Что такое файловое хранилище больших данных?—Portal for ArcGIS
О файловых хранилищах больших данных
Файловое хранилище больших данных представляет собой созданный на портале элемент, который ссылается на данные объектов (точки, полилинии, полигоны или табличные данные) в местоположении, доступном для ArcGIS GeoAnalytics Server. Элемент файлового хранилища больших данных на портале позволяет просматривать зарегистрированные данные с помощью инструментов ArcGIS GeoAnalytics Server. Файловые хранилища больших данных могут ссылаться на следующие источники данных:
- Файловое хранилище – директория наборов данных на локальном или сетевом диске.
- HDFS – каталог наборов данных HDFS (Hadoop Distributed File System).
- Hive – базы данных метахранилища.
- Облачное хранилище – блок Amazon Web Services (AWS) Simple Storage Service (S3) или контейнер Microsoft Azure Blob, содержащий директорию с наборами данных.
 Облачные хранилища доступны начиная с ArcGIS 10.5.1.
Облачные хранилища доступны начиная с ArcGIS 10.5.1.
 Облачные хранилища доступны начиная с ArcGIS 10.5.1.
Облачные хранилища доступны начиная с ArcGIS 10.5.1.Файловое хранилище больших данных доступно, если администратор портала включил GeoAnalytics Server. Подробнее о включении GeoAnalytics Server см. в разделе Настройка ArcGIS GeoAnalytics Server.
Существует несколько причин, почему предпочтительнее использовать файловое хранилище больших данных, общее для всех источников данных. Вы можете хранить свои данные в доступном месте до тех пор, пока не будете готовы выполнить анализ. Файловое хранилище больших данных позволяет работать с данными во время выполнения анализа, поэтому вы можете продолжать добавлять данные в набор, находящийся в файловом хранилище больших данных, без необходимости перерегистрации или опубликования своих данных. Вы также можете изменить манифест, чтобы удалить, добавить или обновить наборы данных в файловом хранилище больших данных. Файловое хранилище больших данных отличается необычайной гибкостью с точки зрения определения геометрии и времени и допускает несколько форматов времени в отдельном наборе данных. Файловые хранилища больших данных позволяют разбивать наборы данных на разделы, сохраняя способность работы с несколькими такими разделами как с единым набором данных.
Файловые хранилища больших данных позволяют разбивать наборы данных на разделы, сохраняя способность работы с несколькими такими разделами как с единым набором данных.
Файловые хранилища больших данных становятся доступны только при запуске GeoAnalytics Tools. Это означает, что вы можете только просматривать и добавлять файлы больших данных в анализ; вы не можете визуализировать эти данные на карте.
Файловые хранилища больших данных являются одним из нескольких доступа GeoAnalytics Tools к вашим данным. Список возможных входных данных, которые используют GeoAnalytics Tools см. в разделе GeoAnalytics Tools. Использование во вьюере карт портала.
Подготовка данных для регистрации файлового хранилища больших данных
Файловые хранилища и HDFS
Чтобы подготовить данные для файлового хранилища больших данных необходимо представить наборы данных вложенными папками отдельной родительской папки, которая будет регистрироваться. В зарегистрированной родительской папке имена вложенных папок будут совпадать с именами наборов данных.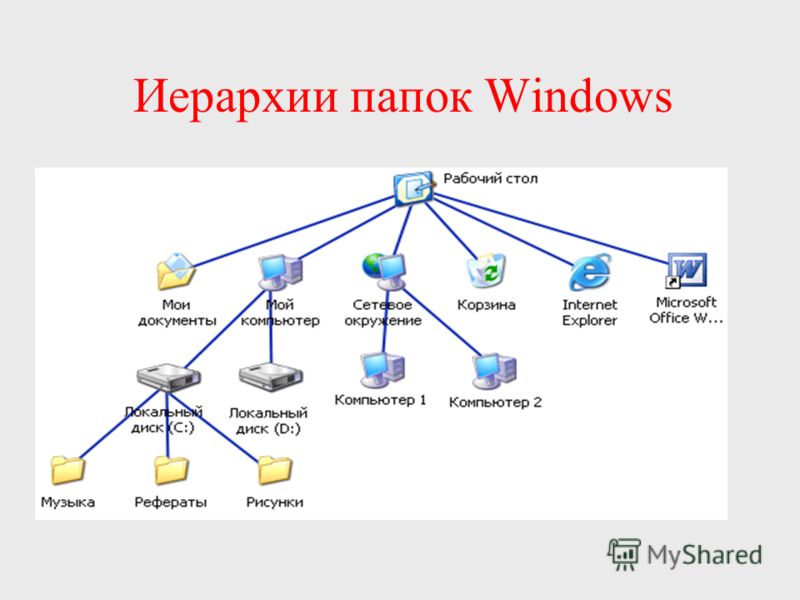 Если эти вложенные папки будут содержать несколько подпапок или файлов, то все содержимое этих вложенных папок высшего уровня будет считаться отдельным набором данных. Ниже – пример, как зарегистрировать папку FileShareFolder, в которой содержится три набора данных, имена которых Earthquakes, Hurricanes и GlobalOceans. При регистрации родительской папки все подкаталоги указанной папки также регистрируются на сервере GeoAnalytics Server. Всегда регистрируйте родительскую папку (например, \\machinename\FileShareFolder), содержащую один или несколько подпапок отдельных наборов данных.
Если эти вложенные папки будут содержать несколько подпапок или файлов, то все содержимое этих вложенных папок высшего уровня будет считаться отдельным набором данных. Ниже – пример, как зарегистрировать папку FileShareFolder, в которой содержится три набора данных, имена которых Earthquakes, Hurricanes и GlobalOceans. При регистрации родительской папки все подкаталоги указанной папки также регистрируются на сервере GeoAnalytics Server. Всегда регистрируйте родительскую папку (например, \\machinename\FileShareFolder), содержащую один или несколько подпапок отдельных наборов данных.
Пример файлового хранилища больших данных, в котором содержится три набора данных: Earthquakes, Hurricanes и GlobalOceans.
|---FileShareFolder < -- The top-level folder is what is registered as a big data file share
|---Earthquakes < -- A dataset is all files and folders within the top-level subfolder
|---1960
|---01_1960.csv
|---02_1960. csv
|---1961
|---01_1961.csv
|---02_1961.csv
|---Hurricanes
|---atlantic_hur.shp
|---pacific_hur.shp
|---otherhurricanes.shp
|---GlobalOceans
|---oceans.shp csv
|---1961
|---01_1961.csv
|---02_1961.csv
|---Hurricanes
|---atlantic_hur.shp
|---pacific_hur.shp
|---otherhurricanes.shp
|---GlobalOceans
|---oceans.shp
csv
|---1961
|---01_1961.csv
|---02_1961.csv
|---Hurricanes
|---atlantic_hur.shp
|---pacific_hur.shp
|---otherhurricanes.shp
|---GlobalOceans
|---oceans.shpТакая же структура используется в файловом хранилище и HDFS, хотя терминология отличается. В файловом хранилище имеется папка или каталог высшего уровня, а наборы данных представлены вложенными папками. В HDFS местоположение файлового хранилища зарегистрировано и содержит наборы данных. В следующей таблице приводится описание различий:
| Файловое хранилище | HDFS | |
|---|---|---|
Местоположение файлового хранилища больших данных | Папка или директория | HDFS-путь |
Наборы данных | Вложенные папки высшего уровня | Наборы данных в HDFS-пути |
После того как данные будут организованы в виде папки с вложенными подпапками наборов данных, сделайте их доступными для GeoAnalytics Server, выполнив шаги, указанные в разделе Предоставление доступа к данным ArcGIS Server и зарегистрируйте папку набора данных.
Корневая ветвь реестра
В Hive – базе данных метахранилища все таблицы в базе данных признаются в качестве наборов данных в файловом хранилище больших данных. В следующем примере показано метахранилище с двумя базами данных, default и CityData. При регистрации файлового хранилища больших данных Hive через ArcGIS Server с GeoAnalytics Server, можно выбрать только одну базу данных. В этом примере, если бы была выбрана база данных CityData, то в файловом хранилище больших данных было бы два набора данных, FireData и LandParcels.
|---HiveMetastore < -- The top-level folder is what is registered as a big data file share |---default < -- A database |---Earthquakes |---Hurricanes |---GlobalOceans |---CityData < -- A database that is registered (specified in Server Manager) |---FireData |---LandParcels
Облачные хранилища
Далее приведены три шага для регистрации файлового хранилища больших данных, имеющего тип облачного хранилища.
- Подготовьте данные вашего облачного хранилища в подходящем формате.
- Зарегистрируйте облачное хранилище с вашим GeoAnalytics Server.
- Зарегистрируйте облачное хранилище в качестве файлового хранилища больших данных на вашем GeoAnalytics Server.
Подготовка ваших данных
Чтобы подготовить данные для файлового хранилища больших данных в облачном хранилище, отформатируйте ваши наборы данных, как вложенные папки внутри отдельной родительской папки.
Ниже приводится пример возможной структуры ваших данных. В данном примере показана регистрация родителькой папки, FileShareFolder, в которой содержится три набора данных с именами Earthquakes, Hurricanes и GlobalOceans. При регистрации родительской папки, все вложенные папки внутри указанной папки также регистрируются на сервере GeoAnalytics Server.
Пример структурирования данных в облачном хранилище, которое будет использоваться в качестве файлового хранилища больших данных.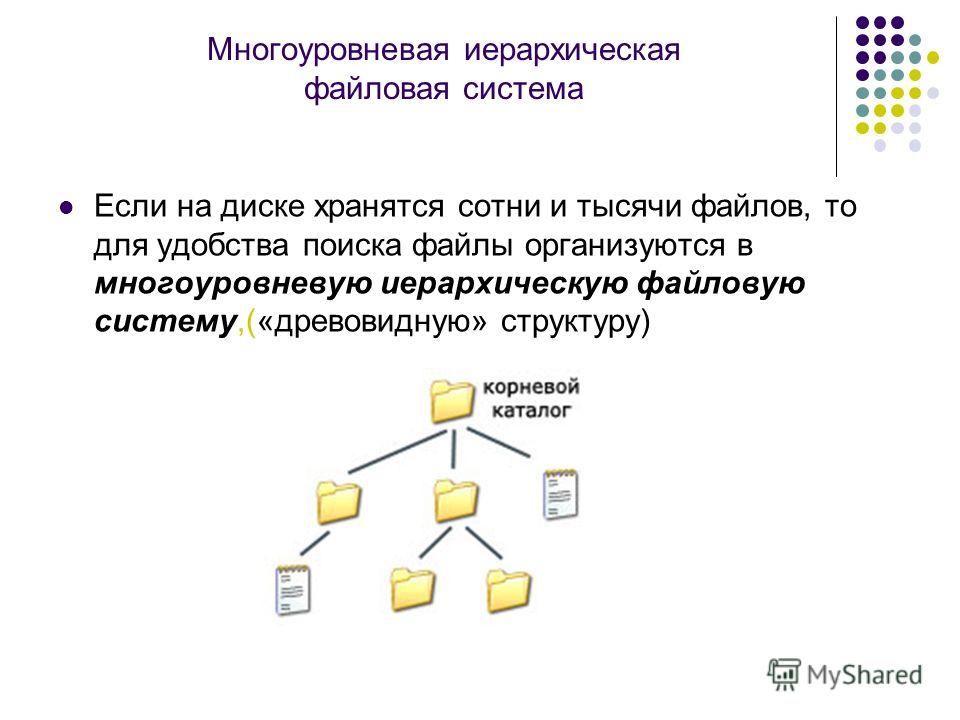
|---Cloud Store < -- The cloud store being registered
|---Container or S3 Bucket Name < -- The container (Azure) or bucket (Amazon) being registered as part of the cloud store
|---FileShareFolder < -- The parent folder that is registered as the 'folder' during cloud store registration
|---Earthquakes < -- The dataset "Earthquakes" composed of 4 csvs
|---1960
|---01_1960.csv
|---02_1960.csv
|---1961
|---01_1961.csv
|---02_1961.csv
|---Hurricanes < -- The dataset "Hurricanes" composed of 3 shapefiles
|---atlantic_hur.shp
|---pacific_hur.shp
|---otherhurricanes.shp
|---GlobalOceans < -- The dataset "GlobalOceans" composed of 1 shapefile
|---oceans. shp
Зарегистрируйте облачное хранилище на вашем GeoAnalytics Server
Подключитесь к своему сайту GeoAnalytics Server из ArcGIS Server Manager для регистрации облачного хранилища. Когда вы регистрируете облачное хранилище, необходимо включить имя контейнера Azure или имя сегмента AWS S3, а также папку внутри контейнера или сегмента. Указанная папка состоит из вложенных папок, и каждая представлена, как отдельный набор данных. Каждый набор данных состоит из всего содержания вложенной папки.
Регистрация облачного хранилища в качестве файлового хранилища больших данных
Метод регистрации облачного хранилища в качестве файлового хранилища больших данных зависит от того, какое облачное хранилище вы используете.
Следуйте приведенным шагам для регистрации облачного хранилища AWS S3, которое вы создали в предыдущем разделе, в качестве файлового хранилища больших данных:
- Выполните вход на ваш сайт GeoAnalytics Server из ArcGIS Server Manager.
- Перейдите к Сайт > Хранилища данных и выберите Файловое хранилище больших данных из ниспадающего списка Зарегистрировать.
- Предоставьте следующую информацию в диалоговом окне Зарегистрировать файловое хранилище больших данных:
- Введите имя файлового хранилища больших данных.
- Выберите Облачное хранилище в ниспадающем списке Тип.
- Выберите имя вашего облачного хранилища данных AWS в ниспадающем списке Облачное хранилище.
- Щелкните Создать, чтобы зарегистрировать ваше облачное хранилище в качестве файлового хранилища больших данных.
Теперь у вас есть файловое хранилище больших данных и манифест для облачного хранилища AWS. Элемент файлового хранилища больших данных на портале ссылается на сервис каталога больших данных в GeoAnalytics Server.
Следуйте приведенным шагам для регистрации облачного хранилища Azure, которое вы создали в последнем разделе, в качестве файлового хранилища больших данных:
ArcGIS Server Administrator Directory требует выполнения входа в качестве администратора. Чтобы подключиться к интегрированному сайту GeoAnalytics Server, необходимо выполнить вход с помощью токена портала, что требует учетных данных администратора, или в качестве основного администратора сайта GeoAnalytics Server. Если вы не являетесь администратором портала или не имеете доступа к информации учетной записи основного администратора сайта, свяжитесь с администратором вашего портала, чтобы он выполнил эти шаги.
- Перейдите к data > registerItem.
- Скопируйте следующий текст и вставьте его в текстовое поле Элемент. Обновите значение <bigDataFileShareName>, используя имя, которое вы хотите использовать для файлового хранилища больших данных, и значение <cloudStoreName>, используя имя, указанное для облачного хранилища Azure при регистрации его на сайте GeoAnalytics Server.
{ "path": "/bigDataFileShares/<bigDataFileShareName>", "type": "bigDataFileShare", "info": { "connectionString": "{\"path\" : \"/cloudStores/<cloudStoreName>\"}", "connectionType": "dataStore" } } - Щелкните Зарегистрировать элемент.
После того, как элемент зарегистрирован, файловое хранилище больших данных появится в качестве хранилища данных в ArcGIS Server Manager.
- Выполните вход на ваш сайт GeoAnalytics Serverсайт GeoAnalytics Server из ArcGIS Server Manager.
Вы можете войти как издатель или как администратор.
- Перейдите к Сайт > Хранилища данных и щелкните кнопку Создать заново манифест рядом с новым файловым хранилищем больших данных.

Теперь у вас есть файловое хранилище больших данных и манифест для облачного хранилища Azure. Элемент файлового хранилища больших данных на портале ссылается на сервис каталога больших данных в GeoAnalytics Server.
Регистрация файлового хранилища больших данных
Чтобы зарегистрировать файловое хранилище, HDFS или облачное хранилище Hive в качестве файлового хранилища больших данных, подключитесь к сайту GeoAnalytics Server через ArcGIS Server Manager. Более подробно о необходимых для регистрации действиях см. Регистрация данных в ArcGIS Server с помощью Manager в ArcGIS Server.
Регистрация данных в ArcGIS Server с помощью Manager в ArcGIS Server.
Подсказка:
Шаги для регистрации облачного хранилища в качестве файлового хранилища больших данных были приведены в предыдущем разделе.
После регистрации файлового хранилища больших данных будет сгенерирован манифест, в котором указывается формат наборов данных в местоположении этого хранилища и в том числе поля, представляющие геометрию и время. Файловое хранилище больших данных создается на портале, который ссылается на сервис каталога больших данных в GeoAnalytics Server, где эти данные зарегистрированы. Более подробно о сервисах каталога больших данных см. документацию Сервис каталога больших данных в Справке ArcGIS Services REST API.
Изменение файлового хранилища больших данных
После создания сервиса каталога больших данных автоматически генерируется манифест, который загружается на сайт GeoAnalytics Server, где эти данные зарегистрированы. В процессе генерации манифеста в наборе данных не всегда правильно определяются поля геометрии и времени, может потребоваться корректировка. Для внесения изменений в манифест выполните шаги из раздела Редактирование файловых хранилищ больших данных в Manager. Дополнительные сведения о манифесте файлового хранилища больших данных см. в разделе Знакомство с манифестом файлового хранилища больших данных Справки ArcGIS Server.
Для внесения изменений в манифест выполните шаги из раздела Редактирование файловых хранилищ больших данных в Manager. Дополнительные сведения о манифесте файлового хранилища больших данных см. в разделе Знакомство с манифестом файлового хранилища больших данных Справки ArcGIS Server.
Выполнение анализа на файловом хранилище больших данных
Выполнение анализа набора данных из файлового хранилища больших данных возможно через любой клиент, который поддерживает GeoAnalytics Server, включая:
- ArcGIS Pro
- Вьюер карт Portal for ArcGIS
- ArcGIS REST API
Для выполнения анализа на файловом хранилище больших данных посредством вьюера карт ArcGIS Pro или Portal for ArcGIS, выберите GeoAnalytics Tools, который вы хотели бы использовать. Перейдите к месту расположения данных, которые будут использоваться в качестве входных для этого инструмента, под Портал в ArcGIS Pro или в диалоговом окне Обзор слоев во вьюере карт Portal for ArcGIS.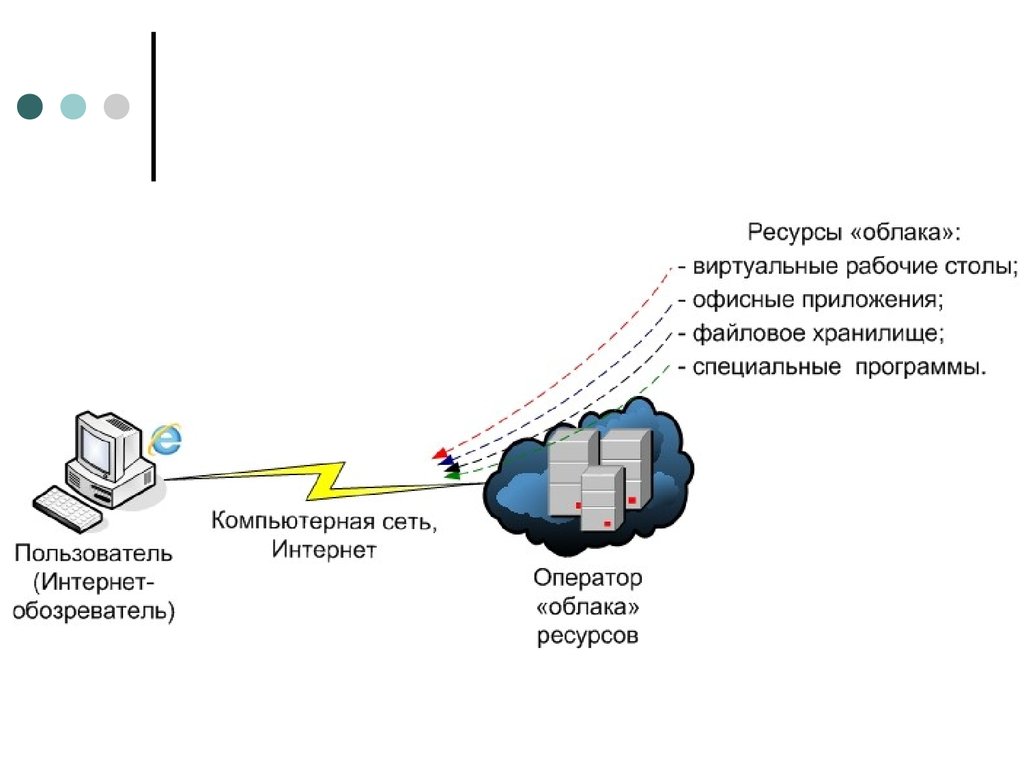
Убедитесь, что вы выполнили вход на портал под учетной записью с доступом к зарегистрированному файловому хранилищу больших данных. Чтобы быстро найти все доступные для вас файловые хранилища больших данных выполните поиск на портале по условию bigDataFileShare*.
Для выполнения анализа на файловом хранилище больших данных посредством ArcGIS REST API используйте в качестве входных данных URL-адрес сервиса каталога больших данных. URL-адрес будет иметь формат {«url»:» https://webadaptorhost.domain.com/webadaptorname/rest/DataStoreCatalogs/bigDataFileShares_filesharename/BigDataCatalogServer/dataset»}. Например, если имя компьютера – example, имя домена – esri, имя Web Adaptor – server, имя файлового хранилища больших данных – MyData, а имя набора данных – Earthquakes, то URL-адрес будет следующим: {«url»:» https://example. esri.com/server/rest/DataStoreCatalogs/bigDataFileShares_MyData/BigDataCatalogServer/Earthquakes»}. Более подробно о вводе данных для анализа больших данных посредством REST, см. раздел Ввод объектов в документации ArcGIS Services REST API.
esri.com/server/rest/DataStoreCatalogs/bigDataFileShares_MyData/BigDataCatalogServer/Earthquakes»}. Более подробно о вводе данных для анализа больших данных посредством REST, см. раздел Ввод объектов в документации ArcGIS Services REST API.
Отзыв по этому разделу?
Что такое облачное хранилище файлов? – AWS
Облачное хранилище файлов – это способ хранения файлов в облаке, позволяющий серверам и приложениям получать доступ к данным через совместно используемые файловые системы. Такая совместимость делает облачное хранилище файлов идеальным решением для рабочих нагрузок с совместно используемыми файловыми системами, и обеспечивает простую интеграцию без внесения изменений в код.
Файловая система в облаке – это иерархическая система хранения, предоставляющая совместный доступ к файловым данным. Она позволяет создавать, удалять, изменять, считывать и записывать файлы, а также упорядочивать их логически в древовидной системе директорий для интуитивно понятного доступа.
Общий доступ к файлам в облаке можно описать как сервис, предоставляющий множеству пользователей одновременный доступ к общему набору файловых данных в облаке. Безопасность общего доступа к файлам в облаке определяется разрешениями для отдельных пользователей и групп, что позволяет администраторам строго контролировать доступ к данным общих файлов.
Хранение файловых данных в облаке дает преимущества в трех главных областях.
1. Масштабируемость. Хотя не каждое решение облачного хранилища файлов можно масштабировать с использованием всех возможностей облака, наиболее продвинутые решения дают возможность начать работу на уровне производительности и ресурсов, актуальном на данный момент, а затем наращивать ресурсы в соответствии с потребностями. Больше не нужно предугадывать будущие потребности и выделять избыточные объемы ресурсов.
2. Совместимость. Многие существующие приложения требуют интеграции с сервисами для совместного доступа к файлам, которые используют семантику существующей файловой системы.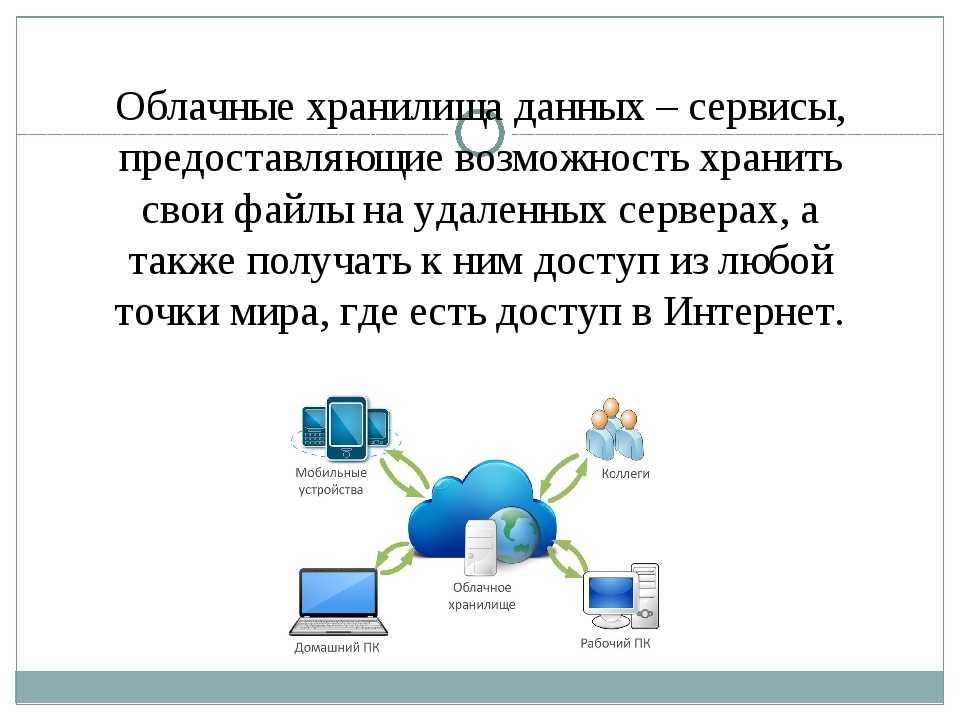 Решения облачных файловых хранилищ обладают явным преимуществом, поскольку для обеспечения безопасного совместного доступа к файлам не требуется ничего программировать.
Решения облачных файловых хранилищ обладают явным преимуществом, поскольку для обеспечения безопасного совместного доступа к файлам не требуется ничего программировать.
3. Бюджет и ресурсы. Работа файловых сервисов в локальном варианте требует расходов на приобретение оборудования, организации текущего обслуживания, обеспечения электропитания, охлаждения и физического пространства. Использование облачного файлового хранилища позволяет организациям перераспределять технические ресурсы в пользу других проектов, более значимых для бизнеса.
Облачные файловые хранилища идеально подходят для таких рабочих нагрузок, как крупные репозитории контента, среды разработки, хранилища мультимедиа и домашние каталоги пользователей.
Решения файловых хранилищ в облаке обладают гибкостью, легко интегрируются с существующими приложениями; их просто развертывать и обслуживать; вопросы управления также решаются без особых усилий. Благодаря этому такие хранилища предоставляют возможность поддержки широкого спектра приложений на различных уровнях.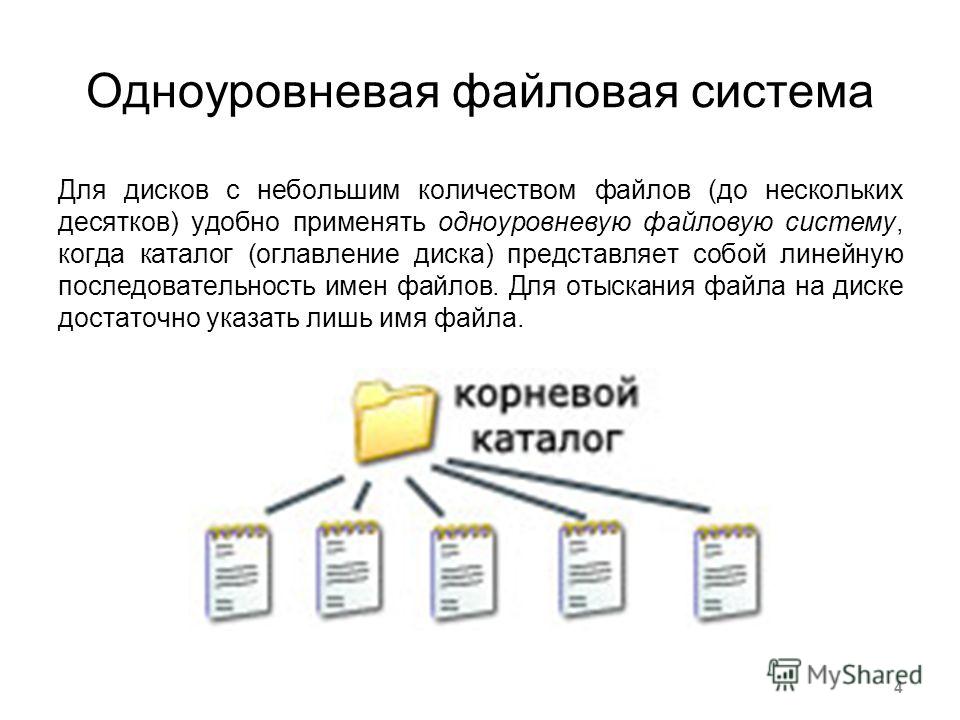
Распространение файлов через Интернет
Потребность в хранилище совместно используемых файлов для приложений, распространяющих файлы через Интернет, может привести к сложностям при интеграции серверных частей приложений. Как правило, существует несколько веб‑серверов, осуществляющих доставку контента веб‑сайта, причем каждый веб‑сервер нуждается в доступе к одному и тому же набору файлов. Поскольку решения для облачных хранилищ файлов поддерживают традиционную семантику файловой системы, соглашения об именах файлов и привычные для веб‑разработчиков разрешения, такое хранилище может легко обеспечить интеграцию нужных интернет‑приложений.
Управление контентом
Для системы управления контентом (CMS) требуется общее пространство имен и доступ к иерархии файловой системы. Как и в примере распространения файлов через Интернет, в средах CMS обычно имеется несколько серверов, которым для обслуживания контента необходим доступ к одному и тому же набору файлов. Поскольку решения для облачных хранилищ файлов поддерживают традиционную семантику файловой системы, соглашения об именах файлов и привычные для веб‑разработчиков разрешения, такие хранилища документов и других файлов можно легко интегрировать в существующие рабочие процессы CMS.
Поскольку решения для облачных хранилищ файлов поддерживают традиционную семантику файловой системы, соглашения об именах файлов и привычные для веб‑разработчиков разрешения, такие хранилища документов и других файлов можно легко интегрировать в существующие рабочие процессы CMS.
Аналитика больших данных
Для больших данных требуется хранилище, которое может выдерживать очень большие объемы данных и масштабироваться по мере роста потребностей, а также обеспечивать производительность, необходимую для доставки данных в инструменты аналитики. Многим аналитическим рабочим нагрузкам нужен файловый интерфейс для взаимодействия с данными и возможность записи в различные части файла. К тому же в таких процессах часто применяется стандартная семантика файлов, например блокировка. Поскольку облачное хранилище файлов поддерживает необходимую семантику файловых систем и позволяет масштабировать ресурсы и производительность, такое хранилище идеально подходит для решений по совместному использованию файлов, которые легко интегрировать в существующие рабочие процессы больших данных.
Средства массовой информации и индустрия развлечений
Рабочие процессы в сфере цифровых мультимедиа и индустрии развлечений постоянно меняются. Во многих случаях используются гибридные облачные развертывания и требуется стандартизованный доступ с использованием таких сетевых файловых протоколов, как NFS. Эти рабочие процессы требуют гибкого, стабильного и безопасного доступа к данным как из готовых, так и из специально разработанных или партнерских решений. Поскольку облачное хранилище файлов поддерживает традиционную семантику файловой системы, хранение мультимедийного контента для обработки и совместной работы можно легко интегрировать в цепочки поставок цифровых мультимедиа, в процессы создания контента, потоковой передачи мультимедиа, организации трансляций, аналитики и архивации.
Домашние каталоги
Использование для хранения файлов домашних каталогов, доступных только для определенных пользователей и групп, оптимально подходит для многих облачных рабочих процессов. Компании, которые рассчитывают воспользоваться преимуществами масштабируемости и экономичности облака, расширяют доступ к домашним каталогам для многих своих пользователей. Поскольку решения для облачных хранилищ файлов поддерживают традиционную семантику файловой системы и стандартные модели предоставления разрешений, клиенты могут легко перенести в облако приложения, для которых необходимы именно эти возможности.
Компании, которые рассчитывают воспользоваться преимуществами масштабируемости и экономичности облака, расширяют доступ к домашним каталогам для многих своих пользователей. Поскольку решения для облачных хранилищ файлов поддерживают традиционную семантику файловой системы и стандартные модели предоставления разрешений, клиенты могут легко перенести в облако приложения, для которых необходимы именно эти возможности.
Резервное копирование баз данных
Резервное копирование данных с использованием существующих механизмов, программного обеспечения и семантики можно использовать для создания сценария изолированного восстановления, обладающего небольшой гибкостью в отношении местоположения. Многие компании стремятся использовать гибкие возможности хранения в облаке для резервных копий баз данных в качестве временной защиты в процессе обновлений либо для решения вопросов разработки и тестирования. Поскольку решения для облачного хранения файлов предоставляют стандартную файловую систему, которую можно просто подключать к серверам баз данных, они могут стать идеальной платформой для создания портативных резервных копий баз данных с использованием встроенных инструментов или корпоративных приложений для резервного копирования.
Инструменты разработки
По ходу совместной работы по разработке инновационных решений в средах разработки могут возникать трудности в вопросах надежного и безопасного совместного использования данных. Когда требуется совместная работа с программным кодом и другими файлами, облачное хранилище файлов обеспечивает упорядоченный и безопасный репозиторий, доступ к которому можно просто получить из облачных сред разработки. Облачное хранилище файлов предоставляет масштабируемое и высокодоступное решение, идеально подходящее для совместной работы.
Хранилище для контейнеров и бессерверных приложений
Контейнеры идеально подходят для создания микросервисов, поскольку их просто выделять и перемещать, при этом они обеспечивают необходимую изоляцию процессов. Для контейнеров, которым необходим доступ к исходным данным при каждом запуске, может требоваться совместно используемая файловая система с возможностью подключения с любого используемого инстанса.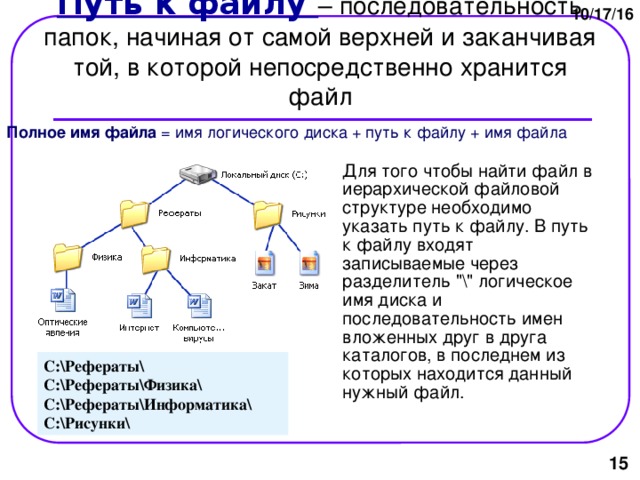 Облачное хранилище файлов может обеспечить постоянный совместный доступ к данным для всех контейнеров в кластере. Используя бессерверные вычисления, можно проявить большую гибкость в работе и при этом не тратить время на обеспечение безопасности, масштабируемости и доступности приложений. AWS Lambda позволяет запускать крупномасштабные и критически важные бессерверные приложения. Облачное хранилище файлов предлагает высокодоступное и надежное бессерверное хранилище для обмена данными, которые необходимо сохранять после и в перерывах между выполнением функций AWS Lambda и задач AWS Fargate.
Облачное хранилище файлов может обеспечить постоянный совместный доступ к данным для всех контейнеров в кластере. Используя бессерверные вычисления, можно проявить большую гибкость в работе и при этом не тратить время на обеспечение безопасности, масштабируемости и доступности приложений. AWS Lambda позволяет запускать крупномасштабные и критически важные бессерверные приложения. Облачное хранилище файлов предлагает высокодоступное и надежное бессерверное хранилище для обмена данными, которые необходимо сохранять после и в перерывах между выполнением функций AWS Lambda и задач AWS Fargate.
Хорошее решение облачного файлового хранилища должно обеспечить производительность и пропускную способность, соответствующие текущим задачам, и возможность эффективно масштабировать их по мере изменения потребностей бизнеса.
Полное управление
Предоставляет полностью управляемую файловую систему, которую можно запустить за считаные минуты.
Производительность
Обеспечивает стабильную пропускную способность и производительность с низкими задержками
Совместимость
Эффективно интегрируется с существующими приложениями без необходимости создания программного кода
Безопасность
Обеспечивает сетевую безопасность и управление разрешениями на доступ
Доступность
Доступность в любое нужное время за счет избыточного копирования в нескольких местоположениях
Экономичность
Оплате подлежат только потребляемые ресурсы; первоначальные затраты на приобретение отсутствуют
Преимущества облачных файловых хранилищ очевидны, но важно также отметить, что не все решения облачных хранилищ имеют одинаковые возможности. Вариантов великое множество. Например, решение для хранения файлов может представлять собой файловый сервер с одним узлом на вычислительном инстансе, где в качестве основы выступает не масштабируемое блочное хранилище с небольшим количеством избыточности для защиты данных. Другие варианты – это самостоятельно настраиваемые кластерные решения, при использовании которых необходимо тратить время на установку, управление и обслуживание. А есть и полностью управляемые решения, такие как Amazon Elastic File System (Amazon EFS), Amazon FSx for NetApp ONTAP, Amazon FSx for OpenZFS, Amazon FSx for Windows File Server и Amazon FSx for Lustre, которые нуждаются в минимальной настройке и обслуживании и отвечают запросам наиболее требовательных рабочих нагрузок приложений.
Другие варианты – это самостоятельно настраиваемые кластерные решения, при использовании которых необходимо тратить время на установку, управление и обслуживание. А есть и полностью управляемые решения, такие как Amazon Elastic File System (Amazon EFS), Amazon FSx for NetApp ONTAP, Amazon FSx for OpenZFS, Amazon FSx for Windows File Server и Amazon FSx for Lustre, которые нуждаются в минимальной настройке и обслуживании и отвечают запросам наиболее требовательных рабочих нагрузок приложений.
Использовать облачное хранилище файлов можно одним из двух способов: посредством полностью управляемых решений с минимальной настройкой и практически без обслуживания или через самостоятельно настраиваемые решения, для которых отдельно выделяются вычислительные ресурсы, хранилище, ПО и лицензии, причем во втором случае необходимо наличие опытного персонала для настройки и технического обслуживания. Amazon EFS, Amazon FSx for NetApp ONTAP, Amazon FSx for OpenZFS, Amazon FSx for Windows File Server и Amazon FSx for Lustre – это полностью управляемые решения, которые предлагают простое масштабируемое файловое хранилище для вычислительных моделей AWS, включая контейнеры AWS бессерверные вычисления, а также для локальных примеров использования.
Существует три типа облачных хранилищ: объектные, файловые и блочные. Каждый тип имеет свои уникальные преимущества.
1. Объектное хранилище. Для приложений, разработанных в облаке, как правило, требуются такие преимущества объектного хранилища, как широкие возможности масштабирования и характеристики метаданных. Объектные хранилища, например Amazon Simple Storage Service (Amazon S3), идеально подходят для разработки с нуля современных приложений, которым требуется гибкость и возможность масштабирования. Кроме того, эти хранилища можно использовать для импорта данных из существующих хранилищ с целью анализа, резервного копирования или архивации.
2. Файловые хранилища. Многим приложениям требуется доступ к совместно используемым файлам и файловая система. Данный тип хранилища часто поддерживается сервером хранилищ, подключенным к сети (NAS). Решения для хранения файлов, например Amazon Elastic File System (EFS), Amazon FSx for NetApp ONTAP, Amazon FSx for OpenZFS, Amazon FSx for Windows File Server и Amazon FSx for Lustre, идеально подходят для использования в крупных репозиториях контента, средах для разработок, машинного обучения, задач по обработке данных, хранилищах мультимедиа и домашних каталогах пользователей.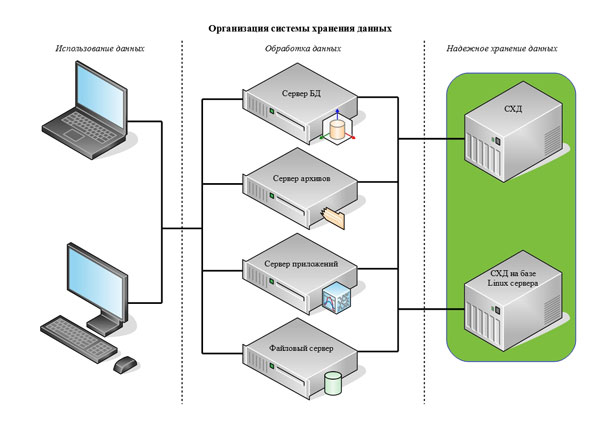 Сервис Amazon FSx for Lustre прекрасно подходит для высокопроизводительных вычислений.
Сервис Amazon FSx for Lustre прекрасно подходит для высокопроизводительных вычислений.
3. Блочные хранилища. Другие корпоративные приложения, например базы данных или системы планирования ресурсов предприятия (ERP), часто нуждаются в выделенном хранилище с низкими задержками для каждого хоста. Такое хранилище работает аналогично хранилищу с прямым подключением (DAS) или сети хранения данных (SAN). Решения облачных хранилищ на основе блоков, такие как Amazon Elastic Block Store (EBS), выделяют хранилище для каждого виртуального сервера и обеспечивают сверхнизкую задержку для рабочих нагрузок, требующих высокой производительности.
Хотя объектные хранилища позволяют хранить файлы как объекты, доступ к ним из существующих приложений требует нового программного кода и использования API, а также достоверного знания семантики пространства имен. Решения файловых хранилищ, которые поддерживают семантику и модели разрешений существующей файловой системы, имеют явное преимущество в том, что не требуют нового программного кода для интеграции с приложениями, которые просто настраиваются для работы с хранилищем совместно используемых файлов.
Блочное хранилище можно использовать в качестве базового компонента хранилища для самостоятельно управляемого решения хранилища файлов. Однако необходимость взаимно‑однозначного соответствия между узлом и томом затрудняет масштабирование, обеспечение доступности и экономичности, присущей полностью управляемым решениям. К тому же для поддержки решения на основе блочного хранилища требуются дополнительные расходы и ресурсы управления. С помощью полностью управляемого облачного хранилища файлов можно устранить сложности, снизить затраты и упростить управление.
В мире существует огромное количество файловых данных, и AWS предоставляет полностью управляемые сервисы для управления файловой системой, которые помогут вам легко удовлетворить разнообразные потребности ваших файловых приложений и рабочих нагрузок.
Для многих организаций требуется высокий уровень доступности критически важных бизнес-приложений, и многие из этих приложений используют общее хранилище файлов. Миграция этих приложений в облако обеспечивает масштабируемость, высокую доступность и долговечность, безопасность и снижение затрат при одновременном повышении гибкости.
AWS предлагает сервисы для хранения файлов, оптимизированные для ваших приложений и примеров использования.
- Amazon EFS – это простая, бессерверная эластичная файловая система, не требующая постоянного контроля, которая позволяет совместно использовать файловые данные для разнообразных приложений на базе Linux без необходимости в предоставлении хранилища или его обслуживании.
- Amazon FSx for NetApp ONTAP предлагает полностью управляемое высоконадежное, масштабируемое, высокопроизводительное общее хранилище для рабочих нагрузок на Linux, Windows и MacOS.
- Amazon FSx for OpenZFS предоставляет полностью управляемое хранилище общих файлов на основе файловой системы OpenZFS, работающее на базе процессоров семейства AWS Graviton и доступное по протоколу NFS (версии 3, 4, 4.1, 4.2).
- Amazon FSx for Windows File Server предоставляет полностью управляемую файловую систему с оптимизацией для Windows с функциями и производительностью, которая отлично подходит для бизнес-приложений на базе Windows.
- Amazon FSx for Lustre предназначен для приложений, требующих больших вычислительных мощностей, например высокопроизводительных вычислений. Amazon FSx for Lustre позволяет легко обрабатывать данные с помощью файловой системы, оптимизированной по производительности и стоимости для коротких и ресурсоемких заданий обработки. Входные и выходные данные хранятся в Amazon S3.
Обратиться в службу продаж
Смотреть вебинар
Обзор сервисов хранилищ AWS
Центр примеров использования
Поддержка AWS для Internet Explorer заканчивается 07/31/2022. Поддерживаемые браузеры: Chrome, Firefox, Edge и Safari. Подробнее »
обзор для новичков / Хабр
Международный рынок гипермасштабируемых дата-центров растет с ежегодными темпами в 11%. Основные «драйверы» — предприятия, подключенные устройства и пользователи — они обеспечивают постоянное появление новых данных. Вместе с объемом рынка растут и требования к надежности хранения и уровню доступности данных.
Основные «драйверы» — предприятия, подключенные устройства и пользователи — они обеспечивают постоянное появление новых данных. Вместе с объемом рынка растут и требования к надежности хранения и уровню доступности данных.
Ключевой фактор, влияющий на оба критерия — системы хранения. Их классификация не ограничивается типами оборудования или брендами. В этой статье мы рассмотрим разновидности хранилищ — блочное, файловое и объектное — и определим, для каких целей подходит каждое из них.
/ Flickr / Jason Baker / CC
Типы хранилищ и их различия
Хранение на уровне блоков лежит в основе работы традиционного жесткого диска или магнитной ленты. Файлы разбиваются на «кусочки» одинакового размера, каждый с собственным адресом, но без метаданных. Пример — ситуация, когда драйвер HDD пишет и считывает блоки по адресам на отформатированном диске. Такие СХД используются многими приложениями, например, большинством реляционных СУБД, в списке которых Oracle, DB2 и др. В сетях доступ к блочным хостам организуется за счет SAN с помощью протоколов Fibre Channel, iSCSI или AoE.
В сетях доступ к блочным хостам организуется за счет SAN с помощью протоколов Fibre Channel, iSCSI или AoE.
Файловая система — это промежуточное звено между блочной системой хранения и вводом-выводом приложений. Наиболее распространенным примером хранилища файлового типа является NAS. Здесь, данные хранятся как файлы и папки, собранные в иерархическую структуру, и доступны через клиентские интерфейсы по имени, названию каталога и др.
/ Wikimedia / Mennis / CC
При этом следует отметить, что разделение «SAN — это только сетевые диски, а NAS — сетевая файловая система» искусственно. Когда появился протокол iSCSI, граница между ними начала размываться. Например, в начале нулевых компания NetApp стала предоставлять iSCSI на своих NAS, а EMC — «ставить» NAS-шлюзы на SAN-массивы. Это делалось для повышения удобства использования систем.
Что касается объектных хранилищ, то они отличаются от файловых и блочных отсутствием файловой системы. Древовидную структуру файлового хранилища здесь заменяет плоское адресное пространство. Никакой иерархии — просто объекты с уникальными идентификаторами, позволяющими пользователю или клиенту извлекать данные.
Древовидную структуру файлового хранилища здесь заменяет плоское адресное пространство. Никакой иерархии — просто объекты с уникальными идентификаторами, позволяющими пользователю или клиенту извлекать данные.
Марк Горос (Mark Goros), генеральный директор и соучредитель Carnigo, сравнивает такой способ организации со службой парковки, предполагающей выдачу автомобиля. Вы просто оставляете свою машину парковщику, который увозит её на стояночное место. Когда вы приходите забирать транспорт, то просто показываете талон — вам возвращают автомобиль. Вы не знаете, на каком парковочном месте он стоял.
Большинство объектных хранилищ позволяют прикреплять метаданные к объектам и агрегировать их в контейнеры. Таким образом, каждый объект в системе состоит из трех элементов: данных, метаданных и уникального идентификатора — присвоенного адреса. При этом объектное хранилище, в отличие от блочного, не ограничивает метаданные атрибутами файлов — здесь их можно настраивать.
/ 1cloud
Применимость систем хранения разных типов
Блочные хранилища
Блочные хранилища обладают набором инструментов, которые обеспечивают повышенную производительность: хост-адаптер шины разгружает процессор и освобождает его ресурсы для выполнения других задач. Поэтому блочные системы хранения часто используются для виртуализации. Также хорошо подходят для работы с базами данных.
Поэтому блочные системы хранения часто используются для виртуализации. Также хорошо подходят для работы с базами данных.
Недостатками блочного хранилища являются высокая стоимость и сложность в управлении. Еще один минус блочных хранилищ (который относится и к файловым, о которых далее) — ограниченный объем метаданных. Любую дополнительную информацию приходится обрабатывать на уровне приложений и баз данных.
Файловые хранилища
Среди плюсов файловых хранилищ выделяют простоту. Файлу присваивается имя, он получает метаданные, а затем «находит» себе место в каталогах и подкаталогах. Файловые хранилища обычно дешевле по сравнению с блочными системами, а иерархическая топология удобна при обработке небольших объемов данных. Поэтому с их помощью организуются системы совместного использования файлов и системы локального архивирования.
Пожалуй, основной недостаток файлового хранилища — его «ограниченность». Трудности возникают по мере накопления большого количества данных — находить нужную информацию в куче папок и вложений становится трудно. По этой причине файловые системы не используются в дата-центрах, где важна скорость.
По этой причине файловые системы не используются в дата-центрах, где важна скорость.
Объектные хранилища
Что касается объектных хранилищ, то они хорошо масштабируются, поэтому способны работать с петабайтами информации. По статистике, объем неструктурированных данных во всем мире достигнет 44 зеттабайт к 2020 году — это в 10 раз больше, чем было в 2013. Объектные хранилища, благодаря своей возможности работать с растущими объемами данных, стали стандартом для большинства из самых популярных сервисов в облаке: от Facebook до DropBox.
Такие хранилища, как Haystack Facebook, ежедневно пополняются 350 млн фотографий и хранят 240 млрд медиафайлов. Общий объем этих данных оценивается в 357 петабайт.
Хранение копий данных — это другая функция, с которой хорошо справляются объектные хранилища. По данным исследований, 70% информации лежит в архиве и редко изменяется. Например, такой информацией могут выступать резервные копии системы, необходимые для аварийного восстановления.
Но недостаточно просто хранить неструктурированные данные, иногда их нужно интерпретировать и организовывать. Файловые системы имеют ограничения в этом плане: управление метаданными, иерархией, резервным копированием — все это становится препятствием. Объектные хранилища оснащены внутренними механизмами для проверки корректности файлов и другими функциями, обеспечивающими доступность данных.
Плоское адресное пространство также выступает преимуществом объектных хранилищ — данные, расположенные на локальном или облачном сервере, извлекаются одинаково просто. Поэтому такие хранилища часто применяются для работы с Big Data и медиа. Например, их используют Netflix и Spotify. Кстати, возможности объектного хранилища сейчас доступны и в сервисе 1cloud.
Благодаря встроенным инструментам защиты данных с помощью объектного хранилища можно создать надежный географически распределенный резервный центр. Его API основан на HTTP, поэтому к нему можно получить доступ, например, через браузер или cURL. Чтобы отправить файл в хранилище объектов из браузера, можно прописать следующее:
Чтобы отправить файл в хранилище объектов из браузера, можно прописать следующее:
<form action = "[url_storage/account/container/object]"
method = "post"
enctype = "multipart/form-data">
<input type="hidden" name="redirect" value="[url_result]">
<input type="hidden" name="signature" value="[hmac]">
<input type="file" name="file_name">
<input type="submit">
</form>
После отправки к файлу добавляются необходимые метаданные. Для этого есть такой запрос:
curl -i [url_storage/account/container/object] -X POST -H "X-Auth-Token: [token]" -H "X-Object-Meta-ValueA: [value-a]"
Богатая метаинформация объектов позволит оптимизировать процесс хранения и минимизировать затраты на него. Эти достоинства — масштабируемость, расширяемость метаданных, высокая скорость доступа к информации — делают объектные системы хранения оптимальным выбором для облачных приложений.
Однако важно помнить, что для некоторых операций, например, работы с транзакционными рабочими нагрузками, эффективность решения уступает блочным хранилищам. А его интеграция может потребовать изменения логики приложения и рабочих процессов.
P.S. Еще несколько материалов о хранении данных из блога 1cloud:
- Масштабирование в облаке: варианты и рекомендации
- Безопасность данных в облаке: 3 главные опасности
- Передача данных в облаке 1cloud: скорость в сетях разного типа
- Объектное хранилище для файлов в облаке
Что такое хранилище файлов | IBM
Что такое хранилище файлов и когда оно наиболее полезно? Это руководство даст определение файловому хранилищу, объяснит его преимущества и рассмотрит некоторые типичные варианты использования.
Что такое хранилище файлов?
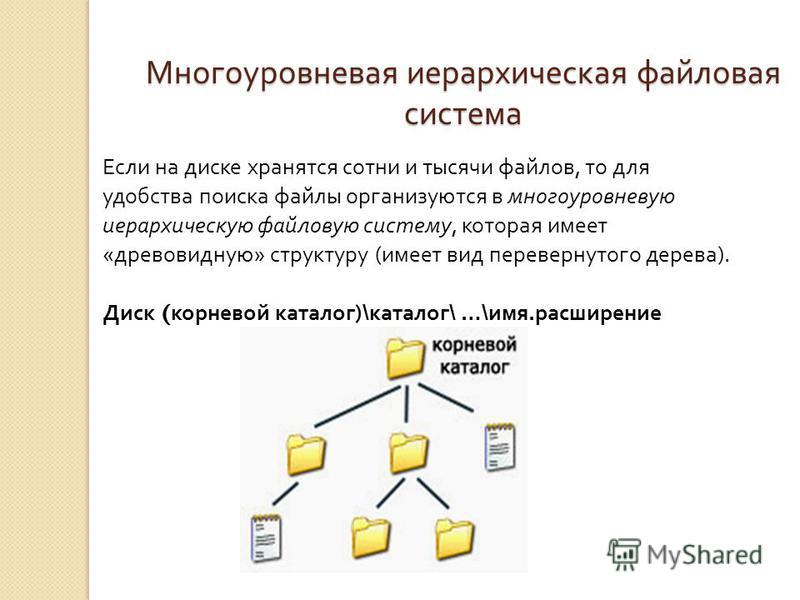
Хранилище файлов, также называемое файловым хранилищем или хранилищем на основе файлов, представляет собой методологию иерархического хранения, используемую для организации и хранения данных на жестком диске компьютера или в сетевом хранилище (NAS). В файловом хранилище данные хранятся в файлах, файлы организованы в папки, а папки организованы в виде иерархии каталогов и подкаталогов. Чтобы найти файл, вам или вашей компьютерной системе нужен только путь — от каталога к подкаталогу, от папки к файлу.
В файловом хранилище данные хранятся в файлах, файлы организованы в папки, а папки организованы в виде иерархии каталогов и подкаталогов. Чтобы найти файл, вам или вашей компьютерной системе нужен только путь — от каталога к подкаталогу, от папки к файлу.
Иерархическое хранилище файлов хорошо работает с легко организованными объемами структурированных данных. Но по мере роста количества файлов процесс извлечения файлов может стать громоздким и трудоемким. Масштабирование требует добавления большего количества аппаратных устройств или постоянной замены их устройствами с большей емкостью, что может быть дорогостоящим.
В некоторой степени эти проблемы с масштабированием и производительностью можно смягчить с помощью облачных служб хранения файлов. Эти сервисы позволяют нескольким пользователям получать доступ и совместно использовать одни и те же файловые данные, расположенные в удаленных центрах обработки данных (облаке). Вы просто платите ежемесячную абонентскую плату за хранение своих файловых данных в облаке, и вы можете легко увеличить емкость и указать критерии производительности и защиты данных. Кроме того, вы избавляетесь от расходов на обслуживание собственного оборудования на месте, поскольку эта инфраструктура управляется и обслуживается поставщиком облачных услуг (CSP) в его центре обработки данных. Это также известно как инфраструктура как услуга (IaaS).
Кроме того, вы избавляетесь от расходов на обслуживание собственного оборудования на месте, поскольку эта инфраструктура управляется и обслуживается поставщиком облачных услуг (CSP) в его центре обработки данных. Это также известно как инфраструктура как услуга (IaaS).
Хранилище файлов, блочное хранилище или хранилище объектов
Хранилище файлов было популярным методом хранения на протяжении десятилетий — оно знакомо практически каждому пользователю компьютера и хорошо подходит для хранения и организации транзакционных данных или управляемых объемов структурированных данных, которые могут быть аккуратно сохранены в базе данных на диске на сервере.
Однако в настоящее время многие организации испытывают трудности с управлением растущими объемами цифрового веб-контента или неструктурированных данных. Если вам нужно хранить очень большие или неструктурированные объемы данных, вам следует рассмотреть блочное или объектное хранилище, которое по-разному организует данные и обеспечивает доступ к ним. В зависимости от различных требований к скорости и производительности ваших ИТ-операций и различных приложений вам может потребоваться сочетание этих подходов.
В зависимости от различных требований к скорости и производительности ваших ИТ-операций и различных приложений вам может потребоваться сочетание этих подходов.
Блочное хранилище
Блочное хранилище обеспечивает большую эффективность хранения (более эффективное использование доступного оборудования для хранения) и более высокую производительность, чем файловое хранилище. Блочное хранилище разбивает файл на куски (или блоки) данных одинакового размера и сохраняет каждый блок отдельно под уникальным адресом.
Вместо жесткой структуры каталогов/подкаталогов/папок блоки могут храниться в любом месте системы. Чтобы получить доступ к любому файлу, операционная система сервера использует уникальный адрес, чтобы объединить блоки в файл, что занимает меньше времени, чем навигация по каталогам и файловым иерархиям для доступа к файлу. Блочное хранилище хорошо подходит для критически важных бизнес-приложений, транзакционных баз данных и виртуальных машин, которым требуется низкая задержка (минимальная задержка). Это также обеспечивает более детальный доступ к данным и стабильную производительность.
Это также обеспечивает более детальный доступ к данным и стабильную производительность.
В следующем видео Эми Блеа рассказывает о различиях между блочным хранилищем и файловым хранилищем:
Блочное хранилище и файловое хранилище (04:03)
Объектное хранилище
Объектное хранилище стало предпочтительным методом для архивирования данных и резервного копирования современных цифровых коммуникаций — неструктурированного медиа и веб-контента, такого как электронная почта, видео, файлы изображений, веб-страницы и данные датчиков, созданные в Интернете. вещей (IoT). Он также идеально подходит для архивирования данных, которые не часто меняются (статические файлы), таких как большие объемы фармацевтических данных или файлов музыки, изображений и видео.
Объекты — это дискретные единицы данных, хранящиеся в структурно плоской среде данных. Опять же, здесь нет папок, каталогов или сложных иерархий; вместо этого каждый объект представляет собой простой автономный репозиторий, включающий данные, метаданные (описательная информация, связанная с объектом) и уникальный идентификационный номер.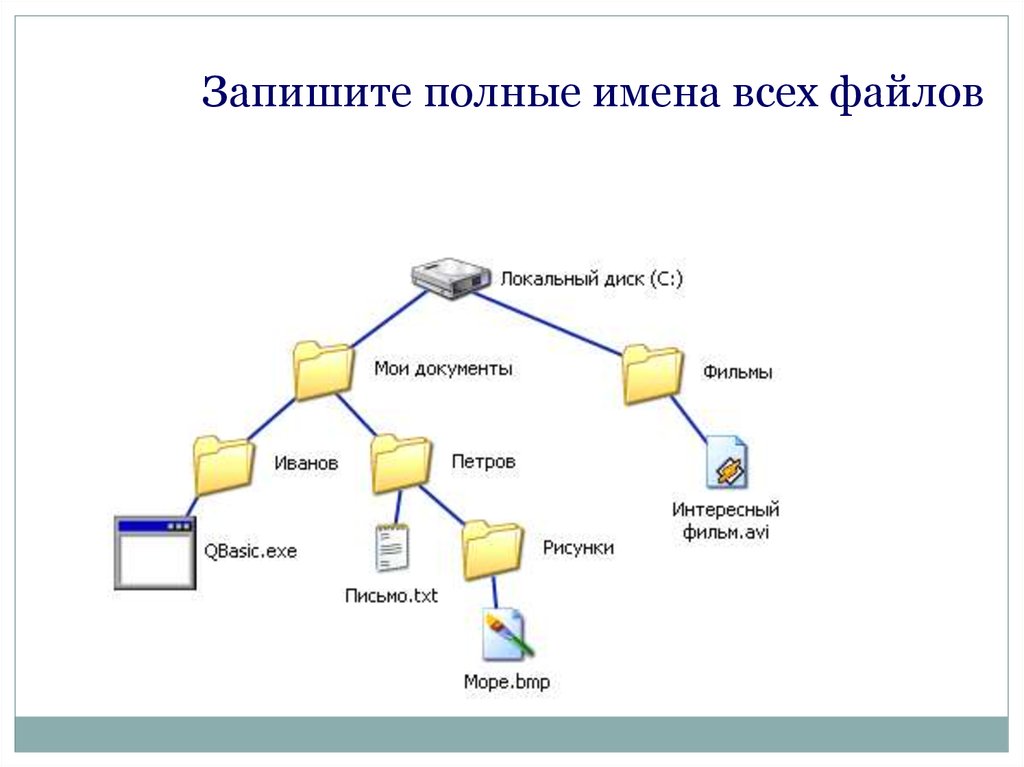 Эта информация позволяет приложению найти объект и получить к нему доступ.
Эта информация позволяет приложению найти объект и получить к нему доступ.
Вы можете объединять устройства хранения объектов в более крупные пулы хранения и распределять эти пулы хранения по местоположениям. Это обеспечивает неограниченное масштабирование и улучшенную отказоустойчивость данных и аварийное восстановление. Объекты могут храниться локально, но чаще всего находятся на облачных серверах с доступом из любой точки мира.
IBM Cloud Object Storage: создано для бизнеса (04:10)
Преимущества
Если вашей организации требуется централизованный, легкодоступный и недорогой способ хранения файлов и папок, хорошим решением будет хранение на уровне файлов. К преимуществам хранения файлов относятся следующие:
- Простота : Хранение файлов — это самый простой, привычный и понятный подход к организации файлов и папок на жестком диске компьютера или устройстве NAS. Вы просто называете файлы, помечаете их метаданными и сохраняете их в папках в иерархии каталогов и подкаталогов. Нет необходимости писать приложения или код для доступа к вашим данным.
- Общий доступ к файлам : Хранилище файлов идеально подходит для централизации и совместного использования файлов в локальной сети (LAN). Файлы, хранящиеся на устройстве NAS, легко доступны любому компьютеру в сети, имеющему соответствующие права доступа.
- Общие протоколы : Хранилище файлов использует общие протоколы уровня файлов, такие как блок сообщений сервера (SMB), общая файловая система Интернета (CIFS) или сетевая файловая система (NFS). Если вы используете операционную систему Windows или Linux (или обе), стандартные протоколы, такие как SMB/CIFS и NFS, позволят вам читать и записывать файлы на сервер под управлением Windows или Linux через вашу локальную сеть (LAN).
- Защита данных : Хранение файлов на отдельном устройстве хранения данных, подключенном к локальной сети, обеспечивает определенный уровень защиты данных в случае сбоя сетевого компьютера. Облачные службы хранения файлов обеспечивают дополнительную защиту данных и аварийное восстановление за счет репликации файлов данных в нескольких географически разнесенных центрах обработки данных.
- Доступность по цене : Хранение файлов с помощью устройства NAS позволяет перемещать файлы с дорогостоящего компьютерного оборудования на более доступное устройство хранения данных, подключенное к локальной сети. Кроме того, если вы решите подписаться на службу облачного хранилища файлов, вы избавитесь от расходов на обновление оборудования на месте и связанных с этим текущих затрат на обслуживание и эксплуатацию.
 Нет необходимости писать приложения или код для доступа к вашим данным.
Нет необходимости писать приложения или код для доступа к вашим данным.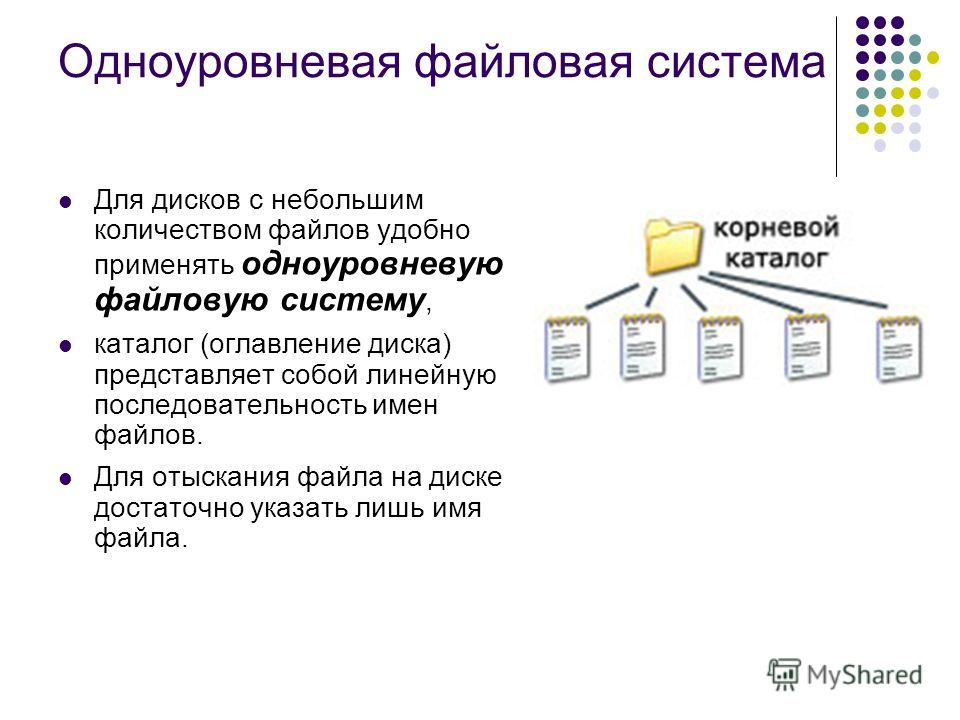 Облачные службы хранения файлов обеспечивают дополнительную защиту данных и аварийное восстановление за счет репликации файлов данных в нескольких географически разнесенных центрах обработки данных.
Облачные службы хранения файлов обеспечивают дополнительную защиту данных и аварийное восстановление за счет репликации файлов данных в нескольких географически разнесенных центрах обработки данных.Варианты использования
Хранилище файлов является хорошим решением для широкого спектра потребностей в данных, включая следующие:
- Локальный общий доступ к файлам : Если ваши потребности в хранении данных в целом непротиворечивы и просты, например, для хранения и обмена файлами с членами команды в офисе рассмотрите простоту хранения на уровне файлов.
- Централизованная совместная работа с файлами : Если вы загружаете, храните и делитесь файлами в централизованной библиотеке — расположенной на месте, за пределами сайта или в облаке — вы можете легко совместно работать над файлами с внутренними и внешними пользователями или с приглашенными гостями. вне вашей сети.
- Архивирование/хранение : Вы можете экономично архивировать файлы на устройствах NAS в среде небольшого центра обработки данных или подписаться на облачное хранилище файлов для хранения и архивирования своих данных.
- Резервное копирование/аварийное восстановление : Вы можете безопасно хранить резервные копии на отдельных устройствах хранения, подключенных к локальной сети. Или вы можете подписаться на облачную службу хранения файлов, чтобы реплицировать файлы данных в нескольких географически разнесенных центрах обработки данных и получить дополнительную защиту данных за счет удаленности и избыточности.

Облачное хранилище файлов (или хостинг файловых хранилищ)
Современные коммуникации быстро перемещаются в облако, чтобы получить преимущества подхода к общему хранилищу, который изначально оптимизирует масштаб и затраты. Вы можете сократить локальную ИТ-инфраструктуру своей организации, используя недорогое облачное хранилище, сохраняя при этом доступ к своим данным, когда они вам нужны.
Подобно системе хранения файлов на месте, облачное хранилище файлов, также называемое хостингом хранилища файлов, позволяет нескольким пользователям совместно использовать одни и те же данные файла. Но вместо того, чтобы хранить файлы данных локально на устройстве NAS, вы можете хранить эти файлы вне офиса в центрах обработки данных (в облаке) и получать к ним доступ через Интернет.
Благодаря облачному хранилищу файлов вам больше не нужно обновлять оборудование для хранения каждые три-пять лет или планировать расходы на установку, обслуживание и персонал, необходимый для управления им. Вместо этого вы просто подписываетесь на услугу облачного хранилища за предсказуемую ежемесячную или годовую плату. Вы можете сократить свой ИТ-персонал или перенаправить эти технические ресурсы на более прибыльные области вашего бизнеса.
Вместо этого вы просто подписываетесь на услугу облачного хранилища за предсказуемую ежемесячную или годовую плату. Вы можете сократить свой ИТ-персонал или перенаправить эти технические ресурсы на более прибыльные области вашего бизнеса.
Хранение файловых данных в облаке также позволяет увеличивать емкость по мере необходимости и по запросу. Облачные службы хранения файлов обычно предлагают простые, предварительно определенные уровни с различными уровнями емкости хранилища и требованиями к производительности рабочей нагрузки (общее количество операций ввода-вывода в секунду или IOPS), а также защиту данных и репликацию в другие центры обработки данных. для обеспечения непрерывности бизнеса — и все это за предсказуемую ежемесячную плату. Или вы можете увеличивать или уменьшать количество операций ввода-вывода в секунду и динамически расширять объемы данных, платя только за то, что вы используете.
Службы облачного хранения на основе подписки имеют стратегические преимущества, особенно для организаций с несколькими площадками и крупных организаций.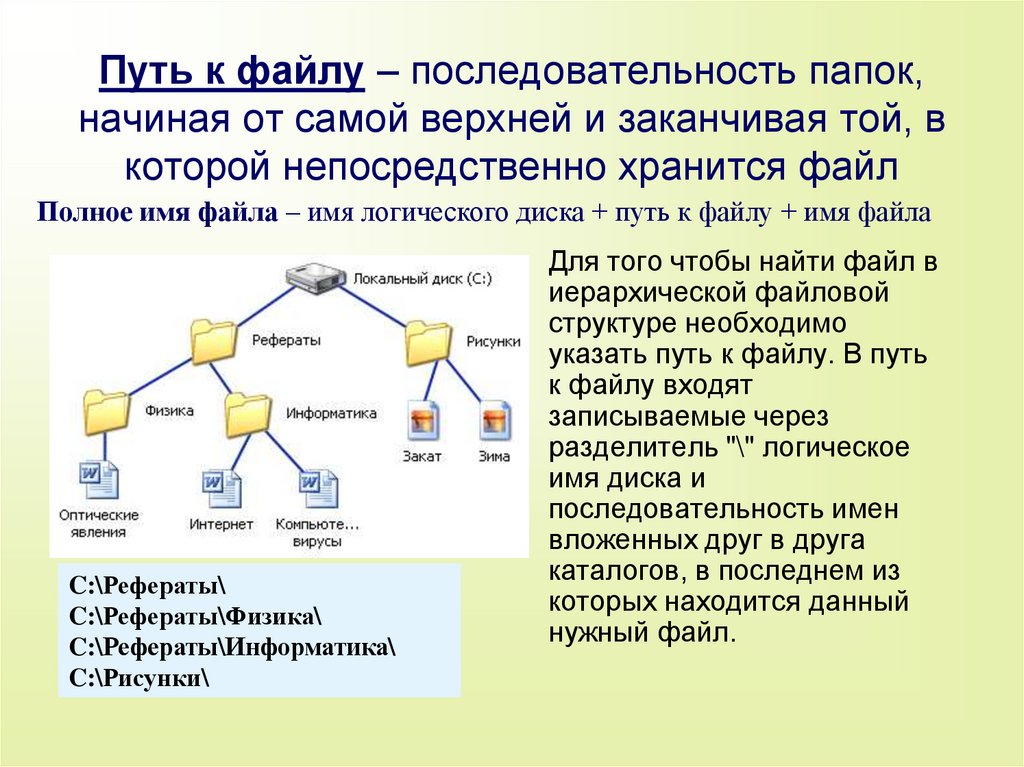 К ним относятся простота совместного использования в локальной сети, аварийное восстановление и простота добавления инноваций и технологий, которые появятся в будущем.
К ним относятся простота совместного использования в локальной сети, аварийное восстановление и простота добавления инноваций и технологий, которые появятся в будущем.
Хранилище файлов и IBM Cloud
Решения IBM Cloud File Storage надежны, быстры и гибки. Вы получите защиту от потери данных во время обслуживания или сбоев благодаря шифрованию данных в состоянии покоя, а также дублированию томов, моментальным снимкам и репликации. Благодаря центрам обработки данных IBM, расположенным по всему миру, вы можете быть уверены в высоком уровне защиты данных, репликации и аварийного восстановления.
IBM Cloud предлагает четыре предварительно определенных уровня Endurance с ценами за гигабайт (ГБ), которые фиксируют ваши расходы, обеспечивая предсказуемую почасовую или ежемесячную оплату для ваших краткосрочных или долгосрочных потребностей в хранении данных. Уровни File Storage Endurance поддерживают производительность до 10 000 (10 000) IOPS/ГБ и могут удовлетворить потребности большинства рабочих нагрузок, независимо от того, требуется ли вам производительность с низкой интенсивностью, общего назначения или высокой интенсивности.
С помощью IBM File Storage вы сможете увеличивать или уменьшать количество операций ввода-вывода в секунду и расширять существующие тома на лету. Кроме того, вы можете дополнительно защитить свои данные, подписавшись на функцию IBM Snapshot, которая создает доступные только для чтения образы вашего тома хранилища файлов в определенных точках, из которых вы можете легко восстановить свои данные в случае случайной потери или повреждения.
Узнайте больше об уровнях и параметрах производительности IBM File Storage Endurance.
Подпишитесь на бесплатную двухмесячную пробную версию и начните бесплатное создание в IBM Cloud.
Что такое хранилище файлов? — Определение из WhatIs.com
По
- Эд Ханнан
Хранилище файлов, также называемое файловым уровнем или файловое хранилище хранит данные в иерархической структуре.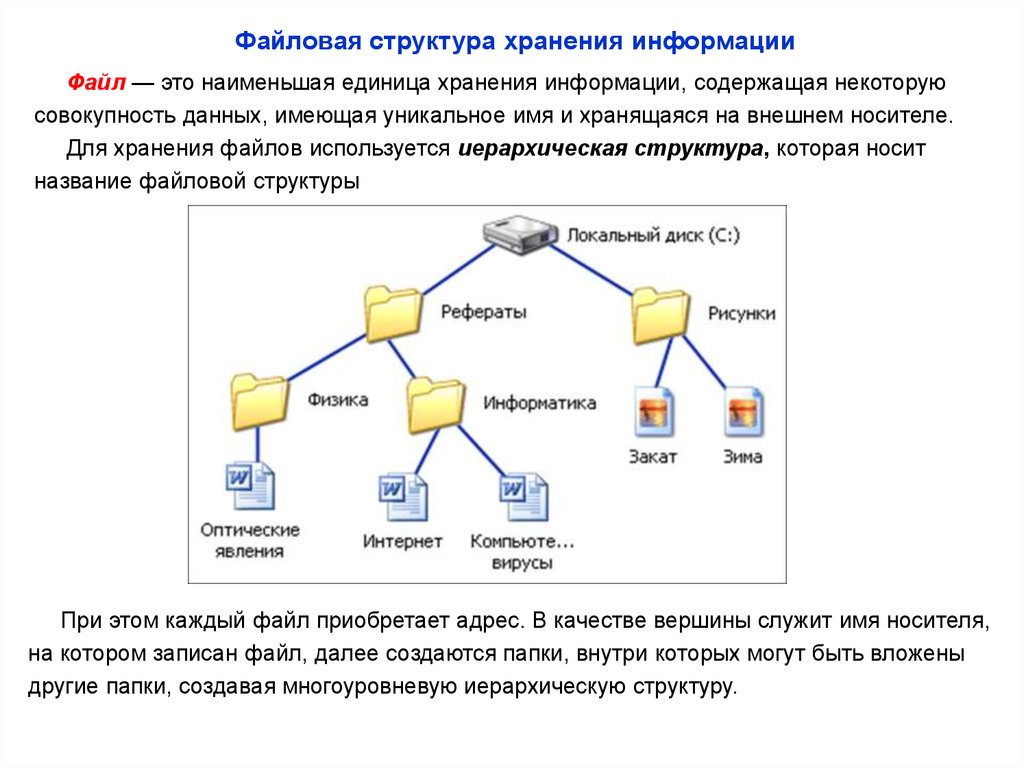 Данные сохраняются в файлах и папках и представляются как системе, хранящей их, так и системе, извлекающей их в одном и том же формате. Доступ к данным можно получить с помощью протокола сетевой файловой системы (NFS) для Unix или Linux или протокола блока сообщений сервера (SMB) для Microsoft Windows.
Данные сохраняются в файлах и папках и представляются как системе, хранящей их, так и системе, извлекающей их в одном и том же формате. Доступ к данным можно получить с помощью протокола сетевой файловой системы (NFS) для Unix или Linux или протокола блока сообщений сервера (SMB) для Microsoft Windows.
NFS, изначально разработанная Sun Microsystems, позволяет клиенту хранить и просматривать файлы на сервере, как если бы они находились на клиентском компьютере. Вся или часть файловой системы может быть смонтирована на сервере, где она будет доступна клиентам с назначенными правами доступа к файлу. SMB использует пакеты данных, отправляемые клиентом на сервер, который отвечает на запрос. Большинство сетевых хранилищ (NAS) поддерживают NFS и SMB, которые ранее были известны как Common Internet File System.
Файловое и блочное хранилище В то время как системы хранения на уровне блоков записывают и извлекают данные из определенных блоков, хранилища на уровне файлов запрашивают данные через интерфейсы представления данных на уровне пользователя. Этот метод связи клиент-сервер возникает, когда клиент использует имя файла данных, расположение каталога, URL-адрес и другую информацию. При использовании хранилища на уровне блоков сервер получает запрос на регистрацию, ищет места хранения данных, в которых хранятся данные, и извлекает их с помощью функций уровня хранилища. Сервер отправляет файл клиенту не в виде блоков, а в виде байтов файла. Протоколы файлового уровня не могут понимать блочные команды, а блочные протоколы не могут передавать запросы и ответы на доступ к файлам.
Этот метод связи клиент-сервер возникает, когда клиент использует имя файла данных, расположение каталога, URL-адрес и другую информацию. При использовании хранилища на уровне блоков сервер получает запрос на регистрацию, ищет места хранения данных, в которых хранятся данные, и извлекает их с помощью функций уровня хранилища. Сервер отправляет файл клиенту не в виде блоков, а в виде байтов файла. Протоколы файлового уровня не могут понимать блочные команды, а блочные протоколы не могут передавать запросы и ответы на доступ к файлам.
, также известное как многопротокольное хранилище , предлагает доступ на уровне блоков Fibre Channel и iSCSI, который можно найти в системах сети хранения данных (SAN), и доступ на уровне файлов NAS в одном устройстве. Унифицированное хранилище было впервые использовано примерно в 2002 году и теперь является общей архитектурой хранения.
Индивидуальные корпоративные файловые хранилища NAS и SAN также могут предлагать расширенные функции управления данными, такие как дедупликация данных и тонкое выделение ресурсов, которые могут повысить ценность виртуальных инфраструктур.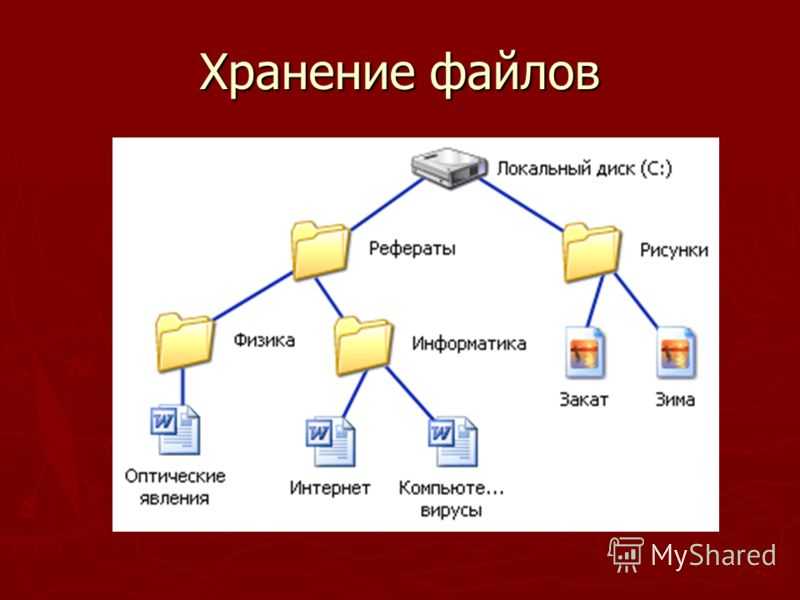
В последние годы тенденции в центрах обработки данных, такие как аналитика больших данных и технологии облачного хранения, способствовали быстрому росту компьютерных хранилищ файлов. Количество приложений, использующих строго файловый доступ, а не доступ к базе данных, стало еще одним фактором.
Файловые устройства NAS, как правило, являются наиболее эффективным способом борьбы с ростом данных в файлах. Но слишком много файловых систем может привести к изоляции, поскольку у пользователей может отсутствовать глобальное пространство имен на нескольких платформах. Это заставляет администраторов запускать несколько систем одновременно.
Несмотря на то, что добавление систем NAS является правильным подходом к решению проблемы резкого увеличения объемов компьютерных хранилищ файлов, предпочтительным методом является использование горизонтально масштабируемой системы NAS, кластерной системы NAS или файловой виртуализации NAS для их одновременного запуска.
См. также : сетевое хранилище (NAS)
Последнее обновление: май 2016 г.
Продолжить чтение О файловом хранилище- Принцип работы хранилища файлов с масштабируемыми сетевыми системами хранения данных
- Как различать хранилище на уровне блоков и файлов
- Сравнение файловых и блочных хранилищ в средах виртуальных серверов
- Файловые системы с открытым исходным кодом могут принести пользу средам хранения
- Управление файловыми ресурсами с помощью Microsoft Azure
NFS, SMB и CIFS: определение протоколов хранения файлов
Автор: Энтони Адсхед
Что такое сетевое хранилище (NAS)? Полное руководство
Автор: Стивен Бигелоу
NAS или облачное хранилище: что лучше для вашего бизнеса?
Автор: Рич Кастанья
Шлюз NAS
Автор: Гарри Кранц
SearchDisasterRecovery
- Почему план аварийного восстановления HIPAA имеет решающее значение
Аварийное восстановление — сложная операция с высокими ставками.
Когда в дело вступают медицинские данные, хороший план аварийного восстановления становится еще более важным… - Используйте ISO 22320:2018 для подготовки плана управления инцидентами
Управление инцидентами имеет решающее значение для обеспечения того, чтобы предприятия могли справляться с незапланированными разрушительными событиями. Узнайте, как ISO:22320:…
- Новый генеральный директор Everbridge вступает в должность в критический момент
Новый генеральный директор Everbridge Дэвид Вагнер подробно описывает сферы своей деятельности в компании. Инвестор Ancora предположил, что частный капитал …
 Когда в дело вступают медицинские данные, хороший план аварийного восстановления становится еще более важным…
Когда в дело вступают медицинские данные, хороший план аварийного восстановления становится еще более важным…SearchDataBackup
- Викторина по защите данных RAID: проверьте свои знания
Насколько хорошо вы знаете RAID? Возможно, пришло время проверить свои ноу-хау. Узнайте, что вы знаете об уровнях RAID, происхождении и их ..
. - Программа LTO надеется превысить 1,4 ПБ на ленту
Программа LTO изложила обновленную дорожную карту, показывающую, что лента может преодолеть барьер в 1 петабайт в течение следующего десятилетия, сохраняя …
- Как получить максимальную отдачу от резервных копий облачных баз данных
При резервном копировании баз данных облако может предоставить безопасную и легко масштабируемую цель. Однако не забывайте о таких важных функциях, как …
 .
.SearchDataCenter
- Как использовать отчеты файлового сервера в FSRM
Отчеты файлового сервера в диспетчере ресурсов файлового сервера могут помочь администраторам выявлять проблемы, а затем устранять неполадки серверов Windows…
- Intel расширяет Developer Cloud, обновляет GPU, CPU
Администраторы, которые управляют многими пользователями, могут сделать еще один шаг к оптимизации назначения лицензий, воспользовавшись преимуществами нового.
.. - Платформа ServiceNow Now «Токио» обеспечивает искусственный интеллект и автоматизацию
ServiceNow удвоила свое стремление упростить проекты цифровой трансформации, выпустив новую версию своей…
 ..
..Что такое хранилище файлов и чем оно отличается от хранилища объектов
В чем разница и почему это важно
Данные — это кровь любой современной организации. Наша способность делиться, хранить и эффективно использовать данные имеет решающее значение для развития бизнеса, повышения операционной эффективности, удовлетворения клиентов и получения конкурентного преимущества. Это также жизненно важно для расширения возможностей сотрудников, предоставляя им доступ к информации, необходимой им для выполнения своей работы. Это особенно верно в связи с тем, что многие из нас работают удаленно во время нынешнего кризиса в области здравоохранения.
Все мы знаем, что объемы данных стремительно растут — организациям приходится покупать больше хранилищ данных, чем когда-либо прежде. И это большая проблема. Однако каждая организация сталкивается с другой большой проблемой, которая затрагивает всех — руководителей бизнеса, ИТ-специалистов и пользователей — хотя и по-разному. И это: не все данные одинаково ценны.
И это большая проблема. Однако каждая организация сталкивается с другой большой проблемой, которая затрагивает всех — руководителей бизнеса, ИТ-специалистов и пользователей — хотя и по-разному. И это: не все данные одинаково ценны.
Данные как деньги. Мы обращаемся с деньгами в нашем кошельке, защищаем их и используем по-разному, в зависимости от их стоимости. Мы гораздо более тщательно относимся к тому, как мы бережем и тратим 100-долларовые купюры, чем 1-долларовые купюры. То же самое верно и для данных. Не все из них одинаково важны и, что более важно, их ценность меняется со временем — обычно из-за содержащейся в них информации, частоты доступа и даже возраста данных. В идеале организации должны иметь платформы хранения данных, созданные для интеллектуальной обработки важных данных, а не просто неразумного хранения битов и байтов. Вот почему поставщики хранилищ данных ввели понятие «температура данных».
Для иллюстрации: обычно бывает короткий всплеск бешеной активности с вновь созданными данными, но эта активность со временем быстро падает. Обычно 90 % операций ввода-вывода приходится на 10 % хранилища данных. И для большинства организаций также верно, что только около 20% всех данных активно используются. Это оставляет 80% данных просто лежать там, пугая. Его можно использовать раз в месяц, или раз в год, или никогда больше. На изображении ниже показано, как температура данных соответствует ее значению. Горячие данные активно используются и представляют наибольшую ценность для организации. Неактивные данные холодные и менее ценные, но вам все равно придется хранить их для возможного использования в будущем, что сделает их снова горячими.
Обычно 90 % операций ввода-вывода приходится на 10 % хранилища данных. И для большинства организаций также верно, что только около 20% всех данных активно используются. Это оставляет 80% данных просто лежать там, пугая. Его можно использовать раз в месяц, или раз в год, или никогда больше. На изображении ниже показано, как температура данных соответствует ее значению. Горячие данные активно используются и представляют наибольшую ценность для организации. Неактивные данные холодные и менее ценные, но вам все равно придется хранить их для возможного использования в будущем, что сделает их снова горячими.
Следует отметить, что доступ к данным не обязательно должен быть единственным определяющим фактором для неактивных/холодных данных. Для неструктурированных данных могут существовать другие бизнес-требования, определяющие, когда данные можно считать неактивными, например возраст данных, стоимость их хранения, уровень защиты, соответствие требованиям и т. д.
Давайте посмотрим на мир неструктурированных данных, где данные более распределены, и на два популярных формата хранения данных: файловая система и хранилище объектов.
Что такое хранилище файлов?
Хранилище файлов (также известное как хранилище на основе файлов или хранилище на уровне файлов) — это тип хранилища данных, в котором данные хранятся в иерархической структуре файлов и папок. Файл хранится целиком без разбивки данных на блоки, как в блочном хранилище. Файлы могут храниться в папках, которые затем могут быть помещены в другие папки во вложенной структуре. Путь к файлу и папка, в которой он хранится, необходимы для повторного вызова этого файла из места его хранения. Системы NAS обычно используют файловое хранилище и сравнительно дешевле, чем блочное хранилище.
Понимание системы хранения файлов Если у вас есть компьютер, вы использовали файловую систему. Файловые системы содержат документы, презентации, изображения и все виды ресурсов, которые мы перемещаем на рабочем столе или храним в папке «Документы». Файловые системы дают нам иерархическую систему для организации. Это аналогичный подход к использованию картотеки с данными, организованными в именованные каталоги, папки, подпапки и файлы.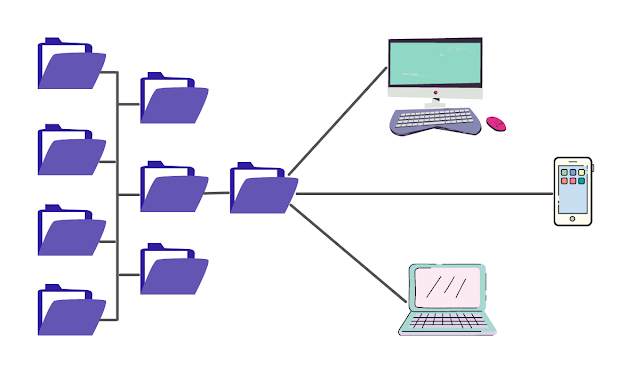 Приложения и пользователи знают, где что находится, на основе имени и местоположения. Файловые системы отлично подходят для простого входа и выхода, если вы знаете расположение того, что ищете.
Приложения и пользователи знают, где что находится, на основе имени и местоположения. Файловые системы отлично подходят для простого входа и выхода, если вы знаете расположение того, что ищете.
Для хранения файлов за пределами обычного настольного компьютера или ноутбука организации используют решения NAS (сетевое хранилище) и файловые серверы, чтобы обеспечить специализированные и оптимизированные возможности обмена файлами в сети. Обычно они обеспечивают поддержку протоколов NFS и SMB для использования в средах Unix, Linux и Windows. Они отлично подходят для хранения файлов и документов или обмена ими.
NAS обычно подходит для хранения или обмена файлами и документами, а также для контроля доступа. Но, как вы знаете из своего рабочего стола, вы работаете только с несколькими файлами одновременно. Большинство файлов на вашем жестком диске холодные или холодные. Если это верно для файлового сервера или NAS, в системе заканчивается место для хранения или производительность падает — точно так же, как и в вашем ноутбуке.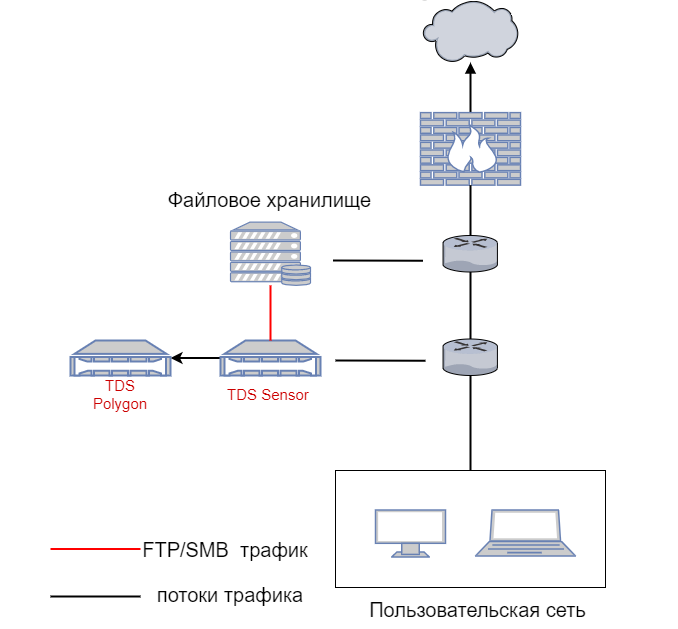 В таких случаях ИТ-организации могут рассматривать объектное хранилище как средство для хранения холодных (или неактивных) данных.
В таких случаях ИТ-организации могут рассматривать объектное хранилище как средство для хранения холодных (или неактивных) данных.
Что такое хранилище объектов?
Хранилище объектов (также известное как объектное хранилище) — это тип хранилища данных, используемый для обработки больших объемов неструктурированных данных, где данные объединяются вместе с тегами метаданных и уникальным идентификатором. Каждый из этих автономных наборов данных объектов помещается в плоское адресное пространство, известное как пул хранения. В отличие от хранилища файлов, хранилище объектов не имеет иерархической структуры. Метаданные содержат описание данных, а уникальный идентификатор используется для простого извлечения объекта вместо имени файла и пути к файлу. Облачное хранилище S3 — популярный вариант объектного хранилища в дополнение к развертыванию локального объектного хранилища.
Понимание системы хранения объектов Хранилище объектов — более современный подход, который не навязывает файловую систему данным. Вместо этого метаданные используются для описания всех деталей базовых данных. Это может включать имя, дату создания, местоположение, владельца и многое другое. Таблицы используются для того, чтобы можно было хранить, отслеживать и извлекать данные на основе этих метаданных.
Вместо этого метаданные используются для описания всех деталей базовых данных. Это может включать имя, дату создания, местоположение, владельца и многое другое. Таблицы используются для того, чтобы можно было хранить, отслеживать и извлекать данные на основе этих метаданных.
Это работает так же, как использование услуги парковщика на автостоянке. Представьте себе миллионы автомобилей на огромной парковке. Служащий выдает парковочный билет в обмен на вашу машину, а затем припарковывает ее для вас. Вам не нужно знать, где он припаркован, просто он в безопасности и будет доступен, когда он вам понадобится. Парковщик может получить его в любое время на основе информации (или метаданных) парковочного талона, независимо от размера парковки.
К преимуществам объектного хранилища относятся низкая стоимость, высокая масштабируемость и возможности глобального доступа. Компромиссы включают задержку и производительность, но со временем они улучшаются. Для пользователей, которым почти никогда не нужен доступ к старым файлам и документам, это практически незаметно.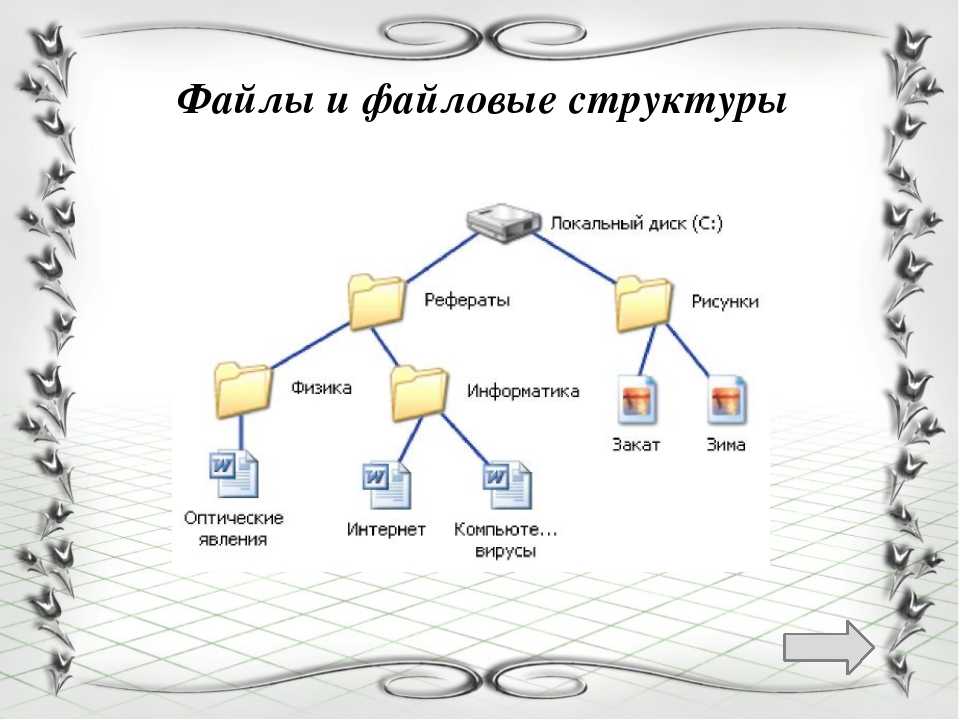 Но для организаций, которым необходимо хранить все для соблюдения нормативных требований или защиты в суде, хранение объектов имеет важное значение.
Но для организаций, которым необходимо хранить все для соблюдения нормативных требований или защиты в суде, хранение объектов имеет важное значение.
Размещение нужных данных в нужном месте в нужное время
Ключевой вывод: разные данные имеют большую или меньшую ценность в зависимости от времени, пользователей и важности. Это означает, что наиболее подходящее хранилище для любых конкретных данных будет зависеть от того, насколько они ценны в данный момент, а также от конкретных потребностей приложений или конечных пользователей, использующих их, или от их актуальности для бизнеса. И администратору хранилища почти невозможно определить это изо дня в день. В конце концов, ваша организация ежегодно создает миллионы документов. Можете ли вы представить администратора хранилища, копающегося в каждом документе, пытаясь определить, является ли он горячим, теплым или холодным, или применяя различные условия бизнес-релевантности вручную и решая, какие данные размещаются на каком устройстве хранения?
Проблема в том, что до сих пор у нас не было хорошего способа убедиться, что данные — будь то на устройствах NAS или в хранилищах объектов — находятся в нужном месте в нужное время, тем более что потребности постоянно меняются, файловые и объектные платформы могут поставляться разными поставщиками или использовать разные наборы инструментов, а ручная миграция одна на другую доставляет массу неудобств.
Именно здесь на помощь приходит современное программно-определяемое решение для хранения данных, такое как DataCore vFilO.
- Он использует автоматическое размещение на основе AI/ML для перемещения данных в наиболее подходящее хранилище в зависимости от его температуры доступа. vFilO проверяет тепловой шаблон данных, хранящихся на устройстве хранения, а затем определяет, следует ли хранить данные на устройстве NAS премиум-класса или переместить их в более дешевые альтернативы (например, хранилища объектов). vFilO не только учитывает частоту доступа к данным, но и другие настраиваемые критерии, основанные на бизнес-релевантности, которые может установить администратор хранилища, такие как возраст файла, местоположение, отказоустойчивость и т. д. Это означает, что вы можете сбалансировать производительность, емкость, операционную Факторы эффективности и стоимости. Высокопроизводительное и дорогостоящее хранилище можно зарезервировать для горячих данных, а монокритические (или неактивные) данные можно перенести в недорогое хранилище или в облако.
- Вы можете задействовать всю доступную емкость в организации, разблокировав карманы неиспользуемого хранилища, о которых вы даже не подозревали. Это означает, что вы можете отложить дорогостоящие обновления или вообще избежать их.
- Глобальное пространство имен позволяет легко находить нужные данные, когда они вам нужны. Все данные файлов и объектов теперь доступны с центральной консоли независимо от того, на каком устройстве/типе хранилища они находятся. Используя операцию поиска и поиска на основе метаданных, vFilO ускоряет процесс поиска и доступа к данным на различных типах устройств хранения (файловые или объект, хранящийся локально или в облаке).

Почему эти факторы так важны для бизнес-лидеров, ИТ-администраторов и пользователей прямо сейчас?
- Потому что они обеспечивают быстрый и удобный доступ к данным в любое время и из любого места, помогая внедрять инновации и получать конкурентные преимущества.
- Потому что вы можете сбалансировать и точно настроить производительность, емкость, операционную эффективность и стоимость для всей вашей системы хранения данных.