Массивы NumPy | NumPy
3.1. Прежде чем читать
Нужно немного знать Python. Причем «немного» означает действительно немного и вовсе не означает, что перед чтением данного руководства вам нужно досконально изучить этот язык. Открытой вкладки с официальным руководством окажется вполне достаточно.
Все примеры выполнены в консоли IDE Spyder дистрибутива Anaconda на Python версии 3.5. и NumPy версии 1.14.0. Приводимые примеры так же будут работать в любом другом дистрибутиве Python 3.х версии и последней версией пакета NumPy. Но если некоторые примеры все же не работают, то ознакомьтесь с официальной документацией вашего дистрибутива, возможно причина связана с его особенностями.
Например, если в своем дистрибутиве вы обнаружили последнюю версию IDE Spyder, то в ней нет Python консоли, к которой привыкают многие новички, учившиеся экспериментировать с кодом в IDLE.
3.2. Основы
Главный объект NumPy — это однородный многомерный массив. Чаще всего это одномерная последовательность или двумерная таблица, заполненные элементами одного типа, как правило числами, которые проиндексированы кортежем положительных целых чисел. В NumPy, элементы этого кортежа называются осями, а число осей рангом.
Что бы перейти к примерам, сначала выполним импорт пакета:
>>> import numpy as np
Импортирование numpy под псевдонимом np уже стало общепринятой, негласной, договоренностью, можно сказать, традицией.
Теперь мы може приступить к примерам. Способов создания массивов NumPy довольно много, но мы начнем с самого тривиального — создание массива из заполненного вручную списка Python:
>>> a = np.array([11, 22, 33, 44, 55, 66, 77, 88, 99]) >>> >>> a array([11, 22, 33, 44, 55, 66, 77, 88, 99])
Теперь у нас есть одномерный массив (словосочетание «ранг массива» вряд ли приживется в русском языке), т.е. у него всего одна ось вдоль которой происходит индексирование его элементов.
Получить доступ к числу 33 можно привычным способом:
>>> a[2] 33
В общем-то, можно подумать, что ничего интересного и нет в этих массивах, но на самом деле это только начало кроличьей норы. Оцените:
>>> a[[7, 0, 3, 3, 3, 0, 7]] array([88, 11, 44, 44, 44, 11, 88])
Вместо одного индекса, указан целый список индексов. А вот еще любопытный пример, теперь вместо индекса укажем логическое выражение:
А вот еще любопытный пример, теперь вместо индекса укажем логическое выражение:
>>> a[a > 50] array([55, 66, 77, 88, 99])
Цель этих двух примеров — не устраивать головоломку, а продемонстрировать расширенные возможности индексирования массивов NumPy. С тем как устроена индексация мы разберемся в другой главе. Что еще интересного можно продемонстрировать? Векторизованные вычисления:
>>> 2*a + 10 array([ 32, 54, 76, 98, 120, 142, 164, 186, 208]) >>> >>> np.sin(a)**2 + np.cos(a)**2 array([1., 1., 1., 1., 1., 1., 1., 1., 1.])
Векторизованные — означает, что все арифметические операции и математические функции выполняются сразу над всеми элементами массивов. А это в свою очередь означает, что нет никакой необходимости выполнять вычисления в цикле. В случае одномерного массива, можно подумать, что это не такой уж бонус, ведь есть генераторы. Но давайте перейдем к двумерным массивам:
>>> a = np.arange(12) >>> a array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]) >>> >>> a = a.reshape(3, 4) >>> a array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]])
 arange(12)
>>> a
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
>>>
>>> a = a.reshape(3, 4)
>>> a
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
arange(12)
>>> a
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
>>>
>>> a = a.reshape(3, 4)
>>> a
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]]) Сейчас мы создали массив с помощью функции np.arange(), которая во многом аналогична функции range() языка Python. Затем, мы изменили форму массива с помощью метода reshape(), т.е. на самом деле создать этот массив мы могли бы и одной командой:
>>> a = np.arange(12).reshape(3, 4)
>>> a
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])Визуально, данный массив выглядит следующим образом:
Глядя на картинку, становится понятно, что первая ось (и индекс соответственно) — это строки, вторая ось — это столбцы. Т.е. получить элемент 9 можно простой командой:
>>> a[2][1] # равносильно команде a[2, 1] 9
Снова можно подумать, что ничего нового — все как в Python. Да, так и есть, и, это круто! Еще круто, то что NumPy добавляет к удобному и привычному синтаксису Python, весьма удобные трюки, например — транслирование массивов:
Да, так и есть, и, это круто! Еще круто, то что NumPy добавляет к удобному и привычному синтаксису Python, весьма удобные трюки, например — транслирование массивов:
>>> b = [2, 3, 4, 5]
>>>
>>> a*b
array([[ 0, 3, 8, 15],
[ 8, 15, 24, 35],
[16, 27, 40, 55]]) В данном примере, без всяких циклов (и генераторов), мы умножили каждый столбец из массива a на соответствующий элемент из массива b. Т.е. мы как бы транслировали (в какой-то степени можно сказать — растянули) массив b по массиву a.
То же самое мы можем проделать с каждой строкой массива a:
>>> c = [[10], [20], [30]]
>>>
>>> a + c
array([[10, 11, 12, 13],
[24, 25, 26, 27],
[38, 39, 40, 41]])a массив-столбец c. И получили, то что хотели. Сейчас мы не будем подробно рассматривать механизм транслирования — это тема другой главы. Вместо этого я хочу отметить, что при работе с двумерными или трехмерными массивами, особенно с массивами большей размерности, становится очень важным удобство работы с элементами массива, которые расположены вдоль отдельных измерений — его осей.
И получили, то что хотели. Сейчас мы не будем подробно рассматривать механизм транслирования — это тема другой главы. Вместо этого я хочу отметить, что при работе с двумерными или трехмерными массивами, особенно с массивами большей размерности, становится очень важным удобство работы с элементами массива, которые расположены вдоль отдельных измерений — его осей.Например, у нас есть двумерный массив и мы хотим узнать его минимальные элементы по строкам и столбцам. Для начала создадим массив из случайных чисел и пусть, для нашего удобства, эти числа будут целыми:
>>> a = np.random.randint(0, 15, size = (4, 6))
>>> a
array([[ 9, 12, 5, 3, 1, 7],
[ 2, 12, 10, 11, 14, 9],
[ 4, 4, 9, 11, 5, 2],
[12, 8, 6, 8, 9, 3]])Минимальный элемент в данном массиве это:
>>> a.min() 1
А вот минимальные элементы по столбцам и строкам:
>>> a.
 min(axis = 0) # минимальные элементы по столбцам
array([2, 4, 5, 3, 1, 2])
>>>
>>> a.min(axis = 1) # минимальные элементы по строкам
array([1, 2, 2, 3])
min(axis = 0) # минимальные элементы по столбцам
array([2, 4, 5, 3, 1, 2])
>>>
>>> a.min(axis = 1) # минимальные элементы по строкам
array([1, 2, 2, 3])Такое поведение заложено практически во все функции и методы NumPy:
>>> a.mean(axis = 0) # среднее по столбцам array([6.75, 9. , 7.5 , 8.25, 7.25, 5.25]) >>> >>> np.std(a, axis = 1) # стандартное отклонение по строкам array([3.67045259, 3.77123617, 3.13138237, 2.74873708])
Чтож, мы рассмотрели одномерные и двумерные массивы, а так же некоторые трюки NumPy. Но данный пакет позиционируется прежде всего как научный инструмент. Что насчет вычислений, их скорости и занимаемой памяти?
Для примера, создадим трехмерный массив:
>>> a = np.arange(48).reshape(4, 3, 4)
>>> a
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]],
[[24, 25, 26, 27],
[28, 29, 30, 31],
[32, 33, 34, 35]],
[[36, 37, 38, 39],
[40, 41, 42, 43],
[44, 45, 46, 47]]]) Почему именно трехмерный? На самом деле реальный мир вовсе не ограничивается таблицами, векторами и матрицами.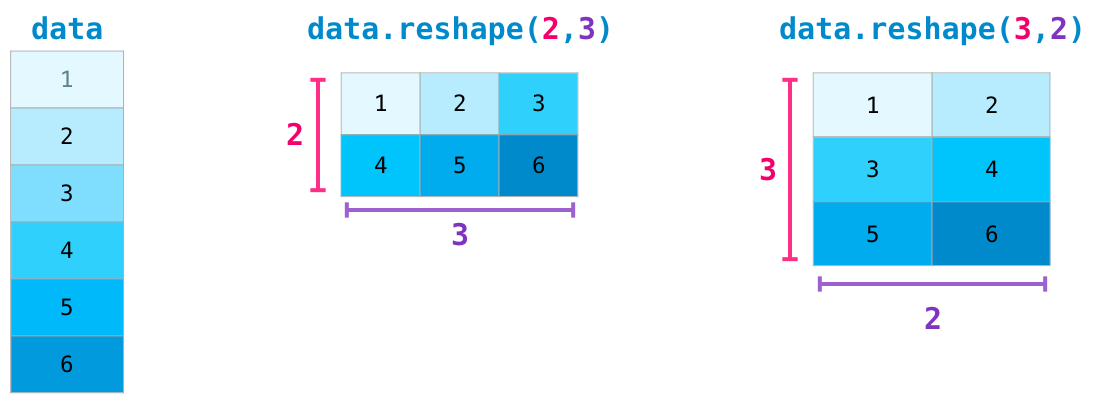 Еще существуют тензоры, кватернионы, октавы. А некоторые данные, гораздо удобнее представлять именно в трехмерном и четырехмерном представлении, например, биржевые торги по всем инструментам, лучше всего представлять в трехмерном виде, а торги нескольких бирж в четырехмерном. Конечно, такими сложными вычислениями занимается очень небольшое количество людей, но надо отметить, что именно эти люди двигают науку и индустрию вперед. Да и слово «
Еще существуют тензоры, кватернионы, октавы. А некоторые данные, гораздо удобнее представлять именно в трехмерном и четырехмерном представлении, например, биржевые торги по всем инструментам, лучше всего представлять в трехмерном виде, а торги нескольких бирж в четырехмерном. Конечно, такими сложными вычислениями занимается очень небольшое количество людей, но надо отметить, что именно эти люди двигают науку и индустрию вперед. Да и слово «
Визуализация (и хорошее воображение) позволяет сразу догадаться, как устроена индексация трехмерных массивов. Например, если нам нужно вытащить из данного массива число 31, то достаточно выполнить:
>>> a[2][1][3] # или a[2, 1, 3] 31
Но, что если мы хотим узнать побольше об этом массиве. В самом деле, у массивов есть целый ряд важных атрибутов. Например, количество осей массива (его размерность), которую при работе с очень большими массивами, не всегда легко увидеть:
Например, количество осей массива (его размерность), которую при работе с очень большими массивами, не всегда легко увидеть:
>>> a.ndim 3
Массив a действительно трехмерный. Но иногда становится интересно, а на сколько же большой массив перед нами. Например, какой он формы, т.е. сколько элементов расположено вдоль каждой оси? Ответить позволяет метод ndarray.shape:
>>> a.shape (4, 3, 4)
Метод ndarray.size просто возвращает общее количество элементов массива:
>>> a.size 48
Еще может встать такой вопрос — сколько памяти занимает наш массив? Иногда даже возникает такой вопрос — влезет ли результирующий массив после всех вычислений в оперативную память? Что бы на него ответить надо знать, сколько «весит» один элемент массива:
>>> a.itemsize # эквивалентно ndarray.
 dtype.itemsize
4
dtype.itemsize
4 ndarray.itemsize возвращает размер элемента в байтах. Теперь мы можем узнать сколько «весит» наш массив:
>>> a.size*a.itemsize 192
Итого — 192 байта. На самом деле, размер занимаемой массивом памяти, зависит не только от количества элементов в нем, но и от испльзуемого типа данных:
>>> a.dtype
dtype('int32') dtype('int32') — означает, что используется целочисленный тип данных, в котором для хранения одного числа выделяется 32 бита памяти. Но если мы выполним какие-нибудь вычисления с массивом, то тип данных может измениться:
>>> b = a/3.14
>>>
>>> b
array([[[ 0. , 0.31847134, 0.63694268, 0.95541401],
[ 1.27388535, 1.59235669, 1.91082803, 2.22929936],
[ 2.5477707 , 2.86624204, 3.18471338, 3.50318471]],
[[ 3. 82165605, 4.14012739, 4.45859873, 4.77707006],
[ 5.0955414 , 5.41401274, 5.73248408, 6.05095541],
[ 6.36942675, 6.68789809, 7.00636943, 7.32484076]],
[[ 7.6433121 , 7.96178344, 8.28025478, 8.59872611],
[ 8.91719745, 9.23566879, 9.55414013, 9.87261146],
[10.1910828 , 10.50955414, 10.82802548, 11.14649682]],
[[11.46496815, 11.78343949, 12.10191083, 12.42038217],
[12.7388535 , 13.05732484, 13.37579618, 13.69426752],
[14.01273885, 14.33121019, 14.64968153, 14.96815287]]])
>>>
>>>
>>> b.dtype
dtype('float64') 82165605, 4.14012739, 4.45859873, 4.77707006],
[ 5.0955414 , 5.41401274, 5.73248408, 6.05095541],
[ 6.36942675, 6.68789809, 7.00636943, 7.32484076]],
[[ 7.6433121 , 7.96178344, 8.28025478, 8.59872611],
[ 8.91719745, 9.23566879, 9.55414013, 9.87261146],
[10.1910828 , 10.50955414, 10.82802548, 11.14649682]],
[[11.46496815, 11.78343949, 12.10191083, 12.42038217],
[12.7388535 , 13.05732484, 13.37579618, 13.69426752],
[14.01273885, 14.33121019, 14.64968153, 14.96815287]]])
>>>
>>>
>>> b.dtype
dtype('float64')
82165605, 4.14012739, 4.45859873, 4.77707006],
[ 5.0955414 , 5.41401274, 5.73248408, 6.05095541],
[ 6.36942675, 6.68789809, 7.00636943, 7.32484076]],
[[ 7.6433121 , 7.96178344, 8.28025478, 8.59872611],
[ 8.91719745, 9.23566879, 9.55414013, 9.87261146],
[10.1910828 , 10.50955414, 10.82802548, 11.14649682]],
[[11.46496815, 11.78343949, 12.10191083, 12.42038217],
[12.7388535 , 13.05732484, 13.37579618, 13.69426752],
[14.01273885, 14.33121019, 14.64968153, 14.96815287]]])
>>>
>>>
>>> b.dtype
dtype('float64') Теперь у нас есть еще один массив — массив b и его тип данных 'float64' — вещественные числа (числа с плавающей точкой) длинной 64 бита. А его размер:
>>> b.size*b.itemsize 384
Тогда массив a — 192 байта, массив b — 384 байта. А в общем, получается, 576 байт — что очень мало для современных объемов оперативной памяти, но и реальные объемы данных, которые сейчас приходится обрабатывать совсем немаленькие.
Мы с вами собирались ответить на вопросы производительности вычислений в NumPy, но это тоже тема отдельной главы. Могу лишь сказать, что на самом деле скорость вычислений, очень сильно зависит от того кода, который вы пишите. Например, частое копирование и присваивание массивов, приводит к бесполезному потреблению памяти, а работа универсальных функций NumPy без дополнительных настроек, особенно в циклах, так же может выполняться несколько медленнее. В общем задача по использованию всего вычислительного потенциала программного обеспечения и железа, не такая уж и простая, но определенно решаемая задача.
3.3. Напоследок
Если вы новичок, то очень скоро поймете, что в использовании NumPy так же прост как и Python. Но, рано или поздно, дело дойдет до сложных задач и вот тогда начнется самое интересное: документации не хватает, ничего не гуглится, а бесчисленные «почти» подходящие советы приводят к необъяснимым сверхъестественным последствиям. Что делать в такой ситуации?
Что делать в такой ситуации?
- гуглить упорнее и спускаться к самому дну поисковой выдачи;
- гуглить на английском языке, потому что, на английском информации на порядки больше чем на русском;
- если не помог пункт 2, то это означает, что вы просто маньяк какой-то, и что бы решить свою маниакальную задачу, вам придется гуглить на китайском языке, потому что на китайском информации на порядки больше чем на английском.
Это шутка и серьезная рекомендация одновременно. Но, если говорить абсолютно серьезно, то просто придерживайтесь здравого смысла. Где этот здравый смысл начинается, а где заканчивается в конкретной задаче сказать очень трудно. import this вам в помощь:
>>> import this The Zen of Python, by Tim Peters Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated.
 Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!Если вы раньше пользовались R или matlab, то вас тоже ожидает много приятных сюрпризов, по крайней мере один — придется меньше стучать по клавиатуре.
| ||
 Объединение и разделение массивов
Объединение и разделение массивов Здесь мы узнаем
как реализуются операции объединения и разделения массивов. Для этой задачи в NumPy реализованы
специальные функции, которые мы сейчас и рассмотрим.
Здесь мы узнаем
как реализуются операции объединения и разделения массивов. Для этой задачи в NumPy реализованы
специальные функции, которые мы сейчас и рассмотрим.
 hstack([a, b]) # размерность 3x6x2
d = np.vstack([a, b]) # размерность 6x3x2
hstack([a, b]) # размерность 3x6x2
d = np.vstack([a, b]) # размерность 6x3x2 column_stack([a, b]) # формирование массива 4x2
column_stack([a, b]) # формирование массива 4x2 Например,
объект r_ создает копии
массивов, следующими способами:
Например,
объект r_ создает копии
массивов, следующими способами:
 Второй параметр 2 указывает число частей,
на которые делится исходный массив. Причем, деление выполняется по горизонтали.
Если в нашем примере указать 3 части, то возникнет ошибка:
Второй параметр 2 указывает число частей,
на которые делится исходный массив. Причем, деление выполняется по горизонтали.
Если в нашем примере указать 3 части, то возникнет ошибка:
 hsplit(a, 2) # разбиение по горизонтали
np.vsplit(a, 2) # разбиение по вертикали
hsplit(a, 2) # разбиение по горизонтали
np.vsplit(a, 2) # разбиение по вертикали Изменение формы массивов, добавление и удаление осей | NumPy уроки
Изменение формы массивов, добавление и удаление осей | NumPy урокиМногомерные массивы в Numpy | Работа с многомерными массивами данных с Python и Numpy
Зарегистрируйтесь для доступа к 15+ бесплатным курсам по программированию с тренажером
Библиотека Numpy дает мощный и удобный высокоуровневый аппарат для работы с многомерными данными. Для работы с ними в Numpy разработана своя собственная структура данных — массив
Для работы с ними в Numpy разработана своя собственная структура данных — массив numpy.ndarray. Именно под эту структуру оптимизирована работа всего функционала библиотеки.
В этом уроке познакомимся с тем, как создавать массив ndarray из стандартных типов данных языка Python и попробуем на практике решить ряд простых аналитических задач.
Структура данных библиотеки Numpy
Чтобы создать структуру numpy.ndarray, нужно конвертировать список list. Для конвертации из множества set требуется дополнительное приведение типа данных.
Рассмотрим на таком примере:
# Импортируем библиотеку numpy с псевдонимом np import numpy as np # Создаем простой пример списка языка Python simple_list = [1, 2, 3, 4, 5] # Конвертируем созданный список в массив Numpy my_first_ndarray = np.array(simple_list, dtype=int) # Тип созданного объекта print(type(my_first_ndarray)) # => <class 'numpy.ndarray'> # Результат стандартного вывода print(my_first_ndarray) # => [1, 2, 3, 4, 5]
А теперь разберем этот код подробнее. Сам пример показывает встроенный функционал для создания структуры
Сам пример показывает встроенный функционал для создания структуры numpy.ndarray. Этот пример показывает встроенный функционал для создания структуры numpy.ndarray. Мы импортируем библиотеку Numpy, создаем короткий список значений simple_list, а затем конвертируем в массив my_first_ndarray. Для этого вызываем конструктор np.array() с объектами для конвертации.
С учетом примера выше, обратная конвертация в список происходит так:
print(ndarray_from_list.tolist())
Конвертация из списка Python — это самая популярная операция, с помощью которой создается структура numpy.ndarray.
Так происходит потому, что обмен данными между функциями и сервисами удобно производить в стандартных структурах данных языка. Другими словами, можно не вводить структуры данных сторонних библиотек и не усложнять программу.
Но при разработке сложных программ, модуль numpy.ndarray может быть только частью общей структуры. В таких случаях используют стандартные типы данных языка для обмена данными между функциональными частями программ.
В таких случаях используют стандартные типы данных языка для обмена данными между функциональными частями программ.
В итоге порядок работы с данными при работе с Numpy выглядит следующим образом:
Как правило, вычислительные и аналитические модули в виде входных данных ожидают списки значений. Всю оптимизацию они делают уже внутри себя в собственных абстракциях, невидимых извне. Это сделано для простоты интеграции.
Допустимые типы данных
Поговорим подробнее о типах элементов массива, которые можно использовать для numpy.ndarray. Продолжим работать с тем же примером и воспользуемся следующим методом:
# Проверяем тип полученного массива print(my_first_ndarray.dtype.type) # => <class 'numpy.int64'>
Как и ожидалось, тип данных — int64. Необязательно ограничиваться только им:
# Целочисленный массив print(np.array([1, 2, 3], dtype=int).dtype.type) # => <class 'numpy.int64'> # Массив строк print(np.array([1, 2, 3], dtype=str).
 dtype.type)
# => <class 'numpy.str_'>
# Массив чисел с плавающей запятой
print(np.array([1, 2, 3], dtype=float).dtype.type)
# => <class 'numpy.float64'>
dtype.type)
# => <class 'numpy.str_'>
# Массив чисел с плавающей запятой
print(np.array([1, 2, 3], dtype=float).dtype.type)
# => <class 'numpy.float64'>
Обратите внимание, что для экземпляра структуры numpy.ndarray нельзя использовать сразу несколько типов данных. Проще говоря, все элементы в массиве должны быть однотипные. Посмотрим, как конструктор сам определит тип данных при конвертации:
# Все элементы списка целочисленные print(np.array([1, 2, 3]).dtype.type) # => <class 'numpy.int64'> # Все элементы списка — это строки print(np.array(['1', '2', '3']).dtype.type) # => <class 'numpy.str_'> # Элементы списка как текстовые, так и целочисленные print(np.array(['1', 2, 3]).dtype.type) # => <class 'numpy.str_'>
Заметим, что ошибки при конвертации смешанного типа элементов массива не произошло. Конвертор просто привел все данные к строковому типу.
Функционал библиотеки Numpy настолько интуитивен, что уже сейчас можно решить простую аналитическую задачку.
Представим продажи ноутбуков в магазине за одну неделю:
| День | Магазин №1 |
|---|---|
| 0 | 7 |
| 1 | 4 |
| 2 | 3 |
| 3 | 8 |
| 4 | 15 |
| 5 | 21 |
| 6 | 25 |
На практике такие данные обычно хранятся в табличном виде в базе данных. Чтобы упростить пример, мы пропустили этап выгрузки — подразумевается, что данные приходят в вычислительный модуль уже в виде списка значений.
Поработаем с данными с помощью библиотеки Numpy:
# Импортируем библиотеку numpy с псевдонимом np import numpy as np # Создаем список продаж — представим, что считали его из базы данных orders_list = [7, 4, 3, 8, 15, 21, 25] # Конвертируем созданный список в массив Numpy orders_ndarray = np.array(orders_list, dtype=int) # Тип созданного объекта print(type(orders_ndarray)) # => <class 'numpy.
 ndarray'>
# Результат стандартного вывода
print(orders_ndarray)
# => [7, 4, 3, 8, 15, 21, 25]
ndarray'>
# Результат стандартного вывода
print(orders_ndarray)
# => [7, 4, 3, 8, 15, 21, 25]
Попробуем найти день недели с самыми низкими продажами. Опыт работы с Python подсказывает, что метод будет называться min() или minimum(). Найдем минимальное количество продаж и заодно день недели, в который оно совершено:
# Находим минимальный элемент массива print(orders.min()) # => 3 # Находим порядковый номер минимального элемента массива print(orders.argmin()) # => 2
Чтобы найти наибольшее количество продаж, достаточно поменять одну функцию:
# Находим мкксимальный элемент массива print(orders.max()) # => 25
На практике часто анализ не ограничивается только одной неделей продаж и одним магазином. В этом случае набор данных представлен в виде списка списков элементов — это уже двумерная структура, которая в математике называется матрицей.
В Numpy реализация инициализации массивов и функций работы с ними не зависит от размерности данных, что существенно упрощает разработку.
В современных библиотеках можно применять одну и ту же функцию к различным типам данных. Рассмотрим это на примере, похожем на предыдущий. Найдем день с самыми низкими доходами во всей сети магазинов. Рассмотрим недельные продажи в четырех магазинах:
| День | Магазин №1 | Магазин №2 | Магазин №3 | Магазин №4 |
|---|---|---|---|---|
| 0 | 7 | 1 | 7 | 8 |
| 1 | 4 | 2 | 4 | 5 |
| 2 | 3 | 5 | 2 | 3 |
| 3 | 8 | 12 | 8 | 7 |
| 4 | 15 | 11 | 13 | 9 |
| 5 | 21 | 18 | 17 | 21 |
| 6 | 25 | 16 | 25 | 17 |
Мы ожидаем, что функционально все должно быть реализовано похожим образом. Давайте в этом убедимся, взглянув на код:
# Импортируем библиотеку numpy с псевдонимом np
import numpy as np
# Создаем «список списков продаж»
orders_list = [
[7, 1, 7, 8],
[4, 2, 4, 5],
[3, 5, 2, 3],
[8, 12, 8, 7],
[15, 11, 13, 9],
[21, 18, 17, 21],
[25, 16, 25, 17]
]
# Конвертируем созданный «список списков» в массив Numpy
orders_ndarray = np. array(orders_list, dtype=int)
# Описываем тип созданного объекта
print(type(orders_ndarray))
# => <class 'numpy.ndarray'>
# Находим минимальный элемент массива
print(orders_ndarray.min())
# => 1
 array(orders_list, dtype=int)
# Описываем тип созданного объекта
print(type(orders_ndarray))
# => <class 'numpy.ndarray'>
# Находим минимальный элемент массива
print(orders_ndarray.min())
# => 1
array(orders_list, dtype=int)
# Описываем тип созданного объекта
print(type(orders_ndarray))
# => <class 'numpy.ndarray'>
# Находим минимальный элемент массива
print(orders_ndarray.min())
# => 1
В приведенном примере метод min() находит минимальный элемент среди всех значений массива.
Большинство функций в Numpy реализованы так, что методы и функции выполняют одинаковые операции, вне зависимости от типа данных на входе.
В программировании такой подход называется полиморфизмом. Он упрощает разработку и делает код более простым для анализа и поддержки.
Выводы
Сегодня мы познакомились с основной структурой данных библиотеки Numpy — массивом numpy.ndarray.
Numpy. Матричные вычисления — Документация compute 0.1
Numeric Python (NumPy)- это несколько модулей для вычислений с многомерными массивами, необходимых для многих
численных приложений. Массив — это набор однородных элементов, доступных по индексам. Массивы модуля Numeric
могут быть многомерными, то есть иметь более одной размерности. Количество размерностей и длина массива по
каждой оси называются формой массива (shape). Размещение массива в памяти проводится в соответствии с опциями
и может быть выполнено как в языке С (по последнему индексу), как в языке Fortran (по первому индексу) или
беспорядочно.
Массивы модуля Numeric
могут быть многомерными, то есть иметь более одной размерности. Количество размерностей и длина массива по
каждой оси называются формой массива (shape). Размещение массива в памяти проводится в соответствии с опциями
и может быть выполнено как в языке С (по последнему индексу), как в языке Fortran (по первому индексу) или
беспорядочно.
Особо подчеркнем отличие массива от набора данных (списка или кортежа). Величины, входящие в массив имеют одинаковый тип и их количество жестко задается при инициализации. Элементы массива не являются объектами, это переменные в обычном понимании этого слова. Массивы позволяют экономить память и увеличивать скорость работы с большим количеством однотипных данных.
Как представлены массивы в Python? В Python массивы – это объекты, содержащие буфер данных и информацию о форме,
размерности, типе данных и т.д. Как и у любого объекта, у массива можно менять атрибуты напрямую: array.shape=(2,3) или через вызов функции np. reshape(array,(2,3)). Такая же ситуация и с методами
(функциями для массивов), заданными в этом классе, многие из них могут вызываться как методы array.resize(2,4) или как самостоятельные функции
reshape(array,(2,3)). Такая же ситуация и с методами
(функциями для массивов), заданными в этом классе, многие из них могут вызываться как методы array.resize(2,4) или как самостоятельные функции NumPy: np.resize(array,(2,4)).
Некоторые функции являются только методами: array.flat, array.flatten, array.T.
Для правильного использования таких функций, необходимо обращаться к их описанию.
Типы данных
В качестве элементов массива можно использовать множество типов, которые перечислены в таблице.
Типы Int, UnsignedInteger, Float и Complex соответствуют наибольшим принятым на данной платформе значениям.
| Тип | Описание | Тип | Описание |
|---|---|---|---|
| Логический | Числа с плавающей точкой | ||
| bool_ | Python bool | half | |
| bool8 | 8 бит | single | C float |
| Целый | double | C double | |
| byte | C char | float_ | Python float |
| short | C short | longfloat | C long float |
| intc | C int | float16 | 16 бит |
| int_ | Python int | float32 | 32 бит |
| longlong | C long long | float64 | 64 бит |
| intp | такой ,что может описывать указатели | float96 | 96 бит,??? |
| int8 | 8 бит | float128 | 128 бит ??? |
| int16 | 16 бит | Комплексные | |
| int32 | 32 бит | csingle | |
| int64 | 64 бит | complex_ | Python complex |
| Целый без знака (натуральное) | clongfloat | ||
| ubyte | C unsigned char | complex64 | два 32- битовых |
| ushort | C unsigned short | complex128 | два 64- битовых |
| uintc | C unsigned int | complex192 | два 96- битовых ??? |
| uint | Python int | complex256 | два 128-битовых |
| ulonglong | C long long | Строки | |
| uintp | такой, что может описывать указатели | str_ | Python str |
| uint8 | 8 бит | unicode_ | Python unicode |
| uint16 | 16 бит | void | |
| uint32 | 32 бит | Объекты Python | |
| uint64 | 64 бит | object_ |
|
Операции для работы с массивами
В NumPy реализовано много операций для работы с массивами:
- создание, модификация массива (изменение формы, транспонирование, поэлементные операции),
- выбор элементов,
- операции с массивами (различные типы умножения), сравнение массивов
- решение задач линейной алгебры (системы линейных уравнений, собственые вектора. собственные значения)
- создание наборов случайных данных
- быстрое преобразование Фурье
 собственные значения)
собственные значения)Создание массивов
В NumPy можно выделить три вида массивов:
- произвольные многомерные массивы (array)
- матрицы (matrix) – двухмерные квадратные массивы, для которых дополнительно определены операции возведения в степень и перемножения. Для работы с матрицами можно вместо “numpy” подключать “numpy.matrix”, в котором реализованы те же самые операции, только массивы – результаты операций будут приводится к типу “matrix”.
- сетки (grid) – массивы, в которых записаны значения координат точек сети (обычно ортогональной). Сетки позволяют удобно вычислять значение функций многих переменных.
Создание массивов из имеющихся данных
Для создания массивов существует множество функций. Самая распространенная из них array().
>>> np.array([[1, 2], [3, 4]])
array([[1, 2],
[3, 4]])
| Команда | Описание |
|---|---|
| array(object[, dtype, copy, order, subok, ndmin]) | Создать массив |
| asarray(a[, dtype, order]) | Преобразовать в массив |
| ascontiguousarray(a[, dtype]) | Размещает в памяти непрерывный массив(порядок данных как в Cи) |
| asmatrix(data[, dtype]) | Представить данные как матрицу |
| copy(a) | Возвращает копию объекта |
| frombuffer(buffer[, dtype, count, offset]) | Использует буфер, как одномерный массив |
| fromfile(file[, dtype, count, sep]) | Создает массив из данных файла |
| fromfunction(function, shape, **kwargs) | Создает и заполняет массив значениями функции от индексов элемента |
| fromiter(iterable, dtype[, count]) | Создает одномерный массив из итератора |
| fromstring(string[, dtype, count, sep]) | Создает одномерный массив из строки |
| loadtxt(fname[, dtype, comments, delimiter, …]) | Создает массив из данных текстового файла |
- a — объект или массив
- object — любой объект с упорядоченными данными
- dtype — тип данных (если не указан определяется по данным объекта)
- copy — да/нет, создать копию данных
- order — {‘C’, ‘F’, ‘A’}– порядок размещения элементов в памяти (Си, Фортран, любой)
- ndmin — минимальное число измерений (добавляет пустые массивы по недостающим измерениям)
- buffer — объект буфера
- count — число данных для чтения
- offset — отступ от начала
- file — объект файла
- sep — шаг чтения файла
- string — строка
- function — функция. Вызывается function(i,j,k,**kwargs), где i,j,k – индексы ячейки массива
- shape — форма массива
- **kwargs — словарь параметров для функции
- fname – имя файла
- comments – символ коментария
- delimiter – разделитель данных
 Вызывается function(i,j,k,**kwargs), где i,j,k – индексы ячейки массива
Вызывается function(i,j,k,**kwargs), где i,j,k – индексы ячейки массиваСоздание сеток
| Команда | Описание | Пример |
|---|---|---|
| arange([start,] stop [, step,][, dtype]) | Похоже на “range()” | >>> np.arange(3.0) array([ 0., 1., 2.]) |
| linspace(start, stop [, num, endpoint, retstep]) | Равномерный набор точек | >>> np.linspace(2.0, 3.0, num=5) array([ 2., 2.25, 2.5, 2.75, 3.]) |
| logspace(start, stop [, num, endpoint, base]) | Логарифмический набор точек | >>> np.logspace(2.0, 3.0, num=4, base=2.0) array([ 4., 5.03968, 6. |
| meshgrid(x, y) | два вектора, описывающих точки ортогональной сетки. | >>> X, Y = np.meshgrid([1,2,3], [4,5,7])
>>> X
array([[1, 2, 3],
[1, 2, 3],
[1, 2, 3]])
>>> Y
array([[4, 4, 4],
[5, 5, 5],
[7, 7, 7]])
|
| mgrid | полный набор данных, описывающий многомерную равномерную ортогональную сетку (X,Y) или (X,Y,Z). Аргументы по каждому измерению: (start : stop : step). Если step – мнимое (5j) – то задается количество интервалов разбиения | >>> np.mgrid[0:5:3j,0:5:3j]
array([[[0., 0., 0.],
[2.5, 2.5, 2.5],
[5., 5., 5.]],
[[0., 2.5, 5.],
[0., 2.5, 5.],
[0., 2.5, 5.]]])
|
| ogrid | сокращенный набор данных, описывающий многомерную равномерную ортогональную сетку (X,Y) или (X,Y,Z). Аргументы по каждому измерению: (start : stop : step). Если step – мнимое (5j) – то задается количество интервалов разбиения | >>> ogrid[0:5,0:5]
[array([[0],
[1],
[2],
[3],
[4]]), array([[0, 1, 2, 3, 4]])]
|
 34960, 8.])
34960, 8.])
- start – начало
- stop – окончание (для «arrange» по умолчанию НЕ включается, для остальных функций — включается)
- step – шаг
- num – число точек в выходном наборе
- endpoint – да/нет, включать крайнюю точку в набор данных
- retstep – да/нет, добавить в данные величину интервала
- x, y – одномерные массивы разбиения для осей.
- base – основание логарифма

Создание массивов определенного вида
| Команда | Описание | Пример |
|---|---|---|
| empty(shape[, dtype, order]), empty_like(a [, dtype, order, subok]) | выделяет место без инициализации (случайные числа) | >>> np.empty([2, 2], dtype=int)
array([[-1073741821, -1067949133],
[ 496041986, 19249760]])
|
| eye(N[, M, k, dtype]) | двухмерный диагональный со сдвигом | >>> np.eye(3, k=1)
array([[ 0., 1., 0.],
[ 0., 0., 1.],
[ 0., 0., 0.]])
|
| identity(N[, dtype]) | единичная матрица (квадратная) | >>> np.identity(3)
array([[ 1., 0., 0.],
[ 0., 1., 0.],
[ 0., 0., 1.]])
|
| ones(shape[, dtype, order]) ones_like(a[, out]) | все единицы | |
| zeros(shape[, dtype, order]) zeros_like(a[, dtype, order, subok]) | все нули | |
| tri(N[, M, k, dtype]) | нижняя треугольная (из единиц) | >>> np. |
| tril(a[, k]) | вырезание нижней треугольной | >>> np.tril([[1,2,3],[4,5,6],[7,8,9], [10,11,12]], -1)
array([[ 0, 0, 0],
[ 4, 0, 0],
[ 7, 8, 0],
[10, 11, 12]])
|
| triu(a[, k]) | вырезание верхней треугольной | >>> np.triu([[1,2,3],[4,5,6],[7,8,9], [10,11,12]], -1)
array([[ 1, 2, 3],
[ 4, 5, 6],
[ 0, 8, 9],
[ 0, 0, 12]])
|
| diag(a[, k]) | вырезает диагональ или создает двумерную диагональную матрицу | |
| diagflat(a[, k]) | двумерная диагональная матрица со всеми элементами из a. | |
| vander(x[, N]) | создает определительВан Дер Монда | >>> x = np.array([1, 2, 3, 5])
>>> N = 3
>>> np.vander(x, N)
array([[ 1, 1, 1],
[ 4, 2, 1],
[ 9, 3, 1],
[25, 5, 1]])
|
| mat(data[, dtype]) | преобразует данные в матрицу | |
| bmat(obj[, ldict, gdict]) | создает матрицу из строки, последовательности или массива |
 tri(3, 5, 2, dtype=int)
array([[1, 1, 1, 0, 0],
[1, 1, 1, 1, 0],
[1, 1, 1, 1, 1]])
tri(3, 5, 2, dtype=int)
array([[1, 1, 1, 0, 0],
[1, 1, 1, 1, 0],
[1, 1, 1, 1, 1]])
- shape – форма массива
- dtype – тип данных
- order – порядок размещения данных(Си, Фортран)
- a – объект типа массива
- N – число строк
- M – число столбцов
- k – задает диагональ (к=0 – главная, к>0 – смещение вверх, к<0 – смещение вниз)
- x – одномерный массив или список
Трансформации массива без изменения элементов
| Команда | Описание |
|---|---|
| resize(a, new_shape) | возвращает новый массив заданной формы (если элементов не хватает, то заполняется циклически) |
| reshape(a, newshape[, order]) | новая форма для данных (полный размер обязан совпадать) |
| ravel(a[, order]) | возвращает новый одномерный массив |
ndarray. flat flat | итератор по массиву (вызывается как метод) |
| ndarray.flatten([order]) | копия массива без формы (вызывается как метод) |
| rollaxis(a, axis[, start]) | сдвигает выбранную ось до нужного положения |
| swapaxes(a, axis1, axis2) | меняет две оси в массиве |
| ndarray.T | То же что и транспонирование. (если размерность=1, то не изменяется) |
| transpose(a[, axes]) | транспонирует массив (переставляет измерения) |
| fliplr(a) | симметрично отображает массив относительно вертикальной оси (право-лево) |
| flipud(a) | симметрично отображает массив относительно горизонтальной оси (верх-низ) |
| roll(a, shift[, axis]) | циклический сдвиг элементов вдоль выбранного направления |
| rot90(a[, k]) | поворот массива против часовой стрелке на 90 градусов |
| tile(A, repeats) | создает матрицу повторением заданной определенное количество |
| repeat(a, repeats[, axis]) | повторяет элементы массива |
- a
- newshape
- order
- start
- axis1, axis2
- shift
- k
- repeats
Слияние и разделение массивов
| Команда | Описание |
|---|---|
| column_stack(tup) | собирает одномерные массивы -столбцы в двухмерный |
| concatenate(tup[, axis]) | соединяет последовательность массивов вместе |
| dstack(tup) | собирает массивы «по глубине» (по третьей оси). |
| hstack(tup) | собирает массивы «по горизонтали» (по столбцам). |
| vstack(tup) | собирает массивы «по вертикали» (по строкам). |
| array_split(a, indices_or_sections[, axis]) | разделяет массив по порциям |
| dsplit(a, indices_or_sections) | разделяет массив «по глубине» (по третьей оси) |
| hsplit(a, indices_or_sections) | разделяет массив «по горизонтали» (по столбцам). |
| split(a, indices_or_sections[, axis]) | разделяет массив на части равной длины |
| vsplit(a, indices_or_sections) | разделяет массив «по вертикали» (по строкам). |
- tup – кортеж массивов
- axis – ось
- a – массив
- indices_or_sections – размер порции при разделении
Функции, определенные для массивов
Алгебраические функции
| Функця | Описание |
|---|---|
| isreal(x) | проверка на действительность (по элементам) |
| iscomplex(x) | проверка на комплексность (по элементам) |
| isfinite(x[, out]) | приверка элементов на числовое значение (не бесконечность и не «не число»).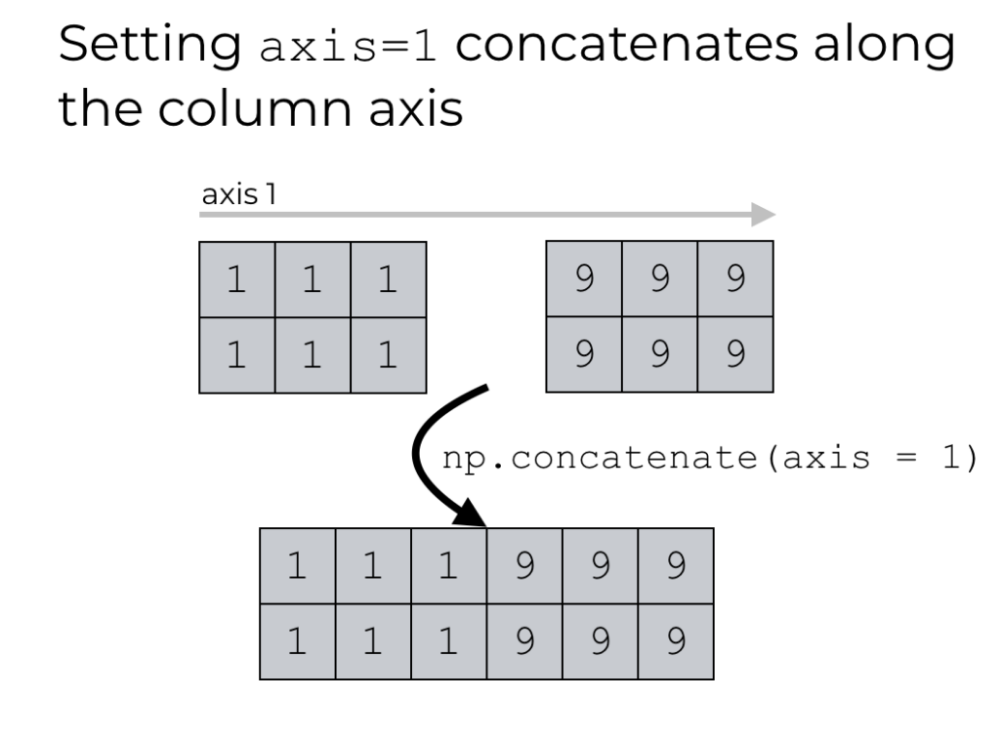 |
| isinf(x[, out]) | проверка на бесконечность (по элементам) |
| isnan(x[, out]) | проверка аргумента на «не число» (NaN), результат – логический массив |
| signbit(x[, out]) | истина, если установлен бит знака (меньше нуля) |
| copysign(x1, x2[, out]) | меняет знак x1 на знак x2 (по элементам |
| nextafter(x1, x2[, out]) | следующее в направлении x2 число, представимое в виде с плавающей точкой (по элементам) |
| modf(x[, out1, out2]) | дробная и целая часть числа |
| ldexp(x1, x2[, out]) | вычисляет y = x1 * 2**x2. |
| frexp(x[, out1, out2]) | разделение числа на нормированную часть и степень |
| absolute(x[, out]) | Calculate the absolute value element-wise. |
| rint(x[, out]) | округление элементов массива |
| trunc(x[, out]) | отбрасывание дробной части (по элементам) |
| floor(x[, out]) | целая часть |
| ceil(x[, out]) | минимальное целое большее числа |
| sign(x[, out]) | знаки элементов |
| conj(x[, out]) | комплексное сопряжение (по элементам). |
| exp(x[, out]) | экспонента (по элементам) |
| exp2(x[, out]) | 2**элемент (по элементам) |
| log(x[, out]) | натуральный логарифм (по элементам) |
| log2(x[, out]) | двоичный логарифм (по элементам) |
| log10(x[, out]) | десятичный логарифм (по элементам) |
| expm1(x[, out]) | exp(x) — 1 (по элементам) |
| log1p(x[, out]) | Return the natural logarithm of one plus the input array, element-wise. |
| sqrt(x[, out]) | квадратный корень (для положительных) (по элементам) |
| square(x[, out]) | квадрат (по элементам) |
| reciprocal(x[, out]) | обратная величина (по элементам) |
- x – массив
- out – место для результата
Тригонометрические функции
Все тригонометрические функции работают с радианами.
| Функция | Обратная функция | Описание |
|---|---|---|
| sin(x[, out]) | arcsin(x[, out]) | синус (по элементам) |
| cos(x[, out]) | arccos(x[, out]) | косинус (по элементам) |
| tan(x[, out]) | arctan(x[, out]) | тангенс (по элементам) |
| arctan2(x1, x2[, out]) | арктангенс x1/x2 с правильным выбором четверти (по элементам) | |
| hypot(x1, x2[, out]) | гипотенуза по двум катетам (по элементам) | |
| sinh(x[, out]) | arcsinh(x[, out]) | гиперболический синус (по элементам) |
| cosh(x[, out]) | arccosh(x[, out]) | гиперболический косинус (по элементам) |
| tanh(x[, out]) | arctanh(x[, out]) | гиперболический тангенс (по элементам) |
| deg2rad(x[, out]) | rad2deg(x[, out]) | преобразование градусов в радианы (по элементам) |
- x, x1, x2 – массивы
- out – место для результата
Функции двух аргументов (бинарные функции)
Для правильной работы с логическими бинарными функциям (AND, OR) необходимо явно их записывать через функции
модуля «NumPy», а не полагаться на встроенные функции питона.
| Функция | Описание |
|---|---|
| add(x1, x2[, out]) | сумма (по элементам) |
| subtract(x1, x2[, out]) | разность (по элементам) |
| multiply(x1, x2[, out]) | произведение (по элементам) |
| divide(x1, x2[, out]) | деление (по элементам) |
| logaddexp(x1, x2[, out]) | логарифм суммы экспонент (по элементам) |
| logaddexp2(x1, x2[, out]) | логарифм по основанию 2 от суммы экспонент (по элементам) |
| true_divide(x1, x2[, out]) | истинное деление (с преобразованием типов) |
| floor_divide(x1, x2[, out]) | деление без преобразования типов (целочисленное) |
| negative(x[, out]) | обратные элементы (по элементам) |
| power(x1, x2[, out]) | элементы первого массива в степени элементов из второго массива (по элементам) |
| remainder(x1, x2[, out]), mod(x1, x2[, out]), fmod(x1, x2[, out]) | остаток от деления (по элементам). |
| greater(x1, x2[, out]) | истина, если (x1 > x2) (по элементам). |
| greater_equal(x1, x2[, out]) | истина, если (x1 > =x2) (по элементам). |
| less(x1, x2[, out]) | истина, если (x1 < x2) (по элементам). |
| less_equal(x1, x2[, out]) | истина, если (x1 =< x2) (по элементам). |
| not_equal(x1, x2[, out]) | истина, если (x1 != x2) (по элементам). |
| equal(x1, x2[, out]) | истина, если (x1 == x2) (по элементам). |
| logical_and(x1, x2[, out]) | истина, если (x1 AND x2) (по элементам). |
| logical_or(x1, x2[, out]) | истина, если (x1 OR x2) (по элементам). |
| logical_xor(x1, x2[, out]) | истина, если (x1 XOR x2) (по элементам). |
| logical_not(x[, out]) | истина, если (NOT x1) (по элементам). |
| maximum(x1, x2[, out]) | максимум из элементов двух массивов(по элементам). |
- x1, x2 – массивы
- out – место для результата
Бинарные функции поддерживают дополнительные методы, позволяющие накапливать значения результата различными способами.
- accumulate() Аккумулирование результата.
- outer() Внешнее «произведение».
- reduce() Сокращение.
- reduceat() Сокращение в заданных точках.
Методы accumulate(), reduce() и reduceat() принимают необязательный аргумент — номер размерности, используемой для соответствующего действия. По умолчанию применяется нулевая размерность.
Другие функций для массивов
| Функция | Описание |
|---|---|
| apply_along_axis(func1d, axis, a, *args) | Применить функцию к одномерному срезу вдоль оси |
| apply_over_axes(func, a, axes) | применить функцию последовательно вдоль осей. |
| vectorize(pyfunc[, otypes, doc]) | обобщить функцию на массивы |
| frompyfunc(func, nin, nout) | берет произвольную функцию Python и возвращает функцию Numpy |
| piecewise(a, condlist, funclist, *args, **kw) | применение кусочно-определенной функции к массиву |
- func1d – функция для вектора
- func – скалярная функция
- axis – индекс оси
- arr – массив
- *args, **kw – дополнительные аргументы
- nin – число входных параметров
- nout – число выходных параметров
- condlist — список условий
- funclist – список функций (для каждого условия)
Сортировка, поиск, подсчет
| Команда | Описание |
|---|---|
| sort(a[, axis, kind, order]) | отсортированная копия массива |
| lexsort(keys[, axis]) | Perform an indirect sort using a sequence of keys. |
| argsort(a[, axis, kind, order]) | аргументы, которые упорядочивают массив |
| array.sort([axis, kind, order]) | сортирует массив на месте (метод массива) |
| msort(a) | копия массива отсортированная по первой оси |
| sort_complex(a) | сортировка комплексного массива по действительной части, потом по мнимой |
| argmax(a[, axis]) | индексы максимальных значений вдоль оси |
| nanargmax(a[, axis]) | индексы максимальных значений вдоль оси (игнорируются NaN). |
| argmin(a[, axis]) | индексы минимальных значений вдоль оси |
| nanargmin(a[, axis]) | индексы минимальных значений вдоль оси (игнорируются NaN). |
| argwhere(a) | массив индексов ненулевых элементов. данные сгруппированы по элементам([x1,y1,..],[x2,y2,..]….) |
| nonzero(a) | массивы индексов ненулевых элементов. сгруппированы по размерностям (индексы X, индексы Y, т.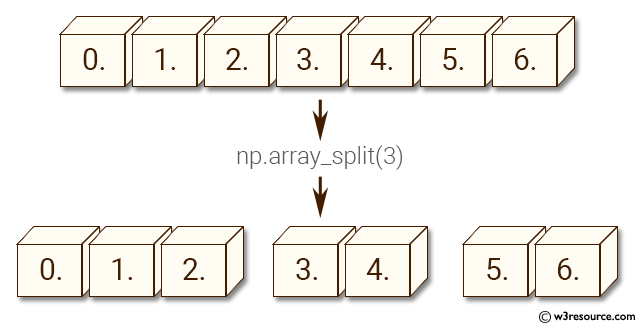 д.) д.) |
| flatnonzero(a) | индексы ненулевых элементов в плоской версии массива |
| where(condition, [x, y]) | возвращает массив составленный из элементов x (если выполнено условие) и y (в противном случае). Если задано только condition, то выдает его «не нули». |
| searchsorted(a, v[, side]) | индексы мест, в которые нужно вставить элементы вектора для сохранения упорядоченности массива |
| extract(condition, a) | возвращает элементы (одномерный массив), по маске (condition) |
| count_nonzero(a) | число ненулевых элементов в массиве |
- a – массив
- axis – индекс оси для сортировки (по умолчанию «–1» — последняя ось)
- kind – {‘quicksort’, ‘mergesort’, ‘heapsort’} тип сортировки
- order – индексы элементов, определяющие порядок сортировки
- keys – (k,N) массив из k элементов размера (N). k “колонок” будут отсортированы. Последний элемент – первичный ключ для сортировки.
- condition – матрица условий (маска)
- x, y – массивы для выбора элементов
- v – вектор
- side – {‘left’, ‘right’} позиция для вставки элемента (слева или справа от найденного индекса)

Дискретное преобразование Фурье (numpy.fft)
| Прямое преобразование | Обратное преобразование | Описание |
|---|---|---|
| fft(a[, s, axis]) | ifft(a[, s, axis]) | одномерное дискретное преобразование Фурье |
| fft2(a[, s, axes]) | ifft2(a[, s, axes]) | двумерное дискретное преобразование Фурье |
| fftn(a[, s, axes]) | ifftn(a[, s, axes]) | многомерное дискретное преобразование Фурье |
| rfft(a[, s, axis]) | irfft(a[, s, axis]) | одномерное дискретное преобразование Фурье (действительные числа) |
| rfft2(a[, s, axes]) | irfft2(a[, s, axes]) | двумерное дискретное преобразование Фурье (действительные числа) |
| rfftn(a[, s, axes]) | irfftn(a[, s, axes]) | многомерное дискретное преобразование Фурье (действительные числа) |
| hfft(a[, s, axis]) | ihfft(a[, s, axis]) | преобразование Фурье сигнала с Эрмитовым спектром |
| fftfreq(n[, d]) | частоты дискретного преобразования Фурье | |
| fftshift(a[, axes]) | ifftshift(a[, axes]) | преобразование Фурье со сдвигом нулевой компоненты в центр спектра |
- a — массив
- s – число элементов вдоль каждого направления преобразования (если больше размерности, то дополняются нулями)
- axes – последовательность осей для преобразования
- n – ширина окна
- d – шаг по частоте при выводе
Линейная алгебра (numpy.
 linalg)
linalg)Модуль numpy.linalg содержит алгоритмы линейной алгебры, в частности нахождение определителя матрицы, решений системы линейных уравнений, обращение матрицы, нахождение собственных чисел и собственных векторов матрицы, разложение матрицы на множители: Холецкого, сингулярное, метод наименьших квадратов и т.д.
| Команда | Описание |
|---|---|
| dot(a, b[, out]) | скалярное произведение массивов |
| vdot(a, b) | векторное произведение векторов |
| inner(a, b) | внутреннее произведение массивов |
| outer(a, b) | внешнее произведение векторов |
| tensordot(a, b[, axes]) | тензорное скалярное произведение вдоль оси (размерность больше 1) |
| einsum(subscripts, *operands[, out, dtype, …]) | суммирование Эйншнейна Evaluates the Einstein summation convention on the operands. |
| linalg.matrix_power(M, n) | возведение квадратной матрицы в степень n |
| kron(a, b) | произведение Кронекера двух массивов |
| linalg.norm(a[, ord]) | норма матрицы или вектора. |
| linalg.cond(a[, ord]) | число обусловленности матрицы. |
| linalg.det(a) | определитель |
| linalg.slogdet(a) | знак и натуральный логарифм определителя |
| trace(a[, offset, axis1, axis2, dtype, out]) | сумма элементов по диагонали. |
| linalg.cholesky(a) | разложение Холецкого |
| linalg.qr(a[, mode]) | разложение QR |
| linalg.svd(a[, full_matrices, compute_uv]) | сингулярное разложение |
| linalg.solve(a, b) | решение линейного матричного уравнения или системы скалярных уравнений. |
| linalg.tensorsolve(a, b[, axes]) | решение тензорного уравнения a x = b для x. |
| linalg.lstsq(a, b[, rcond]) | решение матричного уравнения методом наименьших квадратов |
| linalg.inv(a) | обратная матрица (для умножения) |
| linalg.pinv(a[, rcond]) | псевдо-обратная матрица (Мура-Пенроуза) |
| linalg.tensorinv(a[, ind]) | «обратный» к многомерному массиву |
| linalg.eig(a) | собственные значения и правые собственные вектора квадратной |
| linalg.eigh(a[, UPLO]) | собственные значения и собственные вектора эрмитовой или симметричной матрицы |
| linalg.eigvals(a) | собственные значения произвольной матрицы |
| linalg.eigvalsh(a[, UPLO]) | собственные значения эрмитовой или действительной симметричной матрицы |
- a, b — матрицы
- out — место для результата
- ord – определяет способ вычисления нормы
- axes – массив осей для суммирования
- axis – индекс оси
- subscripts – индексы для суммирования
- *operands – список массивов
- dtype – тип результата
- offset – положение диагонали
- mode — {‘full’, ‘r’, ‘economic’} – выбор алгоритма разложения
- full_matrices – составлять полные матрицы
- compute_uv – выводить все матрицы
- rcond – граница для отбрасывания маленьких собственных значений
- ind – число индексов для вычисления обратной
- UPLO — {‘L’, ‘U’} выбирает часть матрицы для работы
Случайные величины (numpy.
 random)
random)В модуле numpy.random собраны функции для генерации массивов случайных чисел различных распределений и свойств. Их можно применять для математического моделирования. Функция random() создает массивы из псевдослучайных чисел, равномерно распределенных в интервале (0, 1). Функция RandomArray.randint() для получения массива равномерно распределенных чисел из заданного интервала и заданной формы. Можно получать и случайные перестановки с помощью RandomArray.permutation(). Доступны и другие распределения для получения массива нормально распределенных величин с заданным средним и стандартным отклонением:
Следующая таблица приводит основные функции модуля.
seed([seed])- перезапуск генератора случайных чисел
| Команда | Описание |
|---|---|
| rand(d0, d1, …, dn) | набор случайных чисел заданной формы |
| randn([d1, …, dn]) | набор (или наборы) случайных чисел со стандартным нормальным распределением |
| randint(low[, high, size]) | случайные целые числа от low (включая) до high (не включая). {-x/2}\) {-x/2}\) |
| mtrand.dirichlet(alpha[, size]) | числа с распределением Дирихле (alpha – массив параметров). |
| exponential([scale, size]) | числа с экспоненциальным распределением \(f(x,\frac{1}{\beta})=\frac{1}{\beta}exp(-\frac{x}{\beta})\) |
| f(dfnum, dfden[, size]) | числа с F распределением (dfnum – число степеней свободы числителя > 0; dfden –число степеней свободы знаменателя >0.) |
| gamma(shape[, scale, size]) | числа с Гамма — распределением |
| geometric(p[, size]) | числа с геометрическим распределением |
| gumbel([loc, scale, size]) | числа с распределением Гумбеля |
| hypergeometric(ngood, nbad, nsample[, size]) | числа с гипергеометрическим распределением (n = ngood, m = nbad, and N = number of samples) |
| laplace([loc, scale, size]) | числа с распределением Лапласа |
| logistic([loc, scale, size]) | числа с логистическим распределением |
| lognormal([mean, sigma, size]) | числа с логарифмическим нормальным распределением |
| logseries(p[, size]) | числа с распределением логарифмического ряда |
| multinomial(n, pvals[, size]) | числа с мультиномиальным распределением |
| multivariate_normal(mean, cov[, size]) | числа с мульти нормальным распределением (mean – одномерный массив средних значений;
cov – двухмерный симметричный, полож. определенный массив (N, N) ковариаций определенный массив (N, N) ковариаций |
| negative_binomial(n, p[, size]) | числа с отрицательным биномиальным распределением |
| noncentral_chisquare(df, nonc[, size]) | числа с нецентральным распределением хи-квадрат |
| noncentral_f(dfnum, dfden, nonc[, size]) | числа с нецентральным F распределением (dfnum — целое > 1; dfden – целое > 1; nonc : действительное >= 0) |
| normal([loc, scale, size]) | числа с нормальным распределением |
| pareto(a[, size]) | числа с распределением Паретто |
| poisson([lam, size]) | числа с распределением Пуассона |
| power(a[, size]) | числа со степенным распределением [0, 1] |
| rayleigh([scale, size]) | числа с распределением Релея |
| standard_cauchy([size]) | числа со стандартным распределением Коши |
| standard_exponential([size]) | числа со стандартным экспоненциальным распределением |
| standard_gamma(shape[, size]) | числа с гамма- распределением |
| standard_normal([size]) | числа со стандартным нормальным распределением (среднее=0, сигма=1). |
| standard_t(df[, size]) | числа со стандартным распределением Стьюдента с df степенями свободы |
| triangular(left, mode, right[, size]) | числа из треугольного распределения |
| uniform([low, high, size]) | числа с равномерным распределением |
| vonmises(mu, kappa[, size]) | числа с распределением Майсеса (I- модифицированная функция Бесселя) |
| wald(mean, scale[, size]) | числа с распределением Вальда |
| weibull(a[, size]) | числа с распределением Вайбулла |
| zipf(a[, size]) | числа с распределением Зипфа (зетта функция Римана) |
- size — число элементов по каждому измерению
Статистика
| Команда | Описание |
|---|---|
| amin(a[, axis, out]) | минимум в массиве или минимумы вдоль одной из осей |
| amax(a[, axis, out]) | максимум в массиве или максимумы вдоль одной из осей |
| nanmax(a[, axis]) | максимум в массиве или максимумы вдоль одной из осей (игнорируются NaN). |
| nanmin(a[, axis]) | минимум в массиве или минимумы вдоль одной из осей (игнорируются NaN). |
| ptp(a[, axis, out]) | диапазон значений (максимум — минимум) вдоль оси |
| average(a[, axis, weights, returned]) | взвешенное среднее вдоль оси |
| mean(a[, axis, dtype, out]) | арифметическое среднее вдоль оси |
| median(a[, axis, out, overwrite_input]) | вычисление медианы вдоль оси |
| std(a[, axis, dtype, out, ddof]) | стандартное отклонение вдоль оси |
| corrcoef(x[, y, rowvar, bias, ddof]) | коэффициенты корреляции |
| correlate(a, v[, mode, old_behavior]) | кросс-корреляция двух одномерных последовательностей |
| cov(m[, y, rowvar, bias, ddof]) | ковариационная матрица для данных |
| histogram(a[, bins, range, normed, weights, …]) | гистограмма из набора данных |
| histogram2d(x, y[, bins, range, normed, weights]) | двумерная гистограмма для двух наборов данных |
| histogramdd(sample[, bins, range, normed, …]) | многомерная гистограмма для данных |
| bincount(x[, weights, minlength]) | число появление значения в массиве неотрицательных значений |
| digitize(x, bins) | возвращает индексы интервалов к которым принадлежат элементы массива |
- a – массив
- axis – индекс оси
- out – место для результата
- weights- веса
- returned – дополнительно выдать сумму весов
- dtype – тип данных для накопления суммы
- overwrite_input – использовать входящий массив для промежуточных вычислений
- ddof- дельта степеней свободы (см. описание)
- x,y – данные (строки – переменные, колонки — наблюдения)
- rowvar – если не 0, то строка переменные, колонки – наблюдения (если 0, то наоборот)
- bias – определеяет нормировку, совместно с ddof
- mode — {‘valid’, ‘same’, ‘full’} – объем выводимых данных
- old_behavior – совместимость со старой версией (без комплексного сопряжения)
- bins – разбиение по интервалам
- range – массив границ по x и по y
- normed – нормированное
- minlength – минимальное число интервалов при выводе
 описание)
описание)Полиномы (numpy.polynomial)
Модуль полиномов обеспечивает стандартные функции работы с полиномами разного вида. В нем реализованы полиномы
Чебышева, Лежандра, Эрмита, Лагерра. Для полиномов определены стандартные арифметические функции ‘+’, ‘-‘, ‘*’, ‘//’,
деление по модулю, деление с остатком, возведение в степень и вычисление значения полинома. Важно задавать область
определения, т.к. часто свойства полинома (например при интерполяции) сохраняются только на определенном интервале. В зависимости от класса полинома, сохраняются коэффициенты разложения по полиномам определенного типа, что позволяет
получать разложение функций в ряд по полиномам разного типа.
В зависимости от класса полинома, сохраняются коэффициенты разложения по полиномам определенного типа, что позволяет
получать разложение функций в ряд по полиномам разного типа.
| Типы полиномов | Описание |
|---|---|
| Polynomial(coef[, domain, window]) | разложение по степеням «x» |
| Chebyshev(coef[, domain, window]) | разложение по полиномам Чебышева |
| Legendre(coef[, domain, window]) | разложение по полиномам Лежандра |
| Hermite(coef[, domain, window]) | разложение по полиномам Эрмита |
| HermiteE(coef[, domain, window]) | разложение по полиномам Эрмита_Е |
| Laguerre(coef[, domain, window]) | разложение по полиномам Лагерра |
- coef – массив коэффициентов в порядке увеличения
- domain – область определения проецируется на окно
- window – окно. Сдвигается и масштабируется до размера области определения
 Сдвигается и масштабируется до размера области определения
Сдвигается и масштабируется до размера области определенияНекоторые функции (например интерполяция данных) возвращают объект типа полином. У этого объекта есть набор методов, позволяющих извлекать и преобразовывать данные.
| Методы полиномов | Описание |
|---|---|
| __call__(z) | полином можно вызвать как функцию |
| convert([domain, kind, window]) | конвертирует в полином другого типа, с другим окном и т.д |
| copy() | возвращает копию |
| cutdeg(deg) | обрезает полином до нужной степени |
| degree() | возвращает степень полинома |
| deriv([m]) | вычисляет производную порядка m |
| fit(x, y, deg[, domain, rcond, full, w, window]) | формирует полиномиальную интерполяцию степени deg для данных (x,y) по методу наименьших квадратов |
| fromroots(roots[, domain, window]) | формирует полином по заданным корням |
| has_samecoef(p) | проверка на равенство коэффициентов. |
| has_samedomain(p) | проверка на равенство области определения |
| has_samewindow(p) | проверка на равенство окна |
| integ([m, k, lbnd]) | интегрирование |
| linspace([n, domain]) | возвращает x,y — значения на равномерной сетке по области определения |
| mapparms() | возвращает коэффициенты масштабирования |
| roots() | список корней |
| trim([tol]) | создает полином с коэффициентами большими tol |
| truncate(size) | ограничивает ряд по количеству коеффициентов |
- p – полином
- x, y – набор данных для аппроксимации
- deg – степень полинома
- domain – область определения
- rcond – относительное число обусловленности элементы матрицы интерполяции с собственными значениями меньшими данного будут отброшены.
- full – выдавать дополнительную информацию о качестве полинома
- w – веса точек
- window – окно
- roots – набор корней
- m – порядок производной (интеграла)
- k – константы интегрирования
- lbnd – нижняя граница интервала интегрирования
- n – число точек разбиения
- size – число ненулевых коэффициентов
4 приема Python NumPy, которые должен знать каждый новичок
NumPy является одной из самых популярных библиотек в Python, и, учитывая ее преимущества, почти каждый программист Python использовал данную библиотеку для арифметических вычислений. Массивы Numpy более компактны, чем списки Python. Эта библиотека также очень удобна, так как многие обычные матричные операции выполнены очень эффективным вычислительным способом.
Массивы Numpy более компактны, чем списки Python. Эта библиотека также очень удобна, так как многие обычные матричные операции выполнены очень эффективным вычислительным способом.
Помогая коллегам и друзьям с трудностями в NumPy, мы пришли к 4 приемам, которые должен знать каждый новичок Python. Эти фишки помогут вам написать более аккуратные и читаемые коды.
1. Arg-функции — позиции
Для массива функции arr, np.argmax(arr), np.argmin(arr) и np.argwhere(condition(arr)) возвращают показатели максимальных значений, минимальных значений и значений, которые удовлетворяют определенным условиям пользователя соответственно. Хотя эти функции arg широко используются, мы часто игнорируем функцию np.argsort(), возвращающую показатели, которые сортируют массив.
Мы можем использовать np.argsort для сортировки значений массивов по другому массиву. Ниже представлен пример сортировки имен студентов с использованием их результатов экзамена.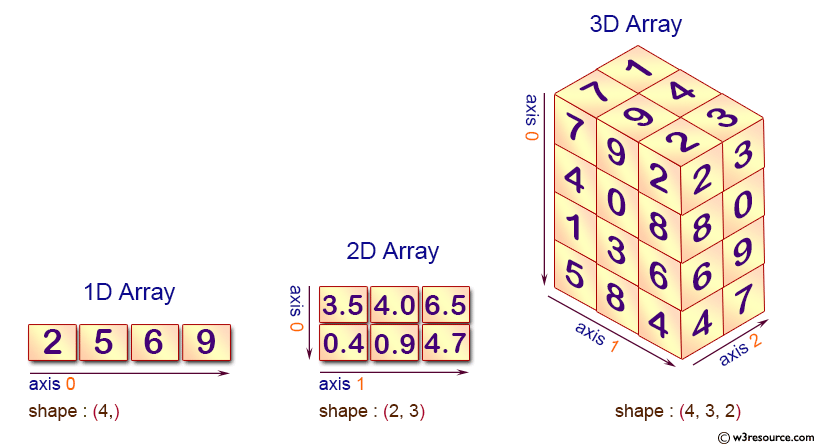 Отсортированный массив имен также можно преобразовать обратно в исходный порядок, используя np.argsort(np.argsort(score)).
Отсортированный массив имен также можно преобразовать обратно в исходный порядок, используя np.argsort(np.argsort(score)).
1. score = np.array([70, 60, 50, 10, 90, 40, 80])
2. name = np.array(['Ada', 'Ben', 'Charlie', 'Danny', 'Eden', 'Fanny', 'George'])
3. sorted_name = name[np.argsort(score)] # an array of names in ascending order of their scores
4. print(sorted_name) # ['Danny' 'Fanny' 'Charlie' 'Ben' 'Ada' 'George' 'Eden']
5.
6. original_name = sorted_name[np.argsort(np.argsort(score))]
7. print(original_name) # ['Ada' 'Ben' 'Charlie' 'Danny' 'Eden' 'Fanny' 'George']
8.
9.
10. %timeit name[np.argsort(score)]
11. # 1.83 µs ± 182 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
12. %timeit sorted(zip(score, name))
13. # 3.2 µs ± 76.7 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
Эффективность данной функции выше, нежели результат использования встроенной функции Python sorted(zip()). Кроме того, она, пожалуй, более читабельна.
2. Бродкастинг — формы
Бродкастинг — это то, что новичок numpy мог уже невольно попробовать сделать. Многие арифметические операции numpy применяются к парам массивов одинаковой формы для каждого элемента. Бродкастинг векторизует операции с массивами без создания ненужных копий данных. Это приводит к эффективной реализации алгоритма и более высокой читаемости кода.
Например, вы можете использовать приращение всех значений в массиве на 1, используя arr + 1 независимо от измерения arr. Вы также можете проверить, все ли значения в массиве больше, чем 2, с помощью arr > 2.
Но как мы узнаем, совместимы ли два массива с бродкастинг?
Argument 1 (4D array): 7 × 5 × 3 × 1
Argument 2 (3D array): 1 × 3 × 9
Output (4D array): 7 × 5 × 3 × 9
Измерение одного массива должно быть либо равно измерению другого массива, либо одно из них равно 1. Массивы необязательно должны иметь одинаковое количество измерений, что продемонстрировано в примере выше.
3. Параметры Ellipsis и NewAxis
Синтаксис для нарезки массива numpy — это i:j где i, j — начальный индекс и индекс остановки соответственно. Например, для массива numpy arr = np.array(range(10)) команда arr[:3] дает [0, 1, 2].
При работе с массивами с более высокими размерностями мы используем : для выбора индекса по каждой оси. Мы также можем использовать … для выбора индексов по нескольким осям. Точное количество осей выводится.
1. arr = np.array(range(1000)).reshape(2,5,2,10,-1)
2. print(arr[:,:,:,3,2] == arr[...,3,2])
3. # [[[ True, True],
4. # [ True, True],
5. # [ True, True],
6. # [ True, True],
7. # [ True, True]],
8. # [[ True, True],
9. # [ True, True],
10. # [ True, True],
11. # [ True, True],
12. # [ True, True]]])
13.
14. print(arr.shape) # (2, 5, 2, 10, 5)
15. print(arr[...,np.newaxis,:,:,:].shape) # (2, 5, 1, 2, 10, 5)
С другой стороны, использование, np. newaxis, как показано выше, вставляет новую ось в заданное пользователем положение оси. Эта операция расширяет форму массива на одну единицу измерения. Хотя это также можно сделать с помощью np.expand_dims(), использование np.newaxis гораздо более читабельно и, пожалуй, изящно.
newaxis, как показано выше, вставляет новую ось в заданное пользователем положение оси. Эта операция расширяет форму массива на одну единицу измерения. Хотя это также можно сделать с помощью np.expand_dims(), использование np.newaxis гораздо более читабельно и, пожалуй, изящно.
4. Замаскированный массив — селекция
Наборы данных несовершенны. Они всегда содержат массивы с отсутствующими или неверными записями, и мы часто хотим игнорировать эти элементы. Например, измерения на метеостанции могут содержать пропущенные значения из-за сбоя датчика.
У Numpy есть подмодуль numpy.ma, который поддерживает массивы данных с масками. Маскированный массив содержит обычный массив numpy и маску, которая указывает положение недопустимых записей.
np.ma.MaskedArray(data=arr, mask=invalid_mask)
Недопустимые записи в массиве иногда помечаются с использованием отрицательных значений или строк. Если мы знаем замаскированное значение, скажем -999, мы можем также создать замаскированный массив, используя np. ma.masked_values(arr, value=-999). Любая операция numpy, принимающая замаскированный массив в качестве аргумента, автоматически игнорирует эти недействительные записи, как показано ниже.
ma.masked_values(arr, value=-999). Любая операция numpy, принимающая замаскированный массив в качестве аргумента, автоматически игнорирует эти недействительные записи, как показано ниже.
1. import math
2. def is_prime(n):
3. assert n > 1, 'Input must be larger than 1'
4. if n % 2 == 0 and n > 2:
5. return False
6. return all(n % i for i in range(3, int(math.sqrt(n)) + 1, 2))
7.
8. arr = np.array(range(2,100))
9. non_prime_mask = [not is_prime(n) for n in a]
10. prime_arr = np.ma.MaskedArray(data=arr, mask=non_prime_mask)
11. print(prime_arr)
12. # [2 3 -- 5 -- 7 -- -- -- 11 -- 13 -- -- -- 17 -- 19 -- -- -- 23 -- -- -- --
13. # -- 29 -- 31 -- -- -- -- -- 37 -- -- -- 41 -- 43 -- -- -- 47 -- -- -- --
14. # -- 53 -- -- -- -- -- 59 -- 61 -- -- -- -- -- 67 -- -- -- 71 -- 73 -- --
15. # -- -- -- 79 -- -- -- 83 -- -- -- -- -- 89 -- -- -- -- -- -- -- 97 -- --]
16.
17. arr = np.array(range(11))
18. print(arr.sum()) # 55
19.
20. arr[-1] = -999 # indicates missing value
21. masked_arr = np.ma.masked_values(arr, -999)
22. print(masked_arr.sum()) # 45
23.

Источник
NumPy Tutorial: Простое Руководство На Основе Примеров
Автор оригинала: Usman Malik.
- Вступление
- Преимущества NumPy
- Операции NumPy
- Создание массива NumPy
- Метод массива
- Метод аранжировки
- Метод нулей
- Метод те
- Метод linspace
- Глазной метод
- Случайный метод
- Изменение формы массива NumPy
- Поиск Максимальных/Минимальных Значений
- Индексация массива в NumPy
- Индексация с 1-D массивами
- Индексация с помощью 2-D массивов
- Арифметические операции с массивами NumPy
- Функция журнала
- Функция exp
- Функция sqrt
- Функция греха
- Операции линейной алгебры с массивами NumPy
- Нахождение векторного точечного произведения
- Матричное умножение
- Нахождение обратной матрицы
- Нахождение определителя матрицы
- Нахождение следа матрицы
- Вывод
Вступление
Библиотека NumPy – это популярная библиотека Python, используемая для научных вычислительных приложений, и является аббревиатурой от “Numerical Python”. Операции Numpy делятся на три основные категории: Преобразование Фурье и Манипулирование формой, Математические и логические операции, а также Линейная алгебра и генерация случайных чисел. Чтобы сделать это как можно быстрее, NumPy написан на C и Python.
Операции Numpy делятся на три основные категории: Преобразование Фурье и Манипулирование формой, Математические и логические операции, а также Линейная алгебра и генерация случайных чисел. Чтобы сделать это как можно быстрее, NumPy написан на C и Python.
В этой статье мы дадим краткое введение в стек NumPy и увидим, как библиотека NumPy может быть использована для выполнения различных математических задач.
Преимущества NumPy
NumPy имеет несколько преимуществ по сравнению с использованием основных математических функций Python, некоторые из которых описаны здесь:
- NumPy чрезвычайно быстр по сравнению с core Python благодаря интенсивному использованию расширений C.
- Многие продвинутые библиотеки Python, такие как Scikit-Learn, Scipy и Keras, широко используют библиотеку NumPy. Поэтому, если вы планируете продолжить карьеру в области науки о данных или машинного обучения, NumPy-очень хороший инструмент для овладения.
- NumPy поставляется с множеством встроенных функций, которые в ядре Python потребовали бы изрядного количества пользовательского кода.

Что касается последнего пункта, взгляните на следующий сценарий:
x = [2, 3, 4, 5, 6] y = [a + 2 for a in x]
Здесь, чтобы добавить 2 к каждому элементу в списке x , мы должны пройти весь список и добавить 2 к каждому элементу в отдельности. Теперь давайте посмотрим, как мы можем выполнить ту же задачу с помощью библиотеки NumPy:
import numpy as np nums = np.
 array([2, 3, 4, 5, 6])
nums2 = nums + 2
array([2, 3, 4, 5, 6])
nums2 = nums + 2
Вы можете видеть, как легко добавить скалярное значение к каждому элементу в списке с помощью NumPy. Он не только читабелен, но и быстрее по сравнению с предыдущим кодом.
Это только верхушка айсберга, на самом деле библиотека NumPy способна выполнять гораздо более сложные операции в мгновение ока. Давайте рассмотрим некоторые из этих операций.
Операции NumPy
Прежде чем мы сможем выполнить какие-либо операции NumPy, нам нужно установить пакет NumPy. Чтобы установить пакет NumPy, вы можете использовать установщик pip. Для установки выполните следующую команду:
$ pip install numpy
В противном случае, если вы запускаете Python через дистрибутив Anaconda, вы можете выполнить вместо этого следующую команду:
$ conda install numpy
Теперь, когда NumPy установлен, давайте рассмотрим некоторые из наиболее распространенных операций библиотеки.
Создание массива NumPy
Массивы NumPy являются строительными блоками большинства операций NumPy. Массивы NumPy можно разделить на два типа: одномерные массивы и двумерные массивы.
Существует несколько способов создания массива NumPy. В этом разделе мы обсудим некоторые из них.
Метод массива
Чтобы создать одномерный массив NumPy, мы можем просто передать список Python в метод array . Проверьте следующий сценарий для примера:
import numpy as np x = [2, 3, 4, 5, 6] nums = np.array([2, 3, 4, 5, 6]) type(nums)
В приведенном выше скрипте мы сначала импортировали библиотеку NumPy как np и создали список x . Затем мы передали этот список функции
Затем мы передали этот список функции array библиотеки NumPy. Наконец, мы напечатали тип массива, который привел к следующему выходу:
numpy.ndarray
Если бы вы напечатали массив nums на экране, вы бы увидели, что он отображается следующим образом:
array([2, 3, 4, 5, 6])
Чтобы создать двумерный массив, вы можете передать список списков в метод array , как показано ниже:
nums = np.
 array([[2,4,6], [8,10,12], [14,16,18]])
array([[2,4,6], [8,10,12], [14,16,18]])
Приведенный выше сценарий приводит к матрице, в которой каждый внутренний список во внешнем списке становится строкой. Количество столбцов равно количеству элементов в каждом внутреннем списке. Выходная матрица будет выглядеть следующим образом:
array([[ 2, 4, 6],
[ 8, 10, 12],
[14, 16, 18]])
Метод аранжировки
Другим часто используемым методом создания массива NumPy является метод arrange . Этот метод принимает начальный индекс массива, конечный индекс и размер шага (который является необязательным). Взгляните на следующий пример:
nums = np.
 arange(2, 7)
arange(2, 7)
Достаточно просто, не так ли? Приведенный выше скрипт вернет массив NumPy размера 5 с элементами 2, 3, 4, 5 и 6. Помните, что метод arange возвращает массив, который начинается с начального индекса и заканчивается на один индекс меньше конечного индекса. Вывод этого кода выглядит следующим образом:
array([2, 3, 4, 5, 6])
Теперь давайте добавим шаг размером 2 к нашему массиву и посмотрим, что произойдет:
nums = np.
 arange(2, 7, 2)
arange(2, 7, 2)
Вывод теперь выглядит следующим образом:
array([2, 4, 6])
Вы можете видеть, что массив начинается с 2, за которым следует размер шага 2 и заканчивается на 6, что на единицу меньше конечного индекса.
Метод нулей
Помимо создания пользовательских массивов с предварительно заполненными данными, вы также можете создавать массивы NumPy с более простым набором данных. Например, вы можете использовать метод zeros для создания массива всех нулей, как показано ниже:
zeros = np.
 zeros(5)
zeros(5)
Приведенный выше скрипт вернет одномерный массив из 5 нулей. Выведите массив zeros , и вы увидите следующее:
array([0., 0., 0., 0., 0.])
Аналогично, чтобы создать двумерный массив, вы можете передать как количество строк, так и столбцов в метод zeros , как показано ниже:
zeros = np.
 zeros((5, 4))
zeros((5, 4))
Приведенный выше скрипт вернет двумерный массив из 5 строк и 4 столбцов:
array([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
Метод те
Аналогично, вы можете создать одномерные и двумерные массивы всех единиц, используя метод ones следующим образом:
ones = np.
 ones(5)
ones(5)
array([1., 1., 1., 1., 1.])
И снова, для двумерного массива, попробуйте следующий код:
ones = np.ones((5, 4))
Теперь, если вы напечатаете массив ones на экране, вы увидите следующий двумерный массив:
[[1.
 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]]
1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]]
Метод linspace
Еще одним очень полезным методом создания массивов NumPy является метод linspace . Этот метод принимает три аргумента: начальный индекс, конечный индекс и количество линейных чисел, которые вы хотите разместить между указанным диапазоном. Например, если первый индекс равен 1, последний индекс равен 10 и вам нужно 10 равномерно расположенных элементов в этом диапазоне, вы можете использовать метод linspace следующим образом:
lin = np.linspace(1, 10, 10)
Выходные данные будут возвращать целые числа от 1 до 10:
array([1.
 , 2., 3., 4., 5., 6., 7., 8., 9., 10.])
, 2., 3., 4., 5., 6., 7., 8., 9., 10.])
Теперь давайте попробуем создать массив с 20 линейно расположенными элементами от 1 до 10. Выполните следующий сценарий:
lin = np.linspace(1, 10, 20)
Это приведет к следующему массиву:
array([ 1. , 1.47368421, 1.94736842, 2.42105263, 2.89473684,
3. 36842105, 3.84210526, 4.31578947, 4.78947368, 5.26315789,
5.73684211, 6.21052632, 6.68421053, 7.15789474, 7.63157895,
8.10526316, 8.57894737, 9.05263158, 9.52631579, 10. ])
 36842105, 3.84210526, 4.31578947, 4.78947368, 5.26315789,
5.73684211, 6.21052632, 6.68421053, 7.15789474, 7.63157895,
8.10526316, 8.57894737, 9.05263158, 9.52631579, 10. ])
36842105, 3.84210526, 4.31578947, 4.78947368, 5.26315789,
5.73684211, 6.21052632, 6.68421053, 7.15789474, 7.63157895,
8.10526316, 8.57894737, 9.05263158, 9.52631579, 10. ])
Обратите внимание, что выходные данные могут выглядеть как матрица, но на самом деле это одномерный массив. Из-за проблемы с интервалом элементы были показаны в нескольких строках.
Глазной метод
Метод eye может быть использован для создания тождественной матрицы , которая может быть очень полезна для выполнения различных операций в линейной алгебре. Тождественная матрица-это матрица с нулями в строках и столбцах, кроме диагонали. Все диагональные значения равны единицам. Давайте создадим матрицу идентичности 4×4 с помощью метода eye :
idn = np.
 eye(4)
eye(4)
Результирующая матрица выглядит следующим образом:
array([[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]])
Случайный метод
Часто вам придется создавать массивы со случайными числами. Для этого можно использовать функцию rand модуля Numpy random . Вот простой пример функции rand :
random = np.
 random.rand(2, 3)
random.rand(2, 3)
Приведенный выше скрипт возвращает матрицу из 2 строк и 3 столбцов. Матрица содержит равномерное распределение чисел от 0 до 1:
array([[0.26818562, 0.65506793, 0.50035001],
[0.527117 , 0.445688 , 0.99661 ]])
Аналогично, чтобы создать матрицу случайных чисел с распределением Гаусса (или “нормальным” распределением), вы можете вместо этого использовать метод randn , как показано ниже:
random = np.
 random.randn(2, 3)
random.randn(2, 3)
Наконец, для создания массива случайных целых чисел существует метод randint для такого случая. Метод randint принимает нижнюю границу, верхнюю границу и количество возвращаемых целых чисел. Например, если вы хотите создать массив из 5 случайных целых чисел в диапазоне от 50 до 100, вы можете использовать этот метод следующим образом:
random = np.random.randint(50, 100, 5)
В нашем случае выход выглядел так:
array([54, 59, 84, 62, 74])
Важно отметить, что эти числа генерируются случайным образом каждый раз, когда вы вызываете метод, поэтому вы увидите другие числа, чем в нашем примере.
Мы видели разные способы создания массивов Python. Давайте теперь рассмотрим некоторые другие функции массива.
Изменение формы массива NumPy
Используя NumPy, вы можете преобразовать одномерный массив в двумерный массив с помощью метода reshape .
Давайте сначала создадим массив из 16 элементов с помощью функции arrange . Выполните следующий код:
nums = np.arange(1, 17)
Массив nums представляет собой одномерный массив из 16 элементов в диапазоне от 1 до 16:
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16])
Nos давайте преобразуем его в двумерный массив из 4 строк и 4 столбцов:
nums2 = nums.
 reshape(4, 4)
reshape(4, 4)
Теперь массив выглядит следующим образом:
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12],
[13, 14, 15, 16]])
Уместно отметить, что вы не можете изменить форму массива, если число элементов в одномерном массиве не равно произведению строк и столбцов измененного массива. Например, если у вас есть 45 элементов в 1-d массиве, вы не можете преобразовать его в матрицу из 5 строк и 10 столбцов, так как матрица 5×10 имеет 50 элементов, а исходная-только 45.
Поиск Максимальных/Минимальных Значений
Вы можете использовать функции min /| max , чтобы легко найти значение наименьшего и наибольшего числа в вашем массиве. Для нашего примера давайте сначала создадим массив из 5 случайных целых чисел:
Для нашего примера давайте сначала создадим массив из 5 случайных целых чисел:
random = np.random.randint(1, 100, 5) print(random)
Наш массив случайных целых чисел выглядит следующим образом:
[51 40 84 38 1]
Помните, что эти числа генерируются случайным образом, поэтому у вас, скорее всего, будет другой набор чисел. Давайте используем функции
Давайте используем функции min и max , чтобы найти минимальное и максимальное значения из массива, который мы только что создали. Для этого выполните следующий код, чтобы найти минимальное значение:
xmin = random.min() print(xmin)
“1” будет напечатано на выходе.
Аналогично, для получения максимального значения выполните следующий код:
xmax = random.
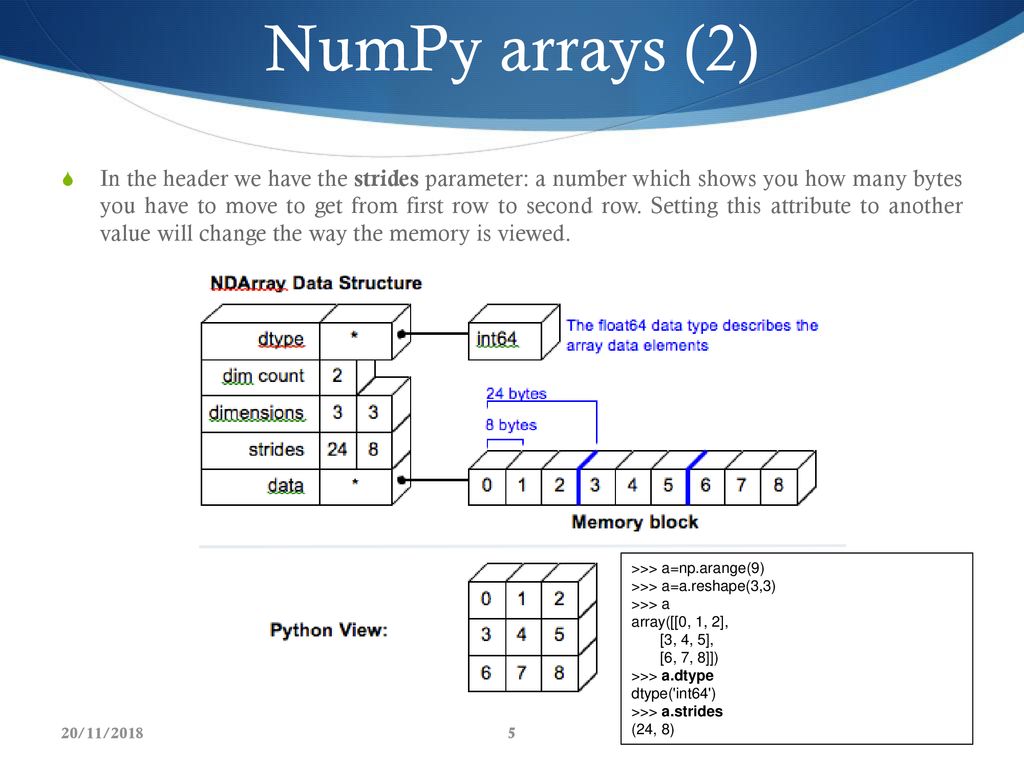 max()
print(xmax)
max()
print(xmax)
Приведенный выше скрипт вернет “84” в качестве выходного сигнала.
Вы также можете найти индекс максимального и минимального значений с помощью функций argmax() и argmin () . Взгляните на следующий сценарий:
print(random.argmax())
Приведенный выше скрипт выведет “2”, так как 84-это самое большое число в списке, и оно находится на второй позиции массива.
Аналогично, argmin() вернет “4”, потому что 1-это наименьшее число и находится на 4-й позиции.
Индексация массива в NumPy
Чтобы эффективно использовать массивы NumPy, очень важно понять, как они индексируются, о чем я расскажу в следующих нескольких разделах.
Индексация с 1-D массивами
Давайте создадим простой массив из 15 чисел:
nums = np.arange(1, 16)
Вы можете получить любой элемент, передав номер индекса. Как и списки Python, массивы Numpy имеют нулевую индексацию. Например, чтобы найти элемент во втором индексе (3-я позиция) массива, можно использовать следующий синтаксис:
print(nums[2])
У нас есть цифра 3 во втором индексе, поэтому она будет напечатана на экране.
Вы также можете распечатать диапазон чисел с помощью индексации. Чтобы получить диапазон, вам нужно передать startindex и один меньше конечного индекса, разделенные двоеточием, внутри квадратных скобок, которые следуют за именем массива. Например, чтобы получить элементы от первого до седьмого индекса, можно использовать следующий синтаксис:
print(nums[1:8])
Приведенный выше скрипт выведет целые числа от 2 до 8:
[2 3 4 5 6 7 8]
Здесь, в массиве nums , у нас есть 2 в индексе 1 и 8 в индексе семь.
Вы также можете разрезать массив и назначить элементы разрезанного массива новому массиву:
nums2 = nums[0:8] print(nums2)
В приведенном выше скрипте мы разрезали массив nums , извлекая его первые 8 элементов. Результирующие элементы присваиваются массиву num2 . Затем мы выводим массив num2 на консоль. На выходе получается новый массив из первых 8 чисел:
[1 2 3 4 5 6 7 8]
Индексация с помощью 2-D массивов
Индексирование двумерного массива NumPy очень похоже на индексирование матрицы. Давайте сначала создадим двумерный массив NumPy размером 3×3. Для этого выполните следующий код:
Давайте сначала создадим двумерный массив NumPy размером 3×3. Для этого выполните следующий код:
nums2d = np.array(([1,2,3],[4,5,6],[7,8,9]))
А теперь давайте распечатаем:
print(nums2d)
[[1 2 3] [4 5 6] [7 8 9]]
Как и 1-D массивы, массивы NumPy с двумя измерениями также следуют нулевому индексу, то есть для доступа к элементам в первой строке необходимо указать 0 в качестве индекса строки. Точно так же, чтобы получить доступ к элементам в первом столбце, вам также нужно указать 0 для индекса столбца.
Точно так же, чтобы получить доступ к элементам в первом столбце, вам также нужно указать 0 для индекса столбца.
Давайте извлекем элемент из массива nums 2d , расположенного в первой строке и первом столбце:
print(nums2d[0, 0])
Вы увидите “1” в выходных данных. Аналогично, мы можем получить элемент в третьей строке и третьем столбце следующим образом:
print(nums2d[2, 2])
Вы увидите “9” на выходе.
В дополнение к извлечению одного элемента, вы можете извлечь всю строку, передав только индекс строки в квадратные скобки. Например, следующий скрипт возвращает первую строку из массива nums2d :
print(nums2d[0])
На выходе просто одномерный массив:
[1 2 3]
Аналогично, чтобы получить только первый столбец, вы можете использовать следующий синтаксис:
print(nums2d[:,0])
Выход снова является массивом, но это комбинация первых элементов каждого массива двумерного массива:
[1 4 7]
Наконец, для извлечения элементов из первых двух строк и первых двух столбцов можно использовать следующий синтаксис:
print(nums2d[:2,:2])
Приведенный выше сценарий возвращает следующие выходные данные:
[[1 2] [4 5]]
Арифметические операции с массивами NumPy
Для примеров в этом разделе мы будем использовать массив nums , который мы создали в предыдущем разделе.
Давайте сначала сложим два массива вместе:
nums3 = nums + nums
Вы можете добавить два массива вместе с одинаковыми размерами. Например, массив nums содержал 15 элементов, поэтому мы можем добавить его к себе. Будут добавлены элементы с соответствующими индексами. Теперь, если вы напечатаете массив nums3 , вывод будет выглядеть следующим образом:
[ 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30]
Как вы можете видеть, каждая позиция является суммой 2 элементов в этой позиции в исходных массивах.
Если вы добавите массив со скалярным значением, то это значение будет добавлено к каждому элементу в массиве. Давайте добавим 10 к массиву nums и выведем результирующий массив на консоль. Вот как вы это сделаете:
nums3 = nums + 10 print(nums3)
И результирующий массив nums 3 становится:
[11 12 13 14 15 16 17 18 19 20 21 22 23 24 25]
Вычитание, сложение, умножение и деление могут быть выполнены таким же образом.
Помимо простой арифметики, вы можете выполнять более сложные функции над массивами Numpy, например log, square root, exponential и т. Д.
Функция журнала
Следующий код просто возвращает массив с журналом всех элементов входного массива:
nums3 = np.log(nums) print(nums3)
Вывод выглядит следующим образом:
[0.
 0.69314718 1.09861229 1.38629436 1.60943791 1.79175947
1.94591015 2.07944154 2.19722458 2.30258509 2.39789527 2.48490665
2.56494936 2.63905733 2.7080502 ]
0.69314718 1.09861229 1.38629436 1.60943791 1.79175947
1.94591015 2.07944154 2.19722458 2.30258509 2.39789527 2.48490665
2.56494936 2.63905733 2.7080502 ]
Функция exp
Следующий скрипт возвращает массив с экспонентами всех элементов входного массива:
nums3 = np.exp(nums) print(nums3)
[2.
 71828183e+00 7.38905610e+00 2.00855369e+01 5.45981500e+01
1.48413159e+02 4.03428793e+02 1.09663316e+03 2.98095799e+03
8.10308393e+03 2.20264658e+04 5.98741417e+04 1.62754791e+05
4.42413392e+05 1.20260428e+06 3.26901737e+06]
71828183e+00 7.38905610e+00 2.00855369e+01 5.45981500e+01
1.48413159e+02 4.03428793e+02 1.09663316e+03 2.98095799e+03
8.10308393e+03 2.20264658e+04 5.98741417e+04 1.62754791e+05
4.42413392e+05 1.20260428e+06 3.26901737e+06]
Функция sqrt
Следующий скрипт возвращает массив с квадратными корнями всех элементов входного массива:
nums3 = np.sqrt(nums) print(nums3)
[1.
 1.41421356 1.73205081 2. 2.23606798 2.44948974
2.64575131 2.82842712 3. 3.16227766 3.31662479 3.46410162
3.60555128 3.74165739 3.87298335]
1.41421356 1.73205081 2. 2.23606798 2.44948974
2.64575131 2.82842712 3. 3.16227766 3.31662479 3.46410162
3.60555128 3.74165739 3.87298335]
Функция греха
Следующий скрипт возвращает массив с синусом всех элементов входного массива:
nums3 = np.sin(nums) print(nums3)
[ 0.
 84147098 0.90929743 0.14112001 -0.7568025 -0.95892427 -0.2794155
0.6569866 0.98935825 0.41211849 -0.54402111 -0.99999021 -0.53657292
0.42016704 0.99060736 0.65028784]
84147098 0.90929743 0.14112001 -0.7568025 -0.95892427 -0.2794155
0.6569866 0.98935825 0.41211849 -0.54402111 -0.99999021 -0.53657292
0.42016704 0.99060736 0.65028784]
Операции линейной алгебры с массивами NumPy
Одним из самых больших преимуществ массивов NumPy является их способность выполнять операции линейной алгебры, такие как векторное точечное произведение и матричное точечное произведение, гораздо быстрее, чем вы можете это сделать со списками Python по умолчанию.
Нахождение векторного точечного произведения
Вычисление векторного точечного произведения для двух векторов может быть вычислено путем умножения соответствующих элементов двух векторов и последующего сложения результатов из произведений.
Давайте создадим два вектора и попробуем найти их точечное произведение вручную. Вектор в NumPy-это в основном просто 1-мерный массив. Выполните следующий скрипт для создания наших векторов:
x = np.
 array([2,4])
y = np.array([1,3])
array([2,4])
y = np.array([1,3])
Точечное произведение двух вышеприведенных векторов равно (2 x 1) + (4 x .
Давайте найдем точечный продукт без использования библиотеки NumPy. Для этого выполните следующий сценарий:
dot_product = 0
for a,b in zip(x,y):
dot_product += a * b
print(dot_product)
В приведенном выше сценарии мы просто перебирали соответствующие элементы в векторах x и y , умножали их и добавляли к предыдущей сумме. Если вы запустите приведенный выше скрипт, то увидите, что на консоли выведено “14”.
Теперь давайте посмотрим, как мы можем найти точечный продукт с помощью библиотеки NumPy. Посмотрите на следующий сценарий:
Посмотрите на следующий сценарий:
a = x * y print(a.sum())
Мы знаем, что если мы умножим два массива NumPy, то соответствующие элементы из обоих массивов будут умножены на основе их индекса. В приведенном выше сценарии мы просто умножили векторы x и y . Затем мы вызываем метод sum для результирующего массива, который суммирует все элементы массива. Приведенный выше скрипт также вернет “14” в выводе.
Вышеприведенный метод прост, однако библиотека NumPy делает еще проще поиск точечного продукта с помощью метода dot , как показано здесь:
print(x.
 dot(y))
dot(y))
Для очень больших массивов вы также должны заметить улучшение скорости по сравнению с нашей версией только для Python, благодаря использованию NumPy кода C для реализации многих своих основных функций и структур данных.
Матричное умножение
Как и точечное произведение двух векторов, вы также можете умножить две матрицы. В NumPy матрица-это не что иное, как двумерный массив. Чтобы умножить две матрицы, внутренние размеры матриц должны совпадать, а это значит, что число столбцов матрицы слева должно быть равно числу строк матрицы справа от произведения. Например, если матрица X имеет размеры [3,4], а другая матрица Y имеет размеры [4,2], то матрицы X и Y можно умножить вместе. Результирующая матрица будет иметь размеры [3,2], которые являются размерами внешних измерений.
Для умножения двух матриц можно использовать функцию dot , как показано ниже:
X = np.
В приведенном выше скрипте мы создали матрицу 3×2 с именем X и матрицу 2×3 с именем Y . Затем мы находим точечное произведение двух матриц и присваиваем результирующую матрицу переменной Z . Наконец, мы выводим полученную матрицу на консоль. На выходе вы должны увидеть матрицу 2×2, как показано ниже:
[[30 36] [66 81]]
Вы также можете умножить две матрицы по элементам. Для этого размеры двух матриц должны совпадать, как при сложении массивов. Функция multiply используется для поэлементного умножения.
Давайте попробуем умножить матрицы X и Y по элементам:
Z = np.multiply(X, Y)
При выполнении приведенного выше кода возникнет следующая ошибка:
ValueError: operands could not be broadcast together with shapes (2,3) (3,2)
Ошибка возникает из-за несоответствия размеров матриц X и Y . Теперь давайте попробуем умножить матрицу X на саму себя с помощью функции multiply :
Z = np.multiply(X, X)
Теперь, если вы напечатаете матрицу Z , вы увидите следующий результат:
[[ 1 4 9] [16 25 36]]
Матрица X была успешно умножена на саму себя, потому что размеры умноженных матриц совпадали.
Нахождение обратной матрицы
Другой очень полезной матричной операцией является нахождение обратной матрицы. Библиотека NumPy содержит функцию end в модуле lineage .
Для нашего примера давайте найдем обратную матрицу 2×2. Взгляните на следующий код:
Y = np.array(([1,2], [3,4])) Z = np.linalg.inv(Y) print(Z)
Вывод приведенного выше кода выглядит следующим образом:
[[-2.
Теперь, чтобы проверить, правильно ли вычислено обратное, мы можем взять точечное произведение матрицы с ее обратным, которое должно дать единичную матрицу.
W = Y.dot(Z) print(W)
[[1.00000000e+00 1.11022302e-16] [0.00000000e+00 1.00000000e+00]]
И результат оказался таким, как мы и ожидали. Единицы в диагонали и нули (или очень близкие к нулю) в другом месте.
Нахождение определителя матрицы
Определитель матрицы может быть вычислен с помощью метода det , который показан здесь:
X = np.array(([1,2,3], [4,5,6], [7,8,9])) Z = np.linalg.det(X) print(Z)
В приведенном выше сценарии мы создали матрицу 3×3 и нашли ее определитель с помощью метода det . В выходных данных вы должны увидеть “6.66133814775094 e-16”.
Нахождение следа матрицы
След матрицы – это сумма всех элементов в диагонали матрицы. Библиотека NumPy содержит функцию trace , которая может быть использована для поиска трассировки матрицы. Посмотрите на следующий пример:
X = np.array(([1,2,3], [4,5,6], [7,8,9])) Z = np.trace(X) print(Z)
На выходе вы должны увидеть “15”, так как сумма диагональных элементов матрицы X равна 1 + 5 + .
Вывод
Библиотека Pythons NumPy – одна из самых популярных библиотек для численных вычислений. В этой статье мы подробно рассмотрели библиотеку NumPy с помощью нескольких примеров. Мы также показали, как выполнять различные операции линейной алгебры с помощью библиотеки NumPy, которые обычно используются во многих приложениях науки о данных.
Хотя мы рассмотрели довольно много основных функций Numpy, нам еще предстоит многому научиться. Если вы хотите узнать больше, я бы предложил вам попробовать такой курс , который охватывает NumPy, Pandas, Scikit-learn и Matplotlib гораздо глубже, чем то, что мы смогли охватить здесь.
Я бы посоветовал вам попрактиковаться в примерах, приведенных в этой статье. Если вы планируете начать карьеру специалиста по обработке данных, библиотека NumPy определенно является одним из инструментов, которые вам необходимо освоить, чтобы стать успешным и продуктивным сотрудником в этой области.
numpy.array — NumPy v1.23 Manual
- Numpy.array ( Object , DTYPE = NONE , * , COPY = TRUE , ORDER = ‘K’ , SUBOK = FALSE , NDMIN = 0 , Нравится = Нет )
Создать массив.
- Параметры
- объект array_like
Массив, любой объект, предоставляющий интерфейс массива, объект, чей Метод __array__ возвращает массив или любую (вложенную) последовательность.
Если объект является скаляром, 0-мерный массив, содержащий объект,
вернулся.- dtype тип данных, необязательный
Требуемый тип данных для массива. Если не указано, то тип будет быть определен как минимальный тип, необходимый для хранения объектов в последовательность.
- копия bool, опционально
Если true (по умолчанию), то объект копируется. В противном случае копия будет быть сделано только в том случае, если __array__ возвращает копию, если obj является вложенной последовательностью, или если копия необходима для удовлетворения любых других требований (
dtype, заказ и т.д.).- порядок {‘K’, ‘A’, ‘C’, ‘F’}, опционально
Укажите структуру памяти массива. Если объект не является массивом, вновь созданный массив будет в порядке C (основной ряд), если только «F» не указан, и в этом случае он будет в порядке Fortran (основной столбец).
Если объект является массивом, выполняется следующее.заказ
нет копии
копия=правда
«К»
без изменений
Заказ F&C сохранен, в остальном наиболее аналогичный заказ
«А»
без изменений
F-заказ, если ввод F, а не C, иначе C-заказ
«С»
C заказ
С заказ
F
Для заказа
Для заказа
Когда
copy=Falseи копирование делается по другим причинам, результат так же, как если быcopy=True, с некоторыми исключениями для ‘A’, см. Раздел заметок. Порядок по умолчанию — «К».- subok bool, необязательный
Если True, то подклассы будут пропущены, иначе возвращаемый массив будет вынужден быть массивом базового класса (по умолчанию).
- ndmin int, необязательный
Задает минимальное количество измерений, которые результирующий массив должен иметь. Единицы будут добавлены к форме как необходимо для удовлетворения этого требования.
- как array_like, необязательный
Ссылочный объект, позволяющий создавать массивы, которые не Массивы NumPy. Если массив передается как
, например,поддерживает протокол__array_function__, результат будет определен этим. В этом случае он обеспечивает создание объекта массива совместим с переданным через этот аргумент.Новое в версии 1.20.0.
- Возвращает
- out ndarray
Объект массива, удовлетворяющий указанным требованиям.
См. также
-
empty_like Возвращает пустой массив с формой и типом ввода.
-
one_like Возвращает массив единиц с формой и типом ввода.
-
zeros_like Возвращает массив нулей с формой и типом ввода.
-
full_like Возвращает новый массив с формой ввода, заполненной значением.
-
пустой Возвращает новый неинициализированный массив.
-
единицы Вернуть новые значения параметров массива к единице.
-
нули Возврат новых значений параметров массива к нулю.
-
полный Возвращает новый массив заданной формы, заполненный значением.
Примечания
Когда порядок «A» и
объектявляется массивом ни в порядке «C», ни в «F», и копирование принудительно производится изменением dtype, то порядок результата такой не обязательно «C», как ожидалось. Вероятно, это ошибка.Примеры
>>> np.массив ([1, 2, 3]) массив([1, 2, 3])
Обновление:
>>> np.
массив ([1, 2, 3.0])
массив([ 1., 2., 3.])
Более одного измерения:
>>> нп.массив([[1, 2], [3, 4]]) массив([[1, 2], [3, 4]])Минимальные размеры 2:
>>> np.array([1, 2, 3], ndmin=2) массив([[1, 2, 3]])
Предоставленный тип:
>>> np.array([1, 2, 3], dtype=complex) массив([ 1.+0.j, 2.+0.j, 3.+0.j])
Тип данных, состоящий из более чем одного элемента:
>>> x = np.array([(1,2),(3,4)],dtype=[('a','Создание массива из подклассов:
>>> np.array(np.mat('1 2; 3 4')) массив([[1, 2], [3, 4]])>>> np.array(np.mat('1 2; 3 4'), subok=True) матрица([[1, 2], [3, 4]])
NumPy Создание массивов
❮ Назад Далее ❯
Создание объекта NumPy ndarray
NumPy используется для работы с массивами. Объект массива в NumPy называется ндаррай .
Мы можем создать NumPy ndarray с помощью функции array() .
Пример
импортировать numpy как np
обр = np.array ([1, 2, 3, 4, 5])
печать (обр)
распечатка (тип (обр))
Попробуйте сами »
type(): Эта встроенная функция Python сообщает нам тип переданного ей объекта. Как в приведенном выше коде
это показывает, что обр тип numpy.ndarray .
Для создания ndarray ,
мы можем передать список, кортеж или любой подобный массиву объект в array() метод, и он будет преобразован в ndarray :
Пример
Используйте кортеж для создания массива NumPy:
импортировать numpy как np
arr = np.array((1, 2, 3, 4, 5))
print(arr)
Попробуйте сами »
Измерения в массивах
Измерение в массивах — это один уровень глубины массива (вложенные массивы).
вложенный массив: — это массивы, элементы которых содержат массивы.
Массивы 0-D
Массивы 0-D, или скаляры — это элементы массива. Каждое значение в массиве представляет собой массив 0-D.
Пример
Создание массива 0-D со значением 42
import numpy as np
arr = np.array(42)
print(arr)
Попробуйте сами »
Одномерные массивы
размерный или одномерный массив.
Это самые распространенные и основные массивы.
Пример
Создайте одномерный массив, содержащий значения 1,2,3,4,5:
импортировать numpy как np
arr = np.array([1, 2, 3, 4, 5])
print(arr)
Попробуйте сами »
2-D Arrays
Массив, который имеет 1 -D массивы в качестве его элементов называются двумерными массивами.
Они часто используются для представления матриц или тензоров 2-го порядка.
В NumPy есть целый подмодуль, посвященный матричным операциям, который называется numpy.mat
Пример
Создайте двумерный массив, содержащий два массива со значениями 1,2,3 и 4,5,6:
импортировать numpy как np
arr = np.array([[1, 2, 3], [4, 5, 6]])
print(arr)
Попробуйте сами »
Трехмерные массивы
Массив, содержащий двумерные массивы (матрицы) в качестве элементов, называется трехмерным массивом.
Они часто используются для представления тензора 3-го порядка.
Пример
Создайте трехмерный массив с двумя двумерными массивами, каждый из которых содержит два массива с значения 1,2,3 и 4,5,6:
импортировать numpy как np
arr = np.array([[[1, 2, 3], [4, 5, 6]], [[1, 2, 3], [4, 5, 6]]])
печать(обр)
Попробуйте сами »
Проверить количество размеров?
Массивы NumPy предоставляют атрибут ndim , который возвращает целое число, указывающее, сколько измерений имеет массив.
Пример
Проверить, сколько измерений имеют массивы:
импортировать numpy как np
a = np.array(42)
b = np.array([1, 2, 3, 4, 5])
c = np.array([[1, 2, 3], [4, 5, 6]])
d = np.array([[[1, 2, 3], [4, 5, 6]] , [[1, 2, 3], [4, 5, 6]]])
print(a.ndim)
print(b.ndim)
print(c.ndim)
print(d.ndim)
Попробуйте сами »
Многомерные массивы
Массив может иметь любое количество измерений.
Когда массив создан, вы можете определить количество измерений, используя
аргумент ndmin .
Пример
Создайте массив с 5 измерениями и убедитесь, что он имеет 5 измерений:
импортировать numpy как np
arr = np.array([1, 2, 3, 4], ndmin=5)
print(arr)
print(‘количество измерений:’, arr.ndim)
Попробуйте Себя »
В этом массиве самое внутреннее измерение (5-й размер) имеет 4 элемента,
4-й размер имеет 1 элемент, который является вектором,
3-й размер имеет 1 элемент, который является матрицей с вектором,
2-й размер имеет 1 элемент, который представляет собой 3D-массив, а 1-й размер имеет 1 элемент, который представляет собой 4D-массив.
Проверьте себя с помощью упражнений
Упражнение:
Вставьте правильный метод для создания массива NumPy.
обр = np.([1, 2, 3, 4, 5])
Начать упражнение
❮ Предыдущий Далее ❯
НОВИНКА
Мы только что запустили
Видео W3Schools
Узнать
ВЫБОР ЦВЕТА
КОД ИГРЫ
Играть в игру
Top Tutorials
Учебное пособие по HTMLУчебное пособие по CSS
Учебное пособие по JavaScript
Учебное пособие
Учебник по SQL
Учебник по Python
Учебник по W3.CSS
Учебник по Bootstrap
Учебник по PHP
Учебник по Java
Учебник по C++
Учебник по jQuery
Лучшие ссылки
Справочник по HTMLСправочник по CSS
Справочник по JavaScript
Справочник по SQL
Справочник по Python
Справочник по W3.CSS
Справочник по Bootstrap
Справочник по PHP
Цвета HTML
Справочник по Java
Справочник по Angular
Справочник по jQuery
0 Лучшие примеры W3Schools оптимизирован для обучения и обучения. Примеры могут быть упрощены для улучшения чтения и обучения.
Учебники, ссылки и примеры постоянно пересматриваются, чтобы избежать ошибок, но мы не можем гарантировать полную правильность всего содержания.
Используя W3Schools, вы соглашаетесь прочитать и принять наши условия использования,
куки-файлы и политика конфиденциальности. Copyright 1999-2022 Refsnes Data. Все права защищены. NumPy означает Numerical Python. Это библиотека Python, используемая для работы с массивом. В Python мы используем список для массива, но он медленно обрабатывается. Массив NumPy — это мощный объект N-мерного массива и его использование в линейной алгебре, преобразовании Фурье и возможностях случайных чисел. Одномерный массив — это тип линейного массива. One Dimensional Array Example: Вывод: Проверьте тип данных для списка и массива: Вывод: Данные в многомерных массивах хранятся в табличной форме. Two Dimensional Array Example: Вывод: Примечание: использовать операторы [ ] внутри numpy.array() для многомерных описывает 1. Ось: 9003 оси an1 порядок индексации в массиве. Ось 0 = одномерная Ось 1 = двухмерная Ось 2 = трехмерная 2. Example: 9 9 9 0051 print Вывод: Example: Выход: Одномерный массив имеет ранг 1. Ранг 1 Двумерный массив имеет ранг 2.0031 4. Объекты типа данных (dtype): Объекты типа данных (dtype) являются экземпляром класса numpy.dtype . Он описывает, как следует интерпретировать байты в блоке памяти фиксированного размера, соответствующем элементу массива. Пример: Output: Другой способ создания массива Numpy: 1. numpy.array() : Объект массива Numpy в Numpy называется ndarray. Мы можем создать ndarray, используя numpy. Syntax: numpy.array(parameter) Example: 9 Выход: 6 31. 2 2 2 2 2 . 2 . 2 . 2 . Синтаксис: numpy.fromiter(iterable, dtype, count=-1) Пример 1: Выход: Fromiter () Array: [0. . Примере 2: 1. Output: массив fromiter() : ['G' 'e' 'e' 'k' 'f' 'o' 'r' 'g' 'e' 'e' 'k' 's'] 3. Syntax: numpy.arange([start, ]stop, [step, ]dtype=None) Example: Вывод: array([ 1., 3., 5., 7., 9., 11., 13., 15., 17., 19.], dtype=float32) 4. Синтаксис: numpy.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None, axis=0) Пример 1: Output : Example 2: Output : 5. numpy.empty() : Эта функция создает новый массив заданной формы и типа без инициализации значения. Syntax: numpy.empty(shape, dtype=float, order='C') Example: Вывод: 6. numpy.ones(): Эта функция используется для получения нового массива заданной формы и типа, заполненного единицами (1). Синтаксис: numpy.ones(shape, dtype=None, order=’C’) Пример: Output: 7. numpy.zeros() : Эта функция используется для получения нового массива заданной формы и типа, заполненного нулями (0). Syntax: numpy.ones(shape, dtype=None) Example: Output: В этом уроке мы будем изучать массивы NumPy. Массивы NumPy являются основным способом хранения данных с помощью библиотеки NumPy. Они похожи на обычные списки в Python, но имеют то преимущество, что работают быстрее и имеют больше встроенных методов. Массивы NumPy создаются путем вызова метода Пример базового массива NumPy показан ниже. Обратите внимание, что хотя я запускаю оператор Последняя строка этого блока кода приведет к выводу, который выглядит следующим образом. Оболочка Существует два разных типа массивов NumPy: векторы и матрицы. Векторы представляют собой одномерные массивы NumPy и выглядят следующим образом: создаются путем передачи списка списков в Вы также можете расширить массивы NumPy для работы с трех-, четырех-, пяти-, шести- или многомерными массивами, но они встречаются редко и в значительной степени выходят за рамки этого курса (в конце концов, это курс по программированию на Python, а не по линейной алгебре). Массивы NumPy поставляются с рядом полезных встроенных методов. Оставшуюся часть этого урока мы посвятим подробному обсуждению этих методов. NumPy имеет полезный метод под названием Ниже приведен пример метода Вы также можете включить третью переменную в Ниже приведен пример использования третьей переменной в методе При программировании вам время от времени потребуется создавать массивы единиц или нулей. NumPy имеет встроенные методы, которые позволяют вам сделать любой из них. Мы можем создавать массивы нулей, используя метод Вы также можете сделать что-то подобное, используя двумерные массивы. Например, Мы можем создавать массивы из единиц, используя аналогичный метод с именем разделить этот диапазон чисел на интервалы. Ниже приведен пример метода Любой, кто изучал линейную алгебру, будет знаком с понятием «единичная матрица», которая представляет собой квадратную матрицу, все диагональные значения которой равны Ниже приведены примеры: NumPy имеет ряд встроенных методов, позволяющих создавать массивы случайных чисел. Очень часто берут массив с определенными размерами и преобразуют этот массив в другую форму. Например, у вас может быть одномерный массив из 10 элементов, и вы хотите переключить его на двумерный массив 2x5. Ниже приведен пример: Результат этой операции: Обратите внимание, что для использования Если вас интересует текущая форма массива NumPy, вы можете определить его форму с помощью атрибута NumPy Вы также можете объединить метод В заключение этого урока давайте узнаем о четырех полезных методах определения максимального и минимального значений в массиве NumPy. Мы можем использовать Мы также можем использовать метод Ниже приведен пример. Точно так же мы можем использовать В этом уроке мы обсудили различные атрибуты и методы массивов NumPy. В следующем уроке мы продолжим работу над некоторыми практическими задачами с массивами NumPy. Массивы Numpy — хорошая замена спискам Python. Они лучше, чем списки Python. Они обеспечивают более высокую скорость и занимают меньше места в памяти. Начнем с его определения для тех, кто не знает о массивах numpy. Это многомерные матрицы или списки фиксированного размера с похожими элементами. Одномерный массив Двухмерный массив Типичная функция массива выглядит примерно так: , subok=False, ndmin=0) Здесь все атрибуты, кроме объектов, необязательны. Так что не волнуйтесь, даже если вы не очень разбираетесь в других параметрах. Массив имеет следующие шесть основных атрибутов: Теперь мы воспользуемся примером, чтобы понять различные атрибуты массива. Код: Вывод: Numpy предоставляет несколько встроенных функций для создания массивов и работы с ними с нуля. Массив можно создать с помощью следующих функций: Код: Вывод: Код: Вывод: Мы можем получить доступ к элементам массива, используя их индексы. Код: Вывод: Код: Вывод: Пример операции с массивом в NumPy поясняется ниже: Код: Вывод: Массив NumPy представляет собой многомерный список однотипных объектов. Это чрезвычайно полезно в научных и математических вычислениях. Таким образом, они находят применение в науке о данных и машинном обучении. Рекомендуемые статьи Это руководство по массивам NumPy. Здесь мы обсудили, как создавать и получать доступ к элементам массива в numpy с примерами и реализацией кода. Вы также можете просмотреть следующие статьи, чтобы узнать больше: Автор Бернд Кляйн . На этой странице ➤ В предыдущей главе нашего руководства по Numpy мы уже видели, что можем создавать массивы Numpy из списков и кортежей. Теперь мы хотим представить дополнительные функции для создания базовых массивов. Numpy предоставляет функции для создания массивов с равномерно распределенными значениями в пределах заданного интервала. Один «аранж»
использует заданное расстояние, а другой «linspace» нуждается в количестве элементов и создает
расстояние автоматически. Синтаксис arange: arange возвращает равномерно распределенные значения в пределах заданного интервала. Значения генерируются
в полуоткрытом интервале '[старт, стоп)'
Если функция используется с целыми числами, она почти эквивалентна встроенной функции Python.
range, но arange возвращает ndarray, а не итератор списка, как это делает range. Будьте осторожны, если вы используете значение с плавающей запятой для шага 9 Справка Следующие варианты использования Этот результат не поддается никакому логическому объяснению. Здесь также помогает взгляд на справку: «При использовании нецелого шага, такого как 0,1, результаты часто не будут согласовываться. Лучше использовать Синтаксис linspace: linspace возвращает ndarray, состоящий из 'num' равноотстоящих выборок в закрытом интервале [start, stop] или полуоткрытом интервале [start, stop). Будет ли возвращен закрытый или полуоткрытый интервал, зависит от
является ли «конечная точка» True или False. Параметр start определяет начальное значение создаваемой последовательности. Пока мы не обсудили один интересный параметр. Если установлен необязательный параметр 'retstep', функция также вернет значение интервала между соседними значениями. Итак, функция вернет кортеж («выборки», «шаг»): Живое обучение Python Нравится эта страница? Мы предлагаем интерактивных учебных курсов Python , охватывающих содержание этого сайта. См.: Обзор курсов Live Python Зарегистрируйтесь здесь В numpy можно создавать многомерные массивы. Скаляры нульмерны. В следующем примере мы создадим скаляр 42. Применив метод ndim к нашему скаляру, мы получим размерность массива. Мы также можем видеть, что это тип «numpy.ndarray». В нашем первоначальном примере мы уже встречались с одномерным массивом, более известным некоторым как векторы. До сих пор мы не упоминали, но вы могли предположить, что массивы numpy являются контейнерами элементов одного и того же типа, например. только целые числа. Однородный тип массива можно определить с помощью атрибута «dtype», как мы можем узнать из следующего примера: Живое обучение Python Нравится эта страница? Мы предлагаем интерактивных обучающих курсов Python , охватывающих содержание этого сайта. См.: Обзор курсов Live Python Предстоящие онлайн-курсы Python для инженеров и ученых с 17 октября 2022 г. по 21 октября 2022 г. Анализ данных с помощью Python с 19 октября 2022 г. по 21 октября 2022 г. Зарегистрироваться здесь Конечно, массивы NumPy не ограничены одним измерением. Они произвольной размерности.
Мы создаем их, передавая вложенные списки (или кортежи) в метод массива numpy. Функция "shape" возвращает форму массива. Фигура представляет собой кортеж целых чисел. Эти числа обозначают длину соответствующего измерения массива. Другими словами: «Форма» массива — это кортеж с количеством элементов на ось (размерность).
В нашем примере форма равна (6, 3), т.е. у нас 6 строк и 3 столбца. Существует также эквивалентное свойство массива: Форма массива также говорит нам кое-что о порядке, в котором обрабатываются индексы, т. е. сначала строки, затем столбцы и после этого остальные измерения. "shape" также можно использовать для изменения формы массива. Вы уже могли догадаться, что новая фигура должна соответствовать количеству элементов массива, т.е. общий размер нового массива должен быть таким же, как у старого. Мы создадим исключение, если это не так. Давайте рассмотрим еще несколько примеров. Форма скаляра представляет собой пустой кортеж: Живое обучение Python Нравится эта страница? Мы предлагаем интерактивных учебных курсов Python , охватывающих содержание этого сайта. См.: Обзор курсов Live Python Зарегистрируйтесь здесь Назначение и доступ к элементам массива аналогичны другим последовательным типам данных Python, то есть спискам и кортежам.
У нас также есть много вариантов индексации, что делает индексацию в Numpy очень мощной и похожей на индексацию списков и кортежей. Одиночное индексирование ведет себя так, как вы, скорее всего, ожидаете: Индексация многомерных массивов: Мы обратились к элементу во второй строке, т.е. к строке с индексом 1 и первому столбцу (индекс 0). Мы получили к нему доступ таким же образом, как и с элементом вложенного списка Python. Вы должны знать, что доступ к многомерным массивам может быть очень неэффективным. Причина в том, что мы создаем промежуточный массив A[1], из которого мы обращаемся к элементу с индексом 0. Таким образом, он ведет себя примерно так: Есть еще один способ доступа к элементам многомерных массивов в Numpy: мы используем только одну пару квадратных скобок и все индексы разделяются запятыми: Мы предполагаем, что вы знакомы с нарезкой списков и кортежей. Синтаксис тот же, что и в numpy для одномерных массивов, но его можно применять и к нескольким измерениям. Общий синтаксис для одномерного массива А выглядит следующим образом: Проиллюстрируем принцип работы «нарезки» на нескольких примерах. Начнем с самого простого случая, т. е. с нарезки одномерного массива: Мы проиллюстрируем многомерные срезы на следующих примерах. Диапазоны для каждого параметра разделены запятыми: В следующих двух примерах используется третий параметр «шаг». Если количество объектов в кортеже выбора меньше измерения N, то : предполагается для любых последующих измерений: Внимание:
В то время как нарезка списков и кортежей создает новые объекты, операция нарезки массива создает представление исходного массива. Проделав то же самое со списками, мы видим, что получаем копию: Если вы хотите проверить, используют ли два имени массива один и тот же блок памяти, вы можете использовать функцию np.may_share_memory. Чтобы определить, могут ли два массива A и B совместно использовать память, вычисляются границы памяти A и B. Функция возвращает True, если они перекрываются, и False в противном случае. Функция может давать ложные срабатывания, т. В следующем коде показан случай, когда использование may_share_memory весьма полезно: Мы видим, что A и B каким-то образом делят память. Атрибут массива «данные» является указателем объекта на начало данных массива. Но мы видели, что если мы изменим элемент одного массива, то другой элемент тоже изменится.
Этот факт отражает may_share_memory: Приведенный выше результат является "ложноположительным" примером для may_share_memory в том смысле, что кто-то может подумать, что массивы одинаковы, что не так. Существует два способа инициализации массивов нулями или единицами. То, что мы сказали о методе one(), аналогично применимо и к методу zeros(), как видно из следующего примера: Есть еще один интересный способ создать массив с единицами или нулями, если он должен иметь ту же форму, что и другой существующий массив 'a'. Numpy предоставляет для этой цели методы one_like(a) и zeros_like(a). Существует также способ создания массива с помощью Живое обучение Python Нравится эта страница? Мы предлагаем интерактивных учебных курсов Python , охватывающих содержание этого сайта. См.: Обзор курсов Live Python Зарегистрируйтесь здесь Возвращает копию массива данного объекта 'obj'. Существует также метод ndarray «copy», который можно напрямую применить к массиву.
Она похожа на приведенную выше функцию, но значения по умолчанию для аргументов порядка отличаются. Возвращает копию массива 'a'. В линейной алгебре единичная матрица или единичная матрица размера n представляет собой квадратную матрицу размера n × n с единицами на главной диагонали и нулями в других местах. В Numpy есть два способа создания массивов идентификаторов: Мы можем создавать массивы идентификаторов с помощью функции identity: Параметры: Вывод идентификатора представляет собой массив 'n' x 'n', главная диагональ которого равна единице, а все остальные элементы равны 0. Еще один способ создания идентификационных массивов — функция eye. Эта функция также создает диагональные массивы, состоящие исключительно из единиц. Возвращает двумерный массив с единицами по диагонали и нулями в других местах. eye возвращает ndarray формы (N,M). Все элементы этого массива равны нулю, кроме 'k'-й диагонали, значения которой равны единице. Принцип работы параметра «d» функции глаза показан на следующей схеме: Живое обучение Python Нравится эта страница? Мы предлагаем интерактивных учебных курсов Python , охватывающих содержание этого сайта. См.: Обзор курсов Live Python Зарегистрируйтесь здесь 1) Создайте произвольный одномерный массив с именем "v". 2) Создать новый массив, состоящий из нечетных индексов ранее созданного массива "v". 3) Создать новый массив в обратном порядке от версии 4) Что выведет следующий код: 5) Создайте двумерный массив с именем "m". 6) Создать новый массив из m, в котором элементы каждой строки расположены в обратном порядке. 7) Еще один, где ряды в обратном порядке. 8) Создайте массив из m, где столбцы и строки расположены в обратном порядке. 9) Вырезать первую и последнюю строку и первый и последний столбец. 1) 2) 3) обратный_порядок = а[::-1] 4) Вывод будет 200, потому что слайсы представляют собой представления в numpy, а не копии.0521
Примеры HTML
Примеры CSS
Примеры JavaScript
Примеры инструкций
Примеры SQL
Примеры Python
Примеры W3. CSS
Примеры Bootstrap
Примеры PHP
Примеры Java
Примеры XML
Примеры jQuery FORUM |
О
W3Schools работает на основе W3.CSS. Основы массивов NumPy — GeeksforGeeks
Он предоставляет объект массива намного быстрее, чем традиционные списки Python. Одномерный массив:
Python3
import numpy as np list = [ 1 , 2 , 3 , 4 ] sample_array = np.array(list1) print ( "List in python : " , list ) print ( "Numpy Array in python :" , sample_array) Список в питоне: [1, 2, 3, 4]
Numpy Array в Python: [1 2 3 4]
Python3
Печать ( типа (список ) ( типа (список ) ( типа (список )) печать ( тип (sample_array)) <класс 'список'>
ndarray'>
Многомерный массив:
Python3
import numpy as np list_1 = [ 1 , 2 , 3 , 4 ] list_2 = [ 5 , 6 , 7 , 8 ] list_3 = [ 9 , 10 , 11 , 12 ] sample_array = np. array([list_1, list_2, list_3]) print ( "Numpy multi dimensional array in python \n" , sample_array) Форма: Количество элементов вдоль каждой оси. Это из кортежа. Python3
import numpy as np list_1 = [ 1 , 2 , 3 , 4 ] LIST_2 = [ 5 , 6 , , 6 , , .0051 8 ] list_3 = [ 9 , 10 , 11 , 12 ] sample_array = NP. Array ([[List_1, LIST_2, LIST_3]) ( "Numpy array :" ) print (sample_array) print ( "Shape of the array :" , sample_array.shape) Массив Numpy:
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
Форма массива: (3, 4)
Python3
import numpy as np sample_array = np. array([[ 0 , 4 , 2 ], [ 3 , 4 , 5 ], [ 23 , 4 , 5 ], [ 2 , 34 , 5 ], [ 5 , .0052 , Образец_аррея.shape) СПАДА ARRAY: (5, 3)
просто количество осей (или размеров), которые он имеет. Python3
Импорт Numpy As NP AS AS .0052 , 4 , 2 ]]) sample_array_2 = np. array([ 0.2 , 0.4 , 2.4 ]) print ( "Data type of the array 1 :" , sample_array_1.dtype) print ( "Data type of array 2 :" , sample_array_2.dtype) Data type of the array 1 : int32
Тип данных массива 2: float64
array() функция. Python3
import numpy as np arr = np.array ([ 3 , 4 , 5 , 5 ]) ])0051 Печать ( "Ассист:" , ARR) Array: [3 4 5 5]
2 . 2 . 2 . 2 2 . 2 . : Функция fromiter() создает новый одномерный массив из итерируемого объекта.
Python3
import numpy as np iterable = (a * a for a in range ( 8 ) ARR = НП.0052 , ARR)
1. 4. 9. 25. 36. 49.] Python3
import numpy as np var = "Geekforgeeks" arr = np.fromiter(var, dtype = 'U2' ) print ( "fromiter() array :" , arr)
numpy.arange() : Это встроенная функция NumPy, которая возвращает равномерно распределенные значения в пределах заданного интервала.
Python3
import numpy as np NP.Arange ( 1 , 20 , 2 , , DTO0143
numpy.linspace() : Эта функция возвращает равномерно распределенные числа в пределах указанного между двумя пределами.
Python3
import numpy as np np.linspace( 3.5 , 10 , 3 ) array([ 3.5 , 6.75, 10. ])
Python3
import numpy as np np. linspace( 3.5 , 10 , 3 , dtype = np.int32) array([ 3, 6, 10])
Python3
import numpy as np np.empty([ 4 , 3 ], dtype = np. int32, order = 'f' ) массив([[ 1, 5, 9],
[ 2, 6, 10],
[3, 7, 11],
[ 4, 8, 12]]) Python3
import numpy as np np.ones([ 4 , 3 ], dtype = np. int32, order = 'f' ) array([[1, 1, 1],
[1, 1, 1],
[1, 1, 1],
[1, 1, 1]]) Python3
import numpy as np np.zeros([ 4 , 3 ], dtype = np. int32, order = 'f' ) array([[0, 0 , 0],
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]]) Полное руководство по массивам NumPy
Что такое массивы NumPy?
array() из библиотеки NumPy. Внутри метода вы должны передать список. import numpy as np в начале этого блока кода, он будет исключен из других блоков кода в этом уроке для краткости. импортировать numpy как np
список_образцов = [1, 2, 3]
np.array(sample_list)
array([1,2,3])
array() указывает, что это больше не обычный список Python. Вместо этого это массив NumPy. Два разных типа массивов NumPy
my_vector = np.array(['this', 'is', 'a', 'vector'])
Метод np.array() . Пример ниже. my_matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
np.array(my_matrix)
Массивы NumPy: встроенные методы
Как получить диапазон чисел в Python с помощью NumPy
arange , который принимает два числа и дает вам массив целых чисел, которые больше или равны ( >= ) первого числа и меньше ( < ) второго числа. arange . np.оранжевый(0,5)
#Returns array([0, 1, 2, 3, 4])
arange метод, определяющий размер шага для возврата функции. Передача 2 в качестве третьей переменной вернет каждое второе число в диапазоне, передача 5 в качестве третьей переменной вернет каждое 5-е число в диапазоне и так далее. arange . np.оранжевый(1,11,2)
#Returns array([1, 3, 5, 7, 9])
Как сгенерировать единицы и нули в Python с помощью NumPy
нулей NumPy. Вы передаете количество целых чисел, которые хотите создать, в качестве аргумента функции. Пример ниже. нп.нули(4)
#Returns array([0, 0, 0, 0])
np.zeros(5, 5) создает матрицу 5x5, содержащую все нули. из единиц . Пример ниже. шт.(5)
#Returns array([1, 1, 1, 1, 1])
Как равномерно разделить диапазон чисел в Python с помощью NumPy
Метод NumPy linspace предназначен для решения этой проблемы. linspace принимает три аргумента: linspace . np.linspace(0, 1, 10)
#Returns array([0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0])
Как создать матрицу идентичности в Python с помощью NumPy
1 . NumPy имеет встроенную функцию, которая принимает один аргумент для построения матриц идентичности. Функция глаз . np.eye(1)
#Возвращает единичную матрицу 1x1
нп.глаз(2)
#Возвращает единичную матрицу 2x2
нп.глаз(50)
#Возвращает идентификационную матрицу 50x50
Как создавать случайные числа в Python с помощью NumPy
Каждый из этих методов начинается с случайный . Несколько примеров приведены ниже: np.random.rand(sample_size)
#Возвращает выборку случайных чисел от 0 до 1.
# Размер выборки может быть либо одним целым числом (для одномерного массива), либо двумя целыми числами, разделенными запятыми (для двумерного массива).
np.random.randn (sample_size)
#Возвращает выборку случайных чисел от 0 до 1 в соответствии с нормальным распределением.
# Размер выборки может быть либо одним целым числом (для одномерного массива), либо двумя целыми числами, разделенными запятыми (для двумерного массива).
np.random.randint (низкий, высокий, размер выборки)
# Возвращает выборку целых чисел, которые больше или равны «низкому» и меньше «высокому»
Как изменить форму массивов NumPy
arr = np.array([0,1,2,3,4,5])
arr.reshape(2,3)
array([[0, 1, 2],
[3, 4, 5]]) reshape исходный массив должен иметь то же количество элементов, что и массив, в который вы пытаетесь его преобразовать. shape . Используя нашу предыдущую структуру переменных arr , ниже приведен пример вызова атрибута формы : arr = np.array([0,1,2,3,4,5])
обр.форма
#Returns (6,) - обратите внимание, что второго элемента нет, так как это одномерный массив
обр = обр.изменить форму (2,3)
обр.форма
#Возвращает (2,3)
reshape с атрибутом shape в одной строке следующим образом: arr.reshape(2,3).shape
#Returns (2,3)
Как найти максимальное и минимальное значение массива NumPy
Мы будем работать с этим массивом: simple_array = [1, 2, 3, 4]
max метод для нахождения максимального значения массива NumPy. Пример ниже. простой_массив.max()
#Returns 4
argmax , чтобы найти индекс максимального значения в массиве NumPy. Это полезно, когда вы хотите найти местоположение максимального значения, но вам не обязательно заботиться о том, каково его значение. простой_массив.argmax()
#Returns 3
min и методы argmin для поиска значения и индекса минимального значения в массиве NumPy. простой_массив.мин()
# Возвращает 1
простой_массив.argmin()
#Returns 0
Идем дальше
Массивы NumPy | Как создать и получить доступ к элементам массива в NumPy?
Атрибуты массива
Пример массивов NumPy
Пример №1 — для иллюстрации атрибутов массива
import numpy as np
#создание массива для понимания его атрибутов
A = np.массив([[1,2,3],[1,2,3],[1,2,3]])
print("Массив A:\n",A)
#тип массива
печать("Тип:", тип(А))
#Форма массива
печать("Форма:", А.форма)
#нет. размеров
print("Ранг:", А.ндим)
#размер массива
печать("Размер:", A.размер)
#тип каждого элемента в массиве
print("Тип элемента:", A.dtype) Как создать массив в NumPy?
Пример №2 — Создание массива NumPy
импортировать numpy как np
#создание массива с помощью ndarray
A = np.
ndarray (форма = (2,2), dtype = с плавающей запятой)
print("Массив со случайными значениями:\n", A)
# Создание массива из списка
B = np.массив ([[1, 2, 3], [4, 5, 6]])
print ("Массив создан со списком:\n", B)
# Создание массива из кортежа
C = np.массив ((1, 2, 3))
print ("Массив, созданный кортежем:\n", C) # Создание массива со всеми единицами
D = np.ones ((3, 3))
print("Массив со всеми единицами:\n", D)
# Создание массива со всеми нулями
E = np.zeros ((3, 3))
print("Массив со всеми нулями:\n",E)
# Создание массива со сложным типом данных
F = np.full ((3, 3), 1, dtype = 'сложный')
print("Массив сложного типа данных:\n", F)
#создание массива с буфером
G = np.ndarray((2,), buffer=np.array([1,2,3]),dtype=int)
print("Массив с указанным буфером:\n", G)
#создание массива с диапазоном
H = np.arange(10)
print("Массив с указанным диапазоном:\n", H) Как получить доступ к элементам массива в NumPy?
Мы можем воспользоваться помощью следующих примеров, чтобы понять это лучше. Пример №3. Доступ к элементу в двумерном массиве
import numpy as np
#создание массива для понимания индексации
A = np.массив([[1,2,1],[7,5,3],[9,4,8]])
print("Массив A:\n",A)
#доступ к элементам по любым заданным индексам
В = А[[0, 1, 2], [0, 1, 2]]
print ("Элементы с индексами (0, 0), (1, 1), (2, 2) равны: \n",B)
#изменение значения элементов по заданному индексу
А[0,0] = 12
А[1,1] = 4
А[2,2] = 7
print("Массив A после изменения:\n", A) Пример № 4. Индексы массива в трехмерном массиве
import numpy as np
#создание 3D-массива для понимания индексации в 3D-массиве
I = np.array([[[ 0, 1, 2, 3],
[4, 5, 6, 7],
[8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
print("Трехмерный массив:\n", I)
print("Элементы с индексом (0,0,1):\n", I[0,0,1])
print("Элементы с индексом (1,0,1):\n", I[1,0,1])
#изменение значения элементов по заданному индексу
Я[1,0,2] = 31
print("Трехмерный массив после изменения:\n", I) Операция с массивом в NumPy
Пример
импортировать numpy как np
A = np.
массив([[1, 2, 3],
[4,5,6],[7,8,9]])
B = np.массив([[1, 2, 3],
[4,5,6],[7,8,9]])
# добавление массивов A и B
print ("Поэлементная сумма массивов A и B равна:\n", A + B)
# умножение массивов A и B
print("Поэлементное умножение массива A и B:\n", A*B) Заключение – Массивы NumPy
2. Создание массивов Numpy | Численное программирование
Последнее изменение: 24 марта 2022 г. Создание массивов с равномерно распределенными значениями
ряд
arange([start,] stop[ step], [ dtype=None]) Если параметр «старт» не указан, он будет установлен в 0. Конец интервала определяется параметром «стоп». Обычно интервал не включает это значение, за исключением некоторых случаев, когда «шаг» не является целым числом, а округление с плавающей запятой влияет на длину выходного ndarray. Расстояние между двумя соседними значениями выходного массива задается необязательным параметром «шаг». Значение по умолчанию для «шага» равно 1. Если
задан параметр «шаг», параметр «начало» не может быть необязательным, т.е. он также должен быть задан. Тип выходного массива можно указать с помощью параметра 'dtype'. Если он не указан, тип будет автоматически выведен из других входных аргументов. импортировать numpy как np
а = np.arange (1, 10)
печать (а)
х = диапазон (1, 10)
print(x) # x - итератор
распечатать (список (х))
# дальнейшие примеры упорядочивания:
х = np.arange (10.4)
печать (х)
х = np.arange (0,5, 10,4, 0,8)
печать (х)
ВЫВОД:
[1 2 3 4 5 6 7 8 9]
диапазон(1, 10)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
[ 0.
1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
[0,5 1,3 2,1 2,9 3,7 4,5 5,3 6,1 6,9 7,7 8,5 9,3 10,1]
0052, как видно из следующего примера: np.оранжевый(12.04, 12.84, 0.08)
ВЫВОД:
массив([12.04, 12.12, 12.2, 12.28, 12.36, 12.44, 12.52, 12.6, 12.68,
12.76, 12.84])
arange должна сказать следующее для параметра стоп : "Конец интервала. Интервал не включает это значение, за исключением некоторых случаев, когда шаг не является целым числом и округление с плавающей запятой влияет на длину из . Это то, что произошло в нашем примере. и диапазона немного необычны. Почему мы должны использовать значения с плавающей запятой, если мы хотим, чтобы в результате были целые числа. В любом случае, результат может быть запутанным. Перед запуском аранжа он будет округлять начальное значение, конечное значение и размер шага: х = np.
arange (0,5, 10,4, 0,8, целое число)
печать (х)
ВЫВОД:
[ 0 1 2 3 4 5 6 7 8 9 10 11 12]
numpy.linspace для этих случаев. Использование linspace в некоторых ситуациях не является простым обходным путем, поскольку необходимо знать количество значений. линспейс
linspace(start, stop, num=50, endpoint=True, retstep=False) 'stop' будет конечным значением последовательности, если для 'endpoint' не установлено значение False. В последнем случае результирующая последовательность будет состоять из всех, кроме последнего, равноотстоящих отсчетов num + 1. Это означает, что «стоп» исключен. Обратите внимание, что размер шага изменяется, когда «конечная точка» имеет значение False. Количество генерируемых выборок может быть установлено с помощью 'num', которое по умолчанию равно 50. Если необязательный параметр 'endpoint' установлен в True (по умолчанию), 'stop' будет последней выборкой последовательности. В противном случае он не включается. импортировать numpy как np
# 50 значений от 1 до 10:
печать (np.linspace (1, 10))
# 7 значений от 1 до 10:
печать (np.linspace (1, 10, 7))
# исключая конечную точку:
печать (np.linspace (1, 10, 7, конечная точка = ложь))
ВЫВОД:
[ 1. 1.18367347 1.36734694 1.55102041 1.73469388 1.
735
2,10204082 2,28571429 2,46938776 2,65306122 2,83673469 3,02040816
3,20408163 3,3877551 3,57142857 3,75510204 3,93877551 4,12244898
4. 30612245 4.48979592 4.67346939 4,85714286 5,04081633 5,2244898
5,40816327 5,573 5,7755102 5,957 6,14285714 6,32653061
6,51020408 6,69387755 6,87755102 7,06122449 7,24489796 7,42857143
7,6122449 7,795 7,97959184 8,16326531 8,34693878 8,53061224
8,71428571 8,89795918 9,08163265 9,26530612 9,44897959 9,63265306
9.81632653 10. ]
[ 1. 2.5 4. 5.5 7. 8.5 10. ]
[1. 2,28571429 3,57142857 4,85714286 6,14285714 7,42857143
8.71428571]
импортировать numpy как np
выборки, интервал = np.linspace(1, 10, retstep=True)
печать (интервал)
образцы, интервал = np.linspace(1, 10, 20, endpoint=True, retstep=True)
печать (интервал)
образцы, интервал = np.linspace(1, 10, 20, endpoint=False, retstep=True)
печать (интервал)
ВЫВОД:
0,1836734693877551
0,47368421052631576
0,45
Нульмерные массивы в Numpy
импортировать numpy как np
х = np.массив (42)
напечатать("х: ", х)
print("Тип x: ", type(x))
print("Размерность x:", np.ndim(x))
ВЫХОД:
х: 42
Тип x:
Одномерные массивы
F = np.
массив([1, 1, 2, 3, 5, 8, 13, 21])
V = np.массив ([3.4, 6.9, 99.8, 12.8])
печать("Ф: ", Ф)
печать("В: ", В)
print("Тип F: ", F.dtype)
print("Тип V: ", V.dtype)
print("Размерность F: ", np.ndim(F))
print("Размерность V: ", np.ndim(V))
ВЫВОД:
F: [ 1 1 2 3 5 8 13 21]
В: [3,4 6,9 99,8 12,8]
Тип F: int64
Тип V: float64
Размер F: 1
Размер V: 1
Двух- и многомерные массивы
A = np.array([[3.4, 8.7, 9.9],
[1,1, -7,8, -0,7],
[4.1, 12.3, 4.8]])
печать(А)
печать (A.ndim)
ВЫВОД:
[[ 3,4 8,7 9,9]
[ 1,1 -7,8 -0,7]
[ 4,1 12,3 4,8]]
2
B = np.массив([[[111, 112], [121, 122]],
[[211, 212], [221, 222]],
[[311, 312], [321, 322]] ])
печать(Б)
печать (B.ndim)
ВЫВОД:
[[[111 112]
[121 122]]
[[211 212]
[221 222]]
[[311 312]
[321 322]]]
3
Форма массива
х = np.массив([ [67, 63, 87],
[77, 69, 59],
[85, 87, 99],
[79, 72, 71],
[63, 89, 93],
[68, 92, 78]])
печать (np. shape (х))
ВЫХОД:
(6, 3)
печать (x.shape)
ВЫХОД:
(6, 3)
x.shape = (3, 6)
печать (х)
ВЫВОД:
[[67 63 87 77 69 59]
[85 87 99 79 72 71]
[63 89 93 68 92 78]]
x.shape = (2, 9)
печать (х)
ВЫВОД:
[[67 63 87 77 69 59 85 87 99]
[79 72 71 63 89 93 68 92 78]]
х = np.
массив (11)
печать (np.shape (х))
ВЫХОД:
B = np.массив([[[111, 112, 113], [121, 122, 123]],
[[211, 212, 213], [221, 222, 223]],
[[311, 312, 313], [321, 322, 323]],
[[411, 412, 413], [421, 422, 423]]])
печать (B.форма)
ВЫХОД:
(4, 2, 3)
Индексация и нарезка
F = np.массив([1, 1, 2, 3, 5, 8, 13, 21])
# напечатать первый элемент F
печать (F [0])
# напечатать последний элемент F
печать (F[-1])
ВЫХОД:
A = np.
array([[3.4, 8.7, 9.9],
[1,1, -7,8, -0,7],
[4.1, 12.3, 4.8]])
печать (А [1] [0])
ВЫХОД:
тмп = А[1]
печать (tmp)
печать (tmp [0])
ВЫХОД:
[ 1,1 -7,8 -0,7]
1.1
печать (А [1, 0])
ВЫХОД:
А[старт:стоп:шаг] S = np.массив ([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
печать (С [2: 5])
печать (С [: 4])
печать (С [6:])
печать (С [:])
ВЫХОД:
[2 3 4]
[0 1 2 3]
[6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]
А = np.массив([
[11, 12, 13, 14, 15],
[21, 22, 23, 24, 25],
[31, 32, 33, 34, 35],
[41, 42, 43, 44, 45],
[51, 52, 53, 54, 55]])
печать (А [: 3, 2:])
ВЫВОД:
[[13 14 15]
[23 24 25]
[33 34 35]]
печать (А [3:, :])
ВЫВОД:
[[41 42 43 44 45]
[51 52 53 54 55]]
печать (А [:, 4:])
ВЫВОД:
[[15]
[25]
[35]
[45]
[55]]
Функция reshape используется для построения двумерного массива. Мы объясним изменение формы в следующем подразделе: X = np.arange(28).reshape(4, 7)
печать (Х)
ВЫВОД:
[[ 0 1 2 3 4 5 6]
[ 7 8 9 10 11 12 13]
[14 15 16 17 18 19 20]
[21 22 23 24 25 26 27]]
печать (X [:: 2, :: 3])
ВЫВОД:
[[ 0 3 6]
[14 17 20]]
печать (X[::, ::3])
ВЫВОД:
[[ 0 3 6]
[ 7 10 13 ]
[14 17 20]
[21 24 27]]
А = np.массив(
[[[45, 12, 4], [45, 13, 5], [46, 12, 6] ],
[[46, 14, 4], [45, 14, 5], [46, 11, 5]],
[[47, 13, 2], [48, 15, 5], [52, 15, 1] ] ])
A[1:3, 0:2] # эквивалентно A[1:3, 0:2, :]
ВЫВОД:
массив([[[46, 14, 4],
[45, 14, 5]],
[[47, 13, 2],
[48, 15, 5]]])
Так мы получаем еще одну возможность доступа к массиву, а лучше к части массива. Из этого следует, что если мы изменим представление, исходный массив также будет изменен. А = np.массив ([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
С = А[2:6]
С[0] = 22
С[1] = 23
печать(А)
ВЫВОД:
[ 0 1 22 23 4 5 6 7 8 9]
лст = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
лст2 = лст[2:6]
лст2[0] = 22
лст2[1] = 23
печать (слева)
ВЫВОД:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
np.may_share_memory(A, B) е. если она возвращает True, это просто означает, что массивы могут быть одинаковыми. np.may_share_memory(A, S)
ВЫХОД:
A = np.arange(12)
B = A. изменить форму (3, 4)
А[0] = 42
печать(Б)
ВЫВОД:
[[42 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
np.may_share_memory(A, B)
ВЫХОД:
Создание массивов с единицами, нулями и пустыми
Метод one(t) берет кортеж t в форме массива и соответственно заполняет массив единицами. По умолчанию он будет заполнен единицами типа float. Если вам нужны целые единицы, вы должны установить необязательный параметр dtype в int: импортировать numpy как np
E = np.ones ((2,3))
печать (Е)
F = np.ones((3,4),dtype=int)
печать (Ф)
ВЫВОД:
[[1. 1. 1.]
[1. 1. 1.]]
[[1 1 1 1]
[1 1 1 1]
[1 1 1 1]]
Z = np.zeros((2,4))
печать (Z)
ВЫВОД:
[[0. 0. 0. 0.]
[0. 0. 0. 0.]]
х = np.массив ([2,5,18,14,4])
E = np.ones_like (x)
печать (Е)
Z = np.zeros_like (х)
печать (Z)
ВЫВОД:
[1 1 1 1 1]
[0 0 0 0 0]
пустой функции. Он создает и возвращает ссылку на новый массив заданной формы и типа без инициализации записей. Иногда записи нули, но вы не должны вводить в заблуждение. Обычно это произвольные значения. нп.пусто((2, 4))
ВЫВОД:
массив([[0., 0., 0., 0.],
[0., 0., 0., 0.]])
Копирование массивов
numpy.copy ()
копия(объект, заказ='K') Параметр Значение объект массив_подобных входных данных. заказ Возможные значения: {'C', 'F', 'A', 'K'}. Этот параметр управляет размещением копии в памяти. «C» означает C-порядок, «F» означает порядок Fortran, «A» означает «F», если объект «obj» является непрерывным Fortran, «C» в противном случае. «K» означает максимально точное соответствие макету «obj». импортировать numpy как np
x = np.array([[42,22,12],[44,53,66]], порядок='F')
у = х.копировать ()
х[0,0] = 1001
печать (х)
печать (у)
ВЫВОД:
[[1001 22 12]
[ 44 53 66]]
[[42 22 12]
[44 53 66]]
печать (x.flags['C_CONTIGUOUS'])
печать (y.flags ['C_CONTIGUOUS'])
ВЫВОД:
Ложь
Истинный
ndarray.copy()
а.копия(заказ='C') Параметр Значение заказ То же, что и с numpy. copy, но значением по умолчанию для порядка является «C». импортировать numpy как np
x = np.array([[42,22,12],[44,53,66]], порядок='F')
у = х.копировать ()
х[0,0] = 1001
печать (х)
печать (у)
печать (x.flags ['C_CONTIGUOUS'])
печать (y.flags ['C_CONTIGUOUS'])
ВЫВОД:
[[1001 22 12]
[ 44 53 66]]
[[42 22 12]
[44 53 66]]
ЛОЖЬ
Истинный
Идентификационный массив
Функция идентификации
идентичность(n, dtype=нет) Параметр Значение нет Целое число, определяющее количество строк и столбцов вывода, т. е. 'n' x 'n' тип Необязательный аргумент, определяющий тип выходных данных. По умолчанию используется значение «с плавающей запятой» . импортировать numpy как np
np.identity (4)
ВЫВОД:
массив([[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]])
np.identity(4, dtype=int) # эквивалентно np.identity(3, int)
ВЫВОД:
массив([[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]])
Функция глаза
глаз (N, M=нет, k=0, dtype=плавающий) Параметр Значение Н Целое число, определяющее строки выходного массива. М Необязательное целое число для установки количества столбцов в выводе. Если это None, по умолчанию используется значение 'N'. к Определение положения диагонали. По умолчанию 0. 0 относится к главной диагонали. Положительное значение относится к верхней диагонали, а отрицательное значение — к нижней диагонали. тип Необязательный тип данных возвращаемого массива. импортировать numpy как np
np.eye(5, 8, k=1, dtype=int)
ВЫВОД:
массив([[0, 1, 0, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0, 0]])
Упражнения:
а = np.массив ([1, 2, 3, 4, 5])
б = а[1:4]
б[0] = 200
печать (а [1])
Решения к упражнениям:
импортировать numpy как np
а = np.массив ([3,8,12,18,7,11,30])
нечетные_элементы = а[1::2]