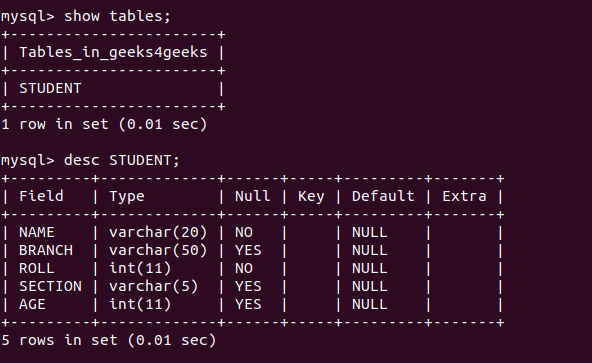
Базы данных и их использование в приложениях на Python
В данной статье мы рассмотрим, что такое базы данных и какие из них чаще всего используются, если речь идет о разработке на Python.
Пожалуй, начнем с определения. База данных – это абстракция над файловой системой операционной системы, которая значительно упрощает создание приложений, создающих, читающих, обновляющих и удаляющих различные данные.
Зачем нужны базы данных?
На высоком уровне веб-приложения хранят данные и представляют их пользователям в удобном виде. Например, Google хранит данные о дорогах и предоставляет маршруты для проезда из одного места в другое при каждом использовании вами Google Maps. Строить такие маршруты движения возможно благодаря тому, что данные хранятся в структурированном формате.
Базы данных делают структурированное хранилище надежным и быстрым. Они также дают представление о том, как данные должны сохраняться и извлекаться. В результате, создавая каждое новое приложение, вы не обдумываете заново, что делать с данными.
Для управления созданием и использованием баз данных создано много реализаций СУБД — систем управления базами данных. Примеры СУБД — PostgreSQL, MySQL, SQLite. Также существуют нереляционные базы данных — NoSQL.
Английский для программистов
Наш телеграм канал с тестами по английскому языку для программистов. Английский это часть карьеры программиста. Поэтому полезно заняться им уже сейчас
Подробнее
×
Реляционные базы данных
В веб-разработке на Python чаще всего используются реляционные базы данных.
В этих базах данные хранятся в виде серии таблиц. Взаимосвязи между таблицами создаются при помощи внешних ключей. (Само определение «реляционные» происходит от англ. relations — «связи, отношения», — прим. перев.)
Внешний ключ – это уникальная ссылка из одной строки в реляционной таблице на другую строку, которая чаще всего находится в другой таблице, хотя может быть и в той же самой.
Реализации хранилищ баз данных различаются по сложности. SQLite — СУБД, встроенная в Python — создает один файл для всех данных каждой базы данных.
Другие СУБД, такие как PostgreSQL, MySQL, Oracle и Microsoft SQL Server, имеют более сложные схемы хранения. Кроме того, они предлагают дополнительные расширенные функции, полезные для хранения данных веб-приложений. Например:
- Репликация данных между главной базой данных и одним или несколькими подчиненными экземплярами, доступными только для чтения.
- Расширенные типы столбцов, которые могут эффективно хранить полуструктурированные данные, такие как JSON (JavaScript Object Notation).
- Сегментирование, которое позволяет горизонтально масштабировать несколько баз данных, каждая из которых служит экземпляром для чтения и записи, за счет задержки в согласованности данных.
- Мониторинг, статистика и другая полезная информация о выполнении для схем и таблиц базы данных.
Обычно веб-приложения начинаются с одного экземпляра базы данных, например PostgreSQL, с простой схемой. Со временем схема базы данных превращается в более сложную структуру с использованием миграций. При этом возрастает потребность в расширенных функциях, таких как репликация, сегментирование и мониторинг, поскольку использование базы данных становится более интенсивным.
Со временем схема базы данных превращается в более сложную структуру с использованием миграций. При этом возрастает потребность в расширенных функциях, таких как репликация, сегментирование и мониторинг, поскольку использование базы данных становится более интенсивным.
Наиболее распространенные базы данных для веб-приложений на Python
PostgreSQL и MySQL – две наиболее распространенные базы данных с открытым исходным кодом для хранения данных веб-приложений на Python.
SQLite – это база данных, которая хранится в одном файле на диске. SQLite встроена в Python, но предназначена только для доступа по одному соединению за раз. Поэтому настоятельно рекомендуется не запускать производственное веб-приложение с SQLite. Эта база данных хороша для учебных проектов, когда вы только осваиваете, как всё работает.
Для продакшена же лучше использовать PostgreSQL или MySQL, или другую базу данных, в том числе нереляционную – всё зависит от специфики вашего приложения.
База данных PostgreSQL
PostgreSQL – это рекомендуемая реляционная СУБД для работы с веб-приложениями на Python. Функционал PostgreSQL, его активное развитие и улучшение, а также стабильность послужили причиной использования этой СУБД в бэкенде миллионов приложений, существующих сегодня в сети.
Функционал PostgreSQL, его активное развитие и улучшение, а также стабильность послужили причиной использования этой СУБД в бэкенде миллионов приложений, существующих сегодня в сети.
База данных MySQL
MySQL – еще одна практичная реализация СУБД для приложений, написанных на Python. Имеет открытый исходный код.
MySQL проще в освоении, чем PostgreSQL, но не так богата функциями.
Подключение к базе данных с помощью Python
Для работы с реляционной базой данных с использованием Python нужны библиотеки. Наиболее распространенные библиотеки для реляционных баз данных:
- psycopg2 (исходный код) для PostgreSQL.
- MySQLdb (исходный код) для MySQL. Обратите внимание, что разработка этого драйвера в основном заморожена. Поэтому будет целесообразно обратить внимание на альтернативные варианты, если в бэкенде вашего приложения используется MySQL.
- cx_Oracle (исходный код) для Oracle Database.
Поддержка SQLite встроена во все версии Python 2. 7+, поэтому отдельная библиотека для подключения не требуется. Просто импортируйте sqlite3 (
7+, поэтому отдельная библиотека для подключения не требуется. Просто импортируйте sqlite3 (import sqlite3), и можно начинать работатьтоirметоyey.
Объектно-реляционное отображение
Объектно-реляционное отображение (англ. object-relational mapping, ORM) позволяет разработчикам получать доступ к данным из бэкенда при помощи Python-кода, а не SQL-запросов. Все структуры веб-приложений по-разному обрабатывают интеграцию ORM. По объектно-реляционному отображению есть множество ресурсов, так что вы без проблем разберетесь в этой теме.
Размещение баз данных на стороннем сервере
Многие компании предлагают свои серверы для хостинга баз данных. В услугах, предоставляемых такими компаниями, часто есть автоматическое резервное копирование и восстановление, усиленные настройки безопасности и простое вертикальное масштабирование.
- Amazon Relational Database Service (RDS) предоставляет предварительно настроенные экземпляры MySQL и PostgreSQL. Экземпляры можно масштабировать до больших или меньших конфигураций в зависимости от требований к хранилищу и производительности.

- Google Cloud SQL – это сервис для работы с серверами MySQL, PostgreSQL и SQL. Позволяет управлять базами данных, делать бэкапы, репликации и вносить автоматические исправления. Cloud SQL интегрируется с Google App Engine, но также может использоваться и независимо.
- BitCan предоставляет размещение баз данных MySQL и MongoDB с обширными услугами резервного копирования.
- ElephantSQL – это SaaS-компания, которая размещает базы данных PostgreSQL и управляет конфигурацией сервера, резервным копированием и подключением к данным поверх экземпляров Amazon Web Services.
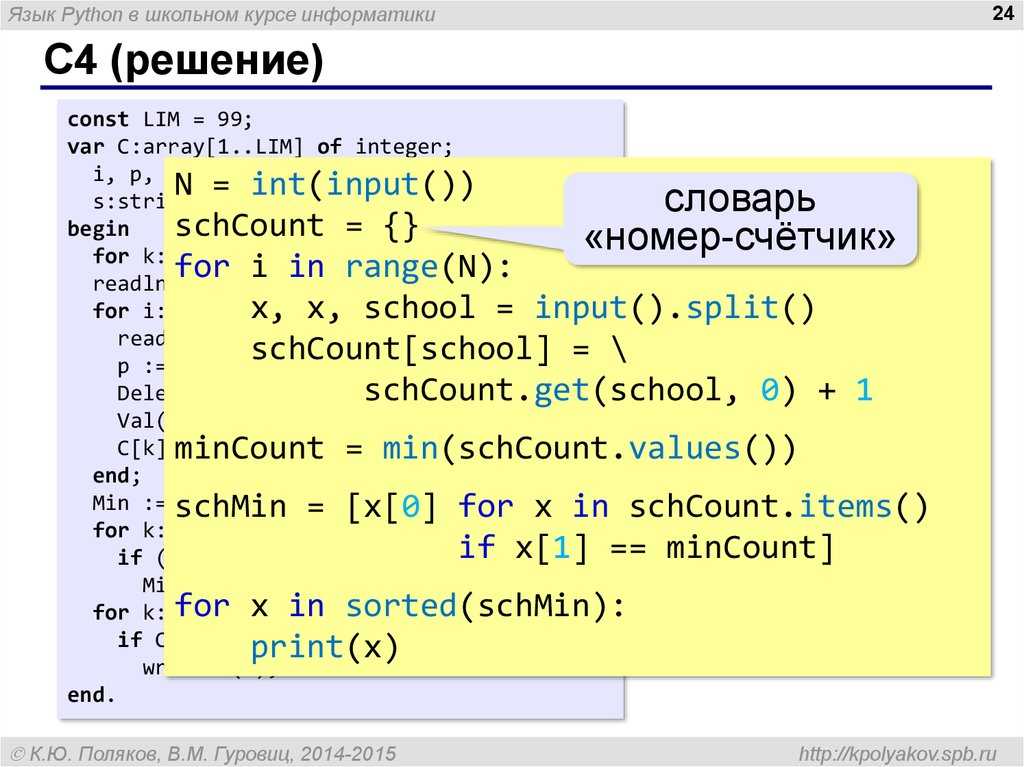
Полезные источники для изучения баз данных
Для того, чтобы хорошенько разобраться в базах данных, вам потребуется немало времени для изучения различных книг и туториалов. Ниже вы можете ознакомиться со списком книг и видеокурсов по данной тематике.
Книги для изучения баз данных:
- «Изучаем SQL», автор — Алан Бьюли. Эта книга отлично подойдет для новичков, только начинающих знакомиться с обширным миром баз данных.
- «SQL», автор — Крис Фиайли. В этой книге подробно и на примерах разбирается использование языка запросов SQL для решения разных задач.
- «SQL. Сборник рецептов», автор — Энтони Молинаро. Данное пособие подойдет тем, кто уже имеет определенные знания об SQL и хочет развивать свои навыки.
- «SQL. Библия пользователя», авторы — Алекс Кригель и др., 2-е издание. Уникальность книги в том, что в ней приведены примеры реализации различных запросов на трех основных диалектах ведущих СУБД.
- «Семь баз данных за семь недель. Введение в современные базы данных и идеологию NoSQL», авторы — Эрик Редмонд, Джим Р. Уилсон. В данной книге рассказывается в основном о нереляционных базах данных. Вы узнаете об особенностях таких СУБД, как Redis, Neo4J, CouchDB, MongoDB, HBase, PostgreSQL и Riak.
- «Работа с PostgreSQL: настройка и масштабирование», автор — А. Ю. Васильев. Это справочник по настройке и масштабированию PostgreSQL и тонкостям его использования.

Видеокурсы:
Если же вы больше предпочитаете видеоуроки и курсы, то существует множество источников для любого уровня подготовки. Ниже приведены примеры таких источников. Они в основном рассчитаны для новичков:
Ниже приведены примеры таких источников. Они в основном рассчитаны для новичков:
- Основы баз данных
- Изучение SQL для начинающих
- Видеокурс по базам данных от Технопарка
- Python and MySQL: Database Manipulation with Python
Контрольный чеклист для изучения баз данных
- Установите PostgreSQL на свой сервер или персональный компьютер. Если вы используете Ubuntu, запустите
sudo apt-get install postgresql. - Убедитесь, что в зависимостях вашего приложения есть библиотека psycopg2.
- Настройте свое веб-приложение для подключения к экземпляру PostgreSQL.
- Создавайте модели в ORM с помощью встроенного ORM Django или SQLAlchemy с Flask.
- Создайте таблицы своей базы данных или синхронизируйте модели ORM с экземпляром PostgreSQL, если вы используете ORM.
- Начните создавать, читать, обновлять и удалять данные в базе данных из вашего веб-приложения.
Заключение
В этой статье мы кратко рассказали про базы данных в Python. Обсудили, какие они бывают и в чем особенности использования той или иной СУБД. Также мы дали вам подборки книг и видеоматериалов для дальнейшего изучения баз данных. Надеемся, что вам все это пригодится. Успехов в освоении баз данных и написании кода!
Обсудили, какие они бывают и в чем особенности использования той или иной СУБД. Также мы дали вам подборки книг и видеоматериалов для дальнейшего изучения баз данных. Надеемся, что вам все это пригодится. Успехов в освоении баз данных и написании кода!
На основе статьи «Databases».
Использование Python для создания запросов к базе данных — Azure SQL Database & SQL Managed Instance
Twitter LinkedIn Facebook Адрес электронной почты
- Статья
- Чтение занимает 2 мин
Область применения: База данных SQL Azure Управляемый экземпляр SQL Azure Azure Synapse Analytics
При работе с этим кратким руководством вы будете использовать Python для подключения к Базе данных SQL Azure, Управляемому экземпляру SQL Azure или базе данных Synapse SQL, а затем выполните запрос данных с помощью инструкций T-SQL.
Предварительные требования
Для работы с этим кратким руководством вам понадобится:
Учетная запись Azure с активной подпиской. Создайте учетную запись бесплатно.
База данных, в которой будет выполняться запрос.
Для создания и настройки базы данных можно использовать одно из этих кратких руководств.
Действие База данных SQL Управляемый экземпляр SQL SQL Server на виртуальной машине Azure Azure Synapse Analytics Создание Портал Портал Портал Портал CLI CLI PowerShell PowerShell PowerShell PowerShell Шаблон развертывания Шаблон развертывания Configure Правило брандмауэра для IP-адресов на уровне сервера Подключение из виртуальной машины Подключение из локальной сети Подключение к экземпляру SQL Server Получение сведений о подключении Azure SQL; Azure SQL; Виртуальная машина SQL Synapse SQL Python 3 и связанное с ним программное обеспечение
Действие macOS Ubuntu Windows Установите драйвер ODBC, SQLCMD и драйвер Python для SQL Server. Выполните шаги 1.2, 1.3 и 2.1 в руководстве Создание приложений Python с использованием SQL Server в macOS. Также будут установлены Homebrew и Python. Настройте среду для разработки с помощью Python pyodbc. Настройте среду для разработки с помощью Python pyodbc. Установите Python и другие требуемые пакеты. Используйте команду sudo apt-get install python python-pip gcc g++ build-essential.Дополнительные сведения Microsoft ODBC driver в macOS Microsoft ODBC driver в Linux Microsoft ODBC driver в Linux

Для дальнейшего изучения Python и базы данных в службе «Базы данных SQL Azure» см. Библиотеки Базы данных SQL Azure для Python, репозитория репозиторий pyodbc и выборку pyodbc.
Создание кода для запроса базы данных
Создайте файл sqltest.py в текстовом редакторе.
Добавьте следующий код. Получите сведения о подключении из раздела о предварительных требованиях и замените параметры <server>, <database>, <username> и <password> собственными значениями.
import pyodbc server = '<server>.database.windows.net' database = '<database>' username = '<username>' password = '{<password>}' driver= '{ODBC Driver 17 for SQL Server}' with pyodbc.connect('DRIVER='+driver+';SERVER=tcp:'+server+';PORT=1433;DATABASE='+database+';UID='+username+';PWD='+ password) as conn: with conn.cursor() as cursor: cursor.execute("SELECT TOP 3 name, collation_name FROM sys.databases") row = cursor.fetchone() while row: print (str(row[0]) + " " + str(row[1])) row = cursor.fetchone()
Выполнение кода
В командной строке выполните следующую команду:
python sqltest.
py
Убедитесь, что возвращены базы данных и их параметры сортировки, и закройте командное окно.
 py
py
Дальнейшие действия
- Руководство по разработке первой базы данных в службе «База данных SQL Azure»
- Сведения о драйверах Microsoft Python для SQL Server
- Центр по разработке на Python
Настройка клиента Python для обработки и анализа данных — SQL Server Machine Learning Services
- Статья
- Чтение занимает 10 мин
Область применения: SQL Server 2016 (13.x), SQL Server 2017 (14. x) и SQL Server 2019 (15.x), SQL Server 2019 (15.x) — Linux
x) и SQL Server 2019 (15.x), SQL Server 2019 (15.x) — Linux
Интеграция Python доступна в SQL Server 2017 и более поздних версиях, если включить параметр для Python во время установки служб машинного обучения (в базе данных).
Примечание
В настоящее время эта статья относится только к SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) и SQL Server 2019 (15.x) и только для Linux.
Чтобы разрабатывать и развертывать решения Python для SQL Server, установите библиотеку Майкрософт revoscalepy и другие библиотеки Python для рабочей станции разработки. Библиотека revoscalepy, которая также находится на удаленном экземпляре SQL Server, координирует вычислительные запросы между обеими системами.
Из этой статьи вы узнаете, как настроить рабочую станцию разработки на Python, чтобы вы могли взаимодействовать с удаленным сервером SQL Server, на котором включены машинное обучение и интеграция Python. После выполнения действий, описанных в этой статье, у вас будут те же библиотеки Python, что и на сервере SQL Server. Вы также узнаете, как отправлять вычисления из локального сеанса Python в удаленный сеанс Python на сервере SQL Server.
Вы также узнаете, как отправлять вычисления из локального сеанса Python в удаленный сеанс Python на сервере SQL Server.
Чтобы проверить установку, можно использовать встроенное приложение Jupyter Notebook, как описано в этой статье, или связать библиотеки с PyCharm или любой другой интегрированной средой разработки, которой вы обычно пользуетесь.
Совет
Видеодемонстрацию этих упражнений см. в статье Удаленный запуск R и Python в SQL Server с помощью Jupyter Notebook.
Часто используемые инструменты
Независимо от того, являетесь ли вы разработчиком Python, который мало знаком с SQL, или разработчиком SQL, который мало знаком с Python и анализом данных в базе данных, для использования всех возможностей анализа баз данных вам потребуется как средство разработки Python, так и редактор запросов T-SQL, например SQL Server Management Studio (SSMS).
Для разработки на Python можно использовать приложение Jupyter Notebook, которое входит в дистрибутив Anaconda, устанавливаемый SQL Server. В этой статье объясняется, как запустить Jupyter Notebook, чтобы можно было выполнять код Python локально и удаленно на SQL Server.
В этой статье объясняется, как запустить Jupyter Notebook, чтобы можно было выполнять код Python локально и удаленно на SQL Server.
Набор средств SSMS необходимо скачать отдельно. Он подходит для создания и выполнения хранимых процедур в SQL Server, в том числе процедур, содержащих код Python. Практически любой код Python, написанный в Jupyter Notebook, можно внедрять в хранимые процедуры. Вы можете ознакомиться с другими пошаговыми руководствами, чтобы получить дополнительные сведения об SSMS и внедрении кода Python.
1. Установка пакетов Python
На локальных рабочих станциях должны быть установлены те же версии пакетов Python, что и в SQL Server, включая базовый дистрибутив Anaconda 4.2.0 с Python 3.5.2, а также пакеты Майкрософт.
Сценарий установки добавляет в клиент Python три библиотеки Майкрософт в клиент Python. Скрипт устанавливает:
- revoscalepy, используемую для определения объектов источника данных и контекста вычислений.
- microsoftml, предоставляющую алгоритмы машинного обучения.
- azureml, который применяется к задачам внедрения, связанным с контекстом отдельного сервера, и использование этого пакета для анализа баз данных может быть ограничено.

Скачайте сценарий установки.
https://aka.ms/mls-py устанавливает версию 9.2.1 пакетов Python Майкрософт. Эта версия соответствует экземпляру SQL Server по умолчанию.
https://aka.ms/mls93-py устанавливает версию 9.3 пакетов Python Майкрософт.
Откройте окно PowerShell с повышенными правами администратора (щелкните правой кнопкой мыши Запуск от имени администратора).
Перейдите в папку, в которую был скачан установщик, и запустите сценарий. Добавьте аргумент командной строки
-InstallFolder, чтобы указать расположение папки для библиотек. Пример.cd {{download-directory}} .\Install-PyForMLS.ps1 -InstallFolder "C:\path-to-python-for-mls"
Если вы не указали папку установки, по умолчанию используется %ProgramFiles%\Microsoft\PyForMLS.
Для выполнения установки требуется некоторое время. Ход выполнения можно отслеживать в окне PowerShell. После завершения установки вы получите полный набор пакетов.
Совет
Общие сведения о запуске программ Python в Windows см. в разделе Часто задаваемые вопросы по Python для Windows.
2. Обнаружение исполняемых файлов
Оставаясь в окне PowerShell, выведите список файлов в папке установки, чтобы убедиться, что файл Python.exe, сценарии и другие пакеты установлены.
Введите
cd \, чтобы перейти к корневому каталогу диска, а затем введите путь, указанный для-InstallFolderна предыдущем шаге. Если этот параметр не был указан во время установки, по умолчанию используетсяcd %ProgramFiles%\Microsoft\PyForMLS.Введите
dir *.exe, чтобы получить список исполняемых файлов. Вы должны увидеть исполняемые файлы python.exe, pythonw.exe и uninstall-anaconda. exe.
 exe.
exe.В системах с несколькими версиями Python не забывайте использовать этот конкретный файл Python.exe, если необходимо загрузить revoscalepy и другие пакеты Майкрософт.
Примечание
Сценарий установки не изменяет переменную среды PATH на компьютере. Это означает, что новые интерпретаторы Python и модули, которые вы только что установили, не будут автоматически доступны для других инструментов. Справку по связыванию интерпретатора Python и библиотек с инструментами см. в разделе Установка интегрированной среды разработки.
3. Открытие Jupyter Notebook
Приложение Jupyter Notebook входит в состав дистрибутива Anaconda. В качестве следующего шага создайте записную книжку и выполните какой-нибудь код Python, в котором используются только что установленные библиотеки.
В командной строке PowerShell, по-прежнему находясь в каталоге
%ProgramFiles%\Microsoft\PyForMLS, откройте приложение Jupyter Notebook из папки Scripts:.
\Scripts\jupyter-notebook
Должна открыться записная книжка в браузере по умолчанию по адресу
https://localhost:8889/tree.Другой способ запуска — дважды щелкнуть файл jupyter-notebook.exe.
Выберите Создать, а затем выберите Python 3.
Введите и выполните команду
import revoscalepy, чтобы загрузить одну из библиотек Майкрософт.Введите и выполните команду
print(revoscalepy.__version__), чтобы получить сведения о версии. Вы должны увидеть версию 9.2.1 или 9.3.0. Вы можете использовать любую из этих версий с библиотекой revoscalepy на сервере.Введите более сложную последовательность инструкций. В этом примере формируется сводная статистика для локального набора данных с помощью метода rx_summary. Другие функции получают расположение демонстрационных данных и создают объект источника данных для локального XDF-файла.
import os from revoscalepy import rx_summary from revoscalepy import RxXdfData from revoscalepy import RxOptions sample_data_path = RxOptions.get_option("sampleDataDir") print(sample_data_path) ds = RxXdfData(os.path.join(sample_data_path, "AirlineDemoSmall.xdf")) summary = rx_summary("ArrDelay+DayOfWeek", ds) print(summary)
 \Scripts\jupyter-notebook
\Scripts\jupyter-notebook

На следующем снимке экрана показаны входные и выходные данные (выходные данные обрезаны для краткости).
4. Получение разрешений SQL
Чтобы подключиться к экземпляру SQL Server для выполнения сценариев и передачи данных, необходимо иметь допустимое имя входа на сервере базы данных. Можно использовать либо имя входа SQL, либо встроенную проверку подлинности Windows. Обычно рекомендуется использовать встроенную проверку подлинности Windows, но в некоторых случаях проще использовать имя входа SQL, особенно если сценарий содержит строки подключения к внешним данным.
У учетной записи, используемой для выполнения кода, должно быть разрешение на чтение для баз данных, с которыми вы работаете, а также специальное разрешение EXECUTE ANY EXTERNAL SCRIPT.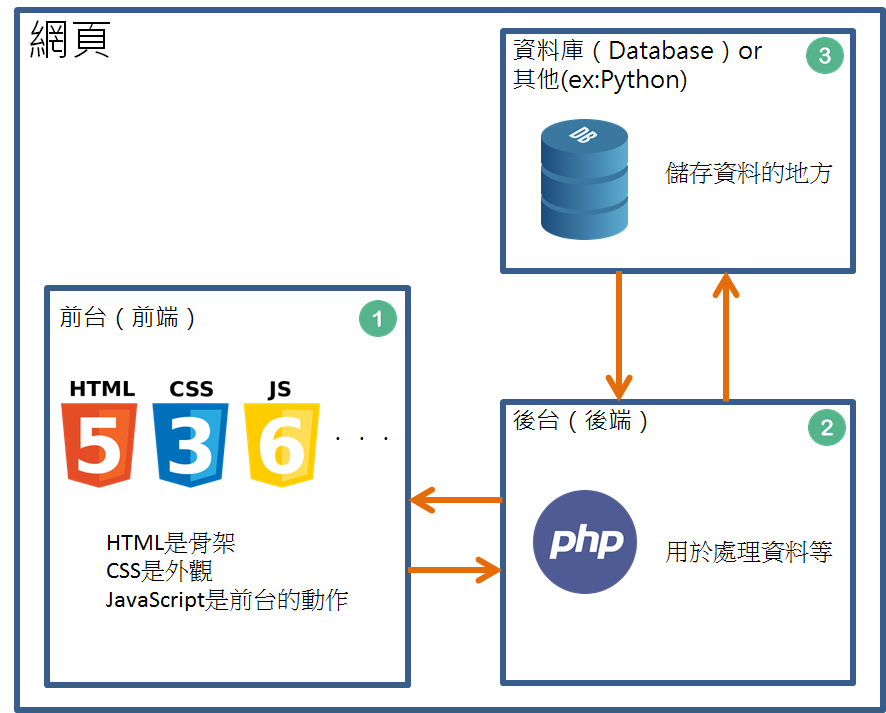 Большинству разработчиков также требуются разрешения на создание хранимых процедур и на запись данных в таблицы, содержащие данные обучения или данные оценки.
Большинству разработчиков также требуются разрешения на создание хранимых процедур и на запись данных в таблицы, содержащие данные обучения или данные оценки.
Попросите администратора базы данных настроить следующие разрешения для учетной записи в базе данных, в которой используется Python:
- EXECUTE ANY EXTERNAL SCRIPT для запуска Python на сервере.
- Привилегии db_datareader для выполнения запросов, используемых для обучения модели.
- db_datawriter для записи данных обучения и данных оценки.
- db_owner для создания таких объектов, как хранимые процедуры, таблицы и функции. Разрешение db_owner также потребуется для создания примеров баз данных и тестовых баз данных.
Если для кода требуются пакеты, которые по умолчанию не установлены в SQL Server, обратитесь к администратору базы данных, чтобы установить необходимые пакеты. SQL Server представляет собой защищенную среду, и существуют ограничения на места установки пакетов. Нерегламентированная установка пакетов в составе вашего кода не рекомендуется, даже если у вас есть необходимые разрешения. Также тщательно оцените влияние на безопасность сервера перед установкой новых пакетов в библиотеку сервера.
Нерегламентированная установка пакетов в составе вашего кода не рекомендуется, даже если у вас есть необходимые разрешения. Также тщательно оцените влияние на безопасность сервера перед установкой новых пакетов в библиотеку сервера.
5. Создание тестовых данных
Если у вас есть разрешения на создание базы данных на удаленном сервере, можно выполнить следующий код, чтобы создать демонстрационную базу данных «Ирисы Фишера», которая будет использоваться для выполнения оставшихся действий в этой статье.
5-1. Удаленное создание базы данных irissql
import pyodbc
# creating a new db to load Iris sample in
new_db_name = "irissql"
connection_string = "Driver=SQL Server;Server=localhost;Database={0};Trusted_Connection=Yes;"
# you can also swap Trusted_Connection for UID={your username};PWD={your password}
cnxn = pyodbc.connect(connection_string.format("master"), autocommit=True)
cnxn.cursor().execute("IF EXISTS(SELECT * FROM sys.databases WHERE [name] = '{0}') DROP DATABASE {0}". format(new_db_name))
cnxn.cursor().execute("CREATE DATABASE " + new_db_name)
cnxn.close()
print("Database created")
 format(new_db_name))
cnxn.cursor().execute("CREATE DATABASE " + new_db_name)
cnxn.close()
print("Database created")
format(new_db_name))
cnxn.cursor().execute("CREATE DATABASE " + new_db_name)
cnxn.close()
print("Database created")
5-2. Импорт примера «Ирисы Фишера» из SkLearn
from sklearn import datasets import pandas as pd # SkLearn has the Iris sample dataset built in to the package iris = datasets.load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names)
5-3. Использование API-интерфейсов Revoscalepy для создания таблицы и загрузки данных «Ирисы Фишера»
from revoscalepy import RxSqlServerData, rx_data_step
# Example of using RX APIs to load data into SQL table. You can also do this with pyodbc
table_ref = RxSqlServerData(connection_string=connection_string.format(new_db_name), table="iris_data")
rx_data_step(input_data = df, output_file = table_ref, overwrite = True)
print("New Table Created: Iris")
print("Sklearn Iris sample loaded into Iris table")
6. Проверка удаленного подключения
Перед выполнением следующего шага убедитесь, что у вас есть разрешения на экземпляр SQL Server и строка подключения к демонстрационной базе данных «Ирисы Фишера». Если база данных не существует и у вас есть необходимые разрешения, можно создать базу данных, используя следующие встроенные инструкции.
Если база данных не существует и у вас есть необходимые разрешения, можно создать базу данных, используя следующие встроенные инструкции.
Замените значения параметров в строке подключения на соответствующие значения параметров для вашей среды. В примере кода используется строка подключения "Driver=SQL Server;Server=localhost;Database=irissql;Trusted_Connection=Yes;", но в вашем коде необходимо указать удаленный сервер, возможно, с именем экземпляра и параметр учетных данных, который сопоставляется с именем входа базы данных.
6-1. Определение функции
В следующем коде определяется функция, которая будет отправлена на сервер SQL Server на более позднем шаге. При выполнении этого кода он использует данные и библиотеки (revoscalepy, pandas, matplotlib) на удаленном сервере для создания точечных диаграмм для набора данных «Ирисы Фишера». Этот код возвращает байтовый поток из файла PNG обратно в Jupyter Notebook для отображения в браузере.
def send_this_func_to_sql():
from revoscalepy import RxSqlServerData, rx_import
from pandas. tools.plotting import scatter_matrix
import matplotlib.pyplot as plt
import io
# remember the scope of the variables in this func are within our SQL Server Python Runtime
connection_string = "Driver=SQL Server;Server=localhost;Database=irissql;Trusted_Connection=Yes;"
# specify a query and load into pandas dataframe df
sql_query = RxSqlServerData(connection_string=connection_string, sql_query = "select * from iris_data")
df = rx_import(sql_query)
scatter_matrix(df)
# return bytestream of image created by scatter_matrix
buf = io.BytesIO()
plt.savefig(buf, format="png")
buf.seek(0)
return buf.getvalue()
 tools.plotting import scatter_matrix
import matplotlib.pyplot as plt
import io
# remember the scope of the variables in this func are within our SQL Server Python Runtime
connection_string = "Driver=SQL Server;Server=localhost;Database=irissql;Trusted_Connection=Yes;"
# specify a query and load into pandas dataframe df
sql_query = RxSqlServerData(connection_string=connection_string, sql_query = "select * from iris_data")
df = rx_import(sql_query)
scatter_matrix(df)
# return bytestream of image created by scatter_matrix
buf = io.BytesIO()
plt.savefig(buf, format="png")
buf.seek(0)
return buf.getvalue()
tools.plotting import scatter_matrix
import matplotlib.pyplot as plt
import io
# remember the scope of the variables in this func are within our SQL Server Python Runtime
connection_string = "Driver=SQL Server;Server=localhost;Database=irissql;Trusted_Connection=Yes;"
# specify a query and load into pandas dataframe df
sql_query = RxSqlServerData(connection_string=connection_string, sql_query = "select * from iris_data")
df = rx_import(sql_query)
scatter_matrix(df)
# return bytestream of image created by scatter_matrix
buf = io.BytesIO()
plt.savefig(buf, format="png")
buf.seek(0)
return buf.getvalue()
6-2. Отправка функции в SQL Server
В этом примере создается удаленный контекст вычислений, и выполнение функции отправляется на сервер SQL Server с помощью rx_exec. Функция rx_exec удобна, так как она принимает контекст вычислений в качестве аргумента. Любая функция, которую требуется выполнить удаленно, должна принимать контекст вычислений в качестве аргумента. Некоторые функции, например rx_lin_mod, поддерживают этот аргумент напрямую. Для операций, которые не принимают этот аргумент, можно использовать rx_exec для доставки кода в удаленный контекст вычислений.
Некоторые функции, например rx_lin_mod, поддерживают этот аргумент напрямую. Для операций, которые не принимают этот аргумент, можно использовать rx_exec для доставки кода в удаленный контекст вычислений.
В этом примере необработанные данные из SQL Server в Jupyter Notebook не передаются. Все вычисления выполняются в базе данных «Ирисы Фишера», и клиенту возвращается только файл изображения.
from IPython import display import matplotlib.pyplot as plt from revoscalepy import RxInSqlServer, rx_exec # create a remote compute context with connection to SQL Server sql_compute_context = RxInSqlServer(connection_string=connection_string.format(new_db_name)) # use rx_exec to send the function execution to SQL Server image = rx_exec(send_this_func_to_sql, compute_context=sql_compute_context)[0] # only an image was returned to my jupyter client. All data remained secure and was manipulated in my db. display.Image(data=image)
На следующем снимке экрана показаны входные данные и выходные данные в виде точечной диаграммы.
7. Запуск Python
Поскольку разработчики часто работают с несколькими версиями Python, программа установки не добавляет путь к Python в переменную PATH. Чтобы использовать исполняемый файл и библиотеки Python, установленные программой установки, свяжите интегрированную среду разработки с файлом Python.exe по пути, по которому также находятся библиотеки revoscalepy и microsoftml.
Командная строка
При запуске файла Python.exe из папки %ProgramFiles%\Microsoft\PyForMLS (или из любого другого расположения, указанного при установке клиентской библиотеки Python) у вас есть доступ ко всему дистрибутиву Anaconda и к модулям Python Майкрософт revoscalepy и microsoftml.
- Перейдите в
%ProgramFiles%\Microsoft\PyForMLSи выполните Python.exe. - Откройте интерактивную справку:
help(). - Введите имя модуля в командной строке справки:
help> revoscalepy. Справка возвращает имя, содержимое пакета, версию и расположение файла. - Получите сведения о версии и пакете в командной строке help>:
revoscalepy. Нажмите клавишу ВВОД несколько раз, чтобы выйти из справки. - Импортируйте модуль:
import revoscalepy.
 Справка возвращает имя, содержимое пакета, версию и расположение файла.
Справка возвращает имя, содержимое пакета, версию и расположение файла.Jupyter Notebook
В этой статье для демонстрации вызовов функций revoscalepy используется встроенное приложение Jupyter Notebook. Если вы не знакомы с этим средством, на следующем снимке экрана показаны его компоненты и механизм их работы.
Родительская папка %ProgramFiles%\Microsoft\PyForMLS содержит дистрибутив Anaconda и пакеты Майкрософт. Приложение Jupyter Notebook включено в состав дистрибутива Anaconda (оно находится в папке Scripts), и исполняемые файлы Python регистрируются с помощью Jupyter Notebook. Пакеты в каталоге site-packages можно импортировать в записную книжку. К этим пакетам относятся три пакета Майкрософт, которые используются для обработки и анализа данных и машинного обучения.
При использовании другой интегрированной среды разработки необходимо связать исполняемые файлы и библиотеки функций Python с вашим инструментом. В следующих разделах приводятся инструкции по часто используемым инструментам.
Visual Studio
Если вы используете Python в Visual Studio, воспользуйтесь следующими параметрами конфигурации, чтобы создать среду Python, включающую пакеты Python Майкрософт.
| Параметр конфигурации | Значение |
|---|---|
| Prefix path (Префикс пути) | %ProgramFiles%\Microsoft\PyForMLS |
| Interpreter path (Путь к интерпретатору) | %ProgramFiles%\Microsoft\PyForMLS\python.exe |
| Windowed interpreter (Оконный интерпретатор) | %ProgramFiles%\Microsoft\PyForMLS\pythonw.exe |
Сведения о настройке среды Python см. в разделе Управление средами Python в Visual Studio.
PyCharm
В PyCharm задайте в качестве интерпретатора установленный исполняемый файл Python.
В новом проекте в окне «Параметры» выберите Добавить локальный путь.
Введите
%ProgramFiles%\Microsoft\PyForMLS\.
Теперь можно импортировать модули revoscalepy, microsoftml или azureml. Также можно открыть интерактивное окно, выбрав Инструменты>Консоль Python.
Дальнейшие действия
Теперь, когда у вас есть инструменты и рабочее подключение к SQL Server, вы можете расширить свои навыки, выполнив краткие пошаговые руководства Python в SQL Server Management Studio (SSMS).
Краткое руководство. Создание и выполнение простых сценариев Python с помощью служб машинного обучения SQL Server
Базы данных | Документация Django 4.0
Django официально поддерживает следующие базы данных:
- PostgreSQL
- MariaDB
- MySQL
- Oracle
- SQLite
Существует также ряд database backends provided by third parties.
Django пытается поддерживать как можно больше функций на всех бэкендах баз данных. Однако, не все базы данных одинаковы, и нам пришлось принимать проектные решения о том, какие функции поддерживать и какие предположения мы можем сделать безопасными.
Этот файл описывает некоторые возможности, которые могут иметь отношение к использованию Django. Он не предназначен для замены документации по конкретному серверу или справочных руководств.
Общие примечания
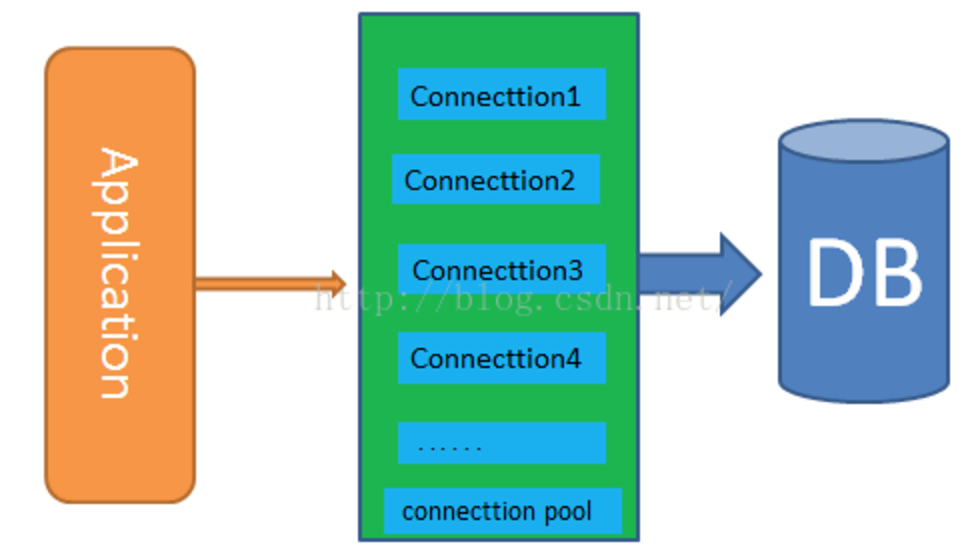
Постоянные соединения
Постоянные соединения позволяют избежать накладных расходов на повторное установление соединения с базой данных при каждом запросе. Они управляются параметром CONN_MAX_AGE, который определяет максимальное время жизни соединения. Он может быть установлен независимо для каждой базы данных.
По умолчанию установлено значение 0, сохраняющее историческое поведение закрытия соединения с базой данных в конце каждого запроса. Чтобы включить постоянные соединения, установите значение CONN_MAX_AGE в целое положительное число секунд. Для неограниченного количества постоянных соединений установите значение
Для неограниченного количества постоянных соединений установите значение None.
Управление соединениями
Django открывает соединение с базой данных при первом запросе к базе данных. Он держит это соединение открытым и повторно использует его в последующих запросах. Django закрывает соединение, когда оно превышает максимальный возраст, определенный параметром CONN_MAX_AGE или когда оно больше не может использоваться.
В деталях, Django автоматически открывает соединение с базой данных всякий раз, когда ему требуется соединение, а его еще нет — либо потому, что это первое соединение, либо потому, что предыдущее соединение было закрыто.
В начале каждого запроса Django закрывает соединение, если оно достигло своего максимального возраста. Если ваша база данных завершает простаивающие соединения через некоторое время, вам следует установить CONN_MAX_AGE на меньшее значение, чтобы Django не пытался использовать соединение, которое было завершено сервером базы данных. (Эта проблема может затрагивать только сайты с очень низким трафиком).
(Эта проблема может затрагивать только сайты с очень низким трафиком).
В конце каждого запроса Django закрывает соединение, если оно достигло своего максимального возраста или находится в состоянии неустранимой ошибки. Если во время обработки запросов возникли ошибки базы данных, Django проверяет, работает ли еще соединение, и закрывает его, если нет. Таким образом, ошибки базы данных затрагивают не более одного запроса; если соединение становится непригодным для использования, следующий запрос получает свежее соединение.
Оговорки
Поскольку каждый поток поддерживает свое собственное соединение, ваша база данных должна поддерживать как минимум столько одновременных соединений, сколько у вас рабочих потоков.
Иногда к базе данных не будет обращаться большинство ваших представлений, например, потому что это база данных внешней системы или благодаря кэшированию. В таких случаях следует установить CONN_MAX_AGE на низкое значение или даже 0, потому что нет смысла поддерживать соединение, которое вряд ли будет использоваться повторно. Это поможет сохранить небольшое количество одновременных соединений с этой базой данных.
Это поможет сохранить небольшое количество одновременных соединений с этой базой данных.
Сервер разработки создает новый поток для каждого обрабатываемого запроса, сводя на нет эффект постоянных соединений. Не включайте их во время разработки.
Когда Django устанавливает соединение с базой данных, он настраивает соответствующие параметры, в зависимости от используемого бэкенда. Если вы включите постоянные соединения, эта настройка больше не будет повторяться при каждом запросе. Если вы изменяете такие параметры, как уровень изоляции соединения или часовой пояс, вам следует либо восстановить значения по умолчанию Django в конце каждого запроса, либо принудительно установить соответствующее значение в начале каждого запроса, либо отключить постоянные соединения.
Кодирование
Django предполагает, что все базы данных используют кодировку UTF-8. Использование других кодировок может привести к неожиданному поведению, например, к ошибкам «значение слишком длинное» от вашей базы данных для данных, которые действительны в Django. Информацию о том, как правильно настроить вашу базу данных, смотрите ниже в примечаниях к конкретным базам данных.
Информацию о том, как правильно настроить вашу базу данных, смотрите ниже в примечаниях к конкретным базам данных.
Заметки о PostgreSQL
Django поддерживает PostgreSQL 10 и выше. Требуется версия psycopg2 2.5.4 или выше, хотя рекомендуется последняя версия.
Настройки подключения к PostgreSQL
Подробнее см. в разделе HOST.
Чтобы подключиться, используя имя службы из connection service file и пароль из password file, вы должны указать их в OPTIONS части конфигурации вашей базы данных в DATABASES:
settings.py
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'OPTIONS': {
'service': 'my_service',
'passfile': '.my_pgpass',
},
}
}
.pg_service.conf
[my_service] host=localhost user=USER dbname=NAME port=5432
.my_pgpass
localhost:5432:NAME:USER:PASSWORD
Changed in Django 4. 0:
0:
Добавлена поддержка подключения по имени службы и указания файла пароля.
Оптимизация конфигурации PostgreSQL
Для подключения к базе данных Django нужны следующие параметры:
client_encoding:'UTF8',default_transaction_isolation:'read committed'по умолчанию, или значение, установленное в опциях соединения (см. ниже),timezone:- когда
USE_TZравноTrue,'UTC'по умолчанию, или значениеTIME_ZONE, установленное для соединения, - когда
USE_TZравноFalse, значение глобальной настройкиTIME_ZONE.
- когда
Если эти параметры уже имеют правильные значения, Django не будет устанавливать их для каждого нового соединения, что немного повышает производительность. Вы можете настроить их непосредственно в postgresql. или более удобно для каждого пользователя базы данных с помощью ALTER ROLE. conf
conf
Django будет прекрасно работать и без этой оптимизации, но каждое новое соединение будет выполнять несколько дополнительных запросов для установки этих параметров.
Уровень изоляции
Как и сам PostgreSQL, Django по умолчанию использует READ COMMITTED isolation level. Если вам нужен более высокий уровень изоляции, такой как REPEATABLE READ или SERIALIZABLE, установите его в OPTIONS части конфигурации вашей базы данных в DATABASES:
import psycopg2.extensions
DATABASES = {
# ...
'OPTIONS': {
'isolation_level': psycopg2.extensions.ISOLATION_LEVEL_SERIALIZABLE,
},
}
Примечание
При более высоких уровнях изоляции ваше приложение должно быть готово к обработке исключений, возникающих при сбоях сериализации. Эта опция предназначена для расширенного использования.
Индексы для столбцов
varchar и textПри указании db_index=True для полей вашей модели, Django обычно выводит единственный оператор CREATE INDEX. Однако, если тип базы данных для поля является varchar или text (например, используется CharField, FileField и TextField), то Django создаст дополнительный индекс, который использует соответствующий PostgreSQL operator class для столбца. Дополнительный индекс необходим для корректного выполнения поиска, использующего оператор LIKE в SQL, как это делается с типами поиска contains и startswith.
Операция миграции для добавления расширений
Если вам нужно добавить расширение PostgreSQL (например, hstore, postgis и т.д.) с помощью миграции, используйте операцию CreateExtension.
Курсоры на стороне сервера
При использовании QuerySet., Django открывает server-side cursor. По умолчанию PostgreSQL предполагает, что будут получены только первые 10% результатов запросов курсора. Планировщик запросов тратит меньше времени на планирование запроса и начинает возвращать результаты быстрее, но это может снизить производительность, если извлекается более 10% результатов. Предположения PostgreSQL о количестве строк, извлекаемых при курсорном запросе, контролируются с помощью опции cursor_tuple_fraction. iterator()
iterator()
Объединение транзакций и курсоры на стороне сервера
Использование пулера соединений в режиме пула транзакций (например, PgBouncer) требует отключения серверных курсоров для этого соединения.
Серверные курсоры являются локальными для соединения и остаются открытыми в конце транзакции, когда AUTOCOMMIT становится True. Последующая транзакция может попытаться получить больше результатов из курсора на стороне сервера. В режиме объединения транзакций нет гарантии, что последующие транзакции будут использовать одно и то же соединение. Если используется другое соединение, то при обращении транзакции к серверному курсору возникает ошибка, поскольку серверные курсоры доступны только в том соединении, в котором они были созданы.
Если используется другое соединение, то при обращении транзакции к серверному курсору возникает ошибка, поскольку серверные курсоры доступны только в том соединении, в котором они были созданы.
Одним из решений является отключение серверных курсоров для соединения в DATABASES, установив DISABLE_SERVER_SIDE_CURSORS в True.
Чтобы получить преимущества от использования серверных курсоров в режиме объединения транзакций, вы можете установить соединение another connection to the database для выполнения запросов, использующих серверные курсоры. Это соединение должно быть либо напрямую с базой данных, либо с пулом соединений в режиме объединения сессий.
Другой вариант — обернуть каждый QuerySet, использующий серверный курсор, в блок atomic(), поскольку это отключает autocommit на время транзакции. Таким образом, курсор на стороне сервера будет жить только в течение транзакции.
Ручное указание значений автоинкрементных первичных ключей
Django использует SERIAL data type PostgreSQL для хранения автоинкрементных первичных ключей. Столбец
Столбец SERIAL заполняется значениями из sequence, который отслеживает следующее доступное значение. Ручное присвоение значения автоинкрементному полю не обновляет последовательность поля, что впоследствии может привести к конфликту. Например:
>>> from django.contrib.auth.models import User >>> User.objects.create(username='alice', pk=1) <User: alice> >>> # The sequence hasn't been updated; its next value is 1. >>> User.objects.create(username='bob') ... IntegrityError: duplicate key value violates unique constraint "auth_user_pkey" DETAIL: Key (id)=(1) already exists.
Если вам нужно указать такие значения, сбросьте последовательность после этого, чтобы избежать повторного использования значения, которое уже есть в таблице. Команда управления sqlsequencereset генерирует SQL-запросы для этого.
Шаблоны тестовых баз данных
Вы можете использовать параметр TEST['TEMPLATE'], чтобы указать template (например, 'template0'), на основе которого будет создана тестовая база данных.
Ускорение выполнения тестов с помощью недолговечных настроек
Вы можете ускорить время выполнения теста с помощью configuring PostgreSQL to be non-durable.
Предупреждение
Это опасно: это сделает вашу базу данных более восприимчивой к потере или повреждению данных в случае аварии сервера или потери питания. Используйте это только на машине разработки, где вы можете легко восстановить все содержимое всех баз данных в кластере.
Заметки о MariaDB
Django поддерживает MariaDB 10.2 и выше.
Чтобы использовать MariaDB, используйте бэкенд MySQL, который является общим для этих двух систем. Более подробную информацию смотрите в MySQL notes.
Заметки по MySQL
Поддержка версий
Django поддерживает MySQL 5.7 и выше.
Функция Django inspectdb использует базу данных information_schema, которая содержит подробные данные обо всех схемах баз данных.
Django ожидает, что база данных будет поддерживать Unicode (кодировка UTF-8) и делегирует ей задачу обеспечения транзакций и ссылочной целостности. Важно знать, что два последних факта не соблюдаются MySQL при использовании механизма хранения MyISAM, см. следующий раздел.
Важно знать, что два последних факта не соблюдаются MySQL при использовании механизма хранения MyISAM, см. следующий раздел.
Двигатели для хранения
MySQL имеет несколько storage engines. Вы можете изменить движок хранения по умолчанию в конфигурации сервера.
По умолчанию в MySQL используется механизм хранения данных InnoDB. Этот механизм является полностью транзакционным и поддерживает ссылки на внешние ключи. Это рекомендуемый выбор. Однако счетчик автоинкремента InnoDB теряется при перезагрузке MySQL, поскольку он не запоминает значение AUTO_INCREMENT, а воссоздает его как «max(id)+1». Это может привести к непреднамеренному повторному использованию значений AutoField.
Основными недостатками MyISAM являются то, что он не поддерживает транзакции и не обеспечивает соблюдение ограничений на иностранные ключи.
Драйверы MySQL DB API
У MySQL есть несколько драйверов, которые реализуют Python Database API, описанный в PEP 249:
- mysqlclient — это родной драйвер. Это рекомендуемый выбор.
- MySQL Connector/Python — это чистый Python драйвер от Oracle, который не требует клиентской библиотеки MySQL или каких-либо модулей Python за пределами стандартной библиотеки.
 Это рекомендуемый выбор.
Это рекомендуемый выбор.Эти драйверы потокобезопасны и обеспечивают объединение соединений.
В дополнение к драйверу DB API, Django нужен адаптер для доступа к драйверам баз данных из его ORM. Django предоставляет адаптер для mysqlclient, в то время как MySQL Connector/Python включает its own.
mysqlclient
Для Django требуется mysqlclient 1.4.0 или более поздняя версия.
MySQL Connector/Python
MySQL Connector/Python доступен по ссылке download page. Адаптер Django доступен в версиях 1.1.X и более поздних. Он может не поддерживать самые последние выпуски Django.
Определения часовых поясов
Если вы планируете использовать timezone support от Django, используйте mysql_tzinfo_to_sql для загрузки таблиц часовых поясов в базу данных MySQL. Это нужно сделать только один раз для вашего сервера MySQL, а не для каждой базы данных.
Это нужно сделать только один раз для вашего сервера MySQL, а не для каждой базы данных.
Создание вашей базы данных
Вы можете create your database использовать инструменты командной строки и этот SQL:
CREATE DATABASE <dbname> CHARACTER SET utf8;
Это гарантирует, что все таблицы и столбцы будут использовать UTF-8 по умолчанию.
Настройки колляции
Настройка collation для столбца управляет порядком сортировки данных, а также тем, какие строки сравниваются как равные. Вы можете указать параметр db_collation, чтобы задать имя collation столбца для CharField и TextField.
Колляцию также можно установить на уровне всей базы данных и для каждой таблицы. Об этом говорится в документации MySQL documented thoroughly. В таких случаях вы должны установить collation, непосредственно манипулируя настройками базы данных или таблицами. Django не предоставляет API для их изменения.
По умолчанию, при использовании базы данных UTF-8, MySQL будет использовать коллизию utf8_general_ci. Это приводит к тому, что все сравнения равенства строк выполняются без учета регистра. То есть,
Это приводит к тому, что все сравнения равенства строк выполняются без учета регистра. То есть, "Fred" и "freD" считаются равными на уровне базы данных. Если у вас есть уникальное ограничение на поле, будет незаконно пытаться вставить "aa" и "AA" в один и тот же столбец, так как они сравниваются как равные (и, следовательно, неуникальные) с использованием стандартной раскладки. Если вам нужны сравнения с учетом регистра в конкретном столбце или таблице, измените столбец или таблицу, чтобы в них использовалась раскладка utf8_bin.
Обратите внимание, что согласно MySQL Unicode Character Sets, сравнения для коллизии utf8_general_ci быстрее, но немного менее корректны, чем сравнения для utf8_unicode_ci. Если это приемлемо для вашего приложения, вам следует использовать utf8_general_ci, так как это быстрее. Если это неприемлемо (например, если вам требуется немецкий порядок словарей), используйте utf8_unicode_ci, так как он более точен.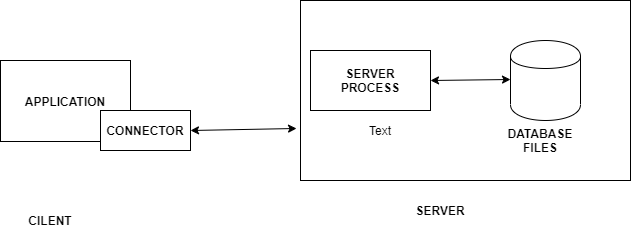
Предупреждение
Модельные наборы форм проверяют уникальные поля с учетом регистра. Таким образом, при использовании нечувствительной к регистру раскладки набор форм с уникальными значениями полей, отличающимися только регистром, пройдет проверку, но при вызове save() возникнет ошибка IntegrityError.
Changed in Django 3.2:
Добавлена поддержка установки collation базы данных для поля.
Подключение к базе данных
Обратитесь к settings documentation.
Настройки подключения используются в таком порядке:
OPTIONS.NAME,USER,PASSWORD,HOST,PORT- Файлы параметров MySQL.
Другими словами, если вы зададите имя базы данных в OPTIONS, оно будет иметь приоритет над NAME, которое отменит все, что находится в MySQL option file.
Вот пример конфигурации, в которой используется файл опций MySQL:
# settings.
 py
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'OPTIONS': {
'read_default_file': '/path/to/my.cnf',
},
}
}
# my.cnf
[client]
database = NAME
user = USER
password = PASSWORD
default-character-set = utf8
py
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'OPTIONS': {
'read_default_file': '/path/to/my.cnf',
},
}
}
# my.cnf
[client]
database = NAME
user = USER
password = PASSWORD
default-character-set = utf8
Могут быть полезны несколько других MySQLdb connection options, например ssl, init_command и sql_mode.
Установка
sql_modeНачиная с MySQL 5.7, значение опции sql_mode по умолчанию содержит STRICT_TRANS_TABLES. Эта опция перерастает предупреждения в ошибки, когда данные усекаются при вставке, поэтому Django настоятельно рекомендует активировать strict mode для MySQL, чтобы предотвратить потерю данных (либо STRICT_TRANS_TABLES, либо STRICT_ALL_TABLES).
Если вам нужно настроить режим SQL, вы можете установить переменную sql_mode как и другие опции MySQL: либо в конфигурационном файле, либо с помощью записи 'init_command': "SET sql_mode='STRICT_TRANS_TABLES'" в OPTIONS части конфигурации вашей базы данных в DATABASES.
Уровень изоляции
При одновременной загрузке транзакции базы данных из разных сессий (скажем, отдельные потоки, обрабатывающие разные запросы) могут взаимодействовать друг с другом. На это взаимодействие влияет уровень изоляции каждого сеанса transaction isolation level. Вы можете установить уровень изоляции соединения с помощью записи 'isolation_level' в OPTIONS части конфигурации вашей базы данных в DATABASES. Допустимыми значениями для этой записи являются четыре стандартных уровня изоляции:
'read uncommitted''read committed''repeatable read''serializable'
или None для использования настроенного уровня изоляции сервера. Однако Django лучше всего работает с read committed и по умолчанию использует read committed, а не повторяющееся чтение, как MySQL по умолчанию. При использовании повторяющегося чтения возможна потеря данных. В частности, вы можете встретить случаи, когда
В частности, вы можете встретить случаи, когда get_or_create() вызовет IntegrityError, но объект не появится в последующем вызове get().
Создание таблиц
Когда Django генерирует схему, он не указывает механизм хранения, поэтому таблицы будут созданы с использованием того механизма хранения по умолчанию, на который настроен ваш сервер баз данных. Самое простое решение — это установить для сервера баз данных движок хранения по умолчанию на нужный движок.
Если вы пользуетесь услугами хостинга и не можете изменить стандартный механизм хранения данных вашего сервера, у вас есть несколько вариантов.
После создания таблиц выполните оператор
ALTER TABLEдля преобразования таблицы в новый механизм хранения (например, InnoDB):ALTER TABLE <tablename> ENGINE=INNODB;
Это может быть утомительно, если у вас много таблиц.
Другой вариант — использовать опцию
init_commandдля MySQLdb перед созданием таблиц:'OPTIONS': { 'init_command': 'SET default_storage_engine=INNODB', }Этот параметр устанавливает механизм хранения данных по умолчанию при подключении к базе данных.
После создания таблиц следует удалить эту опцию, так как она добавляет запрос, который необходим только при создании таблиц, к каждому соединению с базой данных.
 После создания таблиц следует удалить эту опцию, так как она добавляет запрос, который необходим только при создании таблиц, к каждому соединению с базой данных.
После создания таблиц следует удалить эту опцию, так как она добавляет запрос, который необходим только при создании таблиц, к каждому соединению с базой данных.Названия таблиц
Даже в последних версиях MySQL есть known issues, которые могут привести к изменению регистра имени таблицы при выполнении определенных операторов SQL в определенных условиях. Рекомендуется использовать имена таблиц в нижнем регистре, если это возможно, чтобы избежать любых проблем, которые могут возникнуть из-за такого поведения. Django использует имена таблиц в нижнем регистре при автоматической генерации имен таблиц из моделей, так что это в основном касается тех случаев, когда вы переопределяете имя таблицы через параметр db_table.
Точки сохранения
Как Django ORM, так и MySQL (при использовании InnoDB storage engine) поддерживают базу данных savepoints.
Если вы используете механизм хранения MyISAM, пожалуйста, имейте в виду, что при попытке использовать savepoint-related methods of the transactions API вы будете получать ошибки, генерируемые базой данных. Причина этого в том, что определение движка хранения базы данных/таблицы MySQL является дорогостоящей операцией, поэтому было решено, что не стоит динамически преобразовывать эти методы в no-op’ы, основываясь на результатах такого определения.
Причина этого в том, что определение движка хранения базы данных/таблицы MySQL является дорогостоящей операцией, поэтому было решено, что не стоит динамически преобразовывать эти методы в no-op’ы, основываясь на результатах такого определения.
Примечания к конкретным полям
Поля символов
Любые поля, которые хранятся с типами столбцов VARCHAR, могут иметь max_length, ограниченные 255 символами, если вы используете unique=True для поля. Это влияет на CharField, SlugField. Более подробную информацию см. в разделе the MySQL documentation.
TextField ограниченияMySQL может индексировать только первые N символов столбца BLOB или TEXT. Поскольку TextField не имеет определенной длины, вы не можете пометить его как unique=True. MySQL сообщит: «BLOB/TEXT столбец „<db_column>“ использован в спецификации ключа без длины ключа».
Поддержка дробных секунд для полей Time и DateTime
MySQL может хранить дробные секунды, при условии, что определение столбца включает указание на дробь (например, DATETIME(6)).
Django не будет обновлять существующие колонки, чтобы включить в них дробные секунды, если сервер базы данных поддерживает это. Если вы хотите включить их в существующую базу данных, вам придется либо вручную обновить столбец в целевой базе данных, выполнив команду типа:
ALTER TABLE `your_table` MODIFY `your_datetime_column` DATETIME(6)
или использование операции RunSQL в операции data migration.
TIMESTAMP столбцыЕсли вы используете устаревшую базу данных, содержащую TIMESTAMP столбцов, вы должны установить USE_TZ = False, чтобы избежать повреждения данных. inspectdb отображает эти столбцы в DateTimeField, и если вы включите поддержку временных зон, то и MySQL, и Django попытаются преобразовать значения из UTC в местное время.
Блокировка строк с помощью
QuerySet.select_for_update()MySQL и MariaDB не поддерживают некоторые опции оператора SELECT .. Если  .. FOR UPDATE
.. FOR UPDATEselect_for_update() используется с неподдерживаемой опцией, то возникает ошибка NotSupportedError.
| Вариант | MariaDB | MySQL |
|---|---|---|
SKIP LOCKED |
X (≥10.6) | X (≥8.0.1) |
NOWAIT |
X (≥10.3) | X (≥8.0.1) |
OF |
X (≥8.0.1) | |
NO KEY |
При использовании select_for_update() в MySQL убедитесь, что вы фильтруете набор запросов как минимум по набору полей, содержащихся в уникальных ограничениях, или только по полям, покрытым индексами. В противном случае на всю таблицу будет наложена эксклюзивная блокировка записи на время транзакции.
Автоматическая типизация может привести к неожиданным результатам
При выполнении запроса к строковому типу, но с целым значением, MySQL приведет типы всех значений в таблице к целому числу перед выполнением сравнения. Если ваша таблица содержит значения 'abc', 'def' и вы запрашиваете WHERE mycolumn=0, обе строки будут соответствовать. Аналогично, WHERE mycolumn=1 будет соответствовать значению 'abc1'. Поэтому поля строкового типа, включенные в Django, всегда будут приводить значение к строке, прежде чем использовать его в запросе.
Если вы реализуете пользовательские поля модели, которые наследуются от Field напрямую, переопределяют get_prep_value(), или используют RawSQL, extra(), или raw(), вам следует убедиться, что вы выполнили соответствующее приведение типов.
Заметки по SQLite
Django поддерживает SQLite 3.9.0 и более поздние версии.
SQLite является отличной альтернативой для разработки приложений, которые в основном предназначены только для чтения или требуют меньшей площади для установки. Однако, как и для всех серверов баз данных, для SQLite существуют некоторые отличия, о которых следует знать.
Сопоставление подстрок и чувствительность к регистру
Для всех версий SQLite существует несколько неинтуитивное поведение при попытке сопоставления некоторых типов строк. Это происходит при использовании фильтров iexact или contains в Querysets. Поведение разделяется на два случая:
1. For substring matching, all matches are done case-insensitively. That is a
filter such as filter(name__contains="aa") will match a name of "Aabb".
2. For strings containing characters outside the ASCII range, all exact string
matches are performed case-sensitively, even when the case-insensitive options
are passed into the query. So the iexact filter will behave exactly
the same as the exact filter in these cases.
Некоторые возможные обходные пути для этого — documented at sqlite.org, но они не используются бэкендом SQLite по умолчанию в Django, так как их было бы довольно сложно реализовать надежно. Таким образом, Django использует поведение SQLite по умолчанию, и вам следует помнить об этом при выполнении фильтрации без учета регистра или подстроки.
Работа с десятичными дробями
SQLite не имеет реального десятичного внутреннего типа. Десятичные значения внутренне преобразуются в тип данных REAL (8-байтовое число IEEE с плавающей точкой), как объясняется в SQLite datatypes documentation, поэтому они не поддерживают правильно округленную десятичную арифметику с плавающей точкой.
Ошибки «База данных заблокирована»
SQLite предназначен для легковесной базы данных и поэтому не может поддерживать высокий уровень параллелизма. Ошибки OperationalError: database is locked указывают на то, что ваше приложение испытывает больше параллелизма, чем sqlite может обработать в конфигурации по умолчанию. Эта ошибка означает, что один поток или процесс имеет эксклюзивную блокировку на соединение с базой данных, а другой поток затянул время, ожидая освобождения блокировки.
Эта ошибка означает, что один поток или процесс имеет эксклюзивную блокировку на соединение с базой данных, а другой поток затянул время, ожидая освобождения блокировки.
Обертка SQLite в Python имеет значение тайм-аута по умолчанию, которое определяет, как долго второму потоку разрешено ждать блокировки, прежде чем он прервется и выдаст ошибку OperationalError: database is locked.
Если вы получаете эту ошибку, вы можете решить ее следующим образом:
Переход на другой бэкенд базы данных. В определенный момент SQLite становится слишком «легким» для реальных приложений, и подобные ошибки параллелизма указывают на то, что вы достигли этой точки.
Переписывание кода для уменьшения параллелизма и обеспечения кратковременности транзакций с базой данных.
Увеличьте значение тайм-аута по умолчанию, установив параметр базы данных
timeout:'OPTIONS': { # ... 'timeout': 20, # . ..
}
Это заставит SQLite подождать немного дольше, прежде чем выдать ошибку «база данных заблокирована»; на самом деле это ничего не сделает для ее решения.
 ..
}
..
}
QuerySet.select_for_update() не поддерживаетсяSQLite не поддерживает синтаксис SELECT ... FOR UPDATE. Его вызов не даст никакого эффекта.
Стиль параметра «pyformat» в необработанных запросах не поддерживается
Для большинства бэкендов необработанные запросы (Manager.raw() или cursor.execute()) могут использовать стиль параметров «pyformat», при котором заполнители в запросе задаются как '%(name)s', а параметры передаются в виде словаря, а не списка. SQLite этого не поддерживает.
Изоляция при использовании
QuerySet.iterator()Существуют особые соображения, описанные в Isolation In SQLite при модификации таблицы во время итерации по ней с помощью QuerySet.iterator(). Если строка добавляется, изменяется или удаляется внутри цикла, то эта строка может появиться или не появиться, или появиться дважды в последующих результатах, получаемых из итератора. Ваш код должен справиться с этим.
Если строка добавляется, изменяется или удаляется внутри цикла, то эта строка может появиться или не появиться, или появиться дважды в последующих результатах, получаемых из итератора. Ваш код должен справиться с этим.
Включение расширения JSON1 в SQLite
Чтобы использовать JSONField на SQLite, необходимо включить JSON1 extension на Python библиотеку sqlite3. Если расширение не включено на вашей установке, будет выдана системная ошибка (fields.E180).
Чтобы включить расширение JSON1, вы можете следовать инструкции на the wiki page.
Заметки Oracle
Django поддерживает Oracle Database Server версии 19c и выше. Требуется версия 7.0 или выше драйвера cx_Oracle Python.
Для того чтобы команда python manage.py migrate работала, пользователь базы данных Oracle должен иметь привилегии для выполнения следующих команд:
- СОЗДАТЬ ТАБЛИЦУ
- СОЗДАТЬ ПОСЛЕДОВАТЕЛЬНОСТЬ
- СОЗДАТЬ ПРОЦЕДУРУ
- СОЗДАТЬ ТРИГГЕР
Чтобы запустить тестовый пакет проекта, пользователю обычно нужны эти дополнительные привилегии:
- СОЗДАТЬ ПОЛЬЗОВАТЕЛЯ
- ПЕРЕМЕННЫЙ ПОЛЬЗОВАТЕЛЬ
- УВОЛИТЬ ПОЛЬЗОВАТЕЛЯ
- СОЗДАТЬ ТАБЛИЧНОЕ ПРОСТРАНСТВО
- СБРОСИТЬ ТАБЛИЧНОЕ ПРОСТРАНСТВО
- СОЗДАТЬ СЕАНС С ВОЗМОЖНОСТЬЮ АДМИНИСТРИРОВАНИЯ
- СОЗДАНИЕ ТАБЛИЦЫ С ВОЗМОЖНОСТЬЮ АДМИНИСТРИРОВАНИЯ
- СОЗДАНИЕ ПОСЛЕДОВАТЕЛЬНОСТИ С ПОМОЩЬЮ ОПЦИИ АДМИНИСТРАТОРА
- СОЗДАНИЕ ПРОЦЕДУРЫ С ВОЗМОЖНОСТЬЮ АДМИНИСТРИРОВАНИЯ
- СОЗДАНИЕ ТРИГГЕРА С ВОЗМОЖНОСТЬЮ АДМИНИСТРИРОВАНИЯ
Хотя роль RESOURCE имеет необходимые привилегии CREATE TABLE, CREATE SEQUENCE, CREATE PROCEDURE и CREATE TRIGGER, а пользователь с ролью RESOURCE WITH ADMIN OPTION может предоставить RESOURCE, такой пользователь не может предоставить отдельные привилегии (например, CREATE TABLE), и поэтому RESOURCE WITH ADMIN OPTION обычно недостаточно для выполнения тестов.
Некоторые тестовые наборы также создают представления или материализованные представления; для их запуска пользователю также необходимы привилегии CREATE VIEW WITH ADMIN OPTION и CREATE MATERIALIZED VIEW WITH ADMIN OPTION. В частности, это необходимо для собственного тестового пакета Django.
Все эти привилегии входят в роль DBA, которая подходит для использования в базе данных частного разработчика.
Бэкенд базы данных Oracle использует пакеты SYS.DBMS_LOB и SYS.DBMS_RANDOM, поэтому вашему пользователю потребуются права на выполнение. Обычно по умолчанию он доступен всем пользователям, но если это не так, вам нужно будет предоставить права следующим образом:
GRANT EXECUTE ON SYS.DBMS_LOB TO user; GRANT EXECUTE ON SYS.DBMS_RANDOM TO user;
Подключение к базе данных
Чтобы подключиться, используя имя службы вашей базы данных Oracle, ваш файл settings.py должен выглядеть примерно так:
DATABASES = {
'default': {
'ENGINE': 'django. db.backends.oracle',
'NAME': 'xe',
'USER': 'a_user',
'PASSWORD': 'a_password',
'HOST': '',
'PORT': '',
}
}
 db.backends.oracle',
'NAME': 'xe',
'USER': 'a_user',
'PASSWORD': 'a_password',
'HOST': '',
'PORT': '',
}
}
db.backends.oracle',
'NAME': 'xe',
'USER': 'a_user',
'PASSWORD': 'a_password',
'HOST': '',
'PORT': '',
}
}
В этом случае следует оставить пустыми оба HOST и PORT. Однако, если вы не используете tnsnames.ora файл или аналогичный метод именования и хотите подключиться, используя SID («xe» в данном примере), то заполните оба HOST и PORT следующим образом:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.oracle',
'NAME': 'xe',
'USER': 'a_user',
'PASSWORD': 'a_password',
'HOST': 'dbprod01ned.mycompany.com',
'PORT': '1540',
}
}
Вы должны либо указать оба значения HOST и PORT, либо оставить оба значения пустыми строками. Django будет использовать другой дескриптор подключения в зависимости от этого выбора.
Полная DSN и Easy Connect
Полная строка DSN или Easy Connect может использоваться в NAME, если оба HOST и PORT пусты. Этот формат необходим, например, при использовании RAC или подключаемых баз данных без tnsnames.ora.
Пример строки Easy Connect:
'NAME': 'localhost:1521/orclpdb1',
Пример полной строки DSN:
'NAME': (
'(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=localhost)(PORT=1521))'
'(CONNECT_DATA=(SERVICE_NAME=orclpdb1)))'
),
Вариант с резьбой
Если вы планируете запускать Django в многопоточной среде (например, Apache с использованием модуля MPM по умолчанию в любой современной операционной системе), то вы должны установить опцию threaded в конфигурации вашей базы данных Oracle на True:
'OPTIONS': {
'threaded': True,
},
Невыполнение этого требования может привести к сбоям и другим странным действиям.
ВСТАВИТЬ … ВОЗВРАЩЕНИЕ В
По умолчанию бэкенд Oracle использует предложение RETURNING INTO для эффективного получения значения AutoField при вставке новых строк. Такое поведение может привести к появлению DatabaseError в некоторых необычных настройках, например, при вставке в удаленную таблицу или в представление с триггером INSTEAD OF. Пункт DatabaseError можно отключить, установив параметр INSTEAD OF конфигурации базы данных в значение RETURNING INTO:
'OPTIONS': {
'use_returning_into': False,
},
В этом случае бэкенд Oracle будет использовать отдельный запрос SELECT для получения значений AutoField.
Вопросы наименования
Oracle устанавливает ограничение на длину имени в 30 символов. Для этого бэкенд усекает идентификаторы баз данных, заменяя последние четыре символа усеченного имени повторяющимся хэш-значением MD5. Кроме того, бэкэнд переводит идентификаторы баз данных в верхний регистр.
Кроме того, бэкэнд переводит идентификаторы баз данных в верхний регистр.
Чтобы предотвратить эти преобразования (обычно это требуется только при работе с устаревшими базами данных или при доступе к таблицам, принадлежащим другим пользователям), используйте имя в кавычках в качестве значения для db_table:
class LegacyModel(models.Model):
class Meta:
db_table = '"name_left_in_lowercase"'
class ForeignModel(models.Model):
class Meta:
db_table = '"OTHER_USER"."NAME_ONLY_SEEMS_OVER_30"'
Имена в кавычках можно использовать и с другими поддерживаемыми в Django бэкендами баз данных; однако, за исключением Oracle, кавычки не имеют никакого эффекта.
При выполнении migrate может возникнуть ошибка ORA-06552, если некоторые ключевые слова Oracle используются в качестве имени поля модели или значения опции db_column. Django заключает в кавычки все идентификаторы, используемые в запросах, чтобы предотвратить большинство подобных проблем, но эта ошибка все же может возникнуть, если в качестве имени столбца используется тип данных Oracle. В частности, старайтесь избегать использования имен
В частности, старайтесь избегать использования имен date, timestamp, number или float в качестве имени поля.
NULL и пустые строки
Django обычно предпочитает использовать пустую строку (''), а не NULL, но Oracle рассматривает оба варианта одинаково. Чтобы обойти это, бэкенд Oracle игнорирует явную опцию null для полей, которые имеют пустую строку в качестве возможного значения, и генерирует DDL, как если бы null=True. При выборке из базы данных предполагается, что значение NULL в одном из этих полей действительно означает пустую строку, и данные молча преобразуются, чтобы отразить это предположение.
TextField ограниченияБэкенд Oracle хранит TextFields как NCLOB столбцы. Oracle накладывает некоторые ограничения на использование таких LOB-столбцов в целом:
- Столбцы LOB не могут использоваться в качестве первичных ключей.
- LOB-столбцы не могут использоваться в индексах.
- LOB-столбцы не могут использоваться в списке
SELECT DISTINCT. Это означает, что попытка использовать методQuerySet.distinctв модели, которая включаетTextFieldстолбцов, приведет к ошибкеORA-00932при запуске в Oracle. В качестве обходного пути используйте методQuerySet.deferв сочетании сdistinct(), чтобы предотвратить включениеTextFieldстолбцов в списокSELECT DISTINCT.
Подклассы встроенных бэкендов баз данных
Django поставляется со встроенными бэкендами баз данных. Вы можете подклассифицировать существующий бэкенд базы данных, чтобы изменить его поведение, возможности или конфигурацию.
Рассмотрим, например, что вам нужно изменить одну функцию базы данных. Сначала нужно создать новый каталог с модулем base в нем. Например:
mysite/
...
mydbengine/
__init__. py
base.py
 py
base.py
py
base.py
Модуль base.py должен содержать класс с именем DatabaseWrapper, который подклассифицирует существующий движок из модуля django.db.backends. Вот пример подклассификации движка PostgreSQL для изменения функционального класса allows_group_by_selected_pks_on_model:
mysite/mydbengine/base.py
from django.db.backends.postgresql import base, features
class DatabaseFeatures(features.DatabaseFeatures):
def allows_group_by_selected_pks_on_model(self, model):
return True
class DatabaseWrapper(base.DatabaseWrapper):
features_class = DatabaseFeatures
Наконец, вы должны указать DATABASE-ENGINE в вашем settings.py файле:
DATABASES = {
'default': {
'ENGINE': 'mydbengine',
...
},
}
Вы можете посмотреть текущий список движков баз данных, заглянув в django/db/backends.
Использование бэкенда базы данных стороннего производителя
Помимо официально поддерживаемых баз данных, существуют бэкенды, предоставляемые сторонними разработчиками, которые позволяют использовать другие базы данных с Django:
- CockroachDB
- Firebird
- Google Cloud Spanner
- Microsoft SQL Server
Версии Django и возможности ORM, поддерживаемые этими неофициальными бэкендами, значительно различаются. Запросы относительно специфических возможностей этих неофициальных бэкендов, а также любые вопросы поддержки, должны быть направлены в каналы поддержки, предоставляемые каждым сторонним проектом.
Анализ данных с помощью pandas. Часть 8: работа с данными из базы данных SQL
До этого момента, мы получали данные только из csv файлов. Это довольно распространённый способ сохранения данных, но далеко не единственный! Pandas может работать с данными из HTML, JSON, SQL, Excel (!!!), HDF5, Stata, и некоторых других вещей. В этой части мы поговорим о работе с данными из баз данных SQL.
В этой части мы поговорим о работе с данными из баз данных SQL.
In [1]:
import pandas as pd import sqlite3
Чтение из SQL баз данных
Загрузить данные из SQL базы можно с помощью функции pd.read_sql. read_sql автоматически преобразует столбцы SQL в столбцы DataFrame.
read_sql принимает 2 аргумента: запрос SELECT, и connection. Это здорово, так как это означает, что можно читать из любого вида базы данных — неважно, MySQL, SQLite, PostgreSQL, или другая.
В этом примере мы читаем из базы SQLite, но другие читаются точно также. Файл, с которым мы будем работать.
In [2]:
con = sqlite3.connect("data/weather_2012.sqlite")
df = pd.read_sql("SELECT * from weather_2012 LIMIT 3", con)
dfOut[2]:
| id | date_time | temp | |
|---|---|---|---|
| 0 | 1 | 2012-01-01 00:00:00 | -1.8 |
| 1 | 2 | 2012-01-01 01:00:00 | -1. 8 8 |
| 2 | 3 | 2012-01-01 02:00:00 | -1.8 |
read_sql не устанавливает первичный ключ (id) в качестве индекса. Можно это сделать вручную, добавив аргумент index_col к read_sql.
Если вы много использовали read_csv, вы могли заметить, что у него также есть аргумент index_col. И ведёт он себя точно так же.
In [3]:
df = pd.read_sql("SELECT * from weather_2012 LIMIT 3", con, index_col='id')
dfOut[3]:
| date_time | temp | |
|---|---|---|
| id | ||
| 1 | 2012-01-01 00:00:00 | -1.8 |
| 2 | 2012-01-01 01:00:00 | -1.8 |
| 3 | 2012-01-01 02:00:00 | -1.8 |
Если вы хотите, чтобы dataframe был индексирован несколькими столбцами, в index_col можно указать их список:
In [4]:
df = pd.
 read_sql("SELECT * from weather_2012 LIMIT 3", con,
index_col=['id', 'date_time'])
df
read_sql("SELECT * from weather_2012 LIMIT 3", con,
index_col=['id', 'date_time'])
dfOut[4]:
| temp | ||
|---|---|---|
| id | date_time | |
| 1 | 2012-01-01 00:00:00 | -1.8 |
| 2 | 2012-01-01 01:00:00 | -1.8 |
| 3 | 2012-01-01 02:00:00 | -1.8 |
Запись в базу
Запись производится с помощью метода to_sql (по аналогии с CSV):
In [5]:
weather_df = pd.read_csv('data/weather_2012.csv')
con = sqlite3.connect("data/test_db.sqlite")
con.execute("DROP TABLE IF EXISTS weather_2012")
weather_df.to_sql("weather_2012", con)/usr/local/lib/python3.5/dist-packages/pandas/core/generic.py:1345: UserWarning: The spaces in these column names will not be changed. In pandas versions < 0.14, spaces were converted to underscores. chunksize=chunksize, dtype=dtype)
Теперь мы можем загрузить записанные данные:
In [6]:
con = sqlite3.
 connect("data/test_db.sqlite")
df = pd.read_sql("SELECT * from weather_2012 LIMIT 3", con)
df
connect("data/test_db.sqlite")
df = pd.read_sql("SELECT * from weather_2012 LIMIT 3", con)
dfOut[6]:
| index | Date/Time | Temp (C) | Dew Point Temp (C) | Rel Hum (%) | Wind Spd (km/h) | Visibility (km) | Stn Press (kPa) | Weather | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 2012-01-01 00:00:00 | -1.8 | -3.9 | 86 | 4 | 8.0 | 101.24 | Fog |
| 1 | 1 | 2012-01-01 01:00:00 | -1.8 | -3.7 | 87 | 4 | 8.0 | 101.24 | Fog |
| 2 | 2 | 2012-01-01 02:00:00 | -1.8 | -3.4 | 89 | 7 | 4.0 | 101.26 | Freezing Drizzle,Fog |
Главное преимущество хранения данных в базе в том, что можно напрямую делать SQL запросы. Это особенно хорошо, если SQL для вас более родной язык. Например, можно отсортировать по колонке ‘Weather’ с помощью лишь SQL:
In [7]:
con = sqlite3.
 connect("data/test_db.sqlite")
df = pd.read_sql("SELECT * from weather_2012 ORDER BY Weather LIMIT 3", con)
df
connect("data/test_db.sqlite")
df = pd.read_sql("SELECT * from weather_2012 ORDER BY Weather LIMIT 3", con)
dfOut[7]:
| index | Date/Time | Temp (C) | Dew Point Temp (C) | Rel Hum (%) | Wind Spd (km/h) | Visibility (km) | Stn Press (kPa) | Weather | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 67 | 2012-01-03 19:00:00 | -16.9 | -24.8 | 50 | 24 | 25.0 | 101.74 | Clear |
| 1 | 114 | 2012-01-05 18:00:00 | -7.1 | -14.4 | 56 | 11 | 25.0 | 100.71 | Clear |
| 2 | 115 | 2012-01-05 19:00:00 | -9.2 | -15.4 | 61 | 7 | 25.0 | 100.80 | Clear |
Другие базы данных
Для подключения к MySQL:
Чтобы это работало, у вас на машине должна быть установлена соответствующая база данных
In [ ]:
import MySQLdb con = MySQLdb.
 connect(host="localhost", db="test")
connect(host="localhost", db="test")PostgreSQL:
In [ ]:
import psycopg2 con = psycopg2.connect(host="localhost")
Для вставки кода на Python в комментарий заключайте его в теги <pre><code>Ваш код</code></pre>
Свежее
- Модуль csv — чтение и запись CSV файлов
- Создаём сайт на Django, используя хорошие практики. Часть 1: создаём проект
- Онлайн-обучение Python: сравнение популярных программ
Категории
- Книги о Python
- GUI (графический интерфейс пользователя)
- Курсы Python
- Модули
- Новости мира Python
- NumPy
- Обработка данных
- Основы программирования
- Примеры программ
- Типы данных в Python
- Видео
- Python для Web
- Работа для Python-программистов
Полезные материалы
- Сделай свой вклад в развитие сайта!
- Самоучитель Python
- Карта сайта
- Отзывы на книги по Python
- Реклама на сайте
Мы в соцсетях
Как работает модуль sqlite3 в Python 3
26 апреля, 2021 11:42 дп 2 052 views | Комментариев нетDevelopment, Python | Amber | Комментировать запись
SQLite – это файловая база данных SQL, которая поставляется в комплекте с Python и может использоваться в приложениях Python, устраняя необходимость устанавливать дополнительное программное обеспечение.
В этом руководстве мы поговорим о модуле sqlite3 в Python 3. Чтобы потренироваться, мы создадим соединение с базой данных SQLite, добавим в эту БД таблицу, вставим данные, а также извлечем и отредактируем их.
Предположим, у нас есть аквариум и мы хотим создать БД, чтобы хранить в ней данные о рыбах, которые в нем живут.
Требования
Чтобы получить максимальную пользу от этого руководства, вы должны иметь некоторое представление о работе с Python и некоторый базовый опыт работы с SQL.
Для получения необходимой справочной информации вы можете просмотреть эти ресурсы:
- Раздел о Python3
- Запросы в MySQL
1: Создание подключения к базе данных SQLite
Базы данных SQLite – это полнофункциональные механизмы SQL, которые можно использовать для многих целей. Подключаясь к БД SQLite, мы получаем доступ к данным, которые находятся в файле на нашем компьютере. В данном разделе для примера мы рассмотрим базу данных, которая помогает нам отслеживать количество рыб в воображаемом аквариуме.
Подключиться к базе данных SQLite можно с помощью модуля sqlite3:
import sqlite3
connection = sqlite3.connect("aquarium.db")
Строка import sqlite3 дает программе Python доступ к модулю sqlite3. Функция sqlite3.connect () возвращает объект Connection, который мы будем использовать для взаимодействия с базой данных SQLite, хранящейся в файле aquarium.db. Файл aquarium.db создается функцией sqlite3.connect() автоматически (если такой файл еще не существует на компьютере).
Чтобы убедиться, что объект connection создан успешно, запустите:
print(connection.total_changes)
Если мы запустим этот код Python, мы увидим такой результат:
0
connection.total_changes в команде выше – это общее количество строк базы данных, которые были изменены объектом connection. Поскольку мы еще не выполнили ни одной команды SQL, мы ожидаем получить 0.
Если в какой-то момент вы захотите начать это руководство сначала, вы можете удалить файл aquarium. db с компьютера.
db с компьютера.
Примечание: Также можно подключиться к базе данных SQLite, которая находится строго в памяти (а не в файле), передав функции sqlite3.connect()специальную строку “:memory:”. Например:
sqlite3.connect(“:memory:”)
Помните: такая база данных SQLite исчезнет, как только Python завершит работу. Это может быть удобно, если вам нужна временная песочница, в которой вы могли бы опробовать какие-то функции, и вы не хотите сохранять данные после выхода из программы.
2: Добавление данных в БД SQLite
После того как мы подключились к базе данных aquarium.db, мы можем попробовать вставить в нее данные и извлечь их.
В базах SQL данные хранятся в таблицах. Таблицы определяют набор столбцов и содержат 0 или более строк с данными для каждого столбца.
Давайте создадим таблицу fish, в которой будут такие данные:
| name | species | tank_number |
| Willy | shark | 1 |
| Jamie | cuttlefish | 7 |
Итак, таблица fish будет содержать имя (столбец name), вид (species) и номер резервуара (tank_number) для каждой рыбы в аквариуме. Согласно записям, пока что в аквариуме есть два жителя: акула Вилли и каракатица по имени Джейми.
Согласно записям, пока что в аквариуме есть два жителя: акула Вилли и каракатица по имени Джейми.
Создать эту таблицу рыб в SQLite можно при помощи соединения, которое мы установили в разделе 1:
cursor = connection.cursor()
cursor.execute("CREATE TABLE fish (name TEXT, species TEXT, tank_number INTEGER)")
connection.cursor() возвращает объект Cursor. Такие объекты позволяют отправлять SQL-операторы в базу данных SQLite с помощью cursor.execute(). Строка “CREATE TABLE fish …” – это SQL-оператор, который создает таблицу fish с тремя описанными столбцами: name (с типом данных TEXT), species (также с типом TEXT) и tank_number (с типом INTEGER).
Теперь, когда мы создали таблицу, мы можем вставить в нее строки данных:
cursor.execute("INSERT INTO fish VALUES ('Willy', 'shark', 1)")
cursor.execute("INSERT INTO fish VALUES ('Jamie', 'cuttlefish', 7)")
Мы вызываем cursor.execute() дважды: один раз, чтобы вставить строку об акуле Вилли из резервуара 1, и еще раз, чтобы вставить строку о каракатице Джейми из резервуара 7. “INSERT INTO fish VALUES …” – это SQL-оператор, который позволяет добавлять строки в таблицу.
“INSERT INTO fish VALUES …” – это SQL-оператор, который позволяет добавлять строки в таблицу.
В следующем разделе мы познакомимся с SQL-оператором SELECT:он поможет нам проверить строки, которые мы только что вставили в нашу таблицу.
3: Извлечение данных из БД SQLite
В разделе 2 мы добавили в таблицу по имени fish две строки. Извлечь эти строки можно с помощью оператора SELECT:
rows = cursor.execute("SELECT name, species, tank_number FROM fish").fetchall()
print(rows)
Если запустить этот код, мы получим такой результат:
[('Willy', 'shark', 1), ('Jamie', 'cuttlefish', 7)]
Функция cursor.execute() запускает оператор SELECT для получения значений столбцов name, species и tank_number в таблице fish. Функция fetchall() извлекает все результаты оператора SELECT. Когда мы с помощью print(rows) выводим строки на экран, мы видим список из двух кортежей. Каждый кортеж состоит из трех записей – по одной записи для каждого столбца из таблицы. Оба кортежа содержат данные, которые мы вставили в таблицу в предыдущем разделе.
Оба кортежа содержат данные, которые мы вставили в таблицу в предыдущем разделе.
Допустим, нам нужно извлечь из таблицы только строки, которые соответствуют определенному набору критериев. Тогда мы можем использовать оператор WHERE:
target_fish_name = "Jamie"
rows = cursor.execute(
"SELECT name, species, tank_number FROM fish WHERE name = ?",
(target_fish_name,),
).fetchall()
print(rows)
Это даст следующий результат:
[('Jamie', 'cuttlefish', 7)]
Как и в предыдущем примере, cursor.execute(<SQL statement>).fetchall() позволяет извлечь все результаты оператора SELECT. Оператор WHERE в SELECT фильтрует данные и выбирает строки, в которых значение name равно искомому target_fish_name. Обратите внимание: мы используем символ «?», чтобы заменить значение переменной target_fish_name в операторе SELECT. Мы ожидаем, что заданному фильтру будет соответствовать только одна строка, и в результате действительно видим только строку Jamie, cuttlefish, 7.
Важно! Никогда не используйте строковые операции Python, чтобы динамически создать строку оператора SQL. Использование строковых операций Python для сборки операторов SQL открывает все двери атакам на основе SQL-инъекций. Подобные атаки могут использоваться для кражи или изменения данных, хранящихся в вашей БД. Для динамической замены всегда используйте заполнитель «?» в SQL-операторах. Передайте функции Cursor.execute() кортеж значений в качестве второго аргумента, чтобы привязать ваши значения к оператору. Такой подход используется в этом руководстве.
4: Изменение данных в БД SQLite
Строки в базе данных SQLite можно изменять с помощью SQL-операторов UPDATE и DELETE.
Предположим, что акула Вилли переехала в резервуар №2. Следовательно, нам нужно изменить строку в таблице, чтобы отразить это изменение:
new_tank_number = 2
moved_fish_name = "Willy"
cursor.execute(
"UPDATE fish SET tank_number = ? WHERE name = ?",
(new_tank_number, moved_fish_name)
)
SQL-оператор UPDATE изменит значение tank_number для записи Willy на 2.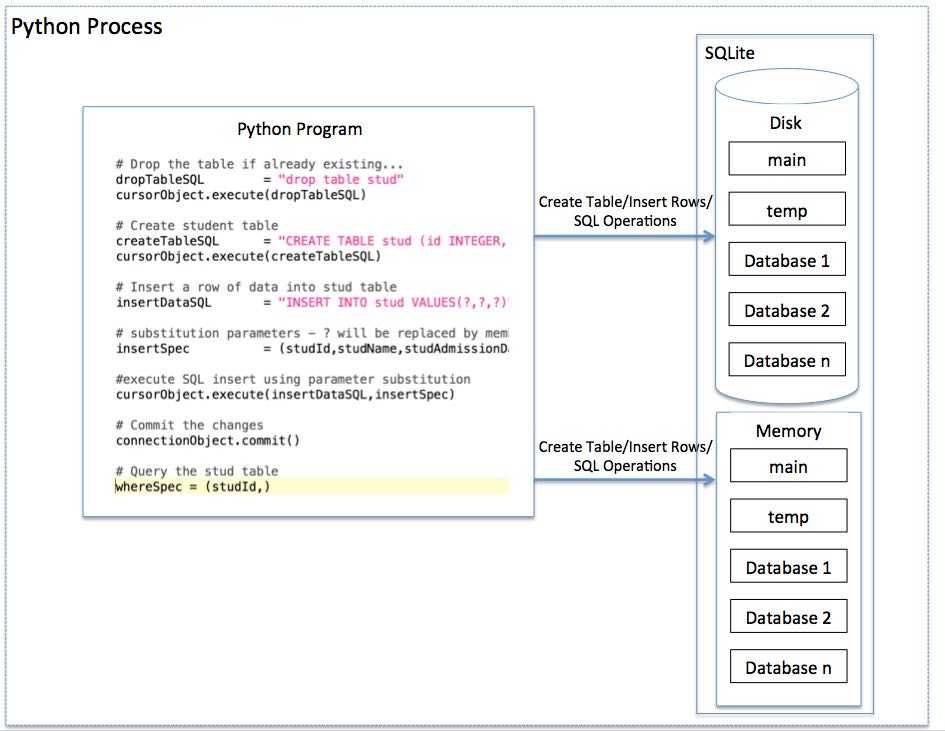 Оператор WHERE внутри UPDATE отфильтрует все остальные записи: значение tank_number изменится только в том случае, если name = “Willy”.
Оператор WHERE внутри UPDATE отфильтрует все остальные записи: значение tank_number изменится только в том случае, если name = “Willy”.
Давайте запустим следующий оператор SELECT, чтобы подтвердить, что данные обновлены правильно:
rows = cursor.execute("SELECT name, species, tank_number FROM fish").fetchall()
print(rows)
Мы увидим следующий результат:
[('Willy', 'shark', 2), ('Jamie', 'cuttlefish', 7)]
Обратите внимание, в строке для Willy столбец tank_number теперь имеет значение 2.
Допустим, акула Вилли была выпущена в дикую природу и больше не живет в нашем аквариуме. Значит, имеет смысл удалить эту строку из таблицы.
Выполните SQL-оператор DELETE, чтобы удалить строку:
released_fish_name = "Willy"
cursor.execute(
"DELETE FROM fish WHERE name = ?",
(released_fish_name,)
)
SQL-оператор DELETE удалит строку, а оператор WHERE поможет ему найти необходимую: строка будет удалена только в том случае, если name = “Willy”.
Следующий оператор SELECT подтвердит, что удаление выполнено правильно:
rows = cursor.execute("SELECT name, species, tank_number FROM fish").fetchall()
print(rows)
Мы получим следующий результат:
[('Jamie', 'cuttlefish', 7)]
Обратите внимание, строки про акулу Вилли больше нет в таблице, остается только каракатица Джейми.
5: Оператор with
В течение работы с этим руководством мы использовали два основных объекта для взаимодействия с базой данных aquarium.db: объект Connection по имени connection и объект Cursor по имени cursor.
Когда файлы Python больше не используются, их нужно закрывать – точно так же следует закрыть и объекты Connection и Cursor, когда они больше не нужны.
Автоматически закрывать объекты Connection и Cursor можно при помощи оператора with.
from contextlib import closing
with closing(sqlite3.connect("aquarium.db")) as connection:
with closing(connection. cursor()) as cursor:
cursor()) as cursor:
rows = cursor.execute("SELECT 1").fetchall()
print(rows)
closing – это удобная функция, предоставляемая модулем contextlib. Когда оператор with завершает работу, closing вызывает функцию close()для любого переданного ему объекта. В этом примере closing используется дважды: один раз для объекта Connection, второй раз – для объекта Cursor.
Этот код даст нам следующий результат:
[(1,)]
Поскольку оператор SELECT 1 всегда возвращает одну строку с одним столбцом со значением 1, в результате мы получаем кортеж с единственным значением 1.
Заключение
Модуль sqlite3 – мощная часть стандартной библиотеки Python; он позволяет работать с полнофункциональной базой данных SQL, не устанавливая никакого дополнительного программного обеспечения.
В этом руководстве вы узнали, как использовать sqlite3 для подключения к базе данных SQLite, добавлять данные в эту БД, а также читать и изменять эти данные. Попутно мы также кратко поговорили об опасности SQL-инъекций и о том, как использовать contextlib. closing, чтобы автоматически закрыть объекты Python.
closing, чтобы автоматически закрыть объекты Python.
Читайте также: Краткий обзор реляционных систем управления базами данных
Tags: Python, Python 3, SQL, SQLiteУчебники по базам данных Python — Real Python
В этом разделе собраны все наши руководства, связанные с работой с базами данных в Python. Мы расскажем о таких вещах, как базы данных SQL и NoSQL, и о том, как взаимодействовать с ними с помощью Python.
Бесплатный бонус: Нажмите здесь, чтобы загрузить скелет проекта Python + MongoDB с полным исходным кодом, который показывает, как получить доступ к MongoDB из Python.
Создание средства сокращения URL-адресов с помощью FastAPI и Python
23 августа 2022 г. API базы данных средний проекты веб-разработчик
Асинхронные задачи с Django и Celery
01 августа 2022 г.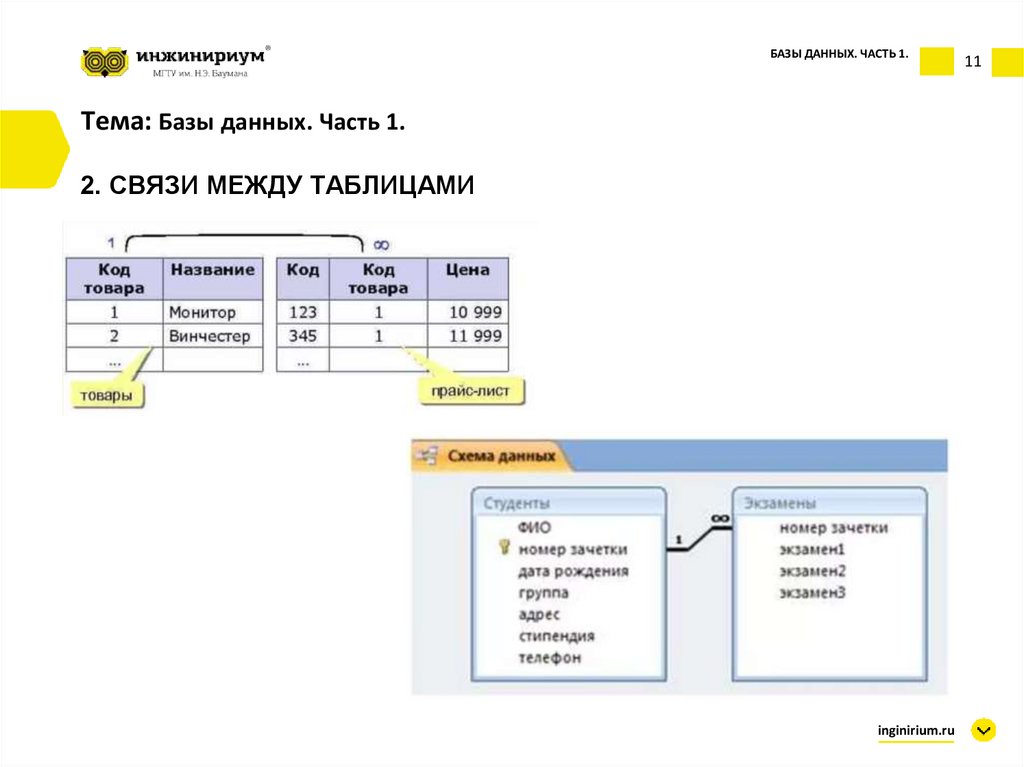 передовой
базы данных
Джанго
веб-разработчик
передовой
базы данных
Джанго
веб-разработчик
SQLite и SQLAlchemy в Python: перемещение ваших данных за пределы плоских файлов
12 июля 2022 г. базы данных средний веб-разработчик
Создание средства сокращения URL-адресов с помощью FastAPI и Python
18 мая 2022 г. API базы данных средний проекты веб-разработчик
Чтение и запись файлов с помощью Pandas
базы данных наука о данных средний
Создание контактной книги с помощью Python, PyQt и SQLite
базы данных графический интерфейс средний проекты
Python и MongoDB: подключение к базам данных NoSQL
базы данных средний
База данных Python и MySQL: практическое введение
базы данных наука о данных средний
Обработка баз данных SQL с помощью PyQt: основы
базы данных графический интерфейс средний
Управление данными с помощью Python, SQLite и SQLAlchemy
базы данных средний веб-разработчик
Введение в библиотеки Python SQL
основы базы данных инструменты
Вопросы для собеседования с Data Engineer с Python
базы данных devops средний
Панды: как читать и записывать файлы
базы данных наука о данных средний
Предотвращение атак SQL-инъекций с помощью Python
лучшие практики базы данных средний
Копаем глубже в миграции Django
базы данных Джанго средний веб-разработчик
Как использовать Redis с Python
базы данных средний
Как создать индекс в Django без простоев
передовой базы данных Джанго
Python REST API с Flask, Connexion и SQLAlchemy — часть 3
API базы данных колба средний веб-разработчик
Django Migrations: учебник для начинающих
основы базы данных Джанго веб-разработчик
Python REST API с Flask, Connexion и SQLAlchemy — часть 2
API базы данных колба средний веб-разработчик
Python + Memcached: эффективное кэширование в распределенных приложениях
базы данных средний веб-разработчик
Создание простого веб-приложения с помощью Bottle, SQLAlchemy и Twitter API
API базы данных проекты веб-разработчик
Начало работы с каналами Django
передовой базы данных Джанго веб-разработчик
Кэширование в Django с Redis
базы данных Джанго средний веб-разработчик
Развертывание Django + Python 3 + PostgreSQL в AWS Elastic Beanstalk
передовой базы данных devops Джанго веб-разработчик
Python, Ruby и Golang: сравнение приложений веб-службы
базы данных колба веб-разработчик
Развлечение с новыми функциями Postgres от Django
передовой базы данных Джанго веб-разработчик
Веб-скрейпинг и сканирование с помощью Scrapy и MongoDB
базы данных просмотр веб-страниц
Развертывание приложения Django на AWS Elastic Beanstalk
передовой базы данных devops Джанго веб-разработчик
Парсинг веб-страниц с помощью Scrapy и MongoDB
базы данных просмотр веб-страниц
Обработка подтверждения по электронной почте во время регистрации в Flask
базы данных колба средний веб-разработчик
Flask на примере — реализация очереди задач Redis
базы данных колба веб-разработчик
Миграция данных
базы данных Джанго веб-разработчик
Flask на примере — настройка Postgres, SQLAlchemy и Alembic
базы данных devops колба веб-разработчик
Управление транзакциями с помощью Django 1.
 6
6передовой базы данных Джанго веб-разработчик
Rethink Flask — простой список задач на базе Flask и RethinkDB
базы данных колба проекты веб-разработчик
Перенос вашего проекта Django на Heroku
передовой базы данных devops Джанго веб-разработчик
Web2py — переход с SQLite на MySQL
передовой базы данных веб-разработчик
Базы данных — Full Stack Python
База данных — это абстракция над
файловая система операционной системы, которая делает
разработчикам проще создавать приложения, которые создают, читают, обновляют
и удалить постоянные данные.
Зачем нужны базы данных?
На высоком уровне веб-приложения хранят данные и представляют их пользователям в полезный способ. Например, Google хранит данные о дорогах и предоставляет направления, чтобы добраться из одного места в другое, проезжая через Приложение Карты. Направления движения возможно, потому что данные хранятся в структурированном формате.
Базы данных делают структурированное хранилище надежным и быстрым. Они также дают вам ментальную основу для того, как данные должны быть сохранены и извлечены вместо необходимость выяснять, что делать с данными каждый раз, когда вы создаете новый заявление.
Базы данных — это концепция, имеющая множество реализаций, включая PostgreSQL, MySQL и SQLite. Также существуют нереляционные базы данных, называемые хранилищами данных NoSQL. Узнайте больше в главе о данных или просмотрите оглавление по всем темам.
Реляционные базы данных
Абстракция хранилища базы данных, наиболее часто используемая в веб-разработке Python. это наборы реляционных таблиц. Объясняются альтернативные абстракции хранения
на странице NoSQL.
это наборы реляционных таблиц. Объясняются альтернативные абстракции хранения
на странице NoSQL.
Реляционные базы данных хранят данные в виде набора таблиц. Соединения между таблицами указаны как внешних ключей . Внешний ключ — это уникальная ссылка из одной строки в реляционной таблице на другую строку в таблица, которая может быть одной и той же таблицей, но чаще всего другой таблицей.
Реализации хранения баз данных различаются по сложности. SQLite, база данных включенный в Python, создает один файл для всех данных для каждой базы данных. Другие базы данных, такие как PostgreSQL, MySQL, Oracle и Microsoft SQL Server имеют больше сложные схемы сохранения, предлагая дополнительные расширенные функции которые полезны для хранения данных веб-приложений. Эти передовые функции включают, но не ограничиваются:
- репликация данных между главной базой данных и одной или несколькими ведомыми только для чтения экземпляров
- расширенный тип столбцов, которые могут эффективно хранить полуструктурированные данные например нотация объектов JavaScript (JSON)
- , который позволяет горизонтально масштабировать несколько баз данных, каждый служит экземпляром для чтения и записи за счет задержки в данных консистенция Мониторинг
- , статистика и другая полезная информация о времени выполнения для схемы базы данных и таблицы
Обычно веб-приложения начинаются с одного экземпляра базы данных, например
как PostgreSQL с простой схемой. Со временем база данных
схема превращается в более сложную структуру с использованием миграции схемы и
расширенные функции, такие как репликация, сегментирование и мониторинг, становятся
более полезным, поскольку использование базы данных увеличивается в зависимости от приложения
потребности пользователей.
Со временем база данных
схема превращается в более сложную структуру с использованием миграции схемы и
расширенные функции, такие как репликация, сегментирование и мониторинг, становятся
более полезным, поскольку использование базы данных увеличивается в зависимости от приложения
потребности пользователей.
Наиболее распространенные базы данных для веб-приложений Python
PostgreSQL и MySQL являются двумя наиболее распространенными системами с открытым исходным кодом. базы данных для хранения данных веб-приложений Python.
SQLite — это база данных, которая хранится в одном файл на диске. SQLite встроен в Python, но создан только для доступа по одному соединению за раз. Поэтому настоятельно рекомендуется не запустить производственное веб-приложение с SQLite.
База данных PostgreSQL
PostgreSQL — рекомендуемая реляционная база данных для работы с Python
веб-приложения. Набор функций PostgreSQL, активное развитие и стабильность
способствовать его использованию в качестве серверной части для миллионов приложений в реальном времени
в Сети сегодня.
Узнайте больше об использовании PostgreSQL с Python на Страница PostgreSQL.
База данных MySQL
MySQL — еще одна жизнеспособная реализация базы данных с открытым исходным кодом для Python. Приложения. MySQL имеет немного более легкую начальную кривую обучения, чем PostgreSQL, но не такой многофункциональный.
Узнайте о приложениях Python с поддержкой MySQL на выделенном Страница MySQL.
Подключение к базе данных с помощью Python
Для работы с реляционной базой данных с помощью Python необходимо использовать код библиотека. Наиболее распространенные библиотеки для реляционных баз данных:
псикопг2 (исходный код) для PostgreSQL.
MySQLdb (исходный код) для MySQL. Обратите внимание, что разработка этого драйвера в основном заморожена, поэтому оценка альтернативных драйверов имеет смысл, если вы используете MySQL в качестве бэкенда.
cx_Oracle для База данных Oracle (исходный код).
Поддержка SQLite встроена в Python 2.7+ и поэтому представляет собой отдельную библиотеку не обязательно. Просто «импортируйте sqlite3», чтобы начать взаимодействие с единая файловая база данных.
Объектно-реляционное сопоставление
Объектно-реляционное сопоставление (ORM) позволяет разработчикам получать доступ к данным из backend, написав код Python вместо SQL-запросов. Каждая сеть Платформа приложения обрабатывает интеграцию ORM по-разному. есть целая страница по объектно-реляционному отображению (ORM), которые вы должны прочитать, чтобы разобраться в этом вопросе.
Сторонние службы баз данных
Многие компании используют масштабируемые серверы баз данных в качестве размещенной службы. Размещенные базы данных часто могут обеспечивать автоматическое резервное копирование и восстановление, ужесточенные настройки безопасности и легкое вертикальное масштабирование в зависимости от провайдер.
Служба реляционных баз данных Amazon (RDS) предоставляет предварительно настроенные экземпляры MySQL и PostgreSQL.
Экземпляры могут
масштабироваться до больших или меньших конфигураций в зависимости от хранилища и производительности
потребности.Google Cloud SQL — это служба с управляемыми, резервными, реплицированными и автоматически исправляемыми экземплярами MySQL. Облако SQL интегрируется с Google App Engine, но может использоваться и независимо.
BitCan обеспечивает размещение как MySQL, так и MongoDB. базы данных с обширными службами резервного копирования.
ElephantSQL — компания, предлагающая программное обеспечение как услугу. который размещает базы данных PostgreSQL и обрабатывает конфигурацию сервера, резервное копирование и подключения к данным поверх экземпляров Amazon Web Services.
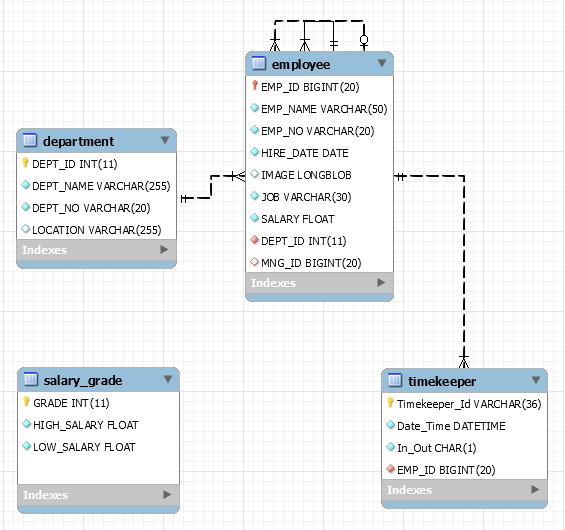 Экземпляры могут
масштабироваться до больших или меньших конфигураций в зависимости от хранилища и производительности
потребности.
Экземпляры могут
масштабироваться до больших или меньших конфигураций в зависимости от хранилища и производительности
потребности.Ресурсы SQL
Возможно, вы планируете использовать
объектно-реляционный преобразователь (ORM)
как ваш основной способ взаимодействия с базой данных, но вы все равно должны
изучите основы SQL для создания схем и понимания кода SQL
генерируется ORM. Следующие ресурсы могут помочь вам подняться до
скорость на SQL, если вы никогда ранее не использовали его.
Следующие ресурсы могут помочь вам подняться до
скорость на SQL, если вы никогда ранее не использовали его.
Select Star SQL — интерактивная книга для изучение SQL. Настоятельно рекомендуется, даже если вы чувствуете, что будете только работать с объектно-реляционным картографом на ваших проектах, потому что вы никогда не знаете, когда вам нужно будет заглянуть в SQL для улучшения низкой производительности сгенерированного запроса.
Руководство для начинающих по SQL хорошо объясняет основные ключевые слова, используемые в операторах SQL например,
ВЫБЕРИТЕ,ГДЕ,ИЗ,ОБНОВЛЕНИЕиУДАЛИТЬ.Учебное пособие по SQL обучает основам SQL, которые можно используется во всех основных реализациях реляционных баз данных.
Срок службы SQL-запроса объясняет, что происходит как концептуально, так и технически в базе данных при выполнении SQL-запроса.
Автор использует
PostgreSQL в качестве примера базы данных и синтаксиса SQL
на протяжении всего поста.Вероятно, неполное исчерпывающее руководство по многим различным способам соединения таблиц в SQL подробно рассказывает об одной из самых сложных частей написания операторов SQL соединяющие одну или несколько таблиц:
ПРИСОЕДИНЯЙТЕСЬ.Написание более разборчивого SQL представляет собой краткое руководство по стилю кода, чтобы упростить чтение ваших запросов.
SQL Intermediate — это учебник, выходящий за рамки основ, который использует открытые данные из Бюро финансовой защиты потребителей США в качестве примеров для подсчета, запроса и использования представлений в PostgreSQL.
Общие ресурсы базы данных
Как работает реляционная база данных? подробный подробный пост о сортировке, поиске, слиянии и других операции, которые мы часто принимаем как должное при использовании установленного реляционного базы данных, такие как PostgreSQL.
Базы данных 101 дает отличный обзор основных концепций реляционной базы данных, который актуален даже не разработчикам в качестве введения.
Пять ошибок, которые допускают новички при работе с базами данных объясняет, почему вы не должны хранить изображения в базах данных, а также почему будьте осторожны с тем, как вы нормализуете свою схему.
DB-Engines — самые популярные системы управления базами данных.
DB Weekly — это еженедельный обзор общей базы данных. статьи и ресурсы.
Проектирование высокомасштабируемых архитектур баз данных охватывает горизонтальное и вертикальное масштабирование, репликацию и кэширование в реляционные архитектуры баз данных.
онлайн-миграции в масштабе отличное чтение о том, как разобраться в сложности схемы базы данных миграция для рабочей базы данных. Подход авторской команды использовался четырехэтапный шаблон двойного письма для тщательной разработки способа данные о подписках сохранялись, чтобы их можно было перенести на новый, более Эффективная модель хранения.
Универсальная база данных не подходит никому объясняет конкретное обоснование Amazon Web Services для того, чтобы иметь так много типов реляционных и нереляционных баз данных на своей платформе, но статья также является хорошим обзором различных моделей баз данных и вариантов их использования.
SQL исполнилось 43 года — вот 8 причин, по которым мы все еще используем его сегодня перечисляет, почему SQL обычно используется почти всеми разработчиками, даже если язык приближается к своему пятидесятилетию.
ключей SQL в глубину дает отличное объяснение того, что такое первичные ключи и как вы следует использовать их.
Изучение набора данных в SQL хороший пример того, как можно использовать только SQL для анализ данных. В этом руководстве используются данные Spotify чтобы показать, как извлечь то, что вы хотите узнать, из набора данных.
Стратегии тестирования интеграции баз данных охватывает сложную тему, которая возникает в каждом реальном проекте.
GitLab предоставили свои вскрытие сбоя базы данных 31 января как способ быть прозрачным для клиентов и помогать другим разработкам команды узнают, как они облажались со своими системами баз данных, а затем нашли способ выздороветь.
Асинхронный Python и базы данных — это подробная статья, в которой рассказывается, почему многие драйверы баз данных Python не могут использоваться без изменений из-за различий в блокировке и асинхронные событийные модели. Определенно стоит прочитать, если вы используете WebSockets через Tornado или gevent.
PostgreSQL против MS SQL Server — один из точки зрения на различия между двумя серверами баз данных с аналитик данных.
Контрольный список для изучения баз данных
Установите PostgreSQL на свой сервер. Предполагая, что вы пошли с запуском Ubuntu
sudo apt-get установить postgresql.Убедитесь, что библиотека psycopg2 находится в вашем зависимости приложения.
Настройте веб-приложение для подключения к экземпляру PostgreSQL.
Создавайте модели в ORM либо с помощью Django встроенный ORM или SQLAlchemy с Flask.
Создайте таблицы базы данных или синхронизируйте модели ORM с PostgreSQL. Например, если вы используете ORM.
Начать создание, чтение, обновление и удаление данных в базе данных из вашего веб-приложения.
Что дальше, чтобы запустить ваше приложение?
Что это за хранилища данных NoSQL, о которых постоянно говорят хипстерские разработчики?
Мое приложение работает, но выглядит ужасно. Как оформить пользовательский интерфейс?
Как мне использовать JavaScript с моим веб-приложением Python?
Использование баз данных с Python | Coursera
Об этом курсе
248 151 недавних просмотров
Этот курс познакомит студентов с основами языка структурированных запросов (SQL), а также с базовым проектированием базы данных для хранения данных в рамках многоэтапного сбора данных, анализа, и усилия по обработке. Курс будет использовать SQLite3 в качестве базы данных. Мы также создадим поисковые роботы и многоэтапные процессы сбора и визуализации данных. Мы будем использовать библиотеку D3.js для базовой визуализации данных. Этот курс охватывает главы 14-15 книги «Python для всех». Чтобы преуспеть в этом курсе, вы должны быть знакомы с материалом, изложенным в главах 1-13 учебника и первых трех курсов по этой специализации. Этот курс охватывает Python 3.
Гибкие сроки
Сброс сроков в соответствии с вашим графиком.
Совместно используемый сертификатСовместно используемый сертификат
Получите сертификат по завершении
100% онлайн100% онлайн
Начните немедленно и учитесь по собственному графику.
СпециализацияКурс 4 из 5 в рамках специализации
Python для всех
Часов для прохожденияПрибл. 15 часов на прохождение
Доступные языкиАнглийский
Субтитры: арабский, французский, португальский (европейский), итальянский, вьетнамский, корейский, немецкий, русский, английский, испанский
Чему вы научитесь
Используйте операции создания, чтения, обновления и удаления для управления базами данных
Объяснить основы объектно-ориентированного Python
Понять, как данные хранятся в нескольких таблицах базы данных
Использовать API Карт Google для визуализации данных
Навыки, которые вы приобретете
- Программирование на Python
- База данных (СУБД)
- Sqlite
- SQL
Гибкие сроки в соответствии с вашим графиком
Сбросить сроки в соответствии с вашим графиком.
Совместно используемый сертификат
Получите сертификат по завершении
100% онлайн100% онлайн
Начните немедленно и учитесь по собственному графику.
СпециализацияКурс 4 из 5 в
Специализация Python для всех
Часов на выполнениеПрибл. 15 часов
Доступные языкиАнглийский
Субтитры: арабский, французский, португальский (европейский), итальянский, вьетнамский, корейский, немецкий, русский, английский, испанский
Инструктор
Чарльз Рассел Северанс
0 Клинический профессор3
Школа информации
3 562 724 Учащиеся
47 Курсы
Предложено
Университетом Мичигана
Миссия Университета Мичигана состоит в том, чтобы служить народу Мичигана и всего мира посредством превосходства в создании, передаче, сохранении и применении знаний, искусства и академических ценностей, а также в развитие лидеров и граждан, которые бросят вызов настоящему и обогатят будущее.
Начните работать над получением степени магистра
Этот курс является частью 100% онлайн-курса магистра прикладных наук о данных Мичиганского университета. Если вы допущены к полной программе, ваши курсы засчитываются для получения степени.
Learn More
Reviews
4.8
Filled StarFilled StarFilled StarFilled StarFilled Star3159 reviews
5 stars
82.31%
4 stars
14.30%
3 stars
2.30%
2 звезды
0,45 %
1 звезда
0,62 %0003
«Лучшие инструкторы» в 176 отзывах
ЛУЧШИЕ ОТЗЫВЫ ОТ ИСПОЛЬЗОВАНИЯ БАЗ ДАННЫХ С PYTHON
Filled StarFilled StarFilled StarFilled StarFilled Starот GB14 января 2018 г.
Это отличный курс. Спасибо за возможность учиться. Спасибо Coursera, Мичиганскому университету и, конечно же, доктору Чаку, очень хорошему и увлеченному учителю! Все лучшее для тебя!
Filled StarFilled StarFilled StarFilled StarFilled Starот ML 6 июля 2018 г.
этот курс очень полезен. Было бы еще более очаровательно, если бы уровень сложности немного увеличился после нескольких обучающих видео, чтобы бросить вызов программисту. Остальное стоит 5 звезд…
Заполненная звездаЗаполненная звездаЗаполненная звездаЗаполненная звездаЗаполненная звездаот JL23 июня 2017 г.
Замечательный курс! Я изучил много полезных операторов SQL и знаю, как объединить операции с базой данных в программу на Python. Лекции доктора Чака всегда понятны и понятны. Спасибо, профессор.
Filled StarFilled StarFilled StarFilled StarFilled Starот ARS27 сентября 2020 г.
Я научился создавать модель базы данных и пытаюсь создавать модели для своих собственных повседневных данных для практики. Это действительно отличный инструмент для сортировки вещей. Спасибо, Coursera, спасибо, доктор Чак 🙂
Просмотреть все отзывы
О специализации Python для всех
Эта специализация основывается на успехе курса Python для всех и знакомит с фундаментальными концепциями программирования, включая структуры данных, сетевые интерфейсы прикладных программ и базы данных, с использованием Python язык программирования.
В проекте Capstone вы будете использовать технологии, изученные в рамках специализации, для разработки и создания собственных приложений для поиска, обработки и визуализации данных.Часто задаваемые вопросы
Когда я получу доступ к лекциям и заданиям?
Что я получу, подписавшись на эту специализацию?
Доступна ли финансовая помощь?
Есть вопросы? Посетите Справочный центр для учащихся.
Базы данных Python 101: что выбрать?
Науку о данных невозможно написать без данных. Ладно, это банально, но это правда! Большую часть времени (если не все) необходимые вам данные хранятся в СУБД (системе управления базами данных) на удаленном сервере или на вашем жестком диске.
Это означает, что вам необходимо взаимодействовать и взаимодействовать с этой СУБД для хранения и извлечения данных, но для взаимодействия с СУБД вам необходимо говорить на ее языке: SQL (язык структурированных запросов).
(Примечание: с годами люди сами стали называть базы данных SQL.)Недавно появился еще один термин: базы данных NoSQL. Если вы только начинаете заниматься наукой о данных или уже некоторое время работаете в этой области, вы, вероятно, слышали как о базах данных SQL, так и о базах данных NoSQL.
Использование баз данных SQL или NoSQL зависит от ваших данных и целевого приложения. Но, допустим, вы используете Python и уже знаете, какую схему базы данных вы собираетесь использовать. Теперь вопрос в том, какую библиотеку Python вы используете?
В этой статье я расскажу о наиболее известных, используемых и разработанных библиотеках баз данных Python. Мы поговорим о каждой библиотеке и о лучших причинах для использования каждой из них.
Skinny на SQLSQLZoo — лучший способ попрактиковаться в SQL
Библиотеки Python SQL
Библиотеки Python SQL
- SQLite
- MySQL
- PostgreSQL
Мы используем библиотеки SQL с реляционными базами данных (RDBMS).
Реляционные базы данных хранят данные в разных таблицах, и каждая таблица содержит несколько записей. Эти таблицы связаны с помощью одного или нескольких отношений.
SQLiteSQLite изначально была библиотекой на языке C, созданной для реализации небольшого, быстрого, автономного, бессерверного и надежного ядра базы данных SQL. Теперь SQLite встроен в ядро Python, а это значит, что вам не нужно его устанавливать. Вы можете использовать его прямо сейчас. В Python эта библиотека связи с базой данных называется sqlite3.
Используйте SQLite, когда…
вы новичок, только начинаете изучать базы данных и способы взаимодействия с ними.
вы используете встроенные приложения. Если вашему приложению требуется переносимость, используйте SQLite, потому что SQLite занимает мало места и очень легкий.
ваши данные хранятся в файле на вашем жестком диске.
Вы можете использовать SQLite в качестве параллельного решения для клиент-серверной СУБД в целях тестирования.вам нужно быстрое подключение к вашим данным. Вам не нужно подключаться к серверу, чтобы использовать SQLite, что также означает, что библиотека имеет низкую задержку.
SQLite не лучший вариант, если параллелизм является серьезной проблемой для вашего приложения, поскольку операции записи сериализуются. Кроме того, SQLite слаб, когда речь идет о многопользовательских приложениях».
Еще от Сары А. МетваллиКак написать псевдокод
Базы данных SQLite с помощью PythonMySQL
MySQL — один из наиболее широко используемых и известных коннекторов СУБД с открытым исходным кодом. Он использует архитектуру сервер/клиент, состоящую из многопоточного SQL-сервера.
Это позволяет MySQL работать хорошо, потому что он легко использует несколько процессоров. Первоначально MySQL был написан на C/C++, а затем расширен для поддержки различных платформ. Ключевыми особенностями MySQL являются масштабируемость, безопасность и репликация.Чтобы использовать MySQL, вам необходимо установить его коннектор. В командной строке вы можете сделать это, запустив:
python -m pip установить mysql-connector-python
Используйте MySQL, когда…
вам нужна дополнительная безопасность. Благодаря преимуществам безопасности MySQL он оптимален для приложений, требующих аутентификации пользователя или пароля.
вам нужна многопользовательская поддержка. В отличие от SQLite, MySQL поддерживает многопользовательские приложения и является хорошим выбором для распределенных систем.
вам нужны расширенные возможности резервного копирования и взаимодействия, но с простым синтаксисом и легкой установкой.
Однако MySQL плохо работает, когда вы выполняете массовые операции INSERT или хотите выполнять операции полнотекстового поиска.
PostgreSQL
PostgreSQL — это еще один соединитель РСУБД с открытым исходным кодом, ориентированный на расширяемость и использующий структуру базы данных клиент/сервер. В PostgresSQL мы называем обмен данными, управляющий файлами и операциями базы данных, «процессом Postgres», откуда библиотека и получила свое название.
Для связи с базой данных PostgresSQL вам необходимо установить драйвер, который позволяет Python делать это. Одним из часто используемых драйверов является psycopg2. Вы можете установить его, выполнив следующую инструкцию командной строки:
pip install psycopg2
Используйте PostgreSQL, когда…
вы запускаете хранилище данных аналитических приложений. PostgresSQL обладает выдающимися возможностями параллельной обработки.
ваша база данных должна соответствовать модели ACID (A: атомарность; C: согласованность; I: изоляция; D: надежность) (в основном финансовые приложения). В этом случае PostgresSQL предоставляет для этого оптимальную платформу.
вам нужны базы данных исследований и научных проектов.
PostgresSQL немного сложнее установить и начать работу, чем MySQL. Тем не менее, это стоит хлопот, учитывая бесчисленные расширенные функции, которые он предоставляет.
Нужна консультация по приложениям для работы? Мы получили вас.4 Базы данных NoSQL более гибкие, чем реляционные базы данных. В этих типах баз данных структура хранения данных разработана и оптимизирована для конкретных требований. There are four main types for NoSQL libraries:
Document-oriented
Key-value pair
Column-oriented
Graph
MongoDB
MongoDB is a well- известное хранилище данных базы данных среди современных разработчиков.
Это система хранения данных с открытым исходным кодом, ориентированная на документы. Обычно мы используем PyMongo, чтобы обеспечить взаимодействие между одним или несколькими экземплярами MongoDB через код Python. MongoEngine — это Python ORM, написанный для MongoDB поверх PyMongo.Чтобы использовать MongoDB, вам необходимо установить модуль и актуальные библиотеки MongoDB.
pip установить пимонго == 3.4.0 pip install mongodb
Используйте MongoDB, когда…
вы хотите создавать легко масштабируемые приложения, которые можно легко развернуть.
ваши данные имеют документальную структуру, но вы хотите использовать возможности реляционных баз данных.
у вас есть приложение с переменными структурами данных, например приложения IoT.
вы работаете с приложениями реального времени, такими как приложения электронной коммерции и системы управления контентом.
Готово3 шага к завершению вашего приложения. Подсказка: начните с конца.
Redis
Redis — это хранилище структур данных в памяти с открытым исходным кодом. Он поддерживает структуры данных, такие как строки, хеш-таблицы, списки, наборы и многое другое. Redis обеспечивает высокую доступность с помощью Redis Sentinel и автоматическое разбиение на разделы с помощью Redis Cluster. Redis также считается самой быстрой базой данных в мире.
Вы можете настроить Redis, выполнив следующие инструкции из командной строки:
wget http://download.redis.io/releases/redis-6.0.8.tar.gz смола xzf redis-6.0.8.tar.gz компакт-диск редис-6.0.8 делать
Используйте Redis, когда…
скорость является приоритетом в ваших приложениях.
у вас хорошо спланированный дизайн. Redis имеет много определенных структур данных и дает вам возможность явно указать, как вы хотите, чтобы ваши данные хранились.
ваша база данных имеет стабильный размер. Redis может увеличить скорость поиска конкретной информации в ваших данных.
Cassandra
Apache Cassandra — это хранилище данных NoSQL, ориентированное на столбцы, предназначенное для приложений хранения с большим количеством операций записи. Cassandra обеспечивает масштабируемость и высокую доступность без ущерба для производительности. Cassandra также обеспечивает меньшую задержку для многопользовательских приложений. Cassandra немного сложна в установке и запуске. Однако вы можете сделать это, следуя руководству по установке на официальном сайте Cassandra.
Используйте Cassandra, когда…
у вас есть огромные объемы данных. Cassandra обладает большой гибкостью и мощностью для работы с невероятными объемами данных, поэтому большинство приложений для работы с большими данными — хороший вариант использования Cassandra.
вам нужна надежность. Cassandra обеспечивает стабильную производительность в режиме реального времени для приложений потоковой передачи и онлайн-обучения.
безопасность превыше всего. Cassandra имеет мощное управление безопасностью, что делает ее идеальной для приложений по обнаружению мошенничества.
Neo4j
Neo4j — это графовая база данных NoSQL, созданная с нуля для использования данных и взаимосвязей данных. Neo4j соединяет данные по мере их хранения, позволяя выполнять запросы с высокой скоростью. Первоначально Neo4j был реализован на Java и Scala, а затем расширен для использования на других платформах, таких как Python.
Neo4j, по сути, является библиотекой базы данных графов и имеет один из лучших веб-сайтов и систем технической документации. Он четкий, лаконичный и охватывает все вопросы, которые могут возникнуть у вас по поводу установки, начала работы и использования библиотеки.
Используйте Neo4j, когда…
вам необходимо визуализировать и анализировать сети и их характеристики.
вы разрабатываете и анализируете системы рекомендаций.
вы анализируете связи в социальных сетях и извлекаете информацию на основе существующих связей.
вы собираетесь выполнять операции по управлению идентификацией и доступом.
вам необходимо выполнить различные оптимизации цепочки поставок.
Что нужно, чтобы стать специалистом по данным?4 Основные навыки, необходимые каждому специалисту по данным
Выводы
Выбор правильной базы данных для вашей структуры данных и приложения может сократить время разработки вашего приложения при одновременном повышении эффективности твоя работа. Развитие способности выбирать правильный тип базы данных на лету может занять некоторое время, но как только вы это сделаете, большая часть утомительной работы над вашим проектом станет намного проще, быстрее и эффективнее.
Единственный способ развить любой навык — это практика. Другой способ исследовать — методом проб и ошибок (обычно мой метод). Пробуйте разные варианты, пока не найдете тот, который лучше всего вам подходит и подходит для вашего приложения.Базы данных | Документация Джанго | Django
Django официально поддерживает следующие базы данных:
- PostgreSQL
- МарияДБ
- MySQL
- Оракул
- SQLite
Существует также ряд серверных баз данных, предоставленных третьими лицами.
Django пытается поддерживать как можно больше функций во всей базе данных бэкенды. Однако не все серверные части баз данных одинаковы, и нам пришлось проектные решения о том, какие функции поддерживать и какие предположения мы можем сделать безопасно.
Этот файл описывает некоторые функции, которые могут иметь отношение к Django. Применение. Он не предназначен для замены документации по конкретному серверу или справочники.
Общие примечания
Постоянные соединения
Постоянные соединения позволяют избежать накладных расходов на повторное установление соединения с базу данных в каждом запросе.
Они находятся под контролем CONN_MAX_AGEпараметр, определяющий максимальное время жизни связь. Его можно установить независимо для каждой базы данных.Значение по умолчанию —
0, сохраняя историческое поведение закрытия подключение к базе данных в конце каждого запроса. Чтобы включить постоянный соединения, задайте дляCONN_MAX_AGEположительное целое число секунд. За неограниченное количество постоянных подключений, установите для него значениеNone.Управление соединением
Django открывает соединение с базой данных при первом создании базы данных запрос. Он сохраняет это соединение открытым и повторно использует его в последующих запросах. Django закрывает соединение, как только оно превышает максимальный возраст, определенный
CONN_MAX_AGEили когда его больше нельзя использовать.В частности, Django автоматически открывает соединение с базой данных всякий раз, когда она нужен, а у него его еще нет — либо потому, что это первый соединение, или потому что предыдущее соединение было закрыто.
В начале каждого запроса Django закрывает соединение, если оно достиг своего максимального возраста. Если ваша база данных прерывает простаивающие соединения после некоторое время вы должны установить
CONN_MAX_AGEна более низкое значение, чтобы Django не пытается использовать соединение, которое было разорвано сервер базы данных. (Эта проблема может затрагивать только сайты с очень низким трафиком.)В конце каждого запроса Django закрывает соединение, если оно достигло своего максимальный возраст или если он находится в состоянии неисправимой ошибки. Если какая-либо база данных при обработке запросов возникли ошибки, Django проверяет, соединение все еще работает, и закрывает его, если это не так. Таким образом, ошибки базы данных воздействовать не более чем на один запрос на каждый рабочий поток приложения; если соединение становится непригодным для использования, следующий запрос получает новое соединение.
Настройка
CONN_HEALTH_CHECKS 9от 0348 доTrueможно использовать для улучшения надежность повторного использования соединения и предотвращение ошибок, когда соединение было закрыт сервером базы данных, который теперь готов принимать и обслуживать новые связи, напр. после перезапуска сервера базы данных. Проверка работоспособности выполняется
только один раз за запрос и только в том случае, если доступ к базе данных осуществляется во время
обработка запроса.Изменено в Django 4.1:
Добавлен параметр
CONN_HEALTH_CHECKS.Предостережения
Поскольку каждый поток поддерживает свое собственное соединение, ваша база данных должна поддерживать как минимум столько же одновременных подключений, сколько у вас есть рабочих потоков.
Иногда база данных не будет доступна для большинства ваших представлений, для например, потому что это база данных внешней системы или благодаря кэшированию. В таких случаях вы должны установить
CONN_MAX_AGEна низкое значение или даже0, потому что нет смысла поддерживать соединение, которое маловероятно для повторного использования. Это поможет сохранить количество одновременных подключений к эта база данных маленькая.Сервер разработки создает новый поток для каждого обрабатываемого им запроса, отрицание эффекта постоянных соединений. Не включайте их во время разработка.
Когда Django устанавливает соединение с базой данных, он устанавливает соответствующий параметры в зависимости от используемого бэкенда. Если вы включите постоянный соединений эта настройка больше не повторяется при каждом запросе. Если вы измените параметры, такие как уровень изоляции соединения или часовой пояс, следует либо восстанавливать значения Django по умолчанию в конце каждого запроса, соответствующее значение в начале каждого запроса или отключить постоянный связи.
Кодировка
Django предполагает, что все базы данных используют кодировку UTF-8. Использование других кодировок может привести к неожиданному поведению, такому как ошибки «значение слишком длинное» из вашего база данных для данных, которые действительны в Django. См. примечания к базе данных ниже для получения информации о том, как правильно настроить базу данных.
Примечания к PostgreSQL
Django поддерживает PostgreSQL 11 и выше. psycopg2 2.8.4 или выше требуется, хотя рекомендуется последняя версия.
Параметры подключения к PostgreSQL
Подробнее см.
HOST.Для подключения с использованием имени службы из файла службы подключения и пароль из файла паролей, необходимо указать их в
ОПЦИИчасть конфигурации вашей базы данных вБАЗЫ ДАННЫХ:settings.pyБАЗЫ ДАННЫХ = { 'дефолт': { 'ДВИГАТЕЛЬ': 'django.db.backends.postgresql', 'ОПЦИИ': { «сервис»: «мой_сервис», 'файл-пароля': '.my_pgpass', }, } }.pg_service.conf[my_service] хост = локальный пользователь=ПОЛЬЗОВАТЕЛЬ имя_базы_данных=ИМЯ порт=5432
.my_pgpasslocalhost:5432:ИМЯ:ПОЛЬЗОВАТЕЛЬ:ПАРОЛЬ
Изменено в Django 4.
0:Поддержка подключения по имени службы и указание файла пароля был добавлен.
Предупреждение
Использование имени службы в целях тестирования не поддерживается. Этот могут быть реализованы позже.
Оптимизация конфигурации PostgreSQL
Django нужны следующие параметры для подключения к базе данных:
-
client_encoding:'UTF8', -
default_transaction_isolation:«чтение зафиксировано»по умолчанию, или значение, установленное в параметрах подключения (см. ниже), -
часовой пояс: - когда
USE_TZравноTrue,'UTC'по умолчанию илиTIME_ZONEзначение, установленное для соединения, - , когда
USE_TZравноFalse, значение глобальногоTIME_ZONEнастройка.
- когда
-
Если эти параметры уже имеют правильные значения, Django не установит их для каждое новое соединение, что немного повышает производительность.
Вы можете настроить
их напрямую в postgresql.confили удобнее для каждой базы данных пользователь с ALTER ROLE.Django будет нормально работать и без этой оптимизации, но каждое новое соединение выполнит несколько дополнительных запросов для установки этих параметров.
Уровень изоляции
Как и сам PostgreSQL, Django по умолчанию использует изоляцию
READ COMMITTEDуровень. Если вам нужен более высокий уровень изоляции, такой какREPEATABLE READилиSERIALIZABLE, установите его вOPTIONSчасти вашей базы данных конфигурация вБАЗЫ ДАННЫХ:импорт psycopg2.extensions БАЗЫ ДАННЫХ = { # ... 'ОПЦИИ': { 'isolation_level': psycopg2.extensions.ISOLATION_LEVEL_SERIALIZABLE, }, }Примечание
При более высоких уровнях изоляции ваше приложение должно быть готово к обрабатывать исключения, возникающие при сбоях сериализации. Этот вариант предназначен для расширенного использования.
Индексы для
varcharиtextстолбцовПри указании
db_index=Trueв полях вашей модели Django обычно выводит один операторCREATE INDEX. Однако, если тип базы данных для поля либоvarchar, либотекст(например, используетсяCharField,FileFieldиTextField), то Django создаст дополнительный индекс, который использует соответствующий класс операторов PostgreSQL для колонки. Дополнительный индекс необходим для правильного выполнения поиски, которые используют операторLIKEв своем SQL, как это делается ссодержит, аначинается стипов поиска.Операция миграции для добавления расширений
Если вам нужно добавить расширение PostgreSQL (например,
hstore,postgisи т. д.) используя миграцию, используйтеОперация CreateExtension.Курсоры на стороне сервера
При использовании
QuerySet.Django открывает серверную курсор. По умолчанию PostgreSQL предполагает, что будут получены только первые 10% результатов запросов курсора. Запрос планировщик тратит меньше времени на планирование запроса и начинает возвращать результаты быстрее, но это может снизить производительность, если более 10% результатов получено. Предположения PostgreSQL о количестве строк, извлекаемых для курсорный запрос управляется с помощью параметра cursor_tuple_fraction. iterator() Пул транзакций и серверные курсоры
Использование пула соединений в режиме пула транзакций (например, PgBouncer) требует отключения курсоров на стороне сервера для этого соединения.
Курсоры на стороне сервера являются локальными для соединения и остаются открытыми в конце соединения. транзакция, когда
AUTOCOMMITравноTrue. А последующая транзакция может попытаться получить больше результатов со стороны сервера курсор. В режиме пула транзакций нет гарантии, что последующие транзакции будут использовать одно и то же соединение. Если используется другое соединение,
возникает ошибка, когда транзакция ссылается на серверный курсор,
потому что курсоры на стороне сервера доступны только в том соединении, в котором они
были созданы.Одним из решений является отключение серверных курсоров для соединения в
БАЗЫ ДАННЫХ, установивDISABLE_SERVER_SIDE_CURSORSнаTrue.Чтобы воспользоваться преимуществами серверных курсоров в режиме пула транзакций, вы можете установить установить другое соединение с базой данных, чтобы выполнять запросы, использующие серверные курсоры. Это соединение должно либо напрямую к базе данных или к пулу соединений в режиме пула сеансов.
Другой вариант — обернуть каждую девятку0347 QuerySet с использованием серверных курсоров в
блок atomic(), потому что он отключаетавтоматическую фиксациюна время сделки. Таким образом, курсор на стороне сервера будет только жить на время сделки.Ручное указание значений автоматически увеличивающихся первичных ключей
Django использует столбцы идентификаторов PostgreSQL для хранения автоматически увеличивающихся первичных ключей ключи.
Столбец идентификаторов заполняется значениями из последовательности, которая сохраняет
отслеживать следующее доступное значение. Ручное присвоение значения
автоинкрементное поле не обновляет последовательность полей, что может позже
вызвать конфликт. Например:>>> из импорта пользователя django.contrib.auth.models >>> User.objects.create(username='alice', pk=1) <Пользователь: Алиса> >>> # Последовательность не была обновлена; его следующее значение равно 1. >>> User.objects.create(username='bob') ... IntegrityError: повторяющееся значение ключа нарушает уникальное ограничение "auth_user_pkey" ДЕТАЛЬ: Ключ (id)=(1) уже существует.
Если вам нужно указать такие значения, сбросьте последовательность впоследствии, чтобы избежать повторное использование значения, которое уже находится в таблице.
sqlsequenceresetКоманда управления генерирует операторы SQL для этого.Изменено в Django 4.1:
В более старых версиях PostgreSQL использовался тип данных
SERIALвместо столбцы идентификации.Тестовые шаблоны базы данных
Можно использовать настройку
TEST['TEMPLATE'], чтобы указать шаблон (например,'template0'), из которого можно создать тестовую базу данных.Ускорение выполнения теста с помощью неустойчивых настроек
Вы можете ускорить выполнение тестов, настроив PostgreSQL на недолговечный.
Предупреждение
Это опасно: это сделает вашу базу данных более восприимчивой к потере данных или повреждения в случае сбоя сервера или потери питания. Используйте это только на машина разработки, где вы можете легко восстановить все содержимое все базы данных в кластере.
Заметки MariaDB
Django поддерживает MariaDB 10.3 и выше.
Чтобы использовать MariaDB, используйте серверную часть MySQL, которая используется ими обоими. См. Заметки MySQL для более подробной информации.
Заметки MySQL
Поддержка версий
Django поддерживает MySQL 5.7 и выше.
Функция Django
inspectdbиспользует базу данныхinformation_schema, которая содержит подробные данные обо всех схемах базы данных.Django ожидает, что база данных будет поддерживать Unicode (кодировку UTF-8) и делегирует это задача обеспечения транзакций и ссылочной целостности. Это важно знать о том факте, что два последних на самом деле не соблюдаются MySQL при использовании механизма хранения MyISAM см. следующий раздел.
Механизмы хранения
MySQL имеет несколько механизмов хранения. Вы можете изменить механизм хранения по умолчанию в конфигурации сервера.
Механизм хранения MySQL по умолчанию — InnoDB. Этот движок полностью транзакционный и поддерживает ссылки на внешние ключи. Это рекомендуемый выбор. Тем не менее Счетчик автоинкремента InnoDB теряется при перезапуске MySQL, потому что он не запомните значение
AUTO_INCREMENT, вместо этого воссоздайте его как «max(id)+1». Это может привести к непреднамеренному повторному использованиюАвтоПолеценности.Основные недостатки MyISAM в том, что он не поддерживает транзакции или применять ограничения внешнего ключа.
Драйверы API базы данных MySQL
У MySQL есть пара драйверов, которые реализуют API базы данных Python, описанный в PEP 249 :
- mysqlclient — это родной драйвер. Это рекомендуемый выбор .
- MySQL Connector/Python — это чистый драйвер Python от Oracle, который не требуется клиентская библиотека MySQL или любые модули Python, выходящие за рамки стандарта библиотека.
Эти драйверы потокобезопасны и обеспечивают пул соединений.
Помимо драйвера API БД, Django требуется адаптер для доступа к базе данных драйверы из своего ORM. Django предоставляет адаптер для mysqlclient, в то время как MySQL Connector/Python включает в себя собственный.
mysqlclient
Для Django требуется mysqlclient 1.4.0 или новее.
MySQL Connector/Python
MySQL Connector/Python доступен на странице загрузки. Адаптер Django доступен в версиях 1.1.X и выше. Это может не поддерживать самые последние выпуски Django.
Определения часовых поясов
Если вы планируете использовать поддержку часовых поясов Django, используйте mysql_tzinfo_to_sql для загрузки таблиц часовых поясов в базу данных MySQL. Это нужно сделать только один раз для вашего сервера MySQL, а не для каждой базы данных.
Создание базы данных
Вы можете создать базу данных с помощью инструментов командной строки и этого SQL:
CREATE DATABASE
CHARACTER SET utf8; Это гарантирует, что все таблицы и столбцы будут использовать кодировку UTF-8 по умолчанию.
Параметры сопоставления
Параметры сопоставления для столбца определяют порядок сортировки данных. а также какие строки сравниваются как равные. Вы можете указать
db_collationпараметр, чтобы установить имя сопоставления столбца дляCharFieldиТекстовое поле.Сопоставление также может быть установлено на уровне всей базы данных и для каждой таблицы.
Это
подробно описаны в документации MySQL. В таких случаях вы должны
установить параметры сортировки, напрямую манипулируя настройками базы данных или таблицами.
Django не предоставляет API для их изменения.По умолчанию для базы данных UTF-8 MySQL будет использовать
utf8_general_ciсопоставление. Это приводит к равенству всех строк сравнения выполняются без учета регистра . То есть"Фред"и"freD"считаются равными на уровне базы данных. Если у вас есть уникальный ограничение на поле, было бы незаконно пытаться вставить"aa"и"AA"в тот же столбец, так как они сравниваются как равные (и, следовательно, неуникальный) с параметрами сортировки по умолчанию. Если вы хотите сравнения с учетом регистра в определенном столбце или таблице измените столбец или таблицу, чтобы использоватьutf8_binсопоставление.Обратите внимание, что в соответствии с наборами символов MySQL Unicode сравнения для сопоставление
utf8_general_ciбыстрее, но немного менее правильно, чем сравнения дляutf8_unicode_ci. Если это приемлемо для вашего приложения,
вы должны использовать utf8_general_ci, потому что это быстрее. Если это неприемлемо (например, если вам требуется порядок немецкого словаря), используйтеutf8_unicode_ciпотому что это точнее.Предупреждение
Наборы форм проверяют уникальные поля с учетом регистра. Таким образом, когда с использованием сортировки без учета регистра, набора форм с уникальными значениями полей, которые отличаются только регистром, пройдут проверку, но при вызове
save()Будет вызвана ошибка IntegrityError.Подключение к базе данных
См. документацию по настройкам.
Параметры подключения используются в следующем порядке:
-
ОПЦИИ. -
ИМЯ,ПОЛЬЗОВАТЕЛЬ,ПАРОЛЬ,ХОЗЯИН,ПОРТ - Файлы опций MySQL.
Другими словами, если вы установите имя базы данных в
OPTIONS, это будет иметь приоритет надИМЯ, которое переопределит что-нибудь в файле опций MySQL.Вот пример конфигурации, в которой используется файл параметров MySQL:
# settings.py БАЗЫ ДАННЫХ = { 'дефолт': { «ДВИГАТЕЛЬ»: «django.db.backends.mysql», 'ОПЦИИ': { 'read_default_file': '/path/to/my.cnf', }, } } # my.cnf [клиент] база данных = ИМЯ пользователь = ПОЛЬЗОВАТЕЛЬ пароль = ПАРОЛЬ набор символов по умолчанию = utf8Могут быть полезны несколько других параметров подключения MySQLdb, например
ssl,init_commandиsql_mode.Параметр
sql_modeНачиная с MySQL 5.7, значение по умолчанию параметра
sql_modeсодержитSTRICT_TRANS_TABLES. Эта опция превращает предупреждения в ошибки, когда данные усекаются при вставке, поэтому Django настоятельно рекомендует активировать строгий режим для MySQL для предотвращения потери данных (либоSTRICT_TRANS_TABLESилиSTRICT_ALL_TABLES).Если вам нужно настроить режим SQL, вы можете установить переменную
sql_modeкак и другие параметры MySQL: либо в файле конфигурации, либо с записью'init_command': "SET sql_mode='STRICT_TRANS_TABLES'"вОПЦИИчасть конфигурации вашей базы данных вБАЗЫ ДАННЫХ.Уровень изоляции
При одновременной загрузке транзакции базы данных из разных сеансов (скажем, отдельные потоки, обрабатывающие разные запросы) могут взаимодействовать с каждым Другой. На эти взаимодействия влияет изоляция транзакций каждого сеанса. уровень. Вы можете установить уровень изоляции соединения с
'isolation_level'запись вOPTIONSчасти вашей базы данных конфигурация вБАЗЫ ДАННЫХ. Допустимые значения для эта запись представляет собой четыре стандартных уровня изоляции:-
«чтение незафиксированных» -
«чтение подтверждено» -
'повторяемое чтение' -
«сериализуемый»
или
Нетдля использования настроенного уровня изоляции сервера. Тем не менее, Джанго
лучше всего работает с и по умолчанию для чтения зафиксировано, а не по умолчанию MySQL,
повторяемое чтение. Потеря данных возможна при повторяющемся чтении. Особенно,
вы можете увидеть случаи, когда get_or_create()вызоветIntegrityError, но объект не появится в последующий вызовget().Создание таблиц
Когда Django генерирует схему, она не указывает механизм хранения, поэтому таблицы будут созданы с любым механизмом хранения по умолчанию, используемым в вашей базе данных. сервер настроен на. Самое простое решение — установить сервер базы данных движок хранения по умолчанию на желаемый движок.
Если вы используете услугу хостинга и не можете изменить настройки своего сервера по умолчанию механизм хранения, у вас есть несколько вариантов.
После создания таблиц выполните оператор
ALTER TABLE, чтобы преобразовать таблицу в новый механизм хранения (например, InnoDB):ALTER TABLE <имя_таблицы> ENGINE=INNODB;
Это может быть утомительно, если у вас много таблиц.
Другой вариант — использовать параметр
init_commandдля MySQLdb до создание ваших таблиц:'ОПЦИИ': { 'init_command': 'SET default_storage_engine=INNODB', }Это устанавливает механизм хранения по умолчанию при подключении к базе данных. После того, как ваши таблицы будут созданы, вы должны удалить эту опцию, так как она добавляет в каждую базу данных запрос, который необходим только при создании таблицы связь.
Имена таблиц
Даже в последних версиях MySQL существуют известные проблемы, которые могут вызвать случай изменения имени таблицы при выполнении определенных операторов SQL при определенных условиях. Рекомендуется использовать таблицу нижнего регистра имена, если это возможно, чтобы избежать проблем, которые могут возникнуть из-за такого поведения. Django использует имена таблиц в нижнем регистре, когда автоматически генерирует имена таблиц из модели, так что это в основном соображение, если вы переопределяете имя таблицы через
параметр db_table.Точки сохранения
Как Django ORM, так и MySQL (при использовании механизма хранения InnoDB) поддерживают точки сохранения базы данных.
Если вы используете механизм хранения MyISAM, имейте в виду, что вы получать ошибки, сгенерированные базой данных, если вы пытаетесь использовать связанную с точкой сохранения методы API транзакций. Причина для этого является то, что обнаружение механизма хранения базы данных/таблицы MySQL является дорогая операция, поэтому было решено, что динамическое преобразование не стоит эти методы в no-op основаны на результатах такого обнаружения.
Примечания к определенным полям
Символьные поля
Любые поля, сохраненные с типами столбцов
VARCHAR, могут иметь своиmax_lengthограничено 255 символами, если вы используетеunique=Trueдля поля. Это влияет наCharField,Слагфилд. См. документацию MySQL для получения дополнительной информации. Детали.TextFieldограниченияMySQL может индексировать только первые N символов
BLOBилиТЕКСТстолбец. СTextFieldне имеет определенной длины, вы не можете пометить его какуникальный=Истинно. MySQL сообщит: «Столбец BLOB/TEXT ‘’ используется в ключе спецификация без длины ключа». Поддержка дробных секунд для полей Time и DateTime
MySQL может хранить дробные секунды при условии, что определение столбца включает дробную индикацию (например,
DATETIME(6)).Django не будет обновлять существующие столбцы для включения дробных секунд, если сервер базы данных поддерживает это. Если вы хотите включить их в существующей базе данных, вам решать вручную обновить столбец в целевой базе данных, выполнение команды вида:
ALTER TABLE `your_table` MODIFY `your_datetime_column` DATETIME(6)
или с помощью операции
RunSQLв перенос данных.TIMESTAMPстолбцовЕсли вы используете устаревшую базу данных, содержащую
столбцов TIMESTAMP, вы должны установитеUSE_TZ = False, чтобы избежать повреждения данных.inspectdbсопоставляет эти столбцы сDateTimeFieldи если вы включите поддержку часового пояса, и MySQL, и Django попытаются преобразовать значения из UTC в местное время.Блокировка строк с помощью
QuerySet.select_for_update()MySQL и MariaDB не поддерживают некоторые параметры
SELECT ... FOR UPDATEутверждение. Еслиselect_for_update()используется с неподдерживаемой опцией, то возникает ошибкаNotSupportedError.Опция МарияДБ MySQL ПРОПУСК ЗАБЛОКИРОВАНХ (≥10,6) Х (≥8. 0.1)СЕЙЧАСх Х (≥8.0.1) ИЗХ (≥8.0.1) БЕЗ КЛЮЧАПри использовании
select_for_update()в MySQL убедитесь, что вы фильтруете набор запросов по крайней мере против набора полей, содержащихся в уникальных ограничениях, или только против полей, покрытых индексами. В противном случае будет установлена эксклюзивная блокировка записи. приобретено за всю таблицу на время транзакции.Автоматическое приведение типов может привести к неожиданным результатам
При выполнении запроса к строковому типу, но с целочисленным значением, MySQL привести типы всех значений в таблице к целому числу перед выполнением сравнение. Если ваша таблица содержит значения
'abc','def'и вы запрос дляWHERE mycolumn=0обе строки будут совпадать. Аналогично, ГДЕ mycolumn=1будет соответствовать значению'abc1'. Поэтому поля строкового типа, включенные в Django всегда будет приводить значение к строке, прежде чем использовать его в запросе.Если вы реализуете пользовательские поля модели, которые наследуются от
Поленапрямую, имеют приоритетget_prep_value()или используйтеRawSQL,экстра()илиraw(), вы должны убедиться, что выполняете соответствующее приведение типов.Заметки SQLite
Django поддерживает SQLite 3.9.0 и более поздние версии.
SQLite предоставляет отличную альтернативу для разработки приложений, которые в основном доступны только для чтения или требуют меньше места для установки. В качестве Однако со всеми серверами баз данных есть некоторые различия, которые специфичные для SQLite, о которых вам следует знать.
Сопоставление подстрок и чувствительность к регистру
Для всех версий SQLite есть некоторое нелогичное поведение, когда попытка сопоставить некоторые типы строк.
Они срабатывают при использовании iexactилисодержитфильтров в наборах запросов. Поведение разбивается на два случая:1. Для сопоставления подстрок все совпадения выполняются без учета регистра. Это фильтр, такой как
filter(name__contains="aa"), будет соответствовать имени"Aabb".2. Для строк, содержащих символы вне диапазона ASCII, все точные строки совпадения выполняются с учетом регистра, даже если параметры без учета регистра передаются в запрос. Так что фильтр
iexactбудет вести себя точно то же самое, что и фильтр, точный фильтрв этих случаях.Некоторые возможные обходные пути описаны на сайте sqlite.org, но они не используются бэкэндом SQLite по умолчанию в Django, так как включают их было бы довольно трудно сделать надежно. Таким образом, Django выставляет значение по умолчанию поведение SQLite, и вы должны знать об этом, когда делаете нечувствительные к регистру или фильтрация подстрок.
Десятичная обработка
SQLite не имеет реального десятичного внутреннего типа. Десятичные значения внутренне преобразуется в тип данных
REAL(8-байтовое число с плавающей запятой IEEE), как объясняется в документации по типам данных SQLite, поэтому они не поддерживают правильно округленная десятичная арифметика с плавающей запятой.Ошибки «База данных заблокирована»
SQLite предназначена для облегченной базы данных и, следовательно, не может поддерживать высокую уровень параллелизма.
OperationalError: база данных заблокированаошибки указывают что ваше приложение испытывает больше параллелизма, чем можетsqliteобрабатывать в конфигурации по умолчанию. Эта ошибка означает, что один поток или процесс эксклюзивная блокировка соединения с базой данных и тайм-аут другого потока ожидание блокировки будет снято.Оболочка Python SQLite имеет значение тайм-аута по умолчанию, которое определяет, как долго второй поток может подождите блокировки до истечения времени ожидания и вызовет
OperationalError: база данных заблокирован 9ошибка 0348.Если вы получаете эту ошибку, вы можете решить ее следующим образом:
Переключение на другой сервер базы данных. В какой-то момент SQLite становится слишком «легкий» для реальных приложений, и такого рода параллелизм ошибки указывают на то, что вы достигли этой точки.
Перепишите свой код, чтобы уменьшить параллелизм и убедиться, что база данных сделки недолговечны.
Увеличьте значение тайм-аута по умолчанию, установив тайм-аут
'ОПЦИИ': { # ... 'тайм-аут': 20, # ... }Это заставит SQLite немного подождать, прежде чем выдать сообщение «база данных заблокирована». ошибки; это ничего не сделает для их решения.
QuerySet.select_for_update()не поддерживаетсяSQLite не поддерживает синтаксис
SELECT ... FOR UPDATE. Звонок будет не имеют никакого эффекта.Стиль параметра «pyformat» в необработанных запросах не поддерживается
Для большинства бэкэндов необработанные запросы (
Manager.или raw() cursor.execute()) можно использовать стиль параметра «pyformat», где заполнители в запросе задаются как'%(name)s', а параметры передаются как словарь а не список. SQLite не поддерживает это.Изоляция при использовании
QuerySet.iterator()Существуют особые соображения, описанные в разделе Изоляция в SQLite, когда изменение таблицы во время итерации по ней с использованием
QuerySet.iterator(). Если строка добавляется, изменяется или удаляется в цикле, то эта строка может или может не отображаться или может появляться дважды в последующих результатах, полученных из итератор. Ваш код должен обрабатывать это.Включение расширения JSON1 в SQLite
Чтобы использовать
JSONFieldв SQLite, необходимо включить Расширение JSON1 для библиотеки Pythonsqlite3. Если расширение не включен в вашей установке, системная ошибка (fields.E180) будет поднятый.Чтобы включить расширение JSON1, вы можете следовать инструкциям на вики-страница.
Примечания Oracle
Django поддерживает версии Oracle Database Server 19c и выше. Версия 7.0 или более поздней версии требуется драйвер cx_Oracle Python.
Чтобы команда
python manage.py migrateработала, ваш Oracle пользователь базы данных должен иметь права на выполнение следующих команд:- CREATE TABLE
- СОЗДАТЬ ПОСЛЕДОВАТЕЛЬНОСТЬ
- СОЗДАТЬ ПРОЦЕДУРУ
- СОЗДАТЬ ТРИГГЕР
Для запуска набора тестов проекта пользователю обычно нужны эти дополнительные привилегии:
- СОЗДАТЬ ПОЛЬЗОВАТЕЛЯ
- ИЗМЕНИТЬ ПОЛЬЗОВАТЕЛЯ
- УДАЛИТЬ ПОЛЬЗОВАТЕЛЯ
- СОЗДАТЬ ТАБЛИЧНОЕ ПРОСТРАНСТВО
- УДАЛИТЬ ТАБЛИЧНОЕ ПРОСТРАНСТВО
- СОЗДАТЬ СЕАНС С ОПЦИЕЙ АДМИНИСТРАТОРА
- СОЗДАТЬ ТАБЛИЦУ С ОПЦИЕЙ АДМИНИСТРАТОРА
- СОЗДАТЬ ПОСЛЕДОВАТЕЛЬНОСТЬ С ОПЦИЕЙ АДМИНИСТРАТОРА
- СОЗДАТЬ ПРОЦЕДУРУ С ОПЦИЕЙ АДМИНИСТРАТОРА
- СОЗДАТЬ ТРИГГЕР С ОПЦИЕЙ АДМИНИСТРАТОРА
В то время как роль
RESOURCEимеет требуемуюCREATE TABLE,CREATE SEQUENCE,CREATE PROCEDUREиCREATE TRIGGERпривилегии, и пользователь, получившийРЕСУРС С ОПЦИЕЙ АДМИНИСТРИРОВАНИЯ, может предоставитьРЕСУРС, например пользователь не может предоставить индивидуальные привилегии (например,CREATE TABLE) и, следовательно,РЕСУРСОВ С ОПЦИЕЙ АДМИНИСТРИРОВАНИЯобычно недостаточно для запуска тестов.Некоторые наборы тестов также создают представления или материализованные представления; чтобы запустить их, пользователю также нужно
СОЗДАТЬ ВИД С ОПЦИЕЙ АДМИНИСТРАТОРАиCREATE MATERIALIZED VIEW WITH ADMIN OPTIONпривилегии. В частности, это необходим для собственного набора тестов Django.Все эти привилегии включены в роль DBA, которая подходит для использования в базе данных частного разработчика.
Серверная часть базы данных Oracle использует
SYS.DBMS_LOBиSYS.DBMS_RANDOMпакеты, поэтому вашему пользователю потребуются права на выполнение. Это обычно доступны для всех пользователей по умолчанию, но если это не так, вам нужно предоставить разрешения вроде так:GRANT EXECUTE ON SYS.DBMS_LOB TO пользователю; GRANT EXECUTE ON SYS.DBMS_RANDOM пользователю;
Подключение к базе данных
Для подключения с использованием имени службы вашей базы данных Oracle ваш
settings.файл должен выглядеть примерно так: py DATABASES = { 'дефолт': { «ДВИГАТЕЛЬ»: «django.db.backends.oracle», «ИМЯ»: «xe», «ПОЛЬЗОВАТЕЛЬ»: «a_user», 'ПАРОЛЬ': 'a_password', 'ХОЗЯИН': '', 'ПОРТ': '', } }В этом случае вы должны оставить как
HOST, так иPORTпустыми. Однако, если вы не используете файлtnsnames.oraили аналогичный метод именования и хотите подключиться с помощью SID (в данном примере «xe»), то заполните обаHOSTиPORTвот так:DATABASES = { 'дефолт': { «ДВИГАТЕЛЬ»: «django.db.backends.oracle», «ИМЯ»: «xe», «ПОЛЬЗОВАТЕЛЬ»: «a_user», 'ПАРОЛЬ': 'a_password', «ХОСТ»: «dbprod01ned.mycompany.com», «ПОРТ»: «1540», } }Вы должны указать оба
HOSTиPORTили оставить оба как пустые строки. Django будет использовать другой дескриптор подключения в зависимости от на том выборе.Полный DSN и Easy Connect
Строка Full DSN или Easy Connect может использоваться в
ИМЯ, если обаHOSTиPORTпусты. Этот формат необходим, когда например, используя RAC или подключаемые базы данных безtnsnames.ora.Пример строки Easy Connect:
'ИМЯ': 'локальный: 1521/orclpdb1',
Пример полной строки DSN:
'ИМЯ': ( '(ОПИСАНИЕ=(АДРЕС=(ПРОТОКОЛ=TCP)(ХОСТ=localhost)(ПОРТ=1521))' '(CONNECT_DATA=(SERVICE_NAME=orclpdb1)))' ),Threaded option
Если вы планируете запускать Django в многопоточной среде (например, Apache с использованием модуль MPM по умолчанию в любой современной операционной системе), то вы должны установить параметр
threadedконфигурации вашей базы данных Oracle наВерно:'ОПЦИИ': { 'резьбовой': правда, },Невыполнение этого требования может привести к сбоям и другим странным действиям.
INSERT … RETURNING INTO
По умолчанию серверная часть Oracle использует предложение
RETURNING INTOдля эффективного получить значениеAutoFieldпри вставке новых строк. Это поведение может привести к ошибкеDatabaseErrorв некоторых необычных настройках, например, когда вставка в удаленную таблицу или в представление сВМЕСТОтриггера. ПредложениеRETURNING INTOможно отключить, установив параметрuse_returning_intoпараметр конфигурации базы данныхFalse:'ОПЦИИ': { 'use_returning_into': Ложь, },В этом случае серверная часть Oracle будет использовать отдельный запрос
SELECTдля получитьзначений AutoField.Проблемы с именами
Oracle ограничивает длину имени в 30 символов. Чтобы учесть это, серверная часть обрезает идентификаторы базы данных, заменяя последние четыре символы усеченного имени с повторяющимся хеш-значением MD5.
Кроме того, серверная часть преобразует идентификаторы базы данных в верхний регистр.Для предотвращения этих преобразований (обычно это требуется только при работе с с устаревшими базами данных или доступом к таблицам, принадлежащим другим пользователям), используйте имя в кавычках в качестве значения для
db_table:класс LegacyModel (models.Model): Мета класса: db_table = '"name_left_in_lowercase"' класс ForeignModel (модели.Модель): Мета класса: db_table = '"OTHER_USER"."NAME_ONLY_SEEMS_OVER_30"'Имена в кавычках также можно использовать с другими поддерживаемыми базами данных Django. серверные части; однако, за исключением Oracle, кавычки не действуют.
При запуске
migrateможет возникнуть ошибкаORA-06552, если некоторые ключевые слова Oracle используются в качестве имени поля модели или значение опцииdb_column. Django цитирует все используемые идентификаторы в запросах, чтобы предотвратить большинство таких проблем, но эта ошибка все еще может возникают, когда тип данных Oracle используется в качестве имени столбца. В
в частности, позаботьтесь о том, чтобы не использовать имена , дата,метка времени,числоиличисло с плавающей запятойв качестве имени поля.NULL и пустые строки
Django обычно предпочитает использовать пустую строку (
''), а неNULL, но Oracle обрабатывает оба значения одинаково. Чтобы обойти это, Серверная часть Oracle игнорирует явный параметрnullдля полей, которые иметь пустую строку в качестве возможного значения и генерирует DDL, как если быноль=Истина. При выборке из базы данных предполагается, что значениеNULLв одном из этих полей действительно означает пустое строка, и данные автоматически преобразуются, чтобы отразить это предположение.Ограничения TextFieldСерверная часть Oracle хранит
TextFieldкакNCLOBстолбцов. Оракул накладывает некоторые ограничения на использование таких столбцов больших объектов в целом:- Столбцы больших объектов нельзя использовать в качестве первичных ключей. Столбцы LOB
- нельзя использовать в индексах. Столбцы LOB
- нельзя использовать в списке
SELECT DISTINCT. Это означает, что попытка использовать методQuerySet.distinctв модели, которая включаетСтолбцы TextFieldприведут к ошибкеORA-00932при работать против Оракула. В качестве обходного пути используйте методQuerySet.deferв в сочетании сdifferent()для предотвращения столбцовTextFieldвключены в списокSELECT DISTINCT.
Создание подклассов встроенных серверных частей базы данных
Django поставляется со встроенными базами данных. Вы можете создать подкласс существующего базы данных, чтобы изменить ее поведение, функции или конфигурацию.
Представьте, например, что вам нужно изменить одну функцию базы данных. Во-первых, вы должны создать новый каталог с модулем
base. За пример:мой сайт/ . ..
mydbengine/
__init__.py
base.py
Модуль
base.pyдолжен содержать класс с именемDatabaseWrapper, который создает подклассы существующего движка из модуляdjango.db.backends. Вот пример создания подкласса механизма PostgreSQL для изменения класса объектовallow_group_by_selected_pks_on_model:mysite/mydbengine/base.pyиз базы импорта django.db.backends.postgresql, функции класс DatabaseFeatures (features.DatabaseFeatures): def allow_group_by_selected_pks_on_model (я, модель): вернуть Истина класс DatabaseWrapper (base.DatabaseWrapper): features_class = Компоненты базы данныхНаконец, вы должны указать
DATABASE-ENGINEв настройках.pyфайл:БАЗЫ ДАННЫХ = { 'дефолт': { «ДВИГАТЕЛЬ»: «mydbengine», ... }, }Текущий список механизмов баз данных можно просмотреть, заглянув в джанго/дб/бэкенды.
Использование базы данных стороннего производителя
В дополнение к официально поддерживаемым базам данных предоставляются серверные части сторонними организациями, которые позволяют вам использовать другие базы данных с Django:
- CockroachDB
- Жар-птица
- Облачный ключ Google
- Microsoft SQL Server
- ТиДБ
- ЮгабайтДБ
Версии Django и функции ORM, поддерживаемые этими неофициальными бэкендами значительно различаются. Запросы относительно конкретных возможностей этих неофициальные серверные части вместе с любыми запросами в службу поддержки следует направлять на каналы поддержки, предоставляемые каждым сторонним проектом.
Python с подключением к MySQL: база данных и таблица [примеры]
Чтобы использовать подключение MySQL к Python, вы должны иметь некоторые знания SQL
Прежде чем углубляться, давайте разберемся
Что такое MySQL?
MySQL — это база данных с открытым исходным кодом и один из лучших типов СУБД (система управления реляционными базами данных).
Соучредителем MySQLdb является Майкл Видениус, а также название MySQL происходит от дочери Майкла.Из этого руководства вы узнаете
- Что такое MySQL?
- Как установить MySQL
- Установите библиотеку соединителя MySQL для Python
- Проверка подключения к базе данных MySQL с помощью Python
- Создание базы данных в MySQL с использованием Python
- Создайте таблицу в MySQL с помощью Python
- Создайте таблицу с первичным ключом
- Таблица ALTER в MySQL с Python
- Операция вставки с MySQL в Python
Как установить MySQL Connector Python в Windows, Linux/Unix
Установить MySQL в Linux/Unix:
Скачать пакет RPM для Linux/Unix с официального сайта: https://www.mysql.com/downloads/
В терминале используйте следующую команду
rpm -i
Пример rpm -i MySQL-5.0.9.0.i386.rpm
Для проверки в Linux
mysql --version
Скачать базу данных MySQL в Windows
7 с официального сайта и установить как обычную установку программ в Windows.
Пошаговое руководство см. в этом руководстве.Как установить библиотеку MySQL Connector для Python
Вот как подключить MySQL к Python:
Для Python 2.7 или ниже установить с помощью pip как:
pip установить mysql-connector
Для Python 3 или более поздней версии установить с помощью pip3 как:
pip3 установить mysql-connector
Проверить соединение базы данных MySQL с Python
Чтобы протестировать подключение к базе данных MySQL в Python здесь, мы будем использовать предварительно установленный коннектор MySQL и передавать учетные данные в функцию connect() , такую как хост, имя пользователя и пароль, как показано в приведенном ниже примере коннектора Python MySQL.
Синтаксис для доступа к MySQL с помощью Python:
import mysql.connector db_connection = mysql.connector.connect( хост="имя хоста", пользователь = "имя пользователя", пароль = "пароль" )Пример :
импорт mysql.
connector
db_connection = mysql.connector.connect(
хост = "локальный хост",
пользователь = «корень»,
пароль = «корень»
)
print(db_connection) Вывод :
<объект mysql.connector.connection.MySQLConnection по адресу 0x000002338A4C6B00>
Здесь вывод показывает, что соединение создано успешно.
Создание базы данных в MySQL с использованием Python
Синтаксис для создания новой базы данных в SQL:
CREATE DATABASE "database_name"
Теперь мы создаем базу данных с помощью программирования баз данных в Python
import mysql.connector db_connection = mysql.connector.connect( хост = "локальный хост", пользователь = "корень", пароль = "корень" ) # создание database_cursor для выполнения операции SQL db_cursor = db_connection.cursor() # выполнение курсора с методом execute и передача SQL-запроса db_cursor.execute("СОЗДАТЬ БАЗУ ДАННЫХ my_first_db") # получить список всех баз данных db_cursor. execute("ПОКАЗАТЬ БАЗЫ ДАННЫХ")
#распечатать все базы данных
для БД в db_cursor:
печать (дб) Вывод :
На приведенном выше изображении показано, что база данных my_first_db создана
Создайте таблицу в MySQL с помощью Python
Давайте создадим простую таблицу «student», которая имеет два столбца, как показано в MySQL ниже. Пример соединителя Python.
Синтаксис SQL :
CREATE TABLE student (id INT, name VARCHAR(255))
Пример:
import mysql.connector db_connection = mysql.connector.connect( хост = "локальный хост", пользователь = «корень», пароль="корень", база данных = "мой_первый_дб" ) db_cursor = db_connection.cursor() #Здесь создается таблица базы данных как студент' db_cursor.execute("СОЗДАТЬ ТАБЛИЦУ ученика (id INT, имя VARCHAR(255))") #Получить таблицу базы данных' db_cursor.execute("ПОКАЗАТЬ ТАБЛИЦЫ") для таблицы в db_cursor: печать (таблица)Вывод :
(«студент»)
Создание таблицы с первичным ключом
Давайте создадим таблицу Employee с тремя разными столбцами.
Мы добавим первичный ключ в столбец id с ограничением AUTO_INCREMENT, как показано в приведенном ниже проекте Python с подключением к базе данных.Синтаксис SQL :
CREATE TABLE employee(id INT AUTO_INCREMENT PRIMARY KEY, имя VARCHAR(255), зарплата INT(6))
Пример :
импорт mysql.connector db_connection = mysql.connector.connect( хост = "локальный хост", пользователь = «корень», пароль="корень", база данных = "мой_первый_дб" ) db_cursor = db_connection.cursor() #Здесь создание таблицы базы данных в качестве сотрудника с первичным ключом db_cursor.execute («СОЗДАТЬ ТАБЛИЦУ сотрудника (id INT AUTO_INCREMENT PRIMARY KEY, имя VARCHAR (255), зарплата INT (6))») #Получить таблицу базы данных db_cursor.execute("ПОКАЗАТЬ ТАБЛИЦЫ") для таблицы в db_cursor: печать(таблица)Вывод :
('сотрудник',) ('студент',)ALTER таблица в MySQL с Python
Команда Alter используется для изменения структуры таблицы в SQL.
Здесь мы изменим таблицу Student и добавим первичный ключ в поле id , как показано в приведенном ниже проекте соединителя Python MySQL.Синтаксис SQL :
ALTER TABLE student MODIFY id INT PRIMARY KEY
Пример :
import mysql.connector db_connection = mysql.connector.connect( хост = "локальный хост", пользователь = «корень», пароль="корень", база данных = "мой_первый_дб" ) db_cursor = db_connection.cursor() #Здесь мы изменяем существующий идентификатор столбца db_cursor.execute("ALTER TABLE student MODIFY id INT PRIMARY KEY")Вывод :
Ниже вы можете видеть, что столбец id изменен.
Операция вставки с MySQL в Python:
Давайте выполним операцию вставки в таблицу базы данных MySQL, которую мы уже создали. Мы будем вставлять данные из таблицы STUDENT и таблицы EMPLOYEE.
Синтаксис SQL :
ВСТАВИТЬ В ЗНАЧЕНИЯ ученика (идентификатор, имя) (01, "Джон") ВСТАВИТЬ В сотрудника (идентификатор, имя, зарплата) ЗНАЧЕНИЯ (01, "Джон", 10000)
Пример :
импорт mysql.