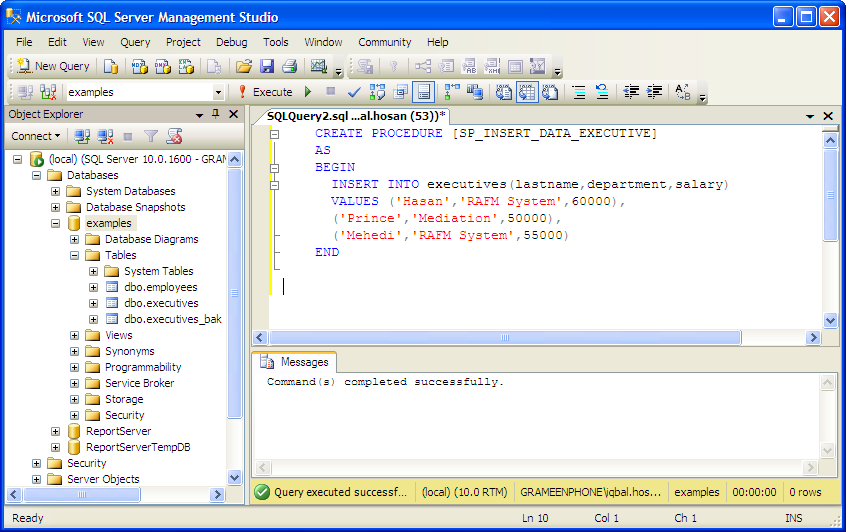
Data types (Transact-SQL) — SQL Server
Изменить
Twitter LinkedIn Facebook Адрес электронной почты
- Статья
- Чтение занимает 2 мин
Applies to: SQL Server (all supported versions) Azure SQL Database Azure SQL Managed Instance Azure Synapse Analytics Analytics Platform System (PDW)
In SQL Server, each column, local variable, expression, and parameter has a related data type. A data type is an attribute that specifies the type of data that the object can hold: integer data, character data, monetary data, date and time data, binary strings, and so on.
A data type is an attribute that specifies the type of data that the object can hold: integer data, character data, monetary data, date and time data, binary strings, and so on.
SQL Server supplies a set of system data types that define all the types of data that can be used with SQL Server. You can also define your own data types in Transact-SQL or the Microsoft .NET Framework. Alias data types are based on the system-supplied data types. For more information about alias data types, see CREATE TYPE (Transact-SQL). User-defined types obtain their characteristics from the methods and operators of a class that you create by using one of the programming languages supported by the .NET Framework.
When two expressions that have different data types, collations, precision, scale, or length are combined by an operator, the characteristics of result are determined by the following:
- The data type of the result is determined by applying the rules of data type precedence to the data types of the input expressions.

- The collation of the result is determined by the rules of collation precedence when the result data type is char, varchar, text, nchar, nvarchar, or ntext. For more information, see Collation Precedence (Transact-SQL).
- The precision, scale, and length of the result depend on the precision, scale, and length of the input expressions. For more information, see Precision, Scale, and Length (Transact-SQL).

SQL Server provides data type synonyms for ISO compatibility. For more information, see Data Type Synonyms (Transact-SQL).
Data type categories
Data types in SQL Server are organized into the following categories:
Exact numerics
Unicode character strings
Approximate numerics
Binary strings
Date and time
Other data types
Character strings
In SQL Server, based on their storage characteristics, some data types are designated as belonging to the following groups:
Large value data types: varchar(max), and nvarchar(max)
Large object data types: text, ntext, image, varbinary(max), and xml
Note
sp_help returns -1 as the length for the large-value and xml data types.

Exact numerics
bigint
numeric
smallint
decimal
smallmoney
tinyint
Approximate numerics
Date and time
datetimeoffset
datetime2
smalldatetime
datetime
Character strings
varchar
Unicode character strings
nvarchar
Binary strings
binary
varbinary
Other data types
rowversion
hierarchyid
uniqueidentifier
sql_variant
Spatial Geometry Types
Spatial Geography Types
See also
CREATE PROCEDURE (Transact-SQL)
CREATE TABLE (Transact-SQL)
DECLARE @local_variable (Transact-SQL)
EXECUTE (Transact-SQL)
Expressions (Transact-SQL)
Functions (Transact-SQL)
LIKE (Transact-SQL)
sp_droptype (Transact-SQL)
sp_help (Transact-SQL)
sp_rename (Transact-SQL)
Техподдержка: Настройка регулярного резервного копирования БД MS SQL Server
Рекомендуется настроить регулярное резервное копирование базы данных (на случай аппаратных или программных сбоев), причем лучше всего с сохранением резервных копий за последние несколько дней, например семь (за последнюю неделю).
Для этого можно использовать либо встроенный в SQL Server планировщик заданий – «SQL Server Agent» (в бесплатную версию не входит), либо стандартный «Планировщик Windows» в сочетании с утилитой SQLCMD.EXE, которая позволяет выполнять запросы к SQL Server из командной строки. В планировщике необходимо создать как минимум семь заданий (по одному на каждый день недели), каждое из которых будет (раз в неделю) заменять один из семи файлов, содержащих соответствующую резервную копию базы данных.
Кроме того, файлы резервных копий рекомендуется хранить не только на жестком диске компьютера, где установлен SQL Server, но и дублировать их на ленту или жесткий диск другого компьютера в сети. Для этого можно использовать либо специальное ПО, которое позволяет делать резервные копии всего диска, либо с помощью того же планировщика копировать файлы на ленту или другой компьютер (вторым шагом).
- С помощью «Планировщика Windows» (для бесплатной версии)
- С помощью «SQL Server Agent» (в бесплатную версию не входит)
С помощью «Планировщика Windows» (для бесплатной версии)
Чтобы создать задание в «Планировщике Windows» надо:
Запустить программу «Блокнот» (Пуск->Все программы->Стандартные->Блокнот) и ввести следующие две строки, после чего сохранить их в виде командного файла (*.
SQLCMD -S (local) -E -Q «BACKUP DATABASE AltaSVHDb TO DISK = ‘D:\BACKUP\ AltaSVHDb_monday.bak’ WITH INIT, NOFORMAT, SKIP, NOUNLOAD»
XCOPY D:\BACKUP\ AltaSVHDb_monday.bak \\BACKUP_SERVER\Folder\*.* /Y
где «(local)» – имя сервера (в случае установки именованного экземпляра SQL Server надо указать имя полностью: «ИМЯ_КОМПА\SQLEXPRESS»), «AltaSVHDb» – имя базы данных, «D:\BACKUP\ AltaSVHDb_monday.bak» – имя файла для создания в нем резервной копии (будет различаться по дням недели),
Запустить мастер планирования заданий (Панель управления->Назначенные задания->Добавить задание) и нажать кнопку «Далее»:
Нажать кнопку «Обзор» и указать путь к командному файлу (*. BAT), созданному на шаге a):
BAT), созданному на шаге a):
Указать имя для задания, выбрать вариант запуска «еженедельно» и нажать кнопку «Далее»:
Поставить галочку возле нужного дня недели, а в поле «Время начала» указать время, когда должен запускаться процесс резервного копирования (обычно это делается ночью), затем нажать кнопку «Далее»:
Ввести имя пользователя и пароль (дважды) учетной записи ОС, от имени которой будет выполняться задание, и нажать кнопку «Далее»:
Внимание! Чтобы задание успешно выполнялось необходимо предоставить указанной здесь учетной записи (домена или локального компьютера) права записи в вышеупомянутую папку «\\BACKUP_SERVER\Folder», а также настроить доступ к самому SQL Server.
Нажать кнопку «Готово»
Примечание. Чтобы проверить работоспособность созданного задания, необходимо в списке заданий (Панель управления->Назначенные задания) нажать правой кнопкой мыши на интересующем задании и в контекстном меню выбрать пункт «Выполнить», затем убедиться, что файл резервной копии БД успешно создался по тем путям, которые были указаны на шаге a).
С помощью «SQL Server Agent» (в бесплатную версию не входит)
Чтобы создать задание в «SQL Server Agent» надо:
Запустить утилиту SQL Server Management Studio и подключиться к серверу под учетной записью администратора.
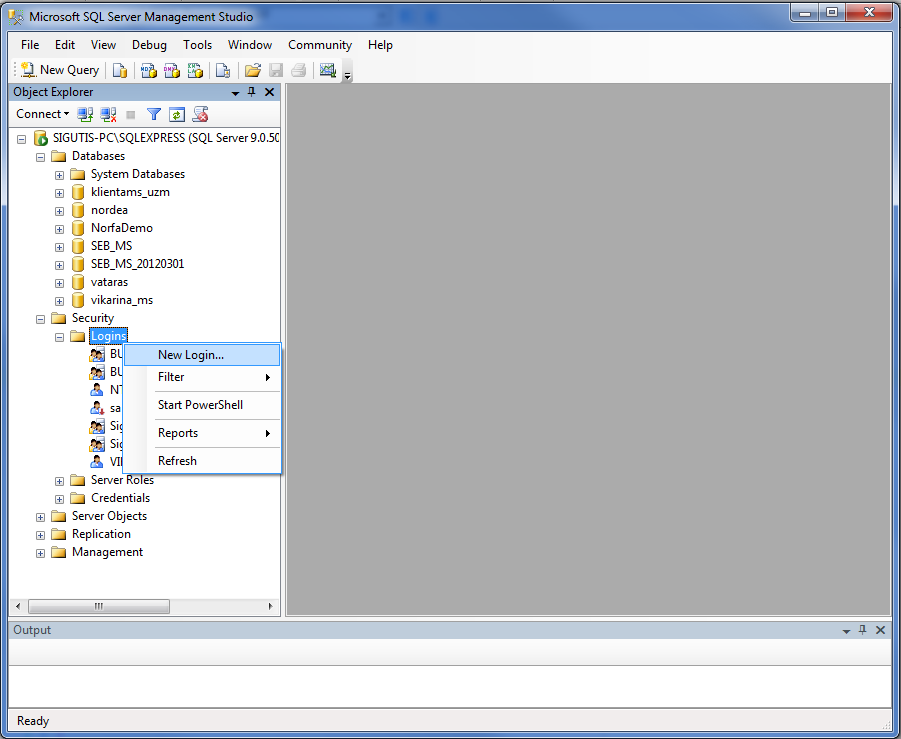
В левой части окна нажать правой кнопкой мыши на разделе «Объекты сервера/Устройства резервного копирования» и в контекстном меню выбрать пункт «Создать устройство резервного копирования»:
В поле «Имя устройства» ввести имя, которое будет ассоциироваться с файлом резервной копии БД, при необходимости изменить путь в поле «Файл» и нажать «ОК»:
В левой части окна нажать правой кнопкой мыши на разделе «Агент SQL Server/Задания» и в контекстном меню выбрать пункт «Создать задание»:
В поле «Имя» ввести имя задания:
На странице «Шаги» нажать кнопку «Создать»:
В появившемся окне ввести имя в поле «Имя шага», проверить, что в поле «Тип» выбрано «Сценарий Transact-SQL (T-SQL)», а в поле «Команда» ввести строку:
BACKUP DATABASE AltaSVHDb TO AltaSVHDb_monday WITH INIT, NOFORMAT, SKIP, NOUNLOAD
где «AltaSVHDb» – имя базы данных, «AltaSVHDb_monday» – имя устройства резервного копирования, созданного на шаге c) (будет различаться по дням недели):
В предыдущем окне нажать кнопку «ОК», в результате на странице «Шаги» должна появиться строка:
Чтобы файл резервной копии БД сразу копировался на другой компьютер в сети необходимо повторить пункты f) – h), в окне «Создание шага задания» выбрав в поле «Тип» значение «Операционная система (CmdExec)», а в поле «Команда» указав строку:
XCOPY D:\MSSQL\BACKUP\AltaSVHDb_monday.
 bak \\BACKUP_SERVER\Folder\*.* /Y
bak \\BACKUP_SERVER\Folder\*.* /Yгде «D:\MSSQL\BACKUP\AltaSVHDb_monday.bak» – путь, указанный на шаге c) (будет различаться по дням недели), «BACKUP_SERVER» – имя компьютера, на который будет выполняться копирование, «Folder» – папка на этом компьютере (к ней должен быть предоставлен общий доступ):
Примечание. Чтобы копирование файла успешно выполнялось необходимо запускать «SQL Server Agent» под учетной записью домена Windows, для которой предоставлены права записи в вышеупомянутую папку (см. также «SQL2005_installation.doc» или «SQL2008_installation.doc»), а также настроен доступ к самому SQL Server (см. раздел «Настройка прав доступа к БД», включить эту учетную запись надо в роль «sysadmin» на странице «Серверные роли», а на страницах «Сопоставление пользователей» и «Защищаемые объекты» ничего не делать).
На странице «Расписания» нажать кнопку «Создать»:
Ввести имя в поле «Имя», проверить, что в поле «Тип расписания» выбрано значение «Повторяющееся задание», а в поле «Выполняется» – «Еженедельно».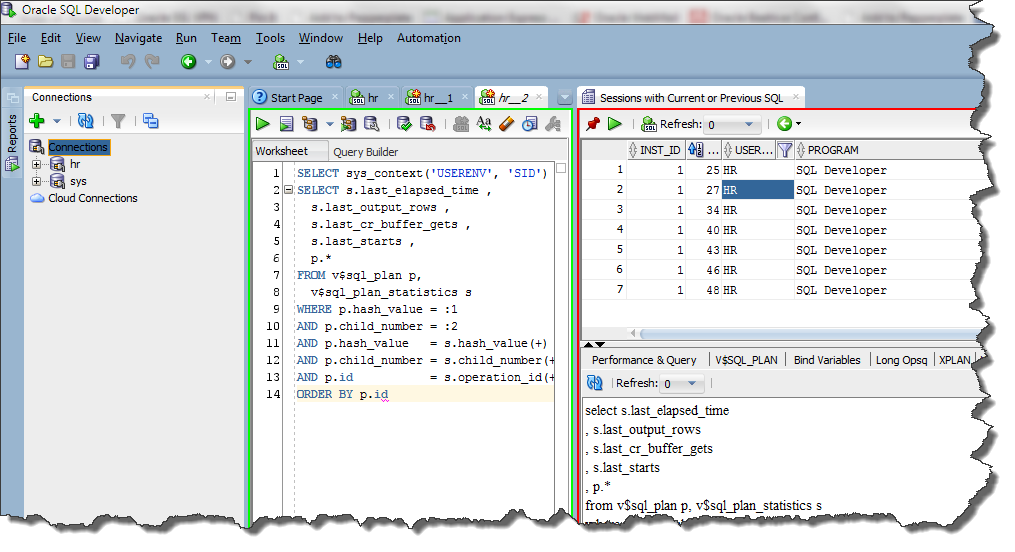 Поставить галочку возле нужного дня недели (остальные снять), а в поле «Однократное задание» указать время, когда должен запускаться процесс резервного копирования (обычно это делается ночью):
Поставить галочку возле нужного дня недели (остальные снять), а в поле «Однократное задание» указать время, когда должен запускаться процесс резервного копирования (обычно это делается ночью):
В предыдущем окне нажать кнопку «ОК», в результате на странице «Расписания» должна появиться строка:
Нажать кнопку «ОК».
Примечание. Чтобы проверить работоспособность созданного задания, необходимо в разделе «Агент SQL Server/Задания» нажать правой кнопкой мыши на интересующем задании и в контекстном меню выбрать пункт «Запустить задание на шаге», в появившемся окне выбрать первый шаг данного задания и нажать «ОК». Далее появится окно отображающее ход выполнения задания. Если выполнение задания закончится с ошибкой, то подробное описание ошибки можно увидеть вызвав пункт «Просмотр журнала» того же контекстного меню.
Настройка связи с MS SQL
r_keeper_7 можно связать только с MS SQL версии 2012 и выше.
Настройка связи с MS SQL 2012
Установка SQL сервера
Для установки SQL сервера:
Установите MS SQL Server 2012 или выше.
Можно использовать выпуск Express.Во время установки сервера используйте смешанный режим аутентификации и задайте пароль для пользователя — sa
- Запустите SQL Management Studio и создайте новую базу, например с именем RK7.
- В Диспетчере конфигурации SQL Server включите протокол TCP/IP. Для этого:
- Раскройте ветку Сетевая конфигурация SQL Server.
- Выберите Протоколы MSSQLSERVER.
- Дважды нажмите по строке TCP/IP.
- В открывшемся окне на вкладке Протокол включите поле Включено.
- Убедитесь, что во вкладке IP-адреса в блоке IPAll указан TCP-порт.
- Перезапустите SQL Server.
 Можно использовать выпуск Express.
Можно использовать выпуск Express.Режим версионности строк
Вы можете перевести базу в режим версионности строк — Row Versioning. Это необязательный режим, поэтому эту настройку можно пропустить.
По умолчанию SQL Server работает в режиме Read Commited, который подразумевает блокирование данных во время запроса. Это может сильно помешать в случае многопользовательской работы. Начиная с версии 2005, поддерживается режим READ COMMITTED using row versioning. В этом режиме блокировки могут помешать только в том случае, когда разные пользователи пишут в одно и то же место,. Чтение данных никогда не блокируется и никого не блокирует.
Для включения режима версионности строк выполните скрипт:
ALTER DATABASE RK7 SET READ_COMMITTED_SNAPSHOT ON;
SQL
Подробнее читайте в официальной документации Microsoft: в статьях Using Row Versioning-based Isolation Levels или SQL Server 2005 Row Versioning-Based Transaction Isolation.
Настройки в менеджерской станции
Чтобы настроить станцию, выполните следующие действия:
- Зайдите в справочник Сервис > Экспорт данных > Настройки Внешних БД и сделайте копию предустановленной настройки «Microsoft SQL Server». Присвойте ей уникальное имя и смените статус настройки на Активный.
- В поле Основное > Строка соединения нажмите на кнопку в конце строки или дважды нажмите на поле ввода.
- Откроется окно ConnectionString. Нажмите кнопку Build…,
- Откроется окно Свойства канала передачи данных. Настройте связь с базой данных, созданной ранее:
- Перейдите во вкладку Поставщик данных и убедитесь, что выбран Microsoft OLE DB Provider for SQL Server.
- Во вкладке Соединение выберите сервер из списка, введите имя пользователя и пароль. Если нужного сервера нет в списке, то необходимо вручную ввести его имя.
Если SQL-север установлен на том же компьютере, что и сервер справочников или отчетов, укажите адрес 127.0.0.1. Если на другом — укажите его IP-адрес и убедитесь, что сервер доступен по сети.
Имя сервера также можно посмотреть при запуске SQL Server Management Studio.
Введите имя пользователя и пароль. Выберите базу данных на сервере и нажмите Проверить подключение. - Если проверка соединения прошла успешно, то нажмите ОК.
В окне Свойства канала передачи данных нажмите ОК. Поле Строка соединения примет вид:
Provider=SQLOLEDB.1;Password=[пароль];Persist Security Info=True;User ID=sa;Initial Catalog=[имя базы];Data Source=[имя сервера или IP-адрес].
CODE
- Перейдите во вкладку Поставщик данных и убедитесь, что выбран Microsoft OLE DB Provider for SQL Server.
- Сохраните настройки.
 Присвойте ей уникальное имя и смените статус настройки на Активный.
Присвойте ей уникальное имя и смените статус настройки на Активный.
Выполните выгрузку в БД SQL, используя созданную настройку:
- Перейдите в меню Сервис > Экспорт данных > Экспорт в другую БД.
- В поле Параметры соединения выберите созданную настройку.
- Укажите Имя пользователя и Пароль.
- В блоке Параметры экспорта оставьте флаги по умолчанию, если выгрузка происходит в чистую БД SQL.
- Нажмите Проверить.
- При удачном соединении кнопка ОК станет активной, нажмите ее. Запустится экспорт данных в БД SQL. В этот момент в SQL создаются таблицы.
При успешной выгрузке окно с настройками экспорта данных закроется. Появится сообщение Экспорт завершен успешно.

Далее необходимо настроить сервер справочников, пролицензировав его и выбрав созданную настройку. Для этого:
- Перейдите в меню Настройки > OLAP Отчеты > Серверы Отчетов, выберите нужный сервер и настройте его:
- Пролицензируйте сервер справочников/отчетов согласно описанию в статье настройка сервера справочников.
- В группе Связь с внешней БД:
- В поле Настройки связи с внешней БД выберите созданную настройку.
- В поле Имя пользователя внешней БД пропишите имя пользователя БД SQL.
- В поле Пароль пользователя внешней БД прописать пароль пользователя БД SQL.
- Укажите такие же настройке в группе Логи справочников:
- В поле Настройки связи с внешней БД выберите созданную настройку.
- В поле Имя пользователя внешней БД пропишите имя пользователя БД SQL.
- В поле Пароль пользователя внешней БД пропишите пароль пользователя БД SQL.
- В группе Основное сделать следующее:
- В поле Источник данных кубов выберите параметр БД SQL.
В поле Протоколирование запросов выберите подходящий параметр:
llAll протоколировать все запросы
llErroneous протоколировать запросы с ошибками
llNone — не протоколировать
В поле Режим базы данных UDB выберите один из режимов: большой, средний, маленький, ультра легкий. Данный режим относиться к накопительной базе Check.
udb.Большой — полная копия. Это режим по умолчанию. Используется для простых ресторанов, не сетевых. Не меняйте параметр Полная копия на другое, пока не настроите соединение с внешней базой данных.
Средний — частичная копия. Режим означает, что кроме данных заказов, все суммы будут сохраняется в check.udb.
Маленький — только чеки. Режим используется, если вы уверены, что будет иметься достаточно много накопительных данных — несколько ресторанов. В большинстве случаев рекомендуется использовать этот режим, чтобы база не становилась слишком большой.
Ультралегкий — только общие смены. В check.udb будет содержаться только информация об общих сменах и ссылки на них в базе SQL.
Если вы решили изменить Режим базы данных UDB с большого на маленький при настроенной связи с SQL, то есть ресторан проработал в таком режиме уже продолжительное время, и выполнить ручной экспорт накопительных данных повторно, то размер файла Check. udb автоматически уменьшится. В результате большая часть информации из этой базы будет удалена, и в базу SQL экспортируются не все данные. Поэтому никогда не делайте экспорт накопительных данных, если вы используете режим базы данных UDB Маленький или Средний.
Выбранный режим базы данных UDB никак не влияет на справочную информацию. Справочная информация всегда сохраняется на каждом сервере отчетов в полном объеме и может быть экспортирована повторно при необходимости.
- В секции Обработка данных выберите ресторан, данные с которых нужно собирать и видеть в отчетах.
В конфигурационном файле сервера справочников rk7srv.INI и в файле сервера отчетов repsserv.ini пропишите параметр UseSQL=1.
- Перезагрузите сервер справочников и сервер отчетов.

 udb.
udb. udb автоматически уменьшится. В результате большая часть информации из этой базы будет удалена, и в базу SQL экспортируются не все данные. Поэтому никогда не делайте экспорт накопительных данных, если вы используете режим базы данных UDB Маленький или Средний.
udb автоматически уменьшится. В результате большая часть информации из этой базы будет удалена, и в базу SQL экспортируются не все данные. Поэтому никогда не делайте экспорт накопительных данных, если вы используете режим базы данных UDB Маленький или Средний.Все изменения в настройках внешней БД происходят во время работы сервера при параметре UseSQL=0.
Если необходимо поменять настройки внешней БД:
- Остановите все серверы отчетов и сервер справочников, которые используют эту настройку.
- В конфигурационном файле сервера справочников rk7srv.INI или сервера отчетов repsserv.ini пропишите параметр UseSQL=0.
- Запустите нужный сервер.
- Поменяйте настройки.
- Вновь остановите сервер.
- В конфигурационном файле верните параметру UseSQL значение 1 — UseSQL=1.
Готово, можно продолжать работу.
Одновременно для нескольких ролей в r_keeper нельзя сделать связь с БД в SQL Server используя одного и того же пользователя в БД SQL. В r_keeper не сохранится информация о пользователе в настройках связи с внешней БД.
Оптимизация производительности
В целях экономии дискового пространства и некоторого увеличения производительности рекомендуется использовать Простую — Simple модель восстановления.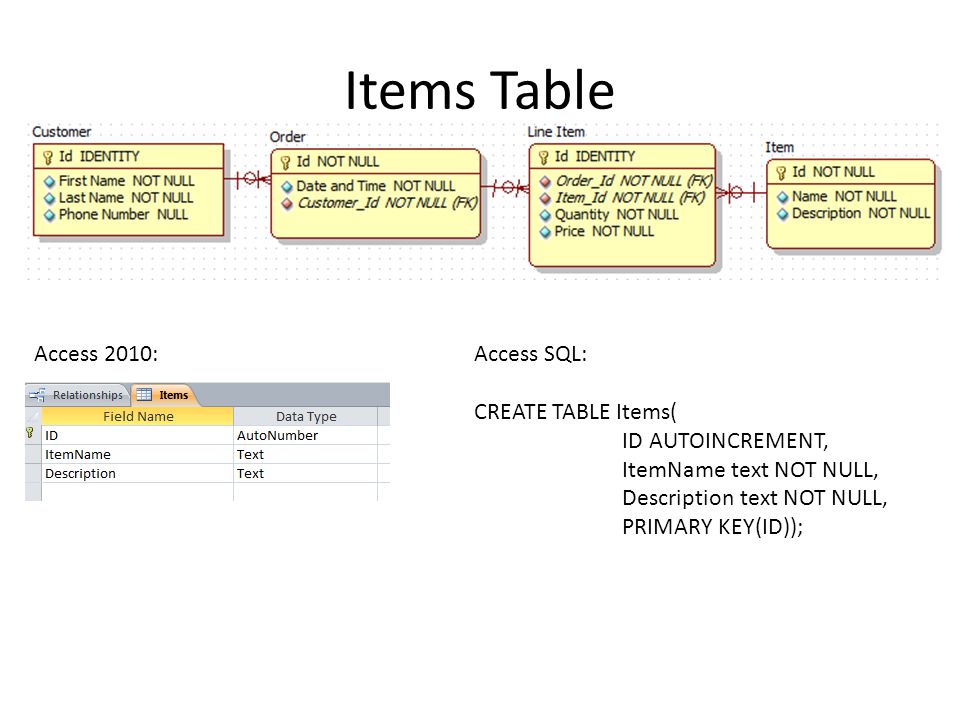
Ознакомиться с различными моделями восстановления SQL, их различиями и особенностями вы можете в официальной документации Microsoft.
После изменения модели восстановления необходимо выполнить сжатие файла лога. Для этого:
- Нажмите правой кнопкой мыши на используемую базу данных
- Выберите Задачи > Сжать > Файлы
- В открывшемся окне выберите тип файла Журнал
- Нажмите на кнопку ОК.
Возможные проблемы
Проблема: Иногда может не идти экспорт в только что созданную БД сервера SQL Server 2008 при выбранном провайдере Native Client.
Решение: Выберите другой провайдер Microsoft OLE DB Provider for SQL Server, создайте заново чистую БД и повторите экспорт.
Проблема: Не строятся прямые отчеты
Решение: Если у роли отличаются права доступа на просмотр отчетов на разные объекты, то для построения прямых отчетов необходимо завести разных пользователей на SQL сервере. Затем настройте роли с такими пользователями в SQL. Для этого:
Затем настройте роли с такими пользователями в SQL. Для этого:
- В менеджерской станции r_keeper перейдите в меню Персонал > Работники
- Выберите роль, которой хотите предоставить доступ, и перейдите в ее Свойства
- Раскройте раздел Связь с внешней БД и дважды нажмите на поле SQL конфигурация
- Укажите Имя пользователя и Пароль для создания нового пользователя в SQL
- Войдите в MS SQL, используя созданные данные. В базе данных появится пользователь.
7 распространенных ошибок в SQL-запросах, которые делал каждый (почти) / Хабр
Сегодня SQL используют уже буквально все на свете: и аналитики, и программисты, и тестировщики, и т.д. Отчасти это связано с тем, что базовые возможности этого языка легко освоить.
Однако работая с большим количеством junior-ов, мы раз от раза находим в их решениях одни и те же ошибки. Реально — иногда просто создается ощущение, что они копируют друг у друга код.
Реально — иногда просто создается ощущение, что они копируют друг у друга код.
Кстати, иногда такая же участь постигает и специалистов более высокого полета.
Сегодня мы решили собрать 7 таких ошибок в одном месте, чтобы как можно меньше людей их совершали.
Примечание: Ошибки будут 2 видов — реальные ошибки и своего рода best practices, которым часто не следуют.
Но, обо всем по порядку 🙂
Кстати, будем рады видеть вас в своих социальных сетях — ВКонтакте Телеграм Инстаграм
1. Преобразование типов
Мы привыкли, что в математике мы всегда можем разделить одно число на другое и получить ответ. Если нацело не получается, то в виде дроби.
В SQL это не всегда так работает. Например, в PostgreSQL деление двух целых чисел друг на друга даст целочисленный ответ. Это можно проверить как для целочисленных столбцов, так и для чисел.
SELECT a/b FROM demo # столбец целых чисел SELECT 1 / 2 # 0
Аналогичные запросы, например, в MySQL дадут дробное число, как и положено.
Если Вы точно не уверены или хотите подстраховаться, то лучше всегда явно делать преобразование типов. Например:
SELECT a::NUMERIC/b FROM demo SELECT a*1.0/b FROM demo SELECT CAST(1 AS FLOAT)/2 FROM demo
Все перечисленные примеры дадут нужный ответ.
2. HAVING вместо WHERE
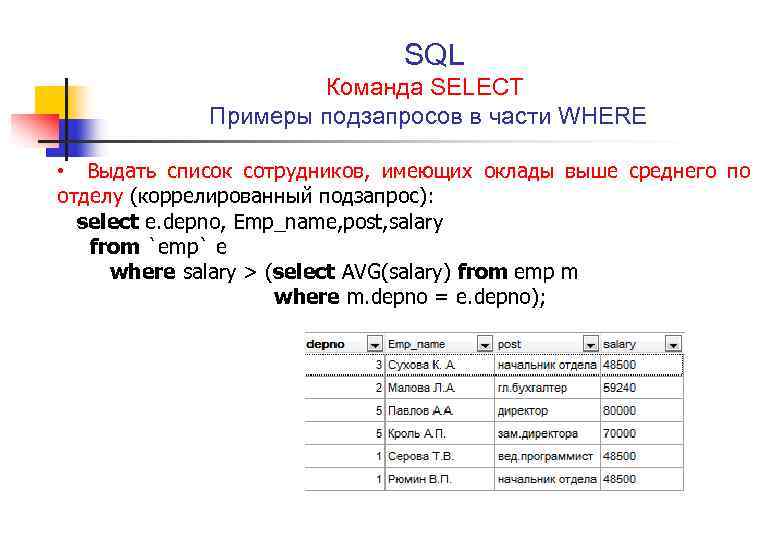
Часто встречается ошибка — оператор HAVING используется вместо WHERE в запросах с агрегацией. Это неверно!
WHERE производит фильтрацию строк в исходном наборе данных, отсеивая неподходящие. После этого GROUP BY формирует группы и оператор HAVING производит фильтрацию уже целых групп (будто группа — одно запись).
Например:
SELECT date, COUNT(*) FROM transactions t WHERE date >= '2019-01-01' GROUP BY date HAVING COUNT(*) = 2
Здесь мы сначала отсеиваем строки, в которых хранятся записи до 2019 года. После этого формируем группы и оставляем только те, в которых ровно две записи.
Некоторые же пишут так:
SELECT date, COUNT(*) FROM transactions t GROUP BY date HAVING COUNT(*) = 2 AND date >= '2019-01-01'
Так делать не нужно 🙂
Кстати, для закрепления этой темы мы специально делали задачку «Отфильтрованные продажи» у себя на платформе. Если интересно порешать и другие задачки по SQL — welcome 🙂
Если интересно порешать и другие задачки по SQL — welcome 🙂
3. Алиасы и план запроса
Если «проговаривать SQL-запрос» словами, то получится что-то такое:
В таблице есть старая цена, а есть новая цена. Их разность я назову diff. Я хочу отобрать только те строки, где значение diff больше 100.
Звучит вполне логично. Но в SQL прям так реализовать не получится — и многие попадаются в эту ловушку.
Вот неправильный запрос:
SELECT old_price - new_price AS diff FROM goods WHERE diff > 100
Ошибка его заключается в том, что мы используем алиас столбца diff внутри оператора WHERE.
Да, это выглядит вполне логичным, но мы не можем так сделать из-за порядка выполнения операторов в SQL-запросе. Дело в том, что фильтр WHERE выполняется сильно раньше оператора SELECT (а значит и AS). Соответственно, в момент выполнения столбца diff просто не существует. Об этом, кстати, и говорит ошибка:
ERROR: column "diff" does not exist
Правильно будет использовать подзапрос или переписать запрос следующим образом:
SELECT old_price - new_price AS diff FROM goods WHERE old_price - new_price > 100
Важно: Внутри ORDER BY вы можете указывать алиас — этот оператор выполняется уже после SELECT.
Кстати, мы тут делали карточку, где наглядно показывается последовательность выполнения операторов. Возможно, это вам пригодится.
4. Не использовать COALESCE
Пришло время неочевидных пунктов. Но сейчас мы поясним свои чаяния.
COALESCE — это оператор, который принимает N значений и возвращает первое, которое не NULL. Если все NULL, то вернется NULL.
Нужен этот оператор для того, чтобы в расчеты случайно не попадали пропуски. Такие пропуски всегда сложно заметить, потому что при расчете среднего на основании ста тысяч строк вы вряд ли заметите подвох, даже если 1000 просто будет отсутствовать. Обычно такие численные пропуски заполняют средними значениями/минимальными/максимальными/медианными/средними или с помощью какой-то интерполяции — зависит от задачи.
Мы же рассмотрим нечисловой пример, а вполне себе бизнесовый. Например, есть таблица клиентов Clients. В поле name заносится имя пользователя.
Отдел маркетинга решил сделать email-рассылку, которая начинается с фразы:
Приветствуем, имя_пользователя!
Очевидно, что если name is NULL, то это превратится в тыкву:
Приветствуем, !
Вот в таких случаях и помогает COALESCE:
SELECT COALESCE(name, 'Дорогой друг') FROM Clients
Совет: Лучше всегда перестраховываться. Особенно это касается вычислений и агрегирований — там вы не найдете ошибку примерно никогда, так что лучше подложить соломку.
Особенно это касается вычислений и агрегирований — там вы не найдете ошибку примерно никогда, так что лучше подложить соломку.
5. Игнорирование CASE
Если вы используете CASE, то иногда вы можете сократить свои запросы в несколько раз.
Вот, например, была задача — вывести поле sum со знаком «-», если type=1 и со знаком «+», если type=0.
Пользователь предложил такое решение:
SELECT id, sum FROM transactions t WHERE type = 0 UNION ALL SELECT id, -sum FROM transactions t WHERE type = 1
В целом, не так плохо. Но это всего лишь промежуточный запрос, задача была намного масштабней и таких конструкций в итоге было наворочено очень много.
А вот то же самое с CASE:
SELECT id, CASE WHEN type = 0 THEN sum ELSE -sum END FROM transactions t
Согласитесь, получше?
Так более того, CASE можно использовать еще много для чего. Например, чтобы сделать из «длинной» таблицы «широкую».
А еще, кстати, COALESCE, который мы обсуждали выше — это просто «синтаксический сахар» и обертка вокруг CASE. Если интересно — мы подробно это описали в статье.
Если интересно — мы подробно это описали в статье.
6. Лишние подзапросы
Из-за того, что многие пишут SQL-запросы также, как это «звучит» в их голове, получается нагромождение подзапросов.
Это проходит с опытом — начинаешь буквально «мыслить на SQL» и все становится ок. Но первое время появляются такие штуки:
SELECT id, LAG(neg) OVER(ORDER BY id) AS lg
FROM (
SELECT id, sm, -sm AS neg
FROM (
SELECT id, sum AS sm FROM transactions t
) t
) t1И это еще не все — можно и побольше накрутить. Но зачем так, если можно так:
SELECT id, LAG(-sum) OVER(ORDER BY id) FROM transactions t
Совет: Если пока сложно, не надо сразу бросаться писать оптимизированными конструкциями. Напишите сначала, как сможете, а потом пытайтесь сократить.
Как говорил дядюшка Кнут:
Преждевременная оптимизация — корень всех зол
7. Неправильное использование оконных функций
Вообще говоря, оконные функции — довольно продвинутый инструмент. Считается, что им владеют специалисты уровня Middle и выше. Но по факту, их нужно знать всем — сейчас без них уже сложно жить (это чистое имхо).
Считается, что им владеют специалисты уровня Middle и выше. Но по факту, их нужно знать всем — сейчас без них уже сложно жить (это чистое имхо).
И если базовые вещи по оконным функциям можно освоить довольно быстро, то всякая экзотика и нестандартное поведение осваивается, как правило, только на собственных шишках.
Одна из таких вещей — поведение оконной функции LAST_VALUE и прочих.
Например, когда мы пишем запрос:
WITH cte AS (
SELECT 'Marketing' AS department, 50 AS employees, 2018 AS year
UNION
SELECT 'Marketing' AS department, 10 AS employees, 2019 AS year
union
SELECT 'Sales' AS department, 35 AS employees, 2018 AS year
UNION
SELECT 'Sales' AS department, 25 AS employees, 2019 AS year
)
SELECT c.*,
LAST_VALUE(employees) OVER (PARTITION BY department ORDER BY year) AS emp
FROM cte cМы ожидаем увидеть 2 раза по 10 для департамента Маркетинг и 2 раза по 25 для Продаж. Однако такой запрос дает иную картину:
Получается, что запрос тупо продублировал значения из столбца employees. Как так?
Как так?
Лезем в документацию PostgreSQL и видим:
Заметьте, что функции first_value, last_value и nth_value рассматривают только строки в «рамке окна», которая по умолчанию содержит строки от начала раздела до последней родственной строки для текущей.
Ага, вот и ответ. То есть каждый раз у нас окно — это не весь набор строк, а только до текущей строки.
Получается, есть два способа вылечить такое поведение:
Вот, например, второй вариант:
WITH cte AS (
SELECT 'Marketing' AS department, 50 AS employees, 2018 AS year
UNION
SELECT 'Marketing' AS department, 10 AS employees, 2019 AS year
union
SELECT 'Sales' AS department, 35 AS employees, 2018 AS year
UNION
SELECT 'Sales' AS department, 25 AS employees, 2019 AS year
)
SELECT c.*,
LAST_VALUE(employees) OVER (
PARTITION BY department
ORDER BY year ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING
) AS emp
FROM cte cКстати, такую тему подняла наша подписчица в Телеграме под постом «7 самых важных оконных функций». Спасибо ей!
Спасибо ей!
А вас рады будем видеть в числе подписчиков 🙂
Эпилог
Эти 7 ошибок — не единственные, которые часто встречаются среди новичков и даже профессионалов. У нас есть еще одна пачка тезисов по этому поводу — но это уже тема другой статьи.
Если вам есть что добавить — будем рады продолжить обсуждение в комментариях. Возможно, чей-то код станет лучше и чище в результате нашей беседы 🙂
Разница между SQL и T-SQL OTUS
SQL (structured query language) — известнейший декларативный язык программирования, используемый при создании, модификации и управлении данными в реляционных БД. T-SQL — это расширенная версия SQL, и ее особенность заключается в том, что она предназначена для работы с сервером от Microsoft. Речь идет о базе данных MS SQL — Microsoft SQL Server. Вдобавок к этому, процедурное расширение с именем T-SQL характеризуется совместимостью с БД компании Sybase (Sybase ASE, Adaptive Server Enterprise).
Но прежде чем продолжить, вспомним некоторые основы.
Теоретическое отступление
База данных представляет собой структуру, где данные имеют связи между собой. Для управления такими данными используют специализированное программное обеспечение — СУБД (системы управления базами данных). Когда говорят о базах реляционного типа (RDBMS), то подразумевают, что данные и связи между данными организованы с помощью таблиц. Кроме непосредственных данных, в таких таблицах есть идентификаторы (id), а также первичные и вторичные ключи, которые имеют связи с идентификаторами.
Работа СУБД предполагает выполнение определенных операций (создание, удаление, обновление и т. п.). Чтобы выполнение этих операций стало возможным, разработчики БД используют язык структурированных запросов SQL. Это язык стандарта ANSI/ISO, помогающий хранить данные и манипулировать ими в рамках какой-нибудь СУБД (MySQL, MSSQL, Oracle Database, IBM DB2 и пр. ).
).
Таким образом, SQL — стандартный язык запросов к реляционным базам данных.
Пример реляционной БД: таблицы со связями и идентификаторамиВыделяют 3 вида SQL-команд:
- DDL (Data Definition Language). Команды для изменения структуры БД и связанных объектов: ALTER, CREATE, DROP.
- DML (Data Manipulation Language). Для управления данными (для вставки, просмотра и выборки, обновления, удаления и пр.): INSERT, SELECT, UPDATE, DELETE.
- DCL (Data Control Language). Для управления пользователями: GRANT, REVOKE.
Несколько слов про TSQL
В указанных выше пояснениях определили, что SQL — это язык запросов для большинства RDBMS-продуктов. Да, совместимость (compatibility) — это хорошо, но совместимости много не бывает. Именно поэтому некоторые поставщики СУБД создали собственные аналоги языков структурированных запросов (languages), а если быть точнее — расширили имеющееся решение, но уже с учетом потребностей своего продукта. Как раз таким аналогом и является процедурное расширение Transact Structure Query Language (TSQL). Это не что иное, как специализированная версия, заточенная под MS SQL Server (2012, 2016 и пр., версия неважна).
Как раз таким аналогом и является процедурное расширение Transact Structure Query Language (TSQL). Это не что иное, как специализированная версия, заточенная под MS SQL Server (2012, 2016 и пр., версия неважна).
Используя TSQL-операторы, разработчик может писать запросы и выполнять нужные операции над таблицами, объединять их, добавлять ограничения, писать хранимые процедуры и индексы, осуществлять транзакции и многое другое. Язык TSQL поддерживает разные полезные функции, многие из которых присутствуют и в версии-первоисточнике. К примеру, агрегатные функции, которые выполняют вычисления на наборе значений. Либо оконные функции и инструкцию OVER (OVER определяет окно для использования оконной функции). Оконные функции не меняют выборку, как GROUP BY, а лишь добавляют дополнительную информацию о ней. Если же вспомнить JOIN, то, несмотря на одинаковую производительность конструкций JOIN и OVER, последняя предоставляет больше свободы, чем жесткий JOIN.
Как бы там не было, есть и отличия, так как в TSQL добавили:
— управляющие операторы;
— поддержку аутентификации Microsoft Windows;
— глобальные и локальные переменные;
— дополнительные функции, предназначенные для обработки дат, строк и пр.
Тезисно о разнице
Для закрепления материала смотрите таблицу ниже, где собраны основные тезисы.
| SQL | TSQL |
| Специфичный для предметной области язык, используется для управления данными в СУБД. | Запатентованная версия SQL от Microsoft, созданная специально для СУБД MS SQL Server в качестве аналога. |
| Язык структурированных запросов (queries). | Transact-язык структурированных запросов. |
| Разработан IBM. | Разработан Microsoft. |
| Можно встраивать SQL в TSQL. | TSQL в SQL встраивать нельзя. |
Помогает обрабатывать и анализировать данные посредством простых запросов. | Помогает добавлять бизнес-логику в приложения. |
Очень надеемся, что после прочтения статьи вы четко уясните разницу между этими двумя аббревиатурами. Если же хотите получить действительно продвинутые знания, связанные с управлением БД, добро пожаловать на специализированный курс OTUS!
Источник
Обзор MS SQL Server — База Знаний Timeweb Community
Веб-ресурсы содержат огромное количество данных – от учетных записей пользователей до контента, опубликованного на страницах. То же относится к «облачным» приложениям вроде CRM, программ для бухучета, складского учета и пр. Везде используется один способ хранения информации – база данных. И этой базой необходимо как-то управлять.
Сегодня мы поговорим об одной из самых популярных систем управления реляционными базами данных – MS SQL Server.
Что такое MS SQL Server
Чтобы упростить работу с такими хранилищами данных и повысить эффективность их применения, создаются специализированные системы управления. Одной из наиболее популярных является разработка от Microsoft – SQL Server. Первый релиз платформы опубликован еще в 1989 году, а последняя версия выпущена в 2019 году (проект продолжает развиваться).
Одной из наиболее популярных является разработка от Microsoft – SQL Server. Первый релиз платформы опубликован еще в 1989 году, а последняя версия выпущена в 2019 году (проект продолжает развиваться).
Преимущества решения:
- Тесная интеграция с операционной системой Windows.
- Высокая производительность, отказоустойчивость.
- Поддержка многопользовательской среды.
- Расширенные функции резервирования данных.
- Работа с удаленным подключением.
Каждый выпуск включает в себя несколько специализированных редакций. Это снижает сложность внедрения и затраты на процесс разработки собственных решений, адаптированных для «узких» задач. При написании программного кода активно используется интеграция с продуктами Microsoft, например, с платформой Visual Studio.
Прямые конкуренты на рынке – Oracle Database, PostgreSQL. Первый проект коммерческий, он создан для поддержки крупных компаний, поэтому сопоставим по возможностям с MS SQL Server. Второй же распространяется на бесплатной основе и не «блещет» функциональностью, хотя весьма популярен среди многих разработчиков (аналог от Oracle MySQL).
Второй же распространяется на бесплатной основе и не «блещет» функциональностью, хотя весьма популярен среди многих разработчиков (аналог от Oracle MySQL).
Что такое СУБД
Появление таких продуктов позволило объединить разное понимание БД (баз данных) со стороны пользователей и системных администраторов. Неискушенные в технических деталях люди «видят» таблицы как некий перечень данных с колонками и строками. Системный подход включает файлы с табличными данными, связанными друг с другом согласно определенному алгоритму.
Функции базы данных:
- Постоянное хранение информации.
- Поиск по ключевым критериям.
- Чтение и редактирование по запросу.
Клиентами БД являются прикладные программы, их интерфейс, различные интерактивные модули сайтов вроде калькуляторов и онлайн-редакторов. Но есть еще один компонент системы – СУБД. Он предназначен для ручного доступа к информации и позволяет извлекать данные на диск, работать с ними в памяти сервера, в том числе с применением структурированного языка SQL.
Всего различают три типа БД – клиент-серверные, файл-серверные и встраиваемые. MS SQL Server относится к первой категории. Плюс система является реляционной, т.е. адаптированной для хранения данных без избыточности, с минимальными рисками появления аномалий и нарушения целостности внутренних таблиц.
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
Расширения языка SQL
Язык SQL представляет собой стандарт, унифицирующий обработку данных всеми реляционными базами данных. Такой подход упрощает перекрестные обращения, дает возможность переходить на «иную платформу» без серьезных переделок проекта. Но здесь нужно учитывать, что в каждой БД имеется собственный язык, который называется диалектом (расширением).
Варианты:
- Transact-SQL (T-SQL) – применяется в MS SQL Server.
- PL/SQL (Procedural Language/Structured Query Language) – аналог от Oracle.
- PL/pgSQL (Procedural Language/PostGres Structured Query Language) – язык используется в PostgreSQL.

Обычно от выбранной СУБД зависит, какой язык предстоит использовать (или от навыков человека, который будет администрировать систему). Синтаксис конструкций у них сильно различается, как и формат обращения ко встроенным функциям, поэтому чаще всего тип БД для проекта выбирается раз и навсегда.
Инсталляция MS SQL Server
Подготовительный шаг – скачать установочный пакет SQL Server Enterprise с официальной страницы сайта Microsoft. После нажатия на кнопку «Бесплатная пробная версия» будет предложено выбрать вариант EXE или Azure («облако») и внести свои анкетные данные, при сохранении которых начнется загрузка инсталляционного файла.
Перед запуском установщика нужно создать учетную запись пользователя. Она пригодится для авторизации на сервере при запросе доступа с клиентских компьютеров (даже при условии, что ПК будет один и тот же).
Последовательность действий:
- В поиске набрать команду lusrmgr.msc и нажать Enter.
- Создать нового пользователя и задать ему пароль доступа.
- Сохранить изменения и перезагрузить компьютер.

Рекомендуется в имени и пароле использовать только буквы латиницы и цифры, кириллица будет привносить риски локальных сбоев из-за особенностей обработки. Теперь можно запускать файл с дистрибутивом MS SQL Server. Программа предложит 3 варианта действий: базовая инсталляция с настройками «по умолчанию», выборочный режим или скачивание файлов «на потом».
В большинстве случаев выбирается первый пункт, при нажатии на который предлагается прочитать и подтвердить лицензионное соглашение. На следующем шаге система позволяет вручную выбрать каталог для установки или согласиться с предложенным значением. Остается нажать на кнопку «Установить» и дождаться завершения процесса.
Файлы в основном скачиваются с официального сервера, поэтому понадобится стабильный доступ к интернету. Такой подход обеспечивает установку последнего релиза и проверку легитимности всех модулей (отсутствие вредоносного ПО). Последнее окно сообщает об успешном завершении, после которого можно сразу подключаться к серверу.
Последнее окно сообщает об успешном завершении, после которого можно сразу подключаться к серверу.
Зачем нужен SQL Server Management Studio
Для удобства администрирования также понадобится SQL Server Management Studio (SSMS). Он представляет собой интегрированную среду для управления инфраструктурой БД и поддерживает любые ее варианты – от локальной до Azure. В него встроены инструменты настройки, наблюдения и редактирования экземпляров баз данных.
Последовательность действий:
- Нажать кнопку «Установить SSMS» в окне инсталлятора SQL Server.
- Произойдет автоматическое перенаправление на официальную страницу продукта.
- Скачать последний релиз программного обеспечения на компьютер.
- Запустить инсталлятор и нажать кнопку «Установить».
Программные пакеты приложения также загружаются напрямую из интернета, поэтому требуется стабильный доступ к сети. После завершения установки будет запрошена перезагрузка компьютера.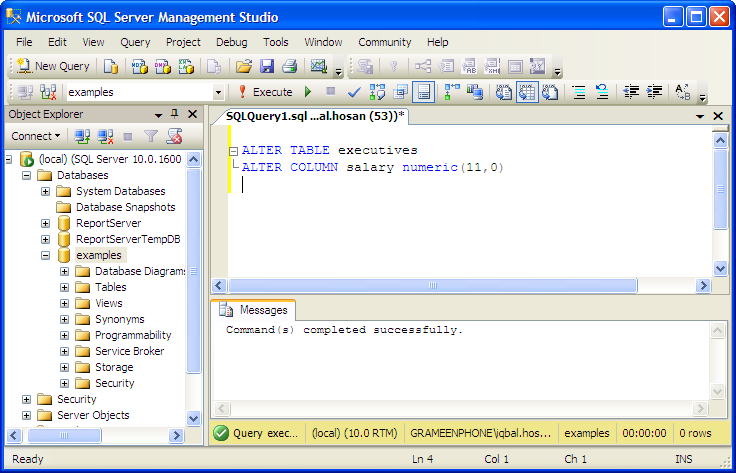 Все, система полностью готова к эксплуатации и созданию первой базы данных.
Все, система полностью готова к эксплуатации и созданию первой базы данных.
Хостинг-провайдеры обычно предлагают предустановленный комплект поддержки баз данных на SQL Server. Он не всегда последней версии, зато наверняка работоспособен в рамках как панели управления, так и публикуемых веб-ресурсов. Пользователю фактически предлагается сразу начать с создания БД – запрашивается всего лишь ее название, имя пользователя и пароль.
SQL-разработчик | Oracle
- Нажмите, чтобы ознакомиться с нашей Политикой доступности
- Перейти к содержимому
Сожалеем. Мы не смогли найти совпадение по вашему запросу.
Мы предлагаем вам попробовать следующее, чтобы найти то, что вы ищете:
- Проверьте правильность написания вашего ключевого слова.
- Используйте синонимы для введенного вами ключевого слова, например, попробуйте «приложение» вместо «программное обеспечение».
- Начать новый поиск.

- База данных
Попробуйте Oracle Cloud Free Tier
Oracle SQL Developer — это бесплатная интегрированная среда разработки, которая упрощает разработку и управление Oracle Database как в традиционных, так и в облачных средах. SQL Developer предлагает полную комплексную разработку ваших приложений PL/SQL, рабочий лист для выполнения запросов и сценариев, консоль администратора базы данных для управления базой данных, интерфейс отчетов, полное решение для моделирования данных и платформу миграции для переноса ваших данных. сторонних баз данных в Oracle.
Загрузить SQL Developer
Загрузить SQL Developer Data Modeler
Интерфейсы приложений SQL Developer
Инструмент №1 в мире для управления вашей базой данных Oracle, Oracle SQL Developer предоставляет пользователям три интерфейса: Рабочий стол, Браузер и Командная строка.
Oracle SQL Developer
Oracle SQL Developer — бесплатная интегрированная среда разработки, упрощающая разработку и управление Oracle Database.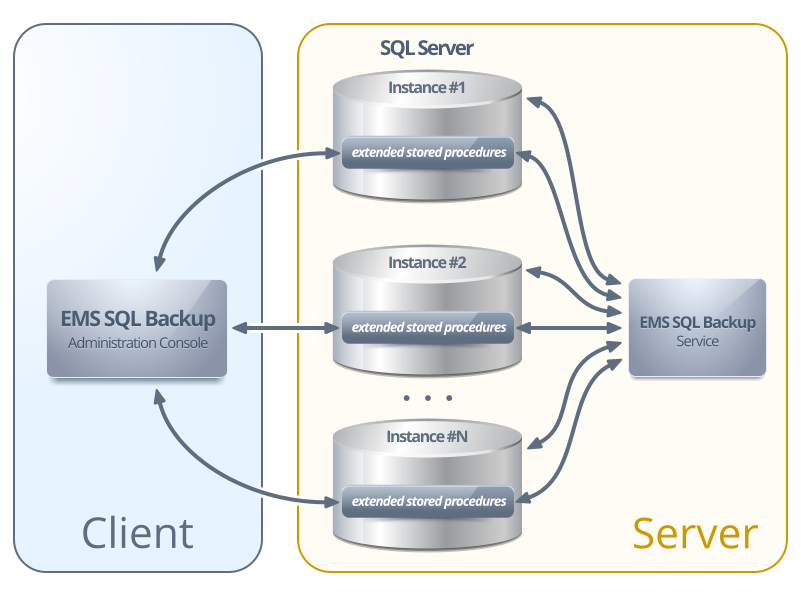 Приложение на базе Java для Windows, OS X и Linux с более чем 5 миллионами пользователей.
Приложение на базе Java для Windows, OS X и Linux с более чем 5 миллионами пользователей.
- Полнофункциональная PL/SQL IDE
- Администрирование базы данных
- Комплексное решение для моделирования данных
- Миграция сторонних СУБД на Oracle
- Миграция Oracle On-Premises в Oracle Cloud
Загрузить SQL Developer
SQL Developer — Начало работы
Oracle Database Actions
Database Actions, ранее известная как SQL Developer Web, предоставляет все функции и возможности вашего любимого настольного инструмента Oracle Database в вашем браузере!
- Включено в Oracle Autonomous Cloud Database
- Доступно с Oracle REST Data Services для ваших локальных экземпляров
- Запуск сценариев, управление пользователями, создание/редактирование объектов, импорт данных, диагностика проблем с производительностью, визуализация схем и т. д.
Действия базы данных
Загрузить действия базы данных
Oracle SQLcl
Командная строка Oracle SQL Developer (SQLcl) — это бесплатный и современный интерфейс командной строки для базы данных Oracle.
- Очень маленький (25 МБ), скачайте, разархивируйте и вперед!
- Автоматическое форматирование (csv, xml, json, INSERT, HTML и др.)
- История SQL
- Завершение вкладки
- Создайте свои собственные команды
- Интеграция Liquibase для управления версиями схемы
Узнать больше о SQLcl
Загрузить SQLcl
Дополнительные ресурсы для разработчиков SQL
Обзор SQL Developer
Oracle SQL Developer может быть таким же простым, как выполнение запросов к вашей базе данных Oracle, или может быть полным решением для разработки, управления и моделирования. Эта демонстрация знакомит вас со всем продуктом.
Введение в SQLcl
Менее чем за 10 минут узнайте, как начать работу из командной строки cmd или оболочки bash с нашим современным интерфейсом командной строки для Oracle. Новые команды, такие как LOAD и DDL, сэкономят вам массу времени, а легко читаемые результаты SQL в нужном вам формате делают эту утилиту обязательной. Также доступно для любой из ваших сред OCI!
Также доступно для любой из ваших сред OCI!
Знакомство с действиями базы данных
В этом плейлисте представлен краткий обзор новейшего члена семейства SQL Developer, а также подробные сведения о Data Modeler, создании и редактировании объектов и импорте данных из CSV или Excel.
Возможности SQL Developer
Основные функцииDesktopCommand lineBrowser
Основные функции
- Поддержка Oracle Database версий 11gR2, 12c, 18c, 19c, 20c
- Поддерживает базу данных Oracle в облаке Oracle и в локальной среде
- Запрос, загрузка и извлечение данных
- Простая установка, клиент Oracle не требуется
Рабочий стол
- Полная PL/SQL IDE — компиляция, отладка, документирование, тестирование, контроль версий и многое другое
- Щелкайте, просматривайте и управляйте содержимым вашей базы данных Oracle
- Управляйте производительностью, безопасностью, хранилищем, настройками и другими параметрами базы данных Oracle
- Разработка служб RESTful и интеграция служб Oracle REST
- Комплексное решение для моделирования данных — ERD, отчеты, сценарии SQL и DDL, управление версиями, DIFF
Командная строка
- Современное оперативное редактирование операторов и сценариев SQL и PL/SQL
- Завершение с помощью табуляции для ключевых слов, команд и имен объектов Oracle
- История SQL — доступ ко всем запросам и сценариям, которые вы уже запускали
- Автоматическое форматирование результатов запроса — легко читаемые результаты SQL или форматирование в JSON, XML, CSV, INSERT и HTML
- Создание объекта DDL или получение метаданных объекта с помощью простых команд, таких как DDL и INFO
- Интеграция с Liquibase для простого управления исходным кодом схемы Oracle
- Чрезвычайно легкий, занимает всего 25 МБ для загрузки и установки
Браузер
- Нечего устанавливать, просто откройте браузер, чтобы начать работу с базой данных Oracle
- Запустите любой Oracle SQL или PL/SQL в полностью функционирующем рабочем листе SQL (история SQL, аналитические сведения, планы объяснений и т. д.)
- Создавайте или редактируйте свои любимые объекты схемы Oracle с помощью простых в использовании мастеров
- Создание расширенных ERD, показывающих ваши текущие схемы Oracle Schema
- Управление производительностью и общей конфигурацией базы данных
- Создание и редактирование пользователей
- Загрузить данные из CSV, JSON и AVRO в новые или существующие таблицы Oracle
 д.)
д.)Начните работу с SQL Developer
Попробуйте Oracle Cloud Free Tier
Создавайте, тестируйте и развертывайте приложения в Oracle Cloud бесплатно.
Попробуйте бесплатно
Проведите семинар
Проведите множество лабораторий и семинаров и испытайте наши лучшие технологии вживую.
Получите сертификат
Доступ к онлайн-обучению и сертификации для облачных сервисов Oracle Database.
Связаться с отделом продаж
Хотите узнать больше? Свяжитесь с одним из наших ведущих экспертов в отрасли.
Свяжитесь с нами
Почему Oracle
- Аналитические отчеты
- Облачная экономика
- с Microsoft Azure
- по сравнению с AWS
- против Google Cloud
- против MongoDB
Узнать
- Что такое ИИ?
- Что такое облачные вычисления?
- Что такое облачное хранилище?
- Что такое HPC?
- Что такое IaaS?
- Что такое PaaS?
Что нового
- Oracle Supports Ukraine
- Облачный бесплатный уровень OCI
- Центр облачной архитектуры
- Облачный подъем
- Награды службы поддержки Oracle
- Оракул Ред Булл Гонки
- Твиттер
- Ютуб
Что такое SQL и как его использовать?
- Язык структурированных запросов (SQL) — это язык программирования, используемый для взаимодействия с базами данных и управления ими.
- SQL был разработан в 1970-х годах исследователями IBM.
- SQL чрезвычайно доступен на различных платформах и в целом удобен для пользователя.
- Эта статья предназначена для владельцев бизнеса, заинтересованных в найме разработчика SQL, чтобы революционизировать способ просмотра, анализа и принятия решений на основе существующих данных.
SQL (язык структурированных запросов) — это язык программирования, используемый для взаимодействия с базами данных и управления ими. Чтобы получить максимальную отдачу от массивов данных, которые они собирают, многие компании должны хорошо разбираться в SQL. Вот все, что вам нужно знать об использовании SQL для доступа к данным и управления ими.
Что такое SQL?
Предприятия и другие организации используют программы SQL для доступа и управления информацией и данными в своих базах данных, а также для создания и изменения новых таблиц. Чтобы полностью понять SQL, вам нужно точно знать, что такое база данных.
Согласно Microsoft, база данных — это инструмент для сбора и организации информации. Базы данных могут хранить информацию о людях, продуктах, заказах или чем-то еще. Многие базы данных начинаются с программы обработки текстов или электронных таблиц. По мере того, как они становятся больше, многие предприятия считают полезным перенести их в базу данных, созданную системой управления базами данных.
Ключевой вывод: SQL-программы получают доступ и манипулируют данными, хранящимися в базах данных, для пользовательского анализа.
Когда использовать SQL
SQL помогает контролировать информацию, хранящуюся в базах данных, позволяя пользователям извлекать определенные данные, которые они ищут, когда они им нужны.
Хотя это простой язык программирования, SQL очень мощный. Фактически SQL может вставлять данные в таблицы базы данных, изменять данные в существующих таблицах базы данных и удалять данные из таблиц базы данных SQL. Кроме того, SQL может изменять саму структуру базы данных, создавая, изменяя и удаляя таблицы и другие объекты базы данных.
Кроме того, SQL может изменять саму структуру базы данных, создавая, изменяя и удаляя таблицы и другие объекты базы данных.
SQL использует набор команд для управления данными в базах данных. Примеры включают SQL INSERT, который используется для добавления данных в таблицы базы данных; SQL SELECT, который извлекает данные из таблиц базы данных; и SQL UPDATE, который изменяет существующие записи базы данных.
Поскольку так много компаний полагаются на аналитику больших данных для определения своего направления, опыт работы с SQL является одним из самых востребованных профессиональных навыков.
Знаете ли вы? Большие данные и инструменты CRM идут рука об руку. Расширенные инструменты CRM могут помочь пользователям малого бизнеса, предоставляя только необходимые данные, когда это наиболее важно.
История SQL
Язык программирования SQL был разработан в 1970-х годах исследователями IBM Рэймондом Бойсом и Дональдом Чемберлином. Язык программирования, известный тогда как SEQUEL, был создан после статьи Эдгара Фрэнка Кодда «Реляционная модель данных для больших общих банков данных» в 1970 году.
Язык программирования, известный тогда как SEQUEL, был создан после статьи Эдгара Фрэнка Кодда «Реляционная модель данных для больших общих банков данных» в 1970 году.
В своей статье Кодд предложил, чтобы все данные в базе данных были представлены в отношения . Основываясь на этой теории, Бойс и Чемберлен придумали SQL. В Краткое руководство по Oracle (Cornelio Books, 2013), автор Малкольм Коксалл пишет, что первоначальная версия SQL была разработана для манипулирования и извлечения данных, хранящихся в оригинальной системе управления реляционными базами данных IBM, System R.
Однако только несколько лет спустя, что язык SQL стал общедоступным. В 1979 году компания Relational Software, позже ставшая Oracle, выпустила на рынок собственную версию SQL под названием Oracle V2.
С тех пор Американский национальный институт стандартов (ANSI) и Международная организация по стандартизации считают SQL стандартным языком для взаимодействия с реляционными базами данных. В то время как основные поставщики SQL изменяют язык по своему усмотрению, большинство из них основывают свои программы SQL на версии, одобренной ANSI.
В то время как основные поставщики SQL изменяют язык по своему усмотрению, большинство из них основывают свои программы SQL на версии, одобренной ANSI.
Знаете ли вы? Oracle известна не только своим первоклассным решением для баз данных. Обширная программа сертификации Oracle включает шесть уровней сертификации, которые охватывают девять категорий с более чем 200 отдельными полномочиями.
Система управления базами данных MySQL
Вместо написания SQL для своих баз данных многие компании используют системы управления базами данных со встроенным SQL. MySQL, разработанная и распространяемая Oracle, является одной из самых популярных систем управления базами данных SQL, доступных в настоящее время.
Что такое MySQL?
MySQL имеет открытый исходный код, что означает, что вы можете скачать и использовать его бесплатно. MySQL — это сложная и мощная реляционная база данных, используемая многими веб-сайтами для быстрого создания и изменения контента.
Когда используется MySQL?
MySQL можно использовать для различных приложений, включая хранение данных, электронную коммерцию и ведение журналов. Однако его часто можно найти на веб-серверах.
Примеры широко используемых систем MySQL
Многие из крупнейших и наиболее известных мировых брендов полагаются на MySQL для обеспечения правильной работы своих веб-сайтов, включая Facebook, Google, Adobe, Alcatel-Lucent и Zappos.
В дополнение к MySQL существует несколько других систем управления базами данных SQL с открытым исходным кодом, включая PostgreSQL, Ingres и Firebird.
Преимущества SQL
SQL — это распространенный язык программирования, используемый для управления и обмена данными. Хотя у SQL есть некоторые недостатки, такие как неуклюжий интерфейс и низкая стоимость, преимущества, как правило, перевешивают его недостатки. SQL чрезвычайно доступен на различных платформах, а его удобство для пользователя может помочь любому стать экспертом.
Если вы не уверены, следует ли вам использовать SQL для своих данных, рассмотрите следующие преимущества:
- SQL является переносимым. Вы можете использовать его на ПК, серверах, ноутбуках и некоторых мобильных устройствах. Он работает в локальном Интернете и интранет-системах. Его портативность делает его удобным вариантом для пользователей, поскольку они могут без проблем переносить его с одного устройства на другое.
- Быстро обрабатывает запросы. Какими бы большими ни были данные, SQL может быстро и эффективно их извлечь. Он также может относительно быстро выполнять такие процессы, как вставка, удаление и обработка данных. Быстрая обработка запросов экономит время и обеспечивает точность, поэтому вам не нужно тратить часы на ожидание ваших данных или обмен ими с другими.
- Не требует навыков программирования. Кодирование — это сложный способ общения с компьютерами. Кодирование, также называемое компьютерным программированием, может потребовать много практики и знаний перед использованием, что затрудняет его интерпретацию для других. К счастью, SQL не требует навыков программирования, достаточно использования простых ключевых слов, таких как «выбрать», «вставить в» и «обновить».
- Используется стандартный язык. Стандартизированный язык, используемый в SQL, делает его очень доступным для всех пользователей. SQL предоставляет единую платформу и использует в основном английские слова и операторы, поэтому его легко изучать и писать даже тем, у кого нет опыта.
- Обеспечивает несколько просмотров данных. При использовании SQL вы можете создавать несколько представлений данных, предоставляя разным пользователям различные представления структуры и содержимого базы данных.
- Имеет открытый исходный код. MySQL, MariaDB и PostGres предлагают бесплатные базы данных SQL, которые большие сообщества могут использовать по низкой цене.
- Используется основными поставщиками систем управления базами данных. Большинство основных систем управления базами данных, таких как IBM, Oracle и Microsoft, используют SQL. Доступность SQL — большое преимущество, о котором следует помнить.
- Очень интерактивный. Даже если вы полностью понимаете SQL, вам может быть интересно, смогут ли другие читать и интерпретировать данные. К счастью, SQL является интерактивным языком для всех пользователей, поэтому вам не нужно беспокоиться о недопонимании или недопонимании. Узнайте, как улучшить коммуникацию в вашем бизнесе.
 К счастью, SQL не требует навыков программирования, достаточно использования простых ключевых слов, таких как «выбрать», «вставить в» и «обновить».
К счастью, SQL не требует навыков программирования, достаточно использования простых ключевых слов, таких как «выбрать», «вставить в» и «обновить». Доступность SQL — большое преимущество, о котором следует помнить.
Доступность SQL — большое преимущество, о котором следует помнить.Использование SQL дает множество преимуществ, а наем сотрудников, обладающих знаниями и опытом работы с SQL, может кардинально изменить способы просмотра, анализа и принятия более эффективных бизнес-решений на основе данных.
Шон Пик участвовал в написании и исследовании этой статьи.
Учебное пособие по SQL — javatpoint
следующий → Учебное пособие по SQLсодержит базовые и расширенные концепции SQL. Наш учебник по SQL предназначен как для начинающих, так и для профессионалов. SQL (язык структурированных запросов) используется для выполнения операций с записями, хранящимися в базе данных, таких как обновление записей, вставка записей, удаление записей, создание и изменение таблиц базы данных, представлений и т. SQL — это не система баз данных, а язык запросов. Предположим, вы хотите выполнять запросы языка SQL к сохраненным данным в базе данных. В ваших системах требуется установить любую систему управления базами данных, например, Oracle, MySQL, MongoDB, PostgreSQL, SQL Server, DB2 и т. д. Что такое SQL?SQL — это краткая форма языка структурированных запросов, которая произносится как S-Q-L или иногда как See-Quell. Этот язык базы данных в основном предназначен для обслуживания данных в системах управления реляционными базами данных. Это специальный инструмент, используемый специалистами по данным для обработки структурированных данных (данных, которые хранятся в виде таблиц). Он также предназначен для потоковой обработки в RDSMS. Вы можете легко создавать и управлять базой данных, получать доступ и изменять строки и столбцы таблицы и т. д. Этот язык запросов стал стандартом ANSI в 1986 году и ISO в 1987 году. Если вы хотите получить работу в области науки о данных, то это самый важный язык запросов для изучения. Почему SQL?В настоящее время SQL широко используется в науке о данных и аналитике. Ниже приведены причины, объясняющие его широкое использование:
История SQL«Реляционная модель данных для больших общих банков данных» — статья, опубликованная великим ученым-компьютерщиком Э. Ф. Коддом в 1970 году. Исследователи IBM Рэймонд Бойс и Дональд Чемберлин первоначально разработали SEQUEL (язык структурированных английских запросов) после изучения статьи, предоставленной Э. Ф. Коддом. Они оба разработали SQL в исследовательской лаборатории корпорации IBM в Сан-Хосе в 1919 году.70. В конце 1970-х компания Relational Software Inc. разработала свой первый SQL, используя концепции Э. Ф. Кодда, Рэймонда Бойса и Дональда Чемберлина. Этот SQL был полностью основан на СУБД. Relational Software Inc., которая сейчас известна как корпорация Oracle, представила Oracle V2 в июне 1979 года, которая является первой реализацией языка SQL. Эта версия Oracle V2 работает на компьютерах VAX. Процесс SQL Когда мы выполняем команду SQL в любой системе управления реляционной базой данных, система автоматически находит наилучшую процедуру для выполнения нашего запроса, а механизм SQL определяет, как интерпретировать эту конкретную команду. Язык структурированных запросов содержит в своем процессе следующие четыре компонента:
Классический механизм запросов позволяет специалистам по данным и пользователям выполнять запросы, отличные от SQL. Архитектура SQL показана на следующей диаграмме: Некоторые команды SQLКоманды SQL помогают в создании базы данных и управлении ею. Наиболее часто используемые команды SQL перечислены ниже:
Команда СОЗДАТЬЭта команда помогает создать новую базу данных, новую таблицу, табличное представление и другие объекты базы данных. Команда ОБНОВЛЕНИЯ Эта команда помогает обновить или изменить сохраненные данные в базе данных. Команда УДАЛИТЬЭта команда помогает удалить или стереть сохраненные записи из таблиц базы данных. Он стирает один или несколько кортежей из таблиц базы данных. Команда ВЫБОРЭта команда помогает получить доступ к одной или нескольким строкам из одной или нескольких таблиц базы данных. Мы также можем использовать эту команду с предложением WHERE. Команда DROPЭта команда помогает удалить всю таблицу, табличное представление и другие объекты из базы данных. Команда ВСТАВИТЬЭта команда помогает вставлять данные или записи в таблицы базы данных. Мы можем легко вставлять записи как в одну, так и в несколько строк таблицы. SQL противбез SQLВ следующей таблице описаны различия между SQL и NoSQL, которые необходимо понимать:
Преимущества SQL SQL предоставляет различные преимущества, которые делают его более популярным в области науки о данных. Это идеальный язык запросов, который позволяет специалистам по данным и пользователям общаться с базой данных. 1. Программирование не требуется SQL не требует большого количества строк кода для управления системами баз данных. Мы можем легко получить доступ к базе данных и поддерживать ее, используя простые синтаксические правила SQL. Эти простые правила делают SQL удобным для пользователя. 2. Высокоскоростная обработка запросов Быстрый и эффективный доступ к большому объему данных из базы данных с помощью запросов SQL. Операции вставки, удаления и обновления данных также выполняются за меньшее время. 3. Стандартизированный язык SQL соответствует давно установленным стандартам ISO и ANSI, которые предлагают единую платформу по всему миру для всех своих пользователей. 4. Портативность Язык структурированных запросов можно легко использовать на настольных компьютерах, ноутбуках, планшетах и даже смартфонах. 5. Интерактивный язык Мы можем легко выучить и понять язык SQL. Мы также можем использовать этот язык для связи с базой данных, потому что это простой язык запросов. Этот язык также используется для получения ответов на сложные запросы за несколько секунд. 6. Более одного просмотра данных Язык SQL также помогает создавать несколько представлений структуры базы данных для разных пользователей базы данных. Недостатки SQLПомимо преимуществ SQL, он также имеет некоторые недостатки, а именно: 1. Стоимость Стоимость эксплуатации некоторых версий SQL высока. Вот почему некоторые программисты не могут использовать язык структурированных запросов. 2. Сложный интерфейс Еще одним большим недостатком является сложный интерфейс языка структурированных запросов, что затрудняет использование и управление пользователями SQL. 3. Частичное управление базой данных Бизнес-правила скрыты. Таким образом, специалисты по данным и пользователи, использующие этот язык запросов, не могут иметь полный контроль над базой данных. Следующая темаСинтаксис SQL следующий → |
 д.
д. Крупные предприятия, такие как Facebook, Instagram и LinkedIn, используют SQL для хранения данных в серверной части.
Крупные предприятия, такие как Facebook, Instagram и LinkedIn, используют SQL для хранения данных в серверной части.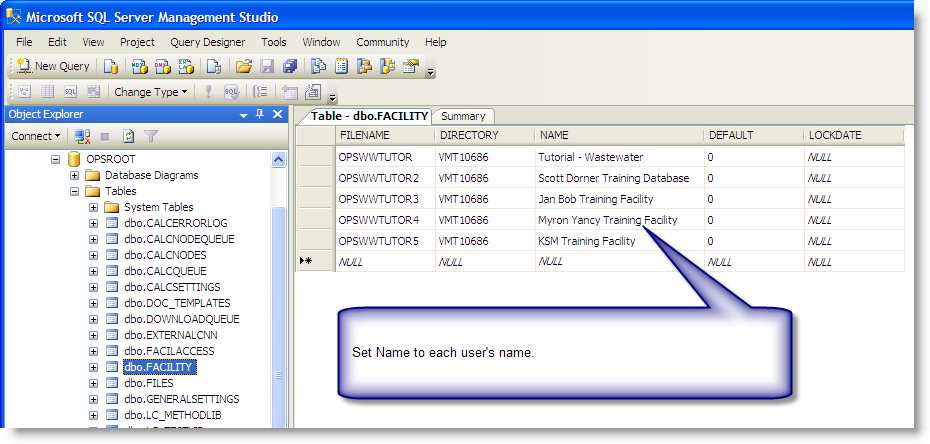

 Ниже приведены лучшие преимущества языка структурированных запросов:
Ниже приведены лучшие преимущества языка структурированных запросов: Его также можно использовать с другими приложениями в соответствии с требованиями пользователя.
Его также можно использовать с другими приложениями в соответствии с требованиями пользователя.
Новейшие вопросы ‘sql’ — Qaru Задавать вопрос
Язык структурированных запросов (SQL) — это язык для запросов к базам данных. Вопросы должны включать примеры кода, структуру таблицы, примеры данных и тег для используемой реализации СУБД (например, MySQL, PostgreSQL, Oracle, MS SQL Server, IBM DB2 и т. д.). Если ваш вопрос относится исключительно к конкретной СУБД (использует определенные расширения/функции), вместо этого используйте тег этой СУБД. В ответах на вопросы, отмеченные тегом SQL, следует использовать стандартный SQL ISO/IEC.
- Учить больше…
- Лучшие пользователи
- Синонимы (6)
642 631 вопросы
Новейший
Активный
Баунти
3
Без ответа
Сортировать поНет ответов
Ответ не принят
Имеет награду
Отсортировано поНовейший
Последние действия
Наивысший балл
Самый частый
Щедрость скоро закончится
ОтмеченМои просматриваемые теги
Следующие теги:
-2 голоса
0 ответы
12 Просмотры
Естественная (человеческая буквенно-цифровая и строковая) сортировка в Microsoft SQL 2017
У меня есть сложные данные в sql, и мне нужно отсортировать эти данные.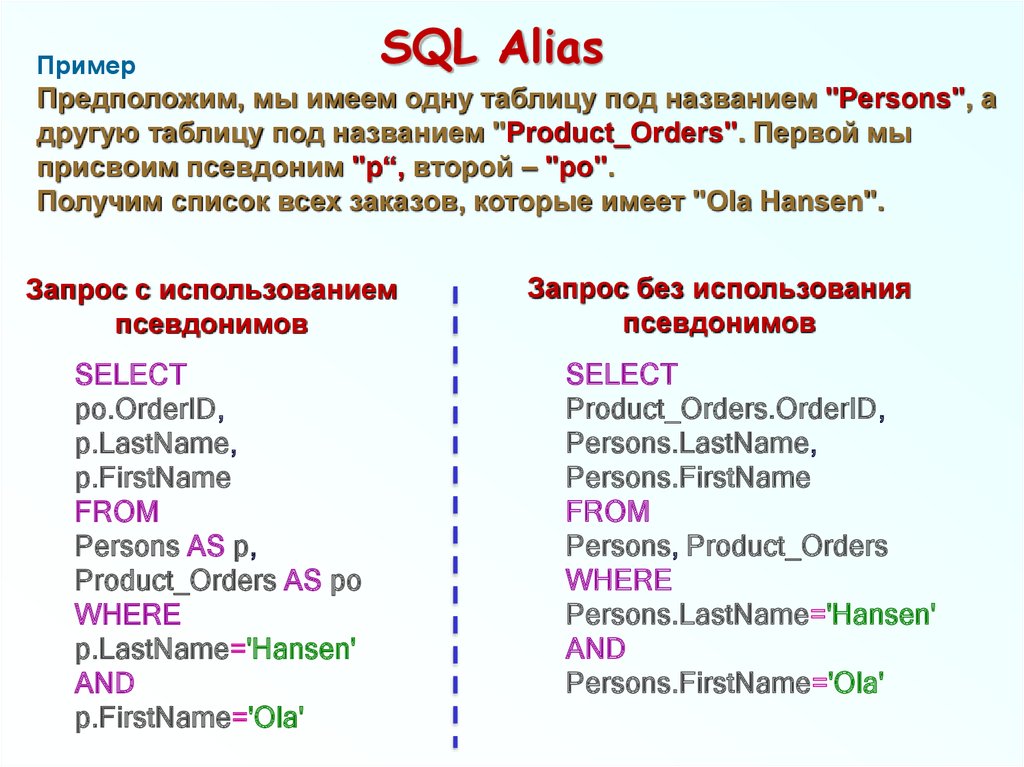 Мой запрос имеет необязательный фильтр для accoutingCode, который иногда может быть пустым.
Мой запрос дает ошибку из-за значений CHAR.
ЗАПРОС:
Выберите топ 1 …
Мой запрос имеет необязательный фильтр для accoutingCode, который иногда может быть пустым.
Мой запрос дает ошибку из-за значений CHAR.
ЗАПРОС:
Выберите топ 1 …
- mysql
- sql
- sql-сервер
0 голоса
0 ответы
15 Просмотры
ASP.NET MVC Отображение изображений из пути к базе данных на основе идентификатора
Я пытаюсь создать веб-приложение для электронной коммерции, в котором во время загрузки объявления вы можете добавить несколько фотографий. Во время загрузки фотографий в базу данных им присваивается значение идентификатора продукта для этих фотографий…
- С#
- sql
- asp.net-mvc
-1 голоса
0 ответы
11 Просмотры
Как использовать билет Kerberos с mssqlclient.
 py?
py?У меня есть билет kerberos для пользователя домена. Этот пользователь допустим в SQL Server. Есть ли способ использовать этот билет Kerberos с инструментом mssqlclient.py для входа на этот SQL Server? Спасибо
- sql
- керберос
-1 голоса
0 ответы
15 Просмотры
Как преобразовать код sql в postgresql? [закрыто]
Я должен преобразовать следующий код sql в postgresql и попытался заменить функцию преобразования на функцию cast и функцию charindex с позицией, но она все еще не работает. Могли бы вы, пожалуйста …
- sql
- postgresql
0 голоса
2 ответы
39 Просмотры
Умножение столбцов, а затем суммирование строк: Oracle SQL
Я пытаюсь сделать запрос в Oracle SQL Developer, который должен показать клиента, который потратил наибольшую сумму денег. Итак, у меня есть 4 таблицы: Cliente (Клиент), Orden (Продажа), Producto (Продукт) и…
Итак, у меня есть 4 таблицы: Cliente (Клиент), Orden (Продажа), Producto (Продукт) и…
- sql
- оракул
- оракул-sqldeveloper
-2 голоса
0 ответы
47 Просмотры
SQL-запрос для поиска сверхурочной работы, выполненной сотрудником [закрыто]
Мне нужна помощь от вас. Запрос для получения сведений о сверхурочной работе, выполненных сотрудником. Пример: — Если пользователи работают после 17:00:01, время будет считаться сверхурочным и может работать сверхурочно до 23:59.0,59 вечера …
- sql
- sql-сервер
- оракул
0 голоса
4 ответы
28 Просмотры
Создать репост последнего и второго последнего значения
У меня таблица аудитов продуктов выглядит так
я бы
Код товара
column_updated
ценность
отметка времени
1
продукт_1
имя
Большая обувь. «18 сентября 2022 г., 18:42:50 по Гринвичу + 05:30»
2.
продукт_1
имя
Зеленый …
«18 сентября 2022 г., 18:42:50 по Гринвичу + 05:30»
2.
продукт_1
имя
Зеленый …
- sql
- наибольший-n-на-группу
0 голоса
1 отвечать
21 Просмотры
Создайте уникальный индекс, когда столбец = значение
У меня есть таблица Решение: id, id_request, id_decision, комментарий, дата. запрос может быть отправлен много раз, пока он не будет принят, после того, как он будет принят, его нельзя будет отправить снова, поэтому мой вопрос заключается в том, как…
- sql
- оракул
0 голоса
0 ответы
13 Просмотры
Должен ли я добавлять ограничение внешнего ключа при создании таблицы фактов в SQL?
Вопрос немного наивный. Но когда я узнал, было сказано, что вы должны добавить как первичный ключ, так и внешний ключ в таблицу фактов, как показано ниже:
О первичном ключе в таблице фактов есть много сообщений на …
Но когда я узнал, было сказано, что вы должны добавить как первичный ключ, так и внешний ключ в таблицу фактов, как показано ниже:
О первичном ключе в таблице фактов есть много сообщений на …
- sql
- база данных
- ssis
- хранилище данных
- таблица фактов
0 голоса
1 отвечать
46 Просмотры
Строка SQL и подсчет с использованием цикла for
Я делаю запрос, который вернет несколько строк, мне нужно найти способ перебирать эти строки и извлекать значение из каждой строки. Как я могу сделать цикл for, который будет начинаться с первой строки…
- java
- sql
- весенняя загрузка
- спящий режим
0 голоса
1 отвечать
23 Просмотры
Выбор SQL в группе, когда группа содержит определенное значение, но не другое
Как я могу иметь условие для значения внутри группы. На основе таблицы, сформированной ниже, я хотел бы проверить при группировке по группе b, что groupa содержит значение GA3 или GA4, если оно содержит значение …
На основе таблицы, сформированной ниже, я хотел бы проверить при группировке по группе b, что groupa содержит значение GA3 или GA4, если оно содержит значение …
- sql
- оракул
-1 голоса
1 отвечать
33 Просмотры
В SQL, как объединить несколько идентификаторов внешних ключей в нескольких столбцах таблицы с одним первичным ключом в другой таблице и однозначно выбрать один?
Таблица A: Встречи пациентов со связанными диагнозами (DX) Encounter_ID Свидание Первичный_DX DX_2 DX_3 DX_4 11111 01.01.2020 234234 256756 254537 678688 11112 01.05.2020 344564 234553 6786667 234234 11113 …
- sql
- левое соединение
- несколько столбцов
- существует
-1 голоса
0 ответы
14 Просмотры
С# Использовать определенный элемент DataTable из источника данных в Visual Studio
Я добавил таблицу SQL в источник данных в Visual Studio и хочу использовать информацию из этой таблицы. Я не понимаю, как получить конкретный элемент из этой таблицы, как вызвать этот DataTable в коде…
Я не понимаю, как получить конкретный элемент из этой таблицы, как вызвать этот DataTable в коде…
- С#
- sql
- .net
- база данных
- визуальная студия
0 голоса
0 ответы
14 Просмотры
Rails, запрос с активной записью не учитывает отрицательное условие where
У меня есть следующая модель данных: пользователь has_many Organization_Users пользователь has_many регистраций у пользователя есть тип столбца в регистрации есть столбцы learning_item_type и learning_item_id Цель …
- sql
- ruby-on-rails
- активрекорд
0 голоса
1 отвечать
25 Просмотры
Как получить разницу смещения столбца без использования `order by` и
Прямо сейчас этот код делает то, что должен делать. Я просто чувствую, что функция LAG должна иметь более простой способ принять в основном OFFSET=-1, что невозможно, поэтому я должен прибегнуть к текущему…
Я просто чувствую, что функция LAG должна иметь более простой способ принять в основном OFFSET=-1, что невозможно, поэтому я должен прибегнуть к текущему…
- sql
- амазон-афена
- предварительно
на страницу
Databricks SQL — Databricks
Лучшее хранилище данных — это домик у озера
Начало работыСмотреть демонстрацию
Databricks SQL (DB SQL) — это бессерверное хранилище данных на платформе Databricks Lakehouse, позволяющее запускать все ваши приложения SQL и BI в масштабе с 12-кратным улучшением соотношения цена/производительность, унифицированной моделью управления, открытыми форматами и API, а также вашими любимыми инструментами — без привязки.
Лучшее соотношение цены и производительности
Снижение затрат, оптимальное соотношение цены и производительности и устранение необходимости в управлении, настройке или масштабировании облачной инфраструктуры с помощью бессерверной инфраструктуры.
Встроенное управление
Создайте единую копию для всех ваших данных, используя открытые стандарты, и один унифицированный уровень управления для всех групп данных, используя стандартный SQL.
Богатая экосистема
Используйте SQL и любой инструмент, такой как Fivetran, dbt, Power BI или Tableau, вместе с Databricks, чтобы получать, преобразовывать и запрашивать все ваши данные на месте.
Устранение разрозненности
Предоставьте каждому аналитику возможность более быстрого доступа к последним данным для последующей аналитики в реальном времени и легкого перехода от BI к ML.
Как это работает?
Полная интеграция с экосистемой
Простота использования
Реальная производительность
Централизованное управление
Открытое и надежное озеро данных как основа0034
Работайте со своими данными, где бы они ни находились. Возможности «под ключ» позволяют аналитикам и инженерам-аналитикам легко получать данные из чего угодно, например, из облачного хранилища, в корпоративные приложения, такие как Salesforce, Google Analytics или Marketo, с помощью Fivetran. Это всего в один клик. Затем просто управляйте зависимостями и преобразуйте данные на месте с помощью встроенных возможностей ETL в Lakehouse или с помощью ваших любимых инструментов, таких как dbt в Databricks SQL, для лучшей в своем классе производительности.
Это всего в один клик. Затем просто управляйте зависимостями и преобразуйте данные на месте с помощью встроенных возможностей ETL в Lakehouse или с помощью ваших любимых инструментов, таких как dbt в Databricks SQL, для лучшей в своем классе производительности.
Узнать больше →
Современная аналитика и бизнес-аналитика с вашими инструментами по выбору
Беспроблемная работа с самыми популярными инструментами бизнес-аналитики, такими как Tableau, Power BI и Looker. Теперь аналитики могут использовать свои любимые инструменты для получения новых бизнес-идей на самых полных и свежих данных. Databricks SQL также позволяет каждому аналитику совместно запрашивать, находить и обмениваться информацией с помощью встроенного редактора SQL, визуализаций и информационных панелей.
Подробнее →
Откажитесь от управления ресурсами с помощью бессерверных вычислений
Databricks SQL serverless избавляет от необходимости управлять, настраивать или масштабировать облачную инфраструктуру в Lakehouse, освобождая вашу команду по работе с данными для того, что у них получается лучше всего. Хранилища Databricks SQL обеспечивают мгновенные эластичные вычисления SQL — независимо от хранилища — и автоматически масштабируются для обеспечения неограниченного параллелизма без сбоев в сценариях использования с высокой степенью параллелизма.
Хранилища Databricks SQL обеспечивают мгновенные эластичные вычисления SQL — независимо от хранилища — и автоматически масштабируются для обеспечения неограниченного параллелизма без сбоев в сценариях использования с высокой степенью параллелизма.
Подробнее →
Создан с нуля для лучшей в своем классе производительности
Databricks SQL содержит тысячи оптимизаций, обеспечивающих максимальную производительность для всех ваших инструментов, типов запросов и реальных приложений. Это включает в себя векторизованный механизм запросов нового поколения Photon, который вместе с хранилищами SQL обеспечивает до 12 раз лучшее соотношение цены и производительности по сравнению с другими облачными хранилищами данных.
Подробнее →
Централизованное хранение и управление всеми вашими данными с помощью стандартного SQL
Создайте единую копию всех ваших данных, используя открытый формат Delta Lake, чтобы избежать блокировки данных, и выполняйте аналитику на месте и ETL/ELT на ваш Lakehouse — больше никаких перемещений и копий данных в разрозненных системах.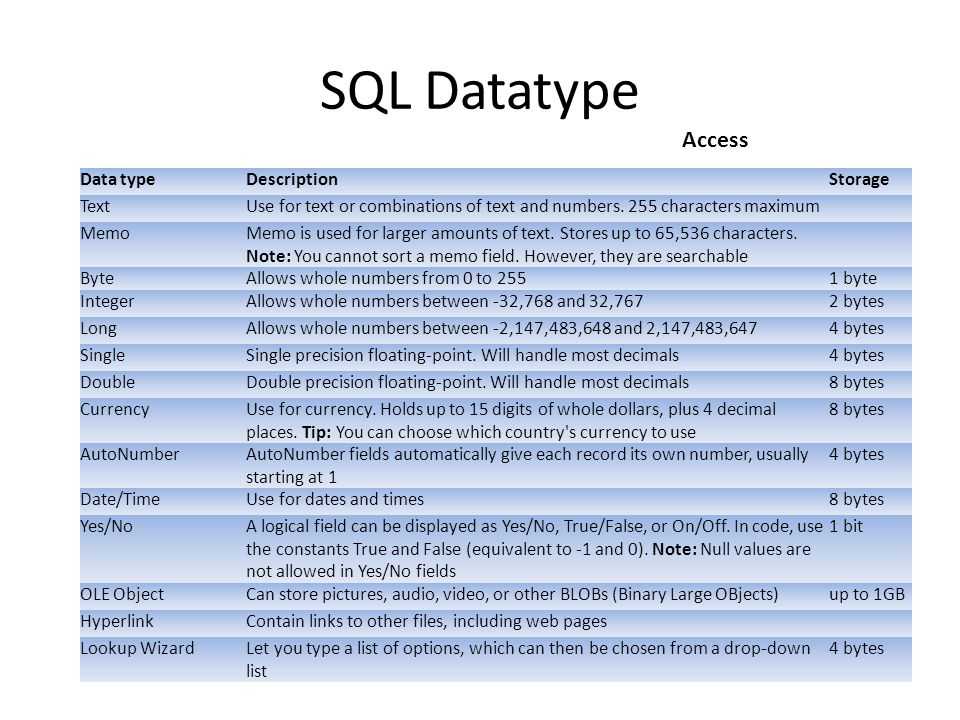 Затем легко обнаруживайте, защищайте и управляйте всеми своими данными с помощью детального управления, происхождения данных и стандартного SQL в облаках с помощью Databricks Unity Catalog.
Затем легко обнаруживайте, защищайте и управляйте всеми своими данными с помощью детального управления, происхождения данных и стандартного SQL в облаках с помощью Databricks Unity Catalog.
Подробнее →
Создан на основе общей базы данных на базе платформы Lakehouse
Платформа Databricks Lakehouse предоставляет наиболее полное сквозное решение для хранения данных для всех ваших современных аналитических потребностей и многого другого. . Получите производительность мирового уровня за небольшую часть стоимости облачных хранилищ данных. Ускорьте преобразование необработанных данных в полезные в масштабе и объедините пакетную и потоковую обработку. Кроме того, Lakehouse позволяет специалистам по работе с данными без особых усилий переходить от описательной к прогнозной аналитике, чтобы получать новые идеи.
Подробнее →
До 12 раз лучше соотношение цены и производительности по сравнению с другими облачными хранилищами данных
Подробнее
Миграция на блоки данных
Устали от разрозненных хранилищ данных, низкой производительности и высоких затрат, связанных с устаревшими системами, такими как Hadoop и корпоративными данными. склады? Перейдите на Databricks Lakehouse: современную платформу для всех ваших хранилищ данных, аналитики и вариантов использования ИИ.
склады? Перейдите на Databricks Lakehouse: современную платформу для всех ваших хранилищ данных, аналитики и вариантов использования ИИ.
Миграция на Databricks
Интеграция
Полная интеграция с экосистемой означает максимальную гибкость для ваших групп обработки данных. Принимайте критически важные для бизнеса данные с помощью Fivetran, преобразуйте их на месте с помощью dbt и находите новые идеи с помощью Power BI, Tableau или Looker, и все это без перемещения ваших данных в устаревшее хранилище данных.
Прием данных и ETL
Управление данными
BI и информационные панели
+ Любой другой клиент, совместимый с Apache Spark™️
«Сейчас, как никогда ранее, организациям нужна стратегия работы с данными, обеспечивающая скорость и гибкость адаптации. Поскольку организации быстро перемещают свои данные в облако, мы наблюдаем растущий интерес к аналитике озера данных. Databricks SQL предоставляет клиентам совершенно новые возможности для доступа к информации из огромных объемов данных с необходимой производительностью, надежностью и масштабируемостью. Мы гордимся тем, что сотрудничаем с Databricks, чтобы воплотить эту возможность в жизнь».
Мы гордимся тем, что сотрудничаем с Databricks, чтобы воплотить эту возможность в жизнь».
— Франсуа Айенстат, директор по продукту, Tableau
Истории клиентов
Узнайте больше
Готовы начать работу с
?
Руководства по началу работы
AWSAzureGCP
Сопутствующее содержимое
Электронные книги
- Создание Data Lakehouse Биллом Инмоном, отцом хранилища данных
- Почему домик у озера — ваше следующее хранилище данных
- Большая книга инженерии данных
События
- Внутреннее устройство домика у озера из данных + мировое турне ИИ
- Веб-семинар по передовым методам настройки производительности в Lakehouse — внутри жизни запроса
- Databricks SQL Бесплатное обучение — по запросу
Блоги
- Блоки данных устанавливают официальный рекорд производительности хранилища данных
- Объявление об общедоступности блоков данных SQL
- Эволюция языка SQL в Databricks: стандарт Ansi по умолчанию и более простая миграция из хранилищ данных
- Развертывание dbt на модулях данных стало еще проще
Готовы начать
?
Руководства по началу работы
AWSAzureGCP
The Rise of SQL — IEEE Spectrum
Dragon никогда не перепродавался — странная судьба одной из наиболее исторически значимых NFT. Новые NFT, такие как
«Слияние», произведение цифрового искусства, которое было продано за сумму, эквивалентную 92 миллионам долларов, оставило позади Dragon, поскольку рынок NFT подскочил до рекордных продаж, составив примерно 18 миллиардов долларов в 2021 году. Может, мир просто перешел к более новым блокчейн-проектам? Или это судьба, которая ожидает все NFT?
Новые NFT, такие как
«Слияние», произведение цифрового искусства, которое было продано за сумму, эквивалентную 92 миллионам долларов, оставило позади Dragon, поскольку рынок NFT подскочил до рекордных продаж, составив примерно 18 миллиардов долларов в 2021 году. Может, мир просто перешел к более новым блокчейн-проектам? Или это судьба, которая ожидает все NFT?
Блокчейны, смарт-контракты и кошачьи гены
Чтобы понять медленную смерть CryptoKitties , вы должны начать с самого начала. Технология блокчейн возможно, началось с статьи 1982 года ученого-компьютерщика Дэвида Чаума, но оно привлекло всеобщее внимание благодаря успеху Биткойн, криптовалюты, созданной анонимным лицом или людьми, известными как Сатоши Накамото. По своей сути блокчейн — это простая книга транзакций, размещенных одна за другой, — мало чем отличающаяся от очень длинной электронной таблицы Excel.
Сложность заключается в том, как блокчейны обеспечивают стабильность и безопасность реестра без центрального органа; детали того, как это делается, различаются в зависимости от блокчейна. Биткойн, хотя и популярен как актив и полезен для денежных транзакций, имеет ограниченную поддержку для чего-либо еще. Новые альтернативы, такие как
Эфириум приобрел популярность, поскольку позволяет создавать сложные «умные контракты» — исполняемый код, хранящийся в блокчейне.
Биткойн, хотя и популярен как актив и полезен для денежных транзакций, имеет ограниченную поддержку для чего-либо еще. Новые альтернативы, такие как
Эфириум приобрел популярность, поскольку позволяет создавать сложные «умные контракты» — исполняемый код, хранящийся в блокчейне.
«До CryptoKitties , если бы вы сказали «блокчейн», все бы предположили, что вы говорите о криптовалюте», — Брайс Блэдон.
CryptoKitties был одним из первых проектов, использующих смарт-контракты путем присоединения кода к конструкциям данных, называемым токенами, в блокчейне Ethereum. Каждый фрагмент игрового кода (называемый «геном») описывает атрибуты цифрового кота. Игроки покупают, собирают, продают и даже разводят новых кошек. Так же, как отдельные токены Ethereum и биткойны, код кота также гарантирует, что токен, представляющий каждого кота, уникален, и именно здесь появляется невзаимозаменяемый токен, или NFT. Взаимозаменяемый товар, по определению, может быть заменен товаром.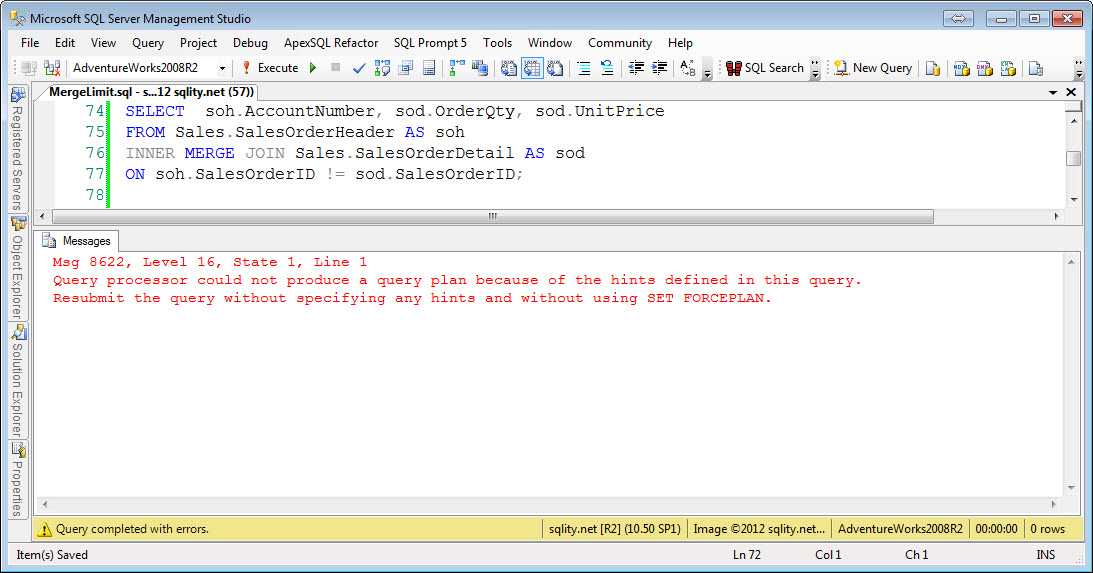 идентичный предмет — один биткойн так же хорош, как и любой другой биткойн. NFT, напротив, имеет уникальный код, который не применяется ни к какому другому NFT.
идентичный предмет — один биткойн так же хорош, как и любой другой биткойн. NFT, напротив, имеет уникальный код, который не применяется ни к какому другому NFT.
Есть еще одна последняя часть головоломки блокчейна, которую вам нужно понять: «газ». Некоторые блокчейны, в том числе Ethereum, взимают плату за вычислительную работу, которую сеть должна выполнить для проверки транзакции. Это создает препятствие для перегрузки сети блокчейна. Высокий спрос означает высокие комиссии, побуждающие пользователей дважды подумать, прежде чем совершать транзакцию. В результате снижение спроса защищает сеть от перегрузки, а время транзакций не становится чрезмерно долгим. Но это может быть слабостью, когда игра NFT становится вирусной.
Взлет и падение CryptoKitties
Запущен 28 ноября 2017 года после пятидневного закрытого бета-тестирования. Популярность CryptoKitties резко возросла благодаря заманчивому слогану: первая в мире игра Ethereum.
«Как только он был запущен, он сразу же стал вирусным», — говорит
Брайс Блэдон, один из основателей команды, создавшей CryptoKitties .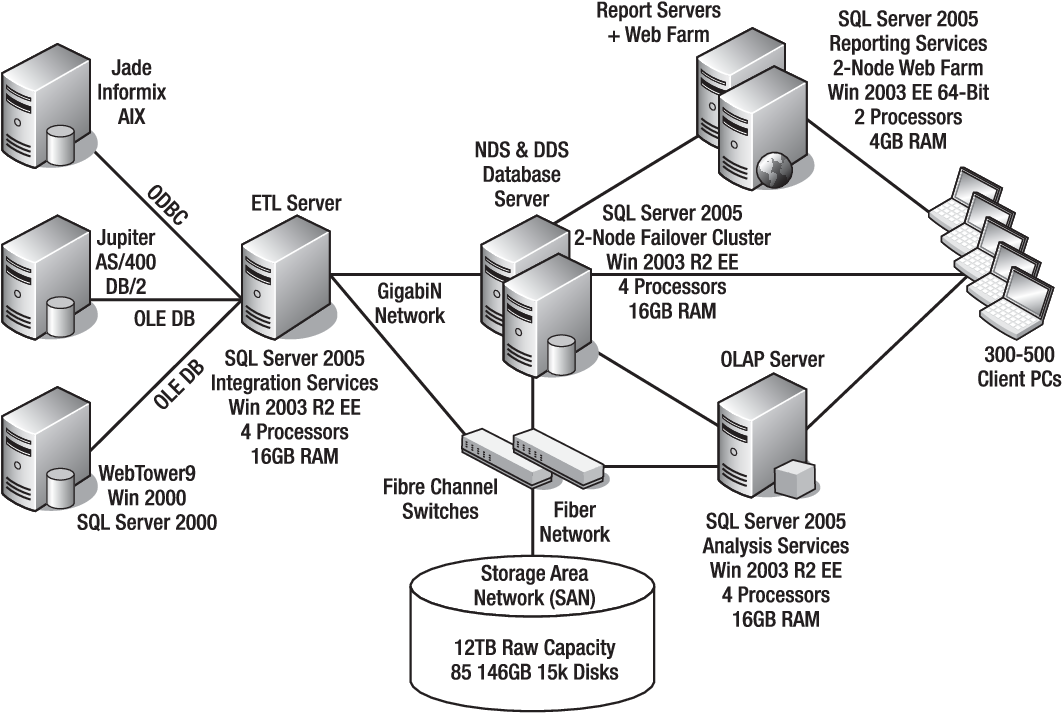 «Это было невероятно сбивающее с толку время».
«Это было невероятно сбивающее с толку время».
Объем продаж вырос с 1500 невзаимозаменяемых кошек в день запуска до более чем 52 000 10 декабря 2017 года, согласно nonfungible.com, при этом многие CryptoKitties продаются по цене в сотни или тысячи долларов. Ценность кошек, сгенерированных алгоритмами в игре, получила освещение в сотнях публикаций.
Что такое CryptoKitty?
Каждый CryptoKitty — это токен, набор данных в блокчейне Ethereum. В отличие от криптовалют Ethereum и Bitcoin, эти токены не взаимозаменяемы; то есть они не взаимозаменяемы.
| Уникальный идентификатор | Удостоверение личности матери, удостоверение личности отца | Гены |
| Уникальный идентификатор делает CryptoKitty невзаимозаменяемым токеном. | Жетон содержит родословную котенка и другие данные. | Гены котенка определяют его уникальный внешний вид. |
Dapper Labs
Более того, игра, возможно, способствовала успеху Ethereum, блокчейна, используемого в игре. Ethereum взлетел как ракета в тандеме с выпуском CryptoKitties , поднявшись с чуть менее 300 долларов за токен в начале ноября 2017 года до чуть более 1360 долларов в январе 2018 года.
Рост Ethereum продолжился с запуском десятки новых игр с блокчейном, основанных на криптовалюте, до конца 2017 и 2018 годов. Ethermon , Ethercraft , Ether Goo , CryptoCountries , CryptoCelebrities и CryptoCities являются одними из лучших примеров . Некоторые прибыли в течение нескольких недель после CryptoKitties .
Это был прорыв, которого ждали поклонники Ethereum. Тем не менее, что стало бы зловещим признаком для здоровья блокчейн-игр, CryptoKitties споткнулись, когда Ethereum рванул вверх.
Ежедневные продажи достигли пика в начале декабря 2017 года, затем снизились в январе и к марту составили в среднем менее 3000 штук.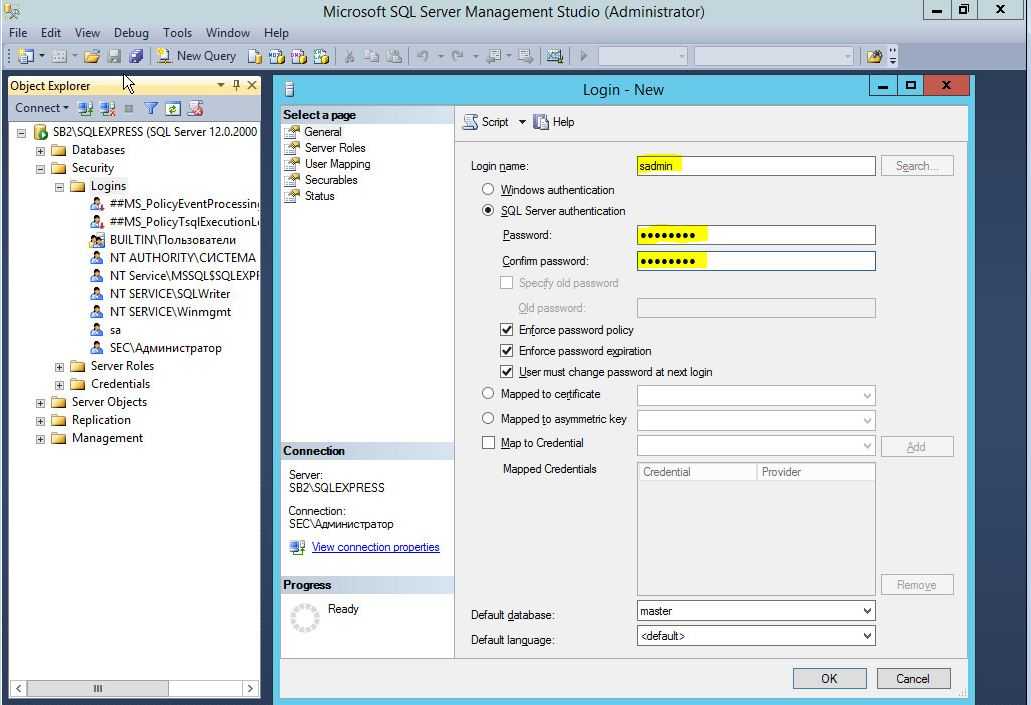 Стоимость самих NFT снижалась медленнее, а это признак того, что у игры была база преданных поклонников, таких как Рабоно, которые купили Dragon задолго до пика игры. Их активность установила рекорды стоимости NFT до 2018 года. Это позволило сохранить игру в новостях, но не привлекло новых игроков.
Стоимость самих NFT снижалась медленнее, а это признак того, что у игры была база преданных поклонников, таких как Рабоно, которые купили Dragon задолго до пика игры. Их активность установила рекорды стоимости NFT до 2018 года. Это позволило сохранить игру в новостях, но не привлекло новых игроков.
Сегодня, КриптоКотята повезло совершить 100 продаж в день, а общая стоимость часто составляет менее 10 000 долларов. Крупные сделки, такие как продажа Основатель Cat # 71 за 60 эфиров (примерно 170 000 долларов США) 30 апреля 2022 года все еще происходит, но только раз в несколько месяцев. Большинство невзаимозаменяемых меховых младенцев продаются за крошечные доли 1 эфира, что в июле 2022 года стоит всего несколько десятков долларов.
CryptoKitties «погружение в безвестность» вряд ли изменится. Dapper Labs, которая владеет CryptoKitties , перешла к таким проектам, как NBA Top Shot, платформе, которая позволяет фанатам баскетбола покупать «моменты» NFT — по сути, видеоклипы — из игр НБА. Dapper Labs не ответила на просьбу дать интервью о КриптоКотята . Блэдон покинул Dapper в 2019 году.
Dapper Labs не ответила на просьбу дать интервью о КриптоКотята . Блэдон покинул Dapper в 2019 году.
Что пошло не так?
Один ключ к кончине игры можно найти в последнем посте на игровой блог (4 июня 2021 г.), посвященный разведению 2-миллионного CryptoKitty. Разведение, основная механика игры, позволяет владельцам объединять свои существующие NFT для создания алгоритмически сгенерированного потомства. Это придавало NFT неотъемлемую ценность в игровой экосистеме. Каждый NFT мог генерировать больше NFT, которые игроки могли затем перепродавать с прибылью. Но этот игровой механизм также насытил рынок. Сяофань Лю, доцент кафедры СМИ и коммуникаций Городского университета Гонконга, соавтор статьи о CryptoKitties ’взлет и падение, считает это недостатком, который игра никогда не сможет преодолеть.
«Цена котенка зависит в первую очередь от редкости, а это зависит от генетической стороны. И второе измерение — это количество котят на рынке», — говорит Лю.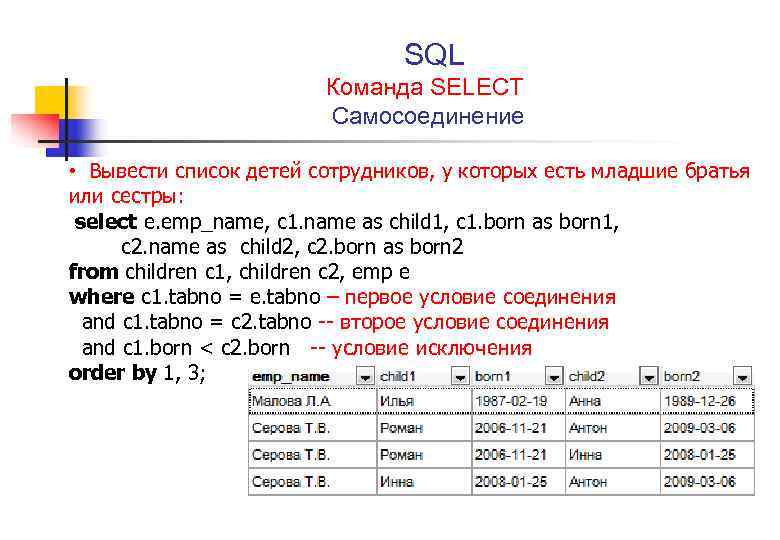 «Чем больше людей, тем больше котят».
«Чем больше людей, тем больше котят».
Больше игроков означало больший спрос, но это также означало больше возможностей для создания предложения за счет разведения новых кошек. Это быстро уменьшило редкость каждого NFT.
Блэдон согласен с этой оценкой механизма размножения. «Я думаю, что критика справедлива», — говорит он, объясняя, что она должна была вызвать чувство открытия и волнения. Он также надеялся, что это побудит игроков удерживать NFT, а не сразу продавать их, поскольку разведение теоретически обеспечивает непреходящую ценность.
Огромный объем CryptoKitties вызвал другую, более неотложную проблему: он функционально сломал блокчейн Ethereum, который является второй по величине криптовалютой в мире по рыночной капитализации (после биткойна). Как объяснялось ранее, Ethereum использует комиссию, называемую газом, для оценки стоимости транзакций. Любой всплеск транзакций — покупка, создание и т. д. — вызовет всплеск платы за газ, и это именно то, что произошло, когда CryptoKitties отправились на Луну.
«Все, что символизировало CryptoKitties — успех был обманут. Все, что не было видно сразу, в основном игнорировалось», — Брайс Блэдон.
«Игроки, которые хотели купить CryptoKitties несли высокие сборы за газ». Об этом заявил в интервью Михай Викол, рыночный аналитик Newzoo. «Эти сборы за газ составляли от 100 до 200 долларов за транзакцию. Вы должны были заплатить цену CryptoKitty плюс плата за газ. Это серьезная проблема».
Высокие гонорары были проблемой не только для КриптоКотята . Это была проблема для всего блокчейна. Любой, кто по какой-либо причине хотел совершать транзакции в Ethereum, должен был платить больше за газ, поскольку игра становилась все более успешной.
Эта динамика остается проблемой для Ethereum и сегодня. 30 апреля 2022 г., когда Yuga Labs
выпустила Otherdeeds — NFT, которые обещают владельцам недвижимость в метавселенной — она подняла плату за газ Ethereum в стратосферу. Средняя цена на газ ненадолго превысила эквивалент 450 долларов по сравнению с примерно 50 долларами накануне.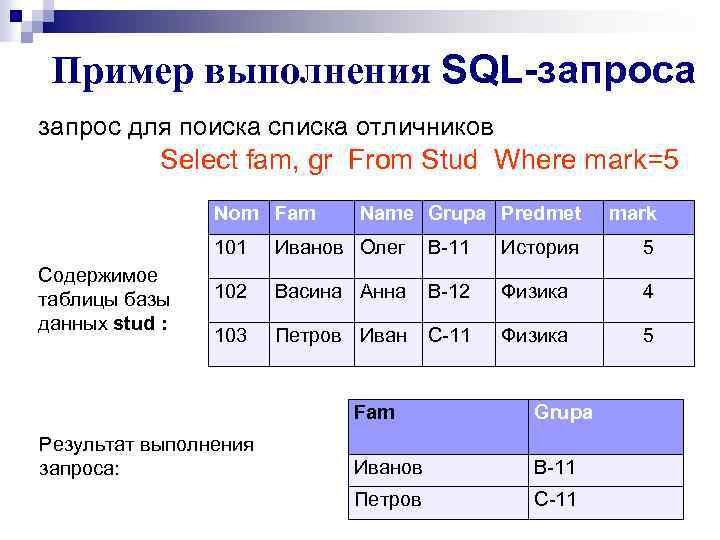
Несмотря на то что CryptoKitties ’ требования к сети снизились, когда игроки ушли, газ, вероятно, станет последним гвоздем в гроб игры. Средняя цена CryptoKitty за последние три месяца составляет около 0,04 эфира, или от 40 до 50 долларов, что часто меньше газа, необходимого для завершения транзакции. Даже те, кто хочет случайно владеть и разводить недорогих CryptoKitties для развлечения, не могут сделать это, не потратив сотни долларов.
Блокчейн-игры: два шага вперед, один шаг назад
Взлет и падение CryptoKitties был драматичным, но дал своим преемникам — которых сотни — возможность учиться на своих ошибках и преодолевать их. Многие не усвоили уроки: современные игровые хиты с блокчейном, такие как Axie Infinity и BinaryX имели аналогичный первоначальный всплеск цены и активности, за которым последовала длинная нисходящая спираль.
«Все, что символизировало CryptoKitties — успех был обманут. Все, что не было сразу видно, в основном игнорировалось», — говорит Блэдон. А оказывается многие из CryptoKitties ’ трудности не были видны публике. «Дело в том, что проект CryptoKitties действительно споткнулся. У нас было много отключений. Нам приходилось иметь дело со многими людьми, которые никогда раньше не использовали блокчейн. У нас была ошибка, которая привела к утечке эфира на десятки тысяч долларов». Подобные проблемы преследовали более поздние проекты NFT, часто в гораздо большем масштабе.
А оказывается многие из CryptoKitties ’ трудности не были видны публике. «Дело в том, что проект CryptoKitties действительно споткнулся. У нас было много отключений. Нам приходилось иметь дело со многими людьми, которые никогда раньше не использовали блокчейн. У нас была ошибка, которая привела к утечке эфира на десятки тысяч долларов». Подобные проблемы преследовали более поздние проекты NFT, часто в гораздо большем масштабе.
Лю не уверен, как игры с блокчейном могут решить эту проблему. «Короткий ответ: я не знаю», — говорит он. «Длинный ответ заключается в том, что это проблема не только игр с блокчейном».
World of Warcraft , например, большую часть жизни игры сталкивался с безудержной инфляцией. Это вызвано постоянным притоком золота от игроков и постоянно растущей стоимостью новых предметов, вводимых дополнениями. Постоянная потребность в новых игроках и предметах связана с другой ключевой проблемой современных игр с блокчейном: зачастую они слишком просты.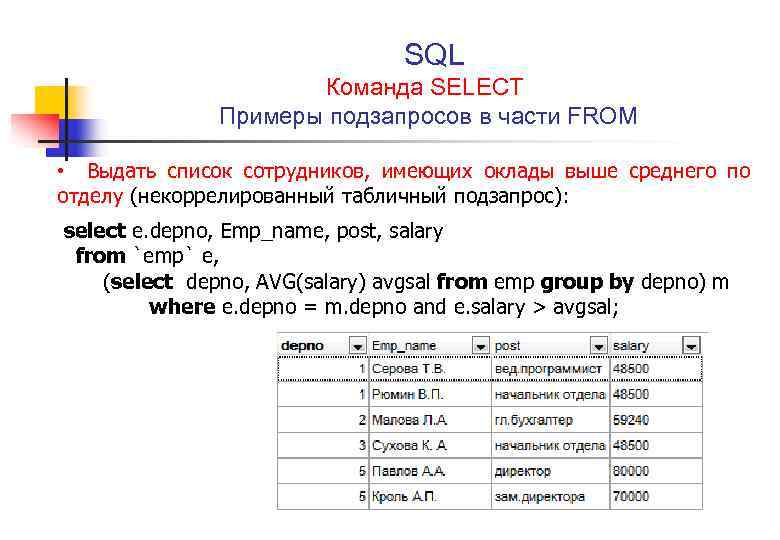
«Я думаю, что самая большая проблема блокчейн-игр сейчас заключается в том, что они неинтересны, а если они неинтересны, люди не хотят вкладывать деньги в саму игру», — говорит Викол из Newzoo. «Каждый, кто тратит деньги, хочет выйти из игры с большим количеством денег, чем они потратили».
Это, возможно, нереальное желание становится невыполнимым, как только начинается нисходящая спираль. Игроки, не чувствуя никакой другой привязанности к игре, кроме роста инвестиций, быстро убегают и не возвращаются.
В то время как некоторые игры с блокчейном, по-видимому, игнорировали опасности CryptoKitties ’ быстрый рост и долгое падение, другие узнали из нагрузки, которую он оказал на сеть Ethereum. В большинстве игр с блокчейном теперь используется сайдчейн, блокчейн, который существует независимо, но соединяется с другим, более заметным «родительским» блокчейном. Цепочки соединены мостом, который облегчает передачу токенов между каждой цепочкой. Это предотвращает рост комиссий на основном блокчейне, поскольку вся игровая активность происходит на сайдчейне.
Тем не менее, даже эта новая стратегия сопряжена с проблемами, потому что боковые цепи оказываются менее безопасными, чем родительский блокчейн. Атака на Ronin, сайдчейн, используемый Акси Бесконечность , пусть хакеры сойдут с рук с суммой, эквивалентной 600 миллионам долларов. Polygon, еще один сайдчейн, часто используемый играми с блокчейном, должен был исправить эксплойт, который поставил под угрозу 850 миллионов долларов, и выплатить награду за ошибку в размере 2 миллионов долларов хакеру, обнаружившему проблему. Игроки, владеющие NFT в сайдчейне, теперь с осторожностью следят за его безопасностью.
Помните дракона
Криптовалютный кошелек, в котором находится котенок Дракон стоимостью почти миллион долларов, теперь содержит эфир едва на 30 долларов и не торговал NFT в течение многих лет. Кошельки анонимны, поэтому вполне возможно, что человек, стоящий за кошельком, перешел на другой. Тем не менее, трудно не рассматривать бездействие кошелька как признак того, что для Rabono веселье длилось недолго.