Интерпретатор — Википедия
Материал из Википедии — свободной энциклопедии
Текущая версия страницы пока не проверялась опытными участниками и может значительно отличаться от версии, проверенной 26 марта 2016; проверки требуют 14 правок. Текущая версия страницы пока не проверялась опытными участниками и может значительно отличаться от версии, проверенной 26 марта 2016; проверки требуют 14 правок. Эта статья включает описание термина «Интерпретация»; см. также другие значения.Интерпретатор (англ. interpreter ıntə:’prıtə[1], от лат. interpretator — толкователь[2]) — программа (разновидность транслятора), выполняющая интерпретацию[3].
Интерпретация — построчный анализ, обработка и выполнение исходного кода программы или запроса (в отличие от компиляции, где весь текст программы, перед запуском, анализируется и транслируется в машинный или байт-код, без её выполнения) [4][5][6].
Первым интерпретированным языком программирования высокого уровня был Lisp. Его интерпретатор был создан в 1958 году Стивом Расселом на компьютере IBM 704. Рассел вдохновился работой Джона Маккарти и выяснил, что функция
Простой интерпретатор анализирует и тут же выполняет (собственно интерпретация) программу покомандно (или построчно), по мере поступления её исходного кода на вход интерпретатора. Достоинством такого подхода является мгновенная реакция. Недостаток — такой интерпретатор обнаруживает ошибки в тексте программы только при попытке выполнения команды (или строки) с ошибкой.
Интерпретатор компилирующего типа — это система из компилятора, переводящего исходный код программы в промежуточное представление, например, в байт-код или p-код, и собственно интерпретатора, который выполняет полученный промежуточный код (так называемая виртуальная машина). Достоинством таких систем является большее быстродействие выполнения программ (за счёт выноса анализа исходного кода в отдельный, разовый проход, и минимизации этого анализа в интерпретаторе). Недостатки — большее требование к ресурсам и требование на корректность исходного кода. Применяется в таких языках, как Java, PHP, Tcl, Perl, REXX (сохраняется результат парсинга исходного кода
В случае разделения интерпретатора компилирующего типа на компоненты получаются компилятор языка и простой интерпретатор с минимизированным анализом исходного кода. Причём исходный код для такого интерпретатора не обязательно должен иметь текстовый формат или быть байт-кодом, который понимает только данный интерпретатор, это может быть машинный код какой-то существующей аппаратной платформы. К примеру, виртуальные машины вроде QEMU, Bochs, VMware включают в себя интерпретаторы машинного кода процессоров семейства x86.
Некоторые интерпретаторы (например, для языков Лисп, Scheme, Python, Бейсик и других) могут работать в режиме диалога или так называемого цикла чтения-вычисления-печати (англ. read-eval-print loop, REPL). В таком режиме интерпретатор считывает законченную конструкцию языка (например, s-expression в языке Лисп), выполняет её, печатает результаты, после чего переходит к ожиданию ввода пользователем следующей конструкции.
Уникальным является язык Forth, который способен работать как в режиме интерпретации, так и компиляции входных данных, позволяя переключаться между этими режимами в произвольный момент, как во время трансляции исходного кода, так и во время работы программ.[9]
Следует также отметить, что режимы интерпретации можно найти не только в программном, но и аппаратном обеспечении. Так, многие микропроцессоры интерпретируют машинный код с помощью встроенных микропрограмм, а процессоры семейства x86, начиная с Pentium (например, на архитектуре Intel P6), во время исполнения машинного кода предварительно транслируют его во внутренний формат (в последовательность микроопераций).
- прочитать инструкцию;
- проанализировать инструкцию и определить соответствующие действия;
- выполнить соответствующие действия;
- если не достигнуто условие завершения программы, прочитать следующую инструкцию и перейти к пункту 2.
Достоинства и недостатки интерпретаторов[править | править код]
Достоинства[править | править код]
- Бо́льшая переносимость интерпретируемых программ — программа будет работать на любой платформе, на которой есть соответствующий интерпретатор.
- Как правило, более совершенные и наглядные средства диагностики ошибок в исходных кодах.
- Меньшие размеры кода по сравнению с машинным кодом, полученным после обычных компиляторов.
Недостатки[править | править код]
- Интерпретируемая программа не может выполняться отдельно без программы-интерпретатора. Сам интерпретатор при этом может быть очень компактным.
- Интерпретируемая программа выполняется медленнее, поскольку промежуточный анализ исходного кода и планирование его выполнения требуют дополнительного времени в сравнении с непосредственным исполнением машинного кода, в который мог бы быть скомпилирован исходный код.
- Практически отсутствует оптимизация кода, что приводит к дополнительным потерям в скорости работы интерпретируемых программ.
- ↑ Кочергин В. И.
- ↑ Интерпретатор // Математический энциклопедический словарь / Гл. ред. Прохоров Ю. В.. — М.: Советская энциклопедия, 1988. — С. 820. — 847 с.
- ↑ ГОСТ 19781-83; СТ ИСО 2382/7-77 // Вычислительная техника. Терминология: Справочное пособие. Выпуск 1 / Рецензент канд. техн. наук Ю. П. Селиванов. — М.: Издательство стандартов, 1989. — 168 с. — 55 000 экз. — ISBN 5-7050-0155-X.
- ↑ Першиков В. И., Савинков В. М. Толковый словарь по информатике / Рецензенты: канд. физ.-мат. наук А. С. Марков и д-р физ.-мат. наук И. В. Поттосин. —
- ↑ Борковский А. Б. Англо-русский словарь по программированию и информатике (с толкованиями). — М.: Русский язык, 1990. — 335 с. — 50 050 (доп,) экз. — ISBN 5-200-01169-3.
- ↑ Толковый словарь по вычислительным системам = Dictionary of Computing / Под ред. В. Иллингуорта и др.: Пер. с англ. А. К. Белоцкого и др.; Под ред. Е. К. Масловского. — М.: Машиностроение, 1990. — 560 с. — 70 000 (доп,) экз. — ISBN 5-217-00617-X (СССР), ISBN 0-19-853913-4 (Великобритания).
- ↑ Graham, Paul. Hackers & painters : big ideas from the computer age. — O’Reilly, 2010. — С. 185. — ISBN 9781449389550, 1449389554.
- ↑ Dave Martin. Why does my OS/2 REXX program run more quickly the second time? (неопр.). Rexx FAQs. Дата обращения 22 декабря 2009. Архивировано 22 августа 2011 года.
- ↑ Jeff Fox. Chapter 2. More Interpretation (англ.). Thoughtful Programming and Forth. UltraTechnology. Дата обращения 25 января 2010. Архивировано 22 августа 2011 года.
Интерпретатор — это… Что такое Интерпретатор?
Эта статья включает описание термина «Интерпретация»; см. также другие значения.Интерпрета́тор — программа (разновидность транслятора) или аппаратное средство, выполняющее интерпретацию.[1]
Интерпрета́ция — пооператорный (покомандный, построчный) анализ, обработка и тут же выполнение исходной программы или запроса (в отличие от компиляции, при которой программа транслируется без её выполнения).[2][3][4]
Типы интерпретаторов
Простой интерпретатор анализирует и тут же выполняет (собственно интерпретация) программу покомандно (или построчно), по мере поступления её исходного кода на вход интерпретатора. Достоинством такого подхода является мгновенная реакция. Недостаток — такой интерпретатор обнаруживает ошибки в тексте программы только при попытке выполнения команды (или строки) с ошибкой.
Интерпретатор компилирующего типа — это система из компилятора, переводящего исходный код программы в промежуточное представление, например, в байт-код или p-код, и собственно интерпретатора, который выполняет полученный промежуточный код (так называемая виртуальная машина). Достоинством таких систем является большее быстродействие выполнения программ (за счёт выноса анализа исходного кода в отдельный, разовый проход, и минимизации этого анализа в интерпретаторе). Недостатки — большее требование к ресурсам и требование на корректность исходного кода. Применяется в таких языках, как Java, Tcl, Perl (используется байт-код
В случае разделения интерпретатора компилирующего типа на компоненты получаются компилятор языка и простой интерпретатор с минимизированным анализом исходного кода. Причём исходный код для такого интерпретатора не обязательно должен иметь текстовый формат или быть байт-кодом, который понимает только данный интерпретатор, это может быть машинный код какой-то существующей аппаратной платформы. К примеру, виртуальные машины вроде QEMU, Bochs, VMware включают в себя интерпретаторы машинного кода процессоров семейства x86.
Некоторые интерпретаторы (например, для языков Лисп, Scheme, Python, Бейсик и других) могут работать в режиме диалога или так называемого цикла чтения-вычисления-печати (англ. read-eval-print loop, REPL). В таком режиме интерпретатор считывает законченную конструкцию языка (например, s-expression в языке Лисп), выполняет её, печатает результаты, после чего переходит к ожиданию ввода пользователем следующей конструкции.
Уникальным является язык Forth, который способен работать как в режиме интерпретации, так и компиляции входных данных, позволяя переключаться между этими режимами в произвольный момент, как во время трансляции исходного кода, так и во время работы программ.[6]
Следует также отметить, что режимы интерпретации можно найти не только в программном, но и аппаратном обеспечении. Так, многие микропроцессоры интерпретируют машинный код с помощью встроенных микропрограмм, а процессоры семейства x86, начиная с Pentium (например, на архитектуре Intel P6), во время исполнения машинного кода предварительно транслируют его во внутренний формат (в последовательность микроопераций).
Алгоритм работы простого интерпретатора
- прочитать инструкцию;
- проанализировать инструкцию и определить соответствующие действия;
- выполнить соответствующие действия;
- если не достигнуто условие завершения программы, прочитать следующую инструкцию и перейти к пункту 2.
Достоинства и недостатки интерпретаторов
Достоинства
- Бо́льшая переносимость интерпретируемых программ — программа будет работать на любой платформе, на которой есть соответствующий интерпретатор.
- Как правило, более совершенные и наглядные средства диагностики ошибок в исходных кодах.
- Упрощение отладки исходных кодов программ[источник не указан 573 дня].
- Меньшие размеры кода по сравнению с машинным кодом, полученным после обычных компиляторов.
Недостатки
- Интерпретируемая программа не может выполняться отдельно без программы-интерпретатора. Сам интерпретатор при этом может быть очень компактным.
- Интерпретируемая программа выполняется медленнее, поскольку промежуточный анализ исходного кода и планирование его выполнения требуют дополнительного времени в сравнении с непосредственным исполнением машинного кода, в который мог бы быть скомпилирован исходный код.
- Практически отсутствует оптимизация кода, что приводит к дополнительным потерям в скорости работы интерпретируемых программ.
См. также
Примечания
- ↑ ГОСТ 19781-83; СТ ИСО 2382/7-77 // Вычислительная техника. Терминология: Справочное пособие. Выпуск 1 / Рецензент канд. техн. наук Ю. П. Селиванов. — М.: Издательство стандартов, 1989. — 168 с. — 55 000 экз. — ISBN 5-7050-0155-X
- ↑ Першиков В. И., Савинков В. М. Толковый словарь по информатике / Рецензенты: канд. физ.-мат. наук А. С. Марков и д-р физ.-мат. наук И. В. Поттосин. — М.: Финансы и статистика, 1991. — 543 с. — 50 000 экз. — ISBN 5-279-00367-0
- ↑ Борковский А. Б. Англо-русский словарь по программированию и информатике (с толкованиями). — М.: Русский язык, 1990. — 335 с. — 50 050 (доп,) экз. — ISBN 5-200-01169-3
- ↑ Толковый словарь по вычислительным системам = Dictionary of Computing / Под ред. В. Иллингуорта и др.: Пер. с англ. А. К. Белоцкого и др.; Под ред. Е. К. Масловского. — М.: Машиностроение, 1990. — 560 с. — 70 000 (доп,) экз. — ISBN 5-217-00617-X (СССР), ISBN 0-19-853913-4 (Великобритания)
- ↑ Dave Martin. Why does my OS/2 REXX program run more quickly the second time?. Rexx FAQs. Архивировано из первоисточника 22 августа 2011. Проверено 22 декабря 2009.
- ↑ Jeff Fox. Chapter 2. More Interpretation (англ.). Thoughtful Programming and Forth. UltraTechnology. Архивировано из первоисточника 22 августа 2011. Проверено 25 января 2010.
dic.academic.ru
Интерпретатор — Национальная библиотека им. Н. Э. Баумана
Материал из Национальной библиотеки им. Н. Э. Баумана
Последнее изменение этой страницы: 17:31, 18 января 2018.
Интерпретатор — программа (разновидность транслятора), выполняющая интерпретацию.
Интерпретация — построчный анализ, обработка и выполнение исходного кода программы или запроса (в отличие от компиляции, где весь текст программы, перед запуском, анализируется и транслируется в машинный или байт-код, без её выполнения) [Источник 1]
История
Первым интерпретатором языка высокого уровня был Lisp. Lisp был впервые реализован в 1958 году Стивом Расселом на компьютере IBM 704. Рассел читать бумаги Джона Маккарти, и понял (к удивлению Маккарти), что lisp-функция оценки может быть реализован в машинный код. В результате получился рабочий интерпретатор Lisp, который мог бы использоваться для запуска программ Lisp, или, более правильно, «оценивать выражения Lisp». [Источник 2]
Типы интерпретаторов
Простой интерпретатор анализирует и тут же выполняет (собственно интерпретация) программу покомандно (или построчно), по мере поступления её исходного кода на вход интерпретатора. Достоинством такого подхода является мгновенная реакция. Недостаток — такой интерпретатор обнаруживает ошибки в тексте программы только при попытке выполнения команды (или строки) с ошибкой. [1]
Интерпретатор компилирующего типа — это система из компилятора, переводящего исходный код программы в промежуточное представление, например, в байт-код или p-код, и собственно интерпретатора, который выполняет полученный промежуточный код (так называемая виртуальная машина). Достоинством таких систем является большее быстродействие выполнения программ (за счёт выноса анализа исходного кода в отдельный, разовый проход, и минимизации этого анализа в интерпретаторе). Недостатки — большее требование к ресурсам и требование на корректность исходного кода. Применяется в таких языках, как Java, PHP, Tcl, Perl, REXX (сохраняется результат парсинга исходного кода), а также в различных СУБД.
В случае разделения интерпретатора компилирующего типа на компоненты получаются компилятор языка и простой интерпретатор с минимизированным анализом исходного кода. Причём [Исходный код|исходного код]] для такого интерпретатора не обязательно должен иметь текстовый формат или быть байт-кодом, который понимает только данный интерпретатор, это может быть машинный код какой-то существующей аппаратной платформы. К примеру, виртуальные машины вроде QEMU, Bochs, VMware включают в себя интерпретаторы машинного кода процессоров семейства x86.
Некоторые интерпретаторы (например, для языков Лисп, Scheme, Python, Бейсик и других) могут работать в режиме диалога или так называемого цикла чтения-вычисления-печати (англ. read-eval-print loop, REPL). В таком режиме интерпретатор считывает законченную конструкцию языка (например, s-expression в языке Лисп), выполняет её, печатает результаты, после чего переходит к ожиданию ввода пользователем следующей конструкции.
Уникальным является язык Forth, который способен работать как в режиме интерпретации, так и компиляции входных данных, позволяя переключаться между этими режимами в произвольный момент, как во время трансляции исходного кода, так и во время работы программ.
Следует также отметить, что режимы интерпретации можно найти не только в программном, но и аппаратном обеспечении. Так, многие микропроцессоры интерпретируют машинный код с помощью встроенных микропрограмм, а процессоры семейства x86, начиная с Pentium (например, на архитектуре Intel P6), во время исполнения машинного кода предварительно транслируют его во внутренний формат (в последовательность микроопераций).
Компиляторы против интерпретаторов [2]
В то время как компиляторы (и ассемблеры) обычно производят машинный код, непосредственно исполняемый компьютерным оборудованием, они могут часто (дополнительно) производить промежуточную форму, названную объектным кодом. Это, в основном, тот же машинный определенный код, но с увеличенной таблицей символов с именами и тегами, чтобы сделать исполнимые блоки (или модули) идентифицируемыми и перемещаемыми. Скомпилированные программы обычно используют стандартные блоки (функции), сохраненные в библиотеке таких модулей объектного кода. Компоновщик используется для объединения предварительно сделанных файлов библиотеки с объектным файлом (файлами) приложения, чтобы сформировать единственный выполняемый файл. Объектные файлы, которые используются, чтобы генерировать исполняемый файл, часто создаются в разное время, и иногда даже различными языками (способный к генерации того же объектного формата).
У простого интерпретатора, записанного на низкоуровневом языке (например, блок), могут быть подобные блоки машинного кода, реализовывая функции высокоуровневого языка, сохраненного и выполняемого, когда запись функции при просмотре таблицы указывает на тот код. Однако интерпретатор, записанный на высокоуровневом языке обычно, использует другой подход, такой как генерация и затем обход дерева синтаксического анализа, или генерировать и выполнять промежуточное звено определенное с помощью программного обеспечения инструкции или оба действия.
Таким образом и компиляторы, и интерпретаторы обычно преобразуют исходный код (текстовые файлы) в знаки, оба могут (или не могут) генерировать дерево синтаксического анализа, и оба могут генерировать непосредственные инструкции (для стековой машины, четырехкратного кода, или другими средствами). Основное различие — то, что система компилятора, включая (встраиваемый или отдельный) компоновщик, генерирует автономную программу машинного кода, в то время как система интерпретатора вместо этого выполняет действия, описанные программой высокого уровня.
Компилятор может, таким образом, сделать почти все преобразования от семантики исходного кода до уровня машины раз и навсегда (т.е. пока программа не была изменена), в то время как интерпретатор должен сделать часть этого преобразования каждый раз, когда оператор или функция выполняются. Однако в эффективном интерпретаторе, большая часть работы перевода (включая анализ типов, и подобное) факторизована и сделана только при первом запуске программы, модуля, функции, или даже оператора, выполнена, таким образом довольно сродни тому, как работает компилятор. Однако скомпилированная программа все еще работает намного быстрее при большинстве обстоятельств, частично потому что компиляторы разработаны, чтобы оптимизировать код и могут давать достаточно времени для этого. Это — особенно верно для более простых высокоуровневых языков без (многих) динамических структур данных, проверок или типовых проверок. В традиционной компиляции, исполнимый вывод компоновщиков (.exe файлы или .dll файлы или библиотека, просмотр картинки) обычно перемещаем, когда выполнен под общей операционной системой, во многом как объектный код, в котором модули всего лишь с тем различием, что это перемещение сделано динамично во время выполнения, т.е. когда программа загружена для работы с ней. С другой стороны, скомпилированные и соединенные программы для маленьких встроенных систем обычно статически выделяются, часто трудно кодируются во флэш-памяти NOR, поскольку часто нет никакой внешней памяти и никакой операционной системы в этом смысле.
Исторически, большинству систем интерпретатора встроили автономный редактор. Он больше распространен также для компиляторов (часто называемый IDE), несмотря на то, что некоторые программисты предпочитают использовать редактор по их выбору и запускать компилятор, компоновщик и другие инструменты вручную. Исторически, компиляторы предшествуют интерпретаторам, потому что аппаратные средства в то время не могли поддерживать интерпретатор и интерпретировали код, и типичная пакетная среда времени ограничила преимущества интерпретации.
Цикл разработки
Во время цикла разработки программного обеспечения программисты вносят частые изменения в исходный код. При использовании компилятора, каждый раз, когда изменение было внесено в исходный код, они должны ожидать компилятор, чтобы перевести измененные исходные файлы и соединить все файлы двоичного кода, прежде чем программа может быть исполнена. Чем больше программа, тем дольше ожидание. В отличие от этого, программист, использующий интерпретатор, делает ждет намного меньше, поскольку интерпретатор обычно просто должен перевести код, работающий на промежуточном представлении (или не перевести его вообще), таким образом требуется намного меньшего количества времени, прежде чем изменения смогут быть протестированы. Эффекты заметны после сохранения исходного кода и перезагрузки программы. Скомпилированный код обычно с меньшей готовностью отлажен для редактирования, компиляции и соединения — последовательные процессы, которые должны быть проведены в надлежащей последовательности с надлежащим набором команд. Поэтому у многих компиляторов также есть исполнительное средство, известное как Make-файл и программа. Make-файл перечисляет командные строки компилятора и компоновщика и файлы исходного кода программы, но мог бы использовать простой ввод меню командной строки (например, «Make 3»), который выбирает третью группу (набор) инструкций, и тогда дает команды компилятору и компоновщику, которые подают указанные файлы исходного кода. [3]
Распределение
Компилятор преобразовывает исходный код в двоичную инструкцию для архитектуры определенного процессора, таким образом делая его менее портативным. Это преобразование сделано только один раз на стадии разработки, и после этого тот же двоичный файл может быть распространен машинам пользователя, где это может быть выполнено без дальнейшего перевода. Кросс-компилятор может генерировать двоичный код для пользовательской машины, даже если у нее есть другой процессор, отличный от машины, где код был скомпилирован. [4]
Интерпретируемая программа может быть записана как исходный код. Она должна быть переведена в каждой конечной машине, что занимает больше времени, но делает распределение программы независимым от архитектуры машины. Однако мобильность интерпретируемого исходного кода зависит от целевой машины, на самом деле имеющей подходящий интерпретатор. Если интерпретатор должен быть предоставлен вместе с источником, полный процесс установки сложнее, чем доставка монолитной исполнимой программы, так как сам интерпретатор — часть того, что должно быть установлено.
Факт, который интерпретировал код, может легко быть считан и скопирован людьми, может представить интерес с точки зрения авторского права. Однако существуют различные системы шифрования. Доставка промежуточного кода, такого как байт-код, имеет подобный эффект к шифрованию, но байт-код может декодироваться при помощи декомпилятора или дизассемблера. Эффективность Основной недостаток интерпретаторов — то, что интерпретируемая программа обычно работает медленнее, чем если бы она была скомпилирована. Различие в скоростях могло быть крошечным или большим; часто на порядок, иногда больше. Обычно для запуска программы под интерпретатором требуется больше времени, чем для запуска скомпилированного кода, но для его интерпретации может потребоваться меньше времени, чем общее время, необходимое для его компиляции и запуска. Это особенно важно при анализе прототипа и тестировании кода, когда цикл «редактирования-интерпретации-отладки», может часто быть намного короче цикла редактирования-компиляции-отладки.
Интерпретация кода медленнее, чем выполнение скомпилированного кода, потому что интерпретатор должен проанализировать каждый оператор в программе каждый раз, когда это выполняется, и затем выполнить желаемое действие, тогда как скомпилированный код просто выполняет действие в фиксированном контексте, определенном компиляцией. Этот анализ во время выполнения известен как «интерпретирующие издержки». Доступ к переменным также медленнее в интерпретаторе, потому что отображение идентификаторов в места хранения должно выполняться повторно во время выполнения, а не во время компиляции. [5]
Есть различные компромиссы между скоростью разработки при использовании интерпретатора и скоростью выполнения при использовании компилятора. Некоторые системы (такие как Lisp) позволяют интерпретируемому и скомпилированному коду вызывать друг друга и совместно использовать переменные. Это означает, что, как только подпрограмма была протестирована и отлажена под интерпретатором, она может быть скомпилирована и таким образом извлечь выгоду из более быстрого выполнения, в то время как другие подпрограммы разрабатываются. Много интерпретаторов не выполняют исходный код как есть но преобразуют его в некоторую более компактную внутреннюю форму. Многие интерпретаторы BASIC заменяют ключевые слова единственными маркерами байта, которые могут использоваться, чтобы найти инструкцию в таблице переходов. Несколько интерпретаторов, таких как интерпретатор PBASIC, достигают еще более высоких уровней уплотнения программы при помощи бит-ориентированной, а не байтовой структуры памяти программы, где маркеры команд занимают, возможно, 5 битов, номинально «16-разрядные» константы сохранены в неравномерном коде, требующем 3, 6, 10, или 18 битов, и операнды адреса включают «разрядное смещение». Многие BASIC интерпретаторов могут сохранить и считать назад свое собственное маркируемое внутреннее представление.
Регрессия
Интерпретация не может использоваться в качестве единственного метода выполнения: даже при том, что интерпретатор может самостоятельно быть интерпретирован и т.д., непосредственно выполняемая программа необходима где-нибудь у основания стека, потому что интерпретируемый код не является, по определению, тем же машинным кодом, который может выполнить ЦП. [6]
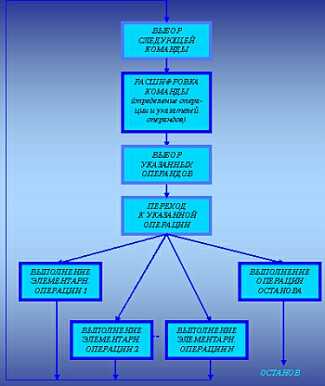
Алгоритм работы
- прочитать инструкцию;
- проанализировать инструкцию и определить соответствующие действия;
- выполнить соответствующие действия;
Достоинства и недостатки интерпретаторов
Достоинства
- Бо́льшая переносимость интерпретируемых программ — программа будет работать на любой платформе, на которой есть соответствующий интерпретатор.
- Как правило, более совершенные и наглядные средства диагностики ошибок в исходных кодах.
- Меньшие размеры кода по сравнению с машинным кодом, полученным после обычных компиляторов.
Недостатки
- Интерпретируемая программа не может выполняться отдельно без программы-интепретатора. Сам интерпретатор при этом может быть очень компактным.
- Интерпретируемая программа выполняется медленнее, поскольку промежуточный анализ исходного кода и планирование его выполнения требуют дополнительного времени в сравнении с непосредственным исполнением машинного кода, в который мог бы быть скомпилирован исходный код.
- Практически отсутствует оптимизация кода, что приводит к дополнительным потерям в скорости работы интерпретируемых программ.
Изменения
Байткод переводчиков
Существует спектр возможностей интерпретации и компиляции, в зависимости от объема анализа, выполненного до выполнения программы. Например, Emacs Lisp компилируется в байт-код, который является сильно сжатым и оптимизированным представлением источника Lisp, но не машинный код (и поэтому не привязан к какому-либо конкретному оборудованию). Этот» скомпилированный » код затем интерпретируется интерпретатором байт-кода (сам написан на языке C). Скомпилированный код в этом случае представляет собой машинный код для виртуальной машины, который реализуется не в аппаратном обеспечении, а в интерпретаторе байт-кода. Такие компилирующие переводчики иногда называют компиляторами. В интерпретаторе байт-кода каждая инструкция начинается с байта, и поэтому интерпретаторы байт-кода имеют до 256 инструкций, хотя не все могут быть использованы. Некоторые байт-коды могут принимать несколько байт и могут быть произвольно сложными. [7]
Управляющие таблицы — это не обязательно когда-нибудь понадобится, чтобы пройти через составление поэтапного диктуют соответствующие алгоритмические поток управления через индивидуальные переводчики в аналогично байт-кода переводчиков.
Переводчики с резьбовым кодом
Потоковые интерпретаторы кода похожи на интерпретаторы байт-кода, но вместо байтов используются указатели. Каждая» инструкция » — это слово, указывающее на функцию или последовательность инструкций, за которой, возможно, следует параметр. Интерпретатор продетого нитку кода либо выполняет циклическую выборку инструкций и вызывает функции, на которые они указывают, либо выбирает первую инструкцию и прыгает к ней, и каждая последовательность инструкций заканчивается выборкой и переходом к следующей инструкции. В отличие от байткода нет эффективного ограничения на количество различных инструкций, кроме доступной памяти и адресного пространства. Классический пример многопоточности-четвертый код, используемый в открытых системах Прошивка: язык исходный код компилируется в код «Ф» (байт-код), который затем интерпретируется виртуальной машиной. [8]
Абстрактные синтаксические интерпретаторы
В спектре между интерпретацией и компиляцией другой подход заключается в преобразовании исходного кода в оптимизированное абстрактное дерево синтаксиса (AST), а затем выполнении программы, следующей за этой древовидной структурой, или использовании его для генерации собственного кода просто в срок. При таком подходе каждое предложение должно быть проанализировано только один раз. Как преимущество над байт-код, АСТ сохраняет глобальную структуру программы и отношения между утверждениями (которые теряются в представлении байт-код), а при сжатии обеспечивает более компактное представление. Таким образом, использование AST было предложено в качестве лучшего промежуточного формата для компиляторов just-in-time, чем байткод. Кроме того, это позволяет системе выполнять лучший анализ во время выполнения. [9]
Однако, для устных переводчиков, АСТ вызывает больше накладных расходов, чем байт-код интерпретатора, из-за узлов, связанных с синтаксисом, выполняющих никакой полезной работы, менее последовательное представление (требуется прохождение нескольких указателей) и накладных осмотреть дерево.
Сборник «точно в срок»
Дальнейшим размыванием различия между интерпретаторами, интерпретаторами байт-кода и компиляцией является компиляция just-in-time (JIT), метод, в котором промежуточное представление компилируется в машинный код машинного кода во время выполнения. Это повышает эффективность выполнения собственного кода за счет времени запуска и увеличения использования памяти при первой компиляции байт-кода или AST. Адаптивная оптимизация-это дополнительный метод, при котором интерпретатор профилирует запущенную программу и компилирует ее наиболее часто выполняемые части в машинный код. Оба метода несколько десятилетий, появляются в языках, таких как Smalltalk в 1980-х.
Просто в момент компиляции завоевала всеобщее внимание среди разработчиков языков в последние годы, с Java, на Framework, у большинства современных реализациях JavaScript, MATLAB, которые сейчас в том числе JITs.
Self-переводчик
Само-переводчика интерпретатора языка программирования, написанный на языке программирования, который может интерпретировать себя; пример-базовый интерпретатор написан на Basic. Собственн-переводчики, связанные с самообслуживанием таких компиляторов.
Если компилятор существует для языка, для интерпретации, создания собственного переводчика требует внедрения языка в принимающем языке (которым может быть другой язык программирования или ассемблер). При наличии первого переводчика, такого как этот, система загрузится и новые версии переводчика могут быть разработаны на самом языке. Это было таким образом, что Дональд Кнут разработал клубок переводчик для языка веб-промышленного стандартная система набирания Текс.
Определение компьютерного языка обычно делается по отношению к абстрактной машине (так называемая операционная семантика) или в качестве математической функции (денотационная семантика). Язык также может быть определен интерпретатором, на котором дана семантика основного языка. Определение языка самостоятельно-переводчик не обоснованные (он не может определить язык), но переводчик рассказывает читателю о выразительность и изящество языка. Это также позволяет интерпретатору интерпретировать его исходный код, первый шаг к отражающей интерпретации.
Важную дизайна аспект в реализации собственной переводчика является ли особенностью интерпретируемый язык реализуется с той же функцией, принимающей в переводчик язык. Пример является ли закрытие в lisp-подобного языка реализуется с помощью замыканий в языке переводчика или реализован «вручную» с помощью структуры данных, явно сохраняя окружающую среду. Чем больше функций реализовано той же функцией на языке хоста, тем меньше контроля программист имеет; разное поведение для борьбы с переполнением числа не может быть реализовано, если арифметические операции делегированы соответствующим операциям на языке хоста.
Некоторые языки имеют элегантный само-переводчик, таких как Лисп или Пролог.[править] много исследований по собственной переводчиков (в частности, отражательная переводчиков) был проведен в схеме язык программирования, диалект Лиспа. В целом, однако, любой Тьюринг-полный язык позволяет писать собственные переводчика. Lisp-это такой язык, потому что программы Lisp являются списками символов и другими списками. XSLT-это такой язык, потому что язык XSLT программы пишутся в XML. Суб-домен Мета-программирование-это написание проблемно-ориентированные языки (DSL-языки).
Клайв Гиффорд представил[править] измерение качества собственн-переводчик (в eigenratio), предел соотношения между компьютерами время, потраченное на работу стека N собственн-переводчики и времени, потраченных на проведение стек из N − 1 самовыдвижение-переводчиков при N стремящемся к бесконечности. Это значение не зависит от программы.
Книга Структура и интерпретация компьютерных программ представлены примеры Мета-круговой перевод схема и его диалектах. Другие примеры языков с собственной переводчика вперед и Паскаль.
Микрокод
Микрокод — это очень часто используемый метод, который накладывает интерпретатор между аппаратным и архитектурным уровнем компьютера ». Таким образом, микрокод является слоем аппаратных инструкций, которые реализуют инструкции машинного кода более высокого уровня или секвенсирование внутреннего состояния во многих элементах цифровой обработки. Микрокод используется в центральных процессорах общего назначения, а также в более специализированных процессорах, таких как микроконтроллеры, цифровые сигнальные процессоры, контроллеры каналов, контроллеры дисков, контроллеры сетевых интерфейсов, сетевые процессоры, графические процессоры и другие аппаратные средства. [10]
Микрокод обычно находится в специальной высокоскоростной памяти и преобразует машинные инструкции, данные конечных автоматов или другой вход в последовательности подробных операций на уровне цепей. Он отделяет машинные инструкции от базовой электроники, так что инструкции могут быть спроектированы и изменены более свободно. Это также облегчает создание сложных многоступенчатых инструкций, одновременно уменьшая сложность компьютерных схем. Написание микрокода часто называют микропрограммированием, а микрокод в конкретной реализации процессора иногда называют микропрограммой.
Более обширное микрокодирование позволяет малым и простым микроархитексам эмулировать более мощные архитектуры с более широкой длиной слова, большим количеством исполнительных блоков и т. Д., Что является относительно простым способом обеспечения совместимости программного обеспечения между различными продуктами семейства процессоров. [11]
Приложения [12]
- Интерпретаторы часто используются для выполнения языков команд, и языки клея, так как каждый оператор, выполняемый на языке команд, обычно является вызовом сложной подпрограммы, такой как редактор или компилятор.
- Самомодифицирующийся код может быть легко реализован на интерпретируемом языке. Это относится к истокам интерпретации в Lisp и исследований искусственного интеллекта.
- Виртуализация. Машинный код, предназначенный для аппаратной архитектуры можно запустить с помощью виртуальной машины. Это часто используется, когда предполагаемая архитектура недоступна или используется для выполнения нескольких копий.
- Песочница: в то время как некоторые типы песочницы полагаются на защиту операционной системы, интерпретатор или виртуальная машина часто используется. Фактическая аппаратная архитектура и первоначально предназначенная аппаратная архитектура могут быть одинаковыми или не совпадать. Это может показаться бессмысленным, за исключением того, что песочницы не вынуждены фактически выполнять все инструкции, которые они обрабатывают. В частности, он может отказаться выполнить код, который нарушает какие-либо ограничения, связанные с безопасностью его эксплуатации в соответствии.
- Эмуляторы для запуска компьютерного программного обеспечения, написанного для устаревшего и недоступного оборудования на более современном оборудовании
Типы языка
Первый наш файл, yobaType.ml, который описывает все возможные виды инструкций, устроен максимально просто: [Источник 3]
type action =
DoNothing
| AddFunction of string * action list
| CallFunction of string
| Stats
| Create of string
| Conditional of int * string * action * action
| Decrement of int * string
| Increment of int * string;;
Каждая конструкция языка будет приводиться к одному из этих типов. DoNothing — это просто оператор NOP, он не делает ровным счётом ничего. Create создаёт переменную (у нас они всегда целочисленны), Decrement и Increment соответственно уменьшают и увеличивают заданную переменную на какое-то число. Кроме этого есть Stats для вывода статистики по всем созданным переменным и Conditional — наша реализация if, которая умеет проверять, есть ли в заданной переменной требуемая величина (или большая). В самом конце я добавил AddFunction и CallFunction — возможность создавать и вызывать собственные функции, которые на самом деле очень даже процедуры.
Грамматика языка
Любая конструкция, кроме запроса статистики (это у нас как бы служебная команда) и создания функции начинается и заканчивается ключевыми словами. Благодаря этому мы можем смело расставлять как угодно переносы строк и отступы. Кроме этого (мы же работаем с русским языком) я специально создал по паре инструкций для случаев, когда надо передавать и переменную, и значение. Позже увидите, зачем это было нужно. Итак, наш файл yobaParser.mly:
%{
open YobaType
%}
%token <string> ID
%token <int> INT
%token RULEZ
%token GIVE TAKE
%token WASSUP DAMN
%token CONTAINS THEN ELSE
%token FUCKOFF
%token STATS
%token MEMORIZE IS
%token CALL
%start main
%type <YobaType.action> main
%%
main:
expr { $1 }
expr:
fullcommand { $1 }
| MEMORIZE ID IS fullcommandlist DAMN { AddFunction($2, $4) }
fullcommandlist:
fullcommand { $1 :: [] }
| fullcommand fullcommandlist { $1 :: $2 }
fullcommand:
WASSUP command DAMN { $2 }
| STATS { Stats }
command:
FUCKOFF { DoNothing }
| GIVE ID INT { Increment($3, $2) }
| GIVE INT ID { Increment($2, $3) }
| TAKE ID INT { Decrement($3, $2) }
| TAKE INT ID { Decrement($2, $3) }
| RULEZ ID { Create($2) }
| CALL ID { CallFunction($2) }
| CONTAINS ID INT THEN command ELSE command { Conditional($3, $2, $5, $7) }
| CONTAINS INT ID THEN command ELSE command { Conditional($2, $3, $5, $7) }
%%
Первым делом мы вставляем заголовок — открытие модуля YobaType, который содержит наш тип action, описанный в самом начале. Для чисел и строк, не являющихся ключевыми словами языка (переменных) мы объявляем два специальных типа, которым указываем, что именно они в себе содержат. Для каждого из ключевых слов с помощью директивы %token мы создаём тоже свой тип, который будет идентифицировать это слово в грамматике. Можно было бы указать их все хоть в одну строчку, просто такая запись группирует всё по видам инструкций. Имейте в виду, что все созданные нами токены — это именно подстановочные типы, по которым парсер грамматики определяет, что ему делать. Обозвать их можно как угодно, то, как они будут выглядеть в самом языке, мы опишем позже. Указываем, что входной точкой для грамматики является main, и что возвращать он всегда должен объект типа action — инструкцию для интерпретатора. Наконец, после двух знаков %% мы описываем саму грамматику:
- Инструкция состоит либо из команды (fullcommand), либо из создания функции.
- Функция, в свою очередь, состоит из списка команд (fullcommandlist).
- Команда бывает либо служебной (STATS), либо обычной (command), в таком случае она должна быть обёрнута в ключевые слова.
- С обычной командой всё просто, даже расписывать не буду.
В фигурных скобках мы указываем, что делать при совпадении строки с данным вариантом, при этом $N обозначает N-ный член конструкции. Например, если мы встречаем «CALL ID» (ID — это строка, не забываем), то мы создаём инструкцию CallFunction, которой в качестве параметра передаём $2 (как раз ID) — имя вызываемой функции.
Лексер — превращаем язык в ключевые слова
Мы дошли одновременно до практически самой простой и самой муторной части. Простая она, потому что всего лишь описывает превращение слов языка в наши токены. А муторная, потому что лексеры (а может, только окамловский лексер) плохо рассчитаны на работу с русским языком, поэтому работать с русскими символами можно только как со строками. Так как я хотел сделать ключевые слова языка регистро-независимыми, это добавило кучу геморроя — вместо простого написания «дай» надо было расписывать вариант написания каждой буквы. В общем, смотрите сами, файл yobaLexer.mll:
{
open YobaParser
exception Eof
}
rule token = parse
("и"|"И") ("д"|"Д") ("и"|"И") (' ')+
("н"|"Н") ("а"|"А") ("х"|"Х") ("у"|"У") ("й"|"Й") { FUCKOFF }
| ("б"|"Б") ("а"|"А") ("л"|"Л") ("а"|"А")
("н"|"Н") ("с"|"С") (' ')+
("н"|"Н") ("а"|"А") ("х"|"Х") { STATS }
| [' ' '\t' '\n' '\r'] { token lexbuf }
| ['0'-'9']+ { INT(int_of_string(Lexing.lexeme lexbuf)) }
| ("д"|"Д") ("а"|"А") ("й"|"Й") { GIVE }
| ("н"|"Н") ("а"|"А") { TAKE }
| ("ч"|"Ч") ("о"|"О") { WASSUP }
| ("й"|"Й") ("о"|"О") ("б"|"Б") ("а"|"А") { DAMN }
| ("л"|"Л") ("ю"|"Ю") ("б"|"Б") ("л"|"Л") ("ю"|"Ю") { RULEZ }
| ("е"|"Е") ("с"|"С") ("т"|"Т") ("ь"|"Ь") { CONTAINS }
| ("т"|"Т") ("а"|"А") ("д"|"Д") ("а"|"А") { THEN }
| ("и"|"И") ("л"|"Л") ("и"|"И") { ELSE }
| ("у"|"У") ("с"|"С") ("е"|"Е") ("к"|"К") ("и"|"И") { MEMORIZE }
| ("э"|"Э") ("т"|"Т") ("о"|"О") { IS }
| ("х"|"Х") ("у"|"У") ("й"|"Й") ("н"|"Н") ("и"|"И") { CALL }
|
("а"|"б"|"в"|"г"|"д"|"е"|"ё"|"ж"
|"з"|"и"|"й"|"к"|"л"|"м"|"н"|"о"
|"п"|"р"|"с"|"т"|"у"|"ф"|"х"|"ц"
|"ч"|"ш"|"щ"|"ъ"|"ы"|"ь"|"э"|"ю"|"я")+ { ID(Lexing.lexeme lexbuf) }
| eof { raise Eof }
Интерпретатор
Осталась последняя часть — сам интерпретатор, который обрабатывает наши конструкции языка.
open YobaType
let identifiers = Hashtbl.create 10;;
let funcs = Hashtbl.create 10;;
let print_stats () =
let print_item id amount =
Printf.printf ">> Йо! У тебя есть %s: %d" id amount;
print_newline ();
flush stdout in
Hashtbl.iter print_item identifiers;;
let arithm id op value () =
try
Hashtbl.replace identifiers id (op (Hashtbl.find identifiers id) value);
Printf.printf ">> Гавно вопрос\n"; flush stdout
with Not_found -> Printf.printf ">> Х@#на, ты %s не любишь\n" id; flush stdout;;
let rec cond amount id act1 act2 () =
try
if Hashtbl.find identifiers id >= amount then process_action act1 () else process_action act2 ()
with Not_found ->
Printf.printf ">> Човаще?!\n";
flush stdout
and process_action = function
| Create(id) -> (function () -> Hashtbl.add identifiers id 0)
| Decrement(amount, id) -> arithm id (-) amount
| Increment(amount, id) -> arithm id (+) amount
| Conditional(amount, id, act1, act2) -> cond amount id act1 act2
| DoNothing -> (function () -> ())
| Stats -> print_stats
| AddFunction(id, funclist) -> (function () -> Hashtbl.add funcs id funclist)
| CallFunction(id) -> callfun id
and callfun id () =
let f: YobaType.action list = Hashtbl.find funcs id in
List.iter (function x -> process_action x ()) f
;;
while true do
try
let lexbuf = Lexing.from_channel stdin in
process_action (YobaParser.main YobaLexer.token lexbuf) ()
with
YobaLexer.Eof ->
print_stats ();
exit 0
| Parsing.Parse_error ->
Printf.printf ">> Ни@#я не понял б@#!\n";
flush stdout
| Failure(_) ->
Printf.printf ">> Ни@#я не понял б@#!\n";
flush stdout
done
Первым делом мы создадим две хэштаблицы — для переменных и для функций. Начальный размер 10 взят от фонаря, у нас же тренировочный язык, зачем нам сразу много функций. Затем объявим две небольших функции: одна — для вывода статистики, вторая — для инкремента/декремента переменных.
Дальше идёт группа из сразу трёх функций: cond обрабатывает условные конструкции (наш if), callfun отвечает за вызов функций, а process_action отвечает за обработку пришедшей на вход инструкции как таковой. Надеюсь, почему все три функции зависят друг от друга, объяснять не надо.
Обратите внимание, все варианты в process_action не выполняют действие, а всего лишь возвращают функцию, которая его выполнит. Изначально это было не так, но именно это маленькое изменение позволило мне легко и непринужденно добавить в язык поддержку пользовательских функций.
Наконец, последняяя часть кода до посинения в цикле читает и обрабатывает результат работы парсера.
Добавим к этому Makefile:
all: ocamlc -c yobaType.ml ocamllex yobaLexer.mll ocamlyacc yobaParser.mly ocamlc -c yobaParser.mli ocamlc -c yobaLexer.ml ocamlc -c yobaParser.ml ocamlc -c yoba.ml ocamlc -o yoba yobaLexer.cmo yobaParser.cmo yoba.cmo clean: rm -f *.cmo *.cmi *.mli yoba yobaLexer.ml yobaParser.ml
Источники
Примечание
- ↑ «Why was the first compiler written before the first interpreter?». Ars Technica. Retrieved 9 November 2014.
- ↑ Short animation, explaining the key conceptual difference between interpreters and compilers
- ↑ Terence Parr, Johannes Luber, The Difference Between Compilers and Interpreters
- ↑ Theodore H. Romer, Dennis Lee, Geoffrey M. Voelker, Alec Wolman, Wayne A. Wong, Jean-Loup Baer, Brian N. Bershad, and Henry M. Levy, The Structure and Performance of Interpreters]
- ↑ Heyne, R. (1984). «Basic-Compreter für U880» [BASIC compreter for U880 (Z80)]. Шаблон:Ill (in German) 1984 (3): 150–152.
- ↑ Kühnel, Claus (1987) [1986]. «4. Kleincomputer — Eigenschaften und Möglichkeiten» [4. Microcomputer — Properties and possibilities]. In Erlekampf, Rainer; Mönk, Hans-Joachim. Mikroelektronik in der Amateurpraxis [Micro-electronics for the practical amateur] (in German) (3 ed.). Berlin: Шаблон:Ill, Leipzig. p. 222. ISBN 3-327-00357-2. 7469332.
- ↑ A Tree-Based Alternative to Java Byte-Codes, Thomas Kistler, Michael Franz
- ↑ Surfin’ Safari — Blog Archive » Announcing SquirrelFish. Webkit.org (2008-06-02). Retrieved on 2013-08-10.
- ↑ L. Deutsch, A. Schiffman, Efficient implementation of the Smalltalk-80 system, Proceedings of 11th POPL symposium, 1984.
- ↑ Kent, Allen; Williams, James G. (April 5, 1993). Encyclopedia of Computer Science and Technology: Volume 28 — Supplement 13. New York: Marcel Dekker, Inc. ISBN 0-8247-2281-7. Retrieved Jan 17, 2016.
- ↑ IBM Card Interpreters, page at Columbia University
- ↑ Theoretical Foundations For Practical ‘Totally Functional Programming’, (Chapter 7 especially) Doctoral dissertation tackling the problem of formalising what is an interpreter
ru.bmstu.wiki
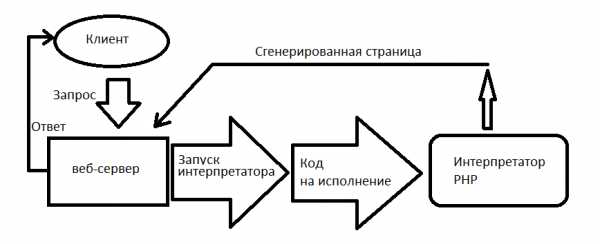
Интерпретация и компиляция | Веб-программирование
Одной из ключевых характеристик PHP является то, что это интерпретируемый язык программирования. С другой стороны, языки программирования наподобие C, изначально разрабатывались для компиляции. Что это значит?
Компилируется ли язык программирования или интерпретируется, на самом деле это не зависит от природы языка программирования. Любой язык программирования может интерпретироваться так называемым интерпретатором или компилироваться с помощью так называемого компилятора.
При использовании любого языка программирования существует определенный рабочий цикл создания кода. Вы пишете его, запускаете, находите ошибки и отлаживаете. Таким образом, вы переписываете и дописываете программу, проверяете ее. То, о чем пойдет речь в этой статье, это «запускаемая» часть программы.
Когда пишете программу, вы хотите, чтобы ее инструкции работали на компьютере. Компьютер обрабатывает информацию с помощью процессора, который поэтапно выполняет инструкции, закодированные в двоичном формате. Как из выражения «a = 3;» получить закодированные инструкции, которые процессор может понять?
Мы делаем это с помощью компиляции. Существует специальные приложения, известные как компиляторы. Они принимают программу, которую вы написали. Затем анализируют и разбирают каждую часть программы и строят машинный код для процессора. Часто его также называют объектным кодом.
На одном из этапов процесса обработки задействуется компоновщик, принимающий части программы, которые отдельно были преобразованы в объектный код, и связывает их в один исполняемый файл. Вот схема, описывающая данный процесс:
Конечным элементом этого процесса является исполняемый файл. Когда вы запускаете или сообщаете компьютеру, что это исполняемый файл, он берет первую же инструкцию из него, не фильтрует, не преобразует, а сразу запускает программу и выполняет ее без какого-либо дополнительного преобразования. Это ключевая характеристика процесса компиляции — его результат должен быть исполняемым файлом, не требующим дополнительного перевода, чтобы процессор мог начать выполнять первую инструкцию и все следующие за ней.
Первые компиляторы были написаны непосредственно через машинный код или с использованием ассемблеров. Но цель компилятора очевидна: перевести программу в исполняемый машинный код для конкретного процессора.
Некоторые языки программирования разрабатывались с учетом компиляции. C, например, предназначался для того, чтобы дать возможность программистам с легкостью реализовать разные вещи. Но в итоге он разрабатывался таким образом, чтобы его можно было легко перевести на машинный код. Компиляция в программировании это серьезно!
Не все языки программирования учитывают это в своей концепции. Например, Java предназначался для запуска в «интерпретирующей» среде, а Python всегда должен интерпретироваться.
Альтернативой компиляции является интерпретация. Основная разница между компилятором и интерпретатором заключается в том, как они работают. Компилятор берет всю программу и преобразует ее в машинный код, который понимает процессор.
Интерпретатор — это исполняемый файл, который поэтапно читает программу, а затем обрабатывает, сразу выполняя ее инструкции.
Другими словами, интерпретатор выполняет программу поэтапно как часть собственного исполняемого файла. Объектный код не передается процессору, интерпретатор сам является объектным кодом, построенным таким образом, чтобы его можно было вызвать в определенное время.
Это ломает рабочий цикл, который был приведен на диаграмме выше. Теперь у нас есть новая диаграмма:
На ней мы видим, что в отличие от компилятора, интерпретатор всегда должен быть под рукой, чтобы мы могли вызвать его и запустить нашу программу. В некотором смысле интерпретатор становится процессором. Программы, написанные для интерпретации, называются «скриптами», потому что они являются сценариями действий для другой программы, а не прямым машинным кодом.
Например, так работают такие языки программирования, как Python. Вы пишете программу. Затем вводите код в интерпретатор Python, и он выполняет все описанные вами шаги. В командной строке вы можете ввести примерно следующее:
В этой команде Python — это исполняемый файл. Вы вводите в него все, что находится в файле myprogram.py, и он выполняет эти инструкции. Компьютер не запустит myprogram.py без Python. Это не машинный код, который понимает процессор. Можно скомпилировать программы Python в объектный или машинный код и запустить его непосредственно в процессоре. Но эта процедура включает в себя компиляцию кода и добавление в качестве ее части всего интерпретатора Python.
Интерпретаторы могут создаваться по-разному. Существуют интерпретаторы, которые читают исходную программу и не выполняют дополнительной обработки. Они просто берут определенное количество строк кода за раз и выполняют его.
Некоторые интерпретаторы выполняют собственную компиляцию, но обычно преобразуют программу байтовый код, который имеет смысл только для интерпретатора. Это своего рода псевдо машинный язык, который понимает только интерпретатор.
Такой код быстрее обрабатывается, и его проще написать для исполнителя (части интерпретатора, которая исполняет), который считывает байтовый код, а не код источника.
Есть интерпретаторы, для которых этот вид байтового кода имеет более важное значение. Например, язык программирования Java «запускается» на так называемой виртуальной машине. Она является исполняемым кодом или частью программы, которая считывает конкретный байтовый код и эмулирует работу процессора. Обрабатывая байтовый код так, как если бы процессор компьютера был виртуальным процессором.
У меня есть эмулятор для игровой приставки NIntendo. Когда я загружаю ROM-файл Dragon Warrior, он форматируется в машинный код, который понимает только процессор NES. Но если я создаю виртуальный процессор, который интерпретирует байтовый код во время работы на другом процессоре, я могу запустить Dragon Warrior на любой машине с эмулятором.
Это использует концепция компиляции Java, а также все интерпретаторы. На любом процессоре, для которого я могу создать интерпретатор / эмулятор, можно запускать мои интерпретируемые программы / байтовый код. В этом заключается основное преимущество интерпретатора над компилятором.
Основным аргументом за использование процесса компиляции является скорость. Возможность компилировать любой программный код в машинный, который может понять процессор ПК, исключает использование промежуточного кода. Можно запускать программы без дополнительных шагов, тем самым увеличивая скорость обработки кода.
Но наибольшим недостатком компиляции является специфичность. Когда компилируете программу для работы на конкретном процессоре, вы создаете объектный код, который будет работать только на этом процессоре. Если хотите, чтобы программа запускалась на другой машине, вам придется перекомпилировать программу под этот процессор. А перекомпиляция может быть довольно сложной, если процессор имеет ограничения или особенности, не присущие первому. А также может вызывать ошибки компиляции.
Основное преимущество интерпретации — гибкость. Можно не только запускать интерпретируемую программу на любом процессоре или платформе, для которых интерпретатор был скомпилирован. Написанный интерпретатор может предложить дополнительную гибкость. В определенном смысле интерпретаторы проще понять и написать, чем компиляторы.
С помощью интерпретатора проще добавить дополнительные функции, реализовать такие элементы, как сборщики мусора, а не расширять язык.
Другим преимуществом интерпретаторов является то, что их проще переписать или перекомпилировать для новых платформ.
Написание компилятора для процессора требует добавления множества функций, или полной переработки. Но как только компилятор написан, можно скомпилировать кучу интерпретаторов и на выходе мы имеем перспективный язык. Не нужно повторно внедрять интерпретатор на базовом уровне для другого процессора.
Самым большим недостатком интерпретаторов является скорость. Для каждой программы выполняется так много переводов, фильтраций, что это приводит к замедлению работы и мешает выполнению программного кода.
Это проблема для конкретных real-time приложений, таких как игры с высоким разрешением и симуляцией. Некоторые интерпретаторы содержат компоненты, которые называются just-in-time компиляторами (JIT). Они компилируют программу непосредственно перед ее исполнением. Это специальные программы, вынесенные за рамки интерпретатора. Но поскольку процессоры становятся все более мощными, данная проблема становится менее актуальной.
Имейте всегда в виду, что некоторые языки программирования специально предназначены для компиляции кода, например, C. В то время как другие языки всегда должны интерпретироваться, например Java.
Для меня не имеет значения, скомпилировано что-то или интерпретировано, если оно может выполнить задачу эффективно.
Некоторые системы не предлагают технические условия для эффективного использования интерпретаторов. Поэтому вы должны запрограммировать их с помощью чего-то, что может быть непосредственно скомпилировано, например C. Иногда нужно выполнить вычисления настолько интенсивно, насколько это возможно. Например, при точном распознавании голоса роботом. В других случаях скорость или вычислительная мощность могут быть не столь критичными, и написать эмулятор на оригинальном языке может быть проще.
Сообщите мне, что бы вы предпочли: интерпретацию или компиляцию? Спасибо за уделенное время!
Данная публикация представляет собой перевод статьи «Interpretation Versus Compilation» , подготовленной дружной командой проекта Интернет-технологии.ру
www.internet-technologies.ru
Что такое компилятор, интерпретатор, транслятор
Для реализации задач, описанных в программном коде, процессор компьютера должен произвести ряд операций. Но процессор, как и другие части компьютерного «железа», не понимает языки программирования высокого уровня. Поэтому для того, чтобы добиться исполнения описанных в программе действий, её переводят в понятный процессору объектный код. Конечный результат этого перевода называется объектным модулем или объектным файлом и содержит в себе набор единичек и нулей, понятных процессору компьютера.
Для проведения переводов исходного кода в объектный или промежуточный код используются специальные программы – трансляторы.
Что такое транслятор?
Транслятор (от английского Translate – переводить) — программа, переводящая исходный код (программу, написанную на одном из высокоуровневых языков программирования) в объектный код, используемый процессором компьютера, или в промежуточный код для последующей интерпретации.
Помимо осуществления перевода, трансляторы могут выявлять в исходном коде ошибки, оптимизировать исходный код, добавлять в исходный код отладочные процедуры, формировать словари идентификаторов и другое.
Существуют также обратные трансляторы, осуществляющие перевод с машинного кода в понятный пользователю язык программирования.
В тех случаях, когда исходный код переводится для последующего исполнения процессором, для трансляции используется компилятор.
Что такое компилятор?
Компилятор (от английского Compile – собирать, накапливать) – это вариант реализации транслятора, который создаётся для перевода программы, написанной на высокоуровневом языке программирования в машинный код, который в последствие будет исполняться процессором компьютера. Этот тип трансляции называется компиляцией.
В большинстве случаев компиляция программы происходит полностью (AOT-компиляция). Компилятор целиком считывает программу, проводит её пошаговый анализ (лексический, синтаксический, семантический), оптимизирует её, очищая от излишних конструкций, но сохраняя исходный смысл операций, и также целиком переводит её в машинный код.
Однако, иногда используется и построчная компиляция. В этом случае машинный код генерируется и исполняется для каждой полной грамматической конструкции исходного кода. От интерпретации такая компиляция отличается способом исполнения.
Для каждого языка программирования и практически для каждой операционной системы используется свой компилятор. Иногда для одного семейства операционных систем может использоваться один и тот же компилятор.
Компиляторы для C++
Так, например, для C++ можно использовать:
- Microsoft Visual C++ 6.0
- MS Visual Studio 2005 Professional
- Intel C++ Compiler 4.5
- Borland Builder 6.0
- Borland C++ Compiler
- g++
- gcc
- MinGW 3.2
Подходящий компилятор выбирается, исходя из особенностей программ, с которыми предстоит работать и, как уже говорилось выше, операционной системы.
Компилятор для Python
Необходимость самостоятельно компилировать исходный код с Питона в exe-файл для последующей интерпретации возникает нечасто. В тех случаях, когда на компьютер, на котором планируется выполнение программы, уже установлен интерпретатор Python, компиляция обычно не требуется.
Если программе всё же необходима компиляция, можно использовать cx_Freeze.
Компилятор для Java
Язык программирования Java работает с виртуальной машиной Java, которая обрабатывает байт-код (промежуточный код) и передаёт инструкции оборудованию. Виртуальная машина Java, по сути, является интерпретатором.
Компиляторы в Java используются для того, чтобы преобразовать исходный код в байт-код, доступный пониманию виртуальной машины и пригодный для последующей интерпретации.
Чаще всего используются:
- GNU Compiler for Java
- Javac
Javac помимо анализа и трансляции, производит ещё и оптимизацию кода.
В целом, за счёт использования виртуальной машины, Java выполняет операции, описанные в исходном коде куда медленнее, чем, скажем, С++. При исполнении некоторых операций Java может уступать в скорости до 7 раз. Для ускорения работы программ на Java используется оптимизация библиотек (в них широко используется native-код), некоторые аппаратные решения для ускоренной обработки байт-кода и JIT-компиляция.
JIT-компиляция
JIT-компиляция – это трансляция байт-кода в машинный код непосредственно во время работы программы. JIT-компиляция может быть применена к любой части программы или ко всей программе в целом.
Использование этой технологии позволяет существенно ускорить процесс исполнения задач, поставленных в исходном коде, по сравнению с пошаговой интерпретацией, традиционно применяемой виртуальными машинами.
Что такое интерпретатор?
Интерпретатор (от английского Interpret – толковать) – программа, выполняющая пошаговую обработку исходного кода, его анализ и техническую реализацию этой же части кода.
Проще говоря, в отличие от большинства компиляторов, интерпретатор обрабатывает, а затем исполняет не всю исходную программу, а отдельно каждую её строку, пока программа не будет закончена.
Интерпретаторы бывают двух типов:
- Простые — осуществляющие исключительно интерпретацию введённого исходного кода.
- Интерпретаторы компилирующего типа – это система, состоящая из компилятора, транслирующего исходный код в промежуточный, и виртуальной машины, реализующей операции, описанные в коде.
Виртуальная машина
Во многих языках программирования реализацию написанного исходного кода выполняет виртуальная машина. Это часть интерпретатора, получающая на вводе скомпилированный промежуточный код и выполняющая описанные в нём операции.
Давайте рассмотрим алгоритм этого процесса на примере PVM (Python Virtual Machine).
По схожей схеме работают виртуальная машина Java, Common Language Runtime (инструмент для интерпретации С#) и некоторые другие интерпретаторы.
Интерпретатор для PHP
Интерпретатор PHP отличается от большей части виртуальных машин отсутствием создания выполняемого файла. То есть в отличие от, скажем, PVM (Python Virtual Machine) он не кеширует сгенерированный байт-код в памяти. Потому при запуске и отладке программы компиляция одного и того же фрагмента байт-кода происходит несколько раз. Это существенно замедляет работу программы.
Сравнение интерпретаторов и компиляторов
Плюсы интерпретаторов
- Использование для реализации исходного кода виртуальной машины позволяет интерпретаторам эффективно работать на всех платформах.
- С интерпретатором можно работать в интерактивном режиме.
Минусы интерпретаторов
- Исходный код не может работать отдельно без наличия интерпретатора.
Плюсы компиляторов
- Возможность эффективной оптимизации кода, сокращающей количество операций и итоговое время выполнения поставленных программе задач.
- Быстродействие – перевод в машинный код и реализация операций процессором происходит в среднем в 1,5 раза быстрее, чем пошаговая трансляция программы в байт-код и последующая реализация её виртуальной машиной.
- Производительность – исполнимый модуль, получившийся в результате компиляции, обладает оптимальными показателями скорости выполнения и задействует в работе минимум ресурсов компьютера.
Минусы компиляторов
- И сами компиляторы, и генерируемый ими код рассчитаны на использование в определённой операционной системе и взаимодействие с определённым типом процессора. В других исходных условиях они работать не будут.
Выбор транслятора
Выбор транслятора для работы с той или иной программой, прежде всего, определяется рекомендациями разработчиков этой программы, затем, целями и личными предпочтениями программиста.
Если Вы хотите разобраться в этой теме глубже, рекомендуем прочесть:
Альфред В. Ахо, Моника С. Лам, Рави Сети, Джеффри Д. Ульман. Компиляторы: принципы, технологии и инструментарий
Это учебник по теории написания компиляторов, в котором подробно описаны принципы работы разноуровневых компиляторов (начиная от простейших однопроходных, заканчивая современным компилятором на языке Java), уделяется повышенное внимание лексическому, синтаксическому и семантическому разбору программ в исходном коде, генерации машинного кода.
В.А.Серебряков, М.П.Галочкин. Основы конструирования компиляторов
Ещё один учебник по созданию компиляторов, только теперь отечественный. Глубоко раскрыты темы лексического и семантического анализа, рассмотрены темы автоматизации процесса разработки компиляторов, получения оптимального кода.
learn-code.ru
Интерпретатор — Википедия
Материал из Википедии — свободной энциклопедии
Эта статья включает описание термина «Интерпретация»; см. также другие значения.Интерпретатор (англ. interpreter ıntə:’prıtə[1], от лат. interpretator — толкователь[2]) — программа (разновидность транслятора), выполняющая интерпретацию[3].
Интерпретация — построчный анализ, обработка и выполнение исходного кода программы или запроса (в отличие от компиляции, где весь текст программы, перед запуском, анализируется и транслируется в машинный или байт-код, без её выполнения) [4][5][6].
Типы интерпретаторов
Простой интерпретатор анализирует и тут же выполняет (собственно интерпретация) программу покомандно (или построчно), по мере поступления её исходного кода на вход интерпретатора. Достоинством такого подхода является мгновенная реакция. Недостаток — такой интерпретатор обнаруживает ошибки в тексте программы только при попытке выполнения команды (или строки) с ошибкой.
Интерпретатор компилирующего типа — это система из компилятора, переводящего исходный код программы в промежуточное представление, например, в байт-код или p-код, и собственно интерпретатора, который выполняет полученный промежуточный код (так называемая виртуальная машина). Достоинством таких систем является большее быстродействие выполнения программ (за счёт выноса анализа исходного кода в отдельный, разовый проход, и минимизации этого анализа в интерпретаторе). Недостатки — большее требование к ресурсам и требование на корректность исходного кода. Применяется в таких языках, как Java, PHP, Tcl, Perl, REXX (сохраняется результат парсинга исходного кода[7]), а также в различных СУБД.
В случае разделения интерпретатора компилирующего типа на компоненты получаются компилятор языка и простой интерпретатор с минимизированным анализом исходного кода. Причём исходный код для такого интерпретатора не обязательно должен иметь текстовый формат или быть байт-кодом, который понимает только данный интерпретатор, это может быть машинный код какой-то существующей аппаратной платформы. К примеру, виртуальные машины вроде QEMU, Bochs, VMware включают в себя интерпретаторы машинного кода процессоров семейства x86.
Некоторые интерпретаторы (например, для языков Лисп, Scheme, Python, Бейсик и других) могут работать в режиме диалога или так называемого цикла чтения-вычисления-печати (англ. read-eval-print loop, REPL). В таком режиме интерпретатор считывает законченную конструкцию языка (например, s-expression в языке Лисп), выполняет её, печатает результаты, после чего переходит к ожиданию ввода пользователем следующей конструкции.
Уникальным является язык Forth, который способен работать как в режиме интерпретации, так и компиляции входных данных, позволяя переключаться между этими режимами в произвольный момент, как во время трансляции исходного кода, так и во время работы программ.[8]
Следует также отметить, что режимы интерпретации можно найти не только в программном, но и аппаратном обеспечении. Так, многие микропроцессоры интерпретируют машинный код с помощью встроенных микропрограмм, а процессоры семейства x86, начиная с Pentium (например, на архитектуре Intel P6), во время исполнения машинного кода предварительно транслируют его во внутренний формат (в последовательность микроопераций).
Алгоритм работы простого интерпретатора
- прочитать инструкцию;
- проанализировать инструкцию и определить соответствующие действия;
- выполнить соответствующие действия;
- если не достигнуто условие завершения программы, прочитать следующую инструкцию и перейти к пункту 2.
Достоинства и недостатки интерпретаторов
Достоинства
- Бо́льшая переносимость интерпретируемых программ — программа будет работать на любой платформе, на которой есть соответствующий интерпретатор.
- Как правило, более совершенные и наглядные средства диагностики ошибок в исходных кодах.
- Меньшие размеры кода по сравнению с машинным кодом, полученным после обычных компиляторов.
Недостатки
- Интерпретируемая программа не может выполняться отдельно без программы-интерпретатора. Сам интерпретатор при этом может быть очень компактным.
- Интерпретируемая программа выполняется медленнее, поскольку промежуточный анализ исходного кода и планирование его выполнения требуют дополнительного времени в сравнении с непосредственным исполнением машинного кода, в который мог бы быть скомпилирован исходный код.
- Практически отсутствует оптимизация кода, что приводит к дополнительным потерям в скорости работы интерпретируемых программ.
См. также
Примечания
- ↑ Кочергин В. И. interpreter // Большой англо-русский толковый научно-технический словарь компьютерных информационных технологий и радиоэлектроники. — 2016. — ISBN 978-5-7511-2332-1.
- ↑ Интерпретатор // Математический энциклопедический словарь / Гл. ред. Прохоров Ю. В.. — М.: Советская энциклопедия, 1988. — С. 820. — 847 с.
- ↑ ГОСТ 19781-83; СТ ИСО 2382/7-77 // Вычислительная техника. Терминология: Справочное пособие. Выпуск 1 / Рецензент канд. техн. наук Ю. П. Селиванов. — М.: Издательство стандартов, 1989. — 168 с. — 55 000 экз. — ISBN 5-7050-0155-X.
- ↑ Першиков В. И., Савинков В. М. Толковый словарь по информатике / Рецензенты: канд. физ.-мат. наук А. С. Марков и д-р физ.-мат. наук И. В. Поттосин. — М.: Финансы и статистика, 1991. — 543 с. — 50 000 экз. — ISBN 5-279-00367-0.
- ↑ Борковский А. Б. Англо-русский словарь по программированию и информатике (с толкованиями). — М.: Русский язык, 1990. — 335 с. — 50 050 (доп,) экз. — ISBN 5-200-01169-3.
- ↑ Толковый словарь по вычислительным системам = Dictionary of Computing / Под ред. В. Иллингуорта и др.: Пер. с англ. А. К. Белоцкого и др.; Под ред. Е. К. Масловского. — М.: Машиностроение, 1990. — 560 с. — 70 000 (доп,) экз. — ISBN 5-217-00617-X (СССР), ISBN 0-19-853913-4 (Великобритания).
- ↑ Dave Martin. Why does my OS/2 REXX program run more quickly the second time?. Rexx FAQs. Проверено 22 декабря 2009. Архивировано 22 августа 2011 года.
- ↑ Jeff Fox. Chapter 2. More Interpretation (англ.). Thoughtful Programming and Forth. UltraTechnology. Проверено 25 января 2010. Архивировано 22 августа 2011 года.
wikipedia.green
Интерпретатор — это… Что такое Интерпретатор?
- Интерпретатор
- Интерпретатор
- Интерпретатор — транслятор, способный параллельно переводить и выполнять программу, написанную на алгоритмическом языке высокого уровня.
См. также: Трансляторы
Финансовый словарь Финам.
.
- Интерполяция
- Интерпретация данных
Смотреть что такое «Интерпретатор» в других словарях:
ИНТЕРПРЕТАТОР — [тэ], интерпретатора, муж. (книжн.). Человек, интерпретирующий что нибудь, толкователь. Интерпретатор древнего текста. Интерпретатор закона. Толковый словарь Ушакова. Д.Н. Ушаков. 1935 1940 … Толковый словарь Ушакова
интерпретатор — переводчик, толкователь; объяснитель, программа, комментатор, истолкователь Словарь русских синонимов. интерпретатор см. толкователь Словарь синонимов русского языка. Практический справочник. М.: Русский язык … Словарь синонимов
интерпретатор — а, м. interprétateur m. Лицо, занимающееся интерпретацией чего л.; истолкователь. БАС 1. Интепретатор древнего текста. Интерпретатор закона. Уш. 1934. Если б Волошин в те годы умерил свое поварское искусство в подаче стихов, он во многом бы… … Исторический словарь галлицизмов русского языка
ИНТЕРПРЕТАТОР — (interpreter) Компьютерная программа, которая выполняет программу, написанную программным языком (programming language) без ее предварительного перевода в машинный код (machine codе). Программа действует, как если бы она была переведена (cм.:… … Словарь бизнес-терминов
интерпретатор — Программа или техническое средство, выполняющие интерпретацию. Примечание Большинство интерпретаторов осуществляют интерпретацию программы путем последовательной интерпретации ее предложений. [ГОСТ 19781 90] интерпретатор переводчик Программа,… … Справочник технического переводчика
ИНТЕРПРЕТАТОР — [тэ ], а, муж. (книжн.). Человек, интерпретирующий что н. | прил. интерпретаторский, ая, ое. Толковый словарь Ожегова. С.И. Ожегов, Н.Ю. Шведова. 1949 1992 … Толковый словарь Ожегова
интерпретатор — (тэ), а, м., одуш. (фр. imerprétateur … Словарь иностранных слов русского языка
Интерпретатор — Эта статья включает описание термина «Интерпретация»; см. также другие значения. Интерпретатор программа (разновидность транслятора) или аппаратное средство, выполняющее интерпретацию.[1] Интерпретация пооператорный (покомандный,… … Википедия
интерпретатор — interpretatorius statusas T sritis automatika atitikmenys: angl. interpreter vok. Übersetzer, m; Interpreter, m; Interpretierer, m; Interpretierprogramm, n rus. интерпретатор, m pranc. interpréteur, m … Automatikos terminų žodynas
Интерпретатор — 43. Интерпретатор Interpreter Программа или техническое средство, выполняющие интерпретацию. Примечание. Большинство интерпретаторов осуществляют интерпретацию программы путем последовательной интерпретации ее предложений Источник: ГОСТ 19781 90 … Словарь-справочник терминов нормативно-технической документации
dic.academic.ru