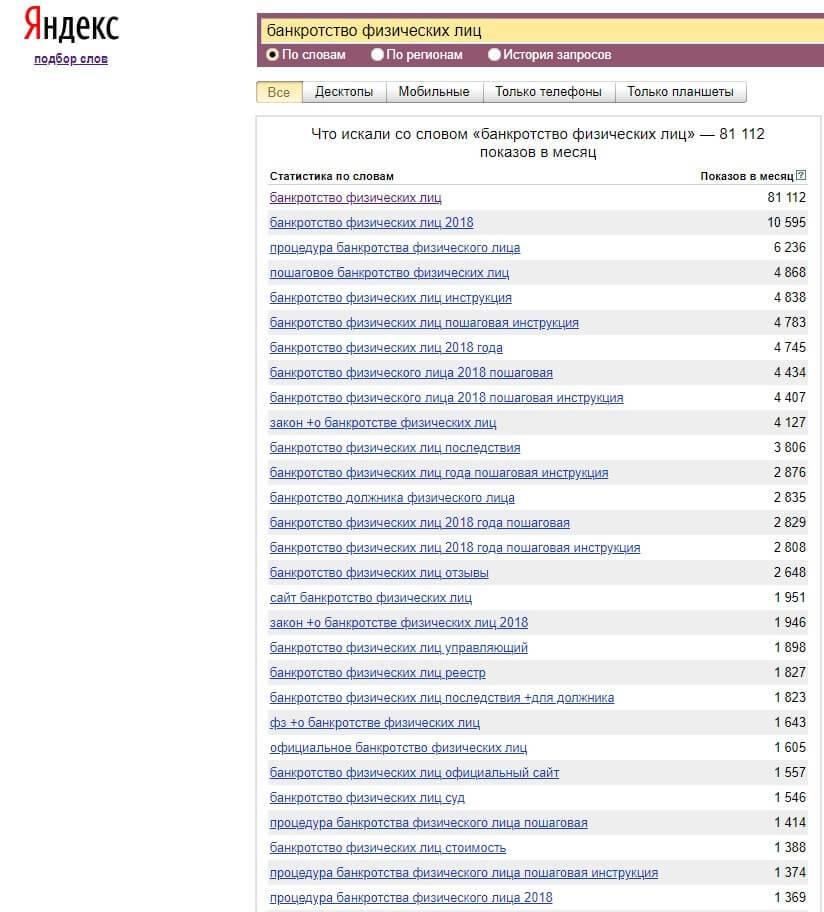
6.5.Тесты
1. База данных – это:
любой текстовый файл;
организованная структура для хранения информации;
любая информация в табличной форме;
любая электронная таблица.
2. Какое из свойств не является свойством реляционной базы?
несколько узлов уровня связаны с узлом одного уровня;
порядок следования строк в таблице произвольный;
каждый столбец имеет уникальное имя;
для каждой таблицы можно определить первичный ключ.
3. Что такое SQL?
язык разметки базы данных;
структурированный язык запросов;
язык программирования высокого уровня.

4. Какая база данных строится на основе таблиц и только таблиц?
сетевая;
иерархическая;
реляционная .
5. Какой из перечисленных элементов не является объектом Access?
модуль;
лист;
запрос;
макрос;
отчет ;
6. В какой модели данных существуют горизонтальные и вертикальные связи между элементами?
сетевой;
иерархической;
реляционной;
объектно-ориентированной.
7. Какой из ниже перечисленных запросов нельзя построить?
простой;
перекрестный;
на создание таблицы;
параллельный;
записи без подчиненных.

8. Что такое поле?
столбец в таблице;
окно конструктора
текст любого размера
строка в таблице
9. Что такое запрос?
окно конструктора;
связанная таблица;
главная таблица;
средство отбора данных.
10. В чем заключается функция ключевого поля?
однозначно определять таблицу;
однозначно определять запись ;
определять заголовок столбца таблицы;
вводить ограничение для проверки правильности ввода данных.
11. Из чего состоит макрос?
из набора тегов;
из совокупности операторов Visual Basic;
из набора гиперссылок;
из набора макрокоманд .

12. Какого раздела не существует в конструкторе форм?
заголовка;
верхнего колонтитула;
область данных;
примечание;
итоговый.
13. Модули предназначены для:
хранения данных;
выбора и обработки данных;
ввода данных и их просмотра;
построения программ на VBA
14.Для чего предназначены запросы?
для хранения данных ;
для выбора и обработки данных ;
для ввода данных и их просмотра;
для вывода данных на принтер.
15. Что из
перечисленного не является объектом Access?
Что из
перечисленного не является объектом Access?
таблицы;
ключи;
формы;
отчеты.
Ответы на тесты главы 6
1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
b | a | b | c | b | a | d | a | d | b | d | e | b | b |
Глава 7.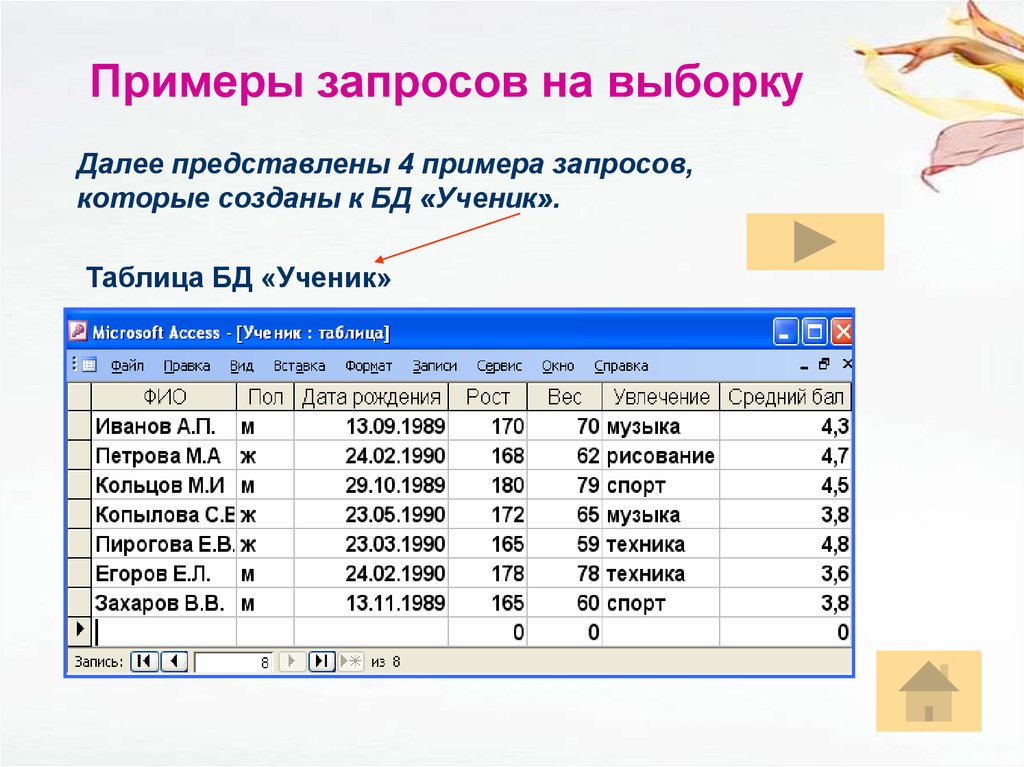 Основы
алгоритмизации и программирования на
языке
Турбо Паскаль 7.0
Основы
алгоритмизации и программирования на
языке
Турбо Паскаль 7.0
Предисловие
Алгоритмический язык Паскаль был создан в начале 70-х годов признанным классиком программирования Николаусом Виртом. Этот язык был назван в честь французского ученого Блеза Паскаля (1623-1662). Великий ученый, вошел в историю как изобретатель арифметического калькулятора — первого в мире механического счетного устройства.
В
80-е годы позиции Паскаля еще более
упрочились в связи с появлением версий
языка, предназначенных для персональных
компьютеров. Возникло целое семейство
языков Паскаль, и в том числе язык Турбо
Паскаль, разработанный программистами
американской фирмы Borland. В настоящее
время Турбо Паскаль представляет собой
мощную систему программирования,
включающую универсальную интегрированную
среду, в которую «погружен» язык. Эта
среда значительно упрощает и облегчает
процесс создания программ, и в то же
время предоставляет пользователю ряд
новых, дополнительных возможностей
(использование средств объектно-ориентированного
программирования, работа с графикой и
звуком и другие).
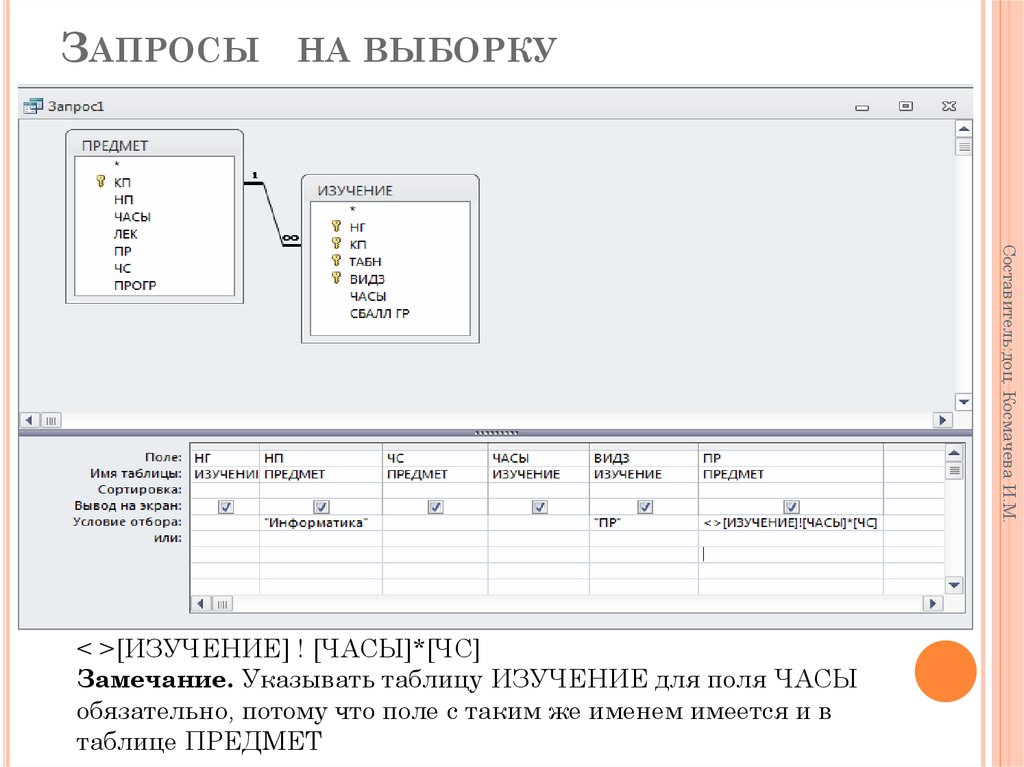
Создание запроса на основе нескольких таблиц
В простейшем случае построение и использование запроса в Access заключается в выборе требуемых полей из таблицы, применении условий (если они нужны) и просмотре результатов запроса. Но чаще необходимо использовать данные, которые находятся в разных таблицах. К счастью, вы можете создавать запросы, объединяющие сведения из нескольких источников. В этой статье объясняется, когда следует получать данные сразу из нескольких таблиц и как это делать.
Выберите нужное действие
-
Уточнение данных в запросе с помощью данных из связанной таблицы
-
Объединение данных в двух таблицах с помощью их связей с третьей таблицей
-
Просмотр всех записей из двух похожих таблиц
Уточнение данных в запросе с помощью данных из связанной таблицы
В некоторых случаях запрос, построенный на основе одной таблицы и предоставляющий необходимые сведения, может стать более информативным и полезным благодаря данным из другой таблицы.
Использование мастера запросов для построения запроса на основе главной и связанной таблицы
-
Убедитесь, что для таблиц задано отношение в окно отношений.
Инструкции
 org/ListItem»>
org/ListItem»>
На вкладке Работа с базами данных в группе Показать или скрыть выберите пункт Отношения.
-
На вкладке Конструктор в группе Связи нажмите кнопку Все связи.
-
Выберите таблицы, которые нужно связать.
-
Если таблицы отображаются в окне схемы данных, убедитесь, что отношение между ними уже установлено.
Отношение отображается в виде линии, соединяющей общие поля двух таблиц. Чтобы узнать, какие поля таблиц связаны отношением, дважды щелкните линию связи.
-
Если таблицы не отображаются в окне схемы данных, следует добавить их.
На вкладке Конструктор в группе Показать или скрыть нажмите кнопку Имена таблиц.
Дважды щелкните каждую из таблиц, которые вы хотите отобразить, а затем нажмите кнопку Закрыть.
-
-
Если между таблицами не установлено отношение, создайте его, перетащив поле из одной таблицы на поле другой. Поля, по которым создается отношение, должны иметь одинаковый тип данных.
Примечание: Создать отношение между полем с типом Тип данных «Счетчик» и полем, имеющим тип данных Числовой тип данных, можно в том случае, если это поле имеет размер «длинное целое».
Это часто бывает так при создании отношение «один-ко-многим».Откроется диалоговое окно Изменение связей.
-
Нажмите кнопку Создать для создания связи.
Дополнительные сведения о параметрах, используемых при создании отношения, см. в статье Создание, изменение и удаление отношения.
-
Закройте окно схемы данных.

 Это часто бывает так при создании отношение «один-ко-многим».
Это часто бывает так при создании отношение «один-ко-многим».На вкладке Создание в группе Запросы нажмите кнопку Мастер запросов.
 org/ListItem»>
org/ListItem»>
В диалоговом окне Новый запрос выберите пункт Простой запрос и нажмите кнопку ОК.
В поле со списком Таблицы и запросы выберите таблицу, содержащую основные сведения, которые вы хотите включить в запрос.
В области Доступные поля щелкните первое поле, которое вы хотите включить в запрос, и нажмите кнопку с одинарной стрелкой вправо, чтобы переместить это поле в список Выбранные поля. Повторите то же самое для каждого поля этой таблицы, которое вы хотите включить в запрос. Это могут быть поля, данные из которых должны выводиться в результатах запроса, или поля, используемые для наложения ограничений на выводимые строки путем задания определенных условий.
В поле со списком Таблицы и запросы выберите таблицу, содержащую дополнительные сведения, с помощью которых вы хотите уточнить результаты запроса.
Добавьте поля, которые следует использовать для уточнения результатов запроса, в список Выбранные поля и нажмите кнопку Далее.
В группе Выберите подробный или итоговый отчет выберите вариант Подробный или Итоговый.
Если не требуется использовать в запросе какие-либо агрегатные функции (Sum, Avg, Min, Max, Count, StDev или Var), выберите подробный запрос.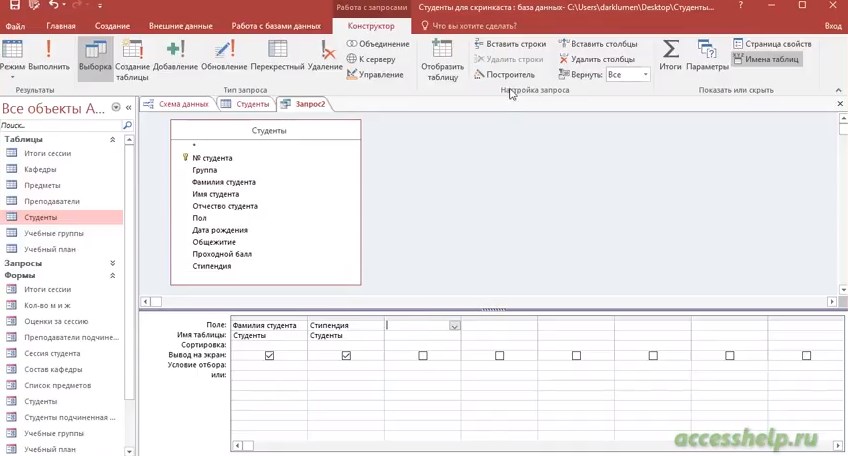 В противном случае выберите вариант «Сводка». Выбрав параметры, нажмите кнопку Далее.
В противном случае выберите вариант «Сводка». Выбрав параметры, нажмите кнопку Далее.
Нажмите кнопку Готово для просмотра результатов.
Пример на основе базы данных «Борей»
В приведенном ниже примере используется мастер запросов, с помощью которого строится запрос, отображающий список заказов, стоимость доставки каждого заказа и фамилию сотрудника, выполнившего заказ.
Примечание: Этот пример подразумевает изменение учебной базы данных «Борей». Рекомендуем сделать ее резервную копию и выполнять инструкции, используя резервную копию.
Построение запроса с помощью мастера запросов
 org/ItemList»>
org/ItemList»>Откройте учебную базу данных «Борей». Закройте форму входа.
На вкладке Создание в группе Запросы нажмите кнопку Мастер запросов.
В диалоговом окне Новый запрос выберите пункт Простой запрос и нажмите кнопку ОК.
В поле со списком Таблицы и запросы выберите пункт Таблица: Заказы.
 org/ListItem»>
org/ListItem»>
В списке Доступные поля дважды щелкните пункт ИД_заказа, чтобы переместить это поле в список Выбранные поля. Дважды щелкните пункт Цена доставки, чтобы переместить это поле в список Выбранные поля.
В поле со списком Таблицы и запросы выберите пункт Таблица: Сотрудники.
В списке Доступные поля дважды щелкните пункт Имя, чтобы переместить это поле в список Выбранные поля. Дважды щелкните пункт Фамилия, чтобы переместить это поле в список Выбранные поля. Нажмите кнопку Далее.
Так как вы создаете список всех заказов, следует использовать подробный запрос. Если нужно суммировать стоимость доставки заказов, выполненных сотрудником, или применить другую агрегатную функцию, следует использовать итоговый запрос. Выберите вариант Подробный (вывод каждого поля каждой записи) и нажмите кнопку Далее.
Нажмите кнопку Готово для просмотра результатов.
Запрос вернет перечень заказов, для каждого из которых будет указана стоимость доставки, а также имя и фамилия сотрудника, выполнившего его.
К началу страницы
Объединение данных в двух таблицах с помощью их связей с третьей таблицей
Часто данные в двух таблицах связаны друг с другом через третью таблицу. Это может быть в том случае, когда данные в первых двух таблицах связаны отношение «многие-ко-многим». Хорошим приемом при проектировании баз данных является разбиение одной связи с отношением «многие-ко-многим» между двумя таблицами на две связи с отношением «один-ко-многим», в которых участвуют три таблицы. Это делается путем создания третьей (связующей) таблицы, в которой есть первичный ключ и внешний ключ для каждой из таблиц. Затем создается связь «один-ко-многим» между каждым внешним ключом связующей таблицы и соответствующим первичным ключом связуемой таблицы. В таких случаях следует включать в запрос все три таблицы, даже если вы хотите получить данные только из двух.
Это может быть в том случае, когда данные в первых двух таблицах связаны отношение «многие-ко-многим». Хорошим приемом при проектировании баз данных является разбиение одной связи с отношением «многие-ко-многим» между двумя таблицами на две связи с отношением «один-ко-многим», в которых участвуют три таблицы. Это делается путем создания третьей (связующей) таблицы, в которой есть первичный ключ и внешний ключ для каждой из таблиц. Затем создается связь «один-ко-многим» между каждым внешним ключом связующей таблицы и соответствующим первичным ключом связуемой таблицы. В таких случаях следует включать в запрос все три таблицы, даже если вы хотите получить данные только из двух.
Создание запроса на выборку с использованием таблиц, связанных отношением «многие-ко-многим»
-
Дважды щелкните две таблицы, содержащие данные, которые вы хотите включить в запрос, а также связуемую таблицу, а затем нажмите кнопку «Закрыть».
Все три таблицы появятся в рабочей области конструктора запросов, связанные по соответствующим полям.
-
Дважды щелкните поля, которые вы хотите использовать в запросе. Каждое поле появится в бланк запроса.
-
В бланке запроса укажите условия для полей в строке Условия отбора.
Чтобы поле, по которому задаются условия, не отображалось в результатах запроса, снимите флажок в строке Показать для него. -
Чтобы отсортировать результаты по значениям поля, в бланке запроса в строке Сортировка для него выберите значение По возрастанию или По убыванию (в зависимости от того, в каком направлении вы хотите выполнить сортировку записей).
-
На вкладке Конструктор в группе Результаты нажмите кнопку Выполнить.
Access выведет результаты запроса в Режим таблицы.
На вкладке Создание в группе Запросы нажмите кнопку Конструктор запросов.
 Чтобы поле, по которому задаются условия, не отображалось в результатах запроса, снимите флажок в строке Показать для него.
Чтобы поле, по которому задаются условия, не отображалось в результатах запроса, снимите флажок в строке Показать для него.Пример на основе базы данных «Борей»
Примечание: Этот пример подразумевает изменение учебной базы данных «Борей». Рекомендуем сделать ее резервную копию и выполнять инструкции, используя резервную копию.
Предположим, что у вас появилась новая возможность: поставщик из Рио-де-Жанейро нашел ваш веб-сайт и хочет с вами сотрудничать. Однако он работает только в Рио-де-Жанейро и Сан-Паулу. Компания поставляет все интересующие вас категории пищевых продуктов. Являясь довольно крупным предприятием, поставщик хочет, чтобы вы гарантировали достаточно большой рынок сбыта, который обеспечил бы ему годовые продажи объемом не менее 20 000 бразильских реалов (около 9 300 долларов США). Можете ли вы обеспечить требуемый рынок сбыта?
Данные, необходимые для ответа на этот вопрос, находятся в двух местах: в таблице «Клиенты» и в таблице «Сведения о заказе». Эти таблицы связаны друг с другом через таблицу «Заказы». Отношения между этими таблицами уже заданы. В таблице «Заказы» для каждого заказа может быть указан только один клиент, связанный с таблицей «Клиенты» по полю «ИДКлиента». Каждая запись в таблице «Сведения о заказе» связана только с одним заказом в таблице «Заказы» по полю «ИД_заказа». Таким образом, у каждого клиента может быть множество заказов, для каждого из которых есть несколько записей со сведениями.
В данном примере следует построить перекрестный запрос, в котором будут отображены годовые продажи в городах Рио-де-Жанейро и Сан-Паулу.
Открытие запроса в Конструкторе
-
Откройте базу данных «Борей». Закройте форму входа.
-
На вкладке Создание в группе Запросы нажмите кнопку Конструктор запросов.
-
В таблице «Клиенты» дважды щелкните поле «Город», чтобы добавить его в бланк запроса.
-
В бланке запроса в строке Условие отбора столбца Город введите In («Рио-де-Жанейро»,»Сан Паулу). Это позволяет включить в запрос только записи о заказах клиентов из этих городов.
-
В таблице «Сведения о заказе» дважды щелкните поля «ДатаИсполнения» и «Цена».
Поля добавляются в бланк запроса.
-
В столбце бланка запроса ДатаИсполнения выберите строку Поле. Замените [ДатаИсполнения] на Год: Format([ДатаИсполнения],»yyyy»). При этом будет создан псевдоним поля (Год), позволяющий использовать только значение года из даты, указанной в поле «ДатаИсполнения».
-
В столбце бланка запроса Цена выберите строку Поле. Замените [Цена] на Продажи: [Сведения о заказе].[Цена]*[Количество]-[Сведения о заказе].[Цена]*[Количество]*[Скидка]. При этом будет создан псевдоним поля (Продажи), вычисляющий сумму продаж для каждой записи.
-
В столбце бланка запроса Город щелкните строку Перекрестная таблица, а затем щелкните Заголовки строк.
Названия городов будут использоваться в качестве заголовков строк (т. е. запрос будет возвращать одну строку для каждого города).
-
В столбце Год щелкните строку Перекрестная таблица, а затем щелкните Заголовки столбцов.
Значения годов будут использоваться в качестве заголовков столбцов (т.
е. запрос будет возвращать один столбец для каждого года). -
В столбце Продажи щелкните строку Перекрестная таблица, а затем щелкните элемент Значение.
Значения продаж будут отображаться на пересечениях строк и столбцов (т. е. запрос будет возвращать одно значение продаж для каждого сочетания города и года).
-
В столбце Продажи щелкните строку Итоги, а затем щелкните элемент Sum.
Запрос будет суммировать все значения столбца.
В строке Итоги для других двух столбцов можно оставить значение по умолчанию Группировка, так как в этих столбцах требуется отобразить отдельные значения, а не агрегированные показатели.
-
На вкладке Конструктор в группе Результаты нажмите кнопку Выполнить.
Дважды щелкните «Клиенты»,«Заказы»и выберите«Сведения о заказе».
Все три таблицы появятся в рабочей области конструктора запросов.

 org/ListItem»>
org/ListItem»>
На вкладке Конструктор в группе Тип запроса щелкните элемент Перекрестная таблица.
В бланке запроса появятся две новые строки: Итоги и Перекрестная таблица.
 е. запрос будет возвращать один столбец для каждого года).
е. запрос будет возвращать один столбец для каждого года).
Теперь у вас есть запрос, возвращающий общие годовые продажи по Рио-де-Жанейро и Сан-Паулу.
К началу страницы
Просмотр всех записей из двух похожих таблиц
Иногда требуется объединить данные из двух таблиц, которые имеют одинаковую структуру, но расположены в разных базах данных. Рассмотрим следующий сценарий.
Предположим, вы являетесь аналитиком и занимаетесь обработкой сведений об учащихся. Вы начинаете работу над новым проектом совместной обработки данных по вашей и другой школе с целью улучшения их учебных планов. По некоторым из исследуемых вопросов удобнее просматривать записи по обеим школам вместе, словно бы они находились в одной таблице.
Вы можете импортировать данные другой школы в новые таблицы в своей базе данных, но в этом случае изменения, внесенные в базу данных другой школы, не будут отражаться в вашей базе данных. Лучшим решением было бы установить связь с таблицами другой школы, а затем создать запросы, объединяющие эти данные во время выполнения. При этом вы сможете анализировать данные в едином наборе вместо того, чтобы выполнять два отдельных анализа, а затем пытаться объединить их в один.
Чтобы просмотреть все записи из двух таблиц с одинаковой структурой, используйте запрос на объединение.
Запросы на объединение невозможно отобразить в Конструкторе. Они создаются с помощью команд SQL, которые нужно вводить на вкладке объекта в режим SQL.
Создание запроса на объединение двух таблиц
-
На вкладке Конструктор в группе Тип запроса нажмите кнопку Объединение.
Запрос переключится из Конструктора в режим SQL. На данном этапе вкладка объекта в режиме SQL будет пуста.
-
В режиме SQL введите SELECT и список полей первой таблицы, которые вы хотите включить в запрос. Имена полей должны быть заключены в квадратные скобки и разделены запятыми. Когда вы закончите вводить имена полей, нажмите клавишу ВВОД. Курсор переместится на одну строку вниз в окне режима SQL.
-
Если вы хотите указать условие для поля первой таблицы, введите WHERE, имя поля, оператор сравнения (обычно знак равенства =) и условие. Можно добавлять дополнительные условия к концу предложения WHERE, используя ключевое слово AND и такой же синтаксис, как и для первого условия (например, WHERE [Уровень]=»100″ AND [Часов]>2). После завершения ввода условий нажмите клавишу ВВОД.
-
Введите слово UNION и нажмите клавишу ВВОД.
-
Введите SELECT и список полей второй таблицы, которые вы хотите включить в запрос.
Следует указать те же поля, что для первой таблицы, и в том же порядке. Имена полей должны быть заключены в квадратные скобки и разделены запятыми. Когда вы закончите вводить имена полей, нажмите клавишу ВВОД. -
Введите FROM и имя второй таблицы, включаемой в запрос. Нажмите клавишу ВВОД.
-
Если вы хотите, добавьте предложение WHERE, как описано в шаге 6.
-
Введите точку с запятой (;), чтобы обозначить конец запроса.
-
На вкладке Конструктор в группе Результаты нажмите кнопку Выполнить.
Результаты будут отображены в режиме таблицы.
 org/ListItem»>
org/ListItem»>
На вкладке Создание в группе Запросы нажмите кнопку Конструктор запросов.
 org/ListItem»>
org/ListItem»>
Введите FROM и имя первой таблицы, включаемой в запрос. Нажмите клавишу ВВОД.
 Следует указать те же поля, что для первой таблицы, и в том же порядке. Имена полей должны быть заключены в квадратные скобки и разделены запятыми. Когда вы закончите вводить имена полей, нажмите клавишу ВВОД.
Следует указать те же поля, что для первой таблицы, и в том же порядке. Имена полей должны быть заключены в квадратные скобки и разделены запятыми. Когда вы закончите вводить имена полей, нажмите клавишу ВВОД.
К началу страницы
См. также
Объединение таблиц и запросов
|
ЧТО НЕ ЯВЛЯЕТСЯ ЭЛЕМЕНТОМ БАЗЫ ДАННЫХ ACCESS? 1.панели 2.модули 3.макросы 4.таблицы |
ЧТО НЕ ЯВЛЯЕТСЯ ЭЛЕМЕНТОМ БАЗЫ ДАННЫХ ACCESS? 1.запросы 2.модули 3.конструктор 4.отчеты |
ЧТО НЕ ЯВЛЯЕТСЯ ЭЛЕМЕНТОМ БАЗЫ ДАННЫХ ACCESS?
1. 2.модули 3.редактор 4.страницы |
|
ЧТО НЕ ЯВЛЯЕТСЯ ЭЛЕМЕНТОМ БАЗЫ ДАННЫХ ACCESS? 1.запросы 2.объекты 3.формы 4.модули |
ЧТО НЕ ЯВЛЯЕТСЯ ЭЛЕМЕНТОМ БАЗЫ ДАННЫХ ACCESS? 1.отчеты 2.панели 3.формы 4.модули |
ЧТО НЕ ЯВЛЯЕТСЯ ОБЪЕКТОМ БАЗЫ ДАННЫХ ACCESS? 1.запросы 2.макрос 3.отчет 4.функции |
|
УКАЖИТЕ НЕПРАВИЛЬНЫЙ ТИП ФОРМ 1.одиночная 2.связанная
3. 4.комбинированная |
УКАЖИТЕ НЕПРАВИЛЬНЫЙ ТИП ФОРМ 1.одиночная 2.связанная 3.кнопочная 4.рассчетная |
УКАЖИТЕ НЕПРАВИЛЬНЫЙ ТИП ФОРМ 1.линейная 2.связанная 3.автоформа 4.подчиненная |
|
КАКАЯ КОМАНДА УСТАНАВЛИВАЕТ ПАНЕЛИ ИНСТРУМЕНТОВ? 1 ВСТАВКА 2 ПРАВКА 3 ВИД 4 ФАЙЛ |
НУЖНЫЙ ШРИФТ В ACCESS МОЖНО УСТАНОВИТЬ КОМАНДОЙ 1 фоpмат — шpифт 2 текст — фоpмат 3 таблица — шpифт 4 вид — фоpмат |
КАКИЕ СИМВОЛЫ НЕЛЬЗЯ ИСПОЛЬЗОВАТЬ В ИМЕНИ ПОЛЯ ACCESS?
1. 2. * 3. ? 4. ! 5. , |
|
УКАЖИТЕ НЕПРАВИЛЬНЫЙ ТИП ДАННЫХ В ACCESS 1. текстовый 2. параметрический 3. числовой 4. логический |
УКАЖИТЕ НЕПРАВИЛЬНЫЙ ТИП ДАННЫХ В ACCESS 1. текстовый 2. мастер подстановок 3. процентный 4. логический |
УКАЖИТЕ НЕПРАВИЛЬНЫЙ ТИП ДАННЫХ В ACCESS 1. логический 2. мастер подстановок 3. числовой 4. алфавитный |
|
УКАЖИТЕ НЕПРАВИЛЬНЫЙ ТИП ДАННЫХ В ACCESS
1. 2. базовый 3. дата 4. логический
|
УКАЖИТЕ НЕПРАВИЛЬНЫЙ ТИП ДАННЫХ В ACCESS 1. денежный 2. счетчик 3. объект OLE 4. цифровой |
УКАЖИТЕ НЕПРАВИЛЬНЫЙ ТИП ДАННЫХ В ACCESS 1. объект OLE 2. финансовый 3. числовой 4. логический |
|
УКАЖИТЕ ПРАВИЛЬНОЕ ВЫРАЖЕНИЕ 1. таблица с параметром 2. форма с параметром 3. запрос с параметром 4. отчет с параметром |
В ТАБЛИЦЕ ACCESS НЕЛЬЗЯ
1. 2.вводить данные 3.менять структуру |
ОТЧЕТ ACCESS НЕЛЬЗЯ СОЗДАТЬ ПО 1.запросу 2.форме 3.таблице 4.нет правильного ответа |
|
ЧТО НЕЛЬЗЯ ВЫПОЛНИТЬ В ЗАПРОСЕ ACCESS? 1.группировку 2.сортировку 3.выбор по условию 4.построить диаграмму |
ЧТО НЕЛЬЗЯ ВЫПОЛНИТЬ С ПОМОЩЬЮ ЗАПРОСА ACCESS? 1.группировку 2.сортировку 3.рассчет 4.печать документа |
ЧТО НЕЛЬЗЯ ВЫПОЛНИТЬ С ПОМОЩЬЮ ЗАПРОСА ACCESS? 1.выход
2. 3.рассчет 4.поиск по условию |
|
ЧТО ОБОЗНАЧАЕТ ШАБЛОН НА ЗАПРОС ПО НАЦИОНАЛЬНОСТИ «РУС*» 1.Все записи с национальностью «русский» 2.Все записи с национальностью «русская» 3.Все записи с национальностью на букву «р» 4.Все записи с национальностью на «рус» |
ЧТО ОБОЗНАЧАЕТ СИМВОЛ «*» В УСЛОВИИ ЗАПРОСА ACCESS? 1.Любое число определенных символов 2.Любой одиночный символ 3.Определенный одиночный символ 4.Любое число любых символов |
ЧТО ОБОЗНАЧАЕТ СИМВОЛ «?» В ШАБЛОНЕ ЗАПРОСА ACCESS? 1.Любое число определенных символов 2.Любой одиночный символ
3. 4.Любое число любых символов |
|
В ЗАПРОСЕ НЕЛЬЗЯ ИСПОЛЬЗОВАТЬ 1.функции 2.несвязанные таблицы 3.связанные таблицы 4.арифметические операции |
В ЗАПРОСЕ НЕЛЬЗЯ ИСПОЛЬЗОВАТЬ 1.построитель выражений 2.диаграммы 3.связанные таблицы 4.арифметические операции |
В ЗАПРОСЕ НЕЛЬЗЯ ИСПОЛЬЗОВАТЬ 1.логические операции 2.другие запросы 3.операции сравнения 4.арифметические операции 5.нет правильного ответа |
|
ДЛЯ ФОРМАТИРОВАНИЯ ФОРМ И ОТЧЕТОВ ACCESS ИСПОЛЬЗУЕТСЯ РЕЖИМ
1. 2.просмотра 3.конструктора 4.форматирования |
ПОДЧИНЕННАЯ ФОРМА СОЗДАЕТСЯ 1. конструктором форм 2. мастером форм 3. автоформами 4. редактором форм |
КНОПОЧНАЯ ФОРМА ACCESS СОЗДАЕТСЯ 1. конструктором форм 2. мастером форм 3. автоформами 4. редактором форм |
|
КНОПКИ В ФОРМЕ УСТАНАВЛИВАЮТСЯ С ПОМОЩЬЮ ПАНЕЛИ 1.стандартная 2.кнопки 3.элементов 4.форматирования |
ПЕРЕКЛЮЧАТЕЛИ В ФОРМЕ УСТАНАВЛИВАЮТСЯ С ПОМОЩЬЮ ПАНЕЛИ
1. 2.формы 3.элементов 4.переключателей |
НАДПИСИ В ФОРМЕ УСТАНАВЛИВАЮТСЯ С ПОМОЩЬЮ ПАНЕЛИ 1.стандартная 2.формы 3.элементов 4.объектов |
|
УСЛОВИЕ НА ВВОДИМОЕ ЗНАЧЕНИЕ ACCESS ЗАДАЕТСЯ В 1. конструкторе таблиц 2. конструкторе запросов 3. конструкторе отчетов 4. команде — условие |
УКАЖИТЕ НЕПРАВИЛЬНЫЕ ТИПЫ СВЯЗЕЙ 1. один к одному 2. один ко многим 3. два к одному 4. многие ко многим |
КАКОЙ КОМАНДОЙ УСТАНАВЛИВАЕТСЯ СВЯЗЬ МЕЖДУ таблицами ACCESS
1. 2. формат — связь 3. данные связь 4. сервис — схема данных |
|
ОБЪЕКТЫ ФОРМЫ НЕЛЬЗЯ 1. перемещать 2. удалять 3. форматировать 4. копировать 5. нет правильного ответа |
УКАЖИТЕ НЕПРАВИЛЬНЫЙ РЕЖИМ ОТОБРАЖЕНИЯ(ВИД) ФОРМЫ ACCESS 1. режим запроса 2. режим таблицы 3. режим формы 4. конструктор |
УКАЖИТЕ НЕПРАВИЛЬНЫЙ РЕЖИМ ОТОБРАЖЕНИЯ ТАБЛИЦЫ ACCESS 1.режим просмотра 2.режим таблицы 3.конструктор |
 автоформа
автоформа .
. текстовый
текстовый производить вычисления
производить вычисления сортировку
сортировку Определенный одиночный символ
Определенный одиночный символ таблицы
таблицы сервис — связь
сервис — связьСводная по таблице с многострочной шапкой
33048
06. 11.2020
Скачать пример
11.2020
Скачать пример
Предположим, что в качестве источника данных вам досталась вот такая «красота»:
Приятная на вид таблица, с которой, тем не менее, страшно неудобно работать. Представьте, например, что вам нужно по этой таблице:
- Вычислить отличие факта от плана по каждому товару за каждый год.
- Сравнить между собой одинаковые кварталы за разные годы.
- Посчитать суммарный или средний факт по каждому товару.
- Сравнить продажи апельсинового сока разных наименований.
Любое из перечисленных выше действий будет требовать кардинального перелопачивания таблицы, ввода большого количества формул, ручного их копирования и т.п.
Поэтому (капитан Очевидность!) это не нужно делать формулами. Гораздо проще и быстрее реализовать подобное будет с помощью сводных таблиц — гибкого, мощного и намного более подходящего инструмента для такой задачи.
Гораздо проще и быстрее реализовать подобное будет с помощью сводных таблиц — гибкого, мощного и намного более подходящего инструмента для такой задачи.
Одна проблема — в Microsoft Excel нельзя построить сводную таблицу, если у неё многострочная шапка, а именно это мы и имеем в нашем примере.
Нас выручит Power Query — мощная надстройка, встроенная в Excel, начиная с 2016-й версии (а для Excel 2010 и 2013 её можно бесплатно скачать с сайта Microsoft).
Шаг 1. Грузим данные в Power Query
Самый простой путь в нашем случае — это выделить весь диапазон с данными (начиная с ячейки B2 и до конца таблицы) и дать ему имя на вкладке Формулы — Задать имя (Formulas — Create name). Давайте оригинально назовём его Данные, например:
Затем, проверив, что выделена вся таблица, выберем на вкладке Данные (или на вкладке Power Query, если вы установили её как отдельную надстройку на Excel 2010-2013), команду Из таблицы / Диапазона (From Table/Range). Наша «красивая» таблица загрузится в редактор запросов Power Query:
Наша «красивая» таблица загрузится в редактор запросов Power Query:
Обратите внимание, что объединенные ячейки разъединились, а образовавшиеся в результате пустые ячейки теперь заполнены null — специальным словом, обозначающим в Power Query «пустоту» или отсутствие чего-либо.
Также Power Query попытался автоматически распознать типы данных в каждом столбце, добавив в правой панели Примененные шаги (Applied Steps) шаг Измененный тип (Changed Type). Делать такое пока рановато, так что этот шаг можно смело удалить, щёлкнув по крестику слева от его названия:
Шаг 2. Преобразуем таблицу в плоскую
Дальнейшие преобразования будут состоять из нескольких операций:
- Во-первых, давайте избавимся от лишних пустых строк (см. строки 9 или 26, например) с помощью команды Главная — Удалить строки — Удалить пустые строки (Home — Remove rows — Remove empty rows):
При необходимости, можно избавиться и от любых других лишних строк (например, строк с итогами и т.
п.) с помощью фильтра, сняв в нём соответствующую галочку. - Чтобы заполнить пустоты с null, выделим два первых столбца (удерживая клавишу Ctrl) и выберем на вкладке Преобразование команду Заполнить — Вниз (Transform — Fill — Down):
- Теперь нам нужно временно склеить три первых столбца в один. Для этого выделим их и выберем команду Преобразование — Столбец «Текст» — Объединить столбцы (Transform — Merge Columns), указав в качестве временного разделителя любой символ, который не встречается в наших данных, например точку с запятой:
- Теперь выполним транспонирование таблицы там же на вкладке Преобразование, нажав кнопку Транспонировать в левом верхнем углу (Transform — Transpose). Строки и столбцы в наших данных поменяются местами:
- Удалим уже знакомым способом пустые столбцы, превратившиеся после транспонирования в пустые строки, командой Главная — Удалить строки — Удалить пустые строки (Home — Remove rows — Remove empty rows).
- Заполним годами и кварталами пустые ячейки в первых двух столбцах командой Преобразование — Заполнить — Вниз (Transform — Fill — Down), как мы уже делали ранее.
- Поднимем текст из первой строки в шапку, выбрав на вкладке Главная команду Использовать первую строку в качестве заголовков (Home — Use first row as headers). Склеенные через точку с запятой категория, наименование и вид заменят стандартные Column1,2,3…
- Теперь выделим первых три столбца и, щёлкнув по заголовку любого из них, выберем команду Отменить свёртывание других столбцов (Unpivot other columns). Все столбцы кроме выделенных превратятся в новые строки, где название столбца и числовое значение попадут в разные ячейки:
- Осталось разделить слипшиеся категорию, наименование и вид в столбце Атрибут с помощью команды Главная — Разделить столбец — По разделителю (Home — Split column — By delimiter):
- Ну, и для пущей красоты переименуем получившиеся столбцы двойным щелчком мыши по заголовкам:
 п.) с помощью фильтра, сняв в нём соответствующую галочку.
п.) с помощью фильтра, сняв в нём соответствующую галочку.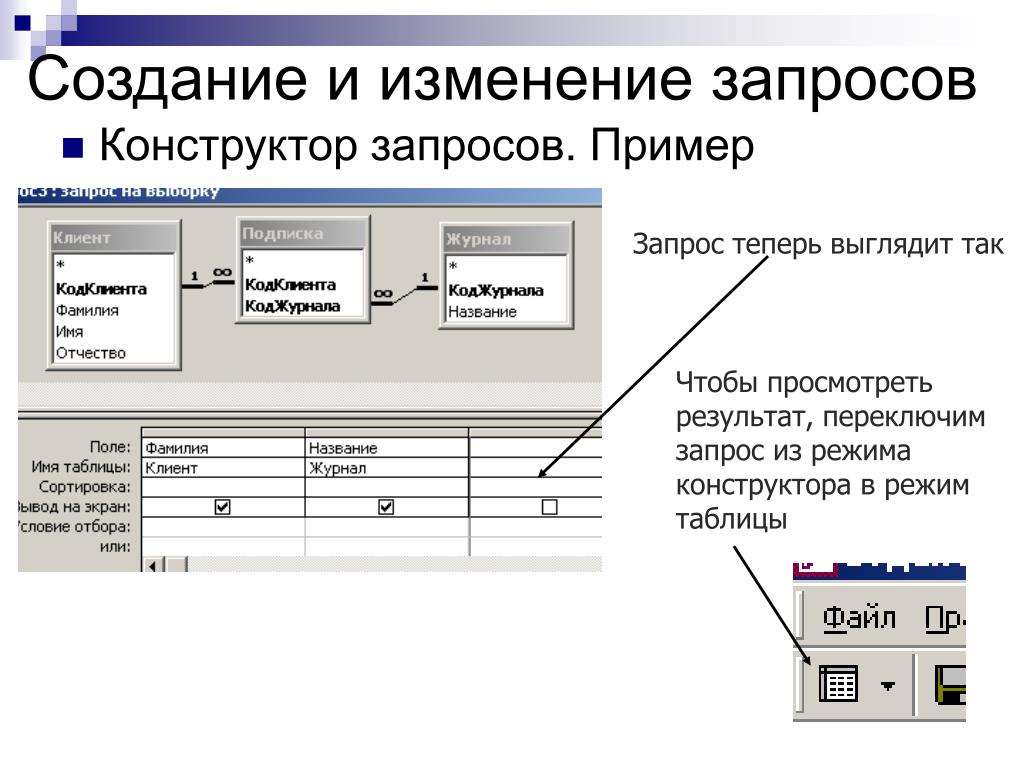
На этом приведение исходных данных в порядок успешно завершено и можно переходить к построение сводной таблицы.
Шаг 3. Строим сводную
На Главной вкладке Power Query выберем команду Закрыть и загрузить — Закрыть и загрузить в… (Home — Close & Load — Close & Load to…):
В следующем окне можно пойти двумя путями:
Если у вас есть в этом окне опция Отчет сводной таблицы (Pivot Table Report) — смело выбирайте его и жмите на ОК. На новом листе будет создана сводная таблица по нашим данным из Power Query.
Если у вас старая версия Excel, то такой опции в этом окне может не быть. Тогда придется «идти в обход»:
- Выбираем вариант Только создать подключение (Create connection only),
- После возвращения в Excel на вкладке Вставка жмём кнопку Сводная таблица (Insert — Pivot Table)
- В окне создания сводной выбираем опцию Использовать внешний источник данных (Use external data source).
- В открывшемся окне выбираем наше подключение из Power Query:

И в том, и в другом случае результатом будет сводная, построенная по нашей исходной красивой, но неудобной таблице:
Теперь наши данные можно крутить-вертеть-анализировать любым нужным образом легко и красиво 🙂
Ссылки по теме
- Редизайн кросс-таблицы в плоскую
- Сводная таблица по нескольким диапазонам данных
- Настройка вычислений в сводной таблице
Реляционные базы данных обречены? / Хабр
Примечание переводчика: хоть статья довольно старая (опубликована 2 года назад) и носит громкое название, в ней все же дается хорошее представление о различиях реляционных БД и NoSQL БД, их преимуществах и недостатках, а также приводится краткий обзор нереляционных хранилищ.
В последнее время появилось много нереляционных баз данных. Это говорит о том, что если вам нужна практически неограниченная масштабируемость по требованию, вам нужна нереляционная БД.
Это говорит о том, что если вам нужна практически неограниченная масштабируемость по требованию, вам нужна нереляционная БД.
Если это правда, значит ли это, что могучие реляционные БД стали уязвимы? Значит ли это, что дни реляционных БД проходят и скоро совсем пройдут? В этой статье мы рассмотрим популярное течение нереляционных баз данных применительно к различным ситуациям и посмотрим, повлияет ли это на будущее реляционных БД.
Реляционные базы данных существуют уже около 30 лет. За это время вспыхивало несколько революций, которые должны были положить конец реляционным хранилищам. Конечно, ни одна из этих революций не состоялась, и одна из них ни на йоту не поколебала позиции реляционных БД.
Начнем с основ
Реляционная база данных представляет собой набор таблиц (сущностей). Таблицы состоят из колонок и строк (кортежей). Внутри таблиц могут быть определены ограничения, между таблицами существуют отношения. При помощи SQL можно выполнять запросы, которые возвращают наборы данных, получаемых из одной или нескольких таблиц. В рамках одного запроса данные получаются из нескольких таблиц путем их соединения (JOIN), чаще всего для соединения используются те же колонки, которые определяют отношения между таблицами. Нормализация — это процесс структурирования модели данных, обеспечивающий связность и отсутствие избыточности в данных.
В рамках одного запроса данные получаются из нескольких таблиц путем их соединения (JOIN), чаще всего для соединения используются те же колонки, которые определяют отношения между таблицами. Нормализация — это процесс структурирования модели данных, обеспечивающий связность и отсутствие избыточности в данных.
Доступ к реляционным базам данных осуществляется через реляционные системы управления базами данных (РСУБД). Почти все системы баз данных, которые мы используем, являются реляционными, такие как Oracle, SQL Server, MySQL, Sybase, DB2, TeraData и так далее.
Причины такого доминирования неочевидны. На протяжении всего существования реляционных БД они постоянно предлагали наилучшую смесь простоты, устойчивости, гибкости, производительности, масштабируемости и совместимости в сфере управлении данными.
Однако чтобы обеспечить все эти особенности, реляционные хранилища невероятно сложны внутри. Например, простой SELECT запрос может иметь сотни потенциальных путей выполнения, которые оптимизатор оценит непосредственно во время выполнения запроса. Все это скрыто от пользователей, однако внутри РСУБД создает план выполнения, основывающийся на вещах вроде алгоритмов оценки стоимости и наилучшим образом отвечающий запросу.
Все это скрыто от пользователей, однако внутри РСУБД создает план выполнения, основывающийся на вещах вроде алгоритмов оценки стоимости и наилучшим образом отвечающий запросу.
Проблемы реляционных БД
Хотя реляционные хранилища и обеспечивают наилучшую смесь простоты, устойчивости, гибкости, производительности, масштабируемости и совместимости, их показатели по каждому из этих пунктов не обязательно выше, чем у аналогичных систем, ориентированных на какую-то одну особенность. Это не являлось большой проблемой, поскольку всеобщее доминирование реляционных СУБД перевешивало какие-либо недочеты. Тем не менее, если обычные РБД не отвечали потребностям, всегда существовали альтернативы.
Сегодня ситуация немного другая. Разнообразие приложений растет, а с ним растет и важность перечисленных особенностей. И с ростом количества баз данных, одна особенность начинает затмевать все другие. Это масштабируемость. Поскольку все больше приложений работают в условиях высокой нагрузки, например, таких как веб-сервисы, их требования к масштабируемости могут очень быстро меняться и сильно расти. Первую проблему может быть очень сложно разрешить, если у вас есть реляционная БД, расположенная на собственном сервере. Предположим, нагрузка на сервер за ночь увеличилась втрое. Как быстро вы сможете проапгрейдить железо? Решение второй проблемы также вызывает трудности в случае использования реляционных БД.
Первую проблему может быть очень сложно разрешить, если у вас есть реляционная БД, расположенная на собственном сервере. Предположим, нагрузка на сервер за ночь увеличилась втрое. Как быстро вы сможете проапгрейдить железо? Решение второй проблемы также вызывает трудности в случае использования реляционных БД.
Реляционные БД хорошо масштабируются только в том случае, если располагаются на единственном сервере. Когда ресурсы этого сервера закончатся, вам необходимо будет добавить больше машин и распределить нагрузку между ними. И вот тут сложность реляционных БД начинает играть против масштабируемости. Если вы попробуете увеличить количество серверов не до нескольких штук, а до сотни или тысячи, сложность возрастет на порядок, и характеристики, которые делают реляционные БД такими привлекательными, стремительно снижают к нулю шансы использовать их в качестве платформы для больших распределенных систем.
Чтобы оставаться конкурентоспособными, вендорам облачных сервисов приходится как-то бороться с этим ограничением, потому что какая ж это облачная платформа без масштабируемого хранилища данных. Поэтому у вендоров остается только один вариант, если они хотят предоставлять пользователям масштабируемое место для хранения данных. Нужно применять другие типы баз данных, которые обладают более высокой способностью к масштабированию, пусть и ценой других возможностей, доступных в реляционных БД.
Поэтому у вендоров остается только один вариант, если они хотят предоставлять пользователям масштабируемое место для хранения данных. Нужно применять другие типы баз данных, которые обладают более высокой способностью к масштабированию, пусть и ценой других возможностей, доступных в реляционных БД.
Эти преимущества, а также существующий спрос на них, привел к волне новых систем управления базами данных.
Новая волна
Такой тип баз данных принято называть хранилище типа ключ-значение (key-value store). Фактически, никакого официального названия не существует, поэтому вы можете встретить его в контексте документо-ориентированных, атрибутно-ориентированных, распределенных баз данных (хотя они также могут быть реляционными), шардированных упорядоченных массивов (sharded sorted arrays), распределенных хэш-таблиц и хранилищ типа ключ-значения. И хотя каждое из этих названий указывает на конкретные особенности системы, все они являются вариациями на тему, которую мы будем назвать хранилище типа ключ-значение.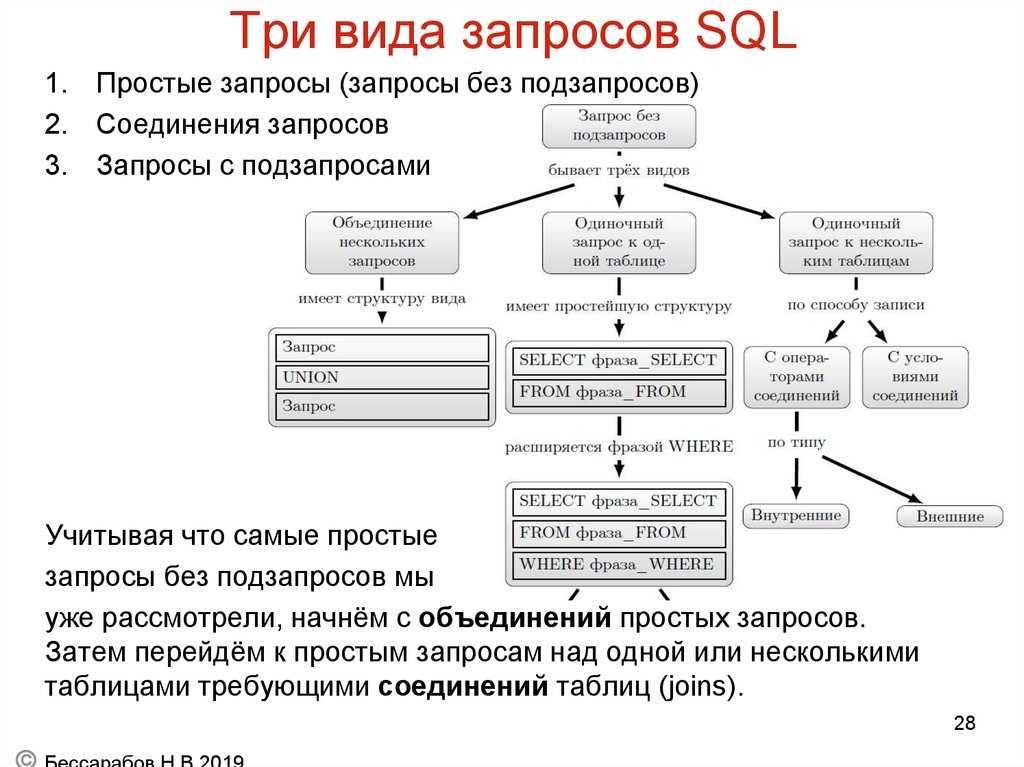
Впрочем, как бы вы его не называли, этот «новый» тип баз данных не такой уж новый и всегда применялся в основном для приложений, для которых использование реляционных БД было бы непригодно. Однако без потребности веба и «облака» в масштабируемости, эти системы оставались не сильно востребованными. Теперь же задача состоит в том, чтобы определить, какой тип хранилища больше подходит для конкретной системы.
Реляционные БД и хранилища типа ключ-значение отличаются коренным образом и предназначены для решения разных задач. Сравнение характеристик позволит всего лишь понять разницу между ними, однако начнем с этого:
Характеристики хранилищ
| Реляционная БД | Хранилище типа ключ-значение |
|---|---|
| База данных состоит из таблиц, таблицы содержат колонки и строки, а строки состоят из значений колонок. Все строки одной таблицы имеют единую структуру. |
Для доменов можно провести аналогию с таблицами, однако в отличие от таблиц для доменов не определяется структура данных. Домен – это такая коробка, в которую вы можете складывать все что угодно. Записи внутри одного домена могут иметь разную структуру. Домен – это такая коробка, в которую вы можете складывать все что угодно. Записи внутри одного домена могут иметь разную структуру. |
| Модель данных1 определена заранее. Является строго типизированной, содержит ограничения и отношения для обеспечения целостности данных. |
Записи идентифицируются по ключу, при этом каждая запись имеет динамический набор атрибутов, связанных с ней. |
| Модель данных основана на естественном представлении содержащихся данных, а не на функциональности приложения. |
В некоторых реализация атрибуты могут быть только строковыми. В других реализациях атрибуты имеют простые типы данных, которые отражают типы, использующиеся в программировании: целые числа, массива строк и списки. |
Модель данных подвергается нормализации, чтобы избежать дублирования данных. Нормализация порождает отношения между таблицами. Отношения связывают данные разных таблиц. |
Между доменами, также как и внутри одного домена, отношения явно не определены. |
Никаких join’ов
Хранилища типа ключ-значение ориентированы на работу с записями. Это значит, что вся информация, относящаяся к данной записи, хранится вместе с ней. Домен (о котором вы можете думать как о таблице) может содержать бессчетное количество различных записей. Например, домен может содержать информацию о клиентах и о заказах. Это означает, что данные, как правило, дублируются между разными доменами. Это приемлемый подход, поскольку дисковое пространство дешево. Главное, что он позволяет все связанные данные хранить в одном месте, что улучшает масштабируемость, поскольку исчезает необходимость соединять данные из различных таблиц. При использовании реляционной БД, потребовалось бы использовать соединения, чтобы сгруппировать в одном месте нужную информацию.
Хотя для хранения пар ключ-значение потребность в отношения резко падает, отношения все же нужны. Такие отношения обычно существуют между основными сущностями. Например, система заказов имела бы записи, которые содержат данные о покупателях, товарах и заказах. При этом неважно, находятся ли эти данные в одном домене или в нескольких. Суть в том, что когда покупатель размещает заказ, вам скорее всего не захочется хранить информацию о покупателе и о заказе в одной записи.
Такие отношения обычно существуют между основными сущностями. Например, система заказов имела бы записи, которые содержат данные о покупателях, товарах и заказах. При этом неважно, находятся ли эти данные в одном домене или в нескольких. Суть в том, что когда покупатель размещает заказ, вам скорее всего не захочется хранить информацию о покупателе и о заказе в одной записи.
Вместо этого, запись о заказе должна содержать ключи, которые указывают на соответствующие записи о покупателе и товаре. Поскольку в записях можно хранить любую информацию, а отношения не определены в самой модели данных, система управления базой данных не сможет проконтролировать целостность отношений. Это значит, что вы можете удалять покупателей и товары, которые они заказывали. Обеспечение целостности данных целиком ложится на приложение.
Доступ к данным
| Реляционная БД | Хранилище типа ключ-значение |
|---|---|
Данные создаются, обновляются, удаляются и запрашиваются с использованием языка структурированных запросов (SQL). |
Данные создаются, обновляются, удаляются и запрашиваются с использованием вызова API методов. |
| SQL-запросы могут извлекать данные как из одиночной таблица, так и из нескольких таблиц, используя при этом соединения (join’ы). |
Некоторые реализации предоставляют SQL-подобный синтаксис для задания условий фильтрации. |
| SQL-запросы могут включать агрегации и сложные фильтры. |
Зачастую можно использовать только базовые операторы сравнений (=, !=, <, >, <= и =>). |
| Реляционная БД обычно содержит встроенную логику, такую как триггеры, хранимые процедуры и функции. |
Вся бизнес-логика и логика для поддержки целостности данных содержится в коде приложений. |
Взаимодействие с приложениями
| Реляционная БД | Хранилище типа ключ-значение |
|---|---|
Чаще всего используются собственные API, или обобщенные, такие как OLE DB или ODBC. |
Чаще всего используются SOAP и/или REST API, с помощью которых осуществляется доступ к данным. |
| Данные хранятся в формате, который отображает их натуральную структуру, поэтому необходим маппинг структур приложения и реляционных структур базы. |
Данные могут более эффективно отображаться в структуры приложения, нужен только код для записи данных в объекты. |
Хранилища типа ключ-значение: преимущества
Есть два четких преимущества таких систем перед реляционными хранилищами.
Подходят для облачных сервисов
Первое преимущество хранилищ типа ключ-значение состоит в том, что они проще, а значит обладают большей масштабируемостью, чем реляционные БД. Если вы размещаете вместе собственную систему, и планируете разместить дюжину или сотню серверов, которым потребуется справляться с возрастающей нагрузкой, за вашим хранилищем данных, тогда ваш выбор – хранилища типа ключ-значение.
Благодаря тому, что такие хранилища легко и динамически расширяются, они также пригодятся вендорам, которые предоставляют многопользовательскую веб-платформу хранения данных. Такая база представляет относительно дешевое средство хранения данных с большим потенциалом к масштабируемости. Пользователи обычно платят только за то, что они используют, однако их потребности могут вырасти. Вендор сможет динамически и практически без ограничений увеличить размер платформы, исходя из нагрузки.
Более естественная интеграция с кодом
Реляционная модель данных и объектная модель кода обычно строятся по-разному, что ведет к некоторой несовместимости. Разработчики решают эту проблему при помощи написания кода, который отображает реляционную модель в объектную модель. Этот процесс не имеет четкой и быстро достижимой ценности и может занять довольно значительное время, которое могло быть потрачено на разработку самого приложения. Тем временем многие хранилища типа ключ-значение хранят данные в такой структуре, которая отображается в объекты более естественно. Это может существенно уменьшить время разработки.
Это может существенно уменьшить время разработки.
Другие аргументы в пользу использования хранилищ типа ключ-значение, наподобие «Реляционные базы могут стать неуклюжими» (кстати, я без понятия, что это значит), являются менее убедительными. Но прежде чем стать сторонником таких хранилищ, ознакомьтесь со следующим разделом.
Хранилища типа ключ-значение: недостатки
Ограничения в реляционных БД гарантируют целостность данных на самом низком уровне. Данные, которые не удовлетворяют ограничениям, физически не могут попасть в базу. В хранилищах типа ключ-значение таких ограничений нет, поэтому контроль целостности данных полностью лежит на приложениях. Однако в любом коде есть ошибки. Если ошибки в правильно спроектированной реляционной БД обычно не ведут к проблемам целостности данных, то ошибки в хранилищах типа ключ-значение обычно приводят к таким проблемам.
Другое преимущество реляционных БД заключается в том, что они вынуждают вас пройти через процесс разработки модели данных.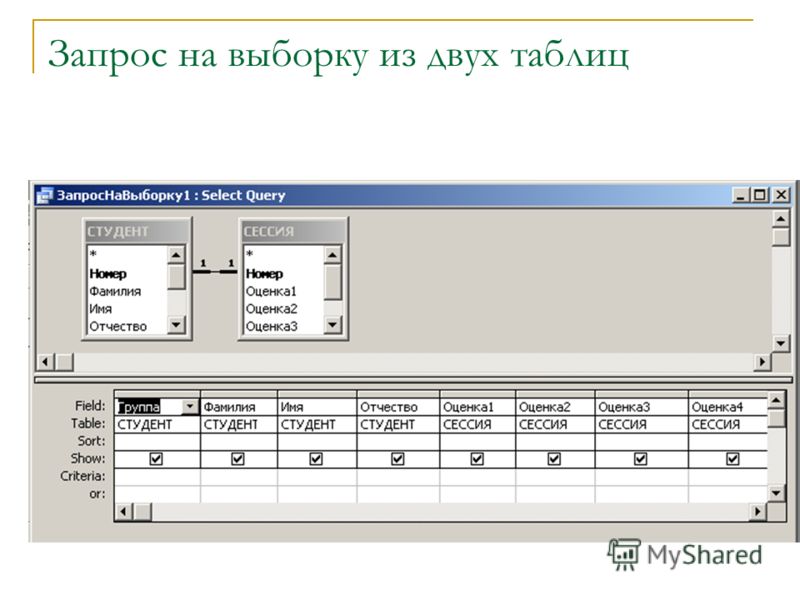 Если вы хорошо спроектировали модель, то база данных будет содержать логическую структуру, которая полностью отражает структуру хранимых данных, однако расходится со структурой приложения. Таким образом, данные становятся независимы от приложения. Это значит, что другое приложение сможет использовать те же самые данные и логика приложения может быть изменена без каких-либо изменений в модели базы. Чтобы проделать то же самое с хранилищем типа ключ-значение, попробуйте заменить процесс проектирования реляционной модели проектированием классов, при котором создаются общие классы, основанные на естественной структуре данных.
Если вы хорошо спроектировали модель, то база данных будет содержать логическую структуру, которая полностью отражает структуру хранимых данных, однако расходится со структурой приложения. Таким образом, данные становятся независимы от приложения. Это значит, что другое приложение сможет использовать те же самые данные и логика приложения может быть изменена без каких-либо изменений в модели базы. Чтобы проделать то же самое с хранилищем типа ключ-значение, попробуйте заменить процесс проектирования реляционной модели проектированием классов, при котором создаются общие классы, основанные на естественной структуре данных.
И не забудьте о совместимости. В отличие от реляционных БД, хранилища, ориентированные на использование в «облаке», имеют гораздо меньше общих стандартов. Хоть концептуально они и не отличаются, они все имеют разные API, интерфейсы запросов и свою специфику. Поэтому вам лучше доверять вашему вендору, потому что в случае чего, вы не сможете легко переключиться на другого поставщика услуг. А учитывая тот факт, что почти все современные хранилища типа ключ-значение находятся в стадии бета-версий2, доверять становится еще рискованнее, чем в случае использования реляционных БД.
А учитывая тот факт, что почти все современные хранилища типа ключ-значение находятся в стадии бета-версий2, доверять становится еще рискованнее, чем в случае использования реляционных БД.
Ограниченная аналитика данных
Обычно все облачные хранилища строятся по типу множественной аренды, что означает, что одну и ту же систему использует большое количество пользователей и приложений. Чтобы предотвратить «захват» общей системы, вендоры обычно каким-то образом ограничивают выполнение запросов. Например, в SimpleDB запрос не может выполняться дольше 5 секунд. В Google AppEngine Datastore за один запрос нельзя получить больше, чем 1000 записей3.
Эти ограничения не страшны для простой логики (создание, обновление, удаление и извлечение небольшого количества записей). Но что если ваше приложение становится популярным? Вы получили много новых пользователей и много новых данных, и теперь хотите сделать новые возможности для пользователей или каким-то образом извлечь выгоду из данных. Тут вы можете жестко обломаться с выполнением даже простых запросов для анализа данных. Фичи наподобие отслеживания шаблонов использования приложения или системы рекомендаций, основанной на истории пользователя, в лучшем случае могут оказаться сложны в реализации. А в худшем — просто невозможны.
Тут вы можете жестко обломаться с выполнением даже простых запросов для анализа данных. Фичи наподобие отслеживания шаблонов использования приложения или системы рекомендаций, основанной на истории пользователя, в лучшем случае могут оказаться сложны в реализации. А в худшем — просто невозможны.
В таком случае для аналитики лучше сделать отдельную базу данных, которая будет заполняться данными из вашего хранилища типа ключ-значение. Продумайте заранее, каким образом это можно будет сделать. Будете ли вы размещать сервер в облаке или у себя? Не будет ли проблем из-за задержек сигнала между вами и вашим провайдером? Поддерживает ли ваше хранилище такой перенос данных? Если у вас 100 миллионов записей, а за один раз вы можете взять 1000 записей, сколько потребуется на перенос всех данных?
Однако не ставьте масштабируемость превыше всего. Она будет бесполезна, если ваши пользователи решат пользоваться услугами другого сервиса, потому что тот предоставляет больше возможностей и настроек.
Облачные хранилища
Множество поставщиков веб-сервисов предлагают многопользовательские хранилища типа ключ-значение. Большинство из них удовлетворяют критериям, перечисленным выше, однако каждое обладает своими отличительными фичами и отличается от стандартов, описанных выше. Давайте взглянем на конкретные пример хранилищ, такие как SimpleDB, Google AppEngine Datastore и SQL Data Services.
Amazon: SimpleDB
SimpleDB — это атрибутно-ориентированное хранилище типа ключ-значение, входящее в состав Amazon WebServices. SimpleDB находится в стадии бета-версии; пользователи могут пользовать ей бесплатно — до тех пор пока их потребности не превысят определенный предел.
У SimpleDB есть несколько ограничений. Первое — время выполнения запроса ограничено 5-ю секундами. Второе — нет никаких типов данных, кроме строк. Все хранится, извлекается и сравнивается как строка, поэтому для того, чтобы сравнить даты, вам нужно будет преобразовать их в формат ISO8601. Третье — максимальные размер любой строки составляет 1024 байта, что ограничивает размер текста (например, описание товара), который вы можете хранить в качестве атрибута. Однако поскольку структура данных гибкая, вы можете обойти это ограничения, добавляя атрибуты «ОписаниеТовара1», «Описание товара2» и т.д. Но количество атрибутов также ограничено — максимум 256 атрибутов. Пока SimpleDB находится в стадии бета-версии, размер домена ограничен 10-ю гигабайтами, а вся база не может занимать больше 1-го терабайта.
Третье — максимальные размер любой строки составляет 1024 байта, что ограничивает размер текста (например, описание товара), который вы можете хранить в качестве атрибута. Однако поскольку структура данных гибкая, вы можете обойти это ограничения, добавляя атрибуты «ОписаниеТовара1», «Описание товара2» и т.д. Но количество атрибутов также ограничено — максимум 256 атрибутов. Пока SimpleDB находится в стадии бета-версии, размер домена ограничен 10-ю гигабайтами, а вся база не может занимать больше 1-го терабайта.
Одной из ключевых особенностей SimpleDB является использование модели конечной констистенции (eventual consistency model). Эта модель подходит для многопоточной работы, однако следует иметь в виду, что после того, как вы изменили значение атрибута в какой-то записи, при последующих операциях чтения эти изменения могут быть не видны. Вероятность такого развития событий достаточно низкая, тем не менее, о ней нужно помнить. Вы же не хотите продать последний билет пяти покупателям только потому, что ваши данные были неконсистентны в момент продажи.
Google AppEngine Data Store
Google’s AppEngine Datastore построен на основе BigTable, внутренней системе хранения структурированных данных от Google. AppEngine Datastore не предоставляет прямой доступ к BigTable, но может восприниматься как упрощенный интерфейс взаимодействия с BigTable.
AppEngine Datastore поддерживает большее число типов данных внутри одной записи, нежели SimpleDB. Например, списки, которые могут содержать коллекции внутри записи.
Скорее всего вы будете использовать именно это хранилище данных при разработке с помощью Google AppEngine. Однако в отличии от SimpleDB, вы не сможете использовать AppEngine Datastore (или BigTable) вне веб-сервисов Google.
Microsoft: SQL Data Services
SQL Data Services является частью платформы Microsoft Azure. SQL Data Services является бесплатной, находится в стадии бета-версии и имеет ограничения на размер базы. SQL Data Services представляет собой отдельное приложение — надстройку над множеством SQL серверов, которые и хранят данные. Эти хранилища могут быть реляционными, однако для вас SDS является хранилищем типа ключ-значение, как и описанные выше продукты.
Эти хранилища могут быть реляционными, однако для вас SDS является хранилищем типа ключ-значение, как и описанные выше продукты.
Необлачные хранилища
Существует также ряд хранилищ, которыми вы можете воспользоваться вне облака, установив их у себя. Почти все эти проекты являются молодыми, находятся в стадии альфа- или бета-версии, и имеют открытый код. С открытыми исходниками вы, возможно, будете больше осведомлены о возможных проблемах и ограничениях, нежели в случае использования закрытых продуктов.
CouchDB
CouchDB — это свободно распространяемая документо-ориентированная БД с открытым исходным кодом. В качестве формата хранения данных используется JSON. CouchDB призвана заполнить пробел между документо-ориентированными и реляционными базами данных с помощью «представлений». Такие представления содержат данные из документов в виде, схожим с табличным, и позволяют строить индексы и выполнять запросы.
В настоящее время CouchDB не является по-настоящему распределенной БД. В ней есть функции репликации, позволяющие синхронизировать данные между серверами, однако это не та распределенность, которая нужна для построения высокомасштабируемого окружения. Однако разработчики CouchDB работают над этим.
Проект Voldemort
Проект Voldemort — это распределенная база данных типа ключ-значение, предназначенная для горизонтального масштабирования на большом количестве серверов. Он родилась в процессе разработки LinkedIn и использовалась для нескольких систем, имеющих высокие требования к масштабируемости. В проекте Voldemort также используется модель конечной консистенции.
Mongo
Mongo — это база данных, разрабатываемая в 10gen Гейром Магнуссоном и Дуайтом Меррименом (которого вы можете знать по DoubleClick). Как и CouchDB, Mongo — это документо-ориентированная база данных, хранящая данные в JSON формате. Однако Mongo скорее является объектной базой, нежели чистым хранилищем типа ключ-значение.
Однако Mongo скорее является объектной базой, нежели чистым хранилищем типа ключ-значение.
Drizzle
Drizzle представляет совсем другой подход к решению проблем, с которыми призваны бороться хранилища типа ключ-значение. Drizzle начинался как одна из веток MySQL 6.0. Позже разработчики удалили ряд функций (включая представления, триггеры, скомпилированные выражения, хранимые процедуры, кэш запросов, ACL, и часть типов данных), с целью создания более простой и быстрой СУБД. Тем не менее, Drizzle все еще можно использовать для хранения реляционных данных. Цель разработчиков — построить полуреляционную платформу, предназначенную для веб-приложений и облачных приложений, работающих на системах с 16-ю и более ядрами.
Решение
В конечном счете, есть четыре причины, по которым вы можете выбрать нереляционное хранилище типа ключ-значение для своего приложения:
- Ваши данные сильно документо-ориентированны, и больше подходят для модели данных ключ-значение, чем для реляционной модели.
- Ваша доменная модель сильно объектно-ориентированна, поэтому использования хранилища типа ключ-значение уменьшит размер дополнительного кода для преобразования данных.
- Хранилище данных дешево и легко интегрируется с веб-сервисами вашего вендора.
- Ваша главная проблема — высокая масштабируемость по запросу.

Однако принимая решение, помните об ограничениях конкретных БД и о рисках, которые вы встретите, пойдя по пути использования нереляционных БД.
Для всех остальных требований лучше выбрать старые добрые реляционные СУБД. Так обречены ли они? Конечно, нет. По крайней мере, пока.
1 — по моему мнению, здесь больше подходит термин «структура данных», однако оставил оригинальное data model.
2 — скорее всего, автор имел в виду, что по своим возможностям нереляционные БД уступают реляционным.
3 — возможно, данные уже устарели, статья датируется февралем 2009 года.
Как сформулировать запрос к психологу
Практически всем людям знакомо состояние внутреннего беспокойства, неопределенности. Кому-то удается справиться с проблемами самостоятельно, а кому-то требуется квалифицированная помощь.
Психологическая грамотность
Принять свою проблему и построить стратегию по ее решению помогает психологическая грамотность. Это комплекс знаний, благодаря которым человек начинает сознательно относиться к себе и окружающим людям.
Находясь в состоянии психологического дискомфорта, первым делом следует попробовать описать свои чувства и симптомы. Психологическая грамотность именно про это: умение идентифицировать проблему, затем помочь себе самостоятельно или обратиться за квалифицированной помощью.
Первый шаг в преодолении трудностей — формулировка психологического запроса. Специалисты разделяют два типа запросов: работающие и неработающие.
Неработающие психологические запросы
- К неработающим относится все, что связано с желанием контролировать эмоции. Например, полюбить себя и стать счастливым, к сожалению, не будет грамотным запросом. Психотерапевт просто не сможет работать с такой задачей, так как это находится за пределами его компетенций, а иногда и за пределами законов реальности.
- Также к неработающим относятся так называемые «запросы мертвеца» — желание перестать испытывать чувства и эмоции. Например, перестать грустить или переживать. Психотерапевт при всем желании не сможет помочь в решении подобной проблемы, потому что никто не может отключить эмоции.
- Следующая категория неработающих запросов — попытка понять причину того или иного события в жизни. Например, почему муж принял решение развестись или почему подруга предала. Специалист обязательно поможет найти, откуда у проблемы «растут ноги», но станет ли вам от этого легче? Как показывает статистика, осознание причины грустного события в жизни не делает человека счастливым.
- И последняя категория неработающих запросов — попытки контролировать поведение других людей. Например, чтобы кто-то вас полюбил. Как уже было сказано ранее, контролировать эмоции невозможно: ни свои, ни чужие.
 Например, полюбить себя и стать счастливым, к сожалению, не будет грамотным запросом. Психотерапевт просто не сможет работать с такой задачей, так как это находится за пределами его компетенций, а иногда и за пределами законов реальности.
Например, полюбить себя и стать счастливым, к сожалению, не будет грамотным запросом. Психотерапевт просто не сможет работать с такой задачей, так как это находится за пределами его компетенций, а иногда и за пределами законов реальности. Например, чтобы кто-то вас полюбил. Как уже было сказано ранее, контролировать эмоции невозможно: ни свои, ни чужие.
Например, чтобы кто-то вас полюбил. Как уже было сказано ранее, контролировать эмоции невозможно: ни свои, ни чужие.Как составить работающий запрос
Мы разобрались с психологическими запросами, которые не помогут вам решить проблему. Теперь поговорим о работающем запросе.
Для того чтобы его сформулировать, следует ответить всего на два вопроса:
- Что не так?
- А как я хочу?
После того, как вы ответите на базовые вопросы, попытайтесь проанализировать глубже. Как давно в жизни пошло что-то не так? Был ли какой-то переломный момент? Как я понял, что что-то идет не по плану? Ответив, вы и получите свой психологический запрос.
Самостоятельно идентифицировать корень проблемы может быть довольно сложно, особенно пребывая в подвешенном состоянии. Не стоит переживать — психотерапевт может помочь с составлением запроса. В таком случае вам следует описать симптоматику проблемы:
- Что именно вам мешает в данный момент жизни?
- Как это сказывается на сферах вашей жизни?
- По вашим предположениям, с чем это может быть связано?
Вместе со специалистом вы найдете суть происходящего, сможете ее проработать.
Методы самопомощи
Один из ключевых вопросов, который мучает многих людей: как понять, что вам вообще требуется помощь психотерапевта? И единственный ответ — полагайтесь на свое субъективное мнение и ощущения. Здесь как раз и приходит на помощь психологическая грамотность. Если вы понимаете проблему и имеете план действий по ее решению — попробуйте справиться сами.
Есть множество способов самопомощи.
- Например, чтение психологической литературы. Старайтесь выбирать качественные книги, авторы которых являются практикующими психологами, а также публикуются в научных медиаресурсах.
- Еще один вариант — прохождение курсов и тренингов по повышению психологической грамотности. Этот метод поможет приобрести инструментарий для определения своего состояния, конкретизации симптомов, желаний и целей, а также полезных практических упражнений.
- Нельзя не отметить практики осознанности — научно обоснованный подход, интегрированный, в числе прочего, и в психотерапию. Некоторым людям именно они помогают в решении проблемы, способствуя расслаблению, фокусированию на своем запросе и способах его воплощения в жизнь.
 Некоторым людям именно они помогают в решении проблемы, способствуя расслаблению, фокусированию на своем запросе и способах его воплощения в жизнь.
Некоторым людям именно они помогают в решении проблемы, способствуя расслаблению, фокусированию на своем запросе и способах его воплощения в жизнь.Но если вы чувствуете, что проходит месяц, два, полгода, а улучшений в вашем состоянии нет, — значит, пора обратиться к специалисту.
Забота о себе
Если же помимо эмоционального дискомфорта, вы испытываете физический — это тоже знак, что вам нужна помощь извне. Люди часто жалуются на проблемы с аппетитом и сном при обращении к психотерапевту. Кстати, все методы самопомощи можно совмещать с курсом психотерапии, но важно ставить в известность специалиста.
Своевременное обращение за квалифицированной помощью крайне важно, потому что длительное пребывание в апатичном, тревожном или любом другом нетипичном состоянии может иметь непредвиденные последствия.
Некоторые люди годами могут жить в измененном состоянии, другие же страдают настолько сильно, что не могут поддерживать свой привычный образ жизни. И в одном, и в другом случае жизнь человека точно станет лучше, если он получит помощь и избавится от проблемы.
Психотерапия — добровольное действие, и никто не будет вас заставлять. Однако это один из самых надежных способов проявить заботу по отношению к себе, узнать себя и улучшить качество жизни.
Использовать запрос в качестве источника записи для формы или отчета
Access для Microsoft 365 Access 2021 Access 2019 Access 2016 Access 2013 Access 2010 Access 2007 Дополнительно…Меньше
Вы можете использовать запрос для предоставления данных в форму или отчет в Access. Вы можете использовать запрос при создании формы или отчета или изменить существующую форму или отчет, задав его свойство «Источник записи». Когда вы устанавливаете свойство «Источник записи», вы можете либо указать существующий запрос, либо создать новый запрос для использования.
Если вы используете запрос в качестве источника записи, вы не сможете редактировать данные. Прежде чем использовать запрос в качестве источника записей, следует подумать, нужно ли вам редактировать данные.
В этой статье объясняется, как установить свойство «Источник записи» для существующей формы или отчета, а также приводятся сведения о том, когда можно и когда нельзя редактировать данные запроса.
В этой статье не объясняется, как создать форму или отчет. Справку по созданию форм и отчетов см. в статьях Создание формы в Access и Создание простого отчета.
В этой статье
Использование существующего запроса в качестве источника записи формы или отчета
Создание запроса в качестве источника записи формы или отчета
Редактирование данных из запроса
Использовать существующий запрос в качестве источника записи формы или отчета
В представлении «Дизайн» задайте для свойства Источник записи существующий запрос, который вы хотите использовать.
Откройте форму или отчет в режиме конструктора.
Если лист свойств еще не открыт, нажмите F4 , чтобы открыть его.
В окне свойств на вкладке Данные щелкните поле свойства Источник записи .
Выполните одно из следующих действий:
Начните вводить имя запроса, который вы хотите использовать.
Access автоматически вводит имя объекта по мере ввода.
— или —
Щелкните стрелку и выберите запрос, который хотите использовать.

Верх страницы
Создание запроса в качестве источника записи формы или отчета
В представлении «Дизайн» используйте Кнопка Build () в поле свойств Record Source , чтобы создать новый запрос для использования в качестве источника записи.
Откройте форму или отчет в режиме конструктора.
Если лист свойств еще не открыт, нажмите F4 , чтобы открыть его.
Щелкните .
В режиме конструктора открывается новый запрос.
Создайте запрос, а затем сохраните и закройте его.
Справку по разработке запроса см. в статье Создание простого запроса на выборку.
 org/ListItem»>
org/ListItem»>В окне свойств на вкладке Данные щелкните Источник записи ящик свойств.
Верх страницы
Редактирование данных из запроса
Одной из основных причин использования форм является ввод и редактирование данных. Некоторые запросы не поддерживают редактирование данных. Прежде чем использовать запрос в качестве источника записи для формы, следует решить, можно ли редактировать данные запроса.
Когда я могу редактировать данные из запроса?
Вы можете редактировать данные из запроса, если:
Запрос основан только на одной таблице.
Запрос основан на двух таблицах со взаимно-однозначным отношением между ними.
Для свойства RecordsetType формы задано значение Dynaset (несовместимые обновления) , и ни одно из условий в следующем разделе не применяется.
Примечание. Даже если вы можете редактировать данные в запросе, некоторые его поля могут быть недоступны для редактирования. Такие случаи перечислены в следующем разделе.
Такие случаи перечислены в следующем разделе.
Когда я не могу редактировать данные из запроса?
Вы не можете редактировать данные из запроса, когда:
Запрос представляет собой кросс-таблицу.
Запрос относится к SQL.
Поле, которое вы пытаетесь изменить, является вычисляемым полем. В этом случае вы можете редактировать данные из других полей запроса.
Запрос содержит предложение GROUP BY.
Верх страницы
Редактировать данные в запросе
Вы можете столкнуться с ситуациями, когда вы не можете редактировать данные в представлении таблицы запроса, чтобы изменить данные в базовой таблице. Эта статья поможет вам понять, когда вы можете редактировать данные запроса, когда вы не можете редактировать данные запроса и как изменить дизайн запроса, чтобы вы могли редактировать его базовые данные.
В этой статье
Введение
Когда я могу редактировать данные в запросе?
Когда я не могу редактировать данные в запросе?
Как изменить запрос, чтобы я мог редактировать его данные?
Введение
Когда вы открываете запрос в режиме таблицы, вы можете обнаружить, что хотите изменить данные. Возможно, вы заметили ошибку или увидели устаревшую информацию. В зависимости от того, как был построен запрос, вы можете редактировать данные непосредственно в таблице запроса.
Возможно, вы заметили ошибку или увидели устаревшую информацию. В зависимости от того, как был построен запрос, вы можете редактировать данные непосредственно в таблице запроса.
Если вы попытаетесь отредактировать данные в таблице запроса, но ничего не произойдет, или Windows воспроизведет звук, а ваше редактирование не произойдет, вы не сможете выполнить редактирование. Может случиться так, что сам запрос недоступен для редактирования, например запрос перекрестной таблицы. Также может случиться так, что только поле, которое вы пытаетесь изменить, недоступно для редактирования — например, если поле основано на агрегатной функции, такой как среднее значение. В любом случае вы можете сделать что-то, чтобы разрешить редактирование.
В дополнение к редактированию данных в представлении таблицы запросов вы также можете использовать запрос на обновление для обновления данных в таблице. В этой статье не рассматриваются запросы на обновление.
Дополнительные сведения о запросах на обновление см. в статье Создание и выполнение запроса на обновление.
в статье Создание и выполнение запроса на обновление.
Обычно, когда вы хотите редактировать данные в представлении таблицы запроса, вы хотите, чтобы ваши изменения сохранялись в таблицах, на которых основан запрос. Если вы не хотите изменять данные в этих таблицах, но все же хотите отредактировать данные и сохранить отредактированные данные после завершения, вы можете использовать запрос на создание таблицы, чтобы сначала создать новую таблицу, данные которой вы можете редактировать. . Вы также можете использовать запрос на создание таблицы, чтобы сохранить результаты запроса, который не позволяет редактировать, как новую таблицу, а затем отредактировать данные в этой новой таблице. В этой статье не обсуждается, как создавать и выполнять запросы на создание таблиц.
Дополнительные сведения о запросах на создание таблицы см. в статье Создание запроса на создание таблицы.
Верх страницы
Когда я могу редактировать данные в запросе?
Вы всегда можете изменить данные в запросе, если запрос основан либо на одной таблице, либо на двух таблицах, которые связаны друг с другом взаимно-однозначным отношением.
Примечание. Даже если вы можете редактировать данные в запросе, некоторые его поля могут быть недоступны для редактирования. Такие случаи перечислены в следующем разделе.
Верх страницы
Когда я не могу редактировать данные в запросе?
Вы никогда не сможете редактировать данные в запросе, если:
Запрос представляет собой кросс-таблицу.
Запрос относится к SQL.
Поле, которое вы пытаетесь изменить, является вычисляемым полем. В этом случае вы можете редактировать другие поля.
Запрос основан на трех или более таблицах и имеет отношение «многие к одному ко многим».
Примечание: Хотя в этом случае вы не можете редактировать таблицу данных запроса, вы можете редактировать данные в форме, если для свойства RecordsetType формы установлено значение Dynaset (несовместимые обновления) .
Запрос содержит предложение GROUP BY.
Верх страницы
Как изменить запрос, чтобы можно было редактировать его данные?
В следующей таблице перечислены случаи, когда вы не можете изменить запрос, а также методы, позволяющие сделать таблицу запроса доступной для редактирования.
Вы не можете редактировать значения в таблице запроса, когда: | Чтобы сделать таблицу запросов доступной для редактирования: |
Для свойства запроса Уникальные значения задано значение Да . | Задайте для свойства Уникальные значения запроса значение Нет . См. следующий раздел «Установите для свойства Уникальные значения значение Нет», чтобы узнать, как установить это свойство. |
Запрос включает связанную таблицу базы данных ODBC без уникального индекса или таблицу Paradox без первичного ключа. | Добавьте первичный ключ или уникальный индекс в связанную таблицу, используя методы, предоставленные поставщиком связанной базы данных. |
У вас нет разрешений на обновление данных для базовой таблицы. | Назначение разрешений на обновление данных. |
Запрос включает несколько таблиц или один запрос, а таблицы или запросы не соединены линией соединения в представлении «Дизайн». | Создайте соответствующие объединения. См. раздел Создание объединений, чтобы узнать, как создавать объединения. |
База данных открыта только для чтения или находится на диске только для чтения. | Закройте базу данных и снова откройте ее, не выбирая Открыть только для чтения ; или, если база данных расположена на диске, доступном только для чтения, удалите с диска атрибут только для чтения или переместите базу данных на диск, не предназначенный только для чтения. |
Поле в записи, которую вы пытаетесь обновить, удалено или заблокировано другим пользователем. | Дождитесь разблокировки записи. Заблокированную запись можно обновить, как только она будет разблокирована. Подождите, пока другой пользователь завершит операцию, которая заблокировала запись. |
Запрос основан на таблицах с отношением «один ко многим», а поле соединения со стороны «многие» не является полем вывода. | Добавьте поле соединения со стороны отношения «многие» в поля вывода запроса. См. раздел Добавление поля соединения со стороны «многих» в поля вывода запроса, чтобы узнать, как добавить поле соединения. |
Поле соединения со стороны «многие» (после редактирования данных) находится на стороне «один». | Нажмите SHIFT+F9 , чтобы зафиксировать изменения и обновить запрос. |
В таблице на стороне «один» отношения «один ко многим» есть пустое поле, а соединение является правым внешним соединением. | Убедитесь, что в этом поле есть значение на стороне «один». |
Вы используете связанную таблицу базы данных ODBC, и не все поля из уникального индекса связанной таблицы присутствуют в выходных данных запроса. | Добавьте все поля из уникального индекса таблицы ODBC в поля вывода запроса. См. раздел Добавление уникальных полей индекса из связанной таблицы ODBC, чтобы узнать, как добавлять поля. |
 При этом данные в поле соединения со стороны «один» редактировать нельзя.
При этом данные в поле соединения со стороны «один» редактировать нельзя. Вы можете редактировать поле объединения на стороне «многие», только если в этом поле есть значение на стороне «один».
Вы можете редактировать поле объединения на стороне «многие», только если в этом поле есть значение на стороне «один».Верх страницы
Задайте для свойства Уникальные значения значение Нет
Если лист свойств не открыт, откройте его, нажав F4 . Щелкните один раз в сетке макета запроса, чтобы убедиться, что на листе свойств отображаются свойства запроса, а не свойства поля.
На странице свойств найдите поле свойств Уникальные значения . Щелкните поле рядом с ним, щелкните стрелку в этом поле и выберите Нет .
 org/ListItem»>
org/ListItem»>Откройте запрос в режиме конструктора.
Создание объединений
Откройте запрос в режиме конструктора.
Для каждой таблицы или запроса, которые вы хотите соединить с другой, перетащите поле соединения из этой таблицы или запроса в соответствующее поле в таблице или запросе, для которого вы хотите создать соединение.

Дополнительные сведения о создании объединений см. в статье Объединение таблиц и запросов.
Добавить поле соединения со стороны «многие» в поля вывода запроса
Откройте запрос в режиме конструктора.
В конструкторе запросов найдите соединение, соответствующее соответствующему отношению «один ко многим».
Дважды щелкните поле соединения со стороны «многие» отношения «один ко многим». Поле соединения появляется в сетке полей, указывая на то, что теперь оно является полем вывода.

Добавление уникальных полей индекса из связанной таблицы ODBC
Откройте запрос в режиме конструктора.
В конструкторе запросов найдите связанную таблицу ODBC.
Поля уникального индекса будут иметь символ ключа рядом с именем поля.
Дважды щелкните каждое поле, которого еще нет в сетке полей. Каждое поле появляется в сетке полей, указывая на то, что теперь оно является полем вывода.
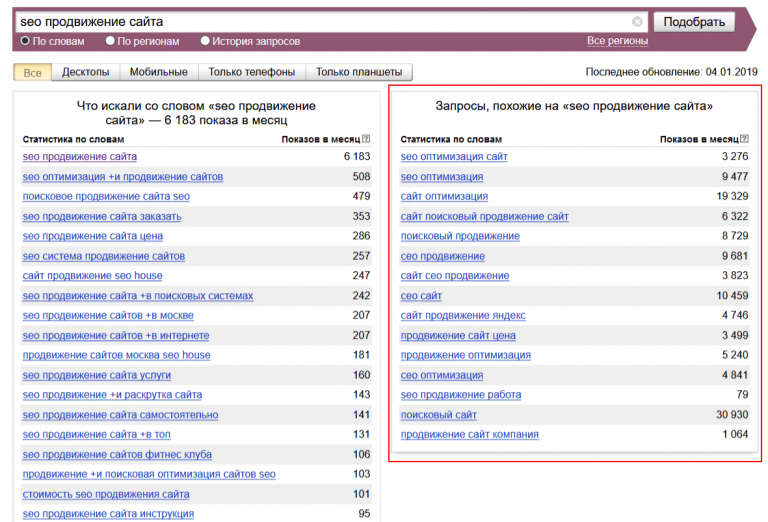 Дважды щелкните каждое поле, которого еще нет в сетке полей. Каждое поле появляется в сетке полей, указывая на то, что теперь оно является полем вывода.
Дважды щелкните каждое поле, которого еще нет в сетке полей. Каждое поле появляется в сетке полей, указывая на то, что теперь оно является полем вывода.Верх страницы
Другие методы | Objection.js
debug()
Привязка этого метода к любому запросу выведет весь выполненный SQL на консоль.
См. документацию knex (открывается в новом окне)
Возвращаемое значение
| Тип | Описание |
|---|---|
| QueryBuilder | этот построитель запросов для цепочки. |
toKnexQuery()
Компилирует запрос в запрос knex и возвращает экземпляр построителя запросов knex.
Некоторые запросы возражений, например, когда используется withGraphFetched , фактически выполняют несколько запросов. В этих случаях возвращается построитель запросов первого запроса
В некоторых редких случаях запрос knex не может быть построен синхронно. В этих случаях вы получите четкое сообщение об ошибке. Эти случаи можно обработать, вызвав необязательный метод инициализации один раз перед ошибкой 9.0500 Вызывается метод toKnexQuery .
В этих случаях вы получите четкое сообщение об ошибке. Эти случаи можно обработать, вызвав необязательный метод инициализации один раз перед ошибкой 9.0500 Вызывается метод toKnexQuery .
for()
Этот метод можно использовать только в сочетании со статическим методом relatedQuery. См. документацию по связанным запросам о том, как его использовать.
Этот метод принимает один аргумент (владельцы отношения) и может иметь любой из следующих типов:
- Одиночный идентификатор (может быть составным)
- Массив идентификаторов (может быть составным)
- QueryBuilder
- Экземпляр модели.
- Массив экземпляров модели.
context()
Устанавливает/получает контекст запроса.
Некоторые методы построителя запросов создают более одного запроса. Контекст запроса — это объект, который используется всеми запросами, запущенными построителем запросов.
Контекст также передается вызовам $beforeInsert, $afterInsert, $beforeUpdate, $afterUpdate, $beforeDelete, $afterDelete и $afterFind, создаваемым запросом.
В дополнение к свойствам, добавленным с помощью этого метода, объект контекста запроса всегда имеет значение транзакция свойство, содержащее активную транзакцию. Если активной транзакции нет, свойство транзакции содержит обычный экземпляр knex. В обоих случаях значение может быть передано везде, где может быть передан объект транзакции, поэтому вам не нужно проверять наличие свойства транзакции .
Этот метод объединяет данный объект с текущим контекстом. Вы можете использовать clearContext для очистки контекста, если это необходимо.
См. методы runBefore, onBuild и runAfter. для получения дополнительной информации о хуках.
Arguments
| Argument | Type | Description |
|---|---|---|
| queryContext | Object | The query context object |
Return value
| Type | Description |
|---|---|
| QueryBuilder | это построитель запросов для цепочки. |
Примеры
Вы можете установить контекст следующим образом:
и получить доступ к контексту следующим образом:
Вы можете установить любые данные для объекта контекста. Вы также можете зарегистрировать методы жизненного цикла QueryBuilder для всех запросов , которые имеют общий контекст:
Например, метод withGraphFetched вызывает выполнение нескольких запросов из одного построителя запросов. Если вы хотите, чтобы все они использовали одну и ту же схему, вы можете написать это:
clearContext()
Заменяет текущий контекст пустым объектом.
Возвращаемое значение
| Тип | Описание |
|---|---|
| QueryBuilder | этот построитель запросов для цепочки . |
tableNameFor()
Возвращает имя таблицы для данного класса модели в запросе. Обычно имя таблицы можно получить через Model., но если исходная таблица была изменена, например, с помощью метода QueryBuilder#table  tableName
tableName tableNameFor вернет правильное значение.
Аргументы
| Аргумент | Тип | Описание |
|---|---|---|
| класс модели | класс A 9.270 функция 9.
Возвращаемое значение
| Тип | Описание | |
|---|---|---|
| строка | модель представления (класс | )0501 . |
tableRefFor()
Возвращает имя, которое должно использоваться для ссылки на таблицу modelClass в запросе.
Обычно на таблицу можно ссылаться по ее имени, но tableRefFor может возвращать другое имя.
значение, например, в случае, если был задан псевдоним.
Аргументы
| Аргумент | Тип | Описание |
|---|---|---|
| modelClass | функция | Модель класса А. |
Возвращаемое значение
| Тип | Описание |
|---|---|
| Строка | Имя, которое должно использоваться для ссылки на таблицу. |
reject()
Пропускает запрос к базе данных и «подделывает» результат ошибки.
Аргументы
| Аргумент | Тип | Описание |
|---|---|---|
| reason | The rejection reason |
Return value
| Type | Description |
|---|---|
| QueryBuilder | this query builder for chaining. |
resolve()
Пропускает запрос к базе данных и «подделывает» результат.
Аргументы
| Аргументы | Тип | Description |
|---|---|---|
| value | The resolve value |
Return value
| Type | Description |
|---|---|
| QueryBuilder | this query builder for chaining. |
isExecutable()
Возвращает false, если этот запрос никогда не будет выполнен.
Это может быть верно в нескольких случаях:
- Запрос разрешен или отклонен явным образом с использованием методов разрешения или отклонения.
- Запрос запускает другой запрос при выполнении.
Возвращаемое значение
| Тип | Описание |
|---|---|
| логическое значение | false, если запрос никогда не будет выполнен. |
isFind()
Возвращает true, если запрос доступен только для чтения.
Возвращаемое значение
| Тип | Описание |
|---|---|
| логическое значение | true, если запрос доступен только для чтения. |
isInsert()
Возвращает значение true, если запрос выполняет операцию вставки.
Возвращаемое значение
| Тип | Описание |
|---|---|
| логическое значение | true, если запрос выполняет операцию вставки. |
isUpdate()
Возвращает значение true, если запрос выполняет операцию обновления или исправления.
Возвращаемое значение
| Тип | Описание |
|---|---|
| логическое значение | true, если запрос выполняет операцию обновления или исправления. |
isDelete()
Возвращает true, если запрос выполняет операцию удаления.
Возвращаемое значение
| Тип | Описание |
|---|---|
| логическое значение | true, если запрос выполняет операцию удаления. |
isRelate()
Возвращает значение true, если запрос выполняет операцию связи.
Возвращаемое значение
| Тип | Описание |
|---|---|
| логическое значение | true, если запрос выполняет операцию связи.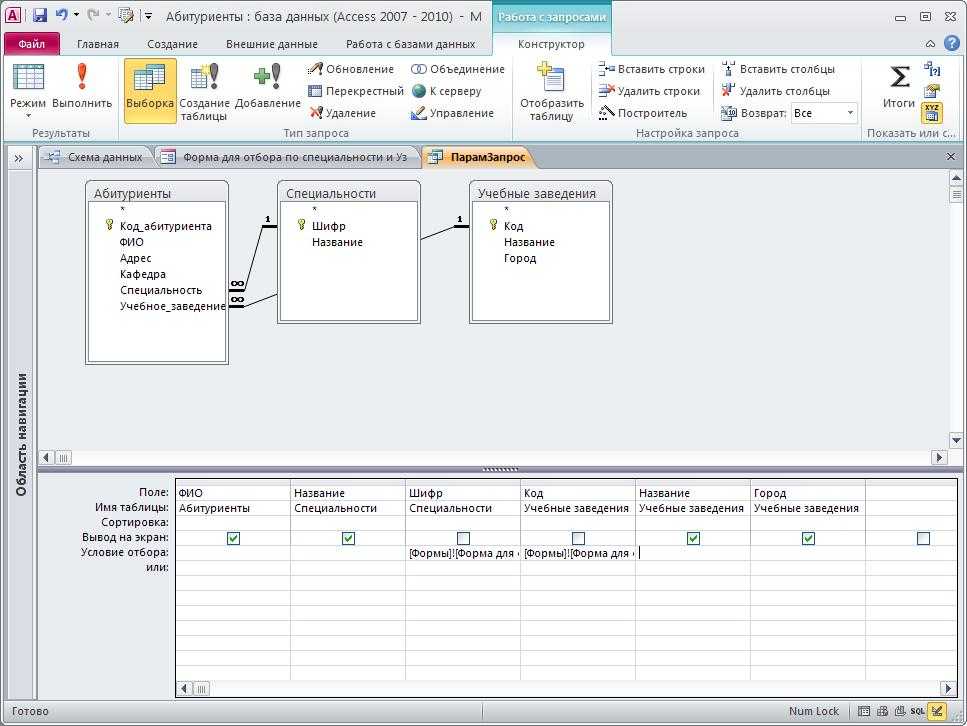 |
isUnrelate()
Возвращает значение true, если запрос выполняет операцию несвязывания.
Возвращаемое значение
| Тип | Описание |
|---|---|
| логическое значение | true, если запрос выполняет несвязанную операцию. |
isInternal()
Возвращает true для внутренних «вспомогательных» запросов, которые не
часть выполняемой операции. Например, выбирают запросов.
выполняемые upsertGraph для получения текущего состояния графа,
внутренние запросы.
Возвращаемое значение
| Тип | Описание |
|---|---|
| логическое значение | true, если запрос выполняет внутреннюю вспомогательную операцию. |
hasWheres()
Возвращает значение true, если запрос содержит операторы where.
Возвращаемое значение
| Тип | Описание |
|---|---|
| логическое значение | true, если запрос содержит операторы where. |
hasSelects()
Возвращает true, если запрос содержит какие-либо конкретные операторы выбора, например: 'select' , 'columns' , 'column' , 'distinct' , 'count' , 'countDistinct' , 'min' , 'max' , ' sum' , 'sumDistinct' , 'avg' , 'avgDistinct'
Возвращаемое значение
| Тип | Описание |
|---|---|
| логическое значение | true, если запрос содержит какие-либо определенные операторы select. |
hasWithGraph()
Возвращает true, если для запроса было вызвано withGraphFetched или withGraphJoined .
Возвращаемое значение
| Тип | Описание |
|---|---|
| логическое значение | true, если withGraph501 или был вызван для запроса. |
has()
Возвращает значение true, если запрос определяет операцию, соответствующую данному селектору.
Аргументы
| Аргумент | Тип | Описание |
|---|---|---|
| селектор | строка | RegExp | Имя или регулярное выражение для сопоставления всех определенных операций. |
Возвращаемое значение
| Тип | Описание |
|---|---|
| логическое значение | true, если запрос определяет операцию, соответствующую данному селектору. |
clear()
Удаляет все операции в запросе, соответствующие данному селектору.
Аргументы
| Аргумент | Тип | Описание |
|---|---|---|
| селектор | строка | регулярное выражение | Имя или регулярное выражение для сопоставления всех операций, которые должны быть удалены. |
Возвращаемое значение
| Тип | Описание |
|---|---|
Примеры
runBefore()
Регистрирует функцию, которая будет вызываться перед запросом к базе данных при выполнении компоновщика. Несколько функций могут быть объединены в цепочку, например, , затем методы промиса.
Аргументы
| Аргумент | Тип | Описание |
|---|---|---|
| RUNBEBEROFOROFOROFORONFOROFORFORFORFORFORFORFORFORFORFORFORFORFORFORFORFORFORFORFORFORFORFORFORFORFORFORO | . Эта функция может быть асинхронной. Обратите внимание, что он должен вернуть результат, используемый для дальнейшей обработки в цепочке вызовов. |
Возвращаемое значение
| Тип | Описание |
|---|---|
| QueryBuilder | этот построитель запросов для цепочки. |
Примеры
onBuild()
Функции, зарегистрированные с помощью этого метода, вызываются каждый раз, когда запрос встраивается в строку SQL. Этот метод запускается после методов runBefore, но перед методами runAfter.
Если вам нужно изменить SQL-запрос во время построения запроса, это место для этого. Вы не должны изменять запрос ни в одном из запустить методов.
В отличие от методов run ( runAfter , runBefore и т. д.) они должны быть синхронными. Также вы не должны регистрировать какие-либо методы run из них. Вы должны только вызывать методы построения запросов построителя, предоставленные в качестве параметра.
Аргумент
| Аргумент | Тип | Описание |
|---|---|---|
| onBuild | Синхронная функция , которую необходимо выполнить.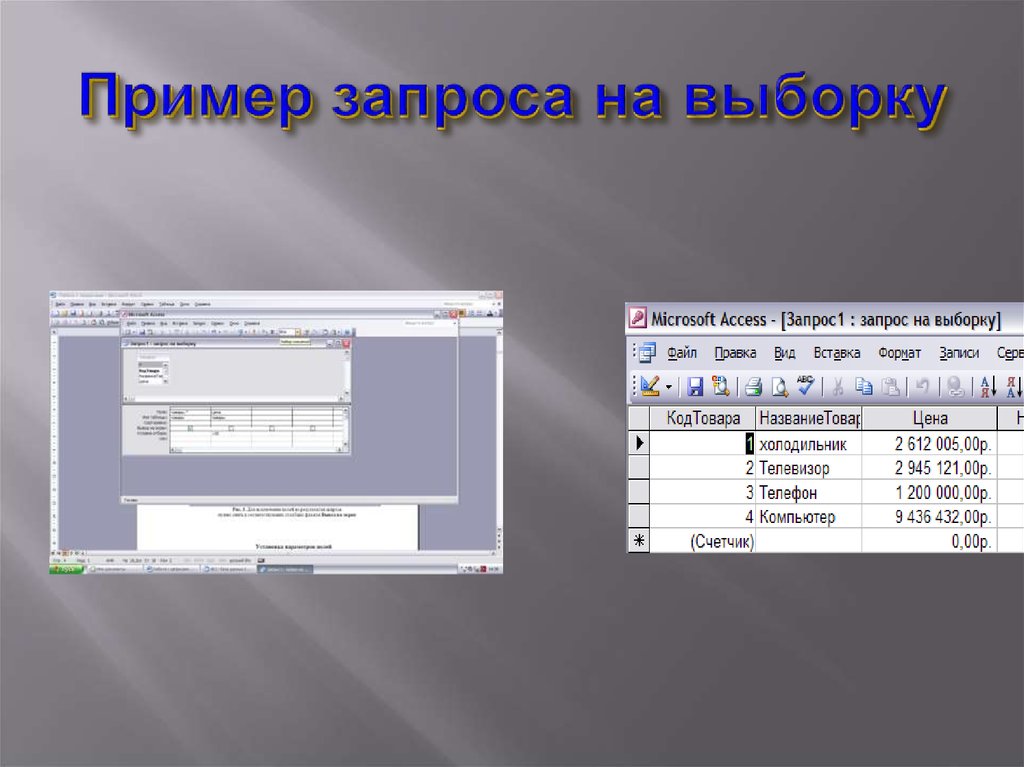 |
Возвращаемое значение
| Тип | Описание |
|---|---|
Примеры
onBuildKnex()
Функции, зарегистрированные с помощью этого метода, вызываются каждый раз, когда запрос встраивается в строку SQL. Этот метод запускается после методов onBuild, но перед методами runAfter.
Если вам нужно изменить SQL-запрос во время построения запроса, это можно сделать в дополнение к onBuild . Единственная разница между onBuildKnex и onBuild заключается в том, что в onBuild можно изменить построитель запросов возражения. В onBuildKnex построитель возражений был скомпилирован в построитель запросов knex, и любые изменения в построителе возражений будут игнорироваться.
В отличие от методов run ( runAfter , runBefore и т. д.) они должны быть синхронными. Также вы не должны регистрировать какие-либо методы
Также вы не должны регистрировать какие-либо методы run из них. Вы должны только вызывать методы построения запросов knexBuilder , предоставленные в качестве параметра.
ПРЕДУПРЕЖДЕНИЕ
В этой функции никогда не следует вызывать какой-либо метод построения запроса (или любой другой метод изменения) для objectionBuilder . Если вы это сделаете, эти звонки будут проигнорированы. На данный момент построитель запросов был скомпилирован в построитель запросов knex, и вам нужно только изменить его. Вы можете вызывать немутирующие методы, такие как hasSelects , hasWheres и т. д. в построителе возражений.
Arguments
| Argument | Type | Description |
|---|---|---|
| onBuildKnex | function( KnexQueryBuilder , QueryBuilder) | The function to be executed. |
Возвращаемое значение
| Тип | Описание |
|---|---|
| QueryBuilder | этот построитель запросов для цепочки. |
Примеры
runAfter()
Регистрирует функцию, которая будет вызываться при выполнении компоновщика.
Эти функции выполняются в последнюю очередь перед любыми обработчиками промисов, зарегистрированными с использованием метода then. Несколько функций могут быть объединены в цепочку, как методы обещания.
Аргументы
| Аргументы | Тип | Описание |
|---|---|---|
| runAfter | function(result, QueryBuilder) | Функция, которую нужно выполнить. Эта функция может быть асинхронной. Обратите внимание, что он должен вернуть результат, используемый для дальнейшей обработки в цепочке вызовов. |
Возвращаемое значение
| Тип | Описание |
|---|---|
Примеры
onError()
Регистрирует обработчик ошибок. Так же, как ловит , но не выполняет запрос.
Аргументы
| Аргумент | Тип | Описание |
|---|---|---|
| ONERROR | (ERRESER ERRESERED. |
Возвращаемое значение
| Тип | Описание |
|---|---|
| QueryBuilder | этот построитель запросов для цепочки. |
Примеры
castTo()
Задает класс модели результирующих строк или, если аргументы не указаны, просто приводит тип результата к предоставленному типу.
Возвращаемое значение
| Тип | Описание |
|---|---|
| ModelClass | Класс модели результирующих строк. |
Возвращаемое значение
| Тип | Описание |
|---|---|
Примеры
В следующем примере создается запрос через Person , присоединяется к группе отношений, выбирает
только связанные столбцы Animal и возвращает результаты как экземпляров Animal вместо человек экземпляр.
Если вы не предоставляете никаких аргументов для метода, но предоставляете аргумент универсального типа, результат не изменяется, но его машинописный тип приводится к заданному универсальному типу.
modelClass()
Получает подкласс модели, к которому привязан этот построитель.
Возвращаемое значение
| Тип | Описание |
|---|---|
| Модель | Подкласс модели, к которому привязан этот построитель |
skipUndefined()
Если этот метод вызывается для построителя, то неопределенные значения, переданные методам построителя запросов, не вызывают исключения, а вместо этого игнорируются.
Например, следующий запрос вернет все строки Person , если req.query.firstName равно undefined .
Возвращаемое значение
| Тип | Описание |
|---|---|
| QueryBuilder | этот построитель запросов для цепочки |
Примеры
transacting()
Устанавливает транзакцию для запроса.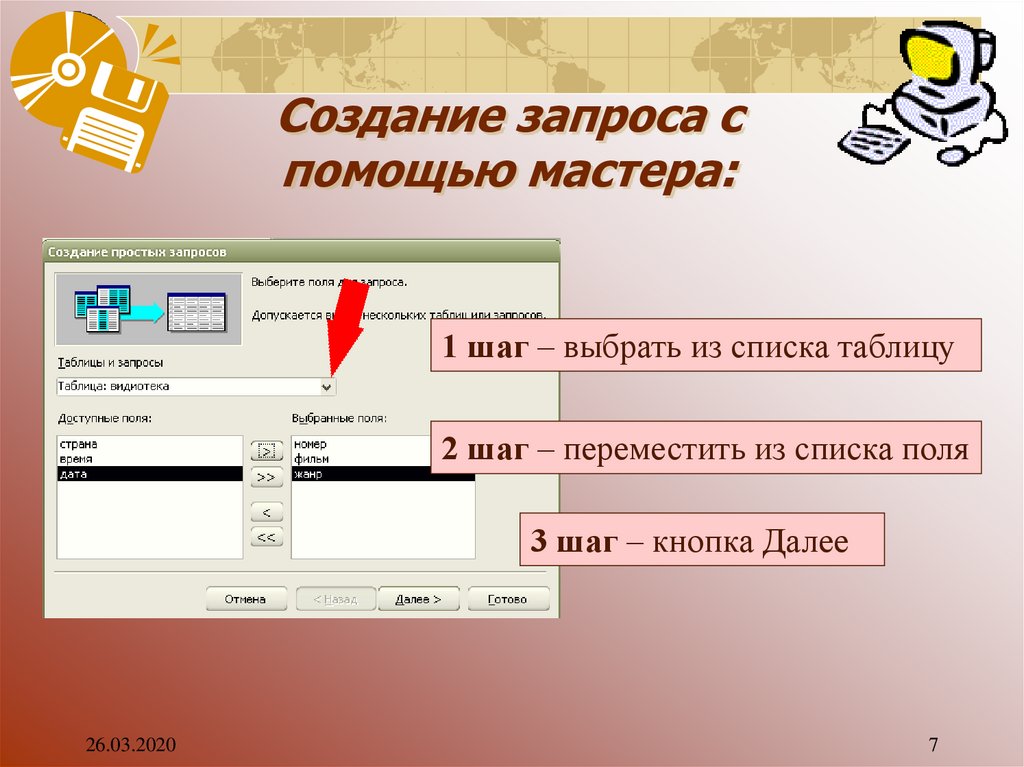
Arguments
| Argument | Type | Description |
|---|---|---|
| transaction | object | A transaction object |
Return value
| Type | Description 9 |
|---|
clone()
Создайте клон этого конструктора.
| Тип | Описание | ||
|---|---|---|---|
| QueryBuilder | Clone Query Builder | Clone Builder | .
| Тип | Описание |
|---|---|
Обещание | Обещание будет разрешено с результатом запроса. |
then()
Выполняет запрос и возвращает обещание.
Аргументы
| Аргумент | Тип | По умолчанию | Описание |
|---|---|---|---|
.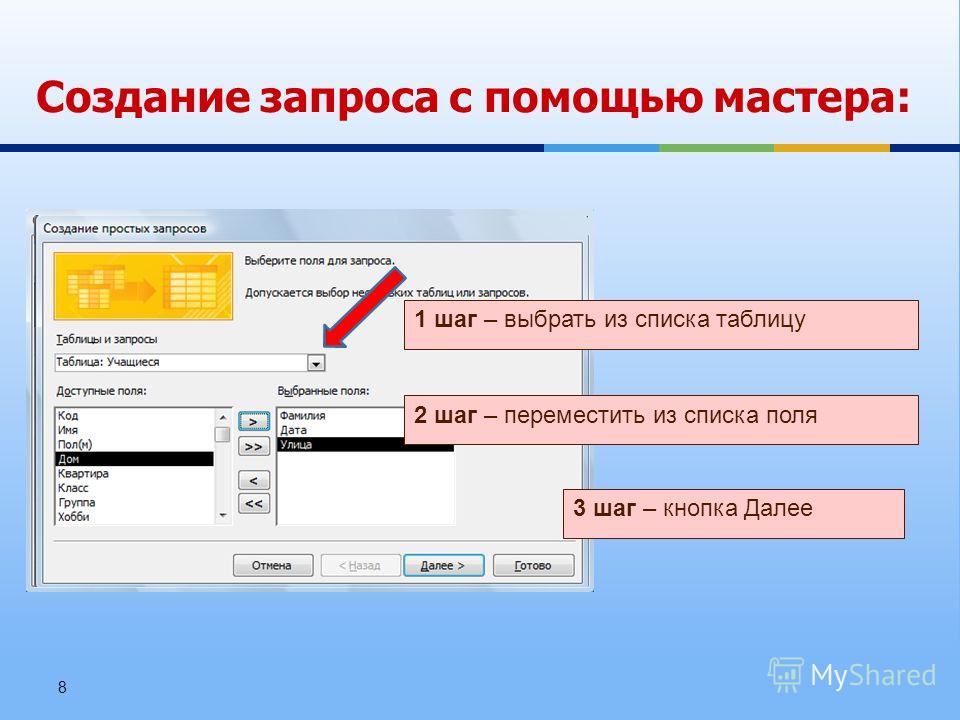 0265 identity 0265 identity | Promise success handler | ||
| errorHandler | function | identity | Promise error handler |
Return value
| Type | Description |
|---|---|
Promise | Обещание будет разрешено с результатом запроса. |
catch()
Выполняет запрос и вызывает catch(errorHandler) для возвращенного промиса.
Arguments
| Argument | Type | Default | Description |
|---|---|---|---|
| errorHandler | function | identity | Error handler |
Return value
| Type | Описание |
|---|---|
Обещание | Обещание, что результат запроса будет решен. |
bind()
Выполняет запрос и вызывает bind(context) для возвращенного обещания.
Arguments
| Argument | Type | Default | Description |
|---|---|---|---|
| context | undefined | Bind context |
Return value
| Тип | Описание |
|---|---|
Обещание | Обещание будет разрешено с результатом запроса. |
resultSize()
Возвращает количество строк, которые текущий запрос выдаст без применения ограничения и смещения. Обратите внимание, что это выполняет копию запроса и возвращает обещание.
Этот метод часто более удобен, чем count , который возвращает массив объектов вместо одного числа.
Возвращаемое значение
| Тип | Описание |
|---|---|
Обещание <число> | Обещание, что результат будет разрешен. |
Примеры
page()
С помощью этого метода выполняются два запроса: фактический запрос и запрос для получения общего количества .
Mysql имеет параметр SQL_CALC_FOUND_ROWS и FOUND_ROWS() , которую можно использовать для вычисления размера результата, но, согласно моим тестам и интернету (opens new window), производительность значительно хуже, чем просто выполнение отдельного запроса на подсчет.
В Postgresql есть оконные функции, которые можно использовать для получения общего количества, например select count(*) over () как total . Проблема в том, что если результирующий набор пуст, мы также не получим общее количество. (Если кто-то может найти способ обойти это, PR очень приветствуется).
Аргументы
| Аргумент | Тип | Описание |
|---|---|---|
| Страница | Номер страницы возврата | .|
| pageSize | number | The page size |
 The index of the first page is 0.
The index of the first page is 0.Return value
| Type | Description |
|---|---|
| QueryBuilder | этот построитель запросов для цепочки |
range()
Возвращает только заданный диапазон результатов.
С помощью этого метода выполняются два запроса: фактический запрос и запрос для получения общего количества .
Mysql имеет параметр SQL_CALC_FOUND_ROWS и функцию FOUND_ROWS() , которые можно использовать для вычисления размера результата, но согласно моим тестам и межсетевым (открывается в новом окне) производительность значительно хуже, чем просто выполнение отдельного подсчета запрос.
В Postgresql есть оконные функции, которые можно использовать для получения общего количества, например select count(*) over () как итог . Проблема в том, что если результирующий набор пуст, мы также не получим общее количество. (Если кто-то может найти способ обойти это, PR очень приветствуется).
Проблема в том, что если результирующий набор пуст, мы также не получим общее количество. (Если кто-то может найти способ обойти это, PR очень приветствуется).
Аргументы
| Аргумент | Тип | Описание | |
|---|---|---|---|
| начало | число | начало | число)0270 |
| end | number | The index of the last result (inclusive) |
Return value
| Type | Description |
|---|---|
| QueryBuilder | this query builder for цепочка |
Примеры
диапазон можно вызывать без аргументов, если вы хотите явно указать предел и смещение:
first()
Если результатом является массив, выбирает первый элемент.
ПРИМЕЧАНИЕ. Это не добавляет к запросу limit 1 по умолчанию. Вы можете переопределить свойство Model.useLimitInFirst, чтобы изменить это поведение.
Вы можете переопределить свойство Model.useLimitInFirst, чтобы изменить это поведение.
См. также сокращенные методы findById и findOne.
Возвращаемое значение
| Тип | Описание |
|---|---|
| QueryBuilder | этот построитель 9 для цепочки запросов0270 |
Примеры
throwIfNotFound()
Вызывает исключение Model.NotFoundError, если результат запроса пуст.
Вы можете заменить Model.NotFoundError своей собственной ошибкой, реализуя статический метод Model.createNotFoundError(ctx).
Аргументы
| Аргумент | Тип | Описание |
|---|---|---|
| DATA | объект | |
| DATA | объект | |
 These extra properties can be leveraged in the error handling middleware
These extra properties can be leveraged in the error handling middlewareReturn value
| Type | Description |
|---|---|
| QueryBuilder | this query builder for chaining |
Examples
timeout()
См. документацию knex (открывается в новом окне)
Возвращаемое значение
| Тип | Описание |
|---|---|
| QueryBuilder | этот построитель запросов для цепочки . |
connection()
See knex documentation (opens new window)
Return value
| Type | Description |
|---|---|
| QueryBuilder | this query builder for chaining. |
modifier()
Работает как функция модификации knex (открывает новое окно), но, кроме того, вы можете указать модификатор, указав имена модификаторов.
См. рецепт модификатора для примеров того, что вы можете делать с модификаторами.
Аргументы
| Аргумент | Тип | Описание |
|---|---|---|
| модификатор | функция (QueryBuilder)| строка | строка [] | Функция обратного вызова модификации, получающая построитель в качестве первого аргумента, за которым следуют необязательные аргументы. Если предоставлена строка или массив строк, вместо этого выполняется соответствующий модификатор. |
| *arguments | …любой | Необязательные аргументы, передаваемые функции модификации |
Примеры
Первый аргумент может быть именем модификатора модели. Остальные аргументы передаются как аргументы для модификатора.
You can also pass an array of modifier names:
The first argument can be a function:
Return value
| Type | Description |
|---|---|
| QueryBuilder | this query builder for цепочка. |
modifiers()
Регистрирует модификаторы для запроса.
Вы можете вызвать этот метод без аргументов, чтобы получить текущие зарегистрированные модификаторы.
См. рецепт модификатора для получения дополнительной информации и примеров.
Возвращаемое значение
| Тип | Описание |
|---|---|
| QueryBuilder | этот построитель запросов для цепочки . |
Примеры
Вы можете получить текущие зарегистрированные модификаторы, вызвав метод без аргументов.
Выражения запросов | Документация Django
Выражения запроса описывают значение или вычисление, которое может использоваться как часть
обновление, создание, фильтрация, упорядочение, аннотация или совокупность. Когда
выражение выводит логическое значение, его можно использовать непосредственно в фильтрах. Там
представляют собой ряд встроенных выражений (задокументированных ниже), которые можно использовать для
помогите написать запросы. Выражения могут быть объединены или, в некоторых случаях, вложены друг в друга.
формировать более сложные вычисления.
Выражения могут быть объединены или, в некоторых случаях, вложены друг в друга.
формировать более сложные вычисления.
Поддерживаемые арифметические операции
Django поддерживает отрицание, сложение, вычитание, умножение, деление, арифметика по модулю и оператор мощности в выражениях запроса с использованием Python константы, переменные и даже другие выражения.
Некоторые примеры
из django.db.models import Count, F, Value
из django.db.models.functions импортировать длину, верхнюю
из django.db.models.lookups импортировать GreaterThan
# Найдите компании, в которых больше сотрудников, чем стульев.
Company.objects.filter(num_employees__gt=F('num_chairs'))
# Найдите компании, у которых как минимум в два раза больше сотрудников
# как стулья. Оба набора запросов ниже эквивалентны.
Company.objects.filter(num_employees__gt=F('num_chairs') * 2)
Компания.объекты.фильтр(
num_employees__gt = F('num_chairs') + F('num_chairs'))
# Сколько стульев необходимо каждой компании для размещения всех сотрудников?
>>> компания = Компания. объекты.фильтр(
... num_employees__gt=F('num_chairs')).аннотировать(
... Chairs_needed=F('num_employees') - F('num_chairs')).first()
>>> компания.num_employees
120
>>> компания.num_chairs
50
>>> company.chairs_needed
70
# Создайте новую компанию, используя выражения.
>>> компания = Company.objects.create(name='Google', ticker=Upper(Value('goog')))
# Обязательно обновите его, если вам нужно получить доступ к полю.
>>> company.refresh_from_db()
>>> компания.тикер
"GOOG"
# Аннотировать модели с агрегированным значением. Обе формы
# ниже эквивалентны.
Company.objects.annotate(num_products=Количество('продукты'))
Company.objects.annotate(num_products=Count(F('products')))
# Агрегаты также могут содержать сложные вычисления
Company.objects.annotate(num_offerings=Count(F('продукты') + F('услуги')))
# Выражения также можно использовать в функции order_by(), либо напрямую
Company.objects.order_by(Длина('имя').asc())
Company.objects.order_by(Длина('имя').desc())
# или используя синтаксис поиска с двойным подчеркиванием.
из django.db.models импортировать CharField
из django.db.models.functions импорт Длина
CharField.register_lookup(Длина)
Company.objects.order_by('name__length')
# Логическое выражение можно использовать непосредственно в фильтрах.
из импорта django.db.models Существует
Компания.объекты.фильтр(
Exists(Employee.objects.filter(company=OuterRef('pk'), зарплата__gt=10))
)
# Выражения поиска также можно использовать непосредственно в фильтрах
Company.objects.filter(GreaterThan(F('num_employees'), F('num_chairs')))
# или аннотации.
Компания.объекты.аннотировать(
need_chairs = больше, чем (F ('количество_сотрудников'), F ('количество стульев')),
)
 объекты.фильтр(
... num_employees__gt=F('num_chairs')).аннотировать(
... Chairs_needed=F('num_employees') - F('num_chairs')).first()
>>> компания.num_employees
120
>>> компания.num_chairs
50
>>> company.chairs_needed
70
# Создайте новую компанию, используя выражения.
>>> компания = Company.objects.create(name='Google', ticker=Upper(Value('goog')))
# Обязательно обновите его, если вам нужно получить доступ к полю.
>>> company.refresh_from_db()
>>> компания.тикер
"GOOG"
# Аннотировать модели с агрегированным значением. Обе формы
# ниже эквивалентны.
Company.objects.annotate(num_products=Количество('продукты'))
Company.objects.annotate(num_products=Count(F('products')))
# Агрегаты также могут содержать сложные вычисления
Company.objects.annotate(num_offerings=Count(F('продукты') + F('услуги')))
# Выражения также можно использовать в функции order_by(), либо напрямую
Company.objects.order_by(Длина('имя').asc())
Company.objects.order_by(Длина('имя').desc())
# или используя синтаксис поиска с двойным подчеркиванием.
объекты.фильтр(
... num_employees__gt=F('num_chairs')).аннотировать(
... Chairs_needed=F('num_employees') - F('num_chairs')).first()
>>> компания.num_employees
120
>>> компания.num_chairs
50
>>> company.chairs_needed
70
# Создайте новую компанию, используя выражения.
>>> компания = Company.objects.create(name='Google', ticker=Upper(Value('goog')))
# Обязательно обновите его, если вам нужно получить доступ к полю.
>>> company.refresh_from_db()
>>> компания.тикер
"GOOG"
# Аннотировать модели с агрегированным значением. Обе формы
# ниже эквивалентны.
Company.objects.annotate(num_products=Количество('продукты'))
Company.objects.annotate(num_products=Count(F('products')))
# Агрегаты также могут содержать сложные вычисления
Company.objects.annotate(num_offerings=Count(F('продукты') + F('услуги')))
# Выражения также можно использовать в функции order_by(), либо напрямую
Company.objects.order_by(Длина('имя').asc())
Company.objects.order_by(Длина('имя').desc())
# или используя синтаксис поиска с двойным подчеркиванием. из django.db.models импортировать CharField
из django.db.models.functions импорт Длина
CharField.register_lookup(Длина)
Company.objects.order_by('name__length')
# Логическое выражение можно использовать непосредственно в фильтрах.
из импорта django.db.models Существует
Компания.объекты.фильтр(
Exists(Employee.objects.filter(company=OuterRef('pk'), зарплата__gt=10))
)
# Выражения поиска также можно использовать непосредственно в фильтрах
Company.objects.filter(GreaterThan(F('num_employees'), F('num_chairs')))
# или аннотации.
Компания.объекты.аннотировать(
need_chairs = больше, чем (F ('количество_сотрудников'), F ('количество стульев')),
)
из django.db.models импортировать CharField
из django.db.models.functions импорт Длина
CharField.register_lookup(Длина)
Company.objects.order_by('name__length')
# Логическое выражение можно использовать непосредственно в фильтрах.
из импорта django.db.models Существует
Компания.объекты.фильтр(
Exists(Employee.objects.filter(company=OuterRef('pk'), зарплата__gt=10))
)
# Выражения поиска также можно использовать непосредственно в фильтрах
Company.objects.filter(GreaterThan(F('num_employees'), F('num_chairs')))
# или аннотации.
Компания.объекты.аннотировать(
need_chairs = больше, чем (F ('количество_сотрудников'), F ('количество стульев')),
)
Встроенные выражения
Примечание
Эти выражения определены в django.db.models.expressions и django.db.models.aggregates , но для удобства они доступны и
обычно импортируется из django.db.models .
F() выражение- класс
F
Объект F() представляет значение поля модели, преобразованное значение
поле модели или аннотированный столбец. Позволяет обращаться к полю модели
значений и выполнять операции с базой данных, используя их без необходимости
вытащить их из базы данных в память Python.
Позволяет обращаться к полю модели
значений и выполнять операции с базой данных, используя их без необходимости
вытащить их из базы данных в память Python.
Вместо этого Django использует объект F() для создания выражения SQL, которое
описывает требуемую операцию на уровне базы данных.
Давайте попробуем это на примере. Обычно можно сделать что-то вроде этого:
# Тинтин подал новость! репортер = Reporters.objects.get(name='Tintin') reporter.stories_filed += 1 репортер.сохранить()
Здесь мы вытащили значение reporter.stories_filed из базы данных.
в память и манипулировал им с помощью знакомых операторов Python, а затем сохранял
объект обратно в базу данных. Но вместо этого мы могли бы также сделать:
из импорта django.db.models F
репортер = Reporters.objects.get(name='Tintin')
reporter.stories_filed = F('stories_filed') + 1
репортер.сохранить()
Хотя reporter.stories_filed = F('stories_filed') + 1 выглядит как
обычное присвоение Python значения атрибуту экземпляра, на самом деле это SQL
конструкция, описывающая операцию над базой данных.
Когда Django встречает экземпляр F() , он переопределяет стандартный Python
операторы для создания инкапсулированного выражения SQL; в данном случае тот, который
инструктирует базу данных увеличить поле базы данных, представленное reporter.stories_filed .
Каким бы ни было значение reporter.stories_filed , Python никогда не доберется до
знать об этом — этим полностью занимается база данных. Все, что делает Python,
через класс Django F() , создайте синтаксис SQL для ссылки на поле
и опишите операцию.
Чтобы получить доступ к новому значению, сохраненному таким образом, необходимо перезагрузить объект:
reporter = Reporters.objects.get(pk=reporter.pk) # Или, более кратко: репортер.refresh_from_db()
Помимо использования в операциях с отдельными экземплярами, как указано выше, F() может
использоваться на QuerySet экземпляров объекта с update() . Это уменьшает
два запроса, которые мы использовали выше —
Это уменьшает
два запроса, которые мы использовали выше — get() и save() — только одному:
reporter = Reporters.objects.filter(name='Tintin')
reporter.update(stories_filed=F('stories_filed') + 1)
Мы также можем использовать update() для увеличения
значение поля для нескольких объектов, что может быть намного быстрее, чем
вытягивая их все в Python из базы данных, перебирая их, увеличивая
значение поля каждого из них и сохранение каждого обратно в базу данных:
Reporter.objects.update(stories_filed=F('stories_filed') + 1)
F() поэтому может предложить преимущества в производительности за счет:
- использования базы данных вместо Python
- сокращение количества запросов, требуемых для некоторых операций
Предотвращение условий гонки с помощью
F() Еще одним полезным преимуществом F() является наличие базы данных, а не
Python — обновить значение поля, чтобы избежать Состояние гонки .
Если два потока Python выполняют код из первого примера выше, один поток может извлекать, увеличивать и сохранять значение поля после того, как другое извлек его из базы данных. Значение, которое сохраняет второй поток, будет на основе первоначального значения; работа первого потока будет потеряна.
Если база данных отвечает за обновление поля, процесс более
надежный: он будет обновлять поле только на основе значения поля в
база данных, когда save() или update() скорее выполняется
чем на основе его значения при извлечении экземпляра.
Использование
F() в фильтрах F() также очень полезно в фильтрах QuerySet , где они делают это
можно фильтровать набор объектов по критериям на основе их поля
значения, а не значения Python.
Это задокументировано при использовании выражений F() в запросах.
Использование
F() с аннотациями F() можно использовать для создания динамических полей в ваших моделях путем объединения
разные поля с арифметикой:
company = Company.
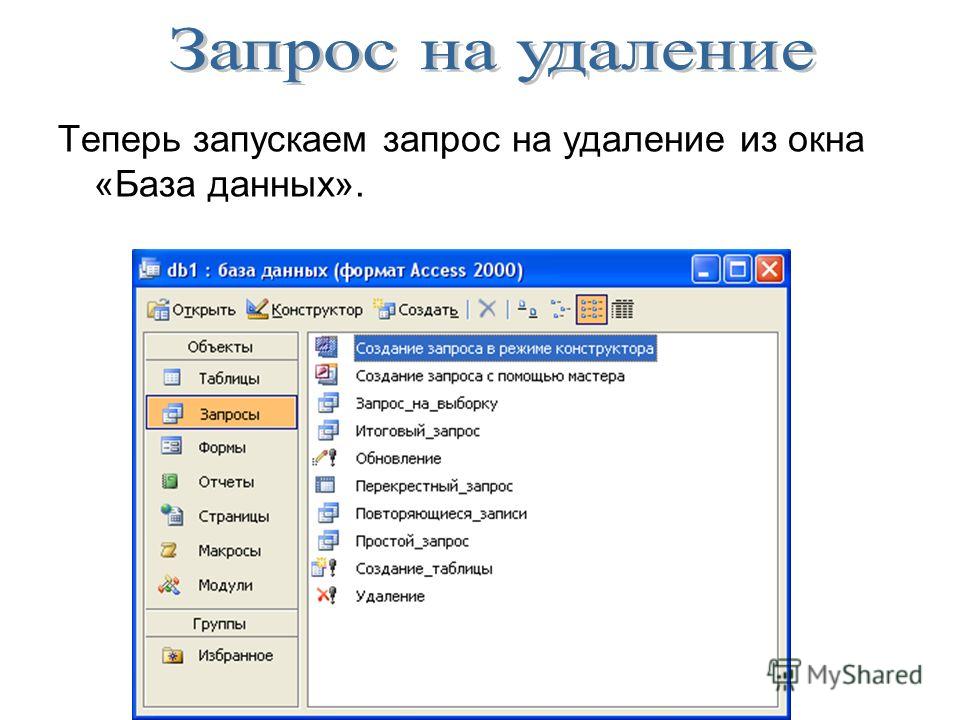 objects.annotate(
Chairs_needed=F('количество_сотрудников') - F('количество_кресел'))
objects.annotate(
Chairs_needed=F('количество_сотрудников') - F('количество_кресел'))
Если поля, которые вы объединяете, относятся к разным типам, вам понадобится
чтобы сообщить Django, какое поле будет возвращено. Поскольку F() не
напрямую поддерживать output_field , вам нужно будет обернуть выражение с помощью ExpressionWrapper :
из импорта django.db.models DateTimeField, ExpressionWrapper, F
Ticket.objects.annotate(
истекает = ExpressionWrapper (
F('active_at') + F('продолжительность'), output_field=DateTimeField()))
При обращении к реляционным полям, таким как ForeignKey , F() возвращает
значение первичного ключа, а не экземпляр модели:
>> car = Company.objects.annotate(built_by=F('производитель'))[0]
>> автомобиль.производитель
<Производитель: Тойота>
>> car.built_by
3
Использование
F() для сортировки нулевых значений Expression. asc() или  asc()
asc() desc() для управления порядком
нулевые значения поля. По умолчанию порядок зависит от вашей базы данных. Например, для сортировки компаний, с которыми не связывались ( last_contacted имеет значение null) после компаний, с которыми связались:
из django.db.models import F
Company.objects.order_by(F('last_contacted').desc(nulls_last=True))
Func() выражений Func() выражений являются базовым типом всех выражений, которые включают
функции базы данных, такие как COALESCE и LOWER , или агрегаты, такие как SUM .
Их можно использовать напрямую:
из django.db.models import F, Func
queryset.annotate (field_lower = Func (F ('поле'), function = 'LOWER'))
или их можно использовать для создания библиотеки функций базы данных:
class Lower(Func):
функция = 'НИЖЕ'
queryset.annotate (field_lower = Ниже ('поле'))
Но оба случая приведут к набору запросов, в котором каждая модель снабжена аннотацией
дополнительный атрибут field_lower получен примерно из следующего SQL:
SELECT
. ..
LOWER("db_table"."field") как "field_lower"
 ..
LOWER("db_table"."field") как "field_lower"
..
LOWER("db_table"."field") как "field_lower"
Список встроенных функций базы данных см. в разделе Функции базы данных.
API Func выглядит следующим образом:
- класс
Func( *выражения , **дополнительно ) -
функция Атрибут класса, описывающий функцию, которая будет создана. В частности, функция
Нет.
- шаблон
Атрибут класса в виде строки формата, который описывает SQL, генерируется для этой функции. По умолчанию
'%(функция)s(%(выражения)s)'.Если вы создаете SQL, например
strftime('%W', 'date')и вам нужен литерал%символ в запросе, учетверить его (%%%%) ватрибут шаблона, потому что строка интерполируется дважды: один раз при интерполяции шаблона вas_sql()и один раз в SQL интерполяция с параметрами запроса в курсоре базы данных.
-
arg_joiner Атрибут класса, обозначающий символ, используемый для присоединения к списку
выраженийвместе. По умолчанию', '.
-
арити Атрибут класса, обозначающий количество аргументов функции. принимает. Если этот атрибут установлен и функция вызывается с разное количество выражений, будет поднято
TypeError. По умолчанию доНет.
-
as_sql(компилятор , соединение , функция = нет , template=Нет , arg_joiner=Нет , **extra_context ) Создает фрагмент SQL для функции базы данных. Возвращает кортеж
(sql, params), гдеsql— это строка SQL, аparams— это список или кортеж параметров запроса.Методы
as_vendor()должны использовать функциюшаблон,arg_joinerи любые другие**extra_contextпараметры для настроить SQL по мере необходимости. Например:django/db/models/functions.pyкласс ConcatPair(Func): ... функция = 'СЦЕПИТЬ' ... def as_mysql (я, компилятор, соединение, ** дополнительный_контекст): вернуть супер().as_sql( компилятор, соединение, функция = 'CONCAT_WS', шаблон="%(функция)s('',%(выражения)s)", **дополнительный_контекст )Чтобы избежать уязвимости SQL-инъекций,
дополнительный_контекстобязательно не содержать ненадежный пользовательский ввод поскольку эти значения интерполируются в строку SQL, а не передаются в качестве параметров запроса, где драйвер базы данных их избегает.
-

 Например:
Например: Аргумент *expressions представляет собой список позиционных выражений, которые
будет применена функция. Выражения будут преобразованы в строки,
объединены вместе с arg_joiner , а затем интерполированы в шаблон как выражений заполнитель.
Позиционные аргументы могут быть выражениями или значениями Python. Строки
предполагается, что это ссылки на столбцы и будут заключены в выражения F() в то время как другие значения будут заключены в выражения Value() .
**extra kwargs — это пар ключ=значение , которые можно интерполировать
в атрибут шаблона . Чтобы избежать уязвимости SQL-инъекций, extra не должен содержать недостоверный пользовательский ввод, так как эти значения интерполируются.
в строку SQL, а не в качестве параметров запроса, где база данных
водитель ускользнет от них.
Для
замените атрибуты с тем же именем, не определяя свои собственные
учебный класс. output_field можно использовать для определения ожидаемого типа возврата.
Aggregate() expressions Агрегированное выражение является частным случаем выражения Func(), которое сообщает запросу, что предложение GROUP BY требуется для. Все агрегатные функции,
нравится
Все агрегатные функции,
нравится Sum() и Count() , наследуется от Aggregate() .
Поскольку Aggregate являются выражениями и переносными выражениями, вы можете представить
некоторые сложные вычисления:
из django.db.models import Count
Компания.объекты.аннотировать(
manager_required=(Count('num_employees') / 4) + Count('num_managers'))
API Aggregate выглядит следующим образом:
- класс
Агрегат( *выражения , output_field=Нет , отличные=Ложь , фильтр=Нет , по умолчанию=Нет , **дополнительно ) - шаблон
Атрибут класса в виде строки формата, который описывает SQL, генерируется для этого агрегата. По умолчанию
'%(функция)s(%(различные)s%(выражения)s)'.
-
функция Атрибут класса, описывающий агрегатную функцию, которая будет сгенерировано.
В частности, функциябудет интерполирована какфункциязаполнитель в шаблонеНет.
-
совместимый с окном По умолчанию
True, так как большинство агрегатных функций можно использовать в качестве исходное выражение вWindow.
-
разрешить_различное Атрибут класса, определяющий, будет ли эта агрегатная функция позволяет пройти
отдельный аргумент ключевого слова. Если установлено значениеFalse(по умолчанию),TypeErrorвозникает, если передаетсяDifferent=True.
-
empty_result_set_value Новое в Django 4.0.
По умолчанию
Нет, так как большинство агрегатных функций даютNULLпри применении к пустому набору результатов.
- шаблон
 В частности,
В частности, выражений позиционных аргументов могут включать выражения, преобразования
поле модели или имена полей модели. Они будут преобразованы в
строка и используется как
Они будут преобразованы в
строка и используется как выражений заполнитель в шаблоне .
Для аргумента output_field требуется экземпляр поля модели, например IntegerField() или BooleanField() , в который Django загрузит значение
после извлечения из базы данных. Обычно аргументы не нужны, когда
создание экземпляра поля модели в качестве любых аргументов, относящихся к проверке данных
( max_length , max_digits и т. д.) не будут применяться к выражениям
выходное значение.
Обратите внимание, что output_field требуется только в том случае, если Django не может определить
какой тип поля должен быть результатом. Сложные выражения, которые смешивают типы полей
должен определить желаемое output_field . Например, добавление IntegerField() и FloatField() вместе, вероятно, должны иметь output_field=FloatField() определено.
Аргумент Different определяет, будет ли агрегатная функция
следует вызывать для каждого отдельного значения выражений (или набор
значения, для нескольких выражений ). Аргумент поддерживается только на
агрегаты, у которых allow_distinct установлено на True .
Аргумент filter принимает объект Q , который
используется для фильтрации строк, которые агрегируются. См. Условная агрегация
и Фильтрация аннотаций, например использование.
Аргумент по умолчанию принимает значение, которое будет передано вместе с
суммировать до Слияние . Это полезно для
указание возвращаемого значения, отличного от Нет , когда набор запросов (или
группировка) не содержит записей.
**extra kwargs — это пар ключ=значение , которые можно интерполировать
в атрибут шаблона .
Изменено в Django 4. 0:
0:
Добавлен аргумент по умолчанию .
Создание собственных агрегатных функций
Вы также можете создавать собственные агрегатные функции. Как минимум, вам нужно
определить функция , но вы также можете полностью настроить SQL, который
сгенерировано. Вот краткий пример:
из django.db.models import Aggregate
Сумма класса (агрегат):
# Поддерживает СУММУ (ВСЕ поля).
функция = 'СУММ'
шаблон = '%(функция)s(%(все_значения)s%(выражения)s)'
allow_distinct = Ложь
def __init__(я, выражение, all_values=False, **дополнительно):
супер().__инициализация__(
выражение,
all_values = 'ВСЕ ', если all_values еще '',
**дополнительный
)
Значение() выражение- класс
Значение( значение , output_field=None )
Объект Value() представляет наименьший возможный компонент
выражение: простое значение. Когда вам нужно представить значение целого числа,
логическое значение или строку в выражении, вы можете обернуть это значение в
Когда вам нужно представить значение целого числа,
логическое значение или строку в выражении, вы можете обернуть это значение в Значение() .
Вам редко придется использовать Value() напрямую. Когда вы пишете выражение F('field') + 1 , Django неявно заключает 1 в Value() ,
позволяет использовать простые значения в более сложных выражениях. Вам нужно будет
используйте Value() , когда вы хотите передать строку выражению. Самый
выражения интерпретируют строковый аргумент как имя поля, например Нижний('имя') .
Аргумент value описывает значение, которое должно быть включено в выражение,
например 1 , Правда или Нет . Django знает, как конвертировать эти Python
значения в соответствующий тип базы данных.
Аргумент output_field должен быть экземпляром поля модели, например IntegerField() или BooleanField() , в который Django загрузит значение
после извлечения из базы данных. Обычно аргументы не нужны, когда
создание экземпляра поля модели в качестве любых аргументов, относящихся к проверке данных
(
Обычно аргументы не нужны, когда
создание экземпляра поля модели в качестве любых аргументов, относящихся к проверке данных
( макс_длина , max_digits и т. д.) не будут применяться к выражениям.
выходное значение. Если output_field не указано, это будет предварительно
выводится из типа предоставленного значения , если это возможно. За
например, передача экземпляра datetime.datetime как значения по умолчанию от output_field до DateTimeField .
ExpressionWrapper() выражение- класс
ExpressionWrapper( выражение , output_field )
ExpressionWrapper окружает другое выражение и обеспечивает доступ к
свойства, такие как output_field , которые могут быть недоступны на других
выражения. ExpressionWrapper необходим при использовании арифметики на F() выражение с разными типами, как описано в
Использование F() с аннотациями.
Условные выражения
Условные выражения позволяют использовать , если … elif … еще логика в запросах. Django изначально поддерживает SQL CASE .
выражения. Дополнительные сведения см. в разделе Условные выражения.
Подзапрос() выражение- класс
Подзапрос( набор запросов , output_field=None )
Вы можете добавить явный подзапрос к QuerySet с помощью Подзапрос выражение.
Например, чтобы аннотировать каждое сообщение адресом электронной почты автора последний комментарий к этому сообщению:
>>> from django.db.models import OuterRef, Subquery
>>> новейший = Comment.objects.filter(post=OuterRef('pk')).order_by('-created_at')
>>> Post.objects.annotate(newest_commenter_email=Subquery(newest.values('email')[:1]))
В PostgreSQL SQL выглядит следующим образом:
SELECT "post".
 "id", (
ВЫБЕРИТЕ U0."электронная почта"
ИЗ "комментарий" U0
ГДЕ U0."post_id" = ("сообщение"."id")
ЗАКАЗАТЬ ПО U0."created_at" DESC LIMIT 1
) AS "newest_commenter_email" FROM "post"
"id", (
ВЫБЕРИТЕ U0."электронная почта"
ИЗ "комментарий" U0
ГДЕ U0."post_id" = ("сообщение"."id")
ЗАКАЗАТЬ ПО U0."created_at" DESC LIMIT 1
) AS "newest_commenter_email" FROM "post"
Примечание
Примеры в этом разделе предназначены для того, чтобы показать, как Django для выполнения подзапроса. В некоторых случаях может оказаться возможным написать эквивалентный набор запросов, который выполняет ту же задачу больше четко или эффективно.
Ссылки на столбцы из внешнего набора запросов
- класс
OuterRef( поле )
Используйте OuterRef , когда набор запросов в подзапросе должен ссылаться на поле
из внешнего запроса или его преобразования. Он действует как F выражение
за исключением того, что проверка, чтобы увидеть, относится ли оно к допустимому полю, не выполняется до тех пор, пока
внешний набор запросов разрешен.
Экземпляры OuterRef могут использоваться вместе с вложенными экземплярами
из Подзапрос для ссылки на содержащий набор запросов, который не является непосредственным
родитель.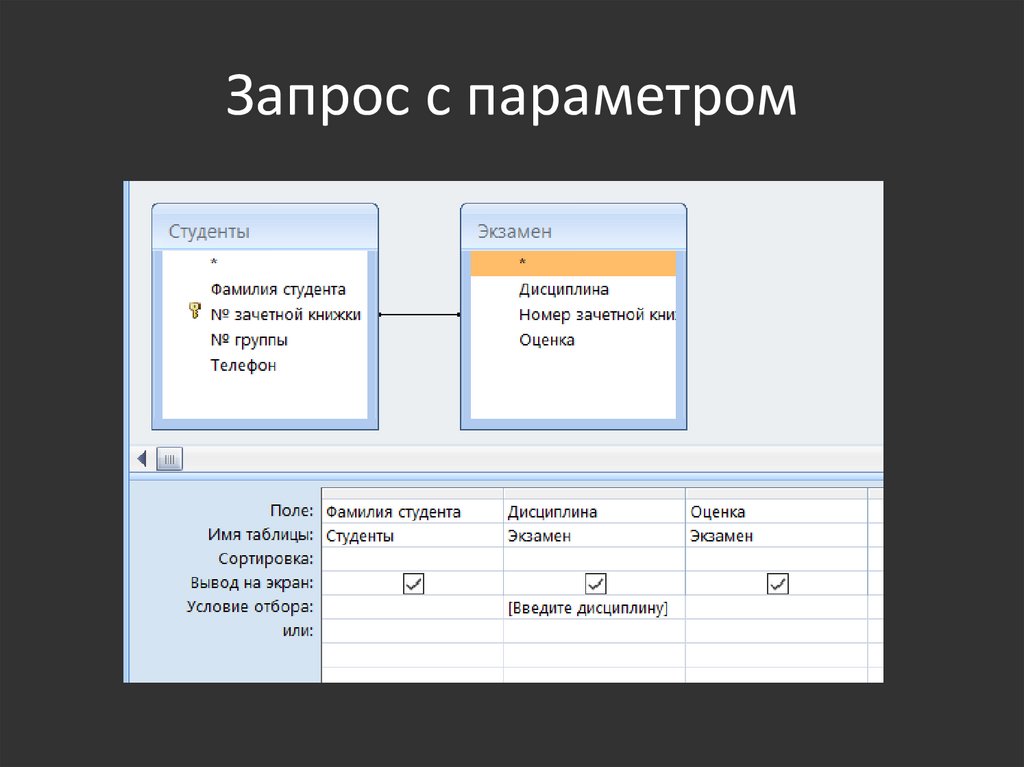 Например, этот набор запросов должен находиться во вложенной паре
Например, этот набор запросов должен находиться во вложенной паре Подзапрос экземпляров для правильного разрешения:
>>> Book.objects.filter(author=OuterRef(OuterRef('pk')))
Exists() подзапрос- класс
Существует( набор запросов )
Exists — это подкласс Subquery , который использует оператор SQL EXISTS . В
во многих случаях он будет работать лучше, чем подзапрос, поскольку база данных способна
остановить оценку подзапроса, когда будет найдена первая совпадающая строка.
Например, чтобы аннотировать каждое сообщение, есть ли у него комментарий от за последние сутки:
>>> из импорта django.db.models Exists, OuterRef >>> из datetime импортировать timedelta >>> из django.utils импортировать часовой пояс >>> one_day_ago = timezone.now() - timedelta(days=1) >>> недавние_комментарии = Комментарий.объекты.фильтр( .
 .. post=OuterRef('pk'),
... created_at__gte=one_day_ago,
... )
>>> Post.objects.annotate(recent_comment=Exists(recent_comments))
.. post=OuterRef('pk'),
... created_at__gte=one_day_ago,
... )
>>> Post.objects.annotate(recent_comment=Exists(recent_comments))
В PostgreSQL SQL выглядит так:
SELECT "post"."id", "post"."published_at", EXISTS(
ВЫБЕРИТЕ (1) как "а"
ИЗ "комментарий" U0
КУДА (
U0."created_at" >= ГГГГ-ММ-ДД ЧЧ:ММ:СС И
U0."post_id" = "сообщение"."id"
)
ПРЕДЕЛ 1
) AS "recent_comment" FROM "post"
Нет необходимости заставлять Exists ссылаться на один столбец, так как
столбцы отбрасываются и возвращается логический результат. Точно так же, поскольку
порядок не важен в подзапросе SQL EXISTS и будет только
снижают производительность, он автоматически удаляется.
Вы можете запросить, используя NOT EXISTS с ~Exists() .
Фильтрация по
Subquery() или Exists() выражения Subquery() , который возвращает логическое значение, и Exists() может использоваться как условие в Когда выражений или для
напрямую фильтровать набор запросов:
>>> Recent_comments = Comment.
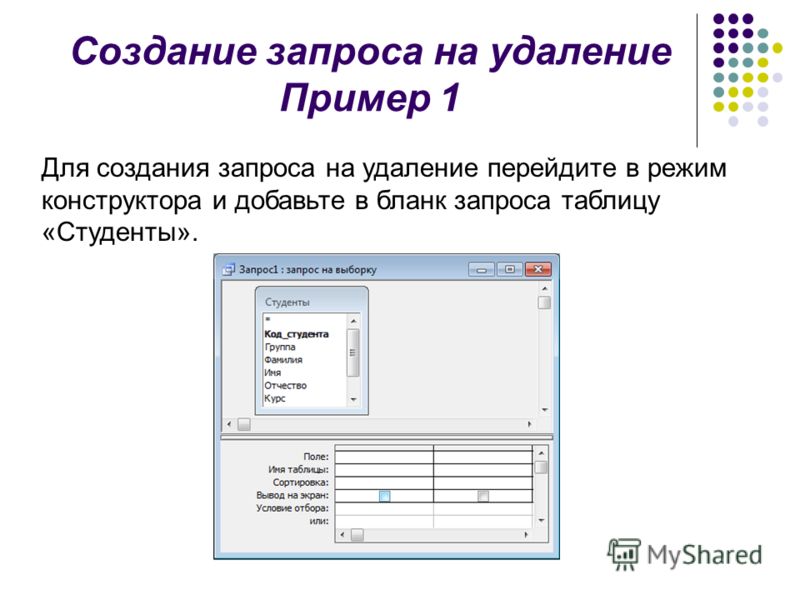 objects.filter(...) # Сверху
>>> Post.objects.filter(Exists(recent_comments))
objects.filter(...) # Сверху
>>> Post.objects.filter(Exists(recent_comments))
Это гарантирует, что подзапрос не будет добавлен в столбцы SELECT ,
что может привести к лучшей производительности.
Использование агрегатов в пределах
Подзапрос выражение Агрегаты могут использоваться в рамках Подзапроса , но они требуют специального
комбинация filter() , values() и annotate() для правильной группировки подзапросов.
Предполагая, что обе модели имеют поле длины , чтобы найти сообщения, в которых сообщение
длина больше, чем общая длина всех объединенных комментариев:
>>> from django.db.models import OuterRef, Subquery, Sum
>>> comments = Comment.objects.filter(post=OuterRef('pk')).order_by().values('post')
>>> total_comments = comments.annotate(total=Sum('длина')).values('total')
>>> Post.objects.filter(length__gt=Подзапрос(всего_комментариев))
Начальный filter(. ограничивает подзапрос соответствующими параметрами.  ..)
..) order_by() удаляет стандартное упорядочивание (если есть) на Комментарий модели . values('post') объединяет комментарии по Пост . Наконец, annotate(...) выполняет агрегацию. Порядок в
то, какие методы набора запросов применяются, важно. В этом случае, поскольку
подзапрос должен быть ограничен одним столбцом, значений («всего») требуется.
Это единственный способ выполнить агрегацию внутри подзапроса , т.к.
используя агрегат() пытается оценить набор запросов (и если
есть OuterRef , это решить не получится).
Необработанные выражения SQL
- класс
RawSQL( sql , параметры , output_field=None )
Иногда выражения базы данных не могут легко выразить сложные ГДЕ статья. В этих крайних случаях используйте выражение
В этих крайних случаях используйте выражение RawSQL . Например:
>>> из django.db.models.expressions импортировать RawSQL
>>> queryset.annotate(val=RawSQL("выберите col from sometable, где othercol = %s", (param,)))
Эти дополнительные операции поиска могут быть не переносимы на другие механизмы баз данных (поскольку вы явно пишете код SQL) и нарушаете принцип DRY, поэтому вы следует избегать их, если это возможно.
RawSQL 9Выражения 0501 также можно использовать в качестве цели фильтров __in :
>>> queryset.filter(id__in=RawSQL("выбрать идентификатор из какой-либо таблицы, где col = %s", (param,)))
Предупреждение
Для защиты от атак путем внедрения кода SQL необходимо избегать любых
параметры, которыми пользователь может управлять с помощью params . параметров это
обязательный аргумент, чтобы заставить вас признать, что вы не интерполируете
ваш SQL с предоставленными пользователем данными.
Вы также не должны заключать в кавычки заполнители в строке SQL. Этот пример
уязвим для SQL-инъекций из-за кавычек около %s :
RawSQL("выберите col from sometable where othercol = '%s'") # небезопасно!
Вы можете узнать больше о том, как работает защита от SQL-инъекций Django.
Оконные функции
Оконные функции позволяют применять функции к разделам. В отличие от нормальная функция агрегирования, которая вычисляет окончательный результат для каждого определенного набора по группе by, оконные функции работают с фреймами и разделы и вычислить результат для каждой строки.
Вы можете указать несколько окон в одном запросе, который в Django ORM был бы эквивалентно включению нескольких выражений в вызов QuerySet.annotate(). ORM не использует именованные окна, вместо этого они являются частью выбранных столбцов.
- класс
Окно( выражение , partition_by = нет , order_by = нет , кадр = нет , output_field = нет ) -
фильтруемый По умолчанию
Ложь. Стандарт SQL запрещает ссылаться на окно
функции в предложении WHERE, и Django вызывает исключение, когда созданиеQuerySet, который сделает это.
- шаблон
По умолчанию
%(выражение)s OVER (%(окно)s)'. Если тольковыражениеаргумент предоставляется, предложение окна будет пустым.
-
 Стандарт SQL запрещает ссылаться на окно
функции в предложении
Стандарт SQL запрещает ссылаться на окно
функции в предложении Класс Window является основным выражением для предложения OVER .
Аргумент выражения является оконной функцией, агрегатной функцией или
выражение, совместимое с предложением окна.
Аргумент partition_by принимает выражение или последовательность
выражения (имена столбцов должны быть заключены в объект F ), которые управляют
разделение строк. Разделение сужает, какие строки используются для
вычислить результирующий набор.
output_field указывается либо как аргумент, либо как выражение.
Аргумент order_by принимает выражение, по которому можно вызвать по восходящей() и по убыванию() , строка имени поля (с
необязательный префикс "-" , который указывает порядок убывания), или кортеж, или список
строк и/или выражений. Порядок управляет порядком, в котором
применяется выражение. Например, если вы суммируете строки в разделе,
первый результат - это значение первой строки, второй - сумма первых
и второй ряд.
Параметр кадра указывает, какие другие строки следует использовать в
вычисление. Подробнее см. в разделе Рамки.
Изменено в Django 4.1:
Добавлена поддержка order_by по ссылкам на имена полей.
Например, чтобы аннотировать каждый фильм средним рейтингом фильмов по та же студия в том же жанре и году выпуска:
>>> from django.db.models import Avg, F, Window
>>> Movie.objects.annotate(
>>> avg_rating=Окно(
>>> выражение=среднее('рейтинг'),
>>> partition_by=[F('студия'), F('жанр')],
>>> order_by='год выпуска__',
>>> ),
>>> )
Это позволяет вам проверить, лучше или хуже рейтинг фильма, чем у его аналогов.
Вы можете применить несколько выражений к одному и тому же окну, т. е. такая же перегородка и рамка. Например, вы можете изменить предыдущий пример чтобы также включить лучший и худший рейтинг в каждой группе фильмов (одна студия, жанр и год выпуска) с помощью трех оконных функций в одном запросе. раздел и порядок из предыдущего примера извлекаются в словарь чтобы уменьшить количество повторений:
>>> из django.db.models import Avg, F, Max, Min, Window
>>> окно = {
>>> 'partition_by': [F('студия'), F('жанр')],
>>> 'order_by': 'выпущен__год',
>>> }
>>> Movie.objects.annotate(
>>> avg_rating=Окно(
>>> выражение=среднее('рейтинг'), **окно,
>>> ),
>>> лучшее=окно(
>>> выражение=Макс('рейтинг'), **окно,
>>> ),
>>> худшее=окно(
>>> выражение=мин('рейтинг'), **окно,
>>> ),
>>> )
Среди встроенных серверных частей базы данных Django MySQL 8.0.2+, PostgreSQL и Oracle
поддержка оконных выражений. Поддержка различных функций выражения окна
варьируется в разных базах данных. Например, варианты в
Например, варианты в по восходящей() и desc() может не поддерживаться. Проконсультируйтесь с
документацию для вашей базы данных по мере необходимости.
Рамки
Для оконной рамы можно выбрать либо последовательность строк на основе диапазона, либо обычная последовательность строк.
- class
ValueRange( start=None , end=None ) -
тип_фрейма Этот атрибут имеет значение
'RANGE'.
PostgreSQL имеет ограниченную поддержку
ValueRangeи поддерживает только использование стандартные начальная и конечная точки, такие какCURRENT ROWиUNBOUNDED СЛЕДУЮЩИЕ.-
- класс
RowRange( начало = нет , конец = нет ) -
тип_фрейма Для этого атрибута установлено значение
'ROWS'.
-

Оба класса возвращают SQL с шаблоном:
%(frame_type)s МЕЖДУ %(start)s И %(end)s
Фреймы сужают строки, используемые для вычисления результата. Они переходят от некоторая начальная точка до некоторой заданной конечной точки. Рамки можно использовать с и без разделов, но часто полезно указать порядок окно для обеспечения детерминированного результата. Во фрейме пиром во фрейме является строка с эквивалентным значением или со всеми строками, если условие упорядочения отсутствует.
Начальной точкой кадра по умолчанию является UNBOUNDED PRECEDING , что является
первый ряд перегородки. Конечная точка всегда явно включается в
SQL генерируется ORM и по умолчанию имеет значение UNBOUNDED FOLLOWING . По умолчанию
кадр включает все строки от раздела до последней строки в наборе.
Допустимые значения для аргументов start и end : Нет ,
целое число или ноль. Отрицательное целое число для
Отрицательное целое число для начало приводит к Н перед ,
в то время как None дает UNBOUNDED PRECEDING . Для начало и конец ,
ноль вернет ТЕКУЩАЯ СТРОКА . Положительные целые числа принимаются для и .
Есть разница в том, что включает CURRENT ROW . Когда указано в ROWS В режиме кадр начинается или заканчивается текущей строкой. Когда указано в RANGE В режиме кадр начинается или заканчивается на первом или последнем узле в соответствии с
оговорка о заказе. Таким образом, RANGE CURRENT ROW оценивает выражение для
строки, которые имеют одно и то же значение, указанное в порядке. Потому что шаблон
включает начальных и конечных точек, это может быть выражено с помощью:
ValueRange(start=0, end=0)
Если «аналогами» фильма являются фильмы, выпущенные одной и той же студией в
того же жанра в том же году, этот пример RowRange аннотирует каждый фильм
со средним рейтингом двух предыдущих и двух последующих аналогов фильма:
>>> из django.
 db.models импортировать Avg, F, RowRange, Window
>>> Movie.objects.annotate(
>>> avg_rating=Окно(
>>> выражение=среднее('рейтинг'),
>>> partition_by=[F('студия'), F('жанр')],
>>> order_by='год выпуска__',
>>> кадр=RowRange(начало=-2, конец=2),
>>> ),
>>> )
db.models импортировать Avg, F, RowRange, Window
>>> Movie.objects.annotate(
>>> avg_rating=Окно(
>>> выражение=среднее('рейтинг'),
>>> partition_by=[F('студия'), F('жанр')],
>>> order_by='год выпуска__',
>>> кадр=RowRange(начало=-2, конец=2),
>>> ),
>>> )
Если база данных поддерживает это, вы можете указать начальную и конечную точки на основе
значения выражения в разделе. Если выпущено поле
Модель Movie хранит месяц выпуска каждого фильма, это ValueRange пример аннотирует каждый фильм средним рейтингом аналогов фильма
выпущено между двенадцатью месяцами до и двенадцатью месяцами после каждого фильма:
>>> from django.db.models import Avg, F, ValueRange, Window
>>> Movie.objects.annotate(
>>> avg_rating=Окно(
>>> выражение=среднее('рейтинг'),
>>> partition_by=[F('студия'), F('жанр')],
>>> order_by='год выпуска__',
>>> frame=ValueRange(начало=-12, конец=12),
>>> ),
>>> )
Техническая информация
Ниже вы найдете детали технической реализации, которые могут быть полезны
авторы библиотеки. Технический API и приведенные ниже примеры помогут
создание общих выражений запросов, которые могут расширить встроенную функциональность
который предоставляет Джанго.
Технический API и приведенные ниже примеры помогут
создание общих выражений запросов, которые могут расширить встроенную функциональность
который предоставляет Джанго.
Expression API
Выражения запроса реализуют API выражения запроса,
но также предоставляет ряд дополнительных методов и атрибутов, перечисленных ниже. Все
выражения запросов должны наследовать от Expression() или соответствующий
подкласс.
Когда выражение запроса включает в себя другое выражение, оно отвечает за вызов соответствующих методов для обернутого выражения.
- класс
Выражение -
содержит_агрегат Сообщает Django, что это выражение содержит агрегат и что
Предложение GROUP BYнеобходимо добавить в запрос.
-
contains_over_clause Сообщает Джанго, что это выражение содержит
Выражение окна. Он используется, например, чтобы запретить выражения оконных функций в запросах, которые изменить данные.
-
фильтруемый Сообщает Django, что на это выражение можно ссылаться в
QuerySet.filter(). По умолчаниюTrue.
-
совместимый с окном Сообщает Django, что это выражение можно использовать в качестве исходного выражения в
Окно. По умолчаниюЛожь.
-
empty_result_set_value Новое в Django 4.0.
Сообщает Django, какое значение должно быть возвращено при использовании выражения чтобы применить функцию к пустому набору результатов. По умолчанию
NotImplemented, который принудительно вычисляет выражение для базу данных.
-
resolve_expression( запрос = Нет , allow_joins = Истина , повторное использование = нет , итог = ложь , for_save = ложь ) Дает возможность выполнить любую предварительную обработку или проверку выражение перед его добавлением в запрос.
разрешение_выражения()также должен вызываться для любых вложенных выражений. Копия()изсебядолжен быть возвращен с любыми необходимыми преобразованиями.запрос— это реализация внутреннего запроса.разрешить_присоединения— логическое значение, разрешающее или запрещающее использование присоединяется к запросу.повторное использование— это набор повторно используемых объединений для сценариев с несколькими соединениями.summary— логическое значение, которое, когдаTrue, сигнализирует о том, что вычисляемый запрос является терминальным совокупным запросом.for_save— это логическое значение, которое приTrueсигнализирует о том, что запрос выполняется, выполняет создание или обновление.
-
get_source_expressions() Возвращает упорядоченный список внутренних выражений.
Например:>>> Сумма(F('foo')).get_source_expressions() [Ф('фу')]
-
set_source_expressions( выражений ) Берет список выражений и сохраняет их так, чтобы
get_source_expressions()может вернуть их.
-
relabeled_clone( change_map ) Возвращает клон (копию)
selfс переименованными псевдонимами столбцов. Псевдонимы столбцов переименовываются при создании подзапросов.relabeled_clone()также следует вызывать для любых вложенных выражений. и присвоен клону.change_map— это словарь, сопоставляющий старые псевдонимы с новыми псевдонимами.Пример:
по определению relabeled_clone(self, change_map): клон = копировать.копировать(я) clone.expression = self.expression.relabeled_clone(change_map) вернуть клон
-
convert_value( значение , выражение , соединение ) Ловушка, позволяющая выражению преобразовать
значениев более соответствующий тип.выражениетакое же, какself.
-
get_group_by_cols( псевдоним = нет ) Отвечает за возврат списка ссылок на столбцы это выражение.
get_group_by_cols()следует вызывать на любом вложенные выражения.F()объектов, в частности, содержат ссылку к столбцу. Параметрaliasбудет иметь значениеNone, если только выражение было аннотировано и используется для группировки.
-
по возрастанию( nulls_first = нет , nulls_last = нет ) Возвращает выражение, готовое к сортировке в порядке возрастания.
nulls_firstиnulls_lastопределяют, как сортируются нулевые значения. См. Использование F() для сортировки нулевых значений для примера использования.Изменено в Django 4.1:
В более старых версиях
nulls_firstиnulls_lastпо умолчаниюЛожь.Устарело, начиная с версии 4.1: передача
nulls_first=Falseилиnulls_last=Falseвasc()устарела. Вместо этого используйтеNone.
-
desc( nulls_first=Нет , nulls_last=Нет ) Возвращает выражение, готовое к сортировке в порядке убывания.
nulls_firstиnulls_lastопределяют, как сортируются нулевые значения. См. Использование F() для сортировки нулевых значений для примера использования.Изменено в Django 4.1:
В более старых версиях
nulls_firstиnulls_lastпо умолчаниюЛожь.Устарело, начиная с версии 4.1: переход
nulls_first=ложьилиnulls_last=ложь отдоdesc()устарела. Вместо этого используйтеNone.
-
обратный_заказ() Возвращает
selfс любыми изменениями, необходимыми для обратной сортировки заказ в рамках вызоваorder_by. Например, выражение
реализация NULLS LASTизменит его значение наНУЛИ ПЕРВЫЕ. Модификации требуются только для выражений, которые реализовать порядок сортировки, напримерЗаказПо. Этот метод вызывается, когдаreverse()вызывается на набор запросов.
-
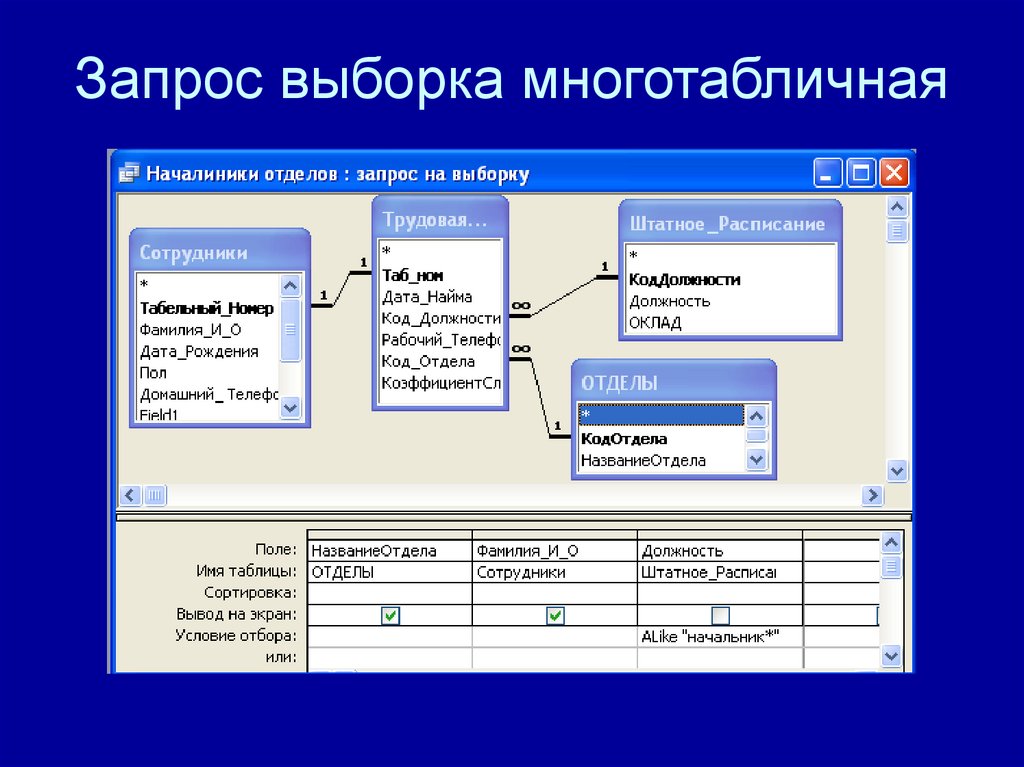
 Например:
Например:

 Например, выражение
реализация
Например, выражение
реализация Написание собственных выражений запросов
Вы можете написать свои собственные классы выражений запросов, которые используют и могут интегрировать
с другими выражениями запроса. Давайте рассмотрим пример, написав
реализация функции COALESCE SQL, без использования встроенного
Выражения Func().
Функция SQL COALESCE определяется как получение списка столбцов или
ценности. Он вернет первый столбец или значение, которое не равно 9.0500 НОЛЬ .
Мы начнем с определения шаблона, который будет использоваться для генерации SQL и
метод __init__() для установки некоторых атрибутов:
импортировать копию из выражения импорта django.
 db.models
класс Coalesce (выражение):
template = 'ОБЪЕДИНИТЬ (% (выражения) s)'
def __init__(self, expressions, output_field):
super().__init__(output_field=output_field)
если len(выражения) < 2:
поднять ValueError('выражения должны иметь не менее 2 элементов')
для выражения в выражениях:
если не hasattr(выражение, 'resolve_expression'):
поднять TypeError('%r не является выражением'% выражение)
self.expressions = выражения
db.models
класс Coalesce (выражение):
template = 'ОБЪЕДИНИТЬ (% (выражения) s)'
def __init__(self, expressions, output_field):
super().__init__(output_field=output_field)
если len(выражения) < 2:
поднять ValueError('выражения должны иметь не менее 2 элементов')
для выражения в выражениях:
если не hasattr(выражение, 'resolve_expression'):
поднять TypeError('%r не является выражением'% выражение)
self.expressions = выражения
Мы проводим базовую проверку параметров, в том числе требуем как минимум
2 столбца или значения и убедитесь, что они являются выражениями. Мы требуем output_field здесь, чтобы Django знал, какое поле модели назначить
конечный результат к.
Теперь мы реализуем предварительную обработку и проверку. Так как у нас нет любую нашу собственную проверку на этом этапе мы делегируем вложенному выражения:
def resolve_expression (self, query = None, allow_joins = True, reuse = None, summary = False, for_save = False):
с = self. copy()
c.is_summary = суммировать
для pos, выражение в enumerate(self.expressions):
c.expressions[pos] = выражение.resolve_expression(запрос, allow_joins, повторное использование, суммирование, for_save)
вернуться с
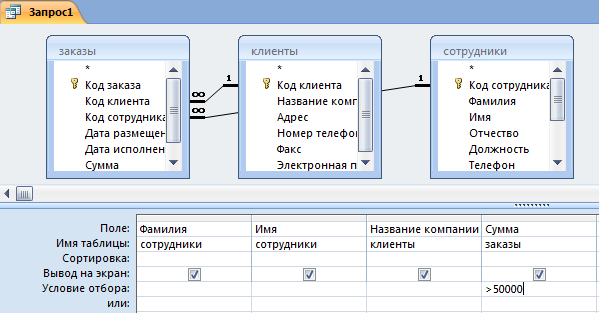 copy()
c.is_summary = суммировать
для pos, выражение в enumerate(self.expressions):
c.expressions[pos] = выражение.resolve_expression(запрос, allow_joins, повторное использование, суммирование, for_save)
вернуться с
copy()
c.is_summary = суммировать
для pos, выражение в enumerate(self.expressions):
c.expressions[pos] = выражение.resolve_expression(запрос, allow_joins, повторное использование, суммирование, for_save)
вернуться с
Далее пишем метод, отвечающий за генерацию SQL:
def as_sql(self,compiler,connection,template=None):
sql_expressions, sql_params = [], []
для выражения в self.expressions:
sql, params = компилятор.компиляция(выражение)
sql_expressions.append(sql)
sql_params.extend (параметры)
шаблон = шаблон или self.template
данные = {'выражения': ','.join(sql_expressions)}
вернуть данные шаблона%, sql_params
def as_oracle (я, компилятор, соединение):
"""
Пример обработки, специфичной для поставщика (в данном случае Oracle).
Сделаем имя функции строчным.
"""
return self.as_sql (компилятор, соединение, шаблон = 'coalesce (% (выражения) s)')
Методы as_sql() могут поддерживать пользовательские аргументы ключевых слов, что позволяет as_vendorname() методов для переопределения данных, используемых для генерации строки SQL. Использование
Использование аргументов ключевого слова as_sql() для настройки предпочтительнее, чем
мутирование self в пределах методов as_vendorname() , так как последнее может привести к
ошибки при работе с разными базами данных. Если ваш класс опирается на
атрибуты класса для определения данных, рассмотрите возможность переопределения в вашем метод as_sql() .
Мы генерируем SQL для каждого из выражений с помощью compile.compile() и соедините результат запятыми.
Затем шаблон заполняется нашими данными и SQL и параметрами
возвращаются.
Мы также определили пользовательскую реализацию, специфичную для Oracle
бэкенд. Функция as_oracle() будет вызываться вместо as_sql() если используется серверная часть Oracle.
Наконец, мы реализуем остальные методы, которые позволяют нашему выражению запроса чтобы хорошо сочетаться с другими выражениями запроса:
def get_source_expressions(self):
вернуть самовыражение
def set_source_expressions (я, выражения):
self. expressions = выражения
 expressions = выражения
expressions = выражения
Давайте посмотрим, как это работает:
>>> from django.db.models import F, Value, CharField
>>> qs = Company.objects.annotate(
... tagline=Объединить([
... F('девиз'),
... F('имя_тикера'),
... F('описание'),
... Значение('Без слогана')
...], output_field=CharField()))
>>> для c в qs:
... print("%s: %s" % (c.name, c.tagline))
...
Гугл: не делай зла
Яблоко: ААПЛ
Yahoo: интернет-компания
Django Software Foundation: Без слогана
Предотвращение внедрения SQL
Поскольку аргументы ключевого слова Func для __init__() ( **extra ) и as_sql() ( **extra_context ) скорее интерполируются в строку SQL
чем передается в качестве параметров запроса (где драйвер базы данных их избегает),
они не должны содержать ненадежный пользовательский ввод.
Например, если подстрока предоставлена пользователем, эта функция уязвима для
SQL-инъекция:
из django.
 db.models импортировать Func
Позиция класса (Функция):
функция = 'ПОЗИЦИЯ'
template = "%(функция)s('%(подстрока)s' в %(выражениях)s)"
def __init__(я, выражение, подстрока):
# substring=substring — это уязвимость SQL-инъекций!
super().__init__(выражение, подстрока=подстрока)
db.models импортировать Func
Позиция класса (Функция):
функция = 'ПОЗИЦИЯ'
template = "%(функция)s('%(подстрока)s' в %(выражениях)s)"
def __init__(я, выражение, подстрока):
# substring=substring — это уязвимость SQL-инъекций!
super().__init__(выражение, подстрока=подстрока)
Эта функция генерирует строку SQL без каких-либо параметров. С подстрока передается в super().__init__() в качестве ключевого аргумента, это
интерполируется в строку SQL перед отправкой запроса в базу данных.
Вот исправленное переписывание:
class Position(Func):
функция = 'ПОЗИЦИЯ'
arg_joiner = 'В '
def __init__(я, выражение, подстрока):
super().__init__(подстрока, выражение)
Если вместо подстрока передается в качестве позиционного аргумента, она будет передана как
параметр в запросе к базе данных.
Добавление поддержки в серверные части сторонних баз данных
Если вы используете серверную часть базы данных, использующую другой синтаксис SQL для
определенную функцию, вы можете добавить поддержку для нее, исправив новый метод
на класс функции.
Допустим, мы пишем бэкенд для Microsoft SQL Server, который использует SQL LEN вместо LENGTH для функции Length .
Мы пропатчим новый метод с именем as_sqlserver() на Length .
класс:
из django.db.models.functions import Длина
def sqlserver_length (я, компилятор, соединение):
вернуть self.as_sql (компилятор, соединение, функция = 'LEN')
Длина.as_sqlserver = длина_sqlserver
Вы также можете настроить SQL, используя параметр шаблона as_sql() .
Мы используем as_sqlserver() , потому что django.db.connection.vendor возвращает sqlserver для серверной части.
Сторонние серверные части могут регистрировать свои функции на верхнем уровне __init__.py файл внутреннего пакета или на верхнем уровне expressions.py файл (или пакет), импортированный с верхнего уровня __init__. .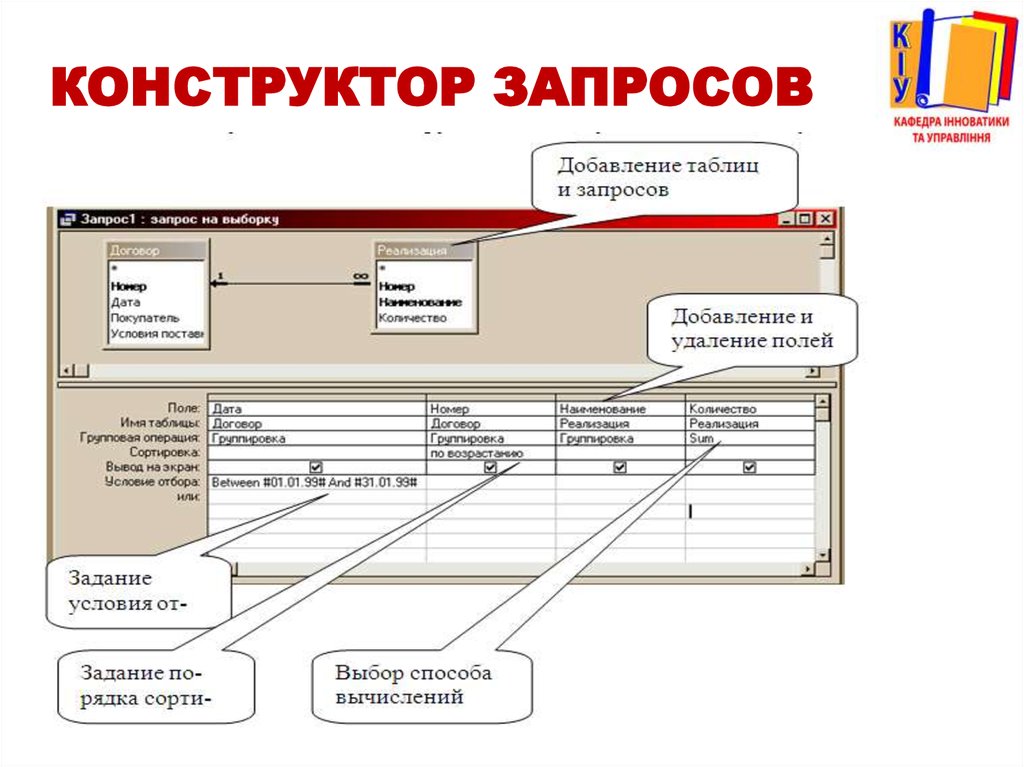 py
py
Для пользовательских проектов, желающих исправить используемую ими серверную часть, этот код должен находиться в методе AppConfig.ready() .
Схемы и типы | GraphQL
На этой странице вы узнаете все, что вам нужно знать о системе типов GraphQL и о том, как она описывает, какие данные можно запрашивать. Поскольку GraphQL можно использовать с любым внутренним фреймворком или языком программирования, мы не будем вдаваться в детали реализации и поговорим только о концепциях.
Введите system#
Если вы уже видели запрос GraphQL, вы знаете, что язык запросов GraphQL в основном предназначен для выбора полей в объектах. Так, например, в следующем запросе:
- Мы начинаем со специального «корневого» объекта
- Мы выбираем поле
heroна этом - Для объекта, возвращаемого
hero, мы выбираем имяпоявляется в полях
Поскольку форма запроса GraphQL близко соответствует результату, вы можете предсказать, что вернет запрос, не зная так много о сервере.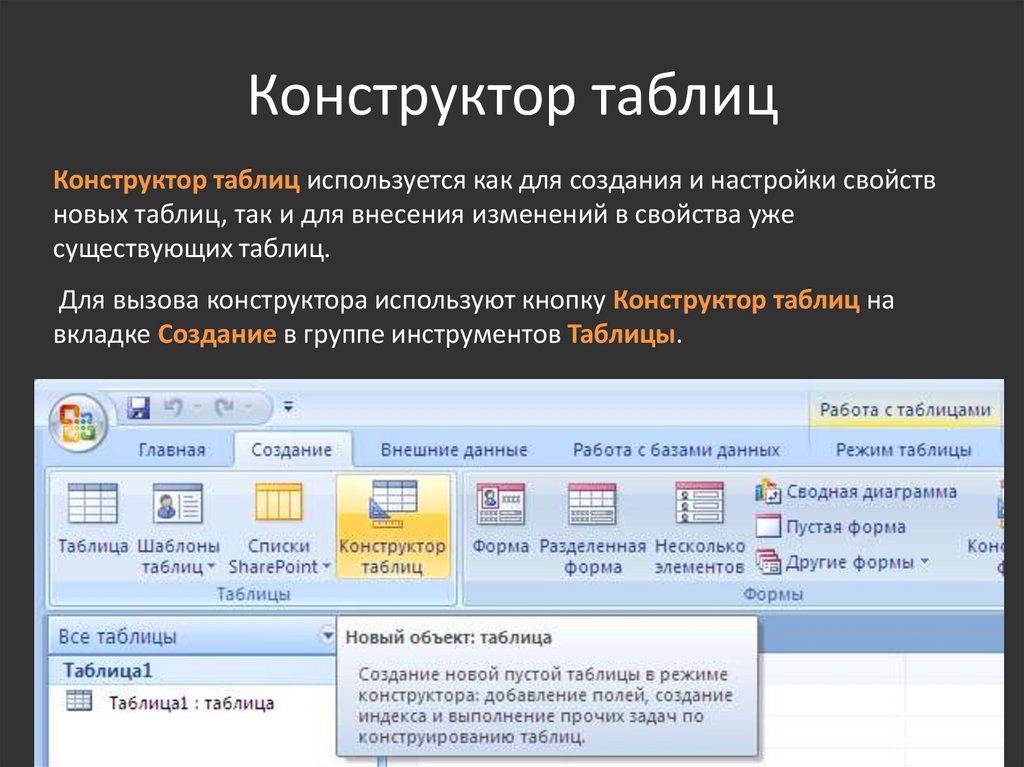 Но полезно иметь точное описание данных, которые мы можем запросить — какие поля мы можем выбрать? Какие объекты они могут вернуть? Какие поля доступны для этих подобъектов? Вот тут-то и появляется схема.
Но полезно иметь точное описание данных, которые мы можем запросить — какие поля мы можем выбрать? Какие объекты они могут вернуть? Какие поля доступны для этих подобъектов? Вот тут-то и появляется схема.
Каждая служба GraphQL определяет набор типов, которые полностью описывают набор возможных данных, которые вы можете запросить в этой службе. Затем, когда приходят запросы, они проверяются и выполняются по этой схеме.
Type language#
Сервисы GraphQL могут быть написаны на любом языке. Поскольку мы не можем полагаться на синтаксис определенного языка программирования, такого как JavaScript, чтобы говорить о схемах GraphQL, мы определим наш собственный простой язык. Мы будем использовать «язык схем GraphQL» — он похож на язык запросов и позволяет нам говорить о схемах GraphQL независимо от языка.
Типы объектов и поля#
Самыми базовыми компонентами схемы GraphQL являются типы объектов, которые просто представляют тип объекта, который вы можете получить из службы, и какие поля у него есть. На языке схемы GraphQL мы могли бы представить это так:
На языке схемы GraphQL мы могли бы представить это так:
type Character {
name: String!
появляется в: [Эпизод!]!
}
Язык довольно удобочитаемый, но давайте пробежимся по нему, чтобы у нас был общий словарь:
-
Символ— это тип объекта GraphQL , что означает, что это тип с некоторыми полями. Большинство типов в вашей схеме будут объектными типами. -
появляется имяиВесть поля насимволов типа. Это означает, чтоимяипоявляются в— это единственные поля, которые могут появляться в любой части запроса GraphQL, который работает с типомсимволов. -
Строка— это один из встроенных скалярных типов — это типы, которые разрешаются в один скалярный объект и не могут иметь подвыборки в запросе. Мы рассмотрим скалярные типы позже. -
Струна!означает, что поле не может быть нулевым , а это означает, что служба GraphQL обещает всегда давать вам значение при запросе этого поля. На языке типов мы будем обозначать их восклицательным знаком. -
[Эпизод!]!представляет собой Массив изобъектов Эпизода. Так как это также ненулевое значение , вы всегда можете ожидать массив (с нулем или более элементов) при запросе поляпоявляющегося в. А сЭпизода!также является необнуляемым , вы всегда можете ожидать, что каждый элемент массива будет объектомEpisode.
 На языке типов мы будем обозначать их восклицательным знаком.
На языке типов мы будем обозначать их восклицательным знаком.Теперь вы знаете, как выглядит тип объекта GraphQL и как читать основы языка типов GraphQL.
Аргументы#
Каждое поле типа объекта GraphQL может иметь ноль или более аргументов, например поле length ниже:
type Starship {
id: ID!
имя: Строка!
длина (единица измерения: LengthUnit = METER): Float
}
Все аргументы именованы. В отличие от таких языков, как JavaScript и Python, где функции принимают список упорядоченных аргументов, все аргументы в GraphQL передаются по имени. В этом случае 9Поле 0500 length имеет один определенный аргумент,
В этом случае 9Поле 0500 length имеет один определенный аргумент, unit .
Аргументы могут быть как обязательными, так и необязательными. Когда аргумент является необязательным, мы можем определить значение по умолчанию — если аргумент unit не передан, он будет установлен на METER по умолчанию.
Типы Query и Mutation#
Большинство типов в вашей схеме будут просто обычными объектными типами, но есть два специальных типа в схеме:
схема {
запрос: запрос
мутация: мутация
}
Каждая служба GraphQL имеет тип запроса и может иметь или не иметь тип мутации . Эти типы аналогичны обычным типам объектов, но они особенные, поскольку определяют точку входа каждого запроса GraphQL. Итак, если вы видите запрос, который выглядит так:
Это означает, что сервис GraphQL должен иметь тип Query с героем и droid fields:
type Query {
hero(episode: Episode): Character
droid(id: ID!): Droid
}
Мутации работают аналогичным образом - вы определяете поля аналогично - вы определяете поля Mutation , и они доступны как поля корневой мутации, которые вы можете вызвать в своем запросе.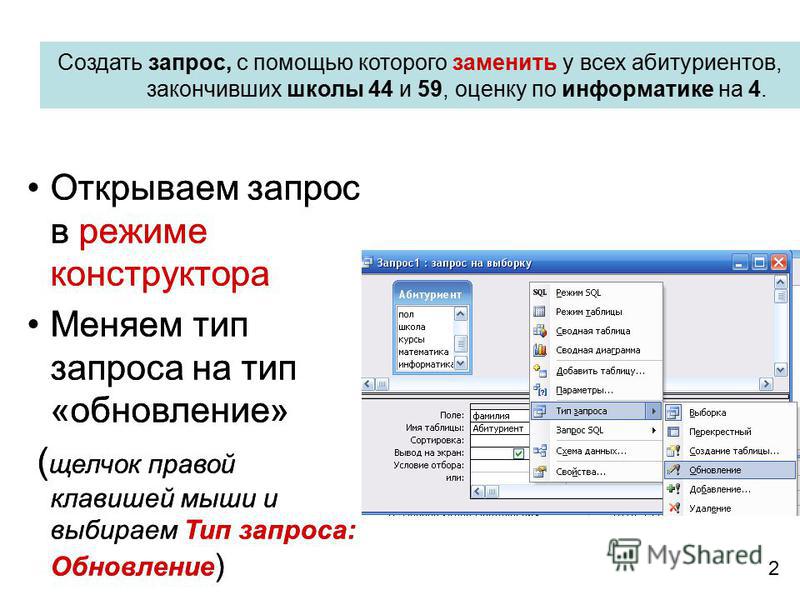
Важно помнить, что помимо особого статуса «точки входа» в схему, Query и Mutation 9Типы 0501 такие же, как и любые другие типы объектов GraphQL, и их поля работают точно так же.
Скалярные типы#
Тип объекта GraphQL имеет имя и поля, но в какой-то момент эти поля должны разрешаться в некоторые конкретные данные. Вот где появляются скалярные типы: они представляют листья запроса.
В следующем запросе появляется имя и . В полях разрешаются скалярные типы:
Мы это знаем, потому что эти поля не имеют подполей — они являются листьями запроса.
GraphQL поставляется с готовым набором скалярных типов по умолчанию:
-
Int: 32-битное целое число со знаком. -
Float: Значение двойной точности с плавающей запятой со знаком. -
Строка: последовательность символов UTF-8. -
Логический:истинаилиложь. -
ID: Скалярный тип ID представляет собой уникальный идентификатор, часто используемый для повторной выборки объекта или в качестве ключа для кэша. Тип ID сериализуется так же, как String; однако, определяя его какIDозначает, что он не предназначен для чтения человеком.
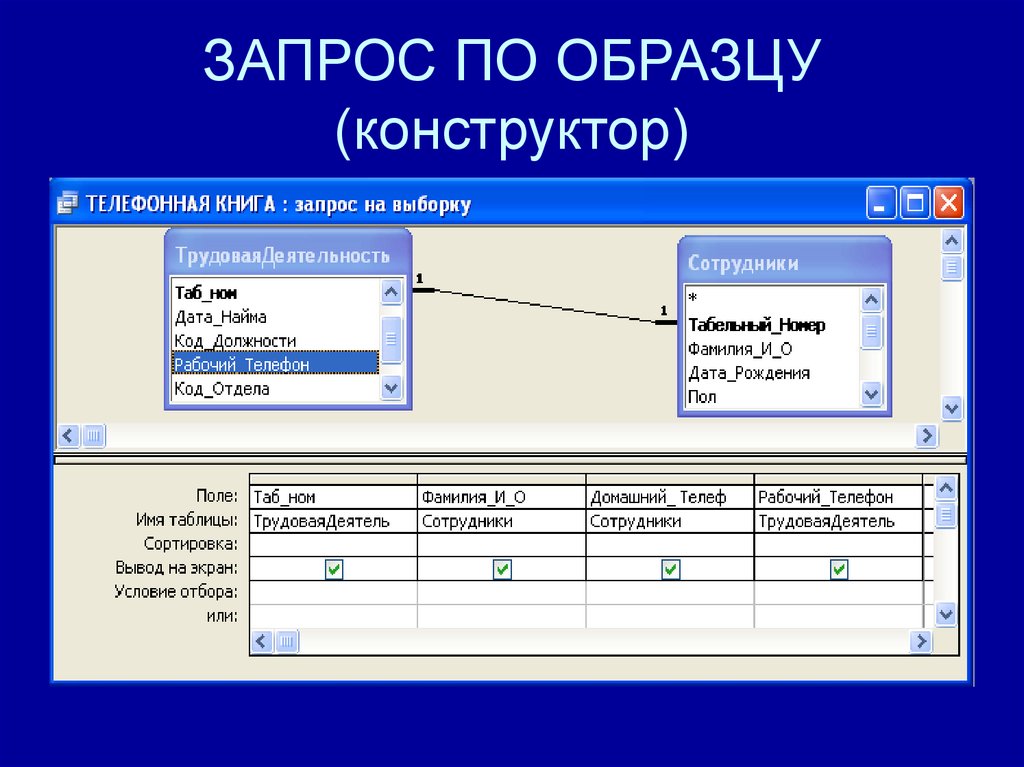
В большинстве реализаций службы GraphQL также есть способ указать пользовательские скалярные типы. Например, мы можем определить тип Date :
scalar Date
Затем наша реализация должна определить, как этот тип должен быть сериализован, десериализован и проверен. Например, вы можете указать, что тип Date всегда должен сериализоваться в целочисленную временную метку, и ваш клиент должен знать, что этот формат следует ожидать для любых полей даты.
Типы перечислений#
Типы перечислений, также называемые Enums , представляют собой особый вид скаляра, который ограничен определенным набором допустимых значений. Это позволяет:
Это позволяет:
- Проверять, что любые аргументы этого типа являются одним из допустимых значений
- Сообщать через систему типов, что поле всегда будет одним из конечного набора значений
Вот что может сделать определение enum выглядеть на языке схемы GraphQL:
Enum Episode {
Newhope
Empire
Jedi
}
Это означает, что, где бы мы ни использовали тип Эпизод в нашей схеме, мы ожидаем, что это будет ровно из Newhope , EMPER, EMPERE 1. , или ДЖЕДАЙ .
Обратите внимание, что реализации службы GraphQL на разных языках будут иметь свой собственный способ работы с перечислениями, зависящий от языка. В языках, поддерживающих перечисления как первоклассных граждан, реализация может использовать это в своих интересах; в таком языке, как JavaScript, без поддержки перечисления, эти значения могут быть внутренне сопоставлены с набором целых чисел. Однако эти детали не передаются клиенту, который может работать исключительно в терминах строковых имен значений перечисления.
Однако эти детали не передаются клиенту, который может работать исключительно в терминах строковых имен значений перечисления.
Списки и Non-Null#
Типы объектов, скаляры и перечисления — это единственные типы типов, которые вы можете определить в GraphQL. Но когда вы используете типы в других частях схемы или в объявлениях переменных запроса, вы можете применять дополнительные модификаторы типов , которые влияют на проверку этих значений. Рассмотрим пример:
type Character {
name: String!
появляется в: [Эпизод]!
}
Здесь мы используем Введите строку и пометьте ее как Non-Null , добавив восклицательный знак, ! после имени типа. Это означает, что наш сервер всегда ожидает возврата ненулевого значения для этого поля, и если он в конечном итоге получит нулевое значение, это фактически вызовет ошибку выполнения GraphQL, сообщив клиенту, что что-то пошло не так.
Модификатор типа Non-Null также можно использовать при определении аргументов для поля, что приведет к тому, что сервер GraphQL вернет ошибку проверки, если в качестве этого аргумента будет передано нулевое значение, будь то в строке GraphQL или в переменных.
Списки работают аналогичным образом: мы можем использовать модификатор типа, чтобы пометить тип как List , что указывает, что это поле будет возвращать массив этого типа. На языке схем это обозначается заключением типа в квадратные скобки: [ и ] . Это работает так же для аргументов, где шаг проверки ожидает массив для этого значения.
Модификаторы Non-Null и List можно комбинировать. Например, у вас может быть список ненулевых строк:
myField: [String!]
Это означает, что сам список может быть нулевым, но он не может содержать пустых элементов. Например, в JSON:
myField: null // допустимо
myField: [] // действительно
myField: ['a', 'b'] // действительно
myField: ['a', null , 'b'] // ошибка
Теперь предположим, что мы определили ненулевой список строк:
myField: [String]!
Это означает, что сам список не может быть нулевым, но может содержать нулевые значения:
myField: null // ошибка
myField: [] // действительно
myField: ['a', 'b'] // действительно
myField: ['a', null, 'b'] / / valid
Вы можете произвольно вложить любое количество модификаторов Non-Null и List в соответствии с вашими потребностями.
Interfaces#
Как и многие системы типов, GraphQL поддерживает интерфейсы. Интерфейс — это абстрактный тип, включающий определенный набор полей, которые тип должен включать для реализации интерфейса.
Например, у вас может быть интерфейс Character , представляющий любого персонажа трилогии «Звездные войны»:
interface Character {
id: ID!
имя: Строка!
друзей: [Персонаж]
появляетсяВ: [Эпизод]!
}
Это означает, что любой тип, который реализует Character , должен иметь именно эти поля, с этими аргументами и возвращаемыми типами.
Например, вот некоторые типы, которые могут реализовать Символ :
тип Человеческие орудия Символ {
id: ID!
имя: Строка!
друзей: [Персонаж]
появляетсяВ: [Эпизод]!
звездолетов: [Звездолет]
ВсегоКредиты: Int
}
Тип Дроид реализует Персонаж {
id: ID!
имя: Строка!
друзей: [Персонаж]
появляетсяВ: [Эпизод]!
основная функция: строка
}
Вы можете видеть, что оба этих типа имеют все поля из интерфейса Character , но также содержат дополнительные поля, totalCredits , starships и primaryFunction , которые специфичны для этого конкретного типа персонажа.
Интерфейсы полезны, когда вы хотите вернуть объект или набор объектов, но они могут быть нескольких разных типов.
Например, обратите внимание, что следующий запрос выдает ошибку:
Поле hero возвращает тип Character , что означает, что это может быть либо Human , либо Droid в зависимости от аргумента Episode . В приведенном выше запросе вы можете запрашивать только поля, которые существуют в интерфейсе символов , который не включает primaryFunction .
Чтобы запросить поле для определенного типа объекта, вам нужно использовать встроенный фрагмент:
Подробнее об этом читайте в разделе встроенных фрагментов в руководстве по запросам.
Типы объединений#
Типы объединений очень похожи на интерфейсы, но они не могут указывать какие-либо общие поля между типами.
union SearchResult = Human | Дроид | Starship
Везде, где мы возвращаем тип SearchResult в нашей схеме, мы можем получить Human , Droid или Starship . Обратите внимание, что члены типа объединения должны быть конкретными типами объектов; вы не можете создать тип объединения из интерфейсов или других объединений.
Обратите внимание, что члены типа объединения должны быть конкретными типами объектов; вы не можете создать тип объединения из интерфейсов или других объединений.
В этом случае, если вы запрашиваете поле, которое возвращает тип объединения SearchResult , вам нужно использовать встроенный фрагмент, чтобы вообще иметь возможность запрашивать любые поля:
Поле __typename разрешается в String который позволяет отличать разные типы данных друг от друга на клиенте.
Кроме того, в этом случае, поскольку Human и Droid имеют общий интерфейс ( Character ), вы можете запрашивать их общие поля в одном месте, а не повторять одни и те же поля для нескольких типов:
{
Поиск (текст: «an») {
__typename
... на символе {
Имя
}
... на человеке {
Высота
}
.. . On Droid {
Первичная функция
}
.
Имя
Длина
}
}
}
 .. On Starship {
.. On Starship { Примечание, что Имя все еще указано на Stast , потому что в противном случае , потому что в противном случае . это не будет отображаться в результатах, учитывая, что Starship — это не персонаж !
Типы ввода#
До сих пор мы говорили только о передаче скалярных значений, таких как перечисления или строки, в качестве аргументов в поле. Но вы также можете легко проходить сложные объекты. Это особенно ценно в случае мутаций, когда вы можете захотеть передать весь объект для создания. В языке схем GraphQL типы ввода выглядят точно так же, как обычные типы объектов, но с ключевым словом input вместо 9.0500 type :
input ReviewInput {
звезды: Int!
комментарий: String
}
Вот как можно использовать тип входного объекта в мутации:
Поля типа входного объекта могут сами ссылаться на типы входных объектов, но вы не можете типы вывода в вашей схеме. Типы входных объектов также не могут иметь аргументов в своих полях.
Типы входных объектов также не могут иметь аргументов в своих полях.
Построение выражения запроса—Справка | ArcGIS for Desktop
- Простая экспрессия SQL
- SQL Syntax
- Поиск строк
- Ключевое слово NULL
- Поиск номеров
- Расчеты
- Оператор PRECEDENCE .
Выражения запросов используются в ArcGIS для выбора подмножества объектов и записей в таблицах. Выражения запросов в ArcGIS соответствуют стандартным выражениям SQL. Например, вы используете этот синтаксис с помощью инструмента «Выбор по атрибутам» или диалогового окна «Построитель запросов», чтобы задать запрос определения слоя.
В этом разделе описывается создание основных выражений предложения WHERE, и он будет полезен, если вы только начинаете работать с SQL. Для получения более подробной информации см. Справочник по SQL для выражений запросов, используемых в ArcGIS.
Для получения более подробной информации см. Справочник по SQL для выражений запросов, используемых в ArcGIS.
Простое выражение SQL
SELECT * FROM составляет первую часть выражения SQL и предоставляется вам автоматически.
Выражения запроса используют общую форму, следующую за предложением Select * From
Вот общая форма выражений запроса ArcGIS:
<Имя_поля> <Оператор> <Значение или строка>
Для составных запросов используется следующая форма:
<Имя_поля> <Оператор> <Значение или строка>
Дополнительно можно использовать круглые скобки () для определения порядка операций в составных запросах.
Поскольку вы выбираете столбцы целиком, вы не можете ограничить SELECT возвратом только некоторых столбцов в соответствующей таблице, поскольку синтаксис SELECT * жестко запрограммирован.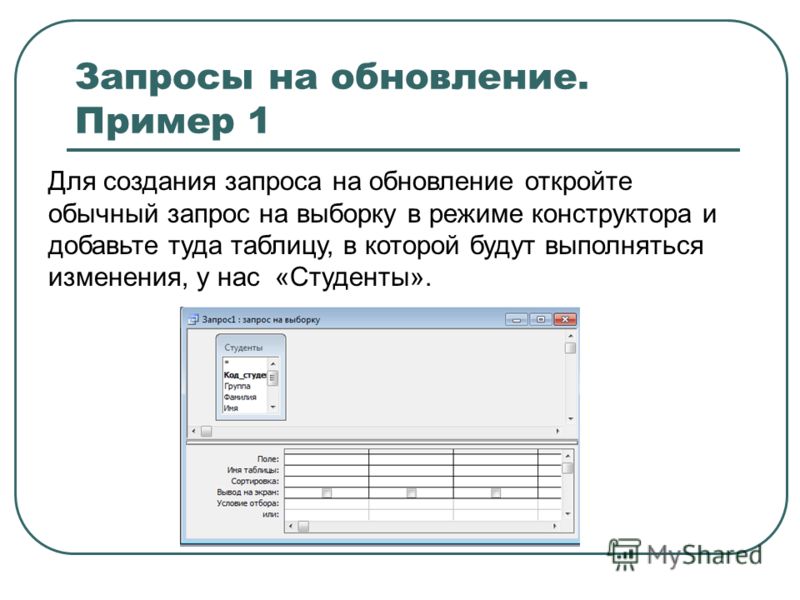 По этой причине ключевые слова, такие как DISTINCT, ORDER BY и GROUP BY, нельзя использовать в запросе SQL в ArcGIS, за исключением случаев использования подзапросов. См. Справочник по SQL для выражений запросов, используемых в ArcGIS, для получения информации о подзапросах.
По этой причине ключевые слова, такие как DISTINCT, ORDER BY и GROUP BY, нельзя использовать в запросе SQL в ArcGIS, за исключением случаев использования подзапросов. См. Справочник по SQL для выражений запросов, используемых в ArcGIS, для получения информации о подзапросах.
В большинстве диалоговых окон ArcGIS, где вы создаете выражение запроса, вам предоставляется имя слоя или таблицы (или вы выбираете его из раскрывающегося списка). Например:
Следующей частью выражения является предложение WHERE, которое необходимо построить. Базовое предложение SQL WHERE будет выглядеть так:
STATE_NAME = 'Alabama'
Это позволит выбрать функции, содержащие "Alabama" в поле с именем STATE_NAME.
Синтаксис SQL
Используемый синтаксис SQL зависит от источника данных. Каждая СУБД имеет свой диалект SQL.
Для запроса файловых данных, включая файловые базы геоданных, покрытия, шейп-файлы, таблицы INFO, таблицы dBASE, а также данные CAD и VPF, вы используете диалект ArcGIS SQL, который поддерживает подмножество возможностей SQL. Для запросов к персональным базам геоданных вы используете синтаксис Microsoft Access. Чтобы запросить базу геоданных ArcSDE, вы используете синтаксис SQL базовой СУБД (то есть Oracle, SQL Server, DB2, Informix или PostgreSQL).
Для запросов к персональным базам геоданных вы используете синтаксис Microsoft Access. Чтобы запросить базу геоданных ArcSDE, вы используете синтаксис SQL базовой СУБД (то есть Oracle, SQL Server, DB2, Informix или PostgreSQL).
Диалоговые окна ArcGIS, в которых вы создаете предложения SQL WHERE, помогут вам использовать правильный синтаксис для запрашиваемой базы данных. В них перечислены правильные имена полей и значения с соответствующими разделителями. Они также выбирают для вас соответствующие ключевые слова и операторы SQL.
Поиск строк
Строки всегда должны заключаться в одинарные кавычки. Например:
STATE_NAME = 'California'
Строки в выражениях чувствительны к регистру, за исключением случаев, когда вы запрашиваете классы объектов и таблицы личной базы геоданных. Чтобы выполнить поиск без учета регистра в других форматах данных, вы можете использовать функцию SQL для преобразования всех значений в один и тот же регистр. Для файловых источников данных, таких как файловые базы геоданных или шейп-файлы, используйте либо функцию ВЕРХНЯЯ, либо НИЖНЯЯ.
Например, следующее выражение выберет клиентов, чья фамилия сохранена как Jones или JONES:
UPPER(LAST_NAME) = 'JONES'
Другие источники данных имеют аналогичные функции. Персональные базы геоданных, например, имеют функции с именами UCASE и LCASE, которые выполняют одну и ту же операцию.
Используйте оператор LIKE (вместо оператора =) для построения частичного поиска строки. Например, это выражение выберет Миссисипи и Миссури среди названий штатов США:
STATE_NAME LIKE 'Miss%'
% означает, что вместо него допустимо что угодно: один символ, сто символов или ни одного символа. В качестве альтернативы, если вы хотите выполнить поиск с помощью подстановочного знака, представляющего один символ, используйте _.
Например, это выражение найдет Кэтрин Смит и Кэтрин Смит:
OWNER_NAME LIKE '_atherine smith'
Приведенные выше подстановочные знаки работают для любых файловых данных или базы геоданных ArcSDE. Подстановочные знаки, которые вы используете для запросов к персональным базам геоданных: * для любого количества символов и ? за одного персонажа.
Подстановочные знаки отображаются как кнопки в диалоговых окнах «Выбор по атрибутам» и «Построитель запросов». Вы можете нажать кнопку, чтобы ввести подстановочный знак в выражение, которое вы создаете. Отображаются только подстановочные знаки, соответствующие источнику данных запрашиваемого слоя или таблицы.
Если вы используете подстановочный знак в строке с оператором =, этот символ рассматривается как часть строки, а не как подстановочный знак.
Вы можете использовать операторы больше (>), меньше (<), больше или равно (>=), меньше или равно (<=) и МЕЖДУ для выбора строковых значений на основе порядка сортировки. Например, это выражение выберет все города в покрытии, названия которых начинаются с букв от M до Z:
CITY_NAME >= 'M'
Оператор не равно (<>) также можно использовать при запросе строк.
Если строка содержит одинарную кавычку, вам сначала нужно будет использовать еще одну одинарную кавычку в качестве escape-символа. Например:
NAME = 'Ловушка Альфи'
Подробнее о подстановочных знаках
Ключевое слово NULL
Вы можете использовать ключевое слово NULL для выбора функций и записей, которые имеют нулевые значения для указанного поля. Ключевому слову NULL всегда предшествует IS или IS NOT.
Ключевому слову NULL всегда предшествует IS или IS NOT.
Например, чтобы найти города, население которых в 1996 г. не было введено, вы можете использовать
POPULATION96 IS NULL
В качестве альтернативы, чтобы найти города, население которых в 1996 г. было введено, вы можете использовать
POPULATION96 IS NOT NULL
Поиск числа
Вы можете запрашивать числа, используя знаки равно (=), не равно (<>), больше (>), меньше (<), больше или равно (>=), меньше или равно (<=) и МЕЖДУ операторами.
Например,
НАСЕЛЕНИЕ96 >= 5000
Числовые значения всегда указываются с использованием точки в качестве десятичного разделителя независимо от региональных настроек. Запятая не может использоваться в выражении как разделитель десятичной дроби или тысяч.
Расчеты
Расчеты могут быть включены в выражения с помощью арифметических операторов +, -, * и /.
Вычисления могут производиться между полями и числами.
Например:
ОБЛАСТЬ >= ПЕРИМЕТР * 100
Расчеты также можно выполнять между полями.
Например, чтобы найти страны с плотностью населения не более 25 человек на квадратную милю, можно использовать следующее выражение:
POP1990 / AREA <= 25
Приоритет оператора стандартные правила приоритета операторов. Например, часть выражения, заключенная в круглые скобки, вычисляется перед той частью, которая не заключена в круглые скобки.
Пример
ДОМОХОЗЯЙСТВА > МУЖЧИНЫ * POP90_SQMI + ОБЛАСТЬ
оценивается иначе, чем
ДОМОХОЗЯЙСТВА > МУЖЧИНЫ * (POP90_SQMI + ОБЛАСТЬ)
Вы можете либо щелкнуть, чтобы добавить круглые скобки и ввести выражение, которое вы хотите заключить, либо выделить существующее выражение, которое вы хотите хотите заключить, затем нажмите кнопку Скобки, чтобы заключить его.
Объединение выражений
Сложные выражения можно создавать, объединяя выражения с операторами И и ИЛИ.
Например, следующее выражение выберет все дома площадью более 1500 квадратных футов и гараж на три или более автомобилей:
ПЛОЩАДЬ > 1500 И ГАРАЖ > 3
сторона выражения двух, разделенных оператором ИЛИ, должна быть истинной для записи, которая будет выбрана.
Например:
ОСАДКИ < 20 ИЛИ НАКЛОН > 35
Используйте оператор НЕ в начале выражения, чтобы найти объекты или записи, которые не соответствуют указанному выражению.
Например:
NOT STATE_NAME = 'Колорадо'
Выражения NOT можно комбинировать с AND и OR.
Например, это выражение выберет все штаты Новой Англии, кроме штата Мэн:
SUB_REGION = 'Новая Англия' AND NOT STATE_NAME = 'Мэн'
Подзапросы
Подзапрос — это запрос, вложенный в другой запрос и поддерживаемый только источники данных базы геоданных. Его можно использовать для применения предикатных или агрегатных функций или для сравнения данных со значениями, хранящимися в другой таблице.