Когда выбрать базу данных MongoDB: гайд для новичков
MongoDB добавляет поле _id с уникальным значением для идентификации документа в коллекции. Это поле обязательно для заполнения в каждом документе. Оно похоже на первичный ключ документа. Если вы создаете новый документ без поля _id, то MongoDB автоматически создаст его и добавит 24-значный уникальный идентификатор к каждому документу в коллекции.
Обратите внимание: сами данные заказа (OrderID, Product и Quantity) в MongoDB фактически хранятся как встроенный документ в самой коллекции, а в реляционных СУБД они обычно хранятся в отдельной таблице. Это одно из ключевых особенностей модели данных MongoDB.
Структура хранилища MongoDB
СУБД MongoDB полагается на концепции базы данных, коллекций и документов. Рассмотрим основные термины, а для лучшего понимания сравним их с терминами из языка структурированных запросов (SQL):
- База данных — это физический контейнер для коллекций.
- Коллекция — группа документов MongoDB. В терминологии SQL это соответствует
- Документ — запись в коллекции MongoDB, набор пар ключ-значение. В терминологии SQL это похоже на строку в таблице базы данных.
- Поле — ключ в документе. В терминологии SQL похоже на столбец в таблице.
- Встроенный документ — в терминологии SQL похоже на создание связей между несколькими таблицами, по которым разбросаны данные, что делается операциями JOIN.
Зачем использовать MongoDB: преимущества этой СУБД
Ниже приведены несколько причин, по которым стоит использовать MongoDB:
- Документоориентированная база — сохранение данных в формате документов вместо формата реляционного типа, это делает MongoDB очень гибкой и адаптируемой к бизнес-требованиям. Возможность хранения разных типов данных особенно важна при работе с большими данными, которые собираются из разных источников и не ложатся в одну структуру.
- Специальные запросы — MongoDB поддерживает поиск по полям, диапазонные запросы и поиск по регулярным выражениям. Могут быть сделаны запросы для возврата определенных полей в документах.
- Индексация — можно создать индексы для улучшения производительности поиска в MongoDB. Любое поле в документе может быть проиндексировано. Это обеспечивает высокую скорость работы СУБД.
- Репликация — эта СУБД может обеспечить высокую доступность с помощью наборов реплик. Набор реплик состоит из двух или более экземпляров MongoDB. Каждая реплика набора может выступать в роли первичной или вторичной. Первичная реплика — главный сервер, который взаимодействует с клиентом и выполняет все операции чтения/записи. Вторичные реплики сохраняют копию данных первичной реплики с помощью встроенной репликации. Если с первичной репликой что-то случилось, происходит автоматическое переключение на вторичную реплику, затем она становится основным сервером.
- Балансировка нагрузки — MongoDB использует концепцию шардинга для горизонтального масштабирования с помощью разделения данных между несколькими экземплярами БД. Она может работать на нескольких серверах, балансируя нагрузку и/или дублируя данные, чтобы поддерживать работоспособность системы в случае аппаратного сбоя.
- Возможность развернуть в облаке — вы получаете готовую к работе, оптимально сконфигурированную, масштабируемую и управляемую базу данных по запросу за две минуты.
- Доступность — MongoDB поддерживает все популярные языки программирования, ее можно использовать бесплатно как open source решение.
Недостатки MongoDB
- Эта база данных не настолько соответствует требованиям ACID (атомарность, согласованность, изолированность и устойчивость), как реляционные базы данных.
- Транзакции с использованием MongoDB являются сложными
- В MongoDB нет положений о хранимых процедурах или функциях, поэтому не получится реализовать какую-либо бизнес-логику на уровне базы данных, что можно сделать в реляционных БД.
Когда стоит и не стоит использовать MongoDB
MongoDB часто выбирают, когда нужна масштабируемая база данных, в настоящее время ее используют в качестве хранилища внутренних данных многие организации, такие как IBM, Twitter, Zendesk, Forbes, Facebook, Google и другие.
Примеры, когда MongoDB подходит для проекта:
- Каталог товаров в электронной коммерции.
- Блоги и системы управления контентом, особенно те, где много контента, в том числе видео и изображений.
- Аналитика в реальном времени и высокоскоростное журналирование, кэширование данных и кейсов, когда важна высокая масштабируемость системы.
- Хранение данных датчиков и устройств.
- Работа с большими данными для машинного обучения и исследований в ритейле и других отраслях.
- Ведение данных на основе местоположения, то есть геопространственных данных.
- Социальные сети, новостные форумы и другие похожие сценарии.
- Слабосвязанные данные без четкой схемы хранения.
- Стартапы и развертывание новых проектов, где структура данных пока неизвестна.
Введение в MongoDB
Что такое MongoDB
Последнее обновление: 30.10.2015
MongoDB реализует новый подход к построению баз данных, где нет таблиц, схем, запросов SQL, внешних ключей и многих других вещей, которые присущи объектно-реляционным базам данных.
Со времен динозавров было обычным делом хранить все данные в реляционных базах данных (MS SQL, MySQL, Oracle, PostgresSQL). При этом было не столь важно, а подходят ли реляционные базы данных для хранения данного типа данных или нет.
В отличие от реляционных баз данных MongoDB предлагает документо-ориентированную модель данных, благодаря чему MongoDB работает быстрее, обладает лучшей масштабируемостью, ее легче использовать.
Но, даже учитывая все недостатки традиционных баз данных и достоинства MongoDB, важно понимать, что задачи бывают разные и методы их решения бывают разные. В какой-то ситуации MongoDB действительно улучшит производительность вашего приложения, например, если надо хранить сложные по структуре данные. В другой же ситуации лучше будет использовать традиционные реляционные базы данных. Кроме того, можно использовать смешенный подход: хранить один тип данных в MongoDB, а другой тип данных — в традиционных БД.
Вся система MongoDB может представлять не только одну базу данных, находящуюся на одном физическом сервере. Функциональность MongoDB позволяет расположить несколько баз данных на нескольких физических серверах, и эти базы данных смогут легко обмениваться данными и сохранять целостность.
Формат данных в MongoDB
Одним из популярных стандартов обмена данными и их хранения является JSON (JavaScript Object Notation). JSON эффективно описывает сложные по структуре данные. Способ хранения данных в MongoDB в этом плане похож на JSON, хотя формально JSON не используется. Для хранения в MongoDB применяется формат, который называется BSON (БиСон) или сокращение от binary JSON.
BSON позволяет работать с данными быстрее: быстрее выполняется поиск и обработка. Хотя надо отметить, что BSON в отличие от хранения данных в формате JSON имеет небольшой недостаток: в целом данные в JSON-формате занимают меньше места, чем в формате BSON, с другой стороны, данный недостаток с лихвой окупается скоростью.
Кроссплатформенность
MongoDB написана на C++, поэтому ее легко портировать на самые разные платформы. MongoDB может быть развернута на платформах Windows, Linux, MacOS, Solaris. Можно также загрузить исходный код и самому скомпилировать MongoDB, но рекомендуется использовать библиотеки с офсайта.
Документы вместо строк
Если реляционные базы данных хранят строки, то MongoDB хранит документы. В отличие от строк документы могут хранить сложную по структуре информацию. Документ можно представить как хранилище ключей и значений.
Ключ представляет простую метку, с которым ассоциировано определенный кусок данных.
Однако при всех различиях есть одна особенность, которая сближает MongoDB и реляционные базы данных. В реляционных СУБД встречается такое понятие как первичный ключ. Это понятие описывает некий столбец, который имеет
уникальные значения. В MongoDB для каждого документа имеется уникальный идентификатор, который называется _id. И если явным образом не указать
его значение, то MongoDB автоматически сгенерирует для него значение.
Каждому ключу сопоставляется определенное значение. Но здесь также надо учитывать одну особенность: если в реляционных базах есть четко очерченная структура, где есть поля,
и если какое-то поле не имеет значение, ему (в зависимости от настроек конкретной бд) можно присвоить значение
Коллекции
Если в традиционном мире SQL есть таблицы, то в мире MongoDB есть коллекции. И если в реляционных БД таблицы хранят однотипные жестко структурированные объекты, то в коллекции могут содержать самые разные объекты, имеющие различную структуру и различный набор свойств.
Репликация
Система хранения данных в MongoDB представляет набор реплик. В этом наборе есть основной узел, а также может быть набор вторичных узлов. Все вторичные узлы сохраняют целостность и автоматически обновляются вместе с обновлением главного узла. И если основной узел по каким-то причинам выходит из строя, то один из вторичных узлов становится главным.
Простота в использовании
Отсутствие жесткой схемы базы данных и в связи с этим потребности при малейшем изменении концепции хранения данных пересоздавать эту схему значительно облегчают работу с базами данных MongoDB и дальнейшим их масштабированием. Кроме того, экономится время разработчиков. Им больше не надо думать о пересоздании базы данных и тратить время на построение сложных запросов.
GridFS
Одной из проблем при работе с любыми системами баз данных является сохранение данных большого размера. Можно сохранять данные в файлах, используя различные языки программирования. Некоторые СУБД предлагают специальные типы данных для хранения бинарных данных в БД (например, BLOB в MySQL).
В отличие от реляционных СУБД MongoDB позволяет сохранять различные документы с различным набором данных, однако при этом размер документа ограничивается 16 мб. Но MongoDB предлагает решение — специальную технологию GridFS, которая позволяет хранить данные по размеру больше, чем 16 мб.
Система GridFS состоит из двух коллекций. В первой коллекции, которая называется files, хранятся имена файлов, а также их метаданные, например, размер.
А в другой коллекции, которая называется chunks, в виде небольших сегментов хранятся данные файлов, обычно сегментами по 256 кб.
Для тестирования GridFS можно использовать специальную утилиту mongofiles, которая идет в пакете mongodb.
Несколько раз я делала неправильный выбор СУБД. Эта история об одном таком выборе — почему мы сделали такой выбор, как бы узнали что выбор был неверен и как мы с этим боролись.Это все произошло на проекте с открытым исходным кодом, называемым Diaspora.
Проект
Diaspora — это распределенная социальная сеть с долгой историей. Давным давно, в 2010 году, четыре студента Нью-Йоркского университета опубликовали на Kickstarter видео с просьбой пожертвовать $10,000 для того разработать распределенную альтернативу Facebook. Они отправили ссылку друзьям, семье и надеялись на лучшее.
Но они попали в самую точку. Только что отгремел очередной скандал из-за приватности на Facebook, и когда пыль улеглась они получили $200,000 инвестиций от 6400 человек для проекта, в котором еще не было написано ни одной строки кода.
Diaspora была одним из первых проектов на Kickstarter, которым удалось значительно превысить цель. Как результат, о них написали в газете New York Times, что обернулось скандалом, потому что на доске на фоне фотографии команды была написана неприличная шутка, но никто этого не заметил, пока фотографию не напечатали… в New York Times. Так я и узнала об этом проекте.
В результате успеха на Kickstarter парни бросили учиться и переехали в Сан-Франциско, чтобы начать писать код. Так они оказались в моем офисе. В то время я работала в Pivotal Labs и один из старших братьев разработчиков Diaspora тоже работал в этой компании, поэтому Pivotal предложили парням рабочие места, интернет, и, конечно, доступ к холодильнику с пивом. Я работала с официальными клиентами компании, а по вечерам зависала с парнями и писала код по выходным.
Закончилось тем, что они оставались в Pivotal более двух лет. Тем не менее, к концу первого лета у них был минимальная, но работающая (в некотором смысле) реализация распределенной социальной сети на Ruby on Rails, использующая MongoDB для хранения данных.
Довольно много баззвородов — давайте разберемся.
Распределенная социальная сеть
Если вы видели Facebook, то вы знаете все, что вам надо знать о Facebook. Это веб-приложение, оно существует в единственном экземпляре и позволяет вам общаться с людьми. Интерфейс Diaspora выглядит почти также, как Facebook.
Лента сообщений посередине показывает посты всех ваших друзей, а вокруг нее куча мусора, на который никто не обращает внимания. Основное отличие Diaspora от Facebook невидимо для пользователей, это «распределенная» часть.
Инфраструктура Disapora не располагается за одним веб-адресом. Есть сотни независимых экземпляров Diaspora. Код открыт, поэтому вы можете развернуть свои серверы. Каждый экземпляр, называется Стручок. Он имеет свою базу данных и свой набор пользователей. Каждый Стручок взаимодействует с другими Стручками, у которых так же своя база и свои пользователи.
Стручки общаются с помощью API на основе протокола HTTP (сейчас это модно называть REST API — прим. пер.). Когда вы развернули свой Стручок, он будет довольно скучным, пока вы не добавите друзей. Вы можете добавлять в друзья пользователей в вашем Стручке, или в других Стручках. Когда кто-либо что-либо опубликует произойдет вот что:
- Сообщение сохранится в базе данных автора.
- Ваш Стручок будет оповещен через API.
- Сообщение сохранится в базе данных вашего Стручка.
- В вашей ленте вы увидите сообщение вместе с сообщениями от других друзей.
Комментарии работают точно так же. Каждое сообщение может быть прокомментировано как пользователями из того же Стручка, так и людьми из других Стручков. Все, у кого есть разрешения просмотреть сообщение, увидят также все комментарии. Как-будто все происходит в одном приложении.
Кого это волнует?
Есть технические и юридические преимущества этой архитектуры. Основным техническим преимуществом является отказоустойчивость.
(такую отказоустойчивую систему надо иметь в каждом офисе)
Если один из Стручков падает, то все остальные продолжают работать. Система вызывает, и даже ожидает, разделение сети. Политические следствия этого — напрмиер если в вашей стране закрывают доступ к Facebook или Twitter, ваш локальный Стручок будет доступен другим людям в вашей стране, даже если все остальные будут недоступны.
Основное юридическое преимущество — это независимость серверов. Каждый Стручок- юридически независимая сущность, управляемая законами той страны, где расположен Стручок. Каждый Стручок также может устанавливать свои условия, на большинстве вы не отдаете права на весь контент, как например на Facebook или Twitter. Diaspora — свободное программное обеспечение, как в смысле «даром», так и в смысле «независимо». Большинство тех, кто запускает свои Стручки, это очень заботит.
Такова архитектура системы, давайте рассмотрим архитектуру отдельного Стручка.
Это Rails приложение.
Каждый Стручок это Ruby on Rails приложение со своей базой на MongoDB. В некотором смысле это «типичное» Rails приложение — оно имеет пользовательский интерфейс, программный API, логику на Ruby и базу данных. Но во всех остальных смыслах оно совсем не типичное.
API используется для мобильных клиентов и для «федерации», то есть для взаимодействия между Стручками. Распределенность добавляет несколько слоев кода, которые отсутствуют в типичном приложении.
И, конечно, MongoDB — далеко не типичный выбор для веб-приложений. Большинство Rails приложений используют PostgreSQL или MySQL. (по состоянию на 2010 год — прим. пер.)
Так вот код. Рассмотрим, какие данные мы храним.
Я не думаю, что это слово означает, что вы думаете, что это означает
«Социальные данные» — это информация о нашей сети друзей, их друзей и их деятельности. Концептуально мы думаем об этом как о сети — неориентированном графе, в котором мы находимся в центре, и наши друзья находятся вокруг нас.
(Фотографии с rubyfriends.com. Благодаря Мэтт Роджерс, Стив Klabnik, Нелл Shamrell, Катрина Оуэн, Сэм Ливингстон-серый, Джош Сассер, Акшай Khole, Прадьюмна Dandwate и Хефзиба Watharkar за вклад в # rubyfriends!)
Когда мы храним социальные данные, мы сохраняем как топологию, так и действия.
Вот уже несколько лет мы знаем, что социальные данные не являются реляционными, если вы храните социальные данные в реляционной базе данных, то вы делаете это неправильно.
Но какие есть альтернативы? Некоторые утверждаю что графовые базы данных подходят лучше всего, но я не буду их рассматривать, так как они слишком нишевые для массовых проектов. Другие говорят что документарные идеально подходят для социальных данных, и они достаточно мейнстримные для реального применения. Давайте рассмотрим почему люди считают, что для социальных данных гораздо лучше подходит MongoDB, а не PostgreSQL.
Как MongoDB хранит данные
MongoDB — это документарная база данных. Вместо хранения данных в таблицах, состоящих из отдельных строк, как в реляционных базах, MongoDB сохраняет данные в коллекциях, состоящих из документов. Документ — это большой JSON объект без заранее определенного формата и схемы.
Давайте рассмотрим набор связей, которые вам необходимо смоделировать. Это очень похоже на проекты в Pivotal, для которых использовалась MongoDB, и это лучший вариант использования для документарной СУБД, который я когда когда-либо видела.
В корне мы имеем набор сериалов. В каждом сериале может быть много сезонов, каждый сезон имеет много эпизодов, каждый эпизод имеет много отзывов и много актеров. Когда пользователь приходит на сайт, обычно он попадает на страницу определенного сериала. На странице отображаются все сезоны, эпизоды, отзывы и актеры, все на одной странице. С точки зрения приложения, когда пользователь попадает на страницу мы хотим получить всю информацию, связанную с сериалом.
Эти данные можно смоделировать несколькими способами. В типичном реляционном хранилище, каждый из прямоугольников будет таблицей. У вас будет таблица tv_shows, таблица seasons с внешним ключом в tv_shows, таблица episodes с внешним ключом в seasons, reviews и cast_members таблицы с внешними ключами в episodes. Таким образом, чтобы получить всю информацию о сериале нужно выполнить соединение пяти таблиц.
Мы могли бы также моделировать эти данные в виде набора вложенных объектов (набор пар ключ-значение). Множество информации о конкретном сериале это одна большая структура вложенных наборов ключ-значение. Внутри сериала, есть множество сезонов, каждый из которых также объект (набор пар ключ-значение). В пределах каждого сезона, массив эпизодов, каждый из которых представляет собой объект, и так далее. Так в MongoDB моделируют данные. Каждый сериал является документом, который содержит всю информацию, об одном сериале.
Вот пример документа одного сериала, Вавилон 5:
У сериала есть название и массив сезонов. Каждый сезон — объект с метаданными и массивом эпизодов. В свою очередь каждый эпизод имеет метаданные и массивы отзывов и актеров.
Похоже на огромную фрактальную структуру данных.
(Множество множеств множеств множеств. Вкусные фракталы.)
Все данные нужные для сериала хранятся одним документом, так что можно очень быстро получить всю информацию сразу, даже если документ очень большой. Есть сериал, называемый «General Hospital», который насчитывает уже 12000 эпизодов в течение 50+ сезонов. На моем ноутбуке, PostgreSQL работает около минуты, чтобы получить денормализованные данные для 12000 эпизодов, в то время как извлечение документа по ID в MongoDB занимает доли секунды.
Так во многих отношениях, это приложение реализует идеальный вариант использования для документарной базы.
Хорошо. Но как насчет социальных данных?
Верно. Когда вы попадаете в социальную сеть, есть только одна важная часть страницы: ваша лента активности. Запрос ленты активности получает все посты от ваших друзей, отсортированных по убыванию даты. Каждый пост содержит содержит вложения, такие как фотографии, лайки, репосты и комментарии.
Вложенная структура ленты активности выглядит очень похоже на сериалы.
Пользователи имеют друзей, друзья имеют посты, посты имеют комментарии и лайки, каждый из которых имеет связан с одним комментатором или лайкером. С точки зрения связей это не сильно сложнее структуры телесериалов. И как в случае сериалов мы хотим получить всю структуру разом как только пользователь войдет в соцсеть. В реляционной СУБД это было бы соединение семи таблиц, чтобы вытащить все данные.
Соединение семи таблиц, ух. Внезапно сохранение всей ленты пользователя в виде одной денормализованной структуры данных, вместо выполнения джоинов, выглядит очень привлекательно. (В PostgreSQL, такие джоины действительно медленно работают вызывают боль — прим. пер.)
В 2010 году команда Diaspora приняла такое решение, статьи Esty об использовании документарных СУБД оказались весьма убедительными, даже несмотря на то, что они публично отказались от MongoDB в последствии. Кроме того, в это время, использование Cassandra в Facebook породило много разговоров об отказе от реляционных СУБД. Выбор MongoDB для Disapora был в духе того времени. Это не было неразумным выбором на тот момент, учитывая знания, которые они имели.
Что могло пойти не так?
Существует очень важное различие между социальным данным Diaspora и Mongo-идеальных данных о сериалах, которое никто не заметил на первый взгляд.
С сериалами, каждый прямоугольник на схеме отношений имеет разный тип. Сериалы отличаются от сезонов, отличаются от эпизодов, отличаются от отзывов, отличаются от актеров. Никто из них не является даже подтипом другого типа.
Но с социальными данными, некоторые из прямоугольников в диаграмме отношений имеют один и тот же тип. На самом деле, все эти зеленые прямоугольники одного типа — они все пользователи диаспоры.
Пользователь имеет друзей, и каждый друг может сами быть пользователем. А может и не быть, потому что это распределенная система. (Это целый пласт сложности, который я пропущу на сегодняшний день.) Таким же образом, комментаторы и лайкеры также могут быть пользователями.
Такое дублирование типов значительно усложняет денормализацию ленты активности в единый документ. Это потому, что в разных местах в документе, вы можете ссылаться на одну и ту же сущность — в данном случае, один тот же пользователь. Пользователь, который лайкнул пост также может быть пользователем, который прокомментировал другую активность.
Дублирование данных дублирование данных
Мы можем по-разному смоделировать это в MongoDB. Самый простой способ — дублирование данных. Вся информация о пользователе копируется сохраняется в лайке к первому посту, а затем отдельная копия сохраняется в комментарии ко второму посту.Преимущество в том, что все данные присутствует везде, где вам это нужно, и вы все еще можете вытащить весь поток активности еще в одном документе.
Примерно так выглядит плотностью денормализованная лента активности.
Все копии пользовательских данных встроены в документ. Это лента Джо, и у него есть копии пользовательских данных, в том числе его имя и URL, на верхнем уровне. Его лента, содержит пост Джейн. Джо лайкнул пост Джейн, так что в лаках к сообщению Джейн, сохранена отдельная копия данных Джо.
Вы можете понять, почему это привлекательно: все данные вам нужно уже находится там, где вам это нужно.
Вы также можете видеть, почему это опасно. Обновление данных пользователя означает обход всех лент активности, чтобы изменить данные во всех местах, где они хранятся. Это очень сильно подвержено ошибкам, и часто приводит к несогласованности данных и загадочным ошибкам, особенно при работе с удалениями.
Неужели нет надежды?
Существует другой подход к решению проблемы в MongoDB, который будет знаком тем, кто имеет опыт работы с реляционными СУБД. Вместо дублирования данных вы можем сохранять ссылки на на пользователей в ленте активности.
При этом подходе вместо встраивания данных там, где они нужны, вы даете каждому пользователю ID. После этого вместо встраивания данных пользователя вы сохраняете только ссылки на пользователей. На картинке ID выделены зеленым:
(MongoDB фактически использует идентификаторы BSON — строки, похожие на GUID. На картинке числа, чтобы легче было читать.)
Это исключает нашу проблему дублирования. При изменении данных пользователей, есть только один документ, который нужно изменить. Тем не менее, мы создали новую проблему для себя. Потому что мы больше не можем построить ленту активности из одного документа. Это менее эффективное и более сложное решение. Построение ленты активности в настоящее время требует, чтобы мы 1) получить документ ленты активности, а затем 2) получили все документы пользователей, чтобы заполнить имена и аватары.
Чего не хватает MongoDB — это операции соединения как в SQL, которая позволяет написать один запрос, объединяющий вместе ленту активности и всех пользователей, на которых есть ссылки из ленты. В конечном итоге приходится вручную делать джоины в коде приложения.
Простые денормализованные данные
Вернемся к сериалам на секунду. Множество отношений для сериалов не имеют много сложностей. Потому что все прямоугольники на диаграмме отношений являются разными сущностями, весь запрос может быть денормализован в один документ, без дублирования и без ссылок. В этой базе данных, нет связей между документами. Поэтому не требуются джоины.
В социальной сети нет самодостаточных сущностей. Каждый раз когда вы видите имя пользователя или аватар вы ожидаете что можно кликнуть и увидеть профиль пользователя, его посты. Сериалы не работают таким образом. Если вы находитесь на эпизоде 1 сезон 1 сериала Вавилона 5, вы не ожидаете, что будет возможность возможность перейти на эпизод 1 сезон 1 General Hospital.
Не. Надо. Ссылаться. На. Документы.
После того, как мы начали делать уродливые джоины вручную в коде Diaspora, мы поняли что это только первая ласточка проблем. Это был сигнал что наши данные на самом деле реляционные, что существует ценность в этой структуре связей и мы двигаемся против базовой идеи документарных СУБД.
Дублируете ли вы важные данные (тьфу), или используете ссылки и делаете джоины в коде приложения (дважды тьфу), если вам нужны ссылки между документами, то вы переросли MongoDB. Когда апологеты MongoDB говорят «документы», то они имеют ввиду вещи, которые вы можете напечатать на бумаге и работать таким образом. Документы имеют внутреннюю структуру — заголовки и подзаголовки, параграфы и футеры, но не имеют ссылок на другие документы. Самодостаточный элемент слабоструктурированных данных.
Если ваши данные выглядят как набор бумажных документов — поздравляю! Это хороший кейс для Mongo. Но если у вас есть ссылки между документами, то у вас на самом деле нет документов. MongoDB в этом случае — плохое решение. Для социальных данных это действительно плохое решение, так как самая важная часть — связи между документами.
Таким образом социальные данные не являются документарными. Это означает что на самом деле социальные данные… реляционны?
Опять это слово
Когда люди говорят «социальные данные не реляционны», это означает не то, что они имеют ввиду. Они имеют ввиду одну из двух вещей:
1. «Концептуально, социальные данные более граф, чем набор таблиц.»
Это абсолютно верно. Но есть на самом деле очень мало понятий в мире, которые, естественно, могут быть смоделированы как нормированные таблицы. Мы используем эту структуру, потому что это эффективно, поскольку это позволяет избежать дублирования, и потому, что, когда это действительно становится медленным, мы знаем, как это исправить.
2. «Гораздо быстрее получить все социальные данные когда они денормализованы в один документ»
Это также абсолютно верно. Когда ваши социальные данные в реляционном хранилище, вам нужно сделать соединение многих таблиц, чтобы получить ленту активности для конкретного пользователя, и что медленнее с ростом объемов таблицы. Тем не менее, у нас есть хорошо понятное решение этой проблемы. Оно называется кеширование.
На конференции All Your Base Conf в Оксфоре, где я сделала доклад по теме этого поста, Neha Narula представила замечательный доклад о кешировании, который я рекомендую посмотреть. Вкратце, кеширование нормализованных данных — это сложная, но вполне изученная проблема. Я видела проекты, в которых лента активности была денормализована в документарной СУБД, как MongoDB, что позволяло получать данные гораздо быстрее. Единственная проблема — инвалидация кеша.
«Есть только две трудные задачи в области информатики: инвалидация кеша и придумывание названий.»
Фил Карлтон
Оказывается, инвалидировать кеш на самом деле довольно трудно. Фил Карлтон написал большую часть SSL версии 3, X11 и OpenGL, так что он знает кое-что о компьютерной науке.
инвалидация кеша как сервис
Но что такое инвалидация кеша, и почему это так сложно?
Инвалидация кеша это знание когда ваши данные в кеше устарели и требуется их обновить или заменить. Вот типичный пример, который я каждый день вижу в веб-приложениях. У нас есть долговременное хранилище, обычно PostgreSQL или MySQL, и перед ними мы имеем слой кеширования, на основе Memcached или Redis. Запрос на чтение ленты активности пользователя обрабатывается из кеша, а не напрямую из базы данных, что делает выполнение запроса очень быстрым.
Запись — гораздо более сложный процесс. Предположим что пользователь с двумя друзьями создает новый пост. Первое что происходит — пост записывается в базу данных. После этого фоновый поток записывает пост в закешированную ленту активности обоих пользователей, которые являются друзьями автора.
Это очень распространенный паттерн. Твитер держит в in-memory кеше ленты последних активных пользователей, в которые добавляются посты когда кто-то из фолловеров создает новый пост. Даже небольшие приложения, которые используют нечто, вроде лент активности, так делают (см: соединение семи таблиц).
Вернемся к нашему примеру. Когда автор меняет существующий пост, обновление обрабатывается также, как и создание, за исключением того что элемент в кеше обновляется, а не добавляется к существующему.
Что произойдет, если фоновый поток, обновляющий кеш, поток прервется посередине? Может упасть сервер, отключатся сетевые кабели, приложение перезапустится. Нестабильность является единственным стабильным фактом в нашей работе. Когда такое случается данные в кеше становятся несогласованными. Некоторые копии постов имеют старое название, а другие — новое. Это нелегкая задача, но с кэшем, всегда есть ядерный вариант.
Всегда можно полностью удалить элемент из кеша и пересобрать его из согласованного долговременного хранилища.
Но что если нет долговременного хранилища? Что если кеш — единственное что у вас есть?
В случае MongoDB это именно так. Это кеш, без долговременного согласованного хранилища. И он обязательно станет несогласованным. Не «согласованным в конечном счете» (eventually consistent), а просто несеогласованным все время (Этого не так сложно добиться, достаточно чтобы обновления происходили чаще, чем, чем среднее время достижения согласованного состояния — прим. пер.). В этом случае у вас нет вариантов, даже «ядерного». У вас нет способа пересобрать кеш в согласованном состоянии.
Когда в Diaspora решили использовать MongoDB, то объединили базу с кешем. База данных и кеш — очень разные вещи. Они основаны на разном представлении о стабильности, скорости, дублировании, связях и целостности данных.
Преобразование
Как только мы поняли, что случайно выбрали кеш для базы данных, что мы могли сделать?
Ну, это вопрос на миллион долларов. Но я уже ответила на вопрос на миллиард долларов. В этом посте я говорила о том, как мы использовали MongoDB в сравнении с тем, для чего оно было разработано. Я говорила об этом так, как будто вся информация была очевидна, и команда Dispora просто не в состоянии провести исследование, прежде чем выбрать.
Но это было совсем не очевидно. Документация MongoDB говорит о том что хорошо, и вообще не говорит о том, что не хорошо.Это естественно. Все так делают. Но в результате потребовалось около 6 месяцев и много жалоб пользователей и много расследований, чтобы выяснить что мы использовали MongoDB не по назначению.
Делать было нечего, кроме извлечения данных из MongoDB и помещения в реляционную СУБД, на ходу решая проблемы несогласованности данных. Сам процесс извлечения данных из MongoDB и помещения в MySQL был прямолинейным. Более подробно в докладе на All Your Base Conf.
Ущерб
У нас были данные за 8 месяцев работы, которые превратились в 1.2 миллиона строк в MySQL. Мы провели восемь недель разрабатывая код для миграции и когда запустили процесс основной сайт ушел в даунтайм на 2 часа. Это было более чем приемлемым результатом для проекта в стадии pre-alpha. Мы бы могли уменьшить даунтайм, но мы закладывали 8 часов, так что два часа выглядело фантастикой.
(NOT BAD)
Эпилог
Помните приложение для телесериалов? Это был идеальный вариант использования для MongoDB. Каждый сериал был одним самодостаточным документом. Нет ссылок на другие документы, нет дублирования, и нет способа сделать данные несогласованными.
После трех месяцев в разработке все прекрасно работало с MongoDB. Но однажды в понедельник на планерке клиент сказал, что один из инвесторов хочет новую фичу. Он хочет иметь возможность кликнуть на на имя актера и посмотреть его карьеру в телесериалах. Он хочет список всех эпизодов во всех сериалах в хронологическом порядке, в которых этот актер снимался.
Мы хранили каждый сериал в виде документа в MongoDB, содержащем все данные, в том числе актеров. Если этот актер встречался в двух эпизодах, даже в одном сериале, информация хранилась в двух местах. Мы не могли даже узнать что это один и тот же актер, кроме как с помощью сравнения имен. Для реализации фичи надо было обойти все документы, найти и дедуплицировать все экземпляры актеров. Ух… Надо было это сделать как минимум один раз, а потом поддерживать внешний индекс всех актеров, который будет испытывать те же проблемы с согласованностью, как и любой другой кеш.
Видите что происходит?
Клиент ожидает что фича будет тривиальной. Если бы данные были в реляционном хранилище, то это было бы действительно так. В первую очередь мы попытались убедить менеджера что эта фича не нужна. Но менеджер не прогнулся и мы придумали несколько более дешевых альтернатив, вроде ссылок на IMDB по имени актера. Но компания делала деньги на рекламе, поэтому им нужно было чтобы клиент не уходил с сайта.
Эта фича подтолкнула проект к переходу на PosgreSQL. После общения с заказчиком выяснилось, что бизнес видит много ценности в связывании эпизодов между собой. Они предполагали просмотр сериалов, снятых одним режиссером и эпизодов, выпущенных в одну неделю и многое другое.
Это было в конечном счете, проблема коммуникации, а не техническая проблема. Если эти разговоры, что произошли раньше, если бы мы взяли время, чтобы действительно понять, как клиент хочет видеть данные и что хочет делать с ним, то мы, вероятно, перешли бы PostgreSQL ранее, когда было меньше данных, и было легче.
Учиться, учиться и еще раз учиться
Из опыта я узнала кое-что: идеальный кейс MongoDB еще уже, чем наши данные о сериалах. Единственное, что удобно хранить в MongoDB — произвольные JSON фрагменты. «Произвольные» в этом контексте означает, что вам абсолютно все равно что внутри JSON. Вы даже не смотрите туда. там нет схемы, даже неявной схемы, как было в наших данных о сериалах. Каждый документ — набор байт, и вы не делаете никаких предположений о том, что внутри.
На RubyConf я столкнулась с Conrad Irwin, который предложил этот сценарий. Он сохранял произвольные данные, пришедшие от клиентов, в виде JSON. Это разумно. CAP теорема не имеет значения, когда в ваших данных нет смысла. Но в любом интересном приложении данные имеют смысл.
От многих людей я слышала, что MongoDB используется как замена PostgreSQL или MySQL.Нет обстоятельств при которых это может быть хорошей идеей. Гибкость схемы (по факту отсутствие схемы — прим. пер.) выглядит как хорошая идея, но на самом деле это полезно только тогда, когда ваш данные не несут ценности. Если у вас есть неявная схема, то есть вы ожидаете некоторую структуру в JSON, то MongoDB — неверный выбор. Я предлагаю взглянуть на hstore в PostgreSQL (в любом случае быстрее, чем MongoDB), и изучить как делать изменения схемы. Они действительно не так сложны, даже в больших таблицах.
Найдите ценность
Когда вы выбираете хранилище данных, самое главное понять где в данных и связях находится ценность для клиента. Если вы пока еще не знаете, то нужно выбирать то, что не загонит вас в угол. Запихивание произвольных JSON данных в базу выглядит гибким решением, но настоящая гибкость заключается в простом добавлении функций для бизнеса.
Делайте ценные вещи простыми.
Конец
Спасибо что дочитали досюда.
MongoDB — Википедия. Что такое MongoDB
MongoDB (от англ. humongous — огромный) — документоориентированная система управления базами данных (СУБД) с открытым исходным кодом, не требующая описания схемы таблиц. Классифицирована как NoSQL, использует JSON-подобные документы и схему базы данных. Написана на языке C++.
Лицензирование и поддержка
MongoDB можно бесплатно получить по общедоступной лицензии Affero (AGPL) GNU. Драйверы для языков программирования находятся под лицензией Apache. В дополнение к этим лицензиям MongoDB Inc. предлагает коммерческую лицензию для MongoDB, которая включает в себя дополнительные функции (например, интеграция с SASL, LDAP, Kerberos, Simple Network Management Protocol и поиска текста Розетта Лингвистика Platform Basis Technology), инструменты управления, мониторинг и резервное копирование, а также поддержку.
Возможности
Ad hoc запросы
Запросы могут возвращать конкретные поля документов и пользовательские JavaScript-функции. Поддерживается поиск по регулярным выражениям. Также можно настроить запрос на возвращение случайного набора результатов.[3]
Индексация
В MongoDB имеется поддержка индексов.
Репликация
MongoDB может работать с набором реплик.[4] Набор реплик состоит из двух и более копий данных. Каждый экземпляр набора реплик может в любой момент выступать в роли основной или вспомогательной реплики. Все операции записи и чтения по умолчанию осуществляются с основной репликой. Вспомогательные реплики поддерживают в актуальном состоянии копии данных. В случае, когда основная реплика дает сбой, набор реплик проводит выбор, который из реплик должен стать основным. Второстепенные реплики могут дополнительно являться источником для операций чтения.
Балансировка нагрузки
MongoDB масштабируется горизонтально, используя шардинг.[5] Пользователь выбирает ключ шарда, который определяет, как данные в коллекции будут распределены. Данные разделятся на диапазоны (в зависимости от ключа шарда) и распределятся по шардам.
Файловое хранилище
MongoDB может быть использован в качестве файлового хранилища с балансировкой нагрузки и репликацией данных.
Эта функция, названная Grid File System,[6] поставляется вместе с драйверами MongoDB. MongoDB предлагает разработчикам функции для работы с файлами и их содержимым. GridFS используется в плагинах для NGINX[7] и lighttpd.[8] GridFS разделяет файл на части и хранит каждую часть как отдельный документ.[9]
Агрегация
Может работать в соответствии с парадигмой MapReduce.
В фреймворке для агрегации есть аналог SQL-инструкции GROUP BY. Операторы агрегации могут быть связаны в конвейер подобно UNIX-конвейрам. Фреймворк так же имеет оператор $lookup для связки документов при выгрузке и статистические операции такие как среднеквадратическое отклонение.
Исполнение JavaScript на стороне сервера
JavaScript может использоваться в запросах, функциях аггрегации (например в MapReduce) и отправлен базе для исполнения.
Коллекции с фиксированным размером
MongoDB поддерживает коллекции с фиксированным размером. Такие коллекции сохраняют порядок вставки и по достижении заданного размера ведут себя как кольцевой буфер.
Архитектура
 Запись записи в MongoDB с Robomongo 0.8.5.
Запись записи в MongoDB с Robomongo 0.8.5.Доступность языка программирования
У MongoDB есть официальные драйверы для основных языков программирования. Существует также большое количество неофициальных или поддерживаемых сообществом драйверов для других языков программирования и фреймворков.
Управление и интерактивный инструментарий
Основным интерфейсом к базе данных была командная оболочка «mongo». С версии MongoDB 3.2 в качестве графической оболочки поставляется «MongoDB Compass». Существуют продукты и сторонние проекты, которые предлагают инструменты с GUI для администрирования и просмотра данных.
Лицензирование
MongoDB доступен бесплатно под лицензией GNU Affero General Public, версия 3. Языковые драйверы доступны под лицензией Apache. Кроме того, MongoDB Inc. предлагает собственные лицензии для MongoDB.
Основные проблемы
Не реализует многодоменные свойства ACID
MongoDB гарантирует ACID в одном документе. Неспособность реализовать свойства ACID означает, что база данных не обеспечивает долговечности, целостности, согласованности и изоляции, необходимых для транзакций. Возможно, что в будущих версиях это будет решено.
На основании этого пункта подробно описаны следующие четыре:
Проблемы с согласованностью
В предыдущих версиях базы данных строго последовательные чтения рассматривают устаревшие версии документов, они также могут возвращать неверные данные из показаний, которые никогда не должны происходить.[10]
Эта проблема считается исправленной с версии 3.4: https://jepsen.io/analyses/mongodb-3-4-0-rc3
Блокировка на уровне документа
MongoDB блокирует базу данных на уровне документа перед каждой операцией записи. Только разные операции записи могут выполняться между различными документами.
Скрипты не являются долговечными или проверяемыми
MongoDB возвращается, когда информация еще не была записана в постоянном хранилище, что может привести к потере информации. В MongoDB 2.2 значение по умолчанию изменяется для записи по крайней мере в одной реплике, но это все еще не удовлетворяет долговечности или проверяемости.
Проблемы с масштабируемостью
Проблемы с производительностью появляются тогда, когда объем данных превышает 100 ТБ.
Варианты использования
База данных MongoDB подходит для следующих применений:
- Хранение и регистрация событий
- Для систем управления документами и контентом
- Электронная коммерция
- Игры
- Проблемы с большим объемом показаний
- Мобильные приложения
- Хранилище операционных данных веб-страницы
- Управление контентом
- Хранение комментариев
- рейтинги
- Регистрация пользователя
- Профили пользователей
- Сеансы данных
- и т.д.
- Проекты, использующие итеративные или гибкие методологии разработки
- Управление статистикой в реальном времени
MongoDB используется для одного или нескольких из этих случаев несколькими компаниями.
История
Компания программного обеспечения 10gen начала разработку MongoDB в 2007 году как компонент планируемой платформы в качестве сервисного продукта. В 2009 году компания перешла на модель разработки с открытым исходным кодом, а компания предлагает коммерческую поддержку и другие услуги. В 2013 году 10gen изменил свое название на MongoDB Inc.
20 октября 2017 года MongoDB стала публичной компанией, зарегистрированной на NASDAQ в качестве MDB с ценой IPO в размере $24 за акцию.
Инструменты MongoDB
Для управления и администрирования системы базы данных могут быть установлены следующие команды:
 Подключение к MongoDB Shell
Подключение к MongoDB Shell- mongo: — интерактивная оболочка, которая позволяет разработчикам и администраторам просматривать, вставлять, удалять и обновлять данные в своей базе данных. Это также позволяет среди других функций репликации данных, настройку осколков, отключить серверы, выполнить JavaScript и все команды, которые могут быть выполнены.
- mongostat: — инструмент командной строки, который суммирует список статистических данных для исполняемого экземпляра MongoDB. Это позволяет вам визуализировать количество вложений, обновлений, удалений, запросов и команд, но также, сколько памяти используется и как долго база данных была закрыта.
- mongotop: — это инструмент командной строки, который предоставляет метод для отслеживания времени, которое считывает или записывает данные в экземпляре. Он также обеспечивает статистику на уровне каждой коллекции. mongosniff: — инструмент командной строки, который обеспечивает обнюхивание в базе данных путем обнюхивания сетевого трафика в MongoDB и обратно.
- mongoimport / mongoexport: представляет собой инструмент командной строки , которая облегчает содержание импорта экспорта из JSON, CSV или TSV. Он также может импортировать или экспортировать в другие форматы.
- mongodump / mongorestore: — инструмент командной строки для создания двоичного образа содержимого базы данных. Эти команды используются для стратегии резервного копирования в MongoDB.
Поддерживаемые языки программирования
У MongoDB есть официальные драйверы для следующих языков программирования:
- С
- C ++
- C # / .NET
- Erlang
- Haskell
- J #
- Java
- JavaScript
- Lisp
- Node.js
- Perl
- PHP
- Python
- Ruby
- Delphi
- Scala
Сотрудничество
6 июня 2012 года компания-разработчик MongoDB 10gen[en] начала длительное сотрудничество с корпорацией Microsoft, предоставив MongoDB её облаку Microsoft Azure. В результате этого партнёрства разработчики получили простой установщик для запуска MongoDB на виртуальных машинах Microsoft Azure. В дополнение к расширению опций облака и хостинга, доступных разработчикам MongoDB, этот шаг объединяет возможности ведущей базы данных NoSQL с технологиями Microsoft, включая Microsoft Azure, .NET и другие технологии с открытым исходным кодом, которые поддерживает Microsoft.
Прочее
Имеется подробная и качественная документация, большое число примеров и драйверов под популярные языки и платформы Java, JavaScript, Node.js, C++, C#, PHP, Python, Perl, Ruby, Grails&Groovy[11].
Заявляется, что релиз MongoDB 1.0.0 готов к использованию в производстве как в качестве единичного мастера, так и в связках «ведущий — ведомые». Код этого релиза достаточно стабилен и проверен в промышленной эксплуатации на протяжении 1,5 лет[12]. По возможности MongoDB должна быть развернута минимум на двух серверах, используя репликацию Master/Slave[13]. Это обеспечивает наличие актуальных данных при выходе из строя одной из СУБД.
Примечания
Литература
- Кайл Бэнкер. MongoDB в действии = MongoDB in Action. — ДМК Пресс, 2014. — 394 с. — ISBN 978-5-97060-057-3.
- Kristina Chodorow. MongoDB: The Definitive Guide, 2nd Edition. — O’Reilly Media, Inc., 2013. — 432 с. — ISBN 978-1-4493-4468-9.
- David Hows, Peter Membrey, Eelco Plugge, Tim Hawkins. The Definitive Guide to MongoDB: A complete guide to dealing with Big Data using MongoDB, Third Edition. — Apress, 2015. — 376 с. — ISBN 978-1-4842-1183-0.
- Eelco Plugge, Peter Membrey, Tim Hawkins. The Definitive Guide to MongoDB: The NoSQL Database for Cloud and Desktop Computing. — Apress, 2010. — 327 с. — ISBN 1-4302-3051-7.
- Mithun Satheesh; Bruno Joseph D’mello; Jason Krol. Web Development with MongoDB and NodeJS — Second Edition. — Packt Publishing, 2015. — 300 с. — ISBN 978-1-78528-745-9.
- Steve Hoberman. Data Modeling for MongoDB. — Technics Publications, 2014. — 226 с. — ISBN 978-1-935504-70-2.
- Mitch Pirtle. MongoDB for Web Development. — Addison-Wesley Professional, 2011. — С. 360. — ISBN 9780321705334.
Ссылки
- Сайты и порталы
- Прочее
MongoDB — Википедия
MongoDB (от англ. humongous — огромный) — документоориентированная система управления базами данных (СУБД) с открытым исходным кодом, не требующая описания схемы таблиц. Классифицирована как NoSQL, использует JSON-подобные документы и схему базы данных. Написана на языке C++.
Лицензирование и поддержка
MongoDB можно бесплатно получить по общедоступной лицензии Affero (AGPL) GNU. Драйверы для языков программирования находятся под лицензией Apache. В дополнение к этим лицензиям MongoDB Inc. предлагает коммерческую лицензию для MongoDB, которая включает в себя дополнительные функции (например, интеграция с SASL, LDAP, Kerberos, Simple Network Management Protocol и поиска текста Розетта Лингвистика Platform Basis Technology), инструменты управления, мониторинг и резервное копирование, а также поддержку.
Возможности
Ad hoc запросы
Запросы могут возвращать конкретные поля документов и пользовательские JavaScript-функции. Поддерживается поиск по регулярным выражениям. Также можно настроить запрос на возвращение случайного набора результатов.[3]
Индексация
В MongoDB имеется поддержка индексов.
Репликация
MongoDB может работать с набором реплик.[4] Набор реплик состоит из двух и более копий данных. Каждый экземпляр набора реплик может в любой момент выступать в роли основной или вспомогательной реплики. Все операции записи и чтения по умолчанию осуществляются с основной репликой. Вспомогательные реплики поддерживают в актуальном состоянии копии данных. В случае, когда основная реплика дает сбой, набор реплик проводит выбор, который из реплик должен стать основным. Второстепенные реплики могут дополнительно являться источником для операций чтения.
Балансировка нагрузки
MongoDB масштабируется горизонтально, используя шардинг.[5] Пользователь выбирает ключ шарда, который определяет, как данные в коллекции будут распределены. Данные разделятся на диапазоны (в зависимости от ключа шарда) и распределятся по шардам.
Файловое хранилище
MongoDB может быть использован в качестве файлового хранилища с балансировкой нагрузки и репликацией данных.
Эта функция, названная Grid File System,[6] поставляется вместе с драйверами MongoDB. MongoDB предлагает разработчикам функции для работы с файлами и их содержимым. GridFS используется в плагинах для NGINX[7] и lighttpd.[8] GridFS разделяет файл на части и хранит каждую часть как отдельный документ.[9]
Агрегация
Может работать в соответствии с парадигмой MapReduce.
В фреймворке для агрегации есть аналог SQL-инструкции GROUP BY. Операторы агрегации могут быть связаны в конвейер подобно UNIX-конвейрам. Фреймворк так же имеет оператор $lookup для связки документов при выгрузке и статистические операции такие как среднеквадратическое отклонение.
Исполнение JavaScript на стороне сервера
JavaScript может использоваться в запросах, функциях аггрегации (например в MapReduce) и отправлен базе для исполнения.
Коллекции с фиксированным размером
MongoDB поддерживает коллекции с фиксированным размером. Такие коллекции сохраняют порядок вставки и по достижении заданного размера ведут себя как кольцевой буфер.
Архитектура
Запись записи в MongoDB с Robomongo 0.8.5.Доступность языка программирования
У MongoDB есть официальные драйверы для основных языков программирования. Существует также большое количество неофициальных или поддерживаемых сообществом драйверов для других языков программирования и фреймворков.
Управление и интерактивный инструментарий
Основным интерфейсом к базе данных была командная оболочка «mongo». С версии MongoDB 3.2 в качестве графической оболочки поставляется «MongoDB Compass». Существуют продукты и сторонние проекты, которые предлагают инструменты с GUI для администрирования и просмотра данных.
Лицензирование
MongoDB доступен бесплатно под лицензией GNU Affero General Public, версия 3. Языковые драйверы доступны под лицензией Apache. Кроме того, MongoDB Inc. предлагает собственные лицензии для MongoDB.
В октябре 2018 года MongoDB Inc. объявила о переходе к более жёсткой по сравнению с AGPL копилефтной лицензии SSPL (Server Side Public License)[10].[11] Вслед за этим было начато изучение новой лицензии представителями Open Source Initiative и Free Software Foundation на предмет соответствия определениям открытого и свободного программного обеспечения[12].
Основные проблемы
Не реализует многодоменные свойства ACID
MongoDB гарантирует ACID в одном документе. Неспособность реализовать свойства ACID означает, что база данных не обеспечивает долговечности, целостности, согласованности и изоляции, необходимых для транзакций. Возможно, что в будущих версиях это будет решено.
На основании этого пункта подробно описаны следующие четыре:
Проблемы с согласованностью
В предыдущих версиях базы данных строго последовательные чтения рассматривают устаревшие версии документов, они также могут возвращать неверные данные из показаний, которые никогда не должны происходить.[13]
Эта проблема считается исправленной с версии 3.4: https://jepsen.io/analyses/mongodb-3-4-0-rc3
Блокировка на уровне документа
MongoDB блокирует базу данных на уровне документа перед каждой операцией записи. Только разные операции записи могут выполняться между различными документами.
Скрипты не являются долговечными или проверяемыми
MongoDB возвращается, когда информация еще не была записана в постоянном хранилище, что может привести к потере информации. В MongoDB 2.2 значение по умолчанию изменяется для записи по крайней мере в одной реплике, но это все еще не удовлетворяет долговечности или проверяемости.
Проблемы с масштабируемостью
Проблемы с производительностью появляются тогда, когда объем данных превышает 100 ТБ.
Варианты использования
База данных MongoDB подходит для следующих применений:
- Хранение и регистрация событий
- Для систем управления документами и контентом
- Электронная коммерция
- Игры
- Проблемы с большим объемом показаний
- Мобильные приложения
- Хранилище операционных данных веб-страницы
- Управление контентом
- Хранение комментариев
- рейтинги
- Регистрация пользователя
- Профили пользователей
- Сеансы данных
- и т.д.
- Проекты, использующие итеративные или гибкие методологии разработки
- Управление статистикой в реальном времени
MongoDB используется для одного или нескольких из этих случаев несколькими компаниями.
История
Компания программного обеспечения 10gen начала разработку MongoDB в 2007 году как компонент планируемой платформы в качестве сервисного продукта. В 2009 году компания перешла на модель разработки с открытым исходным кодом, а компания предлагает коммерческую поддержку и другие услуги. В 2013 году 10gen изменил свое название на MongoDB Inc.
20 октября 2017 года MongoDB стала публичной компанией, зарегистрированной на NASDAQ в качестве MDB с ценой IPO в размере $24 за акцию.
Инструменты MongoDB
Для управления и администрирования системы базы данных могут быть установлены следующие команды:
Подключение к MongoDB Shell- mongo: — интерактивная оболочка, которая позволяет разработчикам и администраторам просматривать, вставлять, удалять и обновлять данные в своей базе данных. Это также позволяет среди других функций репликации данных, настройку осколков, отключить серверы, выполнить JavaScript и все команды, которые могут быть выполнены.
- mongostat: — инструмент командной строки, который суммирует список статистических данных для исполняемого экземпляра MongoDB. Это позволяет вам визуализировать количество вложений, обновлений, удалений, запросов и команд, но также, сколько памяти используется и как долго база данных была закрыта.
- mongotop: — это инструмент командной строки, который предоставляет метод для отслеживания времени, которое считывает или записывает данные в экземпляре. Он также обеспечивает статистику на уровне каждой коллекции. mongosniff: — инструмент командной строки, который обеспечивает обнюхивание в базе данных путем обнюхивания сетевого трафика в MongoDB и обратно.
- mongoimport / mongoexport: представляет собой инструмент командной строки , которая облегчает содержание импорта экспорта из JSON, CSV или TSV. Он также может импортировать или экспортировать в другие форматы.
- mongodump / mongorestore: — инструмент командной строки для создания двоичного образа содержимого базы данных. Эти команды используются для стратегии резервного копирования в MongoDB.
Поддерживаемые языки программирования
У MongoDB есть официальные драйверы для следующих языков программирования:
- С
- C ++
- C # / .NET
- Erlang
- Go
- Haskell
- J #
- Java
- JavaScript
- Lisp
- Node.js
- Perl
- PHP
- Python
- Ruby
- Delphi
- Scala
Сотрудничество
6 июня 2012 года компания-разработчик MongoDB 10gen[en] начала длительное сотрудничество с корпорацией Microsoft, предоставив MongoDB её облаку Microsoft Azure. В результате этого партнёрства разработчики получили простой установщик для запуска MongoDB на виртуальных машинах Microsoft Azure. В дополнение к расширению опций облака и хостинга, доступных разработчикам MongoDB, этот шаг объединяет возможности ведущей базы данных NoSQL с технологиями Microsoft, включая Microsoft Azure, .NET и другие технологии с открытым исходным кодом, которые поддерживает Microsoft.
Прочее
Имеется подробная и качественная документация, большое число примеров и драйверов под популярные языки и платформы Java, JavaScript, Node.js, C++, C#, PHP, Python, Perl, Ruby, Grails&Groovy[14].
Заявляется, что релиз MongoDB 1.0.0 готов к использованию в производстве как в качестве единичного мастера, так и в связках «ведущий — ведомые». Код этого релиза достаточно стабилен и проверен в промышленной эксплуатации на протяжении 1,5 лет[15]. По возможности MongoDB должна быть развернута минимум на двух серверах, используя репликацию Master/Slave[16]. Это обеспечивает наличие актуальных данных при выходе из строя одной из СУБД.
Примечания
Литература
- Кайл Бэнкер. MongoDB в действии = MongoDB in Action. — ДМК Пресс, 2014. — 394 с. — ISBN 978-5-97060-057-3.
- Kristina Chodorow. MongoDB: The Definitive Guide, 2nd Edition. — O’Reilly Media, Inc., 2013. — 432 с. — ISBN 978-1-4493-4468-9.
- David Hows, Peter Membrey, Eelco Plugge, Tim Hawkins. The Definitive Guide to MongoDB: A complete guide to dealing with Big Data using MongoDB, Third Edition. — Apress, 2015. — 376 с. — ISBN 978-1-4842-1183-0.
- Eelco Plugge, Peter Membrey, Tim Hawkins. The Definitive Guide to MongoDB: The NoSQL Database for Cloud and Desktop Computing. — Apress, 2010. — 327 с. — ISBN 1-4302-3051-7.
- Mithun Satheesh; Bruno Joseph D’mello; Jason Krol. Web Development with MongoDB and NodeJS — Second Edition. — Packt Publishing, 2015. — 300 с. — ISBN 978-1-78528-745-9.
- Steve Hoberman. Data Modeling for MongoDB. — Technics Publications, 2014. — 226 с. — ISBN 978-1-935504-70-2.
- Mitch Pirtle. MongoDB for Web Development. — Addison-Wesley Professional, 2011. — С. 360. — ISBN 9780321705334.
Ссылки
- Сайты и порталы
- Прочее
Что такое MongoDB — Программирование с нуля

MongoDB — это система управления базами данных с открытым исходным кодом (СУБД), в которой используется модель данных, ориентированная на документы. MongoDB считается базой данных NoSQL, поскольку не использует реляционную модель и поэтому не использует SQL в качестве языка запросов.
Документно-ориентированная модель позволяет MongoDB хранить полуструктурированные данные, для которых не требуется фиксированная схема. Это может быть достигнуто за счет использования документов JSON.
MongoDB используется рядом крупнейших компаний мира, включая Facebook, Google, Cisco, Forbes и многие другие.
MongoDB также является кроссплатформенной СУБД, в настоящее время поддерживающей Windows, Mac, Solaris и различные дистрибутивы Linux.
База данных MongoDB отличается от реляционной базы данных тем, что MongoDB использует документно-ориентированную модель для хранения данных. В ориентированной на документы модели, данные хранятся в документах коллекции. В реляционной модели данные хранятся в строках таблицы.
Коллекции MongoDB
В MongoDB коллекция — это группа документов. Коллекция обычно содержит документы с похожей темой (например, пользователи, продукты, сообщения и т.д.). Поэтому коллекции во многом похожи на таблицы из реляционной модели.
Документы MongoDB
В MongoDB документы хранятся в виде документов JSON. JSON (JavaScript Object Notation) — это стандарт, облегчающий обмен данными. Документы JSON аналогичны документам XML в том смысле, что данные могут быть представлены в иерархическом порядке и могут быть легко прочитаны как людьми, так и компьютерами.
Вот пример документа JSON, так выглядят документы в базе данных MongoDB.
{
artistname: "Deep Purple",
albums: [
{
album : "Machine Head",
year : 1972,
genre : "Rock"
},
{
album : "Stormbringer",
year : 1974,
genre : "Rock"
}
]
}Поле _id — это уникальный идентификатор документа. MongoDB позволяет извлекать / ссылаться на каждый документ, используя это поле. Вы можете создать идентификатор сами или позволить MongoDB сгенерировать его.
Используя JSON, результаты запросов могут быть легко проанализированы, практически без преобразования, непосредственно с помощью JavaScript и большинства популярных языков программирования. Это связано с тем, что в документах JSON используются имя/пара и соглашения о массивах, знакомые большинству популярных языков программирования, таких как C, C++, C#, Java, JavaScript, Perl, Python и многим другим. Это уменьшает объем бизнес-логики, которая должна быть встроена в приложения, использующие MongoDB.
За кулисами MongoDB фактически хранит документы JSON в двоично-кодированном формате, называемом BSON. BSON расширяет JSON за счет поддержки дополнительных типов данных и обеспечивает эффективность кодирования и декодирования на разных языках.
Schemaless в MongoDB (отстутствие схемы)
Каждый документ JSON в коллекции может содержать свою собственную структуру. Поэтому не существует фиксированной схемы, которая ограничивает тип данных, которые можно вводить в базу данных MongoDB.
Это отличается от реляционной базы данных, где вы должны сначала создать схему (то есть определить таблицы, столбцы, типы данных и т.д.), Прежде чем вводить какие-либо данные. Если данные не соответствуют схеме, они не попадают в базу данных.
В базе данных MongoDB нет правила, чтобы указать, какие поля или сколько полей должен иметь каждый документ. Например, один документ из коллекции может содержать имя, адрес и номер телефона, в то время как другой документ может содержать имя и адрес электронной почты.
MySQL и MongoDB — когда и что лучше использовать / Хабр
Петр Зайцев показывает разницу между MySQL и MongoDB. Это — расшифровка доклада с Highload++ 2016.
Если посмотреть такой известный DB-Engines Ranking, то можно увидеть, что в течении многих лет популярность open source баз данных растет, а коммерческих — постепенно снижается.
Что еще более интересно: если посмотреть на вот это отношение для разных типов баз данных, то видно, что для многих типов — таких, как колунарные базы данных, time series, document stories — open source базы данных наиболее популярны. Только для более старых технологий, таких как реляционные базы данных, или еще более древних, как multivalue база данных, коммерческие лицензии значительно популярнее.
Мы видим, что для многих приложений используют несколько баз данных для того, чтобы задействовать их сильные стороны. Ни одна база данных не оптимизирована для всех всевозможных юзкейсов. Даже если это PostgreSQL [смех на сцене и в зале].
С одной стороны, это хороший выбор, с другой — нужно пытаться найти баланс, так как чем у нас больше разных технологий, тем сложнее их поддерживать, особенно, если компания не очень большая.
Часто что видим, что люди приходят на такие конференции, слушают Facebook или «Яндекс» и говорят: «Ух ты! Сколько вот люди делают интересного. У них технологий разных используется штук 20, и еще штук 10 они написали сами». А потом они тот же самый подход пытаются использовать в своем стартапе из 10 человек, что работает, разумеется, не очень хорошо. Это как раз тот случай, где размер имеет значение.
Очень часто мы видим, что используется основное операционное хранилище и какие-то дополнительные сервисы. Например, для кэширования или полнотекстового поиска.
Другой подход к архитектуре с использованием разных баз данных — это микросервисы, у каждого из которых может быть своя база данных, которая лучше оптимизирована для задач именно этого сервиса. Как пример: основное хранилище может быть на MySQL, Redis и Memcache — для кэширования, Elastic Search или родной Sphinx — для поиска. И что-то вроде Kafka — чтобы передавать данные в систему аналитики, которая часто делалась на чём-то вроде Hadoop.
Если мы говорим про основное операционное хранилище, наверное, у нас есть два выбора. С одной стороны, мы можем выбрать реляционные базы данных, с языком SQL. С другой стороны — что-то нереляционное, а дальше уже смотреть на подвиды, которые доступы в данном случае.
Если говорить про NoSQL-модели данных, то их тоже достаточно много. Наиболее типичные — это либо key value, либо document, либо wide column базы данных. Примеры: Memcache, MongoDB, Cassandra, соответственно.
Почему в данном случае мы сравниваем именно MySQL и MongoDB? На самом деле причин несколько. Если посмотреть на Ranking баз данных, то мы видим, что MySQL, согласно этому рейтингу, — наиболее популярная реляционная база данных, а MongoDB — наиболее популярная нереляционная база данных. Поэтому их разумно сравнивать.
А ещё у меня есть наибольший опыт в использовании этих двух баз данных. Мы в Percona занимаемся плотно именно с ними, работаем с многими клиентами, помогаем им сделать такой выбор. Еще одна причина: обе технологии изначально ориентированы на разработчиков простых приложений. Для тех людей, для которых PostgreSQL — это слишком сложно.
Компания MongoDB изначально очень активно фокусировалась на пользователях MySQL. Поэтому очень часто у людей есть опыт использования и выбор между этими двумя технологиями.
В Percona кроме того, что мы занимаемся поддержкой, консалтингом для этих технологий, у нас есть достаточно много написанного open source софта для обеих технологий. На слайде можно посмотреть. Подробно я рассказывать об этом не буду.
Что следует обо мне лично: я занимаюсь MySQL значительно больше, чем MongoDB. Несмотря на то, что я постараюсь предоставить сбалансированный обзор с моей стороны, у меня могут быть какие-то предрасположенности к MySQL, так как его тараканы я знаю лучше.
Вот список разных вопросов, которые на мой взгляд имеет смысл рассматривать. Сейчас из них рассмотрим каждый более детально.
Что наиболее важно на мой взгляд — это учитывать, какие есть опыт и предпочтения команды. Для многих задач подходят оба решения. Их можно сделать и так, и так, может быть несколько сложнее, может быть несколько проще. Но если у вас команда, которая долго работала с SQL-базами данных и понимает реляционную алгебру и прочее, может быть сложно перетягивать и заставлять их использовать нереляционные базы данных, такие как MongoDB, где нет даже полноценной транзакции.
И наоборот: если есть какая-то команда, которая использует и хорошо знает MongoDB, SQL-язык может быть для неё сложен. Также имеет смысл рассматривать как оригинальную разработку, так и дальнейшее сопровождение и администрирование, поскольку всё это в итоге важно в цикле приложения.
Какие есть преимущества у данных систем?
Если говорить про MySQL — это проверенная технология. Понятно, что MySQL используется крупными компаниями более 15 лет. Так как он использует стандарт SQL, есть возможность достаточно простой миграции на другие SQL-базы данных, если захочется. Есть возможность транзакций. Поддерживаются сложные запросы, включая аналитику. И так далее.
С точки зрения MongoDB, здесь преимущество то, что у нас гибкий JSON-формат документов. Для некоторых задач и каким-то разработчикам это удобнее, чем мучиться с добавлением колонок в SQL-базах данных. Не нужно учить SQL — для некоторых это сложно. Простые запросы реже создают проблемы. Если посмотреть на проблемы производительности, в основном они возникают, когда люди пишут сложные запросы с JOIN в кучу таблиц и GROUP BY. Если такой функциональности в системе нет, то создать сложный запрос получается сложнее.
В MongoDB встроена достаточно простая масштабируемость с использованием технологии шардинга. Сложные запросы если возникают, мы их обычно решаем на стороне приложения. То есть, если нам нужно сделать что-то вроде JOIN, мы можем сходить выбрать данные, потом сходить выбрать данные по ссылкам и затем их обработать на стороне приложения. Для людей, которые знают язык SQL, это выглядит как-то убого и ненатурально. Но на самом деле для многих разработка application-серверов такое куда проще, чем разбираться с JOIN.
Если говорить про приложения, где используется MongoDB, и на чём они фокусируются — это очень быстрая разработка. Потому что всё можно постоянно менять, не нужно постоянно заботиться о строгом формате документа.
Второй момент — это схема данных. Здесь нужно понимать, что у данных всегда есть схема, вопрос лишь в том, где она реализуется. Вы можете реализовывать схему данных у себя в приложении, потому что каким-то же образом вы эти данные используете. Либо эта схема реализуется на уровне базы данных.
Очень часто если у вас есть какое-то приложение, с данными в базе данных работает только это приложение. Например, мы сохраняем данные из этого приложения в эту базу данных. Схема на уровне приложения работает хорошо. Если у нас одни и те же данные используются многими приложениями, то это очень неудобно, сложно контролировать.
Здесь возникает также вопрос времени жизни приложения. С MongoDB хорошо делать приложения, у которых очень ограниченный цикл жизни. То есть если мы делаем приложение, которое живёт недолго, например, сайт для запуска фильма или олимпиады. Мы пожили несколько месяцев после этого, и это приложение практически не используется. Если приложение живёт дольше, то тут уже другой вопрос.
Если говорить про распределение преимуществ и недостатков MySQL и MongoDB с точки зрения цикла разработки приложения, то их можно представить так:
Модель данных очень сильно зависит от приложения и опыта команды. Было бы странным сказать, что у нас реляционный или нереляционный подход к базам данных лучше и лучше всегда.
Если сравнивать их между собой, то понятно, что у нас есть. В MySQL — реляционная база данных. Мы можем с помощью реляционной базы данных легко отображать связи между таблицами. Нормализуя данные, мы можем заставлять изменения данных происходить атомарно в одном месте. Когда данные у нас денормализованы, нам не нужно при каких-то изменениях бежать и модифицировать кучу документов.
Хорошо это или плохо? Результат — всегда таблица. С одной стороны, это просто, с другой — некоторые структуры данных не всегда хорошо ложатся на таблицу, нам может быть неудобно с этим работать.
Это всё в теории. Если говорить о практическом использовании MySQL, мы знаем, что часто денормализуем данные, иногда для некоторых приложений мы используем что-то подобное: храним JSON, XML или другую структуру в колонках приложения.
У MongoDB структура данных основана на документах. Данные многих веб-приложений отображать очень просто. Потому что если храним структуру — что-то вроде ассоциированного массива приложения, то это очень просто и понятно для разработчика сериализуется в JSON-документ. Раскладывать такое в реляционной базе данных по разным табличкам — задача более нетривиальная.
Результаты как список документов, у которых может быть совершенно разная структура — более гибкое решение.
Пример. Мы хотим сохранить контакт-лист с телефона. Понятно, что есть данные, которые хорошо кладутся в одну реляционную табличку: Фамилия, Имя и т.д. Но если посмотреть на телефоны или email-адреса, то у одного человека их может быть несколько. Если подобное хранить в хорошем реляционном виде, то нам неплохо бы это хранить в отдельных таблицах, потом это всё собирать JOIN, что менее удобно, чем хранить это всё в одной коллекции, где находятся иерархические документы.
Следует сказать, что это всё в строго реляционной теории — некоторые базы данных поддерживают массивы. В MySQL поддерживается формат JSON, в который можно засунуть такие вещи, как несколько email-адресов. Или многие годы люди серилизовали это ручками: надо нам сохранить несколько email-адресов, то давайте запишем их через запятую, и дальше приложение разберётся. Но как-то это не очень кошерно.
Интересно, что между MySQL и MongoDB — вообще, между реляционными и нереляционными СУБД — что-то совпадает, что-то различается. Например, в обоих случаях мы говорим о базах данных, но то, что мы называем таблицей в реляционной базе данных, часто в нереляционной называется коллекцией. То, что в MySQL — колонка, в MongoDB — поле. И так далее.
С точки зрения использования JOIN, в MongoDB нет такого понятия — это вообще понятие из реляционной структуры. Там мы либо делаем встроенный документ, что близко к концепту денормализации, либо мы просто сохраняем идентификатор документа в каком-то поле, называем это ссылкой и дальше ручками выбираем данные, которые нам нужны.
Что касается доступа: там, где мы к реляционным данным используем язык SQL, в MongoDB и многих других NoSQL-базах данных используется такой стандарт, как CRUD. Этот стандарт говорит, что есть операции для создания, чтения, удаления и обновления документов.
Несколько примеров.
Как у нас могут выглядеть наиболее типичные задачи по работе с документами в MySQL и MongoDB:
Вот пример вставки.
Пример обновления.
Пример удаления.
Если вы разработчик, который знаком с языком JavaScript, то такой синтаксис, который предоставляет CRUD (MongoDB), для вас будет более естественным, чем синтаксис SQL.
На мой взгляд, когда у нас есть простейшие операции: поиск, вставка, они все работают достаточно хорошо. Когда речь идёт о более интересных операциях выборки, на мой взгляд, язык SQL куда более читаемый.
> вместо простого знака «>». Не очень читаемо, на мой взгляд.
Достаточно легко с помощью интерфейса делать такие вещи, как подсчёт числа строк в таблице или коллекции.
Но если мы делаем более сложные вещи, например, GROUP BY, в MongoDB для этого требуется использовать Aggregation Framework. Это несколько более сложный интерфейс, который показывает, как мы хотим отфильтровать, как мы хотим группировать и т.д. Aggregation Framework уже поддерживает что-то вроде операций JOIN.
Следующий момент — это транзакции и консистентность (ACID). Если пойти и почитать документацию MongoDB, там будет: «Мы поддерживаем ACID-транзакции, но с ограничением». На мой взгляд, стоит сказать: «ACID мы не поддерживаем, но поддерживаем другие минимальные нетранзакционные гарантии».
Какая у нас между ними разница?
Если говорить про MySQL, он поддерживает ACID-транзакции произвольного размера. У нас есть атомарность этих транзакций, у нас есть мультиверсионность, можно выбирать уровень изоляции транзакций, который может начинаться с READ UNCOMMITED и заканчиваться SERIALIZABLE. На уровне узла и репликаций мы можем конфигурировать, как данные хранятся.
Мы можем сконфигурировать у InnoDB, как работать с лог-файлом: сохранять его на диск при коммите транзакции или же делать это периодически. Мы можем сконфигурировать репликацию, включить, например, Semisynchronous Replication, когда у нас данные будут считаться сохранёнными только тогда, когда их копия будет принята на одном из slave’ов.
MongoDB не поддерживает транзакции, но он поддерживает атомарные операции над документом. Это значит, что с точки зрения одного документа операция у нас будет атомарна. Если у нас операция изменяет несколько документов, и во время этой операции произойдет какой-то сбой внутри, то какие-то из этих документов могут быть изменены, а какие-то — не изменены.
Консистентность тоже делается на уровне документов. В кластере мы можем выбирать гибкую консистентность. Мы можем указать, какие мы хотим гарантии — гарантии, что у нас данные были записаны только на один узел, или они были реплицированы на все узлы кластеров. Чтение консистентности тоже происходит на уровне документа.
Есть такой вариант обновления isolated, который позволяет выполнить обновление изолированно от других транзакций, но он очень неэффективен — он переключает базы данных в монопольный режим доступа, поэтому он используется достаточно редко. На мой взгляд, если говорить про транзакции и консистентность, то MongoDB достаточна убогая.
Производительность очень сложно сравнивать напрямую, потому что мы часто делаем разные схемы баз данных, дизайн приложения. Но если говорить в целом, MongoDB изначально была сделана, чтобы хорошо масштабироваться на много узлов через шардинг, поэтому эффективности было уделено меньше внимания.
Это результаты бенчмарка, который делал Марк Каллаган. Здесь видно, что с точки зрения использования процессора, ввода/вывода MySQL — как InnoDB, так и MyRocks — использует значительно меньше процессора и дискового ввода/вывода на операции бенчмарка Linkbench от Facebook.
Масштабируемость.
Что такое масштабируемость в данном контексте? То, насколько легко нам взять наше маленькое приложение и масштабировать его на многие миллионы, может быть, даже на миллиарды пользователей.
Масштабируемость бывает разная. Она бывает средняя, в рамках одной машины, когда мы хотим поддерживать приложения среднего размера, либо масштабируемость на кластере, когда у нас приложения уже очень большие, когда понятно, что даже одна самая мощная машина не справится.
Также имеет смысл говорить о том, масштабируем ли мы чтение, запись или объем данных. В разных приложениях их приоритеты могут различаться, но в целом, если приложение очень большое, обычно им приходится работать со всеми из этих вещей.
В MySQL в новых версиях весьма хорошая масштабируемость в рамках одного узла для LTP-нагрузок. Если у нас маленькие транзакции, есть какое-нибудь железо, в котором 64 процессора, то масштабируется достаточно хорошо. Аналитика или сложные запросы масштабируются плохо, потому что MySQL может использовать для одного запроса только один поток, что плохо.
Традиционно чтение в MySQL масштабируется с репликацией, запись и размер данных — через шардинг. Если смотреть на все большие компании — Facebook, Twitter — они все используют шардинг. Традиционно шардинг в MySQL используется вручную. Есть некоторые фреймворки для этого. Например, Vitess — это фреймворк, который Google использует для scaling сервиса YouTube, они его выпустили в open source. До этого был framework Jetpants. Стандартного решения для шардинга MySQL не предлагает, часто переход на шардинг требует внимания от разработчиков.
В MongoDB фокус изначально был в масштабируемости на многих узлах. Даже в случаях с маленьким приложением многим рекомендуется использовать шардинг с самого начала. Может, всего пару replica set, потом вы будете расти вместе со своим приложением.
В шардинге MongoDB есть некоторые ограничения: не все операторы с ним работают, например, есть isolated-вариант для обеспечения консистентности. Она не работает если использовать шардинг. Но при этом многие основные операции хорошо работают в шардингом, поэтому людям позволяется scale’ить приложения значительно лучше. На мой взгляд, шардинг и вообще репликация в MongoDB сделаны куда лучше, чем MySQL, значительно проще в использовании для пользователя.
Администрирование – это все те вещи, о которых не думают разработчики. По крайней мере в первую очередь. Администрирование — это то, что нам приложение придётся бэкапить, обновлять версии, мониторить, восстановливать при сбоях и так далее.
MySQL достаточно гибок, у него есть много разных подходов. Есть хорошие open source реализации всего, но это множество вариантов порождает сложность. Я часто общаюсь с пользователями, которые только начинают изучать MySQL. Они говорят: «Ёлки-палки, сколько же у вас всего вариантов. Вот только репликация — какую мне использовать: statement-репликацию, raw-репликацию, или mix? А еще есть gtid и стандартная репликация. Почему нельзя сказать „просто работай“?»
В MongoDB всё больше ориентированно на то, что оно работает каким-то одним стандартным образом — есть минимизация администрирования. Но понятно, что это происходит при потере гибкости. Коммьюнити open source решений для MongoDB значительно меньше. Многие вещи в MongoDB с точки зрения рекомендаций достаточно жестко привязаны к Ops Manager — коммерческой разработке MongoDB.
Как в MongoDB, так и в MySQL есть мифы, которые были в прошлом, которые были исправлены, но у людей хорошая память, особенно если что-то не работает. Помню, в MySQL после того как появились транзакции с InnoDB, люди мне лет десять говорили: «А в MySQL нет же транзакций?»
В MongoDB было много разных проблем с производительностью MMAP storage engine: гигантские блокировки, неэффективное использование дискового пространства. Сейчас в стандартном движке WiredTiger уже нет многих из этих проблем. Есть другие проблемы, но не эти.
«Нет контроля схемы» — ещё такой миф. В новых версиях MongoDB можно для каждой коллекции определить на JSON структуру, где данные будут валидироваться. Данные, которые мы пытаемся вставить, и они не соответствуют какому-то формату, можно выкидывать.
«Нет аналога JOIN» — то же самое. В MongoDB это появилось, но нескольких ограниченных вещах. Только на уровне одного шарда и только если мы используем Aggregation Framework, а не в стандартных запросах.
Какие у нас есть мифы в MySQL? Здесь я буду говорить больше о поддержке NoMySQL решений в MySQL, об этом я буду говорить завтра. Следует сказать, что MySQL сейчас тоже можно использовать через интерфейс CRUD’a, использовать в NoSQL режиме примерно как MongoDB.
Типичный пример, где используется MySQL-решение — это сайт электронной коммерции. Когда у нас идёт вопрос о деньгах, часто мы хотим полноценные транзакции и консистентность. Для таких вещей хорошо подходит реляционная структура, которая была проработана, и commerce на реляционных базах данных уже делается многие десятилетия. Так что можно взять один из готовых подходов к структуре данных и использовать его.
Обычно с точки зрения e-commerce объем данных у нас не такой большой, так что даже достаточно большие магазины могут долго работать без шардинга. Приложения у нас постоянно разрабатываются и усовершенствуется на протяжении многих лет. И у этого приложения много компонент, которые работают с одними и теми же данными: кто-то рассчитывает, где цены поменять, кто-то ещё что-то делает.
MongoDB часто задействуется как бэкенд больших онлайн-игр. Electronic Arts для очень многих игр использует MongoDB. Почему? Потому что масштабируемость важна. Если какая-то игра хорошо выстрелит, её приходится масштабировать значительно больше, чем предполагалось.
С другой стороны, если не выстрелит, нам хотелось бы, чтобы инфраструктуру можно было бы уменьшить. Во многих играх это идет так: мы запустили игру, у нее есть какой-то пик, приходится делать большой кластер. Потом игра уже выходит из популярности, для неё бэкенд нужно сжимать, сохранять и использовать. В данном случае есть одно приложение (игра), база данных, с одной стороны, несложная, с другой — сильно привязанная к приложению, в котором хранятся все важные для игры параметры.
Часто консистентность базы данных на уровне объектов здесь достаточна, потому что многие вопросы консистентости решаются на уровне приложения. Например, данные одного игрока сохраняет только один application service.
Всем рекомендую это старое, древнее, но очень смешное видео http://www.mongodb-is-web-scale.com/ [YouTube]. На этом мы закончим.
MySQL и MongoDB — когда что лучше использовать?
Что такое MongoDB и зачем его использовать?
В мире баз данных наиболее распространенными и популярными системами баз данных являются СУБД (реляционные системы управления базами данных). Теперь, если мы хотим разработать приложение, которое обрабатывает большой объем данных, нам нужно выбрать одну из таких баз данных, которая всегда обеспечивает высокопроизводительные решения для хранения данных. Таким образом, мы можем достичь производительности в решении с точки зрения хранения данных и извлечения данных с точностью, скоростью и надежностью.Теперь, если мы классифицировали решения для баз данных, то в основном доступны два типа категорий баз данных: СУБД или реляционная база данных, например, SQL Server, Oracle и т. Д., А другой тип — это база данных NoSQL, такая как MongoDB, CosmosDB и т. Д.
База данных NoSQL фактически используется. альтернатива обычной базе данных SQL, а также база данных этого типа предоставляет в основном все типы функций, которые обычно доступны в системах RDBMS. В настоящее время базы данных NoSQL становятся очень популярными по сравнению с прошлым благодаря простому дизайну, обеспечению как горизонтального, так и вертикального масштабирования, а также легкому и простому управлению хранимыми данными.Этот тип базы данных в основном нарушает обычную традицию хранения данных в реляционной базе данных. Это дает разработчикам возможность хранить данные в базе данных в соответствии с фактическим требованием их программы. Этот тип объекта мы не можем достичь, используя традиционную базу данных RDBMS.
Типы NoSQL
Базы данных NoSQL можно разделить на четыре различных типа, как указано ниже:

Из этих четырех типов база данных документов является самой популярной и широко используемой базой данных в современном мире.Этот тип баз данных всегда разрабатывался на основе документно-ориентированного подхода к хранению данных. Этот тип баз данных всегда играет важную роль для агрегирования данных из документов, а также представляет данные в очень простой и доступной для поиска или организованной форме. MongoDB является наиболее часто используемой базой данных в индустрии разработки в качестве базы данных документов. В базах документов базовая концепция таблицы и строки по сравнению с базой данных SQL была изменена. Здесь строка была заменена термином документ, который является гораздо более гибкой и основанной на модели структурой данных.Мы можем хранить иерархические данные в одном документе в базе данных документов. На самом деле, база данных документов всегда поддерживает полуструктурированную модель данных. В базе данных документов. Таблица была заменена термином Коллекция, который представляет собой контейнер из нескольких одинаковых структурированных или разных структурированных документов.
Что такое MongoDB?
MongoDB — одна из самых популярных баз данных NoSQL с открытым исходным кодом, написанная на C ++. По состоянию на февраль 2015 года MongoDB является четвертой по популярности системой управления базами данных.Он был разработан компанией 10gen, которая в настоящее время известна как MongoDB Inc. Это означает, что вы можете хранить свои записи, не беспокоясь о структуре данных, такой как количество полей или типы полей для хранения значений. Документы MongoDB похожи на объекты JSON.
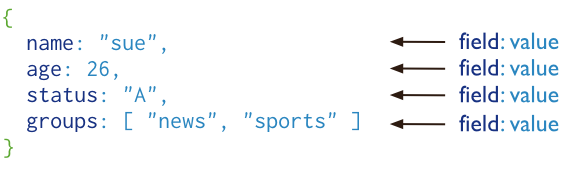
История версий
MongoDB — это база данных на основе документов, разработанная на языках программирования C ++.Слово Монго в основном происходит от Humongous. MongoDB была впервые разработана нью-йоркской организацией под названием 10gen в 2007 году. Позже 10gen изменила название и известна как MongoDB Inc с сегодняшнего дня. Вначале MongoDB в основном разрабатывался как база данных PAAS (платформа как услуга). Но в 2009 году он был представлен как база данных с открытым исходным кодом под названием MongoDB 1.0. Приведенная ниже диаграмма демонстрирует историю выпуска MongoDB до даты. MongoDB 4.0 — текущая стабильная версия, выпущенная в феврале 2018 года.

Кто использует MongoDB?
В современной ИТ-индустрии существует большое количество компаний, которые используют MongoDB в качестве службы базы данных для приложений или систем хранения данных. Согласно опросу, проведенному Siftery на MongoDB, более 4000 компаний подтвердили, что они используют MongoDB в качестве базы данных. Вот некоторые из ключевых имен:
Castlight Health
IBM
Citrix
Twitter
T-Mobile
Zendesk
Sony
000000Foursquare
HTC
InVision
Интерком и т. Д.
Как MongoDB хранит данные?
Как вы знаете, RDMS хранит данные в формате таблиц и использует язык структурированных запросов (SQL) для запросов к базе данных. СУБД также имеет предопределенную схему базы данных, основанную на требованиях, и набор правил для определения отношений между полями в таблицах.

Но MongoDB хранит данные в документах, несмотря на таблицы. Вы можете изменить структуру записей (которые называются документами в MongoDB), просто добавив новые поля или удалив существующие.Эта способность MongoDB поможет вам представить иерархические отношения, легко хранить массивы и другие более сложные структуры. MongoDB обеспечивает высокую производительность, высокую доступность, простую масштабируемость, готовую репликацию и автоматическое разделение.
Почему и где вы должны использовать Mongo DB?
С тех пор MongoDB является базой данных NoSQL, поэтому мы должны понять, когда и почему нам нужно использовать этот тип базы данных в реальных приложениях. Поскольку в нормальных условиях MongoDB всегда предпочитают разработчики или руководители проектов, когда нашей главной заботой является работа с большим объемом данных с высокой производительностью.Если мы хотим вставить тысячи записей в секунду, то MongoDB — лучший выбор для этого. Кроме того, горизонтальное масштабирование (добавление новых столбцов) не так просто в любой системе СУБД. Но в случае MongoDB это очень просто, поскольку это база данных без схемы. Кроме того, этот тип работы может быть непосредственно обработан приложением автоматически. Для выполнения любого типа горизонтального масштабирования в MongoDB не требуется никакой административной работы. MongoDB подходит для следующих типов ситуаций:
Тип приложений на основе продуктов для электронной коммерции
Системы управления блогами и контентом
Высокоскоростное ведение журналов, кэширование и т. Д. В реальном времени
Необходимость сохранения местоположения Геопространственные данные
Для ведения данных, относящихся к типам социальных сетей и сетей
Если приложение является слабосвязанным механизмом — значит, дизайн может измениться в любой момент времени.
Преимущества MongoDB
Поскольку MongoDB — это не только база данных, которая может выполнять только операции CRUD (создание, чтение, обновление и удаление) с данными. Кроме них, MongoDB также содержит так много важных функций, благодаря которым MongoDB становится самой популярной базой данных в категории NoSQL. Вот некоторые из важных функций:
MongoDB — это база данных без схем.
Поле поддержки MongoDB, запрос на основе диапазона, регулярное выражение или регулярное выражение и т. Д. Для поиска данных в сохраненных данных.
MongoDB очень легко масштабировать вверх или вниз.
MongoDB в основном использует внутреннюю память для хранения рабочих временных наборов данных, для которых она намного быстрее.
MongoDB поддерживает первичный и вторичный индекс для любых полей.
MongoDB поддерживает репликацию базы данных.
Мы можем выполнить балансировку нагрузки в MongoDB с помощью Sharding. Он масштабирует базу данных по горизонтали с помощью Sharding.
MongoDB может использоваться как система хранения файлов, известная как GridFS.
MongoDB предоставляет различные способы выполнения операций агрегации с данными, такие как конвейер агрегации, уменьшение карты или отдельные команды агрегации цели.
MongoDB может хранить любой тип файла любого размера без влияния на наш стек.
MongoDB в основном использует JavaScript-объекты вместо процедур.
MongoDB поддерживает специальный тип сбора, такой как TTL (Time-To-Live) для хранения данных, срок действия которого истекает в определенное время
Динамическая схема базы данных, используемая в MongoDB, называется BSON
Поддержка платформ и языков
Как и другие системы СУБД, MongoDB также обеспечивает официальную поддержку большого количества языков программирования и сред.Драйверы Mongo доступны для следующих популярных языков и каркасов:
C
C ++
C # и .NET
Java
Node.js
Perl
PHP, PHP библиотеки, фреймворки и инструменты.
Python
Ruby
Mongoid (Ruby ODM)
Сравнение между SqlDB-схемой и MongoDB-схемой
Поскольку, если мы не очень хорошо знакомы с системами баз данных MongoDB, и мы в основном системы СУБД, представленные в таблицах ниже, представляют собой простые терминологические переводы из базы данных SQL в схему MongoDB.
Присоединение
Связывание и встраивание
Ограничения MongoDB
Поскольку в приведенном выше разделе мы обсуждаем главным образом преимущества, связанные с MongoDB. Но, несмотря на эти преимущества, MongoDB также имеет некоторые ограничения, такие как:
Так как MongoDB не такой сильный ACID (атомарный, согласованность, изоляция и долговечность), как в большинстве систем RDBMS.
Он не может обрабатывать сложные транзакции.
В MongoDB отсутствует положение для хранимой процедуры или функций или триггера, поэтому нет шансов реализовать какую-либо бизнес-логику на уровне базы данных, что можно сделать в любой RBMS. системы.
Резюме
В этой статье мы обсудим основную концепцию базы данных без SQL. Также мы обсудим MongoDB, историю версий MongoDB, преимущества MongoDB и сравнение различной терминологии между базами данных MongoDB и SQL.
Поделиться Артикул
Пройдите наши бесплатные тесты навыков, чтобы оценить свои навыки!
Менее чем за 5 минут с помощью нашего теста навыков вы сможете определить свои пробелы в знаниях и сильные стороны.
mongodb — что такое моноклиент и какова его цель? Переполнение стека- Товары
- Клиенты
- Случаи использования
- Переполнение стека Публичные вопросы и ответы
- Команды Частные вопросы и ответы для вашей команды
- предприятие Частные вопросы и ответы для вашего предприятия
- работы Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимать технический талант
mongos — MongoDB Manual
Закрыть ×MongoDB Руководство
Версия 4.2 (текущая)- Версия 4.4 (ожидается)
- Версия 4.2 (текущая)
- Версия 40
- Версия 3.6
- Версия 3.4
- Версия 3.2
- Версия 30
- Версия 2.6
- Версия 2.4
- Версия 2.2
- Введение
- Начало работы
- Создание кластера свободных уровней Atlas
- Базы данных и коллекции
- Представления
- Материализованные представления по запросу
- Ограниченные коллекции
- Документы
- Типы BSON Sort Order
- MongoDB Extended JSON (v2)
- MongoDB Extended JSON (v1)
- 9000
- Установка
(Shadow) Enterprise (Shadow) (Sharp)- Установка MongoDB Community Edition
- Установка в Linux
- Установка в Red Hat
- Установка с использованием.tgz Tarball
- Установить на Ubuntu
- Установить с помощью .tgz Tarball
- Устранить неполадки при установке Ubuntu
- Установить на Debian
- Установить с помощью .tgz Tarball
- Установить с помощью Sball
- Установить с помощью SUSE
- Установить с помощью SUSE
- Установить с помощью SUSE
- Установить на Amazon
- Установить с помощью .tgz Tarball
- Установить с помощью SUSE
- Установить на macOS
- Установить с помощью .tgz Tarball
- Установить на Windows
- Установить с помощью msiexec.exe
- Установить с помощью SUSE
- Установить MongoDB Enterprise
- Установить в Linux
- Установить в Red Hat
- Установить с помощью .tgz Tarball
- Установить на Ubuntu
- Установить с помощью .tgz Tarball
- Установить на Debian
- Установить с помощью .tgz Tarball
- Установить в Red Hat
- Установить на SUSE
- Установить с помощью .tgz Tarball
- Установить на Amazon
- Установить с помощью .tgz Tarball
- Установить в Linux
- Установить на macOS
- Установить на MacOS
- Установить на ОС Windows Установите с помощью msiexec.exe
- Установить с помощью SUSE
- Установка с Docker
- Установка в Red Hat
- Обновление сообщества MongoDB до MongoDB Enterprise
- Обновление до MongoDB Enterprise (автономно)
- Обновление до MongoDB Enterprise (набор реплик)
- Обновление до MongoDB
Enterprise версии
(Shadow) - Установка в Linux
- Проверка целостности пакетов MongoDB
mongoShell- Настройка
mongoShell - Доступ к
mongoShell Help - Запись сценариев для
mongo0 9015 - Shell
mongoShell Краткое руководство- Операции MongoDB CRUD
,Краткое руководство по- Вставка документов
- Методы вставки
mongo Shell — MongoDB Manual
Закрыть ×MongoDB Руководство
Версия 4.2 (текущая)- Версия 4.4 (ожидается)
- Версия 4.2 (текущая)
- Версия 40
- Версия 3.6
- Версия 3.4
- Версия 3.2
- Версия 30
- Версия 2.6
- Версия 2.4
- Версия 2.2
- Введение
- Начало работы
- Создание кластера свободных уровней Atlas
- Базы данных и коллекции
- Представления
- Материализованные представления по запросу
- Ограниченные коллекции
- Документы
- Типы BSON Sort Order
- MongoDB Extended JSON (v2)
- MongoDB Extended JSON (v1)
- 9000
- Установка
(Shadow) Enterprise (Shadow) (Sharp)- Установка MongoDB Community Edition
- Установка в Linux
- Установка в Red Hat
- Установка с использованием.tgz Tarball
- Установить на Ubuntu
- Установить с помощью .tgz Tarball
- Устранить неполадки при установке Ubuntu
- Установить на Debian
- Установить с помощью .tgz Tarball
- Установить с помощью Sball
- Установить с помощью SUSE
- Установить с помощью SUSE
- Установить с помощью SUSE
- Установить на Amazon
- Установить с помощью .tgz Tarball
- Установить с помощью SUSE
- Установить на macOS
- Установить с помощью .tgz Tarball
- Установить на Windows
- Установить с помощью msiexec.exe
- Установить с помощью SUSE
- Установить MongoDB Enterprise
- Установить в Linux
- Установить в Red Hat
- Установить с помощью .tgz Tarball
- Установить на Ubuntu
- Установить с помощью .tgz Tarball
- Установить на Debian
- Установить с помощью .tgz Tarball
- Установить в Red Hat
- Установить на SUSE
- Установить с помощью .tgz Tarball
- Установить на Amazon
- Установить с помощью .tgz Tarball
- Установить в Linux
- Установить на macOS
- Установить на MacOS
- Установить на ОС Windows Установите с помощью msiexec.exe
- Установить с помощью SUSE
- Установка с Docker
- Установка в Red Hat
- Обновление сообщества MongoDB до MongoDB Enterprise
- Обновление до MongoDB Enterprise (автономно)
- Обновление до MongoDB Enterprise (набор реплик)
- Обновление до MongoDB
Enterprise версии
(Shadow) - Установка в Linux
- Проверка целостности пакетов MongoDB
mongoShell- Настройка
mongoShell - Доступ к
mongoShell Help - Запись сценариев для
mongo0 9015 - Shell
mongoShell Краткое руководство- Операции MongoDB CRUD
,- Вставка документов
- Методы вставки
- Документы запросов