что это такое простыми словами, кодовая таблица символов
ASCII — это таблица кодировки символов, в которой каждой букве, числу или знаку соответствует определенное число. В стандартной таблице ASCII 128 символов, пронумерованных от 0 до 127. В них входят латинские буквы, цифры, знаки препинания и управляющие символы.
Как выглядит таблицаТаблицу разработали в Америке в 60-х, и ее название расшифровывается как American Standard Code for Information Interchange — Американская стандартная кодировка для обмена информацией. Аббревиатура читается как «аски».
Существуют национальные расширения ASCII, которые кодируют буквы и символы, принятые в других алфавитах. «Стандартная» таблица называется US-ASCII, или международной версией. В большинстве национальных расширений заменена только часть символов, например знак доллара на знак фунта. Но для языков, где используются нелатинские алфавиты, заменяется большинство символов. Русский относится к таким языкам.
Русский относится к таким языкам.
Курс Уверенный старт в IT Поможем определить подходящую вам IT-профессию и освоить её с нуля. Вы на практике попробуете разные направления: разработку на разных языках, аналитику данных, Data Science, менеджмент в IT. Это самый подходящий курс для построения карьеры в IT в новой реальности. Хочу в IT!
Цифровое устройство по умолчанию не понимает символы — только числа. Поэтому буквы, цифры и знаки приходится кодировать, чтобы задавать компьютеру соответствие между определенным начертанием и числовым значением. Сейчас вариантов кодирования несколько, и ASCII — одна из наиболее ранних кодировок. Она задала стандарты для последующих решений.
Когда появилась эта кодировка, компьютеров в современном представлении еще не существовало. Ее разработали для телетайпов — устройств обмена информацией, похожих на телеграфы с печатной машинкой.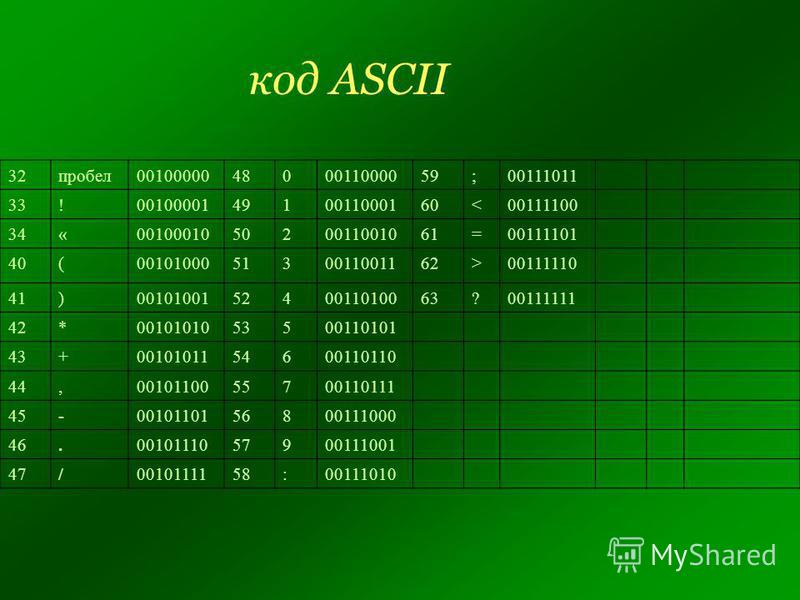 Сейчас ими практически не пользуются, но некоторые стандарты остались с тех времен. В том числе набор ASCII, который теперь применяется для кодирования информации в компьютерах.
Сейчас ими практически не пользуются, но некоторые стандарты остались с тех времен. В том числе набор ASCII, который теперь применяется для кодирования информации в компьютерах.
Сейчас с помощью ASCII кодируются данные в компьютерных устройствах, на ней основано несколько других кодировок, кроме того, ее используют в творчестве — создают с помощью символов картинки. Это называется ASCII art.
- При разработке сайта или приложения разработчику может понадобиться пользоваться ASCII, чтобы закодировать символы, не входящие в национальную кодировку.
- Можно сохранить документ или иной файл в формате ASCII — тогда все символы в нем будут закодированы этим набором. Такое может понадобиться, если человеку нужно передать информацию, которая будет читаться везде, — но некоторые функции форматирования в таком режиме будут недоступны.
 Так можно печатать и символы, которые есть в расширенных версиях набора: смайлики, иероглифы, буквы алфавитов других стран и так далее. Код для таких символов может быть намного длиннее, чем для стандартных 128 букв и цифр.
Так можно печатать и символы, которые есть в расширенных версиях набора: смайлики, иероглифы, буквы алфавитов других стран и так далее. Код для таких символов может быть намного длиннее, чем для стандартных 128 букв и цифр.
 Так можно печатать и символы, которые есть в расширенных версиях набора: смайлики, иероглифы, буквы алфавитов других стран и так далее. Код для таких символов может быть намного длиннее, чем для стандартных 128 букв и цифр.
Так можно печатать и символы, которые есть в расширенных версиях набора: смайлики, иероглифы, буквы алфавитов других стран и так далее. Код для таких символов может быть намного длиннее, чем для стандартных 128 букв и цифр.С помощью ASCII вводят, выводят и передают информацию, поэтому она должна описывать самые часто используемые символы и управляющие элементы (перенос, шаг назад и так далее). Таблица восьмибитная, а числа, которые соответствуют символам, переводятся в двоичный код, чтобы компьютер мог их распознавать. Десятичное же написание удобнее для людей. Еще используют шестнадцатеричное — с его помощью легче представить набор в виде таблицы.
Заглавные и строчные буквы в ASCII — это разные элементы. Причем в таблице строчные буквы расположены под заглавными, в том же столбце, но в разных строчках. Так набор оказывается нагляднее, а информацию легче проверять и работать с ней, например редактировать регистр с помощью автоматических команд.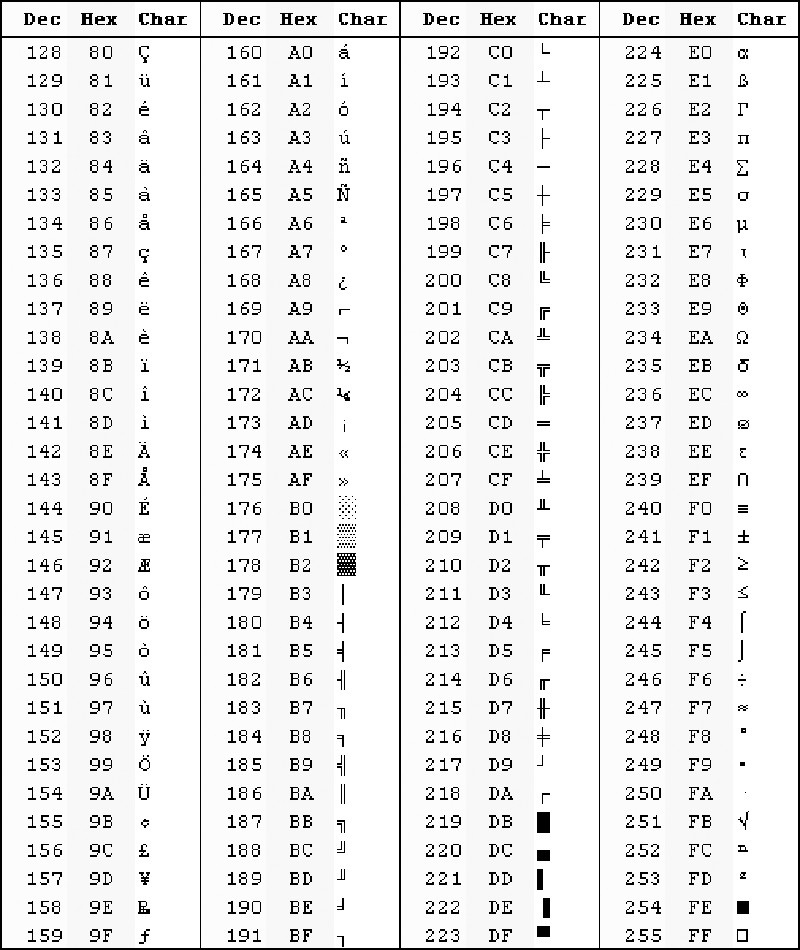
- В третьей строке расположены знаки препинания и специальные символы, такие как процент % или астериск *.
- Четвертая строка — числа и математические символы, а также двоеточие, точка с запятой и вопросительный знак.
- Пятая и шестая строчка — заглавные буквы, а также некоторые другие особые символы.
- Седьмая и восьмая строки описывают строчные буквы и еще несколько символов.
Когда мы говорим о кодировании, сразу вспоминается система международной кодировки символов Unicode. Важно не путать ее с ASCII — эти понятия не идентичны.
ASCII появилась раньше и включает в себя меньше символов. В стандартной таблице их всего 128, если не считать расширений для других языков. А в «Юникоде», который реализуют кодировки UTF-8 и UTF-32, сейчас 2²¹ символов — это больше чем два миллиона. В набор входят практически все существующие сегодня символы, он очень широкий.
А в «Юникоде», который реализуют кодировки UTF-8 и UTF-32, сейчас 2²¹ символов — это больше чем два миллиона. В набор входят практически все существующие сегодня символы, он очень широкий.
Unicode можно рассматривать как «продолжение», расширение ASCII. Первые 128 символов в «Юникоде» кодируются так же, как в ASCII, и это те же самые символы.
Курс Уверенный старт в IT Поможем определить подходящую вам IT-профессию и освоить её с нуля. Вы на практике попробуете разные направления: разработку на разных языках, аналитику данных, Data Science, менеджмент в IT. Это самый подходящий курс для построения карьеры в IT в новой реальности. Хочу в IT!
ascii — с английского на русский
с русского на английский
- С русского на:
- Английский
- С английского на:
- Все языки
- Албанский
- Арабский
- Болгарский
- Иврит
- Индонезийский
- Испанский
- Итальянский
- Казахский
- Каталанский
- Македонский
- Немецкий
- Нидерландский
- Персидский
- Польский
- Португальский
- Русский
- Сербский
- Словацкий
- Тамильский
- Турецкий
- Украинский
- Финский
- Французский
- Хорватский
- Чешский
- Шведский
Толкование Перевод
1 ASCII
Англо-русский словарь по авиации > ASCII
2
Англо-русский словарь компьютерных и интернет терминов > ASCII
3 ASCII
English-Russian SQL Server dictionary > ASCII
4 ASCII
English-Russian dictionary of terms that are used in computer games > ASCII
5 ASCII
ASCII
ASCII terminal — терминал работающий в коде ASCII
English-Russian dictionary of Information technology > ASCII
6 ASCII
ASCII, American Standard Code for Information Interchange
американский стандартный код для обмена информацией
————————
ASCII, automatic synchronous control of intelligence information
автоматическая синхронная проверка разведывательной информации
English-Russian dictionary of planing, cross-planing and slotting machines > ASCII
7 ASCII
ASCII (American Standard Code for Information Interchange)
Американский кодекс стандартных обозначений.
Англо-русский словарь по кондиционированию и вентиляции > ASCII
8 ASCII
ASCII (American Standard Code for Information Interchange)
Американский кодекс стандартных обозначений.
English-Russian dictionary of terms for heating, ventilation, air conditioning and cooling air > ASCII
9 ASCII
ASCII
American Standard Code for Information Interchange
Американская стандартная кодировка для обмена данными
English-Russian dictionary of modern abbreviations > ASCII
10 ASCII
- код для обмена информацией ASCII
- версия КОИ-7
- Американский стандартный код для обмена информацией
- Американский стандартный код для информационного обмена
Американский стандартный код для информационного обмена
Американский 7-битный (плюс 1 бит четности) стандарт кодирования текстовой информации (латинский алфавит, цифры и т. д.), утвержденный ИСО. (На ПК используется так называемый расширенный код ASCII, в котором первые 128 битовых комбинаций совпадают со стандартным ASCII, а остальные используются для представления национальных алфавитов, псевдографики и специальных символов.).
[ http://www.iks-media.ru/glossary/index.html?glossid=2400324]Тематики
- электросвязь, основные понятия
EN
- American standard code for information interchange
- ASCII
Американский стандартный код для обмена информацией
—
[А.С.Гольдберг. Англо-русский энергетический словарь. 2006 г.]Тематики
- энергетика в целом
EN
- American Standard Code for Information Interchange
- ASCII
американский стандартный код для обмена информацией
код ASCII
Набор из 128 кодов символов для машинного представления прописных и строчных букв латинского алфавита, чисел, знаков препинания и специальных символов, каждому их которых соответствует конкретное 7-битовое двоичное число.
[ http://www.morepc.ru/dict/]Тематики
- информационные технологии в целом
Синонимы
- код ASCII
EN
- American Standard Code for Information Interchange
- ASCII
версия КОИ-7
7-битный набор кодированных знаков, состоящий из 128 латинских букв, цифр, специальных графических и управляющих знаков, каждый из которых кодируется 7 битами (8, включая проверку паритета), используемый для обработки и обмена данными между системами обработки информации.
[ ГОСТ 30721-2000]
[ ГОСТ Р 51294.3-99]Тематики
- кодирование штриховое
EN
- ASCII
DE
- ASCII
FR
- ASCII
ASCII
Американский стандартный код для обмена информацией, введен в 1963 г.
Широко используется во многих машинах. Семиразрядный код без каких-либо рекомендаций относительно контроля по четности обеспечивает 128 различных битовых комбинаций, включая управляющие. Стандарт регламентирует порядок кодирования 7-разрядным двоичным кодом 128 различных управляющих сигналов алфавитно-цифровых и специальных графических символов. Символы, задаваемые кодами от 0 до 32, а также особым кодом 127, как правило, не выводятся на дисплей и не печатаются на принтере.
[Е.С.Алексеев, А.А.Мячев. Англо-русский толковый словарь по системотехнике ЭВМ. Москва 1993]Тематики
- информационные технологии в целом
EN
- American Standard Code for Information Interchange
- ASCII
Англо-русский словарь нормативно-технической терминологии > ASCII
11 ASCII
(American Standard Code for Information Interchange) американский стандартный код для обмена информацией, код ASCII (произносится «аски»)
набор из 128 различных кодов символов для машинного представления прописных и строчных букв латинского алфавита, чисел, знаков препинания и специальных символов, каждому из которых соответствует конкретное 7-битовое двоичное число; стандарт ANSI Х3.
4-1967. Первые 32 символа этого кода являются управляющими (такими, как символы «перевод строки», «возврат каретки») и служат для управления печатью и передачей данных. Они не могут быть распечатаны в текстовом виде. Так как в компьютере 7-битовые коды хранятся в 8-битовых ячейках (байтах), восьмой бит при передаче данных может использоваться для контроля чётности либо для расширенного набора символов ASCII, включающего буквы различных языков и графические символы (см. extended ASCII). Введение стандартных кодов позволило упростить обмен данными между различными компьютерными системами. Европейская модификация ASCII — код Latin 1 (стандарт ISO 8859-1), американская национальная версия определена в ISO 646см. тж. character set, control character, EBCDIC, parity, Unicode
Англо-русский толковый словарь терминов и сокращений по ВТ, Интернету и программированию. > ASCII
12 ASCII
код ASCII
ASCII terminal — терминал работающий в коде ASCII
The English-Russian dictionary general scientific > ASCII
13 ASCII
(American Standard Code for Information Interchange — американский стандартный код для обмена информацией) Набор символов ASCII Character Set A character set consisting only of the characters included in the original 128-character ASCII standard.
English-Russian network dictionary > ASCII
14 ASCII
сокр. от American standard code for information interchange Американский стандартныйкод обмена информацией
ASCII
Большой англо-русский и русско-английский словарь > ASCII
15 ASCII
сокр. от American Standard Code for Information Interchange
Американский стандартный код для обмена информацией, код ASCII
Англо-русский словарь технических терминов > ASCII
16 ASCII
1) Компьютерная техника: Американский стандартный код для обмена информацией (American Standard Code for Information Interchange), Американский стандарт по обмену информацией, алфавитная интерпретация компьютерного кода (American Standard for Computer Information Interchange)
2) Военный термин: automatic synchronous control of intelligence information
3) Техника: automatic synchronous control of intelligence information system
4) Шутливое выражение: A Scientific Computer Internal Intelligence, Amsterdam Subversive Code For Information Interchange
5) Автомобильный термин: American standard for character information interchange
6) Телекоммуникации: American Standard Code for Information Interchange (ANSI), Американский стандартный код информационного обмена (128 символов)
7) Сокращение: American National Standard, American National Standard Code for Information Interchange
8) Вычислительная техника: American Standard Code for Information Interchange, American Standard Code of Information Interchange, American standart code for information interchange, американский стандартный код обмена информацией
9) Бытовая техника: код ASCII
10) Сетевые технологии: American National Code for Information Interchange
11) Химическое оружие: American Standard for Code Information Interchange
Универсальный англо-русский словарь > ASCII
17 ASCII
= American Standard Code for Information Interchange
Американский стандартный код для обмена информацией, ASCII-код
English-Russian electronics dictionary > ASCII
18 ASCII
сокр.
от American Standard Code for Information InterchangeАмериканский стандартный код для обмена информацией, ASCII-код
The New English-Russian Dictionary of Radio-electronics > ASCII
19 ASCII
код ASCII
English-Russian household appliances > ASCII
20 ASCII
сокр. от American Standard Code for Information Interchange
Американский стандартный код информационного обмена ( 128 символов)
— extended ASCII
English-Russian dictionary of telecommunications and their abbreviations > ASCII
 д.), утвержденный ИСО. (На ПК используется так называемый расширенный код ASCII, в котором первые 128 битовых комбинаций совпадают со стандартным ASCII, а остальные используются для представления национальных алфавитов, псевдографики и специальных символов.).
д.), утвержденный ИСО. (На ПК используется так называемый расширенный код ASCII, в котором первые 128 битовых комбинаций совпадают со стандартным ASCII, а остальные используются для представления национальных алфавитов, псевдографики и специальных символов.).
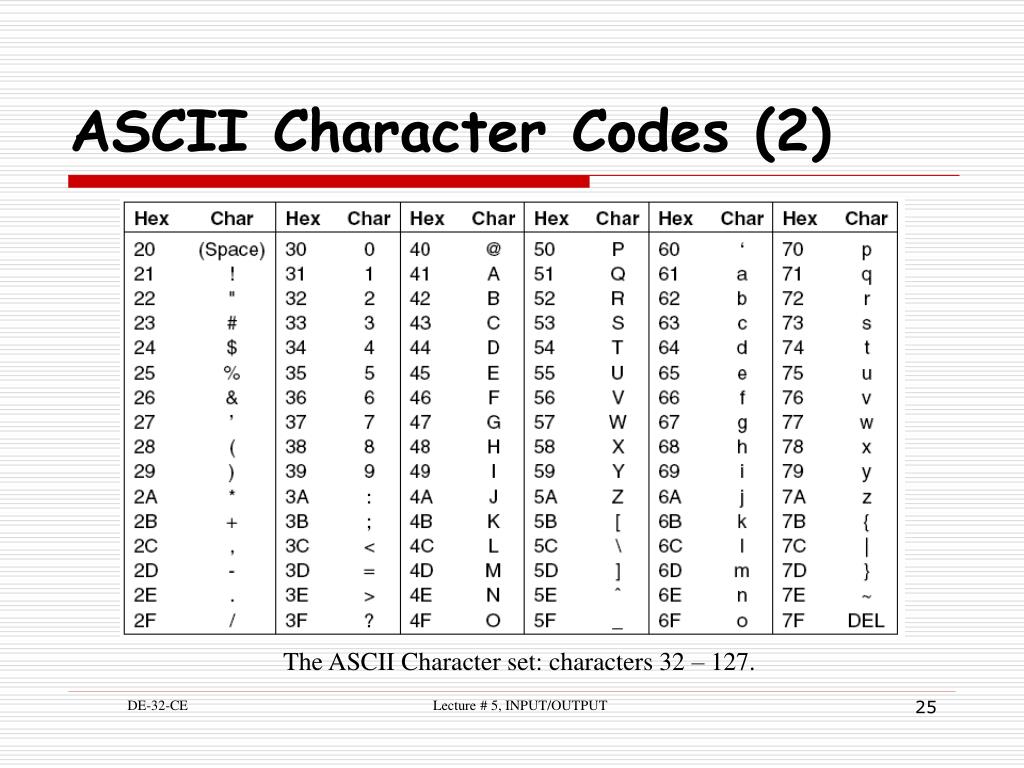 Стандарт регламентирует порядок кодирования 7-разрядным двоичным кодом 128 различных управляющих сигналов алфавитно-цифровых и специальных графических символов. Символы, задаваемые кодами от 0 до 32, а также особым кодом 127, как правило, не выводятся на дисплей и не печатаются на принтере.
Стандарт регламентирует порядок кодирования 7-разрядным двоичным кодом 128 различных управляющих сигналов алфавитно-цифровых и специальных графических символов. Символы, задаваемые кодами от 0 до 32, а также особым кодом 127, как правило, не выводятся на дисплей и не печатаются на принтере. 4-1967. Первые 32 символа этого кода являются управляющими (такими, как символы «перевод строки», «возврат каретки») и служат для управления печатью и передачей данных. Они не могут быть распечатаны в текстовом виде. Так как в компьютере 7-битовые коды хранятся в 8-битовых ячейках (байтах), восьмой бит при передаче данных может использоваться для контроля чётности либо для расширенного набора символов ASCII, включающего буквы различных языков и графические символы (см. extended ASCII). Введение стандартных кодов позволило упростить обмен данными между различными компьютерными системами. Европейская модификация ASCII — код Latin 1 (стандарт ISO 8859-1), американская национальная версия определена в ISO 646
4-1967. Первые 32 символа этого кода являются управляющими (такими, как символы «перевод строки», «возврат каретки») и служат для управления печатью и передачей данных. Они не могут быть распечатаны в текстовом виде. Так как в компьютере 7-битовые коды хранятся в 8-битовых ячейках (байтах), восьмой бит при передаче данных может использоваться для контроля чётности либо для расширенного набора символов ASCII, включающего буквы различных языков и графические символы (см. extended ASCII). Введение стандартных кодов позволило упростить обмен данными между различными компьютерными системами. Европейская модификация ASCII — код Latin 1 (стандарт ISO 8859-1), американская национальная версия определена в ISO 646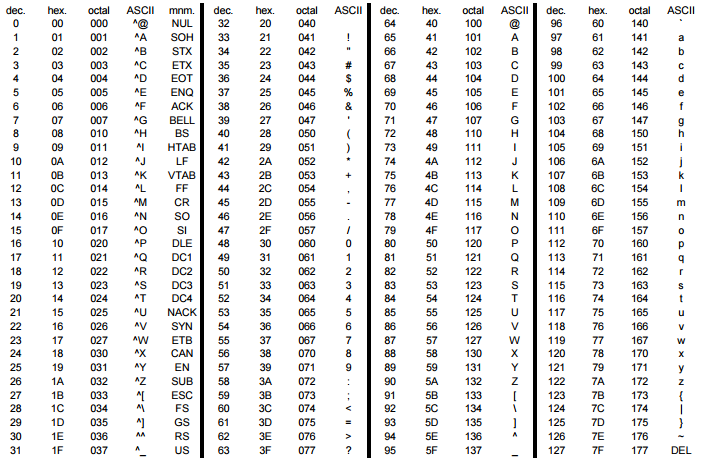
 от American Standard Code for Information Interchange
от American Standard Code for Information InterchangeСтраницы
- Следующая →
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Кодировка текста ASCII (Windows 1251, CP866, KOI8-R) и Юникод (UTF 8, 16, 32) — как исправить проблему с кракозябрами
Сегодня мы поговорим о том, откуда берутся кракозябры на сайте и в программах, какие кодировки текста существуют и какие из них следует использовать. Подробно рассмотрим историю их развития, начиная с базовой ASCII, а также ее расширенных версий CP866, KOI8-R, Windows 1251 и заканчивая современными кодировками консорциума Юникод UTF 16 и 8.
Оглавление:
Подробно рассмотрим историю их развития, начиная с базовой ASCII, а также ее расширенных версий CP866, KOI8-R, Windows 1251 и заканчивая современными кодировками консорциума Юникод UTF 16 и 8.
Оглавление:
- ASCII — базовая кодировка текста для латиницы
- Расширенные версии Аски — кодировки CP866 и KOI8-R
- Windows 1251 — вариация ASCII и почему вылезают кракозябры
- Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
- Кракозябры вместо русских букв — как исправить
Кому-то эти сведения могут показаться излишними, но знали бы вы, сколько мне приходит вопросов именно касаемо вылезших кракозябров (нечитаемого набора символов). Теперь у меня будет возможность отсылать всех к тексту этой статьи и самостоятельно отыскивать свои косяки. Ну что же, приготовьтесь впитывать информацию и постарайтесь следить за ходом повествования.
ASCII — базовая кодировка текста для латиницы
Развитие кодировок текстов происходило одновременно с формированием отрасли IT, и они за это время успели претерпеть достаточно много изменений.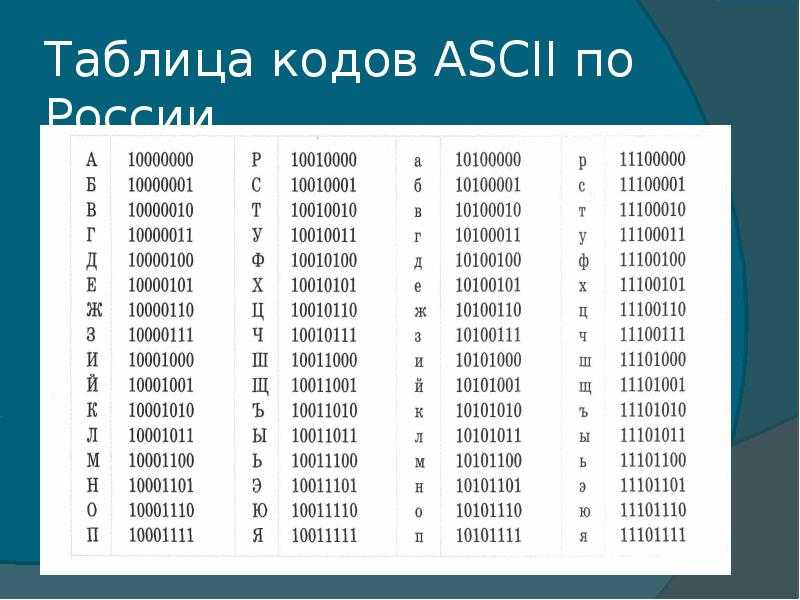 Исторически все начиналось с довольно-таки неблагозвучной в русском произношении EBCDIC, которая позволяла кодировать буквы латинского алфавита, арабские цифры и знаки пунктуации с управляющими символами.
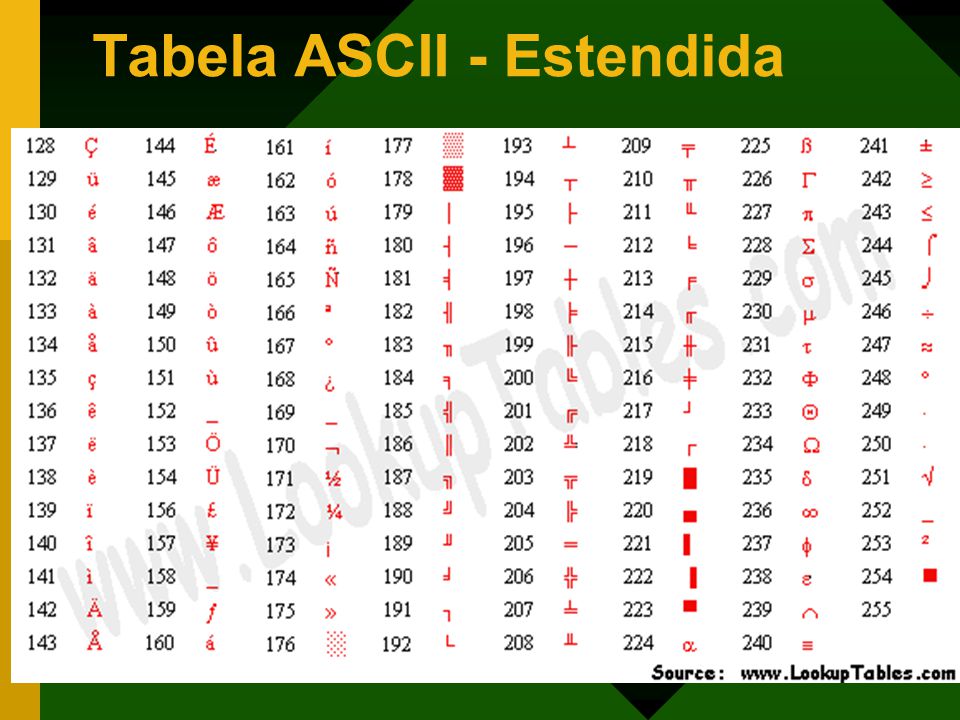
Но все же отправной точкой для развития современных кодировок текстов стоит считать знаменитую ASCII (American Standard Code for Information Interchange, которая по-русски обычно произносится как «аски»). Она описывает первые 128 символов из наиболее часто используемых англоязычными пользователями — латинские буквы, арабские цифры и знаки препинания.
Еще в эти 128 знаков, описанных в ASCII, попадали некоторые служебные символы вроде скобок, решеток, звездочек и т.п. Собственно, вы сами можете увидеть их:
Именно эти 128 символов из первоначального варианта ASCII стали стандартом, и в любой другой кодировке вы их обязательно встретите и стоять они будут именно в таком порядке.
Но дело в том, что с помощью одного байта информации можно закодировать не 128, а целых 256 различных значений (двойка в степени восемь равняется 256), поэтому вслед за базовой версией Аски появился целый ряд расширенных кодировок ASCII, в которых можно было кроме 128 основных знаков закодировать еще и символы национальной кодировки (например, русской).
Исторически все начиналось с довольно-таки неблагозвучной в русском произношении EBCDIC, которая позволяла кодировать буквы латинского алфавита, арабские цифры и знаки пунктуации с управляющими символами.
Но все же отправной точкой для развития современных кодировок текстов стоит считать знаменитую ASCII (American Standard Code for Information Interchange, которая по-русски обычно произносится как «аски»). Она описывает первые 128 символов из наиболее часто используемых англоязычными пользователями — латинские буквы, арабские цифры и знаки препинания.
Еще в эти 128 знаков, описанных в ASCII, попадали некоторые служебные символы вроде скобок, решеток, звездочек и т.п. Собственно, вы сами можете увидеть их:
Именно эти 128 символов из первоначального варианта ASCII стали стандартом, и в любой другой кодировке вы их обязательно встретите и стоять они будут именно в таком порядке.
Но дело в том, что с помощью одного байта информации можно закодировать не 128, а целых 256 различных значений (двойка в степени восемь равняется 256), поэтому вслед за базовой версией Аски появился целый ряд расширенных кодировок ASCII, в которых можно было кроме 128 основных знаков закодировать еще и символы национальной кодировки (например, русской).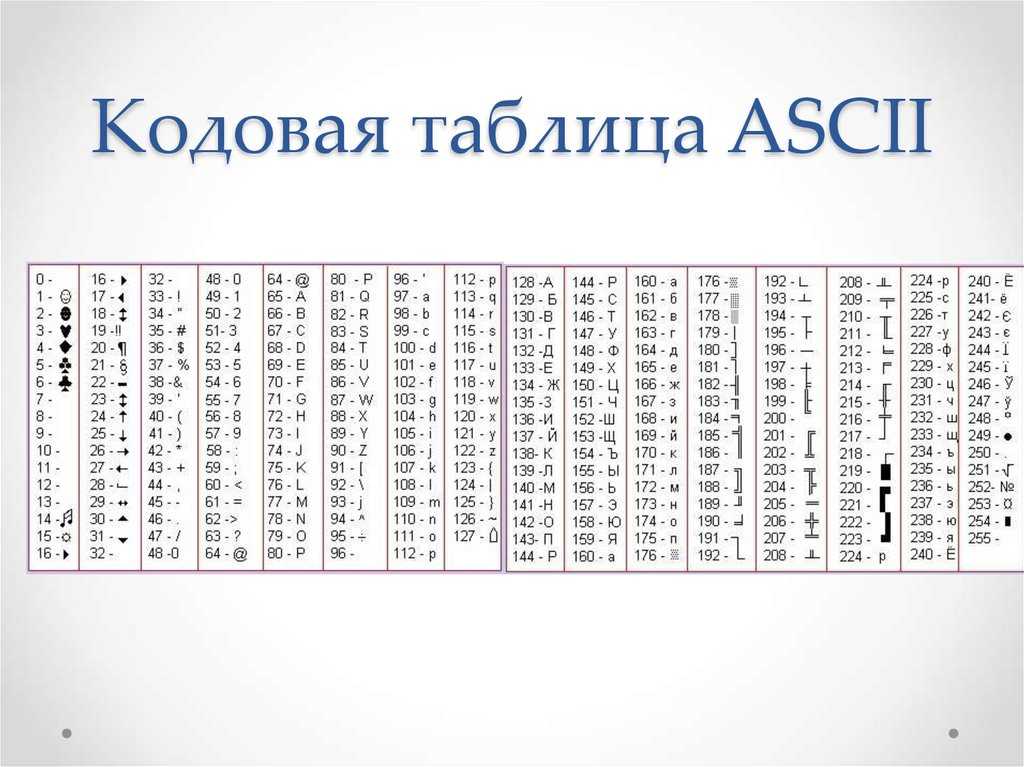 Тут, наверное, стоит еще немного сказать о системах счисления, которые используются при описании. Во-первых, как вы все знаете, компьютер работает только с числами в двоичной системе, а именно с нулями и единицами («булева алгебра», если кто проходил в институте или в школе). Один байт состоит из восьми бит, каждый из которых представляет собой двойку в степени, начиная с нулевой, и до двойки в седьмой: Не трудно понять, что всех возможных комбинаций нулей и единиц в такой конструкции может быть только 256. Переводить число из двоичной системы в десятичную довольно просто. Нужно просто сложить все степени двойки, над которыми стоят единички.
В нашем примере это получается 1 (2 в степени ноль) плюс 8 (два в степени 3), плюс 32 (двойка в пятой степени), плюс 64 (в шестой), плюс 128 (в седьмой). Итого получается 233 в десятичной системе счисления. Как видите, все очень просто.
Но если вы присмотритесь к таблице с символами ASCII, то увидите, что они представлены в шестнадцатеричной кодировке.
Тут, наверное, стоит еще немного сказать о системах счисления, которые используются при описании. Во-первых, как вы все знаете, компьютер работает только с числами в двоичной системе, а именно с нулями и единицами («булева алгебра», если кто проходил в институте или в школе). Один байт состоит из восьми бит, каждый из которых представляет собой двойку в степени, начиная с нулевой, и до двойки в седьмой: Не трудно понять, что всех возможных комбинаций нулей и единиц в такой конструкции может быть только 256. Переводить число из двоичной системы в десятичную довольно просто. Нужно просто сложить все степени двойки, над которыми стоят единички.
В нашем примере это получается 1 (2 в степени ноль) плюс 8 (два в степени 3), плюс 32 (двойка в пятой степени), плюс 64 (в шестой), плюс 128 (в седьмой). Итого получается 233 в десятичной системе счисления. Как видите, все очень просто.
Но если вы присмотритесь к таблице с символами ASCII, то увидите, что они представлены в шестнадцатеричной кодировке.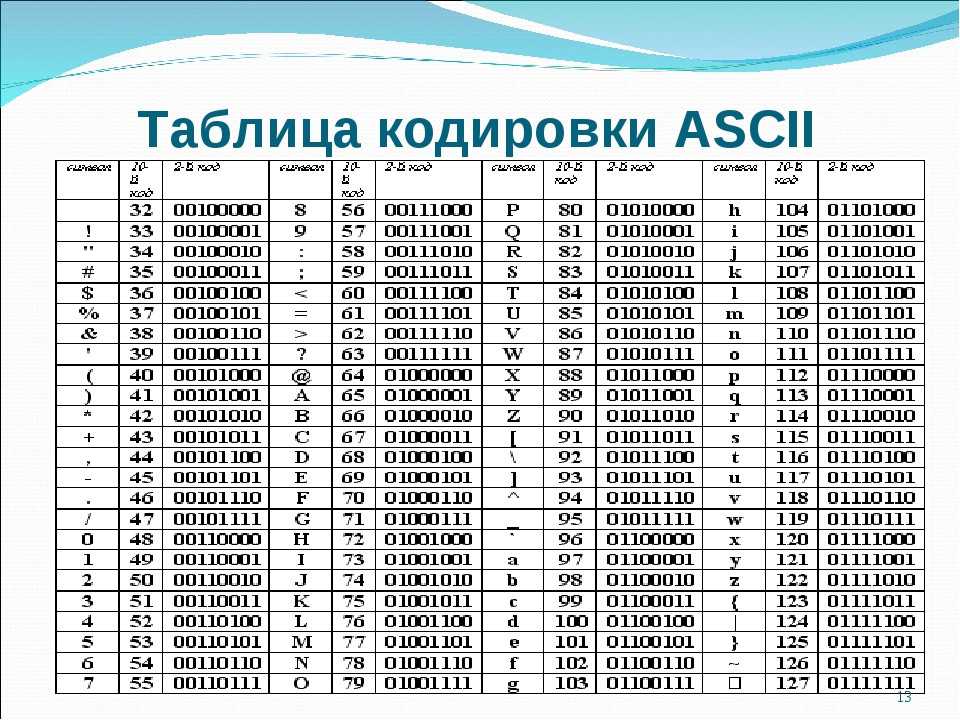 Например, «звездочка» соответствует в Аски шестнадцатеричному числу 2A. Наверное, вам известно, что в шестнадцатеричной системе счисления используются кроме арабских цифр еще и латинские буквы от A (означает десять) до F (означает пятнадцать).
Ну так вот, для перевода двоичного числа в шестнадцатеричное прибегают к следующему простому способу. Каждый байт информации разбивают на две части по четыре бита. Т.е. в каждой половинке байта двоичным кодом можно закодировать только шестнадцать значений (два в четвертой степени), что можно легко представить шестнадцатеричным числом.
Причем в левой половине байта считать степени нужно будет опять начиная с нулевой, а не так, как показано на скриншоте. В результате мы получим, что на скриншоте закодировано число E9. Надеюсь, что ход моих рассуждений и разгадка данного ребуса вам оказались понятны. Ну, а теперь продолжим, собственно, говорить про кодировки текста.
Например, «звездочка» соответствует в Аски шестнадцатеричному числу 2A. Наверное, вам известно, что в шестнадцатеричной системе счисления используются кроме арабских цифр еще и латинские буквы от A (означает десять) до F (означает пятнадцать).
Ну так вот, для перевода двоичного числа в шестнадцатеричное прибегают к следующему простому способу. Каждый байт информации разбивают на две части по четыре бита. Т.е. в каждой половинке байта двоичным кодом можно закодировать только шестнадцать значений (два в четвертой степени), что можно легко представить шестнадцатеричным числом.
Причем в левой половине байта считать степени нужно будет опять начиная с нулевой, а не так, как показано на скриншоте. В результате мы получим, что на скриншоте закодировано число E9. Надеюсь, что ход моих рассуждений и разгадка данного ребуса вам оказались понятны. Ну, а теперь продолжим, собственно, говорить про кодировки текста.
Расширенные версии Аски — кодировки CP866 и KOI8-R с псевдографикой
Итак, мы с вами начали говорить про ASCII, которая являлась как бы отправной точкой для развития всех современных кодировок (Windows 1251, юникод, UTF 8).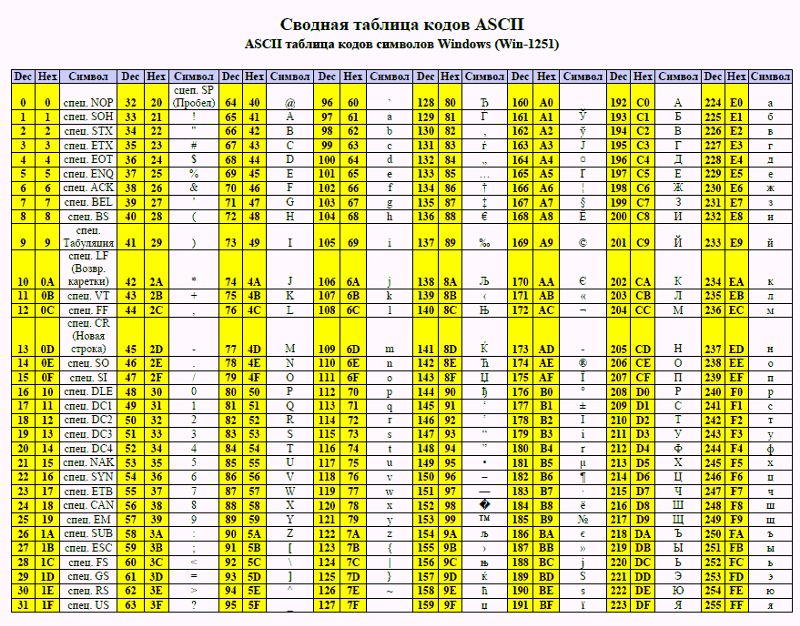 Изначально в нее было заложено только 128 знаков латинского алфавита, арабских цифр и еще чего-то там, но в расширенной версии появилась возможность использовать все 256 значений, которые можно закодировать в одном байте информации. Т.е. появилась возможность добавить в Аски символы букв своего языка.
Тут нужно будет еще раз отвлечься, чтобы пояснить — зачем вообще нужны кодировки текстов и почему это так важно. Символы на экране вашего компьютера формируются на основе двух вещей — наборов векторных форм (представлений) всевозможных знаков (они находятся в файлах со шрифтами, которые установлены на вашем компьютере) и кода, который позволяет выдернуть из этого набора векторных форм (файла шрифта) именно тот символ, который нужно будет вставить в нужное место.
Понятно, что за сами векторные формы отвечают шрифты, а вот за кодирование отвечает операционная система и используемые в ней программы. Т.е. любой текст на вашем компьютере будет представлять собой набор байтов, в каждом из которых закодирован один единственный символ этого самого текста.
Изначально в нее было заложено только 128 знаков латинского алфавита, арабских цифр и еще чего-то там, но в расширенной версии появилась возможность использовать все 256 значений, которые можно закодировать в одном байте информации. Т.е. появилась возможность добавить в Аски символы букв своего языка.
Тут нужно будет еще раз отвлечься, чтобы пояснить — зачем вообще нужны кодировки текстов и почему это так важно. Символы на экране вашего компьютера формируются на основе двух вещей — наборов векторных форм (представлений) всевозможных знаков (они находятся в файлах со шрифтами, которые установлены на вашем компьютере) и кода, который позволяет выдернуть из этого набора векторных форм (файла шрифта) именно тот символ, который нужно будет вставить в нужное место.
Понятно, что за сами векторные формы отвечают шрифты, а вот за кодирование отвечает операционная система и используемые в ней программы. Т.е. любой текст на вашем компьютере будет представлять собой набор байтов, в каждом из которых закодирован один единственный символ этого самого текста. Программа, отображающая этот текст на экране (текстовый редактор, браузер и т.п.), при разборе кода считывает кодировку очередного знака и ищет соответствующую ему векторную форму в нужном файле шрифта, который подключен для отображения данного текстового документа. Все просто и банально.
Значит, чтобы закодировать любой нужный нам символ (например, из национального алфавита), нужно выполнить два условия: векторная форма этого знака должна быть в используемом шрифте, и этот символ можно было бы закодировать в расширенных кодировках ASCII в один байт. Поэтому таких вариантов существует целая куча. Только лишь для кодирования символов русского языка существует несколько разновидностей расширенной Аски.
Например, изначально появилась CP866, в которой была возможность использовать символы русского алфавита, и она являлась расширенной версией ASCII.
То есть, ее верхняя часть полностью совпадала с базовой версией Аски (128 символов латиницы, цифр и еще всякой лабуды), которая представлена на приведенном чуть выше скриншоте, а вот уже нижняя часть таблицы с кодировкой CP866 имела указанный на скриншоте чуть ниже вид и позволяла закодировать еще 128 знаков (русские буквы и всякая там псевдографика): Видите, в правом столбце цифры начинаются с 8, т.
Программа, отображающая этот текст на экране (текстовый редактор, браузер и т.п.), при разборе кода считывает кодировку очередного знака и ищет соответствующую ему векторную форму в нужном файле шрифта, который подключен для отображения данного текстового документа. Все просто и банально.
Значит, чтобы закодировать любой нужный нам символ (например, из национального алфавита), нужно выполнить два условия: векторная форма этого знака должна быть в используемом шрифте, и этот символ можно было бы закодировать в расширенных кодировках ASCII в один байт. Поэтому таких вариантов существует целая куча. Только лишь для кодирования символов русского языка существует несколько разновидностей расширенной Аски.
Например, изначально появилась CP866, в которой была возможность использовать символы русского алфавита, и она являлась расширенной версией ASCII.
То есть, ее верхняя часть полностью совпадала с базовой версией Аски (128 символов латиницы, цифр и еще всякой лабуды), которая представлена на приведенном чуть выше скриншоте, а вот уже нижняя часть таблицы с кодировкой CP866 имела указанный на скриншоте чуть ниже вид и позволяла закодировать еще 128 знаков (русские буквы и всякая там псевдографика): Видите, в правом столбце цифры начинаются с 8, т. к. числа с 0 до 7 относятся к базовой части ASCII (см. первый скриншот). Таким образом, у кириллической буквы «М» в CP866 будет код 9С (она находится на пересечении соответствующих строки с 9 и столбца с цифрой С в шестнадцатеричной системе счисления), который можно записать в одном байте информации, и при наличии подходящего шрифта с русскими символами эта буква без проблем отобразится в тексте.
Откуда взялось такое количество псевдографики в CP866? Тут все дело в том, что эта кодировка для русского текста разрабатывалась еще в те мохнатые года, когда графические операционные системы не были распространены как сейчас. А в Досе и подобных ей текстовых операционках псевдографика позволяла хоть как-то разнообразить оформление текстов и поэтому ею изобилует CP866 и все другие ее ровесницы из разряда расширенных версий Аски.
CP866 распространяла компания IBM, но кроме этого для символов русского языка были разработаны еще ряд кодировок, например, к этому же типу (расширенных ASCII) можно отнести KOI8-R:
Принцип ее работы остался тот же самый, что и у описанной чуть ранее CP866 — каждый символ текста кодируется одним единственным байтом.
к. числа с 0 до 7 относятся к базовой части ASCII (см. первый скриншот). Таким образом, у кириллической буквы «М» в CP866 будет код 9С (она находится на пересечении соответствующих строки с 9 и столбца с цифрой С в шестнадцатеричной системе счисления), который можно записать в одном байте информации, и при наличии подходящего шрифта с русскими символами эта буква без проблем отобразится в тексте.
Откуда взялось такое количество псевдографики в CP866? Тут все дело в том, что эта кодировка для русского текста разрабатывалась еще в те мохнатые года, когда графические операционные системы не были распространены как сейчас. А в Досе и подобных ей текстовых операционках псевдографика позволяла хоть как-то разнообразить оформление текстов и поэтому ею изобилует CP866 и все другие ее ровесницы из разряда расширенных версий Аски.
CP866 распространяла компания IBM, но кроме этого для символов русского языка были разработаны еще ряд кодировок, например, к этому же типу (расширенных ASCII) можно отнести KOI8-R:
Принцип ее работы остался тот же самый, что и у описанной чуть ранее CP866 — каждый символ текста кодируется одним единственным байтом. На скриншоте показана вторая половина таблицы KOI8-R, т.к. первая половина полностью соответствует базовой Аски, которая показана на первом скриншоте в этой статье.
Среди особенностей кодировки KOI8-R можно отметить то, что кириллические буквы в ее таблице идут не в алфавитном порядке, как это сделали в CP866.
Если посмотрите на самый первый скриншот (базовой части, которая входит во все расширенные кодировки), то заметите, что в KOI8-R русские буквы расположены в тех же ячейках таблицы, что и созвучные им буквы латинского алфавита из первой части таблицы. Это было сделано для удобства перехода с русских символов на латинские путем отбрасывания всего одного бита (два в седьмой степени или 128).
На скриншоте показана вторая половина таблицы KOI8-R, т.к. первая половина полностью соответствует базовой Аски, которая показана на первом скриншоте в этой статье.
Среди особенностей кодировки KOI8-R можно отметить то, что кириллические буквы в ее таблице идут не в алфавитном порядке, как это сделали в CP866.
Если посмотрите на самый первый скриншот (базовой части, которая входит во все расширенные кодировки), то заметите, что в KOI8-R русские буквы расположены в тех же ячейках таблицы, что и созвучные им буквы латинского алфавита из первой части таблицы. Это было сделано для удобства перехода с русских символов на латинские путем отбрасывания всего одного бита (два в седьмой степени или 128).
Windows 1251 — современная версия ASCII и почему вылезают кракозябры
Дальнейшее развитие кодировок текста было связано с тем, что набирали популярность графические операционные системы и необходимость использования псевдографики в них со временем пропала.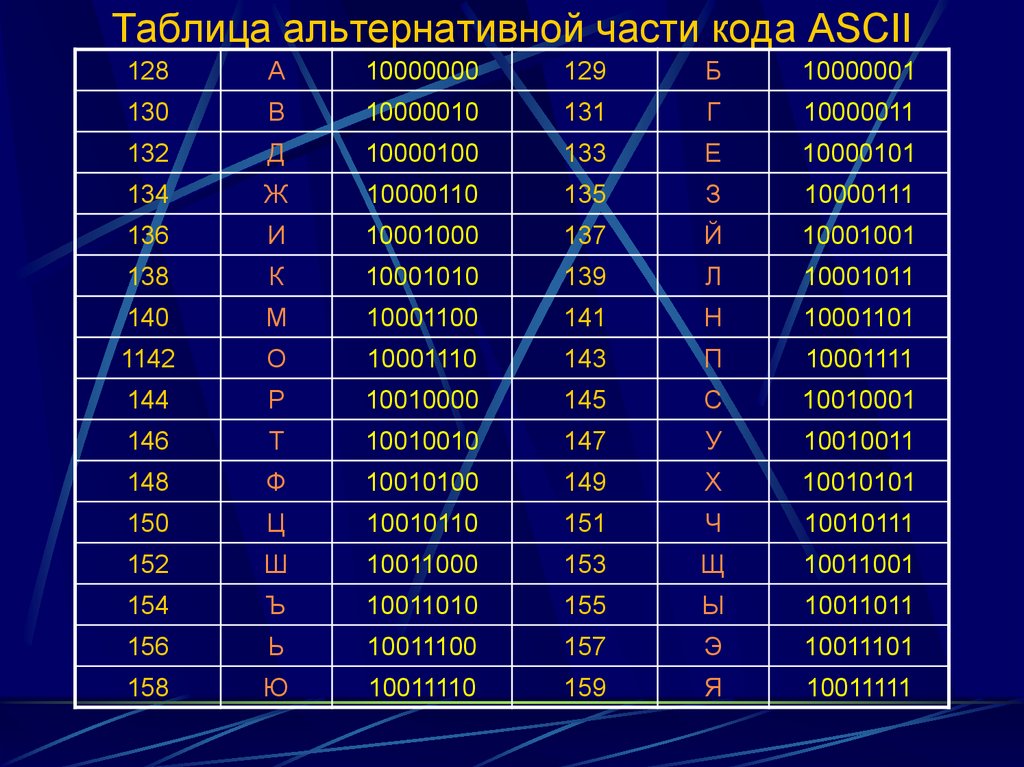 В результате возникла целая группа, которая по своей сути по-прежнему являлись расширенными версиями Аски (один символ текста кодируется всего одним байтом информации), но уже без использования символов псевдографики.
Они относились к так называемым ANSI кодировкам, которые были разработаны американским институтом стандартизации. В просторечии еще использовалось название кириллица для варианта с поддержкой русского языка. Примером такой может служить Windows 1251.
Она выгодно отличалась от используемых ранее CP866 и KOI8-R тем, что место символов псевдографики в ней заняли недостающие символы русской типографики (окромя знака ударения), а также символы, используемые в близких к русскому славянских языках (украинскому, белорусскому и т.д.):
Из-за такого обилия кодировок русского языка, у производителей шрифтов и производителей программного обеспечения постоянно возникала головная боль, а у нас с вам, уважаемые читатели, зачастую вылезали те самые пресловутые кракозябры, когда происходила путаница с используемой в тексте версией.
В результате возникла целая группа, которая по своей сути по-прежнему являлись расширенными версиями Аски (один символ текста кодируется всего одним байтом информации), но уже без использования символов псевдографики.
Они относились к так называемым ANSI кодировкам, которые были разработаны американским институтом стандартизации. В просторечии еще использовалось название кириллица для варианта с поддержкой русского языка. Примером такой может служить Windows 1251.
Она выгодно отличалась от используемых ранее CP866 и KOI8-R тем, что место символов псевдографики в ней заняли недостающие символы русской типографики (окромя знака ударения), а также символы, используемые в близких к русскому славянских языках (украинскому, белорусскому и т.д.):
Из-за такого обилия кодировок русского языка, у производителей шрифтов и производителей программного обеспечения постоянно возникала головная боль, а у нас с вам, уважаемые читатели, зачастую вылезали те самые пресловутые кракозябры, когда происходила путаница с используемой в тексте версией. Очень часто они вылезали при отправке и получении сообщений по электронной почте, что повлекло за собой создание очень сложных перекодировочных таблиц, которые, собственно, решить эту проблему в корне не смогли, и зачастую пользователи для переписки использовали транслит латинских букв, чтобы избежать пресловутых кракозябров при использовании русских кодировок подобных CP866, KOI8-R или Windows 1251.
По сути, кракозябры, вылазящие вместо русского текста, были результатом некорректного использования кодировки данного языка, которая не соответствовала той, в которой было закодировано текстовое сообщение изначально.
Допустим, если символы, закодированные с помощью CP866, попробовать отобразить, используя кодовую таблицу Windows 1251, то эти самые кракозябры (бессмысленный набор знаков) и вылезут, полностью заменив собой текст сообщения.
Аналогичная ситуация очень часто возникает при создании и настройке сайтов, форумов или блогов, когда текст с русскими символами по ошибке сохраняется не в той кодировке, которая используется на сайте по умолчанию, или же не в том текстовом редакторе, который добавляет в код отсебятину не видимую невооруженным глазом.
Очень часто они вылезали при отправке и получении сообщений по электронной почте, что повлекло за собой создание очень сложных перекодировочных таблиц, которые, собственно, решить эту проблему в корне не смогли, и зачастую пользователи для переписки использовали транслит латинских букв, чтобы избежать пресловутых кракозябров при использовании русских кодировок подобных CP866, KOI8-R или Windows 1251.
По сути, кракозябры, вылазящие вместо русского текста, были результатом некорректного использования кодировки данного языка, которая не соответствовала той, в которой было закодировано текстовое сообщение изначально.
Допустим, если символы, закодированные с помощью CP866, попробовать отобразить, используя кодовую таблицу Windows 1251, то эти самые кракозябры (бессмысленный набор знаков) и вылезут, полностью заменив собой текст сообщения.
Аналогичная ситуация очень часто возникает при создании и настройке сайтов, форумов или блогов, когда текст с русскими символами по ошибке сохраняется не в той кодировке, которая используется на сайте по умолчанию, или же не в том текстовом редакторе, который добавляет в код отсебятину не видимую невооруженным глазом. В конце концов такая ситуация с множеством кодировок и постоянно вылезающими кракозябрами многим надоела, появились предпосылки к созданию новой универсальной вариации, которая бы заменила собой все существующие и решила бы проблему с появлением не читаемых текстов. Кроме этого существовала проблема языков подобных китайскому, где символов языка было гораздо больше, чем 256.
В конце концов такая ситуация с множеством кодировок и постоянно вылезающими кракозябрами многим надоела, появились предпосылки к созданию новой универсальной вариации, которая бы заменила собой все существующие и решила бы проблему с появлением не читаемых текстов. Кроме этого существовала проблема языков подобных китайскому, где символов языка было гораздо больше, чем 256.
Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
Эти тысячи знаков языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных версиях ASCII. В результате был создан консорциум под названием Юникод (Unicode — Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста.
Первой вариацией, вышедшей под эгидой консорциума Юникод, была UTF 32. Цифра в названии кодировки означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного знака в новой универсальной кодировке UTF.
В результате чего один и тот же файл с текстом, закодированный в расширенной версии ASCII и в UTF-32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью ЮТФ число знаков, равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом).
Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет-трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить.
Цифра в названии кодировки означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного знака в новой универсальной кодировке UTF.
В результате чего один и тот же файл с текстом, закодированный в расширенной версии ASCII и в UTF-32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью ЮТФ число знаков, равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом).
Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет-трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить.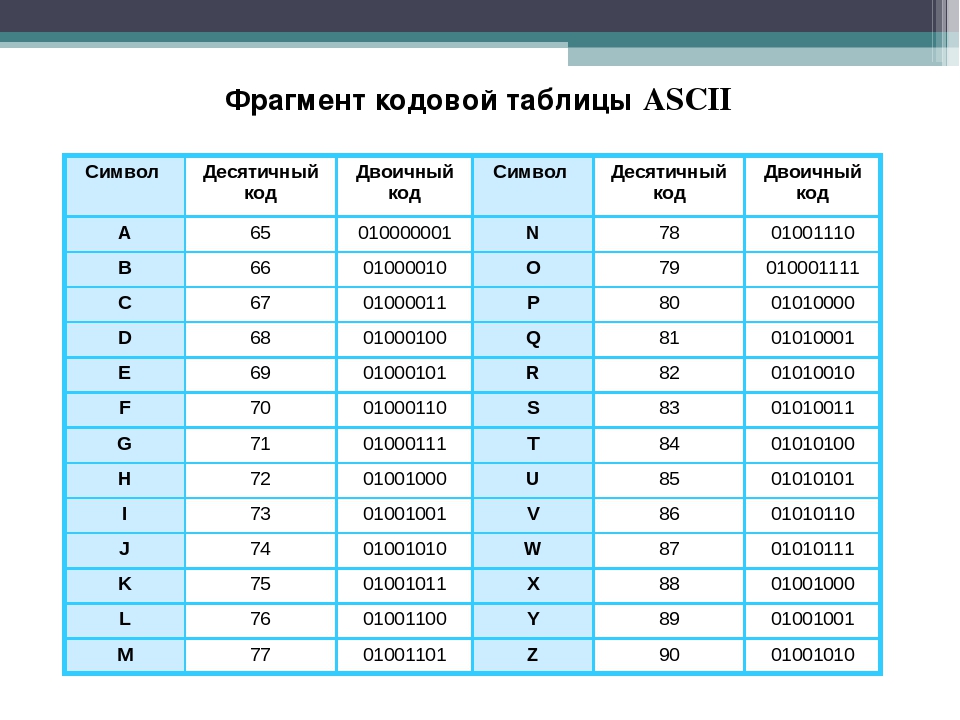 В результате развития Юникода появилась UTF-16, которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. Она использует два байта для кодирования одного знака. Давайте посмотрим, как это дело выглядит.
В операционной системе Windows вы можете пройти по пути «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов». В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов.
Кстати, щелкнув по любому из них, вы сможете увидеть его двухбайтовый код в формате UTF-16, состоящий из четырех шестнадцатеричных цифр:
Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде.
В результате развития Юникода появилась UTF-16, которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. Она использует два байта для кодирования одного знака. Давайте посмотрим, как это дело выглядит.
В операционной системе Windows вы можете пройти по пути «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов». В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов.
Кстати, щелкнув по любому из них, вы сможете увидеть его двухбайтовый код в формате UTF-16, состоящий из четырех шестнадцатеричных цифр:
Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде.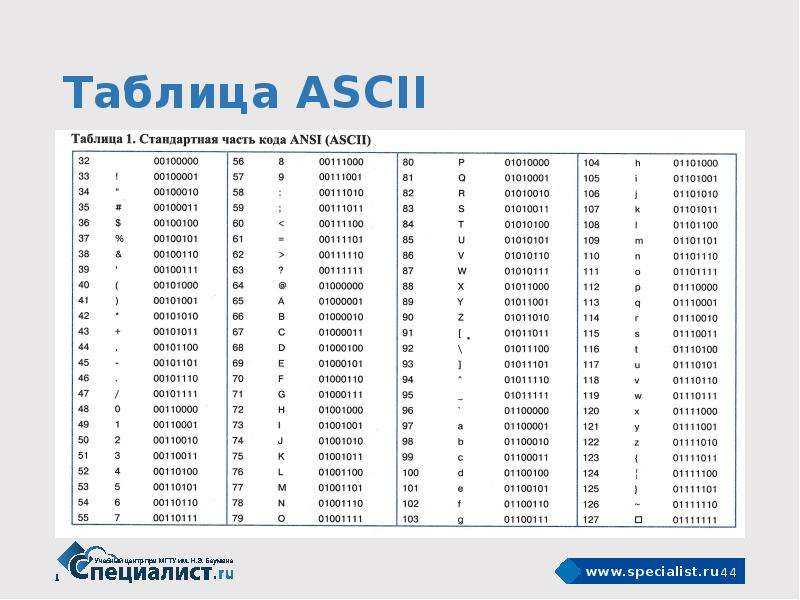 Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста.
Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16).
Вот именно для удовлетворения всех и вся в консорциуме Unicode было решено придумать кодировку переменной длины. Ее назвали UTF-8. Несмотря на восьмерку в названии, она действительно имеет переменную длину, т.е. каждый символ текста может быть закодирован в последовательность длиной от одного до шести байт.
На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII.
Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста.
Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16).
Вот именно для удовлетворения всех и вся в консорциуме Unicode было решено придумать кодировку переменной длины. Ее назвали UTF-8. Несмотря на восьмерку в названии, она действительно имеет переменную длину, т.е. каждый символ текста может быть закодирован в последовательность длиной от одного до шести байт.
На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII. Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. То есть, базовая часть Аски просто перешла в это детище консорциума Unicode.
Кириллические же знаки в UTF-8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания UTF 16 и 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство. И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста.
В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.
Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. То есть, базовая часть Аски просто перешла в это детище консорциума Unicode.
Кириллические же знаки в UTF-8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания UTF 16 и 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство. И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста.
В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.
Кракозябры вместо русских букв — как исправить
Давайте теперь посмотрим, как появляются вместо текста кракозябры или, другими словами, как выбирается правильная кодировка для русского текста.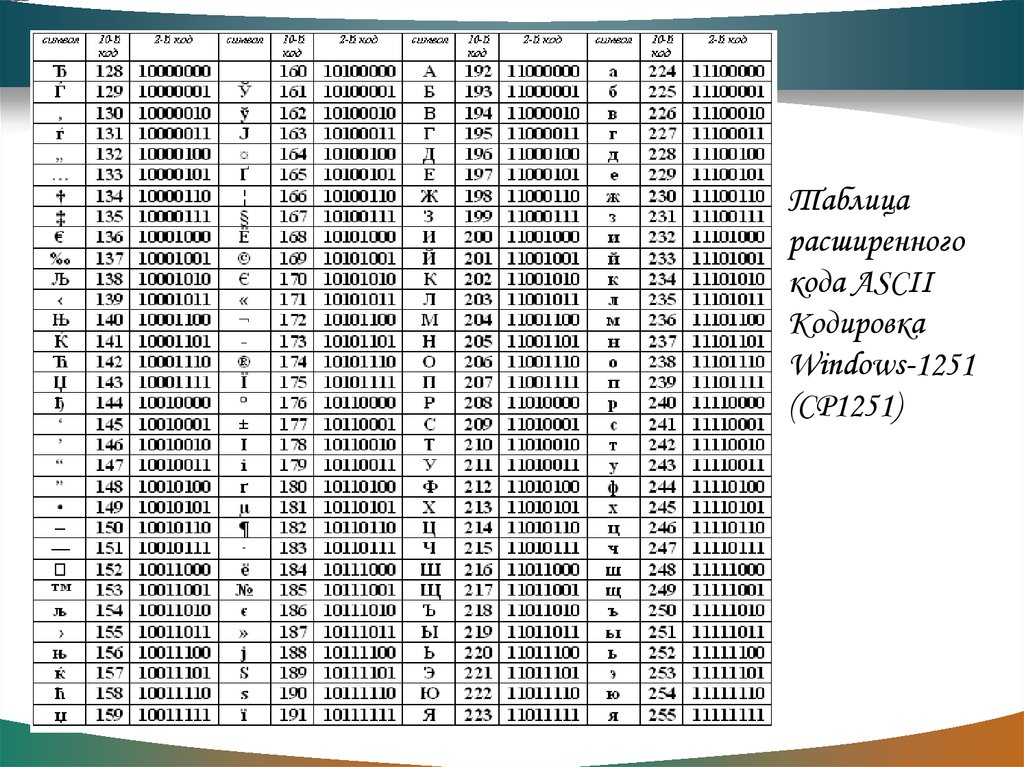 Собственно, она задается в той программе, в которой вы создаете или редактируете этот самый текст, или же код с использованием текстовых фрагментов.
Для редактирования и создания текстовых файлов лично я использую очень хороший, на мой взгляд, Html и PHP редактор Notepad++. Впрочем, он может подсвечивать синтаксис еще доброй сотни языков программирования и разметки, а также имеет возможность расширения с помощью плагинов. Читайте подробный обзор этой замечательной программы по приведенной ссылке.
В верхнем меню Notepad++ есть пункт «Кодировки», где у вас будет возможность преобразовать уже имеющийся вариант в тот, который используется на вашем сайте по умолчанию:
В случае сайта на Joomla 1.5 и выше, а также в случае блога на WordPress следует во избежании появления кракозябров выбирать вариант UTF 8 без BOM. А что такое приставка BOM?
Дело в том, что когда разрабатывали кодировку ЮТФ-16, зачем-то решили прикрутить к ней такую вещь, как возможность записывать код символа, как в прямой последовательности (например, 0A15), так и в обратной (150A).
Собственно, она задается в той программе, в которой вы создаете или редактируете этот самый текст, или же код с использованием текстовых фрагментов.
Для редактирования и создания текстовых файлов лично я использую очень хороший, на мой взгляд, Html и PHP редактор Notepad++. Впрочем, он может подсвечивать синтаксис еще доброй сотни языков программирования и разметки, а также имеет возможность расширения с помощью плагинов. Читайте подробный обзор этой замечательной программы по приведенной ссылке.
В верхнем меню Notepad++ есть пункт «Кодировки», где у вас будет возможность преобразовать уже имеющийся вариант в тот, который используется на вашем сайте по умолчанию:
В случае сайта на Joomla 1.5 и выше, а также в случае блога на WordPress следует во избежании появления кракозябров выбирать вариант UTF 8 без BOM. А что такое приставка BOM?
Дело в том, что когда разрабатывали кодировку ЮТФ-16, зачем-то решили прикрутить к ней такую вещь, как возможность записывать код символа, как в прямой последовательности (например, 0A15), так и в обратной (150A).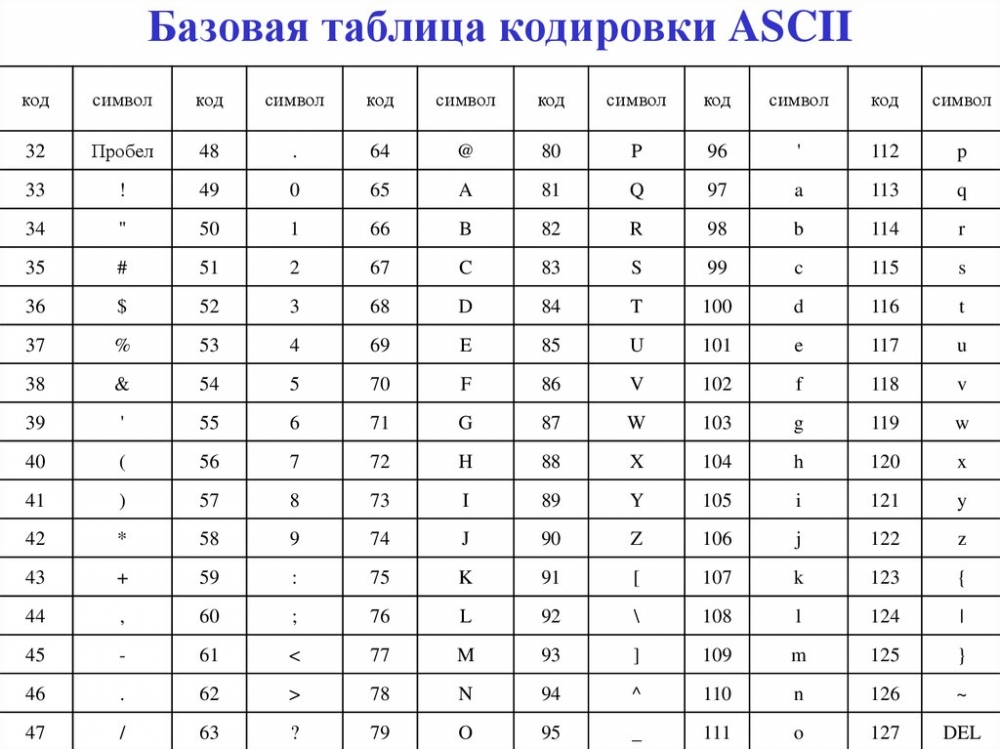 А для того, чтобы программы понимали, в какой именно последовательности читать коды, и был придуман BOM (Byte Order Mark или, другими словами, сигнатура), которая выражалась в добавлении трех дополнительных байтов в самое начало документов.
В кодировке UTF-8 никаких BOM предусмотрено в консорциуме Юникод не было и поэтому добавление сигнатуры (этих самых пресловутых дополнительных трех байтов в начало документа) некоторым программам просто-напросто мешает читать код. Поэтому мы всегда при сохранении файлов в ЮТФ должны выбирать вариант без BOM (без сигнатуры). Таким образом, вы заранее обезопасите себя от вылезания кракозябров.
Что примечательно, некоторые программы в Windows не умеют этого делать (не умеют сохранять текст в ЮТФ-8 без BOM), например, все тот же пресловутый Блокнот Windows. Он сохраняет документ в UTF-8, но все равно добавляет в его начало сигнатуру (три дополнительных байта). Причем эти байты будут всегда одни и те же — читать код в прямой последовательности.
А для того, чтобы программы понимали, в какой именно последовательности читать коды, и был придуман BOM (Byte Order Mark или, другими словами, сигнатура), которая выражалась в добавлении трех дополнительных байтов в самое начало документов.
В кодировке UTF-8 никаких BOM предусмотрено в консорциуме Юникод не было и поэтому добавление сигнатуры (этих самых пресловутых дополнительных трех байтов в начало документа) некоторым программам просто-напросто мешает читать код. Поэтому мы всегда при сохранении файлов в ЮТФ должны выбирать вариант без BOM (без сигнатуры). Таким образом, вы заранее обезопасите себя от вылезания кракозябров.
Что примечательно, некоторые программы в Windows не умеют этого делать (не умеют сохранять текст в ЮТФ-8 без BOM), например, все тот же пресловутый Блокнот Windows. Он сохраняет документ в UTF-8, но все равно добавляет в его начало сигнатуру (три дополнительных байта). Причем эти байты будут всегда одни и те же — читать код в прямой последовательности.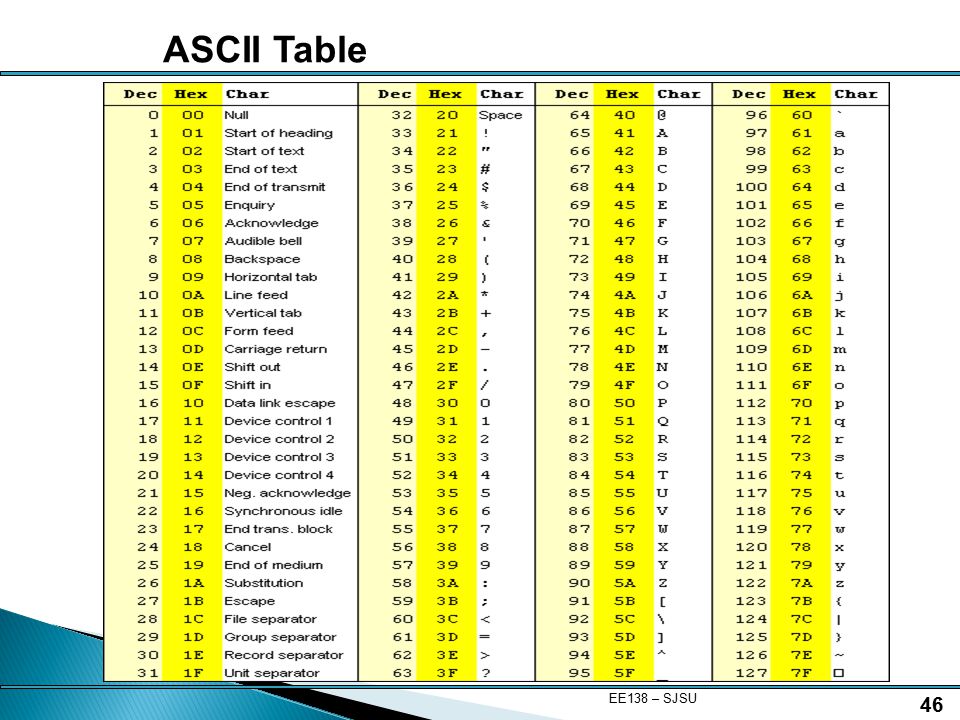 Но на серверах из-за этой мелочи может возникнуть проблема — вылезут кракозябры.
Поэтому ни в коем случае не пользуйтесь обычным блокнотом Windows для редактирования документов вашего сайта, если не хотите появления кракозябров. Лучшим и наиболее простым вариантом я считаю уже упомянутый редактор Notepad++, который практически не имеет недостатков и состоит из одних лишь достоинств.
В Notepad ++ при выборе кодировки у вас будет возможность преобразовать текст в кодировку UCS-2, которая по своей сути очень близка к стандарту Юникод. Также в Нотепаде можно будет закодировать текст в ANSI, т.е. применительно к русскому языку это будет уже описанная нами чуть выше Windows 1251. Откуда берется эта информация?
Она прописана в реестре вашей операционной системы Windows — какую кодировку выбирать в случае ANSI, какую выбирать в случае OEM (для русского языка это будет CP866). Если вы установите на своем компьютере другой язык по умолчанию, то и эти кодировки будут заменены на аналогичные из разряда ANSI или OEM для того самого языка.
Но на серверах из-за этой мелочи может возникнуть проблема — вылезут кракозябры.
Поэтому ни в коем случае не пользуйтесь обычным блокнотом Windows для редактирования документов вашего сайта, если не хотите появления кракозябров. Лучшим и наиболее простым вариантом я считаю уже упомянутый редактор Notepad++, который практически не имеет недостатков и состоит из одних лишь достоинств.
В Notepad ++ при выборе кодировки у вас будет возможность преобразовать текст в кодировку UCS-2, которая по своей сути очень близка к стандарту Юникод. Также в Нотепаде можно будет закодировать текст в ANSI, т.е. применительно к русскому языку это будет уже описанная нами чуть выше Windows 1251. Откуда берется эта информация?
Она прописана в реестре вашей операционной системы Windows — какую кодировку выбирать в случае ANSI, какую выбирать в случае OEM (для русского языка это будет CP866). Если вы установите на своем компьютере другой язык по умолчанию, то и эти кодировки будут заменены на аналогичные из разряда ANSI или OEM для того самого языка. После того, как вы в Notepad++ сохраните документ в нужной вам кодировке или же откроете документ с сайта для редактирования, то в правом нижнем углу редактора сможете увидеть ее название: Чтобы избежать кракозябров, кроме описанных выше действий, будет полезным прописать в его шапке исходного кода всех страниц сайта информацию об этой самой кодировке, чтобы на сервере или локальном хосте не возникло путаницы.
Вообще, во всех языках гипертекстовой разметки кроме Html используется специальное объявление xml, в котором указывается кодировка текста.
После того, как вы в Notepad++ сохраните документ в нужной вам кодировке или же откроете документ с сайта для редактирования, то в правом нижнем углу редактора сможете увидеть ее название: Чтобы избежать кракозябров, кроме описанных выше действий, будет полезным прописать в его шапке исходного кода всех страниц сайта информацию об этой самой кодировке, чтобы на сервере или локальном хосте не возникло путаницы.
Вообще, во всех языках гипертекстовой разметки кроме Html используется специальное объявление xml, в котором указывается кодировка текста.
<?xml version="1.0" encoding="windows-1251"?>
Прежде, чем начать разбирать код, браузер узнает, какая версия используется и как именно нужно интерпретировать коды символов этого языка. Но что примечательно, если вы сохраняете документ в принятом по умолчанию юникоде, это объявление xml можно будет опустить (кодировка будет считаться UTF-8, если нет BOM или ЮТФ-16, если BOM есть).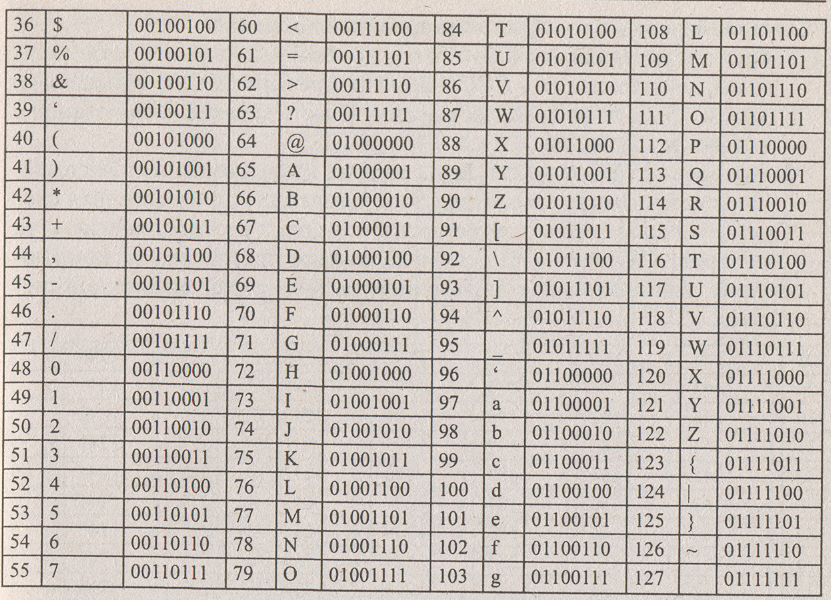 В случае же документа языка Html для указания кодировки используется элемент Meta, который прописывается между открывающим и закрывающим тегом Head:
В случае же документа языка Html для указания кодировки используется элемент Meta, который прописывается между открывающим и закрывающим тегом Head:
<head> ... <meta charset="utf-8"> ... </head>
Эта запись довольно сильно отличается от принятой в стандарте в Html 4.01, но полностью соответствует стандарту Html 5, и она будет стопроцентно правильно понята любыми используемыми на текущий момент браузерами. По идее элемент Meta с указание кодировки Html документа лучше будет ставить как можно выше в шапке документа, чтобы на момент встречи в тексте первого знака не из базовой ANSI (которые правильно прочитаются всегда и в любой вариации) браузер уже должен иметь информацию о том, как интерпретировать коды этих символов. Ссылка на первоисточник: Кодировка текста ASCII (Windows 1251, CP866, KOI8-R) и Юникод (UTF 8, 16, 32) — как исправить проблему с кракозябрами
Коды символов ASCII при создании сайтов
Коды ASCII символов
- Управляющие символы
- Печатные символы
- Расширенные символы ASCII Win-1251 кириллица
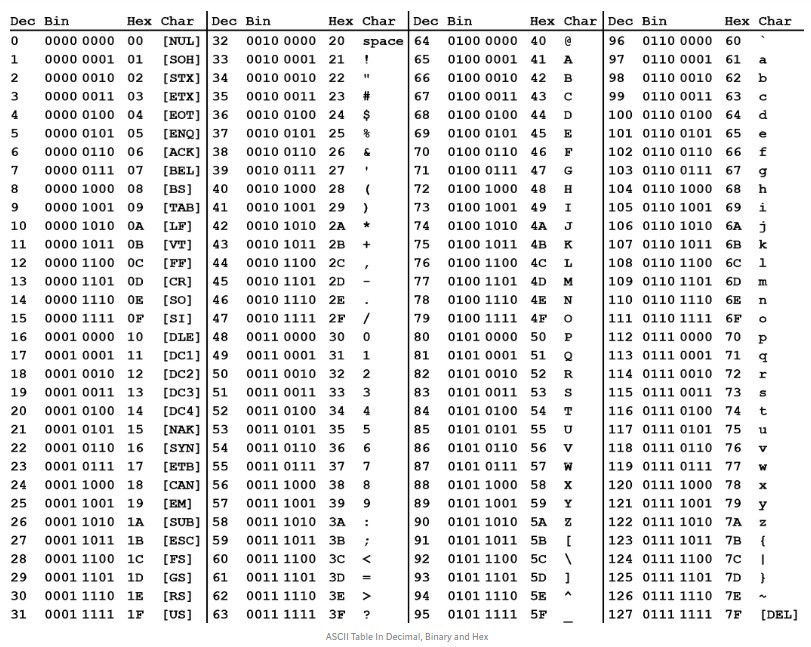
ASCII (полное название American Standard Code for Information Interchange — американский стандартный код для обмена информацией) — содержит код для представления десятичных цифр, латинского алфавита, знаков препинания и управляющих символов. Каждый символ имеет числовой код в диапазоне от 0 до 255.
Каждый символ имеет числовой код в диапазоне от 0 до 255.
ASCII часто используется при разработке сайта в Харькове для определения кодов нажатых символов на клавиатуре через JavaScript, либо кодирования/декодирования, экранирования, анализа данных.
Данный перечень будет полезен при использовании PHP функций Asc и Chr.
Управляющие символы
| DEC | OCT | HEX | BIN | Символ | Escape послед. | HTML код | Описание |
|---|---|---|---|---|---|---|---|
| 0 | 000 | 0x00 | 00000000 | NUL | \0 | � | Нулевой байт |
| 1 | 001 | 0x01 | 00000001 | SOH |  | Начало заголовка | |
| 2 | 002 | 0x02 | 00000010 | STX |  | Начало текста | |
| 3 | 003 | 0x03 | 00000011 | ETX |  | Конец «текста» | |
| 4 | 004 | 0x04 | 00000100 | EOT |  | конец передачи | |
| 5 | 005 | 0x05 | 00000101 | ENQ |  | «Прошу подтверждения!» | |
| 6 | 006 | 0x06 | 00000110 | ACK |  | «Подтверждаю!» | |
| 7 | 007 | 0x07 | 00000111 | BEL | \a |  | Звуковой сигнал – звонок |
| 8 | 010 | 0x08 | 00001000 | BS | \b |  | Возврат на один символ (BACKSPACE) |
| 9 | 011 | 0x09 | 00001001 | TAB | \t | 	 | Табуляция |
| 10 | 012 | 0x0A | 00001010 | LF | \n | 
 | Перевод строки |
| 11 | 013 | 0x0B | 00001011 | VT | \v |  | Вертикальная табуляция |
| 12 | 014 | 0x0C | 00001100 | FF | \f |  | Прогон страницы, новая страница |
| 13 | 015 | 0x0D | 00001101 | CR | \r | 
 | Возврат каретки |
| 14 | 016 | 0x0E | 00001110 | SO |  | Переключиться на другую ленту (кодировку) | |
| 15 | 017 | 0x0F | 00001111 | SI |  | Переключиться на исходную ленту (кодировку) | |
| 16 | 020 | 0x10 | 00010000 | DLE |  | Экранирование канала данных | |
| 17 | 021 | 0x11 | 00010001 | DC1 |  | 1-й символ управления устройством | |
| 18 | 022 | 0x12 | 00010010 | DC2 |  | 2-й символ управления устройством | |
| 19 | 023 | 0x13 | 00010011 | DC3 |  | 3-й символ управления устройством | |
| 20 | 024 | 0x14 | 00010100 | DC4 |  | 4-й символ управления устройством | |
| 21 | 025 | 0x15 | 00010101 | NAK |  | «Не подтверждаю!» | |
| 22 | 026 | 0x16 | 00010110 | SYN |  | Символ для синхронизации | |
| 23 | 027 | 0x17 | 00010111 | ETB |  | Конец текстового блока | |
| 24 | 030 | 0x18 | 00011000 | CAN |  | Отмена | |
| 25 | 031 | 0x19 | 00011001 | EM |  | Конец носителя | |
| 26 | 032 | 0x1A | 00011010 | SUB |  | Подставить | |
| 27 | 033 | 0x1B | 00011011 | ESC | \e |  | Escape (Расширение) |
| 28 | 034 | 0x1C | 00011100 | FS |  | Разделитель файлов | |
| 29 | 035 | 0x1D | 00011101 | GS |  | Разделитель групп | |
| 30 | 036 | 0x1E | 00011110 | RS |  | Разделитель записей | |
| 31 | 037 | 0x1F | 00011111 | US |  | Разделитель юнитов | |
| 127 | 177 | 0x7F | 01111111 | Delete |  | Символ для удаления (на перфолентах) |
Печатные символы
| DEC | OCT | HEX | BIN | Символ | HTML код | Мнемоника |
|---|---|---|---|---|---|---|
| 32 | 040 | 0x20 | 00100000 | Пробел |   | |
| 33 | 041 | 0x21 | 00100001 | ! | ! | |
| 34 | 042 | 0x22 | 00100010 | « | " | " |
| 35 | 043 | 0x23 | 00100011 | # | # | |
| 36 | 044 | 0x24 | 00100100 | $ | $ | |
| 37 | 045 | 0x25 | 00100101 | % | % | |
| 38 | 046 | 0x26 | 00100110 | & | & | & |
| 39 | 047 | 0x27 | 00100111 | ‘ | ' | ' |
| 40 | 050 | 0x28 | 00101000 | ( | ( | |
| 41 | 051 | 0x29 | 00101001 | ) | ) | |
| 42 | 052 | 0x2A | 00101010 | * | * | |
| 43 | 053 | 0x2B | 00101011 | + | + | |
| 44 | 054 | 0x2C | 00101100 | , | , | |
| 45 | 055 | 0x2D | 00101101 | — | - | |
| 46 | 056 | 0x2E | 00101110 | . | . | |
| 47 | 057 | 0x2F | 00101111 | / | / | |
| 48 | 060 | 0x30 | 00110000 | 0 | 0 | |
| 49 | 061 | 0x31 | 00110001 | 1 | 1 | |
| 50 | 062 | 0x32 | 00110010 | 2 | 2 | |
| 51 | 063 | 0x33 | 00110011 | 3 | 3 | |
| 52 | 064 | 0x34 | 00110100 | 4 | 4 | |
| 53 | 065 | 0x35 | 00110101 | 5 | 5 | |
| 54 | 066 | 0x36 | 00110110 | 6 | 6 | |
| 55 | 067 | 0x37 | 00110111 | 7 | 7 | |
| 56 | 070 | 0x38 | 00111000 | 8 | 8 | |
| 57 | 071 | 0x39 | 00111001 | 9 | 9 | |
| 58 | 072 | 0x3A | 00111010 | : | : | |
| 59 | 073 | 0x3B | 00111011 | ; | ; | |
| 60 | 074 | 0x3C | 00111100 | < | < | < |
| 61 | 075 | 0x3D | 00111101 | = | = | |
| 62 | 076 | 0x3E | 00111110 | > | > | > |
| 63 | 077 | 0x3F | 00111111 | ? | ? | |
| 64 | 100 | 0x40 | 01000000 | @ | @ | |
| 65 | 101 | 0x41 | 01000001 | A | A | |
| 66 | 102 | 0x42 | 01000010 | B | B | |
| 67 | 103 | 0x43 | 01000011 | C | C | |
| 68 | 104 | 0x44 | 01000100 | D | D | |
| 69 | 105 | 0x45 | 01000101 | E | E | |
| 70 | 106 | 0x46 | 01000110 | F | F | |
| 71 | 107 | 0x47 | 01000111 | G | G | |
| 72 | 110 | 0x48 | 01001000 | H | H | |
| 73 | 111 | 0x49 | 01001001 | I | I | |
| 74 | 112 | 0x4A | 01001010 | J | J | |
| 75 | 113 | 0x4B | 01001011 | K | K | |
| 76 | 114 | 0x4C | 01001100 | L | L | |
| 77 | 115 | 0x4D | 01001101 | M | M | |
| 78 | 116 | 0x4E | 01001110 | N | N | |
| 79 | 117 | 0x4F | 01001111 | O | O | |
| 80 | 120 | 0x50 | 01010000 | P | P | |
| 81 | 121 | 0x51 | 01010001 | Q | Q | |
| 82 | 122 | 0x52 | 01010010 | R | R | |
| 83 | 123 | 0x53 | 01010011 | S | S | |
| 84 | 124 | 0x54 | 01010100 | T | T | |
| 85 | 125 | 0x55 | 01010101 | U | U | |
| 86 | 126 | 0x56 | 01010110 | V | V | |
| 87 | 127 | 0x57 | 01010111 | W | W | |
| 88 | 130 | 0x58 | 01011000 | X | X | |
| 89 | 131 | 0x59 | 01011001 | Y | Y | |
| 90 | 132 | 0x5A | 01011010 | Z | Z | |
| 91 | 133 | 0x5B | 01011011 | [ | [ | |
| 92 | 134 | 0x5C | 01011100 | \ | \ | |
| 93 | 135 | 0x5D | 01011101 | ] | ] | |
| 94 | 136 | 0x5E | 01011110 | ^ | ^ | |
| 95 | 137 | 0x5F | 01011111 | _ | _ | |
| 96 | 140 | 0x60 | 01100000 | ` | ` | |
| 97 | 141 | 0x61 | 01100001 | a | a | |
| 98 | 142 | 0x62 | 01100010 | b | b | |
| 99 | 143 | 0x63 | 01100011 | c | c | |
| 100 | 144 | 0x64 | 01100100 | d | d | |
| 101 | 145 | 0x65 | 01100101 | e | e | |
| 102 | 146 | 0x66 | 01100110 | f | f | |
| 103 | 147 | 0x67 | 01100111 | g | g | |
| 104 | 150 | 0x68 | 01101000 | h | h | |
| 105 | 151 | 0x69 | 01101001 | i | i | |
| 106 | 152 | 0x6A | 01101010 | j | j | |
| 107 | 153 | 0x6B | 01101011 | k | k | |
| 108 | 154 | 0x6C | 01101100 | l | l | |
| 109 | 155 | 0x6D | 01101101 | m | m | |
| 110 | 156 | 0x6E | 01101110 | n | n | |
| 111 | 157 | 0x6F | 01101111 | o | o | |
| 112 | 160 | 0x70 | 01110000 | p | p | |
| 113 | 161 | 0x71 | 01110001 | q | q | |
| 114 | 162 | 0x72 | 01110010 | r | r | |
| 115 | 163 | 0x73 | 01110011 | s | s | |
| 116 | 164 | 0x74 | 01110100 | t | t | |
| 117 | 165 | 0x75 | 01110101 | u | u | |
| 118 | 166 | 0x76 | 01110110 | v | v | |
| 119 | 167 | 0x77 | 01110111 | w | w | |
| 120 | 170 | 0x78 | 01111000 | x | x | |
| 121 | 171 | 0x79 | 01111001 | y | y | |
| 122 | 172 | 0x7A | 01111010 | z | z | |
| 123 | 173 | 0x7B | 01111011 | { | { | |
| 124 | 174 | 0x7C | 01111100 | | | | | |
| 125 | 175 | 0x7D | 01111101 | } | } | |
| 126 | 176 | 0x7E | 01111110 | ~ | ~ |
Расширенные символы ASCII Win-1251 кириллица
| DEC | OCT | HEX | BIN | Символ | HTML код | Мнемоника |
|---|---|---|---|---|---|---|
| 128 | 200 | 0x80 | 10000000 | Ђ | € | |
| 129 | 201 | 0x81 | 10000001 | Ѓ |  | |
| 130 | 202 | 0x82 | 10000010 | ‚ | ‚ | ‚ |
| 131 | 203 | 0x83 | 10000011 | ѓ | ƒ | |
| 132 | 204 | 0x84 | 10000100 | „ | „ | „ |
| 133 | 205 | 0x85 | 10000101 | … | … | … |
| 134 | 206 | 0x86 | 10000110 | † | † | † |
| 135 | 207 | 0x87 | 10000111 | ‡ | ‡ | ‡ |
| 136 | 210 | 0x88 | 10001000 | € | ˆ | € |
| 137 | 211 | 0x89 | 10001001 | ‰ | ‰ | ‰ |
| 138 | 212 | 0x8A | 10001010 | Љ | Š | |
| 139 | 213 | 0x8B | 10001011 | ‹ | ‹ | ‹ |
| 140 | 214 | 0x8C | 10001100 | Њ | Œ | |
| 141 | 215 | 0x8D | 10001101 | Ќ |  | |
| 142 | 216 | 0x8E | 10001110 | Ћ | Ž | |
| 143 | 217 | 0x8F | 10001111 | Џ |  | |
| 144 | 220 | 0x90 | 10010000 | Ђ |  | |
| 145 | 221 | 0x91 | 10010001 | ‘ | ‘ | ‘ |
| 146 | 222 | 0x92 | 10010010 | ’ | ’ | ’ |
| 147 | 223 | 0x93 | 10010011 | “ | “ | “ |
| 148 | 224 | 0x94 | 10010100 | ” | ” | ” |
| 149 | 225 | 0x95 | 10010101 | • | • | • |
| 150 | 226 | 0x96 | 10010110 | – | – | – |
| 151 | 227 | 0x97 | 10010111 | — | — | — |
| 152 | 230 | 0x98 | 10011000 | Начало строки | ˜ | |
| 153 | 231 | 0x99 | 10011001 | ™ | ™ | ™ |
| 154 | 232 | 0x9A | 10011010 | љ | š | |
| 155 | 233 | 0x9B | 10011011 | › | › | › |
| 156 | 234 | 0x9C | 10011100 | њ | œ | |
| 157 | 235 | 0x9D | 10011101 | ќ |  | |
| 158 | 236 | 0x9E | 10011110 | ћ | ž | |
| 159 | 237 | 0x9F | 10011111 | џ | Ÿ | |
| 160 | 240 | 0xA0 | 10100000 | Неразрывный пробел |   | |
| 161 | 241 | 0xA1 | 10100001 | Ў | ¡ | |
| 162 | 242 | 0xA2 | 10100010 | ў | ¢ | |
| 163 | 243 | 0xA3 | 10100011 | Ј | £ | |
| 164 | 244 | 0xA4 | 10100100 | ¤ | ¤ | ¤ |
| 165 | 245 | 0xA5 | 10100101 | Ґ | ¥ | |
| 166 | 246 | 0xA6 | 10100110 | ¦ | ¦ | ¦ |
| 167 | 247 | 0xA7 | 10100111 | § | § | § |
| 168 | 250 | 0xA8 | 10101000 | Ё | ¨ | |
| 169 | 251 | 0xA9 | 10101001 | © | © | © |
| 170 | 252 | 0xAA | 10101010 | Є | ª | |
| 171 | 253 | 0xAB | 10101011 | « | « | « |
| 172 | 254 | 0xAC | 10101100 | ¬ | ¬ | ¬ |
| 173 | 255 | 0xAD | 10101101 | Мягкий перенос | ­ | ­ |
| 174 | 256 | 0xAE | 10101110 | ® | ® | ® |
| 175 | 257 | 0xAF | 10101111 | Ї | ¯ | |
| 176 | 260 | 0xB0 | 10110000 | ° | ° | ° |
| 177 | 261 | 0xB1 | 10110001 | ± | ± | ± |
| 178 | 262 | 0xB2 | 10110010 | І | ² | |
| 179 | 263 | 0xB3 | 10110011 | і | ³ | |
| 180 | 264 | 0xB4 | 10110100 | ґ | ´ | |
| 181 | 265 | 0xB5 | 10110101 | µ | µ | µ |
| 182 | 266 | 0xB6 | 10110110 | ¶ | ¶ | ¶ |
| 183 | 267 | 0xB7 | 10110111 | · | · | · |
| 184 | 270 | 0xB8 | 10111000 | ё | ¸ | |
| 185 | 271 | 0xB9 | 10111001 | № | ¹ | |
| 186 | 272 | 0xBA | 10111010 | є | º | |
| 187 | 273 | 0xBB | 10111011 | » | » | » |
| 188 | 274 | 0xBC | 10111100 | ј | ¼ | |
| 189 | 275 | 0xBD | 10111101 | Ѕ | ½ | |
| 190 | 276 | 0xBE | 10111110 | ѕ | ¾ | |
| 191 | 277 | 0xBF | 10111111 | ї | ¿ | |
| 192 | 300 | 0xC0 | 11000000 | А | À | |
| 193 | 301 | 0xC1 | 11000001 | Б | Á | |
| 194 | 302 | 0xC2 | 11000010 | В | Â | |
| 195 | 303 | 0xC3 | 11000011 | Г | Ã | |
| 196 | 304 | 0xC4 | 11000100 | Д | Ä | |
| 197 | 305 | 0xC5 | 11000101 | Е | Å | |
| 198 | 306 | 0xC6 | 11000110 | Ж | Æ | |
| 199 | 307 | 0xC7 | 11000111 | З | Ç | |
| 200 | 310 | 0xC8 | 11001000 | И | È | |
| 201 | 311 | 0xC9 | 11001001 | Й | É | |
| 202 | 312 | 0xCA | 11001010 | К | Ê | |
| 203 | 313 | 0xCB | 11001011 | Л | Ë | |
| 204 | 314 | 0xCC | 11001100 | М | Ì | |
| 205 | 315 | 0xCD | 11001101 | Н | Í | |
| 206 | 316 | 0xCE | 11001110 | О | Î | |
| 207 | 317 | 0xCF | 11001111 | П | Ï | |
| 208 | 320 | 0xD0 | 11010000 | Р | Ð | |
| 209 | 321 | 0xD1 | 11010001 | С | Ñ | |
| 210 | 322 | 0xD2 | 11010010 | Т | Ò | |
| 211 | 323 | 0xD3 | 11010011 | У | Ó | |
| 212 | 324 | 0xD4 | 11010100 | Ф | Ô | |
| 213 | 325 | 0xD5 | 11010101 | Х | Õ | |
| 214 | 326 | 0xD6 | 11010110 | Ц | Ö | |
| 215 | 327 | 0xD7 | 11010111 | Ч | × | |
| 216 | 330 | 0xD8 | 11011000 | Ш | Ø | |
| 217 | 331 | 0xD9 | 11011001 | Щ | Ù | |
| 218 | 332 | 0xDA | 11011010 | Ъ | Ú | |
| 219 | 333 | 0xDB | 11011011 | Ы | Û | |
| 220 | 334 | 0xDC | 11011100 | Ь | Ü | |
| 221 | 335 | 0xDD | 11011101 | Э | Ý | |
| 222 | 336 | 0xDE | 11011110 | Ю | Þ | |
| 223 | 337 | 0xDF | 11011111 | Я | ß | |
| 224 | 340 | 0xE0 | 11100000 | а | à | |
| 225 | 341 | 0xE1 | 11100001 | б | á | |
| 226 | 342 | 0xE2 | 11100010 | в | â | |
| 227 | 343 | 0xE3 | 11100011 | г | ã | |
| 228 | 344 | 0xE4 | 11100100 | д | ä | |
| 229 | 345 | 0xE5 | 11100101 | е | å | |
| 230 | 346 | 0xE6 | 11100110 | ж | æ | |
| 231 | 347 | 0xE7 | 11100111 | з | ç | |
| 232 | 350 | 0xE8 | 11101000 | и | è | |
| 233 | 351 | 0xE9 | 11101001 | й | é | |
| 234 | 352 | 0xEA | 11101010 | к | ê | |
| 235 | 353 | 0xEB | 11101011 | л | ë | |
| 236 | 354 | 0xEC | 11101100 | м | ì | |
| 237 | 355 | 0xED | 11101101 | н | í | |
| 238 | 356 | 0xEE | 11101110 | о | î | |
| 239 | 357 | 0xEF | 11101111 | п | ï | |
| 240 | 360 | 0xF0 | 11110000 | р | ð | |
| 241 | 361 | 0xF1 | 11110001 | с | ñ | |
| 242 | 362 | 0xF2 | 11110010 | т | ò | |
| 243 | 363 | 0xF3 | 11110011 | у | ó | |
| 244 | 364 | 0xF4 | 11110100 | ф | ô | |
| 245 | 365 | 0xF5 | 11110101 | х | õ | |
| 246 | 366 | 0xF6 | 11110110 | ц | ö | |
| 247 | 367 | 0xF7 | 11110111 | ч | ÷ | |
| 248 | 370 | 0xF8 | 11111000 | ш | ø | |
| 249 | 371 | 0xF9 | 11111001 | щ | ù | |
| 250 | 372 | 0xFA | 11111010 | ъ | ú | |
| 251 | 373 | 0xFB | 11111011 | ы | û | |
| 252 | 374 | 0xFC | 11111100 | ь | ü | |
| 253 | 375 | 0xFD | 11111101 | э | ý | |
| 254 | 376 | 0xFE | 11111110 | ю | þ | |
| 255 | 377 | 0xFF | 11111111 | я | ÿ |
Помогла ли вам статья?
348 раз уже помогла
Комментарии: (0)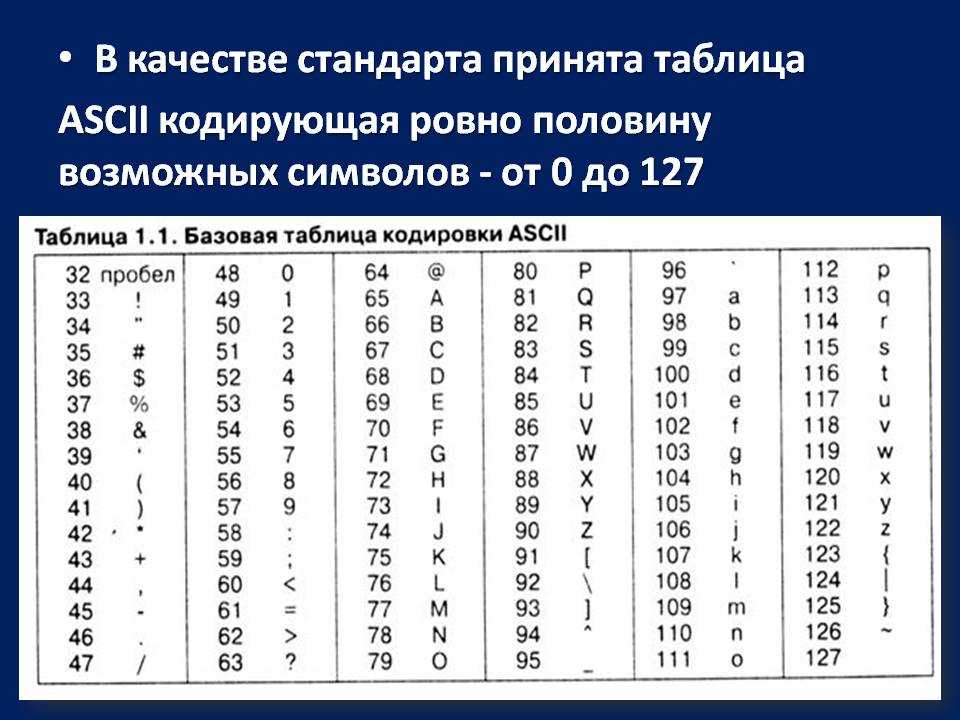 3s»>Читайте также
3s»>Читайте такжеТаблица символов ASCII в языке программирования C++
ASCII ( от англ. American Standard Code for Information Interchange) — американский стандартный код для обмена информацией. ASCII представлена в виде таблицы печатных символов и некоторых специальных управляющих символов, каждому символу соответствует уникальный код в диапазоне от [0;255]. ASCII представляет собой кодировку для представления десятичных цифр, латиницы и кириллицы, знаков препинания и управляющих символов (см. Таблица 1).
| № | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | nul | sox | stx | etx | eot | enq | ack | bel | bs | ht |
| 1 | nl | vt | ff | cr | so | si | dle | dc1 | dc2 | dc3 |
| 2 | dc4 | nak | syn | etb | can | em | sub | esc | fs | gs |
| 3 | rs | us | space | ! | « | # | $ | % | & | ‘ |
| 4 | ( | ) | * | + | , | — | .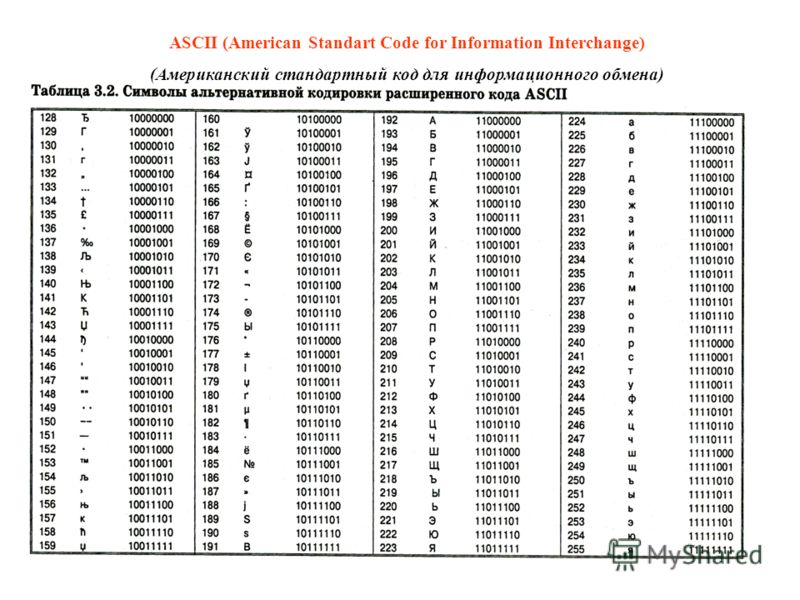 | / | 0 | 1 |
| 5 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; |
| 6 | < | = | > | ? | @ | A | B | C | D | E |
| 7 | F | G | H | I | J | K | L | M | N | O |
| 8 | P | Q | R | S | T | U | V | W | X | Y |
| 9 | Z | [ | \ | ] | ^ | _ | ‘ | a | b | c |
| 10 | d | e | f | g | h | i | j | k | l | m |
| 11 | n | o | p | q | r | s | t | u | v | w |
| 12 | x | y | z | { | | | } | ~ | del | А | Б |
| 13 | В | Г | Д | Е | Ж | З | И | Й | К | Л |
| 14 | М | Н | О | П | Р | С | Т | У | Ф | Х |
| 15 | Ц | Ч | Ш | Щ | ъ | Ы | Ь | Э | Ю | Я |
| 16 | а | б | в | г | д | е | ж | з | и | й |
| 17 | к | л | м | н | о | п | ||||
| 18 | ||||||||||
| 19 | ||||||||||
| 20 | ||||||||||
| 21 | ||||||||||
| 22 | р | с | т | у | ф | х | ||||
| 23 | ц | ч | ш | щ | ъ | ы | ь | э | ю | я |
| 24 | Ё | ё | Є | є | Ї | ї | Ў | ў | ° | · |
| 25 | · | № | ¤ |
Таблица 1 представляет собой полный набор символов ASCII. В таблице ASCII, символы с нулевого по 31 включительно, являются управляющими ASCII символами. Это значит, что данные символы выполняют некоторые действия, причём эти символы печатаются с сочетанием клавиши Ctrl. В таблице 1 записано обозначение управляющих ASCII символов, но не их отображение при печати. Остальные же символы с 32 по 254 не являются управляющими и имеют вид как и в таблице 1.
Благодаря таблице ASCII появилась новая форма представления изображений, с помощью символов таблицы ASCII.
ASCII art — форма изобразительного искусства, использующая символы ASCII для представления изображений. При создании такого изображения используются символы букв, цифр и знаков пунктуации. В ASCII art используется около 95 символов таблицы ASCII. Так как национальные представления таблиц ASCII различаются, поэтому остальные 160 символов не используются в искусстве ASCII.
// искусство ASCII (ASCII art)надпись сгенерирована программой
/* __ __
/\ \__ /\ \ __
___ _____ _____ ____\ \ ,_\ __ __ \_\ \ /\_\ ___ ___ ___ ___ ___
/'___\/\ '__`\ /\ '__`\ /',__\\ \ \/ /\ \/\ \ /'_` \\/\ \ / __`\ /'___\ / __`\ /' __` __`\
/\ \__/\ \ \L\ \\ \ \L\ \/\__, `\\ \ \_\ \ \_\ \/\ \L\ \\ \ \ /\ \L\ \ __ /\ \__/ /\ \L\ \/\ \/\ \/\ \
\ \____\\ \ ,__/ \ \ ,__/\/\____/ \ \__\\ \____/\ \___,_\\ \_\\ \____//\_\\ \____\\ \____/\ \_\ \_\ \_\
\/____/ \ \ \/ \ \ \/ \/___/ \/__/ \/___/ \/__,_ / \/_/ \/___/ \/_/ \/____/ \/___/ \/_/\/_/\/_/
\ \_\ \ \_\
\/_/ \/_/ */Изначально ASCII art выполнялось вручную, и это была рутинная работа. Сейчас существует огромное количество программ, так называемых, генераторов ASCII art. Такие программы автоматически создают ASCII изображения.
Как научить Python русскому языку — Учимся с Python
Специфика работы в Python со строками на русском языке проистекает из того, что существует множество независимых кодировок для представления на компьютере букв, отличных от латинских. Попробуем ответить на вопросы, что такое кодировка символов, почему их так много, и как нам работать с русскими символами и строками в Python.
Вы, конечно, слышали, что все данные в компьютере представлены в цифровом виде. Компьютер в принципе хранит и обрабатывает только числа.
Однако человек работает с текстами, состоящими из букв, цифр, знаков пунктуации и некоторых специальных символов, например, @, #, $. Посмотрите внимательно на символы, из которых состоит текст на экране компьютера. Вы видите их потому, что компьютер, для передачи данных пользователю, представляет хранящиеся в нем числовые данные в виде символов. и &. Введенные вами с клавиатуры символы хранятся в памяти компьютера в виде чисел. Потому что ничего, кроме чисел, в компьютере не может храниться.
Поэтому каждый символ, отображаемый или принимаемый компьютером, кодируется некоторым числом. Ниже представлена таблица кодировки ASCII, которая использует числа от 0 до 127 для кодирования символов, включая латиницу (буквы латинского алфавита), цифры от 0 до 9, знаки пунктуации и специальные символы. Кроме того, коды от 0 до 31 кодируют специальные управляющие символы, такие как табуляция TAB, перевод строки LF и другие. Подробнее познакомиться с таблицей ASCII можно в Википедии.
| 0 | NULL | 32 | Space | 64 | @ | 96 | ` |
| 1 | SOH | 33 | ! | 65 | A | 97 | a |
| 2 | STX | 34 | “ | 66 | B | 98 | b |
| 3 | ETX | 35 | # | 67 | C | 99 | c |
| 4 | EOT | 36 | $ | 68 | D | 100 | d |
| 5 | ENQ | 37 | % | 69 | E | 101 | e |
| 6 | ACK | 38 | & | 70 | F | 102 | f |
| 7 | BEL | 39 | ‘ | 71 | G | 103 | g |
| 8 | BS | 40 | ( | 72 | H | 104 | h |
| 9 | TAB | 41 | ) | 73 | I | 105 | i |
| 10 | LF | 42 | * | 74 | J | 106 | j |
| 11 | VT | 43 | + | 75 | K | 107 | k |
| 12 | FF | 44 | , | 76 | L | 108 | l |
| 13 | CR | 45 | — | 77 | M | 109 | m |
| 14 | SO | 46 | . | 78 | N | 110 | n |
| 15 | SI | 47 | / | 79 | O | 111 | o |
| 16 | DLE | 48 | 0 | 80 | P | 112 | p |
| 17 | DC1 | 49 | 1 | 81 | Q | 113 | q |
| 18 | DC2 | 50 | 2 | 82 | R | 114 | r |
| 19 | DC3 | 51 | 3 | 83 | S | 115 | s |
| 20 | DC4 | 52 | 4 | 84 | T | 116 | t |
| 21 | NAK | 53 | 5 | 85 | U | 117 | u |
| 22 | SYN | 54 | 6 | 86 | V | 118 | v |
| 23 | ETB | 55 | 7 | 87 | W | 119 | w |
| 24 | CAN | 56 | 8 | 88 | X | 120 | x |
| 25 | EM | 57 | 9 | 89 | Y | 121 | y |
| 26 | SUB | 58 | : | 90 | Z | 122 | z |
| 27 | ESC | 59 | ; | 91 | [ | 123 | { |
| 28 | FS | 60 | < | 92 | 124 | | | |
| 29 | GS | 61 | = | 93 | ] | 125 | } |
| 30 | RS | 62 | > | 94 | ^ | 126 | ~ |
| 31 | US | 63 | ? | 95 | _ | 127 | DEL |
Все современные компьютеры и программы понимают и широко используют кодировку ASCII. Вот почему латиница является самым распространенным алфавитом на компьютерах, а англоязычные пользователи компьютеров, по большей части, лишены необходимости задумываться о кодировках символов и переключать раскладку клавиатуры.
Закодируем, используя приведенную выше таблицу кодов ASCII, слово “Hello”. Мы получим следующую последовательностью числовых кодов: 72, 101, 108, 108, 111. Проверить (и узнать) соответствие букв и кодов можно при помощи встроенных функций Python chr и ord. Функция chr принимает в качестве аргумента целочисленный код и возвращает соответствующий ему символ. Функция ord, наоборот, принимает символ и возвращает кодирующее его целое число:
>>> ord('H')
72
>>> ord('e')
101
>>> chr(101)
'e'
>>> type(chr(101))
<type 'str'>
>>>
Посмотрите еще раз на таблицу ASCII. Как видите, в ней нет букв русского алфавита. А также в ней греческих, арабских, японских и других букв и иероглифов, использующихся в разных языках Земли. Для кодирования букв и других символов, отсутствующих в таблице ASCII, используются числа больше 128. На следующем рисунке представлена кодировка cp866, использующая числа от 128 до 255 для кодирования символов кириллицы (букв русского алфавита) и специальных графических символов.
| 128 | А | 160 | а | 192 | └ | 224 | р |
| 129 | Б | 161 | б | 193 | ┴ | 225 | с |
| 130 | В | 162 | в | 194 | ┬ | 226 | т |
| 131 | Г | 163 | г | 195 | ├ | 227 | у |
| 132 | Д | 164 | д | 196 | ─ | 228 | ф |
| 133 | Е | 165 | е | 197 | ┼ | 229 | х |
| 134 | Ж | 166 | ж | 198 | ╞ | 230 | ц |
| 135 | З | 167 | з | 199 | ╟ | 231 | ч |
| 136 | И | 168 | и | 200 | ╚ | 232 | ш |
| 137 | Й | 169 | й | 201 | ╔ | 233 | щ |
| 138 | К | 170 | к | 202 | ╩ | 234 | ъ |
| 139 | Л | 171 | л | 203 | ╦ | 235 | ы |
| 140 | М | 172 | м | 204 | ╠ | 236 | ь |
| 141 | Н | 173 | н | 205 | ═ | 237 | э |
| 142 | О | 174 | о | 206 | ╬ | 238 | ю |
| 143 | П | 175 | п | 207 | ╧ | 239 | я |
| 144 | Р | 176 | ░ | 208 | ╨ | 240 | Ё |
| 145 | С | 177 | ▒ | 209 | ╤ | 241 | ё |
| 146 | Т | 178 | ▓ | 210 | ╥ | 242 | Є |
| 147 | У | 179 | │ | 211 | ╙ | 243 | є |
| 148 | Ф | 180 | ┤ | 212 | ╘ | 244 | Ї |
| 149 | Х | 181 | ╡ | 213 | ╒ | 245 | ї |
| 150 | Ц | 182 | ╢ | 214 | ╓ | 246 | Ў |
| 151 | Ч | 183 | ╖ | 215 | ╫ | 247 | ў |
| 152 | Ш | 184 | ╕ | 216 | ╪ | 248 | ° |
| 153 | Щ | 185 | ╣ | 217 | ┘ | 249 | ∙ |
| 154 | Ъ | 186 | ║ | 218 | ┌ | 250 | · |
| 155 | Ы | 187 | ╗ | 219 | █ | 251 | √ |
| 156 | Ь | 188 | ╝ | 220 | ▄ | 252 | № |
| 157 | Э | 189 | ╜ | 221 | ▌ | 253 | ¤ |
| 158 | Ю | 190 | ╛ | 222 | ▐ | 254 | ■ |
| 159 | Я | 191 | ┐ | 223 | ▀ | 255 |
Кодировка cp866 использовалась в операционной системе MS DOS и теперь по умолчанию используется в консоли MS Windows. Буквы cp в названии этой и других кодировок — сокращение от code page (англ.: кодовая страница).
Случилось так, что числа от 128 до 255 стали использоваться в разных странах для кодирования букв алфавитов разных языков, а не только русского. Но даже если вести речь только о кириллице, то, кроме кодировки cp866, существуют несколько других кодировок, которые иначе сопоставляют буквы кириллицы кодам в диапазоне от 128 до 255. В качестве примера еще одной кириллической кодировки ниже приведена таблица кодов cp1251, используемая графическими приложениями в ОС MS Windows, такими как Блокнот, MS Office и другими.
| 128 | Ђ | 160 | 192 | А | 224 | а | |
| 129 | Ѓ | 161 | Ў | 193 | Б | 225 | б |
| 130 | ‚ | 162 | ў | 194 | В | 226 | в |
| 131 | ѓ | 163 | Ј | 195 | Г | 227 | г |
| 132 | „ | 164 | ¤ | 196 | Д | 228 | д |
| 133 | … | 165 | Ґ | 197 | Е | 229 | е |
| 134 | † | 166 | ¦ | 198 | Ж | 230 | ж |
| 135 | ‡ | 167 | § | 199 | З | 231 | з |
| 136 | € | 168 | Ё | 200 | И | 232 | и |
| 137 | ‰ | 169 | © | 201 | Й | 233 | й |
| 138 | Љ | 170 | Є | 202 | К | 234 | к |
| 139 | ‹ | 171 | « | 203 | Л | 235 | л |
| 140 | Њ | 172 | ¬ | 204 | М | 236 | м |
| 141 | Ќ | 173 | | 205 | Н | 237 | н |
| 142 | Ћ | 174 | ® | 206 | О | 238 | о |
| 143 | Џ | 175 | Ї | 207 | П | 239 | п |
| 144 | ђ | 176 | ° | 208 | Р | 240 | р |
| 145 | ‘ | 177 | ± | 209 | С | 241 | с |
| 146 | ’ | 178 | І | 210 | Т | 242 | т |
| 147 | “ | 179 | і | 211 | У | 243 | у |
| 148 | ” | 180 | ґ | 212 | Ф | 244 | ф |
| 149 | • | 181 | µ | 213 | Х | 245 | х |
| 150 | – | 182 | ¶ | 214 | Ц | 246 | ц |
| 151 | — | 183 | · | 215 | Ч | 247 | ч |
| 152 | | 184 | ё | 216 | Ш | 248 | ш |
| 153 | ™ | 185 | № | 217 | Щ | 249 | щ |
| 154 | љ | 186 | є | 218 | Ъ | 250 | ъ |
| 155 | › | 187 | » | 219 | Ы | 251 | ы |
| 156 | њ | 188 | ј | 220 | Ь | 252 | ь |
| 157 | ќ | 189 | Ѕ | 221 | Э | 253 | э |
| 158 | ћ | 190 | ѕ | 222 | Ю | 254 | ю |
| 159 | џ | 191 | ї | 223 | Я | 255 | я |
Из сказанного можно сделать вывод о том, что для правильного отображения символов на экране компьютеру необходимо знать, в какой кодировке представлены данные, которые нужно отобразить. Например, пускай нам дана следующая последовательность кодов: 232, 227, 226. Если принять, что это символы, представленные в кодировке cp866, то мы получим слово “шут”. А если принять, что это символы, представленные в кодировке cp1251, то мы получим слово “игв”. А в греческой кодировке cp1253 эти же коды дадут нам “θγβ”! На сегодняшний день существуют десятки кодировок, сопоставляющих числовые коды от 128 до 255 различным символам!
Если вы запускаете интерпретатор Python в консоли русскоязычной Windows, то Python ожидает, что строки используют кодировку cp866. Давайте проведем небольшое исследование для того, чтобы подтвердить или опровергнуть это утверждение. Воспользуемся функцией ord для получения числовых кодов нескольких русских букв, введенных с клавиатуры, и таблицей кодов cp866, приведенной выше, чтобы убедиться, что функция ord вернула нам коды букв в кодировке cp866:
>>> print ord('э'), ord('ю'), ord('я')
237 238 239
>>>
А функция chr выведет буквы русского алфавита, соответствующие кодам, взятым нами из таблицы cp866:
>>> print chr(128), chr(129), chr(130) А Б В >>>
Итак, русские буквы, которые мы вводим с клавиатуры при работе в интерактивном режиме Python, представлены в кодировке cp866. Работая в интерактивном режиме Python, мы можем смело использовать русские буквы в строковых значениях:
>>> name = 'мир' >>> print 'Привет', name Привет мир >>>
Таким образом, все примеры работы в интерактивном режиме, приведенные в книге, можно безболезненно русифицировать, заменяя английские слова и предложения на русские.
Однако, для русификации скриптов Python, сохраненных в файлах, нам осталось сделать еще один шаг. Нам нужно ответить на вопрос, в какой кодировке сохранен наш скрипт в файле? Это зависит от текстового редактора, в котором был написан и сохранен скрипт, и от того, была ли явно указана кодировка при сохранении файла.
Как было сказано выше, Блокнот, или Notepad, простой текстовый редактор, имеющийся в ОС Windows, использует кириллическую кодировку cp1251, а консоль Windows, или окно для работы с командной строкой, по умолчанию использует кириллическую кодировку cp866. Это очень неудобно для русскоязычных пользователей.
Например, создайте в Блокноте файл C:\russian.txt с единственной строкой:
Привет мир!
А теперь откройте окно с командной строкой и выведите содержимое этого файла на экран:
C:\>type russian.txt ╧ЁштхЄ ьшЁ!
Что это за кракозябры?
Если вы отыщете эти символы, один за одним, в приведенной выше таблице кодов cp866, то получится последовательность кодов: 207, 240, 232, 226, 229, 242, 32, 252, 248, 240, 33. (Пробел и восклицательный знак имеют коды из диапазона 0 — 127 и кодируются таблицей ASCII.) Теперь переведите эти коды в символы, используя таблицу кодировки cp1251, и вы получите “Привет мир!” Кракозябры в консольном окне мы видим потому, что Блокнот сохранил файл в кодировке cp1251, а консольное окно считает, что коды от 128 до 255 представляют символы из кодировки cp866!
Преодолеть эту проблему можно с помощью консольной команды chcp. Команда chcp без параметров показывает, какая кодировка является текущей:
C:\>chcp Active code page: 866
А в качестве параметра команда chcp принимает номер кодировки, которую необходимо сделать текущей. Если с ее помощью изменить текущую кодировку консольного окна на cp1251, то мы, наконец, сможем увидеть содержимое файла russian.txt неискаженным:
C:\>chcp 1251 Active code page: 1251 C:\>type russian.txt Привет мир!
Скрипт на Python является текстовым файлом точно так же, как файл russian.txt, с которым мы экспериментировали. И если создать и сохранить скрипт, использующий русские буквы, в Блокноте, то скрипт будет сохранен в кодировке cp1251. Давайте откроем в Блокноте файл russian.txt и сохраним его как russian.py, слегка изменив его содержимое:
print 'Привет мир!'
Теперь это файл с очень простым скриптом на языке Python. Выполним его:
C:\>python russian.py File "russian.py", line 1 SyntaxError: Non-ASCII character '\xcf' in file russian.py on line 1, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
Вместо ожидаемого приветствия на русском языке Python вывел сообщение об ошибке. Сообщение говорит о том, что в 1-ой строке файла встретился символ, не являющийся символом ASCII, а кодировка не объявлена. Очевидно, что символы, не являющиеся символами ASCII, в нашем файле — это русские буквы. Но что же в этом плохого?
Дело в том, что Python по умолчанию ожидает, что скрипты, переданные ему для выполнения, имеют кодировку ASCII, то есть, содержат символы с кодами в диапазоне 0 — 127. Для всех, кто использует в своих скриптах только латиницу, цифры и другие символы ASCII, это работает прекрасно. Пользователи, использующие в своих программах строковые значения и комментарии на английском языке, чувствуют себя совершенно комфортно в этой ситуации и, по большей части, не подозревают о проблеме, с которой мы только что столкнулись.
Чтобы сообщить Python о том, что скрипт использует кодировку, отличную от ASCII, нужно в начале файла поместить комментарий специального вида, содержащий информацию о кодировке файла. Для скрипта russian.py, созданного в Блокноте, укажем кодировку cp1251, после чего скрипт будет выглядеть так:
# -*- coding: cp1251 -*- print 'Привет мир!'
После этого сможем успешно выполнить скрипт в консольном окне Windows (только не забудьте установить текущую кодировку командой chcp 1251):
C:\>chcp 1251 Active code page: 1251 C:\>python russian.
Итак, для того, чтобы скрипт Python заговорил по-русски в консольном окне Windows, необходимо:
Указать в начале скрипта кодировку, которую использует файл. Например:
# -*- coding: cp1251 -*-
Установить в консольном окне Windows кодировку, которую использует выполняемый скрипт. Например:
C:\> chcp 1251 Active code page: 1251
В общем случае, скрипт с русскими строками и комментариями может использовать любую из кириллических кодировок, в частности, любую из рассмотренных выше, cp1251 или cp866. Важно, чтобы объявленная в начале файла кодировка была та самая, в которой сохранен файл.
Если скрипт использует кодировку cp866, то в консольном окне русскоязычной Windows не нужно предпринимать никаких специальных действий перед выполнением скрипта, ведь cp866 — кодировка, установленная в консоли по умолчанию. Но если скрипт использует кодировку cp1251, то перед его выполнением в консоли нужно установить текущую кодировку командой chcp 1251.
Ascii для кириллической кодировки (CP855)
Американский стандартный код для обмена информацией ( ASCII ) — широко используемая система кодировки символов , представленная в 1963 году. стандартный набор символов изначально состоял из 128 символов (7-битный код). Первые 32 символа — это управляющие символы (также называемые непечатаемыми символами), которые используются для управления потоками данных, а также такими устройствами, как принтеры. Позже он был расширен для поддержки 256 символов (8-битный код), чтобы предоставить символы, специфичные для языка, различные символы, а также символы для рисования блоков: элементы, используемые для презентационных целей, позволяющие рисовать различные виды рамок и блоков. Символы в диапазоне 128-255 называются расширенным ASCII.
Кодовая страница 855 является альтернативной кодовой страницей , используемой для написания языков на основе кириллицы: белорусского, боснийского, болгарского, македонского, русского, сербского, украинского (славянские языки), а также казахского, киргизского, молдавского, монгольского, таджикского, узбекского. (не славянский). Он не очень популярен, кодовая страница 866 является наиболее широко используемой. Только расширенный набор символов отличается от исходной кодовой страницы, причем как управляющие символы, так и стандартный набор символов представляют собой простой ASCII.
9Таблица символов 0003 ниже показывает графическое представление каждого символа с точностью до пикселя, а также текстовое описание.
Control characters (0 — 31):
| Dec | Hex | Char | Description | Dec | Hex | Char | Description |
| 0 | 0 | NUL (Null ) | 16 | 10 | DLE (выход канала передачи данных) | ||
| 1 | 1 | SOH (Start of Header) | 17 | 11 | DC1 (Device Control 1) | ||
| 2 | 2 | STX (Start of Text) | 18 | 12 | DC2 (Device Control 2) | ||
| 3 | 3 | ETX (End of Text) | 19 | 13 | DC3 (Device Control 3) | ||
| 4 | 4 | EOT (End of Transmission) | 20 | 14 | DC4 (Device Control 4) | ||
| 5 | 5 | ENQ (Enquiry) | 21 | 15 | NAK (Negative Acknowledge) | ||
| 6 | 6 | ACK (Acknowledge) | 22 | 16 | SYN (Synchronous Idle) | ||
| 7 | 7 | BEL (Bell) | 23 | 17 | ETB (End of Transmission Block) | ||
| 8 | 8 | BS (BackSpace) | 24 | 18 | CAN (Cancel) | ||
| 9 | 9 | HT (Horizontal Tabulation) | 25 | 19 | EM (End of Medium) | ||
| 10 | A | LF (Line Feed) | 26 | 1A | SUB (Substitute) | ||
| 11 | B | VT (Vertical Tabulation) | 27 | 1B | ESC (Escape) | ||
| 12 | C | FF (Form Feed) | 28 | 1C | FS (File Separator) | ||
| 13 | D | CR (Carriage Return) | 29 | 1D | GS (Group Separator) | ||
| 14 | E | SO (Shift Out) | 30 | 1E | RS (Record Separator) | ||
| 15 | F | SI (Shift In) | 31 | 1F | US (Unit Separator) |
Standard character set (32 — 127):
| Dec | Hex | Char | Description | Dec | Hex | Char | Description | ||||||||||||||||||||
| 32 | 20 | Space | 80 | 50 | Upper case P | ||||||||||||||||||||||
| 33 | 21 | Exclamation mark | 81 | 51 | Верхний корпус Q | ||||||||||||||||||||||
| 34 | 22 | Цитата Марка | 52 | . 0023 | 35 | 23 | Hash | 83 | 53 | Upper case S | |||||||||||||||||
| 36 | 24 | Dollar | 84 | 54 | Upper case T | ||||||||||||||||||||||
| 37 | 25 | Percent | 85 | 55 | Upper case U | ||||||||||||||||||||||
| 38 | 26 | Ampersand | 86 | 56 | Upper case V | ||||||||||||||||||||||
| 39 | 27 | Apostrophe | 87 | 57 | Upper case W | ||||||||||||||||||||||
| 40 | 28 | Open bracket | 88 | 58 | Верхний корпус x | ||||||||||||||||||||||
| 41 | 29 | Закрыть кронштейн | 59 | Верх0024 2A | Asterisk | 90 | 5A | Upper case Z | |||||||||||||||||||
| 43 | 2B | Plus | 91 | 5B | Open square bracket | ||||||||||||||||||||||
| 44 | 2C | Comma | 92 | 5C | Backslash | ||||||||||||||||||||||
| 45 | 2D | Dash | 93 | 5D | Close square bracket | ||||||||||||||||||||||
| 46 | 2E | Full stop | 94 | 5E | Caret | ||||||||||||||||||||||
| 47 | 2F | Slash | 95 | 5F | Underscore | ||||||||||||||||||||||
| 48 | 30 | Zero | 96 | 60 | Grave accent | ||||||||||||||||||||||
| 49 | 31 | One | 97 | 61 | Lower case a | ||||||||||||||||||||||
| 50 | 32 | Two | 98 | 62 | Lower case b | ||||||||||||||||||||||
| 51 | 33 | Three | 99 | 63 | Нижний чехол C | ||||||||||||||||||||||
| 52 | 34 | Четыре | 100 | 64 | . 0024 Five | 101 | 65 | Lower case e | |||||||||||||||||||
| 54 | 36 | Six | 102 | 66 | Lower case f | ||||||||||||||||||||||
| 55 | 37 | Seven | 103 | 67 | Нижний чехол G | ||||||||||||||||||||||
| 56 | 38 | восемь | 104 | 99969 | 9969 | 9699969 | .0023 | 57 | 39 | Nine | 105 | 69 | Lower case i | ||||||||||||||
| 58 | 3A | Colon | 106 | 6A | Lower case j | ||||||||||||||||||||||
| 59 | 3B | Semicolon | 107 | 6B | Lower case k | ||||||||||||||||||||||
| 60 | 3C | Less than | 108 | 6C | Lower case l | ||||||||||||||||||||||
| 61 | 3D | Equals sign | 109 | 6D | Lower case m | ||||||||||||||||||||||
| 62 | 3E | Greater than | 110 | 6e | Нижний чехол N | ||||||||||||||||||||||
| 63 | 3F | Марк | 111 | 6F | Нижний чехол O | . 0025 | 40 | At | 112 | 70 | Lower case p | ||||||||||||||||
| 65 | 41 | Upper case A | 113 | 71 | Lower case q | ||||||||||||||||||||||
| 66 | 42 | Upper case B | 114 | 72 | Lower case r | ||||||||||||||||||||||
| 67 | 43 | Upper case C | 115 | 73 | Lower case s | ||||||||||||||||||||||
| 68 | 44 | Upper case D | 116 | 74 | Lower case t | ||||||||||||||||||||||
| 69 | 45 | Upper case E | 117 | 75 | Нижний чехол U | ||||||||||||||||||||||
| 70 | 46 | Верхний чехол F | 118 | . Нижний чехол v | .0024 47 | Upper case G | 119 | 77 | Lower case w | ||||||||||||||||||
| 72 | 48 | Upper case H | 120 | 78 | Lower case x | ||||||||||||||||||||||
| 73 | 49 | Верхний корпус I | 121 | 79 | . 0024 7A | Lower case z | |||||||||||||||||||||
| 75 | 4B | Upper case K | 123 | 7B | Open brace | ||||||||||||||||||||||
| 76 | 4C | Upper case L | 124 | 7C | Pipe | ||||||||||||||||||||||
| 77 | 4D | Upper case M | 125 | 7D | Close brace | ||||||||||||||||||||||
| 78 | 4E | Upper case N | 126 | 7E | Tilde | ||||||||||||||||||||||
| 79 | 4F | Upper case O | 127 | 7F | Delete |
Extended character set ( 128 — 255):
| Dec | HEX | HAR | Описание | DEC | HEX | HAR | Описание | ||||||||||||||||||
| 128418 | .0025 | 80 | Cyrillic lower case dje | 192 | C0 | Box drawings light up and right | |||||||||||||||||||
| 129 | 81 | Cyrillic upper case DJE | 193 | C1 | Box рисунки с подсветкой вверх и по горизонтали | ||||||||||||||||||||
| 130 | 82 | Нижний кириллический регистр gje | 194 | C2 | 0025 | ||||||||||||||||||||
| 131 | 83 | Cyrillic upper case GJE | 195 | C3 | Box drawings light vertical and right | ||||||||||||||||||||
| 132 | 84 | Cyrillic lower case io | 196 | C4 | чертежа коробки. 0025 | ||||||||||||||||||||
| 134 | 86 | Cyrillic lower case ukrainian ie | 198 | C6 | Cyrillic lower case ka | ||||||||||||||||||||
| 135 | 87 | Cyrillic upper case ukrainian IE | 199 | C7 | Cyrillic upper case KA | ||||||||||||||||||||
| 136 | 88 | Cyrillic lower case dze | 200 | C8 | Box drawings double up and right | ||||||||||||||||||||
| 137 | 89 | Cyrillic upper case DZE | 201 | C9 | Box drawings double down and right | ||||||||||||||||||||
| 138 | 8A | Cyrillic lower case byelorussian-ukrainian i | 202 | CA | Чертежи коробок двойные и горизонтальные | ||||||||||||||||||||
| 139 | 8B | Кириллица заглавная белорусско-украинская I | 203 | CB | Результаты коробки Double Down and Horizontal | ||||||||||||||||||||
| 140 | 8C | Cyrillic Lower Case YI | 204 | CCCC -BOIL | 8D | Верхний регистр кириллицы YI | 205 | CD | Чертежи коробок двойные горизонтальные | ||||||||||||||||
| 142 | 8E 9020 40024 Cyrillic lower case je206 | CE | Box drawings double vertical and horizontal | ||||||||||||||||||||||
| 143 | 8F | Cyrillic upper case JE | 207 | CF | Currency sign | ||||||||||||||||||||
| 144 | 90 | Cyrillic Lower Case LJE | 208 | D0 | Cyrillic Lower Case EL | ||||||||||||||||||||
| 145 | |||||||||||||||||||||||||
| 145 | 9009 | ||||||||||||||||||||||||
| 145 | |||||||||||||||||||||||||
| 145 | |||||||||||||||||||||||||
| Cyrillic upper case LJE | 209 | D1 | Cyrillic upper case EL | ||||||||||||||||||||||
| 146 | 92 | Cyrillic lower case nje | 210 | D2 | Cyrillic lower case em | ||||||||||||||||||||
| 147 | 93 | Cyrillic Верхний корпус NJE | 211 | D3 | Cyrillic Upper Case EM | ||||||||||||||||||||
| 148 | |||||||||||||||||||||||||
| 148 | |||||||||||||||||||||||||
| 148 | |||||||||||||||||||||||||
| 148 | |||||||||||||||||||||||||
| 148 | |||||||||||||||||||||||||
| 148 | |||||||||||||||||||||||||
| Cyrillic lower case tshe | 212 | D4 | Cyrillic lower case en | ||||||||||||||||||||||
| 149 | 95 | Cyrillic upper case TSHE | 213 | D5 | Cyrillic upper case EN | ||||||||||||||||||||
| 150 | 96 | Cyrillic lower case kje | 214 | D6 | Cyrillic lower case o | ||||||||||||||||||||
| 151 | 97 | Cyrillic upper case KJE | 215 | D7 | Cyrillic upper case O | ||||||||||||||||||||
| 152 | 98 | Cyrillic lower case short u | 216 | D8 | Cyrillic lower case pe | ||||||||||||||||||||
| 153 | 99 | Cyrillic upper case short U | 217 | D9 | Box drawings light up and left | ||||||||||||||||||||
| 154 | 9A | Cyrillic lower case dzhe | 218 | DA | Box drawings light down and right | ||||||||||||||||||||
| 155 | 9B | Cyrillic upper case DZHE | 219 | DB | Full block | ||||||||||||||||||||
| 156 | 9C | Cyrillic lower case yu | 220 | DC | Lower half block | ||||||||||||||||||||
| 157 | 9D | Cyrillic upper case YU | 221 | DD | Cyrillic upper case PE | ||||||||||||||||||||
| 158 | 9E | Cyrillic lower case hard sign | 222 | DE | Cyrillic lower case ya | ||||||||||||||||||||
| 159 | 9F | Cyrillic Верхний корпус. 0046 | Cyrillic lower case a | 224 | E0 | Cyrillic upper case YA | |||||||||||||||||||
| 161 | A1 | Cyrillic upper case A | 225 | E1 | Cyrillic lower case er | ||||||||||||||||||||
| 162 | A2 | Cyrillic Lower Case BE | 226 | E2 | Cyrillic Toper Case ER | ||||||||||||||||||||
| 163 | A3 | ||||||||||||||||||||||||
| 163 | A3 | ||||||||||||||||||||||||
| 163 | A3 | ||||||||||||||||||||||||
| 163 | A3 | ||||||||||||||||||||||||
| 163 | A3 | ||||||||||||||||||||||||
| .0024 Cyrillic upper case BE | 227 | E3 | Cyrillic lower case es | ||||||||||||||||||||||
| 164 | A4 | Cyrillic lower case tse | 228 | E4 | Cyrillic upper case ES | ||||||||||||||||||||
| 165 | A5 | Cyrillic upper case TSE | 229 | E5 | Cyrillic lower case te | ||||||||||||||||||||
| 166 | A6 | Cyrillic lower case de | 230 | E6 | Cyrillic upper case TE | ||||||||||||||||||||
| 167 | A7 | Cyrillic upper case DE | 231 | E7 | Cyrillic lower case u | ||||||||||||||||||||
| 168 | A8 | Нижний регистр кириллицы т. е. | 232 | E8 | Прописная кириллица U | ||||||||||||||||||||
| 169 | A9 | 6 5 Кириллица верхний регистр | IE0024 233 | E9 | Cyrillic lower case zhe | ||||||||||||||||||||
| 170 | AA | Cyrillic lower case ef | 234 | EA | Cyrillic upper case ZHE | ||||||||||||||||||||
| 171 | AB | Верхний регистр кириллицы EF | 235 | EB | Нижний регистр кириллицы ve | ||||||||||||||||||||
| 172 | AC | Нижний регистр кириллицы0024 236 | EC | Cyrillic upper case VE | |||||||||||||||||||||
| 173 | AD | Cyrillic upper case GHE | 237 | ED | Cyrillic lower case soft sign | ||||||||||||||||||||
| 174 | AE | Левый указатель с двойным углом кавычка | 238 | EE | Мягкий знак Cyrillic Upper Case. 0025 | 239 | EF | Numero sign | |||||||||||||||||
| 176 | B0 | Light shade | 240 | F0 | Soft hyphen | ||||||||||||||||||||
| 177 | B1 | Medium shade | 241 | F1 | Cyrillic Lower Case Yeru | ||||||||||||||||||||
| 178 | B2 | Dark Shade | 242 | F2 | 924 | 242 | F2 | 9924 | 242 | F2 | 924 | 242 | F2 | 242 | F2 | 242 | F2 | .0025 | |||||||
| 179 | B3 | Box drawings light vertical | 243 | F3 | Cyrillic lower case ze | ||||||||||||||||||||
| 180 | B4 | Box drawings light vertical and left | 244 | F4 | Кириллический верхний корпус ZE | ||||||||||||||||||||
| 181 | B5 | Cyrillic Lower Case HA | 245 | F5 | . 0025 | ||||||||||||||||||||
| 182 | B6 | Cyrillic upper case HA | 246 | F6 | Cyrillic upper case SHA | ||||||||||||||||||||
| 183 | B7 | Cyrillic lower case i | 247 | F7 | Строчные кириллицы e | ||||||||||||||||||||
| 184 | B8 | Прописные кириллицы I | 248 | F8 | Верхние буквы e | ||||||||||||||||||||
| 185 | B9 | Box drawings double vertical and left | 249 | F9 | Cyrillic lower case shcha | ||||||||||||||||||||
| 186 | BA | Box drawings double vertical | 250 | FA | Кириллический верхний корпус SHCHA | ||||||||||||||||||||
| 187 | BB | Рисунки коробки двойной и слева | 251 | .0025||||||||||||||||||||||
| 188 | BC | Box drawings double up and left | 252 | FC | Cyrillic upper case CHE | ||||||||||||||||||||
| 189 | BD | Cyrillic lower case short i | 253 | FD | Знак секции | ||||||||||||||||||||
| 190 | BE | Cyrillic Верхний корпус Шорт I | 254 | FE | Черная квадрат | FE | FE | FE | FE | FE | FE | 0040 | |||||||||||||
| 191 | BF | Результаты коробки Light Down Down и слева | 255 | FF | Space No-Break |
HEX / Pref-Pref-Prefix Converte.
разделитель и нажмите кнопку Convert (например, 45 78 61 6d 70 6C 65 21):
От BinaryDecimalOctalHexadecimalText
Кому BinaryDecimalOctalHexadecimalText
Вставьте шестнадцатеричные числа или перетащите файл
Кодировка символов ASCIIUnicodeUTF-8UTF-16UTF-16 с прямым порядком байтовUTF-16 с прямым порядком байтовWindows-1252Big5 (китайский)CP866 (русский)EUC-JP (японский)EUC-KR (корейский)GB 18030 (китайский)GB 2312 (китайский)ISO-2022-CN ( Китайский)ISO-2022-JP (японский)ISO-8859-1 (латинский1/западноевропейский)ISO-8859-2 (латинский2/восточноевропейский)ISO-8859-3 (латинский3/южноевропейский)ISO-8859-4 (латинский4 /Северная Европа)ISO-8859-5 (латиница/кириллица)ISO-8859-6 (латиница/арабская)ISO-8859-7 (латиница/греческий)ISO-8859-8 (латиница/иврит)ISO-8859-8- I (латиница/иврит) ISO-8859-10 (Latin6/Северные страны)ISO-8859-13 (Latin7/Балтийские страны)ISO-8859-14 (Latin8/Celtic)ISO-8859-15 (Latin9/Западноевропейские страны)ISO-8859-16 (Latin10/Юго-Восточные страны) Европейский)KOI8-R (русский)KOI8-U (украинский)Macintosh (x-mac-roman)Mac OS Cyrillic (x-mac-cyrillic)Shift JIS (японский)Windows-874 (тайский)Windows-1250 (восточноевропейский) Windows-1251 (кириллица)Windows-1252 (западноевропейская)Windows-1253 (греческая)Windows-1254 (турецкая)Windows-1255 (иврит)Windows-1256 (арабская)Windows-1257 (балтийская)Windows-1258 (вьетнамская)X -Пользовательский
Преобразователь ASCII в шестнадцатеричный ►
Кодирование текста ASCII использует фиксированный 1 байт для каждого символа.
Кодировка текста UTF-8 использует переменное количество байтов для каждого символа. Для этого требуется разделитель между каждым шестнадцатеричным числом.
Как преобразовать шестнадцатеричный код в текст
Преобразовать шестнадцатеричный код ASCII в текст:
- Получить шестнадцатеричный байт
- Преобразовать шестнадцатеричный байт в десятичный
- Получить символ кода ASCII из таблицы ASCII
- Продолжить со следующего байта
Пример
Преобразовать шестнадцатеричный код ASCII «50 6C 61 6E 74 20 74 72 65 65 73» в текст:
Решение:
Используйте таблицу ASCII для получения символа из кода ASCII.
50 16 = 5×16 1 +0×16 0 = 80+0 = 80 => P = 96+12 = 108 => «l»
61 16 = 6×16 1 +1×16 0 = 96+1 = 97 => «a»
⁝ 2
⁝
для всех шестнадцатеричных байтов вы должны получить текст:
«Сажать деревья»
Как преобразовать шестнадцатеричный текст в текст?
- Получить шестнадцатеричный код байта
- Преобразовать шестнадцатеричный байт в десятичный
- Получить символ десятичного кода ASCII из таблицы ASCII
- Продолжить со следующего шестнадцатеричного байта
Как использовать конвертер текста Hex в ASCII?
- Вставьте шестнадцатеричные байтовые коды в текстовое поле ввода.
- Выберите тип кодировки символов.
- Нажмите кнопку Преобразовать.
Как преобразовать шестнадцатеричный код в английский? 90 = 48 = символ ‘0’
Таблица преобразования шестнадцатеричного текста в ASCII
| Шестнадцатеричный | Двоичный | ASCII Символ |
|---|---|---|
| 00 | 00000000 | НУЛ |
| 01 | 00000001 | СОХ |
| 02 | 00000010 | СТХ |
| 03 | 00000011 | ЕТХ |
| 04 | 00000100 | ЕОТ |
| 05 | 00000101 | ENQ |
| 06 | 00000110 | ПОДТВЕРЖДЕНИЕ |
| 07 | 00000111 | бел |
| 08 | 00001000 | БС |
| 09 | 00001001 | НТ |
| 0А | 00001010 | ЛФ |
| 0Б | 00001011 | ВТ |
| 0С | 00001100 | ФФ |
| 0D | 00001101 | CR |
| 0Е | 00001110 | СО |
| 0F | 00001111 | СИ |
| 10 | 00010000 | ДЛЭ |
| 11 | 00010001 | ДС1 |
| 12 | 00010010 | ДС2 |
| 13 | 00010011 | ДС3 |
| 14 | 00010100 | ДС4 |
| 15 | 00010101 | НАК |
| 16 | 00010110 | СИН |
| 17 | 00010111 | ЭТБ |
| 18 | 00011000 | МОЖЕТ |
| 19 | 00011001 | ЭМ |
| 1А | 00011010 | SUB |
| 1Б | 00011011 | ЕСК |
| 1С | 00011100 | ФС |
| 1Д | 00011101 | ГС |
| 1Э | 00011110 | РС |
| 1F | 00011111 | США |
| 20 | 00100000 | Пробел |
| 21 | 00100001 | ! |
| 22 | 00100010 | » |
| 23 | 00100011 | # |
| 24 | 00100100 | $ |
| 25 | 00100101 | % |
| 26 | 00100110 | и |
| 27 | 00100111 | ‘ |
| 28 | 00101000 | ( |
| 29 | 00101001 | ) |
| 2А | 00101010 | * |
| 2Б | 00101011 | + |
| 2С | 00101100 | , |
| 2D | 00101101 | — |
| 2Е | 00101110 | . |
| 2F | 00101111 | / |
| 30 | 00110000 | 0 |
| 31 | 00110001 | 1 |
| 32 | 00110010 | 2 |
| 33 | 00110011 | 3 |
| 34 | 00110100 | 4 |
| 35 | 00110101 | 5 |
| 36 | 00110110 | 6 |
| 37 | 00110111 | 7 |
| 38 | 00111000 | 8 |
| 39 | 00111001 | 9 |
| 3А | 00111010 | : |
| 3Б | 00111011 | ; |
| 3С | 00111100 | < |
| 3D | 00111101 | = |
| 3Е | 00111110 | > |
| 3F | 00111111 | ? |
| 40 | 01000000 | @ |
| 41 | 01000001 | А |
| 42 | 01000010 | Б |
| 43 | 01000011 | С |
| 44 | 01000100 | Д |
| 45 | 01000101 | Е |
| 46 | 01000110 | Ф |
| 47 | 01000111 | Г |
| 48 | 01001000 | Х |
| 49 | 01001001 | я |
| 4А | 01001010 | Дж |
| 4Б | 01001011 | К |
| 4С | 01001100 | л |
| 4D | 01001101 | М |
| 4Е | 01001110 | Н |
| 4F | 01001111 | О |
| 50 | 01010000 | Р |
| 51 | 01010001 | В |
| 52 | 01010010 | Р |
| 53 | 01010011 | С |
| 54 | 01010100 | Т |
| 55 | 01010101 | У |
| 56 | 01010110 | В |
| 57 | 01010111 | Вт |
| 58 | 01011000 | х |
| 59 | 01011001 | Д |
| 5F | 01011111 | _ |
| 60 | 01100000 | ` |
| 61 | 01100001 | и |
| 62 | 01100010 | б |
| 63 | 01100011 | в |
| 64 | 01100100 | д |
| 65 | 01100101 | и |
| 66 | 01100110 | ф |
| 67 | 01100111 | г |
| 68 | 01101000 | ч |
| 69 | 01101001 | и |
| 6А | 01101010 | и |
| 6Б | 01101011 | к |
| 6С | 01101100 | л |
| 6Д | 01101101 | м |
| 6Е | 01101110 | п |
| 6F | 01101111 | или |
| 70 | 01110000 | р |
| 71 | 01110001 | к |
| 72 | 01110010 | р |
| 73 | 01110011 | с |
| 74 | 01110100 | т |
| 75 | 01110101 | и |
| 76 | 01110110 | против |
| 77 | 01110111 | с |
| 78 | 01111000 | х |
| 79 | 01111001 | г |
| 7А | 01111010 | г |
| 7Б | 01111011 | { |
| 7С | 01111100 | | |
| 7Д | 01111101 | } |
| 7Е | 01111110 | ~ |
| 7F | 01111111 | ДЕЛ |
См.
также- Преобразователь ASCII в двоичный код
- Преобразователь ASCII в шестнадцатеричный код
- Преобразователь двоичного кода в ASCII
- ASCII, шестнадцатеричный, двоичный, десятичный, преобразователь Base64
- Шестнадцатеричный/десятичный/восьмеричный/двоичный преобразователь
- Декодер Base64
- Кодер Base64
- Таблица ASCII
- символов Юникода
CHCP — Изменить кодовую страницу — Windows CMD
CHCP — Изменить кодовую страницу — Windows CMD — SS64.com- SS64
- CMD
- Практическое руководство
Изменить кодовую страницу активной консоли. Кодовая страница по умолчанию определяется языковым стандартом Windows.
Синтаксис
CHCP кодовая_страница
Ключ
code_page Номер кодовой страницы (например, 437) Эта команда редко требуется, так как большинство программ с графическим интерфейсом и PowerShell теперь поддерживают Unicode. При работе с символами за пределами диапазона ASCII от 0 до 127, например, с некоторыми символами коробки, выбор кодовой страницы будет определять набор отображаемых символов.
Программы, запускаемые после назначения новой кодовой страницы, будут использовать новую кодовую страницу, однако программы (кроме Cmd.exe), запущенные до назначения новой кодовой страницы, будут использовать исходную кодовую страницу.
| Кодовая страница | Страна/регион/язык | |
|---|---|---|
| 437 | США | кодовая страница по умолчанию в США |
| 850 | Многоязычный (латиница I) | кодовая страница по умолчанию в большинстве стран Европы |
| 852 | Славянский (латиница II) | |
| 855 | Кириллица (русская) | |
| 857 | Турецкий | |
| 860 | Португальский | |
| 861 | Исландский | |
| 863 | Канадско-французский | |
| 865 | Северный | |
| 866 | Русский | |
| 869 | Новогреческий | |
| 1252 | Западноевропейская латынь | |
| 65000 | UTF-7 * | |
| 65001 | UTF-8 * |
* Кодовые страницы 65000/1 закодированы как UTF-7/8, что позволяет работать с данными Unicode в 7-битных и 8-битных средах, однако
Даже если вы используете CHCP для запуска консоли Windows с кодовой страницей Unicode, многие приложения будут считать, что значение по умолчанию все еще применяется, например. Для Java требуется параметр-Dfile: java -Dfile.encoding=UTF-8
символов Unicode будут отображаться только в том случае, если текущий шрифт консоли содержит эти символы. Поэтому используйте шрифт TrueType, например Lucida Console, вместо растрового шрифта CMD по умолчанию.
Оболочка CMD (работает внутри консоли Windows)
CMD.exe поддерживает только две кодировки символов Ascii и Unicode (CMD/A и CMD/U)
Если вам нужна полная поддержка Unicode, используйте PowerShell. По-прежнему существует ОЧЕНЬ ограниченная поддержка юникода в оболочке CMD, конвейерная обработка, перенаправление и большинство команд по-прежнему поддерживают только ANSI. Работают только команды DIR, FOR/F и TYPE, они позволяют читать и записывать (UTF-16LE/BOM) файлы и имена файлов, но не более того.
Кодовые страницы
Количество поддерживаемых кодовых страниц было значительно увеличено в Windows 7.
Чтобы получить полный список кодовых страниц, поддерживаемых на вашем компьютере, запустите NLSINFO (Инструменты Resource Kit).Файлы, сохраненные в Блокноте Windows, по умолчанию будут в формате ANSI, но также могут быть сохранены как Unicode UTF-16LE или UTF-8, а для файлов Unicode будут содержать спецификацию.
Спецификация сделает пакетный файл неисполняемым в Windows, поэтому пакетные файлы должны быть сохранены как ANSI, а не Unicode.
Примеры:
Просмотр текущей кодовой страницы:
ЧКП
Измените кодовую страницу на Unicode/65001:
ЧКП 65001
«Помните, что нет кода быстрее, чем отсутствие кода» ~ Руководство Taligent по разработке программ
Связанные команды:
[Недокументированное] CHCP — Форум.
Транскодирование в ANSI с помощью CHCP — Форум.
Полный список идентификаторов кодовых страниц — docs.microsoft.com
Коды локали Windows.
ТИП — может печатать файлы UTF-16LE со спецификацией вне зависимости от текущей кодовой страницы.
Что должен знать каждый разработчик программного обеспечения о Unicode и наборах символов ~ Джоэл Спольски.
Эквивалент PowerShell: [Console]::OutputEncoding, весь вводимый текст автоматически преобразуется в Unicode.
Эквивалентная команда bash (Linux): LANG — переменная среды категории локали и переменные LC_* для категории локали.
Copyright © 1999-2022 SS64.com
Some rights reserved
Transliterating non-ASCII characters with Python
| 25
The Cyrillic Charset Soup -- (c) Roman Czyborra
Cyrillic Charset Soup -- (c) Роман Чиборра Несмотря на то, что ISO 8859 содержит стандартную кириллицу, существует множество других кириллических кодировок, используемых на компьютерах по всему миру. Эта страница пытается объяснить, почему это так, давая исторический обзор. Каждый набор символов иллюстрируется растровым изображением в формате GIF вместе с лежащей в его основе таблицей отображения Unicode и шрифтом BDF (X/Unix).
Кириллица
Братья и православные монахи-славяне Кирилл и Мефодий изобрели глаголицу в Македонии в 863 году как зашифрованный греческий алфавит с расширениями для особых славянских звуков. Их ученый Климент Охридский позже изобрел «кириллицу» как более удобочитаемую преобразованную глаголицу. На протяжении веков кириллица распространялась и трансформировалась, модернизировавшись в нынешнюю романизированную форму (Гражданку) при царе Петре Великом.
В настоящее время кириллица используется более чем в 70 языках, от восточноевропейских славянских языков русского (ru), украинского (uk), белорусского (be), болгарского (bg), сербского (sr) и македонского (mk) до центральноевропейского Алтайские языки Азии, такие как азербайджанский (az), туркменский (tk), курдский (ku), узбекский (uz), казахский (kk), киргизский (ky) и другие, такие как таджикский (tg) и монгольский (mn). В Вашей библиотеке может быть брошюра Кенесбая Мусаевича Мусаева "Алфавиты языков народов СССР", изданная в 1965.
Благодаря маленькому алфавиту без акцента русский и болгарский языки казались столь же подходящими для компьютерной обработки, как и английский.
ГОСТ-13052
Первый КОИ
Самая старая стандартизированная кириллическая компьютерная кодировка, которую я нашел (в Language Automation Worldwide Джона Кльюса), — это государственный стандарт ГОСТ 13052, 7-битная кодировка, которая кодирует буквы русского алфавита (что также удовлетворяет всем болгарским потребностям) поверх соответствующих Буквы ASCII противоположного регистра (для распознавания русского текста типа "РУССКИЙ ТЕКСТ" по его регистру при представлении в ASCII. Я буду называть это свойство соответствием KOI), пожертвовали точкой л, чтобы сократить алфавит до 32 букв, умещающихся в два строки и удалил редко необходимый ЗАГЛАВНЫЙ ЖЕСТКИЙ ЗНАК, чтобы предотвратить его столкновение с DELETE в позиции =7F или EOF=-1:
charset=koi-0 [TXT] [BDF]
Тот факт, что болгарский язык использует ЗАГЛАВНУЮ ТВЕРДЫЙ ЗНАК гораздо чаще, побудил некоторых болгар вместо этого кодировать свой твердый знак поверх ненужного русского YERY bI.
ГОСТ-19768-74
КОИ-7 и КОИ-8
В 1974 году ГОСТ опубликовал еще один государственный стандарт ГОСТ 19768-74 с двумя наборами символов, которые смешивали латинский и кириллический алфавиты в одном наборе, что сохранило исходную идею соответствия KOI:
Первым был еще один 7-битный набор символов с именем KOI-7 только с заглавными буквами:
charset=koi-7 [TXT] [BDF]
Оригинальный KOI-8
Вторым набором символов, определенным в ГОСТ 19768-74, был знаменитый 8-битный Код для Обмена и Обработки Информации (КОИ-8), который давал расшифровываемый текст ASCII при удалении старшего бита и по праву может называться кириллическим ASCII. Вот изображение его верхней части (G1):
charset=koi8-a [TXT] [BDF]
КОИ-8 с л
KOI-8 использовался на многих сетевых хостах Unix. Естественно, знак доллара ASCII $ стал использоваться вместо знака международной валюты ¤, хотя это было неполиткорректно. И пунктирное л (йо) было добавлено в колонке 3, так что такие слова, как ел (йео), больше не нужно было писать как ee без ударения.
Вернее, последний шаг не был сделан до тех пор, пока компания Demos не начала портировать поддержку кириллицы на Unix-системы для ПК, такие как Xenix, в конце 1980-х и разработала новую русскую кодовую страницу KOI-8, которая позже стала известна как KOI8-R с пунктирный л на своем месте от первого ДИС-6937-8/DIS-8859-5 и все нерусские буквы вычищены и заменены блочной графикой.
Но многие поставщики шрифтов реализовали только подмножество букв. Назовем его КОИ8-Б, это расширенная (большая) база КОИ-8, содержащая буквы (буквы), общие (баса) для всех современных вариантов КОИ-8:
кодировка = koi8-b [TXT] [BDF]
KOI-8 становится европейским
ISO-IR-111 или ECMA-кириллица
В середине 1980-х комитет ECMA, разрабатывавший стандарт ISO-8859Серия и ее кириллица ISO-8859-5 хотели сохранить совместимость с установленной базой десятилетнего стандарта КОИ-8 и изящно добавили недостающие украинские, белорусские, сербские и македонские буквы в неиспользуемые кодовые точки. Их проект был опубликован как стандарт ECMA-113 1-го издания в 1986 году и проект международного стандарта DIS-8859-5 в 1987 году и был зарегистрирован под номером 111 в Международном реестре наборов символов ISO для использования с управляющими последовательностями (ISO-2022). отсюда и название ISO-IR-111 и никнейм ECMA-Cyrillic:
charset=koi8-e [TXT] [BDF]
ГОСТ-19768-87
Все изменено
ISO-IR-111 так и не был принят в качестве окончательного ISO-8859-5, потому что тем временем ГОСТ вдохнул некоторую перестройку и объявил установленную базу и соответствие KOI менее важными и пересмотрел свой стандарт 19768 с 1974 в 1987 году в несовместимый новый ГОСТ 19768. -87, который переместил русские буквы на одну строку вверх и упорядочил их в порядке соответствия родного русского языка (АБВГД) вместо порядка соответствия КОИ (АБВДЭ):
кодировка=ГОСТ-19768-87 [TXT] [BDF]
ISO-8859-5 Кириллица
ECMA немедленно последовала за шагом ГОСТа по совету своих экспертов из Советского Союза, пересмотрев свое первое предложение и заменив свои символы ISO-IR-111 на кодовые позиции нового ГОСТ 19768-87. Разработчики не стали сортировать нерусские буквы в русский алфавит, чтобы обеспечить правильный словарный порядок для всех языков, как, например, в стандарте ISO 9 (Транслитерация кириллицы). Пересмотренное предложение было опубликовано как 2-е издание ECMA-113:19.88 (заменив исходный ECMA-113:1986, который стал жить дальше (популярен благодаря сочетанию нерусских букв с совместимостью с KOI-8) под псевдонимом ECMA-Cyrillic (хотя ECMA отсылает вас к ISO-8859-5 теперь ) или ISO-IR-111) и принят в ISO 8859 (несмотря на то, что Советский Союз проголосовал против знака доллара) как окончательный ISO-8859-5 (ISO-IR-144) в 1988 году. Многие люди, включая меня, считают, что это избавило бы нас от многих проблем, если бы исходный KOI8-совместимый DIS-8859-5:1987 также был выбран ISO-8859.-5:1988. Теперь у нас есть международный стандарт ISO-8859-5, который настолько нестандартен, что его почти никто не любит и не использует:
кодировка = ISO-8859-5 [TXT] [BDF]
Релком KOI8-R
После того, как в RFC 1341 (MIME) было предложено использовать кириллицу ISO-8859-5 в электронной почте, в то время как русский раздел Интернета (группы новостей relcom. *) все еще использовал KOI-8, Андрей Чернов отправился публиковать свой RFC 1489 Регистрация набора кириллических символов «KOI8-R» и установил KOI8-R в качестве стандарта де-факто в Интернете. KOI8-R, который позже был также пронумерован CP878, содержит пунктирный KOI8 плюс множество символов рисования прямоугольника:
кодировка = koi8-r [TXT] [BDF]
Андрей Чернов предлагает много практической информации о KOI8-R на своем сайте.
Украинский КОИ8-У
При всех этих кодировках есть особая украинская проблема. Украинцы читают букву GHE со штрихом вниз как хе. Для правильного написания гхе нужна украинская буква ГЕ С ВВЕРХОМ, которая была запрещена сталинскими чиновниками и восстановлена в 1990 году.
Можно злоупотреблять GHE с акцентом (македонский GJE) в ISO-IR-111 или ISO-8859.-5 для представления GHE WITH UPTURN, но это не кажется предпочтительным вариантом. Украинцы, похоже, предпочитают кодировки, включающие настоящий GHE WITH UPTURN. GHE WITH UPTURN присутствует в CP1251 от Microsoft, KOI8-Unified от Fingertip и, конечно же, в Unicode. Тем не менее, эти варианты не казались достаточно близкими к KOI8-R, чтобы помешать украинским почтмейстерам разработать новый KOI8-U и опубликовать его как RFC2319 в апреле 1998 года. KOI8-U добавил только украинские буквы в позиции, совместимые с ISO-IR. -111 используется многими украинцами и сохранил как можно больше символов для рисования, потому что многие пользователи в этом районе все еще привязаны к MS-DOS. Из-за этого предпочтения в нем отсутствует короткое U с белорусским акцентом, а также сербская и македонская поддержка:
кодировка = koi8-u [TXT] [BDF]
Я предполагаю, что спецификация RFC2319 и RFC1489 для пули KOI8-R как математическая U+2219 BULLET OPERATOR является ошибкой, унаследованной от RFC1345, и должна быть исправлена до U+2022 BULLET, как в собственных таблицах Келда Симонсена для IBM437 или KOI8-R. Вообще обратите внимание, что RFC1345 и все, что основано на нем, например GNU recode 3. 4.1, содержало ряд ошибок, особенно в области кириллицы: его isoir111 больше похож на cp1251, чем на koi8. RFC2319 содержит дополнительную ошибку, заключающуюся в том, что он кодирует CYRILLIC CAPITAL LETTER UKRAINIAN IE как U+0403 вместо U+0404.
КОИ8-унифицированный
Питер Кассетта из Fingertip Software, который также опубликовал хороший справочник кириллической кодировки для своих клиентов, уже разработал и предложил другое решение: его KOI8-Unified объединяет все буквы ISO-IR-111 с украинскими буквами KOI8-U и базовым KOI8. -R блокировать графику и некоторые популярные символы из кодовых страниц Windows 1251 и 1252, уравновешивая различные потребности совместимости:
кодировка = koi8-f [TXT] [BDF]
Вы можете использовать этот шрифт koi8-f для отображения всего текста koi8-*, и все буквы будут отображаться правильно, но некоторые менее используемые графические символы в koi8-r могут отображаться неправильно.
Microsoft CP1251
Другим важным игроком на этом поле является кодовая страница Microsoft WinCyrillic Windows CP1251, для которой Microsoft зарегистрировала метку «utf-8», которую не следует ошибочно принимать за предшественницу 13-го века сегодняшней Windows95 ® . По состоянию на декабрь 1997 года даже новый веб-сервер ГОСТа (Lotus Notes) приветствует вас с помощью charset=utf-8 - ГОСТ (Российский орган по стандартизации и орган-член ISO) больше не следует своим собственным стандартам! CP1251 имеет богатый репертуар в порядке, несовместимом ни с ISO-IR-111 (KOI8), ни с ISO-8859.-5:
кодировка=utf-8 [TXT] [BDF]
МакУкраинский
MacУкраинский (= MacCyrillic + GHE С ВВЕРХОМ) имеет те же буквы, но в другом порядке:
charset=MacУкраинский [TXT] [BDF]
Альтернативный вариант
Более старая популярная кодировка — вариант Альтернативный, поддерживаемый MS-DOS CP866:
кодировка = cp866 [TXT] [BDF]
Болгарский МИК
Болгарский ПК Prawec 16 и болгарская карта клавиатуры в Linux используют кодировку MIK:
charset=болгарский-мик [TXT] [BDF]
Юникод
Вам надоело это изобилие кодировок, среди которых нет лучших? Хотели бы вы иметь одну хорошую кодировку, которая способна заменить все вышеперечисленное и будет принята везде? Хотели бы вы также писать на неславянских кириллических языках? Вы получаете все это и многое другое с Unicode (ISO-10646), который просто кодирует все символы мира.
Это блок кириллицы U+0400 в Unicode. Это соответствует порядку ISO-8859-5:
кодировка = unicode-2-1 [TXT] [BDF]
Ольга Лапко утверждает на страницах 175 и 179 блестящего выпуска 17-2 TUG boat (Материалы ежегодной встречи группы пользователей TeX 1996 года в Дубне, Россия), что около 100 кириллических букв все еще отсутствуют в Unicode. Большинство из них, по-видимому, кодируются с комбинацией акцентов, а остальные могут быть добавлены с помощью процедуры, описанной в Приложении B. Отправка новых символов стандарта Unicode.
Каждая кириллическая буква кодируется двумя байтами в utf-8. Стандартная схема сжатия для Unicode (SCSU) позволяет уменьшить это до традиционного одного байта на букву.
Я все еще занят написанием своего Unicode-HOWTO для Linux. Я добавил кириллическую раскладку клавиатуры, которая злоупотребляет транслитерацией ISO 9 в качестве метода ввода в текстовый редактор Yudit Unicode для системы X Window.
Я рекомендую вам отправлять свои комментарии по адресу [email protected]. Я благодарю Кристофера Неханива, Андреаса Прилопа, Питера Кассетту <[email protected]>, Андрея Чернова, Келда Симонсена, Борислава Стоянова, Гюнчо Скордева, Илью Винарского, Диму Володина, Кристиана Вайсгербера, Алена Кесси и Юрия Демченко за ценную информацию, которую они предоставили. .
________
Роман Чиборра
URL: http://czyborra.com/
Электронная почта: [email protected]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||