Хекслет — больше чем школа программирования. Онлайн курсы, сообщество программистов
Студенты Хекслета проходят гарантированные собеседования в компаниях-партнёрах
Начать учиться бесплатно
Первого студента мы трудоустроили в 2013 году. Тогда требования к знаниям джуниоров были выше, а трава зеленее
Это отразилось на программах обучения, на их проработке и глубине. Собеседования для студентов Хекслета проходят под девизом: «Хм, на Хекслете задачки были сложнее»
Иногда наши студенты попадают на работу без проведения технического интервью, только на основе анализа кода проектов
Сейчас все больше и больше компаний указывают курсы Хекслета как плюс при найме. А наши партнерские компании доверяют нам настолько, что собеседуют выпускников, не заглядывая в резюме
Наши выпускники работают практически во всех крупных IT-компаниях
Некоторые — на позиции технического директора
Хотите стать партнером Хекслета и нанимать лучших выпускников к себе в компанию?
Оставляйте заявку, а дальше мы поможем!
Уговорили! Как начать учиться?
1. Определиться с направлением
Определиться с направлением
Хекслет проводит дни открытых дверей, открытые уроки, публикует истории успехов и аналитику по рынку
Дни открытых дверей
Истории успеха
Перспективность направлений разработки
2. Выбрать программу обучения
Подходит, если вы уже примерно представляете, что хотите. Если не знаете с чего начать, попробуйте профессию «Фронтенд-разработчик». Наиболее универсальный и популярный вариант
Фронтенд-разработчик
Онлайн-буткемп. Фронтенд-разработчик
Аналитик данных
Python-разработчик
Java-разработчик
PHP-разработчик
Инженер по тестированию
Node.js-разработчик
Fullstack-разработчик
Верстальщик
Инженер по автоматизированному тестированию на JavaScript
3. Начать проходить бесплатную часть
Попробуйте наши бесплатные курсы. Их рекомендуют для старта в профессии опытные разработчики, а другие школы используют для обучения своих студентов
Введение в программирование
Основы современной верстки
Основы командной строки
Введение в Git
А что если?
«Я 35-летний гуманитарий, который забыл школьную математику, а вместо английского учил немецкий.Работа отнимает весь день и приходится мотаться в командировки. У меня семья, ипотека и два кота, а друзья говорят: «Зачем тебе это?». Не уверен, что потяну…»
 Работа отнимает весь день и приходится мотаться в командировки. У меня семья, ипотека и два кота, а друзья говорят: «Зачем тебе это?». Не уверен, что потяну…»
Работа отнимает весь день и приходится мотаться в командировки. У меня семья, ипотека и два кота, а друзья говорят: «Зачем тебе это?». Не уверен, что потяну…»Подобные вопросы нам задают буквально каждый день. Ответ здесь один: не попробуешь — не поймешь. Как Хекслет помогает начать, ничего не теряя?
- В начале каждой программы — бесплатные курсы с полноценной практикой
- Возможность переключиться на любую другую программу прямо в процессе
- Мягкие дедлайны. Учитесь в своем темпе и не переживайте насчет отчисления
- Полный возврат денег в течение первых двух недель, если не пошло
Чем ваше обучение отличается от других?
Помимо большого количества практик, тренажера в браузере, проектов, наставников и других атрибутов, входящих в стандартный набор хорошего обучения, у нас есть еще несколько важных отличий
Хекслет создается и развивается программистами, мы даем то, что знаем сами, в чем хорошо разбираемся. И программирование — наш единственный фокус
И программирование — наш единственный фокус
Основатель проекта Кирилл Мокевнин ведет популярный twitter , регулярно выступает на технических конференциях (аж с 2010 года), в подкастах — в качестве приглашенного гостя, проводит публичные интервью и делает вебинары о разработке на YouTube-канале
Немного цифр. С нами работают более 150 наставников, более 20 партнерских компаний. Мы поддерживаем более 10 открытых проектов (Open Source) и создали тысячи практик, доступных в тренажере
3883 студента начали учиться на Хекслете за последнюю неделю
Готовы попробовать?
20 курсов бесплатно
Электронная почта *
Отправляя форму, вы принимаете «Соглашение об обработке персональных данных» и условия «Оферты», а также соглашаетесь с «Условиями использования»
Курсы программирования, обучение онлайн
Еще больше курсов в профессиях Хекслета!
- Курсы в профессиях собраны в логическом для изучения порядке и подкрепляются проектами
- Каждая программа — роадмап для новичка: что учить, чтобы трудоустроиться
- Во всех профессиях есть бесплатные курсы для знакомства с форматом обучения
Выбрать профессию
Курсы JavaScript
Фронтенд-разработчик
Разработка фронтенд-компонентов для веб-приложений
30 марта
10 месяцев
Посмотреть
Онлайн-буткемп.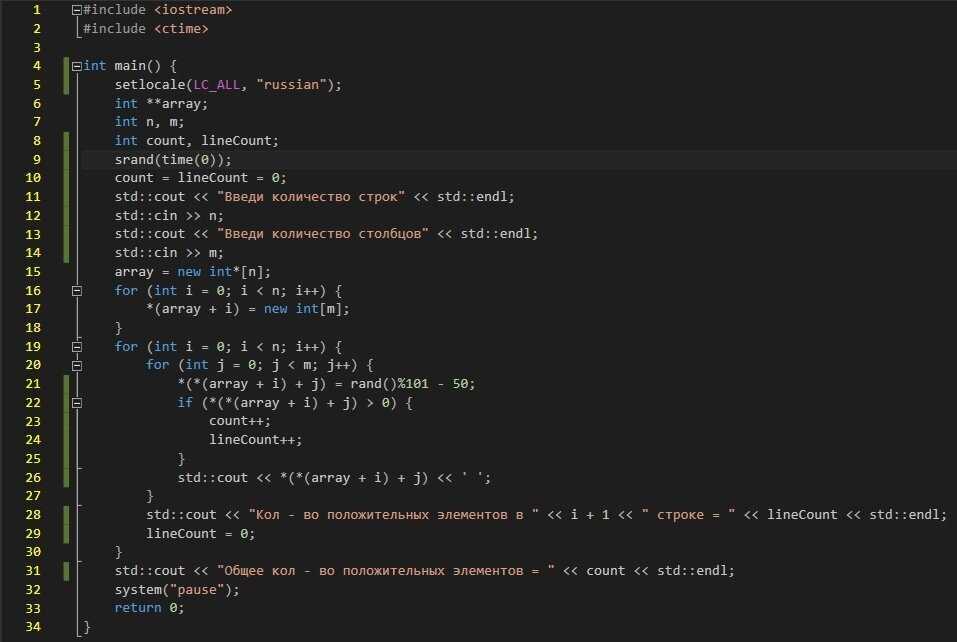 Фронтенд-разработчик
Фронтенд-разработчик
Интенсивное обучение профессии в режиме полного дня
20 апреля
4 месяца
Посмотреть
Node.js-разработчик
Разработка бэкенд-компонентов для веб-приложений
30 марта
10 месяцев
Посмотреть
Fullstack-разработчик
Разработка фронтенд- и бэкенд-компонентов для веб-приложений
30 марта
16 месяцев
Посмотреть
Инженер по автоматизированному тестированию на JavaScript
Автоматизированное тестирование веб-приложений на JavaScript
дата определяется
10 месяцев
Посмотреть
Основы JavaScript
модули
импорты
отладка программы
ошибки
50 часов
Посмотреть
Основы алгоритмов и структур данных
Алгоритмы сортировки
Структуры данных
Бинарный поиск
Жадные алгоритмы
11 часов
Посмотреть
JS: React
состояние
компоненты
производительность
26 часов
Посмотреть
JS: Введение в ООП
классы
инкапсуляция
контекст
прототипы
15 часов
Посмотреть
JS: DOM API
полифиллы
события
селекторы
20 часов
Посмотреть
JS: Redux (React)
middlewares
redux-forms
actions
reselect
5 часов
Посмотреть
JS: Express
шаблонизация
мидлвары
тестирование
11 часов
Посмотреть
JS: Асинхронное программирование
промисы
event loop
обработка ошибок
таймеры
18 часов
Посмотреть
JS: Автоматическое тестирование
утверждения
матчеры
юнит-тесты
14 часов
Посмотреть
Разработка на JavaScript
Все курсы по языку в готовых профессиях:
от 4 месяцев
группа с наставником
портфолио
от 6 300 ₽ в месяц
Учить фронтенд
Фронтенд-буткемп
Учить бэкенд
Стать фулстеком
JS QA-инженер
Курсы PHP
PHP-разработчик
Разработка веб-приложений на Laravel
30 марта
10 месяцев
Посмотреть
Основы PHP
пространства имен
импорты
ссылки
включения файлов
52 часа
Посмотреть
PHP: Автоматическое тестирование
утверждения
PHPUnit
юнит-тесты
покрытие кода
13 часов
Посмотреть
PHP: Eloquent (ORM)
предметная область
Active Record
модели и связи
query builder
10 часов
Посмотреть
Веб-разработка на PHP
slim framework
шаблонизация
отправка форм
24 часа
Посмотреть
PHP: Введение в ООП
классы
инкапсуляция
интерфейсы
исключения
21 час
Посмотреть
PHP: Разработка на Laravel
шаблонизация (blade)
роутинг
контроллеры
20 часов
Посмотреть
PHP-разработчик
Все курсы по языку в профессии:
10 месяцев
группа с наставником
портфолио
6 300 ₽ в месяц
Узнать подробности
Курсы Python
Python-разработчик
Разработка веб-приложений на Django
30 марта
10 месяцев
Посмотреть
Основы Python
модули
пакеты
импорты
ошибки
56 часов
Посмотреть
Python: Автоматическое тестирование
утверждения
pytest
юнит-тесты
покрытие кода
13 часов
Посмотреть
Python: Веб-разработка (Flask)
шаблонизация
методы http
роутинг
21 час
Посмотреть
Python: Введение в ООП
классы
инкапсуляция
связывание
исключения
12 часов
Посмотреть
Python: Разработка на фреймворке Django
роутинг
миграции
шаблонизация
21 час
Посмотреть
Python: Numpy-массивы
Python
массивы
11 часов
Посмотреть
Python: Django ORM
Python Django
11 часов
Посмотреть
Python-разработчик
Все курсы по языку в профессии:
10 месяцев
группа с наставником
портфолио
6 300 ₽ в месяц
Узнать подробности
Курсы HTML и CSS
Верстальщик
Верстка с использованием последних стандартов CSS
в любое время
5 месяцев
Посмотреть
Основы современной верстки
Developer Tools
Верстка
9 часов
Посмотреть
CSS: Адаптивность сайта
Viewport
Гибкие макеты
Media Queries
7 часов
Посмотреть
CSS: Позиционирование элементов
позиционирование
HTML-элементы
вёрстка
9 часов
Посмотреть
Bootstrap 5: Основы верстки
CSS адаптивность
Bootstrap 5
10 часов
Посмотреть
HTML: Препроцессор Pug
Миксины
Шаблонизатор
9 часов
Посмотреть
Таск-менеджер
Автоматизация работы
6 часов
Посмотреть
CSS: Вёрстка на Grid
вёрстка
CSS Grid
6 часов
Посмотреть
Основы верстки контента
селекторы
Доступность
18 часов
Посмотреть
CSS: Основы Flex
CSS Flex
CSS адаптивность
Верстка
10 часов
Посмотреть
SASS: Основы работы
Препроцессоры CSS
Миксины
4 часа
Посмотреть
Верстальщик
Все курсы по языку в профессии:
в любое время
самостоятельно
портфолио
по подписке за 3 900 ₽ в месяц
Узнать подробности
Курсы Java
Java-разработчик
Разработка приложений на языке Java
30 марта
10 месяцев
Посмотреть
Основы Java
основы Java
методы
переменные
константы
37 часов
Посмотреть
Java: Веб-технологии
деплой
сервлет-контейнеры
69 часов
Посмотреть
Java: Введение в ООП
классы
методы
Объекты
интерфейсы
11 часов
Посмотреть
Java: Основы ООП
классы
интерфейсы
полиморфизм
наследование
35 часов
Посмотреть
Java: Автоматическое тестирование
утверждения
матчеры
юнит-тесты
14 часов
Посмотреть
Java-разработчик
Все курсы по языку в профессии:
10 месяцев
группа с наставником
портфолио
6 300 ₽ в месяц
Узнать подробности
Курсы Ruby
Разработчик на Ruby on Rails
Создание веб-приложений со скоростью света
30 марта
5 месяцев
Посмотреть
Основы Ruby
testing
metaprogramming
64 часа
Посмотреть
Основы разработки на Ruby on Rails
rest api
job workers
52 часа
Посмотреть
Разработчик на Ruby on Rails
Все курсы по языку в профессии:
5 месяцев
группа с наставником
портфолио
5 840 ₽ в месяц
Узнать подробности
Курсы SQL
Аналитик данных
Сбор, анализ и интерпретация данных
20 апреля
9 месяцев
Посмотреть
Основы реляционных баз данных
postgresql
транзакции
нормальные формы
27 часов
Посмотреть
Курсы Инструменты
Основы командной строки
терминал
команды linux
22 часа
Посмотреть
Введение в Git
github
рабочая директория
клонирование
восстановление
18 часов
Посмотреть
Основы автоматизации в Ansible
плейбук
файл инвентаризации
деплой
автоматизация развертывания
22 часа
Посмотреть
DevOps: Управление инфраструктурой
terraform
clouds
consul
2 часа
Посмотреть
Docker: Основы
docker
docker-compose
3 часа
Посмотреть
Vagrant: Основы
vagrant
virtualbox
virtualization
3 часа
Посмотреть
Администрирование Linux
интерфейсы
процессы
9 часов
Посмотреть
Продакшен и Деплой
мониторинг
деплой
масштабирование
веб-сервер
3 часа
Посмотреть
Основы Redis
key-value БД
кэширование
брокер сообщений
14 часов
Посмотреть
Terraform: Основы
инфраструктура как код
провайдер
создание ресурсов
автоматизация развертывания
2 часа
Посмотреть
Непрерывная интеграция (CI)
GitHub Actions
Workflows
2 часа
Посмотреть
Курсы Разное
Инженер по тестированию
Ручное тестирование веб-приложений
30 марта
4 месяца
Посмотреть
Операционные системы
компьютер
процессы
4 часа
Посмотреть
Введение в интернет
интернет
компьютерные сети
4 часа
Посмотреть
Изучение английского языка
цели и план обучения
английский язык
инструменты
3 часа
Посмотреть
Трудоустройство для разработчиков
стажировка
портфолио
первая работа
опенсорс
2 часа
Посмотреть
Жизнь программиста
языки программирования
пути карьерного роста
терминология
3 часа
Посмотреть
Трудоустройство
стажировка
резюме
портфолио
первая работа
5 часов
Посмотреть
Введение в тестирование веб-приложений
devtools
тестирование ui
17 часов
Посмотреть
Теория графов
смежные и разомкнутые графы
деревья
изоморфизм
6 часов
Посмотреть
Теория множеств
множества
закон де моргана
операции над множествами
распределительный закон
3 часа
Посмотреть
Введение в математическую логику
логические высказывания
таблица истинности
нормальная форма
предикаты
3 часа
Посмотреть
Комбинаторика
комбинаторика
принцип включения и исключения
подсчет по биекции
порождающая функция
3 часа
Посмотреть
Регулярные выражения (Regexp)
жадность
классы символов
квантификация
14 часов
Посмотреть
Протокол HTTP
редиректы
аутентификация
13 часов
Посмотреть
HTTP API
postman
7 часов
Посмотреть
Курсы Go
Основы Go
модули
импорты
отладка программы
ошибки
43 часа
Посмотреть
Веб-разработка на Go
golang
веб-сервер
веб-разработка
16 часов
Посмотреть
застрял IO | CloudXC
Опубликовано Джош Оджерс
В части 6 мы узнали, как архитектура VMware VMC и кластеров Nutanix выполняет перестроение после сбоев экземпляра на «голом железе», а также основные преимущества отказоустойчивости и производительности, которые может предложить Nutanix.
В этой части мы рассмотрим, как оба продукта обрабатывают сценарии, когда ввод-вывод «застревает» или «зависает» на пути ввода-вывода, а также последствия таких ситуаций.
Прежде чем мы углубимся в эту тему, на концептуальном уровне целью любой инфраструктуры является обеспечение максимальной доступности и целостности данных, поэтому любые сбои необходимо обрабатывать таким образом, чтобы свести к минимуму риск и влияние на инфраструктуру и, конечно же, деловые операции.
С учетом сказанного давайте поговорим о том, что происходит в случае «зависания» ввода-вывода для VMware VMC и кластеров Nutanix в общедоступном облаке.
Компания VMware опубликовала статью KB71207 под названием «Как справиться с потерей зависшего ввода-вывода на хосте в кластере vSAN, в которой рассказывается, как vSAN реагирует на сценарий, когда ввод-вывод «застревает» или «теряется» в какой-то момент в процессе ввода-вывода. Путь O, такой как контроллер хранилища или сами физические диски.
Путь O, такой как контроллер хранилища или сами физические диски.
VMware описывает симптом следующим образом:
Если ввод-вывод застрял или потерян на контроллере хранилища или диске хранилища, стек хранилища ESXi попытается прервать их, используя запрос управления задачами, отображающий следующие сообщения консоли:
СПРАВКА : HTTPS://KB.VMWARE.COM/S/ARTICLE/71207
Далее в статье говорится:
. убедитесь, что это не влияет на другие хосты в кластере.
ССЫЛКА: HTTPS://KB.VMWARE.COM/S/ARTICLE/71207
В статье рассматриваются последствия/риски, в которых подчеркивается: ESXi (контроллер устройства/прошивка), который не завершается и не отвечает на прерывание, и/или прерывание никогда не завершается. Такие операции ввода-вывода могут привести к тому, что диск или группа дисков перестанут отвечать, что, в свою очередь, может привести к зависанию hostd или его зависанию и отключению от vCenter Server.
Поскольку ввод-вывод застрял за пределами ESXi, единственный вариант, который есть у ESXi, — отправить прерывание. Если устройство/контроллер не отреагирует на прерывание в течение 120 секунд (тайм-аут по умолчанию), vSAN выведет хост из строя, чтобы не повлиять на весь кластер vSAN из-за сбоя хоста.
Таким образом, VMware сообщает, что для «зависших» или «потерянных» операций ввода-вывода результатом является фиолетовый экран смерти ( PSD) . В конечном итоге это означает, что виртуальные машины на хосте будут иметь событие высокой доступности и будут перезапущены (не vMotioned) на оставшихся узлах в кластере.
VMware оправдывает обработку PSOD «чтобы гарантировать, что это не повлияет на другие хосты в кластере», что, я согласен, имеет смысл.
Последствия того, как VMC/vSAN обрабатывает этот сценарий, в конечном счете аналогичны сбою экземпляра на «голом железе», как обсуждалось в части 6.
Это означает, что все виртуальные машины, работающие на «голом железе», прекратят работу (событие высокой доступности), сервер будет перезапущен и на каком-то этапе присоединится к кластеру.
В течение этого времени новый ввод-вывод записи для виртуальных машин, объекты хранилища которых размещены на автономном узле, не будет соответствовать настроенной политике хранения.
Если по какой-либо причине экземпляр «голого железа» не присоединится к кластеру (т. е. не перезапустится), тогда VMC имеет дело с отказом полного узла.
Давайте обсудим, как Nutanix Clusters справляется с той же ситуацией.
Первое ключевое отличие состоит в том, что Nutanix Clusters (AOS) работает внутри виртуальной машины («Controller VM» или «CVM»), что означает ее абстрагирование от гипервизора и оборудования.
Это большое преимущество по сравнению с VMC/vSAN, которые ограничены тем, что они «в ядре» и излишне привязаны к гипервизору. Преимущество кластеров Nutanix, характерное для этой ситуации, заключается в том, что CVM может обрабатывать такие сценарии, как зависший ввод-вывод, не влияя на гипервизор и не требуя перезагрузки физического сервера, что вызывает событие высокой доступности для всех виртуальных машин.
Давайте рассмотрим шаги более подробно:
- Когда IO выдается на диск, ядро CVM имеет связанный тайм-аут scsi для устройства, после которого оно попытается прервать IO, используя задачу отмены scsi команды управления.
- В дополнение к обработке в ядре, в stargate мы запускаем таймер всякий раз, когда любой ввод-вывод выдается на диск. По сути, это двойной уровень защиты.
- Если ядро возвращает ошибку ввода-вывода или короткое чтение в результате прерывания в #1, и если этот ввод-вывод связан с файлом egroup, то мы просто помечаем egroup как поврежденную в метаданных и запускаем операцию исправления для повторно реплицируйте эти 4 МБ из другой работоспособной реплики. Таким образом, плохой блок на устройстве влияет только на один файл egroup, сопоставленный с этим блоком, а все остальное продолжает нормально функционировать.
- Иногда ошибка на диске становится более серьезной, что означает, что диск больше не работает. В таких случаях таймер, который мы запустили в #2, сработает, как только мы не получим ответ от этого диска. В этом случае мы помечаем этот конкретный диск в автономном режиме. Таким образом, все остальные диски на этом хосте продолжают работать без проблем. Кроме того, куратор запускает повторную репликацию для всех реплик egroup, у которых есть копия на автономном диске. Таким образом, один неисправный диск не влияет на CVM или хост. Если в vSAN происходит сбой диска, вся группа дисков теряется, если вы используете дедупликацию и сжатие И/ИЛИ, если произошел сбой кэш-диска.
- В некоторых редких случаях, если мы когда-либо сталкиваемся с проблемой ядра/драйвера, из-за которой CVM выходит из строя, монитор высокой доступности в кластере добавляет правило перенаправления на узле, на котором размещалась эта CVM. Это означает, что виртуальная машина ввода-вывода будет просто перенаправлена на другую надежную CVM, а виртуальные машины на хосте продолжат работать в обычном режиме, не требуя событий vMotion или HA. Эта возможность также используется во время запланированных обновлений CVM, когда мы можем просто выполнить последовательное обновление и перезапустить CVM, а хосты и связанные с ними виртуальные машины продолжат работать без какой-либо миграции из-за базовой обработки перенаправления HA кластером Nutanix.
 В этом случае мы помечаем этот конкретный диск в автономном режиме. Таким образом, все остальные диски на этом хосте продолжают работать без проблем. Кроме того, куратор запускает повторную репликацию для всех реплик egroup, у которых есть копия на автономном диске. Таким образом, один неисправный диск не влияет на CVM или хост. Если в vSAN происходит сбой диска, вся группа дисков теряется, если вы используете дедупликацию и сжатие И/ИЛИ, если произошел сбой кэш-диска.
В этом случае мы помечаем этот конкретный диск в автономном режиме. Таким образом, все остальные диски на этом хосте продолжают работать без проблем. Кроме того, куратор запускает повторную репликацию для всех реплик egroup, у которых есть копия на автономном диске. Таким образом, один неисправный диск не влияет на CVM или хост. Если в vSAN происходит сбой диска, вся группа дисков теряется, если вы используете дедупликацию и сжатие И/ИЛИ, если произошел сбой кэш-диска.
Вышеупомянутое возможно, потому что мы проходим PCI через весь контроллер хранилища к CVM.
Таким образом, даже при самых серьезных ошибках и зависании в IO-контроллере все, что нам нужно сделать, это перезапустить CVM или, в худшем случае, оставить CVM выключенным.
На хост никогда не влияют такие события, так как он не управляет контроллером хранения и не отправляет ему никаких запросов ввода-вывода. В любом сценарии, когда CVM находится в автономном режиме, включая техническое обслуживание (например, последовательное изменение ресурсов CVM) и обновления, Nutanix Clusters (AOS) перенаправляет все операции ввода-вывода VM на все оставшиеся CVM в кластере.
С другой стороны, причина, по которой VSAN нуждается в PSOD хоста, заключается в том, что хост-процесс отправил операции ввода-вывода базовому устройству. Таким образом, на самом деле у нас есть потоки ядра/хоста ESX, застрявшие в непрерывном спящем режиме, и сброс хоста — единственный выход, а это означает, что все виртуальные машины необходимо восстанавливать с помощью HA.
Сводка
Таким образом, в этом простом примере среды VMC/vSAN пострадают как минимум от сценария сбоя хоста, когда виртуальные машины столкнутся с событием высокой доступности. ВМ в кластерах Nutanix будут продолжать функционировать без события высокой доступности, и в худшем случае производительность будет снижаться из-за потери локальности данных, когда ввод-вывод перенаправляется через пропускную способность кластера. После перезапуска CVM (что происходит намного быстрее, чем перезапуск физического сервера) преимущества уникальной локализации данных Nutanix возобновляются. 9Кластеры Nutanix (AOS) , весь хост остается в сети для участия в операции распределенного самовосстановления.
Далее в части 8 мы обсудим масштабируемость и отказоустойчивость хранилища в AWS.
Большое спасибо Табрезу Мемону, одному из наших замечательных главных инженеров в Nutanix и руководителю команды Stargate за вклад в эту статью.
Похожие сообщения:
- Проблемы публичного облака — кластеры Nutanix против VMware VMConAWS
- Проблемы общедоступного облака. Часть 1. Производительность сети
- Проблемы общедоступного облака. Часть 2. Совокупная стоимость владения/окупаемость инвестиций и емкость хранилища
- Проблемы общедоступного облака. Часть 3. Совокупная стоимость владения/окупаемость инвестиций и емкость хранилища в масштабе
- Проблемы общедоступного облака. 4 – Технологии эффективности данных и аспекты отказоустойчивости.
- Проблемы общедоступного облака. Часть 5. Сбои устройств хранения и влияние на отказоустойчивость 0070
- Архитектура гиперконвергентной инфраструктуры имеет значение — Nutanix AOS в сравнении с конкурентами, их кэш-дисками и дисковыми группами
- Сравнение полезной емкости — Nutanix ADSF и VMware vSAN
- Сравнение дедупликации и сжатия — Nutanix ADSF и vSAN
- Сравнение Erasure Coding — Nutanix ADSF
- Масштабирование емкости хранилища — Nutanix и vSAN
- Сравнение отказов дисков — Nutanix ADSF и VMware vSAN
- Поддержка гетерогенных кластеров — Nutanix и VMware vSAN
- Сравнение путей ввода-вывода при записи — Nutanix и VMware vSAN
- Сравнение путей ввода-вывода при чтении — Nutanix и VMware vSAN
- Сравнение отказов узлов — Nutanix и VMware vSAN/VxRAIL
- Сравнение обновлений хранилища — Nutanix и VMware vSAN/VxRA vSAN/VxRAIL
- Сравнение полезной емкости, ЧАСТЬ 2 — Nutanix и VMware vSAN/VxRAIL
- Сравнение использования памяти — Nutanix и VMware vSAN/DellEMC VxRAIL
- Сравнение использования сети — Nutanix и VMware vSAN/DellEMC VxRAIL
- Нутаникс | Масштабируемость, отказоустойчивость и производительность
- Nutanix — Erasure Coding (EC-X) Глубокое погружение
- Влияние на производительность и накладные расходы встроенного сжатия в Nutanix?
- Мой флажок больше вашего! Автор Hans De Leenheer
- Не все решения для хранения данных VAAI-NAS одинаковы.
- Автоматическое восстановление памяти на гипервизоре Nutanix Acropolis (AHV)
Опубликовано Джош Оджерс
Ранее в этой серии мы обсуждали преимущества путей чтения и записи Nutanix AOS и то, как они выигрывают от оригинальной и уникальной реализации Nutanix локальности данных.
Я также начал отдельную серию статей о сравнении локализации данных, а также подчеркнул, что локальность данных касается не только максимальной производительности хранилища, но и производительности и функциональности базового кластера и всех виртуальных машин.
Теперь давайте углубимся в отказоустойчивость путей ввода-вывода.
Недавно компания VMware опубликовала статью KB71207 под названием «Как справиться с потерей или зависанием операций ввода-вывода на хосте в кластере vSAN.
В статье рассказывается, как vSAN реагирует на ситуацию, когда ввод-вывод «застревает» или «теряется» в какой-то точке пути ввода-вывода, например в контроллере системы хранения или самих физических дисках.
VMware описывает симптом следующим образом:
Если ввод-вывод зависает или теряется на контроллере хранилища или диске хранилища, стек хранилища ESXi попытается прервать их, используя запрос управления задачами, отображающий следующие сообщения консоли:
Ссылка: https://kb.vmware.com/s/article/71207
Далее в статье говорится:
в PSOD, чтобы гарантировать, что это не повлияет на другие хосты в кластере.
Ссылка: https://kb.vmware.com/s/article/71207
В статье рассматриваются последствия/риски, которые выделяются: ESXi (контроллер устройства/прошивка), который не завершается и не отвечает на прерывание, и/или прерывание никогда не завершается. Такие операции ввода-вывода могут привести к тому, что диск или группа дисков перестанут отвечать, что, в свою очередь, может привести к зависанию hostd или его зависанию и отключению от vCenter Server.
Поскольку ввод-вывод застрял за пределами ESXi, единственный вариант, который есть у ESXi, — отправить прерывание. Если устройство/контроллер не отреагирует на прерывание в течение 120 секунд (тайм-аут по умолчанию), vSAN выведет хост из строя, чтобы не повлиять на весь кластер vSAN из-за сбоя хоста.
Таким образом, VMware сообщает, что для «зависших» или «потерянных» операций ввода-вывода результатом будет PSOD. В конечном итоге это означает, что виртуальные машины на хосте будут иметь событие высокой доступности и будут перезапущены (не vMotioned) на оставшихся узлах в кластере.
VMware оправдывает обработку PSOD «чтобы гарантировать, что это не повлияет на другие хосты в кластере», что, я согласен, имеет смысл.
Давайте обсудим, как Nutanix AOS справляется с той же ситуацией.
Первое ключевое отличие состоит в том, что Nutanix AOS запускается на виртуальной машине («Контроллер ВМ»), что означает, что он абстрагирован от гипервизора.
Это большое преимущество по сравнению с «в ядре», поскольку CVM может обрабатывать такие сценарии, как зависший ввод-вывод, не влияя на гипервизор.
Давайте рассмотрим шаги более подробно:
- Когда IO выдается на диск, ядро CVM имеет связанный тайм-аут scsi для устройства, после которого оно попытается прервать IO, используя задачу отмены scsi команды управления.
- В дополнение к обработке в ядре, в stargate мы запускаем таймер всякий раз, когда любой ввод-вывод выдается на диск. По сути, это двойной уровень защиты.
- Если ядро возвращает ошибку ввода-вывода или короткое чтение в результате прерывания в #1, и если этот ввод-вывод связан с файлом egroup, то мы просто помечаем egroup как поврежденную в метаданных и запускаем операцию исправления для повторно реплицируйте эти 4 МБ из другой работоспособной реплики. Таким образом, плохой блок на устройстве влияет только на один файл egroup, сопоставленный с этим блоком, а все остальное продолжает нормально функционировать.
- Иногда ошибка на диске становится более серьезной, что означает, что диск больше не работает. В таких случаях таймер, который мы запустили в #2, сработает, как только мы не получим ответ от этого диска. В этом случае мы помечаем этот конкретный диск в автономном режиме. Таким образом, все остальные диски на этом хосте продолжают работать без проблем. Кроме того, куратор запускает повторную репликацию для всех реплик egroup, у которых есть копия на автономном диске. Таким образом, один неисправный диск не влияет на CVM или хост. Если в vSAN происходит сбой диска, вся группа дисков теряется, если вы используете дедупликацию и сжатие И/ИЛИ, если произошел сбой кэш-диска.
- В некоторых редких случаях, если мы когда-либо сталкиваемся с проблемой ядра/драйвера, из-за которой CVM выходит из строя, монитор высокой доступности в кластере добавляет правило перенаправления на узле, на котором размещалась эта CVM. Это означает, что виртуальная машина ввода-вывода будет просто перенаправлена на другую надежную CVM, а виртуальные машины на хосте продолжат работать в обычном режиме, не требуя событий vMotion или HA. Эта возможность также используется во время запланированных обновлений CVM, когда мы можем просто выполнить последовательное обновление и перезапустить CVM, а хосты и связанные с ними виртуальные машины продолжат работать без какой-либо миграции из-за базовой обработки перенаправления HA кластером Nutanix.
 Эта возможность также используется во время запланированных обновлений CVM, когда мы можем просто выполнить последовательное обновление и перезапустить CVM, а хосты и связанные с ними виртуальные машины продолжат работать без какой-либо миграции из-за базовой обработки перенаправления HA кластером Nutanix.
Эта возможность также используется во время запланированных обновлений CVM, когда мы можем просто выполнить последовательное обновление и перезапустить CVM, а хосты и связанные с ними виртуальные машины продолжат работать без какой-либо миграции из-за базовой обработки перенаправления HA кластером Nutanix.Вышеупомянутое возможно, потому что мы проходим PCI через весь контроллер хранилища к CVM.
Таким образом, даже при самых серьезных ошибках и зависании в IO-контроллере все, что нам нужно сделать, это перезапустить CVM или, в худшем случае, оставить CVM выключенным.
На хост никогда не влияют такие события, так как он не управляет контроллером хранения и не отправляет ему никаких запросов ввода-вывода. В любом сценарии, когда CVM находится в автономном режиме, включая техническое обслуживание (например, последовательное изменение ресурсов CVM) и обновления, AOS перенаправляет все операции ввода-вывода VM на все оставшиеся CVM в кластере.
С другой стороны, причина, по которой VSAN нуждается в PSOD хоста, заключается в том, что хост-процесс отправил операции ввода-вывода базовому устройству. Таким образом, на самом деле у нас есть потоки ядра/хоста ESX, застрявшие в непрерывном спящем режиме, и сброс хоста — единственный выход, а это означает, что все виртуальные машины необходимо восстанавливать с помощью HA.
Сводка
Таким образом, в этом простом примере среды vSAN/VxRAIL будут как минимум подвержены сценарию сбоя хоста, когда виртуальные машины будут испытывать событие высокой доступности, тогда как виртуальные машины в средах Nutanix продолжат функционировать, в худшем случае с потерей местоположение данных, в то время как ввод-вывод перенаправляется через пропускную способность кластера.
Nutanix AOS Преимущества:
- ВМ НЕ подвергаются событию высокой доступности из-за зависания или зависания операций ввода-вывода
- Не влияет на гипервизор из-за проблем, связанных с контроллером хранилища хост остается в сети для участия в операции распределенного самовосстановления
- Если зависший ввод-вывод вызван повреждением данных, AOS пометит эту реплику как поврежденную и прочитает из оставшихся реплик, одновременно пометив поврежденную реплику и инициирование операции исправления для повторной защиты данных.
- В худшем случае ввод-вывод перенаправляется по всему кластеру, что является обычной операцией для обновления и позволяет виртуальным машинам продолжать функционировать.
- Если для решения проблемы необходимо перезагрузить CVM, хост и виртуальные машины по-прежнему не затронуты, а поскольку AOS работает на виртуальной машине, перезагрузка происходит очень быстро и восстанавливает кластер обратно в его нормальное/устойчивое состояние.
- Минимальное/не требуется вмешательство администратора для самовосстановления платформы до устойчивого состояния
- Программное обеспечение AOS абстрагируется от гипервизора, работая на виртуальной машине!!
Большое спасибо Табрезу Мемону, одному из наших замечательных главных инженеров @ Nutanix и руководителю команды Stargate за вклад в эту статью.
Похожие сообщения:
- In-Kernel и Controller VM
- Nutanix AOS и VMware vSAN / DellEMC VxRAIL INDEX0070
- Сравнение дедупликации и сжатия — Nutanix ADSF и vSAN
- Сравнение кодирования Erasure — Nutanix ADSF и vSAN
- Масштабирование емкости хранилища — Nutanix и vSAN vSAN
- Сравнение путей ввода-вывода при записи — Nutanix и VMware vSAN
- Сравнение путей ввода-вывода при чтении — Nutanix и VMware vSAN
- Сравнение отказов узлов — Nutanix и VMware vSAN/VxRAIL
- Сравнение обновлений хранилища — Nutanix и VMware vSAN/VxRAIL
- Сравнение полезной емкости ЧАСТЬ 2 — Nutanix и VMware vSAN/VxRAIL
- Сравнение использования сети — Nutanix и VMware vSAN/DellEMC VxRAIL
- Сравнение использования памяти DellEMC VxRAIL
- Сравнение влияния сетевого трафика на производительность приема больших данных — Nutanix AOS и VMware vSAN / DellEMC VxRAIL
- Nutanix | Масштабируемость, отказоустойчивость и производительность
- Nutanix — Erasure Coding (EC-X) Глубокий анализ
- Влияние на производительность и накладные расходы встроенного сжатия в Nutanix?
- Мой флажок больше вашего! Автор Hans De Leenheer
- Не все решения для хранения данных VAAI-NAS одинаковы.
- Автоматическое восстановление памяти на гипервизоре Nutanix Acropolis (AHV)
Как принудительно убить программу, зависшую при доступе к IO (firefox)
Задавать вопрос
спросил
Изменено 2 года, 10 месяцев назад
Просмотрено 303 раза
Я использую firefox для отображения некоторых файлов через точку монтирования sshfs. ..
..
Однако бывает, что эта точка монтирования отключается; если я непреднамеренно перезагружу страницу, firefox навсегда зависнет, и нельзя будет даже убить .
Например, я все еще вижу процесс firefox с « D » здесь:
$ ps aux | grep firefox плазмаб 10269 0,8 4,2 3253252 344216 ? Д 18:12 0:51 /usr/lib/firefox/firefox плазмаб 13350 0.0 0.0 21996 1148 pts/3 S+ 19:50 0:00 grep --color=auto firefox
и это, даже через killall -9 firefox .
Пытаться убить -9 10269 бесполезно.
Теперь я выполнил шаги по удалению файлов блокировки и .parentlock , но после этого я все еще вижу процесс «D». Тем не менее, я перезапустил Firefox и снова закрыл его, что привело к исчезновению нежелательного процесса…
Таким образом, удаление файлов блокировки и , перезапуск Firefox, несмотря на зависший процесс, сработало. Есть ли лучший способ?
Я подозреваю, что этот вопрос может быть более общим. Например, я мог бы застрять, выполняя простую
Например, я мог бы застрять, выполняя простую лс . Как убить такие зависшие процессы?
- firefox
- kill
- io
Процесс в состоянии D находится в непрерывном спящем режиме. Никакой сигнал не убьет его, пока его ожидание не закончится. Часто причиной является неполный ввод-вывод.
В вашем случае связь хоть и потеряна, но не закрыта. Либо есть еще какие-то повторные попытки, либо он находится в состоянии CLOSE_WAIT. Если подождать достаточно долго, убить сработает, но только через sshfs сдается.
Вы должны сначала убить процесс sshfs и только потом firefox, которому больше нечего будет ждать, потому что основная файловая система исчезнет (не более sshfs ).
Итак, быстрое решение:
- kill sshfs
- убить фаерфокс
Вы также можете изучить параметр -o reconnect для sshfs .