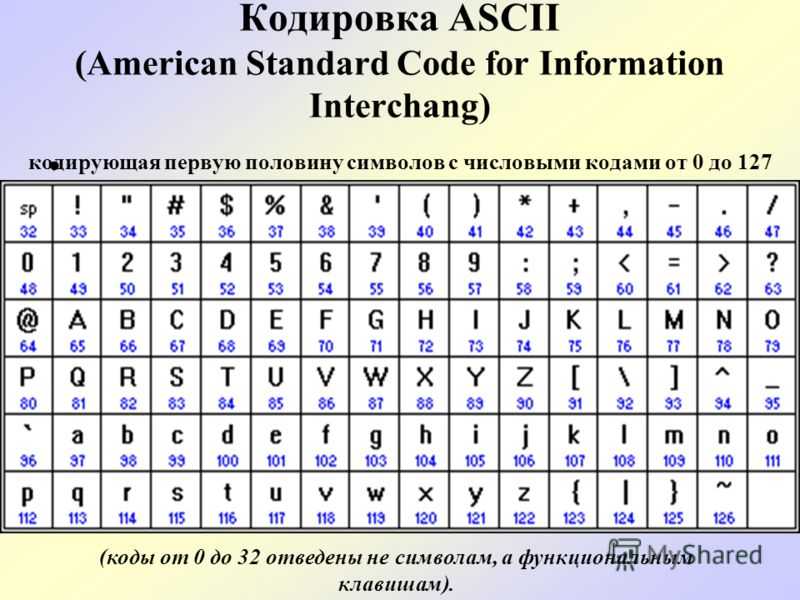
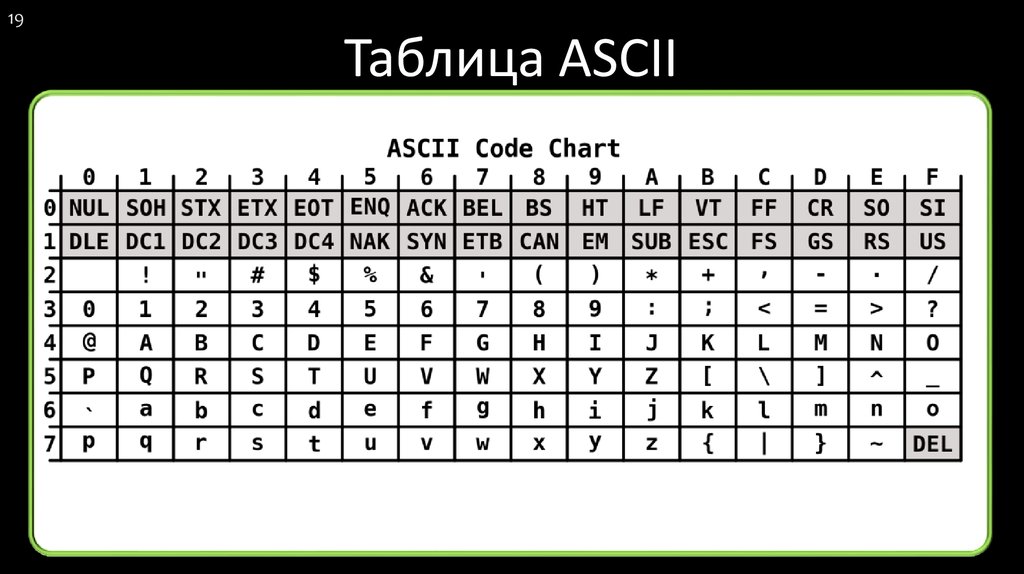
Таблица аски русские буквы
Этот список может помочь при использовании функций Asc и Chr . Таблица основана на ASCII Character Set
Управляющие символы (большинство непечатные; наиболее важные подсвечены жёлтым)
| Символ (Обознач.) | Dec | Hex | Oct | Описание |
|---|---|---|---|---|
| NUL | 00 | 000 | Пустой символ | |
| SOH | 1 | 01 | 001 | Начало заголовка, = console interrupt |
| STX | 2 | 02 | 002 | Начало текста, maintenance mode on HP console |
| ETX | 3 | 03 | 003 | Конец текста |
| EOT | 4 | 04 | 004 | Конец передачи, не тоже самое, что ETB |
| ENQ | 5 | 05 | 005 | Запрос, связан с ACK; old HP flow control |
| ACK | 6 | 06 | 006 | Подтверждение, очищает ENQ logon hand |
| BEL | 7 | 07 | 007 | Звуковой сигнал (Воспроизводит стандартный «бииип» системным динамиком ПК в Windows ) |
| BS | 8 | 08 | 010 | Backspace, works on HP terminals/computers |
| HT | 9 | 09 | 011 | Горизонтальная табуляция, перемещает к следующей позиции табуляции |
| LF | 10 | 0a | 012 | Перенос строки |
| VT | 11 | 0b | 013 | Вертикальная табуляция |
| FF | 12 | 0c | 014 | Смена страницы, извлекает страницу |
| CR | 13 | 0d | 015 | Возврат каретки |
| SO | 14 | 0e | 016 | Shift Out, включает альтернативные символы |
| SI | 15 | 0f | 017 | Shift In, возобновляет символы по умолчанию |
| DLE | 16 | 10 | 020 | Экранирует управляющий символ |
| DC1 | 17 | 11 | 021 | XON, with XOFF to pause listings; «:okay to send». |
| DC2 | 18 | 12 | 022 | Управление устройством, код 2, block-mode flow control |
| DC3 | 19 | 13 | 023 | XOFF, with XON is TERM=18 flow control |
| DC4 | 20 | 14 | 024 | Управление устройством, код 4 |
| NAK | 21 | 15 | 025 | Отрицательное подтверждение |
| SYN | 22 | 16 | 026 | Пустой символ для синхронного режима передачи |
| ETB | 23 | 17 | 027 | Конец передаваемого блока данных, не тоже самое, что EOT |
| CAN | 24 | 18 | 030 | Отмена строки, MPE echoes . |
| EM | 25 | 19 | 031 | Конец носителя, Control-Y interrupt |
| SUB | 26 | 1a | 032 | Замена |
| ESC | 27 | 1b | 033 | Экранирует, следующий символ не отображается |
| FS | 28 | 1c | 034 | Разделитель файлов |
| GS | 29 | 1d | 035 | Разделитель групп |
| RS | 30 | 1e | 036 | Разделитель записей, block-mode terminator |
| US | 31 | 1f | 037 | Разделитель полей |
| DEL | 127 | 7f | 177 | Delete (rubout), cross-hatch box |
Печатные символы (стандартные)
| Символ | Dec | Hex | Oct | Описание |
|---|---|---|---|---|
| 32 | 20 | 040 | Пробел | |
| ! | 33 | 21 | 041 | Восклицательный знак |
| « | 34 | 22 | 042 | Кавычка (» в HTML) |
| # | 35 | 23 | 043 | Решётка (знак числа) |
| $ | 36 | 24 | 044 | Доллар |
| % | 37 | 25 | 045 | Проценты |
| & | 38 | 26 | 046 | Амперсанд |
| ‘ | 39 | 27 | 047 | Закрывающая одиночная кавычка (апостроф) |
| ( | 40 | 28 | 050 | Открывающая скобка |
| ) | 41 | 29 | 051 | Закрывающая скобка |
| * | 42 | 2a | 052 | Звёздочка, умножение |
| + | 43 | 2b | 053 | Плюс |
| , | 44 | 2c | 054 | Запятая |
| – | 45 | 2d | 055 | Дефис, минус |
. | 46 | 2e | 056 | Точка |
| / | 47 | 2f | 057 | Наклонная черта (слеш, деление) |
| 48 | 060 | Ноль | ||
| 1 | 49 | 31 | 061 | Один |
| 2 | 50 | 32 | 062 | Два |
| 3 | 51 | 33 | 063 | Три |
| 4 | 52 | 34 | 064 | Четыре |
| 5 | 53 | 35 | 065 | Пять |
| 6 | 54 | 36 | 066 | Шесть |
| 7 | 55 | 37 | 067 | Семь |
| 8 | 56 | 38 | 070 | Восемь |
| 9 | 57 | 39 | 071 | Девять |
| : | 58 | 3a | 072 | Двоеточие |
| ; | 59 | 3b | 073 | Точка с запятой |
| 62 | 3e | 076 | Знак больше | |
| ? | 63 | 3f | 077 | Знак вопроса |
| @ | 64 | 40 | 100 | эт, собака |
| A | 65 | 41 | 101 | Заглавная A |
| B | 66 | 42 | 102 | Заглавная B |
| C | 67 | 43 | 103 | Заглавная C |
| D | 68 | 44 | 104 | Заглавная D |
| E | 69 | 105 | Заглавная E | |
| F | 70 | 46 | 106 | Заглавная F |
| G | 71 | 47 | 107 | Заглавная G |
| H | 72 | 48 | 110 | Заглавная H |
| I | 73 | 49 | 111 | Заглавная I |
| J | 74 | 4a | 112 | Заглавная J |
| K | 75 | 4b | 113 | Заглавная K |
| L | 76 | 4c | 114 | Заглавная L |
| M | 77 | 4d | 115 | Заглавная M |
| N | 78 | 4e | 116 | Заглавная N |
| O | 79 | 4f | 117 | Заглавная O |
| P | 80 | 50 | 120 | Заглавная P |
| Q | 81 | 51 | 121 | Заглавная Q |
| R | 82 | 52 | 122 | Заглавная R |
| S | 83 | 53 | 123 | Заглавная S |
| T | 84 | 54 | 124 | Заглавная T |
| U | 85 | 55 | 125 | Заглавная U |
| V | 86 | 56 | 126 | Заглавная V |
| W | 87 | 57 | 127 | Заглавная W |
| X | 88 | 58 | 130 | Заглавная X |
| Y | 89 | 59 | 131 | Заглавная Y |
| Z | 90 | 5a | 132 | Заглавная Z |
| [ | 91 | 5b | 133 | Открывающая квадратная скобка |
| 92 | 5c | 134 | Обратная наклонная черта (обратный слеш) | |
| ] | 93 | 5d | 135 | Закрывающая квадратная скобка |
| ^ | 94 | 5e | 136 | Циркумфлекс, возведение в степень, знак вставки |
| _ | 95 | 5f | 137 | Нижнее подчёркивание |
| ` | 96 | 60 | 140 | Открывающая одиночная кавычка, гравис, знак ударения |
| a | 97 | 61 | 141 | Строчная a |
| b | 98 | 62 | 142 | Строчная b |
| c | 99 | 63 | 143 | Строчная c |
| d | 100 | 64 | 144 | Строчная d |
| e | 101 | 65 | 145 | Строчная e |
| f | 102 | 66 | 146 | Строчная f |
| g | 103 | 67 | 147 | Строчная g |
| h | 104 | 68 | 150 | Строчная h |
| i | 105 | 69 | 151 | Строчная i |
| j | 106 | 6a | 152 | Строчная j |
| k | 107 | 6b | 153 | Строчная k |
| l | 108 | 6c | 154 | Строчная l |
| m | 109 | 6d | 155 | Строчная m |
| n | 110 | 6e | 156 | Строчная n |
| o | 111 | 6f | 157 | Строчная o |
| p | 112 | 70 | 160 | Строчная p |
| q | 113 | 71 | 161 | Строчная q |
| r | 114 | 72 | 162 | Строчная r |
| s | 115 | 73 | 163 | Строчная s |
| t | 116 | 74 | 164 | Строчная t |
| u | 117 | 75 | 165 | Строчная u |
| v | 118 | 76 | 166 | Строчная v |
| w | 119 | 77 | 167 | Строчная w |
| x | 120 | 78 | 170 | Строчная x |
| y | 121 | 79 | 171 | Строчная y |
| z | 122 | 7a | 172 | Строчная z |
| < | 123 | 7b | 173 | Открывающая фигурная скобка |
| | | 124 | 7c | 174 | Вертикальная черта |
| > | 125 | 7d | 175 | Закрывающая фигурная скобка |
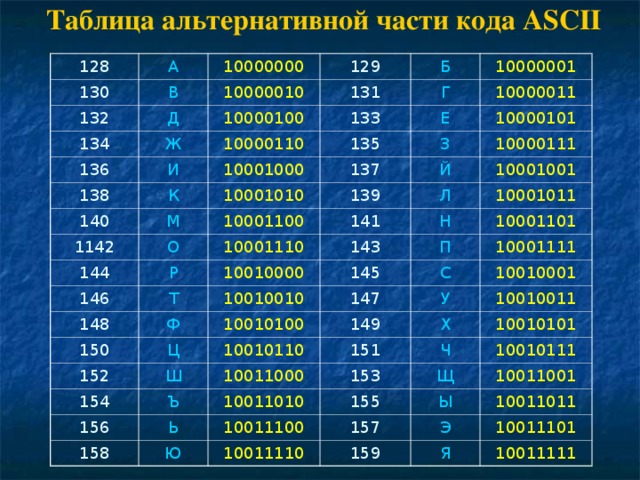
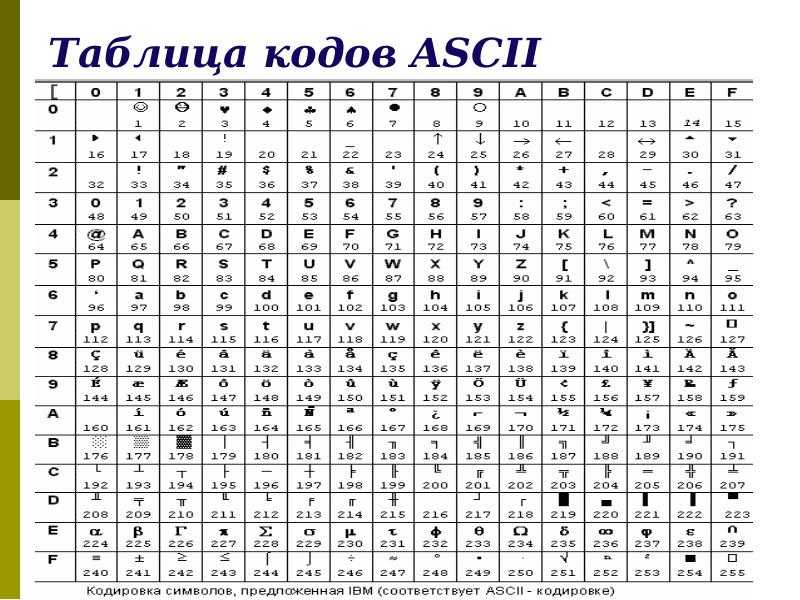
Расширенный набор символов (ANSI) в русской кодировке Win-1251
Ниже представленна русская таблица кодов ASCII.
Таблица ASCII символов чаще всего используется при работе с клавиатурой, например, для отлова нажатых клавиш.
ASCII таблица
| Символ NUL SOH STX ETX EOT ENQ ACK BEL BS TAB LF VT FF CR SO SI DLE DC1 DC2 DC3 DC4 NAK SYN ETB CAN EM SUB ESC FS GS RS US | Символ Space ! » # $ % & ‘ ( ) * + , – . / 0 1 2 3 4 5 6 7 8 9 : ; ? | Символ @ A B C D E F G H I J K L M N O P Q R S T U V W X Y Z [ ] | Символ ` a b c d e f g h i j k l m n o p q r s t u v w x y z |
DEL
Ђ
Ѓ
‚
ѓ
„
…
†
‡
€
‰
Љ
‹
Њ
Ќ
Ћ
Џ
ђ
‘
’
“
”
•
–
—
?
™
љ
›
њ
ќ
ћ
џ
Ў
ў
Ј
¤
Ґ
¦
§
Ё
©
Є
«
¬
®
Ї
°
±
І
і
ґ
µ
¶
·
ё
№
є
»
ј
Ѕ
ѕ
ї
А
Б
В
Г
Д
Е
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
а
б
в
г
д
е
ж
з
и
й
к
л
м
н
о
п
р
с
т
у
ф
х
ц
ч
ш
щ
ъ
ы
ь
э
ю
я
В ASCII таблице сивмолы от 1-31 являются кодами клавиш.
ASCII символы. Форматирование
BS
Backspace (Возврат на один символ). Указывает на движение механизма печати или курсора дисплея назад на одну позицию.
HT
Horizontal Tabulation (Горизонтальное Табулирование). Указывает на движение механизма печати или курсора дисплея до следующей предписанной ‘позиции табуляции’.
LF
Line Feed (Перевод строки). Указывает на движение механизма печати или курсора дисплея к началу следующей строки (на одну строку вниз).
VT
Vertical Tabulation (Вертикальное Табулирование). Указывает на движение механизма печати или курсора дисплея к следующей группе строк.
FF
Form Feed (Перевод страницы). Указывает на движение механизма печати или курсора дисплея к исходной позиции следующей страницы, формы или экрана.
CR
Carriage Return (Перевод каретки). Указывает на движение механизма печати или курсора дисплея к исходной (крайней левой) позиции текущей строки.
ASCII символы. Передача данных
SOH
Start of Heading (Начало Заголовка). Используется для указания начала заголовка, который может содержать информацию о маршрутизации или адрес.
STX
Start of Text (Начало Текста). Указывает на начало текста и одновременно на конец заголовка.
ETX
End of Text (Конец Текста). Используется при завершении текста, который был начат с символа STX.
ENQ
Enquiry (Запрос). Запрос идентификационных данных (типа «Кто Вы?») от удаленной станции.
ACK
Acknowledge (Подтверждение). Приемное устройство передает этот символ отправителю в качестве подтверждения успешного приема данных.
NAK
Negative Acknowledgement (Неподтверждение). Приемное устройство передает этот символ отправителю в случае отрицания (неудачи) приема данных.
SYN
Synchronous/Idle (Синхронизация). Используется в синхронизированных системах передачи. В моменты отсутствия передачи данных система непрерывно посылает символы SYN для обеспечения синхронизации.
В моменты отсутствия передачи данных система непрерывно посылает символы SYN для обеспечения синхронизации.
ETB
End of Transmission Block (Конец Блока Передачи). Указывает на конец блока данных для коммуникационных целей. Используется для разбиения на отдельные блоки больших объемов данных.
FS
File Separator (Разделитель файлов).
GS
Group Separator (Разделитель групп).
RS
Record Separtator (Разделитель записей).
US
Unit Separator (Разделитель элементов).
ASCII символы. Другие символы
NUL
Null. (No character – нет данных). Используется для передачи в случае отсутствия данных.
BEL
Bell (Звонок). Используется для управления устройствами сигнализации.
SO
Shift Out. Указывает, что все последующие кодовые комбинации должны интерпретироваться согласно внешнему набору символов до прихода символа SI.
SI
Shift In. Указывает, что последующие кодовые комбинации должны интерпретироваться согласно стандартному набору символов.
DLE
Data Link Escape (Переключение). Изменение значения идущих следом символов. Используется для дополнительного контроля или для передачи произвольной комбинации бит.
DC1, DC2, DC3, DC4
Device Controls (Контроль Устройства). Символы для управления вспомогательными устройствами (специальными функциями).
CAN
Cancel (Отмена). Указывает, что данные, который предшествовали этому символу в сообщении или блоке, должны игнорироваться (обычно в случае обнаружения ошибки).
EM
End of Medium (Конец Носителя). Указывает на физический конец ленты или другого носителя информации
SUB
Substitute (Заместитель). Используется для подмены ошибочного или недопустимого символа.
ESC
Escape (Расширение). Используется для расширения кода, указывая на то, что последующий символ имеет альтернативное значение.
Используется для расширения кода, указывая на то, что последующий символ имеет альтернативное значение.
(sp)
Space (Пробел). Непечатаемый символ для разделения слов или перемещения механизма печати или курсора дисплея вперед на одну позицию.
DEL
Delete (Удаление). Используется для удаления (стирания) предыдущего знака в сообщении
Люди а что лучше выбрать basic 2010 или basic 06 и почему ?
Хоть вб6 и прост, но он, к сожалению, устарел. По этому советую vb 2010.
FireDay – напиши какую-нибудь полезную программу на VB6 и проверим просто этот язык или нет:]
Начни изучать Visual basic 6, а потом будет легче освоить VB.NET.
вб6 в отличие от 2010 не перегружен ничем лишним, все что можно в 2010(кроме некоторых фич) можно повторить и в вб6, имеется в виду функциональность кода
Полный бред, в vb6 нет ООП, и из-за этого нельзя писать серьезные приложение.
И работать в команде тоже не возможно
«»»Release [03. 05.2012 17:23]
05.2012 17:23]
FireDay – напиши какую-нибудь полезную программу на VB6 и проверим просто этот язык или нет:]»»»
-Уже написал (и далеко не одну).
«»»Саня [07.06.2012 12:47]
Полный бред, в vb6 нет ООП, и из-за этого нельзя писать серьезные приложение.
И работать в команде тоже не возможно»»»
-Не знаешь, не пиши. Не зря говорят, промолчишь – за умного сойдешь. ООП- объектно ориентированное программирование. ВБ – прородитель всего ООП.
🙂
В VB даже наследования нет, абстрактных классов, интерфейсов ))
Там вообще ни чего нет что было бы похоже на ООП.
И не вб прородитель, а скорее с++ )
Я имею ввиду vb6, в vb.net все очень хорошо и продуманно сделано.
«Саня», для глупых еще раз повторю: ВБ – прородитель всего ООП. Не веришь? Интернет в помощь.
Извиняюсь за «для глупых».
САНЬ,напиши на vb.Net то что невозможно написать на vb6 и выложи исходник или статью.. .. Если не зделаешь то ты будишь позор со своими высказываниями (^_^)/!
vb.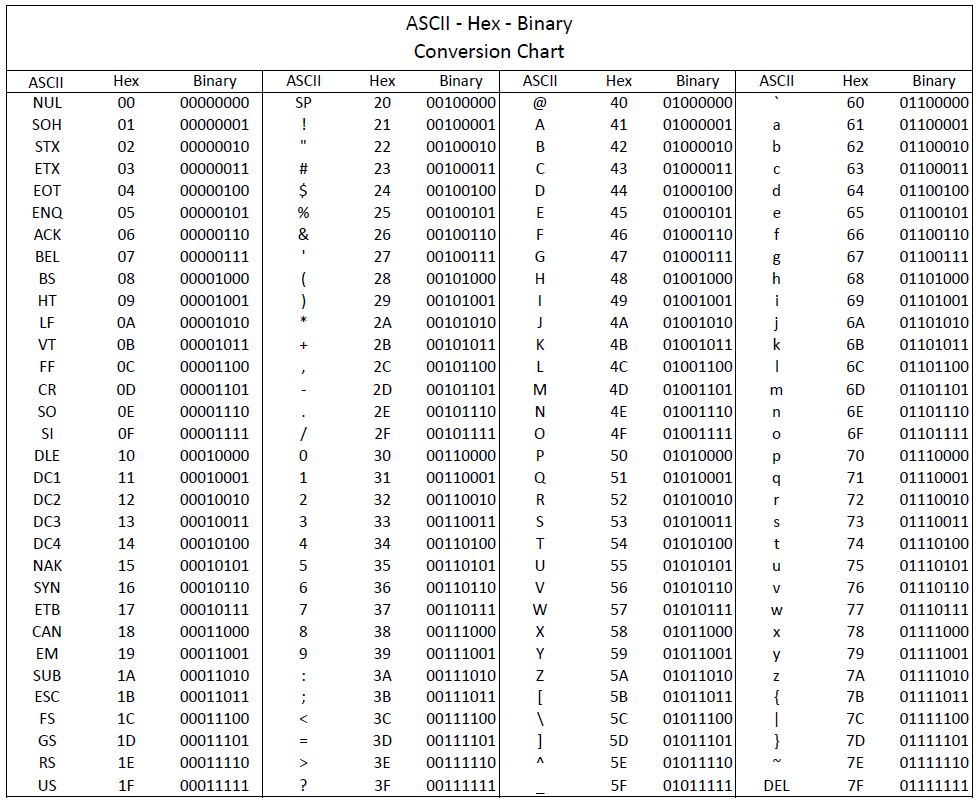 Net кое в чём подстроен для новичков, высвечивая всякие подсказки, но там всякого лищнего приходится писать
Net кое в чём подстроен для новичков, высвечивая всякие подсказки, но там всякого лищнего приходится писать
Сань
И САМОЕ ГЛАВНОЕ я могу сделать на vb6 то что ты не сможешь на vb.Net
VB6 и VB.NET он и так подстроен для новичков.. Для школьников и для студентов..
Не C++, а Smalltalk.
Вот вы спорите, кто прародитель и т.д. Легче было посмотреть в интернете, и узнаете, что прародитель всего программирование является Simula 67(Симула 67 «1967 год»), ведь от него появился Smalltalk, потом Turbo Pascal и С++ и т.д.
Fortran 1957 год,
Lisp 1958 год,
Algol-58 1958 год,
COBOL 1959 год,
SNOBOL 1962 год,
BASIC 1964 год.
SC, таки есть языки программирования и постарше чем Симула67.
Админ у меня екзешничек есть к этой теме.
Если есть желание посмотреть пиши, скину.
Господи, какой админ. Тут ветер гуляет уже много лет, а я-одинокий сталкер.
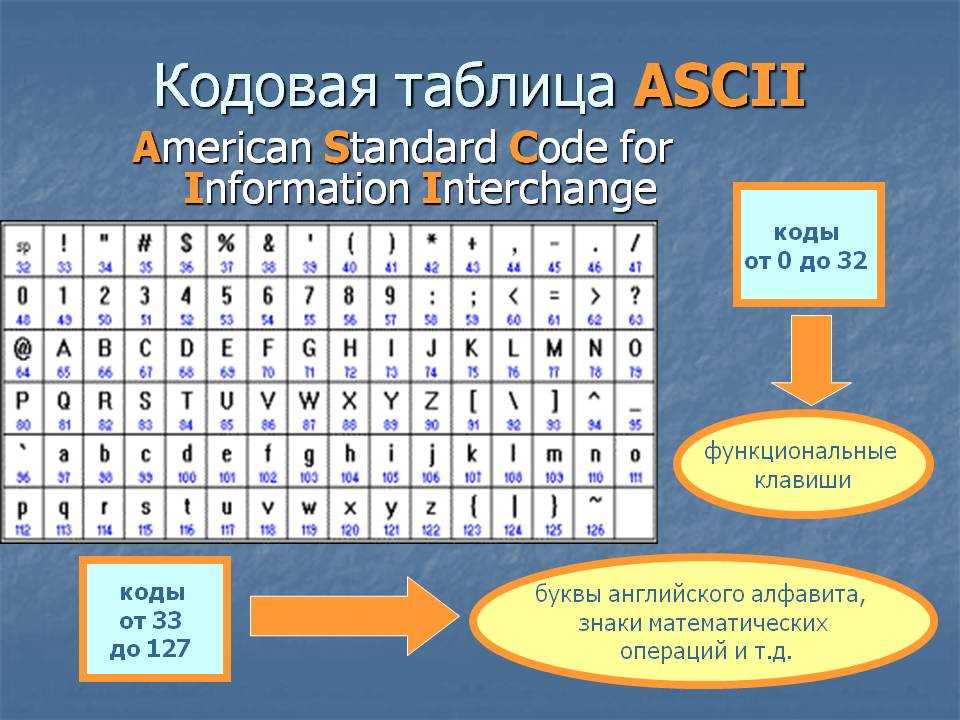
ASCII — A merican S tandard C ode for I nformation I nterchange.
ASCII была разработана (1963 год) для кодирования символов, коды которых помещались в 7 бит (128 символов). Со временем кодировка была расширена до 8-ми бит (256 символов), коды первых 128-и символов не изменились.
Управляющие символы ASCII (код символа 0-31)
Первые 32 символа в ASCII-таблице не имеют печатных кодов и используются для управления периферийными устройствами, телетайпами, принтерами и т.д.
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description |
|---|---|---|---|---|---|---|---|
| 000 | 0x00 | 00000000 | NUL |
Кодировки русского текста | Практическая информатика
Исторически сложилось так, что для представления печатных символов (кодирования текста) в первых ЭВМ отвели 7 бит. 27=128. Этого количества вполне хватало для кодирования всех строчных и прописных букв латинского алфавита, десяти цифр и различных знаков и скобок. Именно такой, 7-битной, является таблица символов ASCII (американский стандартный код для обмена информацией), подробную информацию о которой вы можете получить при помощи команды man ascii операционной системы Linux.
Именно такой, 7-битной, является таблица символов ASCII (американский стандартный код для обмена информацией), подробную информацию о которой вы можете получить при помощи команды man ascii операционной системы Linux.
Когда возникла необходимость кодировать национальные алфавиты, то 128 символов стало недостаточно. Было решено перейти на кодирование с помощью 8 бит (т. е. одного байта). В результате количество символов, которые можно закодировать таким образом стало равно 28=256. При этом символы национальных алфавитов располагались во второй половине кодовой таблицы, т. е. содержали единицу в старшем разряде байта, отведенного для кодирования символа. Так появился стандарт ISO 8859, содержащий множество кодировок для наиболее распространенных языков.
Среди них была и одна из первых таблиц для кодировки русских букв — ISO 8859-5 (воспользуйтесь командой man iso_8859_1 для получения кодов русских букв в этой таблице).
Задачи передачи текстовой информации по сети вынудили разработать еще одну кодировку для русских букв, названную Koi8-R (код отображения информации 8-битный, русифицированный).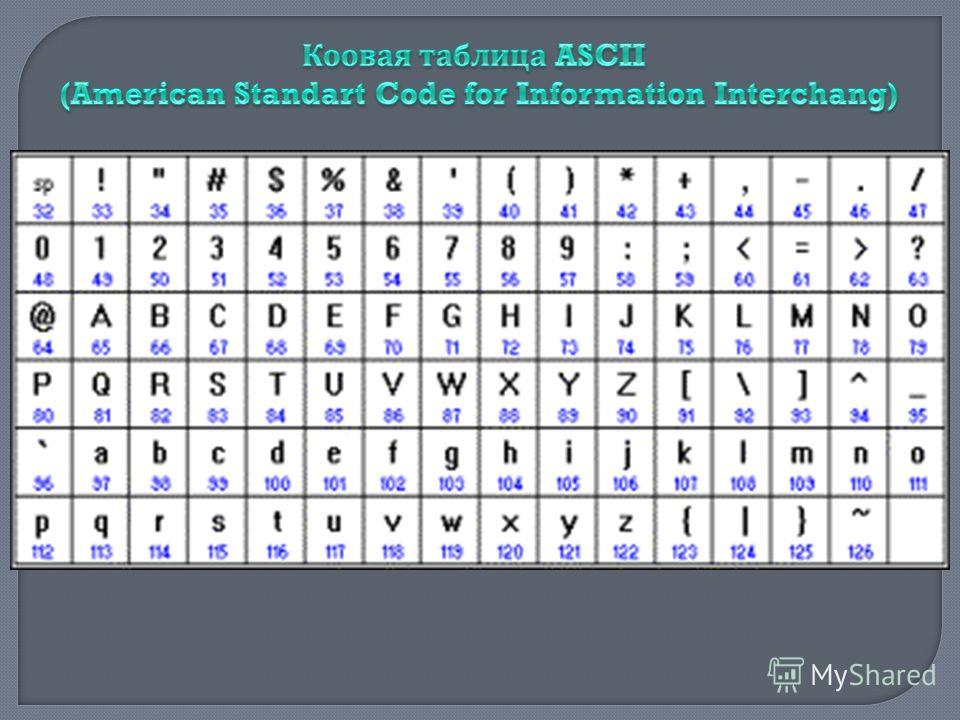 Рассмотрим ситуацию, когда письмо, содержащее русский текст, отправлено по электронной почте. Случалось, что в процессе путешествия по сетям письмо обрабатывалось программой, которая работала с 7-битной кодировкой и обнуляла восьмой бит. В результате такого преобразования код символа уменьшался на 128, превращаясь в код символа латинского алфавита. Возникла необходимость повысить устойчивость передаваемой текстовой информации к обнулению 8 бита.
Рассмотрим ситуацию, когда письмо, содержащее русский текст, отправлено по электронной почте. Случалось, что в процессе путешествия по сетям письмо обрабатывалось программой, которая работала с 7-битной кодировкой и обнуляла восьмой бит. В результате такого преобразования код символа уменьшался на 128, превращаясь в код символа латинского алфавита. Возникла необходимость повысить устойчивость передаваемой текстовой информации к обнулению 8 бита.
К счастью, значительное число букв кириллицы имеет фонетические аналоги в латинском алфавите. Например, Ф и F, Р и R. Есть несколько букв, совпадающих даже по начертанию. Расположив русские буквы в кодовой таблице таким образом, чтобы их код превышал код аналогичных латинских на число 128, добились того, что потеря 8-го бита превращала текст хотя и в состоящий из одной латиницы, но все равно понимаемый русскоязычным пользователем.
Так как из всех операционных систем, распространенных в то время, самыми удобными средствами работы с сетью обладали различные клоны операционной системы Unix, то эта кодировка стала фактическим стандартом в этих системах. Таковой она является и сейчас в ОС Linux. И именно эта кодировка чаще всего применяется для обмена почтой и новостями в Интернет.
Таковой она является и сейчас в ОС Linux. И именно эта кодировка чаще всего применяется для обмена почтой и новостями в Интернет.
Далее наступила эра персональных компьютеров и операционной системы MS DOS. Как выяснилось, кодировка Koi8-R для нее не подходила (так же, как и ISO 8859-5), в ее таблице некоторые русские буквы находились на тех местах, которые многие программы предполагали заполненными псевдографикой (горизонтальные и вертикальные черточки, уголки и т. д.). Поэтому была придумана еще одна кодировка кириллицы, в таблице которой русские буквы «обтекали» со всех сторон графические символы. Назвали эту кодировку альтернативной (alt), поскольку она была альтернативой официальному стандарту — кодировке ISO-8859-5. Неоспоримым достоинством этой кодировки является то, что русские буквы в ней расположены в алфавитном порядке.
После появления ОС Windows от фирмы Microsoft выяснилось, что альтернативная кодировка по некоторым причинам для нее не подходит. Снова передвинув русские буквы в таблице (появилась возможность — ведь псевдографика в Windows не требуется), получили кодировку Windows 1251 (Win-1251).
Снова передвинув русские буквы в таблице (появилась возможность — ведь псевдографика в Windows не требуется), получили кодировку Windows 1251 (Win-1251).
Но компьютерные технологии постоянно совершенствуются и в настоящее время все большее число программ начинает поддерживать стандарт Unicode, который позволяет кодировать практически все языки и диалекты жителей Земли.
Итак, в различных ОС предпочтение отдается разным кодировкам. Для того чтобы стало возможным чтение и редактирования текста, набранного в другой кодировке, используются программы перекодирования русского текста. Некоторые текстовые редакторы содержат встроенные перекодировщики, позволяющие читать текст в различных кодировках (Word и др.). Мы для перекодировки файлов будем использовать ряд утилит в ОС Linux, назначение которых ясно из названия: alt2koi, win2koi, koi2win, alt2win, win2alt, koi2alt (откуда, куда, цифра 2 (two) схожа по звучанию с предлогом to, указывающим направление). Эти команды имеют одинаковый синтаксис: команда <входной_файл >выходной_файл.
Пример
Перекодируем текст, набранный в редакторе Edit в среде MS DOS, в кодировку Koi8-R. Для этого выполним команду
alt2koi file1.txt > filenew
Так как в MS DOS и Linux по разному кодируется перевод строки, рекомендуется выполнить еще команду «fromdos»:
fromdos filenew > file2.txt
Команда с обратным действием называется «todos» и имеет такой же синтаксис.
Пример
Отсортируем файл List.txt, содержащий список фамилий и подготовленный в кодировке Koi8-R, в алфавитном порядке. Воспользуемся командой sort, которая сортирует текстовый файл по возрастанию или убыванию кодов символов. Если применить ее сразу, то, например, буква В окажется в конце списка, аналогично соответствующей ей букве латинского алфавита V. Вспомнив, что в альтернативной кодировке русские буквы расположены строго по алфавиту, выполним ряд операций: перекодируем текст в альтернативную кодировку, отсортируем его и снова вернем в кодировку Koi8-R.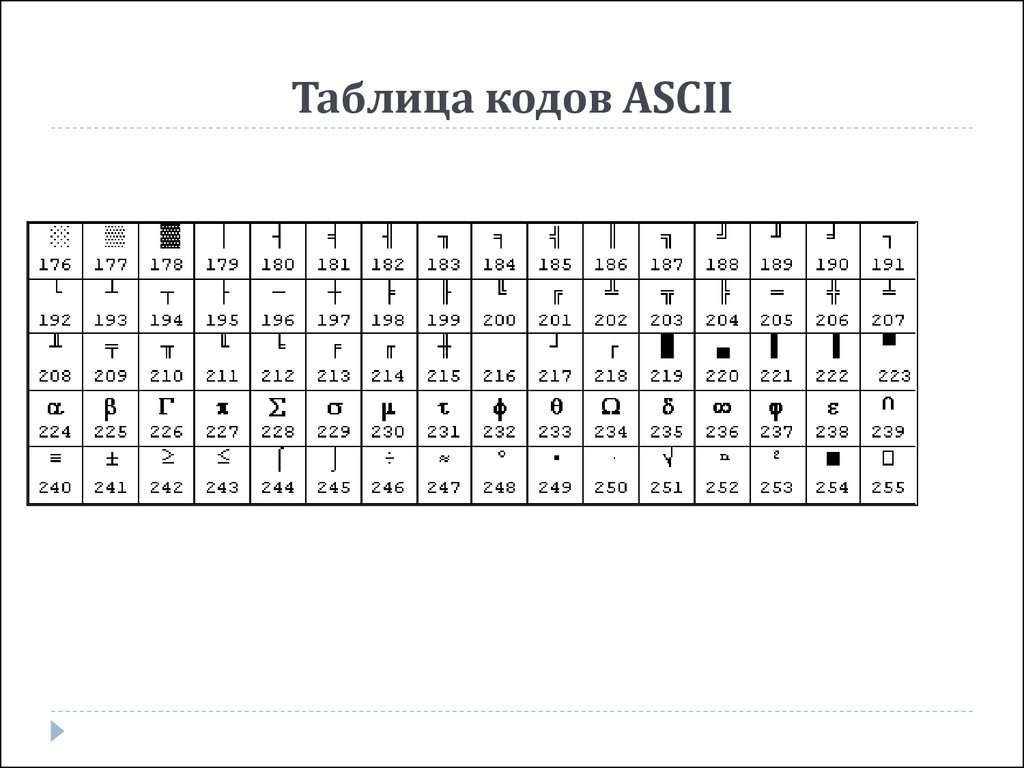 С использованием конвейера команд получаем
С использованием конвейера команд получаем
koi2alt List.txt | sort | alt2koi > List_Sort.txt
В современных дистрибутивах ОС Linux решены многие проблемы, связанные с локализацией программного обеспечения. В частности утилита sort теперь учитывает особенности кодировки Koi8-R и для сортировки файла в алфавитном порядке достаточно выполнить команду
sort List.txt > List_Sort.txt
UTF-8 vs UTF-16. Несколько советов программистам / Хабр
Введение
С появлением первых устройств цифровой передачи информации и электронно-вычислительных машин возникла задача кодирования текстовых символов с помощью последовательностей единиц и нулей. Минимальная единица представления информации – байт. Исходя их этого в 1963 году в США разработана, стандартизована, а впоследствии расширена кодовая таблица ASCII (American standard code for information interchange), использовавшая 8 битную кодировку. В первую очередь с помощью этой таблицы предполагалось кодирование цифр и букв английского языка.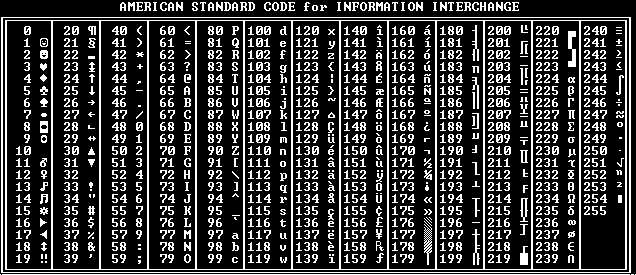 Первые 128 символов таблицы представлены на рис.1:
Первые 128 символов таблицы представлены на рис.1:
Номер ячейки в таблице (рис.1) является кодом символа. В качестве примера рассмотрим кодирование слова Hello. Номера ячеек таблицы ASCII, в которых размещены буквы: 72 (H), 101 (e), 108 (l), 111 (o). Код слова в бинарном представлении выглядит следующим образом:
00010010 (H) 10100110 (e) 00110110 (l) 00110110 (l) 11110110 (o) (старший бит справа).
Выделенные подчеркиванием и жирным коды в двоичном представлении соответствуют номерам ячеек в таблице (рис.1). Алгоритм формирования кода следующий:
1. Выделены жирным – биты управления кодированием (префикс). 010 – кодируется заглавная буква алфавита, 011 – строчная.
2. Выделены подчеркиванием – порядковые номера букв в английском алфавите.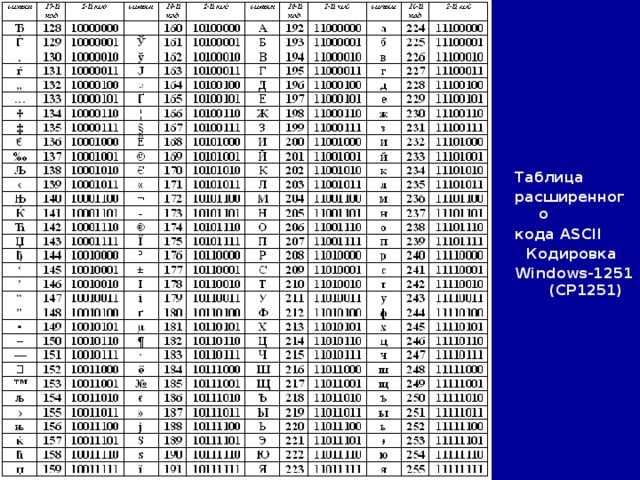
Таким образом, с помощью первых 128 ячеек таблицы ASCII могли быть закодированы основные символы, цифры и буквы английского языка. Остальные 128 ячеек (8 битная кодировка позволяет закодировать 256 символов) могли использоваться для кодирования других языков. Однако, учитывая разнообразие символов и языков, 8 бит недостаточно.
Стандарт Юникод
Консорциум Unicode (Юникод) – некоммерческая организация, главной задачей которой являлась разработка стандарта кодирования (стандарт Юникод) с поддержкой наибольшего числа языков и символов служебного характера. Принцип кодирования на основе таблицы сохранился, а таблица (таблица Юникод) была значительно расширена.
Стандарт Юникод предоставляет пользователям таблицу Юникод и способы кодирования символов.
Символы таблицы Юникод являются элементами «универсального набора символов» UCS (Universal Coded Character Set), определенного международным стандартом ISO/IEC 10646. Таблица Юникод каждому символу UCS сопоставляет кодовую точку, которая является номером ячейки таблицы, содержащей символ.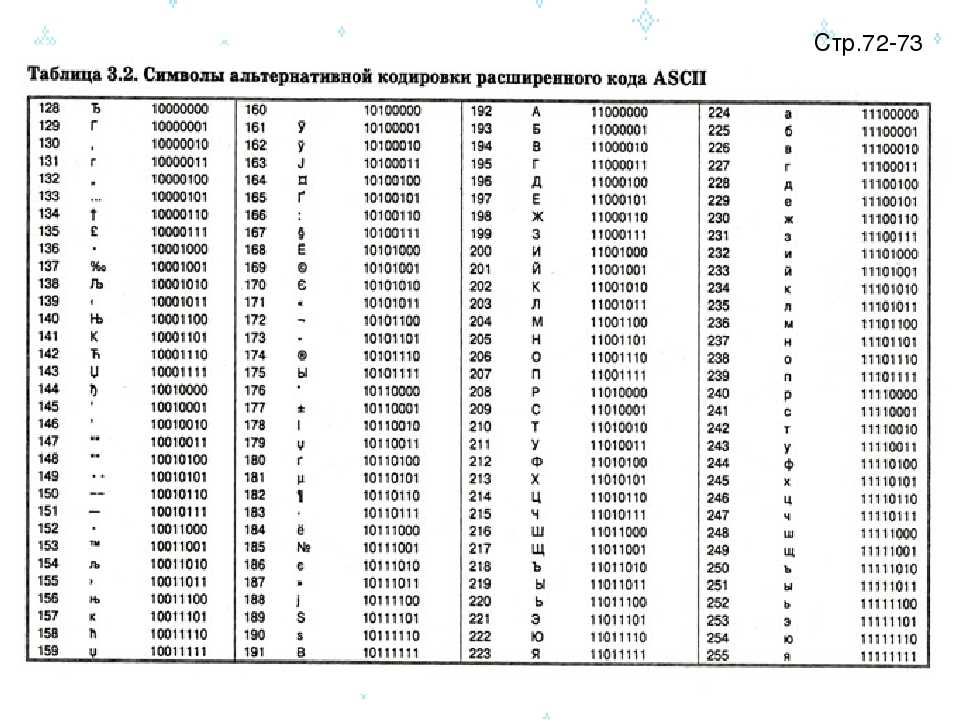
Способы кодирования символов таблицы Юникод, т.е. преобразования номеров ячеек таблицы Юникод в бинарные коды, составляют кодовое пространство, состоящее из трех кодов семейства UTF (Unicode Transformation Format): UTF-8, UTF-16 и UTF-32
UTF-8 – стандарт кодирования, преобразующий номера ячеек таблицы Юникод в бинарные коды с использованием переменного количества бит: 8, 16, 24 или 32.
UTF-16 – стандарт кодирования, преобразующий номера ячеек таблицы Юникод в бинарные коды с использованием переменного количества бит:16 или 32.
Коды UTF-8 и UTF-16 используют разные алгоритмы кодирования набора символов UCS.
Стандарт кодирования UTF-8
Стандарт закреплен в RFC (Request For Comments) 3629. Алгоритм кодирования согласно RFC:
0xxxxxxx
110xxxxx 10xxxxxx
1110xxxx 10xxxxxx 10xxxxxx
11110xx 10xxxxxx 10xxxxxx 10xxxxxx
Старший бит слева.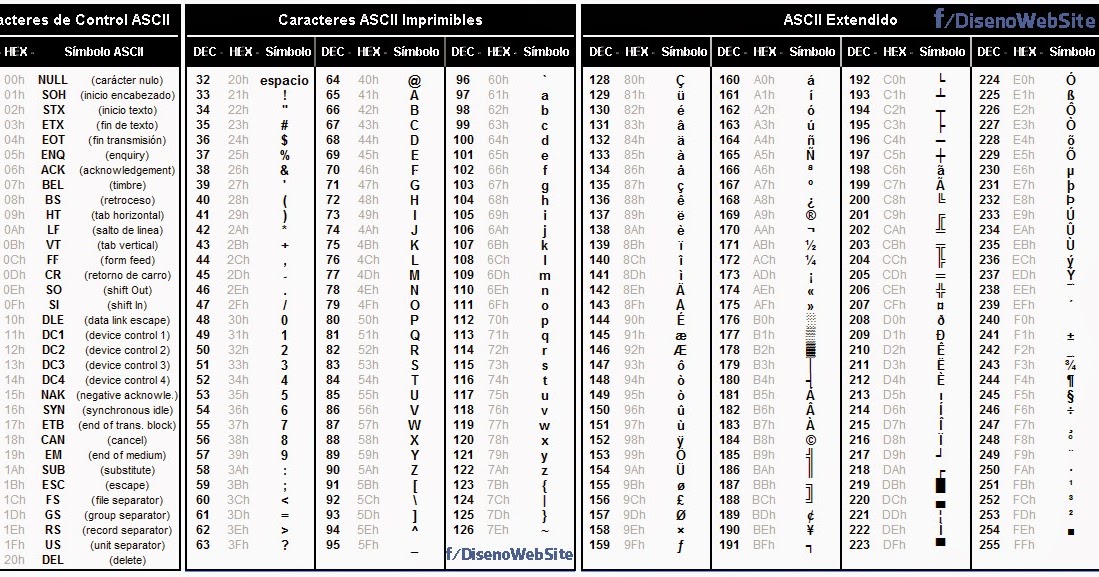 Началом кода является управляющий символ (выделен жирным):
Началом кода является управляющий символ (выделен жирным):
0 – используется 8-битная кодировка,
110 – используется 16-битная кодировка,
1110 – используется 24-битная кодировка,
11110 – используется 32 битная кодировка.
В начале каждого последующего байта – биты 10 – управляющий символ (выделен подчеркиванием), означающий продолжение кодирования.
Первые 128 ячеек таблицы Юникод повторяют таблицу ASCII. Для кодирования заглавных и строчных букв русского алфавита используются ячейки с номерами 1040-1103.
Рассмотрим пример кодирования фразы «Папа Hello».
Код в бинарном виде (старший бит справа):
00001011 11111001 (П) 00001011 00001101 (а) 00001011 11111101 (п) 00001011 00001101 (а) 00000100 (пробел) 00010010 (H) 10100110 (e) 00110110 (l) 00110110 (l) 11110110 (o).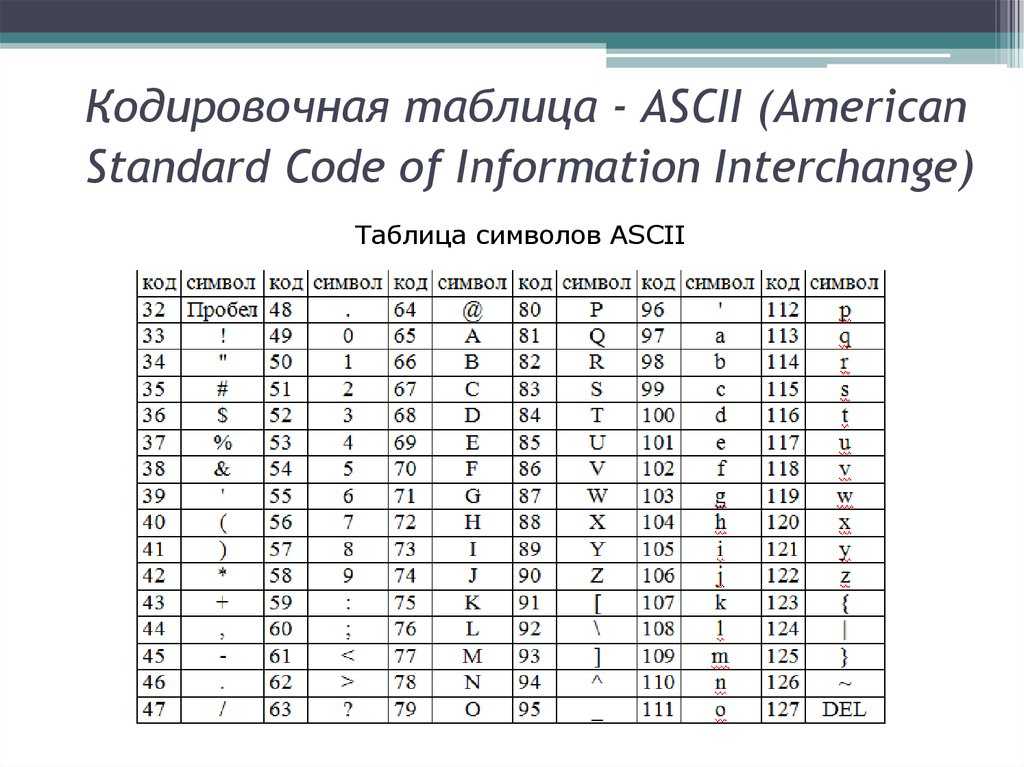
Букве П русского алфавита согласно таблицы Юникод соответствует номер 1055, в бинарном представлении 10000011111 – 11 бит. Соответственно данный символ может быть закодирован двумя байтами с использованием префикса 110 – для первого байта и 10 – для второго байта. Английские буквы слова Hello кодируются 1 байтом, а коды совпадают с кодами в таблице ASCII.
Основными преимуществами способа кодирования UTF-8 являются многообразие символов, которые могут быть закодированы, а также возможность кодирования переменным количеством бит, что позволяет сэкономить количество информации, передаваемое в канале связи.
Стандарт кодирования UTF-16
В феврале 2000 года опубликован документ RFC 2781, в котором закреплен стандарт UTF-16, позволяющий кодировать символы таблицы Юникод с помощью 16 или 32 битных значений. Символы с номерами 0-55295 и 57344-65535 кодируются с помощью 16 бит без изменений (без использования префиксов), а остальные символы, номера которых в двоичном представлении формируются количеством бит больше 16, кодируются 32 битами с использованием специального алгоритма.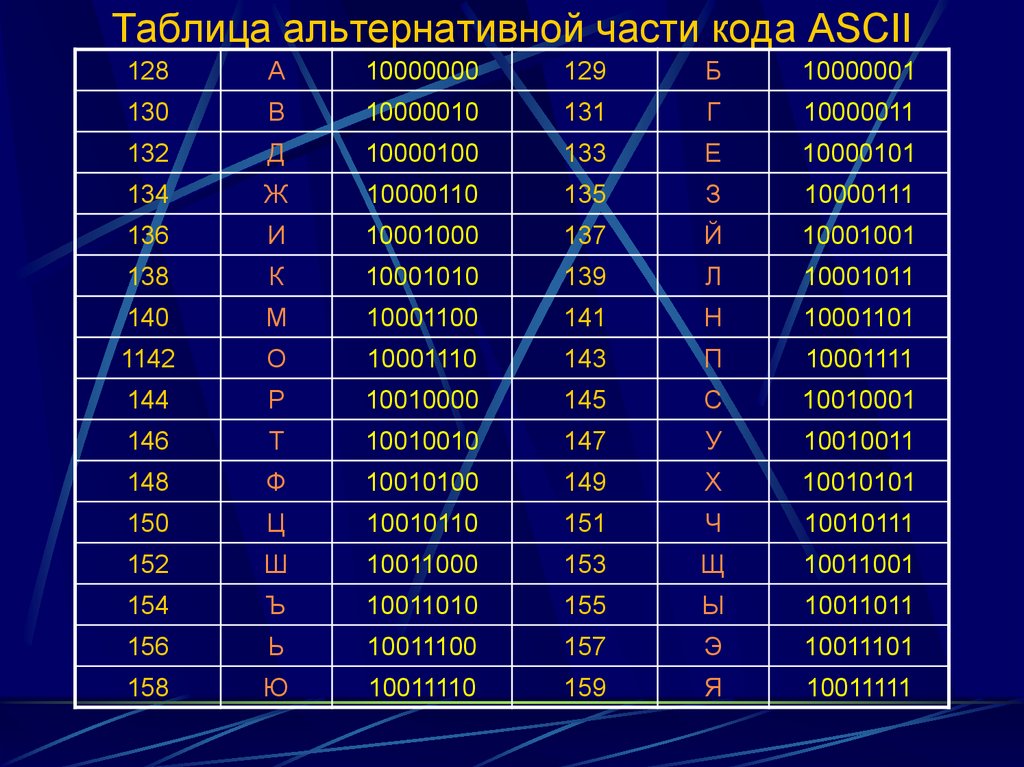 Рассмотрим пример кодирования фразы «Папа Hello».
Рассмотрим пример кодирования фразы «Папа Hello».
Код в бинарном виде (старший бит справа):
11111000 00100000 (П) 00001100 001000000 (а) 11111100 00100000 (п) 00001100 001000000 (а) 00000100 00000000 (пробел) 00010010 00000000 (H) 10100110 00000000 (e) 00110110 00000000 (l) 00110110 00000000 (l) 111110110 00000000 (o).
Номера букв русского и английского алфавитов таблицы Юникод передаются без изменений при помощи 16 бит, старшие незначащие биты принимают нулевое значение.
Рассмотрим подробнее алгоритм кодирования символов, номера которых превышают значение 65535. Для примера в качестве символа используем букву древнетюркского алфавита, представленную на рис.2:
Рис.2. Буква древнетюркского алфавита.Номер предложенного символа в таблице Юникод – 68620 (0х10COC).
Алгоритм преобразования номера символа в код UTF-16 состоит из нескольких шагов:
Из значения номера символа вычесть число 0х10000. Данная операция позволяет привести размерность бинарного представления номера символа к 20 битам.
 Для предложенного символа получим: 0х10COC – 0x10000 = 0xC0C.
Для предложенного символа получим: 0х10COC – 0x10000 = 0xC0C.Для полученного значения выделить старшие 10 бит и младшие 10 бит. В примере число 0хС0С в бинарном виде представляется, как 00000000110000001100, где жирным выделены 10 старших бит, а подчеркиванием – 10 младших.
К шестнадцатеричному значению 0xD800 (11011000 00000000) прибавить значение 0х03 (00000000 00000011), сформированное 10 старшими битами, полученными на предыдущем шаге. 0xD800 + 0х03 = 0хD803 (11011000 00000011) – 16 старших бит кодового слова UTF-16.
К шестнадцатеричному значению 0xDC00 (11011000 00000000) прибавить значение 0х0C (00000000 00001100), сформированное 10 младшими битами, полученными на шаге №2. 0xDС00 + 0х0С = DС0С (11011100 00001100) – 16 младших бит кодового слова UTF-16.
Кодовое слово UTF-16, соответствующее символу в примере, формируется из бит, полученных на шагах 3 и 4: 0хD803DC0C (11011000 00000011 11011100 00001100).
 Для предложенного символа получим: 0х10COC – 0x10000 = 0xC0C.
Для предложенного символа получим: 0х10COC – 0x10000 = 0xC0C.
Сравнение стандартов UTF-8 и UTF-16 с точки зрения объема машинной памяти, используемой кодом для представления символов
Результаты сравнения стандартов представлены в таблице 1.
Таблица 1. Результаты сравнения стандартов.
Диапазон номеров | 0-127 | 128 — 2047 | 2048-32767 | 32768-65535 | 65535- 1048575 | 1048575-… |
UTF-8 | 8 | 16 | 24 | 32 | 32 | _ |
UTF-16 | 16 | 16 | 16 | 16 | 32 | 32 |
В ячейках таблицы 1 содержится количество бит, требуемое для кодирования одного символа из таблицы Юникод.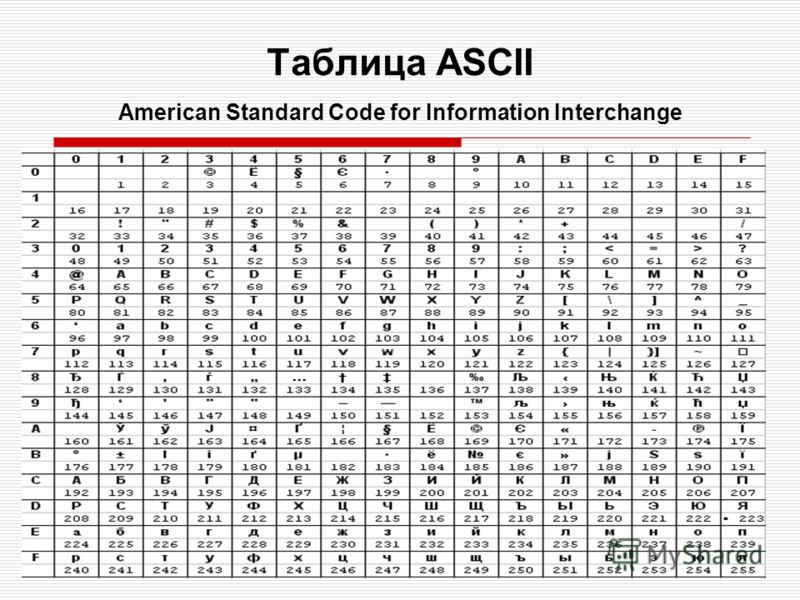 Видно, что для диапазонов номеров ячеек 128-2047, 65535-1048575 стандарты UTF-8 и UTF-16 используют одинаковое количество бит. Для диапазона 0-127 выгодно использование стандарта UTF-8, например, в случае, если программисту поручили реализовать кодер букв английского алфавита. Для диапазонов 2048-32767 и 32768-65535 выгодно использование стандарта UTF-16, например, в случае, если программисту поручили реализовать кодер иероглифов Бопомофо (занимают в таблице Юникод диапазон ячеек 12549-12589). Кодирование символов таблицы Юникод, расположенных в ячейках, номера которых начинаются от 1048575 возможно только с использованием кодировки UTF-16.
Видно, что для диапазонов номеров ячеек 128-2047, 65535-1048575 стандарты UTF-8 и UTF-16 используют одинаковое количество бит. Для диапазона 0-127 выгодно использование стандарта UTF-8, например, в случае, если программисту поручили реализовать кодер букв английского алфавита. Для диапазонов 2048-32767 и 32768-65535 выгодно использование стандарта UTF-16, например, в случае, если программисту поручили реализовать кодер иероглифов Бопомофо (занимают в таблице Юникод диапазон ячеек 12549-12589). Кодирование символов таблицы Юникод, расположенных в ячейках, номера которых начинаются от 1048575 возможно только с использованием кодировки UTF-16.
В предыдущих главах приведены примеры кодирования фразы «Папа Hello» стандартами UTF-8 и UTF-16. Кодировкой UTF-8 используются 14 байт, кодировкой UTF-16 20 байт, что связано с избыточностью кодирования англоязычных символов во втором случае из-за использования дополнительного байта 0х00. Можно сделать вывод, что для кодирования текста содержащего набор букв русского и английского алфавитов, предпочтительно использование кодировки UTF-8.
Вывод: в зависимости от языка алфавита может быть выбрана как кодировка UTF-8, так и кодировка UTF-16. Для английского алфавита однозначно более выгодно использование кодировки UTF-8, для русского алфавита буквы представляются одинаковым количеством бит при использовании как одной, так и другой кодировки.
Несколько советов программистам
Допустим, программист решил реализовать текстовый редактор, поддерживающий алфавит языка Бопомофо. Символы данного языка располагаются в таблице Юникод в диапазоне 12549-12589 и, следовательно, программисту необходимо выбрать стандарт UTF-16 для кодирования. Предположим, что для ввода символов решено использовать программную клавиатуру, состоящую из кнопок, каждая из которых соответствует букве алфавита языка. Кнопки – объекты класса button. Нажатие пользователем на какую-либо из кнопок порождает событие, в результате которого приложению становится известен номер ячейки таблицы Юникод. Программисту рекомендуется:
1.Хранить в памяти приложения символы таблицы Юникод и номера ячеек, соответствующие только языкам, поддержка которых планируется в текстовом редакторе.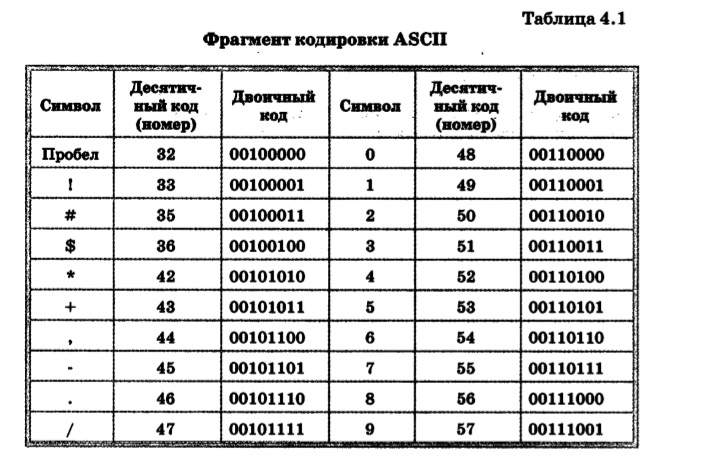 Это уменьшит объем памяти, занимаемой приложением, а также повысит скорость его работы, сузив область поиска номера ячейки.
Это уменьшит объем памяти, занимаемой приложением, а также повысит скорость его работы, сузив область поиска номера ячейки.
2. При реализации приложения заранее выполнить преобразование всех номеров ячеек в их бинарные коды. Результат преобразования сохранить в файле, в формализованном виде. При загрузке приложения выполнить считывание в память номеров ячеек и их бинарных кодов UTF-16. Это позволит снизить вычислительную нагрузку приложения в ходе его работы.
3. Для хранения номеров ячеек и их бинарных кодов использовать объект класса, позволяющего осуществить это в виде ключ-значение, где ключ – номер ячейки, а значение – бинарный код. Классы, реализующие в языках программирования данный функционал, организуют работу таким образом, чтобы минимизировать время поиска ключа, используя сортировку ключей или хеширование.
Отметим проблему кодирования составных символов, которая является важным техническим аспектом. Например, символ ü может быть интерпретирован, как самостоятельный символ, которому соответствует номер ячейки 252 или может быть скомпонован из двух символов: u, которому соответствует номер ячейки 117 и символа ¨, которому соответствует номер ячейки 776.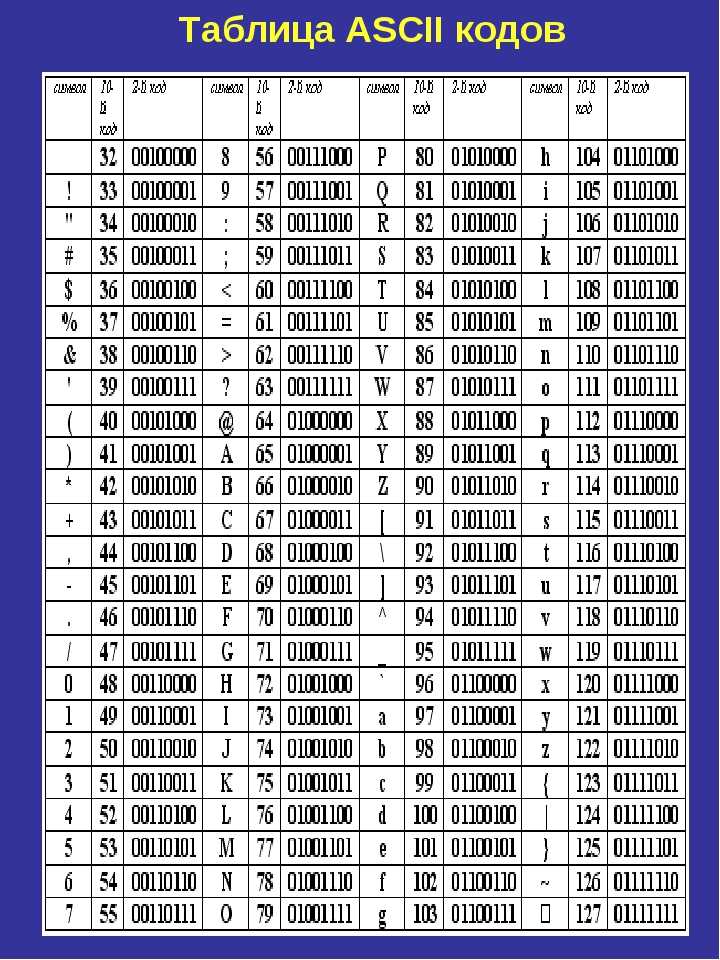 Программист должен строго придерживаться одного из вариантов представления таких символов иначе побайтовое сравнение строк будет невозможно. Рекомендуется использование второго варианта, который может облегчить поиск составных символов в тексте. Например, если пользователь осуществляет поиск символа u, то ему может быть выведен в качестве результата, как составной символ ü, так и самостоятельный u.
Программист должен строго придерживаться одного из вариантов представления таких символов иначе побайтовое сравнение строк будет невозможно. Рекомендуется использование второго варианта, который может облегчить поиск составных символов в тексте. Например, если пользователь осуществляет поиск символа u, то ему может быть выведен в качестве результата, как составной символ ü, так и самостоятельный u.
Кириллизация компьютеров — Детали
КИРИЛЛИЗАЦИЯ WINDOWS ИЛИ MACINTOSH
Если вы уже знаете некоторые подводные камни кириллизации вашего компьютера, пропустите объяснение ниже и сразу перейдите на один из следующих сайтов:
ОБЩИЕ САЙТЫ (Macintosh, Windows, Юникс)
- Кириллица шрифты и драйверы клавиатуры
- Брама (ориентировано на Украину)
- Релком
- Русифицировать все! от СовИнформБюро
- Словофилия (ОСУ)
MACINTOSH
- Apple
Русский сайт
OS X (от Jack Franke, Профессор русского языка, Институт оборонного языка): (1) Скачать все Русские шрифты и положить их в свою папку — /library/fonts. (2) Установить
AATSEEL-фонетическая клавиатура. При необходимости сделайте расширение .rsrc для
клавиатура. (3) Если вам нужны гласные с ударением, используйте «палитру отображения символов» (где
флаг находится в меню после выбора второй клавиатуры в Системных настройках),
введите гласную, а затем выберите «объединение диакритических знаков», и гласная
будет акцентировано. - Релком: Macintosh и KOI-8
- Массачусетский технологический институт Русификация Macintosh (Введите «кириллицу» в поле поиска.)
- Друзья и партнеры Macintosh Русификация
- Ямада Языковой центр (несколько красивых шрифтов и хороший FAQ)
 (2) Установить
AATSEEL-фонетическая клавиатура. При необходимости сделайте расширение .rsrc для
клавиатура. (3) Если вам нужны гласные с ударением, используйте «палитру отображения символов» (где
флаг находится в меню после выбора второй клавиатуры в Системных настройках),
введите гласную, а затем выберите «объединение диакритических знаков», и гласная
будет акцентировано.
(2) Установить
AATSEEL-фонетическая клавиатура. При необходимости сделайте расширение .rsrc для
клавиатура. (3) Если вам нужны гласные с ударением, используйте «палитру отображения символов» (где
флаг находится в меню после выбора второй клавиатуры в Системных настройках),
введите гласную, а затем выберите «объединение диакритических знаков», и гласная
будет акцентировано. Если такие термины, как Unicode, кодовая страница, KOI8, CP 1251 и переназначение клавиатуры звучит как китайская грамота, тогда читайте дальше.
Кириллизация ПК или Macintosh
должно быть легко. Просто добавьте кириллический шрифт и покончим с этим, верно? Что ж,
некоторые люди делают именно это, и именно здесь обычно начинаются проблемы. Понимаете,
очень мало стандартизации кириллических шрифтов. Как результат,
вы можете успешно кириллизировать свой компьютер и написать документ на кириллице.
Но предположим, что вы даете другим копии документа на диске. Они
загружают его в свои компьютеры, и они видят…
9&*(!
Просто добавьте кириллический шрифт и покончим с этим, верно? Что ж,
некоторые люди делают именно это, и именно здесь обычно начинаются проблемы. Понимаете,
очень мало стандартизации кириллических шрифтов. Как результат,
вы можете успешно кириллизировать свой компьютер и написать документ на кириллице.
Но предположим, что вы даете другим копии документа на диске. Они
загружают его в свои компьютеры, и они видят…
9&*(!
Или, может быть, вы видите кучу серия маленьких пустых коробок
Или файл не вообще загрузить!
Почему это происходит? Это почти всегда связано с отсутствием стандартизации для написания кириллицы.
Что означает отсутствие стандартизации
иметь в виду? Ну, возьмем латинский алфавит. Существует общепринятый способ представления
латинские буквы без ударения (а также цифры и знаки препинания на компьютере.
Каждому символу присвоен числовой код. На сегодняшний день все компьютерные дизайнеры
согласен, что заглавные буквы A-Z занимают коды 65-90. Маленькие буквы a-z
возьмите коды 97-122. Числа и знаки препинания также имеют согласованные коды.
На самом деле общеприняты все коды от 1 до 127.
на. Неважно, какой компьютер вы используете: заглавная буква N всегда равна 78.
Маленькие буквы a-z
возьмите коды 97-122. Числа и знаки препинания также имеют согласованные коды.
На самом деле общеприняты все коды от 1 до 127.
на. Неважно, какой компьютер вы используете: заглавная буква N всегда равна 78.
Как насчет романа с акцентом персонажи? До недавнего времени все компьютерные системы использовали расширенные коды для Европейские персонажи. Эти верхние коды варьируются от 128 до 255. Но есть не является универсальным кодированием. Например, буква е с акутом кодируется как 233 в стандартной кодовой странице Windows, 160 в коде Macintosh страницы и 130 в DOS. К счастью, программисты разработали подпрограммы, которые обычно автоматически переводить коды при перемещении документов с одной платформы другому.
Кириллица, с другой
стороны, представляет собой гораздо большую проблему. Кириллические буквы также обычно
кодируется в расширенном диапазоне от 128 до 255. существовала общепринятая система
для DOS и еще одна система для MS Windows.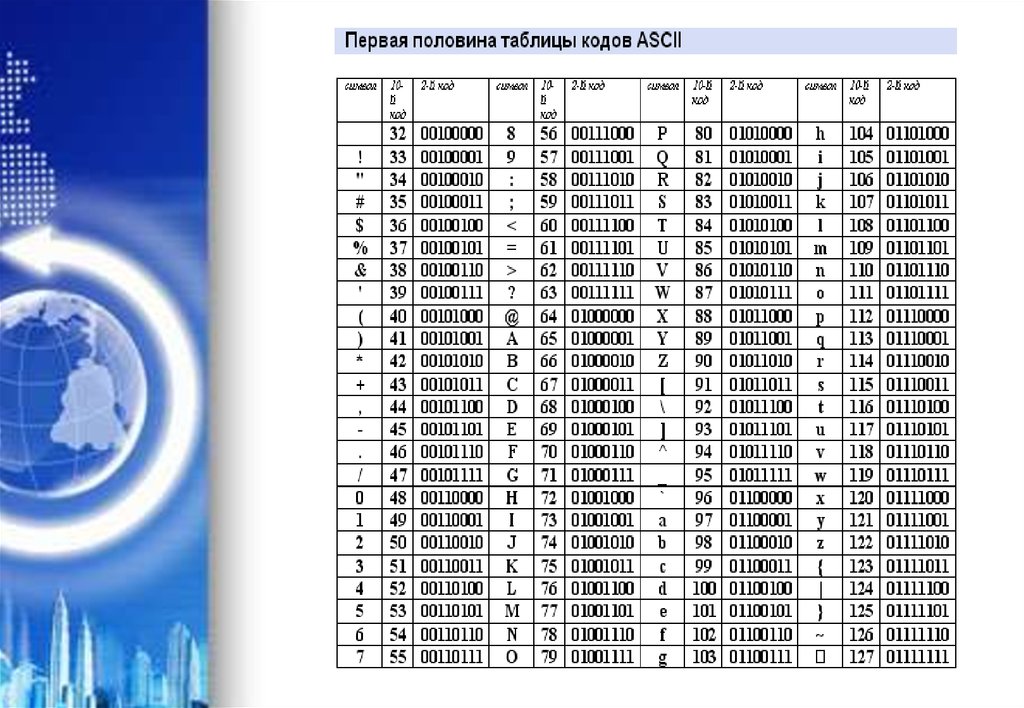 Существует еще одна система для
использовать в Интернете. И только в 1990-х годах появился стандарт Macintosh.
появиться.
Существует еще одна система для
использовать в Интернете. И только в 1990-х годах появился стандарт Macintosh.
появиться.
ЮНИКОД. Сейчас, в
На рубеже тысячелетий Microsoft прилагает все усилия, чтобы сделать еще один универсальный
стандарт кодирования: Юникод. Преимущество Unicodes в том, что он обрабатывает почти
каждая буква каждого алфавита мира, включая множество китайских иероглифов.
Недостатком является то, что он несовместим практически со всеми иностранными шрифтами.
произведенные ранее. Когда Unicode действительно станет универсальным, изучение иностранных языков
между платформами будет намного проще. Беда в том, что переход
в Unicode не безболезненно. Если вы накопили массу великолепных шрифтов
для некоторых других систем вам придется начинать все сначала в Unicode. Офис97
заставляет пользователей делать именно это! Подробнее о схеме кодирования см.
Юникод
сайт графика. Пользователям Windows 95/98 не нужно много делать, чтобы использовать шрифты, которые
совместимы как с Unicode, так и (для многих приложений) с кириллицей Windows.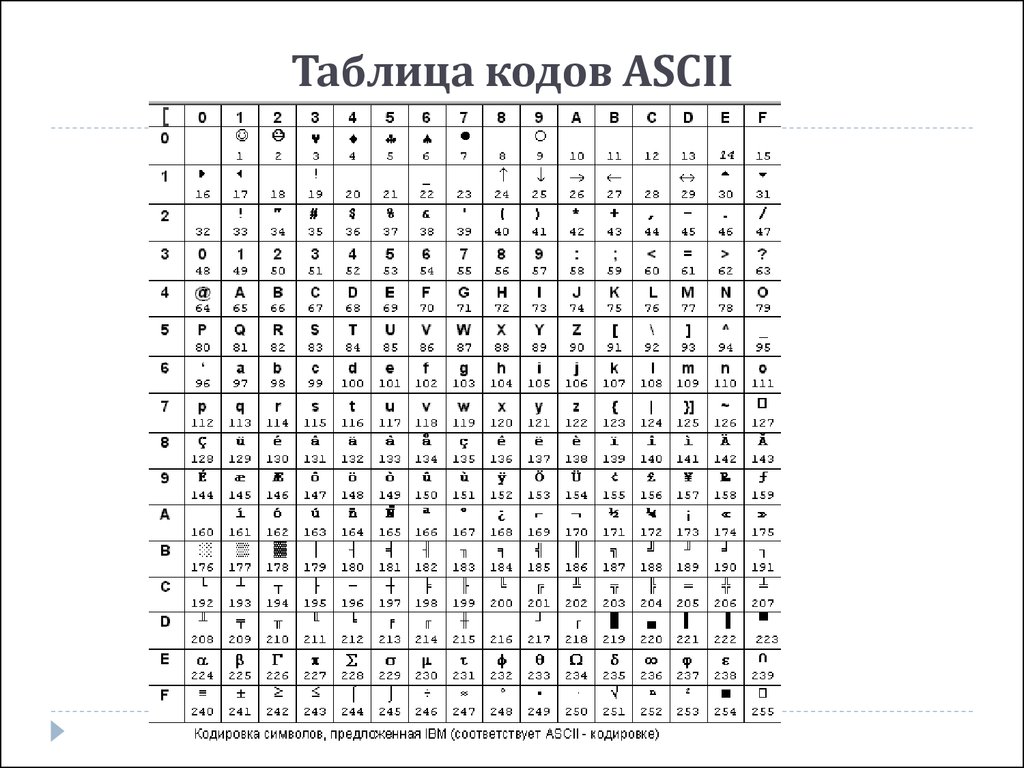 1251. См. инструкцию по использованию непосредственно ниже в разделе WINDOWS CYRILLIC.
(КОД СТРАНИЦЫ MS 1251)
1251. См. инструкцию по использованию непосредственно ниже в разделе WINDOWS CYRILLIC.
(КОД СТРАНИЦЫ MS 1251)
Прямо сейчас многие (но не все) Продукты Microsoft для Windows поддерживают Unicode. Поддержка Юникода для Macintosh набирает обороты, но несколько медленнее. Если вы используете последнюю операционная система на компьютере Windows или Macintosh, а также последнюю версию браузера, такого как Netscape, скорее всего, вы поддерживаете Unicode, хотя Unicode может не быть стандартным способом, которым ваш компьютер использует кириллицу. Совместимость Проблемы наверняка будут беспокоить пользователей кириллических компьютеров в течение первых нескольких лет. 21 века.
Старшие соревнующиеся системы:
ОКНА
КИРИЛИЦА (КОД СТРАНИЦЫ MS 1251) . До недавнего времени это была кодировка
используется в большинстве приложений Microsoft Windows. Он по-прежнему является самым распространенным
система кодирования во Всемирной паутине.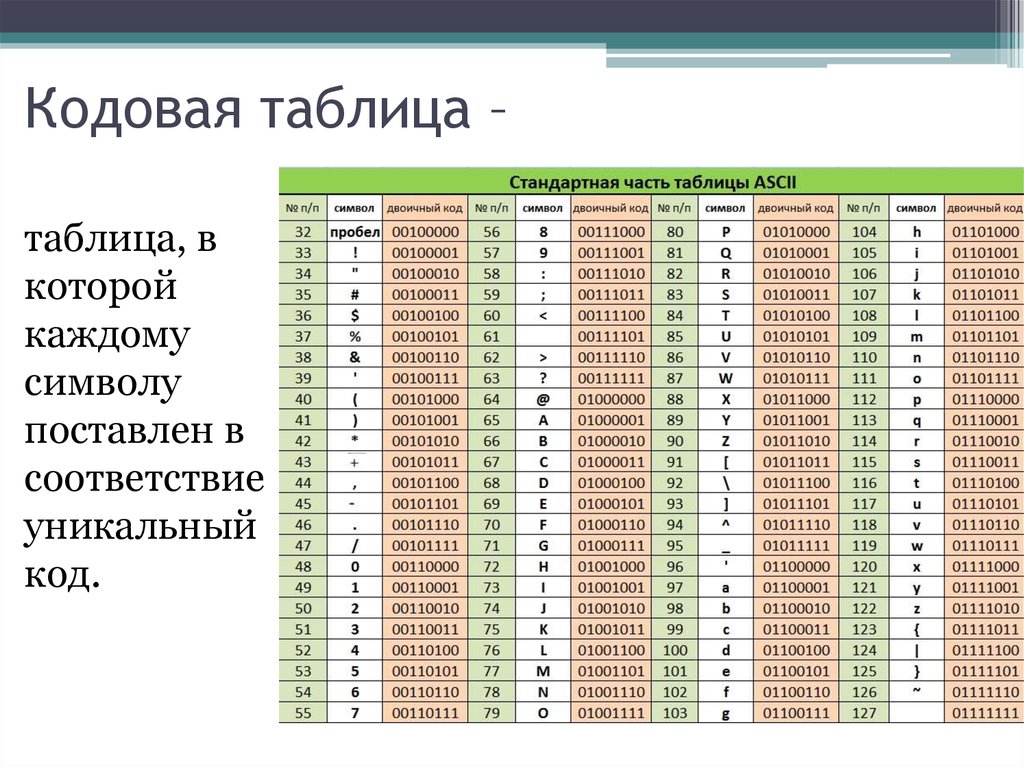 Существуют десятки шрифтов, как коммерческих,
и некоммерческий доступ.
Существуют десятки шрифтов, как коммерческих,
и некоммерческий доступ.
Примечание. В большинстве случаев пользователи Windows95/98
не нужно загружать специальные файлы для CP 1251. Вместо этого выполните следующие действия:
- Вставьте компакт-диск Windows95.
- Перейдите в «Панель управления», «Добавить программное обеспечение», «Настройка Windows» и проверьте «Многоязычность». поддерживать. Нажмите OK, и Windows установит набор русских шрифтов.
- Если у вас нет оригинального компакт-диска с Windows 95/98, вы можете получить Пакет поддержки многоязычной поддержки, lang.exe, бесплатно с сайта Майкрософт. Преимущество шрифтов Microsoft заключается в том, что совместимы как с WinCyrillic, так и с Unicode.
Скачать Шрифты WinCyrillic 1251 для Windows.
WinCyrillic 1251 хорошо
поддерживается коммерческими программами проверки орфографии, грамматики и т. д. WinCyrillic 1251
расставляет русские символы в алфавитном порядке от A-JA и далее a-ja начиная с 192 и заканчивая 255. JO кодируется как 168 и jo на 184. В то время как большинство компьютеров под управлением Windows используют русские шрифты на основе WinCyrillic
1251, есть два места, где его нельзя использовать:
д. WinCyrillic 1251
расставляет русские символы в алфавитном порядке от A-JA и далее a-ja начиная с 192 и заканчивая 255. JO кодируется как 168 и jo на 184. В то время как большинство компьютеров под управлением Windows используют русские шрифты на основе WinCyrillic
1251, есть два места, где его нельзя использовать:
- Microsoft Office97 (включая Word97). Офис Microsoft полностью переехал в Unicode без обеспечения обратной совместимости с сотнями шрифтов WinCyrillic, которые стали доступны в течение последнее десятилетие.
- Некоторые веб-сайты и многие системы электронной почты требуют KOI8.
КОИ8 является продуктом старой системы кодирования, которая использовалась на советских мейнфреймах.
компьютеры. Многие документы в Интернете, большая часть электронной почты, используемой в России, и
почти все русскоязычные группы новостей закодированы в KOI8.
- Загрузите шрифты KOI8 для использования в Windows. Если вы используете Netscape или выше, или Internet Explorer 4 или выше. Ты не нужен отдельный набор шрифтов KOI-8. Оба браузера позволяют для просмотра документов KOI-8 с использованием шрифтов WinCyrillic. См. FAQ в конце этого документа.
КОИ8 работает в попытке английского (!) алфавитного порядка с строчными буквами первый. Нижний регистр a это 193. Прописные твердый знак это 255.
ALTERNATIVA кодировка
(кодовая страница MS 866 и/или 899) используется в основном в приложениях на базе MS DOS, отличных от Windows.
и был довольно распространен в России. Он кодирует заглавные А через строчные р .
в кодах 128-175, а затем снова поднимается с r до ja по 224-239. JO и jo не имеют официальных кодов в этой системе, хотя некоторые
люди придумывают свои собственные шрифты и назначают их на 240 и 241.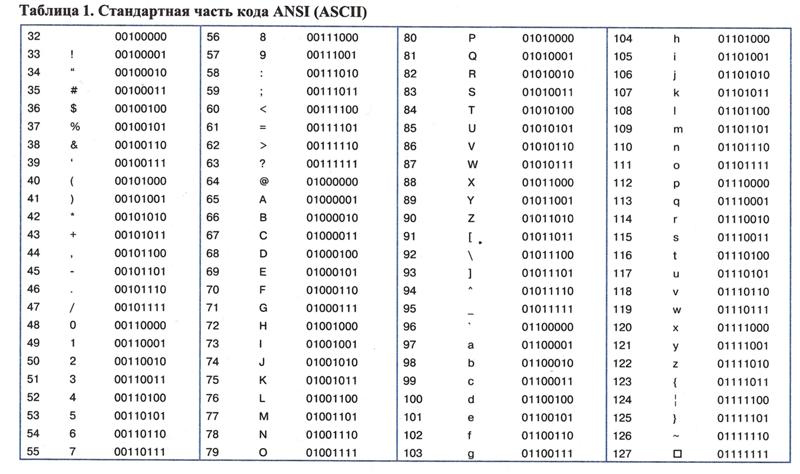
APPLE MACINTOSH КИРИЛЛИЧНЫЙ II использует ASCII 128-159 для верхнего регистра русского языка и от 223 до 255 для нижнего регистра. дела буквы. Все в алфавитном порядке, кроме JO, jo и ja. Самая последняя Mac OS может быть кириллизирована, чтобы Mac читал не только свой собственный Mac Cyrillic II, но и другие системы кодирования. Попробуйте следующее источники для кириллизации Macintosh:
- Релком: Макинтош и КОИ-8
- Массачусетский технологический институт Русификация Macintosh (Введите «кириллицу» в поле поиска.)
- Друзья и партнеры Macintosh Русификация
Ямада Языковой центр (несколько красивых шрифтов и хороший FAQ)
Драйверы клавиатуры. Конечно, если у вас есть шрифт для данной кодировки, вы можете прочитать любой документ.
написано этим шрифтом с этой кодировкой. Но чтобы печатать, вы должны иметь доступ
буквы на клавиатуре.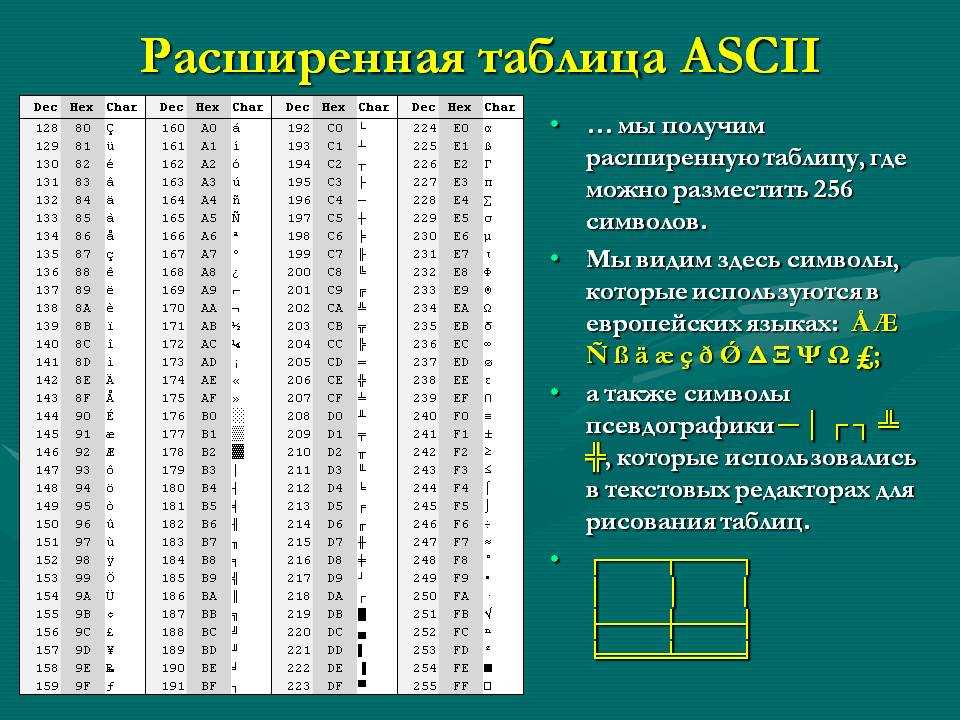 Для этого вам нужно драйвер клавиатуры . Что
позволяет легко переключаться (обычно одним нажатием клавиши) между латинским и
Кириллица. Если у вас уже установлен ваш шрифт, и вы можете перейти к драйверу
меню и выберите соответствующий переназначитель клавиатуры.
Для этого вам нужно драйвер клавиатуры . Что
позволяет легко переключаться (обычно одним нажатием клавиши) между латинским и
Кириллица. Если у вас уже установлен ваш шрифт, и вы можете перейти к драйверу
меню и выберите соответствующий переназначитель клавиатуры.
Драйверы клавиатуры для Windows95. Windows95 включает драйвер клавиатуры как часть многоязычной поддерживать. Однако поддерживает только настоящую русскую клавиатуру, а не американскую студенческая фонетическая клавиатура (русская Н на клавише N, русская С на клавише клавиша S и т.д. и т.п.). Если вы хотите настроить клавиатуру, у вас есть два варианта:
- Получить коммерческий пакет, такой как комплект русификации Parawin, доступный от корпорации Смартлинк. Он бывает разных вкусов и стоит от 100 до 200 долларов.
- Загрузите условно-бесплатный редактор клавиатуры, например, Janko.
редактор.
Вы другие обсуждения по кодированию на иностранном языке можно найти в Интернете:
- Русифицировать все! от Cyber.com.
- Обсуждений Netscape:
- http://home.netscape.com/people/ftang/meta.html
- http://home.netscape.com/people/ftang/i18n.html
ЧАСТО ЗАДАВАЕМЫЕ ВОПРОСЫ
Word для Windows (все версии начиная с Word 6)
Как сделать акцент Метки?
Самое простое решение
приобрести шрифт с акцентированными символами. Смартлинк
Корпорация имеет ряд русских шрифтов с акцентами, а также инструкции.
о том, как печатать ударения. Решение xalyava заключается в создании акцентированного
через поле Words { EQ }. Акцент a выглядит так:
{экв \о(,а)}. Чтобы ввести акцент, убедитесь, что вы печатаете английский язык, а не
Русский. Убедитесь, что индикатор NumLock горит. Затем зажмите клавишу Alt и
на цифровой клавиатуре введите 0180. Очевидно, если вы планируете использовать этот метод
много, вы должны сделать это в макрос. Имейте в виду, что русская программа проверки орфографии
не распознает такой акцентированный символ как законный.
Убедитесь, что индикатор NumLock горит. Затем зажмите клавишу Alt и
на цифровой клавиатуре введите 0180. Очевидно, если вы планируете использовать этот метод
много, вы должны сделать это в макрос. Имейте в виду, что русская программа проверки орфографии
не распознает такой акцентированный символ как законный.
Office97, Word97 (Windows)
У меня в Ворде стояла кириллица 6 и в Word для Windows95. Теперь, когда я набираю кириллицу, у меня немного пусто коробки.
Вероятно, вы используете
шрифт, несовместимый с Unicode. Word97 (действительно весь Office97) использует
Только шрифты, совместимые с Unicode. У сотрудников Microsoft есть способ сопоставить старые
шрифты, отличные от Unicode, на шрифты Unicode, такие как те, которые поставляются с Microsoft
многоязычная поддержка. Но если ваш любимый шрифт был Литературная и это не шрифт Unicode, вам придется довольствоваться более прозаичным шрифтом
TimesNewRomanКириллица. Извиняюсь! См. Картографирование
старые шрифты WinCyrillic в шрифты Microsoft Unicode.
Извиняюсь! См. Картографирование
старые шрифты WinCyrillic в шрифты Microsoft Unicode.
Электронная почта и группы новостей
В то время как WinCyrillic (или в последнее время Unicode) доминирует в большинстве мест, KOI8
Кажется, у него есть блокировка электронной почты и групп Usenet. Имейте это в виду, когда вы
прочитайте следующие пункты.
Как получить кириллицу в Юдоре?
Некоторые версии Eudora
не особенно дружелюбен к кириллице. Но вот что вы можете сделать. Скачать
набор WinCyrillic
1251 шрифт и набор KOI8
шрифты. Шрифты Microsoft, совместимые с Unicode, такие как TimesNewRomanCyr, не будут
показывать кириллицу в текущей версии Eudora! Когда вы получаете сообщение в
Русский, попробуйте переключить шрифт дисплея в настройках на шрифт WinCyrillic
вы скачали (т.е. Е.Р.Букинист). Если сообщение по-прежнему выглядит как мусор, попробуйте
шрифт KOI8. Американцы, отправляющие вам электронные письма на русском языке, скорее всего, используют
WinКириллица.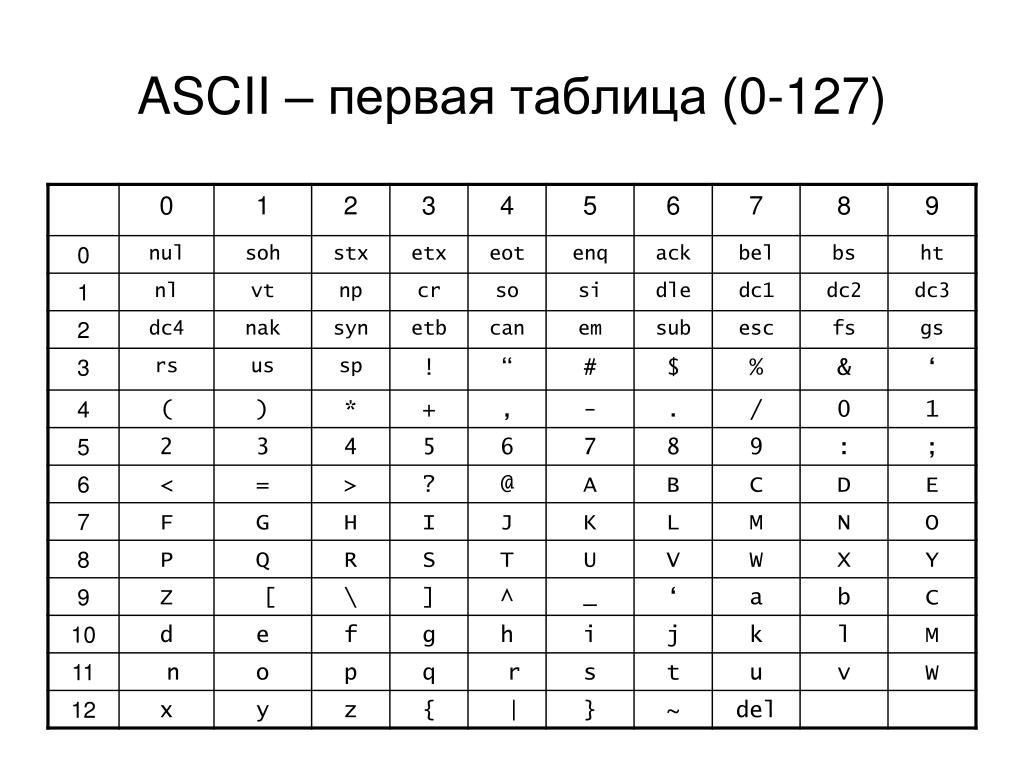 Электронная почта из России, скорее всего, будет в KOI8.
Электронная почта из России, скорее всего, будет в KOI8.
Как сделать кириллицу Нетскейп?
Если у вас Netscape 3, обновитесь до Netscape Communicator (4.0 или выше), который намного лучше поддерживает кириллицу. В Netscape Communicator вам не нужен специальный набор шрифтов KOI8, даже хотя большая часть электронной почты отправляется в KOI8. Netscape делает Windows многоязычной кириллицей шрифты делаю KOI8. Поэтому вы должны убедиться, что Windows95/98 кириллизирован. Затем в Netscape отредактируйте настройки и установите кириллицу (1251) в TimesNewRomanCyr и CourierNewCyr. При чтении электронной почты из России сделайте убедитесь, что для View Encoding установлено значение Cyrillic 1251 (даже если ваши друзья отправляют вы по электронной почте в KOI8).
В редких случаях Netscape
почтовые пользователи будут сталкиваться с сообщениями на русском языке, которые по-прежнему кажутся нечитаемыми,
даже когда все подготовительные шаги сделаны. Если вы видите много кириллицы
мусор заглавными буквами, электронное письмо, которое вы пытаетесь прочитать, было отправлено
в WinCyrillic 1251. Но Netscape предполагает, что вся русская почта в KOI8
и пытается внести коррективы для вас. Слишком глупо знать, когда , а не сделать это. Но вы можете обмануть Netscape, чтобы он не работал так усердно. Сделать это,
вам нужен набор WinCyrillic сторонних производителей, не поддерживающих Unicode
1251, например Букинист1251. В разделе «Изменить настройки» установите эти
шрифты в пользовательской кодировке. Тогда прочитайте любую русскую почту, которую вы
не может нормально читать, изменив пункт меню View, Encoding на User
определенный.
Если вы видите много кириллицы
мусор заглавными буквами, электронное письмо, которое вы пытаетесь прочитать, было отправлено
в WinCyrillic 1251. Но Netscape предполагает, что вся русская почта в KOI8
и пытается внести коррективы для вас. Слишком глупо знать, когда , а не сделать это. Но вы можете обмануть Netscape, чтобы он не работал так усердно. Сделать это,
вам нужен набор WinCyrillic сторонних производителей, не поддерживающих Unicode
1251, например Букинист1251. В разделе «Изменить настройки» установите эти
шрифты в пользовательской кодировке. Тогда прочитайте любую русскую почту, которую вы
не может нормально читать, изменив пункт меню View, Encoding на User
определенный.
Как сделать кириллицу Outlook Express?
При правильной настройке
Outlook Express — наиболее понятная к кириллице программа электронной почты из всех доступных.
Это также бесплатно, так как в комплекте с Internet Explorer.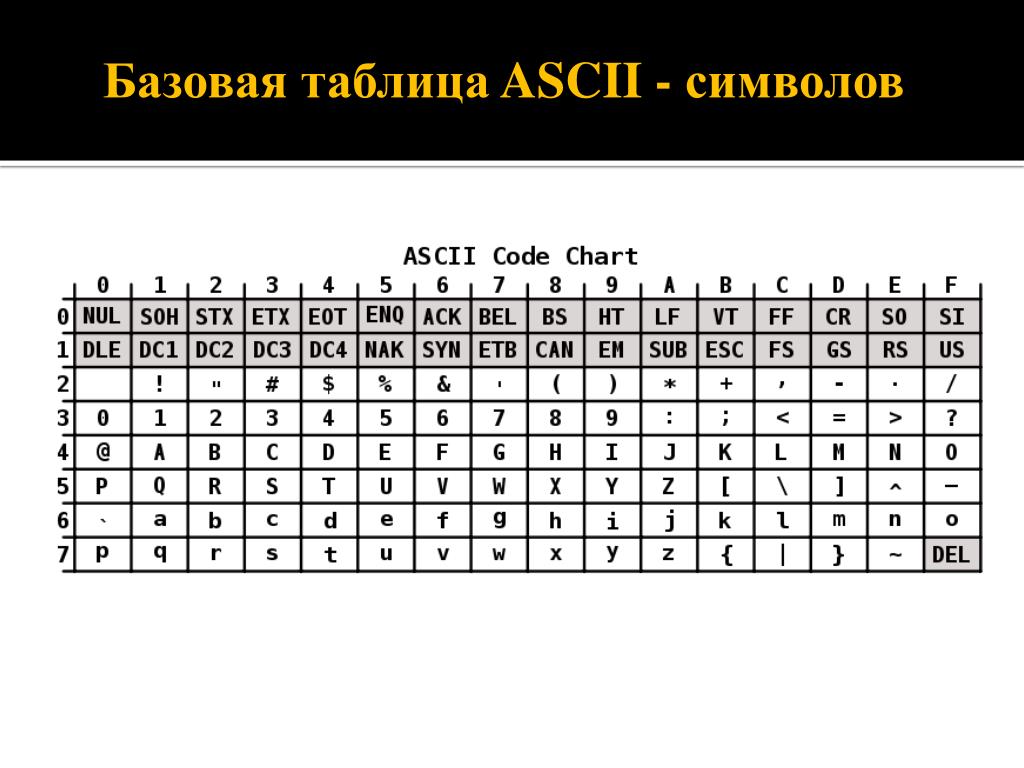 Убедись, что
Windows95/98 кириллизирована. Потом при составлении
или прочитав сообщение, перейдите в «Формат», «Язык» и выберите WinCyrillic
или КОИ8. Если вы получаете ерунду в одном, попробуйте другой.
Убедись, что
Windows95/98 кириллизирована. Потом при составлении
или прочитав сообщение, перейдите в «Формат», «Язык» и выберите WinCyrillic
или КОИ8. Если вы получаете ерунду в одном, попробуйте другой.
Когда я отправляю на русском языке электронное письмо моим друзьям в России, они не могут его прочитать. И это не из-за моя грамматика!
Твоя непостижимость
возможно потому, что вы отправляете WinCyrillic 1251 (стандарт в большинстве
системы в наши дни). Но ожидается, что электронная почта, направляемая в Россию, будет в KOI8.
Российские пользователи Netscape с трудом читают что-либо, кроме KOI8 (по электронной почте).
Самое простое решение — переключиться на программу электронной почты, совместимую с KOI8:
либо Netscape Communicator (который автоматически переводит все русские
электронная почта, которую вы пишете в KOI8, нравится вам это или нет) или Outlook Express,
что дает вам выбор способа отправки кириллицы.
Если по какой-то причине вы не могу переключиться, вы можете получить конвертер кодовых страниц, который поможет вам перевести с одной системы в другую перед отправкой. Существует ряд конвертеров кодовых страниц доступны в Интернете. Или вы можете заказать полнофункциональную модель (CP Tuner) у Корпорация Смартлинк. Но независимо от того, что вы получаете, преобразователи беспокоят.
Я не могу прочитать электронное письмо Я получаю от своих друзей в России, хотя мой компьютер полностью кириллицирован.
Это как раз наоборот проблемы, рассмотренной выше. Ваши друзья присылают вам вещи, которые автоматически преобразуется в KOI8 (используется почти исключительно в электронной почте). Вы возможно, , а не , используя Netscape Communicator или Outlook Express. Мой совет: переключиться на один из них. См. ответ на предыдущий вопрос, почему.
Набор символов KOI-7 (короткий KOI)
Набор символов KOI-7 (короткий KOI) Используется в бывшем Советском Союзе для кодирования как латиницы, так и кириллицы. (Русские) алфавиты в 7-битном пространстве ASCII G0, со строчной латиницей
буквы (и некоторые символы) в столбцах 6 и 7 заменены кириллицей в верхнем регистре
буквы «по звучанию». Таким образом, русский текст КОИ-7 все еще читается на
Отображение только в формате ASCII и возможность ввода на клавиатуре ASCII. Обычно используется в
Эл. адрес. ПРИМЕЧАНИЕ: Эта страница НЕ закодирована в KOI-7, так как ни один известный веб-браузер
будет отображать его правильно; вместо этого он кодируется в UTF-8.
(Русские) алфавиты в 7-битном пространстве ASCII G0, со строчной латиницей
буквы (и некоторые символы) в столбцах 6 и 7 заменены кириллицей в верхнем регистре
буквы «по звучанию». Таким образом, русский текст КОИ-7 все еще читается на
Отображение только в формате ASCII и возможность ввода на клавиатуре ASCII. Обычно используется в
Эл. адрес. ПРИМЕЧАНИЕ: Эта страница НЕ закодирована в KOI-7, так как ни один известный веб-браузер
будет отображать его правильно; вместо этого он кодируется в UTF-8. Легенда:
char 8) код символа
Hex Шестнадцатеричный (с основанием 16) код символа
Символ Dec Col/Row Oct Hex Имя и описание
( ) 32 02/00 40 20 ПРОБЕЛ (!) 33 01.02.41 21 ВОСКЛИЦАТЕЛЬНЫЙ ЗНАК ("") 34 02/02 42 22 КАвычки (#) 35 02/03 43 23 ЗНАК ЦИФРЫ ($) 36 02/04 44 24 ЗНАК ДОЛЛАРА (%) 37 02/05 45 25 ЗНАК ПРОЦЕНТА (&) 38 02/06 46 26 АМПЕРСАНД (') 39 02/07 47 27 АПОСТРОФ (() 40 02/08 50 28 ЛЕВАЯ СКОБКА ()) 41 02/09 51 29 ПРАВАЯ СКОБКА (*) 42 02/10 52 2A ЗВЕЗДОЧКА (+) 43 02/11 53 2B ЗНАК ПЛЮС (,) 44 02/12 54 2С ЗАПЯТАЯ (-) 45 02/13 55 2D ДЕФИС, МИНУС (.
 ) 46 02/14 56 2E ПЕРИОД, ПОЛНАЯ ОСТАНОВКА
(/) 47 15.02 57 2Э СОЛИДУС, СЛЕШ
(0) 48 03/00 60 30 ЗНАЧНЫЙ НОЛЬ
(1) 4903/01 61 31 ЦИФРА ЕДИНИЦА
(2) 50 03/02 62 32 ЦИФРА ДВА
(3) 51 03/03 63 33 ЦИФРА ТРИ
(4) 52 03/04 64 34 ЦИФРА ЧЕТЫРЕ
(5) 53 03/05 65 35 ЦИФРА ПЯТЬ
(6) 54 03/06 66 36 ЦИФРА ШЕСТЬ
(7) 55 03/07 67 37 ЦИФРА СЕДЬМАЯ
(8) 56 03/08 70 38 ЦИФРА ВОСЕМЬ
(9) 57 03/09 71 39 ЦИФРА ДЕВЯТЬ
(:) 58 03/10 72 3A ТОЛСТАЯ КИШКА
(;) 59 03/11 73 3B ТОЧКА С ЗАПЯТОЙ
(<) 60 03/12 74 3C ЗНАК "МЕНЬШЕ", ЛЕВАЯ УГЛОВАЯ СКОБКА
(=) 61 03/13 75 3D ЗНАК РАВНО
(>) 62 03/14 76 3E ЗНАК БОЛЬШЕ, ПРЯМАЯ СКОБКА
(?) 63 03/15 77 3F ВОПРОСИТЕЛЬНЫЙ ЗНАК
(@) 64 04/00 100 40 КОММЕРЧЕСКОЕ ОБЪЯВЛЕНИЕ НА ЗНАКЕ
(A) 65 04/01 101 41 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА A
(B) 66 04/02 102 42 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА B
(C) 67 04/03 103 43 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА C
(D) 68 04/04 104 44 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА D
(Э) 6905/04 105 45 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА E
(F) 70 04/06 106 46 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА F
(G) 71 04/07 107 47 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА G
(H) 72 04/08 110 48 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА H
(I) 73 04/09 111 49 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА I
(J) 74 04/10 112 4A ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА J
(K) 75 04/11 113 4B ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА K
(L) 76 04/12 114 4C ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА L
(M) 77 04/13 115 4D ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА M
(N) 78 04/14 116 4E ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА N
(O) 79 04/15 117 4F ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА O
(P) 80 05/00 120 50 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА P
(Q) 81 05/01 121 51 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА Q
(R) 82 05/02 122 52 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА R
(S) 83 05/03 123 53 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА S
(T) 84 05/04 124 54 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА T
(U) 85 05/05 125 55 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА U
(V) 86 05/06 126 56 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА V
(W) 87 05/07 127 57 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА W
(X) 88 05/08 130 58 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА X
(Д) 89) 94 05/14 136 5E CIRCUMFLEX АКЦЕНТ
(_) 95 05/15 137 5F НИЖНЯЯ ЛИНИЯ, ПОДЧИНКА
(Ю) 96 06/00 140 60 (`) ЗАГЛАВНАЯ БУКВА Ю
(А) 97 06/01 141 61 (а) ЗАГЛАВНАЯ БУКВА А
(Б) 98 02/06 142 62 (б) ЗАГЛАВНАЯ БУКВА ВЕ
(Ц) 99 03/06 143 63 (c) ЗАГЛАВНАЯ БУКВА ЦЭ
(Д) 100 06/04 144 64 (г) ЗАГЛАВНАЯ БУКВА DE
(Е) 101 05/06 145 65 (e) ЗАГЛАВНАЯ БУКВА IE
(Ф) 102 06/06 146 66 (f) ЗАГЛАВНАЯ БУКВА EF
(Г) 103 07/06 147 67 (ж) ЗАГЛАВНАЯ БУКВА ГЕ
(Х) 104 08/06 150 68 (h) ЗАГЛАВНАЯ БУКВА HA
(И) 105 06/09151 69 (i) ЗАГЛАВНАЯ БУКВА I
(Й) 106 06/10 152 6A (j) ЗАГЛАВНАЯ БУКВА КОРОТКАЯ I
(К) 107 06/11 153 6Б (к) ЗАГЛАВНАЯ БУКВА КА
(Л) 108 06/12 154 6C (л) ЗАГЛАВНАЯ БУКВА EL
(М) 109 06/13 155 6D (м) ЗАГЛАВНАЯ БУКВА ЭМ
(Н) 110 06/14 156 6E (н) ЗАГЛАВНАЯ БУКВА EN
(О) 111 06/15 157 6F (o) ЗАГЛАВНАЯ БУКВА O
(П) 112 07/00 160 70 (р) ЗАГЛАВНАЯ БУКВА PE
(Я) 113 01.
) 46 02/14 56 2E ПЕРИОД, ПОЛНАЯ ОСТАНОВКА
(/) 47 15.02 57 2Э СОЛИДУС, СЛЕШ
(0) 48 03/00 60 30 ЗНАЧНЫЙ НОЛЬ
(1) 4903/01 61 31 ЦИФРА ЕДИНИЦА
(2) 50 03/02 62 32 ЦИФРА ДВА
(3) 51 03/03 63 33 ЦИФРА ТРИ
(4) 52 03/04 64 34 ЦИФРА ЧЕТЫРЕ
(5) 53 03/05 65 35 ЦИФРА ПЯТЬ
(6) 54 03/06 66 36 ЦИФРА ШЕСТЬ
(7) 55 03/07 67 37 ЦИФРА СЕДЬМАЯ
(8) 56 03/08 70 38 ЦИФРА ВОСЕМЬ
(9) 57 03/09 71 39 ЦИФРА ДЕВЯТЬ
(:) 58 03/10 72 3A ТОЛСТАЯ КИШКА
(;) 59 03/11 73 3B ТОЧКА С ЗАПЯТОЙ
(<) 60 03/12 74 3C ЗНАК "МЕНЬШЕ", ЛЕВАЯ УГЛОВАЯ СКОБКА
(=) 61 03/13 75 3D ЗНАК РАВНО
(>) 62 03/14 76 3E ЗНАК БОЛЬШЕ, ПРЯМАЯ СКОБКА
(?) 63 03/15 77 3F ВОПРОСИТЕЛЬНЫЙ ЗНАК
(@) 64 04/00 100 40 КОММЕРЧЕСКОЕ ОБЪЯВЛЕНИЕ НА ЗНАКЕ
(A) 65 04/01 101 41 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА A
(B) 66 04/02 102 42 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА B
(C) 67 04/03 103 43 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА C
(D) 68 04/04 104 44 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА D
(Э) 6905/04 105 45 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА E
(F) 70 04/06 106 46 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА F
(G) 71 04/07 107 47 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА G
(H) 72 04/08 110 48 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА H
(I) 73 04/09 111 49 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА I
(J) 74 04/10 112 4A ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА J
(K) 75 04/11 113 4B ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА K
(L) 76 04/12 114 4C ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА L
(M) 77 04/13 115 4D ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА M
(N) 78 04/14 116 4E ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА N
(O) 79 04/15 117 4F ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА O
(P) 80 05/00 120 50 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА P
(Q) 81 05/01 121 51 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА Q
(R) 82 05/02 122 52 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА R
(S) 83 05/03 123 53 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА S
(T) 84 05/04 124 54 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА T
(U) 85 05/05 125 55 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА U
(V) 86 05/06 126 56 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА V
(W) 87 05/07 127 57 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА W
(X) 88 05/08 130 58 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА X
(Д) 89) 94 05/14 136 5E CIRCUMFLEX АКЦЕНТ
(_) 95 05/15 137 5F НИЖНЯЯ ЛИНИЯ, ПОДЧИНКА
(Ю) 96 06/00 140 60 (`) ЗАГЛАВНАЯ БУКВА Ю
(А) 97 06/01 141 61 (а) ЗАГЛАВНАЯ БУКВА А
(Б) 98 02/06 142 62 (б) ЗАГЛАВНАЯ БУКВА ВЕ
(Ц) 99 03/06 143 63 (c) ЗАГЛАВНАЯ БУКВА ЦЭ
(Д) 100 06/04 144 64 (г) ЗАГЛАВНАЯ БУКВА DE
(Е) 101 05/06 145 65 (e) ЗАГЛАВНАЯ БУКВА IE
(Ф) 102 06/06 146 66 (f) ЗАГЛАВНАЯ БУКВА EF
(Г) 103 07/06 147 67 (ж) ЗАГЛАВНАЯ БУКВА ГЕ
(Х) 104 08/06 150 68 (h) ЗАГЛАВНАЯ БУКВА HA
(И) 105 06/09151 69 (i) ЗАГЛАВНАЯ БУКВА I
(Й) 106 06/10 152 6A (j) ЗАГЛАВНАЯ БУКВА КОРОТКАЯ I
(К) 107 06/11 153 6Б (к) ЗАГЛАВНАЯ БУКВА КА
(Л) 108 06/12 154 6C (л) ЗАГЛАВНАЯ БУКВА EL
(М) 109 06/13 155 6D (м) ЗАГЛАВНАЯ БУКВА ЭМ
(Н) 110 06/14 156 6E (н) ЗАГЛАВНАЯ БУКВА EN
(О) 111 06/15 157 6F (o) ЗАГЛАВНАЯ БУКВА O
(П) 112 07/00 160 70 (р) ЗАГЛАВНАЯ БУКВА PE
(Я) 113 01.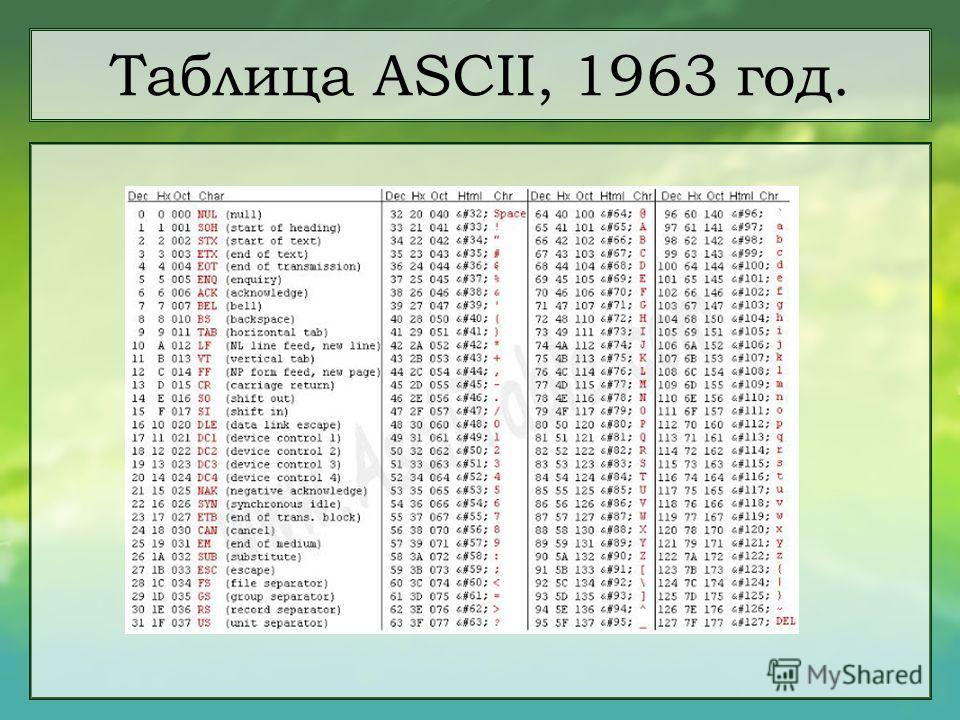 07.161 71 (q) ЗАГЛАВНАЯ БУКВА Я
(Р) 114 07/02 162 72 (r) ЗАГЛАВНАЯ БУКВА ЭР
(С) 115 07/03 163 73 (s) ЗАГЛАВНАЯ БУКВА ES
(Т) 116 07/04 164 74 (т) ЗАГЛАВНАЯ БУКВА ТЕ
(У) 117 05/07 165 75 (u) ЗАГЛАВНАЯ БУКВА U
(Ж) 118 07/06 166 76 (v) ЗАГЛАВНАЯ БУКВА ЖЕ
(В) 11907/07 167 77 (w) ЗАГЛАВНАЯ БУКВА VE
(Ь) 120 07/08 170 78 (x) КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА МЯГКИЙ ЗНАК
(Ы) 121 07/09 171 79 (у) ЗАГЛАВНАЯ БУКВА ЕРУ
(З) 122 07/10 172 7A (z) ЗАГЛАВНАЯ БУКВА ZE
(Ш) 123 07/11 173 7Б ({) ЗАГЛАВНАЯ БУКВА ША
(Э) 124 07/12 174 7C (|) ЗАГЛАВНАЯ БУКВА E
(Щ) 125 07/13 175 7Д (}) ЗАГЛАВНАЯ БУКВА ЩА
(Ч) 126 07/14 176 7E (~) ЗАГЛАВНАЯ БУКВА ЧЕ
( ) 127 15/07 177 7F УДАЛИТЬ
07.161 71 (q) ЗАГЛАВНАЯ БУКВА Я
(Р) 114 07/02 162 72 (r) ЗАГЛАВНАЯ БУКВА ЭР
(С) 115 07/03 163 73 (s) ЗАГЛАВНАЯ БУКВА ES
(Т) 116 07/04 164 74 (т) ЗАГЛАВНАЯ БУКВА ТЕ
(У) 117 05/07 165 75 (u) ЗАГЛАВНАЯ БУКВА U
(Ж) 118 07/06 166 76 (v) ЗАГЛАВНАЯ БУКВА ЖЕ
(В) 11907/07 167 77 (w) ЗАГЛАВНАЯ БУКВА VE
(Ь) 120 07/08 170 78 (x) КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА МЯГКИЙ ЗНАК
(Ы) 121 07/09 171 79 (у) ЗАГЛАВНАЯ БУКВА ЕРУ
(З) 122 07/10 172 7A (z) ЗАГЛАВНАЯ БУКВА ZE
(Ш) 123 07/11 173 7Б ({) ЗАГЛАВНАЯ БУКВА ША
(Э) 124 07/12 174 7C (|) ЗАГЛАВНАЯ БУКВА E
(Щ) 125 07/13 175 7Д (}) ЗАГЛАВНАЯ БУКВА ЩА
(Ч) 126 07/14 176 7E (~) ЗАГЛАВНАЯ БУКВА ЧЕ
( ) 127 15/07 177 7F УДАЛИТЬ
[ Указатель таблиц кодировок ]
Проект Кермит / Колумбийский университет / [email protected]
ISO 8859 Алфавитный суп
ISO 8859 Алфавитный супНОВОСТИ-1998: Эта страница перемещена на http://czyborra.com/charsets/iso8859.html, существенно расширена и обновлен и теперь сопровождается дополнительными страницами на ASCII, код страницы и кириллица кодировки.
ISO 8859 представляет собой полную серию из 10 (а вскоре и больше) стандартизированных многоязычных графических изображений с однобайтовым кодированием (8 бит). наборы символов для письма на алфавитных языках:
- Latin1 (Западноевропейская)
- Latin2 (восточноевропейская)
- Latin3 (южноевропейская)
- Latin4 (Северная Европа)
- Кириллица
- Арабский
- греческий
- Иврит
- Latin5 (турецкий)
- Latin6 (скандинавский)
Unicode (ISO 10646) сделает все это
хаос взаимно несовместимых наборов символов излишен, потому что он унифицирует
расширенный набор всех установленных кодировок и предназначен для покрытия всех
языки мира.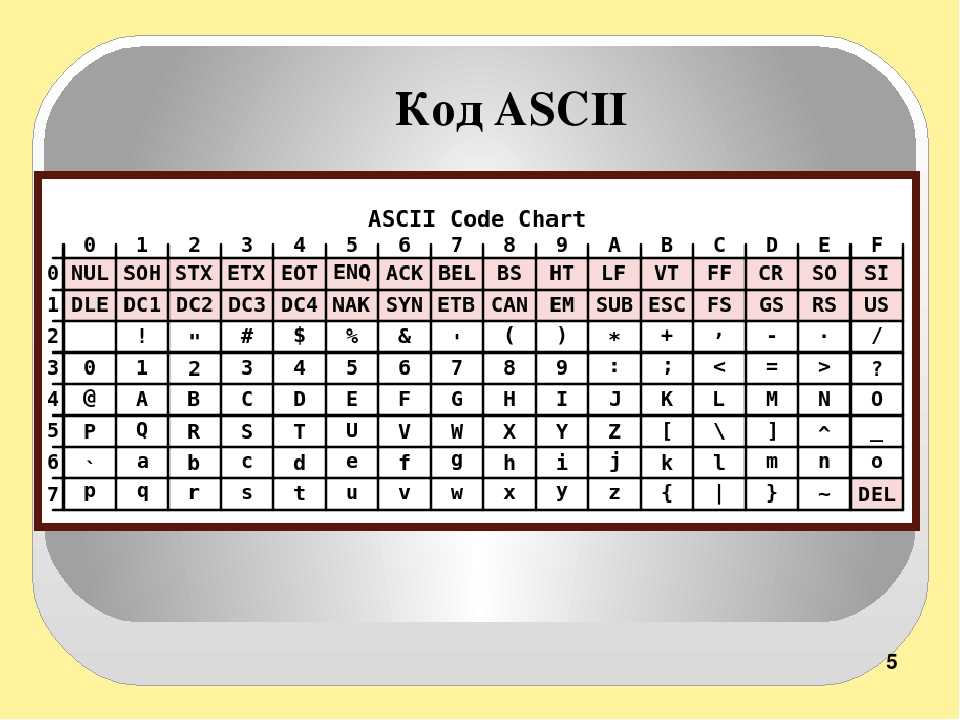 Но я до сих пор не видел никакого программного обеспечения для отображения
весь Unicode на моем экране Unix. Мы работаем над этим.
Но я до сих пор не видел никакого программного обеспечения для отображения
весь Unicode на моем экране Unix. Мы работаем над этим.
Наборы символов ISO 8859 были разработаны в середине 1980-х гг. Европейская ассоциация производителей компьютеров (ECMA) и одобрена Международная организация по стандартизации (ИСО). Эта серия в настоящее время пересматривается ISO/IEC JTC1/SC2/WG3. рабочая группа. 19Все 98 выпусков имеют номера Unicode.
Эта страница существует, потому что ISO не предоставляет бесплатно копии своих опубликованных стандартов (подкомитет по кодировке JTC1/SC2 недавно назвал тем не менее, для бесплатной онлайн-публикации в будущем см. их Redmond резолюция M08.02: Публикация стандартов SC 2 в Интернете) и ECMA предлагает их только на бумаге.
Нажав на мои кнопки [TXT] вы можете скачать текстовую ссылку
таблицы с сопоставлениями Unicode для каждой из кодировок. Вы можете хотеть
чтобы перепроверить их по более авторитетным источникам, таким как Keld
Пионерский RFC 1345 Симонсена или его обновленный
и исправлены чармапы для i18n@dkuug. dk, отраженные во многих каталогах Linux POSIX.2 /usr/share/i18n/charmap/, таблицы сопоставления на
ftp.unicode.org или таблицы, созданные Коста Костисом с помощью транзакций.
dk, отраженные во многих каталогах Linux POSIX.2 /usr/share/i18n/charmap/, таблицы сопоставления на
ftp.unicode.org или таблицы, созданные Коста Костисом с помощью транзакций.
Существуют языковые коды ISO 639 для примерно 150 из нескольких языков мира. тысячи известных языков. Издания 1998 г. латинского алфавита ISO-8859 поставляются с таблицей языков. покрытый. Опрос символов каждого языка был начат Харальдом Альвестрандом. Более полное, но менее компьютеризированное исследование провел Акира Наканиши. красочная книга «Системы письменности мира», ISBN 0-8048-1654-9. Было бы интересно объединить эти два в иллюстративный текстовый файл UTF-8 с Yudit.
Следующие растровые GIF-файлы показывают только верхние части G1 соответствующие кодировки. Символы от 0 до 127 всегда идентичны US-ASCII, а позиции от 128 до 159 сохраняются. некоторые менее используемые управляющие символы: так называемый набор C1 из ISO 6429.
Каждое изображение сопровождается ссылкой на текстовую справочную таблицу и
соответствующий исходный код общедоступного растрового шрифта в формате распространения растрового изображения BDF, чтобы вы могли интегрировать поддержку
для всех кодировок в вашей настройке метапочты, как я делал в 1994 в cs.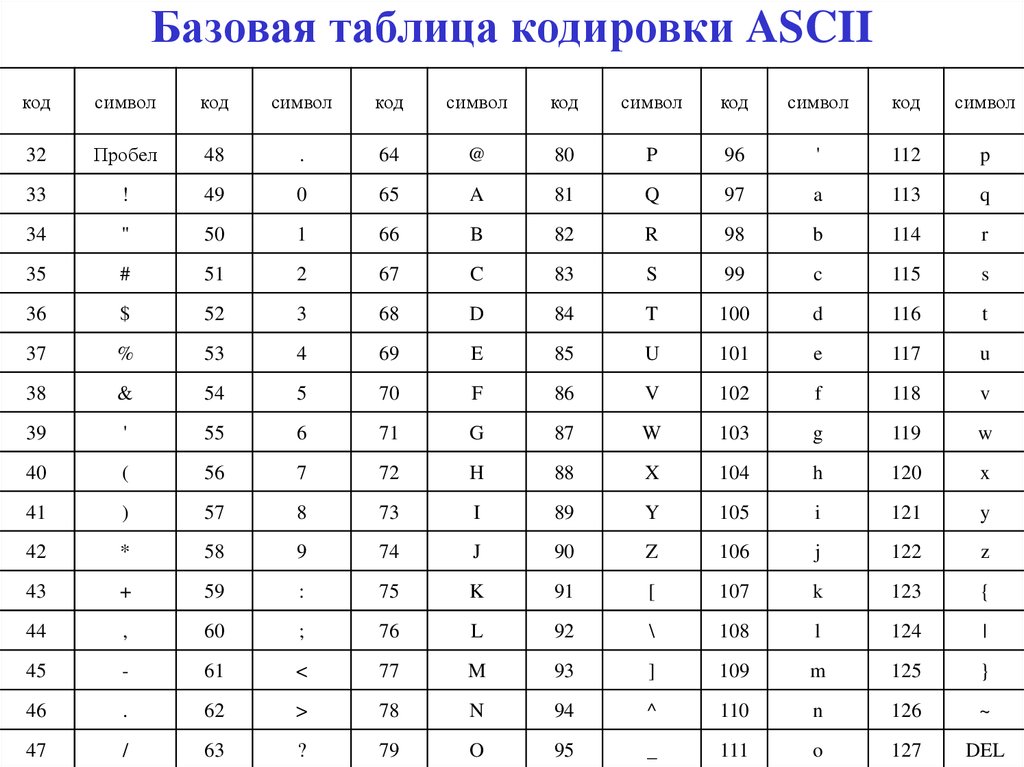 tu-berlin.de:/usr/elm/ перед нашим любимым суперпользователем
конфисковал его, потому что чувствовал себя натянутым или что-то в этом роде.
Проверьте команды mkfontdir и xset, чтобы установить дополнительные шрифты на ваш X-терминал.
Если у кого-нибудь есть конвертеры из BDF в другие форматы растровых изображений, подобные этим
для Windows или MacOS, пришлите их мне!
Большинство глифов были извлечены из etl16-unicode.bdf и
пересобран с помощью кучи perl-скриптов.
tu-berlin.de:/usr/elm/ перед нашим любимым суперпользователем
конфисковал его, потому что чувствовал себя натянутым или что-то в этом роде.
Проверьте команды mkfontdir и xset, чтобы установить дополнительные шрифты на ваш X-терминал.
Если у кого-нибудь есть конвертеры из BDF в другие форматы растровых изображений, подобные этим
для Windows или MacOS, пришлите их мне!
Большинство глифов были извлечены из etl16-unicode.bdf и
пересобран с помощью кучи perl-скриптов.
«Я действительно в ужасе от того, как сложно это может чтобы человек, не владеющий латиницей1, мог печатать на своей матери языком!» — Аким Демай, сопровождающий a2ps, 19 лет.98
кодировка = ISO-8859-1 [ТЕКСТ] [БДФ]
обложек Latin1
большинство западноевропейских языков, таких как французский (fr), испанский
(es), каталанский (ca), баскский (eu), португальский (pt), итальянский (it),
Албанский (sq), ретороманский (rm), голландский (nl), немецкий (de), датский
(da), шведский (sv), норвежский (no), финский (fi), фарерский (fo),
исландский (is), ирландский (ga), шотландский (gd) и английский (en),
кстати, также африкаанс (af) и суахили (sw), таким образом, фактически также
весь американский континент, Австралия и большая часть Африки.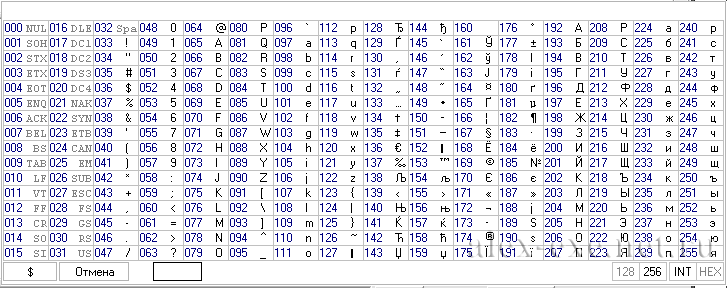 Большинство
заметными исключениями являются зулу (zu) и другие языки банту, использующие латинские расширенные буквы B, и, конечно же, арабский язык в Северной Африке,
и гуарани (gn) отсутствует GEIUY с
~ тильда.
Отсутствие лигатур голландского IJ, французского OE и ,немецкой« кавычки
оценки считается допустимым. Отсутствие нового C=-похожего на евро
символ валюты U+20AC открыл обсуждение новой латиницы0.
Большинство
заметными исключениями являются зулу (zu) и другие языки банту, использующие латинские расширенные буквы B, и, конечно же, арабский язык в Северной Африке,
и гуарани (gn) отсутствует GEIUY с
~ тильда.
Отсутствие лигатур голландского IJ, французского OE и ,немецкой« кавычки
оценки считается допустимым. Отсутствие нового C=-похожего на евро
символ валюты U+20AC открыл обсуждение новой латиницы0.
Latin1 также был принят в качестве первой страницы ISO 10646 (Unicode). Latin1 — это основа HTML. charset, но HTML теперь глобализирован через RFC 2070. Вы можете просмотреть кодировку шведский стол или впечатляющий IUC10 плакат для тестирования вашего браузера или пусть Энди Флавелл расскажет вам больше о практических проблемах.
- ДЭК-МСС
ISO-8859-1 был получен из многонационального набора символов DEC. используется на стандартных терминалах DEC VT-220:
кодировка = DEC-MCS [ТЕКСТ] [БДФ]- CP1252 (WinLatin1)
Вы часто видите пользователей Microsoft Windows (ознакомьтесь с моим обзором кодовых страниц), объявляющих свои тексты как в ISO-8859-1, даже если на самом деле они содержат забавных персонажей из надмножества CP1252 (и они могут стать больше, так как Microsoft также добавила евро к своим кодовым страницам), поэтому здесь у вас есть шрифт Unix для них:
кодировка = Windows-1252 [ТЕКСТ] [БДФ]
кодировка = ISO-8859-2 [ТЕКСТ] [БДФ]
Latin2 охватывает языки Центральная и Восточная Европа :
чешский (cs), венгерский (hu), польский (pl),
Румынский (ro), хорватский (hr), словацкий (sk), словенский (sl), сербский. Для румынского S и T лучше использовать запятые вместо седильи, поскольку
по-турецки: U+015F ЛАТИНСКАЯ СТРОЧНАЯ БУКВА S С CEDILLA в =BA должна
читаться как U+0219 ЛАТИНСКАЯ СТРОЧНАЯ БУКВА S С ЗАПЯТОЙ НИЖЕ и т. д.
Для румынского S и T лучше использовать запятые вместо седильи, поскольку
по-турецки: U+015F ЛАТИНСКАЯ СТРОЧНАЯ БУКВА S С CEDILLA в =BA должна
читаться как U+0219 ЛАТИНСКАЯ СТРОЧНАЯ БУКВА S С ЗАПЯТОЙ НИЖЕ и т. д.
Немецкие умлауты находятся точно на тех же позициях в латиница1, латиница2, латиница3, латиница4, латиница5, латиница6. Таким образом, вы можете написать немецкий+польский с латиницей2 или немецкий+турецкий с латиницей5 но есть Например, нет 8-битной кодировки для правильного сочетания немецкого и русского языков.
кодировка = ISO-8859-3 [ТЕКСТ] [БДФ]
Latin3 популярен среди авторов эсперанто (эо) и Мальтийский (mt), а также турецкий язык до введения Latin5 в 1988 году.
Кодировка= ISO-8859-4 [ТЕКСТ] [БДФ]
Latin4 ввел буквы для эстонского (et), балтийских языков латышского (lv, латышский) и литовского (lt),
гренландский (kl) и саамский. Обратите внимание, что для латышского языка требуется седилья.
на =BB U+0123 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА G С СЕДИЛЬЕЙ, чтобы прыгнуть сверху. За Latin4 последовала Latin6.
За Latin4 последовала Latin6.
кодировка = ISO-8859-5 [ТЕКСТ] [БДФ]
С помощью этих кириллических букв можно набирать болгарский (bg), белорусский (be), македонский (mk), русский (ru), сербский (sr) и до 1990 г. (без гхе с подъемом) Украинский (Великобритания). Заказ основан на (несовместимо) пересмотренном ГОСТ 19768 от 1987 года с русскими буквами кроме отсортированных по Русский алфавит (АБВГДЕ).
Обратите внимание, что несколько других кириллических кодировки используются в сети. Взгляните на мою соседнюю страницу с кириллическими кодировками.
кодировка = ISO-8859-6 [ТЕКСТ] [БДФ]
Это арабский алфавит, к сожалению, основной
только для арабского (ар) языка и не содержит четырех
дополнительные буквы для персидского (fa) или восемь дополнительных букв для
Пакистанский урду (ур). Этот фиксированный шрифт не подходит для текста
отображать. Каждая арабская буква встречается не более чем в четырех (2) презентациях.
формы: начальная, медиальная, конечная или раздельная. Чтобы сделать арабский текст
разборчивым, вам понадобится механизм отображения, который анализирует контекст и
объединяет соответствующие глифы поверх обработчика для обратного
направление письма общее с ивритом.
алгоритм рендеринга описан в юникоде
book, и я реализовал его в своем perl-скрипте арабского языка.
Чтобы сделать арабский текст
разборчивым, вам понадобится механизм отображения, который анализирует контекст и
объединяет соответствующие глифы поверх обработчика для обратного
направление письма общее с ивритом.
алгоритм рендеринга описан в юникоде
book, и я реализовал его в своем perl-скрипте арабского языка.
кодировка = ISO-8859-7 [ТЕКСТ] [БДФ]
Это (современный монотонный) греческий (эль) для меня. ISO-8859-7 был ранее известный как ELOT-928 или ЕСМА-118:1986.
кодировка = ISO-8859-8 [ТЕКСТ] [БДФ]
А это ивритский шрифт, используемый ивритом (iw) и идиш (ji). Нравиться Арабское пишется слева, так что вытащите из шкафа свои пыльные старые двунаправленные пишущие машинки! Мы обещают увидеть эталонную реализацию двунаправленного алгоритма опубликован как Технический отчет Unicode № 9в ближайшем будущем.
кодировка = ISO-8859-9 [ТЕКСТ] [БДФ]
Latin5 заменяет редко используемые исландские буквы в Latin1 на турецких .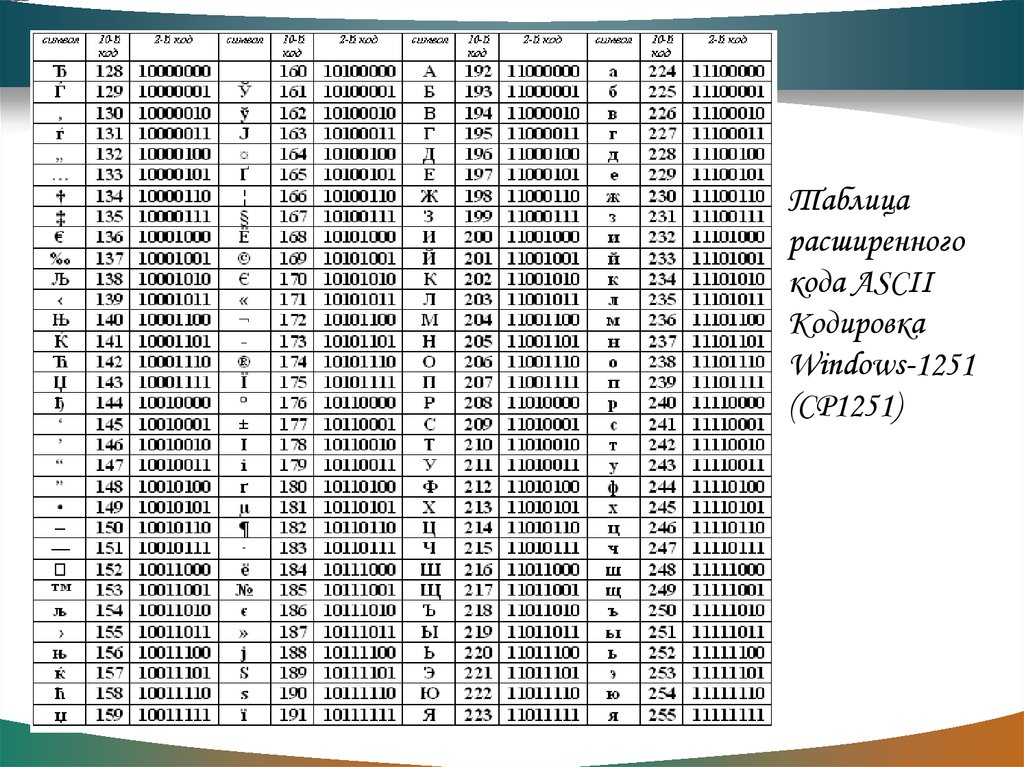
кодировка = ISO-8859-10 [ТЕКСТ] [БДФ]
Представленный в 1992 году, Latin6 изменил порядок символов Latin4, убрал некоторые символы и латышский ŗ, добавлены последние недостающие инуиты (гренландские эскимосы) и несколт-саамы (саамские) буквы и вновь ввели исландский язык, чтобы покрыть вся территория Nordic . Скольт-саамам все еще нужно добавить еще несколько акцентов. Обратите внимание, что RFC 1345 и GNU recode содержат ошибки и используют предварительную и другую латиницу.
Из информации, которую можно найти на веб-сайте Майкла Эверсона и на официальном веб-сайте WG 3, которую я собрал что в ближайшем будущем мы увидим новые части ISO-8859 которые могут выглядеть так:
кодировка = ISO-8859-11 [ТЕКСТ] [БДФ]
Тайский TIS620, вероятно, будет опубликован как ISO-8859-11 Latin/Thai (й). Он содержит некоторые сочетания гласных и знаков тона, которые должны быть пишется над или под согласными.
В настоящее время нет проекта с номером ISO-8859.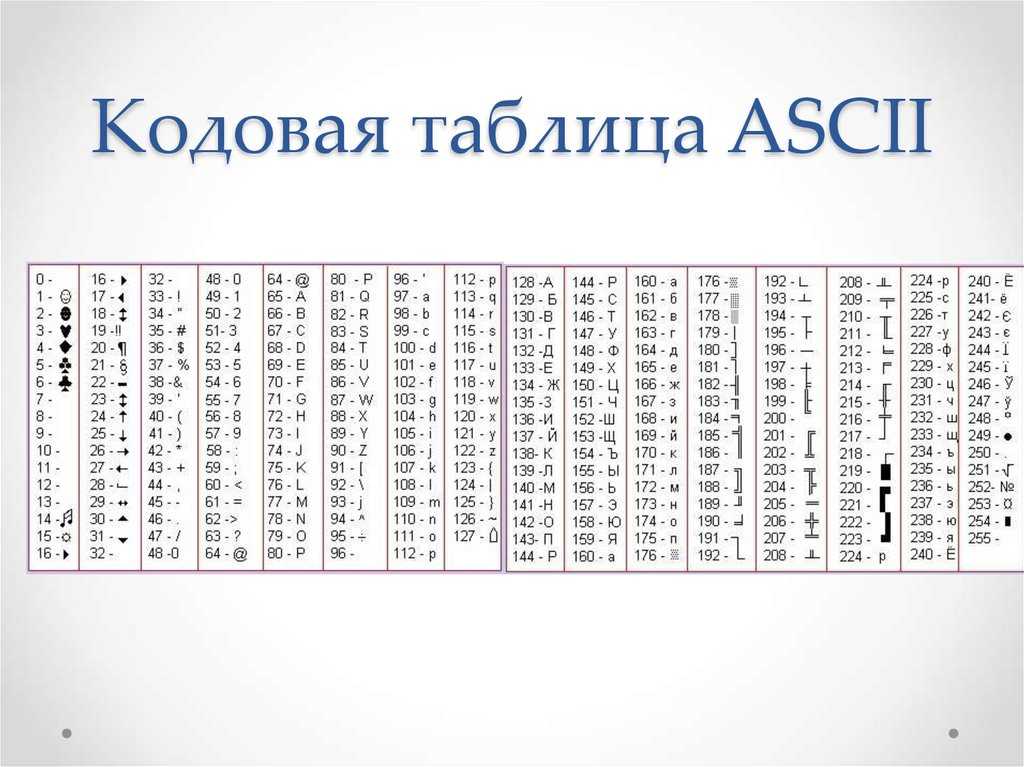 -12. Это число
может быть зарезервирован для индийского языка ISCII.
-12. Это число
может быть зарезервирован для индийского языка ISCII.
Вряд ли когда-нибудь будет вьетнамская часть. Вьетнамский (vi), по-видимому, является языком с наиболее акцентированным буквы всех языков с использованием латиницы. Некоторые буквы несут сочетание двух разных акцентов. Их так много, что они просто не вписываются в модель ISO-8859. Вместо этого вы можете использовать VISCII.
кодировка = ISO-8859-13 [ТЕКСТ] [БДФ]
Latin7 собирается покрыть Baltic Rim и заново установить Латышский (lv) поддержка потеряна в латинице6 и может ввести местный кавычки. Напоминает WinBaltic.
кодировка = ISO-8859-14 [ТЕКСТ] [БДФ]
Latin8 добавляет последние гэльские и валлийские (cy) буквы в Latin1 для охватывает все кельтских языков.
кодировка = ISO-8859-15 [ТЕКСТ] [БДФ]
Новый Latin9 с псевдонимом Latin0 направлен на обновление Latin1 путем замены менее необходимых символов.
с забытыми французскими и финскими буквами и размещением
Знак евро U+20AC в ячейке =A4 прежней международной валюты
знак .
28 июня 1998 г. я предложил принять во внимание извлеченные уроки и Latin9 в ISO-8859-9 вместо Latin1 потому что в турецком гораздо больше пользы, чем в исландском, но по-видимому, это предложение не повлияло на стандартизаторов WG3.
От кого: [email protected]
Дата: 22 июня 1998 г.
Кому: [email protected]
Тема: Re: Перспективы и евро> ISO 8859-15, вероятно, будет внедрен рядом поставщиков, но потребуется некоторое время, пока большой процент пользователи начинают использовать эти версии. До тех пор, возможно, было бы разумно *нет* сделать 8859-15 по умолчанию при отправке почты.
У нас есть место для ISO 8859-15 здесь, в Лондоне. это называется Музеем науки и полон очаровательных исторических реликвий, как разностная машина Бэбаджа, которую использовала Ада Лавлейс (я думаю, что была ее фамилия).
Какое облегчение, что теперь у нас есть Unicode и его не нужно внедрять этот забавный кусочек истории.
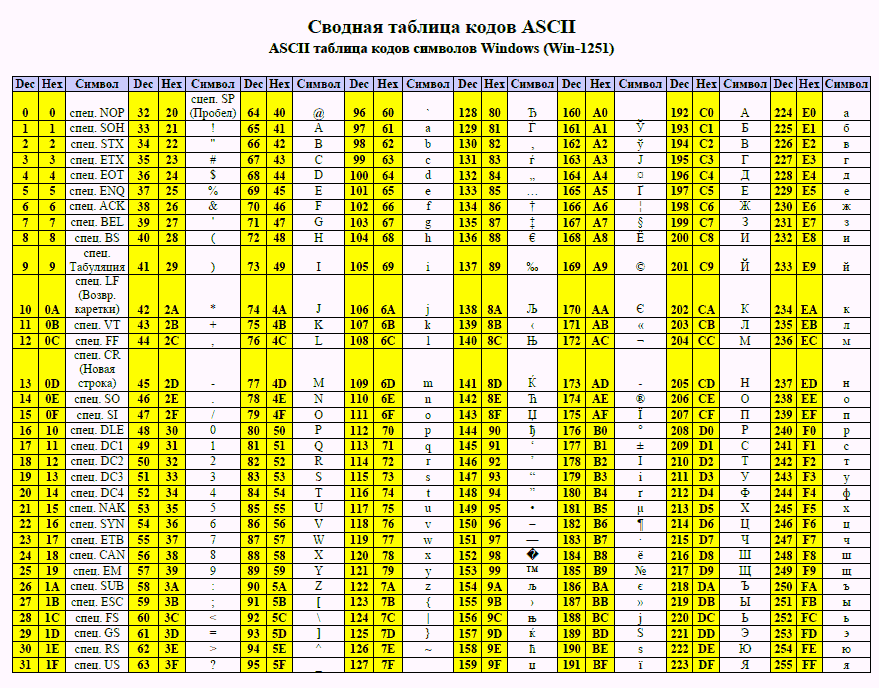
Но с хорошей поддержкой Unicode, добавление еще другая кодировка — кусок пирога. А также евро потребуется для систем, ограниченных 8 битами. ИСО-8859-15 шрифтов и символы клавиш уже были включены в исправление № 02 X11 R6.4.
Реклама
Я начал эту страницу как http://www.cs.tu-berlin.de/~czyborra/charsets/ 27 февраля 1995 г. в ответ на запрос кода ISO-8859. диаграммы на comp.std.internat. До этого были только паршивые сканы плавающих диаграмм ISO. вокруг в сети помимо текстовых таблиц. Я мог бы легко бросить это вместе, так как я уже собрал все необходимые шрифты X11 из МУЛЫ, Барри Боусма и Коста коллекции Костиса. С тех пор на странице кодировок появилось больше чем доступы, скопированные, включенные в книги, компакт-диски и даже переведены на французский язык. Из-за сетевых потрясений на cs.tu-berlin.de, которые потрясли База данных рефереров Я могу предложить вам только старый список тех, кто ссылался на страницу charsets. Спасибо Свен-Уве Вестбергу, Александру Халилу, Андреасу Прилопу,
Джейкоб Андерсен, Ставрос
Макракис, Даг Ньюэлл, Кристофер Неханив, Алан Уотсон, Аарон Ирвин,
Джонатан Розенн, Кристин Клюка, Клинт Адамс, Арнольд Криворук, Ван
Ле, младший
Кнаппен, Томас Хенлих, Крис Маден, Пол Кейннен, Кристиан
Вайсгербер, Кент Карлссон, Маркус Кун, Пино Золло, Имантс
Метра, Юкка Корпела и
Пол Хилл, который дал ценные советы по исправлению этой страницы.