Анализ производительности запросов в Базе данных Azure для MySQL
- Чтение занимает 2 мин
В этой статье
Применимо к: База данных Azure для MySQL 5.7, 8.0.Applies to: Azure Database for MySQL 5.7, 8.0
Этот компонент помогает быстро определить наиболее медленно выполняющиеся запросы, их изменение со временем и ожидания каких действий влияют на них.Query Performance Insight helps you to quickly identify what your longest running queries are, how they change over time, and what waits are affecting them.
Распространенные сценарииCommon scenarios
Длительные запросыLong running queries
- Определение самых медленно выполняющихся запросов за прошедшие X часов.

- Определение основных N запросов, ожидающих ресурсы.Identifying top N queries that are waiting on resources

Статистика ожиданияWait statistics
- Понимание характера ожидания запроса.Understanding wait nature for a query
- Понимание тенденций ожидания ресурсов и причин состязания за ресурсы.Understanding trends for resource waits and where resource contention exists
РазрешенияPermissions
Чтобы просматривать текст запросов в анализе производительности запросов, требуются разрешения Владельца или Участника.Owner or Contributor permissions required to view the text of the queries in Query Performance Insight.
Предварительные требованияPrerequisites
Чтобы компонент «Анализ производительности запросов» работал, данные должны находиться в хранилище запросов.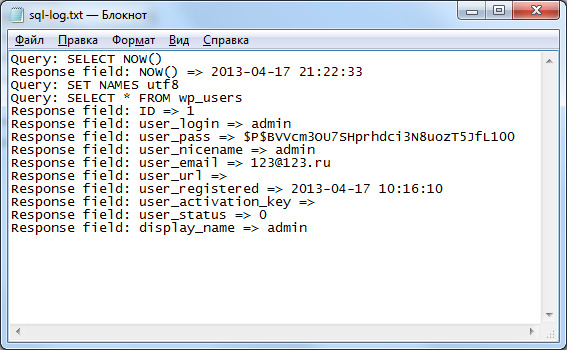 For Query Performance Insight to function, data must exist in the Query Store.
For Query Performance Insight to function, data must exist in the Query Store.
Просмотр анализа производительностиViewing performance insights
Представление анализа производительности запросов на портале Azure содержит визуализации ключевых данных из хранилища запросов.The Query Performance Insight view in the Azure portal will surface visualizations on key information from Query Store.
На странице портала сервера Базы данных Azure для MySQL выберите Анализ производительности запросов в разделе Интеллектуальная производительность в строке меню.In the portal page of your Azure Database for MySQL server, select Query Performance Insight under the Intelligent Performance section of the menu bar.
Длительные запросыLong running queries
На вкладке Длительные запросы отображаются 5 наиболее частых запросов, упорядоченных по средней продолжительности выполнения и объединенных в 15-минутные интервалы.
Чтобы уменьшить временной интервал графика, перетащите его границу.You can click and drag in the chart to narrow down to a specific time window. Кроме того, для просмотра более коротких или более длинных периодов используйте соответственно значки увеличения и уменьшения масштаба.Alternatively, use the zoom in and out icons to view a smaller or larger time period respectively.
Статистика ожиданияWait statistics
Примечание
Статистика ожидания предназначена для устранения проблем с производительностью запросов. Wait statistics are meant for troubleshooting query performance issues. Рекомендуется включать эту функцию только в целях устранения неполадок.It is recommended to be turned on only for troubleshooting purposes.
Wait statistics are meant for troubleshooting query performance issues. Рекомендуется включать эту функцию только в целях устранения неполадок.It is recommended to be turned on only for troubleshooting purposes.
Статистика ожидания обеспечивает представление событий ожидания, происходящих во время выполнения определенного запроса.Wait statistics provides a view of the wait events that occur during the execution of a specific query.
Откройте вкладку Статистика ожидания , чтобы посмотреть визуализации ожидания на сервере.Select the Wait Statistics tab to view the corresponding visualizations on waits in the server.
Сведения, отображаемые в представлении статистики ожидания, группируются по запросам с максимальным временем ожидания на заданном интервале времени.Queries displayed in the wait statistics view are grouped by the queries that exhibit the largest waits during the specified time interval.
Дальнейшие действияNext steps
Логирование запросов от определенных пользователей · Yevhen Lebid’s website
Появилась необходимость логировать запросы к БД MySQL от определенных пользователей. Давайте разберемся как быстро реализовать данный функционал!
Самый простой и очевидный способ — просто включить general_log (лог ВСЕХ запросов — содержит информацию о подключениях и отключениях клиентов, и о всех SQL выполненных запросах).
SET GLOBAL general_log = 'ON';
Проблема состоит в том, что в лог попадает очень большое количество информации (а в высоконагруженных проектах вообще так делать не рекомендуется), лог быстро разрастается, и, чтобы не закончилось место на диске, приходится настраивать ротацию. Кроме того, анализ такого лога усложняется, и тут не обойтись без хитроумных конструкций и конвейеров с использованием sed/grep/awk…
В моем случае не нужно логировать запросы от пользователей root и prometheus
Итак, приступим! Подключаемся к MySQL-серверу и указываем писать все логи в таблицы (а не в файлы, как было до этого):
SET GLOBAL log_output = 'TABLE';
Выключаем лог всех запросов (если включен) и изменяем движок (Engine) таблицы general_log на MyISAM:
SET GLOBAL general_log = 'OFF';
ALTER TABLE mysql. general_log ENGINE = MyISAM;
 general_log ENGINE = MyISAM;
general_log ENGINE = MyISAM;
Включаем лог всех запросов:
SET GLOBAL general_log = 'ON';
Как я уже говорил, в таблицу
SELECT * FROM mysql.general_log;
Для «фильтрации» и хранения только нужных данных нам потребуется еще одна таблица с аналогичной структурой. Смотрим запрос, с помощью которого можно будет ее создать:
SHOW CREATE TABLE mysql.general_log;
Создаем таблицу с именем custom_user_log по запросу из предыдущего шага (запрос копируем полностью меняем только имя и комментарий):
USE mysql; CREATE TABLE `custom_user_log` ( `event_time` timestamp(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6) ON UPDATE CURRENT_TIMESTAMP(6), `user_host` mediumtext NOT NULL, `thread_id` bigint(21) unsigned NOT NULL, `server_id` int(10) unsigned NOT NULL, `command_type` varchar(64) NOT NULL, `argument` mediumblob NOT NULL ) ENGINE=MyISAM DEFAULT CHARSET=utf8 COMMENT='Custom user query log';
Теперь можем выбрать нужным нам записи из таблицы general_log и вставить в таблицу custom_user_log:
INSERT INTO mysql. custom_user_log SELECT * FROM mysql.general_log WHERE user_host NOT LIKE '%root%' AND user_host NOT LIKE '%prometheus%';
 custom_user_log SELECT * FROM mysql.general_log WHERE user_host NOT LIKE '%root%' AND user_host NOT LIKE '%prometheus%';
custom_user_log SELECT * FROM mysql.general_log WHERE user_host NOT LIKE '%root%' AND user_host NOT LIKE '%prometheus%';
Таблицу
TRUNCATE mysql.general_log;
Конечно же два последних шага лучше оформить в bash-скрипт, который будет выполняться по крону (cron) с заданной периодичностью. В моем случае скрипт выглядит так:
#!/bin/bash
#
# Скрипт копирует MySQL-запросы всех пользователей кроме root и prometheus
# в отдельную таблицу mysql.custom_user_log и чистит mysql.general_log
#
MYADMIN="/usr/bin/mysqladmin --defaults-file=/root/.my.cnf"
ping_output=`$MYADMIN ping 2>&1`; ping_alive=$(( ! $? ))
if [ $ping_alive = 0 ]; then
exit
fi
OPTIONS=`cat /root/.mypass`
mysql ${OPTIONS} <<MY_QUERY
USE mysql;
INSERT INTO custom_user_log SELECT * FROM general_log WHERE user_host NOT LIKE '%root%' AND user_host NOT LIKE '%prometheus%';
TRUNCATE general_log;
MY_QUERY
Оптимизация запросов MySQL профилированием на примере
Существует два подхода к профилированию запросов, соответствующие двум вопросам, упомянутым в этой статье. Можно профилировать весь сервер, основываясь на том, какие запросы в наибольшей степени его загружают. (Если вы начали с верхнего уровня, с профилирования на уровне приложений, то, возможно, уже знаете, какие запросы требуют внимания.) Затем, как только настроите конкретные запросы для оптимизации, можете углубиться в их профилирование по отдельности, определяя, какие подзадачи значительнее увеличивают их время отклика.
Можно профилировать весь сервер, основываясь на том, какие запросы в наибольшей степени его загружают. (Если вы начали с верхнего уровня, с профилирования на уровне приложений, то, возможно, уже знаете, какие запросы требуют внимания.) Затем, как только настроите конкретные запросы для оптимизации, можете углубиться в их профилирование по отдельности, определяя, какие подзадачи значительнее увеличивают их время отклика.
Профилирование рабочей нагрузки сервера MySQL
Подход к профилированию на уровне сервера очень полезен, потому что он может помочь вам проверить сервер на предмет неэффективных запросов. Обнаружение и исправление этих запросов позволит улучшить производительность приложения в целом, а также выявить конкретные проблемы. Вы можете снизить общую нагрузку на сервер, тем самым уменьшится конкуренция за совместно используемые ресурсы и увеличится скорость выполнения всех запросов (побочный эффект). Снижение нагрузки на сервер способно помочь вам отложить обновления и другие затратные мероприятия или избежать их, кроме того, вы можете обнаружить и устранить проблемы, связанные с результатами, неприемлемыми для пользователя, такими как выбросы (аномальные результаты измерений).
С каждой следующей версией в MySQL появляется все больше инструментов, и если такая тенденция сохранится, скоро в MySQL будут великолепные инструменты для измерения наиболее важных аспектов ее производительности. Но что касается профилирования запросов и поиска самых затратных из них, нам не нужна вся эта сложность. Необходимый инструмент существует уже довольно давно. Это так называемый журнал медленных запросов.
Фиксация запросов MySQL в журнал
В MySQL журнал медленных запросов изначально предназначался для фиксации только медленных запросов, но для целей профилирования необходима регистрация всех запросов. При этом нам требуется более тонкая детализация времени отклика, чем в MySQL 5.0 и ранних версиях. В этих версиях минимальный временной интервал равнялся 1 секунде. К счастью, прежние ограничения уже неактуальны.
В MySQL 5.1 и более поздних версиях журнал медленных запросов расширен так, что переменную сервера long_query_time можно установить равной нулю, зафиксировав все запросы, а время отклика на запрос детализировано с дискретностью 1 микросекунда. Если вы используете Percona Server, этот функционал доступен уже в версии 5.0, кроме того, Percona Server дает намного больший контроль над содержимым журнала и фиксацией запросов.
Если вы используете Percona Server, этот функционал доступен уже в версии 5.0, кроме того, Percona Server дает намного больший контроль над содержимым журнала и фиксацией запросов.
В существующих версиях MySQL у журнала медленных запросов наименьшие издержки и наибольшая точность измерения времени выполнения запроса. Если вас беспокоит дополнительный ввод/вывод, вызываемый этим журналом, то не тревожьтесь. Мы провели эталонное тестирование и выяснили, что при нагрузках, связанных с вводом/выводом, издержки незначительны. (На самом деле это лучше видно в ходе работ, нагружающих процессор.) Более актуальной проблемой является заполнение диска. Убедитесь, что вы установили смену журнала для журнала медленных запросов, если он включен постоянно. Либо оставьте его выключенным и включайте только на определенное время для получения образца рабочей нагрузки.
У MySQL есть и другой тип журнала запросов — общий журнал, но он не так полезен для анализа и профилирования сервера. Запросы регистрируются по мере их поступления на сервер, поэтому журнал не содержит информации о времени отклика или о плане выполнения запроса. MySQL 5.1 и более поздние версии поддерживают также ведение журнала запросов к таблицам, однако это не самая удачная идея. Данный журнал сильно влияет на производительность: хотя MySQL 5.1 в журнале медленных запросов отмечает время запросов с точностью до 1 микросекунды, медленные запросы к таблице регистрируются с точностью до 1 секунды. Это не очень полезно.
MySQL 5.1 и более поздние версии поддерживают также ведение журнала запросов к таблицам, однако это не самая удачная идея. Данный журнал сильно влияет на производительность: хотя MySQL 5.1 в журнале медленных запросов отмечает время запросов с точностью до 1 микросекунды, медленные запросы к таблице регистрируются с точностью до 1 секунды. Это не очень полезно.
Percona Server регистрирует в журнале медленных запросов значительно более подробную информацию, чем MySQL. Здесь отмечается полезная информация о плане выполнения запроса, блокировке, операциях ввода/вывода и многом другом. Эти дополнительные биты данных добавлялись медленно, поскольку мы столкнулись с различными сценариями оптимизации, которые требовали более подробных сведений о том, как запросы выполняются и где происходят затраты времени. Мы также упростили администрирование. Например, добавили возможность глобально контролировать порог long_query_time для каждого соединения, поэтому вы можете заставить их запускать или останавливать журналирование своих запросов, когда приложение использует пул соединений или постоянные соединения, но не можете сбросить переменные уровня сеанса.
В целом это легкий и полнофункциональный способ профилирования сервера и оптимизации его запросов.
Допустим, вы не хотите регистрировать запросы на сервере или по какой-то причине не можете делать этого, например не имеете доступа к серверу. Мы сталкивались с такими ограничениями, поэтому разработали две альтернативные методики и добавили их в инструмент pt-query-digest пакета Percona Toolkit. Первая методика подразумевает постоянное отслеживание состояния с помощью команды SHOW FULL PROCESSLIST с параметром —processlist. При этом отмечается, когда запросы появляются и исчезают. В некоторых случаях этот метод довольно точен, но он не может зафиксировать все запросы. Очень короткие запросы могут проскочить и завершиться, прежде чем инструмент их заметит.
Второй метод состоит в фиксировании сетевого трафика TCP и его проверки, а затем декодирования протокола «клиент/сервер MySQL» (MySQL client/server protocol). Вы можете использовать утилиту tcpdump для записи трафика на диск, а затем — pt-query-digest с параметром --type=tpcdump для декодирования и анализа запросов. Это гораздо более точная методика, которая зафиксирует все запросы. Методика работает даже с расширенными протоколами, такими как бинарный протокол, используемый для создания и выполнения подготовленных операторов на стороне сервера, и сжатый протокол. Можно также использовать MySQL Proxy со скриптом журналирования, но в практике это нам редко встречалось.
Это гораздо более точная методика, которая зафиксирует все запросы. Методика работает даже с расширенными протоколами, такими как бинарный протокол, используемый для создания и выполнения подготовленных операторов на стороне сервера, и сжатый протокол. Можно также использовать MySQL Proxy со скриптом журналирования, но в практике это нам редко встречалось.
Анализ журнала запросов
Мы рекомендуем по крайней мере время от времени фиксировать в журнале медленных запросов все запросы, выполняемые на сервере, и анализировать их. Запишите запросы, сделанные в течение репрезентативного периода времени, например за час пикового трафика. Если рабочая нагрузка однородна, достаточно будет минуты или даже меньше для нахождения плохих запросов, которые следует оптимизировать.
Не стоит просто открывать журнал и смотреть в него — это пустая трата времени и денег. Сначала создайте профиль и, если это необходимо, просмотрите конкретные выборки в журнале. Лучше всего начинать с верхнего уровня и двигаться вниз, в противном случае, как упоминалось ранее, вы можете деоптимизировать процесс.
Для создания профиля из журнала медленных запросов требуется хороший инструмент анализа журналов. Мы предлагаем утилиту pt-query-digest, которая, возможно, является самым мощным инструментом анализа журнала запросов MySQL. Она поддерживает множество различных функций, включая возможность сохранять отчеты о запросах в базе данных и отслеживать изменения в рабочей нагрузке.
По умолчанию вы просто выполняете утилиту, передаете ей файл журнала медленных запросов в качестве аргумента, и она сама выполняет нужные действия. Утилита выводит профиль запросов в журнале, а затем выбирает важные классы запросов и выдает подробный отчет по каждому из них. В отчете есть десятки мелочей, облегчающих вашу жизнь. Мы продолжаем активно развивать этот инструмент, поэтому лучше прочитать документацию для последней версии, чтобы узнать о ее функциональности.
Приведем краткий обзор отчета pt-query-digest, начиная с профиля. Ниже представлена полная версия профиля, который мы показали ранее в этой статье:
# Profile
# Rank Query ID Response time Calls R/Call V/M Item
# ==== ================== ================ ===== ====== ===== =======
# 1 0xBFCF8E3F293F6466 11256. 3618 68.1% 78069 0.1442 0.21 SELECT InvitesNew?
# 2 0x620B8CAB2B1C76EC 2029.4730 12.3% 14415 0.1408 0.21 SELECT StatusUpdate?
# 3 0xB90978440CC11CC7 1345.3445 8.1% 3520 0.3822 0.00 SHOW STATUS
# 4 0xCB73D6B5B031B4CF 1341.6432 8.1% 3509 0.3823 0.00 SHOW STATUS
# MISC 0xMISC 560.7556 3.4% 23930 0.0234 0.0 <17 ITEMS> 3618 68.1% 78069 0.1442 0.21 SELECT InvitesNew?
# 2 0x620B8CAB2B1C76EC 2029.4730 12.3% 14415 0.1408 0.21 SELECT StatusUpdate?
# 3 0xB90978440CC11CC7 1345.3445 8.1% 3520 0.3822 0.00 SHOW STATUS
# 4 0xCB73D6B5B031B4CF 1341.6432 8.1% 3509 0.3823 0.00 SHOW STATUS
# MISC 0xMISC 560.7556 3.4% 23930 0.0234 0.0 <17 ITEMS>
3618 68.1% 78069 0.1442 0.21 SELECT InvitesNew?
# 2 0x620B8CAB2B1C76EC 2029.4730 12.3% 14415 0.1408 0.21 SELECT StatusUpdate?
# 3 0xB90978440CC11CC7 1345.3445 8.1% 3520 0.3822 0.00 SHOW STATUS
# 4 0xCB73D6B5B031B4CF 1341.6432 8.1% 3509 0.3823 0.00 SHOW STATUS
# MISC 0xMISC 560.7556 3.4% 23930 0.0234 0.0 <17 ITEMS>Здесь показано чуть больше деталей, чем раньше. Во-первых, каждый запрос имеет идентификатор, который является хеш-подписью его цифрового отпечатка. Цифровой отпечаток — это нормализованная каноническая версия запроса с удаленными литералами и пробелами, переведенная в нижний регистр (обратите внимание, что запросы 3 и 4 кажутся одинаковыми, но у них разные отпечатки). Инструмент также объединяет таблицы с похожими именами в каноническую форму. Вопросительный знак в конце имени таблицы invitesNew означает, что к имени таблицы был добавлен идентификатор сегмента данных (шарда), а инструмент удалил его, так что запросы к таблицам, сделанные с похожими целями, объединены вместе. Этот отчет взят из сильно шардированного приложения Facebook.
Этот отчет взят из сильно шардированного приложения Facebook.
Еще один появившийся здесь столбец — отношение рассеяния к среднему значению V/M. Этот показатель называется индексом рассеяния. У запросов с более высоким индексом рассеяния сильнее колеблется время выполнения, и они, как правило, являются хорошими кандидатами на оптимизацию. Если вы укажете параметр --explain в утилите pt-query-digest, то к таблице будет добавлен столбец с кратким описанием плана запроса EXPLAIN — своего рода неформальный код запроса. Это в сочетании со столбцом V/M позволяет быстро определить, какие запросы являются плохими и потенциально легко оптимизируемыми.
Наконец, в нижней части есть дополнительная строка, показывающая наличие 17 других типов запросов, которые инструмент не счел достаточно важными для отдельной строки, и сводная статистика по ним. При задании параметров --limit и --outliers инструмент не будет сворачивать несущественные запросы в одну финальную строку. _ |
# Time range: 2008-09-13 21:51:55 to 22:45:30
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 63 78069
# Exec time 68 11256s 37us 1s 144ms 501ms 175ms 68ms
# Lock time 85 134s 0 650ms 2ms 176us 20ms 57us
# Rows sent 8 70.18k 0 1 0.92 0.99 0.27 0.99
# Rows examine 8 70.84k 0 3 0.93 0.99 0.28 0.99
# Query size 84 10.43M 135 141 140.13 136.99 0.10 136.99
# String:
# Databases production
# Hosts
# Users fbappuser
# Query_time distribution
# 1us
# 10us #
# 100us ####################################################
# 1ms ###
# 10ms ################
# 100ms ################################################################
# 1s #
# 10s+
# Tables
# SHOW TABLE STATUS FROM `production ` LIKE’InvitesNew82’\G
# SHOW CREATE TABLE `production `.
_ |
# Time range: 2008-09-13 21:51:55 to 22:45:30
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 63 78069
# Exec time 68 11256s 37us 1s 144ms 501ms 175ms 68ms
# Lock time 85 134s 0 650ms 2ms 176us 20ms 57us
# Rows sent 8 70.18k 0 1 0.92 0.99 0.27 0.99
# Rows examine 8 70.84k 0 3 0.93 0.99 0.28 0.99
# Query size 84 10.43M 135 141 140.13 136.99 0.10 136.99
# String:
# Databases production
# Hosts
# Users fbappuser
# Query_time distribution
# 1us
# 10us #
# 100us ####################################################
# 1ms ###
# 10ms ################
# 100ms ################################################################
# 1s #
# 10s+
# Tables
# SHOW TABLE STATUS FROM `production ` LIKE’InvitesNew82’\G
# SHOW CREATE TABLE `production `. `InvitesNew82’\G
# EXPLAIN /*!50100 PARTITIONS*/
SELECT InviteId, InviterIdentifier FROM InvitesNew82 WHERE (InviteSetId = 87041469)
AND (InviteeIdentifier = 1138714082) LIMIT 1\G
`InvitesNew82’\G
# EXPLAIN /*!50100 PARTITIONS*/
SELECT InviteId, InviterIdentifier FROM InvitesNew82 WHERE (InviteSetId = 87041469)
AND (InviteeIdentifier = 1138714082) LIMIT 1\G
Вверху отчета содержится множество метаданных, в том числе: как часто выполняется запрос, его средняя конкурентность и смещение (в байтах) до того места, где в файле журнала находится запрос с наихудшей производительностью. Существует табличная распечатка числовых метаданных, включая статистику, такую как, например.стандартное отклонение.
Затем представлена гистограмма времени отклика. Любопытно, что, как вы видите под строкой Query_time distribution, у гистограммы этого запроса два пика. Обычно запрос выполняется за сотни миллисекунд, но есть также значительный всплеск числа запросов, которые были выполнены на три порядка быстрее. Если бы этот журнал был создан в пакете Percona Server, в журнале запросов был бы более богатый набор параметров. Как следствие, мы могли бы проанализировать запросы вдоль и поперек, чтобы понять, почему это происходит. Возможно, это были запросы к определенным значениям, которые непропорционально распределены, поэтому использовался другой индекс, или, возможно, это хиты запросов кэша. В реальных системах гистограмма с двумя пиками не редкость, особенно в случае простых запросов, которые часто имеют лишь несколько альтернативных путей выполнения.
Возможно, это были запросы к определенным значениям, которые непропорционально распределены, поэтому использовался другой индекс, или, возможно, это хиты запросов кэша. В реальных системах гистограмма с двумя пиками не редкость, особенно в случае простых запросов, которые часто имеют лишь несколько альтернативных путей выполнения.
Наконец, раздел деталей отчета заканчивается небольшими вспомогательными фрагментами для облегчения копирования и вставки команд в командную строку, а также проверки схемы и статуса упомянутых таблиц и включает образец запроса EXPLAIN. Образец содержит все литералы, а не «отпечатки пальцев», поэтому это реальный запрос. На самом деле это экземпляр запроса, у которого было худшее время выполнения в нашем примере.
После выбора запросов, которые вы хотите оптимизировать, можете использовать этот отчет, чтобы быстро проверить выполнение запроса. Мы постоянно пользуемся этим инструментом, и потратили много времени на то, чтобы сделать его максимально эффективным и полезным. Настоятельно рекомендуем подружиться с ним. Возможно, в скором времени MySQL будет лучше оснащена встроенными инструментами профилирования, но на момент написания этой статьи нет инструментов лучше, чем журналирование запросов с помощью журнала медленных запросов или использование
Настоятельно рекомендуем подружиться с ним. Возможно, в скором времени MySQL будет лучше оснащена встроенными инструментами профилирования, но на момент написания этой статьи нет инструментов лучше, чем журналирование запросов с помощью журнала медленных запросов или использование tcpdump и запуск полученного журнала с помощью утилиты pt-query-digest.
Профилирование отдельных запросов
После того как вы определили запрос для оптимизации, можете углубиться в него и определить, почему он требует столько времени и как его оптимизировать. Современные методики оптимизации запросов будут описаны в последующих моих блогах вместе с необходимыми для их использования предварительными сведениями. Сейчас наша цель — просто показать, как измерить то, что делает запрос, и сколько времени требует каждый этап. Эти знания помогут вам определить, какие методики оптимизации использовать.
К сожалению, большинство инструментов в MySQL не очень полезны для профилирования запросов. Ситуация меняется, но на момент написания этого блога большинство производственных серверов не поддерживают новейших функций профилирования. Поэтому при их использовании в практических целях мы сильно ограничены командами
Ситуация меняется, но на момент написания этого блога большинство производственных серверов не поддерживают новейших функций профилирования. Поэтому при их использовании в практических целях мы сильно ограничены командами SHOW STATUS, SHOW PROFILE и изучением отдельных записей в журнале медленных запросов (если у вас есть Percona Server — в стандартной системе MySQL в журнале нет дополнительной информации). Мы продемонстрируем все три метода на примере одного и того же запроса и покажем, что вы можете узнать о его выполнении в каждом случае.
Команда SHOW PROFILE
Команда SHOW PROFILE появилась благодаря Джереми Коулу (Jeremy Cole). Она включена в MySQL 5.1 и более поздние версии. Это единственный реальный инструмент профилирования запросов, доступный в GA-релизе MySQL на момент написания блога. Профилирование по умолчанию отключено, но его можно включить во время сеанса, установив значение переменной сервера:
mysql> SET profiling = 1;После этого всякий раз, когда вы посылаете выражение на сервер, он будет замерять прошедшее время и еще некоторые данные, когда запрос будет переходить из одного состояния выполнения в другое. Эта команда имеет довольно широкий функционал и была спроектирована так, что может иметь еще больше, но в следующих релизах она, по всей видимости, будет заменена или вытеснена Performance Schema. Несмотря на это, наиболее полезной функцией данной команды является создание профиля работы, выполняемой сервером во время реализации выражения.
Эта команда имеет довольно широкий функционал и была спроектирована так, что может иметь еще больше, но в следующих релизах она, по всей видимости, будет заменена или вытеснена Performance Schema. Несмотря на это, наиболее полезной функцией данной команды является создание профиля работы, выполняемой сервером во время реализации выражения.
Каждый раз, когда вы отправляете запрос на сервер, он записывает информацию профилирования во временную таблицу и присваивает выражению целочисленный идентификатор, начиная с 1. Приведем пример профилирования представления, включенного в базу данных Sakila:
mysql> SELECT * FROM sakila.nicer_but_slower_film_list;
[query results omitted]
997 rows in set (0.17 sec)Запрос возвратил 997 строк примерно через 1/6 секунды. Посмотрим, что выдаст команда SHOW PROFILES (обратите внимание на множественное число):
mysql> SHOW PROFILES;
+----------+------------+-------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+-------------------------------------------------+
| 1 | 0. 16767900 | SELECT * FROM sakila.nicer_but_slower_film_list |
+----------+------------+-------------------------------------------------+ 16767900 | SELECT * FROM sakila.nicer_but_slower_film_list |
+----------+------------+-------------------------------------------------+
16767900 | SELECT * FROM sakila.nicer_but_slower_film_list |
+----------+------------+-------------------------------------------------+Первое, что мы видим, — то, что время отклика запроса показано с большей точностью, чем принято. Двух десятичных знаков точности, как показано в клиенте
MySQL, часто недостаточно, когда вы работаете с быстрыми запросами. Теперь посмотрим на профиль для этого запроса:
mysql> SHOW PROFILE FOR QUERY 1;
+----------------------+----------+
| Status | Duration |
+----------------------+----------+
| starting | 0.000082 |
| Opening tables | 0.000459 |
| System lock | 0.000010 |
| Table lock | 0.000020 |
| checking permissions | 0.000005 |
| checking permissions | 0.000004 |
| checking permissions | 0.000003 |
| checking permissions | 0.000004 |
| checking permissions | 0.000560 |
| optimizing | 0. 000054 |
| statistics | 0.000174 |
| preparing | 0.000059 |
| Creating tmp table | 0.000463 |
| executing | 0.000006 |
| Copying to tmp table | 0.090623 |
| Sorting result | 0.011555 |
| Sending data | 0.045931 |
| removing tmp table | 0.004782 |
| Sending data | 0.000011 |
| init | 0.000022 |
| optimizing | 0.000005 |
| statistics | 0.000013 |
| preparing | 0.000008 |
| executing | 0.000004 |
| Sending data | 0.010832 |
| end | 0.000008 |
| query end | 0.000003 |
| freeing items | 0.000017 |
| removing tmp table | 0.000010 |
| freeing items | 0.000042 |
| removing tmp table | 0.001098 |
| closing tables | 0.000013 |
| logging slow query | 0.000003 |
| logging slow query | 0.000789 |
| cleaning up | 0. 000007 |
+----------------------+----------+ 000054 |
| statistics | 0.000174 |
| preparing | 0.000059 |
| Creating tmp table | 0.000463 |
| executing | 0.000006 |
| Copying to tmp table | 0.090623 |
| Sorting result | 0.011555 |
| Sending data | 0.045931 |
| removing tmp table | 0.004782 |
| Sending data | 0.000011 |
| init | 0.000022 |
| optimizing | 0.000005 |
| statistics | 0.000013 |
| preparing | 0.000008 |
| executing | 0.000004 |
| Sending data | 0.010832 |
| end | 0.000008 |
| query end | 0.000003 |
| freeing items | 0.000017 |
| removing tmp table | 0.000010 |
| freeing items | 0.000042 |
| removing tmp table | 0.001098 |
| closing tables | 0.000013 |
| logging slow query | 0.000003 |
| logging slow query | 0.000789 |
| cleaning up | 0.
000054 |
| statistics | 0.000174 |
| preparing | 0.000059 |
| Creating tmp table | 0.000463 |
| executing | 0.000006 |
| Copying to tmp table | 0.090623 |
| Sorting result | 0.011555 |
| Sending data | 0.045931 |
| removing tmp table | 0.004782 |
| Sending data | 0.000011 |
| init | 0.000022 |
| optimizing | 0.000005 |
| statistics | 0.000013 |
| preparing | 0.000008 |
| executing | 0.000004 |
| Sending data | 0.010832 |
| end | 0.000008 |
| query end | 0.000003 |
| freeing items | 0.000017 |
| removing tmp table | 0.000010 |
| freeing items | 0.000042 |
| removing tmp table | 0.001098 |
| closing tables | 0.000013 |
| logging slow query | 0.000003 |
| logging slow query | 0.000789 |
| cleaning up | 0. 000007 |
+----------------------+----------+
000007 |
+----------------------+----------+Профиль позволяет следить за каждым шагом выполнения запроса и видеть, сколько прошло времени. Обратите внимание, что не очень легко просмотреть выведенный результат и найти, где затраты времени были максимальными: он сортируется в хронологическом порядке. Однако нас интересует не порядок, в котором выполнялись операции, — мы просто хотим знать, каковы были затраты времени на них. К сожалению, отсортировать вывод с помощью ORDER BY нельзя. Давайте перейдем к использованию команды SHOW PROFILE для запроса связанной таблицы INFORMATION_SCHEMA и формата, который выглядит как просмотренные нами ранее профили:
Так намного лучше! Теперь мы видим, что причина, по которой этот запрос так долго выполнялся, заключалась в копировании данных во временную таблицу, на что затрачено более половины общего времени. Возможно, придется переписать этот запрос так, чтобы он не использовал временную таблицу или хотя бы делал это более эффективно. Следующий крупный потребитель времени, отправка данных, фактически является своеобразной кладовкой, которая может включать в себя любое количество различных действий сервера, в том числе поиск совпадающих строк в соединении и т. д. Трудно сказать, сможем ли мы здесь что-то сэкономить. Обратите внимание на то, что результат сортировки занимает недостаточно много времени, чтобы его можно было оптимизировать. Это довольно типично, поэтому призываем вас не тратить время на «настройку буферов сортировки» и подобные мероприятия.
Следующий крупный потребитель времени, отправка данных, фактически является своеобразной кладовкой, которая может включать в себя любое количество различных действий сервера, в том числе поиск совпадающих строк в соединении и т. д. Трудно сказать, сможем ли мы здесь что-то сэкономить. Обратите внимание на то, что результат сортировки занимает недостаточно много времени, чтобы его можно было оптимизировать. Это довольно типично, поэтому призываем вас не тратить время на «настройку буферов сортировки» и подобные мероприятия.
Как обычно, хотя профиль помогает нам определить, какие виды деятельности вносят наибольший вклад в затраченное на выполнение запроса время, он не говорит нам, почему это происходит. Чтобы узнать, почему потребовалось столько времени для копирования данных во временную таблицу, нам пришлось бы углубиться в этот процесс и создать профиль выполняемых подзадач.
Команда SHOW STATUS
Команда SHOW STATUS MySQL возвращает множество счетчиков.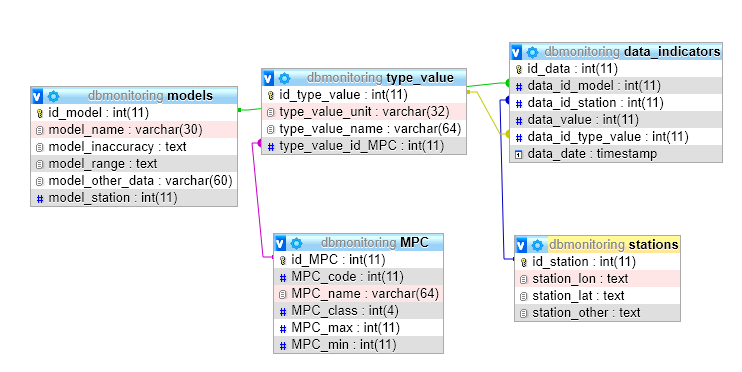 Существует глобальная область действия сервера для счетчиков, а также область сеанса, которая специфична для конкретного соединения. Например, счетчик Queries в начале вашего сеанса равен нулю и увеличивается каждый раз, когда вы делаете запрос. Выполнив команду
Существует глобальная область действия сервера для счетчиков, а также область сеанса, которая специфична для конкретного соединения. Например, счетчик Queries в начале вашего сеанса равен нулю и увеличивается каждый раз, когда вы делаете запрос. Выполнив команду SHOW GLOBAL STATUS (обратите внимание на добавление ключевого слова GLOBAL), вы увидите общее количество запросов, полученных с момента его запуска. Области видимости разных счетчиков различаются — счетчики, которые не имеют области видимости на уровне сеанса, отображаются в SHOW STATUS, маскируясь под счетчики сеансов, и это может ввести в заблуждение. Учитывайте это при использовании данной команды. Как говорилось ранее, подбор должным образом откалиброванных инструментов является ключевым фактором успеха. Если вы пытаетесь оптимизировать что-то, что можете наблюдать только в конкретном соединении с сервером, измерения, которые «засоряются» всей активностью сервера, вам не помогут. В руководстве по MySQL есть отличное описание всех переменных, имеющих как глобальную, так и сеансовую область видимости.
SHOW STATUS может быть полезным инструментом, но на самом деле его применение — это не профилирование. Большинство результатов команды SHOW STATUS — всего лишь счетчики. Они сообщают вам, как часто протекали те или иные виды деятельности, например чтение из индекса, но ничего не говорят о том, сколько времени на это было затрачено. В команде SHOW STATUS есть только один счетчик, который показывает время, израсходованное на операцию (Innodb_row_lock_time), но он имеет лишь глобальную область видимости, поэтому вы не можете использовать его для проверки работы, выполненной в ходе сеанса.
Хотя команда SHOW STATUS не предоставляет информацию о затратах времени, тем не менее иногда может быть полезно использовать ее после выполнения запроса для просмотра значений некоторых счетчиков. Вы можете сделать предположение о том, какие типы затратных операций выполнялись и как они могли повлиять на время запроса. Наиболее важными счетчиками являются счетчики обработчиков запросов и счетчики временных файлов и таблиц. А сейчас приведем пример сброса счетчиков состояния сеанса до нуля, выбора из использованного нами ранее представления и просмотра счетчиков:
А сейчас приведем пример сброса счетчиков состояния сеанса до нуля, выбора из использованного нами ранее представления и просмотра счетчиков:
mysql> SET @query_id = 1;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT STATE, SUM(DURATION) AS Total_R,
-> ROUND(
-> 100 * SUM(DURATION) /
-> (SELECT SUM(DURATION)
-> FROM INFORMATION_SCHEMA.PROFILING
-> WHERE QUERY_ID = @query_id
-> ), 2) AS Pct_R,
-> COUNT(*) AS Calls,
-> SUM(DURATION) / COUNT(*) AS "R/Call"
-> FROM INFORMATION_SCHEMA.PROFILING
-> WHERE QUERY_ID = @query_id
-> GROUP BY STATE
-> ORDER BY Total_R DESC;
+----------------------+----------+-------+-------+--------------+
| STATE | Total_R | Pct_R | Calls | R/Call |
+----------------------+----------+-------+-------+--------------+
| Copying to tmp table | 0. 090623 | 54.05 | 1 | 0.0906230000 |
| Sending data | 0.056774 | 33.86 | 3 | 0.0189246667 |
| Sorting result | 0.011555 | 6.89 | 1 | 0.0115550000 |
| removing tmp table | 0.005890 | 3.51 | 3 | 0.0019633333 |
| logging slow query | 0.000792 | 0.47 | 2 | 0.0003960000 |
| checking permissions | 0.000576 | 0.34 | 5 | 0.0001152000 |
| Creating tmp table | 0.000463 | 0.28 | 1 | 0.0004630000 |
| Opening tables | 0.000459 | 0.27 | 1 | 0.0004590000 |
| statistics | 0.000187 | 0.11 | 2 | 0.0000935000 |
| starting | 0.000082 | 0.05 | 1 | 0.0000820000 |
| preparing | 0.000067 | 0.04 | 2 | 0.0000335000 |
| freeing items | 0.000059 | 0.04 | 2 | 0.0000295000 |
| optimizing | 0.000059 | 0.04 | 2 | 0.0000295000 |
| init | 0.000022 | 0.01 | 1 | 0.0000220000 |
| Table lock | 0. 000020 | 0.01 | 1 | 0.0000200000 |
| closing tables | 0.000013 | 0.01 | 1 | 0.0000130000 |
| System lock | 0.000010 | 0.01 | 1 | 0.0000100000 |
| executing | 0.000010 | 0.01 | 2 | 0.0000050000 |
| end | 0.000008 | 0.00 | 1 | 0.0000080000 |
| cleaning up | 0.000007 | 0.00 | 1 | 0.0000070000 |
| query end | 0.000003 | 0.00 | 1 | 0.0000030000 |
+----------------------+----------+-------+-------+--------------+ 090623 | 54.05 | 1 | 0.0906230000 |
| Sending data | 0.056774 | 33.86 | 3 | 0.0189246667 |
| Sorting result | 0.011555 | 6.89 | 1 | 0.0115550000 |
| removing tmp table | 0.005890 | 3.51 | 3 | 0.0019633333 |
| logging slow query | 0.000792 | 0.47 | 2 | 0.0003960000 |
| checking permissions | 0.000576 | 0.34 | 5 | 0.0001152000 |
| Creating tmp table | 0.000463 | 0.28 | 1 | 0.0004630000 |
| Opening tables | 0.000459 | 0.27 | 1 | 0.0004590000 |
| statistics | 0.000187 | 0.11 | 2 | 0.0000935000 |
| starting | 0.000082 | 0.05 | 1 | 0.0000820000 |
| preparing | 0.000067 | 0.04 | 2 | 0.0000335000 |
| freeing items | 0.000059 | 0.04 | 2 | 0.0000295000 |
| optimizing | 0.000059 | 0.04 | 2 | 0.0000295000 |
| init | 0.000022 | 0.01 | 1 | 0.0000220000 |
| Table lock | 0.
090623 | 54.05 | 1 | 0.0906230000 |
| Sending data | 0.056774 | 33.86 | 3 | 0.0189246667 |
| Sorting result | 0.011555 | 6.89 | 1 | 0.0115550000 |
| removing tmp table | 0.005890 | 3.51 | 3 | 0.0019633333 |
| logging slow query | 0.000792 | 0.47 | 2 | 0.0003960000 |
| checking permissions | 0.000576 | 0.34 | 5 | 0.0001152000 |
| Creating tmp table | 0.000463 | 0.28 | 1 | 0.0004630000 |
| Opening tables | 0.000459 | 0.27 | 1 | 0.0004590000 |
| statistics | 0.000187 | 0.11 | 2 | 0.0000935000 |
| starting | 0.000082 | 0.05 | 1 | 0.0000820000 |
| preparing | 0.000067 | 0.04 | 2 | 0.0000335000 |
| freeing items | 0.000059 | 0.04 | 2 | 0.0000295000 |
| optimizing | 0.000059 | 0.04 | 2 | 0.0000295000 |
| init | 0.000022 | 0.01 | 1 | 0.0000220000 |
| Table lock | 0. 000020 | 0.01 | 1 | 0.0000200000 |
| closing tables | 0.000013 | 0.01 | 1 | 0.0000130000 |
| System lock | 0.000010 | 0.01 | 1 | 0.0000100000 |
| executing | 0.000010 | 0.01 | 2 | 0.0000050000 |
| end | 0.000008 | 0.00 | 1 | 0.0000080000 |
| cleaning up | 0.000007 | 0.00 | 1 | 0.0000070000 |
| query end | 0.000003 | 0.00 | 1 | 0.0000030000 |
+----------------------+----------+-------+-------+--------------+
000020 | 0.01 | 1 | 0.0000200000 |
| closing tables | 0.000013 | 0.01 | 1 | 0.0000130000 |
| System lock | 0.000010 | 0.01 | 1 | 0.0000100000 |
| executing | 0.000010 | 0.01 | 2 | 0.0000050000 |
| end | 0.000008 | 0.00 | 1 | 0.0000080000 |
| cleaning up | 0.000007 | 0.00 | 1 | 0.0000070000 |
| query end | 0.000003 | 0.00 | 1 | 0.0000030000 |
+----------------------+----------+-------+-------+--------------+Похоже, что в запросе использовались три временные таблицы — две из них на диске — и было много неиндексированных чтений (Handler_read_rnd_next). Если бы мы ничего не знали о представлении, к которому только что обращались, то могли бы предположить, что запрос сделал объединение без индекса, возможно, из-за подзапроса, который создал временные таблицы, а затем использовал их с правой стороны в соединении. Временные таблицы, созданные для хранения результатов подзапросов, не имеют индексов, поэтому эта версия кажется правдоподобной.
Используя эту методику, имейте в виду, что команда SHOW STATUS создает временную таблицу и обращается к ней с помощью обработчика операций, поэтому на полученные результаты в действительности влияет и SHOW STATUS. Это зависит от версий сервера. Используя информацию о выполнении запроса, полученную от команды SHOW PROFILES, мы можем предположить, что количество временных таблиц завышено на 2.
Стоит отметить, что большую часть той же информации, по-видимому, можно получить, просмотрев план EXPLAIN для этого запроса. Но EXPLAIN — это оценка того, что сервер планирует делать, а просмотр счетчиков статуса — это измерение того, что он на самом деле сделал. EXPLAIN не скажет вам, например, была ли временная таблица создана на диске, что медленнее, чем в памяти.
Использование журнала медленных запросов
Что расширенный в Percona Server журнал медленных запросов расскажет об этом запросе? Вот что было зафиксировано при выполнении запроса, продемонстрированного в разделе о SHOW PROFILE:
mysql> FLUSH STATUS;
mysql> SELECT * FROM sakila. nicer_but_slower_film_list;
[query results omitted]
mysql> SHOW STATUS WHERE Variable_name LIKE 'Handler%'
OR Variable_name LIKE 'Created%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Created_tmp_disk_tables | 2 |
| Created_tmp_files | 0 |
| Created_tmp_tables | 3 |
| Handler_commit | 1 |
| Handler_delete | 0 |
| Handler_discover | 0 |
| Handler_prepare | 0 |
| Handler_read_first | 1 |
| Handler_read_key | 7483 |
| Handler_read_next | 6462 |
| Handler_read_prev | 0 |
| Handler_read_rnd | 5462 |
| Handler_read_rnd_next | 6478 |
| Handler_rollback | 0 |
| Handler_savepoint | 0 |
| Handler_savepoint_rollback | 0 |
| Handler_update | 0 |
| Handler_write | 6459 |
+----------------------------+-------+ nicer_but_slower_film_list;
[query results omitted]
mysql> SHOW STATUS WHERE Variable_name LIKE 'Handler%'
OR Variable_name LIKE 'Created%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Created_tmp_disk_tables | 2 |
| Created_tmp_files | 0 |
| Created_tmp_tables | 3 |
| Handler_commit | 1 |
| Handler_delete | 0 |
| Handler_discover | 0 |
| Handler_prepare | 0 |
| Handler_read_first | 1 |
| Handler_read_key | 7483 |
| Handler_read_next | 6462 |
| Handler_read_prev | 0 |
| Handler_read_rnd | 5462 |
| Handler_read_rnd_next | 6478 |
| Handler_rollback | 0 |
| Handler_savepoint | 0 |
| Handler_savepoint_rollback | 0 |
| Handler_update | 0 |
| Handler_write | 6459 |
+----------------------------+-------+
nicer_but_slower_film_list;
[query results omitted]
mysql> SHOW STATUS WHERE Variable_name LIKE 'Handler%'
OR Variable_name LIKE 'Created%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Created_tmp_disk_tables | 2 |
| Created_tmp_files | 0 |
| Created_tmp_tables | 3 |
| Handler_commit | 1 |
| Handler_delete | 0 |
| Handler_discover | 0 |
| Handler_prepare | 0 |
| Handler_read_first | 1 |
| Handler_read_key | 7483 |
| Handler_read_next | 6462 |
| Handler_read_prev | 0 |
| Handler_read_rnd | 5462 |
| Handler_read_rnd_next | 6478 |
| Handler_rollback | 0 |
| Handler_savepoint | 0 |
| Handler_savepoint_rollback | 0 |
| Handler_update | 0 |
| Handler_write | 6459 |
+----------------------------+-------+Похоже, что запрос действительно создал три временные таблицы, которые были скрыты от представления в SHOW PROFILE (возможно, из-за особенностей способа выполнения запроса сервером). Две временные таблицы находились на диске. Здесь мы сократили выведенную информацию для улучшения удобочитаемости. В конце концов, данные, полученные при выполнении команды
Две временные таблицы находились на диске. Здесь мы сократили выведенную информацию для улучшения удобочитаемости. В конце концов, данные, полученные при выполнении команды SHOW PROFILE по этому запросу, записываются в журнал, поэтому вы можете журналировать в Percona Server даже такой уровень детализации.
Согласитесь, эта весьма подробная запись в журнале медленных запросов содержит практически все, что вы можете видеть в SHOW PROFILE и SHOW STATUS, и еще кое-что. Это делает журнал очень полезным для поиска более подробной информации при нахождении плохого запроса с помощью утилиты pt-query-digest. Когда вы просмотрите отчет от pt-query-digest, увидите такую строку заголовка:
# Query 1: 0 QPS, 0x concurrency, ID 0xEE758C5E0D7EADEE at byte 3214 _____Вы можете использовать байтовое смещение для фокусировки на нужном разделе журнала следующим образом:
tail -c +3214 /path/to/query. log | head -n100 log | head -n100
log | head -n100Вуаля! Можно рассмотреть все подробности. Кстати, pt-query-digest понимает все добавленные пары «имя — значение» формата медленного журнала запросов Percona Server и автоматически выводит намного более подробный отчет.
Использование Performance Schema
На момент написания этой статьи таблицы Performance Schema, представленные в MySQL 5.5, не поддерживают профилирование на уровне запросов. Performance Schema появилась не так давно. Однако она быстро развивается, приобретая дополнительную функциональность в каждом следующем релизе. Но даже первоначальная функциональность MySQL 5.5 позволяет получать любопытную информацию. Например, следующий запрос покажет основные причины ожидания в системе:
mysql> SELECT event_name, count_star, sum_timer_wait
-> FROM events_waits_summary_global_by_event_name
-> ORDER BY sum_timer_wait DESC LIMIT 5;
+----------------------------------------+------------+------------------+
| event_name | count_star | sum_timer_wait |
+----------------------------------------+------------+------------------+
| innodb_log_file | 205438 | 2552133070220355 |
| Query_cache::COND_cache_status_changed | 8405302 | 2259497326493034 |
| Query_cache::structure_guard_mutex | 55769435 | 361568224932147 |
| innodb_data_file | 62423 | 347302500600411 |
| dict_table_stats | 15330162 | 53005067680923 |
+----------------------------------------+------------+------------------+Сейчас существует несколько моментов, ограничивающих использование Performance Schema в качестве инструмента профилирования общего назначения. Во-первых, она не обеспечивает достаточный уровень детализации выполнения запросов и затрат времени, который можно получить благодаря существующим инструментам. Во-вторых, она довольно долго не использовалась и в данный момент ее применение приводит к большим издержкам, чем применение привычного для многих инструмента профилирования. (Есть основания полагать, что это будет исправлено в ближайшее время.)
Во-первых, она не обеспечивает достаточный уровень детализации выполнения запросов и затрат времени, который можно получить благодаря существующим инструментам. Во-вторых, она довольно долго не использовалась и в данный момент ее применение приводит к большим издержкам, чем применение привычного для многих инструмента профилирования. (Есть основания полагать, что это будет исправлено в ближайшее время.)
Наконец, иногда она слишком сложна и низкоуровнева для использования большинством пользователей. Функции, реализованные к настоящему моменту, в основном нацелены на то, что нужно измерить при изменении исходного кода MySQL для улучшения производительности сервера. Сюда относятся такие элементы, как ожидания и мьютексы. Некоторые из функций MySQL 5.5 полезны для опытных пользователей, а не для разработчиков серверов. Однако пользователи все еще нуждаются в разработке удобных инструментов интерфейса. В настоящее время для написания сложных запросов к разнообразным таблицам метаданных с большим количеством столбцов требуется настоящее мастерство. Это довольно сложный для использования и понимания набор инструментов.
Это довольно сложный для использования и понимания набор инструментов.
Будет здорово, когда Performance Schema в более поздних версиях MySQL получит больше функциональности. И очень приятно, что Oracle реализует ее как таблицы, доступные через SQL, тем самым пользователи могут получать данные любым удобным для них способом. Однако пока она еще не способна заменить журнал медленных запросов или другие инструменты, помогающие сразу увидеть варианты улучшения производительности сервера и выполнения запросов.
Использование профиля для оптимизации
Итак, у вас есть профиль сервера или запроса — что с ним делать? Хороший профиль обычно делает проблему очевидной, но решения может и не быть (хотя чаще всего есть). На этом этапе, особенно при оптимизации запросов, вам нужно полагаться на знания о сервере и о том, как он выполняет запросы. Профиль или те данные, которые вы можете собрать, указывают направление движения и дают основания для применения ваших знаний и нахождения результатов с помощью дополнительных инструментов, таких как EXPLAIN.
В общем, хотя нахождение источника проблемы с помощью профиля со всеми метриками не должно представлять труда, наделе невозможно выполнить измерения абсолютно точно, поскольку оцениваемые системы не поддерживают этой возможности. Ранее, рассматривая пример, мы подозревали, что на временные таблицы и неиндексированные чтения затрачивается большая часть времени отклика, однако не можем этого доказать. Иногда проблемы трудно решить, потому что, возможно, не измерено все, что нужно, либо измерения сделаны в неверном направлении. Например, вы можете определять активность всего сервера вместо изучения того фрагмента, который пытаетесь оптимизировать, или анализировать измерения, проведенные с момента времени до начала выполнения запроса, а не тогда, когда он был запущен.
Существует еще одна возможность. Предположим, вы анализируете журнал медленных запросов и находите простой запрос, на несколько запусков которого затрачено неоправданно много времени, хотя он быстро запускался в тысячах других случаев. Вы снова запускаете запрос, и он выполняется молниеносно, как и должно быть. Применяете
Вы снова запускаете запрос, и он выполняется молниеносно, как и должно быть. Применяете EXPLAIN и обнаруживаете, что он правильно использует индекс. Вы пытаетесь использовать похожие запросы с разными значениями в разделе WHERE, чтобы убедиться, что запрос не обращается к кэшу, и они тоже выполняются быстро. Кажется, что с этим запросом все нормально. Что дальше?
Если у вас есть только стандартный журнал медленных запросов MySQL без плана выполнения или подробной информации о времени, вы знаете только, что запрос плохо работал, когда был журналирован, и не можете понять, почему это произошло. Возможно, что-то еще потребляло ресурсы в системе, например резервное копирование или какая-то блокировка или параллелизм тормозили ход запроса. Периодически возникающие проблемы — это особый случай, который мы рассмотрим в следующей статье.
Вас заинтересует / Intresting for you:
Другие статьи автора:
Производительность MySQL. Часть 1.
 Анализ и оптимизация запросов. Хостинг в деталях
Анализ и оптимизация запросов. Хостинг в деталяхСтраницы сайта генерируются медленно? Возникают ошибки 502 bad gateway и 504 gateway timeout? Хостер говорит, что сайт создает слишком большую нагрузку на процессор? Скорее всего, проблемы связаны с базой данных. В этой статье рассмотрим вопросы оптимизации производительности MySQL.
Как понять, что дело именно в MySQL
Если сайт работает на популярной CMS, то можно воспользоваться отчетом по SQL-запросам, выполняемым при генерации страницы. Например, в Drupal такой отчет доступен в модуле Devel, в Joomla – в режиме отладки, в WordPress – в расширении Debug bar. Если специальных инструментов нет, то можно до и после выполнения каждого SQL-запроса вызвать PHP-функцию microtime() и посчитать разность.
Drupal Devel
Если сайт размещается на VPS или выделенном сервере, аналогичные данные можно получить и непосредственно из MySQL. Например, из журнала медленных запросов.
Заняться оптимизацией однозначно стоит в случаях, когда при генерации страницы суммарное время выполнения запросов к базе данных превышает 1 секунду.
С чего начать оптимизацию
Итак, вы определили, какие запросы выполняются при генерации страницы. Дальше возможны варианты:
- Есть тяжелые запросы, занимающие сотни миллисекунд.
- Запросов много, но все они выполняются достаточно быстро.
В первом случае можно попробовать оптимизировать отдельные запросы. Здесь поможет SQL-оператор EXPLAIN и знания об индексах. Это решение применимо ко всем сайтам, в том числе размещенным на виртуальном хостинге.
Во втором случае имеет смысл заняться углубленным анализом логов и тонкой настройкой MySQL. На виртуальном хостинге сделать это не получится, только на VPS и выделенных серверах.
Но прежде, чем углубляться в детали, стоит сказать о кеше запросов – быстром и простом способе снять многие проблемы. Возможность включить кеш запросов есть у владельцев VPS и выделенных серверов.
Кеш запросов
В кеше запросов (query cache) сохраняются пары запрос-ответ. Когда запрос уже есть в кеше, ответ отдается практически мгновенно. Если данные в таблицах меняются не слишком часто, происходит ощутимый прирост производительности (в противном случае кеш быстро сбрасывается).
Если данные в таблицах меняются не слишком часто, происходит ощутимый прирост производительности (в противном случае кеш быстро сбрасывается).
По умолчанию кеширование выключено. Включить его можно, добавив в конфигурационный файл my.cnf строчку вида query_cache_size = 64M . Через переменную query_cache_size задается размер оперативной памяти, выделяемой под кеш, в данном случае — 64 мегабайта.
Теперь нужно перезапустить MySQL. Сделать это можно из некоторых панелей управления (в ISPmanager: Management tools — Services), либо по SSH из командной строки примерно так:/usr/local/etc/rc.d/mysql-server stop
/usr/local/etc/rc.d/mysql-server start
Всё, кеш включен. Можно попробовать открыть страницу сайта и потом обновить. Во второй раз должна загрузиться быстрее.
Есть еще несколько переменных для настройки кеша:
- query_cache_type задает режим работы кеша, когда query_cache_size установлен больше нуля. Допустимые значения query_cache_type: 0 или OFF — кеширование выключено; 1 или ON — кеширование включено для всех выражений, кроме начинающихся с SELECT SQL_NO_CACHE; 2 или DEMAND — кеширование включено только для запросов, начинающихся с SELECT SQL_CACHE.
- query_cache_limit – максимально допустимый размер, при котором результат выполнения запроса будет сохранен в кеше.
- query_cache_min_res_unit – минимальный размер блоков памяти, выделяемых под кеш. По умолчанию 4 Кб. Если у вас много результатов значительно меньшего объема, query_cache_min_res_unit можно понизить, чтобы память использовалась эффективнее. Подходящее значение можно рассчитать по формуле (query_cache_size — Qcache_free_memory) / Qcache_queries_in_cache.

Пример my.cnf для небольшого VPS:query_cache_size = 64M
query_cache_limit = 2M
query_cache_type = 1
query_cache_min_res_unit = 2K
Посмотреть текущее состояние кеша можно в phpMyAdmin на вкладке Status, либо из командной строки:
# mysql -u root -p Password: ******** mysql> SHOW GLOBAL STATUS LIKE ‘Qcache%’; +----------------------------+------------+ | Variable_name | Value | +----------------------------+------------+ | Qcache_free_blocks | 130 | | Qcache_free_memory | 56705448 | | Qcache_hits | 57092 | | Qcache_inserts | 10412 | | Qcache_lowmem_prunes | 0 | | Qcache_not_cached | 5036 | | Qcache_queries_in_cache | 1023 | | Qcache_total_blocks | 2409 | +----------------------------+------------+ 8 rows in set (0.
 01 sec)
01 sec)- Qcache_free_blocks – количество свободных блоков в кеше.
- Qcache_free_memory – объем свободной ОЗУ, отведенной под кеш.
- Qcache_hits – количество запросов, результаты которых были взяты из кеша.
- Qcache_inserts – количество запросов, которые были добавлены в кеш.
- Qcache_lowmem_prunes – количество запросов, которые были удалены из кеша из-за нехватки памяти.
- Qcache_not_cached – количество запросов, которые не были записаны в кеш (с SQL_NO_CACHE или некешируемые по другим причинам).
- Qcache_queries_in_cache – количество запросов, которые находятся в кеше.
- Qcache_total_blocks – общее количество блоков.
Долю закешированных запросов от их общего числа можно посчитать по формуле Qcache_hits / (Com_select + Qcache_hits). Степень использования кеша — Qcache_hits / Qcache_inserts.
О нюансах работы кеша MySQL можно почитать на mysqlperformanceblog.com (англ.)
Оптимизация отдельных запросов
Чтобы оптимизировать тяжелый запрос, сначала его нужно исследовать. Для этого допишите перед SELECT слово EXPLAIN, и MySQL покажет план выполнения запроса. В первую очередь интерес представляет информация об использовании индексов.
Для этого допишите перед SELECT слово EXPLAIN, и MySQL покажет план выполнения запроса. В первую очередь интерес представляет информация об использовании индексов.
Результат работы оператора EXPLAIN
Индексы – это структуры данных, создаваемые с целью повышения производительности поиска записей в таблицах. Таблицы в базе данных могут иметь большое количество строк, которые хранятся в произвольном порядке, и их поиск по заданному критерию путем последовательного просмотра таблицы строка за строкой может занимать много времени. Индекс формируется из значений одного или нескольких столбцов таблицы и указателей на соответствующие строки таблицы и, таким образом, позволяет искать строки, удовлетворяющие критерию поиска. [источник]
Индексы — ключ к высокой производительности MySQL, их важность увеличивается по мере роста объема данных в базе. Индексы нужно создавать для столбцов, по которым
- производится поиск в части WHERE
- соединяются таблицы при JOIN
- сортируются и группируются записи при ORDER BY и GROUP BY
- производится поиск MIN() и MAX()
Индексы могут быть составными, в этом случае важен порядок столбцов.
Разбирая вывод EXPLAIN, обратите особое внимание на столбцы
- type (значение ALL — плохо)
- key (NULL — плохо)
- ref (NULL — плохо)
- extra (Using filesort, Using temporary, Using where — плохо)
Описание всех значений и пример оптимизации запроса можно посмотреть в документации.
Добавить индексы можно из phpMyAdmin или с помощью запросов вида ALTER TABLE table_name ADD INDEX index_name (column_name)
Журнал медленных запросов
Если определить тяжелые запросы «на глаз» не получается, нужно собрать более обширную статистику. В этом поможет журнал медленных запросов (slow query log).
Для включения журнала в MySQL, начиная с версии 5.1.29, задайте переменной slow_query_log значение 1 или ON; для отключения журнала — 0 или OFF. В более старых версиях используется log-slow-queries = /var/db/mysql/slow_queries.log (путь можно задать другой).
Вторая важная настройка — long_query_time — порог времени выполнения, при превышении которого запрос считается медленным и записывается в журнал. Начиная с MySQL 5.1.21 может задаваться в микросекундах и может быть равен нулю.
Начиная с MySQL 5.1.21 может задаваться в микросекундах и может быть равен нулю.
Пара полезных дополнительных настроек:
- log-queries-not-using-indexes – запись в журнал запросов, не использующих индексы.
- slow_query_log_file – имя файла журнала. По умолчанию host_name-slow.log
Пример для записи в журнал всех запросов, выполняющихся дольше 50 миллисекунд:slow_query_log = 1
slow_query_log_file = /var/db/mysql/slow_queries.log
long_query_time = 0.05
log-queries-not-using-indexes = 1
Пример для старых версий MySQL, все запросы дольше 1 секунды:log-slow-queries = /var/db/mysql/slow_queries.log
long_query_time = 1
Для анализа журнала используются утилиты mysqldumpslow, mysqlsla и mysql_slow_log_filter. Они парсят журнал и выводят агрегированную информацию о медленных запросах.
mysqldumpslow – утилита из состава MySQL. Вызывается таким образом: mysqldumpslow [параметры] [файл_журнала . . Пример: ..]
..]
mysqldumpslow
Reading mysql slow query log from /usr/local/mysql/data/mysqld51-apple-slow.log
Count: 1 Time=4.32s (4s) Lock=0.00s (0s) Rows=0.0 (0), root[root]@localhost
insert into t2 select * from t1
Count: 3 Time=2.53s (7s) Lock=0.00s (0s) Rows=0.0 (0), root[root]@localhost
insert into t2 select * from t1 limit N
Count: 3 Time=2.13s (6s) Lock=0.00s (0s) Rows=0.0 (0), root[root]@localhost
insert into t1 select * from t1
Count – сколько раз был выполнен запрос данного типа. Time – среднее время выполнения запроса, дальше в скобках – суммарное время выполнения всех запросов данного типа.
Некоторые параметры mysqldumpslow:
- -t N – отображать только первые N запросов.
- -g pattern — анализировать только запросы, которые соответствуют шаблону (как grep).
- -s sort_type — как сортировать вывод. Значения sort_type: t или at — сортировать по суммарному или среднему времени выполнения запросов, c — по количеству выполненных запросов данного типа.

mysqlsla – еще одна утилита для анализа логов MySQL с аналогичной функциональностью. Пример использования:
mysqlsla -lt slow /tmp/slow_queries.log
Подробности в документации.
mysql_slow_log_filter — perl-скрипт с похожей функциональностью. Пример использования:
tail –f mysql-slow.log | mysql_slow_log_filter –T 0.5 –R 1000
Эта команда в реальном времени покажет запросы, выполняющиеся дольше 0,5 секунды или сканирующие больше 1000 строк.
Выявленные медленные запросы дальше можно оптимизировать, используя EXPLAIN и индексы.
Вторая часть статьи будет посвящена тонкой настройке MySQL. Материал находится в разработке.
—
Евгений Демин, http://unixzen.ru
Дмитрий Сергеев, http://hosting101.ru
Превышение количества запросов к MySQL (в уведомлениях — mysql.connects )
Количество запросов в MySQL регулируется встроенной возможностью в MySQL. Показания снимаются раз в минуту и делятся на 60 секунд. Соответственно если за минуту у вас было 120 заходов на сайт, это создаст в статистике 120 соединений к базе и в график попадет как среднее — 2 запроса за секунду.
Показания снимаются раз в минуту и делятся на 60 секунд. Соответственно если за минуту у вас было 120 заходов на сайт, это создаст в статистике 120 соединений к базе и в график попадет как среднее — 2 запроса за секунду.
Важно: лимит на тарифе (например 5 c Первого по Шестой тариф) — работает как ограничение. Если у вас будет более чем 5 одновременных запросов к серверу, что равно 18000 посещений (hits) в час, не считая запросы к статическим файлам, у вас появится ошибка Drupal о не возможности связаться с базой, ошибка max_user_connections exeeded. Положительный момент — физическое ограничение работает на каждого MySQL пользователя отдельно. Так что проблема на одном сайте, не создаст проблем на другом.
Что делать: в первую очередь вам надо проверить закладку «По пользователям MySQL» и выяснить, какой пользователь создает эту нагрузку. После этого выяснить, к какому сайту принадлежит база и пользователь, и посмотреть логи доступа к сайту (файл в папке ~/domains/logs/имя домена. log. Если у вас его нет, вам надо включить его в настройках домена в Панели Управления -> Домены -> Редактировать. Учтите, что если вы не включите awstats — лог будет расти и занимать много места). Возможно вы увидите, что идет очень много запросов к одному из новых модулей на вашем сайте и проблема именно в этом. Если самостоятельный поиск ничего не даст — пишите нам, поможем.
log. Если у вас его нет, вам надо включить его в настройках домена в Панели Управления -> Домены -> Редактировать. Учтите, что если вы не включите awstats — лог будет расти и занимать много места). Возможно вы увидите, что идет очень много запросов к одному из новых модулей на вашем сайте и проблема именно в этом. Если самостоятельный поиск ничего не даст — пишите нам, поможем.
Частые случаи: Самый распространенный случай — вы используете одного пользователя для всех ваших сайтов и разделяете их только префиксами в базе данных. Рекомендуем в таком случае разделить все сайты на разные базы данных и пользователей MySQL.
Так же часто бывает проблема из-за установленного стороннего движка магазина, форума или блога с включенным MySQL Persist Connections. Тут мы рекомендуем внимательно почитать настройки и отключить эту опцию. Drupal ее не использует.
Намного реже бывает проблема из-за установки нестабильного модуля на сайт. Настоятельно рекомендуем использовать на ваших сайтах только стабильные версии модулей.
Примеры сложных запросов для выборки данных в СУБД MySQL
Всего лишь пару лет назад, в проектах, которые предусматривали работу с базами данных и построением статистики, основным изобилием используемых SQL-запросов, преобладало в основном множество запросов, ориентированных на стандартную выборку данных и нечасто можно было увидеть другие, которые безо всяких сомнений можно было бы отнести к “эксклюзиву”. Хотя сложность запроса и зависит от количества используемых таблиц, но если мы всего лишь возьмем и выведем данные полей трех или более таблиц имеющих стандартное объединение, то явная сложность такого запроса не выйдет за пределы стандартной.
В данной статье по мере возможности будут рассматриваться те запросы, примеры которых мне найти не удалось и которые, по моему мнению, не относятся к классу простых.
Сравнение данных за две даты
Хотя данная статистика из рода задач довольно редко встречаемых, но все-таки необходимость в ее получении иногда существует. И получить такую статистику ничуть не сложнее других.
И получить такую статистику ничуть не сложнее других.
Работать мы будем с двумя таблицами, структура которых представлена ниже:
Структура таблицы products
CREATE TABLE IF NOT EXISTS `products` ( `id` int(11) NOT NULL AUTO_INCREMENT, `ShopID` int(11) NOT NULL, `Name` varchar(150) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=10 ;
Структура таблицы statistics
CREATE TABLE IF NOT EXISTS `statistics` ( `id` int(11) NOT NULL AUTO_INCREMENT, `ProductID` bigint(20) NOT NULL, `Orders` int(11) NOT NULL, `Date` date NOT NULL DEFAULT '0000-00-00', PRIMARY KEY (`id`), KEY `ProductID` (`ProductID`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=20 ;
Дело в том, что стандарт языка SQL допускает использование вложенных запросов везде, где разрешается использование ссылок на таблицы. Здесь вместо явно указанных таблиц, благодаря использованию псевдонимов, будут применяться результирующие таблицы вложенных запросов с имеющейся связью один – к – одному. Результатом каждой результирующей таблицы будут данные о количестве произведенных заказов некоего товара за определенную дату, полученные путем выполнения запроса на выборку данных из таблицы statistics по требуемым критериям. Иными словами мы свяжем таблицу statistics саму с собой. Пример запроса:
Результатом каждой результирующей таблицы будут данные о количестве произведенных заказов некоего товара за определенную дату, полученные путем выполнения запроса на выборку данных из таблицы statistics по требуемым критериям. Иными словами мы свяжем таблицу statistics саму с собой. Пример запроса:
SELECT stat1.Name, stat1.Orders, stat1.Date, stat2.Orders, stat2.Date FROM (SELECT statistics.ProductID, products.Name, statistics.Orders, statistics.Date FROM products JOIN statistics ON products.id = statistics.ProductID WHERE DATE(statistics.date) = '2014-09-04') AS stat1 JOIN (SELECT statistics.ProductID, statistics.Orders, statistics.Date FROM statistics WHERE DATE(statistics.date) = '2014-09-12') AS stat2 ON stat1.ProductID = stat2.ProductID
В итоге имеем такой результат:
+------------------------+----------+------------+----------+------------+ | Name | Orders1 | Date1 | Orders2 | Date2 | +------------------------+----------+------------+----------+------------+ | Процессоры Pentium II | 1 | 2014-09-04 | 1 | 2014-09-12 | | Процессоры Pentium III | 1 | 2014-09-04 | 10 | 2014-09-12 | | Оптическая мышь Atech | 10 | 2014-09-04 | 3 | 2014-09-12 | | DVD-R | 2 | 2014-09-04 | 5 | 2014-09-12 | | DVD-RW | 22 | 2014-09-04 | 18 | 2014-09-12 | | Клавиатура MS 101 | 5 | 2014-09-04 | 1 | 2014-09-12 | | SDRAM II | 26 | 2014-09-04 | 12 | 2014-09-12 | | Flash RAM 8Gb | 8 | 2014-09-04 | 7 | 2014-09-12 | | Flash RAM 4Gb | 18 | 2014-09-04 | 30 | 2014-09-12 | +------------------------+----------+------------+----------+------------+
Подстановка нескольких значений из другой таблицы
Необходимость в данном запросе не является повседневной, но возникает не совсем уж и редко. Самый распространенный пример, это обычная сетевая игра. Где создается сессия на два игрока. Соответственно в таблице с данными об играх имеются два поля с идентификаторами зарегистрированных игроков. Для того чтобы вывести информацию об имеющихся играх, мы не можем обойтись стандартным объединением таблицы с данными об игроках и таблицы об имеющихся играх. Так как мы имеем два поля с идентификаторами неких игроков. Но мы можем обратиться опять за помощью к псевдонимам таблиц.
Самый распространенный пример, это обычная сетевая игра. Где создается сессия на два игрока. Соответственно в таблице с данными об играх имеются два поля с идентификаторами зарегистрированных игроков. Для того чтобы вывести информацию об имеющихся играх, мы не можем обойтись стандартным объединением таблицы с данными об игроках и таблицы об имеющихся играх. Так как мы имеем два поля с идентификаторами неких игроков. Но мы можем обратиться опять за помощью к псевдонимам таблиц.
Демонстрация данного запроса будет происходить на другом примере, а не на примере сетевой игры. Это чтобы не создавать заново все необходимые таблицы. В качестве данных возьмем таблицу products из примера “сравнение данных за две даты” и создадим еще одну недостающую таблицу replace_com, структура которой представлена ниже:
CREATE TABLE IF NOT EXISTS `replace_com` ( `id` int(11) NOT NULL AUTO_INCREMENT, `sProductID` int(11) NOT NULL, `rProductID` int(11) NOT NULL, `Date` date NOT NULL DEFAULT '0000-00-00', PRIMARY KEY (`id`), KEY `sProductID` (`sProductID`,`rProductID`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=4 ;
Предположим, что у нас есть некий компьютерный салон и мы проводим модификации некоторых компьютерных составляющих, а все операции по замене комплектующих заносим в базу данных. В таблице replace_com интересующими нас полями являются: sProductID и rProductID. Где sProductID – идентификатор заменяемого модуля, а rProductID – идентификатор заменяющего модуля. Запрос, реализующий вывод данных о совершенных операциях выглядит следующим образом:
В таблице replace_com интересующими нас полями являются: sProductID и rProductID. Где sProductID – идентификатор заменяемого модуля, а rProductID – идентификатор заменяющего модуля. Запрос, реализующий вывод данных о совершенных операциях выглядит следующим образом:
SELECT sProducts.Name AS sProduct, rProducts.Name AS rProduct, replace_com.Date FROM replace_com JOIN products AS sProducts ON sProducts.id = replace_com.sProductID JOIN products AS rProducts ON rProducts.id = replace_com.rProductID
Результирующая таблица данных:
+-----------------------+------------------------+------------+ | sProduct | rProduct | Date | +-----------------------+------------------------+------------+ | Процессоры Pentium II | Процессоры Pentium III | 2014-09-15 | | Flash RAM 4Gb | Flash RAM 8Gb | 2014-09-17 | | DVD-R | DVD-RW | 2014-09-18 | +-----------------------+------------------------+------------+
Вывод статистики с накоплением по дате
Предположим, что у нас имеется склад с некими товарами.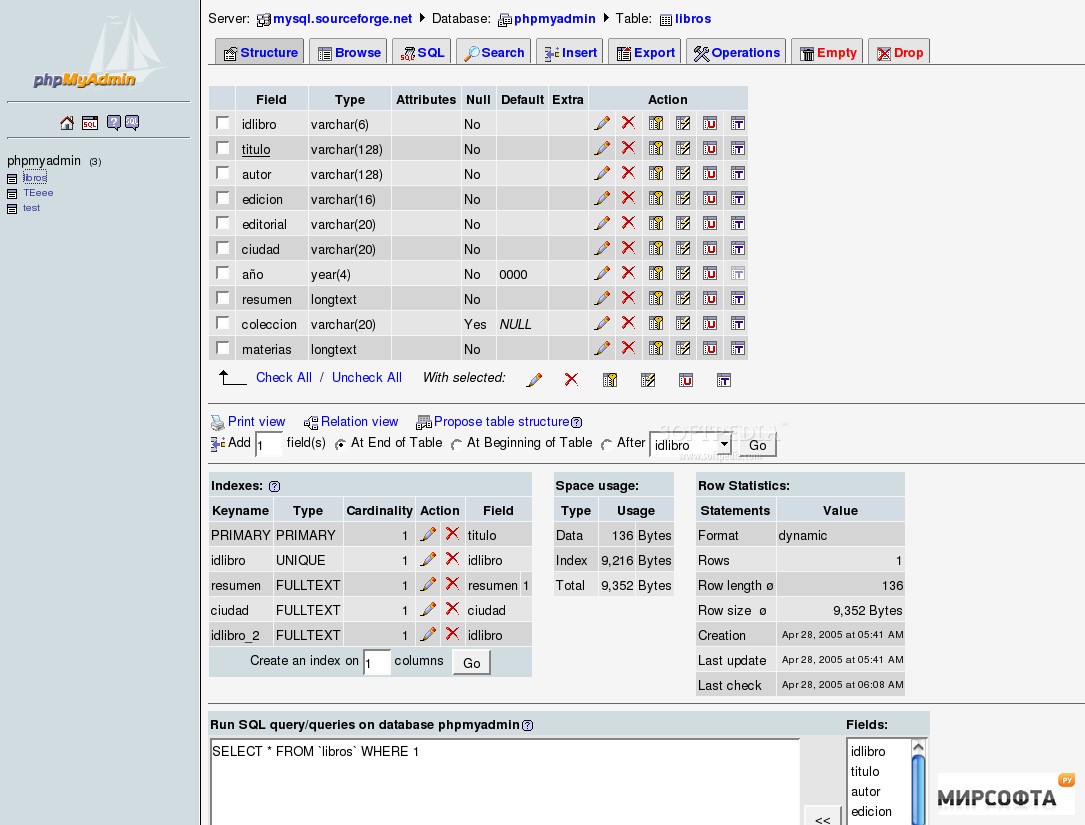 Товары периодически поступают, и нам бы хотелось видеть в отчете остатки товаров по дням. Поскольку данные о наличии товаров необходимо накапливать, то мы введем пользовательскую переменную. Но есть одно небольшое “но”. Мы не можем использовать в запросе переменные пользователя и группировку данных одновременно (вернее можем, но в итоге получим, не то, что ожидаем), но мы можем использовать вложенный запрос, вместо явно указанной таблицы. Данные в таблице будут предварительно сгруппированы по дате. И уже затем на основе этих данных мы произведем расчет статистики с накоплением.
Товары периодически поступают, и нам бы хотелось видеть в отчете остатки товаров по дням. Поскольку данные о наличии товаров необходимо накапливать, то мы введем пользовательскую переменную. Но есть одно небольшое “но”. Мы не можем использовать в запросе переменные пользователя и группировку данных одновременно (вернее можем, но в итоге получим, не то, что ожидаем), но мы можем использовать вложенный запрос, вместо явно указанной таблицы. Данные в таблице будут предварительно сгруппированы по дате. И уже затем на основе этих данных мы произведем расчет статистики с накоплением.
На первом этапе требуется установить переменную и присвоить ей нулевое значение:
SET @cvalue = 0
В следующем запросе, мы созданную ранее переменную и применим:
SELECT products.Name AS Name, (@cvalue := @cvalue + Orders) as Orders, Date FROM (SELECT ProductID AS ProductID, SUM(Orders) AS Orders, DATE(date) AS Date FROM statistics WHERE ProductID = '1' GROUP BY date) AS statistics JOIN products ON statistics.
 ProductID = products.id
ProductID = products.id
Итоговый отчет:
+-----------------------+--------+------------+ | Name | Orders | Date | +-----------------------+--------+------------+ | Процессоры Pentium II | 1 | 2014-09-04 | | Процессоры Pentium II | 2 | 2014-09-12 | | Процессоры Pentium II | 4 | 2014-09-14 | | Процессоры Pentium II | 6 | 2014-09-15 | +-----------------------+--------+------------+
Получить используемую в примерах базу данных можно здесь.
5 стратегий работы с высокими нагрузками в MySQL
MySQL — проверенная и очень мощная технология. В том числе и для построения систем с большой нагрузкой. Даже Facebook использует Mysql для управления огромными объемами данных. Рассмотрим основные стратегии для построения нагруженных систем на основе MySQL.
Оптимизация и индексы
Прежде всего убедитесь, что вы используете все стандартные возможности базы данных. Правильная работа с индексами даст огромные приросты в производительности. Сотни и даже тысячи раз. Освобождая при этом ресурсы для других задач. Сегодня стоимость жестких дисков постоянно снижается, а требования к скорости постоянно растут.
Правильная работа с индексами даст огромные приросты в производительности. Сотни и даже тысячи раз. Освобождая при этом ресурсы для других задач. Сегодня стоимость жестких дисков постоянно снижается, а требования к скорости постоянно растут.
Индексы — это эффективный механизм перенести нагрузку с процессора на жесткий диск в правильных пропорциях.
Не спешите оптимизировать все запросы заранее. Используйте лог медленных запросов, чтобы понять, где существуют реальные проблемы.
Сразу после установки MySQL не забудьте оптимизировать основные параметры. Стандартная настройка очень базовая и ориентирована на скромное железо и жесткие требования к сохранности.
Подстройка стандартных параметров даст существенный прирост в ускорении не только операций чтения, а и записи.
Кэширование
Очень популярным методом оптимизации производительности является кэширование.
Внутренний кэш Mysql
Перед тем как использовать внешнее решение, подумайте, стоит ли использовать внутренний кэш Mysql. Его имеет смысл включать в тех случаях, когда Mysql работает с очень большим количеством чтений (SELECT), но не очень большим (как минимум в 10 раз меньше) записей (INSERT, DELETE и UPDATE).
Лучше не включать внутренний кэш Mysql в средах с большим количеством записей/обновлений.
Настройка кэша выполняется с помощью параметра mysql_query_cache_size.
Внешние решения
Более гибким решением является использование внешних инструментов кэширования, вроде Memcache либо Redis. Существует целый ряд техник кэширования данных в приложениях.
Однако, будьте осторожны. Кэширование — это часто не решение проблемы, а ее откладывание. Медленный запрос становится еще медленнее, а его влияние (при сбросе кэша) менее прогнозируемым.
Кэширование лучше использовать только как промежуточные решения. В конце концов следует избавляться от медленных запросов.
Репликация
Не смотря на то, что репликация может помочь справиться с нагрузкой, ее лучше для этого не применять. Нужно помнить, что на ряду с масштабированием, у вас всегда будет стоять вопрос доступности. Если реплика, которая помогает обслуживать запросы, выйдет из строя, что случиться с системой?
С другой стороны, реплика как раз позволяет обеспечить высокую доступность. Один из подходов выглядит так:
- Использовать master-slave репликацию для каждого сервера БД.
- Приложение всегда работает только с мастером.
- Если мастер выходит из строя, приложение переключается на слейв.
- Мы в это время поднимаем сломанный сервер и превращаем его в слейв ( как это правильно сделать).
Таким образом, в новой схеме мастер и слейв поменялись местами, а приложение (т.е. его пользователи) не заметило никаких проблем.
Репликацию стоит использовать только как механизм резервирования. Не для масштабирования под нагрузки.
Шардинг
Шардинг — это принцип масштабирования базы данных, когда данные разделяются по разным серверам. В нашем распоряжении есть два подхода:
Вертикальный шардинг
Его стоит использовать в первую очередь. Это простое распределение таблиц по серверам. Например, вы помещаете таблицу users на одном сервере, а таблицу orders на другом. В этом случае, группы таблиц, по которым выполняются JOIN, должны находится на одном сервере.
Горизонтальный шардинг
Этот тип шардинга следует использовать следующим этапом. На этом этапе очень большие таблицы, которые перестают помещаться на одном сервере, разделяют на части и помещают разные их части на разных серверах. Это усложняет логику приложения, однако мир еще не придумал лучших механизмов масштабирования.
Шардинг — единственный подход для масштабирования действительно больших данных.
Другие задачи
Следует отметить, что существуют задачи, с которым MySQL справляется крайне плохо. Один из примеров — выборки уникальных значений в разных диапазонах. Либо полнотекстовый поиск.
Обратите внимание на Handlersocket, который может стать заменой любого NoSQL решения, в случае если оно используется для простых Key-Value операций.
MySQL — мощное, но не универсальное решение. Redis, Elastic и другие технологии помогут решить дополнительные задачи.
Самое важное
MySQL вместе с современными подходами к оптимизации и масштабированию — это мощная платформа для построения огромных систем. Не забывайте использовать другие технологии для смежных задач, c которыми MySQL справляется не так эффективно.
Как определить проблемы производительности MySQL с помощью медленных запросов
Проблемы производительности — распространенные проблемы при администрировании баз данных MySQL. Иногда эти проблемы возникают из-за медленных запросов. В этом блоге мы поговорим о медленных запросах и о том, как их идентифицировать.
Проверка журналов медленных запросов
MySQL имеет возможность фильтровать и регистрировать медленные запросы. Есть разные способы их исследования, но наиболее распространенный и эффективный способ — использовать журналы медленных запросов.
Сначала необходимо определить, включены ли журналы медленных запросов. Чтобы справиться с этим, вы можете перейти на свой сервер и запросить следующую переменную:
MariaDB [(none)]> показать глобальные переменные, такие как 'slow% log%';
+ --------------------- + --------------------------- ---- +
| Variable_name | Значение |
+ --------------------- + --------------------------- ---- +
| slow_query_log | ВКЛ |
| slow_query_log_file | /var/log/mysql/mysql-slow.log |
+ --------------------- + --------------------------- ---- +
2 ряда в наборе (0.001 сек) Вы должны убедиться, что для переменной slow_query_log установлено значение ON, а slow_query_log_file определяет путь, по которому вам нужно разместить журналы медленных запросов. Если эта переменная не установлена, она будет использовать DATA_DIR вашего каталога данных MySQL.
Переменная slow_query_log сопровождается long_query_time и min_examined_row_limit, которые влияют на то, как работает медленное ведение журнала запросов. По сути, журналы медленных запросов работают как операторы SQL, выполнение которых занимает более long_query_time секунд, а также требует проверки не менее min_examined_row_limit строк.Его можно использовать для поиска запросов, выполнение которых занимает много времени и поэтому является кандидатом на оптимизацию, а затем вы можете использовать внешние инструменты, чтобы предоставить вам отчет, о котором поговорим позже.
По умолчанию административные операторы (ALTER TABLE, ANALYZE TABLE, CHECK TABLE, CREATE INDEX, DROP INDEX, OPTIMIZE TABLE и REPAIR TABLE) не попадают в журналы медленных запросов. Для этого вам необходимо включить переменную log_slow_admin_statements.
Список процессов запросов и монитор состояния InnoDB
В обычной процедуре администратора базы данных этот шаг является наиболее распространенным способом определения длительно выполняющихся запросов или активных выполняющихся запросов, вызывающих снижение производительности.Это может даже привести к зависанию вашего сервера, а затем скоплению очередей, которые медленно увеличиваются из-за блокировки, перекрываемой выполняющимся запросом. Вы можете просто запустить,
ПОКАЗАТЬ [ПОЛНЫЙ] СПИСОК ПРОЦЕССОВ; или
ПОКАЗАТЬ СТАТУС ДВИГАТЕЛЯ INNODB \ G Если вы используете ClusterControl, вы можете найти его, используя <выберите свой кластер MySQL> → Производительность → Статус InnoDB, как показано ниже,
или с помощью <выберите свой кластер MySQL> → Монитор запросов → Выполнение запросов (которые будут обсуждаться позже) для просмотра активных процессов, точно так же, как SHOW PROCESSLIST работает, но с лучшим контролем запросов.
Анализ запросов MySQL
Журналы медленных запросов покажут вам список запросов, которые были определены как медленные, на основании заданных значений в системных переменных, как упоминалось ранее. Определение медленных запросов может отличаться в разных случаях, поскольку в некоторых случаях даже 10-секундный запрос является приемлемым и все же не медленным. Однако, если ваше приложение является OLTP, очень часто 10-секундный или даже 5-секундный запрос является проблемой или вызывает снижение производительности вашей базы данных.Журнал запросов MySQL действительно помогает вам в этом, но этого недостаточно, чтобы открыть файл журнала, поскольку он не дает вам обзора того, что это за запросы, как они выполняются и какова частота их появления. Следовательно, сторонние инструменты могут помочь вам в этом.
pt-запрос-дайджест
Использование Percona Toolkit, который, я могу сказать, самый распространенный инструмент администраторов баз данных, заключается в использовании pt-query-digest. pt-query-digest предоставляет вам четкий обзор конкретного отчета, полученного из вашего журнала медленных запросов. Например, этот конкретный отчет показывает чистую перспективу понимания отчетов о медленных запросах в определенном узле:
# Доступно обновление программного обеспечения:
# 100 мс пользовательское время, 100 мс системное время, 29.12M RSS, 242,41M VSZ
# Текущая дата: 3 фев, пн, 20:26:11 2020
# Имя хоста: testnode7
# Файлы: /var/log/mysql/mysql-slow.log
# Всего: 24 всего, 14 уникальных, 0,00 QPS, 0,02x параллелизм ______________
# Диапазон времени: 2019-12-12T10: 01: 16 до 2019-12-12T15: 31: 46
# Атрибут total min max avg 95% stddev median
# ============ ======= ======= ======= ======= ======= == ===== =======
# Exec time 345s 1s 98s 14s 30s 19s 7s
# Время блокировки 1 с 0 1 с 58 мс 24 мс 252 мс 786 мкс
# Отправлено строк 5.72M 0 1.91M 244.14k 1.86M 629.44k 0
# Проверено строк 15,26 млн 0 1,91 млн 651,23 тыс. 1,86 млн 710,58 тыс. 961,27 тыс.
Количество строк влияет на 9,54M 0 1,91M 406,90 тыс. 961,27 тыс. 546,96 тыс. 0
# Отправлено байт 305,81M 11 124,83M 12,74M 87,73M 33,48M 56,92
# Размер запроса 1,20k 25 244 51,17 59,77 40,60 38,53
# Профиль
# Рейтинг Запрос ID Время ответа Вызовы R / Call V / M
# ==== ================================ ============= ===== ======= =====
# 1 0x00C8412332B2795DADF0E55C163... 98.0337 28.4% 1 98.0337 0.00 ОБНОВИТЬ sbtest?
# 2 0xDEF289292EA9B2602DC12F70C7A ... 74.1314 21.5% 3 24.7105 6.34 ALTER TABLE sbtest? sbtest3
# 3 0x148D575F62575A20AB9E67E41C3 ... 37.3039 10.8% 6 6.2173 0.23 INSERT SELECT sbtest? sbtest
# 4 0xD76A930681F1B4CC9F748B4398B ... 32.8019 9.5% 3 10.9340 4.24 ВЫБРАТЬ sbtest?
# 5 0x7B9A47FF6967FD9042DD3B ... 20.6685 6.0% 1 20.6685 0.00 ALTER TABLE sbtest? sbtest3
# 6 0xD1834E96EEFF8AC871D51192D8F ... 19.0787 5.5% 1 19.0787 0.00 СОЗДАТЬ
# 7 0x2112E77F825903ED18028C7EA76 ... 18.7133 5.4% 1 18.7133 0.00 ALTER TABLE sbtest? sbtest3
# 8 0xC37F2569578627487D948026820 ... 15.0177 4.3% 2 7.5088 0.00 INSERT SELECT sbtest? sbtest
# 9 0xDE43B2066A66AFA881D6D45C188 ... 13.7180 4.0% 1 13.7180 0.00 ALTER TABLE sbtest? sbtest3
# MISC 0xMISC 15.8605 4,6% 5 3,1721 0,0 <5 ЭЛЕМЕНТОВ>
# Запрос 1: 0 QPS, 0x параллелизм, ID 0x00C8412332B2795DADF0E55C1631626D в байте 5319
# Оценка: V / M = 0.00
# Временной диапазон: все события произошли в 2019-12-12T13: 23: 15
# Атрибут% всего мин. Макс. Сред. 95% стандартное отклонение медиана
# ============ === ======= ======= ======= ======= ====== = ======= =======
# Счет 4 1
# Exec time 28 98s 98s 98s 98s 98s 0 98s
# Время блокировки 1 25 мс 25 мс 25 мс 25 мс 25 мс 0 25 мс
Количество отправленных строк 0 0 0 0 0 0 0 0
# Ряды исследуемого 12 1.91 млн 1,91 млн 1,91 млн 1,91 млн 1,91 млн 0 1,91 млн
Количество затронутых строк 20 1.91M 1.91M 1.91M 1.91M 1.91M 0 1.91M
# Отправлено байт 0 67 67 67 67 67 0 67
# Размер запроса 7 89 89 89 89 89 0 89
# Нить:
# Тест баз данных
# Хосты localhost
# Последняя ошибка 0
# Пользователи root
# Query_time distribution
# 1us
# 10us
# 100us
# 1мс
# 10 мс
# 100 мс
# 1s
# 10s + ############################################# ################
# Таблицы
# ПОКАЗАТЬ СТАТУС ТАБЛИЦЫ ОТ `test` LIKE 'sbtest3' \ G
# SHOW CREATE TABLE `test`.`sbtest3` \ G
обновить sbtest3 set c = substring (MD5 (RAND ()), -16), pad = substring (MD5 (RAND ()), -16) где 1 \ G
# Преобразовано для EXPLAIN
# EXPLAIN / *! 50100 РАЗДЕЛОВ * /
выберите c = substring (MD5 (RAND ()), -16), pad = substring (MD5 (RAND ()), -16) из sbtest3, где 1 \ G
# Запрос 2: 0,00 QPS, 0,01x параллелизм, ID 0xDEF289292EA9B2602DC12F70C7A041A9 в байте 3775
# Оценка: V / M = 6,34
# Временной диапазон: 2019-12-12T12: 41: 47 до 2019-12-12T15: 25: 14
# Атрибут% всего мин. Макс. Сред. 95% стандартное отклонение медиана
# ============ === ======= ======= ======= ======= ====== = ======= =======
# Count 12 3
# Exec time 21 74s 6s 36s 25s 35s 13s 30s
# Время блокировки 0 13 мс 1 мс 8 мс 4 мс 8 мс 3 мс 3 мс
Количество отправленных строк 0 0 0 0 0 0 0 0
# Проверка строк 0 0 0 0 0 0 0 0
# Строки затрагивают 0 0 0 0 0 0 0 0
# Отправлено байт 0 144 44 50 48 49.17 3 49,17
# Размер запроса 8 99 33 33 33 33 0 33
# Нить:
# Тест баз данных
# Хосты localhost
# Последняя ошибка 0 (2/66%), 1317 (1/33%)
# Пользователи root
# Query_time distribution
# 1us
# 10us
# 100us
# 1мс
# 10 мс
# 100 мс
# 1s ###############################
# 10s + ############################################# ################
# Таблицы
# ПОКАЗАТЬ СТАТУС ТАБЛИЦЫ ОТ `test` LIKE 'sbtest3' \ G
# SHOW CREATE TABLE `test`.`sbtest3` \ G
ИЗМЕНИТЬ ТАБЛИЦУ sbtest3 ENGINE = INNODB \ G Использование performance_schema
Медленные журналы запросов могут быть проблемой, если у вас нет прямого доступа к файлу, например, с помощью RDS или с помощью полностью управляемых служб баз данных, таких как Google Cloud SQL или Azure SQL.Хотя для включения этих функций могут потребоваться некоторые переменные, они пригодятся при запросе запросов, зарегистрированных в вашей системе. Вы можете заказать его, используя стандартный оператор SQL, чтобы получить частичный результат. Например,
MySQL> SELECT SCHEMA_NAME, DIGEST, DIGEST_TEXT, COUNT_STAR, SUM_TIMER_WAIT / 1000000000000 SUM_TIMER_WAIT_SEC, MIN_TIMER_WAIT / 1000000000000 MIN_TIMER_WAIT_SEC, AVG_TIMER_WAIT / 1000000000000 AVG_TIMER_WAIT_SEC, MAX_TIMER_WAIT / 1000000000000 MAX_TIMER_WAIT_SEC, SUM_LOCK_TIME / 1000000000000 SUM_LOCK_TIME_SEC, FIRST_SEEN, LAST_SEEN ОТ events_statements_summary_by_digest;
+ -------------------- + ---------------------------- ------ + ------------------------------------------- -------------------------------------------------- -------------------------------------------------- -------------------------------------------------- -------------------------------------------------- -------------------------------------------------- -------------------------------------------------- ---------- + ------------ + -------------------- + ----- --------------- + -------------------- + ------------- ------- + ------------------- + --------------------- + --------------------- +
| SCHEMA_NAME | ДАЙДЖЕСТ | DIGEST_TEXT | COUNT_STAR | SUM_TIMER_WAIT_SEC | MIN_TIMER_WAIT_SEC | AVG_TIMER_WAIT_SEC | MAX_TIMER_WAIT_SEC | SUM_LOCK_TIME_SEC | FIRST_SEEN | LAST_SEEN |
+ -------------------- + ---------------------------- ------ + ------------------------------------------- -------------------------------------------------- -------------------------------------------------- -------------------------------------------------- -------------------------------------------------- -------------------------------------------------- -------------------------------------------------- ---------- + ------------ + -------------------- + ----- --------------- + -------------------- + ------------- ------- + ------------------- + --------------------- + --------------------- +
| NULL | 3
Вы можете использовать таблицу performance_schema.events_statements_summary_by_digest. Хотя есть вероятность, что записи в таблицах из performance_schema будут сброшены, вы можете сохранить это в определенной таблице. Взгляните на этот внешний пост из дайджеста запросов Percona MySQL с Performance Schema.
Если вам интересно, почему нам нужно разделять столбцы времени ожидания (SUM_TIMER_WAIT, MIN_TIMER_WAIT_SEC, AVG_TIMER_WAIT_SEC), эти столбцы используют пикосекунды, поэтому вам может потребоваться выполнить некоторые вычисления или округлить, чтобы сделать его более читаемым.
Анализ медленных запросов с помощью ClusterControl
Если вы используете ClusterControl, есть разные способы справиться с этим. Например, в кластере MariaDB, который у меня ниже, он показывает вам следующую вкладку (Монитор запросов) и ее раскрывающиеся элементы (Самые популярные запросы, Выполняющиеся запросы, Выбросы запросов):
- Самые популярные запросы — агрегированный список всех ваших самых популярных запросов, выполняемых на всех узлах кластера базы данных.
- Running Queries — просмотр текущих запущенных запросов в кластере базы данных аналогично команде SHOW FULL PROCESSLIST в MySQL
- Выбросы запроса — показывает запросы, которые являются выбросами.Выброс — это запрос, который занимает больше времени, чем обычный запрос этого типа.
Вдобавок к этому ClusterControl также фиксирует производительность запросов с помощью графиков, которые позволяют быстро увидеть, как ваша система базы данных работает по отношению к производительности запросов. См. Ниже,
Подождите, это еще не конец. ClusterControl также предлагает метрику с высоким разрешением с помощью Prometheus и демонстрирует очень подробные метрики и собирает статистику в реальном времени с сервера. Мы обсуждали это в наших предыдущих блогах, которые разделены на две части.Просмотрите блоги части 1, а затем части 2. Он предлагает вам, как эффективно отслеживать не только медленные запросы, но и общую производительность серверов баз данных MySQL, MariaDB или Percona.
В ClusterControl есть также другие инструменты, которые предоставляют указатели и подсказки, которые могут вызвать снижение производительности запросов, даже если это еще не произошло или не зафиксировано журналом медленных запросов. Проверьте вкладку «Производительность», как показано ниже,
. этих предметов дает вам следующее:
- Обзор — Вы можете просмотреть графики различных счетчиков базы данных на этой странице
- Advisors — Списки запланированных результатов советников, созданные в ClusterControl> Manage> Developer Studio с использованием ClusterControl DSL.
- Статус БД — Статус БД обеспечивает быстрый обзор статуса MySQL по всем узлам базы данных, аналогично оператору SHOW STATUS
- Переменные БД — переменные БД предоставляют быстрый обзор переменных MySQL, которые установлены на всех узлах базы данных, аналогично оператору SHOW GLOBAL VARIABLES
- DB Growth — Предоставляет сводную информацию о ежедневном росте вашей базы данных и таблиц за последние 30 дней.
- InnoDB Status — Выбирает текущий вывод монитора InnoDB для выбранного хоста, аналогично команде SHOW ENGINE INNODB STATUS.
- Schema Analyzer — анализирует схемы вашей базы данных на отсутствие первичных ключей, избыточных индексов и таблиц с помощью механизма хранения MyISAM.
- Журнал транзакций — перечисляет длительные транзакции и взаимоблокировки в кластере базы данных, где вы можете легко просмотреть, какие транзакции вызывают взаимные блокировки. Пороговое значение времени запроса по умолчанию составляет 30 секунд.
Заключение
Отследить вашу проблему производительности MySQL не так уж сложно с MySQL. Существуют различные внешние инструменты, которые обеспечивают необходимую эффективность и возможности.Самое главное, им легко пользоваться, и вы можете обеспечить продуктивность на работе. Устраняйте наиболее нерешенные проблемы или даже избегайте определенных катастроф, прежде чем они могут произойти.
Общие запросы MySQL
Агрегаты
Агрегаты и статистика
Агрегаты и ленты
Метаданные базы данных
Внешние ключи
Показать
90 108 Период арифметическая
Планирование
Частоты
Графики и иерархии
Miscellania
Значения NULL
Наборы результатов для заказа
0116
Последовательности
Сферическая геометрия
Сохраненные процедуры
9011 9011 9011
9011 запросы в MySQL MySQL имеет оператор под названием «show processlist», чтобы показать вам выполняющиеся запросы на вашем сервере MySQL.Это может быть полезно, чтобы узнать, что происходит, если есть несколько больших, длинных запросов, потребляющих много циклов ЦП, или если вы получаете такие ошибки, как «слишком много соединений».
Синтаксис простой:
показать список процессов;
, который выведет что-то вроде этих строк:
+ -------- + -------- + ----------- + -------- + --------- + ------ + ---------------------- + ------------------- -------------------------------------------------- --------------------------------- +
| Id | Пользователь | Хост | db | Команда | Время | Состояние | Информация |
+ -------- + -------- + ----------- + -------- + --------- + ------ + ---------------------- + -------------------- -------------------------------------------------- -------------------------------- +
| 708163 | корень | localhost | NULL | Запрос | 0 | NULL | показать список процессов |
| 708174 | тест | localhost | тест | Запрос | 2 | Копирование в таблицу tmp | выберите расст.имя, расст. имя файла, количество (*)
from orders_header h
внутреннее соединение orders_detail d на h.ord |
+ -------- + -------- + ----------- + -------- + --------- + ------ + ---------------------- + -------------------- -------------------------------------------------- -------------------------------- +
2 ряда в наборе (0,00 сек)
Столбец «информация» показывает выполняемый запрос m или NULL, если в данный момент ничего не происходит. При запуске «show processlist» будут показаны только первые 100 символов запроса. Чтобы показать полный запрос, вместо этого запустите «показать полный список процессов».
Выполнение указанной выше команды из интерфейса командной строки MySQL с; разделитель может затруднить чтение вывода, особенно если запросы длинные и занимают несколько строк. Вместо этого при использовании разделителя G данные будут отображаться в более удобочитаемом формате, хотя он потребляет больше строк в вашем терминале. Это особенно полезно при запуске «показать полный список процессов», потому что некоторые из отображаемых запросов могут быть довольно длинными.
mysql> показать список процессов
*************************** 6.ряд ***************************
Id: 708163
Пользователь: root
Хост: localhost
db: NULL
Команда: Запрос
Время: 0
Состояние: NULL
Информация: показать список процессов
************************** 7. ряд ******************** *******
Id: 708174
Пользователь: test
Хост: localhost
db: test
Команда: Запрос
Время: 3
Состояние: копирование в таблицу tmp
Информация: выберите dist.name, dist.filename, count (*)
from orders_header h
внутреннее соединение orders_detail d на h.ord
2 ряда в комплекте (0,00 сек)
Если вы работаете как обычный пользователь, у которого нет привилегии «процесс», то «показать список процессов» покажет только те процессы, которые вы выполняете в данный момент.Если у пользователя есть привилегия процесса, он может видеть все.
лучших практик MySQL. Как писать запросы SQL, которые можно… | автор: javinpaul | Лучшее программирование
Как писать SQL-запросы, которые вы можете читать через 6 месяцев
Изображение автора Нет сомнений в том, что написание кода — это больше искусство, чем наука. Не каждый программист может написать красивый код, который будет одновременно читаться и сопровождаться, даже имея опыт.
В общем, кодирование улучшается с опытом, когда вы изучаете искусство кодирования, например, предпочитая композицию наследованию или кодирование для интерфейса, а не реализацию, но лишь немногие разработчики могут освоить эти методы.
То же самое относится к запросам SQL. То, как вы структурируете свой запрос и как вы его пишете, во многом помогает донести ваши намерения до коллег-разработчиков.
Всякий раз, когда я вижу SQL-запросы в электронных письмах от нескольких разработчиков, я вижу резкую разницу в их стиле написания. Некоторые разработчики пишут его аккуратно и правильно делают отступ в запросе, что позволяет легко определить ключевые детали, например, какие столбцы вы извлекаете из какой таблицы и каковы условия.
В реальных проектах SQL-запросы вряд ли однострочные.Изучение правильного способа написания SQL-запросов имеет большое значение, когда вы читаете их позже или делитесь этим запросом с кем-то для просмотра или выполнения.
В этой статье я собираюсь показать вам пару стилей, которые я пробовал в прошлом, их плюсы и минусы, а также то, что я считаю лучшим способом написания SQL-запросов.
Если у вас нет веской причины не использовать мой стиль, например, у вас есть лучший стиль или вы хотите придерживаться стиля, используемого в вашем проекте (согласованность преобладает над всем), нет причин не использовать его.
Кстати, я полагаю, что вы знакомы с SQL и знаете различные предложения и их значение в запросе SQL. Если нет, то лучше, чтобы вы приобрели некоторый опыт работы с SQL, присоединившись к хорошему онлайн-курсу, например:
Это два курса, которые я настоятельно рекомендую новичкам в SQL. Это отличные курсы, которые научат вас основам SQL.
Пришло время изучить несколько способов написания запросов SQL и выяснить, какой из них лучше всего подходит для быстрого выражения намерений.
Как ускорить запросы MySQL в 300 раз
Прежде чем вы сможете профилировать медленные запросы, вам необходимо их найти.
MySQL имеет встроенный журнал медленных запросов. Чтобы использовать его, откройте файл my.cnf и установите для переменной slow_query_log значение «Вкл.». Задайте для long_query_time количество секунд, в течение которых запрос будет считаться медленным, например 0,2. Задайте для slow_query_log_file путь, по которому вы хотите сохранить файл. Затем запустите свой код, и любой запрос выше указанного порога будет добавлен в этот файл.
Как только вы узнаете, какие запросы вызывают нарушение, вы можете начать изучать, что их замедляет. Одним из инструментов, который предлагает MySQL, является ключевое слово EXPLAIN . Он работает с операторами SELECT , DELETE , INSERT , REPLACE и UPDATE . Вы просто префикс запроса, например:
EXPLAIN SELECT picture.id, picture.title
FROM picture
LEFT JOIN album ON picture.album_id = album.id
WHERE album.user_id = 1;
В результате вы получите объяснение того, как осуществляется доступ к данным. Вы видите строку для каждой таблицы, которая была задействована в запросе:
Важными элементами здесь являются имя таблицы, используемый ключ и количество строк, просканированных во время выполнения запроса.
Он сканирует 2 000 000 изображений, затем для каждого изображения просматривает 20 000 альбомов. Это означает, что он фактически просматривает 40 миллиардов строк в поисках таблицы альбома. Однако вы можете сделать этот процесс намного более эффективным.
Индексы
Вы можете значительно повысить производительность с помощью индексов. Думайте о данных как о именах в адресной книге. Вы можете пролистать все страницы или потянуть за правую вкладку с буквами, чтобы быстро найти нужное имя.
Используйте индексы, чтобы избежать ненужных проходов по таблицам. Например, вы можете добавить индекс к изображению picture.album_id следующим образом:
ИЗМЕНИТЬ ТАБЛИЦУ изображение ДОБАВИТЬ ИНДЕКС (идентификатор_альбома);
Теперь, если вы запустите запрос, процесс больше не будет включать сканирование всего списка изображений.Сначала все альбомы сканируются, чтобы найти те, которые принадлежат пользователю. После этого изображения быстро обнаруживаются с помощью индексированного столбца album_id . Это сокращает количество сканируемых строк до 200 000. Запрос также примерно в 317 раз быстрее оригинала.
Вы можете убедиться, что обе таблицы используют ключ, добавив следующий индекс:
ALTER TABLE альбом ADD INDEX (user_id);
На этот раз таблица альбомов не сканируется полностью, но нужные альбомы быстро определяются с помощью ключа user_id .Когда эти 100 альбомов сканируются, соответствующие изображения определяются с помощью ключа album_id . Каждая таблица использует ключ для оптимальной производительности, что делает запрос в 380 раз быстрее, чем исходный.
Это не означает, что вам следует добавлять индексы везде, потому что каждый индекс увеличивает время записи в базу данных. Вы выигрываете при чтении, но теряете при записи. Поэтому добавляйте только те индексы, которые действительно повышают производительность чтения. Используйте EXPLAIN для подтверждения и удаления любого индекса, который не используется в запросах.
Существует множество других способов увеличения производительности, о которых вы можете узнать больше в моем выступлении на OSCON Ускорьте вашу базу данных в 300 раз .
Анна выступит с докладом Ускорьте вашу базу данных в 300 раз на OSCON 2017 в Остине, штат Техас. Если вы заинтересованы в участии в конференции, используйте этот код скидки при регистрации для наших читателей: PCOS .
Что такое MySQL? Объяснение для начинающих
MySQL — это система управления реляционными базами данных SQL с открытым исходным кодом, разработанная и поддерживаемая Oracle.
Это короткий ответ, состоящий из одного предложения, на вопрос «что такое MySQL», но давайте разберем его на термины, которые немного более понятны для человека.
База данных — это просто структурированный набор данных, упорядоченный для удобного использования и поиска. Для сайта WordPress такими «данными» являются текст ваших сообщений в блоге, информация для всех зарегистрированных пользователей на вашем сайте, автоматически загружаемые данные, важные конфигурации настроек и т. Д.
MySQL — это всего лишь одна популярная система, которая может хранить эти данные и управлять ими, и это особенно популярное решение для баз данных для сайтов WordPress.
Предлагаемое чтение: Как исправить ошибку «MySQL Server Has Gone Away» в WordPress и как исправить ошибку MySQL 1064.
Давайте теперь немного углубимся в вопрос.
Что такое MySQL? Подробнее
MySQL был первоначально запущен еще в 1995 году. С тех пор он претерпел несколько изменений в сфере владения / управления, прежде чем в 2010 году перешел в Oracle Corporation. Хотя сейчас Oracle отвечает за MySQL, MySQL по-прежнему имеет открытый исходный код программное обеспечение , что означает, что вы можете свободно использовать и изменять его.
Логотип MySQL (Источник изображения: MySQL / Oracle)
Название происходит от соединения «My» — имени дочери соучредителя — с SQL — аббревиатурой от языка структурированных запросов, который представляет собой язык программирования, который помогает вам получать доступ к данным в реляционной базе данных и управлять ими.
Чтобы понять, как работает MySQL, важно знать две взаимосвязанные концепции:
Реляционные базы данных
Когда дело доходит до хранения данных в базе данных, вы можете использовать разные подходы.
MySQL выбирает подход, называемый реляционной базой данных .
В реляционной базе данных ваши данные разбиваются на несколько отдельных областей хранения, называемых таблицами , вместо того, чтобы собирать все вместе в одну большую единицу хранения.
Например, предположим, вы хотите сохранить два типа информации:
- Клиенты — их имя, адрес, реквизиты и т. Д.
- Заказы — например, какие товары были приобретены, цена, кто сделал заказ и т. Д.
Если вы попытаетесь объединить все эти данные в один большой горшок, у вас будет несколько проблем, например:
- Различные данные — данные, которые вам нужно собрать для заказа, отличаются от данных для клиента.
- Повторяющиеся данные — у каждого покупателя есть имя, и у каждого заказа также есть имя клиента. Обработка дублирующихся данных становится беспорядочной.
- Нет организации — как надежно связать информацию о заказе с информацией о клиенте?
Чтобы решить эти проблемы, реляционная база данных будет использовать одну отдельную таблицу для клиентов и другую отдельную таблицу для заказов.
Однако вы, вероятно, также захотите сказать «покажите мне все заказы для Джона Доу». Именно здесь на помощь приходит реляционная часть .
Используя так называемый «ключ» , вы можете связать данные из этих двух таблиц вместе, чтобы вы могли манипулировать и комбинировать данные в разных таблицах по мере необходимости. Важно отметить, что ключ — это не имя клиента. Вместо этого вы бы использовали что-то 100% уникальное, например числовой идентификационный номер.
Если вы когда-нибудь просматривали базу данных своего сайта WordPress, вы увидите, что она использует эту реляционную модель, в которой все ваши данные разделены на отдельные таблицы.
По умолчанию WordPress использует 12 отдельных таблиц, но многие плагины WordPress также добавляют свои собственные таблицы. Например, база данных для сайта WordPress ниже содержит 44 отдельные таблицы!
Пример различных таблиц в MySQL
Чтобы завершить эту реляционную концепцию, давайте сделаем ее специфичной для WordPress…
WordPress хранит сообщения блога в таблице wp_posts , а пользователей — в таблице wp_users . Однако, поскольку эти две таблицы связаны ключом , вы можете связать каждую учетную запись пользователя со всеми сообщениями в блоге, написанными каждым пользователем.
Вот как это выглядит в базе данных.
Каждому сообщению присваивается post_author , который является уникальным идентификационным номером (это ключ):
Подпишитесь на информационный бюллетень
Мы увеличили наш трафик на 1187% с помощью WordPress.
Мы покажем вам, как это сделать. Присоединяйтесь к более чем 20 000 других людей, которые получают нашу еженедельную рассылку с инсайдерскими советами по WordPress!
Таблица wp_posts
Затем, если вы хотите увидеть, какая учетная запись пользователя соответствует этому номеру, вы можете посмотреть на ID в таблице wp_users :
Таблица wp_users
Ключ — идентификационный номер — это то, что связывает все воедино.И вот как они «связаны» друг с другом, несмотря на то, что хранят данные в отдельных таблицах.
Модель клиент-сервер
MySQL не только является реляционной системой баз данных , но и использует так называемую модель клиент-сервер .
Часть сервера — это место, где на самом деле находятся ваши данные. Однако, чтобы получить доступ к этим данным, вам необходимо запросить их. Вот тут-то и пригодится клиент .
Используя SQL — язык программирования, о котором мы говорили ранее — клиент отправляет запрос на сервер базы данных для данных, которые нужны клиенту.
Например, если кто-то посещает сообщение в блоге на вашем сайте, ваш сайт WordPress отправит несколько запросов SQL на сервер базы данных, чтобы получить всю информацию, необходимую для доставки сообщения в блог в веб-браузер этого посетителя. Было бы:
- Запросите таблицу wp_posts , чтобы получить контент для сообщения в блоге
- Запросите таблицу wp_users , чтобы получить информацию для поля автора (используя ключ , который мы показали вам выше)
- и т. Д.
Если вы хотите точно видеть, какие типы запросов к базе данных выполняются вашим сайтом WordPress, вы можете использовать замечательный бесплатный плагин под названием Query Monitor, чтобы увидеть точное взаимодействие между вашим сайтом WordPress (клиентом) и сервером базы данных:
Плагин Query Monitor показывает вам отдельные запросы SQL, отправленные на сервер MySQL
Еще одно решение премиум-класса, которое вы можете использовать — New Relic. Наши инженеры часто используют этот инструмент для устранения проблем с производительностью на сайте WordPress, которые могут быть вызваны медленным запросом MySQL.
Если ваш сайт WordPress не может получить доступ к серверу базы данных, это вызывает обычную ошибку при установлении соединения с базой данных.
Kinsta использует MariaDB, а не MySQL: в чем разница?
Здесь, в Kinsta, мы используем систему баз данных под названием MariaDB , а не MySQL. Однако все те же характеристики, которые вы видели в MySQL, применимы и к MariaDB.
Фактически, MariaDB на самом деле является ответвлением MySQL, а ведущий разработчик MariaDB является одним из первых создателей MySQL. «Форк» просто означает, что разработчики MariaDB взяли за основу исходный код MySQL с открытым исходным кодом, а затем построили на нем MariaDB.
Таким образом, хотя у MariaDB другое имя, она тесно связана с MySQL и предлагает полную возможность замены (то есть вы можете легко переключиться с MySQL на MariaDB без каких-либо особых мер предосторожности).
Однако, хотя MariaDB действительно предлагает взаимодействие с MySQL, он также предлагает на улучшенную производительность в некоторых областях, что соответствует нашей философии использования наиболее производительной архитектуры для работы вашего сайта WordPress.
Все планы Kinsta включают еженедельную автоматическую оптимизацию базы данных MySQL, чтобы обеспечить лучшую производительность MariaDB. Ознакомьтесь с нашими планами для получения дополнительной информации.
Kinsta использует MariaDB, ответвление MySQL, чтобы обеспечить максимальную производительность вашего сайта WordPress. 🚀Нажмите, чтобы написать твит Резюме: Что такое MySQL?
MySQL — это система управления реляционными базами данных с открытым исходным кодом. Для сайтов WordPress это означает, что он помогает хранить все сообщения в блогах, информацию о пользователях, плагинах и т. Д.
Он хранит эту информацию в отдельных «таблицах» и связывает ее с «ключами», поэтому это реляционный .
Когда вашему сайту WordPress требуется доступ к этой информации, он отправляет запрос на сервер базы данных MySQL, используя SQL (это модель клиент-сервер ).
Kinsta использует MariaDB, а не MySQL. Однако MariaDB является ответвлением MySQL от одного из соучредителей MySQL и предлагает возможность взаимодействия при замене, а также некоторые улучшения производительности.Таким образом, все основные концепции в этой статье также применимы к MariaDB.
Если вы размещаете в Kinsta, мы предлагаем как прямой доступ к базе данных, так и возможность использовать инструменты управления базами данных, такие как phpMyAdmin.
Если вам понравилось это руководство, то вам понравится наша поддержка. Все планы хостинга Kinsta включают круглосуточную поддержку наших опытных разработчиков и инженеров WordPress. Общайтесь с той же командой, которая поддерживает наших клиентов из списка Fortune 500. Ознакомьтесь с нашими тарифами
Кэш запросов MySQL
Я читал о функциях кэширования запросов MySQL в книге «Высокая производительность MySQL» и в Интернете.Я также играл с этим самостоятельно. Я пришел к выводу, что это довольно крутая функция! Для игры вам понадобится MySQL 4.0.1 или выше …
Я думаю, что мне больше всего нравится то, что срок действия кеша истекает автоматически при изменении таблицы (вставки, обновления, удаления и т. Д.). Так что может быть не так уж и вредно просто включить кеш и посмотреть, что произойдет.
В книге High Performance MySQL говорится, что Query Cache идентифицирует кэшируемые (это слово?) Запросы, ища SEL в первых трех символах оператора SQL.Однако в ходе тестирования я обнаружил, что пробелы или комментарии перед оператором SELECT никак не повлияли на кеширование. Возможно, драйвер JDBC удаляет пробелы и комментарии перед отправкой SQL на сервер.
Включение кэша запросов MySQL
Измените свой my.cnf и установите query_cache_type равным 1 и установите query_cache_size на некоторое значение (здесь мы установили его на 25 МБ)
query_cache_type = 1
query_cache_size = 26214400
Если для query_cache_type или query_cache_size установлено нулевое значение, кэширование не будет включено.Если на вашем сервере много оперативной памяти, вы можете соответственно увеличить размер кеша. Вы можете настроить еще несколько параметров, но они помогут вам в этом.
Обратите внимание, что вы также можете редактировать эти параметры с помощью администратора MySQL. Их можно найти в разделе «Здоровье»> «Системные переменные»> «Память»> «Кэш».
Подсказки кеш-памяти
Вы также можете установить query_cache_type = 2 — с этим параметром запросы кэшируются только в том случае, если вы передаете им подсказку SQL_CACHE , например:
ВЫБЕРИТЕ SQL_CACHE что-то ИЗ таблицы
В качестве альтернативы, если у вас query_cache_type = 1 , вы можете сообщить MySQL, что не хотите кэшировать конкретный запрос.Это настоятельно рекомендуется, поскольку вы не хотите заполнять кеш высокодинамичными запросами (такими как форма поиска). Это делается с помощью подсказки SQL_NO_CACHE .
ВЫБЕРИТЕ материал SQL_NO_CACHE ИЗ таблицы
Создание независимости базы данных подсказок
Если вы похожи на меня, вы съеживаетесь при мысли о добавлении в ваши запросы кода SQL, специфичного для сервера базы данных. В книге High Performance MySQL Book есть подсказка, которая позволит вам использовать подсказки без нарушения совместимости:
ВЫБРАТЬ /*! SQL_NO_CACHE * / материал ИЗ таблицы
Этот трюк также работает с подсказкой SQL_CACHE .И если вы действительно похожи на меня, вам будет не хватать этого ! , не забывайте об этом, иначе это не сработает.
Кэш запросов MySQL и подготовленные операторы
Очень хорошая новость заключается в том, что MySQL Query Cache отлично работает с подготовленными операторами. В ColdFusion, если вы используете CFQUERYPARAM , теги using подготовленные операторы. Встроенный механизм кэширования запросов ColdFusion не позволяет кэшировать запросы с CFQUERYPARAM . Однако их можно кэшировать с помощью MySQL Query Cache.
Итак, если у вас есть код вроде этого:
ВЫБРАТЬ материал ИЗ таблицы
ГДЕ name =