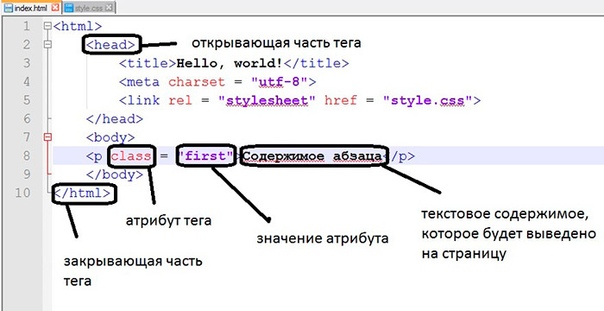
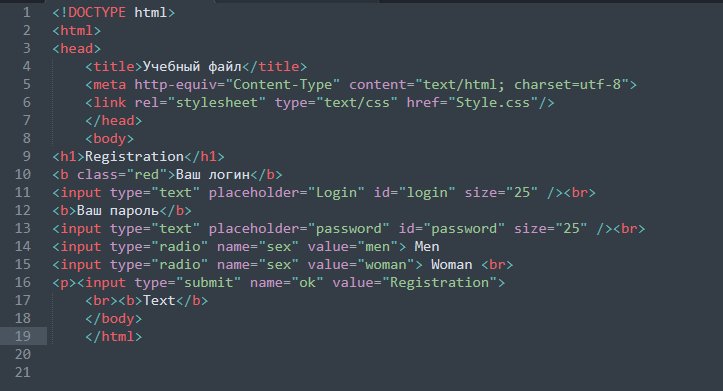
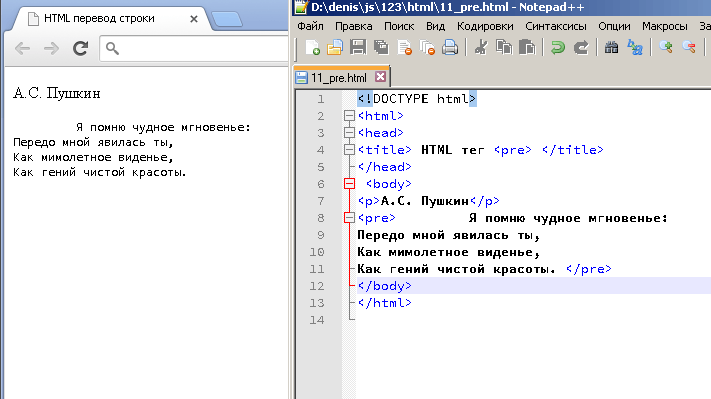
Типы и модель данных
Строки в языке Python представлены неизменяемым типом данных str,
который хранит последовательность символов Юникода. Тип данных str может вызываться как функция для создания строковых объектов – без
аргументов возвращается пустая строка; с аргументом, который не
является строкой, возвращается строковое представление аргумента; а в
случае, когда аргумент является строкой, возвращается его
копия. Функция str() может также использоваться как функция
преобразования. В этом случае первый аргумент должен быть строкой или
объектом, который можно преобразовать в строку, а, кроме того, функции
может быть передано до двух необязательных строковых аргументов, один
из которых определяет используемую кодировку, а второй определяет
порядок обработки ошибок кодирования.
Литералы строк создаются с использованием кавычек или апострофов, при
этом важно, чтобы с обоих концов литерала использовались кавычки
одного и того же типа.
text = """Строки в тройных кавычках могут включать 'апострофы' и "кавычки" без лишних формальностей. Мы можем даже экранировать символ перевода строки \, благодаря чему данная конкретная строка будет занимать всего две строки."""
Если нам потребуется использовать кавычки в строке, это можно сделать без лишних формальностей – при условии, что они отличаются от кавычек, ограничивающих строку; в противном случае символы кавычек или апострофов внутри строки следует экранировать:
a = "Здесь 'апострофы' можно не экранировать, а \"кавычки\" придется." b = 'Здесь \'апострофы\' придется экранировать, а "кавычки" не обязательно.'
В языке Python символ перевода строки интерпретируется как завершающий
символ инструкции, но не внутри круглых скобок (()), квадратных
скобок ([]), фигурных скобок ({}) и строк в тройных кавычках. Символы перевода строки могут без лишних формальностей использоваться
в строках в тройных кавычках, и мы можем включать символы перевода
строки в любые строковые литералы с помощью экранированной
последовательности
Символы перевода строки могут без лишних формальностей использоваться
в строках в тройных кавычках, и мы можем включать символы перевода
строки в любые строковые литералы с помощью экранированной
последовательности
Все экранированные последовательности, допустимые в языке Python, перечислены в табл. 2.6.
Таблица 5. Функции и константы модуля math
| Последовательность | Значение |
\переводстроки | Экранирует (то есть игнорирует) символ перевода строки |
\\ | Символ обратного слеша (\) |
\' | Апостроф (') |
\" | Кавычка ( |
\a | Символ ASCII «сигнал» (bell, BEL) |
\b | Символ ASCII «забой» (backspace, BS) |
\f | Символ ASCII «перевод формата» (formfeed, FF) |
\n | Символ ASCII «перевод строки» (linefeed, LF) |
\N{название} | Символ Юникода с заданным названием |
\ooo | |
\r | Символ ASCII «возврат каретки» (carriage return, CR) |
\t | Символ ASCII «табуляция» (tab, TAB) |
\uhhhh | Символ Юникода с указанным 16-битовым шестнадцатеричным значением |
\Uhhhhhhhh | Символ Юникода с указанным 32-битовым шестнадцатеричным значением |
\v | Символ ASCII «вертикальная табуляция» (vertical tab, VT) |
\xhh | Символ с указанным 8-битовым шестнадцатеричным значением |
Если потребуется записать длинный строковый литерал, занимающий две или более строк, но без использования тройных кавычек, то можно использовать один из приемов, показанных ниже:
t = "Это не самый лучший способ объединения двух длинных строк, " + \
"потому что он основан на использовании неуклюжего экранирования"
s = ("Это отличный способ объединить две длинные строки, "
" потому что он основан на конкатенации строковых литералов. ")
")
 ")
")
Обратите внимание, что во втором случае для создания единственного
выражения мы должны были использовать круглые скобки – без этих
скобок переменной s была бы присвоена только первая строка, а наличие
второй строки вызвало бы исключение IndentationError.
Сравнение строк
Строки поддерживают обычные операторы сравнения <, <=, ==, !=, > и >=. Эти операторы выполняют побайтовое сравнение строк в памяти.
К сожалению, возникают две проблемы при сравнении, например,
строк в отсортированных списках. Обе проблемы проявляются во всех
языках программирования и не являются характерной особенностью
Python.
Первая проблема связана с тем, что символы Юникода могут быть представлены двумя и более последовательностями байтов.
Вторая проблема заключается в том, что порядок сортировки некоторых символов зависит от конкретного языка.
Получение срезов строк
Отдельные элементы последовательности, а, следовательно, и отдельные
символы в строках, могут извлекаться с помощью оператора доступа к
элементам ([]). В действительности этот оператор намного более
универсальный и может использоваться для извлечения не только одного
символа, но и целых комбинаций (подпоследовательностей) элементов или
символов, когда этот оператор используется в контексте оператора
извлечения среза.
В действительности этот оператор намного более
универсальный и может использоваться для извлечения не только одного
символа, но и целых комбинаций (подпоследовательностей) элементов или
символов, когда этот оператор используется в контексте оператора
извлечения среза.
Для начала мы рассмотрим возможность извлечения отдельных
символов. Нумерация позиций символов в строках начинается с 0 и
продолжается до значений длины строки минус 1. Однако допускается
использовать и отрицательные индексы – в этом случае отсчет начинается
с последнего символа и ведется в обратном направлении к первому
символу. На рис. 1 показано, как нумеруются
позиции символов в строке, если предположить, что было выполнено
присваивание s = "Light ray".
Рисунок 1: Номера позиций символов в строке
Отрицательные индексы удивительно удобны, особенно индекс -1,
который всегда соответствует последнему символу строки. Попытка
обращения к индексу, находящемуся за пределами строки (или к любому
индексу в пустой строке), будет вызывать исключение IndexError. Оператор получения среза имеет три формы записи:
Оператор получения среза имеет три формы записи:
seq[start] seq[start:end] seq[start:end:step]
Ссылка seq может представлять любую последовательность, такую как
список, строку или кортеж. Значения start, end и step должны быть
целыми числами (или переменными, хранящими целые числа). Первая форма
— это запись оператора доступа к элементам: с ее помощью извлекается
элемент последовательности с индексом start. Вторая форма записи
извлекает подстроку, начиная с элемента с индексом start и заканчивая
элементом с индексом end, не включая его.
При использовании второй формы записи (с одним двоеточием) мы можем
опустить любой из индексов. Если опустить начальный индекс, по
умолчанию будет использоваться значение 0. Если опустить конечный
индекс, по умолчанию будет использоваться значение len(seq).
Это означает, что если опустить оба индекса, например, s[:], это будет
равносильно выражению s[0:len(s)], и в результате будет извлечена,
то есть скопирована, последовательность целиком.
На рис. 2 приводятся некоторые примеры
извлечения срезов из строки s, которая получена в результате
присваивания s = "The waxwork man".
Рисунок 2: Извлечение срезов из последовательности
Один из способов вставить подстроку в строку состоит в смешивании операторов извлечения среза и операторов конкатенации. Например:
>>> s = s[:12] + "wo" + s[12:] >>> s 'The waxwork woman'
Кроме того, поскольку текст «wo» присутствует в оригинальной строке,
тот же самый эффект можно было бы получить путем присваивания значения
выражения s[:12] + s[7:9] + s[12:].
Оператор конкатенации + и добавления подстроки += не
особенно эффективны, когда в операции участвует множество строк. Для
объединения большого числа строк обычно лучше использовать метод str.join(), с которым мы познакомимся в следующем подразделе.
Третья форма записи (с двумя двоеточиями) напоминает вторую форму, но
в отличие от нее значение step определяет, с каким шагом следует
извлекать символы. Как и при использовании второй формы записи, мы
можем опустить любой из индексов. Если опустить начальный
индекс, по умолчанию будет использоваться значение 0, при условии,
что задано неотрицательное значение step; в противном случае начальный
индекс по умолчанию получит значение -1. Если опустить конечный
индекс, по умолчанию будет использоваться значение len(seq),
при условии, что задано неотрицательное значение step; в противном
случае конечный индекс по умолчанию получит значение индекса перед
началом строки. Мы не можем опустить значение step, и оно не может
быть равно нулю – если задание шага не требуется, то следует
использовать вторую форму записи (с одним двоеточием), в которой шаг
выбора элементов не указывается.
На рис. 3 приводится пара примеров извлечения разреженных срезов из
строки s, которая получена в результате присваивания s = "he ate camel food".
Рисунок 3: Извлечение разреженных срезов
Здесь мы использовали значения по умолчанию для начального и ко- нечного индексов, то есть извлечение среза s[:: – 2] начинается с по- следнего символа строки и извлекается каждый второй символ по на- правлению к началу строки. Аналогично извлечение среза s[::3] на- чинается с первого символа строки и извлекается каждый третий сим- вол по направлению к концу строки. Существует возможность комбинировать индексы с размером шага, как показано на рис. 4.
Рисунок 4: Извлечение срезов из последовательности с определенным шагом
Операция извлечения элементов с определенным шагом часто применяется к последовательностям, отличным от строк, но один из ее вариантов часто применяется к строкам:
Операторы и методы строк
Поскольку строки относятся к категории неизменяемых
последовательностей, все функциональные возможности, применимые к
неизменяемым последовательностям, могут использоваться и со
строками. Сюда входят оператор проверки на вхождение
Сюда входят оператор проверки на вхождение in, оператор
конкатенации +, оператор добавления в конец +=, оператор
дублирования * и комбинированный оператор присваивания с
дублированием *=. Применение всех этих операторов в контексте строк
мы обсудим в этом подразделе, а также обсудим большинство строковых
методов. В табл. 2.7 приводится перечень некоторых строковых методов.
Так как строки являются последовательностями, они являются объектами,
имеющими «размер», и поэтому мы можем вызывать функцию len(),
передавая ей строки в качестве аргумента. Возвращаемая функцией длина
представляет собой количество символов в строке (ноль – для пустых
строк).
Мы уже знаем, что перегруженная версия оператора + для строк
выполняет операцию конкатенации. В случаях, когда требуется объединить
множество строк, лучше использовать метод str.join(). Метод
принимает в качестве аргумента последовательность (то есть список
или кортеж строк) и объединяет их в единую строку, вставляя между
ними строку, относительно которой был вызван метод. Например:
Например:
>>> treatises = ["Arithmetica", "Conics", "Elements"] >>> " ".join(treatises) 'Arithmetica Conics Elements'
>>> "-<>-".join(treatises) 'Arithmetica-<>-Conics-<>-Elements'
>>> "".join(treatises) 'ArithmeticaConicsElements'
Метод str.join() может также использоваться в комбинации со
встроенной функцией reversed(), которая переворачивает строку –
например, "".join(reversed(s)), хотя тот же результат может быть
получен более кратким оператором извлечения разреженного среза –
например, s[:: – 1].
Оператор * обеспечивает возможность дублирования строки:
>>> s = "=" * 5 >>> print(s) =====
>>> s *= 10 >>> print(s) ==================================================
Как показано в примере, мы можем также использовать комбинированный
оператор присваивания с дублированием.
Форматирование строк с помощью метода
str.format() Метод str.format() представляет собой очень мощное и гибкое средство
создания строк. Использование метода str.format() в простых случаях
не вызывает сложностей, но для более сложного форматирования нам
необходимо изучить синтаксис форматирования.
Метод str.format() возвращает новую строку, замещая поля в
контекстной строке соответствующими аргументами. Например:
>>> "The novel '{0}' was published in {1}".format("Hard Times", 1854)
"The novel 'Hard Times' was published in 1854"
Каждое замещаемое поле идентифицируется именем поля в фигурных
скобках. Если в качестве имени поля используется целое число, оно
определяет порядковый номер аргумента, переданного методу str.format(). Поэтому в данном случае поле с именем 0 было замещено
первым аргументом, а поле с именем 1 – вторым аргументом.
Если бы нам потребовалось включить фигурные скобки в строку формата, мы могли бы сделать это, дублируя их, как показано ниже:
>>> "{{{0}}} {1} ;-}}". format("I'm in braces", "I'm not")
"{I'm in braces} I'm not ;-}"
 format("I'm in braces", "I'm not")
"{I'm in braces} I'm not ;-}"
format("I'm in braces", "I'm not")
"{I'm in braces} I'm not ;-}"
Если попытаться объединить строку и число, интерпретатор Python
совершенно справедливо возбудит исключение TypeError. Но это легко
можно сделать с помощью метода str.format():
>>> "{0}{1}".format("The amount due is $", 200)
'The amount due is $200'
С помощью str.format() мы также легко можем объединять строки
(хотя для этой цели лучше подходит метод str.join()):
>>> x = "three"
>>> s ="{0} {1} {2}"
>>> s = s.format("The", x, "tops")
>>> s
'The three tops'
В следующем разделе мы рассмотрим применение функции str.format().
- ← Prev
- Next →
RetailCRM Документация: Страница не найдена
Разделы
Продажи131 статья
- Демо-данные в системе
- Заказы
- Клиенты
- Задачи
- Товары и склад
- Менеджеры
- Финансы
15 статей
- Список Программ
- Настройка
- Регистрация и активация участий
- Уровни
- События
- Запуск
- Участия
- Программа лояльности в карточках заказа и клиента
- Миграция лояльности с 7 версии на 8
- Тарификация
46 статей
- Рассылки
- Сегменты
- Правила
219 статей
- Создание и редактирование API ключа
- Работа с маркетплейсом
- Службы доставки
- Модули интеграции с сайтом
- Телефония
- Складские системы
- Маркетплейсы
- Модули для работы со справочниками
- Платежные сервисы
- Рекомендации
- Коллтрекинг
- Аналитические сервисы
45 статей
- Аналитика по заказам
- Аналитика по клиентам
- Аналитика по товарам
- Аналитика по менеджерам
- Аналитика по коммуникациям
- Аналитика по финансам
98 статей
- Пользователи
- Магазины
- Справочники
- Статусы заказов
- Статусы товаров
- Триггеры
- Коммуникации
- Системные настройки
41 статья
- Функциональность чатов
- Подключение мессенджеров и чатов
- Боты
7 статей
- Создание сайта
- Страницы сайта
- Товары и товарный каталог
- Внешний вид
- Публикация
- Заказы и клиенты
3 статьи
- Импорт базы клиентов в систему
- Импорт заказов в систему
- Импорт товаров в систему
:empty — CSS: Каскадные таблицы стилей
Псевдокласс :empty CSS представляет любой элемент, не имеющий дочерних элементов.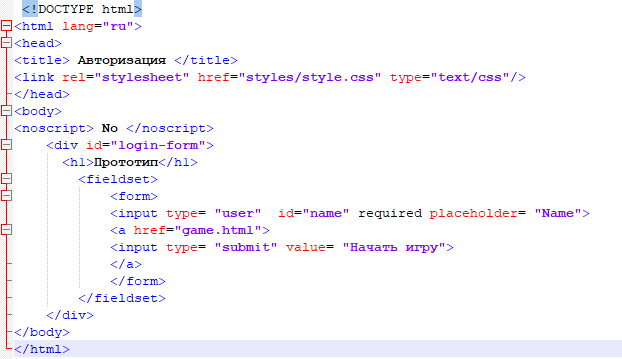 Дочерними элементами могут быть либо узлы элементов, либо текст (включая пробелы). Комментарии, инструкции по обработке и содержимое CSS
Дочерними элементами могут быть либо узлы элементов, либо текст (включая пробелы). Комментарии, инструкции по обработке и содержимое CSS не влияют на то, считается ли элемент пустым.
Примечание: В Selectors Level 4 псевдокласс :empty был изменен, чтобы действовать как :-moz-only-whitespace , но в настоящее время ни один браузер не поддерживает это.
:пусто {
/* ... */
}
HTML
<дел>Я буду розовым.<дел>
CSS
корпус {
дисплей: гибкий;
выравнивание содержимого: пространство вокруг;
}
.ящик {
фон: розовый;
высота: 80 пикселей;
ширина: 80 пикселей;
}
.box: пустой {
фон: лайм;
}
Результат
Вспомогательные технологии, такие как программы чтения с экрана, не могут анализировать пустое интерактивное содержимое. Все интерактивное содержимое должно иметь доступное имя, которое создается путем предоставления текстового значения для родительского элемента интерактивного элемента управления (привязки, кнопки и т. д.). Доступные имена открывают интерактивный элемент управления для дерева специальных возможностей — API, который передает информацию, полезную для вспомогательных технологий.
Все интерактивное содержимое должно иметь доступное имя, которое создается путем предоставления текстового значения для родительского элемента интерактивного элемента управления (привязки, кнопки и т. д.). Доступные имена открывают интерактивный элемент управления для дерева специальных возможностей — API, который передает информацию, полезную для вспомогательных технологий.
Текст, содержащий доступное имя интерактивного элемента управления, можно скрыть с помощью комбинации свойств, которые визуально удаляют его с экрана, но сохраняют возможность анализа вспомогательными технологиями. Это обычно используется для кнопок, которые полагаются исключительно на значок для передачи цели.
- Что такое доступное имя? | Группа Пачиелло
- Скрытый контент для лучшего a11y | Иди делай вещи
- MDN Понимание WCAG, пояснения к Руководству 2.4
- Понимание критерия успеха 2.4.4 | Понимание W3C WCAG 2.0
| Спецификация |
|---|
| Селекторы 4-го уровня # the-empty-pseudo |
 Включите JavaScript для просмотра данных.
Включите JavaScript для просмотра данных.-
:-moz-only-whitespaceНестандартный — Префиксная реализация изменений в Селекторах 4 уровня -
:пустоЭкспериментальный
Обнаружили проблему с содержанием этой страницы?
- Отредактируйте страницу на GitHub.
- Сообщить о проблеме с содержимым.
- Посмотреть исходный код на GitHub.
Хотите принять участие?
Узнайте, как внести свой вклад.
Последний раз эта страница была изменена участниками MDN.
HTML Standard, версия для веб-разработчиков
HTML Standard, версия для веб-разработчиков 9Издание 0002 для веб-разработчиков — последнее обновление 31 марта 2023 г.
- 2.4 URLS
- 2.4.1 Терминология
- 2.4.2 Настройки CORS Атрибуты
- 2.4.3 Атрибуты политики реферателей
- 2.4.4 Атрибуты nonce
- 2.4.5.
- 2.4.7 Получение атрибутов приоритета
- 2.4 URLS
2.4 URL-адреса
2.4.1 Терминология
Строка действительный непустой URL-адрес , если это допустимая строка URL-адреса, но она не пустая строка.
Строка представляет собой действительный URL-адрес, потенциально окруженный пробелами , если после удаления начального и конечного символов ASCII пробел из него, это допустимая строка URL.
Строка представляет собой действительный непустой URL-адрес, потенциально окруженный пробелами , если после удаления начального и конечного символов ASCII пробел из него, это допустимый непустой URL-адрес.
Эта спецификация определяет URL-адрес about:legacy-compat как зарезервированный,
хотя и неразрешимый, about: URL, для использования в DOCTYPE в документах HTML, когда это необходимо для
совместимость с XML-инструментами. [О]
[О]
Эта спецификация определяет URL-адрес about:html-kind как зарезервированный,
хотя и неразрешимый, about: URL, который используется как
идентификатор для видов медиатреков. [О]
Эта спецификация определяет URL-адрес about:srcdoc как зарезервированный, хотя
неразрешимый, about: URL-адрес, который используется в качестве URL-адреса документов iframe srcdoc .
[О]
Резервный базовый URL-адрес объекта Document документа является
Запись URL, полученная при выполнении следующих шагов:
Если документ является документом
iframesrcdoc, то вернуть документ база документов контейнера URL.Если URL-адрес документа
about:blankи просмотр документа базовый URL-адрес создателя контекста не равен нулю, затем верните эту базу создателя URL.Вернуть URL-адрес документа .

Базовый URL-адрес документа объекта Document является
Запись URL, полученная при выполнении следующих шагов:
Если нет базы
hrefв документеРезервный базовый URL документа.В противном случае вернуть замороженный базовый URL первого элемента
baseв документеhref, в порядок дерева.
URL-адрес соответствует about:blank , если его схема « about », его путь содержит одну строку « пустой «, его
имя пользователя и пароль — это пустая строка, а его хост — null.
Такой URL-запрос и фрагмент могут быть ненулевыми. Например, URL-адрес
запись, созданная путем синтаксического анализа « about:blank?foo#bar », соответствует about:blank .
2.4.2 Атрибуты настроек CORS
Атрибуты/перекрестное происхождение
Поддержка во всех текущих двигателях.
FirefoxДаSafariДаChromeДа
Opera?EdgeДа
Edge (устаревший)12+Internet ExplorerДа
Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android?
Атрибут настроек CORS является перечисляемым атрибутом. Следующее В таблице перечислены ключевые слова и состояния для атрибута — состояния, указанные в первой ячейке. строк с ключевыми словами дают состояния, которым соответствуют эти ключевые слова.
| Государство | Ключевые слова | Краткое описание |
|---|---|---|
| Анонимный | анонимный | Запросы элемента будут иметь свои
режим установлен на « cors » и их
режим учетных данных установлен на « того же происхождения ». |
| (пустая строка) | ||
| Использование учетных данных | использование учетных данных | Для запросов элемента будет установлен режим » cors », а их режим учетных данных установлен на « включает ». |
Недопустимое значение атрибута по умолчанию — это анонимное состояние, а его отсутствующее значение по умолчанию — это состояние No CORS .
В целях отражения каноническое ключевое слово
для анонимного состояния является ключевым словом анонимный .
Большинство выборок регулируется настройками CORS Атрибуты будут выполняться с помощью алгоритма запроса потенциального CORS.
Для более современных функций, где режим запроса всегда « cors «, некоторые атрибуты настроек CORS были переназначены, чтобы иметь
немного другое значение, при этом они влияют только на режим учетных данных запроса. Чтобы выполнить этот перевод, мы
определить режим учетных данных атрибута настроек CORS для заданных настроек CORS
атрибут определяется переключением состояния атрибута:
Чтобы выполнить этот перевод, мы
определить режим учетных данных атрибута настроек CORS для заданных настроек CORS
атрибут определяется переключением состояния атрибута:
- Нет CORS
- Анонимно
- »
тот же источник» - Использовать учетные данные
- »
включить»
2.4.3 Атрибуты политики реферера
Атрибут политики реферера является перечисляемым атрибутом. Каждый политика реферера, включая пустую строку, является ключевым словом для этого атрибута, сопоставления в одноименное государство.
Недопустимое значение атрибута по умолчанию и отсутствующее значение по умолчанию являются состоянием пустой строки.
Влияние этих состояний на модель обработки различных выборок более подробно определяется в этой спецификации, в Fetch и Referrer Policy . [FETCH] [REFERREPOLICY]
Несколько сигналов могут влиять на то, какая модель обработки используется для данной выборки; атрибут политики реферера является только одним из
их. В общем, порядок обработки этих сигналов следующий:
В общем, порядок обработки этих сигналов следующий:
Во-первых, наличие
noreferrerссылка тип;Затем значение атрибута политики реферера;
Затем наличие любого метаэлемента
name, установленным наreferrer.Наконец, `
Referrer-Policy` HTTP заголовок.
2.4.4 Одноразовые атрибуты
Global_attributes/nonce
Поддержка во всех текущих движках.
Firefox31+SafariДаChromeДа
Opera?EdgeДа
Edge (устаревший)?Internet ExplorerНет
Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android?
A одноразовый номер содержимое
атрибут представляет собой криптографический одноразовый номер («число, используемое один раз»), который может использоваться Content. Политика безопасности , чтобы определить, будет ли разрешено выполнение данной выборки.
значение — текст. [CSP]
Политика безопасности , чтобы определить, будет ли разрешено выполнение данной выборки.
значение — текст. [CSP]
Элементы с атрибутом содержимого nonce гарантируют, что
криптографический одноразовый номер доступен только для сценария (а не для побочных каналов, таких как атрибут CSS
селекторы), взяв значение из атрибута содержимого и переместив его во внутренний слот.
по имени [[CryptographicNonce]] , раскрывая его скрипту
через миксин интерфейса HTMLOrSVGElement и установив для атрибута содержимого значение
пустая строка. Если не указано иное, значением слота является пустая строка.
-
элемент .nonce Возвращает значение, установленное для криптографического одноразового номера элемента . Если сеттера не было используется, это будет значение, изначально найденное в одноразовом номере
-
элемент .nonce = значение Обновляет элемент значение криптографического одноразового номера.

HTMLElement/nonce
Firefox75+Safari🔰 10+Chrome61+
Opera?Edge79+
Edge (устаревший)?Internet ExplorerNo
Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android?
Атрибут IDL nonce должен при получении возвращать
значение [[CryptographicNonce]] этого элемента; и при настройке установите этот элемент
[[CryptographicNonce]] на заданное значение.
Обратите внимание, что установщик для IDL-атрибута nonce не обновляет соответствующий
атрибут содержания. Это, а также приведенная ниже настройка атрибута содержимого nonce для пустой строки, когда элемент
становится подключенным к контексту просмотра, предназначен для предотвращения утечки одноразового номера
значение с помощью механизмов, которые могут легко считывать атрибуты содержимого, такие как селекторы.![]() Узнайте больше в
проблема № 2369, где это поведение было
представил.
Узнайте больше в
проблема № 2369, где это поведение было
представил.
Изменение следующего атрибута
шаги используются для nonce атрибут содержимого:
Если элемент не включает
HTMLOrSVGElement, то возвращаться.Если localName не
nonceили пространство имен не равно null, затем вернитесь.Если значение равно нулю, то установите элемент [[CryptographicNonce]] в пустую строку.
В противном случае установите для элемента [[CryptographicNonce]] значение значение .
Всякий раз, когда элемент включает HTMLOrSVGElement становится подключенным к контексту просмотра, пользовательский агент должен выполнить следующие шаги
на элементе :
Пусть список CSP будет элементом shadow-включая корневую политику список CSP контейнера.
Если список CSP содержит политику безопасности содержимого, доставленную в заголовке, и элемент имеет
nonceатрибут содержимого attr , значение которого не является пустой строкой, тогда:Пусть nonce будет элементом [[Криптографическийнонс]].
Установите значение атрибута для элемент с использованием «
nonce» и пустого нить.Установить элемент [[CryptographicNonce]] на одноразовый номер .
Если элемент [[CryptographicNonce]] не был восстановлен будет пустой строкой в этот момент.
Этапы клонирования элементов,
include HTMLOrSVGElement должен установить
[[CryptographicNonce]] в копии на значение слота в элементе
клонировано.
2.4.5 Ленивая загрузка атрибутов
Lazy_loading
Поддержка во всех текущих двигателях.
Firefox75+Safari15.4+Chrome77+
Opera?Edge79+
Edge (устаревший)?Internet ExplorerNo
Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android?
Атрибут отложенной загрузки является перечисляемым атрибутом. Следующее В таблице перечислены ключевые слова и состояния для атрибута — ключевые слова в карте левого столбца. к состояниям в ячейке во втором столбце той же строки, что и ключевое слово.
Атрибут предписывает агенту пользователя получить ресурс немедленно или отложить получение до тех пор, пока некоторые условия, связанные с элементом, выполняются в соответствии с текущим значением атрибута. состояние.
| Ключевое слово | Государство | Описание |
|---|---|---|
ленивый | Ленивый | Используется для отсрочки получения ресурса до тех пор, пока не будут выполнены некоторые условия.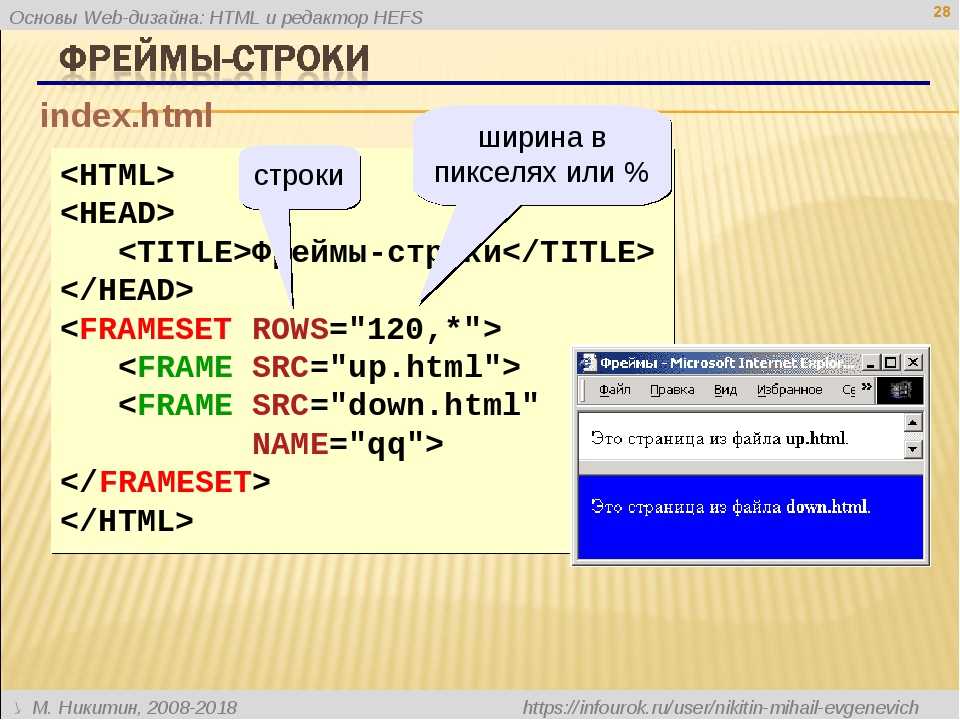 |
жаждущий | Нетерпеливый | Используется для немедленного получения ресурса; состояние по умолчанию. |
Отсутствующее значение атрибута по умолчанию и недопустимое значение по умолчанию оба находятся в состоянии Eager.
будет лениво загружать шаги элемента , учитывая элемент элемент , следующие:
Если скрипты отключены для элемента , затем вернуть ложь.
Это мера против отслеживания, потому что если пользовательский агент поддерживает отложенную загрузку когда сценарии отключены, сайт по-прежнему может отслеживать приблизительную положение прокрутки на протяжении всего сеанса, стратегически размещая изображения в разметке страницы, например что сервер может отслеживать, сколько изображений запрашивается и когда.
Если атрибут отложенной загрузки элемента находится в состоянии Lazy, то возвращается значение true.
Вернуть ложь.
Каждый элемент img и iframe связан с отложенным возобновлением загрузки
шаги , изначально нуль.
Для элементов img и iframe , которые будут лениво загружаться, эти шаги выполняются из ленивой загрузки
обратный вызов наблюдателя пересечения или когда установлен атрибут ленивой загрузки
в состояние Стремления. Это приводит к тому, что элемент
продолжить загрузку.
Каждый документ имеет наблюдатель пересечения с отложенной нагрузкой , изначально настроенный на
null, но может быть установлен на экземпляр IntersectionObserver .
Чтобы начать наблюдение за перекрестком с ленивой загрузкой элемента элемент , запустите эти шагов:
Пусть doc будет документом узла element .
Если наблюдатель пересечения отложенной нагрузки doc имеет значение null, установите для него новое значение.
Экземпляр IntersectionObserver, инициализирован следующим образом:Намерение состоит в том, чтобы использовать исходное значение
IntersectionObserverконструктор. Однако мы вынуждены использовать Конструктор, доступный для JavaScript в этой спецификации, до Intersection Observer предоставляет низкоуровневые хуки для использования в спецификациях. См. ошибку w3c/IntersectionObserver#464. который это отслеживает. [ИНТЕРСЕКЦИОНОБСЕРВЕР]обратный вызов это эти шаги, с аргументами записи и наблюдатель :
Для каждой записи в записи с использованием метода итерация, которая не запускает модифицируемые разработчиком методы доступа к массиву или хуки итерации:
Пусть шаги возобновления равны нулю.
Если запись .
isIntersectingистинно, тогда набор возобновление шагов с по запись .цельленивые шаги возобновления загрузки.Если resumptionSteps равно null, возврат.
Остановить перекресток, наблюдая за элементом ленивой загрузки для запись .
цель.Установить запись .
targetвозобновление ленивой загрузки шаги к нулю.Вызвать возобновление Шаги .
Предполагается использовать исходное значение
пересекается сицелигеттеров. См. w3c/IntersectionObserver#464. [ИНТЕРСЕКЦИОНОБСЕРВЕР]
options — это словарь
IntersectionObserverInitс следующие члены словаря: «[ »rootMargin» → отложенная загрузка root поле ]»Это позволяет выбирать изображение во время прокрутки, когда оно еще не — но вот-вот — пересечет вьюпорт.
Предложения корневого поля отложенной загрузки подразумевают динамические изменения в значение, но API
IntersectionObserverне поддерживает изменение корневого допуск. См. проблему w3c/IntersectionObserver#428.
Вызов doc метод
наблюденияпересечения ленивой нагрузки с элементом в качестве аргумент.Намерение состоит в том, чтобы использовать исходное значение наблюдения
9Метод 0005. См. w3c/IntersectionObserver#464. [ИНТЕРСЕКЦИОНОБСЕРВЕР]


К остановить перекресток-наблюдая за ленивой загрузкой элемента элемент , запустить эти шагов:
Пусть doc будет документом узла element .
Утверждение: doc наблюдатель пересечения отложенной нагрузки не нулевой.
Call doc наблюдатель пересечения отложенной нагрузки
несоблюдение методас элементом как Аргумент.Предполагается использовать исходное значение метода
без наблюдения. См. w3c/IntersectionObserver#464. [ИНТЕРСЕКЦИОНОБСЕРВЕР]
Корневой запас отложенной загрузки является значением, определяемым реализацией, но с следующие предложения для рассмотрения:
Установите минимальное значение, при котором ресурсы чаще всего загружаются до того, как они пересекать область просмотра при обычных шаблонах использования для данного устройства.
Типичная скорость прокрутки: увеличьте значение для устройств с более быстрой типичной прокруткой скорости.
Текущая скорость прокрутки или импульс: ПА может попытаться предсказать, где прокрутка скорее всего, остановится и соответствующим образом отрегулирует значение.
Качество сети: увеличьте значение для медленных соединений или соединений с высокой задержкой.
На значение могут влиять предпочтения пользователя.

Для конфиденциальности важно, чтобы ленивая загрузка корневого поля не пропускает дополнительную информацию. Например, типичный скорость прокрутки на текущем устройстве может быть неточной, чтобы не ввести новый вектор отпечатков пальцев.
2.4.6 Атрибуты блокировки
Атрибут блокировки явно указывает, что определенные операции должны быть заблокированы при получении внешнего ресурса. Операции, которые могут быть заблокированы, представлены возможных блокирующих токенов , которые представляют собой строки, перечисленные следующую таблицу:
| Возможный токен блокировки | Описание |
|---|---|
" визуализация " | Элемент потенциально блокирует рендеринг. |
В будущем может быть больше возможных блокирующих токенов.
Атрибут блокировки должен иметь значение, представляющее собой неупорядоченный набор уникальных
лексемы, разделенные пробелами, каждая из которых возможна
блокировка токенов. Поддерживаемые токены
блокирующий атрибут - возможная блокировка
жетоны. Любой элемент может иметь не более одного атрибута блокировки.
Поддерживаемые токены
блокирующий атрибут - возможная блокировка
жетоны. Любой элемент может иметь не более одного атрибута блокировки.
Набор блокирующих токенов для элемента el являются результатом следующие шаги:
Пусть значение будет значением атрибута блокировки el или пустая строка, если такого атрибута не существует.
Установите значение в значение , преобразованное в нижний регистр ASCII.
Пусть rawTokens будут результатом разделения значения на пробелы ASCII.
Вернуть набор, содержащий элементы rawTokens , которые являются возможными блокирующими токенами.
Элемент потенциально блокирует рендеринг , если установлены его блокирующие токены
содержит " render ", или если это неявно потенциально блокирует рендеринг , который будет определен в индивидуальном порядке. элементы. По умолчанию элемент не является неявно потенциально блокирующим рендеринг.
элементы. По умолчанию элемент не является неявно потенциально блокирующим рендеринг.
2.4.7 Выбрать атрибуты приоритета
Атрибут приоритета выборки является перечисляемым атрибутом. Следующее В таблице перечислены ключевые слова и состояния для атрибута — ключевые слова в левом столбце соответствуют состояния в ячейке во втором столбце той же строки, что и ключевое слово.
| Ключевое слово | Государство | Описание |
|---|---|---|
высокий | высокий | Сигнализирует выборку с высоким приоритетом по сравнению с другими ресурсы с тем же назначением. |
низкий | низкий | Сигнализирует выборку с низким приоритетом по сравнению с другими
ресурсы с тем же назначением. |