Методы HTTP: GET vs. POST
❮ Предыдущий Следующий Ссылка ❯
Два наиболее часто используемые методы HTTP являются: GET и POST.
Что такое HTTP?
Протокол передачи гипертекста (HTTP) предназначена для обеспечения связи между клиентами и серверами.
HTTP работает в качестве протокола запроса-ответа между клиентом и сервером.
Веб-браузер может быть клиентом, а приложение на компьютере, на котором размещен веб-сайт может быть сервером.
Пример: клиент (браузер) подает запрос HTTP на сервер; то сервер возвращает ответ клиенту. Ответ содержит информацию о состоянии запроса и может также содержать запрошенное содержимое.
Два HTTP методы запроса: GET и POST
Два часто используемые методы для запроса-ответа между клиентом и сервером: GET и POST.
- GET — запрашивает данные из указанного ресурса
- POST — Отправляет данные, подлежащие обработке для указанного ресурса
Метод GET
Обратите внимание , что строка запроса (пары имя / значение) передается в URL запроса GET:
/test/demo_form. asp?name1=value1&name2=value2
asp?name1=value1&name2=value2
Некоторые другие заметки о запросах GET:
- GET запросы могут кэшироваться
- GET запросы остаются в истории браузера
- GET запросы могут быть закладкой
- не получать запросы не должны использоваться при работе с конфиденциальными данными
- GET запросы имеют ограничения длины
- GET запросы должны быть использованы только для получения данных
Метод POST
Обратите внимание , что строка запроса (пары имя / значение) передается в теле HTTP—сообщение запроса POST:
POST /test/demo_form.asp HTTP/1.1
Host: w3ii.com
name1=value1&name2=value2
Некоторые другие замечания по запросам POST:
- POST запросы никогда не кэшируются
- POST запросы не остаются в истории браузера
- запросы POST не может быть закладкой
- POST запросы не имеют ограничений по длине данных
Сравнить GET vs.
 POST
POSTВ следующей таблице сравниваются два метода HTTP: GET и POST.
| ПОЛУЧИТЬ | ПОСЛЕ | |
|---|---|---|
| Кнопка BACK / Reload | безвредный | Данные будут представлены вновь (браузер должен предупредить пользователя, что данные собираются быть повторно представлены) |
| Отмеченный | Может быть закладкой | Не может быть закладкой |
| Сохранено в кэше | Может быть кэшируются | Не кэшировать |
| Тип кодирования | применение / х-WWW-форм-urlencoded | применение / х-WWW-форм-urlencoded или многокомпонентные / form-данных. Используйте многослойную кодировки для двоичных данных |
| история | Параметры остаются в истории браузера | Параметры не сохраняются в истории браузера |
| Ограничения по длине данных | Да, используемый при передаче данных, метод GET добавляет данные в URL-адрес; и длина URL ограничена (максимальная длина URL составляет 2048 символов) | Нет ограничений |
| Ограничения по типу данных | Только ASCII символы допускаются | Нет ограничений. Бинарные данные также разрешено Бинарные данные также разрешено |
| Безопасность | GET менее безопасна по сравнению с POST, поскольку данные, отправленные является частью URL Никогда не используйте GET при отправке паролей или другой конфиденциальной информации! | POST немного безопаснее, чем GET, поскольку параметры не сохраняются в истории браузера или в журналах веб-сервера |
| видимость | Данные видны всем пользователям в URL | Данные не отображаются в URL |
Другие способы запроса HTTP
В следующей таблице перечислены некоторые другие методы запроса HTTP:
| метод | Описание |
|---|---|
| HEAD | То же самое, но не GET возвращает только HTTP-заголовки и не тело документа |
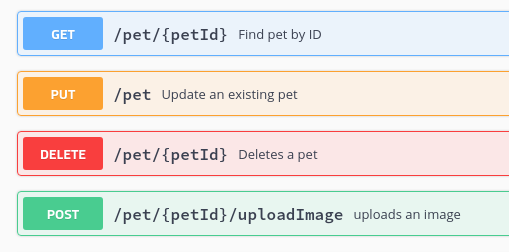
| PUT | Загружает представление заданного URI |
| DELETE | Удаляет указанный ресурс |
| OPTIONS | Возвращает методы HTTP, что сервер поддерживает |
| CONNECT | Преобразует соединение запроса в прозрачный TCP / IP туннеля |
❮ Предыдущий Следующий Ссылка ❯
GET и POST запросы с использованием Python
В современном мире веб-приложения и API играют важную роль в обмене данными и коммуникации.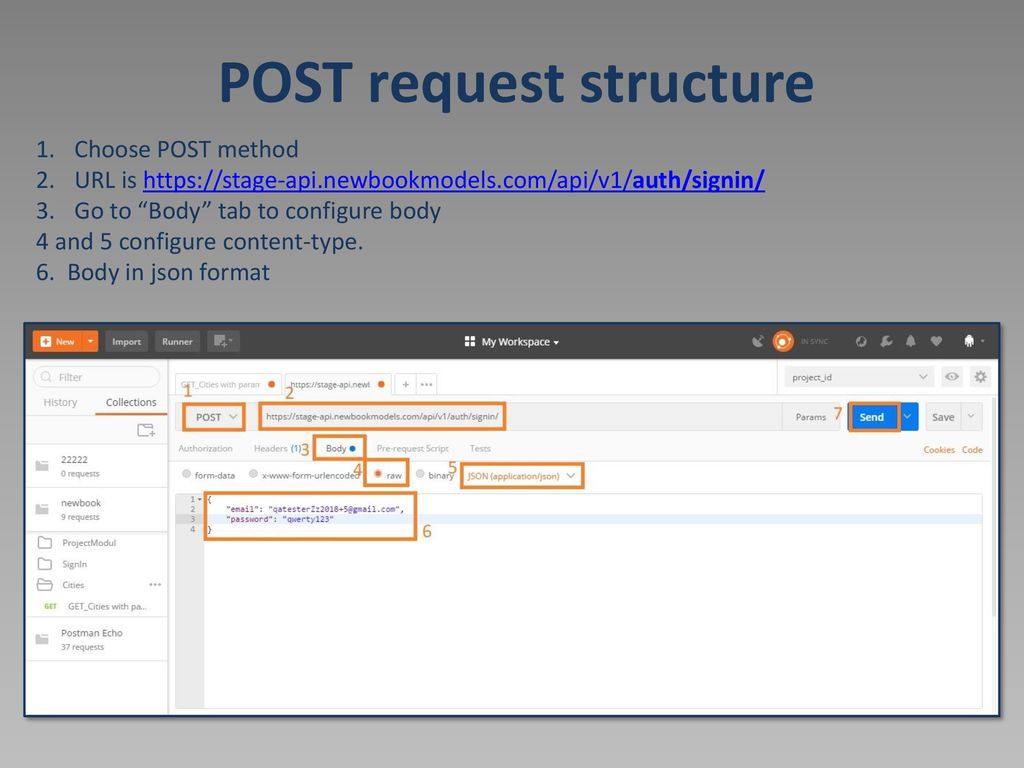 Нам часто приходится отправлять HTTP-запросы, такие как GET и POST, чтобы взаимодействовать с этими веб-сервисами. В этой статье мы рассмотрим основы запросов GET и POST с помощью Python и изучим две популярные библиотеки, которые помогают нам решать эти задачи: Requests и urllib.
Нам часто приходится отправлять HTTP-запросы, такие как GET и POST, чтобы взаимодействовать с этими веб-сервисами. В этой статье мы рассмотрим основы запросов GET и POST с помощью Python и изучим две популярные библиотеки, которые помогают нам решать эти задачи: Requests и urllib.
Содержание
- Библиотеки Python для работы с HTTP-запросами
- Requests
- urllib
- GET-запросы
- GET-запрос с помощью библиотеки Requests
- GET-запрос с помощью библиотеки urllib
- POST-запросы
- POST-запрос с помощью библиотеки Requests
- POST-запрос с помощью библиотеки urllib
- Отправка данных в POST-запросах
- Работа с данными JSON
- Ошибки HTTP
- Исключения
- Аутентификация в API
- Файлы cookie и сеансы
- Тайм-аут и повторные запросы
- Заключение
Библиотеки Python для работы с HTTP-запросами
При работе с HTTP-запросами в Python есть две основные библиотеки, которые вы можете использовать: Requests и urllib.
Requests
Requests — это популярная и удобная библиотека Python для выполнения HTTP-запросов. Она абстрагирует все сложности выполнения запросов за красивым и простым API, позволяя вам отправлять запросы HTTP/1.1. Вы можете установить библиотеку с помощью pip:
pip install requests
Вот пример отправки простого GET-запроса с помощью библиотеки Requests:
import requests
response = requests.get('https://api.example.com/data')
print(response.text)urllib
urllib — это еще одна библиотека в Python, которая предоставляет инструменты для работы с URL-адресами, включая получение данных из Интернета. Это встроенная библиотека, поэтому устанавливать ее отдельно нет необходимости. Однако она немного более низкоуровневая, чем Requests, и работа с ней может показаться вам более сложной.
Чтобы отправить GET-запрос с помощью библиотеки urllib, вы можете использовать следующий код:
from urllib.request import urlopen
response = urlopen('https://api. example.com/data')
print(response.read().decode('utf-8'))
example.com/data')
print(response.read().decode('utf-8')) example.com/data')
print(response.read().decode('utf-8'))
example.com/data')
print(response.read().decode('utf-8'))GET-запросы
GET-запросы используются для получения данных с сервера или API. Давайте подробнее рассмотрим отправку GET-запросов с помощью библиотек Requests и urllib.
GET-запрос с помощью библиотеки Requests
Отправка GET-запроса с помощью библиотеки Requests проста. Вот пример отправки GET-запроса с параметрами запроса:
import requests
url = 'https://api.example.com/search'
params = {'query': 'python', 'page': 1}
response = requests.get(url, params=params)
print(response.text)В этом примере мы отправляем GET-запрос на конечную точку https://api.example.com/search с параметрами запроса query и page. Библиотека Requests автоматически кодирует параметры и добавляет их к URL.
GET-запрос с помощью библиотеки urllib
Вот как можно отправить GET-запрос с параметрами запроса с помощью библиотеки urllib:
from urllib.request import urlopen from urllib.parse import urlencode, urljoin base_url = 'https://api.example.com/search' params = {'query': 'python', 'page': 1} query_string = urlencode(params) url = urljoin(base_url, '?' + query_string) response = urlopen(url) print(response.read().decode('utf-8'))
В этом примере мы используем функцию urlencode для создания строки запроса из параметров и функцию urljoin для создания окончательного URL.
POST-запросы
POST-запросы используются для отправки данных на сервер или API, и обычно они применяются для отправки форм, загрузки файлов или обновления данных на сервере. Давайте подробнее рассмотрим отправку POST-запросов с помощью библиотек Requests и urllib.
POST-запрос с помощью библиотеки Requests
Чтобы отправить POST-запрос с помощью библиотеки Requests, вы можете использовать следующий код:
import requests
data = {'key': 'value'}
response = requests.post('https://api.example.com/submit', data=data)
print(response. text)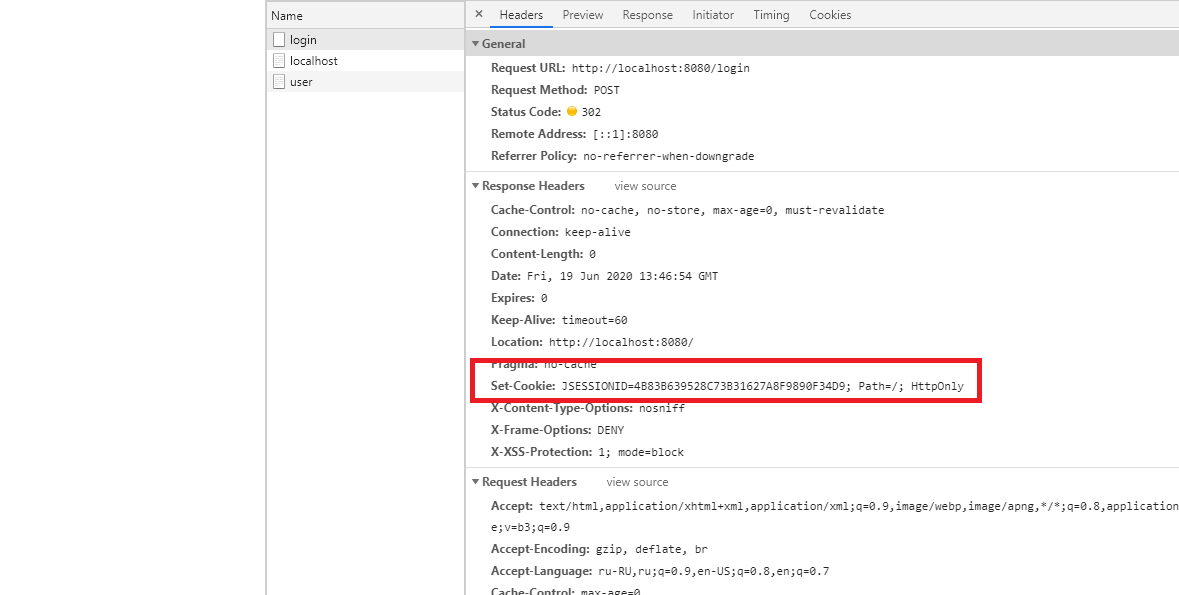 text)
text)В этом примере мы отправляем POST-запрос на конечную точку https://api.example.com/submit с данными формы. Библиотека Requests автоматически кодирует данные и устанавливает заголовок Content-Type в application/x-www-form-urlencoded.
POST-запрос с помощью библиотеки urllib
Отправка POST-запроса с помощью библиотеки urllib включает в себя несколько дополнительных шагов по сравнению с библиотекой Requests:
import urllib.request
import urllib.parse
data = {'key': 'value'}
encoded_data = urllib.parse.urlencode(data).encode('utf-8')
request = urllib.request.Request('https://api.example.com/submit', data=encoded_data)
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))В этом примере мы используем функцию urlencode для кодирования данных формы и класс Request для создания POST-запроса. Затем мы используем функцию urlopen для отправки запроса и чтения ответа.
Отправка данных в POST-запросах
Данные могут быть отправлены в различных форматах, таких как JSON, XML или данные формы. Обе библиотеки позволяют отправлять данные в нужном вам формате. Вот пример отправки данных в формате JSON в POST-запросе с помощью библиотеки Requests:
Обе библиотеки позволяют отправлять данные в нужном вам формате. Вот пример отправки данных в формате JSON в POST-запросе с помощью библиотеки Requests:
import requests
import json
data = {'key': 'value'}
headers = {'Content-Type': 'application/json'}
response = requests.post('https://api.example.com/submit', data=json.dumps(data), headers=headers)
print(response.text)Работа с данными JSON
JSON (JavaScript Object Notation) — это популярный формат обмена данными. Библиотеки Requests и urllib предоставляют встроенную поддержку для работы с данными JSON.
Например, при использовании библиотеки Requests вы можете легко преобразовать ответ JSON в словарь Python с помощью метода json():
import requests
response = requests.get('https://api.example.com/data')
data = response.json()
print(data)С помощью urllib вы можете использовать модуль json для загрузки данных JSON:
import urllib.
 request
import json
response = urllib.request.urlopen('https://api.example.com/data')
data = json.load(response)
print(data)
request
import json
response = urllib.request.urlopen('https://api.example.com/data')
data = json.load(response)
print(data)Обработка ошибок
При выполнении HTTP-запросов вы можете столкнуться с ошибками, такими как недопустимые URL-адреса или проблемы с сервером. Обе библиотеки предлагают способы изящной обработки этих ошибок.
Ошибки HTTP
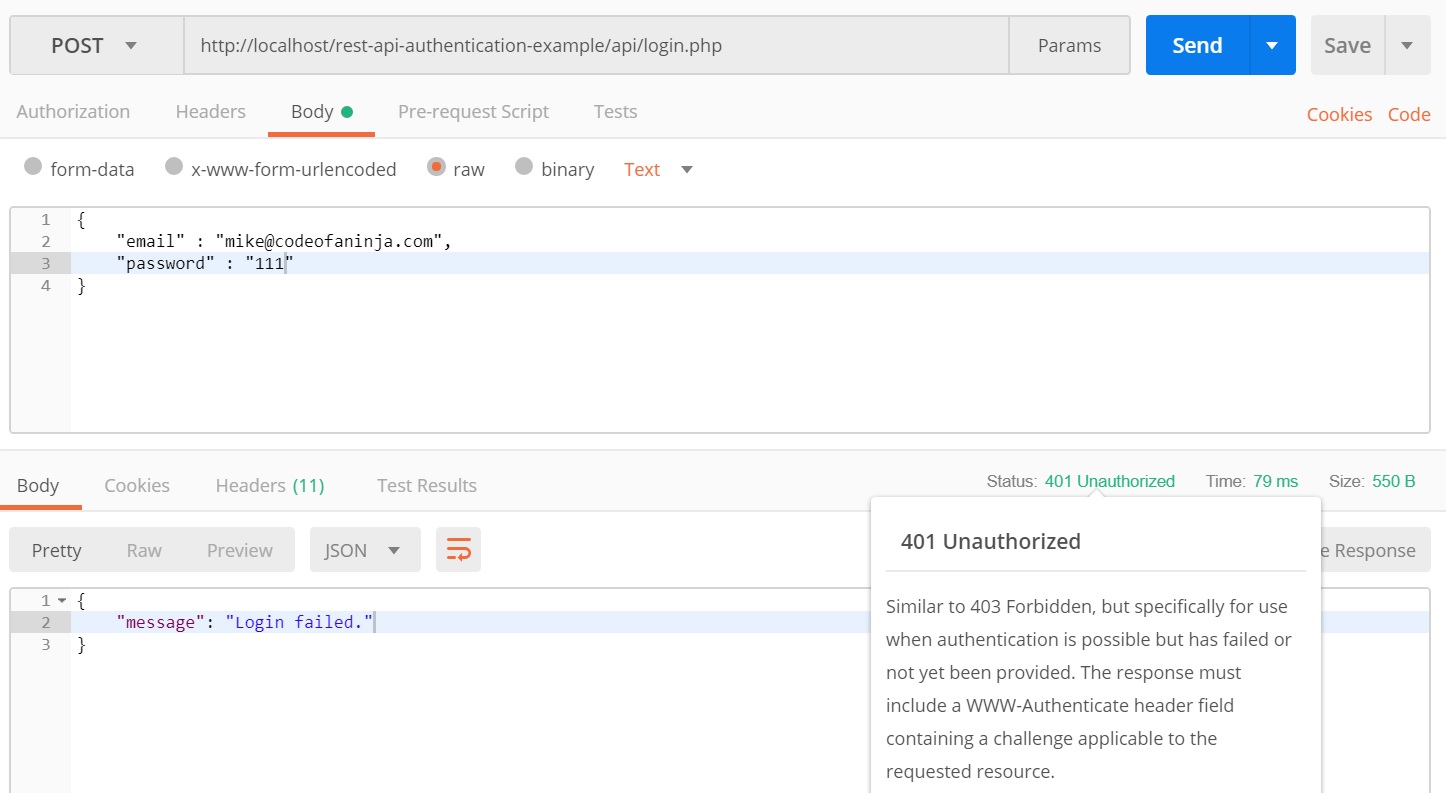
Ошибки HTTP представлены кодами состояния, такими как 404 для «Not Found» или 500 для «Internal Server Error». Вы можете проверить код состояния ответа, чтобы соответствующим образом обработать эти ошибки. Например, используя библиотеку Requests:
import requests
response = requests.get('https://api.example.com/data')
if response.status_code == 200:
print(response.text)
else:
print(f "Error: {response.status_code}")Исключения
Обе библиотеки могут вызывать исключения, если с запросом возникли проблемы. Вы можете перехватить эти исключения, чтобы предотвратить аварийное завершение программы. Например, используя библиотеку urllib:
Например, используя библиотеку urllib:
import urllib.request
try:
response = urllib.request.urlopen('https://api.example.com/data')
print(response.read().decode('utf-8'))
except urllib.error.HTTPError as e:
print(f "Error: {e.code}")
except urllib.error.URLError as e:
print(f "Error: {e.reason}")Аутентификация в API
Некоторые API требуют аутентификации для доступа к своим данным или выполнения действий. Библиотеки Requests и urllib поддерживают различные методы аутентификации, такие как Basic Auth, OAuth и API-ключи. Например, вот как использовать Basic Auth с библиотекой Requests:
import requests
from requests.auth import HTTPBasicAuth
response = requests.get('https://api.example.com/secure', auth=HTTPBasicAuth('username', 'password'))
print(response.text)Файлы cookie и сеансы
Cookies и сессии используются для сохранения состояния между запросами. Обе библиотеки позволяют работать с файлами cookie и данными сеанса, когда это необходимо.
Например, используя библиотеку Requests, вы можете создать объект сессии, который будет автоматически обрабатывать cookies:
import requests
session = requests.Session()
response = session.get('https://api.example.com/login', data={'username': 'user', 'password': 'pass'})
# Последующие запросы с объектом session будут использовать сохраненные cookies
response = session.get('https://api.example.com/secure')
print(response.text)С помощью urllib вы можете использовать модуль http.cookiejar для управления cookies:
import urllib.request
from http.cookiejar import CookieJar
cookie_jar = CookieJar()
cookie_handler = urllib.request.HTTPCookieProcessor(cookie_jar)
opener = urllib.request.build_opener(cookie_handler)
response = opener.open('https://api.example.com/login', data=b'username=user&password=pass')
# Последующие запросы с открывателем будут использовать сохраненные куки
response = opener. open('https://api.example.com/secure')
print(response.read().decode('utf-8'))
Тайм-аут и повторные запросы
Иногда запрос может занять больше времени, чем ожидалось, или завершиться неудачей из-за временных проблем. Обе библиотеки предоставляют опции для установки таймаутов и повторных попыток выполнения неудачных запросов.
Например, в библиотеке Requests вы можете установить тайм-аут для запроса следующим образом:
import requests
try:
response = requests.get('https://api.example.com/data', timeout=5)
print(response.text)
except requests.exceptions.Timeout:
print("Запрос завершился")Для реализации повторных запросов можно использовать объект Session и настроить пользовательскую стратегию Retry:
import requests from requests.adapters import HTTPAdapter from urllib3.util.retry import Retry retry_strategy = Retry( total=3, backoff_factor=1, status_forcelist=[429, 500, 502, 503, 504], method_whitelist=["HEAD", "GET", "OPTIONS", "POST"] ) adapter = HTTPAdapter(max_retries=retry_strategy) session = requests.
 Session()
session.mount("https://", адаптер)
session.mount("http://", adapter)
response = session.get('https://api.example.com/data')
print(response.text)
Session()
session.mount("https://", адаптер)
session.mount("http://", adapter)
response = session.get('https://api.example.com/data')
print(response.text)Заключение
В этой статье мы рассмотрели, как выполнять GET и POST запросы с помощью Python, сосредоточившись на библиотеках Requests и urllib. Мы также рассмотрели работу с данными JSON, обработку ошибок, аутентификацию, cookies, сессии и таймауты. С помощью этих инструментов вы сможете уверенно взаимодействовать с веб-сервисами и API, используя Python.
http — В чем разница между POST и GET?
Задавать вопрос
спросил
Изменено 1 год, 1 месяц назад
Просмотрено 755 тысяч раз
На этот вопрос уже есть ответы здесь :
Когда следует использовать метод GET или POST? В чем разница между ними? (15 ответов)
Закрыта 9 лет назад.
Я только недавно начал заниматься PHP/AJAX/jQuery, и мне кажется, что важной частью этих технологий является технология POST и GET .
Во-первых, в чем разница между POST и GET ? Экспериментируя, я знаю, что GET добавляет возвращаемые переменные и их значения к строке URL
Website.example/directory/index.php?name=YourName&bday=YourBday
, но POST нет.
Итак, это единственная разница или существуют особые правила или соглашения для использования того или другого?
Во-вторых, я также видел POST и GET вне PHP: также в AJAX и jQuery. Как POST и GET различаются между этими тремя? Это одна и та же идея, одна и та же функциональность, просто используемая по-разному?
- http
- post
- get
- http-метод
GET и POST — это два разных типа HTTP-запросов.
Согласно Википедии:
GET запрашивает представление указанного ресурса. Обратите внимание, что GET не следует использовать для операций, вызывающих побочные эффекты, например, для выполнения действий в веб-приложениях. Одной из причин этого является то, что GET может произвольно использоваться роботами или поисковыми роботами, которым не нужно учитывать побочные эффекты, которые должен вызвать запрос.
и
POST отправляет данные для обработки (например, из формы HTML) в указанный ресурс. Данные включаются в тело запроса. Это может привести к созданию нового ресурса или обновлению существующих ресурсов или к тому и другому.
Таким образом, GET используется для извлечения удаленных данных, а POST используется для вставки/обновления удаленных данных.
Спецификация HTTP/1.1 (RFC 2616) раздел 9 Определения методов содержит дополнительную информацию о
GET и POST , а также о других методах HTTP, если вам это интересно.
В дополнение к объяснению предполагаемого использования каждого метода, в спецификации также приводится по крайней мере одно практическое объяснение того, почему GET следует использовать только для получения данных:
Авторы служб, использующих протокол HTTP, НЕ ДОЛЖНЫ использовать формы на основе GET для отправки конфиденциальных данных, поскольку это приведет к тому, что эти данные будут закодированы в Request-URI. Многие существующие серверы, прокси-серверы и пользовательские агенты будут регистрировать URI запроса в каком-то месте, где он может быть виден третьим лицам. Серверы могут использовать отправку форм на основе POST вместо
Наконец, важное соображение при использовании
GET для запросов AJAX заключается в том, что некоторые браузеры, в частности IE, кэшируют результаты запроса GET . Поэтому, если вы, например, выполняете опрос с использованием одного и того же запроса GET , вы всегда будете получать одни и те же результаты, даже если данные, которые вы запрашиваете, обновляются на стороне сервера.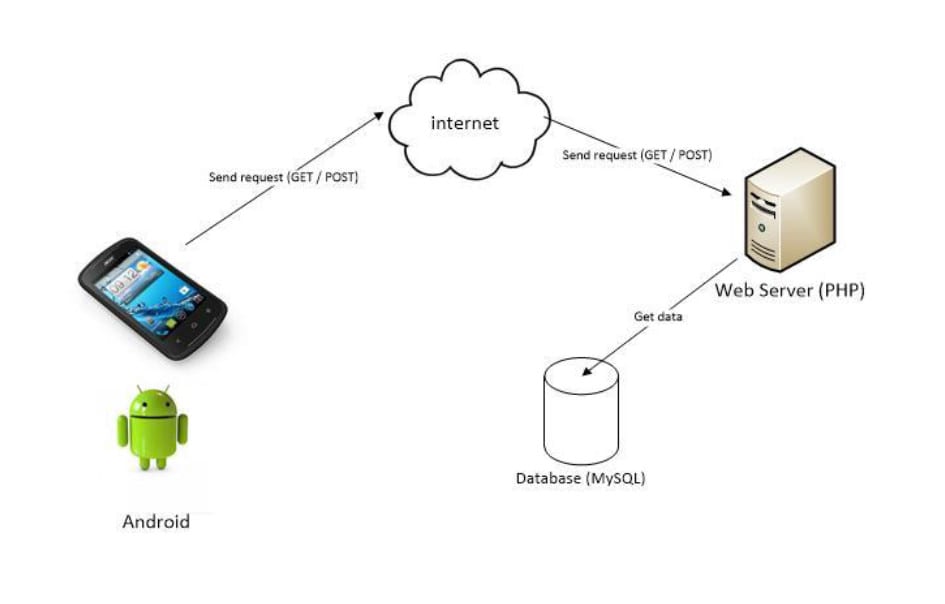 Один из способов решить эту проблему — сделать URL-адрес уникальным для каждого запроса, добавив временную метку. 8
Один из способов решить эту проблему — сделать URL-адрес уникальным для каждого запроса, добавив временную метку. 8 А POST , в отличие от GET , обычно содержит соответствующую информацию в теле запроса. ( GET не должен иметь тела, поэтому, помимо файлов cookie, единственное место для передачи информации — это URL-адрес.) Помимо относительной чистоты URL-адреса, POST также позволяет отправлять гораздо больше информации (поскольку URL-адреса ограничены по длине для всех практических целей) и позволяет отправлять данные практически любого типа (формы загрузки файлов, например, не могут использовать GET — они надо использовать POST плюс специальный тип/кодировка контента).
Кроме того, POST означает, что запрос что-то изменит, и его не следует переделывать волей-неволей. Вот почему вы иногда видите, что ваш браузер спрашивает вас, хотите ли вы повторно отправить данные формы, когда вы нажимаете кнопку «Назад».
GET , с другой стороны, должно быть идемпотентным — это означает, что вы можете сделать это миллион раз, и сервер будет делать одно и то же (и показывать в основном один и тот же результат) каждый раз.
Хотя это и не описание различий, ниже приведено несколько моментов, о которых следует подумать при выборе правильного метода.
- Запросы GET могут кэшироваться браузером, что может быть проблемой (или преимуществом) при использовании ajax.
- Запросы GET предоставляют пользователям параметры (POST тоже делает это, но они менее заметны).
- POST может передавать гораздо больше информации на сервер и может быть практически любой длины.
POST и GET — это два метода запроса HTTP. GET обычно предназначен для извлечения некоторых данных и, как ожидается, будет идемпотентным (повторение запроса не имеет побочных эффектов) и может отправлять на сервер только ограниченное количество данных параметров. Запросы GET часто по умолчанию кэшируются некоторыми браузерами, если вы не будете осторожны.
Запросы GET часто по умолчанию кэшируются некоторыми браузерами, если вы не будете осторожны.
POST предназначен для изменения состояния сервера. Он несет больше данных, и повторение запроса разрешено (и часто ожидается) иметь побочные эффекты, такие как создание двух сообщений вместо одного.
2Если вы работаете в режиме REST, GET следует использовать для запросов, в которых вы только получаете данные, а POST следует использовать для запросов, в которых вы что-то делаете.
Некоторые примеры:
1 С помощью POST вы также можете выполнять многокомпонентное кодирование mime, что означает, что вы также можете прикреплять файлы. Кроме того, если вы используете переменные сообщения для навигации по страницам, пользователь получит предупреждение с вопросом, хотят ли они повторно отправить параметр сообщения. Обычно они выглядят одинаково в HTTP-запросе, но вы должны просто придерживаться POST, если вам нужно «ОТПРАВИТЬ» что-то НА сервер, и «GET», если вам нужно ПОЛУЧИТЬ что-то С сервера, как это было задумано.
Единственная «большая» разница между POST и GET (при использовании их с AJAX) заключается в том, что GET предоставляется по URL-адресу, их длина ограничена (поскольку URL-адрес не бесконечен по длине).
3Очень активный вопрос . Заработайте 10 репутации (не считая бонуса ассоциации), чтобы ответить на этот вопрос. Требование к репутации помогает защитить этот вопрос от спама и отсутствия ответа.
HTTP/1.1: определения методов
HTTP/1.1: определения методов часть протокола передачи гипертекста — HTTP/1.1RFC 2616 Филдинг и др.
Набор общих методов для HTTP/1.1 определен ниже. Хотя этот набор можно расширить, нельзя предполагать, что дополнительные методы используют одну и ту же семантику для отдельно расширенных клиентов и серверов.
Поле заголовка запроса хоста (раздел 14.23) ДОЛЖНО сопровождать все
Запросы HTTP/1. 1.
1.
9.1 Безопасные и идемпотентные методы
9.1.1 Безопасные методы
Разработчики должны знать, что программное обеспечение представляет пользователя в их взаимодействие через Интернет, и следует быть осторожным, чтобы разрешить пользователю быть в курсе любых действий, которые они могут предпринять, которые могут иметь неожиданное значение для себя или других.
В частности, было установлено соглашение о том, что GET и Методы HEAD НЕ ДОЛЖНЫ иметь значение выполнения действия кроме поиска. Эти методы следует считать «безопасными». Это позволяет пользовательским агентам представлять другие методы, такие как POST, PUT. и УДАЛИТЬ, особым образом, чтобы пользователь знал о тот факт, что запрашивается возможно небезопасное действие.
Естественно, невозможно гарантировать, что сервер не
генерировать побочные эффекты в результате выполнения GET-запроса; в
на самом деле, некоторые динамические ресурсы считают это особенностью. Важный
отличие здесь в том, что пользователь не запрашивал побочные эффекты,
поэтому не может нести за них ответственность.
Важный
отличие здесь в том, что пользователь не запрашивал побочные эффекты,
поэтому не может нести за них ответственность.
9.1.2 Идемпотентные методы
Методы также могут обладать свойством «идемпотентности» в том, что (кроме из-за ошибок или проблем с истечением срока действия) побочные эффекты N > 0 идентичны запросы такие же, как и для одного запроса. Методы GET, HEAD, PUT и DELETE разделяют это свойство. Кроме того, методы OPTIONS и TRACE НЕ ДОЛЖЕН иметь побочных эффектов, поэтому они по своей сути идемпотентны.
Однако возможно, что последовательность из нескольких запросов не
идемпотент, даже если все методы, выполняемые в этой последовательности,
идемпотент. (Последовательность является идемпотентной, если одно выполнение
вся последовательность всегда дает результат, который не изменяется
повторного выполнения всей или части этой последовательности.) Например,
последовательность неидемпотентна, если ее результат зависит от значения, которое
позже изменены в той же последовательности.
Последовательность, которая никогда не имеет побочных эффектов, является идемпотентной по определению. (при условии, что на один и тот же набор ресурсов).
9.2 ОПЦИИ
Метод OPTIONS представляет собой запрос информации о варианты связи, доступные в цепочке запросов/ответов определяется Request-URI. Этот метод позволяет клиенту определить варианты и/или требования, связанные с ресурсом, или возможности сервера, не подразумевая действие ресурса или инициирование поиска ресурсов.
Ответы на этот метод не кэшируются.
Если запрос OPTIONS включает тело объекта (как указано
наличие Content-Length или Transfer-Encoding), то тип носителя
ДОЛЖЕН указываться полем Content-Type. Хотя это
спецификация не определяет какое-либо использование такого кузова в будущем
расширения для HTTP могут использовать тело OPTIONS, чтобы сделать более подробными
запросы на сервере. Сервер, который не поддерживает такой
расширение МОЖЕТ отбросить тело запроса.
Если Request-URI представляет собой звездочку («*»), запрос OPTIONS предназначен для применения к серверу в целом, а не к конкретному ресурс. Поскольку параметры связи сервера обычно зависят от ресурс, запрос «*» полезен только как «ping» или «no-op» тип метода; он ничего не делает, кроме как позволяет клиенту протестировать возможности сервера. Например, это можно использовать для проверки прокси для соответствия HTTP/1.1 (или его отсутствия).
Если Request-URI не является звездочкой, применяется запрос OPTIONS. только к тем вариантам, которые доступны при общении с этим ресурс.
Ответ 200 ДОЛЖЕН включать любые поля заголовка, которые указывают
дополнительные функции, реализованные сервером и применимые к этому
ресурс (например, Разрешить), возможно, включая расширения, не определенные
эта спецификация. Тело ответа, если таковое имеется, СЛЕДУЕТ также включать
информация о возможностях связи.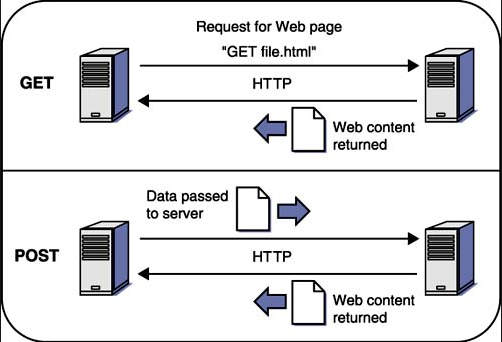 Формат для такого
Формат для такого
body не определяется этой спецификацией, но может быть определено будущие расширения HTTP. Согласование содержимого МОЖЕТ использоваться для выбора соответствующий формат ответа. Если тело ответа не включено, ответ ДОЛЖЕН включать поле Content-Length со значением поля «0».
Поле заголовка запроса Max-Forwards МОЖЕТ использоваться для
конкретный прокси в цепочке запросов. Когда прокси получает OPTIONS
запрос на absoluteURI, для которого разрешена переадресация запроса,
прокси-сервер ДОЛЖЕН проверять наличие поля Max-Forwards. Если Макс-Форвардс
значение поля равно нулю («0»), прокси-сервер НЕ ДОЛЖЕН пересылать сообщение;
вместо этого прокси-сервер ДОЛЖЕН отвечать своими собственными параметрами связи.
Если значение поля Max-Forwards является целым числом больше нуля,
прокси ДОЛЖЕН уменьшать значение поля при пересылке запроса. Если
поле Max-Forwards отсутствует в запросе, то перенаправленный
запрос НЕ ДОЛЖЕН включать поле Max-Forwards.
9.3 ПОЛУЧИТЬ
Метод GET означает получение любой информации (в виде сущность) идентифицируется Request-URI. Если Request-URI ссылается к процессу производства данных именно произведенные данные должны быть возвращается как сущность в ответе, а не как исходный текст процесса, если только этот текст не является результатом процесса.
Семантика метода GET меняется на «условный GET», если сообщение запроса включает в себя If-Modified-Since, If-Unmodified-Since, Поле заголовка If-Match, If-None-Match или If-Range. Условный GET метод требует, чтобы сущность передавалась только под обстоятельства, описываемые условным полем(ями) заголовка. условный метод GET предназначен для сокращения ненужных сетевых запросов. использования, позволяя обновлять кэшированные объекты без необходимости несколько запросов или передача данных, уже имеющихся у клиента.
Семантика метода GET меняется на «частичный GET», если
сообщение запроса включает в себя поле заголовка Range. Частичные GET-запросы
что только часть объекта будет передана, как описано в разделе
14.35. Частичный метод GET предназначен для сокращения ненужных
использования сети, позволяя частично извлеченным объектам быть
завершена без передачи данных, уже имеющихся у клиента.
Частичные GET-запросы
что только часть объекта будет передана, как описано в разделе
14.35. Частичный метод GET предназначен для сокращения ненужных
использования сети, позволяя частично извлеченным объектам быть
завершена без передачи данных, уже имеющихся у клиента.
Ответ на запрос GET кэшируется тогда и только тогда, когда он соответствует требования к кэшированию HTTP, описанные в разделе 13.
См. раздел 15.1.3 по соображениям безопасности при использовании для форм.
9,4 ГОЛОВКА
Метод HEAD идентичен GET, за исключением того, что сервер НЕ ДОЛЖЕН
вернуть тело сообщения в ответ. Метаинформация содержала
в заголовках HTTP в ответ на запрос HEAD ДОЛЖЕН быть идентичным
к информации, отправленной в ответ на запрос GET. Этот метод может
использоваться для получения метаинформации об объекте, подразумеваемом
запрос без передачи самого тела сущности. Этот метод
часто используется для проверки гипертекстовых ссылок на достоверность, доступность,
и недавняя модификация.
Ответ на запрос HEAD МОЖЕТ кэшироваться в том смысле, что информация, содержащаяся в ответе, МОЖЕТ использоваться для обновления ранее кэшированный объект из этого ресурса. Если новые значения поля указать, что кэшированный объект отличается от текущего объекта (как будет указано изменением Content-Length, Content-MD5, ETag или Last-Modified), то кэш ДОЛЖЕН обрабатывать запись кэша как несвежий.
9.5 ПОСТ
Метод POST используется для запроса того, чтобы исходный сервер принял сущность, заключенная в запросе в качестве нового подчиненного ресурса определяется Request-URI в строке запроса. ПОСТ предназначен чтобы позволить единому методу охватить следующие функции:
- Аннотация существующих ресурсов;
- Публикация сообщения на доске объявлений, в группе новостей, в списке рассылки,
или аналогичная группа статей;
- Предоставление блока данных, например, в результате отправки
форма для процесса обработки данных;
- Расширение базы данных с помощью операции добавления.

Фактическая функция, выполняемая методом POST, определяется server и обычно зависит от Request-URI. Размещенный объект является подчиненным этому URI так же, как файл является подчиненным к каталогу, содержащему его, новостная статья подчинена группа новостей, в которую она отправлена, или запись подчинена база данных.
Действие, выполняемое методом POST, может не привести к ресурс, который можно идентифицировать по URI. В этом случае либо 200 (ОК) или 204 (Нет содержимого) — соответствующий статус ответа, в зависимости от того, включает ли ответ объект, который описывает результат.
Если ресурс был создан на исходном сервере, ответ ДОЛЖЕН иметь значение 201 (Создано) и содержать сущность, описывающую статус запроса и относится к новому ресурсу, а местоположение заголовок (см. раздел 14.30).
Ответы на этот метод не кэшируются, если только ответ
включает соответствующие поля заголовка Cache-Control или Expires. Однако,
ответ 303 (см. Другое) может использоваться для направления пользовательского агента к
получить кешируемый ресурс.
Однако,
ответ 303 (см. Другое) может использоваться для направления пользовательского агента к
получить кешируемый ресурс.
Запросы POST ДОЛЖНЫ соответствовать требованиям к передаче сообщений, изложенным в разделе 8.2.
См. раздел 15.1.3 по соображениям безопасности.
9.6 ПУТ
Метод PUT запрашивает, чтобы вложенный объект был сохранен в
предоставленный Request-URI. Если Request-URI ссылается на уже
существующий ресурс, вложенный объект СЛЕДУЕТ рассматривать как
модифицированная версия той, что находится на исходном сервере. Если
Request-URI не указывает на существующий ресурс, и этот URI
может быть определен как новый ресурс запрашивающим пользователем
агент, исходный сервер может создать ресурс с этим URI. Если
создается новый ресурс, исходный сервер ДОЛЖЕН информировать пользовательский агент
через ответ 201 (Создано). Если существующий ресурс изменен,
ДОЛЖНЫ быть отправлены коды ответов 200 (ОК) или 204 (Нет контента). чтобы указать на успешное выполнение запроса. Если ресурс
не может быть создан или изменен с помощью Request-URI, соответствующий
СЛЕДУЕТ давать ответ об ошибке, отражающий природу ошибки.
проблема. Получатель объекта НЕ ДОЛЖЕН игнорировать любой Контент-*
(например, Content-Range) заголовки, которые он не понимает или не реализует
и ДОЛЖЕН возвращать ответ 501 (не реализовано) в таких случаях.
чтобы указать на успешное выполнение запроса. Если ресурс
не может быть создан или изменен с помощью Request-URI, соответствующий
СЛЕДУЕТ давать ответ об ошибке, отражающий природу ошибки.
проблема. Получатель объекта НЕ ДОЛЖЕН игнорировать любой Контент-*
(например, Content-Range) заголовки, которые он не понимает или не реализует
и ДОЛЖЕН возвращать ответ 501 (не реализовано) в таких случаях.
Если запрос проходит через кеш и Request-URI идентифицирует один или несколько кэшированных объектов, эти записи ДОЛЖНЫ быть рассматривается как устаревший. Ответы на этот метод не кэшируются.
Фундаментальное различие между запросами POST и PUT заключается в следующем.
отражается в различном значении Request-URI. URI в
Запрос POST идентифицирует ресурс, который будет обрабатывать вложенный
сущность. Этот ресурс может быть процессом приема данных, шлюзом к
какой-то другой протокол или отдельный объект, который принимает аннотации. Напротив, URI в запросе PUT идентифицирует объект, заключенный
с запросом — пользовательский агент знает, какой URI предназначен, и
сервер НЕ ДОЛЖЕН пытаться применить запрос к какому-либо другому ресурсу.
Если сервер желает, чтобы запрос был применен к другому URI,
Напротив, URI в запросе PUT идентифицирует объект, заключенный
с запросом — пользовательский агент знает, какой URI предназначен, и
сервер НЕ ДОЛЖЕН пытаться применить запрос к какому-либо другому ресурсу.
Если сервер желает, чтобы запрос был применен к другому URI,
он ДОЛЖЕН отправить ответ 301 (перемещен навсегда); пользовательский агент МОЖЕТ затем принять собственное решение относительно того, следует ли перенаправлять запрос.
Один ресурс МОЖЕТ быть идентифицирован многими различными URI. Для например, статья может иметь URI для идентификации «текущего версия», которая отделена от URI, идентифицирующего каждую конкретную версия. В этом случае запрос PUT на общий URI может привести к несколько других URI определяются исходным сервером.
HTTP/1.1 не определяет, как метод PUT влияет на состояние исходный сервер.
Запросы PUT ДОЛЖНЫ соответствовать требованиям к передаче сообщений, изложенным
в разделе 8. 2.
2.
Если иное не указано для конкретного заголовка сущности, заголовки объектов в запросе PUT ДОЛЖНЫ применяться к ресурсу созданный или измененный PUT.
9.7 УДАЛИТЬ
Метод DELETE запрашивает, чтобы исходный сервер удалил ресурс. определяется Request-URI. Этот метод МОЖЕТ быть переопределен человеком вмешательство (или другие средства) на исходном сервере. клиент не может гарантировать, что операция была выполнена, даже если код состояния, возвращенный исходным сервером, указывает, что действие был успешно завершен. Однако сервер НЕ ДОЛЖЕН указывают на успех, если только в момент ответа намеревается удалить ресурс или переместить его в недоступное расположение.
Успешный ответ ДОЛЖЕН быть 200 (ОК), если ответ включает в себя
объект, описывающий статус, 202 (Принято), если действие не было
еще не было выполнено, или 204 (Нет контента), если действие было выполнено.
но ответ не включает сущность.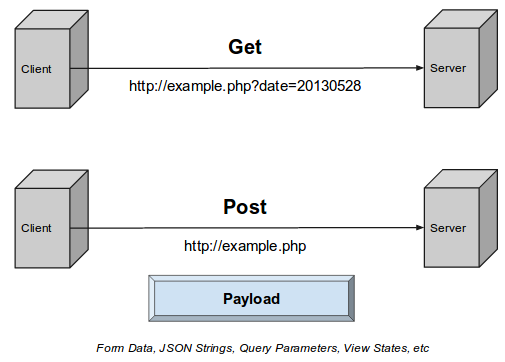
Если запрос проходит через кеш и Request-URI идентифицирует один или несколько кэшированных объектов, эти записи ДОЛЖНЫ быть рассматривается как устаревший. Ответы на этот метод не кэшируются.
9.8 ТРАССА
Метод TRACE используется для вызова удаленного цикла прикладного уровня. обратная сторона сообщения запроса. Конечный получатель запроса СЛЕДУЕТ отражать сообщение, полученное обратно клиенту, как сущность-тело ответа 200 (ОК). Конечным получателем является либо
исходный сервер или первый прокси или шлюз, получивший Max-Forwards значение нуля (0) в запросе (см. раздел 14.31). TRACE-запрос НЕ ДОЛЖЕН включать сущность.
TRACE позволяет клиенту видеть, что принимается на другом
конец цепочки запросов и использовать эти данные для тестирования или диагностики
информация. Значение поля заголовка Via (раздел 14.45) равно
особый интерес, так как он действует как трассировка цепочки запросов.