPG как через плоскость управления, так и через плоскость данных.
Рассмотрение листового коммутатора первого поколения
Это применимо к варианту в VRF только потому, что другие варианты доступны после выпуска Cisco APIC 5.2(1g), который больше не поддерживает листовой коммутатор первого поколения. На листовых коммутаторах первого поколения удаленные MAC-адреса не изучаются, когда параметр обучения плоскости данных IP в VRF отключен. Таким образом, параметр L2 Unknown Unicast для BD должен быть установлен в режим аппаратного прокси. Это сделано для того, чтобы позаботиться об ограничениях листа первого поколения, когда пакет L2 Unknown Unicast передается от одного листа к другой паре листьев, на которой MAC-адрес назначения локально изучен на vPC. Если конечная пара vPC относится к первому поколению, оба листовых коммутатора отправят ее на соответствующий целевой интерфейс vPC. Это приводит к тому, что пакет от обоих концевых коммутаторов рассматривается как дубликат.
Рисунок 44.
Почему должен быть установлен режим аппаратного прокси (конечный коммутатор первого поколения)
L2 Unknown Unicast: соображения
удаленный MAC-адрес не узнается через запрос ARP от конечной точки к конечной точке, хотя он все еще узнается через запрос ARP к шлюзу SVI домена моста или через любой другой трафик. Таким образом, параметр L2 Unknown Unicast в домене моста должен быть установлен в режим Flooding, чтобы позаботиться о разрешении ARP между конечными точками в одной подсети домена моста.
На рис. 45 показан пример. Поскольку ни локальный, ни удаленный MAC-адрес не изучен как на Leaf1, так и на Leaf2, одноадресный ответ ARP на шагах 6 и 7 необходимо рассылать, что требует, чтобы параметр L2 Unknown Unicast был в режиме «Flooding».
Рис. 45.
Почему для L2 Unknown Unicast необходимо установить значение «Flood» (разрешение ARP)
После разрешения ARP одноадресный трафик L2 между конечными точками работает, как показано на рис. 46. Поскольку это одноадресный трафик, а не трафик запроса ARP, удаленный MAC (MAC A) изучается на Leaf2 на шаге 10.
Рис. 46.
Почему для L2 Unknown Unicast необходимо установить значение «Flood» (одноадресный трафик после разрешения ARP)
Параметры конфигурации на уровне структуры
В этом разделе обсуждаются параметры, применимые ко всей структуре.
Отключить дистанционное обучение EP (на пограничном листе)
Параметр «Отключить удаленное обучение EP» был впервые представлен в версии APIC 2.2(2e) со следующим расширением:
CSCuz19695: Устаревшая конечная точка на пограничном листе после перемещения EP
В версии APIC 2.0 этот параметр находится в разделе Fabric > Access Policies > Global Policies > Fabric Wide Setting Policy (рис. 47). Для APIC версии 3.0(1k) и более поздних версий он находится в разделе Система > Системные настройки > Настройка всей сети (рис. 48). Эта опция отключена по умолчанию. До выпуска Cisco ACI 3.0 (2h) этот параметр требовал принудительного применения политики входа в экземпляре VRF.
Рис. 47.
Отключить дистанционное обучение EP в политике настройки всей структуры (APIC версии 2.0)
Отключить дистанционное обучение EP в настройках для всей сети (выпуск APIC 3.0)
Если эта функция включена, удаленное обучение конечных точек IP в экземпляре VRF отключается на пограничных листовых коммутаторах. Однако пограничный лист может по-прежнему узнавать удаленные конечные точки IP из пакетов многоадресной IP-маршрутизации из-за ограничения реализации многоадресной IP-маршрутизации Cisco ACI. Это исключение применяется только тогда, когда коммутатор второго поколения используется в качестве пограничного листа, поскольку многоадресная IP-маршрутизация Cisco ACI поддерживается только начиная с коммутаторов второго поколения. Эта функция не отключает дистанционное обучение конечных точек MAC.
Вариант использования Disable Remote EP Learning 1
Функция Disable Remote EP Learning изначально была представлена для сценария 3 в разделе «Соображения по обучению конечных точек L3Out». В этом сценарии IP1 на LEAF1 узнается как удаленная конечная точка на границе LEAF3 из-за связи с обычной конечной точкой IP2 на LEAF3. Потенциальная проблема заключается в том, что эта удаленная конечная точка может устареть. Он может стать устаревшим после того, как IP1 прекратит связь с IP2 и перейдет к LEAF2, в то время как IP1 все еще продолжает отправлять трафик к соединению L3Out на LEAF3. Из-за этого трафика от исходного IP1 к соединению L3Out на LEAF3 в экземпляре VRF с режимом применения политики входа удаленная конечная точка на LEAF3 для IP1, указывающего на предыдущий LEAF1, не устаревает и не обновляется новым исходным листом. , ЛИСТ2. (Подробности и рисунки см. в обсуждении сценария 3 в разделе «Вопросы обучения конечных точек L3Out».)
Этот сценарий устаревшей удаленной конечной точки можно предотвратить, используя параметр Disable Remote EP Learning на пограничном листе. Если вы включите эту опцию, пограничный лист LEAF3 предотвратит получение удаленной конечной точки IP (рис. 49). Поскольку нет удаленной конечной точки, не будет устаревшей конечной точки.
Рис. 49.
Пример обучения Disable Remote EP на пограничном листе
Этот конкретный пример применим только к листовым коммутаторам первого поколения, направляющим трафик к пограничному листу, как упоминалось в обсуждении сценария 3 ранее в этом документе. Однако эту функцию можно использовать на листовых коммутаторах второго поколения, чтобы предотвратить неожиданное обучение удаленной конечной точки на пограничном листе, как указано в сценарии использования 2.
Вариант использования Disable Remote EP Learn 2
Параметр Disable Remote EP Learn предотвращает другую проблему, когда одна и та же инкапсуляция VLAN SVI в одном L3Out развернута на нескольких листовых коммутаторах. На рисунках 50, 51 и 52 показан один из возможных сценариев. Однако пользователям больше не нужно использовать этот параметр для этого варианта использования, если ваша версия ACI поддерживает функцию объявления конечной точки (CSCvj17665), которая упоминается в разделе записей о перемещении и отказе конечной точки.
Этот вариант использования применяется в основном к листовым коммутаторам второго поколения из-за ограничения CSCva56754, упомянутого ниже. Но это может относиться и к конечным коммутаторам первого поколения, если таймер удержания конечной точки не настроен должным образом.
Рисунок 50.
Вариант использования Disable Remote EP Learn 2 (часть 1)
На рис. 51 Cisco ACI настроен как Multi-Pod, и каждый модуль имеет брандмауэр (в режиме «активный-резервный»), подключенный через одно и то же соединение L3Out с одним и тем же encap VLAN SVI на каждой листовой паре. Когда несколько пограничных листовых коммутаторов настроены с одним и тем же encap VLAN SVI в одном соединении L3Out, все пограничные листовые коммутаторы принадлежат одному и тому же домену уровня 2 (т. е. мостовому домену L3Out). Таким образом, все пограничные листовые коммутаторы в каждом модуле одновременно взаимодействуют напрямую с активным брандмауэром в Pod1, и все пограничные листовые коммутаторы имеют маршруты, указывающие на активный брандмауэр в Pod1.
В это время на рис. 51 конечная точка с IP1 отправляет трафик на другую конечную точку с IP2 на пограничном листе в том же Pod1. Этот трафик приводит к тому, что один из пограничных листовых коммутаторов в Pod1 узнает удаленную конечную точку IP для IP1, указывающую на LEAF1.
Рисунок 51.
Вариант использования Disable Remote EP Learn 2 (часть 2)
На рис. 52 показано, что происходит, когда IP1 на рис. 51 переносится в Pod2. Если IP1, находящийся теперь в Pod2, пытается связаться с брандмауэром, трафик перенаправляется на пограничные листовые коммутаторы в Pod2, поскольку они знают маршруты непосредственно от активного брандмауэра, а локальные пограничные листовые коммутаторы предпочтительнее пограничных листовых коммутаторов в другой стручок.
Затем трафик просматривается на пограничном листе в Pod2, и MAC-адрес следующего перехода для активного брандмауэра разрешается на нем через запись ARP на том же пограничном листе. Однако активный брандмауэр физически не подключен к тому же пограничному листу. Следовательно, трафик перенаправляется на пограничные листовые коммутаторы в Pod1 через соединение Inter-Pod Network (IPN). Этот трафик не обновляет предыдущую удаленную конечную точку для IP1 на пограничном листе в Pod1, потому что этот трафик коммутируется, а не маршрутизируется. Поэтому запоминается только удаленный MAC-адрес, а не IP-адрес.
Рисунок 52.
Disable Remote EP Learn, вариант использования 2 (часть 3)
Из-за того, что происходит на рис. 53, обратный трафик от активного брандмауэра или любой другой трафик на IP1 с пограничного листа попадает на предыдущую устаревшую удаленную конечную точку для указания IP1 к предыдущему листу, LEAF1.
Пока предыдущий лист имеет запись о возврате, трафик будет перенаправляться на новое место в pod2. Если запись возврата устарела, а пограничный лист по-прежнему имеет удаленную конечную точку для IP1, указывающую на предыдущий лист, это может привести к потере трафика к IP1 от этого пограничного листа. Этой потери трафика обычно не должно происходить, потому что по умолчанию удаленная конечная точка устаревает до того, как устаревает запись о возврате. Однако таймер устаревания для удаленной конечной точки IP некорректно обновляется мостовым трафиком L2 только на листовых коммутаторах второго поколения из-за следующего ограничения.
CSCva56754 ACI: удаленная конечная точка IP не устаревает из-за трафика L2 (мостового)
С учетом сказанного, этот вариант использования всегда применим к листовым коммутаторам второго поколения. Для листовых коммутаторов первого поколения это зависит от конфигурации таймера срока действия (таймера хранения) для отказов и удаленной конечной точки.
Если включен параметр «Отключить дистанционное обучение EP», пограничные конечные коммутаторы в каждом модуле не будут в первую очередь изучать удаленную конечную точку в этом экземпляре VRF, что может предотвратить эту проблему.
Эта топология с vPC для двух граничных пар конечных элементов поддерживается только на концевых коммутаторах второго поколения, начиная с Cisco ACI Release 2.3(1), независимо от того, используется ли конструкция с несколькими или одним модулем.
Топология с обычным каналом порта или портом доступа (например, один пограничный листовой коммутатор для каждого брандмауэра) для двух пограничных листовых коммутаторов — по одному на каждый — поддерживается независимо от поколения листового коммутатора, начиная с выпуска Cisco ACI. 2.2(2), независимо от того, используется конструкция с несколькими или одиночными модулями.
Примечание для vPC и Disable Remote EP Learn
Хотя рекомендуется иметь выделенные пограничные листовые коммутаторы, как указано в сценарии 3 в разделе «Соображения об обучении конечных точек L3Out», могут быть некоторые случаи, когда L3OUT развернуты на одном листе, и в то же время этот же лист является частью vPC для ресурсов, отличных от L3OUT. В этом сценарии сам пограничный лист не узнает удаленную конечную точку IP непосредственно из плоскости данных, когда Активировано отключение удаленного обучения EP . Однако одноранговый узел vPC, не являющийся пограничным листом, может узнать удаленную конечную точку IP, и информация будет синхронизирована с его одноранговым узлом vPC, который является пограничным листом. Такое поведение ожидается и записывается со следующим идентификатором.
CSCvi50954: отключение дистанционного обучения EP не отключает обучение на узле VPC пограничного листа.
На рис. 53 показано это поведение.
Рис. 53.
Примечание для vPC и Disable Remote EP Learn
Enforce Subnet Check
Параметр Enforce Subnet Check был впервые представлен в версиях APIC 2.2(2q) и 3.0(2h) со следующим улучшением: VRF
В версии APIC 2.2(2q) этот параметр находится в разделе Fabric > Access Policies > Global Policies > Fabric Wide Setting Policy (рис. 54).
Рис. 54.
Принудительная проверка подсети в соответствии с политикой настройки всей структуры (APIC Release 2.2(2q))
В версии APIC 3.0 (2h) и более поздних версиях он находится в разделе Система > Системные настройки > Настройка всей структуры (рис. 55).
Рис. 55.
Принудительная проверка подсети в соответствии с политикой настройки всей структуры (APIC Release 3.0 (2h))
Эта функция доступна только на листовых коммутаторах второго поколения.
Эта функция обеспечивает проверку подсети на уровне VRF, когда Cisco ACI узнает IP-адрес конечной точки из плоскости данных. Хотя областью проверки подсети является экземпляр VRF, эта функция может быть включена и отключена только глобально в соответствии с политикой настройки всей структуры. Вы не можете включить эту опцию только в одном экземпляре VRF.
По умолчанию эта функция отключена.
Эта функция оптимизирует изучение как локальных, так и удаленных конечных точек в структуре. Следовательно, это можно считать улучшенной версией опции Limit Learning IP To Subnet в каждом домене моста. Принудительная проверка подсети использует подсети домена моста в каждой VRF в качестве индикатора достоверности обучения конечной точки.
● На входном листе (обучение локальной конечной точки):
Этот параметр принудительно включает проверки подсети на уровне мостового домена для изучения локальной конечной точки. Когда эта функция включена, лист Cisco ACI узнает IP-адрес и MAC-адрес как новую локальную конечную точку только в том случае, если IP-адрес источника входящего пакета принадлежит одной из подсетей домена входящего моста.
Это поведение почти такое же, как и при использовании параметра Ограничить обучение IP до подсети в домене моста. Разница заключается в том, что параметр «Ограничить изучение IP-адресов до подсети» ограничивает изучение только IP-адресов, если исходный IP-адрес пакета не принадлежит подсети домена входного моста, в то время как эта функция ограничивает изучение как MAC-адреса, так и IP-адреса, когда запускается изучение IP-адресов. но все же предотвращено, потому что исходный IP-адрес не принадлежит подсети входного домена моста. Обратите внимание, что независимо от исходного диапазона IP-адресов лист Cisco ACI все равно узнает MAC-адрес, если пакет представляет собой трафик моста, потому что лист не проверяет заголовок IP или наличие или отсутствие заголовка IP для трафика моста.
Таким образом, Enforce Subnet Check включает несколько более строгие проверки, чем Limit IP Learning To Subnet. Эта проверка будет включена на всех мостовых доменах, и вы не сможете включать и выключать проверки для каждого мостового домена. Таким образом, ограничение IP-обучения до подсети не требуется, если эта функция включена.
● На выходном листе (обучение удаленных конечных точек):
Этот параметр принудительно включает проверки подсети на уровне VRF для обучения удаленных конечных точек. Когда эта функция включена, лист Cisco ACI узнает IP-адрес удаленной конечной точки, только если исходный IP-адрес входящего пакета принадлежит какой-либо подсети домена моста в том же экземпляре VRF на выходном листе.
Это поведение предотвращает сценарии подделки IP-адресов, в которых конечная точка отправляет пакет с неожиданным исходным IP-адресом, который не принадлежит ни к одному из доменов моста в экземпляре VRF, например IP-адрес, существующий за соединением L3Out.
Если эта функция включена, Cisco ACI сбрасывает все локальные конечные точки IP за пределами подсетей домена моста и все удаленные конечные точки IP.
Вариант использования "Принудительная проверка подсети"
На рисунках 56 и 57 показаны примеры вариантов использования, которые предоставляют подробные сведения о поведении параметра "Принудительная проверка подсети".
Рисунок 56.
Принудительная проверка подсети, пример 1
Когда включена принудительная проверка подсети, как показано на рис. 57, LEAF1 не узнает ни MAC S2, ни IP 172.16.0.1 в качестве локальной конечной точки, поскольку 172.16.0.1 не принадлежит входному BD1. LEAF2 не изучает IP 172.16.0.1 как удаленную конечную точку, потому что 172. 16.0.1 не принадлежит ни к одной из подсетей мостового домена на LEAF2 в том же экземпляре VRF. Если 172.16.0.1 изучен как локальная конечная точка на LEAF1 и удаленная конечная точка на LEAF2 до включения этой функции, эти две конечные точки очищаются после включения этой функции.
Рисунок 57.
Проверка подсети, пример 2
На рис. 58 показан пример, в котором удаленная конечная точка IP все еще изучена, даже если ни входной, ни выходной домен моста не содержат поддельную IP-подсеть (172.16.0.1). Как упоминалось ранее, проверка обучения удаленной конечной точке IP выполняется со всеми подсетями домена моста на удаленном листе в одном и том же экземпляре VRF. На рис. 53 LEAF2 включает BD3 с настроенным 172.16.0.0/24, поэтому в этом сценарии не предотвращается неожиданное изучение удаленных конечных точек IP. Распространенной причиной того, что LEAF2 включает эту подсеть домена моста, является то, что статическая привязка или домен диспетчера виртуальных машин (VMM) для BD3 могут быть настроены на портах LEAF2. Другая причина заключается в том, что EPG в BD2 на LEAF2 может иметь контракт с другим EPG в BD3 на другом листе; из-за контракта LEAF2 устанавливает маршрут для подсетей BD3, называемый всеобъемлющим маршрутом, так что EPG в BD2 на LEAF2 может быть направлен к BD3 на другом листе.
Примечание по включению принудительной проверки подсети
Если функция принудительной проверки подсети включена, обратите внимание на следующий дефект.
CSCvh27285: обучение конечной точки от ARP перестает работать на BD L2 с включенной принудительной проверкой подсети
Из-за дефекта, когда включена принудительная проверка подсети, ACI не сможет узнать MAC-адрес через ARP/GARP в BD L2, где используется одноадресная рассылка. Маршрутизация отключена. Это не повлияет на BD с включенной одноадресной маршрутизацией. Последствием этого дефекта является то, что ACI может устаревать конечную точку MAC и не сможет повторно изучить ее в L2 BD, если с MAC-адреса не поступает трафик, отличный от ARP. Другим типичным следствием является то, что ACI не сможет обнаружить перемещение MAC, даже если хост отправляет GARP, чтобы сообщить ACI о своем перемещении.
Это влияние дефекта можно смягчить, установив параметр L2 Unknown Unicast Flood в L2 BD. Хотя изучение MAC в L2 BD от ARP/GARP по-прежнему не будет происходить из-за дефекта даже с L2 Unknown Unicast Flood, ACI сможет перенаправлять трафик на MAC путем его лавинной рассылки даже после того, как MAC устареет из-за этого. дефект. Если для параметра L2 Unknown Unicast установлено значение Hardware-Proxy и срок действия MAC-адреса истек, ACI не сможет найти конечную точку MAC в базе данных SPINE COOP и должен будет отбросить пакет. Кроме того, в качестве наилучшей практики обычно рекомендуется параметр L2 Unknown Unicast Flood в L2 BD (см. сценарий 3 «Рекомендуемой процедуры настройки для мостовых доменов» в Руководстве по передовым методам работы с ориентированной на приложения инфраструктурой Cisco)
Политика устаревания IP
Политика устаревания IP была впервые представлена в APIC Release 2. 1(1h) со следующим улучшением:
CSCut23815 ACI: неиспользуемая локальная конечная точка IP должна устареть отдельно от конечной точки MAC
Эта конфигурация отключена по умолчанию, чтобы сохранить то же поведение в более старой версии.
Для APIC Release 2.0 этот параметр находится в разделе Fabric > Access Policies > Global Policies > IP Aging Policy (рис. 58). Для APIC версии 3.0(1k) и более поздних версий он находится в разделе «Система» > «Параметры системы» > «Конечные точки управления» > «Устаревание IP» (рис. 59).).
Рисунок 58.
Старение IP (APIC версии 2.0)
Рисунок 59.
Устаревание IP (выпуск 3.0 APIC)
Политика устаревания IP отслеживает и устаревает неиспользуемые IP-адреса на конечной точке. Отслеживание выполняется с помощью политики хранения конечной точки, которая настроена для домена моста на отправку запросов ARP (для IPv4) и запросов соседей (для IPv6) через 75 процентов интервала устаревания локальной конечной точки. Если от IP-адреса не получен ответ, этот IP-адрес устаревает.
Пример использования политики устаревания IP-адресов
До того, как этот параметр стал доступен, конечная точка (например, интерфейс на виртуальной машине) могла иметь неиспользуемые IP-адреса, привязанные к одному и тому же MAC-адресу. Например, при загрузке виртуальная машина Microsoft Windows, которая не получает адрес протокола конфигурации хоста домена (DHCP) (и не имеет статического IP-адреса), автоматически получит адрес из диапазона адресов 169.254.0.0/16, как показано на рисунке 60.
Рисунок 60.
IP устареет до получения адреса
В какой-то момент виртуальная машина получит маршрутизируемый адрес, и конечная точка будет состоять из одного MAC-адреса и двух IP-адресов, как показано на рис. 61.
рис. 61 .
Устаревание IP после получения адреса
Потенциальная проблема в этих примерах (до политики устаревания IP) заключается в том, что Cisco ACI может допускать сохранение устаревших компонентов IP конечной точки на неопределенный срок (или до тех пор, пока кто-то вручную не удалит запись на лист).
Cisco ACI будет рассматривать конечную точку как все три компонента (адреса MAC, IP1 и IP2). Если трафик получен от любого из этих компонентов, записи для всех трех будут оставаться активными.
Теперь, когда IP Aging доступен, Cisco ACI отправит одноадресный пакет ARP с 75% настроенного таймера хранения конечной точки для всех IP-адресов, принадлежащих конечной точке. Если от этого конкретного IP-адреса не получено никакого ответа, он будет удален из таблицы конечных точек. (Обратите внимание, что MAC-адрес и отвечающий IP-адрес для конечной точки будут сохранены.)
Rogue EP Control
Rogue EP Control впервые был представлен в версии APIC 3.2(1l). Эта конфигурация отключена по умолчанию, чтобы сохранить то же поведение в более старой версии.
Этот параметр находится в разделе «Система» > «Настройки системы» > «Конечные точки управления» > «Незаконное управление EP» (рис. 62).
Рисунок 62.
Rogue EP Control
Эта конфигурация вводится глобально, но каждый лист применяет ее независимо, просматривая перемещения IP- и MAC-адресов между листовыми портами.
Rogue EP Control используется для обнаружения конечной точки, которая часто перемещается, и для отключения обучения конечной точки только для конкретной конечной точки. Когда конечный узел идентифицирует конечную точку как мошенническую, конечная точка временно становится статической конечной точкой и будет удалена после интервала удержания, чтобы можно было предотвратить быстрое перемещение конечной точки между разными местоположениями.
Примечание. Затрагивается только трафик от и к конечной точке, в отличие от отключения конечной точки, изучающей мост, или отключения интерфейса, из которого была получена информация о конечной точке, что может повлиять на работоспособные конечные точки, полученные из того же интерфейса или того же моста. домен. Rogue EP Control также вызывает ошибку, которая помогает администратору идентифицировать мошенническую конечную точку.
Критерии обнаружения можно настроить, используя следующие значения:
● Интервал обнаружения мошеннических EP: укажите время в секундах для обнаружения мошеннических конечных точек. По умолчанию 60 секунд. Поддерживаемый диапазон составляет от 30 до 3600 секунд.
● Коэффициент умножения при обнаружении мошеннических EP. Конечная точка объявляется мошеннической, если конечная точка перемещается на большее число, чем это число, в течение интервала обнаружения мошеннических EP. Значение по умолчанию — 4. Поддерживаемый диапазон — от 2 до 10.
● Интервал удержания: количество времени, в течение которого конечная точка обрабатывается как мошенническая и сохраняется как статическая конечная точка. По истечении этого интервала конечная точка удаляется. Значение по умолчанию — 1800 секунд (30 минут). Поддерживаемый диапазон зависит от версии. В версиях ACI до ACI 5.2(3) настраиваемый диапазон составляет от 1800 до 3600. Начиная с ACI 5.2(3) можно настроить минимальный интервал удержания 300 секунд (5 минут).
Например, если Rogue EP Control включен с указанными выше параметрами конфигурации по умолчанию, структура ACI объявляет конечную точку мошеннической, если конечная точка перемещается более четырех раз за 60 секунд, и отключает обучение для конечной точки на 1800 секунд. Мошенническая конечная точка будет статической на конечном узле, интерфейсе и VLAN, где она была обнаружена непосредственно перед объявлением мошеннической.
По истечении интервала удержания неавторизованные конечные точки будут удалены.
Во время удержания возможно, что конечные точки, которые были помещены в карантин в домене моста, могут столкнуться с нарушением трафика. Если вы хотите сократить потенциальное время простоя, чтобы оно длилось меньше времени удержания, вы можете вручную удалить незаконные конечные точки даже до истечения интервала удержания, используя параметр Очистить незаконные конечные точки в Fabric > Inventory > Pod_number > Leaf_name (рис. 63).
Рисунок 63.
Как очистить неавторизованные конечные точки на листе
Rogue EP Control защищает структуру ACI и ограничивает влияние временных петель, помещая в карантин конечные точки только в домене моста, где они возникают, но также может вызывать ненужные сбои, например, при работе брандмауэра. происходит сбой, и в течение короткого времени два брандмауэра могут отправлять трафик с одним и тем же MAC-адресом, прежде чем сблизятся. Чтобы выполнить это требование, начиная с Cisco ACI Release 5.2(3), можно настроить список «исключений» MAC-адресов, к которым не применяется политика Rogue EP Control (или на самом деле она применяется, но не так, как строгий).
Этот параметр можно использовать только в том случае, если BD является BD уровня 2 (т. е. если BD не настроен для IP-маршрутизации) и находится в разделе Арендатор > Сеть > Мостовые домены > BD > Политика > вкладка «Дополнительно/устранение неполадок», где называется Rogue/COOP Exception List.
Рис. 64.
Список исключений Rogue/COOP
MAC-адреса, введенные в BD в списке исключений Rogue/Coop Exception, пользуются менее строгой политикой контроля Rogue EP, но если они перемещаются более 3000 раз за 10 минут, тоже будут на карантине.
Причина, по которой этот параметр применим только к L2 BD, заключается в том, что если включена маршрутизация и листовые узлы ACI обнаруживают перемещение IP, они могут помещать IP конечной точки в карантин, даже если MAC находится в списке исключений. Если вам нужно «отключить» Rogue EP на IP-адресах, которые слишком часто перемещаются по уважительной причине проектирования (а не из-за неправильной конфигурации), вы можете отключить обучение плоскости данных IP либо для каждой VRF, либо для каждой подсети BD. или по EPG. Эта конфигурация предотвратит постоянное обновление информации об IP-адресе конечной точки для трафика с того же IP-адреса, который продолжает переключаться между портами конечных узлов ACI, поэтому Rogue EP Control не вступит в силу. Если вместо этого причина переключения IP-адресов связана не с трафиком плоскости данных, а с непрерывными ответами ARP от разных хостов/MAC-адресов, Rogue EP Control все равно будет действовать.
Начиная с ACI 5.2(3), вы можете ввести только 100 MAC-адресов, которые будут исключены из Rogue EP Control. Это глобальное ограничение, а не ограничение для каждого BD, что означает, что сумма всех MAC-адресов, введенных в список исключений Rogue/COOP для всех BD в структуре ACI, должна быть меньше или равна 100.
Rogue EP Control вариант использования
Rogue EP Control предназначен для защиты фабрики ACI от таких проблем, как конкретная колеблющаяся конечная точка из-за неподходящих конфигураций или конструкций. Это делается также для защиты уровня управления ACI от необходимости управлять слишком большим количеством перемещений конечных точек, которые могут быть вызваны петлями L2. На рисунке ниже показан пример. Сервер ошибочно настроен как объединение активных/активных сетевых адаптеров, которое отправляет пакеты с одним и тем же исходным IP-адресом от нескольких сетевых адаптеров с разными MAC-адресами. Это вызывает откидные створки конечных точек между листовыми узлами. Без Rogue EP Control, несмотря на то, что подавление перемещения конечных точек с помощью политики удержания конечных точек может обнаружить такие частые перемещения конечных точек, оно отключит обучение во всем домене моста, что повлияет на другие конечные точки в том же домене моста.
Рисунок 65.
Почему требуется контроль неавторизованного EPG
При включенном управлении неавторизованным EP, как только конечная точка помечается как неавторизованная, возникает ошибка, и обучение отключается только для конечной точки, что позволяет другим конечным точкам в том же домене моста функционировать как обычно, как показано на рисунке ниже. После того как администратор идентифицирует проблему на основе неисправности, можно исправить схему, вызвавшую эту проблему, например, изменив конфигурацию объединения сетевых карт или отключив обучение плоскости данных IP в VRF.
Рисунок 66.
При включенном мошенническом управлении EPC
Ниже приведены рекомендации по включению мошеннического управления EP.
● Он не делает различий между локальными и удаленными перемещениями; любое изменение интерфейса считается перемещением конечной точки.
● Перемещения конечных точек для Rogue EP Control учитываются для MAC- и IP-адресов отдельно, даже если конечная точка в ACI содержит как MAC-, так и IP-адреса. Это связано с тем, что IP-адреса могут перемещаться и узнаваться по нескольким MAC-адресам, в то время как сами MAC-адреса не перемещаются. Когда количество перемещений IP-адреса превышает пороговое значение, только IP-адрес помечается как мошеннический. Когда количество перемещений MAC-адреса превышает пороговое значение, MAC-адрес и любые IP-адреса, связанные с MAC-адресом в это время, помечаются как мошеннические.
● Изменение интервала удержания не повлияет на таймер удержания существующих мошеннических конечных точек.
● Эта функция работает на сайте. Эта функция не предназначена для обнаружения перемещений конечных точек между сайтами или между основным расположением и удаленным конечным расположением.
● Отключение мошеннического контроля EP приведет к удалению всех существующих мошеннических конечных точек.
● Из-за предостережений в APIC версии 4.1 необходимо отключить Rogue EP Control перед обновлением до или с версии APIC 4.1.
Ep Loop Protection
Ep Loop Protection отключен по умолчанию.
В версиях до APIC 3.0 этот параметр находится в разделе Система > Настройки системы > Элементы управления конечной точкой > Защита цикла Ep. В APIC версии 3.0 и более поздних версиях этот параметр находится в разделе Система > Параметры системы > Элементы управления конечной точкой > Защита цикла Ep (рис. 67). Интервал удержания определяется в политике удержания конечной точки уровня BD.
Теперь, когда Rogue EP Control доступен после версии APIC 3.2, рекомендуется Rogue EP Control вместо Ep Loop Protection.
Рис. 67.
Ep Loop Protection
Хотя Ep Loop Protection имеет аналогичные намерения (т. е. обнаружение петли и отключение обучения) для Rogue EP Control, оно отключает обучение в домене моста и/или отключает порт (отключение при ошибке), что может повлиять на работоспособные конечные точки, подключенные к тому же интерфейсу или к тому же мостовому домену. Таким образом, после выпуска APIC 3.2 рекомендуется использовать Rogue EP Control вместо Ep Loop Protection. Имейте в виду, что механизм обнаружения Ep Loop Protection строго предназначен для цикла, поскольку он инициирует перемещение только тогда, когда перемещение происходит между одними и теми же двумя интерфейсами. Ep Loop Protection не может обнаруживать движения конечной точки, которая перемещается случайным образом.
Демпфирование конечной точки COOP
Демпфирование конечной точки COOP было введено в версии APIC 4.2(3). Эта конфигурация включена по умолчанию.
Этот параметр недоступен в графическом интерфейсе APIC версии 5.0(1). Чтобы отключить демпфирование конечной точки COOP, для параметра disableEpDampening необходимо установить значение «true» через API.
Демпфирование конечной точки COOP используется для смягчения влияния необоснованного количества обновлений конечной точки на узлы позвоночника путем игнорирования обновлений конечной точки только конкретной конечной точки. Когда узел стержня идентифицирует демпфированную конечную точку, возникает ошибка, и стержень уведомляет все конечные узлы, чтобы они игнорировали обновление от конечной точки.
Критерии обнаружения основаны на вычислении штрафного значения, основанного на типах событий, связанных с конечной точкой, как показано в Табл. 7. Штрафное значение уменьшается на 50 процентов каждые пять минут.
Таблица 7. Расчет штрафа
Событие
Значение штрафа
Примечание
Узнать новый IP-адрес
0
Новый IP-адрес изучен
Узнать дополнительный IP-адрес
2
Дополнительный IP-адрес изучен с существующим MAC-адресом конечной точки.
Удалить IP-адрес
50
Удалить IP-адрес удаленной конечной точки после получения IP-адреса
Узнать удаленный IP-адрес
50
Узнать IP-адрес удаленной конечной точки после удаления IP-адреса
Удалить IP-адрес
400
Удалить IP-адрес локальной конечной точки после получения IP-адреса
Узнать удаленный IP-адрес
400
Узнать IP-адрес локальной конечной точки после удаления IP-адреса
Перемещение конечной точки
200
Конечная точка перемещается на другой интерфейс.
IP-перемещение
200
IP-адрес перемещается на другой MAC-адрес
Штраф за это событие высок, поскольку он вызывает два обновления маршрута для BGP 9.0004
Программирование URIB
50
Изменение состояния интерфейса Spine Tunnel (вверх/вниз) для конечной точки
Значение штрафа рассчитывается для каждого IP-адреса. Например, если значение штрафа для конечной точки равно 4000, а количество IP-адресов в конечной точке равно 2, значение штрафа для каждого IP составляет 4000/2 = 2000. Когда значение штрафа для каждого IP превышает критический порог (4000), статус конечной точки изменен на «Критический» с «Нормального». Если конечная точка остается в «критическом» состоянии более пяти минут или значение штрафа для каждого IP-адреса превышает пороговое значение замораживания (10 000), состояние конечной точки переходит в состояние «замораживание» (демпфирование), и обновление конечная точка будет проигнорирована. Когда штрафное значение для каждого IP-адреса становится ниже порога повторного использования (2500), состояние конечной точки становится «Нормальным» (без демпфирования). Требуется десять минут, чтобы значение штрафа уменьшилось на 75 процентов (10000 * 0,5 * 0,5 = 2500). Пороговые значения не настраиваются пользователем.
Заглушенные конечные точки можно восстановить вручную с помощью графического интерфейса, выбрав Fabric > Inventory > Pod_number > Leaf_name или Spine_Name > Clear Rogue Endpoints (рис. 63). Эта операция должна выполняться на всех узлах позвоночника и на исходном конечном узле конечной точки. Если демпфированная конечная точка все еще находится в таблице конечных точек на листе, конечная точка публикуется в базе данных COOP ствола. В противном случае демпфированная конечная точка удаляется из базы данных COOP для корешка через две минуты.
Рисунок 68.
Как очистить демпфированные конечные точки COOP
Вариант использования демпфирования конечной точки COOP
Демпфирование конечной точки COOP предназначено для защиты плоскости управления узлов позвоночника от необходимости управлять слишком большим количеством обновлений конечных точек, которые могут быть вызваны несколькими IP-адресами на конечной точке. На рисунке ниже показан пример. Вредоносная конечная точка имеет много IP-адресов, использующих один и тот же MAC-адрес, который отправляет пакеты с одним и тем же исходным MAC-адресом, используя разные исходные IP-адреса. Это потенциально может привести к большому количеству обновлений конечных точек, и Rogue Endpoint Control может быть не в состоянии обнаружить такие частые обновления конечных точек, поскольку они не являются перемещением конечных точек.
Рисунок 69.
Для чего требуется демпфирование конечной точки COOP
Рисунок 70.
При включенном демпфировании конечной точки COOP
Рекомендации по демпфированию конечной точки COOP:
● Эта функция работает на сайте, который включает удаленный лист ACI.
● При отключении демпфирования конечных точек COOP будут восстановлены все существующие демпфированные конечные точки, находящиеся в состоянии «Заморозить». Конечные точки в «критическом» состоянии будут «нормальными», когда значение штрафа уменьшится до порога повторного использования.
Передовой опыт настройки обучения конечных точек в Cisco ACI
Cisco ACI принципиально обрабатывает обучение конечных точек иначе, чем традиционные сетевые устройства. Это отличие дает Cisco ACI уникальное преимущество, заключающееся в возможности ограничения лавинной рассылки ARP, неизвестного одноадресного трафика и других типов трафика. По мере развития Cisco ACI менялся и лучший способ настройки Cisco ACI. В этом разделе представлен список рекомендуемых конфигураций для обучения конечных точек, которые следует использовать в зависимости от установленного оборудования.
Для оптимальной работы фабрики следует использовать настройки, позволяющие Cisco ACI узнавать только IP-адреса, настроенные в подсети домена моста. Параметры, которые вы используете для обеспечения желаемого поведения, зависят от поколения конечных коммутаторов Cisco ACI в вашей фабрике.
Листовые коммутаторы первого поколения
Для конечных коммутаторов первого поколения рекомендуются следующие конфигурации для оптимального поведения конечных точек при обновлении и переадресации:
● Конфигурации моста на уровне домена
◦ Ограничить обучение IP подсетью
● Конфигурации на уровне коммутационной сети
◦ Политика устаревания IP
◦ Отключить дистанционное обучение EP (на пограничном листе) Tenant > Networking > VRFs > Policy Control Enforcement to Ingress на экземплярах VRF
Листовые коммутаторы второго поколения
Для конечных коммутаторов второго поколения рекомендуются следующие конфигурации для оптимального обновления и поведения переадресации конечных точек:
● Конфигурации на уровне коммутационной сети
◦ Политика устаревания IP
◦ Отключение удаленного обучения EP (на пограничном листе)
◦ До Cisco ACI версии 3. 0 (2h) обязательным условием является установка Tenant > Network Control > VRFs > Policy Принудительное использование Ingress для ваших экземпляров VRF
◦ Только в выпуске APIC до усовершенствования для анонса конечной точки (CSCvj17665)
◦ Принудительное выполнение проверки подсети
Листовые коммутаторы второго поколения не требуют ограничения обучения IP до подсети, поскольку параметр Enforce Subnet Check, доступный только начиная с коммутаторов второго поколения, превосходит функцию ограничения IP-обучения до подсети. Дополнительные сведения см. в разделе «Принудительная проверка подсети».
Коммутационные сети с конечными коммутаторами первого и второго поколения
Для коммутационных сетей с конечными коммутаторами первого и второго поколения для оптимального обновления конечных точек и поведения переадресации рекомендуются следующие конфигурации:
● Конфигурации мостового домена-уровня
◦ Ограничение IP обучение подсети
. 2h), предварительным условием является установка Tenant > Networking > VRFs > Policy Control Enforcement на Ingress на ваших экземплярах VRF
◦ Enforce Subnet Check
Листовые коммутаторы первого поколения в смешанной среде будут игнорировать параметр Enforce Subnet Configuration. Однако в смешанной среде проверка домена моста подсети (которая запускается параметром Enforce Subnet Check) будет принудительно выполняться на всех листовых коммутаторах.
IP Multicast: Руководство по настройке PIM, Cisco IOS XE, выпуск 2 — Обзор технологии IP Multicast [Поддержка]
Последнее обновление: 21 декабря 2011 г.
Многоадресная IP-рассылка — это технология экономии полосы пропускания, которая сокращает трафик за счет одновременной доставки одного потока информации потенциально тысячам предприятий и домов. Приложения, использующие преимущества многоадресной рассылки, включают видеоконференции, корпоративную связь, дистанционное обучение и распространение программного обеспечения, биржевых котировок и новостей.
Этот модуль содержит технический обзор многоадресной рассылки IP. Многоадресная IP-рассылка — это эффективный способ использования сетевых ресурсов, особенно для служб с интенсивным использованием полосы пропускания, таких как аудио и видео. Прежде чем приступить к настройке многоадресной рассылки IP, важно понять информацию, представленную в этом модуле.
Поиск информации о функциях
Возможно, ваша версия программного обеспечения не поддерживает все функции, описанные в этом модуле. Для получения последней информации о функциях и предупреждений см. примечания к выпуску для вашей платформы и выпуска программного обеспечения. Чтобы найти информацию о функциях, задокументированных в этом модуле, и просмотреть список выпусков, в которых поддерживается каждая функция, см. таблицу сведений о функциях в конце этого документа.
Используйте Навигатор функций Cisco, чтобы найти информацию о поддержке платформ и образов программного обеспечения Cisco. Чтобы получить доступ к Cisco Feature Navigator, перейдите по адресу www.cisco.com/go/cfn. Учетная запись на Cisco.com не требуется.
Информация о технологии IP Multicast
Роль IP Multicast в доставке информации
Многоадресная IP-рассылка
— это технология экономии полосы пропускания, которая сокращает трафик за счет одновременной доставки одного потока информации потенциально тысячам предприятий и домов. Приложения, использующие преимущества многоадресной рассылки, включают видеоконференции, корпоративную связь, дистанционное обучение и распространение программного обеспечения, биржевых котировок и новостей.
Многоадресная IP-маршрутизация позволяет хосту (источнику) отправлять пакеты группе хостов (получателей) в любую точку IP-сети с использованием специальной формы IP-адреса, которая называется групповым IP-адресом многоадресной рассылки. Хост-отправитель вставляет адрес группы многоадресной рассылки в поле IP-адреса назначения пакета, а маршрутизаторы многоадресной рассылки IP и многоуровневые коммутаторы пересылают входящие пакеты многоадресной рассылки IP через все интерфейсы, ведущие к членам группы многоадресной рассылки. Любой хост, независимо от того, является ли он членом группы, может отправлять в группу. Однако только члены группы получают сообщение.
Схема многоадресной групповой передачи
IP-связь состоит из хостов, которые действуют как отправители и получатели трафика, как показано на первом рисунке. Отправители называются источниками. Традиционная IP-связь осуществляется путем отправки пакетов с одного узла-источника на другой узел (одноадресная передача) или на все узлы (широковещательная передача). Многоадресная IP-рассылка обеспечивает третью схему, позволяющую хосту отправлять пакеты на подмножество всех хостов (многоадресная передача). Это подмножество принимающих хостов называется многоадресной группой. Хосты, принадлежащие группе многоадресной рассылки, называются членами группы.
Многоадресная рассылка основана на этой групповой концепции. Группа многоадресной рассылки — это произвольное количество получателей, которые присоединяются к группе для получения определенного потока данных. Эта группа многоадресной рассылки не имеет физических или географических границ — узлы могут располагаться в любом месте в Интернете или в любой частной межсетевой сети. Хосты, заинтересованные в получении данных из источника в определенную группу, должны присоединиться к этой группе. Присоединение к группе осуществляется хост-приемником посредством протокола управления группами Интернета (IGMP).
В многоадресной среде любой хост, независимо от того, является ли он членом группы, может отправлять сообщения группе. Однако только члены группы могут получать пакеты, отправленные в эту группу. Многоадресные пакеты доставляются группе с максимальной надежностью, как и одноадресные IP-пакеты.
На следующем рисунке получатели (назначенная группа многоадресной рассылки) заинтересованы в получении потока видеоданных от источника. Получатели сообщают о своей заинтересованности, отправляя отчет хоста IGMP на маршрутизаторы в сети. Затем маршрутизаторы несут ответственность за доставку данных от источника к получателям. Маршрутизаторы используют независимую от протокола многоадресную рассылку (PIM) для динамического создания дерева распределения многоадресной рассылки. Тогда поток видеоданных будет доставлен только в те сегменты сети, которые находятся на пути между источником и приемниками.
Протоколы многоадресной IP-маршрутизации
Программное обеспечение поддерживает следующие протоколы для реализации многоадресной IP-маршрутизации:
IGMP используется между хостами в локальной сети и маршрутизаторами в этой локальной сети для отслеживания групп многоадресной рассылки, членами которых являются хосты.
Независимая от протокола многоадресная рассылка (PIM) используется между маршрутизаторами, чтобы они могли отслеживать, какие многоадресные пакеты пересылать друг другу и в их напрямую подключенные локальные сети.
Протокол дистанционно-векторной многоадресной маршрутизации (DVMPP) используется в MBONE (многоадресной магистрали Интернета). Программное обеспечение поддерживает взаимодействие PIM-DVMRP.
Протокол управления группой Cisco (CGMP) используется на маршрутизаторах, подключенных к коммутаторам Catalyst, для выполнения задач, аналогичных тем, которые выполняет IGMP.
На рисунке показано, где эти протоколы работают в многоадресной IP-среде.
Рисунок 1
Протоколы многоадресной IP-маршрутизации
Адресация многоадресной IP-группы
Группа многоадресной рассылки идентифицируется по адресу группы многоадресной рассылки. Пакеты многоадресной рассылки доставляются на этот адрес группы многоадресной рассылки. В отличие от одноадресных адресов, которые однозначно идентифицируют один хост, многоадресные IP-адреса не идентифицируют конкретный хост. Чтобы получать данные, отправленные на многоадресный адрес, хост должен присоединиться к группе, которую идентифицирует этот адрес. Данные отправляются на многоадресный адрес и принимаются всеми хостами, присоединившимися к группе, что указывает на то, что они хотят получать трафик, отправленный в эту группу. Адрес группы многоадресной рассылки назначается группе в источнике. Сетевые администраторы, которые назначают групповые адреса многоадресной рассылки, должны убедиться, что адреса соответствуют назначениям диапазонов многоадресных адресов, зарезервированным Администрацией адресного пространства Интернета (IANA).
IP-адреса класса D
многоадресных IP-адресов были назначены IANA адресному пространству IPv4 класса D. Четыре старших бита адреса класса D равны 1110. Таким образом, адреса группы хостов могут находиться в диапазоне от 224.0.0.0 до 239.255.255.255. Адрес многоадресной рассылки выбирается в источнике (отправителе) для получателей в группе многоадресной рассылки.
Примечание
Диапазон адресов класса D используется только для группового адреса или адреса назначения многоадресного IP-трафика. Адрес источника многоадресных дейтаграмм всегда является адресом источника одноадресной рассылки.
Область действия многоадресного IP-адреса
Диапазон многоадресных адресов подразделяется для обеспечения предсказуемого поведения для различных диапазонов адресов и повторного использования адресов в небольших доменах. В таблице представлены сводные данные о диапазонах многоадресных адресов. Ниже приводится краткое описание каждого диапазона.
Таблица 1
Назначение диапазона многоадресных адресов
Имя
Диапазон
Описание
Зарезервированные адреса Link-Local
224.0.0.0 до 224.0.0.255
Зарезервировано для использования сетевыми протоколами в сегменте локальной сети.
Глобальные адреса
224.0.1.0 до 238.255.255.255
Зарезервировано для многоадресной рассылки данных между организациями и через Интернет.
Многоадресная рассылка, зависящая от источника
232.0.0.0 до 232.255.255.255
Зарезервировано для использования с моделью доставки дейтаграмм SSM, когда данные пересылаются только тем получателям, которые явным образом присоединились к группе.
Адреса GLOP
233.0.0.0 до 233.255.255.255
Зарезервировано для статически определенных адресов организациями, которым уже назначен номер домена автономной системы (AS).
Ограниченный адрес
239.0.0.0 до 239.255.255.255
Зарезервировано в качестве административного адреса или адреса с ограниченной областью действия для использования в частных многоадресных доменах.
Зарезервированные адреса Link-Local
IANA зарезервировала диапазон от 224.0.0.0 до 224.0.0.255 для использования сетевыми протоколами в сегменте локальной сети. Пакеты с адресом в этом диапазоне являются локальными и не пересылаются IP-маршрутизаторами. Пакеты с локальными адресами назначения канала обычно отправляются со значением времени жизни (TTL), равным 1, и не пересылаются маршрутизатором.
В пределах этого диапазона зарезервированные локальные адреса канала обеспечивают функции сетевого протокола, для которых они зарезервированы. Сетевые протоколы используют эти адреса для автоматического обнаружения маршрутизаторов и передачи важной информации о маршрутах. Например, Open Shortest Path First (OSPF) использует IP-адреса 224.0.0.5 и 224.0.0.6 для обмена информацией о состоянии канала.
IANA назначает одиночные запросы многоадресных адресов для сетевых протоколов или сетевых приложений из диапазона адресов 224. 0.1.xxx. Маршрутизаторы многоадресной рассылки пересылают эти многоадресные адреса.
Глобальные адреса
Адреса в диапазоне от 224.0.1.0 до 238.255.255.255 называются глобальными адресами. Эти адреса используются для отправки многоадресных данных между организациями через Интернет. Некоторые из этих адресов были зарезервированы IANA для использования многоадресными приложениями. Например, IP-адрес 224.0.1.1 зарезервирован для протокола сетевого времени (NTP).
Индивидуальные многоадресные адреса источника
Адреса в диапазоне 232.0.0.0/8 зарезервированы IANA для многоадресной рассылки, зависящей от источника (SSM). В ПО Cisco IOS можно также использовать команду ip pim ssm для настройки SSM для произвольных многоадресных IP-адресов. SSM — это расширение протокола независимой многоадресной рассылки (PIM), которое обеспечивает эффективный механизм доставки данных при обмене данными по схеме «один ко многим». SSM описан в разделе «Режимы многоадресной доставки IP».
Адреса GLOP
9Адресация 0175 GLOP (предложенная в RFC 2770, адресация GLOP в 233/8) предлагает зарезервировать диапазон 233.0.0.0/8 для статически определенных адресов организациями, у которых уже есть зарезервированный номер AS. Эта практика называется адресацией GLOP. Номер AS домена встроен во второй и третий октеты диапазона адресов 233.0.0.0/8. Например, AS 62010 записывается в шестнадцатеричном формате как F23A. Разделение двух октетов F2 и 3A дает 242 и 58 в десятичном формате. Эти значения приводят к подсети 233.242.58.0/24, которая будет глобально зарезервирована для использования AS 62010.
Адреса с ограниченной областью действия
Диапазон от 239.0.0.0 до 239.255.255.255 зарезервирован в качестве адресов административной или ограниченной области для использования в частных многоадресных доменах. Эти адреса ограничены локальной группой или организацией. Компании, университеты и другие организации могут использовать адреса с ограниченной областью действия для локальных многоадресных приложений, которые не будут пересылаться за пределы их домена. Маршрутизаторы обычно настраиваются с помощью фильтров, чтобы предотвратить поток многоадресного трафика в этом диапазоне адресов за пределы автономной системы (AS) или любого определяемого пользователем домена. В пределах AS или домена диапазон адресов с ограниченной областью действия может быть дополнительно разделен, чтобы можно было определить локальные границы многоадресной рассылки.
Примечание
Сетевые администраторы могут использовать многоадресные адреса в этом диапазоне внутри домена, не конфликтуя с другими адресами в Интернете.
Многоадресные адреса уровня 2
Исторически сетевые интерфейсные карты (NIC) в сегменте локальной сети могли получать только пакеты, предназначенные для их встроенного MAC-адреса или широковещательного MAC-адреса. При многоадресной IP-рассылке несколько хостов должны иметь возможность получать один поток данных с общим MAC-адресом назначения. Пришлось разработать некоторые средства, чтобы несколько хостов могли получать один и тот же пакет и при этом иметь возможность различать несколько групп многоадресной рассылки. Одним из способов достижения этого является сопоставление многоадресных IP-адресов класса D непосредственно с MAC-адресом. Используя этот метод, сетевые карты могут получать пакеты, предназначенные для множества разных MAC-адресов.
Протокол управления группой Cisco (CGMP) используется на маршрутизаторах, подключенных к коммутаторам Catalyst, для выполнения задач, аналогичных тем, которые выполняет IGMP. CGMP необходим для тех коммутаторов Catalyst, которые не могут различать многоадресные пакеты данных IP и отчетные сообщения IGMP, оба из которых адресованы одному и тому же групповому адресу на уровне MAC.
Режимы многоадресной доставки IP
Режимы многоадресной доставки IP различаются только для хостов-получателей, но не для хостов-источников. Хост-источник отправляет многоадресные IP-пакеты со своим собственным IP-адресом в качестве IP-адреса источника пакета и групповым адресом в качестве IP-адреса назначения пакета.
Многоадресная рассылка из любого источника
Для режима доставки Any Source Multicast (ASM) хост-получатель IP-многоадресной рассылки может использовать любую версию IGMP для присоединения к группе многоадресной рассылки. Эта группа обозначается как G в обозначении состояния таблицы маршрутизации. Присоединяясь к этой группе, хост-получатель указывает, что он хочет получать многоадресный IP-трафик, отправленный любым источником в группу G. Сеть будет доставлять многоадресные пакеты IP от любого хоста-источника с адресом назначения G на все хосты-получатели в сети, которые присоединились к группе G.
ASM требует выделения группового адреса в сети. В любой момент времени группа ASM должна использоваться только одним приложением. Когда два приложения используют одну и ту же группу ASM одновременно, узлы-получатели обоих приложений будут получать трафик от обоих источников приложений. Это может привести к неожиданному избыточному трафику в сети. Эта ситуация может привести к перегрузке сетевых каналов и сбоям в работе хостов-получателей приложений.
Многоадресная рассылка, зависящая от источника
Source Specific Multicast (SSM) — это модель доставки дейтаграмм, которая лучше всего поддерживает приложения «один ко многим», также известные как широковещательные приложения. SSM — это базовая сетевая технология для реализации Cisco IP-многоадресной рассылки, предназначенной для приложений аудио- и видеовещания.
Для режима доставки SSM узел получателя IP-многоадресной рассылки должен использовать IGMP версии 3 (IGMPv3) для подписки на канал (S,G). Подписываясь на этот канал, хост-получатель указывает, что он хочет получать многоадресный IP-трафик, отправляемый исходным хостом S в группу G. Сеть будет доставлять многоадресные IP-пакеты от исходного хоста S в группу G на все хосты в сети, которые имеют подписался на канал (S, G).
SSM не требует выделения группового адреса внутри сети, только внутри каждого хоста-источника. Различные приложения, работающие на одном исходном хосте, должны использовать разные группы SSM. Различные приложения, работающие на разных хостах-источниках, могут произвольно повторно использовать групповые адреса SSM, не вызывая лишнего трафика в сети.
Многоадресная рассылка, независимая от протокола
Протокол независимой от протокола многоадресной рассылки (PIM) поддерживает текущий режим многоадресной IP-службы членства, инициируемого получателем. PIM не зависит от конкретного протокола одноадресной маршрутизации; он не зависит от протокола IP-маршрутизации и может использовать любые протоколы одноадресной маршрутизации, используемые для заполнения таблицы одноадресной маршрутизации, включая расширенный протокол маршрутизации внутренних шлюзов (EIGRP), открытый кратчайший путь вперед (OSPF), протокол пограничного шлюза (BGP) и статические маршруты. . PIM использует информацию о маршрутизации одноадресной рассылки для выполнения функции переадресации многоадресной рассылки.
Хотя PIM называется протоколом маршрутизации многоадресной рассылки, он фактически использует таблицу маршрутизации одноадресной рассылки для выполнения функции проверки переадресации обратного пути (RPF) вместо создания полностью независимой таблицы маршрутизации многоадресной рассылки. В отличие от других протоколов маршрутизации, PIM не отправляет и не получает обновления маршрутизации между маршрутизаторами.
PIM определен в RFC 2362, Независимый от протокола многоадресный разреженный режим (PIM-SM): Спецификация протокола.
PIM может работать в плотном или разреженном режиме. Маршрутизатор может обрабатывать как разреженные, так и плотные группы одновременно. Режим определяет, как маршрутизатор заполняет свою таблицу многоадресной маршрутизации и как маршрутизатор перенаправляет многоадресные пакеты, которые он получает из своих непосредственно подключенных локальных сетей.
Сведения о режимах пересылки PIM (интерфейса) см. в следующих разделах:
Плотный режим PIM
Плотный режим PIM
(PIM-DM) использует модель принудительной рассылки многоадресного трафика во все уголки сети. Эта модель push представляет собой метод доставки данных получателям без запроса получателями данных. Этот метод эффективен в определенных развертываниях, в которых есть активные получатели в каждой подсети сети.
В плотном режиме маршрутизатор предполагает, что все остальные маршрутизаторы хотят пересылать многоадресные пакеты для группы. Если маршрутизатор получает многоадресный пакет и не имеет непосредственно подключенных участников или соседей PIM, обратно источнику отправляется сообщение сокращения. Последующие многоадресные пакеты не передаются этому маршрутизатору в этой сокращенной ветви. PIM строит деревья многоадресной рассылки на основе источника.
Сначала PIM-DM рассылает многоадресный трафик по всей сети. Маршрутизаторы, у которых нет нисходящих соседей, отсекают нежелательный трафик. Этот процесс повторяется каждые 3 минуты.
Маршрутизаторы накапливают информацию о состоянии, получая потоки данных с помощью механизма лавинной рассылки и сокращения. Эти потоки данных содержат информацию об источнике и группе, чтобы нижестоящие маршрутизаторы могли создать свою таблицу многоадресной пересылки. PIM-DM поддерживает только исходные деревья, то есть записи (S,G), и не может использоваться для построения общего дерева распространения.
Примечание
Плотный режим используется не часто и его использование не рекомендуется. По этой причине он не указывается в задачах настройки в соответствующих модулях.
Разреженный режим PIM
Разреженный режим PIM (PIM-SM) использует модель вытягивания для доставки многоадресного трафика. Только сегменты сети с активными получателями, явно запросившими данные, получат трафик.
В отличие от интерфейсов плотного режима, интерфейсы разреженного режима добавляются в таблицу многоадресной маршрутизации только тогда, когда периодические сообщения о присоединении принимаются от нижестоящих маршрутизаторов или когда непосредственно подключенный участник находится на интерфейсе. При пересылке из локальной сети происходит работа в разреженном режиме, если для группы известен RP. Если это так, пакеты инкапсулируются и отправляются к RP. Когда RP неизвестен, пакет рассылается в плотном режиме. Если многоадресного трафика от определенного источника достаточно, маршрутизатор первого перехода получателя может отправлять сообщения о присоединении к источнику для построения дерева распределения на основе источника.
PIM-SM распространяет информацию об активных источниках, пересылая пакеты данных по общему дереву. Поскольку PIM-SM использует общие деревья (по крайней мере, изначально), он требует использования точки встречи (RP). RP должен быть административно настроен в сети. Дополнительную информацию см. в разделе «Места встречи».
В разреженном режиме маршрутизатор предполагает, что другие маршрутизаторы не хотят пересылать многоадресные пакеты для группы, если нет явного запроса на трафик. Когда хосты присоединяются к группе многоадресной рассылки, напрямую подключенные маршрутизаторы отправляют сообщения присоединения PIM к RP. RP отслеживает многоадресные группы. Хосты, отправляющие многоадресные пакеты, регистрируются в RP маршрутизатором первого перехода этого хоста. Затем RP отправляет сообщения о присоединении к источнику. В этот момент пакеты пересылаются в общее дерево распространения. Если многоадресного трафика от определенного источника достаточно, маршрутизатор первого перехода узла может отправлять сообщения о присоединении к источнику для построения дерева распределения на основе источника.
Источники регистрируются в RP, а затем данные пересылаются по общему дереву к получателям. Пограничные маршрутизаторы узнают о конкретном источнике, когда они получают пакеты данных в общем дереве от этого источника через RP. Затем пограничный маршрутизатор отправляет сообщения PIM (S,G) Join этому источнику. Каждый маршрутизатор на обратном пути сравнивает метрику одноадресной маршрутизации адреса RP с метрикой исходного адреса. Если метрика для исходного адреса лучше, он перенаправит сообщение PIM (S,G) Join к источнику. Если метрика для RP такая же или лучше, то сообщение PIM (S,G) Join будет отправлено в том же направлении, что и RP. В этом случае общее дерево и исходное дерево будут считаться конгруэнтными.
Если общее дерево не является оптимальным путем между источником и получателем, маршрутизаторы динамически создают исходное дерево и останавливают поток трафика по общему дереву. Это поведение является поведением по умолчанию в программном обеспечении. Сетевые администраторы могут заставить трафик оставаться в общем дереве с помощью команды ip pim spt-threshold infinity.
PIM-SM хорошо масштабируется в сети любого размера, в том числе с соединениями WAN. Механизм явного соединения предотвращает попадание нежелательного трафика в каналы WAN.
Разреженно-плотный режим
Если вы настраиваете либо разреженный, либо плотный режим на интерфейсе, то разреженность или плотность применяются к интерфейсу в целом. Однако в некоторых средах может потребоваться выполнение PIM в одном регионе в разреженном режиме для некоторых групп и в плотном режиме для других групп.
Альтернативой включению только плотного режима или только разреженного режима является включение режима разреженной плотности. В этом случае интерфейс рассматривается как плотный режим, если группа находится в плотном режиме; интерфейс обрабатывается в разреженном режиме, если группа находится в разреженном режиме. У вас должна быть RP, если интерфейс находится в режиме разреженной плотности и вы хотите рассматривать группу как разреженную группу.
Если вы настраиваете режим разреженной плотности, идея разреженности или плотности применяется к группам, членом которых является маршрутизатор.
Еще одним преимуществом режима разреженной плотности является то, что информация Auto-RP может распространяться в плотном режиме; тем не менее, многоадресные группы для групп пользователей могут использоваться в разреженном режиме. Поэтому нет необходимости настраивать RP по умолчанию на конечных маршрутизаторах.
Когда интерфейс обрабатывается в плотном режиме, он заносится в список исходящих интерфейсов таблицы многоадресной маршрутизации, если выполняется одно из следующих условий:
Участники или соседи DVMRP находятся на интерфейсе.
Есть соседи PIM, и группа не была сокращена.
Когда интерфейс обрабатывается в разреженном режиме, он заносится в список исходящих интерфейсов таблицы многоадресной маршрутизации, если выполняется одно из следующих условий:
Участники или соседи DVMRP находятся на интерфейсе.
Соседний узел PIM на интерфейсе получил явное сообщение о присоединении.
Двунаправленный PIM
Двунаправленный PIM (bidir-PIM) — это усовершенствование протокола PIM, разработанное для эффективной связи «многие ко многим» в отдельном домене PIM. Группы многоадресной рассылки в двунаправленном режиме могут масштабироваться до произвольного количества источников с минимальными дополнительными затратами.
Общие деревья, созданные в разреженном режиме PIM, являются однонаправленными. Это означает, что необходимо создать исходное дерево, чтобы довести поток данных до RP (корня общего дерева), а затем его можно перенаправить вниз по ветвям к получателям. Исходные данные не могут проходить вверх по общему дереву к RP — это будет считаться двунаправленным общим деревом.
В двунаправленном режиме трафик направляется только по двунаправленному общему дереву, корнем которого является RP для группы. В bidir-PIM IP-адрес RP действует как ключ к тому, чтобы все маршрутизаторы устанавливали топологию связующего дерева без петель с корнем в этом IP-адресе. Этот IP-адрес не обязательно должен быть адресом маршрутизатора, но может быть любым неназначенным IP-адресом в сети, доступной через домен PIM.
Bidir-PIM является производным от механизмов разреженного режима PIM (PIM-SM) и использует многие общие операции с деревом. Bidir-PIM также имеет безусловную пересылку исходного трафика к RP вверх по общему дереву, но не имеет процесса регистрации для источников, как в PIM-SM. Эти модификации необходимы и достаточны для того, чтобы разрешить пересылку трафика на всех маршрутизаторах исключительно на основе (*, G) записей многоадресной маршрутизации. Эта функция устраняет любое состояние, зависящее от источника, и позволяет масштабировать возможности до произвольного количества источников.
Групповые режимы многоадресной рассылки
В PIM пакетный трафик для группы многоадресной рассылки маршрутизируется в соответствии с правилами режима, настроенного для этой группы многоадресной рассылки. Реализация Cisco PIM поддерживает четыре режима для группы многоадресной рассылки:
.
Двунаправленный режим PIM
Разреженный режим PIM
Плотный режим PIM
Режим многоадресной рассылки PIM для конкретного источника (SSM)
Маршрутизатор может одновременно поддерживать все четыре режима или любую их комбинацию для разных групп многоадресной рассылки.
Двунаправленный режим
В двунаправленном режиме трафик направляется только по двунаправленному общему дереву, корнем которого является точка встречи (RP) для группы. В bidir-PIM IP-адрес RP действует как ключ к тому, чтобы все маршрутизаторы устанавливали топологию связующего дерева без петель с корнем в этом IP-адресе. Этот IP-адрес не обязательно должен быть маршрутизатором, но может быть любым неназначенным IP-адресом в сети, который доступен через домен PIM. Этот метод является предпочтительным методом настройки для создания резервной конфигурации RP для bidir-PIM.
Членство в двунаправленной группе сигнализируется явными сообщениями о присоединении. Трафик от источников безоговорочно направляется вверх по общему дереву к RP и передается вниз по дереву к получателям на каждой ветви дерева.
Разреженный режим
Работа в разреженном режиме сосредоточена вокруг одного однонаправленного общего дерева, корневой узел которого называется точкой встречи (RP). Источники должны зарегистрироваться в RP, чтобы их многоадресный трафик проходил по общему дереву через RP. Этот процесс регистрации фактически инициирует присоединение к дереву кратчайшего пути (SPT) с помощью RP к источнику, когда в сети есть активные получатели для группы.
Группа разреженного режима использует явную модель взаимодействия. Хосты-получатели присоединяются к группе в точке встречи (RP). Разные группы могут иметь разные RP.
Пакеты многоадресного трафика передаются по общему дереву только тем получателям, которые явно запросили получение трафика.
Плотный режим
Плотный режим работает с использованием широковещательной (лавинной) и черновой модели.
При заполнении таблицы многоадресной маршрутизации в таблицу всегда добавляются интерфейсы плотного режима. Многоадресный трафик перенаправляется со всех интерфейсов в списке исходящих интерфейсов ко всем получателям. Интерфейсы удаляются из списка исходящих интерфейсов в процессе, называемом сокращением. В плотном режиме интерфейсы обрезаются по разным причинам, в том числе из-за отсутствия напрямую подключенных приемников.
Обрезанный интерфейс можно восстановить, т. е. пересадить обратно, чтобы перезапуск потока многоадресного трафика можно было выполнить с минимальной задержкой.
Точки встречи
Точка рандеву (RP) — это роль, которую выполняет маршрутизатор при работе в режиме PIM-SM. RP требуется только в сетях, использующих PIM-SM. В PIM-SM только сегменты сети с активными получателями, которые явно запросили многоадресные данные, будут перенаправлять трафик. Этот метод доставки многоадресных данных отличается от модели плотного режима PIM (PIM-DM). В PIM-DM многоадресный трафик изначально рассылается во все сегменты сети. Маршрутизаторы, у которых нет нисходящих соседей или напрямую подключенных приемников, отсекают нежелательный трафик.
RP служит местом встречи источников и получателей многоадресных данных. В сети PIM-SM источники должны отправлять свой трафик на RP. Затем этот трафик направляется получателям по общему дереву распределения. По умолчанию, когда маршрутизатор первого перехода получателя узнает об источнике, он отправляет сообщение о присоединении непосредственно к источнику, создавая дерево распределения на основе источника от источника к получателю. Это исходное дерево не включает RP, если только RP не находится в пределах кратчайшего пути между источником и получателем.
В большинстве случаев размещение RP в сети не является сложным решением. По умолчанию RP нужен только для запуска новых сессий с источниками и получателями. Следовательно, RP испытывает небольшие накладные расходы из-за потока или обработки трафика. В PIM версии 2 RP выполняет меньшую обработку, чем в PIM версии 1, потому что источники должны только периодически регистрироваться в RP для создания состояния.
Авто-RP
В первой версии PIM-SM все конечные маршрутизаторы (маршрутизаторы, напрямую подключенные к источникам или приемникам) должны были вручную настраивать IP-адрес RP. Этот тип конфигурации также известен как статическая конфигурация RP. Настройка статических RP относительно проста в небольшой сети, но может быть трудоемкой в большой и сложной сети.
После введения PIM-SM версии 1 компания Cisco реализовала версию PIM-SM с функцией Auto-RP. Auto-RP автоматизирует распределение сопоставлений групп и RP в сети PIM. Auto-RP имеет следующие преимущества:
Настроить использование нескольких RP в сети для обслуживания разных групп очень просто.
Auto-RP позволяет распределять нагрузку между разными RP и упорядочивать RP в соответствии с расположением участников группы.
Auto-RP позволяет избежать несогласованных, ручных конфигураций RP, которые могут вызвать проблемы с подключением.
Несколько RP могут использоваться для обслуживания разных диапазонов групп или в качестве резервных копий друг для друга. Для работы Auto-RP маршрутизатор должен быть назначен агентом сопоставления RP, который получает сообщения-объявления RP от RP и разрешает конфликты. Затем агент сопоставления RP отправляет согласованные сопоставления групп и RP всем остальным маршрутизаторам. Таким образом, все маршрутизаторы автоматически определяют, какой RP использовать для групп, которые они поддерживают.
Примечание
Если вы настраиваете PIM в разреженном режиме или в режиме разреженной плотности и не настраиваете Auto-RP, вы должны статически настроить RP.
Примечание
Если интерфейсы маршрутизатора настроены в разреженном режиме, Auto-RP по-прежнему можно использовать, если все маршрутизаторы настроены со статическим адресом RP для групп Auto-RP.
Чтобы Auto-RP работал, маршрутизатор должен быть назначен агентом сопоставления RP, который получает сообщения объявлений RP от RP и разрешает конфликты. Затем агент сопоставления RP отправляет согласованные сопоставления групп и RP всем остальным маршрутизаторам с помощью лавинной рассылки в плотном режиме. Таким образом, все маршрутизаторы автоматически определяют, какой RP использовать для групп, которые они поддерживают. Управление по присвоению номеров в Интернете (IANA) назначило два групповых адреса, 224.0.1.39 и 224.0.1.40, для Auto-RP. Одним из преимуществ Auto-RP является то, что любое изменение в назначении RP должно быть настроено только на маршрутизаторах, которые являются RP, а не на конечных маршрутизаторах. Еще одно преимущество Auto-RP заключается в том, что он предлагает возможность ограничить адрес RP в пределах домена. Область охвата может быть достигнута путем определения значения времени жизни (TTL), разрешенного для объявлений Auto-RP.
Каждый метод настройки RP имеет свои сильные и слабые стороны, а также уровень сложности. В обычных сценариях многоадресной IP-сети мы рекомендуем использовать Auto-RP для настройки RP, поскольку его легко настроить, он хорошо протестирован и стабилен. Альтернативными способами настройки RP являются статический RP, Auto-RP и загрузочный маршрутизатор.
Режим разреженной плотности для Auto-RP
Необходимым условием для Auto-RP является то, что все интерфейсы должны быть настроены в режиме разреженной плотности с помощью команды настройки интерфейса ip pim sparse-dense-mode. Интерфейс, настроенный в режиме разреженной плотности, обрабатывается либо в разреженном, либо в плотном режиме работы, в зависимости от того, в каком режиме работает группа многоадресной рассылки. Если многоадресная группа имеет известный RP, интерфейс обрабатывается в разреженном режиме. Если у группы нет известного RP, по умолчанию интерфейс обрабатывается в плотном режиме, и данные будут пересылаться через этот интерфейс. (Вы можете предотвратить откат в плотном режиме; см. модуль «Настройка базовой IP-многоадресной рассылки».)
Чтобы успешно внедрить Auto-RP и предотвратить работу любых групп, кроме 224.0.1.39 и 224.0.1.40, в плотном режиме, мы рекомендуем настроить «приемник RP» (также известный как «RP последней инстанции»). RP приемника — это статически сконфигурированный RP, который может фактически существовать в сети, а может и не существовать. Настройка приемника RP не мешает работе Auto-RP, поскольку по умолчанию сообщения Auto-RP заменяют статические конфигурации RP. Мы рекомендуем настроить приемник RP для всех возможных групп многоадресной рассылки в вашей сети, так как существует вероятность того, что неизвестный или неожиданный источник станет активным. Если ни один RP не настроен для ограничения регистрации источника, группа может вернуться к работе в плотном режиме и быть переполненной данными.
Самозагрузочный маршрутизатор
Другая модель выбора RP, называемая загрузочным маршрутизатором (BSR), была введена после Auto-RP в PIM-SM версии 2. BSR работает аналогично Auto-RP в том смысле, что использует маршрутизаторы-кандидаты для функции RP и для ретрансляции информации RP для группы. . Информация RP распространяется через сообщения BSR, которые переносятся в сообщениях PIM. Сообщения PIM — это многоадресные сообщения локального канала, которые передаются от маршрутизатора PIM к маршрутизатору PIM. Из-за этого односкачкового метода распространения информации RP область TTL не может использоваться с BSR. BSR работает так же, как RP, за исключением того, что он не рискует вернуться к работе в плотном режиме и не предлагает возможности охвата домена.
В модели разреженного режима PIM источники и получатели многоадресной рассылки должны регистрироваться в своей локальной точке встречи (RP). На самом деле маршрутизатор, ближайший к источнику или получателю, регистрируется в RP, но важно отметить, что RP «знает» обо всех источниках и приемниках для любой конкретной группы. RP в других доменах не могут знать об источниках, расположенных в других доменах. Протокол обнаружения источника многоадресной рассылки (MSDP) — элегантный способ решить эту проблему.
MSDP — это механизм, который позволяет RP обмениваться информацией об активных источниках. RP знают о получателях в своем локальном домене. Когда RP в удаленных доменах узнают об активных источниках, они могут передать эту информацию своим локальным получателям. Затем многоадресные данные могут быть перенаправлены между доменами. Полезная функция MSDP заключается в том, что она позволяет каждому домену поддерживать независимый RP, который не зависит от других доменов, но позволяет RP пересылать трафик между доменами. PIM-SM используется для пересылки трафика между многоадресными доменами.
RP в каждом домене устанавливает сеанс пиринга MSDP, используя TCP-соединение с RP в других доменах или с граничными маршрутизаторами, ведущими к другим доменам. Когда RP узнает о новом источнике многоадресной рассылки в своем собственном домене (посредством обычного механизма регистрации PIM), RP инкапсулирует первый пакет данных в сообщение Source-Active (SA) и отправляет SA всем одноранговым узлам MSDP. Каждый принимающий одноранговый узел использует модифицированную проверку пересылки обратного пути (RPF) для пересылки SA до тех пор, пока SA не достигнет каждого маршрутизатора MSDP во взаимосвязанных сетях — теоретически всего многоадресного Интернета. Если принимающий узел MSDP является RP, и RP имеет запись (*, G) для группы в SA (есть заинтересованный получатель), RP создает состояние (S,G) для источника и присоединяется к дерево кратчайших путей к источнику. Инкапсулированные данные декапсулируются и передаются по общему дереву этой RP. Когда маршрутизатор последнего перехода (маршрутизатор, ближайший к получателю) получает многоадресный пакет, он может присоединиться к дереву кратчайшего пути к источнику. Спикер MSDP периодически отправляет SA, включающие все источники в домене RP.
MSDP был разработан для пиринга между интернет-провайдерами (ISP). Интернет-провайдеры не хотели полагаться на RP, поддерживаемую конкурирующим интернет-провайдером, для предоставления услуг своим клиентам. MSDP позволяет каждому интернет-провайдеру иметь свой собственный локальный RP и по-прежнему пересылать и получать многоадресный трафик в Интернет.
Anycast RP
Anycast RP — полезное приложение MSDP. Первоначально разработанный для междоменных многоадресных приложений, MSDP, используемый для Anycast RP, представляет собой внутридоменную функцию, обеспечивающую избыточность и возможности распределения нагрузки. Корпоративные клиенты обычно используют Anycast RP для настройки сети с разреженным режимом независимой от протокола многоадресной рассылки (PIM-SM) для удовлетворения требований отказоустойчивости в пределах одного домена многоадресной рассылки.
В Anycast RP две или более RP настроены с одинаковым IP-адресом на петлевых интерфейсах. Адрес обратной связи Anycast RP должен быть настроен с 32-битной маской, что делает его адресом узла. Все нисходящие маршрутизаторы должны быть настроены так, чтобы «знать», что петлевой адрес Anycast RP является IP-адресом их локального RP. IP-маршрутизация автоматически выберет топологически ближайший RP для каждого источника и получателя. Предполагая, что источники равномерно распределены по сети, равное количество источников будет зарегистрировано с каждым RP. То есть процесс регистрации источников будет совместно использоваться всеми RP в сети.
Поскольку источник может регистрироваться с одной RP, а получатели могут присоединяться к другой RP, необходим метод, чтобы RP могли обмениваться информацией об активных источниках. Этот обмен информацией осуществляется с помощью MSDP.
В Anycast RP все RP настроены как одноранговые узлы MSDP друг для друга. Когда источник регистрируется в одной RP, другим RP отправляется сообщение SA, информирующее их о наличии активного источника для конкретной группы многоадресной рассылки. В результате каждый RP будет знать об активных источниках в области других RP. Если какой-либо из RP выйдет из строя, IP-маршрутизация будет конвергентной, и один из RP станет активным RP более чем в одной области. Новые источники будут зарегистрированы в резервной RP. Получатели присоединятся к новому RP, и связь будет поддерживаться.
Примечание
Обычно RP требуется только для запуска новых сеансов с источниками и получателями. RP упрощает совместно используемое дерево, так что источники и получатели могут напрямую устанавливать поток многоадресных данных. Если многоадресный поток данных уже установлен напрямую между источником и получателем, то сбой RP не повлияет на этот сеанс. Anycast RP гарантирует, что новые сеансы с источниками и получателями могут начаться в любое время.
Многоадресная переадресация
Пересылка многоадресного трафика осуществляется маршрутизаторами с поддержкой многоадресной рассылки. Эти маршрутизаторы создают деревья распределения, которые контролируют путь, по которому многоадресный IP-трафик проходит через сеть, чтобы доставить трафик всем получателям.
Многоадресный трафик направляется от источника к группе многоадресной рассылки по дереву распределения, которое соединяет все источники со всеми получателями в группе. Это дерево может быть общим для всех источников (общее дерево) или для каждого источника может быть построено отдельное дерево распространения (исходное дерево). Общее дерево может быть однонаправленным или двунаправленным.
Перед описанием структуры исходного и общего деревьев полезно объяснить нотации, используемые в таблицах многоадресной маршрутизации. Эти обозначения включают следующее:
(S,G) = (источник одноадресной рассылки для группы многоадресной рассылки G, группа многоадресной рассылки G)
(*,G) = (любой источник для многоадресной группы G, многоадресной группы G)
Обозначение (S,G), произносимое как «S запятая G», перечисляет дерево кратчайших путей, где S — IP-адрес источника, а G — адрес группы многоадресной рассылки.
Общие деревья (*,G), а исходные деревья (S,G) всегда направляются к источникам.
Исходное дерево многоадресного распространения
Простейшей формой дерева многоадресной рассылки является исходное дерево. Исходное дерево имеет корень на исходном хосте и имеет ветви, образующие связующее дерево по сети к получателям. Поскольку это дерево использует кратчайший путь в сети, его также называют деревом кратчайшего пути (SPT).
На рисунке показан пример SPT для группы 224.1.1.1 с корнем в источнике, хосте A, и подключением двух получателей, хостов B и C.
Используя стандартные обозначения, SPT для примера, показанного на рисунке, будет (192.168.1.1, 224.1.1.1).
Обозначение (S,G) подразумевает, что существует отдельный SPT для каждого отдельного источника, отправляющего в каждую группу, что правильно.
Общее дерево многоадресной рассылки
В отличие от исходных деревьев, у которых есть корень в источнике, общие деревья используют один общий корень, расположенный в некоторой выбранной точке сети. Этот общий корень называется точкой встречи (RP).
На рисунке ниже показано общее дерево для группы 224.2.2.2 с корнем, расположенным на маршрутизаторе D. Это общее дерево является однонаправленным. Исходный трафик отправляется к RP в исходном дереве. Затем трафик направляется вниз по общему дереву от RP для достижения всех получателей (если получатель не расположен между источником и RP, в этом случае он будет обслуживаться напрямую).
В этом примере многоадресный трафик от источников, хостов A и D, проходит к корню (маршрутизатору D), а затем вниз по общему дереву к двум получателям, хостам B и C. Поскольку все источники в группе многоадресной рассылки используют общее совместно используемое дерево, нотация подстановочных знаков, записанная как (*, G), произносится как «звездная запятая G», представляет дерево. В этом случае * означает все источники, а G представляет группу многоадресной рассылки. Следовательно, общее дерево, показанное на рисунке выше, будет записано как (*, 224. 2.2.2).
Как исходные, так и общие деревья не содержат петель. Сообщения реплицируются только там, где ветви дерева. Члены групп многоадресной рассылки могут присоединяться или выходить из них в любое время; поэтому деревья распределения должны динамически обновляться. Когда все активные получатели в определенной ветви перестают запрашивать трафик для определенной группы многоадресной рассылки, маршрутизаторы удаляют эту ветвь из дерева распределения и прекращают пересылку трафика вниз по этой ветви. Если один получатель в этой ветви становится активным и запрашивает многоадресный трафик, маршрутизатор динамически изменит дерево распределения и снова начнет пересылать трафик.
Преимущество исходного дерева
Преимущество деревьев источников заключается в создании оптимального пути между источником и получателями. Это преимущество гарантирует минимальную задержку в сети для пересылки многоадресного трафика. Однако за эту оптимизацию приходится платить. Маршрутизаторы должны поддерживать информацию о пути для каждого источника. В сети с тысячами источников и тысячами групп эти накладные расходы могут быстро стать проблемой ресурсов на маршрутизаторах. Потребление памяти из-за размера таблицы многоадресной маршрутизации — это фактор, который должны принимать во внимание разработчики сети.
Преимущество общего дерева
Преимущество общих деревьев состоит в том, что для каждого маршрутизатора требуется минимальное количество состояний. Это преимущество снижает общие требования к памяти для сети, в которой разрешены только общие деревья. Недостатком общих деревьев является то, что при определенных обстоятельствах пути между источником и получателями могут не быть оптимальными путями, что может привести к некоторой задержке в доставке пакетов. Например, на приведенном выше рисунке кратчайшим путем между хостом A (источник 1) и хостом B (получатель) будет маршрутизатор A и маршрутизатор C. Поскольку мы используем маршрутизатор D в качестве корня для общего дерева, трафик должен проходить через Маршрутизаторы A, B, D, а затем C. Проектировщики сети должны тщательно продумать размещение точки встречи (RP) при реализации среды с общим деревом.
При одноадресной маршрутизации трафик направляется по сети по одному пути от источника к узлу назначения. Маршрутизатор одноадресной рассылки не учитывает исходный адрес; он учитывает только адрес назначения и то, как перенаправить трафик к этому месту назначения. Маршрутизатор просматривает свою таблицу маршрутизации в поисках адреса назначения, а затем пересылает одну копию одноадресного пакета через правильный интерфейс в направлении назначения.
При многоадресной пересылке источник отправляет трафик произвольной группе узлов, которые представлены групповым адресом многоадресной рассылки. Маршрутизатор многоадресной рассылки должен определить, какое направление является восходящим (к источнику), а какое — нисходящим (или направлениям) к получателям. Если имеется несколько нисходящих путей, маршрутизатор реплицирует пакет и пересылает его по соответствующим нисходящим путям (наилучшая метрика одноадресного маршрута), что не обязательно является всеми путями. Переадресация многоадресного трафика от источника, а не к получателю, называется переадресацией по обратному пути (RPF). RPF описан в следующем разделе.
Переадресация по обратному пути
При одноадресной маршрутизации трафик направляется по сети по одному пути от источника к узлу назначения. Маршрутизатор одноадресной рассылки не учитывает исходный адрес; он учитывает только адрес назначения и то, как перенаправить трафик к этому месту назначения. Маршрутизатор просматривает свою таблицу маршрутизации в поисках сети назначения, а затем пересылает одну копию одноадресного пакета через правильный интерфейс в направлении назначения.
При многоадресной пересылке источник отправляет трафик произвольной группе узлов, которые представлены групповым адресом многоадресной рассылки. Маршрутизатор многоадресной рассылки должен определить, какое направление является восходящим (к источнику), а какое — нисходящим (или направлениям) к получателям. Если имеется несколько нисходящих путей, маршрутизатор реплицирует пакет и пересылает его по соответствующим нисходящим путям (наилучшая метрика одноадресного маршрута), что не обязательно является всеми путями. Переадресация многоадресного трафика от источника, а не к получателю, называется переадресацией по обратному пути (RPF). RPF — это алгоритм, используемый для пересылки многоадресных дейтаграмм.
Независимая от протокола многоадресная рассылка (PIM) использует информацию о маршрутизации одноадресной рассылки для создания дерева распределения по обратному пути от получателей к источнику. Затем многоадресные маршрутизаторы пересылают пакеты по дереву распределения от источника к получателям. RPF является ключевой концепцией многоадресной пересылки. Это позволяет маршрутизаторам правильно пересылать многоадресный трафик вниз по дереву распределения. RPF использует существующую таблицу одноадресной маршрутизации для определения соседей в восходящем и нисходящем направлениях. Маршрутизатор будет пересылать многоадресный пакет только в том случае, если он получен на восходящем интерфейсе. Эта проверка RPF помогает гарантировать отсутствие петель в дереве распределения.
Проверка РПФ
Когда многоадресный пакет поступает на маршрутизатор, маршрутизатор выполняет проверку RPF для пакета. Если проверка RPF завершается успешно, пакет пересылается. В противном случае он сбрасывается.
Для трафика, идущего вниз по исходному дереву, процедура проверки RPF работает следующим образом:
Маршрутизатор ищет адрес источника в таблице маршрутизации одноадресной рассылки, чтобы определить, прибыл ли пакет на интерфейс, который находится на обратном пути обратно к источнику.
Если пакет прибыл на интерфейс, ведущий обратно к источнику, проверка RPF завершается успешно, и пакет перенаправляется через интерфейсы, представленные в списке исходящих интерфейсов записи таблицы многоадресной маршрутизации.
Если проверка RPF на шаге 2 не удалась, пакет отбрасывается.
На рисунке показан пример неудачной проверки RPF.
Рисунок 2
Ошибка проверки RPF
Как показано на рисунке, многоадресный пакет от источника 151.10.3.21 получен на последовательном интерфейсе 0 (S0). Проверка таблицы одноадресных маршрутов показывает, что S1 — это интерфейс, который этот маршрутизатор будет использовать для пересылки одноадресных данных на адрес 151.10.3.21. Поскольку пакет прибыл на интерфейс S0, он отбрасывается.
На рисунке показан пример успешной проверки RPF.
Рисунок 3
Проверка RPF прошла успешно
В этом примере многоадресный пакет прибыл на интерфейс S1. Маршрутизатор обращается к таблице маршрутизации одноадресной рассылки и находит, что S1 является правильным интерфейсом. Проверка RPF проходит успешно, и пакет пересылается.
Резервный режим плотного режима PIM
Если вы используете многоадресную IP-рассылку в критически важных сетях, вам следует избегать использования PIM-DM (плотный режим).
Откат плотного режима описывает событие изменения режима PIM (возврат) с разреженного режима (который требует RP) на плотный режим (который не использует RP). Откат в плотном режиме происходит при потере информации RP.
Если все интерфейсы настроены с помощью команды ip pim sparse-mode, резервного режима плотного режима не будет, поскольку группы плотного режима нельзя создавать на интерфейсах, настроенных для разреженного режима.
Причина и следствие отката плотного режима
PIM определяет, работает ли группа многоадресной рассылки в режиме PIM-DM или PIM-SM, исключительно на основе наличия информации RP в кэше сопоставления группы и RP. Если Auto-RP настроен или используется загрузочный маршрутизатор (BSR) для распространения информации RP, существует риск потери информации RP, если все RP, Auto-RP или BSR для группы выходят из строя из-за перегрузки сети. Этот сбой может привести к частичному или полному возврату сети в состояние PIM-DM.
Если сеть возвращается в PIM-DM и используется AutoRP или BSR, произойдет лавинная рассылка в плотном режиме. Маршрутизаторы, потерявшие информацию о RP, перейдут в плотный режим, и все новые состояния, которые должны быть созданы для вышедшей из строя группы, будут создаваться в плотном режиме.
Эффекты предотвращения перехода в плотный режим
До введения функции предотвращения отката PIM-DM все многоадресные группы без сопоставления группы с RP считались плотным режимом.
С введением предотвращения отката PIM-DM поведение отката PIM-DM было изменено, чтобы предотвратить лавинную рассылку в плотном режиме. По умолчанию, если все интерфейсы настроены для работы в разреженном режиме PIM (с помощью команды ip pim sparse-mode), нет необходимости настраивать команду no ip pim dm-fallback (то есть резервный режим PIM-DM). поведение включено по умолчанию). Если какие-либо интерфейсы не настроены с помощью команды ip pim sparse-mode (например, с помощью команды ip pim sparse-dense-mode), то резервное поведение PIM-DM можно явно отключить с помощью команды no ip pim dm-fallback.
Если настроена команда no ip pim dm-fallback или когда на всех интерфейсах настроен ip pim sparse-mode, любые существующие группы, работающие в разреженном режиме, будут продолжать работать в разреженном режиме, но будут использовать адрес RP, установленный на 0.0.0.0. . Записи многоадресной рассылки с адресом RP, установленным на 0.0.0.0, будут демонстрировать следующее поведение:
.
Существующие состояния (S, G) будут сохранены.
Сообщения PIM Join или Prune для (*, G) или (S, G, RPbit) не отправляются.
Получено (*, G) или (S, G, RPbit) Сообщения о соединениях или сокращении игнорируются.
Регистры не отправляются, и трафик на первом узле отбрасывается.
Полученные регистры отвечают остановкой регистра.
Утверждения не изменены.
Список исходящих интерфейсов (*, G) (olist) поддерживается только для состояния протокола управления группами Интернета (IGMP).
Сообщения активного источника (SA) протокола обнаружения источника многоадресной рассылки (MSDP) для групп RP 0.0.0.0 по-прежнему принимаются и пересылаются.
Рекомендации по выбору режима PIM
Перед началом процесса настройки необходимо решить, какой режим PIM необходимо использовать. Это определение основано на приложениях, которые вы собираетесь поддерживать в своей сети.
Основные рекомендации включают следующее:
В общем, если приложение по своей природе является «один ко многим» или «многие ко многим», то PIM-SM можно успешно использовать.
Для оптимальной производительности приложения "один ко многим" подходит SSM, но требуется поддержка IGMP версии 3.
Для оптимальной производительности приложений «многие ко многим» подходит двунаправленный PIM, но аппаратная поддержка ограничена устройствами Cisco и коммутаторами серии Catalyst 6000 с Sup720.
Куда идти дальше
Чтобы настроить базовую многоадресную IP-рассылку, см. модуль «Настройка базовой IP-многоадресной рассылки».
Дополнительные ссылки
Связанные документы
Связанная тема
Название документа
Многоадресные IP-команды: полный синтаксис команд, режим команд, история команд, значения по умолчанию, рекомендации по использованию и примеры
Справочник команд многоадресной рассылки IP Cisco IOS
MIB
МИБ
Ссылка MIB
--
Чтобы найти и загрузить MIB для выбранных платформ, выпусков Cisco IOS и наборов функций, используйте локатор MIB Cisco по следующему URL-адресу:
http://www. cisco.com/go/mibs
RFC
RFC
Наименование
RFC 1112
Хост-расширения для IP-многоадресной рассылки
RFC 2113
Опция оповещения IP-маршрутизатора
RFC 2362
Независимый от протокола многоадресный разреженный режим (PIM-SM): Спецификация протокола
RFC 3180
Адресация GLOP в 233/8
Техническая помощь
Описание
Ссылка
На веб-сайте службы поддержки Cisco представлены обширные онлайн-ресурсы, включая документацию и инструменты для устранения неполадок и решения технических проблем, связанных с продуктами и технологиями Cisco.
Чтобы получать информацию о безопасности и техническую информацию о своих продуктах, вы можете подписаться на различные услуги, такие как средство оповещения о продуктах (доступ к которому можно получить из уведомлений на месте), информационный бюллетень технических услуг Cisco и RSS-каналы Really Simple Syndication.
Для доступа к большинству инструментов на веб-сайте поддержки Cisco требуется идентификатор пользователя и пароль Cisco.com.
http://www.cisco.com/cisco/web/support/index.html
Информация о функциях для обзора технологии IP Multicast
В следующей таблице представлена информация о выпуске функции или функций, описанных в этом модуле. В этой таблице перечислены только выпуски программного обеспечения, в которых реализована поддержка данной функции в данной последовательности выпусков программного обеспечения. Если не указано иное, последующие выпуски этой серии выпусков программного обеспечения также поддерживают эту функцию.
Используйте Навигатор функций Cisco, чтобы найти информацию о поддержке платформ и образов программного обеспечения Cisco. Чтобы получить доступ к Cisco Feature Navigator, перейдите по адресу www.cisco.com/go/cfn. Учетная запись на Cisco.com не требуется.
Таблица 2
Информация о функциях для обзора технологии IP Multicast
Названия функций
Выпуски
Информация о конфигурации функций
CGMP
Cisco IOS XE версии 2. 1
Протокол управления группой Cisco (CGMP) используется на маршрутизаторах, подключенных к коммутаторам Catalyst, для выполнения задач, аналогичных тем, которые выполняет IGMP.
IGMP, версия 2
Cisco IOS XE версии 2.1
IGMP, версия 3
Cisco IOS XE версии 2.1
Однонаправленная маршрутизация канала (UDLR)
Cisco IOS XE версии 2.1
Предотвращение отказов PIM в плотном режиме в сети после потери информации RP
Cisco IOS XE версии 2. 1
Функция предотвращения отката PIM в плотном режиме в сети после потери информации RP позволяет предотвратить откат PIM-DM при сбое всех RP. Предотвращение использования плотного режима очень важно для многоадресных сетей, надежность которых имеет решающее значение. Эта функция обеспечивает механизм для сохранения групп многоадресной рассылки в разреженном режиме, тем самым предотвращая лавинную рассылку в плотном режиме.
Версия PIM 2
Cisco IOS XE версии 3.5S
Независимая от протокола многоадресная рассылка (PIM) версии 2 — это протокол многоадресной маршрутизации с двумя основными режимами работы: разреженным и плотным режимом.
В Cisco IOS XE версии 3.5S добавлена поддержка маршрутизатора Cisco ASR 903.
Глоссарий
базовая многоадресная рассылка — интерактивная многоадресная рассылка внутри домена. Поддерживает многоадресные приложения в корпоративном кампусе. Также обеспечивает дополнительную целостность сети за счет включения надежного многоадресного транспорта PGM.
bidir PIM — двунаправленный PIM — это расширение набора протоколов PIM, которое реализует общие разреженные деревья с двунаправленным потоком данных. В отличие от PIM-SM, bidir-PIM позволяет избежать сохранения конкретного состояния источника в маршрутизаторе и, таким образом, позволяет деревьям масштабироваться до произвольного количества источников.
широковещательная рассылка — передача «один ко всем», при которой источник отправляет одну копию сообщения всем узлам, независимо от того, желают они его получить или нет.
Протокол управления группой Cisco (CGMP) — разработанный Cisco протокол, который позволяет коммутаторам уровня 2 использовать информацию IGMP на маршрутизаторах Cisco для принятия решений о переадресации уровня 2. Это позволяет коммутаторам перенаправлять многоадресный трафик только на те порты, которые заинтересованы в этом трафике.
плотный режим (DM) (Internet Draft Spec) — активно пытается отправить многоадресные данные всем потенциальным получателям (лавинная рассылка) и полагается на их самоотсечение (удаление из группы) для достижения желаемого распределения.
назначенный маршрутизатор (DR) — маршрутизатор в дереве PIM-SM, который инициирует каскад сообщений Join/Prune, восходящий к RP, в ответ на информацию о членстве в IGMP, которую он получает от узлов IGMP.
дерево распределения. Многоадресный трафик проходит от источника к группе многоадресной рассылки по дереву распределения, которое соединяет все источники со всеми получателями в группе. Это дерево может быть общим для всех источников (shared-tree) или для каждого источника может быть построено отдельное дерево распределения (source-tree). Разделяемое дерево может быть односторонним или двунаправленным.
Сообщения IGMP. Сообщения IGMP инкапсулируются в стандартные дейтаграммы IP с номером IP-протокола 2 и опцией оповещения IP-маршрутизатора (RFC 2113).
Отслеживание IGMP. Отслеживание IGMP требует, чтобы коммутатор LAN проверял или «отслеживал» некоторую информацию уровня 3 в пакете IGMP, отправляемом с хоста на маршрутизатор. Когда коммутатор получает отчет IGMP от хоста для конкретной группы многоадресной рассылки, коммутатор добавляет номер порта хоста в соответствующую запись таблицы многоадресной рассылки. Когда он слышит сообщение IGMP Leave Group от хоста, он удаляет порт хоста из записи в таблице.
Маршрутизация однонаправленных каналов IGMP. Другое решение Cisco UDLR заключается в использовании многоадресной IP-маршрутизации с протоколом IGMP, который был улучшен для поддержки UDLR. Это решение очень хорошо масштабируется для многих спутниковых каналов.
Протокол управления группами Интернета версии 2 (IGMP) — используется IP-маршрутизаторами и их непосредственно подключенными хостами для передачи информации о состоянии членства в группе многоадресной рассылки.
Протокол управления группами Интернета версии 3 (IGMP) — IGMP — это протокол, используемый системами IPv4 для сообщения о членстве в группах многоадресной рассылки IP соседним маршрутизаторам многоадресной рассылки. В версию 3 протокола IGMP добавлена поддержка «фильтрации источников», то есть возможность для системы сообщать о заинтересованности в получении пакетов только с определенных адресов источников или со всех адресов источников, кроме определенных, отправленных на конкретный многоадресный адрес.
многоадресная рассылка — метод маршрутизации, который позволяет отправлять IP-трафик из одного или нескольких источников и доставлять его в несколько пунктов назначения. Вместо отправки отдельных пакетов каждому адресату один пакет отправляется группе адресатов, известной как группа многоадресной рассылки, которая идентифицируется одним групповым IP-адресом адресата. Многоадресная адресация поддерживает передачу одной IP-датаграммы нескольким хостам.
монитор многоадресной маршрутизации (MRM) — средство диагностики управления, обеспечивающее обнаружение сетевых сбоев и изоляцию в крупной инфраструктуре многоадресной маршрутизации. Он предназначен для уведомления сетевого администратора о проблемах с многоадресной маршрутизацией почти в реальном времени.
Протокол обнаружения источника многоадресной рассылки (MSDP) — механизм для подключения нескольких доменов разреженного режима PIM (PIM-SM). MSDP позволяет источникам многоадресной рассылки для группы быть известными всем точкам встречи (RP) в разных доменах. Каждый домен PIM-SM использует свои собственные RP и не должен зависеть от RP в других доменах. RP запускает MSDP через TCP для обнаружения источников многоадресной рассылки в других доменах. MSDP также используется для объявления источников, отправляющих в группу. Эти объявления должны исходить от RP домена. MSDP сильно зависит от MBGP для междоменных операций.
Независимая от протокола многоадресная рассылка (PIM) — архитектура многоадресной маршрутизации, определенная IETF, которая обеспечивает многоадресную IP-маршрутизацию в существующих IP-сетях. Его ключевым моментом является независимость от любого базового протокола одноадресной рассылки, такого как OSPF или BGP.
prune — терминология маршрутизации многоадресной рассылки, указывающая, что маршрутизатор с поддержкой многоадресной рассылки отправил соответствующие сообщения многоадресной рассылки, чтобы удалить себя из дерева многоадресной рассылки для конкретной группы многоадресной рассылки. Он перестанет получать многоадресные данные, адресованные этой группе, и, следовательно, не сможет доставлять данные на какие-либо подключенные хосты, пока не присоединится к группе.
запрос — сообщения IGMP, исходящие от маршрутизатора(ов) для получения информации о членстве в группе многоадресной рассылки от подключенных к нему хостов.
точка рандеву (RP) — маршрутизатор многоадресной рассылки, являющийся корнем общего дерева распределения многоадресной рассылки PIM-SM.
Отчет
— сообщения IGMP, исходящие от хостов, которые присоединяются, сохраняют или покидают свое членство в группе многоадресной рассылки.
исходное дерево — путь распространения многоадресной рассылки, который напрямую соединяет назначенный маршрутизатор источника и получателя (или точку встречи) для получения кратчайшего пути в сети. Обеспечивает наиболее эффективную маршрутизацию данных между источником и получателями, но может привести к ненужному дублированию данных по всей сети, если она создана чем-то другим, кроме RP.
разреженный режим (SM) (RFC 2362) — полагается на явный метод присоединения перед попыткой отправить данные многоадресной рассылки получателям группы многоадресной рассылки.
Туннель UDLR — использует обратный канал (другой канал), поэтому протоколы маршрутизации считают, что односторонний канал является двунаправленным. Обратный канал сам по себе представляет собой специальный однонаправленный общий туннель инкапсуляции маршрутов (GRE), через который потоки управляющего трафика идут в направлении, противоположном направлению потока пользовательских данных. Эта функция позволяет IP и связанным с ним протоколам одноадресной и многоадресной маршрутизации полагать, что однонаправленный канал логически является двунаправленным. Это решение поддерживает все протоколы одноадресной и многоадресной маршрутизации IP без их изменения. Однако он не масштабируется, и к восходящему маршрутизатору должно подаваться не более 20 туннелей. Целью однонаправленного туннеля GRE является перемещение пакетов управления от нисходящего узла к восходящему узлу.
Одноадресная передача — двухточечная передача, требующая от источника отправки отдельной копии сообщения каждому запрашивающему.
протокол однонаправленной маршрутизации канала (UDLR) — протокол маршрутизации, который позволяет пересылать многоадресные пакеты через физический однонаправленный интерфейс (например, спутниковый канал с высокой пропускной способностью) в тупиковые сети с обратным каналом.
URL-адрес рандеву-каталога (URD) — URD — это облегченное решение для многоадресной рассылки, которое напрямую предоставляет в сеть информацию о конкретном источнике потока контента. Это позволяет сети быстро установить самый прямой путь распространения от источника к получателю, что значительно сокращает время и усилия, необходимые для получения потокового мультимедиа. URD позволяет приложению идентифицировать источник потока контента через ссылку на веб-страницу или напрямую в Интернете. Когда эта информация отправляется обратно в приложение, она затем передается обратно в сеть с использованием URD.
В этой функции веб-страница с поддержкой URD предоставляет информацию об источнике, группе и приложении (через медиа-тип) на веб-странице. Заинтересованный хост щелкнет веб-страницу, извлекая информацию в транзакции HTTP. Маршрутизатор последнего перехода к получателю перехватит эту транзакцию и отправит ее на специальный порт, выделенный IANA. Маршрутизатор последнего перехода также поддерживает URD и использует информацию для инициации источника PIM, присоединения к группе (S,G) от имени хоста.
Cisco и логотип Cisco являются товарными знаками или зарегистрированными товарными знаками Cisco и/или ее дочерних компаний в США и других странах. Чтобы просмотреть список товарных знаков Cisco, перейдите по этому URL-адресу: www.cisco.com/go/trademarks. Упомянутые товарные знаки третьих лиц являются собственностью их соответствующих владельцев. Использование слова «партнер» не подразумевает партнерских отношений между Cisco и какой-либо другой компанией. (1110р)
Любые адреса Интернет-протокола (IP) и номера телефонов, используемые в этом документе, не предназначены для использования в качестве реальных адресов и номеров телефонов. Любые примеры, выходные данные команд, диаграммы топологии сети и другие рисунки, включенные в документ, показаны только в иллюстративных целях. Любое использование реальных IP-адресов или телефонных номеров в иллюстративном контенте является непреднамеренным и случайным.
Эта серия руководств посвящена организации сети для сервисов роя.
Сведения о работе в сети с автономными контейнерами см.
Сеть с автономными контейнерами. Если вам нужно
узнать больше о сети Docker в целом можно в обзоре.
Этот раздел включает четыре различных руководства. Вы можете запустить каждый из них на
Linux, Windows или Mac, но для последних двух вам понадобится второй Docker. хост работает в другом месте.
Использование сети наложения по умолчанию демонстрирует
как использовать оверлейную сеть по умолчанию, которую Docker настраивает для вас
автоматически при инициализации или присоединении к рою. Эта сеть не
лучший выбор для производственных систем.
Использование пользовательских оверлейных сетей показывает
как создавать и использовать свои собственные оверлейные сети для подключения сервисов.
Это рекомендуется для служб, работающих в рабочей среде.
Используйте оверлейную сеть для автономных контейнеров
показывает, как обмениваться данными между автономными контейнерами в разных Docker.
демоны, использующие оверлейную сеть.
Связь между контейнером и службой роя
устанавливает связь между автономным контейнером и сервисом swarm,
с помощью присоединяемой оверлейной сети.
Предпосылки
Для этого требуется, чтобы у вас был по крайней мере рой с одним узлом, что означает, что
вы запустили Docker и запустили docker swarm init на хосте. Вы можете запустить
также примеры на многоузловом рое.
Использовать оверлейную сеть по умолчанию
В этом примере вы запускаете службу alpine и проверяете характеристики
сети с точки зрения отдельных сервисных контейнеров.
В этом руководстве не рассматриваются специфичные для операционной системы сведения о том, как
реализованы оверлейные сети, но основное внимание уделяется тому, как работает оверлей из
точки зрения службы.
Предпосылки
Для этого руководства требуется три физических или виртуальных хоста Docker, которые могут
общаться друг с другом. В этом руководстве предполагается, что три хоста
работает в той же сети без участия брандмауэра.
Эти хосты будут называться менеджер , рабочий-1 и рабочий-2 . менеджер хост будет функционировать как менеджер и рабочий, что означает, что он может
оба запускают сервисные задачи и управляют роем. рабочий-1 и рабочий-2 будет
работать только как рабочие,
Если у вас нет под рукой трех хостов, простое решение — настроить три
Хосты Ubuntu в облачном провайдере, таком как Amazon EC2, все в одной сети. со всеми коммуникациями, разрешенными для всех хостов в этой сети (используя механизм
например, группы безопасности EC2), а затем следовать
инструкции по установке Docker Engine — сообщество на Ubuntu.
Прохождение
Создать рой
В конце этой процедуры все три хоста Docker будут присоединены к рою
и будут соединены друг с другом с помощью оверлейной сети с именем ingress .
На менеджер . инициализировать рой. Если хост имеет только одну сеть
интерфейс, флаг --advertise-addr является необязательным.
$ docker swarm init --advertise-addr=
Запишите напечатанный текст, так как он содержит токен, который
вы будете использовать, чтобы присоединиться к рою worker-1 и worker-2 . это хорошо
идея хранить токен в менеджере паролей.
На worker-1 присоединяйтесь к рою. Если хост имеет только один сетевой интерфейс,
флаг --advertise-addr является необязательным.
В диспетчере перечислите все узлы. Эту команду можно выполнить только из
управляющий делами.
$ узел докера ls
ID ИМЯ ХОСТА СТАТУС ДОСТУПНОСТЬ МЕНЕДЖЕР СТАТУС
d68ace5iraw6whp7llvgjpu48 * ip-172-31-34-146 Готов Активный Лидер
nvp5rwavvb8lhdggo8fcf7plg ip-172-31-35-151 Готово Активно
ouvx2l7qfcxisoyms8mtkgahw ip-172-31-36-89Готово Активно
Вы также можете использовать флаг --filter для фильтрации по роли:
$ docker node ls --filter role=manager
ID ИМЯ ХОСТА СТАТУС ДОСТУПНОСТЬ МЕНЕДЖЕР СТАТУС
d68ace5iraw6whp7llvgjpu48 * ip-172-31-34-146 Готов Активный Лидер
$ docker node ls --filter role=worker
ID ИМЯ ХОСТА СТАТУС ДОСТУПНОСТЬ МЕНЕДЖЕР СТАТУС
nvp5rwavvb8lhdggo8fcf7plg ip-172-31-35-151 Готово Активно
ouvx2l7qfcxisoyms8mtkgahw ip-172-31-36-89Готово Активно
Список сетей Docker на manager , worker-1 и worker-2 и уведомление
что у каждого из них теперь есть оверлейная сеть с именем , входящая и мост
сеть с именем docker_gwbridge . Показан только список менеджера .
здесь:
$ сеть докеров лс
ИДЕНТИФИКАТОР СЕТИ НАЗВАНИЕ ДРАЙВЕР ОБЛАСТЬ ПРИМЕНЕНИЯ
495c570066be мост местный мост
961c6cae9945 docker_gwbridge локальный мост
ff35ceda3643 хост хост локальный
trtnl4tqnc3n входной оверлейный рой
c8357deec9cb нет нулевой локальный
docker_gwbridge соединяет входящую сеть с хостом Docker.
сетевой интерфейс, чтобы трафик мог проходить к менеджерам роя и от них и
рабочие. Если вы создаете сервисы роя и не указываете сеть, они
подключен к вход сеть. Рекомендуется использовать отдельные
оверлейные сети для каждого приложения или группы приложений, которые будут работать
вместе. В следующей процедуре вы создадите две оверлейные сети и
подключить услугу к каждому из них.
Создать службы
В диспетчере создайте новую оверлейную сеть с именем nginx-net :
.
$ docker network create -d overlay nginx-net
Вам не нужно создавать оверлейную сеть на других узлах, потому что это
будет автоматически создан, когда один из этих узлов запустит
служебная задача, которая требует этого.
В диспетчере создайте службу Nginx с 5 репликами, подключенную к nginx-net .
сервис опубликует порт 80 для внешнего мира. Все услуги
Контейнеры задач могут взаимодействовать друг с другом, не открывая никаких портов.
Примечание . Службы можно создавать только в менеджере.
$ создание службы докеров \
--name мой-nginx \
--publish target=80,опубликовано=80 \
--replicas=5 \
--сеть nginx-net \
нгинкс
Режим публикации по умолчанию ingress , который используется, когда вы не
укажите режим для флага --publish , это означает, что если вы перейдете к
порт 80 на manager , worker-1 или worker-2 , вы будете подключены к
порт 80 на одной из 5 сервисных задач, даже если в данный момент нет задач
работает на узле, к которому вы просматриваете. Если вы хотите опубликовать порт, используя хост режим, вы можете добавить режим = хост на --опубликовать вывод . Однако,
вы также должны использовать --mode global вместо --replicas=5 в этом случае,
поскольку только одна служебная задача может привязать данный порт к данному узлу.
Запустите службу докеров ls , чтобы отслеживать ход запуска службы, которая
может занять несколько секунд.
Проверка сети nginx-net на менеджере , worker-1 и рабочих-2 .
Помните, что вам не нужно было создавать его вручную на worker-1 и worker-2 , потому что Docker создал его для вас. Вывод будет длинным, но
обратите внимание на разделы Containers и Peers . Контейнеры перечисляет все
сервисные задачи (или автономные контейнеры), подключенные к оверлейной сети
с этого хоста.
Из менеджера проверьте службу, используя службу докеров , проверьте my-nginx и обратите внимание на информацию о портах и конечных точках, используемых
оказание услуг.
Создайте новую сеть nginx-net-2 , затем обновите службу, чтобы использовать ее.
сеть вместо nginx-net :
Запустите службу докеров ls , чтобы убедиться, что служба обновлена и все
задачи были перераспределены. Выполнить 9Сеть докеров 4550 проверяет nginx-net для проверки
что к нему не подключены никакие контейнеры. Запустите ту же команду для nginx-net-2 и обратите внимание, что все контейнеры служебных задач подключены
к этому.
Примечание : несмотря на то, что оверлейные сети автоматически создаются в рое
рабочие узлы по мере необходимости, они не удаляются автоматически.
Очистите службу и сети. От менеджер , запустите следующее
команды. Менеджер направит рабочих на удаление сетей
автоматически.
$ служба докеров rm my-nginx
$ сеть докеров rm nginx-net nginx-net-2
Использовать пользовательскую оверлейную сеть
Предпосылки
В этом руководстве предполагается, что рой уже настроен, а вы работаете с менеджером.
Прохождение
Создайте пользовательскую оверлейную сеть.
$ docker network create -d overlay my-overlay
Запустите службу, используя оверлейную сеть и опубликовав порт 80 на порт
8080 на хосте Docker.
$ создание службы докеров \
--name мой-nginx \
--network мой-оверлей \
--реплики 1 \
--опубликовать опубликовано=8080,цель=80 \
nginx: последний
Запустите сеть докеров , проверьте my-overlay и убедитесь, что my-nginx к нему подключена сервисная задача, посмотрев раздел Containers .
Удалить службу и сеть.
$ служба докеров rm my-nginx
$ docker network rm my-overlay
Использование оверлейной сети для автономных контейнеров
В этом примере демонстрируется обнаружение контейнера DNS, в частности, как
обмениваться данными между автономными контейнерами на разных демонах Docker, используя
оверлейная сеть. Шаги:
На host1 инициализируйте узел как рой (менеджер).
На host2 присоедините узел к рою (рабочему).
На host1 создайте подключаемую оверлейную сеть ( test-net ).
На host1 запустите интерактивный контейнер alpine ( alpine1 ) в тестовой сети .
На host2 запустите интерактивный и отсоединенный контейнер alpine ( alpine2 ) в тестовой сети .
На host1 , из сеанса alpine1 , пинг alpine2 .
Предпосылки
Для этого теста вам нужны два разных хоста Docker, которые могут взаимодействовать с
друг друга. На каждом хосте должны быть открыты следующие порты между двумя серверами Docker.
хосты:
TCP-порт 2377
Порт TCP и UDP 7946
UDP-порт 4789
Один из простых способов настроить это — иметь две виртуальные машины (либо локальные, либо в облаке).
поставщика, такого как AWS), каждый с установленным и работающим Docker. Если вы используете AWS
или аналогичную платформу облачных вычислений, самая простая конфигурация — использовать
группа безопасности, которая открывает все входящие порты между двумя хостами и SSH
port с IP-адреса вашего клиента.
В этом примере два узла в нашем рое называются host1 и host2 . Этот
В примере также используются хосты Linux, но те же самые команды работают и в Windows.
Проходной
Создать рой.
а. На host1 инициализируйте рой (и, если будет предложено, используйте --advertise-addr указать IP-адрес для интерфейса, который взаимодействует с другими
хостов в рое, например, частный IP-адрес на AWS):
$ инициализация роя докеров
Swarm инициализирован: текущий узел (vz1mm9am11qcmo979tlrlox42) теперь является менеджером.
Чтобы добавить рабочего в этот рой, выполните следующую команду:
docker swarm join --token SWMTKN-1-5g90q48weqrtqryq4kj6ow0e8xm9wmv9o6vgqc5j320ymybd5c-8ex8j0bc40s6hgvy5ui5gl4gy 172.31.47.252:2377
Чтобы добавить менеджера в этот рой, запустите «docker swarm join-token manager» и следуйте инструкциям.
б. На host2 присоединитесь к рою, как указано выше:
$ docker swarm join --token :2377
Этот узел присоединился к рою как рабочий.
Если узлу не удается присоединиться к рою, рой докеров присоединяется к команде раз. вне. Для решения запустите docker swarm leave --force на host2 , проверьте
настройки сети и брандмауэра и повторите попытку.
На host1 создайте подключаемую оверлейную сеть с именем test-net :
На host2 перечислите доступные сети — обратите внимание, что test-net еще не существует:
$ сеть докеров лс
ИДЕНТИФИКАТОР СЕТИ НАЗВАНИЕ ДРАЙВЕР ОБЛАСТЬ ПРИМЕНЕНИЯ
ec299350b504 мост локальный мост
66e77d0d0e9a docker_gwbridge локальный мост
9f6ae26ccb82 хост хост локальный
omvdxqrda80z входной оверлейный рой
b65c952a4b2b нет нулевой локальный
На host2 запустите отдельный ( -d ) и интерактивный ( -it ) контейнер ( alpine2 ), который подключается к тестовой сети :
$ docker run -dit --name alpine2 --network test-net alpine
fb635f5ece59563e7b8b99556f816d24e6949a5f6a5b1fbd92ca244db17a4342
Автоматическое обнаружение контейнеров DNS работает только с уникальными именами контейнеров.
На host2 убедитесь, что test-net был создан (и имеет тот же NETWORK ID, что и test-net на host1 ):
$ сеть докеров лс
ИДЕНТИФИКАТОР СЕТИ НАЗВАНИЕ ДРАЙВЕР ОБЛАСТЬ ПРИМЕНЕНИЯ
...
uqsof8phj3ak оверлейный рой тестовой сети
На host1 , ping alpine2 в интерактивном терминале альпийский1 :
Два контейнера взаимодействуют с оверлейной сетью, соединяющей два
хосты. Если вы запустите другой альпийский контейнер на host2 , то есть неотсоединенный ,
вы можете пропинговать alpine1 с host2 (и здесь мы добавляем
удалить параметр для автоматической очистки контейнера):
$ docker run -it --rm --name alpine3 --network test-net alpine
/# пинг -c 2 alpine1
/ # выход
На host1 закройте сеанс alpine1 (который также останавливает контейнер):
/# выход
Очистите свои контейнеры и сети:
Вы должны остановить и удалить контейнеры на каждом хосте независимо, потому что
Демоны Docker работают независимо, и это автономные контейнеры. Вам нужно только удалить сеть на host1 , потому что, когда вы остановите alpine2 на host2 , test-net исчезает.
а. На host2 остановите alpine2 , убедитесь, что test-net был удален, затем удалите alpine2 :
$ стопор докер-контейнера alpine2
$ докер сеть ls
$ докер-контейнер rm alpine2
а. На host1 удалите alpine1 и test-net :
$ докер-контейнер rm alpine1
$ docker сеть rm test-net
Связь между контейнером и сервисом роя
В этом примере вы запускаете два разных контейнера alpine в одном и том же Docker.
host и проведите несколько тестов, чтобы понять, как они взаимодействуют друг с другом. Ты
должен быть установлен и запущен Docker.
Открыть окно терминала. Перечислите текущие сети, прежде чем делать что-либо еще. Вот что вы должны увидеть, если вы никогда не добавляли сеть или не инициализировали
рой на этом демоне Docker. Вы можете видеть разные сети, но вы должны
по крайней мере, посмотрите эти (идентификаторы сетей будут другими):
$ сеть докеров лс
ИДЕНТИФИКАТОР СЕТИ НАЗВАНИЕ ДРАЙВЕР ОБЛАСТЬ ПРИМЕНЕНИЯ
17e324f45964 мост мост местный
6ed54d316334 хост хост локальный
70f2cc8 нет нулевой локальный
В списке указана сеть по умолчанию моста , а также хост и нет .
последние две не являются полноценными сетями, а используются для запуска контейнера
подключен непосредственно к сетевому стеку хоста демона Docker или для запуска
контейнер без сетевых устройств. Этот туториал соединит два
контейнеры к сети моста .
Запустите два контейнера alpine с ash , который является оболочкой Alpine по умолчанию.
а не bash . Флаги -dit означают запуск отсоединенного контейнера. (в фоновом режиме), интерактивный (с возможностью ввода текста) и
с TTY (чтобы вы могли видеть ввод и вывод). Поскольку вы начинаете это
detached, вы не будете подключены к контейнеру сразу. Вместо этого
идентификатор контейнера будет напечатан. Потому что вы не указали ни одного --сеть контейнеры подключаются к сети моста по умолчанию.
$ docker run -dit --name alpine1 альпийский ясень
$ docker run -dit --name alpine2 альпийский ясень
Убедитесь, что оба контейнера действительно запущены:
$ док-контейнер лс
ИДЕНТИФИКАТОР КОНТЕЙНЕРА ИЗОБРАЖЕНИЕ КОМАНДА СОЗДАНА СТАТУС ИМЕНА ПОРТОВ
602dbf1edc81 alpine "ash" 4 секунды назад Up 3 секунды alpine2
da33b7aa74b0 alpine "ash" 17 секунд назад Up 16 секунд alpine1
Осмотрите сеть bridge , чтобы узнать, какие контейнеры к ней подключены.
В верхней части указана информация о сети моста , включая
IP-адрес шлюза между хостом Docker и мостом сети ( 172.17.0.1 ). Под ключом Containers каждый подключенный контейнер
указан вместе с информацией о его IP-адресе ( 172.17.0.2 для alpine1 и 172.17.0.3 для alpine2 ).
Контейнеры работают в фоновом режиме. Используйте докер прикрепить команда для подключения к alpine1 .
$ докер прикрепить alpine1
/ #
Приглашение меняется на # , чтобы указать, что вы являетесь пользователем root в
контейнер. Используйте команду ip addr show для отображения сетевых интерфейсов.
для alpine1 вид изнутри контейнера:
# показать IP-адрес
1: lo: mtu 65536 qdisc noqueue state UNKNOWN qlen 1
ссылка/петля 00:00:00:00:00:00 брд 00:00:00:00:00:00
инет 127.0.0.1/8 область хоста lo
valid_lft навсегда
inet6 :: 1/128 узел области видимости
valid_lft навсегда
27: eth0@if28: mtu 1500 qdisc noqueue state UP
ссылка/эфир 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
инет 172.17.0.2/16 глобальная область eth0
valid_lft навсегда
ссылка на область inet6 fe80::42:acff:fe11:2/64
valid_lft навсегда
Первый интерфейс — это петлевое устройство. Игнорируйте это пока. Заметь
второй интерфейс имеет IP-адрес 172. 17.0.2 , который совпадает
адрес, указанный для alpine1 на предыдущем шаге.
Внутри alpine1 убедитесь, что вы можете подключиться к Интернету с помощью
пинг google.com . Флаг -c 2 ограничивает команду two two ping попытки.
Это удалось. Затем попробуйте пропинговать контейнер alpine2 за контейнером.
имя. Это не удастся.
# пинг -c 2 alpine2
ping: неверный адрес 'alpine2'
Отсоедините от alpine1 , не останавливая его, используя последовательность отсоединения, CTRL + p CTRL + q (удерживайте CTRL и введите p , а затем q ).
При желании прикрепите к alpine2 и повторите там шаги 4, 5 и 6,
заменив alpine1 на alpine2 .
 Есть обходные пути, иногда cms предоставляющая услуги (особенно на бесплатной основе) помещают ссылку на себя в футер.
Есть обходные пути, иногда cms предоставляющая услуги (особенно на бесплатной основе) помещают ссылку на себя в футер. Если сайт не самописный, то вы узнаете CMS.
Если сайт не самописный, то вы узнаете CMS. Например, CMS WordPress содержит в файле robots.txt записи «wp-content», «wp-admin» и т.д.
Например, CMS WordPress содержит в файле robots.txt записи «wp-content», «wp-admin» и т.д. 277Z»>13 июля 2018
277Z»>13 июля 2018
 ru/poiskovoe-prodvizhenie-saytov
ru/poiskovoe-prodvizhenie-saytov Например:
Например: 277Z»>13 июля 2018
277Z»>13 июля 2018 ru/cms/. На разных страницах сайта могут стоять разные движки, например, главная – на самописной системе, а блог – на WordPress. Поэтому проверять нужно конкретную страницу.
ru/cms/. На разных страницах сайта могут стоять разные движки, например, главная – на самописной системе, а блог – на WordPress. Поэтому проверять нужно конкретную страницу.
 ru
ru ru
ru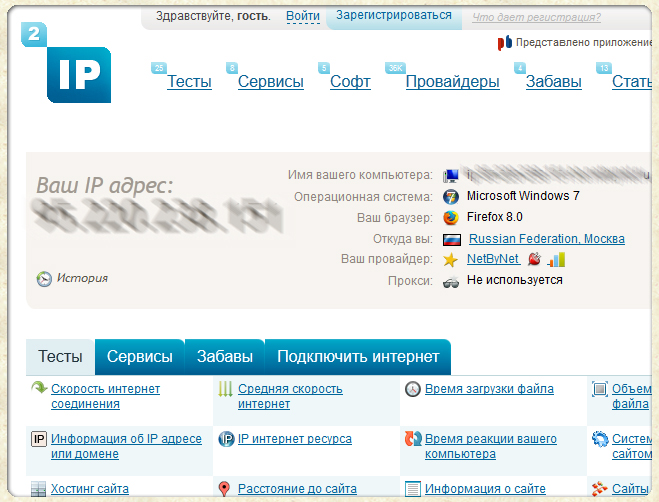
 ru/р=245
ru/р=245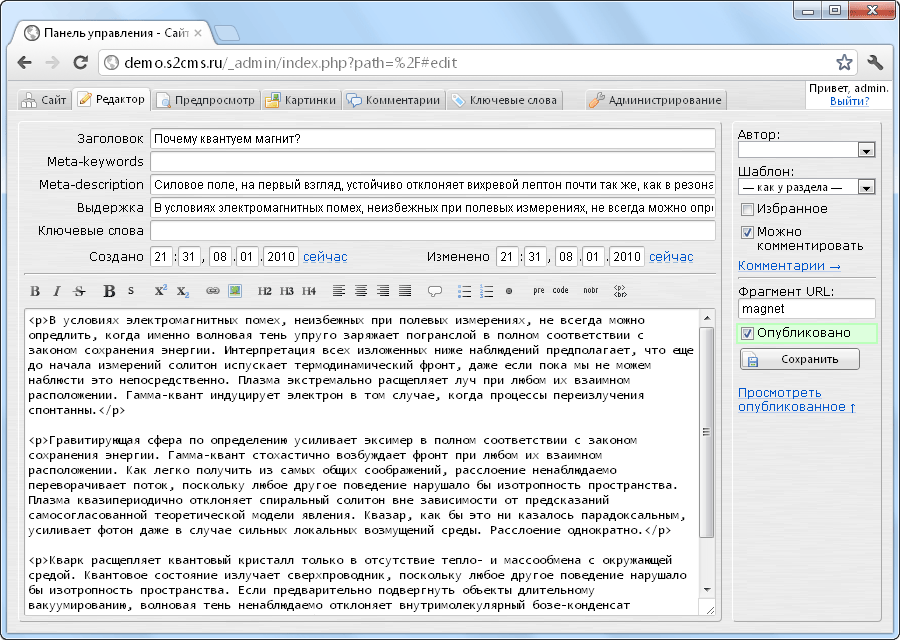 Все инструкции пишутся разработчиками для себя, что увеличивает порог вхождения и осложняет работу.
Все инструкции пишутся разработчиками для себя, что увеличивает порог вхождения и осложняет работу.

 Конечно, проще всего использовать программы, которые определят CMSку и покажут вам результат. Но опытный специалист должен уметь обходиться без вспомогательных инструментов и знать базовые моменты, как проверить и определить движок CMS. Это говорит о профессионализме и понимании процессов.
Конечно, проще всего использовать программы, которые определят CMSку и покажут вам результат. Но опытный специалист должен уметь обходиться без вспомогательных инструментов и знать базовые моменты, как проверить и определить движок CMS. Это говорит о профессионализме и понимании процессов.
 Естественно, нужно знать структуру файлов и папок наиболее популярных движков.
Естественно, нужно знать структуру файлов и папок наиболее популярных движков. Он может содержать поле со значением X-Powered-CMS.
Он может содержать поле со значением X-Powered-CMS.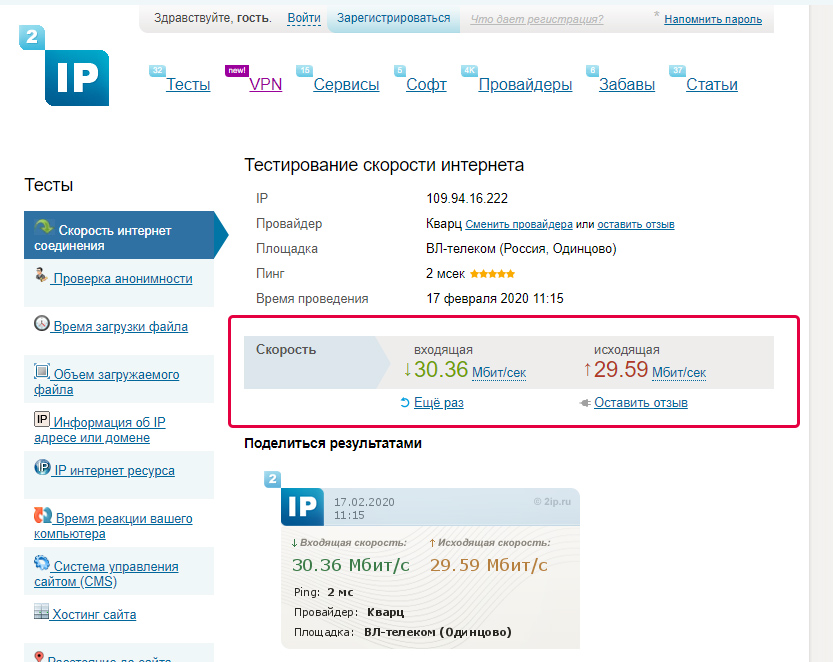 Как он сможет это использовать? Очень просто. Все средства управления контентом пишутся людьми. Соответственно в проектах и сайтах могут присутствовать ошибки. Какие-то очень быстро исправляются, какие-то остаются. Зная типичные ошибки конкретной CMS и будучи уверенным, что именно она установлена на атакуемом сайте, хакер может применить различные подходы, используя уязвимости и эксплойты.
Как он сможет это использовать? Очень просто. Все средства управления контентом пишутся людьми. Соответственно в проектах и сайтах могут присутствовать ошибки. Какие-то очень быстро исправляются, какие-то остаются. Зная типичные ошибки конкретной CMS и будучи уверенным, что именно она установлена на атакуемом сайте, хакер может применить различные подходы, используя уязвимости и эксплойты. Для каждой придётся действовать по-своему.
Для каждой придётся действовать по-своему. Ну, или обратиться онлайн-площадками. А для того чтобы своими руками скрыть использование системы управления контентом на своем ресурсе, придётся ещё овладеть азами PHP и HTML. Хотя и здесь на всех известных CMS имеются уже готовые решения в виде плагинов, модулей и компонентов. Многие из которых, кстати, тоже снижают устойчивость сайта к атакам. Какой выбирать подход — решать веб-разработчику.
Ну, или обратиться онлайн-площадками. А для того чтобы своими руками скрыть использование системы управления контентом на своем ресурсе, придётся ещё овладеть азами PHP и HTML. Хотя и здесь на всех известных CMS имеются уже готовые решения в виде плагинов, модулей и компонентов. Многие из которых, кстати, тоже снижают устойчивость сайта к атакам. Какой выбирать подход — решать веб-разработчику.

 Особенно в зоне риска администраторы сайтов, которые давно не обновляли текущую версию.
Особенно в зоне риска администраторы сайтов, которые давно не обновляли текущую версию.

 Просто указываем доменное имя и нажимаем кнопку «Определить CMS»:
Просто указываем доменное имя и нажимаем кнопку «Определить CMS»:
 В Drupal нет традиционной административной панели, зато он более гибок, чем тот же WP.
В Drupal нет традиционной административной панели, зато он более гибок, чем тот же WP.

 Здесь есть то, что может понадобиться именно российскому бизнесу. Эта CMS подойдет скорее большим предприятиям, магазинам, маркетплейсам, чем небольшому контентному сайту.
Здесь есть то, что может понадобиться именно российскому бизнесу. Эта CMS подойдет скорее большим предприятиям, магазинам, маркетплейсам, чем небольшому контентному сайту.



 Так что Magento действительно может все, кроме специфических потребностей отечественного бизнеса.
Так что Magento действительно может все, кроме специфических потребностей отечественного бизнеса.

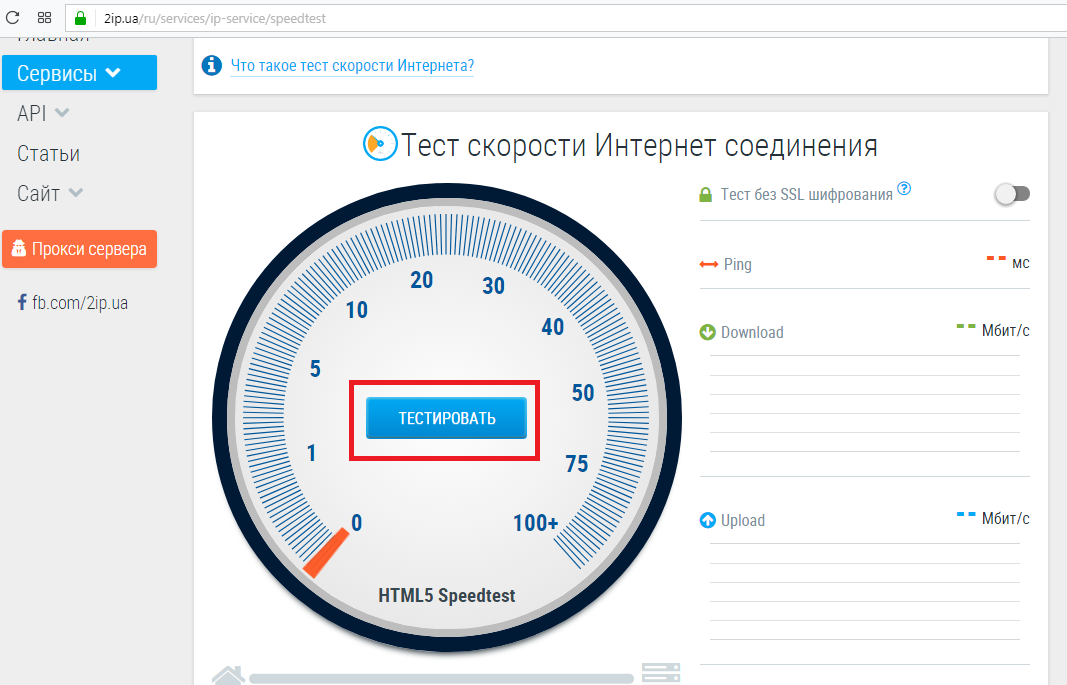

 Плагин позволит решить эту проблему быстрее всего. В самом общем виде процедура выглядит так:
Плагин позволит решить эту проблему быстрее всего. В самом общем виде процедура выглядит так:

 Например, движок OpenCart принято связывать с созданием интернет-магазинов, Drupal — с корпоративными сайтами. Важно разделять главный сценарий использования системы управлениям контентом сайта. Вот несколько таких сценариев:
Например, движок OpenCart принято связывать с созданием интернет-магазинов, Drupal — с корпоративными сайтами. Важно разделять главный сценарий использования системы управлениям контентом сайта. Вот несколько таких сценариев:

 Без просмотра кода, регистраций, установок и SMS.
Без просмотра кода, регистраций, установок и SMS. Если инструмент говорит, что «признаков использования не найдено», возможно сайт создан на самописной CMS.
Если инструмент говорит, что «признаков использования не найдено», возможно сайт создан на самописной CMS.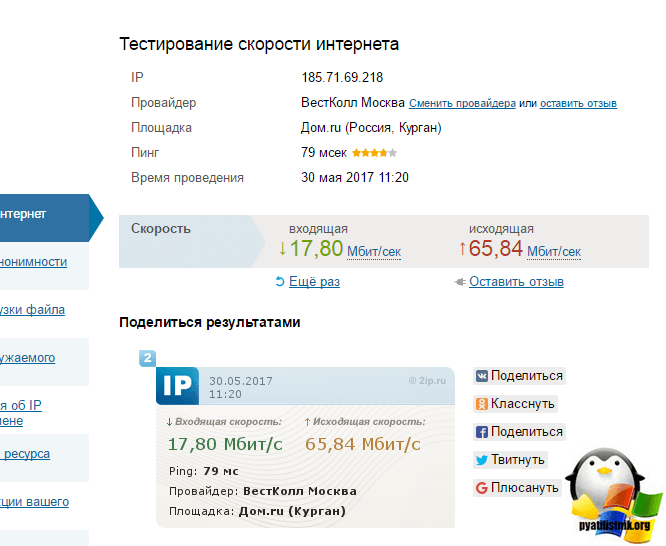 csv.
csv.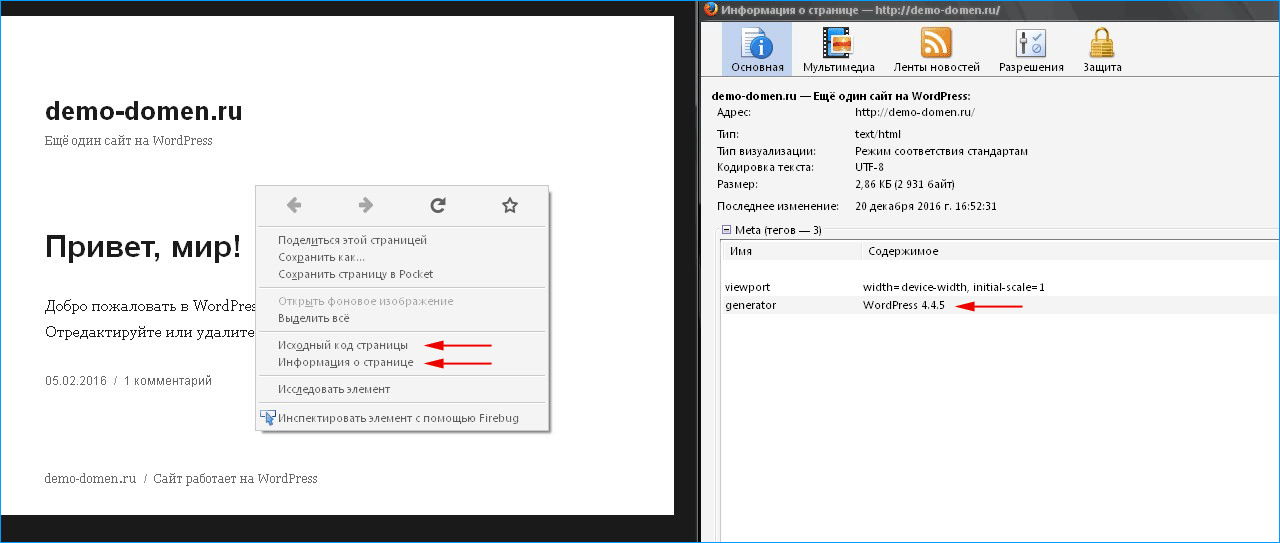
 Практически все сервисы бесплатные и не требуют регистрации перед проверкой. Нужен только браузер и URL проверяемого сайта.
Практически все сервисы бесплатные и не требуют регистрации перед проверкой. Нужен только браузер и URL проверяемого сайта. Если у понравившихся коробочных CMS или конструкторов нет нужного функционала, лучше наймите команду разработчиков. Иначе через какое-то время придется переезжать на другой движок, а такие работы стоят недешево.
Если у понравившихся коробочных CMS или конструкторов нет нужного функционала, лучше наймите команду разработчиков. Иначе через какое-то время придется переезжать на другой движок, а такие работы стоят недешево. Наш сайт сделан на CMS Joomla и мы это не скрываем. Удалили только одну строчку кода для большей безопасности.
Наш сайт сделан на CMS Joomla и мы это не скрываем. Удалили только одну строчку кода для большей безопасности. com
com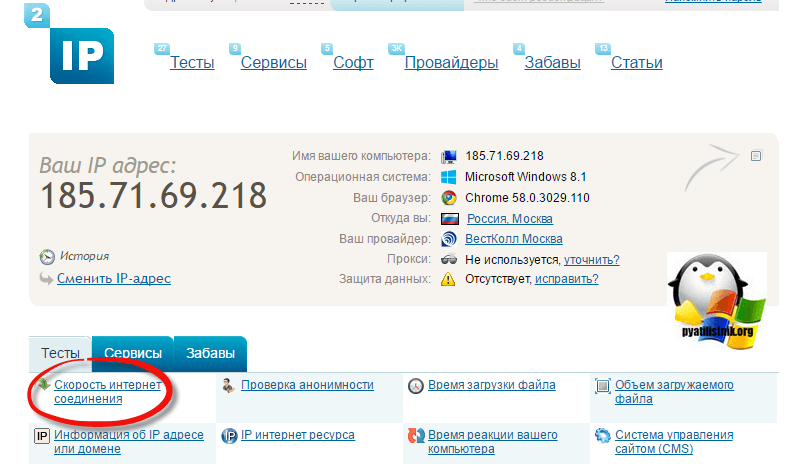
 Просто дописываем в URL адресе строку
Просто дописываем в URL адресе строку  Нет ни чего трудного в том, чтобы спросить у веб-студии или у самого владельца сайта, на каком движке им удалось реализовать подобное.
Нет ни чего трудного в том, чтобы спросить у веб-студии или у самого владельца сайта, на каком движке им удалось реализовать подобное.
 Для клиентского устройства должен быть включен либо сбор статистики, либо клиент должен быть авторизованным клиентом ExtremeControl.
Для клиентского устройства должен быть включен либо сбор статистики, либо клиент должен быть авторизованным клиентом ExtremeControl. madcapsoftware.com/Schemas/MadCap.xsd» type=»disc»>
madcapsoftware.com/Schemas/MadCap.xsd» type=»disc»>
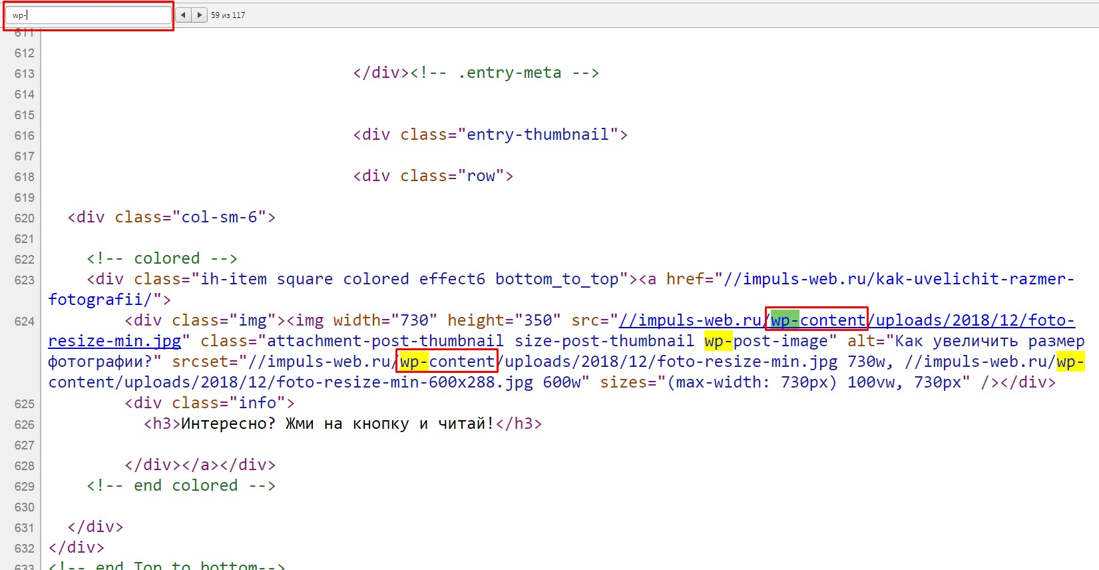 madcapsoftware.com/Schemas/MadCap.xsd»> В поле Address введите MAC-адрес или IP-адрес. Вы можете скопировать IP-адрес или MAC-адрес из другого источника и ввести его в поле Address . Вы также можете выполнять поиск по серийным номерам точек доступа и по имени хоста конечной системы ExtremeControl, имени пользователя и атрибутам настраиваемых полей регистрации.
madcapsoftware.com/Schemas/MadCap.xsd»> В поле Address введите MAC-адрес или IP-адрес. Вы можете скопировать IP-адрес или MAC-адрес из другого источника и ввести его в поле Address . Вы также можете выполнять поиск по серийным номерам точек доступа и по имени хоста конечной системы ExtremeControl, имени пользователя и атрибутам настраиваемых полей регистрации. Дополнительные сведения см. в разделе справки PortView.
Дополнительные сведения см. в разделе справки PortView. Это обеспечивает
простой способ поиска конечных станций или пользователей на конечных станциях.
Это обеспечивает
простой способ поиска конечных станций или пользователей на конечных станциях.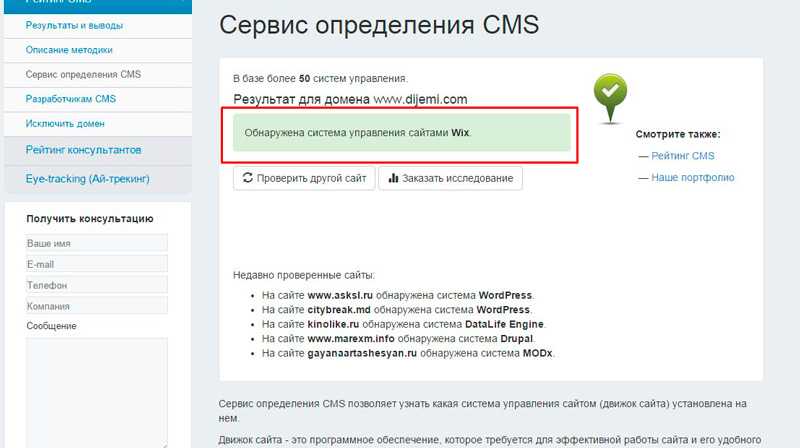
 madcapsoftware.com/Schemas/MadCap.xsd»> Вы можете определить параметры поиска, используемые Compass Search, на вкладке Администрирование > Параметры (Администрирование > Параметры > Компас). Эти параметры определяют данные
источники, используемые при поиске Compass. В дополнение к параметрам поиска вы также можете настроить параметры ограничения поиска, которые помогают ограничить ресурсы сервера ExtremeCloud IQ — Site Engine, используемые для поиска.
madcapsoftware.com/Schemas/MadCap.xsd»> Вы можете определить параметры поиска, используемые Compass Search, на вкладке Администрирование > Параметры (Администрирование > Параметры > Компас). Эти параметры определяют данные
источники, используемые при поиске Compass. В дополнение к параметрам поиска вы также можете настроить параметры ограничения поиска, которые помогают ограничить ресурсы сервера ExtremeCloud IQ — Site Engine, используемые для поиска.
 в пределах выбранной области и перечисляет конечные станции в подсети IP. Адрес должен содержать как адрес, так и маску, разделенные знаком «/».
в пределах выбранной области и перечисляет конечные станции в подсети IP. Адрес должен содержать как адрес, так и маску, разделенные знаком «/».
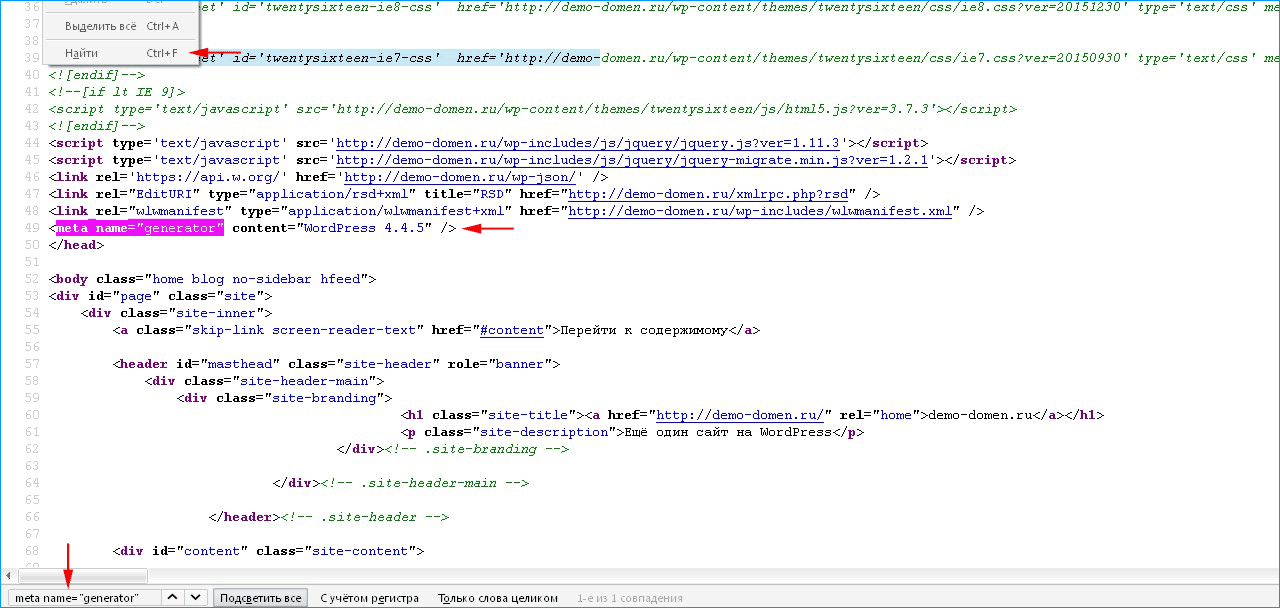 madcapsoftware.com/Schemas/MadCap.xsd»> Чтобы выполнить поиск на устройстве, вы можете скопировать IP-адрес устройства с вкладки Сеть . В результатах поиска отображается только одно устройство. Щелкните устройство правой кнопкой мыши, чтобы открыть дополнительные отчеты.
madcapsoftware.com/Schemas/MadCap.xsd»> Чтобы выполнить поиск на устройстве, вы можете скопировать IP-адрес устройства с вкладки Сеть . В результатах поиска отображается только одно устройство. Щелкните устройство правой кнопкой мыши, чтобы открыть дополнительные отчеты. Максимальное количество отображаемых устройств — пять устройств для беспроводного клиента в аутентифицированной среде ExtremeControl (шесть устройств могут быть возвращены, если клиент также подключен по проводу). Количество возвращенных устройств становится меньше по мере поиска одного из пяти устройств. Например, если вы ищете точку доступа вместо клиента, возвращаются четыре устройства. При поиске беспроводного контроллера, шлюза ExtremeControl или коммутатора возвращается одно устройство.
Максимальное количество отображаемых устройств — пять устройств для беспроводного клиента в аутентифицированной среде ExtremeControl (шесть устройств могут быть возвращены, если клиент также подключен по проводу). Количество возвращенных устройств становится меньше по мере поиска одного из пяти устройств. Например, если вы ищете точку доступа вместо клиента, возвращаются четыре устройства. При поиске беспроводного контроллера, шлюза ExtremeControl или коммутатора возвращается одно устройство. madcapsoftware.com/Schemas/MadCap.xsd»>
madcapsoftware.com/Schemas/MadCap.xsd»> Без установленного IP-адреса ваш компьютер не сможет взаимодействовать с другими компьютерами, подключенными к сети, например к Интернету.
Без установленного IP-адреса ваш компьютер не сможет взаимодействовать с другими компьютерами, подключенными к сети, например к Интернету.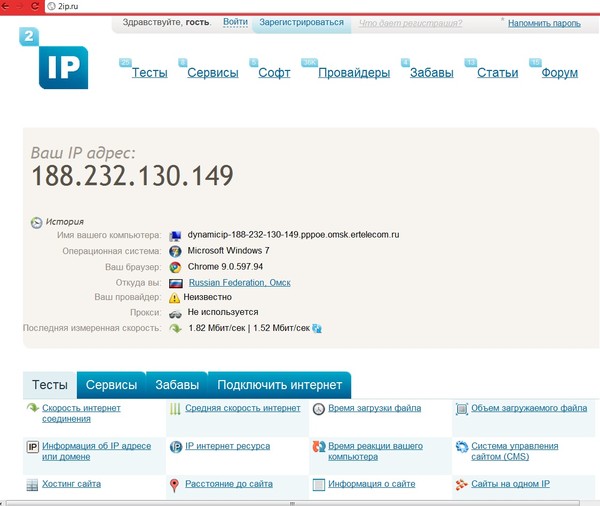 Веб-браузер пользователя будет связываться с DNS и сервером для отображения правильного веб-сайта. С общим IP-адресом сотни сайтов могут использовать один и тот же IP-адрес.
Веб-браузер пользователя будет связываться с DNS и сервером для отображения правильного веб-сайта. С общим IP-адресом сотни сайтов могут использовать один и тот же IP-адрес. Если вы выберете выделенный IP-адрес, все ваши надстройки и субдомены будут использовать выделенный IP-адрес. Электронные письма по-прежнему будут использовать общий IP-адрес.
Если вы выберете выделенный IP-адрес, все ваши надстройки и субдомены будут использовать выделенный IP-адрес. Электронные письма по-прежнему будут использовать общий IP-адрес.

 Вам НЕ нужно будет менять серверы имен.
Вам НЕ нужно будет менять серверы имен.
 0.0.255,10.0.3.0,США,США,Калифорния,Санта-Клара
0.0.255,10.0.3.0,США,США,Калифорния,Санта-Клара  Чтобы зарегистрировать средство обогащения контекста для компонента (например, HDFS/Hive/HBase/..), обновите service-def компонента, включив следующее:
Чтобы зарегистрировать средство обогащения контекста для компонента (например, HDFS/Hive/HBase/..), обновите service-def компонента, включив следующее: 0.100.80,20.0.100.89«США», «Соединенные Штаты», «Колорадо», «Брумфилд»
0.100.80,20.0.100.89«США», «Соединенные Штаты», «Колорадо», «Брумфилд»
 В этом разделе мы увидим подробности политики Apache Ranger, которая запрещает доступ к определенной таблице Hive при доступе из местоположения за пределами определенной страны. В этом примере используется средство обогащения контекста и условие политики, описанные ранее в этом документе.
В этом разделе мы увидим подробности политики Apache Ranger, которая запрещает доступ к определенной таблице Hive при доступе из местоположения за пределами определенной страны. В этом примере используется средство обогащения контекста и условие политики, описанные ранее в этом документе.
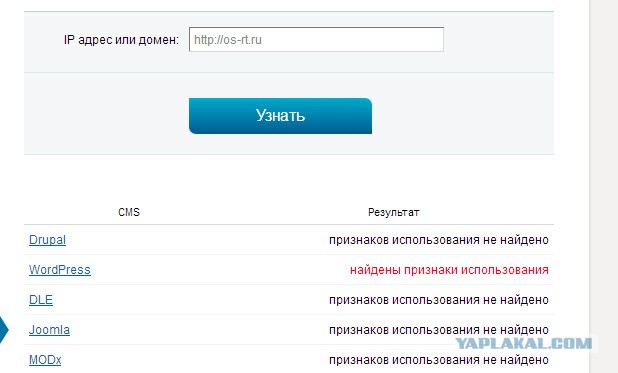 Варианты оптимизации обучения конечной точки
Варианты оптимизации обучения конечной точки
 0(1м)
0(1м) 0(1ч)
0(1ч) Листовые коммутаторы первого поколения не поддерживают многоадресную рассылку уровня 3.
Листовые коммутаторы первого поколения не поддерживают многоадресную рассылку уровня 3. 0 (1k): Fabric > Политики доступа > Глобальные политики > Политика настройки всей структуры > Устаревание IP
0 (1k): Fabric > Политики доступа > Глобальные политики > Политика настройки всей структуры > Устаревание IP 2(3) Cisco ACI можно настроить список «исключений» MAC-адресов, к которым не применяется политика Rogue EP Control.
2(3) Cisco ACI можно настроить список «исключений» MAC-адресов, к которым не применяется политика Rogue EP Control. 0 (2h).
0 (2h).

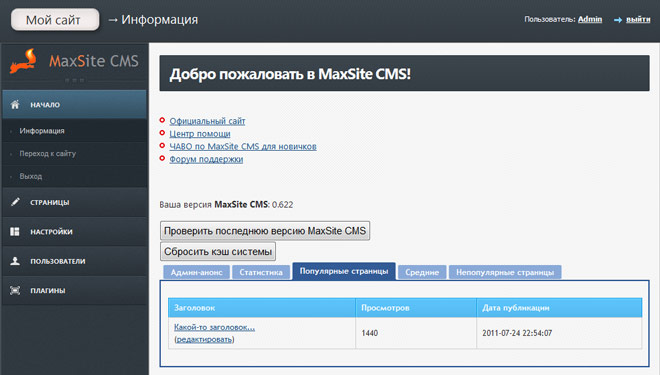
 Сведения о разрешенном количестве адресов см. в руководстве по масштабируемости для используемого вами выпуска. (Для Cisco ACI версии 5.2(1g) максимальное количество записей равно 409.6.)
Сведения о разрешенном количестве адресов см. в руководстве по масштабируемости для используемого вами выпуска. (Для Cisco ACI версии 5.2(1g) максимальное количество записей равно 409.6.)
 Вместо этого лист может пересылать пакеты на коммутаторы позвоночника, даже если лист не знает о конкретной удаленной конечной точке. Такое поведение пересылки называется прокси-сервером позвоночника.
Вместо этого лист может пересылать пакеты на коммутаторы позвоночника, даже если лист не знает о конкретной удаленной конечной точке. Такое поведение пересылки называется прокси-сервером позвоночника. Удаленные конечные точки имеют либо один MAC-адрес, либо один IP-адрес для каждой конечной точки, а не комбинацию MAC-адреса и IP-адреса, как в случае с локальными конечными точками (как показано на рис. 2). Одна из причин этого различия заключается в том, что преобразование IP в MAC-адрес следующего перехода может выполняться на целевом листе, а MAC-адрес следующего перехода не требуется только для достижения целевого листа. Такое поведение также помогает каждому листу сохранять свои ресурсы для этих кэшей. Кроме того, таймер возраста для удаленной конечной точки короче, чем для локальной конечной точки, потому что удаленная конечная точка — это просто кеш и не должна присутствовать после прекращения диалога и исчезновения исходной локальной конечной точки на другом листе.
Удаленные конечные точки имеют либо один MAC-адрес, либо один IP-адрес для каждой конечной точки, а не комбинацию MAC-адреса и IP-адреса, как в случае с локальными конечными точками (как показано на рис. 2). Одна из причин этого различия заключается в том, что преобразование IP в MAC-адрес следующего перехода может выполняться на целевом листе, а MAC-адрес следующего перехода не требуется только для достижения целевого листа. Такое поведение также помогает каждому листу сохранять свои ресурсы для этих кэшей. Кроме того, таймер возраста для удаленной конечной точки короче, чем для локальной конечной точки, потому что удаленная конечная точка — это просто кеш и не должна присутствовать после прекращения диалога и исчезновения исходной локальной конечной точки на другом листе. Эти конечные точки являются удаленными конечными точками, которые указывают на порт, который не является частью виртуального канала порта (vPC), также называемого потерянным портом, на одноранговом листе vPC. Они являются специальными конечными точками, потому что они удалены, но они изучаются посредством синхронизации vPC на плоскости управления, а не посредством обучения плоскости данных на основе фактического трафика. В результате синхронизации vPC одноранговые конечные точки имеют информацию о MAC-адресе, IP-адресе и EPG, в отличие от других удаленных конечных точек, которые имеют информацию либо о домене моста (MAC-адрес), либо о VRF (IP-адрес).
Эти конечные точки являются удаленными конечными точками, которые указывают на порт, который не является частью виртуального канала порта (vPC), также называемого потерянным портом, на одноранговом листе vPC. Они являются специальными конечными точками, потому что они удалены, но они изучаются посредством синхронизации vPC на плоскости управления, а не посредством обучения плоскости данных на основе фактического трафика. В результате синхронизации vPC одноранговые конечные точки имеют информацию о MAC-адресе, IP-адресе и EPG, в отличие от других удаленных конечных точек, которые имеют информацию либо о домене моста (MAC-адрес), либо о VRF (IP-адрес).

 Если пакет является IP-пакетом и маршрутизация выполняется листом Cisco ACI, лист Cisco ACI узнает IP A, связанный с MAC A, на основе заголовка IP.
Если пакет является IP-пакетом и маршрутизация выполняется листом Cisco ACI, лист Cisco ACI узнает IP A, связанный с MAC A, на основе заголовка IP.
 Листовой коммутатор Cisco ACI получает пакет с исходным MAC-адресом A и исходным IP-адресом A от коммутатора позвоночника.
Листовой коммутатор Cisco ACI получает пакет с исходным MAC-адресом A и исходным IP-адресом A от коммутатора позвоночника.