Как спарсить любой сайт? / Хабр
Меня зовут Даниил Охлопков, и я расскажу про свой подход к написанию скриптов, извлекающих данные из интернета: с чего начать, куда смотреть и что использовать.
Написав тонну парсеров, я придумал алгоритм действий, который не только минимизирует затраченное время на разработку, но и увеличивает их живучесть, робастность, масштабируемость.
TL;DR
Чтобы спарсить данные с вебсайта, пробуйте подходы именно в таком порядке:
Найдите официальное API,
Найдите XHR запросы в консоли разработчика вашего браузера,
Найдите сырые JSON в html странице,
Отрендерите код страницы через автоматизацию браузера,
Если ничего не подошло — пишите парсеры HTML кода.
Совет профессионалов: не начинайте с BS4/Scrapy
BeautifulSoup4 и Scrapy — популярные инструменты парсинга HTML страниц (и не только!) для Python.
Крутые вебсайты с крутыми продактами делают тонну A/B тестов, чтобы повышать конверсии, вовлеченности и другие бизнес-метрики. Для нас это значит одно: элементы на вебстранице будут меняться и переставляться. В идеальном мире, наш написанный парсер не должен требовать доработки каждую неделю из-за изменений на сайте.
Для нас это значит одно: элементы на вебстранице будут меняться и переставляться. В идеальном мире, наш написанный парсер не должен требовать доработки каждую неделю из-за изменений на сайте.
Приходим к выводу, что не надо извлекать данные из HTML тегов раньше времени: разметка страницы может сильно поменяться, а CSS-селекторы и XPath могут не помочь. Используйте другие методы, о которых ниже. ⬇️
Используйте официальный API
👀 Ого? Это не очевидно 🤔? Конечно, очевидно! Но сколько раз было: сидите пилите парсер сайта, а потом БАЦ — нашли поддержку древней RSS-ленты, обширный sitemap.xml или другие интерфейсы для разработчиков. Становится обидно, что поленились и потратили время не туда. Даже если API платный, иногда дешевле договориться с владельцами сайта, чем тратить время на разработку и поддержку.
Sitemap.xml — список страниц сайта, которые точно нужно проиндексировать гуглу. Полезно, если нужно найти все объекты на сайте.
Пример: http://techcrunch.com/sitemap.xml
RSS-лента — API, который выдает вам последние посты или новости с сайта. Было раньше популярно, сейчас все реже, но где-то еще есть! Пример: https://habr.com/ru/rss/hubs/all/
 Пример: http://techcrunch.com/sitemap.xml
Пример: http://techcrunch.com/sitemap.xmlПоищите XHR запросы в консоли разработчика
Кабина моего самолетаВсе современные вебсайты (но не в дарк вебе, лол) используют Javascript, чтобы догружать данные с бекенда. Это позволяет сайтам открываться плавно и скачивать контент постепенно после получения структуры страницы (HTML, скелетон страницы).
Обычно, эти данные запрашиваются джаваскриптом через простые GET/POST запросы. А значит, можно подсмотреть эти запросы, их параметры и заголовки — а потом повторить их у себя в коде! Это делается через консоль разработчика вашего браузера (developer tools).
В итоге, даже не имея официального API, можно воспользоваться красивым и удобным закрытым API. ☺️
Даже если фронт поменяется полностью, этот API с большой вероятностью будет работать. Да, добавятся новые поля, да, возможно, некоторые данные уберут из выдачи. Но структура ответа останется, а значит, ваш парсер почти не изменится.
Да, добавятся новые поля, да, возможно, некоторые данные уберут из выдачи. Но структура ответа останется, а значит, ваш парсер почти не изменится.
Алгорим действий такой:
Открывайте вебстраницу, которую хотите спарсить
Правой кнопкой -> Inspect (или открыть dev tools как на скрине выше)
Открывайте вкладку Network и кликайте на фильтр XHR запросов
Обновляйте страницу, чтобы в логах стали появляться запросы
Найдите запрос, который запрашивает данные, которые вам нужны
Копируйте запрос как cURL и переносите его в свой язык программирования для дальнейшей автоматизации.
Вы заметите, что иногда эти XHR запросы включают в себя огромные строки — токены, куки, сессии, которые генерируются фронтендом или бекендом. Не тратьте время на ревёрс фронта, чтобы научить свой парсер генерировать их тоже.
Вместо этого попробуйте просто скопипастить и захардкодить их в своем парсере: очень часто эти строчки валидны 7-30 дней, что может быть окей для ваших задач, а иногда и вообще несколько лет. Или поищите другие XHR запросы, в ответе которых бекенд присылает эти строчки на фронт (обычно это происходит в момент логина на сайт). Если не получилось и без куки/сессий никак, — советую переходить на автоматизацию браузера (Selenium, Puppeteer, Splash — Headless browsers) — об этом ниже.
Или поищите другие XHR запросы, в ответе которых бекенд присылает эти строчки на фронт (обычно это происходит в момент логина на сайт). Если не получилось и без куки/сессий никак, — советую переходить на автоматизацию браузера (Selenium, Puppeteer, Splash — Headless browsers) — об этом ниже.
Поищите JSON в HTML коде страницы
Как было удобно с XHR запросами, да? Ощущение, что ты используешь официальное API. 🤗 Приходит много данных, ты все сохраняешь в базу. Ты счастлив. Ты бог парсинга.
Но тут надо парсить другой сайт, а там нет нужных GET/POST запросов! Ну вот нет и все. И ты думаешь: неужели расчехлять XPath/CSS-selectors? 🙅♀️ Нет! 🙅♂️
Чтобы страница хорошо проиндексировалась поисковиками, необходимо, чтобы в HTML коде уже содержалась вся полезная информация: поисковики не рендерят Javascript, довольствуясь только HTML. А значит, где-то в коде должны быть все данные.
Современные SSR-движки (server-side-rendering) оставляют внизу страницы JSON со всеми данные, добавленный бекендом при генерации страницы. Стоп, это же и есть ответ API, который нам нужен! 😱😱😱
Стоп, это же и есть ответ API, который нам нужен! 😱😱😱
Вот несколько примеров, где такой клад может быть зарыт (не баньте, плиз):
Красивый JSON на главной странице Habr.com. Почти официальный API! Надеюсь, меня не забанят.И наш любимый (у парсеров) Linkedin!Алгоритм действий такой:
В dev tools берете самый первый запрос, где браузер запрашивает HTML страницу (не код текущий уже отрендеренной страницы, а именно ответ GET запроса).
Внизу ищите длинную длинную строчку с данными.
Если нашли — повторяете у себя в парсере этот GET запрос страницы (без рендеринга headless браузерами). Просто
requests.get.Вырезаете JSON из HTML любыми костылямии (я использую
html.find("={")).
Отрендерите JS через Headless Browsers
Если XHR запросы требуют актуальных tokens, sessions, cookies. Если вы нарываетесь на защиту Cloudflare. Если вам обязательно нужно логиниться на сайте. Если вы просто решили рендерить все, что движется загружается, чтобы минимизировать вероятность бана. Во всех случаях — добро пожаловать в мир автоматизации браузеров!
Во всех случаях — добро пожаловать в мир автоматизации браузеров!
Если коротко, то есть инструменты, которые позволяют управлять браузером: открывать страницы, вводить текст, скроллить, кликать. Конечно же, это все было сделано для того, чтобы автоматизировать тесты веб интерфейса. I’m something of a web QA myself.
После того, как вы открыли страницу, чуть подождали (пока JS сделает все свои 100500 запросов), можно смотреть на HTML страницу опять и поискать там тот заветный JSON со всеми данными.
driver.get(url_to_open) html = driver.page_source
Selenoid — open-source remote Selenium cluster
Для масштабируемости и простоты, я советую использовать удалённые браузерные кластеры (remote Selenium grid).
Недавно я нашел офигенный опенсорсный микросервис Selenoid, который по факту позволяет вам запускать браузеры не у себя на компе, а на удаленном сервере, подключаясь к нему по API. Несмотря на то, что Support team у них состоит из токсичных разработчиков, их микросервис довольно просто развернуть (советую это делать под VPN, так как по умолчанию никакой authentication в сервис не встроено). Я запускаю их сервис через DigitalOcean 1-Click apps: 1 клик — и у вас уже создался сервер, на котором настроен и запущен кластер Headless браузеров, готовых запускать джаваскрипт!
Я запускаю их сервис через DigitalOcean 1-Click apps: 1 клик — и у вас уже создался сервер, на котором настроен и запущен кластер Headless браузеров, готовых запускать джаваскрипт!
Вот так я подключаюсь к Selenoid из своего кода: по факту нужно просто указать адрес запущенного Selenoid, но я еще зачем-то передаю кучу параметров бразеру, вдруг вы тоже захотите. На выходе этой функции у меня обычный Selenium driver, который я использую также, как если бы я запускал браузер локально (через файлик chromedriver).
def get_selenoid_driver(
enable_vnc=False, browser_name="firefox"
):
capabilities = {
"browserName": browser_name,
"version": "",
"enableVNC": enable_vnc,
"enableVideo": False,
"screenResolution": "1280x1024x24",
"sessionTimeout": "3m",
# Someone used these params too, let's have them as well
"goog:chromeOptions": {"excludeSwitches": ["enable-automation"]},
"prefs": {
"credentials_enable_service": False,
"profile. password_manager_enabled": False
},
}
driver = webdriver.Remote(
command_executor=SELENOID_URL,
desired_capabilities=capabilities,
)
driver.implicitly_wait(10) # wait for the page load no matter what
if enable_vnc:
print(f"You can view VNC here: {SELENOID_WEB_URL}")
return driver
Заметьте фложок enableVNC. Верно, вы сможете смотреть видосик с тем, что происходит на удалённом браузере. Всегда приятно наблюдать, как ваш скрипт самостоятельно логинится в Linkedin: он такой молодой, но уже хочет познакомиться с крутыми разработчиками.
Парсите HTML теги
Если случилось чудо и у сайта нет ни официального API, ни вкусных XHR запросов, ни жирного JSON внизу HTML, если рендеринг браузерами вам тоже не помог, то остается последний, самый нудный и неблагодарный метод. Да, это взять и начать парсить HTML разметку страницы. То есть, например, из <a href="https://okhlopkov.com">Cool website</a> достать ссылку. Это можно делать как простыми регулярными выражениями, так и через более умные инструменты (в питоне это BeautifulSoup4 и Scrapy) и фильтры (XPath, CSS-selectors).
Это можно делать как простыми регулярными выражениями, так и через более умные инструменты (в питоне это BeautifulSoup4 и Scrapy) и фильтры (XPath, CSS-selectors).
Мой единственный совет: постараться минимизировать число фильтров и условий, чтобы меньше переобучаться на текущей структуре HTML страницы, которая может измениться в следующем A/B тесте.
Даниил Охлопков — Data Lead @ Runa Capital
Подписывайтесь на мой Телеграм канал, где я рассказываю свои истории из парсинга и сливаю датасеты.
Надеюсь, что-то из этого было полезно! Я считаю, что в парсинге важно, с чего ты начинаешь. С чего начать — я рассказал, а дальше ваш ход 😉
Как парсить информацию с любого сайта при помощи Screaming Frog
Если вам нужно просто собрать с сайта мета-данные, можно воспользоваться бесплатным парсером системы Promopult. Но бывает, что надо копать гораздо глубже и добывать больше данных, и тут уже без сложных (и небесплатных) инструментов не обойтись.
Евгений Костин рассказал о том, как спарсить любой сайт, даже если вы совсем не дружите с программированием. Разбор сделан на примере Screaming Frog Seo Spider.
Что такое парсинг и зачем он нужен
ПО для парсинга
Пример 1. Как спарсить цену
Пример 2. Как спарсить фотографии
Пример 3. Как спарсить характеристики товаров
Пример 4. Как парсить отзывы (с рендерингом)
Пример 5. Как спарсить скрытые телефоны на сайте ЦИАН
Пример 6. Как парсить структуру сайта на примере DNS-Shop
Возможности парсинга на основе XPath
Ограничения при парсинге
Что такое парсинг и зачем он нужен
Парсинг нужен, чтобы получить с сайтов некую информацию. Например, собрать данные о ценах с сайтов конкурентов.
Одно из применений парсинга — наполнение каталога новыми товарами на основе уже существующих сайтов в интернете.
Упрощенно, парсинг — это сбор информации. Есть более сложные определения, но так как мы говорим о парсинге «для чайников», то нет никакого смысла усложнять терминологию.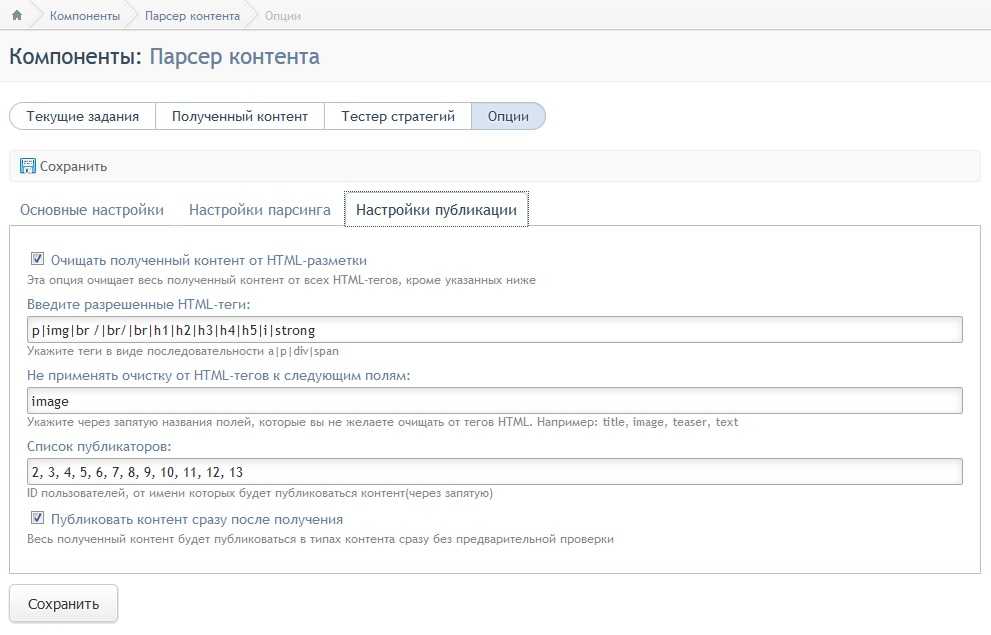 Парсинг — это сбор, как правило, структурированной информации. Чаще всего — в виде таблицы с конкретным набором данных. Например, данных по характеристикам товаров.
Парсинг — это сбор, как правило, структурированной информации. Чаще всего — в виде таблицы с конкретным набором данных. Например, данных по характеристикам товаров.
Парсер — программа, которая осуществляет этот сбор. Она ходит по ссылкам на страницы, которые вы указали, и собирает нужную информацию в Excel-файл либо куда-то еще.
Парсинг работает на основе XPath-запросов. XPath — язык запросов, который обращается к определенному участку кода страницы и собирает из него заданную информацию.
ПО для парсинга
Здесь есть важный момент. Если вы введете в поисковике слово «парсинг» или «заказать парсинг», то, как правило, вам будут предлагаться услуги от компаний, которые создадут парсер под ваши задачи. Стоят такие услуги относительно дорого. В результате программисты под заказ напишут некую программу либо на Python, либо на каком-то еще языке, которая будет собирать информацию с нужного вам сайта. Эта программа нацелена только на сбор конкретных данных, она не гибкая и без знаний программирования вы не сможете ее самостоятельно перенастроить для других задач.
При этом есть готовые решения, которые можно под себя настраивать как угодно и собирать что угодно. Более того, если вы — SEO-специалист, возможно, одной из этих программ вы уже пользуетесь, но просто не знаете, что в ней есть такой функционал. Либо знаете, но никогда не применяли, либо применяли не в полной мере.
Вот две программы, которые являются аналогами.
- Screaming Frog SEO Spider (есть только годовая лицензия).
- Netpeak Spider (есть триал на 14 дней, лицензии на месяц и более).
Эти программы занимаются сбором информации с сайта. То есть они анализируют, например, его заголовки, коды, теги и все остальное. Помимо прочего, они позволяют собрать те данные, которые вы им зададите.
Профессиональные инструменты PromoPult: быстрее, чем руками, дешевле, чем у других, бесплатные опции.
Съем позиций, кластеризация запросов, парсер Wordstat, сбор поисковых подсказок, сбор фраз ассоциаций, парсер мета-тегов и заголовков, анализ индексации страниц, чек-лист оптимизации видео, генератор из YML, парсер ИКС Яндекса, нормализатор и комбинатор фраз, парсер сообществ и пользователей ВКонтакте.

Давайте смотреть на реальных примерах.
Пример 1. Как спарсить цену
Предположим, вы хотите с некого сайта собрать все цены товаров. Это ваш конкурент, и вы хотите узнать, сколько у него стоят товары.
Возьмем для примера сайт mosdommebel.ru.
У нас есть страница карточки товара, есть название и есть цена этого товара. Как нам собрать эту цену и цены всех остальных товаров?
Мы видим, что цена отображается вверху справа, напротив заголовка h2. Теперь нам нужно посмотреть, как эта цена отображается в html-коде.
Нажимаем правой кнопкой мыши прямо на цену (не просто на какой-то фон или пустой участок). Затем выбираем пункт Inspect Element для того, чтобы в коде сразу его определить (Исследовать элемент или Просмотреть код элемента, в зависимости от браузера — прим. ред.).
Мы видим, что цена у нас помещается в тег с классом totalPrice2. Так разработчик обозначил в коде стоимость данного товара, которая отображается в карточке.
Фиксируем: есть некий элемент span с классом totalPrice2. Пока это держим в голове.
Есть два варианта работы с парсерами.
Первый способ. Вы можете прямо в коде (любой браузер) нажать правой кнопкой мыши на тег <span> и выбрать Скопировать > XPath. У вас таким образом скопируется строка, которая обращается к данному участку кода.
Выглядит она так:
/html/body/div[1]/div[2]/div[4]/table/tbody/tr/td/div[1]/div/table[2]/tbody/tr/td[2]/form/table/tbody/tr[1]/td/table/tbody/tr[1]/td/div[1]/span[1]
Но этот вариант не очень надежен: если у вас в другой карточке товара верстка выглядит немного иначе (например, нет каких-то блоков или блоки расположены по-другому), то такой метод обращения может ни к чему не привести. И нужная информация не соберется.
Поэтому мы будем использовать второй способ. Есть специальные справки по языку XPath. Их очень много, можно просто загуглить «XPath примеры».
Например, такая справка:
Здесь указано как что-то получить. Например, если мы хотим получить содержимое заголовка h2, нам нужно написать вот так:
Например, если мы хотим получить содержимое заголовка h2, нам нужно написать вот так:
//h2/text()
Если мы хотим получить текст заголовка с классом productName, мы должны написать вот так:
//h2[@class="productName"]/text()
То есть поставить «//» как обращение к некому элементу на странице, написать тег h2 и указать в квадратных скобках через символ @ «класс равен такому-то».
То есть не копировать что-то, не собирать информацию откуда-то из кода. А написать строку запроса, который обращается к нужному элементу. Куда ее написать — сейчас мы разберемся.
Куда вписывать XPath-запрос
Мы идем в один из парсеров. В данном случае — Screaming Frog Seo Spider.
Эта программа бесплатна для анализа небольшого сайта — до 500 страниц.
Интерфейс Screaming Frog Seo Spider
Например, мы можем — бесплатно — посмотреть заголовки страниц, проверить нет ли у нас каких-нибудь пустых тайтлов или дубликатов тега h2, незаполненных метатегов или каких-нибудь битых ссылок.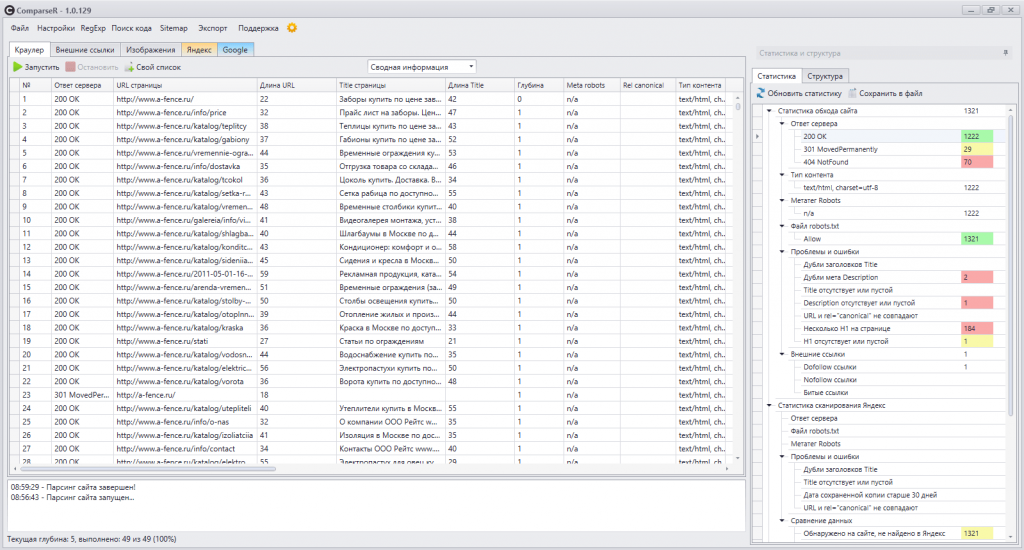
Но за функционал для парсинга в любом случае придется платить, он доступен только в платной версии.
Предположим, вы оплатили годовую лицензию и получили доступ к полному набору функций сервиса. Если вы серьезно занимаетесь анализом данных и регулярно нуждаетесь в функционале сервиса — это разумная трата денег.
Во вкладке меню Configuration у нас есть подпункт Custom, и в нем есть еще один подпункт Extraction. Здесь мы можем дополнительно что-то поискать на тех страницах, которые мы укажем.
Заходим в Extraction. Нам нужно с сайта Московского дома мебели собрать цены товаров.
Мы выяснили в коде, что у нас все цены на карточках товара обозначаются тегом <span> с классом totalPrice2. Формируем вот такой XPath запрос:
//span[@class="totalPrice2"]/span
И указываем его в разделе Configuration > Custom > Extractions. Для удобства можем назвать как-нибудь колонку, которая у нас будет выгружаться. Например, «стоимость»:
Например, «стоимость»:
Таким образом мы будем обращаться к коду страниц и из этого кода вытаскивать содержимое стоимости.
Также в настройках мы можем указать, что парсер будет собирать: весь html-код или только текст. Нам нужен только текст, без разметки, стилей и других элементов.
Нажимаем ОК. Мы задали кастомные параметры парсинга.
Как подобрать страницы для парсинга
Дальше есть еще один важный этап. Это, собственно, подбор страниц, по которым будет осуществляться парсинг.
Если мы просто укажем адрес сайта в Screaming Frog, парсер пойдет по всем страницам сайта. На инфостраницах и страницах категорий у нас нет цен, а нам нужны именно цены, которые указаны на карточках товара. Чтобы не тратить время, лучше загрузить в парсер конкретный список страниц, по которым мы будем ходить, — карточки товаров.
Откуда их взять? Как правило, на любом сайте есть карта сайта XML, и находится она чаще всего по адресу: «адрес сайта/sitemap.xml». В случае с сайтом из нашего примера — это адрес:
В случае с сайтом из нашего примера — это адрес:
https://www.mosdommebel.ru/sitemap.xml.
Либо вы можете зайти в robots.txt (site.ru/robots.txt) и посмотреть. Чаще всего в этом файле внизу содержится ссылка на карту сайта.
Ссылка на карту сайта в файле robots.txt
Даже если карта называется как-то странно, необычно, нестандартно, вы все равно увидите здесь ссылку.
Но если не увидите — если карты сайта нет — то нет никакого решения для отбора карточек товара. Тогда придется запускать стандартный режим в парсере — он будет ходить по всем разделам сайта. Но нужную вам информацию соберет только на карточках товара. Минус здесь в том, что вы потратите больше времени и дольше придется ждать нужных данных.
У нас карта сайта есть, поэтому мы переходим по ссылке https://www.mosdommebel.ru/sitemap.xml и видим, что сама карта разделяется на несколько карт. Отдельная карта по статичным страницам, по категориям, по продуктам (карточкам товаров), по статьям и новостям.
Ссылки на отдельные sitemap-файлы под все типы страниц
Нас интересует карта продуктов, то есть карточек товаров.
Ссылка на sitemap-файл для карточек товара
Возвращаемся в Screaming Frog Seo Spider. Сейчас он запущен в стандартном режиме, в режиме Spider (паук), который ходит по всему сайту и анализирует все страницы. Нам нужно его запустить в режиме List.
Мы загрузим ему конкретный список страниц, по которому он будет ходить. Нажимаем на вкладку Mode и выбираем List.
Жмем кнопку Upload и кликаем по Download Sitemap.
Указываем ссылку на Sitemap карточек товара, нажимаем ОК.
Программа скачает все ссылки, указанные в карте сайта. В нашем случае Screaming Frog обнаружил более 40 тысяч ссылок на карточки товаров:
Нажимаем ОК, и у нас начинается парсинг сайта.
После завершения парсинга на первой вкладке Internal мы можем посмотреть информацию по всем характеристикам: код ответа, индексируется/не индексируется, title страницы, description и все остальное.
Это все полезная информация, но мы шли за другим.
Вернемся к исходной задаче — посмотреть стоимость товаров. Для этого в интерфейсе Screaming Frog нам нужно перейти на вкладку Custom. Чтобы попасть на нее, нужно нажать на стрелочку, которая находится справа от всех вкладок. Из выпадающего списка выбрать пункт Custom.
И на этой вкладке из выпадающего списка фильтров (Filter) выберите Extraction.
Вы как раз и получите ту самую информацию, которую хотели собрать: список страниц и колонка «Стоимость 1» с ценами в рублях.
Задача выполнена, теперь все это можно выгрузить в xlsx или csv-файл.
После выгрузки стандартной заменой вы можете убрать букву «р», которая обозначает рубли. Просто, чтобы у вас были цены в чистом виде, без пробелов, буквы «р» и прочего.
Таким образом, вы получили информацию по стоимости товаров у сайта-конкурента.
Если бы мы хотели получить что-нибудь еще, например, дополнительно еще собрать названия этих товаров, то нам нужно было бы зайти снова в Configuration > Custom > Extraction. И выбрать после этого еще один XPath-запрос и указать, например, что мы хотим собрать тег <h2>.
И выбрать после этого еще один XPath-запрос и указать, например, что мы хотим собрать тег <h2>.
Просто запустив еще раз парсинг, мы собираем уже не только стоимость, но и названия товаров.
В результате получаем такую связку: url товара, его стоимость и название этого товара.
Если мы хотим получить описание или что-то еще — продолжаем в том же духе.
Важный момент: h2 собрать легко. Это стандартный элемент html-кода и для его парсинга можно использовать стандартный XPath-запрос (посмотрите в справке). В случае же с описанием или другими элементами нам нужно всегда возвращаться в код страницы и смотреть: как называется сам тег, какой у него класс/id либо какие-то другие атрибуты, к которым мы можем обратиться с помощью XPath-запроса.
Например, мы хотим собрать описание. Нужно снова идти в Inspect Element.
Оказывается, все описание товара лежит в теге <table> с классом product_description. Если мы его соберем, то у нас в таблицу выгрузится полное описание.
Здесь есть нюанс. Текст описания на странице сайта сделан с разметкой. Например, здесь есть переносы на новую строчку, что-то выделяется жирным.
Если вам нужно спарсить текст описания с уже готовой разметкой, то в настройках Extraction в парсере мы можем выбрать парсинг с html-кодом.
Если вы не хотите собирать весь html-код (потому что он может содержать какие-то классы, которые к вашему сайту никакого отношения не имеют), а нужен текст в чистом виде, выбираем только текст. Но помните, что тогда переносы строк и все остальное придется заполнять вручную.
Собрав все необходимые элементы и прогнав по ним парсинг, вы получите таблицу с исчерпывающей информацией по товарам у конкурента.
Такой парсинг можно запускать регулярно (например, раз в неделю) для отслеживания цен конкурентов. И сравнивать, у кого что стоит дороже/дешевле.
Пример 2. Как спарсить фотографии
Рассмотрим вариант решения другой прикладной задачи — парсинга фотографий.
На сайте Эльдорадо у каждого товара есть довольно-таки немало фотографий. Предположим, вы их хотите взять — это универсальные фото от производителя, которые можно использовать для демонстрации на своем сайте.
Задача: собрать в Excel адреса всех картинок, которые есть у разных карточек товара. Не в виде файлов, а в виде ссылок. Потом по ссылкам вы сможете их скачать либо напрямую загрузить на свой сайт. Большинство движков интернет-магазинов, таких как Битрикс и Shop-Script, поддерживают загрузку фотографий по ссылке. Если вы в CSV-файле, который используете для импорта-экспорта, укажете ссылки на фотографии, то по ним движок сможет загрузить эти фотографии.
Ищем свойства картинок
Для начала нам нужно понять, где в коде указаны свойства, адрес фотографии на каждой карточке товара.
Нажимаем правой клавишей на фотографию, выбираем Inspect Element, начинаем исследовать.
Смотрим, в каком элементе и с каким классом у нас находится данное изображение, что оно из себя представляет, какая у него ссылка и т. д.
д.
Изображения лежат в элементе <span>, у которого id — firstFotoForma. Чтобы спарсить нужные нам картинки, понадобится вот такой XPath-запрос:
//*[@id="firstFotoForma"]/*/img/@src
У нас здесь обращение к элементам с идентификатором firstFotoForma, дальше есть какие-то вложенные элементы (поэтому прописана звездочка), дальше тег img, из которого нужно получить содержимое атрибута src. То есть строку, в которой и прописан URL-адрес фотографии. Попробуем это сделать.
Берем XPath-запрос, в Screaming Frog переходим в Configuration > Custom > Extraction, вставляем и жмем ОК.
Для начала попробуем спарсить одну карточку. Нужно скопировать ее адрес и добавить в Screaming Frog таким образом: Upload > Paste
Нажимаем ОК. У нас начинается парсинг.
Screaming Frog спарсил одну карточку товара и у нас получилась такая табличка. Рассмотрим ее подробнее.
Мы загрузили один URL на входе, и у нас автоматически появилось сразу много столбцов «фото товара». Мы видим, что по этому товару собралось 9 фотографий.
Мы видим, что по этому товару собралось 9 фотографий.
Для проверки попробуем открыть одну из фотографий. Копируем адрес фотографии и вставляем в адресной строке браузера.
Фотография открылась, значит парсер сработал корректно и вытянул нужную нам информацию.
Теперь пройдемся по всему сайту в режиме Spider (для переключения в этот режим нужно нажать Mode > Spider). Укажем адрес https://www.eldorado.ru, нажимаем старт и запускаем парсинг.
Так как программа парсит весь сайт, то по страницам, которые не являются карточками товара, ничего не находится.
А с карточек товаров собираются ссылки на все фотографии.
Таким образом мы сможем собрать их и положить в Excel-таблицу, где будут указаны ссылки на все фотографии для каждого товара.
Если бы мы собирали артикулы, то еще раз зашли бы в Configuration > Custom > Extraction и добавили бы еще два XPath-запроса: для парсинга артикулов, а также тегов h2, чтобы собрать еще названия.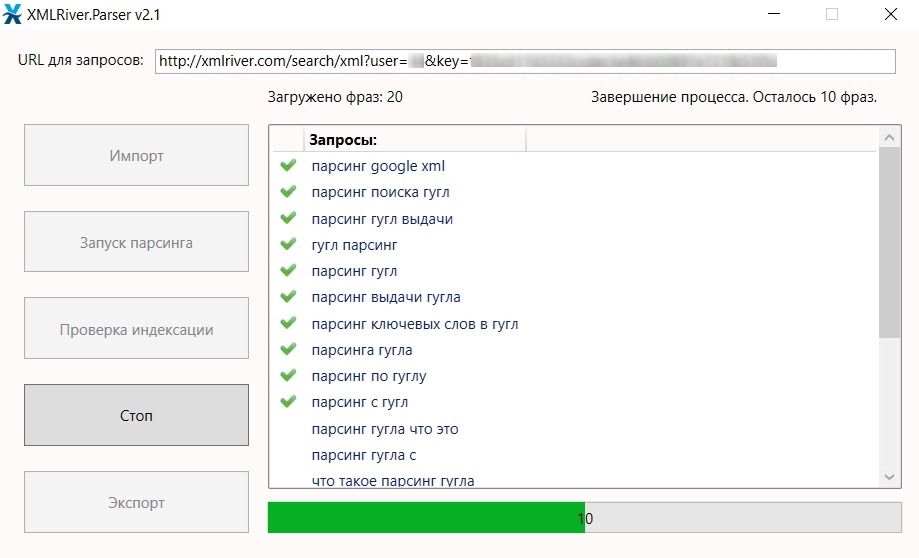 Так мы бы убили сразу двух зайцев и собрали бы связку: название товара + артикул + фото.
Так мы бы убили сразу двух зайцев и собрали бы связку: название товара + артикул + фото.
Пример 3. Как спарсить характеристики товаров
Следующий пример — ситуация, когда нам нужно насытить карточки товаров характеристиками. Представьте, что вы продаете книжки. Для каждой книги у вас указано мало характеристик — всего лишь год выпуска и автор. А у Озона (сильный конкурент, сильный сайт) — характеристик много.
Вы хотите собрать в Excel все эти данные с Озона и использовать их для своего сайта. Это техническая информация, вопросов с авторским правом нет.
Изучаем характеристики
Нажимаете правой кнопкой по характеристике, выбираете Inspect Element и смотрите, как называется элемент, который содержит каждую характеристику.
У нас это элемент <div>, у которого в качестве класса указана строка eItemProperties_Line.
И дальше внутри каждого такого элемента <div> содержится название характеристики и ее значение.
Значит нам нужно собирать элементы <div> с классом eItemProperties_Line.
Для парсинга нам понадобится вот такой XPath-запрос:
//*[@class="eItemProperties_line"]
Идем в Screaming Frog, Configuration > Custom > Extraction. Вставляем XPath-запрос, выбираем Extract Text (так как нам нужен только текст в чистом виде, без разметки), нажимаем ОК.
Переключаемся в режим Mode > List. Нажимаем Upload, указываем адрес страницы, с которой будем собирать характеристики, нажимаем ОК.
После завершения парсинга переключаемся на вкладку Custom, в списке фильтров выбираем Extraction.
И видим — парсер собрал нам все характеристики. В каждой ячейке находится название характеристики (например, «Автор») и ее значение («Игорь Ашманов»).
Пример 4. Как парсить отзывы (с рендерингом)
Следующий пример немного нестандартен — на грани «серого» SEO. Это парсинг отзывов с того же Озона. Допустим, мы хотим собрать и перенести на свой сайт тексты отзывов ко всем книгам.
Покажем процесс на примере одного URL. Начнем с того, что посмотрим, где отзывы лежат в коде.
Начнем с того, что посмотрим, где отзывы лежат в коде.
Они находятся в элементе <div> с классом jsCommentContent:
Следовательно, нам нужен такой XPath-запрос:
//*[@class="jsCommentContents"]
Добавляем его в Screaming Frog. Теперь копируем адрес страницы, которую будем анализировать, и загружаем в парсер.
Жмем ОК и видим, что никакие отзывы у нас не загрузились:
Почему так? Разработчики Озона сделали так, что текст отзывов грузится в момент, когда вы докручиваете до места, где отзывы появляются (чтобы не перегружать страницу). То есть они изначально в коде нигде не видны.
Чтобы с этим справиться, нам нужно зайти в Configuration > Spider, переключиться на вкладку Rendering и выбрать JavaScript. Так при обходе страниц парсером будет срабатывать JavaScript и страница будет отрисовываться полностью — так, как пользователь увидел бы ее в браузере. Screaming Frog также будет делать скриншот отрисованной страницы.
Мы выбираем устройство, с которого мы якобы заходим на сайт (десктоп). Настраиваем время задержки перед тем, как будет делаться скриншот, — одну секунду.
Нажимаем ОК. Введем вручную адрес страницы, включая #comments (якорная ссылка на раздел страницы, где отображаются отзывы).
Для этого жмем Upload > Enter Manually и вводим адрес:
Обратите внимание! При рендеринге (особенно, если страниц много) парсер может работать очень долго.
Итак, парсер собрал 20 отзывов. Внизу они показываются в качестве отрисованной страницы. А вверху в табличном варианте мы видим текст этих отзывов.
Пример 5. Как спарсить скрытые телефоны на сайте ЦИАН
Следующий пример — сбор телефонов с сайта cian.ru. Здесь есть предложения о продаже квартир. Допустим, стоит задача собрать телефоны с каких-то предложений или вообще со всех.
У этой задачи есть особенности. На странице объявления телефон скрыт кнопкой «Показать телефон».
После клика он виден.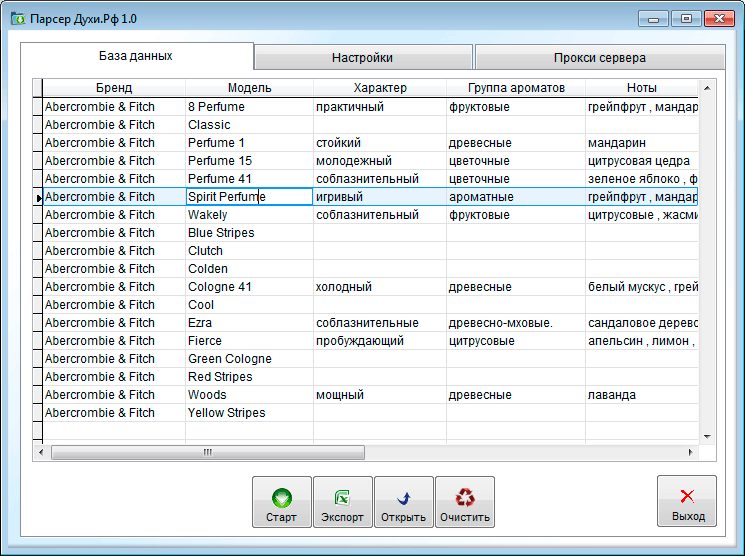 А до этого в коде видна только сама кнопка.
А до этого в коде видна только сама кнопка.
Но на сайте есть недоработка, которой мы воспользуемся. После нажатия на кнопку «Показать телефон» мы видим, что она начинается «+7 967…». Теперь обновим страницу, как будто мы не нажимали кнопку, посмотрим исходный код страницы и поищем в нем «967».
И вот, мы видим, что этот телефон уже есть в коде. Он находится у ссылки, с классом a10a3f92e9—phone—3XYRR. Чтобы собрать все телефоны, нам нужно спарсить содержимое всех элементов с таким классом.
Используем этот класс в XPath-запросе:
//*[@class="a10a3f92e9--phone--3XYRR"]
Идем в Screaming Frog, Custom > Extraction. Указываем XPath-запрос и даем название колонке, в которую будут собираться телефоны:
Берем список ссылок (для примера я отобрал несколько ссылок на страницы объявлений) и добавляем их в парсер.
В итоге мы видим связку: адрес страницы — номер телефона.
Также мы можем собрать в дополнение к телефонам еще что-то. Например, этаж.
Алгоритм такой же:
- Кликаем по этажу, Inspect Element.
- Смотрим, где в коде расположена информация об этажах и как обозначается.
- Используем класс или идентификатор этого элемента в XPath-запросе.
- Добавляем запрос и список страниц, запускаем парсер и собираем информацию.
Пример 6. Как парсить структуру сайта на примере DNS-Shop
И последний пример — сбор структуры сайта. С помощью парсинга можно собрать структуру какого-то большого каталога или интернет-магазина.
Рассмотрим, как собрать структуру dns-shop.ru. Для этого нам нужно понять, как строятся хлебные крошки.
Нажимаем на любую ссылку в хлебных крошках, выбираем Inspect Element.
Эта ссылка в коде находится в элементе <span>, у которого атрибут itemprop (атрибут микроразметки) использует значение «name».
Используем элемент span со значением микроразметки в XPath-запросе:
//span[@itemprop="name"]
Указываем XPath-запрос в парсере:
Пробуем спарсить одну страницу и получаем результат:
Таким образом мы можем пройтись по всем страницам сайта и собрать полную структуру.
Возможности парсинга на основе XPath
Что можно спарсить:
1. Любую информацию с почти любого сайта.
Нужно понимать, что есть сайты с защитой от парсинга. Например, если вы захотите спарсить любой проект Яндекса — у вас ничего не получится. Авито — тоже довольно-таки сложно. Но большинство сайтов можно спарсить.
2. Цены, наличие товаров, любые характеристики, фото, 3D-фото.
3. Описание, отзывы, структуру сайта.
4. Контакты, неочевидные свойства и т.д.
Любой элемент на странице, который есть в коде, вы можете вытянуть в Excel.
Ограничения при парсинге
- Бан по user-agent. При обращении к сайту парсер отсылает запрос user-agent, в котором сообщает сайту информацию о себе. Некоторые сайты сразу блокируют доступ парсеров, которые в user-agent представляются как приложения. Это ограничение можно легко обойти. В Screaming Frog нужно зайти в Configuration > User-Agent и выбрать YandexBot или Googlebot.

Подмена юзер-агента вполне себе решает данное ограничение. К большинству сайтов мы получим доступ таким образом.
- Запрет в robots.txt. Например, в robots.txt может быть прописан запрет индексирования каких-то разделов для Google-бота. Если мы user-agent настроили как Googlebot, то спарсить информацию с этого раздела не сможем.
Чтобы обойти ограничение, заходим в Screaming Frog в Configuration > Robots.txt > Settings
И выбираем игнорировать robots.txt
- Бан по IP. Если вы долгое время парсите какой-то сайт, то вас могут заблокировать на определенное или неопределенное время. Здесь два варианта решения: использовать VPN или в настройках парсера снизить скорость, чтобы не делать лишнюю нагрузку на сайт и уменьшить вероятность бана.
- Анализатор активности / капча. Некоторые сайты защищаются от парсинга с помощью умного анализатора активности. Если ваши действия похожи на роботизированные (когда обращаетесь к странице, у вас нет курсора, который двигается, или браузер не похож на стандартный), то анализатор показывает капчу, которую парсер не может обойти. Такое ограничение можно обойти, но это долго и дорого.
 Такое ограничение можно обойти, но это долго и дорого.
Такое ограничение можно обойти, но это долго и дорого.Теперь вы знаете, как собрать любую нужную информацию с сайтов конкурентов. Пользуйтесь приведенными примерами и помните — почти все можно спарсить. А если нельзя — то, возможно, вы просто не знаете как.
Написание синтаксического анализатора — Часть I: Начало работы | by Supun Setunga
В этой статье обсуждается простой подход к реализации рукописного синтаксического анализатора с нуля и некоторые основные принципы, связанные с ним. Это больше фокусируется на объяснении практических аспектов реализации, а не на формальных определениях синтаксических анализаторов.
Синтаксический анализатор — это самое первое, что приходит нам на ум, когда мы говорим о разработке-компиляторе/конструкции-компилятора. Правильно, синтаксический анализатор играет ключевую роль в архитектуре компилятора, а также может рассматриваться как точка входа в компилятор. Прежде чем мы углубимся в детали того, как написать синтаксический анализатор, давайте посмотрим, что на самом деле означает синтаксический анализ.
Что такое синтаксический анализ
Синтаксический анализ по существу означает преобразование исходного кода в древовидное представление объекта, которое называется «деревом синтаксического анализа» (также иногда называемым «синтаксическим деревом»). Часто абстрактное синтаксическое дерево (AST) путают с деревом разбора/синтаксиса. Дерево синтаксического анализа — это конкретное представление исходного кода. Он сохраняет всю информацию об исходном коде, включая тривиальную информацию, такую как разделители, пробелы, комментарии и т. д. Принимая во внимание, что AST является абстрактным представлением исходного кода и может не содержать часть информации, которая есть в исходном коде. .
В дереве синтаксического анализа каждый элемент называется «узлом». Листовые узлы или конечные узлы рассматриваются как узлы особого типа, которые называются «токенами». Нетерминальные узлы обычно называют просто «узел».
Зачем рукописный парсер?
Если вы осмотритесь, то увидите, что существует довольно много доступных генераторов синтаксических анализаторов, таких как ANTLR, Bison, Yacc и т. д. С помощью этих генераторов синтаксических анализаторов мы можем просто определить грамматику и автоматически сгенерировать синтаксический анализатор в соответствии с этой грамматикой. . Это звучит довольно просто! Если да, то зачем писать парсер с нуля?
д. С помощью этих генераторов синтаксических анализаторов мы можем просто определить грамматику и автоматически сгенерировать синтаксический анализатор в соответствии с этой грамматикой. . Это звучит довольно просто! Если да, то зачем писать парсер с нуля?
Распространенная ошибка при построении компилятора — думать, что нам нужно написать синтаксический анализатор с нуля, или думать, что нам не нужен собственный синтаксический анализатор. Что ж, звучит противоречиво! Загвоздка в том, что оба подхода имеют свои плюсы и минусы. Поэтому важно знать, когда писать парсер вручную или использовать генератор парсеров:
Сгенерированный парсер:
- Простота реализации — Определите грамматику в нужном формате и сгенерируйте парсер. например: Для ANTLR все, что нам нужно, это определить грамматику в
.g4формат. Затем сгенерировать синтаксический анализатор так же просто, как запустить одну команду. - Простота обслуживания — все, что вам нужно сделать, это обновить правило грамматики и заново сгенерировать синтаксический анализатор.
- Может быть компактного размера.
- Однако у него нет преимуществ рукописного парсера (см. ниже).

Написанный вручную синтаксический анализатор:
- Написание синтаксического анализатора вручную — задача средней сложности. Сложность может увеличиться, если языковая грамматика сложна. Однако он имеет следующие преимущества.
- Могут быть улучшенные и содержательные сообщения об ошибках. Автоматически сгенерированные парсеры могут иногда приводить к совершенно бесполезным ошибкам.
- Может поддерживать отказоустойчивый синтаксический анализ. Другими словами, он может создать правильное дерево синтаксического анализа даже при синтаксической ошибке. Это также означает, что рукописный синтаксический анализатор может обнаруживать и обрабатывать несколько синтаксических ошибок одновременно. В сгенерированных синтаксических анализаторах это может быть достигнуто в определенной степени с помощью обширных настроек, но может быть не в состоянии полностью поддерживать отказоустойчивый синтаксический анализ.
- Может поддерживать добавочный анализ — анализировать только часть кода при обновлении исходного кода.
- Обычно лучше с точки зрения производительности.
- Легко настроить. Вы владеете кодом и имеете полный контроль над ним — например: в ANTLR4, если вы хотите настроить логику синтаксического анализа, вам придется либо расширить и немного взломать сгенерированный синтаксический анализатор, либо написать некоторую пользовательскую логику в сам файл грамматики на другом языке. Иногда это может быть запутанно, а уровень настройки, который можно сделать, очень ограничен.
- Может легко обрабатывать контекстно-зависимые грамматики. Не все языки на 100% контекстно-свободны. Могут быть ситуации, когда вы хотите токенизировать входные данные или построить дерево синтаксического анализа по-разному в зависимости от контекста. Это очень сложная или почти невыполнимая задача, когда речь идет о сгенерированных парсерах.
Итак, в общем, если вы хотите получить высокооптимизированный синтаксический анализатор производственного уровня, который является отказоустойчивым, и если у вас достаточно времени, то рукописный синтаксический анализатор — это то, что вам нужно.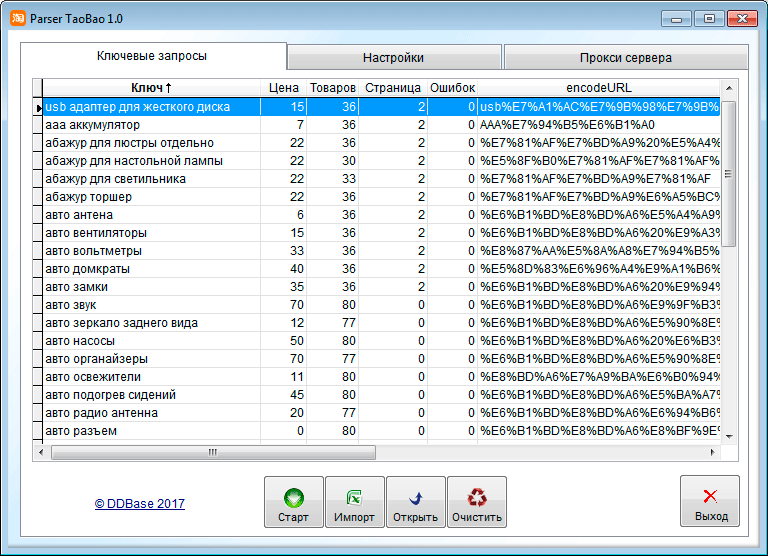 С другой стороны, вам нужен достаточно приличный синтаксический анализатор за очень короткое время, а производительность или отказоустойчивость не являются одним из ваших требований, сгенерированный синтаксический анализатор справится с задачей.
С другой стороны, вам нужен достаточно приличный синтаксический анализатор за очень короткое время, а производительность или отказоустойчивость не являются одним из ваших требований, сгенерированный синтаксический анализатор справится с задачей.
Независимо от того, следует ли реализовать рукописный синтаксический анализатор или использовать сгенерированный синтаксический анализатор, всегда будет необходима одна вещь: четко определенная грамматика (формальная грамматика) для языка, который мы собираемся реализовать. Грамматика определяет лексическую и синтаксическую структуру программы на этом языке. Очень популярным и простым форматом для определения контекстно-свободной грамматики является форма Бэкуса-Наура (BNF) или один из ее вариантов, например расширенная форма Бэкуса-Наура (EBNF).
Несмотря на то, что синтаксический анализатор часто называют отдельным компонентом в архитектуре компилятора, он состоит из нескольких компонентов, включая, помимо прочего, лексер, синтаксический анализатор и несколько других абстракций, таких как устройство(а) чтения ввода/символов и обработчик ошибок. На приведенной ниже диаграмме показаны компоненты и то, как они связаны друг с другом в нашей реализации парсера.
На приведенной ниже диаграмме показаны компоненты и то, как они связаны друг с другом в нашей реализации парсера.
Считыватель символов / Считыватель ввода
Считыватель символов, также называемый устройством чтения ввода, считывает исходный код и предоставляет символы/кодовые точки лексеру по запросу. Исходным кодом может быть что угодно: файл, входной поток или даже строка.
Также возможно встроить возможности чтения ввода в сам лексер. Однако преимущество абстрагирования считывателя от лексера состоит в том, что, в зависимости от входных данных, мы можем подключать разные считыватели к одному и тому же лексеру. И лексеру не нужно беспокоиться об обработке различных типов входных данных.
Считыватель ввода состоит из трех наборов важных методов:
- peek()/peek(k) — Получить следующий символ /следующий k-й символ из ввода. Это используется для просмотра символов без их использования/удаления из входного потока. Вызов метода
peek()более одного раза вернет один и тот же символ. - потреблять()/consume(k) — Получить следующий символ /следующий k-й токен из ввода и удалить его из ввода. Это означает, что вызов
метод Consumer()несколько раз будет возвращать новый символ при каждом вызове. Иногда этот методConsumer()также называютread()илиnext(). - isEOF() — Проверяет, достиг ли читатель конца ввода.
Лексер
Лексер считывает символы из устройства ввода/считывания символов и создает токены. Другими словами, он преобразует поток символов в поток маркеров. Поэтому его иногда также называют токенизатором. Эти токены создаются в соответствии с определенной грамматикой. Обычно реализация лексера несколько сложнее, чем у считывателя символов, но намного проще, чем у синтаксического анализатора.
Важным аспектом лексера является обработка пробелов и комментариев. В большинстве языков языковая семантика не зависит от пробелов. Пробелы требуются только для обозначения конца токена и, следовательно, также называются «пустяками» или «мелоциями», поскольку они не имеют большого значения для AST. Однако это не относится ко всем языкам, потому что в некоторых языках, таких как python, пробелы могут иметь семантическое значение. Разные лексеры по-разному обрабатывают эти пробелы и комментарии:
Пробелы требуются только для обозначения конца токена и, следовательно, также называются «пустяками» или «мелоциями», поскольку они не имеют большого значения для AST. Однако это не относится ко всем языкам, потому что в некоторых языках, таких как python, пробелы могут иметь семантическое значение. Разные лексеры по-разному обрабатывают эти пробелы и комментарии:
- Отбросить их в лексере — Недостаток этого подхода в том, что он не сможет воспроизвести исходный код из дерева синтаксиса/анализа. Это может стать проблемой, если вы планируете использовать дерево синтаксического анализа для таких целей, как форматирование кода и т. д.
- Выдавать пробелы как отдельные токены, но в другой поток/канал, чем обычный токен. Это хороший подход для языков, в которых пробелы имеют семантическое значение.
- Сохранить их в дереве синтаксического анализа, присоединив их к ближайшему токену. В нашей реализации мы будем использовать этот подход.
Подобно считывателю символов, лексер состоит из двух методов:
- peek()/peek(k) — Получить следующий токен /следующий k-й токен. Это используется для просмотра токенов без их использования/удаления из входного потока. Вызов метода
peek()более одного раза вернет один и тот же токен. - потреблять()/consume(k) — Получить следующий токен/следующий k-й токен и удалить его из потока токенов. Это означает, что вызов
Consumer() 9Метод 0025 несколько раз будет возвращать новый токен при каждом вызове. Иногда этот методConsumer()также называютread()илиnext().
 Это используется для просмотра токенов без их использования/удаления из входного потока. Вызов метода
Это используется для просмотра токенов без их использования/удаления из входного потока. Вызов метода Как только лексер достигает конца ввода от устройства чтения символов, он выдает специальный токен, называемый «EOFToken» (маркер конца файла). Синтаксический анализатор использует этот EOFToken для завершения синтаксического анализа.
Анализатор
Анализатор отвечает за чтение токенов из лексера и создание дерева разбора. Он получает следующий токен от лексера, анализирует его и сравнивает с определенной грамматикой. Затем решает, какое из грамматических правил следует учитывать, и продолжает разбор в соответствии с грамматикой. Однако это не всегда очень просто, так как иногда невозможно определить, какой путь выбрать, только взглянув на следующий токен. Таким образом, синтаксическому анализатору, возможно, придется проверить несколько токенов в будущем, чтобы решить, какой путь или правило грамматики следует учитывать. Об этом мы подробно поговорим в следующей статье. Однако из-за такой сложности парсер также является наиболее сложным компонентом для реализации в архитектуре парсера.
Однако это не всегда очень просто, так как иногда невозможно определить, какой путь выбрать, только взглянув на следующий токен. Таким образом, синтаксическому анализатору, возможно, придется проверить несколько токенов в будущем, чтобы решить, какой путь или правило грамматики следует учитывать. Об этом мы подробно поговорим в следующей статье. Однако из-за такой сложности парсер также является наиболее сложным компонентом для реализации в архитектуре парсера.
Как правило, синтаксическому анализатору требуется только один метод — метод parse() , который выполняет весь синтаксический анализ и возвращает дерево синтаксического анализатора.
Учитывая тот факт, что наша цель состоит в том, чтобы реализовать синтаксический анализатор, который одновременно является устойчивым и выдает правильные сообщения об ошибках, очень важным аспектом синтаксического анализатора является правильная обработка синтаксических ошибок. Синтаксическая ошибка — это случай, когда во время синтаксического анализа достигается неожиданный токен или, другими словами, следующий токен не соответствует определенной грамматике. В таких случаях синтаксический анализатор запрашивает «обработчик ошибок» (см. следующий раздел) исправить эту синтаксическую ошибку, и как только обработчик ошибок восстанавливается, синтаксический анализатор продолжает анализировать остальную часть ввода.
В таких случаях синтаксический анализатор запрашивает «обработчик ошибок» (см. следующий раздел) исправить эту синтаксическую ошибку, и как только обработчик ошибок восстанавливается, синтаксический анализатор продолжает анализировать остальную часть ввода.
Обработчик ошибок
Как обсуждалось в предыдущем разделе, целью обработчика ошибок является восстановление после синтаксической ошибки. Он играет ключевую роль в современном отказоустойчивом синтаксическом анализаторе, особенно для создания корректного дерева синтаксического анализа даже с синтаксическими ошибками и выдачи правильных и содержательных сообщений об ошибках.
Возможности обработки ошибок также могут быть встроены в сам синтаксический анализатор. Преимущество этого заключается в том, что, поскольку ошибки будут обрабатываться тут же в синтаксическом анализаторе, в момент восстановления доступно много контекстной информации. Однако недостатков у встраивания возможностей восстановления в сам парсер больше, чем достоинств:
- Попытка восстановить каждое место приведет к большому количеству повторяющихся задач и повторяющихся кодов.
- Логика синтаксического анализатора будет загромождена логикой обработки ошибок, что в конечном итоге сделает кодовую базу трудной для чтения и понимания.
- Имея отдельный обработчик ошибок, можно также подключать разные обработчики ошибок для разных вариантов использования. Например, можно использовать один подход к обработке ошибок для инструментов CLI и другой подход к обработке ошибок для интерактивных IDE. Потому что IDE могут захотеть облегчить завершение кода и т. д., и, следовательно, шаблон восстановления будет более близок к шаблону письма пользователя.
В этой статье мы обсудили базовую архитектуру парсера, некоторые термины, а также когда следует использовать рукописный парсер, а когда нет. Мы также обсудили некоторые высокоуровневые детали различных компонентов парсера и их требования. В следующей статье я подробно расскажу о каждом из этих компонентов и алгоритмах, которым необходимо следовать, включая некоторые детали реализации.
синтаксический анализ - Создание синтаксического анализатора (Часть I)
спросил
Изменено 3 года, 4 месяца назад
Просмотрено 41к раз
Я создаю свой собственный язык программирования на основе javascript (да, это безумие, но это только для обучения.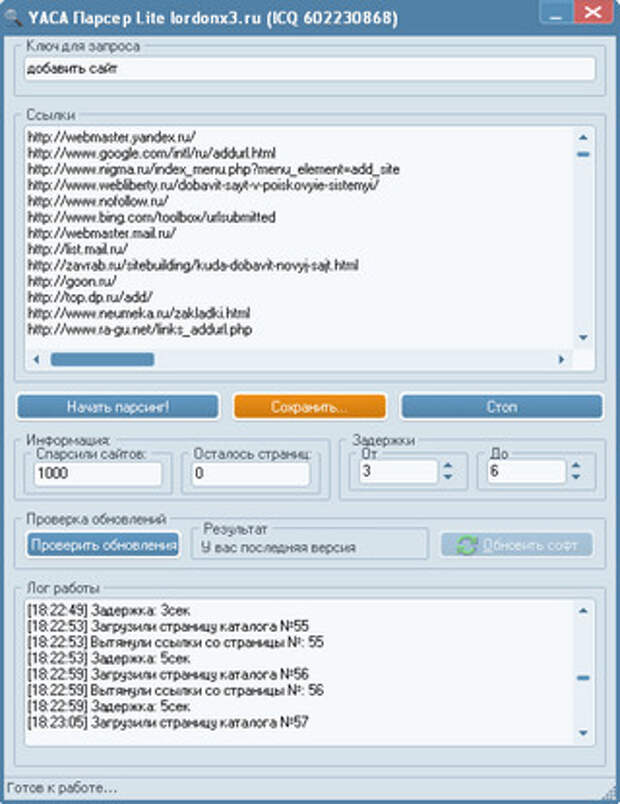
if(x > 5) вернуть истину;
Токенизатор для:
T_IF "если"
Т_ЛПАРЕН "("
T_IDENTIFIER "х"
Т_ГТ ">"
Т_НОМЕР "5"
Т_РПАРЕН ")"
T_IDENTIFIER "возврат"
T_TRUE "правда"
Т_ТЕРМИНАТОР ";"
Пока не знаю, верна ли моя логика. На моем парсере еще лучше ( или нет? ) и транслируем в него (ага, многомерный массив):
T_IF "if"
T_EXPRESSION...
T_IDENTIFIER "х"
Т_ГТ ">"
Т_НОМЕР "5"
Т_ЗАКРЫТИЕ...
T_IDENTIFIER "возврат"
T_TRUE "правда"
У меня есть некоторые сомнения:
- Мой способ лучше или хуже, чем
- Что именно мне нужно сделать после токенизации? Я действительно потерялся на этом перевале!
- Есть хороший учебник, чтобы узнать, как я могу это сделать?
Ну вот. До свидания!
До свидания!
- синтаксический анализ
- языки программирования
- перевод
3
Как правило, вы хотите отделить функции токенизатора (также называемого
Итак, вы превратили своих персонажей в жетоны. Теперь вы хотите преобразовать свой плоский список токенов в осмысленные вложенные выражения, и это то, что обычно называется 9.0167 разбор . Для языка, подобного JavaScript, вы должны изучить синтаксический анализ рекурсивного спуска. Для синтаксического анализа выражений с инфиксными операторами с различными уровнями приоритета очень полезен синтаксический анализ Пратта, и вы можете использовать обычный рекурсивный спусковой синтаксический анализ для особых случаев.
Просто чтобы дать вам более конкретный пример, основанный на вашем случае, я предполагаю, что вы можете написать две функции: accept(token) и expect(token) , которые проверяют следующий токен в потоке, который вы созданный. Вы создадите функцию для каждого типа оператора или выражения в грамматике вашего языка. Вот Pythonish псевдокод для оператор() функция, например:
def оператор():
если принять("если"):
х = выражение ()
у = оператор ()
вернуть IfStatement (x, y)
Элиф принять ("возврат"):
х = выражение ()
вернуть ReturnStatement (x)
Элиф принять("{")
хз = []
пока верно:
xs.append (инструкция ())
если не принять (";"):
ломать
ожидать("}")
вернуть блок (xs)
еще:
ошибка("Неверный оператор!")
Это дает вам так называемое абстрактное синтаксическое дерево (AST) вашей программы, которым вы затем можете манипулировать (оптимизация и анализ), выводить (компиляция) или запускать (интерпретация).
Большинство инструментов разбивают весь процесс на две отдельные
- лексер (он же токенизатор)
- парсер (он же грамматика)
Токенизатор разделит входные данные на токены. Парсер будет работать только с токеном «поток» и строить структуру.
Похоже, ваш вопрос касается токенизатора. Но ваше второе решение смешивает парсер грамматики и токенизатор в один шаг. Теоретически это тоже возможно, но для новичка это намного проще сделать это так же, как и большинство других инструментов/фреймворков: разделите шаги.
К вашему первому решению: я бы токенизировал ваш пример следующим образом:
T_KEYWORD_IF "if"
Т_ЛПАРЕН "("
T_IDENTIFIER "х"
Т_ГТ ">"
Т_ЛИТАРАЛЬНЫЙ "5"
Т_РПАРЕН ")"
T_KEYWORD_RET "возврат"
T_KEYWORD_TRUE "истина"
Т_ТЕРМИНАТОР ";"
В большинстве языков ключевые слова нельзя использовать в качестве имен методов, имен переменных и т.д. Это отражается уже на уровне токенизатора ( T_KEYWORD_IF , T_KEYWORD_RET , T_KEYWORD_TRUE ).
Следующий уровень возьмет этот поток и, применив формальную грамматику, создаст некоторую структуру данных (часто называемую AST — абстрактным синтаксическим деревом), которая может выглядеть так:
IfStatement:
Выражение:
Двоичный оператор:
Оператор: T_GT
Левый операнд:
ИдентификаторВыражение:
"Икс"
Правый операнд:
БуквенноеВыражение
5
ЕслиБлокировать
Заявление о возврате
ВозвратВыражение
БуквенноеВыражение
"истинный"
Другой блок (пусто)
Реализация синтаксического анализатора вручную обычно выполняется некоторыми фреймворками. Реализация чего-то подобного вручную с помощью и обычно выполняется в университете в течение большей части семестра. Так что вам действительно следует использовать какой-то фреймворк.
Входными данными для структуры синтаксического анализатора грамматики обычно является формальная грамматика в какой-либо БНФ.
IfStatement: T_KEYWORD_IF T_LPAREN Expression T_RPAREN Statement ; Выражение: LiteralExpression | ДвоичноеВыражение | ИдентификаторВыражение | ... ; BinaryExpression: LeftOperand BinaryOperator RightOperand; ....
Это только для того, чтобы понять. Разобрать реальный язык, такой как Javascript , правильно — непростая задача. Но смешно.
Мой способ лучше или хуже оригинального способа ? Обратите внимание, что мой код будет прочитан и скомпилирован (переведен на другой язык, например PHP), а не интерпретирован постоянно.
Что такое оригинальный способ ? Существует множество различных способов реализации языков. Я думаю, что на самом деле у вас все в порядке, я однажды пытался сам создать язык, который переводится на C #, язык программирования для взлома. Многие компиляторы языков переводят на промежуточный язык, это довольно распространено.
Что именно мне нужно сделать после токенизации? Я действительно потерялся на этом перевале!
После токенизации вам необходимо разобрать его. Используйте какой-нибудь хороший фреймворк лексера/парсера, например Boost.Spirit, Coco или что-то еще. Их сотни. Или вы можете реализовать свой собственный лексер, но это требует времени и ресурсов. Есть много способов парсить код, я обычно полагаюсь на синтаксический анализ рекурсивного спуска.
Используйте какой-нибудь хороший фреймворк лексера/парсера, например Boost.Spirit, Coco или что-то еще. Их сотни. Или вы можете реализовать свой собственный лексер, но это требует времени и ресурсов. Есть много способов парсить код, я обычно полагаюсь на синтаксический анализ рекурсивного спуска.
Далее вам нужно сделать генерацию кода. Это самая сложная часть на мой взгляд. Для этого тоже есть инструменты, но вы можете сделать это вручную, если хотите, я пытался сделать это в своем проекте, но это было довольно просто и с ошибками, здесь и здесь есть полезный код.
Есть хороший учебник, чтобы узнать, как я могу это сделать?
Как я уже предлагал ранее, используйте для этого инструменты . Существует множество довольно хороших хорошо документированных фреймворков для синтаксического анализатора. Для получения дополнительной информации вы можете попробовать спросить некоторых людей, которые знают об этом. @DeadMG, в Lounge C++, разрабатывает язык программирования под названием «Широкий».