Однако (что самое интересное) символы ( ) { } интерпретируются в BRE как метасимволы, если они экранированы символом обратного слеша, тогда как в ERE присутствие обратного слеша перед этими же метасимволами превращает их в литералы.
Поскольку далее в этой главе мы рассмотрим особенности, являющиеся частью ERE, необходимо использовать другую версию grep. Традиционно диалект ERE поддерживался программой egrep, но GNU-версия grep также поддерживает расширенные регулярные выражения при вызове ее с параметром -E.
posix
На протяжении 1980-х система Unix обрела популярность как коммерческая операционная система, но до 1988-го в мире Unix царила полная анархия. Многие производители компьютеров лицензировали исходный код Unix у ее создателя — компании AT&T и поставляли разные версии операционной системы вместе со своими машинами.
В середине 1980-х институт инженеров электроники и электротехники (Institute of Electrical and Electronics Engineers, IEEE) начал разработку единого пакета стандартов, которые должны были определить особенности работы системы Unix (и Unix-подобных). Эти стандарты, формально известные как IEEE 1003, определяют прикладные программные интерфейсы (Application Programming Interface, API), командную оболочку и утилиты, которые должны присутствовать в стандартной Unix-подобной системе. Название POSIX, сокращенное от «Portable Operating System Interface» (интерфейс переносимой операционной системы, где буква X добавлена для лучшего звучания), было предложено Ричардом Столлманом (да, тем самым Ричардом Столлманом) — и принято IEEE.
Регулярные выражения Bash: полный гайд
Одним из принципов Unix-систем является широкое использование текстовых данных: конфигурационные файлы, входные и выходные данные программ в *nix часто организованы в виде обычного текста. Регулярные выражения — это мощный инструмент для манипуляции текстовой информацией. В этом гайде разберем тонкости работы с регулярными выражениями Bash, которые помогут вам реализовать весь потенциал командной строки и скриптов в Linux.
Что такое регулярные выражения?
Регулярные выражения — это специальным образом записанные строки, используемые для поиска символьных шаблонов в тексте. Чем-то они похожи на групповые символы в оболочке, но их возможности куда шире. Многие утилиты для работы с текстом в Linux и языки программирования включают в себя механизм регулярных выражений. Здесь возникают проблемы: разные программы и языки оперируют различными диалектами регулярных выражений. В этой статье рассмотрим стандарт POSIX, которому соответствуют большинство утилит в Linux.
В этой статье рассмотрим стандарт POSIX, которому соответствуют большинство утилит в Linux.
Утилита grep
Программа grep — это основной инструмент для работы с регулярными выражениями. Grep анализирует данные со стандартного ввода, ищет совпадения с указанным шаблоном и выводит все подходящие строки. Обычно grep предустановлен в большинстве дистрибутивов. Если хотите потренироваться в использовании регулярных выражений, можете повторять описанные команды в виртуальной машине, либо на арендованном сервере.
Grep имеет следующий синтаксис:
grep [параметры] регулярное_выражение [файл…]
Самый простой случай использования grep — поиск строк, содержащих фиксированную подстроку. В следующем примере grep вывел все строки, содержащие последовательность nologin:
grep nologin /etc/passwdOutput:
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
games:x:5:60:games:/usr/games:/usr/sbin/nologin
...
 ..
..У grep имеются множество параметров. Подробно с ними ознакомиться можно в документации. Приведем ключи, полезные при работе с регулярными выражениями:
Ключ -v — инвертировать критерий. В этом случае grep выводит строки, не содержащие совпадений:
ls /bin | grep -v zipOutput:
[
411toppm
7z
7za
7zr
…
Ключ -i — игнорировать регистр символов.
Ключ -o — выводить не строки, а только совпадения с шаблоном:
ls /bin | grep -o zipOutput:
zip
zip
zip
zip
…
Ключ -w — искать только строки, содержащие все слово, которое составляет шаблон.
ls /bin | grep -w zipOutput:
gpg-zip
zip
Для сравнения та же команда без опции. В вывод также попали строки, содержащие шаблон в качестве подслова в слове.
ls /bin | grep zipOutput
bunzip2
bzip2
bzip2recover
funzip
...
Basic Regular Expressions
Ранее упоминалось, что существует множество диалектов регулярных выражений. [A-Za-z0-9]’
[A-Za-z0-9]’
Output:
backup
bin
Books
Desktop
docker
Documents
Downloads
GNS3
…
Классы символов POSIX
[:alnum:]— Алфавитно-цифровые символы; эквивалент диапазона [A-Za-z0-9] в ASCII.[:alpha:]— Алфавитные символы; эквивалент диапазона [A-Za-z] в ASCII.[:digit:]— Цифры от 0 до 9.[:lower:]и[:upper:]— Символы нижнего и верхнего регистра соответственно.[:space:]— Пробельные символы, включая пробел, табуляцию, возврат каретки, перевод строки, вертикальную табуляцию и перевод формата.

Наличие классов символов не дает удобного способа выражения частичных диапазонов, таких как [A-M]. Пример использования:
ls ~ | grep '[[:upper:]].*'
Output:
Books
Desktop
Documents
Downloads
GNS3
GOG GamesLearning
Music
...
Extended Regular Expressions
Особенности, рассматривавшиеся выше, поддерживаются практически всем POSIX-совместимыми приложениями и приложениями, реализующими BRE (например grep и потоковый редактор sed). Стандарт POSIX ERE позволяет создавать более выразительные регулярные выражения, однако не все программы умеют с ним работать. Диалект ERE поддерживался программой egrep, но GNU-версия grep также поддерживает расширенные регулярные выражения при вызове с ключом -E.
В ERE множество метасимволов расширяются следующими:
( ) { } ? + |Чередование
Чередование позволяет выбирать совпадение с одним из нескольких выражений. (bz|gz|zip)’
(bz|gz|zip)’
Output:
bzcat
bzgrep
bzip2
bzip2recover
bzless
bzmore
gzexe
gzip
zip
zipdetails
zipgrep
zipinfo
zipsplit
Квантификаторы
Квантификаторы позволяют определить число совпадений с элементом. BRE поддерживают несколько способов.
Квантификатор ? означает совпадение с элементом ноль или один раз. Иными словами совпадение с предыдущим элементом необязательно:
echo "tet" | grep -E 'tes?t'
Output:
tetecho "test" | grep -E 'tes?t'
Output:
testecho "tesst" | grep -E 'tes?t'
Output:
В последнем случае совпадения не найдены, так как буква «s» встретилась дважды.
Подобно метасимволу ?, звездочка (*) обозначает необязательный элемент; однако, в отличие от знака вопроса, этот элемент может встречаться любое число раз, а не только единожды. Рассмотрим предыдущий пример, используя вместо знака вопроса звездочку:
echo "tet" | grep -E 'tes*t'
Output:
tetecho "test" | grep -E 'tes*t'
Output:
testecho "tesst" | grep -E 'tes*t'
Output:
tesst
На этот раз все три строки совпали с шаблоном.
Метасимвол + действует почти так же, как *, но требует совпадения с предыдущим элементом не менее одного раза:
echo "tet" | grep -E 'tes+t'
Output:echo "test" | grep -E 'tes+t'
Output:
testecho "tesst" | grep -E 'tes+t'
Output:
tesst
Теперь с шаблоном не совпала первая строка, так как метасимвол
В BRE существуют специальные метасимволы { и }, которые, в отличие от предыдущих квантификаторов, позволяют выразить минимальное и максимальное число обязательных совпадений. Всего существует четыре возможных способа задания числа совпадений:
{n}— Совпадение, если предыдущий элемент встречается точно n раз.{n,m}— Совпадение, если предыдущий элемент встречается не менее n и не более m раз.{n,}— Совпадение, если предыдущий элемент встречается n или более раз.{,m}— Совпадение, если предыдущий элемент встречается не более m раз.

Пример:
echo "tet" | grep -E "tes{1,3}t"
Output:echo "test" | grep -E "tes{1,3}t"
Output:
test
echo "tesst" | grep -E "tes{1,3}t"
Output:
tesst
echo "tessst" | grep -E "tes{1,3}t"
Output:
tessst
echo "tesssst" | grep -E "tes{1,3}t"
Output:
С шаблоном совпали только те строки, где буква s встречается один, два или три раза.
Регулярные выражения на практике
В качестве заключения рассмотрим пару примеров, как регулярные выражения могут использоваться на практике.
Проверка номеров телефонов
Допустим, у нас имеется список номеров телефонов. Корректный формат номера: (nnn) nnn-nnnn. В списке 10 номеров, три номера имеют некорректный формат.
cat phonenumbers.txt
Output:
(185) 136-1035
(95) 213-1874
(37) 207-2639
(285) 227-1602
(275) 298-1043
(107) 204-2197
(799) 240-1839
(218) 750-7390
(114) 776-2276
(7012) 219-3089
Задача — найти неправильные номера. -_./0-9a-zA-Z].*’
-_./0-9a-zA-Z].*’
Последовательность .* в начале и конце означает любое количество любых символов. Такой прием необходим, так как find требует совпадения всего пути. В квадратных скобках находится отрицание множества допустимых символов в именах файлов. Таким образом любое имя файла или каталога, содержащее хотя бы один символ, не являющиеся дефисом, подчеркиванием, цифрой или латинской буквой, попадет в вывод.
Заключение
В этой статье мы рассмотрели лишь несколько примеров практического применения регулярных выражений. В начале вам будет сложно придумывать длинные регулярки. Но со временем вы получите опыт, используя регулярные выражения для поиска в разных приложениях, поддерживающих такую возможность.
Кстати, в официальном канале Timeweb Cloud собрали комьюнити из специалистов, которые говорят про IT-тренды, делятся полезными инструкциями и даже приглашают к себе работать.
Базовые и расширенные регулярные выражения POSIX
POSIX или «интерфейс переносимой операционной системы для uniX» — это набор стандартов, определяющих некоторые функции, которые должна поддерживать операционная система (UNIX).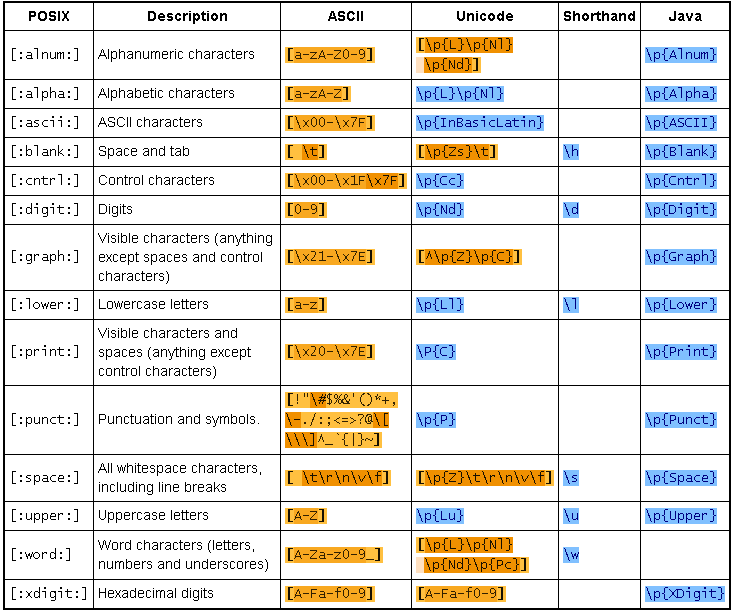 Один из этих стандартов определяет два вида регулярных выражений. Команды, включающие регулярные выражения, такие как grep и egrep, реализуют эти варианты в POSIX-совместимых системах UNIX. Некоторые системы баз данных также используют регулярные выражения POSIX.
Один из этих стандартов определяет два вида регулярных выражений. Команды, включающие регулярные выражения, такие как grep и egrep, реализуют эти варианты в POSIX-совместимых системах UNIX. Некоторые системы баз данных также используют регулярные выражения POSIX.
Вариант Basic Regular Expressions или BRE стандартизирует вариант, аналогичный тому, который используется традиционной командой UNIX grep. Это в значительной степени старейший вариант регулярных выражений, который все еще используется сегодня. Одна вещь, которая отличает эту разновидность, заключается в том, что большинству метасимволов требуется обратная косая черта, чтобы придать метасимволу свой вкус. Большинство других разновидностей, включая POSIX ERE, используют обратную косую черту для подавления значения метасимволов. Использование обратной косой черты для экранирования символа, который никогда не является метасимволом, является ошибкой.
BRE поддерживает выражения в квадратных скобках POSIX, которые аналогичны классам символов в других разновидностях регулярных выражений, но с некоторыми особенностями.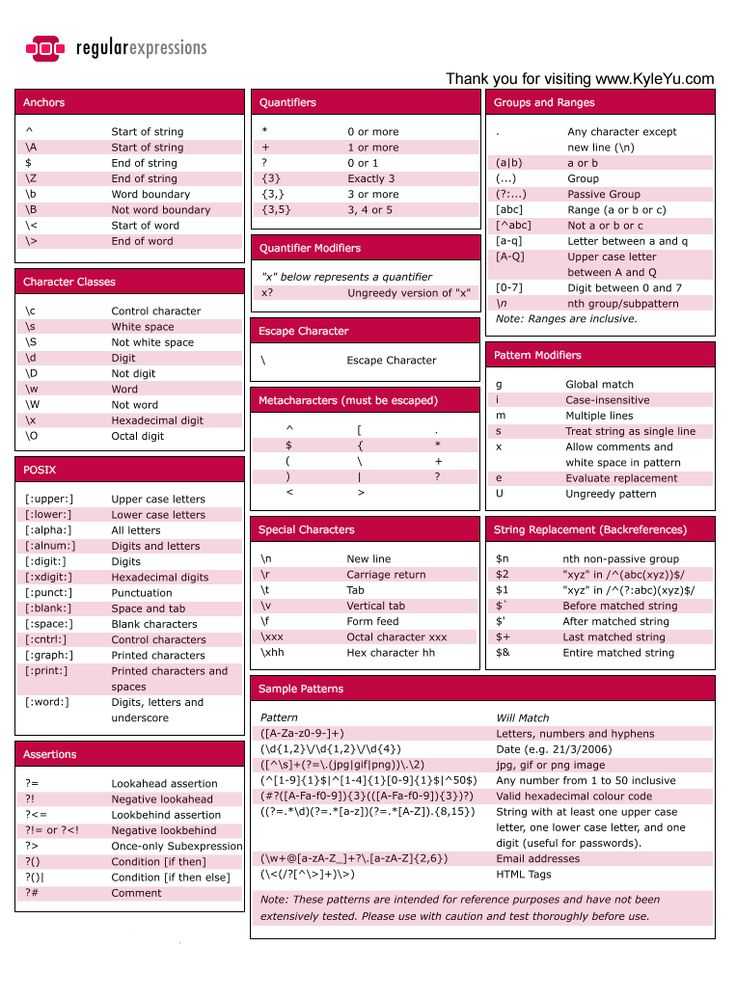 Сокращения не поддерживаются. Другими функциями, использующими обычные метасимволы, являются точка, соответствующая любому символу, кроме разрыва строки, знак вставки и доллар, соответствующие началу и концу строки, и звезда, чтобы повторять токен ноль или более раз. Чтобы буквально сопоставить любой из этих символов, экранируйте их обратной косой чертой.
Сокращения не поддерживаются. Другими функциями, использующими обычные метасимволы, являются точка, соответствующая любому символу, кроме разрыва строки, знак вставки и доллар, соответствующие началу и концу строки, и звезда, чтобы повторять токен ноль или более раз. Чтобы буквально сопоставить любой из этих символов, экранируйте их обратной косой чертой.
Другие метасимволы BRE требуют обратной косой черты, чтобы придать им особое значение. Причина в том, что самые старые версии UNIX grep их не поддерживали. Разработчики grep хотели сохранить совместимость с существующими регулярными выражениями, которые могут использовать эти символы как литеральные. BRE a{1,2} буквально соответствует a{1,2}, а a\{1,2\} соответствует a или aa. Некоторые реализации поддерживают \? и \+ в качестве альтернативы \{0,1\} и \{1,\}, но \? и \+ не являются частью стандарта POSIX. Токены могут быть сгруппированы с помощью \( и \). Обратные ссылки — это обычные от \1 до \9.. Допускается только до 9 групп.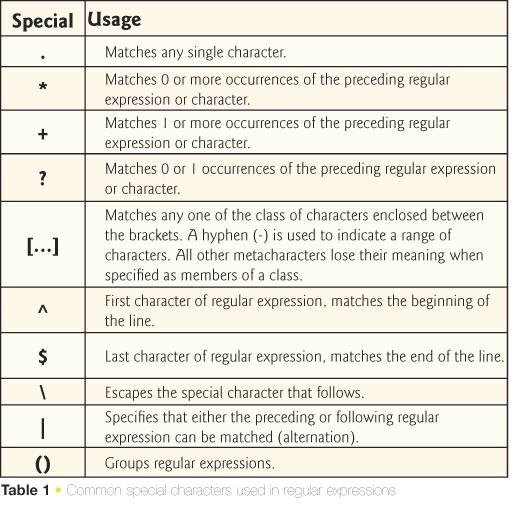 Например. \(ab\)\1 соответствует abab, а (ab)\1 недействителен, так как нет группы захвата, соответствующей обратной ссылке \1. Используйте \\1 для буквального соответствия \1.
Например. \(ab\)\1 соответствует abab, а (ab)\1 недействителен, так как нет группы захвата, соответствующей обратной ссылке \1. Используйте \\1 для буквального соответствия \1.
POSIX BRE не поддерживает никаких других функций. Даже чередование не поддерживается.
Расширенные регулярные выражения POSIX
Вариант расширенных регулярных выражений или ERE стандартизирует вариант, аналогичный тому, который используется командой UNIX egrep. «Расширенный» относится к оригинальному grep UNIX, в котором были только скобочные выражения, точка, знак вставки, доллар и звезда. ERE поддерживает их так же, как BRE. Большинство современных разновидностей регулярных выражений являются расширениями разновидности ERE. По сегодняшним меркам вариант POSIX ERE довольно прост. Стандарт POSIX был определен в 1986, и с тех пор регулярные выражения прошли долгий путь.
Разработчики egrep не пытались поддерживать совместимость с grep, вместо этого создали отдельный инструмент. Таким образом, egrep и POSIX ERE добавляют дополнительные метасимволы без обратной косой черты. Вы можете использовать обратную косую черту, чтобы подавить значение всех метасимволов, как и в современных вариантах регулярных выражений. Экранирование символа, который не является метасимволом, является ошибкой.
Вы можете использовать обратную косую черту, чтобы подавить значение всех метасимволов, как и в современных вариантах регулярных выражений. Экранирование символа, который не является метасимволом, является ошибкой.
Квантификаторы ?, +, {n}, {n,m} и {n,} повторяют предыдущий токен ноль или один раз, один или более раз, n раз, от n до m раз и n или более раз соответственно . Чередование поддерживается через обычную вертикальную черту |. Незакрашенные круглые скобки создают группу, например. (abc){2} соответствует abcabc. Стандарт POSIX не определяет обратные ссылки. Некоторые реализации поддерживают от \1 до \9., но они не являются частью стандарта для ERE. ERE — это расширение старого grep UNIX, а не POSIX BRE.
Именно так далеко идет расширение.
Чередование POSIX ERE возвращает самое длинное совпадение
В разделе руководства о чередовании я объяснил, что механизм регулярных выражений остановится, как только найдет совпадающую альтернативу. Однако стандарт POSIX требует, чтобы возвращалось самое длинное совпадение. При применении Set|SetValue к SetValue механизм регулярных выражений, совместимый с POSIX, будет полностью соответствовать SetValue. Даже если механизм является механизмом NFA, ориентированным на регулярные выражения, POSIX требует, чтобы он имитировал сопоставление DFA, ориентированное на текст, пробуя все альтернативы и возвращая самое длинное совпадение, в данном случае SetValue. Традиционный движок NFA будет соответствовать Set, как и все другие разновидности регулярных выражений, обсуждаемые на этом веб-сайте.
При применении Set|SetValue к SetValue механизм регулярных выражений, совместимый с POSIX, будет полностью соответствовать SetValue. Даже если механизм является механизмом NFA, ориентированным на регулярные выражения, POSIX требует, чтобы он имитировал сопоставление DFA, ориентированное на текст, пробуя все альтернативы и возвращая самое длинное совпадение, в данном случае SetValue. Традиционный движок NFA будет соответствовать Set, как и все другие разновидности регулярных выражений, обсуждаемые на этом веб-сайте.
Механизм, совместимый с POSIX, все равно найдет самое левое совпадение. Если вы примените Set|SetValue к Set или SetValue один раз, оно будет соответствовать Set. Первая позиция в строке — это крайняя левая позиция, в которой наше регулярное выражение может найти действительное совпадение. Тот факт, что дальше в строке можно найти более длинное совпадение, не имеет значения. Если вы примените регулярное выражение во второй раз, продолжая с первого пробела в строке, тогда будет совпадать SetValue. Традиционный механизм NFA будет сопоставлять Set в начале строки в качестве первого совпадения и Set в начале 3-го слова в строке в качестве второго совпадения.
Традиционный механизм NFA будет сопоставлять Set в начале строки в качестве первого совпадения и Set в начале 3-го слова в строке в качестве второго совпадения.
| Быстрый старт | Учебник | Инструменты и языки | Примеры | Ссылка | Обзоры книг |
| грэп | PowerGREP | Регулярное выражение друг | RegexMagic |
| EditPad Lite | EditPad Pro |
| Повышение | Дельфы | GNU (Linux) | Отличный | Ява | JavaScript | .NET | PCRE (C/C++) | PCRE2 (C/C++) | Перл | PHP | POSIX | PowerShell | Питон | Р | Руби | std::regex | Tcl | VBScript | Visual Basic 6 | wxвиджеты | XML-схема | Ходжо | XQuery и XPath | XRegExp |
| MySQL | Оракул | PostgreSQL |
Учебное пособие по регулярным выражениям. Выражения в скобках POSIX
Выражения в скобках POSIX представляют собой особый вид классов символов. Выражения со скобками POSIX соответствуют одному символу из набора символов, как обычные классы символов. Они используют тот же синтаксис с квадратными скобками. или -.
или -.
Основная цель выражений в квадратных скобках заключается в том, что они адаптируются к локали пользователя или приложения. Локаль — это набор правил и настроек, описывающих языковые и культурные соглашения, такие как порядок сортировки, формат даты и т. д. Стандарт POSIX определяет эти локали.
Как правило, только POSIX-совместимые механизмы регулярных выражений имеют надлежащую и полную поддержку выражений скобок POSIX. Некоторые механизмы регулярных выражений, отличные от POSIX, поддерживают классы символов POSIX, но обычно не поддерживают сопоставление последовательностей и эквивалентов символов. Механизмы регулярных выражений, поддерживающие Unicode, используют свойства и сценарии Unicode, чтобы обеспечить функциональность, аналогичную выражениям скобок POSIX. В механизмах регулярных выражений Unicode классы сокращенных символов, такие как \w, обычно соответствуют всем соответствующим символам Unicode, что избавляет от необходимости использовать локали.
Классы символов
Не путайте термин POSIX «класс символов» с тем, что обычно называют классом символов регулярного выражения. [x-z0-9] — это пример того, что в этом руководстве называется «классом символов», а в POSIX — «выражением скобок». [:digit:] — это класс символов POSIX, используемый внутри выражения в квадратных скобках, например [x-z[:digit:]]. Имена классов символов POSIX должны быть написаны строчными буквами.
[x-z0-9] — это пример того, что в этом руководстве называется «классом символов», а в POSIX — «выражением скобок». [:digit:] — это класс символов POSIX, используемый внутри выражения в квадратных скобках, например [x-z[:digit:]]. Имена классов символов POSIX должны быть написаны строчными буквами.
При использовании в строках ASCII эти два регулярных выражения находят одинаковые совпадения: один символ, который может быть x, y, z или цифрой. При использовании в строках с символами, отличными от ASCII, класс [:digit:] может включать цифры в других алфавитах, в зависимости от локали.
Стандарт POSIX определяет 12 классов символов. В таблице ниже перечислены все 12, а также классы [:ascii:] и [:word:], которые также поддерживаются некоторыми разновидностями регулярных выражений. В таблице также показаны эквивалентные классы символов, которые можно использовать в регулярных выражениях ASCII и Unicode, если классы POSIX недоступны. Эквиваленты ASCII точно соответствуют тому, что определено в стандарте POSIX. Эквиваленты Unicode соответствуют тому, что соответствует большинству механизмов регулярных выражений Unicode. Стандарт POSIX не определяет локаль Unicode. Некоторые классы также имеют сокращенные эквиваленты в стиле Perl.
Эквиваленты Unicode соответствуют тому, что соответствует большинству механизмов регулярных выражений Unicode. Стандарт POSIX не определяет локаль Unicode. Некоторые классы также имеют сокращенные эквиваленты в стиле Perl.
Java не поддерживает выражения в квадратных скобках POSIX, но поддерживает классы символов POSIX с использованием оператора \p. Хотя синтаксис \p заимствован из синтаксиса свойств Unicode, классы POSIX в Java соответствуют только символам ASCII, как указано ниже. Имена классов чувствительны к регистру. В отличие от синтаксиса POSIX, который можно использовать только внутри выражения в квадратных скобках, \p в Java можно использовать внутри и вне выражений в квадратных скобках.
В Java 8 и более ранних версиях не имеет значения, используете ли вы префикс Is с синтаксисом \p или нет. Итак, в Java 8 \p{Alnum} и \p{IsAlnum} идентичны. В Яве 9и позже есть разница. Без префикса Is поведение точно такое же, как и в предыдущих версиях Java. Синтаксис с префиксом Is теперь также соответствует символам Unicode. Для \p{IsPunct} это также означает, что он больше не соответствует символам ASCII, которые находятся в категории символов Unicode.
Для \p{IsPunct} это также означает, что он больше не соответствует символам ASCII, которые находятся в категории символов Unicode.
Вариант JGsoft поддерживает синтаксис POSIX и Java. Первоначально он соответствовал символам Unicode, используя любой синтаксис. Начиная с JGsoft V2, он соответствует только символам ASCII при использовании синтаксиса POSIX и символам Unicode при использовании синтаксиса Java.
| POSIX | Описание | ASCII | UNICODE | Shorthand | Java | |
|---|---|---|---|---|---|---|
| [: Alnum:] | Alphanrimicure | . L}\p{Nl} \p{Nd}] | \p{Alnum} | |||
| [:alpha:] | Алфавитные символы | [a-zA-Z] | \p{L }\p{Nl} | \p{Альфа} | ||
| [:ascii:] | ASCII символы | [\ x00- \ x7f] | \ p {inbasiclatin} | \ p {ascii} | ||
| [: blank:] | и Tab | [:] | и Tab | [:]и Tab | [:].\h | \p{Пробел} |
| [:cntrl:] | Управляющие символы | [\x00-\x1F\x7F] | \p{C9007c } | \p{Cntrl} | ||
| [:digit:] | Цифры | [0-9] 9\p{Z}\p{C}] | \p{График} | |||
| [:lower:] | Строчные буквы | [az] | \p{Ll 7 | |||
| [:print:] | Видимые символы и пробелы (любые, кроме управляющих символов) | [\x20-\x7E] | \P{C} | \p{Print} | ||
| [:punct:] | Знаки препинания (и символы). | [!»\#$%&'()*+, 9_'{|}~] | \p{P} | \p{Punct} | ||
| [:space:] | Все пробельные символы, включая разрывы строк | [ \t\r\n\ v\f] | [\p{Z}\t\r\n\v\f] | \s | \p{Пробел} | |
| [:upper:] | Заглавные буквы | [ A-Z] | \p{Lu} | \u | \p{Upper} | |
| [:word:] | Символы слова (буквы, цифры и символы подчеркивания) | [A-Za-z0-9_] | [\p{L}\p{Nl} \p{Nd}\p{Pc}] | \w | \p{IsWord} | |
| [:xdigit:] | Hexadecimal digits | [A-Fa-f0-9] | [A-Fa-f0-9] | \p{XDigit} | ||
| POSIX | Description | ASCII | Unicode | Сокращение | Java |
 [\p{Zs}\t]
[\p{Zs}\t]Последовательности сортировки
Локаль POSIX может иметь последовательности сортировки для описания порядка расположения определенных символов или групп символов. В чешском, например, ch как в chemie («химия» по-чешски) — это орграф. Это означает, что с ним следует обращаться так, как если бы это был один символ. Он расположен между h и i в чешском алфавите. Вы можете использовать элемент последовательности сопоставления [.ch.] внутри выражения в квадратных скобках, чтобы сопоставить ch, когда активна чешская локаль (cs-CZ). Регулярное выражение [[.ch.]]emie соответствует chemie. Обратите внимание на двойные квадратные скобки. Одна пара для выражения в квадратных скобках и одна пара для последовательности сопоставления. 9x] не может соответствовать двум символам ch.
В чешском, например, ch как в chemie («химия» по-чешски) — это орграф. Это означает, что с ним следует обращаться так, как если бы это был один символ. Он расположен между h и i в чешском алфавите. Вы можете использовать элемент последовательности сопоставления [.ch.] внутри выражения в квадратных скобках, чтобы сопоставить ch, когда активна чешская локаль (cs-CZ). Регулярное выражение [[.ch.]]emie соответствует chemie. Обратите внимание на двойные квадратные скобки. Одна пара для выражения в квадратных скобках и одна пара для последовательности сопоставления. 9x] не может соответствовать двум символам ch.
Наконец, обратите внимание, что не все механизмы регулярных выражений, претендующие на реализацию регулярных выражений POSIX, на самом деле имеют полную поддержку сопоставления последовательностей. Иногда эти механизмы используют синтаксис регулярных выражений, определенный POSIX, но не имеют полной поддержки локали. Вы можете попробовать приведенные выше совпадения, чтобы увидеть, работает ли используемый вами движок. Например, команда Tcl regexp поддерживает синтаксис для сопоставления последовательностей. Но Tcl поддерживает только локаль Unicode, которая не определяет никаких последовательностей сопоставления. В результате в Tcl последовательность сопоставления, определяющая один символ, соответствует только этому символу. Все остальные последовательности сопоставления приводят к ошибке.
Например, команда Tcl regexp поддерживает синтаксис для сопоставления последовательностей. Но Tcl поддерживает только локаль Unicode, которая не определяет никаких последовательностей сопоставления. В результате в Tcl последовательность сопоставления, определяющая один символ, соответствует только этому символу. Все остальные последовательности сопоставления приводят к ошибке.
Эквиваленты символов
Локаль POSIX может определять эквиваленты символов, которые указывают, что определенные символы должны рассматриваться как идентичные для сортировки. Например, во французском языке акценты не учитываются при упорядочении слов. élève предшествует être, которое предшествует evénement. é и ê — все то же самое, что и e, но l предшествует t, который предшествует v. Если языковой стандарт установлен на французский, механизм регулярных выражений, совместимый с POSIX, сопоставляет e, é, è и ê, когда вы используете последовательность сопоставления [= e=] в выражении скобок [[=e=]].