Search Condition (Transact-SQL) — SQL Server
- Статья
- Чтение занимает 8 мин
Applies to: SQL Server (all supported versions) Azure SQL Database Azure SQL Managed Instance Azure Synapse Analytics Analytics Platform System (PDW)
A combination of one or more predicates that use the logical operators AND, OR, and NOT.
Transact-SQL Syntax Conventions
Syntax
-- Syntax for SQL Server and Azure SQL Database
<search_condition> ::=
MATCH (<graph_search_pattern>) | <search_condition_without_match> | <search_condition> AND <search_condition>
<search_condition_without_match> ::=
{ [ NOT ] <predicate> | ( <search_condition_without_match> ) }
[ { AND | OR } [ NOT ] { <predicate> | ( <search_condition_without_match> ) } ]
[ .
..n ]
<predicate> ::=
{ expression { = | < > | ! = | > | > = | ! > | < | < = | ! < } expression
| string_expression [ NOT ] LIKE string_expression
[ ESCAPE 'escape_character' ]
| expression [ NOT ] BETWEEN expression AND expression
| expression IS [ NOT ] NULL
| expression IS [ NOT ] DISTINCT FROM
| CONTAINS
( { column | * } , '<contains_search_condition>' )
| FREETEXT ( { column | * } , 'freetext_string' )
| expression [ NOT ] IN ( subquery | expression [ ,...n ] )
| expression { = | < > | ! = | > | > = | ! > | < | < = | ! < }
{ ALL | SOME | ANY} ( subquery )
| EXISTS ( subquery ) }
<graph_search_pattern> ::=
{ <node_alias> {
{ <-( <edge_alias> )- }
| { -( <edge_alias> )-> }
<node_alias>
}
}
<node_alias> ::=
node_table_name | node_table_alias
<edge_alias> ::=
edge_table_name | edge_table_alias
-- Syntax for Azure Synapse Analytics and Parallel Data Warehouse
< search_condition > ::=
{ [ NOT ] <predicate> | ( <search_condition> ) }
[ { AND | OR } [ NOT ] { <predicate> | ( <search_condition> ) } ]
[ . ..n ]
<predicate> ::=
{ expression { = | < > | ! = | > | > = | < | < = } expression
| string_expression [ NOT ] LIKE string_expression
| expression [ NOT ] BETWEEN expression AND expression
| expression IS [ NOT ] NULL
| expression [ NOT ] IN (subquery | expression [ ,...n ] )
| expression [ NOT ] EXISTS (subquery)
}

Note
To view Transact-SQL syntax for SQL Server 2014 and earlier, see Previous versions documentation.
Arguments
<search_condition>
Specifies the conditions for the rows returned in the result set for a SELECT statement, query expression, or subquery. For an UPDATE statement, specifies the rows to be updated. For a DELETE statement, specifies the rows to be deleted. There is no limit to the number of predicates that can be included in a Transact-SQL statement search condition.
<graph_search_pattern>
Specifies the graph match pattern. For more information about the arguments for this clause, see MATCH (Transact-SQL)
NOT
Negates the Boolean expression specified by the predicate. For more information, see NOT (Transact-SQL).
For more information, see NOT (Transact-SQL).
AND
Combines two conditions and evaluates to TRUE when both of the conditions are TRUE. For more information, see AND (Transact-SQL).
OR
Combines two conditions and evaluates to TRUE when either condition is TRUE. For more information, see OR (Transact-SQL).
< predicate >
Is an expression that returns TRUE, FALSE, or UNKNOWN.
expression
Is a column name, a constant, a function, a variable, a scalar subquery, or any combination of column names, constants, and functions connected by an operator or operators, or a subquery. The expression can also contain the CASE expression.
Note
Non-Unicode string constants and variables use the code page that corresponds to the default collation of the database. Code page conversions can occur when working with only non-Unicode character data and referencing the non-Unicode character data types char, varchar, and text. SQL Server converts non-Unicode string constants and variables to the code page that corresponds to the collation of the referenced column or specified using COLLATE, if that code page is different than the code page that corresponds to the default collation of the database. Any characters not found in the new code page will be translated to a similar character, if a best-fit mapping can be found, or else will be converted to the default replacement character of «?».
SQL Server converts non-Unicode string constants and variables to the code page that corresponds to the collation of the referenced column or specified using COLLATE, if that code page is different than the code page that corresponds to the default collation of the database. Any characters not found in the new code page will be translated to a similar character, if a best-fit mapping can be found, or else will be converted to the default replacement character of «?».
When working with multiple code pages, character constants can be prefixed with the uppercase letter ‘N’, and Unicode variables can be used, to avoid code page conversions.
=
Is the operator used to test the equality between two expressions.
<>
Is the operator used to test the condition of two expressions not being equal to each other.
!=
Is the operator used to test the condition of two expressions not being equal to each other.
>
Is the operator used to test the condition of one expression being greater than the other.
>=
Is the operator used to test the condition of one expression being greater than or equal to the other expression.
!>
Is the operator used to test the condition of one expression not being greater than the other expression.
<
Is the operator used to test the condition of one expression being less than the other.
<=
Is the operator used to test the condition of one expression being less than or equal to the other expression.
!<
Is the operator used to test the condition of one expression not being less than the other expression.
string_expression
Is a string of characters and wildcard characters.
[ NOT ] LIKE
Indicates that the subsequent character string is to be used with pattern matching. For more information, see LIKE (Transact-SQL).
ESCAPE ‘escape_ character‘
Allows for a wildcard character to be searched for in a character string instead of functioning as a wildcard. escape_character is the character that is put in front of the wildcard character to indicate this special use.
escape_character is the character that is put in front of the wildcard character to indicate this special use.
[ NOT ] BETWEEN
Specifies an inclusive range of values. Use AND to separate the starting and ending values. For more information, see BETWEEN (Transact-SQL).
IS [ NOT ] NULL
Specifies a search for null values, or for values that are not null, depending on the keywords used. An expression with a bitwise or arithmetic operator evaluates to NULL if any one of the operands is NULL.
IS [ NOT ] DISTINCT FROM
Compares the equality of two expressions and guarantees a true or false result, even if one or both operands are NULL. For more information, see IS [NOT] DISTINCT FROM (Transact-SQL).
CONTAINS
Searches columns that contain character-based data for precise or less precise (fuzzy) matches to single words and phrases, the proximity of words within a certain distance of one another, and weighted matches. This option can only be used with SELECT statements. For more information, see CONTAINS (Transact-SQL).
For more information, see CONTAINS (Transact-SQL).
FREETEXT
Provides a simple form of natural language query by searching columns that contain character-based data for values that match the meaning instead of the exact words in the predicate. This option can only be used with SELECT statements. For more information, see FREETEXT (Transact-SQL).
[ NOT ] IN
Specifies the search for an expression, based on whether the expression is included in or excluded from a list. The search expression can be a constant or a column name, and the list can be a set of constants or, more typically, a subquery. Enclose the list of values in parentheses. For more information, see IN (Transact-SQL).
subquery
Can be considered a restricted SELECT statement and is similar to <query_expression> in the SELECT statement. The ORDER BY clause and the INTO keyword are not allowed. For more information, see SELECT (Transact-SQL).
ALL
Used with a comparison operator and a subquery. Returns TRUE for <predicate> when all values retrieved for the subquery satisfy the comparison operation, or FALSE when not all values satisfy the comparison or when the subquery returns no rows to the outer statement. For more information, see ALL (Transact-SQL).
Returns TRUE for <predicate> when all values retrieved for the subquery satisfy the comparison operation, or FALSE when not all values satisfy the comparison or when the subquery returns no rows to the outer statement. For more information, see ALL (Transact-SQL).
{ SOME | ANY }
Used with a comparison operator and a subquery. Returns TRUE for <predicate> when any value retrieved for the subquery satisfies the comparison operation, or FALSE when no values in the subquery satisfy the comparison or when the subquery returns no rows to the outer statement. Otherwise, the expression is UNKNOWN. For more information, see SOME | ANY (Transact-SQL).
EXISTS
Used with a subquery to test for the existence of rows returned by the subquery. For more information, see EXISTS (Transact-SQL).
The order of precedence for the logical operators is NOT (highest), followed by AND, followed by OR. Parentheses can be used to override this precedence in a search condition. The order of evaluation of logical operators can vary depending on choices made by the query optimizer. For more information about how the logical operators operate on logic values, see AND (Transact-SQL), OR (Transact-SQL), and NOT (Transact-SQL).
The order of evaluation of logical operators can vary depending on choices made by the query optimizer. For more information about how the logical operators operate on logic values, see AND (Transact-SQL), OR (Transact-SQL), and NOT (Transact-SQL).
Examples
A. Using WHERE with LIKE and ESCAPE syntax
The following example searches for the rows in which the LargePhotoFileName column has the characters green_, and uses the ESCAPE option because _ is a wildcard character. Without specifying the ESCAPE option, the query would search for any description values that contain the word green followed by any single character other than the _ character.
USE AdventureWorks2012 ; GO SELECT * FROM Production.ProductPhoto WHERE LargePhotoFileName LIKE '%greena_%' ESCAPE 'a' ;
B. Using WHERE and LIKE syntax with Unicode data
The following example uses the WHERE clause to retrieve the mailing address for any company that is outside the United States (US) and in a city whose name starts with Pa.
USE AdventureWorks2012 ;
GO
SELECT AddressLine1, AddressLine2, City, PostalCode, CountryRegionCode
FROM Person.Address AS a
JOIN Person.StateProvince AS s ON a.StateProvinceID = s.StateProvinceID
WHERE CountryRegionCode NOT IN ('US')
AND City LIKE N'Pa%' ;
Examples: Azure Synapse Analytics and Analytics Platform System (PDW)
C. Using WHERE with LIKE
The following example searches for the rows in which the LastName
and.-- Uses AdventureWorks SELECT EmployeeKey, LastName FROM DimEmployee WHERE LastName LIKE '%and%';
D. Using WHERE and LIKE syntax with Unicode data
The following example uses the WHERE clause to perform a Unicode search on the LastName column.
-- Uses AdventureWorks SELECT EmployeeKey, LastName FROM DimEmployee WHERE LastName LIKE N'%and%';
See also
- Aggregate Functions (Transact-SQL)
- CASE (Transact-SQL)
- CONTAINSTABLE (Transact-SQL)
- Cursors (Transact-SQL)
- DELETE (Transact-SQL)
- Expressions (Transact-SQL)
- FREETEXTTABLE (Transact-SQL)
- FROM (Transact-SQL)
- Operators (Transact-SQL)
- UPDATE (Transact-SQL)
Проверка нескольких условий (операторы OR и AND)
Об объекте
Учебные материалы
Правила описания синтаксиса команд SQL
Выборка данных
Сортировка выбранных данных
Фильтрация данных (предложение WHERE)
Операторы сравнения
Проверка нескольких условий (операторы OR и AND)
Проверка диапазона значений
Списки значений (операторы IN и NOT IN)
Выборка нулевых значений
Использование метасимволов (оператор LIKE)
Создание вычисляемых полей
Агрегирующие функции
Итоговые данные (предложение GROUP BY)
Объединение таблиц
Подзапросы
Комбинированные запросы
Вопросы для самопроверки
Практические задания
Список литературы
Приложение
Проверка нескольких условий (операторы OR и AND)
Если
в предложение WHERE нужно проверить несколько условий, то для их
соединения
можно использовать логические операторы
AND, OR и NOT.
Оператор AND объединяет два и более условий и возвращает истинное значение только при выполнении всех условий.
Примеры
Найти в таблице tbl_clients данные о Bennett Sherry.
SQL:
SELECT * FROM tbl_clients
WHERE
lastname=’Bennett’ AND name=’Sherry’
Найти данные о клиентах проживающих в Сиэтле и имеющих семьи численностью более 3-х человек:
SQL:
SELECT * FROM tbl_clients
WHERE region=’Seattle’ AND
fam_size>3
Оператор OR также связывает два или больше условий, но возвращает истинный результат при выполнении хотя бы одного условия.
Пример
Вывести список клиентов, проживающих в Сиэтле или в Лос-Анджелесе:
SQL:
SELECT * FROM tbl_clients
WHERE
region = ‘Seattle’ OR region=’Los Angeles’
Логический
оператор NOT используется для построения отрицаний и помещается перед
самим
выражением.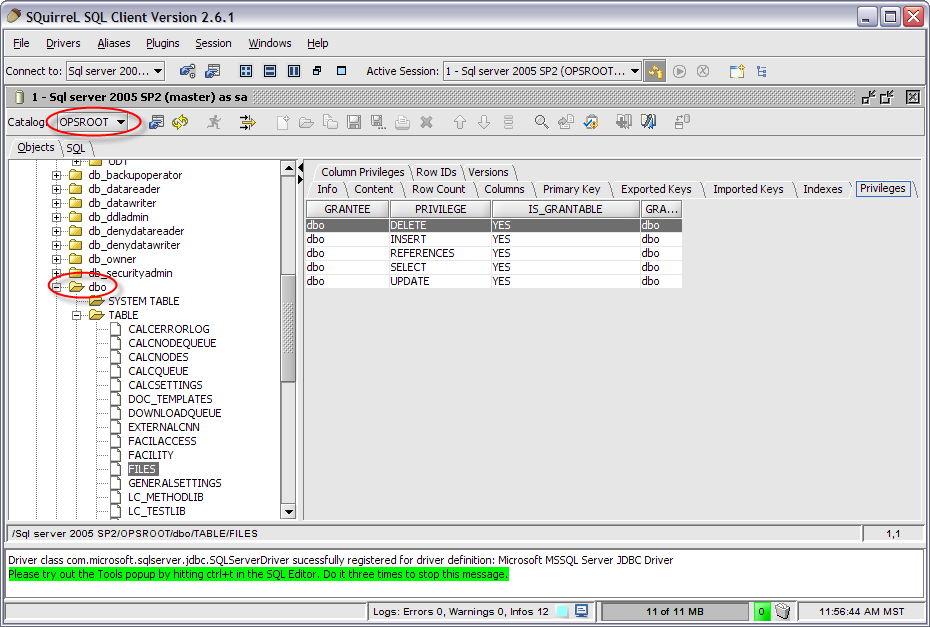
Пример
Получить список всех клиентов, кроме тех, кто проживает Лос-Анджелесе.
SQL:
SELECT * FROM tbl_clients
WHERE
region != ‘Los Angeles’
Или
SQL:
SELECT * FROM tbl_clients WHERE NOT
region = ‘Los Angeles’
Аналогично арифметическим операторам, логические операторы также выполняются в строго определенной последовательности. Если в выражении используется несколько логических операторов, они выполняются в следующей последовательности: сначала NOT, затем AND и, наконец, OR.
Примеры
Вывести данные о всех клиентах, проживающих в Сиэтле и только о тех клиентах из Лос-Анджелеса, численность семьи которых превышает 3-х человек.
SQL:
SELECT lastname, name, region, fam_size
FROM tbl_clients
WHERE region= ‘Seattle’ OR region = ‘Los Angeles’ AND fam_size>3
Результат:
| lastname | name | region | fam_size |
| Stolz | Barbara | Seattle | 6 |
| Abbott | Thomas | Seattle | 2 |
| Vaughn | Jeffrey | Seattle | 2 |
| Sperber | Gregory | Seattle | 3 |
| Org | Liina | Los Angeles | 4 |
| Reynolds | Christian | Los Angeles | 5 |
| Salinas | Danny | Los Angeles | 5 |
| Miller | Robert | Los Angeles | 4 |
| Ausmees | Ingrid | Seattle | 6 |
| Clark | Margaret | Los Angeles | 4 |
| Philbrick | Penny | Seattle | 1 |
. … …
|
….. | ….. |
… |
Ограничение на количество членов семьи в предыдущем запросе применяется только к клиентам из Лос-Анджелеса, так как оператор AND выполняется перед оператором OR. Чтобы первым выполнялся оператор OR, в запросе нужно использовать скобки.
В результате выполнения следующего запроса будут данные о всех клиентах из Сиэтла и Лос-Анджелеса, имеющих семьи численностью больше 3 человек:
SQL:
SELECT lastname, name, region, fam_size
FROM tbl_clients
WHERE (region= ‘Seattle’ OR region = ‘Los Angeles’) AND
fam_size>3
« Previous | Next »
Формирование SQL-запроса с помощью конструктора
Формирование SQL-запроса с помощью конструктора Пожалуйста, включите JavaScript в браузере!Формирование SQL-запроса с помощью конструктора
В KUMA вы можете сформировать SQL-запрос для фильтрации событий с помощью конструктора запросов.
Чтобы сформировать SQL-запрос с помощью конструктора:
- В разделе События веб-интерфейса KUMA нажмите на кнопку .
Откроется окно конструктора запросов.
- Сформулируйте поисковый запрос, указав данные в следующих блоках параметров:
- SELECT – поля событий, которые следует возвращать. По умолчанию выбрано значение *, означающее, что необходимо возвращать все доступные поля события. Для оптимизации поиска в раскрывающемся списке вы можете выбрать определенные поля, тогда данные из других полей загружаться не будут.
Выбрав поле события, вы можете в поле справа от раскрывающегося списка указать псевдоним для столбца выводимых данных, а в крайнем правом раскрывающемся списке можно выбрать операцию, которую следует произвести над данными: count, max, min, avg, sum.
Если вы используете в запросе функции агрегации, настройка отображения таблицы событий, сортировка событий по возрастанию и убыванию, получение статистики, а также ретроспективная проверка недоступны.
В режиме детализированного анализа при фильтрации по событиям, связанным с алертами, невозможно производить операции над данными полей событий и присваивать названия столбцам выводимых данных.
- FROM – источник данных. Выберите значение events.
- WHERE – условия фильтрации событий.
Условия и группы условий можно добавить с помощью кнопок Добавить условие и Добавить группу. По умолчанию в группе условий выбрано значение оператора AND, однако если на него нажать, оператор можно изменить. Доступные значения: AND, OR, NOT. Структуру условий и групп условий можно менять, перетаскивая выражения с помощью мыши за значок .
Добавление условий фильтра:
- В раскрывающемся списке слева выберите поле события, которое вы хотите использовать для фильтрации.
- В среднем раскрывающемся списке выберите нужный оператор. Доступные операторы зависят от типа значения выбранного поля события.
- Введите значение условия. В зависимости от выбранного типа поля вам потребуется ввести значение вручную, выбрать его в раскрывающемся списке или выбрать в календаре.
Условия фильтра можно удалить с помощью кнопки . Группы условий удаляются с помощью кнопки Удалить группу.
- GROUP BY – поля событий или псевдонимы, по которым следует группировать возвращаемые данные.
Если вы используете в запросе группировку данных, настройка отображения таблицы событий, сортировка событий по возрастанию и убыванию, получение статистики, а также ретроспективная проверка недоступны.
В режиме детализированного анализа при фильтрации по событиям, связанным с алертами, невозможно группировать возвращаемые данные.
- ORDER BY – столбцы, по которым следует сортировать возвращаемые данные. В раскрывающемся списке справа можно выбрать порядок: DESC – по убыванию, ASC – по возрастанию.
- LIMIT – количество отображаемых в таблице строк.
Значение по умолчанию – 250.
Если при фильтрации событий по пользовательскому периоду количество строк в результатах поиска превышает заданное значение, вы можете отобразить в таблице дополнительные строки, нажав на кнопку Показать больше записей.
Кнопка не отображается при фильтрации событий по стандартному периоду.
- SELECT – поля событий, которые следует возвращать. По умолчанию выбрано значение *, означающее, что необходимо возвращать все доступные поля события. Для оптимизации поиска в раскрывающемся списке вы можете выбрать определенные поля, тогда данные из других полей загружаться не будут.
- Нажмите на кнопку Применить.
Текущий SQL-запрос будет перезаписан. В поле поиска отобразится сформированный SQL-запрос.
Если вы хотите сбросить настройки конструктора, нажмите на кнопку Запрос по умолчанию.
Если вы хотите закрыть конструктор, не перезаписывая существующий запрос, нажмите на кнопку .
- Для отображения данных в таблице нажмите на кнопку .

 Кнопка не отображается при фильтрации событий по стандартному периоду.
Кнопка не отображается при фильтрации событий по стандартному периоду.В таблице отобразятся результаты поиска по сформированному SQL-запросу.
При переходе в другой раздел веб-интерфейса сформированный в конструкторе запрос не сохраняется. Если вы повторно вернетесь в раздел События, в конструкторе будет отображаться запрос по умолчанию.
После обновления KUMA до версии 1.6 при фильтрации событий с помощью SQL-запроса, содержащего условие inSubnet, может возвращаться ошибка Code: 441. DB::Exception: Invalid IPv4 value. В таких случаях необходимо на серверах хранилища (на каждой машине кластера ClickHouse) в файле /opt/kaspersky/kuma/clickhouse/cfg/config. d/users.xml в разделе profiles → default добавить директиву
d/users.xml в разделе profiles → default добавить директиву <cast_ipv4_ipv6_default_on_conversion_error>true</cast_ipv4_ipv6_default_on_conversion_error>.
Подробнее об SQL см. в справке ClickHouse. Также см. поддерживаемые KUMA SQL-функции и операторы.
В начало
Учебник по языку SQL (DDL, DML) на примере диалекта MS SQL Server. Часть третья / Хабр
Предыдущие части
- Часть первая — habrahabr.ru/post/255361
- Часть вторая — habrahabr.ru/post/255523
О чем будет рассказано в этой части
В этой части мы познакомимся:
- с выражением CASE, которое позволяет включить условные выражения в запрос;
- с агрегатными функциями, которые позволяют получить разного рода итоги (агрегированные значения) рассчитанные на основании детальных данных, полученных оператором «SELECT … WHERE …»;
- с предложением GROUP BY, которое в скупе с агрегатными функциями позволяет получить итоги по детальным данным в разрезе групп;
- с предложением HAVING, которое позволяет произвести фильтрацию по сгруппированным данным.

Выражение CASE – условный оператор языка SQL
Данный оператор позволяет осуществить проверку условий и возвратить в зависимости от выполнения того или иного условия тот или иной результат.
Оператор CASE имеет 2 формы:
| Первая форма: | Вторая форма: |
|---|---|
| CASE WHEN условие_1 THEN возвращаемое_значение_1 … WHEN условие_N THEN возвращаемое_значение_N [ELSE возвращаемое_значение] END |
CASE проверяемое_значение WHEN сравниваемое_значение_1 THEN возвращаемое_значение_1 … WHEN сравниваемое_значение_N THEN возвращаемое_значение_N [ELSE возвращаемое_значение] END |
В качестве значений здесь могут выступать и выражения.
Разберем на примере первую форму CASE:
SELECT
ID,Name,Salary,
CASE
WHEN Salary>=3000 THEN 'ЗП >= 3000'
WHEN Salary>=2000 THEN '2000 <= ЗП < 3000'
ELSE 'ЗП < 2000'
END SalaryTypeWithELSE,
CASE
WHEN Salary>=3000 THEN 'ЗП >= 3000'
WHEN Salary>=2000 THEN '2000 <= ЗП < 3000'
END SalaryTypeWithoutELSE
FROM Employees
| ID | Name | Salary | SalaryTypeWithELSE | SalaryTypeWithoutELSE |
|---|---|---|---|---|
| 1000 | Иванов И. И. И. |
5000 | ЗП >= 3000 | ЗП >= 3000 |
| 1001 | Петров П.П. | 1500 | ЗП < 2000 | NULL |
| 1002 | Сидоров С.С. | 2500 | 2000 <= ЗП < 3000 | 2000 <= ЗП < 3000 |
| 1003 | Андреев А.А. | 2000 | 2000 <= ЗП < 3000 | 2000 <= ЗП < 3000 |
| 1004 | Николаев Н.Н. | 1500 | ЗП < 2000 | NULL |
| 1005 | Александров А.А. | 2000 | 2000 <= ЗП < 3000 | 2000 <= ЗП < 3000 |
WHEN-условия проверяются последовательно, сверху-вниз. При достижении первого удовлетворяющего условия дальнейшая проверка прерывается и возвращается значение, указанное после слова THEN, относящегося к данному блоку WHEN.
Если ни одно из WHEN-условий не выполняется, то возвращается значение, указанное после слова ELSE (что в данном случае означает «ИНАЧЕ ВЕРНИ …»).
Если ELSE-блок не указан и не выполняется ни одно WHEN-условие, то возвращается NULL.
И в первой, и во второй форме ELSE-блок идет в самом конце конструкции CASE, т.е. после всех WHEN-условий.
Разберем на примере вторую форму CASE:
Допустим, на новый год решили премировать всех сотрудников и попросили вычислить сумму бонусов по следующей схеме:
- Сотрудникам ИТ-отдела выдать по 15% от ЗП;
- Сотрудникам Бухгалтерии по 10% от ЗП;
- Всем остальным по 5% от ЗП.
Используем для данной задачи запрос с выражением CASE:
SELECT
ID,Name,Salary,DepartmentID,
-- для наглядности выведем процент в виде строки
CASE DepartmentID -- проверяемое значение
WHEN 2 THEN '10%' -- 10% от ЗП выдать Бухгалтерам
WHEN 3 THEN '15%' -- 15% от ЗП выдать ИТ-шникам
ELSE '5%' -- всем остальным по 5%
END NewYearBonusPercent,
-- построим выражение с использованием CASE, чтобы увидеть сумму бонуса
Salary/100*
CASE DepartmentID
WHEN 2 THEN 10 -- 10% от ЗП выдать Бухгалтерам
WHEN 3 THEN 15 -- 15% от ЗП выдать ИТ-шникам
ELSE 5 -- всем остальным по 5%
END BonusAmount
FROM Employees
| ID | Name | Salary | DepartmentID | NewYearBonusPercent | BonusAmount |
|---|---|---|---|---|---|
| 1000 | Иванов И. И. И. |
5000 | 1 | 5% | 250 |
| 1001 | Петров П.П. | 1500 | 3 | 15% | 225 |
| 1002 | Сидоров С.С. | 2500 | 2 | 10% | 250 |
| 1003 | Андреев А.А. | 2000 | 3 | 15% | 300 |
| 1004 | Николаев Н.Н. | 1500 | 3 | 15% | 225 |
| 1005 | Александров А.А. | 2000 | NULL | 5% | 100 |
Здесь делается последовательная проверка значения DepartmentID с WHEN-значениями. При достижении первого равенства DepartmentID с WHEN-значением, проверка прерывается и возвращается значение, указанное после слова THEN, относящегося к данному блоку WHEN.
Соответственно, значение блока ELSE возвращается в случае, если DepartmentID не совпал ни с одним WHEN-значением.
Если блок ELSE отсутствует, то в случае несовпадения DepartmentID ни с одним WHEN-значением будет возвращено NULL.
Вторую форму CASE несложно представить при помощи первой формы:
SELECT
ID,Name,Salary,DepartmentID,
CASE
WHEN DepartmentID=2 THEN '10%' -- 10% от ЗП выдать Бухгалтерам
WHEN DepartmentID=3 THEN '15%' -- 15% от ЗП выдать ИТ-шникам
ELSE '5%' -- всем остальным по 5%
END NewYearBonusPercent,
-- построим выражение с использованием CASE, чтобы увидеть сумму бонуса
Salary/100*
CASE
WHEN DepartmentID=2 THEN 10 -- 10% от ЗП выдать Бухгалтерам
WHEN DepartmentID=3 THEN 15 -- 15% от ЗП выдать ИТ-шникам
ELSE 5 -- всем остальным по 5%
END BonusAmount
FROM Employees
Так что, вторая форма – это всего лишь упрощенная запись для тех случаев, когда нам нужно сделать сравнение на равенство, одного и того же проверяемого значения с каждым WHEN-значением/выражением.
Примечание. Первая и вторая форма CASE входят в стандарт языка SQL, поэтому скорее всего они должны быть применимы во многих СУБД.
С MS SQL версии 2012 появилась упрощенная форма записи IIF. Она может использоваться для упрощенной записи конструкции CASE, в том случае если возвращаются только 2 значения. Конструкция IIF имеет следующий вид:
IIF(условие, true_значение, false_значение)
Т.е. по сути это обертка для следующей CASE конструкции:
CASE WHEN условие THEN true_значение ELSE false_значение END
Посмотрим на примере:
SELECT ID,Name,Salary, IIF(Salary>=2500,'ЗП >= 2500','ЗП < 2500') DemoIIF, CASE WHEN Salary>=2500 THEN 'ЗП >= 2500' ELSE 'ЗП < 2500' END DemoCASE FROM Employees
Конструкции CASE, IIF могут быть вложенными друг в друга. Рассмотрим абстрактный пример:
SELECT
ID,Name,Salary,
CASE
WHEN DepartmentID IN(1,2) THEN 'A'
WHEN DepartmentID=3 THEN
CASE PositionID -- вложенный CASE
WHEN 3 THEN 'B-1'
WHEN 4 THEN 'B-2'
END
ELSE 'C'
END Demo1,
IIF(DepartmentID IN(1,2),'A',
IIF(DepartmentID=3,CASE PositionID WHEN 3 THEN 'B-1' WHEN 4 THEN 'B-2' END,'C')) Demo2
FROM Employees
Так как конструкция CASE и IIF представляют из себя выражение, которые возвращают результат, то мы можем использовать их не только в блоке SELECT, но и в остальных блоках, допускающих использование выражений, например, в блоках WHERE или ORDER BY.
Для примера, пускай перед нами поставили задачу – создать список на выдачу ЗП на руки, следующим образом:
- Первым делом ЗП должны получить сотрудники у кого оклад меньше 2500
- Те сотрудники у кого оклад больше или равен 2500, получают ЗП во вторую очередь
- Внутри этих двух групп нужно упорядочить строки по ФИО (поле Name)
Попробуем решить эту задачу при помощи добавления CASE-выражение в блок ORDER BY:
SELECT ID,Name,Salary FROM Employees ORDER BY CASE WHEN Salary>=2500 THEN 1 ELSE 0 END, -- выдать ЗП сначала тем у кого она ниже 2500 Name -- дальше упорядочить список в порядке ФИО
| ID | Name | Salary |
|---|---|---|
| 1005 | Александров А.А. | 2000 |
| 1003 | Андреев А.А. | 2000 |
| 1004 | Николаев Н.Н. | 1500 |
| 1001 | Петров П. П. П. |
1500 |
| 1000 | Иванов И.И. | 5000 |
| 1002 | Сидоров С.С. | 2500 |
Как видим, Иванов и Сидоров уйдут с работы последними.
И абстрактный пример использования CASE в блоке WHERE:
SELECT ID,Name,Salary FROM Employees WHERE CASE WHEN Salary>=2500 THEN 1 ELSE 0 END=1 -- все записи у которых выражение равно 1
Можете попытаться самостоятельно переделать 2 последних примера с функцией IIF.
И напоследок, вспомним еще раз о NULL-значениях:
SELECT
ID,Name,Salary,DepartmentID,
CASE
WHEN DepartmentID=2 THEN '10%' -- 10% от ЗП выдать Бухгалтерам
WHEN DepartmentID=3 THEN '15%' -- 15% от ЗП выдать ИТ-шникам
WHEN DepartmentID IS NULL THEN '-' -- внештатникам бонусов не даем (используем IS NULL)
ELSE '5%' -- всем остальным по 5%
END NewYearBonusPercent1,
-- а так проверять на NULL нельзя, вспоминаем что говорилось про NULL во второй части
CASE DepartmentID -- проверяемое значение
WHEN 2 THEN '10%'
WHEN 3 THEN '15%'
WHEN NULL THEN '-' -- !!! в данном случае использование второй формы CASE не подходит
ELSE '5%'
END NewYearBonusPercent2
FROM Employees
| ID | Name | Salary | DepartmentID | NewYearBonusPercent1 | NewYearBonusPercent2 |
|---|---|---|---|---|---|
| 1000 | Иванов И. И. И. |
5000 | 1 | 5% | 5% |
| 1001 | Петров П.П. | 1500 | 3 | 15% | 15% |
| 1002 | Сидоров С.С. | 2500 | 2 | 10% | 10% |
| 1003 | Андреев А.А. | 2000 | 3 | 15% | 15% |
| 1004 | Николаев Н.Н. | 1500 | 3 | 15% | 15% |
| 1005 | Александров А.А. | 2000 | NULL | — | 5% |
Конечно можно было переписать и как-то так:
SELECT
ID,Name,Salary,DepartmentID,
CASE ISNULL(DepartmentID,-1) -- используем замену в случае NULL на -1
WHEN 2 THEN '10%'
WHEN 3 THEN '15%'
WHEN -1 THEN '-' -- если мы уверены, что отдела с ID равным (-1) нет и не будет
ELSE '5%'
END NewYearBonusPercent3
FROM Employees
В общем, полет фантазии в данном случае не ограничен.
Для примера посмотрим, как при помощи CASE и IIF можно смоделировать функцию ISNULL:
SELECT ID,Name,LastName, ISNULL(LastName,'Не указано') DemoISNULL, CASE WHEN LastName IS NULL THEN 'Не указано' ELSE LastName END DemoCASE, IIF(LastName IS NULL,'Не указано',LastName) DemoIIF FROM Employees
Конструкция CASE очень мощное средство языка SQL, которое позволяет наложить дополнительную логику для расчета значений результирующего набора. В данной части владение CASE-конструкцией нам еще пригодится, поэтому в этой части в первую очередь внимание уделено именно ей.
Агрегатные функции
Здесь мы рассмотрим только основные и наиболее часто используемые агрегатные функции:
| Название | Описание |
|---|---|
| COUNT(*) | Возвращает количество строк полученных оператором «SELECT … WHERE …». В случае отсутствии WHERE, количество всех записей таблицы. |
| COUNT(столбец/выражение) | Возвращает количество значений (не равных NULL), в указанном столбце/выражении |
| COUNT(DISTINCT столбец/выражение) | Возвращает количество уникальных значений, не равных NULL в указанном столбце/выражении |
| SUM(столбец/выражение) | Возвращает сумму по значениям столбца/выражения |
| AVG(столбец/выражение) | Возвращает среднее значение по значениям столбца/выражения. NULL значения для подсчета не учитываются. NULL значения для подсчета не учитываются. |
| MIN(столбец/выражение) | Возвращает минимальное значение по значениям столбца/выражения |
| MAX(столбец/выражение) | Возвращает максимальное значение по значениям столбца/выражения |
Агрегатные функции позволяют нам сделать расчет итогового значения для набора строк полученных при помощи оператора SELECT.
Рассмотрим каждую функцию на примере:
SELECT COUNT(*) [Общее кол-во сотрудников], COUNT(DISTINCT DepartmentID) [Число уникальных отделов], COUNT(DISTINCT PositionID) [Число уникальных должностей], COUNT(BonusPercent) [Кол-во сотрудников у которых указан % бонуса], MAX(BonusPercent) [Максимальный процент бонуса], MIN(BonusPercent) [Минимальный процент бонуса], SUM(Salary/100*BonusPercent) [Сумма всех бонусов], AVG(Salary/100*BonusPercent) [Средний размер бонуса], AVG(Salary) [Средний размер ЗП] FROM Employees
| Общее кол-во сотрудников | Число уникальных отделов | Число уникальных должностей | Кол-во сотрудников у которых указан % бонуса | Максимальный процент бонуса | Минимальный процент бонуса | Сумма всех бонусов | Средний размер бонуса | Средний размер ЗП |
|---|---|---|---|---|---|---|---|---|
| 6 | 3 | 4 | 3 | 50 | 15 | 3325 | 1108. 33333333333 33333333333 |
2416.66666666667 |
Для большей наглядности я решил здесь сделать исключение и воспользовался синтаксисом […] для задания псевдонимов колонок.
Разберем каким образом получилось каждое возвращенное значение, а за одно вспомним конструкции базового синтаксиса оператора SELECT.
Во-первых, т.к. мы в запросе не указали WHERE-условия, то итоги будут считаться для детальных данных, которые получаются запросом:
SELECT * FROM Employees
т.е. для всех строк таблицы Employees.
Для наглядности выберем только поля и выражения, которые используются в агрегатных функциях:
SELECT DepartmentID, PositionID, BonusPercent, Salary/100*BonusPercent [Salary/100*BonusPercent], Salary FROM Employees
| DepartmentID | PositionID | BonusPercent | Salary/100*BonusPercent | Salary |
|---|---|---|---|---|
| 1 | 2 | 50 | 2500 | 5000 |
| 3 | 3 | 15 | 225 | 1500 |
| 2 | 1 | NULL | NULL | 2500 |
| 3 | 4 | 30 | 600 | 2000 |
| 3 | 3 | NULL | NULL | 1500 |
| NULL | NULL | NULL | NULL | 2000 |
Это исходные данные (детальные строки), по которым и будут считаться итоги агрегированного запроса.
Теперь разберем каждое агрегированное значение:
COUNT(*) – т.к. мы не задали в запросе условия фильтрации в блоке WHERE, то COUNT(*) дало нам общее количество записей в таблице, т.е. это количество строк, которое возвращает запрос:SELECT * FROM Employees |
| COUNT(DISTINCT DepartmentID) – вернуло нам значение 3, т.е. это число соответствует числу уникальных значений департаментов указанных в столбце DepartmentID без учета NULL значений. Пройдемся по значениям колонки DepartmentID и раскрасим одинаковые значения в один цвет (не стесняйтесь, для обучения все методы хороши): Отбрасываем NULL, после чего, мы получили 3 уникальных значения (1, 2 и 3). Т.е. значение получаемое COUNT(DISTINCT DepartmentID), в развернутом виде можно представить следующей выборкой: SELECT DISTINCT DepartmentID -- 2. берем только уникальные значения FROM Employees WHERE DepartmentID IS NOT NULL -- 1. отбрасываем NULL значения |
| COUNT(DISTINCT PositionID) – то же самое, что было сказано про COUNT(DISTINCT DepartmentID), только полю PositionID. Смотрим на значения колонки PositionID и не жалеем красок: |
| COUNT(BonusPercent) – возвращает количество строк, у которых указано значение BonusPercent, т.е. подсчитывается количество записей, у которых BonusPercent IS NOT NULL. Здесь нам будет проще, т.к. не нужно считать уникальные значения, достаточно просто отбросить записи с NULL значениями. Берем значения колонки BonusPercent и вычеркиваем все NULL значения: Остается 3 значения. Т.е. в развернутом виде выборку можно представить так: SELECT BonusPercent -- 2. берем все значения FROM Employees WHERE BonusPercent IS NOT NULL -- 1. отбрасываем NULL значения Т.к. мы не использовали слова DISTINCT, то посчитаются и повторяющиеся BonusPercent в случае их наличия, без учета BonusPercent равных NULL. Для примера давайте сделаем сравнение результата с использованием DISTINCT и без него. Для большей наглядности воспользуемся значениями поля DepartmentID: SELECT COUNT(*), -- 6 COUNT(DISTINCT DepartmentID), -- 3 COUNT(DepartmentID) -- 5 FROM Employees |
MAX(BonusPercent) – возвращает максимальное значение BonusPercent, опять же без учета NULL значений. Берем значения колонки BonusPercent и ищем среди них максимальное значение, на NULL значения не обращаем внимания: Т.е. мы получаем следующее значение: SELECT TOP 1 BonusPercent FROM Employees WHERE BonusPercent IS NOT NULL ORDER BY BonusPercent DESC -- сортируем по убыванию |
| MIN(BonusPercent) – возвращает минимальное значение BonusPercent, опять же без учета NULL значений. Как в случае с MAX, только ищем минимальное значение, игнорируя NULL: Т.е. мы получаем следующее значение: SELECT TOP 1 BonusPercent FROM Employees WHERE BonusPercent IS NOT NULL ORDER BY BonusPercent -- сортируем по возрастанию Наглядное представление MIN(BonusPercent) и MAX(BonusPercent): |
| SUM(Salary/100*BonusPercent) – возвращает сумму всех не NULL значений. Разбираем значения выражения (Salary/100*BonusPercent): Т.е. происходит суммирование следующих значений: SELECT Salary/100*BonusPercent FROM Employees WHERE Salary/100*BonusPercent IS NOT NULL |
AVG(Salary/100*BonusPercent) – возвращает среднее значений. NULL-выражения не учитываются, т.е. это соответствует второму выражению: NULL-выражения не учитываются, т.е. это соответствует второму выражению:SELECT AVG(Salary/100*BonusPercent), -- 1108.33333333333 SUM(Salary/100*BonusPercent)/COUNT(Salary/100*BonusPercent), -- 1108.33333333333 SUM(Salary/100*BonusPercent)/COUNT(*) -- 554.166666666667 FROM Employees Т.е. опять же NULL-значения не учитываются при подсчете количества. Если же вам необходимо вычислить среднее по всем сотрудникам, как в третьем выражении, которое дает 554.166666666667, то используйте предварительное преобразование NULL значений в ноль: SELECT AVG(ISNULL(Salary/100*BonusPercent,0)), -- 554.166666666667 SUM(Salary/100*BonusPercent)/COUNT(*) -- 554.166666666667 FROM Employees |
| AVG(Salary) – собственно, здесь все то же самое что и в предыдущем случае, т.е. если у сотрудника Salary равен NULL, то он не учтется. Чтобы учесть всех сотрудников, соответственно делаете предварительное преобразование NULL значений AVG(ISNULL(Salary,0)) |
Подведем некоторые итоги:
- COUNT(*) – служит для подсчета общего количества строк, которые получены оператором «SELECT … WHERE …»
- во всех остальных вышеперечисленных агрегатных функциях при расчете итога, NULL-значения не учитываются
- если нам нужно учесть все строки, это больше актуально для функции AVG, то предварительно необходимо осуществить обработку NULL значений, например, как было показано выше «AVG(ISNULL(Salary,0))»
Соответственно при задании с агрегатными функциями дополнительного условия в блоке WHERE, будут подсчитаны только итоги, по строкам удовлетворяющих условию. Т.е. расчет агрегатных значений происходит для итогового набора, который получен при помощи конструкции SELECT. Например, сделаем все тоже самое, но только в разрезе ИТ-отдела:
Т.е. расчет агрегатных значений происходит для итогового набора, который получен при помощи конструкции SELECT. Например, сделаем все тоже самое, но только в разрезе ИТ-отдела:
SELECT COUNT(*) [Общее кол-во сотрудников], COUNT(DISTINCT DepartmentID) [Число уникальных отделов], COUNT(DISTINCT PositionID) [Число уникальных должностей], COUNT(BonusPercent) [Кол-во сотрудников у которых указан % бонуса], MAX(BonusPercent) [Максимальный процент бонуса], MIN(BonusPercent) [Минимальный процент бонуса], SUM(Salary/100*BonusPercent) [Сумма всех бонусов], AVG(Salary/100*BonusPercent) [Средний размер бонуса], AVG(Salary) [Средний размер ЗП] FROM Employees WHERE DepartmentID=3 -- учесть только ИТ-отдел
| Общее кол-во сотрудников | Число уникальных отделов | Число уникальных должностей | Кол-во сотрудников у которых указан % бонуса | Максимальный процент бонуса | Минимальный процент бонуса | Сумма всех бонусов | Средний размер бонуса | Средний размер ЗП |
|---|---|---|---|---|---|---|---|---|
| 3 | 1 | 2 | 2 | 30 | 15 | 825 | 412. 5 5 |
1666.66666666667 |
Предлагаю вам, для большего понимания работы агрегатных функций, самостоятельно проанализировать каждое полученное значение. Расчеты здесь ведем, соответственно, по детальным данным полученным запросом:
SELECT DepartmentID, PositionID, BonusPercent, Salary/100*BonusPercent [Salary/100*BonusPercent], Salary FROM Employees WHERE DepartmentID=3 -- учесть только ИТ-отдел
| DepartmentID | PositionID | BonusPercent | Salary/100*BonusPercent | Salary |
|---|---|---|---|---|
| 3 | 3 | 15 | 225 | 1500 |
| 3 | 4 | 30 | 600 | 2000 |
| 3 | 3 | NULL | NULL | 1500 |
Идем, дальше. В случае, если агрегатная функция возвращает NULL (например, у всех сотрудников не указано значение Salary), или в выборку не попало ни одной записи, а в отчете, для такого случая нам нужно показать 0, то функцией ISNULL можно обернуть агрегатное выражение:
SELECT SUM(Salary), AVG(Salary), -- обрабатываем итог при помощи ISNULL ISNULL(SUM(Salary),0), ISNULL(AVG(Salary),0) FROM Employees WHERE DepartmentID=10 -- здесь специально указан несуществующий отдел, чтобы запрос не вернул записей
| (No column name) | (No column name) | (No column name) | (No column name) |
|---|---|---|---|
| NULL | NULL | 0 | 0 |
Я считаю, что очень важно понимать назначение каждой агрегатной функции и то каким образом они производят расчет, т. к. в SQL это главный инструмент, который служит для расчета итоговых значений.
к. в SQL это главный инструмент, который служит для расчета итоговых значений.
В данном случае мы рассмотрели, как каждая агрегатная функция ведет себя самостоятельно, т.е. она применялась к значениям всего набора записей полученным командой SELECT. Дальше мы рассмотрим, как эти же функции применяются для вычисления итогов по группам, при помощи конструкции GROUP BY.
GROUP BY – группировка данных
До этого мы уже вычисляли итоги для конкретного отдела, примерно следующим образом:
SELECT COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 -- данные только по ИТ отделу
А теперь представьте, что нас попросили получить такие же цифры в разрезе каждого отдела. Конечно мы можем засучить рукава и выполнить этот же запрос для каждого отдела. Итак, сказано-сделано, пишем 4 запроса:
SELECT 'Администрация' Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=1 -- данные по Администрации SELECT 'Бухгалтерия' Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=2 -- данные по Бухгалтерии SELECT 'ИТ' Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 -- данные по ИТ отделу SELECT 'Прочие' Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID IS NULL -- и еще не забываем данные по внештатникам
В результате мы получим 4 набора данных:
Обратите внимание, что мы можем использовать поля, заданные в виде констант – ‘Администрация’, ‘Бухгалтерия’, …
В общем все цифры, о которых нас просили, мы добыли, объединяем все в Excel и отдаем директору.
Отчет директору понравился, и он говорит: «а добавьте еще колонку с информацией по среднему окладу». И как всегда это нужно сделать очень срочно.
Мда, что делать?! Вдобавок представим еще что отделов у нас не 3, а 15.
Вот как раз то примерно для таких случаев служит конструкция GROUP BY:
SELECT DepartmentID, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount, AVG(Salary) SalaryAvg -- плюс выполняем пожелание директора FROM Employees GROUP BY DepartmentID
| DepartmentID | PositionCount | EmplCount | SalaryAmount | SalaryAvg |
|---|---|---|---|---|
| NULL | 0 | 1 | 2000 | 2000 |
| 1 | 1 | 1 | 5000 | 5000 |
| 2 | 1 | 1 | 2500 | 2500 |
| 3 | 2 | 3 | 5000 | 1666. 66666666667 66666666667 |
Мы получили все те же самые данные, но теперь используя только один запрос!
Пока не обращайте внимание, на то что департаменты у нас вывелись в виде цифр, дальше мы научимся выводить все красиво.
В предложении GROUP BY можно указывать несколько полей «GROUP BY поле1, поле2, …, полеN», в этом случае группировка произойдет по группам, которые образовывают значения данных полей «поле1, поле2, …, полеN».
Для примера, сделаем группировку данных в разрезе Отделов и Должностей:
SELECT DepartmentID,PositionID, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID,PositionID
| DepartmentID | PositionID | EmplCount | SalaryAmount |
|---|---|---|---|
| NULL | NULL | 1 | 2000 |
| 2 | 1 | 1 | 2500 |
| 1 | 2 | 1 | 5000 |
| 3 | 3 | 2 | 3000 |
| 3 | 4 | 1 | 2000 |
Давайте, теперь на этом примере, попробуем разобраться как работает GROUP BY
Для полей, перечисленных после GROUP BY из таблицы Employees определяются все уникальные комбинации по значениям DepartmentID и PositionID, т. е. происходит примерно следующее:
SELECT DISTINCT DepartmentID,PositionID FROM Employees
| DepartmentID | PositionID |
|---|---|
| NULL | NULL |
| 1 | 2 |
| 2 | 1 |
| 3 | 3 |
| 3 | 4 |
После чего делается пробежка по каждой комбинации и делаются вычисления агрегатных функций:
SELECT COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID IS NULL AND PositionID IS NULL SELECT COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=1 AND PositionID=2 -- ... SELECT COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 AND PositionID=4
А потом все эти результаты объединяются вместе и отдаются нам в виде одного набора:
Из основного, стоит отметить, что в случае группировки (GROUP BY), в перечне колонок в блоке SELECT:
- Мы можем использовать только колонки, перечисленные в блоке GROUP BY
- Можно использовать выражения с полями из блока GROUP BY
- Можно использовать константы, т. к. они не влияют на результат группировки
- Все остальные поля (не перечисленные в блоке GROUP BY) можно использовать только с агрегатными функциями (COUNT, SUM, MIN, MAX, …)
- Не обязательно перечислять все колонки из блока GROUP BY в списке колонок SELECT
 к. они не влияют на результат группировки
к. они не влияют на результат группировкиИ демонстрация всего сказанного:
SELECT
'Строка константа' Const1, -- константа в виде строки
1 Const2, -- константа в виде числа
-- выражение с использованием полей участвуещих в группировке
CONCAT('Отдел № ',DepartmentID) ConstAndGroupField,
CONCAT('Отдел № ',DepartmentID,', Должность № ',PositionID) ConstAndGroupFields,
DepartmentID, -- поле из списка полей участвующих в группировке
-- PositionID, -- поле учавствующее в группировке, не обязательно дублировать здесь
COUNT(*) EmplCount, -- кол-во строк в каждой группе
-- остальные поля можно использовать только с агрегатными функциями: COUNT, SUM, MIN, MAX, …
SUM(Salary) SalaryAmount,
MIN(ID) MinID
FROM Employees
GROUP BY DepartmentID,PositionID -- группировка по полям DepartmentID,PositionID
| Const1 | Const2 | ConstAndGroupField | ConstAndGroupFields | DepartmentID | EmplCount | SalaryAmount | MinID |
|---|---|---|---|---|---|---|---|
| Строка константа | 1 | Отдел № | Отдел №, Должность № | NULL | 1 | 2000 | 1005 |
| Строка константа | 1 | Отдел № 2 | Отдел № 2, Должность № 1 | 2 | 1 | 2500 | 1002 |
| Строка константа | 1 | Отдел № 1 | Отдел № 1, Должность № 2 | 1 | 1 | 5000 | 1000 |
| Строка константа | 1 | Отдел № 3 | Отдел № 3, Должность № 3 | 3 | 2 | 3000 | 1001 |
| Строка константа | 1 | Отдел № 3 | Отдел № 3, Должность № 4 | 3 | 1 | 2000 | 1003 |
Так же стоит отметить, что группировку можно делать не только по полям, но также и по выражениям. Для примера сгруппируем данные по сотрудникам, по годам рождения:
Для примера сгруппируем данные по сотрудникам, по годам рождения:
SELECT
CONCAT('Год рождения - ',YEAR(Birthday)) YearOfBirthday,
COUNT(*) EmplCount
FROM Employees
GROUP BY YEAR(Birthday)
Рассмотрим пример с более сложным выражением. Для примера, получим градацию сотрудников по годам рождения:
SELECT
CASE
WHEN YEAR(Birthday)>=2000 THEN 'от 2000'
WHEN YEAR(Birthday)>=1990 THEN '1999-1990'
WHEN YEAR(Birthday)>=1980 THEN '1989-1980'
WHEN YEAR(Birthday)>=1970 THEN '1979-1970'
WHEN Birthday IS NOT NULL THEN 'ранее 1970'
ELSE 'не указано'
END RangeName,
COUNT(*) EmplCount
FROM Employees
GROUP BY
CASE
WHEN YEAR(Birthday)>=2000 THEN 'от 2000'
WHEN YEAR(Birthday)>=1990 THEN '1999-1990'
WHEN YEAR(Birthday)>=1980 THEN '1989-1980'
WHEN YEAR(Birthday)>=1970 THEN '1979-1970'
WHEN Birthday IS NOT NULL THEN 'ранее 1970'
ELSE 'не указано'
END
| RangeName | EmplCount |
|---|---|
| 1979-1970 | 1 |
| 1989-1980 | 2 |
| не указано | 2 |
| ранее 1970 | 1 |
Т. е. в данном случае группировка делается по предварительно вычисленному для каждого сотрудника CASE-выражению:
е. в данном случае группировка делается по предварительно вычисленному для каждого сотрудника CASE-выражению:
SELECT
ID,
CASE
WHEN YEAR(Birthday)>=2000 THEN 'от 2000'
WHEN YEAR(Birthday)>=1990 THEN '1999-1990'
WHEN YEAR(Birthday)>=1980 THEN '1989-1980'
WHEN YEAR(Birthday)>=1970 THEN '1979-1970'
WHEN Birthday IS NOT NULL THEN 'ранее 1970'
ELSE 'не указано'
END
FROM Employees
Ну и конечно же вы можете объединять в блоке GROUP BY выражения с полями:
SELECT
DepartmentID,
CONCAT('Год рождения - ',YEAR(Birthday)) YearOfBirthday,
COUNT(*) EmplCount
FROM Employees
GROUP BY YEAR(Birthday),DepartmentID -- порядок может не совпадать с порядком их использования в блоке SELECT
ORDER BY DepartmentID,YearOfBirthday -- напоследок мы можем применить к результату сортировку
Вернемся к нашей изначальной задаче. Как мы уже знаем, отчет очень понравился директору, и он попросил нас делать его еженедельно, дабы он мог мониторить изменения по компании. Чтобы, не перебивать каждый раз в Excel цифровое значение отдела на его наименование, воспользуемся знаниями, которые у нас уже есть, и усовершенствуем наш запрос:
Чтобы, не перебивать каждый раз в Excel цифровое значение отдела на его наименование, воспользуемся знаниями, которые у нас уже есть, и усовершенствуем наш запрос:
SELECT
CASE DepartmentID
WHEN 1 THEN 'Администрация'
WHEN 2 THEN 'Бухгалтерия'
WHEN 3 THEN 'ИТ'
ELSE 'Прочие'
END Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount,
AVG(Salary) SalaryAvg -- плюс выполняем пожелание директора
FROM Employees
GROUP BY DepartmentID
ORDER BY Info -- добавим для большего удобства сортировку по колонке Info
| Info | PositionCount | EmplCount | SalaryAmount | SalaryAvg |
|---|---|---|---|---|
| Администрация | 1 | 1 | 5000 | 5000 |
| Бухгалтерия | 1 | 1 | 2500 | 2500 |
| ИТ | 2 | 3 | 5000 | 1666. 66666666667 66666666667 |
| Прочие | 0 | 1 | 2000 | 2000 |
Хоть со стороны может выглядит и страшно, но все равно это получше чем было изначально. Недостаток в том, что если заведут новый отдел и его сотрудников, то выражение CASE нам нужно будет дописывать, дабы сотрудники нового отдела не попали в группу «Прочие».
Но ничего, со временем, мы научимся делать все красиво, чтобы выборка у нас не зависела от появления в БД новых данных, а была динамической. Немного забегу вперед, чтобы показать к написанию каких запросов мы стремимся прийти:
SELECT ISNULL(dep.Name,'Прочие') DepName, COUNT(DISTINCT emp.PositionID) PositionCount, COUNT(*) EmplCount, SUM(emp.Salary) SalaryAmount, AVG(emp.Salary) SalaryAvg -- плюс выполняем пожелание директора FROM Employees emp LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID GROUP BY emp.DepartmentID,dep.Name ORDER BY DepName
В общем, не переживайте – все начинали с простого.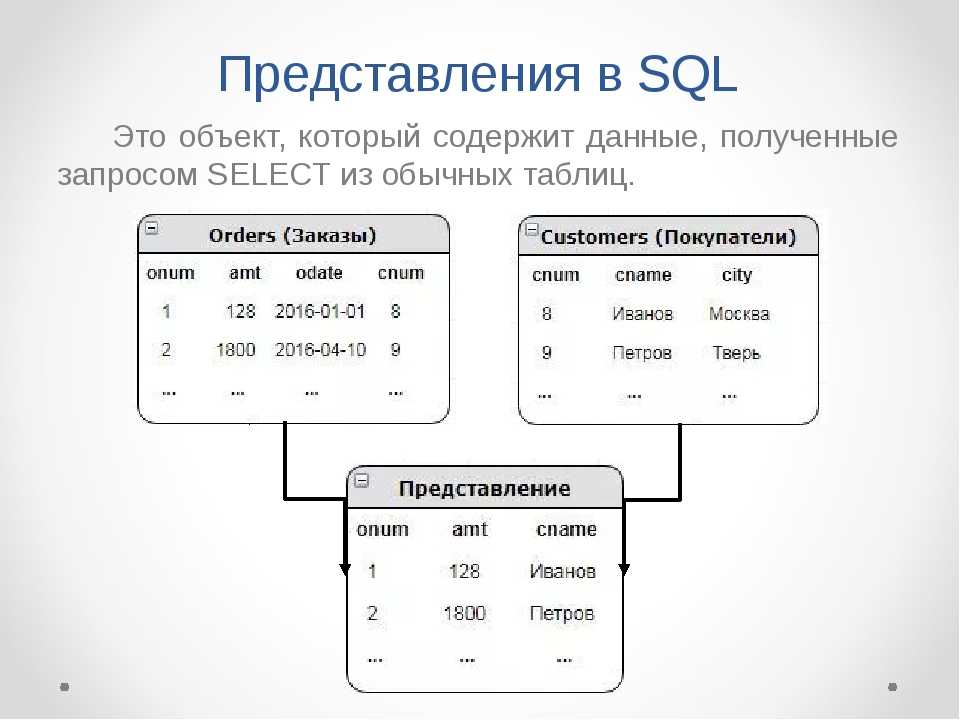 Пока вам просто нужно понять суть конструкции GROUP BY.
Пока вам просто нужно понять суть конструкции GROUP BY.
Напоследок, давайте посмотрим каким образом можно строить сводные отчеты при помощи GROUP BY.
Для примера выведем сводную таблицу, в разрезе отделов, так чтобы была подсчитана суммарная заработная плата, получаемая сотрудниками в разбивке по должностям:
SELECT DepartmentID, SUM(CASE WHEN PositionID=1 THEN Salary END) [Бухгалтера], SUM(CASE WHEN PositionID=2 THEN Salary END) [Директора], SUM(CASE WHEN PositionID=3 THEN Salary END) [Программисты], SUM(CASE WHEN PositionID=4 THEN Salary END) [Старшие программисты], SUM(Salary) [Итого по отделу] FROM Employees GROUP BY DepartmentID
| DepartmentID | Бухгалтера | Директора | Программисты | Старшие программисты | Итого по отделу |
|---|---|---|---|---|---|
| NULL | NULL | NULL | NULL | NULL | 2000 |
| 1 | NULL | 5000 | NULL | NULL | 5000 |
| 2 | 2500 | NULL | NULL | NULL | 2500 |
| 3 | NULL | NULL | 3000 | 2000 | 5000 |
Т.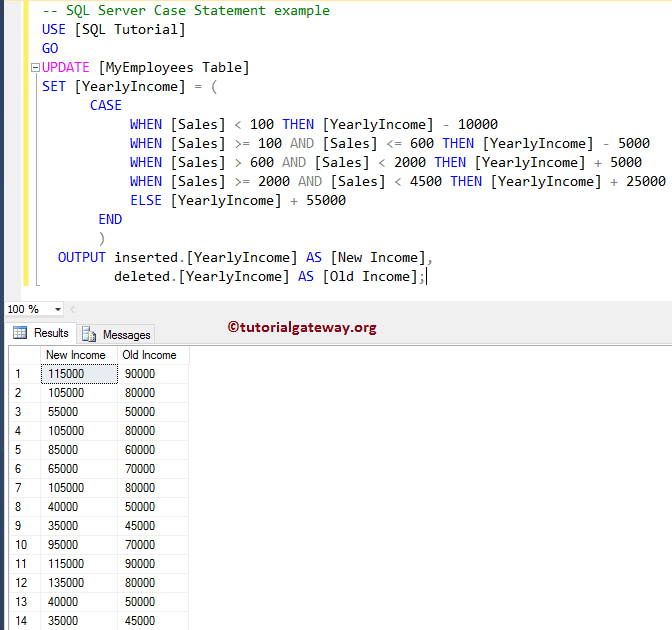 е. мы свободно можем использовать любые выражения внутри агрегатных функций.
е. мы свободно можем использовать любые выражения внутри агрегатных функций.
Можно конечно переписать и при помощи IIF:
SELECT DepartmentID, SUM(IIF(PositionID=1,Salary,NULL)) [Бухгалтера], SUM(IIF(PositionID=2,Salary,NULL)) [Директора], SUM(IIF(PositionID=3,Salary,NULL)) [Программисты], SUM(IIF(PositionID=4,Salary,NULL)) [Старшие программисты], SUM(Salary) [Итого по отделу] FROM Employees GROUP BY DepartmentID
Но в случае с IIF нам придется явно указывать NULL, которое возвращается в случае невыполнения условия.
В аналогичных случаях мне больше нравится использовать CASE без блока ELSE, чем лишний раз писать NULL. Но это конечно дело вкуса, о котором не спорят.
И давайте вспомним, что в агрегатных функциях при агрегации не учитываются NULL значения.
Для закрепления, сделайте самостоятельный анализ полученных данных по развернутому запросу:
SELECT DepartmentID, CASE WHEN PositionID=1 THEN Salary END [Бухгалтера], CASE WHEN PositionID=2 THEN Salary END [Директора], CASE WHEN PositionID=3 THEN Salary END [Программисты], CASE WHEN PositionID=4 THEN Salary END [Старшие программисты], Salary [Итого по отделу] FROM Employees
| DepartmentID | Бухгалтера | Директора | Программисты | Старшие программисты | Итого по отделу |
|---|---|---|---|---|---|
| 1 | NULL | 5000 | NULL | NULL | 5000 |
| 3 | NULL | NULL | 1500 | NULL | 1500 |
| 2 | 2500 | NULL | NULL | NULL | 2500 |
| 3 | NULL | NULL | NULL | 2000 | 2000 |
| 3 | NULL | NULL | 1500 | NULL | 1500 |
| NULL | NULL | NULL | NULL | NULL | 2000 |
И еще давайте вспомним, что если вместо NULL мы хотим увидеть нули, то мы можем обработать значение, возвращаемое агрегатной функцией. Например:
Например:
SELECT DepartmentID, ISNULL(SUM(IIF(PositionID=1,Salary,NULL)),0) [Бухгалтера], ISNULL(SUM(IIF(PositionID=2,Salary,NULL)),0) [Директора], ISNULL(SUM(IIF(PositionID=3,Salary,NULL)),0) [Программисты], ISNULL(SUM(IIF(PositionID=4,Salary,NULL)),0) [Старшие программисты], ISNULL(SUM(Salary),0) [Итого по отделу] FROM Employees GROUP BY DepartmentID
| DepartmentID | Бухгалтера | Директора | Программисты | Старшие программисты | Итого по отделу |
|---|---|---|---|---|---|
| NULL | 0 | 0 | 0 | 0 | 2000 |
| 1 | 0 | 5000 | 0 | 0 | 5000 |
| 2 | 2500 | 0 | 0 | 0 | 2500 |
| 3 | 0 | 0 | 3000 | 2000 | 5000 |
Теперь в целях практики, вы можете:
- вывести названия департаментов вместо их идентификаторов, например, добавив выражение CASE обрабатывающее DepartmentID в блоке SELECT
- добавьте сортировку по имени отдела при помощи ORDER BY
GROUP BY в скупе с агрегатными функциями, одно из основных средств, служащих для получения сводных данных из БД, ведь обычно данные в таком виде и используются, т. к. обычно от нас требуют предоставления сводных отчетов, а не детальных данных (простыней). И конечно же все это крутится вокруг знания базовой конструкции, т.к. прежде чем что-то подытожить (агрегировать), вам нужно первым делом это правильно выбрать, используя «SELECT … WHERE …».
к. обычно от нас требуют предоставления сводных отчетов, а не детальных данных (простыней). И конечно же все это крутится вокруг знания базовой конструкции, т.к. прежде чем что-то подытожить (агрегировать), вам нужно первым делом это правильно выбрать, используя «SELECT … WHERE …».
Важное место здесь имеет практика, поэтому, если вы поставили целью понять язык SQL, не изучить, а именно понять – практикуйтесь, практикуйтесь и практикуйтесь, перебирая самые разные варианты, которые только сможете придумать.
На начальных порах, если вы не уверены в правильности полученных агрегированных данных, делайте детальную выборку, включающую все значения, по которым идет агрегация. И проверяйте правильность расчетов вручную по этим детальным данным. В этом случае очень сильно может помочь использование программы Excel.
Допустим, что вы дошли до этого момента
Допустим, что вы бухгалтер Сидоров С.С., который решил научиться писать SELECT-запросы.
Допустим, что вы уже успели дочитать данный учебник до этого момента, и уже уверено пользуетесь всеми вышеперечисленными базовыми конструкциями, т.е. вы умеете:
- Выбирать детальные данные по условию WHERE из одной таблицы
- Умеете пользоваться агрегатными функциями и группировкой из одной таблицы
Так как на работе посчитали, что вы уже все умеете, то вам предоставили доступ к БД (и такое порой бывает), и теперь вы разработали и вытаскиваете тот самый еженедельный отчет для директора.
Да, но они не учли, что вы пока не умеете строить запросы из нескольких таблиц, а только из одной, т.е. вы не умеете делать что-то вроде такого:
SELECT emp.*, -- вернуть все поля таблицы Employees dep.Name DepartmentName, -- к этим полям добавить поле Name из таблицы Departments pos.Name PositionName -- и еще добавить поле Name из таблицы Positions FROM Employees emp LEFT JOIN Departments dep ON emp.DepartmentID=dep.
 ID
LEFT JOIN Positions pos ON emp.PositionID=pos.ID
ID
LEFT JOIN Positions pos ON emp.PositionID=pos.ID
| ID | Name | Birthday | … | Salary | BonusPercent | DepartmentName | PositionName |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 19.02.1955 | 5000 | 50 | Администрация | Директор | |
| 1001 | Петров П.П. | 03.12.1983 | 1500 | 15 | ИТ | Программист | |
| 1002 | Сидоров С.С. | 07.06.1976 | 2500 | NULL | Бухгалтерия | Бухгалтер | |
| 1003 | Андреев А.А. | 17.04.1982 | 2000 | 30 | ИТ | Старший программист | |
| 1004 | Николаев Н.Н. |
NULL | 1500 | NULL | ИТ | Программист | |
| 1005 | Александров А.А. | NULL | 2000 | NULL | NULL | NULL |
Несмотря на то, что вы этого не умеете, поверьте, вы молодец, и уже, и так много достигли.
И так, как же можно воспользоваться вашими текущими знаниями и получить при этом еще более продуктивные результаты?! Воспользуемся силой коллективного разума – идем к программистам, которые работают у вас, т.е. к Андрееву А.А., Петрову П.П. или Николаеву Н.Н., и попросим кого-нибудь из них написать для вас представление (VIEW или просто «Вьюха», так они даже, думаю, быстрее поймут вас), которое помимо основных полей из таблицы Employees, будет еще возвращать поля с «Названием отдела» и «Названием должности», которых вам так недостает сейчас для еженедельного отчета, которым вас загрузил Иванов И. И.
И.
Т.к. вы все грамотно объяснили, то ИТ-шники, сразу же поняли, что от них хотят и создали, специально для вас, представление с названием ViewEmployeesInfo.
Представляем, что вы следующей команды не видите, т.к. это делают ИТ-шники:
CREATE VIEW ViewEmployeesInfo AS SELECT emp.*, -- вернуть все поля таблицы Employees dep.Name DepartmentName, -- к этим полям добавить поле Name из таблицы Departments pos.Name PositionName -- и еще добавить поле Name из таблицы Positions FROM Employees emp LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID LEFT JOIN Positions pos ON emp.PositionID=pos.ID
Т.е. для вас весь этот, пока страшный и непонятный, текст остается за кадром, а ИТ-шники дают вам только название представления «ViewEmployeesInfo», которое возвращает все вышеуказанные данные (т.е. то что вы у них просили).
Вы теперь можете работать с данным представлением, как с обычной таблицей:
SELECT * FROM ViewEmployeesInfo
| ID | Name | Birthday | … | Salary | BonusPercent | DepartmentName | PositionName |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И. И. И. |
19.02.1955 | 5000 | 50 | Администрация | Директор | |
| 1001 | Петров П.П. | 03.12.1983 | 1500 | 15 | ИТ | Программист | |
| 1002 | Сидоров С.С. | 07.06.1976 | 2500 | NULL | Бухгалтерия | Бухгалтер | |
| 1003 | Андреев А.А. | 17.04.1982 | 2000 | 30 | ИТ | Старший программист | |
| 1004 | Николаев Н.Н. | NULL | 1500 | NULL | ИТ | Программист | |
| 1005 | Александров А.А. | NULL | 2000 | NULL | NULL | NULL |
Т. к. теперь все необходимые для отчета данные есть в одной «таблице» (а-ля вьюха), то вы с легкостью сможете переделать свой еженедельный отчет:
к. теперь все необходимые для отчета данные есть в одной «таблице» (а-ля вьюха), то вы с легкостью сможете переделать свой еженедельный отчет:
SELECT DepartmentName, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount, AVG(Salary) SalaryAvg FROM ViewEmployeesInfo emp GROUP BY DepartmentID,DepartmentName ORDER BY DepartmentName
| DepartmentName | PositionCount | EmplCount | SalaryAmount | SalaryAvg |
|---|---|---|---|---|
| NULL | 0 | 1 | 2000 | 2000 |
| Администрация | 1 | 1 | 5000 | 5000 |
| Бухгалтерия | 1 | 1 | 2500 | 2500 |
| ИТ | 2 | 3 | 5000 | 1666.66666666667 |
Теперь все названия отделов на местах, плюс к тому же запрос стал динамическим, и будет изменяться при добавлении новых отделов и их сотрудников, т. е. вам теперь ничего переделывать не нужно, а достаточно раз в неделю выполнить запрос и отдать его результат директору.
е. вам теперь ничего переделывать не нужно, а достаточно раз в неделю выполнить запрос и отдать его результат директору.
Т.е. для вас в данном случае, будто бы ничего и не поменялось, вы продолжаете так же работать с одной таблицей (только уже правильнее сказать с представлением ViewEmployeesInfo), которое возвращает все необходимые вам данные. Благодаря помощи ИТ-шников, детали по добыванию DepartmentName и PositionName остались для вас в черном ящике. Т.е. представление для вас выглядит так же, как и обычная таблица, считайте, что это расширенная версия таблицы Employees.
Давайте для примера еще сформируем ведомость, чтобы вы убедились, что все действительно так как я и говорил (что вся выборка идет из одного представления):
SELECT ID, Name, Salary FROM ViewEmployeesInfo WHERE Salary IS NOT NULL AND Salary>0 ORDER BY Name
| ID | Name | Salary |
|---|---|---|
| 1005 | Александров А.А. | 2000 |
| 1003 | Андреев А. А. А. |
2000 |
| 1000 | Иванов И.И. | 5000 |
| 1004 | Николаев Н.Н. | 1500 |
| 1001 | Петров П.П. | 1500 |
| 1002 | Сидоров С.С. | 2500 |
Надеюсь, что данный запрос вам понятен.
Использование представлений в некоторых случаях, дает возможность значительно расширить границы пользователей, владеющих написанием базовых SELECT-запросов. В данном случае представление, представляет собой плоскую таблицу со всеми необходимыми пользователю данными (для тех, кто разбирается в OLAP, это можно сравнить с приближенным подобием OLAP-куба с фактами и измерениями).
Вырезка с википедии. Хотя SQL и задумывался как средство работы конечного пользователя, в конце концов он стал настолько сложным, что превратился в инструмент программиста.
Как видите, уважаемые пользователи, язык SQL изначально задумывался, как инструмент для вас.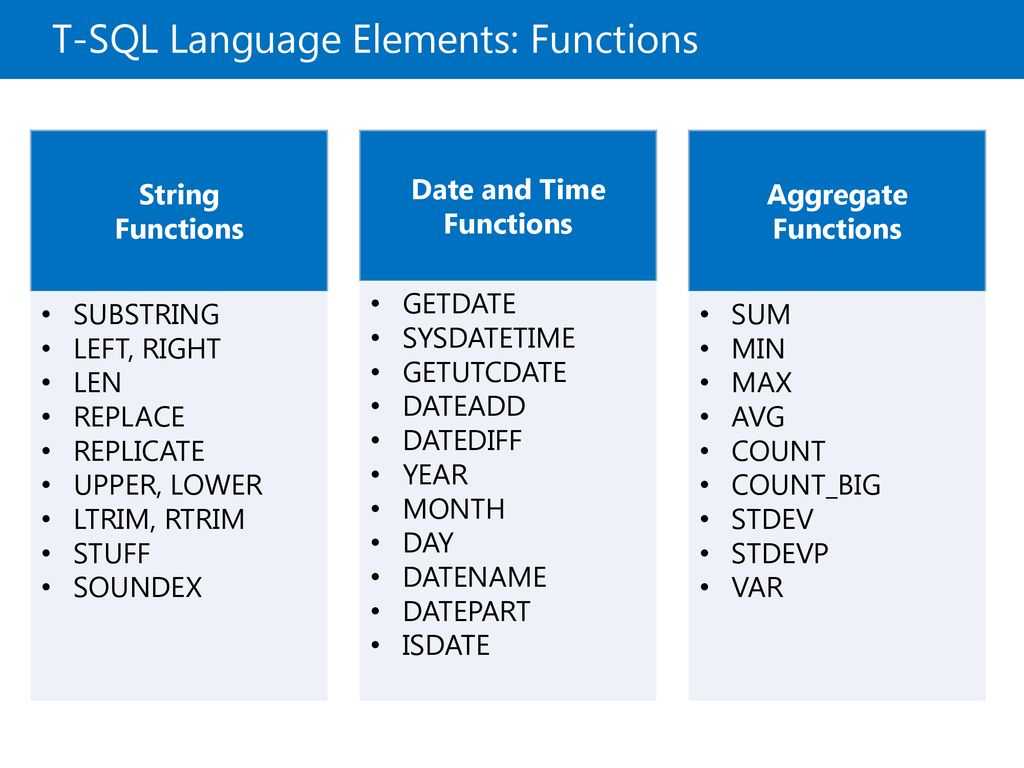 Так что, все в ваших руках и желании, не отпускайте руки.
Так что, все в ваших руках и желании, не отпускайте руки.
HAVING – наложение условия выборки к сгруппированным данным
Собственно, если вы поняли, что такое группировка, то с HAVING ничего сложного нет. HAVING – чем-то подобен WHERE, только если WHERE-условие применяется к детальным данным, то HAVING-условие применяется к уже сгруппированным данным. По этой причине в условиях блока HAVING мы можем использовать либо выражения с полями, входящими в группировку, либо выражения, заключенные в агрегатные функции.
Рассмотрим пример:
SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID HAVING SUM(Salary)>3000
| DepartmentID | SalaryAmount |
|---|---|
| 1 | 5000 |
| 3 | 5000 |
Т.е. данный запрос вернул нам сгруппированные данные только по тем отделам, у которых сумма ЗП всех сотрудников превышает 3000, т. е. «SUM(Salary)>3000».
е. «SUM(Salary)>3000».
Т.е. здесь в первую очередь происходит группировка и вычисляются данные по всем отделам:
SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID -- 1. получаем сгруппированные данные по всем отделам
А уже к этим данным применяется условие указанно в блоке HAVING:
SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID -- 1. получаем сгруппированные данные по всем отделам HAVING SUM(Salary)>3000 -- 2. условие для фильтрации сгруппированных данных
В HAVING-условии так же можно строить сложные условия используя операторы AND, OR и NOT:
SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID HAVING SUM(Salary)>3000 AND COUNT(*)<2 -- и число людей меньше 2-х
Как можно здесь заметить агрегатная функция (см. «COUNT(*)») может быть указана только в блоке HAVING.
Соответственно мы можем отобразить только номер отдела, подпадающего под HAVING-условие:
SELECT DepartmentID FROM Employees GROUP BY DepartmentID HAVING SUM(Salary)>3000 AND COUNT(*)<2 -- и число людей меньше 2-х
Пример использования HAVING-условия по полю включенного в GROUP BY:
SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID -- 1.
 сделать группировку
HAVING DepartmentID=3 -- 2. наложить фильтр на результат группировки
сделать группировку
HAVING DepartmentID=3 -- 2. наложить фильтр на результат группировки
Это только пример, т.к. в данном случае проверку логичнее было бы сделать через WHERE-условие:
SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 -- 1. провести фильтрацию детальных данных GROUP BY DepartmentID -- 2. сделать группировку только по отобранным записям
Т.е. сначала отфильтровать сотрудников по отделу 3, и только потом сделать расчет.
Примечание. На самом деле, несмотря на то, что эти два запроса выглядят по-разному оптимизатор СУБД может выполнить их одинаково.
Думаю, на этом рассказ о HAVING-условиях можно окончить.
Подведем итоги
Сведем данные полученные во второй и третьей части и рассмотрим конкретное месторасположение каждой изученной нами конструкции и укажем порядок их выполнения:
| Конструкция/Блок | Порядок выполнения | Выполняемая функция |
|---|---|---|
| SELECT возвращаемые выражения | 4 | Возврат данных полученных запросом |
| FROM источник | 0 | В нашем случае это пока все строки таблицы |
| WHERE условие выборки из источника | 1 | Отбираются только строки, проходящие по условию |
| GROUP BY выражения группировки | 2 | Создание групп по указанному выражению группировки.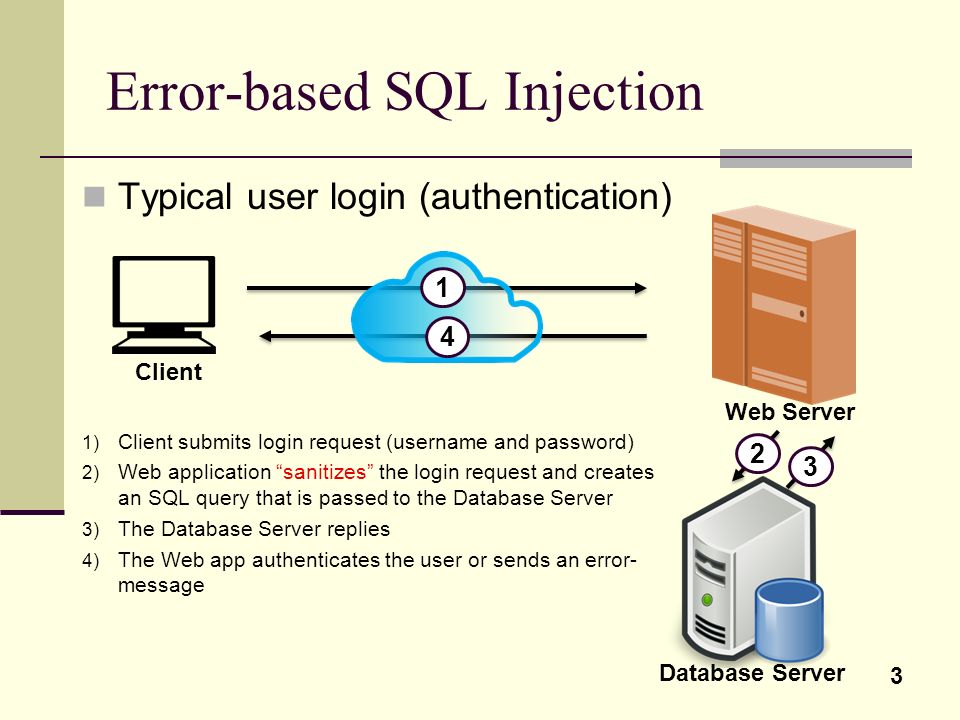 Расчет агрегированных значений по этим группам, используемых в SELECT либо HAVING блоках Расчет агрегированных значений по этим группам, используемых в SELECT либо HAVING блоках |
| HAVING фильтр по сгруппированным данным | 3 | Фильтрация, накладываемая на сгруппированные данные |
| ORDER BY выражение сортировки результата | 5 | Сортировка данных по указанному выражению |
Конечно же, вы так же можете применить к сгруппированным данным предложения DISTINCT и TOP, изученные во второй части.
Эти предложения в данном случае применятся к окончательному результату:
SELECT
TOP 1 -- 6. применится в последнюю очередь
SUM(Salary) SalaryAmount
FROM Employees
GROUP BY DepartmentID
HAVING SUM(Salary)>3000
ORDER BY DepartmentID -- 5. сортировка результата
| SalaryAmount |
|---|
| 5000 |
SELECT
DISTINCT -- показать только уникальные значения SalaryAmount
SUM(Salary) SalaryAmount
FROM Employees
GROUP BY DepartmentID
| SalaryAmount |
|---|
| 2000 |
| 2500 |
| 5000 |
Как получились данные результаты проанализируйте самостоятельно.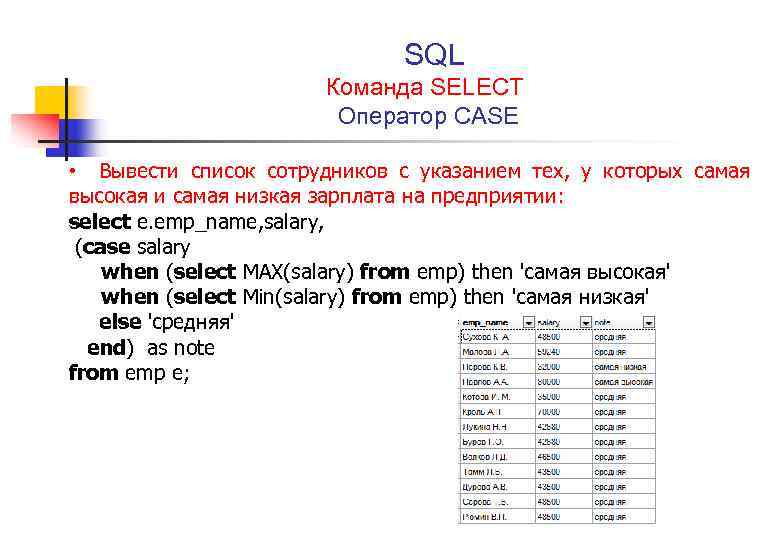
Заключение
Основная цель которую я ставил в данной части – раскрыть для вас суть агрегатных функций и группировок.
Если базовая конструкция позволяла нам получить необходимые детальные данные, то применение агрегатных функций и группировок к этим детальным данным, дало нам возможность получить по ним сводные данные. Так что, как видите здесь все важно, т.к. одно опирается на другое – без знания базовой конструкции мы не сможем, например, правильно отобрать данные, по которым нам нужно просчитать итоги.
Здесь я намеренно стараюсь показывать только основы, чтобы сосредоточить внимание начинающих на самых главных конструкциях и не перегружать их лишней информацией. Твердое понимание основных конструкций (о которых я еще продолжу рассказ в последующих частях) даст вам возможность решить практически любую задачу по выборке данных из РБД. Основные конструкции оператора SELECT применимы в таком же виде практически во всех СУБД (отличия в основном состоят в деталях, например, в реализации функций – для работы со строками, временем, и т. д.).
д.).
В последующем, твердое знание базы даст вам возможность самостоятельно легко изучить разные расширения языка SQL, такие как:
- GROUP BY ROLLUP(…), GROUP BY GROUPING SETS(…), …
- PIVOT, UNPIVOT
- и т.п.
В рамках данного учебника я решил не рассказывать об этих расширениях, т.к. и без их знания, владея только базовыми конструкциями языка SQL, вы сможете решать очень большой спектр задач. Расширения языка SQL по сути служат для решения какого-то определенного круга задач, т.е. позволяют решить задачу определенного класса более изящно (но не всегда эффективней в плане скорости или затраченных ресурсов).
Если вы делаете первые шаги в SQL, то сосредоточьтесь в первую очередь, именно на изучении базовых конструкций, т.к. владея базой, все остальное вам понять будет гораздо легче, и к тому же самостоятельно. Вам в первую очередь, как бы нужно объемно понять возможности языка SQL, т.е. какого рода операции он вообще позволяет совершить над данными.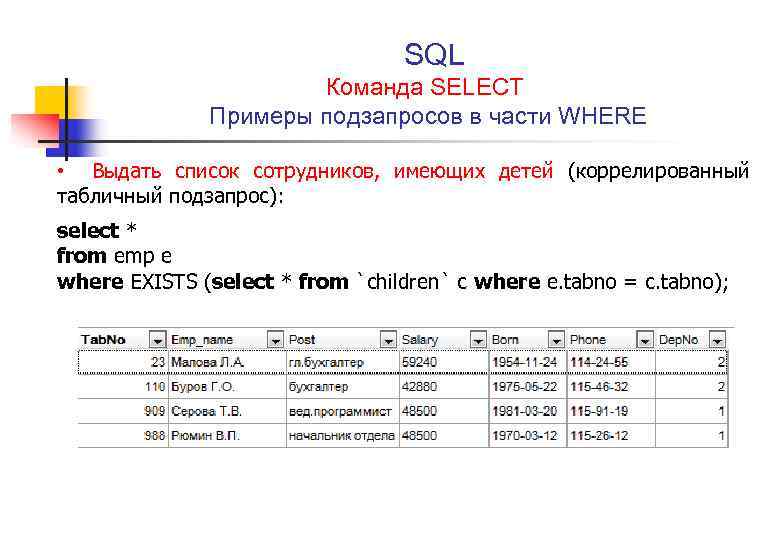 Донести до начинающих информацию в объемном виде – это еще одна из причин, почему я буду показывать только самые главные (железные) конструкции.
Донести до начинающих информацию в объемном виде – это еще одна из причин, почему я буду показывать только самые главные (железные) конструкции.
Удачи вам в изучении и понимании языка SQL.
Часть четвертая — habrahabr.ru/post/256045
Выборка данных
«Задание названий для столбцов таблицы»
«Избавление от повторяющихся записей»
«Ограничение вывода данных»
«Использование псевдонимов»
«Задание условий отбора полей»
«Применение логических операторов»
«Сортировка итоговой таблицы»
Основным действием выполняемым с помощью SQL запросов в системе ZuluGIS является выборка
данных для их вывода в виде таблицы в области результатов запроса. Выборка данных производится
с помощью ключевого слова SELECT, после которого задаются параметры
выборки.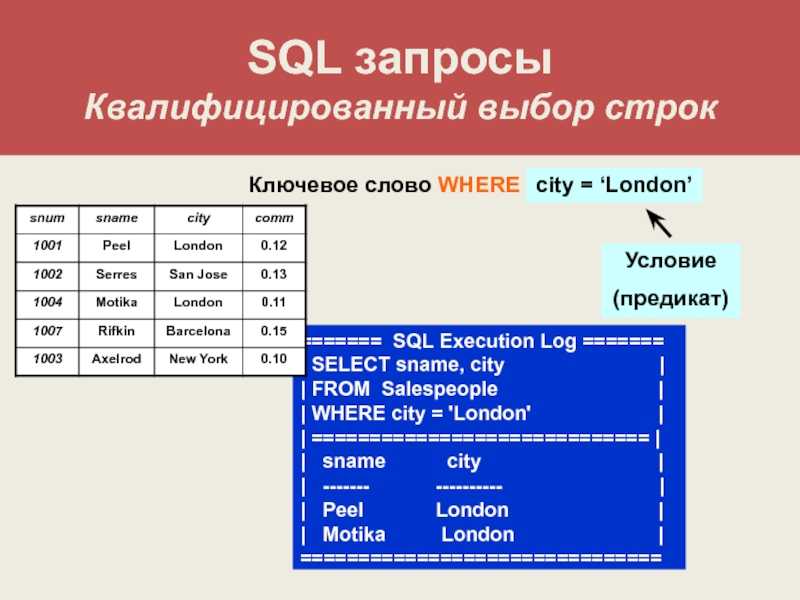
| Примечание | |
|---|---|
Как правило, выборка данных производится из записей полей БД слоев карты, но ключевое слово SELECT также может использоваться для вывода в поле результатов вычисления произвольных выражений, приведенных в строке после SELECT. Можно одновременно вывести результаты вычисления нескольких выражений, перечислив их через запятую. Например, команда |
Строка команды выборки состоит из трех основных частей, в которых задается какие поля
таблиц выводятся в итоговую таблицу, из каких слоев берутся данные и по каким условиям
отбираются данные для итоговой таблицы.
При запросе данных из одного слоя карты, для использования в команде выборки полей данных
достаточно указывать только их названия. Если же в выборке используются поля из нескольких
слоев, то названия полей требуется указывать в формате <Название
слоя>.<Название поля>.
Типовой запрос имеет следующий вид:
SELECT <выводимые колонки> [FROM <список слоев>] [WHERE <условия отбора> ]
где:
SELECT <выводимые колонки>
Часть команды выборки в которой задаются колонки выводимой таблицы данных. В области <выводимые колонки> через запятую перечисляются названия полей,
значения которых выводятся в колонках таблицы, либо выражения, результаты расчета которых
выводятся в таблице («Операторы и функции языка SQL»).
Для вывода в таблице значений всех полей данных из указанных в запросе слоев, задайте вместо списка полей символ « * ». В таком случае, значения полей в таблице будут выводиться в том же порядке, в котором они заданы в БД.
Для того чтобы в итоговой таблице выводились только отличающиеся друг от друга записи, задайте списком полей ключевое слово DISTINCT («Избавление от повторяющихся записей»).
FROM <список слоев>
Часть строки выборки в которой через запятую перечисляются слои карты из которых запрашиваются данные.
Если все поля в запросе указаны в формате <Название
слоя>.<Название поля>, часть запроса с ключевым словом FROM может быть опущена.
Если данные запрашиваются из более чем одного слоя карты, в итоговой таблице будет
выведено декартово пересечение записей запрошенных слоев. Например, в случае запроса полей из
двух слоев в итоговой таблице будет набор записей со всеми возможными комбинациями полей из
записей первого и второго слоя, т.е., например при запросе поля
Например, в случае запроса полей из
двух слоев в итоговой таблице будет набор записей со всеми возможными комбинациями полей из
записей первого и второго слоя, т.е., например при запросе поля А из слоя
содержащего 2 записи и запросе поля B из слоя также содержащего две записи,
в итоговой таблице будет четыре записи со следующими данными: A1+B1, A1+B2, A2+B1, A2+B2.
WHERE <условия отбора>
Часть, в которой задаются условия, в соответствии с которыми отбираются записи данных в таблицу результатов.
В качестве условий могут использоваться операции сравнения, проверки равенства, вхождения значений полей в заданный диапазон, проверки относительного расположения элементов и т.д. Подробно синтаксис условий будет рассмотрен далее.
Если в таблице результатов требуется вывести все записи для указанных полей, эта часть
запроса может быть опущена.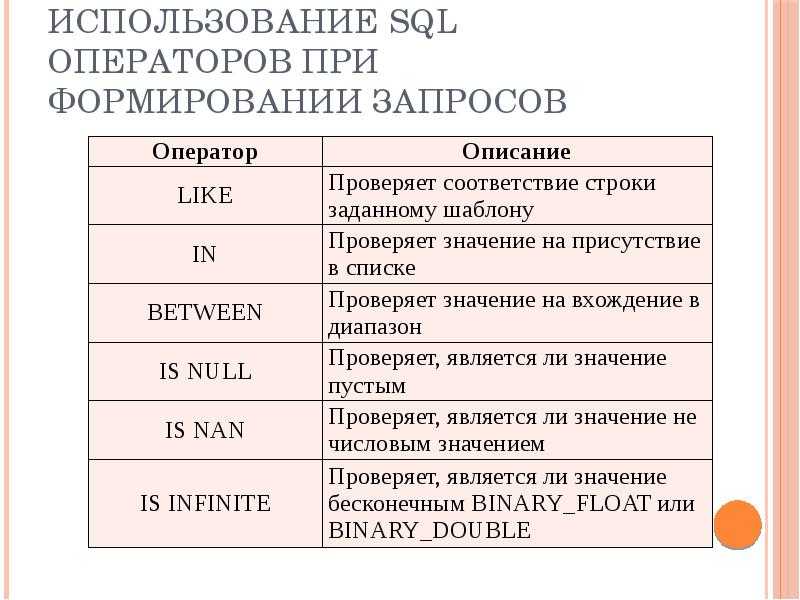
Также в команде выборки могут использоваться различные дополнительные команды, рассматриваемые в последующих подразделах.
Примеры выборок
Простейшая выборка
SELECT * FROM Кварталы
В результате данного запроса выводится таблицу со всеми записями данных об объектах слоя Кварталы, причем в таблице выводятся все доступные поля данных слоя.
Рисунок 663. Пример выполнения запроса
Команда выборки с перечислением требуемых полей
SELECT Sys, perimeter, [Количество этажей] FROM Здания
В результате запроса выводится таблица с полями Sys, perimeter, Количество этажей всех записей слоя Здания.
Команда выборки без FROM части
SELECT Здания.
 Sys, Здания.Адрес
Sys, Здания.АдресВ данном запросе для всех полей явно указан используемый слой, поэтому нет необходимости дополнительно указывать слой с помощью ключевого слова FROM.
Выборка с отбором по условию
SELECT [Номер дома] FROM Здания WHERE Улица='5й Южный пер.'
В результате данного запроса выводится таблица со значениями поля Номер
дома для всех записей слоя Здания у которых значение поля Улица равняется строке 5й Южный пер..
Выборка по нескольким слоям
SELECT Кварталы.sys, Здания.Улица + " " + Здания.[Номер дома] FROM Здания, Кварталы WHERE Здания.Geometry.STWithin(Кварталы.Geometry)
В результате такого запроса будут отобраны объекты слоя Здания располагаются в объектах слоя Квартал и будет выведена таблица из двух
столбцов, в первом из которых выводятся поля Sys объектов слоя Квартал, а во втором — адреса зданий в слое Здания помещающихся в указанных объектах слоя Квартал. Используемая в данном
запросе конструкция
Используемая в данном
запросе конструкция Здания.Geometry.STWithin(Кварталы.Geometry) проверяет, не
располагается ли объект слоя Здания внутри объекта слоя Кварталы (подробнее «Работа с пространственными данными в запросах»).
SQL Server IF…ELSE Заявление условия: Пример запроса T-SQL Select
ByRichard Peterson
ЧасовОбновлено
Зачем нужны условные операторы?
Условные операторы на сервере SQL помогают вам определять различные логические схемы и действия для различных условий. Он позволяет выполнять различные действия на основе условий, определенных в операторе. В реальной жизни вы совершаете множество действий, зависящих от результата какой-то другой деятельности или ситуации.
Некоторые примеры оператора case SQL в реальном времени:
- Если завтра пойдет дождь, я запланирую поездку.
- Если билеты на самолет из моего города стоят менее 400 долларов, то я поеду в отпуск в Европу, в противном случае я предпочту какое-нибудь близлежащее туристическое место.

Здесь вы можете видеть, что одно действие, такое как «Дорожное путешествие» выше, условно зависит от результата другого действия: «будет ли завтра дождь или нет!»
Аналогично, MS SQL также предоставляет возможность условного выполнения оператора T-SQL.
В этом уроке вы узнаете:
- ЕСЛИ… Оператор Else
- IF…ELSE с переменной в логическом выражении.
- ЕСЛИ… ИНАЧЕ с началом конца
- Оператор IF без Else
- Вложенные операторы IF…Else
IF… Else оператор в SQL Server
В MS SQL IF…ELSE является типом Условного оператора .
Любой оператор T-SQL может быть выполнен условно, используя IF… ELSE .
Ниже на рисунке поясняется IF ELSE в SQL-сервере:
- Если условие оценивается как True, , то операторы T-SQL, за которыми следует условие IF в SQL-сервере, будут выполнены.
- Если условие оценивается как False, , то будут выполнены операторы T-SQL, за которыми следует ключевое слово ELSE .
- После выполнения оператора IF T-SQL или оператора ELSE T-SQL выполнение других безусловных операторов T-SQL продолжается.
IF… Else Синтаксис и правила в SQL
Синтаксис:
IF <условие>
{Заявление | Block_of_statement}
[ ЕЩЕ
{Заявление | Block_of_statement}] Правила:
- Условие должно быть Boolean Expression , т. е. условие приводит к логическому значению при оценке.
- Оператор IF ELSE в SQL может условно обрабатывать один оператор T-SQL или блок операторов T-SQL.
- Блок оператора должен начинаться с ключевого слова BEGIN и заканчиваться ключевым словом END.
- Использование BEGIN и END помогает SQL-серверу идентифицировать блок операторов, который необходимо выполнить, и отделить его от остальных операторов T-SQL, которые не являются частью блока IF…ELSE T-SQL.
- ELSE не является обязательным.

IF…ELSE с единственным числовым значением в логическом выражении.
Условие: ИСТИНА
ЕСЛИ (1=1) ПЕЧАТЬ 'ЕСЛИ УТВЕРЖДЕНИЕ: УСЛОВИЕ ИСТИННО' ЕЩЕ ПЕЧАТЬ 'ДРУГОЕ УТВЕРЖДЕНИЕ: УСЛОВИЕ ЛОЖЬ'
Условие: ЛОЖЬ
ЕСЛИ (1=2) ПЕЧАТЬ 'ЕСЛИ УТВЕРЖДЕНИЕ: УСЛОВИЕ ИСТИННО' ЕЩЕ PRINT 'ELSE STATEMENT: CONDITION IS FALSE'
Предположение: Предположим, что у вас есть таблица ‘Guru99’ с двумя столбцами и четырьмя строками, как показано ниже:
Guru99′
таблица в дальнейших примерахIF…ELSE с переменной в логическом выражении.
Условие: TRUE
DECLARE @Course_ID INT = 4 ЕСЛИ (@Course_ID = 4) Выберите * из Guru99, где Tutorial_ID = 4 ЕЩЕ Выберите * из Guru99, где Tutorial_ID != 4
Условие: FALSE
DECLARE @Course_ID INT = 4 ЕСЛИ (@Course_ID != 4) Выберите * из Guru99, где Tutorial_ID = 4 ЕЩЕ Выберите * из Guru99, где Tutorial_ID != 4
IF…ELSE с Begin End
Условие: TRUE
DECLARE @Course_ID INT = 2 ЕСЛИ (@Course_ID <=2) НАЧИНАТЬ Выберите * из Guru99, где Tutorial_ID = 1 Выберите * из Guru99, где Tutorial_ID = 2 КОНЕЦ ЕЩЕ НАЧИНАТЬ Выберите * из Guru99, где Tutorial_ID = 3 Выберите * из Guru99, где Tutorial_ID = 4 КОНЕЦ
Условие: ЛОЖЬ
DECLARE @Course_ID INT = 2 ЕСЛИ (@Course_ID >=3) НАЧИНАТЬ Выберите * из Guru99, где Tutorial_ID = 1 Выберите * из Guru99, где Tutorial_ID = 2 КОНЕЦ ЕЩЕ НАЧИНАТЬ Выберите * из Guru99, где Tutorial_ID = 3 Выберите * из Guru99, где Tutorial_ID = 4 КОНЕЦ
Оператор IF с No Else
Вы можете использовать оператор IF в SQL без части ELSE.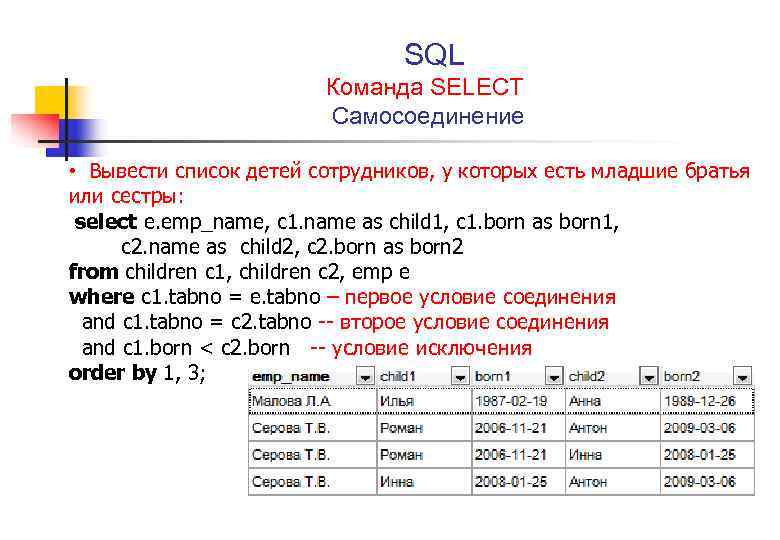 Помните, мы заявили, что часть ELSE не является обязательной. Например:
Помните, мы заявили, что часть ELSE не является обязательной. Например:
DECLARE @Course_ID INT = 2 ЕСЛИ (@Course_ID <=2) Выберите * из Guru99, где Tutorial_ID = 1
Он напечатает следующее:
Выполнение ложного условия не даст никаких результатов. Рассмотрим следующий запрос
DECLARE @Course_ID INT = 2 ЕСЛИ (@Course_ID <=0) Выберите * из Guru99 где Tutorial_ID = 1
Результат it
Вложенные операторы IF…Else
В отличие от других языков программирования, вы не можете добавить оператор ELSE IF в условие IF ELSE в SQL. Вот почему вы можете вкладывать IF ELSE в операторы запроса SQL. Это показано ниже:
DECLARE @age INT;
УСТАНОВИТЬ @возраст = 60;
ЕСЛИ @возраст < 18 лет
ПЕЧАТЬ 'несовершеннолетний';
ЕЩЕ
НАЧИНАТЬ
ЕСЛИ в возрасте < 50 лет
PRINT 'Вам меньше 50';
ЕЩЕ
ПЕЧАТЬ 'Старший';
КОНЕЦ; - В этом примере код будет печатать несовершеннолетний, если значение @age меньше 18.
- Если нет, будет выполнена часть ELSE. Часть ElSE имеет вложенный IF…ELSE.
- Если значение @age ниже 50, будет напечатано You are under 50. Если ни одно из этих условий не выполняется, код напечатает Senior.
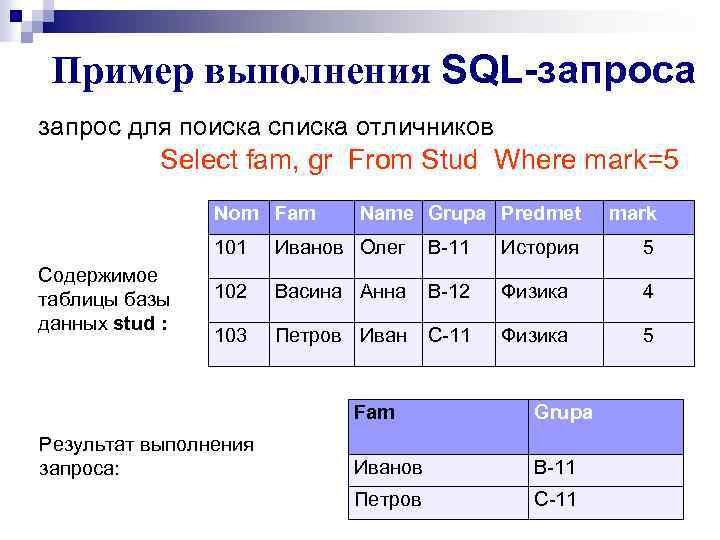
Резюме:
- Переменные — это объект, который действует как заполнитель.
- Блок оператора должен начинаться с ключевого слова BEGIN и заканчиваться ключевым словом END.
- Else не является обязательным для использования в операторе IF… ELSE
- Также возможно вложение условия SQL IF ELSE в другой оператор IF…ELSE.
Условие поиска (Transact-SQL) — SQL Server
- Статья
- 8 минут на чтение
Относится к: SQL Server (все поддерживаемые версии) База данных SQL Azure Управляемый экземпляр Azure SQL Аналитика синапсов Azure Analytics Platform System (PDW)
Комбинация одного или нескольких предикатов, использующих логические операторы И, ИЛИ и НЕ.
Соглашения о синтаксисе Transact-SQL
Синтаксис
-- Синтаксис для SQL Server и базы данных SQL Azure
<условие_поиска> ::=
ПОИСКПОЗ (<шаблон_поиска_графика>) | <условие_поиска_без_совпадения> | <условие_поиска> И <условие_поиска>
<условие_поиска_без_совпадения> ::=
{ [ НЕ ] <предикат> | ( <условие_поиска_без_совпадения> ) }
[ { И | ИЛИ } [ НЕ ] { <предикат> | ( <условие_поиска_без_совпадения> ) } ]
[...н]
<предикат> ::=
{ выражение { = | < > | ! = | > | > = | ! > | < | < = | ! < } выражение
| строковое_выражение [ НЕ ] НРАВИТСЯ строковое_выражение
[ ESCAPE 'escape_character' ]
| выражение [ НЕ ] МЕЖДУ выражением И выражением
| выражение IS [ НЕ ] NULL
| выражение IS [ NOT ] DISTINCT FROM
| СОДЕРЖИТ
( { столбец | * } , '<содержит_условие_поиска>' )
| FREETEXT ({столбец | *}, 'свободная_текстовая_строка')
| выражение [НЕ] В (подзапрос | выражение [...n])
| выражение { = | < > | ! = | > | > = | ! > | < | < = | ! < }
{ ВСЕ | НЕКОТОРЫЕ | ЛЮБОЙ} (подзапрос)
| СУЩЕСТВУЕТ (подзапрос) }
::=
{ {
{ <-( )- }
| {-()->}
}
}
::=
имя_таблицы_узла | node_table_alias
::=
край_таблица_имя | edge_table_alias
-- Синтаксис для Azure Synapse Analytics и хранилища параллельных данных
<условие_поиска> ::=
{ [ НЕ ] <предикат> | ( <условие_поиска> ) }
[ { И | ИЛИ } [ НЕ ] { <предикат> | ( <условие_поиска> ) } ]
[. ..н]
<предикат> ::=
{ выражение { = | < > | ! = | > | > = | < | < = } выражение
| строковое_выражение [ НЕ ] НРАВИТСЯ строковое_выражение
| выражение [ НЕ ] МЕЖДУ выражением И выражением
| выражение IS [ НЕ ] NULL
| выражение [ NOT ] IN (подзапрос | выражение [ ,...n ] )
| выражение [ НЕ ] СУЩЕСТВУЕТ (подзапрос)
}
 ..н]
<предикат> ::=
{ выражение { = | < > | ! = | > | > = | < | < = } выражение
| строковое_выражение [ НЕ ] НРАВИТСЯ строковое_выражение
| выражение [ НЕ ] МЕЖДУ выражением И выражением
| выражение IS [ НЕ ] NULL
| выражение [ NOT ] IN (подзапрос | выражение [ ,...n ] )
| выражение [ НЕ ] СУЩЕСТВУЕТ (подзапрос)
}
..н]
<предикат> ::=
{ выражение { = | < > | ! = | > | > = | < | < = } выражение
| строковое_выражение [ НЕ ] НРАВИТСЯ строковое_выражение
| выражение [ НЕ ] МЕЖДУ выражением И выражением
| выражение IS [ НЕ ] NULL
| выражение [ NOT ] IN (подзапрос | выражение [ ,...n ] )
| выражение [ НЕ ] СУЩЕСТВУЕТ (подзапрос)
}
Примечание
Чтобы просмотреть синтаксис Transact-SQL для SQL Server 2014 и более ранних версий, см. документацию по предыдущим версиям.
Аргументы
Задает условия для строк, возвращаемых в результирующем наборе для инструкции SELECT, выражения запроса или подзапроса. Для оператора UPDATE указывает строки, которые необходимо обновить. Для инструкции DELETE задает удаляемые строки. Количество предикатов, которые можно включить в условие поиска инструкции Transact-SQL, не ограничено.
Задает шаблон сопоставления графа. Дополнительные сведения об аргументах для этого предложения см. в разделе MATCH (Transact-SQL)
в разделе MATCH (Transact-SQL)
NOT
Отменяет логическое выражение, заданное предикатом. Дополнительные сведения см. в разделе НЕ (Transact-SQL).
И
Объединяет два условия и оценивается как ИСТИНА, когда оба условия ИСТИННЫ. Дополнительные сведения см. в разделе AND (Transact-SQL).
ИЛИ
Объединяет два условия и оценивается как ИСТИНА, если одно из условий истинно. Дополнительные сведения см. в разделе ИЛИ (Transact-SQL).
< предикат >
Выражение, возвращающее значение ИСТИНА, ЛОЖЬ или НЕИЗВЕСТНО.
выражение
Имя столбца, константа, функция, переменная, скалярный подзапрос или любая комбинация имен столбцов, констант и функций, связанных оператором или операторами, или подзапросом. Выражение также может содержать выражение CASE.
Примечание
Строковые константы и переменные, отличные от Unicode, используют кодовую страницу, соответствующую параметрам сортировки по умолчанию в базе данных. Преобразования кодовых страниц могут происходить при работе только с символьными данными, отличными от Unicode, и при обращении к символьным типам данных, отличным от Unicode char , varchar и text . SQL Server преобразовывает строковые константы и переменные, отличные от Unicode, в кодовую страницу, соответствующую порядку сортировки столбца, на который указывает ссылка, или указанную с помощью COLLATE, если эта кодовая страница отличается от кодовой страницы, соответствующей сортировке по умолчанию в базе данных. Любые символы, не найденные в новой кодовой странице, будут переведены в аналогичный символ, если будет найдено наиболее подходящее сопоставление, или же будут преобразованы в символ замены по умолчанию "?".
SQL Server преобразовывает строковые константы и переменные, отличные от Unicode, в кодовую страницу, соответствующую порядку сортировки столбца, на который указывает ссылка, или указанную с помощью COLLATE, если эта кодовая страница отличается от кодовой страницы, соответствующей сортировке по умолчанию в базе данных. Любые символы, не найденные в новой кодовой странице, будут переведены в аналогичный символ, если будет найдено наиболее подходящее сопоставление, или же будут преобразованы в символ замены по умолчанию "?".
При работе с несколькими кодовыми страницами символьные константы могут начинаться с прописной буквы «N» и могут использоваться переменные Unicode, чтобы избежать преобразования кодовых страниц.
=
Используется ли оператор для проверки равенства между двумя выражениями.
<>
Оператор, используемый для проверки условия двух выражений, не равных друг другу.
!=
Используется ли оператор для проверки того, что два выражения не равны друг другу.
>
Используется ли оператор для проверки условия того, что одно выражение больше другого.
>=
Оператор, используемый для проверки того, что одно выражение больше или равно другому выражению.
!>
Используется ли оператор для проверки условия того, что одно выражение не больше другого выражения.
<
Оператор, используемый для проверки того, что одно выражение меньше другого.
<=
Оператор, используемый для проверки условия того, что одно выражение меньше или равно другому выражению.
!<
Используется ли оператор для проверки условия того, что одно выражение не меньше другого выражения.
string_expression
Строка символов и подстановочных знаков.
[ NOT ] LIKE
Указывает, что последующая строка символов должна использоваться при сопоставлении с образцом. Дополнительные сведения см. в разделе LIKE (Transact-SQL).
ESCAPE ' escape_ символ '
Позволяет искать подстановочный знак в строке символов вместо использования подстановочного знака. escape_character — это символ, который ставится перед подстановочным знаком, чтобы указать на это специальное использование.
escape_character — это символ, который ставится перед подстановочным знаком, чтобы указать на это специальное использование.
[ НЕ ] МЕЖДУ
Указывает включающий диапазон значений. Используйте И, чтобы разделить начальное и конечное значения. Дополнительные сведения см. в разделе МЕЖДУ (Transact-SQL).
IS [ NOT ] NULL
Задает поиск нулевых значений или значений, которые не являются нулевыми, в зависимости от используемых ключевых слов. Выражение с побитовым или арифметическим оператором оценивается как NULL, если любой из операндов имеет значение NULL.
IS [НЕ ] ОТЛИЧАЕТСЯ ОТ
Сравнивает равенство двух выражений и гарантирует истинный или ложный результат, даже если один или оба операнда равны NULL. Дополнительные сведения см. в разделе IS [NOT] DISTINCT FROM (Transact-SQL).
СОДЕРЖИТ
Ищет в столбцах, содержащих символьные данные, точные или менее точные ( fuzzy ) совпадения отдельных слов и фраз, близость слов на определенном расстоянии друг от друга и взвешенные совпадения. Этот параметр можно использовать только с операторами SELECT. Дополнительные сведения см. в разделе CONTAINS (Transact-SQL).
FREETEXT
Обеспечивает простую форму запроса на естественном языке путем поиска в столбцах, содержащих символьные данные, значений, соответствующих смыслу, а не точных слов в предикате. Этот параметр можно использовать только с операторами SELECT. Дополнительные сведения см. в разделе FREETEXT (Transact-SQL).
[ НЕ ] IN
Задает поиск выражения на основе того, включено ли выражение в список или исключено из него. Выражение поиска может быть константой или именем столбца, а список может быть набором констант или, что более типично, подзапросом. Заключите список значений в круглые скобки. Дополнительные сведения см. в разделе IN (Transact-SQL).
подзапрос
Может рассматриваться как ограниченный оператор SELECT и аналогичен <выражению_запроса> в операторе SELECT. Предложение ORDER BY и ключевое слово INTO не допускаются. Дополнительные сведения см. в разделе SELECT (Transact-SQL).
ВСЕ
Используется с оператором сравнения и подзапросом. Возвращает TRUE для
{ НЕКОТОРЫЕ | ANY }
Используется с оператором сравнения и подзапросом. Возвращает TRUE для
EXISTS
Используется с подзапросом для проверки существования строк, возвращаемых подзапросом. Дополнительные сведения см. в разделе EXISTS (Transact-SQL).
Порядок приоритета логических операторов - НЕ (высший), за которым следует И, за которым следует ИЛИ. Скобки можно использовать для переопределения этого приоритета в условии поиска. Порядок оценки логических операторов может варьироваться в зависимости от выбора, сделанного оптимизатором запросов. Дополнительные сведения о том, как логические операторы работают с логическими значениями, см. в разделах AND (Transact-SQL), OR (Transact-SQL) и NOT (Transact-SQL).
Примеры
A. Использование WHERE с синтаксисом LIKE и ESCAPE
В следующем примере выполняется поиск строк, в которых столбец LargePhotoFileName содержит символы green_ , и используется параметр ESCAPE 373 a7 is73 a7 is73 _ 903 подстановочный знак. Без указания параметра символ. ESCAPE запрос будет искать любые значения описания, содержащие слово зеленый , за которым следует любой символ, кроме 9.0372 _
ИСПОЛЬЗОВАТЬ AdventureWorks2012 ; ИДТИ ВЫБРАТЬ * ОТ Production.ProductPhoto WHERE LargePhotoFileName LIKE '%greena_%' ESCAPE 'a' ;
B. Использование синтаксиса WHERE и LIKE с данными Unicode
В следующем примере используется предложение WHERE для получения почтового адреса любой компании, которая находится за пределами США ( US ) и находится в городе, название которого начинается с Па .
ИСПОЛЬЗОВАТЬ AdventureWorks2012 ;
ИДТИ
ВЫБЕРИТЕ AddressLine1, AddressLine2, город, почтовый индекс, CountryRegionCode
ОТ Person.Address КАК
ПРИСОЕДИНЯЙТЕСЬ к Person.StateProvince AS s ON a.StateProvinceID = s.StateProvinceID
ГДЕ CountryRegionCode НЕ В ('США')
И город НРАВИТСЯ N'Pa%' ;
Примеры: Azure Synapse Analytics and Analytics Platform System (PDW)
C. Использование WHERE с LIKE
В следующем примере выполняется поиск строк, в которых столбец LastName содержит символы и .
-- Использует AdventureWorks ВЫБЕРИТЕ Ключ Сотрудника, Фамилия ОТ DimEmployee ГДЕ Фамилия КАК '%и%';
D. Использование синтаксиса WHERE и LIKE с данными Unicode
В следующем примере используется WHERE для выполнения поиска Unicode в столбце LastName .
-- Использует AdventureWorks ВЫБЕРИТЕ Ключ Сотрудника, Фамилия ОТ DimEmployee ГДЕ Фамилия НРАВИТСЯ N'%and%';
См. также
- Агрегированные функции (Transact-SQL)
- СЛУЧАЙ (Transact-SQL)
- CONTAINSTABLE (Transact-SQL)
- Курсоры (Transact-SQL)
- УДАЛИТЬ (Transact-SQL)
- Выражения (Transact-SQL)
- FREETEXTTABLE (Transact-SQL)
- ОТ (Transact-SQL)
- Операторы (Transact-SQL)
- ОБНОВЛЕНИЕ (Transact-SQL)
SQL Условия И и ИЛИ | Решения для баз данных для Microsoft Access
SQL — несколько условий; используя условия И и ИЛИ:
В предыдущей статье Использование
WHERE с оператором SQL SELECT, мы продемонстрировали, как
вы бы использовали предложение SQL WHERE для условного выбора данных из
таблицу базы данных. Предложение WHERE может быть простым и использовать только
единственное условие (аналогично представленному в предыдущей статье),
или его можно использовать для включения нескольких условий поиска.
SQL позволяет нам комбинировать два или более простых условия с помощью Операторы И и ИЛИ или НЕ. Любое количество простых условий может быть представлены в одном операторе SQL, чтобы мы могли создавать сложные WHERE предложения, которые позволяют нам контролировать, какие строки включены в наш запрос полученные результаты.
Мы будем использовать следующий синтаксис для выполнения запроса SQL SELECT с несколько условий в предложении WHERE:
ВЫБЕРИТЕ список_столбцов
ОТ имя_таблицы
WHERE имя_столбца условие {[И|ИЛИ} имя_столбца условие} Порядок приоритета логических операторов НЕ (самый высокий),
затем И, затем ИЛИ. Порядок оценки при этом
уровень приоритета слева направо. Скобки можно использовать для
отменить этот порядок в условии поиска.
Если мы включаем в запрос несколько операторов, SQL Server оценивает их в следующем порядке:
- Скобки — если вы группируете условные операторы SQL вместе скобками, SQL Server сначала оценивает их содержимое.
- Арифметика - умножение (с использованием операторов *, / или %)
- Арифметика - сложение (с использованием операторов + или -)
- Другое — Конкатенатор строк (+)
- Логический - НЕ
- Логический - И
- Логический - ИЛИ
Теперь давайте посмотрим на пару примеров использования нескольких условий для предложение WHERE в операторе SQL SELECT. Мы будем использовать следующие Таблица данных сотрудников:
| EmpName | ИмпАдрес | Эмптаун | Почтовый индекс | Эмпаж |
|---|---|---|---|---|
| Элейн Джонс | 1 Старая дорога | Манчестер | М27 1СН | 28 |
| Дэвид Томас | 245 Конец Лейн | Линкольн | LN34 2-й | 41 |
| Саймон Ли | 9 Ласточка Лейн | Уиган | WN3 0NR | 58 |
| Лесли Уорд | 3 Норт Энд Роуд | Ноттингем | НГ8 2ЛДЖ | 30 |
| Гарри Уэбб | 1002 Тринити-роуд, ул. | Суиндон | СН2 1ДЖХ | 22 |
| Ронни Скотт | 1 Переулок | Ноттингем | НГ25 9ЛК | 55 |
| Джанет Фуллер | 14 Гаррет Хилл | Лондон | SW1 | 40 |
| Салли Тиммингс | Эджхэм Холлоу | Лондон | WE3 | 24 |
| Саймон Ли | 9 Ласточка Лейн | Уиган | WN3 0NR | 19 |
Использование условия SQL AND:
Использование оператора AND запрос отобразит строку, если ВСЕ перечисленные условия соответствуют действительности. Если мы хотим найти сотрудников, которые
живут в Лондоне И старше 30 лет, мы бы
используйте следующую инструкцию SQL:
SELECT * FROM tblEmployee WHERE EmpTown = 'London' AND EmpAge > 30
Этот оператор вернет только один результат из нашей таблицы, который соответствует оба указанных условий:
| EmpName | ИмпАдрес | Эмптаун | Почтовый индекс | Эмпаж |
|---|---|---|---|---|
| Джанет Фуллер | 14 Гаррет Хилл | Лондон | SW1 | 40 |
Используя условие SQL ИЛИ:
Используя оператор ИЛИ, запрос отобразит строку, если ЛЮБОЙ из перечисленных условий верны. Если мы хотим найти сотрудников которые живут в Лондоне ИЛИ Сотрудники, которые живут в Суиндоне, мы бы использовали следующую инструкцию SQL:
SELECT * FROM tblEmployee WHERE EmpTown = 'London' OR EmpTown = 'Swindon'
Этот оператор вернет три результата из нашей таблицы. Так и будет
вернуть тех сотрудников, которые живут в Лондоне ИЛИ в прямом эфире
в Суиндоне:
| EmpName | ИмпАдрес | Эмптаун | Почтовый индекс | Эмпаж |
|---|---|---|---|---|
| Гарри Уэбб | 1002 Тринити-роуд, ул. | Суиндон | СН2 1ДЖХ | 22 |
| Джанет Фуллер | 14 Гаррет Хилл | Лондон | SW1 | 40 |
| Салли Тиммингс | Эджхэм Холлоу | Лондон | WE3 | 24 |
Сочетание условий SQL И и ИЛИ:
Мы также можем комбинировать условия И и ИЛИ, чтобы создать еще больше
сложные операторы SQL (вам может понадобиться использовать круглые скобки для формирования сложных
выражения). Учтите, что мы хотим найти всех Сотрудников, которые живут
в Лондоне И старше 30 лет ИЛИ Сотрудники, проживающие в Суиндоне, независимо от их возраста. Синтаксис
для этого оператора SQL с несколькими условиями требуется следующее:
SELECT * FROM tblEmployee WHERE (EmpTown = 'London' AND EmpAge > 30) OR EmpTown = 'Swindon'
На этот раз мы видим, что оператор вернет две записи; в рекорд Джанет Фуллер (живет в Лондоне И чей возраст старше 30 лет), а также рекорд Гарри Веба, который живет в Суиндоне.
| EmpName | ИмпАдрес | Эмптаун | Почтовый индекс | Эмпаж |
|---|---|---|---|---|
| Гарри Уэбб | 1002 Тринити-роуд, ул. | Суиндон | СН2 1JH | 22 |
| Джанет Фуллер | 14 Гаррет Хилл | Лондон | SW1 | 40 |
SQL-сервер оценивает условия, которые используют логическое И перед этим
оценивает те, которые используют логическое ИЛИ. Если вы хотите быть уверены в
как SQL Server будет обрабатывать ваши запросы к базе данных, содержащие несколько
операторы, вы всегда должны использовать круглые скобки.
Условные операторы WHERE в SQL
Одной из ключевых особенностей баз данных SQL является поддержка специальных запросов: новые запросы могут выполняться в любое время. Это возможно только потому, что оптимизатор запросов (планировщик запросов) работает во время выполнения; он анализирует каждое полученное заявление и немедленно генерирует разумный план выполнения. Накладные расходы, связанные с оптимизацией времени выполнения, можно минимизировать с помощью параметров привязки.
Суть этого обзора заключается в том, что базы данных оптимизированы для динамического SQL, так что используйте его, если он вам нужен.
От своего имени
Я зарабатываю на жизнь обучением SQL, настройкой и консультированием SQL, а также своей книгой «Объяснение производительности SQL». Узнайте больше на https://winand.at/.
Тем не менее, существует широко распространенная практика отказа от динамического SQL в пользу статического SQL — часто из-за мифа о том, что «динамический SQL медленный». Эта практика приносит больше вреда, чем пользы, если база данных использует общий кэш плана выполнения, такой как DB2, база данных Oracle или SQL Server.
Для демонстрации представьте себе приложение, которое запрашивает СОТРУДНИКИ табл. Приложение позволяет искать идентификатор дочерней компании, идентификатор сотрудника и фамилию (без учета регистра) в любой комбинации. По-прежнему можно написать один запрос, охватывающий все случаи, используя «умную» логику.
ВЫБЕРИТЕ имя_имя, фамилию, идентификатор_дочерней компании, идентификатор_сотрудника ОТ сотрудников ГДЕ (sub_id = :sub_id ИЛИ :sub_id IS NULL) И ( employee_id = :emp_id ИЛИ :emp_id IS NULL ) И ( ПРОПИСНЫЕ(фамилия) = :имя ИЛИ :имя IS NULL )
В запросе используются именованные переменные связывания для удобства чтения. Все возможные выражения фильтра статически закодированы в операторе. Всякий раз, когда фильтр не нужен, вы просто используете NULL вместо условия поиска: это отключает условие с помощью логики ИЛИ .
Вполне разумная инструкция SQL. Использование NULL даже соответствует его определению согласно трехзначной логике SQL. Тем не менее, это один из 90 269 анти-шаблонов с наихудшей производительностью 9.0270 всего.
База данных не может оптимизировать план выполнения для определенного фильтра, поскольку любой из них может быть отменен во время выполнения. База данных должна быть подготовлена к худшему варианту — если все фильтры отключены:
-------------------------------- --------------------
| Идентификатор | Операция | Имя | Ряды | Стоимость |
-------------------------------------------------- --
| 0 | ВЫБЕРИТЕ ЗАЯВЛЕНИЕ | | 2 | 478 |
|* 1 | ДОСТУП К СТОЛУ ПОЛНЫЙ | СОТРУДНИКИ | 2 | 478 |
-------------------------------------------------- --
Информация о предикате (определяется идентификатором операции):
-------------------------------------------------- -
1 - фильтр((:ИМЯ НУЛЕВОЕ ИЛИ ЗАГЛАВНОЕ("LAST_NAME")=:ИМЯ)
И (:EMP_ID IS NULL ИЛИ "EMPLOYEE_ID"=:EMP_ID)
И (:SUB_ID IS NULL ИЛИ "SUBSIDIARY_ID"=:SUB_ID)) Как следствие, база данных использует полное сканирование таблицы даже при наличии индекса для каждого столбца .
Дело не в том, что база данных не может разрешить «умную» логику. Он создает общий план выполнения из-за использования параметров привязки, поэтому его можно кэшировать и повторно использовать с другими значениями позже. Если мы не используем параметры связывания, а записываем фактические значения в оператор SQL, оптимизатор выбирает правильный индекс для активного фильтра:
SELECT имя_имя, фамилия_имя, идентификатор_дочерней компании, идентификатор_сотрудника ОТ сотрудников ГДЕ (дочерний_id = NULL ИЛИ NULL IS NULL) И (employee_id = NULL OR NULL IS NULL) И( UPPER(last_name) = 'WINAND' OR 'WINAND' IS NULL )
------------------------------- --------------------------------
|Идентификатор | Операция | Имя | Ряды | Стоимость |
-------------------------------------------------- -------------
| 0 | ВЫБЕРИТЕ ЗАЯВЛЕНИЕ | | 1 | 2 |
| 1 | ДОСТУП К ТАБЛИЦАМ ПО ИНДЕКСУ ROWID| СОТРУДНИКИ | 1 | 2 |
|*2 | ИНДЕКС ДИАПАЗОН СКАН | EMP_UP_NAME | 1 | 1 |
-------------------------------------------------- -------------
Информация о предикате (определяется идентификатором операции):
-------------------------------------------------- -
2 - доступ(ПРОПИСНАЯ("LAST_NAME")='WINAND') Однако это не решение. Это просто доказывает, что база данных может разрешать эти условия.
Предупреждение
Использование литеральных значений делает ваше приложение уязвимым для атак путем внедрения кода SQL и может вызвать проблемы с производительностью из-за увеличения затрат на оптимизацию.
Очевидным решением для динамических запросов является динамический SQL. Согласно принципу KISS, просто сообщите базе данных, что вам нужно прямо сейчас, и ничего больше.
ВЫБЕРИТЕ имя_имя, фамилию, идентификатор_дочерней компании, идентификатор_сотрудника ОТ сотрудников ГДЕ ЗАГЛАВНАЯ (фамилия) = :имя
Обратите внимание, что в запросе используется параметр связывания.
Совет
Используйте динамический SQL, если вам нужны динамические предложения where .
По-прежнему используйте параметры связывания при создании динамического SQL, иначе миф о том, что динамический SQL работает медленно, сбывается.
Проблема, описанная в этом разделе, широко распространена. Во всех базах данных, использующих общий кэш плана выполнения, есть функция, позволяющая справиться с этим, что часто приводит к новым проблемам и ошибкам.
- DB2
DB2 использует общий кэш планов выполнения и полностью подвержена проблемам, описанным в этом разделе.
DB2 позволяет указать метод повторной оптимизации с помощью подсказки
REOPT. Значение по умолчанию —NONE, что создает общий план выполнения и страдает от проблемы, описанной выше.REOPT(ALWAYS)укажет оптимизатору всегда просматривать фактические переменные связывания для создания наилучшего плана для каждого выполнения. Это фактически отключает кэширование плана выполнения для этого оператора.Последним параметром является
REOPT(ONCE), который будет просматривать параметры привязки только для первого выполнения. Проблема с этим подходом заключается в его недетерминированном поведении: значения из первого выполнения влияют на все выполнения. План выполнения может меняться каждый раз при перезапуске базы данных или, что менее предсказуемо, срок действия кэшированного плана истекает, и оптимизатор воссоздает его с использованием других значений при следующем выполнении оператора.- MySQL
MySQL не страдает от этой конкретной проблемы, потому что у него вообще нет кэша планов выполнения. В запросе функции от 2009 года обсуждается влияние кэширования плана выполнения. Кажется, что оптимизатор MySQL достаточно прост, чтобы кэширование плана выполнения не окупалось.
- Oracle
База данных Oracle использует общий кэш планов выполнения («область SQL») и полностью подвержена проблемам, описанным в этом разделе.
В выпуске 9 i Oracle представила так называемый просмотр привязки. Просмотр привязки позволяет оптимизатору использовать фактические значения привязки первого выполнения при подготовке плана выполнения. Проблема с этим подходом заключается в его недетерминированном поведении: значения из первого выполнения влияют на все выполнения.
План выполнения может меняться каждый раз при перезапуске базы данных или, что менее предсказуемо, срок действия кэшированного плана истекает, и оптимизатор воссоздает его с использованием других значений при следующем выполнении оператора.Выпуск 11 g В введено адаптивное совместное использование курсора для дальнейшего улучшения ситуации. Эта функция позволяет базе данных кэшировать несколько планов выполнения для одного и того же оператора SQL. Далее оптимизатор просматривает параметры привязки и сохраняет их расчетную селективность вместе с планом выполнения. При последующем доступе к кэшу селективность текущих значений привязки должна находиться в пределах диапазонов селективности кэшированного плана выполнения для повторного использования. В противном случае оптимизатор создает новый план выполнения и сравнивает его с уже кэшированными планами выполнения для этого запроса. Если такой план выполнения уже существует, база данных заменяет его новым планом выполнения, который также охватывает оценки селективности текущих значений связывания.
Если нет, он кэширует новый вариант плана выполнения для этого запроса — вместе с оценками селективности, конечно.- PostgreSQL
Кэш планов запросов PostgreSQL работает только для открытых операторов — до тех пор, пока вы держите
PreparedStatementоткрытым. Описанная выше проблема возникает только при повторном использовании дескриптора инструкции. Обратите внимание, что драйвер JDBC PostgresSQL включает кеширование только после пятого выполнения. См. также: Планирование с фактическими значениями привязки.- SQL Server
SQL Server использует так называемый анализ параметров . Отслеживание параметров позволяет оптимизатору использовать фактические значения привязки первого выполнения во время синтаксического анализа. Проблема с этим подходом заключается в его недетерминированном поведении: значения из первого выполнения влияют на все выполнения. План выполнения может меняться каждый раз при перезапуске базы данных или, что менее предсказуемо, срок действия кэшированного плана истекает, и оптимизатор воссоздает его с использованием других значений при следующем выполнении оператора.
В SQL Server 2005 добавлены новые подсказки для запросов, позволяющие лучше контролировать анализ и перекомпиляцию параметров. Подсказка запроса
RECOMPILEобходит кэш плана для выбранного оператора.ОПТИМИЗАЦИЯ ДЛЯпозволяет указать фактические значения параметров, которые используются только для оптимизации. Наконец, вы можете предоставить полный план выполнения с подсказкойUSE PLAN.Первоначальная реализация подсказки
OPTION(RECOMPILE)содержала ошибку, поэтому не учитывались все переменные связывания. В новой реализации, представленной в SQL Server 2008, была еще одна ошибка, которая делала ситуацию очень запутанной. Erland Sommarskog собрал всю необходимую информацию по всем выпускам SQL Server.
Хотя эвристические методы могут в определенной степени решить проблему «умной логики», на самом деле они были созданы для решения проблем связывания параметров в связи со столбцовыми гистограммами и выражениями LIKE .
Самый надежный способ получить наилучший план выполнения — избежать ненужных фильтров в операторе SQL.
СЛУЧАЙ SQL | Промежуточный SQL
Начиная здесь? Этот урок является частью полного учебника по использованию SQL для анализа данных. Проверьте начало.
В этом уроке мы рассмотрим:
- Оператор SQL CASE
- Добавление нескольких условий в оператор CASE
- Краткий обзор основ CASE
- Использование CASE с агрегатными функциями
- Использование CASE внутри агрегатных функций
- Практические задачи
В течение следующих нескольких уроков вы будете работать с данными о футболистах колледжей. Эти данные были собраны с ESPN 15 января 2014 г. из списков, перечисленных на этой странице, с помощью парсера Python, доступного здесь. В этом конкретном уроке вы будете придерживаться информации о ростере. Эта таблица говорит сама за себя — одна строка на игрока со столбцами, описывающими атрибуты этого игрока. Запустите этот запрос, чтобы проверить необработанные данные:
ВЫБЕРИТЕ * ИЗ benn.college_football_players
Оператор CASE — это способ SQL для обработки логики if/then. За оператором CASE следует как минимум одна пара операторов WHEN и THEN — эквивалент SQL оператора IF/THEN в Excel. Из-за этой пары у вас может возникнуть соблазн назвать это SQL CASE WHEN , но CASE является принятым термином.
Каждый оператор CASE должен заканчиваться цифрой 9.0372 КОНЕЦ заявление. Оператор ELSE является необязательным и предоставляет способ захвата значений, не указанных в операторах WHEN / THEN . CASE проще всего понять в контексте примера:
SELECT player_name,
год,
СЛУЧАЙ, КОГДА год = 'SR' THEN 'да'
ELSE NULL END AS is_a_senior
ОТ benn.college_football_players
Проще говоря, вот что происходит:
-
Оператор CASEпроверяет каждую строку на предмет истинности условного оператора —year = 'SR'. - Для любой заданной строки, если это условное утверждение истинно, слово «да» печатается в столбце, который мы назвали
is_a_senior. - В любой строке, для которой условное выражение ложно, ничего не происходит в этой строке, оставляя нулевое значение в столбце
is_a_senior. - В то же время, когда все это происходит, SQL извлекает и отображает все значения в
player_nameигодстолбца.
Приведенный выше запрос довольно легко увидеть, что происходит, потому что мы включили оператор CASE вместе с самим столбцом year . Вы можете проверить каждую строку, чтобы увидеть, соответствует ли год условию год = «SR» , а затем просмотреть результат в столбце, сгенерированном с помощью инструкции CASE .
Но что, если вам не нужны нулевые значения в is_a_senior колонка? Следующий запрос заменяет эти нули на «нет»:
SELECT player_name,
год,
СЛУЧАЙ, КОГДА год = 'SR' THEN 'да'
ELSE 'no' END AS is_a_senior
ОТ benn. college_football_players
Практическая задача
Напишите запрос, включающий столбец с пометкой «да», если игрок из Калифорнии, и сначала отсортируйте результаты с этими игроками.
ПопробуйтеСмотреть ответ
Вы также можете определить количество результатов в CASE , включив любое количество операторов WHEN / THEN :
SELECT player_name,
масса,
СЛУЧАЙ, КОГДА вес > 250, ТОГДА «более 250»
КОГДА вес > 200, ТОГДА "201-250"
КОГДА вес > 175, ТОГДА '176-200'
ELSE '175 или меньше' END AS Weight_group
ОТ benn.college_football_players
В приведенном выше примере операторы WHEN / THEN будут оцениваться в том порядке, в котором они написаны. Итак, если значение в вес столбца данной строки равен 300, это даст результат «более 250». Вот что произойдет, если значение в столбце weight равно 180, SQL сделает следующее:
- Проверьте, больше ли
weight250. 180 не больше 250, поэтому переходите к следующему КОГДА/ТОГДА - Проверьте, не превышает ли
вес200. 180 не больше 200, поэтому переходите к следующемуКОГДА/ЗАТЕМ - Проверьте, не больше ли
weight175. 180 больше 175, поэтому запишите «175-200» в столбцеweight_group.
Хотя приведенное выше работает, на самом деле лучше всего создавать операторы, которые не перекрываются. КОГДА вес > 250 и КОГДА вес > 200 перекрываются для каждого значения больше 250, что немного сбивает с толку. Лучше написать это так:
SELECT player_name,
масса,
СЛУЧАЙ, КОГДА вес > 250, ТОГДА «более 250»
КОГДА вес > 200 И вес <= 250, ТО '201-250'
КОГДА вес > 175 И вес <= 200, ТОГДА '176-200'
ELSE '175 или меньше' END AS Weight_group
ОТ benn.college_football_players
Практическая задача
Напишите запрос, включающий имена игроков и столбец, который классифицирует их по четырем категориям в зависимости от роста. Имейте в виду, что ответ, который мы даем, является лишь одним из многих возможных ответов, поскольку вы можете разделить рост игроков по-разному.
ПопробуйтеСмотреть ответ
Вы также можете объединить несколько условных операторов с И и ИЛИ так же, как в ГДЕ 9Предложение 0373:
ВЫБЕРИТЕ player_name,
СЛУЧАЙ, КОГДА год = 'FR' И позиция = 'WR', ТО 'frosh_wr'
ELSE NULL END AS sample_case_statement
ОТ benn.college_football_players
Краткий обзор основ CASE:
- Оператор
CASEвсегда находится в предложенииSELECT. -
ДЕЛОдолжно включать следующие компоненты:КОГДА,ТОГДАиКОНЕЦ.ELSEявляется дополнительным компонентом. - Вы можете сделать любой условный оператор, используя любой условный оператор (например,
WHERE) междуWHENиTHEN. Это включает в себя объединение нескольких условных операторов с использованием ИиИЛИ. - Вы можете включить несколько операторов
WHEN, а также операторELSEдля работы с любыми неадресованными условиями.
Практическая задача
Напишите запрос, который выбирает все столбцы из benn.college_football_players и добавляет дополнительный столбец, в котором отображается имя игрока, если этот игрок является младшим или старшим.
Попробуйте См. ответ
Использование CASE с агрегатными функциями
Несколько более сложная и существенно более полезная функциональность CASE достигается за счет объединения его с агрегатными функциями. Например, предположим, что вы хотите подсчитывать только те строки, которые соответствуют определенному условию. Поскольку COUNT игнорирует нули, вы можете использовать Оператор CASE для оценки условия и получения нулевых или ненулевых значений в зависимости от результата:
SELECT CASE WHEN year = 'FR' THEN 'FR'
ELSE 'Not FR' END AS year_group,
COUNT(1) КАК считать
ОТ benn. college_football_players
СГРУППИРОВАТЬ ПО РЕГИСТРУ, КОГДА год = 'FR', ТОГДА 'FR'
ELSE 'Не FR' END
Теперь вы можете подумать: "Почему бы мне просто не использовать предложение WHERE для фильтрации строк, которые я не хочу учитывать?" Вы могли бы сделать это — это выглядело бы так:
ВЫБРАТЬ СЧЕТЧИК(1) КАК fr_count ОТ benn.college_football_players ГДЕ год = 'FR'
Но что, если вы также хотите посчитать пару других условий? Использование предложения WHERE позволяет учитывать только одно условие. Вот пример подсчета нескольких условий в одном запросе:
SELECT CASE WHEN year = 'FR' THEN 'FR'
КОГДА год = «ТАК», ТОГДА «ТАК»
КОГДА год = 'JR', ТОГДА 'JR'
КОГДА год = 'SR', ТОГДА 'SR'
ELSE 'Нет данных за год' END AS year_group,
COUNT(1) КАК считать
ОТ benn.college_football_players
СГРУППИРОВАТЬ ПО 1
Приведенный выше запрос — отличное место для использования чисел вместо столбцов в предложении GROUP BY , потому что повторение оператора CASE в предложении GROUP BY сделало бы запрос неприемлемо длинным. В качестве альтернативы вы можете использовать псевдоним столбца в предложении GROUP BY следующим образом:
SELECT CASE WHEN year = 'FR' THEN 'FR'
КОГДА год = «ТАК», ТОГДА «ТАК»
КОГДА год = 'JR', ТОГДА 'JR'
КОГДА год = 'SR', ТОГДА 'SR'
ELSE 'Нет данных за год' END AS year_group,
COUNT(1) КАК считать
ОТ benn.college_football_players
ГРУППА ПО year_group
Обратите внимание: если вы решите повторить весь оператор CASE , вам следует удалить имя столбца AS year_group при копировании/вставке в предложение GROUP BY :
SELECT CASE WHEN year = 'FR' ТОГДА 'ФР'
КОГДА год = «ТАК», ТОГДА «ТАК»
КОГДА год = 'JR', ТОГДА 'JR'
КОГДА год = 'SR', ТОГДА 'SR'
ELSE 'Нет данных за год' END AS year_group,
COUNT(1) КАК считать
ОТ benn.college_football_players
СГРУППИРОВАТЬ ПО РЕГИСТРУ, КОГДА год = 'FR', ТОГДА 'FR'
КОГДА год = «ТАК», ТОГДА «ТАК»
КОГДА год = 'JR', ТОГДА 'JR'
КОГДА год = 'SR', ТОГДА 'SR'
ELSE 'Нет данных за год' END
Объединение операторов CASE с агрегациями поначалу может показаться сложным. Часто полезно сначала написать запрос, содержащий оператор CASE , а затем выполнить его самостоятельно. Используя предыдущий пример, вы можете сначала написать:
SELECT CASE WHEN year = 'FR' THEN 'FR'
КОГДА год = «ТАК», ТОГДА «ТАК»
КОГДА год = 'JR', ТОГДА 'JR'
КОГДА год = 'SR', ТОГДА 'SR'
ELSE 'Нет данных за год' END AS year_group,
*
ОТ benn.college_football_players
Приведенный выше запрос покажет все столбцы таблицы benn.college_football_players , а также столбец, показывающий результаты оператора CASE . Оттуда вы можете заменить * агрегацией и добавить предложение GROUP BY . Попробуйте этот процесс, если вы боретесь с любой из следующих практических проблем.
Практическая задача
Напишите запрос, который подсчитывает количество игроков весом более 300 фунтов для каждого из следующих регионов: Западное побережье (Калифорния, Орегон, Вашингтон), Техас и другие (все остальные).
ПопробуйтеСмотреть ответ
Практическая задача
Напишите запрос, вычисляющий общий вес всех игроков низшего класса (FR/SO) в Калифорнии, а также общий вес всех игроков высшего класса (JR/SR) в Калифорнии.
Попробуйте См. ответ
Использование CASE в агрегатных функциях
В предыдущих примерах данные отображались вертикально, но в некоторых случаях вам может понадобиться отобразить данные горизонтально. Это известно как «сводка» (как сводная таблица в Excel). Возьмем следующий запрос:
ВЫБЕРИТЕ РЕГИСТР, КОГДА год = 'FR', ТОГДА 'FR'
КОГДА год = «ТАК», ТОГДА «ТАК»
КОГДА год = 'JR', ТОГДА 'JR'
КОГДА год = 'SR', ТОГДА 'SR'
ELSE 'Нет данных за год' END AS year_group,
COUNT(1) КАК считать
ОТ benn.college_football_players
СГРУППИРОВАТЬ ПО 1
И переориентировать его по горизонтали:
SELECT COUNT(CASE WHEN year = 'FR' THEN 1 ELSE NULL END) AS fr_count,
COUNT(CASE WHEN year = 'SO' THEN 1 ELSE NULL END) AS so_count,
COUNT(CASE WHEN year = 'JR' THEN 1 ELSE NULL END) КАК jr_count,
COUNT (СЛУЧАЙ, КОГДА год = 'SR' THEN 1 ELSE NULL END) КАК sr_count
ОТ benn. college_football_players
Стоит отметить, что переход от горизонтальной ориентации к вертикальной может быть значительно более сложной задачей в зависимости от обстоятельств, и более подробно эта проблема рассматривается в следующем уроке.
Оттачивайте свои навыки SQL
Практические задачи
Напишите запрос, отображающий количество игроков в каждом штате, с игроками FR, SO, JR и SR в отдельных столбцах и в другом столбце для общего количества игроков. Расположите результаты так, чтобы штаты с наибольшим количеством игроков были первыми.
ПопробуйтеСмотреть ответ
Практическая задача
Напишите запрос, показывающий количество игроков в школах с именами, начинающимися с букв от A до M, и количество игроков в школах с именами, начинающимися с N-Z.
Попробуйте См. ответ
SQL Server WHERE
Резюме : в этом руководстве вы узнаете, как использовать предложение SQL Server WHERE для фильтрации строк, возвращаемых запросом.
Введение в SQL Server
WHERE , предложение Когда вы используете оператор SELECT для запроса данных по таблице, вы получаете все строки этой таблицы, в чем нет необходимости, поскольку приложение может обрабатывать только набор строк за один раз.
Чтобы получить строки из таблицы, удовлетворяющие одному или нескольким условиям, используйте предложение WHERE следующим образом:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT select_list ИЗ имя_таблицы КУДА условие_поиска;
В предложении WHERE вы указываете условие поиска для фильтрации строк, возвращаемых предложением FROM . Предложение WHERE возвращает только те строки, в которых условие поиска оценивается как TRUE .
Условием поиска является логическое выражение или комбинация нескольких логических выражений. В SQL логическое выражение часто называют предикатом .
Обратите внимание, что SQL Server использует логику трехзначных предикатов, где логическое выражение может принимать значение ИСТИНА , ЛОЖЬ или НЕИЗВЕСТНО . Предложение WHERE не вернет строку, в результате которой предикат оценивается как FALSE или UNKNOWN .
SQL Server
WHERE examples Для демонстрации мы будем использовать таблицу production.products из примера базы данных.
A) Поиск строк с помощью простого равенства
Следующий оператор извлекает все продукты с идентификатором категории 1:
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБОР Код товара, наименование товара, id_категории, год выпуска, список цен ИЗ производство.
B) Поиск строк, соответствующих двум условиям
В следующем примере возвращаются продукты, соответствующие двум условиям: идентификатор категории равен 1, а модель — 2018. Он использует логический оператор И для объединения двух условий.
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБОР Код товара, наименование товара, id_категории, год выпуска, список цен ИЗ производство.продукция КУДА category_id = 1 И model_year = 2018 СОРТИРОВАТЬ ПО list_price DESC;
C) Поиск строк с помощью оператора сравнения
Следующее выражение находит продукты, прейскурантная цена которых превышает 300, а модель — 2018.
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБЕРИТЕ Код товара, наименование товара, id_категории, год выпуска, список цен ИЗ производство.продукция КУДА list_price > 300 И model_year = 2018 СОРТИРОВАТЬ ПО list_price DESC;
D) Поиск строк, удовлетворяющих любому из двух условий
Следующий запрос находит продукты, прейскурантная цена которых превышает 3000 или модель которых — 2018. Любой продукт которые удовлетворяют одному из этих условий, включаются в набор результатов.
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБОР Код товара, наименование товара, id_категории, год выпуска, список цен ИЗ производство.
Обратите внимание, что оператор OR объединяет предикаты.
E) Поиск строк со значением между двумя значениями
Следующий оператор находит продукты, прейскурантные цены которых находятся между 1,899 и 1999,99:
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБОР Код товара, наименование товара, id_категории, год выпуска, список цен ИЗ производство.продукция КУДА list_price МЕЖДУ 1899.00 И 1999.99 СОРТИРОВАТЬ ПО list_price DESC;
F) Поиск строк со значением в списке значений 29 лет9,99 или 466,99 или 489,99.