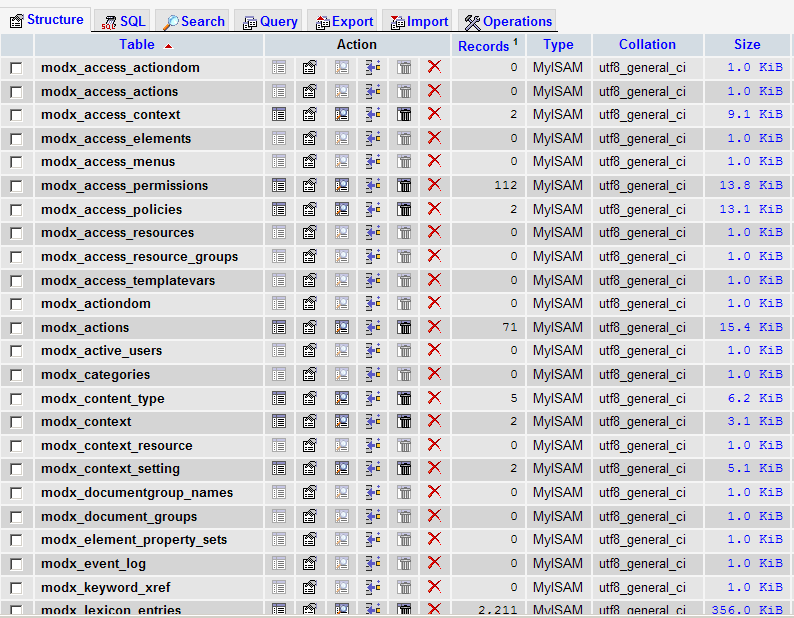
Кодирование и декодирование / Хабр
Причиной разобраться в том, как же работает UTF-8 и что такое Юникод заставил тот факт, что VBScript не имеет встроенных функций работы с UTF-8. А так как ничего рабочего не нашел, то пришлось писть/дописывать самому. Опыт на мой взгляд полезный в любом случае. Для лучшего понимания начну с теории.
О Юникоде
До появления Юникода широко использовались 8-битные кодировки, главные минусы которых очевидны:
- Всего 255 символов, да и то часть из них не графические;
- Возможность открыть документ не с той кодировкой, в которой он был создан;
- Шрифты необходимо создавать для каждой кодировки.
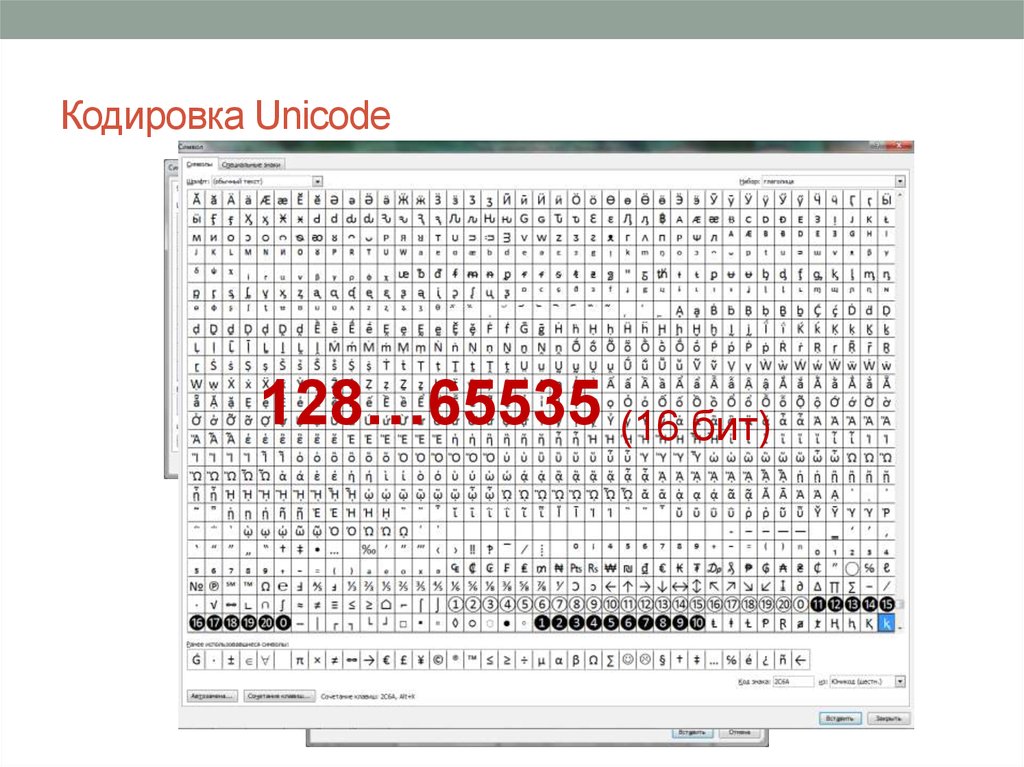
Так и было решено создать единый стандарт «широкой» кодировки, которая включала бы все символы (при чем сначала хотели в нее включить только обычные символы, но потом передумали и начали добавлять и экзотические). Юникод использует 1 112 064 кодовых позиций (больше чем 16 бит). Начало дублирует ASCII, а дальше остаток латиницы, кирилица, другие европейские и азиатские символы. Для обозначений символов используют шестнадцатеричную запись вида «U+xxxx» для первых 65k и с большим количеством цифр для остальных.
Юникод использует 1 112 064 кодовых позиций (больше чем 16 бит). Начало дублирует ASCII, а дальше остаток латиницы, кирилица, другие европейские и азиатские символы. Для обозначений символов используют шестнадцатеричную запись вида «U+xxxx» для первых 65k и с большим количеством цифр для остальных.
О UTF-8
UTF-8 является лишь представлением Юникода в 8-битном виде. Символы с кодами меньше 128 представляются одним байтом, а так как в Юникоде они повторяют ASCII, то текст написанный только этими символами будет являться текстом в ASCII. Символы же с кодами от 128 кодируются 2-мя байтами, с кодами от 2048 — 3-мя, от 65536 — 4-мя. Так можно было бы и до 6-ти байт дойти, но кодировать ими уже ничего.
0x00000000 — 0x0000007F: 0xxxxxxx 0x00000080 — 0x000007FF: 110xxxxx 10xxxxxx 0x00000800 — 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 — 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Кодируем в UTF-8
- Каждый символ превращаем в Юникод.

- Проверяем из какого символ диапазона.
- Если код символа меньше 128, то к результату добавляем его в неизменном виде.
- Если код символа меньше 2048, то берем последние 6 бит и первые 5 бит кода символа. К первым 5 битам добавляем 0xC0 и получаем первый байт последовательности, а к последним 6 битам добавляем 0x80 и получаем второй байт. Конкатенируем и добавляем к результату.
- Похожим образом можем продолжить и для больших кодов, но если символ за пределами U+FFFF придется иметь дело с UTF-16 суррогатами.

Function EncodeUTF8(s)
Dim i, c, utfc, b1, b2, b3
For i=1 to Len(s)
c = ToLong(AscW(Mid(s,i,1)))
If c < 128 Then
utfc = chr( c)
ElseIf c < 2048 Then
b1 = c Mod &h50
b2 = (c - b1) / &h50
utfc = chr(&hC0 + b2) & chr(&h80 + b1)
ElseIf c < 65536 And (c < 55296 Or c > 57343) Then
b1 = c Mod &h50
b2 = ((c - b1) / &h50) Mod &h50
b3 = (c - b1 - (&h50 * b2)) / &h2000
utfc = chr(&hE0 + b3) & chr(&h80 + b2) & chr(&h80 + b1)
Else
' Младший или старший суррогат UTF-16
utfc = Chr(&hEF) & Chr(&hBF) & Chr(&hBD)
End If
EncodeUTF8 = EncodeUTF8 + utfc
Next
End Function
Function ToLong(intVal)
If intVal < 0 Then
ToLong = CLng(intVal) + &h20000
Else
ToLong = CLng(intVal)
End If
End Function
Декодируем UTF-8
- Ищем первый символ вида 11xxxxxx
- Считаем все последующие байты вида 10xxxxxx
- Если последовательность из двух байт и первый байт вида 110xxxxx, то отсекаем приставки и складываем, умножив первый байт на 0x40.
- Аналогично для более длинных последовательностей.
- Заменяем всю последовательность на нужный символ Юникода.

Function DecodeUTF8(s)
Dim i, c, n, b1, b2, b3
i = 1
Do While i <= len(s)
c = asc(mid(s,i,1))
If (c and &hC0) = &hC0 Then
n = 1
Do While i + n <= len(s)
If (asc(mid(s,i+n,1)) and &hC0) <> &h80 Then
Exit Do
End If
n = n + 1
Loop
If n = 2 and ((c and &hE0) = &hC0) Then
b1 = asc(mid(s,i+1,1)) and &h4F
b2 = c and &h2F
c = b1 + b2 * &h50
Elseif n = 3 and ((c and &hF0) = &hE0) Then
b1 = asc(mid(s,i+2,1)) and &h4F
b2 = asc(mid(s,i+1,1)) and &h4F
b3 = c and &h0F
c = b3 * &h2000 + b2 * &h50 + b1
Else
' Символ больше U+FFFF или неправильная последовательность
c = &hFFFD
End if
s = left(s,i-1) + chrw( c) + mid(s,i+n)
Elseif (c and &hC0) = &h80 then
' Неожидаемый продолжающий байт
s = left(s,i-1) + chrw(&hFFFD) + mid(s,i+1)
End If
i = i + 1
Loop
DecodeUTF8 = s
End Function
Ссылки
Юникод на Википедии
Исходник для ASP+VBScript
UPD: Обработка ошибочных последовательностей и ошибка с типом Integer, который возвращает AscW.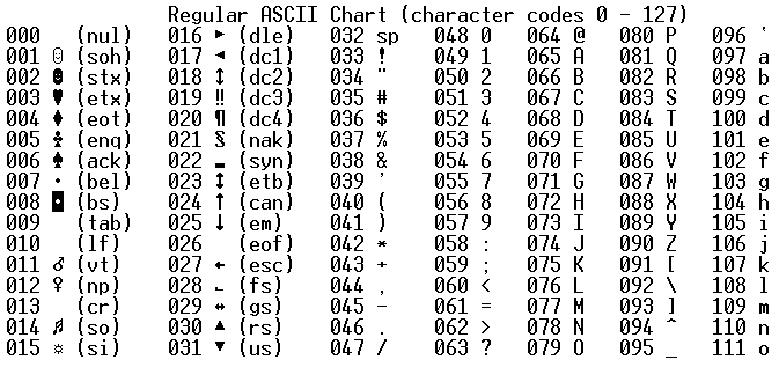
Что такое кодировка UTF-8? Руководство для непрограммистов
Что такое UTF-8?
Двоичный: как компьютеры хранят информацию
ASCII: преобразование символов в двоичные
Юникод: способ хранить каждый символ, когда-либо
UTF-8: последний кусок головоломки
Символы UTF-8 в веб-разработке
UTF-8 против UTF-16
Расшифровка мира кодировки UTF-8
Текст: его важность в Интернете само собой разумеется. Это первая буква «Т» в «HTTP», единственная буква «Т» в «HTML», и практически каждый веб-сайт каким-то образом использует ее, будь то URL-адрес, рекламный текст, обзор продукта, вирусный твит или Сообщение блога. (Всем привет!)
Но веб-текст на самом деле может быть не таким простым, как вы думаете. Рассмотрим тысячи языков, на которых сегодня говорят, или все знаки препинания и символы, которые мы можем добавить, чтобы улучшить их, или тот факт, что создаются новые смайлики, чтобы уловить каждую человеческую эмоцию.
По правде говоря, даже такая простая вещь, как текст, требует хорошо скоординированной, четко определенной системы для отображения в веб-браузерах. В этом посте я объясню основы одной технологии, которая имеет ключевое значение для текста в Интернете, UTF-8. Мы изучим основы хранения и кодирования текста и обсудим, как это помогает размещать привлекательные слова на вашем сайте.
Прежде чем мы начнем, вы должны быть знакомы с основами HTML и готовы погрузиться в легкую информатику.
Что такое UTF-8?
UTF-8 означает «Формат преобразования Unicode – 8 бит». Это пока не помогает нам, поэтому давайте вернемся к основам.
Двоичный: как компьютеры хранят информацию
Для хранения информации компьютеры используют двоичную систему. В двоичном формате все данные представлены в виде последовательностей единиц и нулей. Самая основная единица двоичного кода – это бит, который представляет собой всего лишь 1 или 0. Следующая по величине единица двоичного кода, байт, состоит из 8 бит. Пример байта – «01101011».
Следующая по величине единица двоичного кода, байт, состоит из 8 бит. Пример байта – «01101011».
Каждый цифровой актив, с которым вы когда-либо сталкивались – от программного обеспечения до мобильных приложений, от веб-сайтов до историй в Instagram – построен на этой системе байтов, которые связаны друг с другом таким образом, что это имеет смысл для компьютеров. Когда мы говорим о размерах файлов, мы имеем в виду количество байтов. Например, килобайт – это примерно тысяча байт, а гигабайт – примерно миллиард байтов.
Текст – это один из многих ресурсов, которые компьютеры хранят и обрабатывают. Текст состоит из отдельных символов, каждый из которых представлен в компьютерах строкой битов. Эти строки собираются в цифровые слова, предложения, абзацы, любовные романы и т.д.
ASCII: преобразование символов в двоичные
Американский стандартный код обмена информацией (ASCII) был ранней стандартизированной системой кодирования текста. Кодирование – это процесс преобразования символов человеческих языков в двоичные последовательности, которые могут обрабатывать компьютеры.
Библиотека ASCII включает все буквы в верхнем и нижнем регистре латинского алфавита (A, B, C…), каждую цифру от 0 до 9 и некоторые общие символы (например, /,! И?). Он присваивает каждому из этих символов уникальный трехзначный код и уникальный байт.
В таблице ниже показаны примеры символов ASCII с соответствующими кодами и байтами.
| символ | Код ASCII | БАЙТ |
| А | 065 | 01000001 |
| а | 097 | 01100001 |
| B | 066 | 01000010 |
| б | 098 | 01100010 |
| С УЧАСТИЕМ | 090 | 01011010 |
| с участием | 122 | 01111010 |
| 0 | 048 | 00110000 |
| 9 | 057 | 00111001 |
| ! | 033 | 00100001 |
| ? | 063 | 00111111 |
Подобно тому, как символы объединяются в слова и предложения в языке, двоичный код делает это в текстовых файлах. Итак, фраза «Быстрая коричневая лисица перепрыгивает через ленивого пса». в двоичном формате ASCII будет:
Итак, фраза «Быстрая коричневая лисица перепрыгивает через ленивого пса». в двоичном формате ASCII будет:
01010100 01101000 01100101 00100000 01110001 01110101 01101001 01100011 01101011 00100000 01100010 01110010 01101111 01110111 01101110 00100000 01100110 01101111 01111000 00100000 01101010 01110101 01101101 01110000 01110011 00100000 01101111 01110110 01100101 01110010 00100000 01110100 01101000 01100101 00100000 01101100 01100001 01111010 01111001 00100000 01100100 01101111 01100111 00101110
Это мало что значит для нас, людей, но это хлеб с маслом для компьютера.
Количество символов, которые может представлять ASCII, ограничено количеством доступных уникальных байтов, поскольку каждый символ получает один байт. Если вы посчитаете, то обнаружите, что существует 256 различных способов группировки восьми единиц и нулей вместе. Это дает нам 256 различных байтов или 256 способов представления символа в ASCII. Когда в 1960 году был представлен ASCII, это было нормально, поскольку разработчикам требовалось всего 128 байт для представления всех необходимых им английских символов и символов.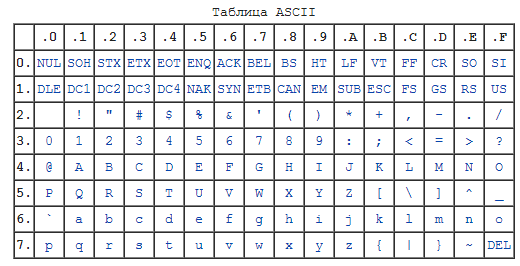
Но по мере глобального распространения компьютерных технологий компьютерные системы начали хранить текст не только на английском, но и на других языках, многие из которых использовали символы, отличные от ASCII. Были созданы новые системы для сопоставления других языков с тем же набором из 256 уникальных байтов, но использование нескольких систем кодирования было неэффективным и запутанным. Разработчикам требовался лучший способ кодирования всех возможных символов с помощью одной системы.
Юникод: способ хранить каждый символ, когда-либо
Используйте Unicode, систему кодирования, которая решает проблему пространства ASCII. Как и ASCII, Unicode присваивает каждому символу уникальный код, называемый кодовой точкой. Однако более сложная система Unicode может генерировать более миллиона кодовых точек, чего более чем достаточно для учета каждого символа на любом языке.
Юникод теперь является универсальным стандартом для кодирования всех человеческих языков. И да, он даже включает смайлы.
Ниже приведены несколько примеров текстовых символов и соответствующих им кодовых точек. Каждая кодовая точка начинается с буквы «U» для «Unicode», за которой следует уникальная строка символов для представления символа.
| символ | Кодовая точка |
| А | U+0041 |
| а | U+0061 |
| 0 | U+0030 |
| 9 | U+0039 |
| ! | U+0021 |
| ОСТРОВ | U + 00D8 |
| ڃ | U+0683 |
| Ch | U + 0C9A |
| 𠜎 | U+2070E |
| 😁 | U+1F601 |
Если вы хотите узнать, как генерируются кодовые точки и что они означают в Unicode, ознакомьтесь с этим подробным объяснением.
Итак, теперь у нас есть стандартизированный способ представления каждого символа, используемого каждым человеческим языком, в единой библиотеке. Это решает проблему нескольких систем маркировки для разных языков – любой компьютер на Земле может использовать Unicode.
Но один только Unicode не хранит слова в двоичном формате. Компьютерам нужен способ перевода Unicode в двоичный код, чтобы его символы можно было хранить в текстовых файлах. Вот где пригодится UTF-8.
UTF-8: последний кусок головоломки
UTF-8 – это система кодирования Unicode. Он может преобразовывать любой символ Юникода в соответствующую уникальную двоичную строку, а также может преобразовывать двоичную строку обратно в символ Юникода. Это значение «UTF» или «Формат преобразования Unicode».
Помимо UTF-8, существуют и другие системы кодирования Unicode, но UTF-8 уникален, поскольку представляет символы в однобайтовых единицах. Помните, что один байт состоит из восьми бит, отсюда и «-8» в его названии.
Более конкретно, UTF-8 преобразует кодовую точку (которая представляет один символ в Unicode) в набор от одного до четырех байтов. Первые 256 символов в библиотеке Unicode, включая символы, которые мы видели в ASCII, представлены как один байт. Символы, которые появляются позже в библиотеке Unicode, кодируются как двухбайтовые, трехбайтовые и, возможно, четырехбайтовые двоичные единицы.
Ниже приведена та же таблица символов, что и выше, с выводом UTF-8 для каждого добавленного символа. Обратите внимание, что некоторые символы представлены одним байтом, а другие используют больше.
| символ | Кодовая точка | Двоичная кодировка UTF-8 |
| А | U+0041 | 01000001 |
| а | U+0061 | 01100001 |
| 0 | U+0030 | 00110000 |
| 9 | U+0039 | 00111001 |
| ! | U+0021 | 00100001 |
| ОСТРОВ | U + 00D8 | 11000011 10011000 |
| ڃ | U+0683 | 11011010 10000011 |
| Ch | U + 0C9A | 11100000 10110010 10011010 |
| 𠜎 | U+2070E | 11110000 10100000 10011100 10001110 |
| 😁 | U+1F601 | 11110000 10011111 10011000 10000001 |
Почему UTF-8 преобразовывает одни символы в один байт, а другие – в четыре байта? Короче для экономии памяти. Используя меньше места для представления более общих символов (например, символов ASCII), UTF-8 уменьшает размер файла, позволяя использовать гораздо большее количество менее распространенных символов. Эти менее распространенные символы кодируются в два или более байта, но это нормально, если они хранятся экономно.
Используя меньше места для представления более общих символов (например, символов ASCII), UTF-8 уменьшает размер файла, позволяя использовать гораздо большее количество менее распространенных символов. Эти менее распространенные символы кодируются в два или более байта, но это нормально, если они хранятся экономно.
Пространственная эффективность – ключевое преимущество кодировки UTF-8. Если бы вместо этого каждый символ Unicode был представлен четырьмя байтами, текстовый файл, написанный на английском языке, был бы в четыре раза больше, чем тот же файл, закодированный с помощью UTF-8.
Еще одно преимущество кодировки UTF-8 – обратная совместимость с ASCII. Первые 128 символов в библиотеке Unicode соответствуют символам в библиотеке ASCII, и UTF-8 переводит эти 128 символов Unicode в те же двоичные строки, что и ASCII. В результате UTF-8 может без проблем преобразовывать текстовый файл, отформатированный в ASCII, в читаемый человеком текст.
Символы UTF-8 в веб-разработке
UTF-8 – наиболее распространенный метод кодирования символов, используемый сегодня в Интернете, и набор символов по умолчанию для HTML5. Таким образом хранятся персонажи более 95% всех веб-сайтов, в том числе и ваш собственный. Кроме того, распространенные методы передачи данных через Интернет, такие как XML и JSON, кодируются стандартами UTF-8.
Таким образом хранятся персонажи более 95% всех веб-сайтов, в том числе и ваш собственный. Кроме того, распространенные методы передачи данных через Интернет, такие как XML и JSON, кодируются стандартами UTF-8.
Поскольку теперь это стандартный метод кодирования текста в Интернете, все страницы вашего сайта и базы данных должны использовать UTF-8. Система управления контентом или конструктор веб-сайтов по умолчанию сохранят ваши файлы в формате UTF-8, но все же рекомендуется убедиться, что вы придерживаетесь этой передовой практики.
Текстовые файлы, закодированные с помощью UTF-8, должны указывать на это программному обеспечению, обрабатывающему их. В противном случае программа не сможет должным образом преобразовать двоичный код обратно в символы. В файлах HTML вы можете увидеть строку кода, подобную следующей, вверху:
<meta charset="UTF-8">
Это сообщает браузеру, что файл HTML закодирован в UTF-8, чтобы браузер мог преобразовать его обратно в разборчивый текст.
UTF-8 против UTF-16
Как я уже упоминал, UTF-8 – не единственный метод кодирования символов Unicode – существует также UTF-16. Эти методы различаются количеством байтов, необходимых для хранения символа. UTF-8 кодирует символ в двоичную строку из одного, двух, трех или четырех байтов. UTF-16 кодирует символ Unicode в строку из двух или четырех байтов.
Это различие видно из их названий. В UTF-8 наименьшее двоичное представление символа составляет один байт или восемь битов. В UTF-16 наименьшее двоичное представление символа составляет два байта или шестнадцать бит.
И UTF-8, и UTF-16 могут переводить символы Unicode в двоичные файлы, удобные для компьютера, и обратно. Однако они несовместимы друг с другом. Эти системы используют разные алгоритмы для сопоставления кодовых точек с двоичными строками, поэтому двоичный вывод для любого заданного символа будет отличаться от обоих методов:
| символ | Двоичная кодировка UTF-8 | Двоичная кодировка UTF-16 |
| А | 01000001 | 01000001 11011000 00001110 11011111 |
| 𠜎 | 11110000 10100000 10011100 10001110 | 01000001 11011000 00001110 11011111 |
Кодировка UTF-8 предпочтительнее UTF-16 на большинстве веб-сайтов, потому что она использует меньше памяти.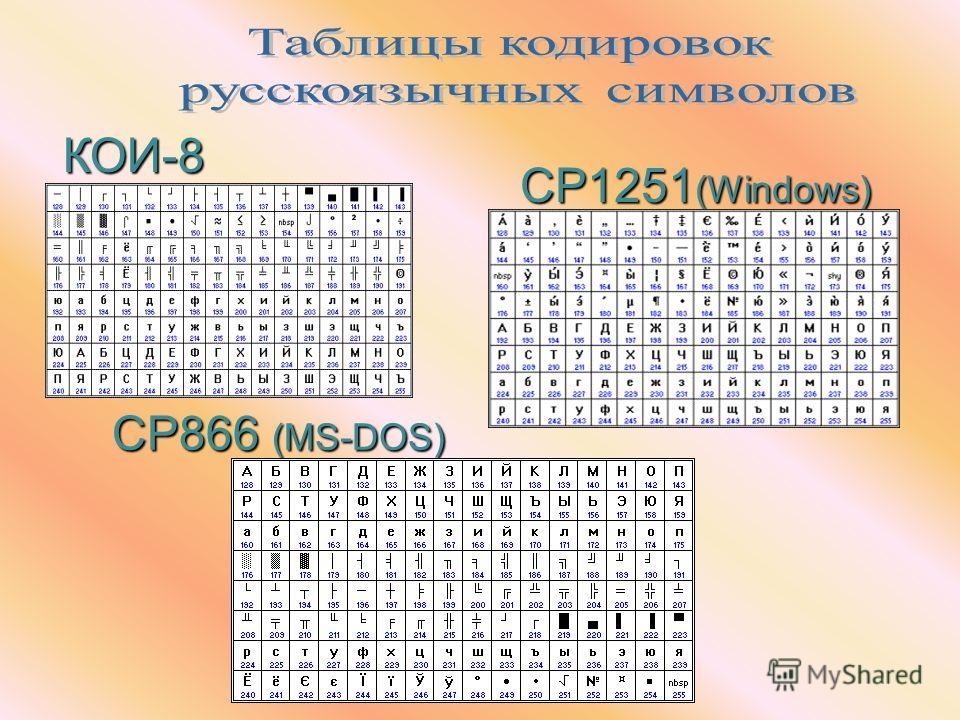 Напомним, что UTF-8 кодирует каждый символ ASCII всего одним байтом. UTF-16 должен кодировать эти же символы в двух или четырех байтах. Это означает, что текстовый файл на английском языке с кодировкой UTF-16 будет как минимум вдвое больше размера того же файла с кодировкой UTF-8.
Напомним, что UTF-8 кодирует каждый символ ASCII всего одним байтом. UTF-16 должен кодировать эти же символы в двух или четырех байтах. Это означает, что текстовый файл на английском языке с кодировкой UTF-16 будет как минимум вдвое больше размера того же файла с кодировкой UTF-8.
UTF-16 более эффективен, чем UTF-8, только на некоторых неанглоязычных сайтах. Если веб-сайт использует язык с символами, находящимися дальше в библиотеке Unicode, UTF-8 будет кодировать все символы как четыре байта, тогда как UTF-16 может кодировать многие из тех же символов только как два байта. Тем не менее, если ваши страницы заполнены буквами ABC и 123, придерживайтесь UTF-8.
Расшифровка мира кодировки UTF-8
Это было много слов о словах, поэтому давайте резюмируем то, что мы рассмотрели:
- Компьютеры хранят данные, включая текстовые символы, как двоичные (единицы и нули).
- ASCII был ранним способом кодирования или отображения символов в двоичный код, чтобы компьютеры могли их хранить. Однако в ASCII не было достаточно места для представления нелатинских символов и чисел в двоичном формате.
- Юникод был решением этой проблемы. Юникод присваивает уникальный «код» каждому символу на каждом человеческом языке.
- UTF-8 – это метод кодировки символов Unicode. Это означает, что UTF-8 берет кодовую точку для данного символа Юникода и переводит ее в строку двоичного кода. Он также делает обратное, считывая двоичные цифры и преобразуя их обратно в символы.
- UTF-8 в настоящее время является самым популярным методом кодирования в Интернете, поскольку он может эффективно хранить текст, содержащий любой символ.
- UTF-16 – еще один метод кодирования, но он менее эффективен для хранения текстовых файлов (за исключением тех, которые написаны на некоторых неанглийских языках).
 Однако в ASCII не было достаточно места для представления нелатинских символов и чисел в двоичном формате.
Однако в ASCII не было достаточно места для представления нелатинских символов и чисел в двоичном формате.Перевод Unicode – это не то, о чем большинству из нас нужно думать при просмотре или разработке веб-сайтов, и именно в этом суть – создать бесшовную систему обработки текста, которая работает для всех языков и веб-браузеров. Если он работает хорошо, вы этого не заметите.
Если он работает хорошо, вы этого не заметите.
Но если вы обнаружите, что страницы вашего веб-сайта занимают чрезмерно много места или если ваш текст завален буквами and и, пора применить ваши новые знания о UTF-8.
Источник записи: https://blog.hubspot.com
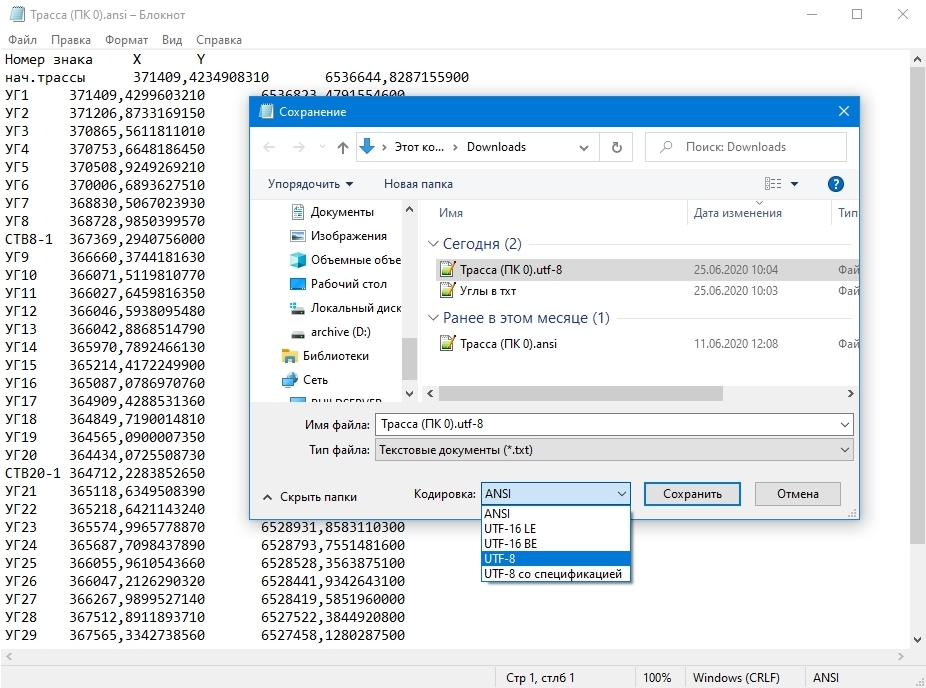
Использование кодовых страниц UTF-8 в приложениях Windows — Windows apps
Twitter LinkedIn Facebook Адрес электронной почты
- Статья
- Чтение занимает 2 мин
Используйте кодировку символов UTF-8 для оптимальной совместимости между веб-приложениями и другими платформами на основе nix (Unix, Linux и варианты), минимизируйте ошибки локализации и сократите затраты на тестирование.
UTF-8 — это универсальная кодовая страница для интернационализации и может кодировать весь набор символов Юникода. Он используется повсеместно в Интернете и используется по умолчанию для платформ на основе *nix.
Установка кодовой страницы процесса на UTF-8
Начиная с Windows версии 1903 (обновление за май 2019 г.), можно использовать свойство ActiveCodePage в appxmanifest для упакованных приложений или манифест слияния для непакованных приложений, чтобы принудительно использовать UTF-8 в качестве кодовой страницы процесса.
Вы можете объявить это свойство и целевой объект или запустить в более ранних Windows сборках, но необходимо обрабатывать обнаружение и преобразование устаревшей кодовой страницы как обычно. С минимальной целевой версией Windows версии 1903 кодовая страница процесса всегда будет иметь значение UTF-8, поэтому обнаружение и преобразование устаревшей кодовой страницы можно избежать.
Примечание
Закодированный символ занимает от 1 до 4 байт. Кодировка UTF-8 поддерживает более длинные последовательности байтов, до 6 байт, но самая большая кодовая точка Юникода 6.0 (U+10FFFF) занимает только 4 байта.
Кодировка UTF-8 поддерживает более длинные последовательности байтов, до 6 байт, но самая большая кодовая точка Юникода 6.0 (U+10FFFF) занимает только 4 байта.
Примеры
Манифест Appx для упаковаемого приложения:
<?xml version="1.0" encoding="utf-8"?>
<Package xmlns="http://schemas.microsoft.com/appx/manifest/foundation/windows10"
...
xmlns:uap7="http://schemas.microsoft.com/appx/manifest/uap/windows10/7"
xmlns:uap8="http://schemas.microsoft.com/appx/manifest/uap/windows10/8"
...
IgnorableNamespaces="... uap7 uap8 ...">
<Applications>
<Application ...>
<uap7:Properties>
<uap8:ActiveCodePage>UTF-8</uap8:ActiveCodePage>
</uap7:Properties>
</Application>
</Applications>
</Package>
Манифест Fusion для распаковки приложения Win32:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <assembly manifestVersion="1.
 0" xmlns="urn:schemas-microsoft-com:asm.v1">
<assemblyIdentity type="win32" name="..." version="6.0.0.0"/>
<application>
<windowsSettings>
<activeCodePage xmlns="http://schemas.microsoft.com/SMI/2019/WindowsSettings">UTF-8</activeCodePage>
</windowsSettings>
</application>
</assembly>
0" xmlns="urn:schemas-microsoft-com:asm.v1">
<assemblyIdentity type="win32" name="..." version="6.0.0.0"/>
<application>
<windowsSettings>
<activeCodePage xmlns="http://schemas.microsoft.com/SMI/2019/WindowsSettings">UTF-8</activeCodePage>
</windowsSettings>
</application>
</assembly>
Примечание
Добавление манифеста в существующий исполняемый файл из командной строки с помощью команды mt.exe -manifest <MANIFEST> -outputresource:<EXE>;#1
-A и API-интерфейсы -W
API Win32 часто поддерживают варианты -A и -W.
-Варианты распознают кодовую страницу ANSI, настроенную в системе и поддержку char*, а варианты -W работают в UTF-16 и поддерживают WCHAR.
До недавнего времени Windows подчеркнули варианты Юникода -W по сравнению с API-интерфейсами -A. Однако последние выпуски использовали кодовую страницу ANSI и API-интерфейсы A в качестве средства для внедрения поддержки UTF-8 для приложений. Если кодовая страница ANSI настроена для UTF-8, API-интерфейсы A обычно работают в UTF-8. Эта модель имеет преимущество поддержки существующего кода, созданного с помощью API-интерфейсов -A без каких-либо изменений кода.
Если кодовая страница ANSI настроена для UTF-8, API-интерфейсы A обычно работают в UTF-8. Эта модель имеет преимущество поддержки существующего кода, созданного с помощью API-интерфейсов -A без каких-либо изменений кода.
Преобразование кодовой страницы
Так как Windows работает изначально в UTF-16 (WCHAR), может потребоваться преобразовать данные UTF-8 в UTF-16 (или наоборот), чтобы взаимодействовать с Windows API.
MultiByteToWideChar и WideCharToMultiByte позволяют выполнять преобразование между UTF-8 и UTF-16 () (WCHARи другими кодовых страницами). Это особенно полезно, если устаревший API Win32 может быть понятен WCHARтолько . Эти функции позволяют преобразовывать входные данные UTF-8 для WCHAR передачи в API -W, а затем при необходимости преобразовывать все результаты.
При использовании этих функций с CodePage заданным значением CP_UTF8, использование dwFlags любого 0 из них или MB_ERR_INVALID_CHARSиным образом ERROR_INVALID_FLAGS происходит.
Примечание
CP_ACPПриравнивается только к CP_UTF8 тому, что в Windows версии 1903 (обновление за май 2019 г.) или более поздней версии, а для свойства ActiveCodePage, описанного выше, задано значение UTF-8. В противном случае она учитывает устаревшую системную кодовую страницу. Рекомендуется использовать CP_UTF8 явно.
- Кодовые страницы
- Идентификаторы кодовой страницы
man UTF-8 (7): ASCII-совместимая многобайтная юникодная кодировка
ОПИСАНИЕ
Набор символов Unicode 3.0 занимает 16-битное кодовое пространство. Наиболее
распространённая юникодная кодировка, известная как UCS-2, содержит
последовательности 16-битных слов. Закодированные таким образом строки могут
состоять из частей 16-битных символов например, ‘\0’ или ‘/’,
которые имеют специальное значение в именах файлов и других параметрах
функций библиотеки языка Си. Кроме того, большинство утилит UNIX
предназначено для обработки ASCII-файлов и не может воспринимать 16-битные
слова как символы. По этим причинам UCS-2 является неподходящей кодировкой
Юникода для имён файлов, текстовых файлов, переменных окружения и т.д. Набор
ISO Universal Character Set (UCS), расширенный набор Юникода, занимает
более 31-битного кодового пространства, а используемая для него кодировка
UCS-4 (последовательность 32-битных слов) имеет те же недостатки, что и
описанные выше.
Кроме того, большинство утилит UNIX
предназначено для обработки ASCII-файлов и не может воспринимать 16-битные
слова как символы. По этим причинам UCS-2 является неподходящей кодировкой
Юникода для имён файлов, текстовых файлов, переменных окружения и т.д. Набор
ISO Universal Character Set (UCS), расширенный набор Юникода, занимает
более 31-битного кодового пространства, а используемая для него кодировка
UCS-4 (последовательность 32-битных слов) имеет те же недостатки, что и
описанные выше.
Кодировка UTF-8 для представления Юникода и UCS лишена этих недостатков и поэтому в UNIX-подобных операционных системах используется наиболее часто.
Свойства
Кодировка UTF-8 обладает следующими полезными свойствами:
- *
- UCS-символы с кодами от 0x00000000 до 0x0000007f (стандартный набор
US-ASCII) кодируются как байты с кодами от 0x00 до 0x7f (для совместимости с
кодовой таблицей ASCII). Это означает, что файлы и строки, содержащие только
7-битные ASCII-символы, будут иметь одинаковое представление как в ASCII так
и в UTF-8. 31 значения UCS.
- *
- В кодировке UTF-8 никогда не используются байты с кодами 0xc0, 0xc1, 0xfe и 0xff.
- *
- Первый байт многобайтовой последовательности, представляющей один не ASCII UCS-символ, всегда находится в диапазоне от 0xc2 до 0xfd и указывает на длину мульбайтовой последовательности. Все последующие байты в многобайтовой последовательности находятся в диапазоне от 0x80 до 0xbf. Это позволяет облегчить ресинхронизацию, устраняет необходимость учитывать состояние кодировки (statelessness) и делает кодировку независимой от пропущенных байтов.
- *
- Символы UCS, закодированные в UTF-8, могут занимать до шести байтов, однако в стандарте Юникода не определены символы выше 0x10ffff, поэтому в UTF-8 юникодные символы могут иметь максимальный размер 4 байта.
 31 значения UCS.
31 значения UCS.Кодирование
Приведённые ниже последовательности байтов используются для отображения символа. Конкретная последовательность зависит от номера символа в кодировке UCS:
- 0x00000000 — 0x0000007F:
- 0xxxxxxx
- 0x00000080 — 0x000007FF:
- 110xxxxx 10xxxxxx
- 0x00000800 — 0x0000FFFF:
- 1110xxxx 10xxxxxx 10xxxxxx
- 0x00010000 — 0x001FFFFF:
- 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
- 0x00200000 — 0x03FFFFFF:
- 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
- 0x04000000 — 0x7FFFFFFF:
- 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
Позиции битов, обозначенные как xxx, заполняются соответствующими битами
из кода символа в двоичном виде.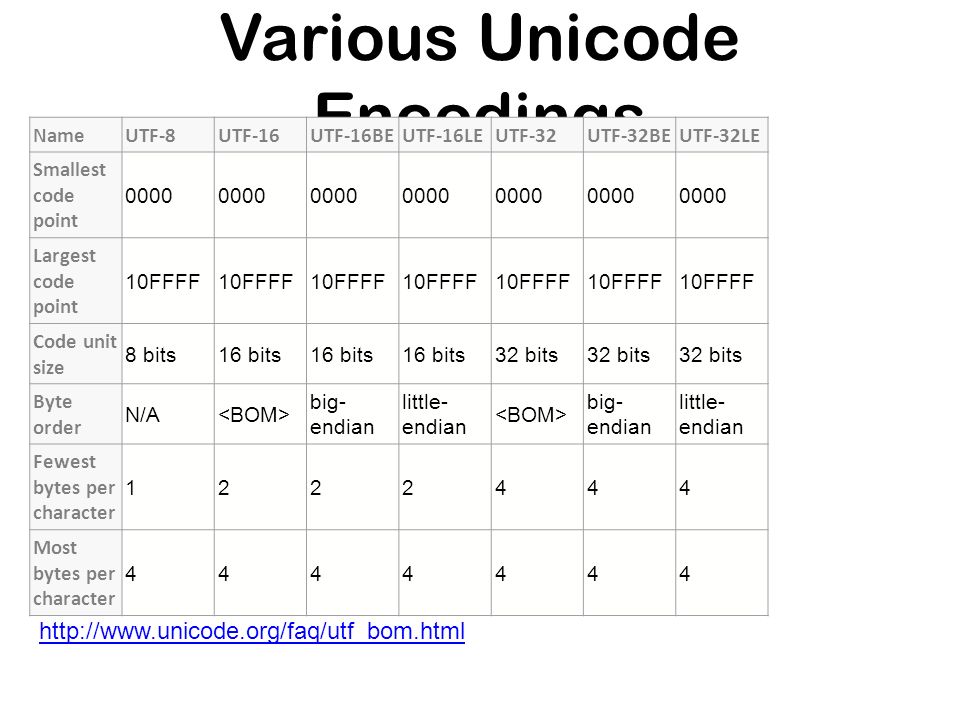 Используется самая короткая из возможных
многобайтовых последовательностей, которые могут представить код символа.
Используется самая короткая из возможных
многобайтовых последовательностей, которые могут представить код символа.
Значения кодов UCS 0xd00-0xdfff (суррогаты UTF-16), а также 0xfffe и 0xffff (несимвольные значения UCS), не должны появляться в потоках UTF-8.
Пример
Символ Юникода с кодом 0xa9 = 1010 1001 (знак авторского права) кодируется в UTF-8 как
- 11000010 10101001 = 0xc2 0xa9
а символ с кодом 0x2260 = 0010 0010 0110 0000 (знак неравенства) кодируется так:
- 11100010 10001001 10100000 = 0xe2 0x89 0xa0
Замечания к применению
Для включения поддержки UTF-8 в приложениях, пользователи должны выбрать локаль UTF-8, например с помощью
- export LANG=en_GB.UTF-8
Программы, в которых учитывается используемая пользователем кодировка, должны всегда устанавливать локаль с помощью
- setlocale(LC_CTYPE, «»)
и затем проверять выражением
- strcmp(nl_langinfo(CODESET), «UTF-8») == 0
что локаль UTF-8 выбрана и во всех стандартных текстовых потоках ввода и
вывода, на терминалах, в содержимом простых текстовых файлов, именах файлов
и переменных окружения будет использоваться кодировка UTF-8.
Программисты, привыкшие к однобайтовым кодировкам, таким как, US-ASCII или ISO 8859, должны учесть, что два предположения, действовавших ранее, в локалях UTF-8 не работают. Первое: один байт теперь не обязательно соответствует одному символу. Второе: современные эмуляторы терминала в режиме UTF-8 также поддерживают китайские, японские и корейские символы двойной ширины (double-width characters), а также комбинированные символы без пробелов, и вывод одного символа необязательно смещает курсор на одну позицию, как это было в ASCII. Для подсчёта количества символов и позиций курсора нужно использовать библиотечные функции, такие как mbsrtowcs(3) и wcswidth(3).
Стандартной ESC-последовательностью для переключения из схемы кодировки ISO
2022 (используется в терминалах VT100) в UTF-8 является ESC % G
(«\x1b%G»). Соответственно, обратной последовательностью для переключения
из UTF-8 в ISO 2022 будет ESC % @ («\x1b%@»). Остальные последовательности
ISO 2022 (такие, как переключение в наборы G0 и G1) в режиме UTF-8 не
работают.
Безопасность
Стандарты Юникода и UCS требуют, чтобы генераторы UTF-8 использовали самую короткую возможную форму представления символов, то есть создание двухбайтной последовательности с первым байтом, равным 0xc0, запрещено. В стандарте Unicode 3.1 это правило расширено и запрещает программам воспринимать не самую короткую форму при вводе. Это сделано из соображений безопасности: если вводимые пользователем символы проверяются системой безопасности на возможные нарушения, то программам остаётся проверить только ASCII версии символов «/../», «;» или NUL, так как для этих символов может быть очень много не ASCII способов представления при не самом коротком кодировании в UTF-8.Стандарты
ISO/IEC 10646-1:2000, Unicode 3.1, RFC 3629, Plan 9.UTF-8 — Википедия Wiki Русский 2023
(перенаправлено с «Utf-8»)
UTF-8 (от англ. Unicode Transformation Format, 8-bit — «формат преобразования Юникода, 8-бит») — распространённый стандарт кодирования символов, позволяющий более компактно хранить и передавать символы Юникода, используя переменное количество байт (от 1 до 4), и обеспечивающий полную обратную совместимость с 7-битной кодировкой ASCII.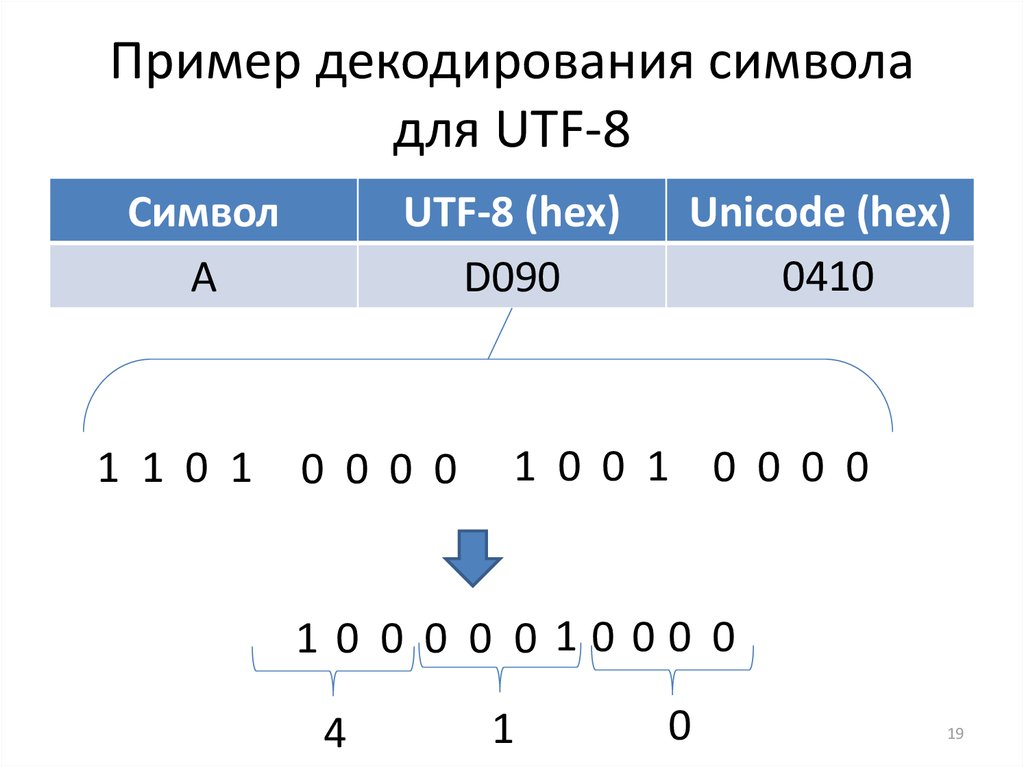 Стандарт UTF-8 официально закреплён в документах RFC 3629 и ISO/IEC 10646 Annex D.
Стандарт UTF-8 официально закреплён в документах RFC 3629 и ISO/IEC 10646 Annex D.
Кодировка UTF-8 сейчас является доминирующей в веб-пространстве. Она также нашла широкое применение в UNIX-подобных операционных системах[2].
Формат UTF-8 был разработан 2 сентября 1992 года Кеном Томпсоном и Робом Пайком, и реализован в Plan 9[3]. Идентификатор кодировки в Windows — 65001[4].
UTF-8, по сравнению с UTF-16, наибольший выигрыш в компактности даёт для текстов на латинице, поскольку латинские буквы без диакритических знаков, цифры и наиболее распространённые знаки препинания кодируются в UTF-8 лишь одним байтом, и коды этих символов соответствуют их кодам в ASCII.[5][6]
Содержание
Show / HideАлгоритм кодирования
Алгоритм кодирования в UTF-8 стандартизирован в RFC 3629 и состоит из 3 этапов:
1. Определить количество октетов (байтов), требуемых для кодирования символа. Номер символа берётся из стандарта Юникода.
| Диапазон номеров символов | Требуемое количество октетов |
|---|---|
00000000-0000007F | 1 |
00000080-000007FF | 2 |
00000800-0000FFFF | 3 |
00010000-0010FFFF | 4 |
Для символов Юникода с номерами от U+0000 до U+007F (занимающими один байт c нулём в старшем бите) кодировка UTF-8 полностью соответствует 7-битной кодировке US-ASCII.
2. Установить старшие биты первого октета в соответствии с необходимым количеством октетов, определённом на первом этапе:
- 0xxxxxxx — если для кодирования потребуется один октет;
- 110xxxxx — если для кодирования потребуется два октета;
- 1110xxxx — если для кодирования потребуется три октета;
- 11110xxx — если для кодирования потребуется четыре октета.
Если для кодирования требуется больше одного октета, то в октетах 2-4 два старших бита всегда устанавливаются равными 102 (10xxxxxx). Это позволяет легко отличать первый октет в потоке, потому что его старшие биты никогда не равны 102.
Это позволяет легко отличать первый октет в потоке, потому что его старшие биты никогда не равны 102.
| Количество октетов | Значащих бит | Шаблон |
|---|---|---|
| 1 | 7 | 0xxxxxxx |
| 2 | 11 | 110xxxxx 10xxxxxx |
| 3 | 16 | 1110xxxx 10xxxxxx 10xxxxxx |
| 4 | 21 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
3. Установить значащие биты октетов в соответствии с номером символа Юникода, выраженном в двоичном виде. Начать заполнение с младших битов номера символа, поставив их в младшие биты последнего октета, продолжить справа налево до первого октета. Свободные биты первого октета, оставшиеся незадействованными, заполнить нулями.
Примеры кодирования
| Символ | Двоичный код символа | UTF-8 в двоичном виде | UTF-8 в шестнадцатеричном виде | |
|---|---|---|---|---|
| $ | U+0024 | 0100100 | 00100100 | 24 |
| ¢ | U+00A2 | 10100010 | 11000010 10100010 | C2 A2 |
| € | U+20AC | 100000 10101100 | 11100010 10000010 10101100 | E2 82 AC |
| 𐍈 | U+10348 | 1 00000011 01001000 | 11110000 10010000 10001101 10001000 | F0 90 8D 88 |
Маркер UTF-8
Для указания, что файл или поток содержит символы Юникода, в начале файла или потока может быть вставлен маркер последовательности байтов (англ. Byte order mark, BOM), который в случае кодирования в UTF-8 принимает форму трёх байтов:
Byte order mark, BOM), который в случае кодирования в UTF-8 принимает форму трёх байтов: EF BB BF16.
Пятый и шестой байты
Изначально кодировка UTF-8 допускала использование до шести байтов для кодирования одного символа, однако в ноябре 2003 года стандарт RFC 3629 запретил использование пятого и шестого байтов, а диапазон кодируемых символов был ограничен символом U+10FFFF. Это было сделано для обеспечения совместимости с UTF-16.
Возможные ошибки декодирования
Не всякая последовательность байтов является допустимой. Декодер UTF-8 должен понимать и адекватно обрабатывать такие ошибки:
- Недопустимый байт.
- Байт продолжения (10xxxxxx) без начального байта.
- Отсутствие нужного количества байтов продолжения 10xxxxxx — например, двух после 1110xxxx).
- Строка обрывается посреди символа.
- Неэкономное кодирование — например, кодирование символа тремя байтами, когда можно двумя. (Существует нестандартный вариант UTF-8, который кодирует символ с кодом 0 как 1100. 0000 1000.0000, отличая его от символа конца строки 0000.0000.)
- Последовательность байтов, декодирующаяся в недопустимую кодовую позицию (например символы суррогатных пар UTF-16).
 0000 1000.0000, отличая его от символа конца строки 0000.0000.)
0000 1000.0000, отличая его от символа конца строки 0000.0000.)Примечания
Ссылки
- UTF-8 encoding table and Unicode characters
- UTF-8: Кодирование и декодирование
- UTF-8, UTF-16, UTF-32 & BOM — Вопросы и ответы
- Compatibility Encoding Scheme for UTF-16: 8-Bit (CESU-8)
- Полное описание стандарта Unicode
- UTF-8 Everywhere Manifesto
- RFC-3629 «UTF-8, a transformation format of ISO 10646»
Если не указано иное, содержание доступно по лицензии CC BY-SA 3.0. Images, videos and audio are available under their respective licenses.
This article uses material from the Wikipedia article utf-8, which is released under the Creative Commons Attribution-ShareAlike 3.0 license («CC BY-SA 3.0»); additional terms may apply. (view authors).
🌐 Wiki languages: 1,000,000+ articlesEnglishРусскийDeutschItalianoPortuguês日本語Français中文العربيةEspañol한국어NederlandsSvenskaPolskiУкраїнськаTiếng Việt
🔥 Top trends keywords Русский Wiki:
Заглавная страницаВоенно-учётная специальностьГруппа ВагнераВторжение России на Украину (2022)Служебная:ПоискМобилизация в России (2022)Категории годности к военной службеМизинцев, Михаил ЕвгеньевичВоенное положение в РоссииБулгаков, Дмитрий ВитальевичРоссияYouTubeПускепалис, Сергей ВитаутоПригожин, Евгений ВикторовичРубальская, Лариса АлексеевнаВоенное положениеПотери сторон в период вторжения России на УкраинуПутин, Владимир ВладимировичСоединённые Штаты АмерикиВКонтактеМобилизацияВооружённые силы Российской ФедерацииСписок стран по численности вооружённых сил и военизированных формированийДамер, ДжеффриУкраинаУткин, Дмитрий ВалерьевичРоссийско-украинская войнаShaman (певец)Остроумова, Ольга МихайловнаЕлизавета IIМоскваТактическое ядерное оружиеСписок умерших в 2022 годуАтака мертвецовВторая чеченская войнаСи ЦзиньпинПервая чеченская войнаBoeing RC-135RobloxАтомные бомбардировки Хиросимы и НагасакиM142 HIMARSКонтрнаступление в Харьковской области (2022)Ту-214РНАТОСанкт-ПетербургШойгу, Сергей КужугетовичСтрелков, Игорь ИвановичВооружённый конфликт в Донбассе (апрель 2014 — февраль 2022)Население РоссииДом ДраконаРадио «Свобода»Медведчук, Виктор ВладимировичКарл III (король Великобритании)Афганская война (1979—1989)КазахстанЗеленский, Владимир АлександровичПервая мировая войнаБайден, ДжоДонецкая Народная РеспубликаРусский языкКитайОднопользовательская играGeneral Atomics MQ-1C Grey EagleGoogle (компания)Бодров, Сергей Сергеевич2021 годДацик, Вячеслав ВалерьевичДелон, АленЯдерное оружиеВластелин колец: Кольца властиВторая мировая войнаХлорпикринОрганизация Договора о коллективной безопасностиЯдерный клубЯндексДиана, принцесса УэльскаяМногопользовательская играКалифорнияПротесты в Иране (2022)🡆 More
Related topics
Использование UTF-8 в HTTP заголовках – Jmix
Как известно, HTTP 1. 1 — это текстовой протокол передачи данных. HTTP сообщения закодированы, используя ISO-8859-1 (которую условно можно считать расширенной версией ASCII, содержащей умляуты, диакритику и другие символы, используемые в западноевропейских языках). При этом в теле сообщений можно использовать другую кодировку, которая должна быть обозначена в заголовке «Content-Type». Но что делать, если нам необходимо задать non-ASCII символы не в теле сообщения, а в самих заголовках? Наверное, самый распространенный кейс — это проставление имени файла в «Content-Disposition» заголовке. Это, казалось бы, довольно распространенная задача, но ее реализация не так очевидна.
1 — это текстовой протокол передачи данных. HTTP сообщения закодированы, используя ISO-8859-1 (которую условно можно считать расширенной версией ASCII, содержащей умляуты, диакритику и другие символы, используемые в западноевропейских языках). При этом в теле сообщений можно использовать другую кодировку, которая должна быть обозначена в заголовке «Content-Type». Но что делать, если нам необходимо задать non-ASCII символы не в теле сообщения, а в самих заголовках? Наверное, самый распространенный кейс — это проставление имени файла в «Content-Disposition» заголовке. Это, казалось бы, довольно распространенная задача, но ее реализация не так очевидна.
TL;DR: Используйте кодировку, описанную в RFC 6266, для «Content-Disposition» и преобразуйте текст в латиницу (транслит) в остальных случаях.
Небольшая вводная в кодировки
В статье упоминаются и используются кодировки US-ASCII (часто именуемую просто ASCII), ISO-8859-1 и UTF-8. Это небольшая вводная в эти кодировки. Раздел предназначен для разработчиков, которые редко или совсем не работают с кодировками и успели подзабыть их. 8 = 256 вариантов.
8 = 256 вариантов.
ISO-8859-1 — кодировка, предназначенная для западноевропейских языков. Содержит французскую диакритику, немецкие умляуты и т.д.
Кодировка содержит 256 символов и, таким образом, может быть представлена одним байтом. Первая половина (128 символов) полностью совпадает с ASCII. Таким образом, если первый бит = 0, то это обычный ASCII символ. Если 1, то это символ, специфичный для ISO-8859-1.
UTF-8 — одна из самых известных кодировок наравне с ASCII. Способна кодировать 1.112.064 символов. Размер каждого символа варьируется от 1-го до 4-х байт (раньше допускались значения до 6 байт).
Программа, работающая с этой кодировкой, определяет по первым битам, как много байтов входит в символ. Если октет начинается с 0, то символ представлен одним байтом. 110 — два байта, 1110 — три байта, 11110 — 4 байта.
Как и в случае с ISO-8859-1, первые 128 символов полностью соответствуют ASCII. Поэтому тексты, использующие только ASCII символы, будут абсолютно идентичны в бинарном представлении, вне зависимости от того, использовалась ли для кодирования US-ASCII, ISO-8859-1 или UTF-8.
Использование UTF-8 в теле сообщения
Прежде чем перейти к заголовкам, давайте быстро взглянем, как использовать UTF-8 в теле сообщений. Для этого используется заголовок «Content-Type».
Если «Content-Type» не задан, то браузер должен обрабатывать сообщения, как будто они написаны в ISO-8859-1. Браузер не должен пытаться отгадать кодировку и, тем более, игнорировать «Content-Type». Но, что реально отобразится в ситуации, когда «Content-Type» не передан, зависит от реализации браузера. Например, Firefox сделает согласно спецификации и прочитает сообщение, будто оно было закодировано в ISO-8859-1. Google Chrome, напротив, будет использовать кодировку операционной системы, которая для многих российских пользователей равна Windows-1251. В любом случае, если сообщение было в UTF-8, то оно будет отображено некорректно.
Проставляем UTF-8 сообщение в значение заголовка
С телом сообщения все достаточно просто. Тело сообщения всегда следует после заголовков, поэтому здесь не возникает технических проблем. Но как быть с заголовками? В спецификации недвусмысленно заявляется, что порядок заголовков в сообщении не имеет значения. Т.е. задать кодировку в одном заголовке через другой заголовок не представляется возможным.
Но как быть с заголовками? В спецификации недвусмысленно заявляется, что порядок заголовков в сообщении не имеет значения. Т.е. задать кодировку в одном заголовке через другой заголовок не представляется возможным.
Что будет, если просто взять и записать UTF-8 значение в значение заголовка? Мы видели, что такой трюк с телом сообщения приведет к тому, что значение будет просто прочитано в ISO-8859-1. Логично было бы предположить, что то же самое произойдет с заголовком. Но это не так. Фактически, во многих, если не в большинстве, случаях такое решение будет работать. Сюда включаются старые айфончики, IE11, Firefox, Google Chrome. Единственным из находящихся у меня под рукой браузеров, когда я писал эту статью, который не захотел работать с таким заголовком, является Edge.
Такое поведение не зафиксировано в спецификациях. Возможно, разработчики браузеров решили облегчить жизнь разработчиков и автоматически определять, что в заголовках сообщение закодировано в UTF-8. В общем-то, это не является такой сложной задачей.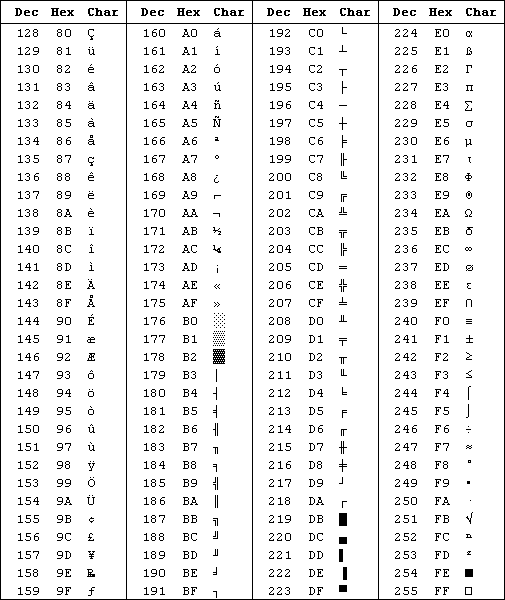 Смотрим на первый бит: если 0, то ASCII, если 1 — то, возможно, UTF-8.
Смотрим на первый бит: если 0, то ASCII, если 1 — то, возможно, UTF-8.
Нет ли в этом случае пересечения с ISO-8859-1? На самом деле, практически нет. Возьмем для примера UTF-8 символ из 2-х октетов (русские буквы представлены двумя октетами). Символ в бинарном представлении будет иметь вид: 110xxxxx 10xxxxxx. В HEX представлении: [0xC0-0x6F] [0x80-0xBF]. В ISO-8859-1 этими символами едва ли можно закодировать что-то, несущее смысловую нагрузку. Поэтому риск того, что браузер неправильно расшифрует сообщение, очень мал.
Однако, при попытке использовать этот способ можно столкнуться с техническими проблемами: ваш веб-сервер или фреймворк может просто не разрешить записывать UTF-8 символы в значение заголовка. Например, Apache Tomcat вместо всех UTF-8 символов проставляет 0x3F (вопросительный знак). Разумеется, это ограничение можно обойти, но, если само приложение бьет по рукам и не дает что-то сделать, то, возможно, вам и не нужно это делать.
Но, независимо от того, разрешает ли вам ваш фреймворк или сервер записать UTF-8 сообщения в заголовок или нет, я не рекомендую этого делать. Это не задокументированное решение, которое в любой момент времени может перестать работать в браузерах.
Это не задокументированное решение, которое в любой момент времени может перестать работать в браузерах.
Транслит
Я думаю, что использовать транслит — eto bolee horoshee reshenie. Многие крупные популярные русские ресурсы не брезгуют использовать транслит в названиях файлов. Это гарантированное решение, которое не сломается с выпуском новых браузеров и которое не надо тестировать отдельно на каждой платформе. Хотя, разумеется, надо подумать, как преобразовывать весь спектр возможных символов, что может быть не совсем тривиально. Например, если приложение рассчитано на российскую аудиторию, то в имя файла могут попасть татарские буквы ә и ң, которые надо как-то обработать, а не просто заменять на «?».
RFC 2047
Как я уже упомянул, томкат не позволил мне проставить UTF-8 в заголовке сообщения. Отражена ли эта особенность поведения в Java docs для сервлетов? Да, отражена:
Упоминается RFC 2047. Я пробовал кодировать сообщения, используя этот формат, — браузер меня не понял.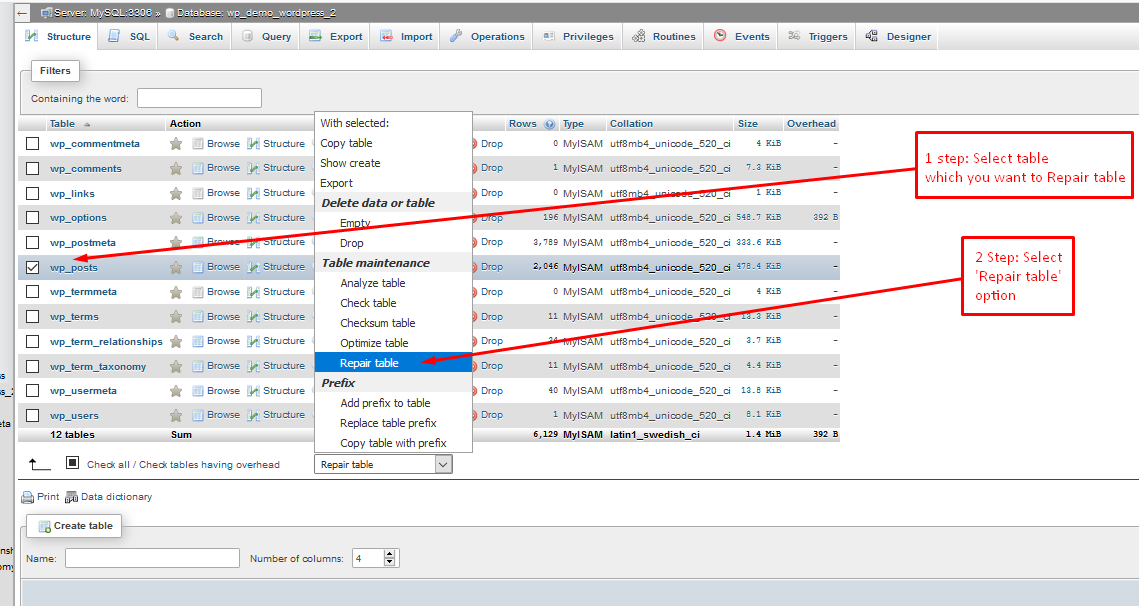 Этот метод кодировки не работает в HTTP. Хотя работал раньше. Вот, например, тикет на удаление поддержки этой кодировки из Firefox.
Этот метод кодировки не работает в HTTP. Хотя работал раньше. Вот, например, тикет на удаление поддержки этой кодировки из Firefox.
RFC 6266
В тикете, ссылка на который содержится в предыдущем разделе, есть упоминания, что даже после прекращения поддержки RFC 2047, все еще есть способ передавать UTF-8 значения в названии скачиваемых файлов: RFC 6266. На мой взгляд, это самое правильно решение на сегодняшний день. Многие популярные интернет ресурсы используют его. Мы в CUBA Platform также используем именно этот RFC для генерации «Content-Disposition».
RFC 6266 — это спецификация, описывающая использование “Content-Disposition” заголовка. Сам способ кодировки подробно описан в другой спецификации — RFC 8187.
Параметр “filename” содержит название файла в ASCII, “filename*” — в любой необходимой кодировке. При наличии обоих атрибутов “filename” игнорируется во всех современных браузерах (включая IE11 и старые версии Safari). Совсем старые браузеры, напротив, игнорируют “filename*”.
При использовании данного способа кодирования в параметре сначала указывается кодировка, после » идет закодированное значение. Видимые символы из ASCII кодирования не требуют. Остальные символы просто пишутся в hex представлении, со стоящим «%» перед каждым октетом.
Что делать с другими заголовками?
Кодирование, описанное в RFC 8187, не является универсальным. Да, можно поместить в заголовок параметр с * префиксом, и это, возможно, будет даже работать для некоторых браузеров, но спецификация предписывает не делать так.
В каждом случае, где в заголовках поддерживается UTF-8, на настоящий момент есть явное упоминание об этом в релевантном RFC. Помимо «Content-Disposition» данная кодировка используется, например, в Web Linking и Digest Access Authentication.
Следует учесть, что стандарты в этой области постоянно меняются. Использование описанной выше кодировки в HTTP было предложено лишь в 2010. Использование данной кодировки именно в «Content-Disposition» было зафиксировано в стандарте в 2011. Несмотря на то, что эти стандарты находятся лишь на стадии «Proposed Standard», они поддержаны повсеместно. Вариант, что в будущем нас ожидают новые стандарты, которые позволят более унифицировано работать с различными кодировками в заголовках, не исключен. Поэтому остается только следить за новостями в мире стандартов HTTP и уровня их поддержки на стороне браузеров.
Несмотря на то, что эти стандарты находятся лишь на стадии «Proposed Standard», они поддержаны повсеместно. Вариант, что в будущем нас ожидают новые стандарты, которые позволят более унифицировано работать с различными кодировками в заголовках, не исключен. Поэтому остается только следить за новостями в мире стандартов HTTP и уровня их поддержки на стороне браузеров.
Как работает кодировка Unicode UTF-8
UTF-8 — это умный способ кодирования текста Unicode. Я упоминал об этом пару раз в последнее время, но я не писал в блоге об UTF-8 как таковой. Вот оно.
Проблема, которую решает UTF-8
Американские клавиатуры часто могут отображать 101 символ, что означает, что 101 символа будет достаточно для большинства текстов на английском языке. Семи бит будет достаточно, чтобы закодировать эти символы, поскольку 2 7 = 128, а именно это и делает ASCII . Он представляет каждый символ с помощью 8 бит, поскольку компьютеры работают с битами в группах размеров, которые являются степенью двойки, но первый бит всегда равен 0, потому что он не нужен. Расширенный ASCII использует оставшееся пространство в ASCII для кодирования дополнительных символов.
Расширенный ASCII использует оставшееся пространство в ASCII для кодирования дополнительных символов.
В общей сложности 256 символов могут быть полезны некоторым пользователям, но они не позволят вам представлять, например, китайский язык. Первоначально Unicode хотел использовать два байта вместо одного байта для представления символов, что дало бы 2 16 = 65 536 возможностей, что было бы достаточно для охвата многих систем письма в мире. Но не все, и поэтому Юникод расширен до четырех байт.
Если бы вы хранили текст на английском языке, используя два байта для каждой буквы, половина пространства была бы потеряна для хранения нулей. И если бы вы использовали четыре байта на букву, три четверти пространства были бы потрачены впустую. Без какой-либо кодировки каждый файл, содержащий английский тест, был бы в два-четыре раза больше необходимого . И не только английский, но и все языки, которые могут быть представлены с помощью ASCII.
UTF-8 — это способ кодирования Unicode, при котором текстовый файл ASCII кодирует сам себя. Никакого лишнего пространства, кроме начального бита каждого байта, который ASCII не использует. И если ваш файл в основном представляет собой текст ASCII с добавлением нескольких символов, отличных от ASCII, символы, отличные от ASCII, просто сделают ваш файл немного длиннее. Вам не нужно внезапно заставлять каждый символ занимать в два или четыре раза больше места только потому, что вы хотите использовать, скажем, знак евро € (U+20AC).
Как это делает UTF-8
Поскольку первый бит символов ASCII установлен в ноль, байты с первым битом, установленным в 1, не используются и могут использоваться специально.
Когда программное обеспечение, читающее кодировку UTF-8, встречает байт, начинающийся с 1, оно подсчитывает, сколько единиц следует за ним, прежде чем встретится с 0. Например, в байте вида 110xxxxx за начальной 1 следует одна 1. Пусть n — количество единиц между начальным 1 и первым 0. Оставшиеся биты в этом байте и некоторые биты в следующих n байт будут представлять символ Unicode. Нет необходимости, чтобы n было больше 3 по причинам, к которым мы вернемся позже. То есть для представления символа Unicode с использованием UTF-8 требуется не более четырех байтов.
Оставшиеся биты в этом байте и некоторые биты в следующих n байт будут представлять символ Unicode. Нет необходимости, чтобы n было больше 3 по причинам, к которым мы вернемся позже. То есть для представления символа Unicode с использованием UTF-8 требуется не более четырех байтов.
Таким образом, байт вида 110xxxxx говорит о том, что первые пять битов символа Юникода хранятся в конце этого байта, а остальные биты идут в следующем байте.
Байт вида 1110xxxx содержит четыре бита символа Unicode и говорит о том, что остальные биты приходятся на следующие два байта.
Байт вида 11110xxx содержит три бита символа Unicode и говорит о том, что остальные биты приходятся на следующие три байта.
После начального байта, уведомляющего о начале символа, распределенного по нескольким байтам, биты сохраняются в байтах формы 10xxxxxx. Поскольку начальные байты многобайтовой последовательности начинаются с двух битов 1, двусмысленности нет: байт, начинающийся с 10, не может обозначать начало новой многобайтовой последовательности. То есть UTF-8 является самопунктуирующим.
То есть UTF-8 является самопунктуирующим.
Итак, многобайтовые последовательности имеют одну из следующих форм.
110ххххх 10ххххххх
1110хххх 10хххххх 10хххххх
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Если посчитать крестики в нижнем ряду, их 21. Таким образом, эта схема может представлять только числа длиной до 21 бита. Разве нам не нужны 32 бита? Оказывается, нет.
Хотя символ Unicode якобы является 32-битным числом, на самом деле для кодирования символа Unicode требуется не более 21 бита по причинам, описанным здесь. Вот почему n , количество единиц, следующих за начальной 1 в начале многобайтовой последовательности, должно быть только 1, 2 или 3. Схема кодирования UTF-8 может быть расширена, чтобы разрешить n = 4, 5, или 6, но это необязательно.
Эффективность
UTF-8 позволяет вам взять обычный файл ASCII и считать его файлом Unicode, закодированным с помощью UTF-8. Таким образом, UTF-8 так же эффективен, как ASCII, с точки зрения пространства. Но не по времени. Если программа знает, что файл на самом деле является ASCII, она может принять каждый байт по номинальному значению, не проверяя, является ли он первым байтом многобайтовой последовательности.
Но не по времени. Если программа знает, что файл на самом деле является ASCII, она может принять каждый байт по номинальному значению, не проверяя, является ли он первым байтом многобайтовой последовательности.
И хотя обычный ASCII допустим в UTF-8, расширенный ASCII — нет. Таким образом, расширенные символы ASCII теперь будут занимать два байта вместо одного. Мой предыдущий пост был о путанице, которая может возникнуть из-за того, что программное обеспечение интерпретирует файл в кодировке UTF-8 как расширенный файл ASCII.
Похожие сообщения
- Безнадежная задача консорциума Unicode
- Сколько символов Unicode возможно?
- Примеры кода префикса
| 0 | U+0000 | 00 | Control character: Null | ||||||||||||||||||||||||||||||||||||||||||||
| 1 | U+0001 | 01 | Control character: Start Of Heading | ||||||||||||||||||||||||||||||||||||||||||||
| 2 | U+ 0002 | 02 | Управляющий символ: начало текста | ||||||||||||||||||||||||||||||||||||||||||||
| 3 | U+0003 | 03 | .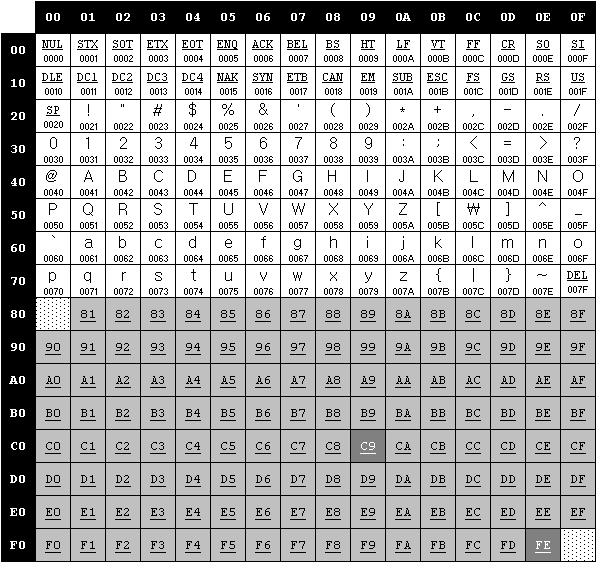 Контрольный персонаж: конец текста Контрольный персонаж: конец текста | ||||||||||||||||||||||||||||||||||||||||||||
| 4. 40076.0077 | 04 | Control character: End Of Transmission | |||||||||||||||||||||||||||||||||||||||||||||
| 5 | U+0005 | 05 | Control character: Enquiry | ||||||||||||||||||||||||||||||||||||||||||||
| 6 | U+0006 | 06 | Control character : Благодарность | ||||||||||||||||||||||||||||||||||||||||||||
| 7 | U+0007 | 07 | Контрольный характер: Bell | ||||||||||||||||||||||||||||||||||||||||||||
| 8 | U+0008 | 08 | U+0008 | 08 | U+0008 | 08 | .0077 | ||||||||||||||||||||||||||||||||||||||||
| 9 | U+0009 | 09 | Control character: Character Tabulation | ||||||||||||||||||||||||||||||||||||||||||||
| 10 | U+000A | 0A | Control character: Line Feed (lf) | ||||||||||||||||||||||||||||||||||||||||||||
| 11 | U+000B | 0B | Контрольный символ: линейная таблица | ||||||||||||||||||||||||||||||||||||||||||||
| 12 | U+000C | 0C | Контрольный характер: FORM FEED (FF) | 775. Управляющий характер: FORM FEED (FF) Управляющий характер: FORM FEED (FF) | 7775|||||||||||||||||||||||||||||||||||||||||||
| .0076 13 | U+000D | 0D | Контрольный характер: возврат перевозки (CR) | ||||||||||||||||||||||||||||||||||||||||||||
| 14 | U+000. | . Сдвиг | : Сдвиг | 0E | . +000F | 0F | Контрольный персонаж: сдвиг в | ||||||||||||||||||||||||||||||||||||||||
| 16 | U+0010 | 10 | . Контрольный характер: Ссылка на канал данных | ||||||||||||||||||||||||||||||||||||||||||||
| 7777777777 | .007711 | Control character: Device Control One | |||||||||||||||||||||||||||||||||||||||||||||
| 18 | U+0012 | 12 | Control character: Device Control Two | ||||||||||||||||||||||||||||||||||||||||||||
| 19 | U+0013 | 13 | Управляющий символ: Device Control Three | ||||||||||||||||||||||||||||||||||||||||||||
| 20 | U+0014 | 14 | Управляющий символ: Device Control Four | ||||||||||||||||||||||||||||||||||||||||||||
| 7 9 7 U+17 | 000760076 15 | Control character: Negative Acknowledge | |||||||||||||||||||||||||||||||||||||||||||||
| 22 | U+0016 | 16 | Control character: Synchronous Idle | ||||||||||||||||||||||||||||||||||||||||||||
| 23 | U+0017 | 17 | Control character: Конец трансмиссионного блока | ||||||||||||||||||||||||||||||||||||||||||||
| 24 | U+0018 | 18 | Контрольный характер: отмена | ||||||||||||||||||||||||||||||||||||||||||||
| 25 | U+0019 | 19 | U+0019 | 70076 19U+0019 | 19 | U+0019 | 19 | U+0019 | 19 | U+0019 | 19 | U+0019 | 19 | 0082Control character: End Of Medium | |||||||||||||||||||||||||||||||||
| 26 | U+001A | 1A | Control character: Substitute | ||||||||||||||||||||||||||||||||||||||||||||
| 27 | U+001B | 1B | Control character: Escape | ||||||||||||||||||||||||||||||||||||||||||||
| 28 | U+001C | 1C | Контрольный характер: информационный сепаратор четыре | ||||||||||||||||||||||||||||||||||||||||||||
| 29 | U+001d | 1D | . 0077 0077 | ||||||||||||||||||||||||||||||||||||||||||||
| 30 | U+001E | 1E | Control character: Information Separator Two | ||||||||||||||||||||||||||||||||||||||||||||
| 31 | U+001F | 1F | Control character: Information Separator One | ||||||||||||||||||||||||||||||||||||||||||||
| 32 | U+0020 | 20 | Пробел | ||||||||||||||||||||||||||||||||||||||||||||
| 33 | U+0021 | 21 | ! | Восклицательный знак | |||||||||||||||||||||||||||||||||||||||||||
| 34 | U+0022 | 22 | » | Quotation Mark | |||||||||||||||||||||||||||||||||||||||||||
| 35 | U+0023 | 23 | # | Number Sign | |||||||||||||||||||||||||||||||||||||||||||
| 36 | U+0024 | 24 | долл. США | Долларовой знак | |||||||||||||||||||||||||||||||||||||||||||
| 37 | U+0025 | 25 | % | процент.0077 | |||||||||||||||||||||||||||||||||||||||||||
| 39 | U+0027 | 27 | ‘ | Apostrophe | |||||||||||||||||||||||||||||||||||||||||||
| 40 | U+0028 | 28 | ( | Left Parenthesis | |||||||||||||||||||||||||||||||||||||||||||
| 41 | U+0029 | 29 | ) | Right Parenthesis | |||||||||||||||||||||||||||||||||||||||||||
| 42 | U+002A | 2A | * | Asterisk | |||||||||||||||||||||||||||||||||||||||||||
| 43 | U+002B | 2B | + | Plus Sign | |||||||||||||||||||||||||||||||||||||||||||
| 44 | U+002C | 2C | , | Comma | |||||||||||||||||||||||||||||||||||||||||||
| 45 | U+002D | 2D | — | Hyphen-minus | |||||||||||||||||||||||||||||||||||||||||||
| 46 | U+002E | 2E | . | Полная остановка | |||||||||||||||||||||||||||||||||||||||||||
| 47 | U+002F | 2F | / | Solidus | |||||||||||||||||||||||||||||||||||||||||||
| 48 | U+0030076 30 | 0 | Digit Zero | ||||||||||||||||||||||||||||||||||||||||||||
| 49 | U+0031 | 31 | 1 | Digit One | |||||||||||||||||||||||||||||||||||||||||||
| 50 | U+0032 | 32 | 2 | Digit Two | |||||||||||||||||||||||||||||||||||||||||||
| 51 | U+0033 | 33 | 3 | Digit Three | |||||||||||||||||||||||||||||||||||||||||||
| 52 | U+0034 | 34 | 4 | Digit Four | |||||||||||||||||||||||||||||||||||||||||||
| 53 | U+0035 | 35 | 5 | Digit Five | |||||||||||||||||||||||||||||||||||||||||||
| 54 | U+0036 | 36 | 6 | Digit Six | |||||||||||||||||||||||||||||||||||||||||||
| 55 | U+0037 | 37 | 7 | Digit Seven | |||||||||||||||||||||||||||||||||||||||||||
| 56 | U+0038 | 38 | 8 | Digit Eight | |||||||||||||||||||||||||||||||||||||||||||
| 57 | U+0039 | 39 | 9 | Digit Nine | |||||||||||||||||||||||||||||||||||||||||||
| 58 | U+003A | 3A | : | Colon | |||||||||||||||||||||||||||||||||||||||||||
| 59 | U+003B | 3B | ; | Semicolon | |||||||||||||||||||||||||||||||||||||||||||
| 60 | U+003C | 3C | < | Less-than Sign | |||||||||||||||||||||||||||||||||||||||||||
| 61 | U+003D | 3D | = | Equals Sign | |||||||||||||||||||||||||||||||||||||||||||
| 62 | U+003E | 3E | > | Знак «больше» | |||||||||||||||||||||||||||||||||||||||||||
| 63 | U+003F | 3F | ? | Question Mark | |||||||||||||||||||||||||||||||||||||||||||
| 64 | U+0040 | 40 | @ | Commercial At | |||||||||||||||||||||||||||||||||||||||||||
| 65 | U+0041 | 41 | A | Latin Capital Letter A | |||||||||||||||||||||||||||||||||||||||||||
| 66 | U+0042 | 42 | B | Латинская заглавная буква B | |||||||||||||||||||||||||||||||||||||||||||
| 67 | U+0043 | 43 | C | Latin Capital Letter C | |||||||||||||||||||||||||||||||||||||||||||
| 68 | U+0044 | 44 | D | Latin Capital Letter D | |||||||||||||||||||||||||||||||||||||||||||
| 69 | U+0045 | 45 | E | Latin Capital Letter E | |||||||||||||||||||||||||||||||||||||||||||
| 70 | U+0046 | 46 | F | Latin Capital Letter F | |||||||||||||||||||||||||||||||||||||||||||
| 71 | U+0047 | 47 | G | Latin Capital Letter G | |||||||||||||||||||||||||||||||||||||||||||
| 72 | U+0048 | 48 | H | Latin Capital Letter H | |||||||||||||||||||||||||||||||||||||||||||
| 73 | U+0049 | 49 | I | Latin Capital Letter I | |||||||||||||||||||||||||||||||||||||||||||
| 74 | U+004A | 4A | J | Latin Capital Letter J | |||||||||||||||||||||||||||||||||||||||||||
| U+004B | 4B | K | 70077 LATIN CAPIT0076 U+004C4C | L | Latin Capital Letter L | ||||||||||||||||||||||||||||||||||||||||||
| U+004D | 4D | M | 70076 LATIN CAPIT 4EN | Latin Capital Letter N | |||||||||||||||||||||||||||||||||||||||||||
| 79 | U+004F | 4F | O | Latin Capital Letter O | |||||||||||||||||||||||||||||||||||||||||||
| 80 | U+0050 | 50 | P | Latin Capital Letter P | |||||||||||||||||||||||||||||||||||||||||||
| 81 | U+0051 | 51 | Q | Latin Capital Letter Q | |||||||||||||||||||||||||||||||||||||||||||
| 82 | U+0052 | 52 | R | Latin Capital Letter R | |||||||||||||||||||||||||||||||||||||||||||
| 83 | U+0053 | 53 | S | Latin Capital Letter S | |||||||||||||||||||||||||||||||||||||||||||
| 84 | U+0054 | 54 | T | Latin Capital Letter T | |||||||||||||||||||||||||||||||||||||||||||
| 85 | U+0055 | 55 | U | Latin Capital Letter U | |||||||||||||||||||||||||||||||||||||||||||
| 86 | U+0056 | 56 | V | Latin Capital Letter V | |||||||||||||||||||||||||||||||||||||||||||
| 87 | U+0057 | 57 | W | Latin Capital Letter W | |||||||||||||||||||||||||||||||||||||||||||
| U+0058 | 58 | x | LATIN | 58 | x | 70076 LATIN.59 | Y | Latin Capital Letter Y | |||||||||||||||||||||||||||||||||||||||
| U+005A | 5A | Z | 77A5A | Z | 77A5A | Z | 77AZ | 7A. 5B[ | Left Square Bracket | ||||||||||||||||||||||||||||||||||||||
| 92 | U+005C | 5C | \ | Reverse Solidus | |||||||||||||||||||||||||||||||||||||||||||
| 93 | U+005D | 5D | ] 9 | Circumflex Accent | |||||||||||||||||||||||||||||||||||||||||||
| 95 | U+005F | 5F | _ | Low Line | |||||||||||||||||||||||||||||||||||||||||||
| 96 | U+0060 | 60 | ` | Grave Accent | |||||||||||||||||||||||||||||||||||||||||||
| 97 | U+0061 | 61 | A | Латинская маленькая буква A | |||||||||||||||||||||||||||||||||||||||||||
| 98 | U+0062 | 62 | B | 70076 Small Small LateU+0063 | 63 | C | Латинская маленькая буква C | ||||||||||||||||||||||||||||||||||||||||
| 100 | U+0064 | 64 | D | LATIN LATIN STALIN | 65 | e | Latin Small Letter E | ||||||||||||||||||||||||||||||||||||||||
| 102 | U+0066 | 66 | f | Latin Small Letter F | |||||||||||||||||||||||||||||||||||||||||||
| 103 | U+0067 | 67 | g | Latin Small Letter G | |||||||||||||||||||||||||||||||||||||||||||
| 104 | U+0068 | 68 | h | Latin Small Letter H | |||||||||||||||||||||||||||||||||||||||||||
| 105 | U+0069 | 69 | i | Latin Small Letter I | |||||||||||||||||||||||||||||||||||||||||||
| 106 | U+006A | 6A | j | Latin Small Letter J | |||||||||||||||||||||||||||||||||||||||||||
| 107 | U+006B | 6B | k | Latin Small Letter K | |||||||||||||||||||||||||||||||||||||||||||
| 108 | U+006C | 6C | l | Latin Small Letter L | |||||||||||||||||||||||||||||||||||||||||||
| 109 | U+006D | 6D | m | Latin Small Letter M | |||||||||||||||||||||||||||||||||||||||||||
| 110 | U+006E | 6E | N | Латинская маленькая буква n | |||||||||||||||||||||||||||||||||||||||||||
| 111 | U+006F | 6F | O | 70076 Small Small Small Small Small Small Small Small Small Small Small Small Small Small Small Small Small Small Small Small LateN Small LateN Small LateN Small LateN Small LateN Small LateN Small LateN Small LateN Small LateN Small LateN STALTIN0076 U+007070 | P | Латинская маленькая буква P | |||||||||||||||||||||||||||||||||||||||||
| U+0071 | Q | 70076 Small Small Small Small Small Small Small Late 72r | Latin Small Letter R | ||||||||||||||||||||||||||||||||||||||||||||
| 115 | U+0073 | 73 | s | Latin Small Letter S | |||||||||||||||||||||||||||||||||||||||||||
| 116 | U+0074 | 74 | t | Латинская небольшая буква T | |||||||||||||||||||||||||||||||||||||||||||
| 117 | U+0075 | U | LATIN SMALT LITCL | ||||||||||||||||||||||||||||||||||||||||||||
| 119 | U+0077 | 77 | w | Latin Small Letter W | |||||||||||||||||||||||||||||||||||||||||||
| 120 | U+0078 | 78 | x | Latin Small Letter X | |||||||||||||||||||||||||||||||||||||||||||
| 121 | U+0079 | 79 | y | Latin Small Letter Y | |||||||||||||||||||||||||||||||||||||||||||
| 122 | U+007A | 7A | z | Latin Small Letter Z | |||||||||||||||||||||||||||||||||||||||||||
| 123 | U+007B | 7B | { | Левая фигурная скобка | |||||||||||||||||||||||||||||||||||||||||||
| 124 | U+007C | 7C | | | Вертикальная линия | |||||||||||||||||||||||||||||||||||||||||||
| 125 | U+007D | 7D | } | Right Curly Bracket | |||||||||||||||||||||||||||||||||||||||||||
| 126 | U+007E | 7E | ~ | Tilde | |||||||||||||||||||||||||||||||||||||||||||
| 127 | U+007F | 7F | | Control character: Delete | |||||||||||||||||||||||||||||||||||||||||||
| 128 | U+0080 | C2 80 | | Control Character or Euro Sign, See Note 1 | |||||||||||||||||||||||||||||||||||||||||||
| 129 | U+0081 | C2 81 | | Control character: Unknown | |||||||||||||||||||||||||||||||||||||||||||
| 130 | U+0082 | C2 82 | | Control character: Break Permitted Here | |||||||||||||||||||||||||||||||||||||||||||
| 131 | U+0083 | C2 83 | | Control character: No Break Here | |||||||||||||||||||||||||||||||||||||||||||
| 132 | U+0084 | C2 84 | | Control character: Unknown | |||||||||||||||||||||||||||||||||||||||||||
| 133 | U+0085 | C2 85 | Control character: Next Line (nel) | ||||||||||||||||||||||||||||||||||||||||||||
| 134 | U+0086 | C2 86 | | Control character: Start Of Selected Area | |||||||||||||||||||||||||||||||||||||||||||
| 135 | U+0087 | C2 87 | Контрольный символ: конец выбранной области | ||||||||||||||||||||||||||||||||||||||||||||
| 136 | U+0088 | C2 88 | Контрольный характер: характерный таблица | ||||||||||||||||||||||||||||||||||||||||||||
. 0076 137 0076 137 | U+0089 | C2 89 | | Control character: Character Tabulation With Justification | |||||||||||||||||||||||||||||||||||||||||||
| 138 | U+008A | C2 8A | | Control character: Line Tabulation Set | |||||||||||||||||||||||||||||||||||||||||||
| 139 | U+008B | C2 8B | | Control character: Partial Line Forward | |||||||||||||||||||||||||||||||||||||||||||
| 140 | U+008C | C2 8C | | Control character: Partial Line Backward | |||||||||||||||||||||||||||||||||||||||||||
| 141 | U+008D | C2 8D | | Control character: Reverse Line Feed | |||||||||||||||||||||||||||||||||||||||||||
| 142 | U+008E | C2 8E | | Control character: Single Shift Two | |||||||||||||||||||||||||||||||||||||||||||
| 143 | U+008F | C2 8F | | Control character: Single Shift Three | |||||||||||||||||||||||||||||||||||||||||||
| 144 | U+0090 | C2 90 | | Control character: Device Control String | |||||||||||||||||||||||||||||||||||||||||||
| 145 | U+0091 | C2 91 | | Control character: Private Use One | |||||||||||||||||||||||||||||||||||||||||||
| 146 | U+0092 | C2 92 | Управляющий характер: частное использование двух | ||||||||||||||||||||||||||||||||||||||||||||
| 147 | U+0093 | C2 93 | Контрольный характер: установленная трансмитта | . Контрольный характер: установленная трансмита Контрольный характер: установленная трансмита | .0075 | 148 | U+0094 | C2 94 | | Control character: Cancel Character | |||||||||||||||||||||||||||||||||||||
| 149 | U+0095 | C2 95 | | Control character: Message Waiting | |||||||||||||||||||||||||||||||||||||||||||
| 150 | U+0096 | C2 96 | Контрольный характер: начало охраняемой зоны | ||||||||||||||||||||||||||||||||||||||||||||
| 151 | U+0097 | C2 | 7777676.0077 | ||||||||||||||||||||||||||||||||||||||||||||
| 152 | U+0098 | C2 98 | | Control character: Start Of String | |||||||||||||||||||||||||||||||||||||||||||
| 153 | U+0099 | C2 99 | | Control character: Unknown | |||||||||||||||||||||||||||||||||||||||||||
| 154 | U+009A | C2 9A | | Control character: Single Character Introducer | |||||||||||||||||||||||||||||||||||||||||||
| 155 | U+009B | C2 9B | | Control character: Control Sequence Introducer | |||||||||||||||||||||||||||||||||||||||||||
| 156 | U+009C | C2 9C | | Control character: String Terminator | |||||||||||||||||||||||||||||||||||||||||||
| 157 | U+009D | C2 9D | | Control character: Operating System Command | |||||||||||||||||||||||||||||||||||||||||||
| 158 | U+009E | C2 9E | | Control character: Privacy Message | |||||||||||||||||||||||||||||||||||||||||||
| 159 | U+009F | C2 9F | | Управляющий символ: команда прикладной программы | |||||||||||||||||||||||||||||||||||||||||||
| 160 | U+00A0 | C2 A0 | NORUF DRACE | ||||||||||||||||||||||||||||||||||||||||||||
| 161 | U+0077 | ||||||||||||||||||||||||||||||||||||||||||||||
| 161 | U+0077 | ||||||||||||||||||||||||||||||||||||||||||||||
| 161 | U+0077 | ||||||||||||||||||||||||||||||||||||||||||||||
| 161 | U+0077 | ||||||||||||||||||||||||||||||||||||||||||||||
| 161 | U+0077 | ||||||||||||||||||||||||||||||||||||||||||||||
| 162 | U+00A2 | C2 A2 | ¢ | Cent Sign | |||||||||||||||||||||||||||||||||||||||||||
| 163 | U+00A3 | C2 A3 | £ | Pound Sign | |||||||||||||||||||||||||||||||||||||||||||
| 164 | U+00A4 | C2 A4 | ¤ | Currency Sign | |||||||||||||||||||||||||||||||||||||||||||
| 165 | U+00A5 | C2 A5 | ¥ | Yen Sign | |||||||||||||||||||||||||||||||||||||||||||
| 166 | U +00A6 | C2 A6 | ¦ | Broken Bar | |||||||||||||||||||||||||||||||||||||||||||
| 167 | U+00A7 | C2 A7 | § | Section Sign | |||||||||||||||||||||||||||||||||||||||||||
| 168 | U+00A8 | C2 A8 | ¨ | Diaeresis | |||||||||||||||||||||||||||||||||||||||||||
| 169 | U+00A9 | C2 A9 | © | Copyright Sign | |||||||||||||||||||||||||||||||||||||||||||
| 170 | U+00AA | C2 AA | ª | Feminine Ordinal Indicator | |||||||||||||||||||||||||||||||||||||||||||
| 171 | U+00AB | C2 AB | « | Стоимость двойного углового знака | |||||||||||||||||||||||||||||||||||||||||||
| 172 | U+00AC | C2.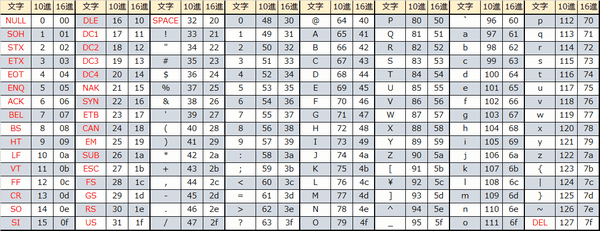 0077 0077 | Not Sign | ||||||||||||||||||||||||||||||||||||||||||||
| 173 | U+00AD | C2 AD | Soft Hyphen | ||||||||||||||||||||||||||||||||||||||||||||
| 174 | U+00AE | C2 AE | ® | Registered Sign | |||||||||||||||||||||||||||||||||||||||||||
| 175 | U+00AF | C2 AF | ¯ | Macron | |||||||||||||||||||||||||||||||||||||||||||
| 176 | U+00B0 | C2 B0 | ° | Degree Sign | |||||||||||||||||||||||||||||||||||||||||||
| 177 | U+00B1 | C2 B1 | ± | Plus-minus Sign | |||||||||||||||||||||||||||||||||||||||||||
| 178 | U+00B2 | C2 B2 | ² | Superscript Two | |||||||||||||||||||||||||||||||||||||||||||
| 179 | U+00B3 | C2 B3 | ³ | Superscript Three | |||||||||||||||||||||||||||||||||||||||||||
| 180 | U+00B4 | C2 B4 | ´ | Acute Accent | |||||||||||||||||||||||||||||||||||||||||||
| 181 | U+00B5 | C2 B5 | µ | Micro Sign | |||||||||||||||||||||||||||||||||||||||||||
| 182 | U+00B6 | C2 B6 | ¶ | Pilcrow Sign | |||||||||||||||||||||||||||||||||||||||||||
| 183 | U+00B7 | C2 B7 | · | Middle Dot | |||||||||||||||||||||||||||||||||||||||||||
| 184 | U +00B8 | C2 B8 | ¸ | Cedilla | |||||||||||||||||||||||||||||||||||||||||||
| 185 | U+00B9 | C2 B9 | ¹ | Superscript One | |||||||||||||||||||||||||||||||||||||||||||
| 186 | U+00BA | C2 BA | º | Masculine Ordinal Indicator | |||||||||||||||||||||||||||||||||||||||||||
| 187 | U+00BB | C2 BB | » | Right-pointing Double Angle Quotation Mark | |||||||||||||||||||||||||||||||||||||||||||
| 188 | U+00BC | C2 BC | ¼ | Vulgar Fraction One Quarter | |||||||||||||||||||||||||||||||||||||||||||
| 189 | U+00BD | C2 BD | ½ | Vulgar Fraction One Half | |||||||||||||||||||||||||||||||||||||||||||
| 190 | U+00BE | C2 BE | ¾ | Vulgar Fraction Three Quarters | |||||||||||||||||||||||||||||||||||||||||||
| 191 | U+00BF | C2 BF | ¿ | Inverted Question Mark | |||||||||||||||||||||||||||||||||||||||||||
| 192 | U+00C0 | C3 80 | À | Latin Capital Letter A With Grave | |||||||||||||||||||||||||||||||||||||||||||
| 193 | U+00C1 | C3 81 | Á | Latin Capital Letter A With Acute | |||||||||||||||||||||||||||||||||||||||||||
| 194 | U+00C2 | C3 82 | â | Латинская столичная буква A с Trinkflex | |||||||||||||||||||||||||||||||||||||||||||
| 195 | U+00C3 | C3 83 | ã | LATIN CAPIT | C3 84 | ä | Латинская столичная буква А с диарезисом | ||||||||||||||||||||||||||||||||||||||||
| 197 | U+00C5 | C3 85 | Å | LATIN CAPIT0075 | 198 | U+00C6 | C3 86 | Æ | Latin Capital Letter Ae | ||||||||||||||||||||||||||||||||||||||
| 199 | U+00C7 | C3 87 | Ç | Latin Capital Letter C With Cedilla | |||||||||||||||||||||||||||||||||||||||||||
| 200 | U+00C8 | C3 88 | è | Latin Capital Letter E с могилой | |||||||||||||||||||||||||||||||||||||||||||
| 201 | U+00C9 | C3 89 | é+00C9 | C3 89 | 66767679 | C3 89 | 66767679 | C3 89 | 66767679 | C3 89 | 667679 | C3 89 | C3 89 | é | . 0077 0077 | ||||||||||||||||||||||||||||||||
| 202 | U+00CA | C3 8A | Ê | Latin Capital Letter E With Circumflex | |||||||||||||||||||||||||||||||||||||||||||
| 203 | U+00CB | C3 8B | Ë | Latin Capital Letter E With Diaeresis | |||||||||||||||||||||||||||||||||||||||||||
| 204 | U+00CC | C3 8C | Ì | Latin Capital Letter I With Grave | |||||||||||||||||||||||||||||||||||||||||||
| 205 | U+00CD | C3 8D | Í | Latin Capital Letter I With Acute | |||||||||||||||||||||||||||||||||||||||||||
| 206 | U+00CE | C3 8E | Î | Latin Capital Letter I With Circumflex | |||||||||||||||||||||||||||||||||||||||||||
| 207 | U+00CF | C3 8F | Ï | Latin Capital Letter I With Diaeresis | |||||||||||||||||||||||||||||||||||||||||||
| 208 | U+00D0 | C3 90 | Ð | Latin Capital Letter Eth | |||||||||||||||||||||||||||||||||||||||||||
| 209 | U+00D1 | C3 91 | Ñ | Latin Capital Letter N With Tilde | |||||||||||||||||||||||||||||||||||||||||||
| 210 | U+00D2 | C3 92 | Ò | Latin Capital Letter O With Grave | |||||||||||||||||||||||||||||||||||||||||||
| 211 | U+00D3 | C3 93 | Ó | Latin Capital Letter O With Acute | |||||||||||||||||||||||||||||||||||||||||||
| 212 | U+00D4 | C3 94 | Ô | Latin Capital Letter O With Circumflex | |||||||||||||||||||||||||||||||||||||||||||
| 213 | U+00D5 | C3 95 | Õ | Latin Capital Letter O With Tilde | |||||||||||||||||||||||||||||||||||||||||||
| 214 | U+00D6 | C3 96 | Ö | Latin Capital Letter O With Diaeresis | |||||||||||||||||||||||||||||||||||||||||||
| 215 | U+00D7 | C3 97 | × | Multiplication Sign | |||||||||||||||||||||||||||||||||||||||||||
| 216 | U+00D8 | C3 98 | Ø | Latin Capital Letter O With Stroke | |||||||||||||||||||||||||||||||||||||||||||
| 217 | U+00D9 | C3 99 | Ù | Latin Capital Letter U With Grave | |||||||||||||||||||||||||||||||||||||||||||
| 218 | U+00DA | C3 9A | Ú | Latin Capital Letter U With Acute | |||||||||||||||||||||||||||||||||||||||||||
| 219 | U+00DB | C3 9B | Û | Latin Capital Letter U With Circumflex | |||||||||||||||||||||||||||||||||||||||||||
| 220 | U+00DC | C3 9C | Ü | Latin Capital Letter U With Diaeresis | |||||||||||||||||||||||||||||||||||||||||||
| 221 | U+00DD | C3 9D | Ý | Latin Capital Letter Y With Acute | |||||||||||||||||||||||||||||||||||||||||||
| 222 | U+00DE | C3 9E | þ | САПИТНАЯ САПИЯ | 224 | U+00E0 | C3 A0 | à | Latin Small Letter A With Grave | ||||||||||||||||||||||||||||||||||||||
| 225 | U+00E1 | C3 A1 | á | Latin Small Letter A With Acute | |||||||||||||||||||||||||||||||||||||||||||
| 226 | U+00E2 | C3 A2 | â | Latin Small Letter A With Circumflex | |||||||||||||||||||||||||||||||||||||||||||
| 227 | U+00E3 | C3 A3 | ã | Latin Small Letter A With Tilde | |||||||||||||||||||||||||||||||||||||||||||
| 228 | U+00E4 | C3 A4 | ä | Latin Small Letter A With Diaeresis | |||||||||||||||||||||||||||||||||||||||||||
| 229 | U+00E5 | C3 A5 | å | Latin Small Letter A With Ring Выше | |||||||||||||||||||||||||||||||||||||||||||
| 230 | U+00E6 | C3 A6 | æ | LATIN STALLET AE | |||||||||||||||||||||||||||||||||||||||||||
| 231 | UE+00E7977 | . | |||||||||||||||||||||||||||||||||||||||||||||
| 232 | U+00E8 | C3 A8 | è | Latin Small Letter E With Grave | |||||||||||||||||||||||||||||||||||||||||||
| 233 | U+00E9 | C3 A9 | é | Latin Small Letter E With Acute | |||||||||||||||||||||||||||||||||||||||||||
| 234 | U+00EA | C3 AA | ê | Latin Small Letter E With Circumflex | |||||||||||||||||||||||||||||||||||||||||||
| 235 | U+00EB | C3 AB | ë | Latin Small Letter E With Diaeresis | |||||||||||||||||||||||||||||||||||||||||||
| 236 | U+00EC | C3 AC | ì | Latin Small Letter I With Grave | |||||||||||||||||||||||||||||||||||||||||||
| 237 | U+00ED | C3 AD | í | Latin Small Letter I With Acute | |||||||||||||||||||||||||||||||||||||||||||
| 238 | U+00EE | C3 AE | î | Latin Small Letter I With Circumflex | |||||||||||||||||||||||||||||||||||||||||||
| 239 | U+00EF | C3 AF | ï | Latin Small Letter I With Diaeresis | |||||||||||||||||||||||||||||||||||||||||||
| 240 | U+00F0 | C3 B0 | ð | Latin Small Letter Eth | |||||||||||||||||||||||||||||||||||||||||||
| 241 | U+00F1 | C3 B1 | ñ | Latin Small Letter N With Tilde | |||||||||||||||||||||||||||||||||||||||||||
| 242 | U+00F2 | C3 B2 | ò | Latin Small Letter O With Grave | |||||||||||||||||||||||||||||||||||||||||||
| 243 | U+00F3 | C3 B3 | ó | Latin Small Letter O With Acute | |||||||||||||||||||||||||||||||||||||||||||
| 244 | U+00F4 | C3 B4 | ô | Latin Small Letter O With Circumflex | |||||||||||||||||||||||||||||||||||||||||||
| 245 | U+00F5 | C3 B5 | õ | Latin Small Letter O With Tilde | |||||||||||||||||||||||||||||||||||||||||||
| 246 | U+00F6 | C3 B6 | ö | Latin Small Letter O With Diaeresis | |||||||||||||||||||||||||||||||||||||||||||
| 247 | U+00F7 | C3 B7 | ÷ | Division Sign | |||||||||||||||||||||||||||||||||||||||||||
| 248 | U+00F8 | C3 B8 | ø | Latin Small Letter O With Stroke | |||||||||||||||||||||||||||||||||||||||||||
| 249 | U+00F9 | C3 B9 | ù | Latin Small Letter U With Grave | |||||||||||||||||||||||||||||||||||||||||||
| 250 | U+00FA | C3 BA | ú | Latin Small Letter U With Acute | |||||||||||||||||||||||||||||||||||||||||||
| 251 | U+00FB | C3 BB | û | Latin Small Letter U With Circumflex | |||||||||||||||||||||||||||||||||||||||||||
| 252 | U+00FC | C3 BC | ü | LATIN SMALT LITE | |||||||||||||||||||||||||||||||||||||||||||
| 254 | U+00FE | C3 BE | þ | LATIN STALLERT THORN | |||||||||||||||||||||||||||||||||||||||||||
| 255 | U+00FF | 255 | U+00ff | U+00ff | C3. | ||||||||||||||||||||||||||||||||||||||||||
| 256 | U+0100 | C4 80 | Ā | Latin Capital Letter A With Macron | |||||||||||||||||||||||||||||||||||||||||||
| 257 | U+0101 | C4 81 | ā | Latin Small Letter A With Macron | |||||||||||||||||||||||||||||||||||||||||||
| 258 | U+0102 | C4 82 | ă | САПИТА | |||||||||||||||||||||||||||||||||||||||||||
| 260 | U+0104 | C4 84 | Ą | Latin Capital Letter A With Ogonek | |||||||||||||||||||||||||||||||||||||||||||
| 261 | U+0105 | C4 85 | ą | Latin Small Letter A With Ogonek | |||||||||||||||||||||||||||||||||||||||||||
| 262 | U+0106 | C4 86 | Ć | Latin Capital Letter C With Acute | |||||||||||||||||||||||||||||||||||||||||||
| 263 | U+0107 | C4 87 | ć | Latin Small Letter C With Acute | |||||||||||||||||||||||||||||||||||||||||||
| 264 | U+0108 | C4 88 | Ĉ | Latin Capital Letter C With Circumflex | |||||||||||||||||||||||||||||||||||||||||||
| 265 | U+0109 | C4 89 | ĉ | Latin Small Letter C With Circumflex | |||||||||||||||||||||||||||||||||||||||||||
| 266 | U+010A | C4 8A | ċ | Latin Capital Letter C с DOT выше | |||||||||||||||||||||||||||||||||||||||||||
| 267 | U+01077 | . Dot Above Dot Above | |||||||||||||||||||||||||||||||||||||||||||||
| 268 | U+010C | C4 8C | Č | Latin Capital Letter C With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 269 | U+010D | C4 8D | č | Latin Small Letter C С Кэрон | |||||||||||||||||||||||||||||||||||||||||||
| 270 | U+010E | C4 8E | Ď | Latin Capital Letter D With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 271 | U+010F | C4 8F | ď | Latin Small Letter D With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 272 | U+0110 | C4 90 | Đ | Latin Capital Letter D With Stroke | |||||||||||||||||||||||||||||||||||||||||||
| 273 | U+0111 | C4 91 | đ | Latin Small Letter D With Stroke | |||||||||||||||||||||||||||||||||||||||||||
| 274 | U+0112 | C4 92 | Ē | Latin Capital Letter E With Macron | |||||||||||||||||||||||||||||||||||||||||||
| 275 | U+0113 | C4 93 | ē | Latin Small Letter E With Macron | |||||||||||||||||||||||||||||||||||||||||||
| 276 | U+0114 | C4 94 | Ĕ | Latin Capital Letter E With Breve | |||||||||||||||||||||||||||||||||||||||||||
| 277 | U+0115 | C4 95 | ĕ | Latin Small Letter E With Breve | |||||||||||||||||||||||||||||||||||||||||||
| 278 | U+0116 | C4 96 | Ė | Latin Capital Letter E With Dot Above | |||||||||||||||||||||||||||||||||||||||||||
| 279 | U+0117 | C4 97 | ė | Latin Small Letter E With Dot Above | |||||||||||||||||||||||||||||||||||||||||||
| 280 | U+0118 | C4 98 | Ę | Latin Capital Letter E With Ogonek | |||||||||||||||||||||||||||||||||||||||||||
| 281 | U+0119 | C4 99 | ę | Latin Small Letter E С Огонек | |||||||||||||||||||||||||||||||||||||||||||
| 282 | U+011A | C4 9A | Ě | Latin Capital Letter E With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 283 | U+011B | C4 9B | ě | Latin Small Letter E With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 284 | U+011C | C4 9C | Ĝ | Latin Capital Letter G With Circumflex | |||||||||||||||||||||||||||||||||||||||||||
| 285 | U+011D | C4 9D | ĝ | Latin Small Letter G With Circumflex | |||||||||||||||||||||||||||||||||||||||||||
| 286 | U+011E | C4 9E | Ğ | Latin Capital Letter G With Breve | |||||||||||||||||||||||||||||||||||||||||||
| 287 | U+011F | C4 9F | ğ | Latin Small Letter G With Breve | |||||||||||||||||||||||||||||||||||||||||||
| 288 | U+0120 | C4 A0 | Ġ | Latin Capital Letter G With Dot Above | |||||||||||||||||||||||||||||||||||||||||||
| 289 | U+0121 | C4 A1 | ġ | Latin Small Letter G With Точка выше | |||||||||||||||||||||||||||||||||||||||||||
| 290 | U+0122 | C4 A2 | Ģ | Latin Capital Letter G With Cedilla | |||||||||||||||||||||||||||||||||||||||||||
| 291 | U+0123 | C4 A3 | ģ | Latin Small Letter G With Cedilla | |||||||||||||||||||||||||||||||||||||||||||
| 292 | U+0124 | C4 A4 | Ĥ | Latin Capital Letter H With Circumflex | |||||||||||||||||||||||||||||||||||||||||||
| 293 | U+0125 | C4 A5 | ĥ | Latin Small Letter H With Circumflex | |||||||||||||||||||||||||||||||||||||||||||
| 294 | U+0126 | C4 A6 | Ħ | Latin Capital Letter H With Stroke | |||||||||||||||||||||||||||||||||||||||||||
| 295 | U+0127 | C4 A7 | ħ | Latin Small Letter H With Stroke | |||||||||||||||||||||||||||||||||||||||||||
| 296 | U+0128 | C4 A8 | Ĩ | Latin Capital Letter I With Tilde | |||||||||||||||||||||||||||||||||||||||||||
| 297 | U+0129 | C4 A9 | ĩ | Latin Small Letter I With Tilde | |||||||||||||||||||||||||||||||||||||||||||
| 298 | U+012A | C4 AA | Ī | Latin Capital Letter I With Macron | |||||||||||||||||||||||||||||||||||||||||||
| 299 | U+012B | C4 AB | ī | Latin Small Letter I With Macron | |||||||||||||||||||||||||||||||||||||||||||
| 300 | U+012C | C4 AC | ĭ | Latin Capital Letter I с Breve | |||||||||||||||||||||||||||||||||||||||||||
| 301 | U+012777 | 767676767677777776767777777777777777777777777777767777777777777777777777777777777777777777777777777777777777777776777777767.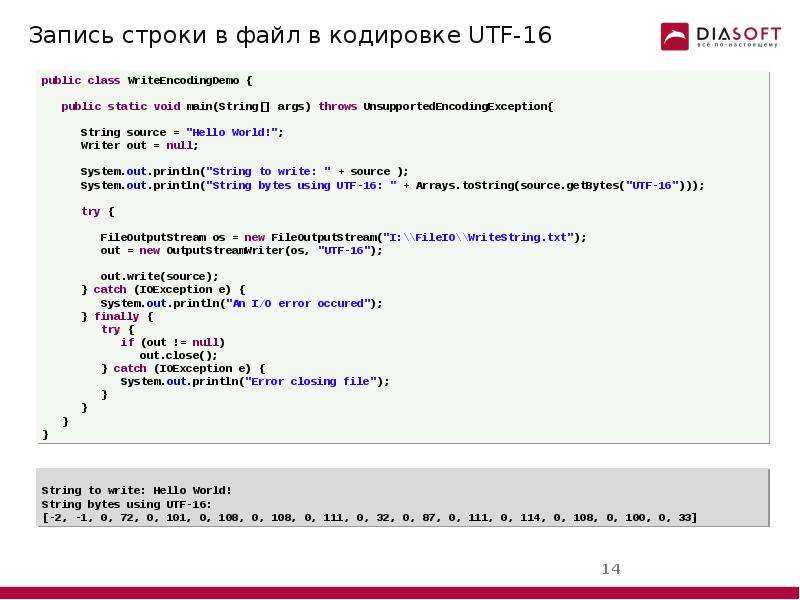 | |||||||||||||||||||||||||||||||||||||||||||||
| 302 | U+012E | C4 AE | Į | Latin Capital Letter I With Ogonek | |||||||||||||||||||||||||||||||||||||||||||
| 303 | U+012F | C4 AF | į | Latin Small Letter I With Ogonek | |||||||||||||||||||||||||||||||||||||||||||
| 304 | U+0130 | C4 B0 | ̇ | Latin Capital Letter I с DOT выше | |||||||||||||||||||||||||||||||||||||||||||
| 305 | U+0131777979 | 70077 70077 70077 70077 7007 7. | |||||||||||||||||||||||||||||||||||||||||||||
| 306 | U+0132 | C4 B2 | IJ | Latin Capital Ligature Ij | |||||||||||||||||||||||||||||||||||||||||||
| 307 | U+0133 | C4 B3 | ij | Latin Small Ligature Ij | |||||||||||||||||||||||||||||||||||||||||||
| 308 | U+0134 | C4 B4 | ĵ | Latin Capital Letter J с Circeflex | |||||||||||||||||||||||||||||||||||||||||||
| 309 | U+0135 | C4 B59779 | |||||||||||||||||||||||||||||||||||||||||||||
| 310 | U+0136 | C4 B6 | Ķ | Latin Capital Letter K With Cedilla | |||||||||||||||||||||||||||||||||||||||||||
| 311 | U+0137 | C4 B7 | ķ | Latin Small Letter K With Cedilla | |||||||||||||||||||||||||||||||||||||||||||
| 312 | U+0138 | C4 B8 | ĸ | LATIN SMALT LITK0077 | |||||||||||||||||||||||||||||||||||||||||||
| 314 | U+013A | C4 BA | ĺ | Latin Small Letter L With Acute | |||||||||||||||||||||||||||||||||||||||||||
| 315 | U+013B | C4 BB | Ļ | Latin Capital Letter L With Cedilla | |||||||||||||||||||||||||||||||||||||||||||
| 316 | U+013C | C4 BC | ļ | Latin Small Letter L With Cedilla | |||||||||||||||||||||||||||||||||||||||||||
| 317 | U+013D | C4 BD | Ľ | Latin Capital Letter L With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 318 | U+013E | C4 BE | ľ | Latin Small Letter L With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 319 | U+013F | C4 BF | Ŀ | Latin Capital Letter L With Middle Dot | |||||||||||||||||||||||||||||||||||||||||||
| 320 | U+0140 | C5 80 | ŀ | Latin Small Letter L With Middle Dot | |||||||||||||||||||||||||||||||||||||||||||
| 321 | U+0141 | C5 81 | Ł | Latin Capital Letter L С инсультом | |||||||||||||||||||||||||||||||||||||||||||
| 322 | U+0142 | C5 82 | LATIN SMALT LITE | ||||||||||||||||||||||||||||||||||||||||||||
| 324 | U+0144 | C5 84 | ń | Latin Small Letter N With Acute | |||||||||||||||||||||||||||||||||||||||||||
| 325 | U+0145 | C5 85 | Ņ | Latin Capital Letter N With Cedilla | |||||||||||||||||||||||||||||||||||||||||||
| 326 | U+0146 | C5 86 | ņ | Latin Small Letter N With Cedilla | |||||||||||||||||||||||||||||||||||||||||||
| 327 | U+0147 | C5 87 | Ň | Latin Capital Letter N With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 328 | U+0148 | C5 88 | ň | Latin Small Letter N With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 329 | U+0149 | C5 89 | ʼn | Latin Small Letter N Preceded By Апостроф | |||||||||||||||||||||||||||||||||||||||||||
| 330 | U+014A | C5 8A | Ŋ | Latin Capital Letter Eng | |||||||||||||||||||||||||||||||||||||||||||
| 331 | U+014B | C5 8B | ŋ | Latin Small Letter Eng | |||||||||||||||||||||||||||||||||||||||||||
| 332 | U+014C | C5 8C | Ō | Latin Capital Letter O With Macron | |||||||||||||||||||||||||||||||||||||||||||
| 333 | U+014D | C5 8D | ō | Latin Small Letter O With Macron | |||||||||||||||||||||||||||||||||||||||||||
| 334 | U+014E | C5 8E | Ŏ | Latin Capital Letter O With Breve | |||||||||||||||||||||||||||||||||||||||||||
| 335 | U+014F | C5 8F | ŏ | Latin Small Letter O With Breve | |||||||||||||||||||||||||||||||||||||||||||
| 336 | U+0150 | C5 90 | Ő | Latin Capital Letter O With Double Acute | |||||||||||||||||||||||||||||||||||||||||||
| 337 | U+0151 | C5 91 | ő | Latin Small Letter O With Двойной острый | |||||||||||||||||||||||||||||||||||||||||||
| 338 | U+0152 | C5 92 | Π| Latin Capital Ligature Oe | |||||||||||||||||||||||||||||||||||||||||||
| 339 | U+0153 | C5 93 | œ | Latin Small Ligature Oe | |||||||||||||||||||||||||||||||||||||||||||
| 340 | U+0154 | C5 94 | ŕ | Latin Capital Letter R с острым | |||||||||||||||||||||||||||||||||||||||||||
| 341 | U+0155 | C5 | u+0155 | C5 | 79. 0077 0077 | ||||||||||||||||||||||||||||||||||||||||||
| 342 | U+0156 | C5 96 | Ŗ | Latin Capital Letter R With Cedilla | |||||||||||||||||||||||||||||||||||||||||||
| 343 | U+0157 | C5 97 | ŗ | Latin Small Letter R With Cedilla | |||||||||||||||||||||||||||||||||||||||||||
| 344 | U+0158 | C5 98 | Ř | Latin Capital Letter R With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 345 | U+0159 | C5 99 | ř | Latin Small Letter R With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 346 | U+015A | C5 9A | Ś | Latin Capital Letter S With Acute | |||||||||||||||||||||||||||||||||||||||||||
| 347 | U+015B | C5 9B | ś | Latin Small Letter S With Acute | |||||||||||||||||||||||||||||||||||||||||||
| 348 | U+015C | C5 9C | Ŝ | Latin Capital Letter S With Circumflex | |||||||||||||||||||||||||||||||||||||||||||
| 349 | U+015D | C5 9D | ŝ | Latin Small Letter S With Circumflex | |||||||||||||||||||||||||||||||||||||||||||
| 350 | U+015E | C5 9E | Ş | Latin Capital Letter S With Cedilla | |||||||||||||||||||||||||||||||||||||||||||
| 351 | U+015F | C5 9F | ş | Latin Small Letter S With Cedilla | |||||||||||||||||||||||||||||||||||||||||||
| 352 | U+0160 | C5 A0 | Š | Latin Capital Letter S With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 353 | U+0161 | C5 A1 | š | Latin Small Letter S With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 354 | U+0162 | C5 A2 | Ţ | Latin Capital Letter T With Cedilla | |||||||||||||||||||||||||||||||||||||||||||
| 355 | U+0163 | C5 A3 | ţ | Latin Small Letter T With Cedilla | |||||||||||||||||||||||||||||||||||||||||||
| 356 | U+0164 | C5 A4 | Ť | Latin Capital Letter T With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 357 | U+0165 | C5 A5 | ť | Latin Small Letter T With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 358 | U+0166 | C5 A6 | Ŧ | Latin Capital Letter T With Stroke | |||||||||||||||||||||||||||||||||||||||||||
| 359 | U+0167 | C5 A7 | ŧ | Latin Small Letter T With Stroke | |||||||||||||||||||||||||||||||||||||||||||
| 360 | U+0168 | C5 A8 | ũ | Latin Capital Letter U с Tilde | |||||||||||||||||||||||||||||||||||||||||||
| 361 | U+019977 | ||||||||||||||||||||||||||||||||||||||||||||||
. | |||||||||||||||||||||||||||||||||||||||||||||||
| 362 | U+016A | C5 AA | Ū | Latin Capital Letter U With Macron | |||||||||||||||||||||||||||||||||||||||||||
| 363 | U+016B | C5 AB | ū | Latin Small Letter U With Macron | |||||||||||||||||||||||||||||||||||||||||||
| 364 | U+016C | C5 AC | ŭ | LATIN Capital Letter U с бревом | |||||||||||||||||||||||||||||||||||||||||||
| 365 | U+016797 | 767767677777. | 70076 70076 70076 70076 70076 | . | |||||||||||||||||||||||||||||||||||||||||||
| 366 | U+016E | C5 AE | Ů | Latin Capital Letter U With Ring Above | |||||||||||||||||||||||||||||||||||||||||||
| 367 | U+016F | C5 AF | ů | Latin Small Letter U With Ring Above | |||||||||||||||||||||||||||||||||||||||||||
| 368 | U+0170 | C5 B0 | Ű | Latin Capital Letter U With Double Acute | |||||||||||||||||||||||||||||||||||||||||||
| 369 | U+0171 | C5 B1 | ű | Latin Small Letter U With Double Acute | |||||||||||||||||||||||||||||||||||||||||||
| 370 | U+0172 | C5 B2 | Ų | Latin Capital Letter U With Ogonek | |||||||||||||||||||||||||||||||||||||||||||
| 371 | U+0173 | C5 B3 | ų | Latin Small Letter U With Ogonek | |||||||||||||||||||||||||||||||||||||||||||
| 372 | U+0174 | C5 B4 | Ŵ | Latin Capital Letter W With Circumflex | |||||||||||||||||||||||||||||||||||||||||||
| 373 | U+0175 | C5 B5 | ŵ | Латинская маленькая буква w с окружением | |||||||||||||||||||||||||||||||||||||||||||
| 374 | U+0176 | C5 B6 | ŷ | LATIN CAPTION CAVIT | C5 B7 | ŷ | Латинская маленькая буква Y с круговым комплексом | ||||||||||||||||||||||||||||||||||||||||
| 376 | U+0178 | C5 B8 | ÿ | LATINE CAVIT0076 377 | U+0179 | C5 B9 | Ź | Latin Capital Letter Z With Acute | |||||||||||||||||||||||||||||||||||||||
| 378 | U+017A | C5 BA | ź | Latin Small Letter Z With Acute | |||||||||||||||||||||||||||||||||||||||||||
| 379 | U+017B | C5 BB | Ż | Latin Capital Letter Z With Dot Above | |||||||||||||||||||||||||||||||||||||||||||
| 380 | U+017C | C5 BC | ż | Latin Small Letter Z With Dot Above | |||||||||||||||||||||||||||||||||||||||||||
| 381 | U+017D | C5 BD | Ž | Latin Capital Letter Z With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 382 | U+017E | C5 BE | ž | Latin Small Letter Z With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 383 | U+017F | C5 BF | ſ | Latin Small Letter Long S | |||||||||||||||||||||||||||||||||||||||||||
| 384 | U+0180 | C6 80 | ƀ | Latin Small Letter B With Stroke | |||||||||||||||||||||||||||||||||||||||||||
| 385 | U+0181 | C6 81 | Ɓ | Latin Capital Letter B With Hook | |||||||||||||||||||||||||||||||||||||||||||
| 386 | U+0182 | C6 82 | Ƃ | Latin Capital Letter B With Topbar | |||||||||||||||||||||||||||||||||||||||||||
| 387 | U+0183 | C6 83 | ƃ | LATIN STALL LITE0077 | |||||||||||||||||||||||||||||||||||||||||||
| 389 | U+0185 | C6 85 | ƅ | Latin Small Letter Tone Six | |||||||||||||||||||||||||||||||||||||||||||
| 390 | U+0186 | C6 86 | Ɔ | Latin Capital Letter Open O | |||||||||||||||||||||||||||||||||||||||||||
| 391 | U+0187 | C6 87 | Ƈ | Latin Capital Letter C With Hook | |||||||||||||||||||||||||||||||||||||||||||
| 392 | U+0188 | C6 88 | ƈ | Latin Small Letter C With Hook | |||||||||||||||||||||||||||||||||||||||||||
| 393 | U+0189 | C6 89 | Ɖ | Latin Capital Letter African D | |||||||||||||||||||||||||||||||||||||||||||
| 394 | U+018A | C6 8A | Ɗ | Latin Capital Letter D With Hook | |||||||||||||||||||||||||||||||||||||||||||
| 395 | U+018B | C6 8B | Ƌ | Latin Capital Letter D With Topbar | |||||||||||||||||||||||||||||||||||||||||||
| 396 | U+018C | C6 8C | ƌ | Latin Small Letter D With Topbar | |||||||||||||||||||||||||||||||||||||||||||
| 397 | U+018D | C6 8D | ƍ | Latin Small Letter Turned Delta | |||||||||||||||||||||||||||||||||||||||||||
| 398 | U+018E | C6 8E | Ǝ | Latin Capital Letter Reversed E | |||||||||||||||||||||||||||||||||||||||||||
| 399 | U+018F | C6 8F | Ə | Latin Capital Letter Schwa | |||||||||||||||||||||||||||||||||||||||||||
| 400 | U+0190 | C6 90 | Ɛ | Latin Capital Letter Open E | |||||||||||||||||||||||||||||||||||||||||||
| 401 | U+0191 | C6 91 | ƒ | Latin Capital Letter F Hook | |||||||||||||||||||||||||||||||||||||||||||
| 402 | U HOUT. | ||||||||||||||||||||||||||||||||||||||||||||||
| 403 | U+0193 | C6 93 | Ɠ | Latin Capital Letter G With Hook | |||||||||||||||||||||||||||||||||||||||||||
| 404 | U+0194 | C6 94 | Ɣ | Latin Capital Letter Gamma | |||||||||||||||||||||||||||||||||||||||||||
| 405 | U+0195 | C6 95 | ƕ | Latin Small Letter Hv | |||||||||||||||||||||||||||||||||||||||||||
| 406 | U+0196 | C6 96 | Ɩ | Latin Capital Letter Iota | |||||||||||||||||||||||||||||||||||||||||||
| 407 | U+0197 | C6 97 | Ɨ | Latin Capital Letter I With Stroke | |||||||||||||||||||||||||||||||||||||||||||
| 408 | U+0198 | C6 98 | Ƙ | Latin Capital Letter K With Hook | |||||||||||||||||||||||||||||||||||||||||||
| 409 | U+0199 | C6 99 | ƙ | Latin Small Letter K With Hook | |||||||||||||||||||||||||||||||||||||||||||
| 410 | U+019A | C6 9A | ƚ | Latin Small Letter L With Bar | |||||||||||||||||||||||||||||||||||||||||||
| 411 | U+019B | C6 9B | ƛ | LATIN STALL LITCL0077 | |||||||||||||||||||||||||||||||||||||||||||
| 413 | U+019D | C6 9D | Ɲ | Latin Capital Letter N With Left Hook | |||||||||||||||||||||||||||||||||||||||||||
| 414 | U+019E | C6 9E | ƞ | Latin Small Letter N With Long Right Leg | |||||||||||||||||||||||||||||||||||||||||||
| 415 | U+019F | C6 9F | Ɵ | Latin Capital Letter O With Middle Tilde | |||||||||||||||||||||||||||||||||||||||||||
| 416 | U+01A0 | C6 A0 | Ơ | Latin Capital Letter O With Horn | |||||||||||||||||||||||||||||||||||||||||||
| 417 | U+01A1 | C6 A1 | ơ | Latin Small Letter O With Horn | |||||||||||||||||||||||||||||||||||||||||||
| 418 | U+01A2 | C6 A2 | Ƣ | Latin Capital Letter Oi | |||||||||||||||||||||||||||||||||||||||||||
| 419 | U+01A3 | C6 A3 | ƣ | Latin Small Letter Oi | |||||||||||||||||||||||||||||||||||||||||||
| 420 | U+01A4 | C6 A4 | Ƥ | Latin Capital Letter P With Hook | |||||||||||||||||||||||||||||||||||||||||||
| 421 | U+01A5 | C6 A5 | ƥ | Latin Small Letter P With Hook | |||||||||||||||||||||||||||||||||||||||||||
| 422 | U+01A6 | C6 A6 | Ʀ | Latin Letter Yr | |||||||||||||||||||||||||||||||||||||||||||
| 423 | U+01A7 | C6 A7 | Ƨ | Latin Capital Letter Tone Two | |||||||||||||||||||||||||||||||||||||||||||
| 424 | U+01A8 | C6 A8 | ƨ | Latin Small Letter Tone Two | |||||||||||||||||||||||||||||||||||||||||||
| 425 | U+01A9 | C6 A9 | Ʃ | Latin Capital Letter Esh | |||||||||||||||||||||||||||||||||||||||||||
| 426 | U+01AA | C6 AA | ƪ | Latin Letter Reversed Esh Loop | |||||||||||||||||||||||||||||||||||||||||||
| 427 | U+01AB | C6 AB | ƫ | Latin Small Letter T With Palatal Hook | |||||||||||||||||||||||||||||||||||||||||||
| 428 | U+01AC | C6 AC | Ƭ | Latin Capital Letter T With Hook | |||||||||||||||||||||||||||||||||||||||||||
| 429 | U+01AD | C6 AD | ƭ | Latin Small Letter T With Hook | |||||||||||||||||||||||||||||||||||||||||||
| 430 | U+01AE | C6 AE | Ʈ | Latin Capital Letter T With Retroflex Hook | |||||||||||||||||||||||||||||||||||||||||||
| 431 | U+01AF | C6 AF | Ư | Latin Capital Letter U With Horn | |||||||||||||||||||||||||||||||||||||||||||
| 432 | U+01B0 | C6 B0 | ư | Latin Small Letter U With Horn | |||||||||||||||||||||||||||||||||||||||||||
| 433 | U+01B1 | C6 B1 | Ʊ | Latin Capital Letter Upsilon | |||||||||||||||||||||||||||||||||||||||||||
| 434 | U+01B2 | C6 B2 | Ʋ | Latin Capital Letter V With Hook | |||||||||||||||||||||||||||||||||||||||||||
| 435 | U+01B3 | C6 B3 | Ƴ | Latin Capital Letter Y With Hook | |||||||||||||||||||||||||||||||||||||||||||
| 436 | U+01B4 | C6 B4 | ƴ | Латинская маленькая буква Y с крючком | |||||||||||||||||||||||||||||||||||||||||||
| 437 | U+01B5 | C6 B5 | ƶ | LATN CAPIT | C6 B6 | ƶ | Латинская маленькая буква Z с ходом | ||||||||||||||||||||||||||||||||||||||||
| 439 | U+01B7 | C6 B7 | ʒ | LATN CAPIT0076 U+01B8 | C6 B8 | Ƹ | Latin Capital Letter Ezh Reversed | ||||||||||||||||||||||||||||||||||||||||
| 441 | U+01B9 | C6 B9 | ƹ | Latin Small Letter Ezh Reversed | |||||||||||||||||||||||||||||||||||||||||||
| 442 | U +01BA | C6 BA | ƺ | Латинская маленькая буква ezh с хвостом | |||||||||||||||||||||||||||||||||||||||||||
| 443 | U+01BB | C6 BB | ƻ | 766666666666666767 | 66666666666669.0076 444 | U+01BC | C6 BC | ƽ | ТОНА ПИТАНИЯ ЛАТИНСКОГО СВОБОДА. | U+01BE | C6 BE | ƾ | Latin Letter Inverted Glottal Stop With Stroke | ||||||||||||||||||||||||||||||||||
| 447 | U+01BF | C6 BF | ƿ | Latin Letter Wynn | |||||||||||||||||||||||||||||||||||||||||||
| 448 | U+01C0 | C7 80 | ǀ | Latin Letter Dental Click | |||||||||||||||||||||||||||||||||||||||||||
| 449 | U+01C1 | C7 81 | ǁ | Latin Letter Lateral Click | |||||||||||||||||||||||||||||||||||||||||||
| 450 | U+01C2 | C7 82 | ǂ | Latin Letter Alveolar Click | |||||||||||||||||||||||||||||||||||||||||||
| 451 | U+01C3 | C7 83 | ǃ | Latin Letter Retroflex Click | |||||||||||||||||||||||||||||||||||||||||||
| 452 | U+01C4 | C7 84 | dž | LATIN CAPIT Z With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 454 | U+01C6 | C7 86 | dž | Latin Small Letter Dz With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 455 | U+01C7 | C7 87 | LJ | Latin Capital Letter Lj | |||||||||||||||||||||||||||||||||||||||||||
| 456 | U+01C8 | C7 88 | Lj | Latin Capital Letter L With Small Letter J | |||||||||||||||||||||||||||||||||||||||||||
| 457 | U+01C9 | C7 89 | lj | Latin Small Letter Lj | |||||||||||||||||||||||||||||||||||||||||||
| 458 | U+01CA | C7 8A | NJ | Latin Capital Letter Nj | |||||||||||||||||||||||||||||||||||||||||||
| 459 | U+01CB | C7 8B | Nj | Latin Capital Letter N With Small Letter J | |||||||||||||||||||||||||||||||||||||||||||
| 460 | U+01CC | C7 8C | nj | Latin Small Letter Nj | |||||||||||||||||||||||||||||||||||||||||||
| 461 | U+01CD | C7 8D | Ǎ | Латинская столичная буква A с Caron | |||||||||||||||||||||||||||||||||||||||||||
| 462 | U+01CE | C7 8E | ǎ | СОЗДАТЕЛЬНА0077 | Ǐ | Latin Capital Letter I With Caron | |||||||||||||||||||||||||||||||||||||||||
| 464 | U+01D0 | C7 90 | ǐ | Latin Small Letter I With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 465 | U+01D1 | C7 91 | Ǒ | Latin Capital Letter O With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 466 | U+01D2 | C7 92 | ǒ | Latin Small Letter O With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 467 | U+01D3 | C7 93 | ǔ | Latin Capital Letter U с Caron | |||||||||||||||||||||||||||||||||||||||||||
| 468 | U+01D4 | C7 94 | ǔ | LATIN STALL STMLAT | C7 95 | ǖ | Latin Capital Letter U с диарезом и Macron | ||||||||||||||||||||||||||||||||||||||||
| 470 | U+01D6 | C7 96 | . 0077 0077 | ||||||||||||||||||||||||||||||||||||||||||||
| 471 | U+01D7 | C7 97 | Ǘ | Latin Capital Letter U With Diaeresis And Acute | |||||||||||||||||||||||||||||||||||||||||||
| 472 | U+01D8 | C7 98 | ǘ | Latin Small Letter U With Diaeresis And Acute | |||||||||||||||||||||||||||||||||||||||||||
| 473 | U+01D9 | C7 99 | Ǚ | Latin Capital Letter U With Diaeresis And Caron | |||||||||||||||||||||||||||||||||||||||||||
| 474 | U+01DA | C7 9A | ǚ | Latin Small Letter U With Diaeresis And Caron | |||||||||||||||||||||||||||||||||||||||||||
| 475 | U+01DB | C7 9B | Ǜ | Latin Capital Letter U With Diaeresis And Grave | |||||||||||||||||||||||||||||||||||||||||||
| 476 | U+ 01DC | C7 9C | ǜ | Latin Small Letter U With Diaeresis And Grave | |||||||||||||||||||||||||||||||||||||||||||
| 477 | U+01DD | C7 9D | ǝ | Latin Small Letter Turned E | |||||||||||||||||||||||||||||||||||||||||||
| 478 | U+01DE | C7 9E | Ǟ | Latin Capital Letter A With Diaeresis And Macron | |||||||||||||||||||||||||||||||||||||||||||
| 479 | U+01DF | C7 9F | ǟ | Latin Small Letter A With Diaeresis И Macron | |||||||||||||||||||||||||||||||||||||||||||
| 480 | U+01E0 | C7 A0 | ǡ | Latin Capital Letter A с Macron | |||||||||||||||||||||||||||||||||||||||||||
| 481 | USTER | ||||||||||||||||||||||||||||||||||||||||||||||
| 481 | USTRAIN | ||||||||||||||||||||||||||||||||||||||||||||||
| 481 | USTRAIN | ||||||||||||||||||||||||||||||||||||||||||||||
| 481 | USTRAIN | ||||||||||||||||||||||||||||||||||||||||||||||
| 481 | |||||||||||||||||||||||||||||||||||||||||||||||
| 481 | |||||||||||||||||||||||||||||||||||||||||||||||
| 481 | . | Latin Small Letter A With Dot Above And Macron | |||||||||||||||||||||||||||||||||||||||||||||
| 482 | U+01E2 | C7 A2 | Ǣ | Latin Capital Letter Ae With Macron | |||||||||||||||||||||||||||||||||||||||||||
| 483 | U+01E3 | C7 A3 | ǣ | Латинская маленькая буква AE с Macron | |||||||||||||||||||||||||||||||||||||||||||
| 484 | U+01E4 | C7 A4 | ǥ | LAT DAPLAT0076 U+01E5 | C7 A5 | ǥ | Latin Small Letter G With Stroke | ||||||||||||||||||||||||||||||||||||||||
| 486 | U+01E6 | C7 A6 | Ǧ | Latin Capital Letter G With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 487 | U+01E7 | C7 A7 | ǧ | Latin Small Letter G With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 488 | U+01E8 | C7 A8 | Ǩ | Latin Capital Letter K With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 489 | U+01E9 | C7 A9 | ǩ | Latin Small Letter K With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 490 | U+01EA | C7 AA | Ǫ | Latin Capital Letter O With Ogonek | |||||||||||||||||||||||||||||||||||||||||||
| 491 | U+01EB | C7 AB | ǫ | LATIN STALTER O с OGONEK | |||||||||||||||||||||||||||||||||||||||||||
| 492 | U+0177 | C77. | |||||||||||||||||||||||||||||||||||||||||||||
| 493 | U+01ED | C7 AD | ǭ | Latin Small Letter O With Ogonek And Macron | |||||||||||||||||||||||||||||||||||||||||||
| 494 | U+01EE | C7 AE | Ǯ | Latin Capital Letter Ezh С Caron | |||||||||||||||||||||||||||||||||||||||||||
| 495 | U+01EF | C7 AF | ǯ | LATIN SMALT LITCH EZH с CARON | |||||||||||||||||||||||||||||||||||||||||||
| 496 | U+010077 | ||||||||||||||||||||||||||||||||||||||||||||||
| 496 | U+0185 | ||||||||||||||||||||||||||||||||||||||||||||||
| 496 | U+0185 | ||||||||||||||||||||||||||||||||||||||||||||||
| 496 | 7. Мал. С Кэрон|||||||||||||||||||||||||||||||||||||||||||||||
| 497 | U+01F1 | C7 B1 | DZ | Latin Capital Letter Dz | |||||||||||||||||||||||||||||||||||||||||||
| 498 | U+01F2 | C7 B2 | Dz | Latin Capital Letter D With Small Letter Z | |||||||||||||||||||||||||||||||||||||||||||
| 499 | U+01F3 | C7 B3 | dz | Latin Small Letter Dz | |||||||||||||||||||||||||||||||||||||||||||
| 500 | U+01F4 | C7 B4 | Ǵ | Latin Capital Letter G With Acute | |||||||||||||||||||||||||||||||||||||||||||
| 501 | U+01F5 | C7 B5 | ǵ | Latin Small Letter G With Acute | |||||||||||||||||||||||||||||||||||||||||||
| 502 | U+01F6 | C7 B6 | Ƕ | Latin Capital Letter Hwair | |||||||||||||||||||||||||||||||||||||||||||
| 503 | U+01F7 | C7 B7 | Ƿ | Latin Capital Letter Wynn | |||||||||||||||||||||||||||||||||||||||||||
| 504 | U+01F8 | C7 B8 | Ǹ | Latin Capital Letter N With Grave | |||||||||||||||||||||||||||||||||||||||||||
| 505 | U+01F9 | C7 B9 | ǹ | Latin Small Letter N With Grave | |||||||||||||||||||||||||||||||||||||||||||
| 506 | U+01FA | C7 BA | Ǻ | Latin Capital Letter A With Ring Above And Acute | |||||||||||||||||||||||||||||||||||||||||||
| 507 | U+01FB | C7 BB | ǻ | Latin Small Letter A With Ring Above And Acute | |||||||||||||||||||||||||||||||||||||||||||
| 508 | U+01FC | C7 BC | Ǽ | Latin Capital Letter Ae With Acute | |||||||||||||||||||||||||||||||||||||||||||
| 509 | U+01FD | C7 BD | ǽ | Latin Small Letter Ae With Acute | |||||||||||||||||||||||||||||||||||||||||||
| 510 | U+01FE | C7 BE | Ǿ | Latin Capital Letter o с инсультом и острым | |||||||||||||||||||||||||||||||||||||||||||
| 511 | U+01FF | C7 BF | ǿ | Латинская маленькая буква O с инсультом и островом0076 U+0200 | C8 80 | Ȁ | Latin Capital Letter A With Double Grave | ||||||||||||||||||||||||||||||||||||||||
| 513 | U+0201 | C8 81 | ȁ | Latin Small Letter A With Double Grave | |||||||||||||||||||||||||||||||||||||||||||
| 514 | U+0202 | C8 82 | Ȃ | Latin Capital Letter A With Inverted Breve | |||||||||||||||||||||||||||||||||||||||||||
| 515 | U+0203 | C8 83 | ȃ | Latin Small Letter A With Inverted Breve | |||||||||||||||||||||||||||||||||||||||||||
| 516 | U+0204 | C8 84 | Ȅ | Latin Capital Letter E With Double Grave | |||||||||||||||||||||||||||||||||||||||||||
| 517 | U+0205 | C8 85 | ȅ | Latin Small Letter E With Double Grave | |||||||||||||||||||||||||||||||||||||||||||
| 518 | U+0206 | C8 86 | Ȇ | Latin Capital Letter E With Inverted Breve | |||||||||||||||||||||||||||||||||||||||||||
| 519 | U+0207 | C8 87 | ȇ | Latin Small Letter E With Inverted Breve | |||||||||||||||||||||||||||||||||||||||||||
| 520 | U+0208 | C8 88 | Ȉ | Latin Capital Letter I With Double Grave | |||||||||||||||||||||||||||||||||||||||||||
| 521 | U+0209 | C8 89 | ȉ | Latin Small Letter I With Double Grave | |||||||||||||||||||||||||||||||||||||||||||
| 522 | U+020A | C8 8A | Ȋ | Latin Capital Letter I With Inverted Breve | |||||||||||||||||||||||||||||||||||||||||||
| 523 | U+020B | C8 8B | ȋ | Latin Small Letter I With Inverted Breve | |||||||||||||||||||||||||||||||||||||||||||
| 524 | U+020C | C8 8C | Ȍ | Latin Capital Letter O With Double Grave | |||||||||||||||||||||||||||||||||||||||||||
| 525 | U+020D | C8 8D | ȍ | Latin Small Letter O With Double Grave | |||||||||||||||||||||||||||||||||||||||||||
| 526 | U+020E | C8 8E | Ȏ | Latin Capital Letter O With Inverted Breve | |||||||||||||||||||||||||||||||||||||||||||
| 527 | U+020F | C8 8F | ȏ | LATIN SMALT LETT Double Grave | |||||||||||||||||||||||||||||||||||||||||||
| 529 | U+0211 | C8 91 | ȑ | Latin Small Letter R With Double Grave | |||||||||||||||||||||||||||||||||||||||||||
| 530 | U+0212 | C8 92 | Ȓ | Latin Capital Letter R With Inverted Breve | |||||||||||||||||||||||||||||||||||||||||||
| 531 | U+0213 | C8 93 | ȓ | Latin Small Letter R With Inverted Breve | |||||||||||||||||||||||||||||||||||||||||||
| 532 | U+0214 | C8 94 | Ȕ | Latin Capital Letter U With Double Grave | |||||||||||||||||||||||||||||||||||||||||||
| 533 | U+0215 | C8 95 | ȕ | Latin Small Letter U With Double Grave | |||||||||||||||||||||||||||||||||||||||||||
| 534 | U+0216 | C8 96 | Ȗ | Latin Capital Letter U With Inverted Breve | |||||||||||||||||||||||||||||||||||||||||||
| 535 | U+0217 | C8 97 | ȗ | Latin Small Letter U With Inverted Breve | |||||||||||||||||||||||||||||||||||||||||||
| 536 | U+0218 | C8 98 | ș | Latin Capital Letter S с запятой ниже | |||||||||||||||||||||||||||||||||||||||||||
| 537 | U+0219 | C8 | . 0077 0077 | ||||||||||||||||||||||||||||||||||||||||||||
| 538 | U+021A | C8 9A | Ț | Latin Capital Letter T With Comma Below | |||||||||||||||||||||||||||||||||||||||||||
| 539 | U+021B | C8 9B | ț | Latin Small Letter T With Comma Below | |||||||||||||||||||||||||||||||||||||||||||
| 540 | U+021C | C8 9C | Ȝ | Latin Capital Letter Yogh | |||||||||||||||||||||||||||||||||||||||||||
| 541 | U+021D | C8 9D | ȝ | Latin Small Letter Yogh | |||||||||||||||||||||||||||||||||||||||||||
| 542 | U+021E | C8 9E | Ȟ | Latin Capital Letter H With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 543 | U+021F | C8 9F | ȟ | Latin Small Letter H With Caron | |||||||||||||||||||||||||||||||||||||||||||
| 544 | U+0220 | C8 A0 | Ƞ | Latin Capital Letter N With Long Right Leg | |||||||||||||||||||||||||||||||||||||||||||
| 545 | U+0221 | C8 A1 | ȡ | Latin Small Letter D С завитком | |||||||||||||||||||||||||||||||||||||||||||
| 546 | U+0222 | C8 A2 | Ȣ | Latin Capital Letter Ou | |||||||||||||||||||||||||||||||||||||||||||
| 547 | U+0223 | C8 A3 | ȣ | Latin Small Letter Ou | |||||||||||||||||||||||||||||||||||||||||||
| 548 | U+0224 | C8 A4 | Ȥ | Latin Capital Letter Z With Hook | |||||||||||||||||||||||||||||||||||||||||||
| 549 | U+0225 | C8 A5 | ȥ | Latin Small Letter Z With Hook | |||||||||||||||||||||||||||||||||||||||||||
| 550 | U+0226 | C8 A6 | ȧ | LATIN CAPTION LITE Dot Above | |||||||||||||||||||||||||||||||||||||||||||
| 552 | U+0228 | C8 A8 | Ȩ | Latin Capital Letter E With Cedilla | |||||||||||||||||||||||||||||||||||||||||||
| 553 | U+0229 | C8 A9 | ȩ | Latin Small Letter E С Седильей | |||||||||||||||||||||||||||||||||||||||||||
| 554 | U+022A | C8 AA | Ȫ | Latin Capital Letter O With Diaeresis And Macron | |||||||||||||||||||||||||||||||||||||||||||
| 555 | U+022B | C8 AB | ȫ | Latin Small Letter O With Diaeresis And Macron | |||||||||||||||||||||||||||||||||||||||||||
| 556 | U+022C | C8 AC | Ȭ | Latin Capital Letter O With Tilde And Macron | |||||||||||||||||||||||||||||||||||||||||||
| 557 | U+022D | C8 AD | ȭ | Латинская маленькая буква o с тильдой и макроном | |||||||||||||||||||||||||||||||||||||||||||
| 558 | U+022E | C8 AE | ȯ | LATN SALITE RITED OF DOT | ȯ | LATN SALIT | C8 AF | ȯ | Латинская маленькая буква o с точкой выше | ||||||||||||||||||||||||||||||||||||||
| 560 | U+0230 | C8 B0 | ȱ | LAT DAPIT SAPTION LITED и MACRON | LAT DAPLAT0075 | 561 | U+0231 | C8 B1 | ȱ | Latin Small Letter O With Dot Above And Macron | |||||||||||||||||||||||||||||||||||||
| 562 | U+0232 | C8 B2 | Ȳ | Latin Capital Letter Y With Macron | |||||||||||||||||||||||||||||||||||||||||||
| 563 | U+0233 | C8 B3 | ȳ | Latin Small Letter Y With Macron | |||||||||||||||||||||||||||||||||||||||||||
| 564 | U+0234 | C8 B4 | ȴ | Latin Small Letter L With Завиток | |||||||||||||||||||||||||||||||||||||||||||
| 565 | U+0235 | C8 B5 | ȵ | Latin Small Letter N With Curl | |||||||||||||||||||||||||||||||||||||||||||
| 566 | U+0236 | C8 B6 | ȶ | Latin Small Letter T With Curl | |||||||||||||||||||||||||||||||||||||||||||
| 567 | U+0237 | C8 B7 | ȷ | Latin Small Letter Dotless J | |||||||||||||||||||||||||||||||||||||||||||
| 568 | U+0238 | C8 B8 | ȸ | Latin Small Letter Db Digraph | |||||||||||||||||||||||||||||||||||||||||||
| 569 | U+0239 | C8 B9 | ȹ | Latin Small Letter Qp Digraph | |||||||||||||||||||||||||||||||||||||||||||
| 570 | U+023A | C8 BA | Ⱥ | Latin Capital Letter A With Stroke | |||||||||||||||||||||||||||||||||||||||||||
| 571 | U+023B | C8 BB | ȼ | Latin Capital Letter C с помощью инсульта | |||||||||||||||||||||||||||||||||||||||||||
| 572 | U+023C | 572 | U+023C | C876. 0077 0077 | |||||||||||||||||||||||||||||||||||||||||||
| 573 | U+023D | C8 BD | Ƚ | Latin Capital Letter L With Bar | |||||||||||||||||||||||||||||||||||||||||||
| 574 | U+023E | C8 BE | Ⱦ | Latin Capital Letter T With Diagonal Stroke | |||||||||||||||||||||||||||||||||||||||||||
| 575 | U+023F | C8 BF | ȿ | Latin Small Letter S With Swash Tail | |||||||||||||||||||||||||||||||||||||||||||
| 576 | U+0240 | C9 80 | ɀ | Latin Small Letter Z С косым хвостом | |||||||||||||||||||||||||||||||||||||||||||
| 577 | U+0241 | C9 81 | Ɂ | Latin Capital Letter Glottal Stop | |||||||||||||||||||||||||||||||||||||||||||
| 578 | U+0242 | C9 82 | ɂ | Latin Small Letter Glottal Stop | |||||||||||||||||||||||||||||||||||||||||||
| 579 | U+0243 | C9 83 | Ƀ | Latin Capital Letter B With Stroke | |||||||||||||||||||||||||||||||||||||||||||
| 580 | U+0244 | C9 84 | Ʉ | Latin Capital Letter U Bar | |||||||||||||||||||||||||||||||||||||||||||
| 581 | U+0245 | C9 85 | ʌ | LATIN CAPIT | |||||||||||||||||||||||||||||||||||||||||||
| 583 | U+0247 | C9 87 | ɇ | Latin Small Letter E With Stroke | |||||||||||||||||||||||||||||||||||||||||||
| 584 | U+0248 | C9 88 | Ɉ | Latin Capital Letter J With Stroke | |||||||||||||||||||||||||||||||||||||||||||
| 585 | U+0249 | C9 89 | ɉ | Latin Small Letter J With Stroke | |||||||||||||||||||||||||||||||||||||||||||
| 586 | U+024A | C9 8A | Ɋ | Latin Capital Letter Small Q With Крюк Хвост | |||||||||||||||||||||||||||||||||||||||||||
| 587 | U+024B | C9 8B | ɋ | LATIN SMALT LITG R с ходом | |||||||||||||||||||||||||||||||||||||||||||
| 589 | U+024D | C9 8D | ɍ | Latin Small Letter R With Stroke | |||||||||||||||||||||||||||||||||||||||||||
| 590 | U+024E | C9 8E | Ɏ | Latin Capital Letter Y With Stroke | |||||||||||||||||||||||||||||||||||||||||||
| 591 | U+024F | C9 8F | ɏ | Latin Small Letter Y With Stroke | |||||||||||||||||||||||||||||||||||||||||||
| 592 | U+0250 | C9 90 | ɐ | Latin Small Letter Turned A | |||||||||||||||||||||||||||||||||||||||||||
| 593 | U+0251 | C9 91 | ɑ | Latin Small Letter Alpha | |||||||||||||||||||||||||||||||||||||||||||
| 594 | U+0252 | C9 92 | ɒ | Latin Small Letter Turned Alpha | |||||||||||||||||||||||||||||||||||||||||||
| 595 | U+0253 | C9 93 | ɓ | Latin Small Letter B With Hook | |||||||||||||||||||||||||||||||||||||||||||
| 596 | U+0254 | C9 94 | ɔ | Latin Small Letter Open O | |||||||||||||||||||||||||||||||||||||||||||
| 597 | U+0255 | C9 95 | ɕ | Latin Small Letter C With Curl | |||||||||||||||||||||||||||||||||||||||||||
| 598 | U+0256 | C9 96 | ɖ | Latin Small Letter D With Tail | |||||||||||||||||||||||||||||||||||||||||||
| 599 | U+0257 | C9 97 | ɗ | Latin Small Letter D With Hook | |||||||||||||||||||||||||||||||||||||||||||
| 600 | U+0258 | C9 98 | ɘ | Latin Small Letter Reversed E | |||||||||||||||||||||||||||||||||||||||||||
| 601 | U+0259 | C9 99 | ə | LATIN SMALT LITK | |||||||||||||||||||||||||||||||||||||||||||
| 603 | U+025B | C9 9B | ɛ | Latin Small Letter Open E | |||||||||||||||||||||||||||||||||||||||||||
| 604 | U+025C | C9 9C | ɜ | Latin Small Letter Reversed Open E | |||||||||||||||||||||||||||||||||||||||||||
| 605 | U+025D | C9 9D | ɝ | Latin Small Letter Reversed Open E With Hook | |||||||||||||||||||||||||||||||||||||||||||
| 606 | U+025E | C9 9E | ɞ | Latin Small Letter Closed Reversed Open E | |||||||||||||||||||||||||||||||||||||||||||
| 607 | U+025F | C9 9F | ɟ | Latin Small Letter Dotless J With Stroke | |||||||||||||||||||||||||||||||||||||||||||
| 608 | U+0260 | C9 A0 | ɠ | Latin Small Letter G With Hook | |||||||||||||||||||||||||||||||||||||||||||
| 609 | U+0261 | C9 A1 | ɡ | Latin Small Letter Script G | |||||||||||||||||||||||||||||||||||||||||||
| 610 | U+0262 | C9 A2 | ɢ | Latin Letter Small Capital G | |||||||||||||||||||||||||||||||||||||||||||
| 611 | U+0263 | C9 A3 | ɣ | Latin Small Letter Gamma | |||||||||||||||||||||||||||||||||||||||||||
| 612 | U+0264 | C9 A4 | ɤ | Латинские маленькие буквы Rams Horn | |||||||||||||||||||||||||||||||||||||||||||
| 613 | U+0265 | C9 A5 | ɥ | LATIN SMALT LITK Latin Small Letter H With Hook | |||||||||||||||||||||||||||||||||||||||||||
| 615 | U+0267 | C9 A7 | ɧ | Latin Small Letter Heng With Hook | |||||||||||||||||||||||||||||||||||||||||||
| 616 | U+0268 | C9 A8 | ɨ | Latin Small Letter I With Stroke | |||||||||||||||||||||||||||||||||||||||||||
| 617 | U+0269 | C9 A9 | ɩ | Latin Small Letter Iota | |||||||||||||||||||||||||||||||||||||||||||
| 618 | U+026A | C9 AA | ɪ | Latin Letter Small Capital I | |||||||||||||||||||||||||||||||||||||||||||
| 619 | U+026B | C9 AB | ɫ | Latin Small Letter L With Middle Tilde | |||||||||||||||||||||||||||||||||||||||||||
| 620 | U+026C | C9AC | ɬ | Латинская маленькая буква L с ремнем | |||||||||||||||||||||||||||||||||||||||||||
| 621 | U+026D | C9 AD | ɭ | LATIN STAL LITGE L СИТА C9 AE | ɮ | Latin Small Letter Lezh | |||||||||||||||||||||||||||||||||||||||||
| 623 | U+026F | C9 AF | ɯ | Latin Small Letter Turned M | |||||||||||||||||||||||||||||||||||||||||||
| 624 | U+0270 | C9 B0 | ɰ | Латинская маленькая буква с длинной ногой | |||||||||||||||||||||||||||||||||||||||||||
| 625 | U+0271 | C9 B1 | ɱ | LATIN STALL STALIN +0272 | C9 B2 | ɲ | Латинская маленькая буква n с левой крючкой | ||||||||||||||||||||||||||||||||||||||||
| 627 | U+0273 | C9 B3 | ɳ | LATINLIX | . 0075 0075 | 628 | U+0274 | C9 B4 | ɴ | Latin Letter Small Capital N | |||||||||||||||||||||||||||||||||||||
| 629 | U+0275 | C9 B5 | ɵ | Latin Small Letter Barred O | |||||||||||||||||||||||||||||||||||||||||||
| 630 | U+0276 | C9 B6 | ɶ | Latin Letter Small Capital Oe | |||||||||||||||||||||||||||||||||||||||||||
| 631 | U+0277 | C9 B7 | ɷ | Latin Small Letter Closed Omega | |||||||||||||||||||||||||||||||||||||||||||
| 632 | U+0278 | C9 B8 | ɸ | Latin Small Letter Phi | |||||||||||||||||||||||||||||||||||||||||||
| 633 | U+0279 | C9 B9 | ɹ | Latin Small Letter Turned R | |||||||||||||||||||||||||||||||||||||||||||
| 634 | U+027A | C9 BA | ɺ | Latin Small Letter Turned R With Long Leg | |||||||||||||||||||||||||||||||||||||||||||
| 635 | U+027B | C9 BB | ɻ | Latin Small Letter Turned R With Hook | |||||||||||||||||||||||||||||||||||||||||||
| 636 | U+027C | C9 до н. э. Хвост э. Хвост | |||||||||||||||||||||||||||||||||||||||||||||
| 638 | U+027E | C9 BE | ɾ | LATIN STALL LITCH R LICTHOOK | |||||||||||||||||||||||||||||||||||||||||||
| 639 | 70076 U+027F|||||||||||||||||||||||||||||||||||||||||||||||
| 639 | 7U+027F | ||||||||||||||||||||||||||||||||||||||||||||||
| 639 | 7U+027F | ||||||||||||||||||||||||||||||||||||||||||||||
| 639 | 7U+027F | ||||||||||||||||||||||||||||||||||||||||||||||
| 639 | 7U+027F | ||||||||||||||||||||||||||||||||||||||||||||||
| 639 | 7. С рыболовным крючком | ||||||||||||||||||||||||||||||||||||||||||||||
| 640 | U+0280 | CA 80 | ʀ | LATIN LITEL SLAIT CAPATE R | |||||||||||||||||||||||||||||||||||||||||||
| 641 | U+02817779 | ||||||||||||||||||||||||||||||||||||||||||||||
| 642 | U+0282 | CA 82 | ʂ | Latin Small Letter S With Hook | |||||||||||||||||||||||||||||||||||||||||||
| 643 | U+0283 | CA 83 | ʃ | Latin Small Letter Esh | |||||||||||||||||||||||||||||||||||||||||||
| 644 | U+0284 | CA 84 | ʄ | Latin Small Letter Dotless J With Stroke And Hook | |||||||||||||||||||||||||||||||||||||||||||
| 645 | U+0285 | CA 85 | ʅ | Latin Small Letter Squat Reversed Esh | |||||||||||||||||||||||||||||||||||||||||||
| 646 | U+0286 | CA 86 | ʆ | Latin Small Letter Esh With Curl | |||||||||||||||||||||||||||||||||||||||||||
| 647 | U+0287 | CA 87 | ʇ | Latin Small Letter Turned T | |||||||||||||||||||||||||||||||||||||||||||
| 648 | U+0288 | CA 88 | ʈ | Latin Small Letter T With Retroflex Hook | |||||||||||||||||||||||||||||||||||||||||||
| 649 | U+0289 | CA 89 | ʉ | Latin Small Letter U Bar | |||||||||||||||||||||||||||||||||||||||||||
| 650 | U+028A | CA 8A | ʊ | Latin Small Letter Upsilon | |||||||||||||||||||||||||||||||||||||||||||
| 651 | U+028B | CA 8B | ʋ | Latin Small Letter V With Hook | |||||||||||||||||||||||||||||||||||||||||||
| 652 | U+028C | CA 8C | ʌ | Latin Small Letter Turned V | |||||||||||||||||||||||||||||||||||||||||||
| 653 | U+028D | CA 8D | ʍ | Latin Small Letter Turned W | |||||||||||||||||||||||||||||||||||||||||||
| 654 | U+028E | CA 8E | ʎ | Latin Small Letter Turned Y | |||||||||||||||||||||||||||||||||||||||||||
| 655 | U+028F | CA 8F | ʏ | Latin Letter Small Capital Y | |||||||||||||||||||||||||||||||||||||||||||
| 656 | U+0290 | CA 90 | ʐ | Latin Small Letter Z With Retroflex Hook | |||||||||||||||||||||||||||||||||||||||||||
| 657 | U+0291 | CA 91 | ʑ | Latin Small Letter Z With Curl | |||||||||||||||||||||||||||||||||||||||||||
| 658 | U+0292 | CA 92 | ʒ | Latin Small Letter Ezh | |||||||||||||||||||||||||||||||||||||||||||
| 659 | U+0293 | CA 93 | ʓ | Latin Small Letter Ezh With Curl | |||||||||||||||||||||||||||||||||||||||||||
| 660 | U+0294 | CA 94 | ʔ | Latin Letter Glottal Stop | |||||||||||||||||||||||||||||||||||||||||||
| 661 | U+0295 | CA 95 | ʕ | Latin Letter Pharyngeal Voiced Fricative | |||||||||||||||||||||||||||||||||||||||||||
| 662 | U+0296 | CA 96 | ʖ | Latin Letter Inverted Glottal Stop | |||||||||||||||||||||||||||||||||||||||||||
| 663 | U+0297 | CA 97 | ʗ | Латинская буква растянута C | |||||||||||||||||||||||||||||||||||||||||||
| 664 | U+0298 | CA 98 | ʘ | LATIN BILABIAL CAM 98 | ʘ | LATIN BILABIAL CAM 98 | ʘ | LATIN BILABIAL CAM 98 | ʘ | LATIN BILABIAL CAM 98 | ʘ | . 99 99 | ʙ | Latin Letter Small Capital B | |||||||||||||||||||||||||||||||||
| 666 | U+029A | CA 9A | ʚ | Latin Small Letter Closed Open E | |||||||||||||||||||||||||||||||||||||||||||
| 667 | U+029B | CA 9B | ʛ | Латинская буква малая столица G с крючком | |||||||||||||||||||||||||||||||||||||||||||
| 668 | U+029C | CA 9. | ʜ | LATNATIN 029D | CA 9D | ʝ | Latin Small Letter J With Crossed-tail | ||||||||||||||||||||||||||||||||||||||||
| 670 | U+029E | CA 9E | ʞ | Latin Small Letter Turned K | |||||||||||||||||||||||||||||||||||||||||||
| 671 | U+029F | CA 9F | ʟ | Latin Letter Small Capital L | |||||||||||||||||||||||||||||||||||||||||||
| 672 | U+02A0 | CA A0 | ʠ | Latin Small Letter Q With Hook | |||||||||||||||||||||||||||||||||||||||||||
| 673 | U+02A1 | CA A1 | ʡ | Латинская буква Глоттальная остановка с помощью хода | |||||||||||||||||||||||||||||||||||||||||||
| 674 | U+02A2 | CA2 | ʢ 02A27667666666666666666666666666666666666666666666666666666666666666666666666666666666666666666666Er. 0077 0077 | ||||||||||||||||||||||||||||||||||||||||||||
| 675 | U+02A3 | CA A3 | ʣ | Latin Small Letter Dz Digraph | |||||||||||||||||||||||||||||||||||||||||||
| 676 | U+02A4 | CA A4 | ʤ | Latin Small Letter Dezh Digraph | |||||||||||||||||||||||||||||||||||||||||||
| 677 | U+02A5 | CA A5 | ʥ | Latin Small Letter Dz Digraph With Curl | |||||||||||||||||||||||||||||||||||||||||||
| 678 | U+02A6 | CA A6 | ʦ | Latin Small Letter Ts Digraph | |||||||||||||||||||||||||||||||||||||||||||
| 679 | U+02A7 | CA A7 | ʧ | Latin Small Letter Tesh Digraph | |||||||||||||||||||||||||||||||||||||||||||
| 680 | U+02A8 | CA A8 | ʨ | Latin Small Letter Tc Digraph With Curl | |||||||||||||||||||||||||||||||||||||||||||
| 681 | U+02A9 | CA A9 | ʩ | Latin Small Letter Feng Digraph | |||||||||||||||||||||||||||||||||||||||||||
| 682 | U+02AA | CA AA | ʪ | Latin Small Letter Ls Digraph | |||||||||||||||||||||||||||||||||||||||||||
| 683 | U+02AB | CA AB | ʫ | Latin Small Letter Lz Digraph | |||||||||||||||||||||||||||||||||||||||||||
| 684 | U+02AC | CA AC | ʬ | Latin Letter Bilabial Percussive | |||||||||||||||||||||||||||||||||||||||||||
| 685 | U+02AD | CA AD | ʭ | Латинская буква BIDATELAL | |||||||||||||||||||||||||||||||||||||||||||
| 686 | U+02AE | CA AE | U+02AE | CA AE | U+02AE | CA AE | U+02AE | CA AE | U+02AE | CA AE | u+02AE | CA AE | u+02AE | . 0077 0077 | |||||||||||||||||||||||||||||||||
| 687 | U+02AF | CA AF | ʯ | LATIN STAL LITG H | |||||||||||||||||||||||||||||||||||||||||||
| 689 | U+02B1 | CA B1 | ʱ | Modifier Letter Small H With Hook | |||||||||||||||||||||||||||||||||||||||||||
| 690 | U+02B2 | CA B2 | ʲ | Modifier Letter Small J | |||||||||||||||||||||||||||||||||||||||||||
| 691 | U+02B3 | CA B3 | ʳ | Modifier Letter Small R | |||||||||||||||||||||||||||||||||||||||||||
| 692 | U+02B4 | CA B4 | ʴ | Modifier Letter Small Turned R | |||||||||||||||||||||||||||||||||||||||||||
| 693 | U+02B5 | CA B5 | ʵ | Modifier Letter Small Turned R With Hook | |||||||||||||||||||||||||||||||||||||||||||
| 694 | U+02B6 | CA B6 | ʶ | Modifier Letter Small Capital Inverted R | |||||||||||||||||||||||||||||||||||||||||||
| 695 | U+02B7 | CA B7 | ʷ | Modifier Letter Small W | |||||||||||||||||||||||||||||||||||||||||||
| 696 | U+02B8 | CA B8 | ʸ | Modifier Letter Small Y | |||||||||||||||||||||||||||||||||||||||||||
| 697 | U+02B9 | CA B9 | ʹ | Modifier Letter Prime | |||||||||||||||||||||||||||||||||||||||||||
| 698 | U+02BA | CA BA | ʺ | Modifier Letter Double Prime | |||||||||||||||||||||||||||||||||||||||||||
| 699 | U+02BB | CA BB | ʻ | Modifier Letter Turned Comma | |||||||||||||||||||||||||||||||||||||||||||
| 700 | U+02BC | CA BC | ʼ | Modifier Letter Apostrophe | |||||||||||||||||||||||||||||||||||||||||||
| 701 | U+02BD | CA BD | ʽ | Модификатор.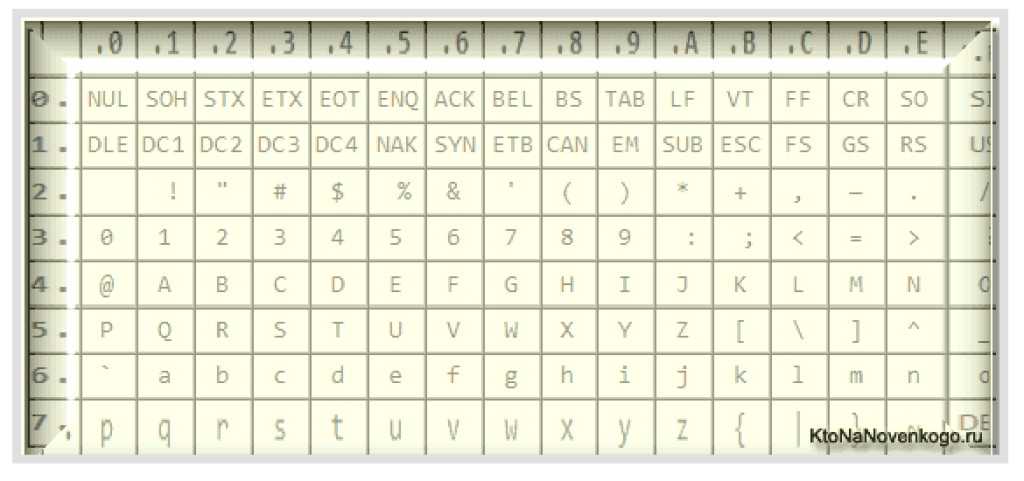 0085 0085 | |||||||||||||||||||||||||||||||||||||||||||
| 703 | U+02BF | CA BF | ʿ | Modifier Letter Left Half Ring | |||||||||||||||||||||||||||||||||||||||||||
| 704 | U+02C0 | CB 80 | ˀ | Modifier Letter Glottal Stop | |||||||||||||||||||||||||||||||||||||||||||
| 705 | U+02C1 | CB 81 | ˁ | Связанная с модификатором.0077 | |||||||||||||||||||||||||||||||||||||||||||
| 707 | U+02C3 | CB 83 | ˃ | Modifier Letter Right Arrowhead | |||||||||||||||||||||||||||||||||||||||||||
| 708 | U+02C4 | CB 84 | ˄ | Modifier Letter Up Arrowhead | |||||||||||||||||||||||||||||||||||||||||||
| 709 | U+02C5 | CB 85 | ˅ | Modifier Letter Down Arrowhead | |||||||||||||||||||||||||||||||||||||||||||
| 710 | U+02C6 | CB 86 | ˆ | Modifier Letter Circumflex Accent | |||||||||||||||||||||||||||||||||||||||||||
| 711 | U+02C7 | CB 87 | ˇ | Caron | |||||||||||||||||||||||||||||||||||||||||||
| 712 | U+02C8 | CB 88 | ˈ | Modifier Letter Vertical Line | |||||||||||||||||||||||||||||||||||||||||||
| 713 | U+02C9 | CB 89 | ˉ | ПИСЬМА МОДИФИФИКЕРА MACRON | |||||||||||||||||||||||||||||||||||||||||||
| 714 | U+02CA | CB 8A | ˊ | CB 8A | ˊ | 666676 | 776777 | 7776767676767676667676767676767676767676676766767676767676767676676769676ˊ | . 0076 715 0076 715 | U+02CB | CB 8B | ˋ | Modifier Letter Grave Accent | ||||||||||||||||||||||||||||||||||
| 716 | U+02CC | CB 8C | ˌ | Modifier Letter Low Vertical Line | |||||||||||||||||||||||||||||||||||||||||||
| 717 | U+02CD | CB 8D | ˍ | СПАСИЖДАЕТ НИЗКИЙ MACRON | |||||||||||||||||||||||||||||||||||||||||||
| 718 | U+02CE | CB 8E | № | CB 8E | № | 7.0085||||||||||||||||||||||||||||||||||||||||||
| 719 | U+02CF | CB 8F | ˏ | Modifier Letter Low Acute Accent | |||||||||||||||||||||||||||||||||||||||||||
| 720 | U+02D0 | CB 90 | ː | Modifier Letter Triangular Colon | |||||||||||||||||||||||||||||||||||||||||||
| 721 | U+02D1 | CB 91 | ˑ | Modifier Letter Half Triangular Colon | |||||||||||||||||||||||||||||||||||||||||||
| 722 | U+02D2 | CB 92 | ˒ | Modifier Letter Centred Right Half Ring | |||||||||||||||||||||||||||||||||||||||||||
| 723 | U+02D3 | CB 93 | ˓ | Связь с модификатором. | |||||||||||||||||||||||||||||||||||||||||||
| 725 | U+02D5 | CB 95 | ˕ | Связанная с модификатором.0077 | |||||||||||||||||||||||||||||||||||||||||||
| 727 | U+02D7 | CB 97 | ˗ | Modifier Letter Minus Sign | |||||||||||||||||||||||||||||||||||||||||||
| 728 | U+02D8 | CB 98 | ˘ | Breve | |||||||||||||||||||||||||||||||||||||||||||
| 729 | U+02D9 | CB 99 | ˙ | Dot Above | |||||||||||||||||||||||||||||||||||||||||||
| 730 | U+02DA | CB 9A | ˚ | Ring Above | |||||||||||||||||||||||||||||||||||||||||||
| 731 | U+02DB | CB 9B | ˛ | Ogonek | |||||||||||||||||||||||||||||||||||||||||||
| 732 | U+02DC | CB 9C | ˜ | Small Tilde | |||||||||||||||||||||||||||||||||||||||||||
| 733 | U+02DD | CB 9D | ˝ | Double Острый акцент | |||||||||||||||||||||||||||||||||||||||||||
| 734 | U+02DE | CB 9E | ˞ | СПАСИЖАТЕЛЬ RHOTIC HLOC0077 | |||||||||||||||||||||||||||||||||||||||||||
| 736 | U+02E0 | CB A0 | ˠ | Modifier Letter Small Gamma | |||||||||||||||||||||||||||||||||||||||||||
| 737 | U+02E1 | CB A1 | ˡ | Modifier Letter Small L | |||||||||||||||||||||||||||||||||||||||||||
| 738 | U+02E2 | CB A2 | ˢ | Modifier Letter Small S | |||||||||||||||||||||||||||||||||||||||||||
| 739 | U+02E3 | CB A3 | ˣ | Modifier Letter Small X | |||||||||||||||||||||||||||||||||||||||||||
| 740 | U+02E4 | CB A4 | ˤ | Modifier Letter Small Reversed Glottal Stop | |||||||||||||||||||||||||||||||||||||||||||
| 741 | U+02E5 | CB A5 | ˥ | Modifier Letter Extra-high Tone Bar | |||||||||||||||||||||||||||||||||||||||||||
| 742 | U+02E6 | CB A6 | ˦ | Modifier Letter High Tone Bar | |||||||||||||||||||||||||||||||||||||||||||
| 743 | U+02E7 | CB A7 | ˧ | Modifier Letter Mid Tone Bar | |||||||||||||||||||||||||||||||||||||||||||
| 744 | U+02E8 | CB A8 | ˨ | Modifier Letter Low Tone Bar | |||||||||||||||||||||||||||||||||||||||||||
| 745 | U+02E9 | CB A9 | ˩ | Modifier Letter Extra-low Tone Bar | |||||||||||||||||||||||||||||||||||||||||||
| 746 | U+02EA | CB AA | ˪ | Modifier Letter Yin Departing Tone Mark | |||||||||||||||||||||||||||||||||||||||||||
| 747 | U+02EB | CB AB | ˫ | Modifier Letter Yang Departing Tone Mark | |||||||||||||||||||||||||||||||||||||||||||
| 748 | U+02EC | CB AC | ˬ | Modifier Letter Voicing | |||||||||||||||||||||||||||||||||||||||||||
| 749 | U+02ED | CB AD | ˭ | Modifier Letter Unaspirated | |||||||||||||||||||||||||||||||||||||||||||
| 750 | u+02ee | CB AE | ˮ | Связанная с модификацией. 0077 0077 | |||||||||||||||||||||||||||||||||||||||||||
| 752 | U+02F0 | CB B0 | ˰ | Modifier Letter Low Up Arrowhead | |||||||||||||||||||||||||||||||||||||||||||
| 753 | U+02F1 | CB B1 | ˱ | Modifier Letter Low Left Arrowhead | |||||||||||||||||||||||||||||||||||||||||||
| 754 | U+02F2 | CB B2 | ˲ | Modifier Letter Low Right Arrowhead | |||||||||||||||||||||||||||||||||||||||||||
| 755 | U+02F3 | CB B3 | ˳ | Modifier Letter Low Ring | |||||||||||||||||||||||||||||||||||||||||||
| 756 | U+02F4 | CB B4 | ˴ | Modifier Letter Middle Grave Accent | |||||||||||||||||||||||||||||||||||||||||||
| 757 | U+02F5 | CB B5 | ˵ | Modifier Letter Middle Double Grave Accent | |||||||||||||||||||||||||||||||||||||||||||
| 758 | U+02F6 | CB B6 | ˶ | Modifier Letter Middle Double Acute Accent | |||||||||||||||||||||||||||||||||||||||||||
| 759 | U+02F7 | CB B7 | ˷ | Modifier Letter Low Tilde | |||||||||||||||||||||||||||||||||||||||||||
| 760 | U+02F8 | CB B8 | ˸ | Modifier Letter Raised Colon | |||||||||||||||||||||||||||||||||||||||||||
| 761 | U+02F9 | CB B9 | ˹ | Modifier Letter Начнется высокий тон | |||||||||||||||||||||||||||||||||||||||||||
| 762 | U+02FA | CB BA | ˺ | 0076 ˻ | Modifier Letter Begin Low Tone | ||||||||||||||||||||||||||||||||||||||||||
| 764 | U+02FC | CB BC | ˼ | Modifier Letter End Low Tone | |||||||||||||||||||||||||||||||||||||||||||
| 765 | U+02FD | CB BD | ˽ | Покрытие буквы модификатора | |||||||||||||||||||||||||||||||||||||||||||
| 766 | U+02FE | CB BE | ˾ | СПАСКА MODIFIER. 0076 ˿ 0076 ˿ | Modifier Letter Low Left Arrow | ||||||||||||||||||||||||||||||||||||||||||
| 768 | U+0300 | CC 80 | ̀ | Combining Grave Accent | |||||||||||||||||||||||||||||||||||||||||||
| 769 | U+0301 | CC 81 | ́ | Combining Acute Accent | |||||||||||||||||||||||||||||||||||||||||||
| 770 | U+0302 | CC 82 | ̂ | Combining Circumflex Accent | |||||||||||||||||||||||||||||||||||||||||||
| 771 | U+0303 | CC 83 | ̃ | Combining Tilde | |||||||||||||||||||||||||||||||||||||||||||
| 772 | U+0304 | CC 84 | ̄ | Combining Macron | |||||||||||||||||||||||||||||||||||||||||||
| 773 | U+0305 | CC 85 | ̅ | Combining Overline | |||||||||||||||||||||||||||||||||||||||||||
| 774 | U+0306 | CC 86 | ̆ | Combining Breve | |||||||||||||||||||||||||||||||||||||||||||
| 775 | U+0307 | CC 87 | ̇ | Combining Dot Above | |||||||||||||||||||||||||||||||||||||||||||
| 776 | U+0308 | CC 88 | ̈ | Combining Diaeresis | |||||||||||||||||||||||||||||||||||||||||||
| 777 | U+0309 | CC 89 | ̉ | Combining Hook Above | |||||||||||||||||||||||||||||||||||||||||||
| 778 | U+ 030A | CC 8A | ̊ | Combining Ring Above | |||||||||||||||||||||||||||||||||||||||||||
| 779 | U+030B | CC 8B | ̋ | Combining Double Acute Accent | |||||||||||||||||||||||||||||||||||||||||||
| 780 | U+030C | CC 8C | ̌ | Combining Caron | |||||||||||||||||||||||||||||||||||||||||||
| 781 | U+030D | CC 8D | ̍ | Combining Vertical Line Above | |||||||||||||||||||||||||||||||||||||||||||
| 782 | U+030E | CC 8E | ̎ | Combining Double Vertical Line Above | |||||||||||||||||||||||||||||||||||||||||||
| 783 | U+030F | CC 8F | ̏ | Combining Double Grave Accent | |||||||||||||||||||||||||||||||||||||||||||
| 784 | U+0310 | CC 90 | ̐ | Combining Candrabindu | |||||||||||||||||||||||||||||||||||||||||||
| 785 | U+0311 | CC 91 | ̑ | Combining Inverted Breve | |||||||||||||||||||||||||||||||||||||||||||
| 786 | U+0312 | CC 92 | ̒ | Combining Turned Comma Above | |||||||||||||||||||||||||||||||||||||||||||
| 787 | U+0313 | CC 93 | ̓ | Combining Comma Above | |||||||||||||||||||||||||||||||||||||||||||
| 788 | U+0314 | CC 94 | ̔ | Combining Reversed Comma Above | |||||||||||||||||||||||||||||||||||||||||||
| 789 | U+0315 | CC 95 | ̕ | Combining Comma Above Right | |||||||||||||||||||||||||||||||||||||||||||
| 790 | U+0316 | CC 96 | ̖ | Combining Grave Accent Below | |||||||||||||||||||||||||||||||||||||||||||
| 791 | U+0317 | CC 97 | ̗ | Combining Acute Accent Below | |||||||||||||||||||||||||||||||||||||||||||
| 792 | U+0318 | CC 98 | ̘ | Сочетание левой привязки ниже | |||||||||||||||||||||||||||||||||||||||||||
| 793 | U+0319 | CC 99 | ̙ | COBCING RIDE RIDE RIDE DOLE DOLE | ̙ | . | ̚ | Сочетание левого угла выше | |||||||||||||||||||||||||||||||||||||||
| 795 | U+031B | CC | 7̛ | ||||||||||||||||||||||||||||||||||||||||||||
| .C | ̜ | Combining Left Half Ring Below | |||||||||||||||||||||||||||||||||||||||||||||
| 797 | U+031D | CC 9D | ̝ | Combining Up Tack Below | |||||||||||||||||||||||||||||||||||||||||||
| 798 | U+031E | CC 9E | ̞ | Combining Down Tack Below | |||||||||||||||||||||||||||||||||||||||||||
| 799 | U+031F | CC 9F | ̟ | Combining Plus Sign Below | |||||||||||||||||||||||||||||||||||||||||||
| 800 | U+0320 | CC A0 | ̠ | Combining Minus Sign Below | |||||||||||||||||||||||||||||||||||||||||||
| 801 | U+0321 | CC A1 | ̡ | Combining Palatalized Hook Below | |||||||||||||||||||||||||||||||||||||||||||
| 802 | U+0322 | CC A2 | ̢ | Combining Retroflex Hook Below | |||||||||||||||||||||||||||||||||||||||||||
| 803 | U+0323 | CC A3 | ̣ | Combining Dot Below | |||||||||||||||||||||||||||||||||||||||||||
| 804 | U+0324 | CC A4 | ̤ | Combining Diaeresis Below | |||||||||||||||||||||||||||||||||||||||||||
| 805 | U+0325 | CC A5 | ̥ | Combining Ring Below | |||||||||||||||||||||||||||||||||||||||||||
| 806 | U+0326 | CC A6 | ̦ | Combining Comma Below | |||||||||||||||||||||||||||||||||||||||||||
| 807 | U+0327 | CC A7 | ̧ | Combining Cedilla | |||||||||||||||||||||||||||||||||||||||||||
| 808 | U+0328 | CC A8 | ̨ | Combining Ogonek | |||||||||||||||||||||||||||||||||||||||||||
| 809 | U+0329 | CC A9 | ̩ | Combining Vertical Line Below | |||||||||||||||||||||||||||||||||||||||||||
| 810 | U+032A | CC AA | ̪ | Combining Bridge Below | |||||||||||||||||||||||||||||||||||||||||||
| 811 | U+032B | CC AB | ̫ | Combining Inverted Double Arch Below | |||||||||||||||||||||||||||||||||||||||||||
| 812 | U+032C | CC AC | ̬ | Combining Caron Below | |||||||||||||||||||||||||||||||||||||||||||
| 813 | U+032D | CC AD | ̭ | Combining Circumflex Accent Below | |||||||||||||||||||||||||||||||||||||||||||
| 814 | U+032E | CC AE | ̮ | Combining Breve Below | |||||||||||||||||||||||||||||||||||||||||||
| 815 | U+032F | CC AF | ̯ | Комбинированный брев ниже | |||||||||||||||||||||||||||||||||||||||||||
| 816 | U+0330 | CC B0 | ̰ 0330 | CC B0 | ̰ 0330 | CC B0 | ̰ 0330 | CC B0 | ̰ 0330 | .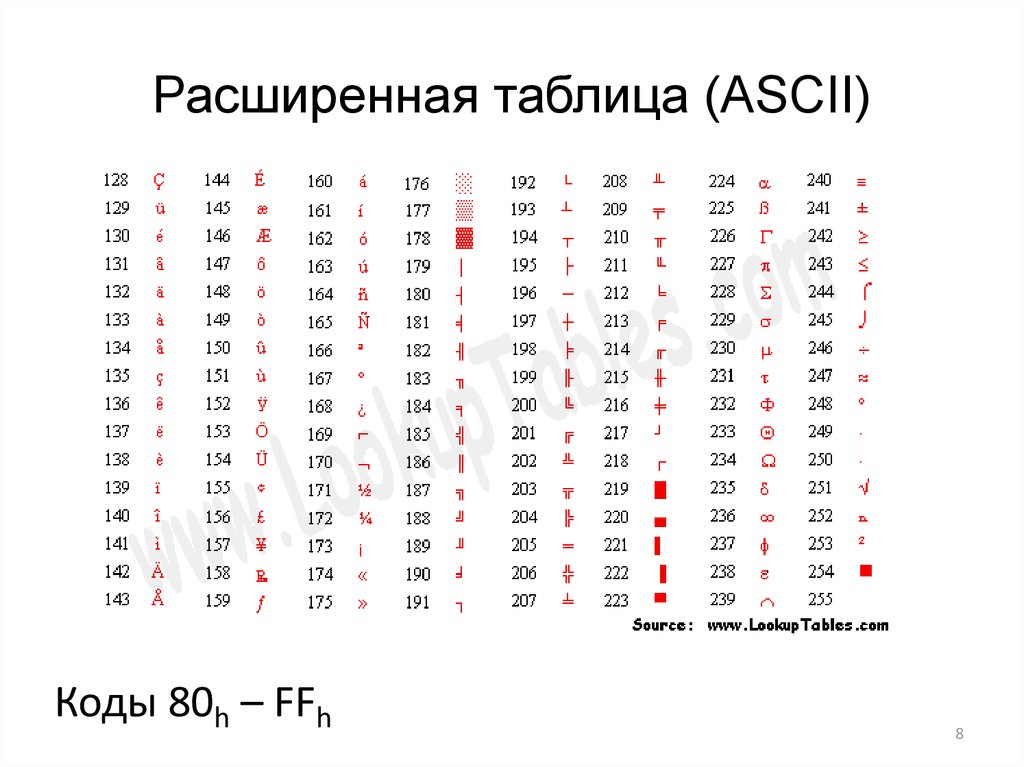 0077 0077 | |||||||||||||||||||||||||||||||||||||
| 817 | U+0331 | CC B1 | ̱ | Combining Macron Below | |||||||||||||||||||||||||||||||||||||||||||
| 818 | U+0332 | CC B2 | ̲ | Combining Low Line | |||||||||||||||||||||||||||||||||||||||||||
| 819 | U+0333 | CC B3 | ̳ | Объединение двойной низкой линии | |||||||||||||||||||||||||||||||||||||||||||
| U+0334 | CC B4 | ̴ | CC B4 | ̴ | CC B4 | ̴ | 67676767676767676767676767676767676767676767676767676767777777777767767679777.0076 821 | U+0335 | CC B5 | ̵ | Combining Short Stroke Overlay | ||||||||||||||||||||||||||||||||||||
| 822 | U+0336 | CC B6 | ̶ | Combining Long Stroke Overlay | |||||||||||||||||||||||||||||||||||||||||||
| 823 | U+0337 | CC B7 | ̷ | Комбинирование короткого наложения Solidus | |||||||||||||||||||||||||||||||||||||||||||
| 824 | U+0338 | CC B8 | ̸ | CC B8 | ̸ | 66666.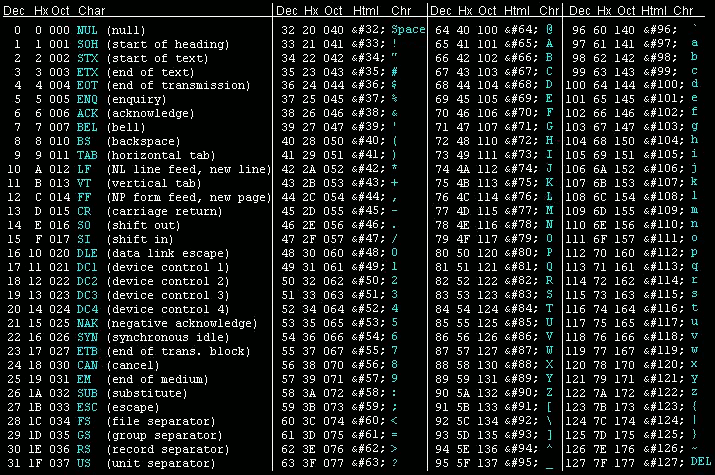 0085 0085 | |||||||||||||||||||||||||||||||||||||||||
| 825 | U+0339 | CC B9 | ̹ | Combining Right Half Ring Below | |||||||||||||||||||||||||||||||||||||||||||
| 826 | U+033A | CC BA | ̺ | Combining Inverted Bridge Below | |||||||||||||||||||||||||||||||||||||||||||
| 827 | U+033B | CC BB | ̻ | Квадрат ниже | |||||||||||||||||||||||||||||||||||||||||||
| 828 | U+033C | CC BC | ̼ 033C | CC BC | 6777 7777 | .0085 | |||||||||||||||||||||||||||||||||||||||||
| 829 | U+033D | CC BD | ̽ | Combining X Above | |||||||||||||||||||||||||||||||||||||||||||
| 830 | U+033E | CC BE | ̾ | Combining Vertical Tilde | |||||||||||||||||||||||||||||||||||||||||||
| 831 | U+033F | CC BF | ̿ | Объединение двойной обшивки | |||||||||||||||||||||||||||||||||||||||||||
| 832 | U+0340 | CD 80777 | ̀ | COMCONIN0076 833 | U+0341 | CD 81 | ́ | Combining Acute Tone Mark | |||||||||||||||||||||||||||||||||||||||
| 834 | U+0342 | CD 82 | ͂ | Combining Greek Perispomeni | |||||||||||||||||||||||||||||||||||||||||||
| 835 | U +0343 | CD 83 | ̓ | Объединение греческого Koronis | |||||||||||||||||||||||||||||||||||||||||||
| 836 | U+0344 | CD 84 | ̈́ | CD 84 | ̈́ | 9676.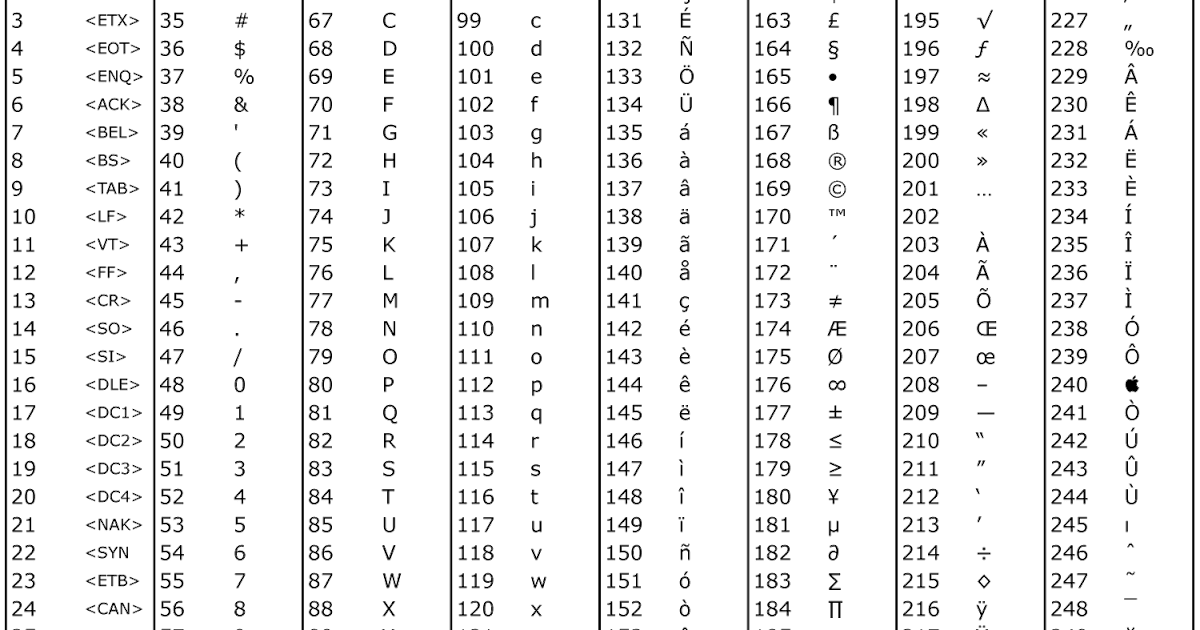 0076 837 0076 837 | U+0345 | CD 85 | ͅ | Combining Greek Ypogegrammeni | |||||||||||||||||||||||||||||||||||||
| 838 | U+0346 | CD 86 | ͆ | Combining Bridge Above | |||||||||||||||||||||||||||||||||||||||||||
| 839 | U+ 0347 | CD 87 | ͇ | Комбинирование знака равных ниже | |||||||||||||||||||||||||||||||||||||||||||
| 840 | U+0348 | CD 88 | ͈ | COMCLING Double Vertical LILE RILE RILE RILE RILE RILE RILE RILE LILE RILE RILE LILE RILE RILE RILE LILE RILE VERTICLAIL WARTICLAIN.0075 | 841 | U+0349 | CD 89 | ͉ | Combining Left Angle Below | ||||||||||||||||||||||||||||||||||||||
| 842 | U+034A | CD 8A | ͊ | Combining Not Tilde Above | |||||||||||||||||||||||||||||||||||||||||||
| 843 | U+034B | CD 8B | ͋ | Объединение гомотетики выше | |||||||||||||||||||||||||||||||||||||||||||
| 844 | U+034C | CD 8C | ͌ | CD 8C | ͌ | CD 8C | ͌ | 7667676 7C | ͌ | 76767676 7C | ͌ | .845 | U+034D | CD 8D | ͍ | Combining Left Right Arrow Below | |||||||||||||||||||||||||||||||
| 846 | U+034E | CD 8E | ͎ | Combining Upwards Arrow Below | |||||||||||||||||||||||||||||||||||||||||||
| 847 | U+034F | CD 8F | ͏ | Комбинирование Grapheme Joiner | |||||||||||||||||||||||||||||||||||||||||||
| 848 | U+0350 | CD 90 | ͐ 0350 | CD 90 | ͐ | .0085 | |||||||||||||||||||||||||||||||||||||||||
| 849 | U+0351 | CD 91 | ͑ | Combining Left Half Ring Above | |||||||||||||||||||||||||||||||||||||||||||
| 850 | U+0352 | CD 92 | ͒ | Combining Fermata | |||||||||||||||||||||||||||||||||||||||||||
| 851 | U+0353 | CD 93 | ͓ | Объединение x ниже | |||||||||||||||||||||||||||||||||||||||||||
| 852 | U+0354 | CD 94 | ͔ | ниже | ͔ | 66676 70077 | ͔ | 666676 70077 | ͔ | 66676.0076 853 | U+0355 | CD 95 | ͕ | Сочетание правой стрелки ниже | |||||||||||||||||||||||||||||||||
| U+0356 | CD | 777996 u+0356u+0356 | U+0356 | . 855 855 | U+0357 | CD 97 | ͗ | Сочетание правого половины кольца выше | |||||||||||||||||||||||||||||||||||||||
| 856 | U+0358 | CD 98 | ͘ 0358 | CD 98 | ͘ Dot | ͘ Dot | ͘ Dot | .0077 | |||||||||||||||||||||||||||||||||||||||
| 857 | U+0359 | CD 99 | ͙ | Combining Asterisk Below | |||||||||||||||||||||||||||||||||||||||||||
| 858 | U+035A | CD 9A | ͚ | Combining Double Ring Below | |||||||||||||||||||||||||||||||||||||||||||
| 859 | U+035B | CD 9B | ͛ | Объединение Zigzag выше | |||||||||||||||||||||||||||||||||||||||||||
| 860 | U+035C | CD | ͜ | .0085 | |||||||||||||||||||||||||||||||||||||||||||
| 861 | U+035D | CD 9D | ͝ | Combining Double Breve | |||||||||||||||||||||||||||||||||||||||||||
| 862 | U+035E | CD 9E | ͞ | Combining Double Macron | |||||||||||||||||||||||||||||||||||||||||||
| 863 | U+035F | CD 9F | ͟ | Combining Double Macron Below | |||||||||||||||||||||||||||||||||||||||||||
| 864 | U+0360 | CD A0 | ͠ | Combining Double Tilde | |||||||||||||||||||||||||||||||||||||||||||
| 865 | U+0361 | CD A1 | ͡ | Combining Double Inverted Breve | |||||||||||||||||||||||||||||||||||||||||||
| 866 | U+0362 | CD A2 | ͢ | Combining Double Rightwards Arrow Below | |||||||||||||||||||||||||||||||||||||||||||
| 867 | U+0363 | CD A3 | ͣ | Объединение латинской маленькой буквы A | |||||||||||||||||||||||||||||||||||||||||||
| 868 | U+0364 | CD A4 | ͤ | CD A4 | ͤ | 7776.||||||||||||||||||||||||||||||||||||||||||
| 869 | U+0365 | CD A5 | ͥ | Combining Latin Small Letter I | |||||||||||||||||||||||||||||||||||||||||||
| 870 | U+0366 | CD A6 | ͦ | Combining Latin Small Letter O | |||||||||||||||||||||||||||||||||||||||||||
| 871 | U+0367 | CD A7 | ͧ | Combining Latin Small Letter U | |||||||||||||||||||||||||||||||||||||||||||
| 872 | U+0368 | CD A8 | ͨ | Combining Latin Small Letter C | |||||||||||||||||||||||||||||||||||||||||||
| 873 | U+0369 | CD A9 | ͩ | Combining Latin Small Letter D | |||||||||||||||||||||||||||||||||||||||||||
| 874 | U+036A | CD AA | ͪ | Combining Latin Small Letter H | |||||||||||||||||||||||||||||||||||||||||||
| 875 | U+036B | CD AB | ͫ | Combining Latin Small Letter M | |||||||||||||||||||||||||||||||||||||||||||
| 876 | U+036C | CD AC | ͬ | Combining Latin Small Letter R | |||||||||||||||||||||||||||||||||||||||||||
| 877 | U+036d | CD AD | ͭ | СОЕДИНЯЕТ ЛАТИН МАЛЕДНА | |||||||||||||||||||||||||||||||||||||||||||
| 879 | U+036F | CD AF | ͯ | Combining Latin Small Letter X | |||||||||||||||||||||||||||||||||||||||||||
| 880 | U+0370 | CD B0 | Ͱ | Greek Capital Letter Heta | |||||||||||||||||||||||||||||||||||||||||||
| 881 | U+0371 | CD B1 | ͱ | Greek Small Letter Heta | |||||||||||||||||||||||||||||||||||||||||||
| 882 | U+0372 | CD B2 | Ͳ | Greek Capital Letter Archaic Sampi | |||||||||||||||||||||||||||||||||||||||||||
| 883 | U+0373 | CD B3 | ͳ | Greek Small Letter Archaic Sampi | |||||||||||||||||||||||||||||||||||||||||||
| 884 | U+0374 | CD B4 | ʹ | Greek Numeral Sign | |||||||||||||||||||||||||||||||||||||||||||
| 885 | U+0375 | CD B5 | ͵ | Greek Lower Numeral Sign | |||||||||||||||||||||||||||||||||||||||||||
| 886 | U+0376 | CD B6 | Ͷ | Greek Capital Letter Pamphylian Digamma | |||||||||||||||||||||||||||||||||||||||||||
| 887 | U+0377 | CD B7 | ͷ | Greek Small Letter Pamphylian Digamma | |||||||||||||||||||||||||||||||||||||||||||
| 888 | U+0378 | CD B8 | | ||||||||||||||||||||||||||||||||||||||||||||
| 889 | U+0379 | CD B9 | | ||||||||||||||||||||||||||||||||||||||||||||
| 890 | U+037A | CD BA | ͺ | Greek Ypogegrammeni | |||||||||||||||||||||||||||||||||||||||||||
| 891 | U+037B | CD BB | ͻ | Greek Small Reversed Lunate Sigma Symbol | |||||||||||||||||||||||||||||||||||||||||||
| 892 | U+037C | CD BC | ͼ | Greek Small Dotted Lunate Sigma Symbol | |||||||||||||||||||||||||||||||||||||||||||
| 893 | U+037d | CD BD | ͽ | Греческий маленький реверс. U+037F U+037F | CD BF | Ϳ | Greek Capital Letter Yot | ||||||||||||||||||||||||||||||||||||||||
| 896 | U+0380 | CE 80 | | ||||||||||||||||||||||||||||||||||||||||||||
| 897 | U+0381 | CE 81 | | ||||||||||||||||||||||||||||||||||||||||||||
| 898 | U+0382 | CE 82 | | ||||||||||||||||||||||||||||||||||||||||||||
| 899 | U+0383 | CE 83 | | ||||||||||||||||||||||||||||||||||||||||||||
| 900 | U+0384 | CE 84 | ΄ | Greek Tonos | |||||||||||||||||||||||||||||||||||||||||||
| 901 | U+0385 | CE 85 | ΅ | Greek Dialytika Tonos | |||||||||||||||||||||||||||||||||||||||||||
| 902 | U+0386 | CE 86 | Ά | Greek Capital Letter Alpha With Tonos | |||||||||||||||||||||||||||||||||||||||||||
| 903 | U+0387 | CE 87 | · | Greek Ano Teleia | |||||||||||||||||||||||||||||||||||||||||||
| 904 | U+0388 | CE 88 | Έ | Greek Capital Letter Epsilon With Tonos | |||||||||||||||||||||||||||||||||||||||||||
| 905 | U+0389 | CE 89 | Ή | Greek Capital Letter Eta With Tonos | |||||||||||||||||||||||||||||||||||||||||||
| 906 | U+038A | CE 8A | Ί | Greek Capital Letter Iota With Tonos | |||||||||||||||||||||||||||||||||||||||||||
| 907 | U+038B | CE 8B | | ||||||||||||||||||||||||||||||||||||||||||||
| 908 | U+038C | CE 8C | Ό | Greek Capital Letter Omicron With Tonos | |||||||||||||||||||||||||||||||||||||||||||
| 909 | U+038D | CE 8D | | ||||||||||||||||||||||||||||||||||||||||||||
| 910 | U+038E | CE 8E | Ύ | Греческая капитальная буква Upsilon с Tonos | |||||||||||||||||||||||||||||||||||||||||||
| 911 | U+038F | CE 8F | ώ | Грека Капитала САПИЯ | Греческая маленькая буква йота с диалитикой и тоносом | ||||||||||||||||||||||||||||||||||||||||||
| 913 | U+0391 | CE 91 | α | САПИТНАЯ ПИСЬМА. 2 2 | CE 92 | Β | Greek Capital Letter Beta | ||||||||||||||||||||||||||||||||||||||||
| 915 | U+0393 | CE 93 | Γ | Greek Capital Letter Gamma | |||||||||||||||||||||||||||||||||||||||||||
| 916 | U+0394 | CE 94 | Δ | Greek Capital Letter Delta | |||||||||||||||||||||||||||||||||||||||||||
| 917 | U+0395 | CE 95 | Ε | Greek Capital Letter Epsilon | |||||||||||||||||||||||||||||||||||||||||||
| 918 | U+0396 | CE 96 | Ζ | Greek Capital Letter Zeta | |||||||||||||||||||||||||||||||||||||||||||
| 919 | U+0397 | CE 97 | Η | Greek Capital Letter Eta | |||||||||||||||||||||||||||||||||||||||||||
| 920 | U+0398 | CE 98 | Θ | Greek Capital Letter Theta | |||||||||||||||||||||||||||||||||||||||||||
| 921 | U+0399 | CE 99 | Ι | Greek Capital Letter Iota | |||||||||||||||||||||||||||||||||||||||||||
| 922 | U+039A | CE | κ | Греческая капитальная буква Каппа | |||||||||||||||||||||||||||||||||||||||||||
| 923 | U+039B | CE | λ | GREEK СПАСИТЕЛЬНА | μ | Греческая столичная буква MU | |||||||||||||||||||||||||||||||||||||||||
| 925 | U+039d | CE | ν | Грека Капитала NU | |||||||||||||||||||||||||||||||||||||||||||
| GEATE | Ξ | Greek Capital Letter Xi | |||||||||||||||||||||||||||||||||||||||||||||
| 927 | U+039F | CE 9F | Ο | Greek Capital Letter Omicron | |||||||||||||||||||||||||||||||||||||||||||
| 928 | U+03A0 | CE A0 | Π | Greek Capital Letter Pi | |||||||||||||||||||||||||||||||||||||||||||
| 929 | U+03A1 | CE A1 | Ρ | Greek Capital Letter Rho | |||||||||||||||||||||||||||||||||||||||||||
| 930 | U+03A2 | CE A2 | | ||||||||||||||||||||||||||||||||||||||||||||
| 931 | U+03A3 | CE A3 | Σ | Greek Capital Letter Sigma | |||||||||||||||||||||||||||||||||||||||||||
| 932 | U+03A4 | CE A4 | Τ | Greek Capital Letter Tau | |||||||||||||||||||||||||||||||||||||||||||
| 933 | U+03A5 | CE A5 | Υ | Greek Capital Letter Upsilon | |||||||||||||||||||||||||||||||||||||||||||
| 934 | U+03A6 | CE A6 | Φ | Greek Capital Letter Phi | |||||||||||||||||||||||||||||||||||||||||||
| 935 | U+03A7 | CE A7 | Χ | Greek Capital Letter Chi | |||||||||||||||||||||||||||||||||||||||||||
| 936 | U+03A8 | CE A8 | Ψ | Greek Capital Letter Psi | |||||||||||||||||||||||||||||||||||||||||||
| 937 | U+03A9 | CE A9 | ω | Грековая столичная буква Омега | |||||||||||||||||||||||||||||||||||||||||||
| 938 | U+03AA | CE AA | u+03AA | CE AA | ϊ 03AA | . 0077 0077 | |||||||||||||||||||||||||||||||||||||||||
| 939 | U+03AB | CE AB | Ϋ | Greek Capital Letter Upsilon With Dialytika | |||||||||||||||||||||||||||||||||||||||||||
| 940 | U+03AC | CE AC | ά | Greek Small Letter Alpha With Tonos | |||||||||||||||||||||||||||||||||||||||||||
| 941 | U+03AD | CE AD | έ | Greek Small Letter Epsilon With Tonos | |||||||||||||||||||||||||||||||||||||||||||
| 942 | U+03AE | CE AE | ή | Greek Small Letter Eta With Tonos | |||||||||||||||||||||||||||||||||||||||||||
| 943 | U+03AF | CE AF | ί | Greek Small Letter Iota With Tonos | |||||||||||||||||||||||||||||||||||||||||||
| 944 | U+03B0 | CE B0 | ΰ | Greek Small Letter Upsilon With Dialytika And Tonos | |||||||||||||||||||||||||||||||||||||||||||
| 945 | U+03B1 | CE B1 | α | Greek Small Letter Alpha | |||||||||||||||||||||||||||||||||||||||||||
| 946 | U+03B2 | CE B2 | β | Greek Small Letter Beta | |||||||||||||||||||||||||||||||||||||||||||
| 947 | U+03B3 | CE B3 | γ | Greek Small Letter Gamma | |||||||||||||||||||||||||||||||||||||||||||
| 948 | U+03B4 | CE B4 | δ | Greek Small Letter Delta | |||||||||||||||||||||||||||||||||||||||||||
| 949 | U+03B5 | CE B5 | ε | Greek Small Letter Epsilon | |||||||||||||||||||||||||||||||||||||||||||
| 950 | U+03B6 | CE B6 | ζ | Greek Small Letter Zeta | |||||||||||||||||||||||||||||||||||||||||||
| 951 | U+03B7 | CE B7 | η | Greek Small Letter Eta | |||||||||||||||||||||||||||||||||||||||||||
| 952 | U+03B8 | CE B8 | θ | Greek Small Letter Theta | |||||||||||||||||||||||||||||||||||||||||||
| 953 | U+03B9 | CE B9 | ι | Greek Small Letter Iota | |||||||||||||||||||||||||||||||||||||||||||
| 954 | U+03BA | CE BA | κ | Greek Small Letter Kappa | |||||||||||||||||||||||||||||||||||||||||||
| 955 | U+03BB | CE BB | λ | Greek Small Letter Lamda | |||||||||||||||||||||||||||||||||||||||||||
| 956 | U+03BC | CE BC | μ | Greek Small Letter Mu | |||||||||||||||||||||||||||||||||||||||||||
| 957 | U+03BD | CE BD | ν | Greek Small Letter Nu | |||||||||||||||||||||||||||||||||||||||||||
| 958 | U+03BE | CE BE | ξ | Greek Small Letter Xi | |||||||||||||||||||||||||||||||||||||||||||
| 959 | U+03BF | CE BF | ο | Greek Small Letter Omicron | |||||||||||||||||||||||||||||||||||||||||||
| 960 | U+03C0 | CF 80 | π | Greek Small Letter Pi | |||||||||||||||||||||||||||||||||||||||||||
| 961 | U+03C1 | CF 81 | ρ | Греческая маленькая буква RHO | |||||||||||||||||||||||||||||||||||||||||||
| 962 | U+03C2 | CF 82 | U+03C2 | CF 82 | 77777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777. 0085 0085 | ||||||||||||||||||||||||||||||||||||||||||
| 963 | U+03C3 | CF 83 | σ | Greek Small Letter Sigma | |||||||||||||||||||||||||||||||||||||||||||
| 964 | U+03C4 | CF 84 | τ | Greek Small Letter Tau | |||||||||||||||||||||||||||||||||||||||||||
| 965 | U+03C5 | CF 85 | υ | Greek Small Letter Upsilon | |||||||||||||||||||||||||||||||||||||||||||
| 966 | U+03C6 | CF 86 | φ | Greek Small Letter Phi | |||||||||||||||||||||||||||||||||||||||||||
| 967 | U+03C7 | CF 87 | χ | Greek Small Letter Chi | |||||||||||||||||||||||||||||||||||||||||||
| 968 | U+03C8 | CF 88 | ψ | Greek Small Letter Psi | |||||||||||||||||||||||||||||||||||||||||||
| 969 | U+03C9 | CF 89 | ω | Греческая маленькая буква Omega | |||||||||||||||||||||||||||||||||||||||||||
| 970 | U+03CA | CF | ϊ | .0076 971 | U+03CB | CF 8B | ϋ | Greek Small Letter Upsilon With Dialytika | |||||||||||||||||||||||||||||||||||||||
| 972 | U+03CC | CF 8C | ό | Greek Small Letter Omicron With Tonos | |||||||||||||||||||||||||||||||||||||||||||
| 973 | U+03CD | CF 8D | ύ | Greek Small Letter Upsilon With Tonos | |||||||||||||||||||||||||||||||||||||||||||
| 974 | U+03CE | CF 8E | ώ | Greek Small Letter Omega With Tonos | |||||||||||||||||||||||||||||||||||||||||||
| 975 | U+03CF | CF 8F | Ϗ | Greek Capital Kai Symbol | |||||||||||||||||||||||||||||||||||||||||||
| 976 | U+03D0 | CF 90 | ϐ | Greek Beta Symbol | |||||||||||||||||||||||||||||||||||||||||||
| 977 | U+03D1 | CF 91 | ϑ | Греческий Theta Symbol | |||||||||||||||||||||||||||||||||||||||||||
| 978 | U+03D2 | CF 978 | . 0076 979 0076 979 | U+03D3 | CF 93 | ϓ | Greek Upsilon With Acute And Hook Symbol | ||||||||||||||||||||||||||||||||||||||||
| 980 | U+03D4 | CF 94 | ϔ | Greek Upsilon With Diaeresis And Hook Symbol | |||||||||||||||||||||||||||||||||||||||||||
| 981 | U+03D5 | CF 95 | ϕ | Greek Phi Symbol | |||||||||||||||||||||||||||||||||||||||||||
| 982 | U+03D6 | CF 96 | ϖ | Greek Pi Symbol | |||||||||||||||||||||||||||||||||||||||||||
| 983 | U+03D7 | CF 97 | ϗ | Greek Kai Symbol | |||||||||||||||||||||||||||||||||||||||||||
| 984 | U+03D8 | CF 98 | Ϙ | Greek Letter Archaic Koppa | |||||||||||||||||||||||||||||||||||||||||||
| 985 | U+03D9 | CF 99 | ϙ | Greek Small Letter Archaic Koppa | |||||||||||||||||||||||||||||||||||||||||||
| 986 | U+03DA | CF 9A | Ϛ | Greek Letter Stigma | |||||||||||||||||||||||||||||||||||||||||||
| 987 | U+03DB | CF 9B | ϛ | Greek Small Letter Stigma | |||||||||||||||||||||||||||||||||||||||||||
| 988 | U+03DC | CF 9C | Ϝ | Greek Letter Digamma | |||||||||||||||||||||||||||||||||||||||||||
| 989 | U+ 03DD | CF 9D | ϝ | Греческая маленькая буква Digamma | |||||||||||||||||||||||||||||||||||||||||||
| 990 | U+03DE | ϟ | ϟ | ϟ | 676 | . 0077 0077 | CF 9F | ϟ | Greek Small Letter Koppa | ||||||||||||||||||||||||||||||||||||||
| 992 | U+03E0 | CF A0 | Ϡ | Greek Letter Sampi | |||||||||||||||||||||||||||||||||||||||||||
| 993 | U+03E1 | CF A1 | ϡ | Греческая маленькая буква Sampi | |||||||||||||||||||||||||||||||||||||||||||
| 994 | U+03E2 | CF A2 | ϣ | СПАСИТЕЛЬНАЯ СИТЕЛЬНА0077 | ϣ | Coptic Small Letter Shei | |||||||||||||||||||||||||||||||||||||||||
| 996 | U+03E4 | CF A4 | Ϥ | Coptic Capital Letter Fei | |||||||||||||||||||||||||||||||||||||||||||
| 997 | U+03E5 | CF A5 | ϥ | Коптская маленькая буква FEI | |||||||||||||||||||||||||||||||||||||||||||
| 998 | U+03E6 | CF A6 | ϧ | СПАСИТЕЛЬНА0076 ϧ | Коптская строчная буква Khei |
 0076 U+0059
0076 U+0059 Mark
Mark
 0076 ǡ
0076 ǡ 0075
0075 0077
0077кодировка — Что такое Unicode, UTF-8 и UTF-16?
Зачем нужен Юникод?
В те (не слишком) ранние дни существовало только ASCII. Это было нормально, так как все, что когда-либо было необходимо, — это несколько управляющих символов, знаков препинания, цифр и букв, подобных тем, что в этом предложении. К сожалению, сегодняшний странный мир глобальной коммуникации и социальных сетей не был предвиден, и нет ничего необычного в том, чтобы увидеть английский язык, العربية, 汉语, עִבְרִית, ελληνικά и ភាសាខ្មែរ в одном и том же документе (надеюсь, я не сломал ни одного старого документа). браузеры).
Это было нормально, так как все, что когда-либо было необходимо, — это несколько управляющих символов, знаков препинания, цифр и букв, подобных тем, что в этом предложении. К сожалению, сегодняшний странный мир глобальной коммуникации и социальных сетей не был предвиден, и нет ничего необычного в том, чтобы увидеть английский язык, العربية, 汉语, עִבְרִית, ελληνικά и ភាសាខ្មែរ в одном и том же документе (надеюсь, я не сломал ни одного старого документа). браузеры).
Но в качестве аргумента предположим, что Джо Средний — разработчик программного обеспечения. Он настаивает на том, что ему всегда будет нужен только английский язык, и поэтому он хочет использовать только ASCII. Это может быть хорошо для пользователя Joe , но не подходит для Joe разработчика программного обеспечения . Приблизительно половина мира использует нелатинские символы, и использование ASCII, возможно, является невнимательным для этих людей, и вдобавок ко всему, он закрывает свое программное обеспечение для большой и растущей экономики.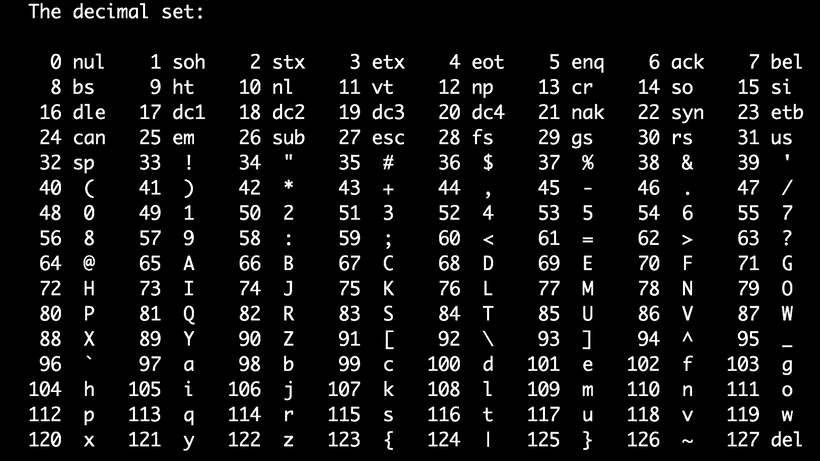
Таким образом, охватывающий набор символов, включающий нужны все языков. Так появился Юникод. Он присваивает каждому символу уникальный номер, называемый кодовой точкой . Одним из преимуществ Unicode перед другими возможными наборами является то, что первые 256 кодовых точек идентичны ISO-8859-1 и, следовательно, также ASCII. Кроме того, подавляющее большинство часто используемых символов могут быть представлены всего двумя байтами в области, называемой Basic Multilingual Plane (BMP) . Теперь для доступа к этому набору символов требуется кодировка, и, поскольку вопрос задается, я сосредоточусь на UTF-8 и UTF-16.
Вопросы памяти
Итак, сколько байт дает доступ к каким символам в этих кодировках?
- UTF-8:
- 1 байт: стандарт ASCII
- 2 байта: арабский, иврит, большинство европейских шрифтов (особенно за исключением грузинского)
- 3 байта: BMP
- 4 байта: все символы Unicode
- UTF-16:
- 2 байта: BMP
- 4 байта: все символы Unicode
Теперь стоит отметить, что символы, отсутствующие в BMP, включают древние письмена, математические символы, музыкальные символы и более редкие китайские, японские и корейские (CJK) символы.
Если вы будете работать в основном с символами ASCII, то UTF-8, безусловно, более эффективно использует память. Однако, если вы работаете в основном с неевропейскими сценариями, использование UTF-8 может быть в 1,5 раза менее эффективным с точки зрения использования памяти, чем UTF-16. При работе с большими объемами текста, такими как большие веб-страницы или длинные текстовые документы, это может повлиять на производительность.
Основы кодирования
Примечание. Если вы знаете, как кодируются UTF-8 и UTF-16, перейдите к следующему разделу для практических применений.
- UTF-8: Для стандартных символов ASCII (0-127) коды UTF-8 идентичны. Это делает UTF-8 идеальной, если требуется обратная совместимость с существующим текстом ASCII. Для других символов требуется от 2 до 4 байтов. Это делается путем резервирования некоторых битов в каждом из этих байтов, чтобы указать, что он является частью многобайтового символа. В частности, первый бит каждого байта равен
1, чтобы избежать конфликтов с символами ASCII. - UTF-16: Для допустимых символов BMP представление UTF-16 — это просто их кодовая точка. Однако для символов, отличных от BMP, UTF-16 вводит суррогатных пар . В этом случае комбинация двух двухбайтовых частей сопоставляется с символом, отличным от BMP. Эти двухбайтовые части взяты из числового диапазона BMP, но стандарт Unicode гарантирует, что они недействительны в качестве символов BMP. Кроме того, поскольку базовая единица UTF-16 состоит из двух байтов, на нее влияет порядок следования байтов. Чтобы компенсировать это, зарезервировано Метка порядка байтов может быть помещена в начало потока данных, что указывает порядок следования байтов. Таким образом, если вы читаете ввод UTF-16, и порядок байтов не указан, вы должны проверить это.
 В частности, первый бит каждого байта равен
В частности, первый бит каждого байта равен Как видно, UTF-8 и UTF-16 далеко не совместимы друг с другом. Поэтому, если вы выполняете ввод-вывод, убедитесь, что вы знаете, какую кодировку вы используете! Дополнительные сведения об этих кодировках см. в FAQ по UTF.
Поэтому, если вы выполняете ввод-вывод, убедитесь, что вы знаете, какую кодировку вы используете! Дополнительные сведения об этих кодировках см. в FAQ по UTF.
Практические рекомендации по программированию
Символьные и строковые типы данных: Как они кодируются в языке программирования? Если это необработанные байты, в ту минуту, когда вы попытаетесь вывести символы, отличные от ASCII, вы можете столкнуться с несколькими проблемами. Кроме того, даже если тип символа основан на UTF, это не означает, что строки являются правильными UTF. Они могут допускать недопустимые последовательности байтов. Как правило, вам придется использовать библиотеку, поддерживающую UTF, например ICU для C, C++ и Java. В любом случае, если вы хотите ввести/вывести что-то отличное от кодировки по умолчанию, вам придется сначала преобразовать ее.
Рекомендуемая кодировка, кодировка по умолчанию и доминирующая: Когда есть выбор, какую UTF использовать, обычно лучше всего следовать рекомендуемым стандартам для среды, в которой вы работаете. Например, UTF-8 преобладает в Интернете, а начиная с HTML5, это рекомендуемая кодировка. И наоборот, среды .NET и Java основаны на символьном типе UTF-16. Сбивая с толку (и неправильно), ссылки часто делаются на «кодировку Unicode», которая обычно относится к доминирующей кодировке UTF в данной среде.
Например, UTF-8 преобладает в Интернете, а начиная с HTML5, это рекомендуемая кодировка. И наоборот, среды .NET и Java основаны на символьном типе UTF-16. Сбивая с толку (и неправильно), ссылки часто делаются на «кодировку Unicode», которая обычно относится к доминирующей кодировке UTF в данной среде.
Поддержка библиотек: Используемые вами библиотеки поддерживают некоторую кодировку. Который из? Поддерживают ли они крайние случаи? Поскольку потребность — это мать изобретения, библиотеки UTF-8, как правило, должным образом поддерживают 4-байтовые символы, поскольку часто встречаются 1-, 2- и даже 3-байтовые символы. Однако не все предполагаемые библиотеки UTF-16 правильно поддерживают суррогатные пары, поскольку они встречаются очень редко.
Подсчет символов: Существует комбинаций символов в Юникоде. Например, кодовая точка U+006E (n) и U+0303 (сочетание тильды) образуют ñ, а кодовая точка U+00F1 образует ñ. Они должны выглядеть одинаково, но простой алгоритм подсчета вернет 2 для первого примера и 1 для второго. Это не обязательно неправильно, но может и не быть желаемым результатом.
Это не обязательно неправильно, но может и не быть желаемым результатом.
Сравнение на равенство: А, А и А выглядят одинаково, но это латиница, кириллица и греческий язык соответственно. У вас также есть такие случаи, как C и Ⅽ. Одна буква, а другая римская цифра. Кроме того, у нас есть комбинированные символы, которые следует учитывать. Для получения дополнительной информации см. Повторяющиеся символы в Unicode .
Суррогатные пары: Они достаточно часто встречаются в Stack Overflow, поэтому я просто приведу несколько примеров ссылок:
- Получение длины строки
- Удаление суррогатных пар
- Проверка палиндрома
8(7) — страница руководства Linux
utf-8(7) — страница руководства LinuxИМЯ | ОПИСАНИЕ | СМОТРИТЕ ТАКЖЕ | КОЛОФОН | |
UTF-8(7) Руководство программиста Linux UTF-8(7)
ИМЯ топ
UTF-8 - многобайтовая кодировка Unicode, совместимая с ASCII.
ОПИСАНИЕ верхний
Набор символов Unicode 3.0 занимает 16-битное кодовое пространство.
самая очевидная кодировка Unicode (известная как UCS-2) состоит из
последовательность 16-битных слов. Такие строки могут содержать — как часть
многие 16-битные символы — байты, такие как '\0' или '/', которые имеют
особое значение в именах файлов и других функциях библиотеки C
аргументы. Кроме того, большинство инструментов UNIX ожидают кодировку ASCII.
файлов и не может читать 16-битные слова как символы без основного
модификации. По этим причинам UCS-2 не подходит.
внешняя кодировка Unicode в именах файлов, текстовых файлах,
переменные окружения и так далее. Универсальный стандарт ISO 10646
Набор символов (UCS), надмножество Unicode, занимает четное
большее кодовое пространство - 31 бит - и очевидное кодирование UCS-4 для него
(последовательность 32-битных слов) имеет те же проблемы. 31 могут быть закодированы с использованием UTF-8.
* Байты 0xc0, 0xc1, 0xfe и 0xff никогда не используются в
Кодировка UTF-8.
* Первый байт многобайтовой последовательности, представляющей
одиночный символ UCS, отличный от ASCII, всегда находится в диапазоне от 0xc2 до
0xfd и указывает длину этой многобайтовой последовательности. Все
последующие байты в многобайтовой последовательности находятся в диапазоне от 0x80 до
0xbf. Это упрощает повторную синхронизацию и делает
кодирование без сохранения состояния и устойчивость к отсутствующим байтам.
* Символы UCS в кодировке UTF-8 могут иметь длину до шести байтов,
однако стандарт Unicode не определяет символы выше
0x10ffff, поэтому символы Unicode могут быть не более четырех байтов.
длинный в UTF-8.
Кодировка
Следующие последовательности байтов используются для представления символа.
Используемая последовательность зависит от номера кода UCS
персонаж:
0x00000000 - 0x0000007F:
0 ххххххх
0x00000080 - 0x000007FF:
110 ххххх 10 хххххх
0x00000800 - 0x0000FFFF:
1110 хххх 10 ххххх 10 хххххх
0x00010000 - 0x001FFFFF:
11110 ххх 10 ххххх 10 ххххх 10 хххххх
0x00200000 - 0x03FFFFFF:
111110 хх 10 xxxxxx 10 xxxxxx 10 xxxxxx 10 xxxxxx
0x04000000 - 0x7FFFFFFFF:
1111110 x 10 xxxxxx 10 xxxxxx 10 xxxxxx 10 xxxxxx 10 xxxxxx
Битовые позиции xxx заполняются битами символа
кодовое число в двоичном представлении, старший бит идет первым
(с обратным порядком байтов). Только самая короткая многобайтовая последовательность
который может представлять кодовый номер символа, который может быть использован.
Значения кода UCS 0xd800–0xdfff (суррогаты UTF-16), а также
0xfffe и 0xffff (несимволы UCS) не должны появляться в
соответствующие потоки UTF-8. Согласно RFC 3629нет пункта выше
Следует использовать U+10FFFF, что ограничивает количество символов четырьмя байтами.
Пример
Символ Unicode 0xa9 = 1010 1001 (знак авторского права)
кодируется в UTF-8 как
10 10 = 0xc2 0xa9
и символ 0x2260 = 0010 0010 0110 0000 ("не равно"
символ) кодируется как:
11 01 10 = 0xe2 0x89 0xa0
Замечания по применению
Пользователи должны выбрать локаль UTF-8, например, с помощью
экспорт LANG=en_GB.UTF-8
чтобы активировать поддержку UTF-8 в приложениях.
Прикладное программное обеспечение, которое должно знать об используемом символе
кодировка всегда должна устанавливать локаль, например,
установить локаль (LC_CTYPE, "")
и программисты могут затем проверить выражение
strcmp(nl_langinfo(CODESET), "UTF-8") == 0
чтобы определить, была ли выбрана локаль UTF-8 и
поэтому весь стандартный ввод и вывод открытого текста, терминал
связь, содержимое файла открытого текста, имена файлов и среда
переменные кодируются в UTF-8.
Программисты, привыкшие к однобайтовым кодировкам, таким как US-ASCII
или ИСО 8859должны знать, что два предположения, сделанные до сих пор,
больше не действует в локалях UTF-8. Во-первых, один байт делает
не обязательно больше соответствовать одному символу.
Во-вторых, поскольку современные эмуляторы терминала в режиме UTF-8 тоже
поддерживают китайские, японские и корейские символы двойной ширины в качестве
а также объединение символов без пробелов, вывод одного
символ не обязательно продвигает курсор на одну позицию
как это было в ASCII. Библиотечные функции, такие как mbsrtowcs(3) и
wcswidth(3) следует использовать сегодня для подсчета символов и курсора
позиции.
Официальная последовательность ESC для переключения с кодировки ISO 2022.
схема (используемая, например, терминалами VT100) в UTF-8 - это ESC
%G("\x1b%G"). Соответствующая последовательность возврата из UTF-8 в
ISO 2022 — это ESC % @ ("\x1b%@"). Другие последовательности ISO 2022 (например,
что касается переключения наборов G0 и G1) не применимы в UTF-8
режим.
Безопасность
Стандарты Unicode и UCS требуют, чтобы производители UTF-8
должен использовать максимально короткую форму, например, производя
двухбайтовая последовательность с первым байтом 0xc0 не соответствует требованиям. Юникод
3.1 добавлено требование о том, что соответствующие программы не должны
принимать некратчайшие формы на входе. Это для безопасности
причины: если пользовательский ввод проверяется на предмет возможной безопасности
нарушений, программа может проверять только ASCII-версию
"/../" или же ";" или NUL и упускают из виду, что есть много не-ASCII
способы представления этих вещей в не самой короткой кодировке UTF-8.
Стандарты
ИСО/МЭК 10646-1:2000, Юникод 3.1, RFC 3629, план 9.
СМ. ТАКЖЕ вверх
локаль (1), nl_langinfo (3), setlocale (3), наборы символов (7), юникод (7)
КОЛОФОН верхний
Эта страница является частью выпуска 5. 13 проекта Linux man-pages .
Описание проекта, информация о сообщениях об ошибках,
и последнюю версию этой страницы можно найти по адресу
https://www.kernel.org/doc/man-pages/.
GNU 2019-03-06 UTF-8(7)
Страницы, ссылающиеся на эту страницу:
юникод_старт (1),
юникод_стоп(1),
локаль (5),
оружие-8(7),
ascii(7),
кодировки (7),
ср1251(7),
ср1252(7),
iso_8859-10(7),
iso_8859-11(7),
iso_8859-13(7),
iso_8859-14(7),
iso_8859-15(7),
iso_8859-16(7),
iso_8859-1(7),
iso_8859-2(7),
iso_8859-3(7),
iso_8859-4(7),
iso_8859-5(7),
iso_8859-6(7),
iso_8859-7(7),
iso_8859-8(7),
iso_8859-9(7),
кои8-р(7),
кои8-у(7),
локаль (7),
справочные страницы (7),
юникод (7),
ури (7),
установить шрифт(8)
Авторские права и лицензия на страницу этого руководства
8-символьная таблица Unicode/UTF
Unicode
кодовая точка символов UTF-8
(шестнадцатеричный) имя U+0000 00 <управление> U+0001 01 <управление> U+0002 02 <управление> U+0003 03 <управление> U+0004 04 <управление> U+0005 05 <управление> U+0006 06 <управление> U+0007 07 <управление> U+0008 08 <управление> U+0009 09 <управление> U+000A 0a <управление> U+000B 0b <управление> U+000C 0c <управление> U+000D 0d <управление> U+000E 0e <управление> U+000F 0f <управление> U+0010 10 <управление> U+0011 11 <управление> U+0012 12 <управление> U+0013 13 <управление> U+0014 14 <управление> U+0015 15 <управление> U+0016 16 <управление> U+0017 17 <управление> U+0018 18 <управление> U+0019 19 <управление> U+001A 1a <управление> U+001B 1b <управление> U+001C 1c <управление> U+001D 1d <управление> U+001E 1e <управление> U+001F 1f <управление> U+0020 20 ПРОБЕЛ U+0021 ! 21 ВОСКЛИЦАТЕЛЬНЫЙ ЗНАК U+0022 » 22 КАвычки U+0023 # 23 ЗНАК НОМЕРА U+0024 $ 24 ЗНАК ДОЛЛАРА U+0025 % 25 ЗНАК ПРОЦЕНТА U+0026 и 26 АМПЕРСАНД U+0027 ‘ 27 АПОСТРОФ U+0028 ( 28 ЛЕВАЯ СКОБКА U+0029 ) 29 ПРАВАЯ СКОБКА U+002A * 2a ЗВЕЗДОЧКА U+002B + 2b ЗНАК ПЛЮС U+002C , 2c ЗАПЯТАЯ U+002D — 2d ДЕФИС-МИНУС U+002E . 2e ПОЛНЫЙ СТОП U+002F / 2f SOLIDUS U+0030 0 30 ЦИФРА НОЛЬ U+0031 1 31 ЦИФРА ЕДИНИЦА U+0032 2 32 ДВА ЦИФРЫ U+0033 3 33 ЦИФРА ТРИ U+0034 4 34 ЧЕТВЕРТАЯ ЦИФРА U+0035 5 35 ПЯТАЯ ЦИФРА U+0036 6 36 ЦИФРА ШЕСТЬ U+0037 7 37 СЕДЬМАЯ ЦИФРА U+0038 8 38 ВОСЕМЬ ЦИФРА U+0039 9 39 ЦИФРА ДЕВЯТЬ U+003A : 3a ТОЛСТАЯ КИШКА U+003B ; 3b ТОЧКА С ЗАПЯТОЙ U+003C < 3c ЗНАК МЕНЬШЕ U+003D = 3d ЗНАК РАВНО U+003E > 3e ЗНАК БОЛЬШЕ U+003F ? 3f ВОПРОСИТЕЛЬНЫЙ ЗНАК U+0040 @ 40 КОММЕРЧЕСКИЙ ПО ТЕЛЕФОНУ U+0041 A 41 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА A U+0042 B 42 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА B U+0043 C 43 ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА C U+0044 D 44 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА D U+0045 E 45 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА E U+0046 F 46 ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА F U+0047 G 47 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА G U+0048 H 48 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА H U+0049 I 49 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА I U+004A J 4a ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА J U+004B K 4b ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА K U+004C L 4c ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА L U+004D M 4d ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА M U+004E N 4e ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА N U+004F O 4f ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА O U+0050 P 50 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА P U+0051 Q 51 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА Q U+0052 R 52 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА R U+0053 S 53 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА S U+0054 T 54 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА T U+0055 U 55 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА U U+0056 V 56 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА V U+0057 W 57 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА W U+0058 X 58 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА X U+0059 Y 59 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА Y U+005A Z 5a ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА Z 9 5e ЦИРКУМФЛЕКС АКЦЕНТ U+005F _ 5f НИЗКАЯ ЛИНИЯ U+0060 ` 60 ГРЕЙВ АКЦЕНТ U+0061 a 61 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A U+0062 b 62 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА B U+0063 в 63 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА C U+0064 d 64 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА D U+0065 e 65 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E U+0066 f 66 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА F U+0067 g 67 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА G U+0068 h 68 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА H U+0069 i 69 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I U+006A j 6a СТРОЧНАЯ ЛАТИНСКАЯ БУКВА J U+006B k 6b СТРОЧНАЯ ЛАТИНСКАЯ БУКВА K U+006C l 6c СТРОЧНАЯ ЛАТИНСКАЯ БУКВА L U+006D m 6d СТРОЧНАЯ ЛАТИНСКАЯ БУКВА M U+006E n 6e СТРОЧНАЯ ЛАТИНСКАЯ БУКВА N U+006F o 6f СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O U+0070 p 70 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА P U+0071 q 71 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Q U+0072 r 72 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА R U+0073 s 73 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА S U+0074 t 74 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА T U+0075 u 75 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U U+0076 v 76 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА V U+0077 w 77 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА W U+0078 x 78 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА X U+0079 y 79 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Y U+007A z 7a СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Z U+007B { 7b ЛЕВАЯ ФИГУРНАЯ СКОБКА U+007C | 7с ВЕРТИКАЛЬНАЯ ЛИНИЯ U+007D } 7d ПРАВАЯ ФИГУРНАЯ КРОНШТЕЙН U+007E ~ 7e ТИЛЬДА U+007F 7f <управление> U+0080 c2 80 <управление> U+0081 c2 81 <управление> U+0082 c2 82 <управление> U+0083 c2 83 <управление> U+0084 c2 84 <управление> U+0085 c2 85 <управление> U+0086 c2 86 <управление> U+0087 c2 87 <управление> U+0088 c2 88 <управление> U+0089 c2 89 <управление> U+008A c2 8a <управление> U+008B c2 8b <управление> U+008C c2 8c <управление> U+008D c2 8d <управление> U+008E c2 8e <управление> U+008F c2 8f <управление> U+0090 c2 90 <управление> U+0091 c2 91 <управление> U+0092 c2 92 <управление> U+0093 c2 93 <управление> U+0094 c2 94 <управление> U+0095 c2 95 <управление> U+0096 c2 96 <управление> U+0097 c2 97 <управление> U+0098 c2 98 <управление> U+0099 c2 99 <управление> U+009A c2 9a <управление> U+009B c2 9b <управление> U+009C c2 9c <управление> U+009D c2 9d <управление> U+009E c2 9e <управление> U+009F c2 9f <управление> U+00A0 c2 a0 НЕРАЗРЫВНЫЙ ПРОБЕЛ U+00A1 ¡ c2 a1 ПЕРЕВЕРНУТЫЙ ВОСКЛИЦАТЕЛЬНЫЙ ЗНАК U+00A2 ¢ c2 a2 ЗНАК ЦЕНТА U+00A3 £ c2 a3 ЗНАК ФУНТА U+00A4 ¤ c2 a4 ЗНАК ВАЛЮТЫ U+00A5 ¥ c2 a5 ЗНАК ЙЕНЫ U+00A6 ¦ c2 a6 СЛОМАННЫЙ БАР U+00A7 § c2 a7 ЗНАК СЕКЦИИ U+00A8 ¨ c2 a8 ДИЭРЕЗИС U+00A9 © c2 a9 ЗНАК АВТОРСКОГО ПРАВА U+00AA ª c2 aa ЖЕНСКИЙ ОРДИНАЛ ИНДИКАТОР U+00AB « c2 ab ДВУХУГОЛЬНАЯ КАТЫЧКА, УКАЗЫВАЮЩАЯ ВЛЕВО U+00AC ¬ c2 ac НЕ ЗНАК U+00AD c2 объявление Мягкий дефис U+00AE ® c2 ae ЗАРЕГИСТРИРОВАННЫЙ ЗНАК U+00AF ¯ c2 af Макрон U+00B0 ° c2 b0 ЗНАК СТЕПЕНИ U+00B1 ± c2 b1 ЗНАК ПЛЮС-МИНУС U+00B2 ² c2 b2 НАДПИСЬ ДВА U+00B3 ³ c2 b3 НАДСТРОЙКА ТРИ U+00B4 ´ c2 b4 ОСТРЫЙ АКЦЕНТ U+00B5 µ c2 b5 МИКРОЗНАК U+00B6 ¶ c2 b6 ЗНАК ПОДШИВКИ U+00B7 · c2 b7 СРЕДНЯЯ ТОЧКА U+00B8 ¸ c2 b8 СЕДИЛЬЯ U+00B9 ¹ c2 b9 НАДПИСЬ ОДИН U+00BA º c2 ba МУЖСКОЙ ОРДИНАЛ U+00BB » c2 bb ДВУХУГЛОВАЯ КАВАЧКА, УКАЗЫВАЮЩАЯ ВПРАВО U+00BC ¼ c2 bc ОБЫЧНАЯ Дробь ЧЕТВЕРТЬ U+00BD ½ c2 bd ВУЛГАРНАЯ Дробь ОДНА ПОЛОВИНА U+00BE ¾ c2 be ОБЫЧНАЯ Дробь ТРИ ЧЕТВЕРТИ U+00BF ¿ c2 bf ПЕРЕВЕРНУТЫЙ ВОПРОСИТЕЛЬНЫЙ ЗНАК U+00C0 À c3 80 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА A С ГРАВОЙ U+00C1 Á c3 81 ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА A С ОСТРОЙ U+00C2 Â c3 82 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА A С CIRCUMFLEX U+00C3 Ã c3 83 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА A С ТИЛЬДОЙ U+00C4 Ä c3 84 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА A С ДИЭРЕЗИСОМ U+00C5 Å c3 85 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА A С КОЛЬЦОМ НАД U+00C6 Æ c3 86 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА AE U+00C7 Ç c3 87 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА C С СЕДИЛЬЕЙ U+00C8 È c3 88 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА E С ГРАВОЙ U+00C9 É c3 89 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА E С ОСТРОЙ СТОЙКОЙ U+00CA Ê c3 8a ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА E С CIRCUMFLEX U+00CB Ë c3 8b ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА E С ДИЭРЕЗИСОМ U+00CC Ì c3 8c ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА I С ГРАВОЙ U+00CD Í c3 8d ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА I С ОСТРОЙ U+00CE Î c3 8e ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА I С CIRCUMFLEX U+00CF Ï c3 8f ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА I С ДИЭРЕЗИСОМ U+00D0 Ð c3 90 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА ETH U+00D1 Ñ c3 91 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА N С ТИЛЬДОЙ U+00D2 Ò c3 92 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА O С ГРАВОЙ U+00D3 Ó c3 93 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА O С ОСТРОЙ U+00D4 Ô c3 94 ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА O С CIRCUMFLEX U+00D5 Õ c3 95 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА O С ТИЛЬДОЙ U+00D6 Ö c3 96 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА O С ДИЕРЕЗИСОМ U+00D7 × c3 97 ЗНАК УМНОЖЕНИЯ U+00D8 Ø c3 98 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА O С ШТРИХОМ U+00D9 Ù c3 99 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА U С ГРАВОЙ U+00DA Ú c3 9a ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА U С ОСТРОЙ U+00DB Û c3 9b ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА U С CIRCUMFLEX U+00DC Ü c3 9c ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА U С ДИЭРЕЗИСОМ U+00DD Ý c3 9d ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА Y С ОСТРОЙ U+00DE Þ c3 9e ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА THORN U+00DF ß c3 9f СТРОЧНАЯ ЛАТИНСКАЯ БУКВА SHARP S U+00E0 à c3 a0 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A С ГРАВОЙ U+00E1 á c3 a1 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A С ОСТРОЙ ЧАСТЬЮ U+00E2 â c3 a2 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A С CIRCUMFLEX U+00E3 ã c3 a3 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A С ТИЛЬДОЙ U+00E4 ä c3 a4 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A С ДИЭРЕЗИСОМ U+00E5 å c3 a5 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A С КОЛЬЦОМ НАД U+00E6 æ c3 a6 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА AE U+00E7 ç c3 a7 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА C С СЕДИЛЬЕЙ U+00E8 и c3 a8 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E С ГРАВОЙ U+00E9 é c3 a9 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E С ОСТРОЙ БУКВОЙ U+00EA ê c3 aa СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E С CIRCUMFLEX U+00EB ë c3 ab СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E С ДИЭРЕЗИСОМ U+00EC ì c3 ac СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I С ГРАВОЙ U+00ED í c3 ad СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I С ОСТРОЙ БУКВОЙ U+00EE î c3 ae СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I С CIRCUMFLEX U+00EF ï c3 af СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I С ДИЭРЕЗИСОМ U+00F0 ð c3 b0 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА ETH У+00Ф1 – c3 b1 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА N С ТИЛЬДОЙ U+00F2 ò c3 b2 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O С ГРАВОЙ U+00F3 ó c3 b3 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O С ОСТРОЙ U+00F4 ô c3 b4 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O С CIRCUMFLEX U+00F5 х c3 b5 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O С ТИЛЬДОЙ U+00F6 ö c3 b6 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O С ДИЭРЕЗИСОМ U+00F7 ÷ c3 b7 ЗНАК РАЗДЕЛЕНИЯ U+00F8 ø c3 b8 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O С ШТРИХОМ U+00F9 ù c3 b9 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U С ГРАВОЙ U+00FA ú c3 ba СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U С ОСТРОЙ U+00FB û c3 bb СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U С CIRCUMFLEX U+00FC ü c3 bc СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U С ДИЭРЕЗИСОМ U+00FD ý c3 bd СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Y С ОСТРОЙ U+00FE þ c3 be СТРОЧНАЯ ЛАТИНСКАЯ БУКВА THORN U+00FF ÿ c3 bf СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Y С ДИЭРЕЗИСОМ
utf-8
utf-8 , где utf — это сокращение от формат преобразования юникода , — это метод кодирования символов юникода с использованием от одного до четырех байтов на символ. Это надмножество ascii, в котором используются легко различимые контекстно-независимые префиксы для различения начала каждого символа, и его можно вероятностно отличить от устаревших расширенных кодировок ascii.
См. также
- Unicode и UTF-8
Tcl Internals
Внутри Tcl использует модифицированную кодировку utf-8, аналогичную utf-8, за исключением того, что символ NUL (\u0000) кодируется как байты 0xC0 0x80, что не является допустимой последовательностью utf-8. Поскольку в такой строке нет нулей, свойство C-строки, состоящее в том, что нулевой байт завершает строку, может быть сохранено.
DKF: Вот небольшая служебная процедура, которую я написал сегодня, когда мне нужно было преобразовать кодировку utf-8 символа Unicode в последовательность шестнадцатеричных цифр для использования в качестве буквального значения в C:
процедура toutf8 с {
set s [кодировка конвертируется в utf-8 $c]
двоичное сканирование $s cu* x
формат [повтор строки \\x%02x [длина строки $s]] {*}$x
} Демонстрация:
% toutf8 \u1234
\xe1\x88\xb4
% toutf8 \u0000
\x00
ferrieux: Могу ли я предложить небольшое улучшение читабельности и, возможно, производительности, хотя это не измерялось и не ожидалось многого:
proc toutf8 c {
set s [кодировка конвертируется в utf-8 $c]
двоичное сканирование $s H* x
regsub -all -expanded {. .} $x {\x&}
} Демонстрируемые выходные данные остаются такими же, как показано выше, как и ожидалось.
jima 2010-01-09: Это работает для символов Юникода в диапазоне от U+010000 до U+10FFFF?
- U+010000 is xF0 x90 x80 x80
According to [L1 ]
In my box
toutf8 \u10000
Produces
\xe1\x80\x80\x30
And (notice the extra 0 введен здесь)
toutf8 \u010000
Производит
\xc4\x80\x30\x30
Я протестировал некоторые коды в других диапазонах, определенных в [L2 ], и все выглядит нормально, пока мы не ставим лишние нули в начале:
toutf8 \u20ac
Правильно производит
\xe2\x82\xac
Ларс Х, 12 января 2010 г. PYK 22 июля 2020 г.: Нет, Tcl может (в настоящее время) представлять символы только в пределах базовой многоязычной плоскости юникода, поэтому нет Таким образом, вы даже можете передать символ U + 10000 в кодировку convertto :-(. Исправление этого нетривиально, поскольку некоторые части библиотеки Tcl C требуют представления строк, где все символы занимают одинаковое количество байтов. Можно скомпилировать Tcl с этим значением TCL_UTF_MAX, равным 4, что означает 32 бита на символ, но это довольно расточительно и, как сообщается, не полностью совместимо с Tk.0003
Что часто можно сделать, так это использовать суррогатные пары для символов за пределами BMP, таким образом рассматривая строки Tcl как представления UTF-16 собственно строк. Однако это не очень хорошо работает с кодировкой convertto utf-8, так как при этом каждый суррогат в паре будет перекодироваться как отдельный символ. Возможно, мне следует что-то сделать с этим…
\u по замыслу захватывает не более четырех шестнадцатеричных цифр, таким образом оставляя лишние нули, и будет продолжать делать это даже после того, как Tcl будет расширен для поддержки полного юникода. Это делается для того, чтобы вы могли поместить шестнадцатеричную цифру сразу после четырехзначной замены \u, что невозможно с \x, который потребляет столько шестнадцатеричных цифр, сколько находит. Возможно, будет замена \U для полного диапазона. регулярное выражение уже реализует это, по крайней мере, синтаксически.
jima, 13 января 2010 г.: Ларс, спасибо за объяснение.
Возможно, другая сторона этой проблемы заключается в том, что даже если кто-то может сгенерировать правильный utf-8 (самостоятельно запрограммировав алгоритм преобразования unicode в utf-8), он не получит надлежащего графического вывода, если не будет инструкций для создания это где-то в недрах Tcl.
Итак (насколько я понимаю), для отображения изображения символа Unicode U+10000, правильно закодированного внутри как utf-8 как \xF0\x90\x80\x80, нам потребуется дополнительная информация помимо алгоритма, изображенного в страница википедии, упомянутая ранее.
Ларс Х, 19 января 2010 г., 26 января 2010 г.: Графический вывод всегда зависит от того, что должно его предоставлять. Tk, вероятно, сложно, но если вы скорее генерируете текст, который должна отображать какая-то другая программа (например, веб-браузер), то 4-байтовые последовательности UTF-8 могут подойти.
Как бы то ни было, я продолжил идею «суррогатных пар внутри Tcl — 4-байтовых последовательностей снаружи»; результат на данный момент можно найти в Half Bakery по адресу https://wiki.tcl-lang.org/_repo/UTF/. Это C-кодированное расширение (ну, файлы, необходимые для одного, которые не совпадают с расширением примера), чье имя пакета — UTF, и которое определяет новую кодировку «UTF-8» (верхний регистр, в то время как встроенный — utf-8). При кодировании convertfrom он преобразует 4-байтовые последовательности (кодовые точки от U+10000 до U+10FFFF) в суррогатные пары, а при кодировании convertto преобразует суррогатные пары в 4-байтовые последовательности. Есть даже тесты, которые она проходит! Предыдущая версия (от 19 января 2010 г.) была ошибка, из-за которой он застревал в бесконечном цикле при использовании в качестве кодировки канала, но текущий, похоже, работает нормально.
Следующим логическим шагом было бы также реализовать UTF-16BE и UTF-16LE в качестве кодировок (встроенная кодировка Unicode почти одна из них, но это зависит от платформы).
 31 могут быть закодированы с использованием UTF-8.
* Байты 0xc0, 0xc1, 0xfe и 0xff никогда не используются в
Кодировка UTF-8.
* Первый байт многобайтовой последовательности, представляющей
одиночный символ UCS, отличный от ASCII, всегда находится в диапазоне от 0xc2 до
0xfd и указывает длину этой многобайтовой последовательности. Все
последующие байты в многобайтовой последовательности находятся в диапазоне от 0x80 до
0xbf. Это упрощает повторную синхронизацию и делает
кодирование без сохранения состояния и устойчивость к отсутствующим байтам.
* Символы UCS в кодировке UTF-8 могут иметь длину до шести байтов,
однако стандарт Unicode не определяет символы выше
0x10ffff, поэтому символы Unicode могут быть не более четырех байтов.
длинный в UTF-8.
Кодировка
Следующие последовательности байтов используются для представления символа.
Используемая последовательность зависит от номера кода UCS
персонаж:
0x00000000 - 0x0000007F:
0 ххххххх
0x00000080 - 0x000007FF:
110 ххххх 10 хххххх
0x00000800 - 0x0000FFFF:
1110 хххх 10 ххххх 10 хххххх
0x00010000 - 0x001FFFFF:
11110 ххх 10 ххххх 10 ххххх 10 хххххх
0x00200000 - 0x03FFFFFF:
111110 хх 10 xxxxxx 10 xxxxxx 10 xxxxxx 10 xxxxxx
0x04000000 - 0x7FFFFFFFF:
1111110 x 10 xxxxxx 10 xxxxxx 10 xxxxxx 10 xxxxxx 10 xxxxxx
Битовые позиции xxx заполняются битами символа
кодовое число в двоичном представлении, старший бит идет первым
(с обратным порядком байтов).
31 могут быть закодированы с использованием UTF-8.
* Байты 0xc0, 0xc1, 0xfe и 0xff никогда не используются в
Кодировка UTF-8.
* Первый байт многобайтовой последовательности, представляющей
одиночный символ UCS, отличный от ASCII, всегда находится в диапазоне от 0xc2 до
0xfd и указывает длину этой многобайтовой последовательности. Все
последующие байты в многобайтовой последовательности находятся в диапазоне от 0x80 до
0xbf. Это упрощает повторную синхронизацию и делает
кодирование без сохранения состояния и устойчивость к отсутствующим байтам.
* Символы UCS в кодировке UTF-8 могут иметь длину до шести байтов,
однако стандарт Unicode не определяет символы выше
0x10ffff, поэтому символы Unicode могут быть не более четырех байтов.
длинный в UTF-8.
Кодировка
Следующие последовательности байтов используются для представления символа.
Используемая последовательность зависит от номера кода UCS
персонаж:
0x00000000 - 0x0000007F:
0 ххххххх
0x00000080 - 0x000007FF:
110 ххххх 10 хххххх
0x00000800 - 0x0000FFFF:
1110 хххх 10 ххххх 10 хххххх
0x00010000 - 0x001FFFFF:
11110 ххх 10 ххххх 10 ххххх 10 хххххх
0x00200000 - 0x03FFFFFF:
111110 хх 10 xxxxxx 10 xxxxxx 10 xxxxxx 10 xxxxxx
0x04000000 - 0x7FFFFFFFF:
1111110 x 10 xxxxxx 10 xxxxxx 10 xxxxxx 10 xxxxxx 10 xxxxxx
Битовые позиции xxx заполняются битами символа
кодовое число в двоичном представлении, старший бит идет первым
(с обратным порядком байтов).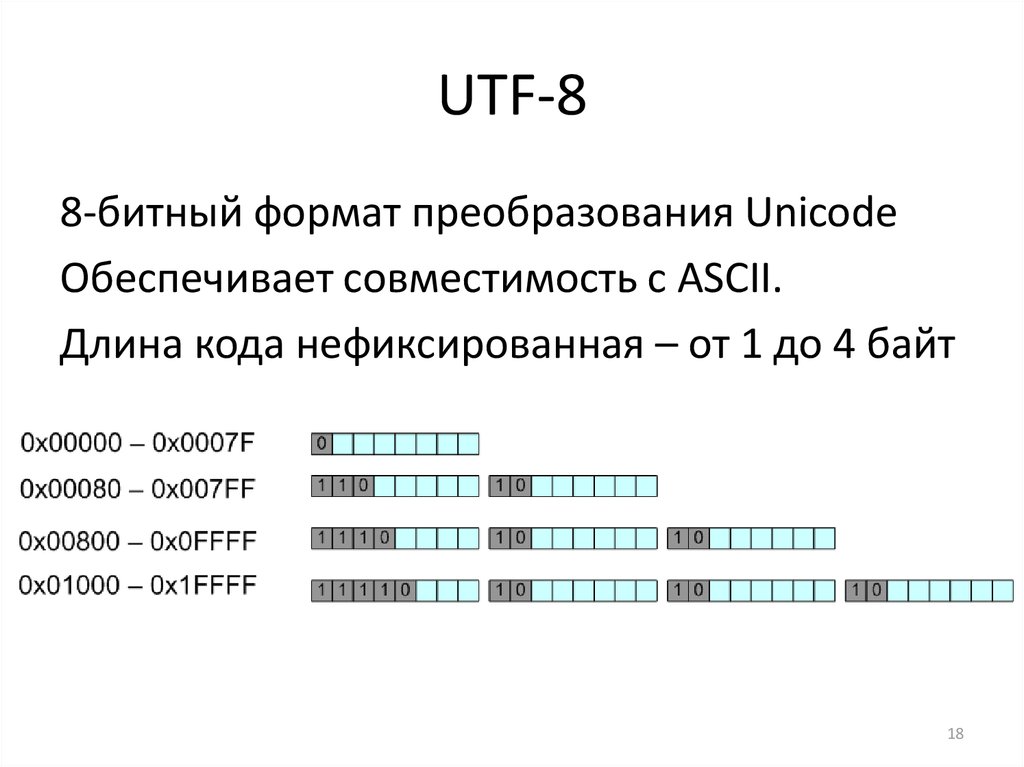 Только самая короткая многобайтовая последовательность
который может представлять кодовый номер символа, который может быть использован.
Значения кода UCS 0xd800–0xdfff (суррогаты UTF-16), а также
0xfffe и 0xffff (несимволы UCS) не должны появляться в
соответствующие потоки UTF-8. Согласно RFC 3629нет пункта выше
Следует использовать U+10FFFF, что ограничивает количество символов четырьмя байтами.
Пример
Символ Unicode 0xa9 = 1010 1001 (знак авторского права)
кодируется в UTF-8 как
10 10 = 0xc2 0xa9
и символ 0x2260 = 0010 0010 0110 0000 ("не равно"
символ) кодируется как:
11
Только самая короткая многобайтовая последовательность
который может представлять кодовый номер символа, который может быть использован.
Значения кода UCS 0xd800–0xdfff (суррогаты UTF-16), а также
0xfffe и 0xffff (несимволы UCS) не должны появляться в
соответствующие потоки UTF-8. Согласно RFC 3629нет пункта выше
Следует использовать U+10FFFF, что ограничивает количество символов четырьмя байтами.
Пример
Символ Unicode 0xa9 = 1010 1001 (знак авторского права)
кодируется в UTF-8 как
10 10 = 0xc2 0xa9
и символ 0x2260 = 0010 0010 0110 0000 ("не равно"
символ) кодируется как:
11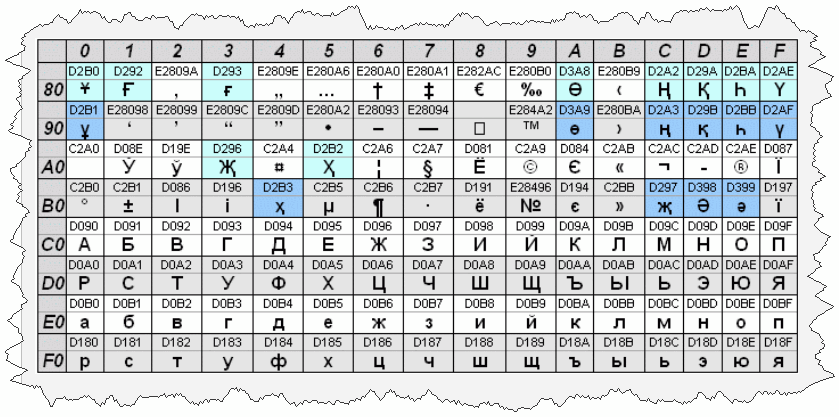 Программисты, привыкшие к однобайтовым кодировкам, таким как US-ASCII
или ИСО 8859должны знать, что два предположения, сделанные до сих пор,
больше не действует в локалях UTF-8. Во-первых, один байт делает
не обязательно больше соответствовать одному символу.
Во-вторых, поскольку современные эмуляторы терминала в режиме UTF-8 тоже
поддерживают китайские, японские и корейские символы двойной ширины в качестве
а также объединение символов без пробелов, вывод одного
символ не обязательно продвигает курсор на одну позицию
как это было в ASCII. Библиотечные функции, такие как mbsrtowcs(3) и
wcswidth(3) следует использовать сегодня для подсчета символов и курсора
позиции.
Официальная последовательность ESC для переключения с кодировки ISO 2022.
схема (используемая, например, терминалами VT100) в UTF-8 - это ESC
%G("\x1b%G"). Соответствующая последовательность возврата из UTF-8 в
ISO 2022 — это ESC % @ ("\x1b%@").
Программисты, привыкшие к однобайтовым кодировкам, таким как US-ASCII
или ИСО 8859должны знать, что два предположения, сделанные до сих пор,
больше не действует в локалях UTF-8. Во-первых, один байт делает
не обязательно больше соответствовать одному символу.
Во-вторых, поскольку современные эмуляторы терминала в режиме UTF-8 тоже
поддерживают китайские, японские и корейские символы двойной ширины в качестве
а также объединение символов без пробелов, вывод одного
символ не обязательно продвигает курсор на одну позицию
как это было в ASCII. Библиотечные функции, такие как mbsrtowcs(3) и
wcswidth(3) следует использовать сегодня для подсчета символов и курсора
позиции.
Официальная последовательность ESC для переключения с кодировки ISO 2022.
схема (используемая, например, терминалами VT100) в UTF-8 - это ESC
%G("\x1b%G"). Соответствующая последовательность возврата из UTF-8 в
ISO 2022 — это ESC % @ ("\x1b%@").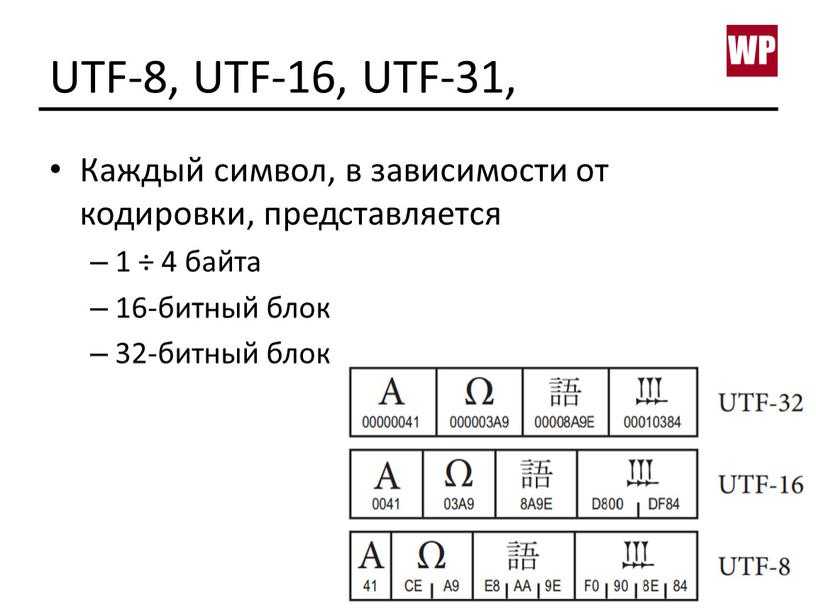 Другие последовательности ISO 2022 (например,
что касается переключения наборов G0 и G1) не применимы в UTF-8
режим.
Безопасность
Стандарты Unicode и UCS требуют, чтобы производители UTF-8
должен использовать максимально короткую форму, например, производя
двухбайтовая последовательность с первым байтом 0xc0 не соответствует требованиям. Юникод
3.1 добавлено требование о том, что соответствующие программы не должны
принимать некратчайшие формы на входе. Это для безопасности
причины: если пользовательский ввод проверяется на предмет возможной безопасности
нарушений, программа может проверять только ASCII-версию
"/../" или же ";" или NUL и упускают из виду, что есть много не-ASCII
способы представления этих вещей в не самой короткой кодировке UTF-8.
Стандарты
ИСО/МЭК 10646-1:2000, Юникод 3.1, RFC 3629, план 9.
Другие последовательности ISO 2022 (например,
что касается переключения наборов G0 и G1) не применимы в UTF-8
режим.
Безопасность
Стандарты Unicode и UCS требуют, чтобы производители UTF-8
должен использовать максимально короткую форму, например, производя
двухбайтовая последовательность с первым байтом 0xc0 не соответствует требованиям. Юникод
3.1 добавлено требование о том, что соответствующие программы не должны
принимать некратчайшие формы на входе. Это для безопасности
причины: если пользовательский ввод проверяется на предмет возможной безопасности
нарушений, программа может проверять только ASCII-версию
"/../" или же ";" или NUL и упускают из виду, что есть много не-ASCII
способы представления этих вещей в не самой короткой кодировке UTF-8.
Стандарты
ИСО/МЭК 10646-1:2000, Юникод 3.1, RFC 3629, план 9.
 13 проекта Linux man-pages .
Описание проекта, информация о сообщениях об ошибках,
и последнюю версию этой страницы можно найти по адресу
https://www.kernel.org/doc/man-pages/.
GNU 2019-03-06 UTF-8(7)
13 проекта Linux man-pages .
Описание проекта, информация о сообщениях об ошибках,
и последнюю версию этой страницы можно найти по адресу
https://www.kernel.org/doc/man-pages/.
GNU 2019-03-06 UTF-8(7)

 Это надмножество ascii, в котором используются легко различимые контекстно-независимые префиксы для различения начала каждого символа, и его можно вероятностно отличить от устаревших расширенных кодировок ascii.
Это надмножество ascii, в котором используются легко различимые контекстно-независимые префиксы для различения начала каждого символа, и его можно вероятностно отличить от устаревших расширенных кодировок ascii. .} $x {\x&}
}
.} $x {\x&}
}  Исправление этого нетривиально, поскольку некоторые части библиотеки Tcl C требуют представления строк, где все символы занимают одинаковое количество байтов. Можно скомпилировать Tcl с этим значением TCL_UTF_MAX, равным 4, что означает 32 бита на символ, но это довольно расточительно и, как сообщается, не полностью совместимо с Tk.0003
Исправление этого нетривиально, поскольку некоторые части библиотеки Tcl C требуют представления строк, где все символы занимают одинаковое количество байтов. Можно скомпилировать Tcl с этим значением TCL_UTF_MAX, равным 4, что означает 32 бита на символ, но это довольно расточительно и, как сообщается, не полностью совместимо с Tk.0003 Возможно, будет замена \U для полного диапазона. регулярное выражение уже реализует это, по крайней мере, синтаксически.
Возможно, будет замена \U для полного диапазона. регулярное выражение уже реализует это, по крайней мере, синтаксически.