Как заменить все символы, не входящие в ASCII, одним пробелом?
Of the множество из похожих SO вопросы, нет адрес символ замена as противоположный в разбор, и дополнительно решают все вопросы, не связанные с ascii символы не конкретный персонаж.
263
dotancohen 19 Ноя 2013 в 22:09
7 ответов
Лучший ответ
Ваше ''.join() выражение фильтрует , удаляя все, что не является ASCII; вместо этого вы можете использовать условное выражение:
return ''.join([i if ord(i) < 128 else ' ' for i in text])
Это обрабатывает символы один за другим и все равно будет использовать один пробел на замененный символ.
Ваше регулярное выражение должно просто заменить последовательные
re. \x00-\x7F]+',' ', text)
\x00-\x7F]+',' ', text)
 \x00-\x7F]+',' ', text)
\x00-\x7F]+',' ', text)
Обратите внимание на + там.
231
Martijn Pieters 19 Ноя 2013 в 18:11
В качестве нативного и эффективного подхода вам не нужно использовать ord или какой-либо цикл над символами. Просто закодируйте с помощью ascii и игнорируйте ошибки.
Следующее просто удалит не-ascii символы:
new_string = old_string.encode('ascii',errors='ignore')
Теперь, если вы хотите заменить удаленные символы, просто сделайте следующее:
final_string = new_string + b' ' * (len(old_string) - len(new_string))
3
Kasramvd 23 Янв 2018 в 14:39
Если символ замены может быть ‘?’ вместо пробела я бы предложил result = text.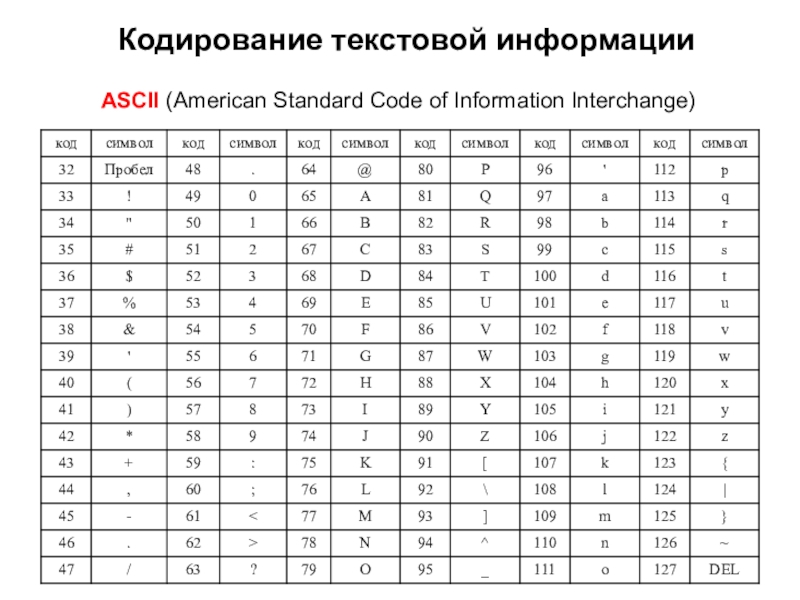 encode('ascii', 'replace').decode()
encode('ascii', 'replace').decode()
"""Test the performance of different non-ASCII replacement methods."""
import re
from timeit import timeit
# 10_000 is typical in the project that I'm working on and most of the text
# is going to be non-ASCII.
text = 'Æ' * 10_000
print(timeit(
"""
result = ''.join([c if ord(c) < 128 else '?' for c in text])
""",
number=1000,
globals=globals(),
))
print(timeit(
"""
result = text.encode('ascii', 'replace').decode()
""",
number=1000,
globals=globals(),
))
Результаты:
0.7208260721400134
0.009975979187503592
9
AXO 3 Янв 2017 в 11:12
Возможно, для другого вопроса, но я предоставляю свою версию ответа @ Alvero (используя unidecode). Я хочу сделать «обычную» полосу для моих строк, то есть начало и конец моей строки для пробельных символов, а затем заменить только другие пробельные символы «обычным» пробелом, т.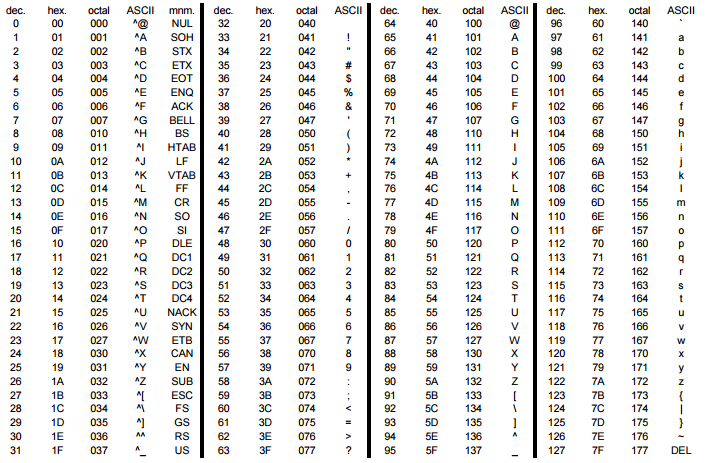 е.
е.
"Ceñíaㅤmañanaㅤㅤㅤㅤ"
Кому
"Ceñía mañana"
,
def safely_stripped(s: str): return ' '.join( stripped for stripped in (bit.strip() for bit in ''.join((c if unidecode(c) else ' ') for c in s).strip().split()) if stripped)
Сначала мы заменим все не-юникодные пробелы обычным пробелом (и снова включим его),
''.join((c if unidecode(c) else ' ') for c in s)
И затем мы разделяем это снова, с нормальным разделением Python, и удаляем каждый «бит»,
(bit.strip() for bit in s.split())
И, наконец, присоединитесь к ним снова, но только если строка прошла тест if,
' '.join(stripped for stripped in s if stripped)
И с этим safely_stripped('ㅤㅤㅤㅤCeñíaㅤmañanaㅤㅤㅤㅤ') правильно возвращает
-1
seaders 8 Апр 2019 в 15:03
Для обработки символа используйте строки Unicode:
PythonWin 3. \x00-\x7f]',r' ',n) # only combining mark replaced
'man ana'
 \x00-\x7f]',r' ',n) # only combining mark replaced
'man ana'
\x00-\x7f]',r' ',n) # only combining mark replaced
'man ana'
19
Mark Tolonen 19 Ноя 2013 в 21:26
def replace_trash(unicode_string):
for i in range(0, len(unicode_string)):
try:
unicode_string[i].encode("ascii")
except:
#means it's non-ASCII
unicode_string=unicode_string[i].replace(" ") #replacing it with a single space
return unicode_string
7
parsecer 20 Авг 2016 в 22:35
Чтобы вы получили наиболее похожее представление вашей исходной строки, я рекомендую модуль unidecode:
from unidecode import unidecode
def remove_non_ascii(text):
return unidecode(unicode(text, encoding = "utf-8"))
Тогда вы можете использовать его в строке:
remove_non_ascii("Ceñía")
Cenia
53
idbrii 22 Фев 2018 в 17:58
В чем разница между текстом ASCII и Unicode?
ASCII и Unicode – это стандарты, которые относятся к цифровому представлению текста, в частности символов, составляющих текст. Однако эти два стандарта существенно различаются, и многие свойства отражают их соответствующий порядок создания.
Однако эти два стандарта существенно различаются, и многие свойства отражают их соответствующий порядок создания.
Америка против Вселенной
Неудивительно, что Американский стандартный код обмена информацией (ASCII) обслуживает американскую аудиторию, пишущую английским алфавитом. Он работает с буквами без ударения, такими как AZ и az, а также с небольшим количеством знаков препинания и управляющих символов.
В частности, невозможно представить заимствованные слова, заимствованные из других языков, таких как « кафе» в кодировке ASCII, без преобразования их в английский язык путем замены акцентированных символов (например, « кафе» ). Локализованные расширения ASCII были разработаны для удовлетворения потребностей различных языков, но эти усилия затрудняли взаимодействие и явно ограничивали возможности ASCII.
Напротив, универсальный набор кодированных символов (Unicode) находится на противоположном конце шкалы амбиций. Unicode пытается удовлетворить как можно больше мировых систем письма, поскольку он охватывает древние языки и всеми любимый набор выразительных символов, эмодзи.
Набор символов или кодировка символов?
Проще говоря, набор символов – это набор символов (например, AZ), в то время как кодировка символов – это отображение между набором символов и значением, которое может быть представлено в цифровом виде (например, A = 1, B = 2).
Стандарт ASCII фактически является и тем, и другим: он определяет набор символов, которые он представляет, и метод сопоставления каждого символа с числовым значением.
Напротив, слово Unicode используется в нескольких разных контекстах для обозначения разных вещей. Вы можете думать об этом как о всеобъемлющем термине, таком как ASCII, для обозначения набора символов и ряда кодировок. Но поскольку существует несколько кодировок, термин Unicode часто используется для обозначения общего набора символов, а не для того, как они отображаются.
Размер
Из-за своего объема Unicode представляет гораздо больше символов, чем ASCII. Стандартный ASCII использует 7-битный диапазон для кодирования 128 различных символов . Юникод, с другой стороны, настолько велик, что нам нужно использовать другую терминологию, чтобы говорить об этом!
Юникод, с другой стороны, настолько велик, что нам нужно использовать другую терминологию, чтобы говорить об этом!
Unicode обслуживает 1111998 адресуемых кодовых точек. Кодовая точка примерно аналогична пространству, зарезервированному для символа, но ситуация намного сложнее, чем когда вы начинаете вникать в детали!
Более полезное сравнение – сколько скриптов (или систем записи) в настоящее время поддерживается. Конечно, ASCII обрабатывает только английский алфавит, в основном латинский или латинский алфавит. Версия Unicode, выпущенная в 2020 году, идет намного дальше: она поддерживает в общей сложности 154 скрипта.
Место хранения
7-битный диапазон ASCII означает, что каждый символ хранится в одном 8-битном байте; запасной бит не используется в стандартном ASCII. Это упрощает расчет размера: длина текста в символах – это размер файла в байтах.
Вы можете подтвердить это с помощью следующей последовательности команд bash. Сначала мы создаем файл, содержащий 12 букв текста:
$ echo -n 'Hello, world' > fooЧтобы проверить, что текст находится в кодировке ASCII, мы можем использовать команду file :
$ file foo
foo: ASCII text, with no line terminatorsНаконец, чтобы получить точное количество байтов, которое занимает файл, мы используем команду stat :
$ stat -f%z foo
12 Поскольку стандарт Unicode имеет дело с гораздо большим диапазоном символов, файл Unicode, естественно, занимает больше места для хранения. Сколько именно зависит от кодировки.
Сколько именно зависит от кодировки.
Повторение того же набора команд, что и ранее, с использованием символа, который не может быть представлен в ASCII, дает следующее:
$ echo -n '€' > foo
$ file foo
foo: UTF-8 Unicode text, with no line terminators
$ stat -f%z foo
3Этот единственный символ занимает 3 байта в файле Unicode. Обратите внимание, что bash автоматически создал файл UTF-8, поскольку файл ASCII не может хранить выбранный символ (€). UTF-8 на сегодняшний день является наиболее распространенной кодировкой символов для Unicode; UTF-16 и UTF-32 – две альтернативные кодировки, но они используются гораздо реже.
UTF-8 – это кодировка переменной ширины, что означает, что он использует разный объем памяти для разных кодовых точек. Каждая кодовая точка будет занимать от одного до четырех байтов с намерением, чтобы более общие символы занимали меньше места, обеспечивая тип встроенного сжатия. Недостатком является то, что определение требований к длине или размеру данного фрагмента текста становится намного более сложным.
ASCII – это Unicode, но Unicode – это не ASCII
Для обратной совместимости первые 128 кодовых точек Unicode представляют собой эквивалентные символы ASCII. Поскольку UTF-8 кодирует каждый из этих символов одним байтом, любой текст ASCII также является текстом UTF-8. Юникод – это надмножество ASCII.
Однако, как показано выше, многие файлы Unicode нельзя использовать в контексте ASCII. Любой символ, который находится за пределами поля, будет отображаться неожиданным образом, часто с замененными символами, которые полностью отличаются от тех, которые были предназначены.
Современное использование
Для большинства целей ASCII в значительной степени считается устаревшим стандартом. Даже в тех случаях, когда поддерживается только латинский алфавит – например, когда полная поддержка сложностей Unicode не требуется – обычно удобнее использовать UTF-8 и воспользоваться преимуществами его совместимости с ASCII.
В частности, веб-страницы следует сохранять и передавать с использованием UTF-8, который используется по умолчанию для HTML5. Это отличается от более ранней сети, которая по умолчанию использовала ASCII, прежде чем она была заменена на Latin 1.
Это отличается от более ранней сети, которая по умолчанию использовала ASCII, прежде чем она была заменена на Latin 1.
Стандарт, который меняется
Последняя ревизия ASCII состоялась в 1986 году.
В отличие от этого, Unicode продолжает обновляться ежегодно. Регулярно добавляются новые сценарии, персонажи и особенно новые смайлы. При выделении лишь небольшой части из них полный набор символов, вероятно, будет расти и развиваться в обозримом будущем.
Связанный: Объяснение 100 самых популярных эмодзи
ASCII против Unicode
ASCII служил своей цели в течение многих десятилетий, но теперь Unicode фактически заменил его для всех практических целей, кроме устаревших систем. Юникод крупнее и, следовательно, выразительнее. Он представляет собой глобальные совместные усилия и предлагает гораздо большую гибкость, хотя и за счет некоторой сложности.
СвязанныйИсчерпывающее руководство по Юникоду и кодировке символов в Python
Работа с кодировкой символов на Python, да и на любом другом языке, временами выглядит довольно сложной. На Stack Overflow можно найти тысячи вопросов, посвящённых таким исключениям, как
На Stack Overflow можно найти тысячи вопросов, посвящённых таким исключениям, как UnicodeEncodeError. Данное руководство призвано прояснить сложные аспекты работы с этими исключениями и продемонстрировать, что работа с текстовыми и двоичными данными на Python 3 может быть приятной. В Python хорошо реализована поддержка Юникода, однако для работы с кодировкой всё же потребуется приложить усилия.
Вводная часть статьи даст общее понимание работы с Юникодом, не привязанное к какому-то определённому языку, однако практические примеры будут приведены именно на Python, а их описание будет довольно лаконичным.
Изучив эту статью, вы:
- Освоите концепции кодировки символов и системы нумерации;
- Поймёте, как кодировка работает с объектами
strиbytes; - Узнаете, как в Python поддерживается система нумерации посредством различных форм литералов
int; - Познакомитесь со встроенными функциями языка, относящимися к кодировке и системе нумерации.
Система нумерации и кодировка символов настолько тесно связаны, что их придётся раскрыть в одном руководстве, в противном случае материал будет неполным.
Прим. Статья ориентирована на Python 3, а все примеры кода созданы с помощью оболочки CPython 3.7.2. Большая часть более ранних версий Python 3 также будут корректно обрабатывать код. Если вы всё ещё используете Python 2 и различия в обработке текста и бинарных данных между 2 и 3 версиями языка вас отпугивают, это руководство может помочь вам преодолеть барьер.
Что такое кодировка символов?
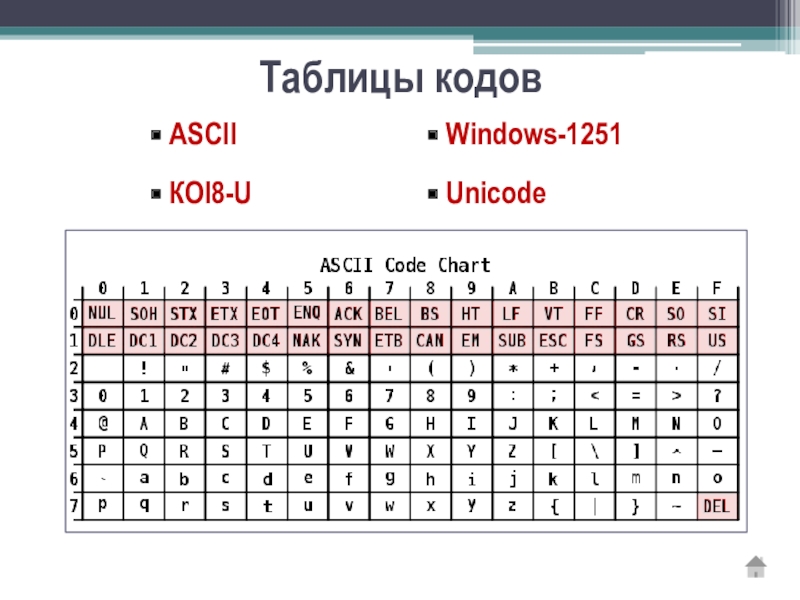
Существуют десятки, если не сотни, кодировок символов. Понять эту концепцию легче всего, разобрав одну из самых простых, ASCII.
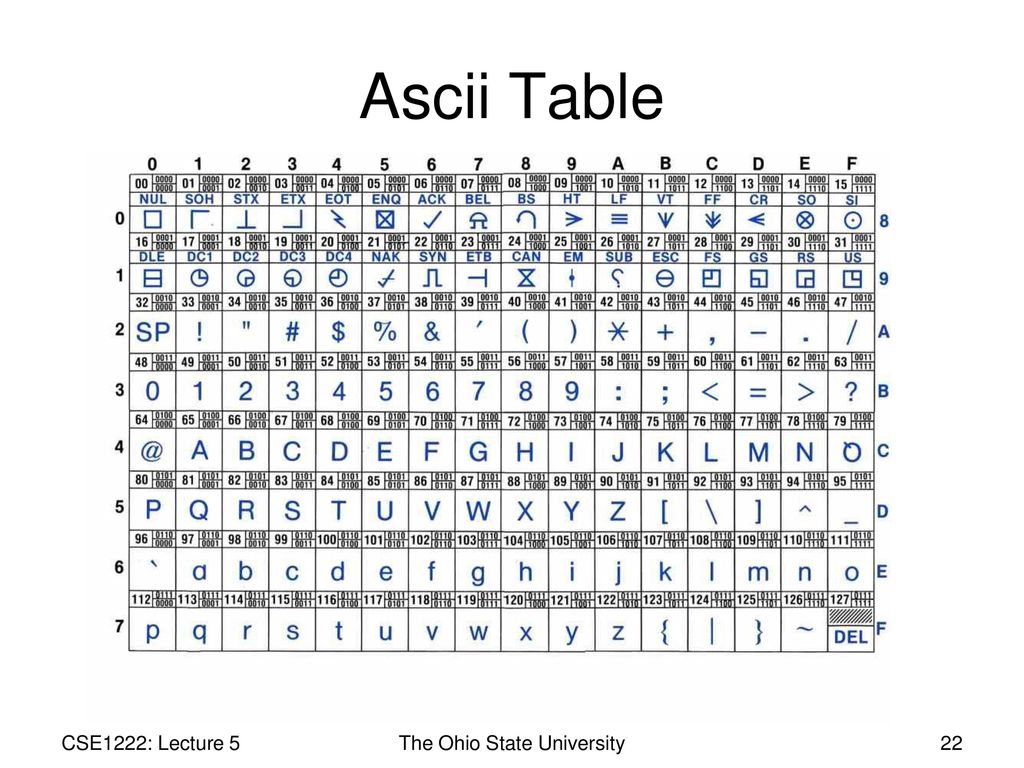
Независимо от того, занимаетесь вы самообразованием или получили более формальное образование в сфере IT , наверняка пару раз вы уже видели таблицу ASCII. Эта таблица — хорошее начало для изучения принципов кодировки, так как она простая и маленькая (как вы увидите дальше, даже слишком маленькая).
Она охватывает следующее:
- Символы английского алфавита в нижнем регистре: от a до z;
- Символы английского алфавита в верхнем регистре: от A до Z;
- Некоторые знаки препинания и символы: например «$» или «!»;
- Символы, отображаемые как пустое место: пробел (« »), символ новой строки, возврата каретки, горизонтальной и вертикальной табуляции и несколько других;
- Некоторые непечатаемые символы: такие как бекспейс, «\b», которые просто невозможно отобразить, так, как к примеру, букву А.
Приведём формальное определение кодировки символов.
На самом высоком уровне — это способ перевода символов (таких как буквы, знаки пунктуации, служебные знаки, пробелы и контрольные символы) в целые числа и затем непосредственно в биты. Каждый символ может быть закодирован уникальным двоичным кодом. Если вы плохо знакомы с концепцией битов, не волнуйтесь, мы вскоре о ней поговорим.
Группы символов выделяют в отдельные категории. Каждому символу соответствует кодовая точка, которую можно рассматривать просто как целое число.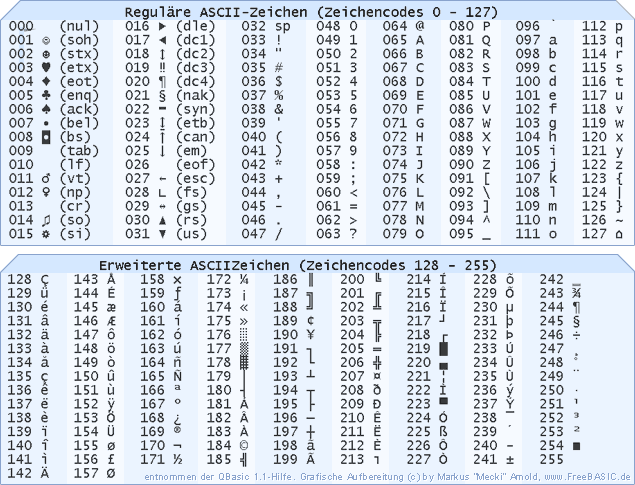 В таблице ASCII символы сегментированы следующим образом:
В таблице ASCII символы сегментированы следующим образом:
| Диапазон кодовых точек | Класс |
|---|---|
| от 0 до 31 | Контрольные и неотображаемые символы |
| от 32 до 64 | Знаки пунктуации, символы, числа и пробел |
| от 65 до 90 | Буквы английского алфавита в верхнем регистре |
| от 91 до 96 | Дополнительные графемы, такие как [ и \ |
| от 97 до 122 | Буквы английского алфавита в нижнем регистре |
| от 123 до 126 | Дополнительные графемы, такие как { и | |
| 127 | Контрольный неотображаемый символ (DEL) |
Всего кодировка ASCII содержит 128 символов. В таблице ниже вы видите исчерпывающий набор знаков, которые позволяет отобразить эта кодировка. Если вы не видите какого-то символа, значит вы просто не сможете его вывести с помощью ASCII.
| Кодовая точка | Символ (имя) | Кодовая точка | Символ (имя) |
|---|---|---|---|
| 0 | NUL (Null) | 64 | @ |
| 1 | SOH (Start of Heading) | 65 | A |
| 2 | STX (Start of Text) | 66 | B |
| 3 | ETX (End of Text) | 67 | C |
| 4 | EOT (End of Transmission) | 68 | D |
| 5 | ENQ (Enquiry) | 69 | E |
| 6 | ACK (Acknowledgment) | 70 | F |
| 7 | BEL (Bell) | 71 | G |
| 8 | BS (Backspace) | 72 | H |
| 9 | HT (Horizontal Tab) | 73 | I |
| 10 | LF (Line Feed) | 74 | J |
| 11 | VT (Vertical Tab) | 75 | K |
| 12 | FF (Form Feed) | 76 | L |
| 13 | CR (Carriage Return) | 77 | M |
| 14 | SO (Shift Out) | 78 | N |
| 15 | SI (Shift In) | 79 | O |
| 16 | DLE (Data Link Escape) | 80 | P |
| 17 | DC1 (Device Control 1) | 81 | Q |
| 18 | DC2 (Device Control 2) | 82 | R |
| 19 | DC3 (Device Control 3) | 83 | S |
| 20 | DC4 (Device Control 4) | 84 | T |
| 21 | NAK (Negative Acknowledgment) | 85 | U |
| 22 | SYN (Synchronous Idle) | 86 | V |
| 23 | ETB (End of Transmission Block) | 87 | W |
| 24 | CAN (Cancel) | 88 | X |
| 25 | EM (End of Medium) | 89 | Y |
| 26 | SUB (Substitute) | 90 | Z |
| 27 | ESC (Escape) | 91 | [ |
| 28 | FS (File Separator) | 92 | \ |
| 29 | GS (Group Separator) | 93 | ] |
| 30 | RS (Record Separator) | 94 | ^ |
| 31 | US (Unit Separator) | 95 | _ |
| 32 | SP (Space) | 96 | ` |
| 33 | ! | 97 | a |
| 34 | " | 98 | b |
| 35 | # | 99 | c |
| 36 | $ | 100 | d |
| 37 | % | 101 | e |
| 38 | & | 102 | f |
| 39 | ' | 103 | g |
| 40 | ( | 104 | h |
| 41 | ) | 105 | i |
| 42 | * | 106 | j |
| 43 | + | 107 | k |
| 44 | , | 108 | l |
| 45 | - | 109 | m |
| 46 | . | 110 | n |
| 47 | / | 111 | o |
| 48 | 0 | 112 | p |
| 49 | 1 | 113 | q |
| 50 | 2 | 114 | r |
| 51 | 3 | 115 | s |
| 52 | 4 | 116 | t |
| 53 | 5 | 117 | u |
| 54 | 6 | 118 | v |
| 55 | 7 | 119 | w |
| 56 | 8 | 120 | x |
| 57 | 9 | 121 | y |
| 58 | : | 122 | z |
| 59 | ; | 123 | { |
| 60 | < | 124 | | |
| 61 | = | 125 | } |
| 62 | > | 126 | ~ |
| 63 | ? | 127 | DEL (delete) |

Модуль string
Модуль string — простой и удобный инструмент, разграничивающий содержащиеся в ASCII символы по группам, разделяя их в строки-константы. _`{|}~»»»
printable = digits + ascii_letters + punctuation + whitespace
_`{|}~»»»
printable = digits + ascii_letters + punctuation + whitespace
Большинство этих констант исчерпывающе описаны их идентификаторами. Мы вкратце коснёмся констант hexdigits и octdigits.
Мы можем использовать определённые в модуле константы для рутинных операций:
>>> import string
>>> s = "What's wrong with ASCII?!?!?"
>>> s.rstrip(string.punctuation)
'What's wrong with ASCII'Прим. Обратите внимание, string.printable включает string.whitespace. Это несколько не соответствует тому, как печатаемые символы определяет метод str.isprintable(), который не рассматривает ни один из символов {'\v', '\n', '\r', '\f', '\t'} как печатаемый.
Это различие происходит из определения метода: str.isprintable() рассматривает что-либо печатаемым, если «все символы рассматриваются как печатаемые методом repr().
Что такое биты
Настало время вспомнить, что такое бит, базовая единица информации, которой оперируют вычислительные устройства.
Бит — это сигнал, который имеет два возможных состояния. Есть различные способы символического отображения этих состояний:
- 0 или 1;
- «да» или «нет»;
TrueилиFalse;- «включено» или «выключено».
Таблица ASCII из предыдущего раздела использует то, что обычно назвали бы числами (от 0 до 127), однако для наших целей важно понимать, что это десятичные числа (с основанием 10).
Каждое из этих десятичных чисел можно выразить последовательностью бит (числом с основанием 2). Вот таблица соотношения двоичных и десятичных чисел:
| Десятичное | Двоичное (кратко) | Двоичное (в байте) |
|---|---|---|
| 0 | 0 | 00000000 |
| 1 | 1 | 00000001 |
| 2 | 10 | 00000010 |
| 3 | 11 | 00000011 |
| 4 | 100 | 00000100 |
| 5 | 101 | 00000101 |
| 6 | 110 | 00000110 |
| 7 | 111 | 00000111 |
| 8 | 1000 | 00001000 |
| 9 | 1001 | 00001001 |
| 10 | 1010 | 00001010 |
Обратите внимание, что при увеличении десятичного числа n для его отображения (а следовательно и для отображения символа, относящегося к этому числу) требуется всё больше значимых бит.
Вот удобный метод представить строки ASCII как последовательность бит. Каждый символ из строки ASCII переводится в последовательность из 8 нолей и единиц с пробелами между этими последовательностями:
>>> def make_bitseq(s: str) -> str:
... if not s.isascii():
... raise ValueError("ASCII only allowed")
... return " ".join(f"{ord(i):08b}" for i in s)
>>> make_bitseq("bits")
'01100010 01101001 01110100 01110011'
>>> make_bitseq("CAPS")
'01000011 01000001 01010000 01010011'
>>> make_bitseq("$25.43")
'00100100 00110010 00110101 00101110 00110100 00110011'
>>> make_bitseq("~5")
'01111110 00110101'Прим. Обратите внимание, что метод .isascii() появился в Python 3.7.
Строковой литерал f-string f"{ord(i):08b}" использует мини-язык форматирования Format Specification Mini-Language, а именно его возможность замещения полей при форматировании строк.
- левая часть выражения,
ord(i), представляет объект, значение которого будет отформатировано и отображено при выводе.ord()возвращает кодовую точку одиночного символаstrв десятичном выражении; - Правая сторона выражения определяет форматирование объекта.
08означает ширина 8, заполнение нулями, аbработает как команда вывести число в двоичном (binary) эквиваленте.
На самом деле этот метод можно использовать разве что для развлечения. Он выдаст ошибку для любого символа, не представленного в ASCII-таблице. Позже мы рассмотрим, как эта проблема решается в других кодировках.
Нам нужно больше бит
Исходя из определения бита, можно вывести следующую закономерность: при определённом количестве бит n с их помощью можно выразить 2n разных значений.
def n_possible_values(nbits: int) -> int:
return 2 ** nbitsВот что это означает:
- 1 бит позволяет выразить 21 == 2 возможных значения;
- 8 бит позволяют выразить 28 == 256 возможных значений;
- 64 бита позволяют выразить 264 == 18 446 744 073 709 551 616 возможных значений.
В качестве естественного вывода из приведённой выше формулы мы можем установить следующее: для того, чтобы вычислить количество бит, необходимых для выражения определённого числа разных значений, нам нужно найти n в уравнении 2n=x, где переменная x известна.
Вот как можно это рассчитать:
>>> from math import ceil, log
>>> def n_bits_required(nvalues: int) -> int:
... return ceil(log(nvalues) / log(2))
>>> n_bits_required(256)
8Округление вверх в методе n_bits_required() требуется для расчёта значений, которые не являются чистой степенью двойки. К примеру, вам нужно сохранить набор из 110 различных символов. Для этого потребуется log(110) / log(2) == 6.781 бит, но поскольку бит для вычислительной техники является мельчайшей неделимой величиной, для отображения 110 различных значений нам понадобится 7 бит, при этом несколько значений останутся невостребованными.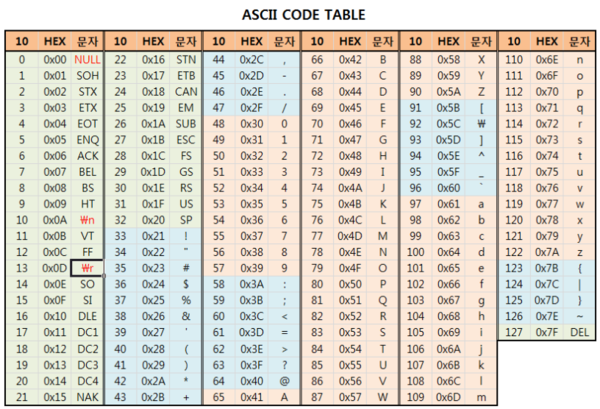
>>> n_bits_required(110)
7Всё сказанное служит для обоснования одной идеи: ASCII, строго говоря, семибитная кодировка. Эта таблица содержит 128 кодовых точек, и, соответственно, символов, от 0 до 127 включительно. Это требует 7 бит:
>>> n_bits_required(128) # от 0 до 127
7
>>> n_possible_values(7)
128Проблема заключается в том, что современные компьютеры не используют для хранения чего-либо семибитные последовательности. Основной единицей хранения информации современных вычислительных устройств являются восьмибитные последовательности, байты.
Прим. В этой статье под байтом подразумевается группа из 8 бит, как повелось с 60-х годов прошлого века. Если вам не по душе это новомодное название, можете называть их октетами.
То, что ASCII-таблица использует 7 бит из доступных 8, означает, что память вычислительного устройства, занятого строками символов ASCII, наполовину пуста. Для того, чтобы лучше понять, почему это происходит, вернитесь к приведённой выше таблице соответствия двоичных и десятичных чисел. Вы можете выразить числа 0 и 1 с помощью 1 бита, или вы можете использовать 8 бит, чтобы выразить их как 00000000 и 00000001 соответственно.
Для того, чтобы лучше понять, почему это происходит, вернитесь к приведённой выше таблице соответствия двоичных и десятичных чисел. Вы можете выразить числа 0 и 1 с помощью 1 бита, или вы можете использовать 8 бит, чтобы выразить их как 00000000 и 00000001 соответственно.
Прим. перев. Если быть точным, то пустой остаётся только одна восьмая часть памяти. Однако с помощью именно этого незадействованного бита можно было бы создать вдвое больше кодовых точек.
Вы можете выразить числа от 0 до 3 всего двумя битами, от 00 до 11, или использовать 8 бит, чтобы выразить их как 00000000, 00000001, 00000010 и 00000011. Самая большая кодовая точка ASCII, 127, требует только 7 значимых бит.
С учётом этого взгляните, как метод make_bitseq() преобразует строки ASCII в строки, состоящие из байт, где каждый символ требует один байт:
>>> make_bitseq("bits")
'01100010 01101001 01110100 01110011'Неэффективное использование восьмибитной структуры памяти современных вычислительных устройств привело к появлению неструктурированного семейства конфликтующих кодировок, задействующих оставшуюся незанятой половину кодовых точек, доступных в одном байте.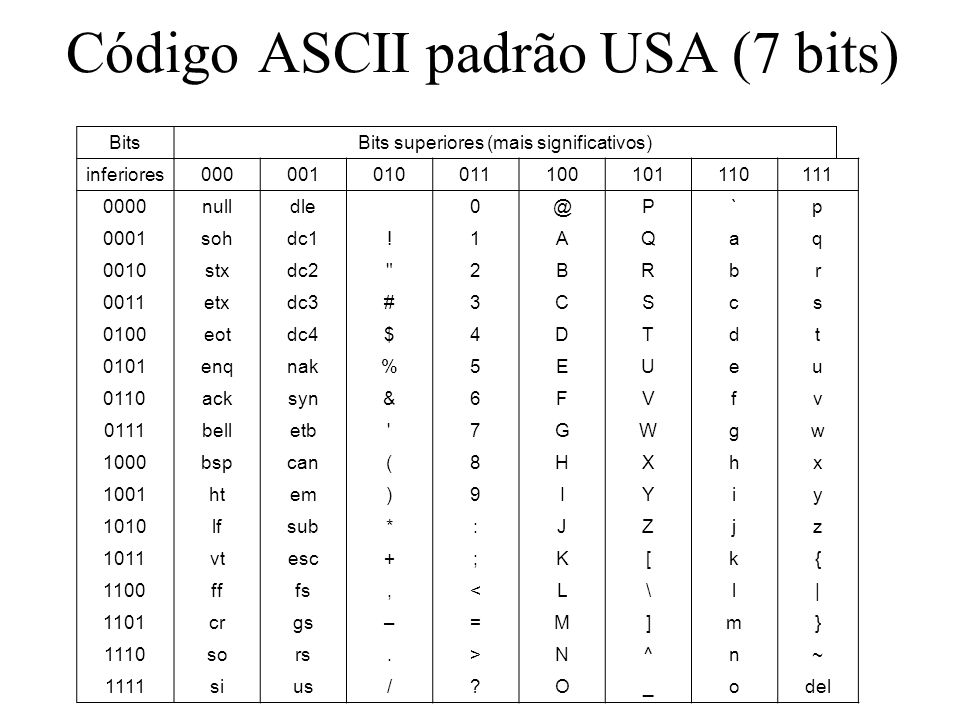
Несмотря на попытку задействовать дополнительный бит, эти конфликтующие кодировки не могли отобразить все возможные символы, используемые человечеством в письменности.
Со временем появилась одна большая схема кодировки, которая объединила их. Однако, прежде чем мы до этого доберёмся, поговорим немного о краеугольных камнях схем кодировки символов — системах счисления.
Изучаем основы: другие системы счисления
В ASCII-таблице, как мы увидели, каждый символ соответствует числу от 0 до 127.
Этот диапазон чисел выражен в десятичной системе счисления. Именно эту систему используют для счёта люди, просто потому что на руках у нас по 10 пальцев.
Однако существуют и другие системы счисления, которые, в частности, широко используются в исходном коде CPython. Следует понимать, что действительное число не изменяется, а системы счисления просто по-разному его выражают.
Вопрос, какое число записано в строке "11" покажется странным, ведь для большинства очевидно, что это одиннадцать.
Однако в строке может быть представлено и другое число, в зависимости от системы счисления. Помимо десятичной, используются такие общепринятые альтернативы:
- Двоичная: с основой 2;
- Восьмеричная: с основой 8;
- Шестнадцатеричная (hex): с основой 16.
Что же мы подразумеваем, говоря что определённая система счисления имеет основу N?
Один из способов объяснения разных систем счисления заключается в том, чтобы представить, что у вас N пальцев.
Если же вам требуется более подробное объяснение систем счисления, обратитесь к книге Чарльза Петцольда «Код». В этой книге детально объясняются основы работы вычислительной техники.
Конструктор int() — один из способов показать, как разные системы счисления преобразуют одну и ту же строку с помощью Python. Если вы передадите str в int(), Python по умолчанию будет считать, что строка содержит число в десятичной системе. Однако вы можете дать другие указания:
>>> int('11')
11
>>> int('11', base=10) # 10 установлено по умолчанию
11
>>> int('11', base=2) # Двоичная
3
>>> int('11', base=8) # Восьмеричная
9
>>> int('11', base=16) # Шестнадцатеричная
17Чаще в Python для обозначения того, что целое число представлено в системе счисления, отличной от десятичной, используют префиксы-литералы. Для каждой из трёх альтернативных систем существует свой литерал.
| Тип литерала | Префикс | Пример |
|---|---|---|
| Нет | Нет | 11 |
| Binary literal | 0b или 0B | 0b11 |
| Octal literal | 0o или 0O | 0o11 |
| Hex literal | 0x или 0X | 0x11 |
Всё это — разновидности целочисленных литералов. Результаты применения префиксов будут такими же, как и в случае использования int() с определением параметра base. Для Python всё это просто целые числа:
>>> 11
11
>>> 0b11 # Двоичный литерал
3
>>> 0o11 # Восьмеричный литерал
9
>>> 0x11 # Шестнадцатеричный литерал
17В таблице ниже отражено, как можно ввести десятичные числа от 0 до 20 в двоичном, восьмеричном и шестнадцатеричном эквиваленте. Любой из этих способов можно использовать как в оболочке интерпретатора Python, так и в исходном коде, и все эти числа будут рассматриваться как относящиеся к типу int.
| Десятичные | Двоичные | Восмеричные | Шестнадцатеричные |
|---|---|---|---|
0 | 0b0 | 0o0 | 0x0 |
1 | 0b1 | 0o1 | 0x1 |
2 | 0b10 | 0o2 | 0x2 |
3 | 0b11 | 0o3 | 0x3 |
4 | 0b100 | 0o4 | 0x4 |
5 | 0b101 | 0o5 | 0x5 |
6 | 0b110 | 0o6 | 0x6 |
7 | 0b111 | 0o7 | 0x7 |
8 | 0b1000 | 0o10 | 0x8 |
9 | 0b1001 | 0o11 | 0x9 |
10 | 0b1010 | 0o12 | 0xa |
11 | 0b1011 | 0o13 | 0xb |
12 | 0b1100 | 0o14 | 0xc |
13 | 0b1101 | 0o15 | 0xd |
14 | 0b1110 | 0o16 | 0xe |
15 | 0b1111 | 0o17 | 0xf |
16 | 0b10000 | 0o20 | 0x10 |
17 | 0b10001 | 0o21 | 0x11 |
18 | 0b10010 | 0o22 | 0x12 |
19 | 0b10011 | 0o23 | 0x13 |
20 | 0b10100 | 0o24 | 0x14 |
Кстати, вы можете сами убедиться, что подобные способы записи чисел очень часто используется в Стандартной Библиотеке Python. Найдите папку lib/python3.7/ в своей системе, перейдите в неё и введите команду:
$ grep -nri --include "*\.py" -e "\b0x" lib/python3.7Команда сработает в любой Unix-системе с утилитой grep. С её помощью вы найдёте все шестнадцатеричные литералы. Для поиска двоичных используйте \b0b, а для восьмеричных — \b0o.
Для чего же нужны альтернативные литералы целых чисел? Если коротко, числа 2, 8 и 16, в отличие от 10, являются степенями двойки. Основанные на них системы счисления выражают численные значения способами, более удобными для обработки бинарными вычислительными устройствами. К примеру, 65536, или 216, в шестнадцатеричной системе просто 10000 или, используя литерал, 0x10000.
Введение в Юникод
Как видите, проблема ASCII в том, что этой таблицы недостаточно для отображения знаков, символов и глифов, использующихся во всех языках и диалектах мира. Её недостаточно даже для английского языка.
Юникод служит тем же целям, что и ASCII, но содержит намного больший набор кодовых точек. В период времени между появлением ASCII и принятием Юникода использовалось ещё несколько различных кодировок, но рассматривать их подробно нет смысла, так как Юникод и одна из его схем, UTF-8, в настоящее время стали использоваться практически повсеместно.
Вы можете представить Юникод как расширенную версию ASCII-таблицы — с 1 114 112 возможными кодовыми точками, от 0 до 1 114 111. Это 17*(216) или 0x10ffff в шестнадцатеричном представлении. Фактически, ASCII является частью Юникода, так как первые 128 символов этих кодировок полностью совпадают.
Чтобы соблюсти технические детали, сам по себе Юникод не является кодировкой. Он скорее реализуется в различных кодировках символов, как вы вскоре увидите. По структуре Юникод скорее ассоциативный массив (что-то вроде dict) или база данных, состоящая из таблицы с двумя колонками. В этой таблице разные символы (такие как "a", "¢", или даже "ቈ") соотносятся с различными целыми положительными числами. Кодировка же должна предоставлять несколько больше возможностей.
Юникод содержит практически любой символ, который только можно представить, включая дополнительные непечатаемые. Например, кодовая точка 8207 соответствует отметке RTL, которая используется для смены направления письма. Она полезна в текстах, где абзацы на одном из европейских языков соседствуют с абзацами на арабских языках.
Прим. Кстати, если уж мы хотим быть совсем точны в деталях, то надо отметить ещё один факт. Исторически сложилось, что в Юникоде доступны только 1 111 998 кодовых точек.
Юникод и UTF-8
Довольно скоро стало понятно, что все необходимые символы невозможно вместить в таблицу, используя только один байт. Современные, более ёмкие кодировки требовали использования больших объёмов.
Ранее мы упоминали, что Юникод сам по себе не является кодировкой. И вот почему.
Юникод не содержит указаний по извлечению из текста бит, он работает только с кодовыми точками. В нём нет стандарта конверсии текста в двоичные данные и обратно.
Юникод является абстрактным стандартом кодировки. Для практического его применения чаще всего используют схему UTF-8. Стандарт Юникод (таблица соответствий символов кодовыми точкам) определяет несколько различных кодировок на основе единого набора символов.
Как и менее распространённые UTF-16 и UTF-32, UTF-8 — формат кодировки для отображения символов Юникода в двоичном виде, используя один или несколько байт на один символ. UTF-16 и UTF-32 мы обсудим чуть позже, но пока нам интересен UTF-8 как самый популярный формат.
Сначала требуется разобрать термины «кодирование» и «декодирование».
Кодирование и декодирование в Python 3
Тип данных str в Python 3 рассчитан на представление текста в удобном для чтения формате и может содержать любые символы Юникода.
Тип bytes, напротив, представляет двоичные данные, последовательность байт, без указания на кодировку.
Кодирование и декодирование — это процесс перехода данных из одной формы в другую.
В методах .encode() и .decode() по умолчанию используется параметр "utf-8", однако для большей уверенности этот параметр можно определить самостоятельно:
>>> "résumé".encode("utf-8")
b'r\xc3\xa9sum\xc3\xa9'
>>> "El Niño".encode("utf-8")
b'El Ni\xc3\xb1o'
>>> b"r\xc3\xa9sum\xc3\xa9".decode("utf-8")
'résumé'
>>> b"El Ni\xc3\xb1o".decode("utf-8")
'El Niño'str.encode() возвращает объект типа bytes. И литералы этого типа объектов (такие как b"r\xc3\xa9sum\xc3\xa9"), и его отображение допускают только символы ASCII.
Вот почему при вызове "El Niño".encode("utf-8"), ASCII-совместимое "El" отображается как есть, а n с тильдой экранируется в "\xc3\xb1". Этой с виду неудобочитаемой последовательностью представлены два байта, 0xc3 и 0xb1 в шестнадцатеричной системе:
>>> " ".join(f"{i:08b}" for i in (0xc3, 0xb1))
'11000011 10110001'Таким образом символ ñ требует два байта для бинарного представления с помощью UTF-8.
Прим. Если вы введёте help(str.encode), скорее всего, увидите параметр по умолчанию encoding='utf-8'. Однако имейте в виду, что настройки Windows для Python 3.6 могут отличаться, поэтому использовать методы кодирования и декодирования без указания необходимой кодировки (например "résumé".encode()) следует с осторожностью.
Python 3: всё на Юникоде
Python 3 полностью реализован на Юникоде, а точнее на UTF-8. Вот что это означает:
- По умолчанию предполагается, что исходный код Python 3 написан с помощью UTF-8. Это значит, что вам не нужно использовать определение
# -*- coding: UTF-8 -*-в начале файлов.pyв этой версии языка. - Все тексты (объекты формата
str) реализованы на Юникоде. Кодированный текст представлен двоичными данными (bytes). Типstrможет содержать любой символ-литерал из Юникода (например"Δv / Δt"), и все они хранятся в Юникоде. - Любой из символов Юникода приемлем в качестве идентификатора. Например, вы можете использовать выражение
résumé = "~/Documents/resume.pdf". - В модуле
reпо умолчанию установлен флагre.UNICODE, а неre.ASCII. Это означает, чтоr"\w"соответствует буквам из Юникода, а не просто символам ASCII. - По умолчанию
encodingвstr.encode()вbytes.decode()установлен в UTF-8.
Нужно отметить также нюанс, касающийся встроенного метода open(). Его параметр encoding зависит от платформы и определяется значением locale.getpreferredencoding():
>>> # Mac OS X High Sierra
>>> import locale
>>> locale.getpreferredencoding()
'UTF-8'
>>> # Windows Server 2012; другие сборки Windows могут использовать UTF-16
>>> import locale
>>> locale.getpreferredencoding()
'cp1252'Мы делаем упор на эти моменты, чтобы вы вдруг не подумали, что кодировка UTF-8 является универсальной. Она действительно широко распространена, но вы вполне можете столкнуться и с другими вариантами. Не будет лишним предусмотреть это в коде.
Один байт, два байта, три байта, четыре…
Одна из важнейших особенностей UTF-8 состоит в том, что это кодировка с переменным размером.
Вспомните раздел, посвящённый ASCII. Любой символ в этой таблице требует максимум одного байта пространства. Это можно быстро проверить с помощью следующего генератора:
>>> all(len(chr(i).encode("ascii")) == 1 for i in range(128))
TrueС UTF-8 дела обстоят по-другому. Символы Юникода могут занимать от одного до четырёх байт. Вот пример четырёхбайтного символа:
>>> ibrow = "🤨"
>>> len(ibrow)
1
>>> ibrow.encode("utf-8")
b'\xf0\x9f\xa4\xa8'
>>> len(ibrow.encode("utf-8"))
4
>>> # Вызов list() с объектом типа bytes возвращает
>>> # значение каждого байта
>>> list(b'\xf0\x9f\xa4\xa8')
[240, 159, 164, 168]Это небольшая, но важная особенность метода len():
- Размер единичного символа Юникода в объекте
strязыка Python всегда будет равен 1, вне зависимости от количества занимаемых байт. - Длина того же символа в объекте типа
bytesбудет варьироваться от 1 до 4.
Таблица ниже показывает, сколько байт занимают основные типы символов.
| Десятичный диапазон | Шестнадцатеричный диапазон | Включённые символы | Примеры |
|---|---|---|---|
| от 0 до 127 | от "\u0000" до "\u007F" | U.S. ASCII | "A", "\n", "7", "&" |
| от 128 до 2047 | от "\u0080" до "\u07FF" | Большая часть латинских алфавитов* | "ę", "±", "ƌ", "ñ" |
| от 2048 до 65535 | от "\u0800" до "\uFFFF" | Дополнительные части многоязыковых символов (BMP)** | "ത", "ᄇ", "ᮈ", "‰" |
| от 65536 до 1114111 | от "\U00010000" до "\U0010FFFF" | Другое*** | "𝕂", "𐀀", "😓", "🂲", |
*Такие как английский, арабский, греческий, ирландский.
**Масса языков и символов, в основном китайский, японский и корейский с разделением по томам (а также ASCII и латиница).
***Дополнительные символы китайского, японского, корейского и вьетнамского, а также другие символы и эмоджи.
Прим. У UTF-8 есть и другие технические особенности. Те, кто работает на Python, редко с ними сталкиваются, поэтому мы не будем раскрывать их в этой статье, но упомянем вкратце, чтобы сохранить полноту картины. Так, UTF-8 использует коды-префиксы, указывающие на количество байт в последовательности. Такой приём позволяет декодеру группировать байты в условиях кодировки с переменным размером. Количество байт в последовательности определяется первым её байтом. Другие технические подробности можно найти на странице Википедии, посвящённой UTF-8 или на официальном сайте.
Особенности UTF-16 и UTF-32
Рассмотрим альтернативные кодировки, UTF-16 и UTF-32. Различие между ними и UTF-8 в основном практическое. Продемонстрируем величину расхождения с помощью перевода туда и обратно:
>>> letters = "αβγδ"
>>> rawdata = letters.encode("utf-8")
>>> rawdata.decode("utf-8")
'αβγδ'
>>> rawdata.decode("utf-16") # 😧
'뇎닎돎듎'В данном случае, когда мы кодируем четыре буквы греческого алфавита в двоичные данные с помощью UTF-8, а декодируем обратно в текст с использованием UTF-16, на выходе получается строка с совершенно другими символами (из корейского алфавита).
Так происходит, если для кодирования и декодирования применяют разные кодировки. Два варианта декодирования одного бинарного объекта могут вернуть текст даже на другом языке.
Таблица ниже демонстрирует количество байт, используемых в разных кодировках:
| Кодировка | Байт на символ (включительно) | Варьируемая длина |
|---|---|---|
| UTF-8 | От 1 до 4 | Да |
| UTF-16 | От 2 до 4 | Да |
| UTF-32 | 4 | Нет |
Любопытный аспект семейства UTF: UTF-8 не всегда занимает меньше памяти, чем UTF-16. Хотя с точки зрения математики это выглядит маловероятным, однако это возможно:
>>> text = "記者 鄭啟源 羅智堅"
>>> len(text.encode("utf-8"))
26
>>> len(text.encode("utf-16"))
22Так получается из-за того, что кодовые точки в диапазоне от U+0800 до U+FFFF (от 2048 до 65535 в десятичной системе) в кодировке UTF-8 занимают три байта, а в UTF-16 только два.
Это не означает, что нужно работать с UTF-16, независимо от того, насколько часто вы работаете с символами в этом диапазоне. Один из самых важных поводов придерживаться UTF-8 — в мире кодировок лучше держаться вместе с большинством.
Кроме того, в 2019 году компьютерная память стоит дёшево, и экономия четырёх байт за счёт использования нестандартной кодировки вряд ли стоит усилий.
Прим. перев. Есть и более весомые причины использовать UTF-8. Среди них её обратная совместимость с ASCII, а также то, что это самосинхронизирующаяся кодировка.
Python и встроенные функции
Вы освоили самую сложную часть статьи. Теперь посмотрим, как всё изученное реализуется на Python.
В Python есть несколько встроенных функций, каким-либо образом относящихся к системам счисления и кодировке:
Логически их можно сгруппировать по назначению.
ascii(),bin(),hex()иoct()предназначены для различного представления вводных данных. Все они возвращаютstr. Первая,ascii(), производит представление объекта в ASCII, экранируя не входящие в эту таблицу символы. Оставшиеся три дают соответственно двоичное, шестнадцатеричное и восьмеричное представление целого числа. Все эти функции меняют только представление объекта, не изменяя непосредственно вводные данные.bytes(),str()иint()— конструкторы классов соответствующих типов:bytes,str, иint. Все они предлагают способы подогнать данные под желаемый тип.ord()иchr()выполняют противоположные действия.ord()конвертирует символ в десятичную кодовую точку, аchr()принимает в качестве аргумента целое число, и возвращает символ, кодовой точкой которого это число является.
В таблице ниже эти функции разобраны более подробно:
| Функция | Форма | Тип аргументов | Тип возвращаемых данных | Назначение |
|---|---|---|---|---|
ascii() | ascii(obj) | Различный | str | Представление объекта символами ASCII. Не входящие в таблицу символы экранируются |
bin() | bin(number) | number: int | str | Бинарное представление целого чиста с префиксом "0b" |
bytes() | bytes(последовательность_целых_чисел)
| Различный | bytes | Приводит аргумент к двоичным данным, типу bytes |
chr() | chr(i) | i: int
| str | Преобразует кодовую точку (целочисленное значение) в символ Юникода |
hex() | hex(number) | number: int | str | Шестнадцатеричное представление целого числа с префиксом "0x" |
int() | int([x])
| Различный | int | Приводит аргумент к типу int |
oct() | oct(number) | number: int | str | Восьмеричное представление целого числа с префиксом "0o" |
ord() | ord(c) | c: str
| int | Возвращает значение кодовой точки символа Юникода |
str() | str(object=’‘)
| Различный | str | Приводит аргумент к текстовому представлению, типу str |
Дальше можно посмотреть полезные примеры использования этих функций.
ascii():
>>> ascii("abcdefg")
"'abcdefg'"
>>> ascii("jalepeño")
"'jalepe\\xf1o'"
>>> ascii((1, 2, 3))
'(1, 2, 3)'
>>> ascii(0xc0ffee) # Шестнадцатеричный литерал (int)
'12648430'bin():
>>> bin(0)
'0b0'
>>> bin(400)
'0b110010000'
>>> bin(0xc0ffee) # Шестнадцатеричный литерал (int)
'0b110000001111111111101110'
>>> [bin(i) for i in [1, 2, 4, 8, 16]] # `int` + обработка списка
['0b1', '0b10', '0b100', '0b1000', '0b10000']bytes():
>>> # Последовательность целых чисел
>>> bytes((104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100))
b'hello world'
>>> bytes(range(97, 123)) # Последовательность целых чисел
b'abcdefghijklmnopqrstuvwxyz'
>>> bytes("real 🐍", "utf-8") # Строка + кодировка
b'real \xf0\x9f\x90\x8d'
>>> bytes(10)
b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
>>> bytes.fromhex('c0 ff ee')
b'\xc0\xff\xee'
>>> bytes.fromhex("72 65 61 6c 70 79 74 68 6f 6e")
b'realpython'chr():
>>> chr(97)
'a'
>>> chr(7048)
'ᮈ'
>>> chr(1114111)
'\U0010ffff'
>>> chr(0x10FFFF) # Шестнадцатеричный литерал (int)
'\U0010ffff'
>>> chr(0b01100100) # Двоичный литерал (int)
'd'hex():
>>> hex(100)
'0x64'
>>> [hex(i) for i in [1, 2, 4, 8, 16]]
['0x1', '0x2', '0x4', '0x8', '0x10']
>>> [hex(i) for i in range(16)]
['0x0', '0x1', '0x2', '0x3', '0x4', '0x5', '0x6', '0x7',
'0x8', '0x9', '0xa', '0xb', '0xc', '0xd', '0xe', '0xf']int():
>>> int(11.0)
11
>>> int('11')
11
>>> int('11', base=2)
3
>>> int('11', base=8)
9
>>> int('11', base=16)
17
>>> int(0xc0ffee - 1.0)
12648429
>>> int.from_bytes(b"\x0f", "little")
15
>>> int.from_bytes(b'\xc0\xff\xee', "big")
12648430oct():
>>> ord("a")
97
>>> ord("ę")
281
>>> ord("ᮈ")
7048
>>> [ord(i) for i in "hello world"]
[104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]str():
>>> str("str of string")
'str of string'
>>> str(5)
'5'
>>> str([1, 2, 3, 4]) # Like [1, 2, 3, 4].__str__(), but use str()
'[1, 2, 3, 4]'
>>> str(b"\xc2\xbc cup of flour", "utf-8")
'¼ cup of flour'
>>> str(0xc0ffee)
'12648430'Литералы для строк на Python
Вместо использования конструктора str(), объект этого типа чаще вводят напрямую:
>>> meal = "shrimp and grits"Выглядит достаточно просто. Но есть один аспект, о котором нужно помнить. Поскольку Python позволяет использовать все возможности Юникода, можно «напечатать» символы, которых вы никогда не найдёте на клавиатуре. Можно скопировать и вставить их прямо в оболочку интерпретатора:
>>> alphabet = 'αβγδεζηθικλμνξοπρςστυφχψ'
>>> print(alphabet)
αβγδεζηθικλμνξοπρςστυφχψКроме ввода через консоль реальных, неэкранированых символов Юникода, существуют и другие способы ввода текстовых строк.
Самые насыщенные разделы документации Python посвящены лексическому анализу. В частности, раздел о строках и литералах. Возможно, для понимания данного аспекта языка этот раздел придётся неоднократно перечитать.
Кроме прочего, там говорится о шести возможных способах ввода одного символа Юникода.
Первый, и самый распространённый метод, как вы уже видели — прямой ввод. Проблема состоит в поиске необходимых сочетаний клавиш. Здесь и могут пригодиться другие способы получения и представления символов. Вот полный список:
| Экранирующая последовательность | Значение | Как отобразить "a" |
|---|---|---|
"\ooo" | Символ с восьмеричным значением ooo | "\141" |
"\xhh" | Символ с шестнадцатеричным значением hh | "\x61" |
"\N{name}" | Символ с именем name в базе данных Юникода | "\N{LATIN SMALL LETTER A}" |
"\uxxxx" | Символ с шестнадцатибитным (двухбайтным) шестнадцатеричным значением xxxx | "\u0061" |
"\Uxxxxxxxx" | Символ с тридцатидвухбитным (четырёхбайтным) шестнадцатеричным значением xxxxxxxx | "\U00000061" |
Это соответствие можно проверить на практике:
>>> (
... "a" ==
... "\x61" ==
... "\N{LATIN SMALL LETTER A}" ==
... "\u0061" ==
... "\U00000061"
... )
TrueНужно однако упомянуть и два основных затруднения при использовании этих методов:
- Не каждый способ работает со всеми символами. Шестнадцатеричное представление числа 300 выглядит как
0x012c, а это значение просто не поместится в экранирующий код"\xhh", так как в нём допускаются всего две цифры. Самая большая кодовая точка, которую можно втиснуть в этот формат —"\xff"("ÿ"). Аналогичо"\ooo"можно использовать только до"\777"("ǿ"). - Для
\xhh,\uxxxx, и\Uxxxxxxxxтребуется вводить ровно столько цифр, сколько указано в примерах. Это может стать неприятным сюрпризом, поскольку обычно основанные на Юникоде таблицы содержат кодовые точки для символов с префиксомU+и варьирующимся количеством шестнадцатеричных символов. В этих таблицах кодовые точки отображают только значимые цифры.
Например, если вы обратитесь к сайту unicode-table.com с целью получить данные готического символа faihu (или fehu), "𐍆", его кодовая точка будет U+10346.
Как же можно разместить его в "\uxxxx" или "\Uxxxxxxxx"? В "\uxxxx" эту кодовую точку вместить невозможно, поскольку она соответствует четырёхбайтному символу. А чтобы представить его в "\Uxxxxxxxx", придётся выровнять последовательность с левой стороны:
>>> "\U00010346"
'𐍆'Это также значит, что экранирующая последовательность "\Uxxxxxxxx" — единственная последовательность, способная вместить любой символ Юникода.
Прим. Вот код небольшой, но удобной функции, переводящей записи типа "U+10346" в приемлемый для Python формат с помощью str.zfill():
>>> def make_uchr(code: str):
... return chr(int(code.lstrip("U+").zfill(8), 16))
>>> make_uchr("U+10346")
'𐍆'
>>> make_uchr("U+0026")
'&'Другие поддерживаемые Python кодировки
Пока что мы рассказали про 4 разные кодировки символов:
- ASCII;
- UTF-8;
- UTF-16;
- UTF-32.
Однако существует большое количество и других вариантов кодировки.
Один из примеров — Latin-1 (другое название ISO-8859-1). Это базовая кодировка для Hypertext Transfer Protocol (HTTP) в спецификации RFC 2616. Для Windows существует собственный вариант Latin-1, который называется cp1252.
Прим. Кодировка ISO-8859-1 всё ещё широко используется. Библиотека requests неукоснительно придерживается спецификации RFC 2616, используя её по умолчанию для содержимого отзывов HTTP/HTTPS. Если в заголовке Content-Type находится слово «text» и не выбрана другая кодировка, requests использует ISO-8859-1.
Полный список допустимых кодировок можно найти в документации модуля codecs, входящего в набор стандартных библиотек Python.
Среди этих кодировок стоит упомянуть ещё одну, зачастую весьма полезную. Это "unicode-escape". Если вы декодировали str и хотите быстро получить представление содержащихся в ней экранированных литералов Юникода, можно определить эту кодировку в .encode:
>>> alef = chr(1575) # Или "\u0627"
>>> alef_hamza = chr(1571) # Или "\u0623"
>>> alef, alef_hamza
('ا', 'أ')
>>> alef.encode("unicode-escape")
b'\\u0627'
>>> alef_hamza.encode("unicode-escape")
b'\\u0623'Вы знаете, что говорят насчёт предположений…
Хотя Python по умолчанию предполагает, что файлы и код созданы на основе кодировки UTF-8, вам, как программисту, не следует делать аналогичное предположение относительно сторонних данных.
Когда вы получаете данные в двоичном коде из внешних источников, из файла или по сетевому соединению, стоит проверить, указана ли кодировка. Если нет — вы можете уточнить.
Все операции ввода-вывода осуществляют в байтах, наборе нулей и единиц, пока вы не сообщите системе кодировку для преобразования этих данных в текст.
Приведём пример того, что может пойти не так. Допустим, вы подписаны на API, который передаёт вам рецепт блюда дня. Вы получаете его в формате bytes и раньше всегда без проблем декодировали с использованием .decode("utf-8") . Но именно в этот день часть рецепта выглядела так:
>>> data = b"\xbc cup of flour"Похоже, нам потребуется мука, но сколько?
>>> data.decode("utf-8")
Traceback (most recent call last):
File "", line 1, in
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbc in position 0: invalid start byteА вот и та самая неприятная ошибка UnicodeDecodeError. Подобное вполне может произойти, когда вы делаете предположение об используемой кодировке. Уточняем у разработчика ресурса, предоставляющего API. Выясняется, что полученный вами файл был закодирован с помощью Latin-1:
>>> data.decode("latin-1")
'¼ cup of flour'Именно в этом и крылась проблема. В Latin-1 каждый символ кодируется одним байтом, в вот в UTF-8 символ «¼» требует два байта ("\xc2\xbc").
Как видите, делать предположения относительно кодировки полученных данных довольно рискованно. Обычно это UTF-8, однако в тех случаях, когда это не так, у вас могут возникнуть проблемы.
Если уж у вас нет другого выхода и кодировку приходится угадывать, обратите внимание на библиотеку chardet. В ней используются разработанные в Mozilla методы, позволяющие сделать обоснованное предположение насчёт кодировки данных. Однако учтите, что такие инструменты должны быть вашим последним средством, не стоит прибегать к ним, если есть возможность решить вопрос другим способом.
Всякая всячина: unicodedata
Нельзя не упомянуть также модуль unicodedata. Он позволяет взаимодействовать с базой данных символов Юникода (Unicode Character Database, UCD).
>>> import unicodedata
>>> unicodedata.name("€")
'EURO SIGN'
>>> unicodedata.lookup("EURO SIGN")
'€'Подводим итоги
Итак, в этой статье вы познакомились со следующими концепциями кодировки символов в Python:
- Фундаментальные принципы кодировки символов и систем счисления;
- Целочисленные, двоичные, восьмеричные, шестнадцатеричные, строковые и байтовые литералы в Python;
- Встроенные функции языка, работающие с кодировкой и системами счисления;
- Особенности обработки текстовых и двоичных данных.
Дополнительные источники
Ещё больше информации можно получить из следующих материалов (на английском языке):
- UTF-8 Everywhere Manifesto.
- Joel Spolsky: Минимальный уровень знаний о Юникоде и наборах символов, требующийся каждому разработчику ПО (Без отговорок!).
- David Zentgraf: Что обязательно должен знать о кодировках и наборах символов каждый программист для работы с текстом.
- Mozilla: Комплексный подход к определению языков и кодировок.
- Wikipedia.
- John Skeet: Юникод и .NET.
- Network Working Group, RFC 3629: UTF-8, формат преобразования ISO 10646.
- Unicode Technical Standard #18: Регулярные выражения Юникода.
В документации языка нашему вопросу посвящены два раздела:
Перевод статьи Unicode & Character Encodings in Python: A Painless Guide
Юникод в Python 3 — Документация Python для сетевых инженеров 3.0
Строки
Примеры строк:
In [11]: hi = 'привет' In [12]: hi Out[12]: 'привет' In [15]: type(hi) Out[15]: str In [13]: beautiful = 'schön' In [14]: beautiful Out[14]: 'schön'
Так как строки — это последовательность кодов Юникод, можно записать строку разными способами.
Символ Юникод можно записать, используя его имя:
In [1]: "\N{LATIN SMALL LETTER O WITH DIAERESIS}"
Out[1]: 'ö'
Или использовав такой формат:
In [4]: "\u00F6" Out[4]: 'ö'
Строку можно записать как последовательность кодов Юникод:
In [19]: hi1 = 'привет' In [20]: hi2 = '\u043f\u0440\u0438\u0432\u0435\u0442' In [21]: hi2 Out[21]: 'привет' In [22]: hi1 == hi2 Out[22]: True In [23]: len(hi2) Out[23]: 6
Функция ord возвращает значение кода Unicode для символа:
In [6]: ord('ö')
Out[6]: 246
Функция chr возвращает символ Юникод, который соответствует коду:
In [7]: chr(246) Out[7]: 'ö'
Байты
Тип bytes — это неизменяемая последовательность байтов. SyntaxError: bytes can only contain ASCII literal characters.
✔️ ❤️ ★ Таблица символов Юникода
Юникод
Юникод (по-английски Unicode) — это стандарт кодирования символов. Проще говоря, это таблица соответствия текстовых знаков (цифр, букв, элементов пунктуации) двоичным кодам. Компьютер понимает только последовательность нулей и единиц. Чтобы он знал, что именно должен отобразить на экране, необходимо присвоить каждому символу свой уникальный номер. В восьмидесятых, знаки кодировали одним байтом, то есть восемью битами (каждый бит это 0 или 1). Таким образом получалось, что одна таблица (она же кодировка или набор) может вместить только 256 знаков. Этого может не хватить даже для одного языка. Поэтому, появилось много разных кодировок, путаница с которыми часто приводила к тому, что на экране вместо читаемого текста появлялись какие-то странные кракозябры. Требовался единый стандарт, которым и стал Юникод. Самая используемая кодировка — UTF-8 (Unicode Transformation Format) для изображения символа задействует от 1 до 4 байт.
Символы
Символы в таблицах Юникода пронумерованы шестнадцатеричными числами. Например, кириллическая заглавная буква М обозначена U+041C. Это значит, что она стоит на пересечении строки 041 и столбца С. Её можно просто скопировать и потом вставить куда-либо. Чтобы не рыться в многокилометровом списке следует воспользоваться поиском. Зайдя на страницу символа, вы увидите его номер в Юникоде и способ начертания в разных шрифтах. В строку поиска можно вбить и сам знак, даже если вместо него отрисовывается квадратик, хотя бы для того, чтобы узнать, что это было. Ещё, на этом сайте есть специальные (и не специальные — случайные) наборы однотипных значков, собранные из разных разделов, для удобства их использования.
Стандарт Юникод — международный. Он включает знаки почти всех письменностей мира. В том числе и тех, которые уже не применяются. Египетские иероглифы, германские руны, письменность майя, клинопись и алфавиты древних государств. Представлены и обозначения мер и весов, нотных грамот, математических понятий.
Сам консорциум Юникода не изобретает новых символов. В таблицы добавляются те значки, которые находят своё применение в обществе. Например, активно использовался в течении шести лет прежде чем был добавлен в Юникод. Пиктограммы эмодзи (смайлики) тоже сначала получили широкое применение в Япониии прежде чем были включены в кодировку. А вот товарные знаки, и логотипы компаний не добавляются принципиально. Даже такие распространённые как яблоко Apple или флаг Windows. На сегодняшний день, в версии 8.0 закодировано около 120 тысяч символов.
man UTF-8 (7): ASCII-совместимая многобайтная юникодная кодировка
UTF-8(7) ASCII-совместимая многобайтная юникодная кодировка
ОПИСАНИЕ
Набор символов Unicode 3.0 занимает 16-битное кодовое пространство. Наиболее распространённая юникодная кодировка, известная как UCS-2, содержит последовательности 16-битных слов. Закодированные таким образом строки могут состоять из частей 16-битных символов например, ‘\0’ или ‘/’, которые имеют специальное значение в именах файлов и других параметрах функций библиотеки языка Си. Кроме того, большинство утилит UNIX предназначено для обработки ASCII-файлов и не может воспринимать 16-битные слова как символы. По этим причинам UCS-2 является неподходящей кодировкой Юникода для имён файлов, текстовых файлов, переменных окружения и т.д. Набор ISO Universal Character Set (UCS), расширенный набор Юникода, занимает более 31-битного кодового пространства, а используемая для него кодировка UCS-4 (последовательность 32-битных слов) имеет те же недостатки, что и описанные выше.Кодировка UTF-8 для представления Юникода и UCS лишена этих недостатков и поэтому в UNIX-подобных операционных системах используется наиболее часто.
Свойства
Кодировка UTF-8 обладает следующими полезными свойствами:- *
- UCS-символы с кодами от 0x00000000 до 0x0000007f (стандартный набор US-ASCII) кодируются как байты с кодами от 0x00 до 0x7f (для совместимости с кодовой таблицей ASCII). Это означает, что файлы и строки, содержащие только 7-битные ASCII-символы, будут иметь одинаковое представление как в ASCII так и в UTF-8.31 значения UCS.
- *
- В кодировке UTF-8 никогда не используются байты с кодами 0xc0, 0xc1, 0xfe и 0xff.
- *
- Первый байт многобайтовой последовательности, представляющей один не ASCII UCS-символ, всегда находится в диапазоне от 0xc2 до 0xfd и указывает на длину мульбайтовой последовательности. Все последующие байты в многобайтовой последовательности находятся в диапазоне от 0x80 до 0xbf. Это позволяет облегчить ресинхронизацию, устраняет необходимость учитывать состояние кодировки (statelessness) и делает кодировку независимой от пропущенных байтов.
- *
- Символы UCS, закодированные в UTF-8, могут занимать до шести байтов, однако в стандарте Юникода не определены символы выше 0x10ffff, поэтому в UTF-8 юникодные символы могут иметь максимальный размер 4 байта.
Кодирование
Приведённые ниже последовательности байтов используются для отображения символа. Конкретная последовательность зависит от номера символа в кодировке UCS:- 0x00000000 — 0x0000007F:
- 0xxxxxxx
- 0x00000080 — 0x000007FF:
- 110xxxxx 10xxxxxx
- 0x00000800 — 0x0000FFFF:
- 1110xxxx 10xxxxxx 10xxxxxx
- 0x00010000 — 0x001FFFFF:
- 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
- 0x00200000 — 0x03FFFFFF:
- 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
- 0x04000000 — 0x7FFFFFFF:
- 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
Позиции битов, обозначенные как xxx, заполняются соответствующими битами из кода символа в двоичном виде. Используется самая короткая из возможных многобайтовых последовательностей, которые могут представить код символа.
Значения кодов UCS 0xd00-0xdfff (суррогаты UTF-16), а также 0xfffe и 0xffff (несимвольные значения UCS), не должны появляться в потоках UTF-8.
Пример
Символ Юникода с кодом 0xa9 = 1010 1001 (знак авторского права) кодируется в UTF-8 как- 11000010 10101001 = 0xc2 0xa9
а символ с кодом 0x2260 = 0010 0010 0110 0000 (знак неравенства) кодируется так:
- 11100010 10001001 10100000 = 0xe2 0x89 0xa0
Замечания к применению
Для включения поддержки UTF-8 в приложениях, пользователи должны выбрать локаль UTF-8, например с помощью- export LANG=en_GB.UTF-8
Программы, в которых учитывается используемая пользователем кодировка, должны всегда устанавливать локаль с помощью
- setlocale(LC_CTYPE, «»)
и затем проверять выражением
- strcmp(nl_langinfo(CODESET), «UTF-8») == 0
что локаль UTF-8 выбрана и во всех стандартных текстовых потоках ввода и вывода, на терминалах, в содержимом простых текстовых файлов, именах файлов и переменных окружения будет использоваться кодировка UTF-8.
Программисты, привыкшие к однобайтовым кодировкам, таким как, US-ASCII или ISO 8859, должны учесть, что два предположения, действовавших ранее, в локалях UTF-8 не работают. Первое: один байт теперь не обязательно соответствует одному символу. Второе: современные эмуляторы терминала в режиме UTF-8 также поддерживают китайские, японские и корейские символы двойной ширины (double-width characters), а также комбинированные символы без пробелов, и вывод одного символа необязательно смещает курсор на одну позицию, как это было в ASCII. Для подсчёта количества символов и позиций курсора нужно использовать библиотечные функции, такие как mbsrtowcs(3) и wcswidth(3).
Стандартной ESC-последовательностью для переключения из схемы кодировки ISO 2022 (используется в терминалах VT100) в UTF-8 является ESC % G («\x1b%G»). Соответственно, обратной последовательностью для переключения из UTF-8 в ISO 2022 будет ESC % @ («\x1b%@»). Остальные последовательности ISO 2022 (такие, как переключение в наборы G0 и G1) в режиме UTF-8 не работают.
Безопасность
Стандарты Юникода и UCS требуют, чтобы генераторы UTF-8 использовали самую короткую возможную форму представления символов, то есть создание двухбайтной последовательности с первым байтом, равным 0xc0, запрещено. В стандарте Unicode 3.1 это правило расширено и запрещает программам воспринимать не самую короткую форму при вводе. Это сделано из соображений безопасности: если вводимые пользователем символы проверяются системой безопасности на возможные нарушения, то программам остаётся проверить только ASCII версии символов «/../», «;» или NUL, так как для этих символов может быть очень много не ASCII способов представления при не самом коротком кодировании в UTF-8.Стандарты
ISO/IEC 10646-1:2000, Unicode 3.1, RFC 3629, Plan 9.Как работать с символами и кодами в Excel — Трюки и приемы в Microsoft Excel
Каждый символ, вводимый вами и отображаемый на экране, имеет свой собственный числовой код. Например, код для прописной буквы А — это 65, а код для амперсанда (&) — 38. Эти коды присутствуют не только для алфавитных символов, вводимых вами с клавиатуры, но и для специальных символов, которые вы можете вывести на экран, используя их коды. Список всех символов и их кодов называется таблицей кодов ASCII.
Например, ASCII-код для символа © равен 169. Для вывода данного символа необходимо ввести на клавиатуре Alt+0169, используя цифровую клавиатуру для ввода цифр. Таблица ASCII содержит коды от 1 до 255, при этом первые 31 цифра используются для непечатаемых символов, таких как возврат каретки и перевод строки.
Функция СИМВОЛ()
Excel позволяет вам определять символы путем ввода их кодов ASCII, используя функцию СИМВОЛ(число), где в качестве аргумента необходимо ввести соответствующий код. Например, если вы хотите ввести символ параграфа (§ с кодом ASCII 167), просто введите =СИМВОЛ(167). Используя функцию СИМВОЛ(), можно сгенерировать таблицу ASCII-символов (см. рис. 4.6). В таблицу не включены первые 31 символ; обратите внимание, что символ с кодом 32 представляет собой знак пробела. В каждой строке символа содержится функция СИМВОЛ(), аргументом которой является число слева от поля.
Политический символ — это знак, выполняющий коммуникативную функцию между личностью и властью. Если исходить из концепции Т. Парсонса, согласно которой культура — это упорядоченная система символов, то можно сказать, что политическая культура — это организованная система символов, подробнее о символах политических партий смотрите на mmk-international.ru. Для того чтобы символ выполнял коммуникативную функцию, он должен иметь сходное значение для множества индивидов, его смысл должен быть, как минимум, интуитивно понятен определенному кругу людей. Кроме коммуникативной, символ обладает интегративной функцией — он способен сплачивать, объединять людей, группы, обеспечивать чувство единства.
Рис. 4.6. Построение таблицы ASCII кодов
Вы можете составить подобную таблицу, просто введя функцию СИМВОЛ() вверху строки и затем заполнив все ноля ниже. В случае если мы начинаем генерацию со второй строки, можно использовать формулу =СИМВОЛ(СТРОКА()+30).
Функция КОДСИМВ()
Данная функция является противоположностью функции СИМВОЛ(число). При вводе в нее текстового символа она возвращает код ASCII: КОДСИМВ{текст), где текст — символ или текстовая строка. В случае ввода строки функция вернет ASCII-код первого символа. Например, следующие формулы вернут 193 как код символа Б: =КОДСИМВ("Б") или =КОДСИМВ("Баланс")
Список непечатаемых символов ASCII
| дек | HEX | ПЕРСОНАЖ |
| 0 | 0 | NULL |
| 1 | 1 | НАЧАЛО ЗАГОЛОВКИ (SOH) |
| 2 | 2 | НАЧАЛО ТЕКСТА (STX) |
| 3 | 3 | КОНЕЦ ТЕКСТА (ETX) |
| 4 | 4 | КОНЕЦ ТРАНСМИССИИ (EOT) |
| 5 | 5 | КОНЕЦ ЗАПРОСА (ENQ) |
| 6 | 6 | ПОДТВЕРЖДЕНИЕ (ПОДТВЕРЖДЕНИЕ) |
| 7 | 7 | BEEP (BEL) |
| 8 | 8 | ЗАДНЯЯ ЧАСТЬ (BS) |
| 9 | 9 | ГОРИЗОНТАЛЬНЫЙ ВКЛАД (HT) |
| 10 | A | ЛИНИЯ ПОДАЧИ (LF) |
| 11 | B | ВЕРТИКАЛЬНАЯ ТАБЛИЦА (VT) |
| 12 | С | FF (ПОДАЧА ФОРМЫ) |
| 13 | D | CR (ВОЗВРАТ ТРАНСПОРТА) |
| 14 | E | ТАК (ВЫКЛЮЧЕНИЕ) |
| 15 | F | SI (С ПЕРЕКЛЮЧЕНИЕМ) |
| 16 | 10 | ОТКЛЮЧЕНИЕ СВЯЗИ ДАННЫХ (DLE) |
| 17 | 11 | УПРАВЛЕНИЕ УСТРОЙСТВОМ 1 (DC1) |
| 18 | 12 | УПРАВЛЕНИЕ УСТРОЙСТВОМ 2 (DC2) |
| 19 | 13 | УПРАВЛЕНИЕ УСТРОЙСТВОМ 3 (DC3) |
| 20 | 14 | УПРАВЛЕНИЕ УСТРОЙСТВОМ 4 (DC4) |
| 21 | 15 | ОТРИЦАТЕЛЬНОЕ ПОДТВЕРЖДЕНИЕ (NAK) |
| 22 | 16 | СИНХРОНИЗАЦИЯ (SYN) |
| 23 | 17 | КОНЕЦ БЛОКА ТРАНСМИССИИ (ETB) |
| 24 | 18 | ОТМЕНА (CAN) |
| 25 | 19 | КОНЕЦ СРЕДЫ (EM) |
| 26 | 1A | ЗАМЕНА (ПОД) |
| 27 | 1Б | ESCAPE (ESC) |
| 28 | 1С | РАЗДЕЛИТЕЛЬ ФАЙЛОВ (FS) СТРЕЛКА ВПРАВО |
| 29 | 1D | ГРУППОВОЙ РАЗДЕЛИТЕЛЬ (GS) СТРЕЛКА ВЛЕВО |
| 30 | 1E | СЕПАРАТОР ЗАПИСИ (RS) СТРЕЛКА ВВЕРХ |
| 31 | 1 этаж | РАЗДЕЛИТЕЛЬ БЛОКА (США) СТРЕЛКА ВНИЗ |
EMLS: Руководство по символам, отличным от ASCII
EMLS: Руководство по символам, отличным от ASCII
Литературоведение раннего нового времени :
Руководство по символам, отличным от ASCII
Вклады, представленные в EMLS в ASCII формат, содержащий символы, отличные от ASCII, должен следовать за коды, установленные в ISO Entity Set Latin 1 , ниже.Код следует заключить в квадратные скобки, [].
- aacute = = маленький a, с острым ударением
- Aacute = = заглавная A, острый ударение
- acirc = = малый a, ударение с циркумфлексом
- Acirc = = заглавная A, ударение с циркумфлексом
- agrave = = малый а, серьезный акцент
- Agrave = = заглавная A, серьезный ударение
- aring = = small a, кольцо
- Aring = = заглавная A, кольцо
- atilde = = маленький a, тильда
- Atilde = = заглавная A, тильда
- auml = = малый a, дирезис или умлаутмарк
- Аумль = = заглавная А, дирезис или умлаутмарк
- aelig = = малый дифтонг ae (лигатура)
- AElig = = заглавная AE дифтонг (лигатура)
- ccedil = = small c, седиль
- Ccedil = = заглавная C, седилья
- eth = = малый eth, исландский
- ETH = = капитал Eth, исландский
- eacute = = маленький e, с острым ударением
- Eacute = = заглавная E, острый ударение
- ecirc = = строчная e, ударение с циркумфлексом
- Ecirc = = заглавная E, ударение с циркумфлексом
- egrave = = маленький e, серьезный ударение
- Egrave = = заглавная E, серьезный ударение
- euml = = small e, dieresis или umlautmark
- Euml = = заглавная E, дирезис или умлаутмарк
- iacute = = маленький i, с острым ударением
- Iacute = = заглавная I, острый ударение
- icirc = = строчный i, ударение с циркумфлексом
- Icirc = = заглавная I, ударение с циркумфлексом
- igrave = = маленький i, ударение могилы
- Igrave = = заглавная I, могильный ударение
- iuml = = small i, дирезис или умлаутмарк
- Iuml = = заглавная I, дирезис или умлаутмарк
- ntilde = = маленький n, тильда
- Ntilde = = заглавная N, тильда
- oacute = = маленький o, острый акцент
- Oacute = = заглавная O, острый ударение
- ocirc = = строчная буква o, ударение с циркумфлексом
- Ocirc = = заглавная O, ударение с циркумфлексом
- ograve = = маленький o, серьезный ударение
- Ограве = = заглавная O, ударение могилы
- oslash = = маленький o, косая черта
- Oslash = = заглавная O, косая черта
- otilde = = маленький o, тильда
- Otilde = = заглавная O, тильда
- ouml = = малое o, дирезис или умлаутмарк
- Ouml = = заглавная O, дирезис или умляутмарк
- szlig = = small sharp s, немецкий (szligature
- шип = = маленький шип, исландский
- THORN = = заглавная THORN, исландское
- uacute = = маленький u, острый ударение
- Uacute = = заглавная U, острый ударение
- ucirc = = строчная буква U, ударение с циркумфлексом
- Ucirc = = заглавная U, ударение с циркумфлексом
- ugrave = = маленький u, серьезный акцент
- Ugrave = = заглавная U, ударение могилы
- uuml = = малый u, дирезис или умлаутмарк
- Uuml = = заглавная U, дирезис или умляутмарк
- yacute = = маленький y, острый акцент
- Якутский = = заглавная Y, острый ударение
- yuml = = small y, dieresis или umlautmark
1997-, р.Г. Сименс (редактор, EMLS ).
Как мне вводить символы, отличные от ascii?
Поделитесь этим сообщением
- А пока давайте отложим вопросы о том, когда вам следует использовать не — символов ASCII против
- вы удерживаете клавишу ALT, а затем введите в виде 4-значного числа символ .
- Когда вы будете готовы ввести , символ , удерживайте клавишу ALT и введите 0237 с цифровой клавиатуры.
Нажмите, чтобы увидеть полный ответ
В этом отношении, каков пример символов, отличных от ascii?
Коды от 0 до 127 — это символов ASCII ; коды от 128 до 255 используются для одного набора символов ASCII , отличного от — (вы можете выбрать, какой набор символов установить, установив переменную nonascii -insert-offset). Первый байт многобайтового символа всегда находится в диапазоне от 128 до 159 (восьмеричное с 0200 по 0237).
Во-вторых, как мне сделать непечатаемые символы? Вы можете ввести код как код клавиши ALT или как управляющий код ASCII, список управляющих кодов ASCII доступен здесь. Таким образом, чтобы ввести символ канала формы , например, вы должны нажать CTRL-P, а затем CTRL-L (или CTRL-P и ALT + 012). Он поместит символ в редактор, представляющий , отличный от — печатный символ ASCII .
Таким образом, как получить символы ascii на клавиатуре?
К вставьте символ ASCII , нажмите и удерживайте ALT, пока набирает код символа .Например, чтобы вставить символ градуса (º), нажмите и удерживайте ALT, пока набирает 0176 на цифровой клавиатуре. Для ввода чисел необходимо использовать цифровую клавиатуру, а не клавиатуру .
Что такое формат ascii?
ASCII (Американский стандартный код для обмена информацией) — наиболее распространенный формат для текстовых файлов на компьютерах и в Интернете. В файле ASCII каждый буквенный, цифровой или специальный символ представлен 7-битным двоичным числом (строкой из семи нулей или единиц).Определено 128 возможных символов.
URL-адресов и имен файлов, отличных от ASCII | Поддержка Tiger Technologies
Наши серверы позволяют использовать имена файлов, содержащие символы, отличные от ASCII. Например, вы можете назвать файл буквой «е» с ударением:
tést.html
Если вы это сделаете, может показаться, что вы можете просто получить доступ к этому файлу, используя этот URL:
http://www.example.com/tést.html
Однако это ненадежно.
В чем проблема?
Имена файлов в формате, отличном от ASCII, хранятся в специальном формате под названием «Unicode». Но в некоторых случаях Unicode предлагает несколько способов написания вещей, которые выглядят одинаково для людей.
Например, символ «é» может быть представлен либо как обычная буква «e», за которой следует комбинированный символ острого ударения, либо как латинская строчная буква e с острым знаком. Хотя они выглядят одинаково, они имеют разные образцы байтов и, следовательно, будут обрабатываться на сервере как два разных имени файла.Может быть трудно даже понять, что вы используете.
Когда вы запрашиваете подобное имя файла в веб-браузере, браузер преобразует его в закодированную в URL-адрес версию одной из двух вышеперечисленных возможностей, которую он будет представлять как одно из:
te% CC% 81st.html t% C3% A9st.html
Затем он отправляет этот закодированный запрос на веб-сервер. Сервер декодирует его обратно в исходный образец байтов и ищет на диске соответствующее имя файла. Если запрос и имя файла совпадают, потому что браузер отправляет одну и ту же версию, он работает, но если они не совпадают, он не работает (вы получите ошибку «404 не найден»).
Это может показаться легко исправить, потому что вы можете подумать, что можете просто предварительно закодировать свои URL-адреса, попробовав их, чтобы увидеть, какой из них работает:
http://www.example.com/te%CC%81st.html http://www.example.com/t%C3%A9st.html
… а затем используя рабочую версию в ваших ссылках. Однако некоторые браузеры (особенно Safari, но не Chrome или Firefox) фактически изменят первую уже закодированную версию на вторую, прежде чем отправить ее на сервер, так что это тоже не совсем надежно.
И мы даже не говорили о возможности того, что что-то может закодировать один из этих символов с использованием набора символов, отличного от Юникода, такого как Windows-1252, что приведет к еще одной версии, «te% E9st.html», которая является еще одним байтом. шаблон. Иногда это происходит случайно при передаче файла по FTP.
Какое решение?
Простой способ избежать всех этих проблем — придерживаться основных символов ASCII в именах файлов и URL-адресах. Если вы используете только буквы, цифры, точки, дефисы и символы подчеркивания, вы никогда не столкнетесь с этой проблемой.
Если вы должны использовать символы, отличные от ASCII:
- Избегайте их передачи через FTP
- Избегайте формы имени файла с «комбинированным ударением», отдавая предпочтение более короткой версии
- Проверьте свои URL-адреса в нескольких браузерах, включая Safari
Как я могу увидеть более подробную техническую информацию?
Хотя это не для слабонервных, выполнение этой команды из оболочки покажет вам правильное имя в кодировке URL (и, следовательно, байтовый шаблон) каждого файла в каталоге:
ls | perl -pe 's / ([\ x20 \ x2c \ x5c \ x80- \ xff]) / "%".uc sprintf "% 02x", ord ($ 1) / eg; '
Опять же, здесь есть оговорка, что закодированная версия, которую вы видите, не обязательно будет работать в браузерах, таких как Safari, которые «канонизируют» кодировку перед ее отправкой на сервер.
| НЕПЕЧАТНЫЕ СИМВОЛЫ | |||||
| дек | ШЕСТИГР. | СИМВОЛ (КОД) | дек | ШЕСТИГР. | СИМВОЛ (КОД) |
| 0 | 0 | NULL | 16 | 10 | ОТКЛЮЧЕНИЕ СВЯЗИ ДАННЫХ (DLE) |
| 1 | 1 | НАЧАЛО ЗАГОЛОВКИ (SOH) | 17 | 11 | УПРАВЛЕНИЕ УСТРОЙСТВОМ 1 (DC1) |
| 2 | 2 | НАЧАЛО ТЕКСТА (STX) | 18 | 12 | УПРАВЛЕНИЕ УСТРОЙСТВОМ 2 (DC2) |
| 3 | 3 | КОНЕЦ ТЕКСТА (ETX) | 19 | 13 | УПРАВЛЕНИЕ УСТРОЙСТВОМ 3 (DC3) |
| 4 | 4 | КОНЕЦ ТРАНСМИССИИ (EOT) | 20 | 14 | УПРАВЛЕНИЕ УСТРОЙСТВОМ 4 (DC4) |
| 5 | 5 | КОНЕЦ ЗАПРОСА (ENQ) | 21 | 15 | ОТРИЦАТЕЛЬНОЕ ПОДТВЕРЖДЕНИЕ (NAK) |
| 6 | 6 | ПОДТВЕРЖДЕНИЕ (ПОДТВЕРЖДЕНИЕ) | 22 | 16 | СИНХРОНИЗАЦИЯ (SYN) |
| 7 | 7 | BEEP (BEL) | 23 | 17 | КОНЕЦ БЛОКА ТРАНСМИССИИ (ETB) |
| 8 | 8 | ЗАДНЯЯ ЧАСТЬ (BS) | 24 | 18 | ОТМЕНА (CAN) |
| 9 | 9 | ГОРИЗОНТАЛЬНЫЙ ВКЛАД (HT) | 25 | 19 | КОНЕЦ СРЕДЫ (EM) |
| 10 | А | ЛИНИЯ ПОДАЧИ (LF) | 26 | 1A | ЗАМЕНА (ПОД) |
| 11 | B | ВЕРТИКАЛЬНАЯ ТАБЛИЦА (VT) | 27 | 1Б | ESCAPE (ESC) |
| 12 | С | FF (ПОДАЧА ФОРМЫ) | 28 | 1С | РАЗДЕЛИТЕЛЬ ФАЙЛОВ (FS) СТРЕЛКА ВПРАВО |
| 13 | D | CR (ВОЗВРАТ ТРАНСПОРТА) | 29 | 1D | ГРУППОВОЙ РАЗДЕЛИТЕЛЬ (GS) СТРЕЛКА ВЛЕВО |
| 14 | E | ТАК (ВЫКЛЮЧЕНИЕ) | 30 | 1E | СЕПАРАТОР ЗАПИСИ (RS) СТРЕЛКА ВВЕРХ |
| 15 | F | SI (С ПЕРЕКЛЮЧЕНИЕМ) | 31 | 1 этаж | РАЗДЕЛИТЕЛЬ БЛОКА (США) СТРЕЛКА ВНИЗ |
Как искать символы, отличные от ASCII, в списке ключевых слов с отступом от табуляции
Вот знакомый сценарий для всех, кто редактирует или создает свои собственные списки ключевых слов: вы начинаете импортировать список в Lightroom, и на полпути процесса импорта все останавливается с менее чем полезным «Только текстовые файлы, закодированные с помощью ASCII или Unicode UTF-8 поддерживаются при импорте сообщения с ключевыми словами.
Привет, я фотограф. Я слышал об ASCII, но не уверен, что это значит. Не понял «unicode UTF-8». Что мне делать дальше?
Не волнуйтесь. Вскоре вы исправите проблему с информацией на этой странице. При создании или редактировании списка ключевых слов с отступом от табуляции, который вы собираетесь импортировать в Lightroom, Breeze Browser, Photo Mechanic или другие популярные программы для управления и хранения изображений, следует избегать определенных символов, поскольку они вызывают ошибку и в во многих случаях импорт списка ключевых слов будет остановлен из-за менее чем полезной ошибки.
Эти символы обычно называются «не-ASCII-символами». Хотя они будут вполне безопасно отображаться в PSPad или многих других текстовых или текстовых процессорах, программы управления изображениями и хранения считают их выходящими за рамки безопасного текста. Присмотревшись к этому чуть внимательнее, мы узнаем, что безопасные символы ASCII определяются как символы с кодами символов в диапазоне 000-127 в десятичной системе счисления, то есть 00-7F в HEX и 000000-1111111 в двоичной системе. Те, которых вы хотите избежать, так называемые «символы, отличные от ASCII», — это символы из диапазона 128–255 в десятичной системе счисления, то есть 80-FF в HEX или 10000000-11111111 в двоичном формате.Подсчитав символы в двух двоичных строках, мы скоро сможем определить настоящую причину их непопулярности: символы, отличные от ASCII, требуют дополнительного бита для их хранения.
Это вызовет проблемы в реальном мире? К сожалению, да, будет. Этот запрещенный диапазон символов включает в себя все иностранные буквы с акцентом: A, E, I, O, U с точками, тире и наклонными линиями над ними, а также ряд других. Если они есть в вашем списке ключевых слов, вам нужно будет транслитерировать их в их приблизительные безопасные эквиваленты — другими словами, поменяйте местами символы на буквы, как если бы они не имели лишних отметок над или под ними.
Другие проблемы, с которыми вы можете столкнуться, возникают при копировании и вставке текста с веб-страницы или PDF-документа в ваш список ключевых слов. Авторы довольно часто используют различные символы, которые « выглядят » так же, как обычные кавычки, кавычки, тире и т. в тот момент, когда вы пытаетесь его использовать.
Итак, теперь мы знаем об этих персонажах, есть ли способ обнаружить их автоматически? Да, есть, и это довольно легко сделать, если ваш текстовый редактор поддерживает «Регулярные выражения».На предыдущих страницах мы использовали текстовый редактор PSPad, поэтому я продолжу использовать его здесь и продемонстрирую, как определять символы, отличные от ASCII.
Откройте файл, который вы хотите проверить, затем нажмите «Поиск»> «Найти» или «Control + F». Откроется окно «Найти», как показано на изображении выше. Скопируйте и вставьте следующие символы в белое окно поиска:
[\ x80- \ xFF]
и установите флажок «Регулярные выражения». Не волнуйтесь — для этого не нужно понимать, что такое регулярные выражения и как они работают! Нажмите «ОК», и будет выделен первый не-ASCII-символ — в нашем случае это буква «e» с акцентом в Алжире.Нажмите кнопку «F3», чтобы найти следующий, и так далее. В качестве альтернативы, вместо того, чтобы нажимать «ОК», вы можете нажать кнопку «Список», и список всех вхождений символа, отличного от ASCII, с номером строки, в которой он был найден, будет отображаться в списке внизу окно PSPad.
Альтернативой вышеуказанному методу является использование автоматического инструмента, который транслитерирует все иностранные символы с диакритическими знаками, а также улавливает другие символы, отличные от ASCII. Он также выявляет ошибки, находит дубликаты, сохраняет комментарии для каждой строки, визуализирует список и многое другое.Вы можете найти его здесь: Инструменты списка вкладок.
Используйте в пароле символы, отличные от ASCII.
Перефразируя Марка Твена, сообщения о смерти пароля сильно преувеличены. Объявлять об их неизбежной кончине — это выдавать желаемое за действительное, потому что они с нами на неопределенное время.
Биометрическая, многофакторная и другие формы аутентификации станут более распространенными, но пароли останутся повсеместной формой аутентификации. Мы должны сосредоточиться на их улучшении, а не на их замене.
Проблемы с паролями
Когда пароли впервые были использованы в Массачусетском технологическом институте в начале 1960-х годов, они состояли из букв, цифр и знаков препинания из кодировки символов Американского стандартного кода обмена информацией (ASCII). ASCII имеет 95 печатных символов (включая пробел) и 33 управляющих символа телетайпа. Несмотря на свой возраст, он остается основным источником паролей во всем мире.
Основной недостаток обычных паролей — ограниченное количество разрешенных символов.Для пароля из x символов, взятых из y разрешенных символов, существует x y комбинаций паролей. Исторически сложилось так, что большинство паролей ограничивались подмножеством 95 печатаемых символов ASCII, но сегодня не осталось никаких веских технических причин для запрета пробела или любого другого «специального» символа в вашем пароле. Тем не менее, этих контрпродуктивных ограничений предостаточно.
Злоумышленники, исследователи и тестеры на проникновение используют оптимизированные инструменты для взлома паролей, такие как hashcat и John the Ripper, для взлома паролей разными способами.Самая плодотворная атака — загрузить в эти инструменты словарь из десятков миллионов паролей, украденных из предыдущих эксплойтов, сначала отсортированных по наиболее распространенным паролям. Если атака по словарю терпит неудачу, взломщик пробует каждую комбинацию разрешенных символов в атаке методом перебора до тех пор, пока пароль не будет правильно угадан.
Сегодня за 20 000 долларов можно купить компьютер с перепрофилированными видеокартами, который может перепробовать до 100 миллиардов паролей 90 865 в секунду. Если злоумышленник знает, что ваш банк запрещает использование пробелов и десяти других знаков пунктуации, то в каждой позиции вашего пароля можно использовать не более 84 символов — исключение одиннадцати символов приводит к сокращению на 100 триллионов 10-значных комбинаций паролей.Таким образом, запрещение даже одного персонажа упрощает задачу для хакеров без уважительной технической причины и, конечно же, без всякой выгоды.
Большинство систем используют «байт» или 8-битное значение для хранения каждого символа в вашем пароле. Байт может принимать одно из 256 числовых значений от 0 до 255. В нашем примере с банком злоумышленнику нужно всего лишь попробовать 84 из 256, или жалкие 32,8 процента возможных значений для каждого символа пароля.
Что нам нужно, так это схема паролей, в которой злоумышленник должен попробовать все 256 возможных значений для каждого символа при атаке методом грубой силы.Разница разительная. Для 10-значного пароля существует еще 10 172 перестановок, когда потенциально используются все 256-байтовые значения, что делает невозможными атаки методом перебора.
Решение
Пароли практически не эволюционировали из телетайпной формы в 1960-х, но решение было в пределах нашей досягаемости с начала 1990-х: стандарт Unicode. Основная цель Unicode — определить все письменные сценарии, современные и древние, включая символы и эмодзи.
Последняя версия Unicode 9.0 определяет почти 130 000 символов. Юникод — это собственная схема кодирования во всех основных операционных системах и в Интернете. Первый блок из 128 символов Unicode, Basic Latin, точно отображается в ASCII, включая неиспользуемые устаревшие коды управления телетайпом.
Одним из полезных атрибутов Unicode является то, что используются все 256-байтовые значения из-за огромного количества закодированных символов, при условии, что в дополнение к базовой латинице используются символы из блоков.Например, символ тайской валюты — бат,? — кодируется как три байта в UTF-8: 224 184 191, ни один из которых не является кодировкой ASCII. Символ бат визуально различим и легко запоминается, и, конечно, не нужно знать, что он представляет, чтобы использовать его в пароле.
Использование хотя бы одного такого символа, отличного от ASCII, в вашем пароле может сделать невозможными брутфорс и атаки по словарю. Поскольку количество перестановок паролей составляет x y , использование символа бата делает пароль более надежным по двум причинам.Во-первых, для кодирования символа в UTF-8 необходимо три байта, поэтому было увеличено x . Во-вторых, использование Unicode вынуждает злоумышленника, проводящего атаку методом перебора, проверить все 256 возможных значений байтов, поэтому y увеличилось с 84 до 256.
Система с поддержкой Unicode также позволяет использовать любой из тысяч символов и смайликов, дополнительно укрепляя пароль. Например, смайлик «семья с матерью, отцом, сыном и дочерью» кодируется в UTF-8 как 25 байтов, ни один из которых не используется в Basic Latin / ASCII.Таким образом, добавление этого единственного эмодзи умножает количество возможных комбинаций на 25 256 или 10 357 .
Куда мы идем дальше?
Бенджамин Франклин сказал: «Опыт держит дорогую школу, но глупцы не научатся ни в какой другой».