старомодные JOINы @ 900913 — Цифровое наше всё
Как лучше писать много-табличные запросы: просто перечисляя таблицы в SELECT через запятую, или же использовать JOIN?
- Программы
- MariaDB / MySQL
- PostgreSQL
- DataBase
- Microsoft
- Образование
Перевод заметки Bad Habits to Kick : Using old-style JOINs.
Уверен, многие ветераны SQL знают, что есть способ лучше, чем соединять таблицы в стиле ANSI-89 (через запятую):
SELECT o.OrderID, od.ProductID FROM dbo.Orders AS o, dbo.OrderDetails AS od WHERE o.OrderDate >= '20091001' AND o.OrderID = od.ProductID;
Одна из причин избегать данного синтаксиса в том, что подобные запросы сложнее читать. Если бы мы разделили критерии соединения таблиц и критерии фильтрации результата соединения, было бы проще понимать запрос. Ниже мы перепишем данный запрос, но в этот раз используем JOIN-ы:
SELECT o.OrderID, od.ProductID FROM dbo.Orders AS o INNER JOIN dbo.OrderDetails AS od ON o.OrderID = od.ProductID WHERE o.OrderDate >= '20091001';
 OrderID, od.ProductID
FROM dbo.Orders AS o
INNER JOIN dbo.OrderDetails AS od
ON o.OrderID = od.ProductID
WHERE o.OrderDate >= '20091001';
OrderID, od.ProductID
FROM dbo.Orders AS o
INNER JOIN dbo.OrderDetails AS od
ON o.OrderID = od.ProductID
WHERE o.OrderDate >= '20091001';Да, термин «проще» звучит субъективно, но по опыту данный подход экономит время при дальнейшей модификаций и поддержке кода запросов.
К примеру, добавим ещё четыре-пять таблиц в запрос и попытаемся понять, почему мы получаем не те строки в результате, что ожидали. Когда таблицы определены рядом с критериями их соединения, понимать или изменять условия соединения становится проще.
Версия данного синтаксиса с OUTER JOIN (через =*) во многих SQL серверах упразднена,
так что это ещё одна причина избегать использования данного синтаксиса (через перечисление таблиц в SELECT).
Многие помнят, как работают данные условия, но пометка «устаревшее» или отсутствие синтаксиса *= и =* –
всё же важный фактор.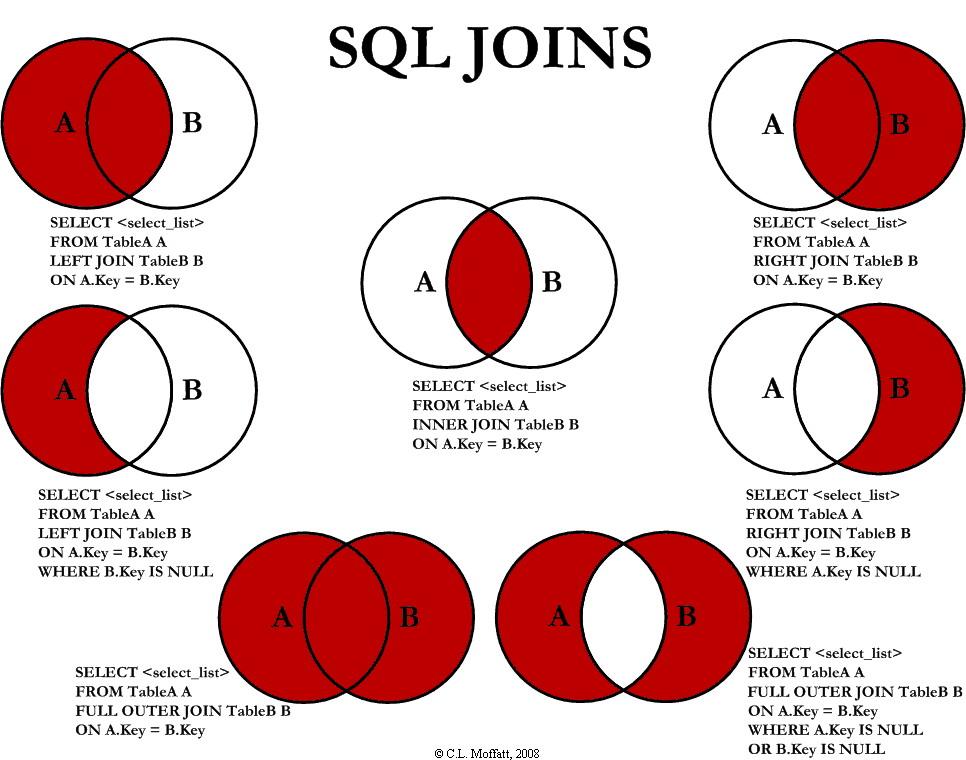 Опять же, лучше ключевыми словами описывать условия соединения во избежание двусмысленности:
Опять же, лучше ключевыми словами описывать условия соединения во избежание двусмысленности:
SELECT p.ProductName, p.ProductID
FROM dbo.Products AS p
LEFT OUTER JOIN dbo.OrderDetails AS od
ON p.ProductID = od.ProductID
WHERE od.ProductID IS NULL;Также есть задокументированные случаи, когда старомодные внешние соединения (аналоги * OUTER JOIN)
выдавали неверные результаты в зависимости от порядка исполнения фильтрующих условий.
Да, они сейчас объявлены устаревшими, где-то упразднены, но данный факт всё же показывает, что лучше не использовать
старомодные соединения.
Если вам ещё не достаточно причин отказаться от старых соединений… Вот ещё большая проблема в использовании
неявного синтаксиса, когда условия соединения описываются там же, где и условия фильтрации.
А что если вы просто забыли в списке прочих критериев указать критерий объединения?
Вы неумышленно получаете 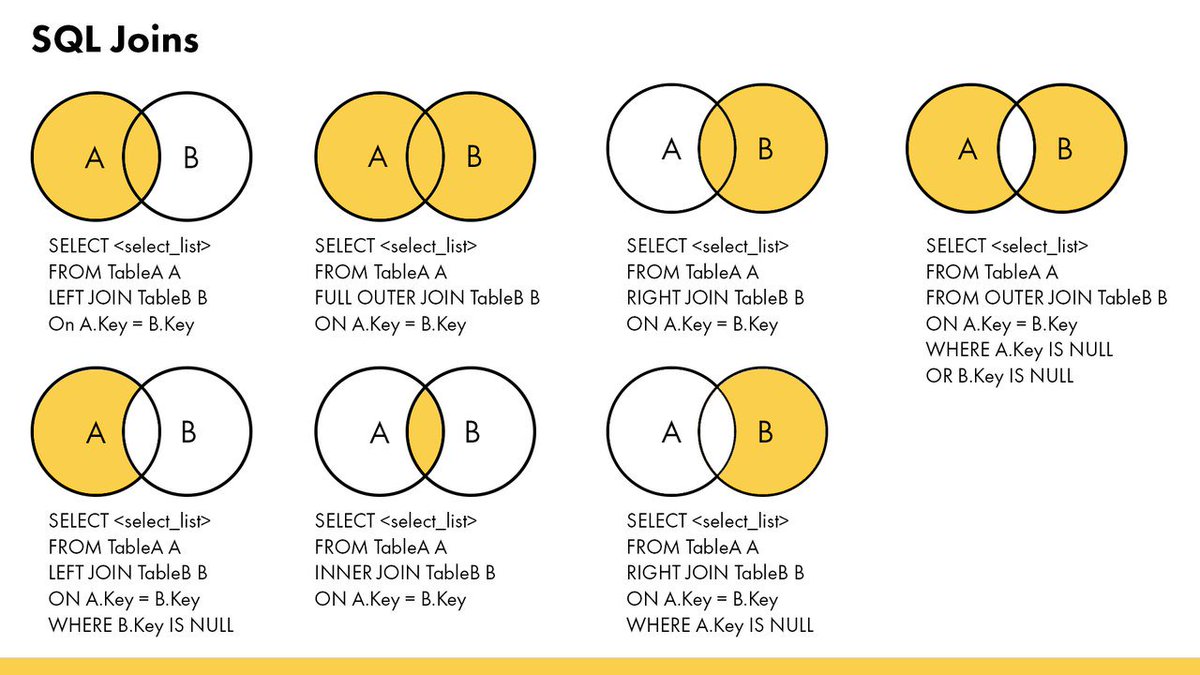 Рассмотрим эту ситуацию на первом примере:
Рассмотрим эту ситуацию на первом примере:
SELECT o.OrderID, od.ProductID FROM dbo.Orders AS o, dbo.OrderDetails AS od WHERE o.OrderDate >= '20091001';
Для каждого заказа из Orders с 1-го октября 2009-го года вы получите копию каждой строки
из таблицы OrderDetails за всё время. Вы потеряли критерий соединения, поэтому для каждой строки из
левой таблицы вы присоедините все строки из правой таблицы. Да, БД оптимизирует по критерию фильтрации, поэтому
из левой таблицы вы возьмёте только лишь все заказы с октября 2009-го…
Это может быть ужасная ошибка на боевом сервере – память от такого соединения быстро закончится, а сам сервер на некоторое время превратится в «тыкву».
С другой стороны, вы могли узнать об этой ошибке ещё на моменте первого написания / тестирования данного кода.
Если использовать явное указание соединения таблиц через INNER JOIN, база данных от вас потребует условие,
так как синтаксис INNER JOIN требует указания условия соединения ON.
Конечно, вы всё ещё можете «выстрелить себе в ногу», указав, например ON o.OrderID = o.OrderID.
Но согласитесь, хорошо, когда синтаксис уменьшает количество вариантов ошибиться!
Моя основная цель – помочь людям избавиться от вредных привычек, которые Майкрософт им прививает, публикуя примеры кода, использующие данный синтаксис. Это не проблема для ветеранов SQL (кроме тех, что не желают развиваться), тех, кто понимает, как соединения работают, и знает историю ANSI-89 и ANSI-92. Однако, новички в SQL могут встретить этот синтаксис в книжках или заметках в интернете.
MySQL и JOINы / Хабр
Поводом для написания данной статьи послужили некоторые дебаты в одной из групп linkedin, связанной с MySQL, а также общение с коллегами и хабролюдьми 🙂В данной статье хотел написать что такое вообще JOINы в MySQL и как можно оптимизировать запросы с ними.
Что такое JOINы в MySQL
В MySQL термин JOIN используется гораздо шире, чем можно было бы предположить.
Все потому, что алгоритм выполнения джоинов в MySQL реализован с использованием вложенных циклов. Т.е. каждый последующий JOIN это дополнительный вложенный цикл. Чтобы выполнить запрос и вернуть все записи удовлетворяющие условию MySQL выполняет цикл и пробегает по записям первой таблицы параллельно проверяя соответствия условиям описанных в теле запроса, когда находятся записи, удовлетворяющие условиям — во вложенном цикле по второй таблице ищутся записи соответствующие первым и удовлетворяющие условиям проверки и т.д.
Прмер обычного запроса с INNER JOIN
SELECT
*
FROM
Table1
INNER JOIN
Table2 ON P1(Table1,Table2)
INNER JOIN
Table3 ON P2(Table2,Table3)
WHERE
P(Table1,Table2,Table3).
* This source code was highlighted with Source Code Highlighter. 
где Р — условия склейки таблиц и фильтры в WHERE условии.
Можно представить такой псевдокод выполнения такого запроса.
FOR each row t1 in Table1 {
IF(P(t1)) {
FOR each row t2 in Table2 {
IF(P(t2)) {
FOR each row t3 in Table3 {
IF P(t3) {
t:=t1||t2||t3; OUTPUT t;
}
}
}
}
}
}
* This source code was highlighted with Source Code Highlighter.где конструкция t1||t2||t3 означает конкатенацию столбцов из разных таблиц.
Если в запросе встречаются OUTER JOINs, например, LEFT OUTER JOIN
SELECT
*
FROM
Table1
LEFT JOIN
(
Table2 LEFT JOIN Table3 ON P2(Table2,Table3)
)
ON P1(Table1,Table2)
WHERE
P(Table1,Table2,Tabke3)
* This source code was highlighted with Source Code Highlighter. 
то алгоритм выполнения этого запроса MySQL будет выглядеть как-то так
FOR each row t1 in T1 {
BOOL f1:=FALSE;
FOR each row t2 in T2 such that P1(t1,t2) {
BOOL f2:=FALSE;
FOR each row t3 in T3 such that P2(t2,t3) {
IF P(t1,t2,t3) {
t:=t1||t2||t3; OUTPUT t;
}
f2=TRUE;
f1=TRUE;
}
IF (!f2) {
IF P(t1,t2,NULL) {
t:=t1||t2||NULL; OUTPUT t;
}
f1=TRUE;
}
}
IF (!f1) {
IF P(t1,NULL,NULL) {
t:=t1||NULL||NULL; OUTPUT t;
}
}
}
* This source code was highlighted with Source Code Highlighter.Более подробно почитать об этом можно здесь — dev.mysql.com/doc/refman/5.1/en/nested-joins.html
Итак, как мы видим, JOINы это просто группа вложенных циклов.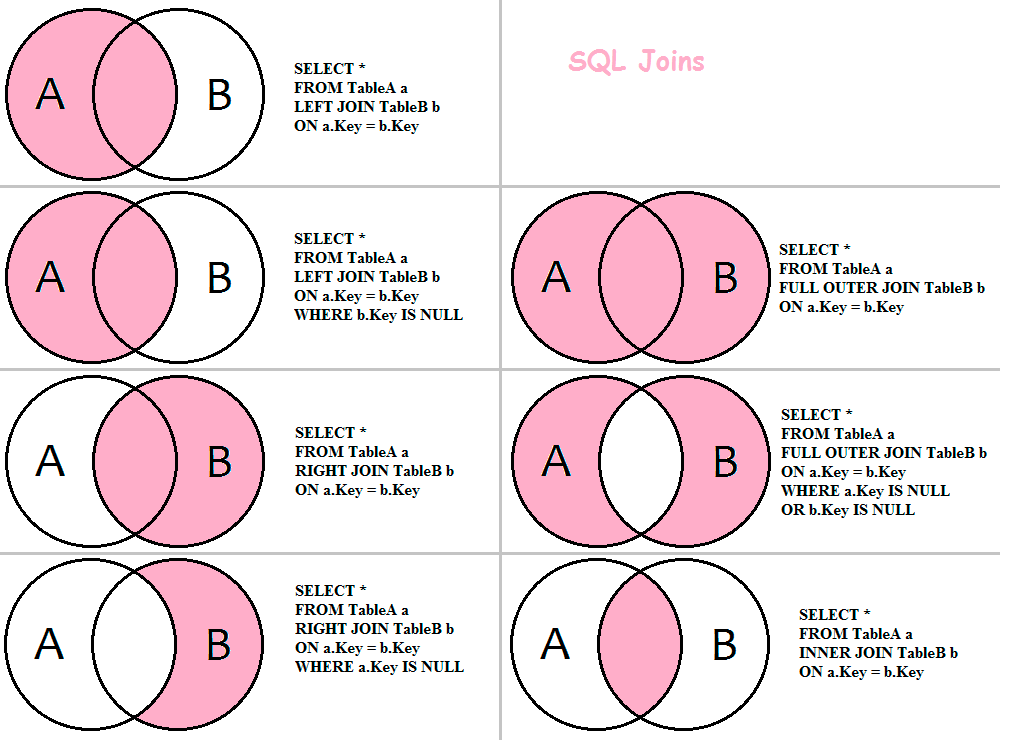 Так почему же в MySQL и UNION и SELECT и запросы с SUBQUERY тоже джоины?
Так почему же в MySQL и UNION и SELECT и запросы с SUBQUERY тоже джоины?
MySQL оптимизатор старается приводить запросы к тому виду к которому ему удобней обрабатывать и выполнять запросы по стандартной схеме.
С SELECT все понятно — просто цикл без вложенных циклов. Все UNION выполняются как отдельные запросы и результаты складываются во временную таблицу, и потом MySQL работает уже с этой таблицей, т.е. проходясь циклом по записям в ней. С Subquery та же история.
Приводя все к одному шаблону, например, МySQL переписывает все RIGHT JOIN запросы на LEFT JOIN эквиваленты.
Но стратегия выполнения запросов через вложенные циклы накладывает некоторые ограничения, например, в связи с такой схемой MySQL не поддерживает выполнение FULL OUTER JOIN запросов.
Но результат такого запроса можно получить с помощью UNION двух запросов на LEFT JOIN и на RIGHT JOIN
Пример самого запроса можно посмотреть по ссылке на вики.
План выполнения JOIN запросов
В отличии от других СУРБД MySQL не генерирует байткод для выполнения запроса, вместо этого MySQL генерирует список инструкций в древовидной форме, которых придерживается engine выполнения запроса выполняя запрос.
Это дерево имеет следующий вид и имеет название «left-deep tree»
В отличии от сбалансированных деревьев (Bushy plan), которые применяются в других СУБД (например Oracle)
JOIN оптимизация
Теперь перейдем к самому интересному — к оптимизации джоинов.
MySQL оптимизатор, а именно та его часть, которая отвечает за оптимизацию JOIN-ов выбирает порядок в котором будет производиться склейка имеющихся таблиц, т.к. можно получить один и тот же результат (датасет) при различном порядке таблиц в склейке. MySQL оптимизатор оценивает стоимость различных планов и выбирает с наименьшей стоимостью. Единицей оценки является операция единичного чтения страницы данных размером в 4 килобайта из произвольного места на диске.
Для выбранного плана можно узнать стоимость путем выполнения команды
SHOW SESSION STATUS LIKE ‘Last_query_cost’;
после выполнения интересующего нас запроса. Переменная Last_query_cost является сессионной переменной. Описание переменной Last_query_cost в MySQL документации можно найти здесь — dev. mysql.com/doc/refman/5.1/en/server-status-variables.html#option_mysqld_Last_query_cost
mysql.com/doc/refman/5.1/en/server-status-variables.html#option_mysqld_Last_query_cost
Оценка основана на статистике: количество страниц памяти, занимаемое таблицей и/или индексами для этой таблицы, cardinality (число уникальных значений) индексов, длинна записей и индексов, их распределение и т.д. Во время своей оценки оптимизатор не рассчитывает на то, что какие-то части попадут в кеш, оптимизатор предполагает, что каждая операция чтения это обращение к диску.
Иногда анализатор-оптимизатор не может проанализировать все возможные планы выполнения и выбирает неправильный. Например, если у нас INNER JOIN по 3м таблицам, то возможных вариантов у анализатора — 3! = 6, а если у нас склейка по 10 таблицам, то тут возможных вариантов уже 10! = 3628800… MySQL не может проанализировать столько вариантов, поэтому в таком случае он использует алгоритм «жадного» поиска.
И вот как раз для решения данной проблемы, нам может пригодиться конструкция STRAIGHT_JOIN. На самом деле я противник подобных хаков как FORCE INDEX и STRAIGH_JOIN, точней против их бездумного использования везде где только можно и нельзя. В данном случае — можно 🙂 Выяснив (либо экспериментальным путем делая запросы с STRAIGH_JOIN и оценивая Last_query_cost, либо эмпирическим путем) нужный порядок джоинов можно переписать запрос с таблицами в соответствующем порядке и добавить STRAIGH_JOIN к данному запросу, таким образом мы сразу убьем двух зайцев — определим правильный план выполнения запроса (это главный заяц) и сэкономим время на стадии «Statistic» (Все стадии выполнения запроса можно посмотреть установив профайлинг запросов командой SET PROFILING =1, я описывал это в своей предыдущей статье по теме профайлинга запросов в MySQL )
В данном случае — можно 🙂 Выяснив (либо экспериментальным путем делая запросы с STRAIGH_JOIN и оценивая Last_query_cost, либо эмпирическим путем) нужный порядок джоинов можно переписать запрос с таблицами в соответствующем порядке и добавить STRAIGH_JOIN к данному запросу, таким образом мы сразу убьем двух зайцев — определим правильный план выполнения запроса (это главный заяц) и сэкономим время на стадии «Statistic» (Все стадии выполнения запроса можно посмотреть установив профайлинг запросов командой SET PROFILING =1, я описывал это в своей предыдущей статье по теме профайлинга запросов в MySQL )
Но не стоит применять этот хак ко всем запросам, расчитывая произвести оптимизацию на спичках и сэкономить время на составление плана выполнения запроса оптимизатором и добавлять STRAIGH_JOIN ко всем запросам с джоинами, т.к. данные меняются и склейка, которая оптимальна сейчас может перестать быть оптимальной со временем, и тогда запросы начнуть очень сильно лагать.
Также, как уже говорилось выше, результаты джоинов помещаются во временные таблицы, поэтому зачастую уместно применять «derived table» в котором мы накладываем все необходимые нам условия на выборку, а также указываем LIMIT и порядок сортировки. В данном случае мы избавимся от избыточности данных во временной таблице, а также проведем сортировку на раннем этапе (по результату одной выборки, а не финальной склейки, что уменьшит размеры записей которые будут сортироваться).
В данном случае мы избавимся от избыточности данных во временной таблице, а также проведем сортировку на раннем этапе (по результату одной выборки, а не финальной склейки, что уменьшит размеры записей которые будут сортироваться).
Стандартный пример подхода описанного выше. Простая выборка для отношения много к многим: новости и теги к ним.
SELECT
t.tid, t.description, n.nid, n.title, n.extract, n.modtime
FROM
(
SELECT
n.nid
FROM
news n
WHERE
n.type = 1321
AND n.published = 1
AND status = 1
ORDER BY
n.modtime DESC
LIMIT
200
) as news
INNER JOIN
news n ON n.nid = news.nid
INNER JOIN
news_tag nt ON n.nid = nt.nid
INNER JOIN
tags t ON nt.tid = t.tid
* This source code was highlighted with Source Code Highlighter. 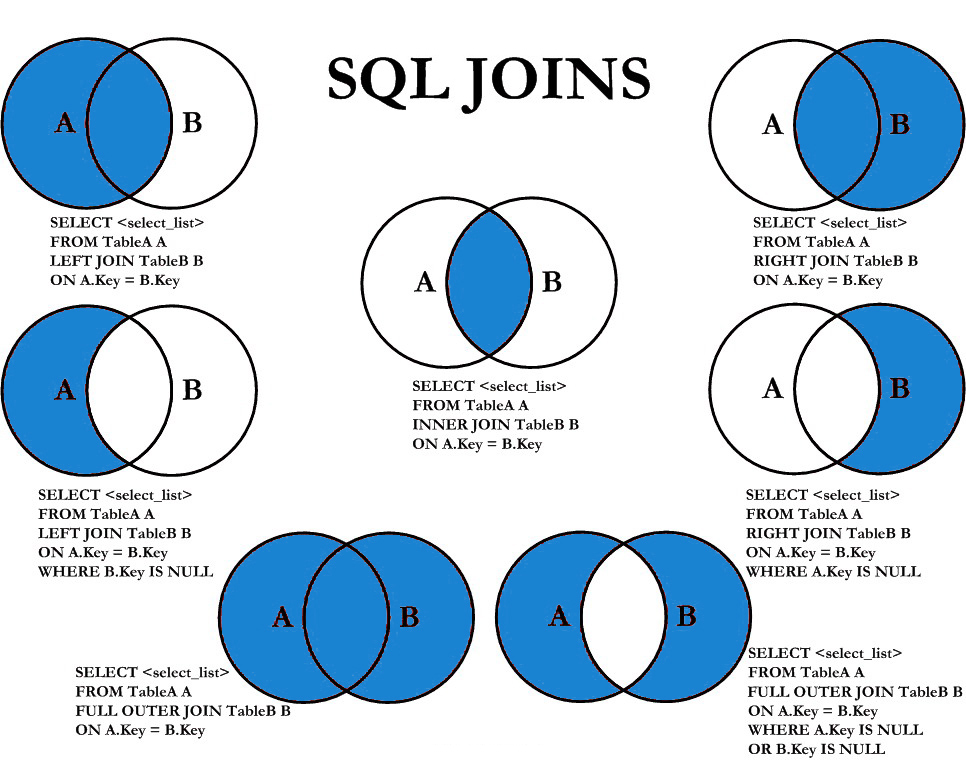
Ну и на последок небольшая задачка, которую я иногда задаю на собеседованиях 🙂
Есть новостной блоггерный сайт. Есть такие сущности как новости и комментарии к ним.
Задача — нужно написать запрос, который выводит список из 10 новостей определенного типа (задается пользователем) отсортированные по времени издания в хронологическом порядке, а также к каждой из этих новостей показать не более 10 последних коментариев, т.е. если коментариев больше — показываем только последние 10.
Все нужно сделать одним запросом. Да, это, может, и не самый лучший способ, и вы вольны предложить другое решение 🙂
ВЫБЕРИТЕ ВНУТРЕННЕЕ СОЕДИНЕНИЕ ВЫБЕРИТЕ в MYSQL
Задавать вопрос
спросил
Изменено 6 лет, 7 месяцев назад
Просмотрено 4к раз
Стол:
|А | |Б | |С | |-----| |-----|-----| |-----|-----|------------|--------| |АКей | |BКлюч |AKey | |CKey |BKey |Дата |Результат | |-----| |-----|-----| |-----|-----|------------|--------| |1 | |1 |1 | |101 |1 |2016-12-01 |F | | | |2 |1 | |102 |1 |2016-12-01 |F | | | |3 |1 | |103 |3 |2016-12-01 |П | | | | | | |104 |1 |2016-12-01 |П |
Я пробовал эту команду SQL:
ВЫБРАТЬ a.
 Akey, b.BKey, c.CKey, Date, Result
ОТ А КАК
ВНУТРЕННЕЕ СОЕДИНЕНИЕ B как b ON a.AKey=b.AKey
ЛЕВОЕ СОЕДИНЕНИЕ (ВЫБЕРИТЕ * ИЗ C, ГДЕ Дата = "2016-12-01"
ЗАКАЗАТЬ ПО CKey DESC
ПРЕДЕЛ 0, 1) AS c ON c.BKey=b.BKey
ГДЕ a.AKey=1
Akey, b.BKey, c.CKey, Date, Result
ОТ А КАК
ВНУТРЕННЕЕ СОЕДИНЕНИЕ B как b ON a.AKey=b.AKey
ЛЕВОЕ СОЕДИНЕНИЕ (ВЫБЕРИТЕ * ИЗ C, ГДЕ Дата = "2016-12-01"
ЗАКАЗАТЬ ПО CKey DESC
ПРЕДЕЛ 0, 1) AS c ON c.BKey=b.BKey
ГДЕ a.AKey=1
Я получил результат следующим образом:
|AKey |BKey |CKey |Date |Result | |-----|-----|-----|------------|--------| |1 |1 |104 |2016-12-01 |П | |1 |2 |НУЛЬ |НУЛЬ |НУЛЬ | |1 |3 |НУЛЬ |НУЛЬ |НУЛЬ |
Но как получить следующий результат?
|AKey |BKey |CKey |Дата |Результат | |-----|-----|-----|------------|--------| |1 |1 |101 |2016-12-01 |П | |1 |2 |НУЛЬ |НУЛЬ |НУЛЬ | |1 |3 |103 |2016-12-01 |П |
- mysql
- join
Вы, вероятно, хотите что-то вроде этого:
SELECT a.Akey, b.BKey, c2.CKey, c2.Date, c2.Result ОТ А КАК ВНУТРЕННЕЕ СОЕДИНЕНИЕ B как b ON a.AKey=b.AKey ЛЕВОЕ СОЕДИНЕНИЕ ( ВЫБЕРИТЕ MIN(CKey) КАК min_CKey, BKey ИЗ С ГДЕ Дата = "2016-12-01" СГРУППИРОВАТЬ ПО BKey ) AS c ON c.
 BKey = b.BKey
ЛЕВОЕ СОЕДИНЕНИЕ C AS c2 ON c.BKey = c2.BKey AND c.min_CKey = c2.CKey
ГДЕ a.AKey=1 И c2.Date = "2016-12-01"
BKey = b.BKey
ЛЕВОЕ СОЕДИНЕНИЕ C AS c2 ON c.BKey = c2.BKey AND c.min_CKey = c2.CKey
ГДЕ a.AKey=1 И c2.Date = "2016-12-01"
Вы должны использовать предложение GROUP BY , чтобы получить минимальное значение CKey на BKey . Затем присоединитесь к таблице C еще раз, чтобы получить остальные поля.
Ваш внутренний запрос всегда выбирает одну и ту же строку. Вы можете получить последнюю запись для каждого Akey с помощью NOT EXISTS() :
SELECT a.Akey, b.BKey, c.CKey, Date, Result
ОТ А КАК
ВНУТРЕННЕЕ СОЕДИНЕНИЕ B как b ON a.AKey=b.AKey
ЛЕВОЕ СОЕДИНЕНИЕ (ВЫБРАТЬ *
ИЗ С
ГДЕ Дата="2016-12-01"
И НЕ СУЩЕСТВУЕТ(ВЫБЕРИТЕ 1 ИЗ c t1
ГДЕ t1.cid > c.cid
и t1.bkey = c.bkey)) AS c
ВКЛ c.BKey=b.BKey
ГДЕ a.AKey=1
0Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя адрес электронной почты и парольОпубликовать как гость
Электронная почтаТребуется, но никогда не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.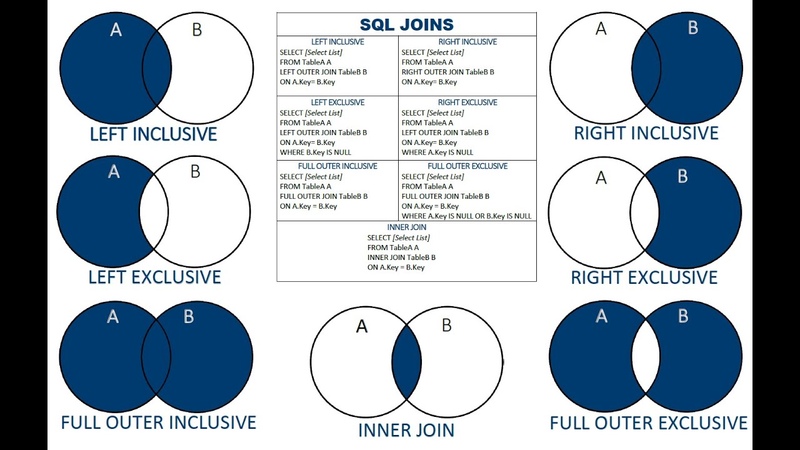
MySQL выбирает соединение с определенным набором значений
спросил
Изменено 1 год, 11 месяцев назад
Просмотрено 278 раз
У меня две таблицы:
- Подписчики
- идентификатор (длинный)
- имя (строка)
- Подписки
- subscriber_id (длинный -> первичный ключ таблицы подписчиков)
- event_id (целое число)
У меня фиксированный набор идентификаторов событий. Например (1, 7, 8) . Как выбрать всех подписчиков , у которых подписки:
- равно набору (1, 7, 8)
- содержит набор (1, 7, 8), например ( 1 , 2, 3, 4, 5, 6, 7 , 8 , 9, 10)
Там, где они содержат эти события, будет выполняться простое внутреннее соединение вместе с подсчетом, чтобы проверить, есть ли у них все три требуемых события (обратите внимание, я предполагаю, что каждый подписчик посетил каждое событие только один раз).
ВЫБЕРИТЕ
s.id
,фамилия
ОТ
Подписчики AS s
INNER JOIN Подписки AS sub
ВКЛ s.id = sub.subscriber_id
И sub.event_id В (1, 7, 8)
ГРУППА ПО
s.id
НАЛИЧИЕ
COUNT(sub.event_id) = 3;
Чтобы найти те, где есть только те, нужно добавить дополнительную проверку, что количество других идентификаторов событий равно нулю. Мы делаем это с помощью левого внешнего соединения, чтобы убедиться, что мы не исключаем тех, кто посетил только три интересующих нас события, а затем проверяем, что количество участников равно нулю.
ВЫБЕРИТЕ
s.id
,фамилия
ОТ
Подписчики AS s
INNER JOIN Подписки AS sub
ВКЛ s.id = sub.subscriber_id
И sub.event_id В (1, 7, 8)
LEFT OUTER JOIN Подписки КАК другие
ПО s.id = other.subscriber_id
И other.event_id НЕ В (1, 7, 8)
ГРУППА ПО
s.id
НАЛИЧИЕ
СЧЁТ(sub.event_id) = 3
И СЧЁТ(others.event_id) = 0;
Вот скрипка SQL, показывающая запросы в действии.
1Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя адрес электронной почты и парольОпубликовать как гость
Электронная почтаТребуется, но не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.