Алгоритмы поиска подстроки на JavaScript / Хабр
Недавно я столкнулся с одной не очень сложной задачей на leetcode. В рамках задачи нужно было реализовать алгоритм поиска подстроки в строке. Пока я пытался сделать задачу, я понял, что я очень мало знаю про то как можно искать подстроку и решил изучить эту тему подробнее, и рассказать результат вам.
Как говорит Википедия “Поиск подстроки в строке — одна из простейших задач поиска информации”, но это не совсем так, ниже я расскажу про разные алгоритмы решения и покажу примеры их реализации. Начнем!
“Алгоритм грубой силы” или “Алгоритм простого поиска”
Алгоритм грубой силы — это простой алгоритм поиска подстроки, он заключается в последовательном переборе всех символов строки и проверки совпадения с искомой подстрокой. Если совпадение не найдено, то алгоритм сдвигает искомую подстроку на один символ вправо и начинает поиск снова.
const findStr = (haystack, needle) => {
const m = needle.length
const n = haystack. length
for (let windowStart = 0; windowStart <= n - m; windowStart++) {
for (let i = 0; i < m; i++) {
if (needle[i] !== haystack[windowStart + i]) {
break
}
if (i === m - 1) {
return windowStart
}
}
}
return -1
}
length
for (let windowStart = 0; windowStart <= n - m; windowStart++) {
for (let i = 0; i < m; i++) {
if (needle[i] !== haystack[windowStart + i]) {
break
}
if (i === m - 1) {
return windowStart
}
}
}
return -1
} length
for (let windowStart = 0; windowStart <= n - m; windowStart++) {
for (let i = 0; i < m; i++) {
if (needle[i] !== haystack[windowStart + i]) {
break
}
if (i === m - 1) {
return windowStart
}
}
}
return -1
}
length
for (let windowStart = 0; windowStart <= n - m; windowStart++) {
for (let i = 0; i < m; i++) {
if (needle[i] !== haystack[windowStart + i]) {
break
}
if (i === m - 1) {
return windowStart
}
}
}
return -1
}Функция поиска состоит из цикла, который ограничивается до n — m (длина искомой строки — длина строки в которой ищем), что позволяет обойти проблему, если строка имеет меньше символов чем искомая строка и избежать лишних проверок. И вложенного цикла, который имеет в себе логику сравнения символов.
Если символы равны, то продолжаем сравнивать символы из строки с искомой строкой до тех пор пока не найдем несовпадающие символы, как только такие находятся выходим из вложенного цикла и повторяем сравнения повторно.
Вторая проверка срабатывает в случае, если мы дошли до конца, и все значения совпали, то мы возвращаем индекс первого символа искомого слова в строке. В противном случае возвращаем -1, что означает что строка не найдена.
Плюсы использования:
Простота реализации и понимания;
Работает для любых типов данных, включая текстовые, числовые и т.д.
Минусы использования:
“Алгоритм Робина — Карпа”
Алгоритм Робина — Карпа является одним из эффективных алгоритмов поиска, он основан на концепции хеширования.
Принцип работы алгоритма заключается в следующем:
Сначала происходит вычисление хешей для первого окна тестов строки и подстроки;
Далее происходит последовательное сравнение хешей. Если хеши совпадают, то происходит дополнительное сравнение посимвольно. Если совпадение найдено — алгоритм завершается;
Если совпадение не найдено- вычисляется хеш-значение следующей подстроки путем сдвига окна на один символ вправо и вычисления хеш-значения для новой подстроки;
const findStr = (haystack, needle) => {
const haystackLen = haystack.length
const needleLen = needle.length
const prime = 101
const d = 256
let haystackHash = 0
let needleHash = 0
let fastHash = 1
// Цикл 1
for (let i = 0; i < needleLen - 1; i++) {
fastHash = (fastHash * d) % prime
}
// Цикл 2
for (let i = 0; i < needleLen; i++) {
haystackHash = (d * haystackHash + haystack. (needleLen-1) % prime.
2-й цикл просто вычисляет хеш для строки и подстроки. Ну а в 3-м цикле происходят поиск совпадений. Если значения хешей совпадают то, проверяем их по отдельности, если встречается не совпадение, то выходим из цикла и повторяем поиск совпадений, если же все символы совпали, то просто вернем индекс первого элемента.
Если значения хешей не совпадают, то вычисляем значения хеша нового окна для следующего сравнения и повторяем поиск совпадений.
Плюсы использования:

Быстрый поиск подстроки в среднем случае, особенно для длинных строк и подстрок;
Возможность эффективного поиска нескольких подстрок сразу, используя одинаковый хеш-код для всех искомых подстрок;
Хеширование позволяет пропустить множество неподходящих подстрок, сокращая количество необходимых сравнений;
Минусы использования:
В некоторых случаях, например, при использовании простых хеш-функций, возможны ложные совпадения, которые необходимо дополнительно проверять посимвольно;
Необходимость выбора эффективной хеш-функции, которая не только быстро вычисляет хеш-значения, но и максимально равномерно распределяет их по всем возможным значениям;
Если встречаются слишком маленькие или слишком большие хеш-значения, то может возникнуть проблема переполнения, которую необходимо обрабатывать;
Подробнее можно почитать тут
“Алгоритм Кнута - Морриса - Пратта (КМП)”
На данный момент этот алгоритм считается самы быстрым, так как он выполняется за линейное время.
Поиск вхождений гена в последовательности ДНК;
Автодополнение в поисковых движках;
Распознавание сигналов в цифровой обработке сигналов;
Ну а теперь перейдем к самому алгоритму. Алгоритм KMP строит таблицу префиксов (это основная часть алгоритма) для подстроки и использует ее для определения наилучшей позиции для продолжения поиска, когда происходит несовпадение символов.
Таблица префиксов - содержит информацию о наибольшем префиксе, который одновременно является суффиксом (т.е. подстрокой, которая начинается с начала строки) этого элемента.
Вот пример реализации префикс функции:
const prefix = (str) => {
const n = str.length
const p = Array(n).fill(0)
let i = 1, j = 0
while (i < str.length) {
if (str[i] === str[j]) {
p[i] = j + 1
i ++
j ++
} else {
if (j === 0) {
p[i] = 0
i ++
} else {
j = p[j - 1]
}
}
}
return p
}Пример: для строки "abcabcd" префикс функция будет выглядеть следующим образом:
[0, 0, 0, 1, 2, 3, 0], где первые три элемента равны 0, потому что ни один префикс не является суффиксом первых трех символов;
1, 2 и 3, потому что "a", "ab" и "abc" являются префиксами, которые также являются суффиксами; и наконец, последний элемент равен 0, потому что "abcabc" является префиксом строки "abcabcd", но не является суффиксом последнего элемента "d".
После того, как реализована префикс-функция можно прейти к реализации алгоритма поиска. Суть алгоритма заключается в сравнении символов строки и подстроки, в случае если символы не равны- мы берем значение из таблицы префиксов и используем его как индекс для перехода, таким образом, мы можем пропускать некоторое количество символов, что позволяет быстрее найти нужную подстроку.
const findStr = (str, searchString) => {
const searchStringPrefix = prefix(searchString)
let i = 0, j = 0
while (i < str.length) {
if (str[i] === searchString[j]) {
j ++
i ++
if (j === searchString.length) {
return i - searchString.length
}
} else {
if (j > 0) {
j = searchStringPrefix[j - 1]
} else {
i ++
}
}
}
if (i === str.length && j !== searchString.length) {
return -1
}
}Плюсы использования:
Линейное время выполнения: O(n+m), где n - длина строки, m - длина подстроки;
Эффективно обрабатывает большие тексты с множеством вхождений;
Минусы использования:
Требует заранее построенной таблицы префиксов, что может занять O(m) времени и O(m) памяти;
Может быть сложным для понимания и реализации, особенно для новичков в программировании;
Также хочу отметить, что КМП дает выигрыш только в случае если в таблицы префиксов есть положительные значения. Лишь в этом случае указатель будет сдвигается более чем на единицу. Но даже в случае “всех нулей” в таблице поиск работает достаточно неплохо.
Лишь в этом случае указатель будет сдвигается более чем на единицу. Но даже в случае “всех нулей” в таблице поиск работает достаточно неплохо.
Подробнее про то, как реализована префикс-функция и сам алгоритм можно посмотреть тут
Уже перед публикацией нашел несколько статей про алгоритмы поиска, где автор очень подробно описал, как они работают и привел примеры скорости работы:
Алгоритм Кнута - Морриса - Пратта
Алгоритм Бойера - Мура
Алгоритм Рабина - Карпа
Надеюсь, эта статья была для Вас полезна. Спасибо!
Извлечение символов из строки | Основы JavaScript
Для перемещения по курсу нужно зарегистрироваться
1. Введение ↳ теория
2. Hello, World! ↳ теория / тесты / упражнение
3. Инструкции ↳ теория / тесты / упражнение
4. Арифметические операции ↳ теория / тесты / упражнение
5. Ошибки оформления (синтаксиса и линтера) ↳ теория / тесты / упражнение
6. Строки ↳ теория / тесты / упражнение
7. Переменные ↳ теория / тесты / упражнение
8. Выражения в определениях
↳
теория
/
тесты
/
упражнение
Выражения в определениях
↳
теория
/
тесты
/
упражнение
9. Именование ↳ теория / тесты / упражнение
10. Интерполяция ↳ теория / тесты / упражнение
11. Извлечение символов из строки ↳ теория / тесты / упражнение
12. Типы данных ↳ теория / тесты / упражнение
13. Неизменяемость и примитивные типы ↳ теория / тесты / упражнение
14. Функции и их вызов ↳ теория / тесты / упражнение
15. Сигнатура функции ↳ теория / тесты / упражнение
16. Вызов функции — выражение ↳ теория / тесты / упражнение
17. Функции с переменным числом параметров ↳ теория / тесты / упражнение
18. Детерминированность ↳ теория / тесты / упражнение
19. Стандартная библиотека ↳ теория / тесты / упражнение
20. Свойства и методы ↳ теория / тесты / упражнение
21. Цепочка вызовов ↳ теория / тесты / упражнение
22. Определение функций ↳ теория / тесты / упражнение
23. Возврат значений ↳ теория / тесты / упражнение
24. Параметры функций ↳ теория / тесты / упражнение
25. Необязательные параметры функций
↳
теория
/
тесты
/
упражнение
Необязательные параметры функций
↳
теория
/
тесты
/
упражнение
26. Упрощенный синтаксис функций ↳ теория / тесты / упражнение
27. Логика ↳ теория / тесты / упражнение
28. Логические операторы ↳ теория / тесты / упражнение
29. Результат логических операций ↳ теория / тесты / упражнение
30. Условные конструкции ↳ теория / тесты / упражнение
31. Тернарный оператор ↳ теория / тесты / упражнение
32. Конструкция Switch ↳ теория / тесты / упражнение
33. Цикл while ↳ теория / тесты / упражнение
34. Агрегация данных ↳ теория / тесты / упражнение
35. Обход строк в цикле ↳ теория / тесты / упражнение
36. Условия внутри тела цикла ↳ теория / тесты / упражнение
37. Инкремент и декремент ↳ теория / тесты / упражнение
38. Цикл for ↳ теория / тесты / упражнение
39. Модули ↳ теория / тесты / упражнение
Испытания
1. Счастливый билет
2. Инвертированный регистр
3. Счастливые числа
4. Фибоначчи
5. Фасад
Фасад
6. Идеальные числа
7. Переворот числа
8. Найди Fizz и Buzz
Порой обучение продвигается с трудом. Сложная теория, непонятные задания… Хочется бросить. Не сдавайтесь, все сложности можно преодолеть. Рассказываем, как
Не понятна формулировка, нашли опечатку?
Выделите текст, нажмите ctrl + enter и опишите проблему, затем отправьте нам. В течение нескольких дней мы улучшим формулировку или исправим опечатку
Что-то не получается в уроке?
Загляните в раздел «Обсуждение»:
- Изучите вопросы, которые задавали по уроку другие студенты — возможно, ответ на ваш уже есть
- Если вопросы остались, задайте свой. Расскажите, что непонятно или сложно, дайте ссылку на ваше решение. Обратите внимание — команда поддержки не отвечает на вопросы по коду, но поможет разобраться с заданием или выводом тестов
- Мы отвечаем на сообщения в течение 2-3 дней. К «Обсуждениям» могут подключаться и другие студенты. Возможно, получится решить вопрос быстрее!
Подробнее о том, как задавать вопросы по уроку
Javascript String Search() - Темы масштабирования
Обзор
JavaScript является одним из самых популярных языков сценариев из-за множества предлагаемых им встроенных методов. Одним из самых утилитарных методов, предлагаемых JavaScript, является метод JavaScript string.search().
Одним из самых утилитарных методов, предлагаемых JavaScript, является метод JavaScript string.search().
Scope
В этой статье мы рассмотрим метод search() в JavaScript. Мы будем искать, используя строку JavaScript search(). Мы также обсудим регулярные выражения, передаваемые в качестве параметров. Были обсуждены все варианты использования строки search() JavaScript, а также совместимость и спецификация браузера.
Знакомство с search() String JavaScript
Предположим, вы прочитали очень интересный и вдохновляющий сборник рассказов. Где-то в рассказе была цитата, которую вы оценили. Вы хотите переместить эту цитату и подчеркнуть ее для дальнейшего использования. Даже если вы знаете, что цитата находится где-то в книге, вам, вероятно, будет трудно ее найти. Возможно, вам даже придется прочитать всю книгу заново. Человеческая ошибка и небрежность неизбежно мешают процессу поиска.
Однако компьютер не склонен к ошибкам. Он обязан проводить безупречный поиск и давать точные результаты.
Он обязан проводить безупречный поиск и давать точные результаты.
Сопоставляя записную книжку с определенной строкой или выражением, методы JavaScript, такие как search(), можно использовать для поиска регулярного выражения в заданной строке.
Проще говоря, search() — это метод JavaScript объекта String, используемый для определения наличия и положения начальной точки совпадающего шаблона или регулярного выражения в предоставленных текстовых данных.
Параметры и аргументы
Регулярные выражения
Регулярное выражение (также называемое регулярным выражением) представляет собой набор символов, создающий шаблон поиска. Упомянутый ниже пример регулярного выражения можно использовать для обозначения данных, которые вы ищете в тексте. Он используется для выполнения функций поиска и замены в тексте. Например:
Этот пример регулярного выражения можно использовать для шифрования и сопоставления с образцом.
Таблица параметров
Ниже приведен список параметров регулярного выражения, которые могут быть переданы в метод search(). 9
9



Синтаксис
Вот синтаксис для использования метода search().
В вышеупомянутом синтаксисе регулярное выражение или регулярное выражение передается в метод search() в качестве параметра. Цель приведенного выше кода — найти регулярное выражение ( regexp ) в заданной строке с именем str . Регулярное выражение хранится как объект.
Если в качестве параметра передается объект, не являющийся регулярным выражением, он сначала преобразуется в объект регулярного выражения.
Этот синтаксис показывает, как нерегулярное выражение может быть преобразовано в новое регулярное выражение.
Возвращаемые значения
Поскольку метод search() используется для поиска индекса совпавшего регулярного выражения, возвращаемое значение — это число, соответствующее индексу регулярного выражения (строки в JavaScript имеют индекс 0).
Если для выражения найдено совпадение, возвращаемое значение является индексом.
Если совпадение в строке не найдено, возвращается значение -1.
Описание
Строковый метод JavaScript search() используется, когда необходимо идентифицировать шаблон символов в заданной строке. Следовательно, search() используется, когда пользователь хочет узнать, найден шаблон или нет, и если найден, то индекс начала шаблона в строке.
Если пользователь хочет только узнать, присутствует шаблон или нет, метод test() можно использовать для регулярного выражения . Возвращается логическое значение.
Здесь regexp — это регулярное выражение, наличие которого мы будем проверять в строке.
| search() | test() |
|---|---|
| search() используется, когда необходимо знать положение индекса регулярного выражения. | test() используется, когда необходимо знать только наличие регулярного выражения. |
| search() возвращает числовое значение | test() возвращает логическое значение. |
Для более описательного вывода также можно использовать метод match(). Однако эта дополнительная информация значительно увеличивает время выполнения по сравнению с test() или search() в JavaScript.
Здесь строка — это входная строка, в которой должно находиться регулярное выражение.
Альтернативой строке search() в JavaScript может быть метод indexOf() в JavaScript.
Здесь searchval — это строка, которую нужно найти в заданной строке, а start обозначает позицию, с которой нужно начать поиск. Если этот параметр не указан, он принимается равным 0. indexOf не может принимать регулярные выражения.
indexOf не может принимать регулярные выражения.
Примеры
Вот несколько примеров, чтобы понять работу строкового метода JavaScript search().
Пример 1:
Рассмотрим типичный пример поиска выражения is в заданной строке и вывода его индекса.
Вывод кода выше: 14 Помните, что индекс первого символа равен 0, а не 1.
Пример 2:
Рассмотрим типичный пример поиска выражения, отсутствующего в заданной строке.
Вывод кода выше: -1 Это очевидно потому, что буква «z» нигде не присутствует во входной строке.
Пример 3
Давайте рассмотрим типичный пример, чтобы определить, что метод search() чувствителен к регистру.
Вывод кода выше: 46
Обратите внимание, что индекс был бы равен 3, если бы пользователь искал l. Однако, поскольку пользователь ищет строку, начинающуюся с буквы L, правильный индекс равен 46.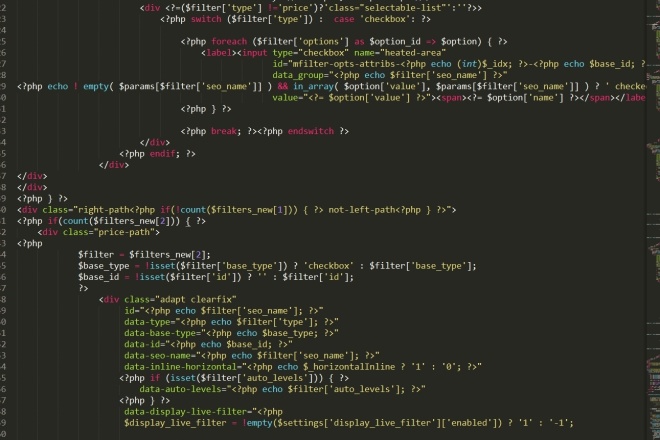
Поведение с учетом регистра можно игнорировать с помощью флагов игнорирования. Это только часть ввода регулярного выражения, и его нельзя использовать со строками.
Например:
Вывод кода выше: 3 'i' означает флаг игнорирования, который игнорирует чувствительность к регистру.
Способ вывода с учетом регистра:
Обратите внимание, что регулярные выражения могут содержать символы разных типов для сопоставления с образцом. Вывод кода выше: 0
Это потому, что первая заглавная буква в последовательности A-Z является первым символом строки. Чтобы игнорировать чувствительность к регистру в строках, можно использовать метод indexOf.
Если текст является строкой, она сначала будет преобразована во все символы нижнего регистра, а затем будет оценен индекс регулярного выражения. Это помогает игнорировать чувствительность к регистру.
Пример 4
Давайте рассмотрим типичный пример, чтобы определить, что в случае нескольких вхождений регулярного выражения функция search() рассматривает только первое вхождение регулярного выражения .
Вывод кода выше: 2 . Это первое вхождение строки 'a'.
Спецификация
Спецификация языка ECMAScript (ECMAScript): String.prototype.search()
Здесь метод search() выполняет поиск соответствия между регулярным выражением и этим объектом String.
Совместимость с браузерами
Браузеры, поддерживающие метод search() в JavaScript:
- Google Chrome версии 1 и выше
- Microsoft Edge версии 12 и выше
- Firefox версии 1 и выше
- Internet Explorer версии 4 и выше
- Opera версии 4 и выше
- Safari-версии 1 и выше
- WebView Android версии 1 и выше
- Chrome Android версии 18 и выше
- Safari на iOS версии 1 и выше
Заключение
- Search() — это метод JavaScript для определения наличия и индекса регулярного выражения в строке.
- Возвращает индекс нужного регулярного выражения.
- Если регулярное выражение отсутствует в строке, возвращается -1.
- Если пользователь хочет только узнать, присутствует шаблон или нет, вместо метода search() можно использовать метод test().
- Метод search() чувствителен к регистру.

Поиск строки в строке с помощью Vanilla JavaScript
Поиск подстроки в строке можно выполнить различными способами в зависимости от ваших потребностей.
JavaScript предоставляет собственные методы для обработки различных случаев. Давайте посмотрим на них и попробуем понять, как они работают.
Чтобы найти строку в строке, вы можете использовать один из собственных методов JavaScript String.
-
включает метод -
indexOfметод -
поискметод -
соответствиеметод -
matchAllметод -
начинается с метода -
заканчивается методом
1.
 включает метод
включает метод включает метод , который выполняет с учетом регистра поиск в целевой строке и определит, содержит ли она строку для поиска. Он вернет логическое значение.
const text = 'Всемирная паутина широко известна как паутина'
text.includes('мир') // ложь
text.includes('Мир') // правда
включает метод принимает два аргумента searchString и position .
searchString — строковое значение для поиска.
позиция — необязательный аргумент, определяющий начальную позицию в строке, с которой следует начинать поиск (значение по умолчанию — 0).
ПРИМЕЧАНИЕ. Метод include просто сообщает вам, существует ли строка в целевой строке, но не указывает позицию.
Поддержка браузера : включает метод .
2. Метод indexOf
Метод indexOf проверяет первое вхождение заданного значения в строку и возвращает его индекс в виде целого числа. Если не найдено, возвращает -1. ПРИМЕЧАНИЕ. Этот метод чувствителен к регистру.
Если не найдено, возвращает -1. ПРИМЕЧАНИЕ. Этот метод чувствителен к регистру.
const text = 'Всемирная паутина широко известна как паутина'
text.indexOf('мир') // -1
text.indexOf('Мир') // 4
Метод indexOf принимает два аргумента searchValue и fromIndex .
searchValue — строковое значение для поиска.
fromIndex — необязательный аргумент, определяющий начальную позицию в строке, с которой следует начинать поиск (значение по умолчанию — 0).
Поддержка браузера : метод indexOf.
3. метод поиска
Метод поиска выполняет сопоставление между регулярным выражением и целевой строкой. Он возвращает свой индекс как целое число. Если не найдено, возвращает -1.
const text = 'Всемирная паутина широко известна как паутина' const regExpSensitive = /мир/г const regExpInsensitive = /world/gi text.search(regExpSensitive) // -1 text.
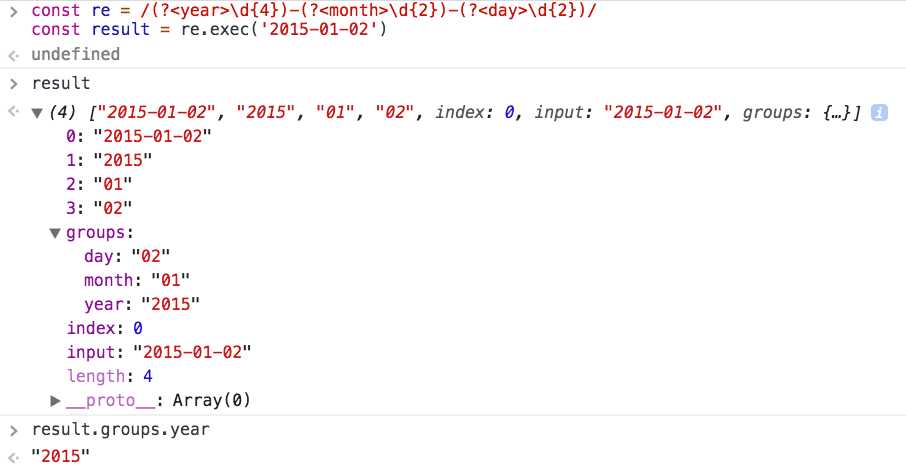 search(regExpInsensitive) // 4
search(regExpInsensitive) // 4
9Метод 0464 search принимает только один аргумент regexp , который является регулярным выражением.
Для составления и тестирования регулярных выражений вы можете использовать инструмент regex101.
Поддержка браузера : метод поиска.
4. метод match
Метод match проверяет строку на соответствие регулярному выражению и возвращает массив найденных строк на основе флагов регулярного выражения. Если строка не найдена, будет возвращено значение null.
const text = 'Всемирная паутина широко известна как паутина' text.match(/Мир/) // [ // 0: "Мир", // группы: не определено, // индекс: 4, // input: "Всемирная паутина широко известна как паутина" // ] text.match(/world/) // ноль
Метод search принимает только один аргумент regexp , который является регулярным выражением.
Поддержка браузера : метод сопоставления.
5. Метод matchAll
Метод matchAll возвращает итератор всех вхождений строки, которые соответствуют параметру регулярного выражения.
const text = 'Всемирная паутина широко известна как паутина' // используем синтаксис расширения, чтобы получить результаты в виде массива // 1. С учетом регистра [...текст.matchAll(/web/g)] // [ // ["сеть", groups: undefined,index: 44, input: "Всемирная паутина широко известна как паутина"] // ] // 2. Регистронезависимый [...text.matchAll(/web/gi)] // [ // ["Сеть", индекс: 15, ввод: "Всемирная паутина широко известна как сеть", группы: не определены], // ["сеть", индекс: 44, ввод: "Всемирная паутина широко известна как сеть", группы: не определены] // ]
Поддержка браузера : метод matchAll.
6. Метод opensWith
Метод opensWith() проверяет, начинается ли строка с указанного символа. Возвращает true , если строка начинается с символа, иначе возвращает false .
const text = 'Всемирная паутина широко известна как паутина'
text.startsWith('The') // правда
text.startsWith('Мир') // правда
text.startsWith('Мир', 0) // правда
text.startsWith('The', 1) // ложь
text.startsWith('the') // ложь
text.startsWith('Мир') // ложь
Метод opensWith() принимает два аргумента searchString и position .
searchString — это искомый символ.
Позиция является необязательным аргументом и представляет индекс, с которого следует начать поиск. Значение по умолчанию: 0 .
Поддержка браузера : метод startWith.
7. Метод endWith
Метод endWith() проверяет, заканчивается ли строка указанным символом. Он возвращает true , если строка заканчивается символом, в противном случае возвращается false .
const text = 'Всемирная паутина широко известна как паутина' text.
