Реляционные базы данных | Computerworld Россия
Реляционные базы данных позволяют хранить информацию в нескольких «плоских» (двухмерных) таблицах, связанных между собой посредством совместно используемых полей данных, называемых ключами.
Определение
Реляционные базы данных позволяют хранить информацию в нескольких «плоских» (двухмерных) таблицах, связанных между собой посредством совместно используемых полей данных, называемых ключами. Реляционные базы данных предоставляют более простой доступ к оперативно составляемым отчетам (обычно через SQL) и обеспечивают повышенную надежность и целостность данных благодаря отсутствию избыточной информации
Всем известно, что представляет собой простая база данных: телефонные справочники, каталоги товаров и словари — все это базы данных. Они могут быть структурированными или организованными каким-то иным образом: как плоские файлы, как иерархические или сетевые структуры или как реляционные таблицы. Чаще всего в организациях для хранения информации используются именно реляционные базы данных.
Чаще всего в организациях для хранения информации используются именно реляционные базы данных.
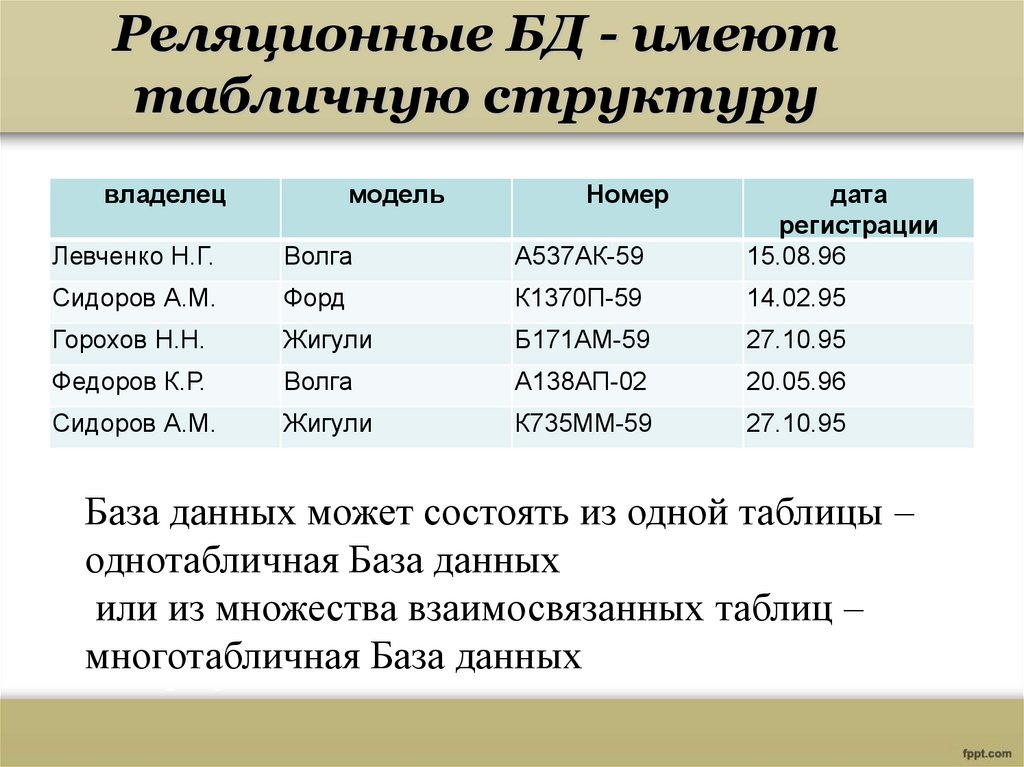
База данных — это набор таблиц, состоящих из столбцов и строк, аналогично электронной таблице. Каждая строка содержит одну запись; каждый столбец содержит все экземпляры конкретного фрагмента данных всех строк. Например, обычный телефонный справочник состоит из столбцов, содержащих телефонные номера, имена абонентов и адреса абонентов. Каждая строка содержит номер, имя и адрес. Эта простая форма называется плоским файлом в силу его двухмерной природы, а также того, что все данные хранятся в одном файле.
В идеале каждая база данных имеет по крайней мере один столбец с уникальным идентификатором, или ключом. Рассмотрим телефонную книгу. В ней может быть несколько записей с абонентом Джон Смит, но ни один из телефонных номеров не повторяется. Телефонный номер и служит ключом.
На самом деле все не так просто. Два или несколько человек, использующих один и тот же телефонный номер, могут быть перечислены в телефонном справочнике по отдельности, в силу чего телефонный номер появляется в двух или более местах, поэтому существует несколько строк с ключами, которые не являются уникальными.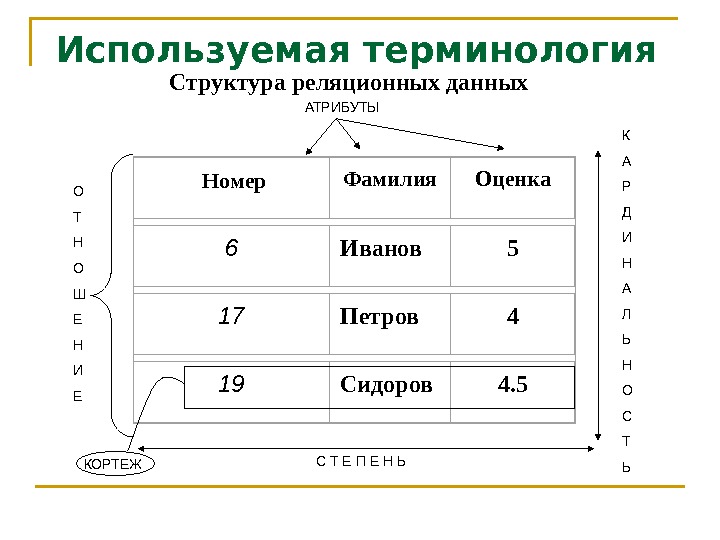
Данные создают проблемы
В самых простых базах данных каждая запись занимает одну строку, иными словами, телефонной компании необходимо заводить отдельный столбец для каждого фрагмента бухгалтерской информации. То есть одну — для второго абонента «спаренного» телефона, еще одну — для третьего и т. д., в зависимости от того, сколько дополнительных абонентов понадобится.
Это значит, что каждая запись в базе данных должна иметь все эти дополнительные колонки, даже если больше они нигде не используются. Это также означает, что база данных должна быть реорганизована всякий раз, когда компания предлагает новую услугу. Вводится обслуживание тонального набора — и меняется структура базы, поскольку добавляется новая колонка. Вводится поддержка идентификации номера звонящего абонента, ожидания звонка и т. д. — и база данных перестраивается снова и снова.
В 60-е годы только самые крупные компании могли позволить себе приобретать компьютеры для управления своими данными. Более того, базы данных, построенные на статических моделях данных и с помощью процедурных языков программирования, таких как Кобол, могут оказаться слишком дорогими в том, что касается поддержки, и не всегда надежными.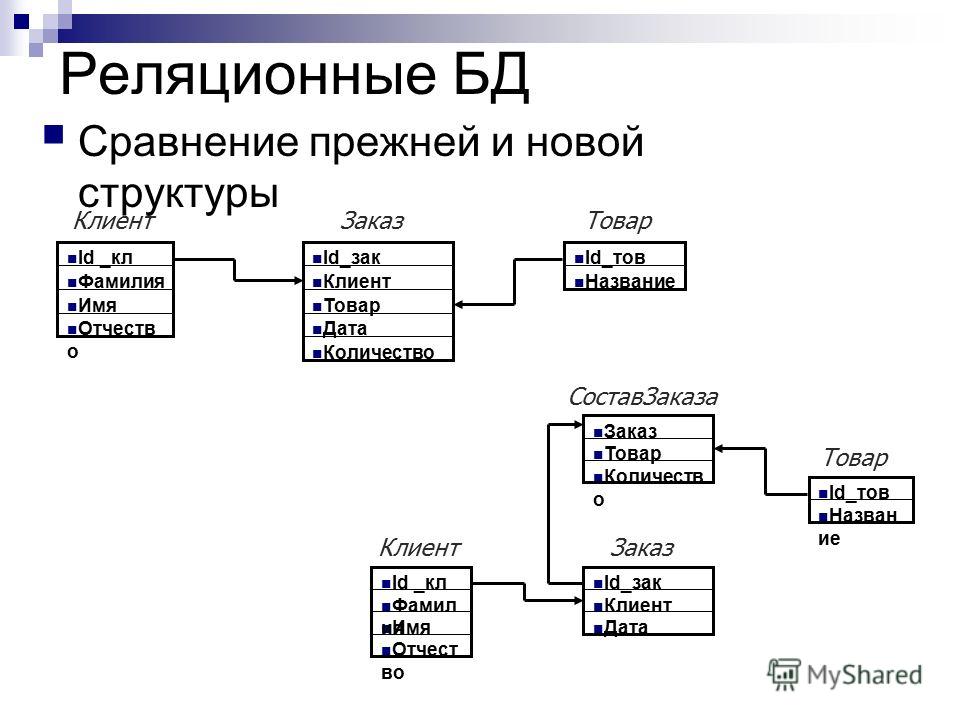 Процедурные языки определяют последовательность событий, через которую компьютер должен пройти, чтобы выполнить задачу. Программирование таких последовательностей было сложным делом, особенно если требовалось менять структуру базы данных или составлять новый вид отчетов.
Процедурные языки определяют последовательность событий, через которую компьютер должен пройти, чтобы выполнить задачу. Программирование таких последовательностей было сложным делом, особенно если требовалось менять структуру базы данных или составлять новый вид отчетов.
Мощные связи
Эдгар Кодд, сотрудник исследовательской лаборатории корпорации IBM в Сан-Хосе, по существу, создал и описал концепцию реляционных баз данных в своей основополагающей работе «Реляционная модель для крупных, совместно используемых банков данных» (A Relational Model of Data for Large Shared Data Banks. Communications of the ACM, июнь 1970).
Кодд предложил модель, которая позволяет разработчикам разделять свои базы данных на отдельные, но взаимосвязанные таблицы, что увеличивает производительность, но при этом внешнее представление остается тем же, что и у исходной базы данных. С тех пор Кодд считается отцом-основателем отрасли реляционных баз данных.
Эта модель работает следующим образом. Телефонная компания может создать основную таблицу, используя в качестве первичного ключа номер телефона, и хранить его с другой базовой информацией о потребителях. Компания может определить отдельную таблицу со столбцами для этого первичного ключа и для дополнительных служб, таких как поддержка идентификации номера звонящего абонента и ожидание звонка. Она также может создать еще одну таблицу для контроля счетов за переговоры, где каждая запись состоит из номера телефона и данных об оплате звонков.
Телефонная компания может создать основную таблицу, используя в качестве первичного ключа номер телефона, и хранить его с другой базовой информацией о потребителях. Компания может определить отдельную таблицу со столбцами для этого первичного ключа и для дополнительных служб, таких как поддержка идентификации номера звонящего абонента и ожидание звонка. Она также может создать еще одну таблицу для контроля счетов за переговоры, где каждая запись состоит из номера телефона и данных об оплате звонков.
Конечные пользователи могут легко получить ту информацию, которую они хотят, и в том виде, в каком она им требуется, хотя эти данные хранятся в различных таблицах. Поэтому представитель службы поддержки потребителей телефонной компании может отобразить на одном и том же экране информацию о счетах абонента, а также о состоянии специальных служб или о том, когда была получена последняя оплата.
Кодд сформулировал 12 правил для реляционных баз данных, большинство которых касаются целостности и обновления данных, а также доступа к ним. Первые два достаточно понятны даже пользователям, не обладающим техническими навыками.
Первые два достаточно понятны даже пользователям, не обладающим техническими навыками.
Правило 1, информационное правило, указывает, что вся информация в реляционной базе данных представляется как набор значений, хранящихся в таблицах.
Правило 2, правило гарантии доступа, определяет, что доступ к каждому элементу данных в реляционной базе данных можно получить с помощью имени таблицы, первичного ключа и названия столбца. Другими словами, все данные хранятся в таблицах, и, если известно название таблицы, первичный ключ и столбец, где находится требуемый элемент данных, его всегда можно извлечь.
Суть работы Кодда заключалась в том, что предлагалось с реляционными базами данных использовать декларативные, а не процедурные языки программирования. Декларативные языки, такие как язык запросов SQL (Structured Query Language), дают пользователям возможность, по существу, сообщить компьютеру: «Я хочу получить следующие биты данных из всех записей, которые удовлетворяют определенному набору критериев». Компьютер сам «поймет», какие необходимо совершить шаги, чтобы получить эту информацию из базы данных.
Компьютер сам «поймет», какие необходимо совершить шаги, чтобы получить эту информацию из базы данных.
Для работы с огромным количеством активно используемых баз данных применяются программные системы управления реляционными базами данных, созданные такими авторитетными производителями, как Oracle, Sybase, IBM, Informix и Microsoft.
Хотя большую часть вариантов реализаций SQL можно назвать интероперабельными лишь с известным приближением, этот утвержденный в качестве международного стандарта механизм позволяет создавать сложные системы, основу которых составляют базы данных. Удобный для программирования интерфейс между Web-сайтами и реляционными базами данных дает конечным пользователям возможность добавлять новые записи и обновлять существующие, а также создавать отчеты для самых разных служб, таких как выполнение интерактивных торговых операций и доступ к интерактивным библиотечным каталогам.
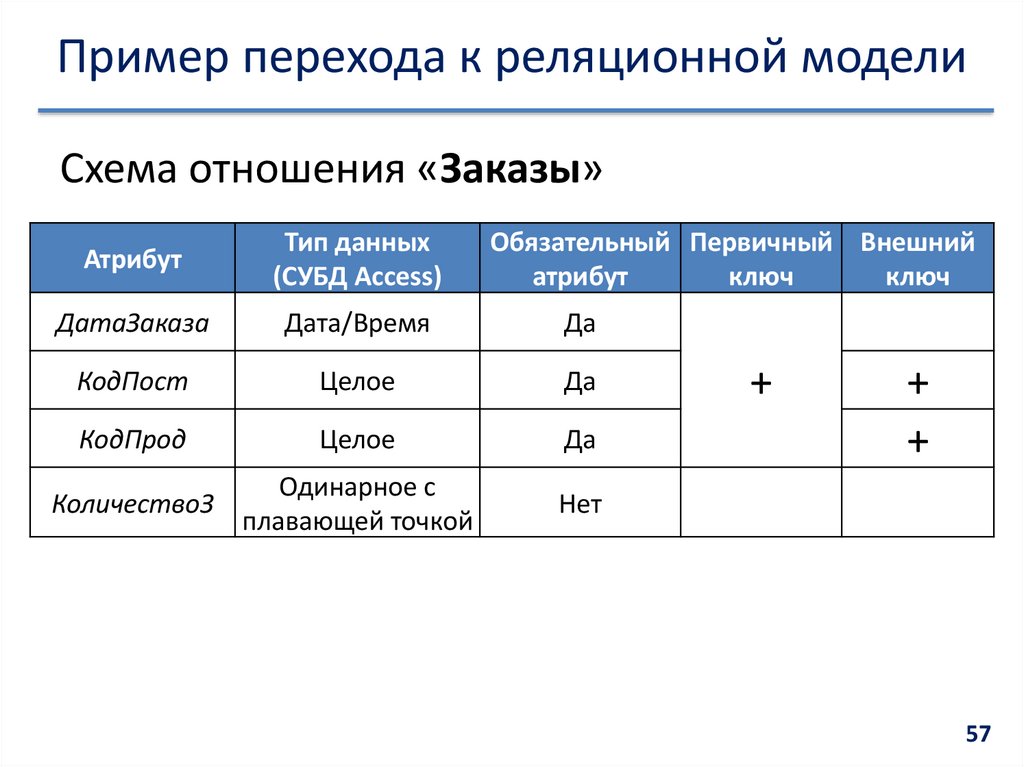
Реляционная модель
Реляционная база данных использует набор таблиц, связанных друг с другом посредством определенного ключа (в данном случае это поле PhoneNumber)
отличия и преимущества — Boodet.
 online
online480 auto
Администрирование
SQL или NoSQL — какую базу данных выбрать? В чем заключается их различие. Преимущества SQL и NoSQL. Сравнение и выводы.
IT GIRL 15
Post Views: 16 196
Реляционные vs. нереляционные базы данных: отличия и преимущества Блог 2020-12-24 ru Реляционные vs. нереляционные базы данных: отличия и преимущества
286 104
Boodet Online
+7 (499) 649 09 90
123022,
Москва,
ул. Рочдельская, дом 15, строение 15
Рочдельская, дом 15, строение 15
286 104
Boodet Online +7 499 649 09 90 123022, Москва, ул. Рочдельская, дом 15, строение 15
Поделиться
Твинтнуть
Поделиться
Запинить
Отправить
SQL vs NoSQL
Любые компьютерные вычисления связаны с обработкой данных. Они бывают структурированными и неструктурированными. Первые размещают в базах данных, где наравне с информацией хранится ее описание. Говоря о БД, часто можно встретить термины SQL и NoSQL.
SQL — это методика обработки (язык, структура, действия), которая используется для того, чтобы проводить чтение и обработку реляционных и нереляционных (NoSQL) баз данных. Как это все работает и для чего нужно — объясняют специалисты Boodet.Online.
Как это все работает и для чего нужно — объясняют специалисты Boodet.Online.
Понятие реляционных и нереляционных баз данных
Термин «реляционный» пришел из алгебры (теория множеств). В формате БД это значит, что данные реляционных баз хранятся в виде таблиц и строк. Нереляционные БД размещают информацию в коллекциях документов JSON.
Реляционные БД используют язык SQL (структурированных запросов). Структура таких баз данных позволяет связывать информацию из разных таблиц с помощью внешних ключей (или индексов), которые используются для уникальной идентификации любого атомарного фрагмента данных в этой таблице. Другие таблицы могут ссылаться на этот внешний ключ, чтобы создать связь между частями данных и частью, на которую указывает внешний ключ.
Зачем нужны нереляционные БД? Их главное преимущество — высокий уровень безопасности и возможность обойти аппаратные ограничения (с помощью Sharding).
Различия SQL и NoSQL
SQL и NoSQL — это термины, которые описывают совершенно разные способы обработки данных.
Язык
SQL используют универсальный язык структурированных запросов для определения и обработки данных. Это накладывает определенные ограничения: прежде чем начать обработку, данные надо разместить внутри таблиц и описать.
NoSQL таких ограничений не имеет. Динамические схемы для неструктурированных данных позволяют:
ориентировать информацию на столбцы или документы;
основывать ее на графике;
организовывать в виде хранилища KeyValue;
создавать документы без предварительного определения их структуры, использовать разный синтаксис;
добавлять поля непосредственно в процессе обработки.
Структура
SQL основаны на таблицах, а NoSQL — на документах, парах ключ-значение, графовых БД, хранилищах с широкими столбцами.
Масштабируемость
В большинстве случаев базы данных SQL можно масштабировать по вертикали. Что это значит? Можно увеличить нагрузку на один сервер, увеличив таким образом ЦП, ОЗУ или объем накопителя.
Что это значит? Можно увеличить нагрузку на один сервер, увеличив таким образом ЦП, ОЗУ или объем накопителя.
В отличие от SQL базы данных NoSQL масштабируются по горизонтали. Это означает, что больший трафик обрабатывается путем разделения или добавления большего количества серверов. Это делает NoSQL удобнее при работе с большими или меняющимися наборами данных.
В каких случаях используют SQL?
SQL подойдет, если нужна обработка большого количества сложных запросов, или рутинного анализа данных. Выбирайте реляционную БД, если нужна надежная обработка транзакций и ссылочная целостность.
А в каких NoSQL?
Если объем данных большой, лучше использовать NoSQL. Отсутствие явных структурированных механизмов ускорит процесс обработки Big Data. А еще это безопаснее — такие БД сложнее взломать.
Выбирайте NoSQL, если:
необходимо хранить массивы в объектах JSON;
записи хранятся в коллекции с разными полями или атрибутами;
необходимо горизонтальное масштабирование.


Самые распространенные реляционные базы данных
Для работы с реляционными БД лучше всего подойдут:
MySQL
Бесплатный продукт с открытым исходным кодом от Oracle. Отличается стабильностью и хорошим тестированием обновлений до их внедрения. MySQL можно доработать под свои нужды или поискать готовые исправления в обширной библиотеке профильного сообщества.
MySQL работает с любыми ОС: Linux, Windows, Mac, BSD и Solaris. Дружит с Node.js, Ruby, C#, C++, Java, Perl, Python и PHP.
Базу данных MySQL можно реплицировать на несколько узлов, что уменьшает рабочую нагрузку при увеличении доступности приложения.
Oracle
Oracle Database часто используют крупные корпорации. Коммерческий вариант БД часто и грамотно обновляется, есть круглосуточная техническая поддержка.
Oracle применяет свой собственный диалект SQL (PL/SQL). Это дает возможность работать со встроенными функциями, процедурами и переменными. Так же, как и MySQL, работает с любыми операционными системами. Если проекту необходимо использовать реляционные БД для работы с Big Data, то Oracle станет хорошей альтернативой NoSQL благодаря особой организации СУБД — группировке объектов по схемам, которые являются подмножеством объектов.
Если проекту необходимо использовать реляционные БД для работы с Big Data, то Oracle станет хорошей альтернативой NoSQL благодаря особой организации СУБД — группировке объектов по схемам, которые являются подмножеством объектов.
Еще одно важное преимущество Oracle — возможность восстановления предыдущей версии БД. Помимо этого, есть индексация растровых изображений, секционирование, индексацию на основе функций и по обратному ключу, оптимизация приоритетных запросов.
Microsoft SQL Server
Microsoft SQL Server — это отличный вариант для малого и среднего бизнеса. Диалект T-SQL обрабатывает процедуры, встроенные функции и переменные. Есть важное ограничение: Microsoft SQL Server будет работать только с Linux или Windows. Простой интерфейс ускорит процесс миграции БД, если до этого вы пользовались другой системой.
Нереляционные базы данных
Согласно рейтингу Boodet.Online, самыми удобными системами для обработки нереляционных баз данных являются: MongoDB, Apache Cassandra и Google Cloud BigTable.
MongoDB
MongoDB — это качественный бесплатный продукт, который чаще всего используют при работе с NoSQL. Решение позволяет менять схемы данных в процессе работы, масштабироваться по горизонтали. Интерфейс очень простой — в нем легко разберется любой сотрудник компании, не обязательно быть IT-профессионалом.
Почему мы поставили Mongo на первое место в списке лидеров обработки нереляционных баз данных? Все дело в новой функции от разработчиков. Теперь в решении есть глобальная облачная БД, что дает возможность развернуть управляемую MongoDB через AWS, Azure, GCP.
Apache Cassandra
Apache Cassandra — это продукт с открытым исходным кодом, а значит, достаточно гибкий, адаптируемый практически для любых задач. Идентичность узлов упрощает масштабирование для наращивания архитектуры БД.
Apache Cassandra подойдет для масштабных проектов. Продукт обеспечивает высокую скорость чтения и записи. Даже если часть решения использует SQL, можно применить подобные SQL операторы: DDL, DML, SELECT.
Apache Cassandra — это один из немногих инструментов обработки баз данных, который гарантирует безотказность работы (подробнее читайте в своем SLA).
Google Cloud BigTable
Неплохой продукт от Google, который гарантирует задержку обработки не более 10 мс. BigTable уделяют безотказности много внимания. Например, благодаря функции репликации базы данных более долговечны, доступны и устойчивы при зональных сбоях. Это отличный вариант для работы с Big Data в режиме реального времени (машинное зрение, AI) — можно изолировать рабочую нагрузку для приоритетной аналитики.
Так что же лучше?
Специалисты Boodet.Online работают с обоими вариантами баз данных. Основной критерий выбора: подходит ли приложение для решения конкретной задачи. Как мы определяем, что лучше для конкретного проекта:
Если в БД есть предопределенная схема — используем SQL, если схема динамическая — NoSQL.
Выбираем приоритетное направление масштабирования — по горизонтали или по вертикали.
Определяем, что будет использоваться в задаче — неструктурированные данные или многострочные транзакции.
Выводы
Нельзя однозначно сказать, что лучше — SQL или NoSQL. Все зависит от конкретной задачи и типа данных. В некоторых случаях необходимо обработать оба типа БД — тогда рекомендуем выбирать гибридное решение, например, PostgreSQL (объектно-ориентированная СУБД).
Для подробной консультации и помощи в выборе СУБД для своего проекта обратитесь к специалистам Boodet.Online.
Поделиться
Твинтнуть
Поделиться
Запинить
Отправить
Facebook
YouTube
Telegram
Реляционные базы данных — определение, структура, примеры » Kupuk.net
Реляционная база данных (БД) — это совокупность связанных между собой двумерных таблиц, в которых хранится информация об объектах. Запись (строка) включает в себя данные об одном объекте, а в полях (столбцах) содержатся различные его характеристики. Основы теории табличной модели впервые были описаны Эдгаром Коддом (IBM) в 1970 году.
Основы теории табличной модели впервые были описаны Эдгаром Коддом (IBM) в 1970 году.
Особенности реляционных БД
БД используются для организации хранения данных. Структура реляционной базы данных полностью определяется перечнем названия полей с указанием их типов и свойств. Все записи имеют одинаковые поля, но в них показываются разные свойства объекта. Аналогом реляционной БД считается двумерная таблица. Характерные особенности файла БД:
Реляционная БД чаще всего не ограничивается одной таблицей. Обычно создаются несколько таблиц со связанной информацией. Это позволяет исполнять более сложные операции над данными. Таблицы реляционной БД обязаны соответствовать требованиям понятия нормализации отношений, то есть ограничениям на формирование, которые позволят избежать дублирования и обеспечат непротиворечивость хранимой информации. Пусть создана таблица «Прокат», содержащая следующие поля: Шифр Клиента, Ф. И. О., Вид устройства, Дата выдачи, Оплата, Срок возврата. Эта организация хранения информации имеет несколько недостатков:
Это позволяет исполнять более сложные операции над данными. Таблицы реляционной БД обязаны соответствовать требованиям понятия нормализации отношений, то есть ограничениям на формирование, которые позволят избежать дублирования и обеспечат непротиворечивость хранимой информации. Пусть создана таблица «Прокат», содержащая следующие поля: Шифр Клиента, Ф. И. О., Вид устройства, Дата выдачи, Оплата, Срок возврата. Эта организация хранения информации имеет несколько недостатков:
- дублирование информации (вид устройства повторяется для разных клиентов), что увеличивает объём БД;
- для обновления информации требуется обрабатывать каждую запись.
Для устранения этих недостатков необходима нормализация с разделением данных на разные таблицы.
Связывание таблиц
Для любой таблицы реляционной БД задаётся первичный ключ (primary key) — поле или сочетание полей, которые определяют каждую запись. Внешний или вторичный ключ (foreign key) — это одно или несколько полей, ссылающихся на поле primary key другой таблицы.
Внешний или вторичный ключ (foreign key) — это одно или несколько полей, ссылающихся на поле primary key другой таблицы.
Составной ключ называется так, потому что создаётся из нескольких полей. При образовании составных ключей не рекомендуется включать в них поля, значения которых точно определяют запись. Например, не следует образовывать ключ, в котором находятся вместе поля «номер паспорта» и «шифр клиента», потому что оба эти атрибута однозначно определяют запись. Поля с повторяющимися в таблице значениями тоже нельзя делать составной частью ключа. По значению ключа возможно найти только одну запись.
Ячейка — это наименьший структурный элемент, который задаёт определённое значение соответствующего поля. Таблицы связываются друг с другом, и поэтому данные могут выбираться сразу из нескольких таблиц. Связь создаётся, если в них присутствуют одинаковые поля. Типы связей:
- один к одному;
- один ко многим;
- многие ко многим.
Связи «один к одному» встречаются довольно редко. «Один ко многим» применяются чаще, например, кассир продаёт много билетов. «Многие ко многим» тоже встречаются часто. Например, студент изучает много предметов. Связи «многие ко многим» нельзя организовывать непосредственно. Для установления отношения необходимо сопоставить каждому primary key внешний ключ, который представляет собой primary key другой таблицы. Реляционные системы базируются на теории реляционной модели, которая включает в себя три аспекта:
- структурный — данные в базе рассматриваются как набор отношений, то есть упорядоченных пар, составленных из заголовка и полей;
- целостности — состоит в проверке правильности согласования данных при обновлении;
- обработки — использование операторов манипулирования таблицами, таких как реляционная алгебра и реляционное исчисление, которые генерируют новые таблицы на основании уже имеющихся.
Управление созданием и использованием БД осуществляется системами управления базами данных (СУБД).
Под их руководством:
- производится добавление, определение, удаление и поиск записей;
- изменяются значения полей.
Для проведения этих операций организуются запросы. Итогом выполнения запросов будут либо изменения в таблицах, либо получение таблицы данных. При этом поддерживается принцип безопасности информации. Для реляционной БД основным языком управления является SQL.
Стадии и пример проектирования хранилища
Приступая к созданию базы, разработчик составляет для объектов манипулирования и их связей представление в терминах реляционной БД (таблицы, поля, записи). Проектирование проходит несколько стадий:
Преимущества этой модели данных состоят в том, что информация отображается в удобной для пользователя форме, а для манипуляций используется развитой математический аппарат.
Примером реляционной базы данных может послужить проект оптимизации деятельности пункта проката. Требуется автоматизировать такие процедуры: учёт клиентов; регистрацию инвентаря, выданного в прокат; отслеживание даты выдачи, сроков возврата, оплаты; получение информации по этим позициям; формирование отчёта по задолженностям. Реляционная БД может быть задана в виде трёх связанных таблиц.
Используя имеющиеся данные, следует определить отношения и объекты этих отношений. Объектами будут являться клиенты и устройства. Отношения между ними состоят в том, что каждый клиент может брать в прокат одно или несколько устройств.
Атрибутами для сопоставления объектов друг другу должны выступать ячейки с уникальным содержимым. В таблицах есть по одному полю с уникальными данными. В № 1 «Клиент» — это шифр клиента, а в № 3 «Склад» — шифр устройства. Это и будут primary keys. Каждая строка таблицы «Прокат» будет связывать два внешних ключа между собой:
- Шифр Клиента — foreign key, ссылающийся на primary key в таблице «Клиент».
- Шифр устройства — foreign key, ссылающийся на первичный ключ в таблице «Склад».
Проблемы модели
Преимущество реляционных хранилищ состоит в том, что они способны обеспечить наилучшее соотношение устойчивости, производительности, гибкости, совместимости и масштабируемости. Реляционные БД предоставляют лёгкий доступ к составляемым отчётам и обеспечивают высокую надёжность и целостность информации из-за отсутствия избыточных данных. Но сейчас, когда всё большее количество приложений работает с высокой нагрузкой, увеличивается значение фактора масштабируемости.
Реляционные БД легко масштабируются, только когда они расположены на одном сервере. Если потребуется увеличить количество серверов и разделить нагрузку между ними, то возрастёт сложность хранилищ, что значительно снизит возможность использовать их как платформу для мощных распределённых систем. Поэтому приходится применять другие типы БД, которые обладают лучшей масштабируемостью и отказываться от возможностей, предоставляемых реляционными хранилищами.
Реляционная БД — это совокупность связей, которые способны структурировать данные, что даёт возможность рационального хранения и эффективного использования информационных материалов.
Реляционная база данных (РБД)
Другие статьи
Реляционные базы данных сокращённо называются РБД, их используют для хранения и предоставления доступа к взаимосвязанным элементам информации. Выстроены на реляционной модели, откуда и пошло название. Это интуитивно понятный табличный способ предоставления сведений.
В таблице РБД каждая строка — это запись с уникальным ключом. У столбцов есть атрибуты данных. И у большинства записей есть значение для каждого атрибута, что позволяет довольно легко устанавливать взаимную связь между элементами.
Структура РБД
Реляционная модель предполагает логическую структуру БД: это таблицы, индексы и представления. Логическую структуру нельзя путать с физической. Это разделение позволяет администраторам управлять физической БД, но при этом сохранять информацию в логической структуре неизменной. Соответственно, изменение имени файла БД не повлияет на то, что именно содержится в его таблицах.
Разделение физического уровня и логического затрагивает также операции, которые являются четко определёнными действиями со структурами и данными БД. Логические операции предоставляют возможность приложениям устанавливать требования к содержанию. А физические операции устанавливают способ доступа к данным, а также к решению задачи.
Для обеспечения точности и доступности данных в РБД нужно соблюдать правила целостности. В них можно прописать запрет на использование дубликатов строк в таблицах. Это уменьшить риск того, что неправильная информация попадёт в базу данных.
Реляционная модель
Изначально данные у каждого приложения находились в отдельной структуре, которая была уникальной. При желании разработчика создать приложение, чтобы использовать такие данные, ему надо тщательно разобраться со структурой. Подобный метод организации в прошлом был не особенно эффективен. Плюс на обслуживание уходило много времени. И с оптимизацией также возникали проблемы. Реляционная модель создана, чтобы убрать потребность в применении разных структур базы данных.
РБД обеспечивает стандартный способ представления информации и отправки запросов. Отличительной особенностью является универсальность. То есть такой подход можно применять в каких угодно приложениях. Разработчики выяснили, что таблицы — это ключевое преимущество РБД, поскольку позволяют обеспечить интуитивно понятный способ хранения сведений, адаптивный и эффективный. Плюс он прекрасно подходит для структурирования сведений и для того, чтобы получить к ним доступ.
По мере развития разработчики начали применять язык структурированных запросов — SQL. На их основании записывали данные в базу и отправляли запросы. И тогда установили и другую сильную сторону реляционной модель. В частности, уже в течение ряда лет SQL довольно широко применяют как язык запросов в БД. Этот подход построен на алгоритмах реляционной алгебры и достаточно чёткой математической структуре. В итоге работа с какими угодно запросами при обращении к базе данных становится простой и эффективной. Плюс уменьшается количество вероятных ошибок. А если использовать другие подходы, придётся работать с уникальными запросами.
Сильные стороны реляционной базы данных
Реляционная модель — простая и функциональная одновременно.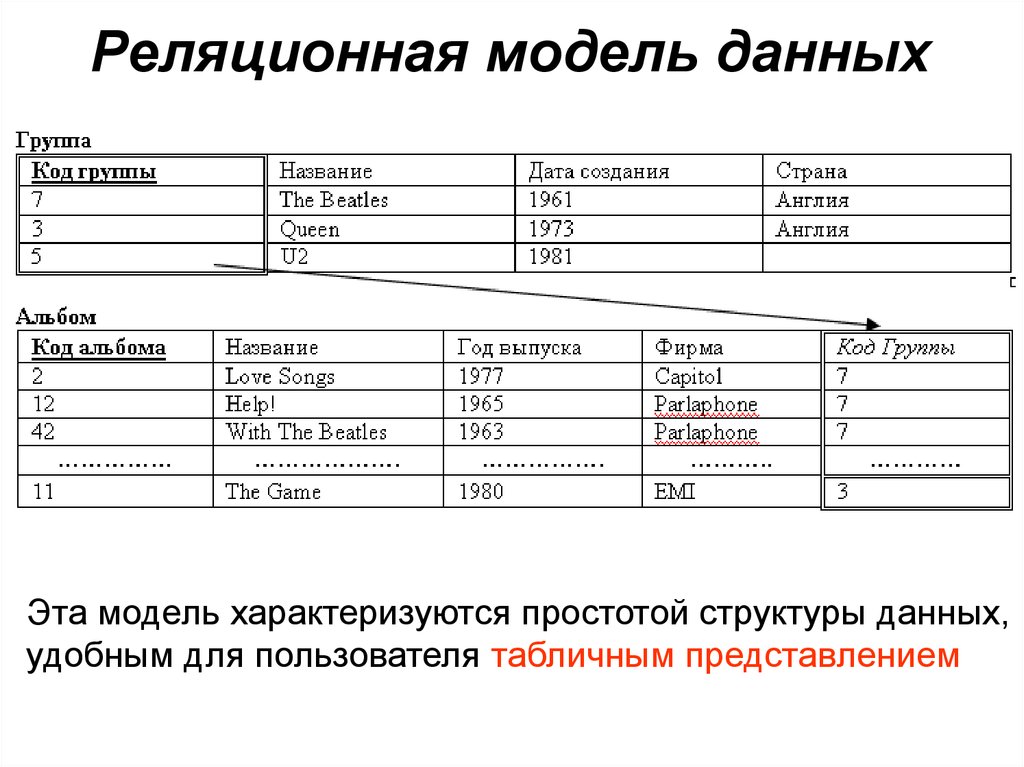 Она подходит для организаций разных размеров и типов. С помощью РБД можно удовлетворять всевозможные информационные потребности. Такие базы данных позволяют контролировать запасы, обрабатывать через Сеть торговые транзакции, управлять данными заказчиков. Последнее становится особенно важным, когда о клиенте нужно знать много информации — реквизиты, контакты и прочее. РБД оптимально подходят для обслуживания разных информационных потребностей при условии, что отдельные элементы системы связаны в общую структуру, а управление происходит на базе правил целостности, причём оно должно быть безопасным и надёжным.
Она подходит для организаций разных размеров и типов. С помощью РБД можно удовлетворять всевозможные информационные потребности. Такие базы данных позволяют контролировать запасы, обрабатывать через Сеть торговые транзакции, управлять данными заказчиков. Последнее становится особенно важным, когда о клиенте нужно знать много информации — реквизиты, контакты и прочее. РБД оптимально подходят для обслуживания разных информационных потребностей при условии, что отдельные элементы системы связаны в общую структуру, а управление происходит на базе правил целостности, причём оно должно быть безопасным и надёжным.
Вообще сами РБД появились ещё в 70-х. Однако сегодня благодаря своим сильным сторонам они стали самыми распространёнными моделями для организации баз данных на планете.
Целостность
Реляционная модель отличается предельной внимательностью к данным в плане целостности. Она поддерживает целостность во всех приложениях и копиях БД. В итоге, когда заказчик кладёт средства на мобильный счёт, то он ждёт, что деньги будут зачислены быстро. И именно РБД гарантируют, что сведения в процессе передачи информации из одной системы в другую не исчезнут.
И именно РБД гарантируют, что сведения в процессе передачи информации из одной системы в другую не исчезнут.
Другие базы данных не в состоянии справиться с задачей поддержания целостности. Поэтому они обычно используются для других целей или же в комбинации с РБД.
Фиксация перемен и атомарность
В РБД приняты детальные и довольно строгие бизнес-правила. Это же касается фиксации перемен в БД, то есть в сохранении действий в отношении данных на стабильной основе. Неразрывность имеет большое значение для корректной отчётности, поэтому такое свойство БД очень ценно для правильного бухгалтерского учёта или для учёта, который ведут в целях управления (финансовый учёт). Атомарность гарантирует, что база данных будет вестись согласно правилам, нормативным положением и в соответствии с бизнес-политикой.
Хранимые процедуры и РБД
Доступ к данным на практике означает большое количество действий, которые будут повторяться снова и снова. Проще всего прописать их в виде программы.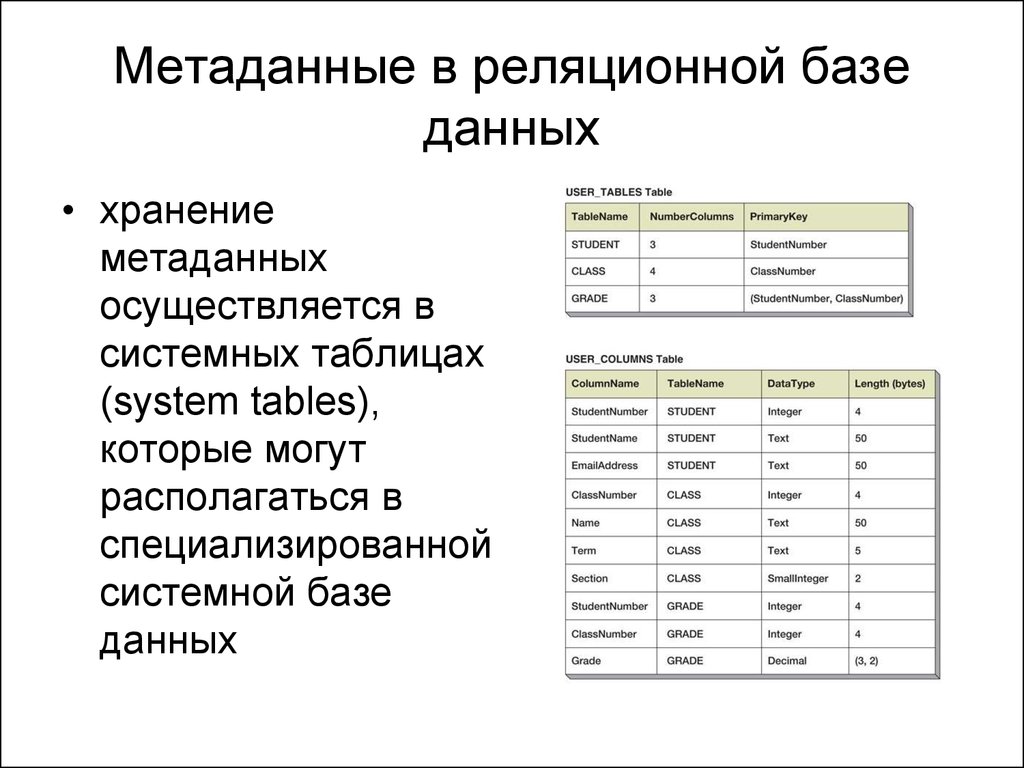 Разработчики не могут в то же время постоянно создавать новые приложения. Это занимает слишком много ресурсов, плюс утяжеляет саму программу.
Разработчики не могут в то же время постоянно создавать новые приложения. Это занимает слишком много ресурсов, плюс утяжеляет саму программу.
Но РБД поддерживают хранимые процедуры. Они представляют собой не полноценные приложения, а блоки кода, и к ним доступ обеспечивается с помощью стандартного вызова, который поступает со стороны кода приложения. То есть по одной и той же хранимой процедуре можно последовательно промаркировать записи для удобства потребителей для самых разных приложений. Хранимые процедуры позволяют разработчикам убедиться, что определённые функции в приложении были правильно реализованы.
РБД и ACID
Транзакции в РБД отличаются 4 важными свойствами:
- атомарность или неразрывность;
- целостность;
- неизменность;
- изолированность.
Эти свойства в комплексе получили название ACID. Неразрывность касается всех частей структуры, которые нужны, чтобы осуществить транзакцию в БД. Целостность или согласованность устанавливает правила сохранения данных после того, как транзакция сделана.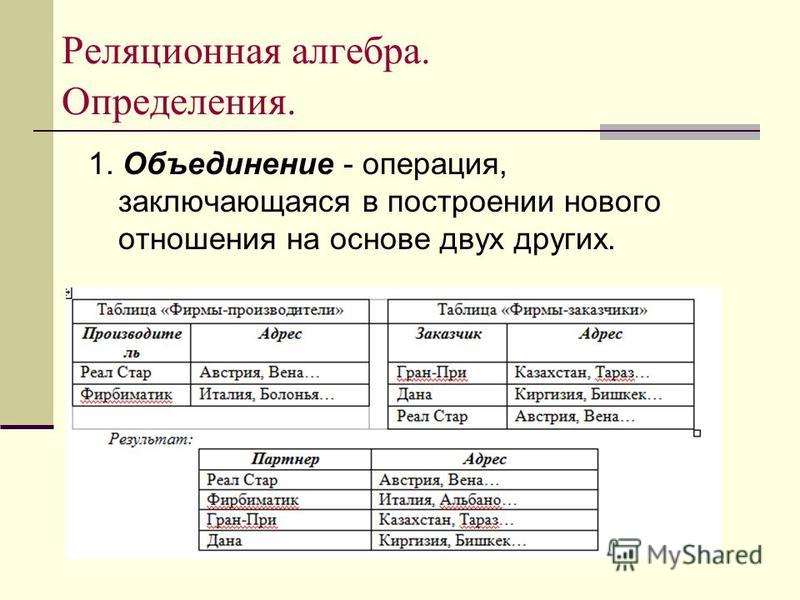 Изолированность — это гарантия того, что транзакция не скажется на другие данные до того, как все изменения будут сохранены. А неизменность гарантирует сохранность данных после того, как изменения были уже сохранены в результате транзакции.
Изолированность — это гарантия того, что транзакция не скажется на другие данные до того, как все изменения будут сохранены. А неизменность гарантирует сохранность данных после того, как изменения были уже сохранены в результате транзакции.
Блокировка БД и параллельный доступ
С данными одновременно могут работать несколько пользователей или приложений. И вполне реалистична ситуация, когда поступит сразу несколько запросов на изменение одной и той же информации. Причём изменения могут быть различного характера. Это вызывает конфликт в БД. В такой ситуации система сохраняет функциональность благодаря функциям «параллельный доступ» и «блокировка».
Блокировка не даёт пользователям или другим приложениям получить какой-либо доступ к данным, пока те обновляются. В отдельных БД блокироваться могут целые таблицы. Это отрицательно сказывается на эффективности такого ПО. Понятно, что работать с ним как с многопользовательским, не выйдет. Однако есть ПО, которые создали реляционные базы, позволяющие выполнять блокировку только на уровне одной единственной записи.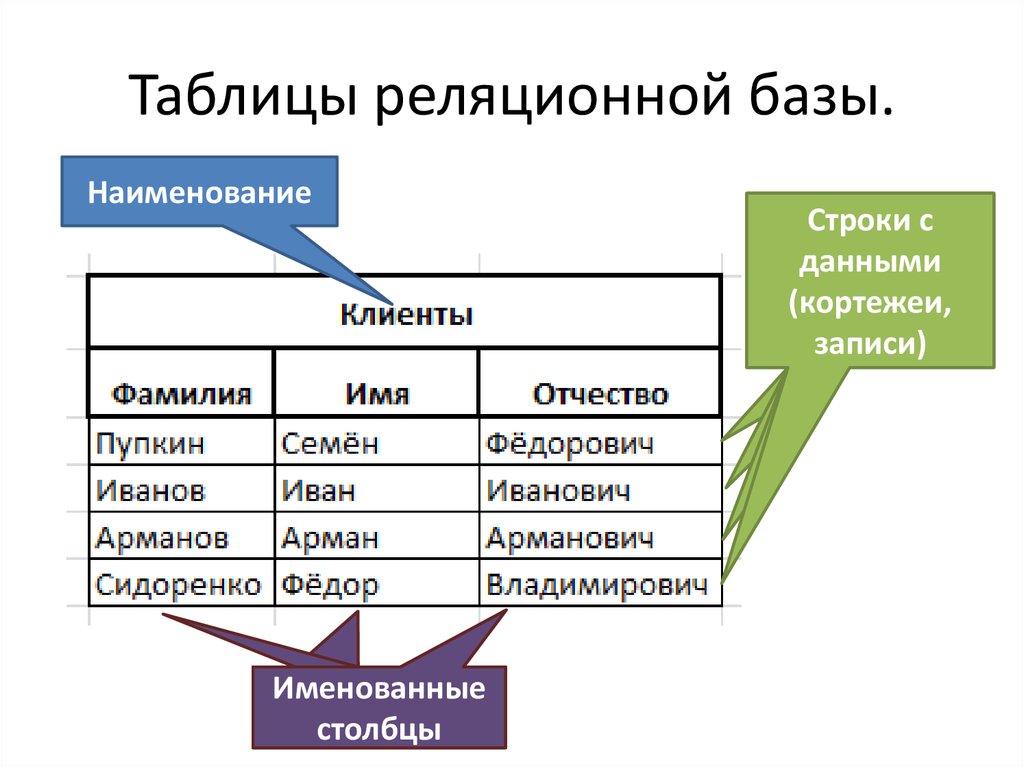 В результате все остальные части таблицы будут доступны. Подобный подход положительно влияет на эффективность ПО.
В результате все остальные части таблицы будут доступны. Подобный подход положительно влияет на эффективность ПО.
Что же касается “параллельного доступа”, то обозначенный инструмент применяется, когда нужно обеспечить одновременный доступ. В этом случае работать начинают политики контроля.
СУРБД – система управления реляционными базами данных
Для управления реляционной базой данных нужно специально ПО. Оно позволяет не только управлять, но и контролировать функциональность РБД, сохранять сведения и извлекать их, обрабатывать запросы. Это система управления РБД или СУРБД. Она отвечает за интерфейс между пользователями, приложениями и БД. Кроме того, СУРБД — это ещё и администрирование как таковое.
При выборе конкретного типа БД и продуктов на основе РБД нужно принимать во внимание ряд факторов. В частности, подбор СУРБД зависит от потребностей компании или предпринимателя. Нужно ответить на ряд вопросов:
- Насколько важна точность данных?
- Нужно ли поддерживать многопользовательский режим работы?
- Есть ли разделение по степени точности для конкретных блоков информации?
- Планируется ли применять бизнес-логику для работы с БД?
- Каковы объёмы данных, с которыми будет происходить работа?
- Важна ли масштабируемость?
- Должна ли модель БД поддерживать зеркальные копии?
- Насколько важна целостность применительно к копиям?
- Важно ли наличие параллельного доступа?
- Нужен ли одновременный доступ нескольким приложениям?
- Должно ли ПО поддерживать параллельный доступ без риска для сохранности данных?
- Насколько важна эффективность и надёжность РБД?
- Насколько быстрым должен быть отклик на поступающий запрос?
- Есть ли какая-то специфика в тех данных, с которыми предстоит работать?
- Будет ли пиковая нагрузка на базу данных?
- Планируется ли постепенное наращивание объёма информации, с которой предполагается работа?
- Возможен ли незапланированный простой?
Это стандартные вопросы.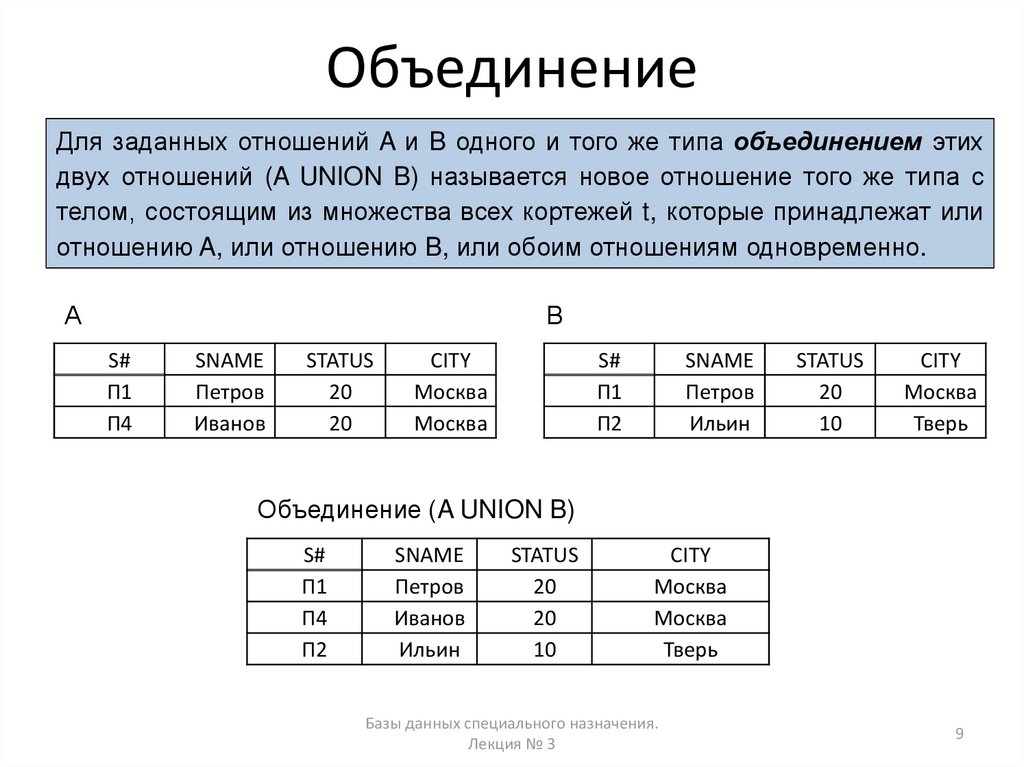 Возможно, у вас появятся какие-то свои. Перечень вопросов нужно тщательно продумать. Вам не нужна идеальная СУРБД. Вам необходима система, которая будет оптимально отвечать поставленным задачам.
Возможно, у вас появятся какие-то свои. Перечень вопросов нужно тщательно продумать. Вам не нужна идеальная СУРБД. Вам необходима система, которая будет оптимально отвечать поставленным задачам.
SQL сервер является СУБД, работающей с реляционной базой данной.
Автономность РБД
РБД не стоят на месте, они постоянно развиваются. Они постоянно улучшали надёжность, производительность, безопасность, становились всё проще и проще в обслуживании. Это приводило к усложнению структуры. В итоге администрирование подобной системы стало требовать серьёзных усилий. Как следствие, разработчикам приходится немало времени тратить на оптимизацию таких систем, чтобы избежать чрезмерной громоздкости.
Поэтому было решено найти выход. И им стали автономные технологии. Они позволили нарастить возможности реляционной модели. Так появилась РБД нового типа. Автономная или же самоуправляемая БД — это система, которая сохраняет возможности и преимущества реляционной модели, а также добавляет к ним средства на базе искусственного интеллекта, автоматизации и машинного обучения для оптимизации и мониторинга скорости осуществления запросов и управления.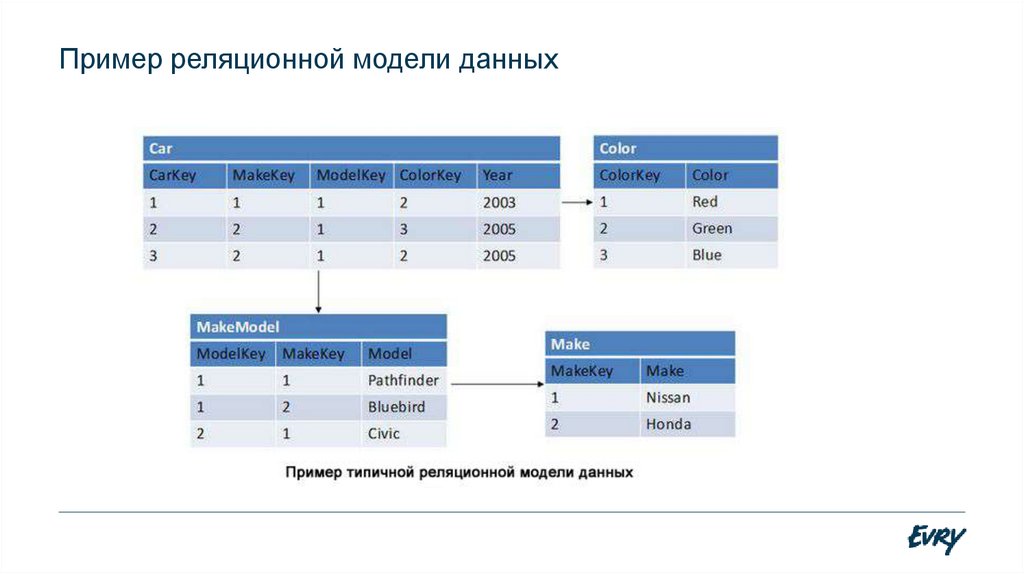
К примеру, чтобы повысить скорость обработки запросов, такая база проверяет индексы, строит прогнозы. Дальше она сама применяет лучшие результаты. То есть система начинает самосовершенствоваться без участия человека.
В итоге автономная РБД позволяет освободить разработчиков от рутинных задач. В частности, не надо заранее определять требования к инфраструктуре. Для этого есть специальные программные решения. Можно заранее взять в аренду вычислительные мощности или память. Дальше вы будете по мере необходимости получать доступ к тем ресурсам, которые вам объективно нужны и платить только то, что применяете. Таким образом, использование автономных РБД позволяет уменьшить расходы вашей компании и оптимизировать подход к работе с вычислительными мощностями.
Подобные базы данных можно использовать для создания приложений нового уровня. При этом из-за уменьшения влияния человеческого фактора на сам процесс риск ошибки по соответствующим причинам тоже сокращается, что выгодно компаниям и другим пользователям.
Получить помощь в работе с РБД
Другие статьи
Реляционные базы данных — определение, структура, примеры
Реляционная база данных (БД) — это совокупность связанных между собой двумерных таблиц, в которых хранится информация об объектах. Запись (строка) включает в себя данные об одном объекте, а в полях (столбцах) содержатся различные его характеристики. Основы теории табличной модели впервые были описаны Эдгаром Коддом (IBM) в 1970 году.
Содержание
- Особенности реляционных БД
- Связывание таблиц
- Стадии и пример проектирования хранилища
- Проблемы модели
Особенности реляционных БД
БД используются для организации хранения данных. Структура реляционной базы данных полностью определяется перечнем названия полей с указанием их типов и свойств. Все записи имеют одинаковые поля, но в них показываются разные свойства объекта. Аналогом реляционной БД считается двумерная таблица. Характерные особенности файла БД:
Характерные особенности файла БД:
Реляционная БД чаще всего не ограничивается одной таблицей. Обычно создаются несколько таблиц со связанной информацией. Это позволяет исполнять более сложные операции над данными. Таблицы реляционной БД обязаны соответствовать требованиям понятия нормализации отношений, то есть ограничениям на формирование, которые позволят избежать дублирования и обеспечат непротиворечивость хранимой информации. Пусть создана таблица «Прокат», содержащая следующие поля: Шифр Клиента, Ф. И. О., Вид устройства, Дата выдачи, Оплата, Срок возврата.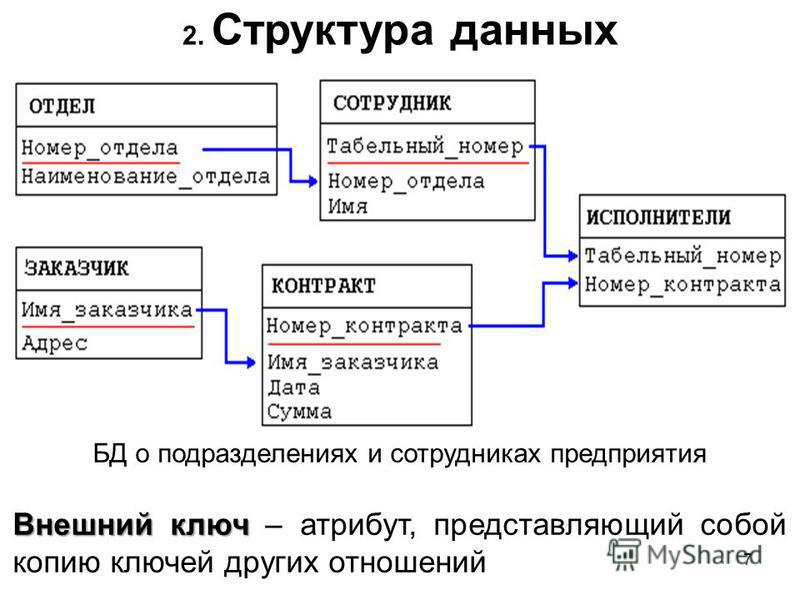 Эта организация хранения информации имеет несколько недостатков:
Эта организация хранения информации имеет несколько недостатков:
- дублирование информации (вид устройства повторяется для разных клиентов), что увеличивает объём БД;
- для обновления информации требуется обрабатывать каждую запись.
Для устранения этих недостатков необходима нормализация с разделением данных на разные таблицы.
Связывание таблиц
Для любой таблицы реляционной БД задаётся первичный ключ (primary key) — поле или сочетание полей, которые определяют каждую запись. Внешний или вторичный ключ (foreign key) — это одно или несколько полей, ссылающихся на поле primary key другой таблицы.
Составной ключ называется так, потому что создаётся из нескольких полей. При образовании составных ключей не рекомендуется включать в них поля, значения которых точно определяют запись. Например, не следует образовывать ключ, в котором находятся вместе поля «номер паспорта» и «шифр клиента», потому что оба эти атрибута однозначно определяют запись. Поля с повторяющимися в таблице значениями тоже нельзя делать составной частью ключа. По значению ключа возможно найти только одну запись.
Например, не следует образовывать ключ, в котором находятся вместе поля «номер паспорта» и «шифр клиента», потому что оба эти атрибута однозначно определяют запись. Поля с повторяющимися в таблице значениями тоже нельзя делать составной частью ключа. По значению ключа возможно найти только одну запись.
Ячейка — это наименьший структурный элемент, который задаёт определённое значение соответствующего поля. Таблицы связываются друг с другом, и поэтому данные могут выбираться сразу из нескольких таблиц. Связь создаётся, если в них присутствуют одинаковые поля. Типы связей:
- один к одному;
- один ко многим;
- многие ко многим.
Связи «один к одному» встречаются довольно редко. «Один ко многим» применяются чаще, например, кассир продаёт много билетов. «Многие ко многим» тоже встречаются часто. Например, студент изучает много предметов. Связи «многие ко многим» нельзя организовывать непосредственно. Для установления отношения необходимо сопоставить каждому primary key внешний ключ, который представляет собой primary key другой таблицы. Реляционные системы базируются на теории реляционной модели, которая включает в себя три аспекта:
Реляционные системы базируются на теории реляционной модели, которая включает в себя три аспекта:
- структурный — данные в базе рассматриваются как набор отношений, то есть упорядоченных пар, составленных из заголовка и полей;
- целостности — состоит в проверке правильности согласования данных при обновлении;
- обработки — использование операторов манипулирования таблицами, таких как реляционная алгебра и реляционное исчисление, которые генерируют новые таблицы на основании уже имеющихся.
Управление созданием и использованием БД осуществляется системами управления базами данных (СУБД).
Под их руководством:
- производится добавление, определение, удаление и поиск записей;
- изменяются значения полей.
Для проведения этих операций организуются запросы. Итогом выполнения запросов будут либо изменения в таблицах, либо получение таблицы данных. При этом поддерживается принцип безопасности информации.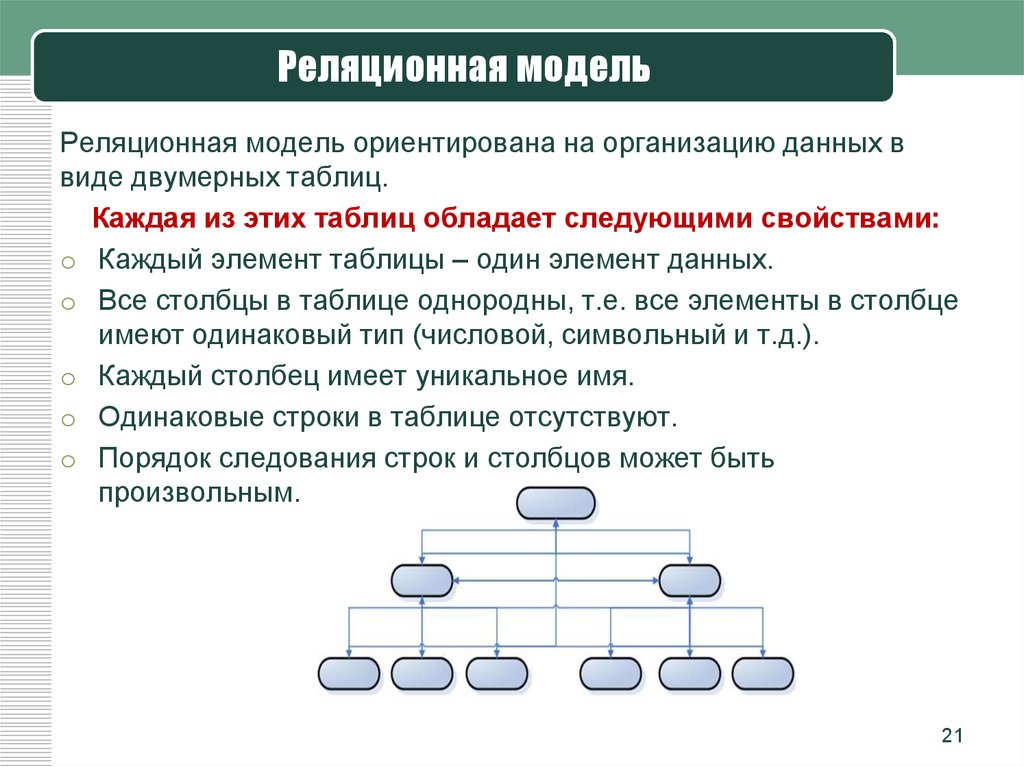 Для реляционной БД основным языком управления является SQL.
Для реляционной БД основным языком управления является SQL.
Стадии и пример проектирования хранилища
Приступая к созданию базы, разработчик составляет для объектов манипулирования и их связей представление в терминах реляционной БД (таблицы, поля, записи). Проектирование проходит несколько стадий:
Преимущества этой модели данных состоят в том, что информация отображается в удобной для пользователя форме, а для манипуляций используется развитой математический аппарат.

Примером реляционной базы данных может послужить проект оптимизации деятельности пункта проката. Требуется автоматизировать такие процедуры: учёт клиентов; регистрацию инвентаря, выданного в прокат; отслеживание даты выдачи, сроков возврата, оплаты; получение информации по этим позициям; формирование отчёта по задолженностям. Реляционная БД может быть задана в виде трёх связанных таблиц.
Используя имеющиеся данные, следует определить отношения и объекты этих отношений. Объектами будут являться клиенты и устройства. Отношения между ними состоят в том, что каждый клиент может брать в прокат одно или несколько устройств.
Атрибутами для сопоставления объектов друг другу должны выступать ячейки с уникальным содержимым. В таблицах есть по одному полю с уникальными данными. В № 1 «Клиент» — это шифр клиента, а в № 3 «Склад» — шифр устройства. Это и будут primary keys. Каждая строка таблицы «Прокат» будет связывать два внешних ключа между собой:
- Шифр Клиента — foreign key, ссылающийся на primary key в таблице «Клиент».
- Шифр устройства — foreign key, ссылающийся на первичный ключ в таблице «Склад».

Проблемы модели
Преимущество реляционных хранилищ состоит в том, что они способны обеспечить наилучшее соотношение устойчивости, производительности, гибкости, совместимости и масштабируемости. Реляционные БД предоставляют лёгкий доступ к составляемым отчётам и обеспечивают высокую надёжность и целостность информации из-за отсутствия избыточных данных. Но сейчас, когда всё большее количество приложений работает с высокой нагрузкой, увеличивается значение фактора масштабируемости.
Реляционные БД легко масштабируются, только когда они расположены на одном сервере. Если потребуется увеличить количество серверов и разделить нагрузку между ними, то возрастёт сложность хранилищ, что значительно снизит возможность использовать их как платформу для мощных распределённых систем. Поэтому приходится применять другие типы БД, которые обладают лучшей масштабируемостью и отказываться от возможностей, предоставляемых реляционными хранилищами.
Поэтому приходится применять другие типы БД, которые обладают лучшей масштабируемостью и отказываться от возможностей, предоставляемых реляционными хранилищами.
Реляционная БД — это совокупность связей, которые способны структурировать данные, что даёт возможность рационального хранения и эффективного использования информационных материалов.
Предыдущая
ИнформатикаТаблица истинности логических операций — алгоритм построения
Следующая
ИнформатикаУстройства вывода информации — виды, классификация и функции
7 основных типов баз данных — Джино • Журнал
В базах данных (БД) содержится упорядоченная информация, которой удобно пользоваться. Они делятся на разные типы — чтобы выбрать нужный, важно учесть, какие именно данные будут там храниться и по какому принципу будет удобнее всего работать с ними.
В целом нельзя сказать, что какие-то БД лучше других, — просто каждая из них подходит для решения каких-то определённых задач. Есть базы данных с открытым кодом, с возможностью масштабирования и с другими преимуществами. Лучше выбирать такие БД, которые вы сможете использовать именно так, как они задуманы.
Реляционные базы данных
Примеры — MySQL, Oracle DB, PostgreSQL. Это самый популярный тип БД, в которых информация хранится в виде таблиц. В строках находится описание каждого отдельного свойства объекта, а столбцы нужны для извлечения определённых свойств из строки. Таблицы могут быть взаимосвязаны.
Реляционная модель проста, но позволяет выполнить множество разных задач. Ею удобно пользоваться, если нужно связать элементы данных между собой и безопасно и надёжно управлять ими. Такие таблицы можно создать для хранения и обработки телефонных номеров пациентов, логинов и паролей пользователей, для отслеживания товарных запасов. При этом БД обеспечивает целостность данных в различных экземплярах базы в одно и то же время.
В реляционных БД есть поддержка SQL, а также индексация, которая позволяет быстрее находить нужные данные. Особый плюс таких баз — нормализация данных: они делятся на разные таблицы, поэтому исключены повторяющиеся или пустые ячейки. Транзакции реляционных БД соответствуют ACID — набору свойств, который гарантирует их надёжную обработку. Из минусов баз можно отметить относительно низкую скорость доступа к данным, плохую поддержку неструктурированных данных, сложность масштабирования и образование большого количества таблиц, из-за чего бывает трудно понять структуру данных.
Резидентные базы данных
Примеры — Redis, Apache Ignite, Tarantool. Сведения хранятся в оперативной памяти. Данные обрабатываются быстро, поэтому резидентные БД популярны там, где нужно обеспечить максимально короткое время отклика. Они помогают управлять телекоммуникационным оборудованием, проводить торги в онлайн-режиме или Real-Time обслуживание. Базы in-memory поддерживают и быстрое написание, и быстрое чтение. В основном они работают с записями «ключ-значение», но также могут работать со столбцами.
В основном они работают с записями «ключ-значение», но также могут работать со столбцами.
Чтобы при неожиданной перезагрузке не потерять данные, нужно сделать запись с предварительным журналированием на энергонезависимом устройстве. Это можно отнести к минусам базы in-memory — приходится вкладываться в дорогостоящие инфраструктурные решения, чтобы обеспечить бесперебойное питание. Также нужно постоянно копировать информацию на твёрдые носители. Ещё один недостаток БД — дорогое масштабирование.
Поисковые базы данных
Пример — Elastic. Этот тип БД нужен для получения сведений через фильтр. Искать можно по любому введённому значению, в том числе по отдельным словам. Можно пользоваться полнотекстовым поиском. Поисковые базы данных хорошо масштабируются и удобны для хранения журналов, объёмных текстовых значений.
Можно использовать поисковые БД для мониторинга оптимизации цен, обнаружения ошибок в приложении по бронированию билетов и решения множества других задач. В базе могут хранится миллиарды документов. Поиск осуществляется быстро. Минусы системы — плохая аналитическая поддержка и ограниченная возможность применения БД (можно использовать только для пакетных вставок).
Поиск осуществляется быстро. Минусы системы — плохая аналитическая поддержка и ограниченная возможность применения БД (можно использовать только для пакетных вставок).
Базы данных с широкими столбцами
Примеры — Cassandra, Google BigTable, HBase. БД с широкими столбцами могут запрашивать большие объёмы данных быстрее, чем обычные реляционные. Сведения хранятся в виде записей «ключ-значение» на жёстком диске или твёрдотельном накопителе. Базы данных с широкими столбцами позволяют выполнять быструю запись построчно и быстрое чтение по ключу.
БД хорошо масштабируются и подходят для организации магазинных каталогов, механизмов обнаружения мошенничества. Их удобно использовать для управления огромными объёмами информации на множестве общих серверов в распределённой системе. Недостатками базы данных считается то, что она работает в формате «ключ-значение» и не имеет поддержки аналитики.
Столбчатые базы данных
Примеры — Clickhouse, Vertica. В БД такого типа данные хранятся в столбцах, а не в строках. Получение доступа к содержимому осуществляется без помощи ключей. При использовании столбчатых баз данных используют пакетную вставку, чтобы можно было готовить информацию для быстрого чтения по столбцам. В столбчатых БД есть поддержка аналитики и возможность удобного масштабирования.
Получение доступа к содержимому осуществляется без помощи ключей. При использовании столбчатых баз данных используют пакетную вставку, чтобы можно было готовить информацию для быстрого чтения по столбцам. В столбчатых БД есть поддержка аналитики и возможность удобного масштабирования.
Такие базы данных используют там, где нужно запрашивать информацию по определёным столбцам, — в системах розничных продаж и финансовых транзакций. Основный минус у БД только один: она подходит только для пакетных вставок.
Документоориентированные базы данных
Примеры — CouchDB, Couchbase, MongoDB. Если в реляционных БД для извлечения данных нужно объединять таблицы, то в этих базах отлично хранится несвязанная информация в больших объёмах. Они поддерживают JSON. Для любого ключа можно создать сложное значение и сразу включить всю структуру данных в одну запись. Выборка по запросу может содержать части множества документов без их полной загрузки в оперативную память.
В документоориентированных базах нет привязки к схеме. Они подходят для OLTP и поддерживают сложные типы. Такие БД предпочитают использовать в системах управления содержимым, для поиска документов, в издательском деле. Три недостатка базы данных — отсутствие хорошей аналитической поддержки и поддержки транзакций, а также сложности с масштабированием.
Они подходят для OLTP и поддерживают сложные типы. Такие БД предпочитают использовать в системах управления содержимым, для поиска документов, в издательском деле. Три недостатка базы данных — отсутствие хорошей аналитической поддержки и поддержки транзакций, а также сложности с масштабированием.
Графовые базы данных
Примеры — OrientDB, Neo4j. Данные хранятся в виде графов, то есть моделей с узлами и связями. Они достаточно гибкие, с логичной структурой. Узлы служат для хранения сущностей данных, а рёбра — для хранения взаимосвязей между сущностями, которыми можно управлять.
Графовые БД применяют для решения задач в биоинформатике, а также для моделирования социальных сетей, чтобы хранить взаимосвязанную информацию о людях. Базы данных такого типа плохо поддаются масштабированию, а второй их недостаток — необходимость использовать особый язык запросов SPARQL, который отличается от SQL.
Определяем базу данных под свои задачи
Как мы уже говорили, всё зависит от задач, которые вы будете выполнять. Нужно определить, какими особенностями должна обладать ваша БД.
Нужно определить, какими особенностями должна обладать ваша БД.
Отталкиваться нужно от следующих факторов:
- наличие аналитического доступа к БД;
- количество таблиц или записей, которые вы планируете хранить;
- необходимость использования столбцов;
- наличие возможности получить доступ к таблицам, которые отфильтрованы по столбцам или по строкам;
- необходимость писать или читать в режиме онлайн.
Что такое реляционная база данных?
Как работают реляционные базы данных и как они контролируются и управляются с помощью систем управления реляционными базами данных
Что такое реляционная база данных?
Реляционные базы данных — это тип базы данных, в котором хранятся и организуются точки данных с определенными отношениями для быстрого доступа. В реляционной базе данных данные организованы в таблицы, которые содержат информацию о каждом объекте и представляют предварительно определенные категории с помощью строк и столбцов. Такая структура данных делает доступ к ним эффективным и гибким, поэтому реляционные базы данных наиболее распространены. Реляционные базы данных также созданы для понимания языка структурированных запросов (SQL), стандартизированного языка программирования, который используется для хранения, обработки и извлечения данных. В SQL есть встроенный язык для создания таблиц, называемый языком определения данных (DDL), и язык для манипулирования данными, называемый языком манипулирования данными (DML).
Такая структура данных делает доступ к ним эффективным и гибким, поэтому реляционные базы данных наиболее распространены. Реляционные базы данных также созданы для понимания языка структурированных запросов (SQL), стандартизированного языка программирования, который используется для хранения, обработки и извлечения данных. В SQL есть встроенный язык для создания таблиц, называемый языком определения данных (DDL), и язык для манипулирования данными, называемый языком манипулирования данными (DML).
Что означает реляционный? Относительный означает указание или установление отношения. В контексте баз данных то, как мы определяем реляционность, в первую очередь относится к самим данным. Наборы данных, которые являются реляционными, имеют заранее определенные отношения между ними. Например, база данных, содержащая информацию о клиентах компании, может также включать данные об отдельных транзакциях, прикрепленных к каждой учетной записи. Реляционные базы данных фокусируют внимание на отношениях между хранимыми элементами данных.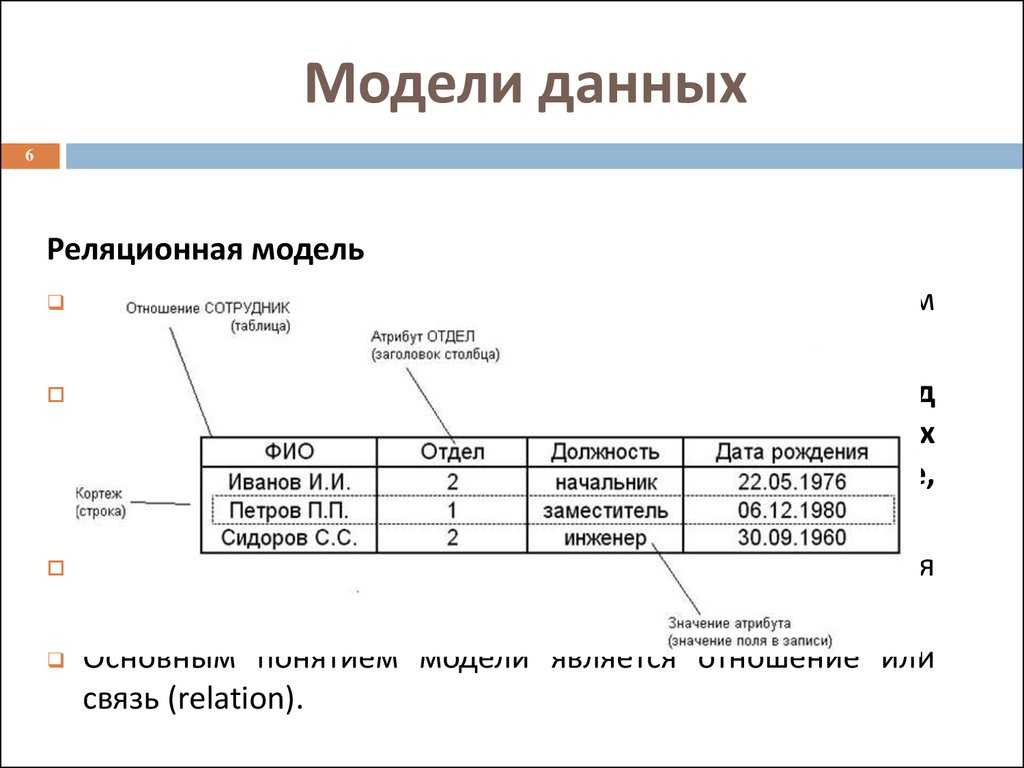
Характеристики реляционных баз данных:
- Базы данных состоят из нескольких объектов
- Стандартный язык запросов (SQL) — стандартный интерфейс
- Хорошо структурированный и представленный с помощью схемы (логической и физической)
- Уменьшает избыточность данных
Как работают реляционные базы данных
Реляционные базы данных обычно используют таблицы с данными, организованными в строки (содержащие объекты) и столбцы (содержащие атрибуты объектов). Этот процесс известен как нормализация. Каждая строка содержит уникальный идентификатор или ключ, который связывает таблицы вместе для установления связи. При запросе к реляционной базе данных ключ используется для поиска связанных данных в наборах данных. Например, служба технической поддержки может захотеть отслеживать взаимодействие с клиентами по типу проблемы, времени решения проблемы и степени удовлетворенности клиентов.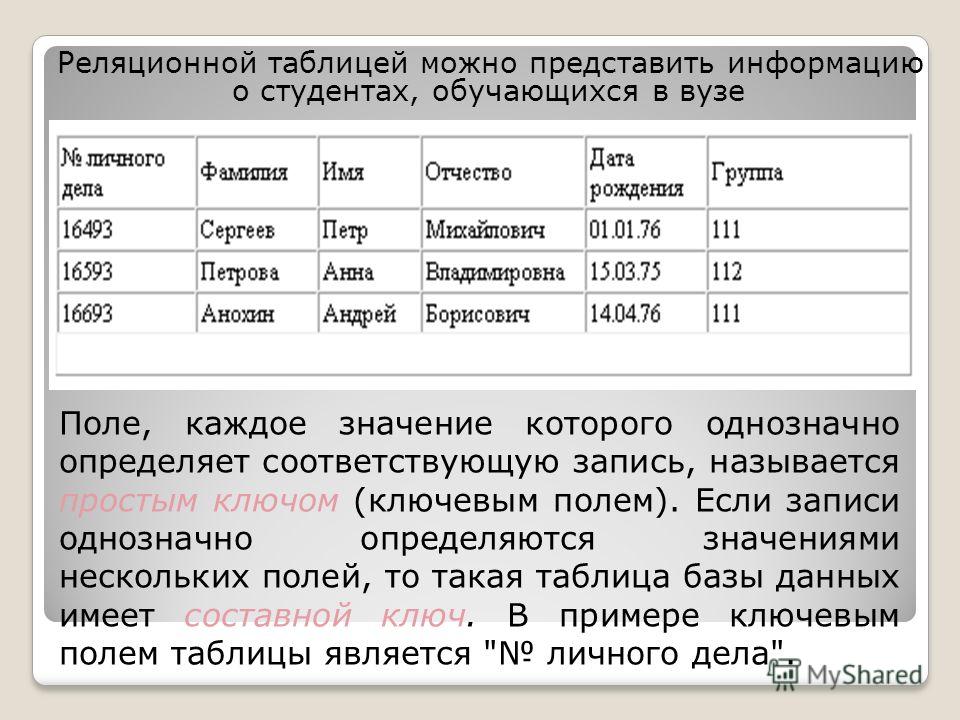 В этой базе данных то, что создает взаимосвязь и обеспечивает хорошее функционирование структуры таблицы, — это объединяющий идентификатор клиента.
В этой базе данных то, что создает взаимосвязь и обеспечивает хорошее функционирование структуры таблицы, — это объединяющий идентификатор клиента.
Узнайте больше о базах данных
Примеры реляционных баз данных
Реляционные базы данных полезны для любых потребностей в информации, когда точки данных связаны друг с другом, а также должны управляться согласованным, безопасным и основанным на правилах способом. Это то, что делает их наиболее популярными для бизнеса и предприятий. Когда компании хотят получить представление о своих собственных данных, они полагаются на реляционные базы данных для создания полезной аналитики. Многие отчеты, которые предприятия генерируют для отслеживания запасов, финансов, продаж или прогнозов на будущее, создаются с использованием реляционных баз данных.
Как организованы данные в реляционной базе данных? Данные в реляционных базах данных хранятся, ищутся и извлекаются из таблиц со связями.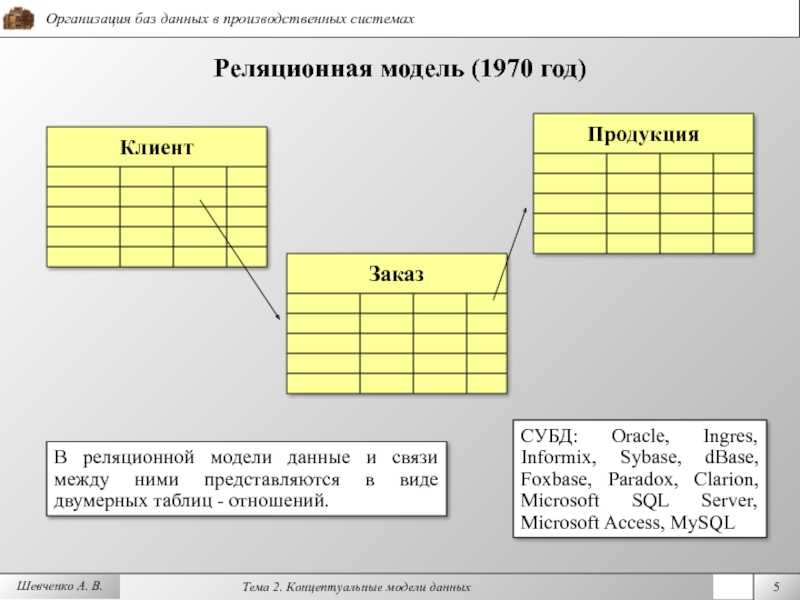 В реляционной базе данных схема базы данных определяет, как данные организованы как логически, так и физически.
В реляционной базе данных схема базы данных определяет, как данные организованы как логически, так и физически.
Реляционные базы данных имеют так называемый режим согласованности или целостности, основанный на четырех критериях: атомарность, согласованность, изоляция и устойчивость (ACID). Вот значение каждого свойства базы данных ACID:
- Атомарность определяет элементы, составляющие полную транзакцию.
- Согласованность определяет правила для поддержания целостности данных после транзакции.
- Изоляция делает результаты транзакций невидимыми для других, чтобы они не конфликтовали друг с другом.
- Durability гарантирует, что изменения данных станут постоянными после каждой зафиксированной транзакции.
Эти критерии делают реляционные базы данных полезными в приложениях, требующих высокой точности, таких как финансовые и розничные транзакции, также известные как оперативная обработка транзакций (OLTP). Финансовые учреждения полагаются на базы данных для отслеживания огромного количества транзакций клиентов — от запросов баланса до переводов между счетами. Реляционная база данных идеально подходит для банковского дела, поскольку она создана для обработки большого количества клиентов, частых изменений данных в результате транзакций и быстрого отклика.
Финансовые учреждения полагаются на базы данных для отслеживания огромного количества транзакций клиентов — от запросов баланса до переводов между счетами. Реляционная база данных идеально подходит для банковского дела, поскольку она создана для обработки большого количества клиентов, частых изменений данных в результате транзакций и быстрого отклика.
Примеры реляционных баз данных включают SQL Server, Управляемый экземпляр Azure SQL, Базу данных SQL Azure, MySQL, PostgreSQL и MariaDB.
Что такое реляционная база данных MySQL?
My Structured Query Language (MySQL) — это обычная реляционная база данных SQL с открытым исходным кодом, которая выполняет все основные команды SQL, такие как запись и запрос данных. Надежная, стабильная и безопасная система управления базами данных (СУБД) MySQL получила широкое распространение, поскольку поддерживает большинство ведущих языков программирования и протоколов. На самом деле MySQL достаточно надежен, чтобы служить основным хранилищем данных для многих крупных организаций. MySQL также подходит в качестве встроенной базы данных для программного обеспечения, оборудования и устройств.
MySQL также подходит в качестве встроенной базы данных для программного обеспечения, оборудования и устройств.
Как правило, MySQL включает усиленные и гибкие функции безопасности, такие как проверка на основе хоста и трафик, зашифрованный паролем. Веб-разработчики часто предпочитают MySQL, поскольку он прост в использовании и содержит функции повышения производительности, такие как обновляемые представления, хранимые процедуры и триггеры (специальные процедуры, которые запускаются, когда на сервере базы данных происходят определенные действия). MySQL является популярным транзакционным механизмом для платформ электронной коммерции, потому что он отлично справляется с управлением такими вещами, как транзакции, профили клиентов и информация о товарных запасах. Разработанный для обеспечения высокой совместимости с другими системами, MySQL также поддерживает развертывание в виртуализированных средах, таких как облачные платформы.
Что такое система управления реляционными базами данных?
Реляционные базы данных предназначены для управления большими объемами важной для бизнеса информации о клиентах. Однако по мере того, как данные в базе данных растут и становятся все более сложными, становится все труднее поддерживать их организованность, доступность и безопасность. Это когда системы управления базами данных (СУБД) помогают, добавляя уровень инструментов управления для реляционных таблиц. Как и различные структуры баз данных, разные системы управления предлагают разные уровни организации, масштабируемости и приложений. Когда администраторы работают с большими объемами структурированных и неструктурированных данных (больших данных), получаемых в режиме реального времени, системы управления реляционными базами данных (БД) помогают им анализировать и агрегировать данные для поиска предопределенных взаимосвязей. Управление данными с помощью СУБД создает наибольшую ценность для бизнеса, поскольку делает данные, которые используются в нескольких приложениях или находятся в нескольких местах, более управляемыми.
Однако по мере того, как данные в базе данных растут и становятся все более сложными, становится все труднее поддерживать их организованность, доступность и безопасность. Это когда системы управления базами данных (СУБД) помогают, добавляя уровень инструментов управления для реляционных таблиц. Как и различные структуры баз данных, разные системы управления предлагают разные уровни организации, масштабируемости и приложений. Когда администраторы работают с большими объемами структурированных и неструктурированных данных (больших данных), получаемых в режиме реального времени, системы управления реляционными базами данных (БД) помогают им анализировать и агрегировать данные для поиска предопределенных взаимосвязей. Управление данными с помощью СУБД создает наибольшую ценность для бизнеса, поскольку делает данные, которые используются в нескольких приложениях или находятся в нескольких местах, более управляемыми.
РСУБД используют программное обеспечение, обеспечивающее согласованный интерфейс между пользователями, приложениями и базой данных, что значительно упрощает навигацию для пользователей данных.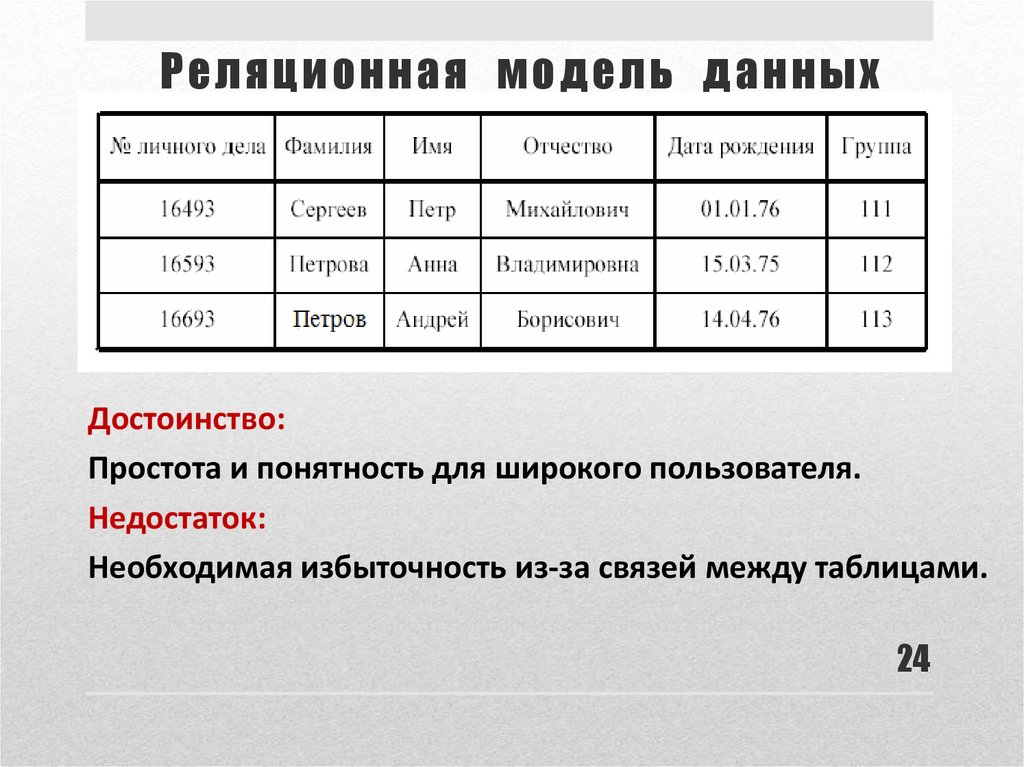 Это особенно эффективно при работе с большими данными, поскольку объем данных диктует такую согласованность для пользователей, присоединяющихся к запросам. Выбор СУБД зависит от того, где находятся ваши данные, типа используемой архитектуры и того, как вы планируете масштабироваться.
Это особенно эффективно при работе с большими данными, поскольку объем данных диктует такую согласованность для пользователей, присоединяющихся к запросам. Выбор СУБД зависит от того, где находятся ваши данные, типа используемой архитектуры и того, как вы планируете масштабироваться.
Что такое реляционная модель базы данных?
Модель реляционной базы данных обычно хорошо структурирована и понимает язык программирования SQL. Многие базы данных используют реляционную модель, поскольку они предназначены для организации данных и определения взаимосвязей между ключевыми точками данных, что упрощает сортировку и поиск информации. Большинство реляционных моделей следуют традиционной структуре таблиц на основе столбцов и строк, обеспечивая эффективный, интуитивно понятный и гибкий способ хранения структурированных данных. Реляционная модель также решает проблему множества произвольных структур данных в базах данных.
Модели реляционных баз данных могут варьироваться от небольших настольных систем до крупных облачных систем. Они используют базу данных SQL или могут обрабатывать операторы SQL для запросов и обновлений. Реляционные модели определяются логическими структурами данных (таблицы, индексы и представления) и хранятся отдельно от физических структур хранения (физических файлов). Непротиворечивость данных является отличительной чертой моделей реляционных баз данных, поскольку они поддерживают целостность данных между приложениями и копиями баз данных, также называемыми экземплярами. В базе данных реляционной модели несколько экземпляров базы данных всегда содержат одни и те же данные.
Они используют базу данных SQL или могут обрабатывать операторы SQL для запросов и обновлений. Реляционные модели определяются логическими структурами данных (таблицы, индексы и представления) и хранятся отдельно от физических структур хранения (физических файлов). Непротиворечивость данных является отличительной чертой моделей реляционных баз данных, поскольку они поддерживают целостность данных между приложениями и копиями баз данных, также называемыми экземплярами. В базе данных реляционной модели несколько экземпляров базы данных всегда содержат одни и те же данные.
Реляционные базы данных, разработанные в облаке, автоматически настраиваются для высокой доступности, что означает, что данные реплицируются или копируются на несколько элементов, каждый из которых находится в отдельной зоне доступности. Таким образом, данные по-прежнему доступны, даже если отдельный центр обработки данных не работает.
Большие данные и реляционные базы данных
Традиционные реляционные базы данных предназначены для обработки больших объемов структурированных данных. Это делает реляционные базы данных особенно подходящими для структурированных больших данных, поскольку они полагаются на SQL и могут использовать системы управления базами данных для управления данными. Однако более крупные и сложные наборы данных больших данных содержат все больше разнообразия, а это означает, что данные становятся все менее и менее структурированными и поступают из новых источников. Это часто требует использования нереляционных баз данных (NoSQL), которые поддерживают использование неструктурированных или частично структурированных данных.
Это делает реляционные базы данных особенно подходящими для структурированных больших данных, поскольку они полагаются на SQL и могут использовать системы управления базами данных для управления данными. Однако более крупные и сложные наборы данных больших данных содержат все больше разнообразия, а это означает, что данные становятся все менее и менее структурированными и поступают из новых источников. Это часто требует использования нереляционных баз данных (NoSQL), которые поддерживают использование неструктурированных или частично структурированных данных.
Часто задаваемые вопросы
Мы можем вам помочь?
реляционных против. Нереляционные базы данных | MongoDB
При планировании нового проекта или приложения часто возникает обсуждение требований к базе данных. Какой тип базы данных следует использовать? В чем разница между реляционными и нереляционными базами данных?
Эта статья призвана ответить на эти вопросы, объяснив, что они из себя представляют и чем они отличаются, а также помочь вам принять обоснованное решение.
Данные цифровой эпохи можно разделить на оперативные и аналитические.
Операционные данные используются для повседневных транзакций и должны быть свежими — например, запасы продуктов и банковский баланс. Такие данные собираются в режиме реального времени с помощью систем оперативной обработки транзакций (OLTP).
Аналитические данные используются предприятиями для получения информации о поведении клиентов, производительности продукта и прогнозирования. Он включает данные, собранные за определенный период времени, и обычно хранится в системах OLAP (онлайн-аналитическая обработка), хранилищах или озерах данных.
Базы данных являются наиболее эффективным способом постоянного хранения и извлечения оперативных и аналитических данных в цифровом виде.
В зависимости от требований проекта компании должны выбрать базу данных, которая может:
- Хранить все типы данных.
- Быстрый доступ к необходимым данным.
- Получите мгновенную информацию для принятия стратегических бизнес-решений.
Большинству компаний для хранения данных требуются как OLTP (операционная), так и OLAP (аналитическая) системы, и они могут использовать реляционную базу данных, нереляционную базу данных или и то, и другое для своих бизнес-целей.
Что такое реляционная база данных?
Реляционная база данных или система управления реляционными базами данных (RDMS) хранит информацию в таблицах. Часто эти таблицы имеют общую информацию между собой, что приводит к формированию отношений между таблицами. Отсюда и название реляционной базы данных.
Таблица использует столбцы для определения сохраняемой информации и строки для фактических данных. В каждой таблице будет столбец с уникальными значениями, известный как первичный ключ 9.0112 . Затем этот столбец можно использовать в других таблицах, если между ними должны быть определены отношения. Когда первичный ключ одной таблицы используется в другой таблице, этот столбец во второй таблице называется внешним ключом .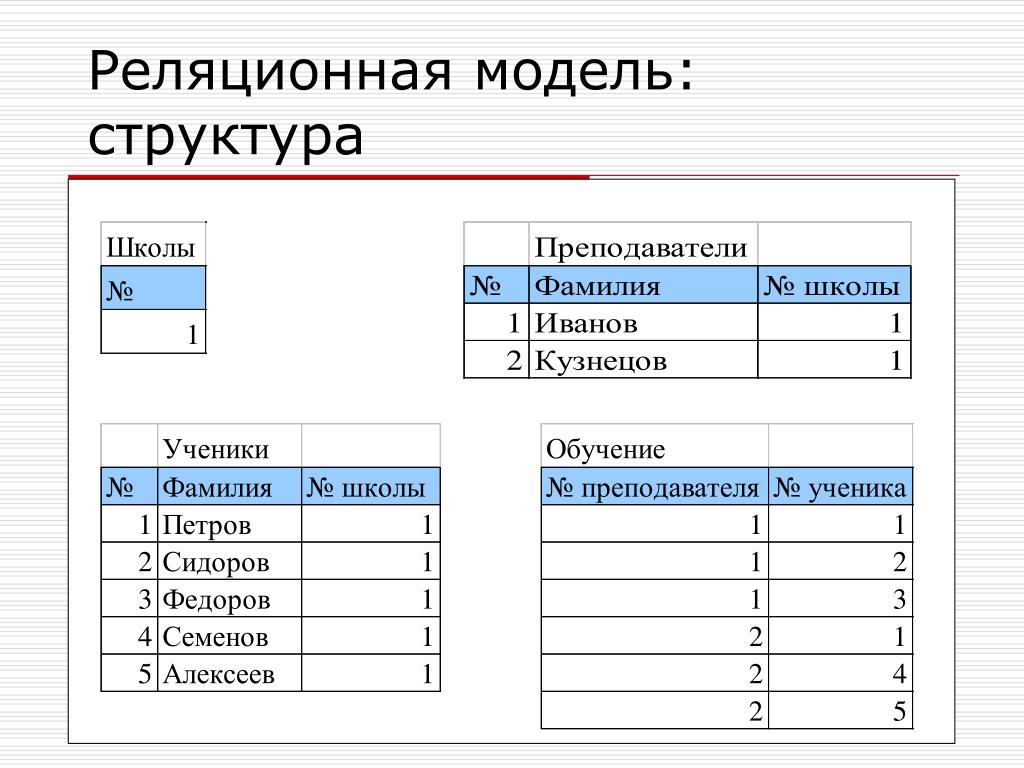
Наиболее распространенным способом взаимодействия с системами реляционных баз данных является использование SQL (язык структурированных запросов). Разработчики могут писать SQL-запросы для выполнения операций CRUD (создание, чтение, обновление, удаление). Простой пример запроса:
ВЫБЕРИТЕ НАЗВАНИЕ ПРОДУКТА, ЦЕНА ИЗ ПРОДУКТА, ГДЕ ПРОДУКТ _ID = 23;
Представьте, что вы занимаетесь онлайн-бизнесом. У вас есть различная информация, которую вы храните, например информация о клиентах, информация о заказах и продуктах. В реляционной базе данных это будет храниться в разных таблицах с ключом для объединения таблиц при необходимости.
Данные хранятся в виде таблиц со строками и столбцами в реляционной базе данных
Здесь в таблице клиента хранится основная информация о клиенте,0151 идентификатор заказа и идентификатор адреса . Если кому-то нужна дополнительная информация о заказе или адресе, он может запросить соответствующие таблицы order и address , используя оператор INNER JOIN с полем id.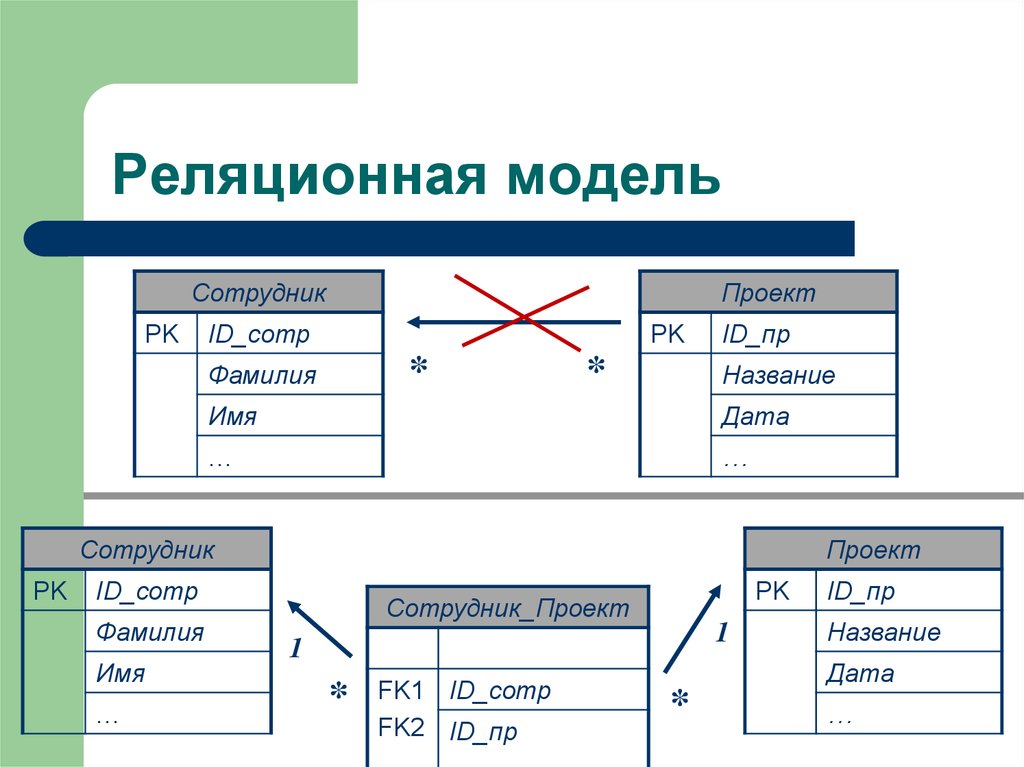 Таблица
Таблица order , в свою очередь, содержит идентификаторы товаров в заказе. Подробная информация о продукте находится в отдельной таблице продуктов. Это делает информацию организованной и более структурированной.
Преимущества реляционных баз данных
Соответствие ACID
Атомарность, непротиворечивость, изоляция и надежность (ACID) — это стандарт, гарантирующий надежность транзакций базы данных. Общий принцип заключается в том, что в случае сбоя одного изменения произойдет сбой всей транзакции, и база данных останется в том состоянии, в котором она была до попытки транзакции.
Это важно, потому что некоторые транзакции будут иметь реальные последствия, если они не будут завершены полностью — например, банковские операции. Для получения дополнительной информации см. нашу документацию, объясняющую ACID.
Точность данных
Использование первичных и внешних ключей позволяет исключить дублирование информации. Это помогает обеспечить точность данных, поскольку повторяющаяся информация никогда не будет повторяться. Это, в свою очередь, снижает затраты на хранение.
Это, в свою очередь, снижает затраты на хранение.
Простота
RDMS, или базы данных SQL, существуют так давно, что было разработано множество инструментов и ресурсов, помогающих начать работу с реляционными базами данных и взаимодействовать с ними. Подобный английскому синтаксис SQL также позволяет не разработчикам создавать отчеты и запросы на основе данных.
Недостатки реляционных баз данных
Масштабируемость
RDMS исторически предназначались для работы на одной машине. Это означает, что если требования к машине недостаточны из-за размера данных или увеличения частоты доступа, вам придется улучшить аппаратное обеспечение машины, также известное как вертикальное масштабирование.
Это может быть невероятно дорого и имеет потолок, так как в конечном итоге затраты перевешивают выгоды. Кроме того, потенциально может наступить этап, когда вы просто не сможете получить оборудование, способное разместить базу данных. Единственным решением было бы купить машину, которая поддерживает лучшее оборудование, но все это недешево.
Гибкость
В реляционных базах данных схема является жесткой. Вы определяете столбцы и типы данных для этих столбцов, включая любые ограничения, такие как формат или длина. Общие примеры ограничений включают длину номера телефона или минимальную/максимальную длину столбца имени.
Хотя это означает, что вы можете легче интерпретировать данные и определять отношения между таблицами, это означает, что внесение изменений в структуру данных очень сложно. Вы должны решить в начале, как будут выглядеть данные, что не всегда возможно. Если вы хотите внести изменения позже, вам придется изменить все данные, что предполагает временное отключение базы данных.
Производительность
Производительность базы данных тесно связана со сложностью таблиц — их количеством, а также объемом данных в каждой таблице. По мере его увеличения увеличивается и время, затрачиваемое на выполнение запросов.
Что такое нереляционная база данных?
Нереляционная база данных, иногда называемая NoSQL (не только SQL), представляет собой любую базу данных, которая не использует концепцию структурированных данных таблиц, полей и столбцов из реляционных баз данных. Нереляционные базы данных разрабатывались с учетом облачных технологий, что делает их идеальными для горизонтального масштабирования.
Нереляционные базы данных разрабатывались с учетом облачных технологий, что делает их идеальными для горизонтального масштабирования.
Существует несколько различных групп типов баз данных, которые хранят данные по-разному:
Базы данных документов
Базы данных документов хранят данные в документах, которые обычно представляют собой структуры, подобные JSON, которые поддерживают различные типы данных. Эти типы включают строки; числа типа int, float и long; даты; объекты; массивы; и даже вложенные документы. Данные хранятся парами, аналогично парам ключ/значение.
Рассмотрим тот же пример клиента, что и выше. Однако в этом случае мы можем просматривать все данные одного клиента в одном месте в виде единого документа.
Как данные хранятся в нереляционной базе данных документов
Ниже приведен запрос для получения названия продукта и цены данного productid с использованием API запросов Mongo (аналогично SQL в предыдущем разделе).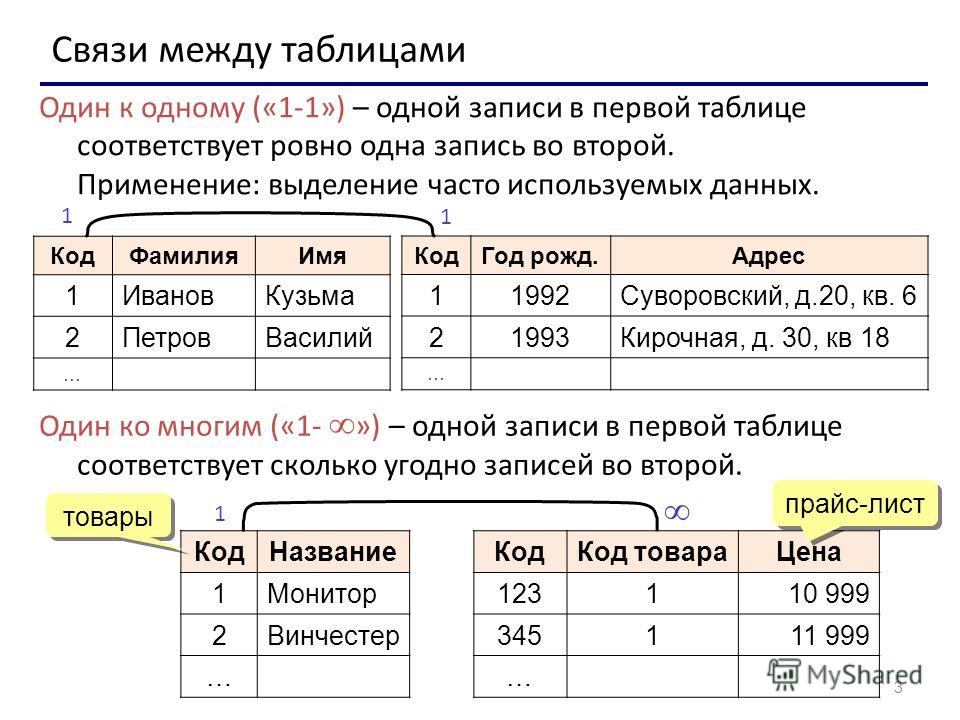 В этом запросе первый аргумент (_id) представляет фильтр для использования в коллекции, а второй — проекцию — поля, которые должны быть возвращены запросом.
В этом запросе первый аргумент (_id) представляет фильтр для использования в коллекции, а второй — проекцию — поля, которые должны быть возвращены запросом.
db.product.find({"_id": 23}, {productName: 1, price: 1}) Поскольку документы имеют формат JSON, их намного легче читать и понимать пользователю. Данные организованы, а также легко просматривать. Нет необходимости ссылаться на несколько документов или коллекций для просмотра данных одного клиента. Документы хорошо сопоставляются с объектами в коде на объектно-ориентированных языках программирования, что значительно упрощает работу с ними.
Также отсутствует схема, что означает гибкость при вставке документов различных форм. Однако некоторые системы баз данных документов позволяют применять проверку схемы, если вам нужны другие преимущества баз данных документов, но с определенной формой данных.
Документы считаются отдельными единицами, что означает, что они могут быть распределены по нескольким серверам.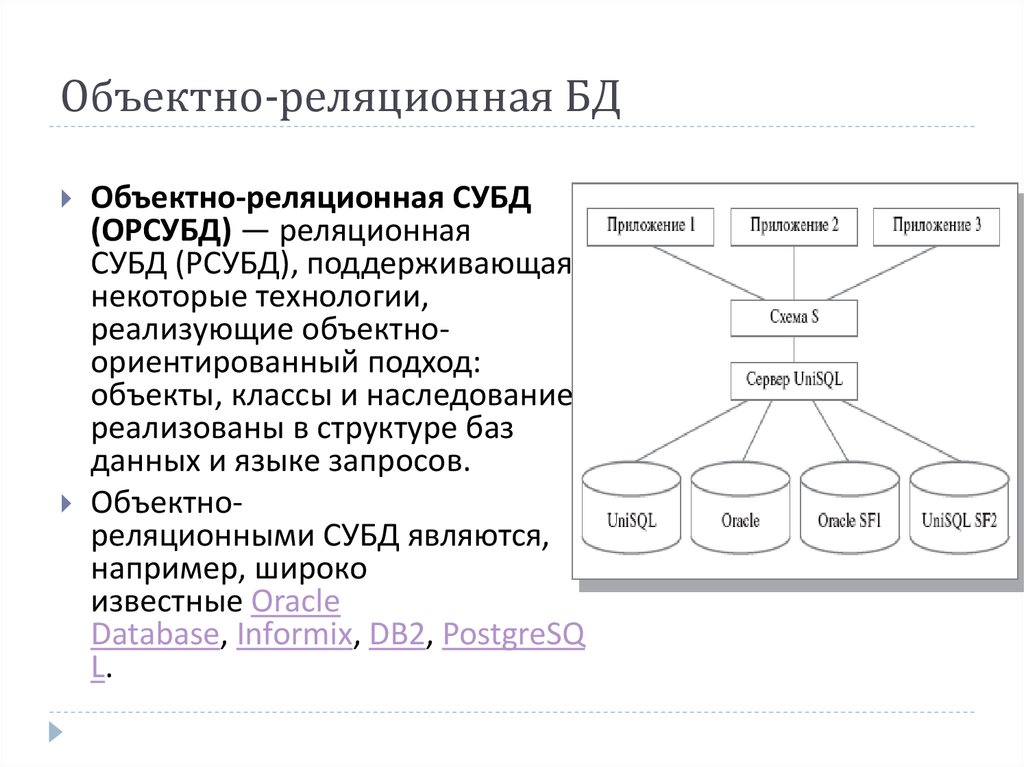 Кроме того, базы данных самовосстанавливаются, что означает высокую доступность.
Кроме того, базы данных самовосстанавливаются, что означает высокую доступность.
Базы данных документов также легко масштабируются. В отличие от реляционных баз данных, где традиционно можно масштабировать только вертикально (процессор, место на жестком диске и т. д.), нереляционные базы данных, включая базы данных документов, можно масштабировать горизонтально. Это означает, что базы данных дублируются на нескольких серверах, но при этом синхронизируются.
База данных «ключ-значение»
Это самый простой тип базы данных, где информация хранится в двух частях: ключ и значение.
Затем ключ используется для извлечения информации из базы данных.
Простота базы данных «ключ-значение» также является преимуществом. Поскольку все хранится в виде уникального ключа и значения, которое является либо данными, либо расположением данных, чтение и запись всегда будут быстрыми.
Однако эта простота ограничивает тип вариантов использования, для которых он может использоваться. Более сложные требования к данным не поддерживаются.
Более сложные требования к данным не поддерживаются.
Базы данных графов
Базы данных графов являются наиболее специализированными типами нереляционных баз данных. Они используют структуру элементов, называемых узлами, которые хранят данные, а ребра между ними содержат атрибуты отношения.
Отношения определяются по краям, что делает поиск, связанный с этими отношениями, естественным образом быстрым. Кроме того, они гибкие, потому что можно легко добавлять новые узлы и ребра. Им также не обязательно иметь определенную схему, как в традиционной реляционной базе данных.
Однако они не очень хороши для запросов ко всей базе данных, где отношения не так хорошо или вообще не определены. У них также нет стандартного языка для запросов, а это означает, что перемещение между различными типами баз данных графов требует обучения.
Базы данных с широкими столбцами
Базы данных с широкими столбцами, как и реляционные базы данных, хранят данные в таблицах, столбцах и строках.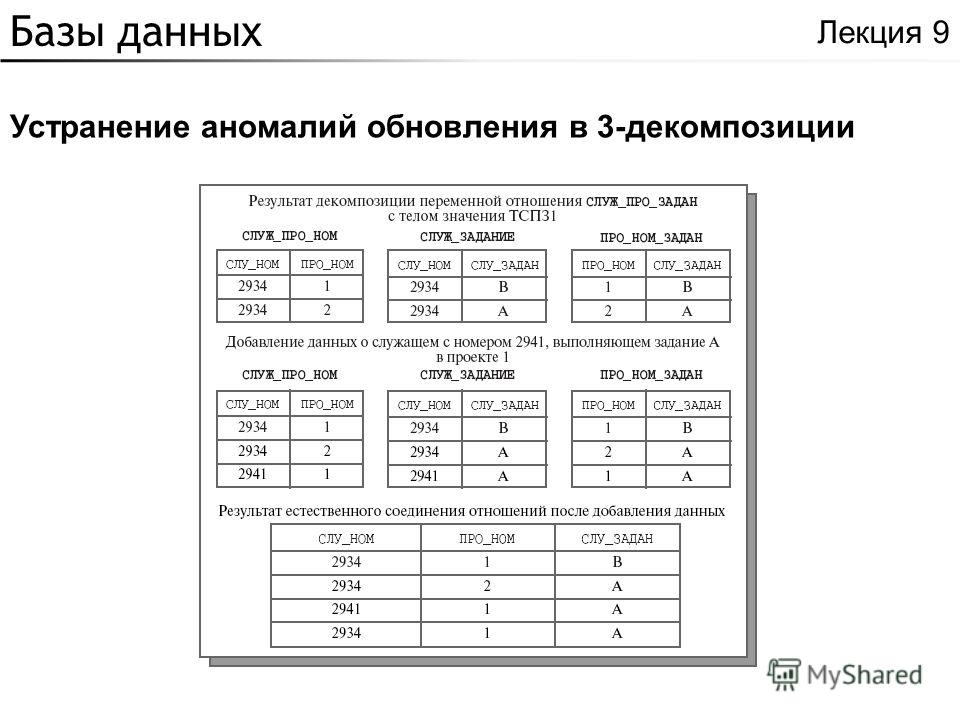 Однако имена и форматирование столбцов не обязательно должны совпадать в каждой строке. Столбцы могут даже храниться на нескольких серверах. Они считаются двумерными хранилищами «ключ-значение», поскольку используют многомерное сопоставление для ссылки на данные по строкам и столбцам.
Однако имена и форматирование столбцов не обязательно должны совпадать в каждой строке. Столбцы могут даже храниться на нескольких серверах. Они считаются двумерными хранилищами «ключ-значение», поскольку используют многомерное сопоставление для ссылки на данные по строкам и столбцам.
Подобно базам данных с двумя столбцами, базы данных с широкими столбцами обладают преимуществом гибкости, поэтому запросы выполняются быстро. Благодаря своей гибкости они хорошо справляются с «большими данными» и неструктурированными данными.
Однако по сравнению с реляционными базами данных базы данных с широкими столбцами намного медленнее обрабатывают транзакции. Столбцы группируют похожие атрибуты, а не используют строки, и хранят их в отдельных файлах, что означает, что транзакции должны выполняться в нескольких файлах.
| Document Database | Column Store Database | Key-Value Store Database | Graph Database | |
|---|---|---|---|---|
| Performance | High | High | High | Moderate |
| Доступность | Высокая | Высокая | Высокая | Высокая |
| Гибкость | Высокая | Moderate | High | High |
| Scalability | High | High | High | Moderate |
| Complexity | Low | Low | Moderate | High |
| База данных документов | |
|---|---|
| Производительность | Высокая |
| Availability | High |
| Flexibility | High |
| Scalability | High |
| Complexity | Low |
| Column Store Database | |
|---|---|
| Производительность | Высокая |
| Доступность | Высокая |
| Flexibility | Moderate |
| Scalability | High |
| Complexity | Low |
| Key-Value Store Database | |
|---|---|
| Performance | Высокий |
| Доступность | Высокий |
| Гибкость | Высокий |
| Scalability | High |
| Complexity | Moderate |
| Graph Database | |
|---|---|
| Performance | Moderate |
| Availability | Высокий |
| Гибкость | Высокий |
| Масштабируемость | Средняя |
| Сложность | Высокая |
Когда использовать реляционную базу данных
Если вы создаете проект, в котором частота, доступ, размер и структура данных предсказуемы реляционные базы данных по-прежнему являются лучшим выбором.
Нормализация может помочь уменьшить размер данных на диске за счет ограничения повторяющихся данных и аномалий, снижая риск необходимости вертикального масштабирования в будущем.
Реляционные базы данных также являются лучшим выбором, если важны отношения между сущностями.
Нереляционные базы данных могут хранить документы внутри документов, что помогает хранить данные, к которым будет осуществляться доступ, в одном и том же месте. Но если это не подходит для ваших нужд, реляционная база данных по-прежнему является решением. Например, если у вас есть большой набор данных со сложной структурой и взаимосвязями, встраивание может не создать достаточно четких взаимосвязей.
Количество времени, которое существует RDMS, также означает, что доступна широкая поддержка, от инструментов до интеграции с данными из других систем.
Когда использовать нереляционную базу данных
Как уже говорилось, существует множество типов нереляционных баз данных, каждая из которых имеет свои преимущества и недостатки.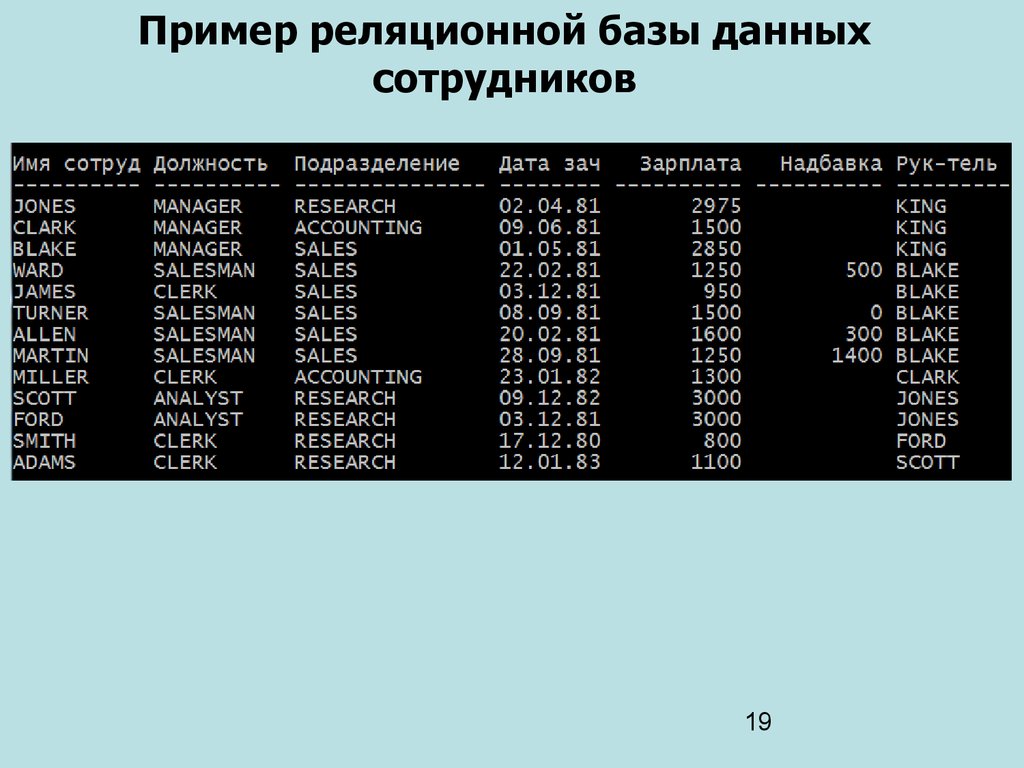
Тем не менее, нереляционные базы данных по-прежнему обладают некоторыми постоянными преимуществами. Если данные, которые вы храните, должны быть гибкими с точки зрения формы или размера, или если они должны быть открыты для изменения в будущем, тогда ответом будет нереляционная база данных.
Современные базы данных NoSQL были разработаны для облачных вычислений, что делает их естественным образом подходящими для горизонтального масштабирования, когда можно развернуть множество небольших серверов для обработки возросшей нагрузки.
Узнайте, как перевести проект с реляционных баз данных на нереляционные базы данных на основе документов.
Почему вы можете предпочесть нереляционную базу данных реляционной базе данных?
Существует множество причин, по которым вы захотите использовать нереляционную базу данных вместо реляционной:
- Нереляционные базы данных подходят как для операционных, так и для транзакционных данных.
- Больше подходят для неструктурированных больших данных.
- Нереляционные базы данных обеспечивают более высокую производительность и доступность.
- Гибкая схема помогает нереляционным базам данных хранить больше данных различных типов, которые можно изменять без существенных изменений схемы.

Резюме
В этой статье вы узнали о реляционных и нереляционных базах данных и о том, чем они отличаются друг от друга. Вы также узнали о преимуществах и недостатках обоих типов баз данных и о том, какой тип базы данных наиболее подходит для различных проектов.
| Функции | Нереляционные | Relational |
|---|---|---|
| Availability | High | High |
| Horizontal Scaling | High | Low |
| Vertical Scaling | High | High |
| Data Storage | Optimized for огромные объемы данных | Данные от среднего до большого |
| Производительность | Высокая | От низкого до среднего |
| Надежность | Medium | High (Acid) |
| Complexity | Low | Medium (Joins) |
| Flexibility | High | Low (Strict-Schema) |
| Suitability | Suitable For OLAP and OLTP | Подходит для OLTP |
MongoDB — это нереляционная база данных, обеспечивающая масштабируемость, высокую производительность, надежность и гибкость.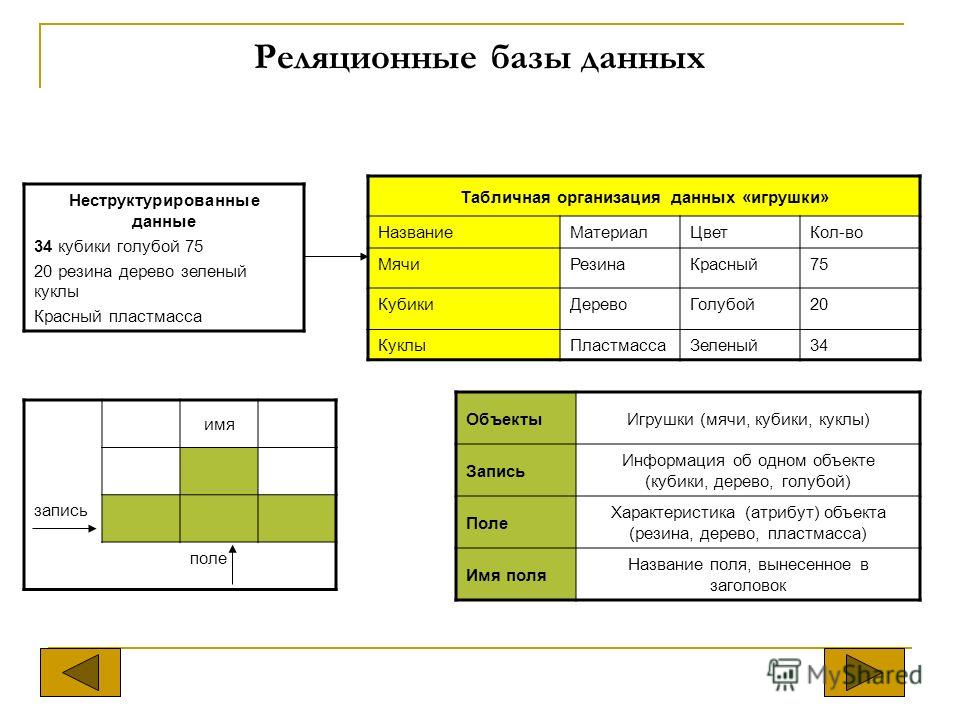 MongoDB превратилась в более широкую платформу данных с MongoDB Atlas, облачной базой данных MongoDB, которая делает данные доступными в любое время.
MongoDB превратилась в более широкую платформу данных с MongoDB Atlas, облачной базой данных MongoDB, которая делает данные доступными в любое время.
Все ли базы данных реляционные?
Нет. Реляционные базы данных, или базы данных SQL, хранят данные в таблицах с общими столбцами между ними (известными как первичные и внешние ключи), формируя отношения между таблицами. Данные всегда структурированы по определенной схеме, которую нелегко изменить.
Но существуют и другие типы баз данных под названием нереляционных баз данных/баз данных NoSQL, которые содержат неструктурированные, полуструктурированные или структурированные данные. Это обеспечивает гибкость и высокую доступность. Некоторыми примерами являются MongoDB, Cassandra и CouchDB.
Является ли MongoDB нереляционной базой данных?
Да. MongoDB — это база данных документов, относящаяся к типу нереляционной базы данных. Данные хранятся в коллекциях в виде документов BSON, структура которых аналогична JSON. Данные считаются неструктурированными, поскольку коллекция может содержать документы с разными полями и типами данных. Это обеспечивает высокую гибкость.
Данные считаются неструктурированными, поскольку коллекция может содержать документы с разными полями и типами данных. Это обеспечивает высокую гибкость.
Каковы некоторые варианты использования нереляционных баз данных?
Благодаря гибкости и масштабируемости (как по горизонтали, так и по вертикали) нереляционных баз данных они отлично подходят для широкого спектра вариантов использования.
Например, для хранения настроек в приложении отлично подойдет база данных «ключ-значение», поскольку у каждой настройки будет только одно значение. Для сайта электронной коммерции база данных документов была бы идеальной, поскольку вы можете хранить документ для каждого клиента, в котором будут храниться их данные и история заказов, поскольку они являются частными и уникальными для каждого клиента.
Для таких задач, как обнаружение мошенничества, когда взаимосвязь между данными имеет жизненно важное значение, но типы данных часто непредсказуемы, графовая база данных является отличным решением.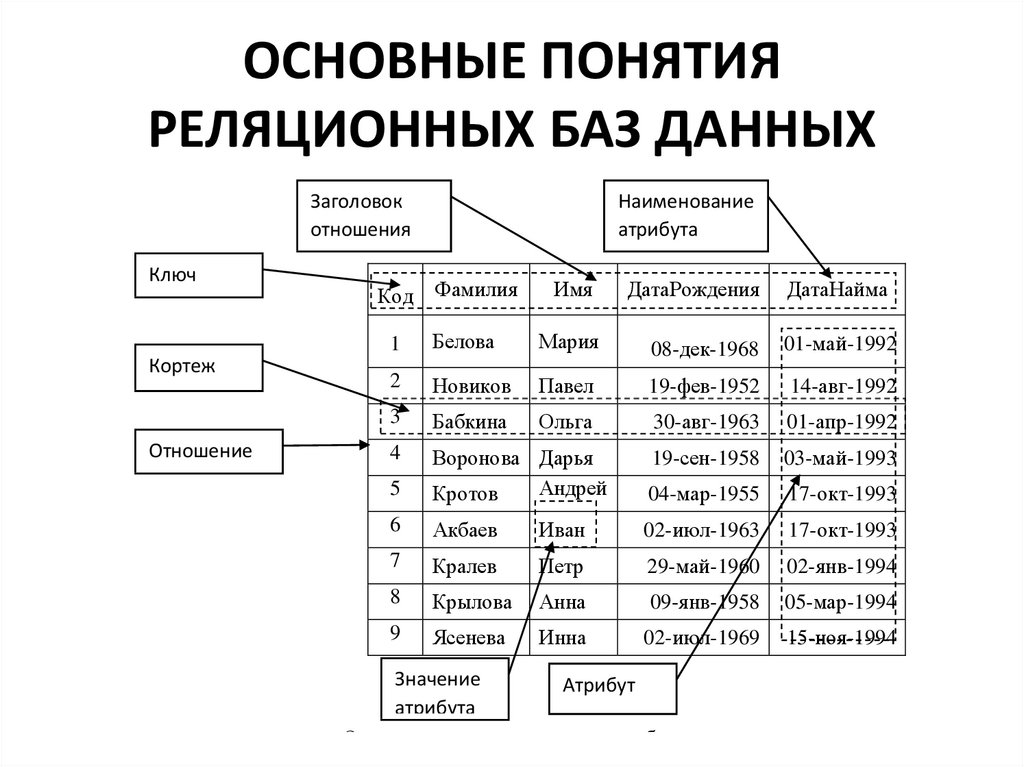
Для получения дополнительной информации о том, когда нереляционная база данных может оказаться не лучшим вариантом, см. технический документ, посвященный этому вопросу.
В чем разница между реляционными и нереляционными базами данных?
Реляционные базы данных хранят данные в табличном формате в виде строк и столбцов. Отношения между данными определяются с помощью нескольких таблиц. Например, чтобы определить взаимосвязь между клиентом и его заказами, нам нужны две или более таблиц: таблица клиентов и таблица заказов. Нереляционные базы данных не имеют жесткой структуры и подходят для хранения огромных объемов данных разных типов в одном представлении. Узнайте больше о реляционных и нереляционных базах данных.
Когда вы будете использовать нереляционную базу данных?
Существует множество вариантов использования нереляционной базы данных. Например, они вполне подходят для получения оперативных данных для оперативных и аналитических целей. Нереляционные базы данных также являются хорошим выбором для приложений на основе ИИ и Интернета вещей, которым требуется превосходная производительность и горизонтальное масштабирование из-за природы больших данных.
Что является примером нереляционной базы данных?
Популярным примером нереляционных баз данных документного типа является MongoDB, которая хранит данные в формате, подобном JSON. Этот формат упрощает просмотр данных и просмотр всех данных в одном представлении. MongoDB также обладает богатыми возможностями запросов и функциями агрегирования, которые упрощают и ускоряют поиск и анализ данных.
Когда вы выберете реляционную или нереляционную базу данных?
Реляционные базы данных больше подходят для данных, которые вряд ли будут часто изменяться. Вы можете использовать реляционные базы данных для средних и больших наборов данных.
Для получения данных в реальном времени и получения более быстрых результатов запросов можно использовать нереляционные базы данных. Кроме того, нереляционные базы данных могут легко хранить огромные объемы неструктурированных данных из-за их гибкой схемы.
Что является примером реляционной базы данных?
Некоторыми популярными примерами реляционных баз данных являются MySQL, SQLServer и Oracle.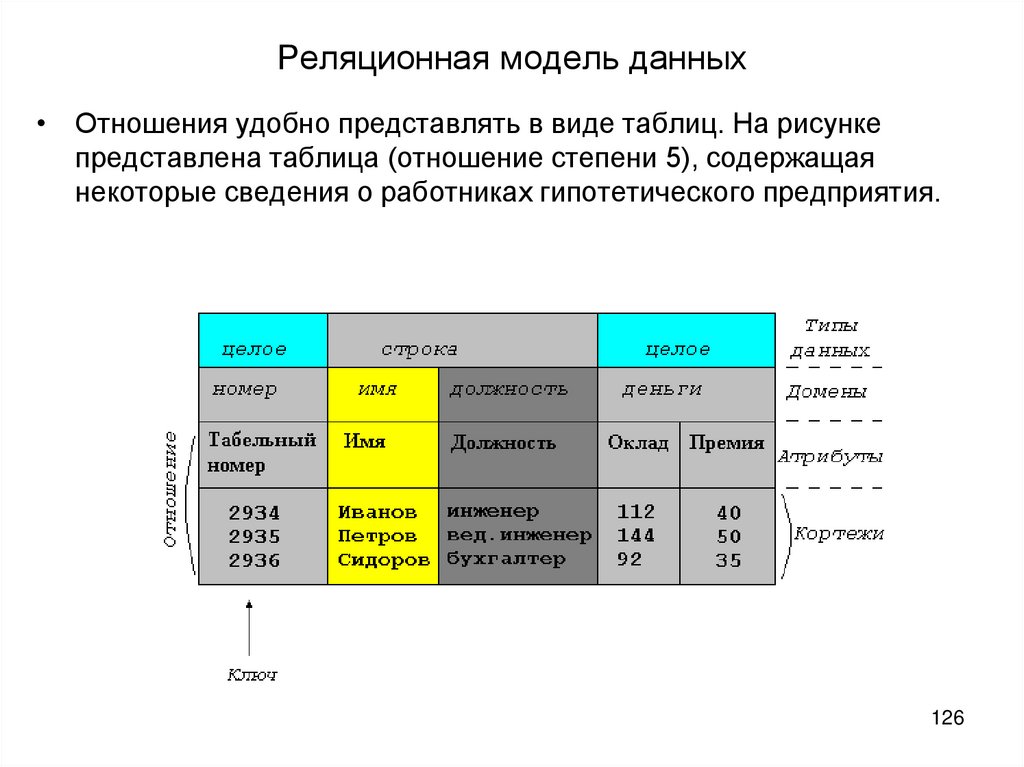
Реляционный vs. Нереляционные базы данных | MongoDB
При планировании нового проекта или приложения часто возникает обсуждение требований к базе данных. Какой тип базы данных следует использовать? В чем разница между реляционными и нереляционными базами данных?
Эта статья призвана ответить на эти вопросы, объяснив, что они из себя представляют и чем они отличаются, а также помочь вам принять обоснованное решение.
Данные цифровой эпохи можно разделить на оперативные и аналитические.
Операционные данные используются для повседневных транзакций и должны быть свежими — например, запасы продуктов и банковский баланс. Такие данные собираются в режиме реального времени с помощью систем оперативной обработки транзакций (OLTP).
Аналитические данные используются предприятиями для получения информации о поведении клиентов, производительности продукта и прогнозирования. Он включает данные, собранные за определенный период времени, и обычно хранится в системах OLAP (онлайн-аналитическая обработка), хранилищах или озерах данных.
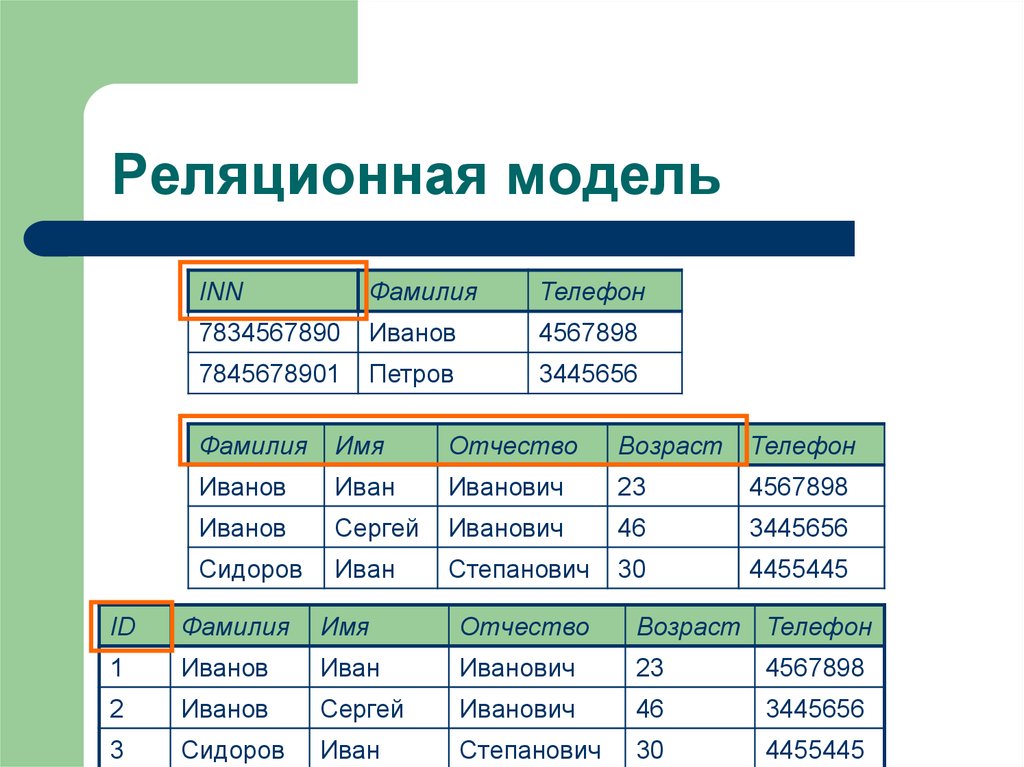
Базы данных являются наиболее эффективным способом постоянного хранения и извлечения оперативных и аналитических данных в цифровом виде.
В зависимости от требований проекта компании должны выбрать базу данных, которая может:
- Хранить все типы данных.
- Быстрый доступ к необходимым данным.
- Получите мгновенную информацию для принятия стратегических бизнес-решений.
Большинству компаний для хранения данных требуются как OLTP (операционная), так и OLAP (аналитическая) системы, и они могут использовать реляционную базу данных, нереляционную базу данных или и то, и другое для своих бизнес-целей.
Что такое реляционная база данных?
Реляционная база данных или система управления реляционными базами данных (RDMS) хранит информацию в таблицах. Часто эти таблицы имеют общую информацию между собой, что приводит к формированию отношений между таблицами. Отсюда и название реляционной базы данных.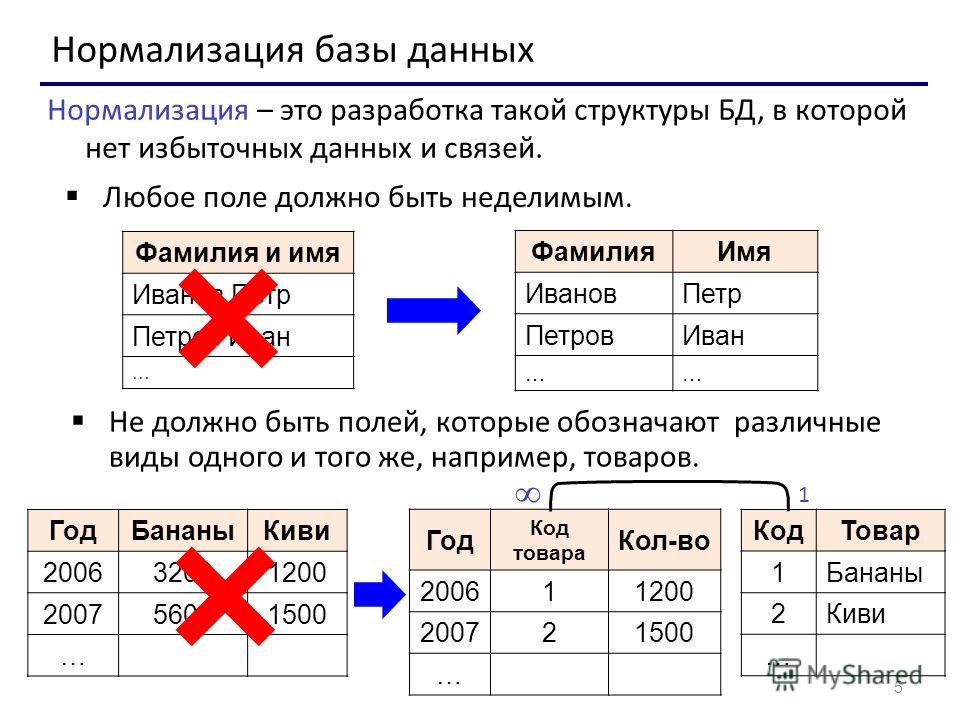
Таблица использует столбцы для определения сохраняемой информации и строки для фактических данных. В каждой таблице будет столбец с уникальными значениями, известный как первичный ключ 9.0112 . Затем этот столбец можно использовать в других таблицах, если между ними должны быть определены отношения. Когда первичный ключ одной таблицы используется в другой таблице, этот столбец во второй таблице называется внешним ключом .
Наиболее распространенным способом взаимодействия с системами реляционных баз данных является использование SQL (язык структурированных запросов). Разработчики могут писать SQL-запросы для выполнения операций CRUD (создание, чтение, обновление, удаление). Простой пример запроса:
ВЫБЕРИТЕ НАЗВАНИЕ ПРОДУКТА, ЦЕНА ИЗ ПРОДУКТА, ГДЕ ПРОДУКТ _ID = 23;
Представьте, что вы занимаетесь онлайн-бизнесом. У вас есть различная информация, которую вы храните, например информация о клиентах, информация о заказах и продуктах.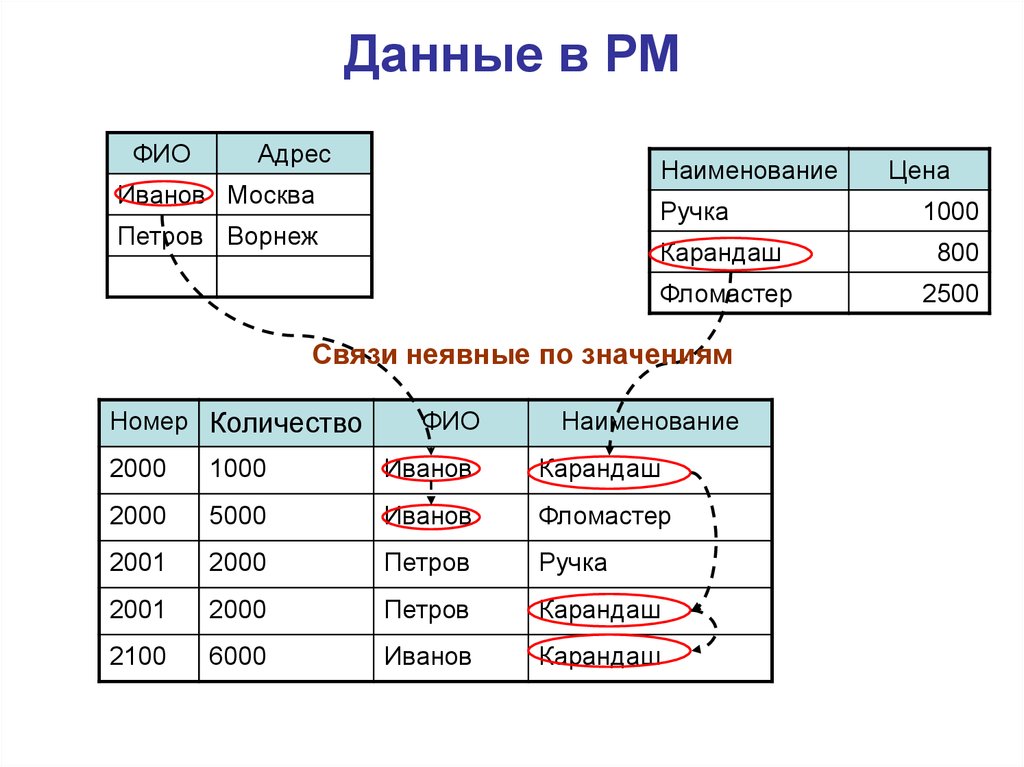 В реляционной базе данных это будет храниться в разных таблицах с ключом для объединения таблиц при необходимости.
В реляционной базе данных это будет храниться в разных таблицах с ключом для объединения таблиц при необходимости.
Данные хранятся в виде таблиц со строками и столбцами в реляционной базе данных
Здесь в таблице клиента хранится основная информация о клиенте,0151 идентификатор заказа и идентификатор адреса . Если кому-то нужна дополнительная информация о заказе или адресе, он может запросить соответствующие таблицы order и address , используя оператор INNER JOIN с полем id. Таблица order , в свою очередь, содержит идентификаторы товаров в заказе. Подробная информация о продукте находится в отдельной таблице продуктов. Это делает информацию организованной и более структурированной.
Преимущества реляционных баз данных
Соответствие ACID
Атомарность, непротиворечивость, изоляция и надежность (ACID) — это стандарт, гарантирующий надежность транзакций базы данных. Общий принцип заключается в том, что в случае сбоя одного изменения произойдет сбой всей транзакции, и база данных останется в том состоянии, в котором она была до попытки транзакции.
Общий принцип заключается в том, что в случае сбоя одного изменения произойдет сбой всей транзакции, и база данных останется в том состоянии, в котором она была до попытки транзакции.
Это важно, потому что некоторые транзакции будут иметь реальные последствия, если они не будут завершены полностью — например, банковские операции. Для получения дополнительной информации см. нашу документацию, объясняющую ACID.
Точность данных
Использование первичных и внешних ключей позволяет исключить дублирование информации. Это помогает обеспечить точность данных, поскольку повторяющаяся информация никогда не будет повторяться. Это, в свою очередь, снижает затраты на хранение.
Простота
RDMS, или базы данных SQL, существуют так давно, что было разработано множество инструментов и ресурсов, помогающих начать работу с реляционными базами данных и взаимодействовать с ними. Подобный английскому синтаксис SQL также позволяет не разработчикам создавать отчеты и запросы на основе данных.
Недостатки реляционных баз данных
Масштабируемость
RDMS исторически предназначались для работы на одной машине. Это означает, что если требования к машине недостаточны из-за размера данных или увеличения частоты доступа, вам придется улучшить аппаратное обеспечение машины, также известное как вертикальное масштабирование.
Это может быть невероятно дорого и имеет потолок, так как в конечном итоге затраты перевешивают выгоды. Кроме того, потенциально может наступить этап, когда вы просто не сможете получить оборудование, способное разместить базу данных. Единственным решением было бы купить машину, которая поддерживает лучшее оборудование, но все это недешево.
Гибкость
В реляционных базах данных схема является жесткой. Вы определяете столбцы и типы данных для этих столбцов, включая любые ограничения, такие как формат или длина. Общие примеры ограничений включают длину номера телефона или минимальную/максимальную длину столбца имени.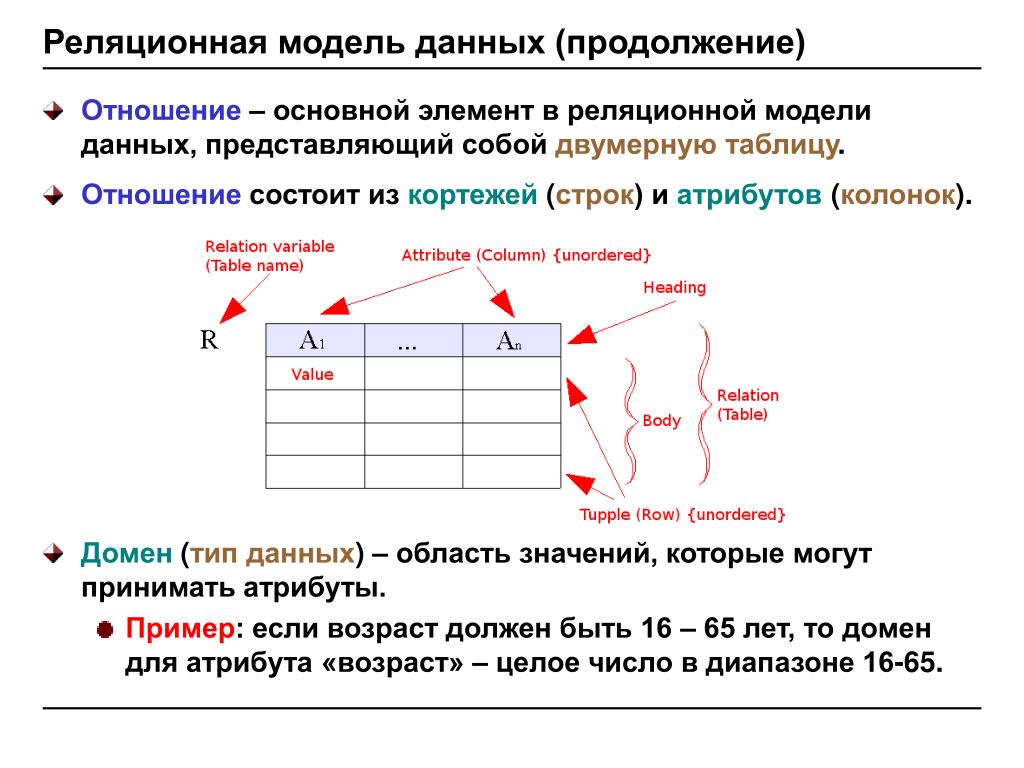
Хотя это означает, что вы можете легче интерпретировать данные и определять отношения между таблицами, это означает, что внесение изменений в структуру данных очень сложно. Вы должны решить в начале, как будут выглядеть данные, что не всегда возможно. Если вы хотите внести изменения позже, вам придется изменить все данные, что предполагает временное отключение базы данных.
Производительность
Производительность базы данных тесно связана со сложностью таблиц — их количеством, а также объемом данных в каждой таблице. По мере его увеличения увеличивается и время, затрачиваемое на выполнение запросов.
Что такое нереляционная база данных?
Нереляционная база данных, иногда называемая NoSQL (не только SQL), представляет собой любую базу данных, которая не использует концепцию структурированных данных таблиц, полей и столбцов из реляционных баз данных. Нереляционные базы данных разрабатывались с учетом облачных технологий, что делает их идеальными для горизонтального масштабирования.
Существует несколько различных групп типов баз данных, которые хранят данные по-разному:
Базы данных документов
Базы данных документов хранят данные в документах, которые обычно представляют собой структуры, подобные JSON, которые поддерживают различные типы данных. Эти типы включают строки; числа типа int, float и long; даты; объекты; массивы; и даже вложенные документы. Данные хранятся парами, аналогично парам ключ/значение.
Рассмотрим тот же пример клиента, что и выше. Однако в этом случае мы можем просматривать все данные одного клиента в одном месте в виде единого документа.
Как данные хранятся в нереляционной базе данных документов
Ниже приведен запрос для получения названия продукта и цены данного productid с использованием API запросов Mongo (аналогично SQL в предыдущем разделе). В этом запросе первый аргумент (_id) представляет фильтр для использования в коллекции, а второй — проекцию — поля, которые должны быть возвращены запросом.
db.product.find({"_id": 23}, {productName: 1, price: 1}) Поскольку документы имеют формат JSON, их намного легче читать и понимать пользователю. Данные организованы, а также легко просматривать. Нет необходимости ссылаться на несколько документов или коллекций для просмотра данных одного клиента. Документы хорошо сопоставляются с объектами в коде на объектно-ориентированных языках программирования, что значительно упрощает работу с ними.
Также отсутствует схема, что означает гибкость при вставке документов различных форм. Однако некоторые системы баз данных документов позволяют применять проверку схемы, если вам нужны другие преимущества баз данных документов, но с определенной формой данных.
Документы считаются отдельными единицами, что означает, что они могут быть распределены по нескольким серверам. Кроме того, базы данных самовосстанавливаются, что означает высокую доступность.
Базы данных документов также легко масштабируются. В отличие от реляционных баз данных, где традиционно можно масштабировать только вертикально (процессор, место на жестком диске и т.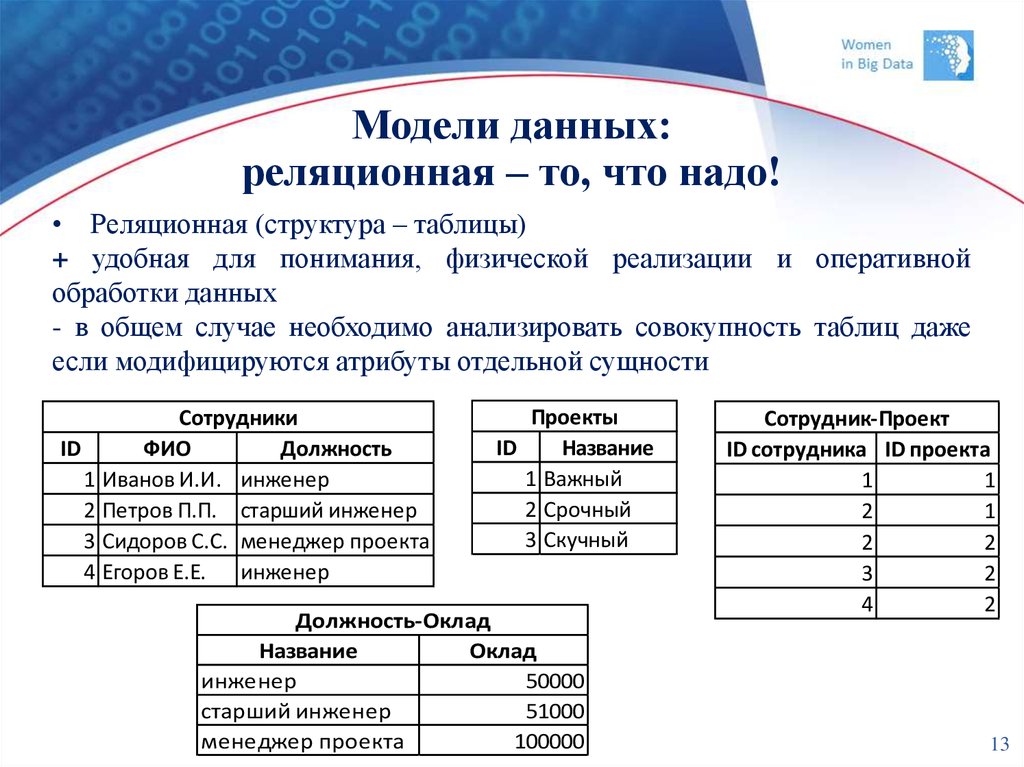 д.), нереляционные базы данных, включая базы данных документов, можно масштабировать горизонтально. Это означает, что базы данных дублируются на нескольких серверах, но при этом синхронизируются.
д.), нереляционные базы данных, включая базы данных документов, можно масштабировать горизонтально. Это означает, что базы данных дублируются на нескольких серверах, но при этом синхронизируются.
База данных «ключ-значение»
Это самый простой тип базы данных, где информация хранится в двух частях: ключ и значение.
Затем ключ используется для извлечения информации из базы данных.
Простота базы данных «ключ-значение» также является преимуществом. Поскольку все хранится в виде уникального ключа и значения, которое является либо данными, либо расположением данных, чтение и запись всегда будут быстрыми.
Однако эта простота ограничивает тип вариантов использования, для которых он может использоваться. Более сложные требования к данным не поддерживаются.
Базы данных графов
Базы данных графов являются наиболее специализированными типами нереляционных баз данных. Они используют структуру элементов, называемых узлами, которые хранят данные, а ребра между ними содержат атрибуты отношения.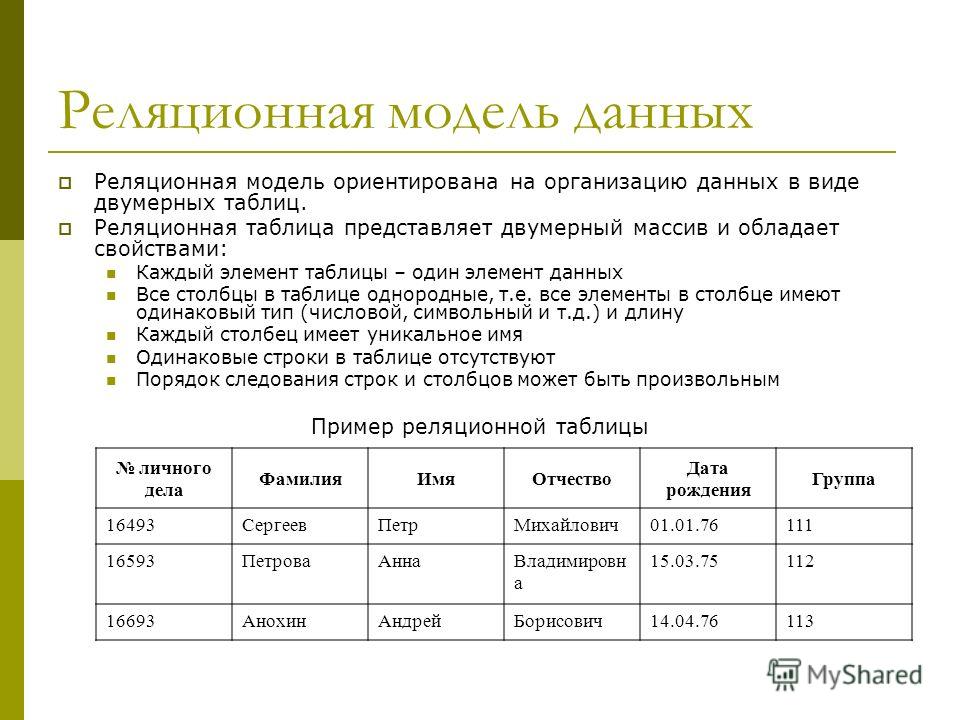
Отношения определяются по краям, что делает поиск, связанный с этими отношениями, естественным образом быстрым. Кроме того, они гибкие, потому что можно легко добавлять новые узлы и ребра. Им также не обязательно иметь определенную схему, как в традиционной реляционной базе данных.
Однако они не очень хороши для запросов ко всей базе данных, где отношения не так хорошо или вообще не определены. У них также нет стандартного языка для запросов, а это означает, что перемещение между различными типами баз данных графов требует обучения.
Базы данных с широкими столбцами
Базы данных с широкими столбцами, как и реляционные базы данных, хранят данные в таблицах, столбцах и строках. Однако имена и форматирование столбцов не обязательно должны совпадать в каждой строке. Столбцы могут даже храниться на нескольких серверах. Они считаются двумерными хранилищами «ключ-значение», поскольку используют многомерное сопоставление для ссылки на данные по строкам и столбцам.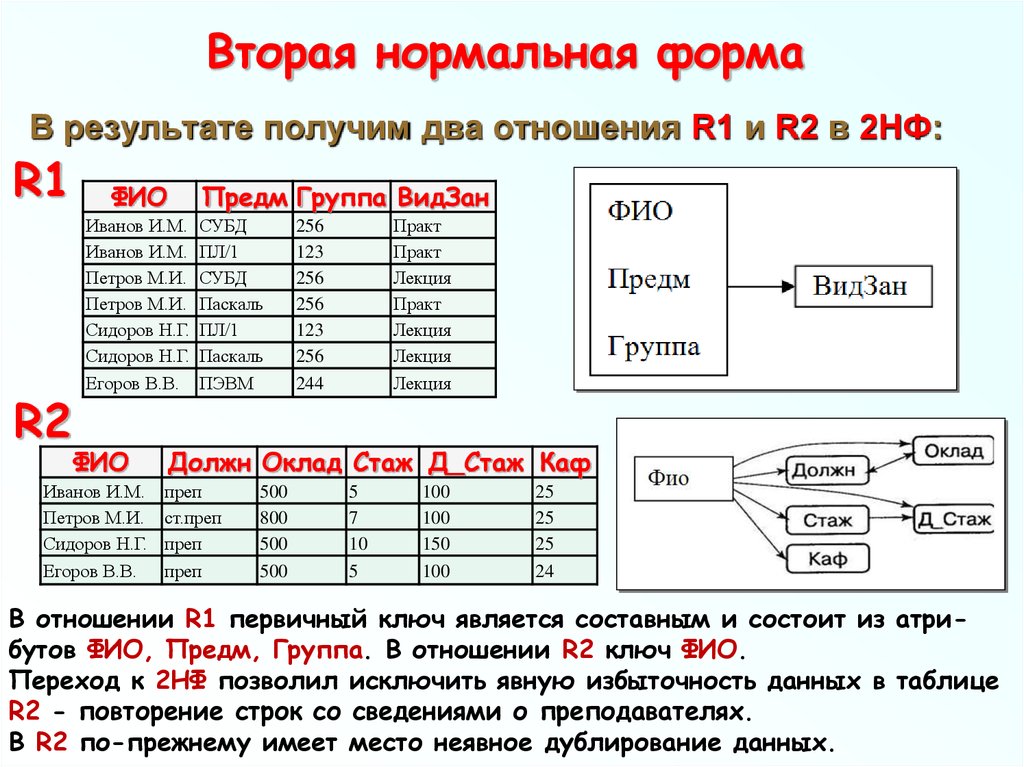
Подобно базам данных с двумя столбцами, базы данных с широкими столбцами обладают преимуществом гибкости, поэтому запросы выполняются быстро. Благодаря своей гибкости они хорошо справляются с «большими данными» и неструктурированными данными.
Однако по сравнению с реляционными базами данных базы данных с широкими столбцами намного медленнее обрабатывают транзакции. Столбцы группируют похожие атрибуты, а не используют строки, и хранят их в отдельных файлах, что означает, что транзакции должны выполняться в нескольких файлах.
| Document Database | Column Store Database | Key-Value Store Database | Graph Database | |
|---|---|---|---|---|
| Performance | High | High | High | Moderate |
| Доступность | Высокая | Высокая | Высокая | Высокая |
| Гибкость | Высокая | Moderate | High | High |
| Scalability | High | High | High | Moderate |
| Complexity | Low | Low | Moderate | High |
| База данных документов | |
|---|---|
| Производительность | Высокая |
| Availability | High |
| Flexibility | High |
| Scalability | High |
| Complexity | Low |
| Column Store Database | |
|---|---|
| Производительность | Высокая |
| Доступность | Высокая |
| Flexibility | Moderate |
| Scalability | High |
| Complexity | Low |
| Key-Value Store Database | |
|---|---|
| Performance | Высокий |
| Доступность | Высокий |
| Гибкость | Высокий |
| Scalability | High |
| Complexity | Moderate |
| Graph Database | |
|---|---|
| Performance | Moderate |
| Availability | Высокий |
| Гибкость | Высокий |
| Масштабируемость | Средняя |
| Сложность | Высокая |
Когда использовать реляционную базу данных
Если вы создаете проект, в котором частота, доступ, размер и структура данных предсказуемы реляционные базы данных по-прежнему являются лучшим выбором.
Нормализация может помочь уменьшить размер данных на диске за счет ограничения повторяющихся данных и аномалий, снижая риск необходимости вертикального масштабирования в будущем.
Реляционные базы данных также являются лучшим выбором, если важны отношения между сущностями.
Нереляционные базы данных могут хранить документы внутри документов, что помогает хранить данные, к которым будет осуществляться доступ, в одном и том же месте. Но если это не подходит для ваших нужд, реляционная база данных по-прежнему является решением. Например, если у вас есть большой набор данных со сложной структурой и взаимосвязями, встраивание может не создать достаточно четких взаимосвязей.
Количество времени, которое существует RDMS, также означает, что доступна широкая поддержка, от инструментов до интеграции с данными из других систем.
Когда использовать нереляционную базу данных
Как уже говорилось, существует множество типов нереляционных баз данных, каждая из которых имеет свои преимущества и недостатки.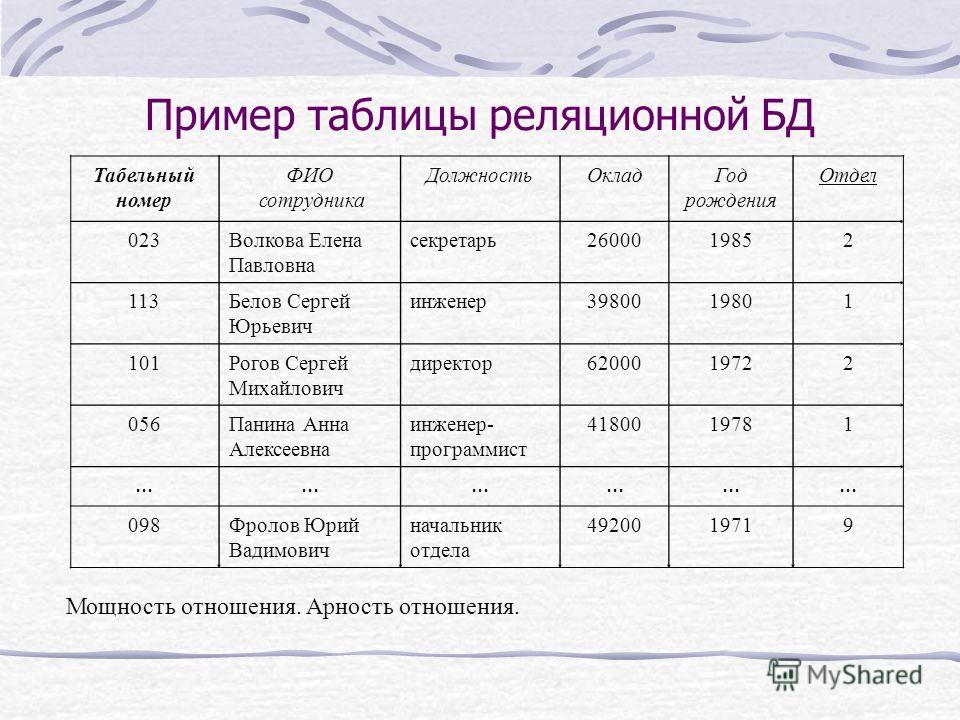
Тем не менее, нереляционные базы данных по-прежнему обладают некоторыми постоянными преимуществами. Если данные, которые вы храните, должны быть гибкими с точки зрения формы или размера, или если они должны быть открыты для изменения в будущем, тогда ответом будет нереляционная база данных.
Современные базы данных NoSQL были разработаны для облачных вычислений, что делает их естественным образом подходящими для горизонтального масштабирования, когда можно развернуть множество небольших серверов для обработки возросшей нагрузки.
Узнайте, как перевести проект с реляционных баз данных на нереляционные базы данных на основе документов.
Почему вы можете предпочесть нереляционную базу данных реляционной базе данных?
Существует множество причин, по которым вы захотите использовать нереляционную базу данных вместо реляционной:
- Нереляционные базы данных подходят как для операционных, так и для транзакционных данных.
- Больше подходят для неструктурированных больших данных.
- Нереляционные базы данных обеспечивают более высокую производительность и доступность.
- Гибкая схема помогает нереляционным базам данных хранить больше данных различных типов, которые можно изменять без существенных изменений схемы.
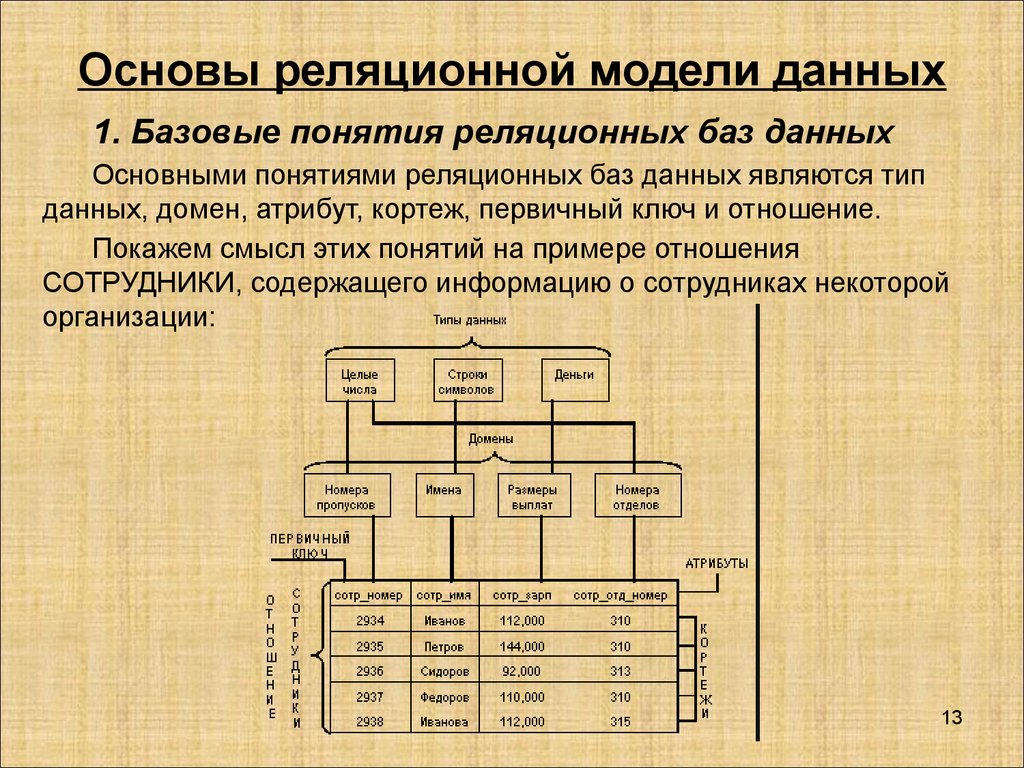
Резюме
В этой статье вы узнали о реляционных и нереляционных базах данных и о том, чем они отличаются друг от друга. Вы также узнали о преимуществах и недостатках обоих типов баз данных и о том, какой тип базы данных наиболее подходит для различных проектов.
| Функции | Нереляционные | Relational |
|---|---|---|
| Availability | High | High |
| Horizontal Scaling | High | Low |
| Vertical Scaling | High | High |
| Data Storage | Optimized for огромные объемы данных | Данные от среднего до большого |
| Производительность | Высокая | От низкого до среднего |
| Надежность | Medium | High (Acid) |
| Complexity | Low | Medium (Joins) |
| Flexibility | High | Low (Strict-Schema) |
| Suitability | Suitable For OLAP and OLTP | Подходит для OLTP |
MongoDB — это нереляционная база данных, обеспечивающая масштабируемость, высокую производительность, надежность и гибкость. MongoDB превратилась в более широкую платформу данных с MongoDB Atlas, облачной базой данных MongoDB, которая делает данные доступными в любое время.
MongoDB превратилась в более широкую платформу данных с MongoDB Atlas, облачной базой данных MongoDB, которая делает данные доступными в любое время.
Все ли базы данных реляционные?
Нет. Реляционные базы данных, или базы данных SQL, хранят данные в таблицах с общими столбцами между ними (известными как первичные и внешние ключи), формируя отношения между таблицами. Данные всегда структурированы по определенной схеме, которую нелегко изменить.
Но существуют и другие типы баз данных под названием нереляционных баз данных/баз данных NoSQL, которые содержат неструктурированные, полуструктурированные или структурированные данные. Это обеспечивает гибкость и высокую доступность. Некоторыми примерами являются MongoDB, Cassandra и CouchDB.
Является ли MongoDB нереляционной базой данных?
Да. MongoDB — это база данных документов, относящаяся к типу нереляционной базы данных. Данные хранятся в коллекциях в виде документов BSON, структура которых аналогична JSON. Данные считаются неструктурированными, поскольку коллекция может содержать документы с разными полями и типами данных. Это обеспечивает высокую гибкость.
Данные считаются неструктурированными, поскольку коллекция может содержать документы с разными полями и типами данных. Это обеспечивает высокую гибкость.
Каковы некоторые варианты использования нереляционных баз данных?
Благодаря гибкости и масштабируемости (как по горизонтали, так и по вертикали) нереляционных баз данных они отлично подходят для широкого спектра вариантов использования.
Например, для хранения настроек в приложении отлично подойдет база данных «ключ-значение», поскольку у каждой настройки будет только одно значение. Для сайта электронной коммерции база данных документов была бы идеальной, поскольку вы можете хранить документ для каждого клиента, в котором будут храниться их данные и история заказов, поскольку они являются частными и уникальными для каждого клиента.
Для таких задач, как обнаружение мошенничества, когда взаимосвязь между данными имеет жизненно важное значение, но типы данных часто непредсказуемы, графовая база данных является отличным решением.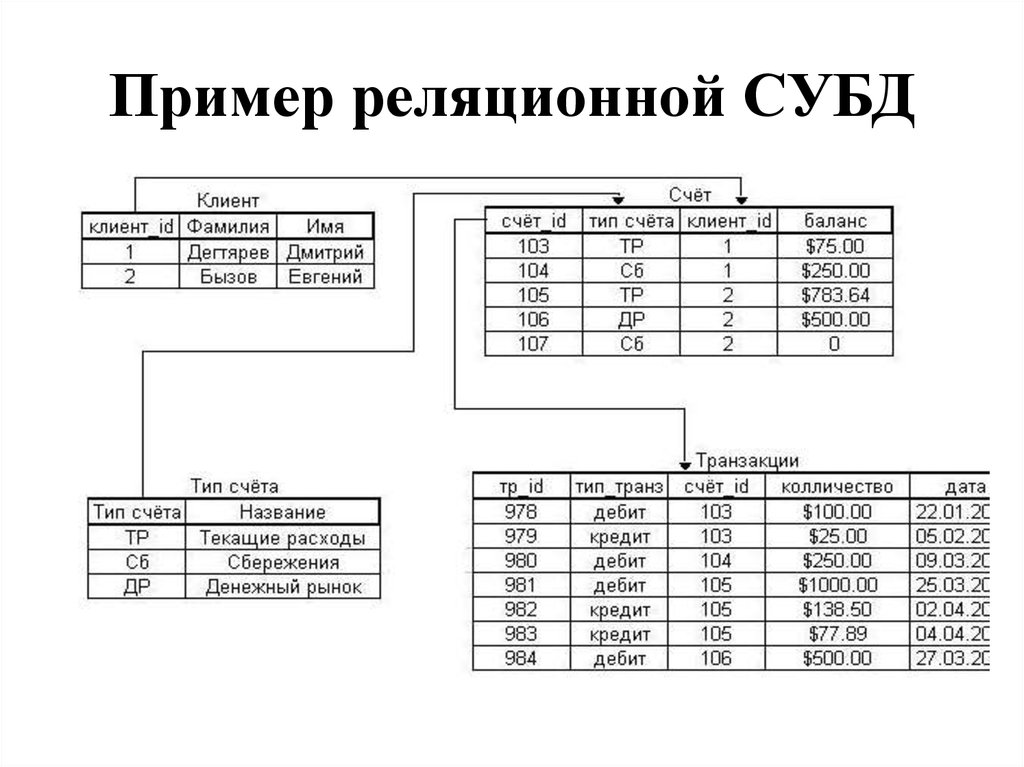
Для получения дополнительной информации о том, когда нереляционная база данных может оказаться не лучшим вариантом, см. технический документ, посвященный этому вопросу.
В чем разница между реляционными и нереляционными базами данных?
Реляционные базы данных хранят данные в табличном формате в виде строк и столбцов. Отношения между данными определяются с помощью нескольких таблиц. Например, чтобы определить взаимосвязь между клиентом и его заказами, нам нужны две или более таблиц: таблица клиентов и таблица заказов. Нереляционные базы данных не имеют жесткой структуры и подходят для хранения огромных объемов данных разных типов в одном представлении. Узнайте больше о реляционных и нереляционных базах данных.
Когда вы будете использовать нереляционную базу данных?
Существует множество вариантов использования нереляционной базы данных. Например, они вполне подходят для получения оперативных данных для оперативных и аналитических целей. Нереляционные базы данных также являются хорошим выбором для приложений на основе ИИ и Интернета вещей, которым требуется превосходная производительность и горизонтальное масштабирование из-за природы больших данных.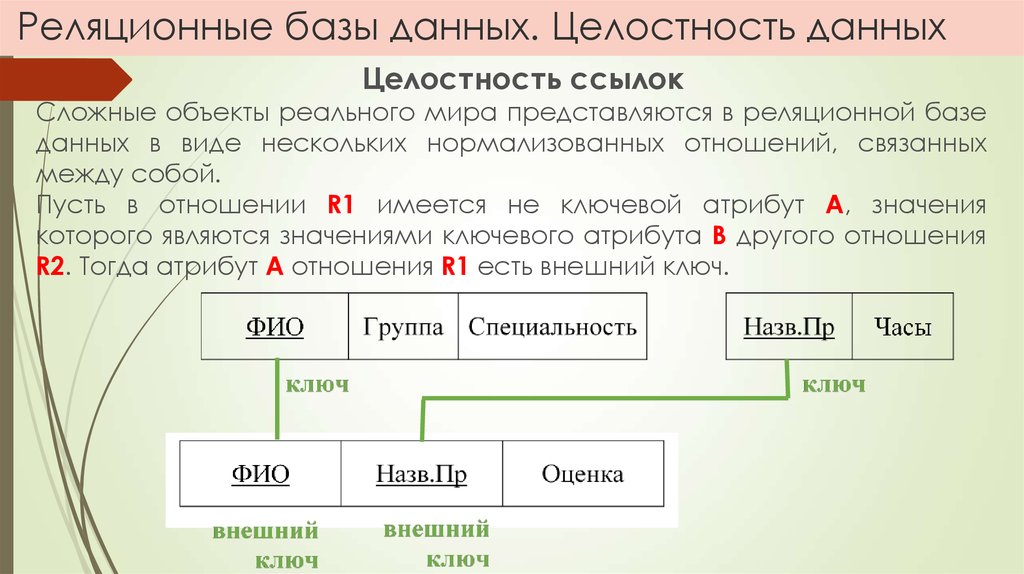
Что является примером нереляционной базы данных?
Популярным примером нереляционных баз данных документного типа является MongoDB, которая хранит данные в формате, подобном JSON. Этот формат упрощает просмотр данных и просмотр всех данных в одном представлении. MongoDB также обладает богатыми возможностями запросов и функциями агрегирования, которые упрощают и ускоряют поиск и анализ данных.
Когда вы выберете реляционную или нереляционную базу данных?
Реляционные базы данных больше подходят для данных, которые вряд ли будут часто изменяться. Вы можете использовать реляционные базы данных для средних и больших наборов данных.
Для получения данных в реальном времени и получения более быстрых результатов запросов можно использовать нереляционные базы данных. Кроме того, нереляционные базы данных могут легко хранить огромные объемы неструктурированных данных из-за их гибкой схемы.
Что является примером реляционной базы данных?
Некоторыми популярными примерами реляционных баз данных являются MySQL, SQLServer и Oracle.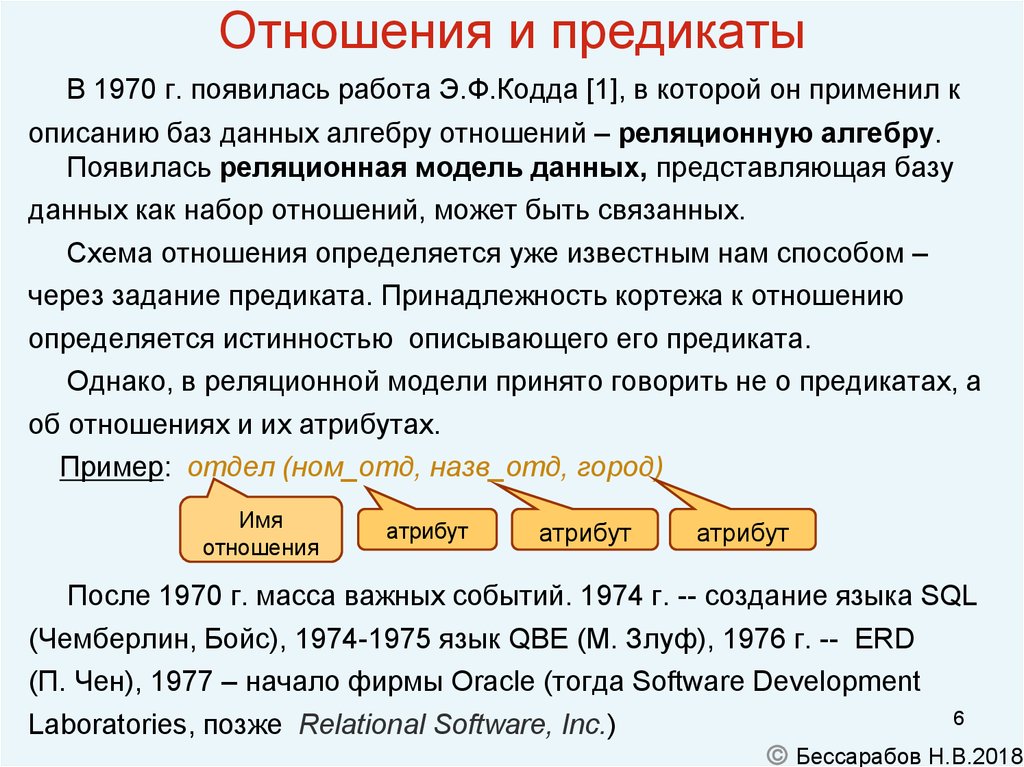
Что такое реляционная база данных? Особенности и использование
Реляционная база данных — это тип базы данных, в которой хранятся и систематизируются связанные точки данных. Данные организованы в таблицы, связанные на основе общих данных. Сегодня они являются наиболее распространенным типом баз данных, используемых предприятиями.
Такая база данных позволяет выполнять поиск в одной или нескольких таблицах с помощью одного запроса. Это также поможет вам понять связи между вашими данными, чтобы вы могли принимать более эффективные бизнес-решения.
Реляционные базы данных идеально подходят для комплексного анализа данных и операций. В нереляционной базе данных таблицы могут совместно использовать одни и те же данные, но они не могут «связываться» друг с другом. С реляционной базой данных они могут.
Одним из способов использования реляционной базы данных является соединение таблиц для данных клиентов и транзакций. У бизнеса будут оба набора данных, но они могут быть разрозненными.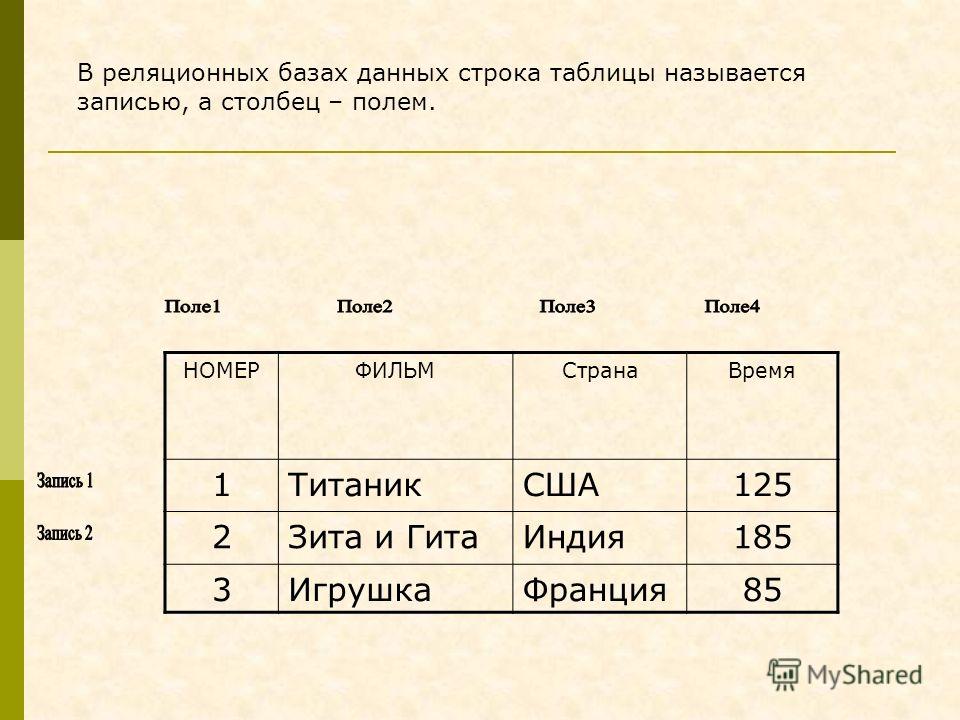 Реляционная база данных объединяет их.
Реляционная база данных объединяет их.
Например, в таблице клиентов могут быть поля для:
В таблице транзакций могут быть такие поля, как:
Поскольку обе таблицы содержат идентификатор клиента, таблицы могут быть связаны. Это означает, что команда склада может найти адрес клиента, соответствующий идентификатору клиента, без записи этой информации в качестве отдельной точки данных для каждой транзакции. Связывание этих наборов данных также можно использовать для создания отчетов, таких как отчет о клиентах.
Ниже мы рассмотрим особенности, использование и преимущества реляционной базы данных. Кроме того, мы описываем функции реляционных данных Salesforce.
Особенности реляционной базы данных
Реляционным базам данных необходимы характеристики ACID.
ACID относится к четырем основным свойствам: атомарность, согласованность, изоляция и долговечность.
Эти функции являются основным отличием реляционной базы данных от нереляционной базы данных.
Атомарность
Атомарность обеспечивает точность данных. Это гарантирует, что все данные соответствуют правилам, положениям и политикам бизнеса.
Также требуется, чтобы все задачи завершились успешно, иначе транзакция будет откатана.
Атомарность определяет все элементы полной транзакции базы данных.
Непротиворечивость
Состояние базы данных должно оставаться согласованным на протяжении всей транзакции.
Непротиворечивость определяет правила сохранения точек данных. Это гарантирует, что они останутся в правильном состоянии после транзакции.
Реляционные базы данных имеют согласованность данных, поскольку информация обновляется в приложениях и копиях базы данных (также называемых «экземплярами»). Это означает, что несколько экземпляров всегда имеют одни и те же данные.
Изоляция
В реляционной базе данных каждая транзакция является отдельной и не зависит от других. Это стало возможным благодаря изоляции.
Это стало возможным благодаря изоляции.
Изоляция делает эффект транзакции невидимым до тех пор, пока она не будет зафиксирована. Это снижает риск путаницы.
Надежность
Надежность означает, что вы можете восстановить данные после неудачной транзакции.
Это также гарантирует, что изменения данных будут постоянными.
Использование и преимущества реляционной базы данных
Реляционные базы данных часто являются основой системы управления взаимоотношениями с клиентами (CRM), такой как Salesforce.
Но отслеживание транзакций клиентов — это только один вариант использования реляционной базы данных. Есть много других. Некоторые из них мы даже используем в повседневной жизни. Например, когда вы снимаете деньги в банкомате, ваш банковский баланс может мгновенно обновляться в вашем мобильном приложении, если оно использует реляционную базу данных. Это связано с тем, что точка данных этого сценария («Баланс счета») постоянно обновляется на всех платформах.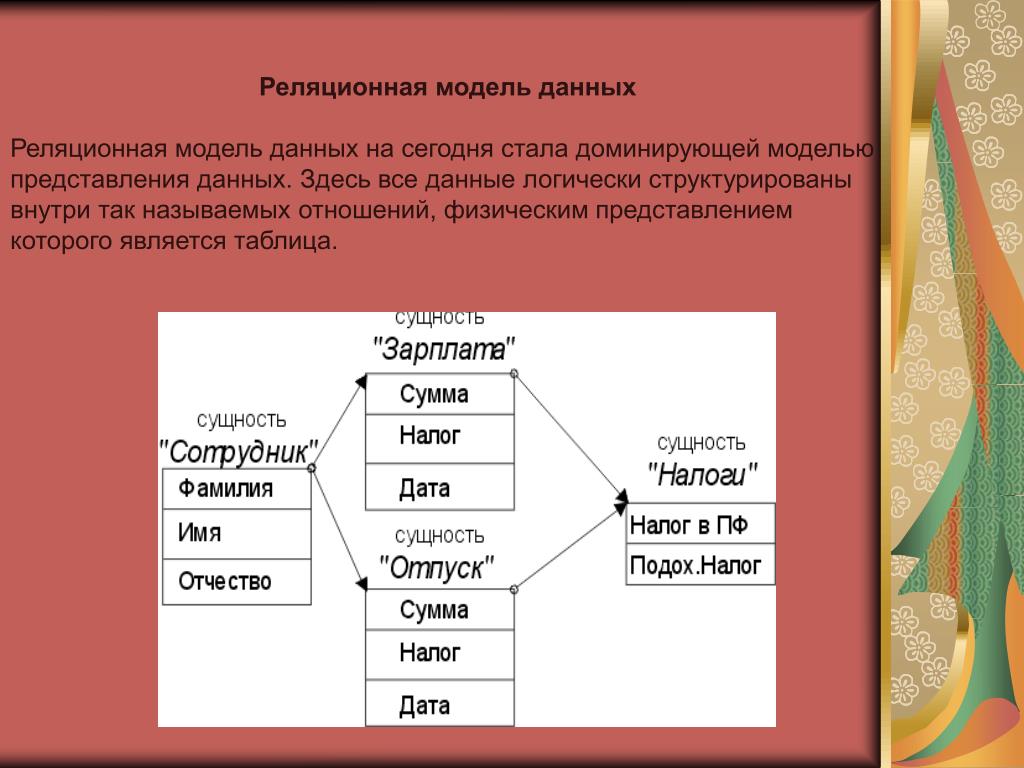
Существует множество преимуществ использования реляционной базы данных по сравнению с нереляционной базой данных. И многие из них влияют на другие системы, включая Salesforce.
Некоторые из основных преимуществ реляционной базы данных:
Непротиворечивость данных
Как уже упоминалось, когда мы говорили о ACID, ключевой частью реляционной базы данных является согласованность.
Модель реляционной базы данных гарантирует, что все пользователи всегда будут видеть одни и те же данные.
Это улучшает понимание в бизнесе, поскольку все видят одну и ту же информацию. Это гарантирует, что никто не будет принимать бизнес-решения на основе устаревшей информации.
Данные, работающие вместе
Все данные в реляционной базе данных имеют «отношения» с другими данными. Столбцы построены таким образом, что легко установить отношения между точками данных.
Совместная работа с данными дает более целостное представление обо всех ваших данных, в том числе о ваших клиентах.
Гибкость данных
Реляционные базы данных обеспечивают гибкость. Пользователи могут изменить то, что они видят. И легко добавить дополнительные данные позже.
Реляционная база данных также позволяет просматривать подмножество данных. Это означает, что вы можете скрыть определенные данные, если некоторым пользователям нужен доступ только к определенному набору столбцов или строк.
Функции реляционных данных в Salesforce CRM
CRM Salesforce построена на реляционной базе данных.
Salesforce называет свои таблицы «объектами». И эти объекты могут относиться друг к другу. Эти отношения можно использовать для обмена информацией и создания подключенных представлений данных.
В Salesforce существует два типа взаимосвязей:
Отношения поиска
Это самая простая реляционная связь в Salesforce.
Отношение поиска связывает два объекта, так что вы можете «искать» один объект среди связанных элементов другого объекта.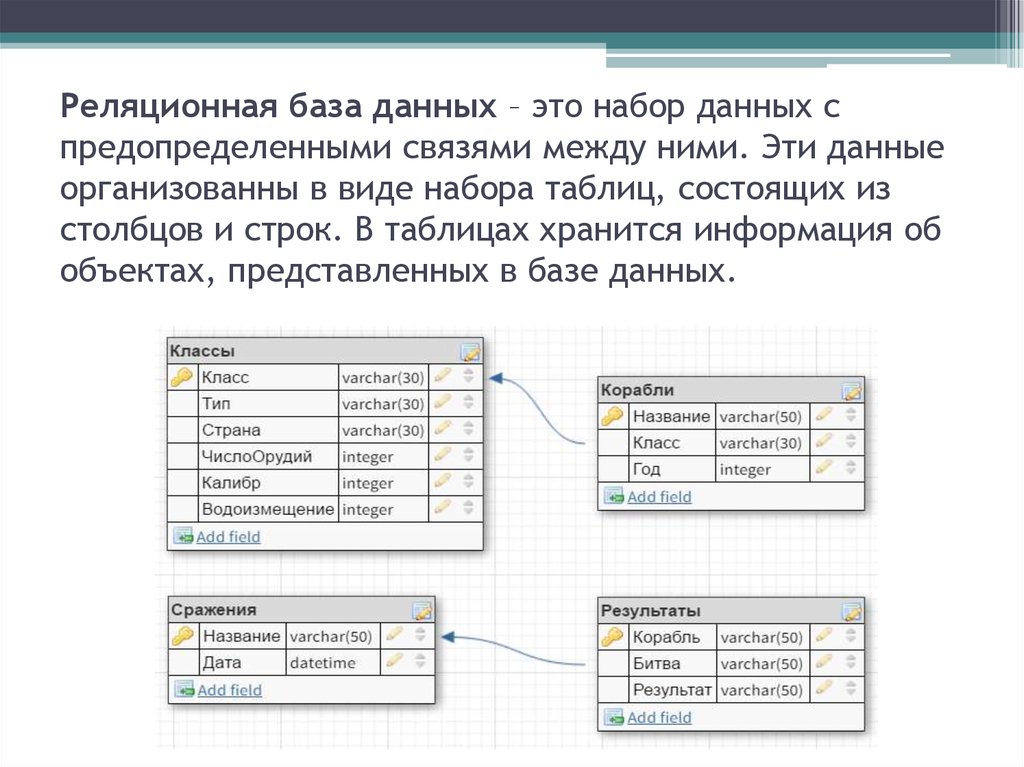 Отношения поиска могут быть «один к одному» или «один ко многим».
Отношения поиска могут быть «один к одному» или «один ко многим».
Стандартное отношение «один ко многим» — это отношение «Организация к контакту». Это позволяет подключить несколько контактов к одному аккаунту.
Связь «один к одному» — это когда необходимо связать только один набор данных. Например, если вы занимаетесь недвижимостью, у вас может быть объект «Недвижимость» и объект «Продавец жилья». У собственности есть только один продавец жилья, поэтому необходимо связать только один набор данных.
Отношения родитель-потомок
Отношения родитель-потомок сложнее, чем отношения поиска.
При этом один объект является родительским, а другой — дочерним. Родительский объект контролирует некоторые действия дочернего объекта, например, кто может просматривать его данные. Это также означает, что если вы удаляете родительский объект, вы удаляете все связанные с ним дочерние объекты.
Например, у вас может быть отношение родитель-потомок между Собственностью и Предложением. Все предложения эксклюзивны для одного объекта. Если имущество будет снято с продажи, вы можете удалить объект Property, чтобы удалить все связанные предложения из вашей системы.
Все предложения эксклюзивны для одного объекта. Если имущество будет снято с продажи, вы можете удалить объект Property, чтобы удалить все связанные предложения из вашей системы.
Родительско-дочерние отношения используются, когда объекты всегда связаны. Когда объекты иногда связаны, это отношение поиска.
Преимущества Salesforce
Salesforce предоставляет вам все преимущества реляционной базы данных с расширенными функциями CRM. Кроме того, Salesforce выводит CRM на новый уровень благодаря таким инновациям, как Salesforce Einstein, в которой используется искусственный интеллект.
Salesforce Customer 360 — CRM-система №1 в мире. Он объединяет продажи, обслуживание, маркетинг, коммерцию, ИТ и аналитику. И все это стало возможным благодаря реляционной базе данных.
Что такое реляционная база данных? RDBMS Definition
Реляционная база данных — это тип базы данных, в которой данные хранятся в таблицах, состоящих из строк и столбцов.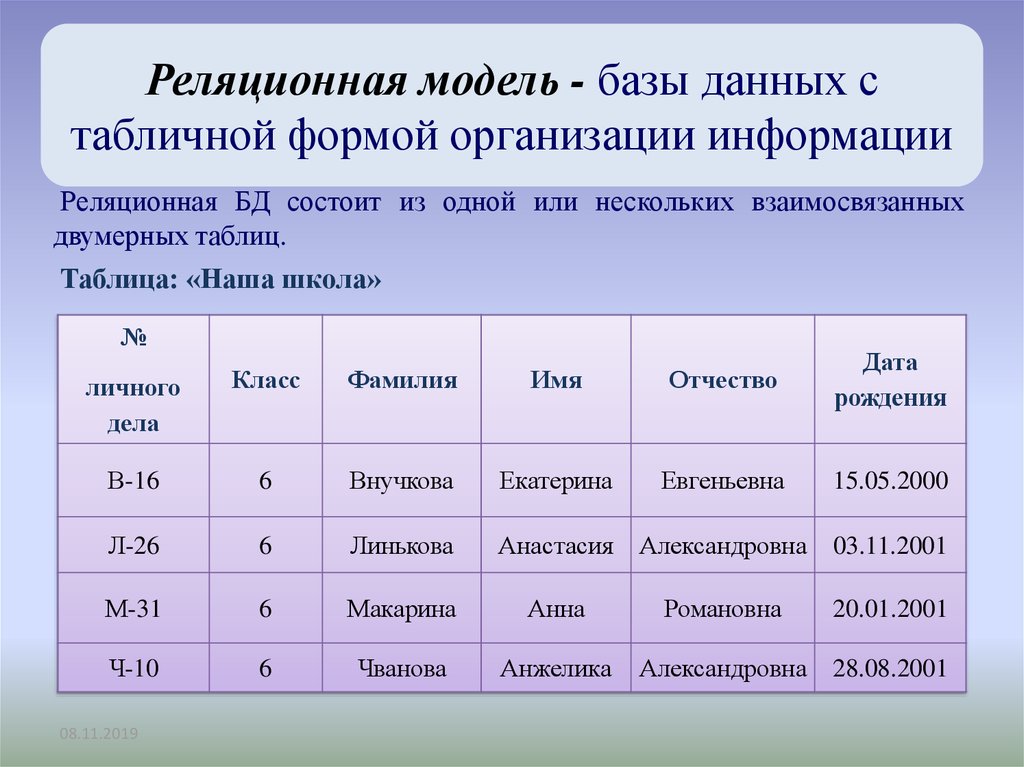 Каждая таблица представляет определенный объект в базе данных, такой как пользователи, продукты, заказы и т. д.
Каждая таблица представляет определенный объект в базе данных, такой как пользователи, продукты, заказы и т. д.
Термин «реляционный» является основной характеристикой, которая делает реляционные базы данных уникальными. Это связано с тем, что каждый объект (таблица) в реляционной базе данных может «связываться» с другим для создания большего количества таблиц, что делает поток данных гибким.
Столбцы обозначают определенный тип данных, которые могут храниться в каждом соответствующем столбце. Примером может служить пользовательская таблица со следующими столбцами: Имя, Дата рождения, Телефон и Страна.
Вы используете строки для заполнения данных в таблице базы данных. Используя приведенные выше имена столбцов в качестве примеров, мы можем заполнить строки такими данными: Джон Доу, 02-04-1970, 555-777-999, Земля.
То есть:
| Имя | ДоБ | Телефон | Страна |
|---|---|---|---|
| Джон Доу | 04.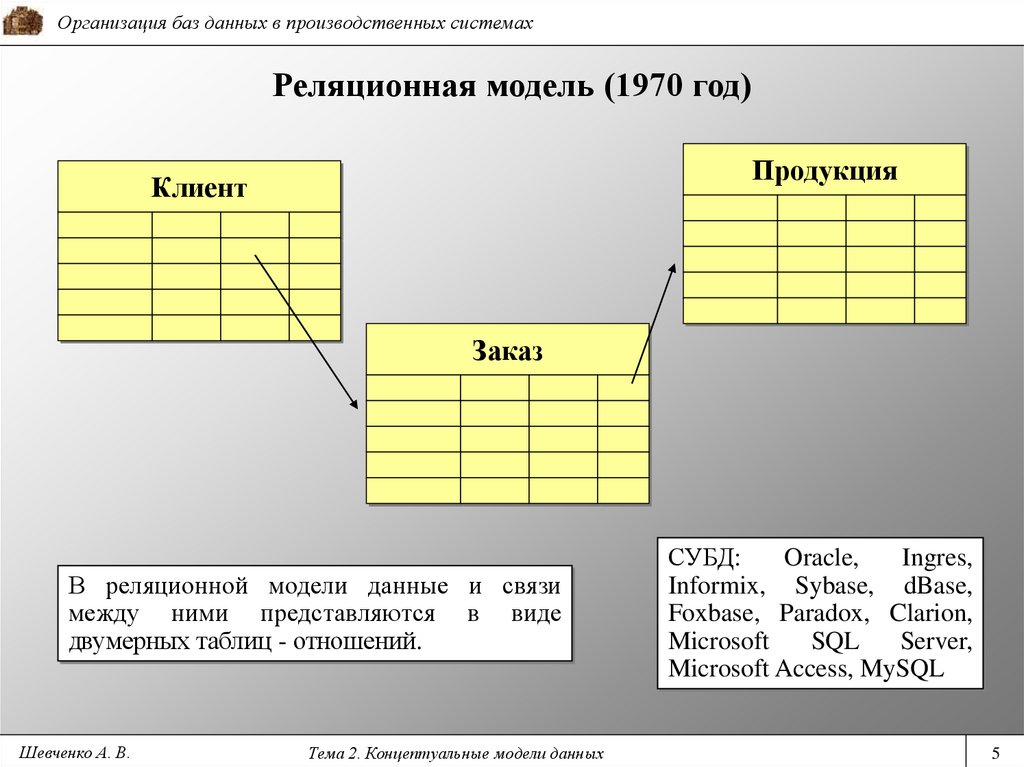 02.1970 02.1970 | 555-777-999 | Земля |
| Джейн делает | 05.03.1980 | 444-222-444 | Нигерия |
| Джейд До | 03.05.1990 | 565-784-437 | Англия |
Как видно выше, в каждой строке есть данные, соответствующие имени столбца.
Что такое первичные и внешние ключи в реляционной базе данных?
В таблице в последнем разделе отсутствует один из важнейших атрибутов реляционной базы данных — уникальный идентификатор/идентификатор.
Таблицы могут связываться друг с другом с помощью уникальных идентификаторов.
Хорошим примером важности идентификаторов является ситуация, когда два или более пользователей с одинаковым именем выполняют одно и то же действие, например, покупают продукт. Единственный способ определить разницу между этими пользователями — использовать их уникальный идентификатор.
Эти уникальные идентификаторы обычно обозначаются как ключей в реляционной базе данных.
В реляционной базе данных может быть либо первичный ключ, либо внешний ключ. Поясним, что они означают.
Что такое первичный ключ в реляционной базе данных?
Первичный ключ — это столбец в столбце базы данных, используемый для идентификации определенных записей/строк. Каждая строка должна иметь свой уникальный ключ.
Первичным ключом может быть любой атрибут в таблице, такой как номер телефона пользователя или любая другая информация, предоставленная пользователем.
В долгосрочной перспективе использование информации, предоставленной пользователями, в качестве первичного ключа может стать вредным, поскольку у вас могут быть повторяющиеся значения. Это затруднит дифференциацию записей.
В большинстве случаев первичные ключи автоматически генерируются системой управления базами данных по мере создания записей. Ни один конкретный первичный ключ не может быть сгенерирован дважды — это делает каждую строку уникальной.
Вот пример таблицы с первичным ключом:
| ID пользователя | Имя | ДоБ | Телефон | Страна |
|---|---|---|---|---|
| 1 | Джон Доу | 04. 02.1970 02.1970 | 555-777-999 | Нигерия |
| 2 | Джон Доу | 05.03.1980 | 444-222-444 | Нигерия |
| 3 | Джон Доу | 03.05.1990 | 565-784-437 | Нигерия |
В приведенной выше таблице у нас есть три пользователя с одинаковым именем и страной.
Если эти пользователи продолжат покупать продукты, их дифференциация по именам станет проблемой.
Обратите внимание, что первичный ключ никогда не должен иметь нулевое значение.
Используя первичный ключ (USER ID), мы делаем каждого пользователя уникальным. Это также устранило бы возможность сделать другой атрибут, предоставленный пользователями — DOB, Phone — первичным ключом.
Что такое внешний ключ в реляционной базе данных?
Внешний ключ — это столбец/группа столбцов, используемые для создания ссылки/ссылки на первичный ключ другой таблицы.
Другими словами, это представление первичного ключа другой таблицы.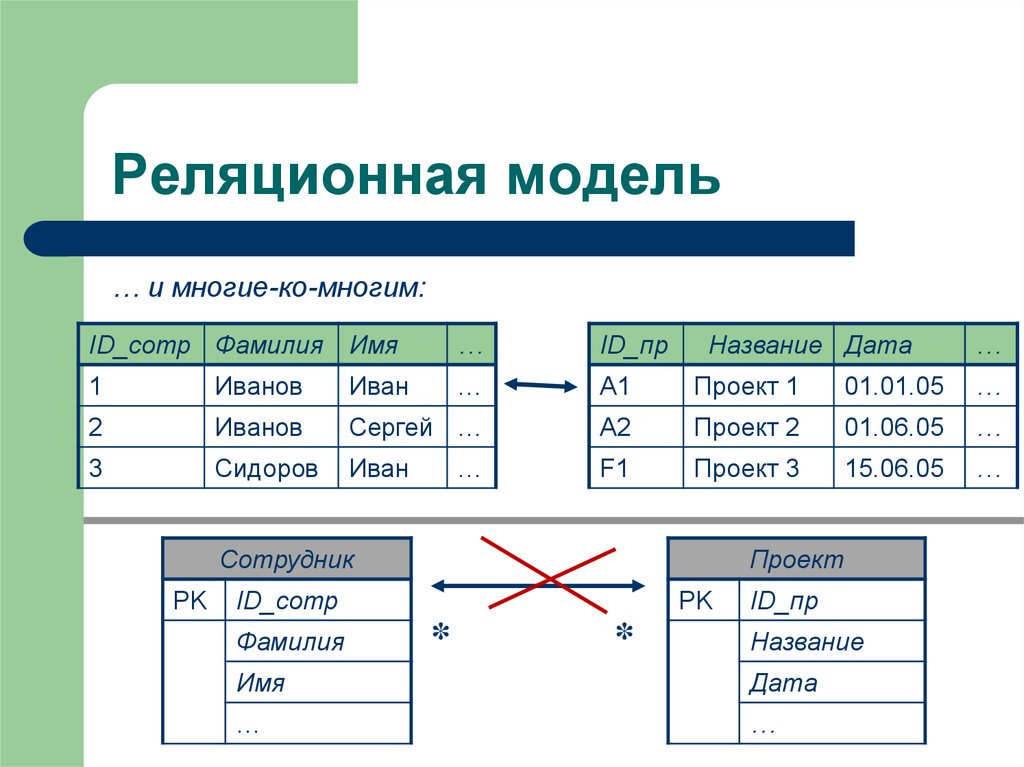
Вот пример, показывающий важность внешних ключей:
| Идентификатор клиента | Имя | ДоБ | Телефон | Страна |
|---|---|---|---|---|
| 1 | Джон Доу | 04.02.1970 | 555-777-999 | Нигерия |
| 2 | Джон Доу | 05.03.1980 | 444-222-444 | Нигерия |
| 3 | Джон Доу | 03.05.1990 | 565-784-437 | Нигерия |
В приведенной выше таблице у нас есть таблица пользователей с первичным ключом, который называется CUSTOMER ID.
В таблице ниже показаны различные продукты, которые могут заказать клиенты:
| Код продукта | Название продукта |
|---|---|
| 10 | Пицца |
| 20 | Кофе |
| 30 | Джон Доу |
Далее мы создадим таблицу для отображения заказов, сделанных клиентами.
| Код заказа | Идентификатор клиента | Название продукта |
|---|---|---|
| 1 | 3 | Пицца |
| 2 | 2 | Пицца |
| 3 | 3 | Кофе |
| 2 | 1 | Кофе |
В приведенной выше таблице CUSTOMER ID является внешним ключом. Он служит ссылкой на первичный ключ в таблице клиентов.
Таблицу заказов легче понять, потому что мы можем идентифицировать каждого клиента, используя его уникальный идентификатор, а не похожие имена.
Таблица может иметь более одного внешнего ключа.
Примеры реляционных баз данных
Вот примеры некоторых популярных реляционных баз данных:
- MySQL.
- PostgreSQL.
- База данных Oracle.
- Microsoft SQL Server.
- IBM Db2.
- МарияДБ.
Существуют также облачные реляционные базы данных, такие как:
- Oracle Cloud.
- Google Cloud SQL.
- IBM Db2 в облаке.
- Базы данных AWS.

Преимущества реляционной базы данных
В этом разделе мы перечислим и объясним некоторые функции реляционной базы данных.
Простота использования
Работа с данными в реляционной базе данных проста и понятна. Вы делаете это, используя SQL (язык структурированных запросов ) .
Гибкость
Вы можете легко масштабировать реляционную базу данных по мере роста данных. Также легко добавлять, обновлять и удалять данные, хранящиеся в базе данных.
Когда определенные данные хранятся во многих таблицах, изменение их в одной таблице приводит к обновлению их значения для всех других таблиц, совместно использующих данные.
Безопасность
Вы можете легко ограничить доступ к определенным таблицам в реляционной базе данных, сделав ее недоступной для неавторизованных пользователей. Вы делаете это с помощью системы управления реляционными базами данных (RDBMS).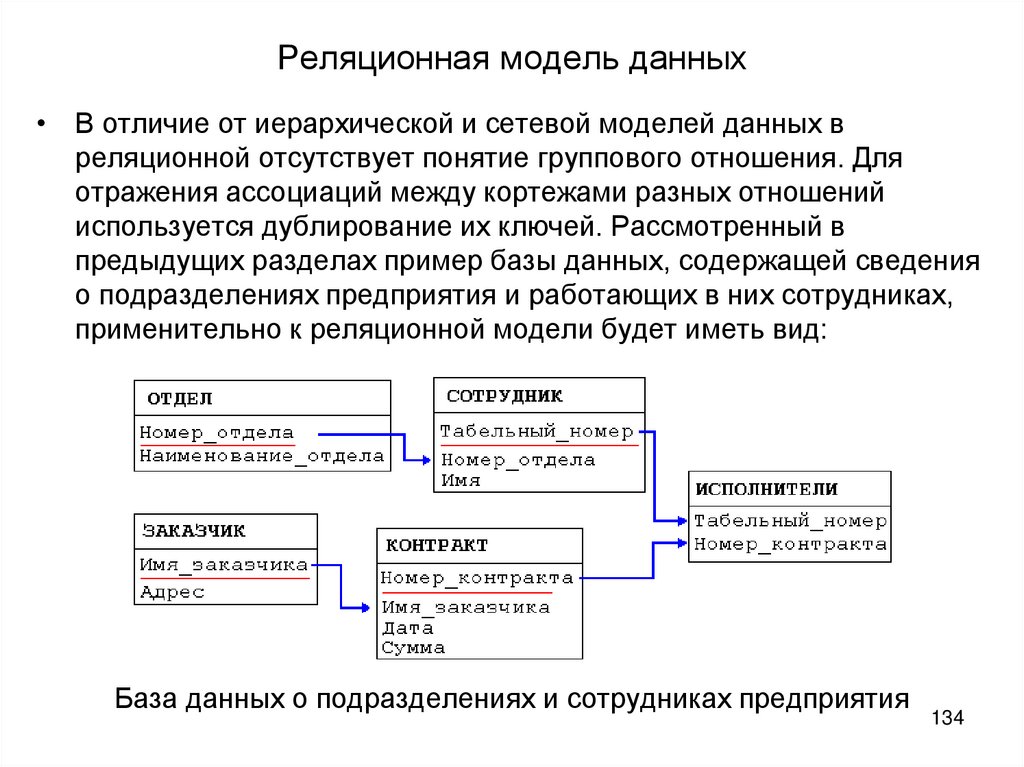
РСУБД в основном используются для создания, чтения, обновления и удаления данных в реляционной базе данных.
Точность
С помощью ключей (первичных и внешних) к каждому фрагменту данных, хранящемуся в реляционной базе данных, можно получить доступ, когда это необходимо, не перепутав его с другим.
Простота
Структура реляционных баз данных позволяет легко понять тип и поток данных, хранящихся в ней. Вы также можете представить данные, хранящиеся в базе данных, графически. Это поможет вам понять взаимосвязь между таблицами.
Что такое СУБД?
РСУБД — это аббревиатура от системы управления реляционными базами данных. Это программа, используемая для управления реляционной базой данных.
Позволяет создавать, читать, обновлять и удалять (операции CRUD) данные в базе данных.
Большинство СУБД используют SQL для взаимодействия с базой данных. SQL — это язык программирования, используемый для управления и выполнения операций в реляционной базе данных.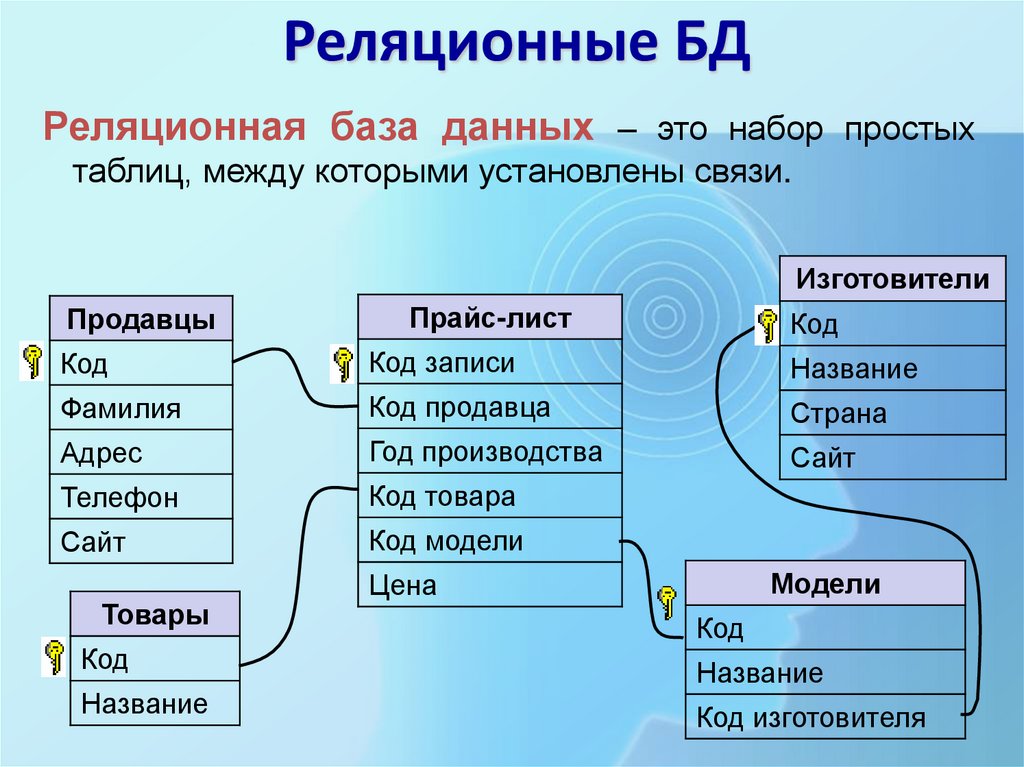 Его несколько легко выучить, потому что его синтаксис похож на английский язык.
Его несколько легко выучить, потому что его синтаксис похож на английский язык.
ВЫБЕРИТЕ * ОТ пользователей;
Приведенный выше код SQL выбирает все столбцы в таблице с именем Users .
Вот некоторые из популярных систем управления реляционными базами данных:
- MySQL.
- Microsoft SQL Server.
- SQLite.
- PostgreSQL.
Резюме
В этой статье мы говорили о реляционных базах данных.
Мы познакомились с некоторыми функциями реляционной базы данных, такими как представление данных в таблицах со строками и столбцами, а также с использованием ключей, позволяющих сделать каждую часть данных уникальной по сравнению с остальными.
Мы также говорили о первичных и внешних ключах с примерами, демонстрирующими, как их использовать.
Наконец, мы рассказали о некоторых преимуществах использования реляционной базы данных.
Чтобы узнать больше о реляционных базах данных, ознакомьтесь с сертификацией freeCodeCamp по реляционным базам данных.
Вы начнете с изучения основных команд Bash и того, как использовать терминал для навигации и управления файловой системой.
Вы также научитесь создавать и использовать реляционную базу данных и использовать Git для управления версиями.
По мере прохождения курса вы будете создавать потрясающие проекты, которые помогут вам углубить свои знания о реляционных базах данных.
Удачного кодирования!
Научитесь программировать бесплатно. Учебная программа freeCodeCamp с открытым исходным кодом помогла более чем 40 000 человек получить работу в качестве разработчиков. Начать
Реляционные базы данных не предназначены для масштабирования
Мэтт Аллен (Matt Allen) — вице-президент по маркетингу продуктов, отвечающий за маркетинг всех функций и преимуществ MarkLogic во всех сферах деятельности. В этой роли Мэтт взаимодействует с командой разработчиков и инженеров, а также с отделами продаж и маркетинга для создания контента и мероприятий, которые обучают и вдохновляют на внедрение технологии.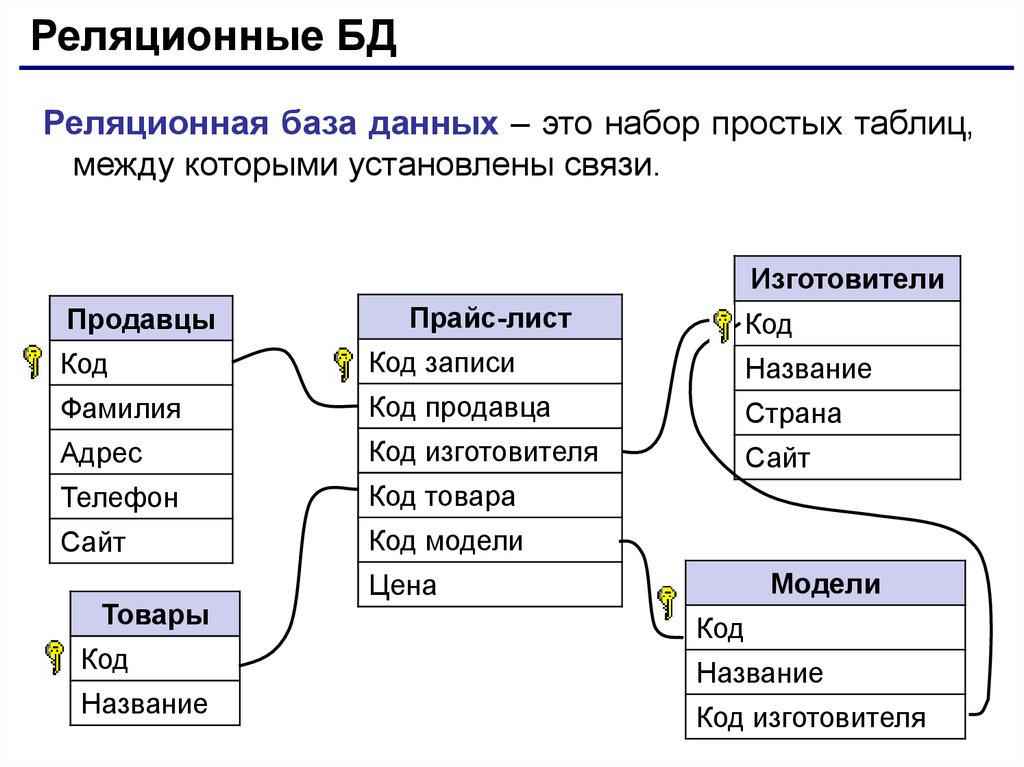 Мэтт живет в…
Мэтт живет в…
Реляционные базы данных предназначены для работы на одном сервере, чтобы поддерживать целостность отображений таблиц и избежать проблем распределенных вычислений.
Мы находимся на переломном этапе с объемом данных. В своем последнем посте я показал статистику EMC о том, как ожидается, что цифровая вселенная вырастет с 4,4 зеттабайт в 2013 году до 44 зеттабайт в 2020 году (помните, что зеттабайт равен 1 триллиону гигабайт). Это рост хоккейной клюшки, и мы только в начале кривой. Организации имеют миллионы пользователей и петабайты данных. Они запускают свои приложения в облаке, чтобы доставлять динамический контент на миллионы настольных компьютеров, планшетов и мобильных устройств в разных географических точках.
Сегодня бизнес стал цифровым
Я вижу большое изменение в том, что бумажные файлы больше не являются системой записи, базы данных — мы храним все. Ранее я занимался управлением продуктами в крупных государственных организациях, где все они проходят или подвергались масштабной «модернизации» (т. е. проекты трансформации бизнеса… вот обзор), которые включают переход от устаревших бумажных процессов, в которых документы отправляются по факсу, сканируются и хранится в устаревшем мейнфрейме или реляционной базе данных, чтобы делать все в электронном виде по запросу. Раньше эти организации просто хранили несколько ключевых элементов документа в электронном виде, но с этими изменениями теперь им необходимо хранить все данные из каждой формы, письма, постановления, профиля, электронной почты, телефонного звонка, чата, расследования, решения, и т. д.
е. проекты трансформации бизнеса… вот обзор), которые включают переход от устаревших бумажных процессов, в которых документы отправляются по факсу, сканируются и хранится в устаревшем мейнфрейме или реляционной базе данных, чтобы делать все в электронном виде по запросу. Раньше эти организации просто хранили несколько ключевых элементов документа в электронном виде, но с этими изменениями теперь им необходимо хранить все данные из каждой формы, письма, постановления, профиля, электронной почты, телефонного звонка, чата, расследования, решения, и т. д.
Такого рода преобразования происходили или происходят в каждой отрасли. Сегодня бизнес работает совершенно иначе, чем даже всего десять лет назад. Мы прошли через период перемен, когда на бумажные документы все еще в значительной степени полагались. Но успешный бизнес теперь управляет всем цифровым способом. В книге Leading Digital авторы обсуждают проведенное ими исследование, согласно которому организации, являющиеся «цифровыми мастерами», успешно использующие технологии для преобразования своего бизнеса, имеют на 26 % более высокую норму прибыли, чем их коллеги.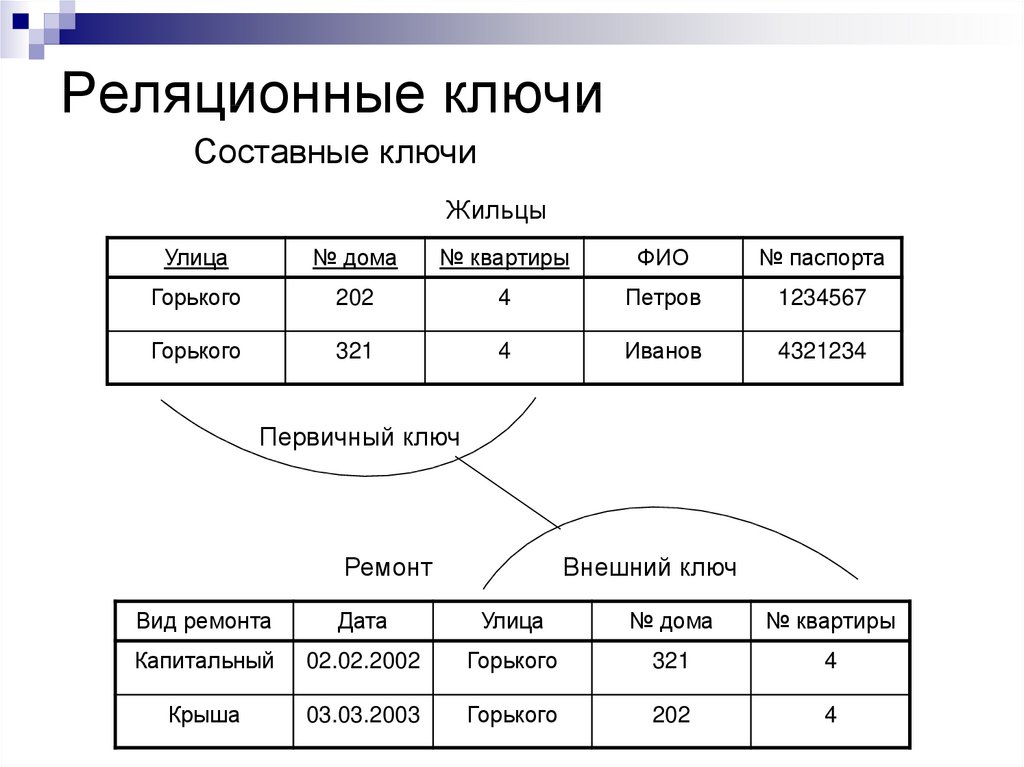
Чтобы справиться с этой новой реальностью, в которой они должны управлять всем своим бизнесом в Интернете, организациям необходима масштабируемость (добавление емкости для большего количества данных и большего количества пользователей) и эластичность (легкость, с которой система масштабируется, обычно имея в виду возможность уменьшения масштаба). вниз, когда пользовательский спрос рассеивается).
Трудно масштабировать реляционные базы данных
Достижение масштабируемости и эластичности — огромная проблема для реляционных баз данных. Реляционные базы данных разрабатывались в то время, когда данные можно было хранить небольшими, аккуратными и упорядоченными. Это просто уже не так. Да, все поставщики баз данных заявляют, что они хорошо масштабируются. Им приходится, чтобы выжить. Но когда вы присмотритесь повнимательнее и увидите, что на самом деле работает, а что нет, фундаментальные проблемы с реляционными базами данных начинают становиться более ясными.
Реляционные базы данных предназначены для масштабирования на дорогостоящих отдельных машинах.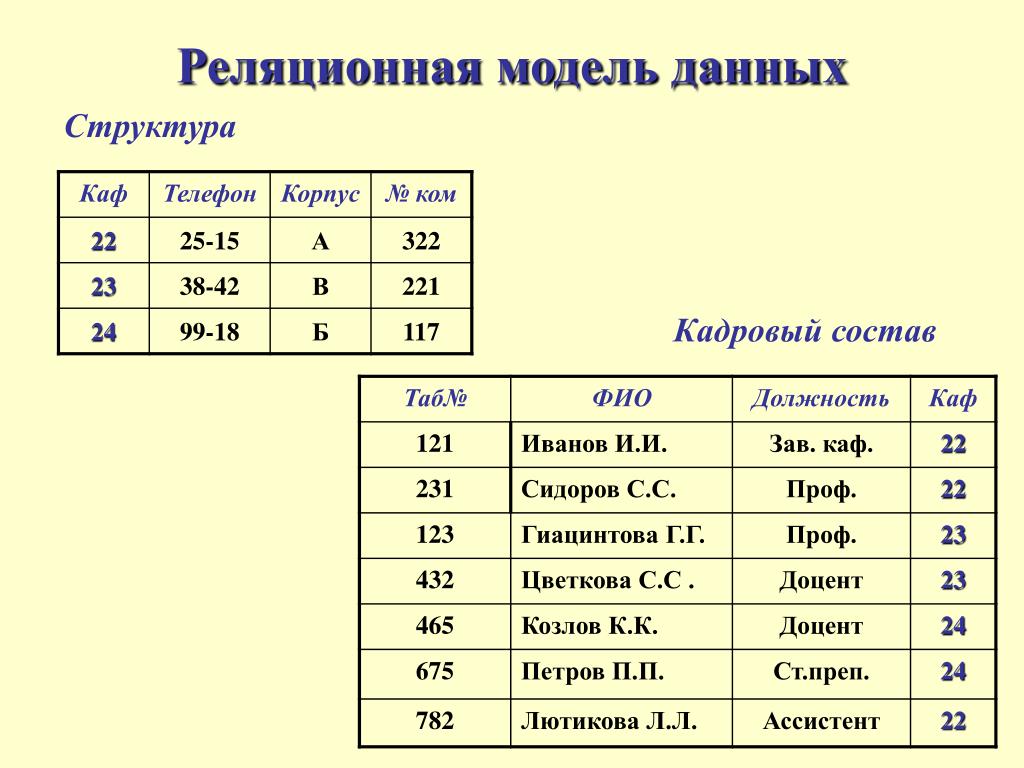
Реляционные базы данных предназначены для работы на одном сервере, чтобы поддерживать целостность отображений таблиц и избежать проблем распределенных вычислений. При таком дизайне, если систему необходимо масштабировать, клиенты должны покупать более крупное, сложное и дорогое проприетарное оборудование с большей вычислительной мощностью, памятью и хранилищем. Обновления также представляют собой проблему, поскольку организация должна пройти длительный процесс приобретения, а затем часто переводить систему в автономный режим, чтобы фактически внести изменения. Все это происходит в то время, когда количество пользователей продолжает увеличиваться, вызывая все большую нагрузку и повышенный риск для недостаточно выделенных ресурсов.
Новые архитектурные изменения лишь скрывают основную проблему
Чтобы справиться с этими проблемами, поставщики реляционных баз данных представили целый ряд улучшений. Сегодня эволюция реляционных баз данных позволяет им использовать более сложные архитектуры, опираясь на модель «ведущий-ведомый», в которой «ведомые» являются дополнительными серверами, которые могут обрабатывать параллельную обработку и реплицированные данные или данные, которые «шардируются» ( разделены и распределены между несколькими серверами или хостами) для снижения нагрузки на главный сервер.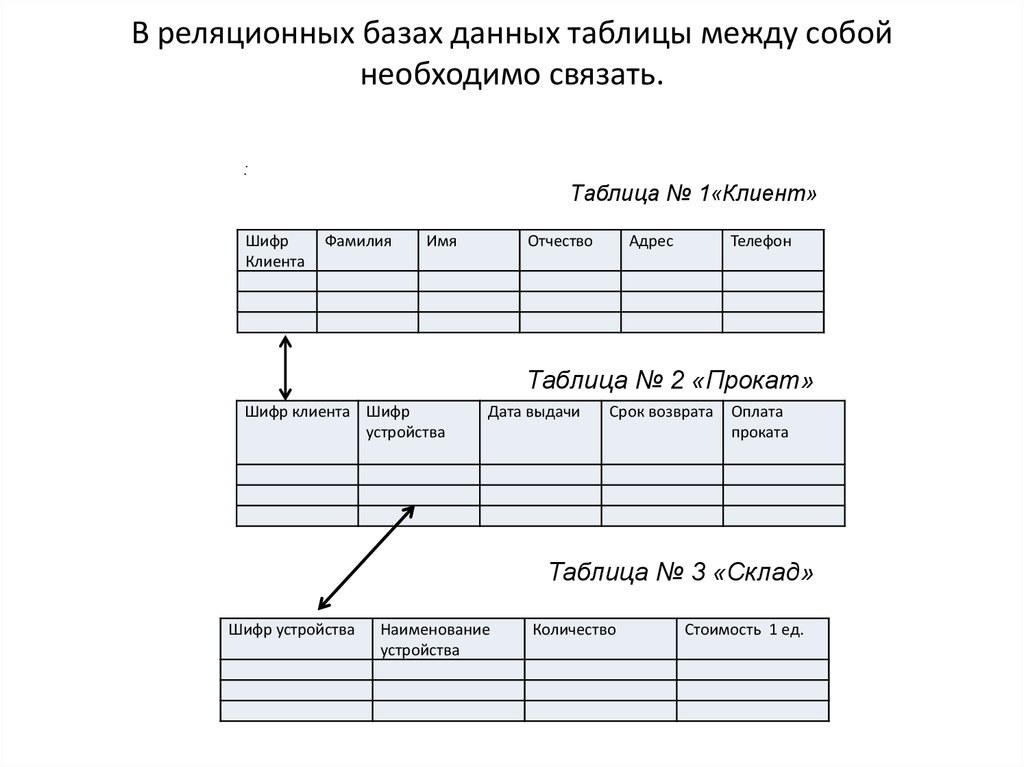
Другие усовершенствования реляционных баз данных, такие как использование общего хранилища, обработка в оперативной памяти, более эффективное использование реплик, распределенное кэширование и другие новые и «инновационные» архитектуры, безусловно, сделали реляционные базы данных более масштабируемыми. Однако под прикрытием нетрудно найти единую систему и единую точку отказа (например, Oracle RAC — это «кластеризованная» реляционная база данных, использующая файловую систему с поддержкой кластеров, но все же есть разделяемая дисковая подсистема внизу). Часто высокая стоимость этих систем также непомерно высока, так как создание единого хранилища данных может легко превысить миллион долларов.
Усовершенствования реляционных баз данных сопровождаются и другими большими компромиссами. Например, когда данные распределяются по реляционной базе данных, они обычно основаны на предварительно определенных запросах для поддержания производительности. Другими словами, гибкость приносится в жертву производительности.
Кроме того, реляционные базы данных не предназначены для уменьшения масштаба — они крайне неэластичны. После того, как данные были распределены и выделено дополнительное пространство, практически невозможно «нераспространить» эти данные.
Базы данных NoSQL предназначены для масштабирования
MarkLogic разработан для обеспечения масштабируемости и эластичности терабайты, а не десятки гигабайт). Они могут масштабироваться «горизонтально», что означает, что они работают на нескольких серверах, которые работают вместе, каждый из которых разделяет часть нагрузки.
При таком подходе база данных NoSQL может работать на сотнях серверов, иметь петабайты данных и миллиарды документов и при этом обрабатывать десятки тысяч транзакций в секунду. И все это можно делать на недорогом массовом (то есть более дешевом) оборудовании, работающем в любой среде (то есть оптимизированной для облака!). Еще одно преимущество заключается в том, что в случае отказа одного узла другие могут взять на себя рабочую нагрузку, что устраняет единую точку отказа.