Основы правил проектирования базы данных / Хабр
Введение
Как это часто бывает, архитектору БД нужно разработать базу данных под конкретное решение.
Однажды в пятницу вечером, возвращаясь на электричке домой с работы, я подумал о том, как бы я создал сервис по найму сотрудников в разные компании. Ведь ни один из существующих сервисов не позволяет быстро понять насколько подходит тебе кандидат. Нет возможности создать сложные фильтры, включающие или исключающие совокупность определенных навыков, проектов или позиций. Максимум, что обычно предлагают сервисы — фильтры по компаниям и частично по навыкам.
В данной статье я позволю себе немного разбавить строгое изложение материала, смешав техническую информацию с не техническими примерами из жизни.
Для начала, разберем создание базы данных в MS SQL Server для сервиса поиска соискателей на работу.
Этот материал можно перенести и на другую СУБД такую как MySQL или PostgreSQL.
Основы правил проектирования
Опишем более детально 7 формальных правил:
- отношение один к одному:
1.1) с обязательной связью:
примером может выступать гражданин и его паспорт: у любого гражданина должен быть паспорт; паспорт один для каждого гражданина
Реализовать данную связь можно двумя способами:
1.1.1) в одной сущности (таблице):
Рис.1. Сущность CitizenЗдесь таблица Citizen представляет собой сущность гражданина, а атрибут (поле) PassportData содержит все паспортные данные гражданина и не может быть пустым (NOT NULL).
1.1.2) в двух разных сущностях (таблицах):
Рис.2. Отношение сущностей Citizen и PassportDataЗдесь таблица Citizen представляет собой сущность гражданина, а таблица PassportData — сущность паспортных данных гражданина (самого паспорта).
 Сущность гражданина содержит атрибут (поле) PassportID, который ссылается на первичный ключ таблицы PassportData. В свою очередь сущность паспортных данных содержит атрибут (поле) CitizenID, которое ссылается на первичный ключ CitizenID таблицы Citizen. Поле PassportID таблицы Citizen не может быть пустым (NOT NULL). Также здесь важно поддерживать целостность поля CitizenID таблицы PassportData, чтобы обеспечить связь один к одному. Иными словами, поле PassportID таблицы Citizen и поле CitizenID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), представленная в пункте 1.1.1.
Сущность гражданина содержит атрибут (поле) PassportID, который ссылается на первичный ключ таблицы PassportData. В свою очередь сущность паспортных данных содержит атрибут (поле) CitizenID, которое ссылается на первичный ключ CitizenID таблицы Citizen. Поле PassportID таблицы Citizen не может быть пустым (NOT NULL). Также здесь важно поддерживать целостность поля CitizenID таблицы PassportData, чтобы обеспечить связь один к одному. Иными словами, поле PassportID таблицы Citizen и поле CitizenID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), представленная в пункте 1.1.1.1.2) с необязательной связью:
примером может выступать человек, имеющий или не имеющий паспорт конкретной страны. В первом случае он будет являться гражданином рассматриваемой страны, а во втором — нет.
Реализовать данную связь можно двумя способами:
1.2.1) в одной сущности (таблице):
Рис.3. Сущность PersonТаблица Person представляет собой сущность человека, а атрибут (поле) PassportData содержит все его паспортные данные и может быть пустым (NULL).
1.2.2) в двух сущностях (таблицах):
Рис.4. Отношение сущностей Person и PassportData
Таблица Person представляет собой сущность человека, а таблица PassportData — сущность паспортных данных человека (самого паспорта). Сущность человека содержит атрибут (поле) PassportID, который ссылается на первичный ключ таблицы PassportData. В свою очередь сущность паспортных данных содержит атрибут (поле) PersonID, которое ссылается на первичный ключ PersonID таблицы Person. Поле PassportID таблицы Person может быть пустым (NULL). Здесь также важно поддерживать целостность поля PersonID таблицы PassportData. Это нужно, чтобы обеспечить связь один к одному. Поле PassportID таблицы Person и поле PersonID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), показанная в пункте 1.2.1. Или же данные поля должны быть неопределенными, то есть, содержать NULL. - отношение один ко многим:
2.
1) с обязательной связью:примером могут выступать родитель и его дети. У каждого родителя есть как минимум один ребенок.
Реализовать данную связь можно двумя способами:
2.1.1) в одной сущности (таблице):
Рис.5. Сущность ParentТаблица Parent представляет сущность родителя, а атрибут (поле) ChildList содержит информацию о детях. Данное поле не может быть пустым (NOT NULL). Обычно типом поля ChildList выступают неполно структурированные данные (NoSQL) такие как XML, JSON и т д.
2.1.2) в двух сущностях (таблицах):
Рис.6. Отношение сущностей Parent и ChildТаблица Parent представляет сущность родителя, а таблица Child — сущность ребенка. У таблицы Child есть поле ParentID, ссылающееся на первичный ключ ParentID таблицы Parent. Поле ParentID таблицы Child не может быть пустым (NOT NULL).
2.2) с необязательной связью:
примером может выступать человек, у которого могут быть дети или их может не быть.
Реализовать данную связь можно двумя способами:
2.
2.1) в одной сущности (таблице):
Рис.7. Сущность Person
Таблица Parent представляет сущность родителя, а атрибут (поле) ChildList содержит информацию о детях. Данное поле может быть пустым (NULL). Обычно типом поля ChildList выступают неполно структурированные данные (NoSQL) такие как XML, JSON и т д.2.2.2) в двух сущностях (таблицах):
Рис.8. Отношение сущностей Person и ChildТаблица Parent представляет сущность родителя, а таблица Child — сущность ребенка. У таблицы Child есть поле ParentID, ссылающееся на первичный ключ ParentID таблицы Parent. Поле ParentID таблицы Child может быть пустым (NULL).
2.2.3) в одной сущности со ссылкой на саму себя при условии, что у сущностей (таблиц) родителя и ребенка будут одинаковые наборы атрибутов (полей) без учета ссылки на родителя:
Рис.9. Сущность Person со связью на саму себя
Сущность (таблица) Person содержит атрибут (поле) ParentID, который ссылается на первичный ключ PersonID этой же таблицы Person и может содержать пустое значение (NULL).Также данная реализация является примером реализации отношения «многие к одному» с необязательной связью.
- отношение многие к одному:
Эту связь можно рассмотреть зеркально к приведенной выше связи один ко многим. Иными словами, отношение сущности «дети» к сущности «родители», где обязательная связь будет при условии, что у ребенка есть хотя бы один родитель. Если же участвуют все дети, в том числе и находящиеся в детских домах, отношение будет с необязательной связью.
- отношение многие ко многим:
Примером может выступить недвижимость: она может быть в собственности как одного человека, так и нескольких. С другой стороны, один человек может владеть несколькими домами или долями нескольких домов.
Реализовать данное отношение, с привлечением NoSQL, можно так же, как в описанных выше отношениях. Однако, в рамках реляционной модели обычно такое отношение реализуют через 3 сущности (таблицы):
Рис.10. Отношение сущностей Person и RealEstateТаблицы Person и RealEstate представляют соответственно сущности человека и недвижимости.
Связываются данные сущности (таблицы) через сущность (таблицы) PersonRealEstate. Атрибуты (поля) PersonID и RealEstateID ссылаются на первичные ключи PersonID таблицы Person и RealEstateID таблицы RealEstate соответственно. Обратите внимание, что для таблицы PersonRealEstate пара (PersonID; RealEstateID) всегда является уникальной и потому может выступать первичный ключем для самой связующей сущности PersonRealEstate.Также данное отношение можно реализовать через более чем три сущности. Для этого добавляются нужные атрибуты, которые ссылаются на первичные ключи необходимых соответствующих сущностей. Такая реализация схожа с примерами, описанными выше в пунктах 1.1.2 и 1.2.2.
 Сущность гражданина содержит атрибут (поле) PassportID, который ссылается на первичный ключ таблицы PassportData. В свою очередь сущность паспортных данных содержит атрибут (поле) CitizenID, которое ссылается на первичный ключ CitizenID таблицы Citizen. Поле PassportID таблицы Citizen не может быть пустым (NOT NULL). Также здесь важно поддерживать целостность поля CitizenID таблицы PassportData, чтобы обеспечить связь один к одному. Иными словами, поле PassportID таблицы Citizen и поле CitizenID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), представленная в пункте 1.1.1.
Сущность гражданина содержит атрибут (поле) PassportID, который ссылается на первичный ключ таблицы PassportData. В свою очередь сущность паспортных данных содержит атрибут (поле) CitizenID, которое ссылается на первичный ключ CitizenID таблицы Citizen. Поле PassportID таблицы Citizen не может быть пустым (NOT NULL). Также здесь важно поддерживать целостность поля CitizenID таблицы PassportData, чтобы обеспечить связь один к одному. Иными словами, поле PassportID таблицы Citizen и поле CitizenID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), представленная в пункте 1.1.1.
 1) с обязательной связью:
1) с обязательной связью: 2.1) в одной сущности (таблице):
2.1) в одной сущности (таблице):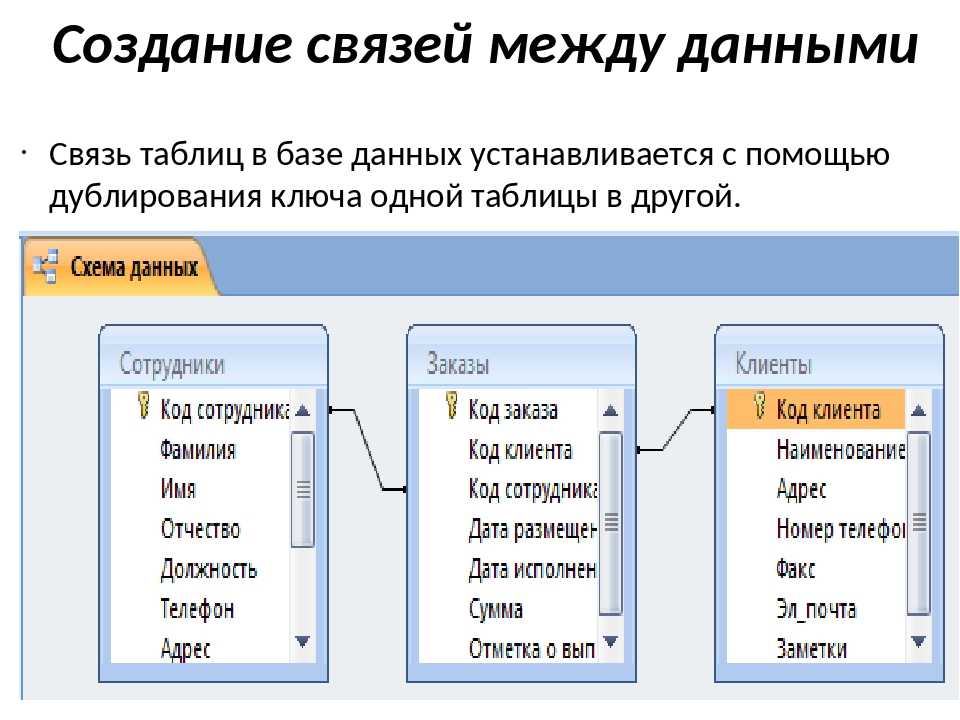
 Связываются данные сущности (таблицы) через сущность (таблицы) PersonRealEstate. Атрибуты (поля) PersonID и RealEstateID ссылаются на первичные ключи PersonID таблицы Person и RealEstateID таблицы RealEstate соответственно. Обратите внимание, что для таблицы PersonRealEstate пара (PersonID; RealEstateID) всегда является уникальной и потому может выступать первичный ключем для самой связующей сущности PersonRealEstate.
Связываются данные сущности (таблицы) через сущность (таблицы) PersonRealEstate. Атрибуты (поля) PersonID и RealEstateID ссылаются на первичные ключи PersonID таблицы Person и RealEstateID таблицы RealEstate соответственно. Обратите внимание, что для таблицы PersonRealEstate пара (PersonID; RealEstateID) всегда является уникальной и потому может выступать первичный ключем для самой связующей сущности PersonRealEstate.Отношения
 1.2 и 1.2.2.
1.2 и 1.2.2.А где же семь формальных правил?
Вот они:
- п.1 (п.1.1 и п.1.2) — первое и второе формальные правила
- п.2 (п.2.1 и п.2.2) — третье и четвертое формальные правила
- п.3 (аналогично п.2) — пятое и шестое формальные правила
- п.4 — седьмое формальное правило
В тексте выше эти семь формальных правил объединены в четыре блока по функционалу.
Говоря о нормализации, нужно понимать ее суть. Нормализация ведет к уменьшению повторяемости хранения информации, а следовательно и к уменьшению возможности появления аномалий в данных. Однако, нормализация при дроблении сущностей приводит к более сложным построениям запросов для манипуляций с данными (вставки, модификации, выборки и удаления).
Обратным процессом нормализации называется денормализация. Это упрощение построения запросов доступа к данным за счет укрупнения и вложенности сущностей (например, как было показано выше в пунктах 2. 1.1 и 2.2.1 с помощью неполно-структурированных данных (NoSQL)).
1.1 и 2.2.1 с помощью неполно-структурированных данных (NoSQL)).
Вот и вся суть правил проектирования баз данных.
А вы уверены, что поняли отношения в семи формальных правилах? Именно поняли, а не узнали? Ведь знать и понимать — две совершенно разных концепции.
Объясню более детально. Спросите себя, можете ли вы за пару часов набросать пусть и укрупненную по сущностям, но модель базы данных для любой предметной области и для любой информационной системы? (тонкости и детали можно достроить, поспрашивав аналитиков и представителей заказчиков). Если вопрос вас удивил, и вы думаете, что это невозможно, значит вы знаете семь формальных правил, но не понимаете их.
Почему-то многие источники игнорируют тот факт, что эти отношения были не придуманы, а выявлены. Они изначально существуют в реальном мире как между субъектами, так и между субъектами и объектами.
Также, эти отношения могут меняться, переходя из один к одному к одному ко многим, многие к одному или многие ко многим. Обязательность связи может меняться или остаться неизменной.
Обязательность связи может меняться или остаться неизменной.
Позволю себе рассказать об одном случае, когда от знания семи формальных правил я пришел именно к пониманию этих отношений.
В свое время меня смущало то, что в ВУЗе я знал эти семь формальных правил, но на производственной практике (ВУЗ отправляет студентов в различные компании для приобретения профессионального опыта) очень долго строил модели баз для разных предметных областей. Я задумался и понял, что не понимаю этих отношений.
Мне помогло наблюдение за людьми, а суть отношений раскрылась в сновидении. Этот сон я перескажу в упрощенной форме: только то, что позволяет лучше понять именно эти семь формальных правил — без детализации всего остального.
Сон был про семью, в которой есть отец, мать и дети. Отец погибает в автомобильной катастрофе, а мать начинает пить, и детей в итоге забирают в детский дом. Эти дети надолго остаются без родителей. Затем у некоторых детей появляются попечители, их тоже несколько.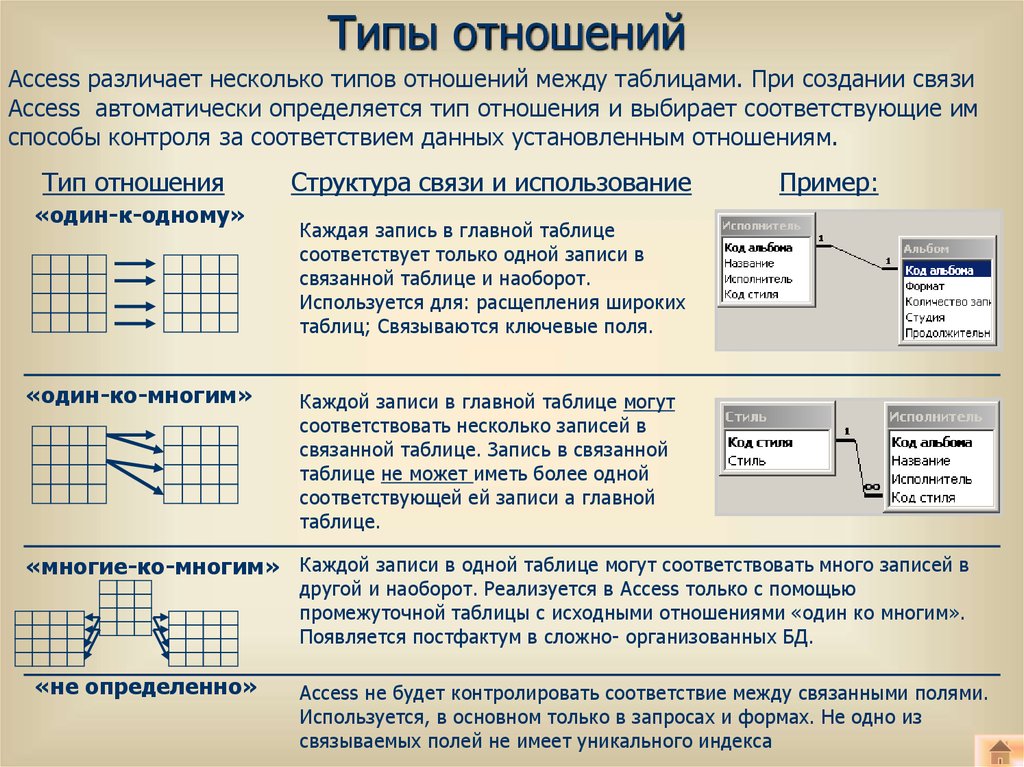
Вы проследили, какие отношения были между субъектами, и как менялись эти отношения?
Давайте присмотримся внимательнее.
- Когда семья была полной, с несколькими детьми, отношение между родителями и детьми имело вид многие ко многим.
- Когда остались мать и дети, отношение между родителем и детьми стало один ко многим с обязательной связью. Однако, в любой семье, где может и не быть детей, это отношение будет таким же, но уже с необязательной связью.
- А вот со стороны детей отношение к родителю было как многие к одному с обязательной связью пока родителя не лишили родительских прав.
- Когда дети оказались в детском доме — отношение изменилось на многие к одному с необязательной связью.
- Когда у детей появились попечители, связь между ними стала многие ко многим: у каждого попечителя могут быть другие подопечные дети, а у каждого ребенка могут быть другие попечители (родители).
Отношение между мужем и женой один к одному с обязательной связью при официальной брака или один к одному с необязательной связью до регистрации. Жена может быть только одна, как и муж может быть только один. По крайней мере, в России. Но в другой стране возможно многоженство, и тогда связь между мужем и женами будет один ко многим, а между женами и мужем — многие к одному.
Надеюсь, теперь вы значительно приблизились к пониманию этих семи формальных правил.
Стоит постоянно практиковаться: наблюдать за людьми и выявлять существующие отношения как между субъектами, так и между субъектами и объектами. Выше описывался гражданин и его паспорт как отношение один к одному с обязательной связью. В тоже время, пример человека и его паспорта — это отношение один к одному с необязательной связью.
Поняв семь формальных правил, вы сможете без труда спроектировать модель базы данных любой сложности для любой информационной системы.
Также вы увидите, что реализовать отношение можно разными способами, а сами отношения могут меняться. Модель (схема) базы данных — это «снимок» отношений между сущностями в определенный момент времени. Именно поэтому важно определить как сами сущности — образы объектов из реального мира или предметной области, так и их отношения между собой с учетом изменений в будущем.
Хорошо спроектированную модель базы данных с учетом изменения отношений в реальности или в предметной области не понадобится менять годами или даже десятилетия. Это особенно важно для хранилищ данных, где изменения влекут пересохранение больших объемов данных (от нескольких гигабайт до многих терабайт).
Важно запомнить, что таблицы в реляционной модели — это отношения сущностей, а строки (кортежи) — это экземпляры этих отношений. Но чтобы было проще, под таблицами часто понимаются сущности, а под строками таблицы — экземпляры сущностей. Их отношения выражаются через связи в форме внешних ключей.
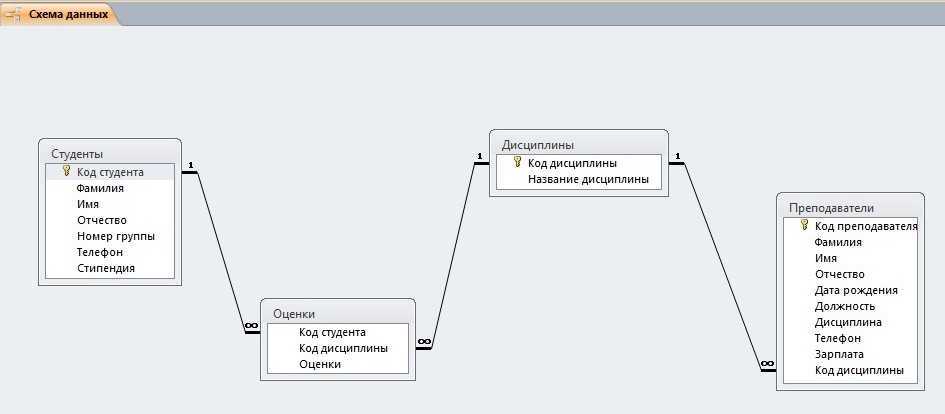
Проектирование схемы базы данных для поиска соискателей на работу
После того, как мы описали основы правил проектирования БД в первой части, давайте создадим схему базы данных для поиска соискателей на работу.
Для начала, определим, что важно для сотрудников из компании, которые ищут кандидатов:
- для HR:
1.1) компании, где работал соискатель
1.2) позиции, которые ранее занимал соискатель в данных компаниях
1.3) навыки и умения, которыми соискатель пользовался в работе;
а также продолжительность работы соискателя в каждой компании на каждой позиции и длительность использования каждого навыка и умения - для технического специалиста:
2.1) позиции, которые занимал соискатель в данных компаниях
2.2) навыки и умения, которыми соискатель пользовался в работе
2.3) проекты, в которых участвовал соискатель;
а также продолжительность работы соискателя на каждой позиции и в каждом проекте, длительность использования каждого навыка и умения
Для начала выявим нужные сущности:
- Сотрудник (Employee)
- Компания (Company)
- Позиция (должность) (Position)
- Проект (Project)
- Навык (Skill)
- Компании и сотрудники относятся как многие ко многим, так как сотрудник мог работать в нескольких компаниях, а в компании работают многие люди.
- Аналогично относятся позиции и сотрудники: несколько сотрудников могут занимать одну позицию как в рамках как одной, так и нескольких компаний.
- С другой стороны, сотрудник мог работать на разных позициях как в рамках одной, так разных компаний. Таким образом, отношение между позициями и компаниями — многие ко многим.
- Аналогично и по проектам: проекты относятся ко всем выше рассмотренным сущностям как многие ко многим.
- Для простоты будем считать, что в проекте сотрудник использует один набор навыков.
- Тогда проекты и навык относятся как многие ко многим.
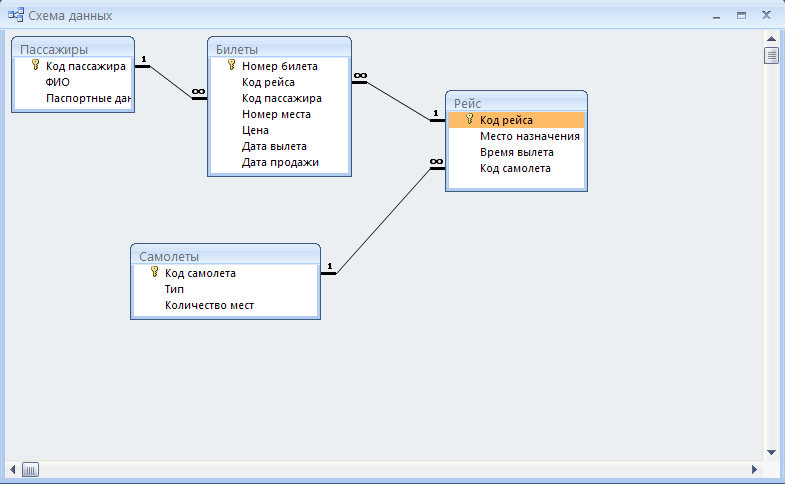
Поскольку очень важно зафиксировать, как долго сотрудник работал на той или иной позиции в той или иной компании, а также на каждом проекте, схема нашей базы данных может быть следующей:
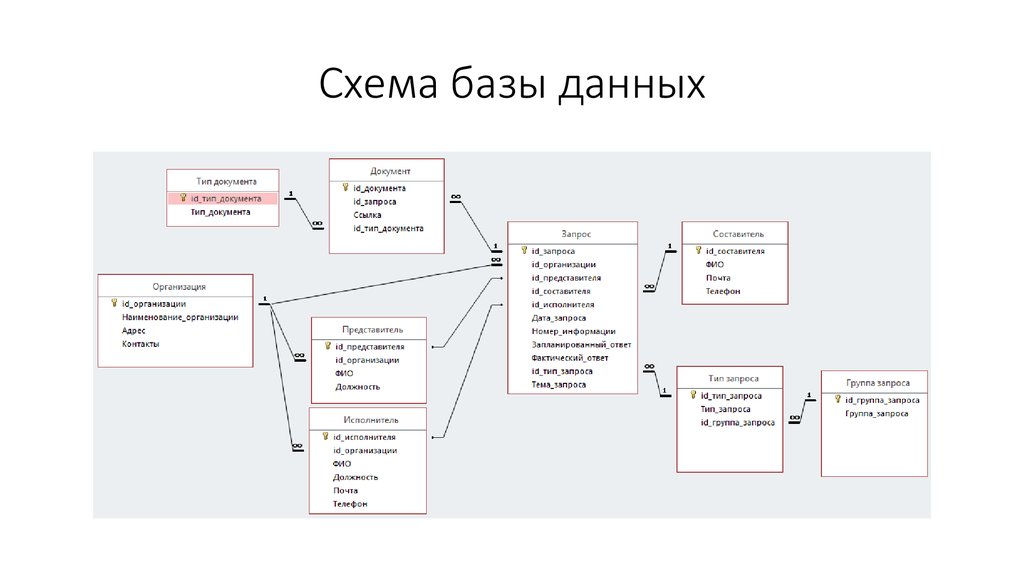
Рис.11. Схема базы данных для поиска соискателей на работу
Здесь таблица JobHistory выступает как сущность истории работы каждого соискателя. То есть, это резюме, которое педставляет отношения многие ко многим между сущностями сотрудник, компания, позиция и проект.
То есть, это резюме, которое педставляет отношения многие ко многим между сущностями сотрудник, компания, позиция и проект.
Проекты и навыки относятся друг другу как многие ко многим и потому связываются между собой через сущность (таблицу) ProjectSkill.
Когда вы понимаете отношения между субъектами и между субъектами и объектами — уже упомянутые семь формальных правил — эту или схожую схему можно реализовать «на коленке»: на листке бумаги, мене чем за час. И это еще с учетом усталости после плодотворного рабочего дня.
Здесь можно было упростить схему добавления данных, если «навыки» вложить в сущность «проекты» через неполно структурированные данные (NoSQL) в виде XML, JSON или просто перечислять названия навыков через точку с запятой. Но это бы усложнило выборку с группировкой по навыкам и фильтрацию по отдельным навыкам.
Подобная модель лежит в основе базы данных проекта Geecko.
Как видите, ничего сложного в проектировании информационных систем в части проектирования базы данных нет. Это всего лишь отражение объектов и субъектов из реальности, перенесенное в «сущности» схемы базы данных. Отношения между этими сущностями фиксируются на определенный момент времени, с учетом будущих изменений.
Это всего лишь отражение объектов и субъектов из реальности, перенесенное в «сущности» схемы базы данных. Отношения между этими сущностями фиксируются на определенный момент времени, с учетом будущих изменений.
Что именно мы возьмем из реальности и вложим в сущность схемы, и какие отношения построим в модели, будет зависеть от того, что мы хотим от информационной системы в общем, здесь и в будущем. Иными словами — какие данные мы хотим получить в текущий момент времени и через определенное время в будущем.
Немного лирики
После того, как вы внедрите модель в работу, остановитесь на миг и подумайте: только что был создан новый маленький мир. В нем есть свои сущности из реального мира и свои отношения. Да, это цифровой мир, но он теперь будет развиваться своей дорогой. Он будет общаться (интегрироваться) с другими системами (мирами), тоже созданными по своим правилам. Данные будут течь в этих системах, как кровь в живом организме.
А перед сном подумайте о том, что семь формальных правил были всегда, и что они окружают нас всюду. Не больше и не меньше, всегда семь. Все отношения реальной жизни можно разложить на эти семь формальных правил. А когда вы думаете или видите сны, как там сущности относятся друг к другу — не по тем же семи формальным правилам?
Не больше и не меньше, всегда семь. Все отношения реальной жизни можно разложить на эти семь формальных правил. А когда вы думаете или видите сны, как там сущности относятся друг к другу — не по тем же семи формальным правилам?
Вообще, я уверен, что эти отношения (семь формальных правил) выявил очень хороший психотерапевт, возможно — женщина. Это было очень давно, задолго до появления самого понятия информационных технологий. И самое интересное, что эти отношения живут вне базы данных и ИТ — последние лишь используют их для моделирования информационных систем.
Но мы немного отошли от темы. Я лишь призываю в момент создания новой системы подойти к этому процессу с душой. И тогда поверьте, случится момент творения. Спроектированная таким образом система будет живее всех живых в цифровом мире.
Послесловие
Диаграммы для примеров были реализованы с помощью инструмента Database Diagram Tool for SQL Server. Однако, подобный функционал есть и в DBeaver.
Источники
- SQL Database Design Basics with Example
- Geecko
- Microsoft SQL documentation
- SSMS
- Database Diagram Tool for SQL Server
Принципы проектирования таблиц баз данных (1)
Начиная с сегодняшнего дня, проектирование базы данных. Обсуждение построения базы данных занимает неделю. Для анализа базы данных это должно быть связано с требованиями. Первая задача сегодня состоит в том, чтобы отсортировать общее количество. Сколько нужно таблиц и как их создать, ночью мы проанализировали только часть. Позвольте мне высказать свое мнение о дизайне стола.
Самым основным при создании базы данных должен быть ряд операций, таких как создание таблиц, создание индексов и процедуры хранения. Когда дело доходит до таблиц, вы должны говорить о сущностях.
Объект данных
Что такое сущность, то, что существует объективно и может отличаться друг от друга, называется сущностью. Здесь мы просто понимаем его как таблицу, описывающую характеристики сущности, мы называем их атрибутами. Можно также сказать, что когда мы рассматриваем таблицу базы данных как сущность, все ли поля в ней являются свойством? Результат положительный.
Здесь мы просто понимаем его как таблицу, описывающую характеристики сущности, мы называем их атрибутами. Можно также сказать, что когда мы рассматриваем таблицу базы данных как сущность, все ли поля в ней являются свойством? Результат положительный.
Связи между сущностями
То, что я хочу сказать, очень просто: между таблицами в базе данных не более трех связей: один к одному, многие ко многим, один ко многим.
Фактически один-к-одному означает, что между созданной нами основной таблицей и связанной с ней таблицей существует взаимно-однозначное соответствие. Например, я создал таблицу базовой информации для учащихся: t_student, а затем создал таблицу оценок, которая содержит Внешний ключ, идентификатор студента, поле идентификатора студента в таблице основной информации учащегося и идентификатор студента в таблице оценок являются однозначными.
«Один ко многим» также похож. Я создаю другую таблицу классов, и в каждом классе есть несколько учеников, и каждый ученик соответствует классу. Конечно, для класса это один ко многим.
Конечно, для класса это один ко многим.
Много-много-много, я также привожу этот пример: я строю таблицу выбора курса, может быть много предметов, у каждого предмета есть много учеников для выбора, и каждый ученик может выбрать несколько предметов. Это много ко многим.
В-третьих, целостность базовой таблицы
(1) Атомный. Поля в базовой таблице неразложимы.
(2) Оригинальность. Записи в базовой таблице являются записями необработанных данных (базовых данных).
(3) дедуктивный. Из данных основной таблицы и таблицы кодов могут быть получены все выходные данные.
(4) Стабильность. Структура базовой таблицы относительно стабильна, и записи в таблице хранятся в течение длительного времени.
Это целостность базовой таблицы и является уникальной для нее. Здесь я хочу сказать, что в базе данных есть несколько таблиц, которые также часто используются, то есть промежуточные таблицы и временные таблицы.
1. Промежуточная таблица
Промежуточная таблица предназначена для отношений «многие ко многим», таких как система запросов шины. Внутри есть две таблицы: таблица станций и таблица маршрутов. Здесь мы называем их t_busstation и t_road. Согласно здравому смыслу, мы также знаем, что у станции есть несколько линий, и у каждой линии есть несколько станций. Как мы можем соединить две таблицы? Если это один к одному Один-ко-многим, у нас есть одна таблица, и две таблицы могут их реализовать, но многие-ко-многим, поэтому мы должны использовать промежуточную таблицу для объединения двух таблиц. Как правило, промежуточная таблица имеет автоинкрементный первичный ключ для этой таблицы, а также первичные ключи для двух других таблиц. Промежуточная таблица не имеет атрибутов, поскольку она не является базовой таблицей.
Внутри есть две таблицы: таблица станций и таблица маршрутов. Здесь мы называем их t_busstation и t_road. Согласно здравому смыслу, мы также знаем, что у станции есть несколько линий, и у каждой линии есть несколько станций. Как мы можем соединить две таблицы? Если это один к одному Один-ко-многим, у нас есть одна таблица, и две таблицы могут их реализовать, но многие-ко-многим, поэтому мы должны использовать промежуточную таблицу для объединения двух таблиц. Как правило, промежуточная таблица имеет автоинкрементный первичный ключ для этой таблицы, а также первичные ключи для двух других таблиц. Промежуточная таблица не имеет атрибутов, поскольку она не является базовой таблицей.
2. Временный стол
В этом проекте мы будем использовать временные таблицы. Давайте сначала посмотрим, что такое временная таблица. Это то, что я нашел в онлайн-книге. Потому что мы используем базу данных MS SQL Server 2000 и поддерживаем временные таблицы в этой базе данных.
Временные таблицы: На самом деле это таблицы данных, начинающиеся с #. Он в основном используется для хранения временных данных. Когда пользователь отключается, но не выходит к данным во временной таблице, система автоматически помещает данные во временную таблицу опорожнить. Здесь следует сказать, что временная таблица помещается в системную базу данных tempdb, а не в текущую базу данных.
Он в основном используется для хранения временных данных. Когда пользователь отключается, но не выходит к данным во временной таблице, система автоматически помещает данные во временную таблицу опорожнить. Здесь следует сказать, что временная таблица помещается в системную базу данных tempdb, а не в текущую базу данных.
Существует два типа временных таблиц: локальные временные таблицы и глобальные временные таблицы.
(1) Здесь нам нужно понять, что локальная временная таблица в базе данных начинается с #, эта временная таблица видна только текущему пользователю базы данных, а другие пользователи не видны. Разумеется, когда экземпляр базы данных отключается, данные теряются, независимо от того, явно ли они очищены или система перезагружена.
(2) Еще одна глобальная временная таблица. Он начинается с «##» и виден всем пользователям. Когда вы отключаете экземпляр базы данных, если на него ссылаются другие системные элементы и база данных подключена, данные существуют. Только когда другие системы отключены, система очистит данные глобальной временной таблицы.
Вот инструкция для создания временной таблицы:
Локальная временная таблица:
create table #student
(
studentID int ,
studentName nvarchar (40),
classID int
)
Глобальная временная таблица:
create table ##student
(
studentID int ,
studentName nvarchar (40).
classID int
)
Здесь мы также можем сделать это с помощью операторов SQL:
select * from employee into #student
Пишите сегодня сегодня и учитесь завтра.
Обратное проектирование реляционных баз данных
Введение Далее описываются действия, необходимые для выполнения обратного проектирования базы данных и связывания получившихся
таблиц модели данных с проектируемыми классами модели
проектирования. Эти действия могут выполняться проектировщиком баз данных в начале внесения изменений в базу данных
в рамках цикла эволюционной разработки. Основные этапы обратного проектирования базы данных и преобразования получившихся элементов модели данных в элементы модели проектирования:
Обратное проектирование базы данных RDBMS или сценария DDL для получения модели данныхРезультатом обратного проектирования базы данных или сценария на языке определения данных (Data Definition Language — DDL) обычно является набор элементов модели (таблиц, представлений, хранимых процедур и т.д.). В зависимости от сложности базы данных может потребоваться разделить полученные элементы модели на пакеты, содержащие логически связанные наборы таблиц. Преобразование модели данных в модель проектирования Далее приводятся инструкции по генерированию классов проектирования на основе элементов модели данных. В следующей таблице дается сводка общего соответствия элементов моделей данных и проектирования.
Некоторым элементам модели данных нельзя четко противопоставить элемент модели проектирования. Преобразование таблицы в классСоздайте класс для каждой преобразовываемой таблицы. Для каждого столбца таблицы создайте в классе атрибут с соответствующим типом. Попытайтесь найти самое близкое соответствие между типами атрибутов и типами полей таблицы. Пример Рассмотрим таблицу Customer, имеющую следующую структуру:
Структура таблицы Customer Для таблицы создается класс с таким же именем, Customer, имеющий следующую структуру: Первоначальная версия класса Customer В первой версии класса Customer для каждого столбца таблицы Customer в нем присутствует соответствующий
атрибут. Значок в виде знака «+» слева от атрибута означает, что область видимости последнего — ‘public’. По умолчанию все атрибуты, получаемые при преобразовании таблиц RDBMS, должны быть общедоступными, так как в RDBMS разрешено делать запросы ко всем столбцам. Идентификация внутренних и неявных классовКлассы, получающиеся в результате прямого преобразования «таблица — класс», часто содержат атрибуты, которые могут быть выделены в отдельный класс, особенно в случаях, когда эти атрибуты присутствуют в нескольких сгенерированных классах. Такие «общие» атрибуты обычно появляются в результате денормализации таблиц для улучшения производительности, или как следствие слишком упрощенной модели данных. В таких случаях разделите класс таким образом, чтобы он являл собой нормализованное представление таблиц. Пример После определения класса Customer можно определить класс Address, содержащий информацию об адресах
(предположив, что в системе будут другие ссылки на адреса). Класс Customer после выделения из него класса Address Тип связи между этими элементами — агрегирование, т.к. один адрес принадлежит только одному клиенту и следовательно является частью полного определения заказчика. Внешние ключиСоздайте ассоциацию между классами для каждой связи по внешнему ключу в таблице. Удалите атрибут из класса, ссылающегося на столбец внешнего ключа. Если столбец внешнего ключа изначально представлялся в виде атрибута, удалите его из класса. Пример Предположим, что таблица Order имеет следующую структуру:
Структура таблицы Order В таблице Order столбец Customer_ID является внешним ключом. Представление связей через внешние ключи в модели проектирования Внешний ключ представляется в виде ассоциации между классами Order и Item. Отношение «многие-ко-многим»В моделях данных RDBMS отношения «многие-ко-многим» представляются таблицей объединения (join table), или таблицей связей (association table). Таким образом, отношения «многие-ко-многим» представляются с помощью вспомогательных таблиц с первичными ключами двух объединяемых таблиц. Такие вспомогательные таблицы нужны из-за того, что поле внешнего ключа может содержать только один первичный ключ. Если одна запись связана с несколькими записями в другой таблице, и наоборот, то возникает необходимость в таблице связей. Пример Рассмотрим случай продуктов, которые могут поставляться любым из поставщиков.
Структура таблиц Product и Supplier Для связи этих таблиц в целях поиска продуктов, доступных у заданного поставщика используется таблица Product-Supplier.
Структура таблицы Product-Supplier В этой таблице объединения содержатся пары первичных ключей продуктов и поставщиков (с возможностью повторения),
таким образом формируя связь между ними. В модели проектирования эта вспомогательная таблица является избыточной, поскольку объектная модель позволяет представлять отношения «многие-ко-многим» напрямую. На рисунке показаны классы Supplier и Product и их взаимосвязь. Кроме того, на нем показан класс Address, извлеченный из Supplier в соответствии с рекомендациями, оговоренными ранее. Классы Product и Supplier Обобщение Часто среди всех таблиц несколько будут иметь схожую структуру. В модели
данных нет понятия обобщения, поэтому она не позволяет представлять схожесть структуры таблиц. Иногда аналогичная
структура получается в результате денормализации (для повышения производительности), как в случае ‘неявной’ таблицы Address, выделенной из другого класса. Пример Рассмотрим таблицы SoftwareProduct и HardwareProduct:
Таблицы SoftwareProduct и HardwareProduct Общие столбцы выделены синим цветом. Классы SoftwareProduct и HardwareProduct — потомки базового класса Product Соберем все основные классы системы заказов вместе. Сводная диаграмма классов для системы заказов Репликация поведения RDBMS в модель проектированияРепликация поведения — более сложная задача, т.к. обычно реляционные базы данных не являются объектно-ориентированными и провести аналогию между их поведением и операциями с классами в объектной модели сложно. Далее приведены действия, которые могут помочь реконструировать поведение классов, идентифицированных ранее:
Организация элементов в модели проектирования Класс проектирования, создаваемые в результате преобразований «таблица — класс», следует организовывать в модели
проектирования в пакеты проектирования и/или подсистемы проектирования, на основе общей архитектуры
приложения. См. Понятия: Разделение на уровни и Понятия:
Архитектура ПО. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 Дизайнер баз данных должен управлять обратной проектированием на протяжении
всего жизненного цикла проекта. В многих случаях обратное проектирование выполняется на ранних стадиях жизненного
цикла проекта, а затем изменения вносятся инкрементально без потребности в по следующем обратном проектировании базы
данных.
Дизайнер баз данных должен управлять обратной проектированием на протяжении
всего жизненного цикла проекта. В многих случаях обратное проектирование выполняется на ранних стадиях жизненного
цикла проекта, а затем изменения вносятся инкрементально без потребности в по следующем обратном проектировании базы
данных. Репликация
структуры базы данных в модели классов выполняется относительно просто. Инструкции, приведенные ниже, содержат алгоритм
преобразования элементов модели данных в элементов модели проектирования.
Репликация
структуры базы данных в модели классов выполняется относительно просто. Инструкции, приведенные ниже, содержат алгоритм
преобразования элементов модели данных в элементов модели проектирования. Примерами таких
элементов являются табличное пространство и собственно база данных, соответствующие физическим параметрам хранения и
представляемые в качестве компонентов. Другим таким элементом являются представления базы данных, фактически являющиеся
«виртуальными» таблицами и не имеющих смысловой нагрузки в модели проектирования. Кроме того, это индексы и
первичные ключи таблиц и триггеров, используемые для оптимизации работы СУБД и имеющие смысловое значение только в
контексте базы данных и модели данных.
Примерами таких
элементов являются табличное пространство и собственно база данных, соответствующие физическим параметрам хранения и
представляемые в качестве компонентов. Другим таким элементом являются представления базы данных, фактически являющиеся
«виртуальными» таблицами и не имеющих смысловой нагрузки в модели проектирования. Кроме того, это индексы и
первичные ключи таблиц и триггеров, используемые для оптимизации работы СУБД и имеющие смысловое значение только в
контексте базы данных и модели данных.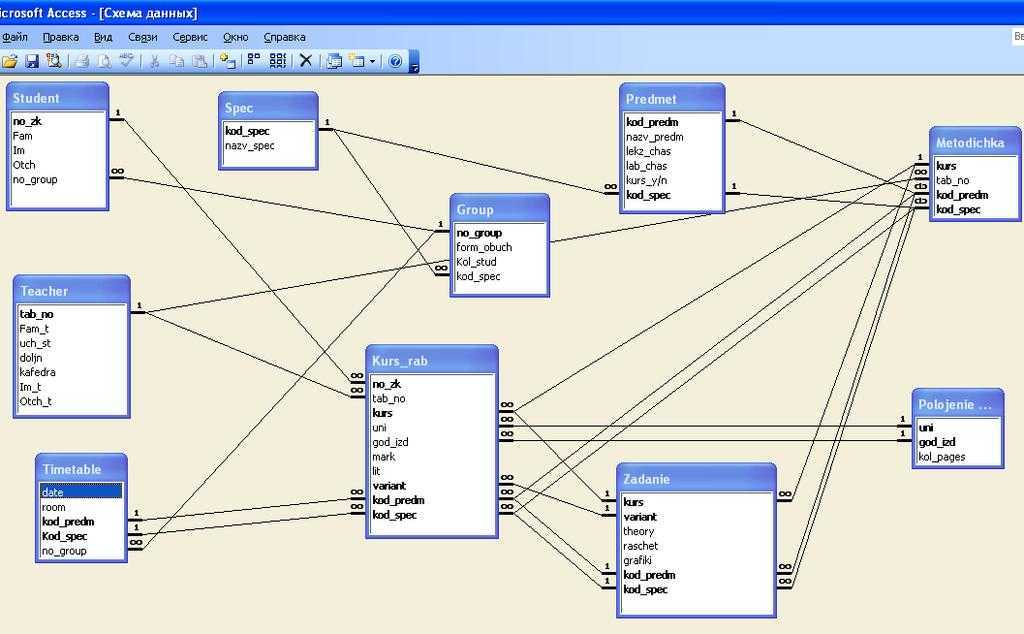 Область видимости всех таких атрибутов — public, т.к. возможен запрос к любому столбцу таблицы.
Область видимости всех таких атрибутов — public, т.к. возможен запрос к любому столбцу таблицы.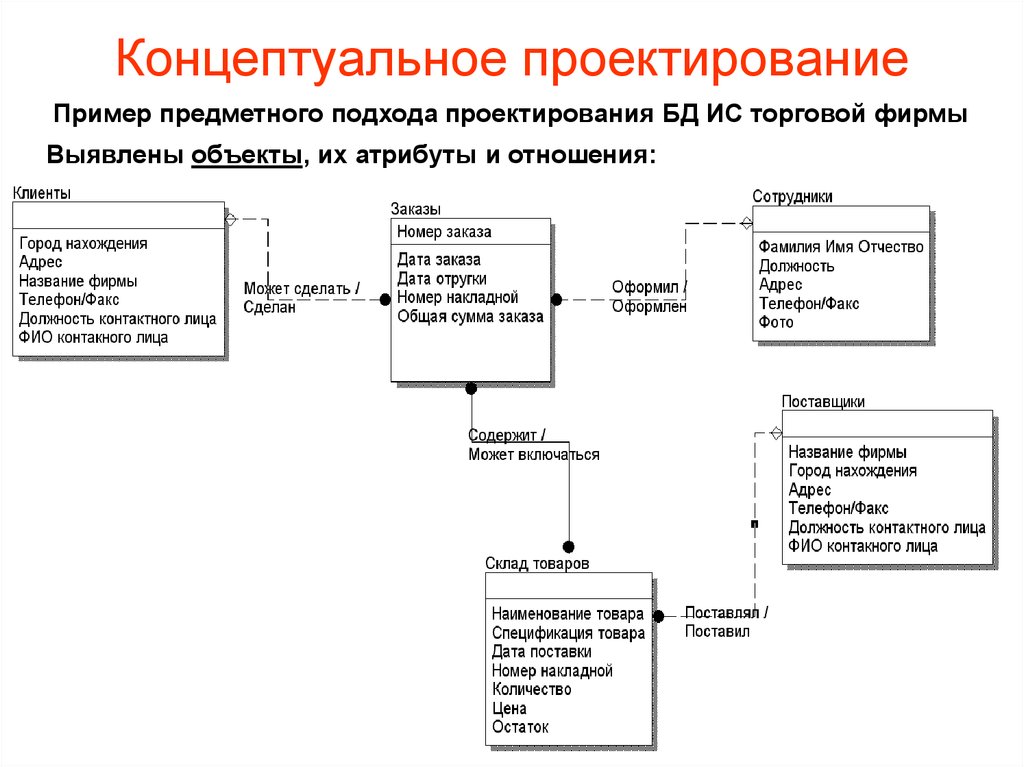 Таким образом, получаем два класса:
Таким образом, получаем два класса: Он содержит первичный ключ таблицы
Customer, связывающий ее с Order. Это представляется в модели проектирования следующим образом:
Он содержит первичный ключ таблицы
Customer, связывающий ее с Order. Это представляется в модели проектирования следующим образом: Поставщик может
заниматься несколькими продуктами. Структура таблиц Product и Supplier:
Поставщик может
заниматься несколькими продуктами. Структура таблиц Product и Supplier:
 Одна строка таблицы показывает, что у конкретного поставщика доступен н
конкретный продукт. Если взять все строки, у которых Supplier_ID равен ИД конкретного поставщика, то получим список
продуктов, доступных у него.
Одна строка таблицы показывает, что у конкретного поставщика доступен н
конкретный продукт. Если взять все строки, у которых Supplier_ID равен ИД конкретного поставщика, то получим список
продуктов, доступных у него.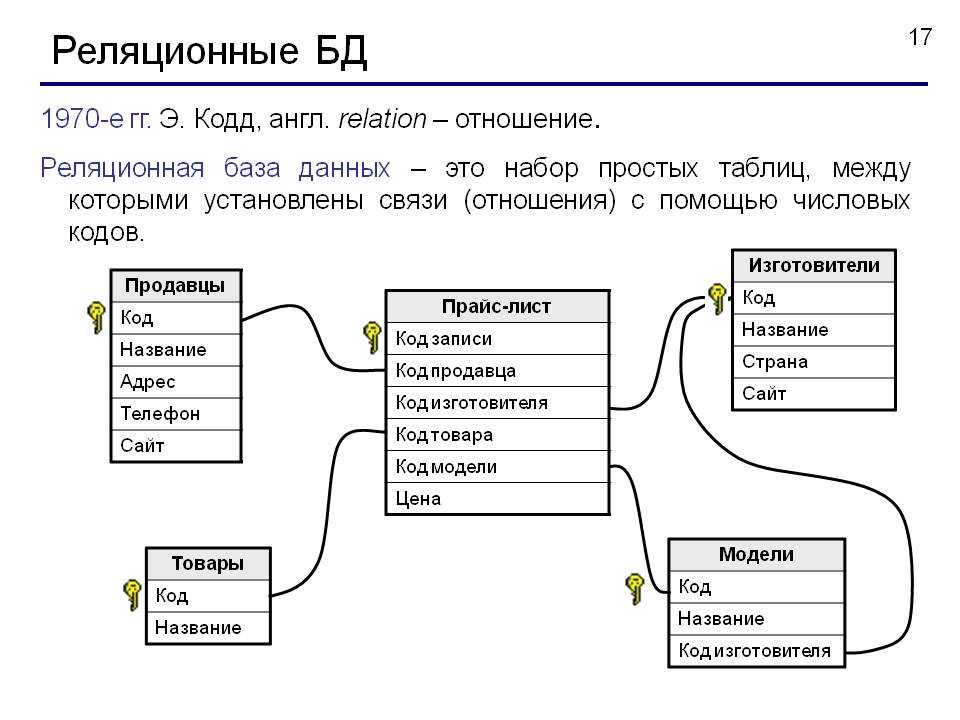 В других случаях более фундаментальные параметры являются общими, которые
можно представить в виде общего базового класса и двух или больше подклассов. Для выявления возможности обобщения ищите
часто повторяющиеся в разных таблицах столбцы, когда таблицы более схожи, чем различны.
В других случаях более фундаментальные параметры являются общими, которые
можно представить в виде общего базового класса и двух или больше подклассов. Для выявления возможности обобщения ищите
часто повторяющиеся в разных таблицах столбцы, когда таблицы более схожи, чем различны. Как видно, общей является большая часть обоих таблиц и они различаются только
одним полем. Эту общность можно представить выделением общего класса Product и объявление классов SoftwareProduct и HardwareProduct подклассами Product:
Как видно, общей является большая часть обоих таблиц и они различаются только
одним полем. Эту общность можно представить выделением общего класса Product и объявление классов SoftwareProduct и HardwareProduct подклассами Product: Необходимо иметь возможность задавать, изменять и запрашивать значения
атрибутов объектов. Это необходимо, поскольку к атрибутам объекта можно обращаться только через методы,
предоставляемые его классом. При создании операций, устанавливающих значение атрибута, не забудьте реализовать
проверку на удовлетворение условиям, накладываемым на значение поля в таблице. Если такая проверка не требуется, то
просто зафиксируйте возможность изменения и получения значений атрибутов, указав для них область
видимости «public», как это было сделано в диаграммах выше (значком слева от имени атрибута).
Необходимо иметь возможность задавать, изменять и запрашивать значения
атрибутов объектов. Это необходимо, поскольку к атрибутам объекта можно обращаться только через методы,
предоставляемые его классом. При создании операций, устанавливающих значение атрибута, не забудьте реализовать
проверку на удовлетворение условиям, накладываемым на значение поля в таблице. Если такая проверка не требуется, то
просто зафиксируйте возможность изменения и получения значений атрибутов, указав для них область
видимости «public», как это было сделано в диаграммах выше (значком слева от имени атрибута).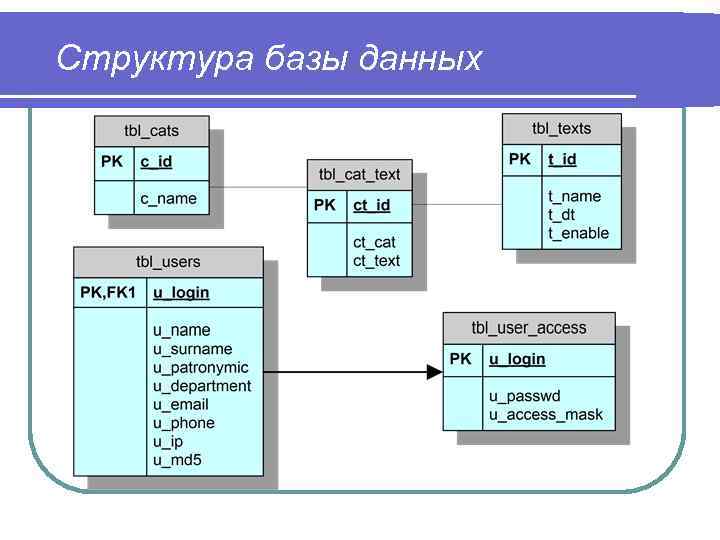 Документируйте поведение хранимой процедуры в созданной
операции, указав в описании метода то, что операция реализуется хранимой процедурой.
Документируйте поведение хранимой процедуры в созданной
операции, указав в описании метода то, что операция реализуется хранимой процедурой. В случае, если в базе данных существуют правила сохранения целостности связей, например, каскадное удаление связанных записей, соответствующее поведение необходимо отразить в задействованных
классах. Например, в базе данных может быть следующее правило: при удалении Order все связанные LineItem также должны удаляться. Если целевой язык поддерживает сбор мусора, создайте механизм удаления
строк из таблиц при освобождении связанного объекта в рамках сбора мусора. Обратите внимание, что корректно
реализовать это достаточно трудно, поскольку вам потребуется реализовать механизм гарантирования того, что среди
подключенных клиентов базы данных нет имеющих ссылки на удаляемый из памяти объект. В данном случае не следует
полагаться на механизм сбора мусора среды выполнения/виртуальной машины, т.к. это всего лишь такой же клиент, как и
любые другие.
В случае, если в базе данных существуют правила сохранения целостности связей, например, каскадное удаление связанных записей, соответствующее поведение необходимо отразить в задействованных
классах. Например, в базе данных может быть следующее правило: при удалении Order все связанные LineItem также должны удаляться. Если целевой язык поддерживает сбор мусора, создайте механизм удаления
строк из таблиц при освобождении связанного объекта в рамках сбора мусора. Обратите внимание, что корректно
реализовать это достаточно трудно, поскольку вам потребуется реализовать механизм гарантирования того, что среди
подключенных клиентов базы данных нет имеющих ссылки на удаляемый из памяти объект. В данном случае не следует
полагаться на механизм сбора мусора среды выполнения/виртуальной машины, т.к. это всего лишь такой же клиент, как и
любые другие. Проанализируйте операторы Select, использующиеся для обращения к базе
данных, для получения картины того, как информация получается и обрабатывается. Для каждого столбца,
непосредственно возвращаемого оператором Select, установите свойство public связанного атрибута равным true; для всех остальных атрибутов укажите private. Для каждого динамически вычисляемого столбца в
операторе Select создайте операцию в связанном классе, рассчитывающую и возвращающую соответствующее значение. В
число рассматриваемых операторов включите встроенные в представления.
Проанализируйте операторы Select, использующиеся для обращения к базе
данных, для получения картины того, как информация получается и обрабатывается. Для каждого столбца,
непосредственно возвращаемого оператором Select, установите свойство public связанного атрибута равным true; для всех остальных атрибутов укажите private. Для каждого динамически вычисляемого столбца в
операторе Select создайте операцию в связанном классе, рассчитывающую и возвращающую соответствующее значение. В
число рассматриваемых операторов включите встроенные в представления.
5 Пример схемы проектирования баз данных: критически важные практики и проекты — обучение
Базы данных являются краеугольным камнем почти всех бизнес-проектов. В результате организации должны сосредоточиться на разработке превосходных баз данных для достижения целей проектов, не теряя направления. В противном случае это может стоить времени, денег и может поставить под угрозу весь проект. Следовательно, схемы проектирования баз данных и пример схемы за последние годы приобрели известность, помогая пользователям легко понять базы данных.
Предприятия используют множество специализированных систем для конкретных приложений. Например, СУБД используются для транзакционных данных, озера данных для рабочих нагрузок с необработанными данными и хранилища данных для пакетной аналитики и аналитики, близкой к реальному времени.
При масштабировании эти особенности становятся сложными для конечного пользователя, поскольку объединение различных источников данных требует отображения каждого источника в схему. Но с хорошо разработанной схемой базы данных организации могут иметь надежный план обслуживания своих конвейеров данных и достижения своих бизнес-целей.
Но с хорошо разработанной схемой базы данных организации могут иметь надежный план обслуживания своих конвейеров данных и достижения своих бизнес-целей.
В этом блоге рассказывается о схемах базы данных и их типах, извлекающих 5 ключевых примеров схемы проектирования базы данных. Он завершается ключевыми практиками, которым необходимо следовать для достижения оптимальной производительности.
Содержание
- Что такое схема базы данных?
- Важность разработки схемы базы данных
- Как разработать схему базы данных?
- Передовой опыт проектирования схемы базы данных
- Понимание модели данных
- Что такое нормализация данных?
- Что такое диаграммы сущность-связь?
- Типы схемы базы данных
- Схема физической базы данных
- : Онлайн-банкинг
- Пример схемы: Бронирование гостиницы
- Пример схемы: Бронирование ресторана
- Пример схемы: финансовая транзакция
- Пример проектирования схемы: ключевые практики
- имеют хорошие стандарты именования
- Нормализация для борьбы с резервированием
- Исправлено правильное количество таблиц
- . Избегайте nulls
- . Правильное число. Целостность данных
- Использование хранимых процедур для доступа к данным
- Создание отношений между сущностями
- Многомерные данные
- Правила целостности данных
- Заключение
 Избегайте nulls
Избегайте nullsЧто такое схема базы данных?
Схема базы данных относится к структуре, которая представляет отношения между данными и определяет, как информация хранится в базе данных. Без надлежащей схемы легко отклониться от цели, учитывая масштаб проектов больших данных. Поскольку схема также представляет отношения между таблицами, разные базы данных имеют разные конструкции схемы для поддержки различных бизнес-требований.
Короче говоря, схемы базы данных необходимы для выполнения следующих задач:
- Непротиворечивое форматирование.
- Сохранение уникальных первичных и внешних ключей.
Важность проектирования схемы базы данных
Схема организует данные в таблицы с соответствующими атрибутами, показывает взаимосвязи между таблицами и столбцами и накладывает ограничения, такие как типы данных. Хорошо продуманная схема в хранилище данных облегчает жизнь аналитикам:
Хорошо продуманная схема в хранилище данных облегчает жизнь аналитикам:
- удаление очистки и другой предварительной обработки из рабочего процесса аналитика
- избавление аналитиков от необходимости реконструировать базовую модель данных
- предоставление аналитикам ясной, понятной отправной точки для аналитики разработанная схема открывает путь к более быстрому и простому созданию отчетов и информационных панелей.
Напротив, несовершенная схема требует от аналитиков данных дополнительного моделирования и вынуждает каждый запрос аналитики занимать больше времени и системных ресурсов, увеличивая затраты организации и раздражая всех, кто хочет получить аналитику прямо сейчас.
Схемы используются для указания элементов данных как в источниках данных, так и в хранилищах данных в поле Аналитика данных. Однако схемы источников данных не создаются с учетом аналитики, будь то базы данных , такие как MySQL, PostgreSQL, или Microsoft SQL Server или службы SaaS , такие как Salesforce, Facebook Ads, или Зуора .
Приложения SaaS, например, могут предлагать некоторые широкие аналитические функции, но они применяются только к данным из этого конкретного приложения. Пользователи также не имеют контроля над Схемы SaaS , которые устанавливаются разработчиками каждой программы.
Когда корпоративные данные дублируются в хранилище данных и связываются с данными из других приложений, они становятся более полезными, и предприятия могут создавать эти архитектуры данных.
Схемы базы данных определяют архитектуру базы данных и помогают обеспечить следующие основные принципы базы данных:
- Данные форматируются последовательно.
- Каждая запись записи имеет отдельный первичный ключ.
- Важная информация не пропущена.
Схема схемы базы данных может существовать как в виде визуального представления, так и в виде набора формул или использования ограничений, управляющих базой данных. В зависимости от системы базы данных разработчики затем будут выражать эти формулы на разных языках определения данных.
Например, несмотря на то, что ведущие системы баз данных имеют немного разные определения того, что такое схемы, оператор CREATE SCHEMA поддерживается MySQL, Oracle Database и Microsoft SQL Server.
Предположим, вы хотите создать базу данных для хранения информации для бухгалтерии вашей компании. Схема этой базы данных может наметить структуру двух простых таблиц:
A) Table1
- Название: Пользователи
- Fields: ID, полное имя, электронное письмо, DOB, DEPT
B) TABLE 2
B).
Название: Плата за сверхурочную работу - Поля: ID, полное имя, период времени, выставленные счета
Эта отдельная схема включает полезную информацию, такую как:
- Название каждой таблицы
- , связывая оплату сверхурочных сотрудников с их личностью через их идентификационный номер)
- Любая другая соответствующая информация
Затем эти таблицы схемы могут быть преобразованы в код SQL разработчиками и администраторами баз данных.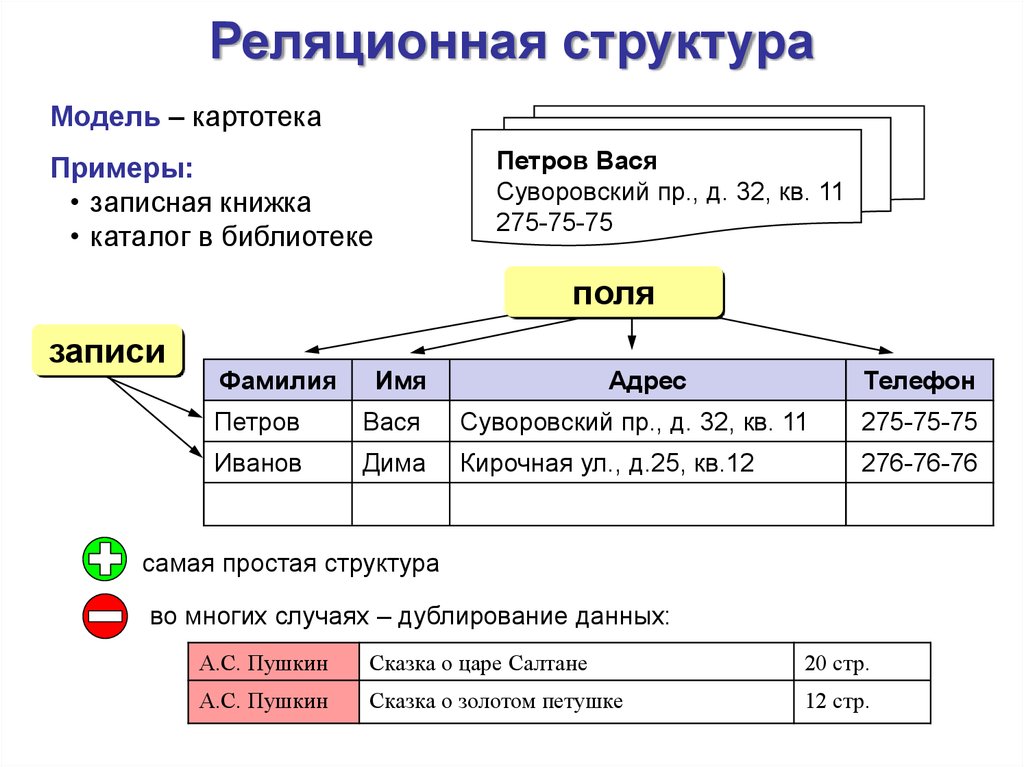
Рекомендации по проектированию схемы базы данных
Очень важно следовать этим рекомендациям, чтобы получить представление об идеальном проекте схемы базы данных.
- Соглашения об именах: Чтобы сделать схему вашей базы данных наиболее эффективной, определите и используйте соответствующие соглашения об именах. Хотя вы можете выбрать конкретный стиль или следовать стандарту ISO, самое главное — быть последовательным в полях имени.
- Избегайте использования зарезервированных слов в именах таблиц, имен столбцов, полей и т. д., так как это почти наверняка приведет к синтаксической ошибке.
- Использование дефисов, кавычек, пробелов, специальных символов и т. д. приведет к неверным результатам или потребует дополнительного шага.
- В именах таблиц используйте существительные в единственном числе, а не во множественном числе (т. е. используйте StudentName вместо StudentNames). Поскольку таблица представляет коллекцию, название не обязательно должно быть во множественном числе.
- Удалите ненужные формулировки из названий таблиц (например, Department вместо DepartmentList, TableDepartments и т.д.).
- Безопасность: Безопасность данных начинается с хорошо спроектированной схемы базы данных. Для конфиденциальных данных, таких как личная информация (PII) и пароли, используйте шифрование. Вместо того, чтобы назначать роли администратора каждому пользователю, запросите аутентификацию пользователя для доступа к базе данных.
- Документация: Схемы базы данных полезны еще долго после их создания, и их будут просматривать многие другие люди, поэтому очень важна хорошая документация. Задокументируйте схему своей базы данных с подробными инструкциями и включите строки комментариев для сценариев, триггеров и т. д.
- Нормализация: В двух словах, нормализация гарантирует, что независимые объекты и отношения не группируются вместе в одной таблице, что снижает избыточность и повышает целостность. При необходимости используйте нормализацию для повышения производительности базы данных. Как чрезмерная, так и недостаточная нормализация могут привести к снижению производительности.
- Квалификация: Хорошее понимание и распознавание ваших данных и атрибутов каждого элемента помогает в разработке наиболее эффективной схемы схемы базы данных. Хорошо спроектированная схема может позволить вашим данным расти в геометрической прогрессии. Продолжая собирать данные, вы можете анализировать каждое поле по отношению к другим в вашей схеме.
 При необходимости используйте нормализацию для повышения производительности базы данных. Как чрезмерная, так и недостаточная нормализация могут привести к снижению производительности.
При необходимости используйте нормализацию для повышения производительности базы данных. Как чрезмерная, так и недостаточная нормализация могут привести к снижению производительности.Понимание модели данных
Понимание базовой модели данных — это первый и наиболее важный шаг в использовании данных из приложения. Поскольку мир состоит из организаций, отдельных лиц, транзакций и других общих бизнес-идей, каждая программа SaaS автоматически включает в себя представление мира. Для понимания данных необходимо знать, какие столбцы данных соответствуют реальным эквивалентам.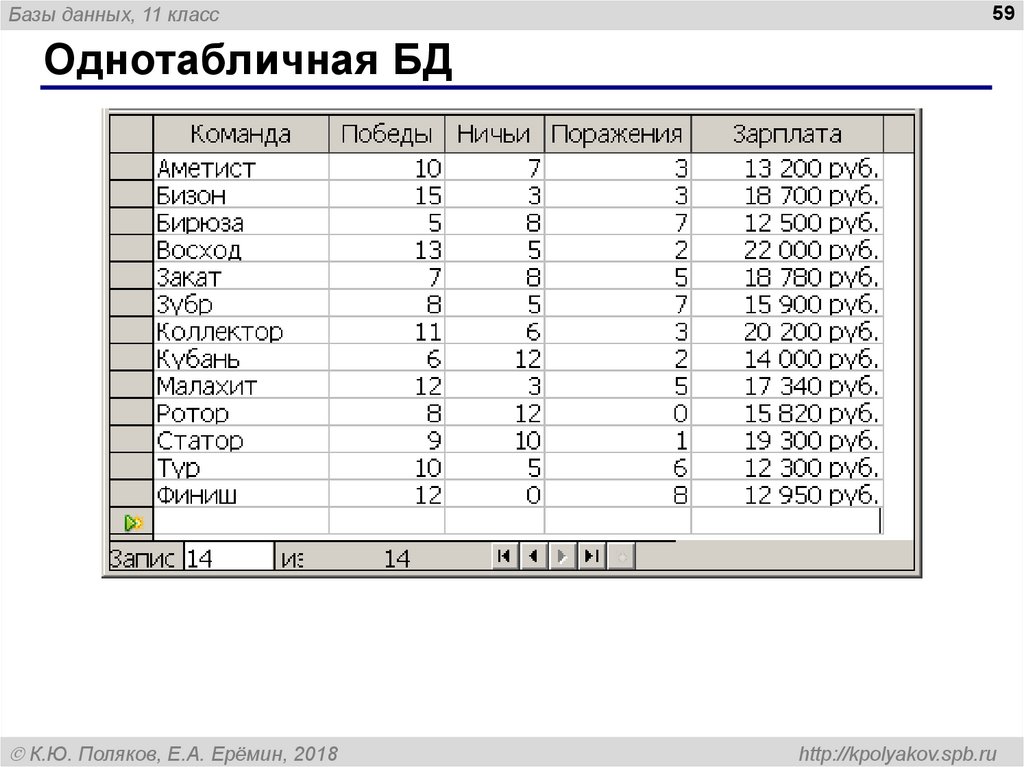
При работе с внутренним 9База данных 0003, Разработчики и Инженеры данных , скорее всего, смогут описать модель. Если у вас нет команды разработчиков и инженеров данных, не беспокойтесь, в этом случае вы должны следовать документации и API поставщика при использовании приложений SaaS.
Что такое нормализация данных?
Нормализация — это подход к проектированию схемы реляционной базы данных.
Нормализация направлена на избавление от повторяющихся, избыточных и производных значений данных. Администратор базы данных может нормализовать логическую структуру модели данных для создания схемы. Конечным результатом процесса нормализации является Определение схемы базы данных , которое представляет собой набор таблиц и столбцов, известных как поля.
Некоторые из полей в определении схемы базы данных являются ключевыми полями , что означает, что они уникальны и могут использоваться для построения индексов, упрощающих хранение и извлечение записей.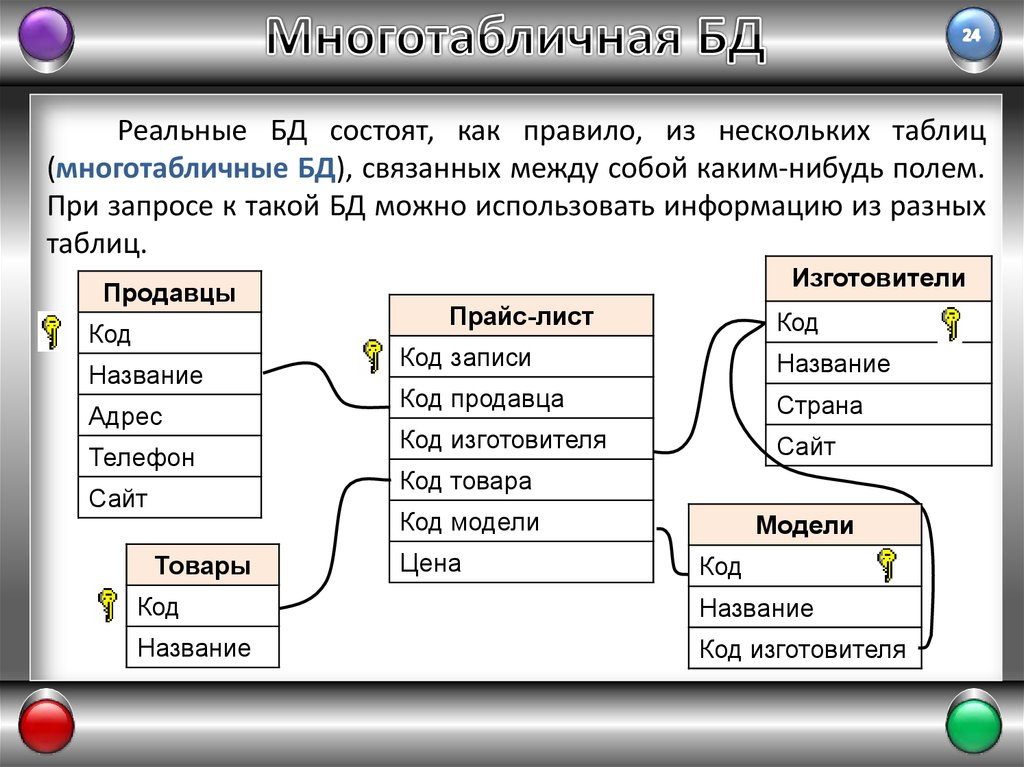 Кроме того, эти таблицы связаны друг с другом, представляя системы управления реляционными базами данных.
Кроме того, эти таблицы связаны друг с другом, представляя системы управления реляционными базами данных.
Что такое диаграммы сущность-связь?
Диаграмма отношения объектов (ERD) , также известная как модель отношения объекта, представляет собой графическое представление отношений между людьми, объектами, местами, концепциями или событиями в системе информационных технологий (ИТ). Вы можете построить их, нарисовав их или используя различные программные инструменты. ERD использует методы моделирования данных, чтобы помочь в определении бизнес-процессов и в качестве основы для реляционной базы данных.
Вот пример схемы логической базы данных , демонстрирующей таблицы, поля и первичные ключи.
Источник изображенияПриведенное выше изображение представляет собой ERD, который иллюстрирует таблицы, поля, взаимосвязи и ключи между различными таблицами.
Первичный ключ в нормализованной базе данных обозначает базовую сущность, которую представляет таблица, и однозначно идентифицирует каждую строку в этой таблице.
Например, в таблице клиентов первичным ключом, скорее всего, будет идентификатор клиента, а таблица, скорее всего, будет содержать такую информацию, как имя клиента, адрес, номер кредитной карты и т. д. Некоторые столбцы называются внешними ключами. А Внешний ключ — это столбец или набор столбцов в одной таблице, которые ссылаются на столбцы первичного ключа в другой. Например, запись о сотруднике может включать внешний ключ, основанный на номере социального страхования сотрудника, который является первичным ключом в таблице доходов сотрудников.
Два типа ключей связывают объект, представленный первичным ключом, с другим объектом, представленным в другой таблице. В ERD ключевые поля представлены специальными символами.
Вы можете представить три типа отношений с помощью первичного и внешнего ключей, а именно:
1) Один к одному
В отношениях один к одному только два объекта могут отображаться друг на друга; никакие другие элементы не могут. Реальным примером могут быть номера социального страхования, которые могут быть назначены только одному человеку за раз.
Реальным примером могут быть номера социального страхования, которые могут быть назначены только одному человеку за раз.
2) Один ко многим
Один объект в одной таблице может соответствовать нескольким записям в другой таблице, но не наоборот. Список вкусов мороженого, продаваемых компанией, и клиентов, которые заказали продукты с их характеристиками, является примером «один ко многим». Эта информация может быть использована продовольственным ритейлером для определения любимого вкуса покупателя. Эта бизнес-информация может быть использована для рекомендации нового мороженого с таким вкусом, когда оно появится на рынке.
Таким образом, демонстрируется коммерческая ценность базы данных «один ко многим»: выявление общих черт в поведении пользователей и генерируемых ею данных и согласование их с действиями, приносящими доход.
У каждого вкуса может быть большое количество покупателей, но у каждого покупателя есть только один фаворит, который стоит выше всех остальных. Когда вы встречаете вложенный объект с отношением «один ко многим» к основной таблице, он преобразуется в отдельную таблицу.
Когда вы встречаете вложенный объект с отношением «один ко многим» к основной таблице, он преобразуется в отдельную таблицу.
3) Многие ко многим
Эти отношения представлены в таблицах соединений. Составной первичный ключ в таблице соединений состоит из первичных ключей двух связанных сущностей. Например, покупательские привычки человека могут привести его во многие магазины, и в каждом магазине будет много покупателей.
Источник изображенияТипы схем базы данных
Источник изображенияСами схемы базы данных можно разделить на следующие категории:
- Физическая схема базы данных
- Логическая схема базы данных
- Схема базы данных просмотра
- Схема «звезда»
- Схема «снежинка»
Схема физической базы данных
Схема физической базы данных показывает, как данные хранятся на дисковом хранилище или в целевом объекте данных. Физическая схема является самой низкой формой абстракции по отношению к схеме.
Он служит основой для других типов схем для создания отношений и индексов. Поэтому физическая схема обычно указывает распределение хранилища, которое определяется с точки зрения ГБ или ТБ.
Логическая схема базы данных
Логическая схема — это концептуальная модель базы данных. Он не зависит от платформы и в основном фокусируется на бизнес-сущностях при создании связей между таблицами. На логическом уровне данные, хранящиеся физически, представлены в виде атрибутов, которым затем можно придать смысловую структуру для упрощения записи, чтения и обновления данных.
Представление схемы базы данных
Его можно определить как структуру базы данных на уровне представления, которая обычно описывает взаимодействие конечного пользователя с системами баз данных. На уровне представления пользователь может взаимодействовать с системой с помощью интерфейса. Пользователи не знают, где и как хранятся данные.
Схема «звезда»
Источник изображения Схема «звезда» — это многомерная модель, используемая в хранилищах данных для поддержки расширенной аналитики.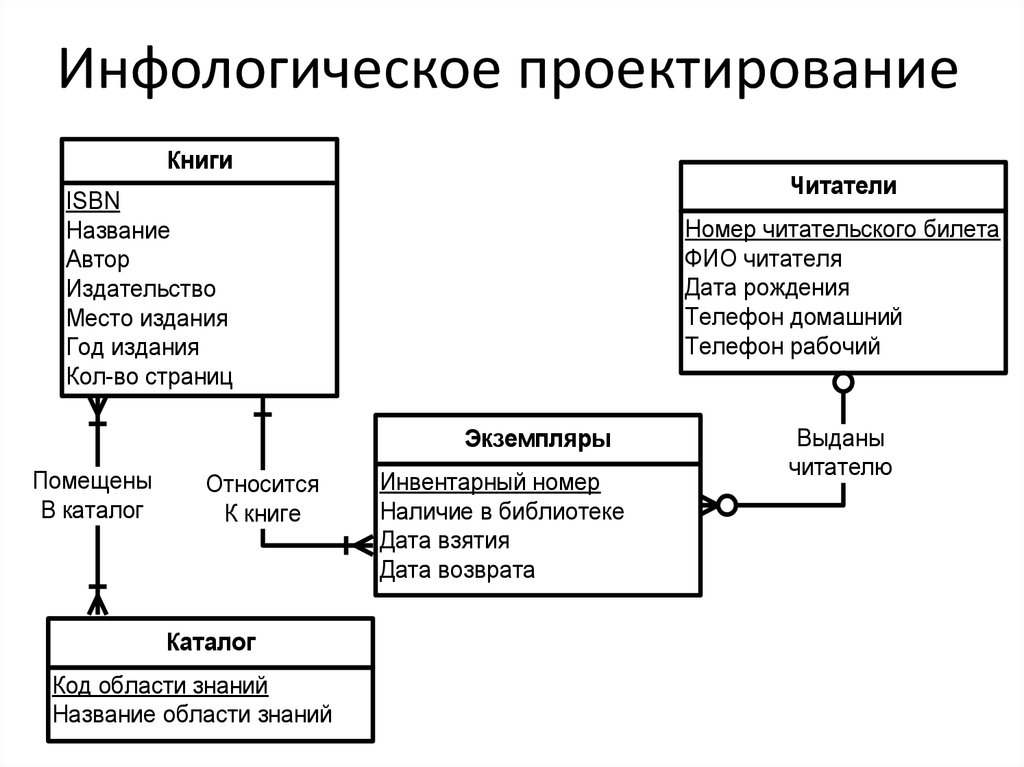 Схема strat содержит центральную таблицу фактов, которая связана с несколькими многомерными таблицами. Несмотря на простоту использования, звездообразная схема занимает много места, поскольку многомерные таблицы не связаны с подразмерными таблицами, что ограничивает расширяемость данных.
Схема strat содержит центральную таблицу фактов, которая связана с несколькими многомерными таблицами. Несмотря на простоту использования, звездообразная схема занимает много места, поскольку многомерные таблицы не связаны с подразмерными таблицами, что ограничивает расширяемость данных.
Схема «снежинка»
Источник изображенияПодобно схеме «звезда», схема «снежинка» также является многомерной моделью, используемой в хранилищах данных для поддержки расширенной аналитики. Хотя в обеих схемах таблицы организованы вокруг центральной таблицы фактов, размерные таблицы в схеме «снежинка» могут дополнительно соединяться с подпространственными таблицами. Преимущество схемы «снежинка» заключается в том, что сохраняется меньше повторяющихся данных, чем в эквивалентной схеме «звезда».
Полностью управляемая платформа конвейера данных без кода, такая как Hevo, помогает вам интегрировать и загружать данные из 100+ различных источников, включая 40+ бесплатных источников , в место назначения по вашему выбору в режиме реального времени без усилий.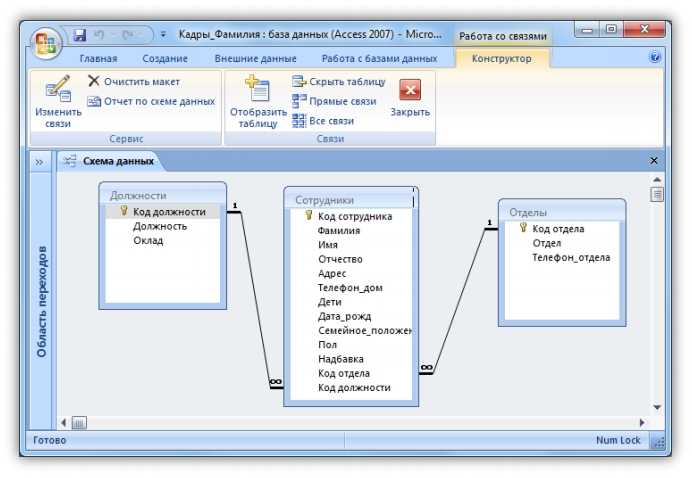 Hevo с его минимальной кривой обучения можно настроить всего за несколько минут, что позволит пользователям загружать данные без ущерба для производительности. Его надежная интеграция с многочисленными источниками позволяет пользователям плавно вводить данные различных типов без необходимости кодировать ни одной строки.
Hevo с его минимальной кривой обучения можно настроить всего за несколько минут, что позволит пользователям загружать данные без ущерба для производительности. Его надежная интеграция с многочисленными источниками позволяет пользователям плавно вводить данные различных типов без необходимости кодировать ни одной строки.
Начните работу с Hevo бесплатно
Ознакомьтесь с некоторыми интересными функциями Hevo:
- Полная автоматизация: Платформа Hevo устанавливается всего за несколько минут и требует минимального обслуживания.
- Преобразования : Hevo обеспечивает преобразования предварительной загрузки с помощью кода Python. Это также позволяет вам запускать код преобразования для каждого события в настроенных вами пайплайнах. Вам необходимо отредактировать свойства объекта события, полученного в методе преобразования в качестве параметра для выполнения преобразования. Hevo также предлагает преобразования перетаскивания, такие как функции даты и управления, JSON и управление событиями, и это лишь некоторые из них. Их можно настроить и протестировать перед использованием.
- Соединители : Hevo поддерживает более 100 интеграций с платформами SaaS, файлами, базами данных, аналитическими и бизнес-инструментами. Он поддерживает различные направления, включая Google BigQuery, Amazon Redshift, хранилища данных Snowflake; Озера данных Amazon S3; и базы данных MySQL, MongoDB, TokuDB, DynamoDB, PostgreSQL и многие другие.
- Передача данных в режиме реального времени: Hevo обеспечивает перенос данных в режиме реального времени, поэтому вы всегда можете иметь готовые к анализу данные.
- 100% полная и точная передача данных: Надежная инфраструктура Hevo обеспечивает надежную передачу данных без потери данных.
- Масштабируемая инфраструктура: Hevo имеет встроенную интеграцию для более чем 100 источников, таких как Google Analytics, которые могут помочь вам масштабировать вашу инфраструктуру данных по мере необходимости.
- Круглосуточная поддержка в режиме реального времени: Команда Hevo доступна круглосуточно, чтобы оказать вам исключительную поддержку через чат, электронную почту и звонки в службу поддержки.
- Управление схемой: Hevo избавляет от утомительной задачи управления схемой и автоматически определяет схему входящих данных и сопоставляет ее со схемой назначения.
- Мониторинг в реальном времени: Hevo позволяет отслеживать поток данных, чтобы вы могли проверить, где находятся ваши данные в определенный момент времени.
 Hevo также предлагает преобразования перетаскивания, такие как функции даты и управления, JSON и управление событиями, и это лишь некоторые из них. Их можно настроить и протестировать перед использованием.
Hevo также предлагает преобразования перетаскивания, такие как функции даты и управления, JSON и управление событиями, и это лишь некоторые из них. Их можно настроить и протестировать перед использованием.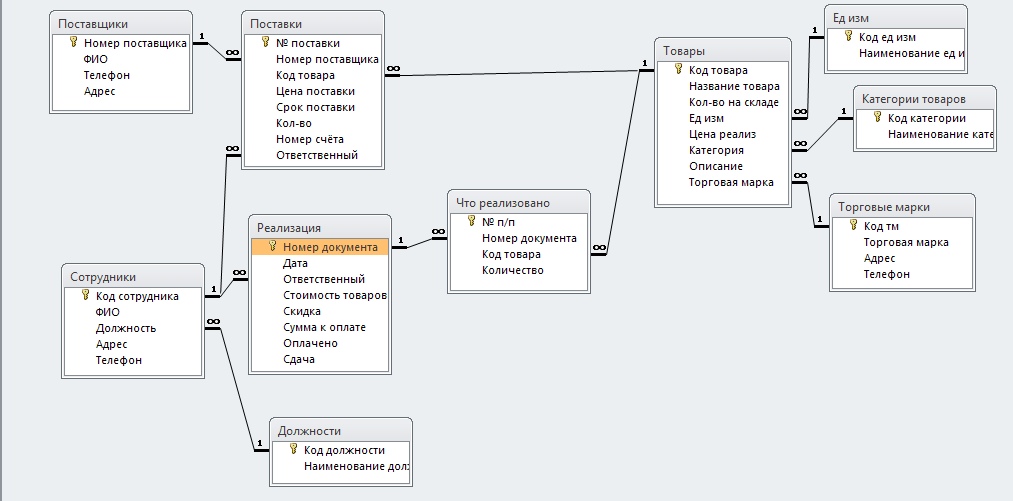
Зарегистрируйтесь здесь, чтобы получить 14-дневную бесплатную пробную версию!
Вы можете попробовать Hevo бесплатно, подписавшись на 14-дневную бесплатную пробную версию.
Пример схемы проектирования базы данных
Вот 5 ключевых проектов базы данных вместе с примером схемы:
- Пример схемы: транзакция электронной коммерции
- Пример схемы: онлайн-банкинг
- Пример схемы: бронирование отеля
- Пример схемы: бронирование ресторана
- Пример схемы: финансовая транзакция
Пример схемы: транзакция электронной коммерции
Возьмем пример клиента на веб-сайте электронной коммерции.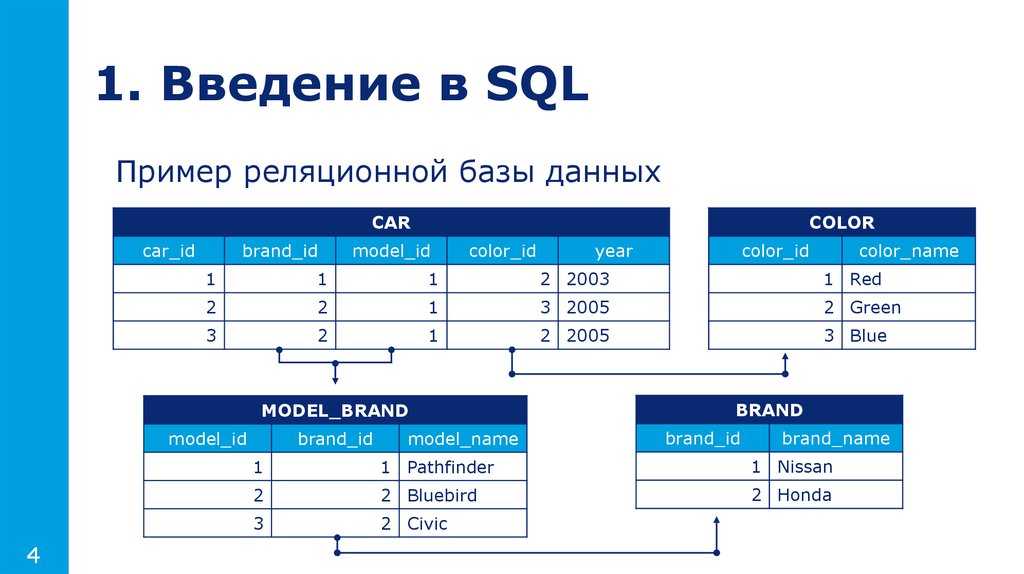 Двумя важными компонентами схемы являются первичный ключ и внешний ключ. При создании диаграммы ER (сущность-связь), подобной показанной выше, первичным ключом объекта могут быть идентификаторы, которые однозначно идентифицируют запись в таблице. Внешний ключ, который является первичным ключом для другой таблицы, связывает связь между таблицами.
Двумя важными компонентами схемы являются первичный ключ и внешний ключ. При создании диаграммы ER (сущность-связь), подобной показанной выше, первичным ключом объекта могут быть идентификаторы, которые однозначно идентифицируют запись в таблице. Внешний ключ, который является первичным ключом для другой таблицы, связывает связь между таблицами.
Схемы SQL определяются на логическом уровне, который обычно используется для доступа и управления данными в таблицах. SQL-серверы имеют команду CREATE для создания новой схемы в базе данных.
Следующее создает схему для клиентов, количества и цены транзакций:
CREATE TABLE клиент ( идентификатор INT AUTO_INCREMENT ПЕРВИЧНЫЙ КЛЮЧ, почтовый код VARCHAR() по умолчанию NULL, ) СОЗДАТЬ ТАБЛИЦУ продукта ( идентификатор INT AUTO_INCREMENT ПЕРВИЧНЫЙ КЛЮЧ, product_name VARCHAR() НЕ NULL, цена VARCHAR() НЕ NULL, )
Пример схемы: Интернет-банкинг
Источник изображенияНиже приведен пример кода для создания схем, подобных приведенным выше, в отношении онлайн-банкинга:
СОЗДАТЬ БАЗУ ДАННЫХ -- Структура таблицы для таблицы `account_customers` УДАЛИТЬ ТАБЛИЦУ, ЕСЛИ СУЩЕСТВУЕТ `account_customers`; СОЗДАТЬ ТАБЛИЦУ `account_customers` ( `Account_id` int(10) unsigned NOT NULL, `Customer_id` int(10) unsigned NOT NULL, ПЕРВИЧНЫЙ КЛЮЧ (`Customer_id`,`Account_id`), КЛЮЧ `fk_Accounts(`Customer_id`), КЛЮЧ `fk_Accounts1_idx` (`Account_id`),
Пример схемы: бронирование отеля
Источник изображения Вышеприведенная схема может быть изменена на основе бизнес-правил, таких как количество запросов на клиента, количество назначений администратором, несколько номеров на одну и ту же дату бронирования, типы оплаты и т.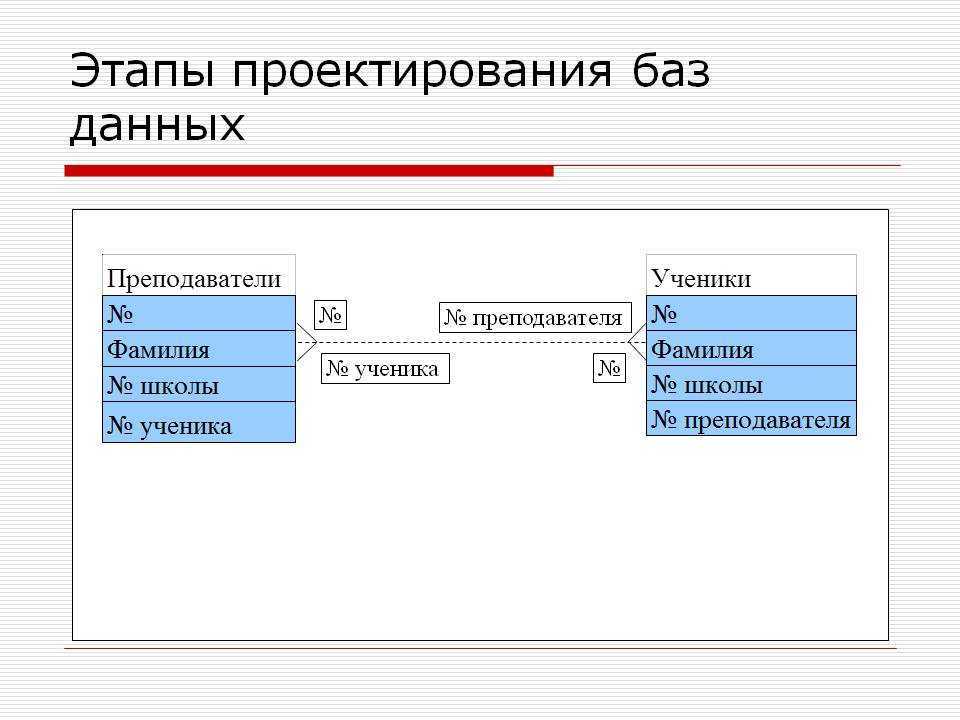 д.
д.
Вот пример кода создания схемы:
CREATE DATABASE example; пример ЕГЭ; УДАЛИТЬ ТАБЛИЦУ, ЕСЛИ СУЩЕСТВУЕТ покупатель; СОЗДАТЬ ТАБЛИЦУ клиента ( идентификатор INT AUTO_INCREMENT ПЕРВИЧНЫЙ КЛЮЧ, почтовый код VARCHAR(15) по умолчанию NULL, ) УДАЛИТЬ ТАБЛИЦУ, ЕСЛИ СУЩЕСТВУЕТ продукт; СОЗДАТЬ ТАБЛИЦУ продукта ( идентификатор INT AUTO_INCREMENT ПЕРВИЧНЫЙ КЛЮЧ, product_name VARCHAR(50) НЕ NULL, цена VARCHAR(7) НЕ НУЛЕВАЯ, количество VARCHAR(4) НЕ NULL ) …. ….
Пример схемы: заказ столика в ресторане
Источник изображенияВ этой схеме клиенту может быть присвоен уникальный идентификатор. Его можно прочитать как ID или customer_id. Точно так же пользовательская таблица, ингредиенты и меню будут включены в бизнес-правила. Пример кода для создания схем, подобных приведенной выше:
CREATE TABLE `restaurant`.`user` ( `id` BIGINT NOT NULL AUTO_INCREMENT, `fName` VARCHAR(50) NULL ПО УМОЛЧАНИЮ NULL, `мобильный` VARCHAR(15) NULL, `электронная почта` VARCHAR(50) NULL, ….
 .
….
ПЕРВИЧНЫЙ КЛЮЧ (`id`),
.
….
ПЕРВИЧНЫЙ КЛЮЧ (`id`), Пример схемы: Финансовая транзакция
Источник изображенияВышеприведенный пример схемы представляет схему звездообразного типа для типичной финансовой транзакции. Как указано в звездообразной схеме, вы можете видеть, что этот дизайн выглядит чистым и легко интерпретируется для будущего сотрудничества между командами. Таблица транзакций связана с таблицей владельцев счетов, а также с банковским персоналом, который руководит транзакцией.
СОЗДАТЬ БАЗУ ДАННЫХ пример ; USE пример ; УДАЛИТЬ ТАБЛИЦУ, ЕСЛИ СУЩЕСТВУЕТ покупатель; СОЗДАТЬ ТАБЛИЦУ клиента ( идентификатор INT AUTO_INCREMENT ПЕРВИЧНЫЙ КЛЮЧ, Код валюты VARCHAR) по умолчанию NULL, ) УДАЛИТЬ ТАБЛИЦУ, ЕСЛИ СУЩЕСТВУЕТ продукт; СОЗДАТЬ ТАБЛИЦУ продукта ( идентификатор INT AUTO_INCREMENT ПЕРВИЧНЫЙ КЛЮЧ, GENERAL_LEDGER_ CODE VARCHAR(50) НЕ NULL, цена VARCHAR(7) НЕ НУЛЕВАЯ, количество VARCHAR(4) НЕ NULL ) …… ……
Пример схемы проектирования: ключевые практики
Хорошая схема обеспечивает оптимальную производительность в масштабе. Хотя дизайн зависит от варианта использования, несколько общих практик применимы почти ко всем проектам баз данных:
Хотя дизайн зависит от варианта использования, несколько общих практик применимы почти ко всем проектам баз данных:
- Иметь хорошие стандарты именования
- Нормализация использования для борьбы с резервированием
- Исправить правильное количество таблиц
- Избегайте Nulls
- . Правильная документация
- Защита Данные Целостность
- Использование. Good Naming Standards
Имена — это первая и самая важная строка документации для приложения. Соответствующее наименование делает схемы проектирования баз данных наиболее эффективными. Имена позволяют определить назначение объекта и упростить совместную работу. При именовании помните следующее:
- Согласованность является ключевым моментом при именовании.
- Старайтесь не использовать зарезервированные слова SQL Server в именах таблиц, столбцов и полей, поскольку это может привести к синтаксической ошибке.
- Избегайте использования дефисов, кавычек, пробелов и специальных символов, поскольку это недопустимо или потребует дополнительного шага.
- Избегайте ненужных префиксов или суффиксов для имен таблиц.
2) Используйте нормализацию для решения проблемы избыточности
Избыточность — обычное явление в проектах баз данных. Сложность здесь в том, что эта избыточность может быть как хорошей, так и плохой в зависимости от варианта использования. Здесь на помощь приходит нормализация. Нормализация базы данных — это процесс структурирования базы данных по ряду нормальных форм для уменьшения избыточности данных.
Как чрезмерная, так и недостаточная нормализация приводят к ухудшению производительности. Следовательно, решение о сохранении или устранении избыточности принимается путем сравнения стоимости операций, связанных с избыточной информацией, и необходимого объема памяти.
3) Исправьте правильное количество таблиц
В хорошей базе данных будет ровно столько таблиц, сколько требуется приложению, не больше и не меньше. Несмотря на то, что не существует единого «правильного» количества таблиц для всех баз данных, сокращение количества таблиц до представления одной «вещи» считается эффективным, поскольку тогда изменения затронут только одну таблицу.
Это, в свою очередь, сократит доработку по мере продвижения.4) Избегайте пустых значений
Это можно сделать, указав NOT NULL всякий раз, когда нужно оставить пустую информацию. Избегайте нулевых значений или используйте их только тогда, когда они вам действительно нужны, поскольку атрибуты с нулевыми значениями не могут формировать первичные ключи.
5) Иметь надлежащую документацию
Это расширение наличия соответствующего этикета присвоения имен. Документация помогает совместной работе между командами и помогает новым программистам легко присоединиться к работе. Хорошая документация состоит из определений таблиц, столбцов, связей и даже ограничений по умолчанию и проверок.
6) Защитить целостность данных
Основные бизнес-правила должны находиться в базе данных. Такие правила, как допустимость значений NULL, длина строки, назначение внешних ключей и т. д., должны быть определены в базе данных.
Когда в базе данных определены базовые правила, их нельзя обойти, и можно писать запросы, не беспокоясь о том, соответствуют ли данные базовым бизнес-правилам.
Используйте средства SQL для поддержания целостности данных.7) Использование хранимых процедур для доступа к данным
Хранимые процедуры обеспечивают эффективную разработку базы данных для совместной работы команд и разработки между базой данных и функциональными программистами.
Эти процедуры дают специалистам по базам данных возможность изменять характеристики кода базы данных без особых затрат. Кроме того, они также могут предоставлять детальный доступ к системе.
Создание отношений между сущностями
Теперь вы готовы изучать связи между таблицами базы данных, поскольку они были преобразованы в таблицы. Количество компонентов, которые взаимодействуют между двумя связанными таблицами, называется кардинальностью. Определение кардинальности помогает обеспечить максимально эффективное разделение данных на таблицы.
Каждый объект может иметь отношения с любым другим объектом, однако эти отношения обычно попадают в одну из трех категорий:
1) Отношение один к одному
Отношение один к одному существует, когда существует является только одним экземпляром сущности A для каждого экземпляра сущности B (часто пишется 1:1).
Источник изображения На диаграмме ER нарисуйте линию с дефисом на каждом конце, чтобы обозначить этот тип отношения:A Отношение 1:1 обычно предполагает, что вам лучше интегрировать данные из двух таблиц в одну таблицу, если у вас нет веских причин не делать этого.
Однако в некоторых случаях может потребоваться создать таблицы с отношением 1:1. Вы можете перенести все описания в их собственную таблицу, если поле с необязательными данными, такими как « описание », пусто для многих записей, экономя пустое пространство и повышая производительность базы данных .
В каждую таблицу необходимо включить как минимум один похожий столбец, скорее всего, первичный ключ, чтобы обеспечить правильное соответствие данных.
2) Отношения «один ко многим»
Когда запись в одной таблице связана с несколькими записями в другой, эти отношения формируются. Один клиент, например, может разместить много заказов, или посетитель может получить в библиотеке несколько книг одновременно.
Источник изображения «Обозначение гусиной лапки» используется для обозначения отношений «один ко многим» (1:M) , как в этом примере:Просто добавьте первичный ключ со стороны отношения « один » атрибут в другой таблице при создании базы данных для построения Связь 1:M .
Внешний ключ — это первичный ключ, указанный в другой таблице таким образом. Для дочерней таблицы на противоположной стороне соединения таблица на стороне «1» рассматривается как родительская таблица.
3) Отношения «многие ко многим»
Отношение «многие ко многим» (M:N) существует, когда многие объекты из одной таблицы могут быть связаны с несколькими объектами из другой таблицы. Это может произойти со студентами и классами, потому что учащийся может посещать несколько классов, а в классе может быть большое количество учеников.
Эти соединения показаны на диаграмме ER.
Источник изображенияК сожалению, этот тип отношений не может быть напрямую реализован в базе данных.
Вместо этого вы должны разделить его на два отношения «один ко многим».Для этого создайте новый объект между этими двумя таблицами. Если бы продажи и продукты имели отношение M:N , вы могли бы назвать новый объект « Проданные продукты », потому что он будет отображать содержание каждой продажи.
Для проданных продуктов таблицы продаж и продуктов будут иметь значение 9.0003 Соединение 1:M. В различных моделях этот тип промежуточного объекта называется таблицей ссылок, ассоциативным объектом или таблицей соединений.
Каждая запись в таблице ссылок соответствует двум сущностям из соседних таблиц (также может содержать дополнительную информацию). Например, таблица связи между учащимися и классами будет выглядеть так:
Источник изображенияМногомерные данные
Некоторые пользователи, особенно в базах данных OLAP, , могут захотеть получить доступ ко многим измерениям одного типа данных.
Например, они могут захотеть узнать о продажах по клиентам, штатам и месяцам. В идеале создать базовую таблицу фактов, на которую в этом случае могут ссылаться другие таблицы клиентов, штатов и месяцев, например:0005 Источник изображенияПравила целостности данных
Вам также следует настроить базу данных так, чтобы данные проверялись в соответствии с правилами. Некоторые из этих правил применяются автоматически многими системами управления базами данных , такими как Microsoft Access.
- Главный ключ никогда не может быть NULL , в соответствии с правилом Entity Integrity Rule . Ни один из столбцов ключа, состоящего из множества столбцов, не может быть NULL. В противном случае запись может оказаться невозможной для индивидуальной идентификации.
- Каждый внешний ключ, указанный в одной таблице, должен быть сопоставлен с одним первичным ключом в таблице, на которую он ссылается, в соответствии с правилом ссылочной целостности . Если первичный ключ изменен или удален, изменения должны быть отражены везде, где этот ключ упоминается в базе данных.
- Правила целостности для бизнес-логики обеспечивают соответствие данных набору логических ограничений. Например, встреча должна состояться в обычное рабочее время.
Заключение
Схема проектирования базы данных необходима организациям для обеспечения эффективных способов хранения и поиска данных. Правильная схема может быть разницей в том, насколько гибкой может быть база данных при различных потребностях. Однако, наряду с гибкостью, организации должны сосредоточиться на оптимизации скорости для удовлетворения важнейших бизнес-требований. В этом блоге говорилось о различных примерах проектирования и схемы базы данных, прежде чем углубиться в передовые методы, которым следует следовать для этих примеров проектирования и схемы базы данных. Вы можете взглянуть на аналитику схемы Star и Snowflake.
Посетите наш веб-сайт, чтобы познакомиться с Hevo
Извлечение сложных данных из разнообразных источников данных может оказаться непростой задачей, и здесь Hevo спасает положение! Hevo предлагает более быстрый способ перемещения данных из баз данных или приложений SaaS в ваше хранилище данных для визуализации в инструменте BI.
Hevo полностью автоматизирован и, следовательно, не требует написания кода.Хотите попробовать Hevo?
Подпишитесь на 14-дневную бесплатную пробную версию. Вы также можете ознакомиться с непревзойденными ценами, которые помогут вам выбрать правильный план для нужд вашего бизнеса.
Поделитесь своим опытом понимания дизайна базы данных и примера схемы в разделе комментариев ниже!
Руководство по проектированию схемы базы данных: примеры и рекомендации
Введение
В базах данных вашей организации хранятся все корпоративные данные, необходимые для ваших программных приложений, систем и ИТ-сред, что помогает вам принимать более обоснованные бизнес-решения на основе данных.
Но не все базы данных одинаковы: структура схемы базы данных может сильно повлиять на эффективность работы базы данных и скорость извлечения информации.Проектирование схемы базы данных — это задача, о которой легче сказать, чем сделать, но, следуя нескольким советам, принципам и передовым методам, вы сможете добиться успеха гораздо лучше. В этой статье будет представлен обзор того, как работает проектирование схемы базы данных, а также примеры и рекомендации, которые помогут вам оптимизировать ваши базы данных.
Ежемесячно получайте эксклюзивные советы и рекомендации, лучшие отраслевые практики и идеи от лидеров мнений!
Ежемесячный информационный бюллетень
Содержание
- Что такое схема базы данных?
- 6 типов схем баз данных
- Что такое схема базы данных?
- Почему важно проектирование схемы базы данных?
- Как разработать схему базы данных
- Передовой опыт проектирования схемы базы данных
- Как Integrate. io может помочь в разработке схемы вашей базы данных
Что такое схема базы данных?
Проще говоря, схема базы данных — это формальное описание структуры или организации конкретной базы данных. Термин «схема базы данных» чаще всего используется в отношении реляционных баз данных, то есть баз данных, которые организуют информацию в таблицы и используют язык запросов SQL. Нереляционные (т. е. «NoSQL») базы данных бывают нескольких разных форматов и обычно не считаются имеющими «схему» в отличие от реляционных баз данных (хотя у них есть базовая структура).
Связанное чтение: SQL и NoSQL: 5 критических различий
Любая схема базы данных состоит из двух основных компонентов:
- Схема физической базы данных: Схема физической базы данных описывает, как данные будут физически храниться в системе хранения, и форму используемого хранилища (файлы, пары ключ-значение, индексы и т. д.).
- Логическая схема базы данных: Логическая схема базы данных описывает логические ограничения, применяемые к данным, и определяет поля, таблицы, отношения, представления, ограничения целостности и т. д. Эти требования предоставляют полезную информацию, которую программисты могут применить к физическому дизайну базы данных. Правила или ограничения, определенные в этой логической модели, помогают определить, как данные в разных таблицах соотносятся друг с другом.
Определение физических таблиц в схеме исходит из логической модели данных. Сущности становятся таблицами, атрибуты сущности становятся полями таблицы и т. д.
6 типов схем баз данных
Какие у вас есть варианты, когда речь идет о различных типах схем баз данных? В этом разделе мы дадим краткий обзор некоторых наиболее распространенных типов схем баз данных.
- Плоская модель: Схема базы данных «плоская модель» организует данные в единый двумерный массив — представьте себе электронную таблицу Microsoft Excel или CSV-файл. Эта схема лучше всего подходит для простых таблиц и баз данных без сложных отношений между различными сущностями.
- Иерархическая модель: Схемы базы данных в иерархической модели имеют «древовидную» структуру с дочерними узлами, отходящими от корневого узла данных. Эта схема идеальна для хранения вложенных данных, например, генеалогических деревьев или биологических таксономий.
- Сетевая модель: Сетевая модель, как и иерархическая модель, рассматривает данные как узлы, связанные друг с другом; однако он допускает более сложные соединения, такие как отношения «многие ко многим» и циклы. Эта схема может моделировать перемещение товаров и материалов между местоположениями или рабочий процесс, необходимый для выполнения конкретной задачи.
- Реляционная модель: Как обсуждалось выше, эта модель упорядочивает данные в виде ряда таблиц, строк и столбцов со связями между различными объектами. В оставшейся части этой статьи мы будем в основном работать с реляционной моделью.
- Звездообразная схема: Звездообразная схема представляет собой эволюцию реляционной модели, которая организует данные в «факты» и «измерения». Фактические данные являются числовыми (например, количество продаж продукта), тогда как размерные данные являются описательными (например, цена продукта, цвет, вес и т. д.).
- Схема снежинки: Схема снежинки – это дополнительная абстракция над схемой звезды. Таблицы фактов указывают на многомерные таблицы, которые также могут иметь свои собственные многомерные таблицы, расширяя возможную описательность в базе данных. (Как вы могли догадаться, схема «снежинка» названа в честь замысловатых узоров снежинки, в которых более мелкие структуры расходятся от центральных ветвей.)
Связанное Чтение: 6 Схемы баз данных и как их использовать
Что такое схема базы данных?
Проект схемы базы данных относится к методам и стратегиям построения схемы базы данных.
Вы можете рассматривать схему базы данных как «чертеж» того, как хранить огромные объемы информации в базе данных. Схема – это абстрактная структура или схема, представляющая логическое представление базы данных в целом. Определяя категории данных и отношения между этими категориями, дизайн схемы базы данных значительно упрощает извлечение, использование, обработку и интерпретацию данных.
Структура схемы базы данных организует данные в отдельные объекты, определяет, как создавать отношения между организованными объектами и как применять ограничения к данным. Дизайнеры создают схемы базы данных, чтобы дать другим пользователям базы данных, таким как программисты и аналитики, логическое понимание данных.
Новый стек хранилища данных для лидеров завтрашнего дня
Инструменты хранилища данных с низким кодом и сотни соединителей для унификации данных и отчетности
Почему важен дизайн схемы базы данных?
Базы данных, которые организованы неэффективно, поглощают тонны энергии и ресурсов, часто приводят к путанице, их сложно поддерживать и администрировать. Вот где в игру вступает дизайн схемы базы данных.
Без четкой, эффективной и согласованной схемы базы данных вам будет сложно максимально эффективно использовать корпоративные данные. Например, одни и те же данные могут дублироваться в нескольких местах или, что еще хуже, могут быть несогласованными между этими местоположениями.
Системы реляционных баз данных сильно зависят от наличия надежной схемы базы данных. Цели хорошего проектирования схемы базы данных включают в себя:
- Сокращение или устранение избыточности данных.
- Предотвращение несоответствий и неточностей данных.
- Обеспечение правильности и целостности ваших данных.
- Содействие быстрому поиску, извлечению и анализу данных.
- Обеспечение безопасности важных и конфиденциальных данных, но доступность для тех, кто в них нуждается.
Как разработать схему базы данных
Схемы базы данных описывают архитектуру базы данных и помогают обеспечить основные принципы базы данных, такие как :
- Данные имеют согласованное форматирование
- Все записи записей имеют уникальный первичный ключ
- Важные данные не пропущены
Проект схемы базы данных может существовать как в виде визуального представления, так и в виде набора формул или использования ограничений, управляющих базой данных.
Затем разработчики выражают эти формулы на разных языках определения данных, в зависимости от используемой вами системы баз данных. Например, несмотря на то, что ведущие системы баз данных имеют немного разные определения того, что такое схемы, MySQL, Oracle Database и Microsoft SQL Server поддерживают оператор CREATE SCHEMA.Например, предположим, что вы хотите создать базу данных для хранения информации для бухгалтерии вашей организации. Конкретная схема для этой базы данных может описывать структуру двух простых таблиц:
Таблица 1
Заголовок: Пользователи
Поля: ID, ФИО, адрес электронной почты, дата рождения, отдел
:
Оплата сверхурочныхПоля: ID, ФИО, Период времени, Счет за часы
Эта отдельная схема содержит ценную информацию, такую как:
- Заголовок каждой таблицы
- Поля, которые содержит каждая таблица
- Отношения между таблицами (например, привязка сверхурочной оплаты сотрудника к его личности через его идентификационный номер)
- Любая дополнительная соответствующая информация
Разработчики и администраторы баз данных могут преобразовать эти таблицы схемы в код SQL.
Передовой опыт проектирования схемы базы данных
Чтобы получить максимальную отдачу от проектирования схемы базы данных, важно следовать этим рекомендациям, чтобы у разработчиков была четкая точка отсчета о том, какие таблицы и поля содержит проект и т. д.
- Соглашения об именах: Определите и используйте соответствующие соглашения об именах, чтобы сделать схему вашей базы данных наиболее эффективной. Хотя вы можете выбрать определенный стиль или придерживаться стандарта ISO, самое главное — быть последовательным в полях имени.
- Старайтесь не использовать зарезервированные слова в именах таблиц, имен столбцов, полей и т. д., что может привести к синтаксической ошибке.
- Не используйте дефисы, кавычки, пробелы, специальные символы и т. д., поскольку они будут недействительны или потребуют дополнительного шага.
- В именах таблиц используйте существительные в единственном числе, а не во множественном числе (т. е. используйте StudentName вместо StudentNames). Таблица представляет собой коллекцию, поэтому нет необходимости ставить название во множественном числе.
- Не использовать лишнее многословие для имен таблиц (т. е. использовать Department вместо DepartmentList, TableDepartments и т. д.)
- Безопасность: Безопасность данных начинается с хорошей схемы базы данных. Используйте шифрование для конфиденциальных данных, таких как личная информация (PII) и пароли. Не давайте роли администратора каждому пользователю; вместо этого запросите аутентификацию пользователя для доступа к базе данных.
- Документация: Схемы баз данных полезны еще долго после того, как они были созданы, и их будут просматривать многие другие люди, поэтому хорошая документация необходима. Задокументируйте схему своей базы данных с подробными инструкциями и напишите строки комментариев для сценариев, триггеров и т. д.
- Нормализация: Вкратце, нормализация гарантирует, что независимые объекты и отношения не группируются вместе в одной таблице, уменьшая избыточность и улучшая целостность. При необходимости используйте нормализацию для оптимизации производительности базы данных. Как чрезмерная, так и недостаточная нормализация могут привести к ухудшению производительности.
- Компетентность: Понимание ваших данных и атрибутов каждого элемента поможет вам создать наиболее эффективную структуру схемы базы данных. Хорошо спроектированная схема может обеспечить экспоненциальный рост ваших данных. Продолжая расширять свои данные, вы можете анализировать каждое поле по отношению к другим полям, которые вы собираете в своей схеме.
Как Integrate.io может помочь в разработке схемы вашей базы данных
Получайте глубокую отраслевую информацию в свой почтовый ящик один раз в месяц
Получайте эксклюзивные советы и рекомендации, лучшие отраслевые практики и идеи от лидеров мнений каждый месяц!
Ежемесячный информационный бюллетень
Проектирование схемы базы данных — это глубокая, технически сложная область, и это руководство по проектированию схемы базы данных лишь поверхностно описывает то, что вам нужно знать.
Надеемся, что эти рекомендации и рекомендации помогут вам начать работу по правильному пути при проектировании схем баз данных.Конечно, разработка схемы базы данных — это только первый шаг к правильному управлению данными. Хорошо разработанные схемы гарантируют, что вы сможете эффективно извлекать и анализировать свои данные, но для фактического выполнения этого извлечения и анализа вам понадобится хороший инструмент ETL, такой как Integrate.io.
Integrate.io — это мощная, многофункциональная платформа ETL и интеграции данных для создания конвейеров данных из ваших баз данных и других источников в централизованное хранилище данных в облаке. Благодаря более чем 100 предварительно созданным соединителям и интеграциям, а также удобному интерфейсу перетаскивания интегрировать корпоративные данные еще никогда не было так просто.
Вы ищете передовой инструмент ETL? Попробуйте Integrate.io. Свяжитесь с нашей командой экспертов по данным сегодня, чтобы поговорить о потребностях и целях вашего бизнеса или начать 7-дневную пробную версию платформы Integrate.
io.11 важных правил проектирования баз данных, которым я следую
Содержание
- Введение
- Правило 1: Какова природа приложения (OLTP или OLAP)?
- Правило 2. Разбивайте данные на логические части, упрощайте жизнь
- Правило 3. Не переусердствуйте с правилом 2
- Правило 4. Относитесь к повторяющимся неоднородным данным как к злейшему врагу
- Правило 5. Следите за данными, разделенными разделителями 7: Тщательно выбирайте производные столбцы
- Правило 8: Не стремитесь избегать избыточности, если ключевым фактором является производительность
- Правило 9: Многомерные данные — это совсем другое дело
- Правило 10: Централизованное проектирование таблиц имен и значений
- Правило 11: Для неограниченных ссылок на иерархические данные PK и FK
Предоставлено: изображение из фильма
Введение
Прежде чем вы начнете читать эту статью, позвольте мне подтвердить вам, что я не гуру в проектировании баз данных .
Нижеприведенные 11 пунктов — это то, чему я научился благодаря проектам, собственному опыту и собственному чтению. Я лично думаю, что это очень помогло мне, когда дело доходит до проектирования БД. Любая критика приветствуется.Причина, по которой я пишу полноценную статью, заключается в том, что когда разработчики проектируют базу данных, они склонны следовать трем нормальным формам, как серебряной пуле. Они склонны думать, что нормализация — единственный способ проектирования. Из-за этого настроя они иногда сталкиваются с препятствиями по мере продвижения проекта.
Если вы новичок в нормализации, нажмите и посмотрите 3 нормальные формы в действии, которые шаг за шагом объясняют все три нормальные формы.
Сказано и сделано правила нормализации являются важными ориентирами, но воспринимать их как отметку на камне влечет за собой проблемы. Ниже приведены мои собственные 11 правил, которые я постоянно вспоминаю при проектировании БД.
Правило 1. Какова природа приложения (OLTP или OLAP)?
Когда вы начинаете проектирование базы данных, первое, что нужно проанализировать, — это характер приложения, для которого вы разрабатываете, является ли оно транзакционным или аналитическим.
Вы обнаружите, что многие разработчики по умолчанию применяют правила нормализации, не задумываясь о характере приложения, а затем вникая в проблемы с производительностью и настройкой. Как уже говорилось, существует два типа приложений: основанные на транзакциях и аналитические, давайте разберемся, что это за типы.Транзакционный : В этом типе приложений ваш конечный пользователь больше заинтересован в CRUD, то есть в создании, чтении, обновлении и удалении записей. Официальное название такой базы данных — OLTP.
Аналитический : В таких приложениях ваш конечный пользователь больше интересуется анализом, составлением отчетов, прогнозированием и т. д. Такие базы данных имеют меньшее количество вставок и обновлений. Основная цель здесь — как можно быстрее получать и анализировать данные. Официальное название такой базы данных — OLAP.
Другими словами, если вы считаете, что операции вставки, обновления и удаления более заметны, выберите нормализованную таблицу, в противном случае создайте плоскую денормализованную структуру базы данных.
Ниже приведена простая диаграмма, показывающая, как имена и адреса в левой части представляют собой простую нормализованную таблицу, и, применяя денормализованную структуру, мы создали плоскую структуру таблицы.
Правило 2. Разбивайте данные на логические части, упрощайте жизнь
Это правило фактически является первым правилом из 1 st нормальной формы. Одним из признаков нарушения этого правила является то, что если в ваших запросах используется слишком много функций анализа строк, таких как подстрока, индекс символов и т. д., то, вероятно, это правило необходимо применить.
Например, вы можете увидеть таблицу ниже, в которой есть имена учеников; если вы когда-нибудь захотите запросить имена студентов, содержащие «Koirala», а не «Harisingh», вы можете себе представить, какой запрос вы получите.
Таким образом, лучшим подходом было бы разбить это поле на дополнительные логические части, чтобы мы могли писать четкие и оптимальные запросы.
Правило 3: Не переусердствуйте с правилом 2
Разработчики милые создания. Если вы скажете им, что это так, они продолжат это делать; ну, они переусердствуют, что приведет к нежелательным последствиям. Это также относится к правилу 2, о котором мы только что говорили выше. Когда вы думаете о разложении, сделайте паузу и спросите себя, нужно ли это? Как сказано, разложение должно быть логичным.
Например, вы можете увидеть поле номера телефона; редко вы будете работать с ISD-кодами телефонных номеров отдельно (пока ваше приложение не потребует этого). Так что было бы мудрым решением просто оставить его, так как это может привести к большим осложнениям.
Правило 4. Относитесь к повторяющимся неоднородным данным как к своему злейшему врагу
Сосредоточьтесь и рефакторинг повторяющихся данных. Меня лично беспокоит дублирование данных не из-за того, что они занимают место на жестком диске, а из-за путаницы, которую они создают.
Например, на приведенной ниже диаграмме вы можете видеть, что «5-й стандарт» и «Пятый стандарт» означают одно и то же. Теперь вы можете сказать, что данные попали в вашу систему из-за неправильного ввода данных или плохой проверки. Если вы когда-нибудь захотите получить отчет, они будут показывать их как разные сущности, что очень сбивает с толку с точки зрения конечного пользователя.
Одним из решений может быть перемещение данных в другую основную таблицу и обращение к ним через внешние ключи. На рисунке ниже вы можете увидеть, как мы создали новую главную таблицу под названием «Стандарты» и связали ее с помощью простого внешнего ключа.
Правило 5: Следите за данными, разделенными разделителями
Второе правило нормальной формы 1 st гласит, что следует избегать повторяющихся групп. Один из примеров повторяющихся групп поясняется на диаграмме ниже. Если вы внимательно посмотрите на поле силлабуса, в одном поле у нас слишком много данных.
Такие поля называются «Повторяющиеся группы». Если нам придется манипулировать этими данными, запрос будет сложным, и я также сомневаюсь в производительности запросов.Столбцы такого типа, в которых есть данные, заполненные разделителями, требуют особого внимания, и лучшим подходом было бы переместить эти поля в другую таблицу и связать их с ключами для лучшего управления.
Теперь применим второе правило нормальной формы 1 st : «Избегайте повторяющихся групп». Вы можете видеть на приведенном выше рисунке, что я создал отдельную таблицу учебных программ, а затем установил связь «многие ко многим» с таблицей предметов.
При таком подходе поле программы в основной таблице больше не повторяется и имеет разделители данных.
Правило 6: Отслеживайте частичные зависимости
Отслеживайте поля, частично зависящие от первичных ключей. Например, в приведенной выше таблице мы видим, что первичный ключ создается по номеру рулона и стандарту.
Теперь внимательно следите за полем программы. Поле программы связано со стандартом, а не со студентом напрямую (номер списка).Учебный план связан со стандартом, по которому учится учащийся, а не непосредственно со учащимся. Так что если завтра мы хотим обновить учебный план, мы должны обновить его для каждого ученика, что кропотливо и нелогично. Имеет смысл убрать эти поля и связать их со стандартной таблицей.
Вы можете видеть, как мы переместили поле программы и прикрепили его к таблице стандартов.
Это правило не что иное, как нормальная форма 2 nd : «Все ключи должны зависеть от полного первичного ключа, а не частично».
Правило 7. Тщательно выбирайте производные столбцы
Если вы работаете с OLTP-приложениями, было бы неплохо избавиться от производных столбцов, если только нет неотложных причин для повышения производительности. В случае OLAP, где мы делаем много суммирования, вычислений, такие поля необходимы для повышения производительности.
На приведенном выше рисунке видно, как среднее поле зависит от оценок и предмета. Это также одна из форм избыточности. Итак, для таких полей, которые являются производными от других полей, подумайте: действительно ли они необходимы?
Это правило также называется нормальной формой 3 rd : «Ни один столбец не должен зависеть от других столбцов, не являющихся первичными ключами». Моя личная мысль: не применяйте это правило вслепую, смотрите на ситуацию; дело не в том, что избыточные данные — это всегда плохо. Если избыточные данные являются расчетными данными, посмотрите на ситуацию, а затем решите, хотите ли вы реализовать 3 рд нормальная форма.
Правило 8: Не стремитесь избегать избыточности, если ключевым фактором является производительность. Если есть острая потребность в производительности, подумайте о денормализации. При нормализации вам нужно выполнять соединения со многими таблицами, а при денормализации соединения снижают и, таким образом, повышают производительность.
Правило 9: Многомерные данные — это совсем другое дело
Проекты OLAP в основном имеют дело с многомерными данными. Например, на приведенном ниже рисунке вы хотите получить данные о продажах по странам, клиентам и датам. Проще говоря, вы смотрите на цифры продаж, которые имеют три пересечения данных измерения.
Для таких ситуаций лучшим подходом является дизайн измерений и фактов. Проще говоря, вы можете создать простую центральную таблицу фактов о продажах, в которой есть поле суммы продаж, и она устанавливает связь со всеми таблицами измерений, используя отношение внешнего ключа.
Правило 10. Централизованный дизайн таблиц значений имен
Много раз я сталкивался с таблицами значений имен. Таблицы имен и значений означают, что у них есть ключ и некоторые данные, связанные с ключом. Например, на приведенном ниже рисунке вы можете видеть, что у нас есть таблица валют и таблица стран.
Если вы внимательно посмотрите на данные, они на самом деле имеют только ключ и значение.Для таких таблиц более целесообразно создание центральной таблицы и дифференциация данных с помощью поля типа.
Правило 11: Для неограниченных иерархических данных самоссылки PK и FK
Много раз мы сталкиваемся с данными с неограниченной родительско-дочерней иерархией. Например, рассмотрим сценарий многоуровневого маркетинга, в котором у продавца может быть несколько продавцов под ним. В таких сценариях использование самоссылающегося первичного ключа и внешнего ключа поможет добиться того же.
Эта статья не предназначена для того, чтобы сказать, что не следуйте обычным формам, вместо этого не следуйте им слепо, сначала посмотрите на характер вашего проекта и тип данных, с которыми вы имеете дело.
Ниже приведено видео, в котором шаг за шагом объясняются три нормальные формы с использованием простой школьной таблицы.
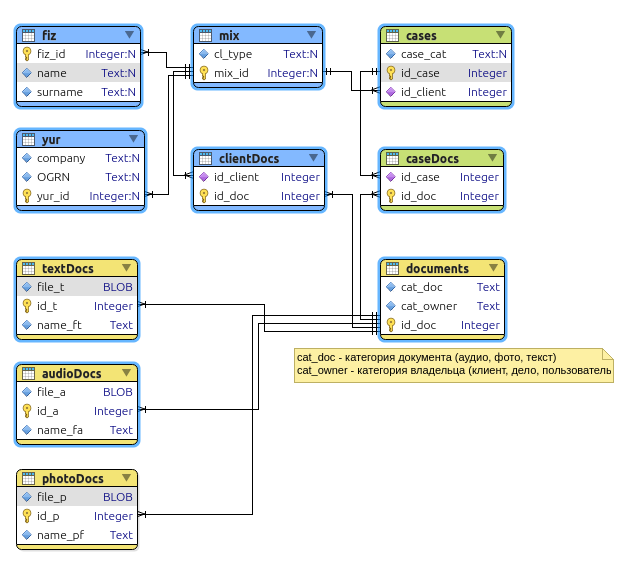 Это, в свою очередь, сократит доработку по мере продвижения.
Это, в свою очередь, сократит доработку по мере продвижения. Используйте средства SQL для поддержания целостности данных.
Используйте средства SQL для поддержания целостности данных. На диаграмме ER нарисуйте линию с дефисом на каждом конце, чтобы обозначить этот тип отношения:
На диаграмме ER нарисуйте линию с дефисом на каждом конце, чтобы обозначить этот тип отношения: «Обозначение гусиной лапки» используется для обозначения отношений «один ко многим» (1:M) , как в этом примере:
«Обозначение гусиной лапки» используется для обозначения отношений «один ко многим» (1:M) , как в этом примере: Вместо этого вы должны разделить его на два отношения «один ко многим».
Вместо этого вы должны разделить его на два отношения «один ко многим». Например, они могут захотеть узнать о продажах по клиентам, штатам и месяцам. В идеале создать базовую таблицу фактов, на которую в этом случае могут ссылаться другие таблицы клиентов, штатов и месяцев, например:0005 Источник изображения
Например, они могут захотеть узнать о продажах по клиентам, штатам и месяцам. В идеале создать базовую таблицу фактов, на которую в этом случае могут ссылаться другие таблицы клиентов, штатов и месяцев, например:0005 Источник изображения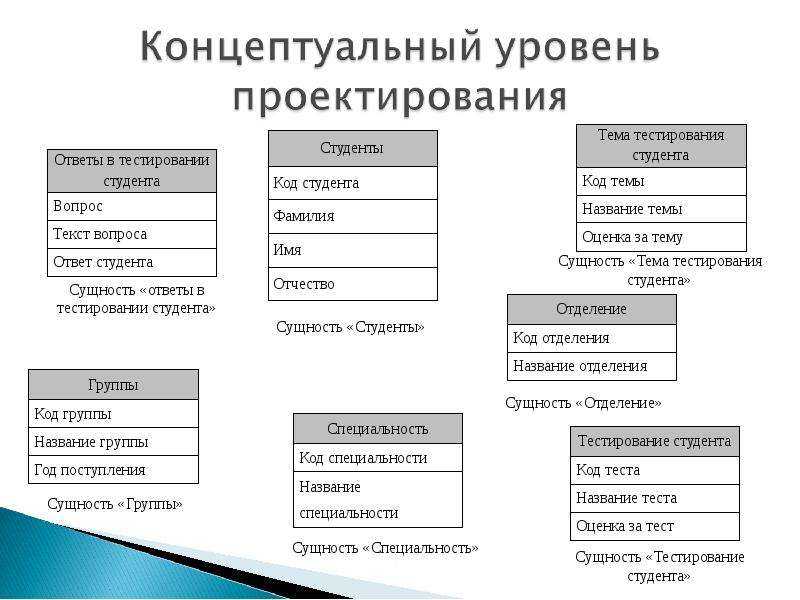 Если первичный ключ изменен или удален, изменения должны быть отражены везде, где этот ключ упоминается в базе данных.
Если первичный ключ изменен или удален, изменения должны быть отражены везде, где этот ключ упоминается в базе данных. Hevo полностью автоматизирован и, следовательно, не требует написания кода.
Hevo полностью автоматизирован и, следовательно, не требует написания кода. Но не все базы данных одинаковы: структура схемы базы данных может сильно повлиять на эффективность работы базы данных и скорость извлечения информации.
Но не все базы данных одинаковы: структура схемы базы данных может сильно повлиять на эффективность работы базы данных и скорость извлечения информации. io может помочь в разработке схемы вашей базы данных
io может помочь в разработке схемы вашей базы данных д. Эти требования предоставляют полезную информацию, которую программисты могут применить к физическому дизайну базы данных. Правила или ограничения, определенные в этой логической модели, помогают определить, как данные в разных таблицах соотносятся друг с другом.
д. Эти требования предоставляют полезную информацию, которую программисты могут применить к физическому дизайну базы данных. Правила или ограничения, определенные в этой логической модели, помогают определить, как данные в разных таблицах соотносятся друг с другом. Эта схема идеальна для хранения вложенных данных, например, генеалогических деревьев или биологических таксономий.
Эта схема идеальна для хранения вложенных данных, например, генеалогических деревьев или биологических таксономий. д.).
д.).

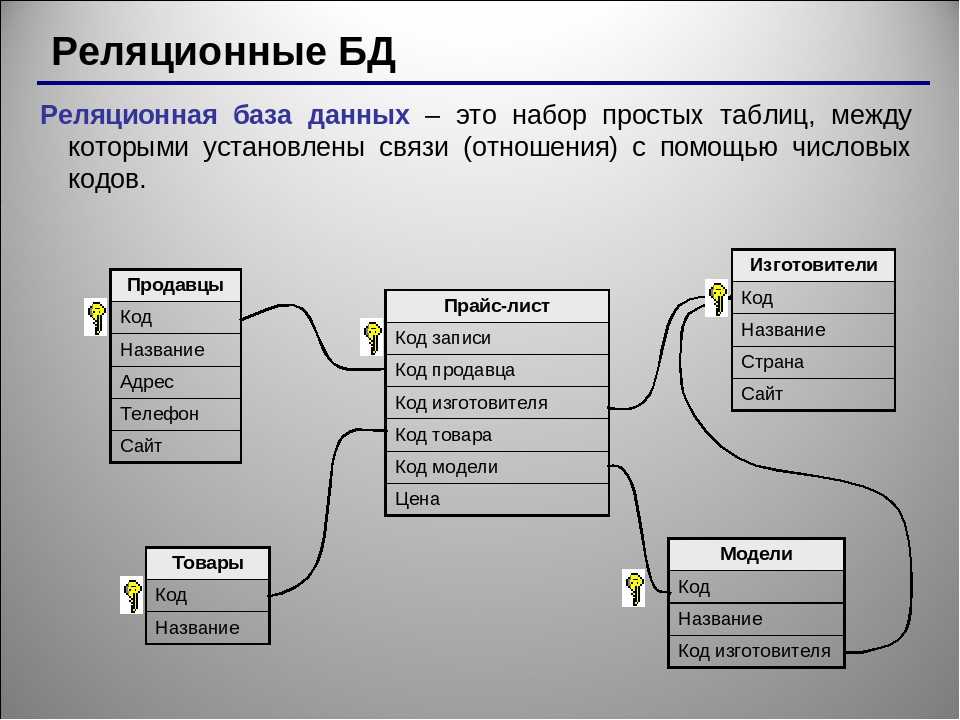 Затем разработчики выражают эти формулы на разных языках определения данных, в зависимости от используемой вами системы баз данных. Например, несмотря на то, что ведущие системы баз данных имеют немного разные определения того, что такое схемы, MySQL, Oracle Database и Microsoft SQL Server поддерживают оператор CREATE SCHEMA.
Затем разработчики выражают эти формулы на разных языках определения данных, в зависимости от используемой вами системы баз данных. Например, несмотря на то, что ведущие системы баз данных имеют немного разные определения того, что такое схемы, MySQL, Oracle Database и Microsoft SQL Server поддерживают оператор CREATE SCHEMA.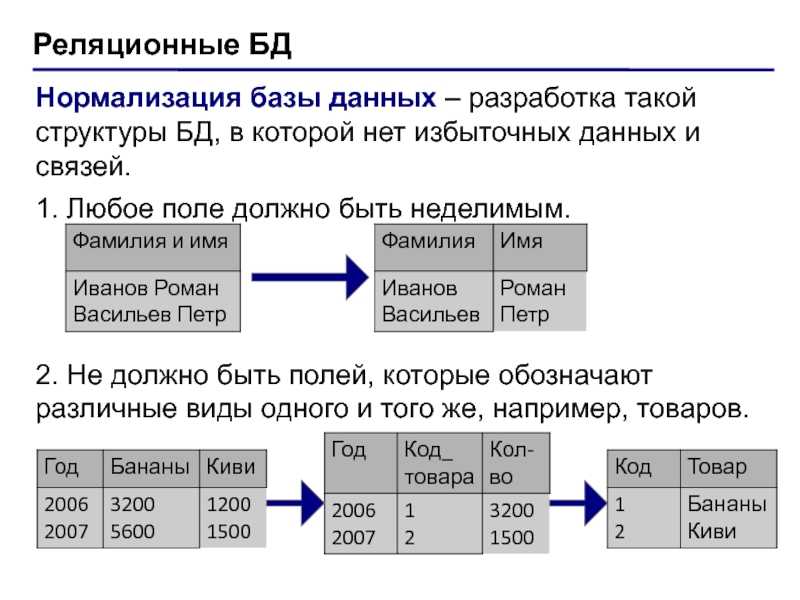
 е. используйте StudentName вместо StudentNames). Таблица представляет собой коллекцию, поэтому нет необходимости ставить название во множественном числе.
е. используйте StudentName вместо StudentNames). Таблица представляет собой коллекцию, поэтому нет необходимости ставить название во множественном числе. При необходимости используйте нормализацию для оптимизации производительности базы данных. Как чрезмерная, так и недостаточная нормализация могут привести к ухудшению производительности.
При необходимости используйте нормализацию для оптимизации производительности базы данных. Как чрезмерная, так и недостаточная нормализация могут привести к ухудшению производительности. Надеемся, что эти рекомендации и рекомендации помогут вам начать работу по правильному пути при проектировании схем баз данных.
Надеемся, что эти рекомендации и рекомендации помогут вам начать работу по правильному пути при проектировании схем баз данных. io.
io. Нижеприведенные 11 пунктов — это то, чему я научился благодаря проектам, собственному опыту и собственному чтению. Я лично думаю, что это очень помогло мне, когда дело доходит до проектирования БД. Любая критика приветствуется.
Нижеприведенные 11 пунктов — это то, чему я научился благодаря проектам, собственному опыту и собственному чтению. Я лично думаю, что это очень помогло мне, когда дело доходит до проектирования БД. Любая критика приветствуется.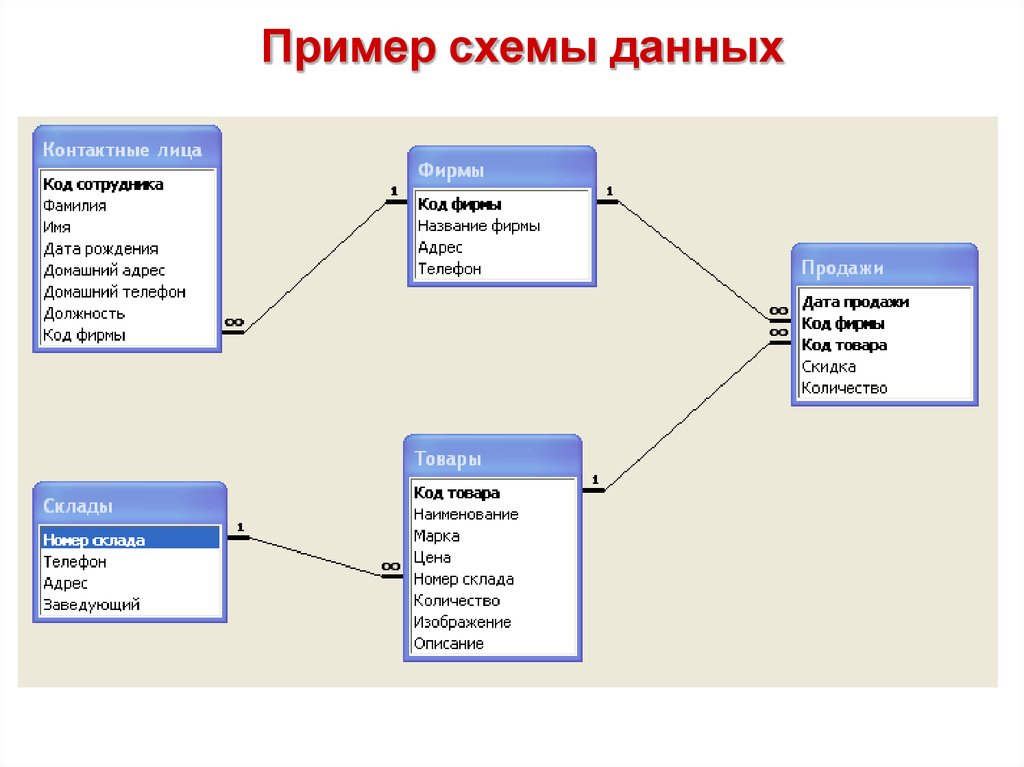 Вы обнаружите, что многие разработчики по умолчанию применяют правила нормализации, не задумываясь о характере приложения, а затем вникая в проблемы с производительностью и настройкой. Как уже говорилось, существует два типа приложений: основанные на транзакциях и аналитические, давайте разберемся, что это за типы.
Вы обнаружите, что многие разработчики по умолчанию применяют правила нормализации, не задумываясь о характере приложения, а затем вникая в проблемы с производительностью и настройкой. Как уже говорилось, существует два типа приложений: основанные на транзакциях и аналитические, давайте разберемся, что это за типы.

 Такие поля называются «Повторяющиеся группы». Если нам придется манипулировать этими данными, запрос будет сложным, и я также сомневаюсь в производительности запросов.
Такие поля называются «Повторяющиеся группы». Если нам придется манипулировать этими данными, запрос будет сложным, и я также сомневаюсь в производительности запросов. Теперь внимательно следите за полем программы. Поле программы связано со стандартом, а не со студентом напрямую (номер списка).
Теперь внимательно следите за полем программы. Поле программы связано со стандартом, а не со студентом напрямую (номер списка).

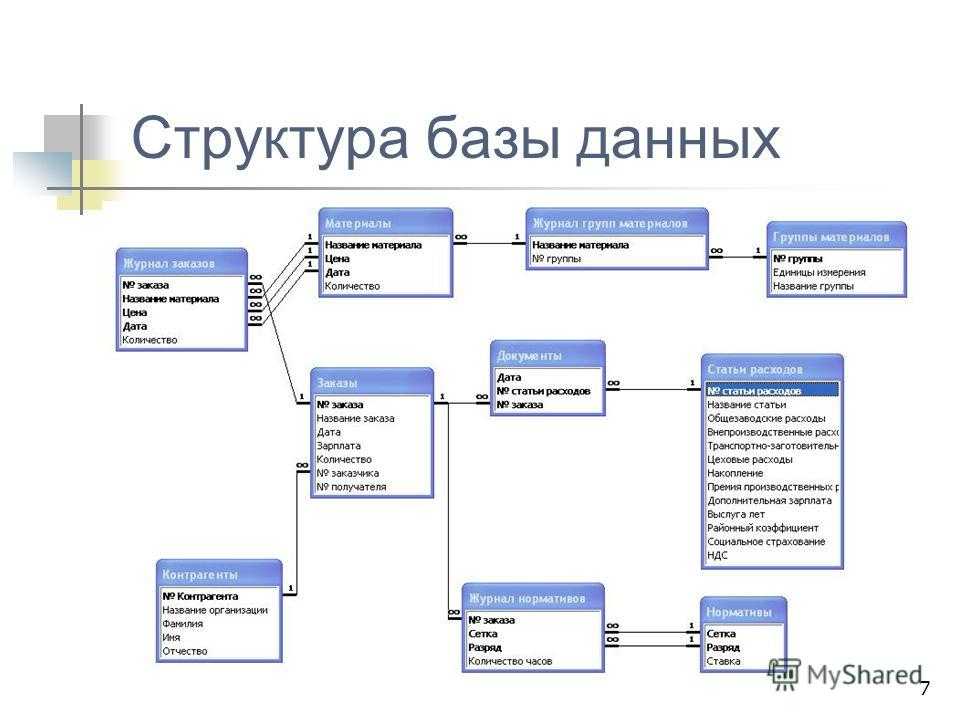 Если вы внимательно посмотрите на данные, они на самом деле имеют только ключ и значение.
Если вы внимательно посмотрите на данные, они на самом деле имеют только ключ и значение.