что это, виды, как устроена
Поисковая система (ПС) — это набор алгоритмов, позволяющих проводить поиск в интернете. Характерная особенность ПС — мгновенное нахождение информации по конкретной фразе или определенному слову. Благодаря процессу индексирования она способна сканировать и затем извлекать данные из миллионов документов. И все это — за считанные миллисекунды.
Присоединяйтесь к нашему Telegram-каналу!
- Теперь Вы можете читать последние новости из мира интернет-маркетинга в мессенджере Telegram на своём мобильном телефоне.
- Для этого вам необходимо подписаться на наш канал.
История поисковых систем
Первой ПС принято считать W3Catalog — она появилась в 1993 году. W3Catalog представлял из себя не классическую поисковую машину (ПМ), а скорее обычный каталог, содержащий списки сайтов / адресов. Полноценная ПМ в интернете появилась в 1994 году: и это была вовсе не Google, а Aliweb 🙂
 Пример сайтов — в разделе Media and Entertainment
Пример сайтов — в разделе Media and Entertainment
Aliweb первой в мире начала обрабатывать контент сайтов: сканировать, индексировать его, перемещая в собственный индекс.
Так выглядел Aliweb в 1995 годуНо даже у Aliweb еще не было краулеров в привычном для нас понимании, т. е. для автоматического сканирования всех новых страниц. Информацию о новых сайтах добавляли сами вебмастеры: они указывали названия и ключевые слова для каждой страницы в общую базу данных (БД), которую позже и сканировал Aliweb.
За несколько десятилетий было создано свыше тысячи разнообразных ПС. Лишь десятки из них сумели дойти до наших дней и остаются работоспособными сегодня. Самыми популярными поисковыми системами в России уже долгие годы остается Google и «Яндекс».
Как устроены поисковые системы
Если проводить аналогию с нецифровым миром, ПС — это картотека в библиотеке, где у каждой книги есть свой уникальный номер. По этому номеру ее можно найти в каталоге.
По этому номеру ее можно найти в каталоге.
Упрощенный алгоритм работы таков:
- Пользователь указывает поисковый запрос.
- ПС анализирует весь ранее собранный индекс и находит документы, которые ему максимально релевантны.
- Наиболее релевантные документы сортируются: от наиболее близких поисковому запросу к наименее.
- Результаты выводятся на странице поисковой выдачи.
Что такое краулер поисковой системы
Краулер — это специальная программа, используемая ПС для перехода по URL, которые он обнаруживает на веб-странице. Затем краулер помечает такие ссылки специальным образом.
Благодаря найденным URL поисковый робот находит все новые и новые страницы (о которых ПС не знала ранее)Последовательность работы ПС: этапы обработки документа
Поисковая система состоит из трех компонентов:
Далее поговорим о том, как индексирование документов помогает функционировать поисковым системам.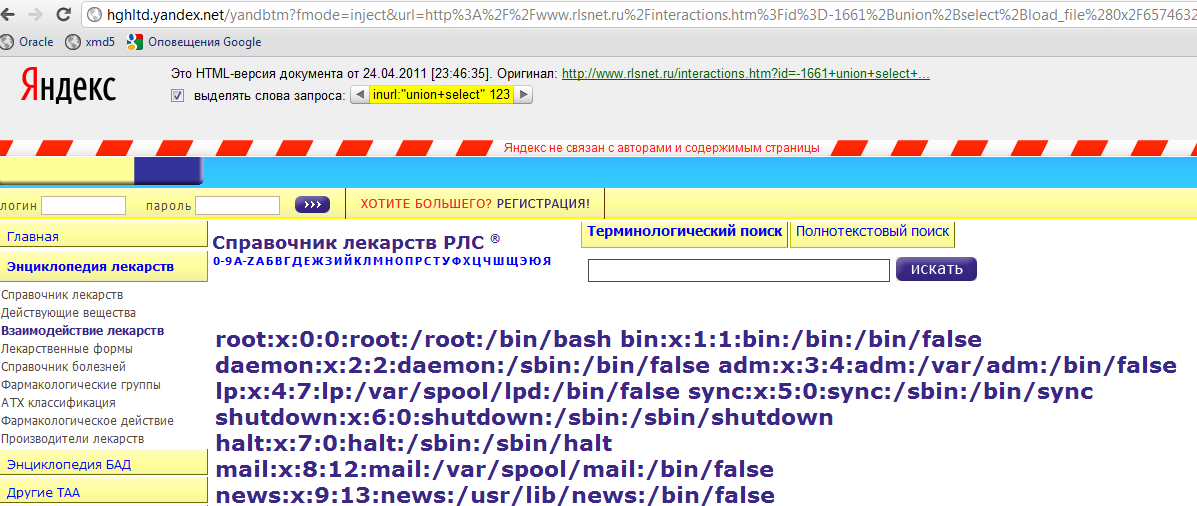
Зачем поисковым системам нужен индекс
Индекс по своей сути — это просто база данных, необходимая для ускорения поискового процесса: извлечения данных о документах, обработки и представлении результатов поиска пользователю. Любые данные из индексной БД «вынимаются» за миллисекунды, ведь в индексе ПС уже хранится информация обо всех страницах в интернете.
Индексация — извлечение важных для ПС данных и дальнейшая их конвертация в понятные поисковой системе форматы
Кэш поисковой системы нужен для ускорения экстракции данных (по аналогии, например, с разархивированием архива в WinRar) с ранее посещенных веб-страниц.
ПС хранят индекс не просто так: они обращаются к нему в дальнейшем, при работе с запросами. Так что хранить эту базу данных где-то, в любом случае, нужно.
Читайте также:
Индексация в поисковых системах: что это простыми словами
Как поисковые системы хранят индекс на своей стороне
Google хранит документы фрагментарно или полностью на своих серверах. Само хранение происходит в кэше (это отдельная память, обладающая высокой скоростью доступа). Другие поисковики хранят только определенные фразы или каждое слово и связывают его с документом в дальнейшем.
Само хранение происходит в кэше (это отдельная память, обладающая высокой скоростью доступа). Другие поисковики хранят только определенные фразы или каждое слово и связывают его с документом в дальнейшем.
Как ПС обновляют свой индекс и базы данных
В среде SEO-специалистов обновления индекса систем называются апдейтами выдачи. У каждой поисковой системы такие апдейты происходят по-разному. Google добавляет новые документы в свой индекс ежедневно, причем несколько раз в сутки. «Яндекс» действует по-другому — новые страницы попадают в индекс произвольно (апдейт происходит 2 раза в неделю, например).
Самыми важными факторами является суммарная релевантность ключевой фразы и подобранного документа, проработанность индекса и особенности морфологических параметров языка пользователя.
Виды поисковых систем
Выделим три классификации:
- По особенностям использования индекса.
- По типу индекса.
- По области поиска.
I По особенностям использования индекса
Безиндексные ПС
Это мультипотоковые системы, которые функционируют через крупные поисковые системы. Безиндексные системы просто агрегатируют их результаты поиска и проводят собственную сортировку.
Безиндексные системы просто агрегатируют их результаты поиска и проводят собственную сортировку.
Примеры: Bing (Microsoft Bing), AskNet, Quintura, Ixuick, MetaCrawler.
«Нигма» — самая известная российская метапоисковая система (ныне не существует)Классические поисковые машины
Еще говорят «поисковый движок», «поисковые машины с индексом». Пауки ПС сканируют все страницы в интернете, затем формируют собственный индекс (базы данных) с информацией о веб-документах. Поиск по БД в случае классической поисковой машины, условно, состоит из трех этапов:
- Нахождение наиболее релевантного поисковой фразе документа.
- Ранжирование остальных документов исходя из их суммарной релевантности.
- Кластеризация документов.
Кроме этих функций, маркер классической ПМ — разные методы поиска ссылок в ручном и автоматическом режимах. В первом случае их добавляют в поисковую машину сами вебмастеры, во втором — краулеры сканируют сеть самостоятельно.
Примеры: Google и «Яндекс».
Гибридные ПС
Относятся к классическим поисковым машинам, однако с неким допущением можно выделить их и в отдельную категорию.
Индекс здесь собирается не только за счет сканирования краулером ПС, но и благодаря пользовательским источникам данных: реестрам документов, каталогам, справочникам.
Примеры: Yahoo, «Яндекс», Google.
«Яндекс» — поисковая машина гибридного типаЧитайте также:
Отличия SEO под Яндекс и Google
Каталожные поисковые системы
Это пользовательские БД, где все данные добавляются вручную. Качество результатов поиска в таких ПС в теории должно быть заметно выше, чем в автогенерируемых системах.
Они могут выглядеть как рубрикатор заданной иерархии с большим количеством категорий и подкатегорий. Для каждого сайта указывается описание контента, заголовок и ссылка на страницу.
Примеры: Russia on the Net, AtRus, Yahoo!, Directory (сейчас некоторые уже не существуют).
II По типу индекса
В 2022 году массово распространены два типа ПС: с инвертированным индексом и с индексом, имеющим предопределенное расположение ключевых слов. Разница между ними легко прослеживается.
Инвертированный индекс (ИИ)
Для слов в наборе документов указаны все страницы в реестре, где они упоминались. В свою очередь, сам ИИ может быть двух видов:
- Лист документов для каждого слова.
- Лист документов для каждого слова + позиция слова в каждом веб-документе.
Пример: Google.
Индекс с предопределенным расположением ключевых слов (устаревший)
Все фразы упорядочены и отсортированы уже изначально по иерархическому принципу. В настоящий момент не известно ни одной крупной поисковой машины с этим типом индекса.
III По области поиска
Локальная ПС
Отдельностоящее ПО либо веб-приложение, которое разворачивается на компьютере пользователя и позволяет искать информацию, например, на жестком диске или в в пределах домашней сети.
Примеры: Tracker, Copernic Desktop Search.
Глобальная ПС
Веб-сайт / веб-приложение / сервис для поиска документов во всем интернете (или, например, в пределах конкретной доменной зоны).
Примеры: Google, Bing, Yandex, Baidu.
При этом они могут содержать в себе элементы локальных поисковых систем: например, поиск в определенной доменной зоне или поддержка китайского языка по умолчанию, как Baidu. Есть также национальные ПС, созданные для использования в конкретной стране — наши «Спутник» и «Поиск Mail.ru».
Также существуют поисковые системы для поиска информации только в определенных каналах. Например:
- на новостных сайтах;
- внутри FTP-хранилищ.
- в RSS-каналах;
- в библиотечных ресурсах;
- в интернет-магазинах;
Юзнет — это глобальная компьютерная сеть для интернет-дискуссий и публикации файлов, состоит из набора групп новостей, организованных по темам. Пользователи размещают статьи или сообщения в этих группах новостей. Затем эти материалы публикуются уже на других платформах.
Пользователи размещают статьи или сообщения в этих группах новостей. Затем эти материалы публикуются уже на других платформах.
Что нужно знать о поисковых системах вебмастеру и пользователю
Поисковая система — это сложный набор алгоритмов, которые работают внутри единой компьютерной программы.
Чтобы новая страница сайта отображалась в результатах поиска, она должна попасть в индекс. Краулеры ПС автоматически обходят все страницы в интернете, добавляя их в специальную базу данных. Обрабатывается также и содержимое страниц.
Читайте также:
Факторы ранжирования Google и «Яндекс»: что это и как работает
Поисковая выдача зависит от суммарной релевантности документа по отношению к запросу. У каждой ПС свои методы определения релевантности, и подробно о них узнать нельзя. Известно лишь об общих принципах оценки:
- Семантический анализ слов в запросе, включая слова в поисковых фразах вместе и по отдельности.

- Идентифицирование типа запроса.
- Интерпретация орфографических ошибок.
- Определение синонимичности запроса.
- Сопоставление поисковой фразы с особенностями языковой модели.
- Определение актуальности информации.
- Определение региональности запроса.

СДЕЛАЕМ САЙТ, КОТОРЫЙ НРАВИТСЯ ПОИСКОВЫМ СИСТЕМАМ
Сайт
Телефон
Что такое поисковый сервер (поисковая система) и как он работает
Сложно представить современную жизнь без поисковиков – как бы иначе мы искали и находили информацию? Однажды придуманная технология навсегда упростила процесс работы с данными.
Сегодня я расскажу, что же представляет собой поисковый сервер, а также объясню принцип его работы.
Что такое поисковая машина
Мы знаем, что поисковый сервер (его еще называют поисковой системой или поисковой машиной) – это сайт, на котором можно быстро найти любую информацию, будь то текст, картинку, видео и многое другое. Но это только красивая обертка. На самом деле это сложный механизм, комплекс программ и алгоритмов, который обрабатывает сотни миллионов пользовательских запросов в минуту. И при этом конкретному человеку результат всегда выводится за доли секунды.
Но это только красивая обертка. На самом деле это сложный механизм, комплекс программ и алгоритмов, который обрабатывает сотни миллионов пользовательских запросов в минуту. И при этом конкретному человеку результат всегда выводится за доли секунды.
Архитектура большинства поисковых машин включает в себя, грубо говоря, три элемента:
- робота, который ищет в интернете данные по ключевому запросу;
- индексатор, который отвечает за сбор сведений о ресурсах в базу данных сервиса;
- графический интерфейс, через который осуществляется взаимодействие с пользователем.
Так работает поисковая машина, использующая специального робота. Но есть и другие виды поисковых машин:
- Управляемая человеком (каталог сайтов). Вся информация в этой системе обновляется людьми. Преимущество системы состоит именно в качественности контента, а недостаток в том, что данные каталогов могут не соответствовать реальному положению дел. К числу таких каталогов относятся dmoz и Galaxy.
- Гибридная система. В таких машинах поиском управляют и специальные роботы, и люди. В качестве примера можно привести Yahoo, Google и MSN.
- Мета-система. Она не имеет собственной базы данных и предоставляет результаты сразу нескольких поисковиков, объединяя их по определенному признаку. Казалось бы, эти машины должны предоставлять пользователю более полную картину, но минус в том, что их механизмы не способны анализировать формы запросов или полностью переводить синтаксис. В итоге ссылки с оплатой за клик часто отображаются первыми. Яркие примеры таких систем – Skyscanner, Kayak.com и Excite.

Во всем мире наиболее популярен поисковый сервер Google (92%). В России лидирующую позицию занимает Яндекс (52,56%).
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
Как работает поисковый сервер
Вроде бы все просто – ввели слово или фразу по интересующей теме, запустили поиск, получаете результаты. Но за всем этим стоят тысячи алгоритмов – они анализируют миллиарды страниц, убирают лишнее и ранжируют сведения в списки по наиболее точному соответствию запросу.
Но за всем этим стоят тысячи алгоритмов – они анализируют миллиарды страниц, убирают лишнее и ранжируют сведения в списки по наиболее точному соответствию запросу.
Но кто сказал, что машина сразу же ищет в интернете информацию после введения запроса пользователем? Картина обстоит совсем иначе – поисковый сервер (сказать точнее, его индексатор) по определенным правилам обрабатывает содержимое сайтов в интернете и собирает по ним сведения в собственную базу данных. А уже потом, когда пользователь введет запрос, сервер обратится к этой самой базе и выведет из нее наиболее релевантную информацию. Отсюда и высокая скорость вывода результатов (пример на скриншоте ниже).
И вот ведь в чем вся соль – все, что делается для SEO-продвижения, направлено именно на то, чтобы «угодить» индексатору. Эта штука при выводе сайта учитывает кучу параметров, в числе которых:
- Наличие ключевых слов в названии сайта или заголовке страницы.
- Индекс цитирования анализируемого ресурса – количество ссылок на него в интернете. Чем их больше, тем выше вероятность отображения сайта в результатах выдачи.
- Частота повторения ключевых слов. Тут главное не переборщить – если ключевых фраз будет слишком много, страница будет отмечена как «заспамленная».
- Оформление, верстка. Учитывается даже то, как написан код.
- Возраст ресурса. Чем этот показатель выше, тем больше уровень «доверия» поисковика. Возрастные домены еще называют трастовыми.
- Тематика как определенной страницы, так и всего ресурса.
- Уникальность текста, изображений и прочих файлов.
 Чем их больше, тем выше вероятность отображения сайта в результатах выдачи.
Чем их больше, тем выше вероятность отображения сайта в результатах выдачи.Существуют, конечно, способы управления индексацией, например, теги noindex и nofollow закрывают определенное содержимое на сайте от роботов. Еще можно выставить запрет на индексацию всей страницы – для этого используется файл robots.txt с директивами Disallow, Allow, Crawl-delay, User-agent и т.д.
Со временем содержимое сайта может меняться, а индексатор не всегда успевает обрабатывать и вводить в свою базу данных эти самые изменения. Кроме того, на индексацию порой уходит несколько недель, иногда и больше – это зависит от алгоритма обработки информации на конкретном сервере. Соответственно, «свежие» страницы сразу в выдаче появляться не будут.
Кроме того, на индексацию порой уходит несколько недель, иногда и больше – это зависит от алгоритма обработки информации на конкретном сервере. Соответственно, «свежие» страницы сразу в выдаче появляться не будут.
Поисковые сети борются с этим явлением разными способами. Например, новостные ленты анализируются чаще. В Яндекс.Вебмастере и Google Search Console есть специальный инструмент для переобхода страниц.
Теперь вернемся к пользователю – вот он ввел запрос и отправил его на обработку. Далее за дело берется система выдачи результатов. Она анализирует ключевые слова и ищет в базе данных подходящие страницы. Все параметры, которые я указала ранее, типа индекса цитирования и заспамленности, тоже учитываются при ранжировании.
Как искать информацию в поисковых системах
Суть работы машины – найти по конкретному запросу пользователя наиболее точные (релевантные) страницы. Но чтобы вышло именно то, что нужно, необходимо максимально правильно сформулировать ключевое слово. Можно воспользоваться несколькими такими словами, составлять из них фразы, также применять различные фильтры и инструменты в интерфейсе поисковика.
Можно воспользоваться несколькими такими словами, составлять из них фразы, также применять различные фильтры и инструменты в интерфейсе поисковика.
Как правильно формулировать запрос? Тут все неоднозначно. Вы можете в половине слов допустить ошибки, но поисковые системы, благодаря использованию современных языковых технологий, все равно распознают, что именно надо найти, и предоставят верные результаты. Еще нет разницы, в каком регистре вводится запрос – результаты во всех случаях будут идентичными.
Для поиска информации на русском языке идеально подойдут Яндекс и Google. А вот если потребуется найти что-то на иностранном языке, то с этим лучше справится Google.
Поисковые машины получают влияние и власть
ПолитикаБез поисковых машин в безграничном информационном пространстве никак не обойтись. Но стоит ли слепо верить в их объективность? Вопрос обсудили в Берлине.
С помощью ключевых слов поисковые машины выуживают из неиссякающего информационного потока представляющие интерес веб-страницы и выстраивают их по прядку в зависимости — по крайней мере, в теории — от важности или точности попадания. Как это делают поисковые машины, снаружи не видно. Чем крупнее и состоятельнее компания, которой принадлежит такой портал, тем больше у нее критиков: особенно у таких гигантов, как Google, Yahoo и майкрософтовский MSN. Их обвиняют в необъективной избирательности. Растущую власть сетевых поисковиков и их влияние на актуальную информационную политику обсуждали участники международного симпозиума, который проходил на этой неделе в Берлине.
Как это делают поисковые машины, снаружи не видно. Чем крупнее и состоятельнее компания, которой принадлежит такой портал, тем больше у нее критиков: особенно у таких гигантов, как Google, Yahoo и майкрософтовский MSN. Их обвиняют в необъективной избирательности. Растущую власть сетевых поисковиков и их влияние на актуальную информационную политику обсуждали участники международного симпозиума, который проходил на этой неделе в Берлине.
Проводил симпозиум близкий Социал-демократической партии Германии фонд имени Фридриха Эберта.
Демократизация доступа к информации
Архив «штази» в БерлинеФото: APДо появления цифровых СМИ отбор фактов производили по традиции журналисты и издатели. Сегодня информационный поток фильтруют электронные поисковые машины. Крупнейшие из них — находящиеся в частном владении гиганты Google, Yahoo и MSN — доминируют на глобальном рынке и перекрывают практически весь воздух своим конкурентам.
Представитель компании Google из Лондона Рашель Ветстоун не видит в этом ничего предосудительного. На симпозиуме в Берлине она сказала: «В настоящий момент мы исходим из того, что всего десять процентов глобального знания присутствует в электронной сети. Но информационный поток постоянно растет и вместе с ним — значение электронных поисковых машин, если хотите, их влияние и власть. Разумеется, это предполагает и повышенную ответственность, которую мы в Google, безусловно, готовы нести. Преимущество лежит, и это очевидно, в демократизации доступа к информации. Традиционно доступ к информации имели богатые и образованные. Теперь же можно задать пару ключевых слов в поисковую машину — и вы уже у цели.»
На симпозиуме в Берлине она сказала: «В настоящий момент мы исходим из того, что всего десять процентов глобального знания присутствует в электронной сети. Но информационный поток постоянно растет и вместе с ним — значение электронных поисковых машин, если хотите, их влияние и власть. Разумеется, это предполагает и повышенную ответственность, которую мы в Google, безусловно, готовы нести. Преимущество лежит, и это очевидно, в демократизации доступа к информации. Традиционно доступ к информации имели богатые и образованные. Теперь же можно задать пару ключевых слов в поисковую машину — и вы уже у цели.»
Уповая на компетентность пользователя
Интернет-кафе в КитаеФото: APНо ведь принадлежат три главные поисковые машины компаниям, которые заинтересованы в получении максимальной прибыли. И это дает повод для беспокойства. Вымываемые поисковыми машинами мириады рекламных страниц также влияют на построение иерархических списков. При этом нет никакой гарантии, что найденная информация соответствует действительности и не является заведомо ложной. Представитель Google Рашель Ветстоун и в этом не видит большой беды, полагаясь на компетентность пользователя, который в состоянии отличить хорошие сервисные источники от плохих, истинную информацию от ложной.
Представитель Google Рашель Ветстоун и в этом не видит большой беды, полагаясь на компетентность пользователя, который в состоянии отличить хорошие сервисные источники от плохих, истинную информацию от ложной.
Критичность в пользовании электронными СМИ повышается, разумеется, с ростом образовательного уровня пользователя, отмечает Рашель Ветстоун. «В таких странах, например, как Великобритания, где 40 процентов жителей имеют диплом о высшем образовании», — уточняет она.
Анализ ключевых слов, задаваемых в поисковые машины в последнее время, показывает, что 25 процентов из них впервые вызвали интерес у пользователей, сообщила Рашель Ветстоун. «Речь идет не о бесчисленных вариантах написаниях слова «секс»! Люди проявляют любопытство и расширяют свой кругозор во многих областях знания. Эффект от поисковых машин поэтому не усыпляющий, а усиливающий любопытство пользователя».
Избирательность поисковых машин
Иного мнения о поисковых машинах придерживается другой участник берлинской конференции — депутат бундестага от оппозиционной партии «зеленых» Гритье Беттин (Grietje Bettin). Она стоит на стороне тех политиков, кого совсем не прельщает фактическая монополия Google. «80 процентов пользователей ищут информацию с помощью Google», — отметила Беттин, напомнив, что даже в толковом словаре немецкого языка уже появился глагол «гуглить» (googeln).
Она стоит на стороне тех политиков, кого совсем не прельщает фактическая монополия Google. «80 процентов пользователей ищут информацию с помощью Google», — отметила Беттин, напомнив, что даже в толковом словаре немецкого языка уже появился глагол «гуглить» (googeln).
Проблематичным политик считает то, что в восприятии пользователя поисковые машины предстают нейтральными инстанциями. Пользователь убежден, что надежный и непредвзятый математический алгоритм поиска выдает оптимальный результат. Бесчисленные беседы показывают, насколько широко распространено это заблуждение, отмечает Гритье Беттин. А ведь стоит только задать определенные ключевые слова в поисковые машины, говорит она, как становится ясно, что одни поисковые машины обращаются с ними иначе, чем другие.
«Поисковые машины не только дают доступ к информации, они решают также, какую информацию и в каком порядке показывать, а какую не показывать вообще», — предостерегает политик.
Альтернатива частным поисковикам
Журналисты, которые в силу бюджетных ограничений, вынуждены пользоваться исключительно Google и подобными поисковыми машинами, в глазах Гритье Беттин не могут претендовать на объективность. Политик требует создания альтернативной поисковой машины — общественной, — результаты поисков которой регулярно проверяли бы компетентные эксперты. Таким образом, утверждает Беттин, можно было бы ограничить практику злоупотребления частными данными пользователей в коммерческих целях. Не ясно, однако, на какие средства может существовать подобный проект.
Политик требует создания альтернативной поисковой машины — общественной, — результаты поисков которой регулярно проверяли бы компетентные эксперты. Таким образом, утверждает Беттин, можно было бы ограничить практику злоупотребления частными данными пользователей в коммерческих целях. Не ясно, однако, на какие средства может существовать подобный проект.
Google зато не знает проблем с финансированием. Уже сейчас компания является самой богатой в медийном мире, оставляя за собой таких гигантов, как Time Warner. Ее стоимость оценивается в 80 миллиардов долларов. Вряд ли какая-нибудь общественная поисковая машина сможет когда-либо стать конкурентом Google и ему подобным.
Поисковые машины (Search engine) — Мировые информационные ресурсы (Информатика и программирование)
Поисковые машины (Search engine)
Поисковые машины позволяют найти WWW-документы, относящиеся к заданным тематикам или снабженные ключевыми словами или их комбинациями. На поисковых серверах отрабатываются два способа поиска:
· По иерархии понятий;
· По ключевым словам.
Заполнение поисковых серверов происходит автоматически или вручную. Поисковый сервер обычно имеет ссылки на остальные поисковые сервера, и передает им запрос на поиск по желанию пользователя.
Существует два типа поисковых машин.
1. «Полнотекстовые» поисковые машины, которые индексируют каждое слово на веб-странице, исключая стоп-слова.
2. «Абстрактные» поисковые машины, которые создают реферат каждой страницы.
Для вебмастеров полнотекстовые машины полезней, поскольку любое слово, встречающееся на веб-странице, подвергается анализу при определении его релевантности к запросам пользователей. Однако абстрактные машины могут индексировать страницы лучше полнотекстовых. Это зависит от алгоритма извлечения информации, например по частоте употребления одинаковых слов.
Основные характеристики поисковых машин.
1. Размер поисковой машины определяется количеством проиндексированных страниц. Однако в каждый момент времени ссылки, выдаваемые в ответ на запросы пользователей, могут быть различной давности. Причины, по которым это происходит:
Причины, по которым это происходит:
· некоторые поисковые машины сразу индексируют страницу по запросу пользователя, а затем продолжают индексировать еще не проиндексированные страницы.
· другие чаще индексируют наиболее популярные страницы сети.
2. Дата индексации. Некоторые поисковые машины показывают дату, когда был проиндексирован документ. Это помогает пользователю определить, когда документ появился в сети.
3. Глубина индексирования показывает сколько страниц после указанной будет индексировать поисковая система. Большинство машин не имеют ограничений по глубине индексирования. Причины, по которым могут быть проиндексированы не все страницы:
· не правильное использование фреймовых структур.
· использование карты сайта без дублирования обычными ссылками
4. Работа с фреймами. Если поисковый робот не умеет работать с фреймовыми структурами, то многие структуры с фреймами будут упущены при индексировании.
5. Частота ссылок. Основные поисковые машины могут определить популярность документа по тому, как часто на него ссылаются. Некоторые машины на основании таких данных «делают вывод» стоит или не стоит индексировать документ.
Некоторые машины на основании таких данных «делают вывод» стоит или не стоит индексировать документ.
6. Частота обновления сервера. Если сервер обновляется часто, то поисковая машина чаще будет его реиндексировать.
7. Контроль индексации. Показывает, какими средствами можно управлять поисковой машиной.
8. Перенаправление. Некоторые сайты перенаправляют посетителей с одного сервера на другой, и этот параметр показывает как это будет связано с найденными документами.
9. Стоп-слова. Некоторые поисковые машины не включают определенные слова в свои индексы или могут не включать эти слова в запросы пользователей. Такими словами обычно считаются предлоги или часто использующиеся слова.
10. Spam-штрафы. Возможность блокирования спама.
11. Удаление старых данных. Параметр, определяющий действия вебмастера при закрытии сервера или перемещении его на другой адрес.
Примеры поисковых машин.
1. Altavista. Система открыта в декабре 1995. Принадлежит компании DEC. С 1996 года сотрудничает с Yahoo. AltaVista — это наилучший вариант для настраиваемого поиска. Однако сортировка результатов по категориям не выполняется и приходится вручную просматривать предоставленную информацию. В AltaVista не предусмотрены средства для получения списков активных узлов, новостей или других возможностей поиска по содержанию.
С 1996 года сотрудничает с Yahoo. AltaVista — это наилучший вариант для настраиваемого поиска. Однако сортировка результатов по категориям не выполняется и приходится вручную просматривать предоставленную информацию. В AltaVista не предусмотрены средства для получения списков активных узлов, новостей или других возможностей поиска по содержанию.
2. Excite Search. Запущена в конце 1995 года. В сентябре 1996 — приобретена WebCrawler. Данный узел имеет мощный поисковый механизм, возможность автоматической индивидуальной настройки предоставляемой информации, а также составленные квалифицированным персоналом описания множества узлов. Excite отличается от других поисковых узлов тем, что позволяет вести поиск в службах новостей и публикует обзоры Web-страниц. В поисковом механизме используются средства стандартного поиска по ключевым словам и эвристические методы поиска по содержанию. Благодаря такому сочетанию, можно найти подходящие по смыслу страницы Web, если они не содержат указанных пользователем ключевых слов. Недостатком Excite является несколько хаотичный интерфейс.
Недостатком Excite является несколько хаотичный интерфейс.
3. HotBot. Запущена в мае 1996. Принадлежит компании Wired. Базируется на технологии поисковой машины Berkeley Inktomi. HotBot — это база данных, содержащая документы, индексированные по полному тексту, и один из наиболее полных поисковых механизмов в Web. Его средства поиска по логическим условиям и средства ограничения поиска любой областью или узлом Web помогают пользователю найти необходимую информацию, отсеивая ненужную. HotBot предоставляет возможность выбрать необходимые параметры поиска из раскрывающихся списков.
4. InfoSeek. Запущена раньше 1995 года, легко доступна. В настоящее время содержит порядка 50 миллионов URL. У Infoseek хорошо продуманный интерфейс, а также отличные поисковые средства. Большинство ответов на запросы сопровождается ссылками «связанные темы » , а после каждого ответа приводятся ссылки «аналогичные страницы » . База данных поискового механизма страниц, индексированных по полному тексту. Ответы упорядочиваются по двум показателям: частоте встреч слово или фраз на страницах, а также метоположению слов или фраз на страницах. Существует каталог Web Directory, подразделяющийся на 12 категорий с сотнями подкатегорий, для которых может быть выполнен поиск. Каждая страница каталога содержит перечень рекомендуемых узлов.
Ответы упорядочиваются по двум показателям: частоте встреч слово или фраз на страницах, а также метоположению слов или фраз на страницах. Существует каталог Web Directory, подразделяющийся на 12 категорий с сотнями подкатегорий, для которых может быть выполнен поиск. Каждая страница каталога содержит перечень рекомендуемых узлов.
5. Lycos. Работает с мая 1994 года. Широко известна и используема. В состав входит каталог с огромным числом URL. и поисковая машина Point с технологией статистического анализа содержимого страниц, в отличии от индексирования по полному тексту. Lycos содержит новости, обзоры узлов, ссылки на популярные узлы, карты городов, а также средства для поиска адресов, изображений и звуковых и видео клипов. Lycos упорядочивает ответы по степени соответствия запросу по нескольким критериям, например, по числу поисковых терминов, встретившихся в аннотации к документу, интервалу между словами в конкретной фразе документа, местоположению терминов в документе.
6. WebCrawler. Открыта 20 апреля 1994 года как проект Вашингтонского Университета. WebCrawler предоставляет возможности синтаксиса для конкретизации запросов, а также большой выбор аннотаций узлов при несложном интерфейсе.
Следом за каждым ответом WebCrawler помешает небольшую пиктограмму с приблизительной оценкой соответствия запросу. Коме того выводит на экран страницу с кратким резюме для каждого ответа, его полным URL, точной оценкой соответствия, а также использует этот ответ в запросе по образцу в качестве его ключевых слов. Графического интерфейса для настройки запросов в WebCrawler нет. Не допускается использование универсальных символов, а также невозможно назначить весовые коэффициенты ключевым словам. Не существует возможности ограничения поля поиска определенной областью.
7. Yahoo. Старейший каталог Yahoo был запущен в начале 1994 года. Широко известен, часто используем и наиболее уважаем. В марте 1996 запущен каталог Yahooligans для детей. Появляются региональные и top-каталоги Yahoo. Yahoo основан на подписке пользователей. Он может служить отправной точкой для любых поисков в Web, поскольку с помощью его системы классификации пользователь найдет узел с хорошо организованной информацией. Содержимое Web подразделяется на 14 общих категорий, перечисленных на домашней странице Yahoo!. В зависимости от специфики запроса пользователя существует возможность или работать с этими категориями, чтобы ознакомиться с подкатегориями и списками узлов, или искать конкретные слова и термины по всей базе данных. Пользователь может также ограничить поиск в пределах любого раздела или подраздела Yahoo!. Благодаря тому, что классификация узлов выполняется людьми, а не компьютером, качество ссылок обычно очень высокое. Однако, уточнение поиска в случае неудачи – сложная задача. В состав Yahoo! входит поисковый механизм AltaVista, поэтому в случае неудачи при поиске на Yahoo! автоматически происходит его повторение с использованием поискового механизма AltaVista.
Появляются региональные и top-каталоги Yahoo. Yahoo основан на подписке пользователей. Он может служить отправной точкой для любых поисков в Web, поскольку с помощью его системы классификации пользователь найдет узел с хорошо организованной информацией. Содержимое Web подразделяется на 14 общих категорий, перечисленных на домашней странице Yahoo!. В зависимости от специфики запроса пользователя существует возможность или работать с этими категориями, чтобы ознакомиться с подкатегориями и списками узлов, или искать конкретные слова и термины по всей базе данных. Пользователь может также ограничить поиск в пределах любого раздела или подраздела Yahoo!. Благодаря тому, что классификация узлов выполняется людьми, а не компьютером, качество ссылок обычно очень высокое. Однако, уточнение поиска в случае неудачи – сложная задача. В состав Yahoo! входит поисковый механизм AltaVista, поэтому в случае неудачи при поиске на Yahoo! автоматически происходит его повторение с использованием поискового механизма AltaVista. Затем полученные результаты передаются в Yahoo!. Yahoo! обеспечивает возможность отправлять запросы для поиска в Usenet и в Fourl1, чтобы узнать адреса электронной почты.
Затем полученные результаты передаются в Yahoo!. Yahoo! обеспечивает возможность отправлять запросы для поиска в Usenet и в Fourl1, чтобы узнать адреса электронной почты.
К российским поисковым машинам относятся:
1. Rambler.Это русскоязычная поисковая система. Разделы, перечисленные на домашней странице Rambler, освещают русскоязычные Web-ресурсы. Существует классификатор информации. Удобной возможностью работы является предоставление списка наиболее посещаемых узлов по каждой предложенной тематике.
2. Апорт Поиск. Апорт входит в число ведущих поисковых систем, сертифицированных Microsoft как локальные поисковые системы для русской версии Microsoft Internet Explorer. Одним из преимуществ Апорта является англо-русский и русско-английский перевод в режиме online запросов и поисков результата, благодаря чему можно вести поиск в русских ресурсах Internet, даже не зная русского языка. Более того можно искать информацию, используя выражения, даже для предложений. Среди основных свойств поисковой системы Апорт можно выделить следующие:
• перевод запроса и результатов поиска с русского на английский язык и наоборот;
• автоматическую проверку орфографических ошибок запроса;
• информативный вывод результатов поиска для найденных сайтов;
• возможность поиска в любой грамматической форме;
• язык расширенных запросов для профессиональных пользователей.
Ещё посмотрите лекцию «3.2 Классификация помещений (условий работ)» по этой теме.
К другим свойствам поиска можно отнести поддержку пяти основных кодовых страниц (разных операционных систем) для русского языка, технологию поиска с использованием ограничений по URL и дате документов, реализацию поиска по заголовкам, комментариям и подписям к картинкам и т. д., сохранение параметров поиска и определенного числа предыдущих запросов пользователя, объединение копий документа, находящихся на разных серверах.
3. List.ru (http://www.list.ru) По своей реализации этот сервер имеет много общего с англоязычной системой Yahoo!. На главной странице сервера расположены ссылки на наиболее популярные поисковые категории.
Список ссылок на основные категории каталога занимает центральную часть. Поиск в каталоге реализован таким образом, что в результате запроса могут быть найдены как отдельные сайты, так и рубрики. В случае успешного поиска выводится URL, название, описание, ключевые слова. Допускается использование языка запросов Яндекс. Ссылка «Структура каталога» открывает в отдельном окне полный рубрикатор каталога. Реализована возможность перехода из рубрикатора в любую выбранную подкатегорию. Более детальное тематическое деление текущей рубрики представлено списком ссылок. Каталог организован таким образом, что все сайты, содержащиеся на нижних уровнях структуры, представлены и в рубриках. Показываемый список ресурсов упорядочен в алфавитном порядке, но можно выбирать сортировку: по времени добавления, по переходам, по порядку добавления в каталог, по популярности среди посетителей каталога.
Допускается использование языка запросов Яндекс. Ссылка «Структура каталога» открывает в отдельном окне полный рубрикатор каталога. Реализована возможность перехода из рубрикатора в любую выбранную подкатегорию. Более детальное тематическое деление текущей рубрики представлено списком ссылок. Каталог организован таким образом, что все сайты, содержащиеся на нижних уровнях структуры, представлены и в рубриках. Показываемый список ресурсов упорядочен в алфавитном порядке, но можно выбирать сортировку: по времени добавления, по переходам, по порядку добавления в каталог, по популярности среди посетителей каталога.
4. Яndex. Программные продукты серии Яndex представляют набор средств полнотекстовой индексации и поиска текстовых данных с учетом морфологии русского языка. Яndex включает модули морфологического анализа и синтеза, индексации и поиска, а также набор вспомогательных модулей, таких как анализатор документов, языки разметки, конверторы форматов, паук.
Алгоритмы морфологического анализа и синтеза, основанные на базовом словаре, умеют нормализовать слова, то есть находить их начальную форму, а также строить гипотезы для слов, не содержащихся в базовом словаре. Система полнотекстового индексирования позволяет создавать компактный индекс и быстро осуществлять поиск с учетом логических операторов.
Система полнотекстового индексирования позволяет создавать компактный индекс и быстро осуществлять поиск с учетом логических операторов.
Яndex предназначен для работы с текстами в локальной и в глобальной сети, а также может быть подключен как модуль к другим системам.
Индекс поисковой системы — глоссарий КСК ГРУПП
Индексирование сайта
Через поисковые системы на многие интернет-сайты приходят новые люди, тем самым пополняя аудиторию проекта. Это может происходить только в том случае, если сайт проиндексирован поисковыми системами; если же этого не произошло, то через поиск его найти будет невозможно. Как правило, веб-мастерам приходится ждать, пока роботы поисковых систем проиндексируют их сайты. Но можно ли ускорить индексирование сайта поисковыми системами?
Начнем с того, что индексация сайта представляет собой проведение анализа контента сайта. Этот анализ проводится автоматически, его осуществляют поисковые роботы, то есть специальное ПО. Затем, исходя из релевантности, сайт будет показываться в поиске, находясь по запросам пользователей поисковиков на определенных позициях.
Затем, исходя из релевантности, сайт будет показываться в поиске, находясь по запросам пользователей поисковиков на определенных позициях.
Человек, который вводит в поисковую строку словосочетание, ожидает, что поисковая машина выдаст ему подходящие результаты. Например, когда пользователь набирает «купить автомобиль в Астрахани», ему должны попасться сайты, через которые можно купить авто в этом городе или регионе. Естественно, на сайты, которые находятся вверху списка, будет переходить множество потенциальных клиентов, а значит, будет и успех. Именно по этой причине все хотят как можно скорее попасть в индекс поисковых систем.
Чтобы ускорить индексирование сайта поисковыми системами, необходимо его зарегистрировать в этих поисковых системах. Это нужно сделать сразу же после публикации сайта в Интернете. Интересно, что многие владельцы сайтов упускают этот момент, хотя сама регистрация нового сайта в поисковых системах занимает всего несколько минут.
Роботы тяжело индексируют скрипты, поэтому стоит продублировать навигационную систему обычными текстовыми ссылками. Понятно, что это нужно сделать, если навигация сделана с помощью скриптов. Такие действия способны привести к более полной и быстрой индексации.
Понятно, что это нужно сделать, если навигация сделана с помощью скриптов. Такие действия способны привести к более полной и быстрой индексации.
Постарайтесь не перегружать сайт большим количеством текстовой информации. Чем больше текстов — тем медленней будет происходить индексация. Хотя бы на первых порах постарайтесь ставить не слишком много текстового материала, а после индексации можно публиковать большое количество текстов.
Важно постоянно обновлять контент, добавлять что-то новое и уникальное. В этом случае сайт будет намного быстрее индексироваться. Поисковые системы в первую очередь работают с такими интернет-проектами.
Ускорить индексирование сайта возможно, если использовать на практике приведенные нами рекомендации.
Выпадение из индекса
С ситуацией, когда отдельная страничка (порой очень важная) или даже весь сайт вдруг выпадает из индексации поисковиками, может столкнуться любой владелец любого ресурса. И не обязательно это происходит по вине самого обладателя сайта. Причин может быть много, однако основные из них уже давно выявлены:
Причин может быть много, однако основные из них уже давно выявлены:
- низкая уникальность контента;
- низкое качество контента;
- попадание под фильтр поисковых систем;
- большое количество повторяющихся элементов на страницах;
- проблемы со связью;
- много «плохих» ссылок;
- черная и серая оптимизация;
- слишком агрессивное продвижение;
- действия злоумышленников;
- «глюки» в самих поисковых машинах.
Некачественный или неуникальный контент
Одна из главных причин, по которой сайт вдруг перестал индексироваться. Поисковые машины очень «трепетно» относятся к уникальности контента. И если ресурс будет замечен в плагиате, его могут вовсе заблокировать. Рекомендация здесь может быть лишь одна: придерживаться полностью уникального контента при наполнении страниц сайта.
Под некачественным же контентом чаще всего подразумевается несоответствие материала заявленной тематике сайта. Если на ресурсе, посвященном строительным материалам, вдруг начинают встречаться статьи про животноводство, поисковики начинают с подозрением относиться к такому сайту и могут отодвинуть его на нижние поисковые позиции или даже вовсе забанить.
Если на ресурсе, посвященном строительным материалам, вдруг начинают встречаться статьи про животноводство, поисковики начинают с подозрением относиться к такому сайту и могут отодвинуть его на нижние поисковые позиции или даже вовсе забанить.
Также некачественным с точки зрения поисковиков является контент, который слабо оптимизирован под индексацию. То есть в нем неравномерно и неоптимально расположены ключевые слова, нет оптимизации под сниппеты, отсутствуют описания в метатегах и т. д.
Получить бан может также ресурс, наполнение которого состоит исключительно из набора ключевых слов, которые представляют собой бессвязный текст. Подобный метод «серой» оптимизации еще недавно с успехом работал, однако современные поисковики получили более продвинутые алгоритмы детектирования, и теперь это просто не имеет смысла.
Решение: провести качественный и полный аудит сайта и на основе анализа оптимизировать ресурс под нужды поисковых систем.
Повторяющиеся элементы
Дело в том, что многие веб-мастера располагают одинаковые ссылки, виджеты, социальные кнопки и бары на всех страничках сайта при слабом количественном наполнении контентом. Если общее количество повторяющихся элементов превышает 50% по сравнению с остальным контентом на странице, то с точки зрения поисковика эти страницы не обладают ценностью для пользователя. Как результат — выпадение из индекса.
Если общее количество повторяющихся элементов превышает 50% по сравнению с остальным контентом на странице, то с точки зрения поисковика эти страницы не обладают ценностью для пользователя. Как результат — выпадение из индекса.
Фильтрация
Также довольно нередкая причина. За всевозможные виды поискового спама сайт вполне может попасть под действие фильтра поисковика. В этом случае требуется провести тщательный анализ возможных причин попадания под фильтр. Возможно, на странице имеется большая масса некачественных внешних ссылок, а также содержатся элементы «нечестной» поисковой оптимизации. Например, перегруженность ключевыми словами в одном месте.
Технические проблемы на хостинге
Если в течение длительного времени у хостинг-провайдера имеются проблемы с качеством связи, то пользователи просто не смогут заходить на данный ресурс, а поисковые машины могут принять решение об исключении такого сайта из индекса. Кроме того, если долгое время на той или иной страничке не происходило событий поведенческого характера, поисковик начинает сомневаться в ее полезности и также исключает из поисковых выдач.
Большая масса «плохих» и нетематических ссылок
Если размещать — пусть и в качестве рекламы — большое количество внешних ссылок, которые мало соприкасаются с заявленной тематикой сайта, то с большой долей вероятности сайт будет выпадать из поисковой индексации. Поэтому владельцы ресурсов предпочитают размещать исключительно тематические ссылки и баннеры.
Под «плохими» ссылками также подразумеваются ссылки, ведущие на сайты, уже прекратившие свое существование, либо те, которые были по тем или иным причинам заблокированы. Например, из-за нарушения действующего на территории страны законодательства.
Действия злоумышленников
Может случиться и так, что сайт был взломан конкурентами или просто ради хулиганства и умышленно переделан таким образом, чтобы поисковые машины проигнорировали его или вовсе заблокировали.
Слишком агрессивное продвижение молодого сайта
С точки зрения поисковика молодым считается ресурс, просуществовавший менее одного года. Если неопытный оптимизатор начнет слишком рьяно продвигать такой сайт в поисковиках, те отнесутся к этому с крайним подозрением и выбросят его из индексации.
Если неопытный оптимизатор начнет слишком рьяно продвигать такой сайт в поисковиках, те отнесутся к этому с крайним подозрением и выбросят его из индексации.
Ошибки в поисковых системах
Случается и такое, что сайт выпадает из индекса просто по причине «глюка» в поисковике. В этом случае можно заглянуть на форум и поинтересоваться, у кого еще возникли подобные проблемы. Если таковых пользователей оказалось много, то нужно подождать несколько дней, когда ошибку исправят.
Возврат к списку
Поисковая машина — Большая Энциклопедия Нефти и Газа, статья, страница 1
Cтраница 1
Поисковая машина просматривает базу данных индексов, составляет список страниц, удовлетворяющих условиям запроса ( точнее, список ссылок на эти страницы) и возвращает его Web-серверу. [1]
Поисковые машины постоянно автоматически исследуют Сеть с целью пополнения своих баз данных документов. Обычно это не требует никаких усилий со стороны человека. Сетевой агент — автоматический робот ( паук — spider) обходит все заданные ему web — серверы и собирает у себя индекс — информацию о том, что и на какой странице найдено. Но индексация выполняется чисто формально, проверяется наличие заданных ключевых слов в текстах документов, и по этим подчас случайным совпадениям делаются содержательные выводы. Поэтому никакой осмысленной классификации в поисковых машинах не выполняется. Такие системы часто называют индексаторами. Поисковые машины часто привлекают для поиска фрагменты классификаторов, заимствованные в каталогах, поскольку последние выполняют более содержательный отбор информации.
[2]
Сетевой агент — автоматический робот ( паук — spider) обходит все заданные ему web — серверы и собирает у себя индекс — информацию о том, что и на какой странице найдено. Но индексация выполняется чисто формально, проверяется наличие заданных ключевых слов в текстах документов, и по этим подчас случайным совпадениям делаются содержательные выводы. Поэтому никакой осмысленной классификации в поисковых машинах не выполняется. Такие системы часто называют индексаторами. Поисковые машины часто привлекают для поиска фрагменты классификаторов, заимствованные в каталогах, поскольку последние выполняют более содержательный отбор информации.
[2]
Поисковые машины — это специальные программы, позволяющие получить перечень ссылок на конкретные Web-страницы, которые содержат ключевые слова, указанные в запросе. С помощью мощных компьютеров сети поисковая машина практически мгновенно выдает список адресов страниц, на которых эти слова встречаются. [3]
Поисковые машины Open Text Index, AltaVista, Yahoo, Lycos и другие представляют собой мощные информационно-поисковые системы, размещенные на серверах свободного доступа, специальные программы которых непрерывно в автоматическом режиме сканируют информацию Сети на основе заданных алгоритмов, проводя индексацию документов. В последующем поисковые машины предоставляют пользователю на основе созданных баз данных доступ к распределенной на узлах Сети информации через выполнение поискового запроса в рамках собственного интерфейса.
[4]
В последующем поисковые машины предоставляют пользователю на основе созданных баз данных доступ к распределенной на узлах Сети информации через выполнение поискового запроса в рамках собственного интерфейса.
[4]
Освоение интерфейса поисковой машины AltaVista является прекрасным фундаментом для работы с другими поисковыми системами. [5]
| Общая архитектура системы WebCrawler. [6] |
Как правило, поисковые машины обеспечивают интерфейс типа меню, с помощью которого пользователь может скомпоновать запрос на поиск информации, используя ключевые слова и / или фразы и логические связки И-ИЛИ-НЕ. Большинство машин поиска находят огромное количество релевантных страниц по запросу пользователя. Каждый найденный документ обычно ранжируется по степени его корреляции с запросом. Релевантность каждого документа оценивается с помощью различных технологий, например учета частоты появления на странице искомых слов. Некоторые поисковые механизмы используют дополнительно другие факторы, такие как частота посещения страницы и / или близость расположения друг к другу искомых терминов.
[7]
Некоторые поисковые механизмы используют дополнительно другие факторы, такие как частота посещения страницы и / или близость расположения друг к другу искомых терминов.
[7]
Самая известная из поисковых машин — Alta Vista ( www. [8]
В процессе сканирования поисковой машине приходится получать доступ к ресурсам Сети, естественно, что такой доступ реализуется в рамках одного из протоколов прикладного уровня. В связи с этим принято различать поисковые машины по области сканирования, прежде всего это — гипертекстовые базы данных Web, ресурсы всемирного пространства GopherSpace, FTP-архивы. [9]
Для WWW наиболее характерны поисковые машины и поисковые каталоги. [10]
Более того, многие поисковые машины WWW позволяют заранее задавать в поисковом запросе то текстовое поле, в котором должен встретиться данный термин. [11]
Процесс управления с помощью поисковых машин осуществляется в результате поиска оптимума на основе имеющегося критерия для получения конечной цели. [12]
[12]
Каталоги в отличие от поисковых машин пополняют свою информацию по инициативе человека. Добавляемая страница должна быть жестко привязана к принятым в каталоге тематическим разделам. Каталог представляет собой упорядоченную по темам коллекцию ссылок на многочисленные web — страницы и сайты. Каталог, как правило, составляется, обслуживается и поддерживается специалистами разного профиля, которые по заявкам владельцев сайтов или самостоятельно пополняют перечень ссылок и составляют обзоры web — страниц, содержащие краткое описание информационного ресурса, его. Каталоги часто называют классификаторами, поскольку они представляют собой иерархические структуры, где все информационные ресурсы расклассифицированы по темам. [13]
| Перекачивается три файла. [14] |
Конечно, обращение к поисковой машине потребует известного времени, но когда с выбранным сервером работа вообще не происходит или идет в час по чайной ложке, a GetRight находит ему замену, пусть и через пару минут, это же здорово. [15]
[15]
Страницы: 1 2 3 4
Как работают поисковые системы? Руководство для начинающих
Джошуа Хардвик
Руководитель отдела контента @ Ahrefs (или, говоря простым языком, я отвечаю за то, чтобы каждый пост в блоге, который мы публикуем, был EPIC).
СТАТИЯ СТАТИСТВА
Ежемесячный трафик 1 753
Связывание веб -сайтов 245
твиты 74
. содержание. Как правило, чем больше веб-сайтов ссылаются на вас, тем выше ваш рейтинг в Google.
Показывает расчетный месячный поисковый трафик этой статьи по данным Ahrefs. Фактический поисковый трафик (по данным Google Analytics) обычно в 3-5 раз больше.
Сколько раз этой статьей поделились в Твиттере.
Поделиться этой статьей
Поисковые системы сканируют миллиарды страниц с помощью поисковых роботов. Также известные как пауки или боты, поисковые роботы перемещаются по сети и переходят по ссылкам, чтобы найти новые страницы. Затем эти страницы добавляются в индекс, из которого поисковые системы извлекают результаты.
Понимание того, как работают поисковые системы, имеет решающее значение, если вы занимаетесь SEO. В конце концов, трудно что-то оптимизировать, если вы не знаете, как это работает.
Этому вы научитесь в этом руководстве.
Contents
Contents
Давайте начнем с изучения того, что такое поисковые системы, почему они существуют и как они зарабатывают деньги.
Что такое поисковые системы?
Поисковые системы — это доступные для поиска базы данных веб-контента. Они состоят из двух основных частей:
- Индекс поиска. Цифровая библиотека информации о веб-страницах.
- Алгоритм(ы) поиска . Компьютерная программа(ы), ранжирующая результаты сопоставления из поискового индекса.
 Компьютерная программа(ы), ранжирующая результаты сопоставления из поискового индекса.
Компьютерная программа(ы), ранжирующая результаты сопоставления из поискового индекса.Какова цель поисковых систем?
Каждая поисковая система стремится предоставить пользователям наилучшие и наиболее релевантные результаты. Отчасти именно так они завоевывают долю рынка.
Как поисковые системы зарабатывают деньги?
Поисковые системы имеют два типа результатов поиска:
- Обычные результаты из поискового индекса. Вы не можете платить за то, чтобы быть здесь.
- Платные результаты от рекламодателей. Вы можете заплатить, чтобы быть здесь.
Каждый раз, когда кто-то нажимает на платный результат поиска, рекламодатель платит поисковой системе. Это известно как реклама с оплатой за клик (PPC), и именно поэтому доля рынка имеет значение. Больше пользователей означает больше кликов по объявлениям и больше доходов.
У каждой поисковой системы свой процесс построения поискового индекса.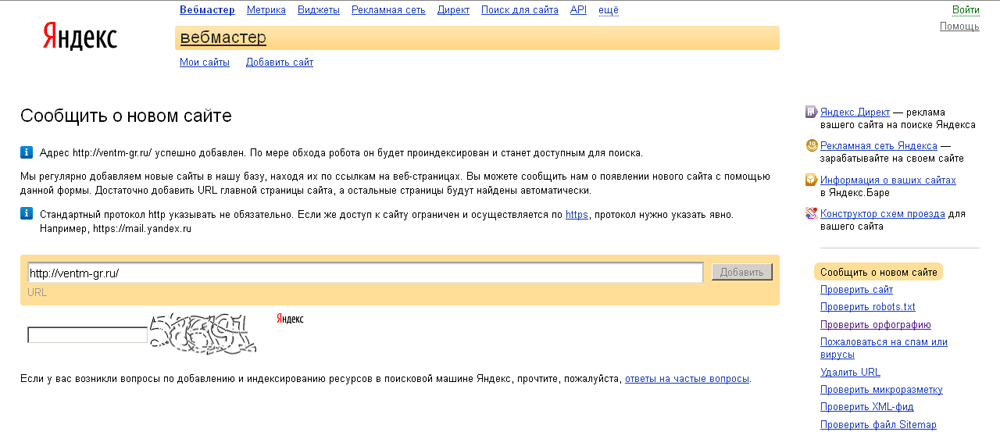 Ниже представлена упрощенная версия процесса, который использует Google. [1]
Ниже представлена упрощенная версия процесса, который использует Google. [1]
Давайте разберемся.
URL-адреса
Все начинается с известного списка URL-адресов. Google обнаруживает их разными способами, но наиболее распространенными являются три:
- По обратным ссылкам. Google имеет индекс сотен миллиардов веб-страниц. [2] Если кто-то ссылается на новую страницу с известной страницы, Google может найти ее оттуда.
- Из карт сайта. Файлы Sitemap сообщают Google, какие страницы и файлы, по вашему мнению, важны на вашем сайте. [3]
- Из отправленных URL. Google позволяет владельцам сайтов запрашивать сканирование отдельных URL-адресов в Google Search Console.
Сканирование
Сканирование — это когда компьютерный бот, называемый пауком, посещает и загружает известные URL-адреса. Поисковый робот Google — Googlebot. [4]
Обработка и рендеринг
Обработка — это то, где Google работает, чтобы понять и извлечь ключевую информацию из просканированных страниц. Для этого он должен отобразить страницу, где он запускает код страницы, чтобы понять, как она выглядит для пользователей.
Для этого он должен отобразить страницу, где он запускает код страницы, чтобы понять, как она выглядит для пользователей.
Никто за пределами Google не знает всех деталей этого процесса. Но это не имеет значения. Все, что нам действительно нужно знать, это то, что это включает в себя извлечение ссылок и сохранение контента для индексации.
Индексирование
Индексирование — это добавление обработанной информации с просканированных страниц в поисковый индекс.
Поисковый индекс — это то, что вы ищете, когда используете поисковую систему. Вот почему индексирование в основных поисковых системах, таких как Google и Bing, так важно. Пользователи не смогут найти вас, если вы не в индексе.
Обнаружение, сканирование и индексирование контента — это только первая часть головоломки. Поисковым системам также нужен способ ранжирования результатов поиска, когда пользователь выполняет поиск. Это работа поисковых алгоритмов.
Что такое алгоритмы поиска?
Алгоритмы поиска — это формулы, которые сопоставляют и ранжируют релевантные результаты индекса. Google использует множество факторов в своих алгоритмах.
Google использует множество факторов в своих алгоритмах.
Ключевые факторы ранжирования Google
Никто не знает всех факторов ранжирования Google, потому что Google их не раскрывает. Но мы знаем некоторые ключевые. Давайте посмотрим на некоторые из них.
Обратные ссылки
Обратные ссылки — это ссылки со страницы одного веб-сайта на другой. Они являются одним из самых сильных факторов ранжирования Google. [6] Вероятно, поэтому мы увидели сильную корреляцию между связывающими доменами и органическим трафиком в нашем исследовании более миллиарда страниц. [7]
Однако дело не только в количестве. Качество тоже имеет значение. Страницы с несколькими высококачественными обратными ссылками часто опережают страницы с большим количеством некачественных обратных ссылок.
Актуальность
Релевантность — полезность данного результата для искателя. У Google есть много способов определить это. На самом базовом уровне он ищет страницы, содержащие те же ключевые слова, что и поисковый запрос. Он также просматривает данные о взаимодействии, чтобы узнать, нашли ли другие результаты полезными. [9]
Он также просматривает данные о взаимодействии, чтобы узнать, нашли ли другие результаты полезными. [9]
Актуальность
Актуальность — это фактор ранжирования, зависящий от запроса. Это сильнее для поисков, которые требуют свежих результатов. [9] Вот почему вы видите недавно опубликованный лучший результат для «новой серии netflix», а не для «как собрать кубик Рубика».
Скорость страницы
Скорость страницы является фактором ранжирования на настольных и мобильных устройствах. [10][11] Но это скорее отрицательный фактор ранжирования, чем положительный. Это связано с тем, что это негативно влияет на самые медленные страницы, а не положительно влияет на молниеносные страницы.
Удобство для мобильных устройств
Удобство для мобильных устройств стало фактором ранжирования на мобильных и настольных устройствах с тех пор, как Google перешел на индексирование, ориентированное на мобильные устройства в 2019 году. [12]
[12]
Google адаптирует результаты поиска для каждого пользователя. Для этого они используют такую информацию, как ваше местоположение, язык и историю поиска. [9] Давайте рассмотрим эти вещи поближе.
Местоположение
Google использует ваше местоположение для персонализации результатов поиска с местными намерениями. Вот почему все результаты поиска по запросу «итальянский ресторан» относятся к местным ресторанам или о них. Google знает, что вы вряд ли пролетите полмира, чтобы пообедать.
Язык
Google знает, что нет смысла показывать результаты на английском языке испанским пользователям. Вот почему он ранжирует локализованные версии контента (если они доступны) среди пользователей, говорящих на разных языках.
История поиска
Google сохраняет ваши действия и места, которые вы посещаете, чтобы сделать поиск более персонализированным. [13] Вы можете отказаться от этого, но большинство людей, вероятно, этого не сделают.
Ключевые выводы
- Поисковые системы состоят из двух основных частей: индекса и алгоритмов.
- Чтобы создать свой индекс, они сканируют известные страницы и переходят по ссылкам, чтобы найти новые.
- Целью алгоритмов поиска является предоставление наилучших и наиболее релевантных результатов.
- Качество результатов поиска важно для увеличения доли рынка.
- Никто не знает всех факторов ранжирования Google для органических результатов.
- Ключевые факторы ранжирования включают обратные ссылки, релевантность и свежесть.
- Google персонализирует свои результаты в зависимости от вашего местоположения, языка и истории поиска.
Ссылки
- «Понимание основ JavaScript SEO». Гугл. Проверено 16 августа 2022 г.
- «Организация информации — как работает поиск Google». Гугл. Проверено 16 августа 2022 г.
- «Узнайте о картах сайта». Гугл. Проверено 16 августа 2022 г.
- «Googlebot». Гугл . Проверено 16 августа 2022 г.
- «Доля рынка поисковых систем в мире». Счетчик статистики . Проверено 16 августа 2022 г.
- «Google Q&A+ #March». Ютуб . Проверено 16 августа 2022 г.
- «90,63% контента не получает трафика от Google. И как быть в других 9,37%». Арефс . 31 января 2020 г. Проверено 16 августа 2022 г.
- «Радар CloudFlare». CloudFlare . Проверено 16 августа 2022 г.
- «Рейтинг результатов поиска — как работает поиск Google». Гугл. Проверено 16 августа 2022 г.
- «Использование скорости сайта в рейтинге веб-поиска». Гугл. Проверено 16 августа 2022 г.
- «Использование скорости страницы в рейтинге мобильного поиска». Гугл. Проверено 16 августа 2022 г.
- «Передовой опыт мобильного индексирования». Гугл. Проверено 16 августа 2022 г.
- «Находите и контролируйте свою активность в Интернете и приложениях». Гугл. Проверено 16 августа 2022 г.

 Гугл. Проверено 16 августа 2022 г.
Гугл. Проверено 16 августа 2022 г.Что такое поисковая система?
Команда Neeva, 11.06.21
Пользоваться поисковой системой очень просто: вы открываете веб-страницу, вводите несколько слов в строку поиска и вуаля — миллионы результатов появляются за доли секунды. . Например, поиск в Google по запросу «поисковая система» дает 1,43 миллиарда результатов за 0,69 секунды. Но как именно ? Вот как дикая, дикая сеть стала полностью индексируемой, доступной для поиска и ранжированной менее чем за десять лет.
Что такое поисковая система?
Поисковая система — это программное обеспечение, предназначенное для поиска определенной информации. Тип поисковой системы, с которой знакомо большинство из нас, — это поисковая система в Интернете, представляющая собой веб-службу, которая находит информацию в Интернете (иногда называемую «всемирной паутиной») на основе запроса пользователя, который обычно представляет собой набор слова.
Сегодня многие считают, что поисковые системы — это синонимы интернет-браузеров, отчасти благодаря тому, что браузер Google Chrome встраивает функции поисковой системы в строку веб-адреса. Но поисковые системы — это веб-службы, специально созданные для получения информации. К ним можно легко получить доступ из браузера, но это разные технологии.
Но поисковые системы — это веб-службы, специально созданные для получения информации. К ним можно легко получить доступ из браузера, но это разные технологии.
Как работают поисковые системы?
Хотя поисковые системы с годами стали более сложными, они по-прежнему следуют довольно простой формуле: сканировать и индексировать все данные в Интернете, чтобы при поиске чего-либо он мог представить вам набор результатов, ранжированных по актуальность. Вот как они это делают.
- Сканирование . Поисковые роботы, также известные как пауки, представляют собой программы, которые постоянно ищут в Интернете, находя новые сайты и идентифицируя новые ссылки. Краулеры также отправляют текст с каждого веб-сайта в индекс для анализа. Поисковые роботы могут даже хранить всю веб-страницу или ее часть, что называется кешем. Веб-мастера (люди, управляющие веб-сайтами) могут добавлять на свои сайты файл robots.txt, который сообщает сканеру, какие страницы следует просматривать, а какие игнорировать.
- Индекс . Данные, которые собирают сканеры, анализируются, систематизируются и сохраняются в индексе, чтобы механизм мог быстро находить информацию. Подобно указателю в конце книги, но гораздо более подробному, индекс поисковой системы включает запись для каждого слова на каждой проиндексированной веб-странице.
- Поиск . Когда вы запрашиваете поисковую систему, поисковая система должна сначала перевести ваши слова в термины, относящиеся к ее индексу. Это делается с помощью множества методов, включая обработку естественного языка (НЛП, которое использует машинное обучение, чтобы понять, что вы ищете). Результатом этого начального процесса перевода является переписанный запрос, в котором определяются важные части вашего запроса, исправляются орфографические ошибки и добавляются синонимы. Затем поисковая система обращается к своему индексу, чтобы найти веб-страницы, соответствующие переписанному запросу.
- Ранг. Поисковые системы используют алгоритмы, чтобы предоставить вам список результатов, ранжированных по тому, что, по их мнению, лучше всего ответит на ваш запрос. Для расплывчатых запросов, таких как «рамен», ваша поисковая система может предоставить ряд ответов, чтобы охватить свои основы, например, общую информацию о том, что такое рамен , наряду с другими популярными результатами, такими как рецепты, местные магазины рамэн и даже « люди также спрашивают», чтобы помочь вам сузить область поиска.

 Для расплывчатых запросов, таких как «рамен», ваша поисковая система может предоставить ряд ответов, чтобы охватить свои основы, например, общую информацию о том, что такое рамен , наряду с другими популярными результатами, такими как рецепты, местные магазины рамэн и даже « люди также спрашивают», чтобы помочь вам сузить область поиска.
Для расплывчатых запросов, таких как «рамен», ваша поисковая система может предоставить ряд ответов, чтобы охватить свои основы, например, общую информацию о том, что такое рамен , наряду с другими популярными результатами, такими как рецепты, местные магазины рамэн и даже « люди также спрашивают», чтобы помочь вам сузить область поиска.Как поисковые системы ранжируют результаты?
Один запрос может найти миллиарды релевантных веб-страниц, поэтому часть работы поисковой системы заключается в сортировке этих списков с использованием алгоритмов ранжирования. И хотя эти алгоритмы предназначены для предоставления вам наилучших ответов на ваши вопросы, они смещены в сторону определенных факторов. Поисковые системы хотят показать вам результаты, на которые вы нажмете, и они используют различные факторы для ранжирования результатов в соответствии с тем, с чем, по их мнению, вы будете взаимодействовать. К ним относятся, но не ограничиваются:
- Использование ключевых слов. Результаты поиска должны соответствовать хотя бы некоторым словам в запросе. Поисковые системы отдают приоритет страницам, на которых эти ключевые слова появляются на видном месте, например в заголовке страницы, или часто по всей странице.
- Содержание страницы. Поисковые системы отдают предпочтение высококачественному контенту, анализируя длину, глубину и широту веб-страниц.
- Обратные ссылки . Обратные ссылки или упоминания одного веб-сайта на другом веб-сайте можно рассматривать как голосование в пользу авторитета этого сайта. Впервые созданный Google PageRank, ранжирование обратных ссылок ранжирует страницы в зависимости от того, сколько других сайтов ссылаются на этот сайт и насколько высоко те сайтов ранжируются.
- Информация о пользователе. Поисковые системы, такие как Google, используют вашу личную информацию, такую как история поиска и местоположение, для предоставления результатов, которые являются уникальными для вас.
 Результаты поиска должны соответствовать хотя бы некоторым словам в запросе. Поисковые системы отдают приоритет страницам, на которых эти ключевые слова появляются на видном месте, например в заголовке страницы, или часто по всей странице.
Результаты поиска должны соответствовать хотя бы некоторым словам в запросе. Поисковые системы отдают приоритет страницам, на которых эти ключевые слова появляются на видном месте, например в заголовке страницы, или часто по всей странице.
4 типа поисковых систем
Основные поисковые системы, такие как Google, могут быть первыми, когда мы думаем о поисковых системах, но есть и другие типы поисковых систем, которые позволяют нам перемещаться по Интернету.
- Основные поисковые системы . Основные поисковые системы, такие как Google, Bing и Yahoo! все они бесплатны для использования и поддерживаются онлайн-рекламой. Все они используют варианты одной и той же стратегии (сканирование, индексирование и ранжирование), чтобы вы могли осуществлять поиск по всему Интернету.
- Частные поисковые системы . В последнее время популярность частных поисковых систем возросла из-за проблем с конфиденциальностью, вызванных практикой сбора данных основных поисковых систем. К ним относятся анонимные поисковые системы с поддержкой рекламы, такие как DuckDuckGo, и частные поисковые системы без рекламы, такие как Neeva.
- Вертикальные поисковые системы . Вертикальный поиск или специализированный поиск — это способ сузить область поиска до одной тематической категории, а не всей сети. Примеры вертикальных поисковых систем включают:
- Строка поиска на торговых сайтах, таких как eBay и Amazon
- Google Scholar, которая индексирует научную литературу по публикациям
- Доступные для поиска сайты социальных сетей и приложения, такие как Pinterest
- Вычислительные поисковые системы . WolframAlpha — это пример вычислительной поисковой системы, предназначенной для ответов на вопросы, связанные с математикой и естественными науками.
 Вертикальный поиск или специализированный поиск — это способ сузить область поиска до одной тематической категории, а не всей сети. Примеры вертикальных поисковых систем включают:
Вертикальный поиск или специализированный поиск — это способ сузить область поиска до одной тематической категории, а не всей сети. Примеры вертикальных поисковых систем включают:Популярные поисковые системы
Технологии поиска сильно изменились с момента разработки первой поисковой системы в 1989 году. Вот основные игроки на сегодняшний день.
- Гугл . Есть только одна поисковая система, настолько популярная, что она стала синонимом глагола «искать». Имея 92,24 процента доли мирового рынка поисковых систем, Google на сегодняшний день является крупнейшей и самой популярной поисковой системой в мире. Чистый внешний вид Google и система ранжирования на основе обратных ссылок заслужили расположение пользователей в 99-м.0s, и он сохранил свое господство благодаря почти постоянным инновациям и множеству эксклюзивных соглашений с производителями устройств, операторами беспроводной связи и разработчиками браузеров, которые направляют около 60 процентов интернет-поиска прямо в Google.
- Бинг . На поисковую систему Microsoft Bing в настоящее время приходится 2,29 процента доли мирового рынка, что делает ее второй по величине поисковой системой в мире. С момента своего запуска в 2009 году Bing размещал фотографии на своей главной странице, что резко контрастировало со строгой целевой страницей Google.
- Yahoo! Комбинация веб-портала Yahoo!, новостного сайта и поисковой системы составляет 1,52 процента доли рынка поисковых систем. С момента своего скромного появления в качестве «Путеводителя Джерри и Дэвида по Всемирной паутине» Yahoo! стала крупной поисковой системой и была продана Verizon за 4,48 миллиарда долларов в 2017 году.
- Baidu . Baidu — китайская поисковая система, на долю которой приходится 1,48% мирового рынка поисковых систем. Как и Google, Baidu начиналась как поисковая система, а сейчас является одной из крупнейших технологических компаний Китая.
- DuckDuckGo . DuckDuckGo — это частная поисковая система с поддержкой рекламы, на долю которой в настоящее время приходится 0,58 процента доли мирового рынка.
 Чистый внешний вид Google и система ранжирования на основе обратных ссылок заслужили расположение пользователей в 99-м.0s, и он сохранил свое господство благодаря почти постоянным инновациям и множеству эксклюзивных соглашений с производителями устройств, операторами беспроводной связи и разработчиками браузеров, которые направляют около 60 процентов интернет-поиска прямо в Google.
Чистый внешний вид Google и система ранжирования на основе обратных ссылок заслужили расположение пользователей в 99-м.0s, и он сохранил свое господство благодаря почти постоянным инновациям и множеству эксклюзивных соглашений с производителями устройств, операторами беспроводной связи и разработчиками браузеров, которые направляют около 60 процентов интернет-поиска прямо в Google.
В 2020 году Neeva объявила о создании первой в мире поисковой системы с частной подпиской без рекламы.
Краткая история поисковых систем
На заре Интернета было так мало веб-серверов (в основном, компьютеров, на которых размещались веб-сайты), что Тим Бернерс-Ли, создатель Всемирной паутины, держал их все на одном список. Используя этот список Бернерса-Ли, вы можете легко получить доступ к каждой существующей веб-странице — в основном к информационным сайтам, управляемым университетами или государственными организациями.
Сегодня существуют миллиарды веб-страниц и нет централизованной системы для их отслеживания, поэтому мы полагаемся на поисковые системы для поиска информации в Интернете.
- 1989: Будучи аспирантом Университета Макгилла, Алан Эмтадж создал первую общедоступную поисковую систему ARCHIE (архив без буквы «V») в 1989 году. Программа Emtage позволила ему легче находить файлы на FTP-сайтах (протокол передачи файлов), которые появились раньше Интернета.
- 1994 : Дэвид Фило и Джерри Янг основали Yahoo! как веб-каталог своих любимых сайтов. К концу 1990-х Yahoo! работал как веб-портал — целевая страница для доступа к различным функциям Интернета — и как поисковая система.
- 1995 : AltaVista была запущена как первая поисковая система на естественном языке, что означает, что она принимала запросы, написанные на разговорном языке, а не только ключевые слова. В то время в Интернете было не менее 30 миллионов страниц, около 20 миллионов из которых были проиндексированы AltaVista.
- 1996 : запущен сервис Ask Jeeves, который поощрял пользователей формулировать свои запросы в виде вопросов. Ask Jeeves использовал редакторов-людей для сопоставления результатов с самыми популярными запросами. Сегодня около 8 процентов поисковых запросов записываются в виде вопросов, и Ask Jeeves (теперь Ask.com) больше не считается основной поисковой системой.
- 1998 : Ларри Пейдж и Сергей Брин основали Google на основе своей поисковой системы 1996 года Backrub, которая использовала обратные ссылки как способ ранжирования результатов поиска. В то время у Google был очень простой интерфейс без рекламы с синими ссылками, за которыми следовало двухстрочное описание каждого сайта. (Реклама появится позже, в 2000 году.)
- 2009 : Microsoft Bing был запущен в качестве ребрендинга MSN/Live search, первоначально запущенного в 1998 году. Вскоре после запуска Bing стал основой Yahoo! поисковый движок.

Основные инновации в технологии поисковых систем
С момента запуска первых поисковых систем в 1990-х годах лидеры отрасли вносили инновации в поисковые технологии, чтобы обслуживать все больше и больше потребностей с помощью единого интерфейса. Теперь нам не обязательно покидать страницу результатов поисковой системы, чтобы получить ответы, которые мы ищем. Вот некоторые из основных моментов в эволюции технологии поисковых систем.
Теперь нам не обязательно покидать страницу результатов поисковой системы, чтобы получить ответы, которые мы ищем. Вот некоторые из основных моментов в эволюции технологии поисковых систем.
- Машинное обучение : Microsoft разработала и запустила RankNet в 2005 году, которая использовала машинное обучение для ранжирования релевантных результатов поиска. Версия RankNet позже будет использоваться Microsoft Bing. Google представил свой собственный компонент машинного обучения, RankBrain, в 2015 году.
- Универсальный поиск : В 2007 году Google запустил универсальный поиск, который интегрировал некоторые из своих различных инструментов вертикального поиска (таких как изображения, новости, видео, карты и книги). ) в одну страницу результатов поисковой системы мультимедиа (SERP). Когда вы ищете «изображения заката» на Google.com и видите коллекцию изображений в верхней части страницы результатов вместо списка ссылок, это универсальный поиск. До универсального поиска вам приходилось заходить в Google Images, чтобы найти изображения.
- Локализованные результаты: В 2012 году Google начал показывать локальные результаты (на основе IP-адреса пользователя) для общих запросов. Это означало, что при поиске «футболки» Google мог предложить ближайший принтер для печати футболок, тогда как раньше только поиск «футболки рядом с Бруклином» запускал интеграцию с Картами. В 2016 году Google начал использовать службы определения местоположения смартфона и позиционирование Wi-Fi (которое использует местоположение ближайших точек доступа, чтобы точно определить ваше местоположение), чтобы предоставить вам локальные результаты на вашем точное местоположение .
- Hummingbird : Google представил свой алгоритм Hummingbird в 2013 году, который выходит за рамки поисковых запросов пользователя, используя контекст, чтобы попытаться определить его намерения. Например, поиск типа «какая погода» выведет результаты местной погоды, а не объяснение концепции погоды. При поиске «погода» без «что есть» будут отображаться новости с сайта Weather.com.
- Knowledge Graph: Google приобрела Metaweb и Freebase, свою базу данных, содержащую «более 12 миллионов вещей», в 2010 году. Это заложило основу для Knowledge Graph, запущенного в 2012 году. Эта технология позволяет пользователям получать информацию с других веб-сайтов без выход из поисковой выдачи. Когда вы видите фрагмент Википедии справа от результатов поиска, это Сеть знаний. Эта функция имела далеко идущие последствия: в 2020 году около 65% поисковых запросов в Google завершились без нажатия пользователем каких-либо результатов, предположительно потому, что они нашли то, что искали, в поисковой выдаче. (Google утверждал, что есть много причин, по которым результат поиска может закончиться без каких-либо кликов, например, из-за переформулировки вопроса.)
 До универсального поиска вам приходилось заходить в Google Images, чтобы найти изображения.
До универсального поиска вам приходилось заходить в Google Images, чтобы найти изображения. При поиске «погода» без «что есть» будут отображаться новости с сайта Weather.com.
При поиске «погода» без «что есть» будут отображаться новости с сайта Weather.com. Хотите попробовать другую поисковую систему, созданную только для людей, а не для рекламы? Neeva — первая в мире частная поисковая система без рекламы, которая стремится показывать вам лучшие результаты для каждого поиска. Мы никогда не будем продавать или передавать ваши данные никому, особенно рекламодателям. Попробуйте Neeva сами на neeva.com.
Мы никогда не будем продавать или передавать ваши данные никому, особенно рекламодателям. Попробуйте Neeva сами на neeva.com.
Поделись этим:
Поисковые системы — информация, люди и технологии
Глава 3: Веб-поиск
Из https://en.wikipedia.org/wiki/Web_search_engine
Веб-поисковик — это программная система, предназначенная для поиска информации во всемирной паутине. Результаты поиска обычно представлены в виде строки результатов, которую часто называют страницами результатов поисковой системы (SERP). Информация может представлять собой сочетание веб-страниц, изображений и других типов файлов. Некоторые поисковые системы также извлекают данные из баз данных или открытых каталогов. В отличие от веб-каталогов, которые поддерживаются только редакторами-людьми, поисковые системы также поддерживают информацию в реальном времени, запуская алгоритм на веб-сканере.
Современная история веб-браузера
JumpStation (созданная в декабре 1993 года [7] Джонатоном Флетчером) использовала веб-робота для поиска веб-страниц и создания их индекса, а также использовала веб-форму в качестве интерфейса для своей программы запроса. Таким образом, это был первый инструмент для обнаружения ресурсов WWW, который сочетал в себе три основные функции веб-поисковика (сканирование, индексирование и поиск), как описано ниже. Из-за ограниченных ресурсов, доступных на платформе, на которой он работал, его индексация и, следовательно, поиск были ограничены заголовками и заголовками, найденными на веб-страницах, с которыми сталкивался сканер.
Таким образом, это был первый инструмент для обнаружения ресурсов WWW, который сочетал в себе три основные функции веб-поисковика (сканирование, индексирование и поиск), как описано ниже. Из-за ограниченных ресурсов, доступных на платформе, на которой он работал, его индексация и, следовательно, поиск были ограничены заголовками и заголовками, найденными на веб-страницах, с которыми сталкивался сканер.
Одной из первых поисковых систем, основанных на поисковых роботах, была WebCrawler, которая появилась в 1994 году. В отличие от своих предшественников, она позволяла пользователям искать любое слово на любой веб-странице, что стало стандартом для всех основных поисковых систем с тех пор. . Он также был первым, широко известным широкой публике. Также в 1994 году была запущена компания Lycos (которая началась в Университете Карнеги-Меллона), которая стала крупным коммерческим предприятием.
Вскоре после этого появилось множество поисковых систем, которые соперничали за популярность. К ним относятся Magellan, Excite, Infoseek, Inktomi, Northern Light и AltaVista. Яху! был одним из самых популярных способов поиска интересующих людей веб-страниц, но его функция поиска работала в веб-каталоге, а не в полнотекстовых копиях веб-страниц. Искатели информации также могли просматривать каталог вместо поиска по ключевым словам.
К ним относятся Magellan, Excite, Infoseek, Inktomi, Northern Light и AltaVista. Яху! был одним из самых популярных способов поиска интересующих людей веб-страниц, но его функция поиска работала в веб-каталоге, а не в полнотекстовых копиях веб-страниц. Искатели информации также могли просматривать каталог вместо поиска по ключевым словам.
В 1996 году Netscape стремилась предоставить единственной поисковой системе эксклюзивную сделку в качестве основной поисковой системы в веб-браузере Netscape. Интерес был настолько велик, что вместо этого Netscape заключила сделки с пятью основными поисковыми системами: за 5 миллионов долларов в год каждая поисковая система будет чередоваться на странице поисковой системы Netscape. Пятью двигателями были Yahoo!, Magellan, Lycos, Infoseek и Excite. [8] [9]
Google принял идею продажи поисковых запросов в 1998 от небольшой поисковой компании goto.com. Этот шаг оказал значительное влияние на бизнес SE, который из затруднительного положения превратился в один из самых прибыльных бизнесов в Интернете. [10]
[10]
Поисковые системы были также известны как одни из самых ярких звезд интернет-инвестиционного безумия, которое произошло в конце 1990-х годов. [11] Несколько компаний эффектно вышли на рынок, получив рекордную прибыль во время своих первичных публичных размещений. Некоторые из них закрыли свою общедоступную поисковую систему и продают только корпоративные издания, такие как Northern Light. Многие поисковые компании оказались втянутыми в пузырь доткомов, вызванный спекуляцией рыночный бум, пик которого пришелся на 1919 год.99 и закончился в 2001 году.
Примерно в 2000 году поисковая система Google приобрела известность. [12] Компания добилась лучших результатов для многих поисковых запросов с инновацией под названием PageRank, как объяснялось в статье Анатомия поисковой системы , написанной Сергеем Брином и Ларри Пейджем, более поздними основателями Google. [13] Этот итеративный алгоритм ранжирует веб-страницы на основе количества и PageRank других веб-сайтов и страниц, которые ссылаются на них, исходя из того, что на хорошие или желательные страницы ссылаются чаще, чем на другие. Google также поддерживал минималистский интерфейс своей поисковой системы. Напротив, многие из его конкурентов встроили поисковую систему в веб-портал. Фактически, поисковая система Google стала настолько популярной, что появились поддельные системы, такие как Mystery Seeker.
Google также поддерживал минималистский интерфейс своей поисковой системы. Напротив, многие из его конкурентов встроили поисковую систему в веб-портал. Фактически, поисковая система Google стала настолько популярной, что появились поддельные системы, такие как Mystery Seeker.
К 2000 году Yahoo! предоставлял поисковые услуги на основе поисковой системы Inktomi. Яху! приобрела Inktomi в 2002 году и Overture (которая владела AlltheWeb и AltaVista) в 2003 году. Yahoo! перешла на поисковую систему Google до 2004 года, когда она запустила собственную поисковую систему на основе объединенных технологий своих приобретений.
Microsoft впервые запустила MSN Search осенью 1998 года, используя результаты поиска от Inktomi. В начале 1999 года сайт начал отображать списки от Looksmart, смешанные с результатами от Inktomi. Ненадолго в 1999, поиск MSN вместо этого использовал результаты из AltaVista. В 2004 году Microsoft начала переход на собственную технологию поиска, основанную на собственном поисковом роботе (msnbot).
Переименованная поисковая система Microsoft, Bing, была запущена 1 июня 2009 г. 29 июля 2009 г. Yahoo! и Microsoft заключили сделку, по которой Yahoo! Поиск будет осуществляться на основе технологии Microsoft Bing.
Что такое поисковые системы и как они работают?
Что такое поисковая система?
Поисковая система — это онлайн-инструмент, предназначенный для поиска веб-сайтов в Интернете на основе поискового запроса пользователя.
Он ищет результаты в собственной базе данных, сортирует их и составляет упорядоченный список этих результатов, используя уникальные алгоритмы поиска. Этот список называется страницей результатов поисковой системы (SERP).
Хотя в мире существуют различные поисковые системы (например, Google, Bing, Yahoo и т. д.), общие принципы поиска и предоставления ответов одинаковы во всех них.
Как работают поисковые системы
Поисковые системы могут отличаться друг от друга по способам предоставления ответов пользователю, но все они построены на 3 фундаментальных принципах:
- Ползание
- Индексация
- Рейтинг
1.
 Сканирование
СканированиеФактическое обнаружение новых веб-страниц в Интернете начинается с процесса, называемого сканированием.
Поисковые системы используют небольшие программы, называемые поисковыми роботами (иногда называемые ботами или роботами-пауками), которые переходят по ссылкам с уже известных страниц на новые, которые необходимо открыть.
Каждый раз, когда поисковый робот находит новую веб-страницу по ссылке, он сканирует и передает ее содержимое для дальнейшей обработки (так называемой индексации) и продолжает обнаружение новых веб-страниц.
2. Индексирование
После того, как боты просканируют данные, наступает время индексации — процесса проверки и сохранения содержимого веб-страниц в базе данных поисковой системы, которая называется «индекс». Это в основном большая библиотека всех веб-сайтов.
Ваш сайт должен быть проиндексирован, чтобы он отображался на странице результатов поисковой системы. Имейте в виду, что и сканирование, и индексирование — это непрерывные процессы, которые выполняются снова и снова, чтобы поддерживать базу данных в актуальном состоянии.
После того, как веб-страница проанализирована и сохранена в индексе, ее можно использовать в качестве результата поиска для потенциального поискового запроса.
3. Ранжирование
Последний шаг включает в себя выбор лучших результатов и создание списка страниц, которые будут отображаться на странице результатов.
Каждая поисковая система использует десятки сигналов ранжирования, и большинство из них держится в секрете, недоступном для общественности.
Как сказал Мартин Сплитт, аналитик тенденций для веб-мастеров:
«У нас есть более 200 сигналов для этого. Поэтому мы смотрим на такие вещи, как заголовок, мета-описание, фактический контент, который есть на вашей странице, изображения, ссылки и многое другое». (Мартин Сплитт, аналитик тенденций для веб-мастеров)
Что такое алгоритм поисковой системы?
Алгоритм поисковой системы — это термин, используемый для определения сложной системы из нескольких алгоритмов, которая оценивает все проиндексированные страницы и определяет, какие из них должны отображаться в результатах поиска по заданному запросу.
Например, алгоритм Google использует десятки факторов (многие из них хорошо известны, а некоторые держат в секрете) в нескольких областях, таких как:
- Значение запроса (понимание того, что пользователь означает использование точных слов, которые они использовали, какова цель поиска и т. д.)
- Релевантность страницы (поисковику необходимо узнать, отвечает ли страница на поисковый запрос)
- Качество контента (алгоритмы определяют, являются ли веб-страницы отличным источником информации на основе внутренних и внешних факторов; здесь важны количество и качество обратных ссылок)
- Удобство использования страницы (учитывает качество веб-страницы с технической точки зрения – отзывчивость, скорость страницы, безопасность и т. д.)
Поисковая оптимизация
Поисковые системы не только предоставляют пользователям полезную информацию, но и помогают брендам продвигать свои веб-сайты.
Оптимизация вашего веб-сайта для релевантных поисковых запросов является важной частью любой стратегии онлайн-маркетинга, поскольку она может привлечь больше трафика на ваши веб-страницы.
Сумма всех практик и методов, которые владельцы веб-сайтов используют для улучшения своего поискового рейтинга, называется поисковой оптимизацией (SEO).
Если бы мы хотели упростить SEO, мы могли бы сказать, что все вращается вокруг трех наиболее важных факторов:
- Техническая оптимизация
- Отличный контент
- Качественные обратные ссылки
Какие поисковые системы самые популярные?
Хотя в мире существуют сотни поисковых систем, лишь немногие из них доминируют на общем рынке поисковых систем и остаются популярными благодаря своему качеству, полезности и т. д. годы. Это список 5 самых популярных поисковых систем:
1. Google
Google — крупнейшая и самая популярная поисковая система в мире.
Компания Google, принадлежащая материнской компании Alphabet, доминирует на рынке поисковых систем, занимая более 90 процентов мирового рынка.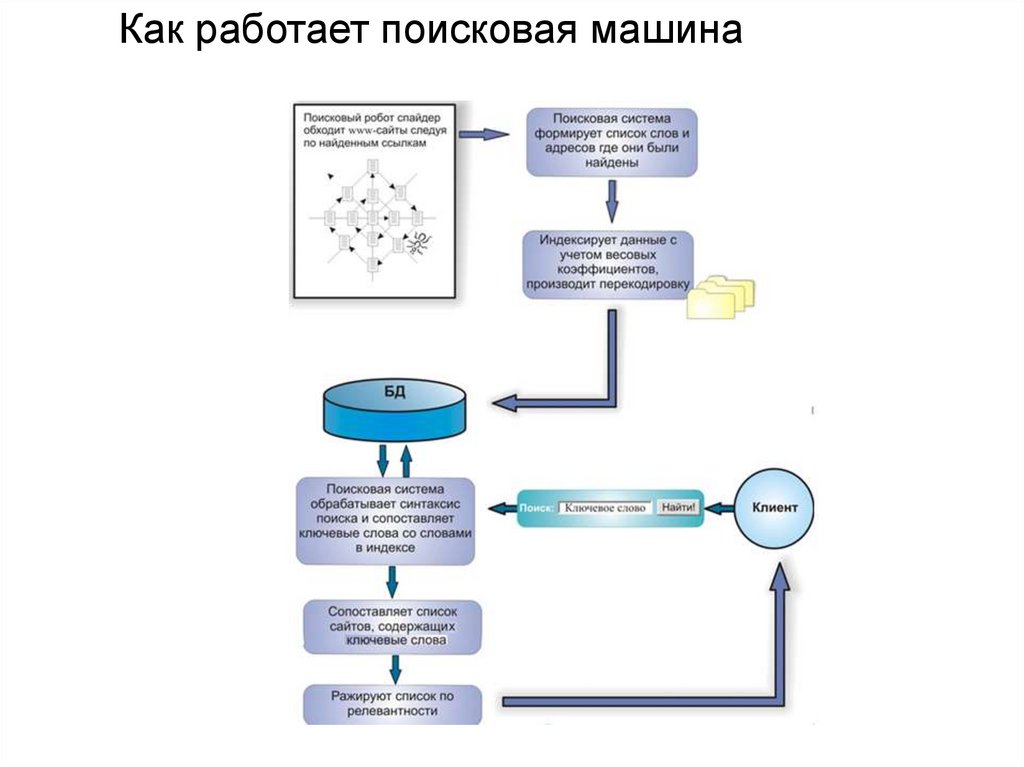
Благодаря всем своим функциям, включая сложные алгоритмы, эффективное сканирование, индексирование и ранжирование, Google обеспечивает отличные результаты поиска не только в своей собственной поисковой системе, но и в некоторых других поисковых системах (например, ask.com).
2. Microsoft Bing
Bing — вторая по величине поисковая система. Он был запущен в 2009 году и принадлежит Microsoft.
Хотя невозможно сравнивать Bing как реального соперника Google, занимающего всего 2–3 процента от общей доли рынка поисковых систем, это все же отличная альтернатива для тех, кто хотел бы попробовать что-то другое.
Microsoft Bing во многом похож на Google, предоставляя такие типы результатов поиска, как изображения, видео, места, карты или новости.
Хотя Bing использует основные принципы поисковых систем (сканирование, индексирование, ранжирование), он также использует специальный алгоритм под названием «Дерево разделов пространства и график», основанный на векторах для категоризации информации и ответов на поисковые запросы.
3. Yahoo!
Yahoo — популярный веб-сайт, провайдер электронной почты и третья по величине поисковая система в мире, на долю которой приходится почти 2% общей доли рынка поисковых систем.
Некогда очень популярная и доминирующая поисковая система Yahoo с годами падала в цене и стала несколько затмеваться Google.
В настоящее время Yahoo конкурирует с более мелкими поисковыми системами, такими как Bing или DuckDuckGo.
4. Яндекс
Яндекс (от термина « Y et Another i NDEX er») — поисковая система, популярная в основном в восточных странах.
Хотя на нее приходится менее 1 процента общей доли рынка поисковых систем, она является одной из самых популярных поисковых систем в таких странах, как Россия (более 60 процентов всех поисковых запросов в стране), Турция, Украина или Беларусь.
Подобно Google, Яндекс предоставляет различные виды услуг, включая Карты, Переводчик, Яндекс Деньги и даже Яндекс Музыку.
5. Baidu
Baidu является самой доминирующей поисковой системой в Китае. Несмотря на то, что его общая доля на мировом рынке составляет всего 1 процент, на него приходится более 80 процентов доли рынка в Китае с миллиардами поисковых запросов каждый день.
Baidu во многом похож на Google. Он предоставляет классические синие ссылки с зелеными URL-адресами и показывает расширенные результаты так же, как это делает Google.
Часто задаваемые вопросы
Ответим на несколько часто задаваемых вопросов о поисковых системах.
Почему Google является самой популярной поисковой системой?
Google, как поисковая система, уже много лет является лидером в своей отрасли и до сих пор доминирует на рынке поисковых систем. Есть несколько причин, по которым Google является наиболее широко используемой поисковой системой.
- Одна из первых поисковых систем
- Предлагает релевантные результаты
- Быстро
- Постоянно совершенствуется
- Подключен к нескольким бесплатным сервисам
Как поисковые системы зарабатывают деньги?
Основным источником дохода поисковых систем, таких как Google, являются различные косвенные источники. Поисковые системы могут монетизировать свои услуги через:
Поисковые системы могут монетизировать свои услуги через:
- Реклама – Google использует собственный рекламный сервис под названием Google Ads, благодаря которому он может помогать брендам отображать свои продукты в результатах поиска, а взамен берет небольшую комиссию каждый раз, когда пользователь кликает по объявлению.
- Интернет-магазины – поисковые системы могут продвигать различные продукты в расширенных результатах поиска. Если пользователь нажимает или покупает один из продуктов, поисковая система взамен берет небольшой процент от покупки.
- Службы — Google объединяет свои службы (например, Play Store, Google Cloud, Google Apps и т. д.) с собственной поисковой системой и, таким образом, получает доход от клиентов, которые их используют.
Какой была первая поисковая система?
Archie (от названия «Архив») — первая поисковая система, созданная в 1990 году студентом Аланом Эмтаджем.
Хотя и раньше существовало несколько программ индексации (например, «X.500» или «Whois»), Archie была первой настоящей поисковой системой, способной находить определенные файлы в Интернете.
Archie работал довольно просто — он просматривал доступные в Интернете сайты и индексировал их как загружаемые файлы. Однако он не мог индексировать содержимое сайтов и поэтому страницы результатов имели вид простого списка.
В чем разница между браузером и поисковой системой?
Веб-браузер (например, Chrome, Firefox, Microsoft Edge и т. д.) — это программное приложение, устанавливаемое на компьютер или смартфон. Целью браузера является предоставление удобного интерфейса для отображения веб-страниц.
Поисковая система (например, Google, Bing, Yahoo! и т. д.) — это онлайн-инструмент, доступный на веб-сайте, к которому можно получить доступ через веб-браузер. Цель поисковой системы — предоставлять ответы на запросы пользователей в виде соответствующих веб-страниц.
Как работают поисковые системы | Поисковые запросы Google
Хотите узнать, как работают Google и другие популярные поисковые системы? Узнайте больше о поисковых системах и о том, как Yext может помочь вашему бизнесу в Интернете.
Запланируйте персональную демонстрацию
Узнайте, как Yext Search Platform позволяет брендам захватывать и удерживать потребительский трафик со всех уголков Интернета.
Что будет дальше?
- Сотрудник команды запланирует короткий звонок, чтобы согласовать цифровую стратегию вашего бренда.
- После этого мы проведем персональную консультацию по поиску, чтобы выявить пробелы в вашей эффективности в Интернете.
- Наконец, вы получите живую демонстрацию решений Yext, которые наилучшим образом соответствуют вашим бизнес-целям и целевой аудитории.
Сегодня любой путь клиента начинается с вопросов. Ответьте на них с помощью Yext.
Приблизительно 3,8 миллиона поисковых запросов Google в минуту мир стал полагаться на поисковых систем, таких как Google, Yahoo и Bing, которые дают им ответы на многие жизненные вопросы. Поисковые системы — это машины, которые сканируют Интернет (и его 1 миллиард веб-сайтов) по указанным ключевым словам, независимо от того, отвечают ли они на обыденные или экстраординарные вопросы, и предоставляют пользователям наиболее релевантные веб-сайты или страницы для их поиска.
Поисковые системы — это машины, которые сканируют Интернет (и его 1 миллиард веб-сайтов) по указанным ключевым словам, независимо от того, отвечают ли они на обыденные или экстраординарные вопросы, и предоставляют пользователям наиболее релевантные веб-сайты или страницы для их поиска.
Целью любой поисковой системы является облегчение поиска пользователем информации на веб-сайте или странице, поскольку без помощи поисковой системы поиск ответа на вопрос занял бы дни, а не секунды. Поисковые системы, такие как Google и Bing, выполняют две основные функции: во-первых, сканирование и индексирование сети, а во-вторых, предоставление пользователям значимых результатов по их запросам.
Прежде чем предоставить результаты пользователю, поисковая система должна просканировать Интернет и проиндексировать каждый уникальный документ в Интернете (обычно это веб-страница, но также может быть файлом в формате PDF, JPG или другим файлом), а затем найти лучшая ссылка или путь к каждому документу. Эти ссылки/пути позволяют поисковым роботам или поисковым роботам достигать миллиардов взаимосвязанных документов в Интернете. Когда поисковые роботы находят новые страницы, они расшифровывают их код, а затем сохраняют выбранные фрагменты в огромных базах данных, чтобы позже вызывать их для поисковых запросов.
Эти ссылки/пути позволяют поисковым роботам или поисковым роботам достигать миллиардов взаимосвязанных документов в Интернете. Когда поисковые роботы находят новые страницы, они расшифровывают их код, а затем сохраняют выбранные фрагменты в огромных базах данных, чтобы позже вызывать их для поисковых запросов.
Поисковые системы — это машины для ответов, поэтому, когда пользователь хочет решить вопрос с помощью Yahoo, Bing или Google, приоритет любой поисковой системы — дать содержательные и релевантные ответы. Для этого поисковые системы начинают с того, что возвращают только те результаты, которые релевантны или полезны для запроса искателя, а затем ранжируют эти результаты в соответствии с популярностью и надежностью веб-сайтов, предоставляющих эту информацию. Страницы могут повысить свой рейтинг на страницах результатов поисковой системы или SERP, практикуя поисковую оптимизацию (SEO), которая представляет собой процесс воздействия на видимость веб-сайта или веб-страницы в обычных или бесплатных результатах поиска поисковой системы.
Поисковые системы также учитывают следующие факторы при ранжировании страницы:
Когда страница была опубликована
Если страница содержит текст, изображения или видео
Качество контента
Насколько хорошо контент соответствует запросам пользователей
Насколько быстро загружается сайт
Сколько ссылок с других веб-сайтов ведут на этот контент
Сколько людей поделились контентом сайта в сети
То, как каждая поисковая система определяет популярность, основано на их индивидуальном алгоритме и в значительной степени неизвестно, но известно их желание предоставлять пользователям точные, надежные и релевантные результаты. Основываясь на популярности сайта, страницы или документа, поисковые системы предполагают, что эта популярность коррелирует с тем, насколько ценной должна быть информация на странице. Их алгоритмы также учитывают удобочитаемость сайта, которую можно улучшить, добавив разметку Schema.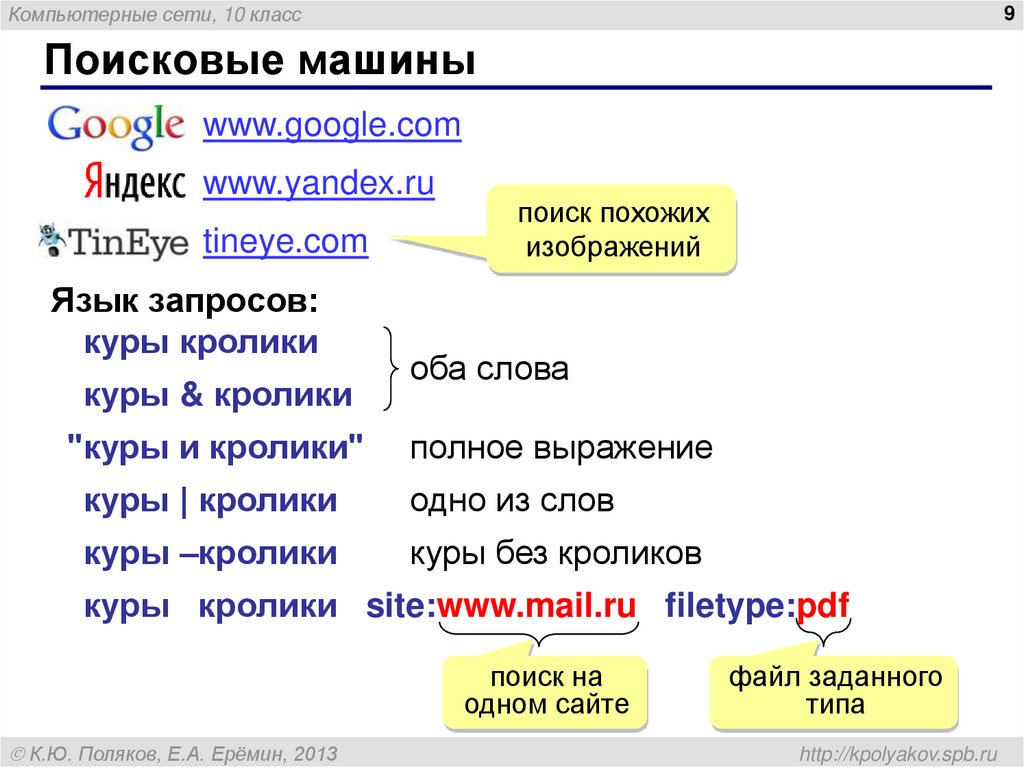
Однако поисковые системы не безупречны, потому что они не могут гарантировать надежность или правдивость для пользователей, просматривающих страницы результатов поисковой системы, или для компаний, размещающих свои локальные списки в Интернете. Со стороны пользователя реклама в верхней части поисковой выдачи может быть оплачена или спонсирована компаниями, которые игнорируют то, как поисковая система естественным образом ранжирует их на предмет доверия. Это создает реальную ценность в естественных результатах поисковой выдачи, а для компаний, размещающих публикации в Интернете, любые усилия по успокоению алгоритмов поисковых систем поднимут список в этих рядах.
Один из способов улучшить локальную поисковую оптимизацию компании — использовать разметку Schema, которая кодирует страницу с использованием языка и словаря, которые легко распознаются основными алгоритмами поисковых систем. Другой метод повышения местного SEO — добавление расширенного контента в листинг в дополнение к данным NAP листинга.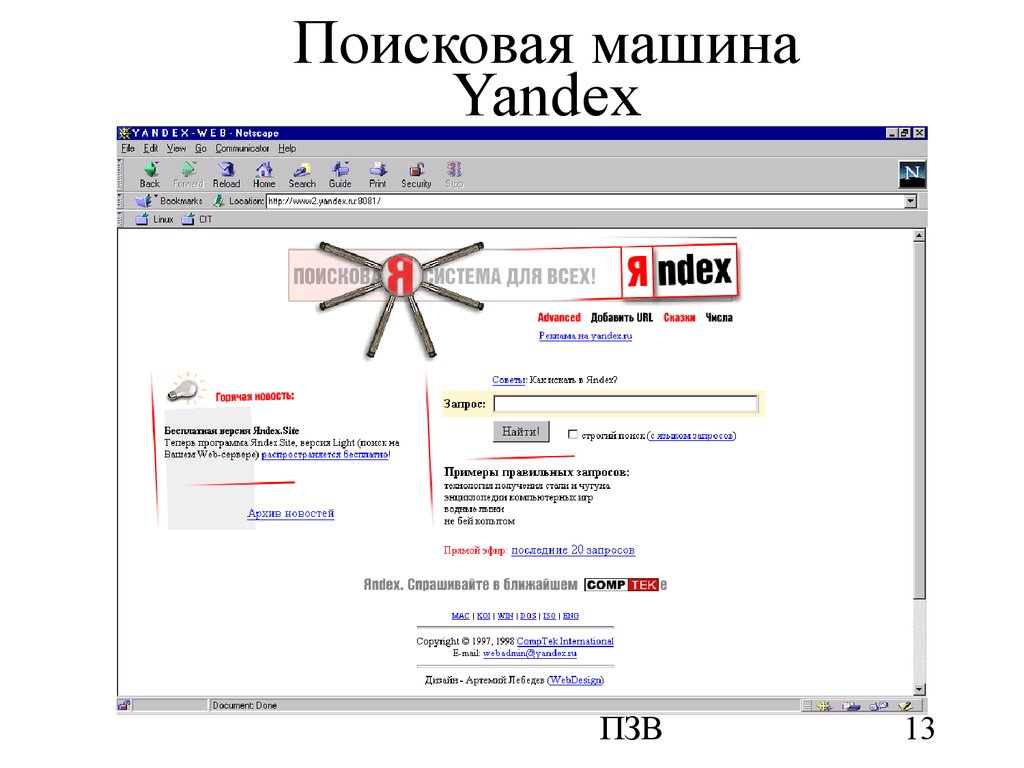 Расширенные списки контента включают информацию о конкретном местоположении, такую как меню, продукты и услуги, биографии, события и предложения. Дополняя страницу тегами Schema, расширенным содержимым и изображениями, компания создает полезный, насыщенный информацией сайт, который дополнительно описывает свое содержимое четким и точным способом.
Расширенные списки контента включают информацию о конкретном местоположении, такую как меню, продукты и услуги, биографии, события и предложения. Дополняя страницу тегами Schema, расширенным содержимым и изображениями, компания создает полезный, насыщенный информацией сайт, который дополнительно описывает свое содержимое четким и точным способом.
Yext помогает компаниям занимать высокие позиции в поисковых системах, управляя тем, как списки компаний отображаются в экосистеме онлайн-поиска, обеспечивая точность и надежность в Интернете. Предприятия могут использовать Yext Knowledge Manager для управления цифровыми знаниями — от традиционного NAP до расширенного контента. Данные во всех нужных местах помогают компаниям занимать более высокие позиции на страницах результатов поисковых систем. Узнайте, как Yext Knowledge Manager может помочь вашему бизнесу.
Что ищут поисковые системы в 2022 году? [16 фактов о SEO]
Последнее изменение: 09.21.2022
Время чтения:
SEO как никогда важно. Если ваш бизнес не отображается в релевантном поиске Google, для клиентов он может и не существовать. Люди исследуют Интернет через поисковые системы, и чтобы оставаться в поле зрения, компании должны разработать надежную стратегию поисковой оптимизации (SEO).
Если ваш бизнес не отображается в релевантном поиске Google, для клиентов он может и не существовать. Люди исследуют Интернет через поисковые системы, и чтобы оставаться в поле зрения, компании должны разработать надежную стратегию поисковой оптимизации (SEO).
Однако, несмотря на признание того факта, что SEO имеет решающее значение для существования в Интернете и общего успеха, компании все еще совершают некоторые основные ошибки, которые могут стоить им реальных платящих клиентов. Обычно это происходит из-за того, что люди неправильно понимают, как работает поиск Google и почему вам нужно SEO для вашего бизнеса.
В этой статье мы приводим некоторые факты о поисковой оптимизации, которые помогут вам понять, что это такое, что ищут поисковые системы и как улучшить свое присутствие в Интернете.
Что делает поисковая система и что такое SEO?
Проще говоря, SEO включает в себя все методы и приемы, которые вы применяете для повышения видимости вашего веб-сайта и его содержимого на страницах результатов поисковых систем (также известных как SERP).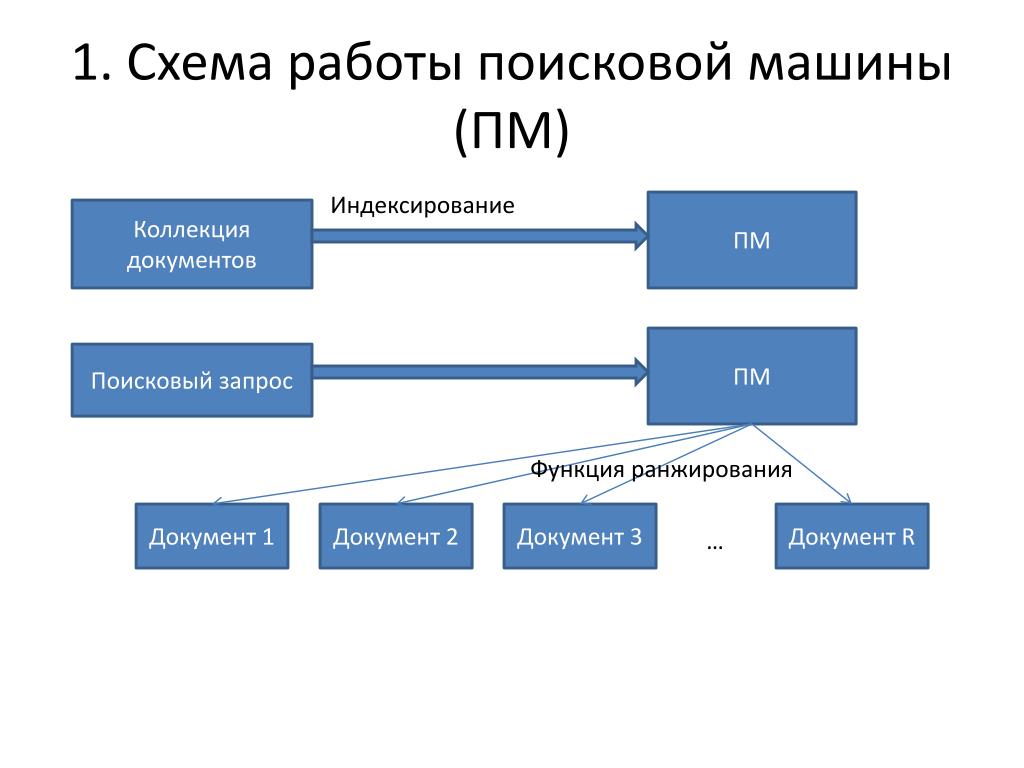 Как правило, существует два основных метода оптимизации вашего веб-сайта — внутреннее и внешнее SEO.
Как правило, существует два основных метода оптимизации вашего веб-сайта — внутреннее и внешнее SEO.
Поисковая оптимизация на странице — это все технические приемы, которые остаются за кулисами, такие как URL-адрес страницы, использование соответствующих тегов, заголовков, подзаголовков, использование ключевых слов, мультимедиа и многое другое.
Методы SEO вне страницы носят более рекламный характер, и вы можете использовать их для повышения видимости сайта. Примеры включают маркетинг в социальных сетях, создание ссылок и т. д. Под видимостью мы подразумеваем, насколько высоко или низко ваш веб-сайт появляется в поисковой выдаче для определенных наборов ключевых слов.
Примечание . В этом посте мы сосредоточимся на обычных результатах поиска, а не на платных. Тем не менее, платный поиск также является важной частью SEO. Взгляните на скриншот ниже, мы выделили для вас органический и платный поиск. Видите, как платные ссылки занимают первые позиции? Вот почему вы должны рассмотреть PPC для своей маркетинговой стратегии.
Почему вам нужно SEO для вашего бизнеса?
Основная цель любого веб-сайта — привлечь как можно больше посетителей.
Теперь, когда дело доходит до трафика, генерируемого поисковыми системами, цифры просто ошеломляющие — и, вероятно, самый ясный показатель того, насколько важна SEO и зачем она нам нужна.
Согласно исследованиям, почти 29% трафика на веб-сайте приходится на поисковые системы. Если вы думали о социальных сетях, знайте, что только 2,5% приходятся на социальные сети и 0,5% — на платные поиски.
Существует множество поисковых систем, и некоторые из вас могут задаться вопросом, какую из них выбрать в первую очередь? По данным, это должен быть Google. Компания насчитывает 92,04% всего глобального органического поискового трафика, а Bing, Baidu, Yahoo!, YANDEX и DuckDuckGo делят оставшиеся менее 8%. Преимущество Google — довольно большое число и явный показатель того, на чем следует сосредоточить внимание.
Что ищут поисковые системы?
- Актуальность
- Качество контента
- Пользовательский опыт
- Скорость
- Совместимость
- Внутренняя связь
- Обратные ссылки
- Метаописания
- Разметка схемы
- Маркировка изображений
- Вечнозеленый контент
- Свежий контент
- Страницы колонн
- описаний YouTube
- Длинные ключевые слова в тегах заголовков
- Идеи уникального контента
Итак, давайте посмотрим, что ищут поисковые системы и как вы можете их предоставить.
1. Релевантность
Поисковые системы становятся умнее, и они стараются предоставлять своим пользователям самую актуальную и актуальную информацию. Будь то простой вопрос или более сложный запрос, поисковые системы всегда будут пытаться отфильтровать наилучшую информацию, которая соответствует намерениям пользователя.
Поисковые системы ищут информацию на основе уникального алгоритма, использующего обработку естественного языка, чтобы понять, что имеет в виду человек, а затем сопоставляют обнаруженные сущности и настроения со своей базой данных и Базой знаний. Хотя они далеки от совершенства, они постоянно совершенствуются и растут точнее с каждым обновлением.
При этом релевантность вашей целевой аудитории может иметь большое значение с точки зрения привлечения органического трафика. Вот почему вы должны исследовать, что ищет ваша аудитория и почему, и попытаться сопоставить их требования с контентом вашего веб-сайта.
2. Качество контента
Если контент важнее, то качество — это армия. Король со слабой армией уязвим, в то время как сильная армия укрепляет правление короля. Привлекательный и интересный контент, представляющий ценность, побудит посетителей проводить больше времени на вашем веб-сайте и может повысить конверсию. Это влияет на общий пользовательский опыт, и это действительно важно для поисковых систем.
Король со слабой армией уязвим, в то время как сильная армия укрепляет правление короля. Привлекательный и интересный контент, представляющий ценность, побудит посетителей проводить больше времени на вашем веб-сайте и может повысить конверсию. Это влияет на общий пользовательский опыт, и это действительно важно для поисковых систем.
Google с годами полюбил качество контента, и теперь оно даже является фактором ранжирования.
Один из способов создания качественного контента — писать для своей аудитории, а не для поисковых систем. Вы также должны следовать правилам Google EAT, чтобы убедиться, что ваши страницы соответствуют стандартам поисковой системы и имеют шанс занять хорошие позиции в поисковой выдаче.
3. Пользовательский опыт
Пользовательский опыт — это то, что на самом деле чувствует посетитель, когда он находится на вашем веб-сайте. Общий дизайн сайта, сочетание цветов, навигация, скорость сайта и контент влияют на взаимодействие с пользователем.
Некоторые из сигналов, которые показывают поисковым системам, что вы не работаете в этом направлении, — это высокий показатель отказов и низкое время ожидания. Это означает, что для того, чтобы быть релевантным в поиске, ваш сайт должен уметь не только привлекать клиентов, но и удерживать их.
4. Скорость
Несколько лет назад скорость веб-сайта не была так важна, но с обновлением ядра webs vitals скорость загрузки вашего веб-сайта может стать решающим фактором с точки зрения SEO.
Время, необходимое странице для загрузки и перехода в интерактивный режим, является основным фактором, определяющим взаимодействие с пользователем. И поскольку в настоящее время всегда есть альтернатива, Google решил отдать приоритет более быстрым и лучше оптимизированным страницам в поисковой выдаче. Это не означает, что сайты с медленной загрузкой не будут ранжироваться. Однако, если Google идентифицирует две похожие страницы, которые соответствуют запросу и намерению пользователя, алгоритм сначала отобразит ту, у которой лучше Core Web Vitals.
5. Совместимость
В настоящее время большинство людей в мире выходят в Интернет со своих мобильных телефонов. На самом деле 59,32 % всего трафика приходится на устройства с маленьким экраном.
Вот почему в последние несколько лет Google работал над индексацией для мобильных устройств, и теперь это норма для всех поисковых запросов. Это означает, что боты поисковой системы сканируют и отображают в поисковой выдаче только мобильные версии сайтов.
Веб-сайты выглядят по-разному на мобильном телефоне, планшете или настольном компьютере, и чтобы обеспечить одинаково первоклассный опыт, компании должны оптимизировать свои свойства, чтобы они одинаково хорошо отображались на экранах всех форм и размеров. Лучший способ сделать это — реализовать адаптивный дизайн и включить автоматическое изменение страницы в зависимости от экрана, на котором она просматривается.
6. Внутренние ссылки
Создание внутренних ссылок – один из самых полезных методов поисковой оптимизации и, вероятно, самый недооцененный. Вот что он может сделать для вашего веб-сайта:
Вот что он может сделать для вашего веб-сайта:
- Помогите читателям найти более релевантный контент.
- Помогает ботам понять, о чем текст.
- Помогает ботам понять связи между страницами.
- Помогите с ботами индексировать страницы лучше.
Когда поисковые системы лучше понимают содержание ваших страниц, алгоритм склонен отображать его в более релевантных результатах поиска. В конечном итоге это может сократить время отказов, увеличить время ожидания и даже повысить конверсию. Все это служит дополнительным положительным сигналом для поисковых систем.
7. Обратные ссылки
Обратные ссылки считаются наиболее важным фактором ранжирования для Google. Идея состоит в том, что ссылки на авторитетные домены показывают, что ваш контент актуален и имеет высокое качество. Например, если Гарвард или НАСА ссылаются на вашу страницу, нет более высокой узнаваемости, чем эта.
Алгоритмы, какими бы продвинутыми они ни были в наши дни, не способны полностью понять, что может быть ценным для человека, а что не имеет значения. Вот почему они используют обратные ссылки как форму рекомендаций от других людей. Если на веб-сайте много ссылок с авторитетных веб-сайтов, их собственный авторитет растет.
Вот почему они используют обратные ссылки как форму рекомендаций от других людей. Если на веб-сайте много ссылок с авторитетных веб-сайтов, их собственный авторитет растет.
Просто чтобы было понятно, авторитетный веб-сайт — это имя, пользующееся доверием на рынке. Он уже признан лидером в своей нише. Вы можете дополнительно повысить авторитет своего веб-сайта, создавая передовой контент и работая над своей онлайн-репутацией.
8. Мета-описания
Мета-описание может не очень помочь в SEO, однако оно делает ваш контент более узнаваемым и доступным для поиска. Если вам интересно, что такое метаописания, это небольшой абзац, который появляется под URL-адресом страницы. Пользователи часто читают этот абзац перед тем, как перейти по ссылке. Для этого описания установлено ограничение в 156 символов.
Даже если вы не создадите их вручную, есть большая вероятность, что Google создаст их автоматически, извлекая текст из содержимого.
Однако лучше написать их самостоятельно, чтобы оптимизировать их с помощью соответствующих ключевых слов. Это может улучшить видимость вашего контента в поиске и упростить пользователям и ботам поиск того, о чем ваш контент.
Это может улучшить видимость вашего контента в поиске и упростить пользователям и ботам поиск того, о чем ваш контент.
9. Разметка схемы
Разметка схемы очень важна для поисковой оптимизации, поскольку она предоставляет еще один способ помочь Google понять и проиндексировать ваш контент. Предоставляя структурированные данные, описывающие характер информации, цели, формат и т. д., боты с большей вероятностью правильно поймут вашу страницу и отобразят ее в релевантных поисковых запросах.
Они могут сделать это в любом случае, однако, если вы возьмете под свой контроль процесс, вы уменьшите вероятность ошибок.
Кроме того, благодаря структурированным данным ваш контент может отображаться в расширенных результатах. Это делает ссылку более привлекательной в поиске с помощью мультимедиа, рейтингов, сведений о продукте и многого другого.
Этот тип результатов поиска более привлекателен, и люди с большей вероятностью нажимают на них.
10. Маркировка изображений
Пока Google активно работает над улучшением того, как они сканируют и понимают изображения, алгоритму еще предстоит пройти долгий путь. Вот почему информация, которую вы предоставляете, чтобы пометить и описать свои изображения, действительно важна.
Вот почему информация, которую вы предоставляете, чтобы пометить и описать свои изображения, действительно важна.
Мы говорим об альтернативном тексте. Это краткое описание изображения, которое помогает поисковым системам идентифицировать его. Вы также можете использовать свои основные ключевые слова в альтернативном тексте, но не переусердствуйте.
Пометка изображений также помогает сделать ваш визуальный контент более узнаваемым в поиске изображений Google. А поскольку количество визуальных поисковых запросов растет в геометрической прогрессии, оптимизируя изображения, вы повышаете свои шансы на попадание в число лучших и привлекаете больше трафика на свой веб-сайт.
11. Вечнозеленый контент
Вечнозеленый контент обычно не ограничен по времени. Это будет полезно независимо от того, когда оно будет прочитано. Да, это сложно создать, так как это требует времени. Однако долгосрочные преимущества такого контента поразительны, и Google это тоже любит.
Вечнозеленый контент обеспечивает регулярный трафик на ваш сайт и показывает поисковым системам, что вы представляете ценность. Кроме того, если вы регулярно обновляете его, добавляя свежую информацию, более свежие исследования, новые ссылки и т. д., со временем он остается еще более актуальным.
Кроме того, если вы регулярно обновляете его, добавляя свежую информацию, более свежие исследования, новые ссылки и т. д., со временем он остается еще более актуальным.
12. Свежий контент
Помимо постоянно обновляемого контента, Google всегда ищет свежий контент по актуальным темам. Раньше это было важно в основном для цифровых издателей, которые хотят попасть в Google News и Top Stories. Однако после недавних обновлений достойная новостей информация со всех веб-сайтов может отображаться в новостях, если она соответствует интересам пользователя.
Освещение интересных новостей, касающихся вашей отрасли и ниши, может помочь вам подняться на новостных платформах поисковой системы и привлечь новую аудиторию. Особенно, если вы быстро отреагируете на событие и продемонстрируете уникальную и актуальную точку зрения.
Компания Google ценит независимую журналистику и хочет показывать различные точки зрения, поэтому даже небольшие веб-сайты могут блистать, если они приносят пользу.
13. Основные страницы
Основные страницы — это отличный способ упорядочить содержимое по темам, актуальным для ваших клиентов. Основная страница объединяет несколько других страниц, которые исследуют информацию с разных точек зрения и охватывают соответствующие подтемы.
Информационные центры такого типа показывают Google, что вы хорошо разбираетесь в теме и можете дать пользователю исчерпывающее объяснение. Экспертиза — важный фактор EAT, и основные страницы — один из способов показать это.
14. Описания YouTube
Видео YouTube часто попадают на первую страницу Google. У них большой потенциал — так что, если у вас еще нет канала, создайте его и начните создавать видео правильно.
Если у вас уже есть канал, вы можете повысить его производительность, а также улучшить поисковую оптимизацию своего веб-сайта, расшифровав свои видео и превратив их в статьи.
Это работает и наоборот: существует множество инструментов, которые позволяют вам превращать ваши статьи и подкасты в видео и охватывать более широкую аудиторию.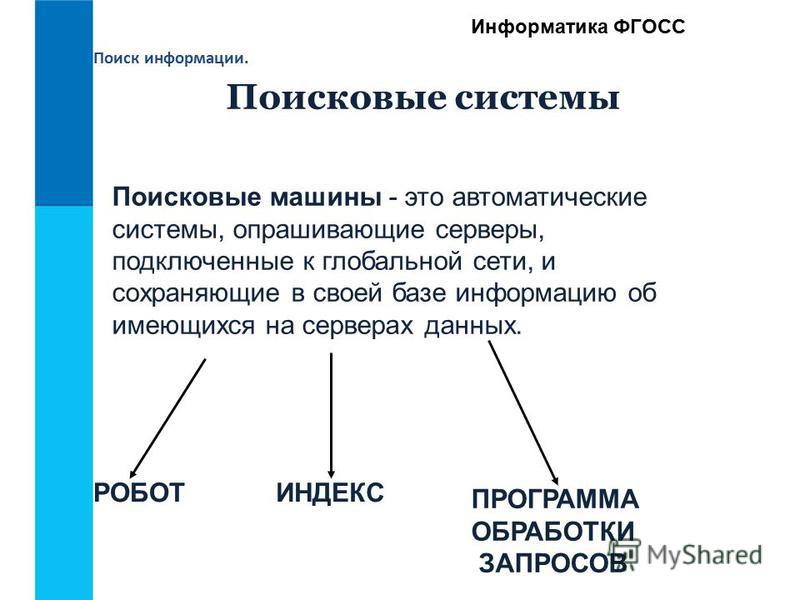
Перепрофилированный контент обеспечивает более богатый опыт и помогает вашему бизнесу улучшить свое присутствие в Интернете.
15. Ключевые слова с длинным хвостом в тегах заголовков
Использование только одного (одного) ключевого слова в заголовке допустимо. Тем не менее, вы потеряете много трафика. Используйте по крайней мере одно, а в идеале два ключевых слова с длинным хвостом в своей статье, чтобы повысить ваш рейтинг.
Кроме того, вы можете использовать ключевые слова с длинным хвостом в заголовках h3 и h4, чтобы улучшить структуру контента и повысить вероятность обнаружения различных разделов в поиске.
16. Уникальные идеи контента
Сложно регулярно придумывать новые идеи контента, соответствующие стратегии вашего бренда. Тем не менее, создание существенного отставания и публикация по расписанию хороши для поддержания вашей релевантности. Ваши клиенты привыкнут ожидать от вас обновлений в определенные дни и часы и, вероятно, будут с нетерпением ждать их. Если вам удастся доставить, это со временем увеличит посещаемость вашего сайта.
Если вам удастся доставить, это со временем увеличит посещаемость вашего сайта.
Вы можете искать свежие идеи контента, используя различные инструменты SEO, выполняя анализ пробелов в ключевых словах, следя за отраслевыми тенденциями и используя свои собственные данные для создания уникальных произведений.
Другим отличным источником ключевых слов и идей для тем является Википедия. Используйте Планировщик ключевых слов Google в сотрудничестве с Википедией и наблюдайте, как происходит волшебство.
Выполните поиск термина в Wiki и обратите особое внимание на поле «Содержание», боковые панели, внутренние ссылки и раздел «См. также» для нестандартных уникальных идей.
Bottom Line
Приведенный выше список методов не является исчерпывающим, поскольку поисковые системы постоянно меняются, и почти невозможно охватить все, что они ищут на веб-сайте. Тем не менее, он дает представление о последних обновлениях и показывает, почему вам нужно SEO для вашего бизнеса.