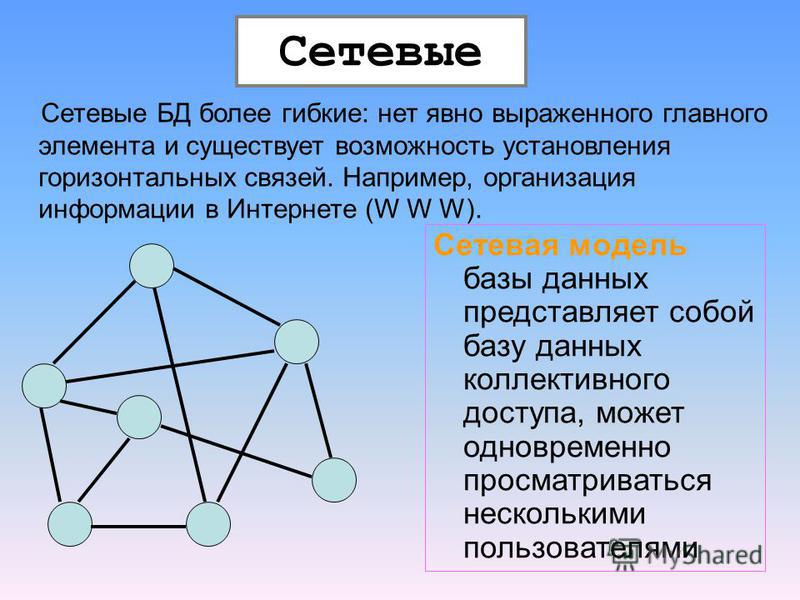
Сетевая модель данных, ее достоинства и недостатки.
На разработку этого стандарта большое влияние оказал американский ученый Ч.Бахман. Основные принципы сетевой модели данных были разработаны в середине 60-х годов, эталонный вариант сетевой модели данных описан в отчетах рабочей группы по языкам баз данных (COnference on DAta SYstem Languages) CODASYL (1971 г.).
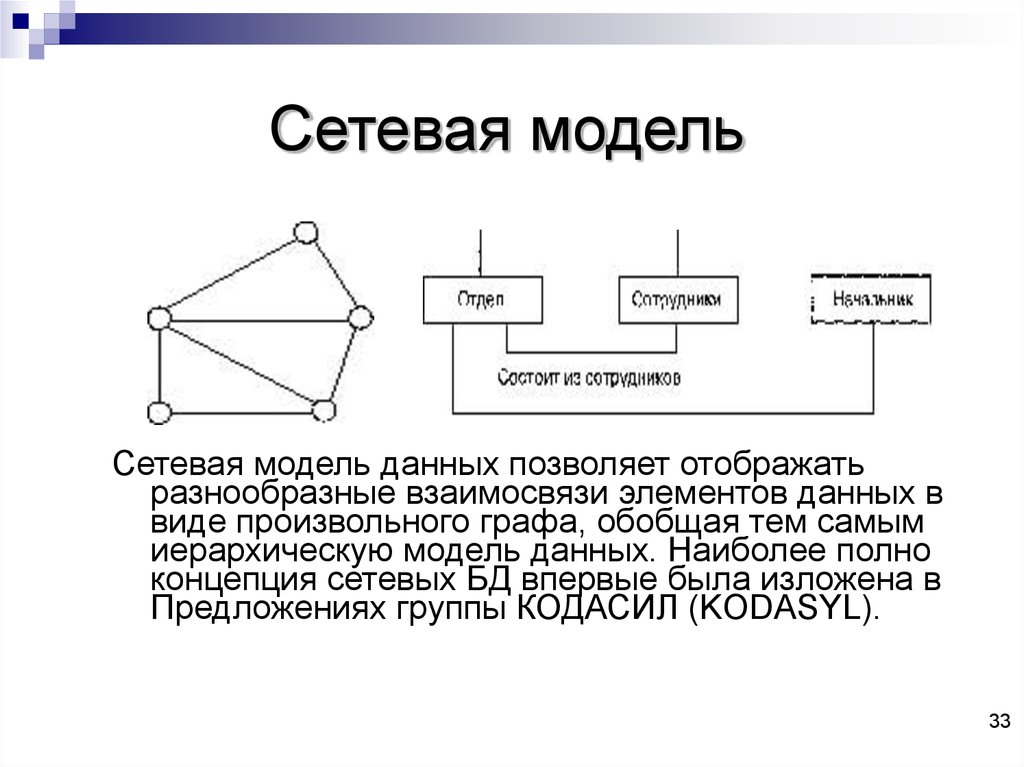
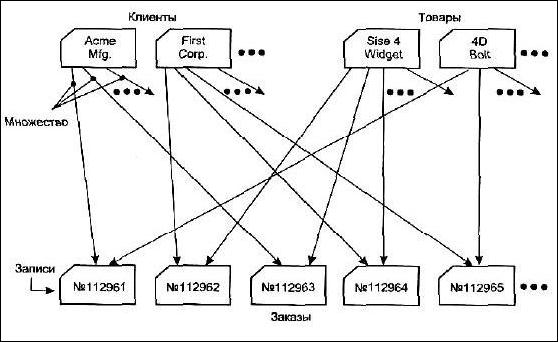
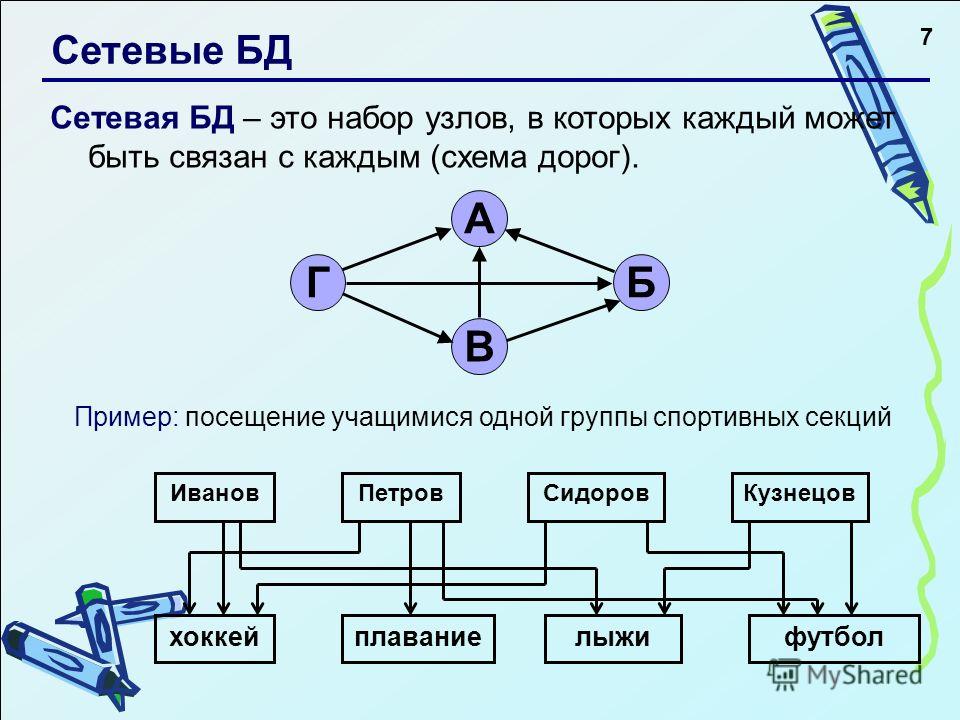
Сетевая модель данных определяется в тех же терминах, что и иерархическая. Она состоит из множества записей, которые могут быть владельцами или членами групповых отношений. Связь между записью-владельцем и записью-членом также имеет вид 1:N.
Основное
различие этих моделей состоит
в том, что в сетевой
модели запись может
быть членом более чем одного группового
отношения. Согласно этой модели каждое
групповое отношение именуется
и проводится различие между его типом
и экземпляром.
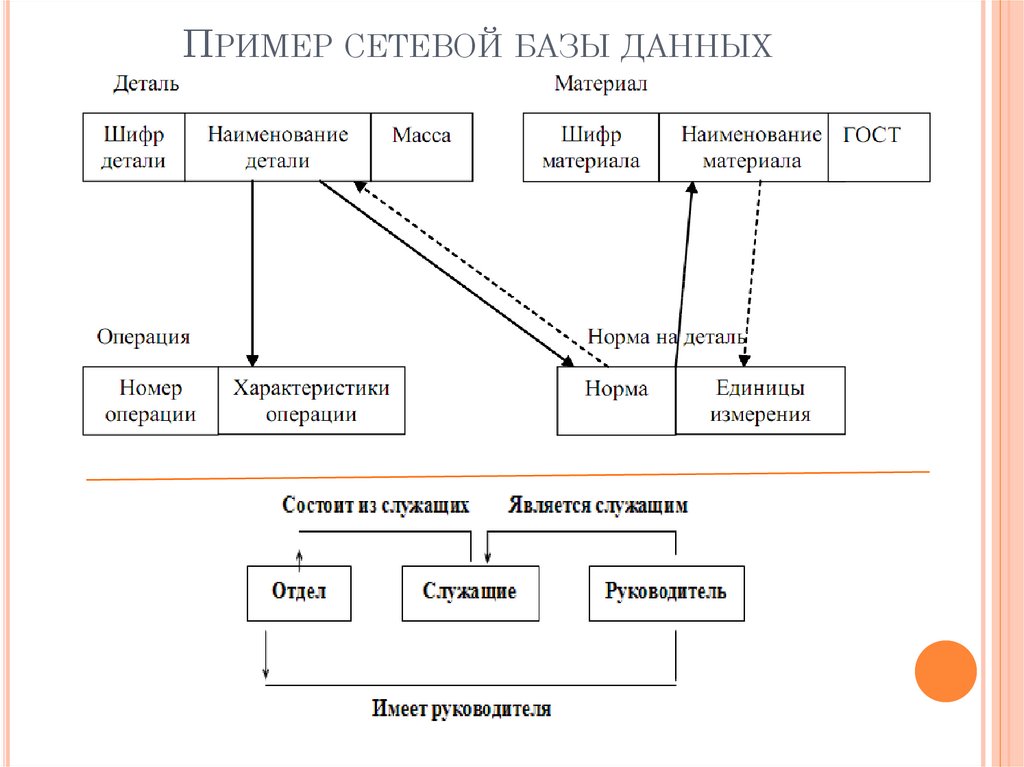
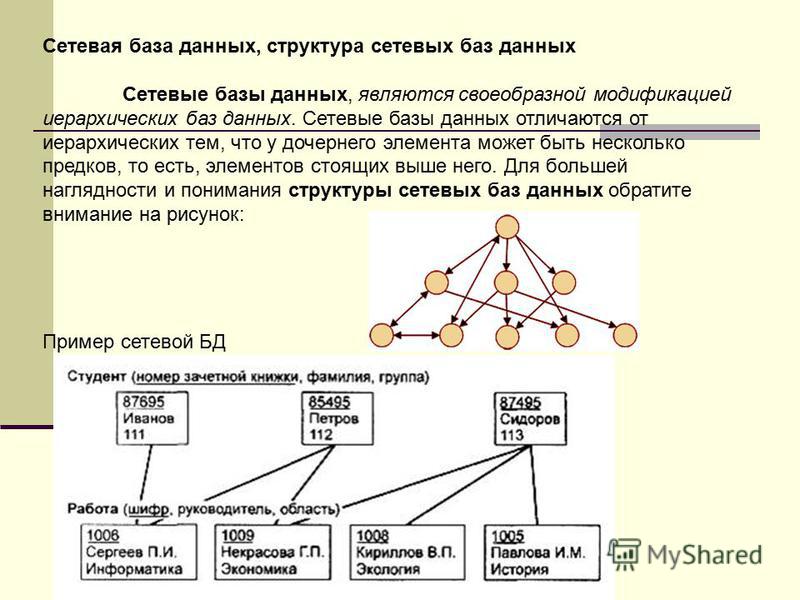
Иерархическая структура рис. 4.2 преобразовывается в сетевую модель, следующим образом (см. рис. 4.3):
деревья (a) и (b), показанные на рис. 4.2, заменяются одной сетевой структурой, в которой запись СОТРУДНИК входит в два групповых отношения;
для отображения типа M:N вводится запись СОТРУДНИК_КОНТРАКТ, которая не имеет полей и служит только для связи записей КОНТРАКТ и СОТРУДНИК, (см. рис. 4.3). Отметим, что в этой записи может храниться и полезная информация, например, доля данного сотрудника в общем вознаграждении по данному контракту.

Рис. 4.3. Сетевая модель базы данных
Каждый экземпляр группового отношения характеризуется следующими признаками:
Способ упорядочения подчиненных записей:
произвольный,
хронологический /очередь/,
обратный хронологический /стек/,
сортированный.
Если запись объявлена подчиненной в нескольких групповых отношениях, то в каждом из них может быть назначен свой способ упорядочивания.
Реляционная модель данных (РМД) — логическая модель данных, прикладная теория построения баз данных, которая является приложением к задачам обработки данных таких разделов математикикак теории множеств и логика первого порядка.
На реляционной
модели данных строятся реляционные
базы данных.
Реляционная модель данных включает следующие компоненты:
Структурный аспект (составляющая) — данные в базе данных представляют собой набор отношений.
Аспект (составляющая) целостности — отношения (таблицы) отвечают определенным условиям целостности. РМД поддерживает декларативные ограничения целостности уровня домена (типа данных), уровня отношения и уровня базы данных.
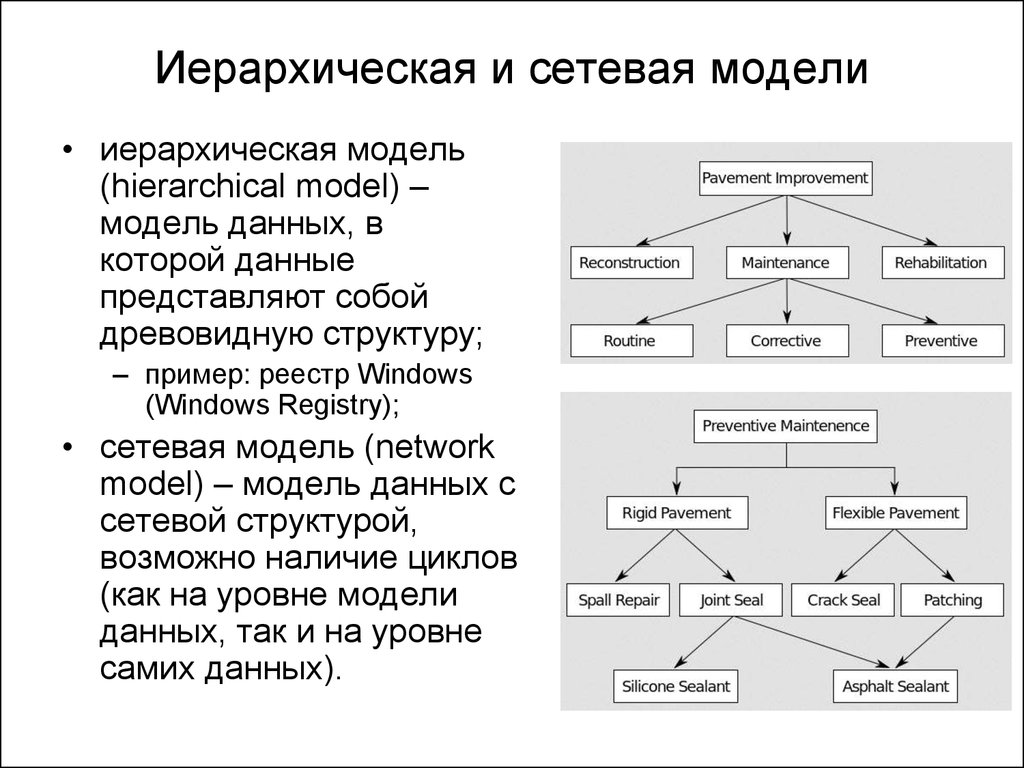
Информация в базе данных некоторым образом структурирована, т. е. ее можно описать моделью представления данных (моделью данных), которые поддерживаются СУБД. Эти модели подразделяют на иерархические, сетевые и реляционные.
При
использовании иерархической
модели представления
данных связи между данными можно
охарактеризовать с помощью упорядоченного
графа (или дерева).
Основными достоинствами иерархической модели данных являются:
1) эффективное использование памяти ЭВМ;
2) высокая скорость выполнения основных операций над данными;
3) удобство работы с иерархически упорядоченной информацией.
К недостаткам иерархической модели представления данных относятся:
1) громоздкость такой модели для обработки информации с достаточно сложными логическими связями;
2) трудность в понимании ее функционирования обычным пользователем.
Сетевая
модель может
быть представлена как развитие и
обобщение иерархической модели данных,
позволяющее отображать разнообразные
взаимосвязи данных в виде произвольного
графа.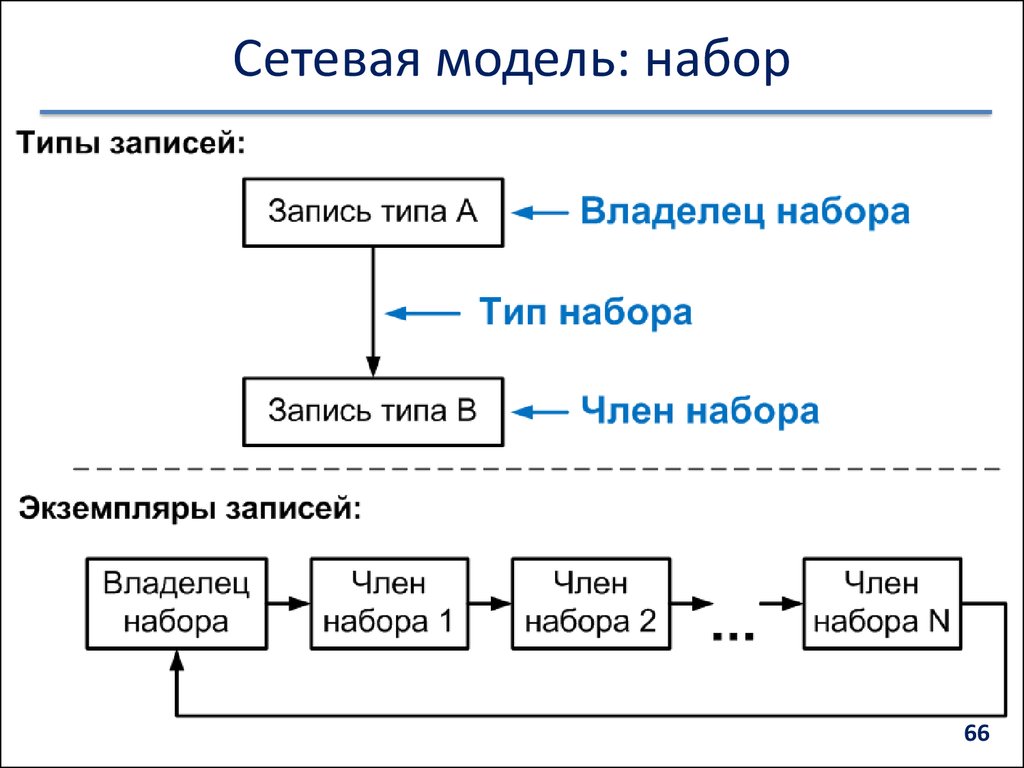
Достоинствами сетевой модели представления данных являются:
1) эффективность в использовании памяти компьютера;
2) высокая скорость выполнения основных операций над данными;
3) огромные возможности (большие, чем у иерархической модели) образования произвольных связей.
К недостаткам сетевой модели представления данных относятся:
1) высокая сложность и жесткость схемы базы данных, которая построена на ее основе;
2) трудность для понимания и выполнения обработки информации в базе данных непрофессиональным пользователем.
Системы управления базами данных, построенные на основе сетевой модели, также не получили широкого распространения на практике.
Реляционная
модель представления
данных была разработана сотрудником
фирмы 1ВМЭ. Коддом.
Его модель основывается на понятии
«отношения» (relation).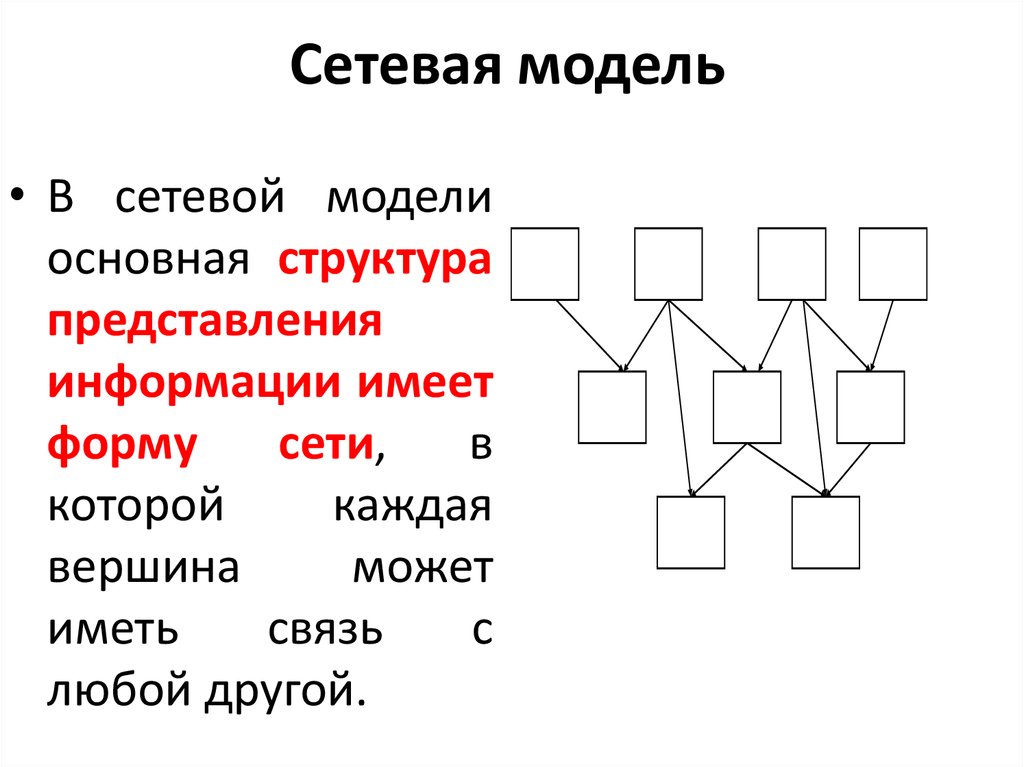
Достоинствами реляционной модели представления данных (по сравнению с иерархической и сетевой моделями) являются ее понятность, простота и удобство практической реализации реляционных баз данных на ЭВМ.
К недостаткам реляционной модели представления данных относятся:
1) отсутствие стандартных средств идентификации отдельных записей;
2) сложность описания иерархических и сетевых связей.
Большинство СУБД, применяемых как профессиональными, так и непрофессиональными пользователями, построены на основе реляционной модели данных (Visual FoxPro и Access фирмы Microsoft, Oracle фирмы Oracle и др.).
Сетевая модель данных — презентация онлайн
Похожие презентации:
Базы данных и язык SQL
Базы данных. Access
Базы данных. Системы управления базами данных
Базы данных. Access 2007
Access 2007
Язык SQL
Системы управления базами данных (СУБД)
SQL. Базовый курс
Управление данными
Базы данных. Введение
Системы управления базами данных (СУБД)
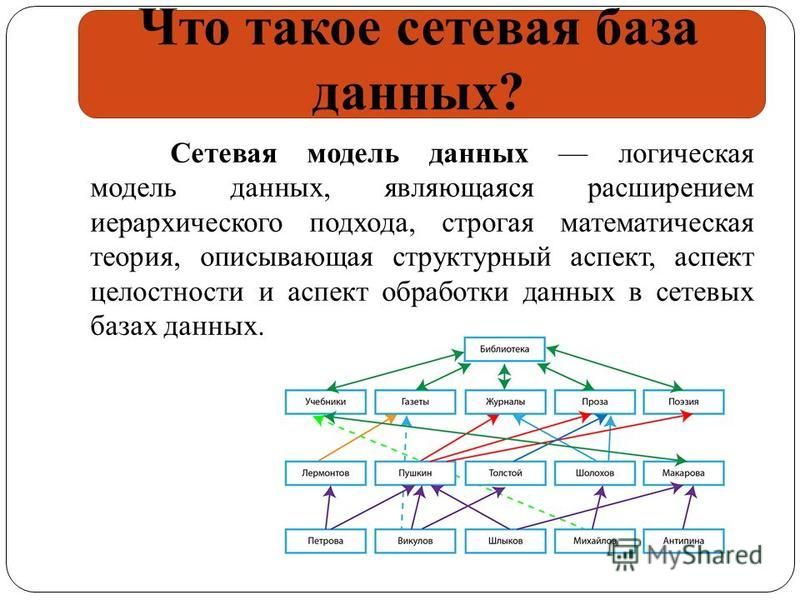
• Сетевая модель данных — логическая модель данных,
являющаяся расширением иерархического подхода,
строгая математическая теория, описывающая
структурный аспект, аспект целостности и аспект
обработки данных в сетевых базах данных.
• Сетевая модель была первым подходом,
использовавшимся при создании баз данных в конце 50-ых
— начале 60-ых годов. Активным пропагандистом этой
модели был Чарльз Бахман. Главным конкурентом тогда у
нее была иерархическая модель данных, представленная
ведущим продуктом компании IBM в области баз данных IBM IMS. В конце 60-ых годов Эдгаром Коддом была
предложена реляционная модель данных и после долгих и
приобрела большую популярность и теперь является
доминирующей на рынке СУБД.
Примерный набор операций манипулирования данными:
найти конкретную запись в наборе однотипных записей;
перейти от предка к первому потомку по некоторой связи;
перейти к следующему потомку в некоторой связи;
перейти от потомка к предку по некоторой связи;
создать новую запись;
уничтожить запись;
модифицировать запись;
включить в связь;
исключить из связи;
переставить в другую связь и т. д.
Элемент данных – минимальная информационная единица доступная пользователю.
агрегата, которую можно рассматривать как единое целое. Имя агрегата используется для его
идентификации в схеме структуры данного более высокого уровня. Агрегат данных может
быть простым, если состоит только из элементов данных, и составным, если включает в свой
состав другие агрегаты.
• Запись — совокупность агрегатов или элементов данных, отражающих некоторую сущность
предметной области.
 Иными словами, запись — это агрегат, который не входит в состав
Иными словами, запись — это агрегат, который не входит в составникакого другого агрегата и может иметь сложную иерархическую структуру, поскольку
допускается многократное применение агрегации. Имя записи используется для
идентификации типа записи в схемах типов структур более высокого уровня.
• Тип записей – эта совокупность подобных записей. Тип записей представляет некоторый класс
реального мира.
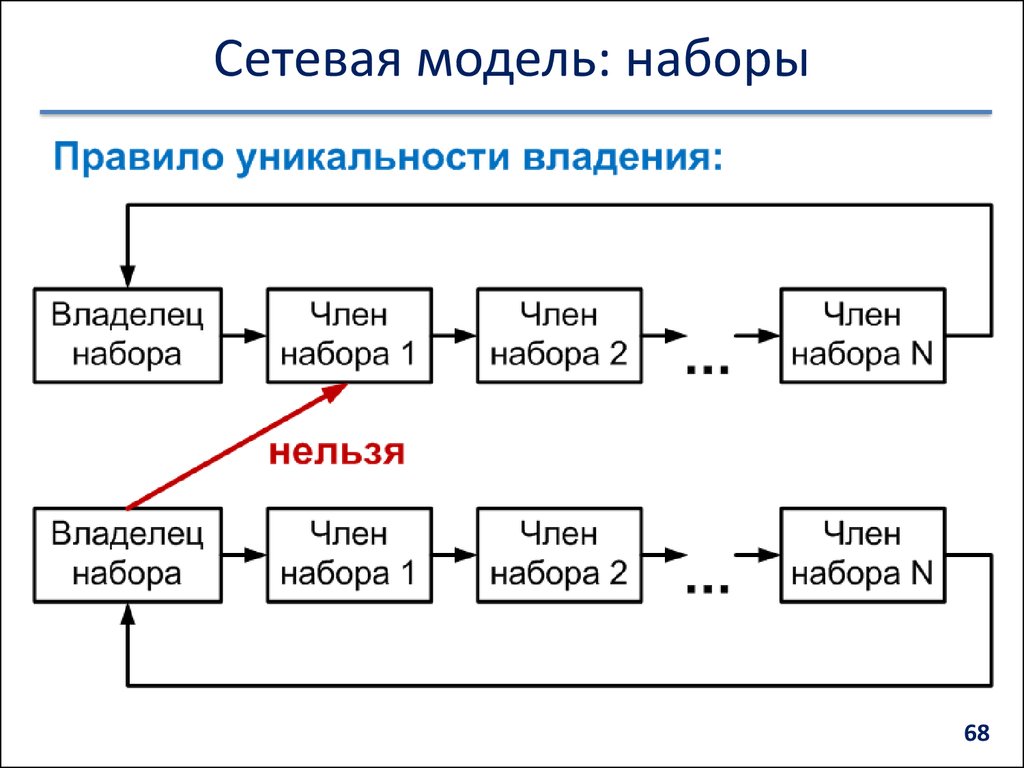
• Набор — именованная двухуровневая иерархическая структура, которая содержит запись
владельца и запись (или записи) членов. Наборы отражают связи «один ко многим» и «один к
одному» между двумя типами записей.
• Наборы бывают нескольких видов:
— С одними и теми же типами записей, но разными типами наборов.
— Наборы из трех записей и более, в том числе с обратной связью.
— Сингулярный набор (только один экземпляр). У такого набора нет естественного владельца и в
качестве него выступает система. В дальнейшем такие наборы могут приобрести запись владельца.
• ДОБАВИТЬ — внести запись в БД и, в зависимости от режима включения, либо
включить ее в групповое отношение, где она объявлена подчиненной, либо не
включать ни в какое групповое отношение.
• ВКЛЮЧИТЬ В ГРУППОВОЕ ОТНОШЕНИЕ — связать существующую подчиненную
запись с записью-владельцем.
• ПЕРЕКЛЮЧИТЬ — связать существующую подчиненную запись с другой записьювладельцем в том же групповом отношении.
• ОБНОВИТЬ — изменить значение элементов предварительно извлеченной записи.
• ИЗВЛЕЧЬ — извлечь записи последовательно по значению ключа, а также используя
групповые отношения — от владельца можно перейти к записям — членам, а от
подчиненной записи к владельцу набора.
• УДАЛИТЬ — убрать из БД запись. Если эта запись является владельцем группового
отношения, то анализируется класс членства подчиненных записей. Обязательные
члены должны быть предварительно исключены из группового отношения,
фиксированные удалены вместе с владельцем, необязательные останутся в БД.

• ИСКЛЮЧИТЬ ИЗ ГРУППОВОГО ОТНОШЕНИЯ — разорвать связь между записьювладельцем и записью-членом.
• сетевая модель данных
• Достоинством сетевой модели данных является
возможность эффективной реализации по показателям
затрат памяти и оперативности.
• Недостатком сетевой модели данных являются высокая
сложность и жесткость схемы БД, построенной на ее
основе. Поскольку логика процедуры выборки данных
зависит от физической организации этих данных, то эта
модель не является полностью независимой от
приложения. Другими словами, если необходимо
изменить структуру данных, то нужно изменить и
приложение.
• Имеется возможность потребовать для конкретного типа
связи отсутствие потомков, не участвующих ни в одном
экземпляре этого типа связи (как в иерархической модели).
Сетевая СУБД — СУБД, построенная на основе сетевой модели данных.
DBMS32 компании DEC
IMAGE/3000 компании Hewlett-Packard
DMS-90 и DMS-1100 компании UNIVAC
IDS (Integrated Database System) компании General Electric — самая первая
сетевая СУБД, разработаная Чарльзом Бахманом в 1960 г.
Integrated Data Store (IDS/2 или IDS/II) компании Honeywell, купившей IDS у
General Electric, позднее — компании Bull[2][3]
Integrated Database Management System компании Cullinet, тоже
разработана Бахманом как развитие IDS
Norsk-Data SYBAS
Burroughs DMS-2
CDC IMF
NCR IDM-9000
Cincom TOTAL
dbVista
СООБЗ Cerebrum
ИСУБД «CronosPRO»
Caché
GT.M
English Русский Правила
Сетевая модель в СУБД — Темы масштабирования
Обзор
Модель базы данных — это логическое представление базы данных, т. е. ограничения и отношения между хранимыми данными. Сетевая модель в СУБД — это иерархическая модель, которая используется для представления отношения «многие ко многим» между ограничениями базы данных. Он представлен в виде графика, следовательно, это простая и легкая в построении модель базы данных. Сетевая модель в СУБД позволяет 1 : 1 (один к одному), 1 : M (многие к одному), M : N (многие к одному) отношения между сущностями или членами.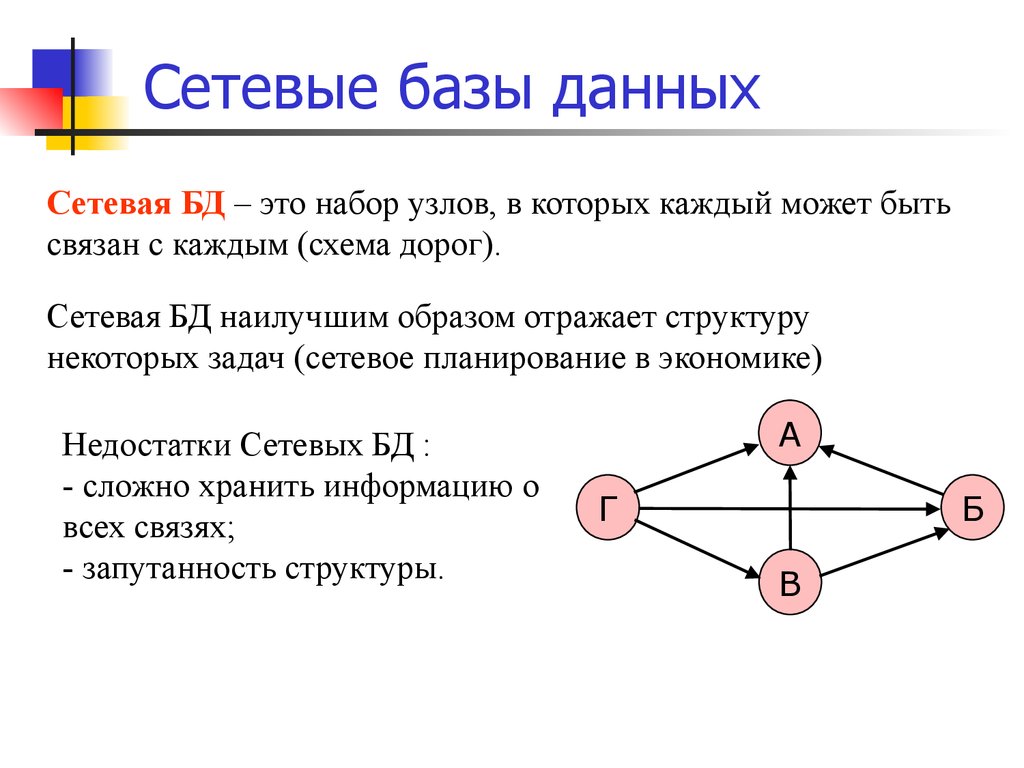 Щелкните здесь, чтобы узнать больше об отношениях в СУБД.
Щелкните здесь, чтобы узнать больше об отношениях в СУБД.
Область применения статьи
Статья охватывает такие темы, как
- Введение в сетевую модель в СУБД.
- Структура сетевой модели в СУБД.
- Характеристики сетевой модели в СУБД.
- Примеры сетевой модели в СУБД и сетевых базах данных.
- Операции над сетевой моделью в СУБД.
- Преимущества и недостатки сетевой модели в СУБД.
- Разница между сетевой моделью, иерархической моделью и реляционной моделью.
Каждая из тем четко объяснена с диаграммами и примерами, где это необходимо.
Введение в сетевую модель в СУБД
СУБД означает систему управления базами данных. СУБД — это компьютерное программное обеспечение, которое используется для организации, управления и манипулирования базами данных. СУБД предоставляет интерфейс для выполнения таких операций, как создание данных, обновление данных, создание таблицы в базе данных и многое другое.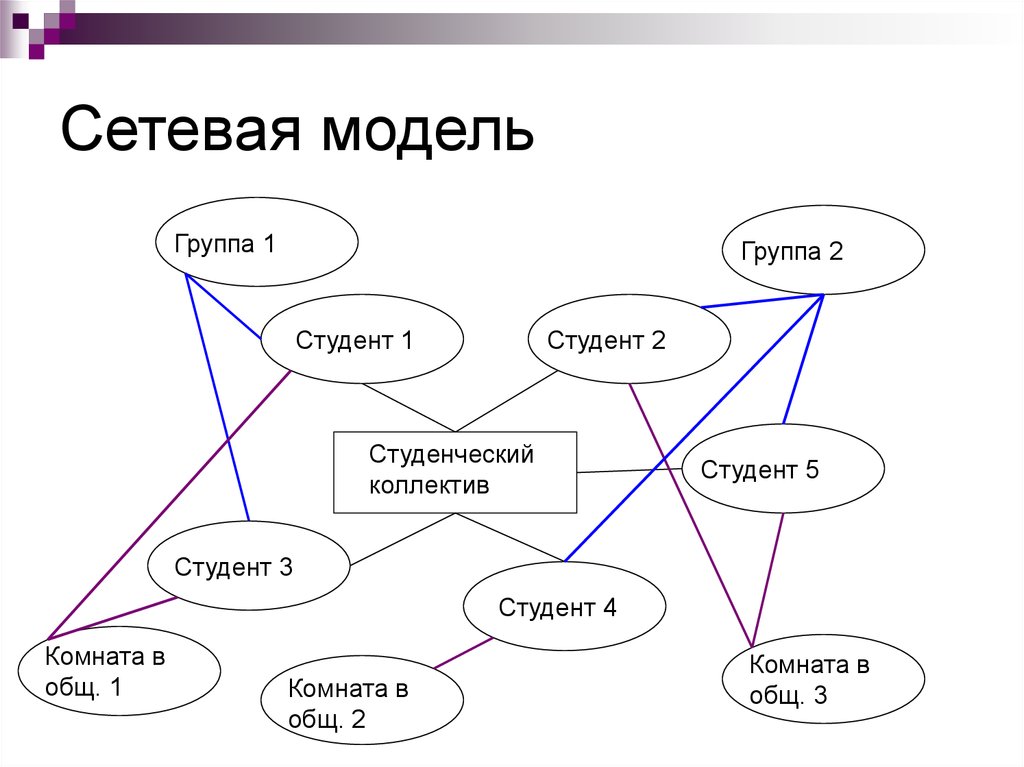
Модель базы данных — это логическое представление базы данных, т. е. ограничений и отношений между хранимыми данными. Модель базы данных обычно представлена в виде блок-схем, называемых диаграммой базы данных . Существуют различные типы моделей баз данных, такие как:
- Реляционная модель
- Иерархическая модель
- Сетевая модель
- Модель объектно-ориентированной базы данных
- Объектно-реляционная модель
- Модель отношения сущности
- Другие модели баз данных
- Модели баз данных NoSQL
- Базы данных в Интернете
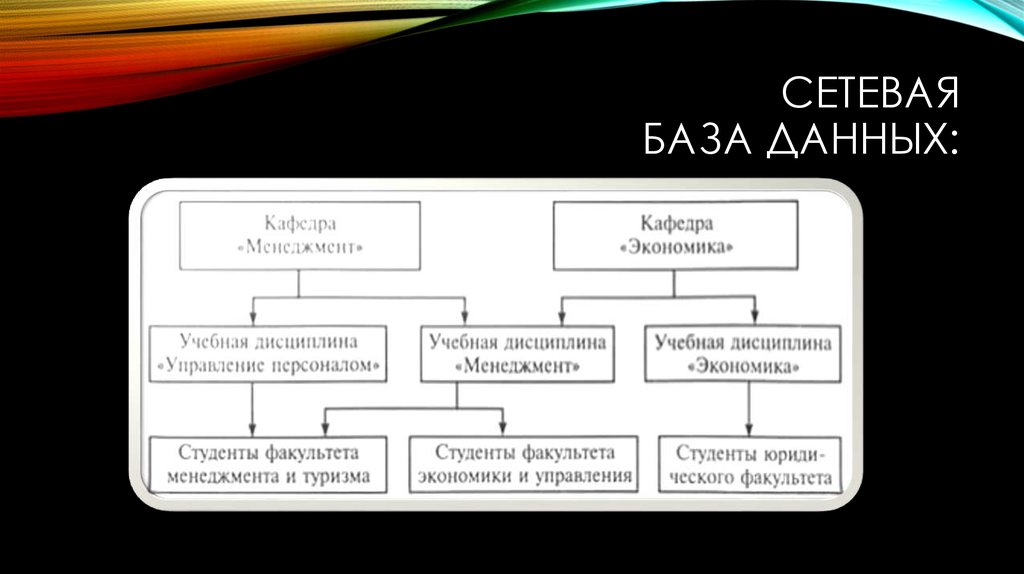
Сетевая модель в СУБД представляет собой иерархическую модель, которая используется для представления отношения «многие ко многим» между ограничениями базы данных. Это простая и легкая в построении модель базы данных. Сетевая модель в СУБД основана на теории множеств (математической теории множеств), поэтому модель базы данных строится с набором связанных записей (данных).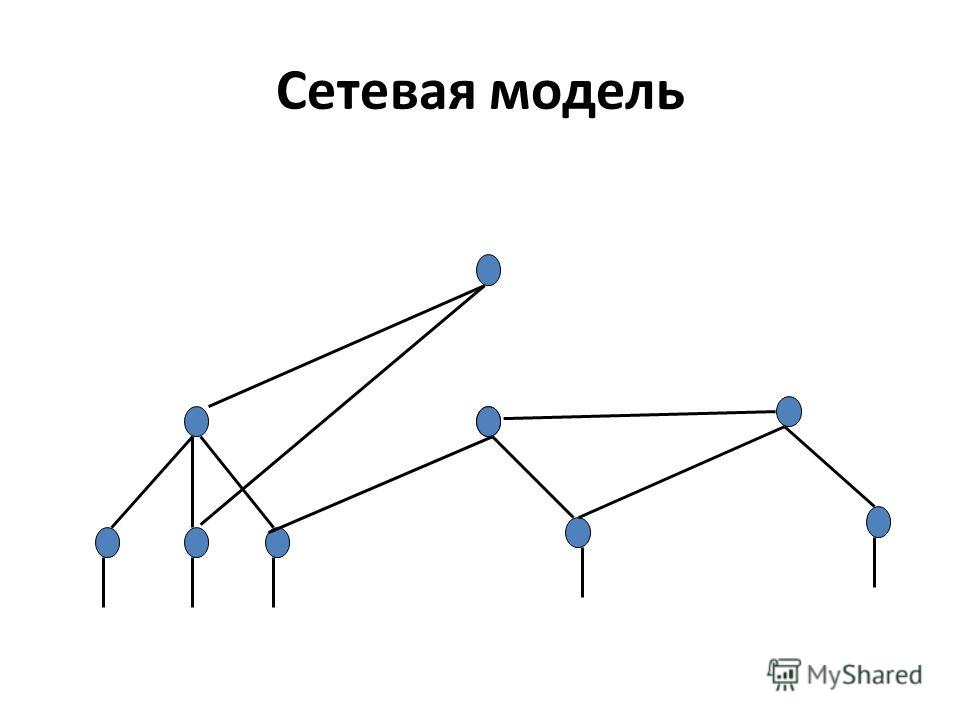
Сетевая модель в СУБД была одной из самых популярных моделей до появления реляционной модели, поскольку ее легко создавать и визуализировать. Он представлен в виде графика. Давайте возьмем пример простой базы данных колледжа, в которой есть два отдела или секции, а именно: отдел CSE и библиотека. Все студенты колледжа могут поступать на оба факультета. Итак, давайте попробуем представить эту иерархическую связь (обратитесь к диаграмме ниже для лучшей визуализации).
В приведенном выше примере у объекта Student есть два родителя, а именно — отдел CSE и библиотека. Отдел CSE и библиотека имеют один и тот же родительский колледж
Примечание . Сетевая модель в СУБД была формализована рабочей группой по базам данных в 1960-х годах.
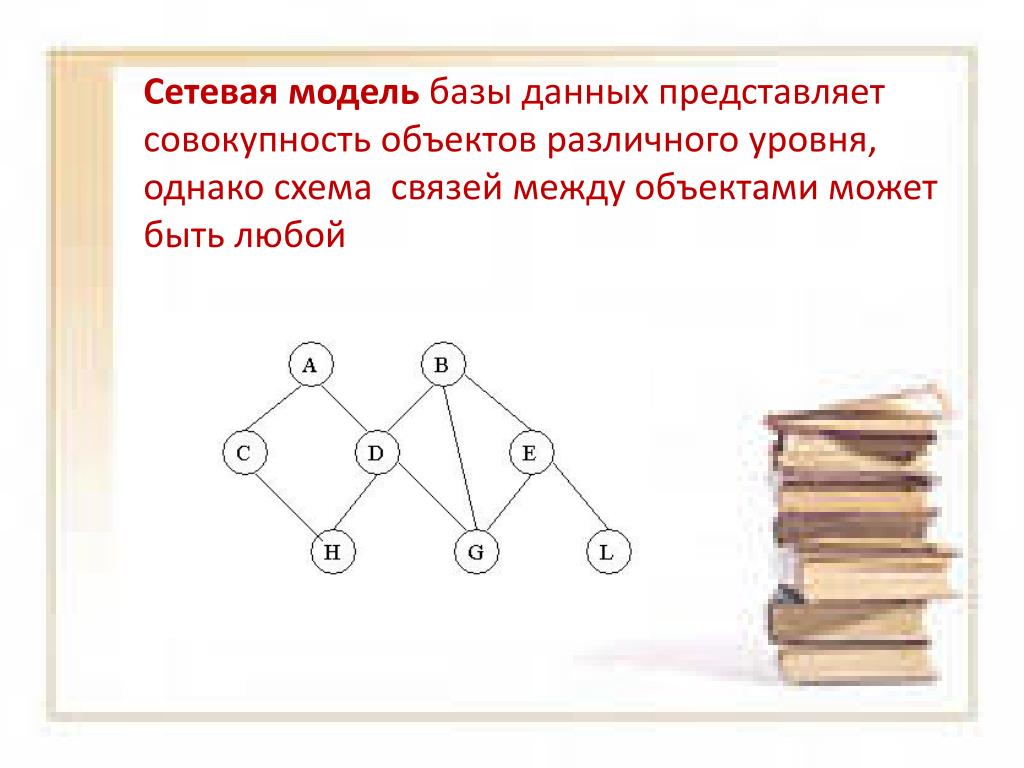
Структура сетевой модели в СУБД
Хотя сетевая модель в СУБД представляет собой иерархическую структуру, она отличается от иерархической модели базы данных тем, что у члена может быть множество родителей.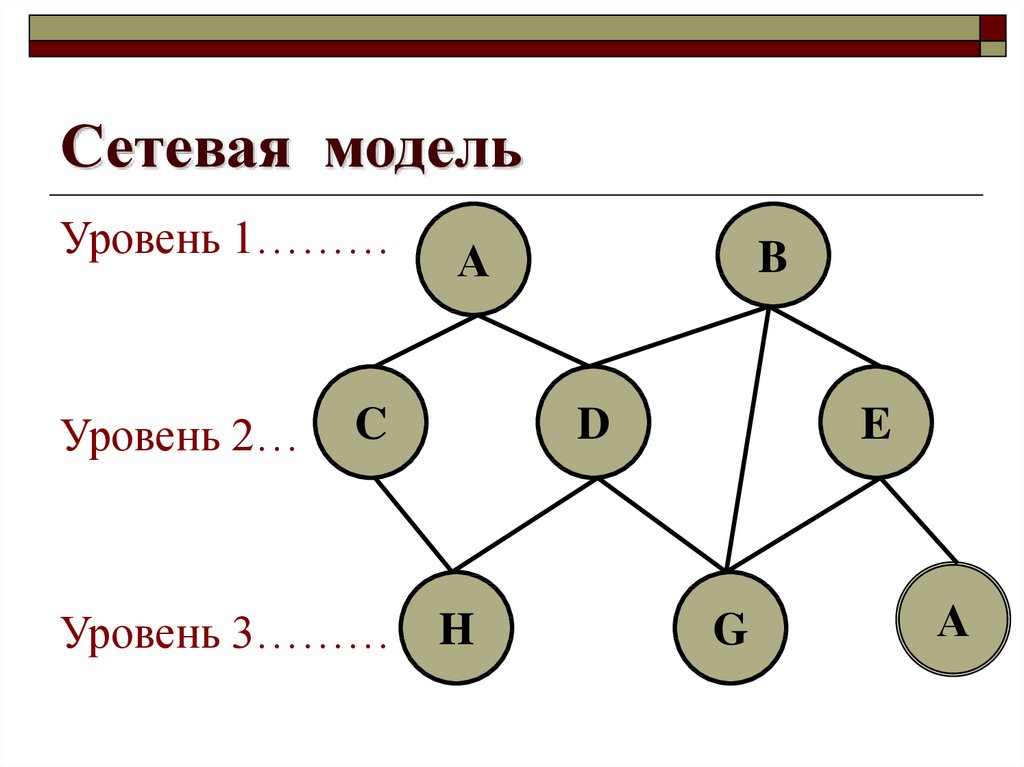
Возьмем базовую иерархическую структуру для визуализации структуры сетевой модели в СУБД.
Приведенная выше структура представляет сетевую модель, в которой ОДИН является основным владельцем модели (проще говоря, мы можем сказать, что остальные члены зависят от ОДНОГО). Аналогично, член ПЯТЬ имеет двух владельцев, а именно — ДВА и ТРИ. Модель сетевой базы данных допускает отношения 1 : 1 (один к одному), 1 : M (многие к одному), M : N (многие к одному) между объектами или элементами. Смоделированная иерархическая структура помогает избежать проблем с избыточностью данных, поскольку существует несколько путей к одной и той же записи.
Обратитесь к разделу «Примеры сетевой модели в СУБД», чтобы лучше понять пример из реальной жизни.
Характеристики сетевой модели
Давайте обсудим различные характеристики модели сетевой базы данных.
- Сетевая модель в СУБД лучше иерархической, так как больше взаимосвязей между сущностями.
- Поддерживает различные отношения, такие как «один к одному», «один ко многим» и «многие ко многим».
- Сущность может иметь разных родителей или владельцев.
- Связанная структура обеспечивает высокую производительность.
- Все объекты взаимосвязаны друг с другом как связанная сеть.
- Связанная сеть сущностей базы данных представлена в виде графика для лучшего представления, рабочего процесса и визуализации.
- Сетевая модель в СУБД не очень гибкая.
- Это также довольно сложная структура.
- К определенной записи в СУБД может быть несколько путей, что делает поиск данных более быстрым и простым.
- Операции, выполняемые в сетевой модели базы данных с использованием кругового связанного списка (дополнительные сведения см. в разделе «Операции в сетевой модели в СУБД»).
- Сетевая модель в СУБД не поддерживает средство запроса.
- Программы 3GL используются программистами для представления отношений между различными объектами сетевой модели в СУБД.
Примеры сетевой модели в СУБД
Возьмем базовый пример для визуализации структуры сетевой модели в СУБД.
Предположим, мы разрабатываем сетевую модель для базы данных Студенты. Как мы видим, сущность Subject имеет отношения как с сущностью Student, так и с сущностью Degree. Таким образом, существует грань, соединяющая сущность Subject со студентом и степенью.
Объект Subject имеет двух родительских объектов, а два других объекта имеют по одному дочернему объекту.
Другими примерами сетевой модели в СУБД могут быть: —
- База данных магазина (имеющая связь между клиентами, менеджером, продавцом, заказом, товарами и т. д.).
- База данных финансового отдела (имеющая связь между клиентами, продуктами, счетами, платежами и т. д.).
Примеры сетевых баз данных
Некоторые из известных сетевых баз данных могут быть:-
- TurboIMAGE
- Интегрированное хранилище данных (IDS)
- Диспетчер баз данных Raima
- Юнивак DMS-1100
- IDMS (интегрированная система управления базами данных) и т. д.
 д.
д.Операции с сетевой моделью в СУБД
Давайте обсудим различные операции, которые можно выполнять с сетевой моделью в СУБД.
Операция вставки — Мы можем вставить или добавить новую запись в модель сетевой базы данных, но перед добавлением любой новой записи администратор базы данных или пользователь должны понять всю структуру.
Операция обновления — Мы можем обновить записи данных. Если определенные данные обновляются, это также влияет на все его дочерние сущности.
Операция удаления — Мы можем удалить запись(и) данных, но удаление является очень важной операцией. Прежде чем удалять какую-либо запись, мы должны сначала проверить различные связанные объекты, чтобы удаление не повлияло на соответствующие объекты.
Операция извлечения — Извлечение записей в сетевой модели в СУБД достаточно сложно запрограммировать, но очень быстро, так как объекты взаимосвязаны и к определенным записям ведут различные пути.
Преимущества сетевой модели в СУБД
Теперь обсудим некоторые преимущества сетевой модели в СУБД:
- Это простая и легкая в построении иерархическая модель базы данных.
- Модель сети в СУБД допускает 1 : 1 (один к одному), 1 : M (многие к одному), M : N (многие к одному) отношения между сущностями или элементами.
- В сетевой модели СУБД существует несколько путей к одной и той же записи, что помогает избежать проблем с избыточностью данных.
- В сетевой модели СУБД существует целостность данных, так как у каждой сущности-члена есть один или несколько владельцев. Только главный родитель не имеет владельца, но имеет различные взаимосвязанные дочерние элементы.
- Извлечение данных происходит быстрее в случае сетевой модели в СУБД, поскольку сущности и данные более взаимосвязаны.
- Из-за отношения родитель-потомок, если есть изменение в родительском объекте, оно также отражается в дочернем объекте. Это также экономит время, поскольку нам не нужно обновлять все связанные дочерние объекты.
 Это также экономит время, поскольку нам не нужно обновлять все связанные дочерние объекты.
Это также экономит время, поскольку нам не нужно обновлять все связанные дочерние объекты.Недостатки сетевой модели в СУБД
Давайте теперь обсудим некоторые недостатки сетевой модели в СУБД:
- Модель сетевой базы данных очень сложна из-за нескольких объектов, взаимосвязанных друг с другом. Так что управлять тоже довольно сложно.
- В случае добавления новых сущностей администратор базы данных или пользователь должны понимать всю структуру.
- Из-за сложной взаимосвязанной структуры добавление, обновление, а также удаление очень затруднены.
- Автоматическая оптимизация запросов в СУБД не предусмотрена.
- Нам нужно использовать указатель для навигации, поэтому существуют операционные аномалии.
Сетевая модель VS Иерархическая модель VS Реляционная модель
Как мы уже видели, сетевая модель, иерархическая модель и реляционная модель несколько связаны друг с другом.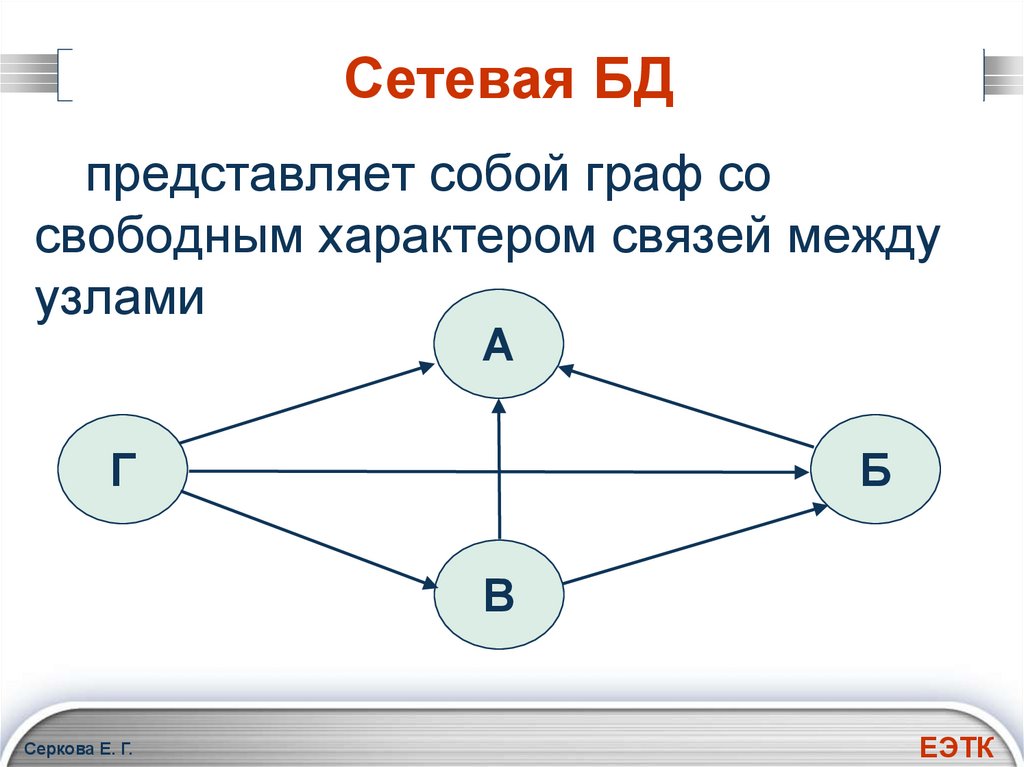 Давайте теперь обсудим разницу между ними.
Давайте теперь обсудим разницу между ними.
| Модель сетевых данных | Модель иерархических данных | Модель реляционных данных |
|---|---|---|
| . | В иерархической модели данных представление выполняется в виде отношения родитель-потомок. | В реляционной модели данных мы используем ключи для представления отношений между записями. |
| Отношение между сущностями может быть в форме отношения «многие ко многим». | Отношение между сущностями не может быть в форме отношения «многие ко многим». | Отношение между сущностями может быть проще в форме отношения «многие ко многим». |
| Нет проблем с несогласованностью данных. | Существует вероятность несогласованности данных при обновлении и удалении данных.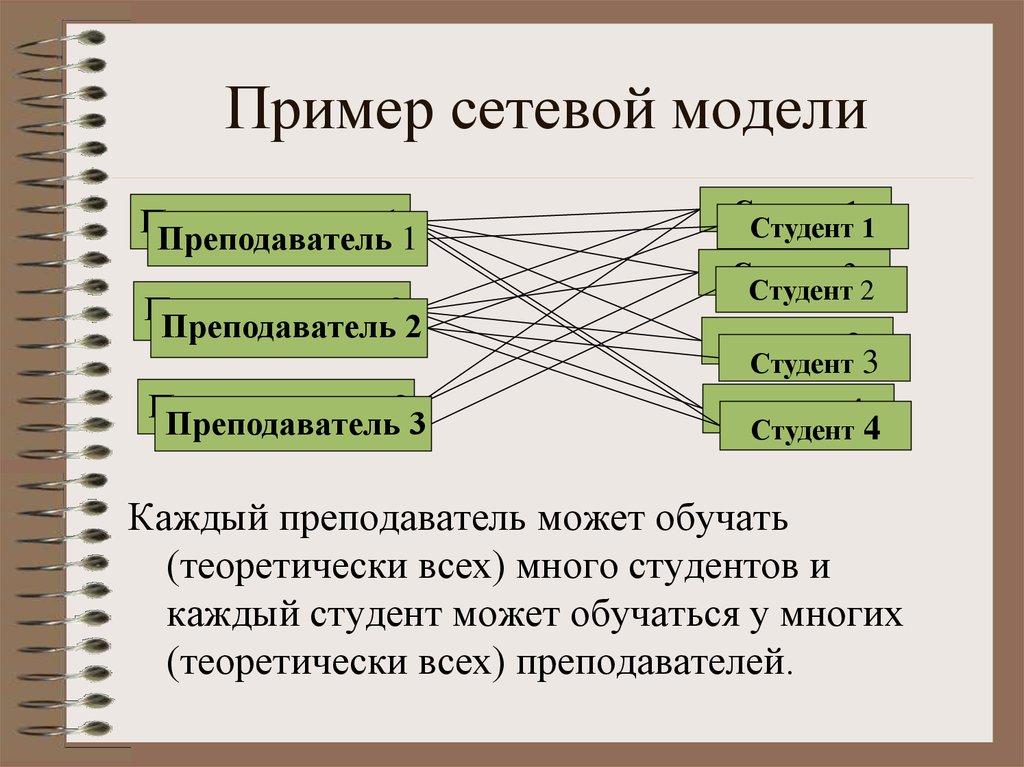 | Поддерживает целостность и согласованность данных с помощью метода нормализации. |
| Отношения между записями довольно сложны из-за использования указателей. | Существуют различные методы реализации связи между сущностями, такие как простой, естественный и прямой. | Мы используем ключи (такие как первичные ключи, внешние ключи, составные ключи и т. д.) для представления отношений между различными сущностями. |
| Поиск записи очень прост, так как существует множество путей к определенной записи. | Поиск записи очень сложен, поскольку дочернюю запись можно найти только после просмотра родительской записи. | Мы используем уникальный ключ (ключ-идентификатор) для поиска записей. |
| Очень полезно представлять записи, имеющие отношение «многие ко многим». | Это очень полезно в тех случаях, когда между сущностями существует некоторая иерархическая связь. | Очень полезно представлять объекты реального мира и отношения между различными объектами. |
Заключение
- Модель базы данных — это логическое представление базы данных, т. е. ограничений и отношений между хранимыми данными.
- Сетевая модель в СУБД — это иерархическая модель, которая используется для представления отношения «многие ко многим» между ограничениями базы данных.
- Сетевая модель в СУБД представляет собой иерархическую структуру, но отличается от иерархической модели базы данных тем, что у члена может быть множество родителей.
- Модель сети в СУБД допускает 1 : 1 (один к одному), 1 : M (многие к одному), M : N (многие к одному) отношения между сущностями или члены.
- В сетевой модели СУБД существует несколько путей к одной и той же записи, что помогает избежать проблем с избыточностью данных.
- В сетевой модели СУБД существует целостность данных, так как у каждой сущности-члена есть один или несколько владельцев. Только главный родитель не имеет владельца, но имеет различные взаимосвязанные дочерние элементы.
- Модель сетевой базы данных очень сложна из-за нескольких объектов, взаимосвязанных друг с другом. Так что управлять тоже довольно сложно.
 Только главный родитель не имеет владельца, но имеет различные взаимосвязанные дочерние элементы.
Только главный родитель не имеет владельца, но имеет различные взаимосвязанные дочерние элементы.Подробнее:
- Кортеж в СУБД.
- Аномалии в СУБД.
- Структура СУБД.
- Типы баз данных.
- Недостатки СУБД.
Модель сетевой базы данных против. Модель реляционной базы данных
Мы анализируем плюсы и минусы модели реляционной и сетевой базы данных. Как работает каждая модель и подчеркивает сильные и слабые стороны и возможности каждой модели. Различия между этими двумя моделями могут привести к успеху или неудаче при разработке приложения.
Далее обсуждается, как работает каждая модель, и выделяются сильные и слабые стороны и возможности каждой модели. Различия между этими двумя моделями могут привести к успеху или неудаче при разработке приложения.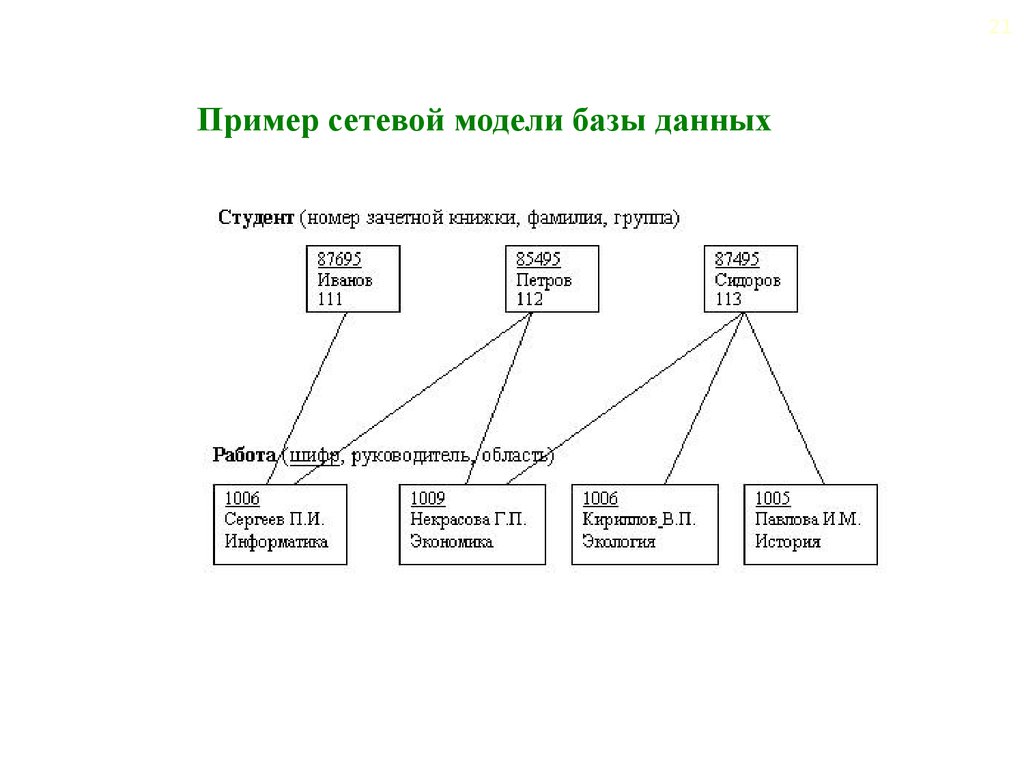
Модель реляционной базы данных
Вы сидите в автобусе и направляетесь домой. Немного уставший, но не такой уж сонный, вы решаете послушать Bon Jovi. Если подумать, вы хотите посмотреть один из его фильмов (на ум приходит Cry Wolf). Поиск в центре внимания iPhone хорош. Введите «Bon Jovi» в качестве ключевого слова, и медиаплеер легко найдет их музыку и фильмы — две разные категории — хранящиеся на устройстве.
Обычные операции, подобные приведенным выше, обычно используют систему управления реляционными базами данных (RDBMS). База данных, назовем ее Media Collection, определяет три таблицы ARTIST, ALBUM и MOVIE, где соответственно хранятся имена исполнителей, альбомов и названий фильмов. Когда выбран конкретный артист, например Bon Jovi в нашем примере, выдается SQL-запрос для получения всех альбомов и названий фильмов, принадлежащих выбранному артисту. Возвращенные данные отображаются на экране iPhone, как правило, в алфавитном порядке.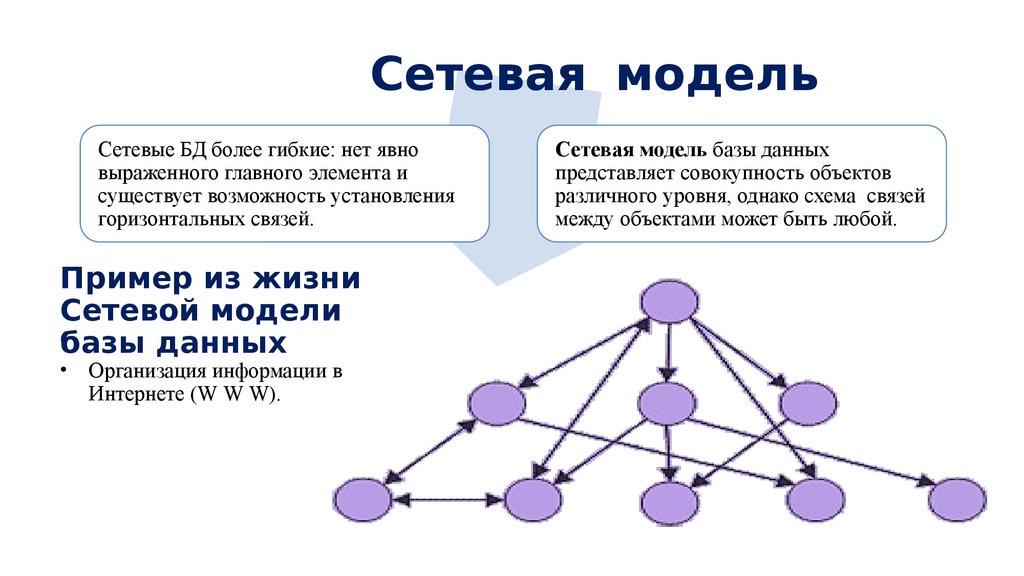
Недостатки реляционной модели данных
Эти, казалось бы, простые шаги раскрывают два основных недостатка, присущих реляционной модели данных. Первая слабость заключается в том, что каждое отношение требует дублирования столбцов в обеих связанных с ним таблицах. Например, обе таблицы ARTIST и ALBUM должны содержать и поддерживать столбец, в котором хранятся имена исполнителей, чтобы можно было установить связь между исполнителем и его альбомами. Это означает, что для поддержания «синхронизации» двух столбцов требуется дополнительное пространство для хранения, а также накладные расходы на программирование. Изменение имени исполнителя означает, что все записи АЛЬБОМА для этого исполнителя должны обновить столбец «имя исполнителя».
Вторым недостатком и более важным аспектом этой статьи является тот факт, что одно отношение может содержать только две таблицы: таблицу первичного ключа (основную) и таблицу внешнего ключа (ссылочную).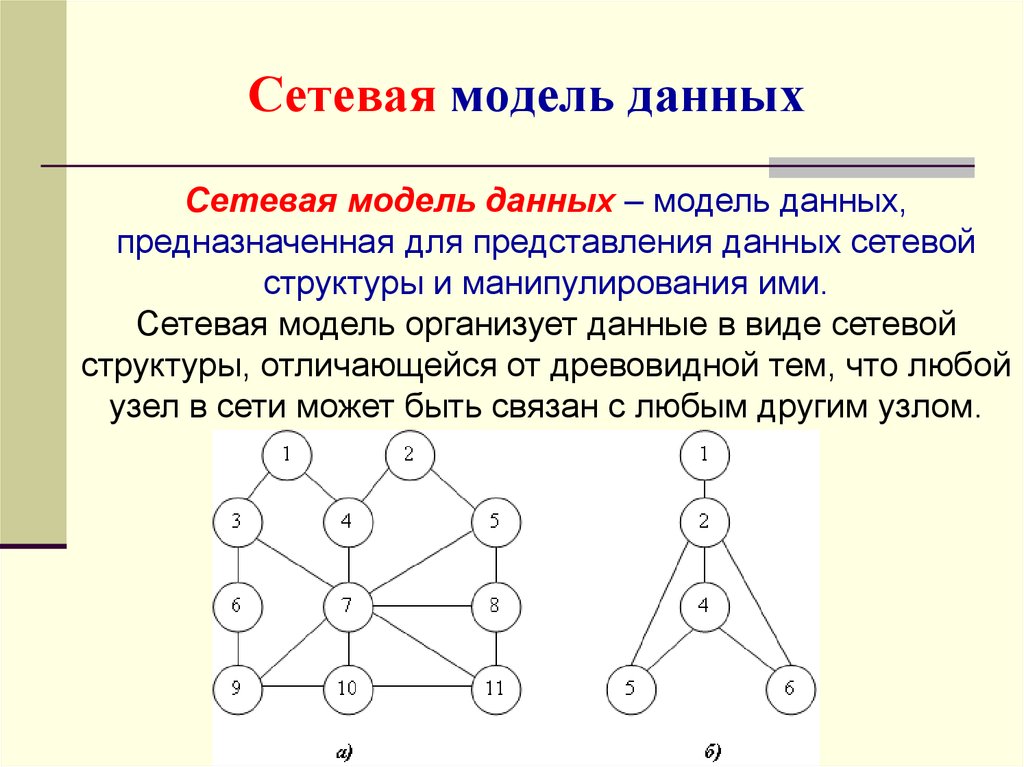 В базе данных Music Collection и таблица ALBUM, и таблица MOVIE должны ссылаться на таблицу ARTIST. Из-за этого ограничения необходимо определить два отдельных отношения; один включает ссылку таблицы ALBUM на таблицу ARTIST, а другой содержит таблицу MOVIE, ссылающуюся на таблицу ARTIST.
В базе данных Music Collection и таблица ALBUM, и таблица MOVIE должны ссылаться на таблицу ARTIST. Из-за этого ограничения необходимо определить два отдельных отношения; один включает ссылку таблицы ALBUM на таблицу ARTIST, а другой содержит таблицу MOVIE, ссылающуюся на таблицу ARTIST.
Неэффективная операция поиска данных — реляционная модель данных
Это приводит к довольно неэффективной операции поиска данных при поиске всех альбомов и фильмов, связанных с исполнителем. Во время первой операции система базы данных извлекает все связанные альбомы из таблицы ALBUM и сохраняет набор результатов во временном расположении. Во время второй операции выполняется тот же процесс, что и в первой, только на этот раз он извлекает результаты из MOVIES. Последняя операция объединяет два набора результатов, при необходимости переупорядочивает их, а затем возвращает объединенный набор результатов.
Неэффективность реляционной модели не может быть решающим фактором, когда объем данных в базе данных относительно невелик, а вычислительных ресурсов достаточно, тем более, что сегодня обычный человек нередко владеет компьютером с тактовой частотой 2 ГГц.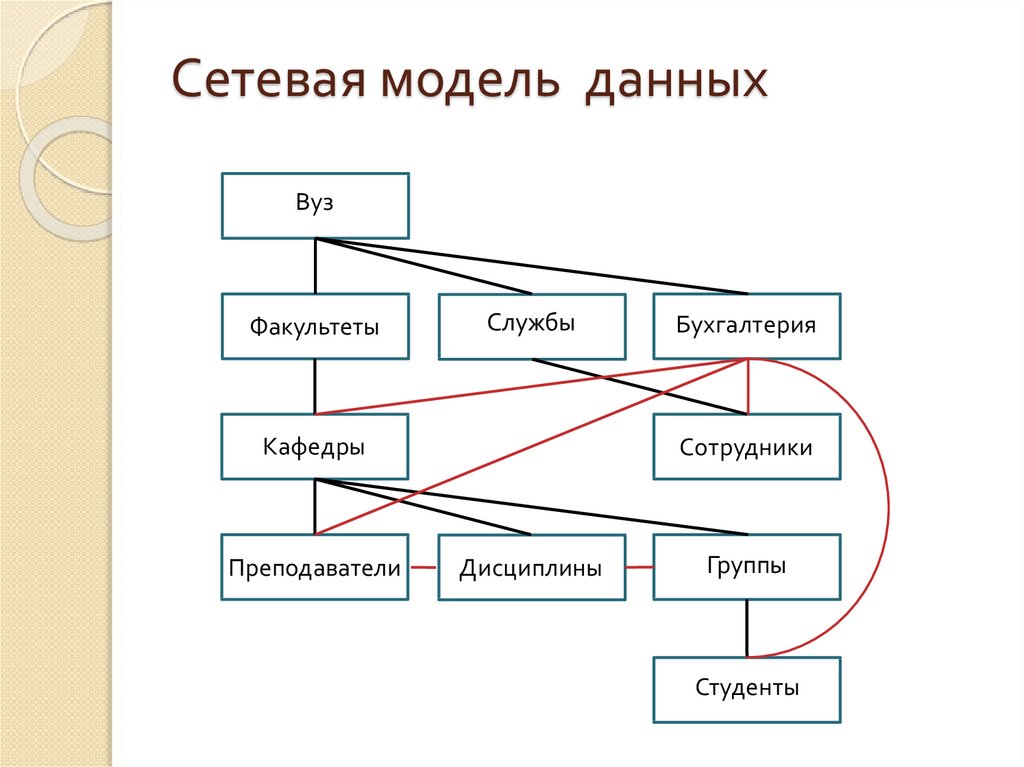 двухъядерный процессор с 2 ГБ памяти и жестким диском на 500 ГБ. С другой стороны, существует быстро развивающийся рынок небольших компьютеров, для которых требуется система баз данных (СУБД) — смартфонов, портативных музыкальных плееров и устройств GPS, и это лишь некоторые из них. При ограниченной скорости ЦП и памяти эти портативные системы могут значительно выиграть от СУБД, которая обеспечивает гибкое и эффективное хранение и извлечение данных с точки зрения как производительности, так и использования дискового пространства.
двухъядерный процессор с 2 ГБ памяти и жестким диском на 500 ГБ. С другой стороны, существует быстро развивающийся рынок небольших компьютеров, для которых требуется система баз данных (СУБД) — смартфонов, портативных музыкальных плееров и устройств GPS, и это лишь некоторые из них. При ограниченной скорости ЦП и памяти эти портативные системы могут значительно выиграть от СУБД, которая обеспечивает гибкое и эффективное хранение и извлечение данных с точки зрения как производительности, так и использования дискового пространства.
Модель сетевой базы данных предлагает именно это.
Модель сетевой базы данных
Расширенная форма иерархической модели данных, сетевая модель представляет данные в виде дерева записей. Отношения между таблицами (записями) выражаются в виде наборов. Набор имеет одну родительскую запись (владелец) и одну или несколько дочерних записей (членов). Связанные записи в наборе напрямую связаны указателями, а не сопоставлением повторяющихся столбцов, как в случае реляционной модели данных.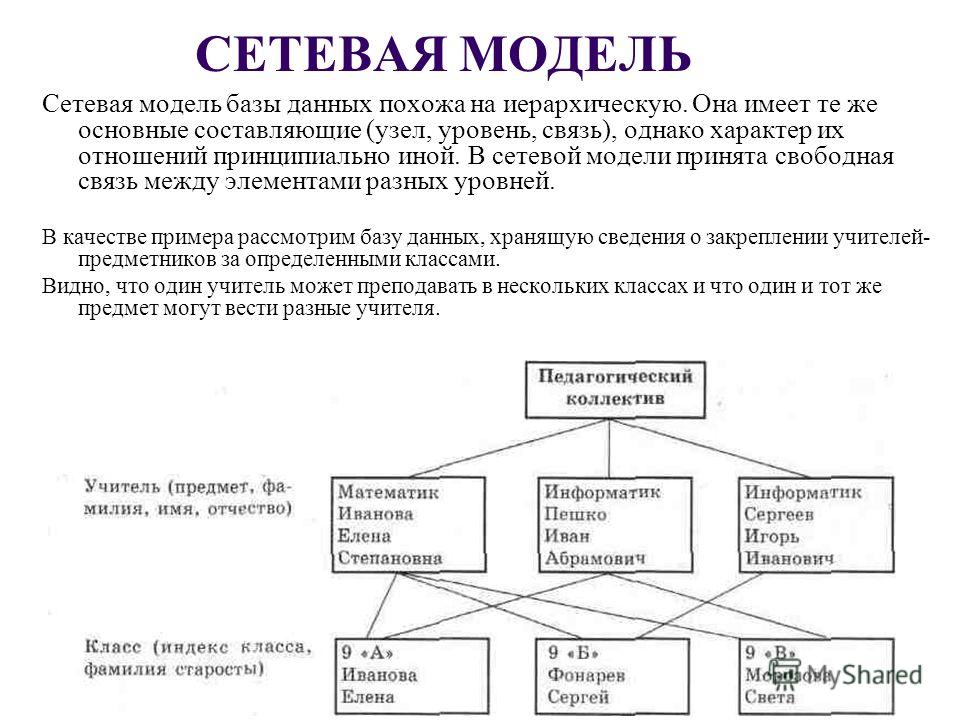
Модель сетевой базы данных позволяет связать записи из более чем одной таблицы с одной записью владельца другой таблицы. Это дает определенное преимущество перед реляционным аналогом при запросе результатов из нескольких таблиц внешних ключей, связанных с одной таблицей первичного ключа. В базе данных Media Collection записи ALBUM и MOVIE также могут быть элементами записи ARTIST в одном наборе, как показано на рис. 2. Это означает, что и альбомы, и фильмы для данного исполнителя могут быть извлечены за одну операцию. Это избавляет от необходимости хранить и потенциально переупорядочивать временные результаты в середине операции, что повышает производительность запросов. Сетевые базы данных без необходимости хранить и поддерживать повторяющиеся столбцы также помогают сократить использование дискового пространства и памяти.
Практический пример производительности
Реальные данные показывают, что прирост производительности и экономия ресурсов при использовании сетевых баз данных могут быть весьма значительными.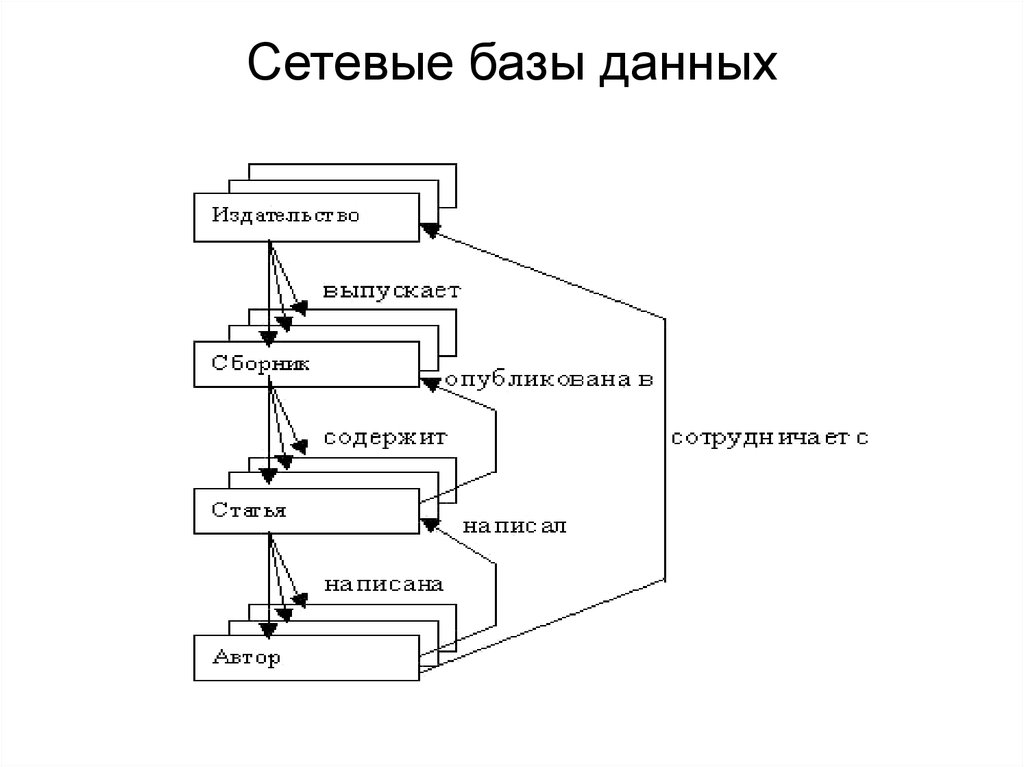 В структуре данных, использующей трехстороннюю связь между таблицами ARTIST, ALBUM и SONG, наши разработчики SQL сравнили модификацию данных и производительность запросов реляционных и сетевых моделей баз данных с использованием как настольных систем, так и небольших потребительских устройств. Они обнаружили, что сетевая модель использовала 29на процент меньше места на диске для хранения такого же количества записей и отношений, как в реляционной модели данных. Всю экономию памяти можно отнести к замене индексов внешнего ключа ARTIST-ALBUM и ALBUM-SONG указателями на наборы.
В структуре данных, использующей трехстороннюю связь между таблицами ARTIST, ALBUM и SONG, наши разработчики SQL сравнили модификацию данных и производительность запросов реляционных и сетевых моделей баз данных с использованием как настольных систем, так и небольших потребительских устройств. Они обнаружили, что сетевая модель использовала 29на процент меньше места на диске для хранения такого же количества записей и отношений, как в реляционной модели данных. Всю экономию памяти можно отнести к замене индексов внешнего ключа ARTIST-ALBUM и ALBUM-SONG указателями на наборы.
Удаление этих структур данных сильно повлияло на требования к хранилищу, поскольку типичный индекс B-Tree требует примерно в 1,3 раза больше места, чем он индексирует. Они также обнаружили, что модель сетевой базы данных обеспечивает до 23 раз более высокую производительность операций вставки и до 123 раз более высокую производительность запросов, как показано в таблице 1.
Таблица 1.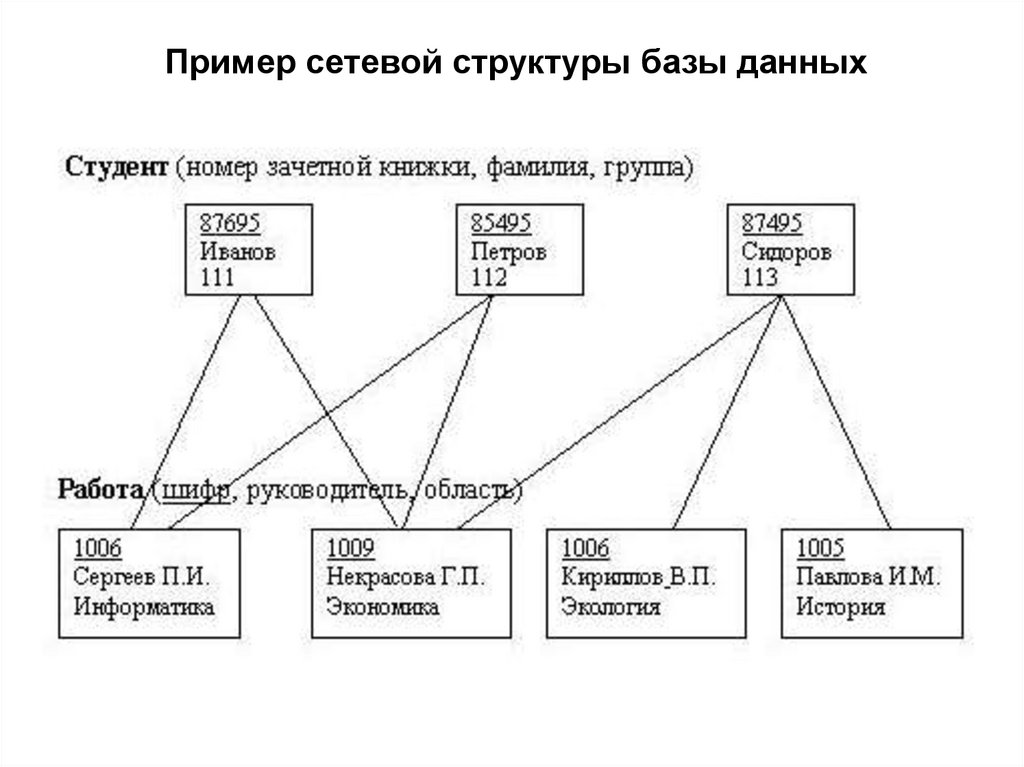 Результаты сравнительного анализа реляционных и сетевых моделей в системах x86 и ARM7.
Результаты сравнительного анализа реляционных и сетевых моделей в системах x86 и ARM7.
Различные требования к управлению означают разные структуры данных и разные методы хранения данных и доступа к ним. Результирующая система может состоять из нескольких таблиц без связей или из сотен таблиц, связанных сложными связями. Хотя реляционная модель данных является стандартом де-факто, теперь мы знаем, что она не всегда обеспечивает оптимальные решения для более сложных задач управления данными. Выбор подходящей модели данных или даже объединение нескольких моделей может дать гораздо более эффективный результат, чем реляционная модель данных в отдельности. Результатом является значительная экономия средств, повышение качества и улучшение пользовательского опыта.
Заключение. Сетевая модель для скорости, реляционная для удобства использования
Хотя реляционная модель данных очень популярна из-за простоты использования, она требует ключевых и индексных таблиц, которые значительно замедляют работу.