Истовый инженер — Как создают и развивают облачные платформы в России
Посмотреть наКак развиваются облачные платформы в России и сильно ли мы отстаем от западных коллег? И какие технические трудности и вызовы пришлось преодолеть команде Yandex для создания публичного облака?
Меня зовут Николай Бутенко. Я руковожу группой архитекторов по взаимодействию с госсектором в Yandex Cloud, которая занимается созданием облачных платформ под задачи государства.
В этой статье я расскажу, как развивается мировой и российский рынок облачных технологий, какие существуют способы создать публичное облако и почему первый запуск платформы Yandex Cloud на OpenStack оказался неудачным. Вы узнаете, как прошла «девопсовизация» в Yandex, почему компания не стала использовать готовые решения, зачем создавали Yandex DataBase и как строили программно ориентированные сети и хранилища. А в заключение поговорим о том, что такое cloud-native- и multi-cloud-подход, и как можно получить действительно отказоустойчивые и масштабируемые сервисы, объединяя их. Подробнее об этих и других темах в моей лекции, которая размещена чуть ниже.
Вы узнаете, как прошла «девопсовизация» в Yandex, почему компания не стала использовать готовые решения, зачем создавали Yandex DataBase и как строили программно ориентированные сети и хранилища. А в заключение поговорим о том, что такое cloud-native- и multi-cloud-подход, и как можно получить действительно отказоустойчивые и масштабируемые сервисы, объединяя их. Подробнее об этих и других темах в моей лекции, которая размещена чуть ниже.
В ближайшие годы на мировом рынке публичных облачных сервисов и инфраструктур ожидается значительный рост. По прогнозам к 2025 году он вырастет более чем вдвое, до $ 832,1 млрд. Совокупный среднегодовой темп роста (CAGR) в этот период ожидается в размере 17,5 %. Для сравнения: этот же показатель для всего мирового IT-рынка оценивается в 8,02 %. Давайте разберемся, с чего началось развитие облачных технологий и как они работают.
Началом развития облачных технологий можно считать 2006 год, когда компания Amazon Web Services (AWS) создала Elastic Compute Cloud (Amazon EC2) и объектное хранилище данных Simple Storage Service (S3), которые стали прообразом облачной модели предоставления ресурсов. То есть пользователям больше не надо было покупать собственное оборудование или арендовать какие-то «железные» ресурсы и обращаться в хостинг. Они могли зайти в веб-интерфейс, нажать пару кнопок и без звонков провайдеру, предварительных согласований и заключения контрактов получить необходимые им ресурсы.
То есть пользователям больше не надо было покупать собственное оборудование или арендовать какие-то «железные» ресурсы и обращаться в хостинг. Они могли зайти в веб-интерфейс, нажать пару кнопок и без звонков провайдеру, предварительных согласований и заключения контрактов получить необходимые им ресурсы.
Технология имела большой успех и стала набирать обороты. Вскоре ее начали развивать Google и Microsoft. На рынке облачных технологий сформировалась большая тройка игроков. Сейчас, правда, это уже четверка — стремительно растет китайская компания Alibaba.
В России пионером в области Public Cloud можно назвать компанию «Ростелеком», которая в 2011 году пыталась запустить национальную облачную платформу. Первый блин вышел комом. Однако с тех пор крупные интернет-компании — «Яндекс», Mail.ru, «Сбербанк» — начали смотреть в эту сторону. При этом если на Западе этот процесс стартовал в 2006 году, то у нас первые серьезные попытки освоить облако были предприняты в 2011 году, а бурное развитие началось в 2014–2015 годах.
Сегодня в нашей стране существует несколько отечественных гиперскейлеров. Самые крупные — это «Ростелеком», «Яндекс», Mail.ru и «Сбербанк». Думаю, их можно назвать большой русской четверкой. Они предоставляют не только виртуальные машины, но также платформенные и софтверные сервисы: готовые пайплайны, витрины с приложениями, платформы для разработки, маркетплейсы. Также есть несколько компаний которые предоставляют меньший набор сервисов по облачным моделям (в основном IaaS), такие как Selectel, DataLine, «КРОК», Softline и прочие.
Говоря о российском рынке облачных технологий, нельзя не отметить такой фактор, как российское законодательство, которое обязывает операторов хранить данные на территории страны. С одной стороны, это плюс, так как у крупных мировых компаний нет своих ЦОД на территории России, и поэтому их присутствие на нашем рынке ограничено. Благодаря этому российские провайдеры чувствуют себя вольготно. Но с другой стороны, из-за отсутствия большой мировой четверки мы находимся в немного расслабленном режиме: можем позволить себе делать что-то не так активно, как если бы делали это в конкуренции с мировыми лидерами.
По моему мнению, Россия до сих пор очень сильно отстает: в сфере облачных технологий — лет на пять-шесть, а в IT в целом — на два-четыре года. Но всё не так плохо и на данный момент 90 % востребованных сервисов российские облачные провайдеры закрывают. Оставшиеся 10 % — это узкопроприетарные технологии.
Есть несколько методов запуска публичного облака:
- Можно взять готовый продукт, например VMWare, и запустить публичное облако на нем.
- Можно взять open-source-продукт типа OpenStack, доработать его и запуститься на нем.
- Можно купить готовый программный аппаратный комплекс, как это сделал «Сбербанк», который приобрел серверное оборудование и софт Huawei.
- Можно не выбирать ни один из этих трех вариантов, а сделать всё свое.
У «Яндекса» давно было приватное облако, где мы крутили контейнеры, виртуальные машины и на базе которого работал «Яндекс.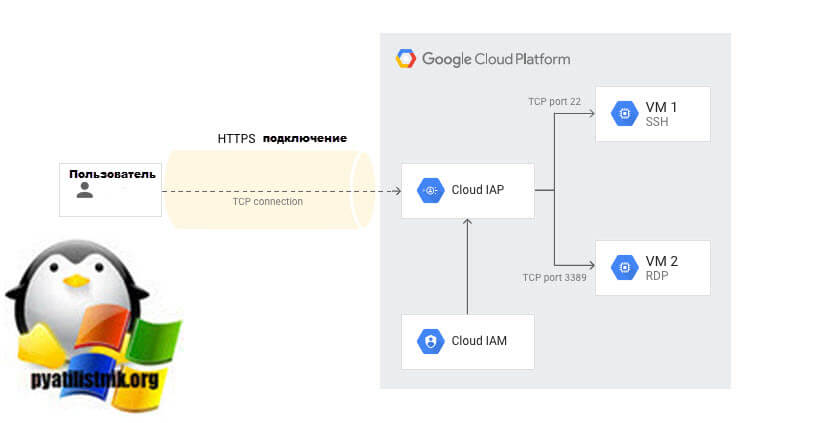 Поиск». Оно создавалось много лет назад, в том числе частично на OpenStack, и успешно использовалось.
Поиск». Оно создавалось много лет назад, в том числе частично на OpenStack, и успешно использовалось.
В 2015–2016 годах мы попытались из этого приватного облака сделать публичное, также на OpenStack. Но потерпели неудачу. Вот три основные причины, почему так произошло:
- OpenStack разработан для частных облаков, а не публичных.
- У нас возникли проблемы со скейлингом платформы построенной на OpenStack.
- Эксплуатация и модификация OpenStack сложны, что могло в дальнейшем замедлить наше развитие.
В итоге мы взяли время, ушли в тень и создали свое решение. В качестве гипервизора мы использовали KVM, а остальную часть написали сами, используя наработки «Яндекса» в области гиперскейлинга и зарекомендовавшие себя open-source-решения.
Сегодня Yandex Cloud работает на базе трех дата-центров, расположенных в Московской, Рязанской и Владимирской областях. Каждый из них оснащен независимой системой энергоснабжения, и взаимодействуют они между собой собственными каналами оптической линии связи.
Стойки и серверы, которые используются в дата-центрах, разработаны в «Яндексе» и производятся на Тайване, но скоро, кстати, их будут делать в России. На ПМЭФ мы заключили соглашение с компаниями Gigabyte и «Ланит» для запуска предприятия по производству серверов в нашей стране. Мы будем брать готовые комплектующие — процессор, сетевую карту, оперативную память, — а всё остальное делать сами. Плата уже разработана и будет печататься в России.
Мы гиперскейлер, потому что у нас есть поиск, очень масштабный и занимающий десятки тысяч серверов, и, в принципе, многие технологии по масштабированию были унаследованы от него. Перечислю основные.
Во-первых, мы используем гиперконвергентную инфраструктуру, подробнее о которой я рассказываю в своей лекции в материалах выше.
Во-вторых, у нас применяется так называемый capacity planning: мы всегда прогнозируем сколько предстоит выдержать нагрузки, и держим огромный запас. Например, наша сеть (SDN) утилизирована примерно на 7 %.
И в-третьих, у нас три зоны доступности. При правильном размещении даже падение целого ЦОД никак не сказывается на сервисе клиента: мы можем, например, обеспечить запуск его новых ресурсов на резервных ЦОД. Более подробно об этом процессе, так как он включает в себя целый ряд методик — affinity, placement group, AZ, — говорим на лекции, которая размещена выше.
Cloud-архитекторы — это очень редкие люди, особенно в России. Готовых специалистов почти нет. У «Яндекса» одна из самых больших команд в стране, порядка 20 специалистов. Мы растим их из разработчиков, devops, архитекторов инфраструктуры и системных администраторов senior-уровня. Архитекторы не занимаются разработкой и эксплуатацией, а работают с проектированием, адаптацией и кастомизацией возможностей нашей платформы под требования клиента.
Что касается разработчиков, то их в нашей компании коснулась «девопсовизация». Это западная практика, которая пришла к нам из таких компаний, как Google. Идея заключается в том, что, если ты пишешь код, ты должен нести за него ответственность и эксплуатировать его. То есть отвечать за работу кода должен не системный администратор, а разработчик.
В «Яндексе» все знали про devops, но он не нравился абсолютно никому. Разработчики считали, что эксплуатация кода — не их дело, а системные администраторы, по сути, должны были выбирать: переквалифицироваться в разработчиков либо уходить. Такой расклад не подходил никому.
Тем не менее с приходом Михаила Парахина, нового технического директора из Microsoft, огнем и мечом «девопсовизацию» в компании провели за несколько лет. Не без потерь, но в долгосрочной перспективе это было правильное решение — качество кода повысилось. За счет этого лучше работают наши сервисы и происходит меньше аварий.
Devops сейчас проповедуют многие компании, но лишь единицы через него прошли. В своей лекции [выше] мы дискутируем о том, насколько это «больно», зачем нужно и можно ли жить в старых парадигмах. Подробный доклад о том, как в «девопсовизацию» проводили в нашей компании можно посмотреть здесь.
В своей лекции [выше] мы дискутируем о том, насколько это «больно», зачем нужно и можно ли жить в старых парадигмах. Подробный доклад о том, как в «девопсовизацию» проводили в нашей компании можно посмотреть здесь.
Сегодня, наверное, все крупные компании в той или иной степени используют облачные технологии. Это тенденция будет расти, и всё движется к тому, что абсолютно всё будет находиться в облаках, за исключением проприетарных приложений, которые хостятся на специфическом оборудовании. Как я говорил в самом начале, рынок облачных технологий растет от года к году быстрее, чем весь IT.
Отмечу здесь также, что сейчас существует некое заблуждение, что облако — это манна небесная. Такое мнение распространено и среди наших клиентов, и в индустрии IT в целом. Но это не так. Чтобы получить реальную выгоду от использования облачного провайдера, нужно уметь его использовать. В работе многих сервисов часто происходят сбои, просто потому что люди не умеют использовать облака. Это очень важный вопрос. 5 августа я расскажу о том, как правильно использовать облачные провайдеры, чтобы от них был прок.
5 августа я расскажу о том, как правильно использовать облачные провайдеры, чтобы от них был прок.
- Краткий обзор Yandex Cloud от его бывшего главы Яна Лещинского
- Доклад об имплементации DevOps в «Яндексе» и «Яндекс.Облаке»
- Мою статью на «Хабре» о том, как построить cloud-native-приложение
- Курс «Инженер облачных сервисов» на «Яндекс.Практикуме»
- Канал Yandex Cloud
- Видео об отказоустойчивости дата-центров «Яндекс.Облака».
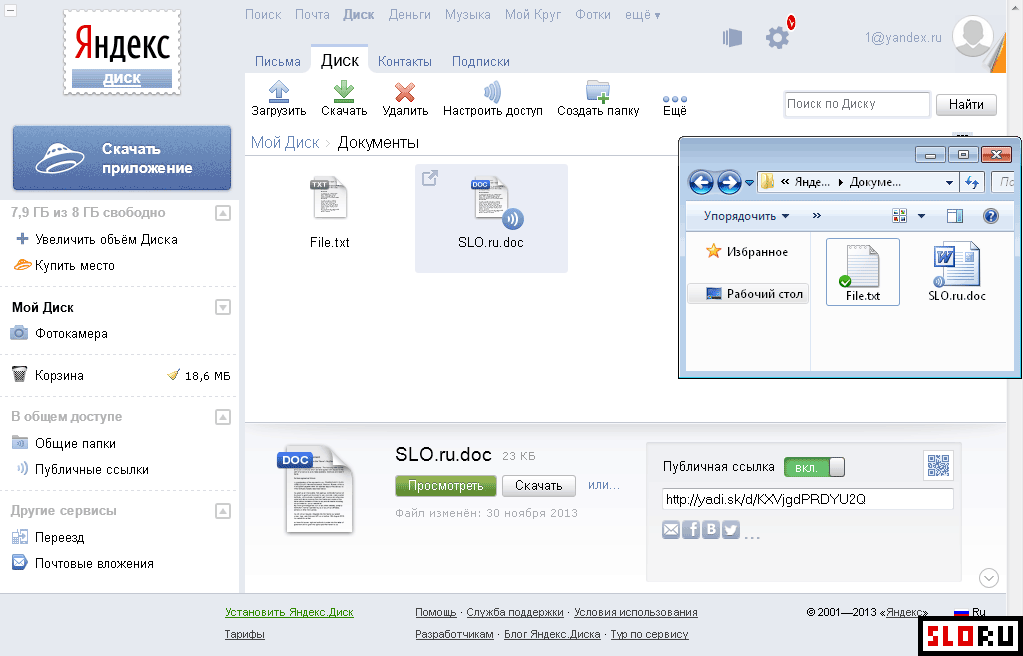
Яндекс Диск – бесплатное облако от Яндекса
Яндекс.Диск – это хранилище для файлов (облако) от компании Яндекс. Получить его может любой желающий после регистрации. Бесплатно выделяется 10 ГБ места. Навсегда!
На заметку. Облачное хранилище – это современный файлообменник. Информация там хранится не в одном каком-то месте, а на множестве небольших серверов, которые находятся в разных концах земного шара. Главное достоинство – крайне низкая вероятность потери данных.
Облако — это удобно, ведь для доступа к сохраненной информации нужно просто иметь интернет. Это позволяет легко получать и передавать разные файлы, в том числе и большого размера.
Облако от Яндекса
Сайт Яндекс уже несколько лет раздает бесплатные «облака» всем желающим. Там можно хранить файлы и передавать их другим пользователям. Причем не только в рамках системы – можно получить ссылку, по которой любой человек сможет скачать файл. Кроме того, сервис даёт возможность настроить автоматическую загрузку фотографий с телефона, планшета и других устройств.
Называется всё это Яндекс.Диск. Чтобы получить себе такую штуку нужно просто зарегистрироваться в системе. А тем, у кого есть почта на Яндексе, облако доступно и без регистрации.
По утверждению создателей сервиса, срок хранения данных на нём неограничен.
Как войти в Яндекс.Диск
Если у вас его ещё нет
Бесплатный диск объемом 10 ГБ выдается любому желающему после регистрации в системе. Но если у вас есть почта в yandex.ru, то специально получать его не нужно – просто зайдите в ящик, а там, наверху, нажмите на «ДИСК».
Но если у вас есть почта в yandex.ru, то специально получать его не нужно – просто зайдите в ящик, а там, наверху, нажмите на «ДИСК».
Если же почты нет, то чтобы получить себе облако, нужно будет зарегистрироваться в системе:
1. Открываем сайт disk.yandex.ru и нажимаем кнопку «Завести свой диск».
2. Отвечаем на несколько вопросов о себе и нажимаем «Зарегистрироваться».
По завершении регистрации вы сразу получите возможность пользоваться сервисом.
Только не забудьте записать выбранный логин и пароль в надежное место. Ведь это данные для входа – без них попасть в облако вы не сможете.
Если Диск уже есть или был когда-то
Значит, чтобы в него попасть, нужно войти на свою страницу. Сделать это можно на официальном сайте disk.yandex.ru. Просто печатаем свой логин/пароль вверху и нажимаем «Войти».
А еще туда можно попасть через главную страницу yandex.ru. Сначала входим в почту через прямоугольник в правом верхнем углу сайта.
Ну, и из почты переходим в Диск.
Как пользоваться
Пользоваться Яндекс.Диском можно так:
- Через веб-интерфейс, то есть через сайт прямо в браузере.
- Через программу: скачать/установить ее на компьютер.
- Через мобильное приложение: установить на телефон или планшет.
Веб-интерфейс
Вот как выглядит диск, когда мы открываем его в браузере (программе для интернета):
Обычно здесь уже есть несколько фотографий, видеозапись и папка с музыкой. Их система создает автоматически, чтобы пользователь мог ознакомиться со всеми возможностями сервиса.
Например, картинки можно не только просматривать, но и редактировать: поворачивать, обрезать, осветлять и др.
Как загрузить свои файлы. Чтобы добавить свой файл в облако, нужно нажать кнопку «Загрузить», которая находится в верхней части страницы.
Откроется окошко (проводник), из которого выбираем файл и жмем кнопку «Открыть». Ну, или просто щелкаем по нему два раза левой кнопкой мыши.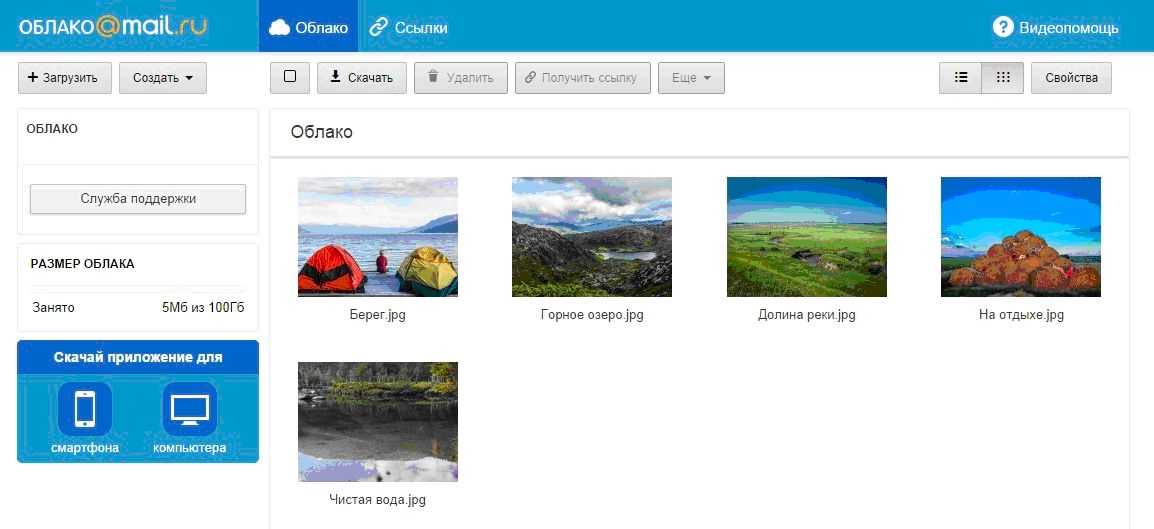
После загрузки файл добавится в Диск. Теперь он будет храниться и на вашем компьютере, и в облаке.
Как поделиться файлом. Любой файл и даже папку с файлами можно передать другому человеку. Отправить по скайпу, почте, опубликовать на своей странице в социальной сети. Для этого нужно получить на него ссылку.
1. Наводим курсор на файл или папку, которую нужно передать, и в появившемся квадратике ставим птичку.
2. С правой стороны, в части «Поделиться ссылкой» щелкаем по «Выкл».
3. Копируем ссылку или сразу же отправляем/публикуем ее, где надо.
Открыть файл, отредактировать его, переместить куда-то, скачать и даже удалить можно точно так же – через меню с правой стороны.
Программа на компьютер
Облаком также можно пользоваться прямо со своего компьютера через специальную программу. Это удобно, когда часто с ним работаешь. Программу эту можно взять из веб-интерфейса. Щелкаем по пункту «Скачать диск для Windows» и на отдельной странице загружаем программу.
После скачивания запускаем файл и устанавливаем. Здесь всё как обычно, единственное, можно снять птички с пунктов «Установить Яндекс.Браузер» и «Установить настройки поиска и сделать Яндекс домашней страницей», чтобы ничего лишнего в ваш не в компьютер не добавилось.
При первом запуске программы откроется окно, где сразу будет выделена кнопка «Начать работу», но нажав внизу на надписи синего цвета можно изменить некоторые настройки (например, папку, где будет храниться информация).
По умолчанию все папки в Яндекс.Диске будут синхронизироваться с компьютером (и наоборот) при любом обновлении содержимого, но для отдельных папок можно отменить синхронизацию.
А еще помимо программы есть приложение для планшетов и телефонов, что весьма удобно для тех, кто часто пользуется сервисом с этих устройств.
P.S.
Подробнее о том, как пользоваться веб-интерфейсом, программой и мобильным приложением можно найти на официальной странице сервиса и в блоге.
Автор: Илья Кривошеев
Прививка облаком. Как одна технология меняет российский бизнес
как одна технология меняет крупные российские компании
Роль облаков в бизнесе изменилась: из технологии, решающей сугубо технические задачи, они превратились в сервис, который помогает пробивать барьеры на пути роста бизнеса.
Облачная платформа Yandex.Cloud и EY провели исследование и выяснили, каких перемен добиваются компании, которые уже в облаке, и как из технологии облака становятся бизнес-платформой. Мы рассказываем самое интересное: как с облаками растет прозрачность IT-расходов, скорость запуска продуктов, происходит демократизация разработки и трансформация операционных процессов.
Ускорение запуска новых продуктов
Руководители компаний часто рассматривают переход в облако как вариант аутсорсинга IT-мощностей, который позволяет сократить капитальные расходы и сэкономить на обслуживании оборудования. Опыт показывает, что основной мотив перехода в облако связан не с прямой или косвенной экономией, а с возможностью ускорить разработку новых цифровых продуктов и обеспечить масштабируемость бизнеса.
В облаках компания получает возможность увеличить число цифровых экспериментов и за счет этого ускорить запуск новых продуктов и сервисов. Быстрее запуск — быстрее рост. К тому же облака обеспечивают максимальную гибкость бизнесу: можно моментально наращивать мощности и платить только за те ресурсы, которые реально использовались, но не за время простоя. Компания «АльфаСтрахование» с помощью Yandex.Cloud сократила время вывода новых продуктов на рынок с года до 1–3 месяцев.
Почему бизнес идет в облако
50
Выросло число бизнес-экспериментов
и пилотных проектов
46
Увеличилась важность
онлайн-сервисов
41
Пришлось увеличить скорость
запуска продуктов
Источник: исследование «Облачные платформы в России 2021: как помочь росту бизнеса»
Какие еще причины приводят
компании в облако Cкачать исследование
Интеграция
в бизнес уникальных
современных
технологий
68
компаний назвали доступ к уникальным технологиям основным критерием выбора облачной платформы
Еще один важный эффект облака — возможность быстро начать применять новейшие сервисы и технологии. У Yandex.Cloud, например, доступна технология распознавания и синтеза речи Yandex SpeechKit. Сервис «Работа.ру» с помощью нее сократил нагрузку на операторов, расходы на работу call-центра и обучение людей. Самостоятельную разработку таких решений могут себе позволить разве что технологические гиганты, а через облака пользоваться ими и получать бизнес-результаты может любой стартап.
То же относится к машинному обучению. Для небольшой компании это слишком сложно и затратно, но через облако технология как услуга доступна всем. В прошлом году сервис машинного обучения принес 14% выручки Yandex.Cloud: им активно пользуются такие компании, как Signal AI, Badoo и АТС, которая разрабатывает голосовые сервисы для «Альфа-Банка», «Мегафона» и других игроков. Такие компании давно воспринимают облака как бизнес-инструмент, от которого зависит успех конкуренции на рынке.
Какие еще преимущества
дают облака бизнесу Скачать исследование
Александр Соколовский
IT-директор группы «М. Видео — Эльдорадо»
Видео — Эльдорадо»
Рост прозрачности IT-расходов
Бизнес приходит в облака из-за растущей потребности в цифровых продуктах и сталкивается с новыми вызовами. Приходится работать над повышением надежности IT-архитектуры, эффективностью бизнес-процессов и управлением временем высококвалифицированных специалистов. Результат — серьезная трансформация операционной модели и внутренних процессов компании.
Одно из ключевых проявлений перехода в облако в том, что расходы на IT становятся более прозрачными, это отметила половина опрошенных компаний. Бизнес-подразделения зачастую плохо представляют себе стоимость услуг, которые они заказывают через IT-департамент.
А что происходит с облаками? Они четко показывают статистику: какое подразделение и какой задачей загрузило сервис и сколько это стоило компании. Нагрузку легко детализировать и анализировать, проще понять и оптимизировать. За счет этого, как показало исследование, повышается ответственность персонала за ресурсы IT. В результате даже далекие от IT специалисты начинают лучше понимать экономику разработки цифрового продукта.
В результате даже далекие от IT специалисты начинают лучше понимать экономику разработки цифрового продукта.
Что еще меняется в операционной модели
бизнеса при переходе на облако Скачать исследование
Антон Исанин
Директор по разработке компании «АльфаСтрахование»
Вовлечение
бизнес-подразделений
в процесс разработки
цифровых продуктов
Более 75% опрошенных в ходе исследования EY и Yandex.Cloud отметили, что заказчиками облачных сервисов в их компании выступают не только IT-подразделения. При этом бизнес-подразделения в этой роли выступают почти так же часто, как IT: их вовлеченность в разработку повышается.
Что это значит? Конечно, они не становятся разработчиками и не начинают вмешиваться в работу IT-отдела. Люди за пределами IT-департамента начинают лучше понимать не только экономику разработки, но и то, как устроен процесс: возможности и требования, сроки реализации. Это позволяет бизнесу избежать «бутылочного горлышка IT», когда амбиции, идеи и смелые проекты упираются в ограниченные возможности IT-отделов.
Как проявляется
демократизация разработки Скачать исследование
Повышение
надежности
IT-инфраструктуры
48
компаний переходят в облака
из-за повышения требований к надежности IT
Для опытных компаний один из главных эффектов облака связан с упрощением IT-архитектуры и повышением ее надежности. Из-за роста значения цифровых сервисов любой технический сбой чреват потерей выручки и неэффективным использованием рабочего времени сотрудников, затратами на возврат клиентов и восстановление данных. Все это со временем может привести к серьезным убыткам, поэтому надежность сервисов — важная составляющая экономического эффекта облаков.
Для создания надежной архитектуры нужны развитые IT-компетенции. Компании, не имеющие их, делегируют задачу облачным провайдерам, которые за счет масштабов вкладывают огромные ресурсы в лучших специалистов и технологии безопасности. Это обеспечивает стабильную работу сервисов и минимизирует риск упустить выгоду из-за технических неполадок.
Это обеспечивает стабильную работу сервисов и минимизирует риск упустить выгоду из-за технических неполадок.
Почему компании боятся
переходить в облака Скачать исследование
Yandex.Cloud Compute Image Exporter — Post-Processors
Скоро будет запущена новая платформа для документации и руководств.
Мы переносим документацию Packer в HashiCorp Developer, наш новый интерфейс для разработчиков.
Присоединяйтесь
Поиск документации Packer
Введите ‘/’ для поискаСообщество
v1.1.2
Тип: yandex-export Artifact BuilderId: packer.post-processor.yandex-export
Постпроцессор Yandex.Cloud Compute Image Exporter экспортирует полученное изображение из сборки yandex в виде файла qcow2 в хранилище объектов Yandex.
Экспортер использует ту же папку Яндекс.Облака и
учетные данные аутентификации в качестве сборки yandex, создавшей образ. Временная виртуальная машина запускается в папке с использованием этих учетных данных. ВМ
монтирует построенный образ как вторичный диск, затем выгружает образ в формате qcow2.
Затем виртуальная машина загружает файл в предоставленные пути Yandex Object Storage
Временная виртуальная машина запускается в папке с использованием этих учетных данных. ВМ
монтирует построенный образ как вторичный диск, затем выгружает образ в формате qcow2.
Затем виртуальная машина загружает файл в предоставленные пути Yandex Object Storage , используя тот же
реквизиты для входа.
Таким образом, назначенный Сервисный аккаунт должен иметь права на запись в Хранилище объектов Яндекса. путей . Новые временные статические ключи доступа из назначенной учетной записи службы, используемые для загрузки
изображение.
Также необходимо настроить коммуникатор ssh. По умолчанию ssh_username до Ubuntu .
»Конфигурация
»Необходимо:
»Доступ
-
токен(строка) — токен OAuth или IAM-токен использовать для аутентификации в Яндекс.Облаке. В качестве альтернативы вы можете установить значение переменной средыYC_TOKEN.
»Export
-
paths([]string) - Список путей к объектному хранилищу Яндекса, куда будет загружено экспортированное изображение. Имейте в виду, что использование пробела внутри пути не поддерживается.
Также этот параметр поддерживает функцию шаблона сборки.
Проверьте доступные данные шаблона для Яндекс Конструктора.
Пути к объектному хранилищу Яндекса, куда будет загружено экспортированное изображение.
Имейте в виду, что использование пробела внутри пути не поддерживается.
Также этот параметр поддерживает функцию шаблона сборки.
Проверьте доступные данные шаблона для Яндекс Конструктора.
Пути к объектному хранилищу Яндекса, куда будет загружено экспортированное изображение.
 Имейте в виду, что использование пробела внутри пути не поддерживается.
Также этот параметр поддерживает функцию шаблона сборки.
Проверьте доступные данные шаблона для Яндекс Конструктора.
Пути к объектному хранилищу Яндекса, куда будет загружено экспортированное изображение.
Имейте в виду, что использование пробела внутри пути не поддерживается.
Также этот параметр поддерживает функцию шаблона сборки.
Проверьте доступные данные шаблона для Яндекс Конструктора.
Пути к объектному хранилищу Яндекса, куда будет загружено экспортированное изображение.»Common
-
folder_id(строка) — идентификатор папки, который будет использоваться для запуска экземпляров и хранения изображений. В качестве альтернативы вы можете установить значение переменной средыYC_FOLDER_ID. Чтобы использовать другую папку для поиска исходного изображения или сохранения целевого изображения в проверьте параметры 'source_image_folder_id' и 'target_image_folder_id'.
-
service_account_id(строка) — идентификатор учетной записи службы с надлежащим разрешением на изменение экземпляра, создание и подключение диска и сделать загрузку по определенным путям Яндекс Объектного Хранилища.
»Необязательно:
»Доступ к конечной точке
api.cloud.yandex.net:443.service_account_key_file(строка) — Путь к файлу с ключом учетной записи службы в формате json. Этот — альтернативный способ авторизации в Яндекс.Облаке. В качестве альтернативы вы можете установить переменную средыYC_SERVICE_ACCOUNT_KEY_FILE.max_retries(int) — максимальное количество раз, когда выполняется запрос API.
 По умолчанию
По умолчанию »Экспорт
source_image_folder_id(строка) — идентификатор папки, содержащей исходное изображение. По умолчаниюстандартные изображения.source_image_family(строка) — исходное семейство изображений для запуска процесса экспорта. По умолчаниюubuntu-1604-lts. Образ должен содержать утилиты или поддерживаемый менеджер пакетов:aptилиyum- требуетсяrootилиsudoбез пароля. Утилиты: qemu-img,aws. Утилитаqemu-imgтребует пользователяrootилиsudoдоступ без пароля.source_image_id(строка) — идентификатор исходного изображения, который будет использоваться для создания нового изображения. Только один из source_image_id или Необходимо указать source_image_family.source_disk_extra_size(целое число) — дополнительный размер исходного диска в ГБ. По умолчанию это0GB. Требуется утилитаlossupна экземпляре.Осторожно! Увеличивает стоимость оплаты. См. производительность.
storage_endpoint(строка) — StorageEndpoint настраиваемая конечная точка объектного хранилища Яндекса для загрузки изображения, по умолчаниюstorage.yandexcloud.net.storage_endpoint_autoresolve(bool) — StorageEndpointAutoresolve для автоматического разрешения конечной точки хранилища через вызов YC Public API ListEndpoints. Вариант имеет
приоритет над параметром «storage_endpoint».storage_region(string) - StorageRegion произвольный регион Яндекс Объекта. По умолчаниюru-central1
 Утилиты:
Утилиты:  Вариант имеет
приоритет над параметром «storage_endpoint».
Вариант имеет
приоритет над параметром «storage_endpoint».»Common
serial_log_file(строка) - Путь к файлу для сохранения вывода последовательного порта запущенного экземпляра.state_timeout(строка продолжительности | например: «1h5m2s») — время ожидания изменения состояния экземпляра. По умолчанию5 м.
»Экземпляр
instance_cores(целое число) — количество ядер, доступных экземпляру.instance_gpus(int) — количество графических процессоров, доступных для экземпляра.instance_mem_gb(int) — объем доступной памяти для экземпляра, указанный в гигабайтах.instance_name(строка) — имя, присвоенное экземпляру.идентификатор_платформы(строка) — Идентификатор конфигурации аппаратной платформы экземпляра. По умолчанию этоstandard-v2.labels(map[string]string) — метки пары ключ/значение для применения к запущенному экземпляру.метаданные(map[string]string) — метаданные, примененные к запущенному экземпляру.metadata_from_file(map[string]string) — метаданные, примененные к запущенному экземпляру. Значения в этой карте — это пути к файлам содержимого для соответствующих ключей метаданных.вытесняемый(bool) — запустить вытесняемый экземпляр. По умолчанию этоfalse.
»Диск
имя_диска(строка) - Имя диска, если не задано имя экземпляра будет использован.disk_size_gb(int) — Размер диска в ГБ. По умолчанию это 10/100 ГБ.disk_type(строка) — укажите тип диска для запускаемого инстанса. По умолчаниюсеть-ssd.disk_labels(map[string]string) — метки пар ключ/значение для применения к диску.

»Network
subnet_id(string) — идентификатор подсети Yandex VPC для использования запущенный экземпляр. Обратите внимание, зона подсети должна соответствовать зона, в которой запускается ВМ.zone(string) — Имя зоны для запуска инстанса. По умолчанию этоru-central1-a.security_group_ids([]string) — идентификаторы групп безопасности для сетевого интерфейса экземпляра.use_ipv4_nat(bool) — если установлено значение true, то запущенный экземпляр будет иметь внешний интернет доступ.use_ipv6(bool) — установите значение true, чтобы включить IPv6 для экземпляра созданный. По умолчанию это falseили не включено.Примечание : Использование IPv6 будет доступно в будущем.
use_internal_ip(bool) — если true, использовать внутренний IP-адрес экземпляра. вместо своего внешнего IP во время сборки.
 По умолчанию это
По умолчанию это »Базовый пример
В следующем примере создается образ Compute в папке с идентификатором b1g8jvfcgmitdrslcn86 с
Учетная запись службы, ключевой файл которой account.json . После сборки образа временная виртуальная машина
будет создан для экспорта изображения в виде файла qcow2 в s3://packer-export/my-exported-image.qcow2 и s3://packer-export/image-number-two.qcow2 . keep_input_artifact истинно, поэтому
исходный образ Compute не будет удален после экспорта.
Чтобы этот пример работал, учетная запись службы, связанная с Builder
должен иметь доступ на запись как к s3://packer-export/my-exported-image., так и  qcow2
qcow2 s3://packer-export/image-number-two.qcow2 и получить разрешение на изменение временного экземпляра
(создать новый диск, подключиться к экземпляру и т. д.).
{
"строители": [
{
"тип": "яндекс",
"folder_id": "b1g8jvfcgmitdrslcn86",
"subnet_id": "e9bp6l8sa4q39yourxzq",
"зона": "ru-central1-a",
"source_image_family": "ubuntu-1604-lts",
"ssh_username": "убунту",
«use_ipv4_nat»: правда
}
],
"постпроцессоры": [
{
"тип": "яндекс-экспорт",
"folder_id": "b1g8jvfcgmitdrslcn86",
"subnet_id": "e9bp6l8sa4q39yourxzq",
"service_account_id": "ajeu0363240rrnn7xgen",
"пути": [
"s3://packer-export-bucket/my-exported-image.qcow2",
"s3://packer-export-bucket/template-supported-get-{{build `ImageID` }}-right-here.qcow2"
],
"keep_input_artifact": правда
}
]
}
Сайты, использующие CDN Яндекс.Облака - Wappalyzer
CDN
Посетите cloud. yandex.com
yandex.comYandex.Cloud CDN помогает оптимизировать доставку статического контента для вашего веб-сервиса.
Обратитесь в CDN Яндекс.Облака пользователи
Создайте список 1900 CDN-сайты Яндекс.Облака с компанией и контактными данными.
Создайте список потенциальных клиентовСайты, использующие CDN Яндекс.Облака
Это лучшие сайты, использующие CDN Яндекс.Облака на основе движение.
| # | Сайт | Трафик |
|---|---|---|
| 1 | yandex.ru | |
| 2 | leroymerlin.ru | |
| 3 | tracker. yandex.ru yandex.ru | |
| 4 | cloud.yandex.ru | |
| 5 | apteka.ru | |
| 6 | st.yandex-team.ru | |
| 7 | sbermarket.ru | |
| 8 | role-editor.com | |
| 9 | boxberry.ru | |
| 10 | spb.leroymerlin.ru |
Получить полный список сайты и компании, использующие CDN Яндекс.Облака.
Отчеты CDN Яндекс.Облака
Создавайте релевантные отчеты для CDN Яндекс.Облака, чтобы находить потенциальных клиентов
или узнайте больше о своей целевой аудитории.
Example reports
| Yandex.Cloud CDN websites in the United States |
| Yandex.Cloud CDN websites in the United Kindom |
| Email addresses and phone numbers of Yandex.Cloud CDN клиенты |
| Сайты CDN Яндекс.Облака с доменом .com |
| Top 5,000 most visited Yandex.Cloud CDN websites |
| 5,000 low-traffic Yandex.Cloud CDN websites |
| Top 500 websites for every technology in the category CDN |
Или же, Создайте собственный отчет CDN Яндекс.Облака.
Тенденция использования CDN Яндекс.Облака
На этом графике показан рост CDN Яндекс. Облака с
декабрь 2021.
Облака с
декабрь 2021.
Демография CDN Яндекс.Облака
Разбивка по странам и языкам, используемым CDN-сайты Яндекс.Облака.
Страны
Языки
Альтернативы CDN Яндекс.Облака
Это самые популярные альтернативы CDN Яндекс.Облака в 2022.
| # | Технология | Сравнить |
|---|---|---|
| 1 | Cloudflare | Яндекс.Облако CDN vs. Cloudflare |
| 2 | Размещенные библиотеки Google | CDN Яндекс. Облака vs.
Размещенные на Google библиотеки Облака vs.
Размещенные на Google библиотеки |
| 3 | cdnjs | Яндекс.Облако CDN vs. cdnjs |
| 4 | jsDelivr | Яндекс.Облако CDN vs. jsDelivr |
| 5 | jQuery CDN | Яндекс.Облако CDN vs. jQuery CDN |
Посмотреть полный список Альтернативы CDN Яндекс.Облака.
Приложения
Wappalyzer работает с инструментами, которые вы используете каждый день.
Хром
Просматривайте технологии веб-сайтов, которые вы посещаете, в своем браузере.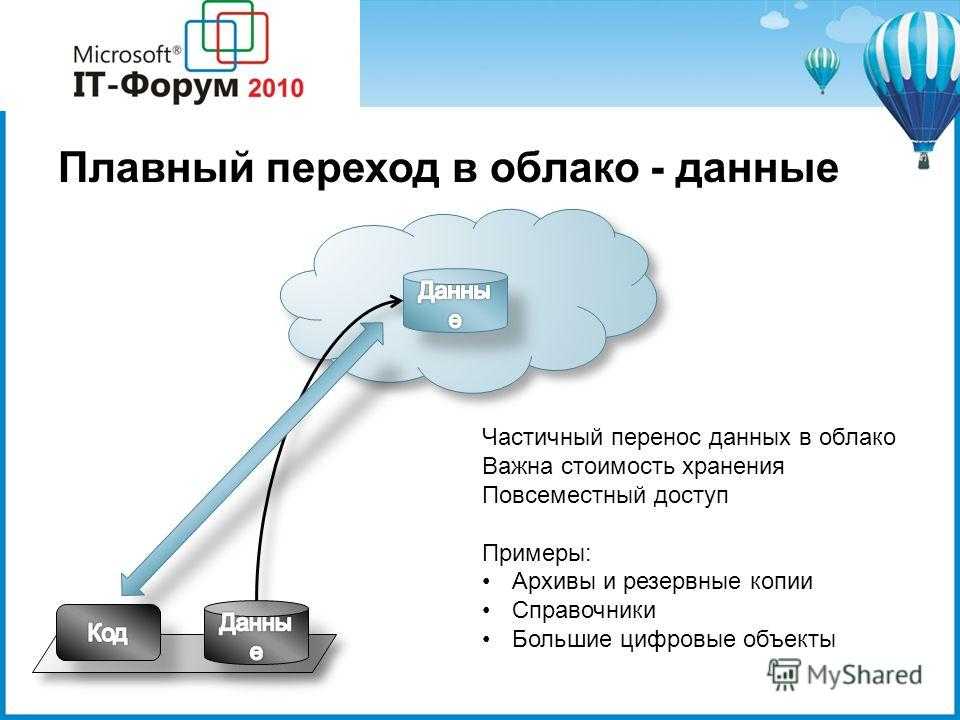
Fire Fox
Просматривайте технологии веб-сайтов, которые вы посещаете, в своем браузере.
Край
Просматривайте технологии веб-сайтов, которые вы посещаете, в своем браузере.
Сафари
Просматривайте технологии веб-сайтов, которые вы посещаете, в своем браузере.
HubSpot
Просматривайте технологические стеки ваших лидов в CRM.
Пайпдрайв
Просматривайте технологические стеки ваших лидов в CRM.
Семруш
Просматривайте стеки технологий ваших клиентов и потенциальных клиентов в вашей CRM.
Паббли
Автоматизированные рабочие процессы и электронный маркетинг.
Запир
Подключите Wappalyzer к приложениям, которые вы используете, код не требуется.
Делать
Подключите Wappalyzer к приложениям, которые вы используете, код не требуется.
Gmail
Просматривайте наборы технологий ваших контактов в Gmail.
Андроид
Ваппалайзер в кармане.
Wappalyzer доверяют тысячи профессионалов по всему миру
Wappalyzer зарекомендовал себя как отличный инструмент, помогающий нам анализировать совокупный анализ того, как работает Интернет с помощью различных технологий.
Илья Григорик 
Главный инженер Shopify
В наши дни вам нужны передовые маркетинговые инструменты, чтобы выделиться среди конкурентов. Wappalyzer поможет нам в этом.
Томас Алиберт
Инженер по развитию в PayFit
Я постоянно пользуюсь Wappalyzer, и это бесценно, так как помогает мне в работе.
Майкл Петселас
Специалист по развитию клиентов в HubSpot
Wappalyzer — неотъемлемая часть нашего процесса продаж, позволяющая оптимизировать сегментацию потенциальных клиентов в масштабе. Это полностью меняет правила игры для нашей организации.
Роман Швайгер
Руководитель отдела развития бизнеса в Boomerank
Wappalyzer был такой полезной частью набора данных HTTP Archive. Это позволило нам по-новому разделять данные и получать более интересные сведения о состоянии Интернета.
Рик Вискоми 
Старший инженер DevRel в Google
Wappalyzer помогает нашим отделам продаж лучше и быстрее понимать потенциальных клиентов, имея четкое представление об их технологическом стеке.
Рабин Нухтабек
Главный инженер по развитию Skedify
Подпишитесь, чтобы получать периодические обновления продукта.
Мультиоблачное хранилище с Yandex.Cloud и Amazon S3
Мультиоблачная архитектура — новая необходимость. Flexify.IO позволяет прозрачно распределять данные между и . Поддерживаются следующие сценарии:
Хранение части данных в Яндекс.Облаке, остальные данные хранятся в Amazon S3.
Обналичивание/выгрузка части данных Amazon S3 в Яндекс.Облако.
Репликация данных между Yandex.Cloud и Amazon S3.
Перенос данных между Amazon S3 и Яндекс.Облаком.

Во всех сценариях виртуальные машины Yandex.Cloud и Amazon Web Service, а также другие сервисы имеют доступ ко всем данным прозрачно и в едином пространстве имен.
Развертывание Flexify.IO
Клиентам Яндекс.Облака мы рекомендуем развертывание Flexify.IO из .
В разделе выберите Compute Cloud.
В выборе выберите и нажмите .
Найдите Flexify и выберите последнюю версию Flexify.IO в качестве базового образа.

Укажите ЦП и ОЗУ ВМ в зависимости от предполагаемого использования (рекомендуется не менее 2 ЦП и 4 ГБ ОЗУ), логин, открытый SSH-ключ и нажмите .
Когда виртуальная машина будет запущена, найдите общедоступный IP-адрес виртуальной машины и откройте его в браузере.
Запуск виртуальной машины может занять несколько минут. Пожалуйста, наберитесь терпения и дождитесь появления диалогового окна «Создание учетной записи».
Пожалуйста, наберитесь терпения и дождитесь появления диалогового окна «Создание учетной записи».
Если вы решите использовать HTTPS для подключения к виртуальной машине, обратите внимание, что исходный сертификат SSL будет самозаверяющим и не будет автоматически приниматься большинством браузеров.
Создайте учетную запись с любым именем пользователя или адресом электронной почты и паролем, которые вы позже будете использовать для входа в эту установку Flexify.IO.
Добавление учетных записей хранения во Flexify.IO
После входа в консоль Flexify.IO вы можете добавить одну или несколько учетных записей облачного хранилища.
Flexify.IO с добавленными учетными записями Yandex.Cloud и Amazon S3
Чтобы добавить учетную запись хранилища, перейдите на вкладку и нажмите . Откроется диалоговое окно «Добавить учетную запись хранения». В этом диалоговом окне вы можете добавить учетную запись хранения из поддерживаемого облачного или локального объектного хранилища, включая Yandex.Cloud, Amazon S3, Azure Blob Storage, Dell EMC ECS и другие.
Добавление Яндекс.Облака
Чтобы добавить объектное хранилище Яндекс.Облака, сначала необходимо сгенерировать ключи доступа к Яндекс.Облаку.
В Консоли Яндекс.
Облака выберите облако и выберите в меню слева.Создайте новую учетную запись службы с этой ролью.
 Облака выберите облако и выберите в меню слева.
Облака выберите облако и выберите в меню слева.Создание новой учетной записи службы с правами storage.admin
Выберите вновь созданную учетную запись, нажмите , а затем .
Создание нового статического ключа доступа для новой учетной записи хранения
Новый идентификатор ключа и секретный ключ
В Консоли Flexify.IO выберите Yandex.Cloud из выпадающего списка и вставьте ключи доступа.
Добавление ключей Yandex.Cloud во Flexify. IO
IO
Нажмите . Это добавит учетную запись хранилища Яндекс.Облака во Flexify.IO и начнет обновлять сегменты для отображения статистики.
Добавление Amazon S3
Чтобы добавить учетную запись хранилища Amazon S3 во Flexify.IO, вам потребуются ключи Amazon S3 с разрешением на доступ к хранилищу Amazon S3.
В консоли Amazon Web Services выберите IAM (доступно по адресу ).
На вкладке нажмите .
Укажите имя пользователя и выберите предоставление программного доступа.

Хотя это самый простой способ, Flexify.IO не требует полных прав доступа к Amazon S3. Для примера политики IAM, совместимой с Flexify.IO, нажмите «Пример политики» в диалоговом окне «Добавить учетную запись хранения».
После создания пользователя скопируйте и вставьте идентификатор ключа доступа и секретный ключ доступа.
В консоли Flexify.IO выберите Yandex.Cloud из выпадающего списка Storage Provider и вставьте сгенерированные ключи доступа.
Перенос данных из Amazon S3 в Yandex.
 Cloud
CloudПосле добавления учетных записей хранения во Flexify.IO вы можете копировать или перемещать данные между ними.
На вкладке нажмите (или нажмите на вкладке).
В поле выберите одну или несколько корзин для переноса данных.
В поле выберите Яндекс.Облачное хранилище объектов. Вы можете выбрать любую существующую корзину или позволить Flexify.IO создать новую корзину.
Перенос данных из Amazon S3 в Яндекс.Облако с помощью Flexify.IO Однако убедитесь, что имя корзины глобально уникально. Даже если у кого-то уже есть ведро с таким именем, вы сможете его использовать.
При необходимости щелкните Дополнительные параметры и настройте параметры переноса.
Нажмите «Начать миграцию» и следите за ходом миграции.
Ход миграции
Объединение данных из Amazon S3 и Яндекс.Облака
Уникальной особенностью Flexify.IO является возможность объединять данные из двух и более облаков в единое виртуальное хранилище и делать их доступными через единый S3- совместимая конечная точка.
Чтобы настроить виртуальную конечную точку Flexify. IO:
IO:
В консоли Flexify.IO перейдите на вкладку.
Если конечная точка еще не создана, щелкните .
Нажмите на знак (+), чтобы подключить Яндекс.Облачное хранилище объектов к виртуальной конечной точке.
Подключение Яндекс.Облака к виртуальной конечной точке
Теперь все объекты из Яндекс.Облака и Amazon S3 объединены и доступны через S3-совместимую конечную точку на вашей виртуальной машине Flexify.IO. Вам нужно указать вашему приложению использовать IP-адрес вашего компьютера (например, 178.154.254.21 в этом примере) с ключом доступа и секретным ключом, отображаемым в настройках конечной точки.
Настройка CyberDuck для использования конечной точки Flexify.IO
Flexify.IO будет принимать запросы S3 и пересылать их во все подключенные хранилища, объединяя результаты. Например, если у вас в аккаунте Amazon S3 plane.jpg и ship.jpg , а в аккаунте Яндекс.Облака ship.jpg и train.jpg , комбинированный просмотр через Flexify.IO Виртуальная конечная точка будет иметь все три объекта: plane.jpg , ship.jpg и train.jpg .
Объединение данных с виртуальной конечной точкой Flexify. IO
IO
Политика чтения
Представьте, что в приведенном выше примере Amazon S3 и Яндекс.Облако имеют разные версии ship.jpg . Какую версию получит клиент, если запросит ship.jpg через виртуальную конечную точку? Это контролируется политикой чтения в настройках конечной точки.
По умолчанию с политикой Flexify.IO будет сравнивать временные метки объектов в Amazon S3 и Яндекс.Облаке и выбирать последнюю версию. Это лучше всего подходит для сценария миграции, когда вы записываете новые данные только в Yandex.Cloud, но вам нужны данные в Amazon S3, чтобы они были легко доступны.
В соответствии с политикой Flexify.IO доставляет из облака ту версию объекта, которая отвечает первой. Это лучше всего подходит для сценария, когда у вас есть реплики идентичных объектов в обоих облаках и вы хотите оптимизировать их для достижения наилучшей производительности.

Политика записи
По умолчанию Flexify.IO будет реплицировать все данные, записанные через виртуальную конечную точку, между всеми подключенными хранилищами: в данном случае как Yandex.Cloud, так и Amazon S3.
Вы можете захотеть, чтобы новые данные сохранялись только в Яндекс.Облаке, а данные оставались видимыми и доступными в Amazon S3. Для этого вы можете отключить запись данных в Amazon S3, щелкнув учетную запись Amazon S3 на панели хранилища и сняв флажок.
Теперь новые данные будут сохраняться только в Объектное хранилище Яндекс.Облака.
Виртуальные сегменты
Имена сегментов должны быть уникальными, и вы не сможете создать сегмент с нужным именем в одном или нескольких облаках. Flexify.IO позволяет отображать имена корзин с помощью виртуальных корзин.
Чтобы создать новую виртуальную корзину, просто нажмите на карточку Конечная точка и укажите имя виртуальной корзины. Затем вы можете присоединить несколько сегментов к виртуальному сегменту и сделать все объекты из подключенных сегментов доступными через виртуальный сегмент.
Конечная точка с виртуальной корзиной «демо»
С помощью виртуальных корзин вы также можете комбинировать данные из нескольких корзин одного и того же облачного провайдера.