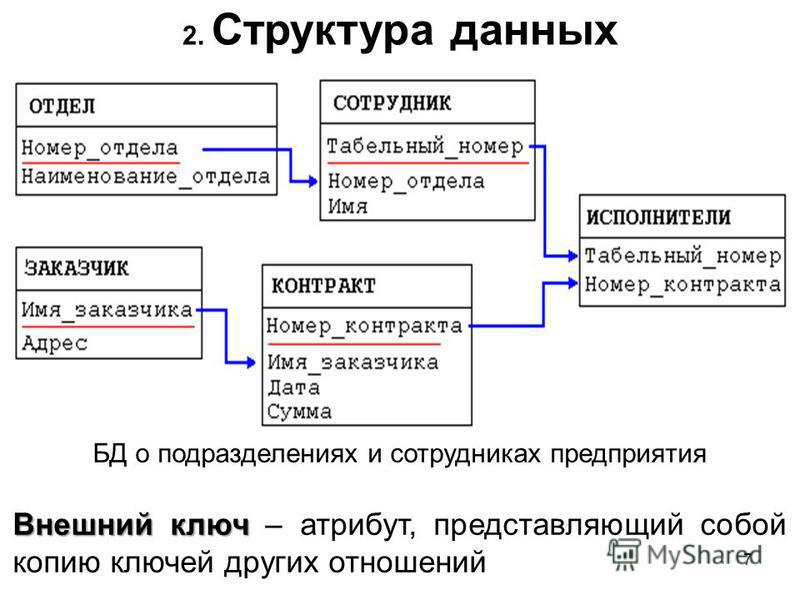
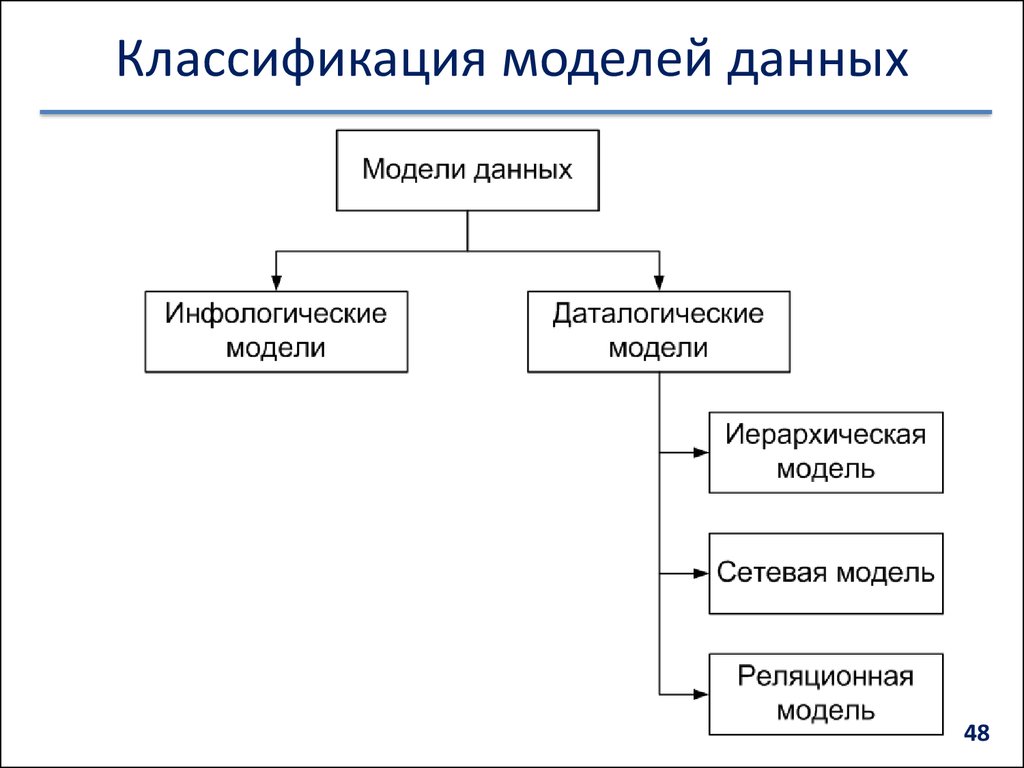
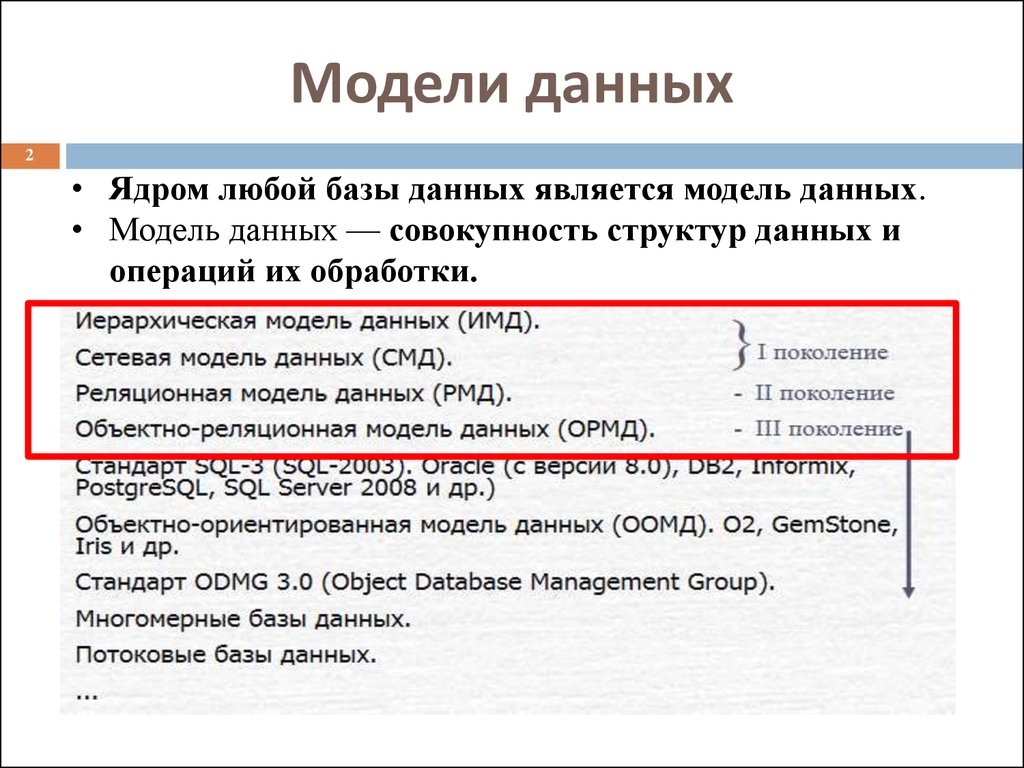
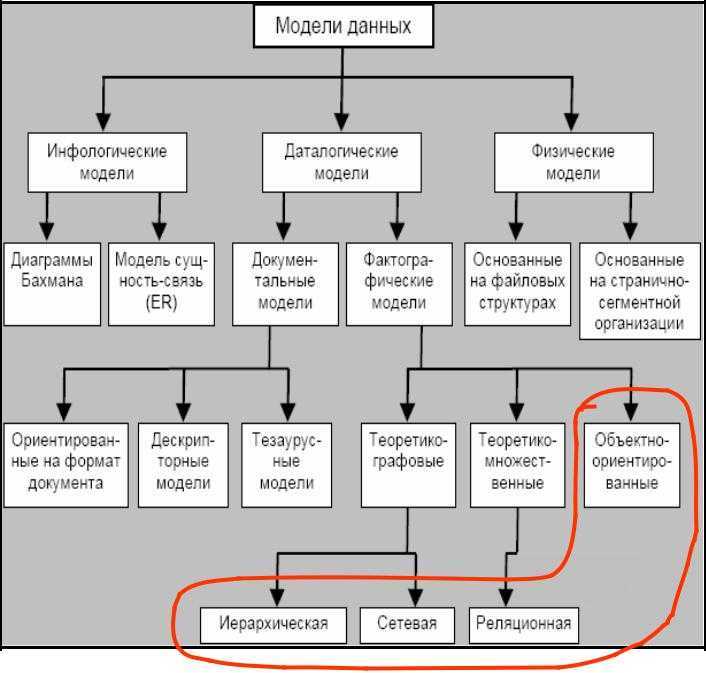
Модели баз данных
- Основные виды баз данных и их модели
- Модели баз данных — иерархическая база данных
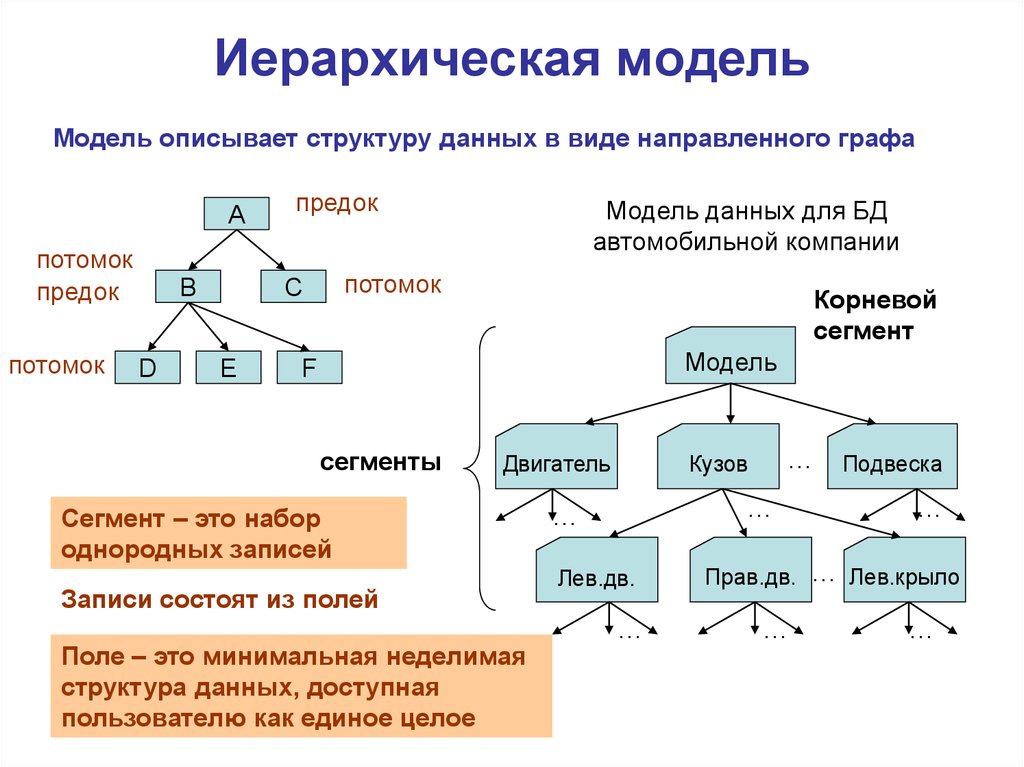
- Иерархическая база данных — пример
- Сетевая модель базы данных
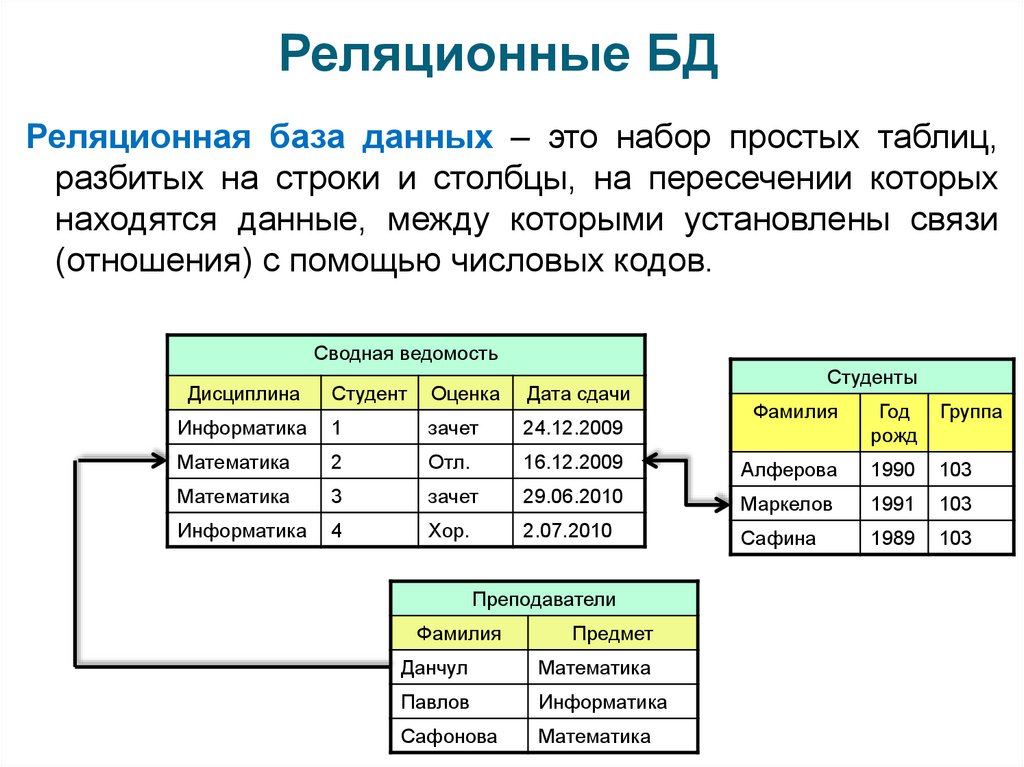
- Реляционная модель базы данных
- Сравниваем три модели баз данных
- «Один к одному»
- «Один ко многим»
- «Многие ко многим»
- Другие модели баз данных (ООСУБД)
СУБД используют различные модели баз данных. Самые старые системы можно разделить на иерархические и сетевые базы данных — это пререляционные модели.
Иерархическая модель базы данных подразумевает, что элементы организованы в структуры, связанные между собой иерархическими или древовидными связями. Родительский элемент может иметь несколько дочерних элементов. Но у дочернего элемента может быть только один предок.
Но у дочернего элемента может быть только один предок.
«Система управления информацией» (Information Management System) компании IMB — пример иерархической СУБД.
Иерархическая модель данных организует их в форме дерева с иерархией родительских и дочерних сегментов. Такая модель подразумевает возможность существования одинаковых (преимущественно дочерних) элементов. Данные здесь хранятся в серии записей с прикреплёнными к ним полями значений. Модель собирает вместе все экземпляры определённой записи в виде «типов записей» — они эквивалентны таблицам в реляционной модели, а отдельные записи — столбцам таблицы. Для создания связей между типами записей иерархическая модель использует отношения типа «родитель-потомок» вида 1:N. Это достигается путём использования древовидной структуры — она «позаимствована» из математики, как и теория множеств, используемая в реляционной модели.
Будем считать, что в рамках данной статьи примером иерархической базы данных является организация, хранящая информацию о своём работнике: имя, номер сотрудника, отдел и зарплату.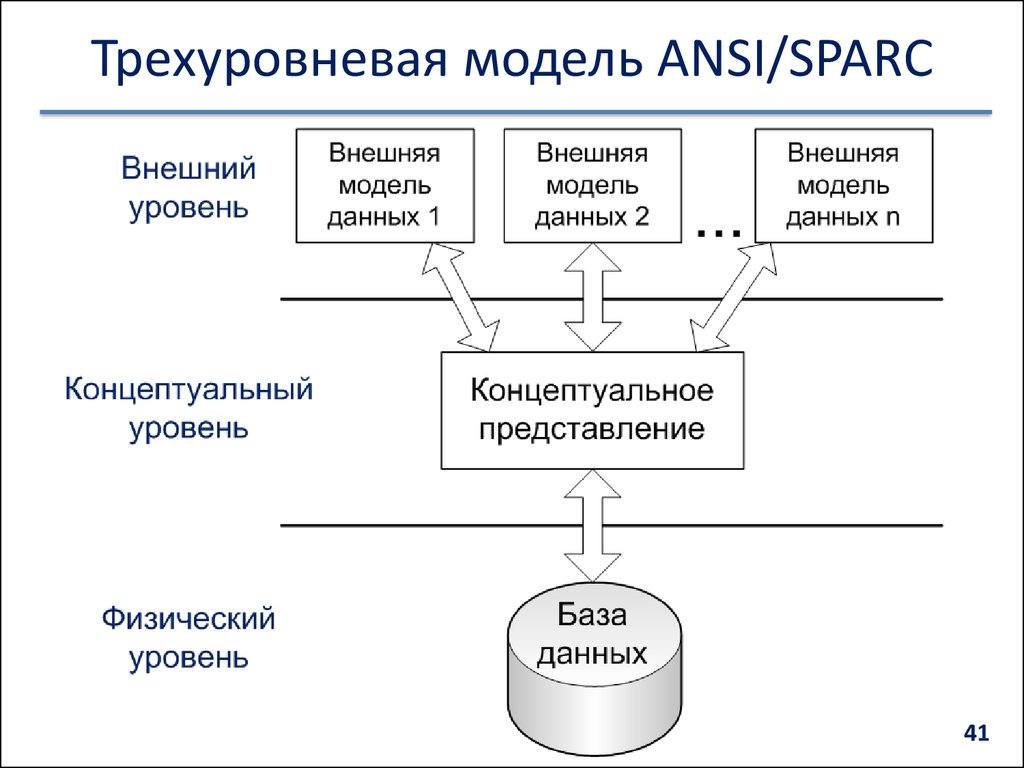 Организация также может хранить информацию о его детях, их имена и даты рождения.
Организация также может хранить информацию о его детях, их имена и даты рождения.
Данные о сотруднике и его детях формируют иерархическую структуру, где информация о сотруднике – это родительский элемент, а информация о детях — дочерний элемент. Если у сотрудника три ребёнка, то с родительским элементом будут связаны три дочерних. Иерархическая база данных подразумевает, что отношение «родитель-потомок» — это отношение «один ко многим». То есть у дочернего элемента не может быть больше одного предка.
Иерархические БД были популярны, начиная с конца 1960-х годов, когда компания IBM представила свою СУБД «Система управления информацией. Иерархическая схема состоит из типов записей и типов «родитель-потомок»:
- Запись — это набор значений полей.
- Записи одного типа группируются в типы записей.
- Отношения «родитель-потомок» — это отношения вида 1:N между двумя типами записей.
- Иерархическая база данных данных состоит из нескольких иерархических схем.

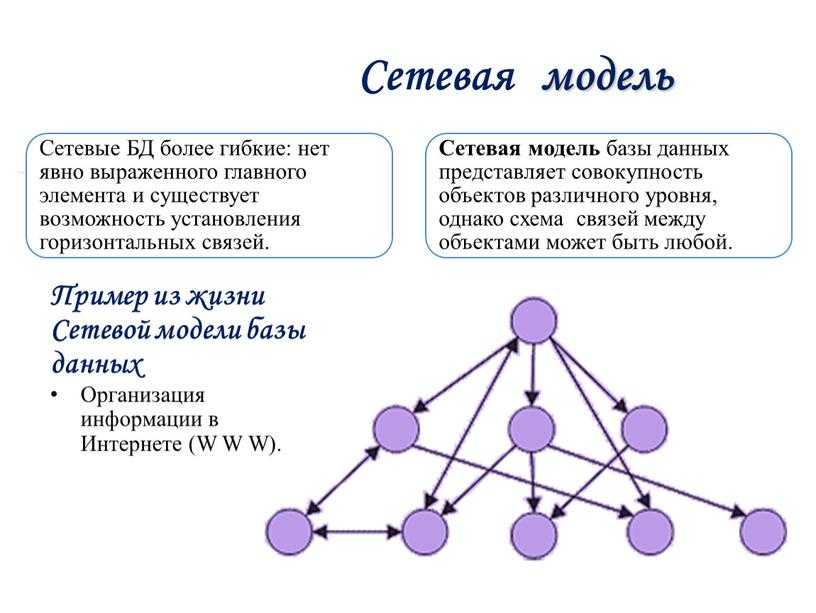
Сетевая модель базы данных подразумевает, что у родительского элемента может быть несколько потомков, а у дочернего элемента — несколько предков. Записи в такой модели связаны списками с указателями. IDMS («Интегрированная система управления данными») от компании Computer Associates international Inc. — пример сетевой СУБД.
Иерархическая модель данных структурирует данные в виде древа записей, где есть один родительский элемент и несколько дочерних. Сетевая модель позволяет иметь несколько предков и потомков, формирующих решётчатую структуру.
Сетевая модель позволяет более естественно моделировать отношения между элементами. И хотя эта модель широко применялась на практике, она так и не стала доминантной по двум основным причинам. Во-первых, компания IBM решила не отказываться от иерархической модели в расширениях для своих продуктов, таких как IMS и DL/I. Во-вторых, через некоторое время её сменила реляционная модель, предлагавшая более высокоуровневый, декларативный интерфейс.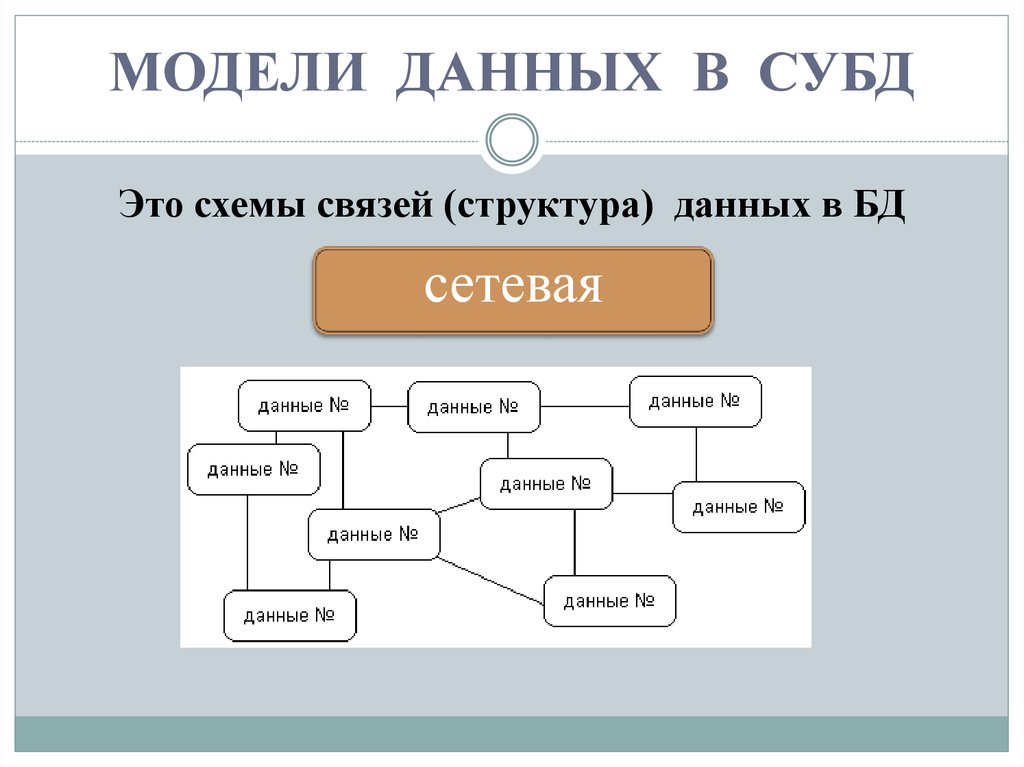
Популярность сетевой модели совпала с популярностью иерархической модели. Некоторые данные намного естественнее моделировать с несколькими предками для одного дочернего элемента. Сетевая модель как раз и позволяла моделировать отношения «многие ко многим». Её стандарты были формально определены в 1971 году на конференции по языкам систем обработки данных (CODASYL).
Основной элемент сетевой модели данных — набор, который состоит из типа «запись-владелец», имени набора и типа «запись-член». Запись подчинённого уровня («запись-член») может выполнять свою роль в нескольких наборах. Соответственно, поддерживается концепция нескольких родительских элементов.
Запись старшего уровня («запись-владелец») также может быть «членом» или «владельцем» в других наборах. Модель данных — это простая сеть, связи, типы пересечения записей (в IDMS они называются junction records, то есть «перекрёстные записи). А также наборы, которые могут их объединять. Таким образом, полная сеть представлена несколькими парными наборами.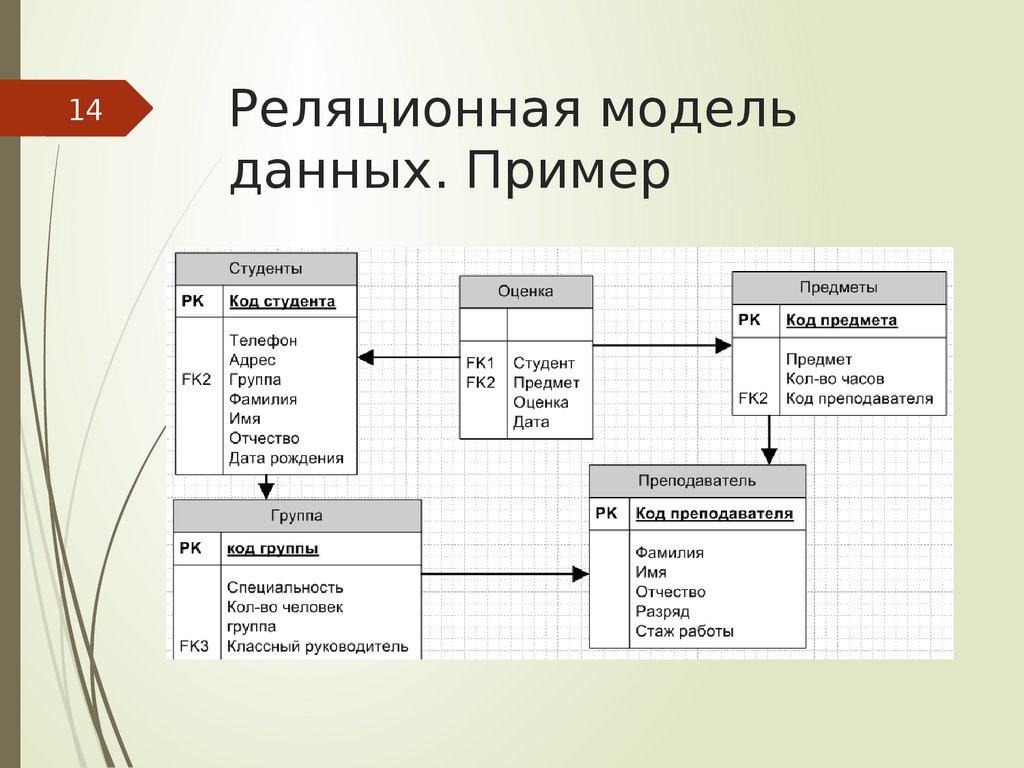
В каждом из них один тип записи является «владельцем» (от него отходит «стрелка» связи), и один или более типов записи являются «членами» (на них указывает «стрелка»). Обычно в наборе существует отношение 1:М, но разрешено и отношение 1:1. Сетевая модель данных CODASYL основана на математической теории множеств.
Известные сетевые базы данных:
- TurboIMAGE;
- IDMS;
- Встроенная RDM;
- Серверная RDM.
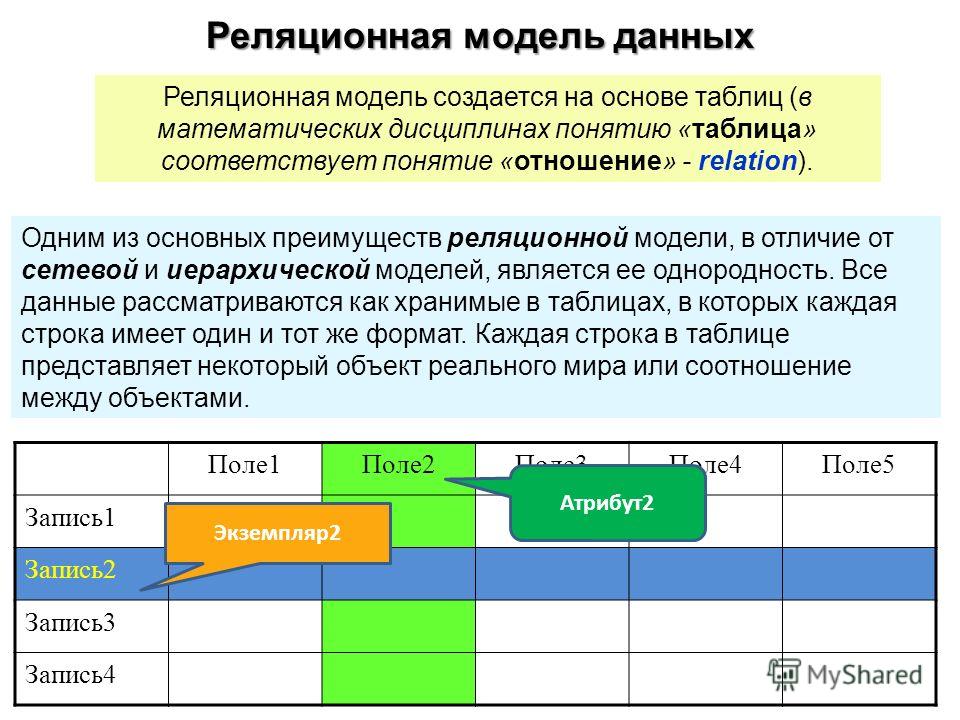
В реляционной модели, в отличие от иерархической или сетевой, не существует физических отношений. Вся информация хранится в виде таблиц (отношений), состоящих из рядов и столбцов. А данные двух таблиц связаны общими столбцами, а не физическими ссылками или указателями. Для манипуляций с рядами данных существуют специальные операторы.
В отличие от двух других типов СУБД, в реляционных моделях данных нет необходимости просматривать все указатели, что облегчает выполнение запросов на выборку информации по сравнению с сетевыми и иерархическими СУБД.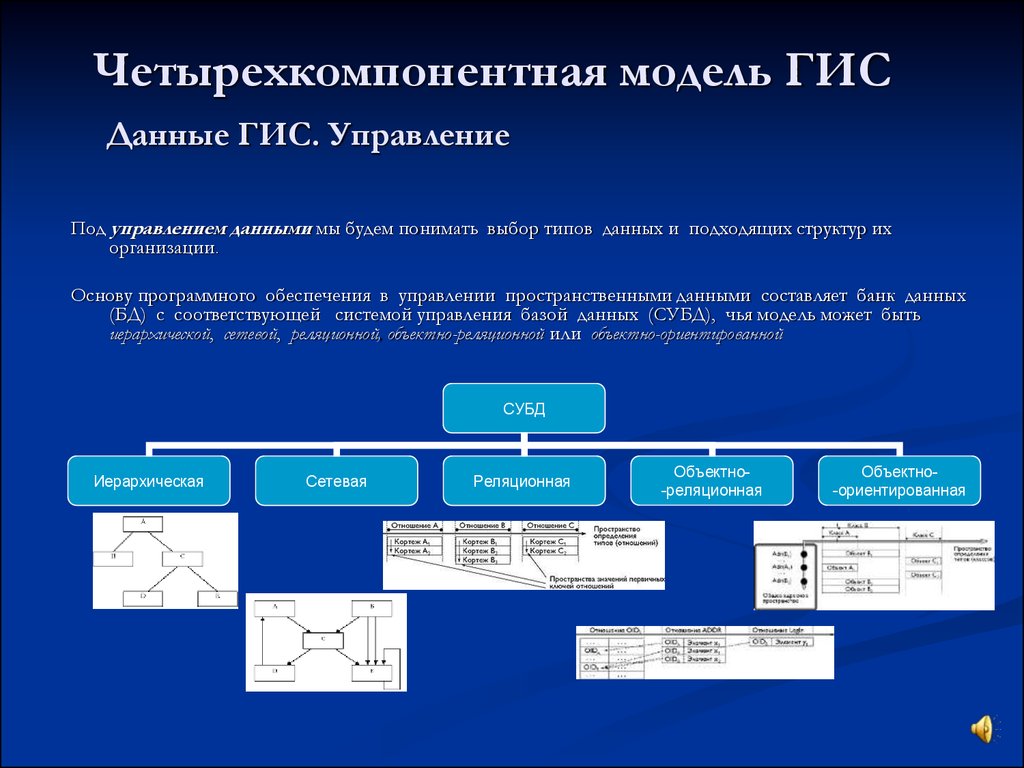 Это одна из основных причин, почему реляционная модель оказалась более удобна. Распространённые реляционные СУБД: Oracle, Sybase, DB2, Ingres, Informix и MS-SQL Server.
Это одна из основных причин, почему реляционная модель оказалась более удобна. Распространённые реляционные СУБД: Oracle, Sybase, DB2, Ingres, Informix и MS-SQL Server.
«В реляционной модели, как объекты, так и их отношения представлены только таблицами, и ничем более».
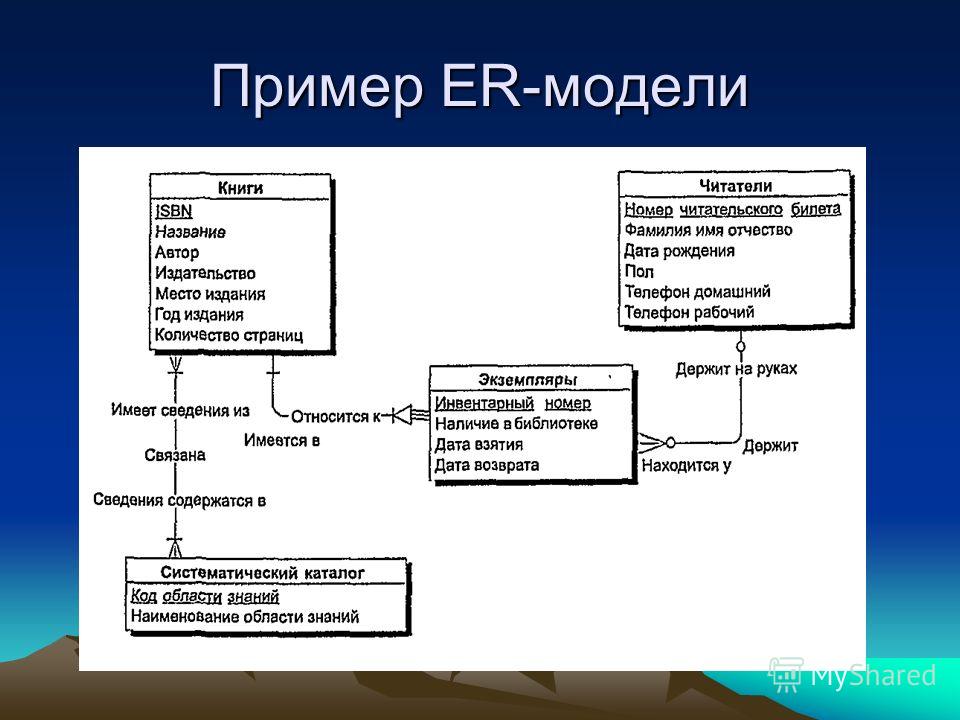
РСУБД — реляционная система управления базами данных, основанная на реляционной модели Э. Ф. Кодда. Она позволяет определять структурные аспекты данных, обработки отношений и их целостности. В такой базе информационное наполнение и отношения внутри него представлены в виде таблиц — наборов записей с общими полями.
Реляционные таблицы обладают следующими свойствами:
- Все значения атомарны.
- Каждый ряд уникален.
- Порядок столбцов не важен.
- Порядок рядов не важен.
- У каждого столбца есть своё уникальное имя.
Некоторые поля могут быть определены как ключевые. Это значит, что для ускорения поиска конкретных значений будет использоваться индексация. Когда поля двух различных таблиц получают данные из одного набора, можно использовать оператор JOIN для выбора связанных записей двух таблиц, сопоставив значения полей.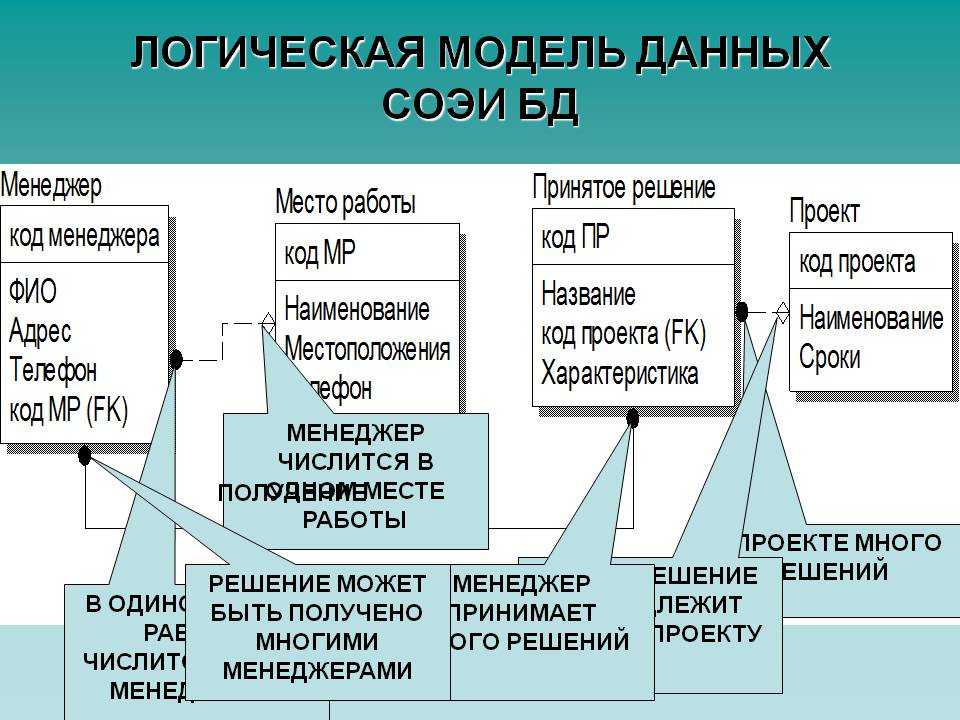
Часто у полей будет одно и то же имя в обеих таблицах. Например, таблица «Заказы» может содержать пары «ID-покупателя» и «код-товара». А в таблице «Товар» могут быть пары «код-товара» и «цена». Поэтому чтобы рассчитать чек для определённого покупателя, необходимо суммировать цену всех купленных им товаров, использовав JOIN в полях «код-товара» этих двух таблиц. Такие действия можно расширить до объединения нескольких полей в нескольких таблицах.
Поскольку отношения здесь определяются только временем поиска, реляционные базы данных классифицируются как динамические системы.
Первая, иерархическая модель данных, имеет древовидную структуру («родитель-потомок»), и поддерживает только отношения типа «один к одному» или «один ко многим». Эта модель позволяет быстро получать данные, но не отличается гибкостью. Иногда роль элемента (родителя или потомка) неясна и не подходит для иерархической модели.
Вторая, сетевая модель данных, имеет более гибкую структуру, чем иерархическая модель данных, и поддерживает отношения «многие ко многим». Но быстро становится слишком сложной и неудобной для управления.
Но быстро становится слишком сложной и неудобной для управления.
Третья модель — реляционная — более гибкая, чем иерархическая и проще для управления, чем сетевая. Реляционная модель сегодня используется чаще всего.
Объект в реляционной модели баз данных определяется как позиция информации, хранимой в базе данных. Объект может быть осязаемым или неосязаемым. Примером осязаемого объекта может быть сотрудник организации, а примером неосязаемой сущности — учётная запись покупателя. Объекты определяются атрибутами — информационным отображением свойств объекта. Эти атрибуты также известны как столбцы, а группа столбцов — как ряд. Ряд также можно определить как экземпляр объекта.
Объекты связываются отношениями, основные типы которых можно определить следующим образом:
В этом виде отношений один объект связан с другим. Например, Менеджер -> Отдел.
У каждого менеджера может быть только один отдел, и наоборот.
В моделях данных отношение одного объекта с несколькими.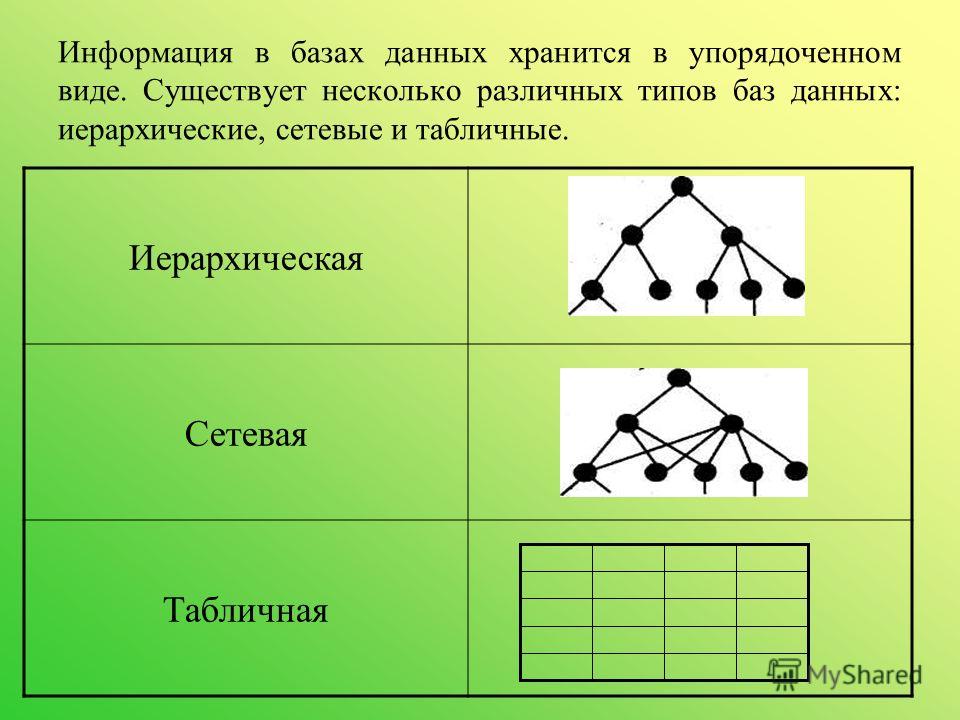 Например, Сотрудник -> Отдел.
Например, Сотрудник -> Отдел.
Каждый сотрудник может быть только в одном отделе, но в самом отделе может быть больше одного сотрудника.
В заданный момент времени объект может быть связан с любым другим. Например, Сотрудник -> Проект.
Сотрудник может участвовать в нескольких проектах, и каждый проект может объединять несколько сотрудников.
В реляционной модели объекты и их отношения представлены двухмерным массивом или таблицей.
Каждая таблица представляет объект.
Каждая таблица состоит из рядов и столбцов.
Отношения между объектами представлены столбцами.
Каждый столбец представляет атрибут объекта.
Значения столбцов выбираются из области или набора всех возможных значений.
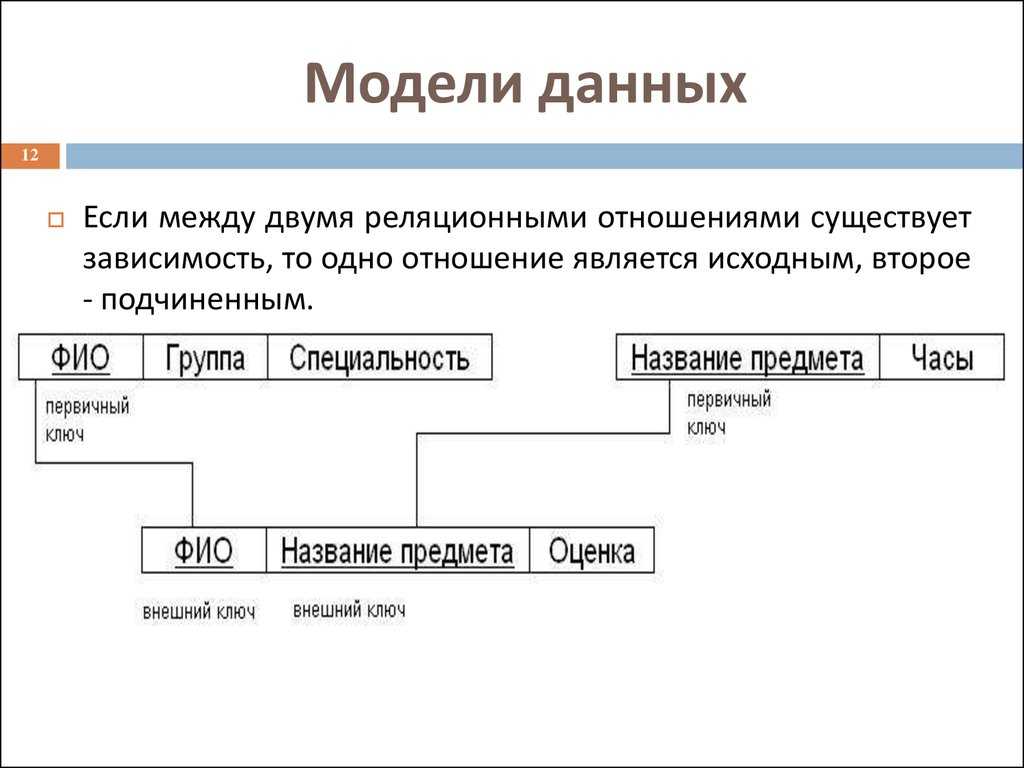
Столбцы, которые используются для связи объектов, называются ключевыми. Есть два типа ключей — первичные и внешние.
Первичные служат для однозначного определения объекта. Внешний ключ — это первичный ключ одного объекта, существующий как атрибут в другой таблице.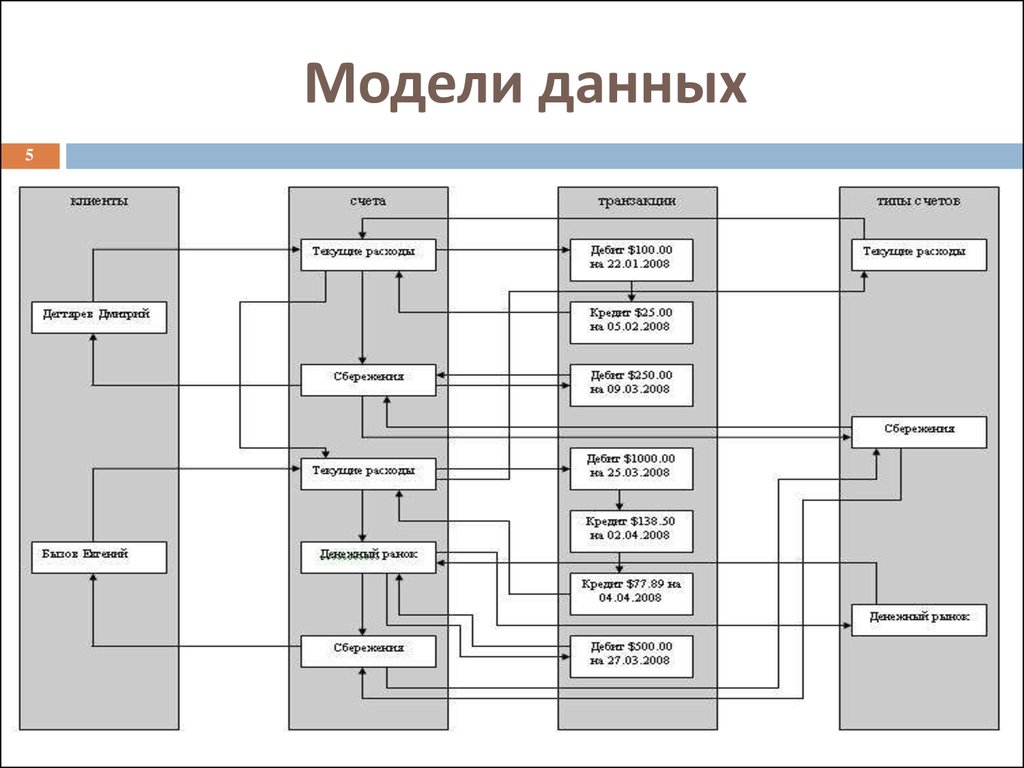
Преимущества реляционной модели данных:
- Простота использования.
- Гибкость.
- Независимость данных.
- Безопасность.
- Простота практического применения.
- Слияние данных.
- Целостность данных.
Недостатки:
- Избыточность данных.
- Низкая производительность.
В последнее время на рынке СУБД появились продукты, представленные объектными и объектно-ориентированной моделью данных, такие как Gem Stone и Versant ОСУБД. Также производятся исследования в области многомерных и логических моделей данных.
Особенности объектно-ориентированных систем управления базами данных (ООСУБД):
- При интеграции возможностей базы данных с объектно-ориентированным языком программирования получается объектно-ориентированная СУБД.
- ООСУБД представляет данные как объекты одного или нескольких языков программирования.
- Такая система должна отвечать двум критериям: являться СУБД и должна быть объектно-ориентированной. То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
- ООСУБД дают возможность моделирования данных в виде объектов.
 То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.А также поддержку классов объектов и наследование свойств и методов классов подклассами и их объектами.
На данный момент не существует общепринятого стандарта ООСУБД. Считается, что подобные модели данных находится на ранней стадии развития.
Примеры ООСУБД:
- D Gemstone;
- IRS;
- ORION;
- ONTOS.
Применение ООСУБД:
- В конструкторских и рассредоточенных базах данных, телекоммуникации, а также в таких научных областях, как физика высоких энергий и молекулярная биология.
- Используются в специализированных областях финансового сектора.
- Во встроенных системах, пакетном программном обеспечении и системах реального времени, чтобы у пользователей была возможность создавать объекты по своему выбору.

Пожалуйста, опубликуйте свои отзывы по текущей теме материала. За комментарии, лайки, дизлайки, подписки, отклики огромное вам спасибо!
МКМихаил Кузнецовавтор-переводчик статьи «Types of Database Models | Database Management System»
Модели баз данных
- Основные виды баз данных и их модели
- Модели баз данных — иерархическая база данных
- Иерархическая база данных — пример
- Сетевая модель базы данных
- Реляционная модель базы данных
- Сравниваем три модели баз данных
- «Один к одному»
- «Один ко многим»
- «Многие ко многим»
- Другие модели баз данных (ООСУБД)
СУБД используют различные модели баз данных. Самые старые системы можно разделить на иерархические и сетевые базы данных — это пререляционные модели.
Самые старые системы можно разделить на иерархические и сетевые базы данных — это пререляционные модели.
Иерархическая модель базы данных подразумевает, что элементы организованы в структуры, связанные между собой иерархическими или древовидными связями. Родительский элемент может иметь несколько дочерних элементов. Но у дочернего элемента может быть только один предок.
«Система управления информацией» (Information Management System) компании IMB — пример иерархической СУБД.
Иерархическая модель данных организует их в форме дерева с иерархией родительских и дочерних сегментов. Такая модель подразумевает возможность существования одинаковых (преимущественно дочерних) элементов. Данные здесь хранятся в серии записей с прикреплёнными к ним полями значений. Модель собирает вместе все экземпляры определённой записи в виде «типов записей» — они эквивалентны таблицам в реляционной модели, а отдельные записи — столбцам таблицы. Для создания связей между типами записей иерархическая модель использует отношения типа «родитель-потомок» вида 1:N. Это достигается путём использования древовидной структуры — она «позаимствована» из математики, как и теория множеств, используемая в реляционной модели.
Это достигается путём использования древовидной структуры — она «позаимствована» из математики, как и теория множеств, используемая в реляционной модели.
Будем считать, что в рамках данной статьи примером иерархической базы данных является организация, хранящая информацию о своём работнике: имя, номер сотрудника, отдел и зарплату. Организация также может хранить информацию о его детях, их имена и даты рождения.
Данные о сотруднике и его детях формируют иерархическую структуру, где информация о сотруднике – это родительский элемент, а информация о детях — дочерний элемент. Если у сотрудника три ребёнка, то с родительским элементом будут связаны три дочерних. Иерархическая база данных подразумевает, что отношение «родитель-потомок» — это отношение «один ко многим». То есть у дочернего элемента не может быть больше одного предка.
Иерархические БД были популярны, начиная с конца 1960-х годов, когда компания IBM представила свою СУБД «Система управления информацией. Иерархическая схема состоит из типов записей и типов «родитель-потомок»:
- Запись — это набор значений полей.
- Записи одного типа группируются в типы записей.
- Отношения «родитель-потомок» — это отношения вида 1:N между двумя типами записей.
- Иерархическая база данных данных состоит из нескольких иерархических схем.
Сетевая модель базы данных подразумевает, что у родительского элемента может быть несколько потомков, а у дочернего элемента — несколько предков. Записи в такой модели связаны списками с указателями. IDMS («Интегрированная система управления данными») от компании Computer Associates international Inc. — пример сетевой СУБД.
Иерархическая модель данных структурирует данные в виде древа записей, где есть один родительский элемент и несколько дочерних. Сетевая модель позволяет иметь несколько предков и потомков, формирующих решётчатую структуру.
Сетевая модель позволяет более естественно моделировать отношения между элементами. И хотя эта модель широко применялась на практике, она так и не стала доминантной по двум основным причинам. Во-первых, компания IBM решила не отказываться от иерархической модели в расширениях для своих продуктов, таких как IMS и DL/I. Во-вторых, через некоторое время её сменила реляционная модель, предлагавшая более высокоуровневый, декларативный интерфейс.
Во-вторых, через некоторое время её сменила реляционная модель, предлагавшая более высокоуровневый, декларативный интерфейс.
Популярность сетевой модели совпала с популярностью иерархической модели. Некоторые данные намного естественнее моделировать с несколькими предками для одного дочернего элемента. Сетевая модель как раз и позволяла моделировать отношения «многие ко многим». Её стандарты были формально определены в 1971 году на конференции по языкам систем обработки данных (CODASYL).
Основной элемент сетевой модели данных — набор, который состоит из типа «запись-владелец», имени набора и типа «запись-член». Запись подчинённого уровня («запись-член») может выполнять свою роль в нескольких наборах. Соответственно, поддерживается концепция нескольких родительских элементов.
Запись старшего уровня («запись-владелец») также может быть «членом» или «владельцем» в других наборах. Модель данных — это простая сеть, связи, типы пересечения записей (в IDMS они называются junction records, то есть «перекрёстные записи). А также наборы, которые могут их объединять. Таким образом, полная сеть представлена несколькими парными наборами.
А также наборы, которые могут их объединять. Таким образом, полная сеть представлена несколькими парными наборами.
В каждом из них один тип записи является «владельцем» (от него отходит «стрелка» связи), и один или более типов записи являются «членами» (на них указывает «стрелка»). Обычно в наборе существует отношение 1:М, но разрешено и отношение 1:1. Сетевая модель данных CODASYL основана на математической теории множеств.
Известные сетевые базы данных:
- TurboIMAGE;
- IDMS;
- Встроенная RDM;
- Серверная RDM.
В реляционной модели, в отличие от иерархической или сетевой, не существует физических отношений. Вся информация хранится в виде таблиц (отношений), состоящих из рядов и столбцов. А данные двух таблиц связаны общими столбцами, а не физическими ссылками или указателями. Для манипуляций с рядами данных существуют специальные операторы.
В отличие от двух других типов СУБД, в реляционных моделях данных нет необходимости просматривать все указатели, что облегчает выполнение запросов на выборку информации по сравнению с сетевыми и иерархическими СУБД.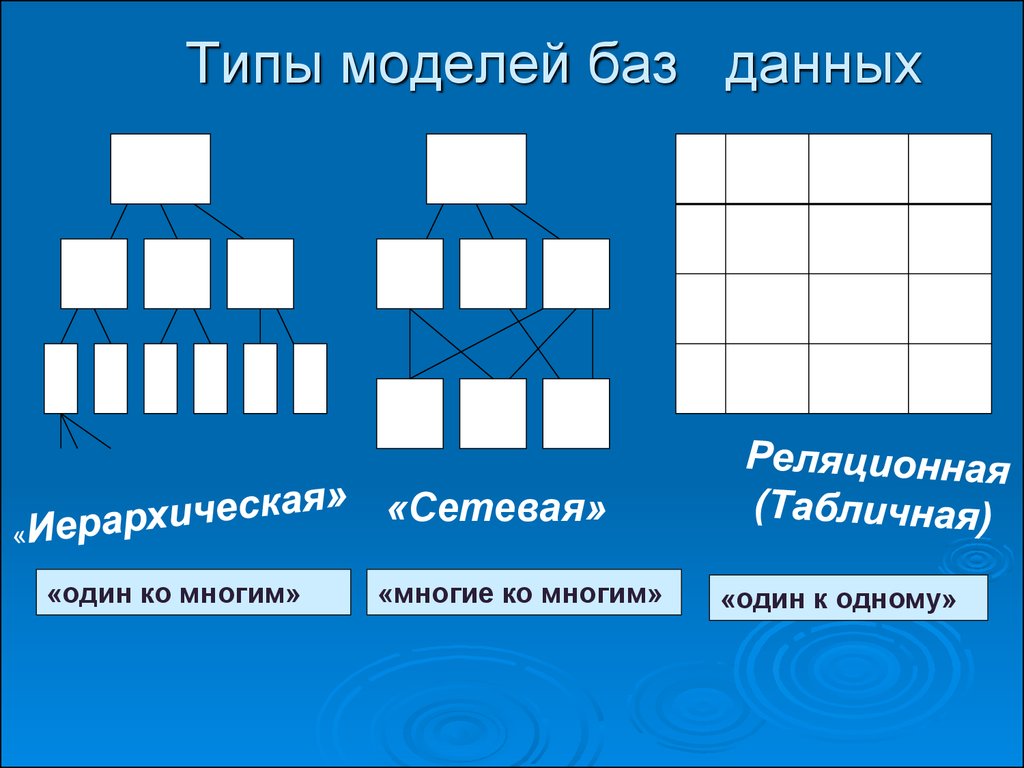 Это одна из основных причин, почему реляционная модель оказалась более удобна. Распространённые реляционные СУБД: Oracle, Sybase, DB2, Ingres, Informix и MS-SQL Server.
Это одна из основных причин, почему реляционная модель оказалась более удобна. Распространённые реляционные СУБД: Oracle, Sybase, DB2, Ingres, Informix и MS-SQL Server.
«В реляционной модели, как объекты, так и их отношения представлены только таблицами, и ничем более».
РСУБД — реляционная система управления базами данных, основанная на реляционной модели Э. Ф. Кодда. Она позволяет определять структурные аспекты данных, обработки отношений и их целостности. В такой базе информационное наполнение и отношения внутри него представлены в виде таблиц — наборов записей с общими полями.
Реляционные таблицы обладают следующими свойствами:
- Все значения атомарны.
- Каждый ряд уникален.
- Порядок столбцов не важен.
- Порядок рядов не важен.
- У каждого столбца есть своё уникальное имя.
Некоторые поля могут быть определены как ключевые. Это значит, что для ускорения поиска конкретных значений будет использоваться индексация. Когда поля двух различных таблиц получают данные из одного набора, можно использовать оператор JOIN для выбора связанных записей двух таблиц, сопоставив значения полей.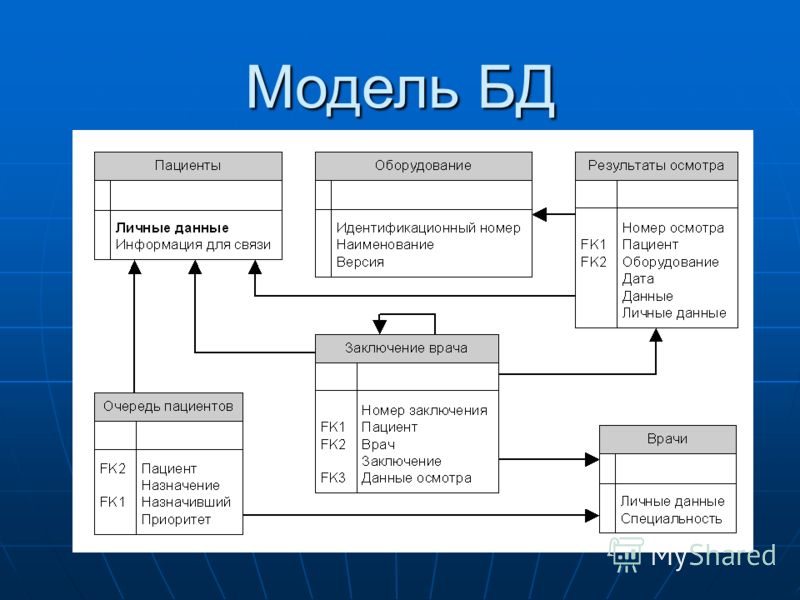
Часто у полей будет одно и то же имя в обеих таблицах. Например, таблица «Заказы» может содержать пары «ID-покупателя» и «код-товара». А в таблице «Товар» могут быть пары «код-товара» и «цена». Поэтому чтобы рассчитать чек для определённого покупателя, необходимо суммировать цену всех купленных им товаров, использовав JOIN в полях «код-товара» этих двух таблиц. Такие действия можно расширить до объединения нескольких полей в нескольких таблицах.
Поскольку отношения здесь определяются только временем поиска, реляционные базы данных классифицируются как динамические системы.
Первая, иерархическая модель данных, имеет древовидную структуру («родитель-потомок»), и поддерживает только отношения типа «один к одному» или «один ко многим». Эта модель позволяет быстро получать данные, но не отличается гибкостью. Иногда роль элемента (родителя или потомка) неясна и не подходит для иерархической модели.
Вторая, сетевая модель данных, имеет более гибкую структуру, чем иерархическая модель данных, и поддерживает отношения «многие ко многим».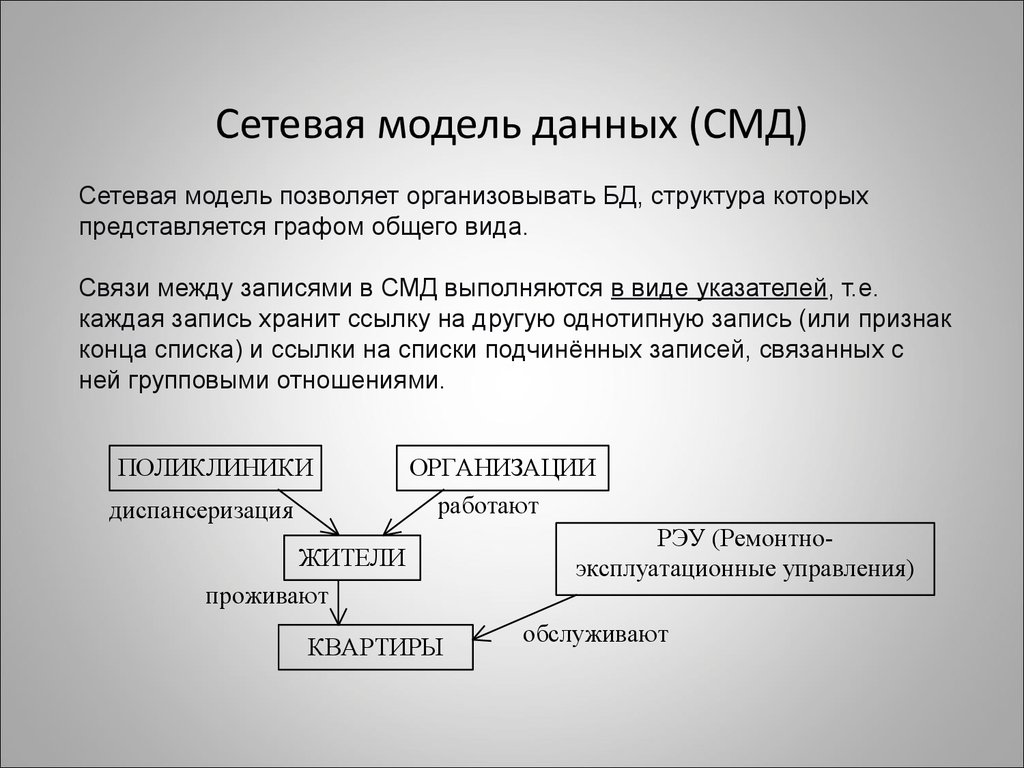 Но быстро становится слишком сложной и неудобной для управления.
Но быстро становится слишком сложной и неудобной для управления.
Третья модель — реляционная — более гибкая, чем иерархическая и проще для управления, чем сетевая. Реляционная модель сегодня используется чаще всего.
Объект в реляционной модели баз данных определяется как позиция информации, хранимой в базе данных. Объект может быть осязаемым или неосязаемым. Примером осязаемого объекта может быть сотрудник организации, а примером неосязаемой сущности — учётная запись покупателя. Объекты определяются атрибутами — информационным отображением свойств объекта. Эти атрибуты также известны как столбцы, а группа столбцов — как ряд. Ряд также можно определить как экземпляр объекта.
Объекты связываются отношениями, основные типы которых можно определить следующим образом:
В этом виде отношений один объект связан с другим. Например, Менеджер -> Отдел.
У каждого менеджера может быть только один отдел, и наоборот.
В моделях данных отношение одного объекта с несколькими.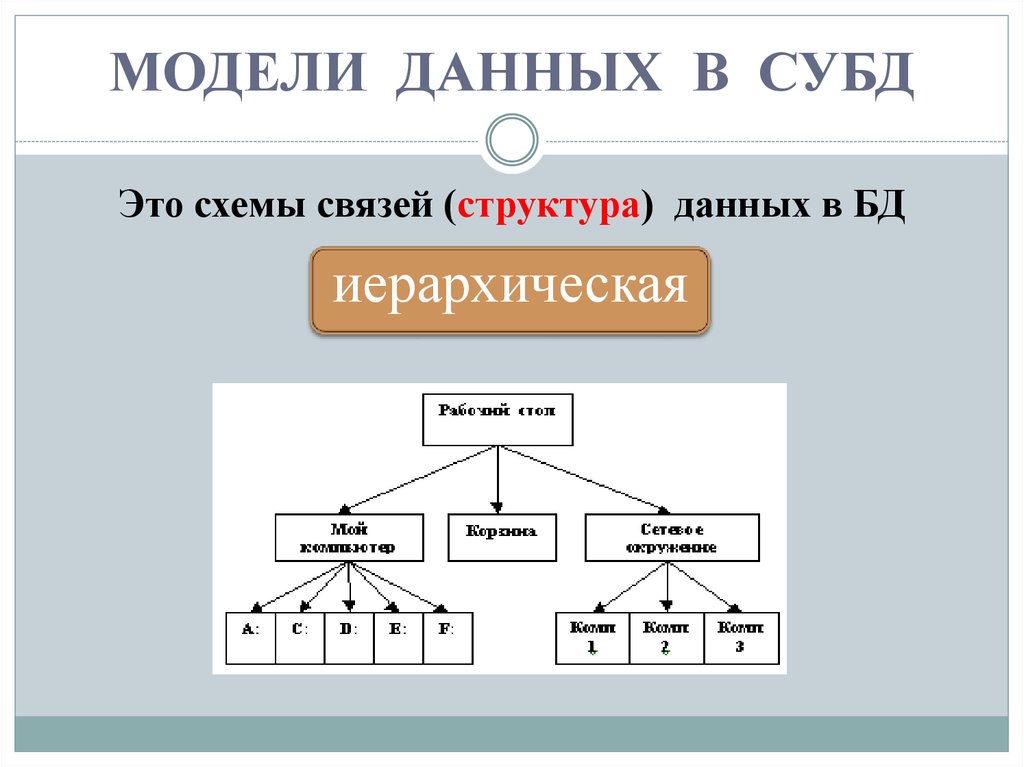 Например, Сотрудник -> Отдел.
Например, Сотрудник -> Отдел.
Каждый сотрудник может быть только в одном отделе, но в самом отделе может быть больше одного сотрудника.
В заданный момент времени объект может быть связан с любым другим. Например, Сотрудник -> Проект.
Сотрудник может участвовать в нескольких проектах, и каждый проект может объединять несколько сотрудников.
В реляционной модели объекты и их отношения представлены двухмерным массивом или таблицей.
Каждая таблица представляет объект.
Каждая таблица состоит из рядов и столбцов.
Отношения между объектами представлены столбцами.
Каждый столбец представляет атрибут объекта.
Значения столбцов выбираются из области или набора всех возможных значений.
Столбцы, которые используются для связи объектов, называются ключевыми. Есть два типа ключей — первичные и внешние.
Первичные служат для однозначного определения объекта. Внешний ключ — это первичный ключ одного объекта, существующий как атрибут в другой таблице.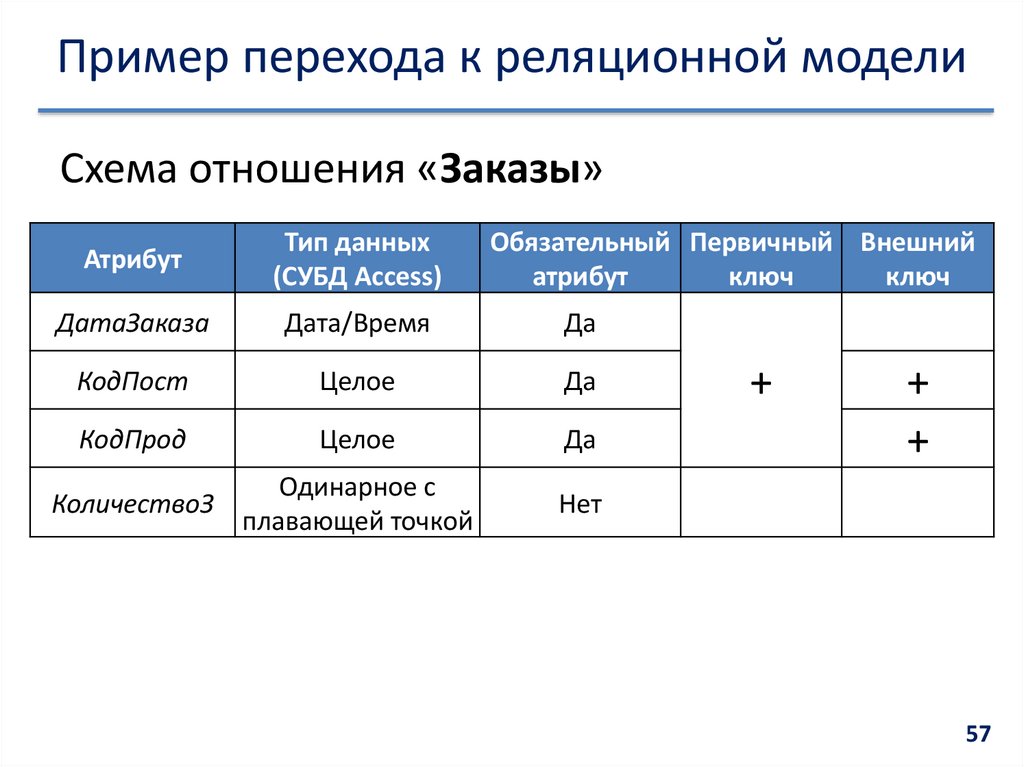
Преимущества реляционной модели данных:
- Простота использования.
- Гибкость.
- Независимость данных.
- Безопасность.
- Простота практического применения.
- Слияние данных.
- Целостность данных.
Недостатки:
- Избыточность данных.
- Низкая производительность.
В последнее время на рынке СУБД появились продукты, представленные объектными и объектно-ориентированной моделью данных, такие как Gem Stone и Versant ОСУБД. Также производятся исследования в области многомерных и логических моделей данных.
Особенности объектно-ориентированных систем управления базами данных (ООСУБД):
- При интеграции возможностей базы данных с объектно-ориентированным языком программирования получается объектно-ориентированная СУБД.
- ООСУБД представляет данные как объекты одного или нескольких языков программирования.
- Такая система должна отвечать двум критериям: являться СУБД и должна быть объектно-ориентированной. То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
- ООСУБД дают возможность моделирования данных в виде объектов.
 То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.А также поддержку классов объектов и наследование свойств и методов классов подклассами и их объектами.
На данный момент не существует общепринятого стандарта ООСУБД. Считается, что подобные модели данных находится на ранней стадии развития.
Примеры ООСУБД:
- D Gemstone;
- IRS;
- ORION;
- ONTOS.
Применение ООСУБД:
- В конструкторских и рассредоточенных базах данных, телекоммуникации, а также в таких научных областях, как физика высоких энергий и молекулярная биология.
- Используются в специализированных областях финансового сектора.
- Во встроенных системах, пакетном программном обеспечении и системах реального времени, чтобы у пользователей была возможность создавать объекты по своему выбору.
Пожалуйста, опубликуйте свои отзывы по текущей теме материала. За комментарии, лайки, дизлайки, подписки, отклики огромное вам спасибо!
МКМихаил Кузнецовавтор-переводчик статьи «Types of Database Models | Database Management System»
Что такое моделирование данных? Обзор, основные понятия и типы в деталях
Данные меняют способ функционирования мира. Это может быть исследование о лечении болезней, стратегии получения доходов компании, эффективном строительстве зданий или целевой рекламе на вашей странице в социальных сетях; это все из-за данных.
Эти данные относятся к информации, которая может быть прочитана машиной, а не человеком. Например, данные о клиентах не имеют смысла для продуктовой команды, если они не указывают на конкретные покупки продукта. Точно так же маркетинговая команда не будет использовать те же данные, если идентификаторы не связаны с конкретными ценовыми категориями во время покупки.
Точно так же маркетинговая команда не будет использовать те же данные, если идентификаторы не связаны с конкретными ценовыми категориями во время покупки.
Здесь на помощь приходит моделирование данных. Это процесс, который назначает реляционные правила данным. Модель данных не усложняет данные, превращая их в полезную информацию, которую организации затем могут использовать для принятия решений и разработки стратегии. Согласно LinkedIn, это самая быстрорастущая профессия на современном рынке труда.
Прежде чем приступить к моделированию данных, давайте подробно разберемся, что такое модель данных.
Что такое модель данных?
Надежные данные позволяют организациям устанавливать базовые уровни, ориентиры и цели, чтобы двигаться вперед. Чтобы данные позволяли это измерение, они должны быть организованы с помощью описания данных, семантики данных и ограничений согласованности данных. Модель данных — это абстрактная модель, которая позволяет в дальнейшем строить концептуальные модели и устанавливать отношения между элементами данных.
Организация может иметь огромное хранилище данных; однако, если нет стандарта, обеспечивающего базовую точность и интерпретируемость этих данных, то это бесполезно. Надлежащая модель данных подтверждает действенные последующие результаты, знание передовых методов работы с данными и лучшие инструменты для доступа к ним.
После понимания того, что такое моделирование данных, давайте обсудим его примеры.
Читайте также: 9 навыков, которые вам понадобятся, чтобы стать специалистом по моделированию данных в 2022 году
Что такое моделирование данных?
Моделирование данных в программной инженерии — это процесс упрощения схемы или модели данных программной системы путем применения определенных формальных методов. Он включает в себя выражение данных и информации через текст и символы. Модель данных обеспечивает основу для создания новой базы данных или реинжиниринга устаревших приложений.
В свете вышеизложенного это первый важный шаг в определении структуры доступных данных. Моделирование данных — это процесс создания моделей данных, с помощью которых ассоциации данных и ограничения описываются и в конечном итоге кодируются для повторного использования. Он концептуально представляет данные с помощью диаграмм, символов или текста для визуализации взаимосвязи.
Моделирование данных — это процесс создания моделей данных, с помощью которых ассоциации данных и ограничения описываются и в конечном итоге кодируются для повторного использования. Он концептуально представляет данные с помощью диаграмм, символов или текста для визуализации взаимосвязи.
помогает повысить согласованность имен, правил, семантики и безопасности. Это, в свою очередь, улучшает анализ данных. Акцент делается на необходимости наличия и организации данных, независимо от способа их применения.
После понимания того, что такое моделирование данных, давайте обсудим его примеры
Примеры моделирования данных
Лучший способ изобразить модель данных — подумать о плане здания архитектора. Архитектурный план здания помогает в построении всех последующих концептуальных моделей, как и модель данных.
Эти примеры моделирования данных пояснят, как модели данных и процесс моделирования данных выделяют важные данные и способы их организации.
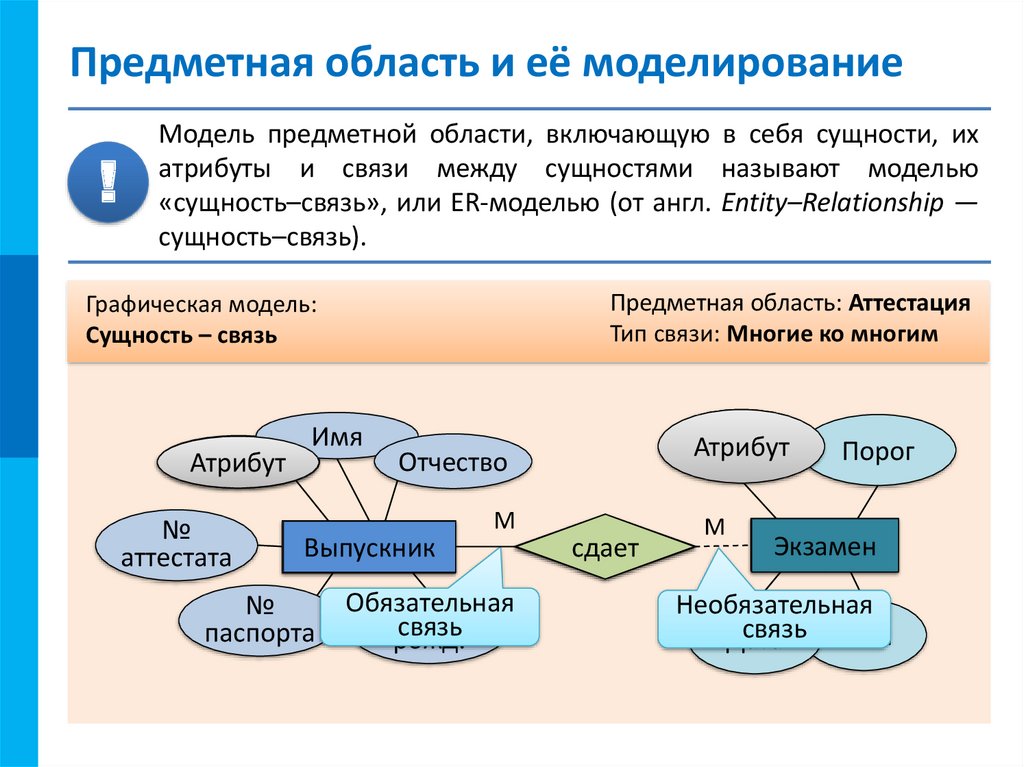
1. ER (сущность-связь), модель
Эта модель основана на представлении о сущностях реального мира и отношениях между ними. Он создает набор сущностей, набор отношений, общие атрибуты и ограничения.
Здесь сущность — это объект реального мира; например, сотрудник является сущностью в базе данных сотрудников. Атрибут — это свойство со значением, и сущность устанавливает общие атрибуты с одинаковым значением. Наконец, существуют отношения между сущностями.
2. Иерархическая модель
Эта модель данных упорядочивает данные в виде дерева с одним корнем, к которому подключены другие данные. Иерархия начинается с корня и расширяется подобно дереву. Эта модель эффективно объясняет несколько отношений в реальном времени с помощью одного отношения «один ко многим» между двумя разными типами данных.
Например, в одном супермаркете могут быть разные отделы и много проходов. Таким образом, у «корневого» узла супермаркета будет два «дочерних» узла: (1) кладовая, (2) упакованная еда.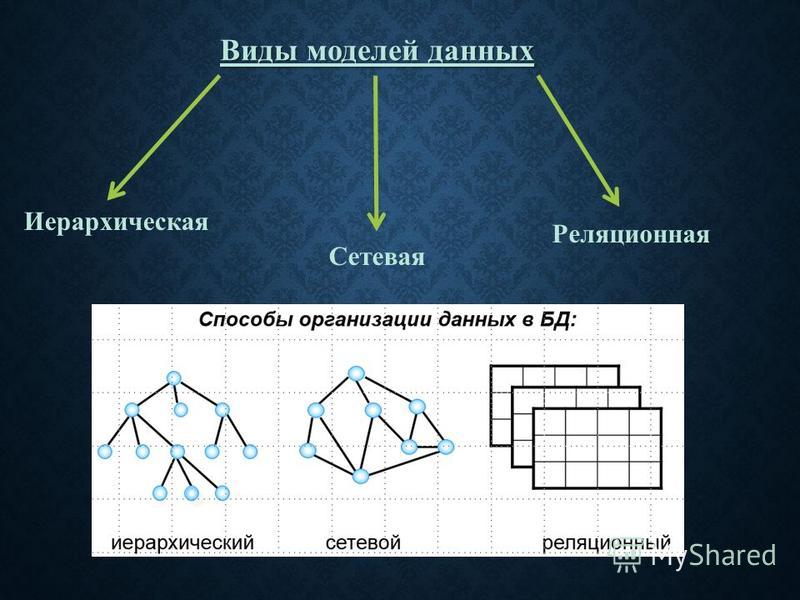
3. Сетевая модель
Эта модель базы данных позволяет устанавливать отношения «многие ко многим» между подключенными узлами. Данные расположены в графообразной структуре, и здесь «дочерние» узлы могут иметь несколько «родительских» узлов. Родительские узлы называются владельцами, а дочерние узлы называются членами.
4. Реляционная модель
В этом примере популярной модели данных данные упорядочиваются в таблицы. В таблицах есть столбцы и строки, каждая из которых каталогизирует атрибут, присутствующий в объекте. Это упрощает идентификацию взаимосвязей между точками данных.
Например, веб-сайты электронной коммерции могут обрабатывать покупки и отслеживать запасы с использованием реляционной модели.
5. Модель объектно-ориентированной базы данных
Эта модель данных определяет базу данных как набор объектов или повторно используемые программные компоненты с соответствующими методами и функциями.
Например, архитектурные и инженерные системы реального времени, используемые в 3D-моделировании, используют этот процесс моделирования данных.
6. Объектно-реляционная модель
Эта модель представляет собой комбинацию модели объектно-ориентированной базы данных и модели реляционной базы данных. Поэтому он сочетает в себе расширенные функциональные возможности объектно-ориентированной модели с простотой реляционной модели данных.
Процесс моделирования данных помогает организациям стать более управляемыми данными. Это начинается с очистки и моделирования данных. Давайте посмотрим, как происходит моделирование данных на разных уровнях.
Это были важные типы, которые мы обсуждали при моделировании данных. Далее, давайте посмотрим на технику.
Типы моделирования данных
Существует три основных типа моделей данных, которые используют организации. Они создаются в ходе планирования проекта в аналитике. Они варьируются от абстрактных до дискретных спецификаций, предполагают участие определенного подмножества заинтересованных сторон и служат разным целям.
1. Концептуальная модель
Это визуальное представление концепций базы данных и взаимосвязей между ними, определяющее высокоуровневое представление данных пользователем.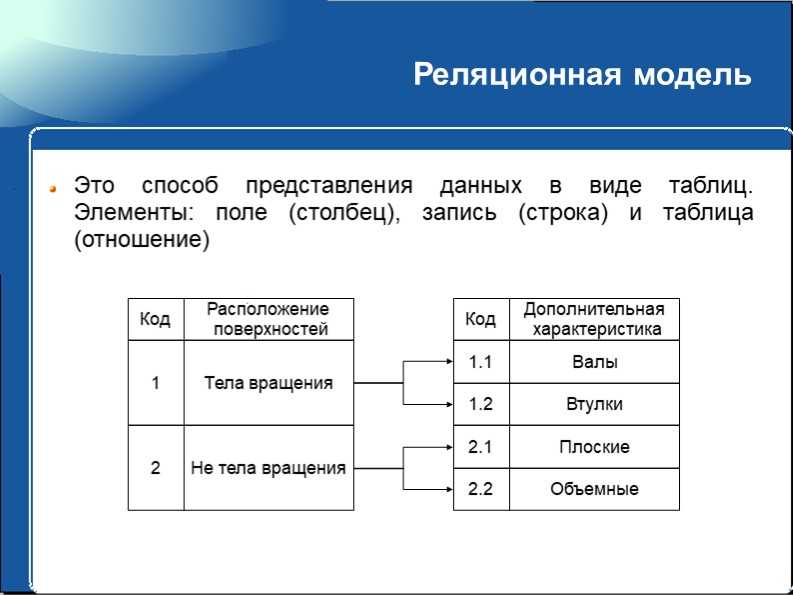
2. Логическая модель
Эта модель дополнительно определяет структуру объектов данных и их отношения. Обычно логическая модель данных используется для конкретного проекта, поскольку целью является разработка технической карты правил и структур данных.
3. Физическая модель
Это схема или структура, определяющая, как данные физически хранятся в базе данных. Он используется для моделирования базы данных, где столбцы включают точные типы и атрибуты. Физическая модель проектирует внутреннюю схему. Целью является фактическая реализация базы данных.
Отличие логической модели от физической модели данных состоит в том, что логическая модель в большей степени описывает данные, но не принимает участия в реализации базы данных, как это делает физическая модель. Другими словами, логическая модель данных является основой для разработки физической модели, которая дает абстракцию базы данных и помогает генерировать схему.
Примеры концептуального моделирования данных можно найти в системах управления персоналом, простом управлении заказами, бронировании отелей и т. д. Эти примеры показывают, что эта конкретная модель данных используется для связи и определения бизнес-требований к базе данных, а также для представления концепций. Это не должно быть техническим, но простым.
Это были важные типы, которые мы обсуждали при моделировании данных. Далее, давайте посмотрим на технику.
Методы моделирования данных
Существует три основных метода моделирования данных. Во-первых, это метод Entity-Relationship Diagram или ERD для моделирования и проектирования реляционных или традиционных баз данных. Во-вторых, UML или диаграммы классов унифицированного языка моделирования представляют собой стандартизированное семейство нотаций для моделирования и проектирования информационных систем. Наконец, третий — это метод моделирования словаря данных, при котором выполняется табличное определение или представление активов данных.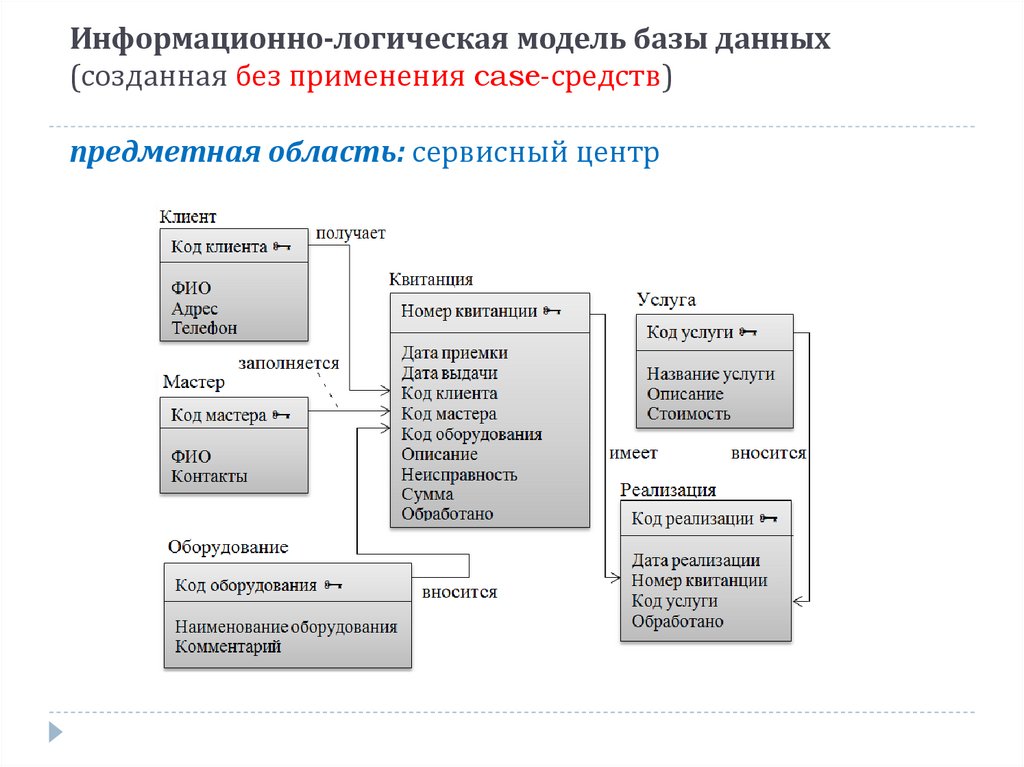
Инструменты моделирования данных
Мы видели, что моделирование данных — это процесс применения к данным определенных методов и методологий для преобразования их в полезную форму. Это делается с помощью инструментов моделирования данных, которые помогают создать структуру базы данных из схематических рисунков. Это упрощает соединение данных и формирует идеальную структуру данных в соответствии с требованиями.
Это важные инструменты, которые мы обсуждали при моделировании данных.
Важность моделирования данных
Теперь ясно, что моделирование данных является необходимой фундаментальной работой. Это позволяет легко хранить данные в базе данных и положительно влияет на анализ данных. Это имеет решающее значение для управления данными, управления данными и анализа данных.
- Это означает лучшую документацию источников данных, более высокое качество и более четкую область использования данных при более высокой производительности и меньшем количестве ошибок.
- С точки зрения соблюдения нормативных требований моделирование данных обеспечивает соблюдение организацией государственных законов и применимых отраслевых норм.
- Он позволяет сотрудникам принимать решения и стратегии на основе данных.
- Он основан на бизнес-аналитике, поскольку позволяет выявлять новые возможности за счет расширения возможностей данных.
На этом все в статье «Что такое моделирование данных».
Хотите стать специалистом по данным? Ознакомьтесь с программой PG по науке о данных и получите сертификат уже сегодня.
Изучение моделирования данных
В этой статье о том, что такое моделирование данных, мы подробно обсудили его типы, концепции и преимущества.
Моделирование данных играет жизненно важную роль в хранении данных в соответствии с требованиями. Поскольку организации имеют дело с огромными объемами данных, они должны быть в состоянии организовать и осмыслить данные, а также иметь возможность передавать их другим.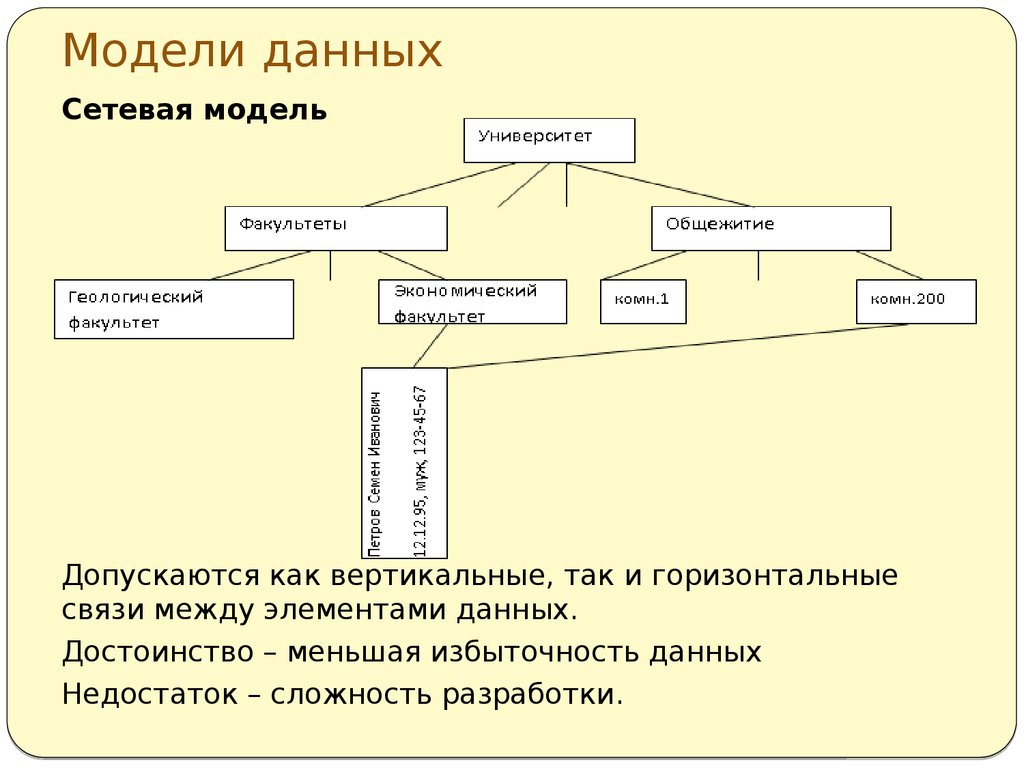 Они должны смоделировать его для понимания или использования и, следовательно, прибегнуть к моделированию данных. Вот четко определенный взгляд на то, как стать специалистом по моделированию данных.
Они должны смоделировать его для понимания или использования и, следовательно, прибегнуть к моделированию данных. Вот четко определенный взгляд на то, как стать специалистом по моделированию данных.
Гарвардский университет назвал эту профессию самой сексуальной работой 21 века. Все начинающие специалисты по моделированию данных, профессионалы и выпускники, заинтересованные в построении карьеры в области моделирования данных, должны знать, что моделирование данных — это очень технологически независимый, динамичный и вневременной навык.
КурсSimplilearn Data Scientist — хорошее место, чтобы начать повышать квалификацию в этом отношении. Как специалист по моделированию данных, нынешние карьерные перспективы направлены на экспоненциальный рост. Если вам нужна помощь, чтобы ответить на вопросы интервью по моделированию данных, Simplilearn предоставит вам ответы и на этот счет.
Это было все о том, что такое моделирование данных, если у вас есть какие-либо сомнения, оставьте сообщение в разделе комментариев ниже.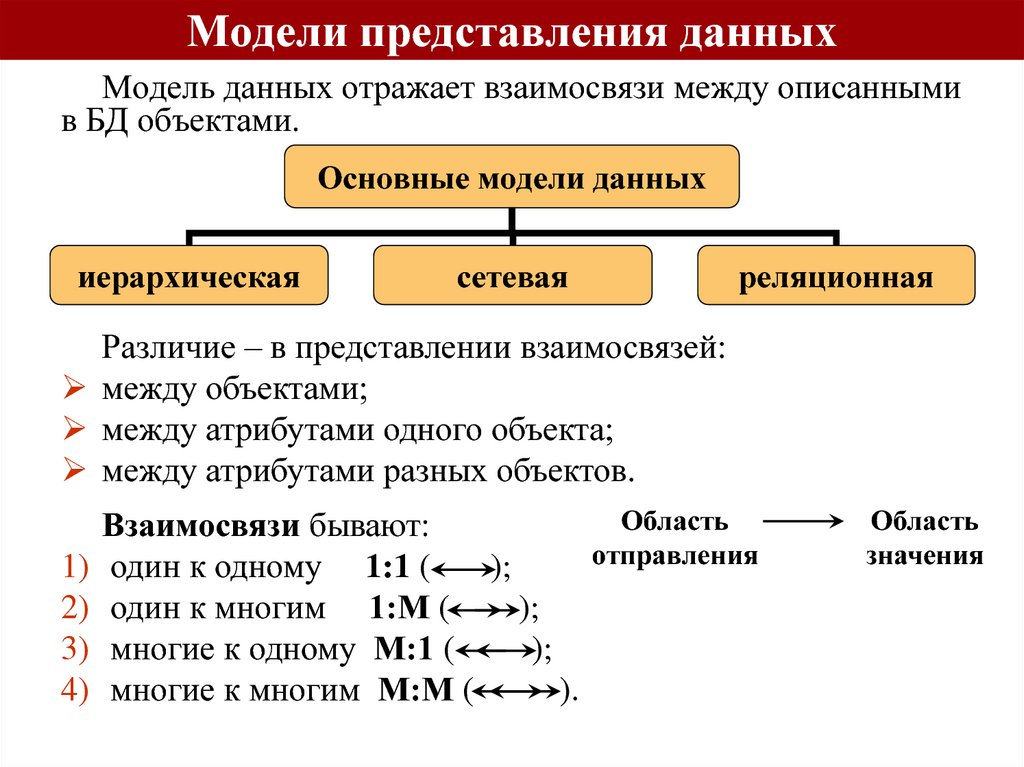
Часто задаваемые вопросы
Q1. Что такое моделирование данных?
Процесс создания визуального представления любой части системы или всей системы для передачи связей между структурами и точками данных с использованием элементов, текстов и символов.
Q2. Какие существуют типы моделей данных?
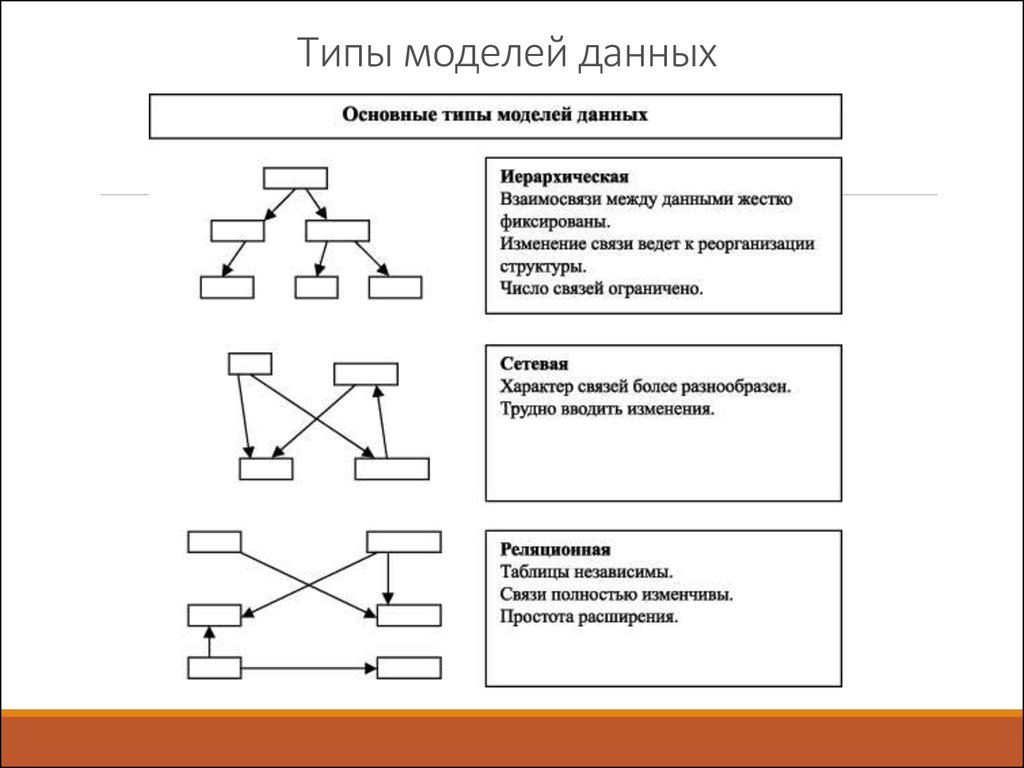
Существует три типа моделей данных: многомерная, реляционная и реляционная сущностная. Эти модели следуют трем подходам: концептуальному, логическому и физическому. Существуют и другие модели данных; однако они устарели, например сетевые, иерархические, объектно-ориентированные и многозначные.
Q3. Какие существуют методы моделирования данных?
Существуют следующие типы методов моделирования данных: иерархический, сетевой, реляционный, объектно-ориентированный, сущность-связь, многомерный и граф.
Q4. Что представляет собой процесс моделирования данных?
Первым шагом в процессе моделирования данных является определение вариантов использования и логических моделей данных.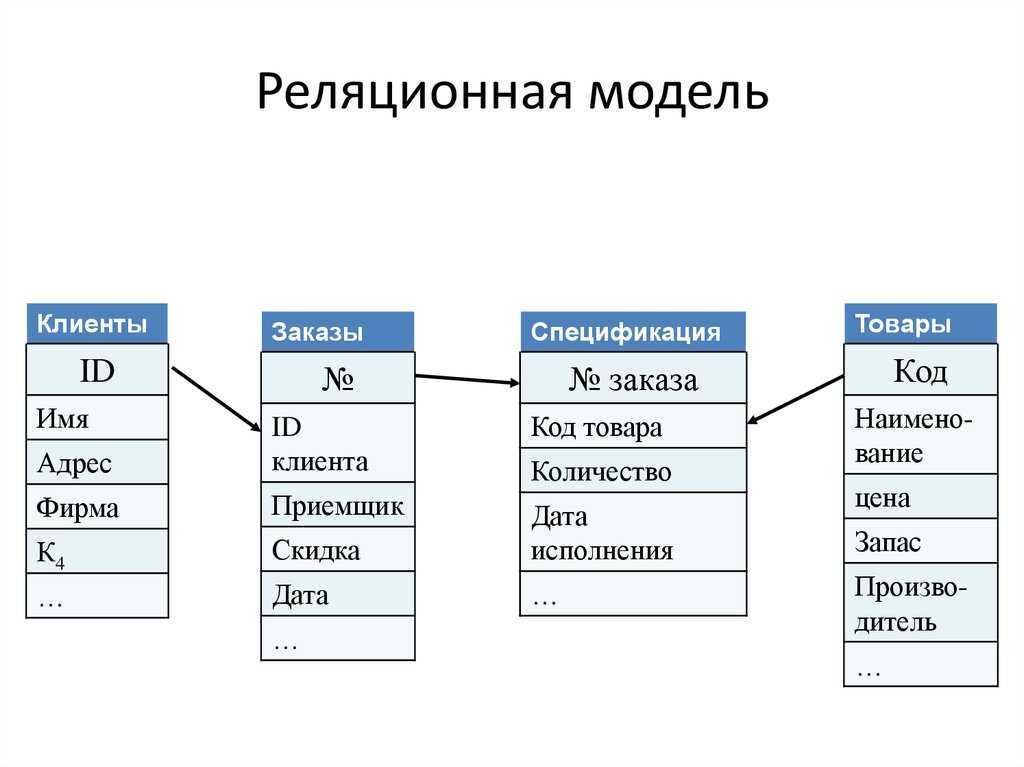 Затем создайте предварительную смету расходов. Определите шаблоны доступа к данным и технические требования. Создайте модель данных DynamoDB и запросы. Проверьте модель и просмотрите оценку стоимости.
Затем создайте предварительную смету расходов. Определите шаблоны доступа к данным и технические требования. Создайте модель данных DynamoDB и запросы. Проверьте модель и просмотрите оценку стоимости.
Q5. Как AWS может помочь в моделировании данных?
Вы можете использовать Amazon RDS (сервис реляционной базы данных) для реализации реляционных моделей данных, Amazon Neptune для реализации графовых моделей данных и AWS Amplify DataStore для более быстрого и простого моделирования данных для создания веб-приложений и мобильных приложений.
Q6. Что такое концепции моделирования данных?
Концепции моделирования данных отвечают на вопрос, ЧТО содержит система. Концептуальная модель помогает организовать, расширить и определить бизнес-концепции и правила. Эти концепции создаются архитекторами данных и заинтересованными сторонами бизнеса.
В7. Почему важно моделирование данных?
Организованное и всестороннее моделирование данных имеет решающее значение для создания упрощенной, логической и физической базы данных.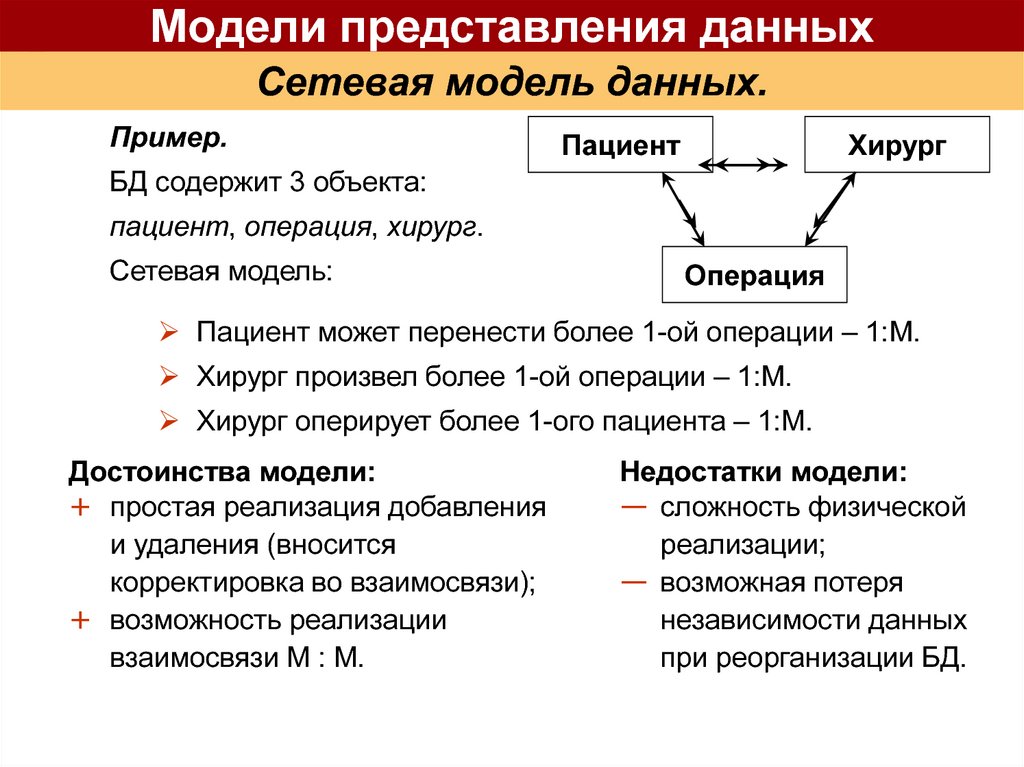 Необходимо устранить требования к хранилищу и избыточность и обеспечить эффективное извлечение данных.
Необходимо устранить требования к хранилищу и избыточность и обеспечить эффективное извлечение данных.
В8. Какие существуют виды моделирования данных?
Преобладающими типами моделирования данных являются иерархическое, сетевое, реляционное и объектно-связное. Эти модели помогают командам управлять данными и преобразовывать их в ценную бизнес-информацию.
Q9. Каковы три уровня абстракции данных?
Три уровня абстракции данных: физический или внутренний, логический или концептуальный и вид или внешний. Низшая форма — физическая, а высшая — воззрение. На логическом уровне информация хранится в базе данных в виде таблиц.
Next Article
Типы моделей баз данных: подробное руководство 101 — Узнайте
Нынешняя потребность в хранении больших блоков данных, относящихся к нескольким связанным или несвязанным категориям, показывает, что базы данных должны быть очень хороши в том, что они должны делать.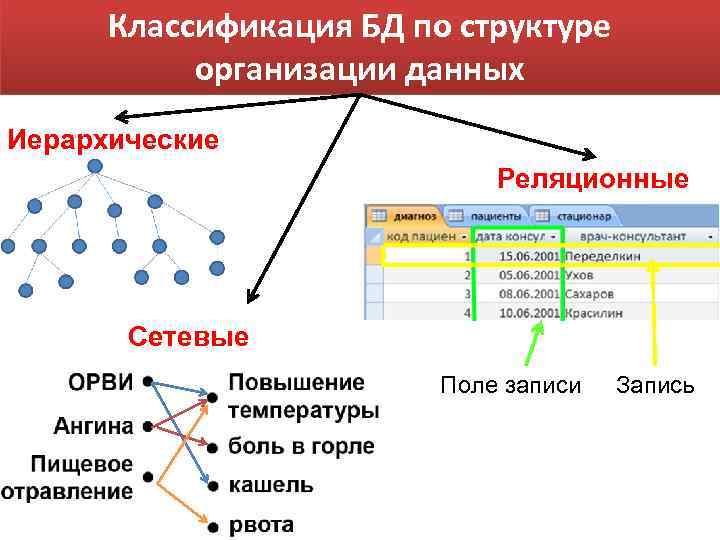 Это происходит не только потому, что вы имеете дело с большим объемом данных, которые постоянно пересматриваются или модифицируются; динамика — не единственное, что имеет значение. Базы данных являются буквально основой образа жизни клиента или стоимости бизнеса из-за социальной ценности, которую каждый человек присваивает им.
Это происходит не только потому, что вы имеете дело с большим объемом данных, которые постоянно пересматриваются или модифицируются; динамика — не единственное, что имеет значение. Базы данных являются буквально основой образа жизни клиента или стоимости бизнеса из-за социальной ценности, которую каждый человек присваивает им.
Содержание
Основой функциональных возможностей, которые они предоставляют пользователям, является проектирование различных типов моделей баз данных. Поскольку данные являются динамическим объектом, они хранятся различными способами. Это также причина, по которой компании создают свои базы данных для удовлетворения своих конкретных требований.
В этой статье подробно рассказывается о типах моделей баз данных . Он также дает краткое введение в модели баз данных.
Содержание
- Что такое модель базы данных?
- Types of Database Models
- Relational Database Model
- Hierarchial Database Model
- Network Database Model
- Object-Oriented Database Model
- Object-Relational Database Model
- Entity Relationship Database Model
- Other Database Models
- Заключение
Что такое модель базы данных?
A Модель базы данных — это тип модели данных, определяющий логическую структуру базы данных.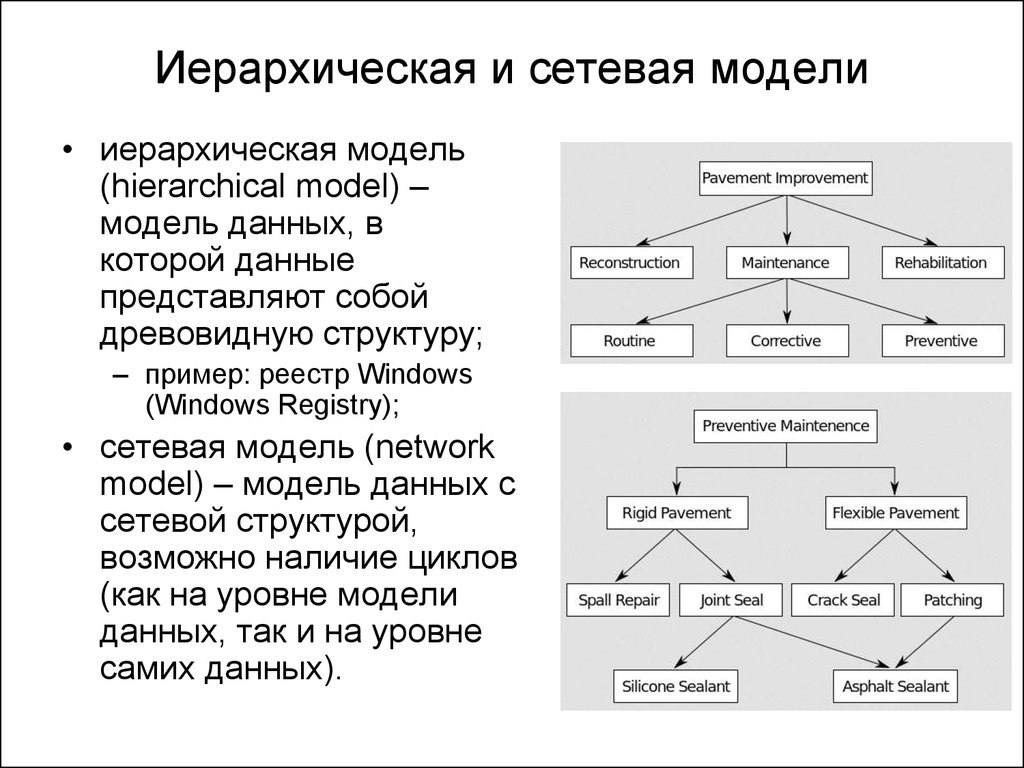 Он определяет, как данные могут храниться, организовываться и манипулироваться в первую очередь. Реляционная модель, в которой используется табличный формат, является наиболее распространенной моделью базы данных. Он демонстрирует, как организованы данные, и различные типы отношений, которые существуют между ними.
Он определяет, как данные могут храниться, организовываться и манипулироваться в первую очередь. Реляционная модель, в которой используется табличный формат, является наиболее распространенной моделью базы данных. Он демонстрирует, как организованы данные, и различные типы отношений, которые существуют между ними.
Сетевая модель, модель объект-связь, иерархическая модель, объектно-ориентированная модель и объектная модель — это некоторые из различных типов моделей базы данных. Эти различные типы моделей баз данных имеют различный внешний вид и операции и могут использоваться по-разному в зависимости от потребностей пользователя.
Факты, которые могут войти в базу данных, или факты, представляющие интерес для потенциальных конечных пользователей, определяются схемой базы данных, которая основана на знаниях администратора базы данных о возможных приложениях. В исчислении предикатов понятие схемы базы данных аналогично понятию теории. База данных, которую можно рассматривать как математический объект в любой момент времени, очень напоминает Модель этой «теории». В результате схема может содержать формулы, которые представляют как ограничения целостности, специфичные для приложения, так и ограничения целостности, специфичные для базы данных, и все они выражены на одном и том же языке базы данных.
В результате схема может содержать формулы, которые представляют как ограничения целостности, специфичные для приложения, так и ограничения целостности, специфичные для базы данных, и все они выражены на одном и том же языке базы данных.
Hevo Data, полностью управляемая платформа Data Pipeline, может помочь вам автоматизировать, упростить и обогатить процесс репликации данных несколькими щелчками мыши. Благодаря широкому выбору коннекторов и невероятно быстрых конвейеров данных Hevo вы можете извлекать и загружать данные из более чем 100 источников данных прямо в свое хранилище данных или любые базы данных. Для дальнейшей оптимизации и подготовки ваших данных к анализу вы можете обрабатывать и обогащать необработанные детализированные данные с помощью надежного и встроенного уровня преобразования Hevo без написания единой строки кода!
НАЧНИТЕ HEVO БЕСПЛАТНО[/hevoButton]
Hevo — это самая быстрая, простая и надежная платформа для репликации данных, которая многократно сэкономит ваши инженерные ресурсы и время. Попробуйте нашу 14-дневную бесплатную пробную версию с полным доступом сегодня, чтобы испытать полностью автоматизированную беспроблемную репликацию данных!
Попробуйте нашу 14-дневную бесплатную пробную версию с полным доступом сегодня, чтобы испытать полностью автоматизированную беспроблемную репликацию данных!
Типы моделей баз данных
Существуют следующие типы моделей баз данных:
- Модель реляционной базы данных
- Модель иерархической базы данных
- Модель сетевой базы данных
- Модель объектно-ориентированной базы данных
- Модель объектно-реляционной базы данных
- Модель базы данных отношений объектов
- Другие модели баз данных
Модель реляционной базы данных
используется для поддержки реляционных баз данных (RDBMS). Данные в модели базы данных этого типа организованы в виде двумерных таблиц со строками и столбцами, а связь поддерживается за счет хранения общего поля. В нем есть три основные части.
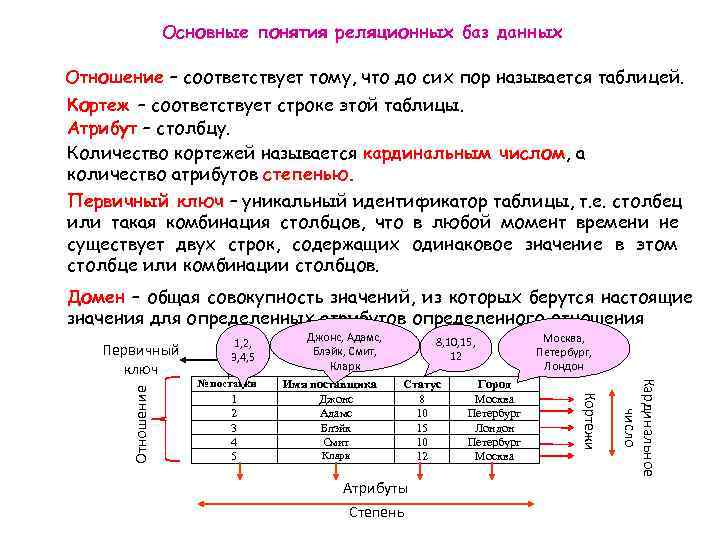
В реляционных моделях часто используются три ключевых термина: отношения, атрибуты, и домены .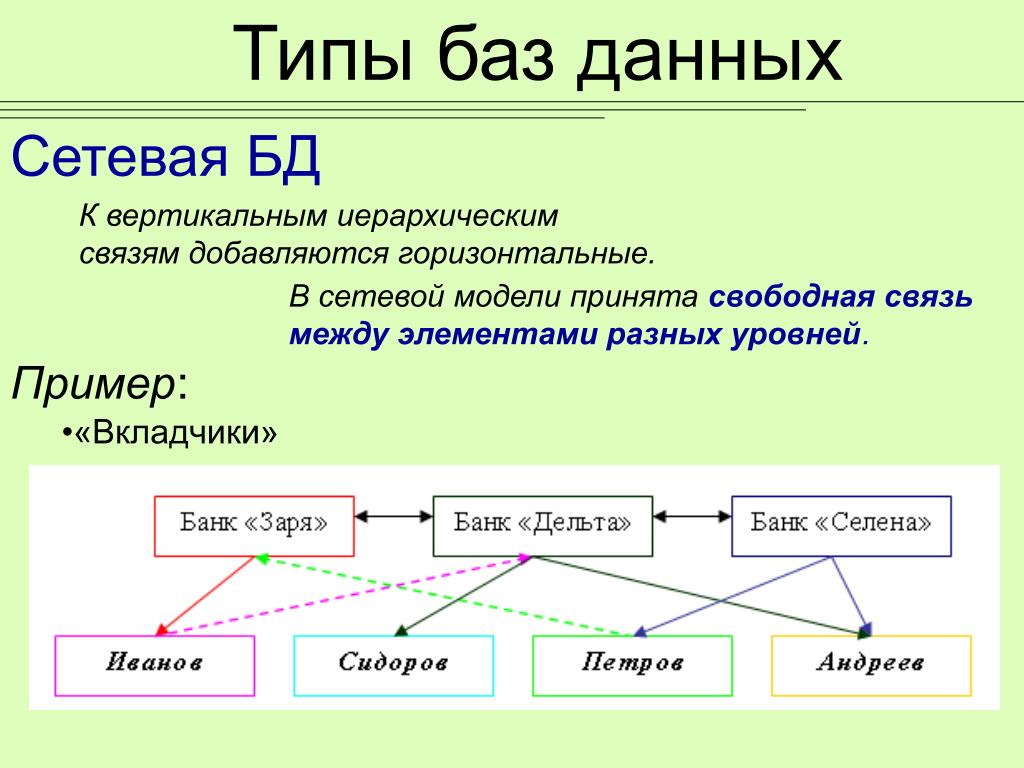 Таблица со строками и столбцами — это то, чем является отношение . В реляционных базах данных Атрибуты являются определяющими характеристиками или свойствами, которые определяют все элементы, принадлежащие к определенной категории, и применяются ко всем ячейкам в столбце. Домен — это не что иное, как набор значений, которые могут принимать атрибуты. Реляционная модель базы данных изображена на следующей диаграмме.
Таблица со строками и столбцами — это то, чем является отношение . В реляционных базах данных Атрибуты являются определяющими характеристиками или свойствами, которые определяют все элементы, принадлежащие к определенной категории, и применяются ко всем ячейкам в столбце. Домен — это не что иное, как набор значений, которые могут принимать атрибуты. Реляционная модель базы данных изображена на следующей диаграмме.
Параметры в реляционной модели
- Кортеж : Кортеж — это одна строка в таблице.
- Мощность отношения : Мощность отношения определяется количеством кортежей в нем. В этом случае отношение имеет мощность 4.
- Степень отношения : Каждый столбец кортежа называется атрибутом. Степень связи определяется количеством атрибутов в ней. Степень связи на рисунке равна 3,9.0112
Ключи отношения
- Первичный ключ : Это идентификатор, который делает таблицу уникальной. В нем нет нулевых значений.
- Внешний ключ : относится к первичному ключу другой таблицы. Разрешены только значения, которые появляются в первичном ключе таблицы, на которую он ссылается.
 В нем нет нулевых значений.
В нем нет нулевых значений.Примеры
- Oracle : База данных Oracle также известна как Oracle RDBMS или просто Oracle. Корпорация Oracle производит и продает многомодельную систему управления базами данных. База данных Oracle представляет собой логическую коллекцию данных. База данных используется для сохранения и извлечения данных. Это первая база данных, созданная специально для сетевых вычислений предприятия, наиболее гибкий и экономичный способ управления данными и приложениями.
- MySQL : MySQL — это система управления реляционными базами данных (RDBMS), основанная на бесплатном языке структурированных запросов (SQL). MySQL доступен практически на любой платформе, включая Linux, UNIX и Windows.
- Microsoft SQL Server : В корпоративных ИТ-средах Microsoft SQL Server представляет собой СУБД, которая поддерживает широкий спектр приложений для обработки транзакций, бизнес-аналитики и аналитики.
- PostgreSQL : PostgreSQL или просто Postgres — это система управления объектно-реляционными базами данных (ORDBMS), ориентированная на расширяемость и соответствие отраслевым стандартам.
- DB2 : DB2 — это продукт базы данных IBM. Это система управления базами данных для реляционных баз данных (RDBMS). Это СУБД, оптимизированная для хранения, анализа и поиска данных. Благодаря XML продукт DB2 теперь поддерживает объектно-ориентированные функции и нереляционные структуры.
В таблицах ниже показан пример модели реляционной базы данных для банковской среды, где данные хранятся в двумерных таблицах.
Источник изображенияПреимущества
Вот несколько ключевых преимуществ моделей реляционных баз данных:
- Изменения в структуре базы данных не влияют на доступ к данным в реляционной модели.
- Представление любой информации в виде таблиц со строками и столбцами значительно упрощает ее понимание.
- В отличие от других моделей, модель реляционной базы данных поддерживает как независимость данных, так и независимость структуры, что значительно упрощает проектирование, обслуживание, администрирование и использование базы данных.
- Вы можете использовать это для написания сложных запросов для доступа или изменения данных базы данных.
- По сравнению с другими моделями легче поддерживать безопасность.
Недостатки
- Сопоставлять объекты в реляционной базе данных сложно.
- В реляционной модели отсутствует объектно-ориентированная парадигма.
- В реляционных базах данных сложно поддерживать целостность данных.
- Реляционная модель подходит для небольших баз данных, но не для больших баз данных, поскольку они не предназначены для изменений. Каждая строка представляет собой уникальную запись, а каждый столбец описывает уникальные атрибуты в реляционных базах данных. Моделирование данных требует заблаговременного планирования и, в зависимости от системы, может занять месяцы или даже годы. Последующие изменения требуют времени и ресурсов, а проекты по моделированию баз данных могут длиться годами и стоить миллионы долларов. Поскольку большие данные постоянно меняются, требуется гибкая и щадящая платформа базы данных.
- Возникают затраты на оборудование, что делает его дорогим.
- Реляционная модель данных подходит не для всех доменов. Эволюция схемы затруднена из-за негибкой модели данных. Плохая горизонтальная масштабируемость приводит к низкой распределенной доступности. Из-за объединений, транзакций ACID и строгих ограничений согласованности производительность страдала (особенно в распределенных средах).
- Сложности реализации и детали физического хранения данных системы реляционной базы данных скрыты от пользователей.
 Последующие изменения требуют времени и ресурсов, а проекты по моделированию баз данных могут длиться годами и стоить миллионы долларов. Поскольку большие данные постоянно меняются, требуется гибкая и щадящая платформа базы данных.
Последующие изменения требуют времени и ресурсов, а проекты по моделированию баз данных могут длиться годами и стоить миллионы долларов. Поскольку большие данные постоянно меняются, требуется гибкая и щадящая платформа базы данных. Агрегирование данных может стать колоссальной задачей без надлежащего набора инструментов. Автоматизированная платформа Hevo предоставляет вам все необходимое для беспрепятственного сбора, обработки и агрегирования данных.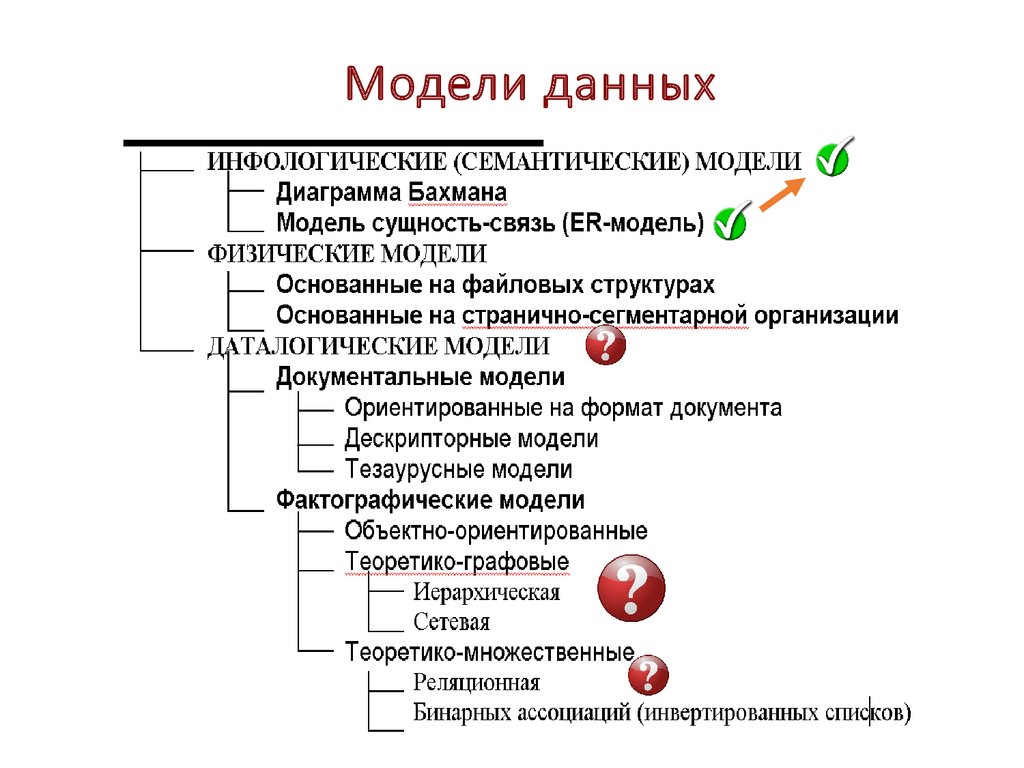 Наша платформа приготовила для вас следующее!
Наша платформа приготовила для вас следующее!
- Исключительная безопасность: Отказоустойчивая архитектура, обеспечивающая согласованность и надежную защиту с нулевой потерей данных.
- Создан для масштабирования: Исключительная горизонтальная масштабируемость с минимальной задержкой для современных потребностей в данных.
- Встроенные соединители: Поддержка более 100 источников данных, включая базы данных, платформы SaaS, файлы и многое другое. Нативные веб-перехватчики и коннектор REST API доступны для пользовательских источников.
- Преобразование данных: Лучшая в своем классе встроенная поддержка сложных преобразований данных. Code & No-code Fexibilty разработан для всех.
- Smooth Schema Mapping: Полностью управляемое автоматическое управление схемой для входящих данных с желаемым назначением.
- Молниеносная установка: Простой интерфейс для работы новых клиентов с минимальным временем настройки.
- Поддержка в режиме реального времени: Команда Hevo доступна круглосуточно, чтобы предоставить исключительную поддержку своим клиентам через чат, электронную почту и звонки в службу поддержки.
ЗАПИСАТЬСЯ НА 14-ДНЕВНУЮ БЕСПЛАТНУЮ ПРОБНУЮ ПРОБНУЮ ВЕРСИЮ
Иерархическая модель базы данных
Это один из первых типов моделей баз данных IBM для управления информацией. Данные организованы в виде древовидной структуры в Модель иерархической базы данных .
В настоящее время такие модели баз данных встречаются редко. Он имеет узлы для записей и ветви для полей. Примером иерархической базы данных является реестр Windows в Windows XP, параметры конфигурации которого сохраняются в виде древовидных структур на основе узлов.
На приведенной ниже диаграмме показана обобщенная иерархическая модель базы данных (данные представлены или хранятся в корневом узле, родительском узле и дочернем узле).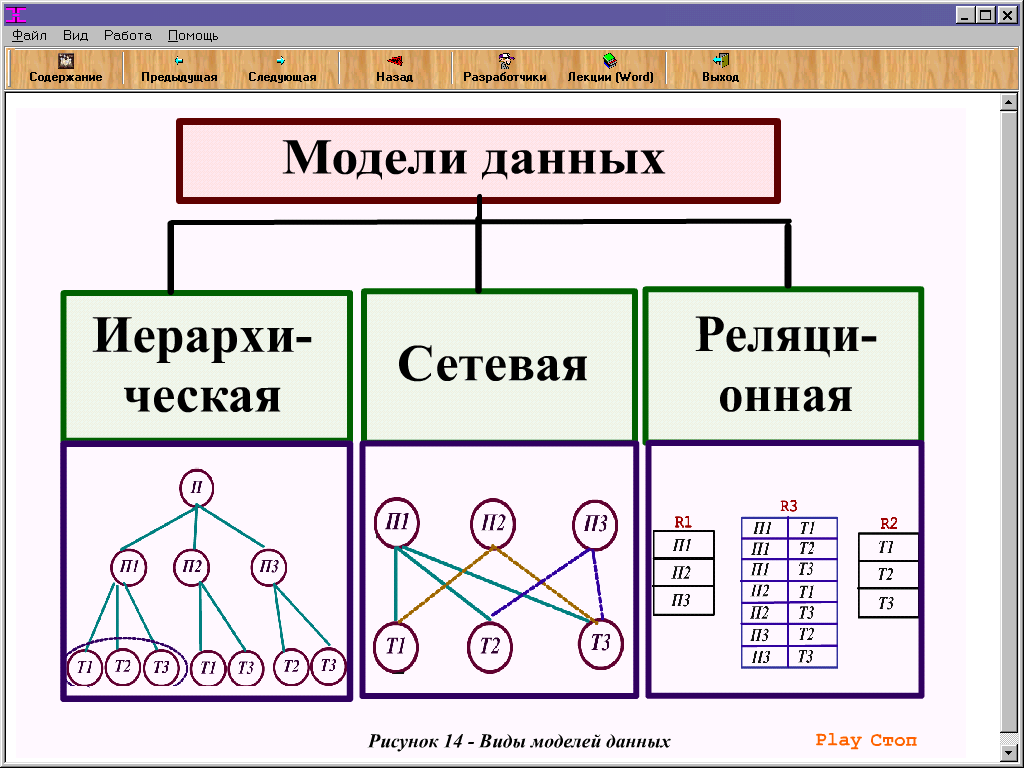
На приведенной выше диаграмме показана иерархическая модель базы данных для системы управления университетом. Отношение «родитель-потомок» используется для хранения данных в этом типе базы данных.
Преимущества
- Модель облегчает добавление и удаление новых данных.
- К данным на вершине иерархии можно получить быстрый доступ.
- Он был совместим с линейными носителями данных, такими как ленты. Иерархическая база данных хорошо подходила для ленточных систем хранения, использовавшихся мейнфреймами в 1970-х годах, и широко использовалась в организациях с базами данных, основанными на этих системах.
- Это относится ко всему, что основано на отношениях «один ко многим». Например, у президента может быть много менеджеров, подчиняющихся ему, и эти менеджеры могут подчиняться многим сотрудникам, но у каждого сотрудника есть только один менеджер.
Недостатки
- Это требует регулярного хранения данных в нескольких объектах.
- Линейные носители данных, такие как ленты, сегодня больше не используются.
- При поиске данных СУБД должна проходить всю Модель сверху вниз, пока не будет найдена необходимая информация, что делает запросы чрезвычайно медленными.
- Эта модель поддерживает только отношения «один ко многим»; отношения «многие ко многим» — нет.
Модель сетевой базы данных
Рабочая группа по базам данных формализовала эту модель в 1960-х годах. В этой модели обобщена иерархическая модель. Эта модель может иметь несколько родительских сегментов, сгруппированных по уровням, но между сегментами, принадлежащими каждому уровню, существует логическая связь. Как правило, любой из двух сегментов имеет логическую связь «многие ко многим».
Поскольку она напоминает модель иерархической базы данных, ее часто называют модифицированной версией иерархической базы данных. Сетевая база данных модели организует данные в виде графа и допускает наличие нескольких родительских узлов.
Сетевые модели — это типы моделей баз данных, предназначенные для гибкого представления объектов и их отношений. Сетевая модель расширяет иерархическую модель, допуская отношения «многие ко многим» между связанными записями, что подразумевает несколько родительских записей.
Типы моделей баз данных строятся с использованием наборов связанных записей и основаны на математической теории множеств. Каждый набор содержит одну запись владельца или родительского элемента, а также одну или несколько дочерних записей или записей участников. Эта модель может отображать сложные отношения, поскольку запись может быть членом или дочерним элементом в нескольких наборах.
После того, как он был официально определен Конференцией по языкам систем данных в 1970-х годах, он стал чрезвычайно популярным (CODASYL).
Источник изображенияПреимущества
- Сетевая модель концептуально проста в реализации.
- Сетевая модель лучше отражает избыточность данных, чем иерархическая модель.
- Сетевая модель может обрабатывать отношения «один ко многим» и «многие ко многим», что чрезвычайно полезно при моделировании реальных сценариев, таких как сетевая модель для финансового отдела, рабочий процесс сети ресторанов и т. д.
- Сетевая модель лучше иерархической модели изолирует программы от сложных деталей физического хранилища. Сетевая модель позволяет каждой записи иметь несколько родительских и дочерних записей, образуя обобщенную структуру графа, тогда как иерархическая модель базы данных структурирует данные в виде дерева записей, где каждая запись имеет одну родительскую запись и множество дочерних.
Недостатки
- Поскольку все записи ведутся с использованием указателей, структура базы данных становится чрезвычайно сложной.
- Любые операции вставки, удаления и обновления записи требуют многочисленных корректировок указателя.
- Изменение структуры базы данных чрезвычайно сложно.
Модель объектно-ориентированной базы данных
В объектно-ориентированном программировании объектная база данных представляет собой систему, в которой данные представлены в виде объектов. Реляционные базы данных, ориентированные на таблицы, отличаются от объектно-ориентированных баз данных. Объектно-ориентированная модель данных — это один из типов моделей баз данных, основанный на широко используемой концепции объектно-ориентированных языков программирования.
Реляционные базы данных, ориентированные на таблицы, отличаются от объектно-ориентированных баз данных. Объектно-ориентированная модель данных — это один из типов моделей баз данных, основанный на широко используемой концепции объектно-ориентированных языков программирования.
Полиморфизм, наследование и перегрузка — все термины, которые приходят на ум, когда речь идет о наследовании. Некоторые из ключевых концепций объектно-ориентированного программирования, которые были применены к моделированию данных, включают идентификацию объекта, инкапсуляцию и сокрытие информации с помощью методов, обеспечивающих интерфейс к объектам. В дополнение к структурированным типам и типам коллекций объектно-ориентированная модель данных поддерживает систему типов данных. Объектно-ориентированные модели, включая базы данных общих объектов без дополнительной пространственной функциональности, являются лучшими базами данных для пространственных данных, особенно векторных данных.
Разница между реляционным и объектно-ориентированным типами моделей баз данных показана на диаграмме ниже.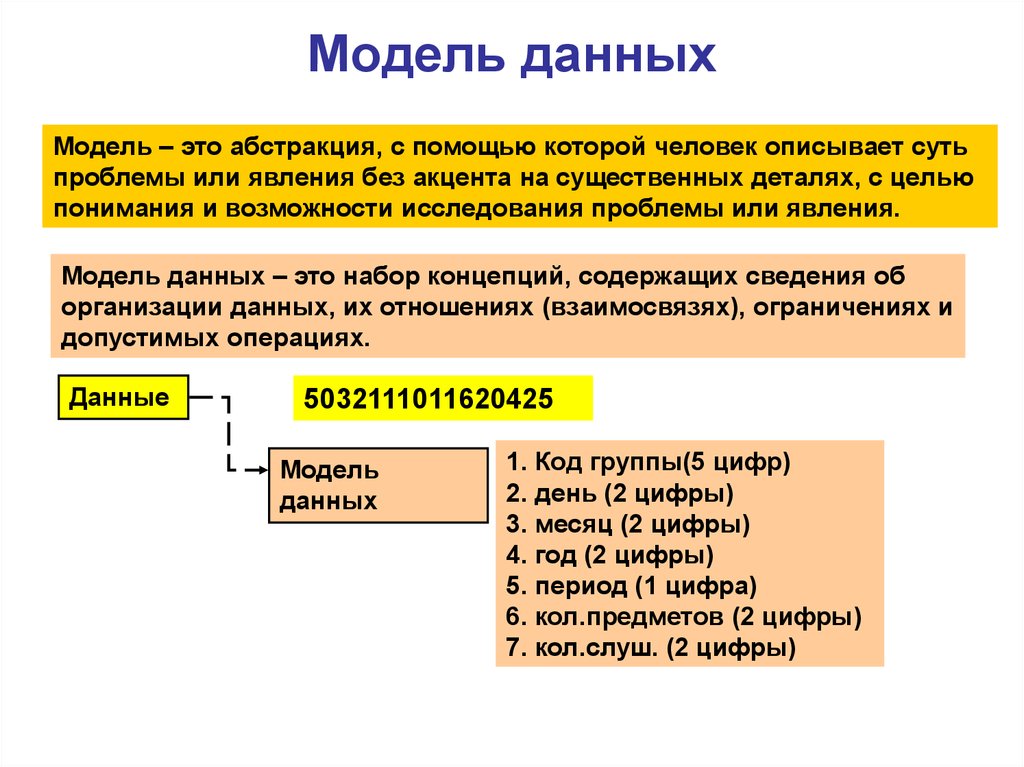
Объектно-ориентированная модель показана на диаграмме ниже.
Источник изображенияПреимущества
- Объектные базы данных могут хранить различные типы данных, тогда как реляционные базы данных хранят только один тип данных. Объектно-ориентированные базы данных, в отличие от традиционных баз данных, таких как иерархические, сетевые и реляционные базы данных, могут обрабатывать различные типы данных, включая изображения, голос, видео, текст и числа.
- Вы можете повторно использовать код, моделировать реальные сценарии и повышать надежность и гибкость с помощью объектно-ориентированных баз данных.
- Поскольку большинство задач в системе инкапсулированы, их можно повторно использовать и включать в новые задачи, объектно-ориентированные базы данных имеют более низкие затраты на обслуживание, чем другие модели.
Недостатки
- ООСУБД не имеет теоретической основы, поскольку не существует универсально определенной модели данных.
- Использование ООСУБД по-прежнему ограничено по сравнению с использованием РСУБД.
- В ООСУБД, которые не включают адекватные механизмы безопасности, отсутствует поддержка безопасности.
- Эта система более сложна, чем обычные системы управления базами данных.
Модель объектно-реляционной базы данных
Эта гибридная модель базы данных является одним из типов моделей баз данных, который сочетает в себе простоту реляционной модели с некоторыми расширенными функциями моделей объектно-ориентированных баз данных. Это позволяет дизайнерам включать объекты в общую структуру таблицы.
SQL3, языки поставщиков, ODBC, JDBC и проприетарные интерфейсы вызовов — все это расширения языков и интерфейсов реляционной модели.
Модели базы данных взаимосвязей сущностей
Модель базы данных взаимосвязей сущностей — это один из типов моделей базы данных, похожий на сетевую модель, он фиксирует отношения между реальными сущностями, но не так тесно связан с физической структурой базы данных.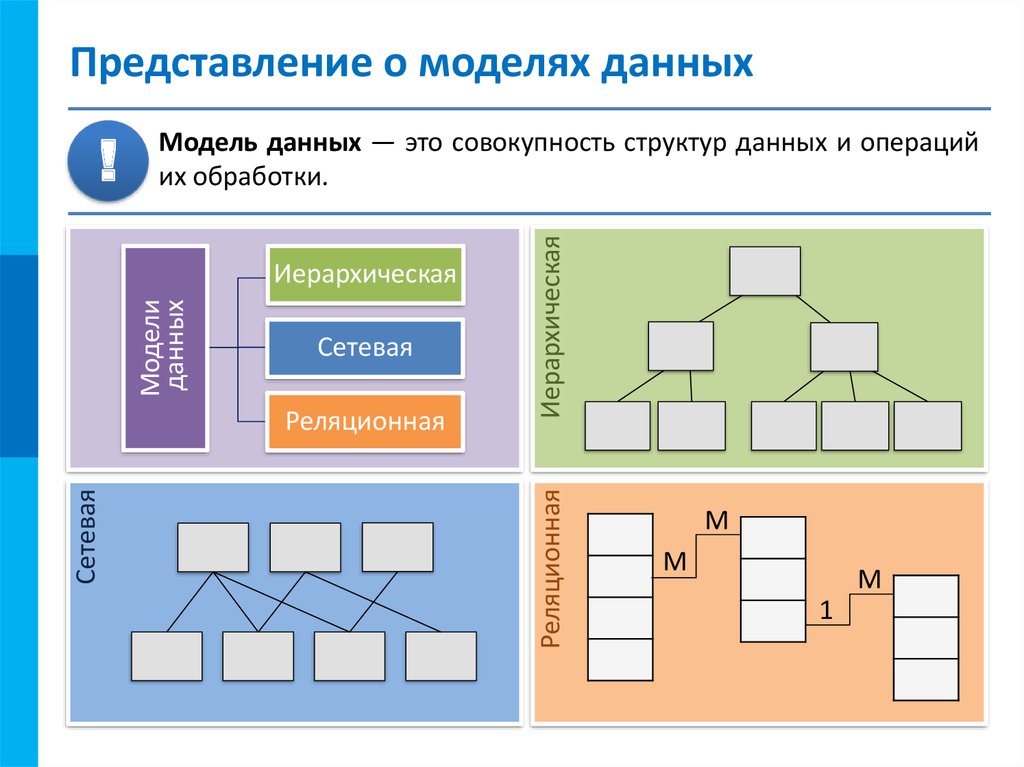 . Он чаще используется для концептуального проектирования базы данных.
. Он чаще используется для концептуального проектирования базы данных.
Люди, места и вещи, о которых хранятся точки данных, называются сущностями, и каждая из них имеет определенные атрибуты, составляющие их домен. Также отображается мощность объектов или отношения между ними.
Источник изображенияЗвездообразная схема — это обычная ER-диаграмма, которая соединяет несколько таблиц измерений через центральную таблицу фактов.
Другие модели баз данных
Ранее использовались другие типы моделей баз данных, а некоторые из них используются до сих пор.
Модель инвертированного файла
База данных инвертированной файловой структуры — это один из других типов моделей баз данных, предназначенных для быстрого полнотекстового поиска. Содержимое данных индексируется как последовательность ключей в таблице поиска со значениями, указывающими на расположение связанных файлов в этой модели. Например, в больших данных и аналитике эта структура может обеспечить почти мгновенную отчетность.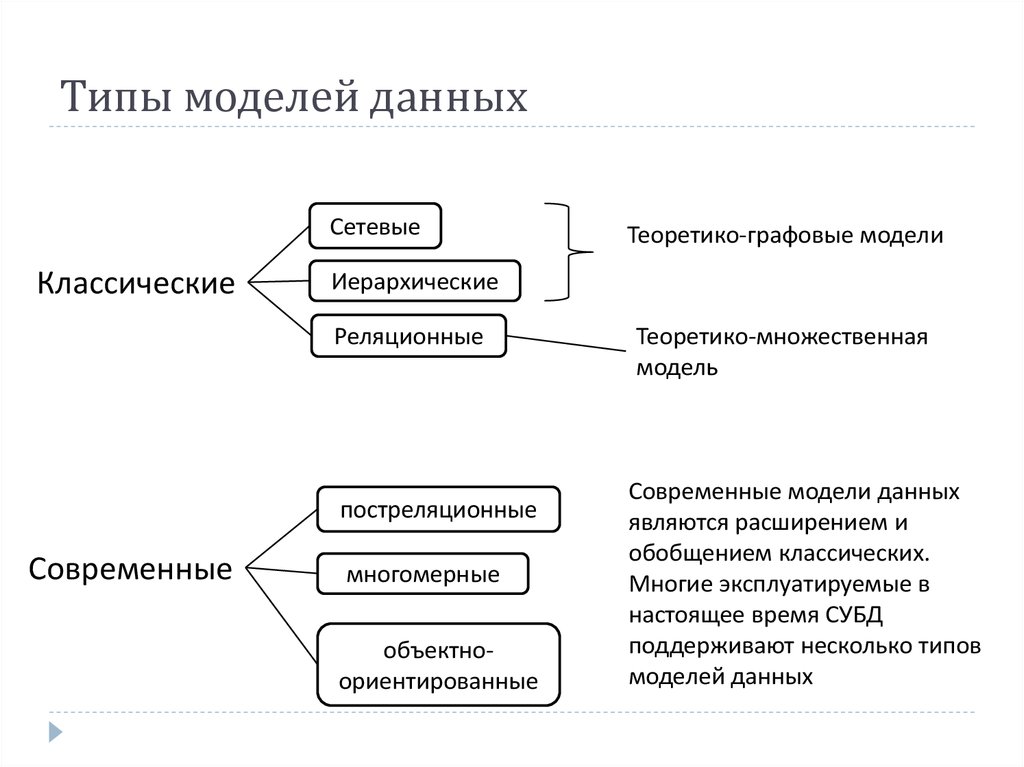
С 1970 года эта модель используется системой управления базами данных ADABAS компании Software AG и поддерживается до сих пор.
Плоская модель
Плоские модели — это самые старые и основные типы моделей данных. Он просто перечисляет всю информацию в одной таблице со столбцами и строками. Компьютер должен прочитать весь плоский файл в память, чтобы получить доступ к данным или управлять ими, что делает эту модель неэффективной для всех, кроме самых маленьких наборов данных.
Многомерная модель
Это типы моделей баз данных, представляющие собой реляционную модель, которая была изменена для облегчения аналитической обработки. Эта модель предназначена для онлайн-аналитической обработки, а реляционная модель оптимизирована для онлайн-обработки транзакций (OLTP) (OLAP).
Ячейки многомерной базы данных содержат информацию об отслеживаемых измерениях. Вместо двухмерных таблиц он выглядит как набор кубов.
Полуструктурированная модель
Полуструктурированная модель — это один из типов моделей базы данных, который обычно находится в схеме базы данных и содержит данные этой модели.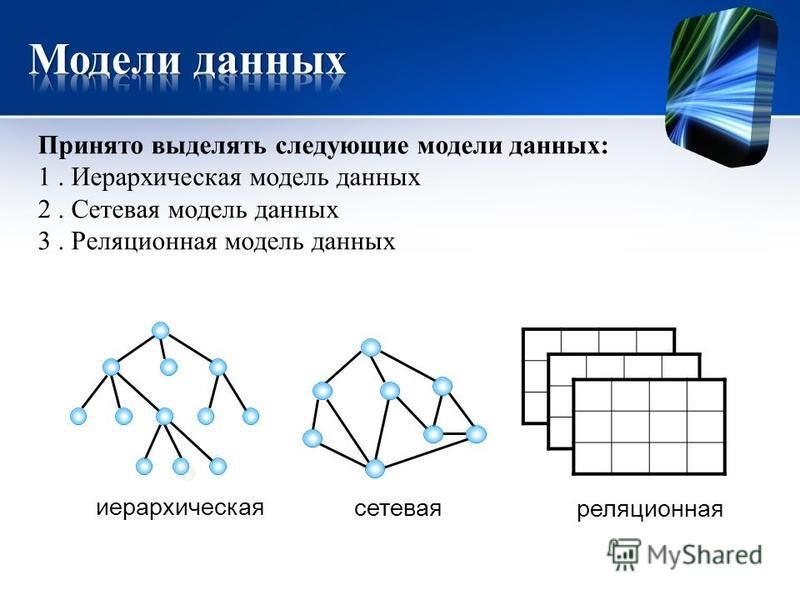 Граница между данными и схемой в лучшем случае размыта. Эти типы моделей баз данных полезны для описания систем, которые рассматриваются как базы данных, но не могут быть ограничены схемой, такой как определенные веб-источники данных. Его также можно использовать для описания взаимодействия между базами данных с разными схемами.
Граница между данными и схемой в лучшем случае размыта. Эти типы моделей баз данных полезны для описания систем, которые рассматриваются как базы данных, но не могут быть ограничены схемой, такой как определенные веб-источники данных. Его также можно использовать для описания взаимодействия между базами данных с разными схемами.
Контекстная модель
При необходимости в эту модель могут быть включены элементы из других типов моделей баз данных. Он сочетает в себе аспекты объектно-ориентированной, полуструктурированной и сетевой моделей.
Ассоциативная модель
Ассоциативные модели — это типы моделей баз данных, которые распределяют все точки данных по двум категориям: объекты и ассоциации. Сущность — это все, что существует независимо в этой Модели, тогда как Ассоциация — это то, что существует только относительно чего-то другого.
Данные разделены на две группы Ассоциативной моделью:
- Набор элементов, каждый со своим уникальным идентификатором, именем и классификацией.
- Набор ссылок, каждая со своим уникальным идентификатором и идентификаторами источника, глагола и цели. Каждый из трех идентификаторов может относиться к ссылке или элементу, а сохраняемый факт относится к источнику.

Другие менее распространенные типы моделей баз данных включают:
- Информация о том, как хранимые данные связаны с реальным миром, включена в семантическую модель.
- Данные можно указать и даже сохранить в формате XML с помощью базы данных XML.
- Именованный граф
- Triplestore
Заключение
В этой статье подробно обсуждаются различные типы моделей баз данных. В дополнение к этому он описывает, что такое модели баз данных.
посетите наш веб-сайт, чтобы ознакомиться с hevo
Hevo Data, конвейер передачи данных без кода, предоставляет последовательное и надежное решение для управления передачей данных между различными источниками и широким спектром желаемых пунктов назначения с помощью нескольких щелчков мышью.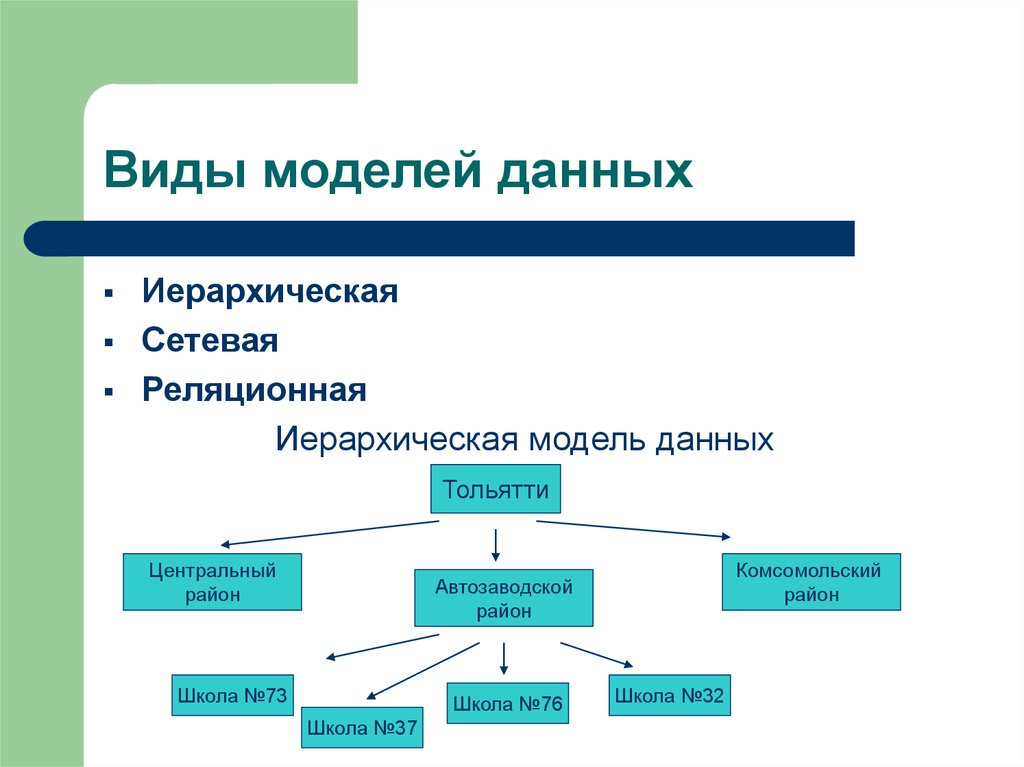 Hevo Data с его надежной интеграцией с более чем 100 источниками ( , включая более 40 бесплатных источников ) позволяет вам не только экспортировать данные из желаемых источников данных и загружать их в место назначения по вашему выбору, но также преобразовывать и обогащать ваши данные, чтобы сделать их готовыми к анализу, чтобы вы могли сосредоточиться на своих ключевые бизнес-потребности и выполнять глубокий анализ с помощью инструментов бизнес-аналитики.
Hevo Data с его надежной интеграцией с более чем 100 источниками ( , включая более 40 бесплатных источников ) позволяет вам не только экспортировать данные из желаемых источников данных и загружать их в место назначения по вашему выбору, но также преобразовывать и обогащать ваши данные, чтобы сделать их готовыми к анализу, чтобы вы могли сосредоточиться на своих ключевые бизнес-потребности и выполнять глубокий анализ с помощью инструментов бизнес-аналитики.
Хотите попробовать Hevo? Подпишитесь на 14-дневную бесплатную пробную версию и испытайте многофункциональный пакет Hevo из первых рук. Вы также можете ознакомиться с непревзойденными ценами, которые помогут вам выбрать правильный план для нужд вашего бизнеса.