Windows 1251 — это… Что такое Windows 1251?
Windows-1251 — (a.k.a. code page CP1251) is a popular 8 bit character encoding, designed to cover languages that use the Cyrillic alphabet such as Russian, Bulgarian, Serbian Cyrillic and other languages. It is the most widely used for encoding the Bulgarian,… … Wikipedia
Windows-1251 — набор символов и кодировка, являющаяся стандартной 8 битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Была создана на базе кодировок, использовавшихся в ранних «самопальных» русификаторах… … Википедия
Windows-1251 — (a.k.a. CP1251) es un popular juego de caracteres de 8 bits, diseñado para cubrir lenguajes que usan el alfabeto cirilico como son el lenguaje Ruso y otros lenguajes. Este es la codifiación más ampliamente usada para codificar Búlgaro, Serbio y… … Wikipedia Español
Windows-1251 — Windows Codepages 874 Thai 932 Japanisch 936 Vereinfachtes Chinesisch 949 Koreanisch 950 Traditionelles Chinesisch 1250 Mitteleuropäisch 1251 Kyrillisch 1252 … Deutsch Wikipedia
Windows (значения) — Windows: Microsoft Windows семейство проприетарных операционных систем корпорации Microsoft, ориентированных на применение графического интерфейса при управлении. Windows (клавиша) клавиша на клавиатурах ПК совместимых компьютеров,… … Википедия
Windows-1252 — ISO 8859 1 Latin 1, Westeuropäisch 2 Latin 2, Mitteleuropäisch 3 Latin 3, Südeuropäisch 4 Latin 4, Baltisch 5 Kyrillisch 6 Arabisch 7 Griechisch 8 … Deutsch Wikipedia
Windows-1252 — ISO/IEC 8859 1 (также известная как ISO 8859 1 и Latin 1) кодовая страница, предназначенная для западноевропейских языков; она базируется на символьном наборе популярных в прошлом терминалов ISO 8859. ISO 8859 1 кодировка, зарегистрированная… … Википедия
Windows code page — Windows code pages are sets of characters or code pages (known as character encodings in other operating systems) used in Microsoft Windows from the 1980s and 1990s. Windows code pages were gradually superseded when Unicode was implemented in… … Wikipedia
Windows Glyph List 4 — (сокр. WGL4, также известен как Общеевропейский набор символов англ. Pan European character set) определённый компанией Майкрософт набор из 652 типографических символов Юникода, призванный помочь разработчикам шрифтов в обеспечении… … Википедия
Windows-1254 — Windows 1254 кодовая страница, используемая Microsoft Windows для представления турецкого языка. Символы с кодами от A0 до FF совместимы с ISO 8859 9. Для современных приложений UTF 8 предпочтительней windows 1254. Таблица кодов Символы с… … Википедия
dic.academic.ru
Кодировка виндовс 1251 таблица.
Не каждый человек обладает большими познаниями в компьютерной технике.
Что такое windows-1251 кодировка и какую роль играет в работе компьютера предстоит узнать.
Что это такое?
Кодировка 1251 представляет собой совокупность символов, которая составляет восьми-битную систему для русифицированных устройств.
Стоит отметить, что довольное широкое применение она нашла на территории Европы.
Считается одной из самых выгодных кодировок, поскольку в ней присутствует все необходимые символы, которые используются в российской типографии. Все кириллические символы имею алфавитную последовательность.
Немного из истории
С наступлением 90-х годов, после распада СССР, границы России стали открыты.
Поэтому на территорию страны стало постепенно проникать оборудование из европейских стран.
Изначально все они были запрограммированы на английском языке.
В этот же промежуток времени начинает активно распространяться интернет.
В результате стало необходимо как можно быстрее русифицировать все оборудование и программное обеспечение. В связи с данной необходимостью появилась кодировка 1251. С ее помощью на компьютерах корректно отображаются .
А значит стало возможным использовать компьютеры со следующими языками:
- Русский
- Белорусский
- Украинский
- Сербский
- Болгарский
- Македонский.
Совместно с двумя российскими компаниями «Параграф» и «Диалог» , представительства компании начали активно заниматься разработкой данной кодировки.
В качестве основы были использованы обыкновенные самостоятельно написанные разработки.
Однако технический прогресс не стоит на месте, поэтому в последнее время широкое применение нашел Юникод UTF-8.
UTF-8 против 1251
Вся информация, которая хранится на компьютере, имеет кодированный вид.
Можно предположить, что символ имеет вес порядком 1 байт. 1251 – это разновидность кодировки однобайтовой, а UTF-8 – восьмибайтная.
Отсюда можно сделать вывод, что первый вариант способен к программированию 256 знаков.
Что касается второго варианта, то он представляет большее количество. Кроме того, для этого выделяют большой размер.
Можно сделать вывод, что
- В верхней части необходимо указывать кодировку, которая необходима для использования . В противном случае, вместо обыкновенных символов появляются нечитаемые иероглифы. Используя (которая считается более универсальной кодировкой), все переводы и расшифровки осуществляются в автоматическом режиме
- Вне зависимости от того, на территории какой страны будет загружаться страница, символика останется без изменения. Важно отметить, что местоположение в данном случае не играет абсолютно никакой роли. Главное обращать внимание на языковые серверы, используемые пользователем. Каждый человек обращается к программному обеспечению на родном языке. Для жителей Европы, 1251 будет недоступна в силу использования латиницы. Соответственно можно сделать вывод о том, что русскоязычные сайты не будут открывать в корректном формате. Что касается , то он присутствует в любой ОС
- Второй вид имеет возможность кодировки большего количества символов. На сегодняшний день стоит отметить 6 и 8 байт. Что касается кириллицы, то для ее кодировки достаточно двух байт.
В связи с выше перечисленными отличиями можно сделать вывод о том, что универсальная кодировка более актуальна для использования, чем 1251, поскольку она подойдет только для славянской группы языков.
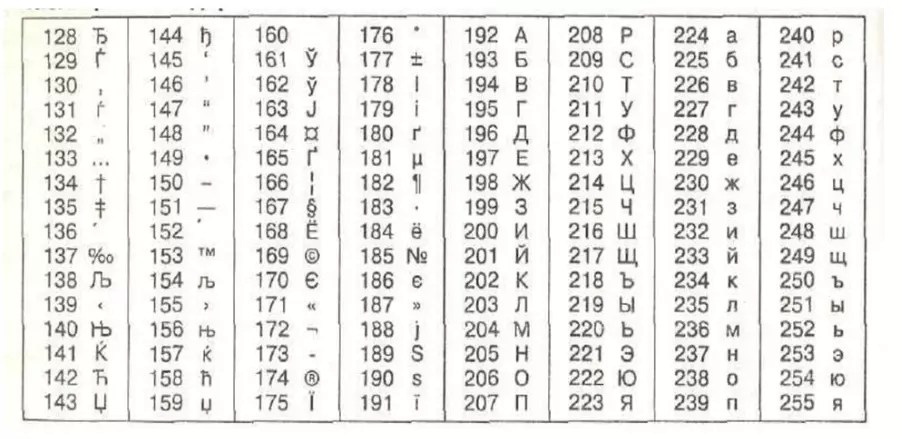
Чтобы символы можно было запомнить быстро и просто, чаще всего используют следующую таблицу:
Инструкция по восстановлению кодировки
Ситуация, когда в командной строке присутствуют непонятные символы, вопросительные знаки или иероглифы довольна распространенная.
Однако исправить положение возможно самостоятельно, не прибегая к помощи специалистов.
Сразу стоит отметить, что это первый признак того, что в седьмом Windows слетела кодировка 1251.
С восьмой версии активно используют UTF-8.
Для того, чтобы решить задачу максимально быстро, возможно использование команды CHCP 866, но это только временная мера и в полной мере проблему она не решит.
Как правило, реестр используется для основательного решения проблемы:
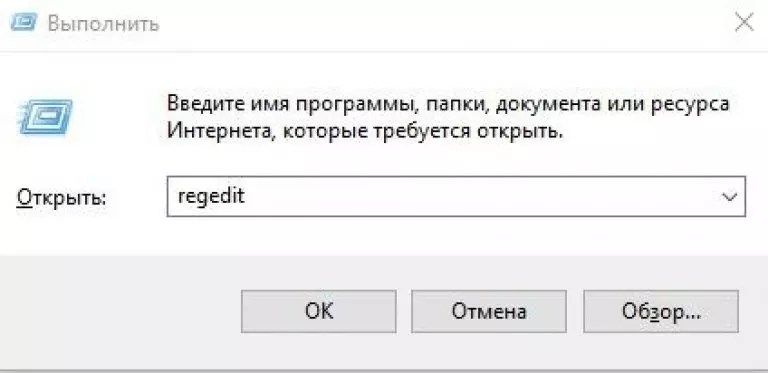
- Чтобы вызвать , нажимаем сочетание клавиш Win и R . Пишем regedit, при помощи которого открывается специальный реестр
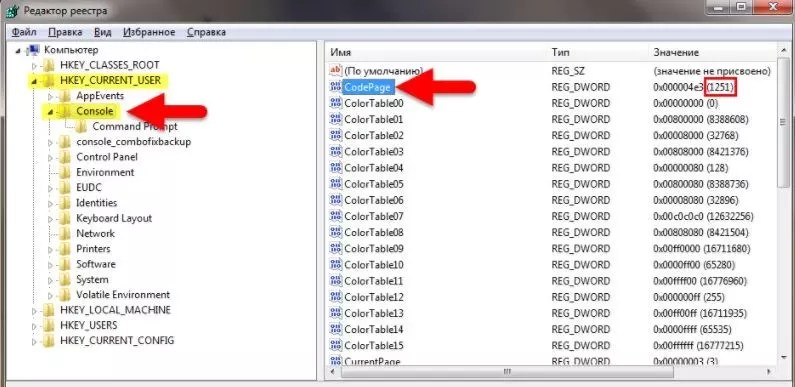
- Как показано на рисунке, находим соответствующую папку HKEY_CURRENT_USER далее выбираем Console . Далее смотрим какой код задан для страниц (Code Page). В том случае, если там стоит число не 866, что скорее всего так и будет, значит проблема была определена верно
- Исправляем в строке на десятичное значение
- Чтобы править, произошли ли изменения, достаточно открыть и снова вызвать командную строчку.
Кодировка windows 1251 была создана в начале 90 годов для русификации программных продуктов, выпускаемых корпорацией Microsoft :
Кодировка является 8-битной и включает в себя символы славянской группы языков, в которую входят русский, белорусский, украинский, болгарский, македонский, сербский – это дает преимущество перед остальными кириллическими кодировками (ISO 8859-5, KOI8-R, CP866 ). Однако у 1251-кодировки имеются и весомые недостатки:
- 0xFF (25510) – это код, который зарезервирован для символа «я». В программах, которые не поддерживают чистый 8-ой бит, часто возникают непредсказуемые проблемы;
- Нет псевдографики, которая присутствует в KOI8 , CP866 .
Ниже приведены символы из Code Page 1251 или сокращенно СР1251 (числа под символами являются кодом в шестнадцат
leally.ru
за что отвечает и как работает
В начале 90-х, когда произошел развал СССР и границы России были открыты, к нам стали поступать программные продукты западного производства. Естественно, все они были англоязычными. В это же время начинает развиваться Интернет. Остро встала проблема русификации ресурсов и программ. Тогда и была придумана русская кодировка Windows 1251. Она позволяет корректно отображать буквы славянских алфавитов:
- русского;
- украинского;
- белорусского;
- сербского;
- болгарского;
- македонского.
Разработка велась русским представительством Microsoft совместно с компаниями «Диалог» и «Параграф». За основу были взяты самописные разработки, которые в 1990-91гг имели хождение среди немногочисленных идеологов ИТ в России.
На сегодняшний день разработан более универсальный способ кодировать символы — UTF-8 (Юникод). В нем представлено почти 90% всех программных и веб-ресурсов. Windows 1251 применяется в 1,6% случаев. (Информация по исследованиям Web Technology Surveys)

Кодировка сайта utf 8 или Windows 1251?
Чтобы ответить на этот вопрос, необходимо немного понять, что такое кодировка и чем они отличаются. Текстовая информация, как впрочем, и любая другая, в компьютере хранится в закодированном виде. Нам легче представить ее как числа. Каждый символ может занимать один или более байт. Windows 1251 является однобайтной кодировкой, а UTF-8 восьмибайтной. Это значит, что в Windows 1251 можно закодировать всего 256 символов.
Так как все сводится к двоичной системе исчисления, а байт – это 8 бит (0 и 1), то и максимальное число сочетаний составляет 28 = 256. Юникод позволяет представлять куда большее число символов, да и на каждый может быть выделен больший размер.
Отсюда и следуют преимущества Юникода:
- В шапке сайта следует указать кодировку, которая используется. Иначе вместо символов отобразятся «кракозяблы». А Юникод является стандартным для всех браузеров – они ловят его «на лету» как установленный по умолчанию.
- Символы сайта останутся одними и теми же, независимо от того, в какой стране загружается ресурс. Это зависит не от географического расположения серверов, а от языка программного обеспечения рабочих станций клиента. Житель Португалии, очевидно, использует клавиатуру и все ПО, включая операционную систему, на родном языке. В его компьютере, скорее всего вообще отсутствует Windows 1251. А если это так, то и сайты на русском языке корректно открываться не будут. Юникод, в свою очередь, «зашит» в любую ОС на любом языке.
- UTF-8 позволяет закодировать большее количество символов. На данный момент используется 6 байт из 8-ми, а русские символы кодируются двумя байтами.
Именно поэтому предпочтительней использовать универсальную кодировку, а не узкоспециализированную, которая применяется только в славянских странах.
Таблица кодировки Windows 1251
Для программистов и разработчиков сайтов бывает необходимо знать номера символов. Для этого используются специальные таблицы кодировки. Ниже представлена таблица для Windows 1251.

Что делать, если слетела кодировка командной строки?
Иногда Вы можете столкнуться с ситуацией, когда в командной строке вместо русских отображаются непонятные символы. Это означает, что возникла проблема кодировки командной строки Windows 7. Почему 7-ка? Потому что, начиная с 8-й версии, используется UTF-8, а в семерке еще Windows 1251.
Единовременно помочь решить проблему может команда chcp 866. Текущий сеанс будет работать корректно. А вот чтобы исправить ошибку кардинально, понадобится реестр.
- Нажмите Win+R и наберите команду regedit. Это позволит попасть в редактор реестра.

- Перейдите по ветке HKEY_CURRENT_USER\Console и посмотрите, чему равно значение для CodePage. Скорее всего, вы увидите что-то, отличное от 866 (правильный вариант).
- Исправьте на 866 в положении «Десятичная».
- Закройте и откройте вновь командную строку. Ситуация должна исправиться.


windowstips.ru
что это и как используется
Здравствуйте, уважаемые читатели моего блога. Сегодня мы поговорим с вами про кодировку. Если вы читали мою статью о том, как посмотреть код страницы в браузере, то знаете, что любой документ в интернете хранится не в том виде, в каком мы привыкли его видеть. Он записан при помощи непонятных человеку символов и знаков. С текстом все точно также.
Существует несколько кодировок, а потому, иногда увидев непонятные символы при открытии книги в мобильном приложении или запилив статью на сайт, вы, поменяв кое-какие значения в настройках, увидите привычный глазу алфавит.

Кодировка windows-1251 – что это такое, какое значение она имеет при создании сайта, какие символы будут доступны и является ли она лучшим решением на сегодняшний день? Обо всем этом в сегодняшней статье. Как всегда, простым языком, максимально понятно и с минимальным количеством терминов.
Немного теории
Любой документ на компьютере или в интернете, как я уже сказал, хранится в виде двоичного кода. К примеру, если вы используете кодировку ASCII, то буква «К» будет записана как 10001010, а windows 1251 под этим числом скрывается символ – Љ. В итоге, если браузер или программа обратится к другой таблице и считает вместо ASCII коды windows 1251, то читатель увидит совершенно непонятные ему символ.
Логичен вопрос, нафига было придумывать множество таблиц с кодами? Дело в том, что помимо русского алфавита существует еще и английский, немецкий, китайский. По некоторым подсчетам, существует около 200 000 символов. Хотя, я не очень доверяю этой статистике, вспоминая про японский.
Не забывайте, что для заглавной и строчной буквы нужно придумать свой код, есть запятые, тире и так далее.
Чем больше в таблице символов, тем длиннее код каждого из них, а значит и вес документа становится больше.

Представьте, если бы одна книга весила 4 Гб! Она бы очень долго загружалась, занимала все свободное место на компьютере. Решение о скачивании представлялось бы делом нелегким.
Если вспомнить о сайтах, то вообще страшно подумать, что бы произошло. Каждая страничка открывалась даже на скоростном оптоволокне по часу с лишним! Думаю, мобильные телефоны можно было бы смело выкидывать. Пользоваться ими на улице даже с 4G? Сомневаюсь.
По этим причинам каждый программист в свое время старался придумать свою таблицу символов. Чтобы было удобно для использования и вес сохранялся оптимальным.
Microsoft, к примеру, для русскоязычного сегмента создали windows-1251. В ней, конечно же, есть свои достоинства и недостатки. Как и у любого другого продукта.
Сейчас уже, лишь 2% всех страниц в интернете написано на 1251. Большинство веб-мастеров используют UTF-8. Почему так?
Недостатки и достоинства
UTF-8, в отличие от windows-1251 универсальная кодировка, в ней содержатся буквы различных алфавитов. Существует даже UTF-128, где есть вообще все языки – теулу, суахили, лаосский, мальтийский и так далее.

UTF-8 победнее, буквы занимают в разы меньше места и занимают всего один байт памяти, как и в 1251. В УТФ есть редкие символы из других языков или специальные символы. Они-то и весят по 5-6 байтов, но в документе используются крайне редко.
Эта кодировка более продумана, а потому ее использует большинство приложений по умолчанию. То есть, если вы не указываете программе, какую кодировку вы используете, то первым делом он проверит именно UTF-8 .
Когда вы создаете html документ для сайта, то указываете браузерам на какую таблицу им обращать внимание при расшифровке записей.
Для этого необходимо вставить в тег head следующие данные. После символов «charset=» идет либо утф, либо виндовс, как в примере ниже.
<meta http-equiv="Content-Type" content="text/html; charset=windows-1251"> |
<meta http-equiv=»Content-Type» content=»text/html; charset=windows-1251″>

Если в дальнейшем вы захотите что-то поменять и вставить фразу на албанском, используя эту таблицу расшифровок, то ничего не получится, ведь этого языка кодировка не поддерживает. UTF‑8 без проблем позволит вам это сделать.
Если вас заинтересовало правильное создание сайта, то я могу порекомендовать вам курс Михаила Русакова «Создание и Раскрутка сайта от А до Я».

Он содержит в себе очень много – 256 уроков, затрагивающих HTML, CSS, JavaScript, PHP, MySQL и XML. Помимо языков программирования вы сможете понять как монетизировать сайт, то есть скорее и больше получать прибыль. Один из немногих курсов, в котором было бы так подробно разъяснено все, что нужно.
Сам я вот уже год обучаюсь в школе блоггеров Александра Борисова. Это занимает в разы больше времени, конца и края пока не видно, но зато не менее исчерпывающе и дисциплинирует. Мотивирует продолжать разработку.
Ну а если возникают вопросы, не нужно искать по интернету. Всегда есть грамотный наставник.

Что-то я отошел от темы. Давайте вернемся к кодировкам.
Базы банных
Когда речь идет о php, все вообще страшно. Я уже рассказывал про базы данных, они используются для ускорения работы сайта. Обычно, вы к ним не обращаетесь, но когда появляется необходимость в переносе сайта становится не по себе.
Сложности случаются у всех, не важно какой у вас опыт работы, стаж и выслуга лет. Некоторые странички в базе могут содержать в себе все доступные символы для виндовс-1251, другие, к примеру, в шаблонах страниц, в другой кодировке.
Пока не нужен перенос все работает и функционирует, хоть и не совсем правильно. Но после переезда начинаются неприятности. В идеале вы должны использовать либо только УТФ, либо виндовс-1251, но по факту всегда и у всех случаются вот такие недочеты.
Чтобы расшифровка согласовалась необходимо вписать код mysql_query(«SET NAMES cp1251»). В этом случае преобразование будет осуществлять по другому протоколу – cp1251.

Htaccess
Если на сайте вы настойчиво решили использовать именно 1251, то вам следует найти или создать файл htaccess. Он отвечает за настройки конфигурации. В него придется добавить еще три строчки, чтобы все сошлось.
DefaultLanguage ru; AddDefaultCharset windows-1251; php_value default_charset "cp1251" |
DefaultLanguage ru; AddDefaultCharset windows-1251; php_value default_charset «cp1251»
Я все же настоятельно рекомендую вам задумать о использовании UTF-8. Он более популярен, прост и богат. Какие бы решения вы не приняли сейчас, важно, чтобы впоследствии можно было все исправить. Добавить англоязычную версию сайта на этой кодировке будет в разы проще. Ничего не нужно исправлять.
Решение остается за вами. Подписывайтесь на рассылку, чтобы узнавать как можно быстрее создавать правильные сайты, где учиться, чтобы не повторять чужих ошибок, а также какие блоггеры получают больше посетителей.
До новых встреч и удачи в ваших начинаниях.
start-luck.ru
Что такое кодировка ANSI и с чем ее едят?
Прежде чем отвечать на вопрос о том, что же такое кодировка ANSI Windows, ответим сначала на другой вопрос: «Что же такое кодировка вообще?»
У каждого компьютера, в каждой системе используется определенный набор символов, зависящий от языка, используемого пользователем, от его профессиональных компетенций и личных предпочтений.
Общее определение кодировки
Так, в русском языке используется 33 символа для обозначения букв, в английском – 26. Также используется 10 цифр для счета (0; 1; 2; 3; 4; 5; 6; 7; 8; 9) и некоторые специальные символы, в том числе запятая, минус, пробел, точка, процент и так далее.
Каждому из этих символов при помощи кодовой таблицы присваивается порядковый номер. К примеру, букве «A» может быть присвоен номер 1; «Z» — 26 и так далее.
Собственно, номер, представляющий символ как целое число, считается кодом символа, а кодировка — это, соответственно, набор символов в такой таблице.
Богатство разнообразия кодовых таблиц
На данный момент существует довольно большое количество кодировок и кодовых таблиц, используемых разными специалистами: это и ASCII, разработанная в 1963 году в Америке, и Windows-1251, совсем недавно еще бывшая популярной благодаря Microsoft, KOI8-R и Guobiao — и многие, многие другие, причем процесс их появления и отмирания происходит и по сей день.
Среди этого огромного списка совершенно особо держится так называемая кодировка ANSI.
Дело в том, что в свое время компания Microsoft создала целый набор кодовых страниц:
| Windows — 874 | Тайский |
| Windows-1250 | Центральноевропейский |
| Windows-1251 | Кириллический (все символы русского языка + символы близких языков) |
| Windows-1252 | Западноевропейский |
| Windows-1253 | Греческий |
| Windows-1254 | Турецкий |
| Windows-1255 | Еврейский |
| Windows-1256 | Арабский |
| Windows-1257 | Балтийский |
| Windows-1258 | Вьетнамский |
Все они получили общее название таблицы кодировки ANSI, или кодовой страницы ANSI.
Интересный факт: одной из первых кодовых таблиц стала ASCII, в 1963 году созданная American National Standards Institute (Американским национальным институтом стандартов), сокращенно называвшимся именно ANSI.
Помимо всего прочего, эта кодировка содержит и непечатные символы, так называемые «Управляющие последовательности», или ESC, уникальные для всех таблиц символов, зачастую несовместимые между собой. При умелом использовании, однако, они позволяли скрывать и восстанавливать курсор, переводить его с одного положения в тексте на другое, устанавливать табуляцию, стирать часть окна терминала, в котором велась работа, изменять форматирование текста на экране и менять цвет (или даже рисовать и подавать звуковые сигналы!). В 1976 году, кстати, это было довольно неплохим подспорьем для программистов. Кстати, терминал — это устройство, требующееся для ввода и вывода информации. В те далекие времена он представлял собой монитор и клавиатуру, подсоединенные к ЭВМ (электронной вычислительной машине).
Некорректное отображение символов
К сожалению, в дальнейшем подобная система вызвала многочисленные сбои в системах, выводя вместо желаемых стихов, лент новостей или описаний любимых компьютерных игр так называемые кракозябры — бессмысленные, нечитаемые наборы символов. Появление этих вездесущих ошибок было вызвано всего лишь попыткой отображать символы, закодированные в одной кодовой таблице, при помощи другой.
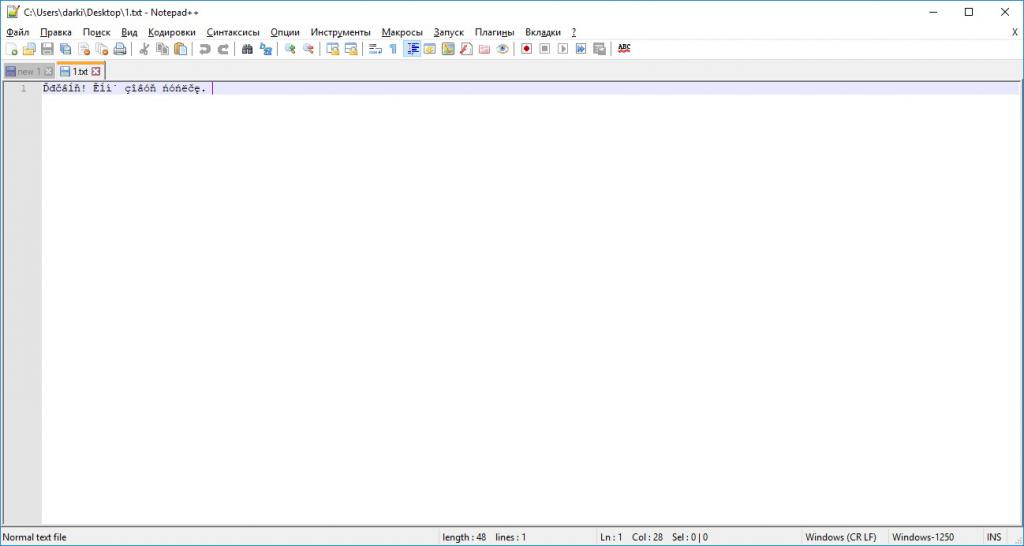
Чаще всего с последствиями неверного чтения этой кодировки мы сталкиваемся в Интернете до сих пор, когда наш браузер по какой-то причине не может достаточно точно определить, какая именно из Windows-**** кодировок используется в данный момент, из-за указания веб-мастером общей кодировки ANSI либо изначально неверной кодировки, к примеру, 1252 вместо 1521. Ниже представлена точная таблица кодировок.
Кириллическая таблица ANSI-кодировок, Windows-1251
№ П/п.
HEX
СИМВОЛ
№ П/п.
HEX
СИМВОЛ
№ П/п.
HEX
СИМВОЛ
000
00
NOP
086
56
V
171
AB
«
001
01
SOH
087
57
W
172
AC
¬
002
02
STX
088
58
X
173
AD
003
03
ETX
089
59
Y
174
AE
®
004
04
EOT
090
5A
Z
175
AF
Ї
005
05
ENQ
091
5B
[
176
B0
°
006
06
ACK
092
5C
\
177
B1
±
007
07
BEL
093
5D
]
178
B2
І
008
08
BS
094
5E
^
179
B3
і
009
09
TAB
095
5F
_
180
B4
ґ
010
0A
LF
096
60
`
181
B5
µ
011
0B
VT
097
61
a
182
B6
¶
012
0C
FF
098
62
b
183
B7
·
013
0D
CR
099
63
c
184
B8
Е
014
0E
SO
100
64
d
185
B9
№
015
0F
SI
101
65
e
186
BA
Є
016
10
DLE
102
66
f
187
BB
»
017
11
DC1
103
67
g
188
BC
ј
018
12
DC2
104
68
h
189
BD
Ѕ
019
13
DC3
105
69
i
190
BE
Ѕ
020
14
DC4
106
6A
j
191
BF
Ї
021
15
NAK
107
6B
k
192
C0
А
022
16
SYN
108
6C
l
193
C1
Б
023
17
ETB
109
6D
m
194
C2
В
024
18
CAN
110
6E
n
195
C3
Г
025
19
EM
111
6F
o
196
C4
Д
026
1A
SUB
112
70
p
197
C5
Е
027
1B
ESC
113
71
q
198
C6
Ж
028
1C
FS
114
72
r
199
C7
З
029
1D
GS
115
73
s
200
C8
И
030
1E
RS
116
74
t
201
C9
Й
031
1F
US
117
75
u
202
CA
К
032
20
Пробел
118
76
v
203
CB
Л
033
21
!
119
77
w
204
CC
М
034
22
«
120
78
x
205
CD
Н
035
23
#
121
79
y
206
CE
О
036
24
$
122
7A
z
207
CF
П
037
25
%
123
7B
{
208
D0
Р
038
26
&
124
7C
|
209
D1
С
039
27
‘
125
7D
}
210
D2
Т
040
28
(
126
7E
~
211
D3
У
041
29
)
127
7F
212
D4
Ф
042
2A
*
128
80
Ђ
213
D5
Х
043
2B
+
129
81
Ѓ
214
D6
Ц
044
2C
,
130
82
‚
215
D7
Ч
045
2D
—
131
83
ѓ
216
D8
Ш
046
2E
.
132
84
„
217
D9
Щ
047
2F
/
133
85
…
218
DA
Ъ
048
30
0
134
86
†
219
DB
Ы
049
31
1
135
87
‡
220
DC
Ь
050
32
2
136
88
€
221
DD
Э
051
33
3
137
89
‰
222
DE
Ю
052
34
4
138
8A
Љ
223
DF
Я
053
35
5
139
8B
‹
224
E0
а
054
36
6
140
8C
Њ
225
E1
б
055
37
7
141
8D
Ќ
226
E2
в
056
38
8
142
8E
Ћ
227
E3
г
057
39
9
143
8F
Џ
228
E4
д
058
3A
:
144
90
Ђ
229
E5
е
059
3B
;
145
91
‘
230
E6
ж
060
3C
<
146
92
’
231
E7
з
061
3D
=
147
93
“
232
E8
и
062
3E
>
148
94
”
233
E9
й
063
3F
?
149
95
•
234
EA
к
064
40
@
150
96
–
235
EB
л
065
41
A
151
97
—
236
EC
м
066
42
B
152
98
237
ED
н
067
43
C
153
99
™
238
EE
о
068
44
D
154
9A
љ
239
EF
п
069
45
E
155
9B
›
240
F0
р
070
46
F
156
9C
њ
241
F1
с
071
47
G
157
9D
ќ
242
F2
т
072
48
H
158
9E
ћ
243
F3
у
073
49
I
159
9F
џ
244
F4
ф
074
4A
J
160
A0
245
F5
х
075
4B
K
161
A1
Ў
246
F6
ц
076
4C
L
162
A2
ў
247
F7
ч
077
4D
M
163
A3
Ј
248
F8
ш
078
4E
N
164
A4
¤
249
F9
щ
079
4F
O
165
A5
Ґ
250
FA
ъ
080
50
P
166
A6
¦
251
FB
ы
081
51
Q
167
A7
§
252
FC
ь
082
52
R
168
A8
Е
253
FD
э
083
53
S
169
A9
©
254
FE
ю
084
54
T
170
AA
Є
255
FF
я
085
55
U
Более того, в 1986 году ANSI была существенно расширена, благодаря Яну Э. Дэвису, написавшему пакет The Draw, позволяющий не просто использовать базовые, с нашей точки зрения, функции, но и полноценно (или почти полноценно) рисовать!
Подводя итоги
Таким образом, можно видеть, что кодировка ANSI, по сути, хоть и была довольно спорным решением, сохраняет свои позиции.
Со временем с легкой руки энтузиастов древний терминал ANSI перекочевал даже на телефоны!
fb.ru
О кодировках и кодовых страницах / Habr
Вряд ли это сейчас сильно актуально, но может кому-то покажется интересным (или просто вспомнит былые годы).Начну с небольшого экскурса в историю компьютера. Поскольку компьютер использовался для обработки информации, то он просто обязан представлять эту информацию в «человеческом» виде. Компьютер хранит информацию в виде чисел (байтов), а человек воспринимает символы (буквы, цифры, различные знаки). Значит, надо сделать сопоставление число <-> символ и задача будет решена. Сначала посчитаем, сколько символов нам надо (не забудем, что «мы» — американцы, использующие латинский алфавит). Нам надо 10 цифр + 26 заглавных букв английского алфавита + 26 строчных букв + математические знаки (хотя бы +-/*=><%) + знаки препинания (.,!?:;’” ) + различные скобки + служебные символы (_^%$@|) + 32 непечатных управляющих символов для работы с устройствами (в первую очередь, с телетайпом). В общем, 128 символов хватает «впритык» и этот стандартный набор символов «мы» назвали ASCII, т.е. «American Standard Code for Information Interchange»
Отлично, для 128 символов достаточно 7 бит. С другой стороны, в байте 8 бит и каналы связи 8-битные (забудем про «доисторические» времена, когда в байте и каналах бит было меньше). По 8-ми битному каналу будем передавать 7 бит кода символа и 1 бит контрольный (для повышения надежности и распознавания ошибок). И все было замечательно, пока компьютеры не стали использоваться в других странах (где латиница содержит больше 26 символов или вообще используется не латинский алфавит). Вместо того, чтобы всем поголовно освоить английский, жители СССР, Франции, Германии, Грузии и десятков других стран захотели, чтобы компьютер общался с ними на их родном языке. Пути были разные (в зависимости от остроты проблемы): одно дело, если к 26 символам латиницы надо добавить 2-3 национальных символа (можно пожертвовать какими-то специальными) и другое дело, когда надо «вклинить» кириллицу. Теперь «мы» — русские, стремящиеся «русифицировать» технику. Первыми были решения на основе замены строчных английских букв прописными русскими. Однако проблема в том, что русских букв (33) и они не влезают на 26 мест. Надо «уплотнить» и первой жертвой этого уплотнения пала буква Ё (еe просто повсеместно заменили на Е). Другой прием – вместо «русских» A,E,K,M,H,O,P,C,T стали использовать похожие английские (таких букв даже больше чем надо, но в некоторых парах прописные похожие, а строчные — не очень: Hh Tt Bb Kk Mm). Но все же «вклинили » и в результате весь вывод шел ПРОПИСНЫМИ БУКВАМИ, что неудобно и некрасиво, однако со временем привыкли. Второй прием – «переключение языка». Код русского символа совпадал с кодом английского символа, но устройство помнило, что сейчас оно в русском режиме и выводило символ кириллицы (а в английском режиме – латиницы). Режим переключался двумя служебными символами: Shift Out (SO, код 14) на русский и Shift IN (SI, код 15) на английский (интересно, что когда-то в печатных машинках использовалась двухцветная лента и SO приводил к физическому подъему ленты и в результате печать шла красным, а SI ставил ленту на место и печать снова шла черным). Текст с большими и маленькими буквами стал выглядеть вполне прилично. Все эти варианты более-менее работали на больших компьютерах, но после выпуска IBM PC началось массовое распространение персональных компьютеров по всему миру и надо было что-то решать централизовано.
Решением стала разработанная фирмой IBM технология кодовых страниц. К этому времени «контрольный символ» при передаче потерял свою актуальность и все 8-бит можно было использовать для кода символа. Вместо диапазона кодов 0-127 стал доступен диапазон 0-255. Кодовая страница (или кодировка)– это сопоставление кода из диапазона 0-255 некоему графическому образу (например, букве «Я» кириллицы или букве «омега» греческого). Нельзя сказать «символ с кодом 211 выглядит так», но можно сказать «символ с кодом 211 в кодовой странице CP1251 выглядит так: У, а в CP1253(греческая) выглядит так: Σ ». Во всех (или почти всех) кодовых таблица первые 128 кодов соответствуют таблице ASCII, только для первых 32 непечатных кодов IBM «назначила» свои картинки (которые показывается при выводе на экран монитора). В верхней части IBM разместила символы псевдографики (для рисования различных рамок), дополнительные символы латиницы, используемые в странах Западной Европы, некоторые математические символы и отдельные символы греческого алфавита. Эта кодовая страница получила название CP437 (IBM разработала и множество других кодовых страниц) и по умолчанию использовалась в видеоадаптерах. Кроме того, различные центры стандартизации (мировые и национальные) создали кодовые страницы для отображения национальных символов. Наши компьютерные «умы» предложили 2 варианта: основная кодировка ДОС и альтернативная кодировка ДОС. Основная предназначалась для работы везде, а альтернативная — в особых случаях, когда использование основной неудобно. Оказалось, что таких особых случаев большинство и основной (не по названию, а по использованию) стала именно «альтернативная» кодировка. Думаю, такой исход был ясен с самого начала для большинства специалистов (кроме «ученых мужей», оторванных от жизни). Дело в том, что в большинстве случаев использовались английские программы, которые «для красоты» активно использовали псевдографику для рисования различных рамок и тп. Типичные пример — суперпопулярный Нортон коммандер, стоящий тогда на большинстве компьютеров. Основная кодировка на местах псевдографики разместила русские символы и панели нортона выглядели просто ужасно (равно как и любой другой псевдографический вывод). А альтернативная кодировка бережно сохранила символы пседографики, использую для русских букв другие места. В результате и с Нортон коммандером и с другими программами вполне можно было работать. Андрей Чернов (широко известная личность в то время) разработал кодировку KOI8-R (КОИ8), пришедшую с «больших» компьютеров, где господствовал UNIX. Ее особенностью было то, что если у русского символа пропадал 8-й бит, то получившийся в результате «обрезания» английский символ будет созвучен исходному русскому. И вместо «Привет» получался «pRIVET», что не совсем то, но хотя бы читаемо. В результате в СССР на компьютерах использовали 3 различных кодовых страницы (основную, альтернативную и KOI8). И это не считая различных «вариаций», когда в альтернативной кодировке, скажем, отдельные символы (а то и строки) изменялись. От KOI8 тоже «отпочковывались» варианты — украинский, белорусский, таджикский, кавказский и др. Оборудование (принтеры, видеодаптеры) тоже надо было настраивать (или «прошивать») для работы со своими кодировками. Коммерсанты могли привезти дешевую партию принтеров (из эмиратов, например, по бартеру) а они не работали с русскими кодировками.
Тем не менее в целом кодовые страницы позволили решить проблему вывода национальных символов (устройство просто должно уметь работать с соответствующей кодовой страницей), но породили проблему множественности кодировок, когда почтовая программа отправляет данные в одной кодировке, а принимающая программа показывает их в другой. В результате пользователь видит так называемые «кракозябры» (вместо «привет» написано «ЏаЁўҐв» или «оПХБЕР»). Потребовались программы-перекодировщики, переводящие данные из одной кодировки в другую. Увы, порой письма при прохождении через почтовые серверы неоднократно автоматически перекодировались (или даже «обрезался» 8-й бит) и нужно было найти и выполнить всю цепочку обратных преобразований.
После массового перехода на Windows к трем кодовым страницам добавилась четвертая (Windows-1251 она же CP1251 она же ANSI ) и пятая (CP866 она же OEM или DOS). Не удивляйтесь — Windows для работы с кириллицей в консоли по-умолчанию использует кодировку CP866 (русские символы такие же как в «альтернативной кодировке», только некоторые спецсимволы отличаются), для других целей — кодировку CP1251. Почему Windows понадобилось две кодировки, неужели нельзя было обойтись одной? Увы, не получается: DOS-кодировка используется в именах файлов (тяжелое наследие DOS) и консольные команды типа dir, copy должны правильно показывать и правильно обрабатывать досовские имена файлов. С другой стороны, в этой кодировке много кодов отведено символам псевдографики (различным рамкам и т.п.), а Windows работает в графическом режиме и ей (а точнее, windows-приложениям) не нужны символы псевдографики (но нужны занятые ими коды, которые в CP1251 использованы для других полезных символов). Пять кириллических кодировок поначалу еще больше усугубили ситуацию, но со временем наиболее популярными стали Windows-1251 и KOI8, а досовскими просто стали меньше пользоваться. Еще при использовании Windows стало неважно, какая кодировка в видеоадаптере (только изредка, до загрузки Windows в диагностических сообщениях можно видеть «кракозябры»).
Решение проблемы кодировок пришло, когда повсеместно стала внедряться система Unicode (и для персональных ОС и для серверов). Unicode каждому национальному символу ставит в соответствие раз и навсегда закрепленное за ним 20-ти битовое число («точку» в кодовом пространстве Unicode, причем чаще всего хватает 16 бит, поскольку 20-битные коды используются для редких символов и иероглифов), поэтому нет необходимости перекодировать (подробнее об Unicode см следующую запись в журнале). Теперь для любой пары <код байта>+<кодовая страница> можно определить соответствующий ей код в Unicode (сейчас в кодовых страницах для каждого 8-битного кода показывается 16-битный код Unicode) и потом при необходимости вывести этот символ для любой кодовой страницы, где он присутствует. В настоящее время проблема кодировок и перекодировок для пользователей практически исчезла, но все же изредка приходят письма, где либо тема письма либо содержание «не в той» кодировке.
Интересно, что примерно год назад проблема кодировок ненадолго всплыла при «наезде» ФАС на сотовых операторов, мол те дискриминируют русскоязычных пользователей, поскольку за передачу кириллицы берут больше. Это объясняется техническим решением, выбранным разработчиком протокола SMS связи. Если бы его россияне разработали, они бы, возможно, отдали приоритет кириллице. В указанной статье «начальник управления контроля транспорта и связи Дмитрий Рутенберг отметил, что существуют и восьмибитные кодировки для кириллицы, которые могли бы использовать операторы.» Во как — на улице 21-й век, Unicode шагает по миру, а господин Рутенберг тянет нас в начало 90-х, когда шла «война кодировок» и проблема перекодировок стояла во весь рост. Интересно, в какой кодировке должен получить СМС Вася Пупкин, пользующийся финским телефоном, находящийся в Турции на отдыхе, от жены с корейским телефоном, отправляющей СМС из Казахстана? А от своего французского компаньона (с японским телефоном), находящегося в Испании? Думаю, никакой начальник ответа на этот вопрос дать не сможет. К счастью, это «экономное» предложение не воплотилось в жизнь.
Юный читатель может спросить — а что помешало сразу использовать Unicode, зачем были придуманы эти заморочки с кодовыми страницами? Думаю, дело в финансовой стороне проблемы. Unicode требует в 2 раза больше памяти, а память стоит денег (и дисковая и ОЗУ). Стал бы американец покупать компьютер на 1-2 тыс дороже из-за того, что «теперь новая ОС требует больше памяти, но позволяет без проблем работать с русским, европейскими, арабскими языками»? Боюсь, простой англоязычный покупатель воспринял бы такой аргумент «неадекватно» (и обратился бы к другим производителям).
habr.com
Universal online Cyrillic decoder — recover your texts
Universal online Cyrillic decoder — recover your textsVersion: 20191102
Output
The resulting text will be displayed here…
| Guestbook Please link to this site! | Custom Work For a small fee I can help you quickly recode/recover large pieces of data — texts, databases, websites… or write custom functions you can use (invoice available). FAQ and contact information. |
About the program
Welcome! You may find this site useful, if you have recieved some texts that you believe are written in the Cyrillic alphabet, but instead are displayed in some strange combination of bizarre characters. This program will try to guess the encoding, and if it does not, it will show samples, examples of all encoding-combinations, so as you will be able to select the good one.
How to
- Paste the text to decode in the big text area. The first few words will be analyzed so they should be (scrambled) in supposed Cyrillic.
- The program will try to decode the text and will print the result below.
- If the translation is successful, you will see the text in Cyrillic characters and will be able to copy it and save it if it’s important.
- If the translation isn’t successful (still the text is not in Cyrillic but in the same or other unintelligible characters), you can choose from the newly created select-listbox the variant that is in Cyrillic (if there are more than one, select the longest). By pressing the button OK you will have the correct text converted.
- If the text is not totally converted, try all other variants in Cyrillic from the select-listbox.
Limits
- If your text contains question marks «???? ?? ??????», the problem is with the sender and no recovery will be possible. Ask them to resend the text, eventually as an ordinary text file or in LibreOffice/OpenOffice/MSOffice format.
- There is no claim that every text is recoverable, even if you are certain that the text is in Cyrillic.
- The analyzed and converted text is limited to 100 KiB.
- A 100% precision is not always achieved — in a conversion from a codepage to another code page, some characters may be lost, like the Bulgarian quotes or rarely some single letters. Some of this depends on your Windows Clipboard character handling.
- The program will try a maximum of 6776 variants in two or three levels: if there had been a multiple encoding like koi8(utf(cp1251(utf))), it will not be detected or tested. Usually the possible and displayed correct variants are between 32 and 255.
- If a part of the text is encoded with one code page, and another part — with another code page, the program could recognize only one of the parts at a time.
Terms of use
Please notice that this freeware program is created with the hope that it would be useful, but has no warranty, not even an implied warranty for fitness for any particular use. Please use it at your own risk.
If you have very long texts to translate, please make sure you have a backup copy.
What’s new
- October 2017 : Added «Select all / Copy» button.
- July 2016 : SSL Certificate installed, you can now access the Decoder on a secure connection.
- October 2013 : I am trying different optimizations for the system which should make the decoder run faster and handle more text. If you notice any problem, please notify me ASAP.
- March 2013 : My hosting provider sent me a warning that the Decoder is using too much server CPU power and its processes were killed more than 100 times. I am making some changes so that the program will use less CPU, especially when reposting a previously sampled text, however, the decoded form may load somewhat slower. Please contact me if you have some difficulties using the program.
- 2012-08-09 : Added French translation, thanks to Arnaud D.
- 2011-03-06 : Added Belorussian translation, thanks to Зыль and Aliaksandr Hliakau.
- 31.07.10 : Added Serbian translation, thanks to Miodrag Danilovic (Boston — Beograd).
- 07.05.09 : Raised limit of MAX text size to 50 kiB.
- may 2009 : Added Ukrainian interface thanks to Barmalini.
- 2008-2009 : A number of small fixes and tweaks of the detection algorithm. Changed interface to default to automatic decoding.
- 12.08.07 : Fixed Russian language translation, thanks to Petr Vasilyev. This page will be significantly restructured in the near future.
- 10.11.06 : Three new postfilters added: «base64», «unix-to-unix» и «bin-to-hex», theoretically the tested combinations are 4725. Changes to the frequency analysis function (testing).
- 11.10.06 : The main site is on a new hardware server, should run faster.
- 11.09.06 : The program now uses PHP5 and should run times faster.
- 19.08.06 : Because of a broken DNS entry, this site was inaccessible from 06:00 on 15 august up to 15:00 on 18 august. That was the reason for me to set two «mirror» sites (5ko.free.fr/decode and www.accent.bg/decode) with the same program. If the original has a problem, you can find the copies in Google and recover your texts.
- 17.06.06 : Added two more antique Cyrillic encodings, MIK и KOI-7, but you better not need them.
- 03.03.06 : Added Slovak translation, thanks to Martin from KPR Slovakia.
- 15.02.06 : More encodings added and tested.
- 20.10.05 : Small improvement to the frequency-analysis function: for texts, written in all-capital letters.
- 14.10.05 : Two more gmail-Cyrillic encodings were added. Theoretically the tested combinations are 2112.
- 15.06.05 : Russian language interface was added. Big thanks to chAlx!
- 16.02.05 : One more postfilter decoding is added, for strings like this: «%u043A%u0438%u0440%u0438%u043B%u0438%u0446%u0430».
- 05.02.05 : More encodings tests added, the number of tested encodings is doubled, but thus the program may work slightly slower.
- 03.02.05 : The frequency analysis function that detects the original encoding works much better now. Currently the program recognises most of the encodings if the first few words are not too weird. It although still needs some improvement.
- 15.01.05 : The input text limit is raised from 10 to 20 kB.
- 01.12.04 : First public release.
Back to the Latin to Cyrillic convertor.
2cyr.com