База данных озера в бессерверных пулах SQL — Azure Synapse Analytics
- Статья
- Чтение занимает 6 мин
Рабочая область Azure Synapse Analytics позволяет создавать два типа баз данных на основе озера данных Spark:
- Базы данных озера, в которых можно определять таблицы на основе данных озера с помощью записных книжек Apache Spark, шаблонов баз данных или Microsoft Dataverse (ранее Common Data Service). Эти таблицы будут доступны для запросов с помощью языка T-SQL (Transact-SQL) через бессерверный пул SQL.
- Базы данных SQL, в которых можно определить собственные базы данных и таблицы непосредственно с помощью бессерверных пулов SQL.

В этой статье рассматриваются базы данных озера в бессерверном пуле SQL в Azure Synapse Analytics.
Azure Synapse Analytics позволяет создавать базы данных и таблицы озера с помощью Spark или конструктора баз данных, а затем анализировать данные в базах данных озера с помощью бессерверного пула SQL. Базы данных и таблицы озера (Parquet или CSV), созданные в пулах Apache Spark, шаблонах баз данных или Dataverse, автоматически становятся доступными для запросов с использованием ядра бессерверного пула SQL. Измененные базы данных и таблицы озера будут доступны в бессерверном пуле SQL через некоторое время. Изменения, внесенные в Spark или конструкторе баз данных, отобразятся в бессерверных средах не сразу.
Управление базой данных озера
Для управления базами данных озера, созданными в Spark, можно использовать пулы Apache Spark или конструктор баз данных.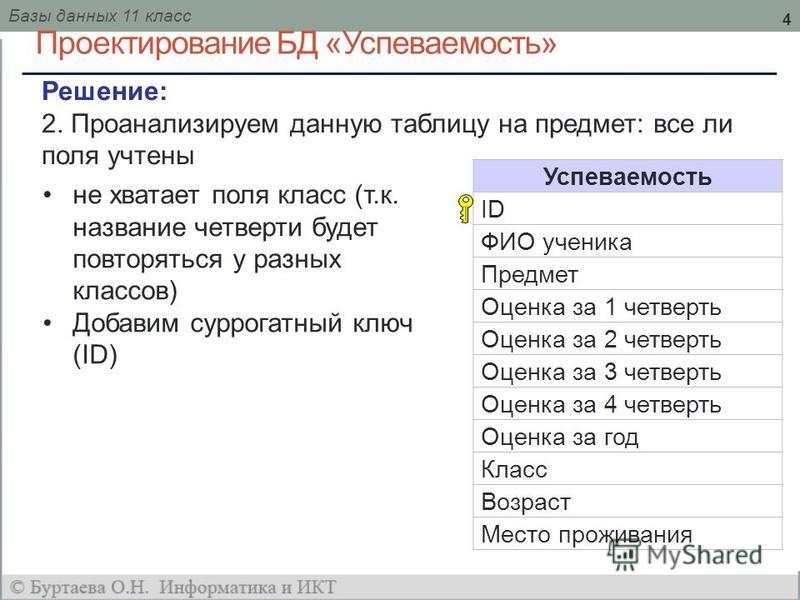 Например, создайте или удалите базу данных озера с помощью задания пула Spark. Базу данных озера или объекты в ней нельзя создать с помощью бессерверного пула SQL.
Например, создайте или удалите базу данных озера с помощью задания пула Spark. Базу данных озера или объекты в ней нельзя создать с помощью бессерверного пула SQL.
Заданная база данных Spark default будет отображаться в контексте бессерверного пула SQL как база данных озера с именем
Примечание
В бессерверном пуле SQL нельзя создать озеро и базу данных SQL с тем же именем.
Таблицы в базах данных озера нельзя изменить из бессерверного пула SQL. Для изменения баз данных озера используйте конструктор баз данных или пулы Apache Spark. Бессерверный пул SQL позволяет вносить следующие изменения в базу данных озера с помощью команд Transact-SQL:
- Добавление, изменение и удаление представлений, процедур, встроенных функций табличного значения в базе данных озера.
- Добавление и удаление пользователей Azure AD в области базы данных.
- Добавление пользователей базы данных Azure AD в роль
 У пользователей базы данных Azure AD в роли db_datareader есть разрешение на чтение всех таблиц в базе данных озера, но они не могут считывать данные из других баз данных.
У пользователей базы данных Azure AD в роли db_datareader есть разрешение на чтение всех таблиц в базе данных озера, но они не могут считывать данные из других баз данных.Модель безопасности
Базы данных и таблицы озера защищены на двух уровнях.
- Базовый уровень хранения задается путем назначения пользователям Azure AD одного из следующих элементов:
- Управление доступом Azure на основе ролей (Azure RBAC)
- Роль управления доступом на основе атрибутов Azure (Azure ABAC)
- Разрешение ACL
- Уровень SQL, где можно определить пользователя Azure AD и предоставить разрешения SQL на выбор данных из таблиц, ссылающихся на данные озера.
Модель безопасности озера
Доступ к файлам базы данных озера контролируется с помощью разрешений озера на уровне хранилища. Только пользователи Azure AD могут использовать таблицы в базах данных озера и могут получить доступ к данным в озере с помощью собственных удостоверений.
Вы можете предоставить доступ к базовым данным, которые используются для внешних таблиц, субъекту безопасности, например пользователю, приложению Azure AD с назначенным субъектом-службой или группе безопасности. Для доступа к данным предоставьте оба следующих разрешения:
- Предоставьте разрешение
read (R)для файлов (например, базовых файлов данных таблицы). - Предоставьте разрешение
execute (X)для папки, в которой хранятся файлы, и в каждой родительской папке вплоть до корневого каталога. Дополнительные сведения об указанных выше разрешениях см. на странице Списки управления доступом.
Например, в https://<storage-name>.dfs.core.windows.net/<fs>/synapse/workspaces/<synapse_ws>/warehouse/mytestdb.db/myparquettable/ субъектам безопасности требуются:
- Разрешения
execute (X)<fs>доmyparquettable. - Разрешения
read (R)дляmyparquettableи файлов в этой папке, чтобы можно было считать таблицу в базе данных (синхронизированную или оригинальную).
Если субъекту безопасности требуется возможность создавать или удалять объекты в базе данных, для папок и файлов в папке warehouse требуются дополнительные разрешения write (W). Объекты в базе данных нельзя изменить из бессерверного пула SQL, это можно сделать только из пулов Spark и конструктора баз данных.
Модель безопасности SQL
- Администраторы: назначьте роль рабочей области Администратор Synapse SQL или роль на уровне сервера sysadmin в бессерверном пуле SQL. Эта роль полностью контролирует все базы данных.
- Читатели рабочих областей: предоставьте пользователю разрешения на уровне сервера GRANT CONNECT ANY DATABASE и GRANT SELECT ALL USER SECURABLES в бессерверном пуле SQL, чтобы он мог получить доступ к любой базе данных и считать ее. Это может быть подходящим вариантом для назначения пользователю доступа для чтения и без прав администратора.
- Читатели баз данных: создайте пользователей базы данных из Azure AD в базе данных озера и добавьте их в роль

Дополнительные сведения о настройке управления доступом к общим базам данных см. здесь.
Пользовательские объекты SQL в базах данных озера
Базы данных озера позволяют создавать пользовательские объекты T-SQL — схемы, процедуры, представления и встроенные функции табличного значения (iTVFs).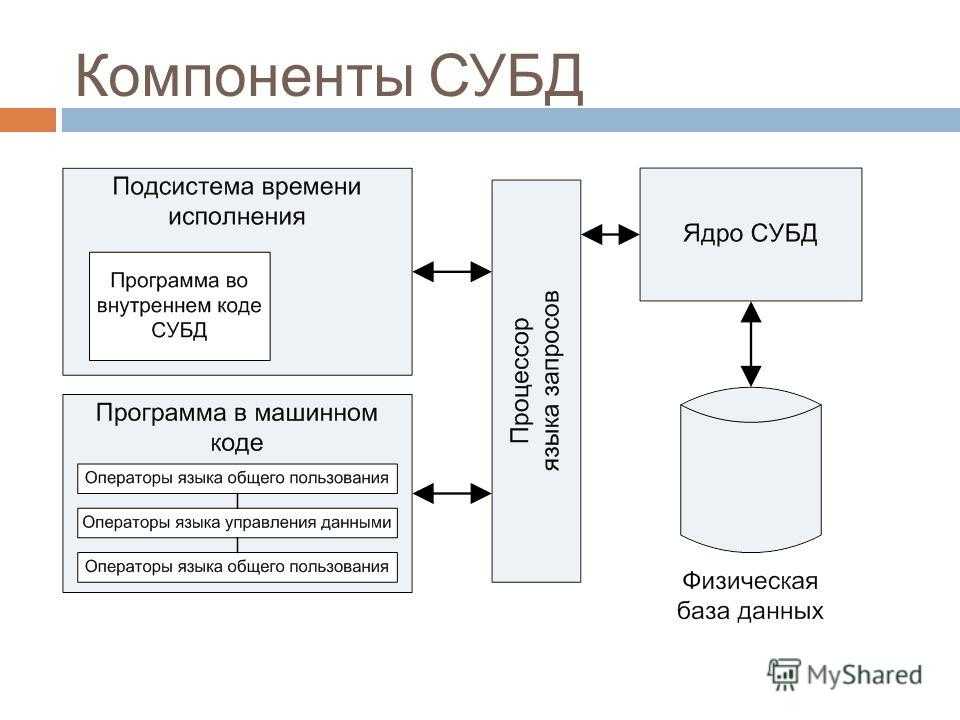 Чтобы создать пользовательские объекты SQL, НЕОБХОДИМО создать схему, в которой будут размещаться объекты. Пользовательские объекты SQL нельзя поместить в схему
Чтобы создать пользовательские объекты SQL, НЕОБХОДИМО создать схему, в которой будут размещаться объекты. Пользовательские объекты SQL нельзя поместить в схему dbo, так как они зарезервированы для таблиц озера, определенных в Spark, конструкторе баз данных или Dataverse.
Важно!
Необходимо создать пользовательскую схему SQL, в которой будут размещаться объекты SQL. Пользовательские объекты SQL нельзя поместить в схему dbo. Схема dbo зарезервирована для таблиц озера, изначально созданных в Spark или конструкторе баз данных.
Примеры
Создание читателя базы данных SQL в базе данных озера
В этом примере мы добавим в базу данных озера пользователя Azure AD, который может считывать данные с помощью общих таблиц. Пользователи добавляются в базу данных озера через бессерверный пул SQL. Затем назначьте пользователю роль db_datareader, чтобы он мог считывать данные.
CREATE USER [customuser@contoso.
 com] FROM EXTERNAL PROVIDER;
GO
ALTER ROLE db_datareader
ADD MEMBER [
com] FROM EXTERNAL PROVIDER;
GO
ALTER ROLE db_datareader
ADD MEMBER [Создание средства чтения данных на уровне рабочей области
Пользователь с разрешениями GRANT CONNECT ANY DATABASE и GRANT SELECT ALL USER SECURABLES может считывать все таблицы с помощью бессерверного пула SQL, но не может создавать базы данных SQL или изменять в них объекты.
CREATE LOGIN [[email protected]] FROM EXTERNAL PROVIDER GRANT CONNECT ANY DATABASE TO [[email protected]] GRANT SELECT ALL USER SECURABLES TO [[email protected]]
Этот скрипт позволяет создавать пользователей без прав администратора, которые могут считывать любую таблицу в базах данных озера.
Создание базы данных Spark и подключение к ней с помощью бессерверного пула SQL
Сначала создайте базу данных Spark с именем  NET для Spark.
NET для Spark.
spark.Sql("CREATE DATABASE mytestlakedb")
После короткой задержки вы увидите базу данных озера в бессерверном пуле SQL. Например, выполните следующую инструкцию из бессерверного пула SQL.
SELECT * FROM sys.databases;
Убедитесь, что mytestlakedb есть в результатах.
Создание пользовательских объектов SQL в базе данных озера
В следующем примере показано, как создать пользовательское представление, процедуру и встроенную функцию табличного значения (iTVF) в схеме
CREATE SCHEMA reports
GO
CREATE OR ALTER VIEW reports.GreenReport
AS SELECT puYear, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
GROUP BY puYear, puMonth
GO
CREATE OR ALTER PROCEDURE reports.GreenReportSummary
AS BEGIN
SELECT puYear, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo. green
GROUP BY puYear, puMonth
END
GO
CREATE OR ALTER FUNCTION reports.GreenDataReportMonthly(@year int)
RETURNS TABLE
RETURN ( SELECT puYear = @year, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
WHERE puYear = @year
GROUP BY puMonth )
GO
 green
GROUP BY puYear, puMonth
END
GO
CREATE OR ALTER FUNCTION reports.GreenDataReportMonthly(@year int)
RETURNS TABLE
RETURN ( SELECT puYear = @year, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
WHERE puYear = @year
GROUP BY puMonth )
GO
green
GROUP BY puYear, puMonth
END
GO
CREATE OR ALTER FUNCTION reports.GreenDataReportMonthly(@year int)
RETURNS TABLE
RETURN ( SELECT puYear = @year, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
WHERE puYear = @year
GROUP BY puMonth )
GO
Дальнейшие действия
- Ознакомьтесь со статьей Общие метаданные Azure Synapse Analytics
- Ознакомьтесь со статьей Общие таблицы метаданных Azure Synapse Analytics
- Краткое руководство. Создание базы данных Lake с использованием шаблонов баз данных
- Руководство по использованию бессерверного пула SQL с Power BI Desktop и созданию отчета
- Синхронизация Apache Spark для определений внешних таблиц Azure Synapse в бессерверном пуле SQL
- Руководство по исследованию и анализу озера данных с помощью бессерверного пула SQL
15 баз данных, где можно найти практически все
Чтобы принимать правильные решения, нужно руководствоваться данными. Поэтому качественные источники информации — это половина успеха и в учебе, и в бизнесе. Приготовили подборку из 15 баз данных, где можно найти статистические показатели на разные темы — от ВВП до количества игроков World of Warcraft. В списке есть международные базы и ресурсы с данными по России и Москве. Узнайте, откуда брать свежую информацию, которой можно доверять. А чтобы прокачать критическое мышление, научиться оценивать релевантность данных и использовать их для решения бизнес-задач, приходите на курс Changellenge >> Польза.
Поэтому качественные источники информации — это половина успеха и в учебе, и в бизнесе. Приготовили подборку из 15 баз данных, где можно найти статистические показатели на разные темы — от ВВП до количества игроков World of Warcraft. В списке есть международные базы и ресурсы с данными по России и Москве. Узнайте, откуда брать свежую информацию, которой можно доверять. А чтобы прокачать критическое мышление, научиться оценивать релевантность данных и использовать их для решения бизнес-задач, приходите на курс Changellenge >> Польза.
Международные базы данных
Показатели развитости стран и индустрий
World Bank Open Data
Что здесь есть: статистические сведения по 570 показателям мирового развития. Временные ряды представлены с 1960 года для 208 стран. Охвачены экономические, социальные, финансовые показатели, данные по природным ресурсам и окружающей среде. Кроме того, база содержит сведения о государственном долге и его выплатах, иностранных инвестициях и финансовых потоках за период с 1970 по 2012 год для 135 стран.
Языки: английский, французский, испанский, арабский, китайский.
Форматы файлов: HTML, PDF.
Кому пригодится: стратегам, консультантам, GR-специалистам.
Лайфхаки: можно подписаться на рассылку новых исследований.
OECD.Stat
Что здесь есть: данные об экономических, финансовых, социальных, научно-технических и отраслевых показателях стран-участников Организации экономического сотрудничества и развития и отдельных стран, не являющихся членами организации. Например, в базе можно найти объем налоговых поступлений и трудовой миграции по индустриям, а также количество патентов разных видов.
Языки: английский, французский.
Форматы файлов: XLS, CSV, HTML.
Кому пригодится: стратегам, консультантам, GR-специалистам.
Лайфхаки: зарегистрированному пользователю доступно больше функций.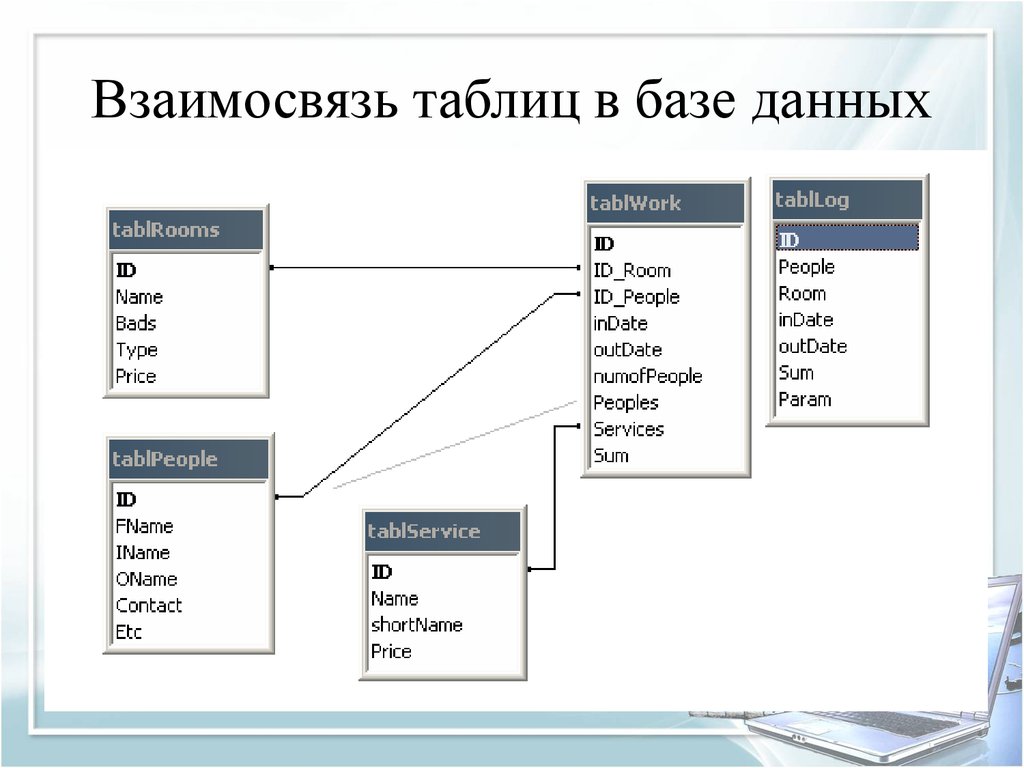 Например, история поиска, создание собственных подборок данных и возможность ими поделиться.
Например, история поиска, создание собственных подборок данных и возможность ими поделиться.
Eurostat
Что здесь есть: информация о странах — членах ЕС. В базе собрана общая и региональная статистика, экономические и финансовые показатели, демографические и социальные условия, данные о промышленности и торговле и многое другое.
Языки: английский, французский, немецкий.
Форматы файлов: PNG, PDF, ZIP, TSV. Файл в формате TSV можно открыть в Excel и сохранить в другом формате.
Кому пригодится: стратегам, консультантам, GR-специалистам.
Лайфхаки: есть опция отправки данных по почте. Зарегистрированные пользователи могут сохранить историю поиска.
Euromonitor International
Что здесь есть: рыночные исследования по странам, индустриям, компаниям и потребителям. Вы получите исчерпывающие данные для анализа бизнес-среды, отраслевых показателей, долей рынка по брендам и компаниям, отраслевого состава крупнейших экономик мира и взаимоотношений между компаниями (B2B).
Языки: английский, французский и немецкий.
Форматы файлов: PDF, XLS, PowerPoint.
Кому пригодится: маркетологам, рекламщикам, PR-специалистам, продакт-менеджерам, инвест-банкирам, стратегам и консультантам.
Лайфхаки: можно купить доступ к онлайн-версии продуктов. Есть специальные тарифы для академических подписок на базы данных. Поэтому на этот ресурс подписаны многие крупные университеты (возможно, и ваш).
Statista
Что здесь есть: необычная статистика и отчеты по 150 странам и 600 отраслям. Например, если вам интересно, сколько людей в мире играют в World of Warcraft или у какой доли населения Индии есть смартфоны, то вам сюда.
Языки: английский, французский, немецкий и испанский.
Форматы файлов: PDF, XLS, PPT, PNG.
Кому пригодится: маркетологам, рекламщикам, GR- и PR-специалистам, бренд-менеджерам, продакт-менеджерам, HR-специалистам, инвест-банкирам, стратегам и консультантам.
Лайфхаки: в бесплатном аккаунте есть доступ только к базовой статистике (без данных по отраслям), скачивать информацию можно в PDF и PNG. За 49 долларов дают полный доступ к базе и возможность скачивать файлы в формате XLS. Есть корпоративная подписка для университетов и компаний. Можно заказать собственное исследование.
Экономические и финансовые показатели
International Monetary Fund Data
Что здесь есть: данные в виде временных рядов по экономическим и финансовым показателям, обменные курсы в масштабе отдельных стран и мира в целом.
Язык: английский.
Форматы файлов: XLS, PDF, PPT, PNG.
Кому пригодится: инвест-банкирам, стратегам, консультантам, GR-специалистам.
Лайфхаки: данные доступны только после регистрации. Можно подписаться на рассылку обновлений. Есть приложение для iOS.
OPEC Data / Graphs
Что здесь есть: данные стран ОПЕК по нефтяной отрасли (цена, налоги, запасы нефти, информация о производстве и продаже).
Языки: английский, французский.
Форматы файлов: XLS, XML.
Кому пригодится: инвест-банкирам, стратегам, консультантам, GR-специалистам.
Лайфхаки: есть приложение для iOS и Android.
WTO Statistics
Что здесь есть: данные о торговых потоках, тарифах, нетарифных мерах и доле торговли в добавленной стоимости по странам мира.
Языки: английский, французский, испанский.
Форматы файлов: XLS, CSV, HTML.
Кому пригодится: стратегам, консультантам, GR-специалистам, продакт-менеджерам, маркетологам.
Лайфхаки: у базы есть два варианта поиска данных: Tariff Analysis Online и The Tariff Download Facility. Tariff Analysis Online содержит данные о тарифах на уровне «тарифной линии» — восемь или более цифр кодов Гармонизированной системы описания и кодирования товаров. Чтобы получить доступ, нужно зарегистрироваться. The Tariff Download Facility содержит упрощенные данные — о связанных, применяемых и преференциальных тарифах и статистике импорта. Данные доступны в виде шестизначных кодов Гармонизированной системы описания и кодирования товаров. Информация находится в открытом доступе.
Tariff Analysis Online содержит данные о тарифах на уровне «тарифной линии» — восемь или более цифр кодов Гармонизированной системы описания и кодирования товаров. Чтобы получить доступ, нужно зарегистрироваться. The Tariff Download Facility содержит упрощенные данные — о связанных, применяемых и преференциальных тарифах и статистике импорта. Данные доступны в виде шестизначных кодов Гармонизированной системы описания и кодирования товаров. Информация находится в открытом доступе.
Базы данных по РФ
Финансовые показатели
Центральный банк РФ / Статистика
Что здесь есть: официальная статистика Центробанка РФ. В базе собраны макроэкономические показатели, показатели банковского сектора, финансового рынка, национальной платежной системы и операций денежно-кредитной политики.
Язык: русский.
Форматы файлов: DOC, XLS, PDF, ARJ. Формат архива ARJ можно открыть архиваторами для ZIP.
Кому пригодится: инвест-банкирам, стратегам, консультантам, GR-специалистам.
Лайфхаки: данные до 2008–2012 годов лежат в Архиве.
Показатели развитости индустрий в стране
Национальное агентство финансовых исследований
Что здесь есть: исследования, аналитика и прогнозы по разным темам (финансы, социальное развитие, предпринимательство, IT и телеком, строительство, рынок труда и HR, бренд и реклама, PR и GR-проекты).
Язык: русский.
Форматы файлов: DOC, XLS, PDF.
Кому пригодится: маркетологам, рекламщикам, GR- и PR-специалистам, бренд-менеджерам, продакт-менеджерам, проджект-менеджерам, HR-специалистам, инвест-банкирам, стратегам и консультантам.
Лайфхаки: часть данных находится в открытом доступе. Можно бесплатно подписаться на рассылку и получать новые исследования. Есть возможность заказать свое исследование.
Есть возможность заказать свое исследование.
JSON.TV
Что здесь есть: исследования преимущественно по техническим тематикам. В базе можно найти данные об интернете вещей, цифровизации, блокчейне, искусственном интеллекте, телекоме, а также рекламе, онлайн-играх, образовании и многом другом.
Языки: русский, английский.
Форматы файлов: DOC, XLS, PDF.
Кому пригодится: Продакт-менеджерам, проджект-менеджерам, стратегам и консультантам.
Лайфхаки: после регистрации доступна краткая версия исследований. За полную нужно заплатить.
Социологические исследования
Всероссийский центр изучения общественного мнения
Что здесь есть: социологические исследования, рейтинги политиков, индексы одобрения государственных и общественных институтов и другие опросы общественного мнения.
Язык: русский.
Форматы файлов: DOC, XLS, PDF.
Кому пригодится: маркетологам, рекламщикам, GR- и PR-специалистам, бренд-менеджерам, HR-специалистам.
Лайфхаки: можно заказать свое исследование.
Аналитический центр Юрия Левады
Что здесь есть: результаты опросов общественного мнениях на разные темы начиная с 1988 года.
Языки: русский, английский.
Форматы файлов: DOC, XLS, PDF.
Кому пригодится: GR- и PR-специалистам.
Лайфхаки: можно оформить бесплатную подписку и получать новые исследования.
Фонд «Общественное мнение»
Что здесь есть: социологические и маркетинговые данные, собранные в результате опросов разных групп населения. Исследования и аналитика по темам: образ жизни, ценности, работа и дом, экономика, СМИ и интернет.
Язык: русский.
Форматы файлов: DOC, XLS, PDF.
Кому пригодится: маркетологам, рекламщикам, GR- и PR-специалистам, бренд-менеджерам, продакт-менеджерам, проджект-менеджерам, HR-специалистам.
Лайфхаки: можно заказать исследование.
База данных по Москве
Портал открытых данных правительства Москвы
Что здесь есть: информация по таким категориям, как транспорт, ЖКХ, здравоохранение, культура, общественное питание, строительство, трудоустройство и так далее.
Языки: русский, английский.
Форматы файлов: XLS, HTML, JSON. Формат JSON можно открыть в «Блокноте» или конвертировать в CSV для работы в Excel.
Кому пригодится: маркетологам, рекламщикам, GR- и PR-специалистам, продакт-менеджерам, проджект-менеджерам, HR-специалистам, стратегам и консультантам.
Лайфхаки: на главной странице есть информация об обновлениях.
Теги
Подборка Изнутри
Что можно узнать об иностранцах в ФРГ из единой базы данных? – DW – 25.06.2021
Фото: Julian Stratenschulte/dpa/picture alliance
Общество
Луиза фон Рихтхофен | Виталий Кропман
25 июня 2021 г.
Бундесрат одобрил закон о единой базе данных иностранцев в ФРГ. Какая информация будет в ней содержаться, кто будет иметь к ней доступ, и не противоречит ли это защите личных данных?
https://www.dw.com/ru/edinaja-baza-dannyh-ob-inostrancah-v-frg-komu-dostupna-lichnaja-informacija/a-58048122
Реклама
Две диктатуры, возникшие на немецкой земле в XX веке, повысили чувствительность общества к проблеме конфиденциальности. Особенно это заметно в те моменты, когда государство хочет собрать как можно больше личной информации о гражданах. Хорошим примером стала недавняя дискуссия по поводу того, какие данные может собирать федеральное правительство для мобильного приложения против COVID-19. В результате тогда был достигнут компромисс: данные могут собирать, но анонимно, а их хранение должно быть децентрализованным.
Хорошим примером стала недавняя дискуссия по поводу того, какие данные может собирать федеральное правительство для мобильного приложения против COVID-19. В результате тогда был достигнут компромисс: данные могут собирать, но анонимно, а их хранение должно быть децентрализованным.
Единая база данных: бундесрат поддержал МВД
Предложение МВД Германии, касающееся личных данных иностранцев, закрепленное в законопроекте, который 25 июня был одобрен бундесратом (представительством федеральных земель), вызывает множество вопросов. Принятый документ предусматривает сбор личных данных иностранцев, проживающих в Германии, в единую централизованную базу. Причем в некоторых случаях речь может идти о конфиденциальной информации, например, о политической и сексуальной ориентации. Эксперты предупреждают, что это может представлять опасность для лиц, включенных в базу.
Акция протеста против высылки из Германии лесбиянки из Уганды — в AZR будет содержаться информация о политической и сексуальной ориентации иностранцевФото: picture-alliance/dpa/S. Hoppe
HoppeЦентральный реестр иностранцев (AZR) — база данных, которую предлагается расширить, уже давно существует. Досье в ней есть на каждого иностранца, получившего вид на жительство в Германии, и прожившего в стране более трех месяцев. На беженцев собирается и хранится дополнительная информация, такая как отпечатки пальцев или справки о состоянии здоровья. Согласно новому закону, к этому прибавятся адрес проживания в Германии, идентификационный номер иностранца, а также документы о предоставлении убежища и решения суда по этому вопросу.
До сих пор этой информацией располагали примерно 600 местных ведомств по делам иностранцев. Теперь она должна быть передана в центральный реестр, где к ней получат доступ различные учреждения, включая центры по трудоустройству, федеральную полицию, федеральное управление уголовной полиции, управления по делам молодежи. Таким образом, в общей сложности около 150 000 чиновников, имеющих право доступа, смогут, приложив незначительные усилия, ознакомиться с самыми интимными деталями жизни иностранцев в Германии.
Тило Вайхерт (Thilo Weichert) из Немецкой ассоциации защиты данных (DVD) говорит, что оцифровка данных об иностранцах, в принципе, не является неправильным шагом. Ведь процедура предоставления убежища часто откладывается, когда люди переезжают. А документы передаются между соответствующими органами властями по почте и могут теряться.
Проситель убежища из Ирака сообщил Deutsche Welle, что таким образом касающиеся его конфиденциальные документы Федерального ведомства по делам миграции и беженцев (BAMF) оказались в почтовом ящике человека, въехавшего в его бывшую квартиру. Двойная регистрация иностранцев различными органами власти также может иметь разрушительные последствия для просителей убежища. Централизованная база данных предотвратила бы это.
Данные беженцев окажутся доступны многим
Эксперт по вопросам информационной безопасности Тило ВайхертФото: picture-alliance/dpa/C.RehderТем не менее Вайхерт, а также многочисленные специалисты, представляющие благотворительные организации, ЛГБТ-ассоциации, а также эксперты по защите данных и некоторые государственные служащие, считают закон несбалансированным и несовершенным. Редко когда эксперты были так единодушны в своей оценке, как на слушаниях 3 мая: законопроект разработан в интересах властей, но мало внимания уделяет правам заинтересованных лиц, у которых не будет возможности узнать, что происходит с их данными и кто к ним обращается. «Я также предполагаю, что спецслужбы государств, граждане которых просят убежище в Германии, имеют своих агентов в немецких учреждениях», — сказал Вайхерт DW. С появлением единого реестра они получат данные «политических беженцев на блюдечке с голубой каемочкой». Потому что почти нет серьезного контроля за тем, кто имеет доступ к этой базе данных.
Редко когда эксперты были так единодушны в своей оценке, как на слушаниях 3 мая: законопроект разработан в интересах властей, но мало внимания уделяет правам заинтересованных лиц, у которых не будет возможности узнать, что происходит с их данными и кто к ним обращается. «Я также предполагаю, что спецслужбы государств, граждане которых просят убежище в Германии, имеют своих агентов в немецких учреждениях», — сказал Вайхерт DW. С появлением единого реестра они получат данные «политических беженцев на блюдечке с голубой каемочкой». Потому что почти нет серьезного контроля за тем, кто имеет доступ к этой базе данных.
Шокирован тем, «что что-то подобное могло произойти в Германии»
Об этом свидетельствует опыт Амина Л. (полное имя известно редакции). Он приехал в Германию в качестве просителя убежища. На его родине мужчина был приговорен к смерти. Амин выучил немецкий язык и начал обучение на работника по уходу за больными и пожилыми людьми. Таким образом у него появились хорошие перспективы на получение вида на жительство в ФРГ. И он написал в Facebook, что закон об иммиграции специалистов дает возможность перебраться в Германию легально.
И он написал в Facebook, что закон об иммиграции специалистов дает возможность перебраться в Германию легально.
Вскоре после этого он получил сообщение в Facebook: некто просил его не давать беженцам ложных надежд. В качестве доказательства того, что он является государственным служащим и, следовательно, представителем власти, отправитель переслал ему выписку из центрального реестра, содержащую конфиденциальную информацию, включая домашний адрес Амина Л. Мужчина испугался, заподозрил, что теперь доступ к его данным могут получить и спецслужбы его родины и его жизнь окажется под угрозой. «Я был потрясен, — рассказал он DW, — что нечто подобное могло произойти в Германии. Я больше не чувствовал себя в безопасности, выехал из своей квартиры, всерьез подумывал о том, чтобы покинуть страну». Амин подал иск против отправителя сообщений, но прокуратура после короткого расследования, прекратила разбирательство.
Журналисты ARD выяснили, что мужчина, отправлявший сообщения Амину, был не сотрудником немецких спецслужб, а чиновником центра занятости. Этот пример, показывающий, что любой госслужащий получает беспрепятственный доступ к конфиденциальной информации, может свидетельствовать о том, что центральный реестр недостаточно защищен от злоупотреблений.
Немецкие политики критикуют закон о базе данных
Законопроект, подготовленный партиями, входящими в правящую коалицию, также резко критикуют некоторые политики. Так Луиза Амтсберг (Luise Amtsberg), представитель партии Союз-90/»Зеленые» по вопросам беженцев, сказала DW: «Мы несем ответственность за людей, ищущих защиту в Германии. Принимая этот закон, мы подвергаем их опасности». Она считает неоправданным массированное вмешательство в информационное пространство иностранцев.
 com/embed/dfcbL8CdTBU»>
com/embed/dfcbL8CdTBU»> Вице-председатель федеральной рабочей группы «Миграция и разнообразие» (AG Migration) в Социал-демократической партии Германии (СДПГ Хуссейн Хедр (Hussien Khedr) называет законопроект, который его партия фактически поддерживает, дискриминационным. «Почему существует центральный реестр для иностранцев? Существует ли немецкий центральный реестр?», — задается вопросами он.
Несмотря на всю критику, правящие партии большой коалиции ХДС/ХСС и СДПГ в мае провели закон через бундестаг. Бундестрат также поддержал законопроект, который теперь будет направлен на подпись федеральному президенту. Как указано на сайте бундесрата, ожидается, что большая часть закона вступит в силу с 1 ноября 2021 года. Обязанность в будущем хранить данные исключительно в AZR будет реализована только после переходного периода в два года. Он дается властям федеральных земель для дополнительной подготовки к технической реализации проекта. Речь идет о корректировке и передаче данных.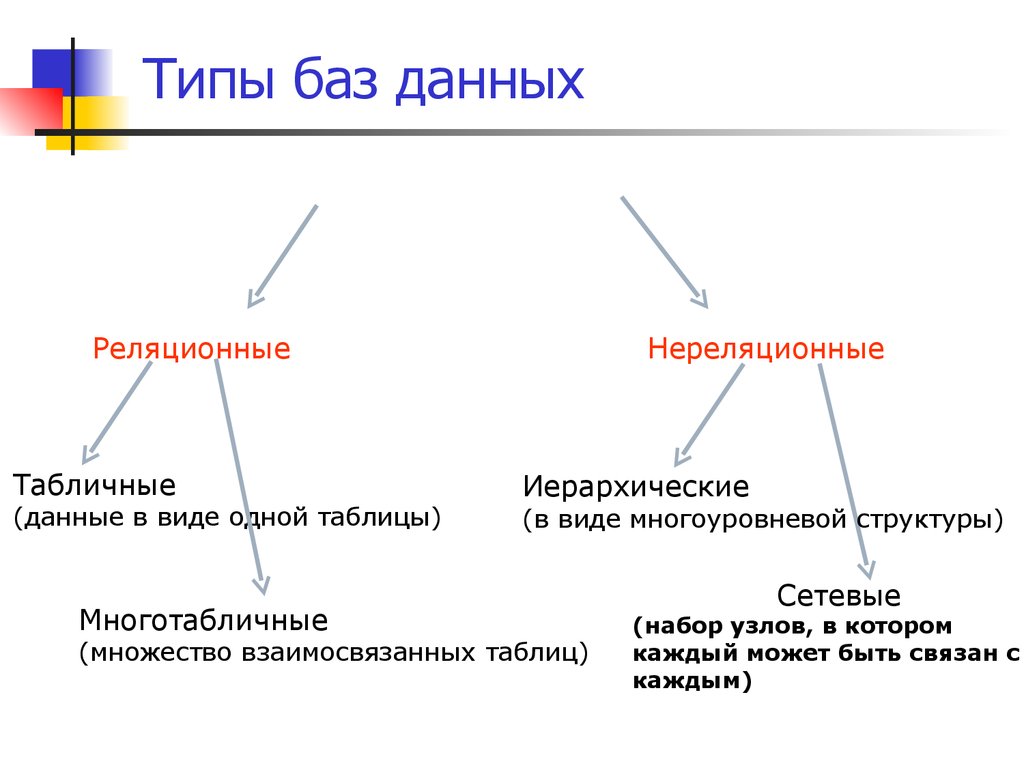
Смотрите также:
Убийство чеченца в Берлине
To view this video please enable JavaScript, and consider upgrading to a web browser that supports HTML5 video
Написать в редакцию
Реклама
Пропустить раздел Топ-тема1 стр. из 3
Пропустить раздел Другие публикации DWНа главную страницу
Госдума одобрила создание единого ресурса с данными россиян — РБК
Госдума одобрила создание ресурса с данными всех жителей страны. По мнению авторов проекта, он поможет вести точный учет населения и лучше планировать, например строительство больниц, но эксперты опасаются роста утечек данных
Фото: Сергей Мальгавко / ТАСС
В четверг, 21 мая, Госдума одобрила в третьем чтении закон о создании «федерального информационного регистра, содержащего сведения о населении России». Это информационный ресурс, на котором будут храниться данные россиян (Ф.И.О., дата и место рождения, пол, гражданство, СНИЛС, ИНН, семейное положение, сведения о выданных паспортах, образовании, регистрации индивидуального предпринимателя, воинской обязанности и др.), а также иностранцев и лиц без гражданства, работающих на территории страны.
Это информационный ресурс, на котором будут храниться данные россиян (Ф.И.О., дата и место рождения, пол, гражданство, СНИЛС, ИНН, семейное положение, сведения о выданных паспортах, образовании, регистрации индивидуального предпринимателя, воинской обязанности и др.), а также иностранцев и лиц без гражданства, работающих на территории страны.
Зачем государству нужна еще одна база данных жителей страны и повысит ли она риск их утечки, разбирался РБК.
Зачем нужна единая база данных
Как пояснил депутат Госдумы, глава комитета по СМИ Александр Хинштейн, законопроект — детище главы правительства и бывшего руководителя ФНС Михаила Мишустина. Задача ресурса — создать масштабную базу данных для стратегического, экономического и социального планирования, сказал Хинштейн. «Сегодня никто не может сказать, сколько будет призывников в Нижегородской области через 18 лет, а зайдя в базу единого регистра, это можно выяснить за несколько секунд», — привел он пример.
Оператором нового ресурса выступит Федеральная налоговая служба (ФНС). Помимо этого ведомства данные в регистр предоставят МВД, Минобороны, Минобрнауки, государственные внебюджетные фонды и др.
Помимо этого ведомства данные в регистр предоставят МВД, Минобороны, Минобрнауки, государственные внебюджетные фонды и др.
Содержащиеся в регистре персональные данные будут использоваться для оказания госуслуг, сказал РБК представитель ФНС. Он предусматривает гармонизацию данных об одном физическом лице в различных госресурсах.
Обезличенные данные будут применять для автоматической переписи населения, учета избирателей, планирования социально-экономического развития регионов — строительства детских садов, школ, поликлиник и т. д.
В пояснительной записке к законопроекту указано, что создание единого регистра сократит сроки оказания госуслуг, а также число «мошеннических действий при получении мер социальной поддержки и уплаты налогов, сборов и других обязательных платежей».
Регистр должен быть создан к 1 января 2022 года, предоставлять сведения органам госвласти в рамках госуслуг — с 2023-го, а сведения гражданину о себе и детях — с 2026-го.
Вопрос, во сколько обойдется создание и поддержание единой системы данных, «пока остается открытым», отметил Хинштейн. Не ответил на него и представитель ФНС.
Не ответил на него и представитель ФНС.
Кто получит доступ к регистру
Сведения из регистра могут предоставляться по запросу госорганам, многофункциональным центрам предоставления государственных и муниципальных услуг, избирательным комиссиям, нотариусу, а также самому гражданину, если он запрашивает сведения о себе или лицах, находящихся на его попечении.
По словам Хинштейна, доступ ко всей базе данных не сможет получить никто, за исключением тех, кто ее будет вести, то есть отвечающих за это сотрудников ФНС. «К регистру будет разный уровень доступа, и каждое из 12 ведомств-субъектов, поставляющих информацию в регистр, будет иметь доступ только в части себя. Условно говоря, сотрудник Пенсионного фонда не сможет зайти посмотреть какие-то еще сведения о человеке», — пояснил он. Кроме того, внутри регистра будут закрытые части, куда будут попадать данные о лицах, находящихся под госзащитой и госохраной. «Эту закрытую часть регистра будут вести сотрудники спецслужб. К ней не будут иметь доступа и сотрудники ФНС в том числе», — рассказал депутат. На вопрос, будут ли спецслужбы иметь возможность обратиться к системе в случае необходимости, например при подозрении в терроризме, Хинштейн ответил, что «это и сегодня сделать несложно». «Можно ли будет использовать эту информацию в том числе для наведения справок? Безусловно. Спецслужбы тоже смогут обращаться за этой информацией. У силовых ведомств должен быть к этому доступ. Не вижу в этом ничего дурного, тем более что значительная часть базы формируется за счет этих ведомств, в частности МВД и Минобороны», — заявил парламентарий. Он подчеркнул, что «это будет прописываться во внутренних документах, пока этот вопрос не регламентирован».
На вопрос, будут ли спецслужбы иметь возможность обратиться к системе в случае необходимости, например при подозрении в терроризме, Хинштейн ответил, что «это и сегодня сделать несложно». «Можно ли будет использовать эту информацию в том числе для наведения справок? Безусловно. Спецслужбы тоже смогут обращаться за этой информацией. У силовых ведомств должен быть к этому доступ. Не вижу в этом ничего дурного, тем более что значительная часть базы формируется за счет этих ведомств, в частности МВД и Минобороны», — заявил парламентарий. Он подчеркнул, что «это будет прописываться во внутренних документах, пока этот вопрос не регламентирован».
Как будут защищать данные
По словам Хинштейна, создан отдельный центр обработки данных в удаленном доступе за пределами Москвы, в городе Городце Нижегородской области. «Там будет обеспечена необходимая инфраструктура с точки зрения безопасности. Там находятся в том числе действующие сотрудники спецслужб. Система будет в первую очередь тестироваться уполномоченными структурами, отвечающими за информационную безопасность, то есть ФСБ», — рассказал Хинштейн.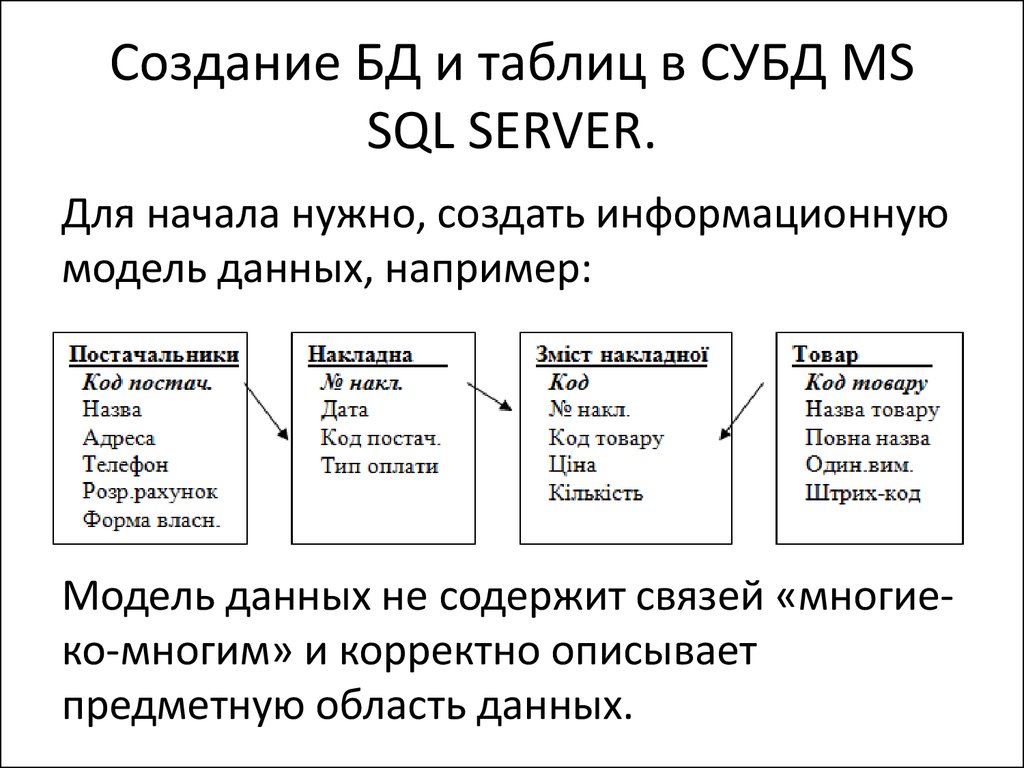 По словам представителя ФНС, в соответствии с требованиями ФСБ и ФСТЭК система пройдет все необходимые аттестационные и сертификационные испытания на соответствие требованиям к защите информации, содержащей персональные данные, и только после этого будет введена в эксплуатацию.
По словам представителя ФНС, в соответствии с требованиями ФСБ и ФСТЭК система пройдет все необходимые аттестационные и сертификационные испытания на соответствие требованиям к защите информации, содержащей персональные данные, и только после этого будет введена в эксплуатацию.
В России уже существуют как минимум четыре крупные базы о россиянах: две из них — у МВД (бывшая база ФМС и база паспортов), а также у ФНС и сайта госуслуг, отметил гендиректор Института исследований интернета Карен Казарян. По его словам, ранее попытки собрать единую базу уже предпринимались неоднократно, в том числе в рамках проекта цифрового профиля, «однако все они разбивались о межведомственную конкуренцию и нехватку политического решения». Законопроект о цифровом профиле был внесен в Госдуму в июле 2019 года группой депутатов. Под цифровым профилем в документе понималась платформа, на которой будут собраны различные сведения о россиянах. Но осенью прошлого года проект раскритиковала ФСБ, а в январе этого года и депутаты Госдумы, указав, что он может спровоцировать рост числа утечек и неправомерного использования персональных данных. Опрошенные РБК эксперты отметили, что технически единый регистр сведений о россиянах с точки зрения информационной безопасности мало чем отличается от цифрового профиля.
Опрошенные РБК эксперты отметили, что технически единый регистр сведений о россиянах с точки зрения информационной безопасности мало чем отличается от цифрового профиля.
В последние годы российские власти активно наращивают технологии слежения за гражданами, а любой сбор данных создает определенные риски злоупотребления, в том числе утечки, предупреждает руководитель международной правозащитной группы «Агора» Павел Чиков. «Существует черный рынок самых разных баз данных. В данном случае речь идет о сведении информации, которая высоко ценится и сохранность которой имеет большое значение, а сохранность данных в нашей стране не является традицией», — объясняет эксперт.
Руководитель департамента системных решений компании в сфере кибербезопасности Group-IB Антон Фишман говорит, что при создании хранилища данных будет важна проработка самого механизма обращения к информации, насколько он будет протестирован, защищен и грамотно реализован. «Очевидно, это потребует времени, инвестиций и, главное, привлечения экспертов рынка, специалистов по кибербезопасности, которые смогут разработать различные модели рисков и адекватные им средства защиты», — отметил он.
Какие проблемы может создать регистр
Фактически все эти данные на россиян у государства уже есть, констатирует эксперт по электоральному праву Андрей Бузин. Есть регистр «ГАС Выборы», в котором перечислены данные всех избирателей, паспортные данные есть в базах у МВД, отдельно ведутся списки избирателей, в которых отмечается, голосовал человек или нет. «Поэтому ничего существенно нового не происходит», — уверен он.
Профессор права Илья Шаблинский не испытывает особого беспокойства в связи с этим законом. «Подобные реестры уже составлялись, и во многих государствах они есть. Все будет зависеть от того, каким будет политический режим в России. Если режим будет ужесточаться, то любой реестр можно использовать не во благо, а во вред гражданам», — указал юрист. По мнению Чикова, есть риск профайлинга — сбора частной информации по необоснованному критерию. «Например, сбор информации о политической оппозиции, или участнике того или иного политического или религиозного движения, или тех или иных предпочтениях людей», — рассуждает эксперт.
При этом президент Фонда информационной демократии Илья Массух считает, что основными проблемами при создании единого регистра станут нестыковка и несовместимость баз данных из разных ведомств. В них могут храниться несовпадающие и неактуальные данные, сведения могут быть записаны по-разному (например, названия «Москва» и «гор. Москва» для автоматизированных систем считаются разными идентификаторами). Вместо того чтобы привести их к единым правилам хранения и использования, всю информацию предполагается объединить в крупный массив данных, объяснил Массух. «Не удивлюсь, если в результате стыковки данных в стране окажется не 144, а 288 млн россиян», — добавил он. Кроме того, возникает риск катастрофичности выхода из строя единой базы: если сейчас выход из строя базы отдельного банка или ведомства в масштабах государства не критичен, то технические неполадки с единым регистром могут вызвать более значимые проблемы.
общая база данных — английский перевод
Общая база данных о поставщиках | Common database of vendors |
64. | Common database of vendors |
Источник Общая база данных ЕЭК ООН. | Source UNECE Common Database. |
B. Общая база данных ЮНЕСИС 9 6 | B. UNESIS Common Database |
Общая база данных, разработанная на страновом уровне | Common database developed at the country level |
Общая база данных охватывает всесторонний массив данных глобальной статистической системы. | The Common Database comprises a comprehensive core of data from the global statistical system. |
Общая терминологическая база данных для персонала языковых служб | Common terminology database for language staff |
ОБДООН Общая база данных Организации Объединенных Наций по | IDPs Internally Displaced Persons |
IV. | IV United Nations roster and common supplier database |
Общая терминологическая база данных для персонала языковых служб | Capacity calculations Common terminology database for language staff |
3. Общая терминологическая база данных для персонала языковых служб | 3. Common terminology database for language staff |
Список и общая база данных о поставщиках Организации Объединенных Наций | IV. United Nations roster and common supplier database |
Список и общая база данных о поставщиках Организации Объединенных Наций | United Nations roster and common supplier database |
В настоящее время эта общая база данных называется Статистической базой данных ЕЭК ООН. | At this time, the overall database is referred to as the UNECE Statistical Database. |
Общая законодательная база | General legislative framework |
Общая правовая база | General legal framework within which human rights are protected |
база выходных данных (база данных PC Axis и или база данных SQL) | Output database (PC Axis database and or SQL database) |
3. Общая нормативно правовая база защиты прав человека Общая правовая база | 3. General legal framework within which human rights are protected |
Основой послужит общая база данных и единообразные и четкие методы оценки. | The foundation will be a common database and uniform, transparent estimation methods. |
IV. СПИСОК И ОБЩАЯ БАЗА ДАННЫХ О ПОСТАВЩИКАХ ОРГАНИЗАЦИИ ОБЪЕДИНЕННЫХ НАЦИЙ | IV UNITED NATIONS ROSTER AND COMMON SUPPLIER DATABASE |
База данных ТИМБЕР и база данных ФАОСТАТ | TIMBER database and FAOSTAT database |
База данных ТИМБЕР и база данных ФАОСТАТ | TIMBER database and FAOSTAT database |
База данных | E. Database |
База данных | Project audits of nationally executed expenditure database |
База данных | TRACES EU database to register import of animals and goods from third countries |
база данных | COMESA Continuation according to the annual work programme. |
база данных | Database |
база данных | EAC Database |
База данных | Database |
База данных | Database |
База данных | Database 160,000 160,000 |
(база данных) | (database) |
База данных | Data Area |
База данных | Range marking the database |
База данных | Data source |
База данных | Database name |
База данных | Databases |
База данных | database |
База данных? | Was it a database? |
база данных | database |
База данных | Database |
База данных. | A database. |
2 База данных Межпарламентского союза база данных ЕЭК ООН. | Inter parliamentary Union database UNECE database. |
III. ОБЩАЯ НОРМАТИВНАЯ БАЗА ПРАВОЗАЩИТНОЙ | III. GENERAL LEGAL FRAMEWORK WITHIN WHICH HUMAN RIGHTS |
Общая база метаданных означает, что | A shared metadata database means that |
 Общая база данных подрядчиков
Общая база данных подрядчиков СПИСОК И ОБЩАЯ БАЗА ДАННЫХ О ПОСТАВЩИКАХ
СПИСОК И ОБЩАЯ БАЗА ДАННЫХ О ПОСТАВЩИКАХ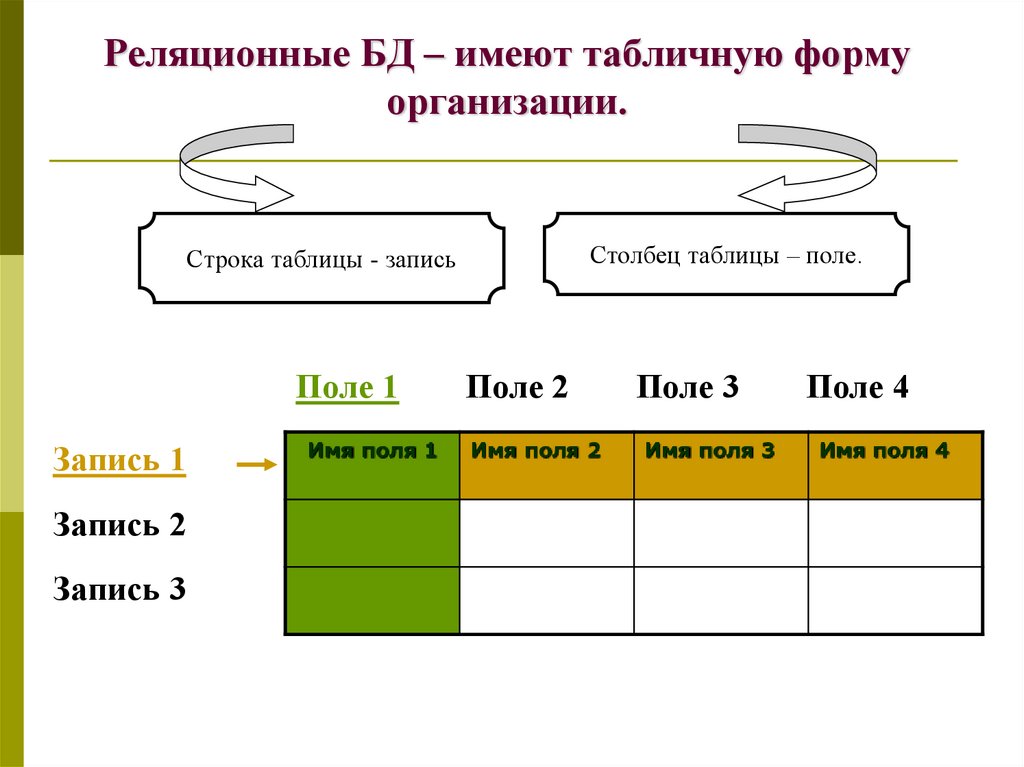

Работа с базой данных
Модель работы с базой данных
Модель базы данных «1С:Предприятия 8» имеет ряд особенностей, отличающих ее от классических моделей систем управления базами данных (например, основанных на реляционных таблицах), с которыми имеют дело разработчики в универсальных системах.
Основное отличие заключается в том, что разработчик «1С:Предприятия 8» не обращается к базе данных напрямую. Непосредственно он работает с платформой «1С:Предприятия 8». При этом он может:
- описывать структуры данных в конфигураторе,
- манипулировать данными с помощью объектов встроенного языка,
- составлять запросы к данным, используя язык запросов.
Платформа «1С:Предприятия 8» обеспечивает операции исполнения запросов, описания структур данных и манипулирования данными, транслируя их в соответствующие команды. Это могут быть команды системы управления базами данных, в случае клиент-серверного варианта работы, или команды собственного движка базы данных для файлового варианта.
Общая система типов
Важной особенностью работы с базой данных является то, что в «1С:Предприятии 8» реализована общая система типов языка и полей баз данных. Иными словами, разработчик одинаковым образом определяет поля базы данных и переменные встроенного языка и одинаковым образом работает с ними.
Иными словами, разработчик одинаковым образом определяет поля базы данных и переменные встроенного языка и одинаковым образом работает с ними.
Этим система «1С:Предприятие 8» выгодно отличается от универсальных инструментальных средств. Обычно, при создании бизнес-приложений с использованием универсальных сред разработки, используются отдельно поставляемые системы управления базами данных. А это значит, что разработчику приходится постоянно заботиться о преобразованиях между типами данных, поддерживаемыми той или иной системы управления базами данных, и типами, поддерживаемыми языком программирования.
Хранение ссылок на объекты
При манипулировании данными, хранящимися в базе данных «1С:Предприятия 8», зачастую используется объектный подход. Это значит, что обращение (чтение и запись) к некоторой совокупности данных, хранящихся в базе, происходит как к единому целому. Например, используя объектную технику, можно манипулировать данными справочников, документов, планов видов характеристик, планов счетов и т. д.
д.
Характерной особенностью объектного манипулирования данными является то, что на каждый объект, как совокупность данных, существует уникальная ссылка, позволяющая однозначно идентифицировать этот объект в базе данных.
Эта ссылка также хранится в поле базы данных, вместе с остальными данными объекта. Кроме того, ссылка может быть использована как значение какого-либо поля другого объекта. Например, ссылка на объект справочника Контрагенты может быть использована как значение соответствующего реквизита документа Приходная накладная.
Составные типы
Существенной возможностью модели данных, которая поддерживается «1С:Предприятием 8», является то, что для поля базы данных можно определить сразу несколько типов данных, значения которых могут храниться в этом поле. При этом значение в каждый момент времени будет храниться одно, но оно может быть разных типов — как ссылочных, так и примитивных — число, строка, дата и т. п.:
п.:
Такая возможность очень важна для экономических задач — например, в расходной накладной в качестве покупателя может быть указано либо юридическое лицо из справочника организаций, либо физическое лицо из справочника частных лиц. Соответственно, при проектировании базы данных разработчик может определить поле, которое будет хранить значение любого из этих типов.
Хранение любых данных как Хранилище значения
Идеология создания прикладных решений в «1С:Предприятии 8» предполагает, что все файлы, имеющие отношение к данному прикладному решению, нужно хранить в самой базе данных.
Для этого введен специальный тип данных — ХранилищеЗначения. Поля базы данных могут хранить значения такого типа, а встроенный язык содержит специальный одноименный объект, позволяющий преобразовывать значения других типов к специальному формату Хранилища значений.
Благодаря этому разработчик имеет возможность сохранять в базе данных значения, тип которых не может быть выбран в качестве типа поля базы данных, например, графические изображения.
Создание и обновление структур данных на основе метаданных
В процессе создания или модификации прикладного решения разработчик избавлен от необходимости каких-либо действий по непосредственному изменению структуры полей базы данных прикладного решения.
Разработчику достаточно путем визуального конструирования описать структуру используемых объектов прикладного решения, состав их реквизитов, табличных частей, форм и пр.
Все действия по созданию или изменению структуры таблиц базы данных платформа выполнит самостоятельно, на основании состава объектов прикладного решения и их характеристик.
Например, для того, чтобы в справочнике сотрудников появилась возможность хранить сведения о составе семьи сотрудника, разработчику «1С:Предприятия 8» не нужно создавать в базе данных специальную новую таблицу, задавать правила, по которым данные, хранящиеся в этой таблице, будут связаны с данными из основной таблицы, программировать алгоритмы совместного доступа к данным этих таблиц, создавать алгоритмы проверки прав доступа к данным, находящимся в подчиненной таблице и пр.
Все, что требуется сделать разработчику — щелчком мыши добавить к справочнику табличную часть и задать два ее строковых реквизита: Имя и Родство. При сохранении или обновлении конфигурации платформа самостоятельно выполнит реорганизацию структуры базы данных, создаст необходимые таблицы и т.д.
Объектный / табличный доступ к данным
Штатной возможностью «1С:Предприятия 8» является поддержка двух способов доступа к данным — объектного (для чтения и записи) и табличного (для чтения).
В объектной модели разработчик оперирует объектами встроенного языка. В этой модели обращения к объекту, например документу, происходят как к единому целому — он полностью загружается в память, вместе с вложенными таблицами, к которым можно обращаться средствами встроенного языка как к коллекциям записей и т.д.
При манипулировании данными в объектной модели обеспечивается сохранение целостности объектов, кэширование объектов, вызов соответствующих обработчиков событий и т. д.
д.
В табличной модели все множество объектов того или иного класса представляется как совокупность связанных между собой таблиц, к которым можно обращаться при помощи запросов — как к отдельной таблице, так и к нескольким таблицам во взаимосвязи:
В этом случае разработчик получает доступ к данным сразу нескольких объектов, что очень удобно для анализа больших объемов данных, например, при создании отчетов. Однако в силу того, что данные, выбираемые таким способом, содержат не все, а лишь некоторые реквизиты анализируемых объектов, табличный способ доступа не позволяет изменять эти данные.
самых популярных баз данных в мире
Вам интересно, какая база данных является самой популярной базой данных в мире? Это MySQL, SQL Server или Oracle? В следующей таблице перечислены самые популярные базы данных в мире с их рейтингом. Более высокий балл означает более высокий рейтинг.
Согласно рейтингу DB-Engine, самой популярной базой данных в мире является Oracle.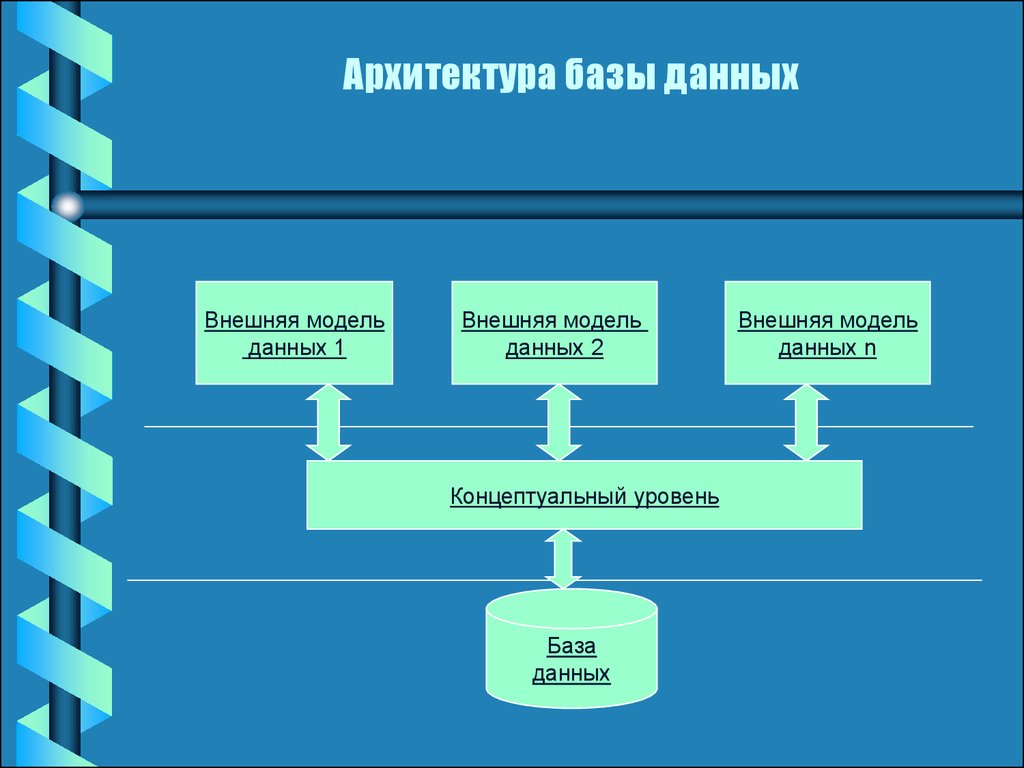 За Oracle в рейтинге следуют MySQL, SQL Server, PostgreSQL и MongoDB.
За Oracle в рейтинге следуют MySQL, SQL Server, PostgreSQL и MongoDB.
В следующей таблице перечислены самые популярные в мире базы данных и их рейтинги.
| База данных | Ранг | |
| 1 | Оракул | 1268,84 |
| 2 | MySQL | 1154.27 |
| 3 | Microsoft SQL Server | 1040.26 |
| 4 | PostgreSQL | 466.11 |
| 5 | МонгоДБ | 387,18 |
| 6 | IBM Db2 | 179,85 |
| 7 | Редис | 149.01 |
| 8 | Эластичный поиск | 143,44 |
| 9 | Microsoft Access | 141,62 |
| 10 | SQLite | 126,8 |
| 11 | Кассандра | 122,98 |
| 12 | Сплунк | 81,43 |
| 13 | МарияДБ | 78,82 |
| 14 | Терадата | 76,19 |
| 15 | Улей | 69,91 |
| 16 | Солр | 61,48 |
| 17 | HBase | 60,39 |
| 18 | FileMaker | 57,15 |
| 19 | SAP HANA | 56,64 |
| 20 | Amazon DynamoDB | 55. 09 09 |
| 21 | Адаптивный сервер SAP | 55.04 |
| 22 | Нео4дж | 46,8 |
| 23 | Подставка под диван | 34,59 |
| 24 | Мемкэш | 29,54 |
| 25 | База данных Microsoft Azure SQL | 27,2 |
Оценка DB Engines рассчитывается на основе следующих факторов:
- Количество результатов в поисковых системах Google, Bing и Yandex
- Частота поиска в Google Trends
- Частота технических дискуссий на известных сайтах вопросов и ответов, связанных с ИТ, Stack Overflow и DBA Stack Exchange 902:30
- Количество предложений о работе на сайтах Indeed и Simply Hired.
- Количество профилей в профессиональных сетях, включая LinkedIn и Upwork.
- Упоминания в Твиттере.
№1. Oracle
Oracle, разработанная корпорацией Oracle, является самой популярной системой реляционных баз данных (RDBMS). Oracle не только является РСУБД, но также предоставляет функциональные возможности для облачных хранилищ, хранилища документов, СУБД Graph, хранилища ключей и значений, хранилищ блогов и PDF-файлов. Совсем недавно. Oracle только что анонсировала автономную функцию, которая позволяет базе данных быть интеллектуальной и самоуправляемой.
Oracle не только является РСУБД, но также предоставляет функциональные возможности для облачных хранилищ, хранилища документов, СУБД Graph, хранилища ключей и значений, хранилищ блогов и PDF-файлов. Совсем недавно. Oracle только что анонсировала автономную функцию, которая позволяет базе данных быть интеллектуальной и самоуправляемой.
Текущая версия базы данных Oracle — 18c.
База данных Oracle является реляционной базой данных (RDBMS). Реляционные базы данных хранят данные в табличной форме строк и столбцов. Столбец таблицы базы данных представляет атрибуты сущности, а строки таблицы хранят записи. СУРБД, которая реализует объектно-ориентированные функции, такие как определяемые пользователем типы, наследование и полиморфизм, называется системой управления объектно-реляционной базой данных (ОРСУБД). Oracle Database расширила реляционную модель до объектно-реляционной модели, что позволяет хранить сложные бизнес-модели в реляционной базе данных.
Одной из характеристик СУБД является независимость физического хранилища данных от логических структур данных.
В Oracle Database схема базы данных представляет собой набор логических структур данных или объектов схемы. Пользователь базы данных владеет схемой базы данных, имя которой совпадает с именем пользователя.
Объекты схемы — это созданные пользователем структуры, которые напрямую ссылаются на данные в базе данных. База данных поддерживает множество типов объектов схемы, наиболее важными из которых являются таблицы и индексы.
Объект схемы — это один из типов объектов базы данных. Некоторые объекты базы данных, такие как профили и роли, не находятся в схемах.
№2. MySQL
MySQL — самая популярная в мире база данных с открытым исходным кодом и бесплатная. MySQL была приобретена Oracle в рамках приобретения Sun Microsystems в 2009 году.
В MySQL часть SQL «MySQL» означает «язык структурированных запросов». SQL является наиболее распространенным стандартизированным языком, используемым для доступа к базам данных. В зависимости от вашей среды программирования вы можете вводить SQL напрямую (например, для создания отчетов), встраивать операторы SQL в код, написанный на другом языке, или использовать API для конкретного языка, который скрывает синтаксис SQL.
Ключевые свойства MySQL:
- MySQL — это система управления базами данных.
- Базы данных MySQL являются реляционными.
- Программное обеспечение MySQL является открытым исходным кодом.
- Сервер базы данных MySQL очень быстр, надежен, масштабируем и прост в использовании.
- MySQL Server работает в клиент-серверных или встроенных системах.
№3. SQL Server
База данных SQL Server, разработанная Microsoft, является одной из самых популярных баз данных в мире. Первоначально запущен в 1989 и написанный на C, C++, SQL Server в настоящее время широко используется крупными компаниями. SQL Server также является частью облака Microsoft Azure как Azure SQL Server. Текущая версия SQL Server — SQL Server 2019.
Подобно Oracle и MySQL, SQL Server также является системой управления реляционными базами данных (RDBMS).
Некоторые популярные выпуски SQL Server:
База данных SQL Azure — это облачная версия Microsoft SQL Server, представленная как платформа как услуга, предлагаемая в Microsoft Azure.
Compact (SQL CE), компактная версия — встроенное ядро базы данных. В отличие от других выпусков SQL Server, механизм SQL CE основан на SQL Mobile (изначально предназначенном для использования с портативными устройствами) и не использует одни и те же двоичные файлы. Из-за своего небольшого размера (1 МБ занимаемой DLL) он имеет заметно уменьшенный набор функций по сравнению с другими выпусками. Например, он поддерживает подмножество стандартных типов данных, не поддерживает хранимые процедуры, представления или пакеты с несколькими операторами (среди прочих ограничений). Он ограничен максимальным размером базы данных 4 ГБ и не может запускаться как служба Windows, Compact Edition должен размещаться в приложении, использующем его. Версия 3.5 включает поддержку служб синхронизации ADO.NET. SQL CE не поддерживает подключение ODBC, в отличие от собственно SQL Server.
SQL Server Enterprise Edition — это основная база данных, приобретаемая большинством компаний, которая поставляется с каждой функцией продукта.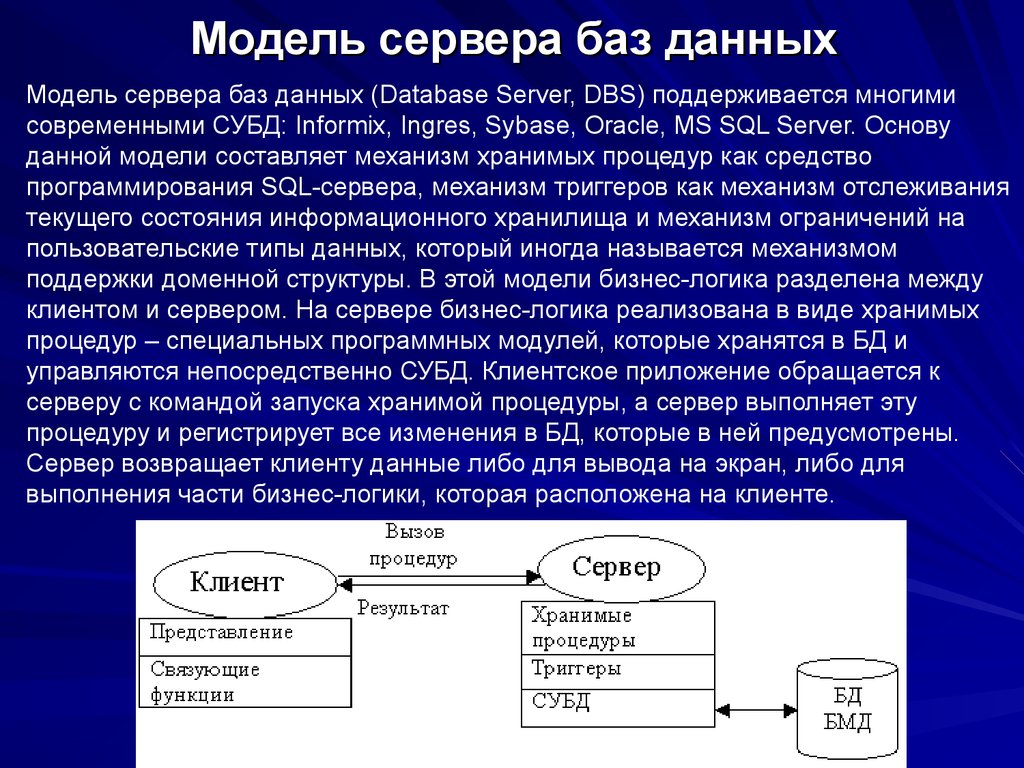
SQL Server Developer Edition включает те же функции, что и SQL Server Enterprise Edition, но ограничен только одной лицензией, которая используется разработчиками программного обеспечения в целях разработки.
Самые популярные базы данных в 2020 году: вот как они складываются
Независимо от того, являетесь ли вы разработчиком или нет, есть вероятность, что вы участвовали в разговоре о базах данных. Хотя сегодня используются разные типы баз данных, может быть трудно понять разницу между каждым из них, если вы не являетесь экспертом.
Итак, в этой статье мы кратко рассмотрим основы баз данных, объясним разницу между реляционными и нереляционными базами данных и рассмотрим 5 самых популярных баз данных, которые сегодня используются разработчиками.
Краткий обзор баз данных
Определение
База данных представляет собой организованный набор данных, к которым можно получить доступ с помощью электронных средств. Techopedia определяет его как метод хранения, управления и извлечения деловой информации. Слово обычно сокращается как «db» и относится к цифровой информации.
Слово обычно сокращается как «db» и относится к цифровой информации.
О многоуровневой архитектуре
Чтобы лучше понять, что такое базы данных, вам необходимо знать об архитектуре программного обеспечения. Наиболее распространенной архитектурой является трехуровневая модель , состоящая из уровня представления, уровня логики и уровня данных.
- Уровень представления — это пользовательский интерфейс, с помощью которого пользователи взаимодействуют с приложением.
- Уровень логики выполняет команды и выполняет вычисления с использованием данных.
- Уровень данных включает хранилище и базу данных, откуда логический уровень получает данные для обработки.
Система управления базами данных (СУБД)
Обычно слово «база данных» относится к системе управления базами данных или СУБД, и в большинстве случаев эти термины полностью взаимозаменяемы.
СУБД — это система, позволяющая управлять, организовывать и модифицировать базы данных.
Хотя существует множество различных типов баз данных и систем управления, все они работают на основе одних и тех же основных принципов работы.
Понимание SQL и NoSQL (реляционные и нереляционные базы данных)
Существуют различные типы баз данных: реляционные, основанные на неструктурированных файлах, иерархические, сетевые или объектно-ориентированные.
Одно из самых больших изменений в дизайне баз данных произошло в 2000-х годах, когда NoSQL начал популяризировать «нереляционную базу данных».
В прошлом почти все базы данных были реляционными. Они использовали заданную структуру данных, что позволило им связать информацию из разных «таблиц» с помощью индексов. Затем эти «сегменты» данных могут быть связаны через «отношения». SQL (язык структурированных запросов) — это язык, используемый для баз данных такого типа. Он предоставляет команды для создания, извлечения, обновления и удаления информации, хранящейся в таблицах.
NoSQL расшифровывается как «No Structured Query Language». Это нереляционный тип базы данных. В этом случае базы данных не используют никакого реляционного принуждения. Архитектор базы данных определяет, какие отношения, если таковые имеются, необходимы для их данных, и создает их.
И реляционные, и нереляционные базы данных лучше подходят для разных целей. SQL, например, лучше подходит для приложения, которое требует чрезвычайно сложных, интенсивных запросов между различными базами данных . Например, для создания системы онлайн-касс SQL был бы идеальным выбором.
С другой стороны, нереляционные базы данных, такие как NoSQL, обычно лучше подходят для приложений, требующих горизонтального масштабирования и более гибкой архитектуры, таких как анализ больших данных и веб-приложения в реальном времени .
Лучшая база данных для ваших нужд зависит от особенностей вашего проекта и целей вашей организации.
Вот самые популярные базы данных
После этого базового обзора дизайна и структуры базы данных давайте обсудим 5 самых популярных систем управления базами данных, которые сегодня используются разработчиками.
1. MySQL
MySQL — это реляционная СУБД с открытым исходным кодом. Впервые он был выпущен в 1995 году и стал важным компонентом почти всех стеков веб-разработки с открытым исходным кодом. Настолько, что это часть веб-архетипа, известного как LAMP (Linux, Apache, MySQL, Perl/PHP/Python).
MySQL написан на C+ и C++ и имеет огромное количество поддержки и документации. Это связано с его популярностью и сроком службы.
MySQL используется почти всеми крупными компаниями. Некоторые крупные веб-сайты, использующие базы данных MySQL, включают Facebook, Google, Twitter, YouTube и Flickr, и это лишь некоторые из них.
- Плюсы: высокая производительность для больших баз данных, открытый исходный код
- Минусы: инкрементное резервное копирование сложно реализовать, нет поддержки XML или OLAP
2. MariaDB
MariaDB — это «форк» (проект, основанный на исходном коде) MySQL, основанный рядом разработчиков, обеспокоенных покупкой MySQL корпорацией Oracle.
Поскольку это ответвление, MariaDB очень похожа на MySQL, когда речь идет о базовой архитектуре и функциональности, и поддерживает высокую совместимость с другой базой данных. Некоторые пользователи MariaDB включают Google, Mozilla и Фонд Викимедиа.
- Плюсы: высокая скорость, масштабируемая архитектура и плагины, шифрование на разных уровнях
- Минусы: перенос данных непрост
3. MongoDB
MongoDB — одна из самых популярных нереляционных баз данных, несмотря на ее недавний выпуск в 2009 году. данные, как текстовые документы. MongoDB не использует схемы.
MongoDB написана на языках программирования C++, C и JavaScript.
- Плюсы : высокая скорость, высокая производительность, простота настройки, поддержка JSON
- Минусы : большой размер данных, высокое использование памяти, ограниченная вложенность файлов, безопасность не установлена по умолчанию
4.
 Redis
RedisRedis, как и MongoDB, относительно молод. Впервые он был выпущен в 2009 году. Название REdis означает «удаленный сервер словарей». Это нереляционная база данных с открытым исходным кодом, в первую очередь предназначенная для использования в качестве хранилища ключей и значений. Он использует ассоциативный массив, в котором ключ связан только с одним значением в коллекции.
Redis написан на ANSI C.
- Плюсы : высокая скорость, простота настройки, поддержка нескольких типов данных
- Минусы : требуется больше памяти, нет поддержки запросов на соединение
5. PostgreSQL
PostgreSQL — это объектно-реляционная СУБД с упором на соответствие стандартам и расширяемость для крупномасштабных проектов. Его основной особенностью является невероятно эффективное масштабирование.
PostgresSQL подходит для одномашинного приложения, большого приложения с выходом в Интернет и для всех промежуточных приложений. Это сделало ее одной из самых популярных реляционных баз данных, используемых сегодня. Apple, например, по умолчанию использует PostgreSQL в операционной системе MacOS Server.
Это сделало ее одной из самых популярных реляционных баз данных, используемых сегодня. Apple, например, по умолчанию использует PostgreSQL в операционной системе MacOS Server.
PostgresSQL написан на языке C.
- Плюсы : высокая масштабируемость, предопределенные функции, поддержка JSON
- Минусы : сложность настройки, недостаточная производительность для высоконагруженных операций
Выбор правильной базы данных для вашего приложения
У каждой СУБД или базы данных есть свои сильные и слабые стороны. Вот почему важно понимать основные различия между типами баз данных, например между реляционными и нереляционными. Мы надеемся, что эта статья дала вам больше информации о том, что такое базы данных и почему они так важны в нашем современном мире, ориентированном на данные.
Хотите увидеть эти базы данных в действии? Запросите индивидуальную демонстрацию Ormuco на этой странице.
10 баз данных, наиболее часто используемых разработчиками в 2020 году
В этом году в опросе разработчиков Stack Overflow приняли участие около 65 000 разработчиков, в ходе которых они проголосовали за свои повседневно используемые инструменты, языки программирования, библиотеки и библиотеки. и более. Согласно опросу, MySQL сохранил первое место, за ним следуют PostgreSQL и Microsoft SQL Server.
и более. Согласно опросу, MySQL сохранил первое место, за ним следуют PostgreSQL и Microsoft SQL Server.
Ниже мы перечислили 10 лучших баз данных из опроса, которые чаще всего используются разработчиками во всем мире в 2020 году.
(Базы данных отсортированы в соответствии с их рейтингом).
MySQLРейтинг: 1
О компании: MySQL — одна из самых популярных систем управления базами данных SQL с открытым исходным кодом. Программное обеспечение базы данных MySQL, разработанное Oracle, представляет собой клиент-серверную систему, состоящую из многопоточного SQL-сервера, поддерживающего различные серверные части, нескольких различных клиентских программ и библиотек, инструментов администрирования и широкого спектра интерфейсов прикладного программирования (API).
Узнайте больше здесь.
PostgreSQLРанг: 2
Описание: PostgreSQL — это мощная система объектно-реляционных баз данных с открытым исходным кодом, которая включает в себя некоторые ключевые функции, такие как надежность, отказоустойчивость и производительность. Он использует и расширяет язык SQL в сочетании со многими функциями, которые безопасно хранят и масштабируют самые сложные рабочие нагрузки данных. PostgreSQL имеет множество функций, призванных помочь разработчикам создавать приложения. Это позволяет администраторам защищать целостность данных и создавать отказоустойчивые среды, а также помогает управлять данными.
Он использует и расширяет язык SQL в сочетании со многими функциями, которые безопасно хранят и масштабируют самые сложные рабочие нагрузки данных. PostgreSQL имеет множество функций, призванных помочь разработчикам создавать приложения. Это позволяет администраторам защищать целостность данных и создавать отказоустойчивые среды, а также помогает управлять данными.
Узнайте больше здесь.
Microsoft SQL ServerРанг: 3
О программе: Microsoft SQL Server — система управления реляционными базами данных, разработанная Microsoft. SQL Server 2019 включает в себя ряд интуитивно понятных функций, таких как получение информации из всех данных путем выполнения запросов к реляционным, нереляционным, структурированным и неструктурированным данным, гибкость использования языка и платформы по выбору пользователя с поддержкой открытого исходного кода, масштабируемость. и производительность для повышения стабильности и времени отклика базы данных и многое другое.
Узнайте больше здесь.
SQLiteРанг: 4
Описание: SQLite — это внутрипроцессная библиотека, которая реализует автономный, бессерверный, не требующий настройки транзакционный механизм базы данных SQL. Это встроенный механизм базы данных SQL, и, в отличие от большинства других баз данных SQL, SQLite не имеет отдельного серверного процесса.
Узнайте больше здесь.
MongoDBРанг: 5
О: MongoDB — это универсальная распределенная база данных на основе документов, созданная для современных разработчиков приложений и для эпохи облачных вычислений. Это одна из популярных баз данных, которая сочетает в себе масштабируемость и гибкость. MongoDB — это база данных документов, что означает, что она хранит данные в документах, подобных JSON.
Узнайте больше здесь.
Redis. Он поддерживает структуры данных, такие как строки, хэши, списки, наборы, отсортированные наборы с запросами диапазона, растровые изображения, гиперлоглоги, геопространственные индексы с запросами радиуса и потоки. Redis написан на ANSI C и работает в большинстве систем POSIX, таких как Linux, *BSD, OS X, без внешних зависимостей.
Redis написан на ANSI C и работает в большинстве систем POSIX, таких как Linux, *BSD, OS X, без внешних зависимостей.Узнайте больше здесь.
MariaDBРанг: 7
О компании: MariaDB Server — один из самых популярных серверов баз данных, который преобразует данные в структурированную информацию для широкого круга приложений, от банковских до веб-сайтов. Он разработан как программное обеспечение с открытым исходным кодом и как реляционная база данных. Он также предоставляет интерфейс SQL для доступа к данным.
Узнайте больше здесь.
ОракулРанг: 8
О компании: Oracle Database — это мультимодельная система управления базами данных, обеспечивающая более безопасное выполнение всех рабочих нагрузок, независимо от того, выполняются ли они локально или автономно в Oracle Cloud Infrastructure. Существует несколько интуитивно понятных функций, таких как система управления базами данных, которая позволяет пользователю выбирать из множества вариантов развертывания, таких как локальное развертывание, Cloud@Customer и общедоступное облако. Он помогает создавать приложения с высокой степенью масштабируемости, поддерживая все типы данных, включая реляционные, графовые, а также структурированные и неструктурированные нереляционные данные.
Он помогает создавать приложения с высокой степенью масштабируемости, поддерживая все типы данных, включая реляционные, графовые, а также структурированные и неструктурированные нереляционные данные.
Узнайте больше здесь.
FirebaseРейтинг: 9
Информация: Разработанная Google, Firebase представляет собой платформу для разработки мобильных и веб-приложений. Он предоставляет разработчикам адекватные инструменты для разработки высококачественных приложений, а также для расширения пользовательской базы. Firebase предоставляет различные функции, такие как аналитика, базы данных, обмен сообщениями и отчеты о сбоях.
Узнайте больше здесь.
Эластичный поискРанг: 10
О компании: Elasticsearch — это распределенная поисковая и аналитическая система с открытым исходным кодом для всех типов данных, включая текстовые, числовые, геопространственные, структурированные и неструктурированные данные.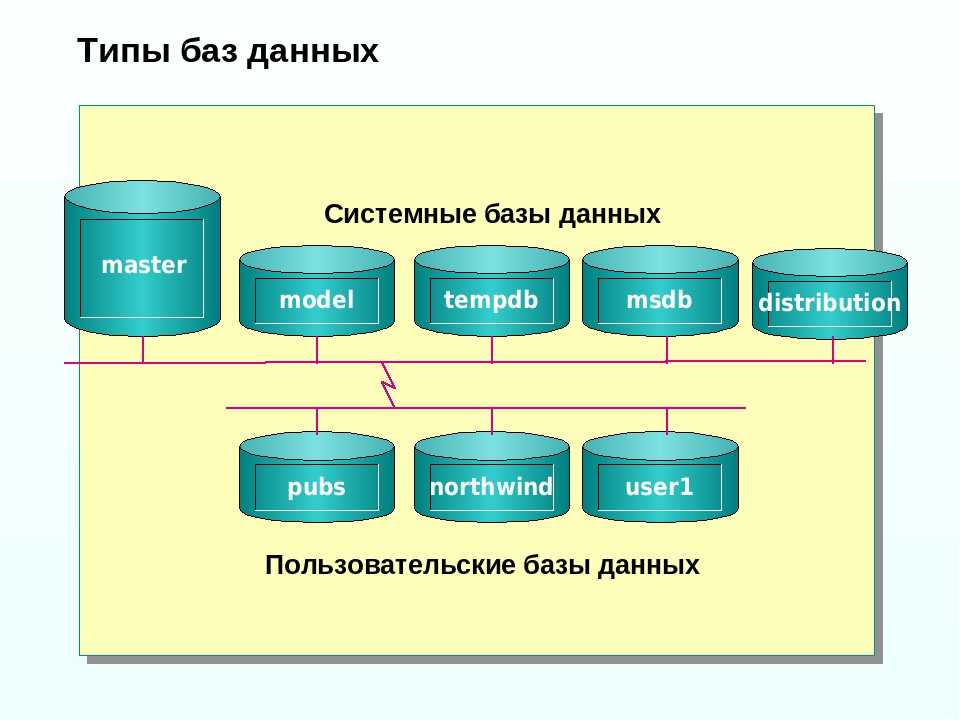 Это центральный компонент Elastic Stack, представляющего собой набор инструментов с открытым исходным кодом для приема, обогащения, хранения, анализа и визуализации данных. Скорость и масштабируемость Elasticsearch можно использовать для поиска приложений, поиска веб-сайтов, ведения журналов и анализа журналов, мониторинга производительности приложений, анализа безопасности и многого другого.
Это центральный компонент Elastic Stack, представляющего собой набор инструментов с открытым исходным кодом для приема, обогащения, хранения, анализа и визуализации данных. Скорость и масштабируемость Elasticsearch можно использовать для поиска приложений, поиска веб-сайтов, ведения журналов и анализа журналов, мониторинга производительности приложений, анализа безопасности и многого другого.
Узнайте больше здесь.
Топ-15 баз данных, которые будут использоваться в 2022 году и далее
Топ-15 баз данных, которые будут использоваться в 2022 году и позжеАпекша Мехта 23 мая 2022 г.
Содержание
- Какая база данных лучше для веб-приложений в 2022 году?
- Какую базу данных проще всего использовать?
- Какая база данных лучше всего подходит для Python?
- Заключительные мысли
Поделитесь этой статьей
Цифровая трансформация, будь то частное предприятие или крупная организация, позволила компаниям получать информацию в каждой точке взаимодействия. Независимо от организации, каждой организации требуется база данных для сортировки и хранения ее основных данных. Чтобы обеспечить такую возможность, на помощь приходит программное обеспечение системы управления базами данных.
Независимо от организации, каждой организации требуется база данных для сортировки и хранения ее основных данных. Чтобы обеспечить такую возможность, на помощь приходит программное обеспечение системы управления базами данных.
Базой данных можно назвать комнату внутри офиса, где хранится вся необходимая информация и отчеты. Сохраняемая информация чрезвычайно чувствительна, поэтому мы должны быть очень осторожны при доступе к информации в базе данных.
С появлением микросервисов, облачных сред, распределенных приложений, полуструктурированных данных, больших данных, данных с малой задержкой и т. д. к обычному списку наиболее популярных баз данных SQL в настоящее время присоединяются различные базы данных NoSQL, NewSQL и облачные.
Констатируя широкое использование и популярность различных типов баз данных в адаптивных приложениях для веб-разработки, вот несколько фактов о лучшей базе данных для веб-приложений в 2022 году или в ближайшие годы:
Согласно отчетам business. com, 91% компаний с более чем 11 сотрудниками используют программное обеспечение CRM.
com, 91% компаний с более чем 11 сотрудниками используют программное обеспечение CRM.
В отчете Nucleus Research говорится, что 65% компаний, использующих CRM для мобильных веб-разработок, выполняют свои квоты продаж.
Согласно Future Market Insights, ожидается, что рынок мобильных CRM будет расти примерно на 13% в год в течение 2019–2029 годов.
Теперь давайте углубимся в типы популярных баз данных для веб-приложений.
Содержание
- Какая база данных является лучшей для веб-приложений в 2022 году? (Лучшие базы данных на 2022 г.) 902:30
- Какую базу данных проще всего использовать?
- Какая база данных лучше всего подходит для Python?
- Заключительные мысли
Oracle — наиболее широко используемая коммерческая система управления реляционными базами данных со встроенными языками ассемблера, такими как C, C++ и Java. Самая последняя версия этой базы данных, 21c, содержит множество новых функций.
Самая последняя версия этой базы данных, 21c, содержит множество новых функций.
Oracle — это система управления базами данных, которая стоит выше других. В целом, это наиболее широко используемая СУБД. Он занимает меньше места и быстрее обрабатывает данные, а также включает в себя несколько новых полезных функций, таких как JSON из SQL.
2. MySQLMySQL — одна из самых популярных баз данных для использования в 2022 году в компьютерном мире, особенно при разработке веб-приложений. Основное внимание в этой базе данных уделяется стабильности, надежности и зрелости. Наиболее популярное применение этой базы данных — решения для веб-разработки.
MySQL написан на C и C++ и использует язык структурированных запросов. MySQL 8.0 — самая последняя версия этой базы данных, и она включает улучшенный вариант восстановления. Лучшая база данных SQL поставляется в различных редакциях, каждая из которых имеет свой собственный набор функций.
3. MS SQL Server
MS SQL Server Microsoft предоставляет отличный набор инструментов для одного из лучших программ для работы с базами данных как локально, так и в облаке. Он хорошо совместим с системами Linux и Windows. MS SQL — это мультимодельная база данных, которая поддерживает структурированные данные (SQL), полуструктурированные данные (JSON) и пространственные данные.
Он не такой изобретательный или продвинутый, как другие современные списки популярных баз данных, но за прошедшие годы он претерпел значительные улучшения и капитальный ремонт.
4. PostgreSQLPOSTGRES было первоначальным именем базы данных. Майкл также был удостоен премии Тьюринга за свой вклад в PostgreSQL.
PostgreSQL — это система управления базами данных, написанная на C и используемая предприятиями, работающими с огромными объемами данных. Это программное обеспечение для управления базами данных используется несколькими игровыми приложениями, инструментами автоматизации баз данных и регистрацией доменов.
Говоря о самых популярных базах данных, которые будут использоваться в 2022 году через базу данных NoSQL, следует учитывать несколько моментов. MongoDB — первое программное обеспечение для управления базой данных документов, выпущенное в 2009 году. Загружать и получать доступ к данным в СУБД с помощью объектно-ориентированных языков программирования, которые также требуют дополнительного сопоставления на уровне приложений, сложно. Таким образом, чтобы преодолеть эту проблему, Mongo был разработан для обработки данных документа.
6. IBM DB2IBM также предлагала DB2 LUW для Windows, Linux и Unix. DB2 11.5 — это самый последний выпуск, в котором ускорено выполнение запросов.
Список баз данных для мобильных приложений поддерживает реляционную модель, но за последние годы он значительно расширился. Теперь он поддерживает объектно-реляционные функции и нереляционные формы, такие как JSON и XML.
7.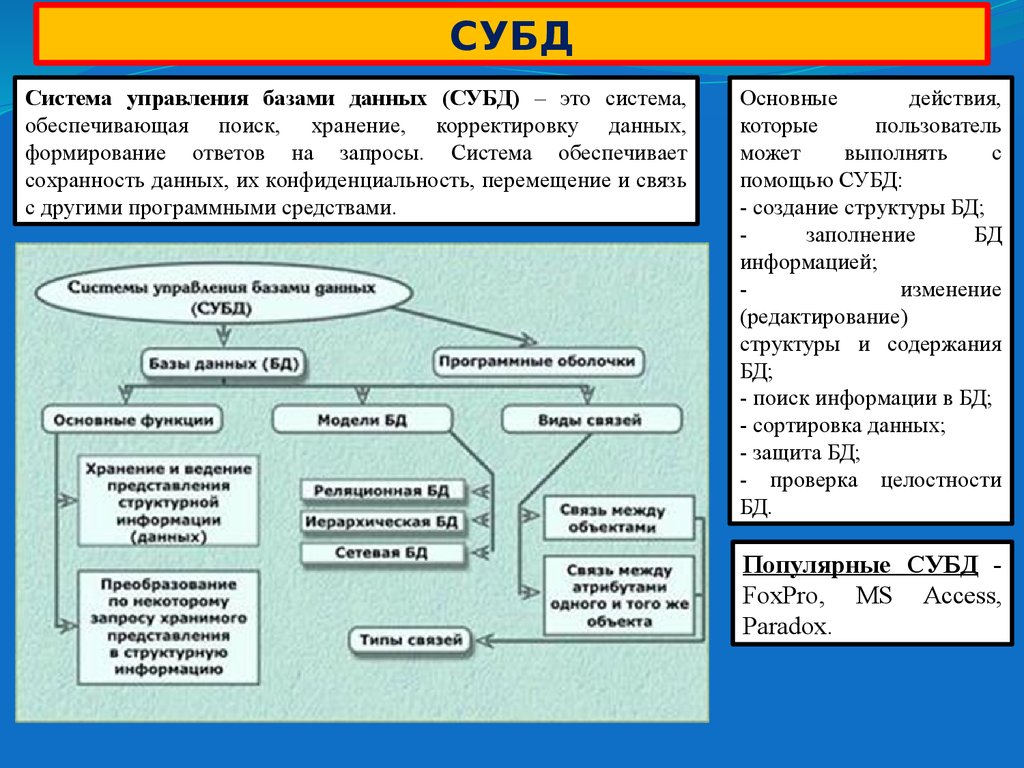 Redis
Redis Это популярный проект базы данных с открытым исходным кодом. Согласно ежегодному опросу разработчиков Stack Overflow, Redis считается самой любимой платформой баз данных. Его можно использовать как распределенную базу данных ключей и значений в памяти. Redis также можно использовать в качестве распределенного кеша и брокера сообщений с возможностью повышения надежности.
8. ElasticsearchElasticsearch – это система полнотекстового поиска с открытым ядром, основанная на Lucene, впервые выпущенная в 2010 году Шей Бэнон. Это полнотекстовая поисковая система с распределенными, многопользовательскими возможностями и REST API.
Обеспечивает горизонтальное масштабирование с помощью автоматического обмена и REST API. Он также поддерживает структурированные данные и данные без схемы (JSON), что особенно подходит для анализа данных регистрации или мониторинга.
9. Cassandra Это открытое ядро, распределенное хранилище с широкими столбцами и широко используемая база данных для приложения, которое было разработано в 2008 году. Это высоко масштабируемое программное обеспечение для управления базами данных, которое широко используется в отраслях для обработки больших объемов данных.
Это высоко масштабируемое программное обеспечение для управления базами данных, которое широко используется в отраслях для обработки больших объемов данных.
Одной из его основных особенностей является его децентрализованная база данных (Leaderless), имеющая автоматическую репликацию и репликацию с несколькими центрами обработки данных, что делает ее отказоустойчивой базой без каких-либо сбоев. Cassandra имеет несколько различных операций и инфраструктуры. Базы данных Cassandra и HBase прошли долгий путь и имеют разные варианты использования в зависимости от их типа.
10.
MariaDBЭто система управления реляционными базами данных, совместимая с протоколом и клиентами MySQL. Сервер MySQL можно легко заменить на MariaDB без каких-либо изменений кода.
Эта система управления обеспечивает хранение по столбцам с массивно-параллельной распределенной архитектурой данных. По сравнению с MySQL, MariaDB больше управляется сообществом.
11.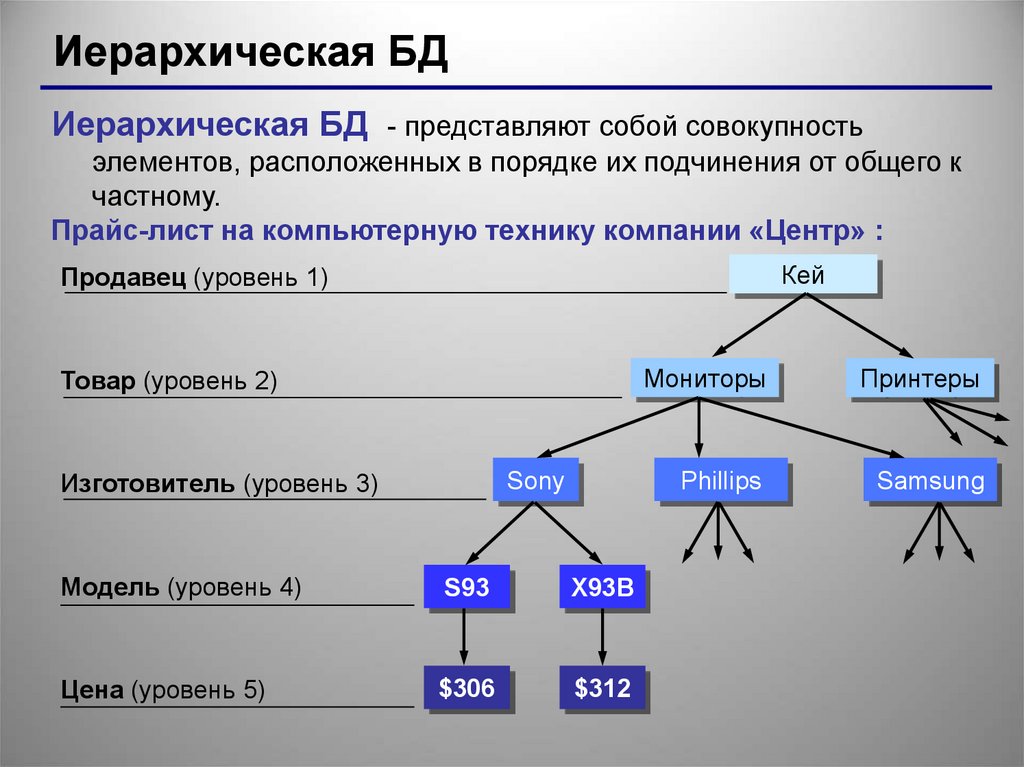 OrientDB
OrientDB OrientDB — это база данных с открытым исходным кодом и многомодельной программой базы данных NoSQL, которая позволяет компаниям использовать возможности программного обеспечения для управления базами данных графов без необходимости создавать несколько систем для обработки разных типов данных.
Это решение для управления с поддержкой моделей графов, документов, значений ключей и объектно-ориентированных баз данных, которое повышает производительность и безопасность, а также обеспечивает масштабируемость.
12. SQLite SQLite — лучшая база данных SQL с открытым исходным кодом и интегрированной системой управления реляционными базами данных. Она была создана в 2000 году. Это лучшая база данных, которая не требует настройки и даже не требует сервера или установки. Несмотря на свою простоту, он содержит множество часто используемых функций программного обеспечения системы управления базами данных, которые можно использовать в мобильной веб-разработке, например, React Native.
DynamoDB — лучшая нереляционная база данных от Amazon. Это бессерверная база данных для мобильных приложений, которая автоматически масштабируется вверх и вниз, а также выполняет резервное копирование ваших данных.
Эта программа базы данных имеет встроенную защиту и кэширование в памяти, а также постоянную задержку.
14. Neo4jNeo4j – это основанная на Java графовая база данных NoSQL с открытым исходным кодом, запущенная в 2007 году. запросы отношений.
В этой системе управления базами данных ваши данные сохраняются в виде графиков, а не таблиц. Система отношений Neo4j работает быстро, что позволяет вам создавать и использовать другие отношения позже, чтобы «сокращать» и ускорять данные домена по мере необходимости.
15. Firebirdsql Firebird — это бесплатная система управления реляционными базами данных SQL, которая работает на Mac OS X, Linux, Microsoft Windows и различных платформах Unix.
Эта лучшая бесплатная база данных для веб-приложений обновила мультиплатформенную СУБД. От членства в Firebird до спонсорских обязательств, он предлагает множество вариантов финансирования.
Какую базу данных проще всего использовать?Программные инструменты для работы с базами данных поддерживают почти все возможные приложения. Но здесь вопрос действительно в том, для какой цели вы ищете. Например, в университете мы обучаем начинающих студентов лучшей базе данных для веб-приложений и программного обеспечения с использованием Microsoft SQL Server. Когда они освоят основы базы данных, они смогут без особых усилий перейти к MySQL и Oracle.
Хотя большинство баз данных для мобильных приложений одинаковы, очень важно ознакомиться с основами наиболее популярных баз данных SQL и пояснениями, поскольку их можно легко применить к большинству популярных систем баз данных. Для вас было бы лучше изучить его, сначала составив операторы SQL, а не используя подход с графическим интерфейсом.
Когда вы поймете ключевые идеи, вы увидите, что это такой простой способ применить их к любому программному обеспечению для управления базами данных, использующему любые IDE, включая графический интерфейс.
Какая база данных лучше всего подходит для Python?Язык программирования Python обладает удивительными возможностями программирования баз данных. Python поддерживает различные списки баз данных, такие как SQLite, Oracle, MySQL, PostgreSQL и так далее. Python также поддерживает язык определения данных (DDL), язык манипулирования данными (DML) и операторы запроса данных. Python DB-API — это стандарт Python для интерфейсов баз данных. Большинство интерфейсов баз данных Python придерживаются этой нормы.
Здесь мы поговорим об одной из лучших баз данных для веб-приложений: SQLite
SQLite
SQLite, вероятно, является самой понятной базой данных и самой популярной базой данных SQL для подключения к приложению Python, поскольку вам не нужно устанавливать внешняя база данных Python SQL или модули типа или базы данных SQL.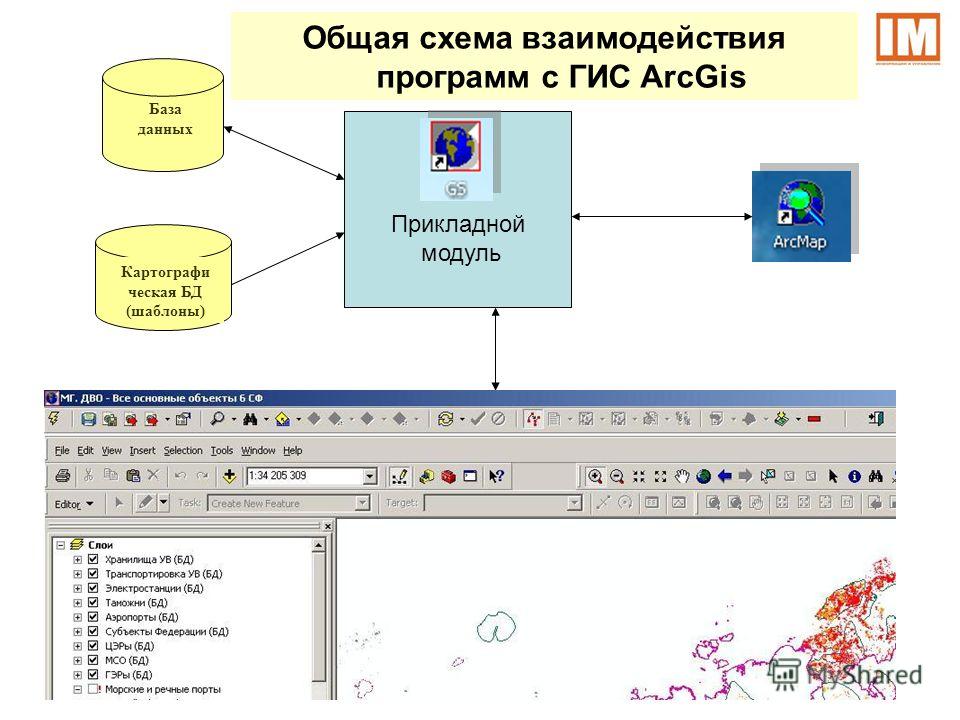 Разумеется, ваша установка Python содержит библиотеку Python SQL с именем SQLite3, которую вы можете использовать для подключения и взаимодействия с базой данных SQLite.
Разумеется, ваша установка Python содержит библиотеку Python SQL с именем SQLite3, которую вы можете использовать для подключения и взаимодействия с базой данных SQLite.
База данных для мобильных приложений считается краеугольным камнем программных приложений и тем, без чего организация не может процветать.
Если вам нужна помощь по типу базы данных SQL и разработке приложений, свяжитесь с нами, поскольку мы являемся одной из ведущих компаний по веб-разработке в США, которая создает масштабируемые приложения и обеспечивает впечатляющие результаты на настольных компьютерах и мобильных устройствах.
Надеемся, что этот список лучших баз данных для веб-приложений в 2022 году рассеял ваши сомнения относительно ее широкого использования.
АВТОР
Апекша Мехта
МЕНЕДЖЕР ТЕХНОЛОГИИ
Предыдущий постСледующий пост
Подробнее блоги
Разработка веб-приложений
Благодаря стремительному развитию микросервисов и постоянному стремлению к быстрому развертыванию приложений API-интерфейсы стали популярными для каждого предпринимателя.
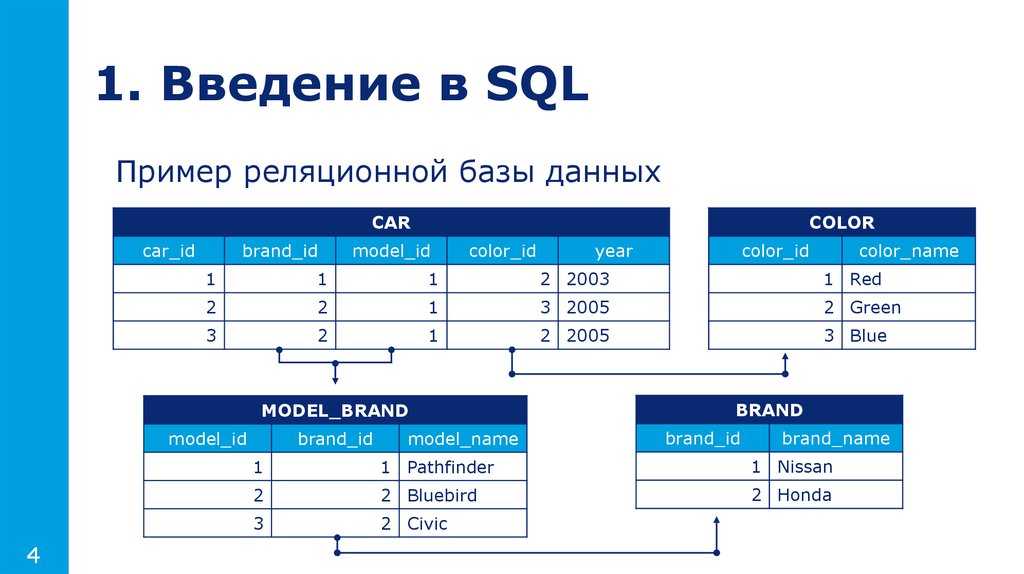 Однако по мере того, как каждая небольшая функция связывается с другим программным обеспечением или продуктами для беспрепятственного взаимодействия с пользователем, API-интерфейсы все чаще становятся центром взломов безопасности. Настолько, что…
Однако по мере того, как каждая небольшая функция связывается с другим программным обеспечением или продуктами для беспрепятственного взаимодействия с пользователем, API-интерфейсы все чаще становятся центром взломов безопасности. Настолько, что…Апекша Мехта
07 Сен 2022
Разработка веб-приложений
Немногим более чем за десятилетие Node.js стал лучшим выбором разработчиков для разработки веб-приложений. Его плюсы делают его превосходной альтернативой для кроссплатформенной разработки за счет интеграции двустороннего канала связи клиент-сервер. Не вдаваясь в технические подробности, дайте нам знать основные статистические данные о разработке Node.js, подтверждающие его превосходство над конкурентами:
Разработка веб-приложений
«Дизайн — это молчаливый посол вашего бизнеса». Не так давно бренды и разработчики были увлечены новейшими технологиями и функциями.
 Раньше они внедряли все новейшие элементы в процесс разработки своих приложений, чтобы предоставить своим пользователям возможность работать в одном месте. Но чаще всего они терпели неудачу. Именно тогда они…
Раньше они внедряли все новейшие элементы в процесс разработки своих приложений, чтобы предоставить своим пользователям возможность работать в одном месте. Но чаще всего они терпели неудачу. Именно тогда они…Судип Шривастава
19 ноя 2019
ПОДПИСАТЬСЯ НА НАШУ РАССЫЛКУ
Получайте новости на свой почтовый ящик
два раза в месяц.
Десять распространенных ошибок при проектировании баз данных
Список ошибок никогда не будет исчерпывающим. Люди (и я в том числе) иногда делают много действительно глупых вещей во имя того, чтобы «довести дело до конца». Этот список просто отражает ошибки проектирования баз данных, о которых я сейчас думаю или, в некоторых случаях, постоянно думаю. Я эту тему уже два раза делал. Если вам интересно послушать версию подкаста, посетите превосходный SQL Down Under Грега Лоу. Я также представил сокращенную десятиминутную версию на PASS для стенда Simple-Talk. Первоначально их было десять, потом шесть, а сегодня снова десять. И это не совсем те десять, с которых я начал; это десять, которые выделяются для меня на сегодняшний день.
Я также представил сокращенную десятиминутную версию на PASS для стенда Simple-Talk. Первоначально их было десять, потом шесть, а сегодня снова десять. И это не совсем те десять, с которых я начал; это десять, которые выделяются для меня на сегодняшний день.
Прежде чем я начну со списка, позвольте мне на минутку быть честным. У меня был проповедник, который обязательно говорил нам перед некоторыми проповедями, что он проповедовал себе столько же, сколько и пастве. Когда я говорю или когда пишу статью, мне приходится прислушиваться к тому крошечному голоску в моей голове, который помогает отфильтровать мои собственные вредные привычки, чтобы убедиться, что я учу только лучшим практикам. Надеюсь, что после прочтения этой статьи тихий голос в вашей голове будет говорить с вами, когда вы начнете отклоняться от того, что правильно с точки зрения методов проектирования баз данных.
Итак, список:
- Плохой дизайн/планирование
- Игнорирование нормализации
- Плохие стандарты именования
- Отсутствие документации
- Одна таблица для хранения всех значений домена
- Использование столбцов идентификаторов и идентификаторов в качестве единственного ключа
- Не использовать средства SQL для защиты целостности данных
- Не использовать хранимые процедуры для доступа к данным
- Попытка создания универсальных объектов
- Отсутствие тестирования
Плохой дизайн/планирование
« Если вы не знаете, куда идете, любая дорога приведет вас туда » — Джордж Харрисон
Пророческие слова для всех сторон жизни и описание типов проблем, которые сегодня преследуют многие проекты.
Позвольте вас спросить: вы бы наняли подрядчика для строительства дома, а затем потребовали бы, чтобы они начали заливку фундамента на следующий день? Хуже того, стали бы вы требовать, чтобы это было сделано без чертежей или планов дома? Надеюсь, вы ответили «нет» на оба вопроса. Нужен дизайн убедитесь, что дом вам хочет, чтобы был построен, и чтобы земля, на которой вы его строите, не ушла в какую-нибудь подземную пещеру. Если вы ответили «да», я не уверен, что мои слова помогут вам.
Как и дом, хорошая база данных строится с предусмотрительностью, с должным вниманием и вниманием к потребностям данных, которые будут населять ее; его нельзя собрать вместе в каком-то обратном имплозии.
Поскольку база данных является краеугольным камнем почти каждого бизнес-проекта, если вы не потратите время на то, чтобы наметить потребности проекта и то, как база данных будет их удовлетворять, то, скорее всего, весь проект будет разрушен. сбиться с курса и потерять направление. Более того, если вы с самого начала не потратите время на то, чтобы правильно спроектировать базу данных, вы обнаружите, что любые существенные изменения в структурах базы данных, которые вам нужно будет внести в дальнейшем, могут оказать огромное влияние на всю систему в целом. проект, и значительно увеличивает вероятность сдвига сроков проекта.
Более того, если вы с самого начала не потратите время на то, чтобы правильно спроектировать базу данных, вы обнаружите, что любые существенные изменения в структурах базы данных, которые вам нужно будет внести в дальнейшем, могут оказать огромное влияние на всю систему в целом. проект, и значительно увеличивает вероятность сдвига сроков проекта.
Слишком часто надлежащий этап планирования игнорируется в пользу того, чтобы просто «выполнить». Проект движется в определенном направлении, и когда неизбежно возникают проблемы — из-за отсутствия надлежащего проектирования и планирования — «нет времени», чтобы вернуться и исправить их должным образом, используя соответствующие методы. Именно тогда начинается «взлом» с завуалированным обещанием вернуться и исправить ситуацию позже, что действительно случается очень редко.
По общему признанию, невозможно предсказать все потребности, которые должен будет удовлетворить ваш проект, и все проблемы, которые могут возникнуть, но важно минимизировать потенциальные проблемы, насколько это возможно, путем тщательного планирования.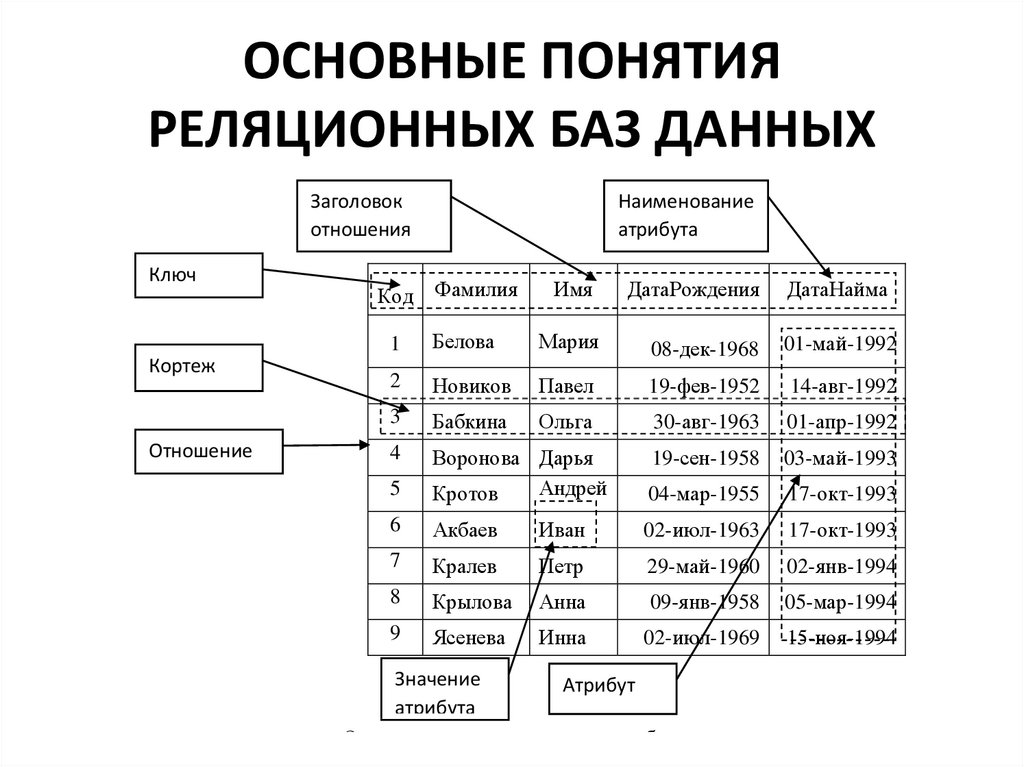
Игнорирование нормализации
Нормализация определяет набор методов для разбиения таблиц на составные части до тех пор, пока каждая таблица не будет представлять одну и только одну «вещь», а ее столбцы будут служить для полного описания только одной «вещи», которую представляет таблица.
Концепция нормализации существует уже 30 лет и является основой, на которой реализованы SQL и реляционные базы данных. Другими словами, SQL был создан для работы с нормализованными структурами данных. Нормализация не просто какой-то замысел программистов баз данных, чтобы досадить программистам приложений (это просто приятный побочный эффект!) набор значений или результатов. В предложении FROM вы берете набор данных (таблицу) и добавляете (JOIN) его в другую таблицу. Вы можете добавить столько наборов данных вместе, сколько захотите, чтобы получить окончательный набор, который вам нужен.
Этот аддитивный характер чрезвычайно важен не только для простоты разработки, но и для производительности.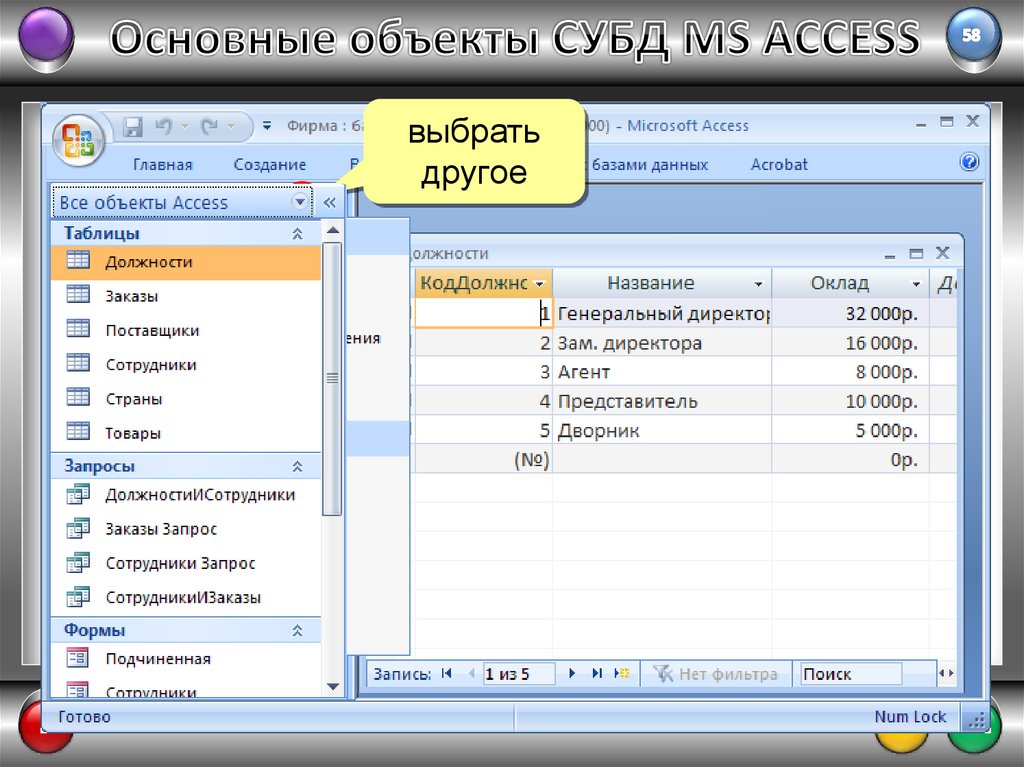 Индексы наиболее эффективны, когда они могут работать со всем значением ключа. Всякий раз, когда вам нужно использовать SUBSTRING , CHARINDEX , LIKE и т. д., чтобы проанализировать значение, объединенное с другими значениями в одном столбце (например, чтобы отделить фамилию человека от столбца полного имени) парадигма SQL начинает разрушаться, и данные становятся все менее доступными для поиска.
Индексы наиболее эффективны, когда они могут работать со всем значением ключа. Всякий раз, когда вам нужно использовать SUBSTRING , CHARINDEX , LIKE и т. д., чтобы проанализировать значение, объединенное с другими значениями в одном столбце (например, чтобы отделить фамилию человека от столбца полного имени) парадигма SQL начинает разрушаться, и данные становятся все менее доступными для поиска.
Таким образом, нормализация ваших данных необходима для хорошей производительности и простоты разработки, но всегда возникает вопрос: «Насколько нормализовано достаточно нормализовано ?» Если вы читали какие-либо книги о нормализации, то вы много раз слышали, что 3-я нормальная форма необходима, но 4-я и 5-я нормальные формы действительно полезны, и, как только вы освоите их, довольно легко следовать и они того стоят. время, необходимое для их реализации.
В действительности, однако, довольно часто даже первая нормальная форма не реализуется правильно.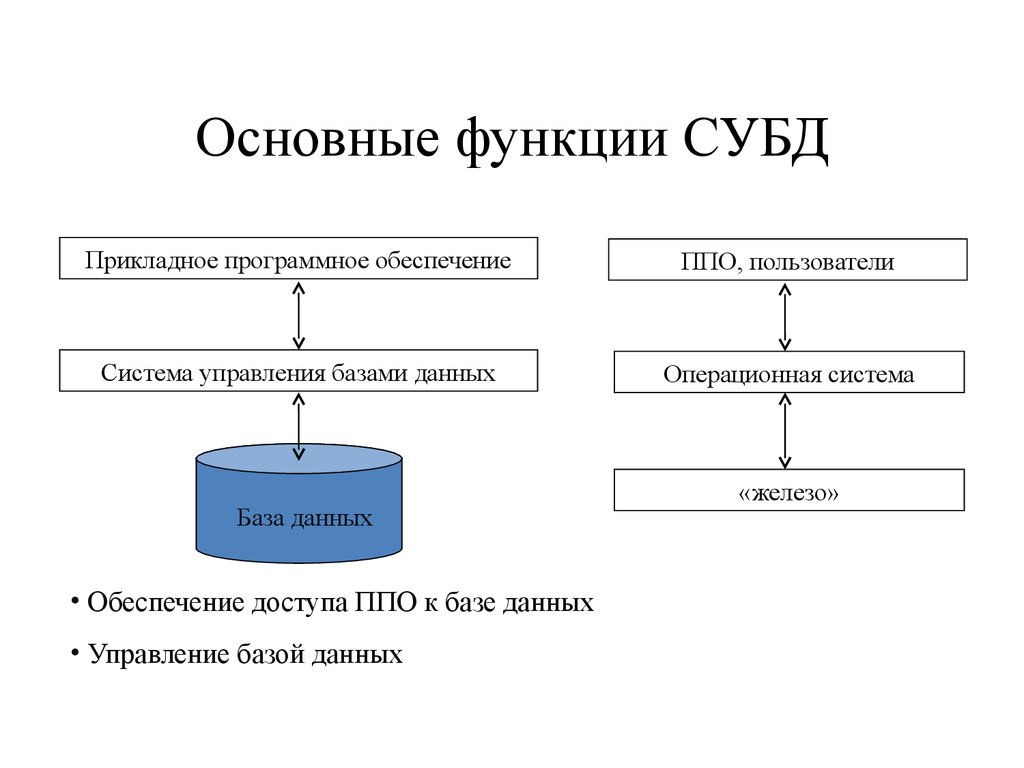
Всякий раз, когда я вижу таблицу с повторяющимися именами столбцов, к которым добавлены числа, я съеживаюсь от ужаса. И я довольно часто вздрагиваю от ужаса. Рассмотрим следующий пример Таблица Customer :
Всегда ли 12 платежей? Имеет ли значение порядок платежей? Значение NULL для платежа означает НЕИЗВЕСТНО (еще не заполнено) или пропущенный платеж? И когда была произведена оплата?!?
Платеж не описывает Клиент и не должен храниться в таблице Клиент . Подробная информация о платежах должна храниться в таблице Paymen t, в которой вы также можете записывать дополнительную информацию о платеже, например, когда был сделан платеж и за что был сделан платеж:
В этом втором дизайне каждый В столбце хранится одна единица информации об одной «вещи» (платеже), а каждая строка представляет конкретный экземпляр платежа.
Этот второй проект потребует немного больше кода в начале процесса, но гораздо более вероятно, что вы сможете выяснить, что происходит в системе, без необходимости выслеживать исходного программиста и пинать его. задница… извините… понять, о чем они думали
задница… извините… понять, о чем они думали
Плохие стандарты именования
» То, что мы называем розой, под любым другим именем пахло бы так же сладко »
Эта цитата из «Ромео и Джульетты» Уильяма Шекспира звучит красиво, и это правда с одного ракурса. Если бы все согласились с тем, что отныне розу будут называть навозом, тогда мы могли бы смириться с этим, и она бы пахла так же сладко. Проблема в том, что если при создании базы данных для флориста дизайнер называет ее навозом, а клиент — розой, то у вас будут встречи, которые больше походят на рутину Эббота и Костелло, чем на серьезный разговор о хранение информации о продукции садоводства.
Имена, хотя и являются личным выбором, являются первой и наиболее важной строкой документации для вашего приложения. Я не буду вдаваться во все подробности того, как лучше называть вещи здесь — это большая и запутанная тема. В этой статье я хочу подчеркнуть необходимость соответствия . Имена, которые вы выбираете, предназначены не только для того, чтобы вы могли определить назначение объекта, но и для того, чтобы все будущие программисты, пользователи и т.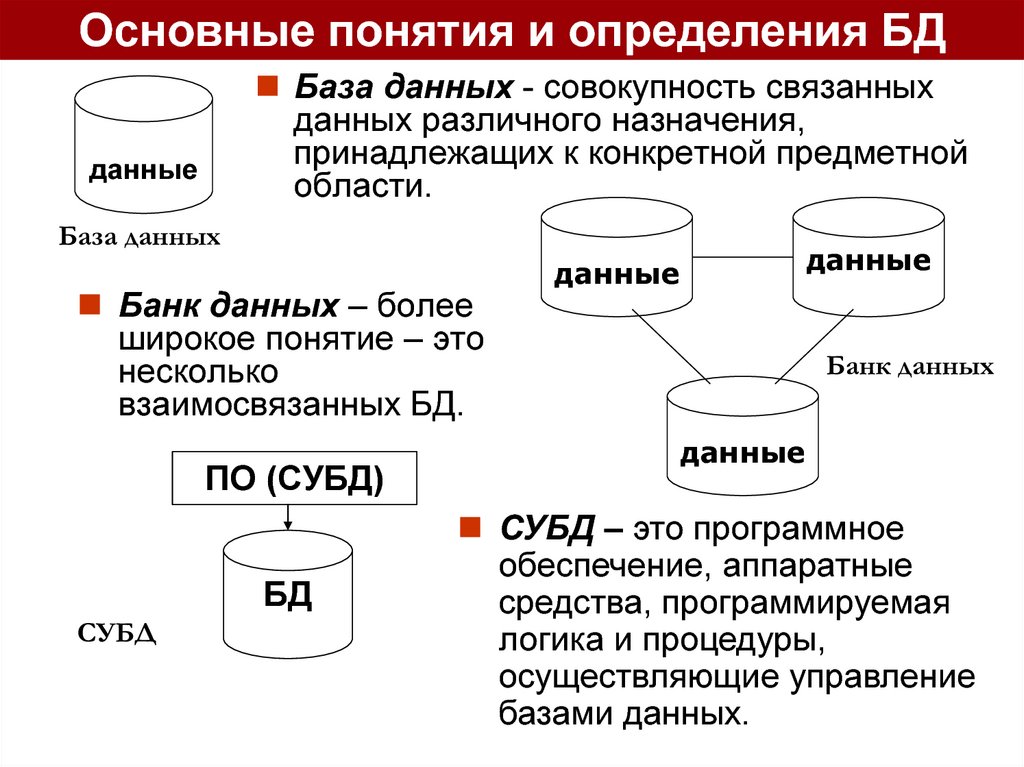 д. могли быстро и легко понять, как предполагается использовать составную часть вашей базы данных и что для этого нужно. данные, которые он хранит. Ни один будущий пользователь вашего дизайна не должен продираться через 500-страничный документ, чтобы определить значение какого-то дурацкого имени.
д. могли быстро и легко понять, как предполагается использовать составную часть вашей базы данных и что для этого нужно. данные, которые он хранит. Ни один будущий пользователь вашего дизайна не должен продираться через 500-страничный документ, чтобы определить значение какого-то дурацкого имени.
Рассмотрим, например, столбец с именем X304_DSCR . Что, черт возьми, это значит? Вы можете решить, почесав голову, что это означает «описание X304». Возможно, да, но может быть DSCR означает дискриминатор или дискретизатор?
Если вы не установили DSCR в качестве корпоративного стандартного сокращения для описания, то X304_DESCRIPTION — гораздо лучшее имя, и ничего не оставляет воображению.
Остается только выяснить, что за X304 часть имени означает. При первом осмотре мне кажется, что X304 больше похож на данные в столбце, а не на имя столбца. Если бы я впоследствии обнаружил, что в организации также есть X305 и X306, я бы отметил это как проблему с дизайном базы данных. Для максимальной гибкости данные хранятся в столбцах, а не в именах столбцов.
Для максимальной гибкости данные хранятся в столбцах, а не в именах столбцов.
В том же духе не поддавайтесь искушению включать «метаданные» в имя объекта. Имя, такое как tblCustomer или colVarcharAddress может показаться полезным с точки зрения разработки, но для конечного пользователя это просто сбивает с толку. Как разработчик, вы должны полагаться на способность определять, что имя таблицы является именем таблицы по контексту в коде или инструменте, и представлять пользователям понятные, простые, описательные имена, такие как Customer и Address .
Я настоятельно не рекомендую использовать пробелы и идентификаторы в кавычках в именах объектов. Вам следует избегать таких имен столбцов, как «Номер детали» или, в стиле Microsoft, [Номер детали], поэтому от пользователей требуется включать эти пробелы и идентификаторы в свой код. Это раздражает и просто не нужно.
Приемлемые альтернативы: номер детали , номер детали или номер детали .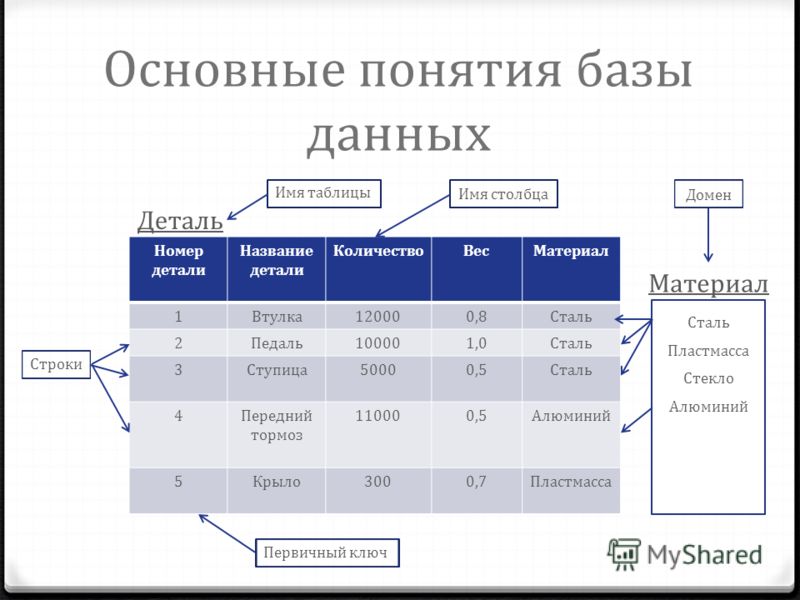 Опять же, важна последовательность. Если вы выберете PartNumber , это нормально, если столбец, содержащий номера счетов, называется InvoiceNumber , а не один из других возможных вариантов.
Опять же, важна последовательность. Если вы выберете PartNumber , это нормально, если столбец, содержащий номера счетов, называется InvoiceNumber , а не один из других возможных вариантов.
Отсутствие документации
Я намекнул во вступлении, что в некоторых случаях пишу для себя не меньше, чем вы. Это тема, где это наиболее верно. Тщательно назвав свои объекты, столбцы и т. д., вы можете объяснить всем, что именно моделирует ваша база данных. Однако это только первый шаг в битве за документацию. К сожалению, реальность такова, что «первый шаг» слишком часто оказывается девятым.0939 только шаг .
Мало того, что хорошо спроектированная модель данных соответствует строгому стандарту именования, она также будет содержать определения своих таблиц, столбцов, отношений и даже ограничений по умолчанию и проверок, чтобы всем было ясно, как они предназначены для использоваться. Во многих случаях вы можете захотеть включить примеры значений, где возникла потребность в объекте, и все остальное, что вы, возможно, захотите узнать через год или два, когда «в будущем» придется вернуться и внести изменения в код.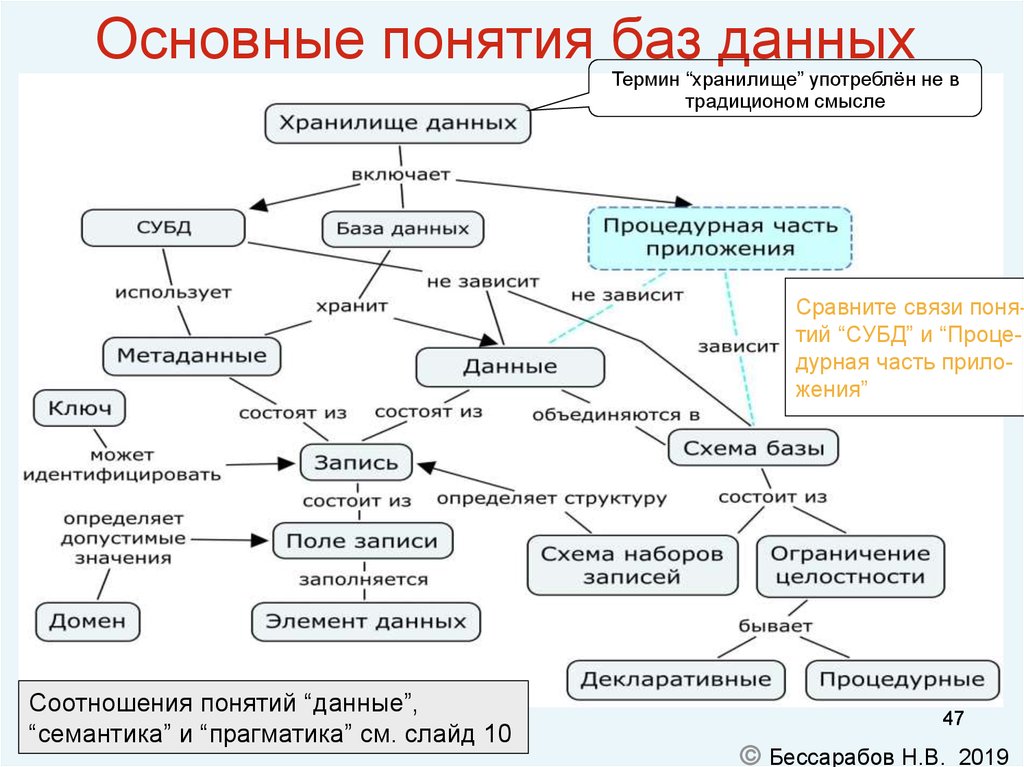
ПРИМЕЧАНИЕ.
Место хранения этой документации во многом зависит от корпоративных стандартов и/или удобства для разработчиков и конечных пользователей. Его можно хранить в самой базе данных, используя расширенные свойства. В качестве альтернативы он может поддерживаться в инструментах моделирования данных. Это может быть даже отдельное хранилище данных, такое как Excel или другая реляционная база данных. Моя компания поддерживает базу данных репозитория метаданных, которую мы разработали для представления этих данных конечным пользователям в удобном для поиска и связываемом формате. Формат и удобство использования важны, но основная задача — обеспечить доступность и актуальность информации.
Ваша цель должна состоять в том, чтобы предоставить достаточно информации, чтобы, когда вы передаете базу данных программисту службы поддержки, он мог выяснить ваши мелкие ошибки и исправить их (да, мы все делаем ошибки в нашем коде!). Я знаю, что есть старая шутка о том, что плохо документированный код — это синоним «гарантии занятости».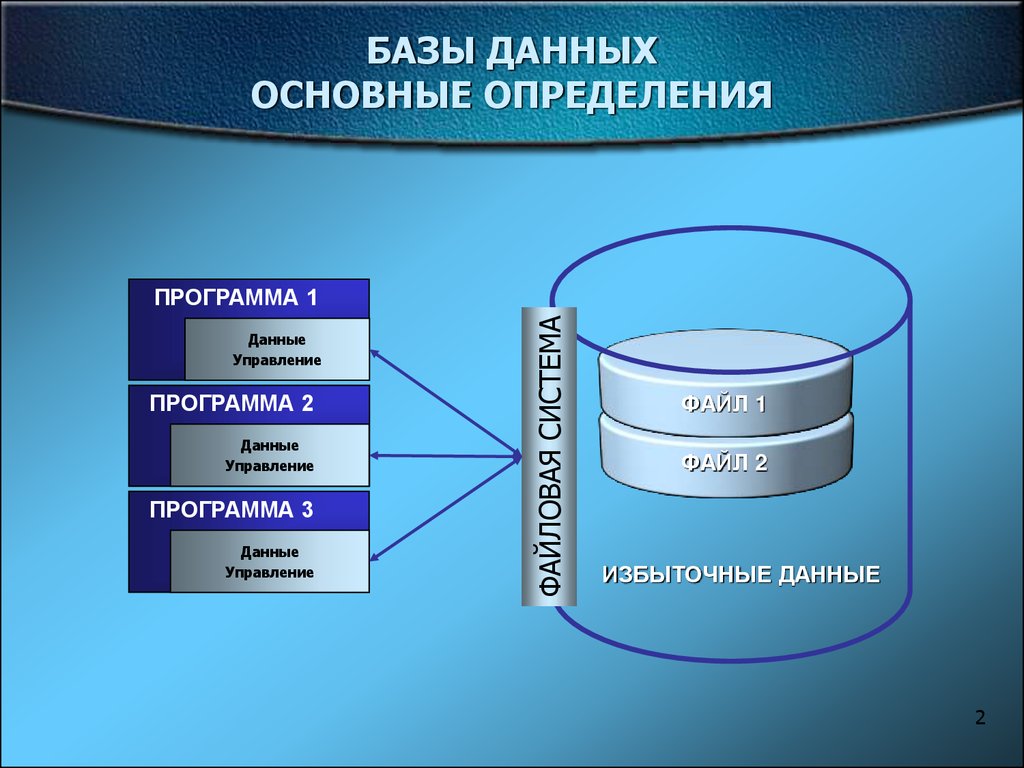 Хотя в этом есть доля правды, это также способ вызвать ненависть коллег и никогда не получить повышения. И ни один хороший программист, которого я знаю, не хочет вернуться и переработать свой собственный код годы спустя. Лучше всего, если ошибки в коде сможет исправить младший программист службы поддержки, пока вы создаете следующую новую вещь. Гарантия занятости наряду с повышением зарплаты достигается за счет того, что человек готов к новым вызовам.
Хотя в этом есть доля правды, это также способ вызвать ненависть коллег и никогда не получить повышения. И ни один хороший программист, которого я знаю, не хочет вернуться и переработать свой собственный код годы спустя. Лучше всего, если ошибки в коде сможет исправить младший программист службы поддержки, пока вы создаете следующую новую вещь. Гарантия занятости наряду с повышением зарплаты достигается за счет того, что человек готов к новым вызовам.
Одна таблица для хранения всех значений домена
» Одно Кольцо, чтобы управлять ими всеми и связывать их во тьме »
Это все хорошо для фэнтезийных знаний, но не так хорошо применительно к дизайну базы данных, в виде «правящей» доменной таблицы. Реляционные базы данных основаны на фундаментальной идее, что каждый объект представляет одну и только одну вещь. Никогда не должно быть никаких сомнений относительно того, к чему относится часть данных. Прослеживая отношения, от имени столбца к имени таблицы и первичному ключу, должно быть легко изучить отношения и точно знать, что означает часть данных.
Большой миф, поддерживаемый архитекторами, которые на самом деле не разбираются в архитектуре реляционных баз данных (включая меня в начале своей карьеры), заключается в том, что чем больше таблиц, тем сложнее будет проект. Так что, наоборот, не должно ли сжатие нескольких таблиц в одну всеобъемлющую таблицу упростить дизайн? Это звучит как хорошая идея, но когда-то дать Поли Шору главную роль в фильме тоже звучало как хорошая идея.
Например, рассмотрим следующий фрагмент модели, где мне нужны значения домена для:
- Состояние кредита клиента
- Тип клиента
- Статус счета
- Статус заказа строки счета-фактуры
- Отправка позиции счета-фактуры перевозчиком
На первый взгляд, это будет пять таблиц доменов… но почему бы просто не использовать одну общую таблицу доменов, вот так?
Это может показаться очень чистым и естественным способом создания таблицы для всех, но проблема в том, что работать с ней в SQL не очень естественно.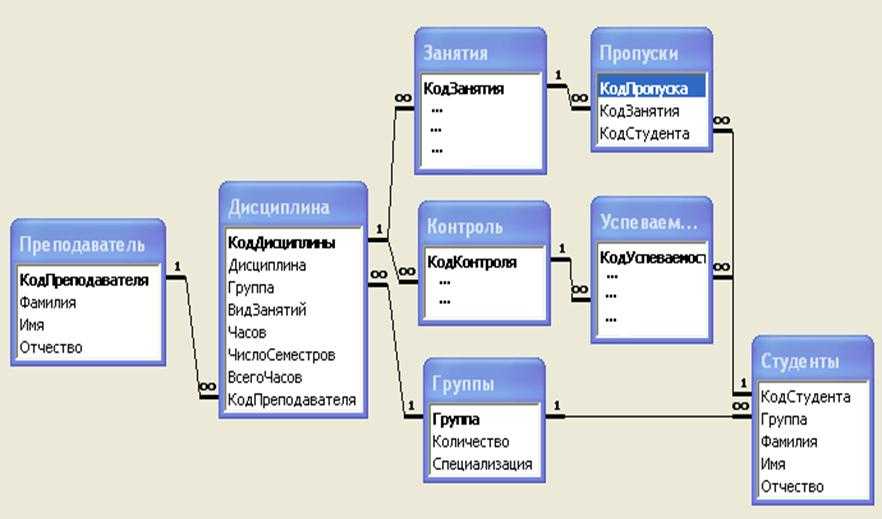 Скажем, нам просто нужны значения домена для Клиент Таблица:
Скажем, нам просто нужны значения домена для Клиент Таблица:
SELECT *
Из клиента
Присоединяйтесь к GenericDomain As CustomerType
на Customer.customertypeid = customertype.genericDomainid
и CustomerType.ReLetateTable = ‘Customer’
и CustomerType. ON Customer.CreditStatusId = CreditStatus.GenericDomainId
и CreditStatus.RelatedToTable = ‘Customer’
and CreditStatus.RelatedToColumn = ‘ CreditStatusId’
Как видите, это далеко не естественное соединение. Это сводится к проблеме смешивания яблок с апельсинами. На первый взгляд доменные таблицы — это просто абстрактное понятие контейнера, содержащего текст. И с точки зрения реализации это вполне верно, но это неправильный способ построения базы данных. В базе данных процесс нормализации как средство разделения и изоляции данных приводит каждую таблицу к точке, где одна строка представляет одну вещь. И каждый домен значений явно отличается от всех других доменов (если только это не так, и в этом случае будет достаточно одной таблицы). Так что вы, по сути, нормализуете данные о каждом использовании, распределяя работу по времени, а не выполняя задачу один раз и заканчивая ею.
Так что вы, по сути, нормализуете данные о каждом использовании, распределяя работу по времени, а не выполняя задачу один раз и заканчивая ею.
Таким образом, вместо единой таблицы для всех доменов вы можете смоделировать ее как:
Выглядит сложнее, не так ли? Ну это изначально. Честно говоря, мне потребовалось больше времени, чтобы конкретизировать таблицы примеров. Но есть несколько потрясающих преимуществ:
- Использование данных в запросе намного проще:
SELECT *FROM Customer JOIN CustomerType ON Customer.CustomerTypeId = CustomerType.CustomerTypeId JOIN CreditStatus ON Customer.CreditStatusId = CreditStatus.CreditStatusId |
- Данные могут быть проверены с использованием ограничений внешнего ключа очень естественным образом, что невозможно для другого решения, если вы не реализуете диапазоны ключей для каждой таблицы — ужасный беспорядок в обслуживании.
- Если окажется, что вам нужно хранить больше информации о ShipViaCarrier , чем просто код «UPS» и описание «United Parcel Service», то это так же просто, как добавить столбец или два. Вы даже можете расширить таблицу, чтобы она стала полноценным представлением предприятий, которые являются перевозчиками товара. 902:30
- Все меньшие таблицы доменов поместятся на одной странице диска. Это обеспечивает однократное чтение (и, вероятно, одну страницу в кеше). В другом случае у вас может быть таблица домена, распределенная по многим страницам, если только вы не кластеризуете по имени ссылающейся таблицы, что может привести к тому, что использование некластеризованного индекса будет более дорогостоящим, если у вас много значений.
- У вас по-прежнему может быть один редактор для всех строк, так как большинство таблиц домена, скорее всего, будут иметь одинаковую базовую структуру/использование. И хотя вы потеряли бы возможность легко запрашивать все значения домена в одном запросе, зачем вам это нужно? (Запрос на объединение можно легко создать из таблиц, если это необходимо, но это кажется маловероятным. ) 902:30
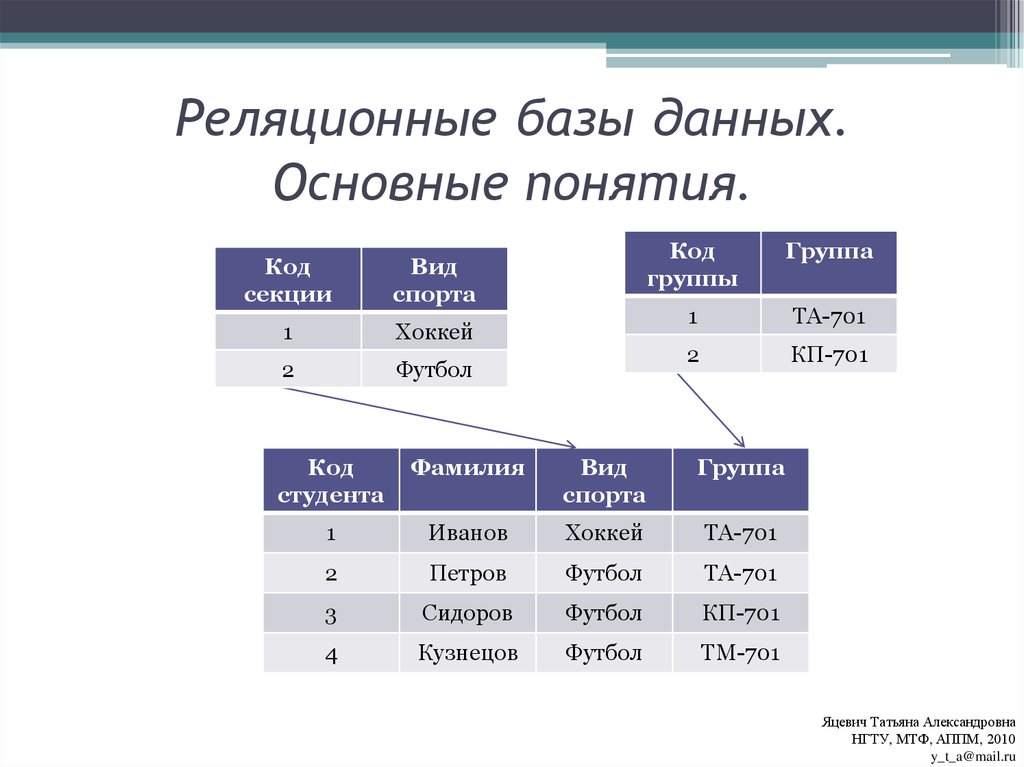
 ) 902:30
) 902:30Наверное, мне следует опровергнуть мысль, которая может прийти вам в голову. «Что, если мне нужно добавить новый столбец во все таблицы домена?» Например, вы забыли, что клиент хочет иметь возможность выполнять пользовательскую сортировку по значениям домена, и ничего не добавили в таблицы, чтобы разрешить это. Это справедливый вопрос, особенно если у вас есть 1000 таких таблиц в очень большой базе данных. Во-первых, такое случается редко, а когда это случается, это в любом случае будет серьезным изменением в вашей базе данных.
Во-вторых, даже если это станет необходимой задачей, в SQL есть полный набор команд, которые можно использовать для добавления столбцов в таблицы, а с помощью системных таблиц довольно просто создать сценарий для добавления того же столбца. на сотни столов одновременно. Это будет не так просто изменить, но не будет намного сложнее перевесить большие преимущества.
Смысл этого совета в том, что лучше выполнить работу заранее, делая конструкции прочными и удобными в обслуживании, чем пытаться выполнить наименьший объем работы для начала проекта.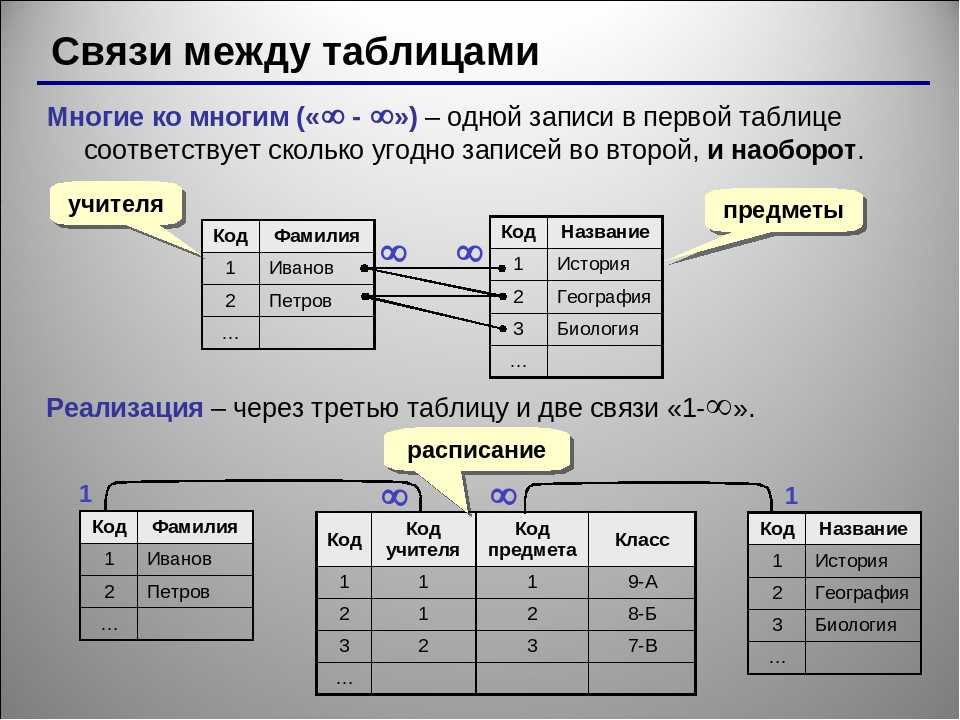 Сокращение количества таблиц до представления одной «вещи» означает, что большинство изменений коснутся только одной таблицы, после чего в будущем у вас будет меньше переделок.
Сокращение количества таблиц до представления одной «вещи» означает, что большинство изменений коснутся только одной таблицы, после чего в будущем у вас будет меньше переделок.
Использование столбцов идентификаторов и идентификаторов в качестве единственного ключа
Первая нормальная форма требует, чтобы все строки в таблице были однозначно идентифицируемыми. Следовательно, каждая таблица должна иметь первичный ключ. SQL Server позволяет определить числовой столбец как столбец IDENTITY , а затем автоматически генерирует уникальное значение для каждой строки. Кроме того, вы можете использовать NEWID() (или NEWSEQUENTIALID() ) для создания случайного 16-байтового уникального значения для каждой строки. Эти типы значений, когда они используются в качестве ключей, известны как суррогатные ключи . Слово суррогатный означает «то, что заменяет», и в этом случае суррогатный ключ должен быть заменой естественного ключа.
Проблема в том, что слишком много дизайнеров используют суррогатный ключевой столбец в качестве ключевого столбца только в данной таблице.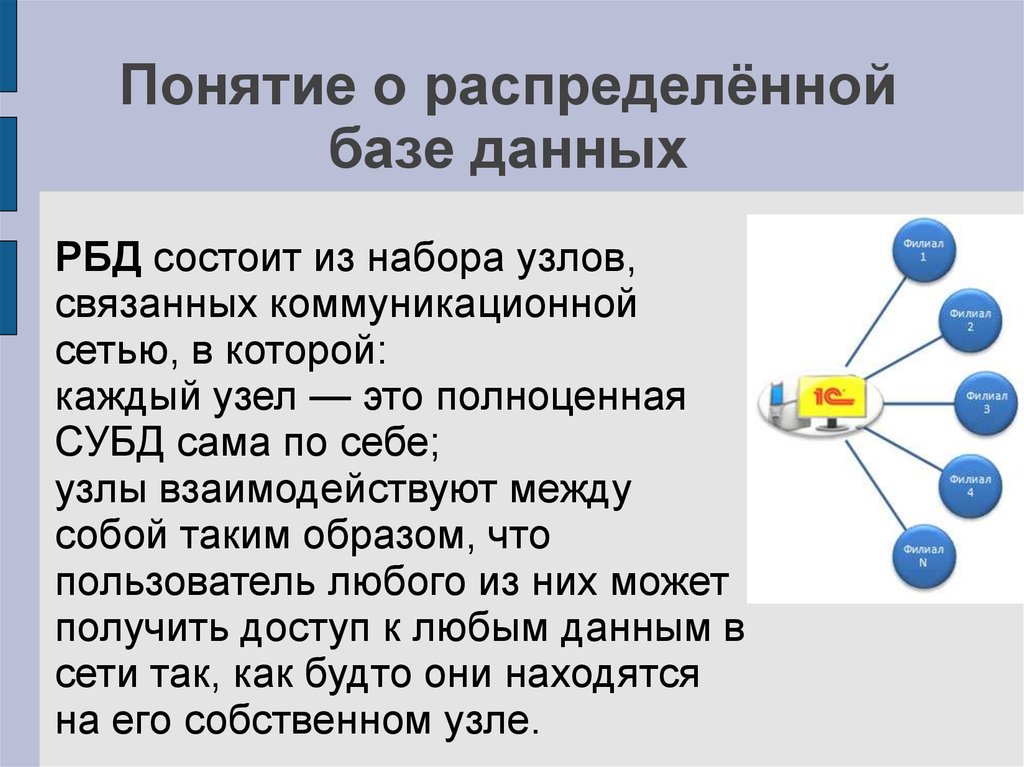 Значения суррогатных ключей не имеют фактического значения в реальном мире; они нужны только для того, чтобы однозначно идентифицировать каждую строку.
Значения суррогатных ключей не имеют фактического значения в реальном мире; они нужны только для того, чтобы однозначно идентифицировать каждую строку.
Теперь рассмотрим следующую таблицу Part , где PartID — это столбец IDENTITY и первичный ключ для таблицы:
PartID | Номер детали | Описание |
1 | ХХХХХХХ | Часть X |
2 | ХХХХХХХ | Часть X |
3 | ГГГГГГГГ | Часть Y |
Сколько строк в этой таблице? Кажется, их три, но строки с PartID s 1 и 2 на самом деле являются одной и той же строкой, дублируются? Или это две разные строки, которые должны быть уникальными, но были введены неправильно?
Эмпирическое правило, которое я использую, простое.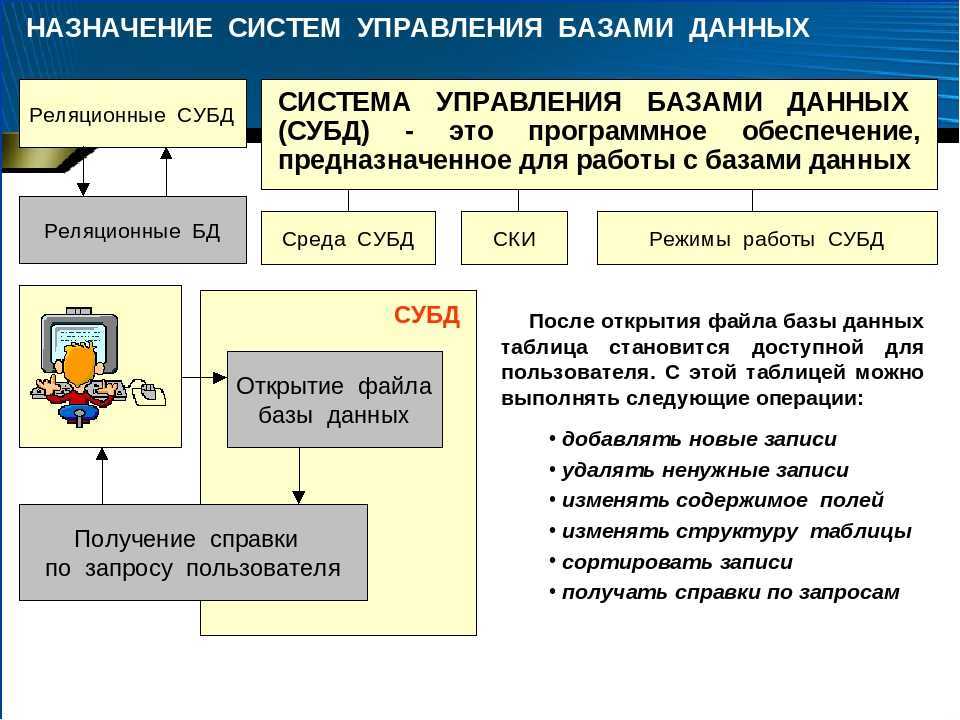 Если человек не может выбрать нужную строку из таблицы, не зная суррогатного ключа, вам нужно пересмотреть свой дизайн. Вот почему на столе должен быть какой-то ключ, чтобы гарантировать уникальность, в данном случае, вероятно, на Номер детали .
Если человек не может выбрать нужную строку из таблицы, не зная суррогатного ключа, вам нужно пересмотреть свой дизайн. Вот почему на столе должен быть какой-то ключ, чтобы гарантировать уникальность, в данном случае, вероятно, на Номер детали .
Подводя итог: как правило, каждая из ваших таблиц должна иметь естественный ключ, который что-то значит для пользователя и может однозначно идентифицировать каждую строку в вашей таблице. В очень редком случае, когда вы не можете найти естественный ключ (например, таблицу с журналом событий), используйте искусственный/суррогатный ключ.
Неиспользование средств SQL для защиты целостности данных
Все фундаментальные, неизменные бизнес-правила должны быть реализованы реляционным механизмом. базовые правила обнуления, длины строки, назначения внешних ключей и т. д. должны быть определены в базе данных .
Существует множество различных способов импорта данных в SQL Server. Если ваши базовые правила определены в самой базе данных, можете ли вы гарантировать, что они никогда не будут обойдены, и вы можете писать свои запросы, не беспокоясь о том, соответствуют ли данные, которые вы просматриваете, базовым бизнес-правилам.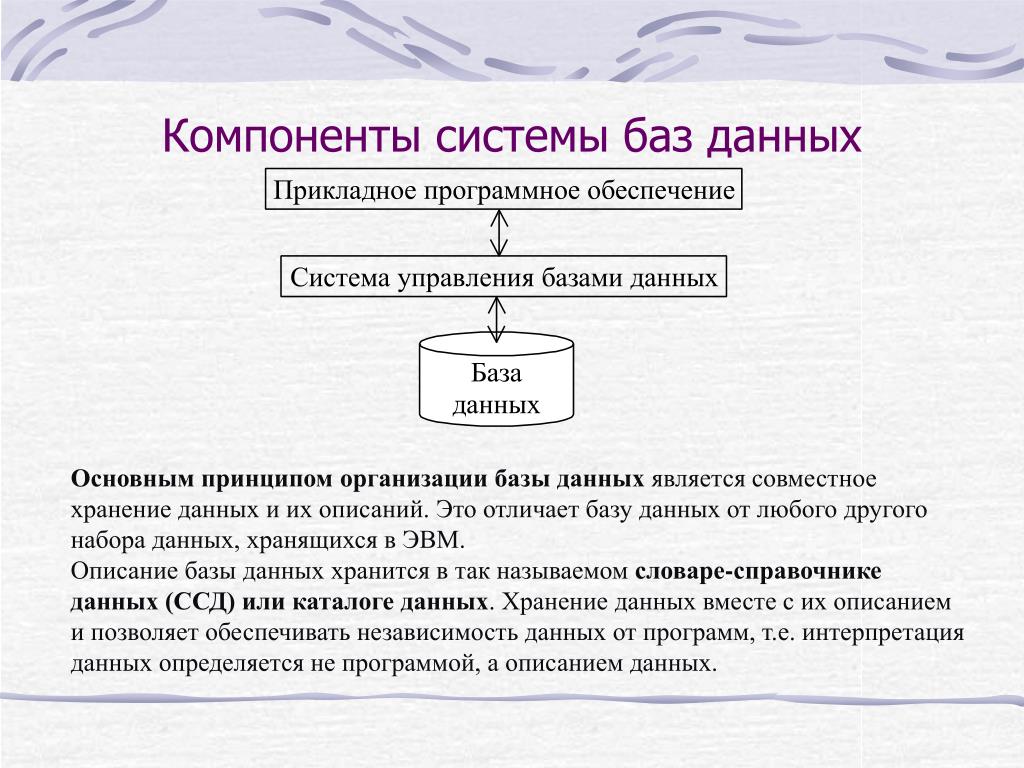
Необязательные правила, с другой стороны, прекрасно подходят для включения в бизнес-уровень приложения. Например, рассмотрим такое правило: «В первой половине месяца ни одна деталь не может продаваться со скидкой более 20% без одобрения менеджера».
В целом это правило попахивает запутанностью, не очень хорошо контролируемым и подверженным частым изменениям. Например, что произойдет, если на следующей неделе максимальная скидка составит 30%? Или когда определение «первая часть месяца» меняется с 15 дней на 20 дней? Скорее всего, вам не захочется преодолевать трудности реализации этих сложных временных бизнес-правил в коде SQL Server — бизнес-уровень — отличное место для реализации таких правил.
Однако рассмотрим правило более внимательно. Есть элементы, которые, вероятно, никогда не изменятся. Например.
- Максимальная скидка, которую можно предложить
- Тот факт, что утверждающий должен быть менеджером
Эти аспекты бизнес-правил в значительной степени должны обеспечиваться базой данных и дизайном. Даже если суть правила реализована на бизнес-уровне, у вас все равно будет таблица в базе данных, в которой записан размер скидки, дата ее предложения, идентификатор лица, утвердившего ее, и так далее. на. На Скидка , у вас должно быть ограничение CHECK , которое ограничивает значения, разрешенные в этом столбце, между 0,00 и 0,90 (или любым другим максимальным значением). Это не только реализует ваше правило «максимальной скидки», но также защитит пользователя от ошибочного ввода 200% или отрицательной скидки. В столбце ManagerID вы должны поместить ограничение внешнего ключа, которое ссылается на таблицу Managers и гарантирует, что введенный идентификатор является идентификатором реального менеджера (или, альтернативно, триггером, который выбирает только EmployeeId с, соответствующий менеджерам).
Даже если суть правила реализована на бизнес-уровне, у вас все равно будет таблица в базе данных, в которой записан размер скидки, дата ее предложения, идентификатор лица, утвердившего ее, и так далее. на. На Скидка , у вас должно быть ограничение CHECK , которое ограничивает значения, разрешенные в этом столбце, между 0,00 и 0,90 (или любым другим максимальным значением). Это не только реализует ваше правило «максимальной скидки», но также защитит пользователя от ошибочного ввода 200% или отрицательной скидки. В столбце ManagerID вы должны поместить ограничение внешнего ключа, которое ссылается на таблицу Managers и гарантирует, что введенный идентификатор является идентификатором реального менеджера (или, альтернативно, триггером, который выбирает только EmployeeId с, соответствующий менеджерам).
Теперь, по крайней мере, мы можем быть уверены, что данные соответствуют самым основным правилам, которым должны следовать данные, поэтому нам никогда не придется кодировать что-то вроде этого, чтобы проверить, что данные хороши:
Мы может чувствовать себя в безопасности, что данные каждый раз соответствуют основным критериям.
Не использовать хранимые процедуры для доступа к данным
Хранимые процедуры — ваш друг. Используйте их, когда это возможно, в качестве метода изоляции уровня базы данных от пользователей данных. Требуют ли они немного больше усилий? Конечно, поначалу, но что хорошего, если не требуется немного больше времени? Хранимые процедуры делают разработку базы данных намного чище и поощряют совместную разработку между вашей базой данных и функциональными программистами. Ниже приведены некоторые другие интересные причины важности хранимых процедур.
Ремонтопригодность
Хранимые процедуры предоставляют известный интерфейс для данных, и для меня это, вероятно, самый большой плюс. Когда код, обращающийся к базе данных, компилируется в другой слой, настройка производительности не может быть выполнена без участия функционального программиста. Хранимые процедуры дают специалисту по базам данных возможность изменять характеристики кода базы данных без привлечения дополнительных ресурсов, упрощая небольшие изменения или крупные обновления (например, изменения синтаксиса SQL).
Инкапсуляция
Хранимые процедуры позволяют «инкапсулировать» любые структурные изменения, которые необходимо внести в базу данных, чтобы свести к минимуму их влияние на пользовательские интерфейсы. Например, предположим, что вы изначально смоделировали один телефонный номер, но теперь хотите иметь неограниченное количество телефонных номеров. Вы можете оставить единственный телефонный номер в вызове процедуры, но сохранить его в другой таблице в качестве временной меры или даже навсегда, если у вас есть какой-то «основной» номер, который вы всегда хотите отображать. Затем можно создать хранимую процедуру для обработки других телефонных номеров. Таким образом, влияние на пользовательские интерфейсы может быть весьма незначительным, а код хранимых процедур может сильно измениться.
Безопасность
Хранимые процедуры могут предоставлять конкретный и детальный доступ к системе. Например, у вас может быть 10 хранимых процедур, которые так или иначе обновляют таблицу X. Если пользователю необходимо иметь возможность обновлять определенный столбец в таблице, и вы хотите, чтобы он никогда не обновлял какие-либо другие, вы можете просто предоставить этому пользователю разрешение на выполнение только одной процедуры из десяти, которая позволяет ему выполнить необходимое обновление.
Производительность
Я считаю, что хранимые процедуры повышают производительность по нескольким причинам. Во-первых, если новичок пишет хреновый код (например, использует курсор, чтобы пройти строку за строкой через всю таблицу из десяти миллионов строк, чтобы найти одно значение, вместо использования предложения WHERE), процедура может быть переписана без воздействия на систему (другие чем отдавать ценные ресурсы.) Вторая причина — повторное использование плана. Если вы не используете динамические вызовы SQL в своей процедуре, SQL Server может хранить план и не должен компилировать его каждый раз, когда он выполняется. Это правда, что в каждой версии SQL Server, начиная с 7. 0, это становится все менее и менее значимым, поскольку SQL Server все лучше хранит планы нерегламентированных вызовов SQL (см. примечание ниже). Однако хранимые процедуры по-прежнему упрощают повторное использование планов и настройку производительности. В случае, когда специальный SQL на самом деле будет быстрее, его можно легко закодировать в хранимой процедуре.
В версии 2005 существует параметр базы данных ( PARAMETERIZATION FORCED ), при включении которого планы всех запросов будут сохраняться. Это не распространяется на более сложные ситуации, которые могли бы охватывать процедуры, но может быть большим подспорьем. Существует также функция, известная как руководства по планам , которые позволяют переопределить план для известного типа запроса. Обе эти функции помогают, когда хранимые процедуры не используются, но хранимые процедуры справляются со своей задачей без ухищрений.
И этот список можно продолжать бесконечно. Есть и недостатки, потому что нет ничего идеального. Кодирование хранимых процедур может занять больше времени, чем просто использование специальных вызовов. Тем не менее, время, затраченное на разработку интерфейса и его реализацию, того стоит, когда все сказано и сделано.
Попытка закодировать общие объекты T-SQL
Я затронул эту тему ранее при обсуждении общих доменных таблиц, но проблема более распространена. Каждый новый программист T-SQL, когда он впервые начинает кодировать хранимые процедуры, начинает думать: «Хотел бы я просто передать имя таблицы в качестве параметра процедуры». Звучит довольно привлекательно: одна универсальная хранимая процедура, которая может выполнять свои операции с любой выбранной вами таблицей. Однако этого следует избегать, так как это может очень негативно сказаться на производительности и на самом деле усложнит жизнь в долгосрочной перспективе.
Объекты T-SQL нелегко сделать «универсальными», в основном потому, что множество соображений дизайна в SQL Server явно сделано для облегчения повторного использования планов, а не кода. SQL Server работает лучше всего, когда вы сводите к минимуму неизвестные, чтобы он мог создать наилучший возможный план. Чем больше он должен обобщать план, тем меньше он может его оптимизировать.
Обратите внимание, что я не говорю конкретно о динамических процедурах SQL. Динамический SQL — отличный инструмент для использования, когда у вас есть процедуры, которые иначе невозможно оптимизировать/управлять. Хорошим примером является процедура поиска с множеством различных вариантов. Предварительно скомпилированное решение с несколькими условиями ИЛИ, возможно, придется применить к плану наихудший сценарий и дать слабые результаты, особенно если параметры используются спорадически.
Однако основной смысл этого совета заключается в том, что вам следует избегать кодирования очень универсальных объектов, таких как те, которые принимают в качестве параметра имя таблицы и двадцать пар имен столбцов/значений и позволяют обновлять значения в таблице. Например, вы можете написать процедуру, которая начинается:
CREATE PROCEDURE updateAnyTable
@tableName системное имя,
@columnName1 системное имя,
@columnName1Value varchar(max)
@columnName2 системное имя,
@columnName2Value varchar(4 …
Идея состоит в том, чтобы динамически указать имя столбца и значение для передачи оператору SQL. Это решение ничем не лучше простого использования специальных вызовов с оператором UPDATE. Вместо этого при построении хранимых процедур вы должны создавать специальные выделенные хранимые процедуры для каждой задачи, выполняемой в таблице (или нескольких таблицах). Это дает вам несколько преимуществ:
- К правильно скомпилированным хранимым процедурам может быть прикреплен один скомпилированный план. и повторно использован. 902:30
- Правильно скомпилированные хранимые процедуры более безопасны, чем специальные процедуры SQL или даже динамические процедуры SQL, что значительно сокращает площадь поверхности для атаки с внедрением, поскольку единственными параметрами для запросов являются аргументы поиска или выходные значения.
- Тестирование и обслуживание скомпилированных хранимых процедур намного проще, так как вам обычно нужно только искать аргументы, а не существование таблиц/столбцов и т. д., и обрабатывать случаи, когда их нет
Хорошим методом является создание инструмента генерации кода на вашем любимом языке программирования (даже T-SQL) с использованием метаданных SQL для создания очень специфических хранимых процедур для каждой таблицы в вашей системе. Сгенерируйте все скучные, простые объекты, включая весь утомительный код для обработки ошибок, который так важен, но мучителен для написания более одного или двух раз.
В моей книге Apress «Проектирование и оптимизация базы данных Pro SQL Server 2005» я привожу несколько таких «шаблонов» (в основном для триггеров, но также и для хранимых процедур), в которые встроена вся обработка ошибок. собственный (возможно, основанный на моем) для использования, когда вам нужно вручную создать триггер/процедуру или что-то еще.
Отсутствие тестирования
Когда циферблат в вашей машине говорит, что ваш двигатель перегревается, что вы вините в первую очередь? Двигатель. Почему бы вам сразу не предположить, что циферблат сломан? Или еще что-то незначительное? Две причины:
- Двигатель является наиболее важным компонентом автомобиля, и обычно в первую очередь обвиняют наиболее важную часть системы.
- Слишком часто это правда.
Как известно профессионалам в области баз данных, когда бизнес-система работает медленно, в первую очередь обвиняют базу данных. Почему? Во-первых, потому что это центральная часть любой бизнес-системы, а во-вторых, потому что это слишком часто верно.
Мы можем сыграть свою роль в развенчании этого представления, приобретя глубокие знания о созданной нами системе и поняв ее ограничения через тестирование .
Но давайте посмотрим правде в глаза; тестирование — это первое, что нужно включить в план проекта, когда время немного уходит. А что больше всего страдает от отсутствия тестирования? Функциональность? Может быть, немного, но пользователи заметят и пожалуются, если кнопка «Сохранить» на самом деле не работает и они не могут сохранить изменения в строке, которую редактировали 10 минут. То, что действительно приносит вал во всем этом процессе, — это глубокое системное тестирование, чтобы убедиться, что дизайн, над которым вы (предположительно) так усердно работали в начале проекта, действительно реализован правильно.
Но, вы говорите, пользователи признали систему работающей, разве этого недостаточно? Проблема с этим утверждением заключается в том, что «тестирование» приемлемости для пользователей обычно сводится к тому, что пользователи ковыряются, пробуют функциональные возможности, которые они понимают, и дают вам одобрение, если их небольшая часть системы работает. Это разумное тестирование? Ни в какой другой отрасли это не было бы приемлемо. Вы хотите, чтобы ваш автомобиль испытывали так? «Ну, один раз мы медленно проехали вокруг квартала, одним солнечным днем без проблем; это хорошо!» Если впоследствии эта машина «подвела» при первом проезде по автостраде или при первом же проезде под дождем или снегом, то водитель имел полное право очень расстроиться.
Слишком много систем баз данных проверяются так же, как эта машина, с небольшой проверкой, чтобы увидеть, работают ли отдельные запросы и модули. Первый настоящий тест проходит в продакшене, когда пользователи пытаются выполнять настоящую работу. Это особенно актуально, когда он реализуется для одного клиента (еще хуже, когда это корпоративный проект, когда руководство настаивает на завершении больше, чем на качестве).
Поначалу основные ошибки появляются быстро и массово, особенно связанные с производительностью. Если вы впервые попробовали полный рабочий набор пользователей, фоновых процессов, рабочих процессов, процедур обслуживания системы, ETL и т. д. в день запуска вашей системы, вы, скорее всего, обнаружите, что не предусмотрели все блокировки. проблемы, которые могут быть вызваны тем, что пользователи создают данные, в то время как другие читают их, или проблемы с оборудованием, вызванные плохой настройкой оборудования. Могут потребоваться недели, чтобы пережить крики «SQL Server не может с этим справиться», даже после того, как вы сделали правильную настройку.
После того, как основные ошибки исправлены, начинают поднимать свои уродливые головы второстепенные случаи (которые встречаются довольно редко, например, когда пользователь вводит отрицательную сумму за отработанные часы). На этом этапе вы в конечном итоге получаете программное обеспечение, которое периодически дает сбой в, казалось бы, странных местах (поскольку большое количество второстепенных ошибок будет проявляться способами, которые не очень очевидны и их действительно трудно найти).
Теперь это гораздо сложнее диагностировать и исправлять, потому что теперь вам приходится иметь дело с тем фактом, что пользователи работают с оперативными данными и пытаются выполнить работу. Кроме того, у вас, вероятно, есть один или два менеджера, сидящих за вашей спиной и говорящих что-то вроде «когда это будет сделано?» каждые 30 секунд, хотя на обнаружение ошибок, приводящих к незначительным (но важным) искажениям данных, могут уйти дни и недели. Если бы было проведено надлежащее тестирование, поиск этих ошибок никогда не занял бы недели тестирования, потому что правильный план тестирования учитывает все возможные типы сбоев, кодирует их в автоматизированный тест и проверяет их снова и снова. Хорошее тестирование не найдет все ошибки, но оно приведет вас к тому, что большинство проблем, связанных с исходным дизайном, будут устранены.
Если бы все настаивали на строгом плане тестирования как на неотъемлемой и неизменной части процесса разработки базы данных, то, возможно, когда-нибудь база данных не будет первой, на что будут обращать внимание при замедлении работы системы.
Проектирование и реализация базы данных являются краеугольным камнем любого проекта, ориентированного на данные (читай, 99,9% бизнес-приложений), и должны рассматриваться как таковые при разработке. Эта статья, хотя, возможно, и немного проповедническая, является таким же напоминанием для меня, как и для всех, кто ее читает. Некоторые из советов, такие как правильное планирование, использование правильной нормализации, использование строгих стандартов именования и документирование вашей работы — это то, за что даже лучшим администраторам баз данных и архитекторам данных приходится бороться, чтобы это произошло. В пылу битвы, когда менеджера вашего менеджера ругают за то, что дела слишком долго не начинаются, нелегко дать отпор и напомнить им, что они платят вам сейчас или платят вам позже. Эти задачи приносят дивиденды, которые очень трудно измерить количественно, потому что для количественного определения успеха вы должны сначала потерпеть неудачу. И даже когда вы преуспеваете в одной области, слишком часто возникают другие мелкие неудачи в других частях проекта, так что некоторые из ваших успехов даже не замечаются.
Приведенные здесь советы — это те, которые я усвоил за годы, которые превратили меня из посредственного человека в хорошего архитектора данных/программиста баз данных. Ни один из них не требует экстраординарного количества времени (за исключением, возможно, проектирования и планирования), но все они требуют больше времени заранее, чем «простой способ». Посмотрим правде в глаза, если бы легкий путь был таким же простым в долгосрочной перспективе, я, например, отказался бы от более сложного пути за секунду. Только когда вы увидите конечный результат, вы поймете, что успех зависит как от правильного начала, так и от правильного завершения.
Плюсы и минусы 8 популярных баз данных
Коди Арсено
Опубликовано 20 апреля 2017 г.
Базы данных хранят информацию, и их содержимое может быть чем угодно: от каталогов продуктов до хранилищ информации о клиентах. Чтобы информация была легко доступной, удобной для использования и понимания, необходимы системы управления базами данных. Системы управления базами данных могут помочь сортировать информацию, а также связывать базы данных друг с другом и предоставлять отчеты об изменениях и тенденциях в информации в базах данных.
В этом посте мы рассмотрим некоторые из самых популярных используемых в настоящее время баз данных и обозначим преимущества и недостатки каждой из них.
Что искать в базе данных?
Хотя все системы управления базами данных выполняют одну и ту же основную задачу, которая заключается в предоставлении пользователям возможности создавать, редактировать и получать доступ к информации в базах данных , то, как они выполняют эту задачу, может различаться. Кроме того, функции, функции и поддержка, связанные с каждой системой управления, могут значительно различаться.
При сравнении различных популярных баз данных вы должны учитывать, насколько удобна и масштабируема каждая СУБД, а также насколько хорошо она будет интегрироваться с другими продуктами, которые вы используете. Кроме того, вы можете принять во внимание стоимость системы управления и доступной для нее поддержки.
Механизмы управления базами данных также должны иметь возможность расти вместе с вашей организацией . Малым предприятиям могут потребоваться только ограниченные функции или небольшие объемы данных для управления, но со временем требования могут существенно возрасти, и переход на другую систему управления базами данных может стать проблемой.
Доступен ряд популярных систем баз данных — как платных, так и бесплатных. Чтобы помочь вам решить, какая система управления может подойти вам или вашей организации, ознакомьтесь с приведенным ниже списком из 8 популярных баз данных.
Список из 8 популярных баз данных
1. Oracle 12c
Неудивительно, что Oracle неизменно возглавляет списки популярных баз данных. Первая версия этого инструмента управления базами данных была создана в конце 70-х годов, и существует несколько версий этого инструмента, доступных для удовлетворения потребностей вашей организации.
Новейшая версия Oracle 12c предназначена для работы в облаке и может размещаться на одном или нескольких серверах. Она позволяет управлять базами данных, содержащими миллиарды записей. Некоторые функции последней версии Oracle включают структуру сетки и использование как физических, так и логических структур.
Это означает, что управление физическими данными не влияет на доступ к логическим структурам. Кроме того, безопасность в этом выпуске превосходна, поскольку каждая транзакция изолирована от других.
Профессионалы
- Вы найдете последние инновации и функции, появившиеся в их продуктах, поскольку Oracle стремится установить планку для других инструментов управления базами данных.
- Инструменты управления базами данных Oracle также невероятно надежны, и вы можете найти такой, который может делать практически все, о чем вы только можете подумать.
Минусы
- Стоимость Oracle может быть непомерно высокой, особенно для небольших организаций.
- После установки системе могут потребоваться значительные ресурсы, поэтому может потребоваться обновление оборудования даже для внедрения Oracle.
Идеально подходит для: Крупных организаций, работающих с огромными базами данных и нуждающихся в различных функциях.
2. MySQL
MySQL — одна из самых популярных баз данных для веб-приложений. Это бесплатное программное обеспечение, но оно часто обновляется функциями и улучшениями безопасности. Существует также множество платных изданий, предназначенных для коммерческого использования. В бесплатной версии больше внимания уделяется скорости и надежности, а не широкому набору функций, которые могут быть хорошими или плохими в зависимости от того, что вы пытаетесь сделать.
Этот механизм базы данных позволяет вам выбирать из множества механизмов хранения, которые позволяют изменять функциональность инструмента и обрабатывать данные из разных типов таблиц. Он также имеет простой в использовании интерфейс, а пакетные команды позволяют обрабатывать огромные объемы данных. Система также невероятно надежна и не потребляет ресурсы.
Профи
- Доступен бесплатно.
- Он предлагает множество функций даже для бесплатного ядра базы данных.
- Существует множество пользовательских интерфейсов, которые можно реализовать.
- Можно настроить для работы с другими базами данных, включая DB2 и Oracle.
Минусы
- Вы можете потратить много времени и усилий, чтобы заставить MySQL делать то, что другие системы делают автоматически, например создавать добавочные резервные копии.
- Нет встроенной поддержки XML или OLAP.
- Поддержка доступна для бесплатной версии, но за нее нужно будет заплатить.
Идеально подходит для: организаций, которым требуется надежное средство управления базами данных, но которые ограничены в средствах.
3. Microsoft SQL Server
Как и в случае с другими популярными базами данных, вы можете выбрать одну из нескольких редакций сервера Microsoft SQL. Этот механизм управления базой данных работает как на облачных, так и на локальных серверах, и его можно настроить для одновременной работы на обоих. Вскоре после выпуска Microsoft SQL Server 2016 Microsoft сделала его доступным как для Linux, так и для платформ на базе Windows.
Некоторые из выдающихся функций версии 2016 года включают поддержку временных данных, что позволяет отслеживать изменения, вносимые в данные с течением времени. Последняя версия Microsoft SQL Server также позволяет динамически маскировать данные, что гарантирует, что конфиденциальные данные будут видны только авторизованным пользователям.
Pros
- Это очень быстро и стабильно.
- Движок предлагает возможность настраивать и отслеживать уровни производительности, что позволяет сократить использование ресурсов.
- Вы можете получить доступ к визуализации на мобильных устройствах.
- Очень хорошо работает с другими продуктами Microsoft.
Минусы
- Цены для предприятий могут быть выше того, что многие организации могут себе позволить.
- Даже при настройке производительности Microsoft SQL Server может потреблять ресурсы.
- У многих людей возникают проблемы с использованием служб SQL Server Integration Services для импорта файлов.
Идеально подходит для: Крупных организаций, использующих ряд продуктов Microsoft.
4. PostgreSQL
PostgreSQL — одна из нескольких популярных бесплатных баз данных, часто используемая для веб-баз данных. Это была одна из первых разработанных систем управления базами данных, позволяющая пользователям управлять как структурированными, так и неструктурированными данными. Его также можно использовать на большинстве основных платформ, в том числе на базе Linux, и с помощью этого инструмента достаточно просто импортировать информацию из других типов баз данных.
Этот механизм управления базой данных может размещаться в различных средах, включая виртуальные, физические и облачные среды. Последняя версия, PostgreSQL 9.5 предлагает большие объемы данных и увеличение количества одновременных пользователей. Безопасность также была улучшена благодаря поддержке как DBMS_SESSION, так и расширенных профилей паролей.
Pros
- Этот механизм управления базой данных является масштабируемым и может обрабатывать терабайты данных.
- Поддерживает JSON.
- Существует множество предустановленных функций.
- Доступен ряд интерфейсов.
Минусы
- Документация может быть разрозненной, поэтому вы можете искать в Интернете, пытаясь понять, как что-то сделать.
- Конфигурация может сбивать с толку.
- Скорость может снижаться при больших объемных операциях или запросах на чтение.
Идеально подходит для: организаций с ограниченным бюджетом, которые хотят иметь возможность выбирать свой интерфейс и использовать JSON.
5. MongoDB
Еще одна бесплатная база данных, которая также имеет коммерческую версию. MongoDB предназначена для приложений, использующих как структурированные, так и неструктурированные данные. Механизм базы данных очень универсален и работает, подключая базы данных к приложениям через драйверы базы данных MongoDB. Доступен широкий выбор драйверов, поэтому легко найти драйвер, который будет работать с используемым языком программирования.
Поскольку MongoDB не предназначена для работы с реляционными моделями данных, даже если это возможно, при попытке использовать ее таким образом могут возникнуть проблемы с производительностью. Однако механизм базы данных предназначен для обработки переменных данных, которые не являются реляционными, и часто может хорошо работать там, где другие механизмы баз данных испытывают трудности или терпят неудачу.
MongoDB 3.2 — это последняя версия с новыми подключаемыми механизмами хранения. Документы также теперь можно проверять во время обновлений и вставок, а функции текстового поиска были улучшены. Новая возможность частичного индексирования также может позволить повысить производительность за счет уменьшения размера индексов.
Pros
- Это быстро и просто в использовании.
- Движок поддерживает JSON и другие документы NoSQL.
- Данные любой структуры могут быть сохранены и доступны быстро и легко.
- Схема может быть написана без простоев.
Минусы
- SQL не используется в качестве языка запросов.
- Инструменты для преобразования запросов SQL в MongoDB доступны, но они добавляют дополнительный шаг к использованию механизма.
- Настройка может быть длительным процессом.
- Настройки по умолчанию не безопасны.
6. MariaDB
Эта система управления базами данных бесплатна, и, как и многие другие бесплатные предложения, MariaDB также предлагает платные версии. Для него доступно множество плагинов, и это самая быстрорастущая база данных с открытым исходным кодом.
Механизм базы данных позволяет вам выбирать из множества механизмов хранения и эффективно использовать ресурсы с помощью оптимизатора, повышающего производительность и обработку запросов. Он также хорошо совместим с MySQL и является заменой точного соответствия команд и API, поскольку многие разработчики MySQL участвовали в его разработке.
Плюсы
- Система работает быстро и стабильно.
- Индикаторы выполнения показывают, как выполняется запрос.
- Расширяемая архитектура и подключаемые модули позволяют настраивать инструмент в соответствии с вашими потребностями.
- Шифрование доступно на уровне сети, сервера и приложения.
Минусы
- Движок все еще довольно новый, поэтому нет гарантии, что будут выпущены дальнейшие обновления и версии.
- Как и в случае со многими другими бесплатными механизмами баз данных, вы должны платить за поддержку.
Идеально подходит для: организаций, которые ищут доступную альтернативу MySQL.
7. DB2
Созданная IBM, DB2 представляет собой ядро базы данных с возможностями NoSQL и может читать файлы JSON и XML. Неудивительно, что он предназначен для использования на серверах IBM iSeries, но версия для рабочих станций работает в Windows, Linux и Unix.
Текущая версия DB2 — LUW — 11.1, предлагающая множество улучшений. Одним из них, в частности, было усовершенствование BLU Acceleration, предназначенное для ускорения работы этого ядра базы данных за счет технологии пропуска данных. Пропуск данных предназначен для повышения скорости систем с большим объемом данных, чем может поместиться в памяти. Последняя версия DB2 также предоставляет улучшенные функции аварийного восстановления, совместимость и аналитику.
Pros
- Blu Ускорение позволяет максимально использовать доступные ресурсы для огромных баз данных.
- Он может быть размещен в облаке, на физическом сервере или в обоих одновременно.
- Несколько заданий могут быть запущены одновременно с помощью планировщика заданий.
- Коды ошибок и коды выхода могут определять, какие задания выполняются через планировщик заданий.
Минусы
- Стоимость выходит за рамки бюджета многих частных лиц и небольших организаций.
- Для работы кластеров или нескольких вторичных узлов требуются сторонние инструменты или дополнительное программное обеспечение.
- Базовая поддержка доступна только в течение трех лет; после этого вы должны заплатить за это.
Идеально подходит для: Крупных организаций, которым необходимо максимально эффективно использовать доступные ресурсы и работать с большими базами данных.
8. SAP HANA
Разработанный SAP SE, SAP HANA представляет собой ядро базы данных, ориентированное на столбцы и способное обрабатывать данные SAP и не-SAP. Механизм предназначен для сохранения и извлечения данных из приложений и других источников на нескольких уровнях хранилища. Помимо возможности размещения на физических серверах, его также можно размещать в облаке.
Плюсы
- Поддерживает SQL, OLTP и OLAP.
- Движок снижает требования к ресурсам за счет сжатия.
- Данные хранятся в памяти, что в некоторых случаях значительно сокращает время доступа.
- Доступны отчеты в режиме реального времени и управление запасами.
- Он может взаимодействовать с рядом других приложений.
Минусы
- Стоимость лицензирования для SAP HANA высока даже для тех, кто привык платить за корпоративное программное обеспечение.
- SAP HANA по-прежнему является относительным новичком, а исправления и обновления настолько часты, что раздражают.
Идеально подходит для: организаций, которые извлекают данные из приложений и не имеют очень ограниченного бюджета.
Резюме
Существует несколько популярных баз данных на выбор, что означает, что вы практически гарантированно найдете ту, которая будет соответствовать вашим потребностям. Благодаря тому, что существует ряд отличных бесплатных вариантов, частные лица и небольшие организации по-прежнему смогут найти инструмент управления базами данных, отвечающий их критериям. С другой стороны, если вашей организации требуется более многофункциональное решение, существует множество доступных платных решений для баз данных.