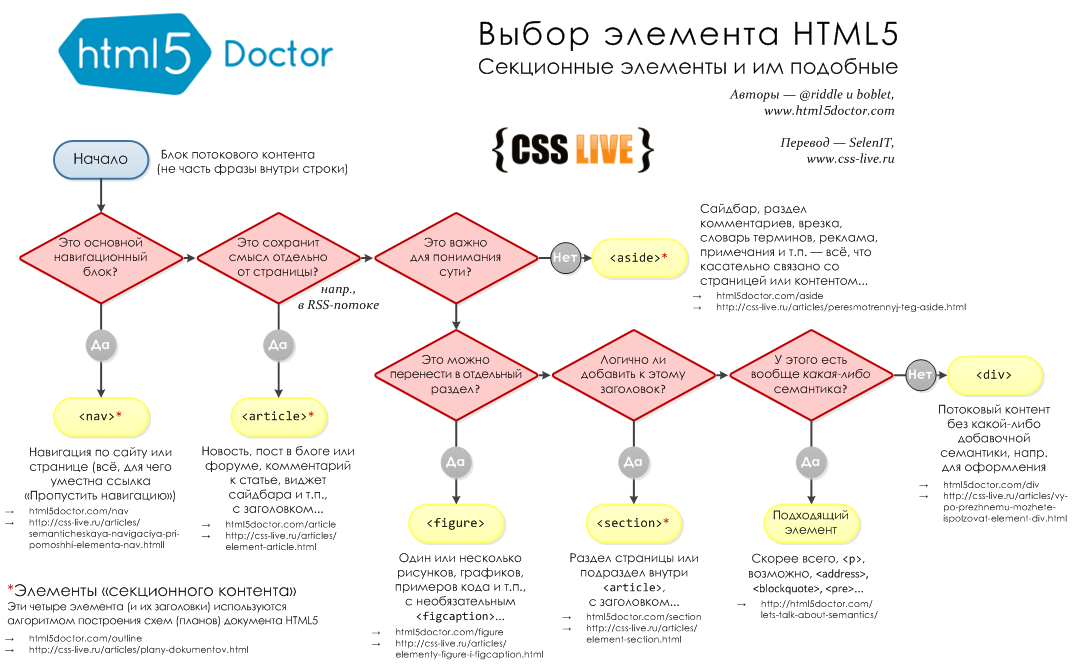
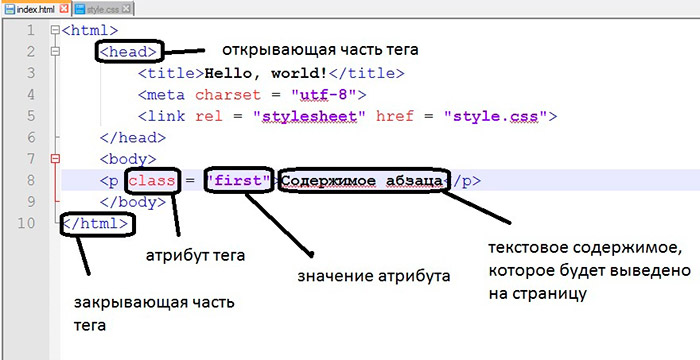
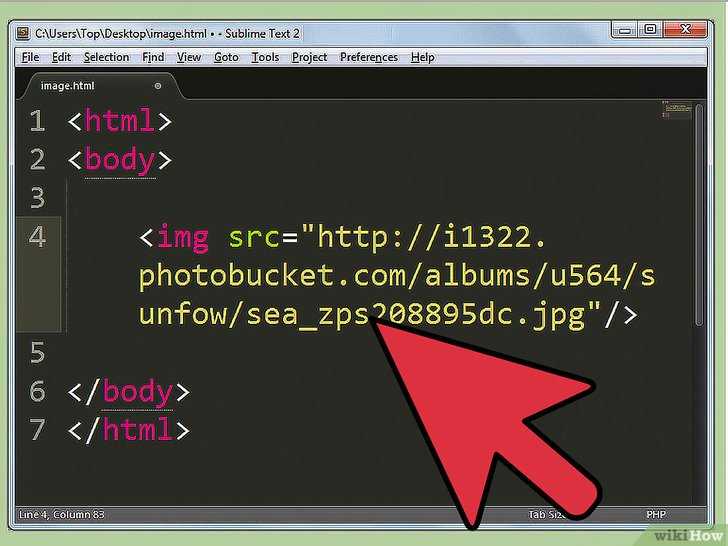
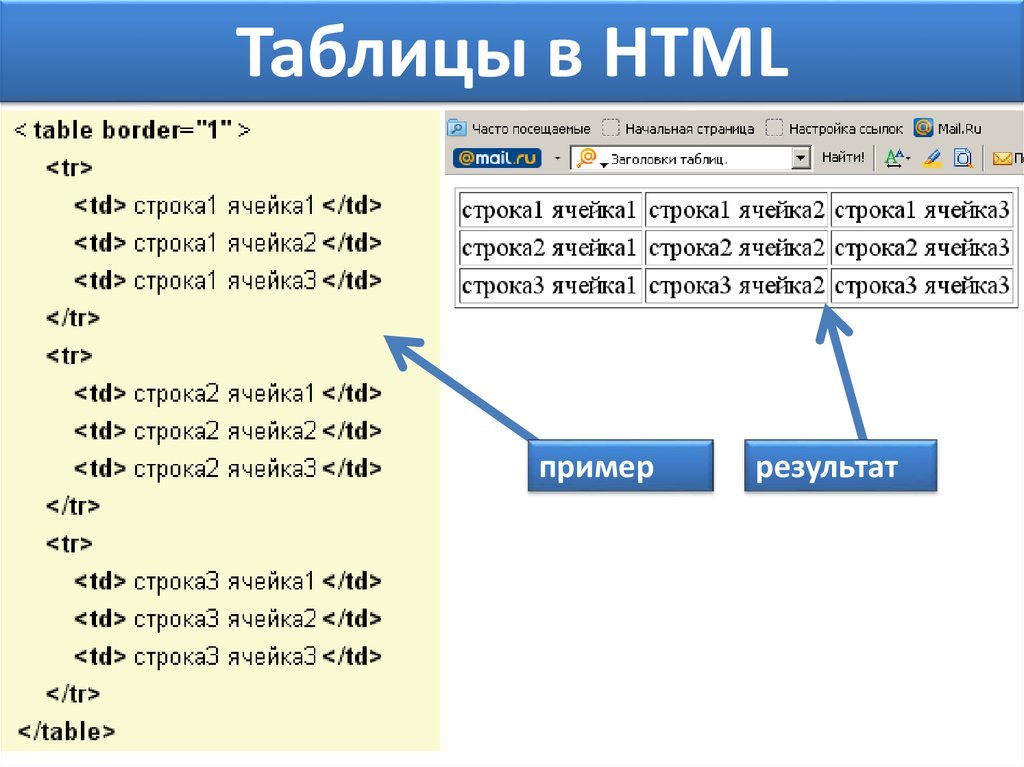
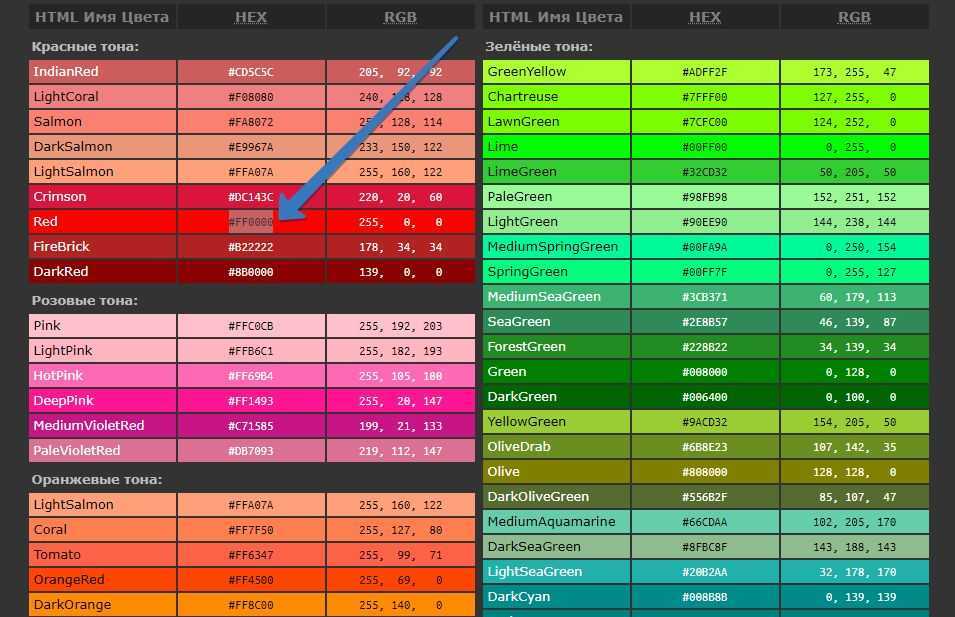
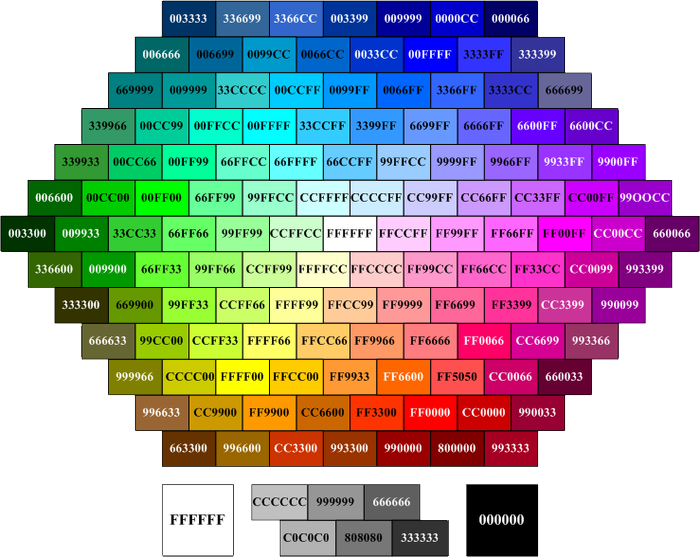
О валидации кода w3c на Page-speed.ru
Что такое валидация HTML?
Валидация HTML является одним из основных факторов, влияющих на качество веб-дизайна.
Консорциум Всемирной паутины (W3C) — это международное сообщество, которое де-факто определило стандарты написания HTML кода на вашем веб-сайте. Эти правила были созданы для того, чтобы браузеры могли корректно обрабатывать код и правильно отображать веб-страницы. Было много версий стандартов HTML, последней версией является HTML5. Она добавила интересные функции, такие как хранение данных локально в браузерах пользователей, встроенная поддержка аудио и видео, поддержка векторной графики и прочее.
В Интернете доступно множество инструментов, которые специально созданы для проверки кода в соответствии со стандартами W3C. Для HTML5 самым популярным является Nu HTML Checker, а для вашего удобства вы можете им воспользоваться на нашем сайте.
На что влияет валидность кода
- Поддержка кроссбраузерности.

- Если ваш HTML-код валиден, он будет корректно отображаться во всех основных веб-браузерах (Chrome, Safari, Firefox, Opera, Edge/Explorer), а также будет выглядеть одинаково или почти одинаково в каждом из них.
- Оптимизация в поисковых системах.
- Это повысит вероятность правильной индексации содержимого вашей страницы поисковыми системами. Ваш контент должен соответствовать семантической верстке, и один из способов обеспечить это является проверка кода. Валидатор поможет убедиться, что все HTML-теги закрыты и вы их правильно используете, а так же покажет другие важные и распространенные проблемы, которые могут помешать нормальной индексации поисковыми роботами. По утверждению Google, правильность кода не влияет на позиции в поисковиках. Но при этом наличие ошибок в коде способно негативно повлиять на сканирование микроразметки и адаптивность под мобильные устройства.
- Возникновение ошибок в браузере.
- Бывают ситуации, когда владелец сайта недоумевает, почему один блок «съехал». Или почему в одном браузере все в порядке, а в другом верстка плывет. И пытается решить это при помощи CSS. Вместо этого в первую очередь следует проверить код на ошибки – высока вероятность того, что проблема кроется именно в этом.
- Чистый HTML-код.
- Если ваш код проверен и написан правильно, он сделает задачу по его обновлению и внесению изменений намного проще. Это значительно снизит шансы, что редактирование CSS или добавление фрагмента кода HTML приведет к нарушению вашей веб-страницы.
- Поддержка новейших версий веб-браузера.
- Браузеры часто обновляются и, как правило, стараются поддерживать и соблюдать стандарты HTML W3C. Если ваш код соответствует требованиям W3C, он должен снизить шансы на появление «сломанной» страницы в будущих версиях.

 Или почему в одном браузере все в порядке, а в другом верстка плывет. И пытается решить это при помощи CSS. Вместо этого в первую очередь следует проверить код на ошибки – высока вероятность того, что проблема кроется именно в этом.
Или почему в одном браузере все в порядке, а в другом верстка плывет. И пытается решить это при помощи CSS. Вместо этого в первую очередь следует проверить код на ошибки – высока вероятность того, что проблема кроется именно в этом.Частые вопросы
- Валидатор показывает ошибки на моем сайте, но он отображается нормально.
- Условно ошибки можно разделить на две категории: критические и не критические. И, несмотря на то, что современные браузеры стараются понимать такой код – это не дает гарантии корректного отображения во всех браузерах и устройствах. Помимо этого, некоторые из ваших материалов могут не индексироваться должным образом поисковыми системами.
- Валидатор ругается на нестандартные атрибуты.
- Атрибуты, которые не задокументированы W3C считаются ошибочными. Однако, в некоторых случаях их удаление может привести к потере функционала. Например, атрибуты flag и price служат для связки целей. Я бы не стал считать это ошибкой, которая может навредить сайту и удалять их не нужно.
- На моем сайте тысячи страниц с ошибками.
- Большинство сайтов и интернет-магазинов работают на различных CMS (система управления сайтом). Это означает, что страницы выводятся с помощью шаблона. Как правило, для того чтобы избавиться от ошибок на типовых страницах – достаточно исправить их в шаблоне. Но иногда код находится в базе данных – в этом случае нужно работать индивидуально над каждой страницей. Такой же вариант работы, если у вас сайт на чистом html.
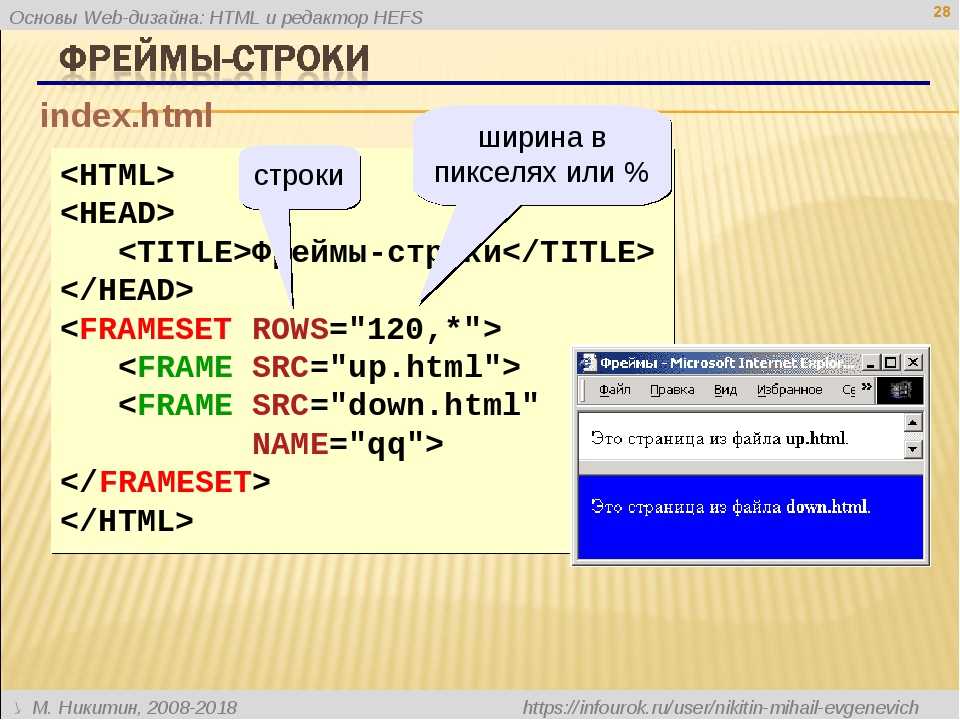 И, несмотря на то, что современные браузеры стараются понимать такой код – это не дает гарантии корректного отображения во всех браузерах и устройствах. Помимо этого, некоторые из ваших материалов могут не индексироваться должным образом поисковыми системами.
И, несмотря на то, что современные браузеры стараются понимать такой код – это не дает гарантии корректного отображения во всех браузерах и устройствах. Помимо этого, некоторые из ваших материалов могут не индексироваться должным образом поисковыми системами.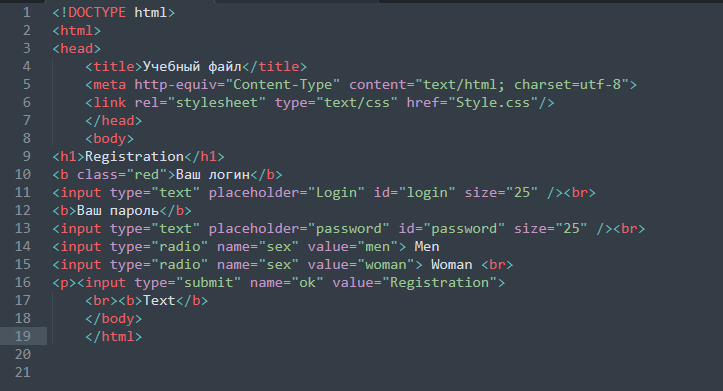 Такой же вариант работы, если у вас сайт на чистом html.
Такой же вариант работы, если у вас сайт на чистом html.Как исправить ошибки кода
Если вы обладаете навыками программирования и верстки, то исправить большинство ошибок для вас не составит особого труда – достаточно понимать смысл ошибки, на которую указывает валидатор.
Владельцам сайтов, не обладающим такими навыками без посторонней помощи не обойтись. На нашем сайте вы можете заполнить заявку на бесплатный анализ и оценку стоимости работ. А при одновременном заказе исправления ошибок кода и ускорения сайта вы получите 10% скидку.
Если вы не знаете, как исправить ту или иную ошибку – спрашивайте в комментариях, постараюсь помочь.
W3C, валидный код, ошибки html
- Поделиться:
HTML5 – Check it Before you Wreck it with Mike[tm] Smith
The W3C’s Mike[tm] Smith (AKA @sideshowbarker) is the man with his head in the W3C validation markup checking tool source code; he makes the magic happen. Questions were asked for the HTML5 Doctor reader’s delight and edification.
Questions were asked for the HTML5 Doctor reader’s delight and edification.
Russian Translation: Не проверив HTML5-кода, не суйся в воду — с Майком™ Смитом
First off tell us a bit about what you do and what you work on
Mike[tm] Smith – Deputy Director @W3C – permissive work mode edition
I don’t work. I’m an old-world boulevardier.http://familycareintl.org/blog/2015/01/15/canadian-viagra-costs/
I drink tea with my pinky extended and I only expend effort on anything if it somehow amuses me to do so. For the last few years it’s amused me to spend time working on software for helping people check whether or not their documents meet certain requirements in the HTML spec.
What’s the difference between DTD and schema based checking?
DTDs are chiseled into stone tablets. And so for processing they require stone-tablet-aware toolchains. Sadly however the Web was not built on stone-tablet processing so we’ve had to look around for other solutions.
 In the case of document-conformance checking we’ve turned to using things like RelaxNG schemas that while lacking the quaintness of DTDs are a far more powerful means for expressing certain kinds of document-conformance requirements. So it’s a tradeoff.
In the case of document-conformance checking we’ve turned to using things like RelaxNG schemas that while lacking the quaintness of DTDs are a far more powerful means for expressing certain kinds of document-conformance requirements. So it’s a tradeoff.What’s the difference between conformance checking and validation?
Validation is an oldthink word. Use it for when you want to make people think you’re a sort of fossil or relic of some earlier time. Kind of like the word groovy or XHTML.Lots of people don’t know this but the etymology of that word validation is from the days when our ancestors were mostly pig thieves and they were given actual badges for spelling their own names correctly, and usually a pat on that back too. Good job!
Document-conformance checking is the current party-approved goodthink way of talking about looking for problems in HTML documents. And do note that we call it document conformance and not authoring conformance, and we talk about conformance requirements for documents, not conformance requirements for authors.
Anyway, document-conformance checking has the nasty ugly part conformance which is a hurtful word really but you gotta look past that part and only pay attention to the word checking which is mostly a happy helpful type of word.
So I call the tool at validator.w3.org/nu the Nu Markup Checker instead of the blah-blah-Validator because I want to spread the happiness of the word checker in the sense of doing something actually useful for people instead of just giving them a pat on the back. It’s an automated thing which checks stuff for you that’d otherwise be really tedious for you to check manually. So it helps you. Maybe it should be called the
Nu Help-You Checker. As far as what it checks, it looks for unintentional mistakes you might have made: misspelled element names or attribute values where some stray character snuck in. That kind of stuff. And it alerts you about those sorts of things so you can fix them.
It also looks at other kinds of requirements defined in the HTML spec designed to help you not make broken HTML documents and web applications that aren’t going to work the way they should or that might otherwise result in degraded user experience. Some of those requirements are gray-area judgment calls, but it’s helpful to have a common baseline-ish set of those kinds of requirements actually defined in a spec.
Other words for what this tool does that aren’t yet party-approved goodthink are words like linter and static-analysis tool. But the difference with this thing I work on is, the linting rules are actually defined in a spec, instead of something, say, Doug Crockford (to pick a name at random) woke up one morning and just pulled out of his hat.
 That’s because you as an author are a human being; a technical specification can’t place requirements on you, it can only place requirements on documents you create. And related tools don’t evaluate you as a human being for conformance to particular technologies; instead they just evaluate the documents you create.
That’s because you as an author are a human being; a technical specification can’t place requirements on you, it can only place requirements on documents you create. And related tools don’t evaluate you as a human being for conformance to particular technologies; instead they just evaluate the documents you create.

What’s the difference between errors and warnings?
An error is for something that’s clearly a mistake, like a misspelled element name or an attribute value that has some crazy garbage characters or whatever that showed up somehow and shouldn’t be there.But an error is also for some cases of stuff that the HTML spec for other reasons just says, this must be an error. The spec explains that the reasons for some of those other things being defined as errors; basically it’s just that they can create certain kinds of problems that are not always easy to anticipate.
There’s a long list of those kinds of problems that are defined as errors but some examples include markup cases that are bad for accessibility, usability, interoperability, security, or maintainability—or that can result in poor performance, or that might cause your scripts to fail in ways that are hard to troubleshoot.
Along with those some cases are defined as errors because they can cause you to run into quirks in HTML parsing and error-handling behavior—so that, say, you’d end up with some unintuitive, unexpected result in the DOM.
Finally there are some other errors defined for markup cases that just don’t make any sense and would most likely only be used by mistake, or cases that clash with default styling behavior.
Warnings, on the other hand, are for things that the spec doesn’t define as an outright errors but that still might be problems. Sometimes warnings get added to the checker experimentally, as a way to test out whether they’re useful to you or not. (That’s part of the reason the checker continues to be labelled as
experimental.)

Is there a use in using HTML4/XHTML doctypes?
There’s absolutely no reason whatsoever for using an HTML4 doctype. Just put the<!DOCTYPE HTML>doctype on your HTML documents and make sure they’re served as text/html and be done with it. Move on with your life. But if for some reason you really want to serve your documents as application/xhtml+xml you don’t have to put an XHTML doctype on them—you can can still just use<!DOCTYPE HTML>like the rest of us.
 (But you probably don’t want to be using application/xhtml+xml and XHTML anyway. Again, lose the haircut—there’s a whole world out there waiting for you.)
(But you probably don’t want to be using application/xhtml+xml and XHTML anyway. Again, lose the haircut—there’s a whole world out there waiting for you.)What are the pitfalls for users of HTML checking/validation tools?
I guess the same pitfalls as you’d running into asking some really helpful and really thoughtful person for help with anything: They’ll actually make an effort to help you instead of just shining you on or giving you a this-pig-thief-can-spell-his/her-own-name badge. The help they give you may not always be what you want to hear, or it may be some advice that you already know yourself you can safely ignore. Such is life.
What are the upsides?
The upsides are that you catch mistakes you might have otherwise missed.
There are differences between W3C HTML and WHATWG HTML conformance rules, how so?
Some things defined as errors are judgment calls.
 Specs are written by human people, not machines. Different people can make different judgment calls—“reasonable people can disagree” or whatever other less trite way there is for expressing that sentiment. If you walk around this world expecting complete consistency from mankind everywhere you’re going to stumble onto a few serious disappointments now and then.
Specs are written by human people, not machines. Different people can make different judgment calls—“reasonable people can disagree” or whatever other less trite way there is for expressing that sentiment. If you walk around this world expecting complete consistency from mankind everywhere you’re going to stumble onto a few serious disappointments now and then.What if I find an error in the W3C HTML validator/checker?
Report it at w3.org/Bugs/Public/enter_bug.cgi?product=Nu%20Markup%20Checker or at bugzilla.validator.nu or github.com/validator/validator/issues.
Can I run a local copy of the W3C HTML conformance checker?
Yeah. The best way to do that is to download a release from github.com/validator/validator/releases and, for using that, to follow the instructions at validator.github.io/validator and at validator.github.io/validator/#web-based-checking.
And if you use grunt, check out github.
com/jzaefferer/grunt-html which is a grunt plugin for HTML checking that uses code from github.com/validator/validator as its backend.

Any tips/advice for sane using of HTML conformance checking tools?
Is this some kind of trick question? I guess the only advice I’d give is that you should remember that tools are machines, and you are not a machine. (Assuming this question wasn’t asked by a machine.) So when evaluating error and warning messages that you get from any HTML checker, use your own human judgment. And if your judgment is that a particular checker message isn’t really helping you, then just ignore it. This isn’t a popularity contest, you won’t be hurting anybody’s feelings.
Or better yet if you care to take the time, use the “Message filtering” feature at validator.w3.org/nu which lets you persistently ignore any checker messages you find unhelpful or annoying or just don’t want to see any more.
Currently the W3C HTML checking tools don’t check/throw errors for SVG1.
 1 and some web component attributes, any plans to add support?
1 and some web component attributes, any plans to add support?
Yeah. That stuff is on my TODO list. I’ll get to it eventually.
What’s the deal with unknown attribute errors? many JS libraries use them, what should developers do?
The problem is that the checker is a machine and it’s not smart enough to tell the difference between some attribute with an unknown name that you’re using on purpose and some attribute whose name you misspelled by mistake. If we just told the checker to let through all unknown attribute names without checking, then we wouldn’t be able to help you catch the case where you misspelled something by mistake.
The workaround is that if you’re using some unknown attribute name on purpose, then exploit the “Message filtering” option at validator.w3.org/nu to tell the checker you don’t want to see messages about that particular attribute any more. And they’ll go away.
Does the validator check for use of ARIA? if so what is it checking?
Yes it checks for errors in the use of ARIA markup in HTML documents, including now some limited checking for errors in use of ARIA with SVG elements in HTML documents and also in standalone SVG documents.
For HTML elements it’s checking against requirements in the HTML spec itself but that are now also specified in ARIA in HTML as a separate standalone document, with the plan that for ARIA, the HTML spec can soon be updated to just reference the ARIA requirements in that document.
For SVG elements, my plan’s to soonishly update the checker to follow a similar standalone document at [Web developer rules for use of ARIA attributes on SVG1.1 elements] – specs.webplatform.org/SVG1.1-ARIA/webspecs/master

ARIA checking in < HTML5 what’s the deal? Will/should/can it be supported?
Nobody should be using anything but “HTML5”, and we shouldn’t be trying to help them do it. HTML5 is just HTML. We outgrew the whole version thing a long time ago now.<!DOCTYPE HTML>will be 10 years old soon. Common sense won. Here in the 21st century we can’t really help anybody who’s putting an HTML4 or whatever ancient doctype on a new document.
 That’s a lost cause. Certainly we’d not be helping by providing some way for them to do that and to put ARIA markup into their documents and then we tell them that’s OK. That’s called enabling behavior, in clinical terms.
That’s a lost cause. Certainly we’d not be helping by providing some way for them to do that and to put ARIA markup into their documents and then we tell them that’s OK. That’s called enabling behavior, in clinical terms.When using the w3c html validator to check my HTML5 I see the following:
“The validator checked your document with an experimental feature: HTML5 Conformance Checker. …” does this mean there is a more stable validation tool I should be using?
The idea of stable doesn’t really apply here. But yeah there is another tool you should be using. You should use validator.w3.org/nu directly. It has more features and is better in every possible way.
That tool is an experimental tool, but in a good sense. And the plan is for it to always remain that way. The validator.w3.org/nu/about.html page tries to help set the right expectations about what the goals are and what
experimental means: The Nu Markup Checker is an experimental tool and its behavior remains subject to change.
The Nu Markup Checker should not be used as a means to attempt to unilaterally enforce pass/fail conformance of documents to any particular specifications; it is intended solely as a checker, not as a pass/fail certification mechanism.
 In particular, because new types of error checks continue to be actively added to the checker, there is no guarantee provided that if the checker reports zero errors for a particular document at one point in time, it will report zero errors for that same document at some later point in time.
In particular, because new types of error checks continue to be actively added to the checker, there is no guarantee provided that if the checker reports zero errors for a particular document at one point in time, it will report zero errors for that same document at some later point in time.Web components checking?
If you mean checking custom elements, my answer is that custom elements aren’t yet widely supported in multiple browser engines, so I don’t think it’s useful for me or anybody else to put too much of time and energy yet into figuring out how to deal with checker behavior for documents that contain custom elements.If/when custom elements do ever become widely supported across more browser engines, then we should figure out how to deal with checker behavior for them.
 That’s actually going to be complicated and messy to do—but that’s the case for a lot of stuff in the Web platform and I’m sure we’ll figure out something together that we can all live with, just as we all have together for lots of other complicated Web-platform stuff.
That’s actually going to be complicated and messy to do—but that’s the case for a lot of stuff in the Web platform and I’m sure we’ll figure out something together that we can all live with, just as we all have together for lots of other complicated Web-platform stuff.What is the difference between the w3c validator and the nu markup checker?
The legacy W3C validator is at validator.w3.org and its core is built on old stuff like Perl and DTDs and SGML and old specs from the 20th century like HTML4 and nobody is actively maintaining its code at this point. The only good news about it is that for checking any document with a modern
<!DOCTYPE html>doctype, it actually uses the backend from the Nu Markup Checker to check the document, and then just passes back all the messages from that.The Nu Markup Checker is at validator.w3.org/nu and it’s built on slightly less old stuff like Java and RelaxNG and on specs from the current century like “HTML5” and has the big advantage of actually being actively maintained.
 And it has more features, like the “Message filtering” feature that lets you filter out message you don’t want to see.
And it has more features, like the “Message filtering” feature that lets you filter out message you don’t want to see.Checking the source code versus the HTML DOM output, one better? issues?
I guess there’s good use cases for both. A limitation with checking the DOM is that at validator.w3.org/nu itself we can’t really provide a way to have it go grab the DOM of some arbitary HTML document on the Web and then check that. There needs to be a browser engine somewhere in between to actually parse the document into a DOM representation in memory and execute your JavaScript on that and then serialize that resulting DOM back out to a text representation you can feed to a checker. But if you have an HTML document you want to check and you actually open it in your browser you can then use something like the bookmarklet at codepen.io/stevef/full/LasCJ to send the serialized DOM from that document to validator.w3.org/nu for checking.
Should pre-HTML5 doctypes be flagged with a warning, in the W3C Validator, now HTML5 is a REC?
I dunno, maybe.
 On the one hand there are gazillions of existing documents out there with older doctypes that are working just fine the way they are now, so no reason to screw with them. On the other hand, if somebody’s actually taking time to run one of those documents through an HTML checker, then they may be doing that for some good reason and maybe we would be helping by alerting them to obsolete doctype in there so they can go in an update it.
On the one hand there are gazillions of existing documents out there with older doctypes that are working just fine the way they are now, so no reason to screw with them. On the other hand, if somebody’s actually taking time to run one of those documents through an HTML checker, then they may be doing that for some good reason and maybe we would be helping by alerting them to obsolete doctype in there so they can go in an update it.
Nothing changed in browsers. Browsers have always supported that and it doesn’t cause any problems and we’d not be helping anybody by making it an error. So we made it a non-error.
On WCAG 2.0 Parsing Criteria
Our client’s accessibility consultant is telling them that they must have valid HTML in order to be WCAG 2.0 compliant. Is that true? – Shoptalk Show
I have no idea. I’m not a WCAG expert and I’ve never even read the WCAG 2.0 spec.
 And the HTML checker is not a WCAG checker. Or at least it doesn’t claim to be.
And the HTML checker is not a WCAG checker. Or at least it doesn’t claim to be.
WCAG 2.0 has a success criterion that requires markup documents have no parsing errors. The nu markup checker flags parsing errors along with other machine checkable HTML conformance criteria. We have created a WCAG 2.0 Parsing error bookmarklet that filters the results from the nu markup checker to only display parsing errors/warnings.Note: this bookmarklet is experimental and not the law and even when filtered some of the errors/warnings displayed may not have any practical negative effect on the accessibility of the document. It is provided as an aid to filter out some of the irrelevant (to WCAG) issues only. Mike and I have talked about providing the filter as a built in feature of the nu markup checker, so hope to make that happen.
Will there be a valid HTML5 icon?
No, there won’t be a Valid HTML icon any time soon and likely not ever.
The reason is basically that “This is valid” icons/badges promote the idea that there’s significant value in making public claims of pass/fail document-conformance requirements in standards.
But the HTML5 checker is by design not intended to encourage anybody to use it as a means to make public assertions of simple pass/fail conformance of any documents to any particular specifications; it’s intended solely as a checker — for people to use to catch unintended mistakes in documents and fix them — not as a pass/fail certification mechanism.
There won’t be any proper Valid HTML5 icon forthcoming, so if you’d like to use one in your content, you’ll probably need to create one on your own.

Thanks Mike!
Pro tip – always check your HTML with Rock’n’Roll playing… LOUD!
More questions people?Скачать CSS HTML Validator 2023 для Windows, Linux и Mac
CSS HTML Validator — All-In-One Проверка HTML, CSS, ссылок, SEO, орфографии и доступности
⯈ Скачать Validator
- Последняя версия версии требуется Windows 10/11 или Linux для htmlval для Linux или Mac для htmlval для Mac.
- Проверка до 200 документов в течение 30 дней в пробной версии.
- Посмотрите, что нового в последней версии.
- Для пробной загрузки доступна только версия Pro. Это издание даст вам отличное представление о том, что доступно во всех изданиях.
- Посмотреть лицензионное соглашение (EULA).
- Свяжитесь с нами, если у вас возникли проблемы или вопросы по загрузке.
Версия 23.01 Теперь доступна версия 2023/v23.01.
Скачать пробную версию CSS HTML Validator Pro БЕСПЛАТНО
Скачать бесплатную пробную версию
Другие места для загрузки
ДОПОЛНИТЕЛЬНО: распечатайте это краткое краткое руководство, чтобы помочь вам начать работу.
Загрузки для зарегистрированных пользователей с платными лицензиями
Скачать платную версию
Скачать для личного/образовательного, некоммерческого использования (БЕСПЛАТНО)
CSS HTML Validator для личного/образовательного, некоммерческого использования – это БЕСПЛАТНАЯ старая версия лицензируется только для личного (или образовательного) некоммерческого использования . Загрузите эту бесплатную версию здесь. Обратите внимание, что требуется более новая платная версия, если вы хотите получить наилучшие и самые актуальные результаты проверки.
Загрузите эту бесплатную версию здесь. Обратите внимание, что требуется более новая платная версия, если вы хотите получить наилучшие и самые актуальные результаты проверки.
Новый CSS HTML Validator для Linux и Mac
Теперь доступен новый инструмент командной строки (консоли) Linux и Mac (macOS) , основанный на основном механизме проверки в CSS HTML Validator . Посетите htmlval для Linux или htmlval для Mac, чтобы загрузить БЕСПЛАТНУЮ пробную версию.
После загрузки
После загрузки запустите программу установки и ответьте Да на запрос User Account Control , затем следуйте простым инструкциям по установке. Программа установки имеет цифровую подпись AI Internet Solutions LLC (если ее нет, не запускайте ее).
ВАЖНО: В некоторых системах для появления диалогового окна User Account Control может потребоваться от 1 до 2 минут, поскольку система проверяет файл.
Если диалоговое окно User Account Control не появляется или появляется сообщение об ошибке, например « Ошибка 5: Доступ запрещен. », попробуйте выполнить одно или несколько из следующих действий:
- Запустите программу установки, щелкнув ее правой кнопкой мыши и выбрав «Запуск от имени администратора».
- Временно отключите любое программное обеспечение безопасности, такое как антивирусное и антишпионское ПО (это может препятствовать запуску программы установки).
- Если проблема сохраняется, см. Известные проблемы с программным обеспечением сторонних производителей.
Скачать словари
Скачать словари
Доступны дополнительные словари для поддержки большего количества языков.
Также доступен инструмент редактирования словаря. Этот инструмент позволяет создавать собственные словари.
Средство проверки веб-сайтов
Домен:Дополнительные аргументы
О средстве проверки веб-сайтов
Какие наиболее распространенные ошибки на вашем веб-сайте? Средство проверки веб-сайтов сканирует веб-сайт, прогоняет содержимое через средство проверки HTML W3, резюмируя содержимое для вас.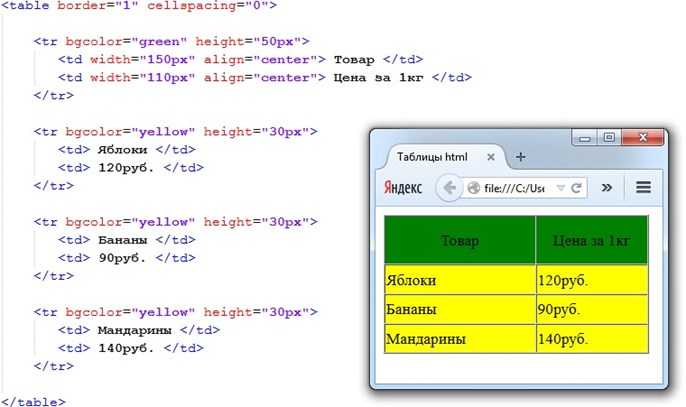 Веб-сайт Валидатор разбивает ошибки и предупреждения по типам, а также дает вам общий процент страниц без ошибок. В 9Вкладка 0079 Error Summary содержит подробное описание всех ошибок, возникших на вашем сайте. Перейдите на вкладку Страницы с ошибками , чтобы начать решать эти проблемные места. Имейте в виду, что не все ошибки в HTML-разметке одинаково проблематичны, и многие ошибки практически не влияют на то, как страница отображается для пользователя.
Веб-сайт Валидатор разбивает ошибки и предупреждения по типам, а также дает вам общий процент страниц без ошибок. В 9Вкладка 0079 Error Summary содержит подробное описание всех ошибок, возникших на вашем сайте. Перейдите на вкладку Страницы с ошибками , чтобы начать решать эти проблемные места. Имейте в виду, что не все ошибки в HTML-разметке одинаково проблематичны, и многие ошибки практически не влияют на то, как страница отображается для пользователя.
Этот инструмент использует веб-сервисы W3C Markup Validation Service и HTML5 Nu HTML Checker. Мы используем эти несколько валидаторов, чтобы уменьшить нагрузку на любой валидатор. Возможно, эти два разных валидатора запускают два разных экземпляра Nu HTML Checker и поэтому могут сообщать о разных ошибках даже при проверке одной и той же страницы.
Мы просим вас быть добрее к сторонним службам. При внесении изменений в URL-адрес используйте «Просмотр проверки» на вкладке Страницы с ошибками , чтобы проверить только эту страницу, а не повторно запускать средство проверки сайта для всего сайта.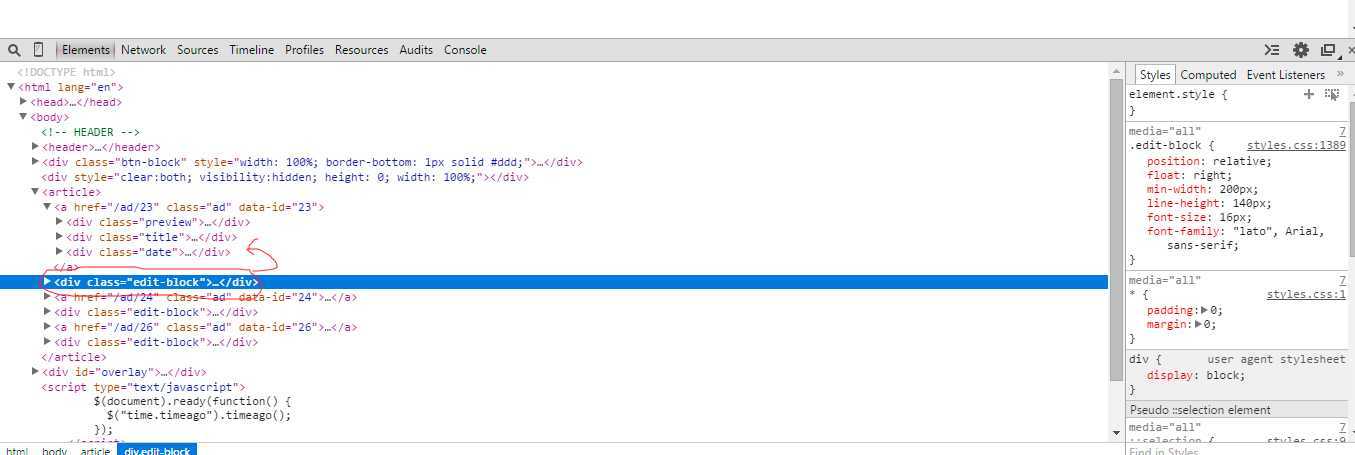 При внесении изменений в шаблон, совместно используемый несколькими страницами, мы рекомендуем убедиться, что шаблон не содержит ошибок, сначала проверив одну страницу, использующую шаблон, перед повторным запуском средства проверки веб-сайта. Наш паук имеет ограничение в 1000 страниц в день, у этих сервисов могут быть свои ограничения.
При внесении изменений в шаблон, совместно используемый несколькими страницами, мы рекомендуем убедиться, что шаблон не содержит ошибок, сначала проверив одну страницу, использующую шаблон, перед повторным запуском средства проверки веб-сайта. Наш паук имеет ограничение в 1000 страниц в день, у этих сервисов могут быть свои ограничения.
О Пауке
Чтобы этот инструмент работал, мы должны просканировать сайт или страницу, которую вы хотите проанализировать. Мы делаем это с DatayzeBot, пауком данных.
Наш паук медленно ползает по 1 странице каждые 1,5 секунды. Хотя паук не отслеживает содержимое просматриваемых им страниц, он отслеживает количество запросов, отправленных каждым посетителем. В настоящее время сканер ограничен 1000 страниц на пользователя в день. Поскольку DatayzeBot не индексирует и не кэширует страницы, которые он сканирует, повторный запуск средства проверки веб-сайта будет учитываться при разрешенном ежедневном количестве сканирований страниц. Вы можете обойти ограничение, приостановив поисковый робот и возобновив его в другой день.
Вы можете обойти ограничение, приостановив поисковый робот и возобновив его в другой день.
DatayzeBot теперь соблюдает стандарт исключения роботов. Чтобы специально разрешить (или запретить) сканеру доступ к странице или каталогу, создайте новый набор правил для « DatayzeBot » в файле robots.txt. DatayzeBot будет следовать самому длинному правилу сопоставления для указанной страницы, а не первому правилу сопоставления. Если соответствующее правило не найдено, DatayzeBot предполагает, что ему разрешено сканировать страницу. Не уверены, что страница исключена из вашего файла robots.txt? Приложение Index/No Index будет анализировать заголовки HTML, метатеги и robots.txt и суммировать результаты для вас.
Заинтересованы в веб-разработке? Попробуйте другие наши инструменты, такие как анализатор навигации по сайту, который позволит вам увидеть, что видит паук. Он может анализировать разнообразие анкорного текста и находить кратчайший путь к любой странице. Thin Content Checker может анализировать содержимое вашего сайта, сообщать вам процент уникальных фраз на странице и генерировать гистограмму длины содержимого страницы.