Что такое реляционная база данных?

Что такое реляционная база данных?
Реляционная база данных — это связанная информация, представленная в виде двумерных таблиц. Представьте себе адресную книгу. Она содержит множество строк, каждая из которых соответствует данному индивидууму. Для каждого из них в ней представлены некоторые независимые данные, например, имя, номер телефона, адрес. Представим такую адресную книгу в виде таблицы, содержащей строки и столбцы. Каждая строка (называемая также записью) соответствует определенному индивидууму, каждый столбец содержит значения соответствующего типа данных: имя, номер телефона и адрес, представленных в каждой строке. Адресная книга может выглядеть таким образом:

То, что мы получили, является основой реляционной базы данных, определенной в начале нашего обсуждения двумерной (строки и столбцы) таблицей информации. Однако, реляционная база данных редко состоит из одной таблицы, которая слишком мала по сравнению с базой данных. При создании нескольких таблиц со связанной информацией можно выполнять более сложные и мощные операции над данными. Мощность базы данных заключается, скорее, в связях, которые вы конструируете между частями информации, чем в самих этих частях.
Установление связи между таблицами
Давайте используем пример адресной книги для того, чтобы обсудить базу данных, которую можно реально использовать в деловой жизни. Предположим, что индивидуумы первой таблицы являются пациентами больницы. Дополнительную информацию о них можно хранить в другой таблице. Столбцы второй таблицы могут быть поименованы таким образом: Patient (Пациент), Doctor (Врач), Insurer (Страховка), Balance (Баланс).

Можно выполнить множество мощных функций при извлечении информации из этих таблиц в соответствии с заданными критериями, особенно, если критерий включает связанные части информации из различных таблиц.
Предположим, Dr.Halben желает получить номера телефонов всех своих Пациентов. Для того чтобы извлечь эту информацию, он должен связать таблицу с номерами телефонов пациентов (адресную книгу) с таблицей, определяющей его пациентов. В данном простом примере он может мысленно проделать эту операцию и узнать телефонные номера своих пациентов Grillet и Brock, в действительности же эти таблицы вполне могут быть больше и намного сложнее.
Программы, обрабатывающие реляционные базы данных, были созданы для работы с большими и сложными наборами тех данных, которые являются наиболее общими в деловой жизни общества. Даже если база данных больницы содержит десятки или тысячи имен (как это, вероятно, и бывает в реальной жизни), единственная команда SQL предоставит доктору Halben необходимую информацию практически мгновенно.
Порядок строк произволен
Для обеспечения максимальной гибкости при работе с данными строки таблицы, по определению, никак не упорядочены. Этот аспект отличает базу данных от адресной книги. Строки в адресной книге обычно упорядочены по алфавиту. Одно из мощных средств, предоставляемых реляционными системами баз данных, состоит в том, что пользователи могут упорядочивать информацию по своему желанию.
Рассмотрим вторую таблицу. Содержащуюся в ней информацию иногда удобно рассматривать упорядоченной по имени, иногда — в порядке возрастания или убывания баланса (Balance), а иногда — сгруппированной по доктору. Внушительное множество возможных порядков строк помешало бы пользователю проявить гибкость в работе с данными, поэтому строки предполагаются неупорядоченными. Именно по этой причине вы не можете просто сказать: «Меня интересует пятая строка таблицы». Независимо от порядка включения данных или какого-либо другого критерия, этой пятой строки не существует по определению. Итак, строки таблицы предполагаются расположенными в произвольном порядке.
Идентификация строк (первичный ключ)
По этой и ряду других причин, необходимо иметь столбец таблицы, который однозначно идентифицирует каждую строку. Обычно этот столбец содержит номер, например, приписанный каждому пациенту. Конечно, можно использовать для идентификации строк имя пациента, но ведь может случиться так, что имеется несколько пациентов с именем Mary Smith. В подобном случае нет простого способа их различить. Именно по этой причине обычно используются номера. Такой уникальный столбец (или их группа), используемый для идентификации каждой строки и обеспечивающий различимость всех строк, называется первичным ключом таблицы (primary key of the table).
Первичный ключ таблицы — жизненно важное понятие структуры базы данных. Он является сердцем системы данных: для того чтобы найти определенную строку в таблице, укажите значение ее первичного ключа. Кроме того, он обеспечивает целостность данных. Если первичный ключ должным образом используется и поддерживается, вы будете твердо уверены в том, что ни одна строка таблицы не является пустой и что каждая из них отлична от остальных.
Столбцы поименованы и пронумерованы
В отличие от строк, столбцы таблицы (также называемые полями (fields) упорядочены и поименованы. Следовательно, в нашей таблице, соответствующей адресной книге, можно сослаться на столбец «Address» как на «столбец номер три». Естественно, это означает, что каждый столбец данной таблицы должен иметь имя, отличное от других имен, для того, чтобы не возникло путаницы. Лучше всего, когда имена определяют содержимое поля. В этой книге мы будем использовать аббревиатуру для именования столбцов в простых таблицах, например: cname — для имени покупателя (customer name), odate — для даты поступления (order date). Предположим также, что таблица содержит единственный цифровой столбец, используемый как первичный ключ.
Пример базы данных
Таблицы 1.1, 1. 2, 1.3 образуют реляционную базу данных, которая достаточно мала для того, чтобы можно было понять ее смысл, но и достаточно сложна для того, чтобы иллюстрировать на ее примере важные понятия и практические выводы, связанные с применением SQL.
Можно заметить, что первый столбец в каждой таблице содержит номера, не повторяющиеся от строки к строке в пределах таблицы. Как вы, наверное, догадались, это первичные ключи таблицы. Некоторые из этих номеров появляются также в столбцах других таблиц (в этом нет ничего предосудительного), что указывает на связь между строками, использующими конкретное значение первичного ключа, и той строкой, в которой это значение применяется непосредственно в первичном ключе.
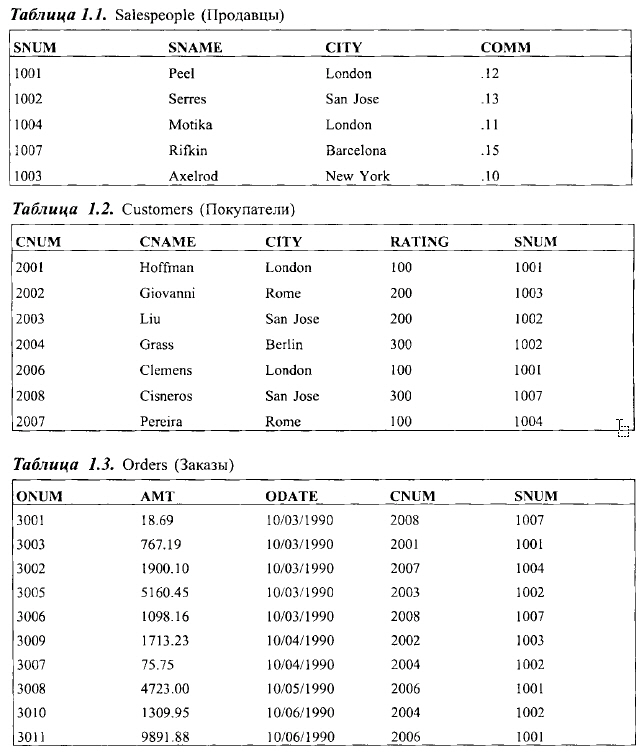
Например, поле snum в таблице Customers определяет, каким продавцом (salespeople) обслуживается конкретный покупатель (customer). Номер поля snum устанавливает связь с таблицей Salespeople, которая дает информацию об этом продавце (salespeople). Очевидно, что продавец, который обслуживает данного покупателя, существует, т.е. значение поля snum в таблице Customers присутствует также и в таблице Salespeople. В этом случае мы говорим, что система находится в состоянии ссылочной целостности (referential integrity).
Сами по себе таблицы предназначены для описания реальных ситуаций в деловой жизни, когда можно использовать SQL для ведения дел, связанных с продавцами, их покупателями и заказами. Давайте зафиксируем состояние этих трех таблиц в какой-либо момент времени и уточним назначение каждого из полей таблицы.
Перед вами объяснение столбцов таблицы 1.1:
| Поле | Содержимое |
| snum | Уникальный номер, приписанный каждому продавцу («номер служащего») |
| sname | Имя продавца |
| city | Место расположения продавца |
| comm | Вознаграждение (комиссионные) продавца в форме с десятичной точкой |
Таблица 1.2 содержит следующие столбцы:
| Поле | |
| cnum | Уникальный номер, присвоенный покупателю |
| cname | Имя покупател |
| city | Место расположения покупателя |
| rating | Цифровой код, определяющий уровень предпочтения данного покупателя. Чем больше число, тем больше предпочтение |
| snum | Номер продавца, назначенного данному покупателю (из таблицы Salesperson) |
И, наконец, столбцы таблицы 1.3:
| Поле | Содержимое |
| onum | Уникальный номер, присвоенный данной покупке |
| amt | Количество |
| odate | Дата покупки |
| cnum | Номер покупателя, сделавшего покупку (из таблицы Customers) |
| snum | Номер продавца, обслужившего покупателя (из таблицы Salespeople) |
Источник: SQL для простых смертных / Мартинн Грабер
С уважением, Артём Санников
Сайт: ArtemSannikov.ru
Теги: MySQL, База данных.
Реляционные базы данных обречены? / Хабр
Примечание переводчика: хоть статья довольно старая (опубликована 2 года назад) и носит громкое название, в ней все же дается хорошее представление о различиях реляционных БД и NoSQL БД, их преимуществах и недостатках, а также приводится краткий обзор нереляционных хранилищ.
В последнее время появилось много нереляционных баз данных. Это говорит о том, что если вам нужна практически неограниченная масштабируемость по требованию, вам нужна нереляционная БД.
Если это правда, значит ли это, что могучие реляционные БД стали уязвимы? Значит ли это, что дни реляционных БД проходят и скоро совсем пройдут? В этой статье мы рассмотрим популярное течение нереляционных баз данных применительно к различным ситуациям и посмотрим, повлияет ли это на будущее реляционных БД.
Реляционные базы данных существуют уже около 30 лет. За это время вспыхивало несколько революций, которые должны были положить конец реляционным хранилищам. Конечно, ни одна из этих революций не состоялась, и одна из них ни на йоту не поколебала позиции реляционных БД.
Начнем с основ
Реляционная база данных представляет собой набор таблиц (сущностей). Таблицы состоят из колонок и строк (кортежей). Внутри таблиц могут быть определены ограничения, между таблицами существуют отношения. При помощи SQL можно выполнять запросы, которые возвращают наборы данных, получаемых из одной или нескольких таблиц. В рамках одного запроса данные получаются из нескольких таблиц путем их соединения (JOIN), чаще всего для соединения используются те же колонки, которые определяют отношения между таблицами. Нормализация — это процесс структурирования модели данных, обеспечивающий связность и отсутствие избыточности в данных.
Доступ к реляционным базам данных осуществляется через реляционные системы управления базами данных (РСУБД). Почти все системы баз данных, которые мы используем, являются реляционными, такие как Oracle, SQL Server, MySQL, Sybase, DB2, TeraData и так далее.
Причины такого доминирования неочевидны. На протяжении всего существования реляционных БД они постоянно предлагали наилучшую смесь простоты, устойчивости, гибкости, производительности, масштабируемости и совместимости в сфере управлении данными.
Однако чтобы обеспечить все эти особенности, реляционные хранилища невероятно сложны внутри. Например, простой SELECT запрос может иметь сотни потенциальных путей выполнения, которые оптимизатор оценит непосредственно во время выполнения запроса. Все это скрыто от пользователей, однако внутри РСУБД создает план выполнения, основывающийся на вещах вроде алгоритмов оценки стоимости и наилучшим образом отвечающий запросу.
Проблемы реляционных БД
Хотя реляционные хранилища и обеспечивают наилучшую смесь простоты, устойчивости, гибкости, производительности, масштабируемости и совместимости, их показатели по каждому из этих пунктов не обязательно выше, чем у аналогичных систем, ориентированных на какую-то одну особенность. Это не являлось большой проблемой, поскольку всеобщее доминирование реляционных СУБД перевешивало какие-либо недочеты. Тем не менее, если обычные РБД не отвечали потребностям, всегда существовали альтернативы.
Сегодня ситуация немного другая. Разнообразие приложений растет, а с ним растет и важность перечисленных особенностей. И с ростом количества баз данных, одна особенность начинает затмевать все другие. Это масштабируемость. Поскольку все больше приложений работают в условиях высокой нагрузки, например, таких как веб-сервисы, их требования к масштабируемости могут очень быстро меняться и сильно расти. Первую проблему может быть очень сложно разрешить, если у вас есть реляционная БД, расположенная на собственном сервере. Предположим, нагрузка на сервер за ночь увеличилась втрое. Как быстро вы сможете проапгрейдить железо? Решение второй проблемы также вызывает трудности в случае использования реляционных БД.
Реляционные БД хорошо масштабируются только в том случае, если располагаются на единственном сервере. Когда ресурсы этого сервера закончатся, вам необходимо будет добавить больше машин и распределить нагрузку между ними. И вот тут сложность реляционных БД начинает играть против масштабируемости. Если вы попробуете увеличить количество серверов не до нескольких штук, а до сотни или тысячи, сложность возрастет на порядок, и характеристики, которые делают реляционные БД такими привлекательными, стремительно снижают к нулю шансы использовать их в качестве платформы для больших распределенных систем.
Чтобы оставаться конкурентоспособными, вендорам облачных сервисов приходится как-то бороться с этим ограничением, потому что какая ж это облачная платформа без масштабируемого хранилища данных. Поэтому у вендоров остается только один вариант, если они хотят предоставлять пользователям масштабируемое место для хранения данных. Нужно применять другие типы баз данных, которые обладают более высокой способностью к масштабированию, пусть и ценой других возможностей, доступных в реляционных БД.
Эти преимущества, а также существующий спрос на них, привел к волне новых систем управления базами данных.
Новая волна
Такой тип баз данных принято называть хранилище типа ключ-значение (key-value store). Фактически, никакого официального названия не существует, поэтому вы можете встретить его в контексте документо-ориентированных, атрибутно-ориентированных, распределенных баз данных (хотя они также могут быть реляционными), шардированных упорядоченных массивов (sharded sorted arrays), распределенных хэш-таблиц и хранилищ типа ключ-значения. И хотя каждое из этих названий указывает на конкретные особенности системы, все они являются вариациями на тему, которую мы будем назвать хранилище типа ключ-значение.
Впрочем, как бы вы его не называли, этот «новый» тип баз данных не такой уж новый и всегда применялся в основном для приложений, для которых использование реляционных БД было бы непригодно. Однако без потребности веба и «облака» в масштабируемости, эти системы оставались не сильно востребованными. Теперь же задача состоит в том, чтобы определить, какой тип хранилища больше подходит для конкретной системы.
Реляционные БД и хранилища типа ключ-значение отличаются коренным образом и предназначены для решения разных задач. Сравнение характеристик позволит всего лишь понять разницу между ними, однако начнем с этого:
Характеристики хранилищ
| Реляционная БД | Хранилище типа ключ-значение |
|---|---|
| База данных состоит из таблиц, таблицы содержат колонки и строки, а строки состоят из значений колонок. Все строки одной таблицы имеют единую структуру. |
Для доменов можно провести аналогию с таблицами, однако в отличие от таблиц для доменов не определяется структура данных. Домен – это такая коробка, в которую вы можете складывать все что угодно. Записи внутри одного домена могут иметь разную структуру. |
| Модель данных1 определена заранее. Является строго типизированной, содержит ограничения и отношения для обеспечения целостности данных. |
Записи идентифицируются по ключу, при этом каждая запись имеет динамический набор атрибутов, связанных с ней. |
| Модель данных основана на естественном представлении содержащихся данных, а не на функциональности приложения. |
В некоторых реализация атрибуты могут быть только строковыми. В других реализациях атрибуты имеют простые типы данных, которые отражают типы, использующиеся в программировании: целые числа, массива строк и списки. |
| Модель данных подвергается нормализации, чтобы избежать дублирования данных. Нормализация порождает отношения между таблицами. Отношения связывают данные разных таблиц. |
Между доменами, также как и внутри одного домена, отношения явно не определены. |
Никаких join’ов
Хранилища типа ключ-значение ориентированы на работу с записями. Это значит, что вся информация, относящаяся к данной записи, хранится вместе с ней. Домен (о котором вы можете думать как о таблице) может содержать бессчетное количество различных записей. Например, домен может содержать информацию о клиентах и о заказах. Это означает, что данные, как правило, дублируются между разными доменами. Это приемлемый подход, поскольку дисковое пространство дешево. Главное, что он позволяет все связанные данные хранить в одном месте, что улучшает масштабируемость, поскольку исчезает необходимость соединять данные из различных таблиц. При использовании реляционной БД, потребовалось бы использовать соединения, чтобы сгруппировать в одном месте нужную информацию.
Хотя для хранения пар ключ-значение потребность в отношения резко падает, отношения все же нужны. Такие отношения обычно существуют между основными сущностями. Например, система заказов имела бы записи, которые содержат данные о покупателях, товарах и заказах. При этом неважно, находятся ли эти данные в одном домене или в нескольких. Суть в том, что когда покупатель размещает заказ, вам скорее всего не захочется хранить информацию о покупателе и о заказе в одной записи.
Вместо этого, запись о заказе должна содержать ключи, которые указывают на соответствующие записи о покупателе и товаре. Поскольку в записях можно хранить любую информацию, а отношения не определены в самой модели данных, система управления базой данных не сможет проконтролировать целостность отношений. Это значит, что вы можете удалять покупателей и товары, которые они заказывали. Обеспечение целостности данных целиком ложится на приложение.
Доступ к данным
| Реляционная БД | Хранилище типа ключ-значение |
|---|---|
| Данные создаются, обновляются, удаляются и запрашиваются с использованием языка структурированных запросов (SQL). |
Данные создаются, обновляются, удаляются и запрашиваются с использованием вызова API методов. |
| SQL-запросы могут извлекать данные как из одиночной таблица, так и из нескольких таблиц, используя при этом соединения (join’ы). |
Некоторые реализации предоставляют SQL-подобный синтаксис для задания условий фильтрации. |
| SQL-запросы могут включать агрегации и сложные фильтры. |
Зачастую можно использовать только базовые операторы сравнений (=, !=, <, >, <= и =>). |
| Реляционная БД обычно содержит встроенную логику, такую как триггеры, хранимые процедуры и функции. |
Вся бизнес-логика и логика для поддержки целостности данных содержится в коде приложений. |
Взаимодействие с приложениями
| Реляционная БД | Хранилище типа ключ-значение |
|---|---|
| Чаще всего используются собственные API, или обобщенные, такие как OLE DB или ODBC. |
Чаще всего используются SOAP и/или REST API, с помощью которых осуществляется доступ к данным. |
| Данные хранятся в формате, который отображает их натуральную структуру, поэтому необходим маппинг структур приложения и реляционных структур базы. |
Данные могут более эффективно отображаться в структуры приложения, нужен только код для записи данных в объекты. |
Хранилища типа ключ-значение: преимущества
Есть два четких преимущества таких систем перед реляционными хранилищами.
Подходят для облачных сервисов
Первое преимущество хранилищ типа ключ-значение состоит в том, что они проще, а значит обладают большей масштабируемостью, чем реляционные БД. Если вы размещаете вместе собственную систему, и планируете разместить дюжину или сотню серверов, которым потребуется справляться с возрастающей нагрузкой, за вашим хранилищем данных, тогда ваш выбор – хранилища типа ключ-значение.
Благодаря тому, что такие хранилища легко и динамически расширяются, они также пригодятся вендорам, которые предоставляют многопользовательскую веб-платформу хранения данных. Такая база представляет относительно дешевое средство хранения данных с большим потенциалом к масштабируемости. Пользователи обычно платят только за то, что они используют, однако их потребности могут вырасти. Вендор сможет динамически и практически без ограничений увеличить размер платформы, исходя из нагрузки.
Более естественная интеграция с кодом
Реляционная модель данных и объектная модель кода обычно строятся по-разному, что ведет к некоторой несовместимости. Разработчики решают эту проблему при помощи написания кода, который отображает реляционную модель в объектную модель. Этот процесс не имеет четкой и быстро достижимой ценности и может занять довольно значительное время, которое могло быть потрачено на разработку самого приложения. Тем временем многие хранилища типа ключ-значение хранят данные в такой структуре, которая отображается в объекты более естественно. Это может существенно уменьшить время разработки.
Другие аргументы в пользу использования хранилищ типа ключ-значение, наподобие «Реляционные базы могут стать неуклюжими» (кстати, я без понятия, что это значит), являются менее убедительными. Но прежде чем стать сторонником таких хранилищ, ознакомьтесь со следующим разделом.
Хранилища типа ключ-значение: недостатки
Ограничения в реляционных БД гарантируют целостность данных на самом низком уровне. Данные, которые не удовлетворяют ограничениям, физически не могут попасть в базу. В хранилищах типа ключ-значение таких ограничений нет, поэтому контроль целостности данных полностью лежит на приложениях. Однако в любом коде есть ошибки. Если ошибки в правильно спроектированной реляционной БД обычно не ведут к проблемам целостности данных, то ошибки в хранилищах типа ключ-значение обычно приводят к таким проблемам.
Другое преимущество реляционных БД заключается в том, что они вынуждают вас пройти через процесс разработки модели данных. Если вы хорошо спроектировали модель, то база данных будет содержать логическую структуру, которая полностью отражает структуру хранимых данных, однако расходится со структурой приложения. Таким образом, данные становятся независимы от приложения. Это значит, что другое приложение сможет использовать те же самые данные и логика приложения может быть изменена без каких-либо изменений в модели базы. Чтобы проделать то же самое с хранилищем типа ключ-значение, попробуйте заменить процесс проектирования реляционной модели проектированием классов, при котором создаются общие классы, основанные на естественной структуре данных.
И не забудьте о совместимости. В отличие от реляционных БД, хранилища, ориентированные на использование в «облаке», имеют гораздо меньше общих стандартов. Хоть концептуально они и не отличаются, они все имеют разные API, интерфейсы запросов и свою специфику. Поэтому вам лучше доверять вашему вендору, потому что в случае чего, вы не сможете легко переключиться на другого поставщика услуг. А учитывая тот факт, что почти все современные хранилища типа ключ-значение находятся в стадии бета-версий2, доверять становится еще рискованнее, чем в случае использования реляционных БД.
Ограниченная аналитика данных
Обычно все облачные хранилища строятся по типу множественной аренды, что означает, что одну и ту же систему использует большое количество пользователей и приложений. Чтобы предотвратить «захват» общей системы, вендоры обычно каким-то образом ограничивают выполнение запросов. Например, в SimpleDB запрос не может выполняться дольше 5 секунд. В Google AppEngine Datastore за один запрос нельзя получить больше, чем 1000 записей3.
Эти ограничения не страшны для простой логики (создание, обновление, удаление и извлечение небольшого количества записей). Но что если ваше приложение становится популярным? Вы получили много новых пользователей и много новых данных, и теперь хотите сделать новые возможности для пользователей или каким-то образом извлечь выгоду из данных. Тут вы можете жестко обломаться с выполнением даже простых запросов для анализа данных. Фичи наподобие отслеживания шаблонов использования приложения или системы рекомендаций, основанной на истории пользователя, в лучшем случае могут оказаться сложны в реализации. А в худшем — просто невозможны.
В таком случае для аналитики лучше сделать отдельную базу данных, которая будет заполняться данными из вашего хранилища типа ключ-значение. Продумайте заранее, каким образом это можно будет сделать. Будете ли вы размещать сервер в облаке или у себя? Не будет ли проблем из-за задержек сигнала между вами и вашим провайдером? Поддерживает ли ваше хранилище такой перенос данных? Если у вас 100 миллионов записей, а за один раз вы можете взять 1000 записей, сколько потребуется на перенос всех данных?
Однако не ставьте масштабируемость превыше всего. Она будет бесполезна, если ваши пользователи решат пользоваться услугами другого сервиса, потому что тот предоставляет больше возможностей и настроек.
Облачные хранилища
Множество поставщиков веб-сервисов предлагают многопользовательские хранилища типа ключ-значение. Большинство из них удовлетворяют критериям, перечисленным выше, однако каждое обладает своими отличительными фичами и отличается от стандартов, описанных выше. Давайте взглянем на конкретные пример хранилищ, такие как SimpleDB, Google AppEngine Datastore и SQL Data Services.
Amazon: SimpleDB
SimpleDB — это атрибутно-ориентированное хранилище типа ключ-значение, входящее в состав Amazon WebServices. SimpleDB находится в стадии бета-версии; пользователи могут пользовать ей бесплатно — до тех пор пока их потребности не превысят определенный предел.
У SimpleDB есть несколько ограничений. Первое — время выполнения запроса ограничено 5-ю секундами. Второе — нет никаких типов данных, кроме строк. Все хранится, извлекается и сравнивается как строка, поэтому для того, чтобы сравнить даты, вам нужно будет преобразовать их в формат ISO8601. Третье — максимальные размер любой строки составляет 1024 байта, что ограничивает размер текста (например, описание товара), который вы можете хранить в качестве атрибута. Однако поскольку структура данных гибкая, вы можете обойти это ограничения, добавляя атрибуты «ОписаниеТовара1», «Описание товара2» и т.д. Но количество атрибутов также ограничено — максимум 256 атрибутов. Пока SimpleDB находится в стадии бета-версии, размер домена ограничен 10-ю гигабайтами, а вся база не может занимать больше 1-го терабайта.
Одной из ключевых особенностей SimpleDB является использование модели конечной констистенции (eventual consistency model). Эта модель подходит для многопоточной работы, однако следует иметь в виду, что после того, как вы изменили значение атрибута в какой-то записи, при последующих операциях чтения эти изменения могут быть не видны. Вероятность такого развития событий достаточно низкая, тем не менее, о ней нужно помнить. Вы же не хотите продать последний билет пяти покупателям только потому, что ваши данные были неконсистентны в момент продажи.
Google AppEngine Data Store
Google’s AppEngine Datastore построен на основе BigTable, внутренней системе хранения структурированных данных от Google. AppEngine Datastore не предоставляет прямой доступ к BigTable, но может восприниматься как упрощенный интерфейс взаимодействия с BigTable.
AppEngine Datastore поддерживает большее число типов данных внутри одной записи, нежели SimpleDB. Например, списки, которые могут содержать коллекции внутри записи.
Скорее всего вы будете использовать именно это хранилище данных при разработке с помощью Google AppEngine. Однако в отличии от SimpleDB, вы не сможете использовать AppEngine Datastore (или BigTable) вне веб-сервисов Google.
Microsoft: SQL Data Services
SQL Data Services является частью платформы Microsoft Azure. SQL Data Services является бесплатной, находится в стадии бета-версии и имеет ограничения на размер базы. SQL Data Services представляет собой отдельное приложение — надстройку над множеством SQL серверов, которые и хранят данные. Эти хранилища могут быть реляционными, однако для вас SDS является хранилищем типа ключ-значение, как и описанные выше продукты.
Необлачные хранилища
Существует также ряд хранилищ, которыми вы можете воспользоваться вне облака, установив их у себя. Почти все эти проекты являются молодыми, находятся в стадии альфа- или бета-версии, и имеют открытый код. С открытыми исходниками вы, возможно, будете больше осведомлены о возможных проблемах и ограничениях, нежели в случае использования закрытых продуктов.
CouchDB
CouchDB — это свободно распространяемая документо-ориентированная БД с открытым исходным кодом. В качестве формата хранения данных используется JSON. CouchDB призвана заполнить пробел между документо-ориентированными и реляционными базами данных с помощью «представлений». Такие представления содержат данные из документов в виде, схожим с табличным, и позволяют строить индексы и выполнять запросы.
В настоящее время CouchDB не является по-настоящему распределенной БД. В ней есть функции репликации, позволяющие синхронизировать данные между серверами, однако это не та распределенность, которая нужна для построения высокомасштабируемого окружения. Однако разработчики CouchDB работают над этим.
Проект Voldemort
Проект Voldemort — это распределенная база данных типа ключ-значение, предназначенная для горизонтального масштабирования на большом количестве серверов. Он родилась в процессе разработки LinkedIn и использовалась для нескольких систем, имеющих высокие требования к масштабируемости. В проекте Voldemort также используется модель конечной консистенции.
Mongo
Mongo — это база данных, разрабатываемая в 10gen Гейром Магнуссоном и Дуайтом Меррименом (которого вы можете знать по DoubleClick). Как и CouchDB, Mongo — это документо-ориентированная база данных, хранящая данные в JSON формате. Однако Mongo скорее является объектной базой, нежели чистым хранилищем типа ключ-значение.
Drizzle
Drizzle представляет совсем другой подход к решению проблем, с которыми призваны бороться хранилища типа ключ-значение. Drizzle начинался как одна из веток MySQL 6.0. Позже разработчики удалили ряд функций (включая представления, триггеры, скомпилированные выражения, хранимые процедуры, кэш запросов, ACL, и часть типов данных), с целью создания более простой и быстрой СУБД. Тем не менее, Drizzle все еще можно использовать для хранения реляционных данных. Цель разработчиков — построить полуреляционную платформу, предназначенную для веб-приложений и облачных приложений, работающих на системах с 16-ю и более ядрами.
Решение
В конечном счете, есть четыре причины, по которым вы можете выбрать нереляционное хранилище типа ключ-значение для своего приложения:
- Ваши данные сильно документо-ориентированны, и больше подходят для модели данных ключ-значение, чем для реляционной модели.
- Ваша доменная модель сильно объектно-ориентированна, поэтому использования хранилища типа ключ-значение уменьшит размер дополнительного кода для преобразования данных.
- Хранилище данных дешево и легко интегрируется с веб-сервисами вашего вендора.
- Ваша главная проблема — высокая масштабируемость по запросу.
Однако принимая решение, помните об ограничениях конкретных БД и о рисках, которые вы встретите, пойдя по пути использования нереляционных БД.
Для всех остальных требований лучше выбрать старые добрые реляционные СУБД. Так обречены ли они? Конечно, нет. По крайней мере, пока.
1 — по моему мнению, здесь больше подходит термин «структура данных», однако оставил оригинальное data model.
2 — скорее всего, автор имел в виду, что по своим возможностям нереляционные БД уступают реляционным.
3 — возможно, данные уже устарели, статья датируется февралем 2009 года.
База данных SQl или NoSQL: какую выбрать для проекта?
Масштабируемость. Вертикальная, то есть при росте нагрузки растет производительность сервера. Если в базу поступает большой объем данных, рано или поздно наступит порог вертикального масштабирования — сервер не сможет далее увеличивать производительность. Тогда понадобится горизонтальное масштабирование — параллельная обработка данных в кластере серверов.
В больших распределенных системах это может привести к тому, что общая производительность системы упадет, так как нужно поддерживать согласованность данных в нескольких узлах. Это не значит, что СУБД на SQL не подходят для больших проектов — они поддерживают кластеризацию, просто нужно приложить усилия, чтобы настроить систему. Либо использовать базы данных в облаке — там можно получить уже настроенные и надежно работающие кластеры в несколько кликов.
Самые известные SQL-базы данных
MySQL — одна из самых популярных open source реляционных баз данных. Подходит небольшим и средним проектам, которым нужен недорогой и надежный инструмент работы с данными. Поддерживает множество типов таблиц, есть огромное количество плагинов и расширений, облегчающих работу с системой.
Отличается простой установкой, может быть интегрирована с другими СУБД, также интеграция с MySQL есть в любой CMS, фреймворке, языке программирования. Среди минусов — не все задачи выполняет автоматически, если что-то нужное не включено в функционал, придется потратить время на доработку, нет встроенной поддержки OLAP.
MySQL доступна как облачный сервис — в облаке не нужно тратить много времени на развертывание и конфигурацию СУБД. MySQL server стоит выбрать на старте бизнеса, чтобы тестировать гипотезы с минимальными затратами или для небольших проектов как транзакционную базу данных общего назначения.PostgreSQL — вторая по популярности open source SQL СУБД. У нее много встроенных функций и дополнений, в том числе для масштабирования в кластер и шардинга таблиц. Подходит, если важна сохранность данных, предполагается их сложная структура. Позволяет работать со структурированными данными, но поддерживает JSON/BSON, что дает некоторую гибкость в схеме данных.
Отличается стабильностью, ее практически невозможно вывести из строя или что-то сломать в таблицах.
Из минусов — сложность конфигурации требует от пользователей некоторого опыта. Также скорость работы может падать во время проведения пакетных операций или при запросах на чтение.
PostgreSQL также можно развернуть в облаке — в отличие от MySQL, она подходит для крупных и масштабных проектов. Кроме того, ее стоит выбрать, если недопустимы ошибки в данных или есть особые требования к базе данных, например поддержка геоданных. Различные расширения PostgreSQL позволяют реализовать многие специализированные запросы.
Нереляционные базы данных, или базы данных NoSQL
Особенности. В отличие от реляционных, в нереляционных базах данных схема данных является динамической и может меняться в любой момент времени. К данным сложнее получить доступ, то есть найти внутри базы что-то нужное — с таблицей это просто, достаточно знать координаты ячейки. Зато такие СУБД отличаются производительностью и скоростью. Физические объекты в NoSQL обычно можно хранить прямо в том виде, в котором с ними потом работает приложение.
Базы данных NoSQL подходят для хранения больших объемов неструктурированной информации, а также хороши для быстрой разработки и тестирования гипотез.
В них можно хранить данные любого типа и добавлять новые в процессе работы.
Масштабируемость. NoSQL базы имеют распределенную архитектуру, поэтому хорошо масштабируются горизонтально и отличаются высокой производительностью. Технологии NoSQL могут автоматически распределять данные по разным серверам. Это повышает скорость чтения данных в распределенной среде.
Четыре вида нереляционных баз данных
Документоориентированные базы данных — данные хранятся в коллекциях документов, обычно с использованием форматов JSON, XML или BSON. Одна запись может содержать столько данных, сколько нужно, в любом типе данных (или типах) — ограничений нет. Внутри одного документа есть внутренняя структура, однако, она может отличаться от одного документа к другому. Также документы можно вкладывать друг в друга.
То есть вместо столбцов и строк мы описываем все данные в одном документе. Если нам нужно было бы добавить новые данные в таблицу реляционной базы данных, пришлось бы изменять ее схему данных. В случае с документами нужно только добавить в них дополнительные пары ключ-значение.
Пример такой базы данных: MongoDB.
Вот так будет выглядеть хранение данных в отдельных документах вместо таблицы со столбцами и строками:
Реляционная база данных ✔️ поля, структура, основной объект хранения, примеры, в каком виде организована информация в реляционной бд, недостатки
Особенности реляционных БД
БД используются для организации хранения данных. Структура реляционной базы данных полностью определяется перечнем названия полей с указанием их типов и свойств. Все записи имеют одинаковые поля, но в них показываются разные свойства объекта. Аналогом реляционной БД считается двумерная таблица. Характерные особенности файла БД:
- Уникальное имя для каждой таблицы.
- Фиксированное число полей.
- На пересечении строки и столбца всегда есть только одно значение.
- Записи отличаются друг от друга хотя бы одним значением элемента.
- Полям присваиваются индивидуальные имена.
- В каждый из столбцов необходимо вставлять однородные данные: целые числа, даты, суммы, имена или фамилии, названия предметов.
Реляционная БД чаще всего не ограничивается одной таблицей. Обычно создаются несколько таблиц со связанной информацией. Это позволяет исполнять более сложные операции над данными. Таблицы реляционной БД обязаны соответствовать требованиям понятия нормализации отношений, то есть ограничениям на формирование, которые позволят избежать дублирования и обеспечат непротиворечивость хранимой информации. Пусть создана таблица «Прокат», содержащая следующие поля: Шифр Клиента, Ф. И. О., Вид устройства, Дата выдачи, Оплата, Срок возврата. Эта организация хранения информации имеет несколько недостатков:
- дублирование информации (вид устройства повторяется для разных клиентов), что увеличивает объём БД;
- для обновления информации требуется обрабатывать каждую запись.
Для устранения этих недостатков необходима нормализация с разделением данных на разные таблицы.
Связывание таблиц
Для любой таблицы реляционной БД задаётся первичный ключ (primary key) — поле или сочетание полей, которые определяют каждую запись. Внешний или вторичный ключ (foreign key) — это одно или несколько полей, ссылающихся на поле primary key другой таблицы.
Составной ключ называется так, потому что создаётся из нескольких полей. При образовании составных ключей не рекомендуется включать в них поля, значения которых точно определяют запись. Например, не следует образовывать ключ, в котором находятся вместе поля «номер паспорта» и «шифр клиента», потому что оба эти атрибута однозначно определяют запись. Поля с повторяющимися в таблице значениями тоже нельзя делать составной частью ключа. По значению ключа возможно найти только одну запись.
Ячейка — это наименьший структурный элемент, который задаёт определённое значение соответствующего поля. Таблицы связываются друг с другом, и поэтому данные могут выбираться сразу из нескольких таблиц. Связь создаётся, если в них присутствуют одинаковые поля. Типы связей:
- один к одному;
- один ко многим;
- многие ко многим.
Связи «один к одному» встречаются довольно редко. «Один ко многим» применяются чаще, например, кассир продаёт много билетов. «Многие ко многим» тоже встречаются часто. Например, студент изучает много предметов. Связи «многие ко многим» нельзя организовывать непосредственно. Для установления отношения необходимо сопоставить каждому primary key внешний ключ, который представляет собой primary key другой таблицы. Реляционные системы базируются на теории реляционной модели, которая включает в себя три аспекта:
- структурный — данные в базе рассматриваются как набор отношений, то есть упорядоченных пар, составленных из заголовка и полей;
- целостности — состоит в проверке правильности согласования данных при обновлении;
- обработки — использование операторов манипулирования таблицами, таких как реляционная алгебра и реляционное исчисление, которые генерируют новые таблицы на основании уже имеющихся.
Управление созданием и использованием БД осуществляется системами управления базами данных (СУБД).
Под их руководством:
- производится добавление, определение, удаление и поиск записей;
- изменяются значения полей.
Для проведения этих операций организуются запросы. Итогом выполнения запросов будут либо изменения в таблицах, либо получение таблицы данных. При этом поддерживается принцип безопасности информации. Для реляционной БД основным языком управления является SQL.
Стадии и пример проектирования хранилища
Приступая к созданию базы, разработчик составляет для объектов манипулирования и их связей представление в терминах реляционной БД (таблицы, поля, записи). Проектирование проходит несколько стадий:
- Первая стадия — это анализ требований. Разработчик должен разрешить главные проблемы: какие элементы данных будут содержаться, как и кто должен к ним обращаться.
- В следующей стадии проектируется логическая структура БД.
- В завершающей стадии проектирования логическая структура БД трансформируется в физическую. Элементы данных определяются как табличные столбцы.
Преимущества этой модели данных состоят в том, что информация отображается в удобной для пользователя форме, а для манипуляций используется развитой математический аппарат.
Примером реляционной базы данных может послужить проект оптимизации деятельности пункта проката. Требуется автоматизировать такие процедуры: учёт клиентов; регистрацию инвентаря, выданного в прокат; отслеживание даты выдачи, сроков возврата, оплаты; получение информации по этим позициям; формирование отчёта по задолженностям. Реляционная БД может быть задана в виде трёх связанных таблиц.
Используя имеющиеся данные, следует определить отношения и объекты этих отношений. Объектами будут являться клиенты и устройства. Отношения между ними состоят в том, что каждый клиент может брать в прокат одно или несколько устройств.
Атрибутами для сопоставления объектов друг другу должны выступать ячейки с уникальным содержимым. В таблицах есть по одному полю с уникальными данными. В № 1 «Клиент» — это шифр клиента, а в № 3 «Склад» — шифр устройства. Это и будут primary keys. Каждая строка таблицы «Прокат» будет связывать два внешних ключа между собой:
- Шифр Клиента — foreign key, ссылающийся на primary key в таблице «Клиент».
- Шифр устройства — foreign key, ссылающийся на первичный ключ в таблице «Склад».
Проблемы модели
Преимущество реляционных хранилищ состоит в том, что они способны обеспечить наилучшее соотношение устойчивости, производительности, гибкости, совместимости и масштабируемости. Реляционные БД предоставляют лёгкий доступ к составляемым отчётам и обеспечивают высокую надёжность и целостность информации из-за отсутствия избыточных данных. Но сейчас, когда всё большее количество приложений работает с высокой нагрузкой, увеличивается значение фактора масштабируемости.
Реляционные БД легко масштабируются, только когда они расположены на одном сервере. Если потребуется увеличить количество серверов и разделить нагрузку между ними, то возрастёт сложность хранилищ, что значительно снизит возможность использовать их как платформу для мощных распределённых систем. Поэтому приходится применять другие типы БД, которые обладают лучшей масштабируемостью и отказываться от возможностей, предоставляемых реляционными хранилищами.
Реляционная БД — это совокупность связей, которые способны структурировать данные, что даёт возможность рационального хранения и эффективного использования информационных материалов.
НОУ ИНТУИТ | Лекция | Введение в реляционную модель данных
Аннотация: В этом курсе, главным образом, обсуждаются различные аспекты реляционных баз данных. Принято считать, что реляционный подход к организации баз данных был заложен в конце 1960-х гг. Эдгаром Коддом. В последние десятилетия этот подход является наиболее распространенным (с оговоркой, что в называемых в обиходе реляционными системах баз данных, основанных на языке SQL, в действительности нарушаются некоторые важные принципы классического реляционного подхода). Достоинствами реляционного подхода принято считать следующие свойства: реляционный подход основывается на небольшом числе интуитивно понятных абстракций, на основе которых возможно простое моделирование наиболее распространенных предметных областей; эти абстракции могут быть точно и формально определены; теоретическим базисом реляционного подхода к организации баз данных служит простой и мощный математический аппарат теории множеств и математической логики; реляционный подход обеспечивает возможность ненавигационного манипулирования данными без необходимости знания конкретной физической организации баз данных во внешней памяти. Компьютерный мир далеко не сразу признал реляционные системы. В 70-е года прошлого века, когда уже были получены почти все основные теоретические результаты и даже существовали первые прототипы реляционных СУБД, многие авторитетные специалисты отрицали возможность добиться эффективной реализации таких систем. Однако преимущества реляционного подхода и развитие методов и алгоритмов организации и управления реляционными базами данных привели к тому, что к концу 80-х годов реляционные системы заняли на мировом рынке СУБД доминирующее положение. В этой лекции на сравнительно неформальном уровне вводятся основные понятия реляционных баз данных, а также определяется сущность реляционной модели данных. Основной целью лекции является демонстрация простоты и возможности интуитивной интерпретации этих понятий. В следующих лекциях будут приводиться более формальные определения, на которых основана теория реляционных баз данных.
Основные понятия реляционных баз данных
Выделим следующие основные понятия реляционных баз данных: тип данных, домен, атрибут, кортеж, отношение, первичный ключ.
Для начала покажем смысл этих понятий на примере отношения СЛУЖАЩИЕ, содержащего информацию о служащих некоторого предприятия (рис. 2.1).

Рис. 2.1. Соотношение основных понятий реляционного подхода
Тип данных
Значения данных, хранимые в реляционной базе данных, являются типизированными, т. е. известен тип каждого хранимого значения. Понятие типа данных в реляционной модели данных полностью соответствует понятию типа данных в языках программирования. Напомним, что традиционное (нестрогое) определение типа данных состоит из трех основных компонентов: определение множества значений данного типа; определение набора операций, применимых к значениям типа; определение способа внешнего представления значений типа (литералов).
Обычно в современных реляционных базах данных допускается хранение символьных, числовых данных (точных и приблизительных), специализированных числовых данных (таких, как «деньги»), а также специальных «темпоральных» данных (дата, время, временной интервал). Кроме того, в реляционных системах поддерживается возможность определения пользователями собственных типов данных (более подробно мы обсудим это в лекции 9, курса «Введение в модель данных SQL»).
В примере на рис. 2.1 мы имеем дело с данными трех типов: строки символов, целые числа и «деньги».
Домен
Понятие домена более специфично для баз данных, хотя и имеются аналогии с подтипами в некоторых языках программирования (более того, в своем «Третьем манифесте» Кристофер Дейт и Хью Дарвен вообще ликвидируют различие между доменом и типом данных ). В общем виде домен определяется путем задания некоторого базового типа данных, к которому относятся элементы домена, и произвольного логического выражения, применяемого к элементу этого типа данных ( ограничения домена ). Элемент данных является элементом домена в том и только в том случае, если вычисление этого логического выражения дает результат истина (для логических значений мы будем попеременно использовать обозначения истина и ложь или true и false ). С каждым доменом связывается имя, уникальное среди имен всех доменов соответствующей базы данных.
Наиболее правильной интуитивной трактовкой понятия домена является его восприятие как допустимого потенциального, ограниченного подмножества значений данного типа. Например, домен ИМЕНА в нашем примере определен на базовом типе символьных строк, но в число его значений могут входить только те строки, которые могут представлять имена (в частности, для возможности представления русских имен такие строки не могут начинаться с мягкого или твердого знака и не могут быть длиннее, например, 20 символов). Если некоторый атрибут отношения определяется на некотором домене (как, например, на рис. 2.1 атрибут СЛУ_ИМЯ определяется на домене ИМЕНА ), то в дальнейшем ограничение домена играет роль ограничения целостности, накладываемого на значения этого атрибута.
Следует отметить также семантическую нагрузку понятия домена: данные считаются сравнимыми только в том случае, когда они относятся к одному домену. В нашем примере значения доменов НОМЕРА ПРОПУСКОВ и НОМЕРА ОТДЕЛОВ относятся к типу целых чисел, но не являются сравнимыми (допускать их сравнение было бы бессмысленно).
Заголовок отношения, кортеж, тело отношения, значение отношения, переменная отношения
Понятие отношения является наиболее фундаментальным в реляционном подходе к организации баз данных, поскольку n -арное отношение является единственной родовой структурой данных, хранящихся в реляционной базе данных. Это отражено и в общем названии подхода – термин реляционный (relational) происходит от relation (отношение). Однако сам термин отношение является исключительно неточным, поскольку, говоря про любые сохраняемые данные, мы должны иметь в виду тип этих данных, значения этого типа и переменные, в которых сохраняются значения. Соответственно, для уточнения термина отношение выделяются понятия заголовка отношения, значения отношения и переменной отношения. Кроме того, нам потребуется вспомогательное понятие кортежа.
Итак, заголовком (или схемой) отношения r ( Hr ) называется конечное множество упорядоченных пар вида <A, T>, где A называется именем атрибута, а T обозначает имя некоторого базового типа или ранее определенного домена . По определению требуется, чтобы все имена атрибутов в заголовке отношения были различны. В примере на рис. 2.1 заголовком отношения СЛУЖАЩИЕ является множество пар {<слу_номер, номера_пропусков>, <слу_имя, имена>, <слу_зарп, размеры_выплат>, <слу_отд_номер, номера_отделов>}.
Если все атрибуты заголовка отношения определены на разных доменах, то, чтобы не плодить лишних имен, разумно использовать для именования атрибутов имена соответствующих доменов (не забывая, конечно, о том, что это всего лишь удобный способ именования, который не устраняет различия между понятиями домена и атрибута ).
Кортежем tr, соответствующим заголовку Hr, называется множество упорядоченных триплетов вида <A, T, v>, по одному такому триплету для каждого атрибута в Hr . Третий элемент – v – триплета <A, T, v> должен являться допустимым значением типа данных или домена T. Заголовку отношения СЛУЖАЩИЕ соответствуют, например, следующие кортежи: {<слу_номер, номера_пропусков, 2934>, <слу_имя, имена, Иванов>, <слу_зарп, размеры_выплат, 22.000>, <слу_отд_номер, номера_отделов, 310>}, {<слу_номер, номера_пропусков, 2940>, <слу_имя, имена, Кузнецов>, <слу_зарп, размеры_выплат, 35.000>, <слу_отд_номер, номера_отделов, 320>}.
Телом Br отношения r называется произвольное множество кортежей tr . Одно из возможных тел отношения СЛУЖАЩИЕ показано на рис. 2.1. Заметим, что в общем случае, как это демонстрируют, в частности, рис. 2.1 и пример предыдущего абзаца, могут существовать такие кортежи tr, которые соответствуют Hr, но не входят в Br.
Значением Vr отношения r называется пара множеств Hr и Br . Одно из допустимых значений отношения СЛУЖАЩИЕ показано на рис. 2.1.
В изменчивой реляционной базе данных хранятся отношения, значения которых изменяются во времени. Переменной VARr называется именованный контейнер, который может содержать любое допустимое значение Vr . Естественно, что при определении любой VARr требуется указывать соответствующий заголовок отношения Hr.
Здесь стоит подчеркнуть, что любая принятая на практике операция обновления базы данных – INSERT (вставка кортежа в переменную отношения ), DELETE (удаление кортежа из значения- отношения переменной отношения ) и UPDATE (модификация кортежа значения- отношения переменной отношения ) – с модельной точки зрения является операцией присваивания переменной отношения некоторого нового значения- отношения. Это совсем не означает, что перечисленные операции должны выполняться именно таким образом в СУБД: главное, чтобы результат операций соответствовал этой модельной семантике.
Заметим, что в дальнейшем в тех случаях, когда точный смысл термина понятен из контекста, мы будем использовать термин отношение как в смысле значение отношения, так и в смысле переменная отношения.
По определению, степенью, или «арностью», заголовка отношения, кортежа, соответствующего этому заголовку, тела отношения, значения отношения и переменной отношения является мощность заголовка отношения . Например, степень отношения СЛУЖАЩИЕ равна четырем, т. е. оно является 4-арным ( кватернарным ).
При приведенных определениях разумно считать схемой реляционной базы данных набор пар <имя_VARr, Hr>, включающий имена и заголовки всех переменных отношения, которые определены в базе данных . Реляционная база данных – это набор пар <VARr, Hr> (конечно, каждая переменная отношения в любой момент времени содержит некоторое значение- отношение, в частности, пустое).
Заметим, что в классических реляционных базах данных после определения схемы базы данных могли изменяться только значения переменных отношений. Однако теперь в большинстве реализаций допускается и изменение схемы базы данных: определение новых и изменение заголовков существующих переменных отношений. Это принято называть эволюцией схемы базы данных.
Первичный ключ и интуитивная интерпретация реляционных понятий
По определению, первичным ключом переменной отношения является такое подмножество1 S множества атрибутов ее заголовка, что в любое время значение первичного ключа (составное, если в состав первичного ключа входит более одного атрибута ) в любом кортеже тела отношения отличается от значения первичного ключа в любом другом кортеже тела этого отношения, а никакое собственное подмножество2 S этим свойством не обладает. В следующем разделе мы покажем, что существование первичного ключа у любого значения отношения является следствием одного из фундаментальных свойств отношений, а именно того свойства, что тело отношения является множеством кортежей.
Обычным житейским представлением отношения является таблица, заголовком которой является схема отношения, а строками – кортежи отношения -экземпляра; в этом случае имена атрибутов соответствуют именам столбцов данной таблицы. Поэтому иногда говорят про «столбцы таблицы», имея в виду » атрибуты отношения «.
Конечно, это достаточно грубая терминология, поскольку у обычных таблиц и строки, и столбцы упорядочены, тогда как атрибуты и кортежи отношений являются элементами неупорядоченных множеств. Тем не менее, когда мы перейдем к рассмотрению практических вопросов организации реляционных баз данных и средств управления, то будем использовать эту «житейскую» терминологию. Подобной терминологии придерживаются в большинстве коммерческих реляционных СУБД. Иногда также используются термины файл как аналог таблицы, запись как аналог строки и поле как аналог столбца. Напомню, что этой терминологией мы пользовались в лекции 1.
Реляционные базы данных — это… Что такое Реляционные базы данных?
- Реляционные базы данных
Реляционные базы данных
Реляционная база данных — база данных, основанная на реляционной модели данных. Слово «реляционный» происходит от англ. relation (отношение[1]). Для работы с реляционными БД применяют реляционные СУБД.
Использование реляционных баз данных было предложено доктором Коддом из компании IBM в 1970 году.
Нормализация
Целью нормализации является устранение недостатков структуры базы данных, приводящих к вредной избыточности в данных, которая в свою очередь потенциально приводит к различным аномалиям и нарушениям целостности данных.
Теоретики реляционных баз данных в процессе развития теории выявили и описали типичные примеры избыточности и способы их устранения.
Нормальные формы
Нормальная форма — формальное свойство отношения, которое характеризует степень избыточности хранимых данных и возможные проблемы. Каждая следующая нормальная форма в нижеприведенном списке (кроме ДКНФ) в некотором смысле является более совершенной, чем предыдущая, с точки зрения устранения избыточности.
См. также
Примечания
- ↑ Строгое изложение предполагает использование строгих математических терминов отношение, домен, атрибут, кортеж, а не смутных и нестрогих понятий таблица, поле, столбец, колонка, запись, строка.
Литература
- К. Дж. Дейт Введение в системы баз данных = Introduction to Database Systems. — 8-е изд. — М.: «Вильямс», 2006. — С. 1328. — ISBN 0-321-19784-4
- ISBN 5-94157-805-9 Рудикова. Разработка баз приложений СУБД
Wikimedia Foundation. 2010.
- Электрический двигатель
- Система управления базами данных
Смотреть что такое «Реляционные базы данных» в других словарях:
Иерархические базы данных — Иерархическая модель базы данных состоит из объектов с указателями от родительских объектов к потомкам, соединяя вместе связанную информацию. Иерархические базы данных могут быть представлены как дерево, состоящее из объектов различных уровней.… … Википедия
Сервер базы данных — Сервер БД выполняет обслуживание и управление базой данных и отвечает за целостность и сохранность данных, а также обеспечивает операции ввода вывода при доступе клиента к информации. Архитектура клиент сервер состоит из клиентов и серверов.… … Википедия
Реляционные БД — Реляционная база данных база данных, основанная на реляционной модели. Слово «реляционный» происходит от английского «relation» (отношение[1]). Для работы с реляционными БД применяют Реляционные СУБД. Использование реляционных баз данных было… … Википедия
Реляционные СУБД — Реляционная СУБД (РСУБД; иначе Система управления реляционными базами данных, СУРБД) СУБД, управляющая реляционными базами данных. Понятие реляционный (англ. relation отношение) связано с разработками известного английского специалиста в… … Википедия
реляционная база данных — База данных, реализованная в соответствии с реляционной моделью данных. [ГОСТ 20886 85] реляционная БД База данных, логически организованная в виде набора отношений ее компонентов. Характерной особенностью реляционной базы данных является… … Справочник технического переводчика
Нормализация баз данных — Нормальная форма требование, предъявляемое к отношениям в теории реляционных баз данных для устранения из базы избыточности, которая потенциально может привести к логически ошибочным результатам выборки или изменения данных. Содержание 1… … Википедия
Реляционная модель данных — (РМД) логическая модель данных, прикладная теория построения баз данных, которая является приложением к задачам обработки данных таких разделов математики как теории множеств и логика первого порядка. На реляционной модели данных строятся… … Википедия
Реляционная модель данных — разработанная Э.Коддом в 1970г. логическая модель данных, описывающая: структуры данных в виде (изменяющихся во времени) наборов отношений; теоретико множественные операции над данными: объединение, пересечение, разность и декартово произведение; … Финансовый словарь
база данных — упорядоченная совокупность данных, предназначенных для хранения, накопления и обработки с помощью ЭВМ. Для создания и ведения баз данных (обновления, обеспечения доступа к ним по запросам и выдачи их пользователю) используется набор языковых и… … Энциклопедический словарь
Хранилище Данных — (англ. Data Warehouse) очень большая предметно ориентированная информационная корпоративная база данных, специально разработанная и предназначенная для подготовки отчётов, анализа бизнес процессов с целью поддержки принятия решений в организации … Википедия
Книги
- Базы данных. Проектирование, реализация и сопровождение. Теория и практика, Коннолли Томас, Бегг Каролин. Авторы книги сконцентрировали на ее страницах весь свой богатый опыт разработки баз данных для нужд промышленности, бизнеса и науки, а также обучения студентов. Результатом их труда стало это… Подробнее Купить за 7259 руб
- Реляционные базы данных, Ульман Д., Уидом Д.. Книга «Реляционные базы данных» написана хорошо известными учеными Станфордского университета Джеффри Ульманом и Дженнифер Уидом. Авторы предлагают ориентированный на пользователя подход к… Подробнее Купить за 1017 руб
- NoSQL. Новая методология разработки нереляционных баз данных, Прамодкумар Дж. Садаладж, Мартин Фаулер. Необходимость обрабатывать все более крупные объемы данных является одним из факторов, влияющих на внедрение нового класса нереляционных баз данных NoSQL. Сторонники баз NoSQL утверждают, что… Подробнее Купить за 597 грн (только Украина)
SQL или NoSQL — вот в чём вопрос / Блог компании RUVDS.com / Хабр
Все мы знаем, что в мире технологий баз данных существует два основных направления: SQL и NoSQL, реляционные и нереляционные базы данных. Различия между ними заключаются в том, как они спроектированы, какие типы данных поддерживают, как хранят информацию.Реляционные БД хранят структурированные данные, которые обычно представляют объекты реального мира. Скажем, это могут быть сведения о человеке, или о содержимом корзины для товаров в магазине, сгруппированные в таблицах, формат которых задан на этапе проектирования хранилища.
Нереляционные БД устроены иначе. Например, документо-ориентированные базы хранят информацию в виде иерархических структур данных. Речь может идти об объектах с произвольным набором атрибутов. То, что в реляционной БД будет разбито на несколько взаимосвязанных таблиц, в нереляционной может храниться в виде целостной сущности.
Внутреннее устройство различных систем управления базами данных влияет на особенности работы с ними. Например, нереляционные базы лучше поддаются масштабированию.
Какую технологию выбрать? Ответ на этот вопрос зависит от особенностей проекта, о котором идёт речь.
О выборе SQL-баз данных
Не существует баз данных, которые подойдут абсолютно всем. Именно поэтому многие компании используют и реляционные, и нереляционные БД для решения различных задач. Хотя NoSQL-базы стали популярными благодаря быстродействию и хорошей масштабируемости, в некоторых ситуациях предпочтительными могут оказаться структурированные SQL-хранилища. Вот две причины, которые могут послужить поводом для выбора SQL-базы:
- Необходимость соответствия базы данных требованиям ACID (Atomicity, Consistency, Isolation, Durability — атомарность, непротиворечивость, изолированность, долговечность). Это позволяет уменьшить вероятность неожиданного поведения системы и обеспечить целостность базы данных. Достигается подобное путём жёсткого определения того, как именно транзакции взаимодействуют с базой данных. Это отличается от подхода, используемого в NoSQL-базах, которые ставят во главу угла гибкость и скорость, а не 100% целостность данных.
- Данные, с которыми вы работаете, структурированы, при этом структура не подвержена частым изменением. Если ваша организация не находится в стадии экспоненциального роста, вероятно, не найдётся убедительных причин использовать БД, которая позволяет достаточно вольно обращаться с типами данных и нацелена на обработку огромных объёмов информации.
О выборе NoSQL-баз данных
Если есть подозрения, что база данных может стать узким местом некоего проекта, основанного на работе с большими объёмами информации, стоит посмотреть в сторону NoSQL-баз, которые позволяют то, чего не умеют реляционные БД.
Вот возможности, которые стали причиной популярности таких NoSQL баз данных, как MongoDB, CouchDB, Cassandra, HBase:
- Хранение больших объёмов неструктурированной информации. База данных NoSQL не накладывает ограничений на типы хранимых данных. Более того, при необходимости в процессе работы можно добавлять новые типы данных.
- Использование облачных вычислений и хранилищ. Облачные хранилища — отличное решение, но они требуют, чтобы данные можно было легко распределить между несколькими серверами для обеспечения масштабирования. Использование, для тестирования и разработки, локального оборудования, а затем перенос системы в облако, где она и работает — это именно то, для чего созданы NoSQL базы данных.
- Быстрая разработка. Если вы разрабатываете систему, используя agile-методы, применение реляционной БД способно замедлить работу. NoSQL базы данных не нуждаются в том же объёме подготовительных действий, которые обычно нужны для реляционных баз.
В следующем разделе рассмотрим некоторые различия между технологиями SQL и NoSQL. А именно, сначала взглянем на простой пример, показывающий фундаментальное различие двух подходов к организации баз данных, потом поговорим о масштабируемости и индексации данных. А в итоге остановимся на примере большой CRM-системы, нуждающейся в высокой производительности хранилища данных.
SQL и NoSQL
Начнём с некоторых ключевых концепций реляционных и нереляционных баз данных. Ниже показана база данных, содержащая сведения о взаимоотношениях людей. Вариант a — это бессхемная структура, построенная в виде графа, характерная для NoSQL-решений. Вариант b показывает, как те же данные можно представить в структурированном виде, типичном для SQL.
Два варианта представления данных
Бессхемность означает, что два документа в структуре данных NoSQL не должны иметь одинаковые поля и могут хранить данные разных типов. Вот, например, массив объектов, набор полей которых не совпадает.
var cars = [
{ Model: "BMW", Color: "Red", Manufactured: 2016 },
{ Model: "Mercedes", Type: "Coupe", Color: "Black", Manufactured: "1-1-2017" }
];При реляционном подходе данные надо хранить в заранее спроектированной структуре, из которой эти данные потом можно извлекать. Например, используя оператор
JOINпри выборке из двух таблиц:SELECT Orders.OrderID, Customers.Name, Orders.Date
FROM Orders
INNER JOIN Customers
ON Orders.CustID = Customers.CustIDКак более продвинутый пример, для демонстрации того, когда SQL предпочтительнее NoSQL, рассмотрим особенности применения в NoSQL-базах алгоритмов уплотнения. Проблема заключается в том, что в некоторых NoSQL-базах (например, в CouchDB и HBase) постоянно приходится формировать так называемые
sstables — строковые таблицы в формате ключ-значение, отсортированные по ключу. В такие таблицы, которые сохраняются на диск, данные попадают из таблиц, хранящихся в памяти, при их переполнении и в других ситуациях. При интенсивной работе с базой создание таблиц, со временем, приводит к тому, что подсистема ввода-вывода устройства хранения данных становится узким местом для операций чтения данных. Как результат, чтение в NoSQL-базе происходит медленнее, чем запись, что сводит на нет одно из главных преимуществ нереляционных баз данных. Именно для того, чтобы уменьшить этот эффект, системы NoSQL используют, в фоновом режиме, алгоритмы уплотнения данных, пытаясь объединить множество таблиц в одну. Но и сама по себе эта операция весьма ресурсоёмка, система работает под повышенной нагрузкой.Масштабируемость
Одно из основных различий рассматриваемых технологий заключается в том, что NoSQL-базы лучше поддаются масштабированию. Например, в MongoDB имеется встроенная поддержка репликации и шардинга (горизонтального разделения данных) для обеспечения масштабируемости. Хотя масштабирование поддерживается и в SQL-базах, это требует гораздо больших затрат человеческих и аппаратных ресурсов.
| Тип хранилища данных |
Сценарий использования |
Пример |
Рекомендации |
| Хранилище типа ключ-значение |
Подходит для простых приложений, с одним типом объектов, в ситуациях, когда поиск объектов выполняют лишь по одному атрибуту. |
Интерактивное обновление домашней страницы пользователя в Facebook. |
Рекомендовано знакомство с технологией memcached. Если приходится искать объекты по нескольким атрибутам, рассмотрите вариант перехода к хранилищу, ориентированному на документы. |
| Хранилище, ориентированное на документы |
Подходит для хранения объектов различных типов. |
Транспортное приложение, оперирующее данными о водителях и автомобилях, работая с которым надо искать объекты по разным полям, например — имя или дата рождения водителя, номер прав, транспортное средство, которым он владеет. |
Подходит для приложений, в ходе работы с которыми допускается реализация принципа «согласованность в конечном счёте» с ограниченными атомарностью и изоляцией. Рекомендуется применять механизм кворумного чтения для обеспечения своевременной атомарной непротиворечивости. |
| Система хранения данных с расширяемыми записями |
Более высокая пропускная способность и лучшие возможности параллельной обработки данных ценой слегка более высокой сложности, нежели у хранилищ, ориентированных на документы. |
Приложения, похожие на eBay. Вертикальное и горизонтальное разделение данных для хранения информации клиентов. |
Для упрощения разделения данных используются HBase или Hypertable. |
| Масштабируемая RDBMS |
Использование семантики ACID освобождает программистов от необходимости работать на достаточно низком уровне, а именно, отвечать за блокировки и непротиворечивость данных, обрабатывать устаревшие данные, коллизии. |
Приложения, которым не требуются обновления или слияния данных, охватывающие множество узлов. |
Стоит обратить внимание на такие системы, как MySQL Cluster, VoltDB, Clustrix, ориентированные на улучшенное масштабирование. |
Более подробное сравнение SQL и NoSQL можно найти в этом материале. Вот его основные положения. А именно, были проведены испытания трёх основных характеристик систем: параллельная обработка данных, работа с хранилищами информации, репликация данных. Возможности параллельной обработки оценивались путём анализа механизмов блокировки, управления параллельным доступом на основе многоверсионности, и ACID. Тестирование хранилищ охватывало и физические носители, и хранилища использующие оперативную память. Репликацию испытывали в синхронном и асинхронном режимах.
Используя данные, полученные в ходе испытаний, авторы делают выводы о том, что SQL-базы с возможностью кластеризации показали многообещающие результаты производительности в расчёте на один узел, и, кроме того, обладают способностью масштабируемости, что даёт системам RDBMS преимущество перед NoSQL за счёт полного соответствия принципам ACID.
Индексация
В системах RDBMS индексация используется для ускорения операций извлечения данных из баз. Отсутствие индекса означает, что таблица должна быть просмотрена целиком для того, чтобы выполнить запрос на чтение.
И в SQL, и в NoSQL-базах индексы служат одной и той же цели — ускорить и оптимизировать извлечение данных. Но то, как именно они работают — различается из-за разных архитектур баз данных и особенностей хранения информации в базе. В то время, как SQL-индексы представлены в виде B-деревьев, которые отражают иерархическую структуру реляционных данных, в NoSQL базах данных они указывают на документы, или на части документов, между которыми, в основном, нет никаких отношений. Вот подробный материал на эту тему.
CRM-системы
CRM-приложения — это один из лучших примеров систем, для которых характерны огромные объёмы ежедневно обрабатываемых данных и очень большое количество транзакций. Все разработчики таких приложений используют и SQL, и NoSQL базы данных. И, хотя большая часть данных транзакций всё ещё хранится в SQL-базах, применение находят общедоступные системы класса DBaaS (data-base-as-a-service, база данных как сервис), наподобие AWS DynamoDB и Azure DocumentDB, в результате, серьёзная нагрузка по обработке данных может быть перенесена в облачные NoSQL-базы.
В то время, как использование подобных служб освобождает разработчика от решения задач по обслуживанию хранилищ, это, кроме того, область, где NoSQL базы применяются для того, для чего они, в основном, и были созданы, например, для глубинного анализа данных. Объёмы информации, хранимой в огромных CRM-системах финансовых и телекоммуникационных компаний, было бы практически невозможно проанализировать, используя инструменты вроде SAS или R. Это потребовало бы огромных аппаратных ресурсов.
Главное преимущество таких систем — использование неструктурированных данных, похожих на документы. Такие данные могут подаваться на вход статистических моделей, которые дают компаниям возможность выполнять различные виды анализа. CRM-приложения, кроме того, являются весьма удачным примером, в котором две системы баз данных выступают не конкурентами, а существуют в гармонии, играя каждая свою роль в большой архитектуре управления данными.
Итоги
Занимаясь поиском системы управления базами данных, можно выбрать одну технологию, а позже, уточнив требования, переключиться на что-то другое. Однако, разумное планирование позволит сэкономить немало времени и средств.
Вот признаки проектов, для которых идеально подойдут SQL-базы:
- Имеются логические требования к данным, которые могут быть определены заранее.
- Очень важна целостность данных.
- Нужна основанная на устоявшихся стандартах, хорошо зарекомендовавшая себя технология, используя которую можно рассчитывать на большой опыт разработчиков и техническую поддержку.
А вот свойства проектов, для которых подойдёт что-то из сферы NoSQL:
- Требования к данным нечёткие, неопределённые, или развивающиеся с развитием проекта.
- Цель проекта может корректироваться со временем, при этом важна возможность немедленного начала разработки.
- Одни из основных требований к базе данных — скорость обработки данных и масштабируемость.
В итоге хочется сказать, что в современном мире нет противостояния между реляционными и нереляционными базами данных. Вместо этого стоит говорить об их совместном использовании для решения задач, на которых та или иная технология показывает себя лучше всего. Кроме того, всё сильнее наблюдается интеграция этих технологий друг в друга. Например, Microsoft, Oracle и Teradata сейчас предлагают некоторые формы интеграции с Hadoop для подключения аналитических инструментов, основанных на SQL, к миру неструктурированных больших данных.
Уважаемые читатели, а вам приходилось выбирать системы управления базами данных для собственных проектов? Если да — поделитесь пожалуйста опытом, расскажите, что и почему вы в итоге выбрали.
Что такое реляционная база данных
Реляционная база данных — это тип базы данных, который хранит и обеспечивает доступ к точкам данных, которые связаны друг с другом. Реляционные базы данных основаны на реляционной модели, интуитивно понятном и простом способе представления данных в таблицах. В реляционной базе данных каждая строка в таблице представляет собой запись с уникальным идентификатором, который называется ключом . Столбцы таблицы содержат атрибуты данных, и каждая запись обычно имеет значение для каждого атрибута, что упрощает установление отношений между точками данных.
Как устроены реляционные базы данных
Реляционная модель означает, что логические структуры данных — таблицы данных, представления и индексы — отделены от физических структур хранения. Это разделение означает, что администраторы баз данных могут управлять физическим хранилищем данных, не влияя на доступ к этим данным как к логической структуре. Например, переименование файла базы данных не приводит к переименованию хранящихся в нем таблиц.
Различие между логическими и физическими также применимо к операциям с базой данных, которые представляют собой четко определенные действия, позволяющие приложениям манипулировать данными и структурами базы данных.Логические операции позволяют приложению указывать необходимый контент, а физические операции определяют, как к этим данным следует обращаться, а затем выполняют задачу.
Чтобы данные всегда были точными и доступными, реляционные базы данных следуют определенным правилам целостности. Например, правило целостности может указывать, что в таблице не допускаются повторяющиеся строки, чтобы исключить возможность попадания в базу данных ошибочной информации.
Реляционная модель
В первые годы существования баз данных каждое приложение хранило данные в своей уникальной структуре.Когда разработчики хотели создавать приложения для использования этих данных, им нужно было много знать о конкретной структуре данных, чтобы найти нужные данные. Эти структуры данных были неэффективными, их трудно было поддерживать и трудно оптимизировать для обеспечения хорошей производительности приложений. Модель реляционной базы данных была разработана для решения проблемы множественных произвольных структур данных.
Реляционная модель предоставляет стандартный способ представления и запроса данных, который может использоваться любым приложением.С самого начала разработчики осознавали, что главная сила модели реляционной базы данных заключается в использовании таблиц, которые представляют собой интуитивно понятный, эффективный и гибкий способ хранения структурированной информации и доступа к ней.
Со временем появилась еще одна сильная сторона реляционной модели: разработчики начали использовать язык структурированных запросов (SQL) для записи и запроса данных в базе данных. В течение многих лет SQL широко использовался как язык запросов к базам данных. Основанный на реляционной алгебре, SQL предоставляет внутренне согласованный математический язык, который упрощает повышение производительности всех запросов к базе данных.Для сравнения, другие подходы должны определять индивидуальные запросы.
Преимущества реляционных баз данных
Простая, но мощная реляционная модель используется организациями всех типов и размеров для удовлетворения самых разнообразных информационных потребностей. Реляционные базы данных используются для отслеживания запасов, обработки транзакций электронной торговли, управления огромными объемами критически важной информации о клиентах и многого другого. Реляционная база данных может быть рассмотрена для любых информационных потребностей, в которых точки данных связаны друг с другом и должны управляться безопасным, согласованным способом на основе правил.
Реляционные базы данных существуют с 1970-х годов. Сегодня преимущества реляционной модели по-прежнему делают ее наиболее широко принятой моделью для баз данных.
Согласованность данных
Реляционная модель лучше всего поддерживает согласованность данных между приложениями и копиями баз данных (так называемые экземпляры ). Например, когда клиент кладет деньги в банкомат, а затем просматривает баланс счета на мобильном телефоне, клиент ожидает, что этот депозит немедленно отразится в обновленном балансе счета.Реляционные базы данных отличаются такой согласованностью данных, гарантируя, что несколько экземпляров базы данных всегда будут иметь одни и те же данные.
Для других типов баз данных сложно поддерживать такой уровень своевременной согласованности с большими объемами данных. Некоторые недавние базы данных, такие как NoSQL, могут обеспечить только «конечную согласованность». Согласно этому принципу, когда база данных масштабируется или когда несколько пользователей получают доступ к одним и тем же данным одновременно, данным требуется некоторое время, чтобы «наверстать упущенное».Конечная согласованность приемлема для некоторых целей, например, для ведения списков в каталоге продуктов, но для критически важных бизнес-операций, таких как транзакции корзины покупок, реляционная база данных по-прежнему остается золотым стандартом.
Обязательства и атомарность
Реляционные базы данных обрабатывают бизнес-правила и политики на очень детальном уровне, со строгими политиками около обязательства (то есть постоянное изменение базы данных). Например, рассмотрим базу данных инвентаризации, в которой отслеживаются три части, которые всегда используются вместе.Когда одна часть вытаскивается из инвентаря, две другие также нужно вытащить. Если одна из трех частей недоступна, не следует извлекать ни одну из частей — все три части должны быть доступны до того, как база данных сделает какие-либо обязательства. Реляционная база данных не выполняет фиксацию для одной части, пока не знает, что может выполнить фиксацию для всех трех. Эта возможность многогранной приверженности называется атомарностью . Атомарность — ключ к сохранению точности данных в базе данных и обеспечению их соответствия правилам, положениям и политикам бизнеса.
Хранимые процедуры и реляционные базы данных
Доступ к данным включает в себя множество повторяющихся действий. Например, простой запрос для получения информации из таблицы данных может потребоваться повторить сотни или тысячи раз для получения желаемого результата. Эти функции доступа к данным требуют определенного кода для доступа к базе данных. Разработчики приложений не хотят писать новый код для этих функций в каждом новом приложении. К счастью, реляционные базы данных позволяют хранить хранимые процедуры, которые представляют собой блоки кода, к которым можно получить доступ с помощью простого вызова приложения.Например, одна хранимая процедура может обеспечить согласованную маркировку записей для пользователей нескольких приложений. Хранимые процедуры также могут помочь разработчикам гарантировать, что определенные функции данных в приложении реализованы определенным образом.
Блокировка и параллелизм базы данных
Конфликты могут возникать в базе данных, когда несколько пользователей или приложений пытаются одновременно изменить одни и те же данные. Методы блокировки и параллелизма снижают вероятность конфликтов при сохранении целостности данных.
Блокировка предотвращает доступ других пользователей и приложений к данным во время их обновления. В некоторых базах данных блокировка применяется ко всей таблице, что отрицательно сказывается на производительности приложения. Другие базы данных, такие как реляционные базы данных Oracle, применяют блокировки на уровне записей, оставляя другие записи в таблице доступными, что помогает обеспечить лучшую производительность приложений.
Параллелизм управляет действиями, когда несколько пользователей или приложений одновременно вызывают запросы к одной и той же базе данных.Эта возможность обеспечивает правильный доступ для пользователей и приложений в соответствии с политиками, определенными для управления данными.
На что обращать внимание при выборе реляционной базы данных
Программное обеспечение, используемое для хранения, управления, запроса и извлечения данных, хранящихся в реляционной базе данных, называется системой управления реляционными базами данных (RDBMSf) . РСУБД обеспечивает интерфейс между пользователями, приложениями и базой данных, а также административные функции для управления хранением данных, доступом и производительностью.
При выборе между типами баз данных и продуктами реляционных баз данных ваше решение может зависеть от нескольких факторов. Выбранная вами СУБД будет зависеть от потребностей вашего бизнеса. Задайте себе следующие вопросы:
- Каковы наши требования к точности данных? Будет ли хранение и точность данных зависеть от бизнес-логики? Есть ли у наших данных строгие требования к точности (например, финансовые данные и правительственные отчеты)?
- Нужна ли масштабируемость? Каков масштаб данных, которыми нужно управлять, и каков его ожидаемый рост? Будет ли модель базы данных должна поддерживать зеркальные копии базы данных (как отдельные экземпляры) для масштабируемости? Если да, может ли он поддерживать согласованность данных в этих экземплярах?
- Насколько важен параллелизм? Потребуется ли одновременный доступ к данным нескольким пользователям и приложениям? Поддерживает ли программное обеспечение базы данных параллелизм при защите данных?
- Каковы наши потребности в производительности и надежности? Нужен ли нам высокопроизводительный и надежный продукт? Каковы требования к производительности запроса-ответа? Каковы обязательства поставщика в отношении соглашений об уровне обслуживания (SLA) или незапланированных простоев?
Реляционная база данных будущего: самоуправляемая база данных
.Что такое реляционные базы данных
Реляционная база данных
Реляционная база данных — это СУБД, которая представляет данные в табличной форме строк и столбцов. Таблица — это представление сущности. Таблица — это комбинация столбцов и строк. Каждый столбец в таблице представляет атрибут объекта, также известный как поля или свойства. Каждая строка в таблице представляет собой запись, данные, связанные с сущностью.
Следующие табличные данные представляют объект «Клиент» с такими атрибутами, как идентификатор, название компании, имя контактного лица, должность контактного лица, адрес, город и т. Д.Каждый столбец таблицы является атрибутом (или свойством) объекта Customer. Каждая строка таблицы представляет данные о клиенте.
Каждый столбец таблицы имеет тип данных, который представляет тип данных, которые столбец может хранить. Например, название компании или имя клиента — это тип varchar, который может хранить символы, но почтовый индекс является числовым полем и может хранить только числа.
История реляционных баз данных
Концепция реляционных баз данных была введена Э.Ф. Кодд из IBM в 1970 году в своей исследовательской работе «Реляционная модель данных для больших общих банков данных». Позже в 1974 году IBM представила System R, которая была прототипом СУБД.
База данных Oracle была первой коммерческой СУБД, выпущенной в 1979 году компанией Relational Software, ныне Oracle Corporation.
Сегодня РСУБД — самые популярные системы управления базами данных в мире.
Отношения в РСУБД
Реляционные базы данных являются реляционными из-за особенностей их отношений.СУБД поддерживает отношения между их объектами и их атрибутами. Столбец таблицы может иметь связь с другим столбцом другой таблицы.
Давайте посмотрим на следующие 4 таблицы базы данных Northwind, Customer. Заказы, детали заказа и продукты.
На приведенной выше диаграмме у клиента может быть несколько заказов, и в каждом заказе может быть несколько продуктов. Связь между двумя столбцами таблицы представлена
Первичные ключи и внешние ключи
Таблица в РСУБД обычно имеет уникальный закрытый ключ (PK), который однозначно идентифицирует каждую строку в таблице.Закрытый ключ может быть одним столбцом или комбинацией нескольких столбцов. Первичный ключ гарантирует уникальность каждой строки в таблице. PK также используется как ограничение для обеспечения целостности данных. Таблица может содержать только один первичный ключ.
Внешний ключ (FK) — это столбец или комбинация столбцов, которые используются для создания связи между двумя таблицами. Когда на PK имеется ссылка в другой таблице, он называется внешним ключом в указанной таблице.
Операции РСУБД
РСУБД позволяют выполнять операции создания, чтения, обновления и удаления (CRUD).
- Операция создания включает в себя вставку новых записей в таблицу.
- Операция чтения включает выбор и чтение записей из таблицы.
- Операция обновления включает обновление значений существующих записей в таблице.
- Операция удаления включает удаление существующих записей из таблицы.
SQL и реляционные базы данных
Язык структурированных запросов (SQL) — это язык, который используется для запроса, обновления и удаления данных в системах управления реляционными базами данных (СУБД).SQL — это стандартный язык запросов. Запросы языка SQL также известны как команды SQL или операторы SQL.
SQL предоставляет команды DML (язык обработки данных), которые используются для вставки, обновления и удаления данных. Общие команды DML — это INSERT, UPDATE и DELETE.
- SQL DDL (язык определения данных) команды используются для управления объектами базы данных, такими как сама база данных, таблицы и другие объекты.
- SQL Команды DCL (Data Control Language) используются для управления доступом к базе данных, включая привилегии для объектов базы данных.Общие команды DCL — это GRANT и REVOKE.
- Команда SQL DQL (Data Query Language) позволяет нам запускать запросы к базе данных и получать данные из базы данных. Команда DQL — это SELECT.
Популярные реляционные базы данных
Существуют сотни СУБД. Вот список самых популярных СУБД.
- Oracle
- MySQL
- SQL Server
- PostgreSQL
- IBM DB2
- Microsoft Access
- SQLite
- MariaDB
- Informix
- Azure SQL
Oracle
разработано Oracle Corporation — самая популярная система реляционных баз данных (СУБД).Oracle не только является СУБД, но также предоставляет функциональные возможности для облака, хранилища документов, СУБД Graph, хранилища ключей и значений, BLOG и хранилищ PDF. В последнее время. Oracle только что анонсировала автономную функцию, которая позволяет базе данных быть интеллектуальной и управляемой.Текущая версия Oracle Database — 18c.
База данных Oracle — это реляционная база данных (СУБД). Реляционные базы данных хранят данные в табличной форме строк и столбцов. Столбец таблицы базы данных представляет атрибуты объекта, а строки таблицы хранят записи.РСУБД, которая реализует объектно-ориентированные функции, такие как определяемые пользователем типы, наследование и полиморфизм, называется системой управления объектно-реляционной базой данных (ORDBMS). Oracle Database расширила реляционную модель до объектно-реляционной модели, что позволяет хранить сложные бизнес-модели в реляционной базе данных.
Одной из характеристик СУБД является независимость физического хранилища данных от логических структур данных.
В Oracle Database схема базы данных — это набор логических структур данных или объектов схемы.Пользователь базы данных владеет схемой базы данных, имя которой совпадает с именем пользователя.
Объекты схемы — это созданные пользователем структуры, которые напрямую ссылаются на данные в базе данных. База данных поддерживает множество типов объектов схемы, наиболее важными из которых являются таблицы и индексы.
Объект схемы — это один тип объекта базы данных. Некоторые объекты базы данных, такие как профили и роли, не находятся в схемах.
MySQL
MySQL — самая популярная в мире база данных с открытым исходным кодом и бесплатная.MySQL был приобретен Oracle в рамках приобретения Sun Microsystems в 2009 году.
В MySQL часть SQL в слове «MySQL» означает «язык структурированных запросов». SQL — это наиболее распространенный стандартизированный язык, используемый для доступа к базам данных. В зависимости от среды программирования вы можете вводить SQL напрямую (например, для создания отчетов), встраивать операторы SQL в код, написанный на другом языке, или использовать API для конкретного языка, который скрывает синтаксис SQL.
Ключевые свойства MySQL:
- MySQL — это система управления базами данных.
- Базы данных MySQL реляционные.
- Программное обеспечение MySQL с открытым исходным кодом.
- Сервер базы данных MySQL очень быстрый, надежный, масштабируемый и простой в использовании.
- MySQL Server работает в клиент-серверных или встроенных системах.
SQL Server
База данных SQL Server, разработанная Microsoft, является одной из самых популярных баз данных в мире. Первоначально запущенный в 1989 году и написанный на C, C ++, SQL Server сейчас широко используется в крупных компаниях.SQL Server также является частью облака Microsoft Azure как Azure SQL Server. Текущая версия SQL Server — SQL Server 2019.
Подобно Oracle и MySQL, SQL Server также является системой управления реляционными базами данных (RDBMS).
Вот некоторые популярные выпуски SQL Server:
База данных SQL Azure — это облачная версия Microsoft SQL Server, представленная как платформа как сервисное предложение в Microsoft Azure.
Compact (SQL CE), компактная версия — это встроенный механизм базы данных.В отличие от других выпусков SQL Server, механизм SQL CE основан на SQL Mobile (изначально предназначен для использования с портативными устройствами) и не использует одни и те же двоичные файлы. Из-за своего небольшого размера (размер DLL 1 МБ) он имеет значительно уменьшенный набор функций по сравнению с другими выпусками. Например, он поддерживает подмножество стандартных типов данных, не поддерживает хранимые процедуры, представления или пакеты с несколькими операторами (среди других ограничений). Он ограничен максимальным размером базы данных 4 ГБ и не может быть запущен как служба Windows, Compact Edition должен размещаться в приложении, использующем его.Версия 3.5 включает поддержку служб синхронизации ADO.NET. SQL CE не поддерживает подключение ODBC, в отличие от собственно SQL Server.
SQL Server Enterprise Edition — это основная база данных, которую покупают большинство компаний, которая поставляется с каждой функцией продукта.
SQL Server Developer Edition включает те же функции, что и SQL Server Enterprise Edition, но ограничен только одной лицензией, которая используется разработчиками программного обеспечения для целей разработки.
PostgreSQL
PostgreSQL — это мощная объектно-реляционная база данных с открытым исходным кодом, которая использует и расширяет язык SQL в сочетании с множеством функций, обеспечивающих безопасное хранение и масштабирование самых сложных рабочих нагрузок с данными.Истоки PostgreSQL восходят к 1986 году в рамках проекта POSTGRES в Калифорнийском университете в Беркли и более 30 лет активно развиваются на базовой платформе. Текущая версия PostgreSQL — 11.4, выпущенная 20 июня 2019 года. PostgreSQL написан на языке C и управляется глобальной группой разработчиков PostgreSQL.
PostgreSQL известен своей архитектурой, надежностью, целостностью данных, надежным набором функций, расширяемостью и приверженностью сообщества разработчиков ПО с открытым исходным кодом к стабильной поставке эффективных и инновационных решений.
IBM DB2
База данных IBM Db2 — это реляционная база данных, которая обеспечивает расширенные возможности управления данными и аналитики для транзакционных рабочих нагрузок и рабочих нагрузок хранилища. Эта оперативная база данных предназначена для обеспечения высокой производительности, действенной аналитической информации, доступности и надежности данных, и она поддерживается в операционных системах Linux, Unix и Windows.
Программное обеспечение базы данных Db2 включает расширенные функции, такие как технология in-memory, расширенные инструменты управления и разработки, оптимизация хранения, управление рабочей нагрузкой, сжатие с возможностью действий и постоянная доступность данных.
В версии 11.5 Db2 включает в себя дополнительные функции искусственного интеллекта, чтобы предприятия могли использовать перспективные технологии обработки данных и искусственного интеллекта, чтобы сохранить конкурентное преимущество. Теперь вы можете использовать одну платформу, основанную на ИИ и созданную для ИИ, чтобы оптимизировать производительность и доступность, одновременно давая возможность вашим специалистам по данным получать более глубокую информацию.
SQLite
SQLite — это библиотека на языке C, которая реализует небольшой, быстрый, автономный, высоконадежный, полнофункциональный механизм базы данных SQL.SQLite — это наиболее часто используемый механизм баз данных в мире. SQLite встроен во все мобильные телефоны и большинство компьютеров и входит в состав множества других приложений, которые люди используют каждый день.
Формат файла SQLite является стабильным, кроссплатформенным и обратно совместимым, и разработчики обязуются поддерживать его в таком виде, по крайней мере, до 2050 года. Файлы базы данных SQLite обычно используются в качестве контейнеров для передачи богатого контента между системами и как формат долгосрочного архивирования данных.Активно используется более 1 триллиона баз данных SQLite.
MariaDB
MariaDB Server — один из самых популярных серверов баз данных в мире. Он создан исходными разработчиками MySQL и гарантированно останется открытым исходным кодом. Среди известных пользователей — Википедия, WordPress.com и Google.
MariaDB превращает данные в структурированную информацию в широком спектре приложений, от банковских до веб-сайтов.Это усовершенствованная замена MySQL. MariaDB используется, потому что он быстрый, масштабируемый и надежный, с богатой экосистемой механизмов хранения, плагинов и многих других инструментов, что делает его очень универсальным для самых разных случаев использования.
MariaDB разработана как программное обеспечение с открытым исходным кодом и как реляционная база данных, она предоставляет интерфейс SQL для доступа к данным. Последние версии MariaDB также включают функции ГИС и JSON.
Informix
IBM Informix® — это быстрая и гибкая база данных с возможностью бесшовной интеграции SQL, NoSQL / JSON, временных рядов и пространственных данных.Ключевые особенности Informix включают аналитику в реальном времени, постоянные транзакции и простоту.
Azure SQL
База данных Azure SQL — это универсальная реляционная база данных как услуга (DBaaS), основанная на последней стабильной версии ядра СУБД Microsoft SQL Server. База данных SQL — это высокопроизводительная, надежная и безопасная облачная база данных, которую вы можете использовать для создания управляемых данными приложений и веб-сайтов на выбранном вами языке программирования без необходимости управлять инфраструктурой.
Azure SQL полностью управляется, и плата взимается по факту использования. Azure SQL обеспечивает повышенную безопасность с помощью проверки подлинности Azure AD, виртуальных сетей, брандмауэров и подключений с постоянным шифрованием. Выявление угроз и уязвимостей с помощью встроенных средств безопасности.
Другие статьи по теме
Вот еще несколько статей, которые могут вас заинтересовать:
Ссылки
https: //en.wikipedia.org / wiki / Relational_database
https://db-engines.com/en/ranking/relational+dbms
.реляционных баз данных | Обзор модели базы данных
Объектно-ориентированная модель базы данных обеспечивает хранение данных как объектов. Объекты модулируются так же, как объектно-ориентированное программирование . Объект, определенный как сущность, содержит:
- Свойства (атрибуты), необходимые для описания сущности
- Связи (отношения) с другими объектами
- Функции, обеспечивающие доступ к сохраненным данным (методам)
- Объект может быть определен как группа данных, интерфейс которых может использоваться для доступа к данным.Объекты — это абстрактных типов данных .
Объектно-ориентированная система управления базами данных (ODBMS) автоматически присваивает идентификатор каждому объекту. Это позволяет однозначно идентифицировать объект и обращаться к нему с помощью методов. Этот идентификатор объекта не зависит от состояния, то есть не связан со значениями объекта. Это позволяет присвоить двум объектам с одинаковыми данными (одинаковым статусом) два разных идентификатора. Это четко отличает объектно-ориентированную модель базы данных от реляционной модели, в которой каждый кортеж можно идентифицировать по его данным (например,грамм. по первичному ключу).
Еще одна характеристика объектно-ориентированной модели базы данных — инкапсуляция данных . Доступ к сохраненным данным можно получить только с помощью ранее определенных методов. Данные, заключенные в объект, затем защищены от обвинений через неопределенные интерфейсы.
Структуры базы данных определены в объектно-ориентированной модели базы данных с использованием иерархической системы классификации . В объектно-ориентированном программировании класс — это набор объектов с одинаковыми характеристиками.Каждый класс объекта основан на определении класса. Эта схема определяет атрибуты и методы всех объектов в классе и, таким образом, определяет, как они создаются и изменяются.
Пользователи взаимодействуют с ODBMS, используя язык запросов на основе SQL для объектных баз данных: язык объектных запросов (OQL) . Результатом запроса OQL является не набор результатов, как в случае с SQL, а список тех объектов, которые удовлетворяют условиям оператора OQL.
Известными реализациями объектно-ориентированной модели базы данных являются Realm, ZODB и Perst.
Объектно-ориентированные базы данных были разработаны как решение проблемы при разработке приложений под названием объектно-реляционное несоответствие импеданса .
Если объекты из объектно-ориентированного языка программирования (например, C #, C ++ или Java) должны храниться в реляционной базе данных, неизбежно возникнет несовместимость из-за фундаментальных различий между двумя парадигмами программирования.
- Реляционные базы данных не поддерживают объектно-ориентированные концепции, такие как классы и наследование
- Идентификация объекта, не зависящая от состояния, не может быть реализована в модели реляционной базы данных
- Механизм защиты инкапсуляции данных недоступен в модели реляционной базы данных
Один Подход, позволяющий избежать этих проблем несовместимости, заключается в том, чтобы отказаться от реляционных баз данных и использовать вместо них объектную базу данных в объектно-ориентированном прикладном программировании.Однако это неизбежно сопровождается недостатком, заключающимся в том, что данные, инкапсулированные в объектах, недоступны независимо от связанного приложения. К этому следует добавить низкого распределения объектных баз данных . Большинство инструментов и интерфейсов для анализа наборов данных по-прежнему предназначены для реляционных баз данных и не поддерживают объектно-ориентированную модель данных.
Однако разработчики приложений, которые не хотят отказываться от преимуществ реляционного хранения данных, могут компенсировать несовместимость с помощью объектно-реляционных преобразователей (преобразователей O / R). Функции объектно-реляционного сопоставления (ORM) реализованы в библиотеках. Они создают уровень абстракции между объектно-ориентированным приложением и данными, хранящимися в таблицах.
Многие производители реляционных баз данных также снабжают свои продукты функциями, которые компенсируют несовместимость в объектно-ориентированном программировании. Такие системы баз данных известны как «объектно-реляционные».
.Реляционные базы данных против нереляционных баз данных
Я вижу много путаницы в отношении места и назначения многих новых решений для баз данных («базы данных NoSQL») по сравнению с решениями для реляционных баз данных, которые существуют уже много лет. Итак, позвольте мне попытаться объяснить различия и лучшие варианты использования для каждого.
Сначала давайте разберем эти решения для баз данных на две группы:
1) Реляционные базы данных , которые также можно назвать системами управления реляционными базами данных (СУБД) или базами данных SQL.Наиболее популярными из них являются Microsoft SQL Server, Oracle Database, MySQL и IBM DB2. Эти СУБД в основном используются в сценариях крупных предприятий, за исключением MySQL, который в основном используется для хранения данных для веб-приложений, обычно как часть популярного стека LAMP (Linux, Apache, MySQL, PHP / Python / Perl).
2) Нереляционные базы данных , также называемые базами данных NoSQL, наиболее популярными из которых являются MongoDB, DocumentDB, Cassandra, Coachbase, HBase, Redis и Neo4j.Эти базы данных обычно сгруппированы в четыре категории: хранилища ключей и значений, хранилища графиков, хранилища столбцов и хранилища документов (см. Типы баз данных NoSQL).
Все реляционные базы данных могут использоваться для управления приложениями, ориентированными на транзакции (OLTP), и большинство нереляционных баз данных, относящихся к категориям «Хранилища документов» и «Хранилища столбцов», также могут использоваться для OLTP, что усугубляет путаницу. Базы данных OLTP можно рассматривать как «оперативные» базы данных, характеризующиеся частыми короткими транзакциями, которые включают обновления и касаются небольшого объема данных, и где параллелизм тысяч транзакций очень важен (например, банковские приложения и онлайн-бронирование).Целостность данных очень важна, поэтому они поддерживают транзакции ACID (атомарность, согласованность, изоляция, надежность). Это противоположно хранилищам данных, которые считаются «аналитическими» базами данных, характеризующимися длинными и сложными запросами, которые затрагивают большой объем данных и требуют много ресурсов. Обновления нечасты. Примером может служить анализ продаж за последний год.
Реляционные базы данных обычно работают со структурированными данными, в то время как нереляционные базы данных обычно работают с полуструктурированными данными (т.е. XML, JSON).
Рассмотрим каждую группу подробнее:
Реляционные базы данных
Реляционная база данных организована на основе реляционной модели данных, предложенной Э. Ф. Коддом в 1970 году. Эта модель организует данные в одну или несколько таблиц (или «отношений») строк и столбцов с уникальным ключом для каждой строки. Как правило, каждый тип сущности, описанный в базе данных, имеет свою собственную таблицу со строками, представляющими экземпляры этого типа сущности, и столбцами, представляющими значения, приписываемые этому экземпляру.Поскольку каждая строка в таблице имеет свой собственный уникальный ключ, строки в таблице могут быть связаны со строками в других таблицах, сохраняя уникальный ключ строки, с которой он должен быть связан (где такой уникальный ключ известен как «внешний ключ »). Кодд показал, что отношения данных произвольной сложности могут быть представлены с помощью этого простого набора концепций.
Практически все системы реляционных баз данных используют SQL (язык структурированных запросов) в качестве языка для запросов и обслуживания базы данных.
Причины доминирования реляционных баз данных: простота, надежность, гибкость, производительность, масштабируемость и совместимость при управлении общими данными.
Но чтобы предложить все это, реляционные базы данных должны быть невероятно сложными внутри. Например, относительно простой оператор SELECT может иметь десятки потенциальных путей выполнения запроса, которые оптимизатор запросов оценит во время выполнения. Все это скрыто от пользователей, но под капотом СУБД определяет лучший «план выполнения» для ответа на запросы, используя такие вещи, как стоимостные алгоритмы.
Для больших баз данных, особенно используемых для веб-приложений, основной проблемой является масштабируемость.Поскольку все больше и больше приложений создается в средах с большими рабочими нагрузками (например, Amazon), их требования к масштабируемости могут очень быстро меняться и становиться очень большими. Реляционные базы данных хорошо масштабируются, но обычно только тогда, когда это масштабирование происходит на одном сервере («масштабирование»). Когда емкость этого отдельного сервера будет достигнута, вам необходимо «масштабировать» и распределить эту нагрузку между несколькими серверами, переходя к так называемым распределенным вычислениям. Это когда сложность реляционных баз данных начинает вызывать проблемы с их потенциалом масштабирования.Если вы попытаетесь масштабироваться до сотен или тысяч серверов, сложности станут огромными. Характеристики, которые делают реляционные базы данных такими привлекательными, те же самые, что также резко снижает их жизнеспособность как платформ для больших распределенных систем.
Нереляционные базы данных
База данных NoSQL предоставляет механизм для хранения и извлечения данных, которые моделируются средствами, отличными от табличных отношений, используемых в реляционных базах данных.
Мотивы для этого подхода включают:
- Простота конструкции .Отсутствие необходимости иметь дело с «несоответствием импеданса» между объектно-ориентированным подходом к написанию приложений и таблицами и строками на основе схемы в реляционной базе данных. Например, хранение всей информации о заказе клиента в одном документе вместо того, чтобы объединять множество таблиц вместе, что приводит к меньшему количеству кода для написания, отладки и обслуживания
- Лучшее «горизонтальное» масштабирование на кластеры машин, которое решает проблему, когда количество одновременных пользователей резко возрастает для приложений, доступных через Интернет и мобильные устройства.Использование документов значительно упрощает масштабирование, так как вся информация для этого заказа клиента хранится в одном месте, а не на нескольких таблицах. Базы данных NoSQL автоматически распределяют данные по серверам, не требуя изменения приложений (автоматическое разделение), что означает, что они изначально и автоматически распределяют данные по произвольному количеству серверов, не требуя, чтобы приложение даже знало о составе пула серверов. Загрузка данных и запросов автоматически распределяется между серверами, и когда сервер выходит из строя, его можно быстро и прозрачно заменить без прерывания работы приложения
- Более точный контроль доступности .Серверы можно добавлять или удалять без простоя приложений. Большинство баз данных NoSQL поддерживают репликацию данных, сохраняя несколько копий данных в кластере или даже в центрах обработки данных, чтобы обеспечить высокую доступность и аварийное восстановление.
- Для простого сбора всех видов данных «Big Data» , которые включают неструктурированные и полуструктурированные данные. Обеспечение гибкой базы данных, которая может легко и быстро вмещать любой новый тип данных и не нарушается изменениями структуры контента.Это связано с тем, что база данных документов не имеет схемы, что позволяет вам свободно добавлять поля в документы JSON без предварительного определения изменений (схема при чтении вместо схемы при записи). У вас могут быть документы с другим количеством полей, чем в других документах. Например, история болезни пациента, которая может содержать или не содержать поля со списком аллергий
- Скорость. Структуры данных, используемые базами данных NoSQL (т. Е. Документы JSON), отличаются от структур, используемых по умолчанию в реляционных базах данных, что делает многие операции в NoSQL более быстрыми, чем в реляционных базах данных, из-за отсутствия необходимости объединять таблицы (за счет увеличения объема памяти из-за дублирования данных — но в настоящее время место для хранения настолько дешево, что обычно это не проблема).Фактически, большинство баз данных NoSQL даже не поддерживают соединения .
- Стоимость . Базы данных NoSQL обычно используют кластеры дешевых обычных серверов, в то время как СУБД, как правило, полагаются на дорогие проприетарные серверы и системы хранения. Кроме того, лицензии на системы РСУБД могут быть довольно дорогими, в то время как многие базы данных NoSQL имеют открытый исходный код и, следовательно, бесплатны.
Конкретная пригодность данной базы данных NoSQL зависит от проблемы, которую она должна решить.
Базы данных NoSQL все чаще используются в больших данных и веб-приложениях реального времени.Они стали популярными с появлением Интернета, когда базы данных перешли от нескольких сотен пользователей во внутреннем приложении компании до тысяч или миллионов пользователей в веб-приложении. Системы NoSQL также называют «Не только SQL», чтобы подчеркнуть, что они также могут поддерживать языки запросов, подобные SQL.
Многие хранилища NoSQL компрометируют согласованность (в смысле теоремы CAP) в пользу доступности и устойчивости к разделению. Некоторые причины, препятствующие внедрению хранилищ NoSQL, включают использование языков запросов низкого уровня, отсутствие стандартизованных интерфейсов и огромные инвестиции в существующий SQL.Кроме того, в большинстве хранилищ NoSQL отсутствуют настоящие транзакции ACID или они поддерживают транзакции только при определенных обстоятельствах и на определенных уровнях (например, на уровне документа). Наконец, СУБД обычно намного проще в использовании, поскольку у них есть графический интерфейс, в котором многие решения NoSQL используют интерфейс командной строки.
Сравнение двух
Одним из наиболее серьезных ограничений реляционных баз данных является то, что каждый элемент может содержать только один атрибут. Если мы используем пример банка, каждый аспект взаимоотношений клиента с банком хранится в виде отдельных строк в отдельных таблицах.Таким образом, основные данные о клиенте находятся в одной таблице, данные счета — в другой, данные о ссуде — в третьей, инвестиции — в другой таблице и так далее. Все эти таблицы связаны друг с другом с помощью таких отношений, как первичные и внешние ключи.
Нереляционные базы данных, в частности хранилища ключей и значений или пары ключ-значение, радикально отличаются от этой модели. Пары ключ-значение позволяют хранить несколько связанных элементов в одной «строке» данных в одной таблице.Мы помещаем слово «строка» в кавычки, потому что строка здесь на самом деле не то же самое, что строка в реляционной таблице. Например, в нереляционной таблице для того же банка каждая строка будет содержать данные клиента, а также сведения об их счете, ссуде и инвестициях. Все данные, относящиеся к одному клиенту, удобно хранить вместе как одну запись.
Кажется, что это явно лучший метод хранения данных, но у него есть серьезный недостаток: хранилища «ключ-значение», в отличие от реляционных баз данных, не могут устанавливать отношения между элементами данных.Например, в нашей базе данных ключ-значение все данные о клиенте (имя, социальное страхование, адрес, номер счета, номер обработки ссуды и т. Д.) Будут храниться как одна запись данных (вместо того, чтобы храниться в нескольких таблицах, как в реляционная модель). Операции клиента (снятие средств со счета, депозиты со счетов, погашение ссуд, банковские сборы и т. Д.) Также будут храниться в виде отдельной записи данных.
В реляционной модели есть встроенный и надежный метод обеспечения и применения бизнес-логики и правил на уровне базы данных, например, что снятие средств взимается с правильного банковского счета через первичные и внешние ключи.В хранилищах «ключ-значение» эта ответственность полностью ложится на логику приложения, и многим людям очень неудобно перекладывать эту важную ответственность только на приложение. Это одна из причин, по которой реляционные базы данных будут продолжать использоваться.
Однако, когда дело доходит до веб-приложений, использующих базы данных, аспект строгого соблюдения бизнес-логики часто не является главным приоритетом. Наивысший приоритет — это способность обслуживать большое количество пользовательских запросов, которые обычно являются запросами только для чтения.Например, на таком сайте, как eBay, большинство пользователей просто просматривают опубликованные элементы (операции только для чтения). Только часть этих пользователей фактически размещает ставки или резервирует товары (операции чтения-записи). И помните, мы говорим о миллионах, а иногда и миллиардах просмотров страниц в день. Администраторы сайта eBay больше заинтересованы в быстром времени отклика, чтобы обеспечить более быструю загрузку страниц для пользователей сайта, чем в традиционных приоритетах соблюдения бизнес-правил или обеспечении баланса между чтением и записью.
Базы данных реляционной модели можно настроить и настроить для выполнения крупномасштабных операций только для чтения через хранилище данных и, таким образом, потенциально обслуживать большое количество пользователей, которые запрашивают большой объем данных, особенно при использовании реляционных архитектур MPP, таких как Analytics Platform System, Teradata, Oracle Exadata или IBM Netezza, которые поддерживают масштабирование. Как упоминалось ранее, хранилища данных отличаются от типичных баз данных тем, что они используются для более сложного анализа данных.Этим она отличается от транзакционной (OLTP) базы данных, основное назначение которой — поддержка операционных систем и предоставление повседневных небольших отчетов.
Однако реальная проблема заключается в отсутствии масштабируемости реляционной модели при работе с приложениями OLTP или любым решением с большим количеством индивидуальных операций записи, что является областью реляционных архитектур SMP. Вот где действительно могут проявить себя нереляционные модели. Они могут легко распределять свои данные по десяткам, сотням, а в крайних случаях (например, поиск Google) даже тысячам серверов.Поскольку каждый сервер обрабатывает лишь небольшой процент от общего количества запросов от пользователей, время ответа очень хорошее для каждого отдельного пользователя. Хотя эта модель распределенных вычислений может быть построена для реляционных баз данных, реализовать ее очень сложно, особенно при большом количестве операций записи (например, OLTP), требующих таких методов, как сегментирование, которое обычно требует значительного кодирования вне бизнес-логики приложения. Это связано с тем, что реляционная модель настаивает на целостности данных на всех уровнях, которую необходимо поддерживать, даже когда к данным получают доступ и изменяют несколько разных серверов.Это причина того, что нереляционная модель является предпочтительной архитектурой для веб-приложений, таких как облачные вычисления и социальные сети.
Итак, СУБД не страдает от горизонтального масштабирования для
.