Что такое функциональное программирование — Журнал «Код» программирование без снобизма
В программировании есть два больших подхода — императивное и функциональное. Они существенно отличаются логикой работы, ещё и создают путаницу в названиях. Сейчас объясним.
🤔 Функциональное — это про функции?
❌ Нет. Функциональное — это не про функции. Функции есть почти в любых языках программирования: и в функциональных, и в императивных. Отличие функционального программирования от императивного — в общем подходе.
Метафора: инструкция или книга правил
Представьте, что вы открываете кафе-столовую. Сейчас у вас там два типа сотрудников: повара и администраторы.
Для поваров вы пишете чёткие пошаговые инструкции для каждого блюда. Например:
- Налить воды в кастрюлю
- Поставить кастрюлю с водой на огонь
- Добавить в кастрюлю с водой столько-то соли
- Если нужно приготовить 10 порций, взять одну свёклу. Если нужно приготовить 20 порций, взять две свёклы.

- Почистить всю свёклу, которую вы взяли
- …

Повар должен следовать этим инструкциям ровно в той последовательности, в которой вы их написали. Нельзя сначала почистить свёклу, а потом взять её. Нельзя посолить кастрюлю, в которой нет воды. Порядок действий важен и определяется вами. Это пример императивного программирования. Вы повелеваете исполнителем. Можно сказать, что исполнители выполняют ваши задания.
Для администратора вы пишете не инструкцию, а как бы книгу правил:
- У нас нельзя со своим. Если гости пришли со своим, то сделать им замечание такое-то.
- В зале должно быть чисто. Если в зале грязно, вызвать уборщика.
- Если образовалась очередь, открыть дополнительную кассу.
Это тоже команды, но исполнять их администратор будет не в этой последовательности, а в любой на своё усмотрение. Можно сказать, что задача этого человека — исполнять функции администратора, и мы описали правила, по которым эти функции исполнять. Это пример функционального программирования.
Это пример функционального программирования.
❌ Программисты, не бомбите
Конечно же, это упрощено для понимания. Вы сами попробуйте это нормально объяснить (можно прямо в комментах).
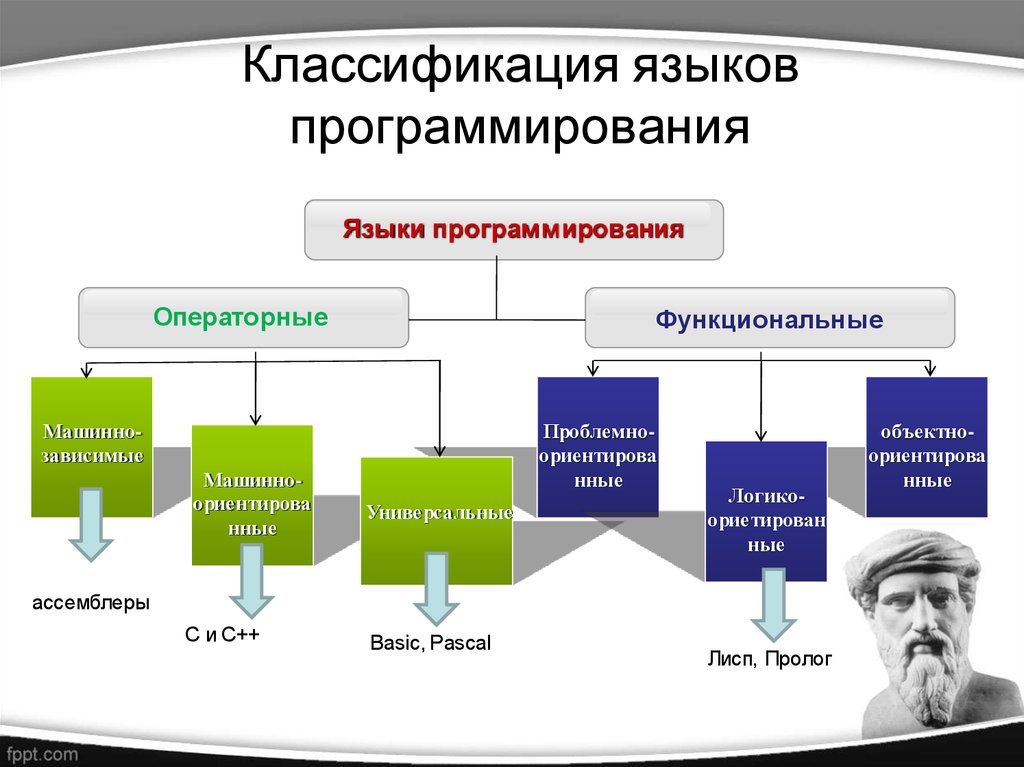
Императивное программирование
Примеры языков: C, С++, Go, Pascal, Java, Python, Ruby
Императивное программирование устроено так:
В языке есть команды, которые этот язык может выполнять. Эти команды можно собрать в подпрограммы, чтобы автоматизировать некоторые однотипные вычисления. В каком порядке записаны команды внутри подпрограммы, в том же порядке они и будут выполняться.
Есть переменные, которые могут хранить данные и изменяться во время работы программы. Переменная — это ячейка для данных. Мы можем создать переменную нужного нам типа, положить туда какое-то значение, а потом поменять его на другое.
Как называть переменные и функции, чтобы вас уважали бывалые программисты
Если подпрограмме на вход подать какое-то значение, то результат будет зависеть не только от исходных данных, но и от других переменных. Например, у нас есть функция, которая возвращает размер скидки при покупке в онлайн-магазине. Мы добавляем в корзину товар стоимостью 1000 ₽, а функция должна нам вернуть размер получившейся скидки. Но если скидка зависит от дня недели, то функция сначала проверит, какой сегодня день, потом посмотрит по таблице, какая сегодня скидка.
Например, у нас есть функция, которая возвращает размер скидки при покупке в онлайн-магазине. Мы добавляем в корзину товар стоимостью 1000 ₽, а функция должна нам вернуть размер получившейся скидки. Но если скидка зависит от дня недели, то функция сначала проверит, какой сегодня день, потом посмотрит по таблице, какая сегодня скидка.
Получается, что в разные дни функция получает на вход 1000 ₽, но возвращает разные значения — так работает императивное программирование, когда всё зависит от других переменных.
Последовательность выполнения подпрограмм регулируется программистом. Он задаёт нужные условия, по которым движется программа. Вся логика полностью продумывается программистом — как он скажет, так и будет. Это значит, что разработчик может точно предсказать, в какой момент какой кусок кода выполнится — код получается предсказуемым, с понятной логикой работы.
Если у нас код, который считает скидку, должен вызываться только при финальном оформлении заказа, то он выполнится именно в этот момент. Он не посчитает скидку заранее и не пропустит момент оформления.
Он не посчитает скидку заранее и не пропустит момент оформления.
👉 Суть императивного программирования в том, что программист описывает чёткие шаги, которые должны привести код к нужной цели.
Звучит логично, и большинство программистов привыкли именно к такому поведению кода. Но функциональное программирование работает совершенно иначе.
Функциональное программирование
Примеры языков: Haskell, Lisp, Erlang, Clojure, F#
Смысл функционального программирования в том, что мы задаём не последовательность нужных нам команд, а описываем взаимодействие между ними и подпрограммами. Это похоже на то, как работают объекты в объектно-ориентированном программировании, только здесь это реализуется на уровне всей программы.
Например, в ООП нужно задать объекты и правила их взаимодействия между собой, но также можно и написать просто код, который не привязан к объектам. Он как бы стоит в стороне и влияет на работу программы в целом — отправляет одни объекты взаимодействовать с другими, обрабатывает какие-то результаты и так далее.
Функциональное программирование здесь идёт ещё дальше. В нём весь код — это правила работы с данными. Вы просто задаёте нужные правила, а код сам разбирается, как их применять.
Если мы сравним принципы функционального подхода с императивным, то единственное, что совпадёт, — и там, и там есть команды, которые язык может выполнять. Всё остальное — разное.
Команды можно собирать в подпрограммы, но их последовательность не имеет значения. Нет разницы, в каком порядке вы напишете подпрограммы — это же просто правила, а правила применяются тогда, когда нужно, а не когда про них сказали.
Переменных нет. Вернее, они есть, но не в том виде, к которому мы привыкли. В функциональном языке мы можем объявить переменную только один раз, и после этого значение переменной измениться не может. Это как константы — записали и всё, теперь можно только прочитать. Сами же промежуточные результаты хранятся в функциях — обратившись к нужной, вы всегда получите искомый результат.
Функции всегда возвращают одно и то же значение, если на вход поступают одни и те же данные. Если в прошлом примере мы отдавали в функцию сумму в 1000 ₽, а на выходе получали скидку в зависимости от дня недели, то в функциональном программировании если функция получит в качестве параметра 1000 ₽, то она всегда вернёт одну и ту же скидку независимо от других переменных.
Можно провести аналогию с математикой и синусами: синус 90 градусов всегда равен единице, в какой бы момент мы его ни посчитали или какие бы углы у нас ещё ни были в задаче. То же самое и здесь — всё предсказуемо и зависит только от входных параметров.
Последовательность выполнения подпрограмм определяет сам код и компилятор, а не программист. Каждая команда — это какое-то правило, поэтому нет разницы, когда мы запишем это правило, в начале или в конце кода. Главное, чтобы у нас это правило было, а компилятор сам разберётся, в какой момент его применять.
В русском языке всё работает точно так же: есть правила правописания и грамматики. Нам неважно, в каком порядке мы их изучили, главное — чтобы мы их вовремя применяли при написании текста или в устной речи. Например, мы можем сначала пройти правило «жи-ши», а потом правило про «не с глаголами», но применять мы их будем в том порядке, какой требуется в тексте.
Нам неважно, в каком порядке мы их изучили, главное — чтобы мы их вовремя применяли при написании текста или в устной речи. Например, мы можем сначала пройти правило «жи-ши», а потом правило про «не с глаголами», но применять мы их будем в том порядке, какой требуется в тексте.
👉 Получается, что смысл функционального программирования в том, чтобы описать не сами чёткие шаги к цели, а правила, по которым компилятор сам должен дойти до нужного результата.
Основные понятия функционального программирования в F # — F#
- Статья
- Чтение занимает 7 мин
Функциональное программирование — это стиль программирования, в котором особое значение придается использованию функций и неизменяемых данных. Типизированное функциональное программирование — это сочетание функционального программирования со статическими типами, как это характерно для F#. В целом в функциональном программировании применяются такие основные подходы:
Типизированное функциональное программирование — это сочетание функционального программирования со статическими типами, как это характерно для F#. В целом в функциональном программировании применяются такие основные подходы:
- функции как основные используемые конструкции;
- выражения вместо инструкций;
- неизменяемые значения имеют приоритет перед переменными;
- декларативное программирование имеет приоритет перед императивным программированием.
В этой серии вы ознакомитесь с основными понятиями и особенностями функционального программирования на F#. Кроме того, в процессе вы немного научитесь писать код на F#.
Терминология
Функциональное программирование, как и другие подходы программирования, имеет свой словарь, который вам придется изучить. Ниже приведены некоторые распространенные термины:
- Функция — это конструкция, которая возвращает выходные данные при наличии входных данных. Фактически она сопоставляет элемент из одного набора с другим набором. На практике такой подход может реализоваться разными способами, особенно при использовании функций, которые работают с коллекциями данных. Это самое простое (и важное) понятие в функциональном программировании.
- Выражение
- Чистота — это свойство функции, которое означает, что возвращаемое значение всегда будет одним и тем же при использовании одних и тех же аргументов, а ее выполнение не имеет побочных эффектов. Чистая функция полностью зависит от своих аргументов.
- Ссылочная прозрачность — это свойство выражений, которое означает, что их можно заменить выходными данными без изменения поведения программы.
- Неизменяемость — означает, что значение нельзя изменить на месте. Но переменные можно изменить на месте.
 На практике такой подход может реализоваться разными способами, особенно при использовании функций, которые работают с коллекциями данных. Это самое простое (и важное) понятие в функциональном программировании.
На практике такой подход может реализоваться разными способами, особенно при использовании функций, которые работают с коллекциями данных. Это самое простое (и важное) понятие в функциональном программировании.Примеры
Все эти основные понятия демонстрируются в приведенных ниже примерах.
Функции
Самая распространенная и основная конструкция функционального программирования — это функция. Ниже приведена простая функция, которая добавляет 1 к целому числу:
let addOne x = x + 1
Ее сигнатура типа имеет следующий вид:
val addOne: x:int -> int
Сигнатуру можно прочитать как «addOne принимает значение типа int с именем x и возвращает значение типа int«. Более формально addOne — addOne значения из набора целых чисел с набором целых чисел. Такое сопоставление обозначено маркером ->. В F# вы можете просмотреть сигнатуру функции, чтобы узнать ее назначение.
Так в чем важность сигнатуры? В типизированном функциональном программировании реализация функции часто менее важна, чем фактическая сигнатура типа. Тот факт, что int , — это то, что будет действительно использовать эту функцию. Кроме того, если эта функция используется правильно (с учетом сигнатуры типа), диагностику проблем можно выполнить только в теле функции
Кроме того, если эта функция используется правильно (с учетом сигнатуры типа), диагностику проблем можно выполнить только в теле функции addOne. Это и обуславливает особенности типизированного функционального программирования.
Выражения
Выражения — это конструкции, возвращающие значения. В отличие от инструкций, выполняющих действия, выражения можно рассматривать как действия с возвратом значения. В функциональном программировании чаще всего используются выражения, а не инструкции.
Давайте рассмотрим предыдущую функцию, addOne. Тело функции addOne — это выражение:
// 'x + 1' is an expression! let addOne x = x + 1
Это результат выражения, определяющий тип результата функции addOne. Например, выражение, образующее эту функцию, можно изменить на другой тип, такой как string:
let addOne x = x.ToString() + "1"
Сигнатура функции теперь выглядит следующим образом:
val addOne: x:'a -> string
Так как в F # может ToString() вызываться любой тип, тип x был сделан универсальным (называемым ToString()), а результирующий тип — string .
Выражения — это не просто тела функций. Вы можете использовать выражения, возвращающие значение, которое затем используется в другой области. Одно из распространенных выражений — это if:
// Checks if 'x' is odd by using the mod operator
let isOdd x = x % 2 <> 0
let addOneIfOdd input =
let result =
if isOdd input then
input + 1
else
input
result
Выражение if возвращает значение с именем result. Обратите внимание, что result можно полностью опустить, сделав выражение if телом функции addOneIfOdd. Главное, о чем нужно помнить при использовании выражений, это то, что они возвращают значение.
Существует специальный тип выражений, unit, который используется, если результат возвращать не нужно. Рассмотрим, например, следующую простую функцию:
let printString (str: string) =
printfn $"String is: {str}"
Сигнатура выглядит следующим образом:
val printString: str:string -> unit
Тип unit указывает, что значение не возвращается. Это полезно, если у вас есть подпрограммы, которые должны выполнять действия, но при этом без возврата результата.
Это полезно, если у вас есть подпрограммы, которые должны выполнять действия, но при этом без возврата результата.
Такой подход сильно отличается от подхода императивного программирования, где эквивалентная конструкция if является инструкцией, а возврат значений часто осуществляется с помощью изменения переменных. Например, в C# код можно написать следующим образом:
bool IsOdd(int x) => x % 2 != 0;
int AddOneIfOdd(int input)
{
var result = input;
if (IsOdd(input))
{
result = input + 1;
}
return result;
}
Стоит отметить, что C# и другие языки в стиле C поддерживают тернарное выражение, что позволяет применять условное программирование на основе выражений.
В функциональном программировании инструкции редко используются для изменения значений. Хотя некоторые функциональные языки поддерживают инструкции и изменения, в функциональном программировании редко используется такой подход.
Чистые функции
Как было сказано ранее, чистые функции — это функции, которые:
- всегда возвращают одно и то же значение для одних и тех же входных данных;
- не имеют побочных эффектов.
В этом контексте чистые функции удобно сравнить с математическими функциями. В математике функции зависят только от своих аргументов и не имеют побочных эффектов. В математической функции f(x) = x + 1 значение f(x) зависит только от значения x. Чистые функции в функциональном программировании ведут себя так же.
При написании чистой функции она должна зависеть только от своих аргументов и не выполнять какие-либо действия, которые приводят к побочному результату.
Ниже приведен пример функции, не являющейся чистой, так как она зависит от глобального изменяемого состояния:
let mutable value = 1 let addOneToValue x = x + value
Очевидно, что функция addOneToValue не является чистой, так как value можно изменить в любое время на другое значение, отличное от 1. В функциональном программировании следует избегать такого подхода с зависимостью от глобального значения.
Ниже приведен еще один пример функции, не являющейся чистой, так как она имеет побочный эффект:
let addOneToValue x =
printfn $"x is %d{x}"
x + 1
Эта функция не зависит от глобального значения, но она записывает значение x в выходные данные программы. Хотя в этом нет ничего плохого, это означает, что функция не является чистой. Если другая часть программы зависит от внешнего для программы объекта, например выходного буфера, вызов этой функции может повлиять на другую часть программы.
Хотя в этом нет ничего плохого, это означает, что функция не является чистой. Если другая часть программы зависит от внешнего для программы объекта, например выходного буфера, вызов этой функции может повлиять на другую часть программы.
Если удалить инструкцию printfn, функция станет чистой:
let addOneToValue x = x + 1
Несмотря на то, что эта функция не является более предпочтительной , чем предыдущая версия с инструкцией, она гарантирует, что вся эта функция возвращает значение. При вызове этой функции любое количество раз вы получите одинаковый результат. Многие разработчики, использующие функциональное программирование, ценят такую предсказуемость, обеспечиваемую чистотой.
Неизменяемость
Наконец, одно из самых основных понятий типизированного функционального программирования — это неизменяемость. В F# все значения являются неизменяемыми по умолчанию. Это означает, что их нельзя изменить без обработки, если только вы не пометите их как изменяемые.
На практике работа с неизменяемыми значениями приводит к тому, что вам придется менять подход к программированию с «мне нужно изменить что-нибудь» на «мне нужно получить новое значение».
Например, если добавить 1 к значению, будет создано новое значение, а не изменено существующее:
let value = 1 let secondValue = value + 1
В языке F # следующий код не изменяет функцию; вместо этого он выполняет проверку на равенство:
let value = 1 value = value + 1 // Produces a 'bool' value!
Некоторые языки функционального программирования совершенно не поддерживают изменяемость. В F# она поддерживается, но не является поведением по умолчанию для значений.
Этот подход применяется и к структурам данных. В функциональном программировании неизменяемые структуры данных, такие как наборы (и многие другие), имеют реализацию, отличную от той, которую вы можете ожидать. Фактически такие действия, как добавление элемента в набор, приводят не к изменению набора, а к созданию нового набора с добавленным значением. На внутреннем уровне при этом часто используется другая структура данных, которая позволяет эффективно отслеживать значение, чтобы в результате можно было получить соответствующее представление данных.
На внутреннем уровне при этом часто используется другая структура данных, которая позволяет эффективно отслеживать значение, чтобы в результате можно было получить соответствующее представление данных.
Такой стиль работы со значениями и структурами данных критически важен, так как он вынуждает рассматривать любые операции, которые вносят изменения, как операции, создающие новые версии целевого объекта. Это позволяет обеспечить согласованность равенства и сравнения в программах.
Дальнейшие действия
В следующем разделе будут подробно рассмотрены функции, а также различные способы их использования в функциональном программировании.
Использование функций в F # позволяет глубоко исследовать функции, показывая, как их можно использовать в различных контекстах.
Дополнительные сведения
Серия Функциональное мышление — это еще один отличный ресурс для изучения функционального программирования на F#. В ней доступно описаны основы функционального программирования с практическими примерами использования функций F# для иллюстрации понятий.
Открытое образование — Функциональное программирование: базовый курс
Select the required university:
———
Закрыть
В курсе изучаются основы функционального подхода к программированию и практические вопросы программирования на языке Lisp. Функциональные языки обладают множеством интересных особенностей, знакомство с которыми расширяет кругозор программиста. Курс содержит видеолекции, опросы и практические задания по программированию. Материал курса рассчитан на 10 недель обучения.
- About
- Format
- Information resources
- Requirements
- Course program
- Education results
- Formed competencies
- Education directions
About
Курс посвящен введению в функциональное программирование. В настоящее время интерес к функциональному программированию неуклонно растет, а функциональные языки программирования и заложенные в них концепции активно применяются в разработке программного обеспечения, работающего под высокой нагрузкой и предъявляющего повышенные требования к безопасности и масштабируемости. Многие приемы функционального программирования можно применять и в традиционных процедурных и объектно-ориентированных языках, особенно учитывая тот факт, что такие языки, как Java, C++, С#, Python, со временем заимствуют все больше и больше инструментов у чистых функциональных языков. Объяснение базовых концепций функционального подхода к написанию программ в курсе иллюстрируется с помощью одного из самых знаковых для функционального программирования языков – Lisp. По окончанию курса обучающиеся смогут применять базовые концепции фукнционального программирования при написании программ на любых языках, а также получат опыт использования языка Lisp для решения практических задач.
В настоящее время интерес к функциональному программированию неуклонно растет, а функциональные языки программирования и заложенные в них концепции активно применяются в разработке программного обеспечения, работающего под высокой нагрузкой и предъявляющего повышенные требования к безопасности и масштабируемости. Многие приемы функционального программирования можно применять и в традиционных процедурных и объектно-ориентированных языках, особенно учитывая тот факт, что такие языки, как Java, C++, С#, Python, со временем заимствуют все больше и больше инструментов у чистых функциональных языков. Объяснение базовых концепций функционального подхода к написанию программ в курсе иллюстрируется с помощью одного из самых знаковых для функционального программирования языков – Lisp. По окончанию курса обучающиеся смогут применять базовые концепции фукнционального программирования при написании программ на любых языках, а также получат опыт использования языка Lisp для решения практических задач.
Format
В состав курса входят видеолекции, сопровождаемые опросами для самоконтроля, и практические задания по программированию. Длительность курса составляет 10 недель. Трудоемкость курса – 4 зачетных единицы. Средняя недельная нагрузка на обучающегося – 9 часов.
1. Siebel P. Practical Common Lisp. – Apress, 2005 (книга на сайте автора (англ.): http://www.gigamonkeys.com/book/, доступен бесплатный и свободно распространяемый перевод на русский язык: http://lisper.ru/pcl/pcl.pdf)
2. Абельсон Х., Сассман Дж. Структура и интерпретация компьютерных программ. – М: КДУ, 2010. – 609 с.
3. Graham P. On Lisp [Электронный ресурс]. – URL: http://paulgraham.com/onlisptext.html.
4. Abelson H., Sussman G., Sussman J. Structure and Interpretation of Computer Programs. – 2nd ed. – MIT Press, 1996.
5. Krishnamurthi S. Programming Languages: Application and Interpretation. – Brown University Press, 2003.
6. Steele G., Gabriel R. The evolution of Lisp / The second ACM SIGPLAN conference on History of programming languages. – New York: ACM. – С. 231–270.
– New York: ACM. – С. 231–270.
Requirements
Необходимым условием для освоения курса является знание основ вычислительной техники и дискретной математики. Для прохождения курса требуется компилятор Lisp, поддерживающий стандарт Common Lisp, например, GNU CLISP или SBCL (http://www.sbcl.org/platform-table.html).
Руководство по установке компилятора можно скачать здесь.
Course program
В курсе рассматриваются следующие темы:
1. Введение в функциональное программирование и формальные основания функционального программирования
2. Базовые синтаксические конструкции, типы, символы и списки в языке Lisp
3. Ввод и вывод в языке Lisp
4. Функции высших порядков
5. Рекурсия
6. Применяющие и отображающие функционалы
7. Замыкания и лямбда-выражения
8. Макросы в языке Lisp
9. Ленивые вычисления
Каждая тема предполагает изучение в течение одной недели. На 10-й неделе запланирован интернет-экзамен.
Education results
- Умение решать задачи прикладного программирования с использованием базовых приемов функционального программирования (РО-1)
- Умение применять язык программирования Lisp для написания программ (РО-2)
Formed competencies
- 02. 04.03 Математическое обеспечение и администрирование информационных систем
- Готовность к использованию основных моделей информационных технологий и способов их применения для решения задач в предметных областях (ПК-2)
- Готовность к разработке моделирующих алгоритмов и реализации их на базе языков и пакетов прикладных программ моделирования (ПК-3)
- 09.03.01 Информатика и вычислительная техника
- Способность разрабатывать модели компонентов информационных систем, включая модели баз данных и модели интерфейсов «человек – электронно-вычислительная машина» (ПК-1)
- Способность разрабатывать компоненты программно-аппаратных комплексов и баз данных, используя современные инструментальные средства и технологии программирования (ПК-2)
- 09.03.02 Информационные системы и технологии
- Способность к проектированию базовых и прикладных информационных технологий (ПК-11)
- Способность к проектированию базовых и прикладных информационных технологий (ПК-12)
- 09. 03.03 Прикладная информатика
- Способность разрабатывать, внедрять и адаптировать прикладное программное обеспечение (ПК-2)
- Способность программировать приложения и создавать программные прототипы решения прикладных задач (ПК-8)
- 09.03.04 Программная инженерия
- Готовность применять основные методы и инструменты разработки программного обеспечения (ПК-1)
- Владение навыками использования различных технологий разработки программного обеспечения (ПК-3)
- 10.03.01 Информационная безопасность
- Способность применять программные средства системного, прикладного и специального назначения, инструментальные средства, языки и системы программирования для решения профессиональных задач (ПК-3)
 04.03 Математическое обеспечение и администрирование информационных систем
04.03 Математическое обеспечение и администрирование информационных систем 03.03 Прикладная информатика
03.03 Прикладная информатикаEducation directions
02.04.03 Математическое обеспечение и администрирование информационных систем
09.00.00 Информатика и вычислительная техника
10.00.00 Информационная безопасность
Университет ИТМО
Гирик Алексей Валерьевич
Кандидат технических наук
Position: доцент кафедры безопасности киберфизических систем
Certificate
По данному курсу возможно получение сертификата.
Similar courses
31 August 2020 — 15 August 2030 г.
Эконометрика
НИУ ВШЭ
7 September 2020 — 15 August 2030 г.
Защита информации
НИУ ВШЭ
7 September 2020 — 15 August 2030 г.
Общая социология
НИУ ВШЭ
К сожалению, мы не гарантируем корректную работу сайта в вашем браузере. Рекомендуем заменить его на один из предложенных.
Также советуем ознакомиться с полным списком рекомендаций.
Google Chrome
Mozilla Firefox
Apple Safari
Функциональное программирование — Образовательная платформа «Юрайт». Для вузов и ссузов.
- Скопировать в буфер библиографическое описание
Кубенский, А. А. Функциональное программирование : учебник и практикум для академического бакалавриата / А. А. Кубенский. — Москва : Издательство Юрайт, 2019. — 348 с. — (Высшее образование). — ISBN 978-5-9916-9242-7. — Текст : электронный // Образовательная платформа Юрайт [сайт]. — URL: https://urait.ru/bcode/433710 (дата обращения: 01.10.2022).
- Добавить в избранное
Учебник и практикум для академического бакалавриата
- 6 Посмотреть кому понравилось
- Поделиться
 Учебник и практикум для академического бакалавриата»>
Нравится
Учебник и практикум для академического бакалавриата»>
Нравится- Описание
- Программа курса
- Тесты: 16
- Задания: 16
- Нет в мобильном приложении
- Аннотация
- Программа курса
- Тесты 16
Функциональное программирование уверенно входит в жизнь каждого программиста. Многие привычные языки, например, Java, вводят расширения в синтаксис языка и стандартные библиотеки для поддержки функциональных средств. Это обусловлено тем фактом, что дальнейшее увеличение производительности работы программ уже не может быть обеспечено только увеличением быстродействия процессоров и памяти, а возможно только за счет развития параллельного программирования. Функциональное программирование позволяет писать короткие и изящные программы, которые, к тому же, хорошо «распараллеливаются». В представленной книге даются практические основы функционального программирования с использованием популярного языка программирования Haskell, излагаются основы лямбда-исчисления и комбинаторной логики.
Многие привычные языки, например, Java, вводят расширения в синтаксис языка и стандартные библиотеки для поддержки функциональных средств. Это обусловлено тем фактом, что дальнейшее увеличение производительности работы программ уже не может быть обеспечено только увеличением быстродействия процессоров и памяти, а возможно только за счет развития параллельного программирования. Функциональное программирование позволяет писать короткие и изящные программы, которые, к тому же, хорошо «распараллеливаются». В представленной книге даются практические основы функционального программирования с использованием популярного языка программирования Haskell, излагаются основы лямбда-исчисления и комбинаторной логики.
Функциональное программирование — особенности , достоинства и…
Сразу хочу сказать, что здесь никакой воды про функциональное программирование, и только нужная информация. Для того чтобы лучше понимать что такое
функциональное программирование, замыкание, каррирование, мемоизация, функции высших порядков, чистые функции, рекурсия, побочные эффекты, side effects, примитивная одержимость, primitive obsession , настоятельно рекомендую прочитать все из категории Функциональное программирование.
функциональное программирование — раздел дискретной математики и парадигма декларативного программирования, в которой процесс вычисления трактуется как вычисление значений функций в математическом понимании последних (в отличие от функций как подпрограмм в процедурном программировании).
Противопоставляется парадигме императивного программирования, которая описывает процесс вычислений как последовательное изменение состояний (в значении, подобном таковому в теории автоматов). При необходимости, в функциональном программировании вся совокупность последовательных состояний вычислительного процесса представляется явным образом, например, как список.
Основные концепции функционального программирования —
чистые функции ,
замыкание ,
каррирование ,
рекурсия ,
мемоизация .
Функциональное программирование предполагает обходиться вычислением результатов функций от исходных данных и результатов других функций, и не предполагает явного хранения состояния программы. Соответственно, не предполагает оно и изменяемость этого состояния (в отличие от императивного, где одной из базовых концепций является переменная, хранящая свое значение и позволяющая менять его по мере выполнения алгоритма).
На практике отличие математической функции от понятия «функции» в императивном программировании заключается в том, что императивные функции могут опираться не только на аргументы, но и на состояние внешних по отношению к функции переменных, а также иметь
побочные эффекты и менять состояние внешних переменных. Таким образом, в императивном программировании при вызове одной и той же функции с одинаковыми параметрами, но на разных этапах выполнения алгоритма, можно получить разные данные на выходе из-за влияния на функцию состояния переменных. А в функциональном языке при вызове функции с одними и теми же аргументами мы всегда получим одинаковый результат: выходные данные зависят только от входных. Это позволяет средам выполнения программ на функциональных языках кешировать результаты функций и вызывать их в порядке, не определяемом алгоритмом и распараллеливать их без каких-либо дополнительных действий со стороны программиста (см.ниже Чистые функции)
А в функциональном языке при вызове функции с одними и теми же аргументами мы всегда получим одинаковый результат: выходные данные зависят только от входных. Это позволяет средам выполнения программ на функциональных языках кешировать результаты функций и вызывать их в порядке, не определяемом алгоритмом и распараллеливать их без каких-либо дополнительных действий со стороны программиста (см.ниже Чистые функции)
λ-исчисления являются основой для функционального программирования, многие функциональные языки можно рассматривать как «надстройку» над ними .
Итак, функциональное программирование — это программирование с математическими функциями.
Математические функции не являются методами в программном смысле. Хотя мы иногда используем слова «метод» и «функция» как синонимы, с точки зрения функционального программирования это разные понятия. Математическую функцию лучше всего рассматривать как канал (pipe), преобразующий любое значение, которое мы передаем, в другое значение:
Вот и все. Математическая функция не оставляет во внешнем мире никаких следов своего существования. Она делает только одно: находит соответствующий объект для каждого объекта, который мы ему скармливаем.
Математическая функция не оставляет во внешнем мире никаких следов своего существования. Она делает только одно: находит соответствующий объект для каждого объекта, который мы ему скармливаем.
Языки функционального программирования
Язык функционального программирования
Наиболее известными языками функционального программирования являются :
- LISP — (Джон МакКарти, 1958) и множество его диалектов, наиболее современные из которых:
- Scheme
- Clojure
- Common Lisp
- Erlang — (Joe Armstrong, 1986) функциональный язык с поддержкой процессов.
- APL — предшественник современных научных вычислительных сред, таких как MATLAB.
- ML (Робин Милнер, 1979, из ныне используемых диалектов известны Standard ML и Objective CAML).
- F# — функциональный язык семейства ML для платформы .NET
- Scala
- Miranda (Дэвид Тернер, 1985, который впоследствии дал развитие языку Haskell).
- Nemerle — гибридный функционально/императивный язык.
- XSLT и XQuery
- Haskell — чистый функциональный. Назван в честь Хаскелла Карри.

Еще не полностью функциональные изначальные версии и Lisp и APL внесли особый вклад в создание и развитие функционального программирования. Более поздние версии Lisp, такие как Scheme, а также различные варианты APL поддерживали все свойства и концепции функционального языка .
Как правило, интерес к функциональным языкам программирования, особенно чисто функциональным, был скорее научный, нежели коммерческий. Однако, такие примечательные языки как Erlang, OCaml, Haskell, Scheme (после 1986) а также специфические R (статистика), Mathematica (символьная математика), J и K (финансовый анализ), и XSLT (XML) находили применение в индустрии коммерческого программирования. Такие широко распространенные декларативные языки какSQL и Lex/Yacc содержат некоторые элементы функционального программирования, например, они остерегаются использовать переменные. Языки работы с электронными таблицами также можно рассматривать как функциональные, потому что в ячейках электронных таблиц задается массив функций, как правило зависящих лишь от других ячеек, а при желании смоделировать переменные приходится прибегать к возможностям императивного языка макросов.
Языки работы с электронными таблицами также можно рассматривать как функциональные, потому что в ячейках электронных таблиц задается массив функций, как правило зависящих лишь от других ячеек, а при желании смоделировать переменные приходится прибегать к возможностям императивного языка макросов.
История развития функционалного программирования
Лямбда-исчисление стало теоретической базой для описания и вычисления функций. Являясь математической абстракцией, а не языком программирования, оно составило базис почти всех языков функционального программирования на сегодняшний день. Сходное теоретическое понятие, комбинаторная логика, является более абстрактным, нежели λ-исчисления и было создано раньше. Эта логика используется в некоторых эзотерических языках, например в Unlambda. И λ-исчисление, и комбинаторная логика были разработаны для более ясного и точного описания принципов и основ математики .
Первым функциональным языком был Lisp, созданный Джоном Маккарти в период его работы в Массачусетском технологическом институте в конце пятидесятых и реализованный, первоначально, для IBM 700/7000 (англ. )русск. . Lisp ввел множество понятий функционального языка, хотя при этом исповедовал не только парадигму функционального программирования . Дальнейшим развитием лиспа стали такие языки как Scheme и Dylan.
)русск. . Lisp ввел множество понятий функционального языка, хотя при этом исповедовал не только парадигму функционального программирования . Дальнейшим развитием лиспа стали такие языки как Scheme и Dylan.
Язык обработки информации (Information Processing Language (англ.)русск., IPL) иногда определяется как самый первый машинный функциональный язык . Это языкассемблерного типа для работы со списком символов. В нем было понятие «генератора», который использовал функцию в качестве аргумента, а также, поскольку это язык ассемблерного уровня, он может позиционироваться как язык, имеющий функции высшего порядка. Однако, в целом IPL акцентирован на использование императивных понятий .
Кеннет Е. Айверсон разработал язык APL в начале шестидесятых, документировав его в своей книге A Programming Language (ISBN 9780471430148)[11]. APL оказал значительное влияние на язык FP (англ.)русск., созданный Джоном Бэкусом. В начале девяностых Айверсон и Роджер Хуэй (англ.)русск. создали преемника APL — язык программирования J. В середине девяностых Артур Витни (англ.)русск., ранее работавший с Айверсоном, создал язык K, который впоследствии использовался в финансовой индустрии на коммерческой основе.
В середине девяностых Артур Витни (англ.)русск., ранее работавший с Айверсоном, создал язык K, который впоследствии использовался в финансовой индустрии на коммерческой основе.
В семидесятых в университете Эдинбурга Робин Милнер создал язык ML, а Дэвид Тернер начинал разработку языка SASL в университете Сент-Эндрюса и, впоследствии, язык Miranda в университете города Кент. В конечном итоге на основе ML были созданы несколько языков, среди которых наиболее известные Objective Caml и Standard ML. Также в семидесятых осуществлялась разработка языка программирования, построенного по принципу Scheme (реализация не только функциональной парадигмы), получившего описание в известной работе «Lambda Papers», а также в книге восемьдесят пятого года «Structure and Interpretation of Computer Programs», в которой принципы функционального программирования были донесены до более широкой аудитории.
В восьмидесятых Пер Мартин-Леф создал интуиционистскую теорию типов (также называемую конструктивной). В этой теории функциональное программирование получило конструктивное доказательство того, что ранее было известно как зависимый тип. Это дало мощный толчок к развитию диалогового доказательства теорем и к последующему созданию множества функциональных языков.
В этой теории функциональное программирование получило конструктивное доказательство того, что ранее было известно как зависимый тип. Это дало мощный толчок к развитию диалогового доказательства теорем и к последующему созданию множества функциональных языков.
Haskell был создан в конце восьмидесятых в попытке соединить множество идей, полученных в ходе исследования функционального программирования.
Концепции функционального программирования
Некоторые концепции и парадигмы специфичны для функционального программирования и в основном чужды императивному программированию (включая объектно-ориентированное программирование). Тем не менее, языки программирования обычно представляют собой гибрид нескольких парадигм программирования, поэтому «большей частью императивные» языки программирования могут использовать какие-либо из этих концепций.
функции высших порядков , частичное применение и каррингФункции высших порядков — это такие функции, которые могут принимать в качестве аргументов и возвращать другие функции.
Математики такую функцию чаще называют оператором, например, оператор взятия производной или оператор интегрирования.
Функции высших порядков позволяют использовать карринг(каррирование) — преобразование функции от пары аргументов в функцию, берущую свои аргументы по одному. Это преобразование получило свое название в честь Х. Карри.
подробнее про каррирование будет рассмотрено в следующих главах.
Чистые функцииЧистыми называют функции, которые не имеют побочных эффектов ввода-вывода и памяти (они зависят только от своих параметров и возвращают только свой результат). Чистые функции обладают несколькими полезными свойствами, многие из которых можно использовать для оптимизации кода:
- Если результат чистой функции не используется, ее вызов может быть удален без вреда для других выражений.
- Результат вызова чистой функции может быть мемоизирован, то есть сохранен в таблице значений вместе с аргументами вызова. Если в дальнейшем функция вызывается с этими же аргументами, ее результат может быть взят прямо из таблицы, не вычисляясь (иногда это называется принципом прозрачности ссылок).Мемоизация, ценой небольшого расхода памяти, позволяет существенно увеличить производительность и уменьшить порядок роста некоторых рекурсивных алгоритмов.
- Если нет никакой зависимости по данным между двумя чистыми функциями, то порядок их вычисления можно поменять или распараллелить (говоря иначе вычисление чистых функций удовлетворяет принципам thread-safe)
- Если весь язык не допускает побочных эффектов, то можно использовать любую политику вычисления . Об этом говорит сайт https://intellect.icu . Это предоставляет свободу компилятору комбинировать и реорганизовывать вычисление выражений в программе (например, исключить древовидные структуры).
 Если в дальнейшем функция вызывается с этими же аргументами, ее результат может быть взят прямо из таблицы, не вычисляясь (иногда это называется принципом прозрачности ссылок).Мемоизация, ценой небольшого расхода памяти, позволяет существенно увеличить производительность и уменьшить порядок роста некоторых рекурсивных алгоритмов.
Если в дальнейшем функция вызывается с этими же аргументами, ее результат может быть взят прямо из таблицы, не вычисляясь (иногда это называется принципом прозрачности ссылок).Мемоизация, ценой небольшого расхода памяти, позволяет существенно увеличить производительность и уменьшить порядок роста некоторых рекурсивных алгоритмов.Хотя большинство компиляторов императивных языков программирования распознают чистые функции и удаляют общие подвыражения для вызовов чистых функций, они не могут делать это всегда для предварительно скомпилированных библиотек, которые, как правило, не предоставляют эту информацию. Некоторые компиляторы, такие как gcc, в целях оптимизации предоставляют программисту ключевые слова для обозначения чистых функций . Fortran 95 позволяет обозначать функции как «pure» (чистые) .
Некоторые компиляторы, такие как gcc, в целях оптимизации предоставляют программисту ключевые слова для обозначения чистых функций . Fortran 95 позволяет обозначать функции как «pure» (чистые) .
В функциональных языках цикл обычно реализуется в виде рекурсии. Строго говоря, в функциональной парадигме программирования нет такого понятия, как цикл. Рекурсивные функции вызывают сами себя, позволяя операции выполняться снова и снова. Для использования рекурсии может потребоваться большой стек, но этого можно избежать в случае хвостовой рекурсии. Хвостовая рекурсия может быть распознана и оптимизирована компилятором в код, получаемый после компиляции аналогичной итерации в императивном языке программирования. Стандарты языка Scheme требуют распознавать и оптимизировать хвостовую рекурсию. Оптимизировать хвостовую рекурсию можно путем преобразования программы в стиле использования продолжений при ее компиляции, как один из способов
Рекурсивные функции можно обобщить с помощью функций высших порядков, используя, например, катаморфизм и анаморфизм (или «свертка» и «развертка»). Функции такого рода играют роль такого понятия как цикл в императивных языках программирования.
Функции такого рода играют роль такого понятия как цикл в императивных языках программирования.
Функциональные языки можно классифицировать по тому, как обрабатываются аргументы функции в процессе ее вычисления. Технически различие заключается в денотационной семантике выражения. К примеру, при строгом подходе к вычислению выражения
print(len([2+1, 3*2, 1/0, 5-4]))
на выходе будет ошибка, так как в третьем элементе списка присутствует деление на ноль. При нестрогом подходе значением выражения будет 4, поскольку для вычисления длины списка значения его элементов, строго говоря, не важны и могут вообще не вычисляться. При строгом (аппликативном) порядке вычисления заранее подсчитываются значения всех аргументов перед вычислением самой функции. При нестрогом подходе (нормальный порядок вычисления) значения аргументов не вычисляются до тех пор, пока их значение не понадобится при вычислении функции[17].
Как правило, нестрогий подход реализуется в виде редукции графа. Нестрогое вычисление используется по умолчанию в нескольких чисто функциональных языках, в том числе Miranda, Clean и Haskell.
МемоизацияМемоизация (запоминание, от англ. memoization) — в программировании сохранение результатов выполнения функций для предотвращения повторных вычислений. Это один из способов оптимизации, применяемый для увеличения скорости выполнения компьютерных программ. Перед вызовом функции проверяется, вызывалась ли функция ранее:
- если не вызывалась, то функция вызывается, и результат ее выполнения сохраняется;
- если вызывалась, то используется сохраненный результат.
подробее будет рассотредо в следущих главах.
Понятие замыкания в функциональном программрованиииЗамыкание (англ. closure) в программировании — функция первого класса, в теле которой присутствуют ссылки на переменные, объявленные вне тела этой функции в окружающем коде и не являющиеся ее параметрами. Говоря другим языком, замыкание — функция, которая ссылается на свободные переменные в своей области видимости.
Говоря другим языком, замыкание — функция, которая ссылается на свободные переменные в своей области видимости.
Замыкание, так же как и экземпляр объекта, есть способ представления функциональности и данных, связанных и упакованных вместе.
Замыкание — это особый вид функции. Она определена в теле другой функции и создается каждый раз во время ее выполнения. Синтаксически это выглядит как функция, находящаяся целиком в теле другой функции. При этом вложенная внутренняя функция содержит ссылки на локальные переменные внешней функции. Каждый раз при выполнении внешней функции происходит создание нового экземпляра внутренней функции, с новыми ссылками на переменные внешней функции.
В случае замыкания ссылки на переменные внешней функции действительны внутри вложенной функции до тех пор, пока работает вложенная функция, даже если внешняя функция закончила работу, и переменные вышли из области видимости.
Замыкание связывает код функции с ее лексическим окружением (местом, в котором она определена в коде). Лексические переменные замыкания отличаются от глобальных переменных тем, что они не занимают глобальное пространство имен. От переменных в объектах они отличаются тем, что привязаны к функциям, а не объектам.
Лексические переменные замыкания отличаются от глобальных переменных тем, что они не занимают глобальное пространство имен. От переменных в объектах они отличаются тем, что привязаны к функциям, а не объектам.
Примеры замыкания на Javascript , Java, Scheme
Чем функциональное программирование отличается от обычного процедурного подхода?
Разбиение императивного кода на процедуры и функции в процедурной парадигме служит как инструмент абстракции в руках умелых или только для избавления от копипасты в руках обычных. Функции рассчитывают результат, а процедуры что-то куда-то записывают. Ведь нет смысла вызывать процедуру, которая ничего не возвращает и ничего при этом не делает.
В нашем парсере ничего записывать не надо и императивная пошаговость не нужна. Мы просто в потоке преобразуем одни данные в другие, не перезаписывая старые значения. Поэтому в функциональной парадигме можно выкинуть процедуры и переменные за ненадобностью и оставить лишь константы и функции.
Принципиально нет препятствий для написания программ в функциональном стиле на языках, которые традиционно не считаются функциональными, точно так же, как программы в объектно-ориентированном стиле можно писать на структурных языках. Некоторые императивные языки поддерживают типичные для функциональных языков конструкции, такие как функции высшего порядка и списковые включения (list comprehensions), что облегчает использование функционального стиля в этих языках. Примером может быть функциональное программирование на языке Python. Другим примером является язык Ruby, который имеет возможность создания как lambda-объектов, так и возможность организации анонимных функций высшего порядка через блок с помощью конструкции yield.
В языке C указатели на функцию в качестве типов аргументов могут быть использованы для создания функций высшего порядка. Функции высшего порядка и отложенная списковая структура реализованы в библиотеках С++. В языке C# версии 3.0 и выше можно использовать λ-функции для написания программы в функциональном стиле. В сложных языках, типа Алгол-68, имеющиеся средства метапрограммирования (фактически, дополнения языка новыми конструкциями) позволяют создать специфичные для функционального стиля объекты данных и программные конструкции, после чего можно писать функциональные программы с их использованием.
В языке C# версии 3.0 и выше можно использовать λ-функции для написания программы в функциональном стиле. В сложных языках, типа Алгол-68, имеющиеся средства метапрограммирования (фактически, дополнения языка новыми конструкциями) позволяют создать специфичные для функционального стиля объекты данных и программные конструкции, после чего можно писать функциональные программы с их использованием.
Стили программирования
Императивные программы имеют склонность акцентировать последовательности шагов для выполнения какого-то действия, а функциональные программы к расположению и композиции функций, часто не обозначая точной последовательности шагов. Простой пример двух решений одной задачи (используется один и тот же язык Python) иллюстрирует это.
# императивный стиль
target = [] # создать пустой список
for item in source_list: # для каждого элемента исходного списка
trans1 = G(item) # применить функцию G()
trans2 = F(trans1) # применить функцию F()
target. append(trans2) # добавить преобразованный элемент в список
 append(trans2) # добавить преобразованный элемент в список
append(trans2) # добавить преобразованный элемент в список
Функциональная версия выглядит по-другому:
# функциональный стиль # языки ФП часто имеют встроенную функцию compose() compose2 = lambda A, B: lambda x: A(B(x)) target = map(compose2(F, G), source_list)
В отличие от императивного стиля, описывающего шаги, ведущие к достижению цели, функциональный стиль описывает математические отношения между данными и целью.
Для того чтобы метод стал математической функцией, он должен соответствовать двум требованиям. Прежде всего, он должен быть ссылочно прозрачным (referentially transparent). Ссылочно прозрачная функция всегда дает один и тот же результат, если вы предоставляете ей одни и те же аргументы. Это означает, что такая функция должна работать только со значениями, которые мы передаем, она не должна ссылаться на глобальное состояние.
Вот еще пример функонального программрования:
Этот метод не является ссылочно прозрачным, потому что он возвращает разные результаты, даже если мы передаем в него один и тот же год. Причина здесь в том, что он ссылается на глобальное свойство DatetTime.Now.
Причина здесь в том, что он ссылается на глобальное свойство DatetTime.Now.
Ссылочно прозрачной альтернативой этому методу может быть (Эта версия работает только с переданными параметрами):
Во-вторых, сигнатура математической функции должна передавать всю информацию о возможных входных значениях, которые она принимает, и о возможных результатах, которые она может дать. Можно называть эту черту честность сигнатуры метода (method signature honesty).
Посмотрите на этот пример кода:
Метод Divide, несмотря на то, что он ссылочно прозрачный, не является математической функцией. В его сигнатуре указано, что он принимает любые два целых числа и возвращает другое целое число. Но что произойдет, если мы передадим ему 1 и 0 в качестве входных параметров?
Вместо того, чтобы вернуть целое число, как мы ожидали, он вызовет исключение «Divide By Zero». Это означает, что сигнатура метода не передает достаточно информации о результате операции. Он обманывает вызывающего, делая вид, что может обрабатывать любые два параметра целочисленного типа, тогда как на практике он имеет особый случай, который не может быть обработан.
Он обманывает вызывающего, делая вид, что может обрабатывать любые два параметра целочисленного типа, тогда как на практике он имеет особый случай, который не может быть обработан.
Чтобы преобразовать метод в математическую функцию, нам нужно изменить тип параметра «y», например:
Здесь NonZeroInteger — это пользовательский тип, который может содержать любое целое число, кроме нуля. Таким образом, мы сделали метод честным, поскольку теперь он не ведет себя неожиданно для любых значений из входного диапазона. Другой вариант — изменить его возвращаемый тип:
Эта версия также честна, поскольку теперь не гарантирует, что она вернет целое число для любой возможной комбинации входных значений.
Несмотря на простоту определения функционального программирования, оно включает в себя множество приемов, которые многим программистам могут показаться новыми. Посмотрим, что они из себя представляют.
Побочные эффекты (Side effects)Первая такая практика — максимально избегать побочных эффектов за счет использования иммутабельности по всей базе кода. Этот метод важен, потому что акт изменения состояния противоречит функциональным принципам.
Этот метод важен, потому что акт изменения состояния противоречит функциональным принципам.
Сигнатура метода с побочным эффектом не передает достаточно информации о фактическом результате операции. Чтобы проверить свои предположения относительно кода, который вы пишете, вам нужно не только взглянуть на саму сигнатуру метода, но также необходимо перейти к деталям его реализации и посмотреть, оставляет ли этот метод какие-либо побочные эффекты, которых вы не ожидали:
В целом, код со структурами данных, которые меняются со временем, сложнее отлаживать и более подвержен ошибкам. Это создает еще больше проблем в многопоточных приложениях, где у вас могут возникнуть всевозможные неприятные условия гонки.
Когда вы работаете только с иммутабельными данными, вы заставляете себя обнаруживать скрытые побочные эффекты, указывая их в сигнатуре метода и тем самым делая его честным. Это делает код более читабельным, потому что вам не нужно останавливаться на деталях реализации методов, чтобы понять ход выполнения программы. С иммутабельными классами вы можете просто взглянуть на сигнатуру метода и сразу же получить хорошее представление о том, что происходит, без особых усилий.
С иммутабельными классами вы можете просто взглянуть на сигнатуру метода и сразу же получить хорошее представление о том, что происходит, без особых усилий.
Исключения — еще один источник нечестности для вашей кодовой базы. Методы, которые используют исключения для управления потоком программы, не являются математическими функциями, потому что, как и побочные эффекты, исключения скрывают фактический результат операции.
Более того, исключения имеют семантику goto, что означает, что они позволяют легко переходить из любой точки вашей программы в блок catch. На самом деле, исключения работают еще хуже, потому что оператор goto не позволяет выходить за пределы определенного метода, тогда как с исключениями вы можете легко пересекать несколько уровней в своей базе кода.
примитивная одержимость (Primitive Obsession)В то время как побочные эффекты и исключения делают ваши методы нечестными в отношении их результатов, примитивная одержимость вводит читателя в заблуждение относительно входных значений методов. Вот пример:
Вот пример:
Что нам говорит сигнатура метода CreateUser? Она говорит, что для любой входной строки он возвращает экземпляр User. Однако на практике он принимает только строки, отформатированные определенным образом, и выдает исключения, если это не так. Следовательно, этот метод нечестен, поскольку не передает достаточно информации о типах строк, с которыми работает.
По сути, это та же проблема, которую вы видели с методом Divide:
Тип параметра для электронной почты, а также тип параметра для «y» являются более грубыми, чем фактическая концепция, которую они представляют. Количество состояний, в которых может находиться экземпляр строкового типа, превышает количество допустимых состояний для правильно отформатированного электронного письма. Это несоответствие приводит к обману разработчика, который использует такой метод. Это заставляет программиста думать, что метод работает с примитивными строками, тогда как на самом деле эта строка представляет концепцию предметной области со своими инвариантами.
Как и в случае с методом Divide, нечестность можно исправить, введя отдельный класс Email и используя его вместо строки.
Nulls
Еще одна практика в этом списке — избегать nulls. Оказывается, использование значений NULL делает ваш код нечестным, поскольку сигнатура методов, использующих их, не сообщает всю информацию о возможном результате соответствующей операции.
Но тут, конечно, зависит от языка. Автор оригинала работает с C#, в котором до 8 версии нельзя было указывать является ли значение nullable (https://docs.microsoft.com/en-us/dotnet/csharp/language-reference/builtin-types/nullable-value-types). Так как оригинал статьи 2016 года, на тот момент еще не было такой возможности в C#.
Фактически, в C # все ссылочные типы действуют как контейнер для двух типов значений. Один из них является экземпляром объявленного типа, а другой — null. И нет никакого способа провести различие между ними, поскольку эта функциональность встроена в сам язык. Вы всегда должны помнить, что, объявляя переменную ссылочного типа, вы фактически объявляете переменную пользовательского двойного типа, которая может содержать либо нулевую ссылку, либо фактический экземпляр:
Вы всегда должны помнить, что, объявляя переменную ссылочного типа, вы фактически объявляете переменную пользовательского двойного типа, которая может содержать либо нулевую ссылку, либо фактический экземпляр:
В некоторых случаях это именно то, что вам нужно, но иногда вы хотите просто вернуть MyClass без возможности его преобразования в null. Проблема в том, что в C # это невозможно сделать. Невозможно различить ссылочные типы, допускающие значение NULL, и ссылочные типы, не допускающие значения NULL. Это означает, что методы со ссылочными типами в своей сигнатуре по своей сути нечестны.
Эту проблему можно решить, введя тип Maybe и соглашение внутри команды о том, что всякий раз, когда вы определяете переменную, допускающую значение NULL, вы используете для этого тип Maybe.
Почему функциональное программирование?
Важный вопрос, который приходит на ум, когда вы читаете о функциональном программировании: зачем вообще беспокоиться об этом?
Одной из самых больших проблем, возникающих при разработке корпоративного программного обеспечения, является сложность. Сложность кодовой базы, над которой мы работаем, является единственным наиболее важным фактором, влияющим на такие вещи, как скорость разработки, количество ошибок и способность быстро приспосабливаться к постоянно меняющимся потребностям рынка.
Сложность кодовой базы, над которой мы работаем, является единственным наиболее важным фактором, влияющим на такие вещи, как скорость разработки, количество ошибок и способность быстро приспосабливаться к постоянно меняющимся потребностям рынка.
Существует некий предел сложности, с которой мы можем справиться за раз. Если кодовая база проекта превышает этот предел, становится действительно трудно, а в какой-то момент даже невозможно что-либо изменить в программном обеспечении без каких-либо неожиданных побочных эффектов.
Применение принципов функционального программирования помогает снизить сложность кода. Оказывается, программирование с использованием математических функций значительно упрощает нашу работу. Благодаря двум характеристикам, которыми они обладают — честности сигнатуры метода и ссылочной прозрачности — мы можем гораздо проще понимать и рассуждать о таком коде.
Каждый метод в нашей кодовой базе — если он написан как математическая функция — можно рассматривать отдельно от других. Когда мы уверены, что наши методы не влияют на глобальное состояние или не работают с исключением, мы можем рассматривать их как строительные блоки и компоновать их так, как мы хотим. Это, в свою очередь, открывает большие возможности для создания сложной функциональности, которую создать ненамного сложнее, чем части, из которых она состоит.
Когда мы уверены, что наши методы не влияют на глобальное состояние или не работают с исключением, мы можем рассматривать их как строительные блоки и компоновать их так, как мы хотим. Это, в свою очередь, открывает большие возможности для создания сложной функциональности, которую создать ненамного сложнее, чем части, из которых она состоит.
Имея честную сигнатуру метода, нам не нужно останавливаться на деталях реализации метода или обращаться к документации, чтобы узнать, есть ли что-то еще, что нам нужно учесть перед его использованием. Сама сигнатура сообщает нам, что может случиться после того, как мы вызовем такой метод. Модульное тестирование также становится намного проще. Все сводится к паре строк, в которых вы просто указываете входное значение и проверяете результат. Нет необходимости создавать сложные тестовые двойники, такие как mocks, и поддерживать их в дальнейшем.
Особенности функционального программирования (достонства и недостатки)
Основной особенностью функционального программирования, определяющей как преимущества, так и недостатки данной парадигмы, является то, что в ней реализуется модель вычислений без состояний. Если императивная программа на любом этапе исполнения имеет состояние, то есть совокупность значений всех переменных, и производит побочные эффекты, то чисто функциональная программа ни целиком, ни частями состояния не имеет и побочных эффектов не производит. То, что в императивных языках делается путем присваивания значений переменным, в функциональных достигается путем передачи выражений в параметры функций. Непосредственным следствием становится то, что чисто функциональная программа не может изменять уже имеющиеся у нее данные, а может лишь порождать новые путем копирования и/или расширения старых. Следствием того же является отказ от циклов в пользу рекурсии.
Если императивная программа на любом этапе исполнения имеет состояние, то есть совокупность значений всех переменных, и производит побочные эффекты, то чисто функциональная программа ни целиком, ни частями состояния не имеет и побочных эффектов не производит. То, что в императивных языках делается путем присваивания значений переменным, в функциональных достигается путем передачи выражений в параметры функций. Непосредственным следствием становится то, что чисто функциональная программа не может изменять уже имеющиеся у нее данные, а может лишь порождать новые путем копирования и/или расширения старых. Следствием того же является отказ от циклов в пользу рекурсии.
Сильные стороны функционального программирования
Повышение надежности кода
Привлекательная сторона вычислений без состояний — повышение надежности кода за счет четкой структуризации и отсутствия необходимости отслеживания побочных эффектов. Любая функция работает только с локальными данными и работает с ними всегда одинаково, независимо от того, где, как и при каких обстоятельствах она вызывается. Невозможность мутации данных при пользовании ими в разных местах программы исключает появление труднообнаруживаемых ошибок (таких, например, как случайное присваивание неверного значения глобальной переменной в императивной программе).
Невозможность мутации данных при пользовании ими в разных местах программы исключает появление труднообнаруживаемых ошибок (таких, например, как случайное присваивание неверного значения глобальной переменной в императивной программе).
Удобство организации модульного тестирования
Поскольку функция в функциональном программировании не может порождать побочные эффекты, менять объекты нельзя как внутри области видимости, так и снаружи (в отличие от императивных программ, где одна функция может установить какую-нибудь внешнюю переменную, считываемую второй функцией). Единственным эффектом от вычисления функции является возвращаемый ей результат, и единственный фактор, оказывающий влияние на результат — это значения аргументов.
Таким образом, имеется возможность протестировать каждую функцию в программе, просто вычислив ее от различных наборов значений аргументов. При этом можно не беспокоиться ни о вызове функций в правильном порядке, ни о правильном формировании внешнего состояния. Если любая функция в программе проходит модульные тесты, то можно быть уверенным в качестве всей программы. В императивных программах проверка возвращаемого значения функции недостаточна: функция может модифицировать внешнее состояние, которое тоже нужно проверять, чего не нужно делать в функциональных программах[18].
Если любая функция в программе проходит модульные тесты, то можно быть уверенным в качестве всей программы. В императивных программах проверка возвращаемого значения функции недостаточна: функция может модифицировать внешнее состояние, которое тоже нужно проверять, чего не нужно делать в функциональных программах[18].
Возможности оптимизации при компиляции
Традиционно упоминаемой положительной особенностью функционального программирования является то, что оно позволяет описывать программу в так называемом «декларативном» виде, когда жесткая последовательность выполнения многих операций, необходимых для вычисления результата, в явном виде не задается, а формируется автоматически в процессе вычисления функций. Это обстоятельство, а также отсутствие состояний дает возможность применять к функциональным программам достаточно сложные методы автоматической оптимизации.
Возможности параллелизма
Еще одним преимуществом функциональных программ является то, что они предоставляют широчайшие возможности для автоматического распараллеливаниявычислений. Поскольку отсутствие побочных эффектов гарантировано, в любом вызове функции всегда допустимо параллельное вычисление двух различных параметров — порядок их вычисления не может оказать влияния на результат вызова.
Поскольку отсутствие побочных эффектов гарантировано, в любом вызове функции всегда допустимо параллельное вычисление двух различных параметров — порядок их вычисления не может оказать влияния на результат вызова.
Недостатки функционального программирования
Недостатки функционального программирования вытекают из тех же самых его особенностей. Отсутствие присваиваний и замена их на порождение новых данных приводят к необходимости постоянного выделения и автоматического освобождения памяти, поэтому в системе исполнения функциональной программы обязательным компонентом становится высокоэффективный сборщик мусора. Нестрогая модель вычислений приводит к непредсказуемому порядку вызова функций, что создает проблемы при вводе-выводе, где порядок выполнения операций важен. Кроме того, очевидно, функции ввода в своем естественном виде (например, getchar из стандартной библиотеки языка C) не являются чистыми, поскольку способны возвращать различные значения для одних и тех же аргументов, и для устранения этого требуются определенные ухищрения.
Для преодоления недостатков функциональных программ уже первые языки функционального программирования включали не только чисто функциональные средства, но и механизмы императивного программирования (присваивание, цикл, «неявный PROGN» были уже в LISPе). Использование таких средств позволяет решить некоторые практические проблемы, но означает отход от идей (и преимуществ) функционального программирования и написание императивных программ на функциональных языках. В чистых функциональных языках эти проблемы решаются другими средствами, например, в языке Haskell ввод-вывод реализован при помощи монад — нетривиальной концепции, позаимствованной из теории категорий.
Выводы
не обязательно делать весь проект на функциональном программировании, в проекте с логикой могут быть некие комбинированные расчеты, где ООП неудобен.
Если рассматриваем проект как совокупность «ящиков», то удобно использовать ООП. Если как потоки преобразований данных, то удобнее ФП. Если это не подходит, то делаем гибрид или придумываем что-нибудь другое. Весьма забавно выглядят порой попытки спрограммировать «ящики» на функциональном подходе или реализовать гибкие преобразователи данных на ООП. И какой из этого главный вывод?
Весьма забавно выглядят порой попытки спрограммировать «ящики» на функциональном подходе или реализовать гибкие преобразователи данных на ООП. И какой из этого главный вывод?
Чем больше парадигм и фреймворков знаешь (и умеешь), тем адекватнее можешь их сравнивать и выбирать.
Функциональное программирование — это программирование с использованием математических функций. Для преобразования методов в математические функции нам нужно сделать их сигнатуры честными в том смысле, что они должны полностью отражать все возможные входные данные и результаты, и нам также необходимо убедиться, что метод работает только с теми значениями, которые мы передаем, и ничего больше.
Практики, которые помогают преобразовать методы в математические функции:
-
Иммутабельность.
-
Избегать исключения для управления потоком программы.
-
Избавляться от примитивной одержимости.
-
Делать nulls явными.

См. также
- каррирование , мемоизация , декаррирование ,
А как ты думаешь, при улучшении функциональное программирование, будет лучше нам? Надеюсь, что теперь ты понял что такое функциональное программирование, замыкание, каррирование, мемоизация, функции высших порядков, чистые функции, рекурсия, побочные эффекты, side effects, примитивная одержимость, primitive obsession и для чего все это нужно, а если не понял, или есть замечания, то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Функциональное программирование
Функциональное программирование на языке Python | Журнал ВРМ World | Пресс-центр
Хотя пользователи обычно думают о Python как о процедурном и
объектно-ориентированном языке, он содержит все необходимое для поддержки
полностью функционального подхода к программированию.
 В статье рассматриваются
В статье рассматриваютсяобщие концепции функционального программирования и иллюстрируются способы
реализации функционального подхода на Python.
Хотя пользователи обычно думают о Python как о
процедурном и объектно-ориентированном языке, он
содержит все необходимое для поддержки
полностью функционального подхода к
программированию.
В этой статье рассматриваются общие концепции
функционального программирования и
иллюстрируются способы реализации
функционального подхода на Python.
Что такое Python?
Python — свободно распространяемый, очень высокоуровневый интерпретируемый язык, разработанный Гвидо ван Россумом (Guido van Rossum). Он сочетает прозрачный синтаксис с мощной (но необязательной) объектно-ориентированной семантикой. Python доступен почти на всех существующих ныне платформах и обладает очень высокой переносимостью между платформами.
Что такое функциональное программирование?
Лучше всего начать с труднейшего вопроса — а
что, собственно, такое «функциональное
программирование (FP)»? Один из возможных
ответов — «это когда вы пишете на языке
наподобие Lisp, Scheme, Haskell, ML, OCAML, Clean, Mercury или Erlang
(или еще на некоторых других)». Этот ответ,
безусловно, верен, но не сильно проясняет суть. К
сожалению, получить четкое мнение о том, что же
такое FP, оказывается очень трудно даже среди
собственно функциональных программистов.
Вспоминается притча о трех слепцах и слоне.
Возможно также определить FP, противопоставив его
«императивному программированию» (тому, что
вы делаете на языках наподобие C, Pascal, C++, Java, Perl, Awk,
TCL и на многих других — по крайнее мере, большей
частью).
Этот ответ,
безусловно, верен, но не сильно проясняет суть. К
сожалению, получить четкое мнение о том, что же
такое FP, оказывается очень трудно даже среди
собственно функциональных программистов.
Вспоминается притча о трех слепцах и слоне.
Возможно также определить FP, противопоставив его
«императивному программированию» (тому, что
вы делаете на языках наподобие C, Pascal, C++, Java, Perl, Awk,
TCL и на многих других — по крайнее мере, большей
частью).
Хотя автор всеми силами приветствует советы со стороны тех, кто лучше него знает предмет, он мог бы приблизительно охарактеризовать функциональное программирование как обладающее как минимум несколькими из следующих свойств. В языках, называемых функциональными, хорошо поддерживаются нижеперечисленные подходы, а все прочие подходы поддерживаются плохо или не поддерживаются вовсе:
- Функции — объекты первого класса. Т.е., все, что
можно делать с «данными», можно делать и с
функциями (вроде передачи функции другой функции
в качестве параметра).
- Использование рекурсии в качестве основной структуры контроля потока управления. В некоторых языках не существует иной конструкции цикла, кроме рекурсии.
- Акцент на обработке списков (lists, отсюда название Lisp — LISt Processing). Списки с рекурсивным обходом подсписков часто используются в качестве замены циклов.
- «Чистые» функциональные языки избегают побочных эффектов. Это исключает почти повсеместно распространенный в императивных языках подход, при котором одной и той же переменной последовательно присваиваются различные значения для отслеживания состояния программы.
- FP не одобряет или совершенно запрещает утверждения (statements), используя вместо этого вычисление выражений (т.е. функций с аргументами). В предельном случае, одна программа есть одно выражение (плюс дополнительные определения).
- FP акцентируется на том, что должно быть
вычислено, а не как.
- Большая часть FP использует функции «высокого порядка» (функции, оперирующие функциями, оперирующими функциями).


Защитники функционального программирования доказывают, что все эти характеристики приводят к более быстрой разработке более короткого и безошибочного кода. Более того, высокие теоретики от компьютерной науки, логики и математики находят, что процесс доказательства формальных свойств для функциональных языков и программ много проще, чем для императивных.
Функциональные возможности, присущие Python
Python поддерживает большую часть
характеристик функционального
программирования, начиная с версии Python 1.0. Но, как
большинство возможностей Python, они присутствуют в
очень смешанном языке. Так же как и с
объектно-ориентированными возможностями Python, вы
можете использовать то, что вам нужно, и
игнорировать все остальное (пока оно вам не
понадобится). В Python 2.0 было добавлено очень
удачное «синтаксическое украшение» —
списочные встраивания (list comprehensions). Хотя и не
добавляя принципиально новых возможностей,
списочные встраивания делают использование
многих старых возможностей значительно
приятнее.
Хотя и не
добавляя принципиально новых возможностей,
списочные встраивания делают использование
многих старых возможностей значительно
приятнее.
Базовые элементы FP в Python — функции map(), reduce(), filter() и оператор lambda. В Python 1.x
введена также функция apply(), удобная для прямого
применения функции к списку, возвращаемому
другой. Python 2.0 предоставляет для этого улучшенный
синтаксис. Несколько неожиданно, но этих функций
и всего нескольких базовых операторов почти
достаточно для написания любой программы на Python;
в частности, все управляющие утверждения (‘if’, ‘elif’, ‘else’, ‘assert’, ‘try’, ‘except’, ‘finally’, ‘for’, ‘break’, ‘continue’, ‘while’, ‘def’) можно представить в
функциональном стиле, используя исключительно
функции и операторы. Несмотря на то, что задача
реального удаления всех команд управления
потоком, возможно, полезна только для
представления на конкурс «невразумительный
Python» (с кодом, выглядящим как программа на Lisp’е),
стоит уяснить, как FP выражает управляющие
структуры через вызовы функций и рекурсию.
Исключение команд управления потоком
Первое, о чем стоит вспомнить в нашем упражнении — то, что Python «замыкает накоротко» вычисление логических выражений.1 Оказывается, это предоставляет эквивалент блока ‘if’/’elif’/’else’ в виде выражения. Итак:
#------ "Короткозамкнутые" условные вызовы
в Python -----#
# Обычные управляющие конструкции
if <cond1>: func1()
elif <cond2>: func2()
else: func3()
# Эквивалентное «накоротко замкнутое»
выражение
(<cond1> and func1()) or (<cond2> and func2()) or (func3())
# Пример «накоротко замкнутого» выражения
>>> x = 3
>>> def pr(s): return s
>>> (x==1 and pr(‘one’)) or (x==2 and pr(‘two’)) or (pr(‘other’))
‘other’
>>> x = 2
>>> (x==1 and pr(‘one’)) or (x==2 and pr(‘two’)) or (pr(‘other’))
‘two’
Казалось бы, наша версия условных вызовов с
помощью выражений — не более, чем салонный фокус;
однако все становится гораздо интересней, если
учесть, что оператор lambda может содержать
только выражения! Раз, как мы только что показали,
выражения могут содержать условные блоки,
используя короткое замыкание, выражение lambda позволяет в общей форме представить условные
возвращаемые значения. Базируясь на предыдущем
примере:
Базируясь на предыдущем
примере:
#--------- Lambda с короткозамкнутыми условными
выражениями в Python -------#
>>> pr = lambda s:s
>>> namenum = lambda x: (x==1 and pr("one")) \
... or (x==2 and pr("two")) \
... or (pr("other"))
>>> namenum(1)
'one'
>>> namenum(2)
'two'
>>> namenum(3)
'other'
Функции как объекты первого класса
Приведенные примеры уже засвидетельствовали,
хотя и неочевидным образом, статус функций как
объектов первого класса в Python. Дело в том, что,
создав объект функции оператором lambda, мы
произвели чрезвычайно общее действие. Мы имели
возможность привязать наш объект к именам pr и namenum в точности тем же способом, как могли
бы привязать к этим именам число 23 или строку
«spam». Но точно так же, как число 23 можно
использовать, не привязывая ни к какому имени
(например, как аргумент функции), мы можем
использовать объект функции, созданный lambda,
не привязывая ни к какому имени. Функция в Python —
всего лишь еще одно значение, с которым можно
что-то сделать.
Функция в Python —
всего лишь еще одно значение, с которым можно
что-то сделать.
Главное, что мы делаем с нашими объектами
первого класса — передаем их во встроенные
функции map(), reduce() и filter().
Каждая из этих функций принимает объект функции
в качестве первого аргумента. map() применяет переданную функцию к каждому элементу
в переданном списке (списках) и возвращает список
результатов. reduce() применяет переданную
функцию к каждому значению в списке и ко
внутреннему накопителю результата; например, reduce(lambda
n,m:n*m, range(1,10)) означает 10! (факториал 10 —
умножить каждый элемент на результат
предыдущего умножения). filter() применяет
переданную функцию к каждому элементу списка и
возвращает список тех элементов исходного
списка, для которых переданная функция вернула
значение истинности. Мы также часто передаем
функциональные объекты нашим собственным
функциям, но чаще некоторым комбинациям
вышеупомянутых встроенных функций.
Комбинируя три этих встроенных FP-функции, можно реализовать неожиданно широкий диапазон операций потока управления, не прибегая к утверждениям (statements), а используя лишь выражения.
Функциональные циклы в Python
Замена циклов на выражения так же проста, как и замена условных блоков. ‘for’ может быть впрямую переведено в map(). Так же, как и с условным выполнением, нам понадобится упростить блок утверждений до одного вызова функции (мы близки к тому, чтобы научиться делать это в общем случае):
#---------- Функциональный цикл 'for' в Python ----------#
for e in lst: func(e) # цикл на утверждении 'for'
map(func,lst) # цикл, основанный на map()
Кстати, похожая техника применяется для
реализации последовательного выполнения
программы, используя функциональный подход. Т.е.,
императивное программирование по большей части
состоит из утверждений, требующих «сделать
это, затем сделать то, затем сделать что-то
еще». ‘map()’ позволяет это выразить так:
‘map()’ позволяет это выразить так:
#----- Функциональное последовательное
выполнение в Python ----------#
# создадим вспомогательную функцию вызова
функции
do_it = lambda f: f()
# Пусть f1, f2, f3 (etc) — функции, выполняющие полезные
действия
map(do_it, [f1,f2,f3]) # последовательное выполнение,
реализованное на map()
В общем случае, вся главная программа может быть вызовом ‘map()’ со списком функций, которые надо последовательно вызвать, чтобы выполнить программу. Еще одно удобное свойство функций как объектов — то, что вы можете поместить их в список.
Перевести ‘while’ впрямую немного сложнее, но вполне получается :
#-------- Функциональный цикл 'while' в Python ----------#
# Обычный (основаный на утверждении 'while') цикл
while <cond>:
<pre-suite>
if <break_condition>:
break
else:
<suite>
# Рекурсивный цикл в функциональном стиле
def while_block():
<pre-suite>
if <break_condition>:
return 1
else:
<suite>
return 0
while_FP = lambda: (<cond> and while_block()) or while_FP()
while_FP()
Наш вариант ‘while’ все еще требует функцию while_block(),
которая сама по себе может содержать не только
выражения, но и утверждения (statements). Но мы могли бы
продолжить дальнейшее исключение утверждений в
этой функции (как, например, замену блока ‘if/else’ в вышеописанном шаблоне на короткозамкнутое
выражение). К тому же, обычная проверка на месте
<cond> (наподобие ‘while myvar==7’) вряд ли
окажется полезной, поскольку тело цикла (в
представленном виде) не может изменить
какие-либо переменные (хотя глобальные
переменные могут быть изменены в while_block()).
Один из способов применить более полезное
условие — заставить while_block() возвращать
более осмысленное значение и сравнивать его с
условием завершения. Стоит взглянуть на реальный
пример исключения утверждений:
Но мы могли бы
продолжить дальнейшее исключение утверждений в
этой функции (как, например, замену блока ‘if/else’ в вышеописанном шаблоне на короткозамкнутое
выражение). К тому же, обычная проверка на месте
<cond> (наподобие ‘while myvar==7’) вряд ли
окажется полезной, поскольку тело цикла (в
представленном виде) не может изменить
какие-либо переменные (хотя глобальные
переменные могут быть изменены в while_block()).
Один из способов применить более полезное
условие — заставить while_block() возвращать
более осмысленное значение и сравнивать его с
условием завершения. Стоит взглянуть на реальный
пример исключения утверждений:
#---------- Функциональный цикл 'echo' в Python ------------#
# Императивная версия "echo()"
def echo_IMP():
while 1:
x = raw_input("IMP -- ")
if x == 'quit':
break
else
print x
echo_IMP()
# Служебная функция, реализующая «тождество с
побочным эффектом»
def monadic_print(x):
print x
return x
# FP версия «echo()»
echo_FP = lambda: monadic_print(raw_input(«FP — «))==’quit’ or echo_FP()
echo_FP()
Мы достигли того, что выразили небольшую
программу, включающую ввод/вывод, циклы и условия
в виде чистого выражения с рекурсией (фактически
— в виде функционального объекта, который при
необходимости может быть передан куда угодно). Мы
все еще используем служебную функцию monadic_print(),
но эта функция совершенно общая и может
использоваться в любых функциональных
выражениях , которые мы создадим позже (это
однократные затраты).2 3
Заметьте, что любое выражение, содержащее monadic_print(x) вычисляется так же, как если бы оно содержало
просто x. В FP (в частности, в Haskell) есть
понятие «монады» для функции, которая «не
делает ничего, и вызывает побочный эффект при
выполнении».
Мы
все еще используем служебную функцию monadic_print(),
но эта функция совершенно общая и может
использоваться в любых функциональных
выражениях , которые мы создадим позже (это
однократные затраты).2 3
Заметьте, что любое выражение, содержащее monadic_print(x) вычисляется так же, как если бы оно содержало
просто x. В FP (в частности, в Haskell) есть
понятие «монады» для функции, которая «не
делает ничего, и вызывает побочный эффект при
выполнении».
Исключение побочных эффектов
После всей проделанной работы по избавлению от
совершенно осмысленных конструкций и замене их
на невразумительные вложенные выражения,
возникает естественный вопрос — «Зачем?!».
Перечитывая мои описания характеристик FP, мы
можем видеть, что все они достигнуты в Python. Но
важнейшая (и, скорее всего, в наибольшей степени
реально используемая) характеристика —
исключение побочных эффектов или, по крайней
мере, ограничение их применения специальными
областями наподобие монад. Огромный процент
программных ошибок и главная проблема, требующая
применения отладчиков, случается из-за того, что
переменные получают неверные значения в
процессе выполнения программы. Функциональное
программирование обходит эту проблему, просто
вовсе не присваивая значения переменным.
Огромный процент
программных ошибок и главная проблема, требующая
применения отладчиков, случается из-за того, что
переменные получают неверные значения в
процессе выполнения программы. Функциональное
программирование обходит эту проблему, просто
вовсе не присваивая значения переменным.
Взглянем на совершенно обычный участок императивного кода. Его цель — распечатать список пар чисел, чье произведение больше 25. Числа, составляющие пары, сами берутся из двух других списков. Все это весьма напоминает то, что программисты реально делают во многих участках своих программ. Императивный подход к этой задаче мог бы выглядеть так:
#--- Императивный код для "печати
произведений" ----#
# Процедурный стиль - поиск больших произведений
с помощью вложенных циклов
xs = (1,2,3,4)
ys = (10,15,3,22)
bigmuls = []
#...прочий код...
for x in xs:
for y in ys:
#...прочий код...
if x*y > 25:
bigmuls.append((x,y))
#. ..прочий
код...
..прочий
код...
#...прочий код...
print bigmuls
Этот проект слишком мал для того, чтобы что-нибудь пошло не так. Но, возможно, он встроен в код, предназначенный для достижения множества других целей в то же самое время. Секции, комментированные как «#…прочий код…» — места, где побочные эффекты с наибольшей вероятностью могут привести к ошибкам. В любой из этих точек переменные xs, ys, bigmuls, x, y могут приобрести неожиданные значения в гипотетическом коде. Далее, после завершения этого куска кода все переменные могут иметь значения, которые могут ожидаются, а могут и не ожидаться посдедующим кодом. Очевидно, что инкапсуляция в функциях/объектах и тщательное управление областью видимости могут использоваться, чтобы защититься от этого рода проблем. Вы также можете всегда удалять (‘del’) ваши переменные после использования. Но, на практике, указанный тип ошибок весьма обычен.
Функциональный подход к нашей задаче полностью
исключает ошибки, связанные с побочными
эффектами. Возможное решение могло бы быть таким:
Возможное решение могло бы быть таким:
#--- Функциональный код для поиска/печати
больших произведений на Python ----#
bigmuls = lambda xs,ys: filter(lambda (x,y):x*y > 25, combine(xs,ys))
combine = lambda xs,ys: map(None, xs*len(ys), dupelms(ys,len(xs)))
dupelms = lambda lst,n: reduce(lambda s,t:s+t, map(lambda l,n=n: [l]*n, lst))
print bigmuls((1,2,3,4),(10,15,3,22))
Мы связываем в примере анонимные (‘lambda’)
функции с именами, но это не необходимо. Вместо
этого мы могли просто вложить определения. Мы
использовали имена как ради большей читаемости,
так и потому, что combine() — в любом случае
отличная служебная функция (генерирует список
всех возможных пар элементов из двух списков). В
свою очередь, dupelms() в основном лишь
вспомогательная часть combine(). Хотя этот
функциональный пример более многословен, чем
императивный, при повторном использовании
служебных функций код в собственно bigmuls() окажется, вероятно, более лаконичным, чем в
императивном варианте.
Реальное преимущество этого функционального примера в том, что в нем абсолютно ни одна переменная не меняет своего значения. Какое-либо неожиданное побочное влияние на последующий код (или со стороны предыдущего кода) просто невозможно. Конечно, само по себе отсутствие побочных эффектов не гарантирует безошибочность кода, но в любом случае это преимущество. Однако заметьте, что Python, в отличие от многих функциональных языков, не предотвращает повторное привязывание имен bigmuls, combine и dupelms. Если дальше в процессе выполнения программы combine() начнет значить что-нибудь другое — увы! Можно было бы разработать класс-одиночку (Singleton) для поддержки однократного связывания такого типа (напр. ‘s.bigmuls’, etc.), но это выходит за рамки настоящей статьи.
Еще стоит отметить, что задача, которую мы только что решили, скроена в точности под новые возможности Python 2.0. Вместо вышеприведенных примеров — императивного или функционального — наилучшая (и функциональная) техника выглядит следующим образом:
#----- Код Python для "bigmuls" с использованием
списочных встраиваний (list comprehensions) -----#
print [(x,y) for x in (1,2,3,4) for y in (10,15,3,22) if x*y > 25]
Заключение
Эта статья продемонстрировала способы замены
практически любой конструкции управления
потоком в Python на функциональный эквивалент
(избавляясь при этом от побочных эффектов). Эффективный перевод конкретной программы
требует дополнительного обдумывания, но мы
увидели, что встроенные функциональные
примитивы являются полными и общими. В
последующих статьях мы рассмотрим более мощные
подходы к функциональному программированию; и, я
надеюсь, сможем подробнее рассмотреть «pro» и
«contra» функционального подхода.
Эффективный перевод конкретной программы
требует дополнительного обдумывания, но мы
увидели, что встроенные функциональные
примитивы являются полными и общими. В
последующих статьях мы рассмотрим более мощные
подходы к функциональному программированию; и, я
надеюсь, сможем подробнее рассмотреть «pro» и
«contra» функционального подхода.
Ресурсы
Библиотека «xoltar toolkit» Брина Келлера (Bryn Keller), включающий модуль [functional], добавляет множество полезных FP-расширений к Python. Поскольку сам модуль [functional] написан на чистом Python, то, что он делает, можно сделать и без него. Но Келлер создал замечательно интегрированный набор расширений, предоставляющий высокую мощность в компактном определении. Пакет можно найти по адресу: http://sourceforge.net/projects/xoltar-toolkit
Питер Норвиг (Peter Norvig) написал интересную
статью, «Питон для программистов на
Лиспе» («Python for Lisp Programmers»).
Несмотря на то, что статья в основном
сфокусирована на вопросах, противоположных
только что рассмотренным, в ней проводится
отличное общее сравнение Python и Lisp: http://www. norvig.com/python-lisp.html
norvig.com/python-lisp.html
Отличной исходной точкой для изучения функционального программирования может служить FAQ для comp.lang.functional: http://www.cs.nott.ac.uk/~gmh//faq.html#functional-languages
Автор нашел, что понять суть функционального программирования много проще через язык Haskell, нежели через Lisp (несмотря на то, что последний, вероятно, используется шире — хотя бы в Emacs). Возможно, другим программистам на Python тоже окажется легче жить без такого количества скобок и префиксной (польской) записи.
Блестящее введение в язык:
Haskell: The Craft of Functional Programming (2nd Edition), Simon Thompson, Addison-Wesley (1999).
Об авторе
{Изображение автора: http://gnosis.cx/cgi/img_dqm.cgi}
Поскольку постижение без интуиции бесплодно, а
интуиция без постижения слепа, Давид Мертц хочет
поставить литую скульптуру Мильтона в свой офис.
Запланируйте подарить ему на день рождения.
Давида можно найти по адресу mertz@gnosis. cx;
его жизнь протекает на http://gnosis.cx/publish.
cx;
его жизнь протекает на http://gnosis.cx/publish.
Примечания
1. T.е. вычисление логического выражения заканчивается сразу, как только становится известен его логический результат. Стоит также заметить, что в Python, так же как и в Lisp, значением логического выражения является не true/false, а значение последнего вычисленного подвыражения — например, 4 and «Hello!» or 2*2 будет иметь значение «Hello!». прим. перев.
2. monadic_print() может быть реализована в полностью функциональном стиле, без использования утверждения print:
monadic_print = lambda x: sys.write(str(x) + '\n') and xприм. перев.
3. Следует обратить внимание, что
пример работает только в том случае, если
переменная echo_FP глобальна. Это связано с
тем, что в Python всех версий до 2.0 включительно
отсутствует статическая вложенность области
действия имен. Любое имя, встретившееся в
контексте функции или метода, ищется сначала
среди локальных имен функции, а потом сразу среди
глобальных имен (затем среди встроенных имен). Это отличается от логики языков со статическими
областями действия имен (C, C++, Pascal, etc.), где имя
последовательно ищется во всех объемлющих
блоках. Из этого, в частности, следует, что
рекурсивный вызов lambda-функции, привязанной к
неглобальному имени, в Python версии меньше 2.1
невозможен. В Python 2.1 введены опциональные
статические области действия. Таким образом,
начиная с версии 2.1 Python можно рассматривать и как
полноценный FP-язык (помимо всего прочего).
Вышеприведенный комментарий относится почти ко
всем функциональным примерам в статье. прим.
Это отличается от логики языков со статическими
областями действия имен (C, C++, Pascal, etc.), где имя
последовательно ищется во всех объемлющих
блоках. Из этого, в частности, следует, что
рекурсивный вызов lambda-функции, привязанной к
неглобальному имени, в Python версии меньше 2.1
невозможен. В Python 2.1 введены опциональные
статические области действия. Таким образом,
начиная с версии 2.1 Python можно рассматривать и как
полноценный FP-язык (помимо всего прочего).
Вышеприведенный комментарий относится почти ко
всем функциональным примерам в статье. прим.
Автор: David Mertz, Ph.D., Applied Metaphysician, Gnosis Software, Inc.
Почему разработчики влюбляются в функциональное программирование | Ари Джоури, доктор философии
Тенденция от Python к Haskell не исчезнет в ближайшее время
Функциональный код набирает обороты. Фото Брук Кейгл на Unsplash
Фото Брук Кейгл на UnsplashФункциональное программирование существует уже 60 лет, но до сих пор оно всегда было нишевым явлением. Хотя такие революционеры, как Google, полагаются на свои ключевые концепции, современный программист почти ничего об этом не знает.
Это скоро изменится. Такие языки, как Java или Python, не только перенимают все больше и больше концепций функционального программирования. Новые языки, такие как Haskell, становятся полностью функциональными.
Проще говоря, функциональное программирование — это построение функций для неизменяемых переменных. Напротив, в объектно-ориентированном программировании используется относительно фиксированный набор функций, и вы в основном изменяете или добавляете новые переменные.
Благодаря своей природе функциональное программирование отлично подходит для таких востребованных задач, как анализ данных и машинное обучение. Это не означает, что вы должны попрощаться с объектно-ориентированным программированием и перейти на полностью функциональное. Однако полезно знать об основных принципах, чтобы при необходимости использовать их в своих интересах.
Однако полезно знать об основных принципах, чтобы при необходимости использовать их в своих интересах.
Функциональное программирование на подъеме
Существует тенденция к более функциональному стилю в языках программирования. Что это значит и где мы находимся на этом пути?
medium.com
Чтобы понять функциональное программирование, нам нужно сначала понять функции. Это может показаться скучным, но, в конце концов, это довольно проницательно. Так что продолжайте читать.
Наивно сформулированная функция — это вещь, которая преобразует некоторый ввод в некоторый вывод. Вот только это не всегда так просто. Рассмотрим эту функцию в Python:
def square(x):
return x*x
Эта функция тупая и простая; он принимает одну переменную x , предположительно int , или, возможно, float или double , и выдает квадрат этого числа.
Теперь рассмотрим эту функцию:
global_list = []def append_to_list(x):
global_list.
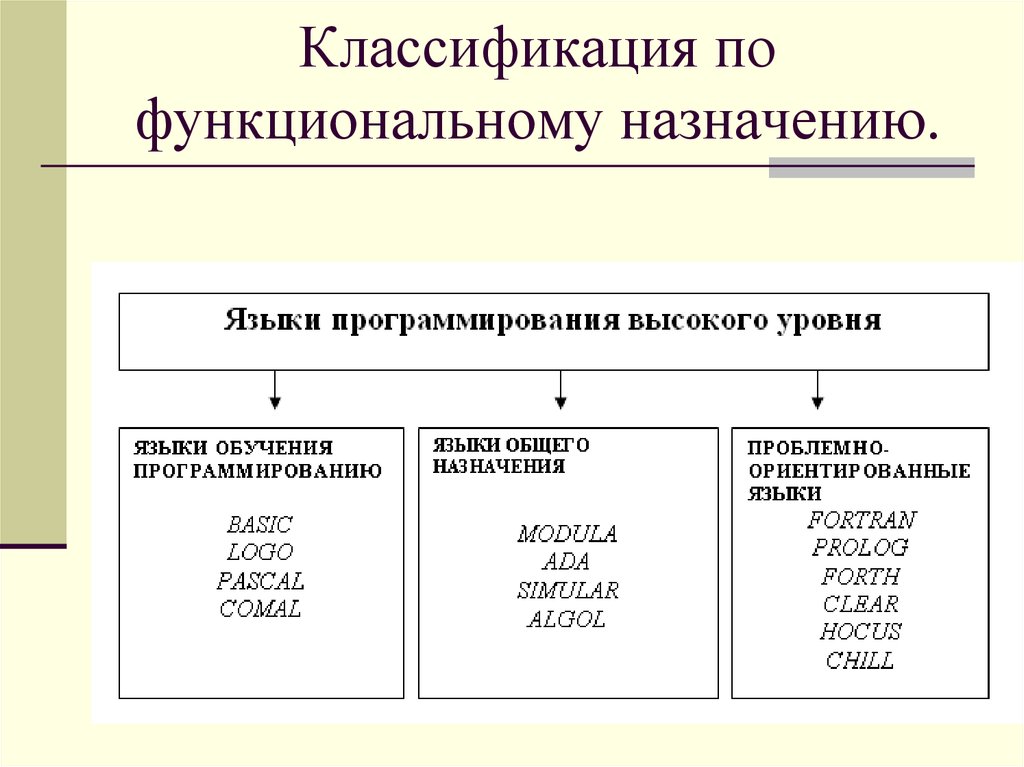 append(x)
append(x) На первый взгляд кажется, что функция принимает переменную x любого типа, и ничего не возвращает, так как нет возвращает оператор . Но ждать!
Функция не работала бы, если бы global_list не был определен заранее, а ее вывод — тот же список, хотя и измененный. Несмотря на то, что global_list никогда не объявлялся как ввод, он меняется, когда мы используем функцию:
append_to_list(1)
append_to_list(2)
global_list
Вместо пустого списка возвращается [1,2] . Это показывает, что список действительно является входом функции, даже если мы не указали это явно. И это может быть проблемой.
Нечестность в отношении функций
Эти неявные входы — или выходы, в других случаях — имеют официальное название: побочные эффекты . Хотя мы использовали только простой пример, в более сложных программах это может вызвать серьезные трудности.
Подумайте, как бы вы протестировали append_to_list : вместо того, чтобы просто прочитать первую строку и протестировать функцию с любым x , вам нужно прочитать определение целиком, понять, что оно делает, определить global_list и протестируйте его таким образом. То, что просто в этом примере, может быстро стать утомительным, когда вы имеете дело с программами, состоящими из тысяч строк кода.
То, что просто в этом примере, может быстро стать утомительным, когда вы имеете дело с программами, состоящими из тысяч строк кода.
Хорошей новостью является то, что есть простое решение: быть честным в отношении того, что функция принимает в качестве входных данных. Это намного лучше:
newlist = []def append_to_list2(x, some_list):
some_list.append(x)append_to_list2(1,newlist)
append_to_list2(2,newlist)
newlist
На самом деле мы мало что изменили . Выход по-прежнему [1,2] , а все остальное тоже осталось прежним.
Однако мы изменили одну вещь: код теперь свободен от побочных эффектов. И это отличная новость.
Когда вы сейчас посмотрите на объявление функции, вы точно поймете, что происходит. Поэтому, если программа ведет себя не так, как ожидалось, вы можете легко протестировать каждую функцию по отдельности и определить, какая из них неисправна.
Поддержание чистоты ваших функций означает их удобство обслуживания. Фото Кристины @ wocintechchat.com на Unsplash
Фото Кристины @ wocintechchat.com на UnsplashФункциональное программирование — это написание чистых функций
Функция с четко объявленными входами и выходами не имеет побочных эффектов. А функция без побочных эффектов — это чистая функция.
Очень простое определение функционального программирования таково: написание программы только на чистых функциях. Чистые функции никогда не изменяют переменные, а только создают новые на выходе. (Я немного схитрил в приведенном выше примере: он идет по пути функционального программирования, но все еще использует глобальный список. Вы можете найти примеры получше, но здесь речь шла об основном принципе.)
Более того, вы можете ожидать определенного результата от чистой функции с заданным входом. Напротив, нечистая функция может зависеть от некоторой глобальной переменной; поэтому одни и те же входные переменные могут привести к разным результатам, если глобальная переменная отличается. Последнее может значительно усложнить отладку и сопровождение кода.
Существует простое правило обнаружения побочных эффектов: поскольку каждая функция должна иметь какие-то входные и выходные данные, объявления функций, которые идут без каких-либо входных или выходных данных, должны быть нечистыми. Это первые объявления, которые вы, возможно, захотите изменить, если будете внедрять функциональное программирование.
Карта и уменьшить В функциональном программировании нет циклов. Рассмотрим эти циклы Python:
целых чисел = [1,2,3,4,5,6]
нечетных_целых = []
квадратных_нечетных = []
всего = 0 для i в целых числах:
, если i%2 == 1
нечетных_целых .append(i)для i в нечетных_целых:
в квадрате.append(i*i)для i в квадратных_нечетных:
итого += i
Для простых операций, которые вы пытаетесь выполнить, этот код довольно длинный. Это также не работает, потому что вы изменяете глобальные переменные.
Вместо этого рассмотрим следующее:
из functools import reduceintegers = [1,2,3,4,5,6]
нечетные_целые = фильтр(лямбда n: n % 2 == 1, целые числа) n: n * n, нечетные_целые)
итого = уменьшить (лямбда-акк, n: акк + n, квадрат_нечетных)
Это полностью функционально. Это короче. Это быстрее, потому что вы не перебираете множество элементов массива. И как только вы поймете, как
Это короче. Это быстрее, потому что вы не перебираете множество элементов массива. И как только вы поймете, как фильтрует , отображает и уменьшает , код становится не намного сложнее для понимания.
Это не значит, что весь функциональный код использует map , reduce и тому подобное. Это не означает, что вам нужно функциональное программирование, чтобы понять map и reduce . Просто когда вы абстрагируете циклы, эти функции всплывают довольно часто.
Лямбда-функции
Говоря об истории функционального программирования, многие начинают с изобретения лямбда-функций. Но хотя лямбда-выражения, без сомнения, являются краеугольным камнем функционального программирования, они не являются основной причиной.
Лямбда-функции — это инструменты, с помощью которых можно сделать программу функциональной. Но вы можете использовать лямбда-выражения и в объектно-ориентированном программировании.
Статическая типизация
Приведенный выше пример не имеет статической типизации. При этом он функционален.
Несмотря на то, что статическая типизация добавляет дополнительный уровень безопасности вашему коду, необязательно делать его функциональным. Хотя это может быть хорошим дополнением.
Функциональное программирование на одних языках проще, чем на других. Фото Кристины @ wocintechchat.com на UnsplashPerl
Perl использует совершенно иной подход к побочным эффектам, чем большинство языков программирования. Он включает магический аргумент $_ , что делает побочные эффекты одной из его основных функций. У Perl есть свои достоинства, но я бы не стал пробовать на нем функциональное программирование.
Java
Желаю вам удачи в написании функционального кода на Java. Мало того, что половина вашей программы будет состоять из статических ключевых слов; большинство других Java-разработчиков также назовут вашу программу позором.
Это не значит, что Java плохая. Но он не предназначен для тех задач, которые лучше всего решаются с помощью функционального программирования, таких как управление базами данных или приложения для машинного обучения.
Scala
Это интересно: цель Scala — объединить объектно-ориентированное и функциональное программирование. Если вы находите это странным, вы не одиноки: в то время как функциональное программирование направлено на полное устранение побочных эффектов, объектно-ориентированное программирование пытается сохранить их внутри объектов.
При этом многие разработчики рассматривают Scala как язык, который поможет им перейти от объектно-ориентированного программирования к функциональному. Это может помочь им стать полностью функциональными в ближайшие годы.
Что такое функциональное программирование?
расшифровка, казалось бы, сложной концепции
medium.com
Python
Python активно поддерживает функциональное программирование. Вы можете видеть это по тому факту, что каждая функция по умолчанию имеет хотя бы один вход,
Вы можете видеть это по тому факту, что каждая функция по умолчанию имеет хотя бы один вход, сам . Это очень похоже на дзен Python: явное лучше, чем неявное!
Clojure
По словам его создателя, Clojure примерно на 80% функционален. Все значения неизменяемы по умолчанию, точно так же, как они нужны вам в функциональном программировании. Однако вы можете обойти это, используя оболочки изменяемых значений вокруг этих неизменяемых значений. Когда вы открываете такую обертку, вещь, которую вы получаете, снова неизменна.
Haskell
Это один из немногих языков, полностью функциональных и статически типизированных. Хотя это может показаться тратой времени во время разработки, это очень окупается, когда вы отлаживаете программу. Его не так просто выучить, как другие языки, но он определенно стоит вложений!
Это еще не начало эры больших данных. Фото Остина Дистела на Unsplash По сравнению с объектно-ориентированным программированием функциональное программирование по-прежнему остается нишевым явлением. Однако если включение принципов функционального программирования в Python и другие языки имеет какое-либо значение, то функциональное программирование, похоже, набирает обороты.
Однако если включение принципов функционального программирования в Python и другие языки имеет какое-либо значение, то функциональное программирование, похоже, набирает обороты.
В этом есть смысл: функциональное программирование отлично подходит для больших баз данных, параллельного программирования и машинного обучения. И все это процветало в последнее десятилетие.
В то время как объектно-ориентированный код обладает бесчисленными достоинствами, нельзя пренебрегать достоинствами функционального кода. Изучения некоторых основных принципов часто бывает достаточно, чтобы улучшить свою игру как разработчика и быть готовым к будущему.
Спасибо за внимание! Если вы хотите узнать, как реализовать больше элементов функционального программирования в коде Python, следите за обновлениями. Я расскажу об этом в своем следующем рассказе.
Освойте JavaScript Интервью: что такое функциональное программирование? | Эрик Эллиот | JavaScript-сцена
Structure Synth — Orihaus (CC BY 2. 0)
0)«Собеседование по изучению JavaScript» — это серия постов, предназначенных для подготовки кандидатов к ответам на распространенные вопросы, с которыми они могут столкнуться при подаче заявления на должность JavaScript среднего и старшего уровня. Эти вопросы я часто использую в реальных интервью.
Функциональное программирование стало действительно горячей темой в мире JavaScript. Всего несколько лет назад лишь немногие программисты на JavaScript знали, что такое функциональное программирование, но каждая крупная кодовая база приложений, которую я видел за последние 3 года, интенсивно использует идеи функционального программирования.
Функциональное программирование (часто сокращенно FP) — это процесс создания программного обеспечения путем составления чистых функций , избегая общего состояния, изменяемых данных, и побочных эффектов . Функциональное программирование является декларативным , а не императивным , а состояние приложения передается через чистые функции. В отличие от объектно-ориентированного программирования, где состояние приложения обычно совместно используется и размещается вместе с методами в объектах.
В отличие от объектно-ориентированного программирования, где состояние приложения обычно совместно используется и размещается вместе с методами в объектах.
Функциональное программирование — это парадигма программирования , означающая, что это способ мышления о создании программного обеспечения, основанный на некоторых фундаментальных, определяющих принципах (перечисленных выше). Другие примеры парадигм программирования включают объектно-ориентированное программирование и процедурное программирование.
Функциональный код имеет тенденцию быть более кратким, более предсказуемым и легче тестируемым, чем императивный или объектно-ориентированный код, но если вы не знакомы с ним и связанными с ним общими шаблонами, функциональный код также может показаться намного более сложным, а соответствующая литература может быть непонятна для новичков.
Если вы начнете гуглить термины функционального программирования, вы быстро наткнетесь на кирпичную стену академического жаргона, который может быть очень пугающим для новичков. Сказать, что у него есть кривая обучения, — серьезное преуменьшение. Но если вы какое-то время программировали на JavaScript, велика вероятность, что вы использовали множество концепций и утилит функционального программирования в своем реальном программном обеспечении.
Сказать, что у него есть кривая обучения, — серьезное преуменьшение. Но если вы какое-то время программировали на JavaScript, велика вероятность, что вы использовали множество концепций и утилит функционального программирования в своем реальном программном обеспечении.
Пусть вас не пугают новые слова. Это намного проще, чем кажется.
Самое сложное — это усвоить весь незнакомый словарь. В приведенном выше невинно выглядящем определении есть много идей, которые необходимо понять, прежде чем вы сможете понять смысл функционального программирования:
- Чистые функции
- Состав функций
- Избегать общего состояния
- Избегать мутирующего состояния
- Избегайте побочных эффектов
Другими словами, если вы хотите узнать, что означает функциональное программирование на практике, вы должны начать с понимания этих основных концепций.
Чистая функция — это функция, которая:
- При одних и тех же входных данных всегда возвращает один и тот же результат и
- Не имеет побочных эффектов
Чистые функции обладают множеством свойств, важных в функциональном программировании, в том числе ссылочная прозрачность (можно заменить вызов функции ее результирующим значением без изменения смысла программы). Прочитайте «Что такое чистая функция?» Больше подробностей.
Прочитайте «Что такое чистая функция?» Больше подробностей.
Функциональный состав — это процесс объединения двух или более функций для создания новой функции или выполнения некоторых вычислений. Например, композиция ф. g (точка означает «составлено из») эквивалентно f(g(x)) в JavaScript. Понимание композиции функций — важный шаг к пониманию того, как создается программное обеспечение с использованием функционального программирования. Прочитайте «Что такое функциональная композиция?» для большего.
Общее состояние — это любая переменная, объект или пространство памяти, которое существует в общей области или как свойство объекта, передаваемого между областями. Общая область может включать в себя глобальную область или области закрытия. Часто в объектно-ориентированном программировании объекты распределяются между областями действия путем добавления свойств к другим объектам.
Например, компьютерная игра может иметь главный игровой объект, в котором персонажи и игровые элементы хранятся как свойства, принадлежащие этому объекту. Функциональное программирование избегает совместного использования состояния, вместо этого полагаясь на неизменяемые структуры данных и чистые вычисления для получения новых данных из существующих данных. Дополнительные сведения о том, как функциональное программное обеспечение может обрабатывать состояние приложения, см. в разделе «10 советов по улучшению архитектуры Redux».
Функциональное программирование избегает совместного использования состояния, вместо этого полагаясь на неизменяемые структуры данных и чистые вычисления для получения новых данных из существующих данных. Дополнительные сведения о том, как функциональное программное обеспечение может обрабатывать состояние приложения, см. в разделе «10 советов по улучшению архитектуры Redux».
Проблема с общим состоянием заключается в том, что для понимания эффектов функции необходимо знать всю историю каждой общей переменной, которую функция использует или на которую влияет.
Представьте, что у вас есть пользовательский объект, который нужно сохранить. Ваша функция saveUser() делает запрос к API на сервере. Пока это происходит, пользователь меняет изображение своего профиля с помощью updateAvatar() и запускает другой запрос saveUser() . При сохранении сервер отправляет обратно канонический пользовательский объект, который должен заменить все, что находится в памяти, чтобы синхронизироваться с изменениями, происходящими на сервере, или в ответ на другие вызовы API.
К сожалению, второй ответ поступает раньше первого, поэтому, когда возвращается первый (ныне устаревший) ответ, новое изображение профиля стирается из памяти и заменяется старым. Это пример состояния гонки — очень распространенной ошибки, связанной с общим состоянием.
Еще одна распространенная проблема, связанная с общим состоянием, заключается в том, что изменение порядка вызова функций может вызвать каскад сбоев, поскольку функции, работающие с общим состоянием, зависят от времени:
Пример временной зависимостипорядок вызовов функций не меняет результат вызова функции. С чистыми функциями при одних и тех же входных данных вы всегда будете получать одинаковые выходные данные. Это делает вызовы функций полностью независимыми от вызовов других функций, что может радикально упростить изменения и рефакторинг. Изменение в одной функции или время вызова функции не повлияет на другие части программы и не сломает их.
В приведенном выше примере мы используем Object. и передаем пустой объект в качестве первого параметра, чтобы скопировать свойства  assign()
assign() x вместо того, чтобы изменять его на месте. В этом случае это было бы эквивалентно простому созданию нового объекта с нуля без Object.assign() , но это распространенный шаблон в JavaScript для создания копий существующего состояния вместо использования мутаций, что мы продемонстрировали в первый пример.
Если внимательно посмотреть на console.log() операторов в этом примере, вы должны заметить то, о чем я уже упоминал: композиция функций. Напомним, композиция функций выглядит так: f(g(x)) . В этом случае мы заменяем f() и g() на x1() и x2() для композиции: x1 . х2 .
Конечно, если изменить порядок композиции, вывод изменится. Порядок действий по-прежнему имеет значение. ф(г(х)) не всегда равно g(f(x)) , но больше не имеет значения, что происходит с переменными вне функции — и это большое дело. С нечистыми функциями невозможно полностью понять, что делает функция, если вы не знаете всю историю каждой переменной, которую функция использует или на которую воздействует.
С нечистыми функциями невозможно полностью понять, что делает функция, если вы не знаете всю историю каждой переменной, которую функция использует или на которую воздействует.
Удалите зависимость от времени вызова функции, и вы устраните целый класс потенциальных ошибок.
Неизменный объект — это объект, который нельзя изменить после его создания. И наоборот, изменяемый объект — это любой объект, который можно изменить после его создания.
Неизменность — центральная концепция функционального программирования, поскольку без нее поток данных в вашей программе будет с потерями. История состояния заброшена, и в ваше программное обеспечение могут закрасться странные ошибки. Чтобы узнать больше о значении неизменности, см. «Дао неизменности».
В JavaScript важно не путать const с неизменностью. const создает привязку имени переменной, которую нельзя переназначить после создания. const не создает неизменяемых объектов. Вы не можете изменить объект, на который ссылается привязка, но вы все равно можете изменить свойства объекта, что означает, что привязки, созданные с помощью
Вы не можете изменить объект, на который ссылается привязка, но вы все равно можете изменить свойства объекта, что означает, что привязки, созданные с помощью const , являются изменяемыми, а не неизменяемыми.
Неизменяемые объекты вообще нельзя изменять. Вы можете сделать значение действительно неизменным, глубоко заморозив объект. В JavaScript есть метод, который замораживает объект на один уровень в глубину:
Но замороженные объекты неизменяемы только внешне. Например, следующий объект является изменяемым:
Как видите, примитивные свойства верхнего уровня замороженного объекта не могут измениться, но любое свойство, которое также является объектом (включая массивы и т. д.), все еще может быть изменено — так что даже замороженные объекты не являются неизменяемыми, если вы не пройтись по всему дереву объектов и заморозить каждое свойство объекта.
Во многих языках функционального программирования существуют специальные неизменяемые структуры данных, называемые trie-структурами данных (произносится как «дерево»), которые эффективно «замораживаются» — это означает, что ни одно свойство не может измениться, независимо от уровня свойства в иерархии объектов. .
.
Пытается использовать структурное совместное использование для совместного использования ячеек памяти ссылок для всех частей объекта, которые не изменились после того, как объект был скопирован оператором, что использует меньше памяти и позволяет значительно повысить производительность для некоторых видов операций.
Например, для сравнения можно использовать сравнения идентификаторов в корне дерева объектов. Если идентификатор один и тот же, вам не нужно проходить все дерево в поисках различий.
В JavaScript есть несколько библиотек, использующих попытки, включая Immutable.js и Mori.
Я экспериментировал с обоими и предпочитаю использовать Immutable.js в крупных проектах, требующих значительных объемов неизменяемого состояния. Подробнее об этом см. в разделе «10 советов по улучшению архитектуры Redux».
Побочным эффектом является любое изменение состояния приложения, наблюдаемое вне вызываемой функции, кроме возвращаемого значения. К побочным эффектам относятся:
К побочным эффектам относятся:
- Изменение любой внешней переменной или свойства объекта (например, глобальной переменной или переменной в цепочке областей действия родительской функции)
- Вход в консоль
- Запись на экран
- Запись в файл
- Запись в сеть
- Запуск любого внешнего процесса
- Вызов любых других функций с побочными эффектами
В функционале побочные эффекты в основном исключены программирование, что значительно упрощает понимание и тестирование эффектов программы.
Haskell и другие функциональные языки часто изолируют и инкапсулируют побочные эффекты от чистых функций, используя монады . Тема монад достаточно глубока, чтобы написать о ней книгу, так что мы оставим ее на потом.
Что вам нужно знать прямо сейчас, так это то, что действия с побочными эффектами должны быть изолированы от остальной части вашего программного обеспечения. Если вы будете отделять побочные эффекты от остальной логики программы, ваше программное обеспечение будет намного проще расширять, реорганизовывать, отлаживать, тестировать и поддерживать.
По этой причине большинство интерфейсных фреймворков поощряют пользователей управлять состоянием и отрисовкой компонентов в отдельных, слабо связанных модулях.
Функциональное программирование имеет тенденцию к повторному использованию общего набора функциональных утилит для обработки данных. Объектно-ориентированное программирование имеет тенденцию размещать методы и данные в объектах. Эти совмещенные методы могут работать только с тем типом данных, для которого они предназначены, и часто только с данными, содержащимися в этом конкретном экземпляре объекта.
В функциональном программировании любой тип данных является честной игрой. Та же утилита map() может отображать объекты, строки, числа или любой другой тип данных, потому что она принимает функцию в качестве аргумента, которая соответствующим образом обрабатывает данный тип данных. FP реализует свой общий трюк с утилитами, используя функции высшего порядка .
JavaScript имеет функций первого класса , что позволяет нам обращаться с функциями как с данными — назначать их переменным, передавать их другим функциям, возвращать их из функций и т. д. функция в качестве аргумента, возвращает функцию или и то, и другое. Функции высшего порядка часто используются для того, чтобы:
д. функция в качестве аргумента, возвращает функцию или и то, и другое. Функции высшего порядка часто используются для того, чтобы:
- Абстрагировать или изолировать действия, эффекты или асинхронное управление потоком с помощью функций обратного вызова, промисов, монад и т. д.
- Создание утилит, которые могут работать с широким спектром типов данных
- Частично применить функцию к ее аргументам или создать каррированную функцию с целью повторного использования или композиции функций
- Взять список функций и вернуть некоторую композицию этих входных данных functions
Контейнеры, функторы, списки и потоки
Функтор — это то, что можно отображать. Другими словами, это контейнер с интерфейсом, который можно использовать для применения функции к значениям внутри него. Когда вы видите слово функтор, вы должны думать «отображаемый».
Ранее мы узнали, что одна и та же утилита map() может работать с различными типами данных. Он делает это, поднимая операцию сопоставления для работы с функторным API. Важные операции управления потоком, используемые
Он делает это, поднимая операцию сопоставления для работы с функторным API. Важные операции управления потоком, используемые map() , используют этот интерфейс. В случае Array.prototype.map() контейнер представляет собой массив, но другие структуры данных также могут быть функторами — если они предоставляют API сопоставления.
Давайте посмотрим, как Array.prototype.map() позволяет вам абстрагировать тип данных от утилиты сопоставления, чтобы сделать map() применимым с любым типом данных. Мы создадим простое отображение double() , которое просто умножает любые переданные значения на 2:
Что, если мы хотим воздействовать на цели в игре, чтобы удвоить количество очков, которые они присуждают? Все, что нам нужно сделать, это внести небольшое изменение в функцию double() , которую мы передаем в map() , и все по-прежнему работает:
Концепция использования абстракций, таких как функторы и функции более высокого порядка, для использования общие служебные функции для управления любым количеством различных типов данных важны в функциональном программировании.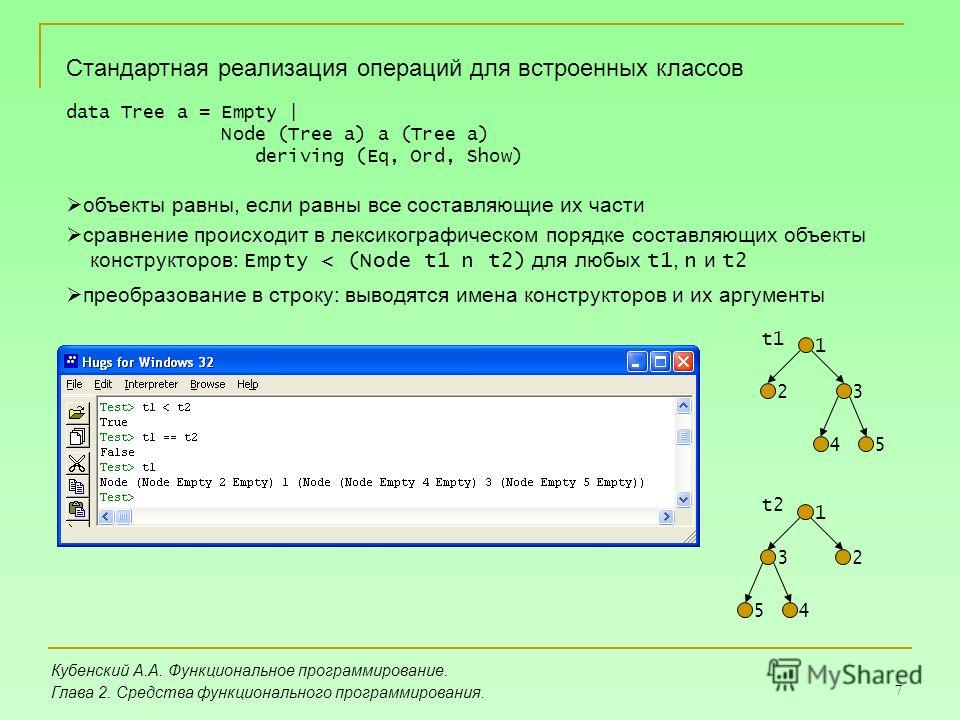 Вы увидите, что подобная концепция применяется самыми разными способами.
Вы увидите, что подобная концепция применяется самыми разными способами.
«Список, выраженный во времени, является потоком».
Все, что вам нужно понять на данный момент, это то, что массивы и функторы — не единственный способ применения этой концепции контейнеров и значений в контейнерах. Например, массив — это просто список вещей. Список, выраженный во времени, представляет собой поток, поэтому вы можете применять те же утилиты для обработки потоков входящих событий, что вы часто будете видеть, когда начнете создавать настоящее программное обеспечение с помощью FP.
Функциональное программирование — это декларативная парадигма, означающая, что логика программы выражается без явного описания управления потоком.
Императивные программы тратят строки кода, описывающие конкретные шаги, используемые для достижения желаемых результатов — управление потоком : Как делать вещи.
Декларативные программы абстрагируют процесс управления потоком и вместо этого тратят строки кода, описывающие поток данных : что делать. , как абстрагируется .
, как абстрагируется .
Например, это императивное сопоставление принимает массив чисел и возвращает новый массив с каждым числом, умноженным на 2:
Императивное отображение данных Это декларативное отображение делает то же самое, но абстрагирует управление потоком с помощью функциональной утилиты Array.prototype.map() , которая позволяет более четко выразить поток данных:
Императивный код часто использует операторы. Оператор — это фрагмент кода, который выполняет некоторое действие. Примеры часто используемых операторов включают для , для , для переключения 9.0031 , throw и т. д.
Декларативный код больше полагается на выражения. Выражение — это фрагмент кода, который возвращает некоторое значение. Выражения обычно представляют собой некоторую комбинацию вызовов функций, значений и операторов, которые оцениваются для получения результирующего значения.
Вот все примеры выражений:
2 * 2
doubleMap([2, 3, 4])
Math.max(4, 3, 2)
Обычно в коде вы увидите, что выражения присваиваются идентификатор, возвращенный из функций или переданный в функцию. Прежде чем присваиваться, возвращаться или передаваться, выражение сначала вычисляется и используется полученное значение.
Преимущества функционального программирования:
- Чистые функции вместо общего состояния и побочных эффектов
- Неизменяемость вместо изменяемых данных
- Композиция функций вместо императивного управления потоком типы вместо методов, которые работают только с их совмещенными данными
- Декларативный, а не императивный код (что делать, а не как это делать)
- Выражения над операторами
- Контейнеры и функции более высокого порядка над специальным полиморфизмом
Изучите и попрактикуйтесь в этой основной группе дополнений к функциональным массивам:
-
. map() -
.filter() - 1
- 1
- 1
 map()
map() Используйте карту, чтобы преобразовать следующий массив значений в массив имен элементов:
Используйте фильтр, чтобы выбрать элементы, в которых баллы больше или равны 3:
Используйте сокращение, чтобы суммировать баллы:
Ознакомьтесь с серией
- Что такое замыкание?
- В чем разница между классовым и прототипным наследованием?
- Что такое чистая функция?
- Что такое композиция функций?
- Что такое функциональное программирование?
- Что такое обещание?
- Soft Skills
Начните бесплатный урок на Ericelliottjs.comЭтот пост был включен в книгу «Составление программного обеспечения».
Купить книгу | Индекс | < Предыдущий | Далее>
Eric Elliott — это технологический продукт и консультант по платформе, автор «СООБЩЕНИЕ» , COFOUNDRERST « , COFOUNDERSTERSTREST » , COFOUNDERERSTRES и DevAnywhere. io и наставник команды разработчиков. Он участвовал в разработке программного обеспечения для Adobe Systems, Zumba Fitness, 9.0068 The Wall Street Journal, ESPN, BBC, and top recording artists including Usher, Frank Ocean, Metallica, and many более.
io и наставник команды разработчиков. Он участвовал в разработке программного обеспечения для Adobe Systems, Zumba Fitness, 9.0068 The Wall Street Journal, ESPN, BBC, and top recording artists including Usher, Frank Ocean, Metallica, and many более.
Он наслаждается уединенным образом жизни с самой красивой женщиной в мире.
Что такое функциональное программирование? Учебное пособие с примером
Автор: Мэтью Мартин
ЧасыОбновлено
Что такое функциональное программирование?
Функциональное программирование (также называемое FP) — это способ мышления о создании программного обеспечения путем создания чистых функций. Это позволяет избежать концепций общего состояния, изменяемых данных, наблюдаемых в объектно-ориентированном программировании.
Это позволяет избежать концепций общего состояния, изменяемых данных, наблюдаемых в объектно-ориентированном программировании.
Функциональные языки делают акцент на выражениях и объявлениях, а не на выполнении операторов. Следовательно, в отличие от других процедур, которые зависят от локального или глобального состояния, вывод значения в FP зависит только от аргументов, переданных функции.
В этом уроке вы узнаете-
- Что такое функциональное программирование?
- Характеристики функционального программирования
- История функционального программирования
- Функциональные языки программирования
- Базовая терминология и концепции функционального программирования
- Преимущества функционального программирования
- Ограничения функционального программирования
- Функциональное программирование и объектно-ориентированное программирование
Характеристики функционального программирования
- Метод функционального программирования фокусируется на результатах, а не на процессе
- Акцент делается на том, что должно быть вычислено
- Данные неизменны
- Функциональное программирование Разложить задачу на «функции»
- Он построен на концепции математических функций, которые используют условные выражения и рекурсию для выполнения вычислений
- Он не поддерживает итерации, такие как операторы цикла и условные операторы, такие как If-Else
История функционального программирования
- Основой функционального программирования является лямбда-исчисление. Он был разработан в 1930-х годах для функционального приложения, определения и рекурсии .
- LISP был первым функциональным языком программирования. Маккарти разработал его в 1960 году
- В конце 70-х годов исследователи из Эдинбургского университета определили ML (мета-язык)
- В начале 80-х в язык Hope были добавлены алгебраические типы данных для рекурсии и рассуждений по уравнениям
- В 2004 году Инновация функционального языка «Scala».
 Он был разработан в 1930-х годах для функционального приложения, определения и рекурсии
Он был разработан в 1930-х годах для функционального приложения, определения и рекурсииЯзыки функционального программирования
Целью любого языка FP является имитация математических функций. Однако основной процесс вычислений в функциональном программировании отличается.
Вот некоторые наиболее известные языки функционального программирования:
- Haskell
- СМЛ
- Кложур
- Скала
- Эрланг
- Чистый
- F#
- ML/OCaml Lisp/схема
- XSLT
- SQL
- Математика
Базовая терминология и концепции функционального программирования
Неизменяемые данные
Неизменяемые данные означают, что вы должны легко создавать структуры данных вместо изменения уже существующих.
Ссылочная прозрачность
Функциональные программы должны выполнять операции так же, как если бы это было в первый раз. Таким образом, вы будете знать, что могло или не могло произойти во время выполнения программы, и его побочные эффекты. В терминах ФП это называется ссылочной прозрачностью.
Модульность
Модульная конструкция повышает производительность. Небольшие модули могут быть написаны быстро и имеют больше шансов на повторное использование, что, безусловно, приводит к более быстрой разработке программ. Кроме того, модули можно тестировать отдельно, что помогает сократить время, затрачиваемое на модульное тестирование и отладку.
Ремонтопригодность
Ремонтопригодность — это простой термин, который означает, что программирование FP легче поддерживать, поскольку вам не нужно беспокоиться о случайном изменении чего-либо за пределами данной функции.
Функция первого класса
«Функция первого класса» — это определение, относящееся к сущностям языка программирования, которые не имеют ограничений на их использование. Поэтому первоклассные функции могут появляться в любом месте программы.
Поэтому первоклассные функции могут появляться в любом месте программы.
Закрытие
Закрытие — это внутренняя функция, которая может обращаться к переменным родительской функции даже после выполнения родительской функции.
Функции высшего порядка
Функции высшего порядка либо принимают другие функции в качестве аргументов, либо возвращают их в качестве результатов.
Функции высшего порядка допускают частичное применение или каррирование. Этот метод применяет функцию к своим аргументам по одному, так как каждое приложение возвращает новую функцию, которая принимает следующий аргумент.
Чистая функция
«Чистая функция» — это функция, входы которой объявлены как входы, и ни один из них не должен быть скрыт. Выходы также объявляются как выходы.
Чистые функции действуют на свои параметры. Это неэффективно, если ничего не возвращается. Более того, он предлагает тот же результат для заданных параметров
Пример:
Функция Pure(a,b)
{
вернуть а+б;
} Нечистые функции
Нечистые функции прямо противоположны чистым. У них есть скрытые входы или выходы; это называется нечистым. Нечистые функции нельзя использовать или тестировать изолированно, поскольку они имеют зависимости.
У них есть скрытые входы или выходы; это называется нечистым. Нечистые функции нельзя использовать или тестировать изолированно, поскольку они имеют зависимости.
Пример
int z;
функция нечистая () {
г = г+10;
} Композиция функций
Композиция функций объединяет две или более функций для создания новой.
Общие состояния
Общие состояния — важная концепция в ООП-программировании. По сути, это добавление свойств к объектам. Например, если жесткий диск является объектом, в качестве свойств можно добавить емкость хранилища и размер диска.
Побочные эффекты
Побочные эффекты — это любые изменения состояния, происходящие вне вызываемой функции. Самая большая цель любого языка программирования FP — свести к минимуму побочные эффекты, отделив их от остального программного кода. В программировании FP жизненно важно убрать побочные эффекты из остальной логики вашего программирования.
Преимущества функционального программирования
- Позволяет избежать путаницы и ошибок в коде
- Проще тестировать и выполнять модульное тестирование и отлаживать код FP.
- Параллельная обработка и параллелизм
- Развертывание горячего кода и отказоустойчивость
- Предлагает лучшую модульность с более коротким кодом
- Повышение производительности разработчика
- поддерживает вложенные функции
- Функциональные конструкции, такие как ленивые карты и списки и т. д.
- Позволяет эффективно использовать лямбда-исчисление

Ограничения функционального программирования
- Парадигма функционального программирования непроста, поэтому ее трудно понять новичку
- Трудно поддерживать, так как многие объекты развиваются во время кодирования
- Требуется много насмешек и обширная настройка окружения
- Повторное использование очень сложно и требует постоянного рефакторинга
- Объекты могут неправильно отображать проблему
Функциональное программирование в сравнении с объектно-ориентированным программированием
| Функциональное программирование | ООП |
|---|---|
FP использует неизменяемые данные. | : ООП использует изменяемые данные. |
| Следует модели на основе декларативного программирования. | следует императивной модели программирования. |
| Основное внимание уделяется: «Что вы делаете. в программе». | Основное внимание уделяется тому, «как вы программируете». |
| Поддерживает параллельное программирование. | Параллельное программирование не поддерживается. |
| Его функции не имеют побочных эффектов. | Методможет иметь множество побочных эффектов. |
| Управление потоком выполняется с использованием вызовов функций и вызовов функций с рекурсией. | Процесс управления потоком выполняется с использованием циклов и условных операторов. |
| Порядок выполнения операторов не очень важен. | Порядок выполнения операторов важен. |
Поддерживает как «Абстракцию над данными», так и «Абстракцию над поведением». | Поддерживает только «Абстракцию над данными». |
Заключение
- Функциональное программирование или FP — это способ мышления о создании программного обеспечения, основанный на некоторых основополагающих определяющих принципах
- Концепции функционального программирования фокусируются на результатах, а не на процессе
- Целью любого языка FP является имитация математических функций
- Некоторые наиболее известные языки функционального программирования: 1) Haskell 2) SM 3) Clojure 4) Scala 5) Erlang 6) Clean
- «Чистая функция» — это функция, входы которой объявлены как входы, и ни один из них не должен быть скрыт. Выходы также объявляются как выходы.
- Immutable Data означает, что вы должны легко создавать структуры данных вместо изменения уже существующих
- Позволяет избежать путаницы и ошибок в коде
- Функциональный код непрост, поэтому его трудно понять новичку
- FP использует неизменяемые данные, в то время как OOP использует изменяемые данные
Функциональное программирование, наконец, становится мейнстримом · GitHub
У Пола Лаута была отличная команда разработчиков в Meddbase, компании по разработке программного обеспечения для здравоохранения, которую он основал в 2005 году. Но по мере роста компании росло и количество ошибок. Это ожидаемо, до определенного момента. Больше кода и больше функций — больше дефектов. Но уровень брака рос быстрее, чем ожидал Лаут.
Но по мере роста компании росло и количество ошибок. Это ожидаемо, до определенного момента. Больше кода и больше функций — больше дефектов. Но уровень брака рос быстрее, чем ожидал Лаут.
«Мы видели все больше и больше одних и тех же типов ошибок, — говорит Лаут. «Было ясно, что есть проблема, но не было ясно, что это было. Мой инстинкт подсказывал мне, что проблема в сложности».
Лаут и компания использовали C#, который только что добавил поддержку Language Integrated Query (LINQ), альтернативного языка для запросов к источникам данных, начиная от баз данных и заканчивая объектами в кодовых базах. LINQ представил способы применения парадигмы программирования, известной как «функциональное программирование», к коду C#, и изучение того, как работает LINQ, привело его к большему изучению функционального программирования в целом.
Функции — фрагменты кода, которые могут выполнять заданную задачу снова и снова в программе без необходимости переписывать код снова и снова — являются стандартной частью программирования. Например, вы можете написать функцию, которая возвращает длину окружности по заданному диаметру, или функцию, которая возвращает астрологический знак на основе чьей-либо даты рождения. Но, как пишет Кэссиди Уильямс в своем руководстве по функциональному программированию для проекта ReadME, функциональное программирование — это больше, чем просто написание функций. Это парадигма, которая делает упор на написание программ с использованием «чистых функций»: функций без сохранения состояния, которые всегда возвращают одно и то же значение при получении одних и тех же входных данных и не производят «побочных эффектов» при возврате своих выходных данных. Другими словами, чистые функции не изменяют никаких существующих данных или других частей логики приложения. Если бы наша функция окружности изменила, например, глобальную переменную, она не была бы чистой.
Например, вы можете написать функцию, которая возвращает длину окружности по заданному диаметру, или функцию, которая возвращает астрологический знак на основе чьей-либо даты рождения. Но, как пишет Кэссиди Уильямс в своем руководстве по функциональному программированию для проекта ReadME, функциональное программирование — это больше, чем просто написание функций. Это парадигма, которая делает упор на написание программ с использованием «чистых функций»: функций без сохранения состояния, которые всегда возвращают одно и то же значение при получении одних и тех же входных данных и не производят «побочных эффектов» при возврате своих выходных данных. Другими словами, чистые функции не изменяют никаких существующих данных или других частей логики приложения. Если бы наша функция окружности изменила, например, глобальную переменную, она не была бы чистой.
В функциональном программировании данные обычно считаются неизменяемыми. Например, вместо изменения содержимого массива программа, написанная в функциональном стиле, создаст копию массива с новыми внесенными изменениями. В отличие от объектно-ориентированного программирования, где структуры данных и логика переплетены, функциональное программирование делает упор на разделение данных и логики.
В отличие от объектно-ориентированного программирования, где структуры данных и логика переплетены, функциональное программирование делает упор на разделение данных и логики.
«Когда вы думаете о хорошо структурированном программном обеспечении, вы можете подумать о программном обеспечении, которое легко написать, легко отладить и которое можно использовать повторно», — пишет Уильямс, руководитель отдела разработки в Remote, компании, которая использует функциональный язык программирования Elixir для их внутреннего программного обеспечения. «Это функциональное программирование в двух словах!»
Функциональное программирование может быть благом для растущих команд, работающих с большими кодовыми базами. При написании кода с небольшим количеством побочных эффектов и неизменяемыми структурами данных меньше вероятность того, что программист, работающий над одной частью кодовой базы, нарушит функцию, над которой работает другой программист. И может быть проще отслеживать ошибки, поскольку, как пишет Уильямс, в коде меньше мест, где могут происходить изменения.
По мере того, как Лаут все глубже погружался в мир функционального программирования, он понял, что этот подход может помочь решить некоторые проблемы, связанные с крупномасштабными объектно-ориентированными кодовыми базами, например те, с которыми его команда начала сталкиваться в Meddbase. Он был не один. Интерес к функциональному программированию резко возрос за последнее десятилетие, поскольку все больше и больше разработчиков и организаций ищут способы укротить сложность и создать более безопасное и надежное программное обеспечение.
«Как только функциональное программирование по-настоящему щелкнуло в моем мозгу, я подумал: «А зачем делать это по-другому?», — говорит Уильямс, который влюбился в функциональное программирование во время занятий в колледже, где использовались диалекты языка программирования LISP Scheme и Racket. «Объектно-ориентированное программирование — это неплохо, оно по-прежнему работает во многих странах мира. Но многие разработчики становятся проповедниками функционального программирования, как только начинают с ним работать».
Несомненно, объектно-ориентированное и императивное программирование остаются доминирующими парадигмами современной разработки программного обеспечения, а «чистые» языки функционального программирования, такие как Haskell и Elm, относительно редко встречаются в производственных кодовых базах. Но по мере того, как языки программирования расширяют поддержку методов функционального программирования, а новые фреймворки охватывают альтернативные подходы к разработке программного обеспечения, функциональное программирование быстро находит применение во все большем числе кодовых баз различными способами.
Как только функциональное программирование по-настоящему щелкнуло в моей голове, я подумал: «А почему бы и нет?»
Расцвет функционального программирования в основных языках
Истоки функционального программирования восходят к зарождению языков программирования с созданием LISP в конце 1950-х годов. Но в то время как LISP и его диалекты, такие как Common LISP и Scheme, десятилетиями сохраняли преданных поклонников, объектно-ориентированное программирование затмило функциональное программирование в 1970-х и 1919 годах. 80-е годы.
80-е годы.
К 2010 году интерес к функциональному программированию резко возрос, поскольку разработчики обнаружили, что им приходится работать со все большими кодовыми базами, и команды столкнулись с теми же проблемами, что и Лаут и его команда разработчиков. Scala и Clojure привнесли функциональное программирование в виртуальную машину Java, а F# привнес парадигму в .NET. Twitter перенес большую часть своего кода на Scala, а Facebook развернул почтенные функциональные языки, такие как Haskell и Erlang, для решения конкретных проблем.
Тем временем возрос интерес к применению методов функционального программирования в объектно-ориентированных языках, таких как JavaScript, Ruby и Python. «Все эти языки все чаще поддерживают функции, облегчающие создание функционального стиля», — говорит 9.0961 Вяз в действии автора Ричард Фельдман. «Почти каждый язык становится все более мультипарадигмальным».
В 2014 году Apple представила Swift, новый мультипарадигмальный язык, который включает надежную поддержку функционального программирования. Запуск доказал, что поддержка функционального программирования стала обязательной функцией новых языков программирования, как уже была поддержка объектно-ориентированного программирования. В докладе 2019 года под названием «Почему функциональное программирование не является нормой?» Фельдман пришел к выводу, что функциональный стиль программирования действительно становится нормой. Или хотя бы часть нормы. «Что-то изменилось, — сказал он. «Этот стиль не то, что люди считали положительным моментом в 90, и идея о том, что это позитив, теперь стала чем-то вроде мейнстрима».
Запуск доказал, что поддержка функционального программирования стала обязательной функцией новых языков программирования, как уже была поддержка объектно-ориентированного программирования. В докладе 2019 года под названием «Почему функциональное программирование не является нормой?» Фельдман пришел к выводу, что функциональный стиль программирования действительно становится нормой. Или хотя бы часть нормы. «Что-то изменилось, — сказал он. «Этот стиль не то, что люди считали положительным моментом в 90, и идея о том, что это позитив, теперь стала чем-то вроде мейнстрима».
Уровень и характер поддержки функционального программирования зависят от языка, но одна особенность стала стандартной. «То, что, казалось бы, «победило», так сказать, — это функции более высокого порядка — функции, которые принимают или возвращают другую функцию», — говорит Тобиас Пфайффер, бэкенд-инженер в Remote. «Это позволяет создавать блоки функций для элегантного решения проблем».
Поддержка функций высшего порядка позволила разработчикам внедрить функциональное программирование в свои кодовые базы без изменения архитектуры существующих приложений. Когда Лаут и его команда решили перейти к модели функционального программирования, они остановились на использовании F# для нового кода в существующих приложениях, поскольку он обеспечивает надежную функциональную поддержку при сохранении совместимости с платформой .NET. Для существующего кода C# они использовали собственную поддержку языка для функционального программирования, а также language-ext, собственную платформу Лаута с открытым исходным кодом для функционального C#.
Когда Лаут и его команда решили перейти к модели функционального программирования, они остановились на использовании F# для нового кода в существующих приложениях, поскольку он обеспечивает надежную функциональную поддержку при сохранении совместимости с платформой .NET. Для существующего кода C# они использовали собственную поддержку языка для функционального программирования, а также language-ext, собственную платформу Лаута с открытым исходным кодом для функционального C#.
«Полная переработка невозможна, — говорит Лаут. «Поэтому, когда мы добавляем новые функции в существующий код, мы пишем его в соответствии с парадигмой функционального программирования».
Для некоторых использование объектно-ориентированного языка, такого как Java, JavaScript или C#, для функционального программирования может показаться плыть против течения. «Язык может направить вас к определенным решениям или стилям решений», — говорит Габриэлла Гонсалес, технический менеджер Arista Networks. «В Haskell путь наименьшего сопротивления — это функциональное программирование. Вы можете заниматься функциональным программированием на Java, но это не путь наименьшего сопротивления».
Вы можете заниматься функциональным программированием на Java, но это не путь наименьшего сопротивления».
Более серьезная проблема для тех, кто смешивает парадигмы, заключается в том, что вы не можете ожидать тех же гарантий, которые вы могли бы получить от чистых функций, если ваш код включает другие стили программирования. «Если вы пишете код, который может иметь побочные эффекты, он больше не работает», — говорит Уильямс. «Возможно, вы сможете положиться на части этой кодовой базы. Я сделал различные функции очень модульными, чтобы их ничто не касалось».
Работа со строго функциональными языками программирования затрудняет случайное введение побочных эффектов в ваш код. «Ключевым моментом в написании функционального программирования на чем-то вроде C# является то, что вы должны быть осторожны, потому что вы можете использовать ярлыки, и тогда вы получите точно такой же беспорядок, который был бы, если бы вы вообще не использовали функциональное программирование», Лаут говорит. «Haskell поддерживает функциональный стиль, он побуждает вас делать все правильно с первого раза». Вот почему Лаут и его команда используют Haskell для некоторых своих совершенно новых проектов.
«Haskell поддерживает функциональный стиль, он побуждает вас делать все правильно с первого раза». Вот почему Лаут и его команда используют Haskell для некоторых своих совершенно новых проектов.
Но чистота часто в глазах смотрящего. «LISP — это исходный язык функционального программирования с изменяемыми структурами данных, — говорит Пфайффер. Даже если ваш язык является чисто функциональным и использует неизменяемые структуры данных, примеси вносятся в тот момент, когда вы включаете пользовательский ввод. В то время как пользовательский ввод считается «нечистым» элементом, большинство программ не были бы очень полезными без него, так что чистота — это далеко не все. Haskell управляет пользовательским вводом и другими неизбежными «примесями», сохраняя их четко обозначенными и дискретными, но разные языки имеют разные границы.
Расширение функционального мышления
Несмотря на то, что функциональное программирование теперь доступно на большинстве основных языков программирования, разработчики не обязательно пользуются этими функциями. Подход функционального программирования требует существенно иного подхода к программированию, чем императивное или объектно-ориентированное программирование. «Что меня поразило, так это то, что в функциональном программировании нельзя создавать традиционные структуры данных, — говорит Уильямс. «Мне не нужно было делать объект для дерева, я мог просто сделать это. Кажется, что это не должно работать, но это работает».
Подход функционального программирования требует существенно иного подхода к программированию, чем императивное или объектно-ориентированное программирование. «Что меня поразило, так это то, что в функциональном программировании нельзя создавать традиционные структуры данных, — говорит Уильямс. «Мне не нужно было делать объект для дерева, я мог просто сделать это. Кажется, что это не должно работать, но это работает».
Библиотека JavaScript React — это один из самых больших способов, с помощью которых разработчики могут познакомиться с этим новым образом мышления сегодня. Поскольку React позволяет так много изменчивости, вероятно, лучше думать о нем как о «функционально смежном», но экосистема действительно позволяет и продвигает функциональные решения общих проблем программирования, которые традиционно решались бы другими методами.
«Несмотря на то, что React выглядел объектно-ориентированным, он предоставил первый удобный подход к программированию пользовательского интерфейса», — написал Дэвид Нолен, специалист по сопровождению ClojureScript, диалекта LISP, который компилируется в JavaScript, в своей статье для проекта ReadME.
Например, недавно представленные React Hooks — это набор функций, которые помогают разработчикам управлять состоянием и побочными эффектами, а Redux — популярная библиотека для управления состоянием, часто используемая с React и другими внешними библиотеками — использует в основном функциональный подход. .
«React побуждает людей мыслить более функционально, даже если это не чисто функционально», — говорит Уильямс. «Например, он знакомит разработчиков интерфейса с идеей использования функций map и reduce вместо циклов for. Теперь вы можете быть фронтенд-разработчиком на полную ставку и никогда не писать ни одного цикла for». Ознакомьтесь с руководством Уильямса, чтобы увидеть пример того, как это может работать в JavaScript.
Между тем, Гонсалес считает, что функциональное программирование становится все более популярным благодаря еще одному направлению: предметно-ориентированным языкам. Если вы действительно хороши в чем-то одном, это часто является более легким путем к усыновлению. Например, язык выражений системы управления пакетами Nix. «Он даже более функционален, чем Haskell, в том смысле, что на нем еще сложнее писать с побочными эффектами или изменчивостью», — говорит она. Nix не будет полезен, скажем, для создания веб-сервера. Он предназначен только для одной цели: создания пакетов. Но поскольку он создан для этой конкретной задачи, разработчики, которым нужен инструмент сборки, могут использовать его, даже если в противном случае они не стали бы пробовать функциональный язык программирования. «Я думаю, что со временем вы увидите меньше языков общего назначения и больше специализированных», — говорит она. «Многие из них будут функциональными».
Например, язык выражений системы управления пакетами Nix. «Он даже более функционален, чем Haskell, в том смысле, что на нем еще сложнее писать с побочными эффектами или изменчивостью», — говорит она. Nix не будет полезен, скажем, для создания веб-сервера. Он предназначен только для одной цели: создания пакетов. Но поскольку он создан для этой конкретной задачи, разработчики, которым нужен инструмент сборки, могут использовать его, даже если в противном случае они не стали бы пробовать функциональный язык программирования. «Я думаю, что со временем вы увидите меньше языков общего назначения и больше специализированных», — говорит она. «Многие из них будут функциональными».
«React побуждает людей мыслить более функционально, даже если это не чисто функционально».
Построение будущего функционального программирования
Как и многое другое в разработке программного обеспечения, будущее функционального программирования во многом зависит от сообществ с открытым исходным кодом, построенных вокруг функциональных языков и концепций. Например, одним из препятствий на пути внедрения чисто функционального программирования является то, что существует гораздо больше библиотек, написанных для объектно-ориентированного или императивного программирования. От пакетов для математики и научных вычислений для Python до веб-фреймворков для Node.js — людям не имеет большого смысла игнорировать весь этот существующий код, решающий распространенные проблемы, только потому, что он написан не в функциональном стиле. Это то, что Лаут иногда испытывает с Haskell. «У него довольно зрелая экосистема, но она испещрена заброшенными или непрофессиональными библиотеками», — говорит он.
Например, одним из препятствий на пути внедрения чисто функционального программирования является то, что существует гораздо больше библиотек, написанных для объектно-ориентированного или императивного программирования. От пакетов для математики и научных вычислений для Python до веб-фреймворков для Node.js — людям не имеет большого смысла игнорировать весь этот существующий код, решающий распространенные проблемы, только потому, что он написан не в функциональном стиле. Это то, что Лаут иногда испытывает с Haskell. «У него довольно зрелая экосистема, но она испещрена заброшенными или непрофессиональными библиотеками», — говорит он.
Чтобы преодолеть это препятствие, сообществу функционального программирования придется объединиться для создания новых библиотек, которые облегчат разработчикам выбор функционального программирования, а не более склонных к побочным эффектам подходов.
От библиотеки language-ext до Redux и Nix эта работа уже ведется.
Clojure — функциональное программирование
функциональное программирование
Содержание
- Функции первого класса
- Неизменяемые структуры данных
- Расширяемые абстракции
- Рекурсивный цикл
Clojure — это функциональный язык программирования. Он предоставляет инструменты, позволяющие избежать изменяемого состояния, предоставляет функции как первоклассные объекты и делает упор на рекурсивную итерацию вместо зацикливания на основе побочных эффектов. Clojure — это нечистый , поскольку он не заставляет вашу программу быть ссылочно прозрачной и не стремится к «доказуемым» программам. Философия Clojure заключается в том, что большинство частей большинства программ должны быть функциональными, а более функциональные программы более надежными.
Он предоставляет инструменты, позволяющие избежать изменяемого состояния, предоставляет функции как первоклассные объекты и делает упор на рекурсивную итерацию вместо зацикливания на основе побочных эффектов. Clojure — это нечистый , поскольку он не заставляет вашу программу быть ссылочно прозрачной и не стремится к «доказуемым» программам. Философия Clojure заключается в том, что большинство частей большинства программ должны быть функциональными, а более функциональные программы более надежными.
Функции первого класса
fn создает объект функции. Он дает значение, как и любое другое — вы можете сохранить его в var, передать его функциям и т. д.
(def hello (fn [] "Hello world")) -> #'пользователь/привет (привет) -> "Hello world"
defn — это макрос, который немного упрощает определение функций. Clojure поддерживает перегрузку арности в одном функциональном объекте , самоссылку и функции с переменной арностью, используя и :
; сфабрикованный пример (определить количество аргументов ([] 0) ([х] 1) ([х у] 2) ([x y & more] (+ (argcount x y) (ещё больше)))) -> #'пользователь/число_аргументов (число аргументов) -> 0 (счетчик аргументов 1) -> 1 (число аргументов 1 2) -> 2 (число аргументов 1 2 3 4 5) -> 5
Вы можете создавать локальные имена для значений внутри функции, используя let. Область действия любых локальных имен является лексической, поэтому функция, созданная в области действия локальных имен, закроет их значения:
Область действия любых локальных имен является лексической, поэтому функция, созданная в области действия локальных имен, закроет их значения:
(defn make-adder [x]
(пусть [у х]
(фн [з] (+ у з))))
(def add2 (сделать-adder 2))
(добавить2 4)
-> 6 Локальные переменные, созданные с помощью let, не являются переменными. Однажды созданные их значения никогда не меняются!
Неизменяемые структуры данных
Самый простой способ избежать изменения состояния — использовать неизменяемые структуры данных. Clojure предоставляет набор неизменяемых списков, векторов, наборов и карт. Поскольку их нельзя изменить, «добавление» или «удаление» чего-либо из неизменяемой коллекции означает создание новой коллекции, такой же, как старая, но с необходимыми изменениями. Постоянство — это термин, используемый для описания свойства, при котором старая версия коллекции по-прежнему доступна после «изменения», и что коллекция сохраняет свои гарантии производительности для большинства операций. В частности, это означает, что новая версия не может быть создана с использованием полной копии, так как это потребует линейного времени. Неизбежно, что постоянные коллекции реализуются с использованием связанных структур данных, так что новые версии могут иметь общую структуру с предыдущей версией. Односвязные списки и деревья являются базовыми функциональными структурами данных, к которым Clojure добавляет хэш-карту, набор и вектор, основанные на хэш-попытках сопоставления с массивом. Коллекции имеют удобочитаемые представления и общие интерфейсы:
В частности, это означает, что новая версия не может быть создана с использованием полной копии, так как это потребует линейного времени. Неизбежно, что постоянные коллекции реализуются с использованием связанных структур данных, так что новые версии могут иметь общую структуру с предыдущей версией. Односвязные списки и деревья являются базовыми функциональными структурами данных, к которым Clojure добавляет хэш-карту, набор и вектор, основанные на хэш-попытках сопоставления с массивом. Коллекции имеют удобочитаемые представления и общие интерфейсы:
(пусть [мой-вектор [1 2 3 4]
моя карта {:fred "этель"}
мой список (список 4 3 2 1)]
(список
(conj мой-вектор 5)
(ассоциация с моей картой: ricky "lucy")
(conj мой список 5)
; оригиналы целы
мой вектор
моя карта
мой список))
-> ([1 2 3 4 5] {:ricky "lucy", :fred "ethel"} (5 4 3 2 1) [1 2 3 4] {:fred "ethel"} (4 3 2 1)) Приложениям часто требуется связать атрибуты и другие данные о данных, которые ортогональны логическому значению данных. Clojure обеспечивает прямую поддержку этих метаданных. Символы и все коллекции поддерживают карту метаданных. Доступ к нему можно получить с помощью метафункции. Метаданные делают , а не влияют на семантику равенства, и метаданные не будут видны в операциях над значением коллекции. Метаданные можно прочитать и распечатать.
Clojure обеспечивает прямую поддержку этих метаданных. Символы и все коллекции поддерживают карту метаданных. Доступ к нему можно получить с помощью метафункции. Метаданные делают , а не влияют на семантику равенства, и метаданные не будут видны в операциях над значением коллекции. Метаданные можно прочитать и распечатать.
(по умолчанию v [1 2 3])
(def attribute-v (with-meta v {:source:trusted}))
(: источник (мета атрибут-v))
-> : доверенный
(= v атрибут-v)
-> true Расширяемые абстракции
Clojure использует интерфейсы Java для определения основных структур данных. Это позволяет расширять Clojure для новых конкретных реализаций этих интерфейсов, и библиотечные функции будут работать с этими расширениями. Это большое улучшение по сравнению с жесткой привязкой языка к конкретным реализациям его типов данных.
Хорошим примером этого является интерфейс seq. Превращая базовую конструкцию списка Lisp в абстракцию, множество библиотечных функций распространяется на любую структуру данных, которая может обеспечить последовательный интерфейс для своего содержимого. Все структуры данных Clojure могут предоставлять последовательности. Последовательности можно использовать так же, как итераторы или генераторы в других языках, со значительным преимуществом, заключающимся в том, что последовательности являются неизменяемыми и постоянными. Seq чрезвычайно просты, предоставляя функцию first , которая возвращает первый элемент в последовательности, и функцию rest функция, которая возвращает остальную часть последовательности, которая сама является либо последовательностью, либо nil.
Все структуры данных Clojure могут предоставлять последовательности. Последовательности можно использовать так же, как итераторы или генераторы в других языках, со значительным преимуществом, заключающимся в том, что последовательности являются неизменяемыми и постоянными. Seq чрезвычайно просты, предоставляя функцию first , которая возвращает первый элемент в последовательности, и функцию rest функция, которая возвращает остальную часть последовательности, которая сама является либо последовательностью, либо nil.
(пусть [мой-вектор [1 2 3 4]
моя карта {: фред "этель" : рикки "люси"}
мой список (список 4 3 2 1)]
[(первый мой вектор)
(отдых мой вектор)
(ключи моя карта)
(vals my-map)
(первый мой список)
(остальное мой список)])
-> [1 (2 3 4) (:ricky :fred) ("lucy" "ethel") 4 (3 2 1)] Многие функции библиотеки Clojure создают и потребляют последовательности лениво :
;цикл производит "бесконечную" последовательность! (возьмите 15 (цикл [1 2 3 4])) -> (1 2 3 4 1 2 3 4 1 2 3 4 1 2 3)
Вы можете определить свои собственные ленивые функции создания последовательностей с помощью макроса lazy-seq, который принимает набор выражений, которые будут вызываться по запросу. для создания списка из 0 или более элементов. Вот упрощенный вариант:
для создания списка из 0 или более элементов. Вот упрощенный вариант:
(defn take [n coll]
(ленивая последовательность
(когда (поз?н)
(когда-пусть [s (seq coll)]
(минусы (первые с) (взять (уб. н) (остальные с))))))) Рекурсивный цикл
При отсутствии изменяемых локальных переменных циклы и итерации должны иметь другую форму, чем в языках со встроенными конструкциями for или while , которые управляются изменением состояния. В функциональных языках циклы и итерации заменяются/реализуются с помощью рекурсивных вызовов функций. Многие такие языки гарантируют, что вызовы функций, выполняемые в хвостовой позиции, не занимают место в стеке, и поэтому рекурсивные циклы используют постоянное пространство. Поскольку Clojure использует соглашения о вызовах Java, он не может и не дает таких же гарантий оптимизации хвостовых вызовов. Вместо этого он предоставляет специальный оператор recur, который выполняет рекурсивный цикл в постоянном пространстве путем повторного связывания и перехода к ближайшему охватывающему циклу или функциональному фрейму. Хотя он и не такой общий, как оптимизация хвостового вызова, он допускает большинство тех же элегантных конструкций и предлагает преимущество проверки того, что повторные вызовы могут происходить только в хвостовой позиции.
Хотя он и не такой общий, как оптимизация хвостового вызова, он допускает большинство тех же элегантных конструкций и предлагает преимущество проверки того, что повторные вызовы могут происходить только в хвостовой позиции.
(определить my-zipmap [keys vals]
(петля [моя-карта {}
my-keys (последовательные ключи)
my-vals (seq vals)]
(if (и my-keys my-vals)
(recur (сопоставить мою-карту (первые мои-ключи) (первые мои-валы))
(далее мои-ключи)
(следующие мои-валы))
моя карта)))
(мой-zipmap [:a:b:c] [1 2 3])
-> {:b 2, :c 3, :a 1} В ситуациях, когда требуется взаимная рекурсия, recur использовать нельзя. Вместо этого хорошим вариантом может быть батут.
Динамичное развитие Лисп
Принципы функционального программирования в Scala
Об этом курсе
97 295 недавних просмотров
Функциональное программирование получает все более широкое распространение в промышленности. Эта тенденция обусловлена принятием Scala в качестве основного языка программирования для многих приложений. Scala объединяет функциональное и объектно-ориентированное программирование в практичном пакете. Он без проблем взаимодействует как с Java, так и с Javascript. Scala — это язык реализации многих важных фреймворков, включая Apache Spark, Kafka и Akka. Он обеспечивает базовую инфраструктуру для таких сайтов, как Twitter, Netflix, Zalando, а также Coursera.
Эта тенденция обусловлена принятием Scala в качестве основного языка программирования для многих приложений. Scala объединяет функциональное и объектно-ориентированное программирование в практичном пакете. Он без проблем взаимодействует как с Java, так и с Javascript. Scala — это язык реализации многих важных фреймворков, включая Apache Spark, Kafka и Akka. Он обеспечивает базовую инфраструктуру для таких сайтов, как Twitter, Netflix, Zalando, а также Coursera.
 Курс дополняется серией проектов по программированию в качестве домашних заданий.
Рекомендуемый опыт: у вас должен быть не менее одного года опыта программирования. Знание Java или C# идеально, но также достаточно опыта работы с другими языками, такими как C/C++, Python, Javascript или Ruby. Вы должны иметь некоторое представление об использовании командной строки.
Курс дополняется серией проектов по программированию в качестве домашних заданий.
Рекомендуемый опыт: у вас должен быть не менее одного года опыта программирования. Знание Java или C# идеально, но также достаточно опыта работы с другими языками, такими как C/C++, Python, Javascript или Ruby. Вы должны иметь некоторое представление об использовании командной строки.Гибкие сроки
Сброс сроков в соответствии с вашим графиком.
Общий сертификатОбщий сертификат
Получите сертификат по завершении
100% онлайн100% онлайн
Начните сразу и учитесь по собственному графику.
СпециализацияКурс 1 из 5 в рамках специализации
Функциональное программирование на Scala
Средний уровеньСредний уровень
Не менее одного года программирования (на любом языке)
Часов на выполнениеПрибл. 56 часов на выполнение
Доступные языкиАнглийский
Субтитры: английский
Чему вы научитесь
Понимать принципы функционального программирования
Написание чисто функциональных программ с использованием рекурсии, сопоставления функций с образцом и функций высшего порядка
Разработка неизменяемых структур данных
Сочетание функционального программирования с объектами и классами
Навыки.
 Вы получите
Вы получите- Scala Programming
- Рекурсия
- Функциональные программы
- Имматируемые типы данных
- FILCE
.
Общий сертификатОбщий сертификат
Получите сертификат по завершении
100% онлайн100% онлайн
Начните сразу и учитесь по собственному графику.
СпециализацияКурс 1 из 5 специализации
Функциональное программирование на Scala
Средний уровеньСредний уровень
Минимум один год программирования (на любом языке)
Часов для завершенияПрибл. 56 часов
Доступные языкиАнглийский
Субтитры: английский
Инструктор
Мартин Одерски
Профессор
Информатика
215,2200005
6 Courses
Offered by
École Polytechnique Fédérale de Lausanne
Reviews
4. 8
8
1644 reviews
5 stars
83.54%
4 звездочки
13,54%
3 звезды
1,70%
2 звезды
0,63%
5 90 90 0002 0.56%
ЛУЧШИЕ ОТЗЫВЫ О ПРИНЦИПАХ ФУНКЦИОНАЛЬНОГО ПРОГРАММИРОВАНИЯ В SCALA
Filled StarFilled StarFilled StarFilled StarFilled Starот AW 10 января 2021 г.
Я думаю, что курс был фантастическим. Упражнения были как раз правильной сложности, а лекции были очень понятными. Мартин очень понятно и доступно объясняет концепции.
Filled StarFilled StarFilled StarFilled StarStarby DF 14 января 2019 г.
Курс в целом носит теоретический характер. Некоторые домашние задания довольно сложные. Я нашел его полезным дополнением к книге «Программирование на Scala», над которой я сейчас работаю.
Filled StarFilled StarFilled StarFilled StarFilled Star от VPS14 сентября 2018 г.
Мне потребовалось гораздо больше времени, чем я ожидал, чтобы закончить курс, и иногда я чувствовал себя глупо и беспомощно. Погружение в функциональное программирование было головокружительным опытом, который стоил потраченного времени!
Filled StarFilled StarFilled StarFilled StarFilled Starот LK13 июля 2016 г.
Курс очень хороший, лабораторные работы иногда сложны, но полезны. Однако какой-то материал не был пройден, и так всегда, но все же он может включать в себя итераторы и некоторые другие главы
Просмотреть все обзоры
О специализации «Функциональное программирование в Scala»
Узнайте, как писать элегантный код, который работает с первого запуска.
